2015/12/251 hierarchical document clustering using frequent itemsets benjamin c.m. fung, ke wangy...
TRANSCRIPT

112/04/21 1
Hierarchical Document Clustering Using Frequent Itemsets
Benjamin C.M. Fung, Ke Wangy and Martin Ester
Proceeding of International Conference on Data Mining, SIAM 2003
報告人 : 吳建良

Outline Hierarchical Document Clustering Proposed Approach
Frequent Itemset-based Hierarchical Clustering (FIHC)
Experimental Evaluation Conclusions
2

Hierarchical Document Clustering
Document Clustering Automatically organize documents into clusters Documents within a cluster have high similarity Documents within different clusters are very dissimilar
Hierarchical Document Clustering
3
Sports
Soccer Tennis
Tennis ball

Challenges in Hierarchical Document Clustering
High dimensionality. High volume of data Consistently high clustering quality. Meaningful cluster description
4
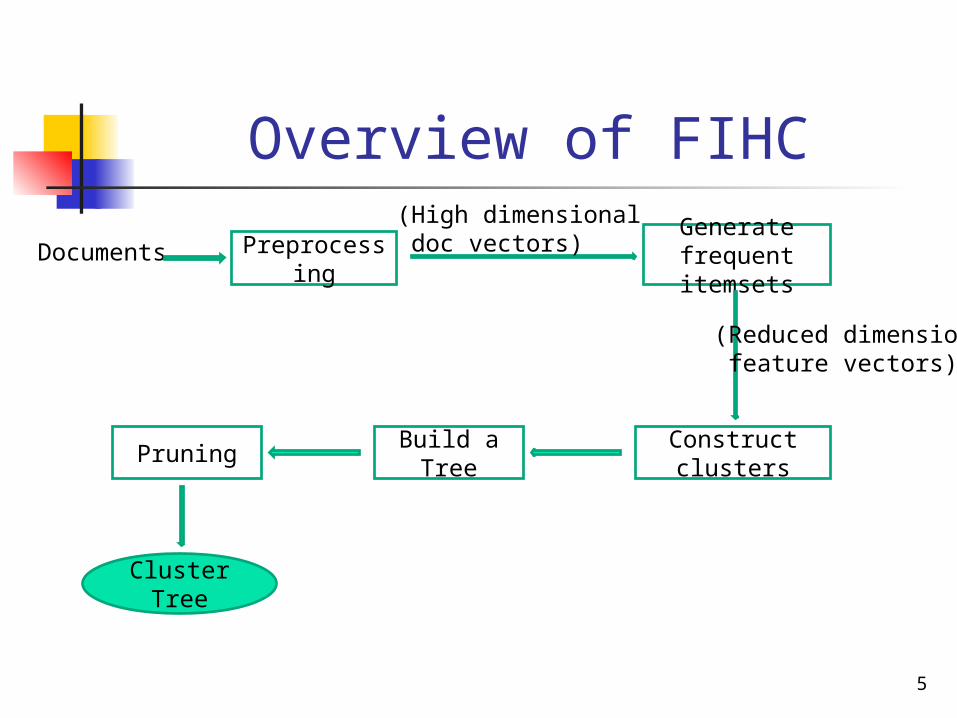
Overview of FIHC
5
PreprocessingDocuments
(High dimensional doc vectors) Generate
frequent itemsets
(Reduced dimensions feature vectors)
Construct clustersBuild a TreePruning
Cluster Tree

Preprocessing Remove stop words and Stemming Construct vector model
doci= ( item frequency1, if2, if3, …, ifm) EX:
6

Generate Frequent Itemsets Use Agrawal et al. proposed algorithm to find global
frequent itemsets Minimum global support
a percentage of all documents Global frequent itemset
a set of items (words) that appear together in more than a minimum global support of the whole document set
Global frequent item an item that belongs to some global frequent itemset
7

Reduced Dimensions Vector Model High dimensional vector model Set the minimum global support to 35% Store the frequencies only for global frequent items
8

Construct Initial Clusters Construct a cluster for each global frequent itemset All documents containing this itemset are included in
the same cluster
9
C(flow)
C(form)
C(layer)C(patient
)
cran.1cran.2cran.3cran.4cran.5
Its cluster label is {result}
C(result)
C(treatment)
C(flow, layer)
C(patient,treatment
)cisi.1cran.1cran.3med.2med.5
cran.1cran.2cran.3cran.4cran.5
med.1med.2med.3med.4med.5med.6
cran.3med.1med.2med.4med.6
med.1med.2med.3med.4med.6
cran.1cran.2cran.3cran.4cran.5
med.1med.2med.3med.4med.6

Cluster Frequent Items A global frequent item is cluster frequent in a cluster Ci if
the item is contained in some minimum fraction of documents in Ci
Suppose the minimum cluster support is set to 70%
10
C(patient)
(flow, form, layer, patient, result, treatment)
med.1=( 0 0 0 8 1 2 )med.2=( 0 1 0 4 3 1 )med.3=( 0 0 0 3 0 2 )med.4=( 0 0 0 6 3 3 )med.5=( 0 1 0 4 0 0 )med.6=( 0 0 0 9 1 1 )
C(patient)
Item Cluster Support
form 33%
patient 100%
result 66%
treatment 83%

11Initial Cluster (minimum cluster support=70%)

Cluster Label vs. Cluster Frequent Items
Cluster label Use global frequent itemset as cluster label A set of mandatory items in the cluster Every document in the cluster must contain all the items in the
cluster label Used in hierarchical structure establishment
Cluster frequent items Appear in some minimum fraction of documents in the cluster Used in similarity measurement Topic description of the cluster
12

Make Clusters Disjoint Initial clusters are not disjoint
Remove the overlapping of clusters Assign a document to the “best” initial cluster
Define the score function Score(Ci ← docj)
Measure the goodness of a cluster Ci for a document docj
13

Score Function
Assign each docj to the initial cluster Ci that has the highest score
14
)]()([)]()([)( x_supportglobalxnx_supportclusterxndocCScorexx
ji
• x represents a global frequent item in docj and the item is also cluster frequent in Ci
• x’ represents a global frequent item in docj but the item is not cluster frequent in Ci
• n(x) is the frequency of x in the feature vector of docj
• n(x’) is the frequency of x’ in the feature vector of docj

Score Function (cont.)
If the highest score are more than one Choose the one that has the most number of items in
the cluster label Key idea:
A cluster Ci is good for a document docj if there are many global frequent items in docj that appear in many documents in Ci
15

Score Function - Example
16
C(flow)
flow=100%layer=100%
C(form)
form=100%
C(layer)flow=100%layer=100%
C(patient)patient=100%
treatment=83%
C(result)result=100%
patient=80%
treatment=80%
C(treatment)
patient=100%
treatment=100%result=80%
C(flow, layer)flow=100%layer=100%
C(patient,treatment)patient=100%
treatment=100%result=80%
(flow, form, layer, patient, result, treatment)
med.6=( 0 0 0 9 1 1 )
0+0-[(9 × 0.5)+(1 × 0.42)+(1 × 0.42)]= -5.34
-5.34 -5.34 9.41
10.6 10.8 -5.34
(9 × 1)+(1 × 1)+(1 × 0.8)= 10.8
global support of patient, result, and treatment

Recompute the Cluster Frequent Items
17
• Recompute Ci, also include all descendants of Ci
• A descendant of Ci if its cluster label is a superset of the cluster label of Ci
none
(flow, form, layer, patient, result, treatment)
med.5=( 0 1 0 4 0 0 )
• Consider C(patient)
C(patient). original
Item Cluster Support
form 100%
patient 100%
C(patient). descendant
Item Cluster Support
form 33%
patient 100%
result 66%
treatment 83%
Include descendant:C(patient, treatment)
Disjoint cluster result

Building the Cluster Tree Put the more specific clusters at the bottom of the tree Put the more general clusters at the top of the tree
18

Building the Cluster Tree (cont.)
Tree level Level 0: root, mark “null” and store unclustered documents Level k: cluster label is global frequent k-itemset
Bottom-up manner Start from the cluster Ci with the largest number k of items in
its cluster label Identify all potential parents that are (k-1)-clusters and have
the cluster label being a subset of Ci’s cluster label Choose the “best” among potential parents
19

Building the Cluster Tree (contd.)
The criterion for selecting the best Similar to choosing the best cluster for a document Method:
(1)Merge all the documents in the subtree of Ci into a single conceptual document doc(Ci)
(2)Compute the score of doc(Ci) against each potential parent Cj
The potential parent with the highest score would become the parent of Ci
All leaf clusters that contain no document can be removed
20
))(( ij CdocCScore

Example Start from 2-cluster
C(flow, layer) and C(patient, treatment) C(flow, layer) is emptye remove C(patient, treatment)
Potential parents: C(patient) and C(treatment) C(treatment) is empty remove C(patient) gets a higher score and becomes
the parent of C(patient, treatment)
21
null
C(flow)
cran.1cran.2cran.3cran.4cran.5
C(form)
cisi.1
C(patient)
med.5
C(patient, treatment)
med.1med.2med.3med.4med.6

Prune Cluster Tree A small minimum global support
A cluster tree can be broad and deep Documents of the same topic are distributed over
several small clusters Poor clustering accuracy
The aim of tree pruning Produce a natural topic hierarchy for browsing Increase the clustering accuracy
22

Inter-Cluster Similarity Inter_Sim of Ca and Cb
Reuse the score function to calculate Sim(Ci←Cj)
23
2
1
)]()([)( abbaba CCSimCCSimCCSim_Inter
1)()(
))(()(
x x
jiji xnxn
CdocCScoreCCSim

Property of Sim(Ci←Cj)
Global support and cluster support are between 0 and 1 Maximum value of Score= , minimum is Normalize Score by , Sim is within -1~1 Avoid negative similarity value, add the term +1 The range of Sim function is 0~2, so is Inter_Sim Inter_Sim value is below 1
Weight of dissimilar items has exceeded the weight of similar items
A good threshold to distinguish two clusters24
)]()([)]()([)( x_supportglobalxnx_supportclusterxndocCScorexx
ji
xxn )(
x
xn )(
xxxnxn )()(

Child Pruning Objective: shorten the depth of a tree Procedure
1. Scan the tree in the bottom-up order
2. For each non-leaf node, calculate Inter_Sim between the node and each of its children
3. If Inter_Sim is above 1, prune the child cluster
4. If a cluster is pruned, its children become the children of their grandparent
Child pruning is only applicable to level 2
25

Example Determine whether cluster C(patient, treatment) should be
pruned Compute the inter-cluster similarity between C(patient) and
C(patient, treatment) Sim(C(patient)←C(patient, treatment))
Combine all the documents in cluster C(patient, treatment) by adding up their feature vectors
26
med.1=( 0 0 0 8 1 2 )med.2=( 0 1 0 4 3 1 )med.3=( 0 0 0 3 0 2 )med.4=( 0 0 0 6 3 3 )med.6=( 0 0 0 9 1 1 )
Sum = ( 0 1 0 30 8 9 )
(flow, form, layer, patient, result, treatment)
70.11)81()930(
)42.0*842.0*1()83.0*91*30(
)),()((
treatmentpatientCpatientCSim

Example(cont.)
Sim(C(patient, treatment)←C(patient))=1.92 Inter_Sim(C(patient)↔C(patient, treatment))= Inter_Sim is above 1, cluster C(patient, treatment) is pruned
27
81.1)92.1*70.1( 2
1
null
C(flow)
cran.1cran.2cran.3cran.4cran.5
C(form)
cisi.1
C(patient)
med.1med.2med.3med.4med.5med.6

Sibling Merging Sibling merging is applicable to level 1 Procedure
1. Calculate the Inter_Sim for each pair of clusters at level 1
2. Merge the cluster pair that has the highest Inter_Sim
Repeat above steps until1. User-specified number of clusters is reached,
or
2. All cluster pairs at level 1 have Inter_Sim below or equal to 1
28
null
C(flow)
cran.1cran.2cran.3cran.4cran.5cisi.1
C(patient)
med.1med.2med.3med.4med.5med.6

Experimental Evaluation Dataset
Clustering Quality (F-measure) Recall , Precision Corresponding F-measure: F-measure for whole clustering result:
29
iij nnjiR ),( jij nnjiP ),(
Cluster j
Natural Class i
nij

30

Efficiency & Scalability
31

Conclusions & Discussion This research exploits frequent itemsets for
Define a cluster Use score function, construct initial clusters, make disjoint clusters
Organize the cluster hierarchy Build cluster tree, prune cluster tree
Discussion: Use unordered frequent word sets
Different order of words may deliver different meaning
Multiple topics of documents
32