20170510 再送付ws ディープラーニング実装の勘所と最新動向 … ·...
TRANSCRIPT

1
「ディープラーニングチップ実装の勘所と最新動向」
北海道大学 大学院情報科学研究科
百瀬 啓
2017年5月16日
関係者外秘

2
- ディープラーニングの最新動向
- ディープラーニングチップの最新動向
- ディープラーニングチップ実装の勘所
- その圧縮(Sparsity)と量子化技術
- ディープラーニングのシステム例
- まとめ
内容
北海道大学 大学院情報理工学研究科
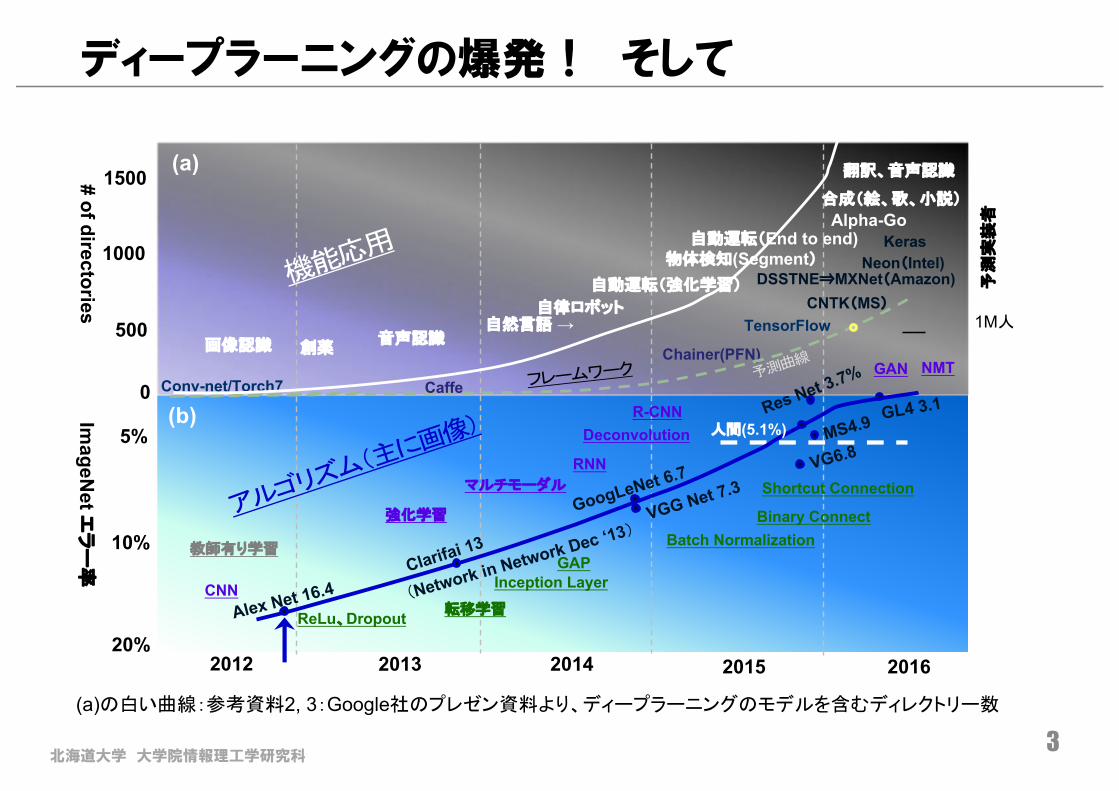
ディープラーニングの爆発! そして
3(a)の白い曲線:参考資料2, 3:Google社のプレゼン資料より、ディープラーニングのモデルを含むディレクトリー数
2012 2013 2014 2015 2016
画像認識 音声認識
自動運転(強化学習)
自然言語 →Chainer(PFN)
TensorFlow
Conv-net/Torch70
1500
1000
500
# of directories 自律ロボット
自動運転(End to end)
Caffe
CNTK(MS)
合成(絵、歌、小説)
Alpha-Go
創薬
翻訳、音声認識
物体検知(Segment)
(a)
1M人
予測
実装
者
20%
R-CNNDeconvolution
10%
5%
ImageN
et エラ
ー率
人間(5.1%)
ReLu、Dropout
GAP
転移学習
Inception Layer
Binary Connect
RNNマルチモーダル
強化学習
Batch Normalization
(b)
教師有り学習
Shortcut Connection
CNN
GAN NMT
DSSTNE⇒MXNet(Amazon)Neon(Intel)
Keras

北海道大学 大学院情報理工学研究科
デンソー 安全(‘14/3) 位置・高さと方向性
4
スナップショット ① 2014年
IBM(TrueNorth) (‘14/8月) 脳型チップ
http://techon.nikkeibp.co.jp/article/MAG/20140910/375623/?ST=lsi&P=5
nDARPAプロジェクト、Synapse University
nNeuromorphic Chip:1Mニューロン、70mW
Qualcomm(‘14/3) スマホにNPUを!
http://on-demand.gputechconf.com/gtc/2014/presentations/S4621-deep-neural-networks-automotive-safety.pdf
nGTC 2014@サンノゼ)nDeep CNN+JETSON
http://www.cs.utah.edu/asplos14/files/Jeff_Gehlhaar_ASPLOS_Keynote.pdf
NPU:Neural Processing Unit
Neuromorphic回路
JetPac社(‘14/9) Googleに買収された
nDBN (Deep Brief Network)⇒画像認識/SDK
nスマホ、Instagram ⇒Apple Store ⇒Googlehttp://itpro.nikkeibp.co.jp/atcl/news/14/081900470/

北海道大学 大学院情報理工学研究科
NVIDIA Drive PX2 (’16/1)
n 2CPU + 2GPU (Maxwell→Pascal)p 画像認識+判断(Semantic RNN)
自動運転(‘16CES)
5
スナップショット ② 2015〜2016年
PFN (‘16/1)
出典:NVIDIA Deep Learning 2016での岡野原氏講演より
車の運転(強化学習)
Preferred Networks, Inc.
http://pc.watch.impress.co.jp/docs/news/20160116_739223.htmlhttp://www.slideshare.net/NVIDIAJapan/ss-56854919
CNN+RNN
man walkingdog walking
NVIDIA自動運転(E to E Learning) (‘16/4)nEnd to End (CNN)
n画像とハンドル角度
nワンシーン毎に学習⇒Udacity Self-driving Car (CNN+RNN)
n出展:NVIDIA M.Bojarski, 20160425, “End to End Learning for Self-Driving Cars”, http://arxiv.org/abs/1604.07316
ADAS 行動予測(R-CNN + RNN) KAIST(‘16/2)
出展:KAIST, ISSCC2015 14.2
n自動運転への適用(物体検知プラス 行動構想)
n R-CNNで検知した座標と速度から将来を予測(警告)

北海道大学 大学院情報理工学研究科
自動彩色 Dilated CNN (‘16/1⇒10月)Colorful Image Colorization
R. Zhang+(UCB) , 20161005, arXiv:1603.08511
GAN 画像の自動生成 (‘16/1〜)
開発者:Radford+ ICLR2016nGenerative Adversarial Network (CNN+DCNN)
碁「CNN+強化学習+MCTS」(‘16/1)
Facebook:http://arxiv.org/abs/1511.06410Deepmind:http://deepmind.com/alpha-go.html
nFacebook(2ヶ月でアマ5段・・・これから強化学習)
nGoogle (ヨーロッパプロに勝利)・・・3月に李 世乭(イ・セドル)
Movidius社(Myriad2)+Google⇒Intel
Movidius社HP: http://www.movidius.com/
情報:http://techon.nikkeibp.co.jp/atcl/news/16/012900368/?rt=nocnt&d=1454166307943
スマホ用DeepLearningチップ (‘16/1)CMU:金出武雄教授
6
スナップショット ③ 2016年〜
Facebook (1/26)Google Deepmind (1/26) Nature
Monte Carlo Tree Search

北海道大学 大学院情報理工学研究科7
スナップショット ④ 2016〜2017年NMT:ニューラル機械翻訳:Google スタン大 (‘16/9)
Google出展:Google Cloud Platform Blog 20160926
n Google:自動翻訳(英語⇔中国語)・・・かなり精度向上
n STDU:RNN/LSTM に圧縮技術適用、モバイル適用Google(GNMT) スタンフォード大
音声認識(Amazon, スタンフォード大学)(’16年)
n Amazon: Echo/ALEXAで新プラットフォーム 支配へ
n STDU:RNN/LSTM 圧縮技術 (FPGA)
n出展 ホームページ: https://www.nervanasys.com/スタンフォード大 ‘17/2
きゅうり仕分け (農家+TensorFlow) ‘16/8
n きゅうりの仕分けにDL 20160805 農家小池さん:https://cloudplatform-jp.googleblog.com/2016/08/tensorflow_5.html?m=1
•お母さんの仕事•手間:色、形・・・・・・•A+R3+TensorFlow•CNN 80x80x3⇒9クラス
•面白い「AI」とは、身近な現場の「やってみた」から生まれる!
GreenWave電子情報: http://www.eetimes.com/document.asp?doc_id=1330188
TPUのエッジ/IoT ? GreenWave社 (‘16/7)pIoT:画像、ソフトモデム⇒振動解析、電気グリッドモニタpGAP8 RISC+ OFDM + TFPp12GOPS/sec 400MHZ 20mWの低消費電力
GAP8

北海道大学 大学院情報理工学研究科8
スナップショット ⑤ 2016〜2017年
Intel + Nervana AI 戦略 (‘16/9)Tensor Processing Unit (TPU) Google(‘16/5)
Google出展:Google Proud Platform Blog 20160518
n実行用のアクセラレータ (8bit 10倍のエネルギー効率)
n‘15年より運用(Street View, Alpha-Go, GNMT・・・)
DeepLearning Unit (富士通) (‘16/11)
Facebook:https://code.facebook.com/posts/804694409665581/powering-facebook-experiences-with-ai/
Big Basin (次世代ハード):Facebook(‘17/3)
n出展 ホームページ: https://www.nervanasys.com/
A) Neon: python based Framework:高速学習B) Nervana Engine (2017)C) Binarized Neural Network
n‘18年アクセラレータ (10倍のエネルギー効率)
nZinrai プラットフォーム 30種API
n 学習用p テキスト翻訳p 音声認識、画像認識、動画認識p コンテンツ理解(Prediction)
n 8個 GPUサーバ(ラック)n NVIDIA Tesla P100 GPUn 32bit, 7→10.6 TFLOPS 16bit可n x1.3ネットサイズ, 12GB→16GBn ×2のスループット、ResNet50
’16年11月30日:http://monoist.atmarkit.co.jp/mn/articles/1611/30/news041_2.html#l_km_fujitsu6.jpg
北海道大学 大学院情報理工学研究科
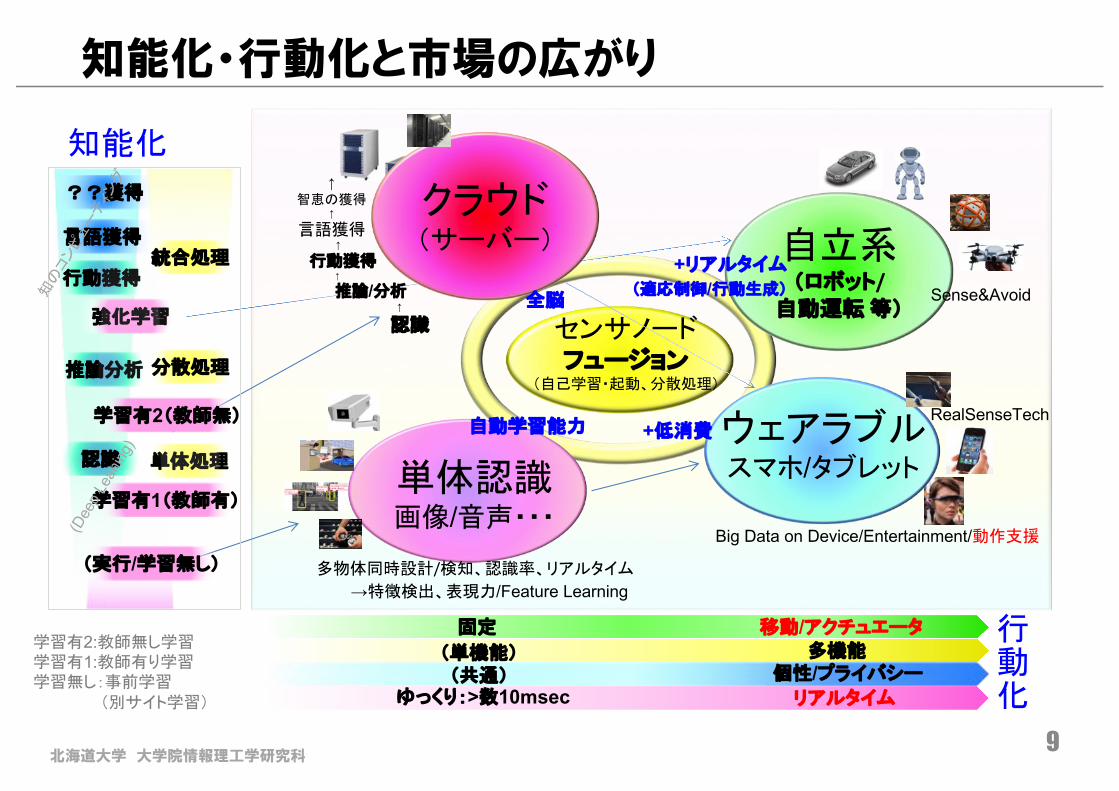
知能化・行動化と市場の広がり
知能化
センサノードフュージョン
(自己学習・起動、分散処理)
行動化
強化学習
推論分析
行動獲得
→特徴検出、表現力/Feature Learning
単体認識画像/音声・・・
多物体同時設計/検知、認識率、リアルタイム
自動学習能力
単体処理
(共通)(単機能)
自立系(ロボット/
自動運転 等)
+リアルタイム
(適応制御/行動生成) Sense&Avoid
移動/アクチュエータ
リアルタイム
固定
ゆっくり:>数10msec
↑智恵の獲得
↑
言語獲得↑
行動獲得↑
推論/分析↑
認識
クラウド(サーバー)
全脳
分散処理
統合処理
学習有1(教師有)
(実行/学習無し)
学習有2(教師無)
認識
学習有2:教師無し学習学習有1:教師有り学習学習無し:事前学習
(別サイト学習)
言語獲得
??獲得
+低消費
Big Data on Device/Entertainment/動作支援
RealSenseTechウェアラブルスマホ/タブレット
個性/プライバシー多機能
9

北海道大学 大学院情報理工学研究科10
ニューラルネットワークモデル・アルゴリズム展開
n 3つの方向性がある(高性能、高機能、システム化)
未来予測機が欲しい!
北海道大学 大学院情報理工学研究科11
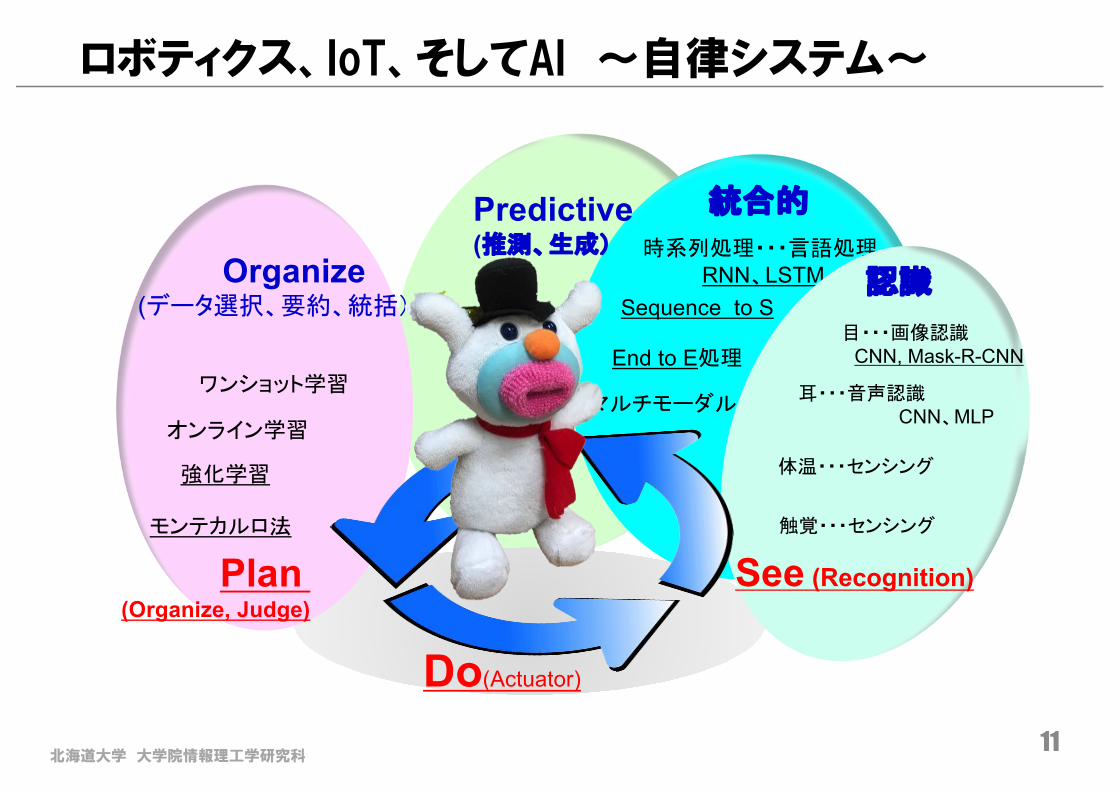
ロボティクス、IoT、そしてAI 〜自律システム〜
時系列処理・・・言語処理RNN、LSTM、GRN - -
マルチモーダル
強化学習
モンテカルロ法
ワンショット学習
オンライン学習
End to E処理
Sequence to S
耳・・・音声認識CNN、MLP
目・・・画像認識CNN, Mask-R-CNN
体温・・・センシング
触覚・・・センシング
See (Recognition)
Organize(データ選択、要約、統括)
Plan(Organize, Judge)
Do(Actuator)
Predictive(推測、生成)
統合的
認識

12
- ディープラーニングの最新動向
- ディープラーニングチップの最新動向
- ディープラーニングチップ実装の勘所
- その圧縮(Sparsity)と量子化技術
- ディープラーニングのシステム例
- まとめ
内容
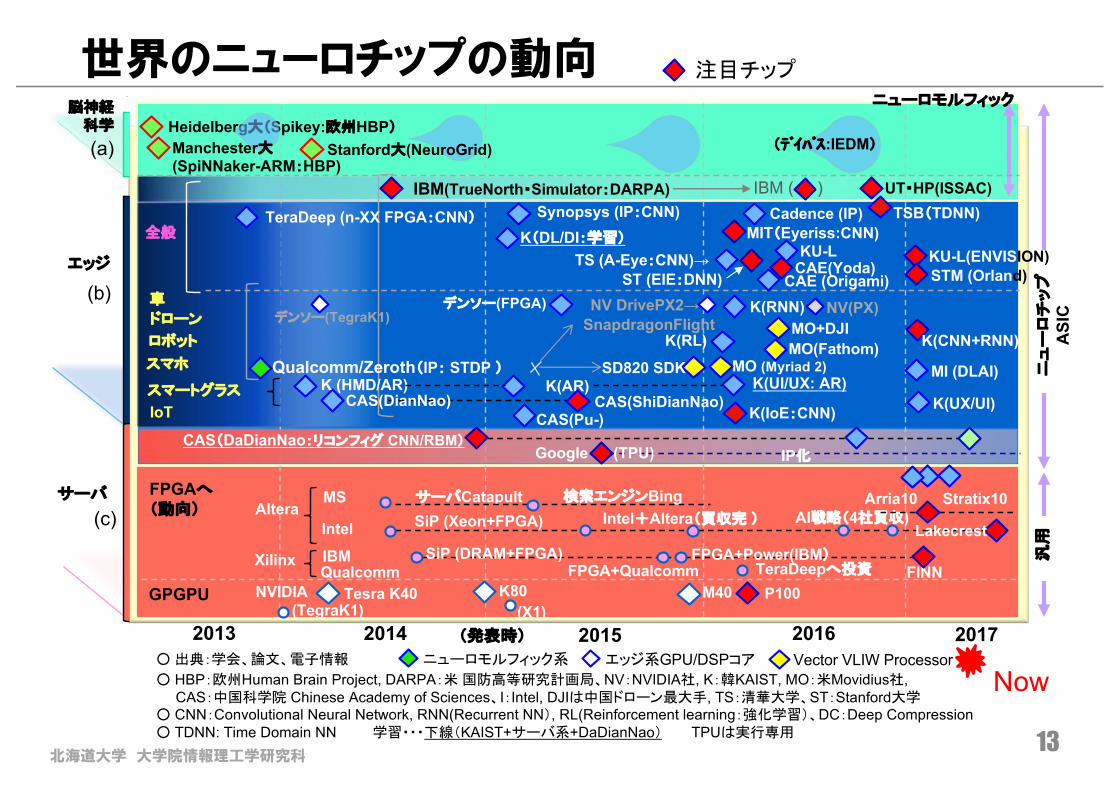
北海道大学 大学院情報理工学研究科13
エッジ系GPU/DSPコア Vector VLIW Processor○ 出典:学会、論文、電子情報
○ HBP:欧州Human Brain Project, DARPA:米 国防高等研究計画局、NV:NVIDIA社, K:韓KAIST, MO:米Movidius社, CAS:中国科学院 Chinese Academy of Sciences、I:Intel, DJIは中国ドローン最大手, TS:清華大学、ST:Stanford大学
○ CNN:Convolutional Neural Network, RNN(Recurrent NN), RL(Reinforcement learning:強化学習)、DC:Deep Compression○ TDNN: Time Domain NN 学習・・・下線(KAIST+サーバ系+DaDianNao) TPUは実行専用
ニューロモルフィック系
エッジ
サーバ
脳神経科学
2013 2014 2015 2016
GPGPU
FPGAへ(動向)
サーバCatapult SiP (Xeon+FPGA)
Heidelberg大(Spikey:欧州HBP)
Stanford大(NeuroGrid)
ニューロモルフィック
(a)
(c) Intel+Altera(買収完 )
MS
Intel
検索エンジンBingAltera
Xilinx IBMTeraDeepへ投資FPGA+QualcommQualcomm
M40 P100NVIDIA(TegraK1) (X1)
(発表時)
K80Tesra K40
全般
(b)
Manchester大(SpiNNaker-ARM:HBP)
汎用
車
ロボット
スマホ
スマートグラス
IoT
ドローン
Synopsys (IP:CNN)MIT(Eyeriss:CNN)
TeraDeep (n-XX FPGA:CNN)
CAS(DaDianNao:リコンフィグ CNN/RBM)
ニュ
ーロ
チッ
プAS
IC
K(DL/DI:学習)
CAS(ShiDianNao)CAS(Pu-)
Qualcomm/Zeroth(IP: STDP )K (HMD/AR)
MO (Myriad 2)
K(IoE:CNN)
SD820 SDKK(UI/UX: AR)
K(RL)
K(RNN) NV(PX)
MO(Fathom)
NV DrivePX2→MO+DJISnapdragonFlightデンソー(TegraK1)
デンソー(FPGA)
K(AR)
Cadence (IP)
TS (A-Eye:CNN)→ST (EIE:DNN)
CAS(DianNao)
2017
CAE (Origami)
UT・HP(ISSAC)
STM (Orland)
TSB(TDNN)
KU-L
K(CNN+RNN)
AI戦略(4社買収)
Google (TPU) IP化
K(UX/UI)
FPGA+Power(IBM)SiP (DRAM+FPGA)
KU-L(ENVISION)
MI (DLAI)
IBM(TrueNorth・Simulator:DARPA)
(デイバス:IEDM)
Now
IBM ( )
FINN
Arria10 Stratix10
Lakecrest
CAE(Yoda)
世界のニューロチップの動向 注目チップ

北海道大学 大学院情報理工学研究科14
【参考】 IEDM2016 技術(ニューロモルフィック・・・)
C A(%)AV 4> CB3> DV TV N 4 4TT 5GRU +
.% :L C B %(-%( % E54 FBB3> 8OS87D + 6 ) :65 : U V6OR%(-%) BB3> DG :L) (->H ( SR (HO /HO > CD 0-%,(-%- 573 7D B3> DO :L ) -+PH ( SR 85 C(-%. > RVO TV(-%/ BB3> +D(B CD6A CB6A(0% 7A8 A5 D87D F ) H N VROTSOI H NV +RF J IGJ > 4 LL V J+%, budyxl >D F ) k awx %/F % F)% FBB3> :L + HO I / / H + SR 6 6 TD
BB3> DO CO ) S LL 2( + 7SJ VGSI B3M CO 4O JOV I OTSG
+%+ B B3> DG) , :L ) M S+%, 573 7D BB3>+%- OR I BB3> B S OTS+%. 573 7D 8O GR S BB3>+%/ B B3> + SR 8VGI OTSG C TING OI RTJ.%- A D75 54B3>(-% B B3> -,SR S 88 TD F AVTI TV(-%, DC>5 BB3> S CB3>)(%) OR I 54B3> 5 3 ) BC :BC B S OTS)(% BB3> :L >DC )(%+ tnyo auey xrab OR I BB3>+%+ F ) TD napyfi+%/ shy v ey c tb BB3> N 4 )6 BB3>
+%( S A5>+%) 4> E F35 A5> 3 6 OS V 7SJ VGSI ) ())(%( 4> D% % A5> 9G CH 9 ()/>H+%- maiugyr A5> 3M :L ) DNV NT J C O IN
C DA1CNTV GSJ TSM D VR A G OIO A5 D87D ANG 5NGSM D SS OSM 87D 3 6 3 TROI G V 6 UT O OTSCD6A1CUOP DOROSM 6 U SJ S A G OIO >D OS G TV T R G C5> C TVGM 5 G > RTVCB6A CUOP BG 6 U SJ S A G OIO BB3> B O O C O INOSM R RTV F> RH JJ J F>
C5> F>
,
+%
北海道大学 大学院情報理工学研究科
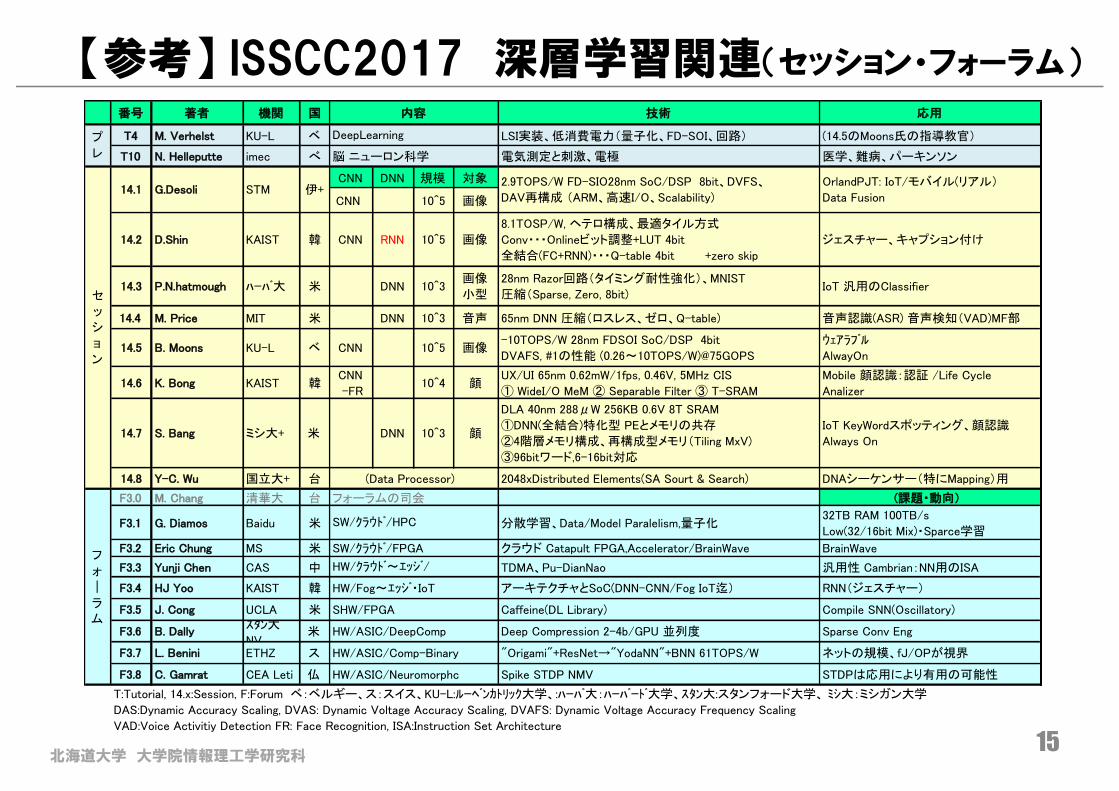
【参考】 ISSCC2017 深層学習関連(セッション・フォーラム)
15
I� WR =i � 1X .F
�� �{r�¨µ«¨¯¶· ��z� î ���%YÃ�Abl�Āh �Ã��z���Ã�cā v~�{�È�²²±¶>È2(3#ā
�~} �{r�¨¯¯¨³¸··¨ ¬°¨¦ Ê l?C$Æ�DÃl: �"ÃkJÃéÿÔýßý
��� ��� Z< 'a
���r ~}£� G�
~�{� �{�«¬± ����� m ��� ��� ~}£� G�
�{~����|�yríãû;0Ã7fàÏù6,
�²±¹þþþ�±¯¬±¨êâä_5x���r�¥¬·
O�v��x���wþþþ�z·¤¥¯¨r�¥¬·rrrrrrrrx½¨µ²r¶®¬³
ÛÑÜáôÿÃÔôìÚöý�Å
~�{� �{�{«¤·°²¸ª« đćđę� N ��� ~}£�G�
)�
��±°r�¤½²µ�cĀàÏðý×S/-�āÃ�����
�PĀ�³¤µ¶¨yr¢¨µ²yr�¥¬·w�²�r@FÈ�¯¤¶¶¬©¬¨µ
~�{� �{r�µ¬¦¨ ��� N ��� ~}£� n� ��±°r���r�PĀûÜúÜÃÞûÃ�z·¤¥¯¨w n�]`v���wrn�9KĀ���w��g
~�{� �{r�²²±¶ ��z� î ��� ~}£� G�z~}����|�r��±°r�����r�²�|���rr�¥¬·
�����yrt~È/Trv}{��Ą~}����|�w�������
ĉąĈĕĒęė
�¯º¤¼�±
~�{� �{r�²±ª ����� m���
rz��~}£� p
� |��r��±°r}{��°�|~©³¶yr}{���yr���½r���
Àr�¬§¨�|�r�¨�rÁr�¨³¤µ¤¥¯¨r�¬¯·¨µrÂr�z����
�²¥¬¯¨rp]`Ă]\r|�¬©¨r�¼¦¯¨
�±¤¯¬½¨µ
~�{� �{r�¤±ª ðÚ�x N ��� ~}£� p
���r�}±°r���¾�r�����r}{��r��r����
À���vO�wE��r��ÆòóøÈ!
Á�j*òóø;0Ã�;0�òóøĀ�¬¯¬±ªr�»�w
Â��¥¬·üÿåy�z~�¥¬·'.
�²�r�¨¼�²µ§ÜïâãÎý×Ãp]`
�¯º¤¼¶r�±
~�{� ¡z�{r�¸ �M�x � �}��»�¬¶·µ¬¥¸·¨§r�¯¨°¨±·¶v��r�²¸µ·rur�¨¤µ¦«w ���ÚÿØýÙÿĀEÇ�¤³³¬±ªāF
��{} �{r�«¤±ª BV� � v^oþ��ā
��{~ �{r�¬¤°²¶ �¤¬§¸ N 4"QÃ�¤·¤|�²§¨¯r�¤µ¤¯¨¯¬¶°yh �����r���r~}}��|¶
�²ºv��|~�¥¬·r�¬»wþ�³¤µ¦¨"Q
��{� �µ¬¦r�«¸±ª �� N Ö÷Ðår�¤·¤³¸¯·r����y�¦¦¨¯¨µ¤·²µ|�µ¤¬±�¤¹¨ �µ¤¬±�¤¹¨
��{� ¡¸±¬r�«¨± ��� � ����Ã�¸z�¬¤±�¤² @F/r�¤°¥µ¬¤±Ă��FÈ���
��{� ��r¡²² ����� m ÍÿÔãÖáôÆ�²�v���z���|�²ªr�²�dā ���ĀÛÑÜáôÿā
��{� �{r�²±ª ���� N �¤©©¨¬±¨v��r�¬¥µ¤µ¼w �²°³¬¯¨r���v�¶¦¬¯¯¤·²µ¼w
��{� �{r�¤¯¯¼ĎďĘ�
��N �¨¨³r�²°³µ¨¶¶¬²±r�z�¥|���r��+ �³¤µ¶¨r�²±¹r�±ª
��{� �{r�¨±¬±¬ ���¢ Ü s�µ¬ª¤°¬sx�¨¶�¨·¿s¡²§¤��sx���r�~����|� çâäÈZ<é�|��Ä[H
��{� �{r�¤°µ¤· ���r�¨·¬ � �³¬®¨r����r��� ����É.FÇËÌ8FÈ�T/
���¸·²µ¬¤¯yr~�{»��¨¶¶¬²±yr���²µ¸°rrîĂîùÕÿÃÜĂÜÏÜÃ��z��ėćēęĘċĐĖĆČ�"Ã�đćđę�ĂđćđęćĐę�"ÃĎďĘ��ÜàýëÒÿå�"ÃrĔč�ĂðÚÓý�"
�����¼±¤°¬¦r�¦¦¸µ¤¦¼r�¦¤¯¬±ªyr�����r�¼±¤°¬¦r�²¯·¤ª¨r�¦¦¸µ¤¦¼r�¦¤¯¬±ªyr������r�¼±¤°¬¦r�²¯·¤ª¨r�¦¦¸µ¤¦¼r�µ¨´¸¨±¦¼r�¦¤¯¬±ª
�����²¬¦¨r�¦·¬¹¬·¬¼r�¨·¨¦·¬²±r���r�¤¦¨r�¨¦²ª±¬·¬²±yr�����±¶·µ¸¦·¬²±r�¨·r�µ¦«¬·¨¦·¸µ¨
�{�����|�r��z�����±°r�²�|���rr�¥¬·Ã����Ã
����;0rĀ���Ãqe�|�Ã�¦¤¯¤¥¬¯¬·¼w
�µ¯¤±§����r�²�|óèÏùvøÍùā
�¤·¤r�¸¶¬²±
�&
�¨¨³�¨¤µ±¬±ª
UræõÿûýL"
Ý
â
Ú
ö
ý
~�{~ �{�¨¶²¯¬ ��� �x
v�¤·¤r�µ²¦¨¶¶²µw
ëÒÿ÷ñÈ��
��|ČĕĉĐę|���
��|ČĕĉĐę|����
��|ČĕĉĐęĄĊĆčę|
��|�²ªĄĊĆčęþ�²�
���|����
��|����|�¨¨³�²°³
��|����|�²°³z�¬±¤µ¼
��|����|�¨¸µ²°²µ³«¦
ì
ú
ë
Ò
ă
÷
ñ
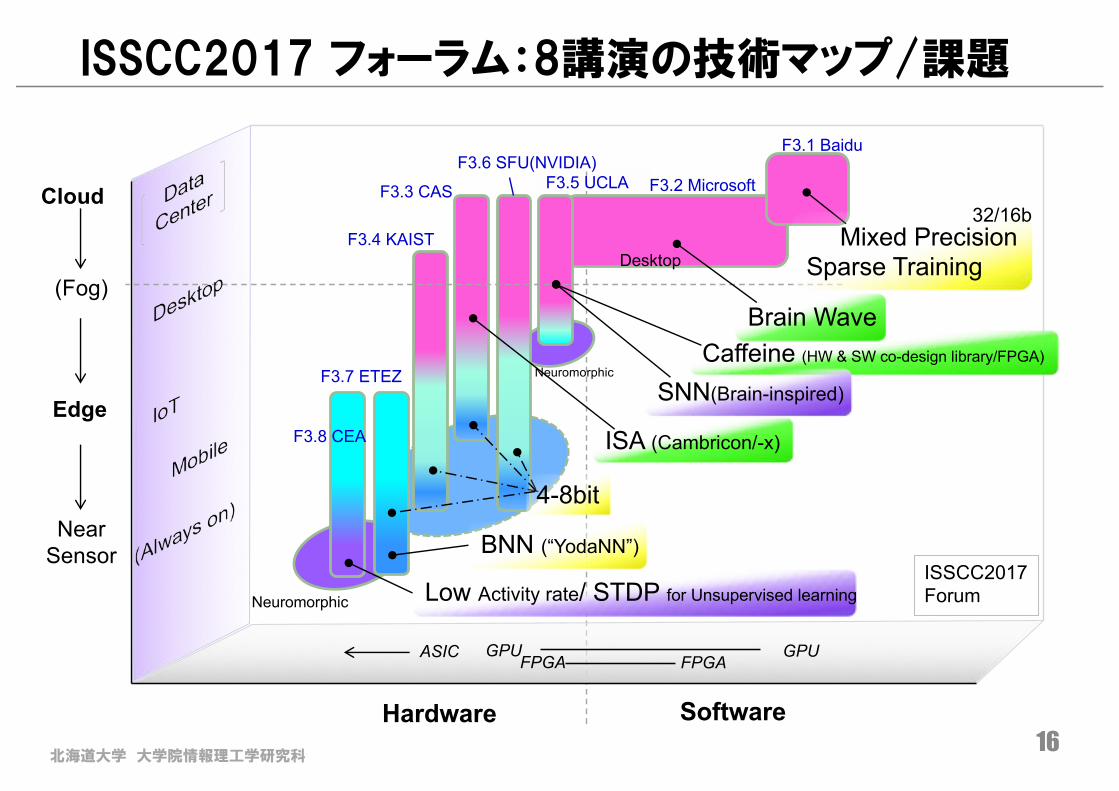
北海道大学 大学院情報理工学研究科16
ISSCC2017 フォーラム:8講演の技術マップ/課題
SoftwareHardware
F3.1 Baidu
F3.2 MicrosoftF3.5 UCLA
F3.4 KAIST
F3.3 CAS
F3.7 ETEZ
F3.8 CEA
FPGAGPUASIC GPU
FPGA
Cloud
Edge
NearSensor
(Fog)
F3.6 SFU(NVIDIA)
Mixed PrecisionSparse Training
Brain Wave
ISA (Cambricon/-x)
BNN (“YodaNN”)
Low Activity rate/ STDP for Unsupervised learning
4-8bit
Caffeine (HW & SW co-design library/FPGA)
SNN(Brain-inspired)
32/16b
Neuromorphic
Neuromorphic
ISSCC2017 Forum
Desktop

北海道大学 大学院情報理工学研究科
【参考】 FPGA2017 深層学習関連(セッション・ポスター)
17
e êÞî ÎñÑ .; ��© �
�¤��¡�
�������
}s v�o
�ª§«�©����l�£©�¡ D }¡¡ 7U
tsnw
nsnr�¶}§§��rqp�©§�©�rqi«¨i��©�£�i���
���©Â9\i���}¾�Ëò s��©mir��©mi��£¤�§�� k
ÕñâñåìÝß
äÐñèC�
}t rv �oi���¤l Óñáî!l D ��� �~� ��� r� «�§���¡�i¬��©�i¡�£�i�ª���§j�~�kiiii���jh��-ó
}u sv �oi���£�l��n
����¨¤£D ��� ���
�¥�£
��rw�
�¥£��� i��¬i��§£�¡i��¨��£ ij��¢¤§®i��¡�£��k
}§§��irqi��rrvq
}v tv �oi���£�l ��� D ��� ������n���}i���§��i���mi�¤ª�¡�i~ª���§mi��}p���
s�i�¤£«¤¡«�§i�£i �§�¦ª�£�®i�¤¢��£
}w uv �oi��lÎíÚà
(!D
���
in���¤¤¥
��¨��£i�ª���i��£�ij�¤¤¥i�¥©�¢��¯�©�¤£k
���i}§§��irq�rrvqiwuqi����miuy¢¨
~r vv�o
}®�¤£�©l�£©�¡ D ��� ~ª���§
�¥�£
��·}§§��rqiirou����i²��}j���¥i���§£�£�i}��nnk
³¤£n���¥i¨©§��¢i�ª���§i´���©§�¯�©�¤£iµ��£¤�§��
�¥���irqi||
&��©�£�ij���k
~s wv�o
�¢ª§¤�¡ªl��¡�£l D j���k
��©�§
¤n���� r�
%N{��©�§¤ni�©§��¢�£�i}§��i²§¤¤�¡�£�i³~��
i¢�¥¥�£�i¤¥©�¢�¯�©�¤£i´~��i�¤£¨©§ª�©�¤£i�¤¤¡
I�][
ïæÝß¹}�
~t xv �oi��£l ���l D���
������ rw�
d�TWmi���¥i�¤¢¥§�¨¨�¤£mi���l _éêí
l���}j}���¡�§�©¤§kmi����jrw�k
d�TW
Õñâ
�w syv �oi�§�¬�¡l Òîä! ��¡���n
¢�£©
#Fõ�ZÃ�}�`EÎîÔíØèÆãÛñð
±�fQ:ÆP�iiò��¡�£i�¡©§����¡�k
�¡���¢�£©
�<
�rr szt �oi���£l�©¤£®
~§¤¤ i!D �� ~�}� ¶ ~¡¤� �}�Æ5^�.;ò��ÃXLÆâìð×ó
��'Æ
SR.;
�v��
i¸�Yl6)¹�! 3 ��� ����
r�
¬p¤~�
²i~�©��i�¤§¢�¡�¯�©�¤£>À
³�£¥ª©p�����©i¬�©�i21���¨
�¢������
�®¨©�¢
�w �oi�� ÎíÚà!ô D ��� r� � *jBaÃ4aó¹ixox����pyos�izq��� &i��©�£�
�y �oi��£l äïíÜ! D ����©¤��
�¨©��
�©¤���¨©��j�©§��¢i�¤¢¥oi�¤��p§�£�¤¢i¨�¢¥¡�£�k
°i���¡���¡�©®mi�£�§�®i�������£�®
���¡i��¢�p
����n¥��¡i�o
�z�o
��£��§�¨l�¢¥�§��¡ K ��� ��� �®£��§¤£¤ª¨i��©��¡¤¬j���ki�§�¥�
����?ɽ
I�SR.;
�x szt �oi��£�©¤£®
~§¤¤ i!D j���k
��¥¥
n�£�
��©�i�¡¤¬i�§�¥�j���ki��¥¥�£�Å���Æ.;Ì+@
ò���Ã��}j�§¤��¨¨i�¡�¢�£©i}§§�®óÌ���Å��ó���Æ0Jö
nV=ÆA�j}rm}snnkÇ$��¿ÁÈƹ»e¼Çc"äÍÏîÂÆe1º»�g¼Æ».;¼Ç¹��©�¤�¤¡¤�®Äʹ�§�¢�¬¤§ Æ,�Â�@ÀÁº
���iúûþýøù
üÿ!�oi��£>}r nsnr�}¡¡D
/O +@pG
ç
×
Û
÷ syz
Ù
Ý
Ö
ë
ð
A� MH 8b �¸�giiiii¬{i��£¤��§�
�ª©¤§��¡{i���¥i�¤¢¥§�¨¨�¤£m
~�£�§®p��§£�§®mi��£¤�§��¶

北海道大学 大学院情報理工学研究科18
全体の動向 4つの動向
nハード/半導体関連での全体の動き (ISSCC2017のフォーラムでの印象)Ø 学習での量子化(高速化)Ø 再構成容易化技術Ø 実行での量子化(低ビット化)Ø スパイキングニューラルネットワークの可能性
n学会での動きØ ニューロモルフィック/NVMとオンライン学習 ・・・IEDM 2016Ø 低消費電力化/量子化 (mobile) ・・・ISSCC2017Ø 新規演算(Winograd) Bi/Ternary ・・・FPGA2017(先行性有り)
l 生成系/GAN、強化学習、外部記憶 ・・・NIPS2016(Open AI Universe/DeepMind Lab)n参考20161217:Qiita http://qiita.com/yoh_okuno/items/2494bc79630eb57e81ba

北海道大学 大学院情報理工学研究科19
サーバ スパコン
1G
10G
100G
1T
デジタル アナログ
アナログメモリ
ノイマン型 非ノイマン型(ニューロチップ)
(IBM 92:Binary)
九工大656DaDianNao 558(16bit)620
性能指標GOPS/W
- ラフな傾向(半/単精度、メモリアクセス、固/浮動、通信・・・)◇はボードもしくはメモリ含み、●はIPもしくはメモリ含まず等
- 学習用は下線 DaDianNaoとTeslaシリーズ、KAIST一部- CAS, TeraDeep社の他社ベンチマーク値も参考
DaDianNao 209 (32bit)
10T
確率共鳴
参考資料13 ISSCC2014 Plenary 1.1Mark Horowitz, pp10-
Tesla 35(P100) 29(K80) 27(M40) 16(K20)Tegra73 (K1) 51(X1)
32bit (Max値)
e-DRAM
- 参考値:TrueNorth:GOPS=2 x SGOPS(仮定), 92はCMOSリーク電流で劣化
e-SRAM
【参考】 回路アーキテクチャとエネルギー効率
1000T

20
- ディープラーニングの最新動向
- ディープラーニングチップの最新動向
- ディープラーニングチップ実装の勘所
- その圧縮(Sparsity)と量子化技術
- ディープラーニングのシステム例
- まとめ
内容

北海道大学 大学院情報理工学研究科
KJN 7?? A??KRJQH.JDTGO*@GOEGNQHML 7MLSMJRQHMLDJ*?? AGEROOGLQ.??
_\^
fhX
���(�!�
+:RJJT*7MLLGEQGF*=DTGO,
�'W�kahdgY�
i7/-*70-*7:j
�!�
k*:6`[kZh^
�"�V
_\^
A6>U5RQM9LEMFGO
86?
A.7??-*>DPI*A.7??
8GEMLSMJRQHMLA??U=BC>U;A6
�"�
��
VXc[
���i>?<BCj��$&U) $&
����
#%��U) $&
����U��b]e
�� 2�0/*� 3�031� 2�4*�
代表的ニューラルネットワーク
21n出展:KAIST ISSCC2017 Session 14.3
Input
Output
Hidden
t-1
Input
Output
HiddenConvolution Pooling
Output
t
FC
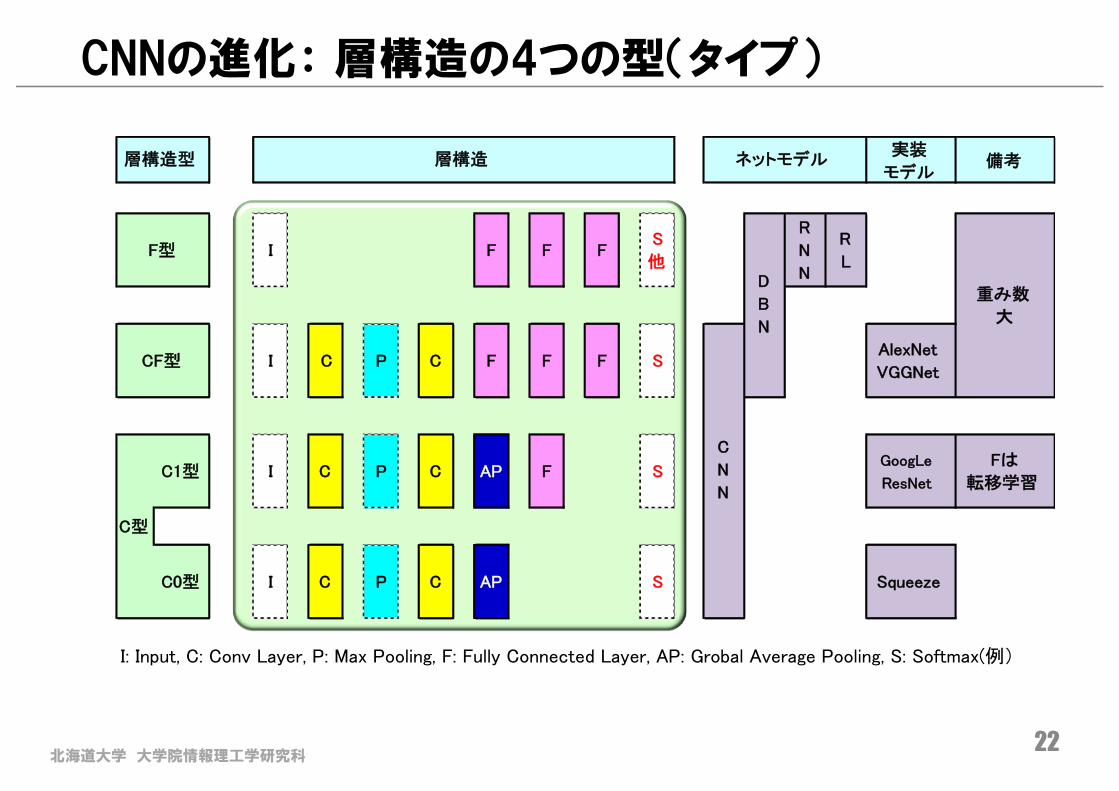
北海道大学 大学院情報理工学研究科22
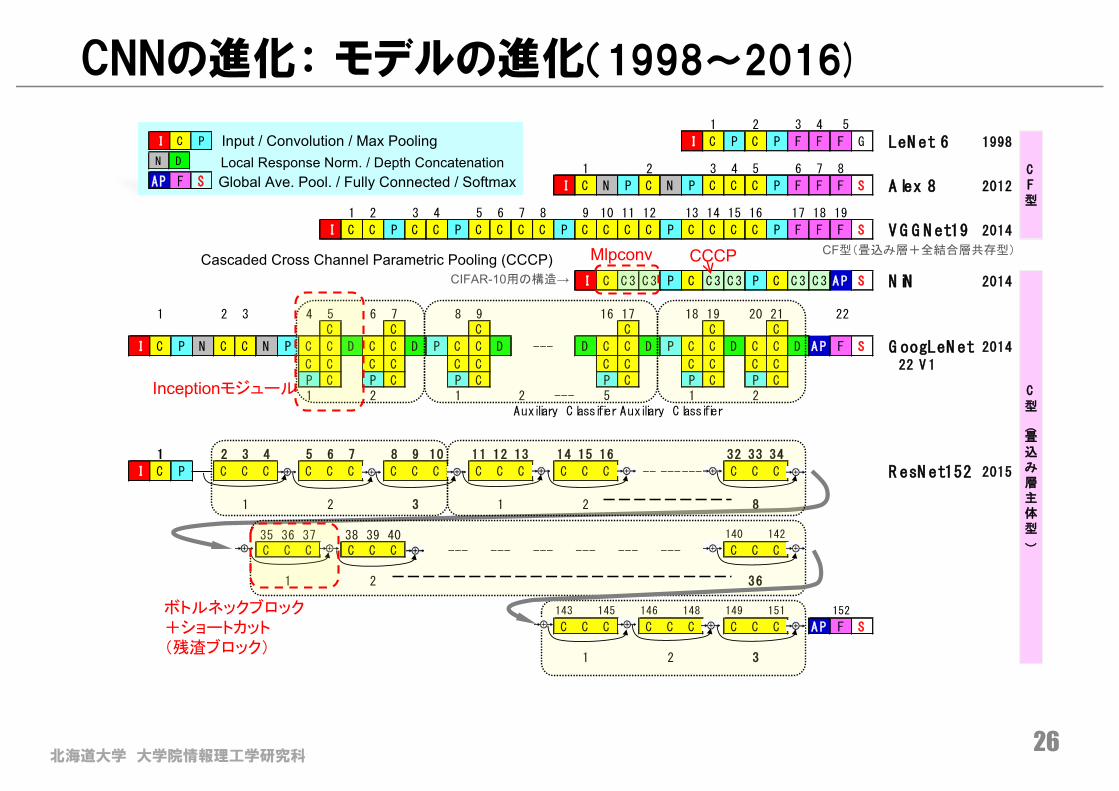
CNNの進化: 層構造の4つの型(タイプ)
��
B?C�
� � � �$
�
#
!
!
#
�
� � " � � � � $�.*9!*6
%��!*6
��� � � " � �" � $�11,�*
#*5!*6
�<
����
��
��� � � " � �" $ $37**;*
����0276������108��&:*4��"�� &9�"11.-0,������7..:��100*(6*)��&:*4���"���41'&.��8*4&,*�"11.-0,��$��$1+6/&9��D
�=
�
���
�
!
!
��� �� A>@B?C
��
�
�
!
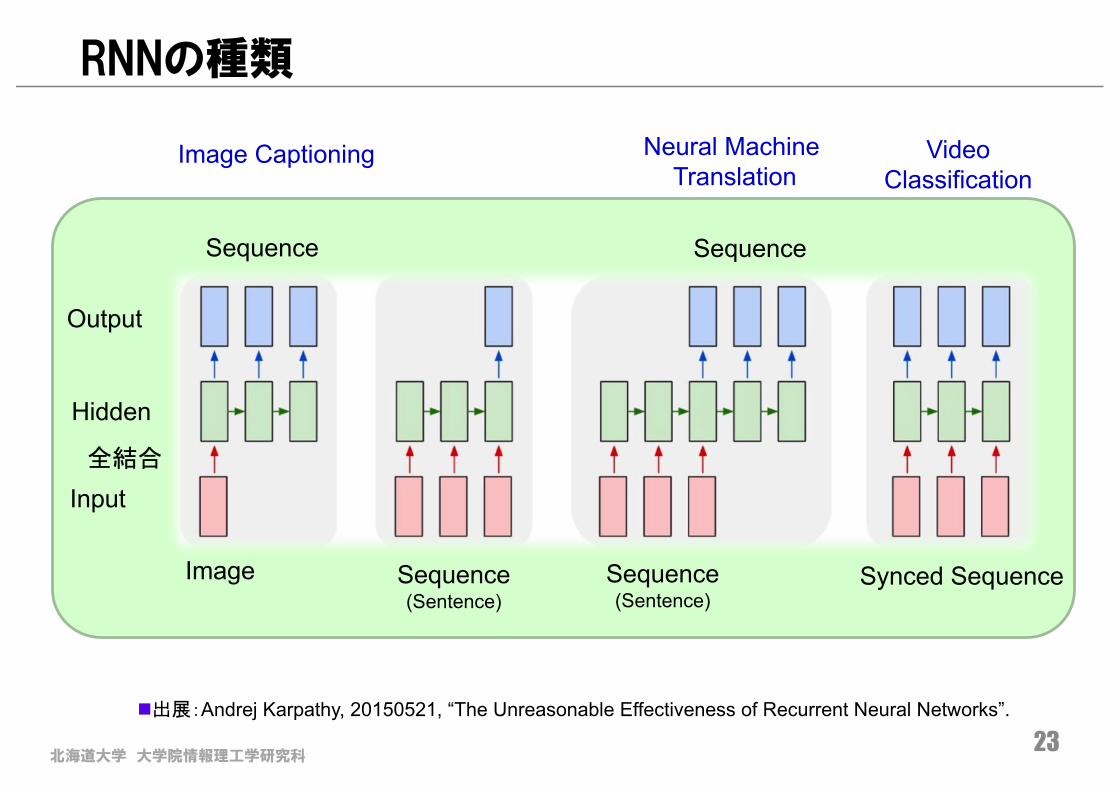
北海道大学 大学院情報理工学研究科23
RNNの種類
n出展:Andrej Karpathy, 20150521, “The Unreasonable Effectiveness of Recurrent Neural Networks”.
Sequence Sequence
Input
Hidden
Output
全結合
Image Captioning
Sequence(Sentence)
Neural MachineTranslation
Image
VideoClassification
Sequence(Sentence)
Synced Sequence

北海道大学 大学院情報理工学研究科24
CNN/Alex Net・・・代表的なネットワークモデル
nILSVRC (Image Net Large Scale Visual Recognition Challenge)-2012p 1000クラスの識別:エラー率 26%→16%(10%改善)
nAlex Net (5x畳込み層、3xプーリング層、2x コントラスト正規化層、3x全結合層)n学習:教師有り(Back Propagation): ①活性化関数(ReLU)、②GPU実装、③Drop-Out 等
n教師サンプル:1000カテゴリ×1000枚→100万枚⇒2週間(2つのGPU)→1sec/1枚
n 1000クラスの識別(オリンピック級:ハイエンド)
出展:A. Krizhevsky, I. Sutskever and G. E. Hinton. "ImageNet Classification with Deep Convolutional Neural Networks." NIPS. Vol. 1. No. 2. 2012.
1k4M
4k17M
4k27M
43k0.89M
65k1.33M
64k0.89M
186 k614k
Neuron = 253kSynapse =35k
1CONV-2LRN-3POOL4CONV-5LRN-6POOL 7CONV 8CONV 9CONV-10POOL 11CLASS 12CLASS 13CLASS55x55→27x27
全結合全結合
合計
0.7M ニューロン
62M シナプス
合計
2G ビット
1G接続
注:パラメータの図の記載は無い
北海道大学 大学院情報理工学研究科
�������
�������
�������
������
������
�������
�������
����� �
25
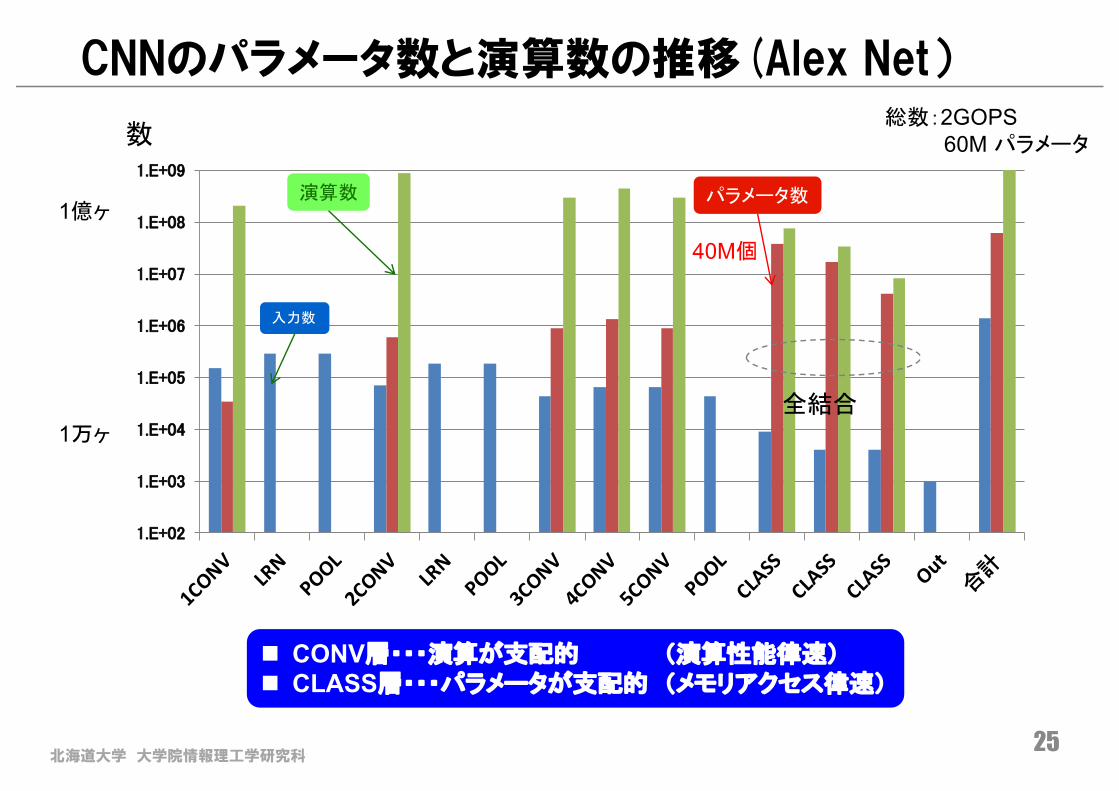
CNNのパラメータ数と演算数の推移(Alex Net)
n CONV層・・・演算が支配的 (演算性能律速)n CLASS層・・・パラメータが支配的 (メモリアクセス律速)
数
全結合
演算数
40M個
1万ヶ
1億ヶ
総数:2GOPS60M パラメータ
パラメータ数
入力数
北海道大学 大学院情報理工学研究科26
1 2 3 4 5
I C P C P F F F G LeN et 6 1998
1 2 3 4 5 6 7 8
I C N P C N P C C C P F F F S A lex 8 2012
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
I C C P C C P C C C C P C C C C P C C C C P F F F S V G G N et19 2014
I C C 3 C 3 P C C 3 C 3 P C C 3 C 3 A P S N iN 2014
1 2 3 4 5 6 7 8 9 16 17 18 19 20 21 22C C C C C C
I C P N C C N P C C D C C D P C C D --- D C C D P C C D C C D A P F S G oogLeN et 2014
C C C C C C C C C C C C 22 V 1P C P C P C P C P C P C1 2 1 2 --- 5 1 2
Auxiliary Classifier Auxiliary Classifier
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 32 33 34
I C P C C C C C C C C C C C C C C C -- ------ C C C R esN et152 2015
1 2 3 1 2 8
35 36 37 38 39 40C C C C C C --- --- --- --- --- --- C C C
1 2 36
C C C C C C C C C A P F S
1 2 3
CF型
C型
畳込み層主体型
152151149146145143
142140
148ボトルネックブロック+ショートカット(残渣ブロック)
Inceptionモジュール
Mlpconv
AP F S Global Ave. Pool. / Fully Connected / Softmax
Input / Convolution / Max PoolingI C P
N D Local Response Norm. / Depth Concatenation
CF型(畳込み層+全結合層共存型)
CIFAR-10用の構造→
CCCPCascaded Cross Channel Parametric Pooling (CCCP)
CNNの進化: モデルの進化(1998~2016)

北海道大学 大学院情報理工学研究科27
【参考】 CNNの進化: ネットモデルの構成一覧f�y�oy�c ukk\a ukk\d o}o k��{myoy�]] qy�oy�^_ qy�oy�\`] �Xk�Sp��}w�T �Xk�Suv��yT
�§¶·§� U\\ k��{�y
][\] ][\_ ][\_
\`Y^Q XXbY^^Q
SaYcQTXXX
aYaaQPS _Yc]Q�
^Y`cQ�^Y[cQTSV\Y`QT ^Y`bQ
� XXX ` \^ \a XXX ]\ ^^ \`\ \^ \`
©³¯¸¤ n� ^Yc \`Y[[ ][ XXX `Yda ]\Y[ ``Y[ ^Yd ^Yd
+8¹!<"º g� \Y[c \`Y^ \dY` XXX \Y` ^Ya_ \\Y^ \Yb \Yb^
� XXX ^ ^ ^ XXX \ \ \ XXX ]
©³¯¸¤ n� `cYa \]_ \]_ XXX \Y[` \Y[[ \Y[[ XXX [Y[d
+8¹!<"º g� [Y[`ca [Y\]_ [Y\]_ XXX [Y[[\[` [Y[[\ [Y[[\ XXX [Y[[[\
� XXX c \a \d XXX ]] ^_ \`] \^ \b
©³¯¸¤ n� a]Y_ \^d \__ XXX bY[\ ]]Y[ `aY[[ ^Yd ^Ydd
+8¹!<"º g� \Y\_ \`Y_ \dYa XXX \Y`[ ^Ya_ \\Y^ \Yb[ \Yb^
©³¯¸¤ XXX [Y_` \ \Y[_ XXX [Y[` [Y\a [Y_[ [Y[^ [Y[^
+8¹!<"º XXX [Y[b \ \Y]b XXX [Y\[ [Y]_ [Yb^ [Y\\ [Y\\
h[� h]�
H< - ]WP^ ]WP_ \V] ] ]�o
� XXX XXX _'
XXX n��w��� l�wy��}��Pn�xY
XXX � � XXX
XXX XXX XXX
\\�\\ VP\�\ \�\WP^�^WPS`�`T ^�^
]b�]b XXX `a�`a
qymt
mqo mqo
XXX XXX S�Tu]��
Snv�Zf�yT
XXX �
XXX \ XXX ]
� � �Skfpº XXX XXX
� � �|v�|
C�6 �N� �J�@M $��� �.
,�®¥"P_c
XXX
ee
XXX
XXX
XXX
k��{�y
][\a
qymt
]\�]\
`�`W^�^W\�\
XXX
XXX
XXX
XXX
XXX
2F�
�³¸.
SDE�O¼s��X`Py����º
\
P�¥�¢«�¸¨� nrqf
][\`
]�xh�����£
²¸§�¥§µ¸
g����y�yw~�S\�\T
°¡±¸µZ¬¶¥� �
:=
][\_
�;�
¤� hj�¹2F��»�;��º h�S2F�����º
°¦µPS�"º
2F
��
)���
%A�SmqoT
¸´·��
����¸´·�� SkfpT
�;��
r�z�nv�
�
'
I
'
I
(.
�B
3?SlmruqhTPP
«�µ¤¸��£
G��,�®¥ª·�
9�\[[��75¹0#4º
^�o
�
�
\�\WP^�^
XXX
�R&*¹�y�}x�v�º¬¶¥�
&*���,�®¥ª·�
�
XXX
\\]�\\]
XXX
XXX
XXX
XXX
XXX
XXX
^�^
i������ �
/� �¹K1º,�
nv�
^
�>
�
L��
qymt
`a�`a
�
XXX
nv�
%A�Sgv�w|Po���v�}�v�}��T XXX

北海道大学 大学院情報理工学研究科28
CNNの進化:構成の勘所
�
ofumyjgl jgl�SSzrgw+0Q0Tjp+.Q.+-
) ,5CCL-
0) 4KJP�T/Q:) 4KJP�T
cXWa0Q:) 4KJP�eiuyq^X]
!d(Y
��z?GBC- 1�z6KKE8C:CN`b{
4KJPsktyu 9HLAKJPT7JACLNGKJT��pvnh�
�W]c#VU[\X&��"`�+|�
Z`��_a62;�
4KJP� <C8>
��� =KDNI@Q
5MKLKON
3@NAF+JKMI@HGR@NGKJ,�%�{
�'b�
� �*�
�"�x��
����
$�
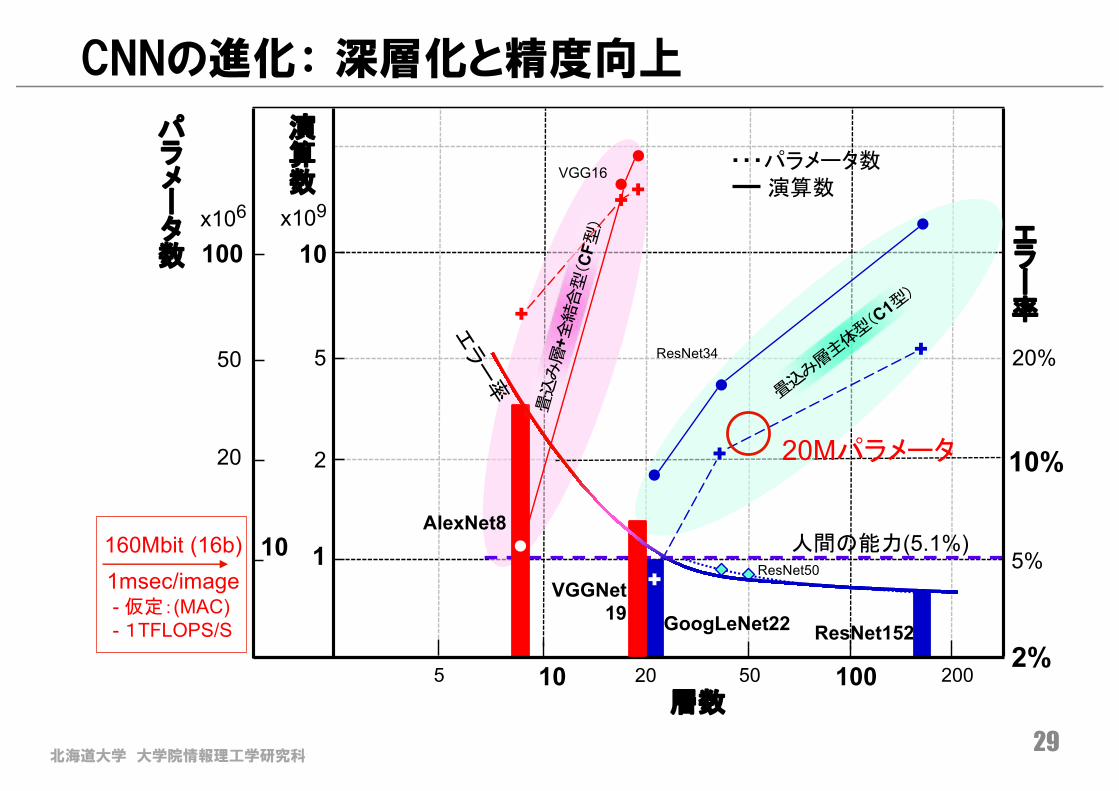
北海道大学 大学院情報理工学研究科29
10層数
10
1
100
ResNet34
10
100
10%
2%
5%
20%
2
5
20 505 200
エラ
率
50
20
演算数
パラメ
タ数
x109x106
AlexNet8
VGGNet19 GoogLeNet22 ResNet152
人間の能力(5.1%)
1msec/image- 仮定:(MAC)- 1TFLOPS/S
・・・パラメータ数演算数
160Mbit (16b)
VGG16
ResNet50
CNNの進化: 深層化と精度向上
20Mパラメータ

北海道大学 大学院情報理工学研究科
ネットワークとLSI回路アーキテクチャの位置関係
30
MLP (multilayer perceptron)RBM (Restricted Boltzmann Machine)DBN (Deep Brief Network)AE (Auto Encoder)CDBN (Convolutional DBN)
z ���W
z
z
���Y
���Y 0HDR:DP @66:DP
��� �X$�"
opt opt\ycdl
|�%���}
5�
2::
�� #�
z <19+31: 5�
<8 04 5�
z 231: 25�
25�
<::
=MQDDTD:DP
=IAHH'5GHPDN
=IAHH'5GHPDN;
N
Q
J
G
J
E
^
s
`
b
U
�
w
`
v
`
�
�
�
�
&
�
&
�
j[k`��
:7: ���!
4RLAJC'8ASDN <DO:DP
�z��hr{wy
2,+2-�
j`��*:K2
60;
:7:=IAHH'2FAJJDH
�
8=7$Z{]e^cq{
3:: 98; 98; 5�
;
N
Q
J
G
J
E
^
s
`
b
U
�
w
`
v
`
^w`j{��
9GBNKvmu���|5GHPDNV2FAJJDH)
/,�-,,R
./�/,R (R-,)6KKEHD:DP+7JBDLPGKJ'8ASDN
idgx{^pfu(Zu_tan)
����Y
9ABNKvmu���(8ASDNV�!)
8=>9+6<?zz
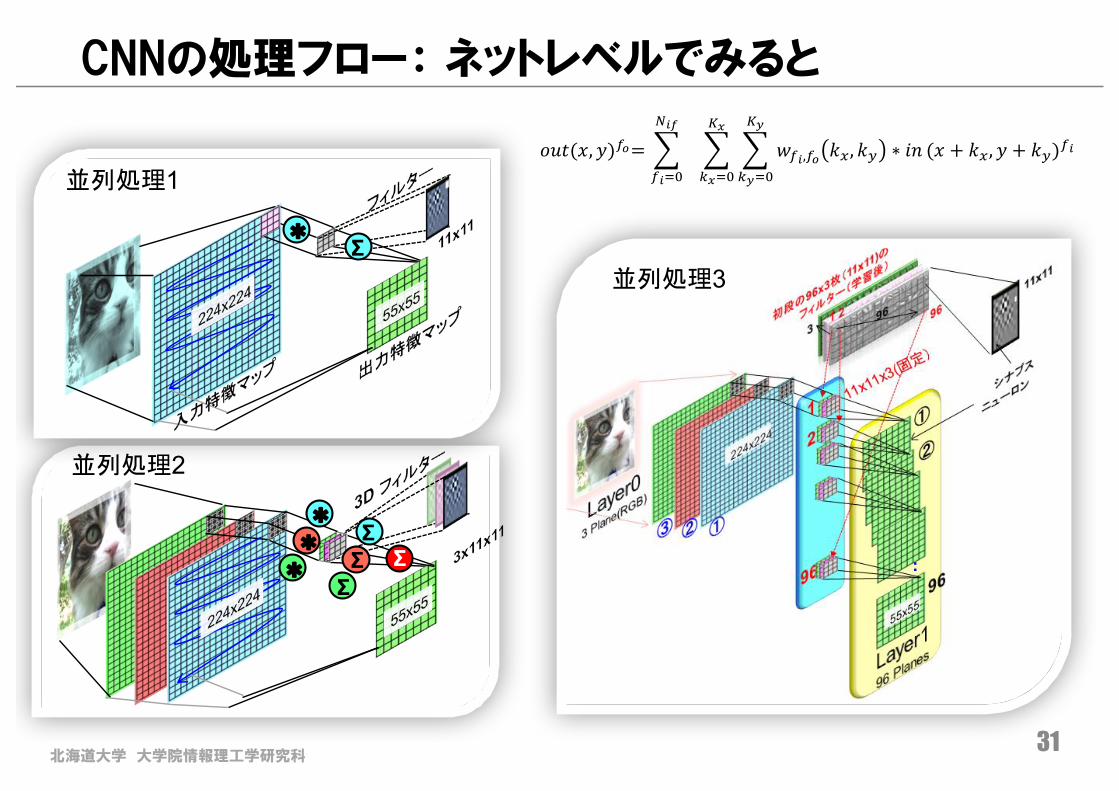
北海道大学 大学院情報理工学研究科31
CNNの処理フロー: ネットレベルでみると
Σ*
並列処理1
* Σ*Σ* Σ
Σ
並列処理2
並列処理3
𝑜𝑢𝑡(𝑥, 𝑦))*= , , , 𝑤)/,)* 𝑘1, 𝑘2 ∗ 𝑖𝑛67
879:
6;
8;9:
</=
)/9:
(𝑥 + 𝑘1, 𝑦 + 𝑘2))/

北海道大学 大学院情報理工学研究科
CNNの処理フロー:回路レベルで見ると
32n出展(参考):清華大学 他, Jiantao Qiu+, “Going Deeper with Embedded FPGA --”, https://nicsefc.ee.tsinghua.edu.cn/media/publications/2016/FPGA2016_None_6tAJnDW.pdf
全体構成 (コア、チップ) PE(Processing Element)
Convolver
並列処理3(出力特徴マップ)
並列処理1(演算子) 並列処理2(入力特徴マップ)

北海道大学 大学院情報理工学研究科
SB:Buffer for synaptic weights
Tile
4096b
1024ROW 1.89mm2=1.4mm□
SBeDRAMBank1
Bank1
Bank2 Bank3
NFU
x4096
16 inputneurons 16 output
neurons
33
Chip
NFU(Reconfigurability)
Tile eDRAM256synapse
Tile0
Tile15
Tile1
eDRAMBin Bout
Router
Fat tree
2MB2MB
Hyper Transport
x16x16
2MBx16=32MB
67.7mm2=8.2mm□
SRAM(8kB) SRAM(8kB)
Multi Add
NBin NBout
Act
P-sumorgradients
Synapse
Updated Synapse
Input x16 Output
Stage1 Stage2 Stage3
Machine Learning Super Computerp 2014年12月発表:Micro47BestPaperp 28nm(ST 0.9V)/67.7mm2、16タイルp 機能:再構成機能 (実行と学習)・・・NFUp 性能:速度 x451、低消費 x150 対 K20M
Ø 5.58(16bit)、2.09(32bit)TeraOps/s
e-DRAM
出典(参考): Yunji Chen +, http://novel.ict.ac.cn/ychen/pdf/DaDianNao.pdf
DNN: DaDianNao(中国CAS):構成 ‘14/12月

北海道大学 大学院情報理工学研究科
DaDianNao32MB e-DRAM
*2
EIE10MB SRAM on Chip
34
103 105104
106
109
103
入力次元数(x) :処理対象画素数+データ数
(1x32x32) (1x100x100) (3x224x224)
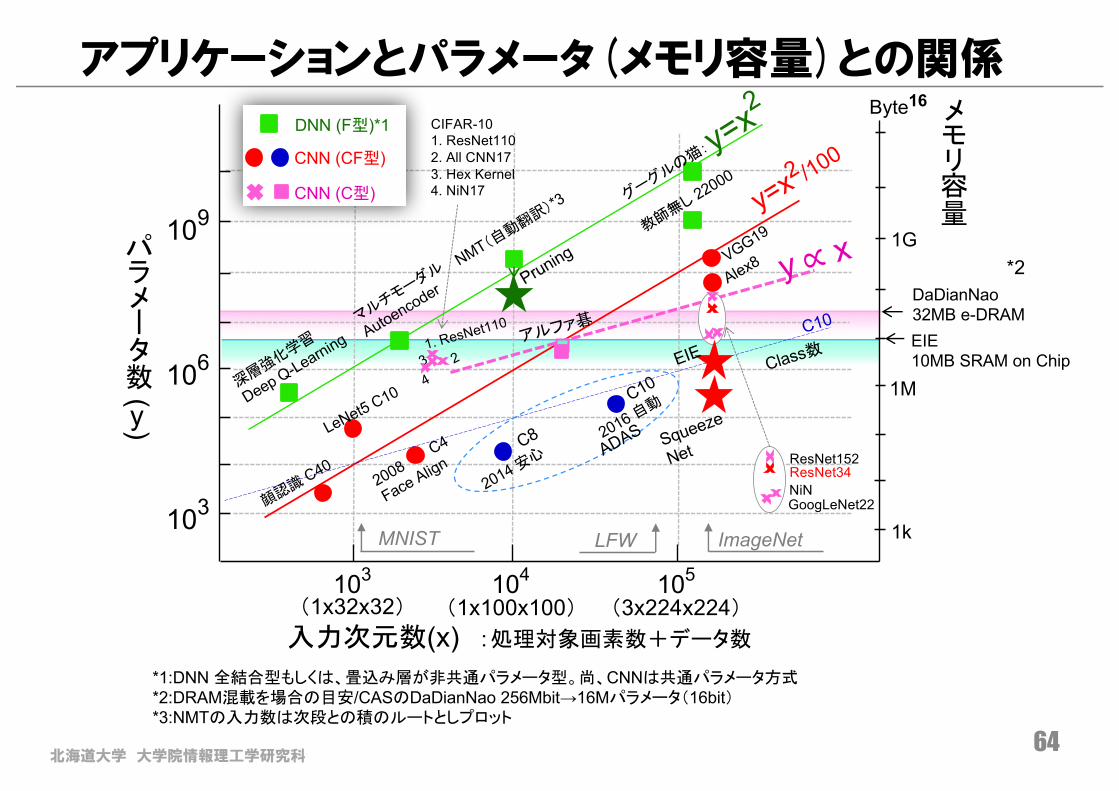
*1:DNN 全結合型もしくは、畳込み層が非共通パラメータ型。尚、CNNは共通パラメータ方式*2:DRAM混載を場合の目安/CASのDaDianNao 256Mbit→16Mパラメータ(16bit)*3:NMTの入力数は次段との積のルートとしプロット
1M
1G
1k
Byte16メモリ容量
DNN (F型)*1
CNN (CF型)
CNN (C型)
パラメ
タ数( )y
GoogLeNet22
ResNet34ResNet152
NiN
CIFAR-101. ResNet1102. All CNN173. Hex Kernel4. NiN17
ネットワークモデルとパラメータ(メモリ容量)
ImageNetMNIST LFW
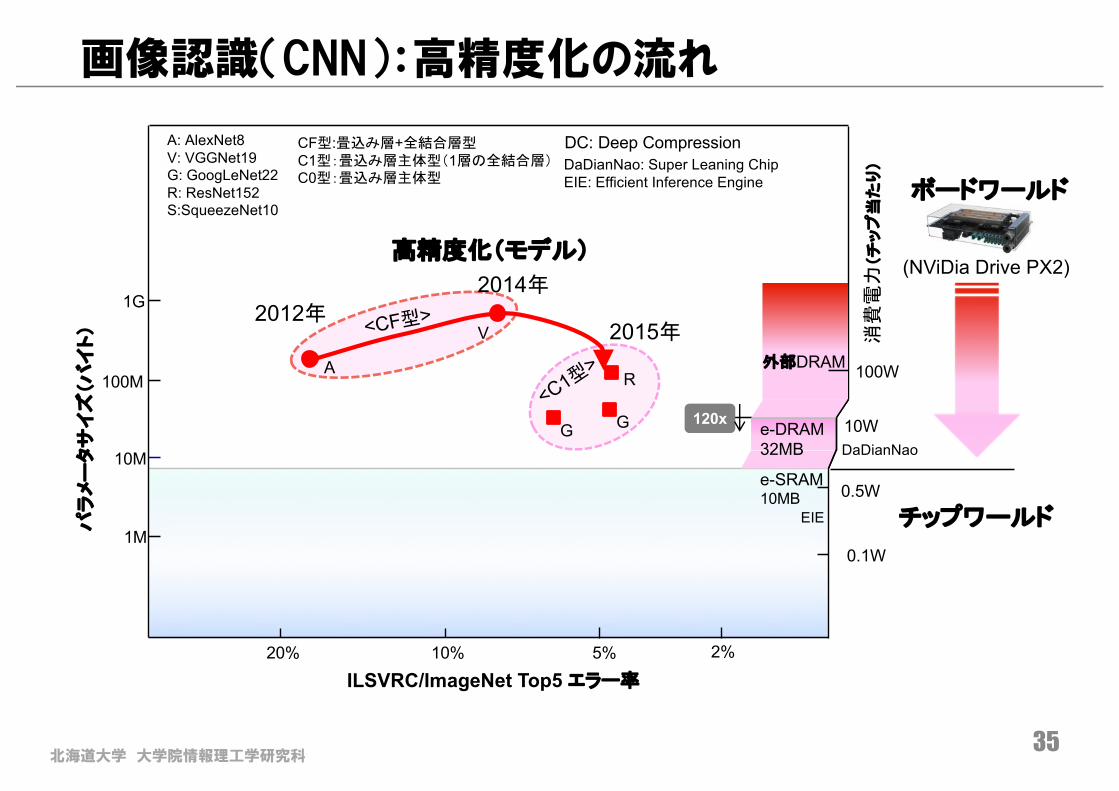
北海道大学 大学院情報理工学研究科
画像認識(CNN):高精度化の流れ
35
ILSVRC/ImageNet Top5 エラー率
パラ
メー
タサ
イズ
(バ
イト
)
20% 10% 5%
1M
10M
100M
1G
A
V
G
R
2012年
2014年
A: AlexNet8V: VGGNet19G: GoogLeNet22R: ResNet152S:SqueezeNet10
2015年
0.5W
10W
100W
0.1W
CF型:畳込み層+全結合層型C1型:畳込み層主体型(1層の全結合層)C0型:畳込み層主体型
2%
G
消費
電力
(チ
ップ
当た
り)DaDianNao: Super Leaning Chip
EIE: Efficient Inference Engine
高精度化(モデル)
ボードワールド
チップワールド
(NViDia Drive PX2)
DaDianNaoe-DRAM32MB
e-SRAM 10MB
外部DRAM
EIE
DC: Deep Compression
120x

36
- ディープラーニングの最新動向
- ディープラーニングチップの最新動向
- ディープラーニングチップ実装の勘所
- その圧縮(Sparsity)と量子化技術
- ディープラーニングのシステム例
- まとめ
内容

北海道大学 大学院情報理工学研究科37
圧縮技術の流れ ~2015年後半から激化~
Rd �V <Y1P
�2�
�@
��
MG
ö��-�?÷
����-
�?�¯¯¨¬¦ ���
Öõã
y
�7�O
&`�N���� ���
����Ā
����-
×óÑéõð
�W$
�¯¯¨¬¦
����X
*!æÌðÛõ ö�·���·�~
�¯®µ,ÅìØíõð
���,Å)�|X�a
kmNËÝç
#,�ö���,~
äîëõÛ8¼
[
����
�¯¯¨�¦�¦³Æ
+x�
�¦²�¦³pj#8
����-
��?
����
����-
�?
ìóßï
Ðõð$
Õòó
åË$
�
��ø äîÅÈ� �¾
>:Æ'8¿'hZÆ
�³¯¤©¢²³ª¤Ä»�Êt3
���ø �� É��0Ä
� �½ôôô��
�a
ìã
Íð
&US ���
�����������
Â'i¿
�0Æ�¢¨¦®¦³Â
Ci
����-�?
����-
��?
����
���
I,&`Ä�[�À¾
]@Ê�����Ä+x¾
�³¯¤©¢²³ª¤Ä�O�a
ÙäÍÒóÔ
ýýÃI,&`
ÃÅAÀE���
úýý
�����sP
����-�?
äîëõÛ _
}�¦¦°
�¯°±¦²²ª¯®~
����-
�?
ÙÛó
æÏõà$
���$
ýÿüûüù
�±´®ª®¨}4^ÅTQ~
&`
¡¦ª¨©³Åw%��×ÎË
�´§§¢®|�¯¥ª®¨
�a
ìã
Íð
ìãÍðÇÅ
$fD
âÝß5o
��Ā
���
�¬¦·
��
��}���~'e
���\�
����-�?
�£ª³�
öw%�÷
����-
�?
�¯¯¨¬¦
�¦³¦¡¢¥¦®
'cÅÈ
��£ª³}H�÷���
�£ª³98LZ}�����~
�a
Öõã
ÖÍÓð8ËÝç
ìãÍðsPÉ
gv
�Ā�
�
�¦®²¯±�¬¯¶
�x�
��þÜÝçRd
����-�?
�¸¢®¢ª¤
���£ª³
}w%�~
����-
���?
����¦´µ¦®$
Jb$&
w%��,F
*8BÊl9}Jb$÷
ìãÍ
ðìãÍðÇÅsP
���ñèð
Jb$&ö����~
����-
�?
�����
����
� ����
"u����nq�=
òÙñÙ _ô�/
öîóñóÔÙ÷
�a
ìã
Íð
ÍëõØÞõÛÅ
_||������
��®�¦²³�©ª°
Ci�È
���|����¢³¤©|�¯±¢¬ª¹¢³ª¯® ��|���ø�°ª«ª®¨|�¦´±¢¬½�¦³¶¯±« ���ëìïw _Å�@ö(��£ª³~
<Y�z
ÞõÛ _
òÙñÙ
ãÍáïõ�
��ø�ª®¢±¸
�¯®®¦¤³
ô
���ø
�ª®¢±ª¹¦¥|��
ö���É
Á;.÷
äîëõÛ8�K
öìÞðÅ6�÷
�7ô{r�|ìÞð
äîñïÚê
ä
î
ë
º
Û
ô
Þ
º
Û
å
Ý
ß
�
º
_
º
(2016年6月時点の状況)
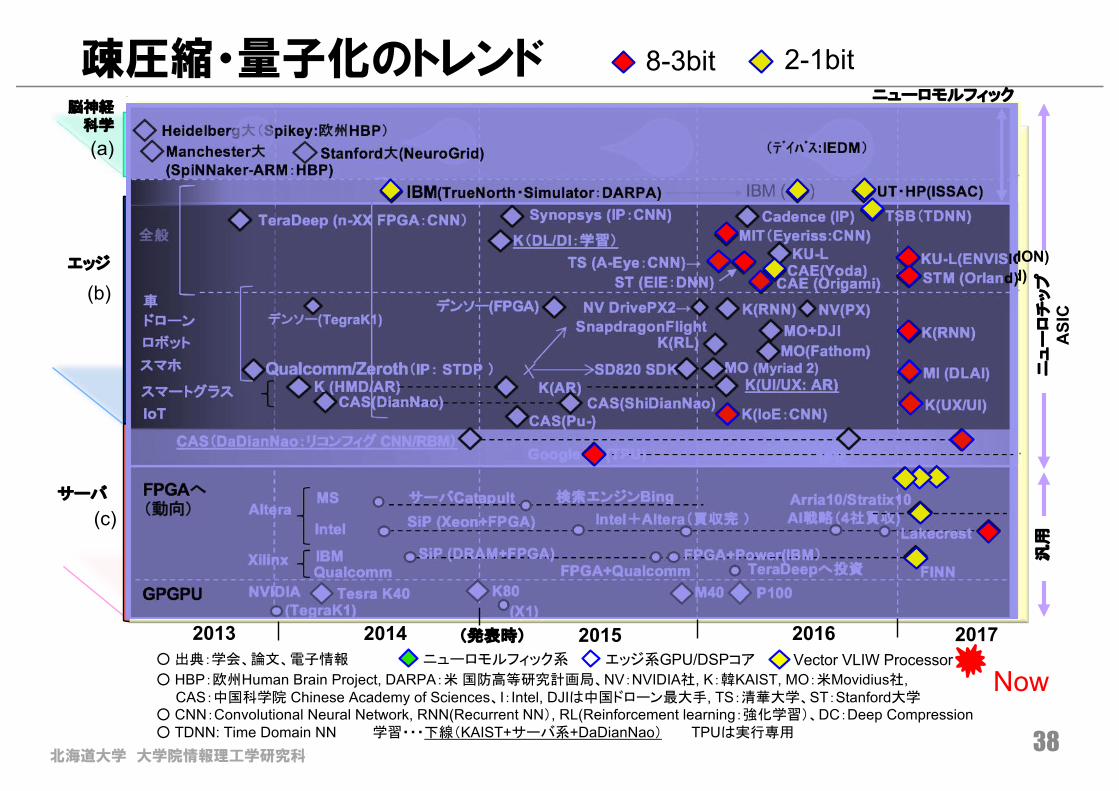
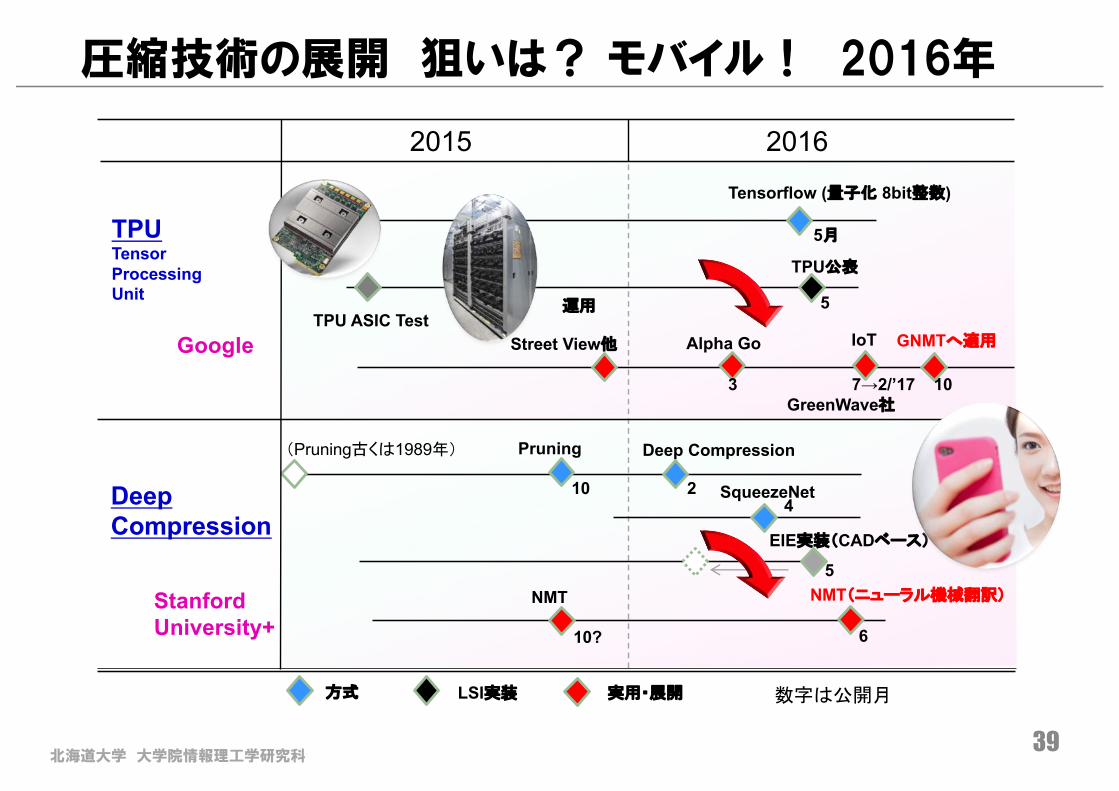
北海道大学 大学院情報理工学研究科38
エッジ
サーバ
脳神経科学
2013 2014 2015 2016
GPGPU
FPGAへ(動向)
サーバCatapult SiP (Xeon+FPGA)
Heidelberg大(Spikey:欧州HBP)
Stanford大(NeuroGrid)
ニューロモルフィック
(a)
(c) Intel+Altera(買収完 )
MS
Intel
検索エンジンBingAltera
Xilinx IBMTeraDeepへ投資FPGA+QualcommQualcomm
M40 P100NVIDIA(TegraK1) (X1)
(発表時)
K80Tesra K40
全般
(b)
Manchester大(SpiNNaker-ARM:HBP)
汎用
車
ロボット
スマホ
スマートグラス
IoT
ドローン
Synopsys (IP:CNN)MIT(Eyeriss:CNN)
TeraDeep (n-XX FPGA:CNN)
CAS(DaDianNao:リコンフィグ CNN/RBM)
ニュ
ーロ
チッ
プAS
IC
K(DL/DI:学習)
CAS(ShiDianNao)CAS(Pu-)
Qualcomm/Zeroth(IP: STDP )K (HMD/AR)
MO (Myriad 2)
K(IoE:CNN)
SD820 SDKK(UI/UX: AR)
K(RL)
K(RNN) NV(PX)
MO(Fathom)
NV DrivePX2→MO+DJISnapdragonFlightデンソー(TegraK1)
デンソー(FPGA)
K(AR)
Cadence (IP)
TS (A-Eye:CNN)→ST (EIE:DNN)
CAS(DianNao)
2017
CAE (Origami)
UT・HP(ISSAC)
STM (Orland)
TSB(TDNN)
KU-L
K(RNN)
AI戦略(4社買収)
Google (TPU) IP化
K(UX/UI)
FPGA+Power(IBM)SiP (DRAM+FPGA)
KU-L(ENVISION)
MI (DLAI)
IBM(TrueNorth・Simulator:DARPA)
(デイバス:IEDM)
Now
IBM ( )
FINN
Arria10/Stratix10
Lakecrest
CAE(Yoda)
疎圧縮・量子化のトレンド
エッジ系GPU/DSPコア Vector VLIW Processor○ 出典:学会、論文、電子情報
○ HBP:欧州Human Brain Project, DARPA:米 国防高等研究計画局、NV:NVIDIA社, K:韓KAIST, MO:米Movidius社, CAS:中国科学院 Chinese Academy of Sciences、I:Intel, DJIは中国ドローン最大手, TS:清華大学、ST:Stanford大学
○ CNN:Convolutional Neural Network, RNN(Recurrent NN), RL(Reinforcement learning:強化学習)、DC:Deep Compression○ TDNN: Time Domain NN 学習・・・下線(KAIST+サーバ系+DaDianNao) TPUは実行専用
ニューロモルフィック系
8-3bit 2-1bit
北海道大学 大学院情報理工学研究科39
圧縮技術の展開 狙いは? モバイル! 2016年
20162015
Tensorflow (量子化 8bit整数)
TPU公表
TPU ASIC Test運用
Alpha Go GNMTへ適用Street View他
NMT(ニューラル機械翻訳)NMT
Pruning Deep Compression(Pruning古くは1989年)
IoT
SqueezeNet
TPUTensorProcessingUnit
DeepCompression
StanfordUniversity+
5月
5
7→2/’17 103
610?
4210
方式 LSI実装 実用・展開 数字は公開月
EIE実装(CADベース)
5
GreenWave社
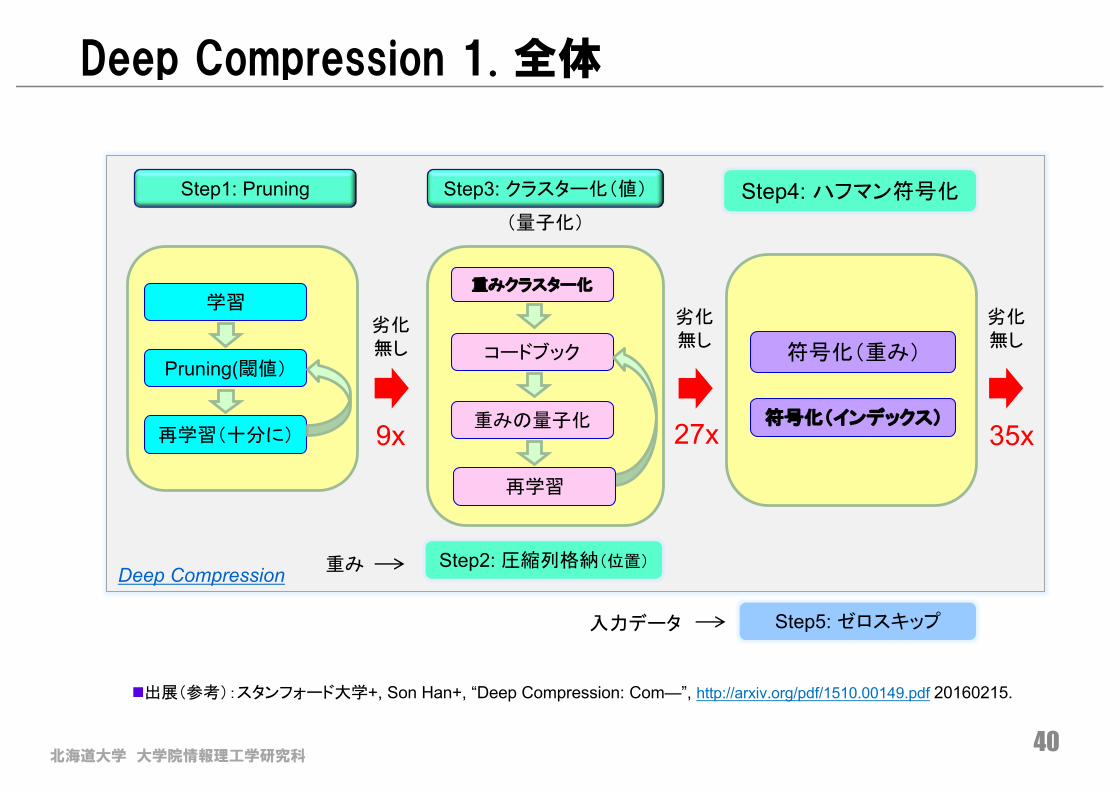
北海道大学 大学院情報理工学研究科40
n出展(参考):スタンフォード大学+, Son Han+, “Deep Compression: Com—”, http://arxiv.org/pdf/1510.00149.pdf 20160215.
Deep Compression 1. 全体
Step1: Pruning Step3: クラスター化(値) Step4: ハフマン符号化
学習
Pruning(閾値)
再学習(十分に) 9x 27x 35x
劣化無し
劣化無し
劣化無し
重みクラスター化
コードブック
重みの量子化
再学習
符号化(重み)
符号化(インデックス)
(量子化)
Step2: 圧縮列格納(位置)重み
Step5: ゼロスキップ入力データ
Deep Compression
北海道大学 大学院情報理工学研究科41
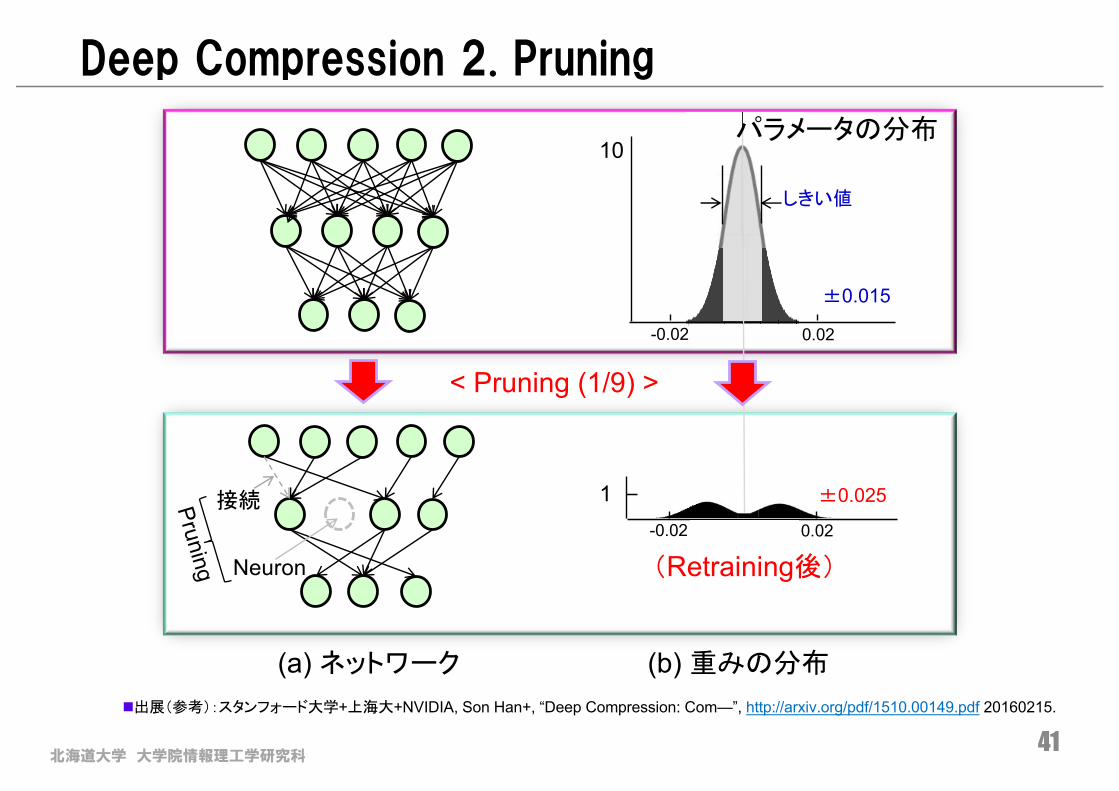
Deep Compression 2. Pruning
n出展(参考):スタンフォード大学+上海大+NVIDIA, Son Han+, “Deep Compression: Com—”, http://arxiv.org/pdf/1510.00149.pdf 20160215.
Neuron (Retraining後)
-0.02 0.02
±0.015
10
しきい値
-0.02 0.02
1 ±0.025接続
< Pruning (1/9) >
(a) ネットワーク (b) 重みの分布
パラメータの分布
北海道大学 大学院情報理工学研究科
演算
EIE実行時
42
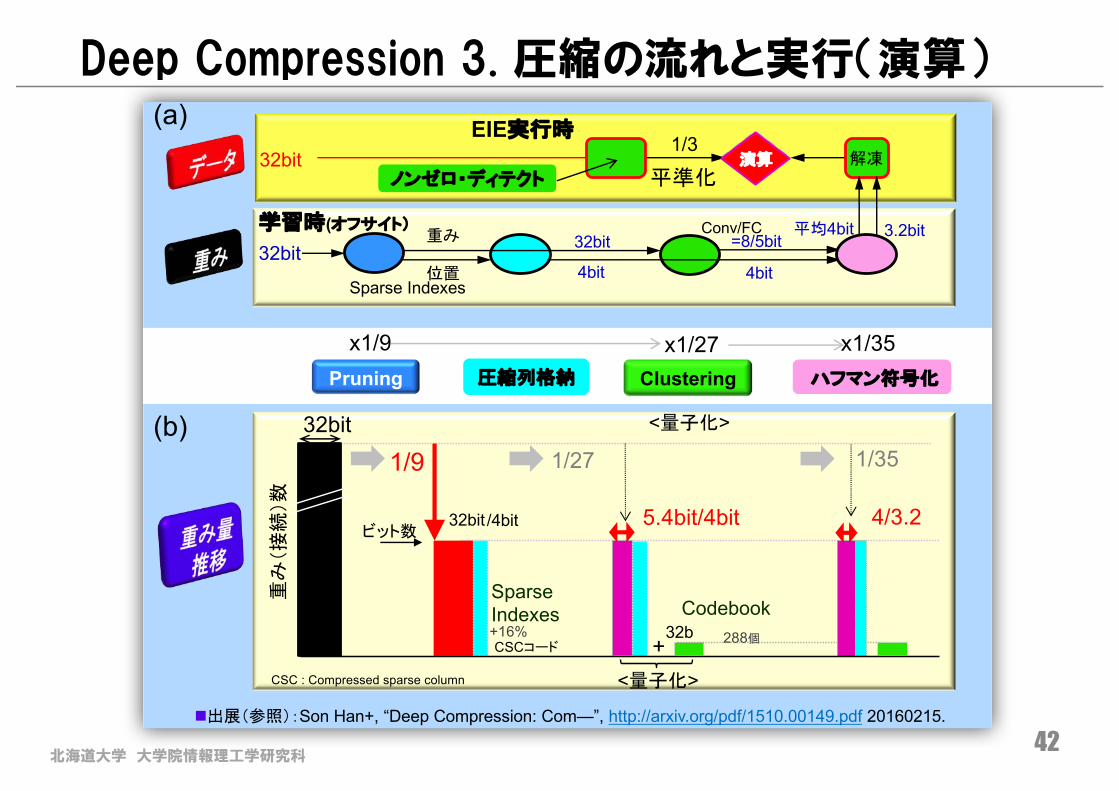
Deep Compression 3. 圧縮の流れと実行(演算)
Pruning
32bit
32bit
32bit
重み
(接
続)数
x1/9
1/9
n出展(参照):Son Han+, “Deep Compression: Com—”, http://arxiv.org/pdf/1510.00149.pdf 20160215.
CSC : Compressed sparse column
Clusteringx1/27
1/27
<量子化>
=8/5bitConv/FC
32b
<量子化>
288個+
5.4bit/4bit
Codebook
4bit
(a)
(b)
圧縮列格納
位置Sparse Indexes
32bitビット数
重み 32bit
ノンゼロ・ディテクト
学習時(オフサイト)
解凍
+16%
4bit
CSCコード
Sparse Indexes
/4bit
平均4bit 3.2bit
ハフマン符号化
x1/35
1/35
4/3.2
演算平準化
1/3

北海道大学 大学院情報理工学研究科43
n出展:スタンフォード大学+NVIDIA, Son Han+, “EIE: Efficient Inference Engine—”, http://arxiv.org/pdf/1602.01528v2.pdf 20160503.
Address accum.(相対→実番地)
Output Act. read Add Output Act Write
Codebook lookup Input Act. multi Shift
4 Stage 1.15ns (Critical Path)
Act Value
Act Index
a 16bit
j範囲
Iij
Indexrow#32kB
128KB
2KB
Deep Compression 4. PEの回路構成

北海道大学 大学院情報理工学研究科44
KU.ルーベンB. Moons
nDynamic(精度とパワーの制御)スケーリングnエネルギー効率(0.26~10TOPS/W)⇒Always On
nエネルギー効率改善:Eyriss x1.5, Moons x8.2① (Q-)Dynamic量子化(16bit〜4bit変換: 各Layer毎:負荷とデータ)② Subword DVAFS方式⇒x40のパワー(精度)スケーラビリティ
n精度↓(8b/4bit) →MACの未使用部分使用→周波数↓)③ FD-SOI
ISSCC’17 14.5:ENVISION: A 0.26-to-10TOPS/W Subword-Parallel Comp. Accuracy-Voltage-Frequency-Scalable CNN Processor in 28nm FDSOI
Dynamic(瞬時)な精度アップが可能
B. Moon, 20160322, Arxiv:1603.06777v1
①
②
③
顔(150x150x3)識別 5670人(クラス) 90-95% - Alex Conv: 47fps 44mW(1.87mm2)- VGG Conv16:1.7fps 26mW
量子化 1. CNN・・・(ENVISION) ISSCC’17/14.5
Always On

北海道大学 大学院情報理工学研究科
エネルギー効率改善 (量子化と低電力化)
45参考:ISSCC 2017 14.5 KU.ルーベン, B. Moons 他
Alex Conv 44mW@47fps ⇒ 102 GOPS/sec 2.3 TOPS/W (4-6b)VGG16 Conv [email protected] ⇒ 52.4 GOPS/sec 2.0 TOPS/W (4-6b)
EIE/DC
14.2 DNPU
14.6UX/UI
Eyeriss
0.110G 100G 1T
エネ
ルギ
ー効
率(TO
PS/W)
1
10
実・演算性能 (OPS/sec)1G
ShiDianNao
10T
16bit--- 300mW 1.05V
3-4bit---7.5mW 0.63V
4bit8bit16bit
Always On Mobile
40x
IoE
DaDianNao
DL/DI
UIUX
TPU
100T
14.5 ENVISIONSubword-DVAFS
75GOPS/s一定
14.1 OrlandDVFS
VLSI2016

北海道大学 大学院情報理工学研究科46
KU.ルーベンB. Moons
ENVISION: A 0.26-to-10TOPS/W Subword-Parallel Comp. Accuracy-Voltage-Frequency-Scalable CNN Processor in 28nm FDSOI
VGG16 based
量子化とアプリケーションの関係

北海道大学 大学院情報理工学研究科47
KAISTD. Shin
ISSCC’17 14.2 DNPU: An 8.1TOPS/W Reconfigurable CNN-RNN Processor for General-Purpose Deep Neural Networks
nDNPU(Deep Neural Processing Unit)・・・4つの特徴ØConv +FC:ヘテロ型再構成ØConv: Tileの最適化(VGG16>13:Image→Mix→Channel)ØConv:データ/オンライン調整(ワード/小数部)、重み/LUTØRNN:Q-Table型乗算(4bit量子化と積結果の事前Q-Table)
畳込み層Conv
全結合層FC+LSTM
CNN
Configurability
Low Power
量子化 2. CNN+RNN・(DNPU) ISSCC’17/14.2
北海道大学 大学院情報理工学研究科
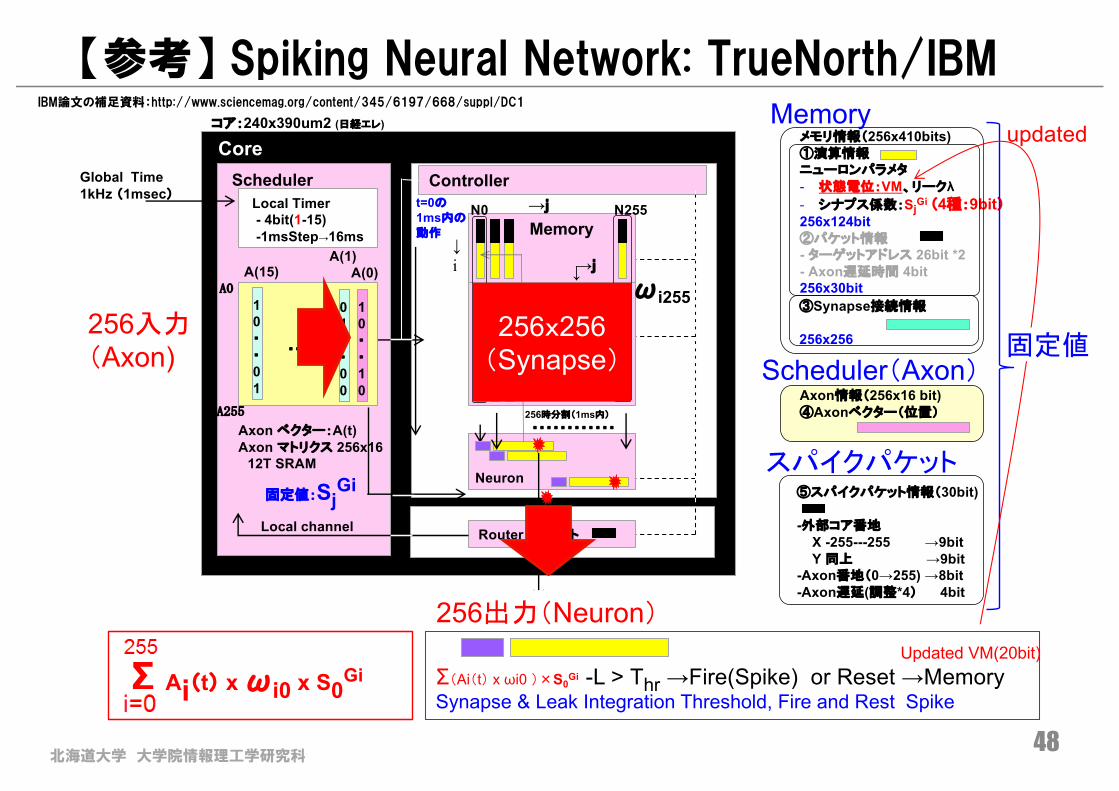
コア:240x390um2 (日経エレ)
IBM論文の補足資料:http://www.sciencemag.org/content/345/6197/668/suppl/DC1
48
Controller
Neuron
Router パケット
11・
・01
00・
・00
01・
・00
・・・・・・・・・・・・
11・
・01
t=0の
1ms内の
動作 Memory
256時分割(1ms内)
Local channel
N0 N255
・・・・・・・・・・・・
Crossbar256x256
CoreScheduler
Axon ベクター:A(t)Axon マトリクス 256x16
12T SRAM
10・
・10
01・
・00
10・
・01
A(15)
・・・・・
Local Timer- 4bit(1-15) -1msStep→16ms
Global Time1kHz (1msec)
A0
A255
ωi2ωi255
固定値:SjGi
A(0)
↓i
ωij
A(1)
→j
→j↓i
256x256(Synapse)
256入力(Axon)
256出力(Neuron)
Σ Ai(t) x ωi0 x S0Gi Σ(Ai(t) x ωi0 )×S0
Gi -L > Thr →Fire(Spike) or Reset →MemorySynapse & Leak Integration Threshold, Fire and Rest Spike
Updated VM(20bit)
メモリ情報(256x410bits)①演算情報ニューロンパラメタ
- 状態電位:VM、リークλ- シナプス係数:Sj
Gi (4種:9bit)256x124bit②パケット情報- ターゲットアドレス 26bit *2- Axon遅延時間 4bit256x30bit③Synapse接続情報
256x256
Axon情報(256x16 bit)④Axonベクター(位置)
⑤スパイクパケット情報(30bit)
-外部コア番地
X -255---255 →9bitY 同上 →9bit
-Axon番地(0→255) →8bit-Axon遅延(調整*4) 4bit
Memory
Scheduler(Axon)
スパイクパケット
updated
固定値
【参考】 Spiking Neural Network: TrueNorth/IBM
北海道大学 大学院情報理工学研究科49
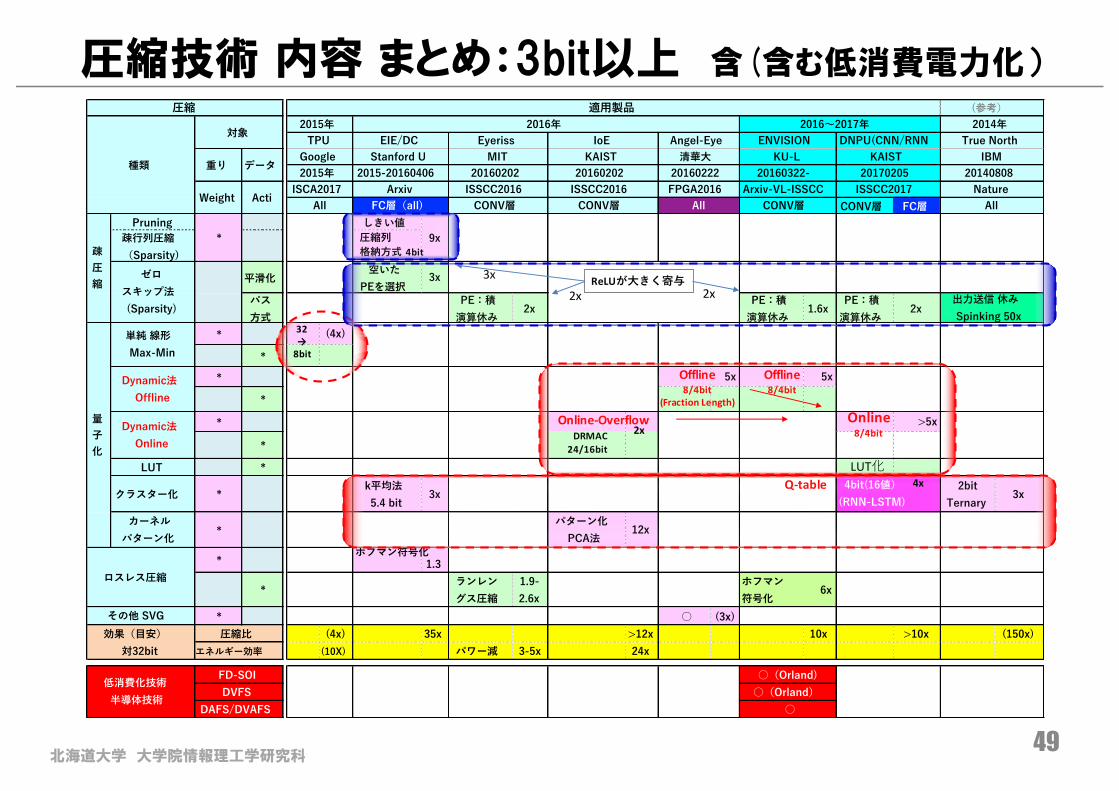
圧縮技術 内容 まとめ:3bit以上 含(含む低消費電力化)
2 B 52TW M K eca
SETUMV ag
4k(
xr 4i
4i
4i
)
* *
/*
9A
p rtN* ) FMV
(FMV
IT ET(
mxt
xt20
(
r. y
( ) (* / / * D x ( * )
iSM NM K *
*
2 B
( ) - -7 22 0T MX B9 7 22 7 22 EVWTI
6RRKOI VE RT A 7 807 8A 9 807 71
* )3 A 2 >
7 20 0T MX 7 22 5 60
)FMV> 9
TOE TOE
53 73B5
305 3B05
CIMKLV 0GVM
474 32 4 ITMUU 0 KIO 4 I
0OO
4 B7 7
* )
3 EPMGOM I
srnu
SETUMV
3 EPMGOM I
A 7R4 TWI RTVL
.
0OO0OO 52 EOO 2 B 2 B
v t *
( FMV l o
E M
fh B6
r r
32→8bit
4bit
ReLUb cd
Offline8/4bit
Offline8/4bit
(Fraction Length)Online8/4bitDRMAC
24/16bit
2x
y
LUT�4x
Online-Overflow
Q-table
2x2x3x
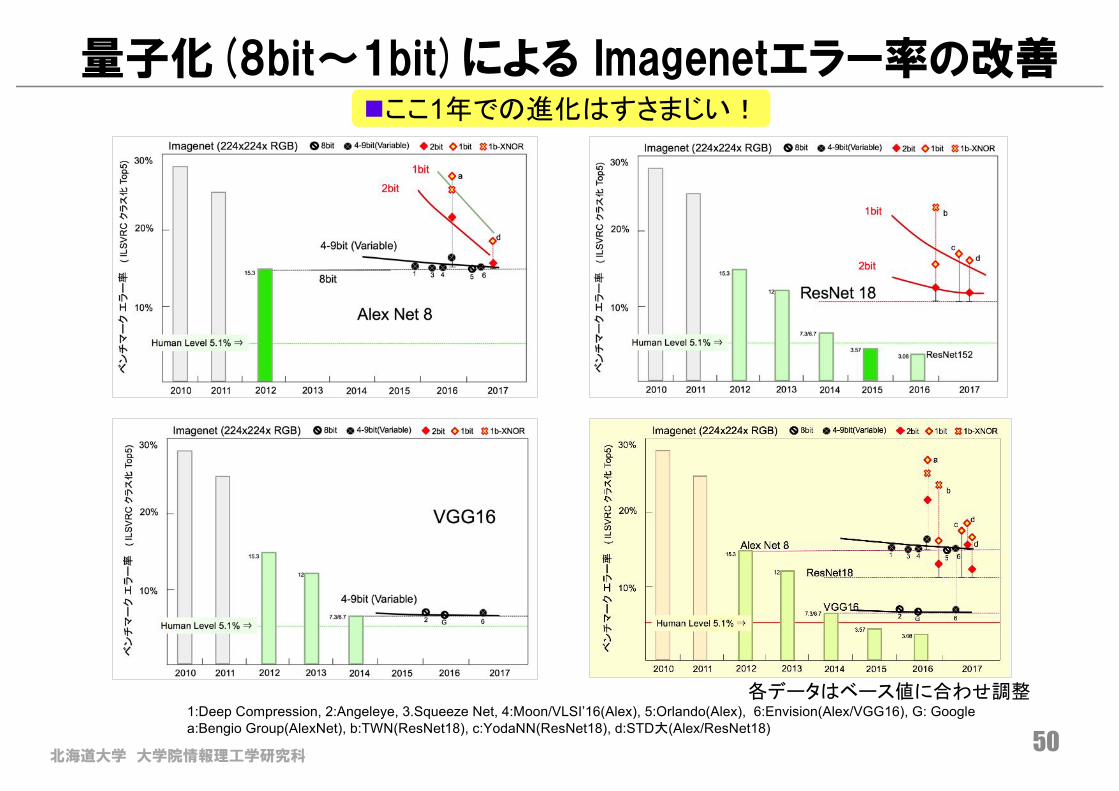
北海道大学 大学院情報理工学研究科50
量子化(8bit〜1bit)による Imagenetエラー率の改善nここ1年での進化はすさまじい!
各データはベース値に合わせ調整1:Deep Compression, 2:Angeleye, 3.Squeeze Net, 4:Moon/VLSI’16(Alex), 5:Orlando(Alex), 6:Envision(Alex/VGG16), G: Googlea:Bengio Group(AlexNet), b:TWN(ResNet18), c:YodaNN(ResNet18), d:STD大(Alex/ResNet18)

北海道大学 大学院情報理工学研究科
画像認識(CNN):小型化・低消費電力化の流れ
51
ILSVRC/ImageNet Top5 エラー率
パラ
メー
タサ
イズ
(バ
イト
)
20% 10% 5%
1M
10M
100M
1G
A
V
G
R
2012年
2014年
A: AlexNet8V: VGGNet19G: GoogLeNet22R: ResNet152S:SqueezeNet10
e-DRAM32MB
2015年
e-SRAM 10MB 0.5W
10W
100W外部DRAM
0.1W
CF型:畳込み層+全結合層型C1型:畳込み層主体型(1層の全結合層)C0型:畳込み層主体型
2%
GDaDianNao
EIE
消費
電力
(チ
ップ
当た
り)
120x
DaDianNao: Super Leaning ChipEIE: Efficient Inference Engine
高精度化(モデル)
(60000x)510x2016年
S+DC
ボードワールド
チップワールド(Movidius/Myriad2)
(NViDia Drive PX2)
DC: Deep Compression
A+DC V+DC
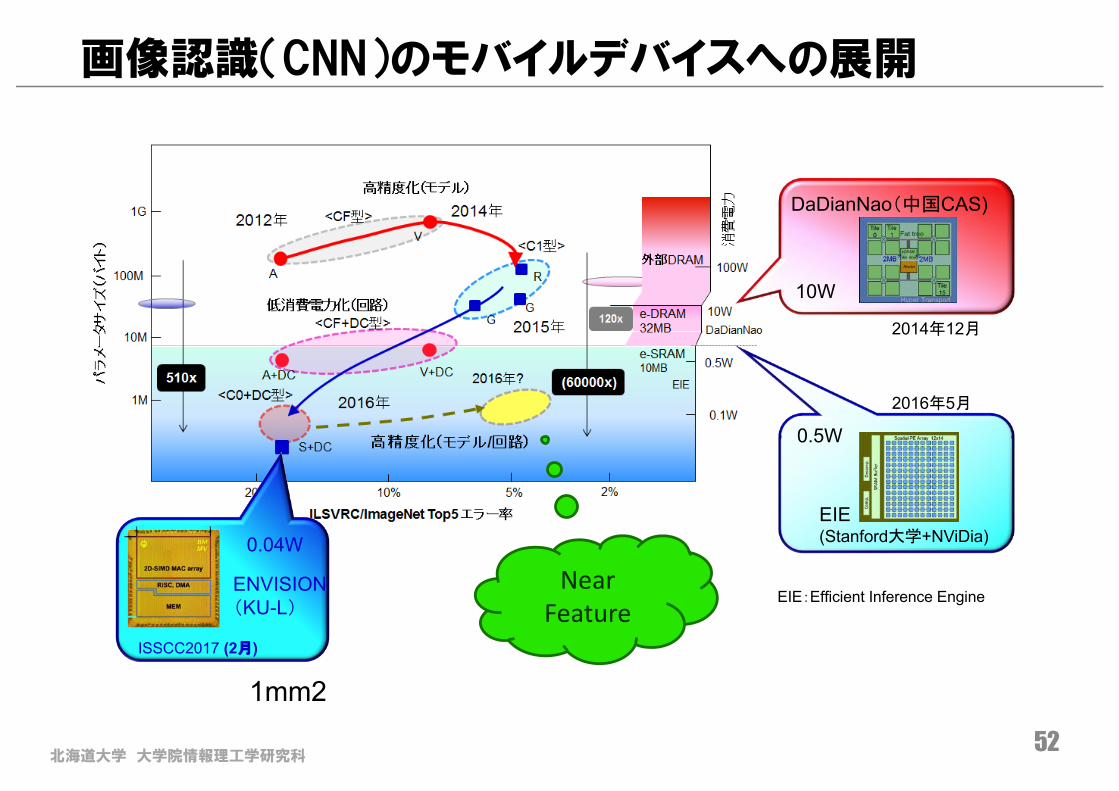
北海道大学 大学院情報理工学研究科
画像認識(CNN)のモバイルデバイスへの展開
52
EIE (Stanford大学+NViDia)
0.5W
NearFeature
10W
DaDianNao(中国CAS)
0.05W
IoEチップ(KAIST)
ISSCC2016 (2月)
2016年5月
2014年12月
EIE:Efficient Inference Engine
0.04W
ENVISION(KU-L)
ISSCC2017 (2月)
1mm2

北海道大学 大学院情報理工学研究科53
TPU (Tensor Processing Unit)
n出展:Google 20170416: https://arxiv.org/pdf/1704.04760.pdf
n2015年チップ、データセンターで使用中-2013年当時、将来の稼働逼迫を予測 (実行専用) -Sparsity対応は時間が無く対応できずとコメント
nコア部8bit, 64kMAC、700MHz⇒92TOPS/s28nm, 300mm2(推定),75W→220W(含DRAM)

北海道大学 大学院情報理工学研究科54
チップサイズと性能比較(Peak値:ほぼ理想値)
チップ面積 (mm2)
演算
性能
(TOPS/s)
101 100 1000
DaDianNao16b/10W(16W)
Orland8b/0.80W面積 x0.3 推定
10
1
0.1
10092TOPS/sはピーク性能チップ面積(300mm2)は推定単体TDP75W
EIE4b+/0.59W
注:28nm, 700MHzに単純比例 TPU8b/200W
ENVISION16b/0.30W
Eyriss16b/0.28W
SiDianNao16b/0.32W
外部DRAMe-DRAM
e-SRAM
x30 Sparsityx10 Weightx3 DataX4 Subword
利用
4b

55
- ディープラーニングの最新動向
- ディープラーニングチップの最新動向
- ディープラーニングチップ実装の勘所
- その圧縮(Sparsity)と量子化技術
- ディープラーニングのシステム例
- まとめ
内容

北海道大学 大学院情報理工学研究科56
mlp: 自動車保険会社(AXA)の大損失予測
n出展:アクサダイレクト 20170329 Google Proud Platform (Kaz Sato)https://cloud.google.com/blog/big-data/2017/03/using-machine-learning-for-insurance-pricing-optimization?1490806008189=1
10 6 3 2
年齢のレンジ
地域
保険のランク
車の年式
70
・・
・・
・・
・・
・・
nアクサダイレクト(日本)nラージロス予測(100万円以上)
nTensorFlowØmlp 入力次元数〜70
Ø78%の精度
Ø値段の最適化に寄与Ø新しい保険の種類
(ex. リアルタイム保険)
Ø古典機械学習:Random ForestØ40%以下

北海道大学 大学院情報理工学研究科 Copyright(C) 2015 STARC All Rights Reserved. 57n出展:NVIDIA M.Bojarski, 20160425, “End to End Learning for Self-Driving Cars”, http://arxiv.org/abs/1604.07316
CNN:EtoE Learning for Self-Driving NViDia 20160425
n End to End Learning for 自動運転・・・原理は至って簡単!Ø この方法 ⇒ ハンドルの角度(~ -5度, -1度°, 0度, 1度, 2度, 3°~ )
ハンドル角度 (ドライバ)
-0.73度 -0.01度 -0.35度
視野(ドライバー)
n従来⇒ 白い自動車、白線、ランプ、山、陸橋、掲示板、赤い車・・・
n人間の運転を原理的に100%模倣できる(ただし、100%は越えない)?!

北海道大学 大学院情報理工学研究科58
n出展:NVIDIA M.Bojarski, 20160425, “End to End Learning for Self-Driving Cars”, http://arxiv.org/abs/1604.07316
明るい部分~CNN対象領域 (66x200 YUV)水平ラインより下が対象
250kパラメータ (解像度取り過ぎ?)
CNN:EtoE Learning for Self-Driving NViDia 20160425
The Udacity Self-Driving Car 2016 (4月〜12月) #1〜#3 CNN+RNNhttps://medium.com/udacity/teaching-a-machine-to-steer-a-car-d73217f2492c
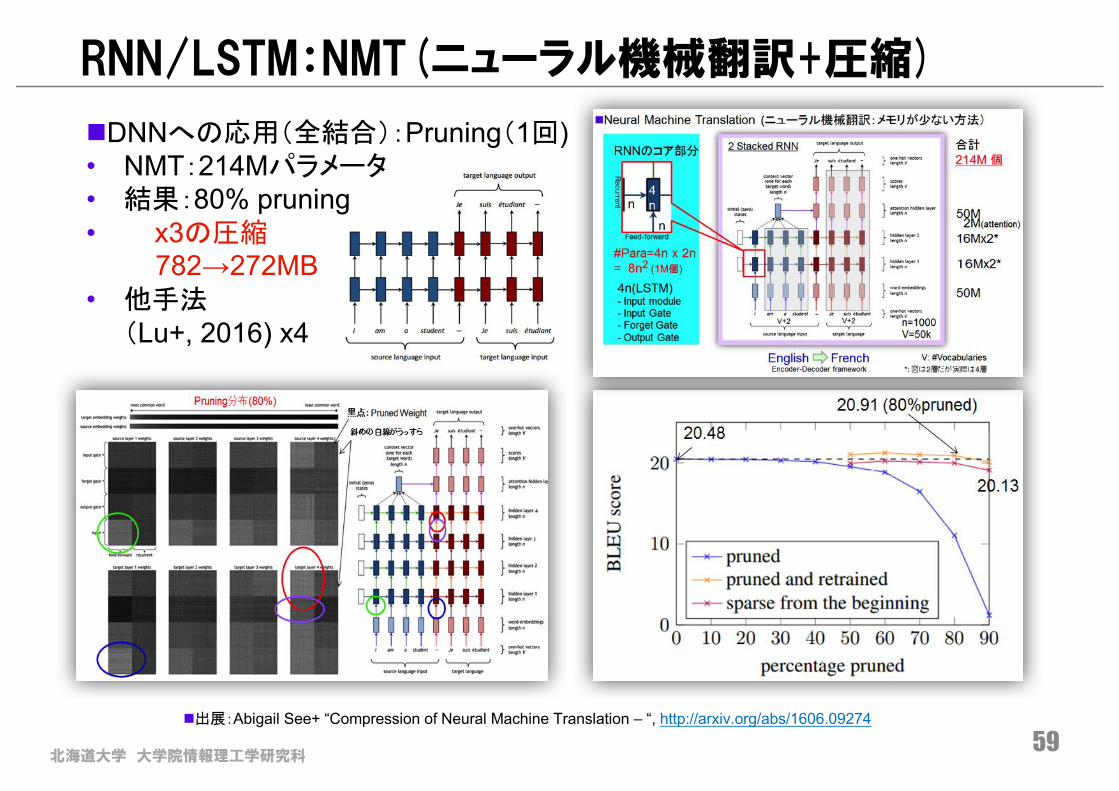
北海道大学 大学院情報理工学研究科59
n出展:Abigail See+ “Compression of Neural Machine Translation – “, http://arxiv.org/abs/1606.09274
nDNNへの応用(全結合):Pruning(1回)• NMT:214Mパラメータ• 結果:80% pruning• x3の圧縮
782→272MB• 他手法
(Lu+, 2016) x4
RNN/LSTM:NMT(ニューラル機械翻訳+圧縮)

北海道大学 大学院情報理工学研究科60
RNN/LSTM:NMT(ニューラル機械翻訳+圧縮)
n出展(参考):Abigail See+ “Compression of Neural Machine Translation – “20160629, http://arxiv.org/abs/1606.09274
4n
nn
4n(LSTM)- Input module- Input Gate- Forget Gate- Output Gate
#Para=4n x 2n= 8n2 (8M個)
2M(attention)
パラメータ
合計
214M 個
n=1000V=50k
RNNのコア部分
V: ボキャブラリー数
Recurrent
Feed-forward
nNeural Machine Translation (ニューラル機械翻訳):スタンフォード大学
50M
ソース言語入力 ターゲット言語入力
2 Stacked RNN
I am a man Je suis homme-
ターゲット言語出力
8M x 2
50M x 2
初期値Context Vector
Je suis homme -学習時の構成
8M x 2
8M x 2
8M x 2
Encoder-Decoderone hot Vector (V)
attention layer
hidden layer1
hidden layer4
分散表現(n)
分散表現(n)
one hot Vector(V)
n: 分散表現 次元数

北海道大学 大学院情報理工学研究科61
CNNと強化学習: Alpha-Go 学習と対戦
n出展:DeepMind Nature 20160128 http://www.nature.com/nature/journal/v529/n7587/full/nature16961.htmlアルファ碁(技術解説)20160617 http://hypertree.blog.so-net.ne.jp/2016-06-17
19x19 CONV層1348マップ(1st)⇒192 (他)3x3 stride 1(主に)
次の一手
CNN
大局観
CNN
指し切り回帰分析
勝率
勝率
2μsec25%
3msec
3msec57%
Value
Fast Rollout
今
次の手
次の次の手
ロールアウト(指し切りで勝敗)
確率
モンテカルロ・木探索
19x19 CONV層1348マップ(1st)⇒192 (他)+全結合層(1x1) 23x3 stride1(主に)
次の一手(強化版)
+強化学習
RL Policy
次の一手CNN
SL Policy次の一手
CNN
大局観
CNN
学習 実行(対戦)
単に画像認識をしているのみ(常識を学習する能力)!しかも遅い(104倍高速化)
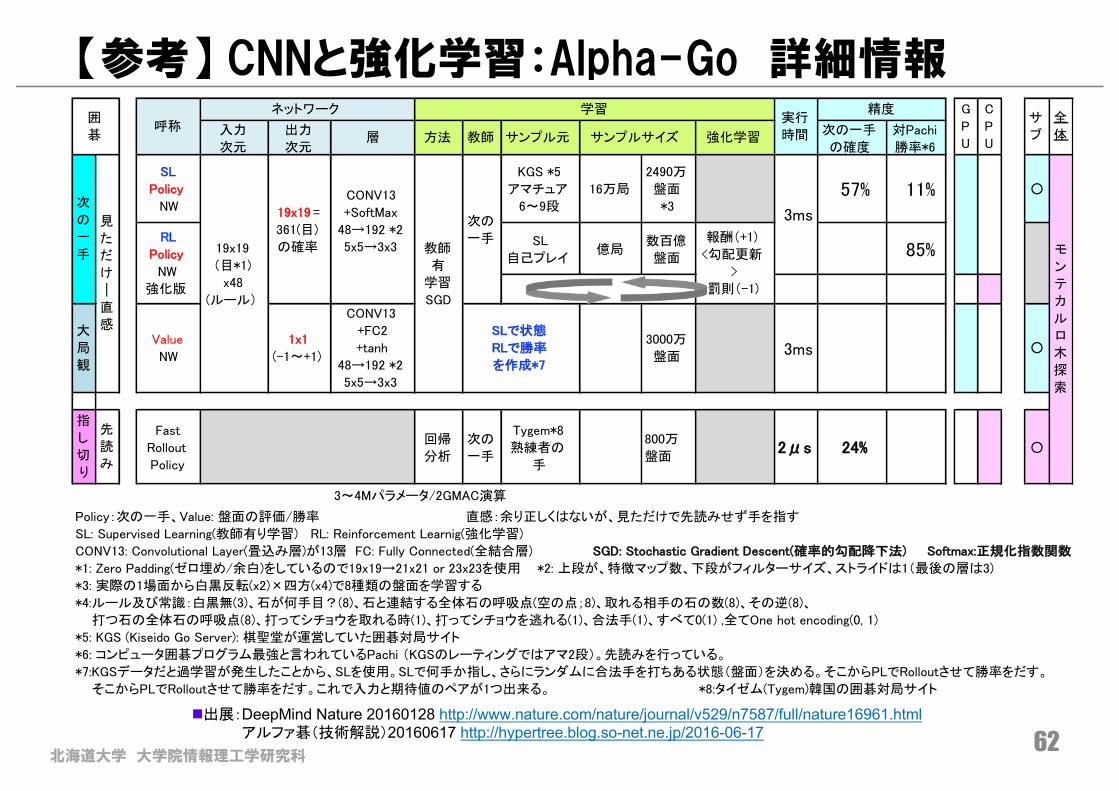
北海道大学 大学院情報理工学研究科62
【参考】 CNNと強化学習:Alpha-Go 詳細情報
°ª
s/čėõ -
@^
`� ���
=
Ø
�
î
�
z
ë
§¶ÄÅ
¯Á¾¾ÁÆÅ
®Á¾½·É
"1
�J
Lç
�;
±É»¹¿��
Tnqç
;
����
`��ËÄ ��� Í
���«ĉĕđěĀ��¨«¤¥Qj
®Á¾½·ÉĞLç�;γ¶¾Æ¹ �`�çy���X b8Ğ�îMØÔèåÑÓÎuÝÞÕã�zëÛÚ;ò=Ù
°ª �°Æ¹ÃǽŸ�ª¹¶ÃÀ½À»�?0Fî*p����¯ª �¯¹½ÀºÁ÷¹¿¹ÀÅ�ª¹¶ÃÀ½»�4�*p�
¥¬³�� �¥ÁÀÇÁ¾ÆŽÁÀ¶¾�ª¶É¹Ã�[}ë.�Ó��.��§¥ �§Æ¾¾É�¥ÁÀÀ¹·Å¹¸��m�.����� °¨¦ �°ÅÁ·¼¶ÄŽ·�¨Ã¶¸½¹ÀÅ�¦¹Ä·¹ÀÅ�fX_����P������°ÁºÅ¿¶È Mv�=@�@
�� �µ¹ÃÁ�®¶¸¸½À»�ÿĘ%ì��]�òØâÑïçã��È��Ì��È���ÁÃ���È��òZ������ ��NÓÎV7ďăč@Î�NÓċôĖĀěûõþÎýĆĕõćè�ĜE6ç.è��
�� �+�ç�(�Òí]��|�È��Ê!B�È��ã�h�ç`�ò*pÙï
�� ĖěĖ�é2{Ğ]�S���ÎdÓ�;aĠ���Îdä�mÙï��dç��R�içRğ��Î�ðïc;çdç@���ÎÜç����Î
����<ádç��dç��R���Î<àâüĂĔöò�ðïC���Î<àâüĂĔöò~ðï���Î�P;���ÎÙêâ�������âÀ¹�¼ÁÅ�¹À·Á¸½À»������
�� �©¨°��©½Ä¹½¸Á�¨Á�°¹ÃǹÃ� �Kr&Ó� ØâÑÝ#e,-ûõĆ
�� �úĚĊēěĀ#ečĘùĕĐE4äxñðâÑ﮶·¼½�Ĝ©¨°çėěĄôĚùãèóď�NĝÏ�zëòtàâÑïÏ
�� ©¨°ąěĀÞä�*pÓ\YØÝÖäÒíΰªòZÏ°ªã�;Ò=ØÎ×íæĕĚāĐæ�P;ò<ßÐïW9Ĝ`�ĝòOìïÏÜÖÒí®ªã¯Á¾¾ÁÆÅ×Ûâ�XòÞÙÏ
����ÜÖÒí®ªã¯Á¾¾ÁÆÅ×Ûâ�XòÞÙÏÖðã��äG5�çĎóÓ�á�IïÏ �� ĀõÿĐ�±É»¹¿��$ç#e,-ûõĆ
�
�
Ē
Ě
Ą
÷
Ė
Ę
H
>
l
��
L�
��
L�.
ĈăĆęěø
ûĚčĖ� ûĚčĖûõþ 4�*p
*p
¥¬³��
�§¥�
�ŶÀ¼
��������
����
°ªãW9
¯ªã�X
ò:��
+t
C� Lç�;
çf3
û
Č
Í
Í
)
-
w
�¿Ä
¨
®
²
¥
®
²
L
ç
�
;
'�Ĝ���
¡��DA
£
o�Ĝ���
����
Ĝa���
��
�ĖěĖĝ
��È�� ¢
����a�
çfX
Lç
�;?0
F
*p
°¨¦
¥¬³��
�°ÁºÅ«¶È
��������
����
���-
�����
`�
��
��
�������
©¨°���
óďĂēó
���Nu
Ý
Þ
Õ
ġ
b
8
�g
°ª
®Á¾½·É
�¬´
¯ª
®Á¾½·É
¬´
4�U
#
e BP ?0
�����
`�
³¶¾Æ¹
¬´
���
,®¶·¼½
�X��
k3
���
�¿Ä
n出展:DeepMind Nature 20160128 http://www.nature.com/nature/journal/v529/n7587/full/nature16961.htmlアルファ碁(技術解説)20160617 http://hypertree.blog.so-net.ne.jp/2016-06-17

63
- ディープラーニングの最新動向
- ディープラーニングチップの最新動向
- ディープラーニングチップ実装の勘所
- その圧縮(Sparsity)と量子化技術
- ディープラーニングのシステム例
- まとめ
内容
北海道大学 大学院情報理工学研究科
DaDianNao32MB e-DRAM
*2
EIE10MB SRAM on Chip
64
103 105104
106
109
103
入力次元数(x) :処理対象画素数+データ数
(1x32x32) (1x100x100) (3x224x224)
*1:DNN 全結合型もしくは、畳込み層が非共通パラメータ型。尚、CNNは共通パラメータ方式*2:DRAM混載を場合の目安/CASのDaDianNao 256Mbit→16Mパラメータ(16bit)*3:NMTの入力数は次段との積のルートとしプロット
1M
1G
1k
Byte16メモリ容量
DNN (F型)*1
CNN (CF型)
CNN (C型)
パラメ
タ数( )y
GoogLeNet22
ResNet34ResNet152
NiN
CIFAR-101. ResNet1102. All CNN173. Hex Kernel4. NiN17
アプリケーションとパラメータ(メモリ容量)との関係
ImageNetMNIST LFW
北海道大学 大学院情報理工学研究科65
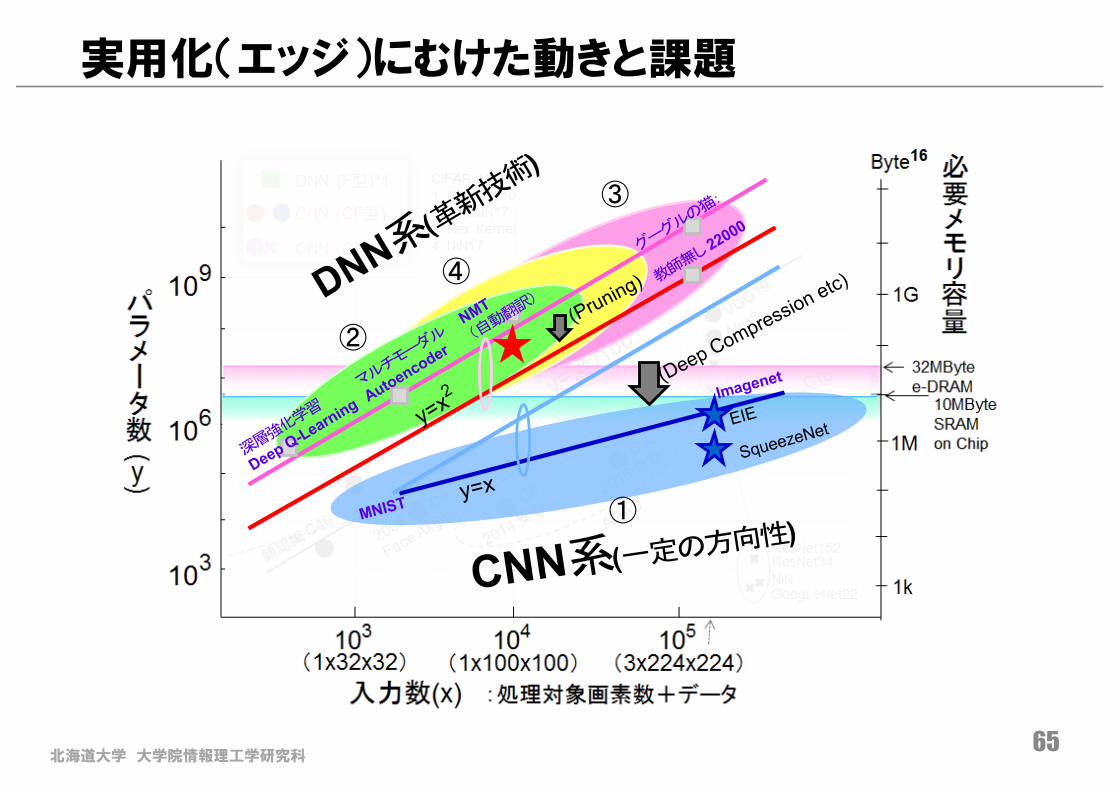
実用化(エッジ)にむけた動きと課題
①
②
④
③

北海道大学 大学院情報理工学研究科
まだ頂きの2~3合目に来たばかり(Beyond Deep Leaning)
66
半導体の出番
第二の?!
2012年 2016年
DeepLearning

北海道大学 大学院情報理工学研究科67
最後に 〜今後の課題〜
n課題・・・パターン認識/系列処理p CNN(畳込み層のみ)・・・画像認識
l 人間並み、50mW ⇒ 1fps程度の能力(遅すぎる)
p DNN(全結合)・・・例えば 自動翻訳、音声認識
l 5万単語(教養人並み)⇒大きなバリア(数W〜数10W)p 高速技術(精度と速度のトレードオフ:レイテンシー)
p NVM、アナログメモリ、高度の表現力(シナプス、ニューロン)l SRAM 200F2 vs. ReRAM 4〜6F2⇒ 2F2
p 未来予測機(Prediction、Generation)がほしい!
p 選択・統合能力(Organize)、環境学習能力(常識獲得)
p ワンショット学習/オンライン学習、 /教師無し学習、ノイズ対応
n注目・・・一段レベルアップが期待される技術
n現状・・・ディープラーニングチップも昨年より本格化!!!p 疎圧縮、量子化、およびリコンフィギュラビリティー
Let’sEnjoyAI!!

68
以上
ご清聴有り難うございました。