step by stepで学ぶ自然言語処理における深層学習の勘所
TRANSCRIPT

Step by Step で学ぶ自然言語処理における深層学習の勘所

自己紹介大串 正矢 @SnowGushiGit
ポート株式会社 Web 開発事業部 研究チーム Tech-Circle 運営スタッフ 機械学習/自然言語処理 インフラ自動構築 /並列分散処理 Python

Agenda• 機械学習
• 深層学習(ニューラルネットワーク)• 自然言語処理における深層学習
• 勉強方法

機械学習とは

機械学習とは• 人がルールを教えるのではなくデータからルールを学習する方法
人 ルール
データ ルール学習

機械学習の利点と欠点

機械学習の利点と欠点• 利点
• 欠点 速い 24 時間動作 分野によっては高精度
データ依存 精度が出せる分野が限られる適切なデータの準備

機械学習をどこで使うか

機械学習をどこで使うか• 値の予測
• 分類
商品のレコメンド購入者が好きそうな商品のスコアを計算しレコメンド
迷惑フィルタ無限に近いパターンから迷惑メールとそうでないパターンを分類

機械学習の適用が難しい所

機械学習の適用が難しい所
データの用意が難しい分野法的な問題(プライバシーなど) 少量のデータしかない
人でも分からない問題ミスが許されない分野

機械学習の仕組み

機械学習の仕組み
特徴を抽出・茶色、肌色・丸みがある・ etc
学習データ

学習の仕組み

機械学習の仕組み教師有り学習 教師なし学習 強化学習
特徴データ
女性
特徴 女性
答え
特徴 女性
特徴 男性
特徴データ
特徴
特徴
特徴
特徴空間ゴール
女性の特徴である髪が長いかなどの特徴を軸とした空間で行動して女性を探すように学習させる

どれが良いの???

どれが良いの???• 結論:教師有り学習:人間と同じで良い教師がいた方が良くなります。
• 教師なし学習• データの分析や特徴量の選出に役に立つ• 教師有り学習の前の準備に使用するのがベター
• 強化学習• 特徴量空間の設定とゴールの設定が難しい• 適用分野や適用方法を絞れば効果的• ゲームなど明確にルールが決まった分野では強力

深層学習の学習方法はどれでしょう?

深層学習の学習方法はどれでしょう?教師有り学習 教師なし学習 強化学習
特徴データ
女性
特徴 女性
答え
特徴 女性
特徴 男性
特徴データ
特徴
特徴
特徴
特徴空間
女性の特徴である髪が長いかなどの特徴を軸とした空間で行動して女性を探すように学習させる
ゴール

深層学習の適用分野教師有り学習 教師なし学習 強化学習
特徴データ
女性
特徴 女性
答え
特徴 女性
特徴 男性
特徴データ
特徴
特徴
特徴
特徴空間
女性の特徴である髪が長いかなどの特徴を軸とした空間で行動して女性を探すように学習させる
全部できるよ
ゴール

深層学習が効果を発揮している分野

深層学習が効果を発揮している分野• 画像認識の分野で 2 位以下に圧倒的な精度の差を出す
• 音声認識の分野でも従来手法を上回る精度

なぜ効果を発揮しているか
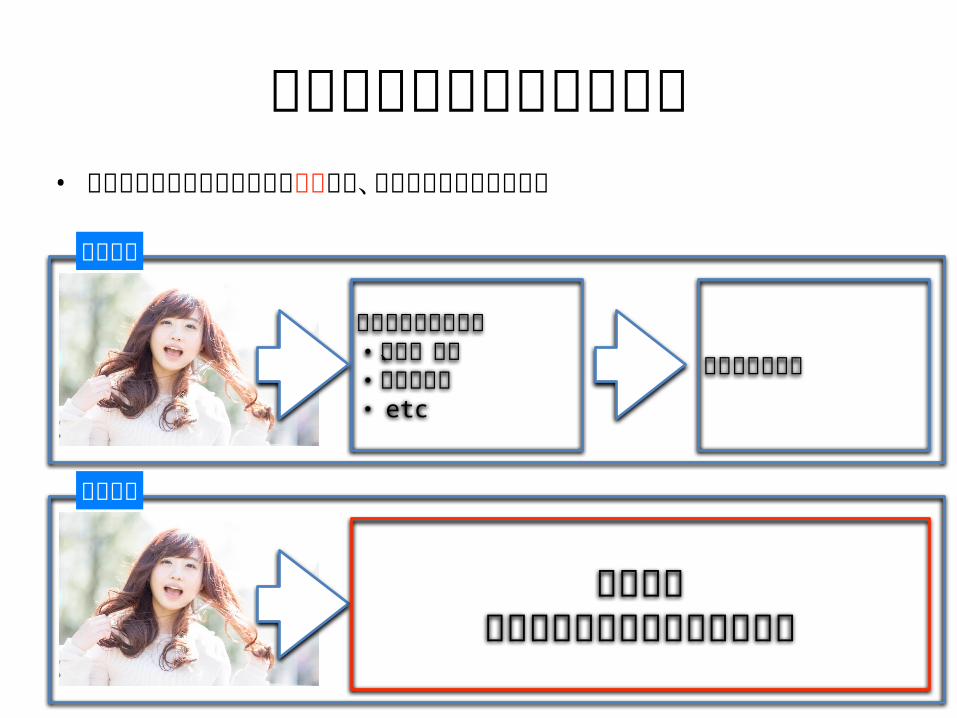
なぜ効果を発揮しているか• 大量の情報から適切な情報を選択して、それを元に学習している従来手法
人手で特徴量を抽出・茶色、肌色・丸みがある・ etc
従来の機械学習
深層学習
深層学習特徴量の抽出から学習まで行う

非構造化データ
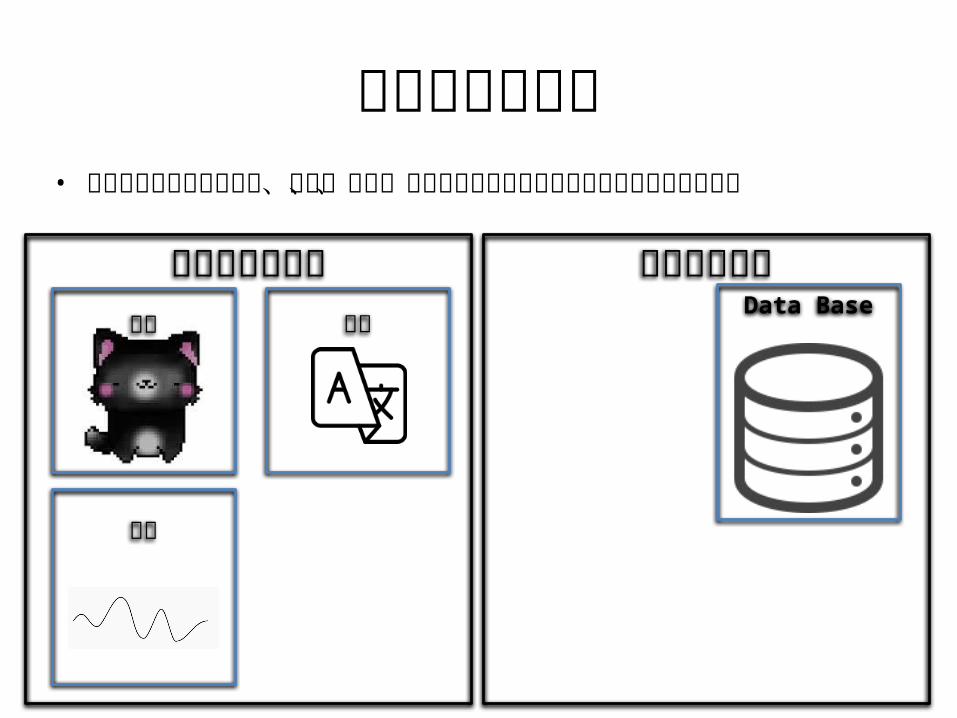
非構造化データ• 非構造化データとは画像、音声、動画、言語など情報の意味づけがされていないデータ
画像
音声
Data Base言語構造化データ非構造化データ

なぜ効果を発揮しているか• 画像、音声には大量の情報を含んだ情報源がある。
エッジ 部分 猫
ピクセル情報
音素 単語 発話
波形情報
低次 高次

なぜ効果を発揮しているか• 低次の情報から高次への情報へ変換する技術が上手く適用されている。
エッジ 部分 猫
ピクセル情報
音素 単語 発話
波形情報
低次 高次
深層学習

非構造化データ• 次ページから画像、音声で成果を出した深層学習が言語においてどのような位置づけか述べます。
画像
音声
Data Base言語構造化データ非構造化データ

自然言語処理の概要の説明

自然言語処理の概要の説明• 自然言語(人の話す言葉)をコンピューターで処理させるための技術• 主な応用:日本語入力の予測変換、機械翻訳、検索など
予測変換 機械翻訳 検索

自然言語処理の概要の説明• 自然言語処理の方向性
• 言語の構造を明らかにする
• 言語から情報を得ること
対話 検索
分かち書き 構文解析S
NP
VP
NP
Neural networks improve the accuracy

自然言語処理における深層学習の位置づけ

自然言語処理における深層学習の位置づけ
エッジ 部分 猫ピクセル情報
音素 単語 発話波形情報
低次 高次
単語 フレーズ 文表現深層学習

自然言語処理における深層学習の位置づけ低次 高次
単語 フレーズ 文表現
I show am me your you … when are1, 0, 0, 0, 0, 0, … 0, 0I
am
Shota
I show am me your you … when are0, 0, 1, 0, 0, 0, … 0, 0
I show am me your you … when are0, 0, 0, 0, 0, 0, … 0, 0
数万語以上あるがほとんどが使用されないデータ

単語で数万以上…表現だともっと多いのでは

深層学習により単語の空間を圧縮して表現の空間を表します

自然言語処理における深層学習の位置づけ低次 高次
単語 フレーズ 文表現
0.5, 0.0, 1.0, 1.0, 0.3, 0.0I
am
Shota
深層学習により単語の空間を圧縮
深層学習
0.5, 0.0, 1.0, 1.0, 0.0, 0.0
0.5, 0.0, 1.0, 0.5, 0.3, 0.0
データ

自然言語処理における深層学習の位置づけ
圧縮された空間を分散表現と呼びます。

深層学習による自然言語の分散表現

深層学習による自然言語の分散表現
I :0am:0show:1me:0your:0you:0:when:0are:0
I :0am:0show:1me:0your:0you:0:when:0are:0
中間層が分散表現

分散表現の学習方法

分散表現の学習方法• CBOW
• 単語を直接予測• 小規模なデータセットに良い
• Skip-gram
• 単語から周りの単語を予測• 大規模なデータセットに使われる
性能が早く高速なので Skip-Gramが人気

分散表現の学習方法
I :0am:1show:0me:0your:0you:0:when:0are:0
• CBOW• 例文: I am Ken
I :0am:1show:0me:0your:0you:0:when:0Ken:0
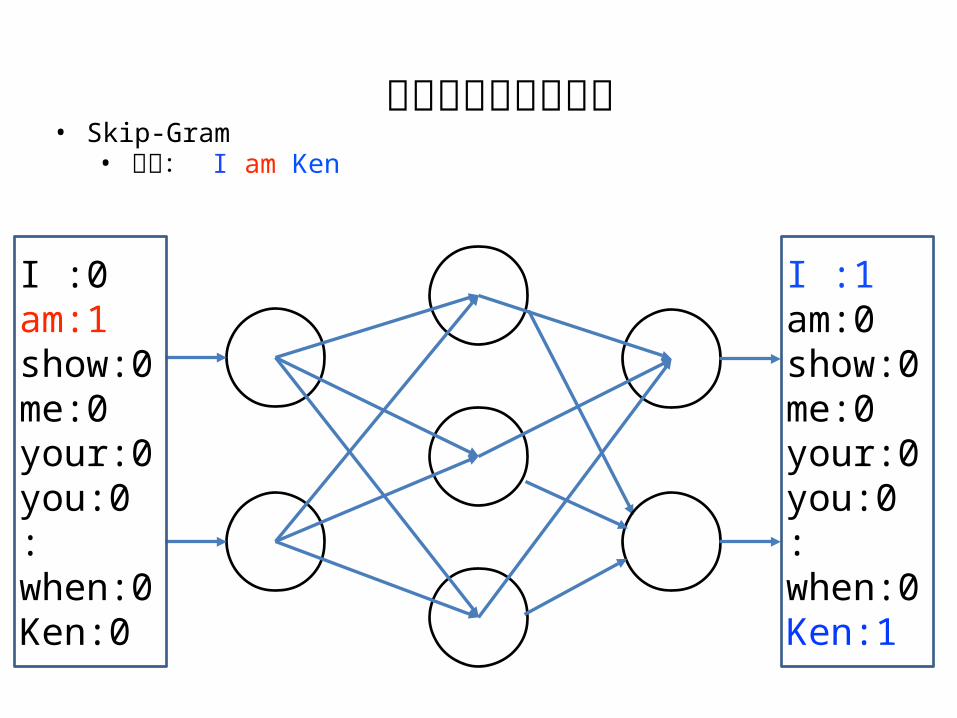
分散表現の学習方法
I :0am:1show:0me:0your:0you:0:when:0Ken:0
• Skip-Gram• 例文: I am Ken
I :1am:0show:0me:0your:0you:0:when:0Ken:1

分散表現を行うことが可能な深層学習のモデル

分散表現を行うことが可能な深層学習のモデル
• Skip-gram(先ほど説明したモデル)• Recurrent Neural Network (実装で使用しているモデル)• Recursive Neural Network

分散表現を行うことが可能な深層学習のモデル
• Recurrent Neural Network
00001:0
出力層
例文: Show me your hair
yourhair隠れ層
me の時の隠れ層
変換行列
過去の値をコピー
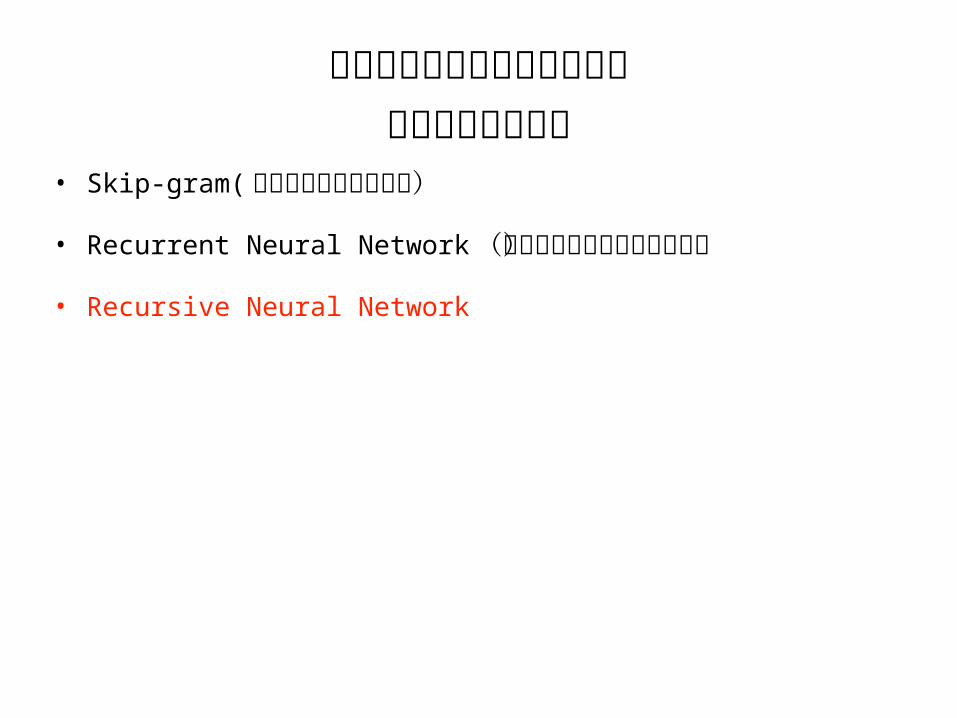
分散表現を行うことが可能な深層学習のモデル
• Skip-gram(先ほど説明したモデル)• Recurrent Neural Network (実装で使用しているモデル)• Recursive Neural Network

分散表現を行うことが可能な深層学習のモデル
• Recursive Neural Network• 合成ベクトルを単語から再帰的に予測するニューラルネットワークを構築
S
Neural単語ベクトル networks単語ベクトル improve単語ベクトル the単語ベクトル accuracy単語ベクトル
合成ベクトル
合成ベクトル合成ベクトル

デモに使用したモデル
デモに使用したモデル
太郎 さん こんにちは
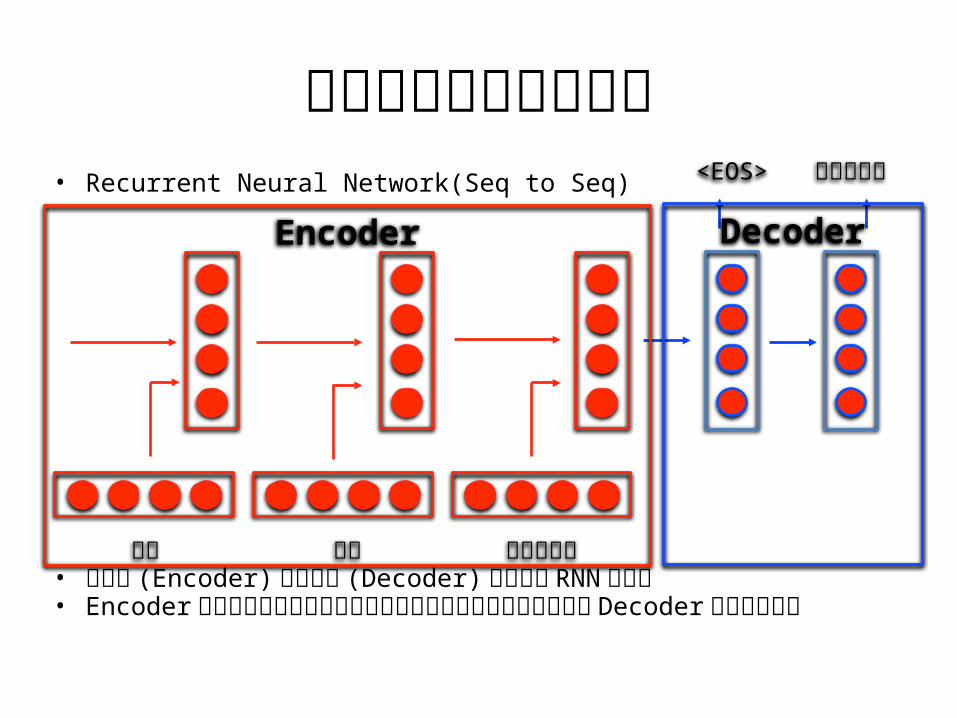
こんにちは<EOS>• Recurrent Neural Network(Seq to Seq)
• 入力側 (Encoder) と出力側 (Decoder) それぞれ RNN を用意• Encoder によって入力系列を中間ノードに変換しその情報をもとに
Decoder が系列を出力
Encoder Decoder

デモに使用したモデル
太郎 さん こんにちは
こんにちは<EOS>• Attention Model• 出力ステップで、その時の隠れ層を使い入力側の隠れ層を加重平均したベクトルを出力で使用
+Encoder
Decoder

システム構成

System Architecture
SQLite
対話破綻コーパス
ファインチューニング用学習データ
プレトレイン WikiPedia タイトルデータ学習
データ取得 データ出力
チューニング
ボット応答
ユーザーアクション
Word NetWikipedia
Entity Vector
Word NetWikipedia
Entity Vector

Wikipedia Entity Vector と Word Netを用いた話題選定
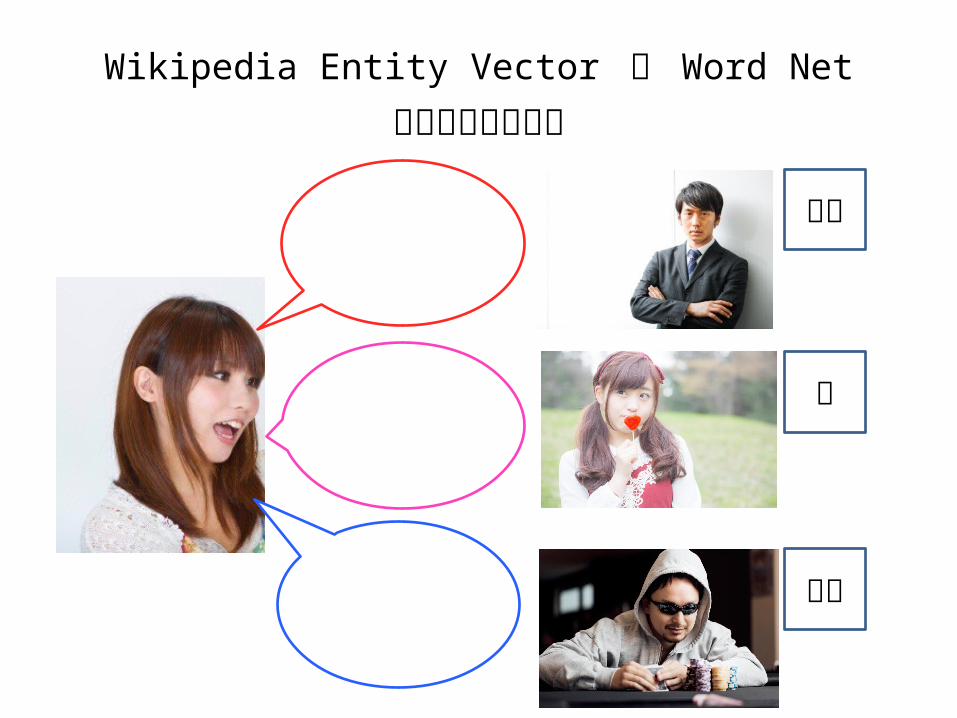
Wikipedia Entity Vector と Word Netを用いた話題選定
彼氏
妹
パパ

Wikipedia Entity Vector と Word Netを用いた話題選定
• Word Net は何??– 単語に概念を付与してグループ化してくれているデータセット
スコティッシュホールド クロネコ オレンジネコ
ネコ

Wikipedia Entity Vector と Word Netを用いた話題選定
しかし概念数が多い:その数 57,238 概念概念数が多いとデータを用意しづらい

Wikipedia Entity Vector と Word Netを用いた話題選定
同じような概念があるはず:それをまとめたい

Wikipedia Entity Vector と Word Netを用いた話題選定
• Wikipedia Entity Vector は何??– 単語、および Wikipedia で記事となっているエンティティの分散表現ベクトル

Wikipedia Entity Vector と Word Netを用いた話題選定
概念にベクトルが付与できる:つまり計算が可能に(注意:今回は計算量とメモリの関係で 20万単語のみ使用)

Wikipedia Entity Vector と Word Netを用いた話題選定
Word NetとWikipedia Entity Vectorを組み合わせることで概念クラスを分散ベクトル化

Wikipedia Entity Vector と Word Netを用いた話題選定
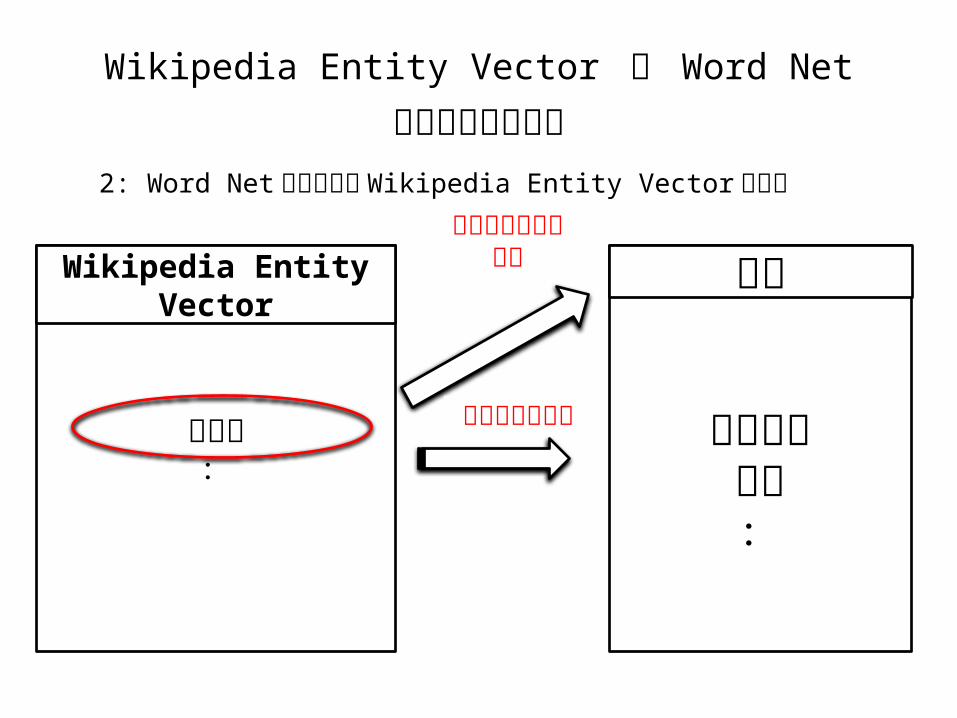
• Word Net と Wikipedia Entity Vector を組み合わせ1: Word Net の概念クラスを Wikipedia Entity Vector を用いて サマライズ2: Word Net の未知語を Wikipedia Entity Vector で付与3:概念クラスの平均ベクトルを Wikipedia Entity Vector で 導出4:概念クラスをサマライズ5:概念クラス内の単語の頻度が 1000 以上だけ残す

Wikipedia Entity Vector と Word Netを用いた話題選定
1 : Word Net の概念クラスを Wikipedia Entity Vector を用いてサマライズ ネコ :[0.2, 0.3, 0.4…]
犬 :[0.3, 0.4, 0.5…]Wikipedia
Entity Vector
うさぎ :[0.2, 0.5, 0.4…]
コサイン類似度計算
Wikipedia Entity Vector と Word Netを用いた話題選定
2: Word Net の未知語を Wikipedia Entity Vector で付与
クロネコ白猫:三毛猫:
ネコWikipedia Entity Vector
コサイン類似度近い
未知語なら追加

Wikipedia Entity Vector と Word Netを用いた話題選定
各概念に属する単語数が増えある程度まとまったが:まだ多い

Wikipedia Entity Vector と Word Netを用いた話題選定
3: 概念クラスの平均ベクトルを Wikipedia Entity Vector で導出
クロネコ :[0.2, 0.3, 0.4…]白猫 :[0.1, 0.3, 0.…]:
ネコ
柴犬 :[0.1, 0.3, 0.4…]土佐犬 :[0.1, 0.2, 0.…]:
犬
平均ベクトル
平均ベクトル

Wikipedia Entity Vector と Word Netを用いた話題選定
4: 概念クラスをサマライズ
クロネコ :[0.2, 0.3, 0.4…]白猫 :[0.1, 0.3, 0.…]:
ネコ
柴犬 :[0.1, 0.3, 0.4…]土佐犬 :[0.1, 0.2, 0.…]:
犬
平均ベクトル
平均ベクトルコサイン類似度計算

Wikipedia Entity Vector と Word Netを用いた話題選定
各概念に属する単語数が増えある程度まとまったが:まだ多い( 20000程度)

Wikipedia Entity Vector と Word Netを用いた話題選定
5: 概念クラス内の単語の頻度が 1000 以上だけ残す
クロネコ白猫:
ネコ
柴犬土佐犬:
犬
白鳥アヒル:
トリ
コアラコアラ

Wikipedia Entity Vector と Word Netを用いた話題選定
これで 76概念まで減少:他は概念を与えないことに全てのベクトル使えばもっと良くなるはず・・

Wikipedia Entity Vector と Word Netを用いた話題選定
その 服 可愛いどこ で買ったの?
彼氏イケメンかっこいい:妹可愛い服:パパお金小遣い:
単語の平均一致率計算

Attention Model を用いた言葉へのフォーカス
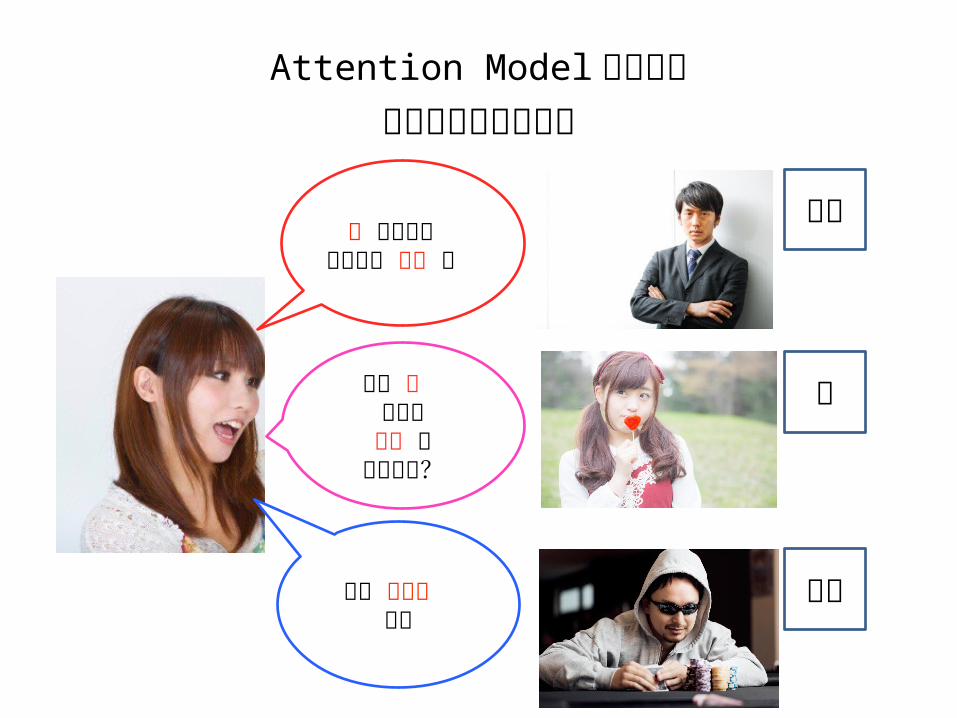
Attention Model を用いた言葉へのフォーカス私 と仕事のどっちが 大事 ?
その 服 可愛いどこ で買ったの?
パパ 小遣い 頂戴
彼氏
妹
パパ

デモに使用したモデル
太郎 さん こんにちは
こんにちは<EOS>• Attention Model
+

Attention Model を用いた言葉へのフォーカス
• Attention Model
• 詳しくは下記のスライドでhttp://www.slideshare.net/yutakikuchi927/deep-learning-nlp-attention

深層学習を実際に適用するには

深層学習を実際に適用するには
データの用意が難しい分野法的な問題(プライバシーなど) 少量の教師データしかない
人でも分からない問題ミスが許されない分野

深層学習を実際に適用するには
データの用意が難しい分野法的な問題(プライバシーなど)
人でも分からない問題ミスが許されない分野
少量の教師データしかない
深層学習を実際に適用するには• データの問題
• 法的な問題• ・・・
• 少量の教師データしかない問題• 既にある資源の有効活用
• Wikipedia• WordNet• etc
• 転移学習• 事前に他のデータで学習したモデルの重みを使用
• バイトを雇う。外注(クラウドワークス)• 教師データを作成してもらう。

深層学習を実際に適用するには
データの用意が難しい分野法的な問題(プライバシーなど)
人でも分からない問題ミスが許されない分野
少量の教師データしかない

深層学習を実際に適用するには• ミスが許されない分野
• 人と機械学習のハイブリッド• 機械学習で効率化+人で最終チェック
+

深層学習を実際に適用するには
データの用意が難しい分野法的な問題(プライバシーなど)
人でも分からない問題ミスが許されない分野
少量の教師データしかない

深層学習を実際に適用するには• 人でも分からない問題
• 哲学的なものは厳しい(人はなぜ生きるのかなど)• フィーリングと勘でやっていて言葉にできない。(営業など)
• 難しい・・けどコミュニケーションを取れば何らかの傾向や細分化できる部分があるはず。その部分のみ解決することは可能

勉強方法

勉強方法• 王道
• 時間の使い方を変える• 付き合う人を変える• 環境を変える
• 独学コース• 勉強会を主催して、発表することが一番早いと思います!!

勉強方法• 勉強のための教材• Coursera
• https://www.coursera.org/learn/machine-learning/home/info
• Stanford University CNN• http://cs231n.stanford.edu/

Conclusion

Conclusion• 機械学習• 深層学習(ニューラルネットワーク)• 自然言語処理における深層学習• 勉強方法• Githubに Starをくれるとやる気が加速します!!
– githubを“ Chainer Slack Twitter”で検索

Reference

Reference• Chainer で学習した対話用のボットを Slack で使用 +Twitter から学習データを取得してファインチューニング
– http://qiita.com/GushiSnow/items/79ca7deeb976f50126d7• WordNet
– http://nlpwww.nict.go.jp/wn-ja/• 日本語 Wikipedia エンティティベクトル
– http://www.cl.ecei.tohoku.ac.jp/~m-suzuki/jawiki_vector/• PAKUTASO
– https://www.pakutaso.com/• A Neural Attention Model for Sentence Summarization
– http://www.aclweb.org/anthology/D15-1044• 猫の画像( 10 ページ)
• http://photobucket.com/images/gif%20pixel%20cat%20kitten%20black%20cat%20cute• 構文解析
• http://qiita.com/laco0416/items/b75dc8689cf4f08b21f6

Reference• 分かち書き画像
• http://www.dinf.ne.jp/doc/japanese/access/daisy/seminar20090211/session1_1.html
• 波形の画像( 10 ページ)• http://www.maroon.dti.ne.jp/koten-kairo/works/fft/intro1.html
• Large Scale Visual Recognition Challenge 2012• http://image-net.org/challenges/LSVRC/2012/results.html
• 音声認識技術 - 大規模テキストアーカイブ研究分野 - 京都大学• http://www.ar.media.kyoto-u.ac.jp/lab/project/paper/KAW-
IEICEK15.pdf• iconfinder
• https://www.iconfinder.com/search/?q=Program&price=free• Machine learningbootstrap For Business
• http://www.slideshare.net/takahirokubo7792/machine-learningbootstrap-for-business
• A Neural Attention Model for Sentence Summarization [Rush+2015] (Slide Share)– http://www.slideshare.net/yutakikuchi927/a-neural-attention-model-for-sentence-
summarization