基本統計量について
TRANSCRIPT

基本統計量について

背景
これからのアドテクはデータサイエンスが重要コンバージョンがとれる確率が高い案件or枠or人に対して適切な価格で入札する
分析者だけでなく開発者も統計の知識を身につける

今日これだけは覚えて帰ってください

_人人人人人人人人人人人人人人人人_
>「平均」は評価指標としてはクソ<
 ̄Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y ̄

少し冷静になりましょう
データの特徴を「平均」のみで表すのは不十分様々な指標を用いてデータを評価しなければならない
「様々な指標」って何よ

基本統計量 (FUNDAMENTAL STATISTICS)
代表値 (representative value)集団の真ん中を表す値
e.x. 平均値(average), 中央値(median), 最頻値(mode)散布度 (dispersion)集団のバラつき
e.x. 分散(variance), 標準偏差(standard deviation)

代表値 (REPRESENTATIVE VALUE)
日常生活で出てくるのは平均値
: サンプル数、 : i番目のサンプルの値いわゆる相加平均
他には相乗平均・調和平均など
=x̄1N*N
i=1 xi
N xi

例1. 平均年収
高い給料をもらっているのは一部の人間
平均給与: 約1300万円明らかに実態・実感と異なる

「平均値」ではなく「中央値」
中央に位置する値
サンプル数が奇数の場合 -> 真ん中の値サンプル数が偶数の場合 -> 真ん中2つの平均
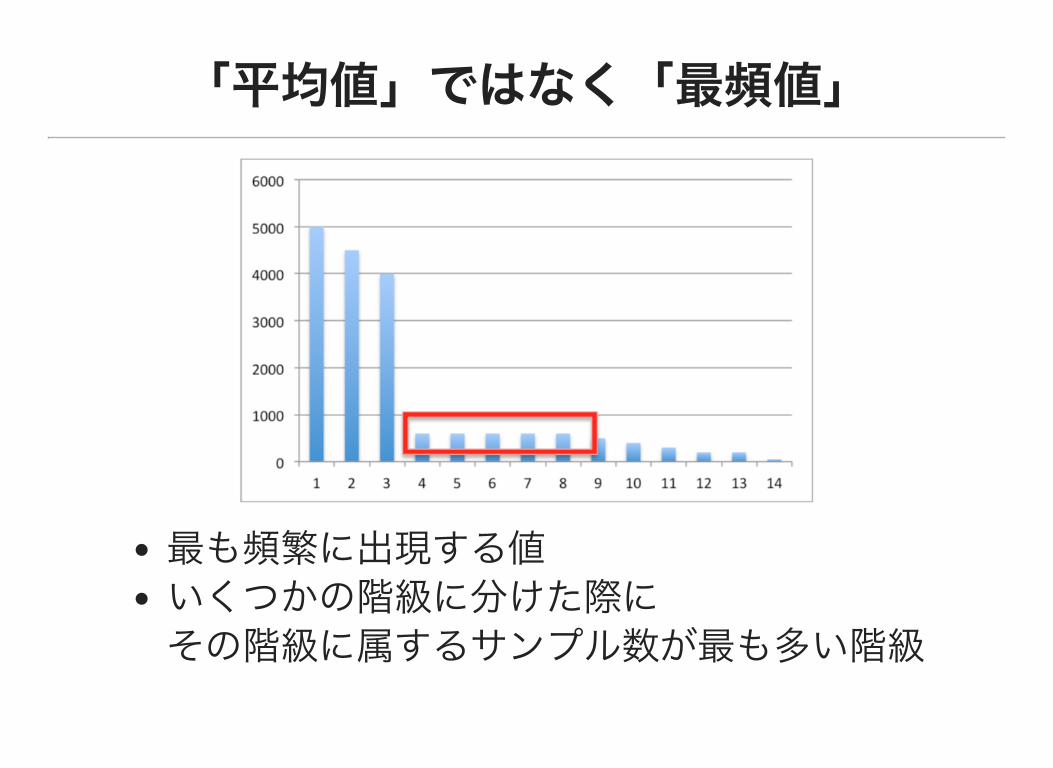
「平均値」ではなく「最頻値」
最も頻繁に出現する値
いくつかの階級に分けた際に
その階級に属するサンプル数が最も多い階級

例2: 平均CVR
広告主 案件 クリック数 CV数 CVR
1111 2345 5000 500 0.1
平均で見ると優秀な案件に見える

枠ごとに見てみる
広告主 案件 枠 クリック数 CV数 CVR
1111 2345 10 500 300 0.6
1111 2345 11 400 200 0.5
1111 2345 100 1500 30 0.02
1111 2345 101 1000 20 0.02
1111 2345 102 1000 10 0.01
枠別で見るとCVRの高い枠と低い枠の差が顕著

平均の弱点
外れ値に引っ張られやすい
全体の分布がどうなっているかわからない
分布って何よ

散布度 (DISPERSION)
データの散らばり具合を表す分散 (variance)
標準偏差 (standard deviation)
= ( +σ2 1N*N
i=1 x̄ xi)2
σ = ( +1N*N
i=1 x̄ xi)2‾ ‾‾‾‾‾‾‾‾‾‾‾‾‾‾
√

分散 (VARIANCE)
平均と比較したときのサンプルの散らばり具合
分散大 => 散らばり具合大分散小 => 散らばり具合小
= ( +σ2 1N*N
i=1 x̄ xi)2

標準偏差 (STANDARD DEVIATION)
分散の平方根をとったもの
いわば平均からの誤差
平均 ± 標準偏差 => 偏差値
σ = ( +1N*N
i=1 x̄ xi)2‾ ‾‾‾‾‾‾‾‾‾‾‾‾‾‾
√

まとめ
データを表す指標は代表値と散布度の2種類がある代表値: 平均値・中央値・最頻値散布度: 分散・標準偏差
平均だけに頼るのはやめましょう
× 「そのデータの平均教えて」○ 「そのデータの平均と分布見せて」

ご清聴ありがとうございました

参考ページ
http://www.mm-lab.jp/analysis/data-analysis-start-with-excel-4th/http://ronri2.web.fc2.com/tokei09.htmlhttp://www.albert2005.co.jp/technology/data/univariate.html