a framework for mapping periodic real-time applications on multicomputers
TRANSCRIPT

778 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 5, NO. I, JULY 1994
[I81 V. Prasanna and C.S. Raghavendra, “Array processor with multiple broadcasting,” J. Parallel Distrib. Computing, vol. 2, pp. 173-190, 1987.
[19] J. Rothstein, “Bus automata, brains and mental models,” IEEE Trans. Syst., Man, Cybemetics vol. 18, 1988.
[20] Q.F. Stout, “Meshes with multiple buses,” Proc. 27th IEEE Symp. Foundations Comput. Sci., 1986, pp. 264273.
A Framework for Mapping Periodic Real-Time Applications on Multicomputers
Shridhar B. Shukla and Dharma P. Agrawal
Abstract-This short paper presents a framework for periodic execution of task-flow graphs that enables schedulability analysis of the commu- nication requirements. The analysis performs the steps of segmenting messages, assigning the segments to specific links and time intervals, and ordering them within the intervals to generate node switching schedules that provide contention-free message routing at run-time. The analysis is also used to integrate task allocation with message routing using a contention-based objective function. Usefulness of the proposed scheme in ensuring guaranteed communication performance is demonstrated by an appropriate example.
Index Terms-Interval sequencing, message-interval assignment, path assignment, periodic real-time, scheduled routing, task-flow graph
I. INTRODUCTION Multicomputer programming, often mathematically referred to as
mapping, can be looked upon as solving optimization problems that determine partitioning, task allocation, node scheduling, and message routing in sequence (Fig. 1). The formulation and solution of each are constrained by the solutions selected for the previous ones. In case of real-time applications, the mapping procedure must characterize the collective effect of the different stages on the run-time behavior at compile-time (i.e., statically) to provide the required performance guarantees.
Previous efforts to integrate mapping stages have used heuristics to integrate task allocation either with node scheduling and/or with message routing to minimize task response time [I21 or to satisfy periodicity, precedence, and replication constraints [ 1 31. Several researchers have attempted to integrate task allocation with message routing directly by assuming one-to-one mapping of tasks to nodes to eliminate the complexity added by node scheduling [2], [5] , [6]. These approaches perform explicit bandwidth allocation to minimize contention, but do not specify any switching mechanism to enforce it.
Compile-time (static) resource allocation is preferred for real-time applications, because it is easier to obtain performance guarantees based on a pr ior i information about the run-time requirements. However, it results in inflexible systems, because it requires the
Manuscript received April 1, 1992; revised January 3, 1994. This work was supported in part by National Science Foundation (NSF) under Grant MIP-8912767, and in part by the Research Initiation Program of the Naval Postgraduate School.
S.B. Shukla is with the Department of Electrical and Computer Engineering, Code EC/Sh, Naval Postgraduate School, Monterey, CA 93943-5000 USA; e-mail: [email protected].
D. P. Agrawal is with the Department of Electrical and Computer Engineer- ing, North Carolina State University, Raleigh, NC 27695-791 1 USA; e-mail: [email protected].
IEEE Log Number 9401212.
Application code
U partitioning
U performance vbible
to the user
Fig. 1.
run-time demands on resources to be known precisely. On the other hand, run-time (dynamic) techniques are flexible, because they do not depend on such accurate characterization of resource requirements [18]. However, they may suffer from high overheads for particular applications, and they make it difficult to achieve performance guarantees. This makes a combination of compile- and run-time mechanisms desirable for guaranteed performance. The subject of this short paper is a framework for compile-time allocation of tasks to nodes and messages to network links for contention-free routing. Its first contribution is to provide a routing technique that guarantees timing constraints without losing the desirable properties of the current routing mechanisms, viz., ease of implementation, local forwarding decisions, low latency, and use of multiple shortest paths. Its second contribution is integration of task allocation and message routing to solve the following problem common in many throughput- critical real-time applications, such as vision, signal processing, and radar data processing. Given a precedence-based task graph that is invoked periodically, how can it be guaranteed at compile-time that every invocation will have identical latency?
The general approach is to derive the communication requirements from the application described as a directed acyclic graph that specifies the task execution time and sizes of intertask messages. These requirements are first expressed as release-times and deadlines on message delivery, and they are then used in formulating message scheduling problems as integer programs leading to an estimation of the traffic pattern across the network for any given allocation. The allocation scheme attempts to remove the hot-spots in this traffic pattern. The set of feasible solutions to the integer programs is then used to obtain a set of switching schedules that are independently executable by node communication processors. The spatial and tem- poral locality in intertask communication is exploited to reduce the integer program sizes.
In Section 11, the model of computation is described. Section 111 gives an overview of scheduled routing with respect to periodically invoked task flow graphs and provides a detailed example. A method to compute switching schedules is described in Section I V . Section V describes a contention-based objective function for task allocation. Results supporting the use of this framework in reducing network contention and in compile-time analysis with respect to schedulability
Dependencies between stages of the mapping procedure.
1045-92 19/94$04.00 0 1994 IEEE

IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 5 , NO. 1, JULY 1994 779
of communication are presented in Section VI. The paper ends with conclusions in Section VII.
11. MODEL OF COMPUTATION We consider applications represented as a directed acyclic graph,
hereafter referred to as a taskfiow graph (TFG), with each vertex representing a task and each directed arc representing the flow of data. We are concerned with the periodic data-flow execution of this graph. A TFG is specified by a pair of sets ( S T , S M ) . ST = {TI, Tz, . . .} is the set of tasks, with the execution time of T, being e , . SM = { M I , 342,. . .} is the set of intertask messages. Message M, is m, bytes long. S M defines a precedence relationship over ST such that TJ < T k if there is a path from T3 to Tk.
Assume a static one-to-one task to node allocation with input period r,,, and a uniform link capacity of C bytesls. Let T, be the longest task execution time, and let r, be the longest message transmission time, with T,,, 2 T~ 2 7,. This implies that the input period is bounded from below by the longest task execution time, and that the task-level partitioning used has attempted to minimize intertask communication. The latency of a TFG invocation consists of task execution times as well as intertask message transfer times. Let the following sequence represent some TFG critical path: {T21,M11,T,2,M1P, . . . ,T, k r M l k r T , k+l , . . . ,T ,L} ,whereT, , isan input task, TtL is an output task, TZk 4 T z k + l , 1 1. k 5 ( L - l ) , and every message in the sequence is from the task on its left to the task on its right. Therefore, the latency of any invocation, A, is such that the following expression is true:
r - 1
In the absence of communication with guaranteed performance, X may exceed the minimum value, because of delays due to pipelining of invocations as messages from distinct, yet overlapping, invocations face contention. Considering the latencies of distinct invocations, if the TFG output data generation is to be identical to the input data amval, we need:
where X J is the latency of invocation 1. The output period, T,",,, which is the interval between completions of the j t h and ( j - 11th invocations, becomes r&, = T,,, + X3 - X J - ' . Equation (1 ) is equivalent to r,,, = r,, V J = l , 2 , 3 ;... We require that the periodic execution of a TFG must satisfy this requirement; otherwise, it is defined to be output inconsistent.
111. SCHEDULED ROUTING In current multicomputers, the channel assignment is typically
made on a first-come-first-served basis or by using some priority order among messages contending locally at a node [14, 81. Such nondeter- ministic or local policies cannot maintain the latency identical across invocations, because of nonuniform contention-related delays, making them unsuitable for the computation model described above. The scheduled routing technique introduced here addresses this problem by using its compile-time and run-time elements. The compile- time element uses knowledge about the TFG and the topology to determine if the communication requirements can be met, and it determines the exact path for each message (path assignment). Then it determines if the message should be segmented and generates periodic schedules that guarantee contention-free transfer (flow-control). The run-time element makes use of these schedules, called node switching schedules, to establish clear paths between the source and the destination. A clear path for a message segment is a sequence of
M4.2pkts
,Ipkt
t
An example task-flow graph Fig. 2.
channels from the source node to the destination node along which all of the resources, such as buffers and physical links, are available.
A. Organization of the Communication Processor A functional organization of an ideal communication processor
(CP) to be used with scheduled routing could be described as follows. The CP at each node is required to store and execute its switching schedule. If the multicomputer topology has degree n , each CP has n + 1 input and output connections, n of which are from and to adjacent nodes, respectively. It also connects the local application processor (AP) to the input and output buffers. A message coming from a neighboring node can be sent on any outgoing channel. Execution of a switching schedule at a CP results in setting up a sequence of configurations of input and output connections. In scheduled routing, by simultaneously, yet independently, setting up the configurations at all nodes, clear paths are established for delivering each message.
The following assumptions are made in scheduled routing. Ex- ecution of switching schedules assumes the basic time unit to be the time for a single packet transmission. Task-level parallelism, in which the message sizes are large enough to make the propagation delay negligible compared to the transmission delay, is assumed. The time required to switch to a new configuration and local buffer management overhead in a CP are assumed to be negligible. The network links are assumed to support bidirectional, half-duplex traffic, and the time taken to reverse the direction of traffic on a link is also assumed negligible.
B. Illustration of Scheduled Routing Consider the TFG shown in Fig. 2, consisting of seven tasks and
seven messages to be executed on a 3-cube. The number of time units to execute a task is shown inside the circle, and the size of each message in number of packets is shown alongside the edges. Assume an arbitrary task allocation as shown by the node addresses alongside the circles. The critical path length for the TFG is 18, assuming unit time for an operation and a packet transmission. The largest task time of 6 implies a minimum possible invocation period of 6.
Table I summarizes the message attributes. For simplicity, an arbitrary assignment of paths (sequence of nodes) to each message is assumed (column 3). If an invocation of this TFG must have the minimum latency of 18, the interval during which a message must be transmitted is determined by using critical path analysis. For example, a latency of 18 requires that all messages to T7 must be received at node 011 at time 12. This requires transmission of A42 and lVs and execution of T d to complete in the interval [6, 121.

780
Message No.
IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 5, NO. 7, JULY 1994
Source, Dcst. Path Length Interval Releasetime, Addresses (Scq. of nodes) (no. of packets) deadline
M1 M4 M1
M4 M7 link 4-5: I
M1 M1 M7
(a) Fig. 3. (a) Example TFG mapping on a 3-cube. (b) Assignment of M I , M4, M7 over [0, 61
TABLE I MESSAGE DATA FOR ILLUSTRATING EXPLICIT
FLOW-CONTROL (MINIMUM INVOCATION PERIOD = 6)
For the given message and task attributes, this permits a slack of 1 for transmission of M2 or M S . Assuming that this slack is assigned to MS (arbitrarily, the shorter message is chosen), the intervals for transmission of MZ and M5 become [6, 81 and 110, 121, respectively. Intervals for the remaining messages, given in column 5 of Table I, are obtained similarly. The release-time and deadline for each message (column 6) are obtained by performing modulo 6 operation on each endpoint of the intervals in column 5. This maps each interval of column 5 on a single time frame of length 6. For example, M I must be transmitted over interval [4, 21, i.e., over [O, 21 and [4, 61; M3 must be transmitted over interval [O, 21; M4 must be transmitted over interval 12, 41; and so forth.
Consider the subset of three messages, MI, M 4 , and M 7 , which share links as shown in Fig. 3(a), and therefore are likely to contend. Fig. 3(b) shows how M I , M4, and My can be transmitted over [O, 61. The timing constraints are met, and contention-free transmission is possible, only if M7 is scheduled over [5 , 63, although it could potentially be scheduled over any unit length subinterval of [2, 61. Such explicit scheduling of messages can be realized by periodic execution of a set of schedules for setting up the switch configurations at the individual node CP’s [ 161. These schedules are referred to as node switching schedules. Each configuration of a CP’s schedule specifies the time at which it must set up the configuration and the connections from input channels/output buffers to input buffers/output channels. The foregoing example illustrates the decisions that determine the timing constraints, message segmentation, and segment assignment to links and intervals for switching schedule computation.
Iv. SPECIFICATION OF SWITCHING SCHEDULES
A. TFG Communication Requirements
The release-time and deadline for each message above have been obtained by imposing the following requirement: The run-time latency for all invocations must be identical to the critical path length.
Since our objective is to meet a given throughput (determined by the input arrival rate), not latency, the proposed framework first alters the TFG critical path length. It extends the latency without affecting the maximum possible throughput, which is determined by the longest task. Thus, it is assumed that each TFG message transmission can be completed in an interval equal to the execution time of the longest task. This permits delaying of messages to reduce contention without affecting the minimum input period. Release-time and deadline assignment are then performed in the same manner as illustrated in the example: by using critical path analysis, but with the window for each message transmission time equal to the longest task execution time.
Each task must receive messages from its preceding tasks every r,, time units. Two conditions can be imposed on each message transfer. First, invocation at the minimum period of T~ requires that each message transfer must be completed in r, time units. Second, each transfer must occur once in T,, time units. The time bounds over a single interval [O,T,,] are assigned as follows. Consider the first (0th) TFG invocation starting at t = 0. The instant, T : , at which M, is available for transmission is the finish time of its source task as obtained by critical path analysis. According to the first condition above, M , must complete transmission by instant dp, where d: = T: + T ~ , where T~ is the longest task execution time. Using the second condition, we assign two time instants to M, -a release-time, T ~ , and a deadline, d, -such that the following condition exists:
(2) Fig. 4(a) shows instants T : , dy, T,” , and d,”, obtained by critical path analysis performed after extending latency, for messages MI and M2 of invocation 0. Fig. 4(b) shows instants r i , d ; , ~ ; , and d: for invocation 1 , which is shifted from invocation 0 by T , ~ . Fig. 4(c) shows these instants mapped on a single invocation period. Fig. 4(d) shows how M I and M2 actually get sent when successive invocations are pipelined.
To guarantee that (1) is satisfied, when the TFG is invoked periodically with period T,, 2 T ~ , M, must be transmitted in the interval [ ~ % , d ~ ] if d , > T~ or in the intervals [O,d,] and [ T , , T , , ]
when d , 5 T , . Scheduled routing guarantees these time-bounds by incorporating them in path assignment and flow control.
B. Path Assignment
Scheduled routing assumes that all packets of a message travel along the same path. For example, MI of Fig. 3(a), travels along 000 + 001 --t 101 + 111 between [0, 21 and also between [4, 51. In Fig. 2, consider a change in size of M4 to 4 packets instead of
T , = T: mod r,”; d , = dp mod T,”.

IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 5, NO. 7, JULY 1994 781
M2 LA (C)
Fig. 4. single period. (d) Transmission of M1 and M2 in successive invocations.
Assignment of time-bounds to a message. (a) M1 and M2 in invoc
2, because of a change in the algorithms that T3 and Tg use. Now, the path assignment of Table I cannot he used, because link 1-5 is required to carry five units of traffic over the subinterval [2, 61. This can he resolved by choosing the paths 000 + 001 + 011 -+ 11 1 and 100 + 110 + 111 -+ 011 for M I and M7, respectively. In general, once time-bounds have been assigned, each message with alternative equivalent paths should be assigned a path, so that none of the links in the network is overloaded in 10, q,] or in any of its subintervals. We express this path assignment problem using the notation below.
The distinct r Z and d, values for all messages, when sorted in the increasing order, divide [0, T,,,] into nonoverlapping intervals. Let t o = 0 < tl < t 2 < t 3 < . . . < t~ = T , ~ be the I< distinct endpoints of intervals formed by the time-bounds assigned to messages. Interval [ t k , t k + l ] is denoted by Ak, and a message is active in Ak if it is a subinterval of the interval(s) corresponding to the time-bounds of (2) for that message. If the TFG has IVm intertask messages, let A = [a,c] he an Xm x 11- matrix, called the message activity matrix, such that a& = 1 if hf, is active in .&, and 0 otherwise. For each message, we have the following relation:
I< - 1
( 3 ) m C a , k A k 2 2.
k=O
An equality in (3) indicates that M, is a no-slack message that fully uses the capacity of all the links in its path during its active intervals. If there are NI links in the topology, we define an IV, x NI path assignment matrix B = [b,,] such that b,, = 1 if message Mz uses link L,, and b,, = 0 otherwise. Using matrices A and B , two different link utilizations may be defined.
Dejnition I : Link Utilization, LU,, for link L , is defined as the ratio of the sum of transmission times of all messages carried by LJ and the sum of lengths of all intervals in which at least one message is active on L,. Thus, if Q, is the set of values of index k such that 3 a message hft with n,kbz, # 0, we get the following equality:
MI in MI in M2 in invocation i invocation (i+l) invocation (i-1)
MI M2 in invo- cation i M2
1 i+ 1 i+2
( 4
:ation 0. (b) M1 and M2 in invocation 1. (c) Mapping of M1 and M2 on a
Using these definitions, the path assignment problem can be stated as follows. Given matrix A and a one-task-to-one-node allocation, determine matrix B such that su,k 5 1 b'jk and Lu, 5 1 V j . Although the utilization values can be used to determine a feasible path assignment, they do not provide information about the utilization projiile over the invocation period for a link. Such a profile is required to compute node switching schedules.'
C. Message-Interval Assignment
In the example of Table I, the interval [0, r,,] is divided into subintervals [0, 21, [2, 41, and [4, 61. M4 is active in [2, 41, and M 7 is active in [2, 41 and [4, 61. For the given path assignment, M4 and M, share the link between nodes 4 and 5. Since M4 is without slack, it must be determined that A& can be sent only during [4, 61, and not during [2, 41. Similarly, it must be determined how the three packets of M I must he split between intervals [0, 21 and [4, 61. These decisions are interdependent, because M7 shares link 4-5 with M 4 and both are candidates for using it in the interval [4, 61. Thus, partitioning of messages into segments and their assignment to subintervals must ensure that no link exceeds its capacity in any suhinterval(s) of [0, r,,]. The messages to be considered together to determine the message-interval assignment are determined by using the closed, transitive binary relation between messages defined below.
Dejinition 3: Two messages M , and M , are related if and only if either 3 a link Lt and an interval & such that b,, = b,, = 1 and apk = a,k = 1 or 3 a message M,, which is related to both M p and M,.
Dejinition 4: A message set, SR, is maximal if and only if V M Z , M, E SR, hfL and hf, are related and 3 Mk $? SR, such that Mk and M, are related.
Let Sk denote the i th maximal subset. The maximality of each subset ensures that Sk n Sk = 0 for I # j. Such subsets of SM (the set of all TFG messages) can he obtained by performing row operations on an identity matrix and the matrices A and B.
C::; b r J m 2 Thus, the message-interval assignment problem can now be solved separately for all the maximal subsets of S?W. Consider a maximal subset SR with Qn = { n l , n2 , . . .} as the indices of messages in it. Let Q 1 = { Z l , l ~ , . . . ] , and let Q k = { k l , k z , . . . ] he the indices of the links and intervals used by messages in SR. Let S h , denote the time for which Mnh is transmitted in Ak,. A feasible assignment of
' I t is not guaranteed that LCI,,SC;k 5 1 V j , k leads to feasible node
LcTJ = CCkEQJ Ak'
Link utilization by itself does not capture all the hot-spots in the network. Therefore, spot utilization for every link-interval pair is defined as follows.
Spot utilization, suJk, is defined as the number of no-slack messages using L, in the interval Ak. Thus, ~ ~ , ' l k =
Definition 2:
n z k b z , b'hft, for which ( 3 ) is an equality. switching schedules.

in2 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 5, NO. I , JULY 1994
each message to its active intervals is obtained by assigning values to X I $ , such that the following conditions exist:
(4)
Constraints (4) and ( 5 ) refer to the capacity requirement for a message and link, respectively. This assignment problem is analogous to scheduling of periodic tasks on multiple processors [lo], with the difference that some messages are sent over more than one link simultaneously, but a task is always processed by exactly one processor at any time. If the set of constraints (4)-(5) is feasible, a suitable message-interval assignment can be obtained. The values of .zhl given by a feasible solution are then used to initialize an -V, x I< message-interval assignment matrix, P = [Pzk], where p ,k gives the time for which A%ft is transmitted in &.
D. Interval Sequencing The message-interval assignment merely performs analysis with
respect to availability and requirement of the capacity. It does not ensure that if there are multiple CP's in the path for a message, all will set up their switches to create a clear path for the message simultaneously. For example, in Fig. 3(a), to achieve message transfer from node 0 to node 7, the CP's at nodes 000,001, 101, and 1 I 1 must simultaneously connect channel-pairs (from 0, 1). (0, 5), (1 , 7), and (5 , to 7), respectively, for ensuring a clear path for 1 -unit segment of 3f1 during [4, 61. During the second time unit of the same interval, the CP's at 100, 101, 111, and 011 must make the connections to create a clear path for M T .
The interval sequencing probleh is identical to the following problem: Find a preemptive schedule for a set of tasks to be run on a set of identical processors where a task may require simultaneous use of more than one processors. The set of links used in an interval can be considered the set of processors, and message segments assigned to that interval can be considered the tasks. In each interval, all possible combinations of segments assigned to that interval such that no two segments in a combination share links are identified. A subset of these combinations is scheduled in the interval so that each segment gets the required time and the length of the schedule is minimized. If the length is not greater than the interval length itself, the required sequencing is found. An integer programming formulation for minimizing the length of the preemptive schedule required in this problem has been described in [3] and is adapted here.
Let (2: = { 11 I . I I 2 , . . .} be the indices of messages in a maximal related set of messages that have segments assigned in Ak. We first define a linkfeasible set of messages.
Definition 5: A message set Q , f s = { 72 712, . . .} is link-feasible if ,B n L . r i , E Qlfs such that Mnt and use the same link.
Clearly, messages in a link-feasible set can be transmitted simul- taneously. Let h- l f , be the number of link feasible sets possible for Q:. Associate a variable yJ with j ' " link-feasible set representing the time for which all the messages in it are transmitted simultaneously. Let Q , be the set of indices of link-feasible sets of messages in Q: that contain message M z . Consider the integer programming problem of minimizing the following summation:
4-1 f s E y, such that y, = p , h V i E Q:. , = l J E Q ,
The minimum value of y, is the minimum time required to send all the message segments assigned to AI; in the maximal related
TFG, Topology
Assianment
Interval Sequencing
1 Node switching schedules
Fig. 5. Steps in computation of node switching schedules.
set Qk without causing a link to be used by two messages at the same time. Therefore, if ~ ~ ! ~ ' y, 5 &, then interval sequencing is possible; otherwise, the message segments assigned to Ak require more time than the interval length.
Solution of the interval sequencing problem for each interval of each maximal set enables derivation of switching schedules. Given a sequence of link feasible sets, the starting time for messages in a set is determined by adding the total time for which sets before it are scheduled to the starting point of the interval. This time is then used to derive the scheduling commands. The steps in computation of node switching schedules for a TFG are summarized in Fig. 5.
These node switching schedules provide contention-free message routing by explicit scheduling of segments for a message. Therefore, if feasible switching schedules do not exist, no other routing technique can guarantee the timing constraints. Thus, by making use of this framework in selecting a task allocation and path assignment, the schedulability of the communication requirement can be checked.
v. CONTENTION-BASED TASK ALLOCATION AND PATH ASSIGNMENT Task allocation algorithms reported in the literature optimize vari-
ous measures of communication cost, such as cardinality [4], dilation [15], and weighted network distance [ l l ] .
All these measures attempt to place communicating tasks as closely as possible. Since scheduled routing guarantees communication per- formance, the compile-time objective becomes computation of a feasible set of node switching schedules. Thus, a task allocation or path assignment can be characterized by whether it yields a feasible set of switching schedules. Since lower values of link and spot utilization make existence of a set of feasible schedules more likely, the objective function to be minimized becomes as follows:
U = max(LL',.SU,k), (6)
where the maximum is taken over all possible values of j and k. If 5 I, there are no hot-spots in the network, and a set of node switching schedules is likely to exist.
VI. COMPILE-TIME RESULTS For illustration of the proposed framework's effectiveness, we have
selected discrete Fourier Transform (DlT) as the target application and 64-node binary hypercube as the target topology. For results on 2-D torus, see [16]. Although the TFG for DFT is regular, it has the following interesting feature. The TFG for a 16 x 16 D I T is shown in Fig. 6. For details of how this TFG represents the 2-D DFT computation, the reader is referred to [16]. As shown in Fig.

IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 5, NO. 7 , JULY 1994
50
40
183
-
+: number of sets
0: msgs in the largest set -
Fig. 6. Task
(a)
flow graph for DFT. (a) 1-D 16-point FFT.
(b)
(b) 2-D 16 x 16 DFT
0.8 1
row transforms m
x: wormhole, 0: schedulable 0.6
0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
normalized invocation rate
Fig. 7. 2-D DFT, binary 6-cube. C = 64 bytes/ps
6, the amount of communication between successive stages of the TFG varies significantly. When the TFG is invoked with the highest input arrival rate, according to (2), the release-time and deadline for all messages become 0 and 7in, respectively. In this case, message- interval assignment does not play any role and interval sequencing alone determines schedulability. For results pertaining to an irregular TFG, the reader is referred to [16], [17].
A. Schedulability and Output Inconsistency Fig. 7 presents the results of schedulability and simulation using
wormhole routing on the same plots for a 256 x 256 DFT. The network load is changed by varying the TFG execution rate, and it is plotted on the x-axis as the rate of execution normalized with respect to the maximum rate at which a TFG can be invoked, i.e., 2.
The ratio of the output period (interval between successive invo- cation outputs) and the input period corresponding to the load point (i.e., (T)) is plotted on the y-axis. When the TFG communication is schedulable, it is plotted as unity, indicating that riUt = r;, V j if communication hardware for scheduled routing is available. If worm- hole routing results in output inconsistency (as defined in Section II), it is indicated by plotting an up-down spike for the corresponding load value to indicate that the interval between successive outputs is not constant across invocations at that input period. Task execution times and link capacity have been selected so that for the longest
t x: In(max link-feasible sets)
I 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
normalized invocation rate
Fig. 8. Statistics for 2-D DFT, binary 6-cube.
message transmission time equals the longest task execution time; i.e., 2 = 1. Twelve different values of the input rate ( l / ~ ) are selected between (1 /5~, ) and the maximum of ( l / rC) .
In Fig. 8, statistics about the size of the integer programming problems solved are shown. The 88 messages in the D F I TFG get partitioned into a large number of maximal related sets. It is found that, typically, there are a few large sets of related messages and a number of small sets. The size of the largest set for different load points is plotted. The number of link feasible sets formed in interval sequencing can be large for large related message sets; however, the amount of computation for a large percentage of the sets is insignificant.
B. Reduction in Network Contention
We have obtained values of U of (6) using task allocation that minimizes the communication cost, measured as the sum of message distances weighted by message sizes (quadratic assignment problem (QAP) [9] followed by E-cube’ path selection and compared them with those obtained by using a simple heuristic for task allocation.
* E-cube path selection refers to determining the path for a message based on dimension traversal according to a linear order. Such routing is deadlock- free and refers to the route obtained by changing the source address one bit at a time in one direction only until it becomes the destination address [7].
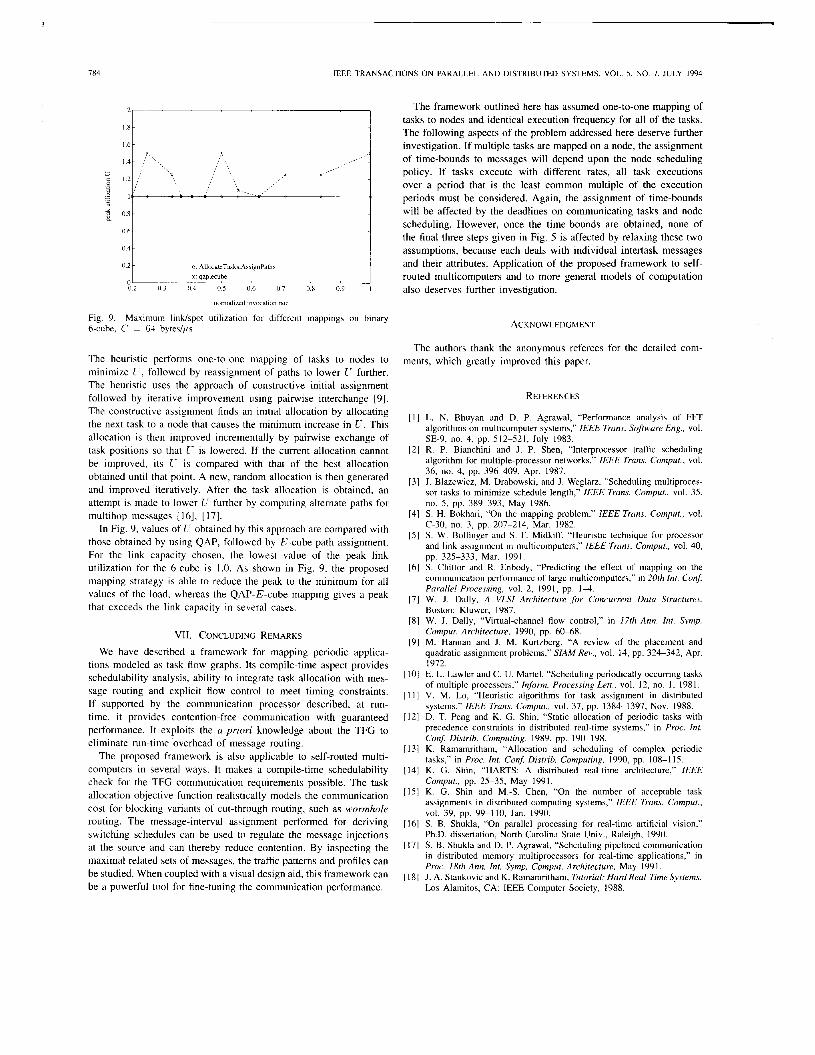
784
I .6 t
IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 5 , NO. I , JULY 1994
0 2 o AllocateTasks.AssignPalhs x: qap.ecube
U I 0.2 (I 3 (1.4 0.5 0.6 0.7 o x 0.9 I
normalized invocation rate
Fig. 9. 6-cube, C = G-l bytes/ps.
Maximum IinWspot utilization for different mappings on binary
The heuristic performs one-to-one mapping of tasks to nodes to minimize C*, followed by reassignment of paths to lower I’ further. The heuristic uses the approach of constructive initial assignment followed by iterative improvement using painvise interchange [9]. The constructive assignment finds an initial allocation by allocating the next task to a node that causes the minimum increase in c‘. This allocation is then improved incrementally by painvise exchange of task positions so that I - is lowered. If the current allocation cannot be improved, its I- is compared with that of the best allocation obtained until that point. A new, random allocation is then generated and improved iteratively. After the task allocation is obtained, an attempt is made to lower I - further by computing alternate paths for multihop messages [16], [ 171.
In Fig. 9, values of I - obtained by this approach are compared with those obtained by using QAP, followed by E-cube path assignment. For the link capacity chosen, the lowest value of the peak link utilization for the 6-cube is 1.0. As shown in Fig. 9, the proposed mapping strategy is able to reduce the peak to the minimum for all values of the load, whereas the QAP-E-cube mapping gives a peak that exceeds the link capacity in several cases.
VII. CONCLUDING REMARKS We have described a framework for mapping periodic applica-
tions modeled as task flow graphs. Its compile-time aspect provides schedulability analysis, ability to integrate task allocation with mes- sage routing and explicit flow control to meet timing constraints. If supported by the communication processor described, at mn- time, it provides contention-free communication with guaranteed performance. It exploits the a priori knowledge about the TFG to eliminate run-time overhead of message routing.
The proposed framework is also applicable to self-routed multi- computers in several ways. It makes a compile-time schedulability check for the TFG communication requirements possible. The task allocation objective function realistically models the communication cost for blocking variants of cut-through routing, such as wormhole routing. The message-interval assignment performed for deriving switching schedules can be used to regulate the message injections at the source and can thereby reduce contention. By inspecting the maximal related sets of messages, the traffic patterns and profiles can be studied. When coupled with a visual design aid, this framework can be a powerful tool for fine-tuning the communication performance.
The framework outlined here has assumed one-to-one mapping of tasks to nodes and identical execution frequency for all of the tasks. The following aspects of the problem addressed here deserve further investigation. If multiple tasks are mapped on a node, the assignment of time-bounds to messages will depend upon the node scheduling policy. If tasks execute with different rates, all task executions over a period that is the least common multiple of the execution periods must be considered. Again, the assignment of time-bounds will be affected by the deadlines on communicating tasks and node scheduling. However, once the time-bounds are obtained, none of the final three steps given in Fig. 5 is affected by relaxing these two assumptions, because each deals with individual intertask messages and their attributes. Application of the proposed framework to self- routed multicomputers and to more general models of computation also deserves further investigation.
ACKNOWLEDGMENT
The authors thank the anonymous referees for the detailed com- ments, which greatly improved this paper.
REFERENCES
L. N. Bhuyan and D. P. Agrawal, “Performance analysis of FFT algorithms on multicomputer systems,” IEEE Trans. Sojiwure Eng., vol. SE-9, no. 4, pp. 512-521, July 1983. R. P. Bianchini and J. P. Shen, “Interprocessor traffic scheduling algorithm for multiple-processor networks,” IEEE Trans. Comput., vol. 36, no. 4, pp. 39G409, Apr. 1987. J. Blazewicz, M. Drabowski, and J. Weglarz, “Scheduling multiproces- sor tasks to minimize schedule length,” IEEE Trans. Comput., vol. 35, no. 5, pp. 389-393, May 1986. S. H. Bokhari, “On the mapping problem,” IEEE Trans. Comput., vol. C-30, no. 3, pp. 207-214, Mar. 1982. S. W. Bollinger and S. F. Midkiff, “Heuristic technique for processor and link assignment in multicomputers,” IEEE Trans. Comput., vol. 40, pp. 325-333, Mar. 1991. S. Chittor and R. Enbody, “Predicting the effect of mapping on the communication performance of large multicomputers,” in 20th Int. Con$ Parallel Processing, vol. 2, 1991, pp. 1 4 . W. J. Dally, A VLSI Architecture for Concurrent Data Structures. Boston: Kluwer, 1987. W. J. Dally, “Virtual-channel flow control,” in 17th Ann. In?. Symp. Comput. Architecture, 1990, pp. 60-68. M. Hannan and J. M. Kurtzberg, “A review of the placement and quadratic assignment problems,” SIAM Rev., vol. 14, pp. 32&342, Apr. 1972. E. L. Lawler and C. U. Martel, “Scheduling periodically occurring tasks of multiple processors,” Inform. Processing Lett., vol. 12, no. I , 1981. V. M. Lo, “Heuristic algorithms for task assignment in distributed systems,” IEEE Trans. Comput., vol. 37, pp. 1384-1397, Nov. 1988. D. T. Peng and K. G. Shin, “Static allocation of periodic tasks with precedence constraints in distributed real-time systems,” in Proc. Int. Con$ Distrib. Computing, 1989, pp. 19&198. K. Ramamritham, “Allocation and scheduling of complex periodic tasks,” in Proc. Int. Con$ Distrib. Computing, 1990, pp. 108-1 IS. K. G. Shin, “HARTS: A distributed real-time architecture,” IEEE Comput., pp. 25-35, May 1991. K. G. Shin and M . 3 . Chen, “On the number of acceptable task assignments in distributed computing systems,” IEEE Trans. Comput., vol. 39, pp. 99-1 IO, Jan. 1990. S. B. Shukla, “On parallel processing for real-time artificial vision,” Ph.D. dissertation, North Carolina State Univ., Raleigh, 1990. S. B. Shukla and D. P. Agrawal, “Scheduling pipelined communication in distributed memory multiprocessors for real-time applications,” in Proc. 18th Ann. Int. Symp. Comput. Architecture, May 1991. J. A. Stankovic and K. Ramamritham, Tutorial: Hard Real-Time Systems. Los Alamitos, CA: IEEE Computer Society, 1988.