analisis stochastic dominance untuk … filesurabaya 2008 . analisis stochastic dominance untuk...
TRANSCRIPT

TESIS – ST 2309
ANALISIS STOCHASTIC DOMINANCE UNTUK PERBANDINGAN TINGKAT KEMISKINAN DI PROVINSI SUMATERA SELATAN TAHUN 2002-2005 FAHARUDDIN 1306 201 721 DOSEN PEMBIMBING Prof. Dra. Susanti Linuwih, M.Stat. Ph.D. Sodikin Baidowi, M.Stat. Dr. Purhadi, M.Sc. PROGRAM MAGISTER JURUSAN STATISTIKA FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT TEKNOLOGI SEPULUH NOPEMBER SURABAYA 2008


ANALISIS STOCHASTIC DOMINANCE UNTUK PERBANDINGAN TINGKAT KEMISKINAN DI PROVINSI SUMATERA SELATAN
TAHUN 2002-2005
Tesis disusun untuk memenuhi salah satu syarat memperoleh gelah Magister Sains (M.Si.)
di Institut Teknologi Sepuluh Nopember
oleh:
FAHARUDDIN NRP. 1306201721
Tanggal Ujian : 12 Februari 2008 Periode Wisuda : Maret 2008
Disetujui oleh Tim Penguji Tesis: 1. Prof. Dra. Susanti Linuwih, M.Stat, Ph.D. (Pembimbing I) NIP: 130 368 808
2. Sodikin Baidowi, M.Stat. (Pembimbing II) NIP: 340 010 714 3. Dr. Purhadi, M.Sc. (Pembimbing III) NIP: 131 652 051 4. Prof. Drs. Nur Iriawan, MIKom, Ph.D. (Penguji) NIP: 131 782 011
5. Dr. Sony Sunaryo, M.Si. (Penguji) NIP: 131 843 380 6. Drs. I Nyoman Latra, M.S. (Penguji) NIP: 130 701 283
7. Dr. Ir. Setiawan, MS. (Penguji) NIP: 131 651 428
Direktur Program Pasca Sarjana
Prof. Dr. Ir. Suparno, MSIE NIP. 130 532 035


i
ANALISIS STOCHASTIC DOMINANCE UNTUK PERBANDINGAN TINGKAT KEMISKINAN
DI PROVINSI SUMATERA SELATAN TAHUN 2002-2005
Nama : FAHARUDDIN
NRP : 1306201721
Nama Pembimbing : Prof. Dra. Susanti Linuwih, M.Stat. Ph.D.
Nama Co Pembimbing : Sodikin Baidowi, M.Stat.
Dr. Purhadi, M.Sc.
ABSTRAK
Analisis perbandingan kemiskinan menggunakan ukuran-ukuran kemiskinan yang umum seperti headcount index, poverty gap index dan poverty severity index mempunyai kelemahan karena sangat sensitif terhadap pemilihan ukuran dan garis kemiskinan. Analisis poverty dominance yang merupakan penerapan dari konsep stochastic dominance dapat mengatasi hal ini di mana lebih robust terhadap pemilihan ukuran dan garis kemiskinan. Penelitian ini membahas inferensi statistik berupa penaksiran dan pengujian hipotesis dari stocahstic dominance serta menggunakan analisis poverty dominance tersebut untuk membandingkan tingkat kemiskinan di Sumatera Selatan tahun 2002-2005 menggunakan data pengeluaran rumah tangga hasil Susenas 2002 dan 2005. Hasil analisis tersebut kemudian dibandingkan dengan hasil yang diperoleh dengan menggunakan indeks kemiskinan yang umum dari keluarga F-G-T index. Dengan menggunakan teorema limit pusat (CLT), diperoleh statistik uji yang berdistribusi asimptotik normal standar untuk menguji adanya dominance antara dua distribusi pendapatan. Analisis perbandingan kemiskinan menggunakan poverty dominance menyimpulkan bahwa telah terjadi penurunan tingkat kemiskinan di Sumatera Selatan periode 2002 – 2005. Kata Kunci: Stochastic dominance, Poverty dominance, Perbandingan tingkat
kemiskinan, F-G-T index

ii
STOCHASTIC DOMINANCE ANALYSIS
FOR POVERTY COMPARISON IN SUMATERA SELATAN PROVINCE 2002 – 2005
By : FAHARUDDIN
Student Identity Number : 1306201721
Supervisor : Prof. Dra. Susanti Linuwih, M.Stat. Ph.D.
Co-Supervisor : Sodikin Baidowi, M.Stat.
Dr. Purhadi, M.Sc.
ABSTRACT
Poverty comparison analysis using convensional poverty measures as headcount index, poverty gap index and poverty severity index has a limitation that the result is very sensitive to the choice of poverty measure and poverty line. Poverty dominance analysis as an application of stochastic dominance concept can solve this problem, for it more robust to the choice of poverty measures and poverty line. This research study statistical inferences (estimation and testing hypothesis) for stochastic dominance and use this poverty dominance analysis to perform poverty comparison analysis in Sumatera Selatan Province 2002 – 2005 using household expenditure data from Susenas (National Socio-Economic Survey) 2002 and 2005. The results obtained from poverty dominance analysis are then compared to poverty analysis using conventional poverty measure of F-G-T indices. Using Central Limit Theorem (CLT), we found that the statistical test used to test dominance for two income distribution is asymptotically standard normal distributed. Poverty comparison analysis using poverty dominance found that there is a significant decrease in poverty rate from 2002 to 2005 in Sumatera Selatan Province. Keyword: Stochastic dominance, Poverty dominance, Poverty comparison, F-G-T
indices

iii
KATA PENGANTAR
Alhamdulillah, puji dan syukur kepada Allah SWT, akhirnya penulis dapat
menyelesaikan tesis ini dengan judul: ’Analisis Stochastic Dominance untuk
Perbandingan Tingkat Kemiskinan di Sumatera Selatan Tahun 2002 – 2005’. Penulis
menyadari bahwa banyak pihak yang terlibat dalam penyelesaian tesis ini baik secara
langsung maupun tidak langsung. Karena itu penulis menyampaikan ucapan terima
kasih dan penghargaan yang sebesar-besarnya kepada:
1. Ibu Prof. Dra. Susanti Linuwih, M.Stat., Ph.D. selaku pembimbing utama yang
telah memberikan bimbingan dan arahan sampai terselesaikannya tesis ini.
2. Bapak Dr. Purhadi, M.Sc. dan Bapak Sodikin Baidowi, M.Stat. juga selaku
pembimbing yang telah banyak membantu memberikan bimbingan dan arahan.
3. Bapak dan Ibu dosen pengajar serta staf administrasi pada Jurusan Statistika ITS
Surabaya.
4. Teman-teman mahasiswa program Magister Statistika ITS Surabaya atas bantuan
dan kerjasamanya selama proses penyelesaian studi.
5. Orang tua kami yang tercinta yang senantiasa mendoakan baik di Ereke Buton
Utara maupun di Ngronggo Kediri.
Tidak lupa penulis secara khusus menyampaikan ucapan terima kasih kepada istri
tersayang Darma Endrawati serta anak-anak tercinta Abdullah Muhammad Idris,
Fathiyah Nur Shohwah dan Afifah Nur Ramadhani Zakiyah atas cinta, pengorbanan
maupun doa yang senantiasa terpanjatkan setiap saat.
Akhirnya, penulis berharap semoga tesis ini menjadi karya ilmiah yang dapat
memberikan manfaat baik bagi kalangan akademik maupun untuk masyarakat pada
umumnya.
Surabaya, Februari 2008
Penulis


v
DAFTAR ISI
Halaman
ABSTRAK ........................................................................................................... i
KATA PENGANTAR ......................................................................................... iii
DAFTAR ISI ........................................................................................................ v
DAFTAR TABEL ................................................................................................ vii
DAFTAR GAMBAR ........................................................................................... ix
DAFTAR LAMPIRAN........................................................................................ xi
BAB 1 PENDAHULUAN
1.1. Latar Belakang ............................................................................ 1
1.2. Permasalahan .............................................................................. 3
1.3. Tujuan Penelitian ........................................................................ 4
1.4. Manfaat Penelitian ...................................................................... 4
1.5. Batasan Permasalahan ................................................................ 5
BAB 2 TINJAUAN PUSTAKA
2.1. Inferensi Terhadap Fungsi Distribusi ......................................... 7
2.2. Ukuran-ukuran Kemiskinan ....................................................... 8
2.2.1. Headcount Index ............................................................ 10
2.2.2. Poverty Gap Index ......................................................... 11
2.2.3. Poverty Severity Index ................................................... 11
2.2.4. F-G-T Index .................................................................... 12
2.3. Stochastic Dominance ............................................................... 13
2.3.1. Definisi Stochastic Dominance ...................................... 13
2.3.2. Poverty Dominance......................................................... 15
2.4. Perkembangan Sosial-Ekonomi dan Kemiskinan
di Sumatera Selatan ..................................................................... 19
BAB 3 METODOLOGI PENELITIAN
3.1. Data yang Digunakan .................................................................. 23

vi
3.2. Metode Penelitian ....................................................................... 23
BAB 4 ANALISIS DAN PEMBAHASAN
4.1. Inferensi Terhadap Stochastic Dominance ................................ 27
4.1.1. Penaksiran Fungsi Dominance....................................... 27
4.1.2. Pengujian Hipotesis ........................................................ 31
4.2. Analisis Perbandingan Tingkat Kemiskinan
Di Sumatera Selatan Tahun 2002 – 2005 .................................. 33
4.2.1. Analisis Poverty Dominance ......................................... 34
4.2.2. Perbandingan Analisis Poverty Dominance
dan F-G-T Index.............................................................. 43
BAB 5 KESIMPULAN DAN SARAN
5.1. Kesimpulan ................................................................................. 49
5.2. Saran ............................................................................................ 50
DAFTAR PUSTAKA ......................................................................................... 51
LAMPIRAN.......................................................................................................... 55

vii
DAFTAR TABEL
Tabel Judul Halaman
2.1 Beberapa Indikator Sosial dan Ekonomi Sumatera Selatan
Tahun 2002 – 2005 .............................................................................. 20
4.2 Garis Kemiskinan (Rupiah Per Kapita Sebulan) dan Persentase
Penduduk Miskin di Sumatera Selatan Tahun 1993 – 2004 ............. 36
4.3 Nilai Taksiran, Standard Error dan Statistik Uji
Fungsi Dominance Orde Pertama ....................................................... 38
4.4 Nilai Taksiran, Standard Error dan Statistik Uji
Fungsi Dominance Orde Kedua .......................................................... 40
4.5 Nilai Taksiran, Standard Error dan Statistik Uji
Fungsi Dominance Orde Ketiga .......................................................... 42
4.6 Hasil Penghitungan F-G-T Index Provinsi Sumatera Selatan
Tahun 2002 dan 2005 .......................................................................... 44


ix
DAFTAR GAMBAR
Gambar Judul Halaman
2.1 Ilustrasi Analisis Poverty Dominance antara
Distribusi A dan B ............................................................................ 18
2.2 Perkembangan Tingkat Kemiskinan Sumatera Selatan
Tahun 1993 – 2004 ........................................................................... 21
4.1 Poverty Incidence Curve (PIC) Provinsi Sumatera Selatan
Tahun 2002 – 2005 .......................................................................... 37
4.2 Poverty Deficit Curve (PDC) Provinsi Sumatera Selatan
Tahun 2002 – 2005 .......................................................................... 39
4.3 Poverty Severity Curve (PSC) Provinsi Sumatera Selatan
Tahun 2002 – 2005 .......................................................................... 41


xi
DAFTAR LAMPIRAN
Lampiran Keterangan Halaman
1 Penghitungan Faktor Pengali Data Pengeluaran
Per Kapita ....................................................................................... 55
2 Output Pengolahan Analisis Perbandingan
Kemiskinan .................................................................................... 62


1
BAB 1
PENDAHULUAN
1.1 Latar Belakang
Dewasa ini pengentasan kemiskinan menjadi salah satu tujuan pembangunan
global sebagaimana tertuang dalam Milenium Development Goals (MDGs).
Perubahan tingkat kemiskinan menjadi salah satu tolok ukur keberhasilan pem-
bangunan yang dilakukan. Program pembangunan yang dilakukan dikatakan berhasil
apabila dapat menurunkan tingkat kemiskinan secara signifikan antar waktu atau ting-
kat kemiskinan yang ada di suatu wilayah tertentu menjadi lebih rendah relatif terha-
dap wilayah yang lain.
Perbandingan tingkat kemiskinan antar waktu maupun antar wilayah sering-
kali melibatkan ukuran-ukuran kemiskinan yang umum seperti headcount index,
poverty gap index, dan poverty severity index. Artinya tingkat kemiskinan dibanding-
kan dengan melihat perbedaan nilai-nilai yang ditunjukan oleh ukuran-ukuran kemis-
kinan tersebut. Tingkat kemiskinan yang lebih tinggi tercermin dari nilai indeks-
indeks tersebut di suatu wilayah atau suatu waktu tertentu lebih tinggi dibandingkan
wilayah atau waktu yang lainnya. Namun demikian, perbandingan tingkat kemiskinan
menggunakan ukuran-ukuran ini mempunyai kelemahan yaitu sangat sensitif terha-
dap ukuran kemiskinan maupun garis kemiskinan yang dipilih (Madden dan Smith,
2000). Karena ukuran kemiskinan dan garis kemiskinan yang digunakan ditentukan
oleh peneliti sendiri, sangat mungkin terjadi bila ukuran kemiskinan atau garis kemis-
kinan yang diambil berbeda, hasil perbandingan yang diperoleh akan berbeda juga.
Dalam kondisi demikian, metode perbandingan yang digunakan dikatakan tidak
robust (kokoh) terhadap pemilihan ukuran maupun garis kemiskinan. Hal ini tentu
saja tidak disukai dalam analisis kemiskinan karena hasil perbandingan yang diper-
oleh menjadi tidak pasti dan penarikan kesimpulan menjadi lebih sulit.
Analisis poverty dominance, yang merupakan penerapan dari konsep stochatic
dominance, merupakan salah satu metode yang digunakan untuk memperbandingkan

2
tingkat kemiskinan antar wilayah maupun antar waktu. Secara sederhana, metode ini
membandingkan dua buah fungsi distribusi pendapatan, apakah secara stokastik suatu
fungsi distribusi pendapatan lebih tinggi atau tidak dalam hal tingkat kemiskinan
dibandingkan dengan fungsi distribusi yang lain. Perbandingan fungsi distribusi
pendapatan dengan stochastic dominance dapat dilakukan untuk keseluruhan fungsi
distribusi pendapatan atau pada range pendapatan tertentu yang diinginkan. Dalam
kaitan dengan perbandingan tingkat kemiskinan, dapat dipilih range pendapatan
rendah yang dicurigai di dalamnya terdapat garis kemiskinan. Dengan cara ini tidak
perlu menentukan garis kemiskinan secara spesifik, sehingga hasil yang diperoleh
akan lebih robust (Ravallion, 1992; Madden dan Smith, 2000).
Penelitian yang mengkaji inferensi mengenai kemiskinan khususnya yang
menggunakan analisis stochastic dominance sudah banyak dijumpai dalam berbagai
literatur. Bishop, Chakraborti dan Thistle (1989) mengembangkan uji asimptotik
untuk kurva generalized Lorenz. Kaur, Rao dan Singh (1994) menurunkan uji
stochastic dominance orde kedua untuk dua distribusi. Schmid dan Trede (1996)
mengembangkan uji stochastic dominance untuk orde pertama. Sedangkan Anderson
(1996) menguji stochastic dominance orde pertama menggunakan pendekatan
nonparametrik. Davidson dan Duclos (2000) mengembangkan uji dominance dua
distribusi pendapatan berdasarkan pendekatan distribusi asimptotik yang
mempertimbangkan struktur kovarian antara dua distribusi tersebut. Uji-uji tersebut
kemudian ditelaah oleh Tse dan Zhang (2002) dengan pendekatan Monte Carlo,
hasilnya diperoleh bahwa uji yang dikemukakan oleh Davidson dan Duclos memiliki
kuasa uji yang lebih besar.
Aplikasi kriteria dominance dalam perbandingan kemiskinan juga telah
banyak dilakukan. Ravallion (1992) membandingkan perubahan tingkat kemiskinan
di beberapa negara di Asia seperti Indonesia, India dan Bangladesh menggunakan
indeks kemiskinan yang umum serta analisis stochastic dominance. Jenkins dan
Lambert (1997) menganalisis tren kemiskinan di Inggris menggunakan tiga macam
kurva yang didasarkan pada ukuran F-G-T index yang dinamakan kurva Three I’s of

3
Poverty (TIP). Dercon dan Krishnan (1998) menggunakan kriteria dominance untuk
menganalisis perubahan tingkat kemiskinan di Ethiopia tahun 1989-1995. Madden
dan Smith (2000) menerapkan kriteria dominance untuk mengkaji perubahan
kemiskinan di Irlandia tahun 1987-1994 menggunakan data dari Luxemburg Income
Survey. Sedangkan Chen (2006) menerapkan stochastic dominance untuk melihat
perbandingan tingkat kemiskinan antar wilayah di Canada menggunakan data dari
Survey of Labor and Income Dynamics tahun 2000.
Di Sumatera Selatan, analisis perbandingan kemiskinan umumnya dilakukan
menggunakan headcount index karena tren angka-angka kemiskinan yang disajikan
BPS selama ini umumnya adalah headcount index. Angka-angka seperti poverty gap
index maupun poverty severity index masih jarang tersedia. Sedangkan analisis
perbandingan kemiskinan menggunakan stochastic dominance belum pernah
dilakukan.
Dilihat dari tren headcount index, tingkat kemiskinan di Sumatera Selatan
cenderung menurun sejak tahun 1999 (BPS 2003 dan 2005). Tren angka headcount
index atau persentase penduduk miskin untuk Provinsi Sumatera Selatan tahun 1999,
2002, 2003 dan 2004 masing-masing sebesar 23,53 %, 22,32 %, 21,54 % dan
20,92%. Meskipun dilihat dari tren angka-angka ini cenderung menurun, inferensi
terhadap angka-angka tersebut masih jarang dilakukan, sehingga belum diketahui
tingkat signifikansi penurunannya secara statistik. Analisis yang dilakukan selama
masih cenderung bersifat deskriptif yaitu dengan membandingkan besarnya angka-
angka tersebut secara deskriptif.
1.2 Permasalahan
Sebagaimana telah dikemukakan di atas bahwa perbandingan tingkat kemis-
kinan menggunakan ukuran kemiskinan seperti headcount index, poverty gap index,
dan poverty severity index sangat sensitif terhadap ukuran dan garis kemiskinan yang
dipilih. Akibatnya hasil yang diperoleh menjadi tidak pasti dan penarikan kesimpulan

4
menjadi lebih sulit. Analisis poverty dominance dapat mengatasi hal ini, sehingga
permasalahan yang akan dikemukakan di sini adalah:
1. Bagaimana menggunakan analisis stochastic dominance dalam membandingkan
tingkat kemiskinan (analisis poverty dominance).
2. Bagaimana melakukan analisis perbandingan tingkat kemiskinan dengan
stochastic dominance pada fungsi distribusi pendapatan di Sumatera Selatan
tahun 2002 dan 2005 untuk melihat perubahan tingkat kemiskinan antar periode
tersebut.
3. Bagaimana perbandingan tingkat kemiskinan di Sumatera Selatan tahun 2002 –
2005 menggunakan stochastic dominance dan dengan menggunakan indeks
kemiskinan yang umum dari keluarga F-G-T index.
1.3 Tujuan Penelitian
Berdasarkan permalasahan yang disebutkan di atas, penelitian mempunyai
tiga tujuan utama, sebagai berikut:
1. Mengkaji penaksiran dan pengujian hipotesis dari stochastic dominance dalam
membandingkan dua fungsi distribusi pendapatan.
2. Melakukan analisis perbandingan tingkat kemiskinan dengan stochastic dom-
inance pada fungsi distribusi pendapatan di Sumatera Selatan tahun 2002 dan
2005 untuk melihat perubahan tingkat kemiskinan antar periode tersebut.
3. Membandingkan hasil yang diperoleh melalui pendekatan stochastic dominance
terhadap hasil yang diperoleh dengan menggunakan indeks kemiskinan keluarga
F-G-T index.
1.4 Manfaat Penelitian
Dengan adanya penelitian ini diharapkan dapat bermanfaat sebagai berikut:
1. Memberikan alternatif metode perbandingan tingkat kemiskinan yang lebih
robust terhadap pemilihan ukuran maupun garis kemiskinan

5
2. Mengembangkan wawasan keilmuan dan pengetahuan mengenai analisis
perbandingan tingkat kemiskinan menggunakan pendekatan stochastic
dominance.
1.5 Batasan Permasalahan
Dalam penelitian ini, permasalahan yang dibahas dibatasi pada perbandingan
tingkat kemiskinan untuk dua populasi yang saling independen. Tingkat kemiskinan
yang menjadi fokus penelitian dibatasi pada level provinsi sehingga perbandingan
kemiskinan yang dibahas adalah perbandingan tingkat kemiskinan Provinsi Sumatera
Selatan antar dua titik waktu yaitu tahun 2002 dan 2005. Dalam penghitungan F-G-T
index, diasumsikan garis kemiskinan diketahui yaitu diambil dari garis kemiskinan
Provinsi Sumatera Selatan yang dikeluarkan oleh BPS.
Data konsumsi rumah tangga yang digunakan diambil dari Susenas 2002 yang
dilaksanakan pada bulan Februari 2002 (BPS, 2001) dan Susenas 2005 yang
dilaksanakan pada bulan Juni 2005 (BPS, 2005b). Data konsumsi yang dikumpulkan
melalui Susenas mempunyai periode referensi setahun sebelum survei untuk data
konsumsi non makanan dan seminggu sebelum survei untuk konsumsi makanan.
Karena itu, secara spesifik perbandingan kemiskinan yang dicakup dalam analisis ini
adalah perbandingan antara periode Maret 2001 – Februari 2002 dengan Juli 2004 –
Juni 2005. Karena itu dampak kenaikan harga BBM pada bulan Oktober 2005 belum
tercakup dalam analisis ini.


7
BAB 2
TINJAUAN PUSTAKA
2.1 Inferensi Terhadap Fungsi Distribusi
Andaikan y1, y2, ..., yn adalah sampel random berukuran n yang berasal dari
fungsi distribusi F(y), maka fungsi distribusi sampel Fn(y) atau disebut juga fungsi
distribusi empiris, di definisikan sebagai:
( ) ( )
( )1
1 banyaknya y kurang dari atau sama dengan
1
n i
n
ii
F y yn
I y yn =
=
= ≤∑ (2.1)
di mana I(.) adalah fungsi indikator yang bernilai 1 jika pernyataan dalam kurung
terpenuhi dan selain itu nilainya 0. Untuk y yang tetap, I(yi ≤ y) adalah variabel
random berdistribusi bernoulli dengan parameter p = F(y), sehingga nFn(y) akan
berdistribusi binomial dengan mean ( )( ) ( )nE F y F y= . Dengan demikian penaksir
tak bias untuk F(y) adalah sebagai berikut:
( ) ( )ˆnF y F y= . (2.2)
dan mempunyai varians ( )( ) ( ) ( )1var 1nF y F y F yn
= − (Mood, Graybill dan Boes,
1974).
Dengan menggunakan hukum bilangan besar (Law of Large Number),
diperoleh bahwa Fn(y) merupakan penaksir yang konsisten untuk F(y), karena
( )( )var 0nF y → jika n → ∞ . Sedangkan dengan menggunakan teorema limit pusat
(Central Limit Theorem) akan diperoleh bahwa ( ) ( )( )nn F y F y− konvergen ke
distribusi normal ( ) ( )( )0, 1N F y F y − (Sen dan Singer, 1993), atau dapat
dituliskan:
( ) ( )( ) ( ) ( )( )0, 1dnn F y F y N F y F y − → − (2.3)

8
Jika diambil sampel dari dua populasi yang berbeda, misalkan populasi A dan
populasi B dengan fungsi distribusi (dalam hal ini adalah distribusi pendapatan) yaitu
masing-masing FA(y) dan FB(y), akan terdapat dua fungsi distribusi empiris yaitu
berturut-turut ( )AnF y dan ( )B
nF y . Penaksir tak bias untuk [FB(y) – FA(y)] adalah
( ) ( )B An nF y F y − , sedangkan kovarians dari ( )A
nF x dan ( )AnF x adalah
( ) ( )1 1A BF y F yn
− , sehingga diperoleh bahwa varians dari ( ) ( )B An nF y F y − ada-
lah ( ) ( ) ( ) ( )1 1B A B AF y F y F y F yn
− − + . Penaksir ( ) ( )B An nF y F y − juga meru-
pakan penaksir yang konsisten untuk [FB(y) – FA(y)].
2.2 Ukuran Kemiskinan
Proses mengukur kemiskinan biasanya memiliki dua tahap. Tahap pertama
adalah tahap identifikasi penduduk yang dikategorikan miskin dan tidak miskin.
Seseorang atau rumah tangga dikatakan miskin jika mempunyai pendapatan kurang
dari garis batas (threshold) tertentu. Garis batas ini biasanya disebut dengan garis
kemiskinan (poverty line). Dalam praktek data pengeluaran rumah tangga biasanya
digunakan sebagai proksi terhadap pendapatan.
Pada prakteknya penentuan garis kemiskinan biasanya dilakukan dengan dua
metode yaitu food-energy-intake method dan cost-of-basic-needs method (Ravallion,
1998). Food-energy-intake method dilakukan dengan menghitung nilai rupiah dari
pengeluaran terhadap sejumlah komoditi makanan yang memenuhi persyaratan
konsumsi energi minimum. Sedangkan cost-of-basic-needs method dilakukan dengan
menghitung nilai rupiah sejumlah komoditi yang dianggap merupakan kebutuhan
dasar minimum. Di Indonesia kedua metode ini digunakan oleh BPS untuk
menentukan garis kemiskinan. Metode food-energy-intake dilakukan untuk
menghitung garis kemiskinan makanan, di mana standar yang digunakan adalah
konsumsi energi minimal 2100 kkal per kapita per hari, sedangkan metode cost-of-
basic-needs digunakan untuk menghitung garis kemiskinan non makanan. Garis

9
kemiskinan makanan dan non makanan kemudian dijumlahkan untuk memperoleh
garis kemiskinan total (BPS, 2000).
Tahap kedua adalah agregasi, yaitu membentuk suatu indeks tunggal yang
menggambarkan kondisi keseluruhan penduduk miskin di suatu wilayah. Beberapa
indeks kemiskinan yang menggambarkan kondisi agregat penduduk miskin di suatu
wilayah misalnya headcount index, poverty gap index, poverty severity index, Sen
index, Watts index dan lain-lain. Indeks-indeks ini banyak dibahas dalam literatur-
literatur analisis kemiskinan, sebagai contoh yang dijadikan acuan di sini adalah
World Bank (2005) dan Rio Group (2006).
Indeks kemiskinan yang baik dapat dilihat dari beberapa kriteria atau aksioma
sebagai berikut (Sen, 1976; Foster, Greer dan Thorbecke, 1984 serta Rio Group,
2006):
1. Focus axiom: indeks atau ukuran kemiskinan yang baik seharusnya tidak
dipengaruhi oleh informasi yang berkaitan dengan pendapatan penduduk yang
tidak miskin.
2. Monotonicity axiom: indeks atau ukuran kemiskinan yang baik seharusnya
meningkat jika pendapatan dari penduduk miskin berkurang. Ini berarti ada
korelasi antara indeks kemiskinan dengan jarak penduduk miskin dari garis
kemiskinan
3. Transfer axiom: adanya transfer pendapatan antar penduduk miskin seharusnya
mengurangi besarnya indeks. Ini berarti bahwa ukuran kemiskinan yang baik
harus merefleksikan bagaimana pendapatan terdistribusi di antara penduduk
miskin.
4. Subgroup monotonicity axiom: jika indeks kemiskinan salah satu bagian dari
populasi meningkat sedangkan indeks untuk bagian populasi lainnya konstan,
maka indeks kemiskinan untuk keseluruhan populasi seharusnya meningkat.

10
2.2.1 Headcount Index
Headcount index merupakan indeks kemiskinan yang paling luas
penggunaannya, di mana secara sederhana merupakan proporsi penduduk yang
tergolong miskin dari keseluruhan populasi. Dalam bentuk matematis headcount
index ini dituliskan sebagai berikut:
NN
P p=0 , (2.4)
di mana: P0 = headcount index
Np = jumlah penduduk yang miskin
N = total keseluruhan populasi (penduduk)
(2.4) di atas sering juga dituliskan dalam bentuk fungsi indikator sebagai berikut:
∑=
<=N
ii zyI
NP
10 )(1 , (2.5)
di mana I(.) adalah fungsi indikator yang akan bernilai 1 jika pernyataan dalam ku-
rung terpenuhi, yi adalah besarnya pendapatan atau pengeluaran penduduk ke-i dan z
adalah garis kemiskinan.
Kelebihan utama dari headcount index ini adalah mudah dihitung dan mudah
diinterpretasi, meskipun indeks ini memiliki beberapa kelemahan. Pertama, ditinjau
dari kriteria indeks kemiskinan yang baik seperti dijelaskan di atas, indeks ini
memenuhi focus axiom, tetapi tidak memenuhi kriteria montonicity axiom dan
transfer axiom. Indeks ini tidak dapat menjelaskan kedalaman kemiskinan yaitu
seberapa miskin penduduk yang berada di bawah garis kemiskinan serta tidak
mempertimbangkan sama sekali aspek distribusi pendapatan penduduk miskin.
Kedua, estimasi headcount index harus dilakukan berdasarkan data individu bukan
data rumah tangga, padahal hampir seluruh data survei untuk menghitung kemiskinan
berbasiskan rumah tangga.

11
2.2.2 Poverty Gap Index
Poverty gap index mengukur tingkat kedalaman kemiskinan di suatu wilayah
relatif terhadap garis kemiskinan. Dalam bentuk matematis, poverty gap index
dirumuskan sebagai berikut:
∑=
=N
i
i
zG
NP
11
1 , (2.6)
di mana : P1 = poverty gap index
Gi = poverty gap: garis kemiskinan dikurangi pendapatan
penduduk miskin ke-i
= )()( zyIyz ii <−
z = garis kemiskinan
Indeks ini merupakan rata-rata proporsi poverty gap terhadap garis
kemiskinan, di mana untuk penduduk tidak miskin nilai poverty gap adalah nol.
Karena poverty gap Gi merupakan jarak antara pendapatan penduduk miskin terhadap
garis kemiskinan, maka indeks ini sering dikaitkan dengan besarnya biaya yang
dibutuhkan untuk mengentaskan kemiskinan. Untuk menghilangkan kemiskinan,
secara sederhana besarnya biaya yang harus diberikan kepada penduduk miskin
adalah sebesar jumlah dari poverty gap Gi.
Indeks ini memenuhi kriteria focus axiom dan monotonicity axiom tetapi tidak
memenuhi transfer axiom. Jika orang yang paling tinggi pendapatannya dalam
kelompok penduduk miskin meningkat pendapatannya sehingga keluar dari
kemiskinan maka besarnya indeks akan bertambah padahal headcount index akan
menurun. Ini bertentangan dengan kriteria transfer axiom yang disebutkan di atas.
2.2.3 Poverty Severity Index
Poverty Severity Index mengukur tingkat keparahan kemiskinan, yaitu
merupakan indeks tertimbang dari poverty gap dengan angka tertimbangnya adalah
poverty gap itu sendiri. Secara formal poverty severity index dituliskan sebagai
berikut:

12
∑=
=
N
i
i
zG
NP
1
2
21 , (2.7)
di mana P2 adalah poverty severity index
Dalam praktek, indeks ini jarang digunakan karena lebih sulit untuk
diinterpretasi. Namun demikian indeks ini memiliki kelebihan karena memenuhi
focus axiom, monotonicity axiom maupun transfer axiom.
2.2.4 F-G-T Index
Ketiga macam indeks kemiskinan yang telah diuraikan di atas yaitu headcount
index, poverty gap index dan poverty severity index merupakan keluarga indeks yang
dikenal dengan nama F-G-T index sehingga dapat dituliskan dalam bentuk rumusan
yang sama. Secara matematis F-G-T index dituliskan sebagai berikut (Foster, Greer
dan Thorbecke, 1984):
1
1 ( )aN
ia i
i
z yP I y zN z=
− = < ∑ , (2.8)
di mana a = 0, 1, 2. Jika a = 0 maka nilai indeks ini sama dengan headcount index,
a = 1 diperoleh poverty gap index dan a = 2 akan diperoleh poverty severity index.
Dalam bentuk fungsi kontinyu, F-G-T index ini dapat juga dituliskan menjadi
(Kakwani, 1993):
( )0
az
az yP dF y
z− =
∫ (2.9)
di mana f(y) adalah fungsi densitas dari pendapatan per kapita Y.
F-G-T index ini mempunyai sifat strictly decreasing terhadap standar hidup
penduduk miskin, yaitu semakin rendah standar hidup yang dimiliki maka akan
semakin rendah nilai indeks ini atau semakin miskin penduduk tersebut. Keuntungan
lain dari ukuran ini adalah bahwa untuk ketiga a , ukuran ini mempunyai sifat
subgroup monotonicity axiom (Foster, Greer dan Thorbecke, 1984).
Inferensi terhadap F-G-T index ini telah dikaji oleh Kakwani (1993)
berdasarkan sifat asimptotik dari penduga F-G-T index ini. Menurut Kakwani (1993),

13
( )a an P P− berdistribusi asimptotik ( )( )ˆ0, var aN P , di mana aP adalah nilai
taksiran F-G-T index yang diperoleh dari sampel yang dirumuskan:
1
1ˆ ( )an
ia i
i
z yP I y zn z=
− = <
∑ , (2.10)
dengan n adalah jumlah sampel. Sedangkan varians dari aP diduga dengan:
¶ ( ) ( )22
ˆ ˆ ˆvar a a aP n P P= − (2.11)
2.3 Stochastic Dominance Perbandingan fungsi distribusi telah menjadi topik utama berbagai penelitian
khususnya berkaitan dengan distribusi pendapatan maupun investasi portofolio.
Berkaitan dengan distribusi pendapatan, studi umumnya diarahkan pada
perbandingan tingkat kemiskinan maupun ketimpangan pendapatan. Stochastic
dominance (SD) adalah suatu istilah yang merujuk pada hubungan antara dua fungsi
distribusi, yaitu apakah suatu fungsi distribusi lebih dominan dibandingkan fungsi
distribusi yang lain.
2.3.1 Definisi Stochastic Dominance
Stochastic dominance mula-mula berkembang di bidang keuangan yaitu da-
lam pengambilan keputusan keuangan menggunakan fungsi utilitas. Dalam ilmu
ekonomi, utilitas adalah ukuran relatif tingkat kepuasan seseorang terhadap barang-
barang yang dikonsumsi. Utilitas biasanya digambarkan dalam suatu fungsi yang
dinamakan indifference curve, yaitu titik-titik yang menggambarkan kombinasi
komoditas yang diperlukan oleh seseorang atau masyarakat untuk mendapatkan level
kepuasan tertentu. Menurut pandangan para penganut teori utilitas, memaksimumkan
utilitas merupakan tujuan yang ingin selalu dicapai oleh seseorang atau perusahaan.
Dalam teori pengambilan keputusan menghadapi ketidakpastian (uncertainty),
suatu perusahaan biasanya bertujuan untuk memaksimumkan nilai harapan dari
fungsi utilitas (expected utility), suatu fungsi tujuan tertentu yang ditetapkan oleh

14
perusahaan berdasarkan pilihan kondisi yang ada. Andaikan ada dua pilihan kondisi,
A dan B, maka kondisi A akan lebih disukai dibandingkan kondisi B jika dan hanya
jika nilai harapan utilitas dari A lebih tinggi atau sama dibandingkan nilai harapan
dari utilitas B. Dalam bentuk matematis, jika Y adalah variabel random non negatif
dengan fungsi densitas f(y) dan fungsi distribusi F(y) serta UA(y) dan UB(y) adalah
fungsi utilitas A dan B, diasumsikan memiliki derivatif ke-s, maka kondisi B lebih
disukai dari A jika dan hanya jika (Heyer, 2001):
( ) ( ) ( ) ( ) ( ) ( )B B A AE U Y U t f t dt U t f t dt E U Y+∞ +∞
−∞ −∞
= ≥ = ∫ ∫ (2.12)
di mana (2.12) ini merupakan definisi umum dari stochastic dominance.
Stochastic dominance orde ke-s didefinisikan berdasarkan karakteristik dari
fungsi utilitas yang digunakan. Ada beberapa karakteristik dari fungsi utilitas yang
sering digunakan yaitu: monotonicity, concavity (risk aversion) dan ruin aversion
(Heyer, 2001). Fungsi utilitas memiliki sifat monotonicity (monoton naik) artinya se-
makin tinggi tingkat utilitas semakin baik, secara matematis dinyatakan bahwa suatu
fungsi utilitas memiliki sifat monoton naik jika dan hanya jika ( )' 0U y ≥ untuk se-
mua y. Fungsi utilitas memiliki sifat concavity (atau risk aversion) jika dan hanya jika
memiliki sifat monoton naik dan ( )'' 0U y ≤ untuk semua y. Sedangkan sifat ruin
aversion terjadi jika dan hanya jika memenuhi kondisi risk aversion dan ( )''' 0U y ≥ .
Stochastic dominance (SD) orde pertama diturunkan dari sifat fungsi utilitas yang
monoton naik, SD orde kedua diturunkan dari sifat risk aversion serta SD orde ketiga
diturunkan dari sifat ruin aversion (Heyer, 2001).
Dengan demikian didefinisikan stochastic dominance untuk orde pertama,
kedua dan ketiga sebagai berikut (Heyer, 2001):
1. Stochastic dominance orde pertama
B mendominasi A secara stokastik pada orde pertama jika dan hanya jika
( ) ( ) 0A BF y F y− ≥
2. Stochastic dominance orde kedua

15
B mendominasi A secara stokastik pada orde kedua jika dan hanya jika
( ) ( ) 0y y
A BF t dt F t dt−∞ −∞
− ≥∫ ∫ .
3. Stochastic dominance orde ketiga
B mendominasi A secara stokastik pada orde ketiga jika dan hanya jika
( ) ( ) 0y yu u
A Bu t u t
F t dtdu F t dtdu=−∞ =−∞ =−∞ =−∞
− ≥∫ ∫ ∫ ∫ .
2.3.2 Poverty Dominance
Dalam analisis kemiskinan, SD biasanya digunakan untuk membandingkan
dua buah distribusi pendapatan baik antar dua kelompok populasi maupun dua
periode waktu dalam hal tingkat kemiskinan. Dengan memperbandingkan dua
distribusi pendapatan tersebut akan dapat ditarik kesimpulan distribusi mana yang
lebih dominan secara stokastik di antara keduanya dalam hal tingkat kemiskinan.
Penggunaan stocahastic dominance dalam perbandingan kemiskinan telah banyak
dilakukan oleh para ahli, sebagai contoh Ravallion (1992), Jenkins dan Lambert
(1997), Dercon dan Krishnan (1998), Madden dan Smith (2000) serta Chen (2006).
Misalkan Y adalah random variabel yang melambangkan pendapatan rumah
tangga per kapita sebulan. Andaikan terdapat dua distribusi pendapatan dari populasi
A dan B yang masing-masing memiliki distribusi kumulatif (CDF) FA(y) dan FB(y).
Menurut Davidson dan Duclos (2000), dalam kaitan dengan analisis kemiskinan
definisi deratan fungsi dominance ( )sD x adalah sebagai berikut:
( ) ( )
( ) ( )
1
0
1
0
1( )( 1)!
1( 1)!
xss
xs
D x x y f y dys
x y dF ys
−
−
= −−
= −−
∫
∫. (2.13)
di mana s ≥ 1. Distribusi populasi B dikatakan dominan secara stokastik terhadap
distribusi populasi A dalam hal tingkat kemiskinan pada orde s jika dan hanya jika:

16
( ) ( )s sA BD x D x≥ (2.14)
untuk semua x∈ R. Definisi ini sebenarnya analog dengan (2.12) yaitu jika fungsi
utilitas ( ) ( ) ( ) 111 !
ssU y x ys
−= −−
.
Jika s = 1, maka berlaku )()()()( 11 xFxDxDxF BBAA =≥= , dan dikatakan
distribusi populasi B first-order stochastic dominance (FSD) terhadap distribusi
populasi A. Sedangkan jika diambil s = 2 maka berlaku )()( 22 xDxD BA ≥ atau
( ) ( )∫∫ −≥−x
B
x
A ydFyxydFyx00
)()( dan dikatakan bahwa distribusi populasi B
mempunyai sifat second-order stochastic dominance (SSD) terhadap distribusi
populasi A. Selanjutnya jika diambil s = 3, berlaku )()( 33 xDxD BA ≥ atau
( ) ( )∫∫ −≥−x
B
x
A ydFyxydFyx0
2
0
2 )()( dan dikatakan bahwa distribusi populasi B
mempunyai sifat third-order stochastic dominance (TSD) terhadap distribusi populasi
A.
Kembali pada ukuran kemiskinan F-G-T index yang telah dikemukakan pada
(2.9) di atas. Dalam bentuk fungsi kontinyu, dengan mengganti a dengan s – 1, z
dengan x serta menghilangkan faktor pembagi x, ukuran tersebut dapat dimodifikasi
menjadi ( ) ∫∫ −− =−=∆x
sx
ss ydFyxgydFyxx0
1
0
1 )(),()()( . Indeks ini jelas berkaitan
dengan kriteria stochastic dominance di atas, karena berdasarkan (2.13), diperoleh
hubungan )()!1(
1)( xs
xD ss ∆−
= .
Berdasarkan (2.14), andaikan garis kemiskinan terletak pada suatu level
pendapatan z > 0, maka dikatakan bahwa distribusi populasi B secara stokastik
mendominasi distribusi populasi A pada orde s sampai dengan garis kemiskinan z
jika )()( xDxD sB
sA ≥ untuk semua x ≤ z. Jika s = 1, kurva Ds(x) merupakan fungsi

17
distribusi atau CDF dan Ravallion (1992) menyebutnya sebagai poverty incidence
curve (PIC). Setiap titik pada kurva menunjukkan proporsi penduduk yang
mengkonsumsi kurang dari jumlah (rupiah) yang ditunjukkan oleh sumbu x
(horisontal). Jika titik x diambil sama dengan z (garis kemiskinan), maka nilai Ds(x)
akan identik dengan headcount index. Dalam kaitan dengan kemiskinan, distribusi
populasi B dominan terhadap distribusi populasi A pada orde pertama sampai dengan
garis kemiskinan z mengandung arti bahwa proporsi individu yang berada di bawah
garis kemiskinan lebih besar pada populasi A dibandingkan pada populasi B untuk
sembarang garis kemiskinan tidak melebihi z.
Untuk s = 2, kurva yang terbentuk dinamakan poverty deficit curve (PDC), di
mana setiap titik pada kurva menunjukkan nilai dari poverty gap Gx. Jika titik x
diambil sama dengan z (garis kemiskinan), maka nilai yang diperoleh akan
proporsional dengan poverty gap index (P1). Distribusi populasi B dominan pada orde
kedua terhadap distribusi populasi A sampai dengan garis kemiskinan z berarti bahwa
untuk semua garis kemiskinan x ≤ z rata-rata poverty gap pada populasi A lebih
tinggi dibandingkan rata-rata poverty gap pada populasi B.
Sedangkan untuk s = 3, kurva yang terbentuk dinamakan poverty severity
curve (PSC), di mana setiap titik pada kurva proporsional dengan nilai P2. Distribusi
B dominan pada orde ketiga terhadap distribusi A sampai dengan garis kemiskinan z
berarti bahwa untuk semua garis kemiskinan x ≤ z nilai P2 pada populasi A selalu
lebih tinggi dibandingkan pada populasi B.
Ilustrasi analisis poverty dominance diberikan dengan menggunakan grafik
sebagai berikut. Andaikan terdapat 2 buah distribusi pendapatan yang ingin
dibandingkan tingkat kemiskinannya yaitu populasi A dan populasi B. Jika kurva PIC
populasi A berada di atas populasi B di semua titik, maka secara sempurna dapat
dikatakan bahwa populasi B FSD terhadap populasi A (Gambar 2.1 (a)). Tetapi jika
kurva PIC populasi A dan populasi B berpotongan di satu titik atau lebih maka
perbandingan kemiskinan dengan FSD tidak memberikan kesimpulan yang jelas.
Karena itu perlu analisis SD untuk orde yang lebih tinggi yaitu SSD dengan
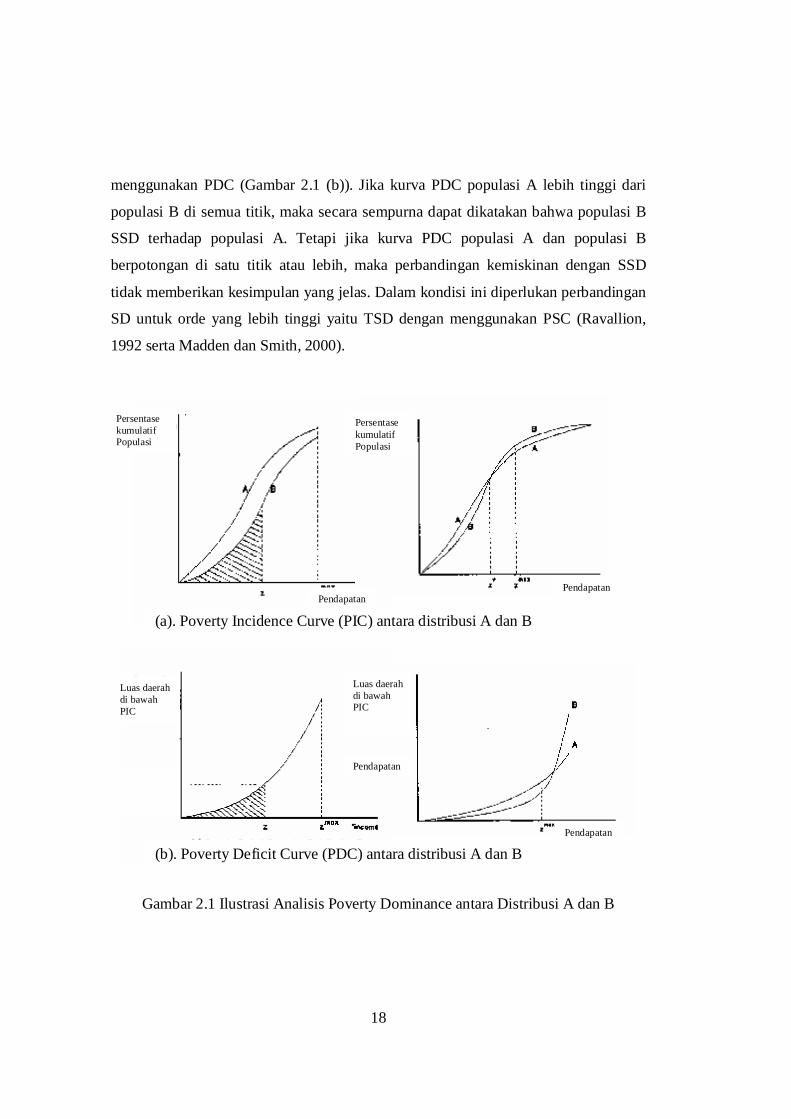
18
menggunakan PDC (Gambar 2.1 (b)). Jika kurva PDC populasi A lebih tinggi dari
populasi B di semua titik, maka secara sempurna dapat dikatakan bahwa populasi B
SSD terhadap populasi A. Tetapi jika kurva PDC populasi A dan populasi B
berpotongan di satu titik atau lebih, maka perbandingan kemiskinan dengan SSD
tidak memberikan kesimpulan yang jelas. Dalam kondisi ini diperlukan perbandingan
SD untuk orde yang lebih tinggi yaitu TSD dengan menggunakan PSC (Ravallion,
1992 serta Madden dan Smith, 2000).
Gambar 2.1 Ilustrasi Analisis Poverty Dominance antara Distribusi A dan B
Gambar 2.1 Ilustrasi Analisis Poverty Dominance antara Distribusi A dan B
Luas daerah di bawah PIC
Persentase kumulatif Populasi
Persentase kumulatif Populasi
Pendapatan
(a). Poverty Incidence Curve (PIC) antara distribusi A dan B
Pendapatan
Pendapatan
Pendapatan
Luas daerah di bawah PIC
(b). Poverty Deficit Curve (PDC) antara distribusi A dan B

19
Jika SD untuk orde yang lebih rendah terpenuhi, SD untuk semua orde yang
lebih tinggi pasti terpenuhi, tetapi tidak berlaku sebaliknya (Davidson dan Duclos,
2000). Dengan demikian jika FSD terpenuhi tidak perlu diuji SSD dan TSD, hanya
jika FSD tidak memberikan kesimpulan yang jelas (inconclusive) baru dilakukan
pengujian untuk SSD, demikian seterusnya. Pada prinsipnya pengujian dengan SD
dapat dilakukan untuk semua orde yang lebih tinggi, namun pada prakteknya jarang
dilakukan untuk orde yang lebih tinggi dari 3 (Madden dan Smith, 2000).
2.4 Perkembangan Sosial-Ekonomi dan Kemiskinan di Sumatera Selatan
Provinsi Sumatera Selatan terletak antara 1o – 4o LS dan 102o – 106o BT
dengan luas wilayah seluruhnya mencapai 97.159,32 km2. Provinsi ini memiliki
batas-batas wilayah, sebelah utara dengan Provinsi Jambi, sebelah selatan dengan
Provinsi Lampung, sebelah timur dengan Provinsi Kepulauan Bangka Belitung dan
sebelah barat dengan Provinsi Bengkulu. Sebagian besar tanahnya terdiri atas rawa
dan payau yang dipengaruhi oleh pasang surut. Provinsi Sumatera Selatan dilalui oleh
sungai-sungai besar seperti Sungai Musi, Sungai Lematang, Sungai Ogan dan Sungai
Komering.
Sampai tahun 2005, Provinsi Sumatera Selatan memiliki wilayah administrasi
pemerintahan meliputi 14 kabupaten/kota, 157 kecamatan dan 2.778 desa/kelurahan.
Pada tahun 2005 jumlah penduduk Sumatera Selatan mencapai 6,756 juta jiwa
dengan kepadatan penduduk 70 jiwa per km2. Laju pertumbuhan penduduk rata-rata
mencapai 1,6 persen per tahun. Provinsi ini didiami oleh suku asli Melayu sebagai
penghuni terbanyak diikuti oleh Suku Jawa dan Sunda.
Sebagian besar penduduk bekerja di sektor pertanian khususnya pertanian
tanaman pangan dan perkebunan. Namun demikian kontribusi sektor pertanian
terhadap PDRB Sumatera Selatan masih relatif kecil. Pertumbuhan ekonomi
mempunyai tren yang meningkat sejak tahun 2002, sedangkan angka pengangguran
cenderung menurun (Tabel 2.1). Ditinjau dari angka-angka makro, kondisi ekonomi
di Sumatera Selatan cenderung membaik selama periode 2002 – 2005.
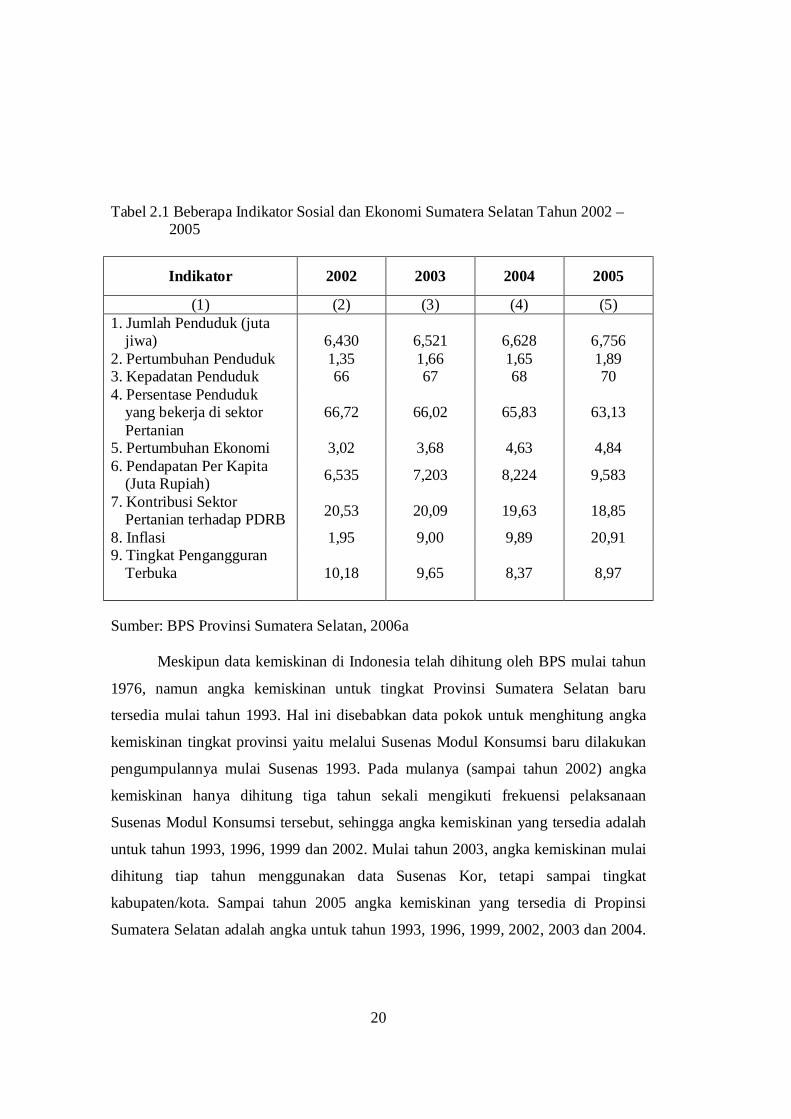
20
Tabel 2.1 Beberapa Indikator Sosial dan Ekonomi Sumatera Selatan Tahun 2002 – 2005
Indikator 2002 2003 2004 2005
(1) (2) (3) (4) (5) 1. Jumlah Penduduk (juta
jiwa)
6,430
6,521
6,628
6,756 2. Pertumbuhan Penduduk 1,35 1,66 1,65 1,89 3. Kepadatan Penduduk 66 67 68 70 4. Persentase Penduduk
yang bekerja di sektor Pertanian
66,72 66,02 65,83 63,13
5. Pertumbuhan Ekonomi 3,02 3,68 4,63 4,84 6. Pendapatan Per Kapita
(Juta Rupiah) 6,535 7,203 8,224 9,583
7. Kontribusi Sektor Pertanian terhadap PDRB 20,53 20,09 19,63 18,85
8. Inflasi 1,95 9,00 9,89 20,91 9. Tingkat Pengangguran
Terbuka
10,18
9,65
8,37
8,97
Sumber: BPS Provinsi Sumatera Selatan, 2006a
Meskipun data kemiskinan di Indonesia telah dihitung oleh BPS mulai tahun
1976, namun angka kemiskinan untuk tingkat Provinsi Sumatera Selatan baru
tersedia mulai tahun 1993. Hal ini disebabkan data pokok untuk menghitung angka
kemiskinan tingkat provinsi yaitu melalui Susenas Modul Konsumsi baru dilakukan
pengumpulannya mulai Susenas 1993. Pada mulanya (sampai tahun 2002) angka
kemiskinan hanya dihitung tiga tahun sekali mengikuti frekuensi pelaksanaan
Susenas Modul Konsumsi tersebut, sehingga angka kemiskinan yang tersedia adalah
untuk tahun 1993, 1996, 1999 dan 2002. Mulai tahun 2003, angka kemiskinan mulai
dihitung tiap tahun menggunakan data Susenas Kor, tetapi sampai tingkat
kabupaten/kota. Sampai tahun 2005 angka kemiskinan yang tersedia di Propinsi
Sumatera Selatan adalah angka untuk tahun 1993, 1996, 1999, 2002, 2003 dan 2004.
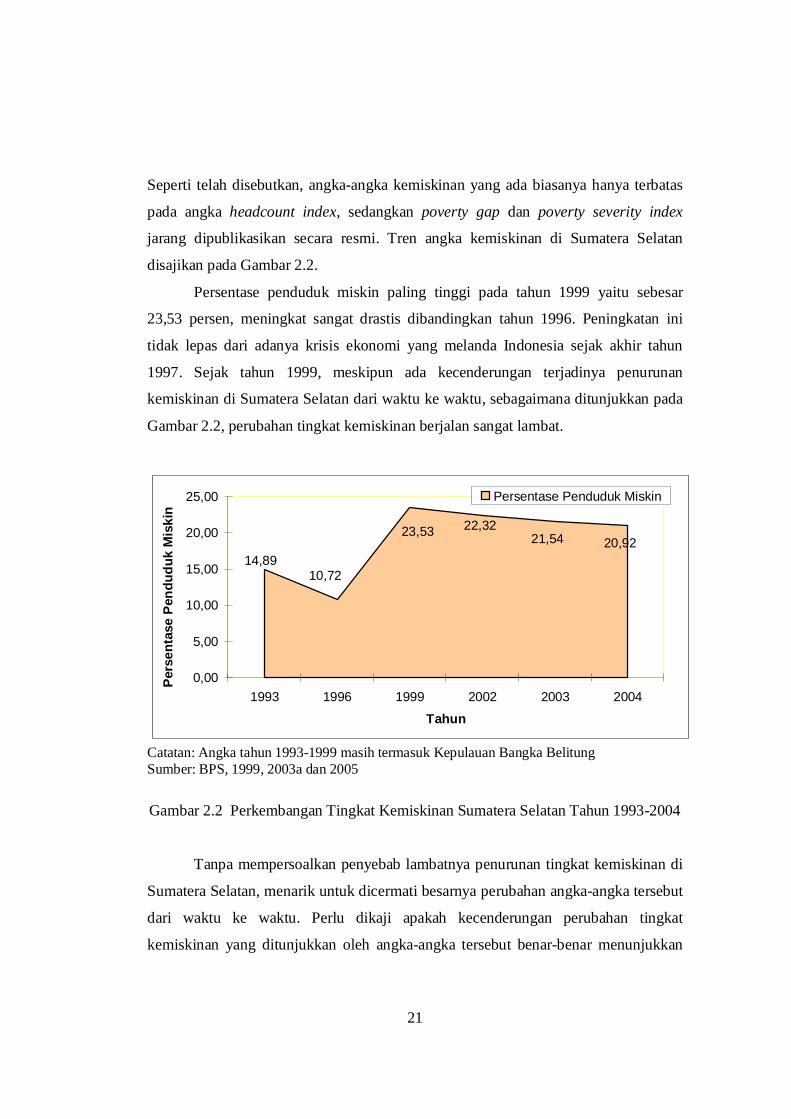
21
Seperti telah disebutkan, angka-angka kemiskinan yang ada biasanya hanya terbatas
pada angka headcount index, sedangkan poverty gap dan poverty severity index
jarang dipublikasikan secara resmi. Tren angka kemiskinan di Sumatera Selatan
disajikan pada Gambar 2.2.
Persentase penduduk miskin paling tinggi pada tahun 1999 yaitu sebesar
23,53 persen, meningkat sangat drastis dibandingkan tahun 1996. Peningkatan ini
tidak lepas dari adanya krisis ekonomi yang melanda Indonesia sejak akhir tahun
1997. Sejak tahun 1999, meskipun ada kecenderungan terjadinya penurunan
kemiskinan di Sumatera Selatan dari waktu ke waktu, sebagaimana ditunjukkan pada
Gambar 2.2, perubahan tingkat kemiskinan berjalan sangat lambat.
20,9221,5422,3223,53
10,7214,89
0,00
5,00
10,00
15,00
20,00
25,00
1993 1996 1999 2002 2003 2004
Tahun
Pers
enta
se P
endu
duk
Mis
kin
Persentase Penduduk Miskin
Catatan: Angka tahun 1993-1999 masih termasuk Kepulauan Bangka Belitung Sumber: BPS, 1999, 2003a dan 2005
Gambar 2.2 Perkembangan Tingkat Kemiskinan Sumatera Selatan Tahun 1993-2004
Tanpa mempersoalkan penyebab lambatnya penurunan tingkat kemiskinan di
Sumatera Selatan, menarik untuk dicermati besarnya perubahan angka-angka tersebut
dari waktu ke waktu. Perlu dikaji apakah kecenderungan perubahan tingkat
kemiskinan yang ditunjukkan oleh angka-angka tersebut benar-benar menunjukkan

22
penurunan yang berarti secara statistik. Pengkajian ini tentu saja akan sangat
bermanfaat untuk mengetahui apakah program-program pembangunan yang telah
dilakukan selama ini benar-benar berdampak nyata pada penurunan tingkat
kemiskinan di Sumatera Selatan.

23
BAB 3
METODOLOGI PENELITIAN
3.1 Data yang Digunakan
Data yang digunakan dalam penelitian ini adalah data pengeluaran rumah
tangga yang diperoleh dari Survei Sosial Ekonomi Nasional (Susenas) tahun 2002
dan 2005 untuk Provinsi Sumatera Selatan. Susenas merupakan survei rumah tangga
yang mengumpulkan data mengenai sosial ekonomi rumah tangga termasuk besarnya
konsumsi rumah tangga. Pertanyaan yang rinci mengenai konsumsi rumah tangga
melalui Susenas dikumpulkan 3 tahun sekali melalui modul konsumsi, yang
pengumpulan terakhirnya dilakukan tahun 2005. Ukuran sampel yang digunakan
untuk modul konsumsi ini pada tahun 2002 dan 2005 di Sumatera Selatan masing-
masing 1.824 rumah tangga dan 1.862 rumah tangga serta representatif untuk tingkat
provinsi.
Data pengeluaran rumah tangga digunakan sebagai data proksi (pendekatan)
bagi pendapatan karena tidak tersedianya data pendapatan yang lengkap. Di samping
itu data pengeluaran rumah tangga yang dihasilkan dari Susenas tersebut selama ini
digunakan oleh BPS untuk melakukan penghitungan dan analisis penduduk miskin di
Indonesia.
3.2 Metode Penelitian
Untuk mencapai tujuan penelitian, secara sistematis langkah-langkah analisis
diuraikan sebagai berikut:
1. Mengkaji inferensi (penaksiran dan pengujian) stochastic dominance dalam
membandingkan dua distribusi pendapatan. Langkah-langkah yang ditempuh
adalah sebagai berikut:
a. Menentukan dua populasi pengeluaran rumah tangga per kapita sebulan
yang akan dibandingkan tingkat kemiskinannya yaitu populasi rumah
tangga tahun 2002 (A) dan populasi rumah tangga tahun 2005 (B).

24
b. Mengambil sampel random sebanyak nA = 1.824 rumah tangga dari populasi
A (tahun 2002) dan sebanyak nB = 1.862 rumah tangga dari populasi B
(tahun 2005) secara independen.
c. Menentukan penaksir fungsi distribusi dari Y (pengeluaran rumah tangga per
kapita sebulan) yaitu ( )nF y di mana ( )nF y adalah distribusi empiris yang
diperoleh dari sampel. Dengan demikian akan terdapat dua buah fungsi
distribusi empiris sebagai penaksir dari fungsi distribusi populasi yaitu
( )AnF y dan ( )B
nF y .
d. Menentukan penaksir fungsi dominance untuk kedua populasi yaitu ( )ˆ sAD x
dan ( )ˆ sBD x di mana penaksir ini diperoleh dengan mensubstitusikan
penaksir fungsi distribusi Y dalam fungsi dominance.
e. Menentukan varians dari penaksir fungsi dominance dan penaksir untuk
varian tersebut.
f. Menetapkan hipotesis untuk menguji apakah terdapat stochastic dominance
antara dua distribusi A dan B.
H0 : ( ) ( ) 0s sA BD x D x− = ,
dengan tiga macam hipotesis alternatif, yaitu:
(i). H1 : ( ) ( ) 0s sA BD x D x− ≠ atau
(ii). H1 : ( ) ( ) 0s sA BD x D x− > atau (3.1)
(iii). H1 : ( ) ( ) 0s sA BD x D x− <
g. Menentukan distribusi asimptotik dari penaksir untuk stochastic dominance
antara dua distribusi pendapatan tersebut yaitu dengan menerapkan Central
Limit Theorem (CLT) pada ( ) ( )( )12 ˆ s s
K K Kn D x D x− di mana K = A, B. Hal ini
analog dengan distribusi asimptotik untuk fungsi distribusi empiris yang
telah dibahas pada bagian 2.1.

25
h. Menentukan statistik uji untuk menguji stochastic dominance antara dua
fungsi distribusi pendapatan.
(i) Menentukan distribusi dari statistik:
( ) ( ) ¶ ( ) ( )( )ˆ ˆ ˆ ˆvars s s sA B A BT D x D x D x D x = − −
berdasarkan distribusi normal asimptotik dari ( ) ( )( )12 ˆ s s
K K Kn D x D x− , di
mana K = A, B.
(ii) Mendapatkan daerah kritis dari pengujian sesuai dengan hipotesis nol
masing-masing hipotesis alternatif pada (3.1).
2. Melakukan analisis perbandingan tingkat kemiskinan dengan stochastic dom-
inance pada distribusi pendapatan di Sumatera Selatan tahun 2002 dan 2005 un-
tuk melihat perubahan tingkat kemiskinan antar periode tersebut:
a. Menyesuaikan data pengeluaran tahun 2002 menggunakan indeks harga
konsumen (Jolliffe, 2005 dan Muller, 2005). Tujuannya adalah untuk
menghilangkan perbedaan harga karena adanya inflasi selama periode 2002
– 2005, sehingga adanya perbedaan besarnya pengeluaran per kapita
(rupiah) penduduk antara tahun 2002 dan 2005 semata-mata disebabkan
oleh perbedaan daya beli masyarakat. Langkah-langkah yang diambil adalah
sebagai berikut:
(i) Mendapatkan data indeks harga konsumen periode referensi Susenas
2002 dan 2005 Provinsi Sumatera Selatan untuk kelompok makanan
dan non makanan. Indeks harga untuk kelompok makanan dan non
makanan di perkotaan diperoleh dengan menggunakan penimbang
yang digunakan oleh BPS untuk penghitungan indeks harga konsumen
di Kota Palembang hasil Survei Biaya Hidup 2002 (BPS, 2003).
Sedangkan untuk daerah pedesaan digunakan indeks harga konsumen
pedesaan dengan penimbang untuk kelompok makanan dan non
makanan diperoleh dari Susenas.
(ii) Menetapkan angka indeks tahun 2005 dengan tahun dasar 2002.

26
(iii) Mengalikan data pengeluran tahun 2002 dengan indeks harga 2005 di
mana tahun 2002 sebagai dasar untuk masing-masing kelompok
makanan dan non makanan
b. Menghitung nilai-nilai taksiran dari fungsi dominance orde 1, 2 dan 3 beser-
ta standar error masing-masing.
c. Menentukan garis kemiskinan maksimum. Garis kemiskinan maksimum
diperoleh dengan melihat tren garis kemiskinan Provinsi Sumatera Selatan
dari waktu ke waktu yang dipublikasikan BPS.
d. Menguji adanya stochastic dominance antara kedua distribusi tersebut pada
interval garis kemiskinan yang tidak melebihi garis kemiskinan maksimum.
3. Membandingkan hasil analisis yang diperoleh melalui pendekatan stochastic
dominance dengan hasil analisis yang diperoleh menggunakan indeks kemiskinan
yang umum. Tujuan ini dapat dicapai melalui langkah-langkah sebagai berikut:
a. Menerapkan garis kemiskinan BPS untuk Provinsi Sumatera Selatan pada
distribusi pengeluaran rumah tangga per kapita di Provinsi Sumatera Selatan
tahun 2002 dan 2005.
b. Menghitung indeks kemiskinan yang umum yaitu headcount index, poverty
gap index dan poverty severity index untuk kedua populasi rumah tangga
yaitu tahun 2002 dan 2005.
c. Membandingkan dan menganalisis tingkat kemiskinan antara kedua
populasi tersebut berdasarkan ketiga indeks di atas dengan melihat besarnya
nilai indeks antara kedua populasi tersebut.
d. Membandingkan hasil yang diperoleh pada point 3.c. dengan hasil yang
diperoleh pada 2.d.

27
BAB 4
ANALISIS DAN PEMBAHASAN
4.1 Inferensi Terhadap Stochastic Dominance
Penelitian yang mengkaji inferensi mengenai stochastic dominance khususnya
yang mengkaji pengujian adanya stochastic dominance telah banyak ditemui dalam
berbagai literatur. Mengenai hal ini, telah ditelusuri secara ringkas dan terurut oleh
Klaver (2006) dalam disertasi doktoralnya. Inferensi terhadap stochastic dominance
yang meliputi penaksiran serta pengujian hipotesis adanya dominance antara dua
fungsi distribusi yang dikaji dan digunakan dalam penelitian ini mengacu pada
inferensi yang dikemukakan oleh Davidson dan Duclos (2000), yaitu inferensi yang
bebas distribusi.
4.1.1 Penaksiran Fungsi Dominance
Andaikan 1 2, y , ..., y A
A A Any adalah sampel random berukuran nA yang berasal
dari ( )AF y , fungsi distribusi pengeluaran tahun 2002 dan 1 2, y , ..., y B
B B Bny adalah
sampel random berukuran nB yang berasal dari ( )BF y , fungsi distribusi pengeluaran
tahun 2005. Maka sebagaimana disebutkan pada (2.2), penaksir tak bias untuk ( )AF y
dan ( )BF y berturut-turut adalah ( )AnF y dan ( )B
nF y , di mana ( )AnF y dan ( )B
nF y
keduanya merupakan fungsi distribusi sampel atau distribusi empiris seperti yang
didefinisikan pada (2.1).
Dengan mensubstitusikan penaksir fungsi distribusi dari (2.2) pada fungsi
dominance (2.11), diperoleh penaksir fungsi dominance sebagai berikut:
( ) ( )
( ) ( )
1
0
1
0
1ˆ ˆ( )( 1)!
1( 1)!
xss
xs
n
D x x y dF ys
x y dF ys
−
−
= −−
= −−
∫
∫

28
( ) ( )1
1
1ˆ ( )( 1)!
n ssi ii
D x x y I y xn s
−
== − ≤
− ∑ (4.1)
Sehingga untuk dua populasi A dan B, akan terdapat dua penaksir fungsi dominance
yaitu:
( ) ( )1
1
1ˆ ( )( 1)!
A sns A AA i ii
A
D x x y I y xn s
−
== − ≤
− ∑ dan
( ) ( )1
1
1ˆ ( )( 1)!
B sns B BB i ii
B
D x x y I y xn s
−
== − ≤
− ∑
Untuk mendapatkan nilai harapan dan varians dari ˆ ( )sD x , dimisalkan suatu
fungsi sebagai berikut:
( ) ( ) ( )1si i iU x x y I y x−= − ≤ (4.2)
di mana ( )iU x , i = 1, 2, ..., n adalah variabel random yang identik dan independen,
misalkan mempunyai mean µ dan varians 2σ . Selanjutnya diperoleh rata-rata
sampel dari ( )iU x sebagai berikut:
( ) ( )
( ) ( )
( ) ( )
1
1
1
1
1
ˆ1 !
n
iin
si i
i
s
U x U xn
x y I y xns D x
=
−
=
=
= − ≤
= −
∑
∑
atau
( ) ( ) ( )1ˆ1 !
sD x U xs
=−
(4.3)
Nilai harapan dan varians dari ( )U x adalah:
( ) ( ) ( )
( ) ( ) ( ) ( )
1 1
1 1
0 01
1 1
1
n n
i ii i
n x xs s
i
E U x E U x E U xn n
x y dF y x y dF yn
= =
− −
=
= =
= − = −
∑ ∑
∑∫ ∫
( ) ( ) ( )1 ! sE U x s D x = − (4.4)

29
( )( ) ( ) ( )( )
( )( ) ( )( )
( )( ) ( ) ( )( )
( ) ( ) ( ) ( ) ( )( )
21 1
222
1
222
1
22 1
2 01
1 1var var var
1
1 1 !
1 1 !
n n
i ii i
n
iin
si
in x s s
i
U x U x U xn n
E U x U xn
E U x s D xn
x y dF y s D xn
= =
=
=
−
=
= =
= −
= − −
= − − −
∑ ∑
∑
∑
∑ ∫
( )( ) ( ) ( ) ( ) ( ) ( )( )22 1
0
1var 1 !x s sU x x y dF y s D x
n− = − − − ∫ (4.5)
Nilai harapan dari ˆ ( )sD x diperoleh dengan mengambil ekspektasi dari (4.3)
dan mensubstitusikan (4.4) sebagai berikut:
( ) ( ) ( ) ( )( )
( ) ( ) ( )
1 1ˆ ( )1 ! 1 !
1 1 !1 !
s
s
E D x E U x E U xs s
s D xs
= = − −
= − −
( )ˆ ( )s sE D x D x = . (4.6)
Demikian juga varians dari ˆ ( )sD x diperoleh dengan mengambil varians dari (4.3)
dan mensubstitusikan (4.5) sebagai berikut:
( ) ( )( )( )
( )( )
( )( )( ) ( ) ( ) ( ) ( )( )
2
22 12 0
1 1ˆvar ( ) var var1 ! 1 !
1 1 1 !1 !
s
x s s
D x U x U xs s
x y dF y s D xns
−
= = − −
= − − − − ∫
( )( )( ) ( ) ( ) ( )( )22 1
2 0
1 1ˆvar ( )1 !
x ss sD x x y dF y D xn s
− = − − −
∫ (4.7)
Sedangkan penaksir varians tersebut adalah:

30
¶( )( )
( ) ( ) ( ) ( )( )22 12 0
1 1ˆ ˆ ˆvar ( )1 !
x ss sD x x y dF y D xn s
− = − − −
∫
¶[ ]
( ) ( ) ( ) ( )22 1
2 1
1 1ˆ ˆvar ( )( 1)!
n ss si ii
D x x y I y x D xn n s
−
=
= − ≤ − − ∑ (4.8)
Berdasarkan (4.6) dan (4.7) di atas, diperoleh bahwa penaksir fungsi dominance yang
diberikan pada (4.1) merupakan penaksir yang tak bias serta konsisten karena
ˆvar ( ) 0sD x → untuk n → ∞ .
Dengan demikian terdapat dua penaksir fungsi varians yaitu penaksir varians
untuk populasi A dan untuk populasi B, sebagai berikut:
¶[ ]
( ) ( ) ( ) ( )22 1
2 1
1 1ˆ ˆvar ( )( 1)!
A sns A A sA i i Ai
A A
D x x y I y x D xn n s
−
=
= − ≤ − − ∑ dan
¶[ ]
( ) ( ) ( ) ( )22 1
2 1
1 1ˆ ˆvar ( )( 1)!
B sns B B sB i i Bi
B B
D x x y I y x D xn n s
−
=
= − ≤ − − ∑
Dalam penelitian ini dibandingkan dua populasi A dan B tersebut dengan
membandingkan selisih fungsi dominance dari kedua populasi, yaitu ( ) ( )s sA BD x D x− .
Penaksir dari selisih fungsi dominance ini adalah:
ˆ ˆ( ) ( )s sA BD x D x− =
( ) ( ) ( ) ( )1 1
1 1
1 1 1( 1)!
A Bs sn nA A B Bi i i ii i
A B
x y I y x x y I y xs n n
− −
= =
− ≤ − − ≤ −
∑ ∑ (4.9)
Sedangkan penaksir variannya adalah:
¶ ¶ ¶ ¶ˆ ˆ ˆ ˆ ˆ ˆvar ( ) ( ) var ( ) var ( ) 2 ( ), ( )s s s s s sA B A B A BD x D x D x D x cov D x D x − = + −
Dalam kasus populasi A dan B independen, suku terakhir dari komponen varians
tersebut adalah nol, sehingga variansnya menjadi:
¶ ¶ ¶ˆ ˆ ˆ ˆvar ( ) ( ) var ( ) var ( )s s s sA B A BD x D x D x D x − = +

31
¶[ ]
( ) ( ) ( )
[ ]( ) ( ) ( ) ( )
22 2
2 1
22 1
2 1
1 1ˆ ˆ ˆvar ( ) ( )( 1)!
1 1 ˆ ( 1)!
A
B
sns s A A sA B i i Ai
A A
sn B B si i Bi
B B
D x D x x y I y x D xn n s
x y I y x D xn n s
−
=
−
=
− = − ≤ − − + − ≤ − −
∑
∑ (4.10)
4.1.2 Pengujian Hipotesis
Pada bagian ini akan dibahas statistik uji untuk menguji adanya stochastic
dominance antara dua populasi A dan B yang saling independen. Statistik uji tersebut
didasarkan pada hipotesis sebagai berikut:
H0 : ( ) ( ) 0s sA BD x D x− = ,
dengan tiga macam hipotesis alternatif, yaitu:
1. H1 : ( ) ( ) 0s sA BD x D x− ≠ atau (4.11)
2. H1 : ( ) ( ) 0s sA BD x D x− > atau
3. H1 : ( ) ( ) 0s sA BD x D x− <
Tse dan Zhang (2002) meneliti beberapa uji mengenai stochastic dominance
melalui simulasi monte carlo dan mereka menemukan bahwa uji yang dikemukakan
oleh Davidson dan Duclos (2000) mempunyai power yang lebih tinggi. Uji Davidson
dan Duclos (DD) ini didasarkan pada sifat asimptotik dari penaksir fungsi dominance
yang diberikan pada Teorema 4.1 di bawah ini.
Teorema 4.1 (Davidson dan Duclos, 2000):
Asumsikan bahwa momen orde ke-(2s-2) dari yA dan yB ada, maka
( ) ( )( )ˆ s sK K Kn D x D x− berdistribusi asimptotik ( )( )ˆ0, var s
K KN n D x , di mana K =
A, B adalah dua populasi yang saling independen sehingga variannya diberikan pada
(4.7).

32
Teorema ini analog dengan (2.3). Untuk membuktikan teorema ini merujuk
pada definisi ( )iU x pada (4.2). Menurut teorema limit pusat (Teorema 3.3.1 dalam
Sen dan Singer, 1993), jika ( )iU x adalah variabel random yang identik dan
independen dengan mean µ dan varian berhingga 2σ serta ( ) ( )1
1 nii
U x U xn =
= ∑ ,
maka diperoleh bahwa ( )
( )0,1dn
n U xZ N
µ
σ
− = → , atau dituliskan
( ) ( )20,dn U x Nµ σ − → .
Berdasarkan (4.3) diketahui bahwa ( ) ( ) ( )ˆ1 ! sU x s D x= − dan karena ( )iU x adalah
variabel random yang identik dan independen dengan mean µ dan varians 2σ , maka
( )E U x µ = dan ( ) 2var U x n
σ = . Sehingga diperoleh ( ) ( )1 ! ss D xµ = − dan
( ) ( )22 ˆ1 ! var sn s D xσ = − . Akibatnya:
( ) ( ) ( ) ( )
( ) ( )( )
2
ˆ1 ! 1 !0,1
ˆ1 ! var
s sd
s
n s D x s D xN
n s D x
− − − → −
( ) ( ) ( ) ( )
( ) ( )( )
ˆ1 ! 1 !0,1
ˆ1 ! var
s sd
s
n s D x s D xN
s n D x
− − − → −
( ) ( )
( )( )
ˆ0,1
ˆvar
s sd
s
n D x D xN
n D x
− →
( ) ( ) ( )( )ˆ ˆ0, vards s sn D x D x N n D x − → .
Dengan demikian Teorema 4.1 telah terbukti.
Kenyataannya ( )ˆvar sKD x
tidak diketahui, sehingga diduga dengan
¶ ( )ˆvar sKD x
sebagaimana diberikan pada (4.8). Oleh karena itu dirumuskan suatu

33
statistik ( ) ( ) ¶ ( )ˆ ˆvars s sK K K KT D x D x D x = − . Sebagaimana telah ditunjukkan
bahwa statistik ( ) ( )( )ˆ s sK K Kn D x D x− berditribusi asimptotik dengan mean 0 dan
varians ( )ˆvar sKD x , sehingga menurut Sen dan Singer (1993) diperoleh bahwa:
( ) ( ) ¶ ( ) ( )ˆ ˆvar 0,1ds s sK K K KT D x D x D x N = − → (4.12)
Berdasarkan sifat asimptotik penaksir fungsi dominance tersebut di atas maka
untuk menguji adanya stochastic dominance antara dua populasi A dan B identik
dengan membandingkan dua fungsi yang berdistribusi asimptotik normal standar.
Dengan demikian dirumuskan statistik uji sebagai berikut:
( ) ( ) ¶ ( ) ( )( )ˆ ˆ ˆ ˆvars s s sA B A BT D x D x D x D x = − − (4.13)
di mana, ( ) ( )ˆ ˆs sA BD x D x− diberikan pada (4.9) sedangkan ¶ ( ) ( )( )ˆ ˆvar s s
A BD x D x−
diberikan pada (4.10). Analog dengan (4.12) di atas, statistik uji ini secara asimptotik
juga berdistribusi normal standar.
Daerah kritis pengujian pada taraf signifikansi α ditentukan berdasarkan
masing-masing hipotesis alternatif pada (4.11) di atas, sebagai berikut:
1. 21T Z α−>
2. 1T Z α−> (4.14)
3. 1T Z α−< −
di mana Z adalah titik kritis pada distribusi normal standar dan tingkat signifikansi α
adalah luas daerah di sebelah kiri kurva distribusi normal.
4.2 Analisis Perbandingan Tingkat Kemiskinan Di Sumatera Selatan
Tahun 2002 – 2005
Pada bagian ini pembahasan difokuskan pada perbandingan tingkat
kemiskinan di Sumatera Selatan antar dua periode waktu yaitu tahun 2002 dan 2005
menggunakan analisis stocahstic dominance dan membandingkan hasilnya dengan

34
analisis F-G-T index. Data yang digunakan adalah data pengeluaran rumah tangga per
kapita sebulan yang diperoleh dari Susenas 2002 dan 2005 yang dikumpulkan oleh
BPS. Data pengeluaran ini digunakan sebagai proxy bagi data pendapatan yang tidak
tersedia secara lengkap untuk analisis kemiskinan. Selain itu, data pengeluaran rumah
tangga ini telah digunakan oleh BPS untuk menghitung angka kemiskinan di
Indonesia sejak tahun 1976 (BPS, 2000). Data konsumsi atau pengeluaran rumah
tangga yang umumnya diperoleh melalui survei-survei rumah tangga juga merupakan
sumber data utama untuk analisis kemiskinan di berbagai negara (Ravallion, 1992).
4.2.1 Analisis Poverty Dominance
Salah satu permasalahan mendasar dalam melakukan perbandingan tingkat
kemiskinan baik antar periode waktu maupun antar wilayah menggunakan data
pengeluaran rumah tangga adalah adanya perbedaan biaya hidup antar periode waktu
dan antar wilayah yang disebabkan oleh adanya perbedaan harga. Akibatnya
pengeluaran rumah tangga antar perode waktu maupun antar wilayah tidak dapat
dibandingkan secara langsung, demikian juga ukuran kemiskinan yang dihasilkan.
Cara yang sering digunakan untuk mengatasi hal ini adalah dengan membuat garis
kemiskinan yang berbeda-beda antar periode waktu maupun antar wilayah menurut
perbedaan harga yang ada (Ravallion, 1992). Di Indonesia, hal ini telah dilakukan
oleh BPS dengan membedakan garis kemiskinan antara perkotaan dan pedesaan
(BPS, 2000) serta belakangan muncul adanya garis kemiskinan menurut
kabupaten/kota. Beberapa penulis juga melakukan penyesuaian baik terhadap garis
kemiskinan maupun terhadap data konsumsi rumah tangga menggunakan indeks
harga. Jolliffe (2005) dalam membandingkan tingkat kemiskinan di Amerika Serikat
melakukan penyesuaian garis kemiskinan antar periode waktu menggunakan indeks
harga. Sedangkan Muller (2005) membandingkan angka-angka kemiskinan
triwulanan di Rwanda setelah pengeluaran rumah tangga dijastifikasi menggunakan
indeks harga triwulanan.

35
Untuk membandingkan distribusi pengeluaran antar periode 2002 dan 2005 di
Provinsi Sumatera Selatan, penulis melakukan penyesuaian terhadap data
pengeluaran tahun 2002 menggunakan indeks harga konsumen. Agar bisa
dibandingkan, perbedaan harga antara tahun 2002 dan 2005 harus dihilangkan dari
data pengeluaran, sehingga diharapkan jika terdapat perbedaan pada distribusi
pengeluaran antara tahun 2002 dan 2005, perbedaan semata-mata disebabkan oleh
perbedaan tingkat kemampuan masyarakat dalam hal ini karena menurunnya atau
meningkatnya tingkat kesejahteraan masyarakat.
Penyesuaian terhadap konsumsi 2002 dibedakan menurut kelompok makanan
dan non makanan baik untuk daerah perkotaan maupun daerah pedesaan. Untuk
daerah perkotaan digunakan indeks harga konsumen bulanan di Kota Palembang
periode 2001 – 2005 (data diambil dari BPS Provinsi Sumatera Selatan, 2002, 2003,
2004, 2005 dan 2006), sedangkan untuk daerah pedesaan digunakan indeks harga
konsumen pedesaan bulanan periode 2001 – 2005 (data diambil dari BPS, 2003b,
2005a, 2007). Indeks harga yang digunakan serta faktor pengali yang dihasilkan
disajikan pada Lampiran 1.
Penghitungan nilai-nilai dari fungsi dominance ( )sKD x orde ke-s (s = 1,2,3)
untuk kedua distribusi pengeluaran (K = A,B, di mana A adalah indeks untuk tahun
2002 dan B untuk tahun 2005) dilakukan dengan menggunakan paket program DAD
versi 4.4 yang dibuat oleh Duclos, Arar dan Fortin (2006) pada berbagai titik garis
kemiskinan. Hasilnya disajikan pada Tabel 4.2, Tabel 4.3 dan Tabel 4.4, sedangkan
hasil pengolahan selengkapnya disajikan pada Lampiran 2. Secara manual,
penghitungan nilai-nilai duga fungsi dominance mengacu pada (4.1) dan (4.9)
sedangkan standar errornya dihitung mengacu pada (4.8) dan (4.10)
Untuk dapat menyimpulkan apakah terdapat stochastic dominance orde
pertama antara kedua distribusi tersebut, maka perlu ditentukan besarnya garis
kemiskinan maksimum yaitu zmaks. Untuk itu perlu dilihat perkembangan garis
kemiskinan di Sumatera Selatan dari waktu ke waktu yang pernah dipublikasikan
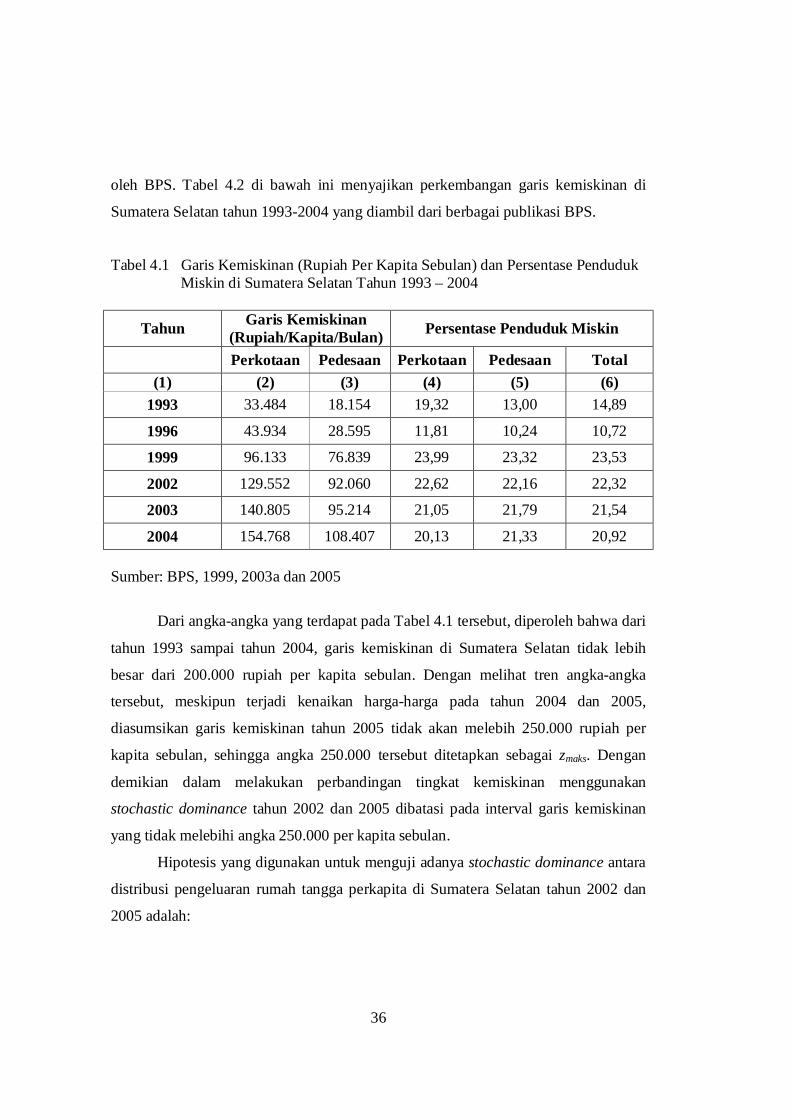
36
oleh BPS. Tabel 4.2 di bawah ini menyajikan perkembangan garis kemiskinan di
Sumatera Selatan tahun 1993-2004 yang diambil dari berbagai publikasi BPS.
Tabel 4.1 Garis Kemiskinan (Rupiah Per Kapita Sebulan) dan Persentase Penduduk Miskin di Sumatera Selatan Tahun 1993 – 2004
Tahun Garis Kemiskinan (Rupiah/Kapita/Bulan) Persentase Penduduk Miskin
Perkotaan Pedesaan Perkotaan Pedesaan Total (1) (2) (3) (4) (5) (6)
1993 33.484 18.154 19,32 13,00 14,89
1996 43.934 28.595 11,81 10,24 10,72
1999 96.133 76.839 23,99 23,32 23,53
2002 129.552 92.060 22,62 22,16 22,32
2003 140.805 95.214 21,05 21,79 21,54
2004 154.768 108.407 20,13 21,33 20,92 Sumber: BPS, 1999, 2003a dan 2005
Dari angka-angka yang terdapat pada Tabel 4.1 tersebut, diperoleh bahwa dari
tahun 1993 sampai tahun 2004, garis kemiskinan di Sumatera Selatan tidak lebih
besar dari 200.000 rupiah per kapita sebulan. Dengan melihat tren angka-angka
tersebut, meskipun terjadi kenaikan harga-harga pada tahun 2004 dan 2005,
diasumsikan garis kemiskinan tahun 2005 tidak akan melebih 250.000 rupiah per
kapita sebulan, sehingga angka 250.000 tersebut ditetapkan sebagai zmaks. Dengan
demikian dalam melakukan perbandingan tingkat kemiskinan menggunakan
stochastic dominance tahun 2002 dan 2005 dibatasi pada interval garis kemiskinan
yang tidak melebihi angka 250.000 per kapita sebulan.
Hipotesis yang digunakan untuk menguji adanya stochastic dominance antara
distribusi pengeluaran rumah tangga perkapita di Sumatera Selatan tahun 2002 dan
2005 adalah:
37
H0 : ( ) ( ) 0s sA BD x D x− =
(Tidak terdapat stochastic dominance orde ke-s (s = 1,2,3) antara kedua
distribusi pengeluaran)
H1 : ( ) ( ) 0s sA BD x D x− >
(Distribusi pengeluaran tahun 2005 lebih dominan dibandingkan distribusi
pengeluaran tahun 2002).
Statistik uji yang digunakan adalah ( ) ( ) ¶ ( ) ( )( )ˆ ˆ ˆ ˆvars s s sA B A BT D x D x D x D x = − −
yang berdistibusi asimptotik normal standar. Sesuai dengan (4.14), maka hipotesis
nol ditolak bila T > Z1-α .
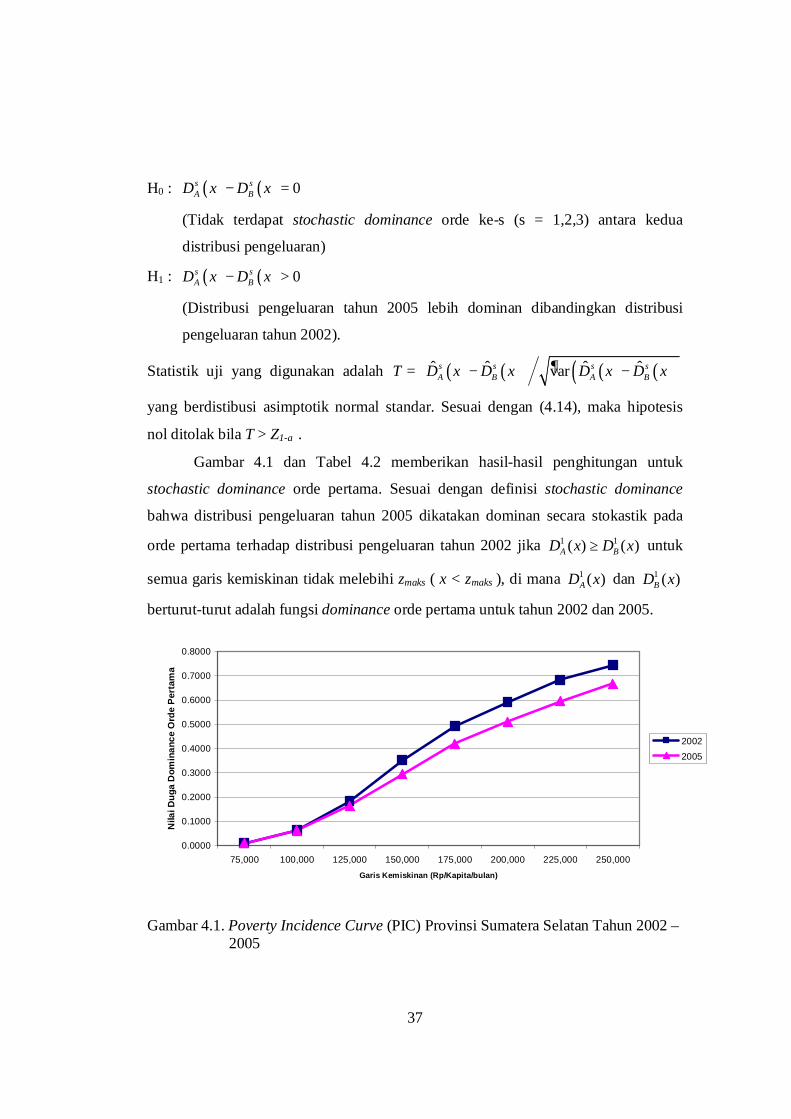
Gambar 4.1 dan Tabel 4.2 memberikan hasil-hasil penghitungan untuk
stochastic dominance orde pertama. Sesuai dengan definisi stochastic dominance
bahwa distribusi pengeluaran tahun 2005 dikatakan dominan secara stokastik pada
orde pertama terhadap distribusi pengeluaran tahun 2002 jika 1 1( ) ( )A BD x D x≥ untuk
semua garis kemiskinan tidak melebihi zmaks ( x < zmaks ), di mana 1 ( )AD x dan 1 ( )BD x
berturut-turut adalah fungsi dominance orde pertama untuk tahun 2002 dan 2005.
0.0000
0.1000
0.2000
0.3000
0.4000
0.5000
0.6000
0.7000
0.8000
75,000 100,000 125,000 150,000 175,000 200,000 225,000 250,000Garis Kemiskinan (Rp/Kapita/bulan)
Nila
i Dug
a D
omin
ance
Ord
e Pe
rtam
a
20022005
Gambar 4.1. Poverty Incidence Curve (PIC) Provinsi Sumatera Selatan Tahun 2002 –
2005
38
Berdasarkan Gambar 4.1 sampai dengan garis kemiskinan maksimum,
diperoleh bahwa nilai duga fungsi dominance orde pertama untuk tahun 2002 hampir
selalu lebih tinggi dibandingkan tahun 2005. Pada interval 100.000 ≤ x ≤ 250.000,
kurva PIC untuk tahun 2002 selalu berada di atas kurva PIC untuk tahun 2005.
Sedangkan pada interval x < 100.000 terjadi perpotongan kurva PIC untuk tahun
2002 dan 2005. Adanya perpotongan kurva PIC ini juga dtunjukkan oleh adanya nilai
kolom (6) pada Tabel 4.2 di bawah ini.
Besarnya nilai dominance orde pertama pada kolom (2) dan (3) Tabel 4.2
proporsional atau sebanding dengan angka headcount index. Meskipun angka-angka
ini tidak sama dengan headcount index pada berbagai titik X (garis kemiskinan),
semakin tinggi angka-angka ini menunjukkan semakin besarnya angka headcount
index. Dengan demikian adanya tanda negatif dari angka-angka pada kolom (6)
mengandung makna bahwa angka headcount index untuk tahun 2002 lebih rendah
dibandingkan tahun 2005 pada titik X (garis kemiskinan) tertentu. Sebaliknya tanda
positif berarti angka headcount index tahun 2002 lebih tinggi dibandingkan tahun
2005.
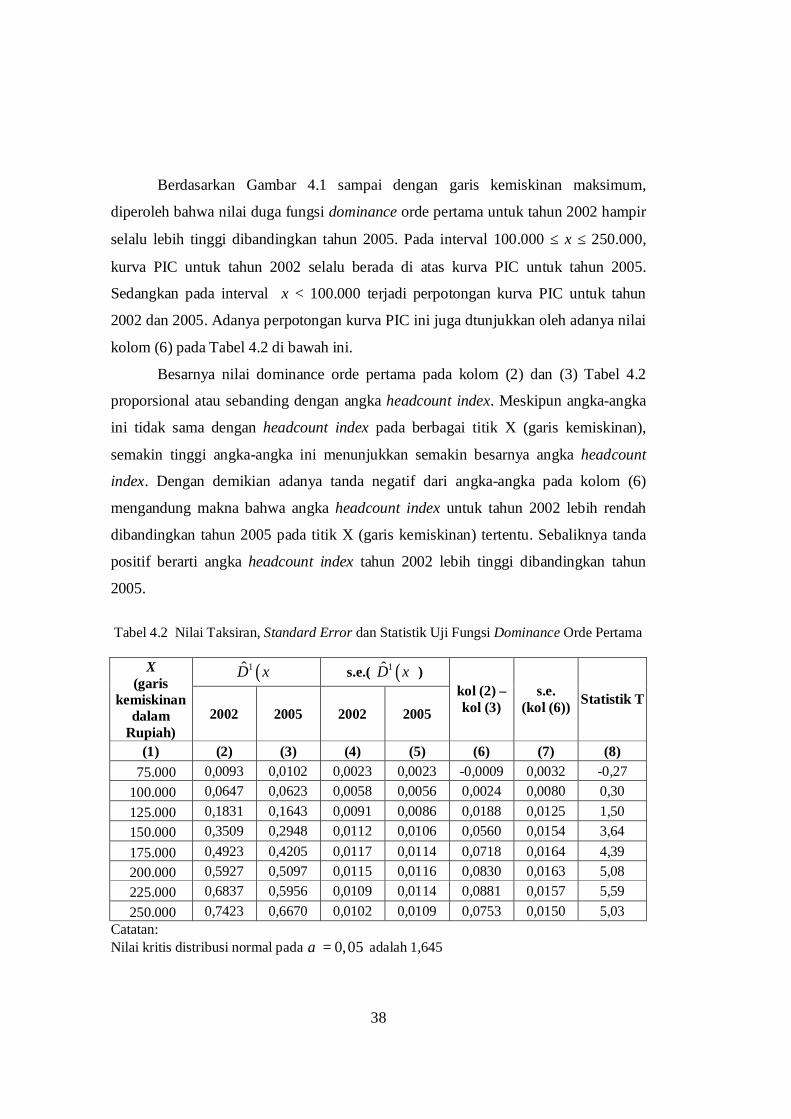
Tabel 4.2 Nilai Taksiran, Standard Error dan Statistik Uji Fungsi Dominance Orde Pertama
( )1D x s.e.( ( )1D x ) X (garis
kemiskinan dalam
Rupiah) 2002 2005 2002 2005
kol (2) – kol (3)
s.e. (kol (6)) Statistik T
(1) (2) (3) (4) (5) (6) (7) (8) 75.000 0,0093 0,0102 0,0023 0,0023 -0,0009 0,0032 -0,27
100.000 0,0647 0,0623 0,0058 0,0056 0,0024 0,0080 0,30 125.000 0,1831 0,1643 0,0091 0,0086 0,0188 0,0125 1,50 150.000 0,3509 0,2948 0,0112 0,0106 0,0560 0,0154 3,64 175.000 0,4923 0,4205 0,0117 0,0114 0,0718 0,0164 4,39 200.000 0,5927 0,5097 0,0115 0,0116 0,0830 0,0163 5,08 225.000 0,6837 0,5956 0,0109 0,0114 0,0881 0,0157 5,59 250.000 0,7423 0,6670 0,0102 0,0109 0,0753 0,0150 5,03
Catatan: Nilai kritis distribusi normal pada 0,05α = adalah 1,645
39
Pengujian adanya stochastic dominance orde pertama dilakukan dengan uji T
yang berdistribusi asimptotik normal, sebagaimana ditunjukkan pada Tabel 4.2. Pada
interval 150.000 ≤ x ≤ 250.000 diperoleh bahwa T > 1,645 sehingga distribusi
pengeluaran tahun 2005 lebih dominan dibandingkan distribusi pengeluaran tahun
2002, sedangkan pada interval x < 150.000 perbedaan yang ada tidak signifikan (T <
1,645). Meskipun pada interval x < 150.000 tidak ditemui adanya perbedaan yang
signifikan pada nilai-nilai fungsi dominance antara kedua distribusi pengeluaran,
namun karena terdapat perpotongan kurva PIC untuk kehatian-hatian penarikan
kesimpulan perlu dilanjutkan untuk melihat fungsi dominance orde yang lebih tinggi
yaitu orde kedua.
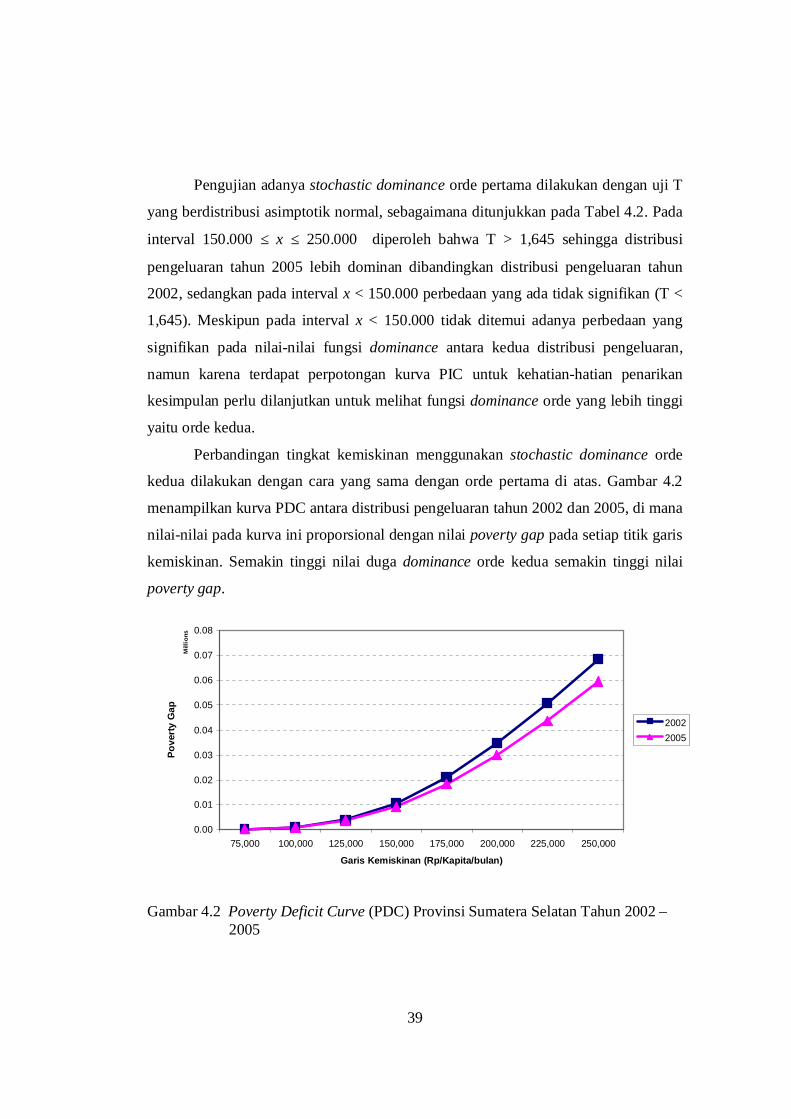
Perbandingan tingkat kemiskinan menggunakan stochastic dominance orde
kedua dilakukan dengan cara yang sama dengan orde pertama di atas. Gambar 4.2
menampilkan kurva PDC antara distribusi pengeluaran tahun 2002 dan 2005, di mana
nilai-nilai pada kurva ini proporsional dengan nilai poverty gap pada setiap titik garis
kemiskinan. Semakin tinggi nilai duga dominance orde kedua semakin tinggi nilai
poverty gap.
0.00
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
75,000 100,000 125,000 150,000 175,000 200,000 225,000 250,000
Mill
ions
Garis Kemiskinan (Rp/Kapita/bulan)
Pove
rty
Gap
20022005
Gambar 4.2 Poverty Deficit Curve (PDC) Provinsi Sumatera Selatan Tahun 2002 –
2005
40
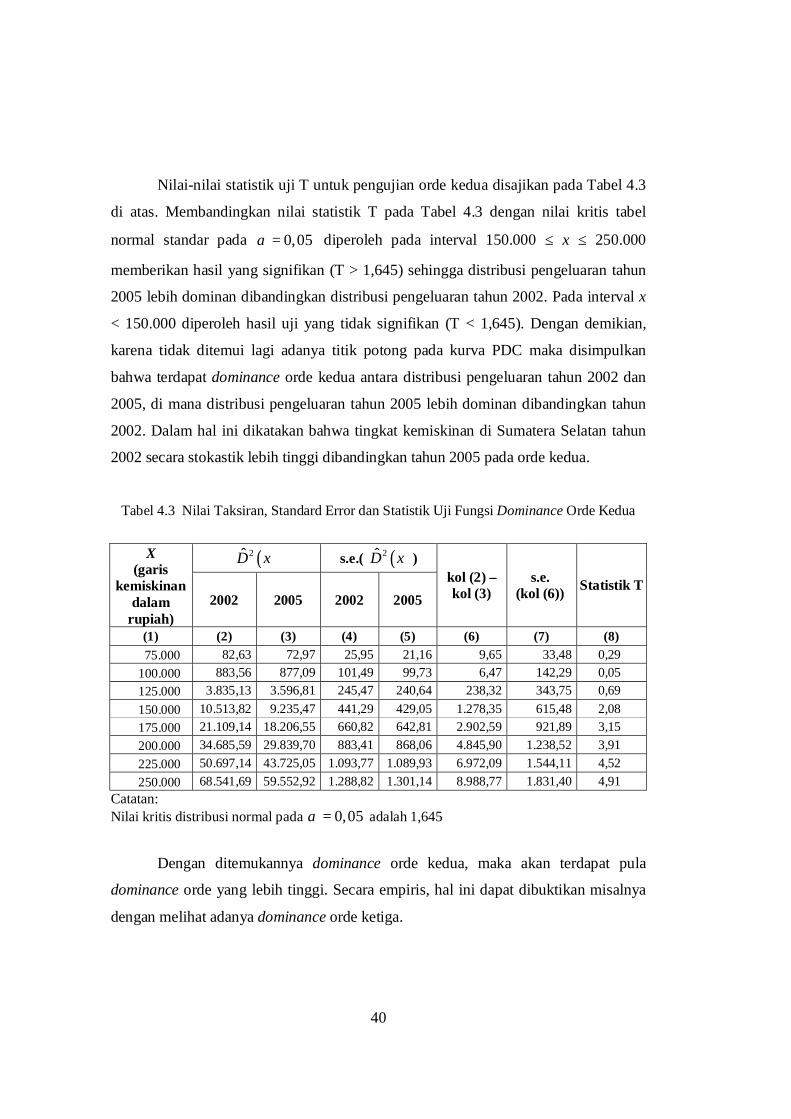
Nilai-nilai statistik uji T untuk pengujian orde kedua disajikan pada Tabel 4.3
di atas. Membandingkan nilai statistik T pada Tabel 4.3 dengan nilai kritis tabel
normal standar pada 0,05α = diperoleh pada interval 150.000 ≤ x ≤ 250.000
memberikan hasil yang signifikan (T > 1,645) sehingga distribusi pengeluaran tahun
2005 lebih dominan dibandingkan distribusi pengeluaran tahun 2002. Pada interval x
< 150.000 diperoleh hasil uji yang tidak signifikan (T < 1,645). Dengan demikian,
karena tidak ditemui lagi adanya titik potong pada kurva PDC maka disimpulkan
bahwa terdapat dominance orde kedua antara distribusi pengeluaran tahun 2002 dan
2005, di mana distribusi pengeluaran tahun 2005 lebih dominan dibandingkan tahun
2002. Dalam hal ini dikatakan bahwa tingkat kemiskinan di Sumatera Selatan tahun
2002 secara stokastik lebih tinggi dibandingkan tahun 2005 pada orde kedua.
Tabel 4.3 Nilai Taksiran, Standard Error dan Statistik Uji Fungsi Dominance Orde Kedua
( )2D x s.e.( ( )2D x ) X (garis
kemiskinan dalam
rupiah) 2002 2005 2002 2005
kol (2) – kol (3)
s.e. (kol (6)) Statistik T
(1) (2) (3) (4) (5) (6) (7) (8) 75.000 82,63 72,97 25,95 21,16 9,65 33,48 0,29
100.000 883,56 877,09 101,49 99,73 6,47 142,29 0,05 125.000 3.835,13 3.596,81 245,47 240,64 238,32 343,75 0,69 150.000 10.513,82 9.235,47 441,29 429,05 1.278,35 615,48 2,08 175.000 21.109,14 18.206,55 660,82 642,81 2.902,59 921,89 3,15 200.000 34.685,59 29.839,70 883,41 868,06 4.845,90 1.238,52 3,91 225.000 50.697,14 43.725,05 1.093,77 1.089,93 6.972,09 1.544,11 4,52 250.000 68.541,69 59.552,92 1.288,82 1.301,14 8.988,77 1.831,40 4,91
Catatan: Nilai kritis distribusi normal pada 0,05α = adalah 1,645
Dengan ditemukannya dominance orde kedua, maka akan terdapat pula
dominance orde yang lebih tinggi. Secara empiris, hal ini dapat dibuktikan misalnya
dengan melihat adanya dominance orde ketiga.
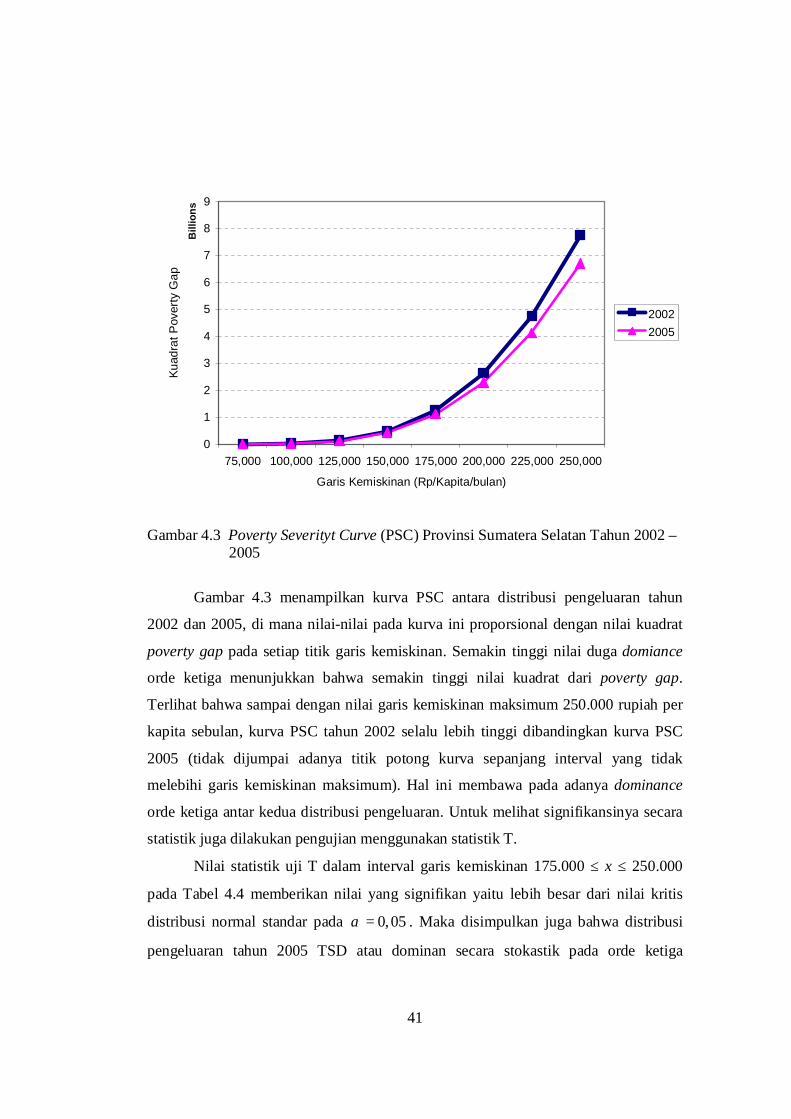
41
0
1
2
3
4
5
6
7
8
9
75,000 100,000 125,000 150,000 175,000 200,000 225,000 250,000
Bill
ions
Garis Kemiskinan (Rp/Kapita/bulan)
Kuad
rat P
over
ty G
ap
20022005
Gambar 4.3 Poverty Severityt Curve (PSC) Provinsi Sumatera Selatan Tahun 2002 –
2005
Gambar 4.3 menampilkan kurva PSC antara distribusi pengeluaran tahun
2002 dan 2005, di mana nilai-nilai pada kurva ini proporsional dengan nilai kuadrat
poverty gap pada setiap titik garis kemiskinan. Semakin tinggi nilai duga domiance
orde ketiga menunjukkan bahwa semakin tinggi nilai kuadrat dari poverty gap.
Terlihat bahwa sampai dengan nilai garis kemiskinan maksimum 250.000 rupiah per
kapita sebulan, kurva PSC tahun 2002 selalu lebih tinggi dibandingkan kurva PSC
2005 (tidak dijumpai adanya titik potong kurva sepanjang interval yang tidak
melebihi garis kemiskinan maksimum). Hal ini membawa pada adanya dominance
orde ketiga antar kedua distribusi pengeluaran. Untuk melihat signifikansinya secara
statistik juga dilakukan pengujian menggunakan statistik T.
Nilai statistik uji T dalam interval garis kemiskinan 175.000 ≤ x ≤ 250.000
pada Tabel 4.4 memberikan nilai yang signifikan yaitu lebih besar dari nilai kritis
distribusi normal standar pada 0,05α = . Maka disimpulkan juga bahwa distribusi
pengeluaran tahun 2005 TSD atau dominan secara stokastik pada orde ketiga
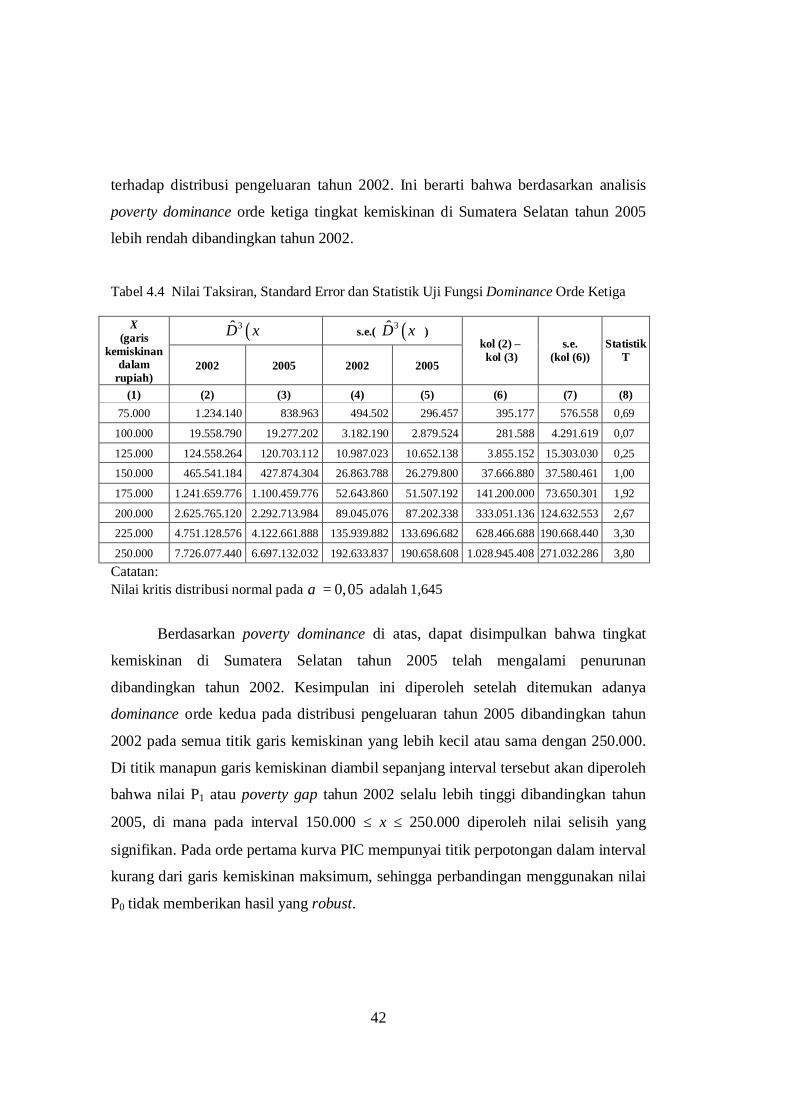
42
terhadap distribusi pengeluaran tahun 2002. Ini berarti bahwa berdasarkan analisis
poverty dominance orde ketiga tingkat kemiskinan di Sumatera Selatan tahun 2005
lebih rendah dibandingkan tahun 2002.
Tabel 4.4 Nilai Taksiran, Standard Error dan Statistik Uji Fungsi Dominance Orde Ketiga
( )3D x s.e.( ( )3D x ) X (garis
kemiskinan dalam
rupiah) 2002 2005 2002 2005
kol (2) – kol (3)
s.e. (kol (6))
Statistik T
(1) (2) (3) (4) (5) (6) (7) (8) 75.000 1.234.140 838.963 494.502 296.457 395.177 576.558 0,69
100.000 19.558.790 19.277.202 3.182.190 2.879.524 281.588 4.291.619 0,07
125.000 124.558.264 120.703.112 10.987.023 10.652.138 3.855.152 15.303.030 0,25
150.000 465.541.184 427.874.304 26.863.788 26.279.800 37.666.880 37.580.461 1,00
175.000 1.241.659.776 1.100.459.776 52.643.860 51.507.192 141.200.000 73.650.301 1,92
200.000 2.625.765.120 2.292.713.984 89.045.076 87.202.338 333.051.136 124.632.553 2,67
225.000 4.751.128.576 4.122.661.888 135.939.882 133.696.682 628.466.688 190.668.440 3,30
250.000 7.726.077.440 6.697.132.032 192.633.837 190.658.608 1.028.945.408 271.032.286 3,80 Catatan: Nilai kritis distribusi normal pada 0,05α = adalah 1,645
Berdasarkan poverty dominance di atas, dapat disimpulkan bahwa tingkat
kemiskinan di Sumatera Selatan tahun 2005 telah mengalami penurunan
dibandingkan tahun 2002. Kesimpulan ini diperoleh setelah ditemukan adanya
dominance orde kedua pada distribusi pengeluaran tahun 2005 dibandingkan tahun
2002 pada semua titik garis kemiskinan yang lebih kecil atau sama dengan 250.000.
Di titik manapun garis kemiskinan diambil sepanjang interval tersebut akan diperoleh
bahwa nilai P1 atau poverty gap tahun 2002 selalu lebih tinggi dibandingkan tahun
2005, di mana pada interval 150.000 ≤ x ≤ 250.000 diperoleh nilai selisih yang
signifikan. Pada orde pertama kurva PIC mempunyai titik perpotongan dalam interval
kurang dari garis kemiskinan maksimum, sehingga perbandingan menggunakan nilai
P0 tidak memberikan hasil yang robust.

43
4.2.2 Perbandingan Analisis Poverty Dominance dan F-G-T Index
Analisis perbandingan tingkat kemiskinan menggunakan keluarga F-G-T
index diawali dengan menentukan garis kemiskinan yang akan menjadi acuan untuk
penghitungan nilai-nilai P0, P1 dan P2. Garis kemiskinan yang digunakan mengacu
pada garis kemiskinan dan angka persentase penduduk miskin BPS tahun 2002 untuk
provinsi Sumatera Selatan (Tabel 4.1). Nilai pengeluaran rumah tangga per kapita
tahun 2002 yang digunakan dalam analisis ini telah dikalikan dengan faktor pengali
yang diperoleh melalui penyesuaian indeks harga, sehingga garis kemiskinan tersebut
tidak sepenuhnya dapat diterapkan. Karena itu digunakan nilai-nilai persentase
penduduk miskin sebagai dasar untuk menentukan garis kemiskinan yang analog.
Persentase penduduk miskin tahun 2002 adalah 22,32 % sehingga digunakan nilai
kuantil ke-22,32 pada data pengeluaran rumah tangga per kapita tahun 2002 yang
telah disesuaikan menggunakan indeks harga yaitu sebesar 131.000. Dengan
demikian nilai 131.000. digunakan sebagai pendekatan garis kemiskinan tahun 2005.
Selanjutnya berdasarkan garis kemiskinan tersebut dilakukan penghitungan
nilai-nilai F-G-T index yaitu P0, P1 dan P2 untuk data pengeluaran rumah tangga per
kapita tahun 2005 dan untuk data pengeluaran rumah tangga perkapita tahun 2002
yang telah disesuaikan menggunakan indeks harga. Penghitungan P0, P1 dan P2
mengacu pada (2.10), sedangkan pengujian terhadap selisih indeks 2002 dan 2005
mengacu pada Kakwani (1993) dengan hipotesis nol:
H0 : 0A Ba aP P− =
(nilai indeks tahun 2002 sama dengan nilai indeks tahun 2005)
H1 : 0A Ba aP P− >
(nilai indeks tahun 2002 lebih tinggi dibandingkan tahun 2005).
Sedangkan statistik uji yang digunakan adalah ¶ ( )ˆ ˆ ˆ ˆvarA B A Ba a a aT P P P P = − − yang
berdistibusi asimptotik normal standar, di mana ˆ AaP dan ˆ B
aP masing-masing adalah
nilai taksiran F-G-T index masing-masing untuk tahun 2002 dan 2005 sebagaimana
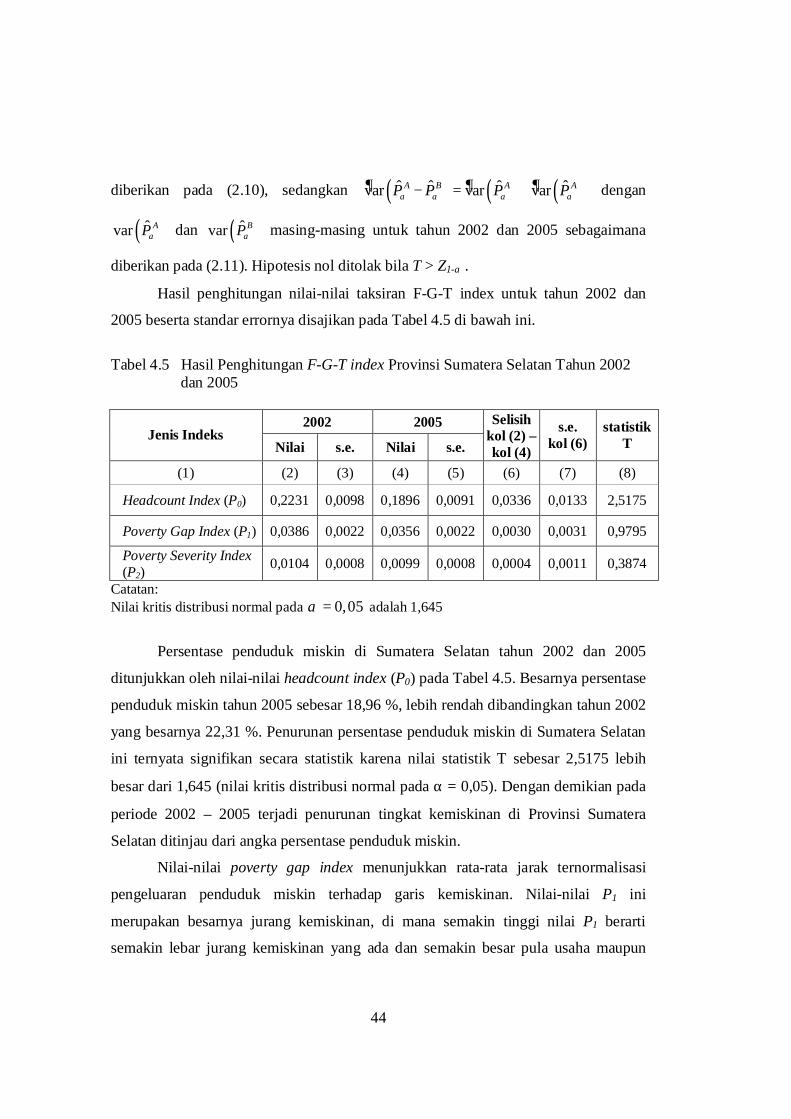
44
diberikan pada (2.10), sedangkan ¶ ( ) ¶ ( ) ¶ ( )ˆ ˆ ˆ ˆvar var varA B A Aa a a aP P P P− = + dengan
( )ˆvar AaP dan ( )ˆvar B
aP masing-masing untuk tahun 2002 dan 2005 sebagaimana
diberikan pada (2.11). Hipotesis nol ditolak bila T > Z1-α .
Hasil penghitungan nilai-nilai taksiran F-G-T index untuk tahun 2002 dan
2005 beserta standar errornya disajikan pada Tabel 4.5 di bawah ini.
Tabel 4.5 Hasil Penghitungan F-G-T index Provinsi Sumatera Selatan Tahun 2002
dan 2005
2002 2005 Jenis Indeks
Nilai s.e. Nilai s.e.
Selisih kol (2) – kol (4)
s.e. kol (6)
statistik T
(1) (2) (3) (4) (5) (6) (7) (8)
Headcount Index (P0) 0,2231 0,0098 0,1896 0,0091 0,0336 0,0133 2,5175
Poverty Gap Index (P1) 0,0386 0,0022 0,0356 0,0022 0,0030 0,0031 0,9795
Poverty Severity Index (P2)
0,0104 0,0008 0,0099 0,0008 0,0004 0,0011 0,3874
Catatan: Nilai kritis distribusi normal pada 0,05α = adalah 1,645
Persentase penduduk miskin di Sumatera Selatan tahun 2002 dan 2005
ditunjukkan oleh nilai-nilai headcount index (P0) pada Tabel 4.5. Besarnya persentase
penduduk miskin tahun 2005 sebesar 18,96 %, lebih rendah dibandingkan tahun 2002
yang besarnya 22,31 %. Penurunan persentase penduduk miskin di Sumatera Selatan
ini ternyata signifikan secara statistik karena nilai statistik T sebesar 2,5175 lebih
besar dari 1,645 (nilai kritis distribusi normal pada α = 0,05). Dengan demikian pada
periode 2002 – 2005 terjadi penurunan tingkat kemiskinan di Provinsi Sumatera
Selatan ditinjau dari angka persentase penduduk miskin.
Nilai-nilai poverty gap index menunjukkan rata-rata jarak ternormalisasi
pengeluaran penduduk miskin terhadap garis kemiskinan. Nilai-nilai P1 ini
merupakan besarnya jurang kemiskinan, di mana semakin tinggi nilai P1 berarti
semakin lebar jurang kemiskinan yang ada dan semakin besar pula usaha maupun

45
biaya yang dibutuhkan untuk mengeluarkan penduduk miskin dari kemiskinan.
Membandingkan angka-angka poverty gap index di Sumatera Selatan tahun 2002 dan
2005, seperti ditunjukkan pada Tabel 4.5, besarnya poverty gap index tahun 2005
turun dibandingkan tahun 2002. Dilihat dari besarnya statistik T, penurunan ini
ternyata tidak signifikan pada α = 0,05 karena nilai statistik T adalah 0,9795 lebih
kecil dari nilai kritis distribusi normal standar yaitu 1,645. Dengan demikian, ditinjau
dari besarnya poverty gap index, tingkat kemiskinan di Sumatera Selatan tidak
mengalami penurunan yang signifikan pada periode 2002 – 2005.
Besarnya nilai P2 atau poverty severity index lebih sulit untuk diinterpretasi
karena merupakan kuadrat dari poverty gap. Namun demikian, tingginya nilai indeks
akan menunjukkan tingginya tingkat kemiskinan di suatu wilayah. Pada periode 2002
– 2005, poverty severity index di Sumatera Selatan mengalami penurunan ditunjukkan
oleh nilai indeks yang semakin kecil, tetapi penurunan tersebut tidak signifikan secara
statistik menggunakan statistik T (nilai statistik T sebesar 0,3874, lebih kecil
dibandingkan nilai kritis distribusi normal standar yaitu 1,645).
Membandingkan hasil analisis F-G-T index dan poverty dominance di atas,
perlu digarisbawahi bahwa pada analisis F-G-T index, pengujian dilakukan pada satu
titik tertentu (garis kemiskinan) yang diperoleh dari sumber tertentu, sehingga
ketepatan kesimpulan yang diambil akan sangat dipengaruhi oleh garis kemiskinan
tersebut. Jika garis kemiskinan yang diambil ternyata salah, maka dengan sendirinya
kesimpulan yang diperoleh tidak dapat diandalkan. Sedangkan pada analisis poverty
dominance, perbandingan tingkat kemiskinan dilakukan dengan mengamati titik-titik
sepanjang kurva yang tidak melebihi garis kemiskinan maksimum. Akibatnya
kesimpulan yang diperoleh akan sangat kuat dan lebih dapat dipercaya, karena tidak
tergantung pada titik garis kemiskinan tertentu.
Berdasarkan analisis F-G-T index di atas, dengan asumsi bahwa garis
kemiskinan yang digunakan adalah benar, penurunan yang signifikan pada tingkat
kemiskinan di Sumatera Selatan periode 2002 – 2005 hanya ditunjukkan oleh angka
headcount index (P0). Sedangkan jika dilihat dari P1 dan P2 meskipun besarnya kedua

46
indeks turun dari pada periode 2002 – 2005, tidak ditemukan adanya penurunan
tingkat kemiskinan yang signifikan Dengan demikian tingkat kemiskinan di Sumatera
Selatan selama periode 2002-2005 hanya mengalami perubahan dari sisi jumlah atau
persentase penduduk miskin saja tetapi dari sisi poverty gap yaitu kedalaman dan
keparahan kemiskinan relatif tidak mengalami perubahan yang berarti. Perbedaan
hasil pengujian menggunakan F-G-T index ini menyebabkan sulit untuk mengambil
kesimpulan tentang adanya penurunan kemiskinan di Sumatera Selatan.
Berdasarkan analisis poverty dominance secara meyakinkan diperoleh bahwa
tingkat kemiskinan di Sumatera Selatan tahun 2005 telah mengalami penurunan
dibandingkan tahun 2002. Pada orde pertama kurva PIC masih mempunyai titik
perpotongan dalam interval kurang dari garis kemiskinan maksimum meskipun tidak
signifikan secara statistik. Namun demikian, adanya dominance distribusi
pengeluaran tahun 2005 dibandingkan tahun 2002 diperkuat oleh hasil pengujian
pada orde kedua dan ketiga pada semua titik garis kemiskinan yang lebih kecil atau
sama dengan 250.000. Di titik manapun garis kemiskinan diambil sepanjang interval
tersebut akan diperoleh bahwa nilai P1 atau poverty gap dan P2 atau kuadrat poverty
gap tahun 2002 selalu lebih tinggi dibandingkan tahun 2005, di mana pada beberapa
titik tertentu diperoleh perbedaan nilai yang signifikan

49
BAB 5
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Tulisan ini mendapatkan beberapa hasil penting yang berkaitan dengan
analisis perbandingan kemiskinan menggunakan stochastic dominance khususnya di
Sumatera Selatan tahun 2002 dan 2005, sebagai berikut:
1. Statistik uji untuk menguji hipotesis dari stochastic dominance antara dua
buah distribusi pendapatan atau pengeluaran adalah:
( ) ( ) ¶ ( ) ( )( )ˆ ˆ ˆ ˆvars s s sA B A BT D x D x D x D x = − − yang berdistibusi asimptotik
normal standar. Dengan demikain terbukti sama dengan statistik uji yang
dikemukakan oleh Davidson dan Duclos (2000).
2. Tingkat kemiskinan di Sumatera Selatan tahun 2005 telah mengalami
penurunan dibandingkan tahun 2002. Pada orde pertama kurva PIC masih
mempunyai titik perpotongan dalam interval kurang dari garis kemiskinan
maksimum meskipun tidak signifikan secara statistik. Namun demikian
adanya dominance pada distribusi pengeluaran tahun 2005 dibandingkan
tahun 2002 diperkuat hasil pengujian pada orde kedua dan ketiga pada semua
titik garis kemiskinan yang lebih kecil atau sama dengan 250.000. Di titik
manapun garis kemiskinan diambil sepanjang interval tersebut akan diperoleh
bahwa nilai P1 atau poverty gap maupun P2 atau kuadrat poverty gap tahun
2002 selalu lebih tinggi dibandingkan tahun 2005, di mana pada beberapa titik
tertentu diperoleh perbedaan nilai yang signifikan.
3. Berdasarkan analisis F-G-T index, kesimpulan adanya penurunan pada tingkat
kemiskinan di Sumatera Selatan periode 2002 – 2005 tidak dapat diambil
secara meyakinkan karena penurunan yang signifikan hanya ditunjukkan oleh
angka headcount index (P0). Sedangkan jika dilihat dari P1 dan P2 meskipun

50
besarnya kedua indeks turun dari pada periode 2002 – 2005, tidak ditemukan
adanya penurunan tingkat kemiskinan yang signifikan.
5.2 Saran
Berdasarkan temuan-temuan yang diperoleh dalam penelitian ini, penulis
menyarankan beberapa hal sebagai berikut:
1. Dalam analisis perbandingan tingkat kemiskinan antar waktu maupun antar
wilayah sebagaimana yang sering dilakukan selama ini khususnya oleh BPS
perlu ditambahkan inferensi terhadap angka-angka kemiskinan tersebut
khususnya pengujian signifikansi perbedaan angka kemiskinan tersebut secara
statistik
2. Dalam melakukan analisis perbandingan tingkat kemiskinan selain digunakan
F-G-T index yang telah dikenal luas, perlu ditambahkan analisis poverty
dominance untuk mendapatkan kesimpulan yang lebih meyakinkan.
Sebagaimana ditunjukkan di atas, dengan menggunakan F-G-T index dapat
diperoleh kesimpulan yang berbeda antara ketiga indeks dari F-G-T.

51
DAFTAR PUSTAKA
Anderson, G., (1996), Nonparametric Test of Stochastic Dominance in Income Distribution, Econometrica, Vol. 64, 1183 – 1193.
Bishop, J.A., Chakraborti, S. Dan Thistle, P.D., (1989), Asymptotically Distribution –Free Statistical Inference for Generalized Lorenz Curves, The Review of Economics and Statistics, Vol. 71, 725 – 727.
BPS, (1999), Statistik Indonesia 1998, Badan Pusat Statistik, Jakarta.
-----, (2000), Pengukuran Tingkat Kemiskinan di Indonesia 1976-1999: Metode BPS. Badan Pusat Statistik, Jakarta.
-----, (2001), Susenas (Survei Sosial Ekonomi Nasional) 2002, Pedoman Pencacah Modul Konsumsi, Badan Pusat Statistik, Jakarta
-----, (2003), Diagram Timbang Indeks Harga Konsumen 2002, Badan Pusat Statistik, Jakarta.
-----, (2003a), Statistik Indonesia 2002, Badan Pusat Statistik, Jakarta.
-----, (2003b), Statistik Nilai Tukar Petani di Indonesia 1999 – 2002, Badan Pusat Statistik, Jakarta.
-----, (2005), Statistik Indonesia 2004, Badan Pusat Statistik, Jakarta.
-----, (2005a), Statistik Nilai Tukar Petani di Indonesia 2001 – 2004, Badan Pusat Statistik, Jakarta.
-----, (2005b), Susenas (Survei Sosial Ekonomi Nasional) 2005, Pedoman Pencacah Modul Konsumsi, Badan Pusat Statistik, Jakarta
-----, (2007), Statistik Nilai Tukar Petani di Indonesia 2003 – 2006, Badan Pusat Statistik, Jakarta.
BPS Provinsi Sumatera Selatan, (2002), Inflasi Kota Palembang 2001, Badan Pusat Statistik Provinsi Sumatera Selatan, Palembang.
--------------------------------------, (2003), Inflasi Kota Palembang 2002, Badan Pusat Statistik Provinsi Sumatera Selatan, Palembang.

52
--------------------------------------, (2004), Inflasi Kota Palembang 2003, Badan Pusat Statistik Provinsi Sumatera Selatan, Palembang.
--------------------------------------, (2005), Inflasi Kota Palembang 2004, Badan Pusat Statistik Provinsi Sumatera Selatan, Palembang.
--------------------------------------, (2006), Inflasi Kota Palembang 2005, Badan Pusat Statistik Provinsi Sumatera Selatan, Palembang.
--------------------------------------, (2006a), Laporan Perekonomian Provinsi Sumatera Selatan Tahun 2005, Badan Pusat Statistik Provinsi Sumatera Selatan, Palembang.
Chen, W., (2006), Where is Poverty Greatest in Canada? Comparing Regional Poverty Profile Without Poverty Lines: A Stochastic Dominance Approach, Family and Labor Studies, Statistics Canada, Canada.
Davidson, R. dan Duclos, J.Y., (2000), Statistical Inference for Stocahstic Dominance and for the Measurement of Poverty and Inequality, Econometrica, Vol. 68, 1435 – 1464.
Dercon, S. dan Krishnan, P., (1998), Changes in Poverty in Rural Ethiopia 1989-1995: Measurement, Robustness, Tests and Decomposition, WPS/98-7, Centre for the Study of African Economies, Institute of Economics and Statistics, University of Oxford, Oxford.
Duclos, J.Y., Araar, A. dan Fortin, C., (2006), DAD, A Software for Distributive Analysis / Analyse Distributive, MIMAP Programme, International Development Research Centre, Government of Canada and CREFA, Universite Laval.
Foster, J., Greer, J. dan Thorbecke, E., (1984), A Class of Decomposable Poverty Measures, Econometrica, Vol. 52, 761 – 766.
Heyer, D. D., (2001), Stochastic Dominance: A Tool for Evaluating Reinsurance Alternatives, CAS (Casualty Actuarial Society) Forum.
Jenkins, S.P. dan Lambert, P.J., (1997), Three I’s of Poverty Curves, with an Analysis of UK Poverty Trends, Oxford Economic Papers, Vol. 49, 317 – 327.
Jollife, D., (2005), Poverty, Prices and Place: How Sensitive is the Spatial Distributiom of Poverty to Cost of Living Adjustment?, Working Paper No. 04 – 13,, National Poverty Center, U.S. Department of Agriculture.

53
Kakwani, N., (1993), Statistical Inferences in The Measurement of Poverty, Review of Economics and Statistics, Vol. 75, 632 – 639.
Kaur, A., Rao, P. dan Singh, H., (1994), Testing for Second Order Stochastic Dominance of Two Distributions, Economic Theory, Vol. 10, 849 – 866.
Klaver, H., (2006), Tests of Stochastic Dominance for Time Series Data, Theory and Empirical Application, Dissertation, Universitat zu Koln, Koln.
Madden, D. dan Smith, F., (2000), Poverty in Ireland, 1987-1994: A Stochastic Dominance Approach, The Economic and Social Review, Vol. 31, 187 – 214.
Mood, A.M., Graybill, F.A., dan Boes, D.C., (1974), Introduction to the Theory of Statistics, Edisi ke-2, McGraw-Hill, Singapore.
Muller, C., (2005), The Measurement of Poverty with Geographical and Intertemporal Price Dispersion, Evidence from Rwanda, Document de Travail no. DT/2005-16, Development Institution and Analyses de Long terme.
Ravallion, M., (1992), Poverty Comparisons. A Guide to Concepts and Methods, LSMS Working Paper Number 88, The World Bank, Washington, D.C.
---------------, (1998), Poverty Lines in Theory and Practice, LSMS Working Paper Number 133, The World Bank, Washington, D.C.
Rio Group, (2006), Compendium Best Practice in Poverty Measurements, Rio de Janeiro, September 2006.
Schmid, F. dan Trede, M., (1996), Testing for Stochastic Dominance: A New Distribution – Free Test, The Statistician, Vol. 45, No. 3, 371 – 380.
Sen, A., (1976), Poverty: An Ordinal Approach to Measurement, Econometrica, Vol. 44, 219 – 231.
Sen, P.K. dan Singer, J.M., (1993), Large Sample Methods in Statistics, An Introduction with Applications, Chapman & Hall, London.
Tse, Y.K. dan Zhang, X.B., (2002), A Monte Carlo Investigation of Some Tests fo Stochastic Dominance, Working Paper, School of Economics and Social Sciences, Singapore Management University, Singapore.
World Bank, (2005), Introduction to Poverty Analysis, World Bank Institute, Washington, D.C.
Lampiran 1. Penghitungan Faktor Pengali Data Pengeluaran Per Kapita
JAN FEB MAR APR MEI JUN JUL AGS SEP OKT NOP DES RATA-2
Umum 230,45 232,59 233,64 234,07 238,61 245,38 251,32 249,32 253,12 255,03 260,8 265,23 245,8
MakananBahan Makanan 276,89 285,16 284,43 280,84 288,28 296,03 296,37 289,34 286,64 291,03 311,17 318,71 292,07Makanan Jadi,Minuman,Rokok & Tembakau 237,85 238,11 239,94 241,62 248,02 256,94 266,85 263,15 268,1 269,17 270,32 276,39 256,37Non MakananPerumahan, Air, Listrik, Gas & Bhn Bakar 207,46 207,33 208,75 210,99 215,02 220,81 224,03 228,51 232,34 232,76 233,68 236,35 221,5Sandang 276,25 275,61 279,15 282,09 287,72 290,31 301,32 291,79 293,33 298,29 299,87 307,03 290,23Kesehatan 210,6 211,06 215,3 216,4 217,95 224,51 229,97 231,14 231,39 231,45 231,6 232,05 223,62Pendidikan, Rekreasi, Dan Olahraga 179,88 180,34 189,67 181,51 181,51 181,67 184,77 187,41 217,36 217,36 217,36 217,36 194,68Transpor, Komunikasi Dan Jasa Keuangan 165,25 165,29 165,39 166,57 166,57 179,75 197,35 197,37 197,45 197,45 197,45 198,76 182,89
JAN FEB MAR APR MEI JUN JUL AGS SEP OKT NOP DES RATA-2
Umum 269,71 276,07 275,14 273,09 275,97 277,07 277,65 280,61 283,42 285,25 293,07 297,73 280,4
MakananBahan Makanan 327,84 338,9 329,9 320,95 323,63 318,8 317,9 319,19 321,28 325,56 343,35 354,19 328,46Makanan Jadi,Minuman,Rokok & Tembakau 276,02 284,08 283,06 281,38 281 282,54 283,14 283,28 283,7 285,9 299,27 299,54 285,24Non MakananPerumahan, Air, Listrik, Gas & Bhn Bakar 240,28 243,23 246,05 246,11 250,46 252,63 253,32 262,2 266,66 266,97 267,86 270,27 255,5Sandang 309,12 311,11 310,48 310,58 312,47 316,95 319,01 321,85 325,1 326,19 334,2 340,59 319,8Kesehatan 233,15 288,56 242,48 243,28 243,28 243,28 243,28 243,28 244,16 244,21 244,21 244,21 246,45Pendidikan, Rekreasi, Dan Olahraga 217,36 217,86 217,9 219,21 219,21 219,28 222,63 224,7 233,97 235,02 235,96 235,96 224,92Transpor, Komunikasi Dan Jasa Keuangan 207,8 217,59 224,59 227,84 237,19 247,78 248,21 247,97 247,34 248,37 248,81 254,22 238,14
Indeks Harga Konsumen Kota Palembang Tahun 2001(1996 = 100)
Kelompok/SubkelompokB U L A N
Indeks Harga Konsumen Kota Palembang Tahun 2002(1996 = 100)
Kelompok/SubkelompokB U L A N
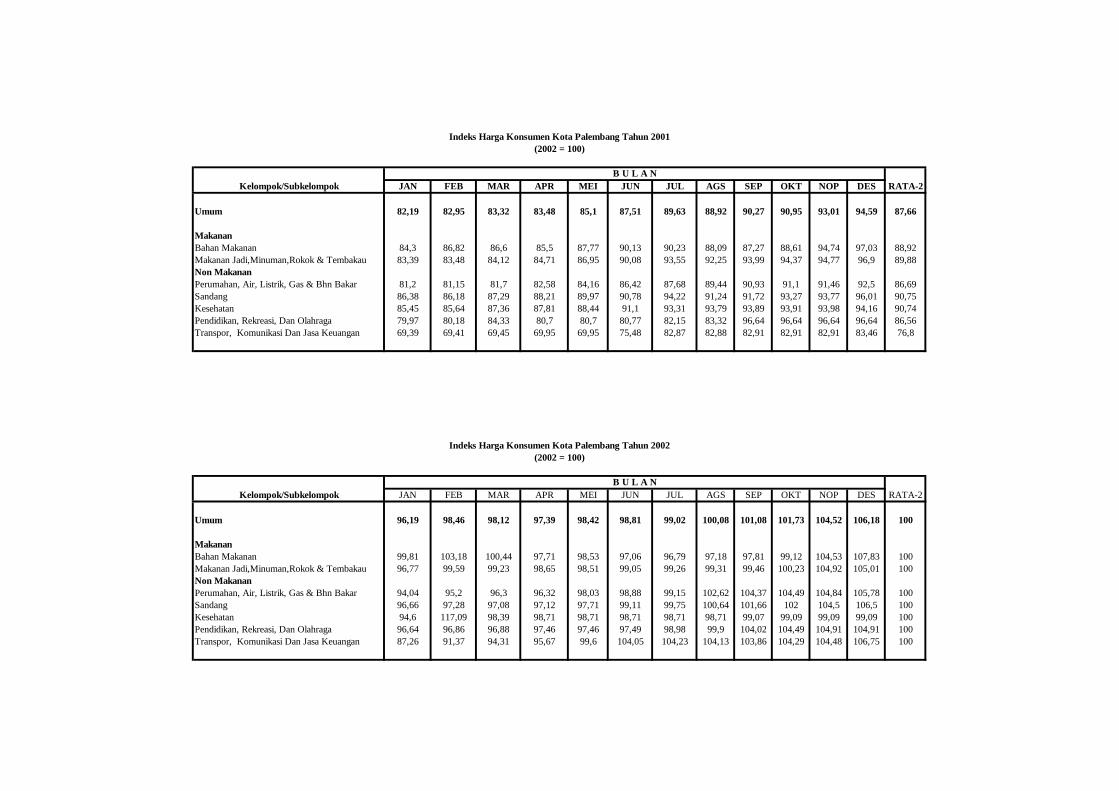
JAN FEB MAR APR MEI JUN JUL AGS SEP OKT NOP DES RATA-2
Umum 82,19 82,95 83,32 83,48 85,1 87,51 89,63 88,92 90,27 90,95 93,01 94,59 87,66
MakananBahan Makanan 84,3 86,82 86,6 85,5 87,77 90,13 90,23 88,09 87,27 88,61 94,74 97,03 88,92Makanan Jadi,Minuman,Rokok & Tembakau 83,39 83,48 84,12 84,71 86,95 90,08 93,55 92,25 93,99 94,37 94,77 96,9 89,88Non MakananPerumahan, Air, Listrik, Gas & Bhn Bakar 81,2 81,15 81,7 82,58 84,16 86,42 87,68 89,44 90,93 91,1 91,46 92,5 86,69Sandang 86,38 86,18 87,29 88,21 89,97 90,78 94,22 91,24 91,72 93,27 93,77 96,01 90,75Kesehatan 85,45 85,64 87,36 87,81 88,44 91,1 93,31 93,79 93,89 93,91 93,98 94,16 90,74Pendidikan, Rekreasi, Dan Olahraga 79,97 80,18 84,33 80,7 80,7 80,77 82,15 83,32 96,64 96,64 96,64 96,64 86,56Transpor, Komunikasi Dan Jasa Keuangan 69,39 69,41 69,45 69,95 69,95 75,48 82,87 82,88 82,91 82,91 82,91 83,46 76,8
JAN FEB MAR APR MEI JUN JUL AGS SEP OKT NOP DES RATA-2
Umum 96,19 98,46 98,12 97,39 98,42 98,81 99,02 100,08 101,08 101,73 104,52 106,18 100
MakananBahan Makanan 99,81 103,18 100,44 97,71 98,53 97,06 96,79 97,18 97,81 99,12 104,53 107,83 100Makanan Jadi,Minuman,Rokok & Tembakau 96,77 99,59 99,23 98,65 98,51 99,05 99,26 99,31 99,46 100,23 104,92 105,01 100Non MakananPerumahan, Air, Listrik, Gas & Bhn Bakar 94,04 95,2 96,3 96,32 98,03 98,88 99,15 102,62 104,37 104,49 104,84 105,78 100Sandang 96,66 97,28 97,08 97,12 97,71 99,11 99,75 100,64 101,66 102 104,5 106,5 100Kesehatan 94,6 117,09 98,39 98,71 98,71 98,71 98,71 98,71 99,07 99,09 99,09 99,09 100Pendidikan, Rekreasi, Dan Olahraga 96,64 96,86 96,88 97,46 97,46 97,49 98,98 99,9 104,02 104,49 104,91 104,91 100Transpor, Komunikasi Dan Jasa Keuangan 87,26 91,37 94,31 95,67 99,6 104,05 104,23 104,13 103,86 104,29 104,48 106,75 100
Indeks Harga Konsumen Kota Palembang Tahun 2001(2002 = 100)
Kelompok/SubkelompokB U L A N
Indeks Harga Konsumen Kota Palembang Tahun 2002(2002 = 100)
Kelompok/SubkelompokB U L A N
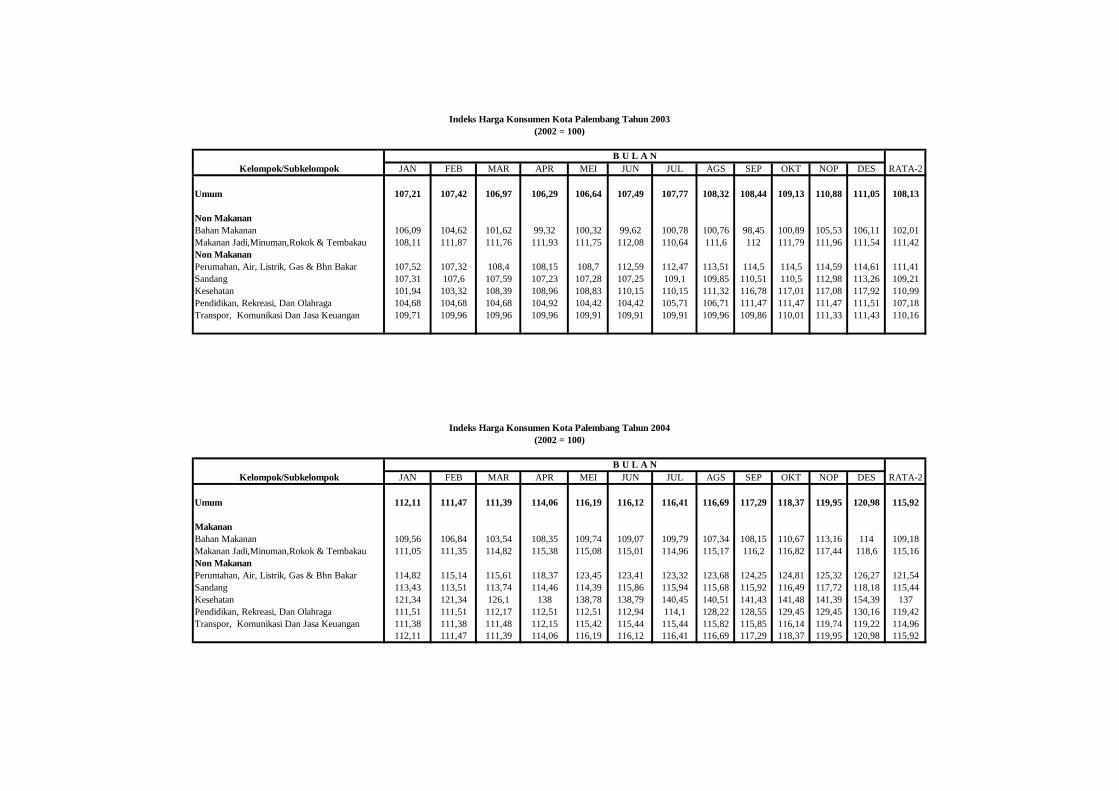
JAN FEB MAR APR MEI JUN JUL AGS SEP OKT NOP DES RATA-2
Umum 107,21 107,42 106,97 106,29 106,64 107,49 107,77 108,32 108,44 109,13 110,88 111,05 108,13
Non MakananBahan Makanan 106,09 104,62 101,62 99,32 100,32 99,62 100,78 100,76 98,45 100,89 105,53 106,11 102,01Makanan Jadi,Minuman,Rokok & Tembakau 108,11 111,87 111,76 111,93 111,75 112,08 110,64 111,6 112 111,79 111,96 111,54 111,42Non MakananPerumahan, Air, Listrik, Gas & Bhn Bakar 107,52 107,32 108,4 108,15 108,7 112,59 112,47 113,51 114,5 114,5 114,59 114,61 111,41Sandang 107,31 107,6 107,59 107,23 107,28 107,25 109,1 109,85 110,51 110,5 112,98 113,26 109,21Kesehatan 101,94 103,32 108,39 108,96 108,83 110,15 110,15 111,32 116,78 117,01 117,08 117,92 110,99Pendidikan, Rekreasi, Dan Olahraga 104,68 104,68 104,68 104,92 104,42 104,42 105,71 106,71 111,47 111,47 111,47 111,51 107,18Transpor, Komunikasi Dan Jasa Keuangan 109,71 109,96 109,96 109,96 109,91 109,91 109,91 109,96 109,86 110,01 111,33 111,43 110,16
JAN FEB MAR APR MEI JUN JUL AGS SEP OKT NOP DES RATA-2
Umum 112,11 111,47 111,39 114,06 116,19 116,12 116,41 116,69 117,29 118,37 119,95 120,98 115,92
MakananBahan Makanan 109,56 106,84 103,54 108,35 109,74 109,07 109,79 107,34 108,15 110,67 113,16 114 109,18Makanan Jadi,Minuman,Rokok & Tembakau 111,05 111,35 114,82 115,38 115,08 115,01 114,96 115,17 116,2 116,82 117,44 118,6 115,16Non MakananPerumahan, Air, Listrik, Gas & Bhn Bakar 114,82 115,14 115,61 118,37 123,45 123,41 123,32 123,68 124,25 124,81 125,32 126,27 121,54Sandang 113,43 113,51 113,74 114,46 114,39 115,86 115,94 115,68 115,92 116,49 117,72 118,18 115,44Kesehatan 121,34 121,34 126,1 138 138,78 138,79 140,45 140,51 141,43 141,48 141,39 154,39 137Pendidikan, Rekreasi, Dan Olahraga 111,51 111,51 112,17 112,51 112,51 112,94 114,1 128,22 128,55 129,45 129,45 130,16 119,42Transpor, Komunikasi Dan Jasa Keuangan 111,38 111,38 111,48 112,15 115,42 115,44 115,44 115,82 115,85 116,14 119,74 119,22 114,96
112,11 111,47 111,39 114,06 116,19 116,12 116,41 116,69 117,29 118,37 119,95 120,98 115,92
Indeks Harga Konsumen Kota Palembang Tahun 2003(2002 = 100)
Kelompok/SubkelompokB U L A N
Indeks Harga Konsumen Kota Palembang Tahun 2004(2002 = 100)
Kelompok/SubkelompokB U L A N
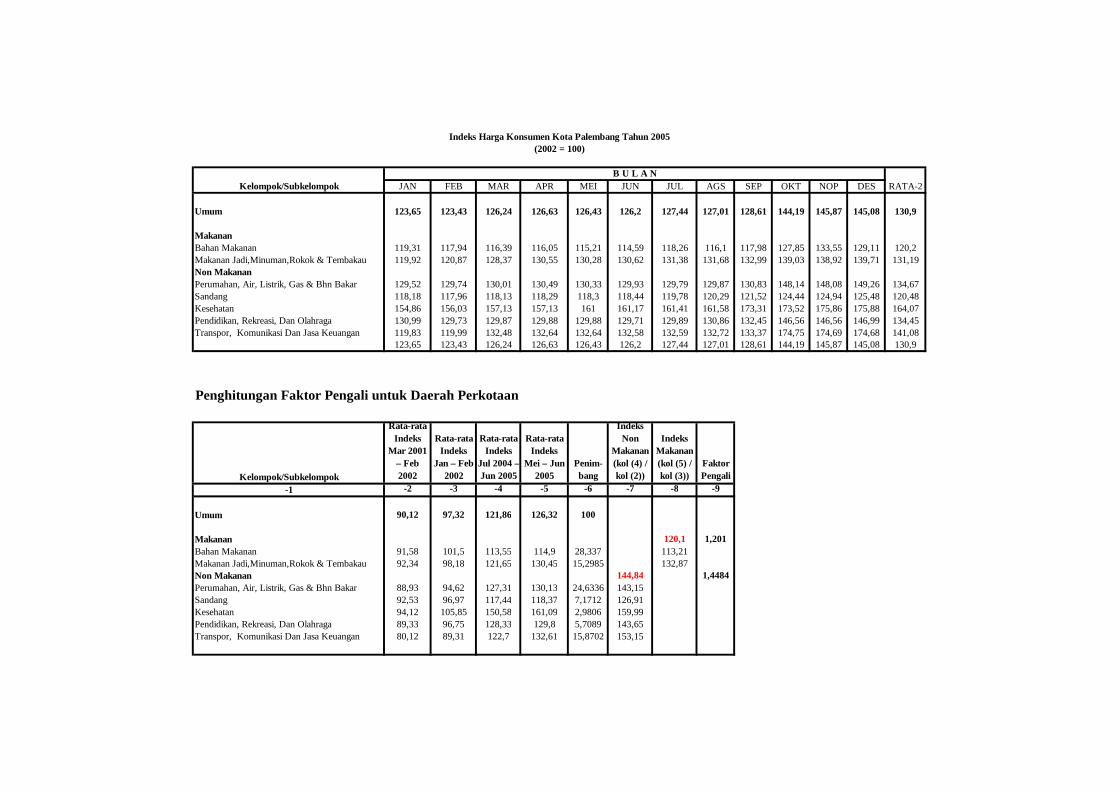
JAN FEB MAR APR MEI JUN JUL AGS SEP OKT NOP DES RATA-2
Umum 123,65 123,43 126,24 126,63 126,43 126,2 127,44 127,01 128,61 144,19 145,87 145,08 130,9
MakananBahan Makanan 119,31 117,94 116,39 116,05 115,21 114,59 118,26 116,1 117,98 127,85 133,55 129,11 120,2Makanan Jadi,Minuman,Rokok & Tembakau 119,92 120,87 128,37 130,55 130,28 130,62 131,38 131,68 132,99 139,03 138,92 139,71 131,19Non MakananPerumahan, Air, Listrik, Gas & Bhn Bakar 129,52 129,74 130,01 130,49 130,33 129,93 129,79 129,87 130,83 148,14 148,08 149,26 134,67Sandang 118,18 117,96 118,13 118,29 118,3 118,44 119,78 120,29 121,52 124,44 124,94 125,48 120,48Kesehatan 154,86 156,03 157,13 157,13 161 161,17 161,41 161,58 173,31 173,52 175,86 175,88 164,07Pendidikan, Rekreasi, Dan Olahraga 130,99 129,73 129,87 129,88 129,88 129,71 129,89 130,86 132,45 146,56 146,56 146,99 134,45Transpor, Komunikasi Dan Jasa Keuangan 119,83 119,99 132,48 132,64 132,64 132,58 132,59 132,72 133,37 174,75 174,69 174,68 141,08
123,65 123,43 126,24 126,63 126,43 126,2 127,44 127,01 128,61 144,19 145,87 145,08 130,9
Penghitungan Faktor Pengali untuk Daerah Perkotaan
Kelompok/Subkelompok
Rata-rata Indeks
Mar 2001 – Feb 2002
Rata-rata Indeks
Jan – Feb 2002
Rata-rata Indeks
Jul 2004 – Jun 2005
Rata-rata Indeks
Mei – Jun 2005
Penim-bang
Indeks Non
Makanan (kol (4) / kol (2))
Indeks Makanan (kol (5) / kol (3))
Faktor Pengali
-1 -2 -3 -4 -5 -6 -7 -8 -9
Umum 90,12 97,32 121,86 126,32 100
Makanan 120,1 1,201Bahan Makanan 91,58 101,5 113,55 114,9 28,337 113,21Makanan Jadi,Minuman,Rokok & Tembakau 92,34 98,18 121,65 130,45 15,2985 132,87Non Makanan 144,84 1,4484Perumahan, Air, Listrik, Gas & Bhn Bakar 88,93 94,62 127,31 130,13 24,6336 143,15Sandang 92,53 96,97 117,44 118,37 7,1712 126,91Kesehatan 94,12 105,85 150,58 161,09 2,9806 159,99Pendidikan, Rekreasi, Dan Olahraga 89,33 96,75 128,33 129,8 5,7089 143,65Transpor, Komunikasi Dan Jasa Keuangan 80,12 89,31 122,7 132,61 15,8702 153,15
Indeks Harga Konsumen Kota Palembang Tahun 2005(2002 = 100)
Kelompok/SubkelompokB U L A N
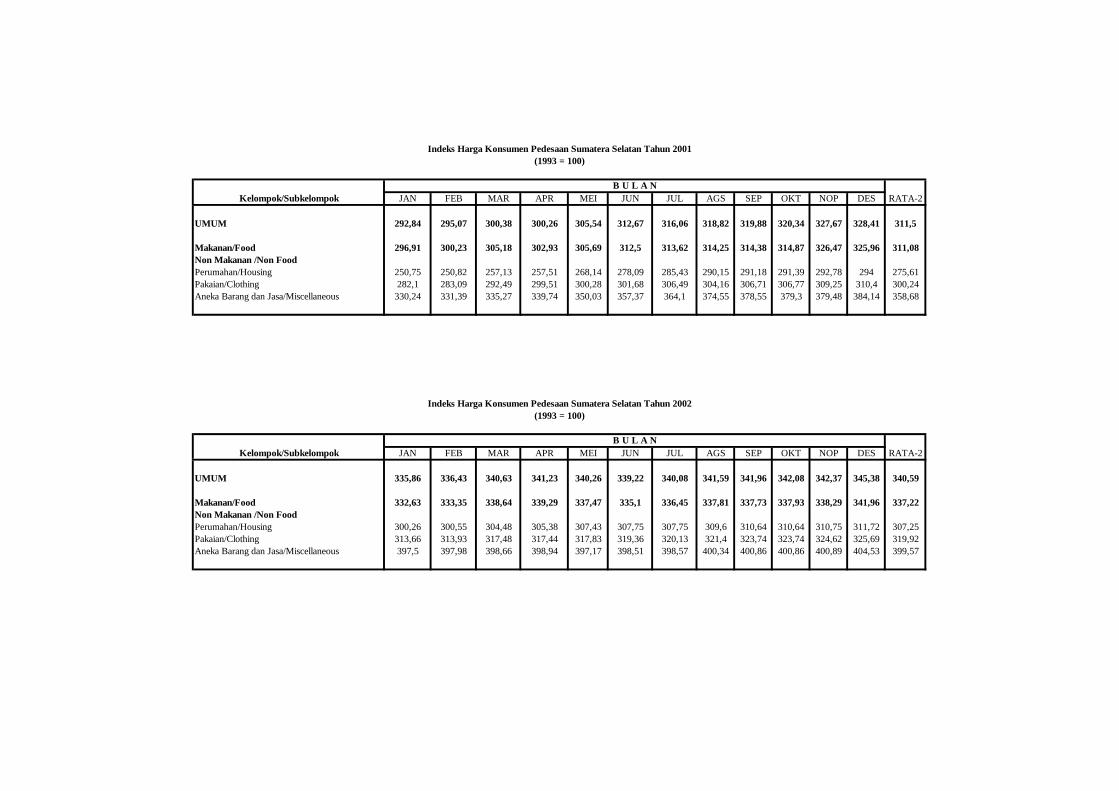
JAN FEB MAR APR MEI JUN JUL AGS SEP OKT NOP DES RATA-2
UMUM 292,84 295,07 300,38 300,26 305,54 312,67 316,06 318,82 319,88 320,34 327,67 328,41 311,5
Makanan/Food 296,91 300,23 305,18 302,93 305,69 312,5 313,62 314,25 314,38 314,87 326,47 325,96 311,08Non Makanan /Non FoodPerumahan/Housing 250,75 250,82 257,13 257,51 268,14 278,09 285,43 290,15 291,18 291,39 292,78 294 275,61Pakaian/Clothing 282,1 283,09 292,49 299,51 300,28 301,68 306,49 304,16 306,71 306,77 309,25 310,4 300,24Aneka Barang dan Jasa/Miscellaneous 330,24 331,39 335,27 339,74 350,03 357,37 364,1 374,55 378,55 379,3 379,48 384,14 358,68
JAN FEB MAR APR MEI JUN JUL AGS SEP OKT NOP DES RATA-2
UMUM 335,86 336,43 340,63 341,23 340,26 339,22 340,08 341,59 341,96 342,08 342,37 345,38 340,59
Makanan/Food 332,63 333,35 338,64 339,29 337,47 335,1 336,45 337,81 337,73 337,93 338,29 341,96 337,22Non Makanan /Non FoodPerumahan/Housing 300,26 300,55 304,48 305,38 307,43 307,75 307,75 309,6 310,64 310,64 310,75 311,72 307,25Pakaian/Clothing 313,66 313,93 317,48 317,44 317,83 319,36 320,13 321,4 323,74 323,74 324,62 325,69 319,92Aneka Barang dan Jasa/Miscellaneous 397,5 397,98 398,66 398,94 397,17 398,51 398,57 400,34 400,86 400,86 400,89 404,53 399,57
Indeks Harga Konsumen Pedesaan Sumatera Selatan Tahun 2001(1993 = 100)
Kelompok/SubkelompokB U L A N
Indeks Harga Konsumen Pedesaan Sumatera Selatan Tahun 2002(1993 = 100)
Kelompok/SubkelompokB U L A N
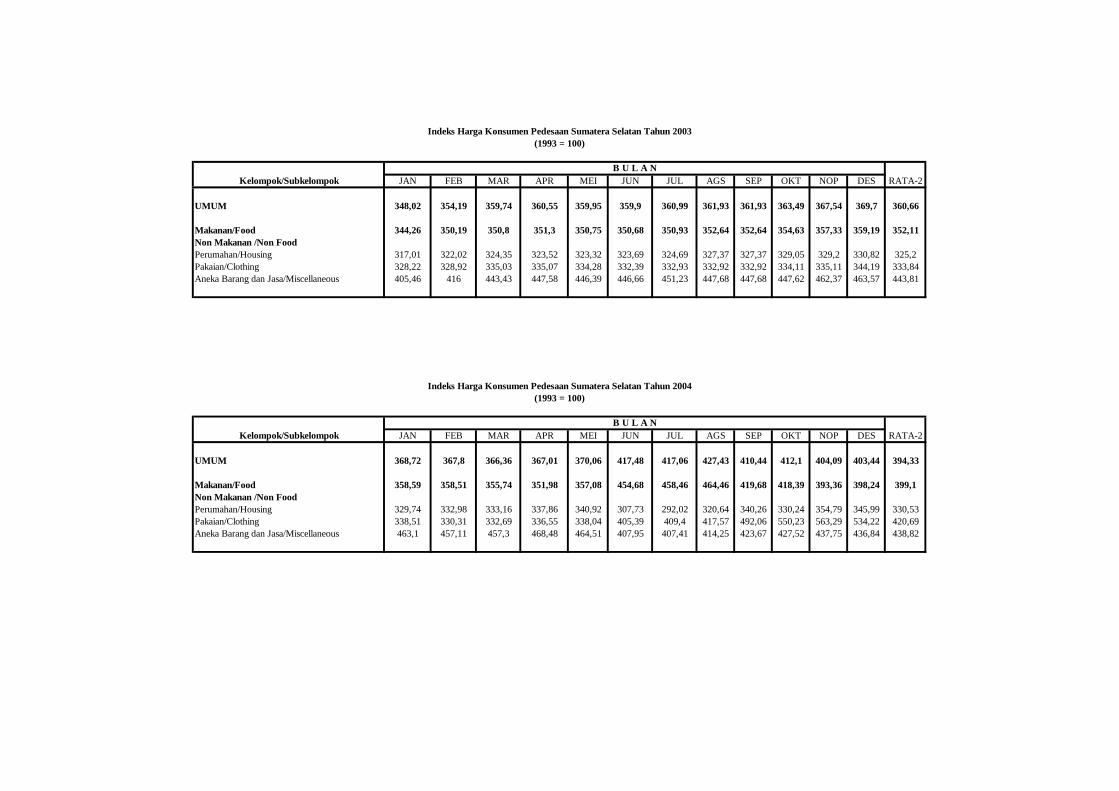
JAN FEB MAR APR MEI JUN JUL AGS SEP OKT NOP DES RATA-2
UMUM 348,02 354,19 359,74 360,55 359,95 359,9 360,99 361,93 361,93 363,49 367,54 369,7 360,66
Makanan/Food 344,26 350,19 350,8 351,3 350,75 350,68 350,93 352,64 352,64 354,63 357,33 359,19 352,11Non Makanan /Non FoodPerumahan/Housing 317,01 322,02 324,35 323,52 323,32 323,69 324,69 327,37 327,37 329,05 329,2 330,82 325,2Pakaian/Clothing 328,22 328,92 335,03 335,07 334,28 332,39 332,93 332,92 332,92 334,11 335,11 344,19 333,84Aneka Barang dan Jasa/Miscellaneous 405,46 416 443,43 447,58 446,39 446,66 451,23 447,68 447,68 447,62 462,37 463,57 443,81
JAN FEB MAR APR MEI JUN JUL AGS SEP OKT NOP DES RATA-2
UMUM 368,72 367,8 366,36 367,01 370,06 417,48 417,06 427,43 410,44 412,1 404,09 403,44 394,33
Makanan/Food 358,59 358,51 355,74 351,98 357,08 454,68 458,46 464,46 419,68 418,39 393,36 398,24 399,1Non Makanan /Non FoodPerumahan/Housing 329,74 332,98 333,16 337,86 340,92 307,73 292,02 320,64 340,26 330,24 354,79 345,99 330,53Pakaian/Clothing 338,51 330,31 332,69 336,55 338,04 405,39 409,4 417,57 492,06 550,23 563,29 534,22 420,69Aneka Barang dan Jasa/Miscellaneous 463,1 457,11 457,3 468,48 464,51 407,95 407,41 414,25 423,67 427,52 437,75 436,84 438,82
Indeks Harga Konsumen Pedesaan Sumatera Selatan Tahun 2003(1993 = 100)
Kelompok/SubkelompokB U L A N
Indeks Harga Konsumen Pedesaan Sumatera Selatan Tahun 2004(1993 = 100)
Kelompok/SubkelompokB U L A N
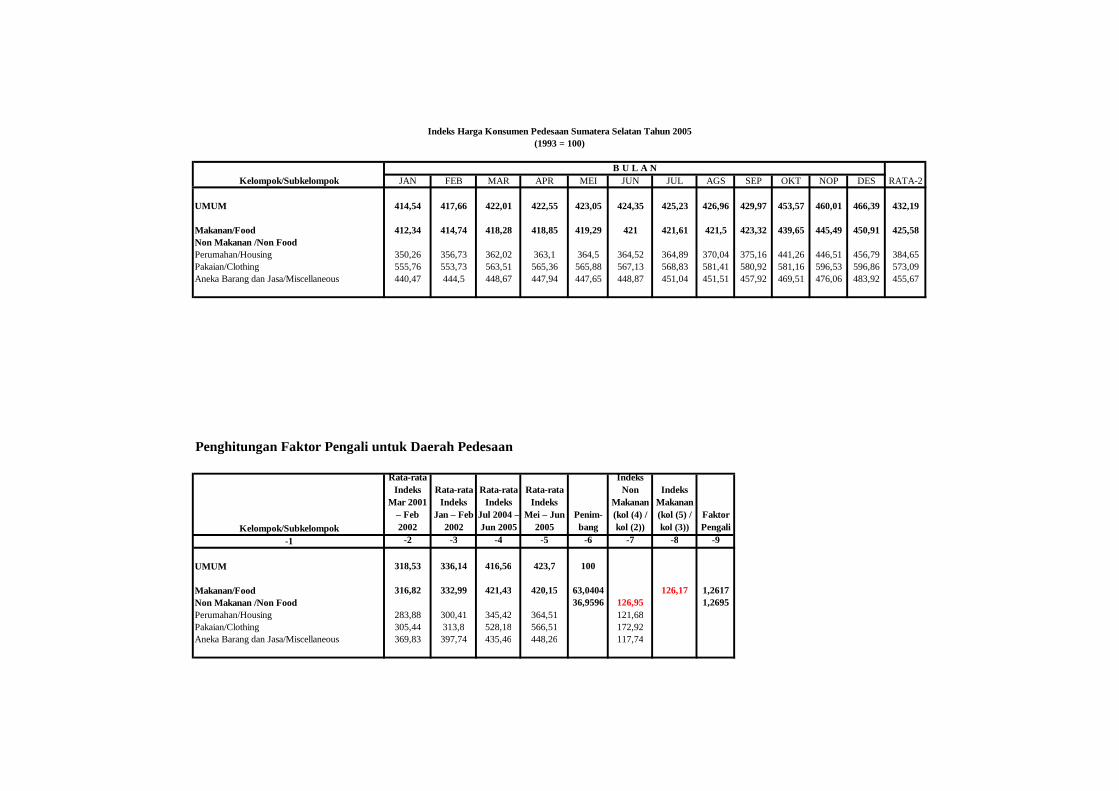
JAN FEB MAR APR MEI JUN JUL AGS SEP OKT NOP DES RATA-2
UMUM 414,54 417,66 422,01 422,55 423,05 424,35 425,23 426,96 429,97 453,57 460,01 466,39 432,19
Makanan/Food 412,34 414,74 418,28 418,85 419,29 421 421,61 421,5 423,32 439,65 445,49 450,91 425,58Non Makanan /Non FoodPerumahan/Housing 350,26 356,73 362,02 363,1 364,5 364,52 364,89 370,04 375,16 441,26 446,51 456,79 384,65Pakaian/Clothing 555,76 553,73 563,51 565,36 565,88 567,13 568,83 581,41 580,92 581,16 596,53 596,86 573,09Aneka Barang dan Jasa/Miscellaneous 440,47 444,5 448,67 447,94 447,65 448,87 451,04 451,51 457,92 469,51 476,06 483,92 455,67
Penghitungan Faktor Pengali untuk Daerah Pedesaan
Kelompok/Subkelompok
Rata-rata Indeks
Mar 2001 – Feb 2002
Rata-rata Indeks
Jan – Feb 2002
Rata-rata Indeks
Jul 2004 – Jun 2005
Rata-rata Indeks
Mei – Jun 2005
Penim-bang
Indeks Non
Makanan (kol (4) / kol (2))
Indeks Makanan (kol (5) / kol (3))
Faktor Pengali
-1 -2 -3 -4 -5 -6 -7 -8 -9
UMUM 318,53 336,14 416,56 423,7 100
Makanan/Food 316,82 332,99 421,43 420,15 63,0404 126,17 1,2617Non Makanan /Non Food 36,9596 126,95 1,2695Perumahan/Housing 283,88 300,41 345,42 364,51 121,68Pakaian/Clothing 305,44 313,8 528,18 566,51 172,92Aneka Barang dan Jasa/Miscellaneous 369,83 397,74 435,46 448,26 117,74
Indeks Harga Konsumen Pedesaan Sumatera Selatan Tahun 2005(1993 = 100)
Kelompok/SubkelompokB U L A N
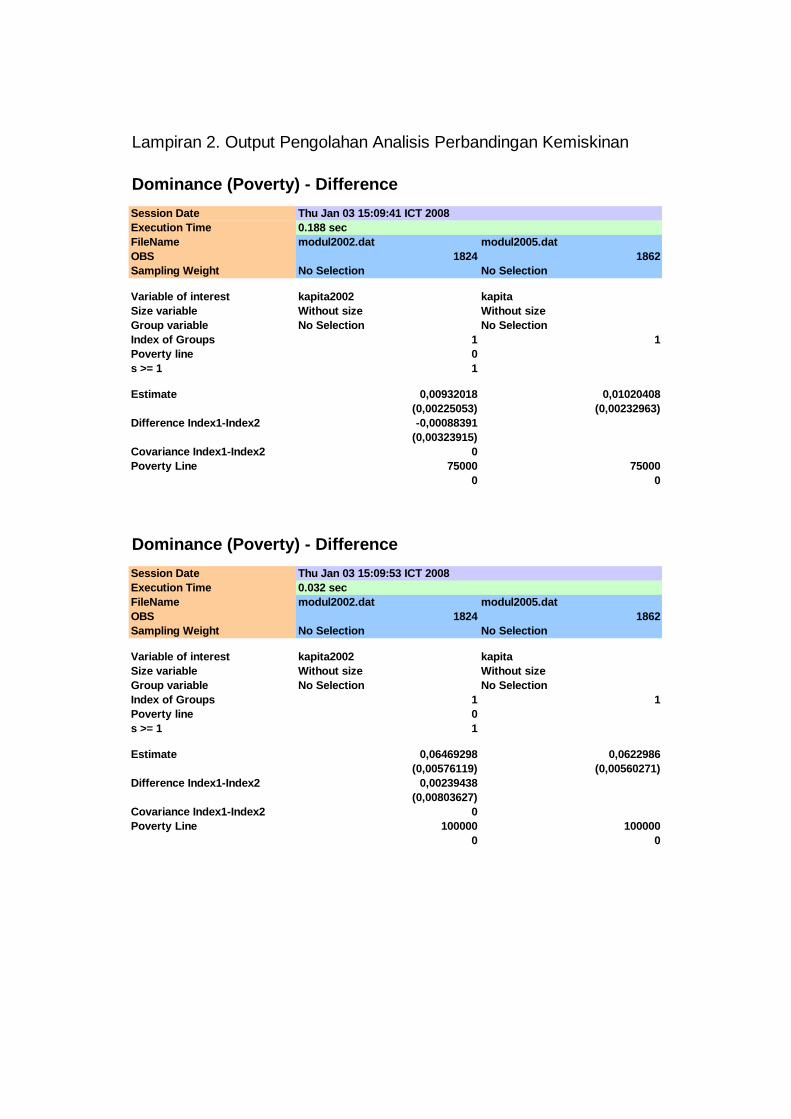
Lampiran 2. Output Pengolahan Analisis Perbandingan Kemiskinan
Dominance (Poverty) - DifferenceSession Date Thu Jan 03 15:09:41 ICT 2008 Execution Time 0.188 sec FileName modul2002.dat modul2005.dat OBS 1824 1862Sampling Weight No Selection No Selection
Variable of interest kapita2002 kapita Size variable Without size Without size Group variable No Selection No Selection Index of Groups 1 1Poverty line 0s >= 1 1
Estimate 0,00932018 0,01020408(0,00225053) (0,00232963)
Difference Index1-Index2 -0,00088391(0,00323915)
Covariance Index1-Index2 0Poverty Line 75000 75000
0 0
Dominance (Poverty) - DifferenceSession Date Thu Jan 03 15:09:53 ICT 2008 Execution Time 0.032 sec FileName modul2002.dat modul2005.dat OBS 1824 1862Sampling Weight No Selection No Selection
Variable of interest kapita2002 kapita Size variable Without size Without size Group variable No Selection No Selection Index of Groups 1 1Poverty line 0s >= 1 1
Estimate 0,06469298 0,0622986(0,00576119) (0,00560271)
Difference Index1-Index2 0,00239438(0,00803627)
Covariance Index1-Index2 0Poverty Line 100000 100000
0 0
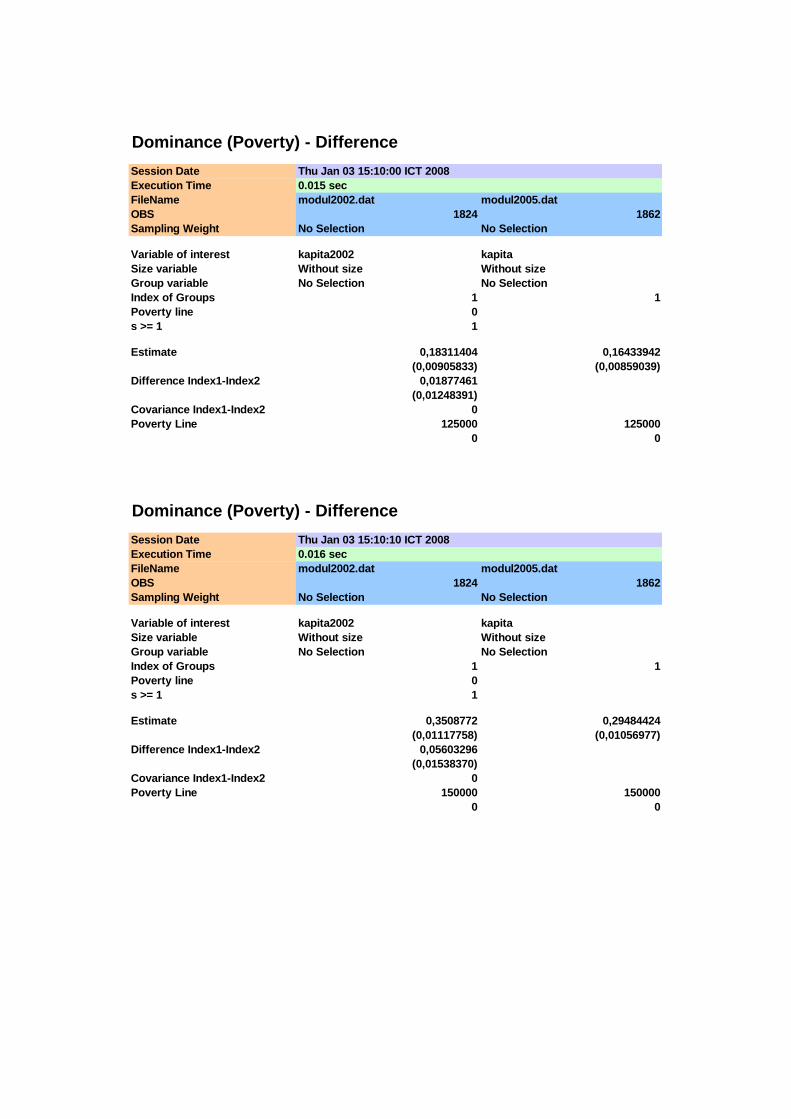
Dominance (Poverty) - DifferenceSession Date Thu Jan 03 15:10:00 ICT 2008 Execution Time 0.015 sec FileName modul2002.dat modul2005.dat OBS 1824 1862Sampling Weight No Selection No Selection
Variable of interest kapita2002 kapita Size variable Without size Without size Group variable No Selection No Selection Index of Groups 1 1Poverty line 0s >= 1 1
Estimate 0,18311404 0,16433942(0,00905833) (0,00859039)
Difference Index1-Index2 0,01877461(0,01248391)
Covariance Index1-Index2 0Poverty Line 125000 125000
0 0
Dominance (Poverty) - DifferenceSession Date Thu Jan 03 15:10:10 ICT 2008 Execution Time 0.016 sec FileName modul2002.dat modul2005.dat OBS 1824 1862Sampling Weight No Selection No Selection
Variable of interest kapita2002 kapita Size variable Without size Without size Group variable No Selection No Selection Index of Groups 1 1Poverty line 0s >= 1 1
Estimate 0,3508772 0,29484424(0,01117758) (0,01056977)
Difference Index1-Index2 0,05603296(0,01538370)
Covariance Index1-Index2 0Poverty Line 150000 150000
0 0
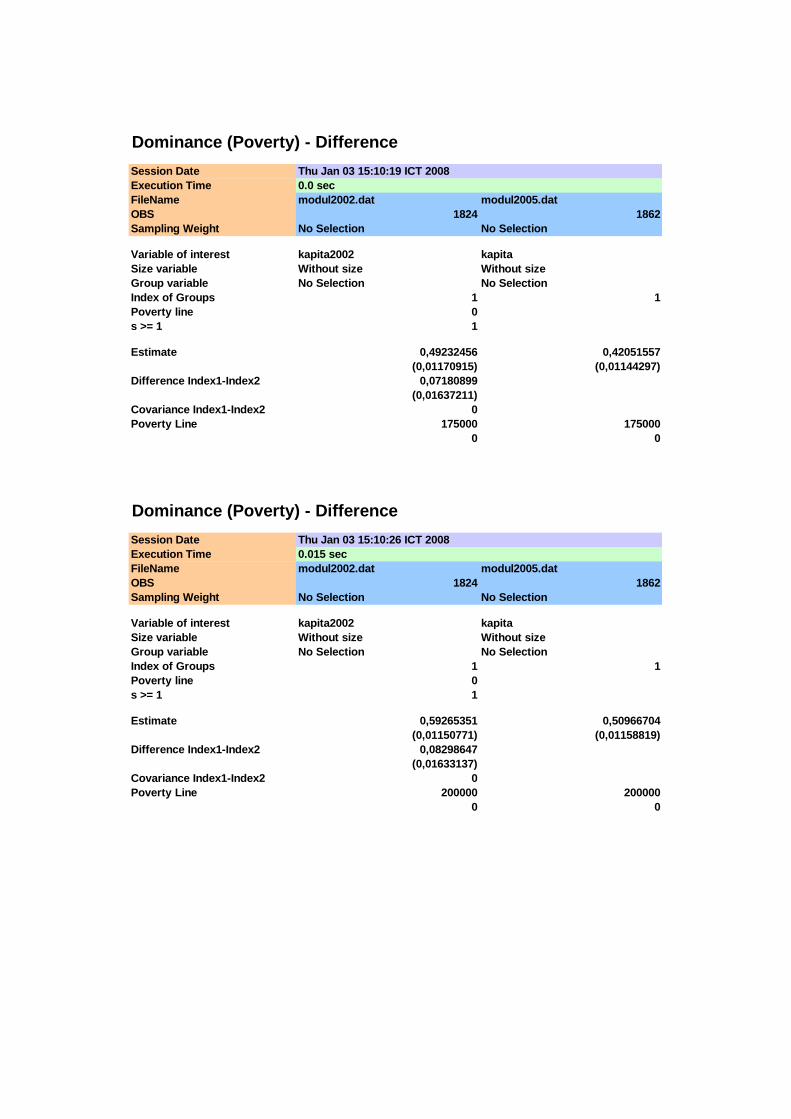
Dominance (Poverty) - DifferenceSession Date Thu Jan 03 15:10:19 ICT 2008 Execution Time 0.0 sec FileName modul2002.dat modul2005.dat OBS 1824 1862Sampling Weight No Selection No Selection
Variable of interest kapita2002 kapita Size variable Without size Without size Group variable No Selection No Selection Index of Groups 1 1Poverty line 0s >= 1 1
Estimate 0,49232456 0,42051557(0,01170915) (0,01144297)
Difference Index1-Index2 0,07180899(0,01637211)
Covariance Index1-Index2 0Poverty Line 175000 175000
0 0
Dominance (Poverty) - DifferenceSession Date Thu Jan 03 15:10:26 ICT 2008 Execution Time 0.015 sec FileName modul2002.dat modul2005.dat OBS 1824 1862Sampling Weight No Selection No Selection
Variable of interest kapita2002 kapita Size variable Without size Without size Group variable No Selection No Selection Index of Groups 1 1Poverty line 0s >= 1 1
Estimate 0,59265351 0,50966704(0,01150771) (0,01158819)
Difference Index1-Index2 0,08298647(0,01633137)
Covariance Index1-Index2 0Poverty Line 200000 200000
0 0
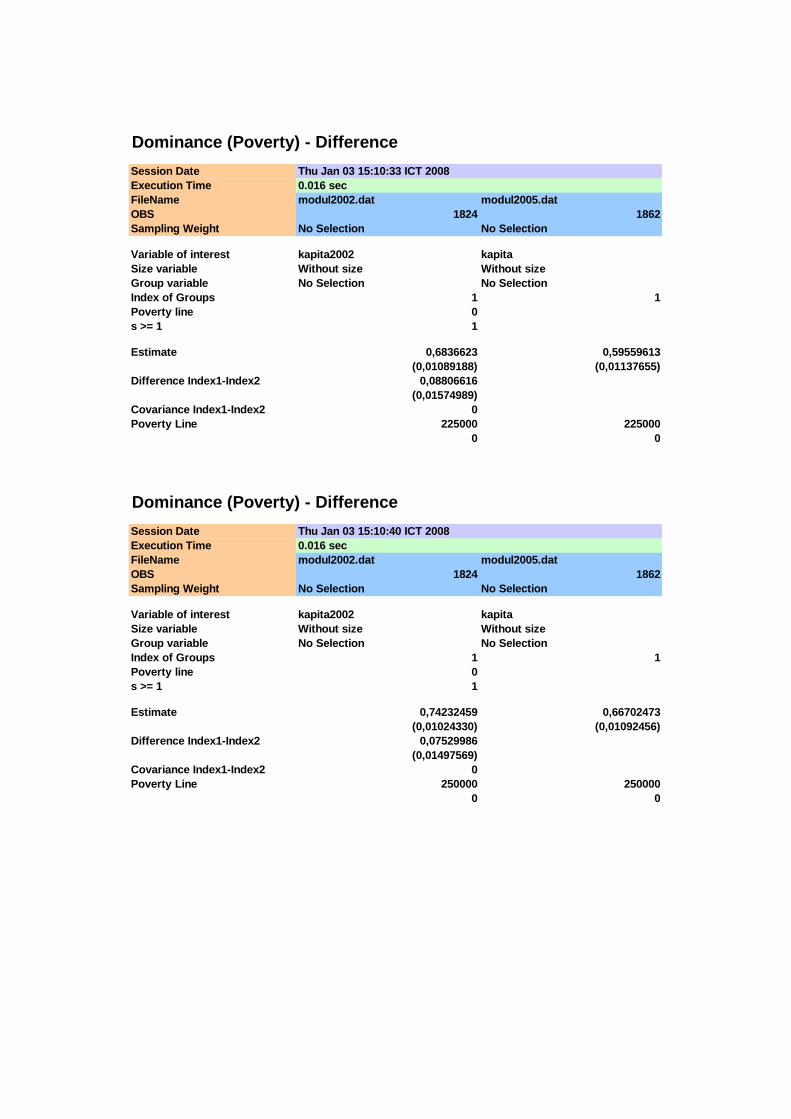
Dominance (Poverty) - DifferenceSession Date Thu Jan 03 15:10:33 ICT 2008 Execution Time 0.016 sec FileName modul2002.dat modul2005.dat OBS 1824 1862Sampling Weight No Selection No Selection
Variable of interest kapita2002 kapita Size variable Without size Without size Group variable No Selection No Selection Index of Groups 1 1Poverty line 0s >= 1 1
Estimate 0,6836623 0,59559613(0,01089188) (0,01137655)
Difference Index1-Index2 0,08806616(0,01574989)
Covariance Index1-Index2 0Poverty Line 225000 225000
0 0
Dominance (Poverty) - DifferenceSession Date Thu Jan 03 15:10:40 ICT 2008 Execution Time 0.016 sec FileName modul2002.dat modul2005.dat OBS 1824 1862Sampling Weight No Selection No Selection
Variable of interest kapita2002 kapita Size variable Without size Without size Group variable No Selection No Selection Index of Groups 1 1Poverty line 0s >= 1 1
Estimate 0,74232459 0,66702473(0,01024330) (0,01092456)
Difference Index1-Index2 0,07529986(0,01497569)
Covariance Index1-Index2 0Poverty Line 250000 250000
0 0
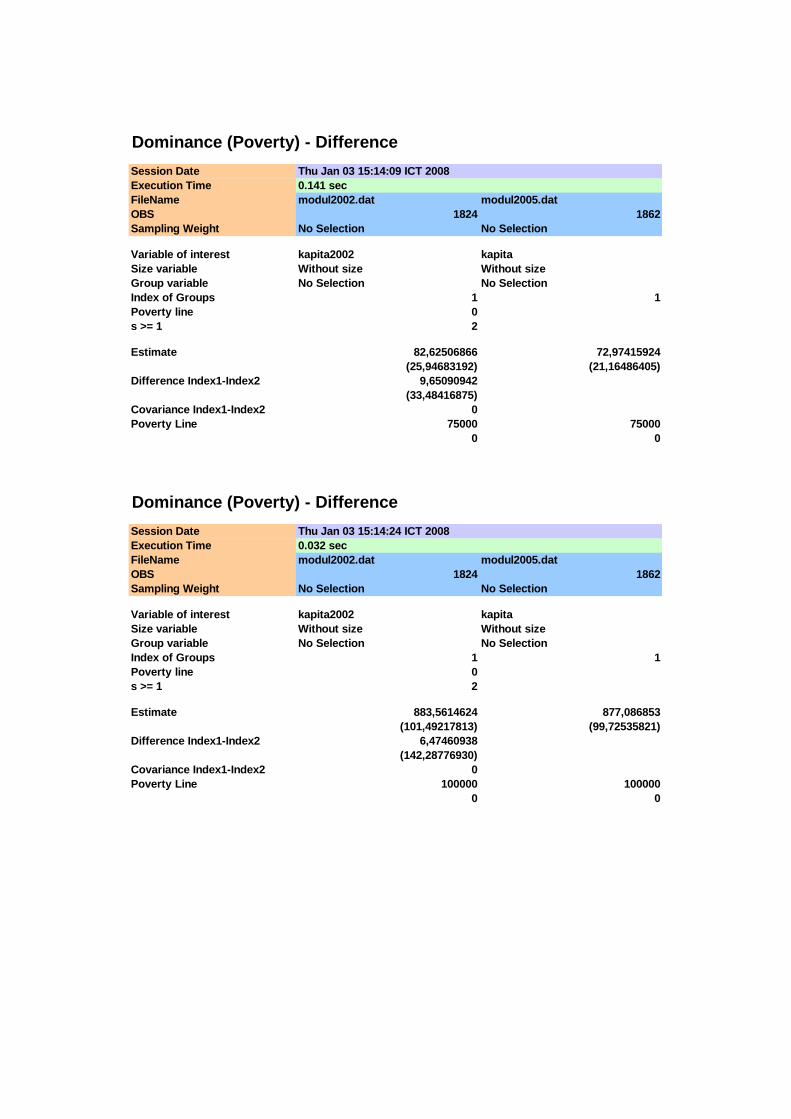
Dominance (Poverty) - DifferenceSession Date Thu Jan 03 15:14:09 ICT 2008 Execution Time 0.141 sec FileName modul2002.dat modul2005.dat OBS 1824 1862Sampling Weight No Selection No Selection
Variable of interest kapita2002 kapita Size variable Without size Without size Group variable No Selection No Selection Index of Groups 1 1Poverty line 0s >= 1 2
Estimate 82,62506866 72,97415924(25,94683192) (21,16486405)
Difference Index1-Index2 9,65090942(33,48416875)
Covariance Index1-Index2 0Poverty Line 75000 75000
0 0
Dominance (Poverty) - DifferenceSession Date Thu Jan 03 15:14:24 ICT 2008 Execution Time 0.032 sec FileName modul2002.dat modul2005.dat OBS 1824 1862Sampling Weight No Selection No Selection
Variable of interest kapita2002 kapita Size variable Without size Without size Group variable No Selection No Selection Index of Groups 1 1Poverty line 0s >= 1 2
Estimate 883,5614624 877,086853(101,49217813) (99,72535821)
Difference Index1-Index2 6,47460938(142,28776930)
Covariance Index1-Index2 0Poverty Line 100000 100000
0 0
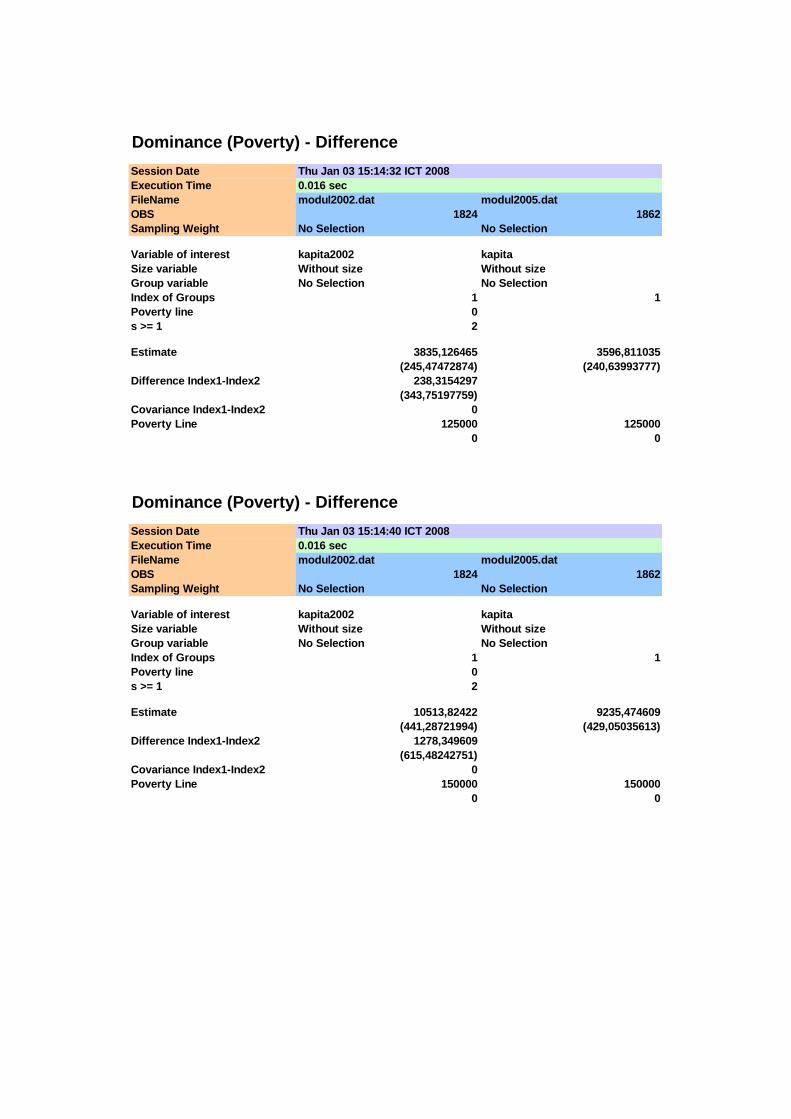
Dominance (Poverty) - DifferenceSession Date Thu Jan 03 15:14:32 ICT 2008 Execution Time 0.016 sec FileName modul2002.dat modul2005.dat OBS 1824 1862Sampling Weight No Selection No Selection
Variable of interest kapita2002 kapita Size variable Without size Without size Group variable No Selection No Selection Index of Groups 1 1Poverty line 0s >= 1 2
Estimate 3835,126465 3596,811035(245,47472874) (240,63993777)
Difference Index1-Index2 238,3154297(343,75197759)
Covariance Index1-Index2 0Poverty Line 125000 125000
0 0
Dominance (Poverty) - DifferenceSession Date Thu Jan 03 15:14:40 ICT 2008 Execution Time 0.016 sec FileName modul2002.dat modul2005.dat OBS 1824 1862Sampling Weight No Selection No Selection
Variable of interest kapita2002 kapita Size variable Without size Without size Group variable No Selection No Selection Index of Groups 1 1Poverty line 0s >= 1 2
Estimate 10513,82422 9235,474609(441,28721994) (429,05035613)
Difference Index1-Index2 1278,349609(615,48242751)
Covariance Index1-Index2 0Poverty Line 150000 150000
0 0
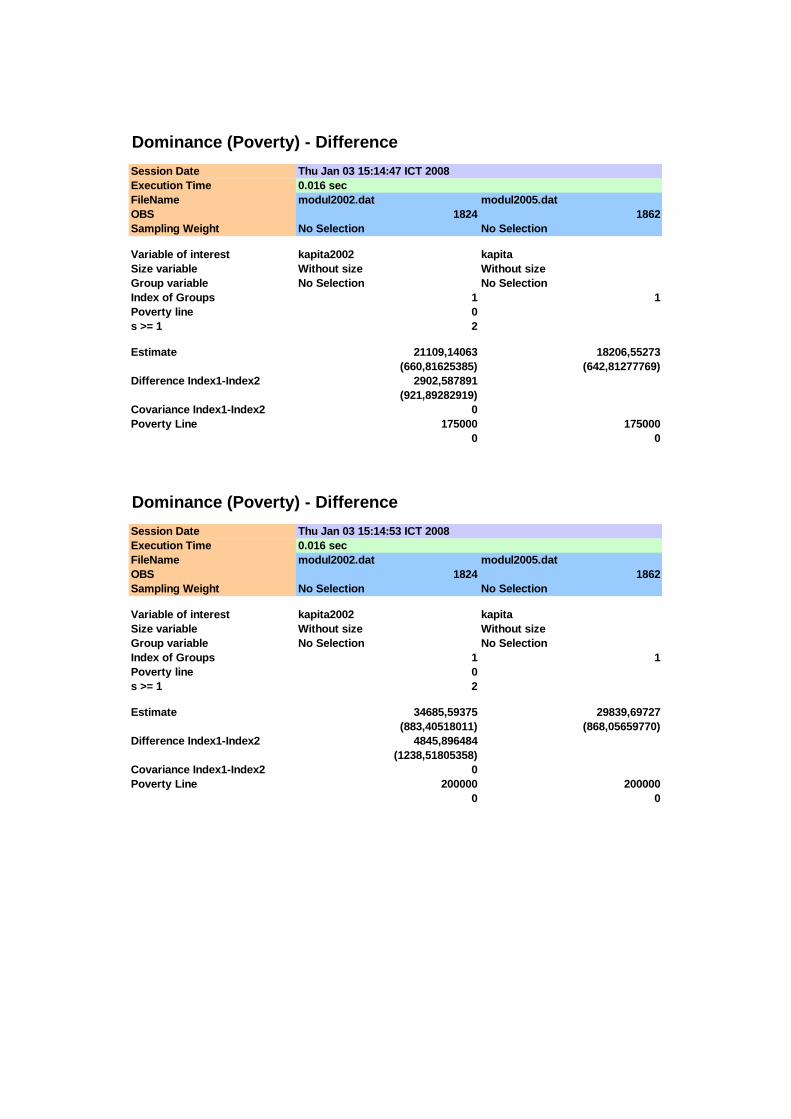
Dominance (Poverty) - DifferenceSession Date Thu Jan 03 15:14:47 ICT 2008 Execution Time 0.016 sec FileName modul2002.dat modul2005.dat OBS 1824 1862Sampling Weight No Selection No Selection
Variable of interest kapita2002 kapita Size variable Without size Without size Group variable No Selection No Selection Index of Groups 1 1Poverty line 0s >= 1 2
Estimate 21109,14063 18206,55273(660,81625385) (642,81277769)
Difference Index1-Index2 2902,587891(921,89282919)
Covariance Index1-Index2 0Poverty Line 175000 175000
0 0
Dominance (Poverty) - DifferenceSession Date Thu Jan 03 15:14:53 ICT 2008 Execution Time 0.016 sec FileName modul2002.dat modul2005.dat OBS 1824 1862Sampling Weight No Selection No Selection
Variable of interest kapita2002 kapita Size variable Without size Without size Group variable No Selection No Selection Index of Groups 1 1Poverty line 0s >= 1 2
Estimate 34685,59375 29839,69727(883,40518011) (868,05659770)
Difference Index1-Index2 4845,896484(1238,51805358)
Covariance Index1-Index2 0Poverty Line 200000 200000
0 0
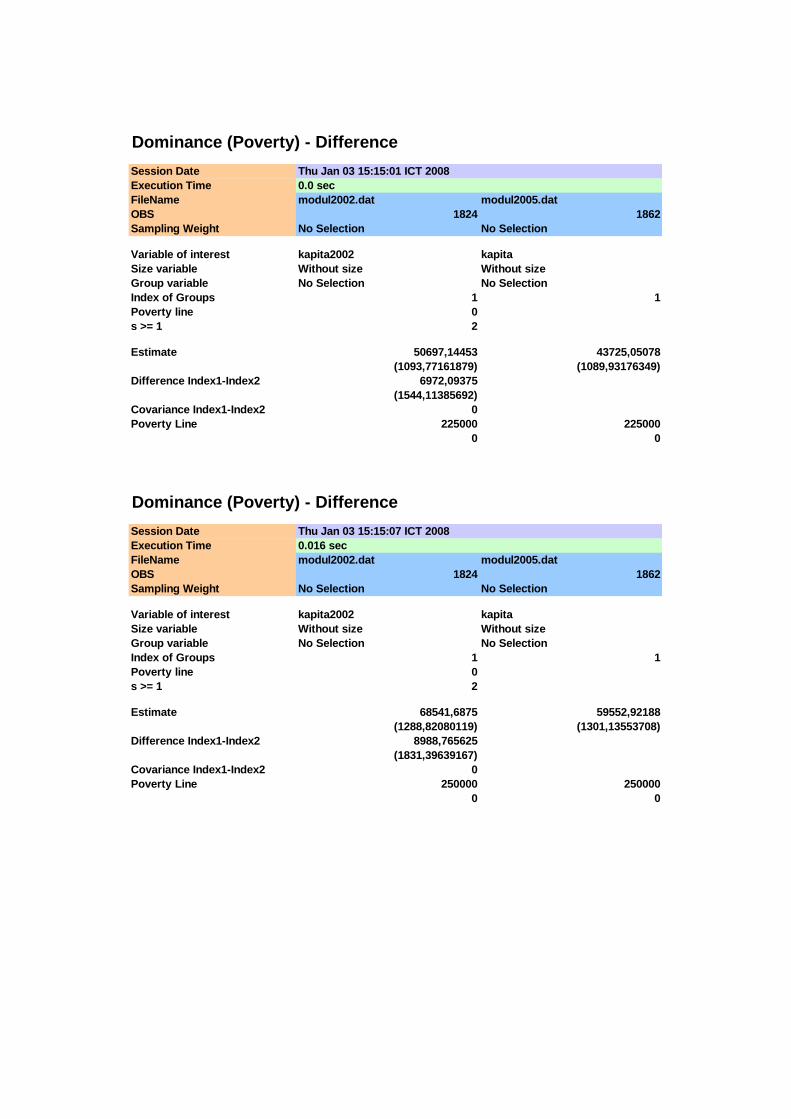
Dominance (Poverty) - DifferenceSession Date Thu Jan 03 15:15:01 ICT 2008 Execution Time 0.0 sec FileName modul2002.dat modul2005.dat OBS 1824 1862Sampling Weight No Selection No Selection
Variable of interest kapita2002 kapita Size variable Without size Without size Group variable No Selection No Selection Index of Groups 1 1Poverty line 0s >= 1 2
Estimate 50697,14453 43725,05078(1093,77161879) (1089,93176349)
Difference Index1-Index2 6972,09375(1544,11385692)
Covariance Index1-Index2 0Poverty Line 225000 225000
0 0
Dominance (Poverty) - DifferenceSession Date Thu Jan 03 15:15:07 ICT 2008 Execution Time 0.016 sec FileName modul2002.dat modul2005.dat OBS 1824 1862Sampling Weight No Selection No Selection
Variable of interest kapita2002 kapita Size variable Without size Without size Group variable No Selection No Selection Index of Groups 1 1Poverty line 0s >= 1 2
Estimate 68541,6875 59552,92188(1288,82080119) (1301,13553708)
Difference Index1-Index2 8988,765625(1831,39639167)
Covariance Index1-Index2 0Poverty Line 250000 250000
0 0
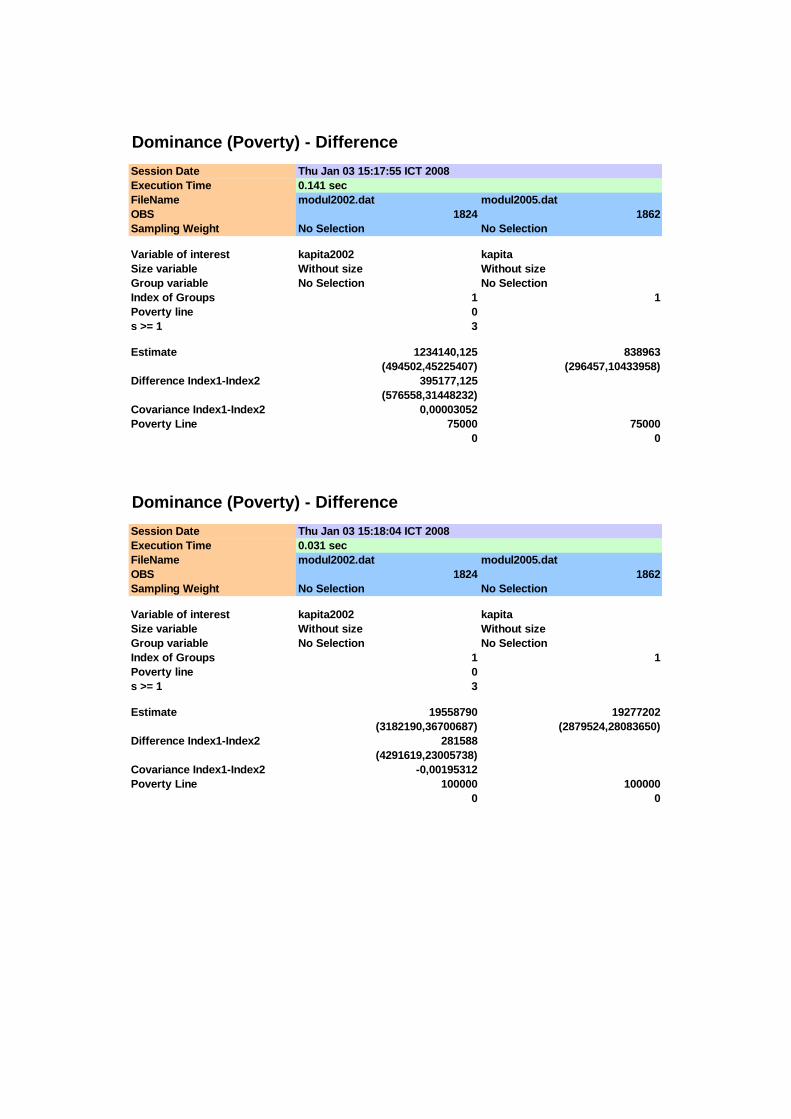
Dominance (Poverty) - DifferenceSession Date Thu Jan 03 15:17:55 ICT 2008 Execution Time 0.141 sec FileName modul2002.dat modul2005.dat OBS 1824 1862Sampling Weight No Selection No Selection
Variable of interest kapita2002 kapita Size variable Without size Without size Group variable No Selection No Selection Index of Groups 1 1Poverty line 0s >= 1 3
Estimate 1234140,125 838963(494502,45225407) (296457,10433958)
Difference Index1-Index2 395177,125(576558,31448232)
Covariance Index1-Index2 0,00003052Poverty Line 75000 75000
0 0
Dominance (Poverty) - DifferenceSession Date Thu Jan 03 15:18:04 ICT 2008 Execution Time 0.031 sec FileName modul2002.dat modul2005.dat OBS 1824 1862Sampling Weight No Selection No Selection
Variable of interest kapita2002 kapita Size variable Without size Without size Group variable No Selection No Selection Index of Groups 1 1Poverty line 0s >= 1 3
Estimate 19558790 19277202(3182190,36700687) (2879524,28083650)
Difference Index1-Index2 281588(4291619,23005738)
Covariance Index1-Index2 -0,00195312Poverty Line 100000 100000
0 0
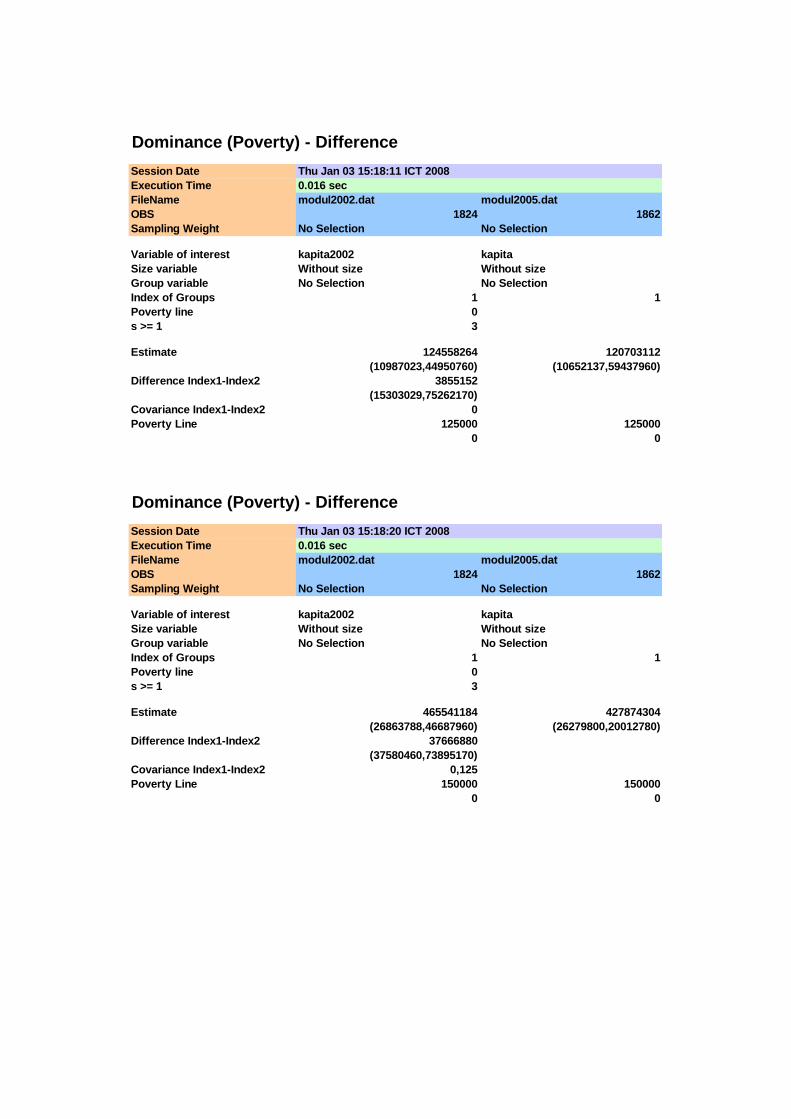
Dominance (Poverty) - DifferenceSession Date Thu Jan 03 15:18:11 ICT 2008 Execution Time 0.016 sec FileName modul2002.dat modul2005.dat OBS 1824 1862Sampling Weight No Selection No Selection
Variable of interest kapita2002 kapita Size variable Without size Without size Group variable No Selection No Selection Index of Groups 1 1Poverty line 0s >= 1 3
Estimate 124558264 120703112(10987023,44950760) (10652137,59437960)
Difference Index1-Index2 3855152(15303029,75262170)
Covariance Index1-Index2 0Poverty Line 125000 125000
0 0
Dominance (Poverty) - DifferenceSession Date Thu Jan 03 15:18:20 ICT 2008 Execution Time 0.016 sec FileName modul2002.dat modul2005.dat OBS 1824 1862Sampling Weight No Selection No Selection
Variable of interest kapita2002 kapita Size variable Without size Without size Group variable No Selection No Selection Index of Groups 1 1Poverty line 0s >= 1 3
Estimate 465541184 427874304(26863788,46687960) (26279800,20012780)
Difference Index1-Index2 37666880(37580460,73895170)
Covariance Index1-Index2 0,125Poverty Line 150000 150000
0 0
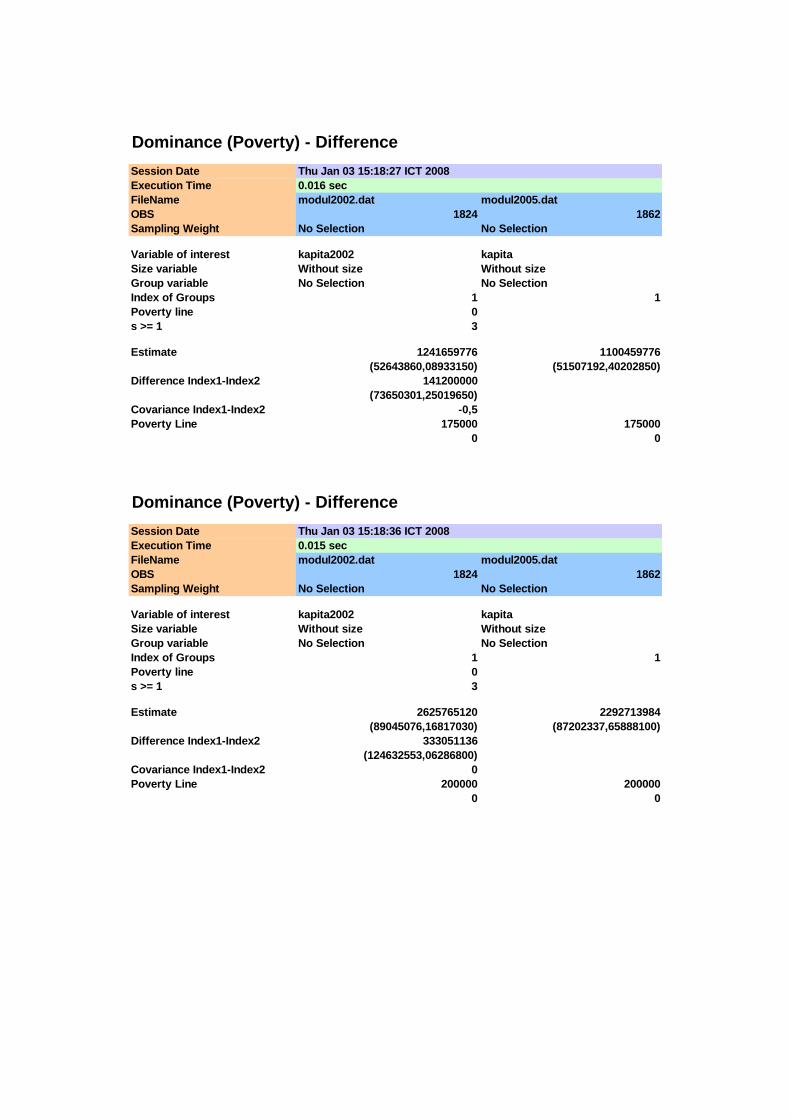
Dominance (Poverty) - DifferenceSession Date Thu Jan 03 15:18:27 ICT 2008 Execution Time 0.016 sec FileName modul2002.dat modul2005.dat OBS 1824 1862Sampling Weight No Selection No Selection
Variable of interest kapita2002 kapita Size variable Without size Without size Group variable No Selection No Selection Index of Groups 1 1Poverty line 0s >= 1 3
Estimate 1241659776 1100459776(52643860,08933150) (51507192,40202850)
Difference Index1-Index2 141200000(73650301,25019650)
Covariance Index1-Index2 -0,5Poverty Line 175000 175000
0 0
Dominance (Poverty) - DifferenceSession Date Thu Jan 03 15:18:36 ICT 2008 Execution Time 0.015 sec FileName modul2002.dat modul2005.dat OBS 1824 1862Sampling Weight No Selection No Selection
Variable of interest kapita2002 kapita Size variable Without size Without size Group variable No Selection No Selection Index of Groups 1 1Poverty line 0s >= 1 3
Estimate 2625765120 2292713984(89045076,16817030) (87202337,65888100)
Difference Index1-Index2 333051136(124632553,06286800)
Covariance Index1-Index2 0Poverty Line 200000 200000
0 0
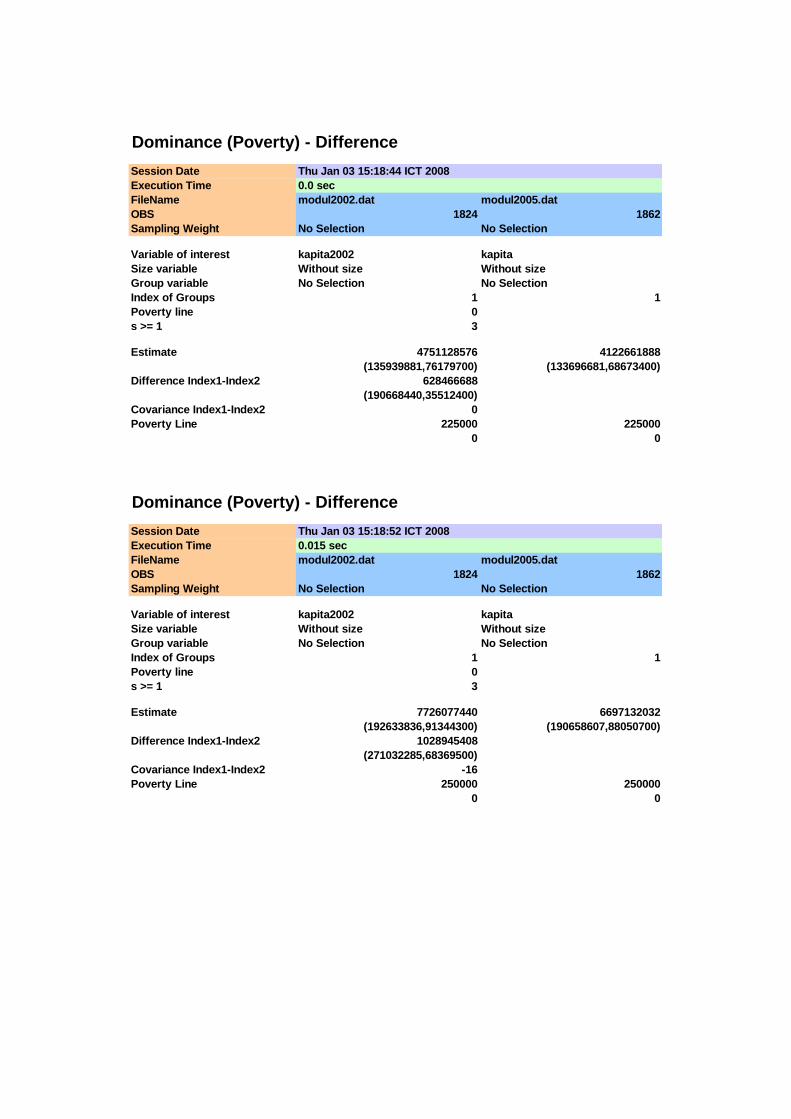
Dominance (Poverty) - DifferenceSession Date Thu Jan 03 15:18:44 ICT 2008 Execution Time 0.0 sec FileName modul2002.dat modul2005.dat OBS 1824 1862Sampling Weight No Selection No Selection
Variable of interest kapita2002 kapita Size variable Without size Without size Group variable No Selection No Selection Index of Groups 1 1Poverty line 0s >= 1 3
Estimate 4751128576 4122661888(135939881,76179700) (133696681,68673400)
Difference Index1-Index2 628466688(190668440,35512400)
Covariance Index1-Index2 0Poverty Line 225000 225000
0 0
Dominance (Poverty) - DifferenceSession Date Thu Jan 03 15:18:52 ICT 2008 Execution Time 0.015 sec FileName modul2002.dat modul2005.dat OBS 1824 1862Sampling Weight No Selection No Selection
Variable of interest kapita2002 kapita Size variable Without size Without size Group variable No Selection No Selection Index of Groups 1 1Poverty line 0s >= 1 3
Estimate 7726077440 6697132032(192633836,91344300) (190658607,88050700)
Difference Index1-Index2 1028945408(271032285,68369500)
Covariance Index1-Index2 -16Poverty Line 250000 250000
0 0
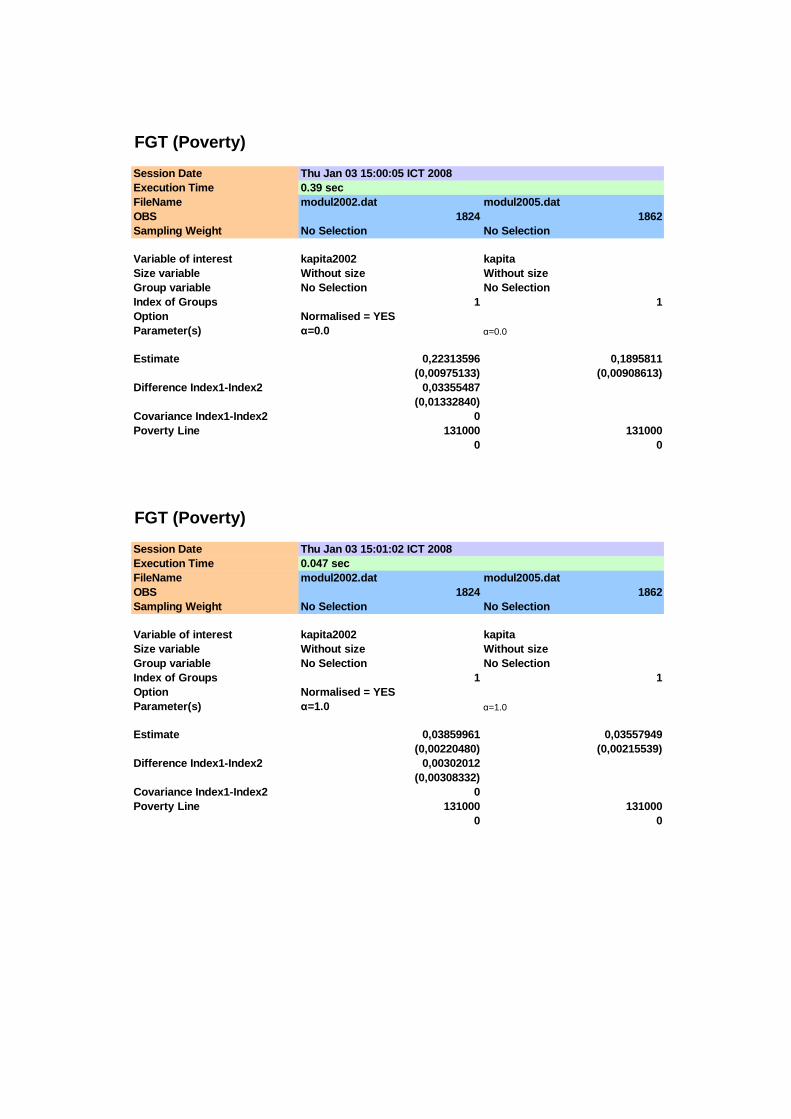
FGT (Poverty)
Session Date Thu Jan 03 15:00:05 ICT 2008 Execution Time 0.39 sec FileName modul2002.dat modul2005.dat OBS 1824 1862Sampling Weight No Selection No Selection
Variable of interest kapita2002 kapita Size variable Without size Without size Group variable No Selection No Selection Index of Groups 1 1Option Normalised = YES Parameter(s) α=0.0 α=0.0
Estimate 0,22313596 0,1895811(0,00975133) (0,00908613)
Difference Index1-Index2 0,03355487(0,01332840)
Covariance Index1-Index2 0Poverty Line 131000 131000
0 0
FGT (Poverty)
Session Date Thu Jan 03 15:01:02 ICT 2008 Execution Time 0.047 sec FileName modul2002.dat modul2005.dat OBS 1824 1862Sampling Weight No Selection No Selection
Variable of interest kapita2002 kapita Size variable Without size Without size Group variable No Selection No Selection Index of Groups 1 1Option Normalised = YES Parameter(s) α=1.0 α=1.0
Estimate 0,03859961 0,03557949(0,00220480) (0,00215539)
Difference Index1-Index2 0,00302012(0,00308332)
Covariance Index1-Index2 0Poverty Line 131000 131000
0 0
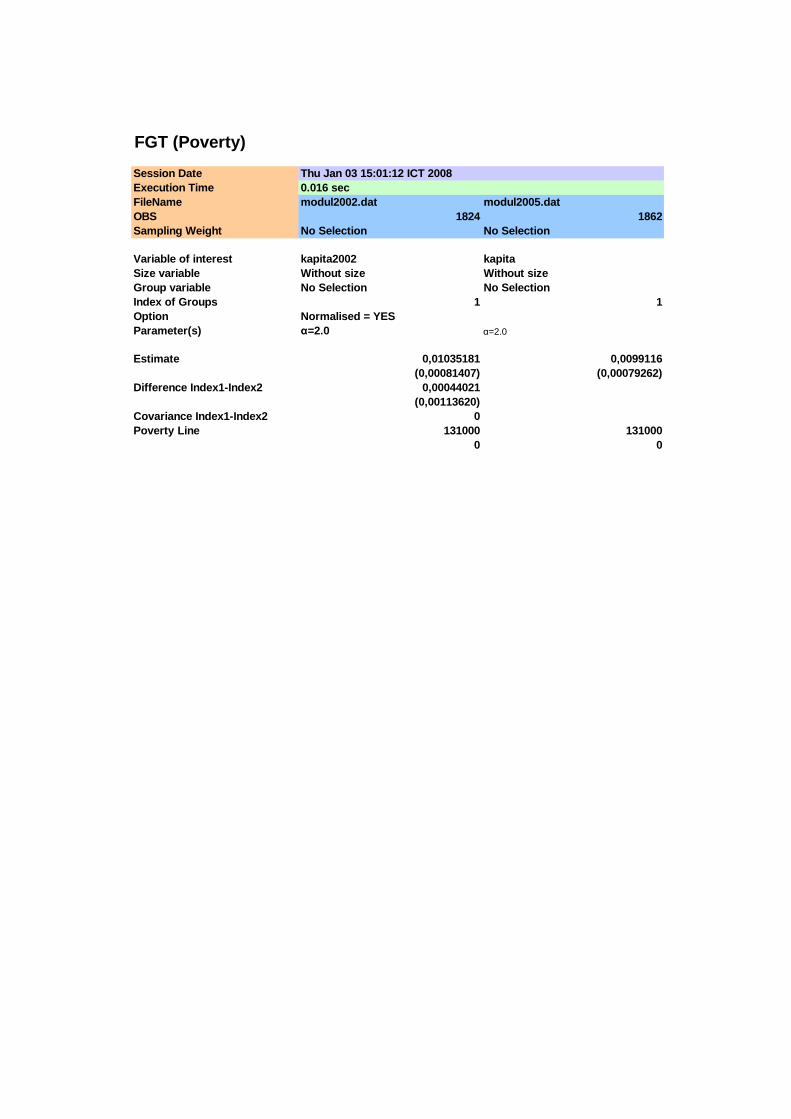
FGT (Poverty)
Session Date Thu Jan 03 15:01:12 ICT 2008 Execution Time 0.016 sec FileName modul2002.dat modul2005.dat OBS 1824 1862Sampling Weight No Selection No Selection
Variable of interest kapita2002 kapita Size variable Without size Without size Group variable No Selection No Selection Index of Groups 1 1Option Normalised = YES Parameter(s) α=2.0 α=2.0
Estimate 0,01035181 0,0099116(0,00081407) (0,00079262)
Difference Index1-Index2 0,00044021(0,00113620)
Covariance Index1-Index2 0Poverty Line 131000 131000
0 0