analyse des données
DESCRIPTION
cours d analyse de donnees application des tests statistiquesTRANSCRIPT

UNIVERSITE DE DOUALA
Faculté des Sciences Economiques et de Gestion Appl iquée (FSEGA)
Département des techniques quantitatives
Année académique 2012/2013
COURS ANALYSE DES DONNEES
CF4 - ECOMO4 - FICO4 - MARKETING4
Par M. NANA YAKAM André
Email : [email protected] Programme :
1. Méthodologie d’analyse des données 2. Analyse univariée 3. Analyse bivariée 4. Analyse multivariée
Bibliographie :
− Qu’est ce que l’analyse de données ? Jean-Pierre FENELON, édition LEFONEN − Initiation à l’analyse des données, Jean de Lagarde, édition DUNOD − Analyse des données multidimensionnelles, Patrice Bertier & J M Bouroche,
Presses Universitaire de France − Statistique appliquée à la gestion, Vincent GIARD, édition ECONOMICA − Analyse statistique des données : application et cas pour le marketing, H.
Fernneleau, édition Ellipses

2
CHAPITRE I :
METHODOLOGIE D’ANALYSE DES DONNEES
INTRODUCTION
L’analyse de données est un processus d’extraction des connaissances à partir des données (ECD). Elle vise à décrire, à résumer et à interpréter des phénomènes dont le caractère essentiel est la variabilité. Elle fournit de la manière la plus rigoureuse possible des éléments d'appréciation utiles à l'explication ou à la prévision de ces phénomènes. L’analyse des données fournit à toutes les personnes confrontées à l'interprétation de résultats d'observation ou d'expérimentation, un outil d'interprétation adapté aux conditions particulières de leur domaine d'activité.
Avant de se lancer dans le processus d’analyse des données, l’analyste doit avoir un problème bien délimité à résoudre. Il ne se lance pas dans l’analyse sans avoir une idée des objectifs de son opération et des moyens informationnels et technologiques dont il dispose. Par exemple, il cherche des liens entre certains phénomènes.
Une fois le problème posé, la première phase vise à cibler, même de façon grossière, l’espace des données qui va être exploré. L’analyste définit de ce fait des zones de prospection, étant persuadé que certaines régions seront probablement vite abandonnées si elles ne recèlent aucun ou peu d’intérêt. L’acquisition met en œuvre des méthodes pour collecter les données potentiellement utiles selon le point de vue de l’analyste.
NB : La collecte des données est la phase la plus déterminante en analyse de données, car toute analyse, aussi sérieuse soit-elle, faite sur de données erronées ou de mauvaise qualité est biaisée d’avance et ne peut aboutir qu’à des conclusions erronées. Par ailleurs, Le processus d’ECD n’est pas linéaire car il arrive aussi que l’on revienne, après analyse, rechercher de nouvelles données.
A l’issue de la phase de collecte de données, il convient de les nettoyer. Par exemple, si l’une des variables retenues s’avère peu ou mal renseignée, on peut ne pas la prendre en considération. On peut également explicitement chercher à limiter le nombre d’enregistrements que l’on souhaite traiter. On construit alors un filtre idoine, comme un échantillonnage selon une procédure de tirage aléatoire simple ou systématique par exemple.
Après cette phase de pré-traitement des données, l’analyste est, a priori, en possession d’un stock de données contenant potentiellement l’information ou la connaissance recherchée. C’est en ce moment qu’il peut commencer son analyse. Selon que l’analyse porte sur une, deux ou plus de deux variables, et en fonction de la nature de ces variables, de nombreux outils statistiques sont à la disposition de l’analyste pour résoudre son problème. Le schéma suivant résume la méthodologie d’analyse des données ainsi que les outils qui seront développés dans ce cours.

3
ORIGINE ET METHODES DE COLLECTE DES DONNEES
1. ORIGINE
Les données utilisées en statistiques peuvent provenir d’un recensement, d’une enquête statistique, des données administratives ou d’un entrepôt de données d’une organisation.
a) Recensement Le recensement est une opération statistique d’observation exhaustive de tous les éléments d’une population. Les données individuelles de tous les éléments de la population sont prises en compte pour le caractère étudié. C’est le cas par exemple des clients d’une banque, des salariés d’une entreprise, …
b) Enquête statistique Une enquête statistique est la collecte de données sur une partie ou la totalité des unités d'une population à l'aide de concepts, de méthodes et de procédures bien définis. Le sondage en est l’une de ces méthodes, qui permet de construire un échantillon et qui ne prélève qu’une partie des informations existantes.
c) Données administratives Les organismes et les Etats recueillent des données administratives dans le cadre de leurs activités quotidiennes, ces données peuvent être utilisées à titre de substitut pour une enquête par sondage ou pour un recensement.
d) Entrepôt de données Grâce à l’évolution informatique, avec la fabrication des ordinateurs ayant des grandes capacités de stockage, les entreprises, les institutions et les organisations conservent de nos jours, des quantités importantes d’information dans leurs bases de données. Ces entrepôts de données renferment à n’en point douter des informations dont la fouille par les techniques d’analyse de données peut permettre d’apporter des réponses, même aux questions les complexes que se poses ces organisations. Remarque : Les sources potentielles peuvent être regroupée en deux : Soit les données existent déjà quelque part et elles sont accessibles, au quel cas il faut aller à sa recherche, sinon nous devons les collecter nous même auprès des individus concernés.
Origine et Collecte des Données
Prétraitement, Codification, Mise des données en tableaux
Analyse descriptive (Analyse Univariée)
- Estimation des paramètres de tendance centrale (moyenne, mode, médiane)
Analyse Bivariée
- Estimation et signification des paramètres de Dispersion (variance, écart type, intervalle interquartile)
- Graphiques - Tests d’inférence sur une variable
- ANOVA à un facteur
- Test d’association, - Test de Corrélation - Autres tests - ANOVA à 2 facteurs
- Modélisation (modèle de régression, …)
Analyse Multivariée
- Modélisation (modèle de régression multiple)
- Analyse Factoriel (ACP, AFC, ACM, Analyse
discriminante)
- Prévision
- Prévision
Problème à résoudre

4
2. METHODES DE COLLECTE DES DONNEES
La collecte des données vise à répondre aux questions suivantes : Quels sont les individus à prendre en
compte dans mon étude ? Où vais-je les retrouver ? Par quel moyen ? Combien en faut-il ? Comment vais-je les sélectionner ? Les réponses à ces questions varient selon que les données sont dans des entrepôts de données ou alors s’il faut les collecter auprès des individus concernés.
Très souvent, les données issues des bases de données et des enquêtes statistiques ne sont pas toutes exploitables. On est parfois amené à procéder à une sélection pour choisir l’échantillon propice pour l’analyse. Parmi ces méthodes d’échantillonnage nous pouvons citer :
− Echantillonnage aléatoire simple : l’échantillon est choisi de telle sorte que chaque unité de la population ait la même probabilité d’être sélectionnée dans l’échantillon et que chaque échantillon de même taille ait la même probabilité d’être tiré.
− Echantillonnage Systématique : On souhaite sélectionner n individus parmi N sujets numérotés de 1 à
N. pour ce faire, On calcule le pas : n
Np = , puis on tire un nombre aléatoire entre 1 et Ent(p), c’est du
premier individu choisi. Les autres seront obtenus en ajoutant Ent(p) au numéro précédemment choisi.
− Échantillonnage avec probabilité proportionnelle à la taille : Si la base de sondage renferme de l'information sur la taille de chaque unité (comme le nombre de filles) et si la taille de ces unités varie, on peut utiliser cette information dans le cadre de la sélection de l'échantillonnage afin d'en accroître l'efficacité.
− Échantillonnage stratifié : on divise la population en groupes homogènes appelés strates, qui sont mutuellement exclusifs (comme l'âge, la ville de résidence, le revenu, etc.) puis on sélectionne à partir de chaque strate des échantillons indépendants. On peut utiliser n'importe quelle des méthodes d'échantillonnage pour sélectionner l'échantillon à l'intérieur de chaque strate.
3. PRETRAITEMENT DES DONNEES Les données issues des entrepôts ou des enquêtes ne sont pas nécessairement toutes exploitables par des
techniques d’analyse de données. Les données acquises peuvent être de types différents pour la même variable, on peut avoir les données manquantes ou aberrantes. Dans certaines situations, les données exigent une transformation telle qu’un centrage par rapport à la moyenne ou une normalisation. La préparation consiste à homogénéiser les données et à les disposer en tableau lignes/colonnes. Car il s’agit presque toujours de la structure la mieux adaptée à l’exploitation des données. Les principales opérations de préparation peuvent être listées comme suit :
a) Sélection de ligne/colonne.
Elle s’effectue sur des données qui sont déjà sous forme tabulaire. Il s’agit de définir un filtre qui permet de sélectionner un sous-ensemble de lignes ou de colonnes. L’objectif étant, soit de réduire le nombre de données soit de sélectionner les lignes ou colonnes les plus pertinentes par rapport aux préoccupations de l’utilisateur. Les techniques mises en œuvre dans ce but relèvent des méthodes statistiques d’échantillonnage. Cette sélection peut également s’effectuer selon des conditions exprimées par l’utilisateur. Par exemple, il peut ne garder que les attributs dont la moyenne est supérieure à un seuil donné ou ne conserver que les attributs qui ont un lien statistique significatif avec un attribut particulier.

5
b) Le traitement des données manquantes ou aberrantes.
Certaines données peuvent être absentes ou aberrantes et gêner ainsi l’analyse. Il convient alors de définir des règles pour gérer ces données manquantes et les valeurs aberrantes ou anormales.
i.) Valeurs manquantes Lorsqu’on est en face d’une donnée manquante, une des solutions consiste à supprimer l’observation correspondante, quand on en a suffisamment. On peut aussi envisager d’estimer cette dernière. De nombreuses solutions sont proposées, comme le remplacement, dans le cas des variables qualitatives et quantitatives continues, de toute donnée manquante par la valeur la plus fréquente de la variable concernée. On peut également chercher à estimer ces valeurs manquantes par des méthodes d’induction comme la régression pour les variables quantitatives.
ii.) Valeurs aberrantes Selon la méthode de l’intervalle de confiance, est considérée comme valeur aberrante pour une variable quantitative X donnée, toutes les données dont la valeur est extérieure à l’intervalle [ ]XX XX σσ 96.1;96.1 +−
où X est la moyenne de X et Xσ son écart type. La valeur détectée comme aberrante est ramenée à la limite haute ou basse de cet intervalle de confiance. On peut également chercher à l’estimer par des méthodes régression.
c) Les transformations de variables
Il s’agit de transformer un attribut A en une autre variable A’ qui serait, selon les objectifs de l’étude, plus appropriée. Différentes méthodes sont pratiquées comme la discrétisation qui consiste à transformer des attributs continus en découpant le domaine de valeurs de ces attributs en intervalles afin d’obtenir des attributs qualitatifs. On peut également centrer les valeurs des variables continues par rapport à la moyenne et réduire par l’écart type. Ce traitement leur confère certaines propriétés mathématiques intéressantes lors de la mise en œuvre de méthodes d’analyse des données multidimensionnelles.

6
CHAPITRE II :
ANALYSE UNIVARIEE
Introduction L’analyse univariée porte sur une variable. Elle peut être subdivisée en deux grandes parties : l’analyse descriptive et les tests d’inférence. I. ANALYSE DESCRIPTIVE Elle comprend les étapes suivantes :
- Représentations Graphiques - l’estimation des paramètres de tendance centrale - l’estimation des paramètres de dispersion - l’estimation des paramètres de forme
1. Représentations graphiques La représentation graphique des données relatives à une variable repose sur la proportionnalité des
longueurs (ou des aires) des graphiques par rapport aux effectifs ou aux fréquences, des différentes modalités de la variable. A chaque type de variable correspond des types de graphiques. Parmi les graphes les plus utilisés, nous pouvons citer :
- Diagramme en bâtons - Histogramme - Diagramme en secteurs - Courbes - Boite à moustache (ou Boxplot en Anglais)
2. Paramètres de position (ou de tendance centrale)
Ce sont principalement : la moyenne, le mode et la médiane. Ils permettent de savoir autour de quelles valeurs se situent les modalités d'une variable statistique.
3. paramètres de dispersion
Ils permettent d’apprécier comment les valeurs d’une variable sont concentrer autour de la tendance centrale. Il s’agit principalement de l’étendue, la variance, l’écart type et les quartiles.
4. Schéma d’un box plot
Valeurs aberrantes
1er Quartile Médiane 3e Quartile
Maximum
Valeurs aberrantes
Minimum

7
Le box plot permet d’analyser :
• La symétrie de la courbe, (la symétrie du corps et la symétrie par rapport aux moustaches), • L’existence de valeurs extrêmes (aberrantes). Ces valeurs méritent une attention toute
particulière car elles pourraient représenter une erreur de mesure, d’enregistrement des données ou d’entrée des données. Tout comme il pourrait s’agir d’une valeur légitime qui est tout simplement (et par hasard) extrême.
NB : la moyenne, l’écart type et la variance sont largement influencés par la présence de valeurs extrêmes.
5. Paramètres de formes Ils permettent d’apprécier la distribution en comparaison à une loi normale de même moyenne et de même écart-type. Ce principalement les coefficients d’asymétrie et d’aplatissement.
- Coefficients d’asymétrie Il existe plusieurs coefficients d'asymétrie. Les principaux sont les suivants. Le coefficient d'asymétrie de Pearson :
X
oMXP
σ−
=
Le coefficient d'asymétrie de Yule :
)(2
2
13
31
MQQY e
−−+
=
Lorsque le coefficient d'asymétrie est positif, la distribution est plus étalée à droite, lorsque le coefficient d'asymétrie est négatif, la distribution est plus étalée à gauche.
- Coefficient d'aplatissement.
Le coefficient le plus utilisé est celui de Fisher : 3)(
44
2 −=X
X
σµγ , avec )(4 Xµ : le moment d’ordre 4 de
X, ∑=
−=n
ii mx
nX
1
44 )(
1)(µ
Il est d’autant plus grand que les valeurs de la série statistique sont plus regroupées autour de la moyenne. • Si 02 =γ , la distribution a le même aspect qu’une loi normale de même moyenne et de même
écart-type • Si 02 >γ , la distribution est moins aplatie que la loi normale
• Si 02 <γ , la distribution est plus aplatie que la loi normale
II. UTILISATION DE TESTS STATISTIQUES
Nous conduisons une recherche de façon à déterminer l'acceptabilité d'hypothèses découlant de nos connaissances (théories). Après avoir sélectionné une hypothèse, qui nous paraît importante, nous récoltons des données empiriques qui devraient nous apporter des informations directes sur l'acceptabilité de cette hypothèse. Notre décision concernant la signification des données nous conduit soit à retenir, soit à réviser ou soit à rejeter l'hypothèse et la théorie qui en est la source.
Pour atteindre une décision objective concernant une hypothèse particulière, nous devons suivre une procédure objective (méthodes publiques et répétables par d'autres chercheurs) permettant soit

8
d'accepter soit de rejeter cette hypothèse. Cela consiste à formuler, en termes probabilistes, un jugement sur une hypothèse relative à une population, à partir des résultats observés sur un échantillon extrait au hasard de cette population.
Cette procédure suit les étapes suivantes : 1- établir l'hypothèse nulle (H0) [considérer l'hypothèse alternative H1]. 2- choisir le test statistique approprié pour tester H0, 3- spécifier un niveau de signification (α ) et la taille de l'échantillon (n), 4- trouver la distribution d'échantillonnage du test statistique sous H0, 5- sur la base de 2, 3, 4, définir la région de rejet, (Valeur critique) 6- calculer la valeur de la statistique du test à l'aide des données de l'échantillon.
1. L'hypothèse nulle
C'est la première étape de la procédure. L'hypothèse nulle H0 est généralement une hypothèse de non différence « il n'y a pas de différence significative entre les échantillons A et B ». Elle est formulée de façon à être rejetée. Dans le cas de son rejet, l'hypothèse alternative (H1) « il y a une différence significative entre les échantillons A et B » doit être acceptée. Cette dernière est la prédiction dérivée de la théorie à tester. Un test d'hypothèse constitue donc une sorte de démonstration par l'absurde en probabilité.
Supposons qu'une théorie scientifique nous conduise à prédire que deux groupes spécifiques d’individus diffèrent par le temps qu'ils passent dans une activité donnée. Cette prédiction sera notre hypothèse de recherche. Pour tester cette hypothèse de recherche, nous la formulons en hypothèse alternative H1. Cette dernière pose que la moyenne de temps passée dans cette activité par les membres des deux populations est différente ( 21 µµ ≠ ), alors que pour H0 la moyenne de temps passée dans cette activité
par les deux populations est la même ( 21 µµ = ). Si les données nous permettent de rejeter H0, alors H1 peut être acceptée, et cela supportera l'idée de la validité de l'hypothèse de recherche et de sa théorie sous-jacente.
La nature de l'hypothèse de recherche détermine comment H1 doit être formulée :
• Si elle pose que deux groupes différeront simplement par leur moyenne, alors H1 est telle que
21 µµ ≠ . Les tests statistiques seront bilatéraux. • Au contraire, si la théorie prédit la direction de la différence, c'est-à-dire qu'un des groupes spécifiés aura une moyenne supérieure à celle de l'autre groupe, alors H1 est telle que soit 21 µµ > soit
21 µµ < . Les tests applicables seront alors unilatéraux.
Les tables statistiques (et maintenant les logiciels statistiques) fournissent les valeurs statistiques critiques dans les deux cas. Pour tous les tests, on définit donc une hypothèse nulle. Le calcul de probabilité p correspond à la probabilité que l'hypothèse nulle soit vraie (ou à la probabilité de se tromper en rejetant l'hypothèse nulle). Si p>0,05 (5%) ou p>0,01 (1%), on ne peut pas rejeter l'hypothèse nulle. On dit qu'on a une différence non significative entre les deux échantillons.
2. Choix du test statistique
On dispose actuellement de nombreux tests statistiques différents qui peuvent être utilisés pour arriver à une décision concernant une hypothèse. Le choix doit se faire sur des bases rationnelles.
3. Niveau de signification et la taille de l'échantillon

9
L'ensemble des valeurs observées pour lesquelles l'hypothèse nulle est admissible forme la région d'acceptation ou de non-rejet et les autres valeurs constituent la région de rejet ou domaine de rejet ou région critique. Mais le hasard de l'échantillonnage peut fausser les conclusions. Quatre situations doivent être envisagées :
- l'acceptation de l'hypothèse nulle alors qu'elle est vraie, - le rejet de l'hypothèse nulle alors qu'elle est vraie, - l'acceptation de l'hypothèse nulle alors qu'elle est fausse, - le rejet de l'hypothèse nulle alors qu'elle est fausse.
Dans le premier et le dernier cas, la conclusion obtenue est correcte, mais pas dans les deux cas intermédiaires. L'erreur qui consiste à rejeter une hypothèse vraie est appelée erreur de première espèce (α ) et celle commise en acceptant une hypothèse fausse est l'erreur de seconde espèce ( β ). Idéalement, α et β devraient être déterminés par l'expérimentateur préalablement à la recherche, ce qui détermine la taille de l'échantillon (N). Une diminution du risque alpha, augmente le risque bêta pour tout échantillon donné. La probabilité de commettre l'erreur de seconde espèce décroît lorsque la taille de l'échantillon augmente.
Pratiquement, on se donne une limite supérieure du risque de première espèce, le plus souvent 5% (significatif), 1% (très significatif) ou l°/oo (hautement significatif). Cette limite constitue aussi le niveau de signification du test et permet de définir la condition de rejet de l'hypothèse nulle. Le plus souvent, les logiciels de statistique donnent le niveau de signification réel. On rejette alors l'hypothèse nulle au niveau de signification nominal choisi (par exemple 0,05) si (et seulement si) le niveau de signification réel est inférieur ou égal au niveau de signification nominal (p = 0,003 < 0,05, rejet de H0). Cette attitude est dite conservatrice.
Le risque de première espèce étant donné, on peut s'efforcer de calculer le risque de deuxième espèce, grâce à la notion de puissance de test (P = 1-β ). Mais ce problème possède rarement une solution simple et l'on perd souvent de vue l'existence même de ce risque. Cependant, la puissance d'un test dépend de la nature du test choisi, du niveau de signification du test, de la taille de l'échantillon, de la vraie valeur du paramètre ou mesure testée. En particulier, elle est liée à la nature de l'hypothèse alternative H1. Un test unilatéral est plus puissant qu'un test bilatéral. Aussi, souvent on se contente de préciser l'importance du risque de première espèce, sans se soucier de l'existence d'une seconde possibilité d'erreur.
4. Distribution d'échantillonnage
C'est une distribution théorique. Par exemple, celle que l'on obtiendrait si nous prenions tous les échantillons possibles de même taille tirés chacun au hasard de la même population. Autrement dit, c'est la distribution sous H0, de toutes les valeurs possibles qu'une statistique (ou variable statistique, la moyenne par exemple) peut avoir lorsque cette statistique est calculée à partir d'échantillons de même taille tirés au hasard.
5. Région de rejet
Cette région est constituée par le sous-ensemble des valeurs de la distribution d'échantillonnage qui sont si extrêmes que lorsque H0 est vrai, la probabilité que l'échantillon observé ait une valeur parmi celles-ci est très faible (la probabilité est α ).
La position de cette région de rejet est affectée par la nature de H1 : Dans un test unilatéral, la région de rejet est entièrement située à une des extrémités de la distribution d'échantillonnage, alors que dans un test bilatéral, cette région est située aux deux extrémités de la distribution.

10
La taille de cette région de rejet est définie parα . Si α = 5%, la taille de la région de rejet correspond à 5% de l'espace inclus dans la courbe de la distribution d'échantillonnage. Cela signifie que dans une distribution suivant une loi normale, il n'y a que 5 chances sur 100 pour que l'écart entre la variable et sa valeur moyenne dépasse 2 fois l'écart-type.
6. La décision
Si le test statistique donne une valeur comprise dans la région de rejet, nous rejetons H0 [on adopte alors H1]. Quand la probabilité associée à une valeur du test statistique est inférieure ou égale à la valeur alpha préalablement déterminée, nous concluons que H0 est faux. En effet, en rejetant l'hypothèse nulle au niveau 5%, par exemple, nous avons 5 chances sur 100 seulement d'aboutir à une telle conclusion par le simple fait du hasard. Cette valeur est dite significative.
III. CHOISIR LE TEST STATISTIQUE APPROPRIE
Le plus souvent nous disposons de différents tests pour une recherche (validation d'hypothèse) donnée, il est alors nécessaire d'employer une méthode rationnelle pour choisir le test le plus approprié.
Nous avons vu que l'un des critères de choix est la puissance du test utilisé. Mais d'autres critères sont importants pour déterminer l'adéquation d'un test lors de l'analyse de données particulières. Ces critères concernent :
• la façon dont l'échantillon a été réalisé ; • la nature de la population de laquelle a été tiré l'échantillon ; • la nature des mesures réalisées.
1. Le modèle statistique
Lorsque nous définissons la nature de la population et le mode d'échantillonnage, nous établissons un modèle statistique (c'est à dire une formulation mathématique des hypothèses faites sur les observations). A chaque test statistique est associé un modèle et des contraintes de mesure. Ce test n'est alors valide que si les conditions imposées par le modèle et les contraintes de mesure sont respectées. Il est difficile de dire si les conditions d'un modèle sont remplies, et le plus souvent nous nous contentons d'admettre qu'elles le sont. Aussi devrions nous préciser, chaque fois : "Si le modèle utilisé et le mode de mesure sont corrects, alors....).
Il est clair que moins les exigences imposées par le modèle sont nombreuses et restrictives, plus les conclusions que l'on tire sont générales. De ce fait, les tests les plus puissants sont ceux qui ont les hypothèses les plus strictes. Si ces hypothèses sont valides, ces tests sont alors les mieux à même de rejeter H0 quand elle est fausse et de ne pas rejeter H0 quand elle est vraie.
2. Nature des observations et échelle de mesure Il est très important de considérer la nature des données (observations) que l'on va tester. D'elle dépend la nature des opérations possibles et donc des statistiques utilisables dans chaque situation. Les observations peuvent être soit quantitatives soit qualitatives. Les données quantitatives comprennent les dénombrements (ou comptages) et les mesures (ou mensurations). Dans le cas des dénombrements, la caractéristique étudiée est une variable discrète ou discontinue, ne pouvant prendre que des valeurs entières non négatives (nombre d’employés par entreprise, nombre de clients par catégorie, nombre d’articles vendus par magasins..). Il suffit de compter le nombre d'individus affectés par chacune des valeurs (fréquences) de la variable.

11
Dans le cas des mesures, la variable est de nature continue (hauteur, poids, surface, prix, température..). Les valeurs possibles sont illimitées mais du fait des méthodes de mesures et du degré de précision de l'appareil de mesure, les données varient toujours de façon discontinue. Les mensurations peuvent être réalisées dans deux échelles de mesure : l'échelle de rapport et l'échelle d'intervalle. Elles sont manipulables suivant les opérations de l'arithmétique. Les données qualitatives peuvent être réalisées dans deux échelles de mesure : échelle de rangement et l'échelle nominale. Ces données ne sont pas manipulables par l'arithmétique. Dans l'échelle ordinale (de rangement), il existe une certaine relation entre les objets du type plus grand que, supérieur à, plus difficile que, préférée à.... Exemple : Les nombres de candidats à un examen obtenant les degrés A, B, C. Le degré A est meilleur que le degré B, lui-même meilleur que le degré C. Une transformation ne changeant pas l'ordre des objets est admissible. La statistique la plus appropriée pour décrire la tendance centrale des données est la médiane. Dans l'échelle nominale, les nombres ou symboles identifient les groupes auxquels divers objets appartiennent. C'est le cas des numéros d'immatriculation des voitures ou de matricule d’étudiants (chaînes de caractères). Le même nombre peut être donné aux différentes personnes habitant le même département ou de même sexe constituant des sous-classes. Les symboles désignant les différentes sous-classes dans l'échelle nominale peuvent être modifiés sans altérer l'information essentielle de l'échelle. Les seules statistiques descriptives utilisables dans ce cas sont le mode, la fréquence... et les tests applicables seront centrés sur les fréquences des diverses catégories.
3. Tests paramétriques et non paramétriques : avantages et inconvénients
Un test paramétrique requiert un modèle à fortes contraintes (normalité des distributions, égalité des variances) pour lequel les mesures doivent avoir été réalisées dans une échelle au moins d'intervalle. Ces hypothèses sont d'autant plus difficiles à vérifier que les effectifs étudiés sont plus réduits. Un test non paramétrique est un test dont le modèle ne précise pas les conditions que doivent remplir les paramètres de la population dont a été extrait l'échantillon. Cependant certaines conditions d'application doivent être vérifiées. Les échantillons considérées doivent être aléatoires et simples [tous les individus qui doivent former l'échantillon sont prélevés indépendamment les uns des autres]. Les variables aléatoires prises en considération sont généralement supposées continues.
3.1. Avantages des tests non paramétriques
1. Leur emploi se justifie lorsque les conditions d'applications des autres méthodes ne sont pas satisfaites, même après d'éventuelles transformations de variables.
2. Les probabilités des résultats de la plupart des tests non paramétriques sont des probabilités exactes quelle que soit la forme de la distribution de la population dont est tiré l'échantillon.
3. Pour des échantillons de taille très faible jusqu'à N = 6, la seule possibilité est l'utilisation d'un test non paramétrique, sauf si la nature exacte de la distribution de la population est précisément connue. Ceci permet une diminution du coût ou du temps nécessaire à la collecte des informations.
4. Il existe des tests non paramétriques permettant de traiter des échantillons composés à partir d'observations provenant de populations différentes. De telles données ne peuvent être traitées par les tests paramétriques sans faire des hypothèses irréalistes.
5. Seuls des tests non paramétriques existent qui permettent le traitement de données qualitatives : soit exprimées en rangs ou en plus ou moins (échelle ordinale), soit nominales.
6. Les tests non paramétriques sont plus faciles à apprendre et à appliquer que les tests paramétriques. Leur relative simplicité résulte souvent du remplacement des valeurs observées

12
soit par des variables alternatives, indiquant l'appartenance à l'une ou à l'autre classe d'observation, soit par les rangs, c'est-à-dire les numéros d'ordre des valeurs observées rangées par ordre croissant. C'est ainsi que la médiane est généralement préférée à la moyenne, comme paramètre de position.
3.2. Désavantages des tests non paramétriques
1. Les tests paramétriques, quand leurs conditions sont remplies, sont les plus puissants que les tests non paramétriques.
2. Un second inconvénient réside dans la difficulté à trouver la description des tests et de leurs tables de valeurs significatives, surtout en langue française. Heureusement, les niveaux de significativité sont donnés directement par les logiciels statistiques courants.
On choisira les tests appropriés en fonction du type de mesure, de la forme de la distribution de fréquences et du nombre d'échantillons dont on dispose.
IV. Quelques applications pratiques des méthodes de statistique non paramétrique
1. Cas d'un échantillon isolé
Des tests permettent de vérifier si un échantillon observé peut être considéré comme extrait d'une population donnée (Test d'ajustement). Ces tests peuvent permettre de répondre aux questions suivantes:
- Y a t-il une différence significative de localisation (tendance centrale) entre l'échantillon et la population ?
- Y a t-il une différence significative entre les fréquences observées et les fréquences attendues sur la base d'un principe ?
- Y a t-il une différence significative entre des proportions observées et des proportions espérées? - Est-il raisonnable de penser que cet échantillon a été tiré d'une population d'une forme
particulière? - Est-il raisonnable de penser que cet échantillon est un échantillon d'une certaine population
connue?
2. Cas de deux échantillons
Ce type de test est utile lorsque l'on veut établir si deux traitements sont différents ou si un traitement est "meilleur" qu'un autre. Dans tous les cas, le groupe qui a subi le traitement est comparé à celui qui n'en a pas subi, ou qui a subi un traitement différent. Ce cas se présente, par exemple, quand on compare deux méthodes de mesure en soumettant à ces deux méthodes les mêmes individus, choisis dans une population donnée : à chacune des méthodes correspond alors une population de mesures, mais ces populations et les échantillons que l'on peut en extraire, ne sont pas indépendants.
Il est aussi possible de soumettre les mêmes sujets à deux traitements différents. Chaque sujet est alors utilisé comme son propre contrôle et il suffit alors de contrebalancer l'effet d'ordre des traitements. Une dernière façon de faire consiste à apparier des sujets et d'assigner aléatoirement les membres de chaque paire aux deux conditions. Cet appariement est toujours délicat. Il faut sélectionner pour chaque paire les sujets les plus semblables possibles par rapport aux variables étrangères qui pourraient affecter le résultat de la recherche entreprise. En effet, dans de telles comparaisons de deux groupes appariés, des différences significatives peuvent être observées qui ne sont pas le résultat du traitement.
Bien que l'utilisation de deux échantillons non indépendants soit préférable, cette méthode est fréquemment impraticable. En effet, la nature de la variable étudiée exclue l'utilisation des sujets comme leur propre contrôle.

13
V. TEST D’INFERENCE POUR UNE VARIABLE
1. Test d’Ajustement du Khi-2 Ce test est applicable aux variables qualitatives nominales, il consiste à analyser un échantillon d’observation d’une variable a fin de tester l’ajustement à la distribution d’une population standard. On peut chercher par exemple à tester si la fréquence ou la proportion observée dans les classes d’âge des personnes interrogées lors d’une enquête sont significativement différents de celles observées pour les mêmes classes d’âges dans la population de référence. a) Hypothèses à tester On teste l’hypothèse Ho : il n’y a pas de différence significative entre les fréquences (ou proportions) observées et les fréquences (ou proportion) théoriques. Contre l’hypothèse H1 : il y’a des différences significatives entre les fréquences observées et les fréquences théoriques b) Statistique du test
La statistique du test mesure les écarts entre la distribution observée et la distribution théorique. Elle est donnée par :
( )∑
=
−=
k
i i
ii
T
TO
1
22χ
Où Ti est la fréquence théorique de la catégorie i, Oi, la fréquence observée de la catégorie i et k, le nombre total de catégories c) Valeur critique
Sous l’hypothèse Ho, la statistique 2χ suit une loi de Khi-2 à (k-1) degrés de liberté. Ainsi, Pour
un coefficient de risque α fixé, la valeur critique : 1)-k(2αχ est lue dans la table du Khi-2 à (k-1)
degrés de liberté. d) Règle de Décision On compare 2χ à la valeur critique :
• Si 1)-k(22αχχ > , on rejette Ho
• Si non on accepte Ho e) Exemple :
On voudrait savoir si les clients de ce magasin apprécient plus les produits Alimentaires ou non.
Or les clients de ce magasin peuvent acheter, soit uniquement les produits Alimentaires, soit les produits non alimentaires ou alors les deux. On veut tester si la fréquence d’achat est répartie de façon égale dans ces trois niveaux de fréquence. Une enquête faite sur un échantillon de 60 clients de ce magasin à permis d’avoir les résultats suivants :

14
Produits achetés Fréquences observées Alimentaire 26 Non Alimentaire 18 Les deux 16
Résolution : Ici, k = 3, n = 60
8,220
)2016(
20
)2018(
20
)2026( 2222 =−+−+−=χ
5,9 2)(1)-k( 5%,Pour 22 === αα χχα
9,21 2)(1)-k( 1%,Pour 22 === αα χχα
On a 1)-k(22αχχ < donc on accepte Ho. En d’autres termes, les clients de ce supermarché achètent
à égale fréquence les produits alimentaires, les produits non alimentaires ou alors les deux. On ne peut donc conclure qu’ils apprécient plus les produits Alimentaires. 2. Test de Kolmogorov-Smirnov
C’est un test d’ajustement tout comme le test du Khi-2, qui s’applique aux variables qualitatives ordinales.
a) Hypothèses à tester
Les hypothèses à tester sont les suivantes : Ho : les valeurs observées dans l’échantillon ne sont pas significativement différentes des valeurs théoriques. H1 : ces valeurs sont significativement différentes. b) Statistique du test
Le principe du test consiste à calculer la distribution cumulée des proportions théoriques et à la comparer avec celles observées de l’échantillon. On considère comme statistique du test : D, l’écart maximum en valeur absolue entre les proportions cumulées observées et les proportions cumulées théoriques
[ ]PcTPcOD −= max .
c) Valeur critique
La valeur critique : αD , au seuil α, pour un échantillon de taille n (n > 35) est donnée par :
α 1% 5%
n
63.1 n
36.1 αD
Produits achetés Fréquences observées Fréquences théoriques Alimentaire 26 20 Non Alimentaire 18 20 Les deux 16 20

15
d) Règle de décision : Si >D , on rejette Ho, si non, on accepte Ho
NB. Le Test de Kolmogorov-Smirnov s’applique aussi pour déterminer si les fréquences observées pour deux échantillons indépendants sont significativement différentes.
a) Exemple : On veut tester si la répartition des fréquences d’achat d’un produit est significativement différente
d’une répartition théorique où les produits seraient achetés à proportion égale à chaque niveau de fréquence. Une enquête sur un échantillon de 46 consommateurs de ce produit a donné les résultats suivants :
Niveau Une fois Très peu souvent De temps en temps Régulièrement Fréquence 21 16 8 1
Résolution :
Niveau Fréquence Observée
Proportion Observée
Proportion Observée cumulée
Proportion Théorique
Proportion Théorique cumulée
Diff.
1 21 0.46 0.46 0.25 0.25 0.21 2 16 0.35 0.81 0.25 0.50 0.31 3 8 0.17 0.98 0.25 0.75 0.23 4 1 0.02 1 0.25 1 0
D = 0.31 pour α = 1% , 24.046
63.1 ==αD
>D , donc on rejette Ho, en d’autre termes la répartition des achats est significativement plus
importante chez les personnes dont les fréquences d’achats sont faibles. 3. Tests utilisant la loi normale ou de Student
Les tests de loi normale (Z) ou de Student permettent d’évaluer si la tendance centrale des données d’un échantillon de taille n est significativement différente d’une norme standard. Ces tests s’appliquent pour les variables quantitatives. Le test de loi normale est approprié dans le cas où n>30 dans le cas contraire, on utilise le test de Student. a) Cas de la moyenne Soit à tester l’hypothèse Ho : mX = contre H1 : mX ≠
On prend comme statistique du test : nS
mXZ
−= pour n>30 ou 1−
−=nS
mXT pour n<30
Où S est l’écart type observé à partir de l’échantillon. ( ∑=
−=n
ii Xx
nS
1
22 )(1
)
La règle de décision est la suivante : Pour n>30, Si 2/αZZ > on rejette Ho, si non, on accepte Ho
Pour n<30, si )1(2/ −> ntT α on rejette Ho, si non, on accepte Ho
αD
αD

16
Où 2/αZ et )1(2/ −ntα sont respectivement les fractiles de la loi normale et de la loi de Student.
α 1% 5% 10%
2αZ 2.576 1.960 1.645
b) Exemple
Sur un échantillon de 90 emballages, tiré de la production d’une entreprise, on a observé que le
poids moyen est de 22,84 kg, avec un écart type de 3,22 kg on voudrait savoir si la production de cette entreprise est conforme à la norme qui fixe le poids de l’emballage en question à 22 kg. Résolution Ici, n = 90 > 30,
47.29022.3
2284.22 =−=Z
Au seuil %5=α , 96,12
=αZ
On a 2αZZ > , on rejette Ho
Donc le poids moyen des emballages fabriqués par cette entreprise est significativement différent de la norme. 4. Analyse de variance à un facteur pour échantillons indépendants.
Hypothèses à tester :
L'hypothèse nulle () est l'égalité des moyennes des populations dont sont extraits les échantillons : H0 : m1 = m2 = m3 =... = mk L’hypothèse alternative (H1) est l’inégalité d’au moins deux de ces moyennes H1 : il )(, jiji ≠∃ tel que ji mm ≠
Statistique du test :
Considérons que le nombre d'échantillons est noté k, le nombre de mesures par échantillon est désigné par n et le nombre total de mesures, kn. Le tableau des données étant le suivant :
échantillon 1 échantillon j échantillon k
11x jx1 kx1
21x jx2 kx2
... ... ...
La détermination de la statistique du test passe par la construction du tableau d’analyse de la variance qui se présente ainsi qu’il suit :
Source de variation ddl SCE CM (Variance) F
Effet facteur k-1 FS 1−
=k
SV F
F R
F
V
VF =
Effet Résiduel kn-k RS kkn
SV R
R −=
Total kn-1 TS

17
Avec :
( )∑=
−=k
jjjF xxnS
1
2 ( )∑∑= =
−=n
i
k
jjijR xxS
1 1
2 ( )∑∑= =
−=n
i
k
jijT xxS
1 1
2
∑∑= =
=n
i
k
jijx
knx
1 1
1 ∑
=
=n
iijj x
nx
1
1
NB : ST = SF + SR VF , est la variance inter-groupe et VR, la variance intra-groupe
Manuellement, les calculs intermédiaires à réaliser pour construire le tableau de l’analyse de la variance sont les suivants :
échantillon 1 échantillon j échantillon k
11x jx1 kx1
21x jx2 kx2
... ... ...
1ix ijx ikx
... ... ...
1nx njx nkx Total
∑=
n
iijx
1
T1 Tj Tk ∑∑=
=n
iijxG
1
n
T 2
n
T 21
n
Tj2
n
Tk2
n
T∑ 2
∑=
n
iij
x1
2 ∑=
n
ii
x1
2
1 ∑
=
n
iij
x1
2 ∑=
n
iik
x1
2 ∑ ∑
=
n
ij
x1
2
1
kn
G
n
TSF
22
−= ∑ kn
GxS ijT
22 −
=∑ ∑
Seuil critique : Pour un seuil α fixé, la valeur critique est donnée par la table de Fisher Snedecor à [(k-1), (kn-k)] ddl. Flu = k)]-(kn 1),-[(kαF
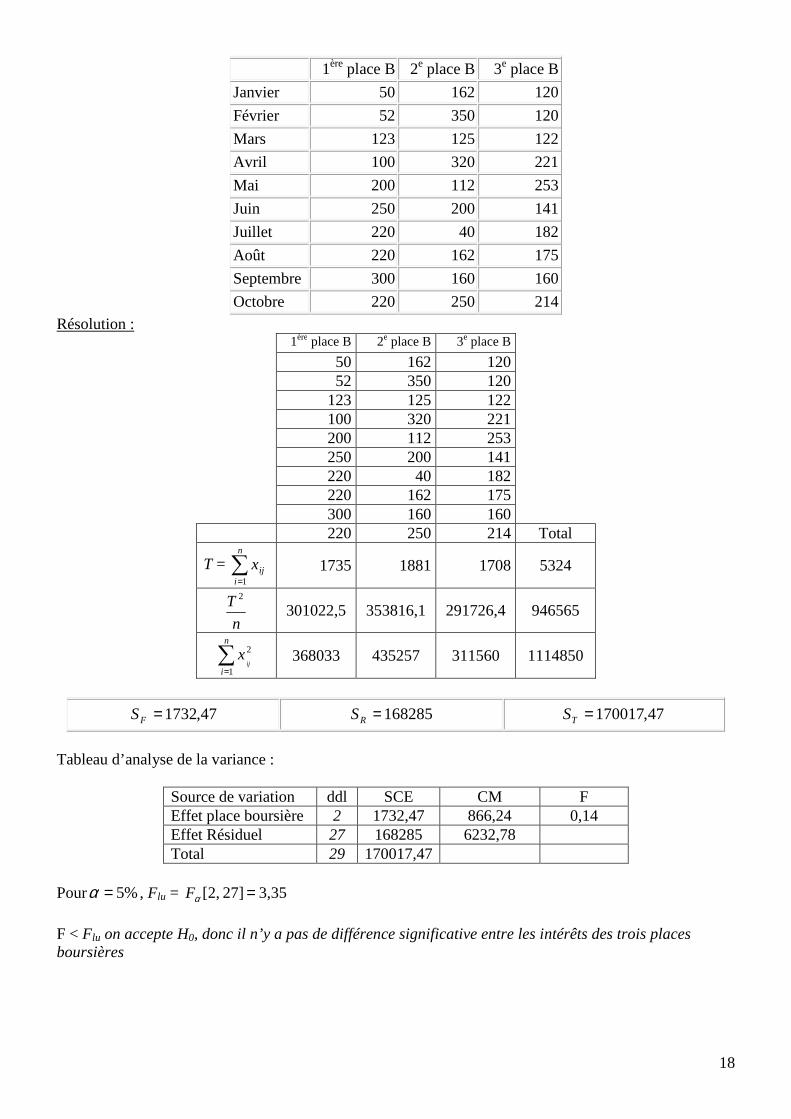
Règle de décision : Si F > Flu, on rejette H0 .Si non on l’accepte Exemple : On veut savoir si les intérêts boursiers varient d'une place boursière à l'autre. Pour cela, on prélève les intérêts mensuels moyens enregistrés lors des 10 premiers mois de l’année (n = 10) dans 3 places boursières différentes (k = 3). Les données se présentent comme suit :
n
TxS ijR
∑∑ ∑ −
=
22
18
1ère place B 2e place B 3e place B
Janvier 50 162 120
Février 52 350 120
Mars 123 125 122
Avril 100 320 221
Mai 200 112 253
Juin 250 200 141
Juillet 220 40 182
Août 220 162 175
Septembre 300 160 160
Octobre 220 250 214
Résolution : 1ère place B 2e place B 3e place B 50 162 120 52 350 120 123 125 122 100 320 221 200 112 253 250 200 141 220 40 182 220 162 175 300 160 160 220 250 214 Total
T = ∑=
n
iijx
1
1735 1881 1708 5324
n
T 2
301022,5 353816,1 291726,4 946565
∑=
n
iij
x1
2 368033 435257 311560 1114850
47,1732=FS 168285=RS 47,170017=TS
Tableau d’analyse de la variance :
Source de variation ddl SCE CM F Effet place boursière 2 1732,47 866,24 0,14 Effet Résiduel 27 168285 6232,78 Total 29 170017,47
Pour %5=α , Flu = 3,35 27] [2, =αF
F < Flu on accepte H0, donc il n’y a pas de différence significative entre les intérêts des trois places boursières

19
CHAPITRE III :
ANALYSE BIVARIEE
Lorsque qu’une étude statistique porte sur deux variables, on parle d’analyse bivariée. Il est généralement question ici de décrire l’évolution commune des deux variables, de rechercher d’éventuels liens entres elles ou alors d’expliquer une variable par l’autre. Selon l’objectif de l’étude et de la nature des variables, les techniques utilisées dans ce cas sont les suivantes :
Variable à Expliquer (Y) Qualitative Quantitative
Var
iabl
e ex
plic
ativ
e (X
) Qualitative
Correspondance Tableaux d’effectifs (tableau croisé) Test d’association (Chi-2) Description – modélisation - prévision
Comparaison Tableau des moyennes Analyse de la variance Test de Fisher Modélisation - Prévision
Quantitative
Comparaison Tableau de moyennes Analyse de la variance (ANOVA) Test de Fisher Modélisation - Prévision
Corrélation Nuage de points Test de corrélation Modélisation - Prévision
I. THEORIE DE LA CORRELATION
Lorsque deux phénomènes ont une évolution commune, nous disons qu’ils sont corrélés. La corrélation simple mesure le degré de liaison existant entre ces deux phénomènes. Cette corrélation peut être linéaire ou non, négative ou positive.
1. Coefficient de corrélation linéaire simple
Soient X et Y deux variables aléatoires quantitatives, le coefficient de corrélation linéaire entre X et Y est donné par la relation :
On démontre que ce coefficient est compris entre -l et +1.
• S’il est proche de +1, les variables X et Y sont corrélés positivement • S’il est proche de -1 les variables X et Y sont corrélés négativement • S’il est proche de 0, les variables X et Y ne sont pas corrélés Dans la pratique, ce coefficient est rarement proche de ces trois valeurs, on est alors amené à procéder
à un test pour vérifier la corrélation entre deux variables.
( )( )
( ) ( )2
11
2
2
11
2
111
1 1
22
1),cov(
−
−
−=
−−
−−==
∑∑∑∑
∑∑∑
∑ ∑
∑
====
===
= =
=
n
ii
n
ii
n
ii
n
ii
n
ii
n
ii
n
iii
n
i
n
iii
n
iii
YXXY
YYnXXn
YXYXn
YYXX
YYXXYX
rσσ

20
)2(2
0 −= ntt α
2. Test de corrélation
• Les hypothèses à tester sont les suivantes
Ho : 0=XYr
H1 : 0≠XYr
• La statistique du test est donnée par :
• On démontre que, sous l’hypothèse Ho, t suit une loi de Student, à n-2 degrés de liberté. Pour un seuil α fixé, la valeur critique du test est donnée par :
• Si 0tt > , on rejette Ho. Si non on l’accepte
II. MODELE DE REGRESSION SIMPLE
Ayant détecté une corrélation entre deux variables quantitatives X et Y, on peut matérialiser le lien sous forme d’une équation mathématique : c’est la modélisation. Un des modèles qui s’adaptent sur la plupart des données économiques est le modèle de régression simple. Il est question ici de rechercher un lien entre X et Y sous la forme : Y = aX + b + ε (1) où a et b sont les coefficients inconnus du modèle, et ε, une perturbation aléatoire, appelée aléa ou résidu. On peut considérer que le terme aléatoire: ~, rassemble toutes les influences autres que celle de la variable explicative : X d’incidence secondaire sur la variable à expliquer: Y, et non explicitement prises en compte dans le modèle.
1. Estimation des coefficients du modèle
Ayant supposé X et Y liés par le modèle précédent, c’est à dire chaque couple d’observations dans une relation : yi = = a.xi + b + εi où les valeurs de a, b et εi sont à déterminer.
À partir des n couples de données observées: (x1,y), il faut estimer ces différentes quantités, et juger de la pertinence du modèle.
On montre, par la méthode des moindres canés ordinaires, que les coefficients a et b peuvent être estimés respectivement par :
•
∑
∑
=
=
−
−==
n
ii
n
iii
xnx
yxnyx
x
yxa
1
22
1
)var(
),cov(ˆ
• xayb .ˆˆ −= On suppose que les aléas: iε , suivent la même loi normale: ( )2,0 σN et sont indépendants.
Remarque: L’estimateur des MCO est unique, sans biais et de moindre variance parmi les estimateurs linéaires.
Après avoir estimé les coefficients a et b, il reste à vérifier s’ils peuvent être considérés comme nuls ou pas. Pour cela on possède au test de Student.
2
1 2
−−
=
n
r
rt
XY
XY

21
2. Test de Student pour la significativité des coefficients a et b
a) hypothèses Ayant obtenu le modèle (1) de la régression linéaire précédente, on désire tester les hypothèses HO : a = 0 (resp. b = 0) contre H1 : a ≠ 0 (resp. b ≠ 0)
b) Statistique du test
Soient:
∑=−
=n
iin 1
22
2
1ˆ εσ , une estimation de la variance du résidu ( )ε
( )∑=
−=
n
ii
a
xx1
2
22 ˆ
ˆσσ , l’estimateur empirique de la variance du coefficient a
( )
−+=∑
=
n
ii
b
xx
x
n
1
2
222 1
ˆˆ σσ , l’estimateur empirique de la variance du coefficient b
La statistique du test est :
==
b
b
a
ab
trespa
tσσ ˆ
ˆ.
ˆ
ˆ **
c) Valeur critique
On démontre que, sous H0 ,ba
bbet
aa
σσ ˆ
ˆ
ˆ
ˆ −− suivent une loi de Student à n- 2 degrés de liberté
La valeur critique du test est donnée par : ( )22
0 −= ntt α
d) Règle de décision Pour un seuil α fixé, - Si | at * | > ( )2
2−ntα , on rejette l’hypothèse Ho, et donc a est significativement différent de zéro.
- Si ( ) ( )222
*
2−≤≤−− nttnt a αα , on accepte Ho
Il en est de même pour b L’intervalle de confiance de a, au seuil α, est donné par ( )2.ˆˆ
2−±= ntaa a ασ
e) Exemple
Revenu (X) 8 9 9.5 9.5 9.8 11 12 13 15 16 Consommation (Y) 7.5 8.2 8.0 8.6 8.8 10.5 10.6 11.5 12 14.8
Test de corrélation
8.112=∑X 54.13362 =∑X 5.100=∑Y 79.10562 =∑Y 74.1186=∑XY
rxy = 0.969 t = 11.17

22
( )22
−ntα = 2.3 (α = 5% et n = 10)
t > ( )22
−ntα , donc X et Y sont corrélées.
Estimation des coefficients de corrélation
a = 0,828 b = 0,714 Test de Student
∑=
n
ii
1
2ε = 2,82
2σ̂ = 0,35196501
a2σ̂ = 0,00548608
b2σ̂ = 0,43221304
( )at * = 11,1744494
( )bt * = 1,085886884
t*(a) > ( )2
2−ntα , donc a est significativement différent de zéro
t*(b)< ) ( )2
2−ntα , donc b est n’est pas significativement différent de zéro
Le modèle de régression de la consommation en fonction du revenu est donc: ε+= XY 828.0
III. MESURE D’ASSOCIATION POUR DEUX VARIABLES QUALI TATIVES
1. Test d’association du Khi-2
Etant donné deux variables qualitatives nominales X et Y, observées sur un échantillon de taille n,
l’on désire savoir si ces deux variables sont indépendantes ou s’il existe une liaison entre elles. Le test de khi-2 permet de mettre en évidence une éventuelle liaison entre les deux variables.
a) Tableau de contingence
Supposons que la variable X ait k catégories : X1, X2, . .,Xk et que Y ait , m catégories : Y1, …, Ym. La première étape du test consiste à construire le tableau de contingence (ou tableau croisé) de la manière suivante :
X Y 1X 2X … jX … kX Total
1Y 11O 12O … jO1 … kO1 n1
2Y 21O 22O … jO2 … kO2 n2
… … … … … … … …
iY 1iO 2iO … ijO … ikO ni
… … … … … … … …
mY 1mO … … mjO … mkO nm
Total 1t 2t … jt … kt n

23
Où ijO est l’effectif observé de la catégorie (iY , jX ),
jt , l’effectif total observé de la catégoriejX ,
ni, l’effectif total observé de la catégorieiY
b) Construction du test
• Les hypothèses à tester sont les suivantes : Ho : les deux variables X et Y sont indépendantes H1 : les variables X et Y ne sont pas indépendantes
• La statistique du test est donnée par :
( )∑ ∑
= =
−=
m
i
k
j ij
ijij
T
TO
1 1
2
2χ
Où, n
tnT ji
ij = , est l’effectif théorique de la catégorie ( )ij YX ,
On démontre que, sous l’hypothèse Ho, la statistique du test suit une loi de Khi-2 à v degrés de liberté. (Avec v = (k-1)(m-1)).
• Pour un coefficient de risque α fixé, la valeur critique du test est donnée par :
( )( )νχχ α22
0 = , valeur lue dans la table du Khi2 à v degrés de liberté
• Si 20
2 χχ ≥ , on rejette Ho , Si non on l’accepte.
c) Exemple
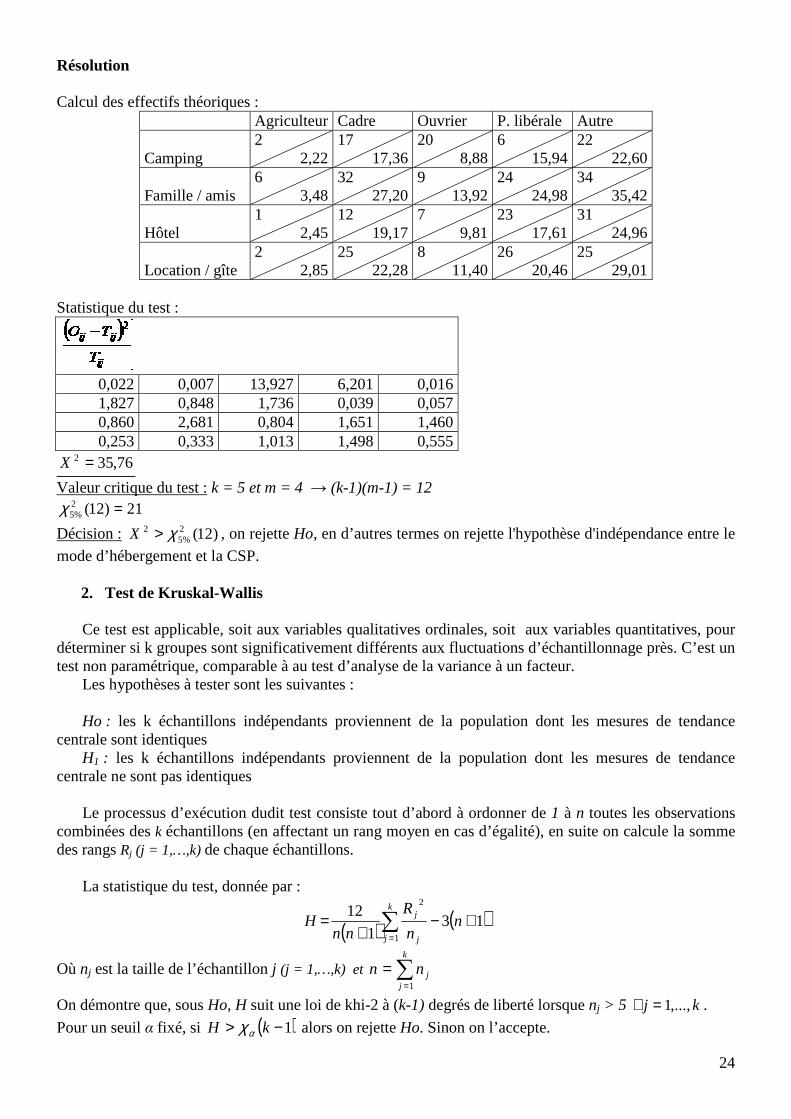
Une enquête a été réalisée auprès de 332 touristes auxquels on a demandé leurs modes d’hébergement durant le séjours dans un pays. Les données obtenues pour chaque catégorie socio professionnelle (CSP) des personnes interrogées se présentent ainsi qu’il suit :
CSP Hébergement
Agriculteur Cadre Ouvrier Profession libérale Autre
Camping 2 17 20 6 22 Famille / amis 6 32 9 24 34 Hôtel 1 12 7 23 31 Location / gîte 2 25 8 26 25
Peut-on rejeter l'hypothèse d'indépendance entre le mode d’hébergement et la CSP ?
24
Résolution Calcul des effectifs théoriques :
Agriculteur Cadre Ouvrier P. libérale Autre
Camping 2
2,22 17
17,36 20
8,88 6
15,94 22
22,60
Famille / amis 6
3,48 32
27,20 9
13,92 24
24,98 34
35,42
Hôtel 1
2,45 12
19,17 7
9,81 23
17,61 31
24,96
Location / gîte 2
2,85 25
22,28 8
11,40 26
20,46 25
29,01 Statistique du test :
0,022 0,007 13,927 6,201 0,016 1,827 0,848 1,736 0,039 0,057 0,860 2,681 0,804 1,651 1,460 0,253 0,333 1,013 1,498 0,555
76,352 =X
Valeur critique du test : k = 5 et m = 4 → (k-1)(m-1) = 12 21)12(2
%5 =χ
Décision : )12(2%5
2 χ>X , on rejette Ho, en d’autres termes on rejette l'hypothèse d'indépendance entre le
mode d’hébergement et la CSP.
2. Test de Kruskal-Wallis Ce test est applicable, soit aux variables qualitatives ordinales, soit aux variables quantitatives, pour
déterminer si k groupes sont significativement différents aux fluctuations d’échantillonnage près. C’est un test non paramétrique, comparable à au test d’analyse de la variance à un facteur.
Les hypothèses à tester sont les suivantes : Ho : les k échantillons indépendants proviennent de la population dont les mesures de tendance
centrale sont identiques H1 : les k échantillons indépendants proviennent de la population dont les mesures de tendance
centrale ne sont pas identiques Le processus d’exécution dudit test consiste tout d’abord à ordonner de 1 à n toutes les observations
combinées des k échantillons (en affectant un rang moyen en cas d’égalité), en suite on calcule la somme des rangs Rj (j = 1,…,k) de chaque échantillons.
La statistique du test, donnée par :
( ) ( )131
12
1
2
+−+
= ∑=
nn
R
nnH
k
j j
j
Où nj est la taille de l’échantillon j (j = 1,…,k) et ∑=
=k
jjnn
1
On démontre que, sous Ho, H suit une loi de khi-2 à (k-1) degrés de liberté lorsque nj > 5 kj ,...,1=∀ .
Pour un seuil α fixé, si ( )1−> kH αχ alors on rejette Ho. Sinon on l’accepte.
25
Exemple: Pour évaluer l’efficacité relative des différentes méthodes de promotion d’un produit de nettoyage (Echantillons gratuit, Rabais de 30%, Annonce à la radio et Emission à la radio) appliquée à 4 groupes de potentiels consommateurs, ces derniers devraient indiquer, dans chacune des situations de promotion, par une note allant de 1 à 7 jusqu’à quel point ils croyaient à l’efficacité de ce produit. Les résultats se présentent ainsi qu’il suit :
Echantillon gratuit Rabais de 30% Annonce à la radio Emission à la radio 1 1 5 5 3 2 6 7 4 2 4 6 2 3 3 5 5 1 5 7 1 2 7 6 1 1 6 7
Résolution: Nous avons 4 échantillons et 28 observations au total. Après avoir combiné et ordonné les
observations on obtient :
( )( ) ( ) ( ) ( ) ( ) [ ] 67.188736.7150
812
121283
7
5.160
7
134
7
48
7
5.63
12828
12 2222
=−=+−
+++
+=H
Or ( ) ( ) ( ) 34.113141 %1%1%1 ==−=− χχχ k
( )3%1χ>H d’où rejet de Ho, en d’autres termes, les observations des 4 échantillons sont
significativement différentes et donc le degré de croyance dans l’efficacité de ce produit de nettoyage n’est pas le même pour les quatre méthodes de promotion.
3. Test de Wilcoxon pour séries appariées Ce test est utilisé lorsqu’on veut comparer deux séries d’une variable ordinale ou quantitatives,
chaque observation d’un échantillon étant liée à une observation homologue de l’autre échantillon. C’et un test non paramétrique.
Les hypothèses à tester sont les suivantes : Ho : la différence entre les deux séries n’est pas significative H1 : la différence entre les deux séries est significative
Echantillon gratuit Rabais de 30% Annonce à la radio Emission à la radio 3.5 3.5 18 18 12 8.5 22.5 26.5
14.5 8.5 14.5 22.5 8.5 12 12 18 18 3.5 18 26.5 3.5 8.5 26.5 22.5 3.5 3.5 22.5 26.5
R1=63.5 R2=48 R3=134 R4=160.5

26
Pour déterminer la statistique du test, on calcule tout d’abord la différence di entre les scores de deux observations jumelées (si la différence est nulle, on élimine l’observation correspondante), ensuite on indique le rang de toutes les différences di en valeur absolue, de la plus petite à la plus grande et on affecte à chaque rang le signe de la différence dont il provient (en cas d’égalité des |di|, les rangs sont attribués de la même façon qu’au test précédent).
La statistique du test : T est la plus petite des deux sommes de rangs positifs ou de rangs négatifs. Sous l’hypothèse Ho, lorsque n ≥ 8, on démontre que T suit une loi normale ),( 2σµN
Avec, ( ) ( )( )
24
121
4
1 ++=+= nnnet
nn σµ
D’où σ
µ−= TZ suit une loi normale )1,0(N
Pour un seuil α fixé, si |Z| > 2αZ , on rejette Ho, si non on l’accepte.
Le test de Wilcoxon est particulièrement utilisé pour évaluer si on observe un changement
statistiquement significatif dans un plan d’expérience «avant-après » sur les mêmes sujets, lorsque l’une des deux variables est ordinale ou quantitative. C’est le cas par exemple lorsqu’on veut évaluer l’effet d’une promotion sur les préférences des consommateurs à l’égard de certains produits.
L’hypothèse nulle dans ce cas est : Ho : l’intention des individus ne change pas après l’expérience
Exemple:
Lors de l’arrivée des clients dans un magasin de commercialisation des produits alimentaires, il
leur est demandé de donner un score d’intention d’achat d’une marque de produit alimentaire, par une note allant de 1 (très incertain) à 10 (presque certain). Après avoir fait goûter le produit en question lors d’une démonstration, on demande à nouveau aux mêmes consommateurs leur score d’intention d’achat. Les données obtenues auprès de 10 consommateurs se présentent comme suit :
Intention à priori 3 9 5 5 4 8 8 6 3 4 Intention à posteriori 10 8 9 7 5 8 9 4 6 9
Pouvons-nous conclure au seuil de confiance de 5% que cette promotion a changé l’intention des consommateurs ? Résolution :
Intention à priori 3 9 5 5 4 8 8 6 3 4 Intention à posteriori 10 8 9 7 5 8 9 4 6 9 différence ( di) -7 1 -4 -2 -1 0 -1 2 -3 -5 |di| 7 1 4 2 1 0 1 2 3 5 rang de |di| 9 2 7 4,5 2 - 2 4,5 6 8 somme Rang négatif -9 -7 -4,5 -2 - -2 -6 -8 38,5 rang positif 2 - 4,5 6,5
T = 6.5

27
( )
( )( )
( )
( )( )90.1
44.8
16
24
191094
1095.6
24
1214
1
−=−=−
=++
+−=
nnn
nnT
Z
Au seuil de 5%, Z < 1.96, donc, on accepte l’hypothèse Ho. En d’autres termes, on ne peut pas conclure que le fait de goûter le produit alimentaire en question ait changé de façon statistiquement significative les intentions d’achat des consommateurs.
IV. ANALYSE DE LA VARIANCE A DEUX FACTEURS
Prenons l’exemple suivant pour illustrer cette partie du cours : Une entreprise a disposé ses
produits dans des magasins situés dans cinq quartiers de la ville de Douala, dans chaque magasin, les produits sont disposés sur des étalages à trois niveaux de hauteur (Bas, moyen, haut). A l’issue d’une semaine d’observation, les ventes dans ces quartiers se répartissent ainsi qu’il suit :
Hauteur étalage
Quartier Bas moyen Haut Total
Akwa 18 22 29 69 Bonandjo 17 20 26 63 Deido 16 17 24 57 New-Bell 15 16 21 52 Cité SIC 12 14 14 40 Total 78 89 114 281
Dans cet exemple, les ventes peuvent être influencées par le niveau d’appréciation du produit en
question dans le quartier ou par la hauteur de l’étalage. L’analyse de la variance consiste à vérifier si ces effets sont significatifs ou pas. La vente pour le Quartier i, hauteur de l’étalage j, peut être modélisée par la variable
ijjiijY εβαµ +++=
Où • µ est la moyenne générale des ventes
• iα , l’effet Quartier (i =1, …, n)
• jβ , l’effet de la hauteur de l’étalage (j =1, …, p)
• ijε , l’erreur ou résidu (ε ~ ),0( 2σN )
1. Hypothèses du test
Le test statistique des différences dans les ventes causées par la hauteur de l’étalage va consister à tester les hypothèses suivantes :
Ho : 0=jβ pour tout j =1, …, p
H1 . : il existe au moins un 0≠jβ
De même, le test des différences dans les ventes causées par le quartier consistera à tester Ho : 0=jα pour tout i =1, …, n

28
H1 . : il existe au moins un 0≠iα
2. Statistique du test
La détermination des statistiques des deux tests en question ici passe par la construction du Tableau d’analyse de la variance suivant :
Source de variation (SV)
Degré de liberté (DDL)
Somme des Carrés (SCE)
Carré moyen (CM)
Fisher (F)
Effet étalage p-1 Se
1−=
p
SV e
e r
ee V
VF =
Effet quartier n-1 Sq
1−=
n
SV q
q r
qq V
VF =
Résidu (p-1)(n-1) Sr
Total np-1 ST
Avec :
• ( )∑=
−=p
jje YYnS
1
2
.
• ( )∑=
−=n
iiq YYpS
1
2
.
• ( )∑∑= =
−=n
i
p
jijT YYS
1 1
2
• qeTr SSSS −−=
∑∑∑∑=== =
====p
jiji
n
iijj
n
i
p
jij Y
pYY
nYY
npYY
1.
1.
1 1..
1;
1;
1
La statistique du test des différences dans les ventes causées par la hauteur de l’étalage est donnée par eF .
De même, la statistique du test des différences dans les ventes causées par le quartier est donnée parqF
3. Seuil critique
Pour un seuil α fixé, la valeur critique du test des différences dans les ventes causées par la hauteur de l’étalage est donnée par ),( 21 νναF , Avec 11 −= pν et )1)(1(2 −−= pnν
La valeur critique du test des différences dans les ventes causées par le quartier est donnée par ),( 23 νναF ,
Avec 13 −= nν et )1)(1(2 −−= pnν
( )( )11 −−=
np
SV r
e

29
4. Règle de décision
• Si eF > ),( 21 νναF , On rejette Ho, et donc la hauteur de l’étalage influence significativement les
ventes. • Si qF > ),( 23 νναF , On rejette Ho, et donc le produit est plus vendu dans certains quartiers que dans
d’autres. • Dans le cas contraire, ces on accepte Ho et donc ces effets sont non significatifs.
5. Application à l’exemple précédent
j i
1 2 3 .Yi ( )2. YYi −
1 18 22 29 23 18.2 2 17 20 26 21 5.14 3 16 17 24 19 0.07 4 15 16 21 17.33 1.96 5 12 14 14 13.33 29.16
15.6 17.8 22.8 73.18=Y ( )∑ =− 53,54.2
YYi
( )2. YjY − 9.82 0.87 16.54 ( )∑ =− 23,27.
2YjY
Tableau d’analyse de la variance
SV ddl SCE CM F Effet étalage 2 136.13 68.07 18.65 Effet quartier 4 163.6 40.9 11.21 Résidu 8 29.2 3.65 Total 14 328.93
• Pour %5=α et ( ) 84.38,4%5 =F
( )8,2%5FFe > , donc la hauteur de l’étalage influence significativement les ventes.
( )8,4%5FFq > , donc le quartier influence significativement les ventes
• Pour %1=α ( ) 65.88,2%1 =F et ( ) 01.78,4%1 =F
( )8,2%5FFe > et ( )8,4%1FFq > , même conclusion que précédemment
jY.
( ) 46.48,2%5 =F

30
CHAPITRE IV :
LES PRINCIPALES METHODES D’ANALYSE MULTIVARIEE
INTRODUCTION L’analyse des données multidimensionnelles recouvre un ensemble de méthodes destinées à synthétiser l’information issue de plusieurs variables, pour mieux l’expliquer. Ces méthodes peuvent être regroupées en deux grandes catégories : les méthodes descriptives et les méthodes explicatives. Les méthodes descriptives visent à structurer et simplifier les données issues de plusieurs variables, sans privilégier l’une d’entre elles. Les techniques les plus utilisées ici sont : l’analyse en composantes principales (ACP), l’analyse factorielle des correspondances (AFC), l’analyse des correspondances multiples (ACM), la typologie et la classification. Les méthodes explicatives visent à expliquer une variable (variable à expliquer) par plusieurs variables explicatives. Les principales méthodes utilisées sont : la régression multiple, l’analyse discriminante et la segmentation. Ces méthodes d’analyse multivariée permettent de résoudre des problèmes divers et variés. Le choix d’une méthode dépend de l’objectif de l’étude, des types de variables manipulées et de la forme des résultats obtenus (qui peuvent être plus ou moins faciles interpréter).Le tableau suivant présente les techniques utilisées en analyse multivariée en fonction de l’objectif visé.
Objectif Types de variables Méthode
Résumer l’information en minimisant la déperdition
Variable quantitatives ou qualitative ordinale
ACP
Deux variables qualitatives AFC Plus de deux variables qualitatives ACM
Constituer des groupes d’individus similaires
Tout type de variable (Nombre de groupes fixé au préalable)
Analyse Typologique
Tout type de variable (Nombre de groupes non fixé)
Classification
Expliquer une variable par plusieurs autres variables
Variable à expliquer numérique Régression multiple Variable à expliquer qualitative et variables explicatives quantitatives
Analyse Discriminante
Variable à expliquer qualitative et variables explicatives qualitatives
Segmentation
I. LES METHODES DESCRIPTIVES 1. L’ACP
Le tableau de départ de l’ACP comporte les individus en ligne et les variables en colonne, avec dans chaque cellule, la valeur observée de l’individu sur la variable correspondante. Les variables ordinales sont recodifiées. l’ACP permet de positionner les individus sur un ou plusieurs plans, en fonction de la proximité de leurs valeurs observées sur les variables sélectionnées. Elle permet également de représenter les variables sur un ou plusieurs plans, de manière indépendante des individus. Ce qui permet de mettre en évidence le regroupement des individus ainsi que des variables.

31
Les axes du graphique correspondent généralement à un regroupement optimal de plusieurs variables. Par exemple, le revenu et le niveau d’étude peuvent participer ensemble à la formation d’un axe si elles sont fortement corrélées. L’ACP est très pratique lorsque l’on travaille sur un ensemble limité et identifié d’individus. Par exemple, si l’on désire analyser des points de ventes en fonction de plusieurs critères tels que la surface, le CA, les quantités de vente, le personnel, l’ACP permet d’obtenir une cartographie qui regroupe les points de ventes selon tous les critères retenus, ce qui peut permettre d’identifier les cas hors norme comme une surface et un personnel important, mais un CA faible. L’algorithme de l’ACP effectue sur la matrice Individus/variables les opérations telles que le centrage et la réduction des données, la diagonalisation de la matrice, l’extraction des valeurs propres et vecteurs propres, en vue de passer du nombre de variable initial à un petit nombre de variables obtenues par combinaison des premières. Ces nouvelles composantes forment les axes du graphique. La première composante est celle qui résume le mieux les informations contenues dans le tableau, la deuxième apporte un pourcentage d’information inférieur, mais complémentaire et ainsi de suite. Le graphique de l’ACP représente d’abord la première composante (axe horizontal) et la seconde (axe vertical). La somme des pourcentages d’explication des deux composantes renseigne sur le taux de déperdition d’information à partir des données initiales. Ainsi, si la première composante résume 60% du tableau et la seconde 20%, l’information représentée sur le graphique est de 80%. L’information « perdue » est donc de 20%. Les points individus sont représentés sont représentés sur le graphique en fonction de leur coordonnées sur les facteurs. Les points proches correspondent à des individus ayant des profils proches, à priori, quant aux valeurs observées sur les variables prises en compte dans l’analyse. Les points variables sont également représentés sur le graphique, mais de façon indépendante des individus. Leur représentation indique leur corrélation avec les facteurs, à l’intérieur d’un cercle de rayon unité, avec une échelle arbitraire. Ces points variables renseignent su le sens à donner aux axes : un point proche du cercle de corrélation et proche d’un axe participe beaucoup à la formation de cet axe. Les angles inter-variables (en partant de l’origine) renseignent sur les corrélations entre elles. Ainsi, deux variables formant un petit angle sont fortement corrélés alors qu’un angle droit signifierait qu’elles sont indépendantes.
2. L’AFC Le tableau de départ de l’AFC simple est un tableau croisé (tableau de contingence). L’AFC s’applique à deux variables qualitatives nominales. Elle permet de positionner les modalités des deux variables sur un graphique. Le graphique de l’AFC affiche les points modalités. On peut par exemple positionner une série de marque d’automobile sur le même plan avec la caractéristique des clients (âges, CSP, Sexe,…), ce qui permet de repérer les affinités entre chaque marque et les différentes cibles. En pratique, on utilise l’AFC pour représenter graphiquement et expliquer le croisement de deux variables. Si le test du khi-2 indique une dépendance entre ces deux variables, l’interprétation du graphique sera plus aisée.
3. L’ACM L’ACM est une généralisation de l’AFC à un nombre quelconque de variables. Elle permet de représenter sur le même graphique, les modalités de plus de deux variables qualitatives. L’ACM part d’un tableau disjonctif complet (tableau de Burt) qui présente en ligne les individus et en colonne toutes les modalités des variables retenues pour l’analyse. Les cases d’intersection (cellules) comportent la valeur 1 si l’individu répond au critère en colonne et 0 dans le cas contraire.

32
Comme l’ACP, les deux premiers axes du graphique de l’ACM fournissent une partie généralement importante de l’information contenue dans les données. La proximité des points renseigne sur leurs associations. La disposition des modalités de chaque variable les unes par rapport aux autres aide à donner un sens à chaque axe.
4. LA TYPOLOGIE L’analyse typologique s’applique à tous types de variables. Elle permet de répartir la population en un nombre défini de sous groupes aussi différents que possible les uns des autres et dans lesquels les individus sont aussi semblables que possible entre eux. Les différentes méthodes d’analyse typologique partent des individus eux-mêmes et essaient de les classer progressivement selon la ressemblance de leurs observations sur les variables retenues. Il existe plusieurs méthodes d’analyse typologique, qui aboutissent toutes au classement des individus dans le nombre de groupes défini initialement. L’effectif de ces groupes peut être très différent. La visualisation graphique du résultat de l’analyse typologique est un graphique qui met en évidence les différents groupes. Certains logiciels d’analyse de données permettent de créer à partir des résultats de la typologie, une nouvelle variable indiquant, pour chaque individu, son numéro de groupe d’appartenance.
5. LA CLASSIFICATION Tout comme la typologie, la classification est une méthode qui permet de regrouper les individus selon leurs ressemblances. La différence ici est que le nombre de groupe n’est fixé d’avance et que le résultat est représenté sous forme d’un arbre de classification. L’élaboration de cet arbre peut être ascendante par regroupement successif des individus (méthode fréquemment utilisé) ou descendante par divisions successives. L’arbre de classification relie un individu à un autre ou à un sous-groupe d’individus issus eux-mêmes de regroupements. Lorsque l’on coupe l’arbre à un niveau, on obtient les groupes d’individus. Par exemple, en coupant l’arbre ai niveau du dernier regroupement, on obtient deux groupes, au niveau de l’avant-dernier regroupement, on obtient trois groupes, ainsi de suite. Il est également possible d’appliquer une classification pour regrouper des variables. On obtient ainsi des groupes de variables dont les profils des valeurs/modalités observées se ressemblent.
II. LES METHODES EXPLICATIVES 1. LA REGRESSION MULTIPLE
Elle permet d’expliquer une variable quantitative (Y) par plusieurs autres variables quantitatives indépendantes (X1, X2, …, Xp). Elle modélise la relation sous la forme : pp2211 Xb X bXb a Y +…+++=, où a, b1, b2, …, bp sont les coefficients du modèle. Si le modèle de régression est satisfaisant, On peut ainsi prédire les valeurs de la variable Y en fonction des valeurs des variables explicatives. L’appréciation de la qualité de la régression se fait grâce à plusieurs indicateurs tels que :

33
− Le coefficient de détermination multiple (R²) qui calcule le % de la variation de la variable Y dû
aux variables explicatives. (la régression est d’autant satisfaisante que R² est proche de 1). − Le coefficient de corrélation multiple (R) qui mesure le degré de la liaison entre la variable à
expliquer et les différentes variables explicatives. − Le test de Fisher qui permet d’estimer la qualité de l’ajustement dans la population.
Certains logiciels calculent directement la probabilité que aucune des variables explicatives n’aient d’effet sur la variable à expliquer. Cette probabilité doit être très faible pour conclure que l’ajustement est valable.
2. L’ANALYSE DISCRIMINANTE (AD) C’est une méthode factorielle qui cherche à expliquer une variable qualitative par plusieurs variables quantitatives. Comme la régression, elle permet de mettre en équation une variable à expliquer et des variables explicatives. C’est donc une méthode prédictive dans la mesure où elle permet de déterminer quelle modalité prendra un individu pour la variable qualitative à expliquer, si on connaît ses valeurs observées sur les variables quantitatives. Par exemple, l’analyse discriminante peut être appliquée pour attribuer un score à un client d’une banque ou d’une compagnie d’assurance, en déterminant automatiquement un niveau de risque en fonction de différents paramètres connus tels que l’âge, le revenu, l’endettement,… Les résultats de l’AD peuvent être visualisés sur un graphique similaire à celui de l’ACP où les points individus sont réunis en fonction de leur appartenance aux groupes.
3. LA SEGMENTATION Elle partage les mêmes objectifs que l’AD mais s’applique lorsque les variables explicatives sont qualitatives. Elle consiste à découper une population en sous groupes homogènes, mais uniquement par rapport à la variable à expliquer. Le processus de la segmentation est itératif : à chaque étape, l’algorithme choisit la variable explicative la plus corrélée la variable à expliquer pour réaliser une partition à partir des modalités de la première. Le résultat de la segmentation est une sorte d’arbre de décision, avec un découpage de chaque groupe en deux sous-groupes. La première partition permet d’obtenir les deux premiers groupes. Chacun de ces deux groupes est ensuite divisée en deux à l’aide de la variable permettant la meilleure partition et qui n’est généralement pas la même pour les deux groupes. Le processus se poursuit ainsi avec des interruptions lorsque la taille du groupe tombe en dessous d’un seuil ou quand le découpage optimal expliquerait un faible % de variance.
III. FORMALISATION ET CAS PRATIQUES
1. Formalisation de l’ACP On note X la matrice n.p des données (ie portant les observations en ligne, éléments de Rp, et les variables, quantitatives, en colonnes, éléments de Rn), on suppose les colonnes de X préalablement centrées et réduites si nécessaire. Soit u un vecteur (en colonne) unitaire de Rp, le vecteur X.u de Rn a pour composantes les produits scalaires des observations avec u, c’est à dire encore, les distances à l’origine des projections des observations selon la direction de u, tandis que l’inertie totale du nuage dans cette direction est donnée par le produit matriciel : u’.X’.X.u .
34
La matrice symétrique X’.X est la matrice d’inertie du nuage, tandis que le produit u’.X’.X.u , qui donne l’inertie dans cette direction, est l’application de la forme bilinéaire symétrique de matrice X'.X au vecteur unitaire u. On remarque que X’.X est simplement, au facteur 1/n près, la matrice des corrélations entre les variables-colonnes initiales. La recherche des directions principales, c’est à dire des directions successives d’inertie maximale du nuage, se traduit donc par le problème de maximisation sous contrainte :
max��
(��’. �’. �. ��) ������’. �� = 1
Les vecteurs uk successifs devant en outre être orthogonaux.
L’algèbre linéaire enseigne que les vecteurs propres normés : uk, associés à la suite décroissante des valeurs propres (positives) de X'.X : λk , apportent la solution du problème, la valeur propre λk mesurant l’inertie dans la k-ième direction principale uk :
uk’.X’.X.uk = λk.uk’.uk = λk Les vecteurs ck = X.uk de Rn sont les composantes principales successives du nuage, centrées, de variances respectives λk/n et non corrélées (de covariances : uk'.uh/n, nulles), ce sont les « nouvelles variables », dont les composantes donnent les coordonnées des points du nuage sur les axes factoriels. Les diverses contributions, corrélations et autres aides à l’interprétation, enfin, sont aisées à écrire, en fonction des λk, ui et cj . Ainsi, par exemple, la contribution de l’observation i à l’axe k est : ck(i)²/λk , où ck(i) désigne la i-ème composante de ck… Exemple : On étudie les données sur 50 clients d’un hypermarché constituées de l’âge, du revenu, du montant des achats, du nombre d’enfants. La taille de ce tableau est insuffisante pour que les interprétations soient intéressantes. Mais elle permet de donner la totalité des résultats concernant les variables et d’effectuer des calculs sur quelques unités statistiques à l’aide d’une simple calculatrice. Nous donnons ci-dessous la représentation graphique des 50 clients sur le plan principal 1x2. Au groupe (25, 31, 43) détecté par la représentation graphique des couples (âge, revenu) s’ajoute le client de rang 28. On peut définir un groupe opposé au précédent : (9, 11, 37, 7, 6, 45). Le client de rang 10 est assez particulier.

35
Exemple : cercle de corrélation C1xC2 des données de l’hypermarché. Ce cercle de corrélation montre que la seconde composante principale est fortement corrélée au revenu et surtout à l’âge : un client de l’hypermarché dont la coordonnée est élevée sur l’axe 2 aura très vraisemblablement un âge supérieur à la moyenne et inversement. C’est le cas des n°1 et 10. On retrouve les clients n° 25, 31 et 43 dont la coordonnée élevée sur l’axe 1 montre que le nombre d’enfants et le montant des achats sont faibles. Réciproquement, les clients 9 et 37 dont les coordonnées sur l’axe 2 sont fortement négatives sont jeunes et ont un revenu faible. Rappelons que ces propriétés peuvent être inexactes sur des cas particuliers, et que l’orientation des axes peut être inversée si l’on utilise un autre logiciel.
Formalisation de l’AFC L’AFC, comme il a été dit, est une forme particulière de l’ACP appliquée aux tableaux de contingence : non centrée-réduite, avec pondérations, et utilisant la métrique dite du chi-deux (ie des inverses des fréquences marginales) au lieu de la métrique euclidienne usuelle. On note K le tableau de contingence, ou tableau croisé, initial, de dimension n.p, FJ/I le tableau des profils en ligne (fréquences conditionnelles, conditionnées par les items en ligne) et FI/J celui des profils en colonne. DI désigne la matrice diagonale portant sur sa diagonale les totaux en ligne (ou totaux marginaux) et DJ celle des totaux en colonne. Les différentes matrices précédentes sont naturellement liées: FJ/I = DI
-1.K et FI/J = K.DJ-1

36
Le produit scalaire de deux vecteurs u et v dans Rp pour la métrique du chi-deux est donné par le produit matriciel: u’.DJ
-1.v , à un facteur multiplicatif près, par suite l’inertie dans la direction du vecteur DJ-1-
unitaire u du nuage des profils en ligne, pour la métrique précédente avec pour pondérations les totaux en ligne, est donnée, au même facteur près, par le produit matriciel:
u’.DJ-1.FJ/I’.D I.FJ/I.DJ
-1.u = u’.DJ-1.K’.D I
-1.K.DJ-1.u
Les directions principales d’inertie sont obtenues en maximisant la quantité précédente sous la contrainte: u’.DJ
-1.u = 1 , dans des directions DJ-1-orthogonales successives. La théorie indique que la solution est la
suite des vecteurs propres DJ-1-normés uk associée à la suite décroissante des valeurs propres λk de la
matrice (non symétrique):
FJ/I’.D I.FJ/I.DJ-1 = K’.D I
-1.K.DJ-1
Les composantes principales :
ck = FJ/I.DJ-1.uk = DI
-1.K.DJ-1.uk
donnent à nouveau les coordonnées des profils en ligne sur les axes factoriels, tandis que les différentes aides à l'interprétations s'obtiennent aisément en tenant compte de la métrique DJ
-1 et des pondérations données par DI.
L’analyse des profils en colonne est étroitement liée à la précédente, du fait des relations entre FI/J et FJ/I. Les directions principales de cette analyse sont données par les vecteurs propres DI
-1-normés et orthogonaux:
vk = λk-1/2.K.DJ
-1.uk
de la matrice: FI/J.DJ.FI/J'.DI
-1 = K.DJ-1.K'.DI
-1
et les composantes principales par:
dk = FI/J'.DI-1.vk = λ k
-1/2.FI/J'.ck
La j-ième composante: dk(j), de dk est donc:
dk(j) = λ k-1/2.Σ (nij/n.j).ck(i)
i
relation barycentrique, au facteur λ k
-1/2 près, qui relie les deux analyses et justifie la représentation simultanée.