aws初心者向けwebinar awsでbig data活用
TRANSCRIPT

1
AWSでBig Data活用
2015/12/10
Ryosuke Iwanaga
Solutions Architect, Amazon Web Services Japan

2
Abstract
Big Dataを活用する動きが世の中に広く見られる様になってきましたが、まだまだ自分事とは思えない方も多いと思います。本WebinarではAWSを利用したBig Data活用のお客様事例を中心にご紹介します。また、実際にサンプルのシステムをお見せしながら最近の流行であるSQLを使ったBig Data分析をご覧頂く予定です。エンジニアでない方や、エンジニアでも今までBig Data活用や分析をしたことの無い方にも分かりやすい様にお話しますので、お気軽にご参加下さい。

3
Agenda
• なぜBig Data? なぜAWS?
• Big Data on AWSの事例とサービス紹介
• Amazon EMRの特徴と事例
• SQL on Big Data

4
なぜBig Data? なぜAWS?

5
Big Dataとは?
• 全データを扱い、常に増え新しくなる– サンプリングせず、全ての種類・量のデータを扱う
– 扱うべきデータは絶え間なく生み出される
• 因果関係より相関関係– “風が吹けば桶屋が儲かる”
• 個にフィードバックする– 単なるレポートで終わらず、製品・サービスにする
規模が重要ではない全ての企業がBig Dataを持っている

6
Big Dataの例
領域 分析 内容
公共 電力消費量予測 スマートメーターによる消費量測定、発電設備監視
スマートシティ センサーNW センサーを使った交通や環境などのリスク分析
サービス モニタリング 種々のログからのシステムパフォーマンス分析
通信 顧客分析 顧客離反分析
マーケティング 感情分析 ソーシャルからの評判分析
小売 One to One ソーシャルの顔画像分析によるロイヤルティ計画
小売マーケティング ターゲティング モバイル/GPSによるキャンペーン、ターゲットマーケティング
金融/ヘルスケア 不正利用検知 リアルタイムでのトランザクション分析

7
Big Dataの例
領域 分析 内容
公共 電力消費量予測 スマートメーターによる消費量測定、発電設備監視
スマートシティ センサーNW センサーを使った交通や環境などのリスク分析
サービス モニタリング 種々のログからのシステムパフォーマンス分析
通信 顧客分析 顧客離反分析
マーケティング 感情分析 ソーシャルからの評判分析
小売 One to One ソーシャルの顔画像分析によるロイヤルティ計画
小売マーケティング ターゲティング モバイル/GPSによるキャンペーン、ターゲットマーケティング
金融/ヘルスケア 不正利用検知 リアルタイムでのトランザクション分析
• ヘルスモニタリング
• リスク分析
• 需給分析
• 顧客接点強化
• 製品開発/品質改善
5つにカテゴライズ可能
これらの分析をどの範囲で実施するか:1システム内、1事業部内、1企業内、業界(企業間)
8
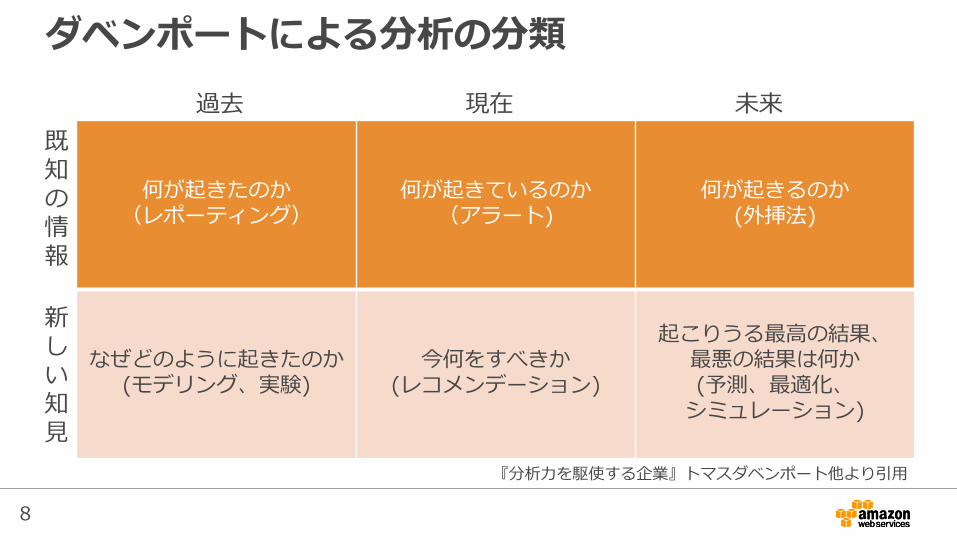
ダベンポートによる分析の分類
何が起きたのか(レポーティング)
何が起きているのか(アラート)
何が起きるのか(外挿法)
なぜどのように起きたのか(モデリング、実験)
今何をすべきか(レコメンデーション)
起こりうる最高の結果、最悪の結果は何か(予測、最適化、シミュレーション)
過去 現在 未来
既知の情報
新しい知見
『分析力を駆使する企業』トマスダベンポート他より引用

9
ダベンポートによる分析の分類
何が起きたのか(レポーティング)
何が起きているのか(アラート)
何が起きるのか(外挿法)
なぜどのように起きたのか(モデリング、実験)
今何をすべきか(レコメンデーション)
起こりうる最高の結果、最悪の結果は何か(予測、最適化、シミュレーション)
過去 現在 未来
既知の情報
新しい知見
『分析力を駆使する企業』トマスダベンポート他より引用
ヘルスモニタリング
リスク分析需給分析
顧客接点強化
製品開発/品質改善

10
なぜBig Data?
• データに基づく、科学的で質の高い判断– 属人性の排除 → 組織のスケール
• 全てを科学的にはしない (例: Netflixは 科学的:アート的 = 7:3)
• 世界は常に姿を変える– 状況を速く・正確に把握し、反応できる企業が優位に立つ
• 判断に人間が介在していたら間に合わない
– 新しい発見、ビジネスチャンス

11
Big Dataちょっと試してみたいけど、、、
• 「利用が拡大するかもしれないし、
実験的な取り組みで終わるかもしれない。」
• 「すぐデータを分析してみて、
有意義な結果が出るかやってみたい。」

12
なぜ、AWSなのか?
• 「利用が拡大するかもしれないし、実験的な取り組みで終わるかもしれない。」
規模が拡大しても、処理できて、コストも抑えられる仕組みが必要。
– スケールアウトが簡単
– オンデマンド課金

13
なぜ、AWSなのか?
• 「利用が拡大するかもしれないし、
実験的な取り組みで終わるかもしれない。」
特に最初は出来る限り
コストを抑えて始めたい。
– 初期費用不要

14
なぜ、AWSなのか?
• 「すぐデータを分析してみて、有意義な利用ができるかやってみたい」
すぐに利用開始できるインフラ
– 数クリックで利用開始
– Big Dataに利用できるサービスが揃っているので実現を加速
Deploy

15
Big Data on AWSの事例とサービス紹介

16
Big Data on AWS
• 豊富な成功事例– 今回ご紹介: AdRoll, Zillow, スシロー, Netflix, FINRA
– Appendix: HEARST, Nasdaq, AOL
• それを支える豊富なサービス群– 50を超えるサービス、スケーラブル、安定、簡単
• コスト– Big Data = 高価ではない

Amazon S3
Amazon Kinesis
Amazon DynamoDB
Amazon RDS (Aurora)
AWS Lambda
KCL Apps
Amazon
EMRAmazon
Redshift
Amazon Machine
Learning
収集 処理 分析
保存
データ収集と保存
データ処理イベント処理 データ分析
データ 答え

Amazon S3
Amazon Kinesis
Amazon DynamoDB
Amazon RDS (Aurora)
AWS Lambda
KCL Apps
Amazon
EMRAmazon
Redshift
Amazon Machine
Learning
収集 処理 分析
保存
データ収集と保存
データ処理イベント処理 データ分析
データ 答え

© 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Adi Krishnan, Principal PM Amazon Kinesis
Nick Barrash, SDE, AdRoll
10/08/2015
Amazon Kinesis
Capture, Deliver, and Process
Real-time Data Streams on AWS

20
Kinesis at AdRollNick Barrash

AdRoll我々のデータ
• AdRollにおけるリアルタイムデータ• 広告のウェブサイトのクリックストリームデータ
• 広告の配信• インプレッション / クリック / コンバージョン• リアルタイムビッディング (RTB) データ
• 近年はパフォーマンスに直結している

AdRoll我々の規模感
• 毎日のインプレッションデータ: 2億イベント / 240GB
• 毎日のユーザデータ: 16億イベント / 700GB
• 毎日のRTBデータ: 600億イベント / 80TB

23
Amazon S3 (Simple Storage Service)
処理データを耐久性が高く低コストなクラウドストレージに格納。各サービス間のデータハブに。
• REST API、SDK、CLIなどを使って読み書き
• データを3つ以上のデータセンターに自動複製
• 1GBあたり月約4円 容量は無制限で保存した分だけ課金
東京リージョン 設計上の耐久性99.9999999%
データセンターA
データセンターB
データセンターC
ファイル
HTTP/
HTTPS
物理サーバ
IoTデバイス
AWS各種サービス

10分 ~5分
~15分
Dynamo
DBS3 Lambda
S3
HBase
EC2
EC2
EC2
...
SQS
SQS
SQS
...
リアルタイム処理アプリケーション
EC2
EC2
EC2
...
ログ発生
データパイプラインアーキテクチャKinesis導入前
25
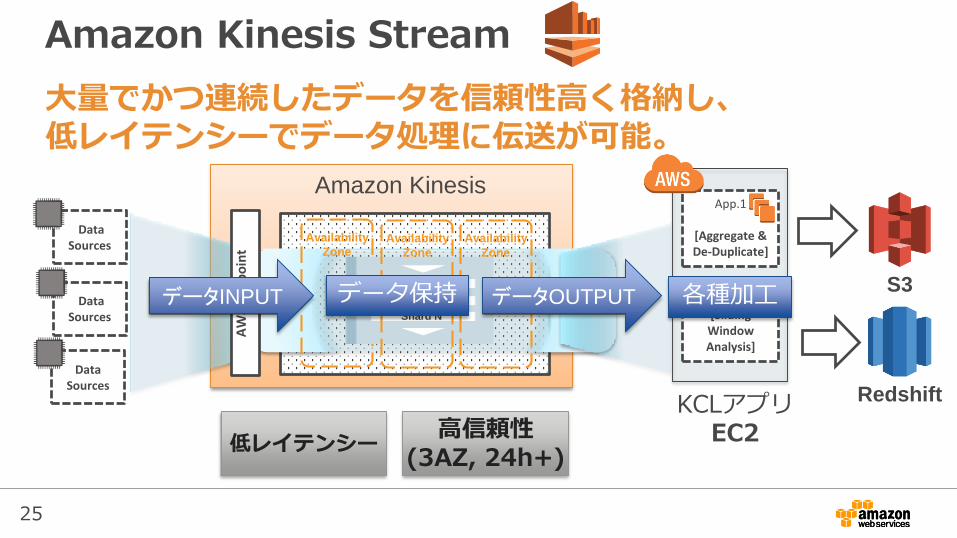
Amazon Kinesis Stream
大量でかつ連続したデータを信頼性高く格納し、低レイテンシーでデータ処理に伝送が可能。
Data Sources
AW
S En
dp
oin
t
App.1
[Aggregate & De-Duplicate]
Data Sources
Data Sources
S3
Redshift
App.2[Sliding Window Analysis]
Availability
Zone
Shard 1
Shard 2
Shard N
Availability
Zone
Availability
Zone
Amazon Kinesis
データINPUT データOUTPUT 各種加工データ保持
低レイテンシー高信頼性
(3AZ, 24h+)
KCLアプリEC2

10分 ~5分
~15分
Dynamo
DBS3 Lambda
S3
HBase
EC2
EC2
EC2
...
SQS
SQS
SQS
...
リアルタイム処理アプリケーション
EC2
EC2
EC2
...
ログ発生
データパイプラインアーキテクチャKinesis導入前
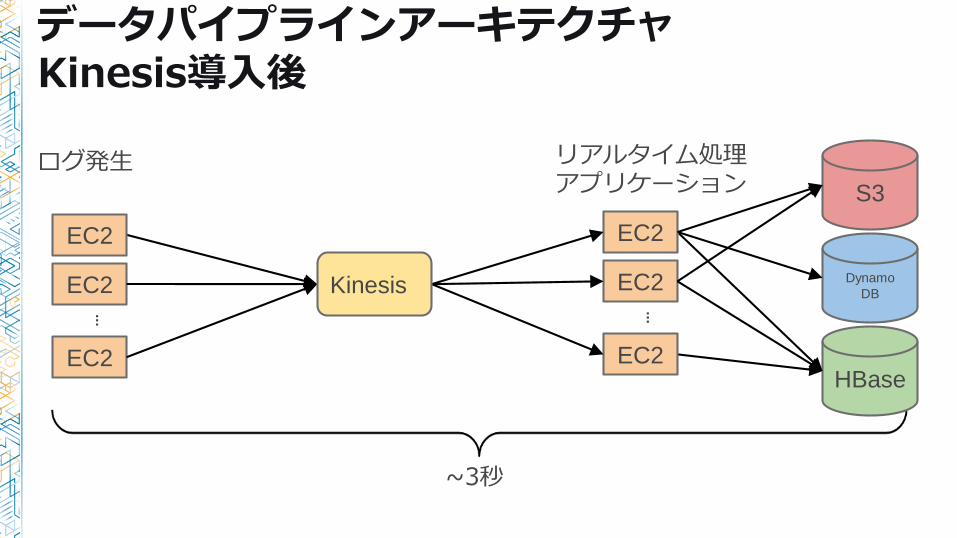
~3秒
Dynamo
DB
S3
HBaseEC2
EC2
EC2
...
EC2
EC2
EC2
...Kinesis
データパイプラインアーキテクチャKinesis導入後
ログ発生 リアルタイム処理アプリケーション

► 5つのリージョン► 155 ストリーム► 264 シャード► 25億 イベント (1億 Kinesis レコード) / 日
Kinesisの利用量
※約36万円 ($1=120円)
/ 月

► 15 分 -> 3 秒► それと同時に...
Kinesisによる勝利
安定性向上
コスト節約

Amazon S3
Amazon Kinesis
Amazon DynamoDB
Amazon RDS (Aurora)
AWS Lambda
KCL Apps
Amazon
EMRAmazon
Redshift
Amazon Machine
Learning
収集 処理 分析
保存
データ収集と保存
データ処理イベント処理 データ分析
データ 答え

© 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Roger Barga, GM Amazon Kinesis
Adi Krishnan, Product Manager Amazon Kinesis
October 2015
BDT320
Streaming Data Flows with Amazon Kinesis Firehose
and Amazon Kinesis Analytics

スシロー: 回転寿司レストラン380店舗の寿司皿についたセンサーから送られるストリームデータをKinesisへ
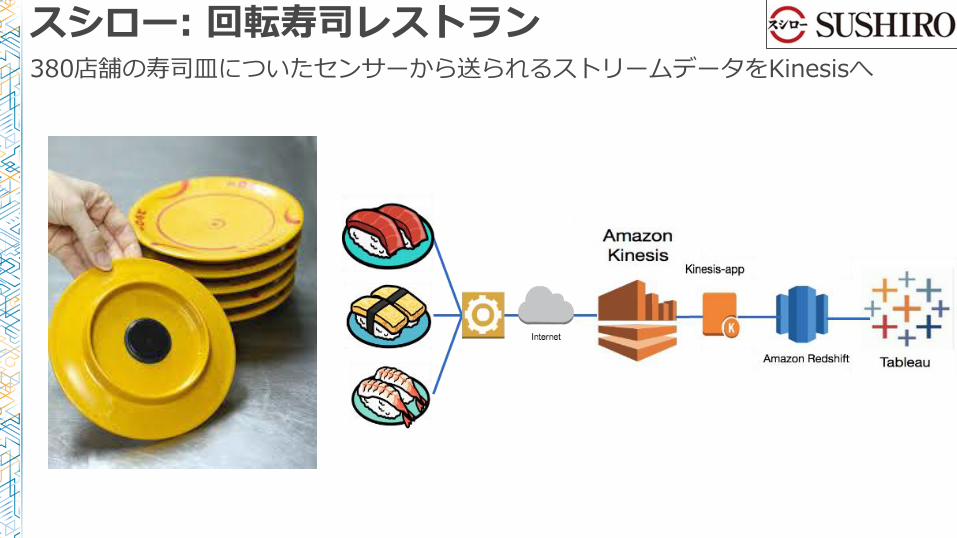
スシロー: 回転寿司レストラン380店舗の寿司皿についたセンサーから送られるストリームデータをKinesisへ
34
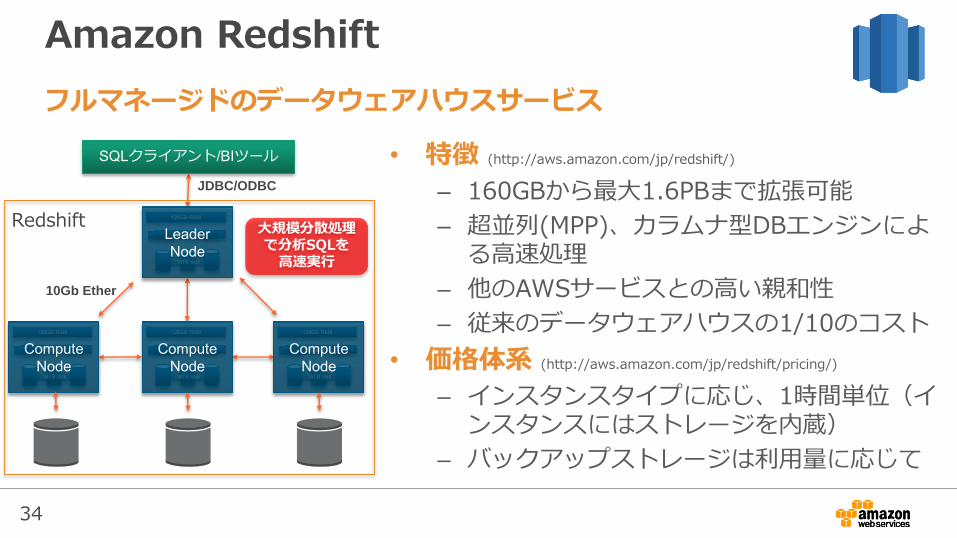
Amazon Redshift
• 特徴 (http://aws.amazon.com/jp/redshift/)
– 160GBから最大1.6PBまで拡張可能
– 超並列(MPP)、カラムナ型DBエンジンによる高速処理
– 他のAWSサービスとの高い親和性
– 従来のデータウェアハウスの1/10のコスト
• 価格体系 (http://aws.amazon.com/jp/redshift/pricing/)
– インスタンスタイプに応じ、1時間単位(インスタンスにはストレージを内蔵)
– バックアップストレージは利用量に応じて
フルマネージドのデータウェアハウスサービス
10Gb Ether
JDBC/ODBC
Redshift 大規模分散処理で分析SQLを高速実行

スシロー: 回転寿司レストラン380店舗の寿司皿についたセンサーから送られるストリームデータをKinesisへ
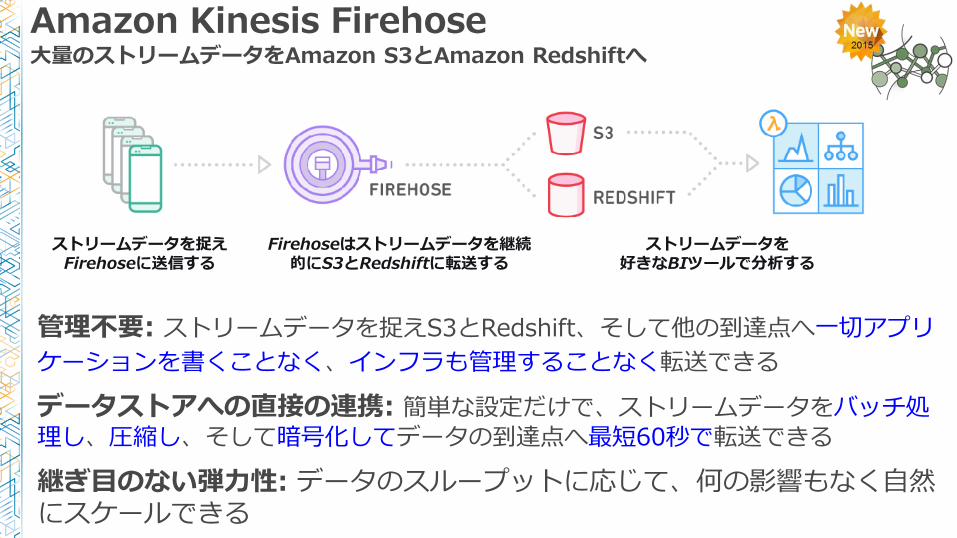
Amazon Kinesis Firehose大量のストリームデータをAmazon S3とAmazon Redshiftへ
管理不要: ストリームデータを捉えS3とRedshift、そして他の到達点へ一切アプリ
ケーションを書くことなく、インフラも管理することなく転送できる
データストアへの直接の連携: 簡単な設定だけで、ストリームデータをバッチ処理し、圧縮し、そして暗号化してデータの到達点へ最短60秒で転送できる
継ぎ目のない弾力性: データのスループットに応じて、何の影響もなく自然にスケールできる
ストリームデータを捉えFirehoseに送信する
Firehoseはストリームデータを継続的にS3とRedshiftに転送する
ストリームデータを好きなBIツールで分析する
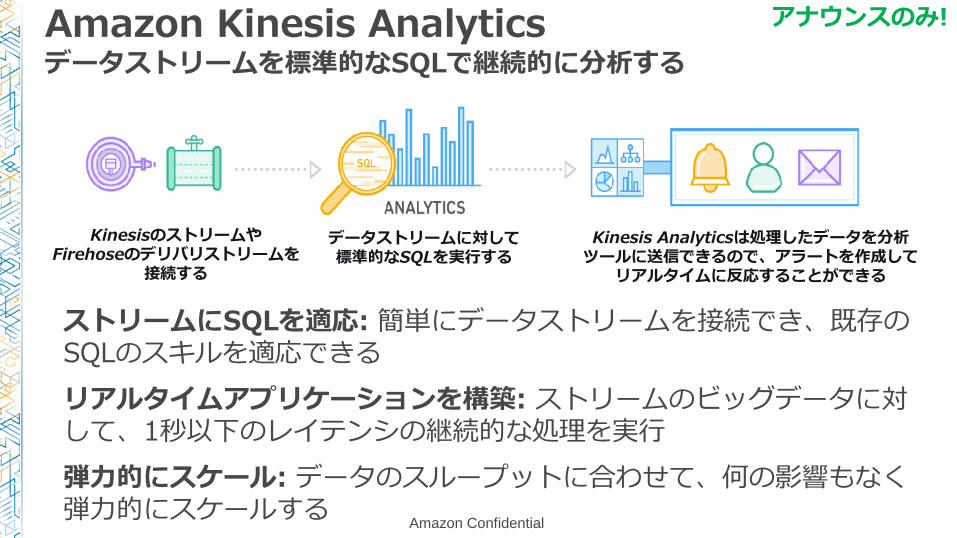
Amazon Kinesis Analyticsデータストリームを標準的なSQLで継続的に分析する
ストリームにSQLを適応: 簡単にデータストリームを接続でき、既存のSQLのスキルを適応できる
リアルタイムアプリケーションを構築: ストリームのビッグデータに対して、1秒以下のレイテンシの継続的な処理を実行
弾力的にスケール: データのスループットに合わせて、何の影響もなく弾力的にスケールする
アナウンスのみ!
Amazon Confidential
KinesisのストリームやFirehoseのデリバリストリームを
接続する
データストリームに対して標準的なSQLを実行する
Kinesis Analyticsは処理したデータを分析ツールに送信できるので、アラートを作成して
リアルタイムに反応することができる

Amazon S3
Amazon Kinesis
Amazon DynamoDB
Amazon RDS (Aurora)
AWS Lambda
KCL Apps
Amazon
EMRAmazon
Redshift
Amazon Machine
Learning
収集 処理 分析
保存
データ収集と保存
データ処理イベント処理 データ分析
データ 答え

© 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Steve Abraham, Solutions Architect - AWS
Brian Filppu, Director of Business Intelligence - Zillow
October 2015
BDT307
Zero Infrastructure, Real-Time
Data Collection, and Analytics

Zillowのケーススタディ

Zillow – ユースケース
• モバイルアプリのメトリクスのいくつかを集める必要
• 3週間以内に本番投入される必要
• メトリクスを集約しビジネスオーナーに1日に何度かレポートする必要
• 我々は既にいくつかのデータウェアハウス処理をAWS上で動かしていたので、担当のソリューションアーキテクトのSteveに相談した

Zillow – アーキテクチャ図

43
イベントをトリガーに処理を実行可能。
AWS Lambda
コードの持ち込み
インフラ考慮が不要
AWSサービス / APIからのイベント呼び出し
オリジナル画像 サムネイル画像
1
2
3
exports.handler_name = function(event, context) {console.log("value1 = " + event.key1); ...context.done(null, "some message");
}
実行100ms単位で課金インフラはAWSが管理

44
Amazon Elastic MapReduce(EMR)
収集したデータの処理をHadoop/Sparkなどの分散処理フレームワークを使って効率的に処理。
AWS上の分散処理サービス• 簡単かつ安全にBig Dataを処理• 多数のアプリケーションサポート
簡単スタート• 数クリックでセットアップ完了• 分散処理アプリも簡単セットアップ
低コスト• ハードウェアへの投資不要• 従量課金制• 処理の完了後、クラスタ削除• Spotインスタンスの活用
Hadoop
分散処理アプリ
分散処理基盤
Amazon EMRクラスタ
簡単に複製できるリサイズも1クリックRI/Spotも利用可能

Zillow – 我々は何を作ったか?
• Amazon API Gateway上のカスタムURLエンドポイント
• 1,600万+ POST / 日 – 開始時点
• データはAPI GatewayからAWS Lambdaを使ってAmazon Kinesisに送られる
• Lambdaを使って、AWS KMSで暗号化したデータをAmazon S3に保存する
• 我々のデータをAmazon EMR上のSparkを使って分析する
• データを使うSparkジョブをAWS Data Pipelineを使って実行する
• もし必要になれば、Amazon EMR上のSparkでAmazon Kinesisのデータをリアルタイムに処理したり分析したりできる

Zillow – データ収集のコスト
• Amazon Kinesisを3シャード使って、時間課金とPUTのコストを合わせても、約$1.30/日
• AWS Lambdaには、我々は128MBのメモリを割り当ててていて、毎日$6以下で動いている
• LambdaとAmazon Kinesisは短い開発期間でコスト的に有利なデータ保存のソリューションを与えてくれた

47
Amazon EMRの特徴と事例

Amazon S3
Amazon Kinesis
Amazon DynamoDB
Amazon RDS (Aurora)
AWS Lambda
KCL Apps
Amazon
EMRAmazon
Redshift
Amazon Machine
Learning
収集 処理 分析
保存
データ収集と保存
データ処理イベント処理 データ分析
データ 答え

© 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Abhishek Sinha, Amazon Web Services
Gaurav Agrawal, AOL Inc
October 2015
BDT208
A Technical Introduction to
Amazon EMR

EMR File System (EMRFS)を使ってAmazon S3を有効活用

HDFSからAmazon S3へ
CREATE EXTERNAL TABLE serde_regex(
host STRING,
referer STRING,
agent STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe'
)
LOCATION 'samples/pig-apache/input/'

HDFSからAmazon S3へ
CREATE EXTERNAL TABLE serde_regex(
host STRING,
referer STRING,
agent STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe'
)
LOCATION 's3://elasticmapreduce.samples/pig-apache/input/'

オンプレミス環境の場合
密結合している

コンピュートとストレージが一緒に大きくなる
密結合している
ストレージはコンピュートと共に大きくなる
コンピュートの要件は異なる
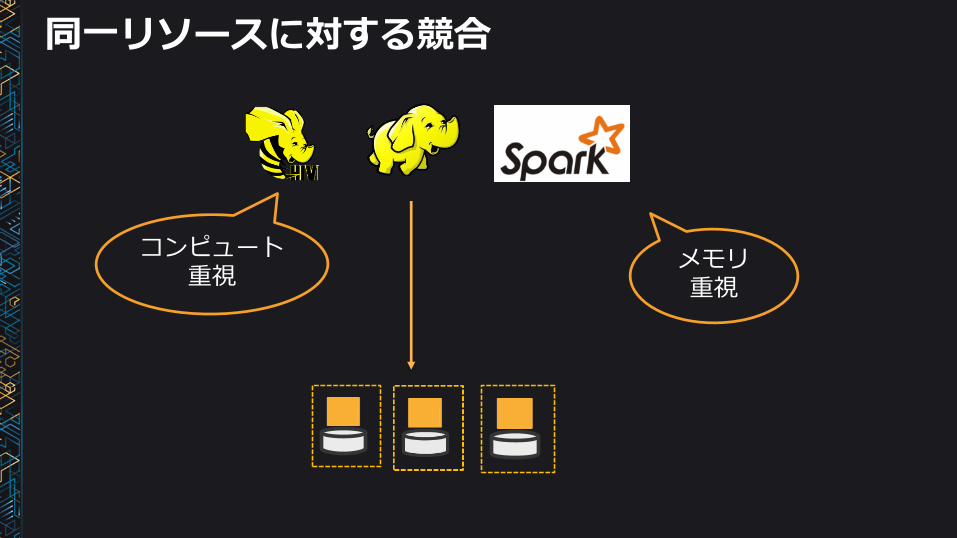
同一リソースに対する競合
コンピュート重視
メモリ重視

リソースを分割すると、データがサイロ化
チームA

レプリケーションがさらにコストになる
3倍
単一のデータセンタ

Amazon EMRでは、いかにしてこれらの問題を解決したのか?
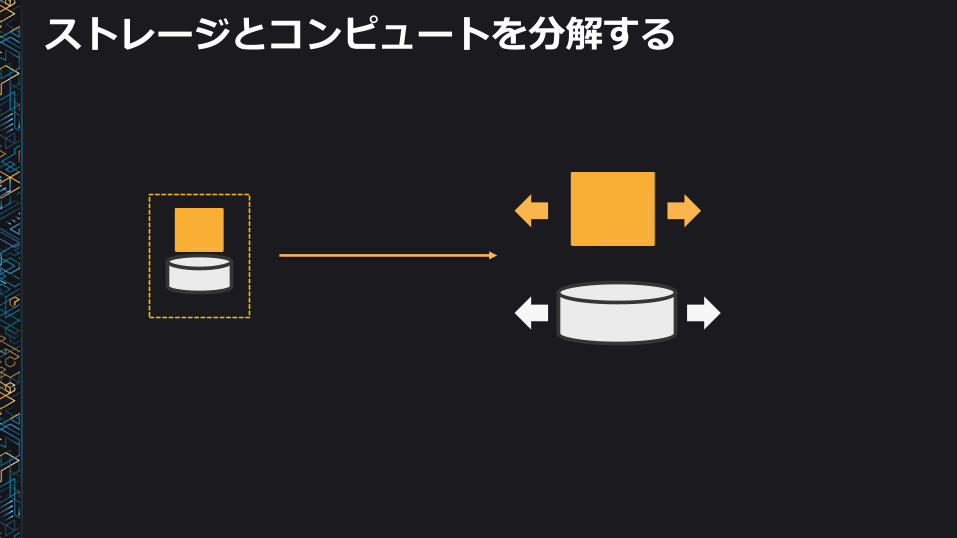
ストレージとコンピュートを分解する

Amazon S3が永続的データストアに
イレブン9の耐久性
$0.03 / GB / 月 (US-East)
ライフサイクルポリシー
バージョニング
標準で分散構成
EMRFSAmazon S3

利点1: クラスタを落とせる
Amazon S3Amazon S3 Amazon S3
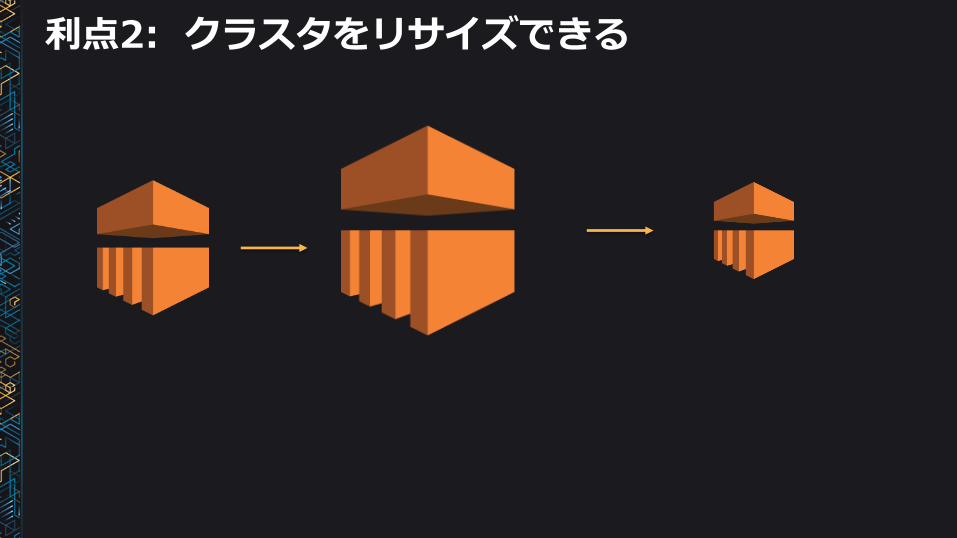
利点2: クラスタをリサイズできる

利点3: ジョブを論理的に分割できる
Hive, Pig,
Cascading
Prod
Presto Ad-Hoc
Amazon S3

利点4: ディザスタリカバリが組み込まれている
Cluster 1 Cluster 2
Cluster 3 Cluster 4
Amazon S3
Availability Zone Availability Zone

© 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Eva Tse and Daniel Weeks, Netflix
October 2015
BDT303
Running Presto and Spark on the
Netflix
Big Data Platform


Netflixで鍵となるビジネス上のメトリクス
6500万人以上の会員
50の国1000以上のデバイスをサポート
100億時間 / 四半期

我々のBig Dataの規模感
トータル ~25PB のデータウェアがAmazon S3に
読み出し ~10% (データ/日)
書き込み ~10% (読み出しデータ/日)
~ 5500億イベント/日
~ 350のアクティブなプラットフォームユーザ

クラウドアプリ
Kafka Ursula
CassandraAegisthus
ディメンションデータ
イベントデータ
15分
日次
Amazon S3
SSテーブル
データパイプライン

Amazon S3をデータウェアストレージとして使う
Amazon S3を唯一の正しいデータソースに(HDFSではなく)
イレブン9の耐久性と99.99%の可用性が設計されている
コンピュートとストレージを分離
鍵となる追加機能
- 複数の多様なクラスタ
- Red-Blackデプロイで簡単に更新
S3

パフォーマンスはどうなのか?
Amaozn S3は自分たちのクラスタより遥かに巨大
ネットワークの負荷をオフロードできる
読み込みのパフォーマンス
- 読み込みのみの1ステージのジョブで、5-10%の影響
- 複数ステージに渡る定期的なジョブでは、さほど深刻ではない
書き込みのパフォーマンス
- Amazon S3は結果整合なので高スループットならむしろ速いことも

© 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Rahul Pathak, AWS
Scott Donaldson, FINRA
Clayton Kovar, FINRA
October 2015
Amazon EMR Deep Dive
& Best Practices
BDT305

© 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Scott Donaldson, Senior Director
Clayton Kovar, Principal Architect
EMR と
対話的な分析

最大で750億件の
イベントが
毎日5 PBを超えるストレージ
投資家を保護する
マーケットを清廉に保つ
アメリカの99%の株取引と70%のオプションを監視している
マーケットの再構築は10兆ものノードとエッジが含まれる
大きく考える
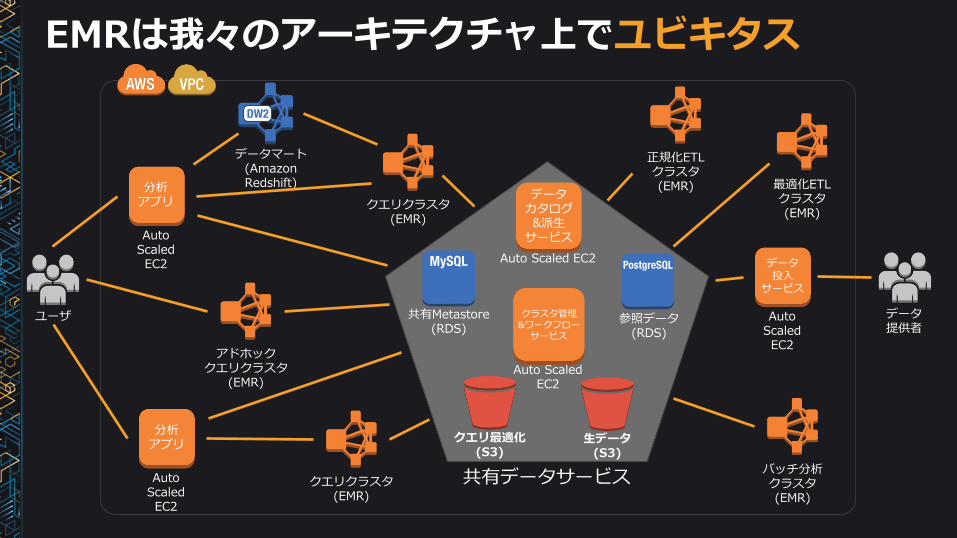
EMRは我々のアーキテクチャ上でユビキタス
データマート(Amazon Redshift)
クエリクラスタ(EMR)
クエリクラスタ(EMR)
Auto ScaledEC2
分析アプリ
正規化ETLクラスタ(EMR)
バッチ分析クラスタ(EMR)
アドホッククエリクラスタ
(EMR)
Auto ScaledEC2
分析アプリ
ユーザ データ提供者
Auto ScaledEC2
データ投入
サービス
最適化ETLクラスタ(EMR)
共有Metastore(RDS)
クエリ最適化(S3)
Auto Scaled EC2
データカタログ&派生サービス
参照データ(RDS)
共有データサービス
Auto ScaledEC2
クラスタ管理&ワークフローサービス
生データ(S3)

最も合うものを選択
我々のユースケースでは、HDFSはコスト的に不可能30×D2.8XLが2テーブルを保存するだけで必要: ~$1.5M/年 HDFS vs ~$120K/年 S3
90×D2.8XLが全てのクエリするテーブル保存に必要: ~$4.5M/年 HDFS vs ~$360K/年 S3
データの局所性は欲しいが、我々の規模なら実践的には必須ではないEMRとパーティションしたS3データの組み合わせがとてもフィットする
チューニングされたクエリとデータ構造のS3でも、完全に局所性の効いた状況のHDFSに対して、約2倍かかる
もし3回以上利用するなら、S3DistCpを使ってコアノードのHDFSに配置する
多層のストレージを考慮するHiveの外部テーブルは、いくつかのパーティションはHDFSでそれ以外S3というブレンドができる
パーティションのメンテナンスのために運用の複雑さが生まれてくる
複数クラスタでmetastoreを共有すると、うまく動かない

1つのmetastoreで全てを統制する
共有のhive metastoreを作ることを考える
Multi-AZ RDSによって、耐障害性とDRを可能に
metastoreのテーブルとパーティションの合成をオフロード一時的なクラスタの初期化をより高速に数百万パーティション/日だと、テーブル毎に7分/日以上かかる別々の開発チームで重複してしまう労力を排除する
Hive 0.13.1とHive 1.0とPresto用に別々のmetastoreが必要ただし、1つのRDSインスタンス上に同居可能
metastoreの更新のオーケストレーションにFINRAデータ管理サービスを活用新しいテーブルやパーティションはデータが到着すると通知を経由して登録される

スポットインスタンスでスケールアップする
10ノードのクラスタが14時間稼働コスト = $1.0 * 10 * 14 = $140

スポットインスタンスでクラスタをリサイズ
スポットで10ノードを追加する

スポットインスタンスでクラスタをリサイズ
20ノードのクラスタが7時間稼働コスト = $1.0 * 10 * 7 = $70
= $0.5 * 10 * 7 = $35
トータル $105

スポットインスタンスでクラスタをリサイズ
50% の実行時間削減 (14 7)
25% のコスト削減 ($140 $105)

82
Workflow tools from re:Invent 2015
• Dataduct / AWS Data Pipeline– BDT404: Building and Managing Large-Scale ETL Data Flows with AWS
Data Pipeline and Dataduct (Coursera)
• Airflow– DAT308: How Yahoo! Analyzes Billions of Events a Day on Amazon
Redshift (Yahoo)
• Luigi– CMP310: Building Robust Data Processing Pipelines Using Containers
and Spot Instances (AdRoll)
• Others: Oozie (EMR4.1.0~), Azkaban
83
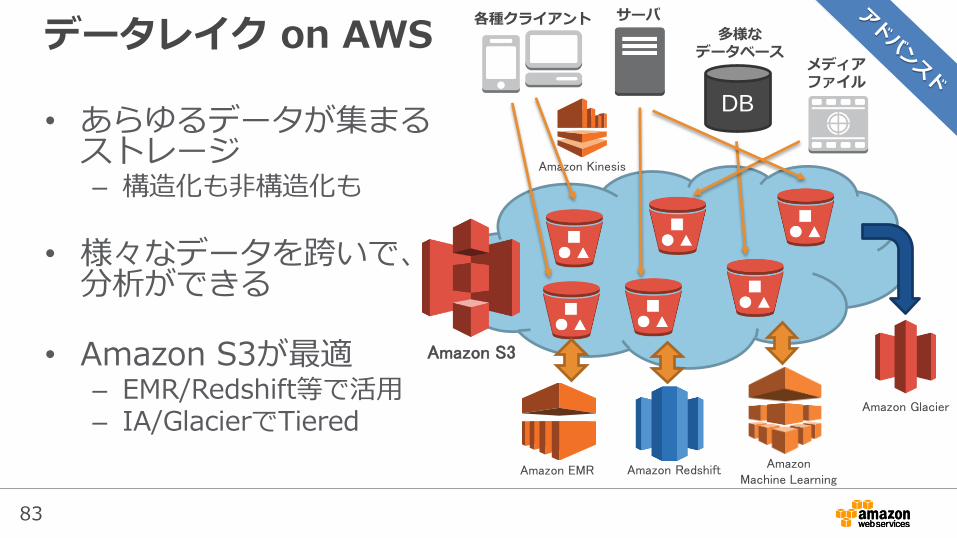
データレイク on AWS
• あらゆるデータが集まるストレージ– 構造化も非構造化も
• 様々なデータを跨いで、分析ができる
• Amazon S3が最適– EMR/Redshift等で活用– IA/GlacierでTiered
DB
各種クライアント
メディアファイル
多様なデータベース
サーバ
Amazon Kinesis
Amazon S3
Amazon Glacier
Amazon EMR Amazon Redshift AmazonMachine Learning

84
SQL on Big Data
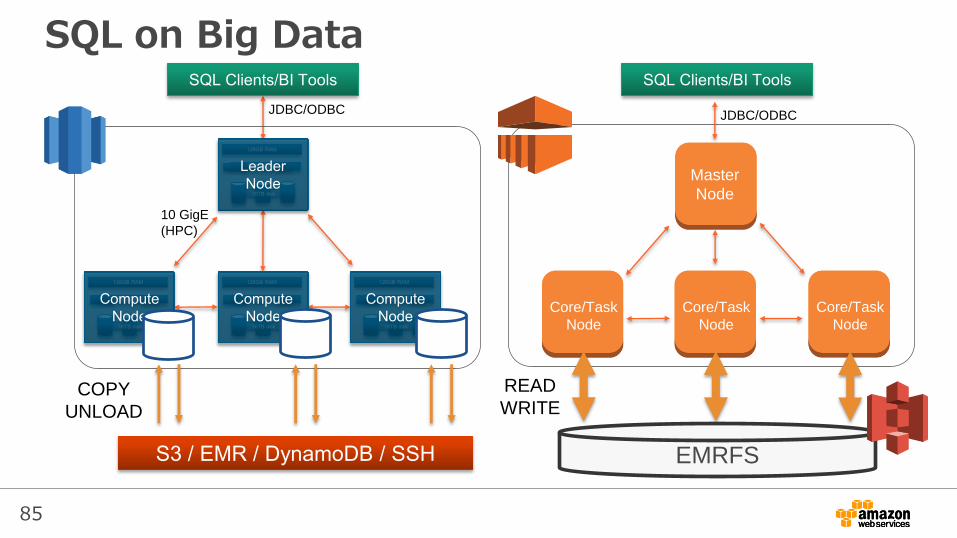
85
SQL on Big Data
10 GigE
(HPC)
COPY
UNLOAD
JDBC/ODBC JDBC/ODBC
Master
Node
Core/Task
Node
Core/Task
Node
Core/Task
Node
READ
WRITE
EMRFS

86
SQL on EMR
Query EngineApplication Storage
YARN
Map
ReduceTez Spark
HiveSpark
SQL
Presto
JD
BC
/ O
DB
C
Hiv
e M
eta
sto
re
HDFS
EMRFS
Hue
Zeppelin
SELECT COUNT(*)

87
Lambda Architecture: Example
Speed Layer
Batch Layer
Serve Layer
SQL
SQL

88
Summary

89
AWSでBig Data活用
• Big Dataは誰もが持っていて、活用するかしないか– 全量分析、相関関係、個にフィードバック
• AWSならすぐに始められて、どんな規模にも対応– 初期投資不要、従量課金、豊富な大規模事例
• SQL on Big Dataの台頭– とても簡単かつ高速に、全件検索可能

90
参考文献・資料• 書籍
– 『分析力を駆使する企業』『データ・アナリティクス3.0』
• re:Inventセッション資料– BDT403: Best Practices for Building Real-time Streaming Applications with
Amazon Kinesis (AdRoll)– BDT320: Streaming Data Flows with Amazon Kinesis Firehose and Amazon
Kinesis Analytics (スシロー)– BDT307: Zero Infrastructure, Real-Time Data Collection, and Analytics (Zillow)– BDT208: A Technical Introduction to Amazon Elastic MapReduce (AOL)– BDT303: Running Spark and Presto on the Netflix Big Data Platform (Netflix)– BDT305: Amazon EMR Deep Dive and Best Practices (FINRA)– BDT205: Your First Big Data Application on AWS– BDT306: The Life of a Click: How Hearst Publishing Manages Clickstream
Analytics with AWS (HEARST)– BDT314: Running a Big Data and Analytics Application on Amazon EMR and
Amazon Redshift with a Focus on Security (Nasdaq)

91
公式Twitter/FacebookAWSの最新情報をお届けします
@awscloud_jp
検索
最新技術情報、イベント情報、お役立ち情報、お得なキャンペーン情報などを日々更新しています!
もしくはhttp://on.fb.me/1vR8yWm
92
AWSの導入、お問い合わせのご相談
• AWSクラウド導入に関するご質問、お見積り、資料請求をご希望のお客様は、以下のリンクよりお気軽にご相談くださいhttps://aws.amazon.com/jp/contact-us/aws-sales/
※「AWS 問い合わせ」で検索してください

93

94
Appendix

© 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Matt Yanchyshyn, Sr. Mgr. Solutions Architecture
October 2015
BDT2015
Building Your First Big Data Application

最初のBig Dataアプリケーション on AWS

収集 処理 分析
保存データ 答え

収集 処理 分析
保存データ 答え

SQL
収集 処理 分析
保存データ 答え
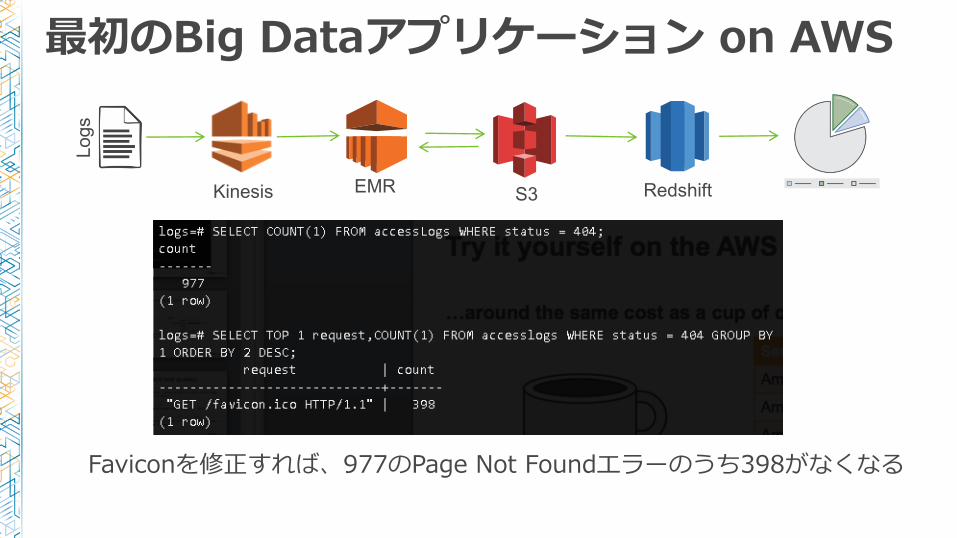
Faviconを修正すれば、977のPage Not Foundエラーのうち398がなくなる
最初のBig Dataアプリケーション on AWS

© 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Roy Ben-Alta, Business Development Manager, AWS
Rick McFarland, VP of Data Services, Hearst
October 2015
BDT306
The Life of a Click
How Hearst Publishing Manages
Clickstream Analytics with AWS


バズりによるビジネス価値
• 我々の読者からの記事に対する素早いフィードバック
• メディアを超えて、人気の記事を定期的に再配信する(例えばトレンドになっている新聞記事は雑誌にも取り上げられる)
• 記事を書く編集者に、我々の読者により関係のある情報や、どのチャネルがより我々の読者に記事を読んでもらえるかという情報を与える
• 究極的には、定期的な価値を生み出す
• ページビューが25%上がれば、定期的な価値につながる訪問者が15%増加する

• スループット目標: 250以上の世界中のHearst所有メディアからデータを送る
• レイテンシ目標: クリックからツールへの反映が5分以下
• 変更速度: クリックストリームへ簡単に新しいデータフィールドを追加できる
• データサイエンスチームが定義する特有のメトリクス(例えば標準偏差や回帰)の要求
• データレポートは1時間分から1週間分までの期間が選べる
• フロントエンドはゼロから開発されるので、APIを通して開発チームの特有の要求に応じてデータが提供される
そして最も大事なことは、既存サイトの運用に影響があってはいけない!
バズりのためのエンジニアリングの必要条件は…

データパイプラインの最終形
Buzzing API
APIで使えるデータ
Amazon Kinesis
S3 Storage
Node.JS
App- ProxyHearst所有メディアのユーザ
クリックストリーム
データサイエンスアプリケーション
Amazon Redshift
ETL on EMR
100秒1GB/日
30秒5GB/日
5 秒1GB/日
数ミリ秒100GB/日
レイテンシスループット モデル
集約データ

Data Science
Amazon Redshift
ETL
もっと”視覚的に”我々のパイプラインを表現してみると
クリックストリームデータAmazon Kinesis 結果のAPI

© 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Nate Sammons, Principal Architect, Nasdaq, Inc.
October 2015
BDT314
Running a Big Data and Analytics
Application on Amazon EMR and Amazon
Redshift with a Focus on Security

N A S D A Q は3,600のグローバル企業の
$96兆もの価値をもつ上場企業があり業界の多様性と、世界中によ く 知 ら れ る
イノベーティブなブランドを代表している
アメリカだけでなく41,000を超え多 地 域 に 渡 る10兆規模のグローバルなマーケットと紐付いている
5 0 カ 国 の100マーケット以上でN A S DA Qの技術が使われている
我々のグローバルプラットフォームは
毎 秒 1 0 0 万メッセージ以上を平均
4 0マイクロ秒以下の速度で処理できる
我 々 N A S D A Q は
2 6のマーケットを所有・運用しており
そ の 中 に は1つのクリアリング機構5つの証券保管振替機構
が含まれている

Amazon RedshiftをNasdaqのメインDWHとした
• オンプレミスのDWHからAmazon Redshiftへ転換した
• 1,000を超えるテーブルを移行
• 必要に応じて、更にデータソースを追加
• 約2年分のデータが入っている
• 毎日平均70億行以上のデータが入ってくる

絶対に何一つ捨てない
• 23台のds2.8xlarge Amazon Redshiftクラスタ
• 828 vCPU、5.48 TBのRAM
• 368 TBのストレージ容量、1PBを超えるローカルディスク
• 92 GB/秒 のディスクI/O
• 四半期に1回のリサイズ
• 27兆行: 18兆がソースから、9兆がそこから生成される

Amazon EMRとAmazon S3へ拡張した動機
• 300 TBを超えるAmazon Redshiftクラスタのリサイズはすぐには終わらない
• クラスタが継続的に成長すると高価になってくる
• 頻繁にアクセスされないデータのためにCPUとディスクのお金を払うのはナンセンス
• データは増え続けるので、どんな箱も一杯になってしまう

DWHを拡張していく

目標
• 安全で、コスト効率が良い、長期データストアを構築
• 全てのデータに対してSQLのインタフェースを提供
• 新しいMPPの分析ワークロードサポート (Spark, ML等)
• Amazon Redshiftクラスタのサイズを一定に抑える
• ストレージとコンピュートを別々に管理する

ハイレベルな俯瞰図

ストレージとコンピュートリソースを分離する
それぞれを必要に応じて独立してスケールさせ、共通のス
トレージシステムの上に複数の異なるアプリを実行する
特に古くてそれほど頻繁にアクセスされないデータは、24
時間365日動いているコンピュートリソースを持つ必要は
ない – そうすることでデータを”永遠に”保持可能
時間軸によって、アクセス要求は劇的に下がっていく
• 昨日 >> 先月 >> 前四半期 >> 昨年

データ投入の俯瞰図

鍵管理による暗号化
• オンプレミスに鍵保存用のSafenet LUNA HSMクラスタ
• Amazon Redshiftは我々のHSMと直接連携できる
• Nasdaq KMS:
• 内部的には”Vinz Clortho”という名前で知られている
• ルートの暗号化鍵はHSMクラスタの中にある
• 鍵がどこに保管されどこで使われたかを完全に制御できる

Prestoの俯瞰図

Prestoでのデータ暗号化
• PrestoはAmazon S3のアクセスにEMRFSを使わない
• Amazon S3のEncryptionMaterialsProviderのサポートをPrestoS3FileSystem.javaに追加
• コードはgithub.com/nasdaqで入手可能
• これらの変更の連携のためにFacebookと協力している

© 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Abhishek Sinha, Amazon Web Services
Gaurav Agrawal, AOL Inc
October 2015
BDT208
A Technical Introduction to
Amazon EMR

どのようにしてAOL Inc. は 2 PBのHadoopクラスタをAWSクラウドに移行したか
Gaurav Agrawal
Senior Software Engineer, AOL Inc.
AWS Certified Associate Solutions Architect

AOLデータプラットフォームアーキテクチャ 2014

データの統計と洞察
クラスタサイズ2 PB
自前のクラスタ100ノード
行データ/日2-3 TB
データ保持期間13-24ヶ月

AOLデータプラットフォームアーキテクチャ2015
12
2
34
56

AWS vs. 自前クラスタ コスト比較
0 2 4 6
サービス
コスト比較
AWS
自前
ソース: AOL & AWS Billing Tool
4x自前 / 月
1xAWS / 月
** 自前クラスタには、ストレージ、電源、ネットワークのコストを含む