best practices for large scale text mining processing
TRANSCRIPT

Oct 13, 2016
Ivelina Nikolova
Senior NLP Engineer
Best Practices for Large Scale Text Mining Process

2Oct 13, 2016
In this webinar you will learn …
• Industry applications that maximize Return on Investment (ROI) of your text mining process
• To describe your text mining problem
• To define the output of the text mining
• To select the appropriate text analysis techniques
• To plan the prerequisites for a successful text mining solution
• DOs and DON’Ts in setting up a text mining process.

3Oct 13, 2016
Outline
• Business need for text mining solutions
• Introduction to NLP and information extraction
• How to tailor your text analysis process
• Applications and demonstrations
4Oct 13, 2016
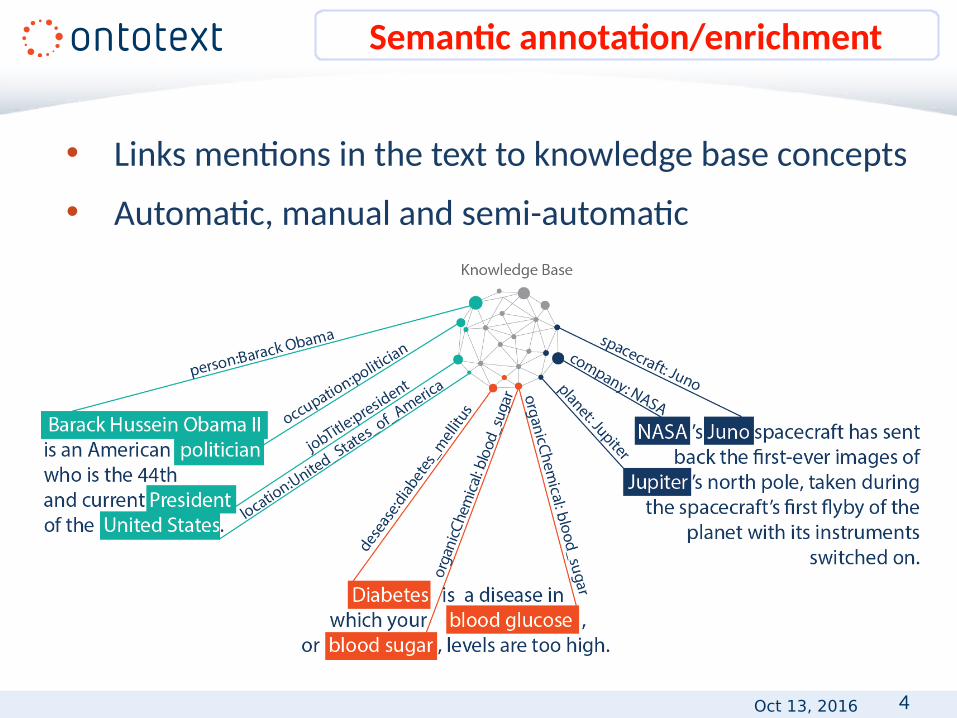
• Links mentions in the text to knowledge base concepts
• Automatic, manual and semi-automatic
Semantic annotation/enrichment

5Oct 13, 2016
• Semantic annotation facilitates:– data search– data management– data understanding – and more abstract modeling of the textual content
like…
Business needs for text mining solutions

6Oct 13, 2016
• Text summarization
• Content recommendation
• Document classification
• Topic extraction
• Document search and retrieval
• Question answering
• Sentiment analysis
Business needs for text mining solutions

7Oct 13, 2016
Some of our customers

8Oct 13, 2016
• Computational Linguistics (CS)• Natural Language Processing (NLP)• Text Mining (TM) • Information Extraction (IE) • Named Entity Recognition (NER)
NLP and IE

9Oct 13, 2016
• Named Entity Recognition– 60% F1 [OKE-challenge@ESWC2015]– 82.9% F1 [Leaman and Lu, 2016] in the biomedical
domain– above 90% for more specific tasks
State-of-the art

10Oct 13, 2016
• Language and domain dependent
• The input is free text “President Barack Obama labels Donald Trump comments as 'disturbing'”“Barack Obama labels Donald Trump comments as 'disturbing'”“President Obama labels Donald Trump comments as 'disturbing'”
• Natural language ambiguity
I cleaned the dishes in my pajamas. I cleaned the dishes in the sink.
Georgia was happy with the meal, her boyfriend cooked. Maria is excited about her trip to Georgia next month.
Why is NLP so hard?

11Oct 13, 2016
Designing the text mining process
• Know your business problem
• Know your data
• Find appropriate samples
• Use common formats or formats which can be easily transformed to such
• Get together domain experts, technical staff, NLP engineers and potential users
• Narrow the business problem to information extraction task
• Clear the annotation types
• Clear the annotation guidelines
• Apply the appropriate algorithm for IE
• Do iterations of evaluation and improvement
• Insure continuous adaptation by curation and re-training

12Oct 13, 2016

13Oct 13, 2016
Clear problem definition
• Define clearly your business problem • specific smart search • content recommendation• content enrichment• content aggregation etc.
E.g. the system must do <A, B, C>
• Define clearly the text analysis problem• Reduce the business problem to information extraction problem
Business problem: faceted search by Persons, Organizations, LocationsInformation extraction problem: extract mentions of Persons, Organizations, Locations and link them to the corresponding concepts in the knowledge base
14Oct 13, 2016
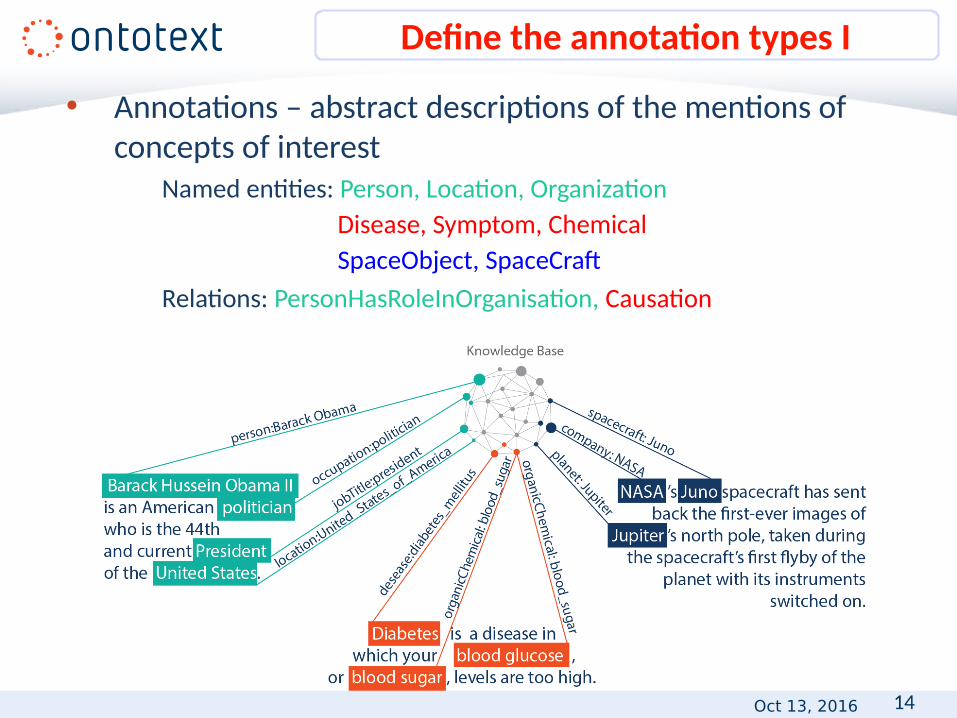
• Annotations – abstract descriptions of the mentions of concepts of interest
Named entities: Person, Location, OrganizationDisease, Symptom, Chemical SpaceObject, SpaceCraf
Relations: PersonHasRoleInOrganisation, Causation
Define the annotation types I

15Oct 13, 2016
• Annotation types• Person, Organization, Location• Person, Organization, City• Person, Organization, City, Country
• Annotation features
Location: string, geonames instance, latitude, longitude
Define the annotation types II
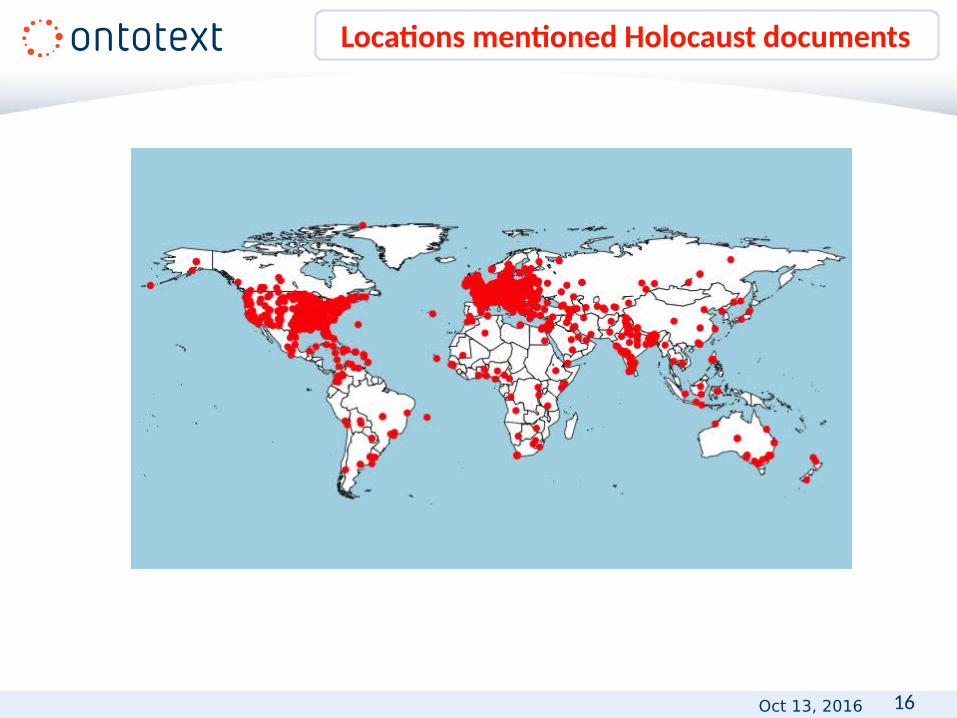
16Oct 13, 2016
Locations mentioned Holocaust documents

17Oct 13, 2016
• Annotation types• Person, Organization, Location• Person, Organization, City• Person, Organization, City, Country
• Annotation features
Location: string, geonames instance, latitude, longitudeChemical: string, inChi, SMILES, CASPersonHasRoleInOrganization: person instance, role instance, organization instance, timestamp
Define the annotation types II
string: the Gulf of MexicostartOffset: 71endOffset: 89type: Locationinst: http://ontology.ontotext.com/resource/tsk7b61yf5dslinks: [http://sws.geonames.org/3523271/
http://dbpedia.org/resource/Gulf_of_Mexico]latitude:25.368611longitude:-90.390556

18Oct 13, 2016
• Realistic
• Demonstrating the desired output
• Positive and negative• “It therefore increases insulin secretion and reduces POS[glucose] levels,
especially postprandially.”• “It acts by increasing POS[NEG[glucose]-induced insulin] release and by
reducing glucagon secretion postprandially.”
• Representative and balanced set of the types of problems
• In appropriate/commonly used format – XML, HTML, TXT, CSV, DOC, PDF.
Provide examples
19Oct 13, 2016
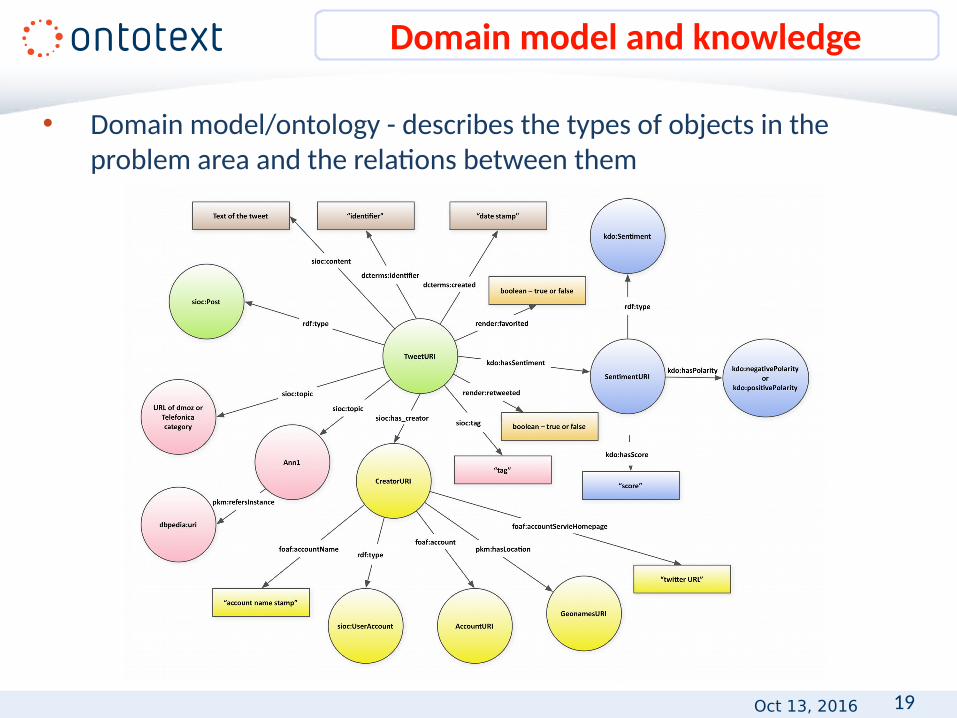
Domain model and knowledge
• Domain model/ontology - describes the types of objects in the problem area and the relations between them

20Oct 13, 2016
• Data sources - proprietary data, public data, professional data
• Data cleanup
• Data formats
• Data stores • For metadata - GraphDB (http://ontotext.com/graphdb/)• For content – MongoDB, MarkLogic etc.
• Data modeling is inevitable part of the process of semantic data enrichment• Start it as early as possible• Keep to the common data formats• Mistakes and underestimations are expensive because they influence the
whole process of developing a text mining solution
Data

21Oct 13, 2016
• Gold standard – annotated data with superior quality
• Annotation guidelines - used as guidance for manually annotating the documents.
POS[London] universities = universities located in LondonNEG[London] City CouncilNEG[London] Mayor
• Manual annotation tools – intuitive UI, visualization features, export formats• MANT – Ontotext's in-house tool• GATE – http://gate.ac.uk/ and https://gate.ac.uk/teamware/• Brad - http://brat.nlplab.org/
• Annotation approach• Manual vs. semi-automatic• Domain experts vs. crowd annotation• E.g. Mechanical Turk - https://www.mturk.com/
• Inter-annotator agreement
• Train:Test ratio – 60:40, 70:30
Gold standard

22Oct 13, 2016
• Rule-based approach• lower number of clear patterns which do not change over time or slightly change• high precision • appropriate for domains where it is important to know how the decision for extracting
given annotation is taken – e.g. bio-medical domain
• Machine learning approach• higher number of patterns which do change over time• requires annotated data• allows for retraining over time
• Neural Network approach• Deep Neural Networks - getting closer to AI• Recent advances promise true natural language understanding via complex neural
networks• Great results in Speech recognition, Image recognition and Machine translation;
breakthrough expected in NLP• Still unclear why and how it works thus difficult to optimize
Text analysis approach

23Oct 13, 2016
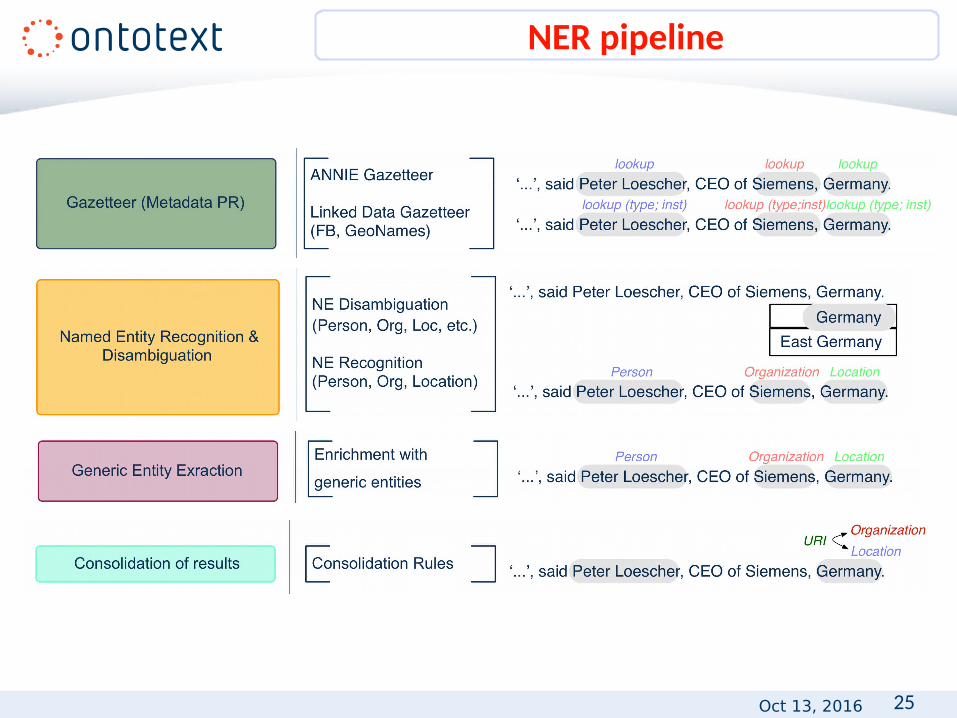
• Preprocessing
• Keyphrase extraction
• Gazetteer based enrichment
• Named entity recognition and disambiguation
• Generic entity extraction
• Result consolidation
• Relation extraction
NER Pipeline

24Oct 13, 2016
NER pipeline
25Oct 13, 2016
NER pipeline

26Oct 13, 2016
NER pipeline

27Oct 13, 2016
• Curation of results - domain experts assess manually the work of the text analysis components
• Testing interfaces
• Feedback• Select representative set of documents to evaluate manually• Provide as full description of the results and the used component as
possible: <pipeline version> <input as send for processing> <description of the wrong behavior> <description of the correct behavior>
• The earlier this happens it triggers revision of the models and improvement of the annotation
Results curation / Error analysis

28Oct 13, 2016
• Gold standard split train:test • 70:30• 80:20
• Which task you want to evaluate • E.g. extraction at document level
or inline annotation
• Evaluation metrics• Information extraction tasks – precision, recall, F-measure• Recommendations – A/B-testing
Evaluation of the results
29Oct 13, 2016
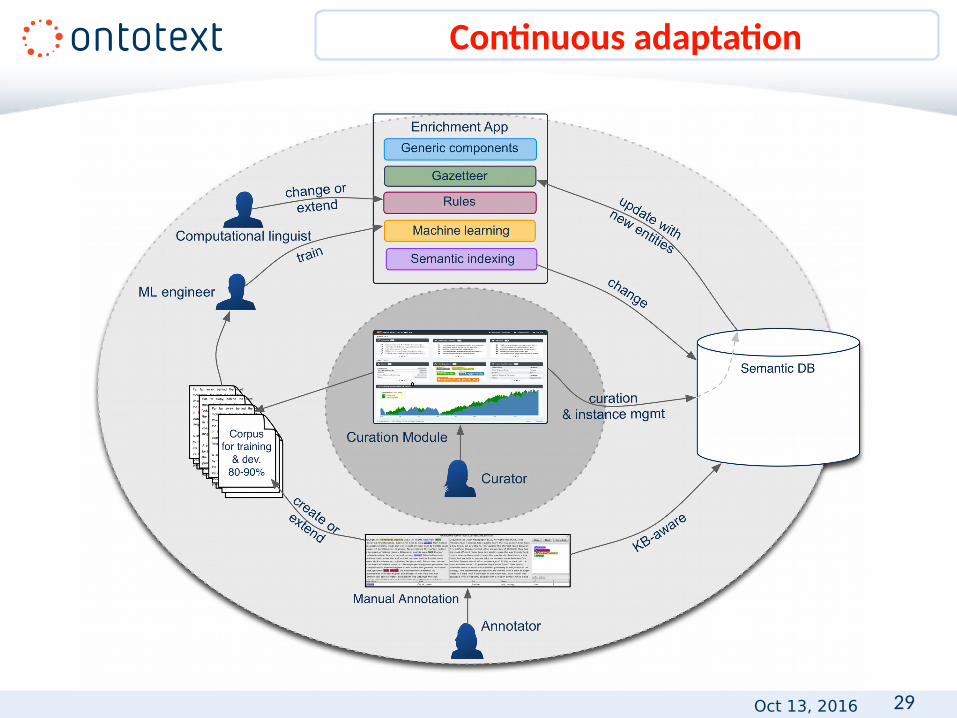
Continuous adaptation

30Oct 13, 2016
• Document categorization • post, political news, sport news, etc.;
• Topic extraction• important words and phrases in the text;
• Named entity recognition • People, Organization, Location, Time, Amounts of money, etc.;
• Keyterm assignment from predefined hierarchies
• Concept extraction• entities from a knowledge base;
• Relation extraction • relations between types of entities.
Types of extracted information
31Oct 13, 2016
• TAG (http://tag.ontotext.com)
• NOW (http://now.ontotext.com)
• Patient Insights (http://patient.ontotext.com/) - contact [email protected] for credentials.
Applications

32Oct 13, 2016
• Clearly defined business problem needs to be broken down to a clearly defined information extraction problem
• Requires combined efforts from business decision makers, domain experts, natural language processing experts and technical staff
• Data modeling is inevitable part of the process, consider it as early as possible
• Create clear annotation guidelines based on real-world examples
• Start with an initial small set of balanced and representative documents
• Plan the evaluation of the results in advance
• Choose appropriate manual annotation tool
• While annotating content check how the quantity influences the performance
• Select the appropriate text analysis approach
• Plan iterations of curation by domain experts followed by revision of the text analysis approach
• Plan the aspects of continuous adaptation – document quantity, timing, temporality of the information fed in the model
Take away messages
33Oct 13, 2016
Thank you very much for the attention!
You are welcome to try our demos at http://ontotext.com