caジャーナルクラブ tao: facebook’s distributed data store for the social graph
TRANSCRIPT

CAジャーナルクラブ TAO: Facebook’s Distributed Data Store for the Social Graph2014/12/19 山田 直行

今回取り上げる論文・資料TAO: Facebook's Distributed Data Store for the Social Graph | Publications | Research at Facebookhttps://research.facebook.com/publications/161988287341248/tao-facebook-s-distributed-data-store-for-the-social-graph/
TAO: The power of the graph https://www.facebook.com/notes/facebook-engineering/tao-the-power-of-the-graph/10151525983993920
TAO: Facebook’s Distributed Data Store for the Social Graph | USENIXhttps://www.usenix.org/conference/atc13/technical-sessions/presentation/bronson

課題意識と狙い
ソーシャルグラフのデータを、大規模なトラフィック上で、リアルタイムに取得する方法について、Facebookの事例から考える
データストアの設計として、永続化データレイヤーと、キャッシュレイヤーを作るのは一般的だが、そのキャッシュレイヤー自体がデータモデルを持つという、変わった構成について

目次- Abstract
- 1. Introduction
- 2. Background
- 3. TAO Data Model and API
- 4. TAO Architecture
- 5. Implementation
- 6. Consistency and Fault Tolerance
- 7. Production Workload
- 8. Performance
- 9. Related Work
- 10. Conclusion

AbstractTAOというデータストアについて取り上げる
Facebookのサービスでソーシャルグラフのデータを取得するのに実際に用いられている
地理的に分散しており、かつFacebookのワークロードを捌くのに十分なパフォーマンス- 10億read/秒、100万Write/秒
memcacheをただのキャッシュとしてではなく、データモデルに組み入れる形で使っている

1. IntroductionTAOができる以前は、MySQLをデータストアとしてmemcacheをキャッシュとして使う一般的な構成にしていた(“lookaside cache”)
TAOはMySQLを永続化データストアとして使いつつ、memcacheのレイヤーがグラフデータベースとして機能するのが特徴
必要最小限のAPIを持つ
AvailabilityとPer-machine Efficiencyを重視して、Strong Consistencyを妥協している

2. Background
Facebookはそれぞれのユーザーに対して、各個人にカスタマイズした内容を、かつプライバシー設定も考慮したうえで表示内容を動的に生成する必要がある
この動的生成するデータをあらかじめ用意しておくのは不可能なので、都度ソーシャルグラフを取得してコンテンツを組み立てるためread処理が圧倒的に重要
効率的で、可用性が高く、スケールする必要がある

2.1 Serving the Graph from MemcacheMemcacheをlookasideキャッシュとして使うことの問題点について- PHPコードがキャッシュの一部
Inefficient edge lists- 単純なKey-ValueストアはEdgeを扱うのに非効率
Distributed control logic- client side(PHP側)にロジックがある
Expensive read-after-write consistency - MySQLのmaster/slave構成を前提にするとコストが高い

2.2 TAO’s GoalTAOは複数のリージョンにまたがったデータベースとして、絶えず変化するグラフデータのnodeとedgeを高いパフォーマンスで取得することができる
READにパフォーマンス最適化
基本的にはデータは最新のものを取得できるが、古いデータを読んでしまうことも一部許容する
これはFacebookをはじめとしたソーシャルネットワークサービスの要件に適合する
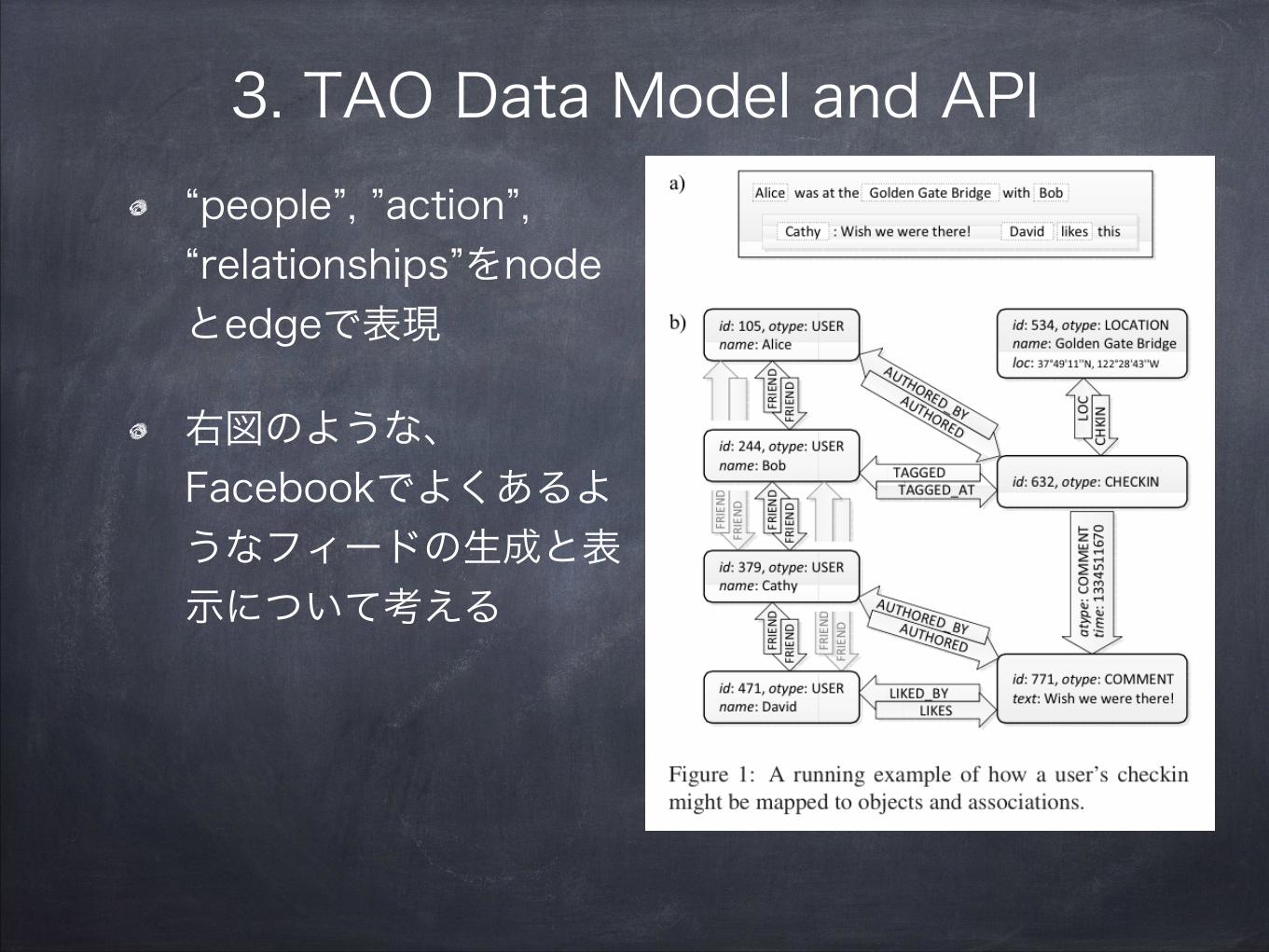
3. TAO Data Model and API“people”, ”action”, “relationships”をnodeとedgeで表現
右図のような、Facebookでよくあるようなフィードの生成と表示について考える

3.1 Objects and Associations
Object = node- ユーザー、場所、チェックイン、コメントなど
Assoc. (Association) = edge- 友だち関係、「いいね!」、タグ付けなど

3.2 Object APIidをキーにしたCRUD(Create, Read, Update, Delete)機能
Field(Value)の一部に対してのみUpdateをかけることも可能

3.3 Association APIedgeの多くは双方向- 友だち関係のように、相互に対称なもの- 許可している←→されているのように非対称なもの
atypeはinverse-typeを持ち、対になっているAssociationを1つの操作で扱えるようにしている

3.4 Association Query API”Association List”という単位でデータをクエリする
AliceのCheckinに関するコメント最新50件→assoc_range
GG Bridgeに対するChekin数→ assoc_count
GG BridgeのCheckIn履歴を取得→assoc_get


4. TAO ArchitectureTAOの、複数のレイヤーの集計からなる構造について説明し、それをどうスケールさせているのか説明する
TAOは2つのCaching Layerと1つのStorage Layerから構成される

4.1 Storage Layer
永続化ストレージレイヤーはMySQL
データはシャードに分割され、複数のサーバーにまたがって分散配置される
Objectはあるシャードにアサインされたらずっとそこに保存される
Associationはid1のObjectが属するシャードに保存される

4.2 Caching Layer
Tierといわれる複数のキャッシュサーバーの集合という単位で管理される
それぞれのTierはTAOのどのクエリについても応答できるように作られている
各キャッシュサーバーにクエリが飛んだとき、キャッシュサーバーは自分自身でデータを返せないときは他のキャッシュサーバー/データベースに問い合わせる機構を持つ

4.3 Client Communication Stack
1つのFacebookページを表示するのに、数百のObject/Associationをクエリするのは珍しくない
Client Stackとしては”Scaling Memcache at Facebook”で述べられているシステムと共用している
ただしTAOのほうはデータベースを参照しにいくケースがあるため、レイテンシは高い。そのため順序関係なくレスポンスしていくプロトコルにしている

4.4 Leaders and FollowersTierは、Leader Tier(各リージョンに1つだけ存在)とFollower Tier(複数存在)の2つに分けられる
Follower Tierは、クライアントからのリクエストを受け付ける。自身で結果を戻せない場合には、Leaderにリクエストをフォワードして結果を取得してクライアントに返す
Leader Tierは各Followerからのリクエストを受けてRead/Writeを行う。Leaderが直接クライアントのリクエストを受けることはない


4.5 Scaling Geographically
Readは同一Region内で完結する
WriteはMaster RegionのLeaderに集約される

5. Implementation前章では、TAOがいかにして大量のデータとクエリを捌くためにサーバーを使っているかを述べた
本章ではより細部の、パフォーマンスとストレージ効率の最適化について述べる

5.1 Caching ServersTAOのキャッシュサーバーは”Scaling Memcache at Facebook”で述べられている仕組みをベースに、memcacheのslab allocatorの仕組みを用いて管理している
さらに、Object/Associationごとの生存期間を個別に最適化するため、RAM全体をarenaといわれるゾーン別に分けて管理している(例えばCheckinのキャッシュは短くてよいがFriendのキャッシュは長め、など)
Countなどの固定長のアイテムは、ポインタを持つのがオーバーヘッドなので直接データを持つようにしている

5.2 MySQL Mapping
データはシャードという単位に分割されている
シャード=MySQLの1データベース
Objectテーブル、Associationテーブルの2つのテーブルがあり、各データはシリアライズされて”data”カラムに格納される
Association Countの結果を格納するテーブルなど、いくつかのカスタムテーブルがある

5.3 Cache Sharding and Hot Spots
ShardはTier内にConsistent Hashingにもとづいて配置されるが、それだけだと使われる頻度の高いデータとそうでないものでLoadの偏りが生じる
ShardはCloneしてさらに分散配置して偏りを解消させている
特によく参照されるデータについては、クライアントサイドに小さなキャッシュを持ち、キャッシュサーバーへのアクセスを不要にして高速化を図っている

5.4 High-Degree ObjectsObjectによっては6000以上のAssociationを持つため、全てをキャッシュはしていない。そのままクエリをしたのではMySQLを参照しにいくリクエストが増えてしまう
それに対応するため、- assoc_countを用いて逆のedgeをたどることによりキャッシュにヒットさせる- 逆のedgeも同様に多くのAssociationがある場合、 ”Association create time > Object create time”という条件をつけてクエリする

6. Consistency and Fault ToleranceTAOの最重要な要件は可用性とパフォーマンス
仮に一部のリクエストがFailしてもページの表示はしなければならない
本章では、TAOの平常時の一貫性モデルと、Failした場合に一貫性をどのように犠牲にしているかを説明する

6.1 ConsistencyObject/Associationは結果整合性
同一Tier内では、read-after-writeの整合性がある
キャッシュの変更は常に安全に適用できるとは限らないため、バージョン番号を付与して整合性を担保
criticalにマークされたリクエスト(認証など)は必ずMasterDBを参照しにいく

6.2 Failure Detection and HandlingDatabase failures- masterダウン時にはslave昇格- slaveダウン時にはLeaderにフォワード
Leader failures- Leaderの一貫性を復旧しようと試みる、復活するまでは古いデータを返す
Refill and invalidation failures- ディスクのキューに保存
Follower failures- バックアップのFollowerが対応
等々

7. Production Workload
TAOはFacebook全体で1つのインスタンスのみ存在
さまざまなソーシャルグラフを1つのシステムで扱えることは、運用コスト・サーバーキャパシティプランニング・高速な開発などにおいてさまざまなメリットがある
TAOほどのスケールで実現しているグラフデータストアは他に例が無い

FacebookでのProduction環境におけるデータやワークロードの傾向についての説明
readはwriteよりもはるかに多い
多くのedgeに対するクエリの結果は空
クエリの頻度や、nodeのつながり、データサイズ等にはロングテールの傾向がある

8. Performance
「可用性」「Followerのキャパシティ」「キャッシュヒットレートとレイテンシ」「レプリケーションのラグ」「フェイルオーバー」のそれぞれについてFacebookのProduction環境での実測値を示している

9. Related WorkEventual Consistency(結果整合性)- read-after-write consistencyは結果整合性の一種
地理的に分散したデータストア- Coda file system- Megastore - Spanner(Google)
分散ハッシュテーブルとKey-Valueシステム- Amazon Dynamo- Voldemort(LinkedIn)

階層構造のネットワーク接続(Leader and Follower)- Akamaiのコンテンツキャッシュ
構造化ストレージ(RelationalDBでないもの)- Bigtable(Google) - PNUTS(Yahoo!)- SimpleDB(Amazon)- HBase(Apache)- Redis

グラフDB- Neo4J- FlockDB(Twitter)
より進んだグラフDBの操作API- PEGASUS- Pig Latin(Yahoo!)- Pregel(Google)

10. Conclusion
Facebookでのチャレンジについて述べた。高いスループット、低いレイテンシでの、変更頻度の高いデータに対するクエリをどう実現するか
Facebookのソーシャルグラフをどうデータモデルに落としこんでいるか解説した
TAOという、地理的に分散した、ソーシャルグラフデータをクエリできるシステムについて説明した

キャッシュと永続化のレイヤーが分かれていることで、独立してデザインでき、スケールしやすく、運用も楽になった
その一方、効率と一貫性に関するトレードオフもある
TAOのAPIやデータモデルは、Facebookのアプリケーション開発者にも利用してもらうことができている