统计学是一门科学、技术、逻辑, 更是一门艺术 -...
TRANSCRIPT

统计学是一门科学、技术、逻辑,更是一门艺术
统计学没有任何固定的对象,是一门独特的学问。依赖于解决其他领域内的问题而存在并兴旺发达的。
L.J.Savage 说:统计学基本是寄生的:靠研究其他领域
内的工作而生存。这不是对统计学表示轻视,这是因为对大多数寄主来说,如果没有寄生虫就会死。对有的动物来说,不能消化它们的食物。因而,人类奋斗的很多领域,如果没有统计学,虽然不会死,但一定会变得很弱。

统计学
1. 区分科学真理和科学虚伪。
2. 在可利用的资源上,收集和处理所得的信息,从而能做出最佳的决策。
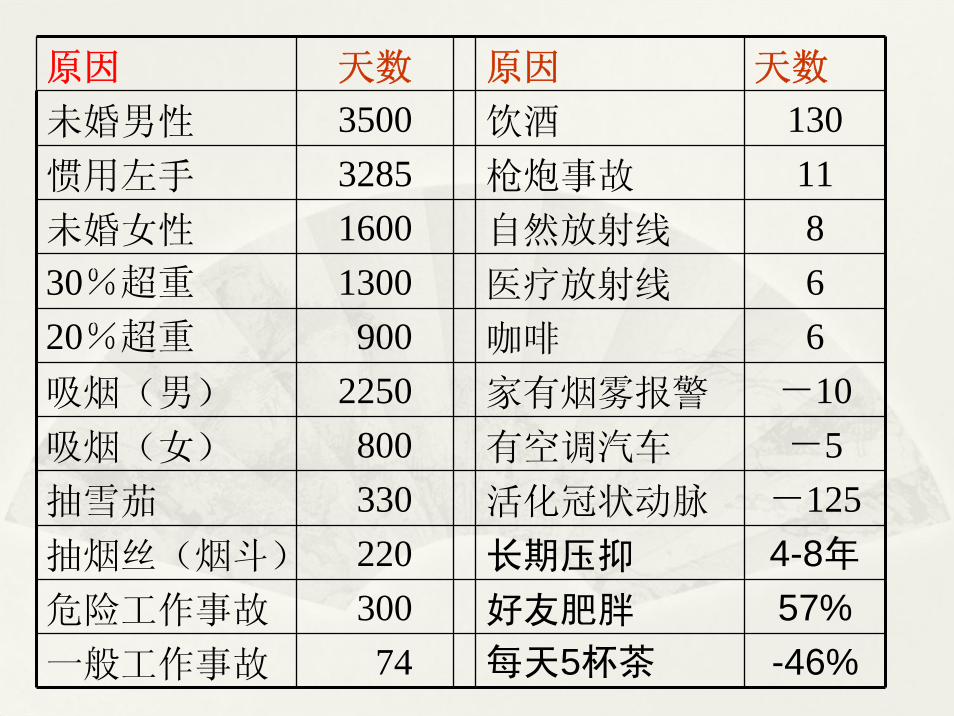
原因 天数 原因 天数
未婚男性 3500 饮酒 130惯用左手 3285 枪炮事故 11未婚女性 1600 自然放射线 830%超重 1300 医疗放射线 620%超重 900 咖啡 6吸烟(男) 2250 家有烟雾报警 -10吸烟(女) 800 有空调汽车 -5抽雪茄 330 活化冠状动脉 -125抽烟丝(烟斗) 220 长期压抑 4-8年危险工作事故 300 好友肥胖 57%一般工作事故 74 每天5杯茶 -46%

提纲
第一章数据收集
第二章统计描述
第三章统计数据预处理
第四章统计指数
第五章非参数统计
第六章贝叶斯方法
第七章常用算法
第八章分布滞后模型和时间序列模型

第一章 数据收集
什么是数据?一种描述性的定义是:可以由它作出推断的已知事情或事物。数据有不同的表达形式:数字,类别,性
别等数据的完整性是一个 大的问题。够用。数据的质量。数据有偏差或误导可以毁掉
一个有效的决策过程。

为决策而准备数据前,首先要明确问题是什么?难点是什么?
在收集数据时我们要考虑:1.什么是我们考虑的相关总体(population)?2.数据从何处而来?3.在分析所收集的数据时要进一步分析一下我们提问了多少人,他们是如何被挑选出来的?4.如何从这些回答者中收集信息?5.谁没有回答提问?6.收集的数据类型是什么?

数据来源二大来源:原始数据(primary data) ,
二手数据(secondary data)。
配额( 比 例)抽样随机抽样
抽样(sampling)普查(census)
原始数据

二手数据:已有的数据(别人调查所得,包括政府数据),如“年鉴”,别的公司调查结果等。来源:行业或地区组织内部;国内外有关资料。二手数据大部分来自官方统计,如
年鉴(Annual Abstract of Statistics)月度统计报表(The Monthly Digest of
Statistics)财经统计(Financial Statistics)经济趋势(Economic Trends)……

原始数据:自己经过调查所获得的数据。它的特点是为指定目的而收集。原始数据得到的方式如下:面试、电话访谈、发信调查、一般抽样访查、跟踪研究
普查:普查:仅局限于总体较小时仅局限于总体较小时。。

样本大小(sample size)的选择:当总体太大时不能全面调查,这时要用抽样方法,关键是样本要有代表性,即全面反映该总体观点,所以抽样前要做好抽样方案。确定要调查多少人,调查什么样的人等。抽样代表性是指每个人都可能被抽到,且抽到的可能性相同。这样的抽样称为随机抽样(random sampling)。

例1. 抽查时,不抽身高≥1.80米,则不能反映1.80米以上人群的观点,因此这种抽样是非随机的。如何做到抽样有很好的随机性?通常用如下手段:首先把总体中要调查的每个人编上号。然后用计算机,随机数表,摇奖机等方法得一组随机数。把随机数对应的人群构成一个样本。

提问(asking questions)认定调查总体及决定用问卷方式以得到所需信息后,下一步是确定问什么,如何问。● 问卷设计(questionnaire design)问卷结构特点:问答由一个问题顺势转入下一个问题;由一个主题转到另一主题。不要有跳跃以导致回答的无方向性。建议:从一般问题到特殊问题。盖洛普(Gallup)组织总结提问的目的有如下5种:1.找出回答者是否觉察到这一结果,例. 你是否知道合肥和徐州之间要修条高速公路的计划?知道/不知道

2.获得关于结果的一般感觉例. 你是否同意合肥和徐州之间要修条高速公路?请在下列选择中选择一个:强烈同意、同意、无所谓、不同意、强烈不同意3.获得该结果指定部分的答案例.你认为高速公路会对当地环境产生影响吗?有/没有
对是否影响环境,有时可分得再细一点,如指出是噪音还是风景。4.获得反映回答者观点的理由例. 如果反对,那你反对的理由是:
(a)已有一条可用的主干道(b)合肥和徐州之间运量不足

(c)高速公路会损坏美丽的乡村风景(d)道路会破坏历史文物(e)其他,请指定……
这一条是先知道他(她)的观点,然后给机会以让他(她)说明理由。把条件叙述“如果反对”看作一种预先设定的过滤。此外,这一条也可提成"为什么你反对修这条高速公路"。这种提法称为开放式的。这两种设定互有优缺点。预先设定的容易回答;开放式的结论需要回答者有较高的文化修养。

5.找出持有这些观点的强烈程度例. 你准备用下列哪一种行动来支持你的观点?(a)给地区人大代表写信(b)给本单位的全国人大代表写信(c)给新闻单位写信(d)在政府召开的公众听证会上发言(e)在网上发表呼吁文章进行调查
建设高速公路将会毁坏一些历史文物,因此可以提这样的问题:这些历史文物的重要性有多大?请在下列小格中打√(应不惜一切代价保存) 1 2 3 4 5 6 7(不重要)

一、提问的方式开放式提问的优缺点:缺点:1. 导致偏爱社区中有文化和教育程度高的人,因他们能很快地组织和表达他们的思想和理念。优点:有助于人们回答自己想要表达的观点。预先设定答案提问的优缺点:优点:容易回答缺点:不能准确和全面反映被调查者的意见。例如,你的提问是“你同意在某国布置核武器吗”? 预先设定的答案如下: 同意, 不同意,不知道
某些回答者可能说“是的,但仅仅是某一种核武器”,或“不,但没有可以代替它们的”,或“是的,只要它们的发射受到严格控制”。
对这类问题的解决办法是试图扩大预设答案的范围。
如果不行,只能提成开放式的。

二、提问的措辞(wording questions)提问的措辞在诱导出有代表性回答中是非常重要的。
一个有偏差的或诱导性提问将偏离给定的回答。在问卷设计中发现的偏差主要有:1.把两个或两个以上问题表达为一个。例如在调查一个小区建公用车库还是建自有车库时,如果你的问题设计为“由于自有车库使用方便和比较清洁,因此你赞成修自有车库”。使用方便和比较清洁是两个不同的问题,有人愿意修自有车库是因为使用方便,但不一定清洁。2.问题中含有含糊或不熟悉的单词。例
①你通常到哪儿去购物?问题是几次算通常?②感冒后你吃盐酸马啉脒胍片吗?盐酸马啉脒胍片是医学用的专业词汇。通常百姓只知道
感冒灵。

三、用软化难度或方向的词开始的提问。如对一个女孩提如下问题:
我希望你不要在意我提出这个问题,你多大了?回答者会立即警惕起来。向你发出警告(不回答)。
再举一个例:像大多数人那样,你是否认为在北大西洋公约组织
里应该有英国的声音? 是/不是这类引导性问题有两种可能反应:(a)导致同意这种论述,以作出和大多数人一样的
回答(b)单纯为了不同意而不同意。
在两种情况下,回答者都不一定能反应出自已所持的观点。

四、包含条件或假设条款。例:如果你有6个小孩,你认为你的生活会有多少改变?一般情况下,有6个孩子的情况很难发生,因此回答者无法回答你的问题。五、包含对回答者一个或多个指令的提问。例:如果你拿到周薪后,在你预留下所有日常支出的钱以及小孩上学费用后你还有多少钱可以消费或存起来?一般机关事业人员拿月薪或年薪,水电费也是一个月或两个月收一次费,而孩子上学费用一般是半年一次。因此被访者无法回答你的问题。

数据的类型
根据数据的来源,我们可以把数据分成四类:⒈ 定性数据:又称分类(名义)数据(categorical or nominal data)或分类标志,例如⒉ 定量数据:(1)有序数据 它们之间有大小之分,但没有大多
少的概念。例如可以把人们对某一事件的态度进行量化,用1,2,…来表示对某一事件的态度。(2)间隔数据 间隔数据是有序数据,他们之间的
差是有意义的。例如温度是一个典型的间隔数据例子。0°C不表示没有热量,40°C和30°C的温差在数量上等于80°C和70°C之间的温差,但它们代表的热量是不一样的。

(3)比例数据 测量的 高水平是比例数据。这类数据有一个起点,记为0。例如距离和时间,0是有意义的,可以看作距离和时间的起点。两倍的距离和两倍的时间也是有意义的数据也可以根据定性或定量被分类,前者由定性数据产生,后者由定量数据产生。
定量数据可进一步分为离散数据和连续数据,这在统计上是本质的,即离散数据是可以一个一个地数的,而连续数据往往用一个区间或一条直线上的数值来表示。

第一节第一节 统计表与统计图统计表与统计图
统计表的概念:统计表的概念:对统计调查所获得的对统计调查所获得的原始资料进行整理,得到的数据,把这些原始资料进行整理,得到的数据,把这些数据按一定的顺利排列在表格上,就形成数据按一定的顺利排列在表格上,就形成了统计表。了统计表。
一、统计表(一)统计表的定义和结构(一)统计表的定义和结构
第二章第二章 统计描述统计描述
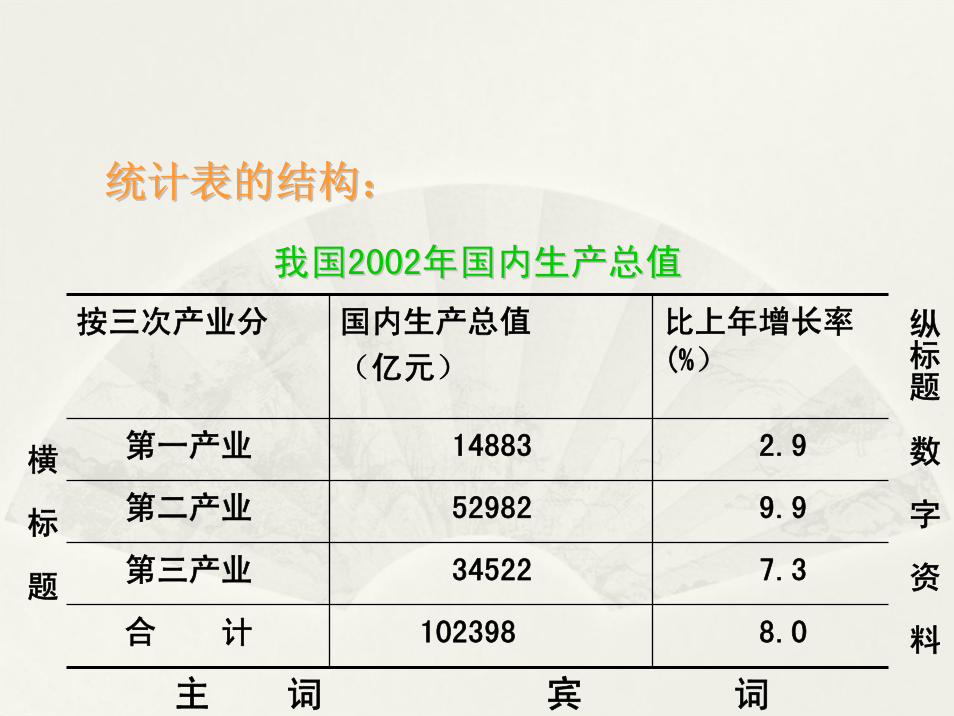
我国我国20022002年国内生产总值年国内生产总值
统计表的结构:统计表的结构:
按三次产业分 国内生产总值
(亿元)
比上年增长率(%)
第一产业 14883 2.9
第二产业 52982 9.9
第三产业 34522 7.3
合 计 102398 8.0
纵标题
数
字
资
料
主 词 宾 词
横
标
题

((33))复合表复合表::主词按两个或两个以主词按两个或两个以上标志进行分组的统计表,也称复合分组表。上标志进行分组的统计表,也称复合分组表。
(二)统计表的分类(二)统计表的分类
11、按主词的结构分类,根据主词是否分组和、按主词的结构分类,根据主词是否分组和分组的程度,分为简单表、分组表和复合表。分组的程度,分为简单表、分组表和复合表。
((11))简单表:简单表:主词未经任何分组的统计表称主词未经任何分组的统计表称为简单表,也称一览表。为简单表,也称一览表。
((22))分组表:分组表:主词只按一个标志进行分组主词只按一个标志进行分组形成的统计表,也称简单分组表。形成的统计表,也称简单分组表。

1999年国际旅游收入居世界前十名的国家
国 家 位次 旅游收入收
入(亿美
元)
占世界比重
(%)
美国 1 730 16
西班牙 2 315 6.9
意大利 3 310 6.8
法国 4 307 6.7
英国 5 209.7 4.6
德国 6 165 3.6
中国 7 141 3.1
奥地利 8 112 2.5
加拿大 9 102.8 2.3
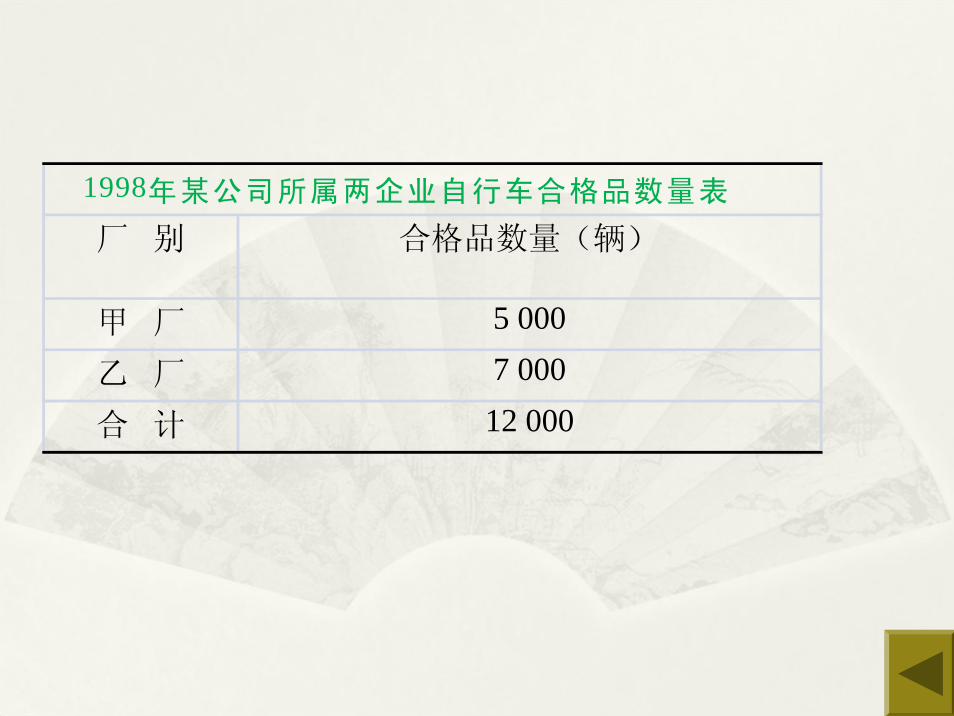
1998年某公司所属两企业自行车合格品数量表
厂 别
甲 厂乙 厂合 计
合格品数量(辆)
5 0007 00012 000

人口数/万人 比例/%
男 64 189 50.98
女 61 720 49.02
男 38 892 30.89
女 87 017 69.11
资料来源:《中国统计年鉴(2000)》第95页
市镇
乡村
1999年我国人口数及构成

22、按宾词设计分类,可分为宾词简单、按宾词设计分类,可分为宾词简单排列、分组平行排列和分组层叠排列等。排列、分组平行排列和分组层叠排列等。
((11)宾词简单排列。)宾词简单排列。宾词不进行任何分组,按宾词不进行任何分组,按一定顺序排列在统计表上。一定顺序排列在统计表上。
((22)宾词分组平行排列。)宾词分组平行排列。宾词栏中各分组标宾词栏中各分组标志彼此分开,平行排列。志彼此分开,平行排列。
((33)宾词分组层叠排列。)宾词分组层叠排列。统计指标同时有层次统计指标同时有层次地按两个或两个以上标志分组,各种分组层叠在一地按两个或两个以上标志分组,各种分组层叠在一起,宾词的栏数等于各种分组的组数连乘积。起,宾词的栏数等于各种分组的组数连乘积。

(三)统计表的设计(三)统计表的设计统计表设计总的要求是:统计表设计总的要求是:简练、明确、实用、简练、明确、实用、
美观、便于比较。美观、便于比较。((11)线条的绘制。)线条的绘制。表的上下端应以粗线绘表的上下端应以粗线绘
制,表内纵横线以细线绘制。两端一般不划线,制,表内纵横线以细线绘制。两端一般不划线,采用采用““开口式开口式””。。
((22)合计栏的设置。)合计栏的设置。
((33)标题设计。)标题设计。统计表的总标题,横栏、纵统计表的总标题,横栏、纵栏标题应简明扼要,以简练而又准确的文字表述栏标题应简明扼要,以简练而又准确的文字表述统计资料的内容、资料所属的空间和时间范围。统计资料的内容、资料所属的空间和时间范围。

((44)指标数值。)指标数值。表中数字应该填写整齐,对表中数字应该填写整齐,对准位数。当数字小且可略而不计时,可写上准位数。当数字小且可略而不计时,可写上““00””;;当缺某项数字资料时,可用符号当缺某项数字资料时,可用符号““…”…” ;不应有数;不应有数字时用符号字时用符号““--””表示。表示。
((55)计量单位。)计量单位。统计表必须注明数字资料的统计表必须注明数字资料的计量单位。当全表只有一种计量单位时,可以把计量单位。当全表只有一种计量单位时,可以把它写在表头的上方。如果表中各格的指标数值计它写在表头的上方。如果表中各格的指标数值计量单位不同,可在横行标题后添一列计量单位。量单位不同,可在横行标题后添一列计量单位。
((66)注解或资料来源。)注解或资料来源。必要时,在统计表下必要时,在统计表下应加注解或说明,以便查考。应加注解或说明,以便查考。

((四四))数据初步处理数据初步处理--茎叶表茎叶表 ((RR命令命令stemstem())())
把每个观测值分成茎和叶两个部分。茎视实际需要可以是任何位数,而叶子只能是一位数
把茎由小到大,从上往下写成一列。
把每片叶子写在它所属的茎的右边,由小到大排成一列。

例 观察每观察每1010分钟进入某小超市的人数,分钟进入某小超市的人数,144144个数据个数据
如下如下:23,23,35, 7, 29, 3,15,20,30,18,23,32,34,40,17, 25,30,33, 51,37,43,52,67,34,20,26,46,68,79,82,57,61,96,75,59,64, 77,99,87,48,58,95,96,68,46,73,57,39,45,28,24,35,43,25,27,30,42,30,22,18,21,26,21, 8,19,15, 24,12, 8, 8, 6, 8,20, 8,25, 29,26,36,26,28,36,22,41,37,30,50,28,35,24,36, 50,44,48,38,47,55,30,44,50,40,47,83,75,64,66,75,83,90, 87,59,63,78,75,86,86,77,64,70,65,69,56,55,42,47,33,36, 34,29,33,25,16,30,22,18,9,14,16,20, 26,10,18, 9,7, 8
如何加工?
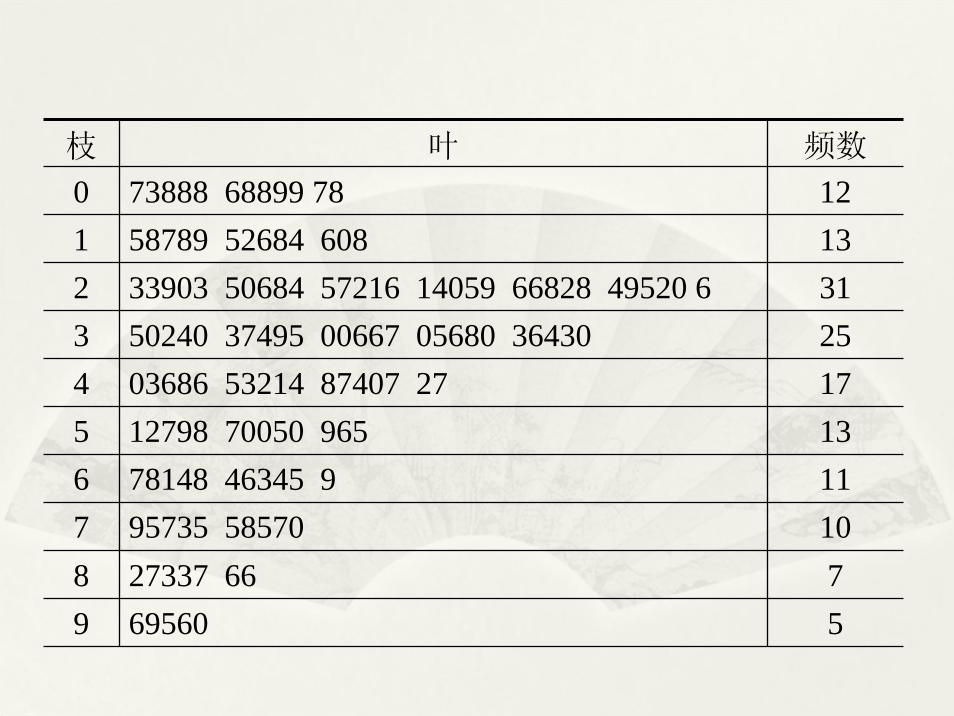
枝 叶 频数
0 73888 68899 78 121 58789 52684 608 132 33903 50684 57216 14059 66828 49520 6 313 50240 37495 00667 05680 36430 254 03686 53214 87407 27 175 12798 70050 965 136 78148 46345 9 117 95735 58570 108 27337 66 79 69560 5

1515
1212
99
66
33
105105 110110 115115 120120 125125 130130 135135 140140
统计图:统计图是借助几何图形或具体形象来统计图:统计图是借助几何图形或具体形象来
显示统计数据的一种形式。显示统计数据的一种形式。
(一)直方图(一)直方图((RR命令命令histhist())())
二、统计图二、统计图
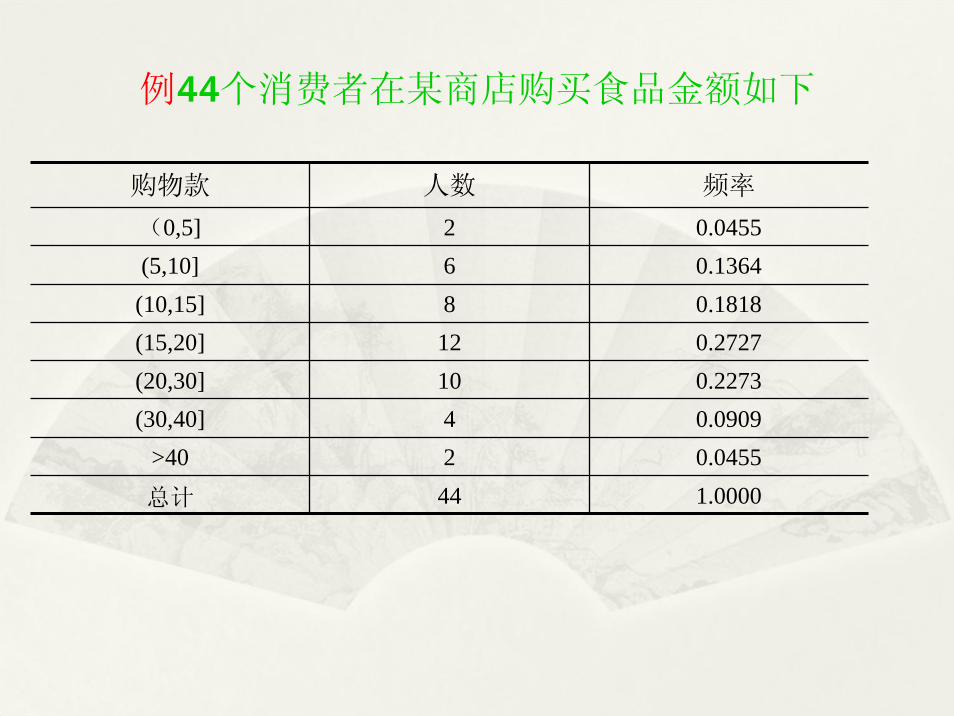
例44个消费者在某商店购买食品金额如下
购物款 人数 频率
(0,5] 2 0.0455(5,10] 6 0.1364(10,15] 8 0.1818(15,20] 12 0.2727(20,30] 10 0.2273(30,40] 4 0.0909
>40 2 0.0455
总计 44 1.0000
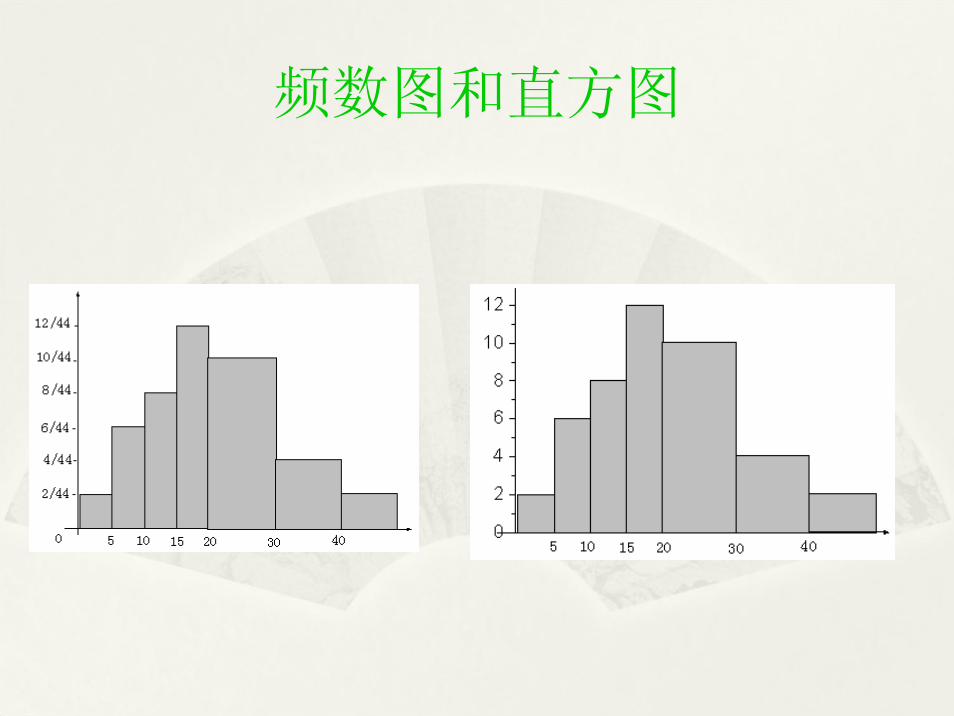
频数图和直方图
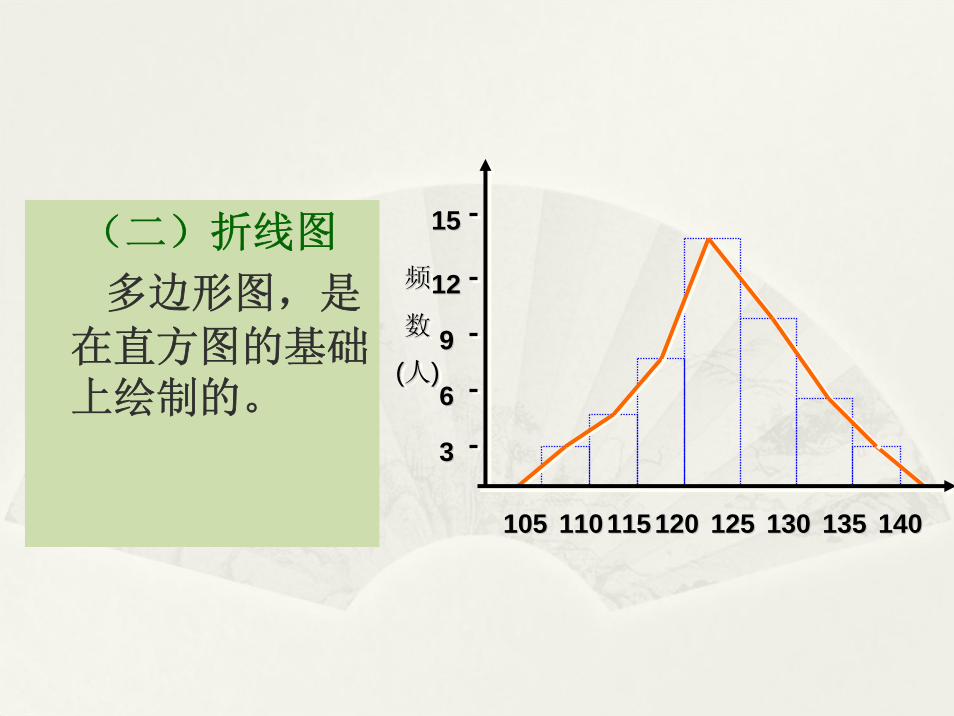
(二)折线图
多边形图,是
在直方图的基础上绘制的。
1515
1212
99
66
33
105105 110110 115115 120120 125125 130130 135135 140140
频
数
(人)
频频
数数
((人人))
(三)曲线图(三)曲线图当变量数列的组数无限时,折线便表现为一条平滑曲线。当变量数列的组数无限时,折线便表现为一条平滑曲线。 曲线图曲线图
的绘制方法与折线图基本相同,只是在连接各组次数坐标点时应当用的绘制方法与折线图基本相同,只是在连接各组次数坐标点时应当用平滑曲线。平滑曲线。
(四)累计曲线图(四)累计曲线图
频
数
(人)
频频
数数
((人人))
1515
1212
99
66
33

(五)洛伦兹(Lorenz)曲线(R语言Lc {ineq} )
洛伦兹曲线常用来描述财富(或收入)的分配是否公平.当然它并不蕴含公平或不公平的判断价值,仅仅表达当前的真实情况。设有如下数
据:
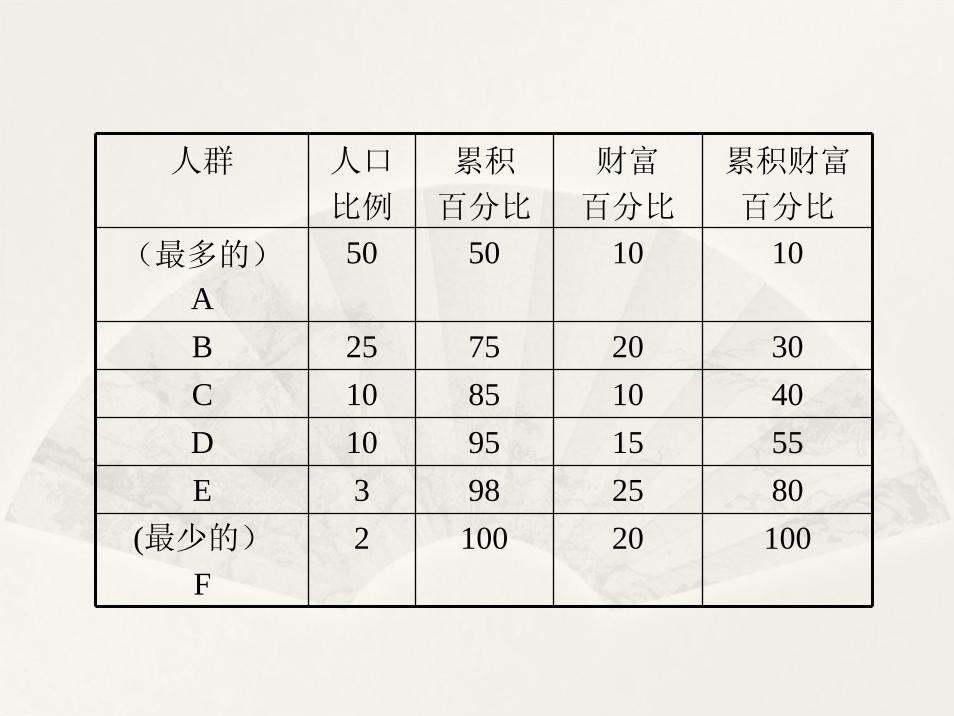
人群 人口
比例
累积
百分比
财富
百分比
累积财富
百分比
( 多的)
A50 50 10 10
B 25 75 20 30C 10 85 10 40D 10 95 15 55E 3 98 25 80
( 少的)
F2 100 20 100

累计家庭数%
累计收入%
公平分配线
洛伦茨曲线
税后
税前
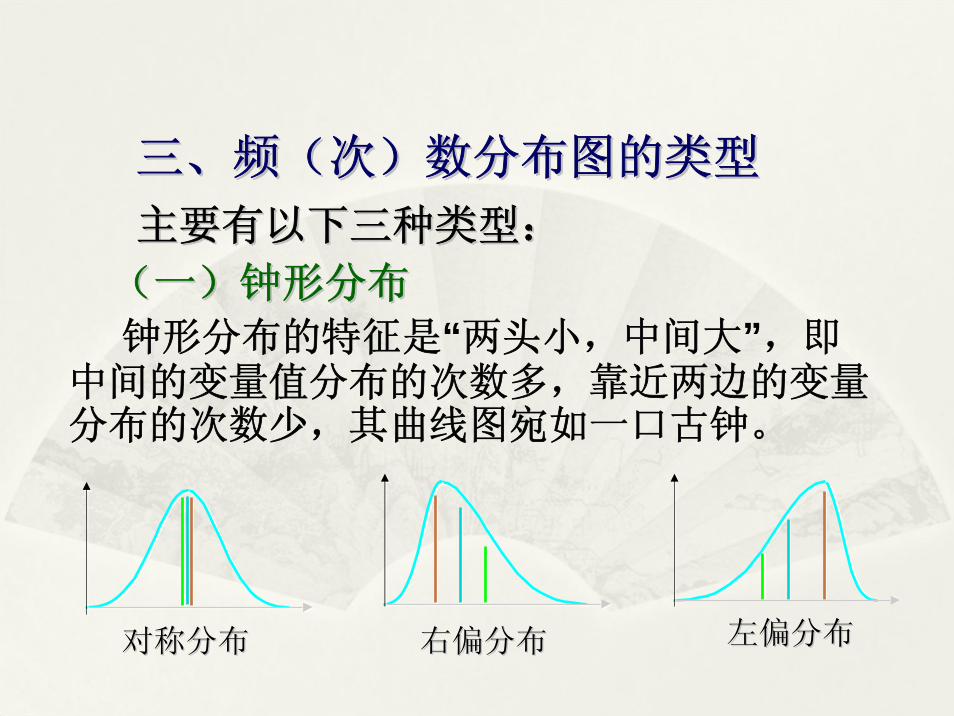
钟形分布的特征是“两头小,中间大”,即中间的变量值分布的次数多,靠近两边的变量分布的次数少,其曲线图宛如一口古钟。
对称分布对称分布对称分布 右偏分布右偏分布右偏分布 左偏分布左偏分布左偏分布
三、频(次)数分布图的类型三、频(次)数分布图的类型
主要有以下三种类型:主要有以下三种类型:
(一)钟形分布(一)钟形分布

U型分布的形状与钟
形分布相反,靠近中间的
变量值分布次数少,靠近
两端的变量值分布次数多,
形成“两头大,中间小”的U型分布。
U型分布UU型分布型分布
(二)(二)UU型分布型分布
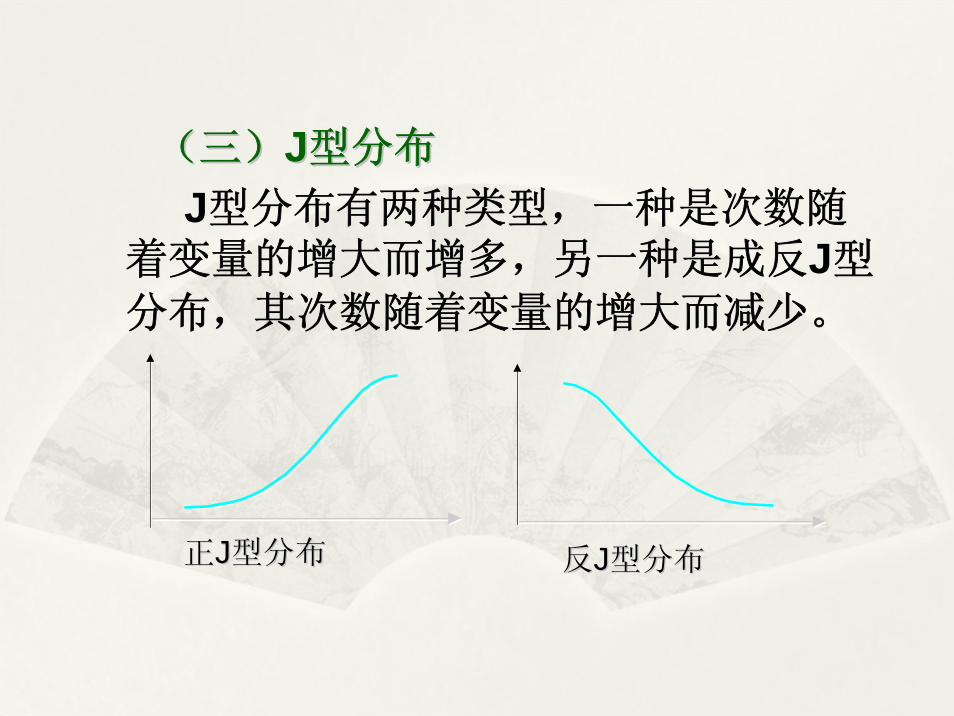
J型分布有两种类型,一种是次数随着变量的增大而增多,另一种是成反J型分布,其次数随着变量的增大而减少。
正J型分布正正JJ型分布型分布 反J型分布反反JJ型分布型分布
(三)(三)JJ型分布型分布

第二节第二节 分布的集中趋势分布的集中趋势
(一)(一)平均指标含义平均指标含义指概括地描述统计分布的一般水平或集中指概括地描述统计分布的一般水平或集中
趋势的数值。趋势的数值。
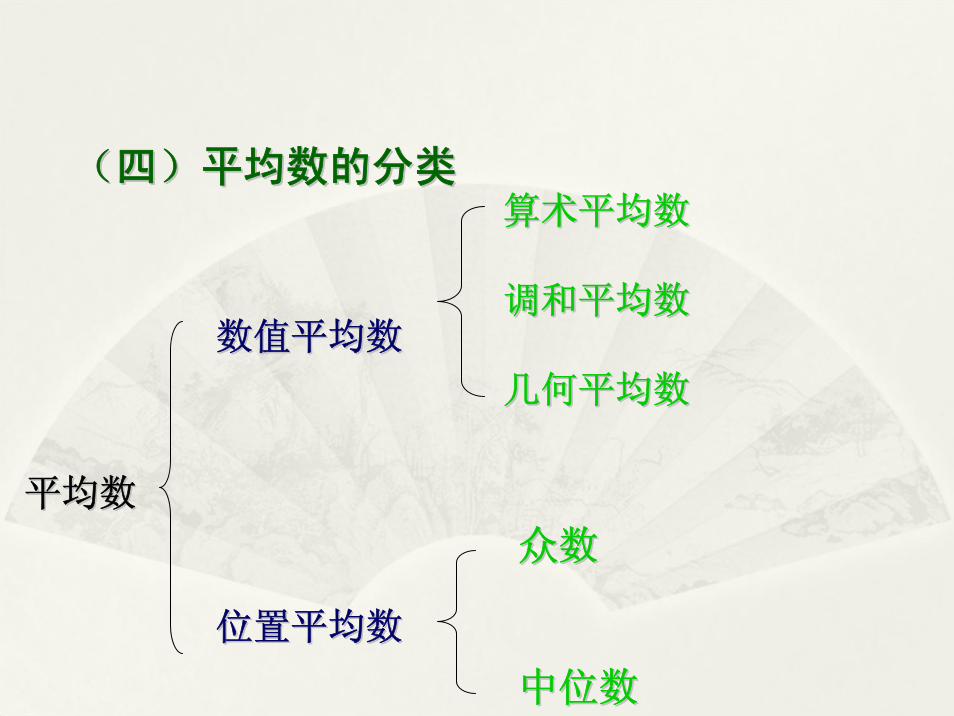
一、描述一、描述分布集中趋势的主要指标及其分类分布集中趋势的主要指标及其分类
(二)平均指标的特点(二)平均指标的特点具有代表性和抽象性。具有代表性和抽象性。

44、分析现象之间的依存关系。、分析现象之间的依存关系。
(三)平均指标的作用(三)平均指标的作用
统计平均数具有重要作用,主要体现在统计平均数具有重要作用,主要体现在以下几点:以下几点:
11、反映总体各变量分布的集中趋势和一般水平。、反映总体各变量分布的集中趋势和一般水平。
22、便于比较同类现象在不同单位间的发展水平。、便于比较同类现象在不同单位间的发展水平。
33、能够比较同类现象在不同时间的发展变化趋势、能够比较同类现象在不同时间的发展变化趋势或规律。或规律。
众数众数
中位数中位数
平均数平均数
位置平均数位置平均数
数值平均数数值平均数
算术平均数算术平均数
调和平均数调和平均数
几何平均数几何平均数
(四)平均数的分类(四)平均数的分类

二、数值平均数
总体单位数:总体单位数:
表示的是一个总体内所包含的总体单位表示的是一个总体内所包含的总体单位数。数。
数值平均数是对总体各单位某一标志值数值平均数是对总体各单位某一标志值的平均,表明总体单位标志值的一般水平。的平均,表明总体单位标志值的一般水平。
基本计算公式是:基本计算公式是:
总体标志总量总体标志总量//总体单位数。总体单位数。
总体标志总量:总体标志总量:
总体各单位某种数量标志值的总和。总体各单位某种数量标志值的总和。

公式公式中,中,
1 2 3 1
n
in i
xx x x xx
n n=+ + + ⋅⋅⋅ +
= =∑
_xxn
(一)(一)算术平均数算术平均数
11、算术平均数的计算、算术平均数的计算
计算算术平均数有两种式:计算算术平均数有两种式:
((11)简单算术平均数)简单算术平均数
适用于未分组资料,用总体各单位标志值适用于未分组资料,用总体各单位标志值加总得到标志总量除以总体单位总量而得。加总得到标志总量除以总体单位总量而得。
计算公式为:计算公式为:
代表算术平均数。代表算术平均数。
表示各单位标志值。表示各单位标志值。
表示总体单位数。表示总体单位数。

((22)加权算术平均数)加权算术平均数①根据单项数列计算加权算术平均数
计算公式:计算公式:
1 1 2 2 3 3 1
1 1
n
i in n i
n n
i ii i
x fx f x f x f x fxf f
=
= =
+ + + ⋅⋅ ⋅ += =∑
∑ ∑
应用条件:单项式分组,各组次数不同。应用条件:单项式分组,各组次数不同。

根据组距数列计算加权算术平均数根据组距数列计算加权算术平均数
应用条件:应用条件:组距式分组,各组次数不同。组距式分组,各组次数不同。
按日产量分组(公斤)
工人数f 组中值x 日产总量xf
20—30 10 25 250
30—40 70 35 2450
40—50 90 45 4150
50—60 30 55 1650
合 计 200 — 8400
( )公斤
平均日产量
42200
8400
=
=
例:例:某车间某车间200200名工人日产量资料:名工人日产量资料:

22、权数、权数
((11)概念)概念对平均数的大小起着权衡轻重的作用。平均数对平均数的大小起着权衡轻重的作用。平均数
总是趋向于出现次数 多的哪个标志值。总是趋向于出现次数 多的哪个标志值。
((22)权数的表现形式)权数的表现形式
绝对数形式绝对数形式
相对数形式相对数形式

33、是非标志的平均数、是非标志的平均数
是非标志是非标志::也称交替标志,当总体单位某也称交替标志,当总体单位某种品质标志的具体表现为种品质标志的具体表现为““是是””与与““非非””或或““有有””与与““无无””两种情况时,这种品质标志就称为是非标两种情况时,这种品质标志就称为是非标志。志。
是非标志x
单位数 f 比重
1
0
合 计 N 1
0N1N
∑ ff
pNN1 =
qNN0 =
1
1
1 01 0
n
i ii
n
ii
x fx
f
N NN
P
=
=
=
× + ×=
=
∑
∑是
平均数的计算:平均数的计算:把具有某种特征的用把具有某种特征的用““11””表表示,不具有该种特征的用示,不具有该种特征的用““00””表示。表示。

(二)调和平均数((二)调和平均数(HH))是社会经济统计中常用的另一种平均指是社会经济统计中常用的另一种平均指
标,它是根据标志值的倒数计算的,所以又称标,它是根据标志值的倒数计算的,所以又称倒数平均数。与算术平均数一样,调和平均数倒数平均数。与算术平均数一样,调和平均数有简单调和平均数和加权调和平均数两种。有简单调和平均数和加权调和平均数两种。
1 2 3
1 1 1 1
1
1n
nx x x x
i i
n nH
x=
= =+ + + ⋅ ⋅ ⋅ + ∑
1 11 0 2 0
2 11 3 ( )3
=+
里小 时
例例::一个人步行两里,走第一里时速度为每小时候一个人步行两里,走第一里时速度为每小时候
1010里,走第二里时为每小时里,走第二里时为每小时2020里,则平均速度为:里,则平均速度为:
应用条件:应用条件:资料未分组,各个变量值次数都是资料未分组,各个变量值次数都是11。。
计算公式计算公式::
11、简单调和平均数、简单调和平均数
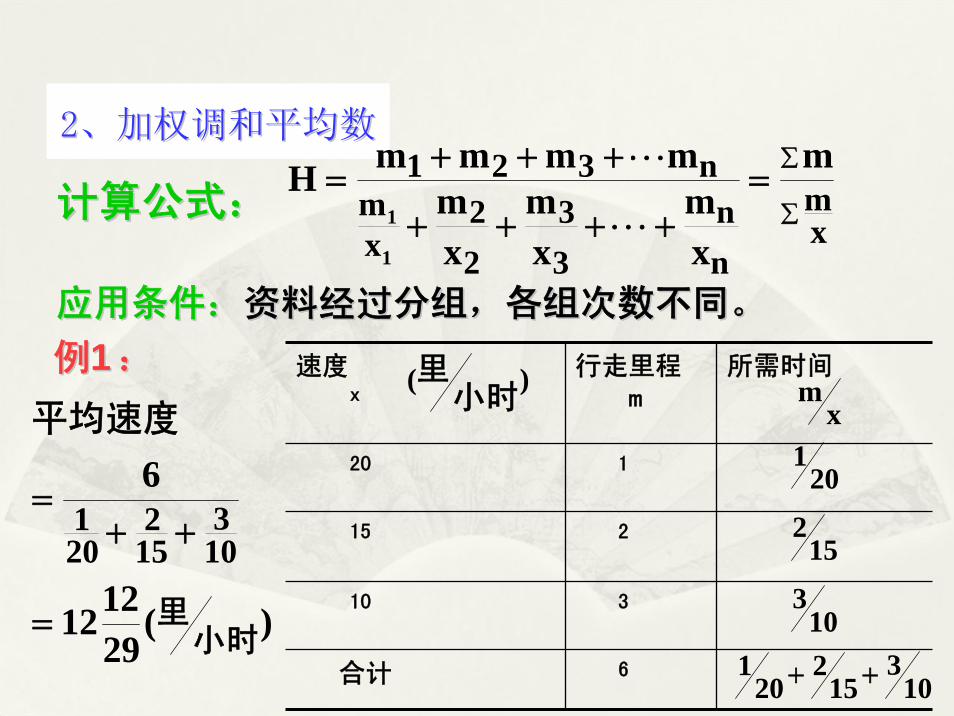
22、加权调和平均数、加权调和平均数
计算公式:计算公式: ∑
∑=
+⋅⋅⋅+++
⋅⋅⋅+++=
xm
nn
33
22
xm
n321 m
xm
xm
xm
mmmmH
1
1
速度x
行走里程m
所需时间
20 1
15 2
10 3
合计 6
)(小时
里
xm
201
152
103
103
152
201 ++
)(291212
6
103
152
201
小时里
平均速度
=
++=
例例11::
应用条件:应用条件:资料经过分组,各组次数不同。资料经过分组,各组次数不同。

例2班 组 平均劳动
生产率 x实际工时
产品产量(件)
m
一 10 100 1000
二 12 200 2400
三 15 300 4500
四 20 300 6000
五 30 200 6000
合计 — 1100 19900
xm
)(09.18
110019900
)xm(
)m(
工时件
车间实际工时
车间产品产量
平均劳动生产率
=
=
=∑
∑

(三)几何平均数((三)几何平均数(GG))是另一种形式的平均数,是是另一种形式的平均数,是N N 个变量个变量
值乘积的值乘积的 N N 次方根。主要用于计算平均次方根。主要用于计算平均比率和平均速度。几何平均数也有简单比率和平均速度。几何平均数也有简单几何平均数和加权几何平均数两种。几何平均数和加权几何平均数两种。
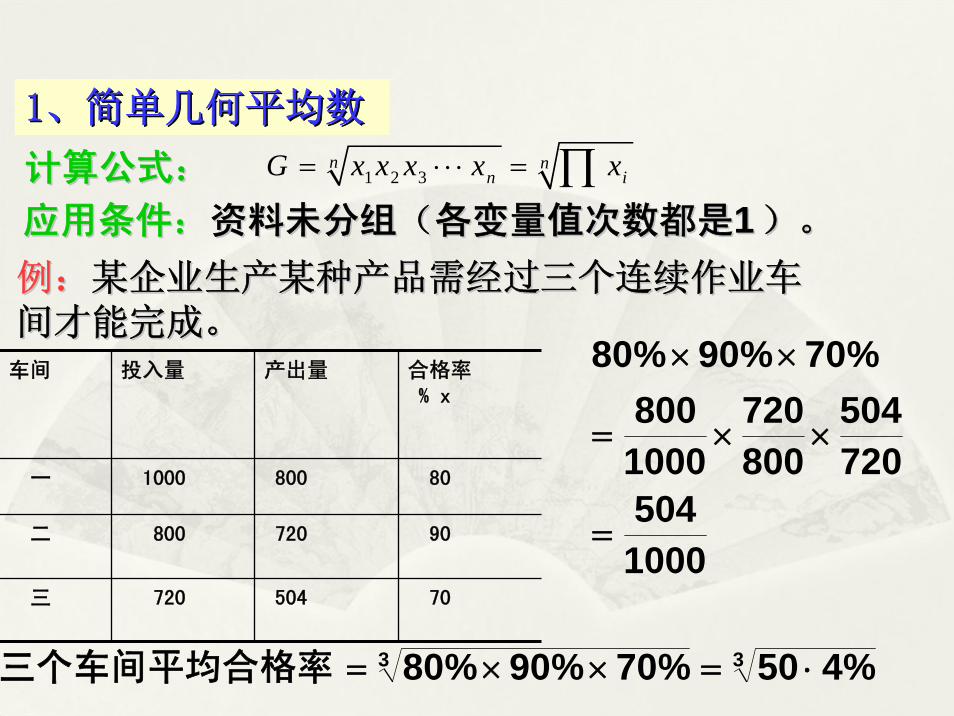
11、简单几何平均数、简单几何平均数
1 2 3n n
n iG x x x x x= ⋅ ⋅ ⋅ = ∏
车间 投入量 产出量 合格率% x
一 1000 800 80
二 800 720 90
三 720 504 70
33 %450%70%90%80 ⋅=××=三个车间平均合格率
1000504
720504
800720
1000800
%70%90%80
=
××=
××
例:例:某企业生产某种产品需经过三个连续作业车某企业生产某种产品需经过三个连续作业车间才能完成。间才能完成。
应用条件:应用条件:资料未分组(各变量值次数都是资料未分组(各变量值次数都是11)。)。
计算公式:计算公式:

22、加权几何平均数、加权几何平均数
计算公式:计算公式: 31 21 11 2 31
n ni i
n ii i
nf ff f ff fn i
i
G x x x x x= =
=
∑ ∑= ⋅ ⋅ ⋅ = ∏
年份 累计存款额 本利率%
第1年 105%
第2年 105%
第3年 108%
… … …
第10年 112%
%105%5 000 xxx =+2
000 %105%5%105%105 xxx =+%108%105%8%105%105 2
02
02
0 xxx =+
23320 %112%110%108%105x
例:例:将一笔钱存入银行,存期将一笔钱存入银行,存期1010年,以复利计息,年,以复利计息,1010年的利率分配是第年的利率分配是第11年至第年至第22年为年为5%5%、第、第33年至年至55年为年为8%8%、、第第66年至第年至第88年为年为10%10%、第、第99年至第年至第1010年年12%12%,计算平均年,计算平均年利率利率 0x 设本金为设本金为
应用条件:应用条件:资料经过分组,各组次数不同。资料经过分组,各组次数不同。

%77108%112%110%108%10510 2332
⋅=×××=
平均本利率
本利率x 年数f
105% 2
108% 3
110% 3
112% 2
合 计 10
•平均年利率=8.77%
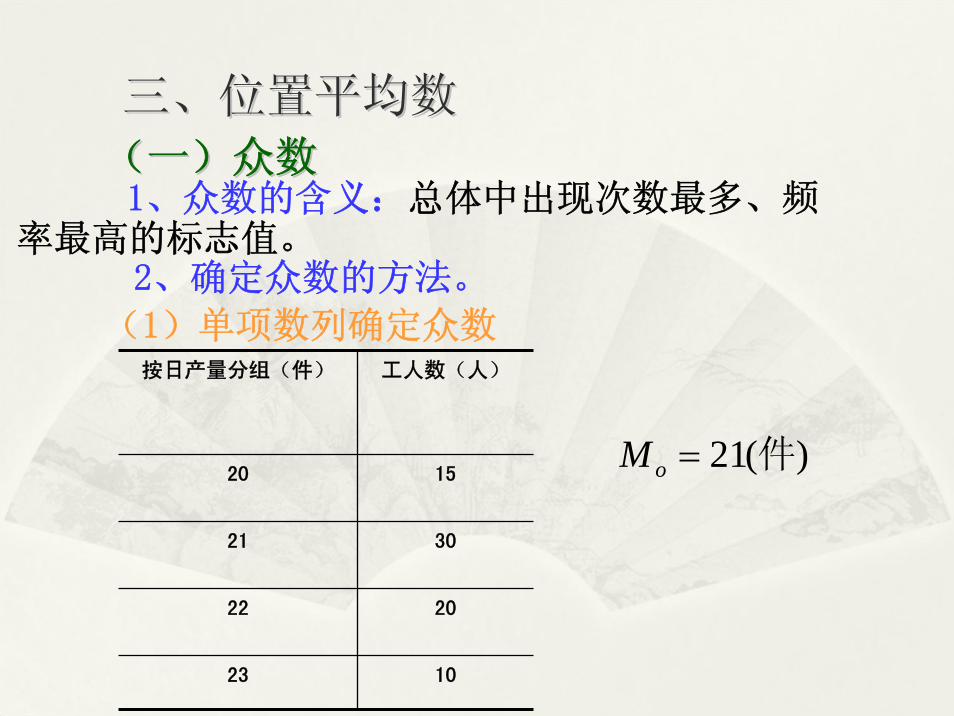
三、位置平均数三、位置平均数
(一)众数(一)众数1、众数的含义:总体中出现次数 多、频
率 高的标志值。2、确定众数的方法。
(1)单项数列确定众数按日产量分组(件) 工人数(人)
20 15
21 30
22 20
23 10
21( )oM = 件

((22)由组距数列确定众数)由组距数列确定众数
11、计算公式:、计算公式:
)()()( 0
0000
00
011
10 下限公式M
MMMM
MMM d
ffffff
lM+−
−
−+−
−+=
)()()( 0
0000
00
011
10 上限公式M
MMMM
MMM d
ffffff
UM+−
+
−+−
−−=

例:
0
0000
00
0 )()( 11
10 M
MMMM
MMM d
ffffff
lM+−
−
−+−
−+=
)(6161)7001100()4801100(
48011006 千元⋅=×−+−
−+=
年人均纯收入(千元) 农户数(户)
5以下 240
5—6 480
6—7 1100
7—8 700
8—9 320
9以上 160
合计 3000
农户年人均收入众数计算表

(二)中位数(二)中位数1、中位数的含义:将总体各单位按其标志值
大小顺序排列起来居于中间位置的那个数就是中位数。
2、确定中位数的方法
(1)由未分组资料确定中位数
①标志值的个数是奇数
例:7名工人生产某种产品,日产量(件)分别为4、6、6、8、9、12、14。位于中间位置的第四名工人的日产量8件为中位数。

上例增加为上例增加为88名工人,日产量为名工人,日产量为44、、66、、66、、88、、
99、、1212、、1313、、1414。中位数为(。中位数为(8+98+9))/2=8.5/2=8.5
②标志值的个数是偶数
,,
其位置在第四和第五名中间其位置在第四和第五名中间..
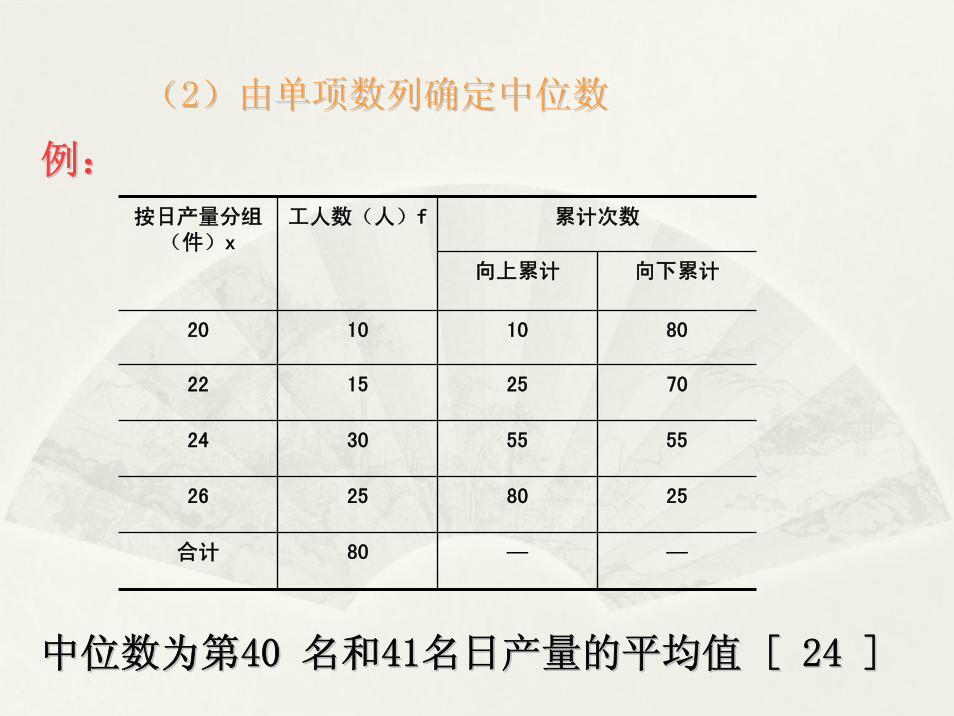
((22)由单项数列确定中位数)由单项数列确定中位数
例:例:
中位数为第中位数为第40 40 名和名和4141名日产量的平均值名日产量的平均值 [ 24 ][ 24 ]
累计次数按日产量分组(件)x
工人数(人)f
向上累计 向下累计
20 10 10 80
22 15 25 70
24 30 55 55
26 25 80 25
合计 80 — —

((33)由组距数列确定中位数)由组距数列确定中位数
计算公式
12 ( )e
e e
e
fM
e M MM
sM L d
f−
∑ −= + × 下 限 公 式
12 ( )e
e e
e
fM
e M MM
sM U d
f+
∑ −= − × 上限公式
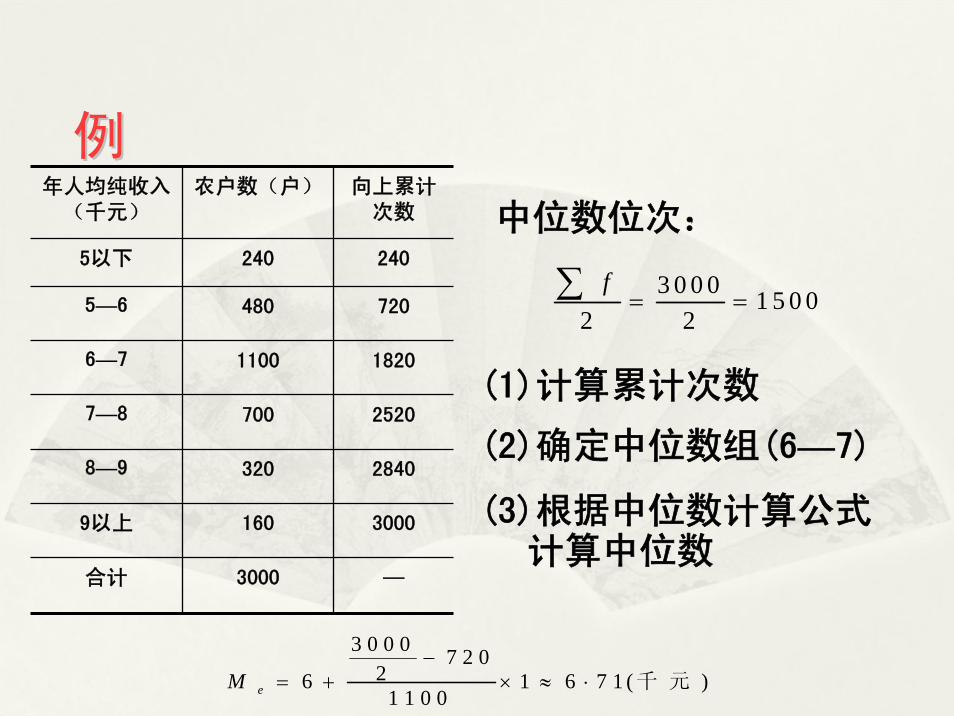
例例年人均纯收入
(千元)农户数(户) 向上累计
次数
5以下 240 240
5—6 480 720
6—7 1100 1820
7—8 700 2520
8—9 320 2840
9以上 160 3000
合计 3000 —
3 0 0 0 7 2 026 1 6 7 1 ( )
1 1 0 0eM−
= + × ≈ ⋅ 千 元
(1)计算累计次数
(2)确定中位数组(6—7)
(3)根据中位数计算公式计算中位数
3 0 0 0 1 5 0 02 2
f= =∑
中位数位次:

(三)众数、中位数、和算术平均数(三)众数、中位数、和算术平均数和的关系和的关系
e ox M M< < 0 eM M x< <0ex M M= =
对称分布对称分布 左左((负负))偏分布偏分布 右右((正正))偏分布偏分布
众数mode、中位数median和算术平均数average数量关系的经验公式为:算术平均数和众数的距离约等于算术平均数与中位数距离的三倍: 3( )o ex M x M− ≈ −

第三节第三节 分布的离中趋势分布的离中趋势
一、描述分布离中趋势的主要变异指标及其作用
常见的变异指标有:极差、分位差、标准差、方常见的变异指标有:极差、分位差、标准差、方差和变异系数。差和变异系数。
变异指标是用来刻画总体分布的离散程度或变变异指标是用来刻画总体分布的离散程度或变异状况,变异指标越大,表明总体各单位标志值的异状况,变异指标越大,表明总体各单位标志值的变异程度越大。它是反映总体各标志值间差异程度变异程度越大。它是反映总体各标志值间差异程度的的,,且能衡量总体平均数的代表性。且能衡量总体平均数的代表性。
(一)变异指标的含义(一)变异指标的含义

22、反映社会经济活动的均衡性。、反映社会经济活动的均衡性。
(二)变异指标的作用(二)变异指标的作用
11、用于衡量平均指标的代表性。、用于衡量平均指标的代表性。
33、研究总体标志值分布偏离正态的情况。、研究总体标志值分布偏离正态的情况。

极差也称全距,用极差也称全距,用RR表示。表示。
二、极差与四分位距二、极差与四分位距
(一)极差(一)极差
例:5名学生的成绩为50、69、76、88、97 则R=97-50=47
优点:计算简便
公式: R =最大值—最小值
缺点:易受极端值的影响

四分位距是从变量数列中剔除 大和四分位距是从变量数列中剔除 大和小各小各1/41/4的单位,用上四分位数的单位,用上四分位数Q3Q3和下四和下四
分位数分位数Q1Q1的标志值之差来表示。的标志值之差来表示。
(二)四分位距(二)四分位距
公式:公式:IQR=Q3IQR=Q3--Q1Q1
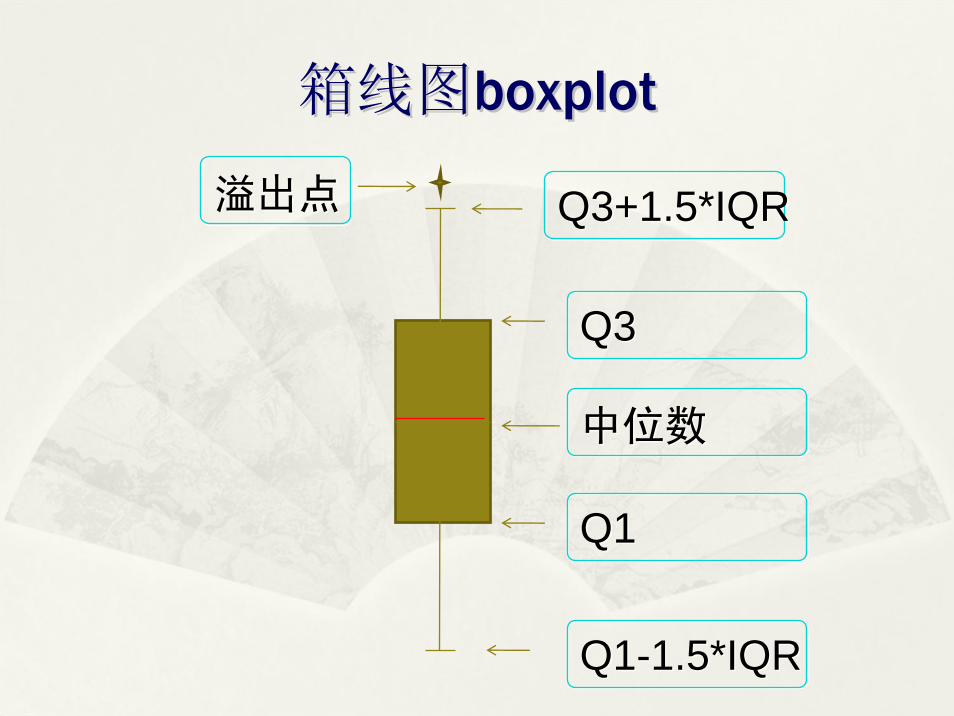
箱线图箱线图boxplotboxplot
Q3+1.5*IQRQ3+1.5*IQR
Q3Q3
中位数中位数
Q1Q1
Q1-1.5*IQRQ1-1.5*IQR
溢出点溢出点

三、方差与标准差三、方差与标准差
方差:方差:各变量值与其均值离差平方的平均数。各变量值与其均值离差平方的平均数。
(一)数量标志的方差与标准差(一)数量标志的方差与标准差
标准差:标准差:方差的平方根,也称均方差。方差的平方根,也称均方差。
11、数量标志的方差与标准差计算、数量标志的方差与标准差计算,其,其计算计算公式为:公式为:
2
1
( )n
ii
x x
nσ =
−=
∑2
2 1
( )n
ii
x x
nσ =
−=∑
资料未分组:资料未分组:
资料已分组:资料已分组:2
1
1
( )n
i ii
n
ii
x x f
fσ =
=
−=
∑
∑
2
2 1
1
( )n
i ii
n
ii
x x f
fσ =
=
−=∑
∑

例1:
日产量(件)
20 9
22 1
23 0
24 1
26 9
合计 20
23( )x = 件
20 2( )5
σ = = 件
2)xx( −
2 20 4( )5
σ = = 件

例2:42( )x = 公斤 日产量(公
斤)工人数f 组中值x
20—30 10 25 2880
30—40 70 35 3430
40—50 90 45 810
50—60 30 55 5070
合 计 200 — 12190
f)xx( 2−
12190200
60 957 81( )
σ =
= ⋅
= ⋅ 公斤
2 12190200
60 95( )
σ =
= ⋅ 公斤

组内方差反映组内标志值对组平均数的方组内方差反映组内标志值对组平均数的方差,组间方差反映组平均数对总平均数的方差。差,组间方差反映组平均数对总平均数的方差。
22、总方差、组间方差和组内方差。、总方差、组间方差和组内方差。
它们之间的关系为:
2 2 2iσ δ δ= +

((11)变量的方差等于变量平方的)变量的方差等于变量平方的平均数减去变量平均数的平方。平均数减去变量平均数的平方。
33、方差与标准差的数学性质、方差与标准差的数学性质
即: 2 2 2( )x xσ = −((22)变量对算术平均数的方差小于对)变量对算术平均数的方差小于对
任何常数的方差。任何常数的方差。
((33))nn个同性质独立变量和的方差等于个同性质独立变量和的方差等于各个变量方差的和各个变量方差的和
1 2 3
2 2 2 2 2nx x x x xσ σ σ σ σ= + + + +L

((44))nn个同性质独立变量平均数的方个同性质独立变量平均数的方差等于各变量方差平均数的差等于各变量方差平均数的1/n1/n。。
((55)变量线性变换的方差等于变量的)变量线性变换的方差等于变量的方差乘以变量系数的平方。方差乘以变量系数的平方。
1 2 3
2 2 2 22 2
2
1nx x x xx in n
σ σ σ σσ σ
+ + + += =
L
2 2 2y xbσ σ=

(二)是非标志的方差与标准差(二)是非标志的方差与标准差
如前:如前:是非标志的平均数为是非标志的平均数为PP。。
标志值x 单位数f
1
0
合计 N
2 21 0(1 )
(1 )
P N P NN
P P
σ
− +=
= −
是
2
由于标准差有良好的数学性质,相比较而言,由于标准差有良好的数学性质,相比较而言,它的应用 为广泛。它的应用 为广泛。
(1 )P P
σ
= −
是
1N
0N1
2 N)P1( −
02 N)P0( −
f)xx( 2−

第四节第四节 分布的偏度和峰度分布的偏度和峰度
(一)动差的概念(一)动差的概念
一、统计动差一、统计动差
动差原是物理学中的概念:矩,表示力和力臂对动差原是物理学中的概念:矩,表示力和力臂对重心的关系。这种关系,与统计学中变量和权数对平重心的关系。这种关系,与统计学中变量和权数对平均数的关系很相似。故统计学中也用动差来说明次数均数的关系很相似。故统计学中也用动差来说明次数分配的性质。分配的性质。

原点矩:原点矩:是是KK阶动差的一般形式,公式为:阶动差的一般形式,公式为:
(二)原点矩和中心矩(二)原点矩和中心矩
1
1
nk
ii
k n
ii
x f
fμ =
=
=∑
∑
中点矩:中点矩:如果把原点移动到算术平均数的位如果把原点移动到算术平均数的位置,就可以得到一个以频数分配各组标志值置,就可以得到一个以频数分配各组标志值 对对平均数平均数 的的KK阶中心动差,即称中心矩,通常用阶中心动差,即称中心矩,通常用表示。表示。
x kv
1
1
( )n
ki k
ik n
ii
x x fv
f
=
=
−=∑
∑

二、偏度二、偏度(一)概念要点(一)概念要点
( )3
3i i
i
X X ff
ασ
−= ∑
∑( )3
3i i
i
X X ff
ασ
−= ∑
∑
11、数据分布偏斜程度的测度、数据分布偏斜程度的测度
22、偏态系数、偏态系数=0=0为为对称分布对称分布
33、偏态系数、偏态系数>> 00为为右偏分布右偏分布
44、偏态系数、偏态系数< 0< 0为为左偏分布左偏分布
(二)计算公式(二)计算公式

例例11::已知已知19971997年年我国农村居民家庭我国农村居民家庭按纯收入分组的有按纯收入分组的有关数据如表。试计关数据如表。试计算偏态系数算偏态系数
1997年农村居民家庭纯收入数据
按纯收入分组(元) 户数比重(%)
500以下
500~10001000~15001500~20002000~25002500~30003000~35003500~40004000~45004500~50005000以上
2.2812.4520.3519.5214.9310.356.564.132.681.814.94

农村居民家庭纯收入数据偏态及峰度计算表
按纯收入分组
(百元)
组中值
Xi
户数比重(%)Fi
(Xi- X ) Fi3 (Xi- X ) Fi
4
5以下
5—1010—1515—2020—2525—3030—3535—4040—4545—5050以上
2.57.512.517.522.527.532.537.542.547.552.5
2.2812.4520.3519.5214.9310.356.564.132.681.814.94
-154.64-336.46-144.87-11.840.18
23.1689.02171.43250.72320.741481.81
2927.154686.511293.5346.520.20
140.60985.492755.005282.948361.9846041.33
合计 — 100 1689.25 72521.25
例例22::

根据上表数据计算得根据上表数据计算得
将计算结果代入公式得将计算结果代入公式得
结论:结论:偏态系数为正值,而且数值较大,说明农偏态系数为正值,而且数值较大,说明农村居民家庭纯收入的分布为右偏分布,即收入较村居民家庭纯收入的分布为右偏分布,即收入较少的家庭占据多数,而收入较高的家庭则占少数少的家庭占据多数,而收入较高的家庭则占少数,而且偏斜的程度较大,而且偏斜的程度较大
( ) ( )
( )
113 3
1 133
21.4291689.25 0.956
1766.73391 12.089
K
i i i ii i
X X F X F
Nα
σ= =
− −= = = =
×
∑ ∑( ) ( )
( )
113 3
1 133
21.4291689.25 0.956
1766.73391 12.089
K
i i i ii i
X X F X F
Nα
σ= =
− −= = = =
×
∑ ∑
(百元)429.21
1
1=•=
∑∑
=
=
&& K
ii
iK
ii
F
FXX (百元)429.21
1
1=•=
∑∑
=
=
&& K
ii
iK
ii
F
FXX (百元)089.12
1
1=•=
∑∑
=
=
&& K
ii
iK
ii
F
FXσ (百元)089.12
1
1=•=
∑∑
=
=
&& K
ii
iK
ii
F
FXσ

左偏分布左偏分布 右偏分布右偏分布
偏态分布的形状偏态分布的形状

三、峰度三、峰度(一)概念要点(一)概念要点
11、数据分布扁平程度的测度、数据分布扁平程度的测度
22、峰度系数、峰度系数=3=3扁平程度适中扁平程度适中
33、偏态系数、偏态系数<3<3为为扁平分布扁平分布
44、偏态系数、偏态系数>3>3为为尖峰分布尖峰分布
( )4
4i
i
X X ff
βσ
−= ∑
∑( )4
4i
i
X X ff
βσ
−= ∑
∑(二)计算公式(二)计算公式

代入公式得代入公式得
例:例:根据表中的计算结果,计算农村居民家庭根据表中的计算结果,计算农村居民家庭
纯收入分布的峰度系数。纯收入分布的峰度系数。
结论:结论:由于由于=3.4>3=3.4>3,说明我国农村居民家庭纯收,说明我国农村居民家庭纯收
入的分布为尖峰分布,说明低收入家庭占有较大入的分布为尖峰分布,说明低收入家庭占有较大的比重。的比重。
( )( )
4
24
72521.25 3.41 12.089
i i
i
X X ff
βσ
−= = =
×∑
∑( )
( )
4
24
72521.25 3.41 12.089
i i
i
X X ff
βσ
−= = =
×∑
∑
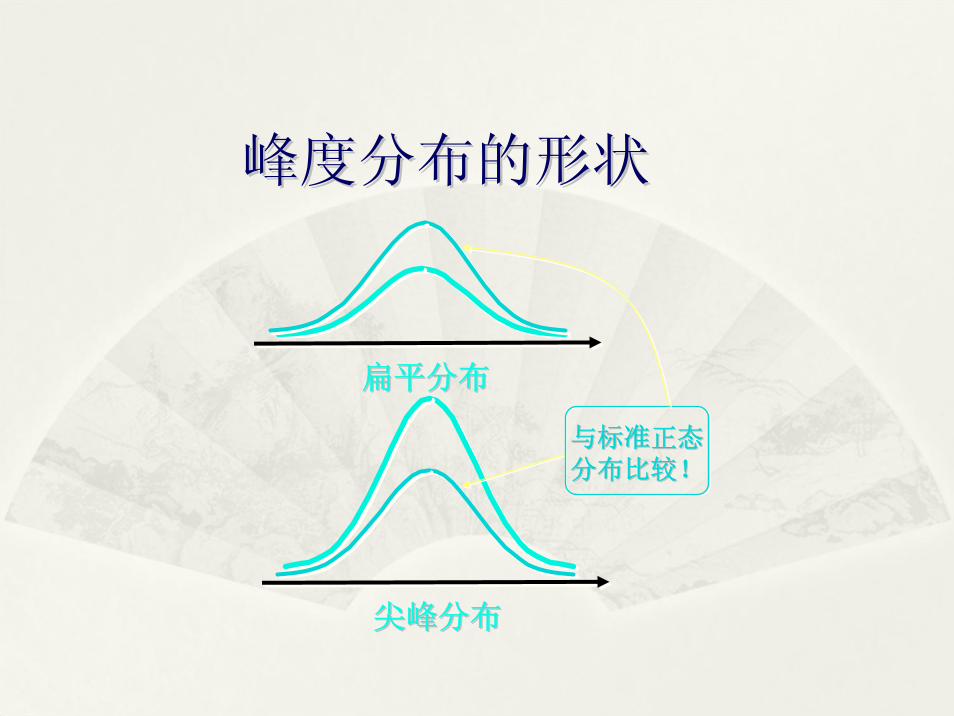
扁平分布扁平分布
尖峰分布尖峰分布
与标准正态与标准正态分布比较!分布比较!
峰度分布的形状峰度分布的形状

户数比重
(%)
户户数数比比重重
(%)(%)
2525
2020
1515
1010
55
偏态与峰度偏态与峰度(从直方图上观察)
按纯收入分组(元)按纯收入分组(元)
10001000500500←← 15001500 20002000 25002500 30003000 35003500 40004000 45004500 50005000 →→
结论:结论:1. 1. 为右偏分布为右偏分布
2. 2. 峰度适中峰度适中