Download - Dl hacks paperreading_20150527

Deep Visual-Semantic Alignments for Generating Image Descriptions
Andrej Karpathy, Li Fei-Fei Department of Computer Science, Stanford University
CVPR’15 June 8-10

Abstract入力された画像の各領域に関する説明を自由記述する• 画像領域と単語の対応を学習
- inter-modal embedding space ✓画像領域(CNN)× 文(BRNN)
• 説明文の生成 - 新しいRNN構造の提案
• 実データに適用する - Flickr8K / Flickr30K / COCO
2

Introduction人間は画像を一見するだけで説明できる• コンピュータに理解させようとする先行研究は多い
- 視覚的なカテゴリによるラベリング ✓人間がつくるものに比べたら制限的
- 画像説明の生成 ✓固定されたコンセプトやテンプレに依存 ✓複雑なシーンに対して短文のみ
3

Introduction人間は画像を一見するだけで説明できる• コンピュータに理解させようとする先行研究は多い
- 視覚的なカテゴリによるラベリング ✓人間がつくるものに比べたら制限的
- 画像説明の生成 ✓固定されたコンセプトやテンプレに依存 ✓複雑なシーンに対して短文のみ
4
いずれの先行研究も不必要な制限をしてしまっている

Challenge画像領域に対する複雑な自由記述の生成• 画像と言語を同時に扱えるモデルの提案
- 固定されたテンプレやルール,カテゴリ,学習データに依存しない
• 実際のデータを用いて生成できること - 多くの説明文は画像のどこを示しているかわからない
5
画像のどこかしらを示す弱いラベルとして文章を扱う
“trampolines are fun way to exercise.”

Contributions文章と画像の領域における潜在的な関係性を推定するdeep neural network modelを提案
• 2つのモーダリティを組み込み空間とstructued objectiveを通して連携させる
multimodal RNNの提案
• 入力を画像にすると,テキストで説明文を出力する
6

Related WorksDense image annotation• Barnardら,Socherら:単語と画像の対応づけ
• 画像のシーンカテゴリを推定
• 指定されたキーワードしか使われていない
7

Related WorksGenerating textual description• シーンレベルで文章をアノテーション
• 情報探索問題 - 文章と一致している画像を発見する - 間違ってアノテーションされてしまっているペアを発見 - 大量の学習データ必要だったり非線形
• 固定テンプレを用いた文章生成 - 文法的には正しいが,出力の種類が制限される
8

Related WorksGenerating textual description• 文法生成による文章
- SrivastavaらのDBM - フレーズは増やせていない
• 一文全ての生成 - Kirosらのlog-bilinearモデル - 固定ウインドウサイズで確率的ではない
9

Related WorksGrounding natural language in images• マルコフランダムフィールド
• 連結言語認識モデル
• Karpathyらの依存関係ツリー
Neural networks in visual and language domains• 畳み込みニューラルネット
• RNNは文章に使われているが,画像には未使用10

Related WorksGrounding natural language in images• マルコフランダムフィールド
• 連結言語認識モデル
• Karpathyらの依存関係ツリー
Neural networks in visual and language domains• 畳み込みニューラルネット
• RNNは文章に使われているが,画像には未使用11
ベースラインとして用いる

Approach: Overview1:複数の処理を行って,画像の一部とフレーズを対応付ける
2:対応付けたものを学習してフレーズを新たに生成する
• multimodal RNNで学習
12

Approach:画像の表現R-CNNによる画像の領域抽出
• Pre-training:ImageNet
• Fine-tuning:ImageNet Detection Challenge(200クラス)
• 検出された上位19個の領域+画像全体(20種類)
- Karpathyらの研究と比較のため
13

Approach:画像の表現Region Convolutional Neural Network• 各領域内のピクセルIbをベクトルvで表現する
- CNN(Ib):Ib → 4096次元ベクトル(activations)
- θc:6000万のパラメータ
- アーキテクチャ:Krizhevskyらのものに類似
- Wm:h × 4096次元
- h:multimodal embedding spaceのサイズ(1000 < h < 1600)14

Approach:画像の表現Region Convolutional Neural Network• 各領域内のピクセルIbをベクトルvで表現する
- CNN(Ib):Ib → 4096次元ベクトル(activations)
- θc:6000万のパラメータ
- アーキテクチャ:Krizhevskyらのものに類似
- Wm:h × 4096次元
- h:multimodal embedding spaceのサイズ(1000 < h < 1600)15
1つの画像は20個のh次元ベクトルの集合で表現される

Approach:文章の表現フレーズを単語毎に切り分けて素性ベクトルで表す
• 単語もh次元ベクトルで表現されるべき
• 単語毎にmultimodal embedding spaceに入れること - 出現の順番や文脈を無視してる
• bigramや依存関係ツリー - コンテクストウインドウサイズやツリーパーサーが必要
16

Approach:文章の表現フレーズを単語毎に切り分けて素性ベクトルで表す
• 単語もh次元ベクトルで表現されるべき
• 単語毎にmultimodal embedding spaceに入れること - 出現の順番や文脈を無視してる
• bigramや依存関係ツリー - コンテクストウインドウサイズやツリーパーサーが必要
17
bidirectional recurrent neural networkの提案
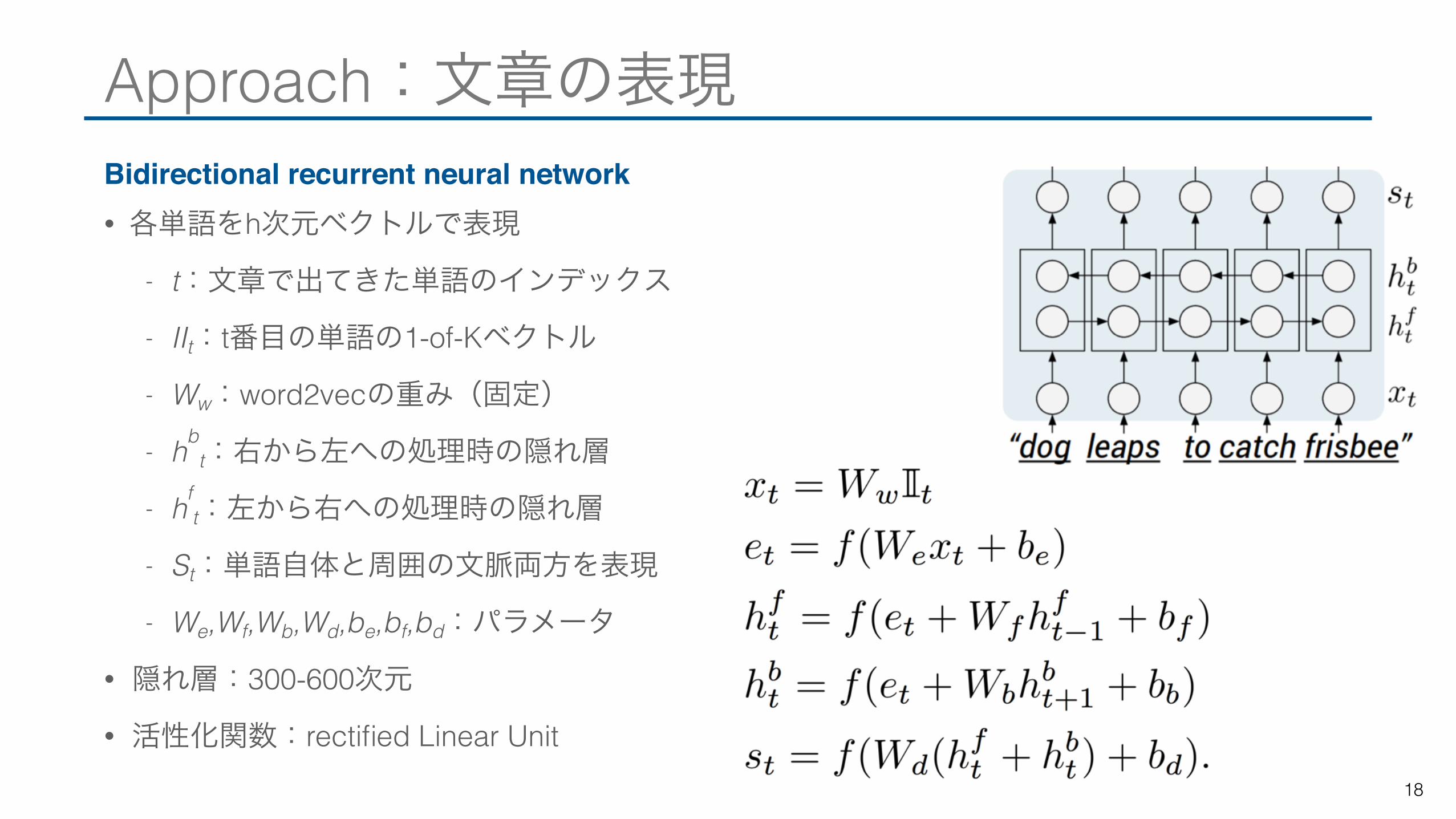
Approach:文章の表現Bidirectional recurrent neural network• 各単語をh次元ベクトルで表現
- t:文章で出てきた単語のインデックス
- Ⅱt:t番目の単語の1-of-Kベクトル
- Ww:word2vecの重み(固定)
- hbt:右から左への処理時の隠れ層
- hft:左から右への処理時の隠れ層
- St:単語自体と周囲の文脈両方を表現
- We,Wf,Wb,Wd,be,bf,bd:パラメータ
• 隠れ層:300-600次元
• 活性化関数:rectified Linear Unit18
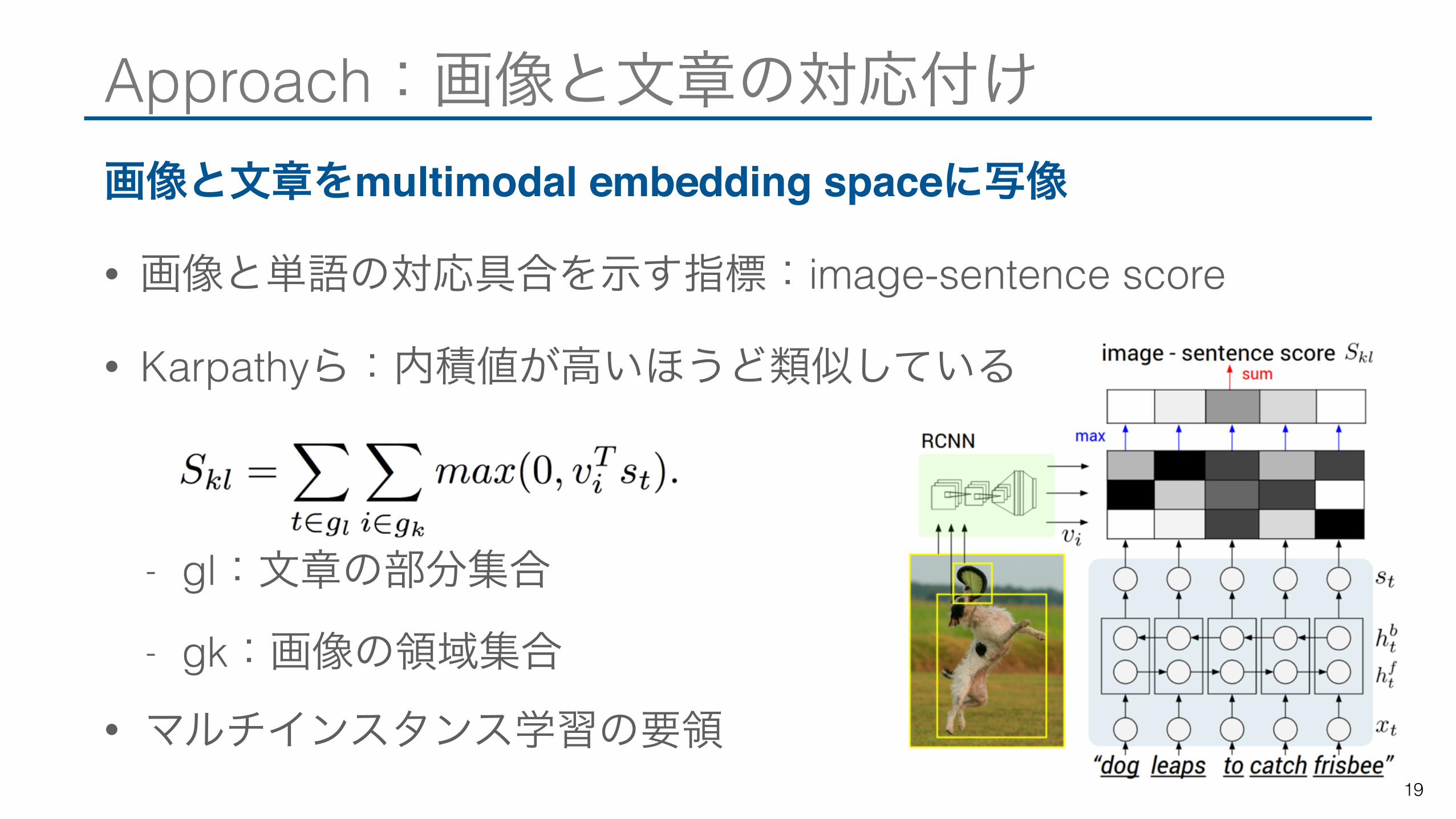
Approach:画像と文章の対応付け画像と文章をmultimodal embedding spaceに写像
• 画像と単語の対応具合を示す指標:image-sentence score
• Karpathyら:内積値が高いほうど類似している
- gl:文章の部分集合
- gk:画像の領域集合 • マルチインスタンス学習の要領
19

Approach:画像と文章の対応付けImage-Sentence Scoreの単純化
• 内積値が最も大きいところが対応している
※ちょっとよくわからなかった
20

Approach:フレーズの画像への対応付け単語ではなく,フレーズを画像に対応付けさせる
• は単語がある画像領域iに対応している非正規化対数確率
• ナイーブな手法 - 各領域におけるハイスコアな単語を集める ✓単語が分散してしまう
21

Approach:フレーズの画像への対応付け単語ではなく,フレーズを画像に対応付けさせる
• は単語がある画像領域iに対応している非正規化対数確率
• ナイーブな手法 - 各領域におけるハイスコアな単語を集める ✓単語が分散してしまう
22
マルコフランダムフィールドを適用する

Approach:フレーズの画像への対応付けMarkov Random Field• 隣接する単語の相互作用により同領域になるようにする
• N個の単語が含まれる文章×M個の領域が含まれる画像
23
- 隠れ変数:aj ∈ {1..M}
- j:1…N
- β:単語の結びつきを決めるハイパーパラメータ
✓ β=0:1個の単語が領域に対応する
✓ βが大きい:一文全てが領域に対応する
Approach:フレーズの画像への対応付けMarkov Random Field• 隣接する単語の相互作用により同領域になるようにする
• N個の単語が含まれる文章×M個の領域が含まれる画像
24
- 隠れ変数:aj ∈ {1..M}
- j:1…N
- β:単語の結びつきを決めるハイパーパラメータ
✓ β=0:1個の単語が領域に対応する
✓ βが大きい:一文全てが領域に対応する
出力:フレーズでアノテーションされた画像領域

Approach:フレーズの予測multimodal Recurrent Neural Network• 入力画像から可変長のフレーズを生成する
- y:語彙の単語次元数+1次元(ENDトークン分)
- bv:単語生成毎に画像コンテクストを保持させる必要をなくすため
• 学習時:h0=0, x1=STARTトークン(the), y1=最初の単語
• テスト時:bvを計算,h0=0, x1=theでフォワーディング25

Optimization確率的勾配降下法(ミニバッチ法)
• 100種類の画像文章ペア
• momentum = 0.9 • 交差検定で学習率とweight decayを学習
• dropout regularizationをrecurrent層以外に適用
• RMSpropも適用
26

Experiments:Overviewデータセット
• Flickr2種類(Flickr8K, Flickr30K)+COCO
- 8000, 31000, 123000種類の画像
✓それぞれ5種類の説明文付き(via Amazon Mechanical Turk)
- Flickrは1000種類ずつ検証,テストに使用,残りは学習に使用
- COCOは5000種類ずつ検証,テストに使用
前処理
• 全てを小文字に変換,英数字以外の文字と”an”,”a”,”the”を除去
• 20000単語存在27

Experiments: Overview画像とフレーズの対応付けの評価• ランキングによるベースラインとの比較評価
- 画像からフレーズを検索 - フレーズから画像を検索
画像領域に対するフレーズ生成の評価
• BLEUによるベースラインとの比較評価
- 正解データのn-gramsの出現割合で評価28
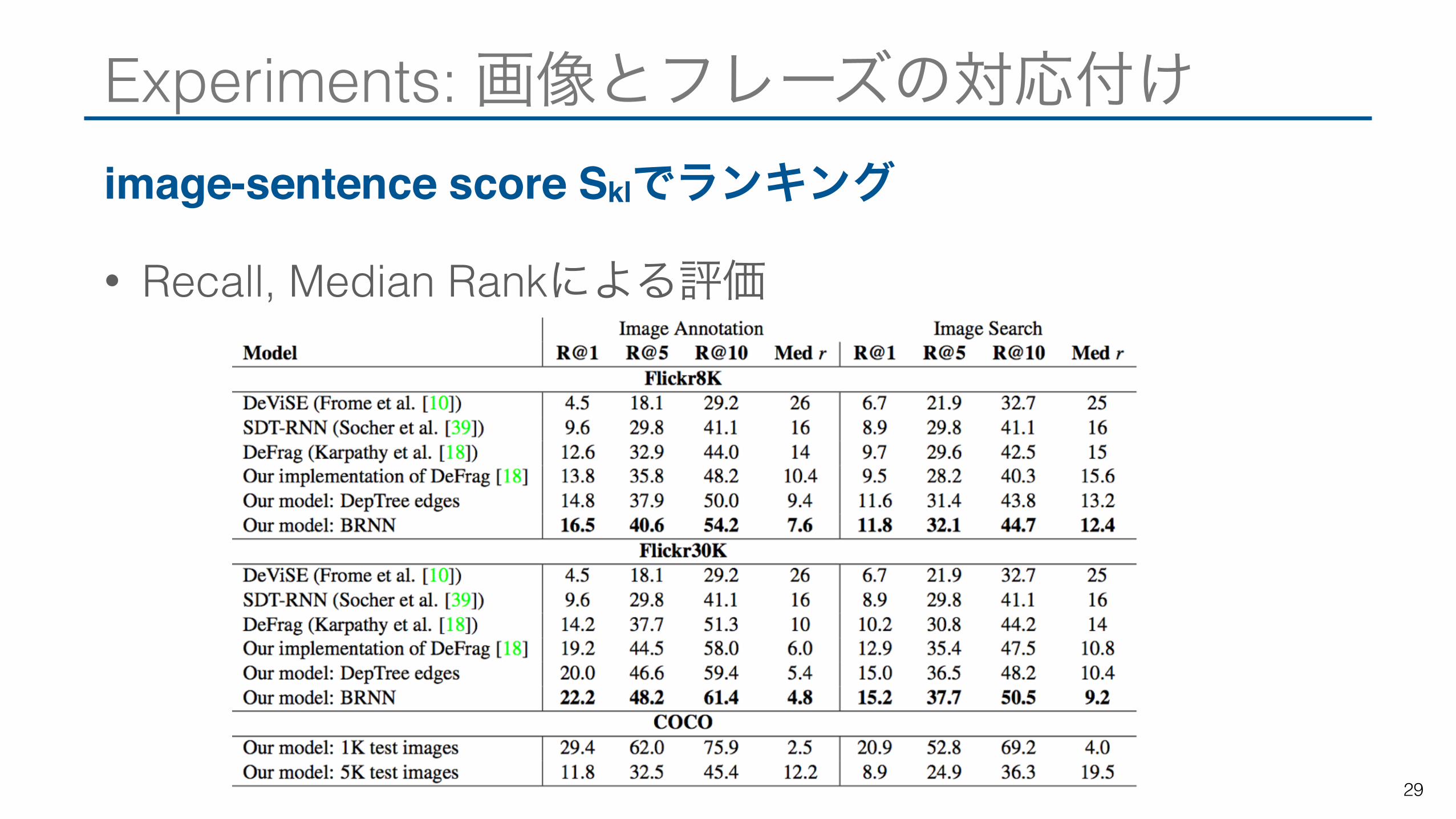
Experiments: 画像とフレーズの対応付けimage-sentence score Sklでランキング
• Recall, Median Rankによる評価
29

Experiments: 画像とフレーズの対応付けimage-sentence score Sklでランキング
• Recall, Median Rankによる評価
30
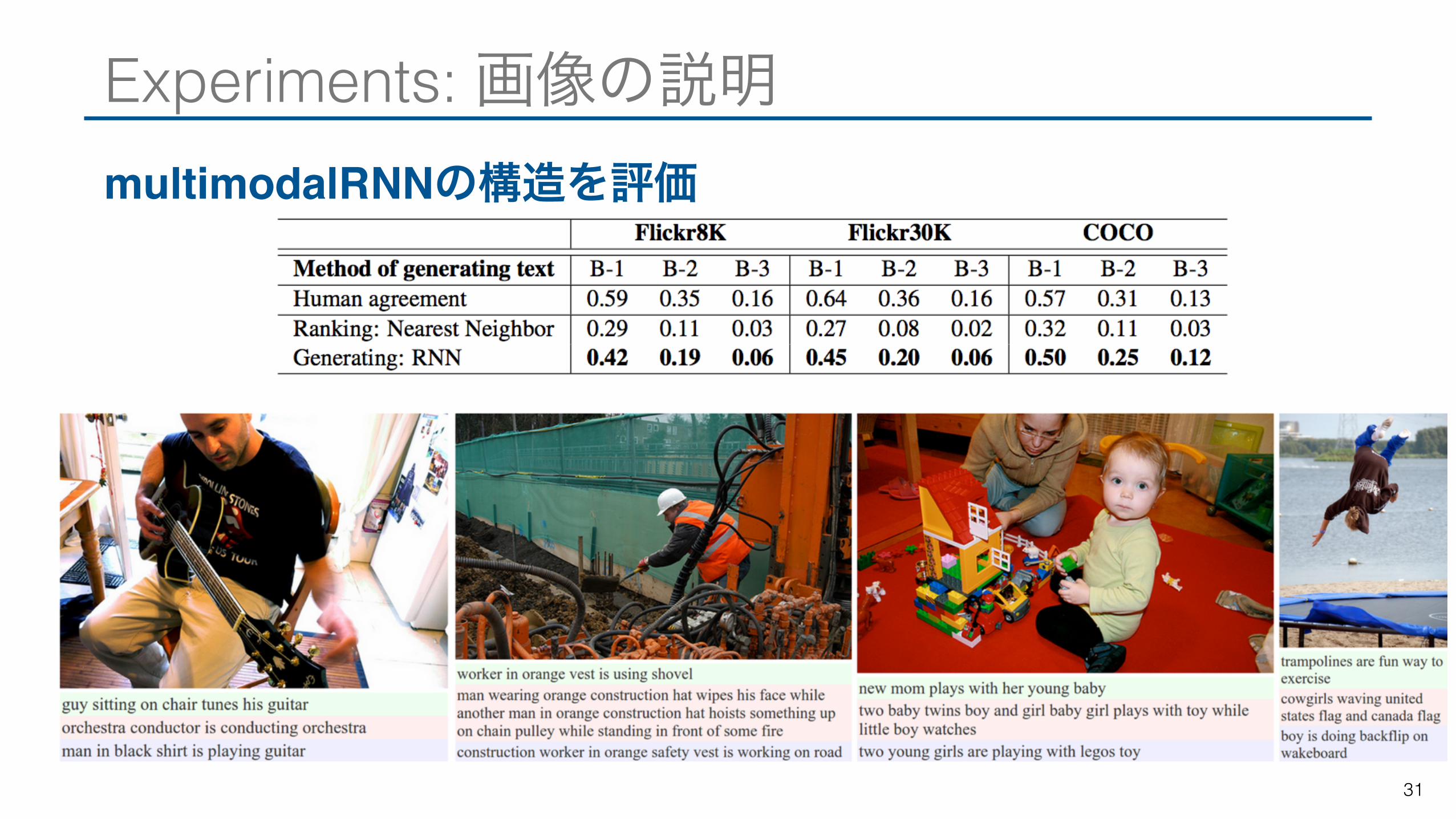
Experiments: 画像の説明multimodalRNNの構造を評価
31

Experiments: 画像の説明一部(region)の評価
32

Conclusion画像領域に対するフレーズの自動生成手法の提案• 画像と文章を同一空間への写像手法
- ランキングにおいてstate-of-artな結果を得た
• 入力画像からフレーズを生成するmultimodal RNN - 画像全体,領域別において良い結果を得た
Limitation• 固定された解像度の画像しか文章を提案できない
• 足し算しかRNNは隠れ層に表現できない33

感想deep learningで注目されてる手法を組合せた応用例
• おそらくテクニックがいっぱい隠れている
• コードも公開されているので,実行してみる
• Googleはやはりいろいろやってそう
34

![[UniteKorea2013] Unity Hacks](https://cdn.vdocuments.pub/doc/165x107/558c6a30d8b42ae7508b475c/unitekorea2013-unity-hacks.jpg)





