Download - Introduction to Auto Loader

Introduction to Auto LoaderHow to easily ingest PBs of data into your Delta lakehousePranav AnandSoftware Engineer at Databricks
s3:/logs
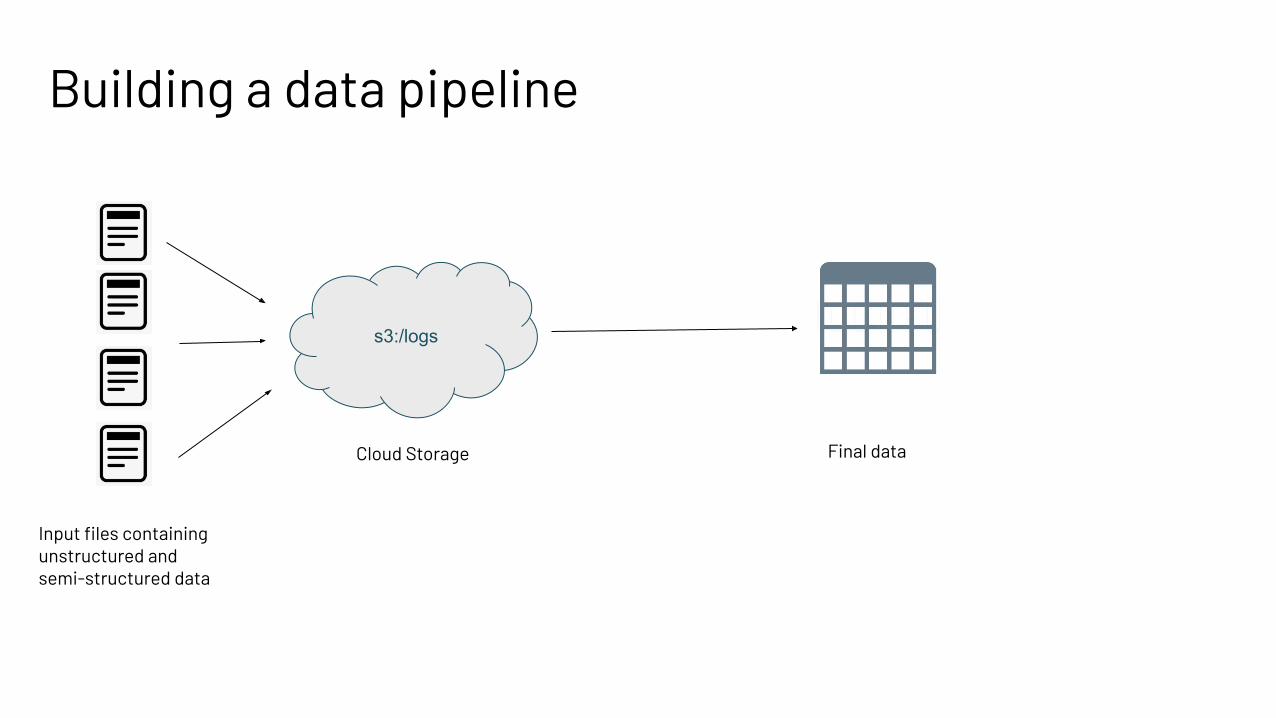
Cloud Storage
Input files containingunstructured and semi-structured data
Final data
Building a data pipeline

Building a data pipeline: Step one
s3:/logs
Cloud StorageStructured Streaming
Input files containingunstructured and semi-structured data
Structured tables
Data Ingestion

s3:/logs
Cloud StorageStructured Streaming
Input files
Structured tables
“Here be dragons”
Building a data pipeline: Step one

input path: s3:/logs
Cloud Storage File Stream Source Final data
a.json, b.json
List on trigger at t = 0 Transformed
data
Challenge: Scalability

input path: s3:/logs
Cloud Storage File Stream Source Final data
c.json, a.json, b.json
List on trigger at t = 5 Transformed
data
Challenge: Scalability
Seen file paths
a.jsonb.json

input path: s3:/logs
Cloud Storage File Stream Source Final data
c.json, a.json, b.json
List on trigger at t = 5 Transformed
data
Challenge: Scalability
Seen file paths
a.jsonb.json
Repeated listing is slow and expensive

input path: s3:/logs
Cloud Storage File Stream Source Final data
c.json, a.json, b.json
List on trigger at t = 5 Transformed
data
Challenge: Scalability
Seen file paths mapa.jsonb.json
In-memory map does not scaleRepeated listing is
slow and expensive

Challenge: Schema
Cloud Storage
{ id: 5 name: “John”}
{ id: 7 name: “Amy”}
a.json
b.json
Manually infer and set schema asid: Intname: String
Ready to go!
Input files


Challenge: Schema
Cloud StorageInput files
{ id: 18, name: “Olivia”}
{ id: 23, name: “Alex”, age: 31}
e.json
f.json
Data loss!
Manually handle this column. User intervention needed every time.
How do I deal with all this?!

Auto Loader
▪ New Structured
Streaming source
▪ Solves biggest
ingestion challenges:▪ Scalability
▪ Schema management

Challenge: ScalabilityFile Notification Mode
s3:/logs
Cloud Storage
Input files

Challenge: ScalabilityFile Notification Mode
s3:/logs
Cloud StorageInput files
a.json
File notificationgenerated for a.json
a.json
s3:/logs

Challenge: ScalabilityFile Notification Mode
Input files
Cloud files source
Pull a.json from queue
Delete a.json from queue once ingested
a.json s3:/logs
Cloud Storage
a.json
File notificationgenerated for a.json
s3:/logs
No listing!
Files ingested as they arrive.

Challenge: ScalabilityFile Notification Mode
Input files
Pull a.json from queue
Delete a.json from queue once ingested
a.json s3:/logs
Cloud Storage
a.json
File notificationgenerated for a.json
s3:/logs
Cloud files source
Seen file paths map
in RocksDBa.json
RocksDB deduplication means no scalability limits
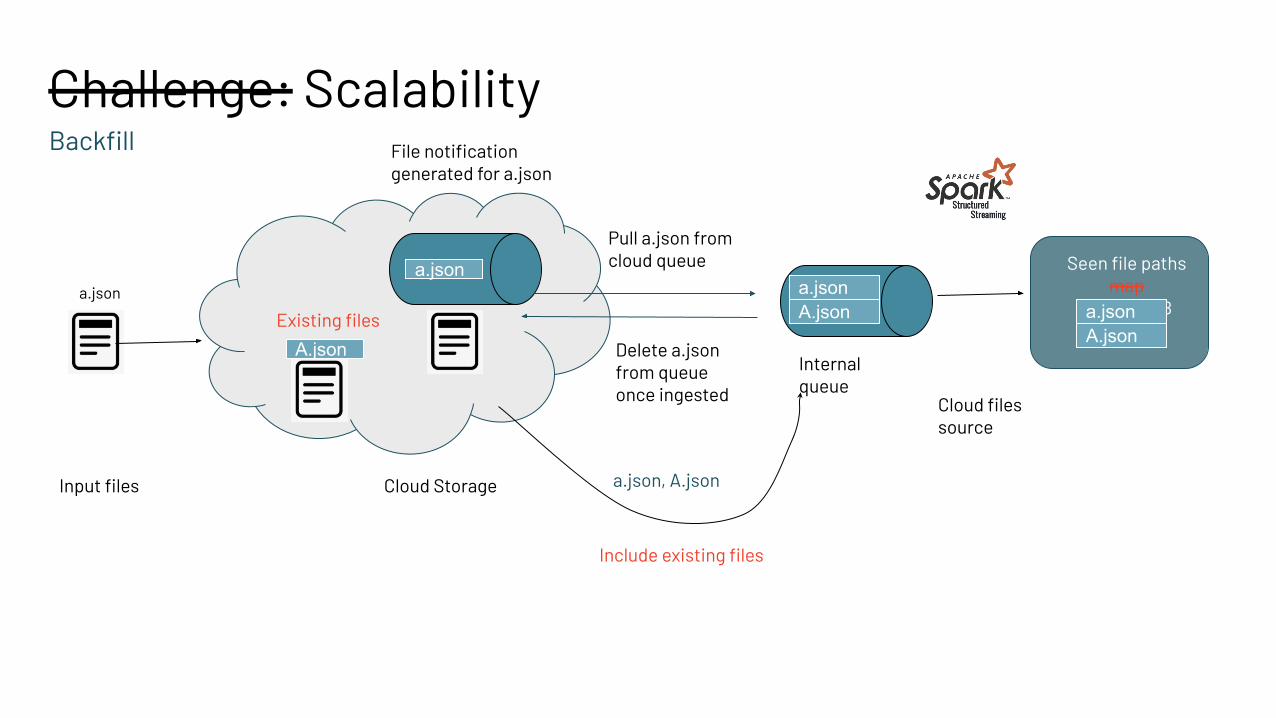
Challenge: ScalabilityBackfill
Input files
Pull a.json from cloud queue
Delete a.json from queue once ingested
a.json
Cloud Storage
a.json
File notificationgenerated for a.json
Cloud files source
Seen file paths map
in RocksDBa.jsonA.json
a.json, A.json
Include existing files
A.jsonInternal queue
a.jsonA.jsonExisting files

Challenge: ScalabilityFile Notification Mode
spark.readStream.format(“cloudFiles”).option(“cloudFiles.format”, “json”).option(“cloudFiles.useNotifications”, “true”).option(“cloudFiles.includeExistingFiles”,
“true”).load()
▪ No repeated listing▪ Scalable to many millions of files▪ Done simply

Challenge: Schema
Cloud StorageInput files
a.jsonStarting off more simply
{ id: 5 name: “John”}
{ id: 7 name: “Amy”}
b.json
Automatically infer and set schema asid: Intname: String
Ready to go!

Challenge: Schema
Cloud StorageInput files
{ id: 18, name: “Olivia”}
{ id: 23, name: “Alex”, age: 31}
e.json
f.json
Where we hit a dead end...
How do I deal with all this?!
Data loss!
Manually handle this column. User intervention needed every time.

Challenge: Schema
Cloud StorageInput files
{ id: 18, name: “Olivia”}
{ id: 23, name: “Alex”, age: 31}
e.json
f.json
What we can do about it
How do I deal with all this?!
+ Auto Loader
Data loss!
Manually handle this column. User intervention needed every time.

Challenge: Schema
Cloud StorageInput files
{ id: 18, name: “Olivia”}
{ id: 23, name: “Alex”, age: 31}
e.json
f.json
Self-sustaining stream - Evolve schema Schema was inferred asid: Intname: String
New schema:id: Intname: Stringage: Int

Challenge: Schema
Cloud StorageInput files
{ id: 18, name: “Olivia”}
{ id: 23, name: “Alex”, age: 31}
e.json
f.json
Self-sustaining stream - Evolve schema Schema was inferred asid: Intname: String
New schema:id: Intname: Stringage: Int
Set and forget!
.option(“cloudFiles.schemaEvolutionMode”, “addNewColumns”)

Challenge: Schema
Cloud StorageInput files
{ id: 18, name: “Olivia”}
{ id: 23, name: “Alex”, age: 31}
e.json
f.json
Self-sustaining stream: Rescue data Schema was inferred asid: Intname: String_rescued_data: String
New schema:id: Intname: String_rescued_data: String
Set and forget!
.option(“cloudFiles.schemaEvolutionMode”, “rescue”)

Challenge: Schema
Cloud StorageInput files
{ id: 18, name: “Olivia”}
{ id: 23, name: “Alex”, age: 31}
e.json
f.json
Self-sustaining stream: Rescue data Schema was inferred asid: Intname: String_rescued_data: String
New schema:id: Intname: String_rescued_data: String
Set and forget!
.option(“cloudFiles.schemaEvolutionMode”, “rescue”)
Other modes like “failOnNewColumns” and “none”

Let’s look at the code

In practice
▪ 50+ TB per day of logs ingested at Databricks using Auto Loader
▪ Customers have used Auto Loader to ingest 10s of PB of data

Feedback
Your feedback is important to us.
Don’t forget to rate and review the sessions.








