econometrie van de financiële markten -...
TRANSCRIPT

UNIVERSITEIT GENTFACULTEIT ECONOMIE
EN BEDRIJFSKUNDE
ACADEMIEJAAR 1998-1999
Econometrie van de Financiële Markten
Scriptie voorgedragen tot het bekomen van de graad:
licentiaat in de toegepaste economische wetenschappen,
door
Koen Inghelbrecht
Onder leiding van
Prof. Dr. H. Reynaerts

Ondergetekende, Koen Inghelbrecht, bevestigt hierbij dat onderhevige scriptie enkel mag
worden geraadpleegd en gefotokopieerd mits schriftelijke toestemming van de auteur. Bij het
citeren moet steeds de titel en de auteur van de scriptie worden vermeld.

Inleiding I
Woord voorafBij aanvang van deze scriptie is het mij een genoegen een woord van dank te richten aan alle
personen die bijgedragen hebben tot het welslagen van deze scriptie.
In de eerste plaats wil ik mijn promotor, Prof. dr. H. Reynaerts, bedanken voor het begeleiden,
evalueren en raadgeven doorheen de volledige eindverhandeling.
Verder wil ik graag mijn dank betuigen aan de volgende personen:
• Assistent J. Crombez voor de raadgevingen, nuttige informatie en het evalueren van mijn
scriptie
• Prof. dr. M. Vanmaele en de assistenten L. Gilbert, K. Zahidi, S. Everaert en J. Dhaene voor
het bijwonen van de presentaties en hun medewerking bij het oplossen van enkele specifieke
problemen
• Assistent S. Vansteelandt voor de tips en raadgevingen
• Mijn ouders die mij de kans geboden hebben deze studies te volgen
Koen Inghelbrecht
Mei 1999

Inleiding II
InhoudsopgaveWoord vooraf .................................................................................................................................. I
Inhoudsopgave...............................................................................................................................II
Lijst van figuren............................................................................................................................IV
Lijst van tabellen............................................................................................................................ V
Inleiding ..........................................................................................................................................1
1 DE “RANDOM WALK” HYPOTHESE .........................................................................................................3
1.1 HET MARTINGAAL MODEL ..............................................................................................................................3
1.2 HET “RANDOM WALK” MODEL.......................................................................................................................4
1.2.1 Het Kansmodel ......................................................................................................................................4
1.2.2 De Opeenvolgende Prijsveranderingen Zijn Onafhankelijk van Elkaar. ..............................................6
1.2.3 De Opeenvolgende Prijsveranderingen Zijn Identiek Verdeeld ............................................................9
1.3 MARTINGAAL MODEL VERSUS “RANDOM WALK” MODEL............................................................................14
2 DE SOORTEN “RANDOM WALK”.............................................................................................................15
Besluit..........................................................................................................................................119
Bibliografie ...................................................................................................................................VI
Bijlagen .........................................................................................................................................IX

Inleiding IV
Lijst van figurenFIGUUR 1: DE 3 SOORTEN “RANDOM WALK”. 15
FIGUUR 2: HET VERLOOP VAN DE PRIJZEN BIJ DE RW1. 19
FIGUUR 3: HET VERLOOP VAN DE PRIJSVERANDERINGEN BIJ DE RW1. 20
FIGUUR 4: HET VERLOOP VAN DE PRIJZEN BIJ DE RW2. 24
FIGUUR 5: HET VERLOOP VAN DE PRIJSVERANDERINGEN BIJ DE RW2. 24
FIGUUR 6: HET VERLOOP VAN DE PRIJZEN BIJ DE RW3. 28
FIGUUR 7: HET VERLOOP VAN DE PRIJSVERANDERINGEN BIJ DE RW3. 29
FIGUUR 8: DE MAANDELIJKSE PRIJZEN (UCB). 31
FIGUUR 9: DE MAANDELIJKSE PRIJS ∆ (UCB). 31
FIGUUR 10: DE MAANDELIJKSE PRIJZEN (BEL20). 32
FIGUUR 11: DE MAANDELIJKSE PRIJS ∆ (BEL20). 32
FIGUUR 12: DE NORMALE VERDELING MET GEMIDDELDE µ . 34
FIGUUR 13: DE EXPONENTIËLE FUNCTIE VAN 1−− tt pp . 35
FIGUUR 14: HISTOGRAM MAAND. PRIJS ∆ (UCB). 37
FIGUUR 15: HISTOGRAM MAAND. LOGPRIJS ∆ (UCB). 37
FIGUUR 16: VERLOOP VAN PRIJS ∆ (UCB). 41
FIGUUR 17: VERLOOP VAN LOGPRIJS ∆ (UCB). 41
FIGUUR 18: HET VERLOOP VAN DE FUNCTIE ( ) 412 +−= πππf . 50
FIGUUR 19: WAARDEN VOOR CJ -RATIO VOOR GEGEVEN α EN β . 57
FIGUUR 20: HET VERWACHTE AANTAL RUNS VOOR DE RW1 MET DRIFT µ . 66

Inleiding V
Lijst van tabellen
TABEL 1: DE COWLES-JONES TEST VOOR DAGELIJKSE, WEKELIJKSE EN
MAANDELIJKSE RENDEMENTEN. 58
TABEL 2: DE RUNS-TEST VOOR DAGELIJKSE, WEKELIJKSE EN MAANDELIJKSE
RENDEMENTEN. 67
TABEL 3: DE DICKEY-FULLER TEST VOOR DE DAGELIJKSE, WEKELIJKSE EN
MAANDELIJKSE RENDEMENTEN. 70
TABEL 4: AUTOCORRELATIE-TEST VOOR DAGELIJKSE, WEKELIJKSE EN
MAANDELIJKSE RENDEMENTEN (RW1). 80
TABEL 5: DE RESULTATEN VAN ENKELE ONDERZOEKEN UITGEVOERD M.B.T. DE
EERST-ORDE AUTOCORRELATIES. 81
TABEL 6: DE PORTMANTEAU STATISTIEKEN VOOR DAGELIJKSE, WEKELIJKSE EN
MAANDELIJKSE RENDEMENTEN 85
TABEL 7: DE VARIANTIERATIOS VOOR DAGELIJKSE, WEKELIJKSE EN MAANDELIJKSE
RENDEMENTEN (RW1). 105
TABEL 8: DE VARIANTIERATIOS VOOR DE DAGELIJKSE, WEKELIJKSE EN
MAANDELIJKSE RENDEMENTEN (RW3). 117
TABEL 9: AUTOCORRELATIE-TEST VOOR DAGELIJKSE, WEKELIJKSE EN
MAANDELIJKSE RENDEMENTEN (RW3). 117

Inleiding 1
InleidingDe theorie over de financiële markten is een zeer uitgebreid domein. Een centrale rol in de
financiële theorie en zijn empirische implementatie is de invloed van de onzekerheid op het
gedrag van de investeerders en de marktprijzen. De financiële modellen worden dus overheerst
door onzekerheid. De financiële econometrie zal dan ook een belangrijke rol spelen bij het
schatten en testen van financiële modellen. Een belangrijk aspect binnen de financiële
econometrie is het voorspellen van de aandelenrendementen. Zijn de aandelenrendementen
voorspelbaar? Dit is één van de meest controversiële vragen van de financiële econometrie.
Reeds vele tientallen jaren houden vooraanstaande wiskundigen en onderzoekers zich bezig met
het oplossen van de vraag. Vaak leidde dit tot tegengestelde meningen. De dag van vandaag
levert nog altijd geen sluitend antwoord. De uitdaging is echter enorm. Wie wil er de markt niet
verslaan? (CAMPBELL J. et al., 1997, blz. 3 en 27).
Om de aandelenrendementen te voorspellen kan men gebruik maken van allerhande informatie,
zowel publieke als private informatie. De nadruk zal hier echter gelegd worden op het
voorspellen van de toekomstige prijsveranderingen van aandelen, enkel gebruik makend van de
prijsveranderingen uit het verleden. Men kan dan gemakkelijk de link leggen met de definitie
van “zwak efficiënte markten”. Zwak efficiënte markten impliceren namelijk dat alle informatie
die vervat zit in de historische prijzen ook volledig gereflecteerd is in de huidige prijzen. Indien
een markt zwak efficiënt is, dan zal het niet mogelijk zijn op basis van de vroegere prijzen de
toekomstige prijsveranderingen te voorspellen. De nieuwe informatie die vrij komt over een
bepaald bedrijf zal voldoende snel in de prijs geïncorporeerd worden zodat het niet mogelijk is
voor de investeerder om op basis van het verloop van de aandelenprijzen een extra winst te
genereren. In een zwak efficiënte markt zal het dus waardeloos zijn om te handelen in functie
van het verloop van de aandelenkoersen (ELTON E. en GRUBER M., 1995, blz.407).
Een model dat het verloop van de prijzen kan omvatten onder de hypothese van “zwak efficiënte
markten” is het “random walk” model. Als de “random walk” geldig is voor alle aandelen, dan
zal de markt zwak efficiënt zijn en zullen de toekomstige prijsveranderingen niet voorspelbaar
zijn op basis van de historische prijzen. Door middel van het “random walk” model kan er dus
getest worden of de aandelenprijzen voorspelbaar zijn. Het “random walk” model zal uitvoerig
besproken en getest worden om een antwoord te kunnen geven op de vraag: “Zijn de
prijsveranderingen van de aandelen voorspelbaar?”

Inleiding 2
De werkwijze die gevolgd wordt, is deze van Campbell, Lo en MacKinlay (1997). Een deel van
hoofdstuk 2 over de voorspelbaarheid van de aandelenrendementen (blz. 27-55) uit hun boek
“ECONOMETRICS OF THE FINANCIAL MARKETS” wordt grondig uitgewerkt en
aangevuld met talrijke interessante topics over de “random walk”. De theorie wordt vervolledigd
met enkele empirische bevindingen. Er zal niet telkens verwezen worden naar hoofdstuk 2 van
Campbell, Lo en MacKinlay (1997). Als er in de tekst geen expliciete bronvermelding is, kan er
aangenomen worden dat het deel van de tekst handelt over dit hoofdstuk.
In hoofdstuk 1 wordt het “random walk” model gedefinieerd en worden de veronderstellingen
die daaraan verbonden zijn, in detail besproken. Er wordt vooral de nadruk gelegd op het
ontstaan van de “random walk”. Vervolgens wordt het “random walk” model in hoofdstuk 2
opgedeeld in drie verschillende soorten (“random walk” 1, 2 en 3) waarbij de veronderstellingen
in zekere mate zullen verschillen van elkaar. Voor iedere soort wordt een model opgesteld die
uitvoerig gesproken wordt. Er wordt ook telkens een tijdsreeks gesimuleerd voor iedere soort om
de bevindingen empirisch te testen. Hoofdstuk 3 wordt gewijd aan het gebruik van de logaritmen
van de prijzen in plaats van de prijzen zelf bij het modelleren van de “random walk”. Er zullen
enkele belangrijke eigenschappen aan bod komen die de lezer ervan moeten overtuigen dat het
gebruik van logaritmen de aangewezen weg is.
Vervolgens kunnen er enkele testen voor de “random walk” uitgewerkt worden. De nadruk zal
vooral gelegd worden op de “random walk” 1. In hoofdstuk 4 worden er zes testen voor de
“random walk” 1 afgeleid. De resultaten ervan kunnnen gebruikt worden om de test uit te voeren
op bestaande tijdsreeksen van aandelenprijzen. Hoofdstuk 5 handelt over de “random walk” 2.
Dit hoofdstuk geeft een beschrijving van de implicaties van de “random walk” 2. Er wordt ook
weergegeven hoe de “random walk” 2 eventueel kan getest worden. Tenslotte worden er in
hoofdstuk 6 drie testen uitgewerkt voor de “random walk” 3 die dan kunnen gebruikt worden om
de geldigheid van de “random walk” 3 na te gaan voor tijdsreeksen van aandelenprijzen.
De testen voor de “random walk” 1 en 3 zullen ook telkens empirisch toegepast worden. Het
empirisch onderzoek wordt uitgevoerd op twee tijdsreeksen: de prijzen van het aandeel UCB en
de prijzen van de Bel20-index. Via het onderzoek wordt geprobeerd om afwijkingen van de
“random walk” hypothese te detecteren. Het onderzoek voor de “random walk” 1 wordt
uitgevoerd telkens er een test uitgewerkt is. Het empirisch onderzoek voor de drie testen van de
“random walk” 3 wordt gezamenlijk in een aparte sectie behandeld.

Hoofdstuk 1: De “Random Walk” Hypothese 3
1 De “Random Walk” HypotheseIn dit hoofdstuk zal de “random walk” uitvoerig besproken worden en zullen enkele belangrijke
eigenschappen aan bod komen. Het “random walk” model is ontstaan uit een ander model, het
martingaal model. Het eerste deel van dit hoofdstuk brengt dan ook een korte bespreking omtrent
het martingaal model. Het “random walk” model, dat eigenlijk een speciaal geval is van het
martingaal model, wordt behandelt in het tweede deel. In een laatste deel worden de twee
modellen met elkaar geconfronteerd.
1.1 Het Martingaal Model
Eén van de eerste modellen om de prijzen van aandelen te modelleren is het martingaal model,
ook wel een “fair game” model genoemd. Een “fair game” is als het ware een kansspel waarbij
de kans dat men zal winnen gelijk is aan de kans dat men zal verliezen. Het principe van een
“fair game” kan het best geïllustreerd worden aan de hand van een kansspel zoals roulette. Op
het roulettewiel zijn er evenveel rode nummers als zwarte nummers. Stel men beschikt over 100
fiches van 1 euro. Als er nu één fiche gelegd wordt op rood, dan is er evenveel kans op het
verliezen van die fiche als op het verdubbelen ervan. In iedere spelronde zal de verwachte winst
dan ook gelijk zijn aan nul onafhankelijk van het verloop van het spel. Dit is nu precies wat er
bedoeld wordt met een fair game (ROBERTS H., 1959; blz. 9).
Een martingaal is nu het stochastisch proces dat uitgaat van de eigenschappen van een “fair
game”. Het martingaal model is dan het model die voldoet aan de volgende voorwaarde:
[ ] tttt PPPP =Ε −+ ,..., 11 , (1.1.1)
waarbij tP het totale bezit is van fiches op tijdstip t. De verwachte bezittingen op tijdstip t+1 zijn
gelijk aan de bezittingen op tijdstip t, geconditioneerd op het verloop van de bezittingen in het
verleden. Dus als men op tijdstip t over 100 fiches beschikt dan kan er verwacht worden dat men
op tijdstip t+1 eveneens over 100 fiches zal beschikken, onafhankelijk van het bezit in het
verleden. Uitdrukking (1.1.1) kan vervolgens ook nog geschreven worden als:
[ ] 0,..., 11 =−Ε −+ tttt PPPP , (1.1.2)

Hoofdstuk 1: De “Random Walk” Hypothese 4
of nog, de verwachte winst per spelronde is gelijk aan nul, geconditioneerd op het verloop van
het spel. De opeenvolgingen van uitkomsten van het roulettewiel, waarbij rood leidt tot een
stijging van de fiches met één en zwart tot een daling van de fiches met één, zal dan een
martingaal volgen (CAMPBELL J. et al., 1997, blz. 30).
Deze redenering kan nu overgebracht worden op aandelenprijzen. Het martingaal model kan
namelijk gebruikt worden van om de prijzen van aandelen te modelleren. Stel tP is gelijk aan de
prijs van het aandeel op tijdstip t, dan impliceert het martingaal model dat de beste voorspelling
die gemaakt kan worden voor de prijs van morgen, de prijs van vandaag is, rekening houdend
met het verloop van de prijzen uit het verleden. Het is dus even waarschijnlijk dat de prijs van
het aandeel zal dalen als dat hij zal stijgen. De verwachte winst zal dan ook gelijk zijn aan 0.
Het martingaal model heeft geleid tot de ontwikkeling van het “random walk” model.
1.2 Het “Random Walk” Model
Het “random walk” model is een speciaal geval van het martingaal model. Het “random walk”
model zal dus dezelfde eigenschappen hebben als het martingaal model. Daarnaast zal het
“random walk” model een meer gedetailleerde verklaring geven over de economische omgeving
(FAMA E., 1970, blz. 387). Er worden dus enkele aanvullende veronderstellingen gemaakt:
• De opeenvolgende prijsveranderingen zijn onafhankelijk van elkaar.
• De opeenvolgende prijsveranderingen zijn identiek verdeeld.
Als deze twee aanvullende veronderstellingen geldig zijn, spreekt men van een “random walk”,
ook wel stochastische wandeling genoemd (FAMA E., 1965, blz. 34-35). Vaak stelt men de
“random walk” intuïtief voor als de dronkemanswandeling. De dronkaard wijkt voortdurend op
willekeurige wijze af van de ideale weg, maar keert er telkens naar terug..
1.2.1 Het Kansmodel
Een eerste werk omtrent de “random walk” kwam van de Franse wiskundige Louis Bachelier
(1900) in zijn “Theory of Speculation”. Daarin stelde hij dat de speculatieve prijzen te
omschrijven zijn als een “random walk”. Hij baseerde zich hierbij vooral op empirische
bevindingen. In zijn eenvoudigste model vergeleek hij het “random walk” proces met het gooien
van een muntstuk, waarbij munt een prijsstijging voorstelt en kop een even grote prijsdaling. De

Hoofdstuk 1: De “Random Walk” Hypothese 5
kans op een prijsstijging is dus even groot als de kans op een prijsdaling (MANDELBROT,
1998, blz. 66). Bachelier maakte de veronderstelling dat de verwachte winst gelijk is aan nul
(ALEXANDER S., 1961,blz. 200). Zijn eenvoudigste model lijkt dan ook meer in
overeenstemming te zijn met de definitie van een “fair game”. Bachelier bedoelde dus eigenlijk
met dit model dat de speculatieve prijzen een “fair game” volgen (FAMA E., 1970, blz. 389).
Het is evenwel vanuit het principe van het gooien van een muntstuk dat men vertrekt bij het
modelleren van de “random walk”. De “random walk” veronderstelt namelijk dat de
opeenvolgende prijsveranderingen onafhankelijk zijn van elkaar en als iedere prijsverandering
bekomen wordt door het gooien van een muntstuk, dan zullen de prijsveranderingen
onafhankelijk zijn (COOTNER P., 1964, blz. 2). 1 Later stelde Bachelier, in zijn meest
ontwikkeld model voor de “random walk”, dat de prijsverandering tTt PP −+ van een aandeel, een
normaal verdeelde stochastische variabele is met een verwachtingswaarde 0 en een variantie
proportioneel met T . Dit model wordt ook wel de Brownse beweging genoemd
(MANDELBROT B., 1966, blz. 243).
De theorie van de “random walk” kwam geleidelijk tot stand uit de vele onderzoeken van
tijdsreeksen in de jaren ’50 en ’60 (FAMA E., 1970, blz. 389). Een belangrijk werk bij deze
ontwikkeling kwam van Kendall (1953). Kendall was één van de eersten om de
veronderstellingen van de “random walk” te testen op tijdsreeksen. Hij bestudeerde het gedrag
van de wekelijkse veranderingen van 19 Britse indexen van industriële aandelenprijzen, de
wekelijkse en maandelijkse verandering van de tarwe-prijzen op beurs van Chicago en de
maandelijkse veranderingen van de katoenprijzen op de beurs van New York. Zijn resultaten in
verband met de wekelijkse veranderingen van de tijdsreeksen lijken consistent te zijn met de
veronderstellingen van de “random walk”. Deze laatste omschrijft hij als een proces waarbij er
wekelijks een willekeurig getal getrokken wordt uit een symmetrische verdeling die dan bij de
wekelijkse prijs van de index gevoegd wordt (KENDALL M., 1953, blz. 86-87). Volgens
Kendall kan het “random walk” model het best omschreven worden door het kansspel, roulette.
We beschikken over een roulettewiel. Een belangrijke eigenschap van een roulettewiel is dat
iedere uitkomst onafhankelijk is van het verloop van de vorige uitkomsten..2 Het wiel heeft dus
geen “geheugen”. Als er vervolgens verondersteld wordt dat iedere uitkomst een zekere kans
1 Het is namelijk zo dat het gooien van muntstukken onafhankelijke gebeurtenissen zijn. De voorwaardelijkeprobabiliteiten zullen dus gelijk zijn aan de onvoorwaardelijke probabiliteiten. De kans dat men op tijdstip t muntgooit nadat op tijdstip t-1 munt gegooid heeft zal dus gelijk zijn aan de onvoorwaardelijke kans dat men munt gooit.2 Iedere draai aan het wiel is een onafhankelijke gebeurtenis.

Hoofdstuk 1: De “Random Walk” Hypothese 6
heeft van optreden, dan weet men dat deze kansen stabiel zullen blijven doorheen de tijd indien
het wiel geen imperfecties vertoont (ROBERTS H., 1959, blz. 9).
Vervolgens kan nu de link gelegd worden met de tijdsreeksen van de aandelenprijzen.
Veronderstel een roulettewiel met daarop verschillende prijsveranderingen. Iedere periode wordt
aan het wiel gedraaid. De prijsverandering van het aandeel per periode kan dan gezien worden
als een uitkomst van het roulettewiel. Aangezien de opeenvolgende uitkomsten van het
roulettewiel niet gerelateerd zijn, zullen de opeenvolgende prijsveranderingen onafhankelijk zijn
van elkaar. Er zal ook telkens aan hetzelfde wiel gedraaid worden zodat de opeenvolgende
prijsveranderingen identiek verdeeld zullen zijn. Iedere prijsverandering kan dus gezien worden
als een trekking uit een verdeling die stabiel blijft doorheen de tijd. De twee veronderstellingen
van de “random walk” zijn voldaan (ELTON E. en GRUBER M., 1995, blz.410).
Het kansmodel dat door Kendall geconstrueerd is, zegt evenwel niets over de verdeling van de
mogelijke uitkomsten. Deze kan wel benaderd worden door een waarschijnlijkheidsverdeling op
te stellen op basis van de vroegere prijsveranderingen (ROBERTS H., 1959, blz.9). De
prijsveranderingen uit het verleden kunnen dus van belang zijn bij de beoordeling van de
verdeling van de toekomstige prijsveranderingen, des te meer omdat de verdelingen van de
prijsveranderingen stationair zijn doorheen de tijd in het geval dat de “random walk” geldig is.
Het “random walk” model zegt dus niet dat prijsveranderingen uit het verleden van geen belang
zijn bij de beoordeling van de toekomstige prijsveranderingen, maar dat de opeenvolging van de
prijsveranderingen van geen belang is (FAMA E., 1970, blz. 387).
In wat volgt worden de 2 veronderstellingen van de “random walk” verder in detail bestudeerd.
1.2.2 De Opeenvolgende Prijsveranderingen Zijn Onafhankelijk van Elkaar.
Een eerste veronderstelling die men maakt bij het “random walk” model is dat de opeenvolgende
prijsveranderingen onafhankelijke stochastische variabelen zijn.3 Stel dat tz gelijk is aan de
prijsverandering van een aandeel op tijdstip t, dan geldt de hypothese van onafhankelijkheid
indien
3 Stochastische variabelen zijn variabelen die bepaald zijn door een waarschijnlijkheidsverdeling. Iedere observatievoor een stochastische variabele kan gezien worden als een trekking uit zijn verdeling (FAMA E., 1977, blz. 3-4).

Hoofdstuk 1: De “Random Walk” Hypothese 7
( ) ( )tttz zfzzzf ~,...,~21 =−− , t∀ , (1.2.1)
of nog, de voorwaardelijke en marginale waarschijnlijkheidsverdelingen van de onafhankelijke
stochastische variabele tz~ zijn identiek.4 De “random walk” hypothese zegt dus dat de volledige
verdeling van de prijsverandering op tijdstip t onafhankelijk is van de prijsveranderingen uit het
verleden (FAMA E., 1970, blz. 386-387). Indien (1.2.1) opgaat, dan kan er geen gebruik
gemaakt worden van de prijsveranderingen in het verleden om een voorspelling te doen omtrent
de toekomstige prijsveranderingen (FAMA E., 1965, blz. 34-35). Als er nu teruggegrepen wordt
naar het kansmodel opgesteld door Kendall, dan kan men afleiden dat er op basis van vroegere
uitkomsten van het roulettewiel geen voorspellingen kunnen gedaan worden omtrent
toekomstige uitkomsten. Er bestaat dus geen gokregel die tot een positieve verwachte winst leidt
indien de opeenvolgende uitkomsten onafhankelijk zijn van elkaar.
Bachelier-Osborne model
De meest voor de hand liggende verklaring voor de onafhankelijkheid bij het “random walk”
model, kwam van Bachelier en Osborne, twee belangrijke personen bij de ontwikkeling van de
theorie van de “random walk”. Hun verklaring steunt op het feit dat aandelenprijzen beïnvloed
worden door het vrijkomen van informatie. Het is geweten dat in een efficiënte markt de
aandelenprijzen alle beschikbare informatie zullen reflecteren. In dit geval zal de
voorwaardelijke verwachtingswaarde van de prijs van morgen gegeven de prijs van vandaag, de
prijs van vandaag zijn (supra, blz. 1). Er zou dan kunnen verwacht worden dat er enkel
prijsveranderingen zullen optreden indien er nieuwe informatie vrijkomt. Het Bachelier-Osborne
model stelt dat indien de opeenvolging van nieuwe informatie onafhankelijk is van elkaar, de
opeenvolging van prijsveranderingen ook onafhankelijk zal zijn van elkaar (FAMA E., 1965,
blz. 37) (COOTNER P., 1962, blz. 232).
Enkele bedenkingen
Er moeten hierbij wel twee bedenkingen gemaakt worden. Ten eerste kan er verwacht worden
dat in sommige gevallen de opeenvolging van nieuwe informatie niet onafhankelijk zal zijn. Het
is namelijk meer waarschijnlijk dat “goed nieuws” gevolgd wordt door “goed nieuws” dan dat
het gevolgd wordt door “slecht nieuws”, en omgekeerd. Op die manier kan er toch een zekere
afhankelijkheid zijn in het proces dat de informatie genereert. Dit hoeft echter niet noodzakelijk
4 Het teken ~ boven een waarde wijst erop dat het een stochastische variabele is. De waarden zonder ~ zijn dangeobserveerde waarden.

Hoofdstuk 1: De “Random Walk” Hypothese 8
tot afhankelijkheid te leiden tussen de opeenvolgende prijsveranderingen. Stel bijvoorbeeld dat
er positieve afhankelijkheid is tussen de opeenvolging van nieuwe informatie. Indien er goede
informatie vrijkomt over een bepaald bedrijf dan zullen de investeerders, die kennis hebben van
deze positieve afhankelijkheid, er rekening mee houden dat er in de toekomst nog positieve
informatie zal volgen. Deze toekomstige informatie zal dan reeds gereflecteerd worden in de
huidige prijs. Indien er voldoende investeerders zijn die deze toekomstige informatie gebruiken
bij de waardering van de huidige prijs, dan zullen de prijsveranderingen uiteindelijk toch
onafhankelijk zijn van elkaar (FAMA E., 1965, blz. 37-38).
Ten tweede kan ook de veronderstelling van efficiënte markten in vraag gesteld worden. Het is
namelijk mogelijk dat de nieuwe informatie niet onmiddellijk in de prijs gereflecteerd wordt. Er
kan dus een zekere vertraging optreden waarmee de informatie opgenomen wordt in de
aandelenprijs. Hierdoor zal de prijs slechts geleidelijk naar zijn nieuwe intrinsieke waarde
evolueren wat dan kan leiden tot positieve afhankelijkheid tussen opeenvolgende
prijsveranderingen. Indien er nu echter voldoende investeerders zijn, die kennis hebben van deze
geleidelijke beweging, dan zullen zij het aandeel kopen aan het begin van een positieve
beweging. Zo zullen zij ervoor zorgen dat de aandelenprijs sneller naar zijn nieuwe intrinsieke
waarde stijgt zodat de afhankelijk uiteindelijk beperkt zal zijn (FAMA E., 1965, blz. 39).
“Perfecte” onafhankelijkheid
Men kan uit de vorige twee alinea’s afleiden dat het in werkelijkheid praktisch onmogelijk zal
zijn om tijdsreeksen te vinden die gekenmerkt worden door “perfecte” onafhankelijkheid.
Daardoor kan de “random walk” geen volledige en accurate beschrijving geven voor de realiteit.
Het is wel zo dat men in de praktijk de veronderstelling van onafhankelijkheid zal aanvaarden
zolang de afhankelijkheid in de reeks van opeenvolgende prijsveranderingen niet boven een
minimum aanvaardbare grens komt te liggen. De interpretatie van deze grens zal verschillen
naargelang het uitgangspunt van het onderzoek dat uitgevoerd wordt. Een investeerder op de
kapitaalmarkten zal het “random walk” model aanvaarden zolang hij geen gebruik kan maken
van de afhankelijkheid in de tijdsreeks om zijn verwachte winsten te verhogen. Iemand die
statistisch werk doet daarentegen zal kijken naar de significantie van de afhankelijkheid. Stel dat
de statisticus een regressie uitvoert waarbij de prijsverandering een variabele is. Indien er
afhankelijkheid is tussen de prijsveranderingen dan zal er seriële correlatie ontstaan tussen de
residuen van de regressievergelijking zodat de resultaten van de regressie ongeldig zullen zijn.
Indien de afhankelijkheid echter niet significant is dan zullen de resultaten toch geldig zijn.
Daarnaast zal de statisticus ook kijken naar de invloed van de afhankelijkheid van de

Hoofdstuk 1: De “Random Walk” Hypothese 9
prijsveranderingen op de verdeling van de prijsveranderingen. Indien er geen significante
invloed is dan zal hij de afhankelijk niet aanvaarden. De statisticus zal dus het “random walk”
model aanvaarden zolang de afhankelijkheid van de prijsveranderingen niet significant is. Op die
manier wordt de hypothese van de onafhankelijkheid iets afgezwakt (FAMA E., 1965, blz. 35)
(FAMA E. en BLUME M., 1966, blz. 226-227).
1.2.3 De Opeenvolgende Prijsveranderingen Zijn Identiek Verdeeld
Een tweede belangrijke eigenschap van de “random walk” is dat de opeenvolgende
prijsveranderingen identiek verdeeld moeten zijn. De verdelingen van de opeenvolgende
prijsveranderingen moeten stabiel blijven doorheen de tijd. Er is dus voldaan aan deze
eigenschap indien geldt dat
( ) ( )1~~
−= tt zfzf , t∀ , (1.2.2)
waarbij tz~ nog steeds een stochastische variabele is die de prijsverandering weergeeft op tijdstip
t.5 De verdelingfunctie moet dus dezelfde zijn voor ieder tijdstip (FAMA E., 1970, blz.386).
Van de twee veronderstellingen die noodzakelijk zijn bij een “random walk”, is de
veronderstelling dat de opeenvolgende prijsveranderingen onafhankelijk zijn, de belangrijkste.
De prijsveranderingen moeten onafhankelijk zijn of toch zeker ongecorreleerd zijn indien de
“random walk” geldig is (infra, figuur 1 blz. 15). Wat betreft de verdelingen is het zo dat in de
algemene theorie van de “random walk” het niet noodzakelijk is om de verdeling van de
prijsveranderingen te specifiëren. Er bestaan ook vormen van de “random walk” waarbij de
veronderstelling van identiek verdeelde prijsveranderingen niet vereist is.6 Niettegenstaande is
het toch wenselijk om de vorm van de verdeling te specifiëren. Vanuit het standpunt van de
investeerder is de verdeling van de prijsveranderingen zeer belangrijk bij het beoordelen van het
risico dat verbonden is aan het aandeel.7 Daarnaast zal het ook voor personen die een statistisch
onderzoek willen doorvoeren, interessant zijn indien men beschikt over een
waarschijnlijkheidsverdeling van de te onderzoeken data. Deze kan immers interessante
informatie opleveren, zoals het gemiddelde en de variantie. Sommige statistische testen kunnen
5 De geobserveerde waarde tz voor de prijsverandering is dan een trekking uit de verdeling van tz .6 Voor meer uitleg hieromtrent zie hoofdstuk 2.7 De standaardafwijking is een belangrijke maatstaf bij de beoordeling van het risico van een aandeel.

Hoofdstuk 1: De “Random Walk” Hypothese 10
zelfs maar doorgevoerd worden indien de verdeling van de data aan bepaalde eigenschappen
voldoet. Voor statistische doeleinden is het ook interessant dat de parameters van de verdeling
vast zijn voor de periode die onderzocht wordt (FAMA E., 1965, blz. 41).8
Bachelier-Osborne Model: de normale verdeling
De veronderstelling van identiek verdeelde prijsveranderingen impliceert dat de prijsveranderin-
gen in overeenstemming moeten zijn met een bepaalde waarschijnlijkheidsverdeling. Bachelier
en Osborne hebben een model opgesteld dat zegt dat de prijsveranderingen van speculatieve
tijdsreeksen normaal verdeelde stochastische variabelen zijn. Hun model vertrekt van de
veronderstelling dat de prijsveranderingen van een individueel aandeel, van transactie tot
transactie, onafhankelijke en identiek verdeelde stochastische variabelen zijn met een eindige
variantie.9 Vervolgens ging het Bachelier-Osborne model er ook vanuit dat de transacties
uniform verdeeld zijn over de tijd. De prijsverandering over een bepaald tijdsinterval is dan de
som van de prijsveranderingen van transactie tot transactie, m.a.w de som van onafhankelijke en
identiek verdeelde stochastische variabelen. Indien het aantal transacties per tijdsinterval
voldoende groot is, en gebruik makend van de centrale limietstelling, kan er afgeleid worden dat
de prijsverandering over het tijdsinterval normaal verdeeld zal zijn (FAMA E., 1965, blz. 41-42)
(FAMA E., 1963, blz. 297).
Vervolgens kan er gesteld worden dat, indien de “random walk” geldig is, hoe langer het
tijdsinterval wordt, hoe meer de verdeling van de prijsveranderingen over het tijdsinterval de
normale verdeling zal benaderen. Dit is een rechtstreeks gevolg van de centrale limietstelling.
Dus de maandelijkse prijsveranderingen zullen beter de normale verdeling benaderen dan de
wekelijkse prijsveranderingen, indien de “random walk” geldig is (COOTNER P., 1962, blz.
237).
Er kan ook een verklaring voor de normaliteit gegeven worden vanuit economisch standpunt.
Stel dat de opeenvolging van nieuwe informatie onafhankelijk is van elkaar. In dit geval zullen
de opeenvolgende prijsveranderingen ook onafhankelijk zijn van elkaar (supra, blz. ???). Als er
nu regelmatig nieuwe informatie in kleine hoeveelheden vrijkomt, dan kan er verwacht worden
dat de opeenvolgende prijsveranderingen over voldoende lange tijdsintervallen normaal
verdeelde variabelen zullen zijn t.g.v. de centrale limietstelling (MOORE A., 1962, blz. 140).
8 Het is dus interessant dat de prijsveranderingen identiek verdeeld zijn omdat er dan meer statistische proevenkunnen doorvoerd worden op de gegevens.9 In feite gaat men er dan vanuit dat de “random walk” geldig is voor de prijsveranderingen van transactie tottransactie (er is voldaan aan de twee veronderstellingen).

Hoofdstuk 1: De “Random Walk” Hypothese 11
Een belangrijke implicatie van de normale verdeling is dat de variantie van de verdeling
evenredig is met de respectievelijke tijdsintervallen. De variantie van de maandelijkse
prijsveranderingen zal dan ongeveer 4 maal zo groot zijn als de variantie van de wekelijkse
prijsveranderingen indien er dus sprake is van normaliteit (infra, variantieratios) (FAMA E.,
1965, blz. 42).
Leptokurtosis
Niettegenstaande dat de normale verdeling zeer gebruiksvriendelijk is bij het uitvoeren van
statistisch onderzoek, kan het gebruik ervan in twijfel getrokken worden. De theorie van de
normale verdeling werd namelijk serieus in vraag gesteld, vooral door Mandelbrot. Hij
argumenteerde dat de eigenschappen van de prijsveranderingen van aandelen niet consistent zijn
met de normale verdeling. Meestal zijn de staarten van de verdeling van de prijsveranderingen
dikker dan er kan verwacht worden onder de hypothese van normaliteit. Dus normaliteit
onderschat de waarschijnlijkheid van extreme prijsveranderingen (FAMA E., 1963, blz.297-
298).
Het bestaan van dikke staarten kan nagegaan worden door de kurtosis, ook wel het
genormaliseerd vierde moment genoemd, te berekenen. De kurtosis wordt gedefinieerd als
[ ] ( ) ���
� −≡ 4
4
σµzEzK , (1.2.3)
waarbij z de stochastische variabele is die de prijsverandering weergeeft, µ het gemiddelde van z
en 2σ het kwadraat van de variantie van z. In het geval van een normale verdeling zal de kurtosis
gelijk zijn aan 3, maar indien de verdeling dikkere staarten heeft, zal de kurtosis groter zijn dan
3. In het laatste geval zal men spreken van leptokurtosis. De variantie zal dan groter zijn dan de
variantie van de normale verdeling en kan zelfs oneindig groot worden met als gevolg dat de
kurtosis oneindig groot kan worden (CAMPBELL J. et al., 1997, blz. 16-17).
Dit probleem kan eventueel opgelost worden door de uitzonderlijk grote prijsveranderingen uit
de steekproef te halen zodat de normale verdeling toch een goede benadering is. Maar volgens
Mandelbrot zou dit de significantie van de testen, uitgevoerd op de resterende gegevens, kunnen
aantasten, vooral indien het aantal uitzonderingen groot is (FAMA E., 1965, blz.42).
Daarnaast hebben empirische bevindingen vaak aangetoond dat de prijsveranderingen meer
geconcentreerd zijn rond het gemiddelde dan onder de normale verdeling (MANDELBROT B.,
1963, blz. 307-308).

Hoofdstuk 1: De “Random Walk” Hypothese 12
Stabiele Pareto-verdelingen
Mandelbrot stelde dat de afwijkingen van de normaliteit beter verklaard kunnen worden door een
algemene vorm van het Bachelier-Osborne model. Het algemene model maakt niet de
veronderstelling dat de verdelingen van de prijsveranderingen van transactie tot transactie een
eindige variantie hebben. Dus verdelingen met een oneindige variantie zijn toegelaten. De
verdelingen van de prijsveranderingen over bepaalde tijdsintervallen zullen dan behoren tot een
klasse van verdelingen, de stabiele Pareto-verdelingen. De normale verdeling zal ook een
element zijn van deze klasse. De niet-normale stabiele verdelingen bieden wel een betere
beschrijving voor de empirische verdelingen omdat ze dikkere staarten toelaten dan de normale
verdeling. Deze verdelingen steunen dus op de veronderstelling dat de verdelingen van de
prijsveranderingen van transactie tot transactie een oneindige variantie hebben (FAMA E., 1970,
blz. 399).
De stabiele Pareto-verdelingen hebben drie belangrijke eigenschappen:
• Zoals reeds gezegd, zal de variantie enkel eindig zijn in het geval van de normale verdeling.
Alle niet-normale stabiele verdelingen hebben een oneindige variantie waardoor de
verdelingen dikkere uiteinden hebben dan de normale verdeling. Deze oneindige variantie
wijst dan ook op een groter risico dat verbonden is aan het aandeel.
• De verdeling van de som van onafhankelijke en identiek verdeelde stabiele Pareto-variabelen
is zelf ook Pareto-stabiel en heeft dezelfde vorm als de afzonderlijke delen. Deze vorm van
stabiliteit is zeer belangrijk bij de beschrijving van de empirische verdelingen die Pareto-
stabiel zijn. Het is namelijk zo dat de prijsveranderingen over een bepaald tijdsinterval de
som zijn van prijsveranderingen van transactie tot transactie gedurende het tijdsinterval. Als
de prijsveranderingen van transactie tot transactie onafhankelijk en identiek verdeelde
stabiele Pareto-variabelen zijn en de transacties uniform verdeeld zijn over de tijd, dan zullen
de prijsveranderingen over het tijdsinterval een stabiele Pareto-verdeling hebben van
dezelfde vorm, maar met een andere schaalfactor. Deze eigenschap kan zeer belangrijk zijn
bij het testen van de “random walk”.
• Een derde belangrijke eigenschap is het feit dat de stabiele Pareto-verdelingen de enige
asymptotische verdelingen zijn van de som van onafhankelijke en identiek verdeelde
stochastische variabelen zijn. Dus als deze variabelen een oneindige variantie hebben, dan
zal de som van deze variabelen een asymptotische niet-normale stabiele Pareto-verdeling
hebben. (FAMA E., 1963, blz.300-302).

Hoofdstuk 1: De “Random Walk” Hypothese 13
Uit deze eigenschappen kan men eigenlijk afleiden dat de hypothese van Mandelbrot eigenlijk
een uitbreiding is van het Bachelier-Osborne model waarbij de prijsveranderingen een oneindige
variantie mogen hebben (FAMA E., 1965, blz.44).
Alternatieve modellen
Velen stonden weigerachtig tegenover de resultaten van Mandelbrot. Door het feit dat de niet-
normale verdelingen dikke uiteinden hebben die tot een oneindige variantie leidt, zullen veel
statische instrumenten die gebaseerd zijn op de veronderstelling van eindige variantie, niet meer
gebruikt kunnen worden bij het uitvoeren van onderzoek. Er zal ook geen gebruik meer kunnen
gemaakt worden van de steekproefvariantie om de variabiliteit van de tijdsreeks na te gaan. Men
gaat er dan liever vanuit dat de prijsveranderingen normaal verdeelde variabelen door het ruime
aanbod statistische technieken die er bestaan om onderzoek uit te voeren op normaal verdeelde
variabelen (FAMA E., 1963, blz. 298).
Vervolgens ging men ook op zoek naar alternatieve modellen om een verklaring te geven voor
de afwijkingen van normaliteit bij de steekproefverdelingen, in het bijzonder voor de wijde
uiteinden. Er werden twee verklaringen naar voor gebracht. Ten eerste verklaarde men dat de
empirische verdelingen met wijde uiteinden en een grote concentratie rond het gemiddelde,
kunnen gezien worden als een mix van normale verdelingen met telkens een verschillende
variantie. Enkele verdelingen met kleine varianties zorgen ervoor dat er meer waarnemingen
opgehoopt zijn rond het gemiddelde dan bij de normale verdeling. Enkele verdelingen met grote
varianties zorgen dan dat de uiteinden dikker zijn als verwacht onder de normale verdeling. Dus
de mix van normale verdelingen zal dan een betere beschrijving bieden voor de empirische
verdelingen (FAMA E., 1965, blz. 55) (CAMPBELL J., 1997, blz. 481).
Een tweede verklaring voor de wijde uiteinden is de niet-stationariteit. De empirische verdeling
kan dan gezien worden als een verdeling met veranderende parameters doorheen de tijd. De
variantie van de prijsveranderingen kan namelijk groter worden indien het bedrijf risicovoller
wordt. Dus op een bepaald moment kan de verdeling normaal zijn, maar door het groter worden
van de variantie doorheen de tijd, t.g.v. van een stijgende risico, kunnen de uiteinden van de
verdeling dan uiteindelijk dikker worden. Op een analoge manier zou men ook een verklaring
kunnen geven voor de ophoping van waarnemingen rond het gemiddelde. Het kleiner worden
van het risico zou dan aanleiding kunnen geven tot een kleinere variantie. Daarnaast kan ook een
tweede parameter van de verdeling, met name het gemiddelde van de prijsveranderingen,
evolueren doorheen de tijd. Men betwijfelt wel of het veranderen van het gemiddelde een
verklaring kan bieden voor de extreme prijsveranderingen (FAMA E., 1965, blz. 56-58).

Hoofdstuk 1: De “Random Walk” Hypothese 14
Algemeen kan er gesteld worden dat er geen unanimiteit is tussen de onderzoekers omtrent de
verdeling van de prijsveranderingen van aandelen die een “random walk vogen”.
1.3 Martingaal Model versus “Random Walk” Model
Uit de beschrijving van het martingaal model kan men afleiden dat de verwachte toekomstige
aandelenprijzen onafhankelijk zijn van de prijzen uit het verleden. Het is nu wel zo dat de
verdeling van de toekomstige prijzen niet onafhankelijk hoeft te zijn van de vroegere prijzen. Er
kan dus sprake zijn van een zekere afhankelijkheid bij het martingaal proces. Een martingaal is
dus niet noodzakelijk een “random walk”. Een “random walk” zal wel altijd een martingaal zijn
omdat de “random walk” vertrekt van de veronderstellingen van een martingaal en nog twee
extra veronderstellingen maakt. Deze zijn:
• De opeenvolgende prijsveranderingen zijn onafhankelijke stochastische variabelen.
• De opeenvolgende prijsveranderingen zijn identiek verdeelde stochastische variabelen
(of nog, de opeenvolgende prijsveranderingen zijn waarnemingen uit een bepaalde waar-
schijnlijkheidsverdeling).
In het vorige deel werden deze twee veronderstellingen besproken en de testen van “random
walk” zullen de geldigheid van deze twee veronderstellingen nagaan.
Het is nu wel zo dat in de meeste gevallen de afhankelijkheid in het martingaal proces zo klein
zal zijn dat het tot geen al te grote schending zal leiden van de veronderstelling van
onafhankelijkheid van het “random walk” model. De afhankelijkheid zal namelijk niet gebruikt
kunnen worden door de investeerder om zijn verwachte winsten te verhogen (FAMA E. en
BLUME M., 1966, blz.226).
Efficiënte aandelenmarkten
De martingaal werd lang gezien als de noodzakelijke voorwaarde voor een zwak efficiënte
kapitaalmarkt. Niettegenstaande dat een martingaal een noodzakelijke voorwaarde is voor een
zwak efficiënte markt, hoeft dit geenszins te impliceren dat dit een voldoende voorwaarde is. Als
daarentegen de “random walk” geldig is voor alle aandelen, dan kan men wel met zekerheid
concluderen dat de markt zwak efficiënt is. Het omgekeerde is echter niet waar (ELTON E. en
GRUBER M., 1995, blz. 410).
In het volgende hoofdstuk zal het “random walk” model opgedeeld worden in drie soorten.
Iedere soort zal in detail besproken worden.

15
2 De Soorten “Random Walk”Er zijn drie verschillende “random walk” modellen. Het eerste model (RW1) houdt rekening met
de twee veronderstellingen die in hoofdstuk 1 uitvoerig besproken werden. Voor de twee andere
modellen (RW2 en RW3) zullen deze veronderstellingen iets afgezwakt worden. De drie soorten
“random walk” worden schematisch weergegeven in figuur 1 met hun belangrijkste kenmerken.
Figuur 1: De 3 soorten “random walk”.
(Eigen werk; Microsoft Word)
De drie verschillende “random walk” modellen zullen nu één voor één uitvoerig behandeld
worden. Er wordt vanzelfsprekend begonnen met de “random walk” 1.
2.1 De “Random Walk” 1
Bij de “random walk” 1 (RW1) zal men zware veronderstellingen opleggen aan de
prijsveranderingen. Deze veronderstellingen zijn de volgende:
• De prijsveranderingen moeten onafhankelijk zijn van elkaar.
• De prijsveranderingen moeten identiek verdeeld zijn.
De RW1 zal dus geldig zijn indien de prijsveranderingen onafhankelijke en identiek verdeelde
stochastische variabelen zijn. Stel nu dat tP de prijs van het aandeel is op tijdstip t, dan kan de
RW1 als volgt voorgesteld worden:
ttt PP ε+= −1 , ( )2,0~ σε IIDt (2.1.1)
RW1
RW2
RW1
Random walk
Onafhankelijk ( )I
Identiek Verdeeld ( )ID
Ongecorreleerd ( )URW3
Niet Identiek Verdeeld ( )NID

16
waarbij tε de residuen zijn en ( )2,0 σIID geeft aan dat de residuen onafhankelijk en identiek
verdeeld zijn met verwachtingswaarde 0 en variantie 2σ . Deze residuen zijn in feite niets anders
dan de prijsveranderingen die zich voordoen.10 De prijsveranderingen zijn dan onafhankelijk en
identiek verdeeld met verwachtingswaarde 0 en variantie 2σ . Ze voldoen dus aan de twee
veronderstellingen van de RW1, m.a.w. de prijsveranderingen volgen een “random walk” rond
de waarde 0. De prijsveranderingen zullen op een willekeurige manier schommelen rond de
waarde 0, indien de RW1 geldig is.
Drift of verwachte prijsverandering
Het is nu wel zo dat men meestal nog een constante zal toevoegen aan de vergelijking uit (2.1.1).
Men spreekt dan van de “random walk” met drift. Het nieuwe RW1-model ziet er dan als volgt
uit:
ttt PP εµ ++= −1 , ( )2,0~ σε IIDt (2.1.2)
waarbij de constante µ de verwachte prijsverandering of drift is.
Door de aanwezigheid van de drift zal de verwachtingswaarde van de prijsveranderingen niet
meer gelijk zijn aan 0 (FAMA E., 1965, blz. 37). Uit (2.1.2) volgt namelijk dat
( )21 ,~ σµIIDPP tt −− . (2.1.3)
De prijsveranderingen zijn nu onafhankelijk en identiek verdeeld met verwachtingswaarde µ en
variantie 2σ . De prijsveranderingen volgen dus een “random walk” rond de drift. De
prijsveranderingen schommelen op een willekeurige manier schommelen rond de waarde µ in
geval van een RW1 met drift.
Als men nu verder veronderstelt dat de prijsveranderingen normaal verdeeld zijn, dan kan er uit
(2.1.3) afgeleid worden dat door de aanwezigheid van een drift de kans op een prijsstijging
verschillend is van de kans op een prijsdaling (infra, blz. 48). Dit impliceert geenszins dat de
“random walk” niet geldig is.
10 Uit (2.1.1) kan er namelijk afgeleid worden dat ttt PP ε=− −1 , dus het residu op tijdstip t is gelijk aan deprijsverandering op tijdstip t.

17
Het nieuwe model voor de RW1 biedt een betere beschrijving voor de werkelijkheid. De
aanwezigheid van een drift kan namelijk verklaard worden door een aantal factoren zoals het
risico dat verbonden is aan het bedrijf, de dividenden die uitgekeerd worden, de inflatie die zich
voordoet,…Dit kan het best geïllustreerd worden aan de hand van een voorbeeld. Stel er zijn
twee bedrijven die volledig identiek zijn, uitgezonderd hun dividendenpolitiek. Het éne bedrijf
keert al zijn winsten uit als dividenden en zal dan eventueel nieuwe aandelen uitgeven om zijn
investeringsuitgaven te financieren. Het andere bedrijf zal echter maar dividenden uitkeren
indien er na de financiering van de investeringen nog een deel overblijft van de huidige winst.
Door het feit dat de bedrijven identiek zijn, zullen de aandelen van beide bedrijven een zelfde
risico hebben. In dit geval kan men verwachten dat de verwachte rendementen op ieder aandeel
dezelfde zullen zijn. Dit kan enkel zo zijn indien het aandeel van het bedrijf dat een laag
dividend uitkeert, een hogere verwachte prijsverandering heeft dan het bedrijf dat al zijn winsten
uitkeert als dividenden. Vandaar het belang van het invoeren van een drift (FAMA E., 1965,
blz.37).
Een ander voorbeeld betreft de aanwezigheid van inflatie. Stel er is een jaarlijkse inflatie van
3%. In dit geval kan men verwachten dat de prijs van het aandeel jaarlijks zeker met 3% zal
toenemen. Er is dus een jaarlijkse verwachte prijsverandering van minimum 3%. Zo zijn er nog
tal van factoren die een verklaring kunnen geven voor de aanwezigheid van een drift.
Niet-Stationariteit
Het model uitgedrukt in (2.1.2) kan nu verder uitgewerkt worden om de voorwaardelijke
verwachtingswaarde en variantie te bekomen:
++=
=++++=
++=
=
−−
−
t
it
ttt
ttt
tP
PPP
10
12
1
εµ
εεµµεµ
�
[ ] µtPPPE t += 00 (2.1.4)
[ ] 20var σtPPt = . (2.1.5)

18
Uit (2.1.4) en (2.1.5) volgt onmiddellijk dat een tijdsreeks van aandelenprijzen die een RW1
volgen, niet stationair is.11 De voorwaardelijke verwachtingswaarde en variantie zijn namelijk
lineaire functies van de tijd.12 De oorzaak van de niet-stationariteit is het feit dat een “random
walk” met drift gedomineerd wordt door een lineaire deterministische trend.13 Op iedere tijdstip
zal er een constante opgeteld worden bij de prijs van het vorige tijdstip. Er zal dus een trend
aanwezig zijn in het prijsniveau. Men spreekt dan ook vaak over een ““random walk” met trend”
(CAMPBELL J. et al., 1997, blz. 30) (O’DONOVAN T., 1983, blz. 136-137).
Het “witte ruis” model
Omwille van de niet-stationariteit is het beter om de sprongen te bekijken die de prijzen maken
i.p.v. de prijzen zelf. Het is namelijk zo dat de eerste differentie van de prijzen, die dan niets
anders zijn dan de prijsveranderingen, wel stationair is. De prijsveranderingen zullen namelijk
voldoen aan het “witte ruis”-model dat stationariteit impliceert. Het “witte ruis”-model ziet er als
volgt uit:
ttZ εµ +=
met ( )2,0~ σε IIDt ,
waarbij µ een constante is. Het “witte ruis”-proces is de rij van onafhankelijke stochastische
variabelen tε met een gemiddelde 0 en een constante variantie 2σ . Het “witte ruis”-proces
beschrijft het zuivere toeval. Hoe groter 2σ , hoe sterker het zuiver toeval zal schommelen.
Gebruik makend van (2.1.2), kan men nu gemakkelijk inzien dat de prijsveranderingen voldoen
aan het “witte ruis”-model. Het verschil van de prijsverandering en de drift zal dan een “witte
ruis”-proces volgen. De reeks van de prijsveranderingen zal dus op een constante na, het zuiver
toeval beschrijven zodat het onmogelijk is om op basis van vroegere prijsveranderingen de
toekomstige prijsveranderingen te voorspellen (O’DONOVAN T., 1983, blz. 30, blz. 136-137)
(REYNAERTS H., 1997).
11 Ook voor de andere modellen van de “random walk” zal deze vaststelling opgaan.12 Merk op dat een tijdsreeks van aandelenprijzen die een RW1 volgen zonder drift, ook niet stationair is daar devariantie van de prijzen afhankelijk is van de tijd.13 Deze deterministische trend is gelijk aan µtP +0 .

19
Voorbeeld
Bij wijze van illustratie, kan er nu een reeks gesimuleerd worden die voldoet aan de
veronderstellingen van de RW1. Er wordt hierbij gebruik gemaakt van het statistische
programma Eviews. Stel
nrndPP tt *52 1 ++= − , voor 200,,2,1 �=t
waarbij 5*nrnd aangeeft dat de residuen identiek normaal verdeeld zijn met verwachtingswaarde
0 en standaardafwijking 5 (of variantie 25). De steekproef bestaat uit 200 waarnemingen. De
beginwaarde op tijdstip 0 is gelijk aan 100. Er is een drift van 2 aanwezig (zie bijlage 1a).
De tijdsreeks van prijzen die aan de hand van het model gesimuleerd is, komt tot uiting in figuur
2. Het valt meteen op dat de prijzen een stijgend verloop vertonen. De verklaring ligt voor
Figuur 2: Het verloop van de prijzen bij de RW1.
(Eigen werk; Eviews)
de hand. Er is namelijk een drift aanwezig. Hierdoor ontstaat er een trend in het prijsniveau. Dit
wil echter niet zeggen dat de “random walk” niet geldig is.
Het is beter om de sprongen van de prijzen te bekijken. Deze sprongen (of prijsveranderingen)
zijn uitgezet in figuur 3 (zie ook bijlage 1b). Uit deze figuur kunnen we afleiden dat de tijdsreeks
van prijsveranderingen een stationair verloop heeft. Deze figuur lijkt consistent te zijn met de
definitie van de RW1. De prijsveranderingen schommelen op een willekeurige wijze rond de
waarde 2, met name de drift (cfr. dronkemanswandeling).
0
100
200
300
400
500
600
20 40 60 80 100 120 140 160 180 200
PRIJS

20
Figuur 3: Het verloop van de prijsveranderingen bij de RW1.
(Eigen werk; Eviews)
2.2 De “random walk” 2
In werkelijkheid zal er praktisch nooit voldaan zijn aan de twee veronderstellingen van het RW1-
model. Het is namelijk zo dat de veronderstelling dat de prijsveranderingen identiek verdeeld
zijn, niet opgaat voor financiële aandelen over een lange tijdsperiode. Dit komt omdat de
omgeving, waarin de aandelenprijzen bepaald worden, vaak verandert (CAMPBELL J. et al.,
1997, blz. 32).
De meest voorkomende oorzaak van het feit dat de prijsveranderingen niet identiek verdeeld
zijn, is dat de variantie van de prijsveranderingen of m.a.w. het risico dat verbonden is aan het
aandeel, varieert doorheen de tijd. Er zal dan ook meestal sprake zijn van heteroscedasticiteit in
het RW1-model. 14 De heteroscadasticiteit kan als volgt weergegeven worden:
[ ]εεεεV I2σ≠
�
���
�
�
=2
21
0
0
nσ
σ� (2.2.1)
14 Met heteroscedasticiteit bedoelt men eigenlijk dat de variabelen een verschillende spreiding hebben.
-10
-5
0
5
10
15
20 40 60 80 100 120 140 160 180 200
D(PRIJS)

21
waarbij εεεε de vector is van de residuen tε voor t = 1,…,n. De variantie van de residuen of van de
prijsveranderingen kan variëren doorheen de tijd (GREENE E., 1993).
Het zou nu moeilijk te aanvaarden zijn, moest de “random walk” verworpen worden omwille van
de aanwezigheid van heteroscedasticiteit. De “random walk” impliceert eigenlijk dat de
prijsveranderingen niet voorspeld kunnen worden op basis van vroegere prijsveranderingen.
Zelfs indien de prijsveranderingen niet identiek verdeeld zijn kan deze eigenschap opgaan.
Hierdoor is het wenselijk om de veronderstelling van de identieke verdeling van het RW1-model
af te zwakken. Op die manier verkrijgt men het RW2-model:
ttt PP εµ ++= −1 , ( )2,0~ tt INID σε (2.2.2)
waarbij ( )2,0 tINID σ aangeeft dat de residuen onafhankelijk, maar niet identiek verdeelde
variabelen zijn met verwachtingswaarde 0 en variantie 2tσ die afhankelijk is van de tijd t. Het
RW2-model laat dus toe dat er heteroscedasticiteit is.15
Volatiliteit
De heteroscedasticitieit in het RW2-model is een belangrijk kenmerk aangezien er een groeiende
consensus is tussen de financiële economisten dat de volatiliteit van de tijdsreeksen van
financiële aandelen verandert doorheen de tijd (CAMPBELL J. et al., 1997, blz. 53). Stel
bijvoorbeeld dat er zich een beurscrash heeft voorgedaan (bijvoorbeeld de beurscrash in 1987).
In de periode hierop volgend zal er heel wat meer onzekerheid zijn dan in de periode vóór de
crash. De volatiliteit zal dan ook hoger zijn in de periode na de beurscrash. De volatiliteit
verandert dus naargelang de situatie (VERBEEK M., 1998, blz. 11).
Er zal nu sprake zijn van volatiliteit in de tijdsreeks van prijsveranderingen indien de
voorwaardelijke variantie van de prijsveranderingen niet constant is en dus varieert doorheen de
tijd. De onvoorwaardelijke variantie moet wel constant zijn. Hierdoor zal men aannemen dat de
variantie 2tσ uit (2.2.2) de voorwaardelijke variantie is zodat het RW2-model een accurate
beschrijving kan geven voor de volatiliteit die aanwezig is in de tijdsreeksen van de
prijsveranderingen over een lange tijdsperiode (REYNAERTS H., 1998).16
15Het feit dat de residuen niet identiek verdeeld zijn, hoeft echter niet noodzakelijk te impliceren dat de variantievarieert. Er kunnen ook nog andere oorzaken zijn. Toch kan men aannemen dat de veranderende variantie doorheende tijd praktisch altijd de oorzaak zal zijn van het feit dat de prijsveranderingen niet identiek verdeeld zijn.16 Men zal dan ook eerder spreken van voorwaardelijke heteroscedasticiteit in plaats van heteroscedasticiteit.

22
Vervolgens kan er nu een model vooropgesteld worden dat de volatiliteit zal beschrijven. Stel
11 ++ = ttt ησε , (2.2.3)
met 1+tη een onafhankelijke en identiek normaal verdeelde stochastische variabele met
verwachtingswaarde 0 en variantie 1. Stel bovendien dat tσ een onafhankelijke trekking is uit
een normale verdeling met verwachtingswaarde 0 en variantie σ . 1+tε is dan niets anders dan
het residu op tijdstip t+1 van het RW2-model beschreven in (2.2.2) met als onvoorwaardelijke
variantie (eigen werk)
[ ] [ ][ ] [ ][ ]
)4.2.2(,2
2
21
2
21
21
σ
σ
ησ
ησε
=
=
=
=
+
++
t
tt
ttt
E
EE
EVar
waarbij de tweede gelijkheid volgt uit de onafhankelijkheid van tσ en 1+tη . De voorwaardelijke
variantie wordt als volgt bekomen (eigen werk):
[ ] [ ][ ]
)5.2.2(,2
21
2
21
21
t
tt
tttt
E
EVar
σ
ησ
ησσε
=
=
=
+
++
met 2tσ de geobserveerde waarde voor 2
tσ . De variantie zal dus variëren doorheen de tijd. Uit
(2.2.4) en (2.2.5) kan men afleiden dat er voldaan is aan de voorwaarden van de volatiliteit. Het
model zoals voorgesteld in (2.2.3) zal dus het goede model zijn om de volatiliteit te beschrijven
(CAMPBELL J., 1997, blz. 480)
Daarnaast kan er ook gemakkelijk ingezien worden dat de tε ’s uit het model (2.2.3)
onafhankelijk zijn van elkaar aangezien zowel de tσ ’s als de tη ’s onafhankelijk zijn van elkaar.
Het model (2.2.2) waarbij tε beschreven wordt door (2.2.3) voldoet dus aan de voorwaarden van
de RW2.

23
De RW2 is nu wel een zwakkere vorm van de “random walk” dan de RW1, maar toch bezit ze
nog de belangrijkste eigenschap van de “random walk”: de opeenvolgende prijsveranderingen
zijn onafhankelijk zodat het niet mogelijk is om de toekomstige prijsveranderingen te
voorspellen gebruik makend van de prijsveranderingen uit het verleden. Bovendien biedt de
RW2 een betere beschrijving voor de werkelijkheid (CAMPBELL J., 1997, blz. 33).
Voorbeeld
Om nu een voorbeeld te geven van de RW2, kan er een reeks gesimuleerd worden die voldoet
aan de veronderstellingen van de RW2.17 Er wordt gebruik gemaakt van het voorbeeld van de
RW1 waarbij de residuen beschreven zullen worden door een model die voldoet aan (2.2.3). Men
bekomt dan het volgende:
ttt PP ε++= −12 voor 200,,2,1 �=t
met nrndtt *σε = .
Vervolgens stel dat nrndt *5=σ voor t=1,2,...,200 (zie bijlage 2a). Op basis van deze tσ
kunnen de residuen tε gesimuleerd worden (zie bijlage 2b). Deze residuen zullen dan de
volatiliteit beschrijven zoals tot uiting zal komen in de figuur van de prijsveranderingen.
Gebruik makend van (2.2.4), kan men afleiden dat de onvoorwaardelijke variantie van de
residuen gelijk is aan 25 (dit is precies de variantie van de residuen bij het voorbeeld van de
RW1).
Uit de simulatie van de tijdsreeks van de prijzen, die weergegeven is in figuur 4, kunnen
dezelfde conclusies getrokken worden als bij de RW1 (zie ook bijlage 2c). De tijdsreeks kent een
stijgend verloop dat te wijten is aan de aanwezigheid van de drift. Er moet wel opgemerkt
worden dat het verloop van de curve grilliger is dan bij de RW1.
17 Er wordt opnieuw gebruik gemaakt van het programma Eviews om de reeks te simuleren.
24
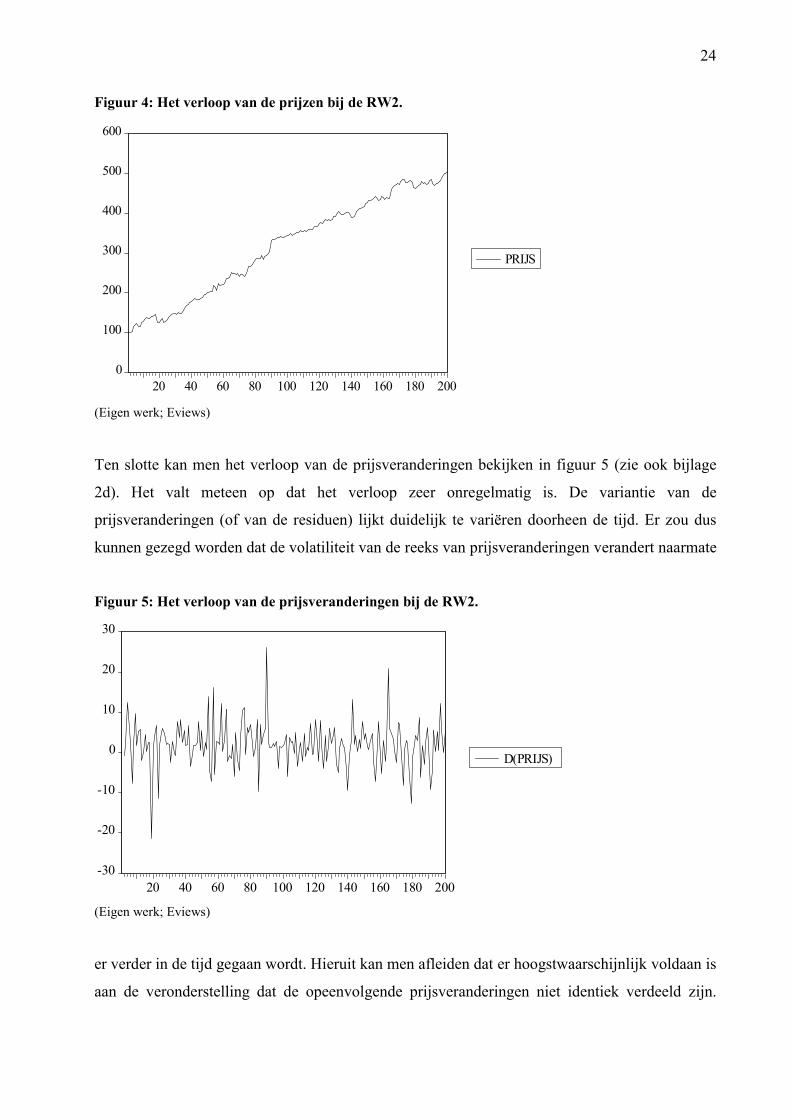
Figuur 4: Het verloop van de prijzen bij de RW2.
(Eigen werk; Eviews)
Ten slotte kan men het verloop van de prijsveranderingen bekijken in figuur 5 (zie ook bijlage
2d). Het valt meteen op dat het verloop zeer onregelmatig is. De variantie van de
prijsveranderingen (of van de residuen) lijkt duidelijk te variëren doorheen de tijd. Er zou dus
kunnen gezegd worden dat de volatiliteit van de reeks van prijsveranderingen verandert naarmate
Figuur 5: Het verloop van de prijsveranderingen bij de RW2.
(Eigen werk; Eviews)
er verder in de tijd gegaan wordt. Hieruit kan men afleiden dat er hoogstwaarschijnlijk voldaan is
aan de veronderstelling dat de opeenvolgende prijsveranderingen niet identiek verdeeld zijn.
0
100
200
300
400
500
600
20 40 60 80 100 120 140 160 180 200
PRIJS
-30
-20
-10
0
10
20
30
20 40 60 80 100 120 140 160 180 200
D(PRIJS)

25
Vervolgens kan men ook zien in figuur 5 dat de varianties willekeurig veranderen zodat er
waarschijnlijk ook voldaan is aan de veronderstelling van onafhankelijke prijsveranderingen. Het
voorbeeld lijkt dus consistent te zijn met het RW2-model.
2.3 De “Random Walk” 3
De derde en meest algemene vorm van de “random walk” is het RW3-model. Dit model ontstaat
uit het RW2-model waarbij de veronderstelling van de onafhankelijkheid afgezwakt wordt. Het
RW3-model laat processen toe met afhankelijke maar ongecorreleerde residuen. Men bekomt
dan het volgende model:
ttt PP εµ ++= −1 , ( )2,0~ tt ONID σε (2.3.1)
waarbij ( )2,0 tONID σ aangeeft dat de residuen ongecorreleerde en niet identiek verdeelde
stochastische variabelen zijn met verwachtingswaarde 0 en voorwaardelijke variantie 2tσ . Het
RW3-model laat dus processen toe waarbij de prijsveranderingen afhankelijk zijn van elkaar en
heteroscedasticiteit vertonen. Het is wel zo dat de prijsveranderingen ongecorreleerd moeten zijn
indien de RW3 geldig is, zodat het nog steeds niet mogelijk is om op basis van vroegere
prijsveranderingen de toekomstige prijsverandering te voorspellen.
Afhankelijk en ongecorreleerd
Een voorbeeld van een proces dat voldoet aan de veronderstellingen van de RW3, maar niet aan
deze van de RW1 en RW2, is het proces dat voldoet aan de volgende voorwaarden:
[ ] 0, =−kttCov εε , voor alle 0≠k (2.3.2)
[ ] 0, 22 ≠−kttCov εε , voor minstens één 0≠k (2.3.3)
Vergelijking (2.3.2) impliceert dat de residuen ongecorreleerd zijn, terwijl (2.3.3) impliceert dat
de residuen niet onafhankelijk zijn van elkaar (CAMPBELL J. et al., 1997, blz.33) .
Het RW3-model dat voldoet aan de voorwaarden (2.3.2) en (2.3.3), biedt een betere beschrijving
voor de werkelijkheid dan het RW2-model. Het is namelijk zo dat als men de prijsveranderingen
van de aandelen observeert, grote prijsveranderingen de neiging hebben om gevolgd te worden
door grote prijsveranderingen onafhankelijk van het teken. Kleine prijsveranderingen zullen dan

26
eerder de neiging hebben om gevolgd te worden door kleine prijsveranderingen onafhankelijk
van het teken.. De volatiliteit van de prijsveranderingen van de aandelen lijkt dus serieel
gecorreleerd te zijn. De kwadraten van de opeenvolgende prijsveranderingen zullen dan ook
gecorreleerd zijn zodat (2.3.3) geldig is voor k=1. Er zal dus een zekere afhankelijkheid zijn
tussen de opeenvolgende prijsveranderingen in dit opzicht dat kennis over de prijsverandering
van vandaag zal kunnen gebruikt worden bij de voorspelling van de grootte van de
prijsverandering voor morgen. Statistisch impliceert dit dat de voorwaardelijke
waarschijnlijkheid dat de prijsverandering voor morgen groot zal zijn, gegeven dat de
prijsverandering van vandaag groot is, hoger zal zijn dan de onvoorwaardelijke
waarschijnlijkheid dat de prijsverandering voor morgen groot zal zijn. De opeenvolgende
prijsveranderingen zijn wel nog altijd ongecorreleerd aangezien het teken van de veranderingen
niet te voorspellen is. Het RW3-model dat voldoet aan (2.3.2) en (2.3.3), zal dus een goede
beschrijving bieden voor de geobserveerde tijdsreeksen van de aandelenprijzen (FAMA E.,
1965, blz.85) (CAMPBELL J. et al., 1997, blz. 481-482).
Arch-model
Het ARCH-model van Engel (1982) is een goed voorbeeld van een model dat voldoet aan de
voorwaarden (2.3.2) en (2.3.3).18 Stel het multiplicatief ARCH-model:
ttt ηεααε 2110 −+= , ( )1,0~ ΝIIDtη (2.3.4)
waarbij ( )1,0ΝIID aangeeft dat tη onafhankelijk en identiek normaal verdeeld is met
verwachtingswaarde 0 en variantie 1 (CAMPBELL J. et al., 1997, blz 480-483). Er kan nu
aangetoond worden dat de vergelijking (2.3.4) voldoet aan de (2.3.2) en (2.3.3) (eigen werk):
[ ] [ ] [ ] [ ]
[ ] [ ] [ ]
[ ] [ ] [ ] [ ] [ ]0
,
12
11012
110
12
11012
110
111
=
+−+=
+−+=
−=
−−−−
−−−−
−−−
tttttt
tttttt
tttttt
EEEEE
EEE
EEECov
εεααηεεααη
εεααηεεααη
εεεεεε
18 Het ARCH-model is een eerste-orde autoregressief proces met voorwaardelijke heteroscedasticiteit.

27
waarbij de derde gelijkheid volgt uit het feit dat tη en 1−tε onafhankelijk zijn van elkaar. Merk
wel op dat de k uit (2.3.2) hier gelijk is aan 1, maar er kan gemakkelijk nagegaan worden dat de
afleiding ook zal gelden voor k>1. Vervolgens kan de geldigheid van (2.3.3) nagegaan worden
(eigen werk):
[ ] ( )[ ] ( )[ ] [ ][ ] ( )[ ] [ ] [ ] [ ]
[ ] [ ] [ ] [ ][ ] [ ]( )
0
1112
1
2211
210
411
210
21
2110
221
2110
2
21
2110
221
2110
221
2
≠
−=
−−+=
+−+=
+−+=
−−
−−−−
−−−−
−−−−−
tt
tttt
tttttt
tttttttt
KVar
EEEE
EEEEE
EEECov
εεα
εαεαεαεα
εεααηεεααη
εεααηεεααηεε
waarbij [ ]1−tK ε de kurtosis is van de verdeling van 1−tε die als volgt gedefinieerd is:
[ ] [ ]( )[ ][ ]1
2
411
1
−
−−−
−=t
ttt
Var
EEKεεεε (2.3.5)
De vierde gelijkheid bekomt men door gebruik te maken van (2.3.5). De [ ]21
2, −ttCov εε zal dan
zeker verschillend zijn van 0 aangezien de kurtosis steeds groter is dan 1. In geval van een
normale verdeling is de kurtosis namelijk gelijk aan 3. Indien de verdeling wijdere staarten heeft,
zal de kurtosis zelfs groter worden dan 3. De residuen zijn dus ongecorreleerd, maar niet
onafhankelijk omdat (2.3.4) zal opgaan voor k=1.
Als er vervolgens verondersteld wordt dat tε stationair is dan wordt het volgende bekomen voor
de onvoorwaardelijke en de voorwaardelijke variantie:
[ ]1
0
1 αα
ε−
=tVar (2.3.6)
[ ] 21101 −− += tttVar εααε , (2.3.7)
waarbij 21−tε de geobserveerde waarde is voor 1−tε . De onvoorwaardelijke variantie is dus
constant en de voorwaardelijke variantie is afhankelijk van de tijd zodat tε de volatiliteit zal
beschrijven (GREENE W., 1993, blz. 439).

28
Men kan besluiten dat de residuen die beschreven worden door het model (2.3.4), zullen voldoen
aan de veronderstelingen van het RW3-model (2.3.1).
Voorbeeld
Er kan nu een reeks gesimuleerd worden die voldoet aan het RW3-model en waarvan de residuen
voldoen aan het ARCH-model dat zopas besproken is. De reeks zal zodanig gesimuleerd worden
dat men gemakkelijk de band kan leggen met de voorbeelden die gesimuleerd zijn voor de RW1
en de RW2. Stel
ttt PP ε++= −12 voor 200,,2,1 �=t
met nrndtt 15,05,12 −+= εε .
De residuen tε beschrijven opnieuw de volatiliteit (zie bijlage 3a). Merk op dat de
onvoorwaardelijke variantie gelijk is aan 25 zoals bij het voorbeeld van de RW1 en RW2.19
De reeks voor de prijzen kan nu gesimuleerd worden (zie bijlage 3b). Het verloop ervan komt tot
uiting in figuur 6. Net zoals bij de RW1 en de RW2 is het verloop stijgend. Dit is opnieuw te
wijten aan de aanwezigheid van de drift die tot een positieve trend leidt. Het is nu wel zo dat er
Figuur 6 : Het verloop van de prijzen bij de RW3.
(Eigen werk; Eviews)
19 Deze variantie kan gemakkelijk berekend worden aan de hand van formule (2.3.6).
0
100
200
300
400
500
600
20 40 60 80 100 120 140 160 180 200
PRIJS

Hoofdstuk 2: De Soorten “Random Walk” 29
plaatselijk een trendverschuiving lijkt op te treden. Dit komt omdat er een zekere positieve
afhankelijkheid is tussen de opeenvolgende prijsveranderingen die te verklaren is door het model
(2.3.4).
Vervolgens kan men dan ook het verloop van de prijsveranderingen bekijken in figuur 7 (zie ook
bijlage 3c). Men kan direct zien dat de volatiliteit varieert doorheen de tijd zoals bij figuur 5 van
de RW2. Toch is er een groot verschil op te merken. De volatiliteit bij de RW3 verandert slechts
geleidelijk terwijl de volatiliteit bij de RW2 willekeurig verandert. Bij de RW3 zijn er perioden z
met een grote volatiliteit en perioden met een kleine volatiliteit zoals men kan zien in figuur 7.
Figuur 7: Het verloop van de prijsveranderingen bij de RW3.
(Eigen werk; Eviews)
Er is dus een zekere volharding in de beweging van de prijsveranderingen. Dit komt opnieuw
omdat er een positieve afhankelijkheid is tussen de opeenvolgende prijsveranderingen zodat de
volatiliteiten serieel gecorreleerd zijn. De prijsveranderingen lijken wel ongecorreleerd te zijn
omdat de prijsveranderingen in een willekeurige richting variëren rond de drift. De
prijsveranderingen die gesimuleerd zijn, lijken consistent te zijn met de veronderstellingen van
het RW3-model.
-40
-20
0
20
40
60
20 40 60 80 100 120 140 160 180 200
D(PRIJS)

Hoofdstuk 2: De Soorten “Random Walk” 30
2.4 Het Testen van de “Random Walk”
Bij het testen of een tijdsreeks van aandelenprijzen een “random walk” volgt, moet er nagegaan
worden of de prijsveranderingen uit het verleden kunnen gebruikt worden om de toekomstige
prijsveranderingen te voorspellen. In het geval dat de tijdsreeksen een “random walk” volgen, zal
dit niet mogelijk zijn (FAMA E., 1965, blz. 34).
In feite moet er getest worden of er voldaan is aan de veronderstellingen van de “random walk”.
Men kan dit doen door steekproefschattingen te maken van bepaalde testwaarden en de
resultaten daarvan te vergelijken met wat er zou verwacht worden indien de “random walk”
geldig is (FAMA E., 1965, blz. 81).
In hoofdstuk 4 zullen er een aantal testen uitgewerkt worden die voldoen aan de
veronderstellingen van het RW1-model. Deze testen kunnen dan gebruikt worden om na te gaan
of een tijdsreeks van aandelenprijzen voldoet aan het RW1-model.
In hoofdstuk 5 wordt een beschrijving gegeven van hoe men kan nagaan wanneer een tijdsreeks
voldoet aan het RW2-model.
Vervolgens zullen er in hoofstuk 6 enkele testen in verband met het RW3-model worden
uitgewerkt. Men zal hierbij vertrekken van de testen van de RW1 waarbij de veronderstellingen
afgezwakt zullen worden.
Iedere test die uitgewerkt wordt voor de RW1 en de RW3, zal gevolgd worden (in een aparte
sectie) door een kort empirisch onderzoek. De testwaarde en de steekproefverdeling van de
testwaarde die bekomen worden voor iedere test, zal gebruikt worden om de geldigheid van de
“random walk” na te gaan voor de prijzen van het aandeel UCB en voor de prijzen van de Bel20-
index. De steefproef beloopt de periode van 1 januari 1973 tot 26 februari 1999. De testen
worden uitgevoerd op zowel de dagelijkse, wekelijkse als de maandelijkse gegevens.
UCB “Group”
Het bedrijf UCB (“Group”) is één van de grootste firma’s in België. Het is een farmaceutische en
chemische groep van wereldklasse dat vooral aktief is in de Pharma Sector, de Chemische Sector
en de Film Sector. Sinds 1970 kent UCB een regelmatig groeipatroon wat zich vertaald heeft in
een stijgend prijsverloop van de aandeelprijzen doorheen de tijd <http://www.ucb-group.com>.
Het verloop van de maandelijkse prijzen van het aandeel UCB is weergegeven in figuur 8. Er is
een matige stijging tot 1995. Er zal dan ook een kleine drift aanwezig te zijn. Vanaf 1995 lijkt er
evenwel een trendverschuiving op te treden. De prijzen stijgen veel sneller dan voorheen.

Hoofdstuk 2: De Soorten “Random Walk” 31
Vervolgens kan het verloop van de prijsveranderingen bekeken worden. Dit wordt weergegeven
in figuur 9. Het valt meteen op dat de volatiliteit stijgt naarmate er verder in de tijd gegaan
wordt. Vooral sinds 1995 is de variabiliteit veel groter geworden. Er lijkt dus sprake te zijn van
conditionele hetroscedasticiteit en ook een zekere afhankelijkheid tussen de opeenvolgende
prijsveranderingen. Dus op het eerste zicht lijken de maandelijkse prijsveranderingen een RW3
te volgen. Voor de dagelijkse en wekelijkse prijsveranderingen kan men soortgelijke conclusies
(zie bijlage 4).
Figuur 8: De maandelijkse prijzen (UCB). Figuur 9: De maandelijkse prijs ∆ (UCB).
(Gegevens van Datastream; Eviews) (Gegevens van Datastream; Eviews)
Bel 20-index
De Bel20-index bestaat uit 20 toonaangevende Belgische aandelen (“blue chips”), die represen-
tatief zijn voor de ontwikkeling van alle Belgische aandelen op de Termijnmarkt noteren.
Officieel werd de index op 18 maart 1991 opgestart <http://bewoner.dma.be/Herbots/b_bel20>.
Via datastream kan men echter noteringen terugvinden voor de Bel20 tot in het begin van 1973.
Deze noteringen zijn berekend gebruik makend van de korf van de aandelen bij de start van de
Bel20 en van de toen geldende correlaties tussen de aandelen. Men heeft dan teruggerekend tot 1
januari 1973.
Het maandelijks prijsverloop van de Bel20-index is weergegeven in figuur 10. Er is een stijgend
verloop merkbaar wat wijst op de aanwezigheid van een drift. Af en toe lijkt er een
trendverschuiving op te treden. Er zou dus sprake kunnen zijn van een zekere afhankelijkheid.
De maandelijkse prijsveranderingen weergegeven zijn in figuur 11. Net zoals bij het aandeel
UCB varieert de volatiliteit doorheen de tijd, zij het minder uitgesproken. Naar het einde van de
jaren ’90 lijkt de variabiliteit het grootst te zijn. Op het eerste zich lijkt ook de tijdsreeks van de
0
10
20
30
40
50
60
74 76 78 80 82 84 86 88 90 92 94 96 98
UCB
-8
-4
0
4
8
12
74 76 78 80 82 84 86 88 90 92 94 96 98
DUCB

Hoofdstuk 2: De Soorten “Random Walk” 32
maandelijkse prijzen van de Bel20 consistent te zijn met het RW3-model. Ook voor de
dagelijkse en wekelijkse prijsveranderingen kan men soortgelijke conclusies (zie bijlage 5).
Figuur 10: De maandelijkse prijzen (Bel20). Figuur 11: De maandelijkse prijs ∆ (Bel20).
(Gegevens van Datastream; Eviews) (Gegevens van Datastream; Eviews)
Vooraleer over te gaan tot de uiteenzetting van de testen en het daarop telkens volgend empirisch
onderzoek, wordt er eerst nog een hoofdstuk gewijd aan het gebruik van de logaritmen van
aandelenprijzen. Daaruit zal blijken dat het beter is om te werken met de logaritmen van de
aandelenprijzen in plaats van met de absolute prijzen. Het “random walk”-model zal dan
aangepast worden. De prijzen tP zullen vervangen worden door de logaritmen van de prijzen.
Op die manier bekomt men een beter model.
0
200
400
600
800
1000
74 76 78 80 82 84 86 88 90 92 94 96 98
BEL20
-150
-100
-50
0
50
100
150
74 76 78 80 82 84 86 88 90 92 94 96 98
DBEL20

33
3 Het Gebruik van LogaritmenBij het opstellen van de “random walk”-modellen werd steeds gebruik gemaakt van de absolute
waarden van de aandelenprijzen. In dit hoofdstuk zullen enkele redenen naar voor gebracht
worden waarom het beter is om te werken met de natuurlijke logaritmen van de aandelenprijzen
bij het modelleren van de “random walk”.
3.4 Schending van de Beperkende Betrouwbaarheid
Er kan aangetoond worden dat indien de prijsveranderingen normaal verdeeld zijn, er een
positieve kans bestaat dat de prijs van het aandeel negatief zal worden. Dit strookt natuurlijk niet
met de realiteit (CAMPBELL J. et al., 1997, blz. 32).
Er wordt vertrokken van het RW1-model waarbij de residuen normaal verdeeld zijn. Het model
ziet er als volgt uit (eigen werk):
ttt PP εµ ++= −1 , ( )2,0~ σε ΝIIDt (3.1.1)
Het model (3.1.1) kan verder omgevormd worden tot:
( )21 ,~ σµΝ− − IIDPP tt . (3.1.2)
Aldus maakt men de veronderstelling dat de prijsveranderingen normaal verdeeld zijn met
verwachtingswaarde µ en variantie 2σ . De veronderstelling dat de prijsveranderingen normaal
verdeeld zijn, wordt vaak gemaakt in de realiteit.
De normale verdelingsfunctie van de prijsveranderingen is uitgezet in figuur 12. Op de
horizontale as bevinden zich de prijsveranderingen. Op de vertikale as kan de
waarschijnlijkheidsdichtheid afgelezen worden van de mogelijke prijsveranderingen. Men weet
nu dat bij een normale verdeling de kans op extreme uitkomsten zeer klein is, maar dat deze toch
verschillend is van nul. Hieruit kan er afgeleid worden, gebruik makend van figuur 12, dat er een
kans bestaat, zij het een zeer kleine kans, dat de prijs van het aandeel kleiner wordt dan nul. Er is
namelijk een kans dat 1−− tt PP kleiner zal zijn dan 1−tP waardoor de prijs tP kleiner zal worden
dan nul. Dit is onmogelijk aangezien de prijs van het aandeel niet negatief kan worden.
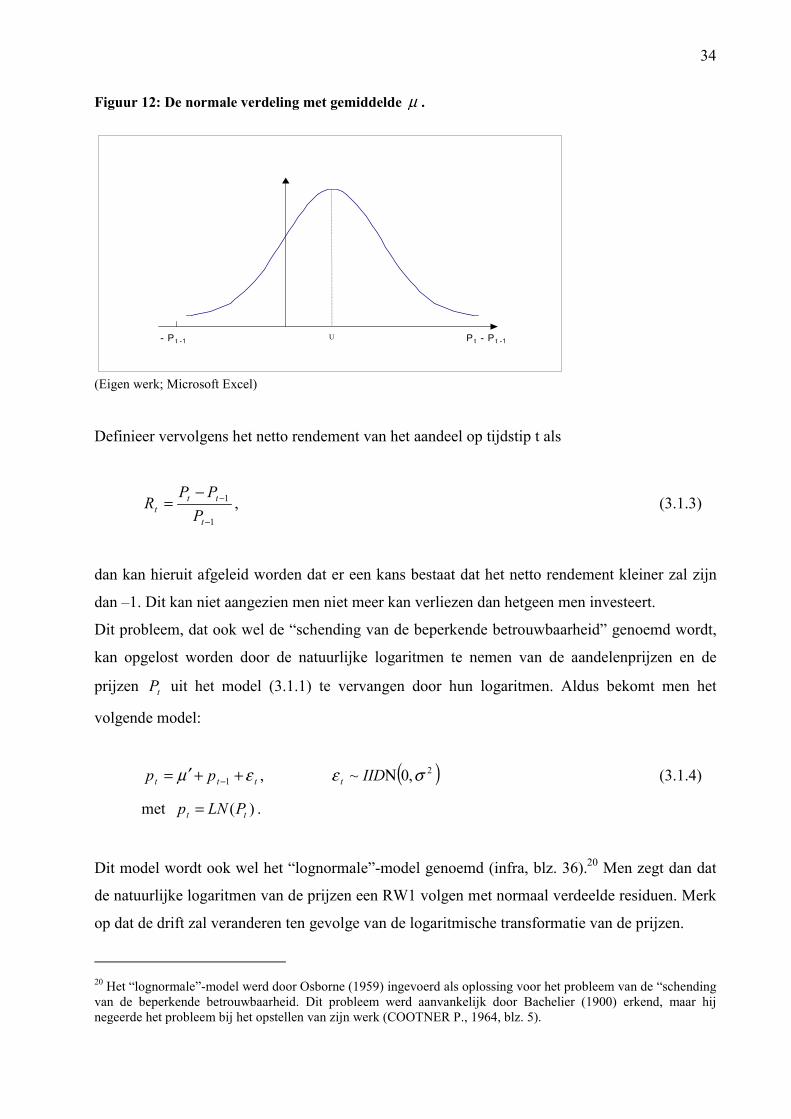
34
Figuur 12: De normale verdeling met gemiddelde µ .
(Eigen werk; Microsoft Excel)
Definieer vervolgens het netto rendement van het aandeel op tijdstip t als
1
1
−
−−=
t
ttt P
PPR , (3.1.3)
dan kan hieruit afgeleid worden dat er een kans bestaat dat het netto rendement kleiner zal zijn
dan –1. Dit kan niet aangezien men niet meer kan verliezen dan hetgeen men investeert.
Dit probleem, dat ook wel de “schending van de beperkende betrouwbaarheid” genoemd wordt,
kan opgelost worden door de natuurlijke logaritmen te nemen van de aandelenprijzen en de
prijzen tP uit het model (3.1.1) te vervangen door hun logaritmen. Aldus bekomt men het
volgende model:
ttt pp εµ ++′= −1 , ( )2,0~ σε ΝIIDt (3.1.4)
met )( tt PLNp = .
Dit model wordt ook wel het “lognormale”-model genoemd (infra, blz. 36).20 Men zegt dan dat
de natuurlijke logaritmen van de prijzen een RW1 volgen met normaal verdeelde residuen. Merk
op dat de drift zal veranderen ten gevolge van de logaritmische transformatie van de prijzen.
20 Het “lognormale”-model werd door Osborne (1959) ingevoerd als oplossing voor het probleem van de “schendingvan de beperkende betrouwbaarheid. Dit probleem werd aanvankelijk door Bachelier (1900) erkend, maar hijnegeerde het probleem bij het opstellen van zijn werk (COOTNER P., 1964, blz. 5).
U P t - P t -1- P t -1
35
Vervolgens kan (3.1.4) omgevormd worden tot:
( )21 ,~ σµ′Ν− − IIDpp tt . (3.1.5)
)6.1.3()(
)()(
1
11
−
−−
=
−=−
t
t
tttt
PPLN
PLNPLNppmet
Het verschil van de natuurlijke logaritmen van de prijzen is dus normaal verdeeld met
verwachtingswaarde µ′ en variantie 2σ .
Men kan nu de exponentiële functie nemen van beide leden van vergelijking (3.1.6). Aldus
bekomt men:
)8.1.3(,1
)7.1.3()(1
1
t
t
ttt
R
PP
ppEXP
+=
=−−
−
waarbij de tweede gelijkheid bekomen wordt door gebruik te maken van (3.1.3). tR+1 noemt
men het bruto rendement. Het verloop van de exponentiële functie van 1−− tt pp wordt
weergegeven in figuur 13 (VANMAELE M., 1995). Uit deze figuur kan onmiddellijk afgeleid
Figuur 13: De exponentiële functie van 1−− tt pp .
(Eigen werk; Microsoft Excel)
0
1
p t - p t-1
1 + R t

36
worden dat 1−− tt pp alle mogelijke waarden kan aannemen, zowel positieve als negatieve. De
exponentiële functie hiervan heeft echter een onderlimiet van 0. Uit (3.1.8) volgt dan dat tR+1
een onderlimiet van 0 heeft zodat het netto rendement niet kleiner kan zijn dan –1. Het nieuwe
model is dus wel in overeenstemming met de realiteit daar de prijs niet meer negatief kan
worden. Het probleem van de “schending van de beperkende betrouwbaarheid” is opgelost
(Eigen werk).
Stabiele Pareto-verdeling
Er kan nu ook gesteld worden dat in het geval dat de verdeling afwijkt van de normale verdeling,
het gebruik van logaritmen toch het probleem van de “schending van de beperkende
betrouwbaarheid” zal oplossen. Stel namelijk dat de prijsveranderingen stabiel Pareto-verdeeld
zijn in plaats van normaal verdeeld. Dit is een veel voorkomende verklaring voor de afwijkingen
van de normale verdeling. De verdeling heeft dan wijdere staarten. Ook in dit geval bestaat er
een kans, zelfs een grotere kans dan bij de normale verdeling, dat de prijs negatief wordt. Indien
er nu opnieuw gebruik gemaakt wordt van de logaritmen van de prijzen, dan zal dit probleem
zich niet voordoen. Dezelfde redenering kan hierbij gevolgd worden als bij de normale
verdeling. Dus ook bij een stabiele Pareto-verdeling zal het logaritmische model het probleem
van de “schending van de beperkende betrouwbaarheid” oplossen (Eigen redenering).
Ook voor het RW2-model en het RW3-model zou men soortgelijke conclusies kunnen trekken
als bij het RW1-model wat betreft de “schending van de beperkende betrouwbaarheid”.
3.5 Betere Benadering voor de Normaliteit
Een tweede voordeel in verband met het gebruik van logaritmen, heeft te maken met het
“lognormale”-model van Osborne (1959). Osborne stelde dat de veranderingen in de logaritmen
van de prijzen beter de normale verdeling benaderen dan de gewone prijsveranderingen zodat het
“lognormale”-model, weergegeven in (3.1.4), beter in overeenstemming zal zijn met de realiteit
dan het gewone normale “random walk” model uit (3.1.1). Bij zijn verklaring vertrekt hij van het
feit dat er iedere dag tientallen transacties zijn per aandeel (zie Bachelier-Osborne Model, blz.
10). De dagelijkse verandering in de logaritmen van de prijzen is dan de som van de
veranderingen per transactie. Indien de veranderingen per transactie onafhankelijk en identiek
verdeeld zijn dan kan men afleiden, gebruik makend van de centrale limietstelling, dat de
veranderingen in de logaritmen van de prijzen normaal verdeeld zijn. Een gevolg hiervan is dat

37
de standaardafwijking van de prijsveranderingen proportioneel zal zijn met de vierkantswortel
van de lengte van de tijdsperiode. Dit laatste is een belangrijke eigenschap van de “random
walk” die voor het eerst door Bachelier naar voor werd gebracht (zie variantieratios)
(ALEXANDER S., 1961, blz. 206).
De bekomen normaliteit voor de veranderingen in de logaritmen is een zeer interessant gegeven.
De normale verdeling heeft namelijk het grote voordeel dat de volledige verdeling kan
beschreven worden door slechts twee maatstaven, de verwachtingswaarde en de variatie. De
analyse van de tijdsreeksen wordt dan ook veel simpeler (HARRINGTON D., 1983, blz. 6-7).
Empirisch onderzoek
De bevindingen van Osborne kunnen nu nagegaan worden aan de hand van een tijdsreeks van
aandelenprijzen. Stel de maandelijkse prijzen van het aandeel UCB, zoals weergegeven in figuur
8. De maandelijkse prijsveranderingen zijn weergegeven in figuur 14, door middel van een
histogram. De verwachte normale verdeling is weergegeven via de curve. Er kan direct
opgemerkt worden dat de verdeling van de prijsveranderingen serieus afwijkt van de normale
verdeling. De kurtosis is trouwens gelijk aan 30,379.
Figuur 14: Histogram maand. prijs ∆ (UCB). Figuur15:Histogram maand. logprijs ∆ (UCB).
(Eigen werk; Spss 7.5) (Eigen werk; Spss 7.5)
De verdeling van de veranderingen in de logaritmen van de prijzen is weergeven in figuur 15.
Het valt direct op dat deze verdeling veel beter de normale verdeling benadert. Dit is ook af te
leiden uit de kurtosis (=2,009), die veel dichter aansluit bij de kurtosis van de normale verdeling.
De bevindingen van Osborne lijken consistent te zijn met de eigenschappen van het aandeel
UCB.
DIFF(UCB,1)
9,08,0
7,06,0
5,04,0
3,02,0
1,00,0
-1,0-2,0
-3,0-4,0
-5,0
300
200
100
0
Std. Dev = 1,13
Mean = ,2
Kurt. = 30,379
DIFF(LNUCB,1)
,75,32,27,22,17,12,07,02-
,02
-
,07
-
,12
-
,17
-
,22
-
,27
60
50
40
30
20
10
0
Std. Dev = ,08
Mean = ,014
Kurt. = 2,009

Hoofdstuk 3: Het Gebruik van Logaritmen 38
3.3 Het Continu Samengesteld Rendement
Een derde voordeel houdt verband met de invoering van de term “continu samengesteld
rendement”. Dit rendement is niets anders dan het verschil van de logaritmen van de
aandelenprijzen. Gebruik makend van (3.1.6) kan men het continu samengesteld rendement tr ,
ook wel lognormale rendement genoemd, als volgt definiëren:
( )tt
tttt RLN
PP
LNppr +=�
���
�=−=
−− 1
11 , (3.2.1)
waarbij tR het netto rendement is zoals gedefinieerd in (3.1.3).
Gebruik makend van de definitie van het continu samengesteld rendement, kan het
“lognormale”-model, gedefinieerd in (3.1.5), als volgt voorgesteld worden:
( )2,~ σµ′ΝIIDrt . (3.2.4)
Het “lognormale”-model impliceert dan dat de continu samengestelde rendementen
onafhankelijke en identiek normaal verdeelde variabelen zijn met verwachtingswaarde µ′
variantie 2σ .
Het voordeel doet zich voor wanneer men het rendement wil berekenen over meerdere perioden.
Indien er gewerkt wordt met netto rendementen dan zal het rendement over k perioden er als
volgt uitzien:
( )( ) ( )( ) ( )11 1111 +−− +++≡+ ktttt RRRkR � . (3.2.2)
( )kRt is het netto rendement over k perioden, terwijl ( )kRt+1 het bruto rendement is over k
perioden. Als men nu stelt dat de netto rendementen normaal verdeeld zijn dan kan er uit (3.2.2)
afgeleid worden dat het rendement over meerdere perioden niet normaal verdeeld zal zijn daar de
vermenigvuldiging van normale verdelingen geen normale verdeling is (CAMPBELL J., 1997,
blz. 11).
Indien men echter werkt met continu samengestelde rendementen, dan wordt het volgende
bekomen voor het rendement over meerdere perioden:

Hoofdstuk 3: Het Gebruik van Logaritmen 39
( ) ( )( )( )( ) ( )( )
( ) ( ) ( ))3.2.3(,
111111
1
11
11
11
+−−
+−−
+−−
+++=++++++=
+++=+=
kttt
kttt
kttt
tt
rrrRLNRLNRLN
RRRLNkRLNkr
�
�
�
waarbij ( )krt het continu samengestelde rendement is over meerdere perioden. De tweede
gelijkheid bekomt men door gebruik te maken van (3.2.2). Uit (3.2.3) kan er afgeleid worden dat
het continu samengestelde rendement over meerdere perioden gelijk is aan de som van de
samengestelde rendementen over één periode. Als er nu verondersteld wordt dat deze laatsten
normaal verdeeld zijn, dan zal het continu samengestelde rendement over meerdere perioden ook
normaal verdeeld zijn want de som van normale verdelingen is ook normaal verdeeld. Dus de
vermenigvuldiging is omgezet in een optelling door de natuurlijke logaritmen te nemen van de
prijzen. Dit is zeer interessant omdat het veel gemakkelijker is om tijdsreekseigenschappen af te
leiden van een additief proces dan van een vermenigvuldigingsproces (CAMPBELL J., 1997,
blz. 11).
3.4 Percentage van de Prijsverandering
Een vierde voordeel is dat voor prijsveranderingen van minder dan 15 per cent (onafhankelijk
van de tijdshorizon), de verandering in de logaritmen van de prijzen of het continu samengesteld
rendement quasi gelijk zal zijn aan het percentage van de prijsverandering. Dit is zeer interessant
omdat de investeerders en ook wel de onderzoekers, het zeer handig vinden om te kunnen
werken met de percentages van de prijsveranderingen in plaats van met de prijsveranderingen
zelf (FAMA E., 1965, blz. 46).
Veelal wordt er ook gebruik gemaakt van het netto rendement zoals gedefinieerd in (3.1.3) om
de proportionele prijsverandering te berekenen. Men leest dan ook vaak dat de “random walk”
geldig is indien de rendementen onafhankelijk en identiek verdeeld zijn in plaats van de
prijsveranderingen. Het is nu wel zo dat indien de netto rendementen onafhankelijk en identiek
verdeeld zijn, de prijzen van de aandelen geen “random walk” zullen volgen aangezien de
prijsveranderingen afhankelijk zullen zijn van het prijsniveau. De residuen tε in het “random
walk”-model zouden dan namelijk afhankelijk zijn van de prijzen 1−tP zodat de
basisveronderstellingen van het klassiek lineair model niet meer geldig zijn (FAMA E., 1970,

Hoofdstuk 3: Het Gebruik van Logaritmen 40
blz. 386-387). Men kan dan ook besluiten dat het beter is om met continu samengesteld
rendementen te werken dan met netto rendementen.
3.5 Het Neutraliseren van de Variabiliteit
Het algemeen “random walk” model van Bachelier impliceert dat de variantie van de
toekomstige prijsveranderingen onafhankelijk is van het prijsniveau op het huidige tijdstip. Er
zijn echter wel redenen om te verwachten dat de standaardafwijking van de prijsveranderingen
proportioneel zal stijgen met het prijsniveau (MANDELBROT B., 1963, blz. 307). Stel
bijvoorbeeld dat een aandeel is genoteerd aan 100. Een prijsstijging van 10 per cent komt dan
overeen met een stijging van 100 naar 110. Stel vervolgens dat het aandeel genoteerd is aan 500.
Een prijsstijging van 10 per cent zal nu overeenkomen met een stijging van 50. Dus een even
grote prijsstijging in percentage zal leiden tot een hogere stijging in absolute waarde als het
prijsniveau hoger is. Vandaar de stijgende standaardafwijking naarmate het prijsniveau hoger is.
De variabiliteit of de volatiliteit van de prijsveranderingen voor een bepaald aandeel is dus een
stijgende functie van het prijsniveau van het aandeel (d.i. het “prijsniveau-effect”). Bijgevolg
kan de volatiliteit veranderen zonder dat het risico, dat verbonden is aan een aandeel, verandert.
De RW1 zou dus verworpen kunnen worden, enkel omdat het prijsniveau van het aandeel
verandert. Dit is niet echt realistisch (Eigen redenering).
Als men nu de natuurlijke logaritmen neemt van de prijzen dan zal het meeste van dit
prijsniveau-effect geneutraliseerd zijn (FAMA E., 1965, blz. 45-46). De verandering in de
logaritmen van de prijzen zal namelijk onafhankelijk zijn van het prijsniveau. De stijging in de
logaritmen zal dezelfde zijn bij een stijging van de prijs van 100 naar 110 als bij een stijging van
500 en 550. In beide gevallen is de stijging in de logaritmen ongeveer gelijk aan het percentage
van de prijsstijging (zie sectie 3.4). Dus door logaritmisch te transformeren kan ervoor gezorgd
worden dat de volatiliteit constant blijft en dus niet afhankelijk is van het prijsniveau. In feite is
dit een transformatie om de tijdsreeks van de prijsveranderingen stationair te maken.
Het grote voordeel is dan dat de parameters constant blijven en zoals reeds vermeld, is het voor
statistische doelen zeer interessant dat de parameters van de verdeling vast zijn voor de periode
die onderzocht wordt (FAMA E., 1965, blz. 41).
Empirisch onderzoek
De hierboven beschreven theorie kan nu getest worden voor het aandeel UCB. Het verloop van
de maandelijkse prijsveranderingen is weergegeven in figuur 16. Er kan onmiddellijk opgemerkt
worden dat de volatiliteit stijgt met de tijd, vooral doorheen de jaren ‘90. Uit figuur 8 kon er

Hoofdstuk 3: Het Gebruik van Logaritmen 41
reeds afgeleid worden dat het prijsniveau stijgt doorheen de tijd. Dus de volatiliteit van de
prijsveranderingen van het aandeel UCB is een stijgende functie van het prijsniveau. De prijzen
zullen zeker geen RW1 volgen omwille van het prijsniveau-effect.
Figuur 16: Verloop van prijs ∆ (UCB). Figuur 17: Verloop van logprijs ∆ (UCB).
(Eigen werk; Eviews) (Eigen werk; Eviews)
Het verloop van de veranderingen in de logaritmen van de prijzen is weergegeven in figuur 17.
Het verloop ziet er redelijk stabiel uit. Het prijsniveau-effect lijkt geneutraliseerd te zijn door
logaritmisch te transformeren. Dit is dan ook consistent met de beschreven theorie. Het zal dus
beter zijn om na te gaan of de logaritmen van de prijzen een RW1 volgen.
In dit hoofdstuk werden enkele belangrijke redenen naar voor gebracht waarom het interessanter
is om te werken met de natuurlijke logaritmen van de prijzen in plaats van met de prijzen zelf.
Het “random walk”-model kan dan het best voorgesteld worden zoals in (3.1.4).21 Bij het
afleiden van de testen voor de “random walk”, die in de volgende hoofdstukken aan bod zullen
komen, zal men dan ook meestal vertrekken van dit logaritmisch model.
21 Merk op dat dit het logaritmisch model is voor de RW1. Analoog kan men echter het model bekomen voor deRW2 en de RW3.
-8
-4
0
4
8
12
74 76 78 80 82 84 86 88 90 92 94 96 98
DUCB
-0.4
-0.2
0.0
0.2
0.4
0.6
74 76 78 80 82 84 86 88 90 92 94 96 98
DLNUCB

42
4 De Testen van de “Random Walk” 1De meeste testen die vroeger ontwikkeld werden over de “random walk”, zijn testen in verband
met de RW1. Het RW1-model ziet er als volgt uit (zie sectie 3.1):
ttt pp εµ ++= −1 , ( )2,0~ σε IIDt
met )( tt PLNp = .
Er wordt dus gebruik gemaakt van het logaritmisch model omdat dit tal van voordelen oplevert,
zoals uiteengezet in het vorige hoofdstuk.22 De meeste testen zullen dan ook vertrekken van het
logaritmisch model.
Het logaritmisch RW1-model, wat vanaf nu het RW1-model genoemd wordt, betreft de twee
volgende veronderstelligen :
• De veranderingen in de logaritmen van de prijzen zijn onafhankelijk van elkaar.
• De veranderingen in de logaritmen van de prijzen zijn identiek verdeeld met
verwachtingswaarde µ en variantie 2σ .
Ondanks het feit dat het RW1-model geen accurate beschrijving kan geven voor de reeksen van
aandelenprijzen, kan er uit de testen van de RW1 veel geleerd worden over de eigenschappen
van de “random walk” (CAMPBELL J., 1997, blz. 34).
Er worden 6 testen i.v.m. de RW1 besproken. Deze zijn de volgende:
1) De Cowles-Jones test.
2) De Runs-test.
3) De Dickey-Fuller test.
4) De Autocorrelatie-test.
5) De Portmanteau Statistieken.
6) De Variantieratios.
De testen worden één voor één uitgewerkt en aan het einde van iedere test, wordt de test
uitgevoerd op de tijdsreeksen van het aandeel UCB en van de Bel 20-index.
22 Merk op dat de drift in het vervolg genoteerd wordt als µ en niet als µ′ zoals aanvankelijk bij het logaritmischmodel. Deze veronderstelling wordt gemaakt om de termen zo eenvoudig mogelijk te houden.

43
4.3 De Cowles-Jones Test
Eén van de eerste testen voor de RW1 werd voorgesteld door Cowles en Jones (1937). De test
maakt een vergelijking van het aantal opeenvolgingen en omkeringen van de rendementen van
een aandeel. Een opeenvolging of “sequence” is een paar van opeenvolgende rendementen met
een zelfde teken. Een omkering of “reversal” is een paar van opeenvolgende rendementen met
een tegengesteld teken. De eigenlijke test bestaat er dan in om het aantal opeenvolgingen en
omkeringen uit een tijdsreeks van rendementen van een aandeel te vergelijken met hetgeen er
zou verwacht worden indien de RW1 geldig is.
De uitwerking van de test kan nu onderverdeeld worden in twee delen. In een eerste deel wordt
er uitgegaan van het logaritmisch RW1-model zonder drift. In het tweede deel wordt een drift
ingevoerd en wordt de test verder uitgewerkd rekening houdend met deze drift. Uiteindelijk
volgt er nog een derde deel waarin een probleem besproken wordt dat de test kan beïnvloeden.
4.3.1 Het RW1-Model zonder Drift
Er wordt vertrokken van het logaritmische RW1-model in hetwelke de logaritme van de prijs tP
een RW1 volgt zonder drift:
ttt pp ε+= −1 , ( )2,0~ σε IIDt (4.1.1)
met )( tt PLNp = .
Beschouw vervolgens een Bernouilli-verdeelde stochastische variabele tI :
���
≤−≡
>−≡=
−
−
,00
01
1
1
ttt
ttt
tpprals
ppralsI (4.1.2)
waarbij tr het continu samengesteld rendement is zoals gedefinieerd in (3.2.1).23 De variabele tI
geeft dus aan wanneer het rendement positief of negatief is. Als de variabele gelijk is aan 1 dan
is het rendement strikt positief en als de variabele gelijk is aan 0 dan is het rendement kleiner of
gelijk aan nul.
23 Als men in het verdere verloop van dit hoofdstuk spreekt over het rendement, dan bedoelt men het continusamengesteld rendement.

44
Er wordt nu ook nog een extra voorwaarde opgelegd aan tε : stel tε is symmetrisch verdeeld.24
De kans op een strikt positief rendement zal dan gelijk zijn aan de kans op een negatief
rendement.25 Het is dus even waarschijnlijk dat tI gelijk is aan 1 als dat het gelijk is aan 0. Het
proces dat de waarnemingen genereert voor de variabele tI , kan dan intuïtief het best
voorgesteld worden als het gooien van een muntstuk waarbij dat munt een strikt positief
rendement voorstelt en kop een negatief rendement voorstelt. Indien het muntstuk geen
imperfecties vertoont, zal de kans op een positief rendement gelijk zijn aan de kans op negatief
rendement (COOTNER P., 1964, blz. 2).
De test van Cowles en Jones bestaat er nu in om het aantal opeenvolgingen en omkeringen van
de rendementen te vergelijken met elkaar. Beschouw een steekproef van n+1 rendementen
121 ,,, +nrrr � . Het aantal opeenvolgingen SN (“Sequences”) en het aantal omkeringen RN
(“Reversals”) kan dan als volgt berekend worden:
=++ −−+≡≡
n
tttttttS IIIIYmetYN
111 )1)(1( (4.1.3)
SR NnN −≡ , (4.1.4)
waarbij dat tY een Bernouilli-verdeelde variabele is die gelijk is aan 1 in geval van een
opeenvolging en 0 in geval van een omkering (zie sectie 4.1.2). De waarde n is het totaal aantal
waarnemingen voor tY of het totaal aantal paren van op elkaar volgende rendementen.
Vervolgens hebben Cowles en Jones een ratio bepaald, de Cowles-Jones ratio ∧
CJ , die de
verhouding weergeeft tussen het aantal opeenvolgingen en het aantal omkeringen:
S
S
S
S
R
S
R
S
nNnnN
nNnN
NN
CJπ
πˆ1
ˆ−
=−
==≡∧
, (4.1.5)
waarbij Sπ̂ de geschatte kans is op een opeenvolging (de verhouding van het aantal
24 Het rendement tr zal dan ook symmetrisch verdeeld zijn omdat tr in feite gelijk is aan tε .25 In het vervolg van de tekst zal men het woord “strikt” gebruiken om aan te geven dat het rendement niet gelijkmag zijn aan 0. Indien men het woord “strikt” niet vermeld dan kan het rendement wel gelijk zijn aan 0.

45
opeenvolgingen en het totaal aantal waarnemingen voor tY ). Sπ̂1− is dan de geschatte kans op
een omkering.
De ∧
CJ -ratio moet bij benadering gelijk zijn aan 1 indien de RW1 geldig is. De kans op een
opeenvolging moet namelijk gelijk zijn aan de kans op een omkering ten gevolge van de
symmetrische verdeling van tr rond de waarde 0.
De ∧
CJ -ratio, gedefinieerd in (4.1.5), is dan een consistente schatter van de werkelijke CJ -ratio.
Dit kan als volgt weergegeven worden:
12
12
1
1ˆ1ˆ
===−
→−
=∧
CJCJS
Swa
S
S
ππ
ππ
,
waarbij “ wa ” aanduidt dat schatter convergeert in waarschijnlijkheid. Sπ is de verwachte kans
op een opeenvolging indien de RW1 geldig is en is bijgevolg gelijk aan 21 . Bij deze test van
Cowles en Jones moet men dus het aantal opeenvolgingen en omkeringen berekenen en nagaan
of hun verhouding bij benadering gelijk is aan 1.
Uit het onderzoek dat Cowles en Jones (1937) uitgevoerd hebben op historische aandelen-
rendementen, zowel voor dagelijkse, wekelijkse, maandelijkse als voor jaarlijkse gegevens,
bleek dat voor de meeste aandelen de schatter voor de CJ -ratio groter is dan 1. Hieruit zou men
kunnen afleiden dat er een positieve correlatie aanwezig is tussen de opeenvolgende
rendementen aangezien er meer kans is op opeenvolgingen dan op omkeringen. Er lijken dus
bewijzen te zijn voor een zekere volharding in de beweging van de aandelenrendementen
(CAMPBELL J. et al., 1997, blz. 36).
Het “averaging”-effect
Als reactie op de resultaten van Cowles en Jones, stelde Working (1960) dat de positieve seriële
correlatie het gevolg kan zijn van het gebruik van gemiddelden van prijzen (het “averaging”-
effect). Hij heeft namelijk aangetoond dat het gebruik van gemiddelden van prijzen, correlatie
kan introduceren tussen de opeenvolgende differenties van de gemiddelden, zelfs als deze
correlatie niet aanwezig is tussen de opeenvolgende prijsveranderingen in de originele tijdsreeks
van de prijzen. Het principe werkt als volgt: stel de tijdsreeks van de wekelijkse prijzen van een

46
aandeel volgt een RW1.26 Dit impliceert dat er geen significante correlatie aanwezig is tussen de
opeenvolgende wekelijkse rendementen. Stel nu vervolgens dat men wil nagaan of de
maandelijkse prijzen een RW1 volgen. Indien de maandelijkse prijzen bekomen worden door het
nemen van het gemiddelde van de wekelijkse prijzen in de maand, dan zal door het nemen van
de gemiddelden correlatie geïntroduceerd worden tussen de opeenvolgende maandelijkse
rendementen. De maandelijkse prijzen zullen dan hoogstwaarschijnlijk geen RW1 volgen. Het is
wel mogelijk dat de maandelijkse prijzen een RW1 volgen indien men de maandelijkse prijzen
berekent als de laatste notering van de maand. Dus het gebruik van gemiddelden zal
autocorrelatie introduceren zelfs indien de originele tijdsreeks geen correlatie vertoont. Working
haalde het gebruik van gemiddelden aan als mogelijke oorzaak voor de positieve seriële
correlatie die Cowles en Jones ontdekten in hun onderzoek, dit vooral voor de maandelijkse
prijzen. Dus het effect van het nemen van gemiddelden kan de verklaring zijn voor de schijnbare
hoge voorspelbaarheid van maandelijkse rendementen (WORKING H., 1960, blz. 916-918)
(COWLES A., 1960, blz. 909).
Als reactie hierop heeft Cowles (1960) het onderzoek uit 1937 opnieuw uitgevoerd waarbij hij
voor de prijzen van iedere tijdseenheid, een bepaalde waarneming uit de tijdseenheid gebruikt,
zoals de eindnotering, om zo het “averaging”-effect te vermijden. Vooral voor de maandelijkse
gegevens kan men een groot verschil opmerken tussen de resultaten van 1937 en de resultaten
van 1960. Het surplus van opeenvolgingen op de omkeringen is drastisch verminderd vergeleken
met de resultaten uit 1937. Dit lijkt consistent te zijn met de bevindingen van Working.
Niettemin is er nog steeds een surplus aan opeenvolgingen bij zowel de dagelijkse, de
wekelijkse, de maandelijkse als de jaarlijkse gegevens. Er zal dus nog steeds sprake zijn van een
positieve correlatie tussen de opeenvolgende rendementen die niet te verklaren is door het effect
van het nemen van gemiddelden (COWLES A., 1960, blz. 912-914).
Makelaarskosten
De resultaten van Cowles (1960) leiden tot de conclusie dat er een zekere tendens is tot
volharding in de beweging van de aandelenprijzen. Er lijkt dus een mogelijkheid te bestaan om
op basis van vroegere waarnemingen van de aandelenrendementen een winst te behalen. Cowles
stelde wel dat indien men rekening houdt met de makelaarskosten die moeten betaald worden bij
het verhandelen van aandelen, de winsten verwaarloosbaar zijn zodat de kapitaalmarkten nog
26 Met de wekelijkse prijzen bedoelt men de logaritmische prijzen om zo de link te kunnen leggen met de test vanCowles en Jones. Het principe is evenwel hetzelfde voor de gewone prijzen.

47
altijd efficiënt zijn en het onmogelijk wordt om op basis van de vroegere rendementen een
behoorlijke winst te behalen (COWLES A., 1960, blz. 914).
Stel nu dat de correlatie toch voldoende groot is zodat het mogelijk wordt om kapitaalwinsten te
genereren die merkbaar groter zijn dan de makelaarskosten. Het marktmechanisme zal er dan
voor zorgen dat deze extra rendementen voldoende snel zullen verdwijnen. Het is namelijk zo
dat er voldoende professionele handelaars zijn die op de hoogte zijn van deze potentieel hoge
winsten. Zij zullen dan het aandeel direct willen kopen. Dit zal dan op zijn beurt ervoor zorgen
dat de prijs voldoende snel stijgt naar zijn nieuw evenwicht in plaats van geleidelijk zodat het
niet mogelijk zal zijn om extra winsten te genereren (zie inleiding, blz. 1). Dus de handelingen
van de handelaars zullen ervoor zorgen dat de volharding in de prijsbewegingen, waarvan ze
willen profiteren, verdwijnt. Er kan dus besloten worden dat de correlatie tussen de
opeenvolgende rendementen onvoldoende groot zal zijn om een meer dan verwaarloosbare winst
te behalen na het betalen van de makelaarskosten (COWLES A., 1960, blz. 915).
Aanwezigheid van een drift
Bij de uitwerking van de test van Cowles en Jones heeft men de veronderstelling gemaakt dat de
drift gelijk is aan nul. Dit is niet realistisch aangezien het verloop van de meeste aandelenprijzen
een drift vertonen. Er moet hiermee dan ook rekening gehouden worden. Door de aanwezigheid
van een drift zal de CJ -ratio zeker groter zijn dan 1 omdat een drift een opeenvolging
waarschijnlijker maakt dan een omkering. Dit zou dan ook de oorzaak kunnen zijn van het feit
dat het aantal opeenvolgingen steeds groter is dan het aantal omkeringen in het onderzoek van
Cowles (1960). Het wil dus niet zeggen omdat een CJ -ratio groter is dan 1 dat de RW1 niet
opgaat. Daarom zal er in het volgende deel rekening gehouden worden met de aanwezigheid van
een drift bij de bepaling van de formule voor de CJ -ratio (CAMPBELL J., 1997, blz. 36).
4.3.2 Het RW1-Model met Drift
In dit deel zal er nagegaan worden wat de invloed is van de invoering van de drift op de formule
voor de CJ -ratio en hoe men aan de hand van deze ratio kan testen wanneer de RW1 geldig is.
Veronderstel daartoe dat de logaritmen van de prijzen een RW1 volgen met drift:
ttt pp εµ ++= −1 , ( )2,0~ σε ΝIIDt , (4.1.6)
waarbij de extra veronderstelling gemaakt wordt dat de residuen normaal verdeeld zijn.

48
Het model (4.1.6) kan dan omgevormd worden tot het volgende model:
( )2,~ σµΝIIDrt . (4.1.7)
De rendementen zijn dus onafhankelijk en identiek normaal verdeeld indien de RW1-hypothese
geldig is.
Beschouw vervolgens opnieuw de Bernouilli-verdeelde stochastiche variabele tI :
���
−≤
>=
.100
01
π
π
lijkheidwaarschijnmetrals
lijkheidwaarschijnmetralsI
t
t
t (4.1.8)
Merk op dat de kans op een strikt positief rendement niet meer gelijk is aan de kans op een
negatief rendement aangezien een positieve drift een positief rendement meer waarschijnlijk
maakt dan een negatief rendement en omgekeerd bij een negatieve drift. De variabele tI kan dan
niet langer voorgesteld worden door het gooien van een zuiver muntstuk waarbij munt een strikt
positief rendement is en kop een negatief rendement. Het gooien zal een neiging hebben in de
richting van de drift.
De waarschijnlijkheid π op een positief rendement kan nu als volgt voorgesteld worden:
[ ]
)9.1.4(,
0
���
�<=
��
��
�−>
−=
>=
σµ
σµ
σ
µ
π
t
t
t
ZP
rP
rP
waarbij in de tweede gelijkheid overgegaan wordt op de standaard normaal verdeelde variabele
gebruik makend van (4.1.7). Men kan dan door middel van de tabellen van de standaard normaal
verdeelde variabelen nagaan wat de kans is. In geval van een positieve drift zal de kans groter
zijn dan 21 en in geval van een negatieve drift kleiner dan 21 .

49
Vervolgens kan men nu de nieuwe CJ -ratio afleiden (eigen werk):
[ ] [ ][ ] [ ][ ] [ ] [ ] [ ][ ] [ ] [ ] [ ]
( )( )
)10.1.4(,12
1
0000
0000
0000
0000
1
22
11
11
11
11
ππππ
π
π
−
−+=
><+<>
<<+>>=
><+<>
<<+>>=
−=
++
++
++
++
tttt
tttt
tttt
tttt
S
S
rPrPrPrP
rPrPrPrP
renrPrenrP
renrPrenrP
CJ
waarbij de derde gelijkheid volgt uit het feit dat de opeenvolgende rendementen onafhankelijk
zijn van elkaar indien de RW1 geldig is. Uit (4.1.7) volgt namelijk dat de rendementen tr
onafhankelijke en identiek verdeelde stochastische variabelen zijn.
De CJ-ratio is altijd ≥ 1
Er kan nu gemakkelijk aangetoond worden dat de nieuwe CJ -ratio steeds groter of gelijk zal
zijn aan 1 indien de RW1 geldig is. Om te beginnen kan (4.1.10) omgevormd worden tot (eigen
werk):
( )( )
)11.1.4(.122
1
22
221
12
1
2
2
2
22
−−
=
−
+−=
−
−+=
ππ
ππππ
ππππCJ
Er moet nu nagegaan worden of de vergelijking (4.1.11) al dan niet groter of gelijk is aan 1. Dit
kan als volgt bewezen worden:
222 4
1411122
1 ππππππ
−≥≥−
≥−−
.

50
Merk op het teken bij de laatste ongelijkheid niet omkeert omdat 2ππ − steeds positief is daar
π kleiner is dan 1. De laatste ongelijkheid kan vervolgens herleid worden tot de volgende
vergelijking:
0412 ≥+−ππ . (4.1.12)
Er moet nu nagegaan worden of de functie ( ) 412 +−= πππf , groter of gelijk is aan nul. Deze
functie is een kwadratische functie. π kan enkel de reële waarden aannemen in het open interval
] [1,0 . De discriminant is gelijk aan 0 zodat er maar één nulpunt is. Het nulpunt is gelijk aan
21 . Dit is het geval wanneer de drift gelijk is aan 0 zodat de kans op een strikt positief
rendement gelijk is aan de kans op een negatief rendement. De CJ -ratio zal dan gelijk zijn aan
1. De eerste afgeleide in het nulpunt is gelijk aan nul en de tweede afgeleide is groter dan nul
zodat het nulpunt het minimum is van de functie. Dit kan ook onmiddellijk afgeleid worden uit
Figuur 18: Het verloop van de functie ( ) 412 +−= πππf .
figuur 18 waarin de grafiek van de functie uitgezet is. Op de horizontale as ziet men de waarden
voor π en op de vertikale as de functiewaarden. Daar er maar één minimum is en er geen
maximum is, zullen alle andere functiewaarden boven 0 liggen zodat er voldaan is aan (4.1.12)
(VANMAELE M., 1995). Er kan dus gesteld worden dat:
1/2 10

51
( )( ) .1121 22
≥−−+=ππππCJ
Dit is eigenlijk vanzelfsprekend omdat een drift verschillend van 0, een opeenvolging meer
waarschijnlijk maakt dan een omkering. De drift zal namelijk een trend induceren in het proces
dat de prijzen genereert (Eigen werk).
Bij het testen of de RW1 geldig is, moet men dus een schatting maken voor de CJ -ratio van een
bepaalde tijdsreeks van aandelenprijzen en kijken of deze al dan niet significant verschillend is
van de ratio die zou bekomen worden indien de RW1 geldig is. De schatter voor de CJ -ratio,
voorgesteld als ∧CJ , bekomt men door de verhouding te berekenen van het aantal
opeenvolgingen en het aantal omkeringen. Om nu de test uit te voeren zal het noodzakelijk zijn
om een steekproefverdeling op te stellen voor de schatter van de CJ -ratio om de significantie te
kunnen nagaan.
De steekproefverdeling voor de CJ-ratio
Om te beginnen kan de Bernouilli-verdeelde variabele tY die in (4.1.3) gedefinieerd is, als volgt
voorsteld worden:
( )
���
−
−+==
S
St
lijkheidwaarschijnmet
lijkheidwaarschijnmetY
π
πππ
10
11 22
(4.1.13)
Merk op dat de variabele tY aanduidt wanneer er een opeenvolging is en wanneer er een
omkering is. Als de variabele gelijk is aan 1, dan heeft men te maken met een opeenvolging. Als
de variabele gelijk is aan 0, dan heeft men te maken met een omkering. De kans Sπ kan
bekomen worden uit (4.1.9).
De schatter SN (d.i. het aantal opeenvolgingen), gedefinieerd in (4.1.3), is dan de som van de
Bernouilli-verdeelde variabelen tY en is bijgevolg een binomiaal verdeelde stochastische
variabele met verwachtingswaarde [ ] SS nNE π= en variantie [ ]SNvar . Normaal zou men
verwachten dat de variantie gelijk is aan ( )SSn ππ −1 , maar aangezien dat de aangrenzende tY ’s
afhankelijk zijn van elkaar, wordt de volgende variantie bekomen (eigen werk):

52
[ ] [ ][ ] [ ] [ ] [ ] [ ]nnn
nS
YYCovYYCovYVarYVarYVar
YYYVarNVar
,2,2 12121
21
−++++++=
+++=
��
�
[ ] ( )[ ] [ ] 1,,3,2,,
,,2,11
11 −==
=−=
+− ntvoorYYCovYYCov
ntvoorYVarmet
tttt
SSt
�
�ππ
[ ] ( ) ( ) [ ]1,121 +−+−= ttSSS YYCovnnNVar ππ
Bij benadering, d.i. als het aantal waarnemingen zeer groot is, kan er dan gesteld worden dat:27
[ ] ( ) [ ]1,21 ++−= ttSSS YYCovnnNVar ππ . (4.1.14)
Vervolgens moet men nu de covariantie berekenen tussen twee aangrenzende tY ’s. Hierbij kan
als volgt tewerk gegaan worden:
[ ] [ ]( ) [ ]( )[ ][ ] [ ] [ ] )15.1.4(
,
11
111
++
+++
−=
−−=
tttt
tttttt
YEYEYYE
YEYYEYEYYCov
Men weet nu dat de verwachtingswaarde van een Bernouilli-verdeelde variabele gelijk is aan de
kans dat de Bernouilli-verdeelde variabele gelijk is aan 1 en dat de vermenigvuldiging van twee
Bernouilli-verdeelde variabelen ook een Bernouilli-verdeelde variabele is. Hiervan gebruik
makend kan de vergelijking (4.1.15) verder uitgewerkt worden:
[ ] [ ] [ ] [ ][ ] [ ] [ ] [ ]
[ ] )16.1.4(,11
11111
111,
21
11
111
SStt
ttttt
tttttt
YYP
YPYPYPYYP
YPYPYYPYYCov
ππ −===
==−====
==−==
+
++
+++
waarbij men bij de tweede gelijkheid gebruik maakt van de vermenigvuldigingswet.28
27 Later zal er gesteld worden dat het aantal waarnemingen zeer groot is om de normale verdeling in te voeren zodater nu reeds gebruik zal gemaakt worden van (4.1.14).28 De vermenigvuldigingswet ziet er als volgt uit: [ ] [ ] [ ]APABPBAP =∩ (REYNAERTS H., 1995).

53
De enige onbekende term in (4.1.16) is [ ]111 ==+ tt YYP . Deze term kan als volgt uitgewerkt
worden:
[ ] ( ) ( )[ ][ ]
( ) ( )( ) ( ) ( )( )[ ][ ]
( ) ( )[ ][ ]
( ) )17.1.4(,1
1
01
1
0101
1
1111
33
2121
112121
11
S
t
tttttt
t
tttttttt
t
tttt
YP
IIIIIIP
YP
IIIIIIIIP
YP
YYPYYP
πππ
φφ
−+=
=
===∪∪∪====
=
==∪==∩==∪===
=
=∩====
++++
++++++
++
waarbij de eerste gelijkheid volgt uit de vermenigvuldigingswet en de derde gelijkheid volgt uit
het feit dat de doorsnede van de unies gelijk is aan de unie van de doorsneden.29
Als men nu vergelijking (4.1.17) in vergelijking (4.1.16) brengt dan wordt het volgende
bekomen voor de covariantie:
[ ] ( ) 2331 1, Stt YYCov πππ −−+=+ . (4.1.18)
Men kan nu vervolgens de covariantie in de formule (4.1.14) vervangen door (4.1.18) zodat dan
uiteindelijk de variantie voor SN bekomen wordt:
[ ] ( ) ( )( )233 121 SSSS nnNVar πππππ −−++−= . (4.1.19)
(Eigen werk)
Indien het aantal waarnemingen n voor tY zeer groot is, zal de verdeling van SN de normale
verdeling benaderen, ten gevolge van de centrale limietstelling, met als verwachtingswaarde
[ ] SS nNE π= en als variantie [ ]SNVar zoals weergegeven in formule (4.1.19). SN zal dus
asymptotisch normaal verdeeld zijn.
29 Dit kan als volgt weergegeven worden: ( ) ( ) ( ) ( ) ( ) ( )DBCBDACADCBA ∩∪∩∪∩∪∩=∪∩∪ .

54
Om nu de steekproefverdeling voor de ∧CJ -ratio te bepalen, kan de eerste-orde Taylor
benadering of de delta methode toegepast worden op ( )SS NnNCJ −=∧
, gebruik makend van
de normale asymptotische benadering voor de verdeling van SN . Er wordt dus vertrokken van
de verdeling van SN :
( ) ( )( )( )233 121,~ SSSS
a
S nnnN ππππππ −−++−Ν , (4.1.20)
waarbij dat “ a ” aanduidt dat het een asymptotische verdeling is.
Als men nu de delta methode toepast op een functie van SN dan bekomt men de volgende
verdeling voor de functie:
( ) ( ) ( )( )22,~ σππ SS
a
S nfnfNf ′Ν , (4.1.21)
( )S
SS
Nn
NCJNfmet
−==
∧ .
(CAMPBELL J. et al., 1997, blz. 540).
De verdeling voor ∧CJ kan dus bekomen worden door (4.1.21) uit te werken (eigen werk):
( )
( )( ) ( ) ( )
( ) ( ) ( )( )[ ]( )
)23.1.4(.1
121
1
1
)22.1.4(,1
42
23322
222
S
SSSS
SSS
SSS
S
S
S
SS
n
nnf
nnn
n
nn
nnnnf
nn
nnf
ππππππσπ
ππππππ
ππ
πππ
−
−−++−=′
−=
−=
−
+−=′•
−=
−=•

55
Als men nu (4.1.22) en (4.1.23) invoegt in (4.1.21), dan wordt de eigenlijke steekproefverdeling
voor ∧CJ bekomen:
( ) ( )( )( )
�
��
�
�
−
−−++−
−Ν
∧
4
233
1
121,1
~S
SSS
S
Sa
nCJ
ππππππ
ππ . (4.1.24)
De test om na te gaan of de RW1 geldig is, kan nu gemakkelijk uitgevoerd worden. Men maakt
een schatting voor de CJ -ratio door de verhouding van het aantal opeenvolgingen en het aantal
omkeringen te berekenen en vervolgens kijkt men of deze waarde in het 95%
betrouwbaarheidsinterval ligt. Indien de schatter in het interval ligt, dan kan de RW1 aanvaard
worden.
4.1.3 Wat Is de Invloed van Afwijkingen van de RW1 op de CJ-Ratio?
De CJ -ratio is opgesteld in de veronderstelling dat de RW1 geldig is. Stel nu dat de RW1-
hypothese niet geldig is, zou dit dan kunnen opgespoord worden door de CJ -ratio?
Er kan nu onderzocht worden welke invloed de afwijkingen van de RW1 hebben op de CJ -ratio.
Als de RW1 niet geldig is, dan zal de variabele tI een Markov-keten met 2 toestanden volgen.
De overgangsmatrix van deze Markov-keten ziet er als volgt uit:
)25.1.4(,1
101
01
1
����
�
−−
+
ββαα
t
t
I
I
waarbij α de kans is dat het rendement op tijdstip t+1 negatief is, als het rendement op tijdstip t
positief was en waarbij β de kans is dat het rendement op tijdstip t+1 positief is, als het
rendement op tijdstip t negatief was. De RW1 zal enkel geldig zijn als βα −= 1 . Als βα −≠ 1
dan zullen de opeenvolgende tI ’s gecorreleerd zijn met elkaar waardoor de RW1-hypothese

56
niet meer geldig is.30 De theoretische waarde voor de CJ -ratio zal dan niet langer kunnen
gegeven worden door (4.1.9). De nieuwe waarde voor de CJ -ratio kan nu als volgt afgeleid
worden (eigen werk):
( ) ( )[ ] ( ) ( )[ ]( ) ( )[ ] ( ) ( )[ ]
[ ] [ ] [ ] [ ][ ] [ ] [ ] [ ]
( ) [ ] ( ) [ ][ ] [ ]
( ) [ ][ ]
( )
[ ][ ]
)26.1.4(.
0
1
10
11
10
0111
110001
000111
1001
0011
11
11
11
11
=
=+
−+=
=−
=
=+=
=−+=−=
===+===
===+====
=∩=+=∩=
=∩=+=∩==
++
++
++
++
t
t
t
t
tt
tt
tttttt
tttttt
tttt
tttt
IP
IPIP
IP
IPIP
IPIP
IPIIPIPIIP
IPIIPIPIIP
IIPIIP
IIPIIPCJ
αβ
βα
αββα
Er moet nu nog uitgerekend worden waaraan [ ] [ ]01 == tt IPIP gelijk is. Men gaat hierbij als
volgt tewerk (eigen werk):
[ ] [ ] [ ] [ ] [ ][ ] [ ]
[ ] [ ] [ ][ ]
( ) [ ][ ]
[ ][ ]
)27.1.4(.0
1
1
011
1
001111
11
0011111
11
1
111
αβ
βα
==
=
=
=+−=
=
===+===
===
===+=====
++
+
+++
t
t
t
t
t
ttttt
tt
ttttttt
IP
IP
IP
IP
IP
IPIIPIIP
IPIPmet
IPIIPIPIIPIP
30 Als de opeenvolgende tI ’s gecorreleerd zijn dan zullen de opeenvolgende rendementen namelijk ookgecorreleerd zijn, vandaar dat de RW1-hypothese dan niet geldig is.

57
Als men nu (4.1.27) inbrengt in (4.1.26), dan wordt de waarde voor de CJ -ratio bekomen indien
de RW1-hypothese niet geldig is:
( ) ( )αβ
αββα2
11 −+−=CJ . (4.1.28)
De waarden die de CJ -ratio kan aannemen, voor de gegeven α en β , zijn uitgezet in figuur 19.
Als α en β naar 1 gaan, dan verhoogt de waarschijnlijkheid op omkeringen en nadert de CJ -
ratio naar 0. Als α of β naar 0 gaat, verhoogt de waarschijnlijkheid op opeenvolgingenen stijgt
de CJ -ratio boven 1 uit. Uit de figuur lijkt men dan ook te kunnen afleiden dat CJ , zoals
gedefinieerd in (4.1.28), een goede maatstaf is om de afwijkingen van de RW1 te detecteren. Er
Figuur 19: Waarden voor CJ -ratio voor gegeven α en β .
(zie boek Campbell, Lo en MacKinlay (1997), figuur p. 38)
moet evenwel voorzichtigheid geboden worden daar er combinaties bestaan van α en β
waarvoor βα −≠ 1 en de CJ -ratio toch gelijk is aan 1 zodat men de neiging zou kunnen hebben
om de RW1 te aanvaarden. Dus voor deze gevallen kan er niet op basis van de CJ -ratio beslist
worden of de RW1 al dan niet geldig is (CAMPBELL J. et al., 1997, blz. 38).
4.1.4 Empirisch Onderzoek
De bekomen steekproefverdeling voor de CJ -ratio, gedefinieerd in (4.1.24), kan nu gebruikt
worden om de geldigheid van de RW1 na te gaan voor de tijdsreeksen van het aandeel UCB en
de Bel20-index. De test zal uitgevoerd worden voor zowel de maandelijkse, wekelijkse als de
dagelijkse prijzen. Daar de Cowles-Jones test opgesteld is voor het logaritmisch RW1-model, zal
er gebruik gemaakt worden van de logaritmische prijzen. Het verloop van de logaritmische

58
prijzen en het verloop van de veranderingen in de logaritmen van de prijzen zijn weergegeven in
bijlage 6 voor het aandeel UCB en in bijlage 7 voor de Bel20-index.
De resultaten voor de Cowles-Jones test zijn weergegeven in tabel 1. Hieruit kan onmiddellijk
afgeleid worden dat, wat betreft de daggegevens, de RW1-hypothese met grote zekerheid moet
verworpen worden voor het aandeel UCB. Dit is ook het geval voor de Bel20-index, zij het
minder uitgesproken. In beide gevallen lijken de rendementen positief afhankelijk te zijn daar het
aantal opeenvolgingen veel groter is dan het aantal omkeringen. Deze overschot aan
opeenvolgingen kan niet verklaard worden door de drift daar deze eerder klein is.
Tabel 1: De Cowles-Jones test voor dagelijkse, wekelijkse en maandelijkse rendementen.
Aandeel/Index TijdseenheidSteekproef-
grootteπ
Sπ ∧
CJ95%-betrouw-
baarheidinterval
UCB Dag 6824 0.5013 0.5000 1.5421 [0.9526;1.0475]
Week 1364 0.5296 0.5017 1.1066 [0.8535;1.1606]
Maand 313 0.5776 0.5120 1.0129 [0.8110;1.2877]
Bel20-index Dag 6824 0.5155 0.5005 1.2904 [0.9543;1.0495]
Week 1364 0.5299 0.5018 1.1231 [0.8999;1.1145]
Maand 313 0.5541 0.5059 1.0260 [0.7939;1.2535]
(Eigen werk; Microsoft Word)
Voor de weekgegevens lijkt het aandeel UCB te voldoen aan de veronderstellingen van de RW1.
De testwaarde voor de Bel20-index daarentegen ligt net buiten het 95%-betrouwbaarheids-
interval voor de weekgegevens. Er zijn meer opeenvolgingen dan verwacht onder de RW1-
hypothese. Er lijkt dus een zekere positieve afhankelijkheid te zijn tussen de opeenvolgende
wekelijkse rendementen van de Bel20-index, net zoals voor de dagelijkse rendementen. Een
mogelijke verklaring voor beide gevallen is het feit dat alle aandelen van de Bel20-index
beïnvloed worden door een bepaalde marktfactor. Als er nu een verandering is in de marktfactor,
dan zullen de prijzen van de individuele aandelen ook veranderen. Aangezien niet alle aandelen
verhandeld worden op het tijdstip van de verandering van de marktfactor, zullen er aandelen zijn
die slechts met vertraging reageren op de verandering van de marktfactor. Dit kan dan leiden tot
een positieve afhankelijkheid tussen de opeenvolgende rendementen van de Bel20-index, zelfs al
zijn de rendementen van de individuele aandelen onafhankelijk van elkaar (zoals voor de

59
wekelijkse rendementen van het aandeel UCB dat trouwens opgenomen is in de Bel20 index)
(FAMA F. en BLUME M., 1966, blz. 235-236).
De maandgegevens tenslotte zijn zowel voor het aandeel UCB als voor de Bel20-index
consistent met het RW1-model. Er moet wel opgemerkt worden dat de resultaten voor de
maandgevens minder betrouwbaar zijn daar er gewerkt wordt met een asymptotische verdeling
en voor de maandgegevens is de steekproefgrootte eerder klein.
Er wordt nu overgegaan naar de volgende test, de runs-test. Deze test leunt zeer dicht aan bij de
Cowles-Jones test. Bij de afleiding van de verdeling zal dezelfde werkwijze gevolgd worden als
bij de Cowles Jones test.
4.2 De Runs-Test
Een tweede veelgebruikte test voor de RW1 is de runs-test. Een run kan gedefinieerd worden als
een opeenvolging van tijdsintervallen in dewelke de prijs van het aandeel in dezelfde richting
beweegt. De runs-test zal dan het aantal runs in de data vergelijken met het verwachte aantal runs
indien de RW1 geldig is. Mood (1940) was de eerste die een uitgebreide analyse maakte in
verband met de runs. Hij ontwikkelde de runs-test.
In een eerste deel zullen enkele kenmerken van de run en de runs-test besproken worden. In het
tweede deel zal dan de verdeling voor het aantal runs afgeleid worden. In het derde deel tenslotte
worden nog enkele opmerkingen gemaakt over de runs-test.
4.2.4 Relatie tussen het Aantal Runs en de Runs-Test
Een run kan algemeen gedefinieerd worden als een opeenvolging van rendementen met een
zelfde teken Hieruit kan onmiddellijk afgeleid worden dat er twee soorten runs zijn:
• Een run met een positief teken ofwel een opeenvolging van positieve rendementen (een plus
run).
• Een run met een negatief teken ofwel een opeenvolging van negatieve rendementen (een min
run).31
Een run wordt ook nog gekenmerkt door zijn lengte. De lengte is het aantal rendementen met een
zelfde teken in de run.
31 Een rendement van 0 zal beschouwd worden als een negatief rendement.

60
Als een positief rendement voorgesteld wordt door een 1 en een negatief rendement door een 0,
dan kan een opeenvolging van 10 rendementen als volgt voorgesteld worden: 1100010011. Deze
opeenvolging bevat drie plus runs met respectievelijke lengtes 2, 1 en 2 en twee min runs met
respectievelijke lengtes 3 en 2.
De runs-test bestaat erin om het aantal runs in een tijdsreeks van rendementen te vergelijken met
het aantal verwachte runs indien de RW1 geldig zou zijn. Het verschil tussen het werkelijk aantal
runs en het verwachte aantal runs kan op 3 verschillende manieren geanalyseerd worden:
• Het verschil tussen totaal verwachte aantal runs en de het werkelijke aantal.
• Het verschil tussen het verwachte aantal runs van ieder teken en het werkelijke aantal runs
van ieder teken.
• Het verschil tussen het verwachte aantal runs van iedere lengte en het werkelijke aantal runs
van iedere lengte.
(FAMA E., 1965, blz. 74).
De nadruk zal vooral gelegd worden op het eerste punt: het totale aantal runs.
Indien de RW1 geldig is voor een bepaalde tijdsreeks dan moet het aantal runs in de data
ongeveer hetzelfde zijn als verwacht. Als er echter een positieve afhankelijkheid is tussen de
rendementen dan zullen er langere opeenvolgingen zijn van positieve rendementen of van
negatieve rendementen die niet te wijten zijn aan het zuivere toeval. Het aantal runs in de data
zal dan ook kleiner zijn dan het verwachte aantal runs onder de RW1-hypothese. Er kan ook
sprake zijn van negatieve afhankelijkheid tussen de rendementen. In dit geval zal het aantal runs
in de data groter zijn dan verwacht onder de RW1-hypothese (ELTON E. en GRUBER M., 1995,
blz. 417).
Om nu te kunnen nagaan of het aantal runs in de data al dan niet gelijk is aan het verwachte
aantal runs onder de RW1-hypothese, is het noodzakelijk om een steekproefverdeling op te
stellen voor het aantal runs en dit onder de RW1-hypothese.
4.2.5 De Steekproefverdeling voor het Aantal Runs
Bij de afleiding van de verdeling zal er opnieuw vertrokken worden van het logaritmisch RW1-
model:
ttr εµ += , ( )2,0~ σε t . (4.2.1)

61
De werkwijze die gevolgd wordt, zal dicht aanleunen bij de werkwijze die gehanteerd werd bij
de afleiding van de verdeling voor de CJ -ratio. Er wordt opnieuw vertrokken van de Bernouilli-
verdeelde variabele tI :
���
−≤
>=
.100
01
π
π
lijkheidwaarschijnmetrals
lijkheidwaarschijnmetralsI
t
t
t (4.2.2)
Vervolgens wordt er een nieuwe Bernouilli-verdeelde variabele tX geconstrueerd (eigen werk):
���
−=
,10
1
RUN
RUN
tlijkheidwaarschijnmetisrunnieuwegeenerals
lijkheidwaarschijnmetisrunnieuweeeneralsX
π
π
waarbij RUNπ de kans is op een run. De variabele tX zal dus gelijk zijn aan 1 als er een nieuwe
run is op tijdstip t, d.i. als het rendement op tijdstip t van teken verandert. tX is gelijk aan 0 als er
geen nieuwe run is op tijdstip t, d.i. als het rendement niet van teken verandert. De kans op een
run kan dan als volgt afgeleid worden:
[ ] [ ][ ] [ ] [ ] [ ]( ) ( )
( ) )3.2.4(.12
11
1001
1001
11
11
ππ
ππππ
π
−=
−+−=
==+===
==+===
−−
−−
tttt
ttttRUN
IPIPIPIP
IenIPIenIP
Stel er is een steekproef van n rendementen nrrr ,,, 21 � . Het aantal runs is dan de som van de
Bernouilli-verdeelde variabelen tX . Dit kan als volgt voorgesteld worden:
=
=n
ttRUNS XN
1
. (4.2.4)
Het aantal runs RUNSN is bijgevolg binomiaal verdeeld. Als het aantal waarnemingen voor de
rendementen zeer groot is, dan zal RUNSN benaderd normaal verdeeld zijn, ten gevolge van de
centrale limietstelling (Eigen werk).

62
Verwachtingswaarde van RUNSN
De verwachtingswaarde van RUNSN zou er normaal gezien als volgt moeten uitzien:
[ ] ( )ππ −= 12 nNE RUNS . (4.2.5)
Het is evenwel zo dat in realiteit de verwachtingwaarde de volgende vorm aanneemt:
[ ] ( ) ( )22 112 ππππ −++−= nNE RUNS . (4.2.6)
Er zijn dus twee aanvullende termen bijgekomen. Dit kan eenvoudig verklaard worden. Er is
reeds gesteld dat er sprake is van een run op een bepaalde tijdstip als het rendement
voorafgegaan wordt door een rendement met een tegengesteld teken. Het is nu zo dat het op
tijdstip 1 niet geweten is welk rendement er was vóór het tijdstip 1. Als gevolg hiervan zal er
zeker een run zijn op tijdstip 1 onafhankelijk van het feit wat er voor komt. Dus zelfs als het
rendement op tijdstip 0, wat niet behoort tot de steekproef, een zelfde teken heeft als het
rendement op tijdstip 1, toch zal er een run zijn op tijdstip 1. De kans op een run op tijdstip 1 kan
dan als volgt weergegeven worden:
( ) [ ] [ ][ ] [ ]
( ) ( ) ( )
( ) ( ) )7.2.4(.112
111
0011
01101
22
22
1010
1010
ππππ
ππππππ
π
−++−=
−++−+−=
==+==
+==+===
IenIPIenIP
IenIPIenIPtijdstipRUN
De twee laatste termen uit (4.2.7) zijn dan de 2 extra termen die er in (4.2.6) bijkomen (Eigen
werk).
Indien het aantal waarnemingen voor de rendementen zeer groot wordt (wat het geval is als de
normale verdeling gebruikt wordt) dan zullen de termen 2π en ( )21 π− verwaarloosbaar zijn
t.o.v. de term ( )ππ −12 n zodat de verwachtingswaarde bij benadering zal voldoen aan (4.2.5).
Daar er zal gewerkt worden met de normale verdeling, kan de verwachtingswaarde van RUNSN
gedefinieerd worden zoals in (4.2.5).

63
Variantie van RUNSN
Wat betreft de variantie zou er kunnen verwacht worden dat deze er als volgt uitziet:
[ ] ( )( ) ( )( ) )8.2.4(.12112
1
ππππ
ππ
−−−=
−=
n
nNVar RUNRUNRUNS
Dit zal evenwel niet het geval zijn aangezien de aangrenzende tX ’s afhankelijk zijn van elkaar.
De werkelijke variantie kan dan als volgt afgeleid worden (eigen werk):
[ ] [ ][ ] [ ] [ ] [ ] [ ]nnn
nRUNS
XXCovXXCovXVarXVarXVar
XXXVarNVar
,, 12121
21
−++++++=
+++=
��
�
[ ] ( ) ( )( )[ ] [ ] 1,,3,2,,
,,2,112112
11 −==
=−−−=
+− ntvoorXXCovXXCov
ntvoorYVarmet
tttt
t
�
�ππππ
[ ] ( ) ( )( ) ( ) [ ] .,1212112 1+−+−−−= ttRUNS XXCovnnNVar ππππ
Voor een groot aantal waarnemingen n kan er dan bij benadering gesteld worden dat:
[ ] ( ) ( )( ) [ ]1,212112 ++−−−= ttRUNS XXCovnnNVar ππππ . (4.2.9)
De [ ]1, +tt XXCov kan als volgt berekend worden:32
[ ] [ ] [ ] [ ][ ] [ ] [ ][ ] ( ) )10.2.4(.141
111
,
221
11
111
ππ −−==
==−==
−=
+
++
+++
tt
tttt
tttttt
XXP
XPXPXXP
XEXEXXEXXCov
Er blijft nu nog één onbekende over, namelijk [ ]11 =+tt XXP . Deze kan als volgt uitgewerkt
worden:

64
[ ]( ) ( )[ ]( ) ( )( ) ( ) ( )( )[ ]
( ) ( )( ) ( ) ( )( )[ ]( ) ( ) ( )[ ] ( ) ( ) ( )[ ] .010101
01101001
10011001
11
1111
1111
1111
1
1
=∩=∩=+=∩=∩==
∪=∩=∩=∩=∪=∩=∩=∩=∪=
=∩=∪=∩=∩=∩=∪=∩==
=∩==
+−+−
+−+−
++−−
+
+
tttttt
tttttttt
tttttttt
tt
tt
IIIPIIIP
IIIIIIIIP
IIIIIIIIP
XXP
XXP
φφ
waarbij dat de derde gelijkheid volgt uit het feit dat de doorsnede van de unies gelijk is aan de
unie van de doorsneden (cfr. voetnoot 28). De laatste gelijkheid kan nu nog verder uitgewerkt
worden waarbij er gebruik gemaakt wordt van de eigenschap dat de tI ’s onafhankelijk zijn van
elkaar:
[ ] [ ] [ ] [ ] [ ] [ ] [ ]( ) ( ) ( )
( ) ( )( ) )11.2.4(.1
11
111
010101
22
11111
ππ
ππππ
ππππππ
−=
−+−=
−−+−=
===+==== +−+−+ tttttttt IPIPIPIPIPIPXXP
Door (4.2.11) in te brengen in (4.2.10) wordt het volgende bekomen voor de covariantie:
[ ] ( ) ( )221 141, ππππ −−−=+tt XXCov . (4.2.12)
Ten slotte kan (4.2.12) ingebracht worden in (4.2.9) zodat dan uiteindelijk de variantie voor
RUNSN bekomen wordt:
[ ] ( ) ( )( ) ( ) ( )( ) ( ) ( )( )( ) ( )( ) )13.2.4(13114
14112112
181212112 22
ππππ
ππππππ
ππππππππ
−−−=
−−+−−−=
−−−+−−−=
n
n
nnnNVar RUNS
(Eigen werk).
32 Dit gebeurt op een analoge manier als bij de afleiding van de verdeling voor de CJ-ratio.

65
De verdeling voor RUNSN kan nu, gebruik makend van (4.2.5) en (4.2.13), als volgt
weergegeven worden:
( ) ( ) ( )( )( )ππππππ −−−−Ν 13114,12~ nnNa
RUNS . (4.2.14)
Er wordt aangenomen dat het aantal waarnemingen voor de rendementen zeer groot is zodat de
verdeling een asymptotische normale verdeling is. Dit is ook de verdeling die door Mood (1940)
als eerste naar voor werd gebracht.
Continuïteitscorrectie
Er kan nu overgegaan worden tot de standaard normaal verdeelde variabele z . Hiervoor moet
(4.2.14) omgevormd worden tot:
( )( ) ( )( )
( )1,013112
12~ Ν
−−−
−−=
aRUNS
n
nNz
ππππ
ππ . (4.2.15)
Vervolgens moet er nog een kleine aanpassing gemaakt worden aan (4.2.15) daar er gewerkt
wordt met de normale benadering van de binomiale verdeling. De normale verdeling levert
namelijk verschillende probabiliteiten op voor de realisaties in het interval [ ]1, +RUNSRUNS NN ,
terwijl de exacte probabiliteiten constant zijn over dit interval omdat RUNSN een gehele waarde
aanneemt. Er moet dus een continuïteitscorrectie doorgevoerd worden zodat de z-waarde
overeenkomt met het middelpunt van het interval (REYNAERTS H., 1995). De verdeling ziet er
dan als volgt uit:
( )( ) ( )( )
( )1,013112
1221~ Ν
−−−
−−+=
aRUNS
n
nNz
ππππ
ππ . (4.2.16)
Op basis van deze verdeling kan de runs-test uitgevoerd worden. Ten eerste berekent men het
aantal runs die zich voordoen in een tijdsreeks van rendementen. Ten tweede bepaalt men de
parameters van de verdeling onder de RW1-hypothese zodat de testwaarde z kan bepaald
worden. Ten slotte moet men kijken of de testwaarde z binnen het 95% betrouwbaarheidsinterval
valt. Indien dit het geval is dan kan de RW1 aanvaard worden voor het onderzochte aandeel.

66
4.2.6 Enkele Opmerkingen over de Runs-Test
Er kunnen nu nog 2 opmerkingen gemaakt worden in verband met de runs-test. Ten eerste, door
het feit dat de runs-test enkel het teken van de rendementen onderzoekt, zal de test dezelfde
resultaten opleveren indien men werkt met de prijsveranderingen in plaats van met de
rendementen.33 Dus de test kan zowel de geldigheid nagaan van het gewone RW1-model als van
het logaritmisch RW1-model. De resultaten zullen identiek zijn. Deze opmerking kan ook
gemaakt worden voor de Cowles-Jones test daar deze test ook enkel het teken van het rendement
of de prijsverandering onderzoekt (ELTON E. en GRUBER M., 1995, blz. 417).
Ten tweede kan er nog opgemerkt worden dat de aanwezigheid van de drift het totale aantal
verwachte runs doet verminderen. Het is namelijk zo dat een drift runs met een langere lengte zal
toelaten waardoor het totale aantal runs zal afnemen. Dit hoeft evenwel niet te impliceren dat de
RW1 niet geldig is. Uit figuur 20 kan het effect van de drift µ op het aantal runs afgeleid
worden.34 Hoe groter de drift, hoe kleiner het totaal aantal verwachte runs [ ]RUNSNE . Het aantal
Figuur 20: Het verwachte aantal runs voor de RW1 met drift µ .
(zie boek Campbell, Lo en MacKinlay (1997), tabel 2.2 p. 38)
verwachte runs daalt aanzienlijk naarmate de drift groter wordt. De RW1 zonder drift
maximaliseert het totaal aantal verwachte runs voor iedere vaste steekproefgrootte. Al de
waarden voor [ ]RUNSNE zijn echter wel consistent met de RW1-hypothese (CAMPBELL J. et al.,
1997, blz. 40).
33 Met het rendement wordt nog steeds het continu samengesteld rendement bedoeld.34 Merk op dat er in figuur 15 uitgegaan wordt van het logaritmische RW1-model met normaal verdeelde residuenmet een standaardafwijking σ = 21%. Gebruik makend van (4.1.9) kan de kans π op een positief rendementgemakkelijk afgeleid worden.
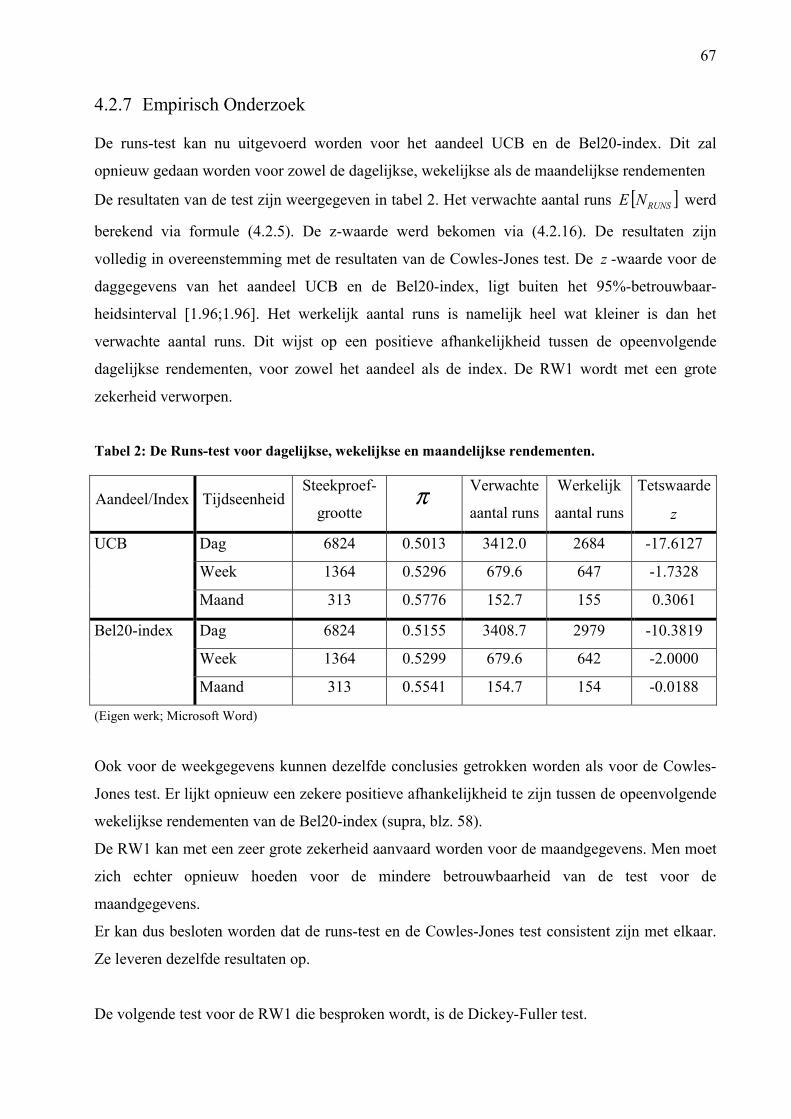
67
4.2.7 Empirisch Onderzoek
De runs-test kan nu uitgevoerd worden voor het aandeel UCB en de Bel20-index. Dit zal
opnieuw gedaan worden voor zowel de dagelijkse, wekelijkse als de maandelijkse rendementen
De resultaten van de test zijn weergegeven in tabel 2. Het verwachte aantal runs [ ]RUNSNE werd
berekend via formule (4.2.5). De z-waarde werd bekomen via (4.2.16). De resultaten zijn
volledig in overeenstemming met de resultaten van de Cowles-Jones test. De z -waarde voor de
daggegevens van het aandeel UCB en de Bel20-index, ligt buiten het 95%-betrouwbaar-
heidsinterval [1.96;1.96]. Het werkelijk aantal runs is namelijk heel wat kleiner is dan het
verwachte aantal runs. Dit wijst op een positieve afhankelijkheid tussen de opeenvolgende
dagelijkse rendementen, voor zowel het aandeel als de index. De RW1 wordt met een grote
zekerheid verworpen.
Tabel 2: De Runs-test voor dagelijkse, wekelijkse en maandelijkse rendementen.
Aandeel/Index TijdseenheidSteekproef-
grootteπ Verwachte
aantal runs
Werkelijk
aantal runs
Tetswaarde
z
UCB Dag 6824 0.5013 3412.0 2684 -17.6127
Week 1364 0.5296 679.6 647 -1.7328
Maand 313 0.5776 152.7 155 0.3061
Bel20-index Dag 6824 0.5155 3408.7 2979 -10.3819
Week 1364 0.5299 679.6 642 -2.0000
Maand 313 0.5541 154.7 154 -0.0188
(Eigen werk; Microsoft Word)
Ook voor de weekgegevens kunnen dezelfde conclusies getrokken worden als voor de Cowles-
Jones test. Er lijkt opnieuw een zekere positieve afhankelijkheid te zijn tussen de opeenvolgende
wekelijkse rendementen van de Bel20-index (supra, blz. 58).
De RW1 kan met een zeer grote zekerheid aanvaard worden voor de maandgegevens. Men moet
zich echter opnieuw hoeden voor de mindere betrouwbaarheid van de test voor de
maandgegevens.
Er kan dus besloten worden dat de runs-test en de Cowles-Jones test consistent zijn met elkaar.
Ze leveren dezelfde resultaten op.
De volgende test voor de RW1 die besproken wordt, is de Dickey-Fuller test.

68
4.3 De Dickey-Fuller Test
De Dickey-Fuller test, ook wel een “unit root” test genoemd, is eigenlijk een test die de
stationariteit van een tijdsreeks nagaat. Niettemin kan deze test ook gebruikt worden om de
geldigheid van de RW1 na te gaan.
4.3.4 Het Testen naar een “Unit Root”
Bij het opzetten van de test, wordt er vertrokken van een autoregressief proces van de eerste
orde. Het AR(1)-proces ziet er als volgt uit:
ttt pp ερµ ++= −1 , (4.3.1)
waarbij µ en ρ de parameters zijn en de tε ’s zijn verondersteld om onafhankelijk en identiek
verdeeld te zijn met een verwachtingswaarde 0 en een gelijke variantie. Indien 1=ρ , dan zal het
model (4.3.1) een RW1-model voorstellen met een drift µ . Het proces is in dit geval niet
stationair daar de variantie van tp stijgt met de tijd. De test voor de RW1 zal er dan ook in
bestaan om de geldigheid van de nulhypothese 1:0 =ρH na te gaan. Indien de nulhypothese
aanvaard wordt, dan zal het proces een eenheidswortel (een “unit root”) bevatten en zal de RW1
aanvaard worden (DICKEY D. en FULLER W., 1979, blz. 427).
De beste manier om de nulhypothese te testen is door eerst het AR (1)-proces uit (4.3.1) om te
vormen tot:
ttt pp εγµ ++=∆ −1 , (4.3.2)
waarbij ργ −= 1 . De nieuwe nulhypothese is dan 0:0 =γH . De nieuwe nulhypothese zou nu
kunnen getest worden door een regressie door te voeren van de prijsverandering op tijdstip t op
een constante en de prijs op tijdstip t-1. Op die manier wordt de schatter µτ̂ voor γ bekomen.35
Vervolgens kan de significantie van µτ̂ nagegaan worden. Normaal wordt er gebruik gemaakt
van de t-waarden die vermeld zijn in de output van de regressie. Deze waarden kunnen dan
35 De µ uit µτ̂ geeft aan dat er een constante µ aanwezig is in het AR (1)-proces.

69
vergeleken worden met de kritische waarden uit de tabellen voor de t-verdeling. Deze werkwijze
mag echter niet gehanteerd worden omdat de prijs tp niet stationair is onder de nulhypothese.
Deze niet-stationariteit heeft namelijk tot gevolg dat de variantie van de storingsterm niet
constant is zodat de geschatte variantie 2ˆµτs van µτ̂ geen zuivere schatter is van de werkelijke
variantie. De testwaarde t,
µτ
µτ
ˆ
ˆ
st = , (4.3.3)
is dan niet meer t-verdeeld onder de nulhypothese zodat de tabellen van de t-verdeling niet
mogen gebruikt worden om de significantie van de coëfficiënt µτ̂ na te gaan (REYNEARTS H.,
1998).
Dickey en Fuller hebben dit probleem opgelost. Zij hebben, door middel van Monte-Carlo
methoden, een gepaste set van kritische waarden afgeleid voor het testen van de nulhypothese
dat γ gelijk is aan 0. Om de geldigheid van de RW1 na te gaan, kan dan de gewone t-test
uitgevoerd worden, maar in plaats van naar de tabellen van de t-verdeling te kijken om de
significantie van µτ̂ na te gaan, moet er dan naar de kritische waarden van Dickey en Fuller
gekeken worden. Hierdoor wordt deze test de Dickey-Fuller-test genoemd. De kritische waarden
zijn weergegeven in bijlage 8 (GREENE W., 1993, blz. 564).
De tabel in bijlage 8 bevat ook de kritische waarden voor de schatter τ̂ van de coëfficiënt γ
voor een AR (1)-proces waarbij de constante µ gelijk is aan 0.
De kritische waarden van MacKinnon
Meer recent heeft MacKinnon (1991) kritische waarden opgesteld voor iedere mogelijke
steekproefgrootte waarmee de significantie van de coëfficiënt γ afzonderlijk kan nagegaan
worden en waarmee de gezamenlijke significantie van µ en γ kan nagegaan worden. De
kritische waarden van MacKinnon zijn weergegeven indien men de “Augmented Dickey-Fuller”
test uitvoert in Eviews. De Dickey-Fuller-testwaarde, zoals gedefinieerd in (4.3.3), moet dan
vergeleken worden met de MacKinnon kritische waarden. Indien de Dickey-Fuller testwaarde (in
absolute waarde) kleiner is dan de MacKinnon kritische waarden, dan kan de nulhypothese niet
verworpen worden en zal er een “unit root” aanwezig zijn in de tijdsreeks van de prijzen. De
RW1 is dan geldig (EVIEWS, 1994-95).
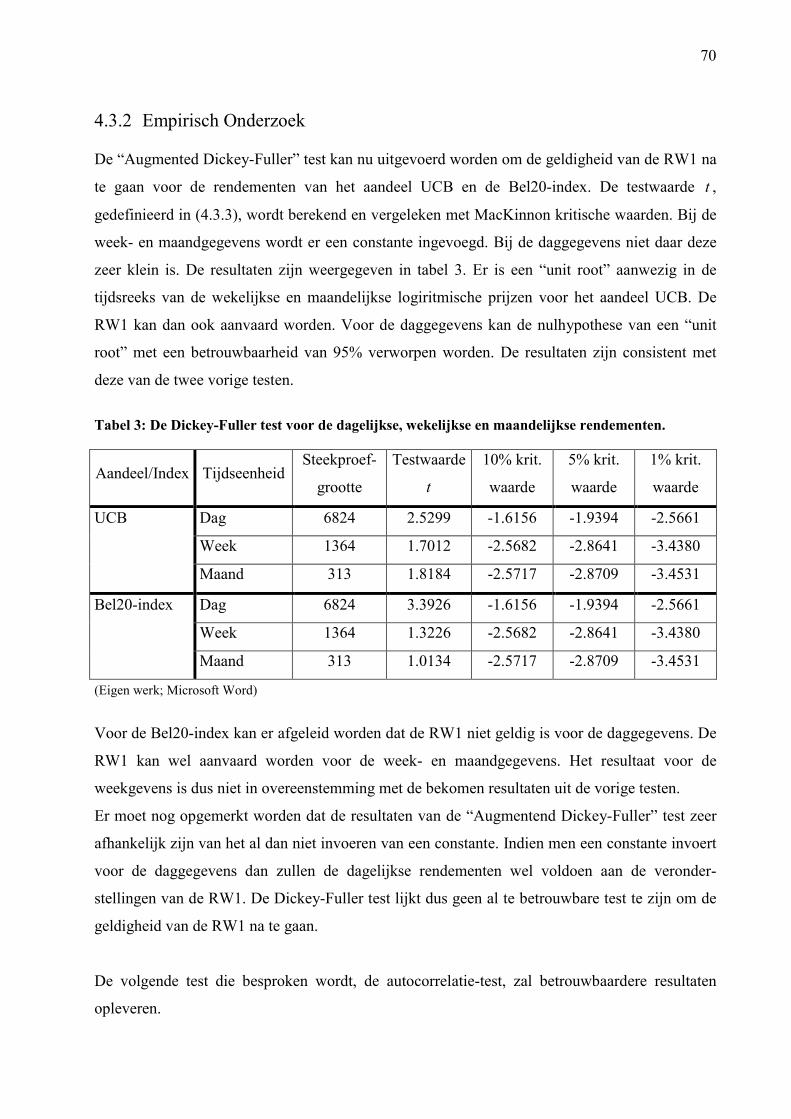
70
4.3.2 Empirisch Onderzoek
De “Augmented Dickey-Fuller” test kan nu uitgevoerd worden om de geldigheid van de RW1 na
te gaan voor de rendementen van het aandeel UCB en de Bel20-index. De testwaarde t ,
gedefinieerd in (4.3.3), wordt berekend en vergeleken met MacKinnon kritische waarden. Bij de
week- en maandgegevens wordt er een constante ingevoegd. Bij de daggegevens niet daar deze
zeer klein is. De resultaten zijn weergegeven in tabel 3. Er is een “unit root” aanwezig in de
tijdsreeks van de wekelijkse en maandelijkse logiritmische prijzen voor het aandeel UCB. De
RW1 kan dan ook aanvaard worden. Voor de daggegevens kan de nulhypothese van een “unit
root” met een betrouwbaarheid van 95% verworpen worden. De resultaten zijn consistent met
deze van de twee vorige testen.
Tabel 3: De Dickey-Fuller test voor de dagelijkse, wekelijkse en maandelijkse rendementen.
Aandeel/Index TijdseenheidSteekproef-
grootte
Testwaarde
t
10% krit.
waarde
5% krit.
waarde
1% krit.
waarde
UCB Dag 6824 2.5299 -1.6156 -1.9394 -2.5661
Week 1364 1.7012 -2.5682 -2.8641 -3.4380
Maand 313 1.8184 -2.5717 -2.8709 -3.4531
Bel20-index Dag 6824 3.3926 -1.6156 -1.9394 -2.5661
Week 1364 1.3226 -2.5682 -2.8641 -3.4380
Maand 313 1.0134 -2.5717 -2.8709 -3.4531
(Eigen werk; Microsoft Word)
Voor de Bel20-index kan er afgeleid worden dat de RW1 niet geldig is voor de daggegevens. De
RW1 kan wel aanvaard worden voor de week- en maandgegevens. Het resultaat voor de
weekgevens is dus niet in overeenstemming met de bekomen resultaten uit de vorige testen.
Er moet nog opgemerkt worden dat de resultaten van de “Augmentend Dickey-Fuller” test zeer
afhankelijk zijn van het al dan niet invoeren van een constante. Indien men een constante invoert
voor de daggegevens dan zullen de dagelijkse rendementen wel voldoen aan de veronder-
stellingen van de RW1. De Dickey-Fuller test lijkt dus geen al te betrouwbare test te zijn om de
geldigheid van de RW1 na te gaan.
De volgende test die besproken wordt, de autocorrelatie-test, zal betrouwbaardere resultaten
opleveren.

71
4.4 De Autocorrelatie-Test
Eén van de meest intuïtieve testen voor de “random walk”-hypothese is het nagaan of er
autocorrelatie aanwezig is in de tijdsreeks van de prijsveranderingen of de rendementen van een
aandeel. De autocorrelatie is de correlatie tussen twee observaties van dezelfde tijdsreeks, maar
op verschillende tijdstippen. Het is dus een maatstaf voor het verband tussen de waarde van een
stochastische variabele op een bepaald tijdstip en zijn waarde één of meerdere perioden terug
(FAMA E., 1965, blz.69). De test voor de “random walk” bestaat er dan in om na te gaan of de
prijsveranderingen of rendementen al dan niet ongecorreleerd zijn voor alle vertragingen. Indien
de “random walk” geldig is, moeten de prijsveranderingen of rendementen ongecorreleerd zijn.
Deze test lijkt dan ook vooral geschikt om de geldigheid van het RW3-model na te gaan, daar dit
model enkel ongecorreleerde residuen veronderstelt. Niettemin kan er ook een test en
steekproefverdeling opgesteld worden voor de autocorrelaties die de geldigheid van de RW1
kunnen nagaan. Deze test zal in dit deel besproken worden. De test zal gebaseerd zijn op de
autocorelaties zelf. Later zullen er enkele krachtigere testen afgeleid worden die ook gebaseerd
zijn op de autocorrelaties, zoals de test met de Portmanteau statistieken (zie sectie 4.5) en de test
met de variantieratios (zie sectie 4.6) (CAMPBELL J., 1997, blz. 44).
In een eerste deel zullen de autocorrelatiecoëfficiënten gedefinieerd en besproken worden. In het
tweede deel zal de steekproefverdeling voor de autocorrelatiecoëfficiënten afgeleid worden. In
het laatste zullen er ten slotte nog enkele belangrijke opmerkingen gemaakt worden in verband
met de autocorrelatie-test.
4.4.2 De Autocorrelatiecoëfficiënten
Als er uitgegaan wordt van een stationaire tijdsreeks van de rendementen tr , dan kunnen de
autocovariantie- en de autocorrelatiecoëfficiënten, respectievelijk ( )kγ en ( )kρ , als volgt
gedefinieerd worden:36
( ) [ ]ktt rrCovk +≡ ,γ , (4.4.1)
( ) [ ][ ] [ ]
[ ][ ]
( )( )0
,,
γγρ k
rVar
rrCov
rVarrVar
rrCovk
t
ktt
ktt
ktt ==≡ +
+
+ , (4.4.2)
36 De veronderstelling dat de tijdsreeksen stationair zijn, wordt gemaakt zodat ( )kγ en ( )kρ enkel functies zijn vank en niet van het tijdstip t. Op die manier zullen de definities niet nodeloos ingewikkeld worden.

72
waarbij de tweede gelijkheid in (4.4.2) volgt uit de stationariteit van de tijdsreeks.37 De
autocorrelatiecoëfficiënten kunnen dus simpel bekomen worden door de variantie en de
covariantie te berekenen voor een bepaalde tijdsreeks van rendementen en voor een zekere k en
de bekomen covariantie te delen door de variantie (CAMPBELL J., 1997, blz. 45).
Een andere manier om de autocorrelatiecoëfficiënt ( )kρ te bekomen is door een lineaire
regressie uit te voeren van de variabele ktr + op een constante en de k vertraagde variabele tr . De
regressievergelijking ziet er dan als volgt uit:
ttkt rbar ε++=+ , (4.4.3)
waarbij a het verwachte rendement meet, dat niet gerelateerd is aan het vorige rendement en
waarbij b het verband meet tussen het rendement op tijdstip t+k en het rendement op tijdstip t.
tε is een kansvariabele die de variabiliteit incorporeert van het rendement dat niet gerelateerd is
aan de vorige rendementen. De coëfficiënt b is in feite niets anders dan de
autocorrelatiecoëfficiënt daar b als volgt kan gedefinieerd worden:
[ ][ ]t
tkt
rVar
rrCovb
,+= . (4.4.4)
(4.4.2) en (4.4.4) zijn dus gelijk aan elkaar. Merk op dat indien de tijdsreeks tr niet stationair is,
de gelijkheid niet zal opgaan daar de overgang van de eerste gelijkheid naar de tweede gelijkheid
in (4.4.2) dan niet mag gemaakt worden omdat de varianties van de tr ’s niet noodzakelijk gelijk
zijn aan elkaar (ELTON E. en GRUBER M., 1995, blz. 414).
Een belangrijke eigenschap van de autocorrelatiecoëfficiënten is dat het kwadraat ervan de
fractie weergeeft van de variantie van het rendement op tijdstip t+k dat kan verklaard worden
door het rendement op tijdstip t. Deze fractie is in feite de 2R die bekomen wordt door de
regressie, weergeven in (4.4.3), uit te voeren (FAMA E., 1977, blz. 116).
37 Merk op dat de definitie voor de autocorrelatiecoëfficiënt in (4.4.2) volgt uit de welbekende definitie voor de
correlatiecoëfficiënt tussen twee stochastische variabelen x en y : [ ] [ ][ ] [ ]yVarxVar
yxCovyxCorr ,, =

73
Schatters voor ( )kγ en ( )kρ
Indien men beschikt over een steekproef van n waarnemingen voor tr , d.i. nrrr ,,, 21 � , dan
kunnen de autocovariantie- en de autocorrelatiecoëfficiënt als volgt geschat worden:
( ) ( )( ) nkrrrrn
kkn
tnktnt <≤−−=
−
=+ 0,1
1
γ (4.4.5)
( ) ( )( )0γ
γρ kk = , (4.4.6)
=
=n
ttn r
nrmet
1
1 . (4.4.7)
( )kγ en ( )kρ zijn dus de schatters voor respectievelijk de autocovariantiecoëfficiënt ( )kγ en
de autocorrelatiecoëfficiënt ( )kρ . Merk wel op dat de schatters voor de varianties van tr en ktr +
wel kunnen verschillen van elkaar, ondanks de veronderstelling dat de tijdsreeks stationair is en
de varianties dus gelijk zijn aan elkaar. De oorzaak is dat er meer waarnemingen zijn (namelijk
k) om de variantie van tr te bepalen. Hierdoor zal de tweede gelijkheid uit (4.4.2) niet opgaan
indien de populatiewaarden vervangen worden door hun schatters zodat (4.4.6) geen goede
schatter zou zijn voor de autocorrelatiecoëfficiënt ( )kρ . Het verschil tussen de varianties zal
echter zeer klein zijn, dit vooral als het aantal waarnemingen n groot is ten opzichte van k zodat
het verschil verwaarloosd kan worden. Er kan dus gesteld worden dat ( )kρ een goede schatter
is voor ( )kρ (FAMA E., 1977, blz.116-117).
Om nu de test uit te voeren of een bepaalde tijdsreeks van aandelenprijzen een RW1 volgt, moet
de schatter ( )kρ berekent worden. Indien deze niet significant verschillend is van 0, dan kan de
RW1 aanvaard worden. Om dit te kunnen nagaan is het wel noodzakelijk om de
steekproefverdeling te bepalen voor ( )kρ onder de RW1. De verdeling zal afgeleid worden in
het volgende deel.

74
4.4.3 De Steekproefverdeling voor ( )kρ
Om de verdeling af te leiden, moet er vertrokken worden van een data-genererend proces voor de
rendementen tr . Stel tr is een glijdend gemiddelde met een eindige orde M:
=−=
M
kktktr
0εα , (4.4.8)
waarbij de tε ’s onafhankelijk zijn van elkaar met verwachtingswaarde 0, variantie 2σ , vierde
moment 4ση en eindig zesde moment. Fuller (1976, Theorema 6.3.5) toont nu aan dat de
verdeling van de vector van de schatters van de autocovariantiecoëfficiënten, d.i.
( ) ( ) ( ) ( ) ( ) ( )[ ]′−−− KKn γγγγγγ ,,11,00 � asymptotisch multivariaat normaal is met
verwachtingswaarde 0 en covariantie matrix V waarbij
[ ]ijvV =
( ) ( ) ( ) ( ) ( ) ( ) ( )[ ]∞
−∞=
−+++−+−≡l
ij iljljilljiv γγγγγγη 3 . (4.4.9)
Hij gaat hierbij als volgt tewerk. Stel de geschatte covariantie voor Kk ,,2,1,0 �= , wordt op de
volgende manier uitgewerkt:
( ) ( )( )
( ) )10.4.4(.11
1
1
2
1
1
−
=+
−
=+
−
=+
−++−=
−−=
kn
tnkttn
kn
tktt
kn
tnktnt
rn
knrrrn
rrn
rrrrn
kγ
Uit (4.4.8) kan er afgeleid worden dat [ ] 0=trE zodat, gebruik makend van de centrale
limietstelling, trn zal convergeren naar 0.38 Hieruit volgt dan dat de twee laatste termen van
(4.4.10) zullen convergeren naar nul als ze vermenigvuldigd worden met n . Bij de afleiding
38 Als de centrale limietstelling toegepast wordt op tr , wordt namelijk het volgende bekomen:
( ) ( )2,0 σµ Ν→− anrn (HAMILTON J.,1994, blz. 185).

75
van de asymptotische verdeling voor ( ) ( )[ ]kkn γγ − kan men zich dus beperken tot de eerste
term van (4.4.10). Het volgende kan dan gesteld worden:
( )
[ ][ ] [ ] ( )= =
−
=
−
=
−
=
−
=
−
=+
−+−=
���
�−=
K
k
K
kk
kn
ttkk
K
k
kn
ttktkk
K
k
kn
tkttkn
knzEnzEzn
krrn
nS
0 01
21
0 1
21
0 1
)11.4.4(,
1
γλλλ
γλ
waarbij de kλ ’s arbitraire reële getallen zijn (niet allen gelijk aan 0) en waarbij
Kkrrz ktttk ,,2,1,0, �== + . (4.4.12)
Uit (4.4.10) en (4.4.12) kan het volgende afgeleid worden (eigen werk):
( )[ ] ( ) [ ] ( )−
=
−
==
−=
−=
kn
ttk
kn
tr kzE
knk
knkE
11
11 γγγ . (4.4.13)
Gebruik makend van (4.4.13), kan (4.4.11) verder uitgewerkt worden:
[ ][ ] ( ) ( ) ( )
[ ][ ] ( ) )14.4.4(0
21
0 1
21
0 0
21
0 1
21
=
−
=
−
=
−
= =
−
=
−
=
−
−−=
−−+−=
K
kk
K
k
kn
ttktkk
K
k
K
kkk
K
k
kn
ttktkkn
kknzEzn
knkknnzEznS
γλλ
γλγλλ
(Eigen werk).
tkz is nu een (M+k)-afhankelijke covariantie stationaire tijdsreeks met verwachtingswaarde
( )krγ en de covariantie functie
( )( ) ( )( )[ ]
( ) ( ) ( ) ( ) ( ) ( ),3 224 kskssk
rrrrEs
jksjsjkjj
kststkttzt
−++++−=
=
∞
−∞=++++
++++
γγγγααααση
γ

76
waarbij dat 0=jα voor Mj > en 0<j . De covariantie functie is dus onafhankelijk van het
tijdstip t zodat de tijdsreeks tkz stationair is. Bijgevolg is het gewogen gemiddelde van de tkz ’s,
=+
===K
kkttk
K
ktkkt rrzy
00λλ ,
ook een stationaire reeks. Daarnaast is de tijdsreeks ty (M+k)-afhankelijk en heeft het een
eindig derde moment, en is
( ) .0lim0
21
=
−
∞→=
K
kkn
kkn γλ
Via theorema 6.3.2 van Fuller (1976), zal nS in verdeling convergeren naar een normale
stochastische variabele. Daar de kλ ’s arbitrair gekozen zijn, kan er gesteld worden dat de
verdeling van de vector stochastische variabele ( ) ( ) ( ) ( ) ( ) ( )[ ]′−−− KKn γγγγγγ ,,11,00 � zal
convergeren naar een multivariate normale verdeling via theorema 5.3.3 met een
verwachtingswaarde 0 en een covariantie matrix gegeven door (4.4.9).39
Vervolgens heeft Fuller (1976, gevolg 6.3.5.1) aangetoond dat de asymptotische verdeling van
de vector van de schatters van de autocorrelatiecoëfficiënten ook multivariaat normaal verdeeld
is:
( ) ( ) ( ) ( ) ( ) ( )[ ] ( )Gmmna
,0,,11,00 ~Ν′−−− ρρρρρρ � , (4.4.15)
waarbij
[ ]ijgG =
( ) ( ) ( ) ( ) ( ) ( ) ( )[
( ) ( ) ( ) ( ) ( ) ( )] )16.4.4(.22
2
2 ljijlli
illjiljljillgl
ij
ρρρρρρ
ρρρρρρρ
+−
−−−−++−−=∞
−∞=
39 Theorema 5.3.3 zegt het volgende: stel nn zS λ′= met nz een vector stochastische variabele. Als de verdeling van
nS convergeert naar een normale verdelingsfunctie dan zal de verdeling van de variabele nz convergeren naar eenmultivariate normale verdeling.

77
De verdeling indien de RW1 geldig is
Voor het testen van de RW1-hypothese, in dewelke alle autocorrelaties ( )kρ nul zijn, zal de
asymptotische benadering in (4.4.15) kunnen herleid worden tot een eenvoudigere vorm. Als tr
voldoet aan de RW1 hypothese en een variantie 2σ heeft en een zesde moment proportioneel
met 6σ , dan zal de schatter ( )kρ de volgende eigenschappen hebben:
( )[ ]( )
( )
( ) ( )[ ]( )
( ))18.4.4(
.
0,
)17.4.4(1
2
2
2
2
�
�
�
Ο
≠=Ο+−
=
Ο+−
−−=
−
−
−
gevalanderehetinn
lkalsnn
kn
lkCov
nnn
knkE
ρρ
ρ
Uit (4.4.17) kan er onmiddellijk afgeleid worden dat de schatter ( )kρ negatief onzuiver is onder
de RW1 ( ( )kρ is dan namelijk gelijk aan 0). Deze negatieve neiging ontstaat door het feit dat de
autocorrelatiecoëfficiënt een som is van kruisproducten van de afwijkingen van tr van zijn
steekproefgemiddelde. De som van de afwijkingen is echter gelijk aan 0 omdat het zo
geconstrueerd is. Hierdoor moeten positieve afwijkingen gemiddeld gezien gevolgd worden door
negatieve afwijkingen en omgekeerd en vandaar dat de verwachte waarde van de kruisproducten
van de afwijkingen negatief is. Voor kleine steekproeven zal deze onzuiverheid aanzienlijk zijn
(CAMPBELL J. et al., 1997, blz. 46). Als reactie hierop stelde Fuller (1976) de volgende
schatter ( )kρ~ voor onder de RW1, die gecorrigeerd is voor de onzuiverheid:
( ) ( )( )
( )( )kn
knkk 2
21
1~ ρρρ −
−
−+= . (4.4.19)
Deze schatter ( )kρ~ bevat de volgende eigenschappen:
( )[ ] ( )
( ) ( )[ ]( )
( ))21.4.4(
.
0~,~
)20.4.4(~
2
2
2
2
�
�
�
Ο
>=Ο+−
=
Ο=
−
−
−
gevalanderehetinn
lkalsnn
kn
lkCov
nkE
ρρ
ρ

78
Uiteindelijk heeft Fuller (1976), gebruik makend van respectievelijk (4.4.17) en (4.4.18) en
(4.4.20) en (4.4.21), de volgende steekproefverdelingen afgeleid voor de respectievelijke
schatters ( )kρ en ( )kρ~ van de autocorrelatiecoëfficiënten ( )kρ waarbij de rendementen tr
eindige uniform verdeelde zesde momenten hebben:
( ) ( )1,0~ Νa
kn ρ (4.4.22)
( ) ( )1,0~ ~ Ν−
a
kkn
n ρ . (4.4.23)
De schatters zijn dus asymptotisch onafhankelijk en normaal verdeeld. De test voor de RW1 kan
nu gemakkelijk uitgevoerd worden door de testwaarde te berekenen en na te gaan of de
testwaarde in het 95% betrouwbaarheidsinterval ligt.
4.4.4 Enkele Belangrijke Opmerkingen
Uiteindelijk kunnen er enkele belangrijke opmerkingen gemaakt worden over test voor de RW1
via de verdelingen (4.4.22) en (4.4.23) . Ten eerste kan er uit (4.4.22) en (4.4.23) afgeleid
worden dat de statistische “significantie” van de resultaten grotendeels een reflectie is van de
grootte van de steekproef. De standaardafwijking van de autocorrelatiecoëfficiënten is namelijk
invers gerelateerd aan de grootte van de steekproef. Hoe groter de steekproef, hoe kleiner de
standaardafwijking en hoe meer kans op significante coëfficiënten. De autocorrelatie tussen de
rendementen tr hoeft dus niet noodzakelijk groot te zijn om significant te zijn. Stel men beschikt
over een steekproef van 1100 waarnemingen. De standaardafwijking (= n1 ) is dan bij
benadering gelijk aan 0.03. Een autocorrelatiecoëfficiënt van 0.06 is reeds twee maal zo groot als
de standaardafwijking en bijgevolg significant. Er zou dan kunnen gesteld worden dat de
rendementen afhankelijk zijn van elkaar. Maar een coëfficiënt van deze grootte impliceert dat de
lineaire relatie met het vertraagde rendement, slechts kan gebruikt worden om 0.36% van de
variantie van het huidige rendement te verklaren. “Afhankelijkheid” van zulke grootte is vanuit
een praktisch standpunt, waarschijnlijk zowel voor de statisticus als de investeerder niet
belangrijk. De investeerder zal de afhankelijkheid hoogst waarschijnlijk niet kunnen uitbuiten
om zijn winst te verhogen (FAMA E., 1965, blz. 70) (FAMA E., 1970, blz. 394).
Ten tweede wordt er ook vaak gesteld dat de standaardafwijking de werkelijke variabiliteit van
de coëfficiënten onderschat daar de rendementen vaak groter zijn dan verwacht onder de normale

79
verdeling. Velen zijn er van overtuigd dat de verdeling van tr Pareto stabiel is waardoor de
veronderstelling van een eindige variantie waarschijnlijk niet geldig is. n1 is dan geen
precieze maat voor de standaardafwijking van de autocorrelatiecoëfficiënt, zelfs niet voor
extreem grote steekproeven (FAMA E., 1965, blz. 69).
Een derde opmerking betreft de regressievergelijking (4.4.3). Er is reeds uitgelegd dat de
coëfficiënt b uit de regressievergelijking eigenlijk de autocorrelatiecoëfficiënt is. De test voor de
RW1 zou dan ook kunnen uitgevoerd worden door de t-waarde van de coëfficiënt te bekijken en
na te gaan in de tabellen voor de t-verdeling of deze significant is. Indien ze niet significant is,
dan kan de RW1 aanvaard worden (VERBEEK M., 1998, blz. 11).
Ten vierde is het zo dat, zelfs als de autocorrelatiecoëfficiënt gelijk is aan 0 en dus aangeeft dat
er geen verband is tussen de rendementen, er eventueel een niet-lineair verband kan zijn tussen
de rendementen (zie Hoofdstuk 5). De autocorrelatie-test kan namelijk enkel de lineaire
verbanden nagaan (ELTON E. en GRUBER M., 1995, blz. 414).
Ten laatste, kan er gesteld worden dat het niet uitmaakt of er nu gewerkt wordt met
prijsveranderingen of met (continu samengestelde) rendementen bij de autocorrelatie-test. Als de
test gebruik makend van rendementen geen verband toont, dan zal de test gebruik makend van
prijsveranderingen ook geen verband tonen (ELTON E. en GRUBER M., 1995, blz. 414).
4.4.5 Empirisch Onderzoek
De autocorrelatie-test zal nu toegepast worden op de tijdreeksen van het aandeel UCB en de
Bel20-index. Er wordt gebruikt gemaakt van de verdeling in (4.4.22) om de geldigheid van de
RW1 na te gaan.40 De standaardafwijking van de autocorrelatiecoëfficiënten is dus gelijk aan
n1 . De schatters ( )kρ van de autocorrelatiecoëfficiënten, voor k van 1 tot 5, zijn weer-
gegeven in tabel 4. De resultaten zijn niet allen consistent met de vorige resultaten. Wat betreft
de wekelijkse rendementen van het aandeeel UCB, kan er uit de autocorrelaties afgeleid worden
dat er een significante negatieve autocorrelatie is tussen de opeenvolgende rendementen. Ook
voor twee vertragingen is er een significante negatieve correlatie merkbaar. Deze bevindingen
staan in contrast met deze van de Cowles-Jones test en de Runs-test. Uit deze twee laatste testen
kon er afgeleid worden dat er een positieve afhankelijkheid is tussen de rendementen. Deze
40 De resultaten zijn identiek indien er gebruik gemaakt wordt van de verdeling in (4.4.23) daar het aantalwaarnemeingen voldoende groot is.

80
resultaten moeten echter met enige voorzichtigheid geïnterpreteerd worden. Het is namelijk zo
dat bij de dagelijkse rendemeten van een individueel aandeel er veel rendementen van 0 zijn. Een
opeenvolging van rendementen van 0 doet dan het aantal “sequenses” stijgen ten opzichte van
het aantal “reversals” en zorgt ervoor dat er minder runs zijn. Er zal echter geen correlatie
merkbaar zijn tussen de rendementen van 0. De resultaten van de autocorrelatie-test kan dan ook
merkbaar verschillen van de resultaten van de Cowles-Jones test en de runs-test vooral daar het
aantal dagelijkse rendementen van 0 voor het aandeel UCB zeer groot is (meer dan 1/3 van het
totale aantal waarnemingen). De resultaten van de autocorrelatie-test zullen betrouwbaarder zijn.
Merk wel op dat negatieve autocorrelatie voor de dagelijkse rendementen zeer klein is. De
steekproef is namelijk zeer groot waardoor de standaardafwijking van de coëfficiënten zeer klein
is. Hierdoor is een coëfficiënt van –0.028 reeds significant. Maar een coëfficiënt van deze
grootte impliceert dat slechts 0.0008 van de variantie van het huidig rendement kan voorspeld
worden door gebruik te maken van het rendement van de vorige periode (supra, blz. 78). Er lijkt
dus enige twijfel te bestaan over het al dan niet aanvaarden van de RW1.
Tabel 4: Autocorrelatie-test voor dagelijkse, wekelijkse en maandelijkse rendementen (RW1).
Aandeel/Index TijdseenheidSteekproef-
grootte( )1ρ ( )2ρ ( )3ρ ( )4ρ ( )5ρ
UCB Dag 6824 -0.028* -0.027* -0.015 -0.014 -0.003
Week 1364 -0.049 0.027 0.025 -0.003 0.025
Maand 313 0.014 0.028 0.009 0.017 0.025
Bel20-index Dag 6824 0.154* 0.029* -0.004 0.015 0.035*
Week 1364 0.072* 0.130* 0.084* 0.006 0.019
Maand 313 0.136* -0.054 -0.050 -0.055 -0.037* geeft aan dat de autocorrelatiecoëfficiënt twee maal zijn standaardafwijking is en bijgevolg significant is.
(Eigen werk; Microsoft Word)
De wekelijkse en maandelijkse rendementen van het aandeel UCB zijn in overeenstemming met
de veronderstellingen van het RW1-model. Alle autocorrelaties zijn niet significant verschillend
van 0. De rendementen beschrijven een ongecorreleerd proces. De RW1 wordt aanvaard.
De resultaten voor de Bel20-index zijn min of meer in overeenstemming met de resultaten van
de vorige testen. De eerste-orde autocorrelatiecoëfficiënt van de dagelijkse rendementen is
significant voor alle mogelijke betrouwbaarheidsintervallen. De autocorrelatiecoëfficiënt
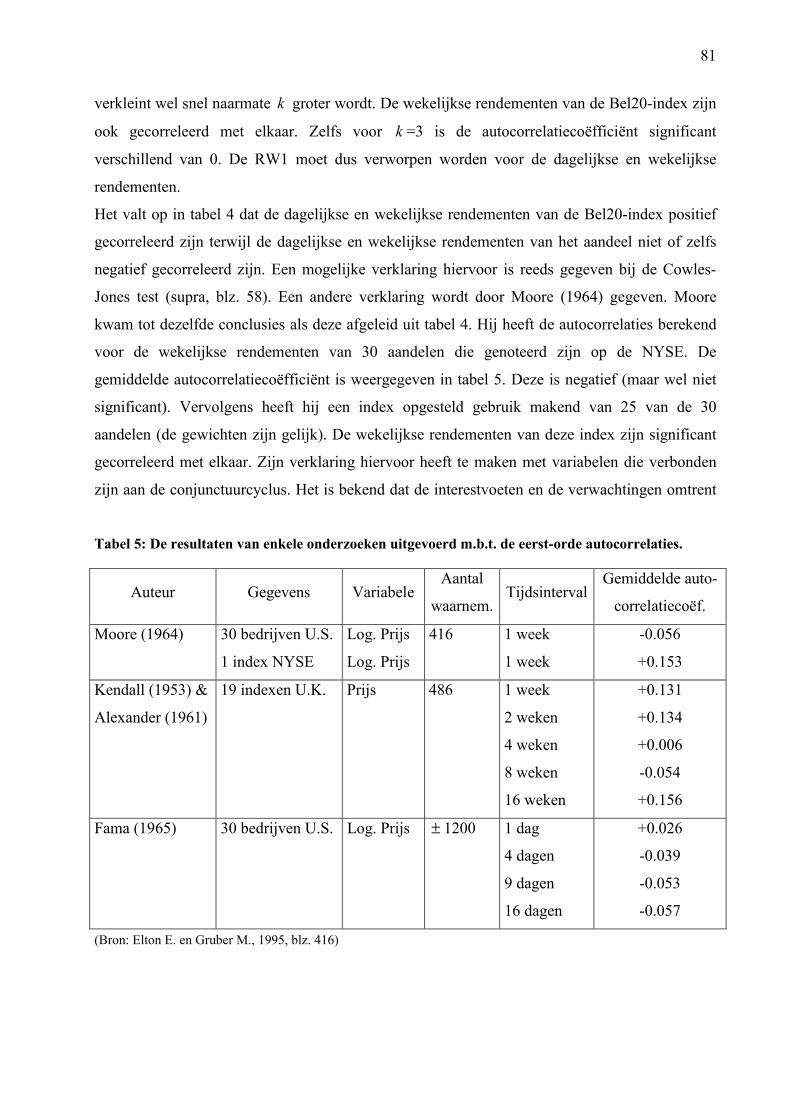
81
verkleint wel snel naarmate k groter wordt. De wekelijkse rendementen van de Bel20-index zijn
ook gecorreleerd met elkaar. Zelfs voor k =3 is de autocorrelatiecoëfficiënt significant
verschillend van 0. De RW1 moet dus verworpen worden voor de dagelijkse en wekelijkse
rendementen.
Het valt op in tabel 4 dat de dagelijkse en wekelijkse rendementen van de Bel20-index positief
gecorreleerd zijn terwijl de dagelijkse en wekelijkse rendementen van het aandeel niet of zelfs
negatief gecorreleerd zijn. Een mogelijke verklaring hiervoor is reeds gegeven bij de Cowles-
Jones test (supra, blz. 58). Een andere verklaring wordt door Moore (1964) gegeven. Moore
kwam tot dezelfde conclusies als deze afgeleid uit tabel 4. Hij heeft de autocorrelaties berekend
voor de wekelijkse rendementen van 30 aandelen die genoteerd zijn op de NYSE. De
gemiddelde autocorrelatiecoëfficiënt is weergegeven in tabel 5. Deze is negatief (maar wel niet
significant). Vervolgens heeft hij een index opgesteld gebruik makend van 25 van de 30
aandelen (de gewichten zijn gelijk). De wekelijkse rendementen van deze index zijn significant
gecorreleerd met elkaar. Zijn verklaring hiervoor heeft te maken met variabelen die verbonden
zijn aan de conjunctuurcyclus. Het is bekend dat de interestvoeten en de verwachtingen omtrent
Tabel 5: De resultaten van enkele onderzoeken uitgevoerd m.b.t. de eerst-orde autocorrelaties.
Auteur Gegevens VariabeleAantal
waarnem.Tijdsinterval
Gemiddelde auto-
correlatiecoëf.
Moore (1964) 30 bedrijven U.S.
1 index NYSE
Log. Prijs
Log. Prijs
416 1 week
1 week
-0.056
+0.153
Kendall (1953) &
Alexander (1961)
19 indexen U.K. Prijs 486 1 week
2 weken
4 weken
8 weken
16 weken
+0.131
+0.134
+0.006
-0.054
+0.156
Fama (1965) 30 bedrijven U.S. Log. Prijs ± 1200 1 dag
4 dagen
9 dagen
16 dagen
+0.026
-0.039
-0.053
-0.057
(Bron: Elton E. en Gruber M., 1995, blz. 416)

82
het toekomstige conjunctuurverloop systematisch veranderen doorheen de fasen van de
conjunctuurcyclus. Een index van vele aandelen kan dan gedomineerd worden door deze
veranderingen indien de veranderingen ook de individuele aandelen beïnvloeden. Als dit het
geval is, kan er een positieve correlatie ontstaan tussen de rendementen van de index. Daar de
individuele aandelen ook nog beïnvloed worden door specifieke informatie, is het toch nog
mogelijk dat de rendementen van een individueel aandeel negatief gecorreleerd zijn. Deze
negatieve correlatie zal zich niet doorzetten in de index omdat het rendement van een index het
gemiddelde is van de rendementen van verschillende aandelen. Door het nemen van
gemiddelden zullen de positieve en negatieve rendemeten elkaar opheffen waardoor de negatieve
correlaties van de individuele aandelen zullen verdwijnen (MOORE A, 1964, blz. 149-150).
De resultaten van Kendall (1953) en Alexander (1961) sluiten aan bij de resultaten van Moore en
bekomen resultaten in tabel 4. De wekelijkse prijsveranderingen van de onderzochte indices zijn
gemiddeld gezien (zwak) positief gecorreleerd.41 Voor de tijdsintervallen van 4 en 8 weken, kan
er gesteld worden dat er voldaan is aan de RW1.
Tenslotte kan er uit het onderzoek van Fama (1965) afgeleid worden dat voor ieder tijdsinterval
de gemiddelde autocorrelatiecoëfficiënt van de 30 individuele aandelen niet significant
verschillend zijn van nul. Dit lijkt min of meer in overeenstemming te zijn met de bekomen
resultaten voor het aandeel UCB. Fama merkte wel op dat de autocorrelatiecoëfficiënten van de
verschillende aandelen de neiging hebben om een zelfde teken te hebben. Dit kan opnieuw
verklaard worden door het feit dat de individuele aandelen afhankelijk zijn van een bepaalde
marktfactor.
Algemeen kan er besloten worden dat de rendementen van de indices de neiging hebben om
positief gecorreleerd te zijn voor tijdsintervallen kleiner dan twee weken. De rendementen van
de individuele aandelen daarentegen zijn over het algemeen niet gecorreleerd met elkaar, voor
gelijk welke tijdsinterval. De indices lijken dan ook beter in overeenstemming te zijn met de
veronderstellingen van de RW1.
De volgende test die besproken wordt is de test met de Portmanteau statistieken. Deze test leunt
zeer dicht aan bij de autocorrelatie-test
41 Merk op dat de Kendall en Alexander werken met gewone prijzen. Zij hebben dan ook de correlaties tussen deprijsveranderingen berekend.

83
4.5 Portmanteau Statistieken
Bij de autocorrelatie-test wordt er nagaan of de autocorrelaticoëfficiënten (met verschillende
vertragingen) gelijk zijn aan nul. De RW1 is geldig als alle autocorrelatiecoëfficiënten gelijk zijn
aan nul. De residuen zullen dan een ongecorreleerd proces beschrijven. De residuen zijn dus
ongecorreleerd als alle coëfficiënten gelijk zijn aan 0. Stel nu dat er één coëfficiënt wel
significant verschillend is van 0. Is dit dan voldoende om te besluiten dat de residuen geen
ongecorreleerd proces beschrijven en dat de RW1 bijgevolg niet geldig is? Het is namelijk
mogelijk dat alle andere coëfficiënten gelijk zijn aan 0 terwijl die éne coëfficiënt slecht in
geringe mate significant verschillend is van 0.42 Het zou niet geloofwaardig zijn, moest de RW1
verworpen worden omwille van deze kleine autocorrelatie. Om dit probleem op te lossen werd
de Portmanteau Q -statistiek opgesteld (REYNAERTS H., 1998).
4.5.1 Box Pierce Q -Statistiek
De Q -statistiek werd geformuleerd door Box en Pierce (1970) en ziet er als volgt uit:
( )=
≡m
km kTQ
1
2ρ . (4.5.1)
De Q -statistiek is dus gelijk aan de som van de kwadraten van de m -eerste
autocorrelatiecoëfficiënten, vermenigvuldigd met het aantal waarnemingen. Door het sommeren
van de kwadraten van de autocorrelatiecoëfficiënten, zal de Box-Pierce Q -statistiek de
afwijkingen van de autocorrelaties van 0 detecteren in iedere richting en voor alle vertragingen.
De RW1 zal geldig zijn indien de statistiek voldoende klein is. Om dit te kunnen testen, is het
terug noodzakelijk om een steekproefverdeling op te stellen. Als de autocorrelatiecoëfficiëten
geschat worden door ( )kρ , gedefinieerd in (4.4.6), dan kan er onmiddellijk uit (4.4.22) afgeleid
worden dat onder de RW1-hypothese de schatter mQ van de Q -statistiek asymptotisch 2χ -
verdeeld is met m vrijheidsgraden. Dit kan als volgt weergegeven worden:
42Merk op dat er in sectie 4.4.3 reeds gesteld is dat een autocorrelatiecoëfficiënt van 0.06 soms significant kan zijn..

84
( ) ( )=
≡m
k
a
m mknQ1
22 ~ χρ . (4.5.2)
De RW1 zal dan aanvaard worden indien de testwaarde mQ binnen het 95%
betrouwbaarheidsinterval ligt. Deze testwaarde zal niet noodzakelijk de RW1-hypothese
verwerpen omdat er één autocorrelatiecoëfficiënt significant verschillend is van 0. Indien de
andere coëfficiëten zeer klein zijn dan zal de RW1 waarschijnlijk niet verworpen worden, tenzij
die éne coëfficiënt zeer groot is (BOX G. en PIERCE D., 1970, blz. 1509-1510).
Er wordt echter vaak opgemerkt dat de verdeling van de testwaarde mQ afwijkt van de 2χ -
verdeling. Een mogelijke oorzaak hiervan is het feit dat de verdeling van de geschatte
autocorrelatiecoëfficiënten vaak afwijkt van de normaliteit. De verdeling (4.5.2) is dan geen
goede benadering. Dit probleem treedt vaak op als het aantal waarnemigen voor de rendementen
niet groot is. Als reactie hierop stelden Ljung en Box (1978) de volgende testwaarde voor die de2χ -verdeling beter benadert voor kleinere steekproeven:
( ) ( )=
∗
−+≡
m
km
kn
knnQ1
2
2 ρ . (4.5.3)
Asymptotisch gezien zullen de twee testwaarden mQ en ∗mQ hetzelfde resultaat bekomen daar
( ) ( )2+− nnkn bij benadering gelijk is aan n1 , maar voor kleinere steekproeven kunnen er
toch aanzienlijke verschillen optreden (LJUNG G. en BOX G, 1978, blz. 298).
Het enige probleem die zich nu nog stelt, is de bepaling van m , m.a.w de bepaling van het aantal
autocorrelatiecoëfficiënten die moeten opgenomen worden in de Q -statistiek. Enerzijds mogen
er niet te weinig gebruikt worden omdat er dan eventueel significante autocorrelaties van een
hogere orde kunnen gemist worden. Anderzijds mogen er ook niet te veel gebruikt worden omdat
de test dan niet krachtig genoeg zal zijn ten gevolge van insignificante autocorrelaties van een
hogere orde (CAMPBELL J., 1997, blz. 47).
Bij het uitvoeren van de test zullen er Q -statistieken worden berekend voor verschillende
waarden voor m . Op die manier kan men nagaan wat de invloed is van de autocorrelaties van
een hogere orde.

85
4.5.2 Empirisch Onderzoek
De test wordt nu uitgevoerd op het aandeel UCB en de Bel20-index. Er wordt gebruik gemaakt
van de verdeling (4.5.3). De Q -statistieken worden berekend voor 15,10,5=m en 20. De resul-
taten zijn weergegeven in tabel 6.
De resultaten voor de Portmanteau statistieken zijn volledig in overeenstemming met de
bevindingen voor de autocorrelatie-test. Wat betreft het aandeel UCB, kan de RW1 niet
verworpen worden voor zowel de weekgegevens als voor de maandgegevens. Enkel omtrent de
daggegevens lijkt er enige twijfel te bestaan. De Ljung-Box Q -statistiek voor 5 autocorrelaties
valt binnen het 95%-betrouwbaarheidsinterval, maar buiten het 99%-betrouwbaarheidsinterval.
Indien er meerdere autocorrelaties opgenomen worden in de Q -statistiek, dan kan de RW1 met
zekerheid aanvaard worden.
Tabel 6: De Portmanteau Statistieken voor dagelijkse, wekelijkse en maandelijkse rendementen
Aandeel/Index TijdseenheidSteekproef-
grootte∗
5Q∗
10Q∗
15Q∗
20Q
UCB Dag 6824 13.163* 14.945 19.898 22.166
Week 1364 5.9524 9.4407 14.957 18.718
Maand 313 0.6192 11.378 13.660 17.702
Bel20-index Dag 6824 178.30* 252.89* 272.99* 275.24*
Week 1364 40.340* 46.828* 57.297* 61.218*
Maand 313 8.9576 13.633 16.970 23.040
* geeft aan dat de Q -statistiek significant is voor het 95%-betrouwbaarheidsinterval.
(Eigen werk; Microsoft Word)
Wat betreft de Bel20-index is er weinig twijfel. De RW1 kan met grote zekerheid verworpen
worden voor de daggegevens daar de Q -statistieken significant zijn voor alle betrouwbaarheids-
intervallen. Ook voor de weekgegevens kan de RW1 met zekerheid verworpen worden. De
maandelijkse rendementen daarentegen voldoen wel aan de veronderstellingen van de RW1.
Algemeen kan er gesteld worden dat de autocorrelatie-test en de test met de Portmanteau
statistieken dezelfde resultaten opleveren voor de bestudeerde tijdsreeksen.
Een betere test voor de RW1, houdt verband met de variantierarios. Dit wordt in het volgende
deel besproken.

86
4.6 De Variantieratios
Een belangrijke eigenschap van de RW1 is dat de variantie van de residuen een lineaire functie
moet zijn van het tijdsinterval. Stel het logaritmisch RW1-model:
ttt pp εµ ++= −1 , ( )2,0~ σε IIDt .
De variantie van het residu over een tijdsinterval van bijvoorbeeld twee weken moet gelijk zijn
aan twee maal de variantie van het residu over een tijdsinterval van één week.
Als er gewerkt wordt met het continu samengesteld rendement dan kan het RW1-model
omgevormd worden tot
( )21 ,~ σµIIDppr ttt −−= .
De eigenschap die geldig is voor de residuen zal dan ook geldig zijn voor de rendementen tr .
Het RW1-model impliceert dan bijvoorbeeld dat de variantie van 1++ tt rr gelijk is aan de twee
maal de variantie van tr . De geloofwaardigheid van het RW1-model kan dus nagegaan worden
door de variantie van 1++ tt rr te vergelijken met twee maal de variantie van tr . De test van de
RW1 zal er dan in bestaan om de schatters van de variantie van de tijdsreeks van de rendementen
met een verschillende frequentie te vergelijken met elkaar (CAMPBELL J. et al., 1997, blz. 48).
In het eerste deel zal het begrip “variantieratio” gedefinieerd worden en zullen er enkele
eigenschappen van de ratios besproken worden. In het tweede deel zal de verdeling voor de
variantieratios afgeleid worden. In een laatste deel zullen er nog enkele verfijningen aangebracht
worden aan de variantieratios.
4.6.1 Wat zijn Variantieratios?
De variantieratio kan gedefinieerd worden als de verhouding van de variantie van het
rendement over meerdere perioden en de som van de varianties van de enkelvoudige
rendementen. De variantieratio voor een tweevoudige periode is dan de verhouding van de
variantie van 1++ tt rr en de som van de variantie van tr en de variantie van 1+tr . Deze
variantieratio kan dan als volgt genoteerd worden:

87
( ) ( )[ ][ ] [ ]1
22
++=
tt
t
rVarrVar
rVarVR , (4.6.1)
( ) .2 1++= ttt rrrmet
Daar het RW1-model stationariteit impliceert, kan (4.6.1) verder als volgt uitgewerkt worden:
( ) [ ][ ]
[ ] [ ][ ]
( ) )3.6.4(,11
2
,22
)2.6.4(2
2
1
1
ρ+=
+=
+=
+
+
t
ttt
t
tt
rVar
rrCovrVar
rVar
rrVarVR
waarbij ( )1ρ de eerste-orde autocorrelatiecoëfficiënt is van de rendementen tr . De
populatiewaarde voor )2(VR is dus gelijk 1 plus de eerste-orde autocorrelatiecoëfficiënt ( )1ρ .
Uit sectie 4.4 volgt er dat de autocorrelatie gelijk moet zijn aan 0 indien de RW1 geldig is. Dit
impliceert dat de variantieratio )2(VR gelijk moet zijn aan 1 indien de RW1 geldig is.
Als de RW1 niet geldig is, dan zal de )2(VR verschillend zijn van 1. Er zijn twee gevallen
denkbaar wanneer dit zo is. Ten eerste, als de opeenvolgende rendementen positief gecorreleerd
zijn, dan zal de eerste-orde autocorrelatiecoëfficiënt groter zijn dan 0 zodat de variantie ratio
)2(VR groter is dan 1. De variantie van de som van de enkelvoudige rendementen is dan groter
dan de som van de varianties van de enkelvoudige rendementen. Ten tweede, indien de
opeenvolgende rendementen negatief gecorreleerd zijn dan zal de eerste-orde
autocorrelatiecoëfficiënt kleiner zijn dan 0 en is de variantieratio )2(VR bijgevolg kleiner dan 1.
De variantie van de som van de enkelvoudige rendementen is kleiner dan de som van de
varianties van de enkelvoudige rendementen. Het risico van een aandeel zal dan ook kleiner zijn
indien de rendementen negatief gecorreleerd zijn.
Dit zijn de twee mogelijke gevallen die kunnen optreden indien de RW1 niet geldig is. De
aanwezigheid van autocorrelatie maakt het immers mogelijk om de toekomstige rendementen te
voorspellen op basis van vroegere rendementen.

88
De variantieratio voor q-perioden
Er kan nu overgegaan worden naar de algemene definitie voor de variantieratios. Op die manier
kan de variantie over meerdere perioden vergeleken worden met de varianties over de
enkelvoudige perioden. Er zal dan ook rekening moeten gehouden worden met autocorrelaties
van een hogere orde dan 1. De algemene definitie van de variantieratio voor q perioden ziet er
als volgt uit:
( ) ( )[ ][ ]tt
rVarq
qrVarqVR = , (4.6.4)
( ) 11 +−− +++= qtttt rrrqrmet �
waarbij ( )qrt het continu samengestelde rendement is over q perioden. Merk op dat de noemer
uit (4.6.4) volgt uit de eigenschap van stationariteit van de rendementen. De variantieratio ( )qVR
kan als volgt uitgewerkt worden (eigen werk):
( ) [ ] [ ] [ ] [ ][ ]
[ ] [ ] [ ][ ]
[ ][ ]
[ ][ ]
[ ][ ]
[ ][ ]
[ ][ ]
[ ][ ]
( ) ( ) ( ) )5.6.4(,122)2(21)1(21
,2,,2
,,2
,2,2,2
,2,2
1132
121
1132
1211
−++−+−+=
++�
��
�
�++
+���
��
�
�+++=
+++++
+++++=
+−+−+−−
+−+−−
+−+−+−−
+−+−−+−
qqq
q
q
q
rVar
rrCov
qrVar
rrCov
rVar
rrCov
q
rVar
rrCov
rVar
rrCov
qrVarq
rVarq
rVarq
rrCovrrCovrrCov
rVarq
rrCovrrCovrVarrVarqVR
t
qtt
t
qtqt
t
tt
t
qtqt
t
tt
t
t
t
qttqtqttt
t
qtqtttqtt
ρρρ �
��
�
��
��
( ) [ ][ ]
1,,2,1,
−== − qkvoorrVar
rrCovkmet
t
ktt�ρ .
waarbij ( )kρ de k-de orde autocorrelatiecoëfficiënt is voor de rendementen tr . Uiteindelijk
wordt het volgende bekomen uit (6.4.4) voor de variantieratio ( )qVR :

89
( ) ( )−
=
�
��
�
� −+=
1
121q
kk
q
kqqVR ρ . (4.6.6)
De variantieratio ( )qVR is bijgevolg een lineaire combinatie van de q-1 eerste
autocorrelatiecoëfficiënten met afnemende gewichten. De RW1 zal opnieuw geldig zijn indien
( ) 1=qVR , d.i. indien de variantie van het rendement over q perioden gelijk is aan q keer de
variantie van het rendement over één periode. De RW1 impliceert dus dat alle
autocorrelatiecoëfficiënten (van iedere orde) gelijk zijn aan 0.
Om nu te kunnen te zeggen of een variantieratio al dan niet statistisch verschillend is van 1, is
het noodzakelijk om een steekproefverdeling voor de variantieratios op te stellen. De
steekproefverdeling maakt het dan mogelijk om de varianties kwantitatief te vergelijken. De
afleiding van de verdeling gebeurt in het volgende deel.
4.6.2 De Steekproefverdeling voor de Variantieratios
In dit deel zal de steekproefverdeling afgeleid worden voor de schatter ( )qVR van de
variantieratio ( )qVR . De werkwijze die gevolgd wordt is deze van Lo en MacKinley (1988). Er
wordt vertrokken van de nulhypothese dat de logaritmische prijzen een RW1 volgen met
normaal verdeelde residuen:43
( )21 ,0~, σεεµ Ν+=−= − IIDppr ttttt . (4.6.7)
Eerst zullen de schatters voor µ en 2σ bepaald worden. Vervolgens zal de verdeling afgeleid
worden voor ( )2VR . Later in dit deel zal dan de verdeling bepaalt worden voor de algemene
variantieratio ( )qVR .
43 De veronderstelling van normaliteit wordt gemaakt om de uiteenzetting niet nodeloos ingewikkeld te maken.

90
De schatters voor µ en 2σ
Onderstel dat er 2n +1 waarnemingen zijn voor de logaritmische prijzen, d.i. nppp 210 ,,, � .
Vervolgens kunnen nu de schatters voor de verwachtingswaarde µ en de variantie 2σ bepaald
worden:
( ) ( )02
2
11
2
1
2
1 ppn
ppn
n
n
kkk −=−≡
=−µ (4.6.8)
( )=
− −−≡n
kkka pp
n
2
1
21
2
2
1 µσ . (4.6.9)
De schatters µ en 2aσ zijn respectievelijk het steekproefgemiddelde en de steekproefvariantie.
Het zijn allebei de meest waarschijnlijke schatters waardoor het ook consistente, asymptotisch
efficiënte en asymptotisch normale schatters zijn (LO A. en MACKINLAY A., 1989, blz. 206).
Een andere schatter voor 2σ kan bepaald worden als de helft van de steekproefvariantie van de
residuen voor een steekproef bestaande uit de prijzen die even genummerd zijn. De steekproef
bestaat dan uit n+1 waarnemingen, namelijk de prijzen nppp 220 ,,, � . Deze schatter 2bσ ziet er
dan als volgt uit:
( )=
− −−≡n
kkkb pp
n 1
2222
2 22
1 µσ . (4.6.10)
De schatter 2bσ is dan in feite de helft van de schatter voor de variantie van het rendement over
twee perioden, d.i. 1++ tt rr . Er wordt hier in feite gebruik gemaakt van de eigenschap van de
RW1 dat de variantie van de rendementen een lineaire functie is van het tijdsinterval, vandaar
dat de variantie 2σ kan geschat worden als de helft van de steekproefvariantie van de
rendementen nrrr 242 ,,, � met 2−−= kkk ppr . Onder de nulhypothese van het normale RW1-
model, zullen de twee schatters 2aσ en 2
bσ dan ook dicht bij elkaar liggen.
Er zijn twee manieren om de geldigheid van de RW1 te testen:
• De eerste test houdt verband met de schatter ( )2VD . Deze schatter kan als volgt gedefinieerd
worden: ( ) 222 abVD σσ −≡ . ( )2VD is dus de schatter van het variantieverschil. De test voor
de RW1 bestaat er dan in om ( )2VD te berekenen en te kijken of de schatter al dan niet

91
statistisch verschillend is van 0. Indien de RW1 geldig is, dan moet deze schatter gelijk zijn
aan nul.
• Een tweede test is gebaseerd op de dimensieloze schatter ( )2VR van de variantieratio zoals
gedefinieerd in (4.6.2). Deze schatter is gelijk aan de verhouding van 2bσ en 2
aσ . Indien de
RW1 geldig is, dan moet ( )2VR statistisch niet te onderscheiden zijn van 1.
Om de testen uit te voeren zal het noodzakelijk zijn om de verdelingen van ( )2VD en ( )2VR te
bepalen. Eerst zal de verdeling voor ( )2VD afgeleid worden en gebruik makend van deze
verdeling zal dan de verdeling voor ( )2VR afgeleid worden.
De steekproefverdeling voor ( )2VD
Eerst zal de verdeling bepaald worden voor 2aσ en 2
bσ . Gebruik makend van deze verdelingen
zal de verdeling voor ( )2VD afgeleid worden.
Uit (4.6.9) kan men afleiden dat 2aσ de som is van toevalsveranderlijken met een eindige
verwachtingswaarde en een eindige variantie zodat 2aσ altijd asymptotisch normaal verdeeld is
ten gevolge van de centrale limietstelling. De toevalsveranderlijke is gelijk aan ( )21 µ−− −kk pp .
Vervolgens kunnen de verwachtingswaarde en de variantie bepaald worden voor deze
toevalsveranderlijke (eigen werk):44
( )[ ] [ ] [ ] 2221 σεεµ ===−− − kkkk VarEppE , (4.6.11)
( )[ ] ( )[ ] ( )[ ]( )[ ] ( )
)12.6.4(.2
3
4
44
224
221
41
21
σ
σσ
σε
µµµ
=
−=
−=
−−−−−=−− −−−
k
kkkkkk
E
ppEppEppVar
44 Bij de afleiding mag µ gelijkgesteld worden aan µ daar de asymptotische verdeling bepaald wordt voor deschatters van de variantie. Het aantal waarnemingen zal dus zeer groot zijn zodat het gemiddelde µ zalconvergeren naar zijn populatiewaarde µ .

92
Gebruik makend van de centrale limietstelling en (4.6.11) en (4.6.12) wordt de volgende
verdeling bekomen voor de som van 2n toevalsveranderlijken:
( )( )( )1,0
2~2
1
4
2
1
221
Ν−−−
=
=− a
n
k
n
kkk pp
σ
σµ . (4.6.13)
De verdeling (4.6.13) kan verder uitgewerkt worden, gebruik makend van (4.6.9):
( ) ( )1,022
2~4
22
Ν− a
a
n
n
σ
σσ .
(Eigen werk)
Uiteindelijk wordt de volgende welbekende asymptotische normale verdeling bekomen:
( ) ( )422 2,02 ~ σσσ Ν−a
an . (4.6.14)
Het principe van de centrale limietstelling kan nu ook toegepast worden voor 2bσ . De
toevalsveranderlijke is gelijk aan ( )2222 2 µ−− −kk pp . Vervolgens kan opnieuw de
verwachtingswaarde en de variantie van de toevalsveranderlijke bepaald worden (eigen werk):
( )[ ] ( )[ ][ ] [ ] [ ] [ ]
)15.6.4(.2
2
2
2
1222
1222
2122
2222
σ
εεεε
εεµ
=
−+=
+=−−
−−
−−
kkkk
kkkk
EEEE
EppE
( )[ ] ( )[ ] ( )[ ]( )[ ] [ ] [ ] [ ] ( )[ ]( )
( ))16.6.4(.8
2633
6
2
4
222244
22122
212
22
412
42
22122
4122
2222
σ
σσσσσ
εεεεεε
εεεεµ
=
−++=
+−++=
+−+=−−
−−−
−−−
kkkkkk
kkkkkk
EEEEE
EEppVar

93
Gebuik makend van de centrale limietstelling en (4.6.15) en (4.6.16), wordt de volgende
verdeling bekomen voor de som van n toevalsveranderlijken:
( )( )( )1,0
8
22
~1
4
1
22222
Ν−−−
=
=− a
n
k
n
kkk pp
σ
σµ . (4.6.17)
2bσ kan nu ingebracht worden in (4.6.17) en na enige uitwerking wordt de volgende verdeling
bekomen:
( ) ( )1,042
2~4
22
Ν− a
b
n
n
σ
σσ .
(Eigen werk)
Uiteindelijk wordt de volgende asymptotische normale verdeling bekomen:
( ) ( )422 4,02 ~ σσσ Ν−a
bn . (4.6.18)
Op basis van (4.6.14) en (4.6.18) kan nu de verdeling bepaald worden voor de schatter van het
variantieverschil, ( ) 222 abVD σσ −≡ . De schatter ( )2VD kan als volgt herschreven worden
(eigen werk):
( ) ( ) ( )
( ) ( ) ( ) )19.6.4(.2222
2
2222
2222
σσσσ
σσσσ
−−−=
−−−=
ab
ab
nnVDn
VD
Aangezien het verschil van twee asymptotische normale verdelingen ook asymptotisch normaal
verdeeld is, kan er uit (4.6.19) afgeleid worden dat ( )22 VDn asymptotisch normaal verdeeld
is. De verwachtingswaarde van ( )22 VDn is dan het verschil van de verwachtingswaarden van
( )222 σσ −bn en ( )222 σσ −an en zal bijgevolg gelijk zijn aan 0.

94
De bepaling van de variantie voor ( )22 VDn zal niet zo evident zijn daar de 2 schatters 2aσ en
2bσ asymptotsch niet ongecorreleerd zijn. Er kan echter gebruikt gemaakt worden van een
eigenschap ontwikkeld door Hausman (1978). Hausman heeft bewezen dat de asymptotische
variantie van het verschil van een consistente schatter en een asymptotisch efficiënte schatter
gelijk is aan het verschil van de asymptotische varianties. Het bewijs hiervan kan nu gegeven
worden voor de schatter 2aσ en 2
bσ . 2aσ en 2
bσ zijn twee consistente schatters van 2σ . 2aσ is
daarenboven een asymptotisch efficiënte schatter van 2σ .45 Dit impliceert dan dat 2aσ
asymptotisch ongecorreleerd is met 22ab σσ − anders zou er een lineaire combinatie bestaan van
2aσ en 22
ab σσ − die efficiënter is dan 2aσ , wat niet kan, gegeven de asymptotische efficiëntie
van 2aσ . Het resultaat van Hausman kan nu gemakkelijk als volgt bekomen worden:
[ ] [ ] [ ] [ ]
[ ] [ ] [ ] )20.6.4(,2222
2222222
abab
abaabab
aVaraVaraVar
aVaraVaraVaraVar
σσσσ
σσσσσσσ
−=−
−+=−+=
waarbij [ ]aVar de operator is voor de asymptotische variantie (CAMPBELL J. et al., 1997,
blz. 51).
Gebruik makend van (4.6.19) en (4.6.20) kan de variantie voor ( )22 VDn als volgt afgeleid
worden (eigen werk):
( )[ ] ( )[ ] ( )[ ]
.2
24
2222
4
44
22
σ
σσ
σσσσ
=
−=
−−−= ab naVarnaVarVDnaVar
45 2
aσ is namelijk de meest waarschijnlijke schatter van 2σ en de meest waarschijnlijke schatter is altijdasymptotisch efficiënt (GREENE W., 1993, blz. 114).

95
Uiteindelijk kan de verdeling van ( )22 VDn als volgt voorgesteld worden:
( ) ( )42,022 ~ σΝa
VDn . (4.6.21)
De nulhypothese van het RW1-model kan nu getest worden door middel van de verdeling
(4.6.21) en iedere consistente schatter 2σ voor 2σ . De gestandardiseerde testwaarde
( ) 2222 σVDn heeft dan een asymptotisch standaard normale verdeling onder de RW1-
hypothese. De RW1 kan dus aanvaard worden indien de testwaarde in het 95%-betrouwbaar-
heidsinterval ligt.
Vervolgens kan nu de verdeling voor de schatter ( )2VR van de variantieratio over 2 perioden
afgeleid worden, gebruik makend van (4.6.21).
De steekproefverdeling voor ( )2VR
De verdeling voor ( ) 222 abVR σσ≡ zal volgen uit (4.6.21) door het toepassen van de eerste-orde
Taylor-reeks benadering op de functie ( ) 2121 , xxxxf = met 221 abx σσ −= en 2
2 ax σ= . Merk
op dat 1x en 2x ongecorreleerd zijn daar 2aσ een efficiënte schatter is. De Taylor-
reeksontwikkeling voor de functie ( )21 , xxf ziet er als volgt uit:
( ) ( ) ( ) ( ) ( ) ( )
[ ][ ] .
0
)22.6.4(,,,,
222
221
21
2
2221
1
112121
σσ
σσ
==
=−=
+∂
∂−+∂
∂−+=
a
ab
Ex
Exmet
xxx
fxxxxx
fxxxxfxxf �
1x en 2x zijn de verwachte waarden voor de onbekenden 1x en 2x indien het aantal
waarnemingen zeer groot wordt (er wordt dus opnieuw asymptotisch gewerkt). Merk op dat de
termen met een afgeleide van een hogere orde dan 1, verwaarloosbaar zijn zodat deze termen
mogen weggelaten worden.
Om nu de vergelijking (4.6.22) te kunnen uitwerken is het eerst noodzakelijk om de afgeleiden te
berekenen (eigen werk):

96
( ) ,11,2
1
21
1 σ==
∂
∂
xxx
x
f (4.6.23)
( ) ( ) 422
121
2
0,σ
=−=∂
∂
x
xxx
x
f . (4.6.24)
Vervolgens kunnen (4.6.23) en (4.6.24) ingebracht worden in de functie (4.6.22):
( ) ( ) ( )2
1
4
2221221
0100,σσ
σσσ
xxxxxf =
����
�−−+−+= . (4.6.25)
De volgende verwachtingswaarde en variantie kunnen nu bekomen worden gebruik makend van
(4.6.21) en (4.6.25) waarin ( )2221 VDx ab ≡−= σσ en 2
2 ax σ= :
( )[ ] 0212 22
22
22
=−=�
��
�
� −ab
a
ab nEnE σσσσ
σσ , (4.6.26)
( )[ ]4
422
42
22 2212σσσσ
σσσσ =−=
�
��
�
� −ab
a
ab naVarnaVar . (4.6.27)
(Eigen werk)
Via (4.6.26) en (4.6.27) bekomt men dan uiteindelijk de steekproefverdeling voor ( )2VR :
( )( ) ( )2,01222 ~2
22
Ν−=�
��
�
� − a
a
ab VRnnσ
σσ . (4.6.28)
De test voor de RW1 kan nu uitgevoerd worden door de gestandardiseerde testwaarde
( )( ) 2122 −VRn , die asymptotisch standaard normaal verdeeld is, te berekenen en te kijken
of deze in het 95% betrouwbaarheidsinterval [ ]96.1;96.1− ligt. Valt de testwaarde buiten dit
interval, dan wordt de RW1-hypothese verworpen.

Hoofdstuk 4: De Testen van de “Random Walk” 1 97
Meestal zal de variantieratio verkozen worden boven het variantieverschil om de geldigheid van
de RW1 na te gaan omdat deze eerste dimensieloos is. Het is wel zo dat beide testwaarden
equivalent zijn. Ze zullen dezelfde resultaten opleveren. Stel namelijk dat 2aσ gebruikt wordt als
schatter voor 2σ , dan bekomt men het volgende:
( ) ( ) ( )( ) ( )1,02
122
2
2
2
22 ~2
22
4Ν
−=
−=
a
a
ab
a
VRn
nVDn
σ
σσ
σ ,
zodat het gelijk is welke testwaarde er gehanteerd wordt om de geldigheid van de RW1-
hypothese na te gaan (CAMPBELL J. et al., 1997, blz. 51).
De resultaten die bekomen zijn voor ( )2VD en ( )2VR kunnen nu gemakkelijk veralgemeend
worden zodat er rekening kan gehouden worden met rendementen over meerdere perioden.
De steekproefverdeling voor ( )qVD en ( )qVR
De werkwijze die gevolgd wordt bij de afleiding van de verdeling is dezelfde als bij de verdeling
voor ( )2VD en ( )2VR . Stel de steekproef bestaat uit nq+1 waarnemingen voor de logaritmische
prijzen van een aandeel, d.i. nqpppp ,,,, 210 � met 1>q . De schatters voor de
verwachtingswaarde en de variantie zien er dan als volgt uit:
( ) ( )01
111 ppnq
ppnq
nq
nq
kkk −=−≡
=−µ , (4.6.29)
( )=
− −−≡nq
kkka pp
nq 1
21
2 1 µσ , (4.6.30)
( ) ( )=
− −−≡n
kqqkqkb qpp
nqq
1
22 1 µσ . (4.6.31)
De schatter ( )qVD voor het variantieverschil en de schatter ( )qVR voor de variantieratio kunnen
dan als volgt gedefinieerd worden:
( ) 22)( ab qqVD σσ −≡ , (4.6.32)

Hoofdstuk 4: De Testen van de “Random Walk” 1 98
( ) ( )2
2
a
b qqVR
σ
σ≡ . (4.6.33)
De volgende welbekende asymptotische normale verdelingen kunnen op een analoge manier
bewezen worden als de verdelingen (4.6.14) en (4.6.18):
( ) ( )422 2,0~ σσσ Ν−a
aqn , (4.6.34)
( )( ) ( )422 2,0~ σσσ qqqna
b Ν− . (4.6.35)
Er kan nu opnieuw gebruik gemaakt worden van de aanpak van Hausman (1978) om de
verdeling van ( )qVD te bepalen. Daar 2aσ een asymptotisch efficiënte schatter is en ( )qb
2σ een
consistente schatter is voor 2σ , dan kan er via (4.6.20) gemakkelijk geconcludeerd worden dat
asymptotische variantie van ( )( )22ab qqn σσ − gelijk is aan het verschil van de asymptotische
varianties van ( )( )22 σσ −qqn b en ( )22 σσ −aqn . Uiteindelijk bekomt men dan de volgende
verdeling voor ( )qVD :
( )( ) ( ) ( )( )422 12,0~ σσσ −Ν=− qqVDqnqqna
ab . (4.6.36)
Gebruik makend van de eerste-orde Taylor benadering kan de steekproefverdeling voor ( )qVR
afgeleid worden uit (4.6.36). Dit gebeurt op een analoge manier als voor ( )2VR . De volgende
verdeling wordt bekomen voor ( )qVR :
( ) ( )( ) ( )( )12,01 ~2
22
−Ν−=�
��
�
� −qqVRqn
qqn
a
a
ab
σ
σσ . (4.6.37)
In het volgende deel zullen er twee belangrijke verfijningen aangebracht worden aan de
testwaarden uit (4.6.36) en (4.6.37) zodat er nieuwe steekproefverdelingen bekomen worden die
de test voor de RW1 zullen verbeteren.

Hoofdstuk 4: De Testen van de “Random Walk” 1 99
4.6.3 Twee Belangrijke Verfijningen
Een eerste verfijning die kan aangebracht worden is het gebruik van overlappende rendementen
over q perioden bij het schatten van de variantie voor de rendementen over q perioden. Op die
manier bekomt men de volgende alternatieve schatter ( )qc2σ voor 2σ i.p.v. ( )qb
2σ :
( ) ( )=
− −−≡nq
qkqkkc qpp
nqq 2
2
2 1 µσ . (4.6.38)
Deze schatter bevat nq-q+1 termen terwijl de schatter ( )qb2σ slechts n termen bevat. ( )qc
2σ is
dus een efficiëntere schatter en zal dus een krachtere test toelaten.
Een tweede verfijning houdt verband met de onzuiverheid van de schatters 2aσ en ( )qc
2σ .
Wegens deze onzuiverheid zullen de schatters ( )qVD en ( )qVR ook onzuiver zijn. Dit probleem
kan opgelost worden door de schatters 2aσ en ( )qc
2σ te corrigeren voor hun onzuiverheid. Na
enige uitwerking bekomt men de volgende zuivere schatter 2~aσ voor 2σ in plaats van de
onzuivere schatter 2aσ :
( )=
− −−−
=nq
kkka pp
nq 1
21
2
1
1~ µσ . (4.6.39)
De afleiding van de zuivere schatter ( )qc2~σ voor 2σ in plaats van de onzuivere schatter ( )qc
2σ
is minder evident (zie bijlage 9). Uiteindelijk ziet de zuivere schatter ( )qc2~σ er als volgt uit:
( ) ( )=
− −−≡nq
qkqkkc qpp
mq 22 1~ µσ , (4.6.40)
( )�
��
�
�−+−≡
nq
qqnqqmmet 11 .
Gebruik makend van deze zuivere schatters, worden de volgende schatters bekomen voor het
variantieverschil en de variantieratio:

Hoofdstuk 4: De Testen van de “Random Walk” 1 100
( ) ( ) 22 ~~ac qqVD σσ −= , (4.6.41)
( ) ( )2
2
~
~
a
c qqVR
σ
σ= . (4.6.42)
De schatter ( )qVD , als het verschil van twee zuivere schatters, zal nu ook een zuivere schatter
zijn. De schatter ( )qVR zal echter wel nog altijd onzuiver zijn ten gevolge van een uitbreiding
van de ongelijkheid van Jensen. Stel namelijk dat f een strikt convexe (resp. concave) functie is
en X een univariate stochastische variabele, dan ziet de ongelijkheid van Jensen er als volgt uit:
( )[ ]XfE > (resp. <) [ ]XEf . (4.6.43)
(STUNDT B., 1993, blz. 199).
De ongelijkheid kan gemakkelijk uitgebreid worden naar multivariate variabelen. Uiteindelijk
wordt er bekomen dat de verwachtingswaarde van ( )qVR verschillend is van 1 onder de
hypothese van de RW1, terwijl deze eigenlijk gelijk moet zijn aan 1. ( )qVR is dus nog steeds
onzuiver. Niettemin zijn Lo en MacKinlay (1989) na enig onderzoek tot de conclusie gekomen
dat de testen die gebaseerd zijn op ( )qVR meer betrouwbare gevolgtrekkingen opleveren dan de
testen gebaseerd op ( )qVR (LO A. en MACKINLAY A., 1989, blz. 211).
Uiteindelijk kunnen nu de steekproefverdelingen afgeleid worden voor ( )qVD en ( )qVR onder
de RW1-hypothese.
De steekproefverdeling voor ( )qVD en ( )qVR
Om tot de steekproefverdeling voor ( )qVD te komen, zal de steekproefverdeling afgeleid
worden voor ( )( )22ac qqn σσ − . Daar deze verdeling een asymptotische verdeling is en daar
asymptotisch gezien de schatters ( )qc2σ en ( )qc
2~σ en de schatters 2aσ en 2~
aσ equivalent zijn, zal
de bekomen verdeling ook gelden voor qn ( )qVD . Vervolgens kan dan de verdeling voor
qn ( )qVR afgeleid worden via de eerste-orde Taylor benadering. De werkwijze die gevolgd
wordt, is deze van Lo en MacKinlay (1988).

Hoofdstuk 4: De Testen van de “Random Walk” 1 101
Er wordt vertrokken van de schatter ( )qc2σ . Deze kan uitgedrukt worden als een lineaire
combinatie van autocovarianties. De afleiding gebeurt als volgt:
( ) ( )
( )
)44.6.4(,1
1
1
2
112
2
112
2
2
2
= =+−
= =−+−
=−
���
�=
��
��
�−−=
−−=
nq
qk
q
jjk
nq
qk
q
jjkjk
nq
qkqkkc
nq
ppnq
qppnq
q
ε
µ
µσ
µε −−= −+−+− jkjkjk ppmet 11 .
Vervolgens kan de vergelijking (4.6.44) als volgt herschreven worden:
( )= =
−
=
−
=−−−−+−−+−+−
����
�++++=
nq
qk
q
j
q
j
q
jqkkjkjkjkjkjkc
nqq
1
1
1
2
1111112
2 2221 εεεεεεεσ � . (4.6.45)
Iedere term uit (4.6.45) kan verder uitgewerkt worden. Enkel de eerste term zal uitgewerkt
worden. De afleiding van de andere termen gebeurt op een analoge manier. De uitwerking van de
eerste term gebeurt als volgt (eigen werk):
)46.6.4(.2
2
1
2
1
221
1
2
1
23
1
2
1
222
1
2
1
2
1
1
1
22
1
1
1
1
22
2
22
2
222
21
22
22
21
2
1
21
���
�−+�
���
�−−++
��
��
�−−+�
���
�−−+�
���
�−=
+++++=
+++++=
+−==+−==
−=
−
==
−
===
−
=
−
−=
+−
=
+−
=
−
−==
= =+−
=+−
=−−
== =+−
nq
qnqkk
nq
kk
nq
qnqkk
nq
kk
nq
nqkk
q
kk
nq
kknq
q
kk
nq
kk
nq
k
q
kkk
nq
qk
qnq
kk
qnq
kk
nq
qkkk
nq
qkk
nq
qk
nq
qkqk
nq
qkqk
nq
qkkk
nq
qkk
nq
qk
q
jjk
εεεεε
εεεεεεεε
εεεεε
εεεεεε
�
�
�
In iedere groepering uit (4.6.46) komt dezelfde term voor. Deze termen worden samengenomen.
De overige termen worden verder uitgewerkt:

Hoofdstuk 4: De Testen van de “Random Walk” 1 102
)47.6.4(.1
1
21
1
1
21
1
2
1
2
2
2
1
21
2
21
1
2
1
21
2
21
1
2221
1
1
21
1
2
1
2
1
21
−
=++−
−
=
−
==
+−=+−=
−
=
−
=
−=
−
−=
−
=−
−
=
−
=== =+−
−+−=
−−�
��
�−−−
−��
��
�−−−�
���
�−−−=
q
kkqnq
q
kk
q
kk
nq
kk
nq
qnqkk
nq
qnqkk
q
kk
q
kk
nq
nqkk
q
qkk
q
kknqq
q
kk
q
kk
nq
kk
nq
qk
q
jjk
kkqq
q
εεεε
εεεε
εεεεεεεεε
�
(Eigen werk)
Als nu ook de andere termen uit (4.6.45) op een analoge manier uitgewerkt worden als de eerste
term en de resultaten ingebracht worden in (4.6.45) dan bekomt men het volgende voor de
schatter ( )qc2σ :
( ) ( )[ ]
( ) ( ) ( )[ ]
( ) ( ) ( )[ ]
)48.6.4(.2
22221
12121
1
1
1
3112
322
1
211
212
1
1
21
2
1
2
2
2
=+−
−
=−+−++−−
=−
−
=+−++−−
=−
−
=++−
=
++
���
�−+−−−+
��
��
�−+−−−+
��
��
�+−−=
nq
qkqkk
q
kkqnqkqnqkk
nq
kkk
q
kkqnqkqnqkk
nq
kkk
q
kkqnqk
nq
kkc
kkqqnq
kkqqnq
kkqqnq
q
εε
εεεεεε
εεεεεε
εεεσ
�
�
�
Uit iedere groepering in (4.6.48) is enkel de eerste term relevant. De andere termen zijn namelijk
verwaarloosbaar. Uiteindelijk kan de vergelijking (4.6.48) als volgt weergegeven worden:
( ) ( ) ( ) ( ) ( ) ( )1222211202 −++−+−+= qqq
q
q
qc γγγγσ � , (4.6.49)
( )+=
−≡nq
jkjkk
nqjmet
1
1 εεγ .
De ( )jγ is in feite niets anders dan de geschatte covariantie zoals gedefinieerd in (4.4.5).
Definieer nu de ( )1×q vector ( ) ( ) ( )[ ]′−≡ 110 qγγγγ � . De standaard limiettheorema voor

Hoofdstuk 4: De Testen van de “Random Walk” 1 103
steekproefautocovarianties van stationaire tijdsreeksen met onafhankelijke normale residuen ziet
er dan als volgt uit (FULLER W., 1976, blz. 254-257):
( ) ( )( )114
12 ,0~ eeIeqn q
a′+Ν− σσγ , (4.6.50)
waarbij 1e de ( )1×q vector [ ]′001 � en qI de identieke matrix van de q -de orde is. Gebruik
makend van (4.6.49) kan ( )( )22 σσ −qqn c nu als volgt uitgedrukt worden:
( )( ) ( )( ) ( ) ( ) ( ) ( ) ( )�
���
�−++
−+
−+−=− 122
221
120 222 q
q
q
qqnqqn c γγγσγσσ �
(4.6.51)
Dit is dus een lineaire combinatie van normaal verdeelde variabelen. Via (4.6.50) en (4.6.51)
bekomt men dan de volgende steekproefverdeling voor ( )( )22 σσ −qqn c :
( )( ) ( )c
a
c Vqqn ,0~22 Ν−σσ , (4.6.52)
( ) �
��
�
�+=
���
��
�
�++
���
��
�
� −+=
q
q
qVmet c
3
1
3
22212
2 44
2
4
2
4 σσσσ � .
Zoals bij de andere afleidingen van de steekproefverdelingen kan de stelling van Hausman
(1978) toegepast worden gebruik makend van (4.6.34) en (4.6.52). Uiteindelijk bekomt men dan
de verdeling voor ( )( )22ac qqn σσ − en bijgevolg ook de verdeling voor qn ( )qVD . De
asymptotische variantie voor qn ( )qVD kan via Hausman (1978) als volgt bekomen worden
(eigen werk):
( ) ( )( )[ ] ( )[ ]
( )( ).
3
1122
23
1
3
22
4
22
2222
σ
σσ
σσσσ
q
q
q
qnaVarqqnaVarqVDqnaVar ac
−−=
−�
��
�
�+=
−−−=����

Hoofdstuk 4: De Testen van de “Random Walk” 1 104
De steekproefverdeling voor qn ( )qVD ziet er dus als volgt uit:
( ) ( )( ) ����
� −−Ν 4
31122,0~ σ
qqqqVDqn
a
. (4.6.52)
Via de eerste-orde Taylor benadering kan de steekproefverdeling voor qn ( ) ���� −1qVR
bekomen worden:
( ) ( )( )���
�
� −−Ν����� −
q
qqqVRqna
3
1122,01 ~ . (4.6.53)
Vervolgens kan de gestandaardiseerde variantieratie-testwaarde ( )qψ uit (4.6.53) afgeleid
worden:
( ) ( ) ( )( ) ( )1,03
11221 ~21
Ν�
��
�
� −−���
�� −=
−a
q
qqqVRqnqψ . (4.6.54)
De test voor de RW1 bestaat er dan ook in om de testwaarde ( )qψ te berekenen voor een zekere
tijdsreeks en te kijken of de testwaarde in het 95% betrouwbaarheidsinterval [ ]96.1;96.1− ligt.
Indien de testwaarde in het interval ligt, wordt de RW1-hypothese aanvaard.
Ten slotte zou er nog op een analoge manier als in sectie 4.6.2 kunnen aangetoond worden dat de
verdelingen (4.6.52) en (4.6.53) eigenlijk equivalent zijn zodat ze dezelfde resultaten zullen
opleveren.
4.6.4 Empirisch Onderzoek
De test met de variantieratios zal nu uitgevoerd worden op het aandeel UCB en de Bel20-index.
Er wordt gebruik gemaakt van de verdeling (4.6.54) omdat deze verdeling de beste benadering
is. De variantieratios worden berekend op basis van de zuivere schatters voor 2σ , weergegeven
in (4.6.39) en (4.6.40), en dit voor de rendementen over 2, 4 en 8 perioden. De testwaarde ( )qψ
wordt weergegeven tussen vierkante haakjes. Indien deze testwaarde in het interval [ ]96.1;96.1−

Hoofdstuk 4: De Testen van de “Random Walk” 1 105
ligt, dan wordt de RW1 aanvaard met een betrouwbaarheid van 95%. De resultaten van de test
zijn weergegeven in tabel 7.
De bekomen resultaten zijn volledig in overeenstemming met de resulataten van de
autocorrelatie-test. Dit was te verwachten daar de variantieratios een lineaire combinatie zijn van
de autocorrelaties. De variantieratios voor de daggegevens van het aandeel UCB zijn significant
kleiner dan 1, wat opnieuw wijst op een (kleine) negatieve afhankelijkheid tussen de dagelijkse
rendementen. Voor de week- en maandgegevens kan de RW1 met grote zekerheid aanvaard
worden. De wekelijkse en maandelijkse rendementen hebben dus statistisch insignificante
autocorrelaties (zie tabel 4, blz.80).
Tabel 7: De variantieratios voor dagelijkse, wekelijkse en maandelijkse rendementen (RW1).
Aandeel/Index TijdseenheidSteekproef-
grootte( )2VR ( )[ ]2ψ ( )4VR ( )[ ]4ψ ( )8VR ( )[ ]8ψ
UCB Dag 6824 0.97 [-2.30]* 0.92 [-3.34]* 0.88 [-3.29]*
Week 1364 0.95 [-1.77] 0.97 [-0.64] 1.00 [0.04]
Maand 313 1.02 [0.36] 1.07 [0.69] 1.21 [1.27]
Bel20-index Dag 6824 1.15 [12.73]* 1.26 [11.40]* 1.37 [10.26]*
Week 1364 1.07 [2.69]* 1.28 [5.58]* 1.46 [5.75]*
Maand 313 1.14 [2.50]* 1.14 [1.28] 1.06 [0.37]* geeft aan dat de variantieratio significant verschillend is van 1 voor een 95%-betrouwbaarheidsinterval.
(Eigen werk; Microsoft Word)
Net zoals bij de vorige testen wordt de RW1 met grote zekerheid verworpen voor de Bel20-index
wat betreft de dag- en weekgegevens. Dit was te verwachten gezien de sterke positieve
autocorrelaties tussen de rendementen (zie tabel 4, blz. 80). De dagelijkse en de wekelijkse
rendementen lijken dus voor een deel voorspelbaar te zijn. De verwerping van de RW1 is wel
sterker voor de daggegevens. Opnieuw bestaat er twijfel omtrent het aanvaarden van de RW1
voor de maandgegevens van de Bel20-index. De variantieratio is significant groter dan 1 voor
tweevoudige rendementen. De variantieratios voor de vier- en achtvoudige rendementen zijn
daarentegen niet significant verschillend van 1. Er kan dus niet met zekerheid gezegd worden dat
de RW1 niet geldig is voor de maandgegevens. Algemeen kan er wel gesteld worden voor de
Bel20-index dat de graad van voorspelbaarheid afneemt naarmate de tijdseenheid groter wordt
De testen voor de RW1 zijn volledig besproken. Er kan nu overgegaan worden tot de bespreking
van de testen voor de RW2

Hoofdstuk 5: De Testen van de “Random Walk” 2 106
5 De Testen van de “Random Walk” 2In hoofdstuk 2 is er reeds uiteengezet dat de veronderstelling van identieke verdelingen
onwaarschijnlijk is bij financiële tijdsreeksen over verschillende decennia. Het zou dan ook
jammer zijn om de “random walk” te verwerpen omwille van het feit dat de rendementen niet
identiek verdeeld zijn, in het bijzonder omwille van de aanwezigheid van heteroscedaticiteit in
de tijdsreeksen van de aandelenprijzen. De RW2 zal wel toelaten dat de volatiliteiten variëren
doorheen de tijd. De test voor de RW2 bestaat er dan ook in om de hypothese van onafhankelijke
prijsveranderingen of rendementen te testen zonder de veronderstelling te maken dat de
prijsveranderingen identiek verdeeld zijn.
Er zullen twee onderwerpen besproken worden die kunnen gezien worden als een economische
test voor de RW2:
• De technische analyse.
• De filterregels.
De filterregels zijn eigenlijk een onderdeel van de bredere klasse van handelsregels die ontstaan
uit de technische analyse (CAMPBELL J. et al., 1997, blz. 43).
In dit hoofdstuk zal er een economische beschrijving gegeven voor de testen van de RW2
zonder dat er een testwaarde en een kansverdeling afgeleid worden.
5.1 De Technische Analyse
De technische analyse is het analyseren van patronen in de aandelenmarkt. Terwijl de financiële
analisten het er over eens zijn dat de onderliggende economische feiten en verbanden belangrijk
zijn, zijn er anderen die geloven dat het historische verloop van aandelenprijzen patronen bevat
die het mogelijk maken om het toekomstige verloop van de prijzen te voorspellen, enkel als deze
patronen op de juiste manier kunnen begrepen worden.46 De “technician” zal dus de grafieken
van de prijzen bestuderen vandaar dat de technische analyse ook wel “charting” genoemd wordt,
d.i. het lezen van grafieken. De technische analist bestudeert het verloop van de prijsbewegingen
uit het verleden om indicaties af te leiden omtrent de prijsbewegingen in de nabije toekomst. Hij
zal hierbij vaak proberen een reeks te simuleren die zoveel mogelijk overeenkomt met de
tijdsreeks van de aandeelprijzen en zal dan op basis van de gesimuleerde reeks voorspellingen
doen over het toekomstige verloop van de aandelenprijzen (ROBERTS H., 1959, blz. 7).
46 Vaak kunnen er tijdspatronen geobserveerd worden in de tijdsreeks van de aandelenprijzen. Het is namelijk zo dathet rendement op maandag vaak kleiner is dan op andere dagen. De maand januari levert dan meestal weer hogererendementen op dan de andere maanden (ELTON E. en GRUBER M., 1995, blz. 411-412).

Hoofdstuk 5: De Testen van de “Random Walk” 2 107
Economische verklaring
De technische analist heeft een speciaal talent in het detecteren van afhankelijkheden in de
tijdsreeksen van de prijsveranderingen van individuele aandelen. De analist gelooft erin dat de
marktprijzen van de aandelen slechts traag en over lange perioden reageren op nieuwe
informatie. Hij zegt dus dat de prijzen slechts geleidelijk naar hun nieuwe intrinsieke waarde
bewegen zodat de prijsbewegingen de tendens hebben om te volharden d.i. wanneer prijzen
gestegen zijn in het recente verleden, dan kan er verwacht worden dat ze zullen doorgaan met
stijgen in de nabije toekomst. Er zal dan ook een zekere afhankelijkheid zijn tussen de
opeenvolgende prijsveranderingen. Deze trage aanpassing staat in contrast met de theorie van de
efficiënte markten die stelt dat de prijzen zich volledig en direct aanpassen wanneer er nieuwe
informatie beschikbaar komt (zie inleiding). Daarenboven zegt de technische analist dat de
reactie van de marktprijzen op nieuwe informatie zo traag is dat er geen rekening hoeft gehouden
te worden met de informatie zelf. Door het bestuderen van de patronen in de opeenvolging van
de prijzen uit het verleden, kan men leren hoe de prijzen van een aandeel lijken te reageren op
nieuwe informatie. De patronen in de prijsopeenvolgingen zullen dan sterk genoeg zijn en zullen
frequent genoeg optreden zodat het voor het getrainde oog mogelijk wordt om de toekomstige
prijsbeweging van het aandeel te voorspellen op basis van de recente prijsbeweging uit het
verleden en op basis van de kennis van de typische patronen in het prijsgedrag van het aandeel.
Afhankelijkheid tussen de prijsveranderingen maakt het dus mogelijk om voorspellingen te doen
op basis van de geobserveerde patronen (FAMA E., 1977, blz. 140-141).
Indien de RW2 echter geldig is, zullen de opeenvolgende prijsveranderingen onafhankelijk zijn
van elkaar. In dit geval zal het lezen van grafieken geen winstgevende activiteit meer zijn. Er kan
dan niets meer geleerd worden over de toekomstige prijsveranderingen door te kijken naar het
verloop van de vroegere prijsveranderingen. Het kopen van een aandeel op basis van signalen
afgeleid uit een grafiek, zal geen betere resultaten opleveren dan deze van het gooien van een
muntstuk waarbij munt een positieve prijsverandering en kop een negatieve prijsverandering
voorstelt. De test van de RW2 bestaat er dan ook in om na te gaan of het mogelijk is om, via het
bestuderen van de patronen in het verloop van de aandelenprijzen, een hogere winst te bekomen
dan verwacht onder de RW2-hypothese (COOTNER P., 1962, blz. 232).
Het kansmodel
De link kan nu gelegd worden met het kansmodel uit hoofdstuk 1 (blz. 4-5). Zoals het
onmogelijk is bij het spelen van het kansspel roulette, om een strategie te hebben die zeker leidt
tot winst, is het onmogelijk om een strategie op te bouwen op basis van het verloop van de

Hoofdstuk 5: De Testen van de “Random Walk” 2 108
prijzen van aandelen die een “random walk” volgen, die zeker leidt tot winst. Het kansmodel kan
het verleden slechts nabootsen zoals een avond gokken in het casino een andere avond nabootst.
Stel nu dat de prijsveranderingen toch afhankelijk zijn van elkaar. De technische analist zal dan
handelen in functie van deze afhankelijkheid. Indien er nu voldoende analisten zijn die dit doen,
dan zullen zij ervoor zorgen dat de prijs voldoende snel naar zijn nieuwe intrinsieke waarde stijgt
zodat de afhankelijkheid zal verdwijnen. Dit is dan ook de verklaring van de aanhangers van de
“random walk” die stellen dat de prijzen van de aandelen een “random walk” volgen (ROBERTS
H., 1959, blz. 12).
Niet-lineaire onafhankelijkheid
De meeste testen van de “random walk”, zoals de autocorrelatie-test en de test met de
variantieratios, gaan na of er lineaire afhankelijkheid is tussen de opeenvolgende
prijsveranderingen. Indien deze laatsten lineair onafhankelijk zijn dan wordt de “random walk”-
hypothese aanvaard. De lineaire verbanden die door het autocorrelatie-test nagegaan worden,
zijn echter veel te ongesofisticeerd om de gecompliceerde patronen te identificeren die de
technische analist afleidt uit de grafieken van de aandelenprijzen.47 Er kan namelijk sprake zijn
van niet-lineaire afhankelijkheid die door de gewone statistische testen niet kan gedetecteerd
worden. De technische analist zal dus nood hebben aan een meer gesofisticeerde methode die de
niet-lineaire afhankelijkheid wel kan detecteren zodoende dat ze kunnen handelen in functie van
deze afhankelijkheid om een hogere winst te bekomen. Dus zelfs als de autocorrelaties gelijk zijn
aan 0, kunnen er types van niet-lineaire afhankelijkheid bestaan die tot winstgevende
handelssystemen leiden door de patronen te bestuderen. Hierdoor is het wenselijk om direct de
winstgevendheid van verschillende handelsregels te testen (FAMA E. en BLUME M., 1966, blz.
227) (FAMA E., 1965, blz. 80)
Een voorbeeld van zo’n handelsregel is de filterregel die door Alexander (1961) opgesteld werd.
De filterregel wordt in het volgende deel besproken.
5.2 De Filterregels
Alexander was met zijn filterregel de eerste die een test voor aandelenprijzen opstelde die niet-lineaire afhankelijkheid kan onderscheiden tussen opeenvolgende prijsveranderingen. Dat wasdan ook de belangrijkste reden om de filterregel te bestuderen. De prijsveranderingen zijn
47 Merk op dat testen zoals de runs-test en Cowles-Jones test ook veel te ongesofisticeerd zijn daar zij enkelrekening houden met het teken van de prijsveranderingen en niet met de grootte van de prijsveranderingen. Voor detechnische analist zal de grootte van de prijsveranderingen natuurlijk zeer belangrijk zijn.

Hoofdstuk 5: De Testen van de “Random Walk” 2 109
namelijk zo gecompliceerd dat gewone statistische instrumenten misleidende resultaten kunnenopleveren over de graad van afhankelijkheid in de data (COOTNER P., 1964, blz.189).De x% filter van Alexander (1961) luidt als volgt. Als de sluitingsprijs van een bepaald aandeelten minste x% hoger is dan het vorige minimum, koop en hou het aandeel totdat de prijs tenminste x% lager is dan het vorige maximum. Verkoop dan het aandeel en “go short”. Dezepositie wordt dan behouden totdat de sluitingsprijs opnieuw x% percent hoger is dan het vorigeminimum. Het aandeel wordt dan terug aangekocht. Prijsbewegingen van minder dan x%worden dus genegeerd (FAMA E., 1965, blz. 81).Alexander heeft de filtertechniek geformuleerd om de overtuiging van vele markt professionelente testen dat de prijzen zich slechts geleidelijk aanpassen aan nieuwe informatie (zie sectie 5.1).Als de prijs met x% stijgt, ten gevolge van nieuwe positieve informatie, dan is het zeerwaarschijnlijk dat de prijs uiteindelijk met meer dan x% zal stijgen vooraleer ze terug zal dalen.Door het toepassen van de x% filter kan er dan een rendement gehaald worden op de stijgendeprijsbeweging. Hetzelfde principe geldt ook bij een daling van de prijs ten gevolge van negatieveinformatie. Door het aandeel “short” te verkopen kan er dan geprofiteerd worden van deneergaande beweging (FAMA E. en BLUME M., 1966, blz. 228).
De RW2-test
Hoe kan men nu weten door middel van de filtertechniek wanneer de “random walk” geldig is?Wel, voor het RW2-model zonder drift is een positieve prijsverandering even waarschijnlijk alseen negatieve prijsverandering. De prijsveranderingen zijn daarenboven onafhankelijk vanelkaar. Er kan dan ook verwacht worden dat de filter van Alexander geen winsten zal opleveren.Dus als de x% filter, toegepast op een bepaald aandeel, geen winsten oplevert, dan kan menverwachten dat het aandeel een RW2 volgt zonder drift (ALEXANDER S., 1964, blz.347).Als er een drift aanwezig is in het RW2-model, dan zal de waarschijnlijkheid op een positieveprijsverandering niet gelijk zijn aan de waarschijnlijkheid op een negatieve prijsverandering. Erkan dan ook verwacht worden dat de filter een winst verschillend van 0 zal opleveren bij eenRW2-model met drift. Dus als de filter een positieve winst oplevert, hoeft dit niet noodzakelijk teimpliceren dat het RW2-model niet geldig is. De winst van de filter kan dan vergeleken wordenmet de winst van een “buy-and-hold” strategie.48 Indien de RW2 geldig is, dan kan er verwachtworden dat de winst van een x% filter kleiner zal zijn dan de winst van de “buy-and-hold”strategie. Het is wel zo dat hoe groter de filter is, hoe meer de winst van de filter zalovereenkomen met de winst van de “buy-and-hold” strategie eens het aandeel gekocht is.Niettemin zal de winst toch kleiner zijn dan deze van de “buy-and-hold” strategie. Daarnaast zal
48 Met een “buy and hold” strategie wordt bedoeld dat het aandeel aan het begin van de periode gekocht wordt enverkocht wordt aan het einde van de periode waarop de filter toegepast wordt.

Hoofdstuk 5: De Testen van de “Random Walk” 2 110
de winst van een filter ook meer en meer de winst van de “buy-and-hold” strategie benaderennaarmate de drift groter wordt (ALEXANDER S., 1961, blz. 217).Fama (1965) en Fama en Blume (1966) hebben een gedetailleerde empirische analyse gedaan inverband met de filterregels. Zij kwamen tot de conclusie dat enkel de winst van de kleinste filtersgroter is dan de winst van een “buy-and-hold” strategie. Hieruit zou er kunnen besloten wordendat er een zekere afhankelijkheid is tussen opeenvolgende prijsveranderingen. Indien er echterrekening gehouden wordt met de transactiekosten (b.v. de commissie-kosten) die verbonden zijnaan het verhandelen van aandelen dan zou de winst volledig geëlimineerd zijn. Bij een kleinefilter zullen de transactiekosten namelijk zeer hoog oplopen omdat het aandeel frequent moetverhandeld worden. Dus indien de transactiekosten in rekening worden gebracht, zou er kunnengeconcludeerd worden dat de RW2 geldig is (CAMPBELL J. et al. , 1997, blz. 42-43).
Enkele bedenkingen
Alexander (1964) stelde wel dat zowel de commissie-kosten als de winsten van de “buy-and-hold” strategie niet relevant zijn bij het testen van de “random walk”.Ten eerste, wat betreft de commissie-kosten redeneert hij als volgt. Stel dat het proces van deprijsveranderingen voorgesteld wordt als het gooien van een muntstuk waarbij munt leidt tot eenpositieve prijsverandering van 1 euro en kop tot een negatieve prijsverandering van 1 euro. Bijiedere worp wordt er een commissie aangerekend van 10 cent. Na 100 maal de munt gegooid tehebben, kan er verwacht worden dat de prijs niet veranderd is, daar het even waarschijnlijk is datde prijs zal stijgen als dat hij zal dalen. Door het betalen van de commissies zou er toch eenverlies zijn van 10 euro. Het zou nu niet realistisch zijn om te zeggen dat de munt imperfectiesvertoont omdat er verlies geleden is van 10 euro.Stel nu dat een aandeel een “random walk” volgt zonder drift. Er kan dan verwacht worden datde filter een winst zal opleveren van 0. Door het betalen van de commissies zal er evenwel eenverlies geleden worden. Het zal dan ook niet realistisch zijn om de “random walk” te verwerpenomdat de winst niet gelijk is aan nul.Ten tweede is de vergelijking met de “buy-and-hold” strategie ook niet relevant. Het is namelijkgoed mogelijk dat de “random walk” niet geldig is en dat de filter toch een winst oplevert diekleiner is dan de winst van de “buy-and-hold” strategie. Het is de vergelijking van degeobserveerde winst van de filter en de “verwachte“ winst van de filter onder de “random walk”-hypothese die relevant is (ALEXANDER S., 1964,.blz. 351-352). De test voor de RW2 zal erdan ook in bestaan om de geobserveerde winst te vergelijken met de “verwachte” winst.
Er wordt geen empirsch onderzoek uitgevoerd voor de filterregels daar de Beurs van Brusselgeen “short sale” toelaat. Daarenboven zal interessanter zijn om de RW3 te testen i.p.v. de RW2omdat deze eerste beter bij de realiteit aansluit. Dit gebeurt in het volgende deel.

Hoofdstuk 6: De Testen van de “Random Walk” 3 111
6 De Testen van de “Random Walk” 3Er is een groeiende consensus onder financiële economisten dat de volatiliteiten van de
prijsveranderingen geleidelijk variëren doorheen de tijd. Dit impliceert dan dat er sprake zal zijn
van heteroscedasticiteit in de tijdsreeks van de prijsveranderingen en dat de opeenvolgende
prijsveranderingen afhankelijk zullen zijn van elkaar. Het zal namelijk mogelijk zijn om de
grootte van de toekomstige prijsverandering te voorspellen op basis van de recente
prijsveranderingen. Het RW3-model houdt hier rekening mee. Het RW3-model laat dus toe dat
er heteroscedasticiteit is en dat de prijsveranderingen afhankelijk zijn van elkaar. Het RW3-
model zal dan ook een betere beschrijving bieden voor de geobserveerde prijsveranderingen van
de aandelen. De RW3 impliceert wel dat de prijsveranderingen of rendementen ongecorreleerd
zijn. Niettegenstaande men eventueel de grootte van de prijsveranderingen kan voorspellen van
tijdsreeksen die een RW3 volgen, er zal niet kunnen voorspeld worden in welke richting de
toekomstige prijsverandering zal bewegen indien de prijsveranderingen ongecorreleerd zijn. De
test voor de RW3 bestaat er dan ook in om na te gaan of de opeenvolgende prijsveranderingen al
dan niet ongecorreleerd zijn (FAMA E., 1965, blz. 85).
Er worden drie testen besproken die de geldigheid van het RW3-model kunnen nagaan:
1) De variantieratios.
2) De autocorrelatie-test.
3) De Portmanteau statistieken.
De eerste test die aan bod komt, is de test in verband met de variantieratios.
6.1 De Variantieratios
De variantieratios zijn reeds gedefinieerd in sectie 4.6. Ze zijn in feite niets anders dan de
verhouding van de variantie van het rendement over een meervoudige periode en de som van de
varianties over de enkelvoudige perioden.49 Indien de RW1 geldig is, dan is de variantieratio niet
significant verschillend van 1. Wat zal nu de invloed zijn van de heteroscedasticiteit en de
afhankelijkheid op de variantieratios? Wel als het RW3-model geldig is, dan zullen de
variantieratios convergeren naar 1 in waarschijnlijkheid, zelfs met heteroscedastische schokken.
Zolang de residuen ongecorreleerd zijn, zal de variantie van de som van de residuen (of
rendementen) nog altijd gelijk zijn aan de som van de varianties van de residuen (of
49 Er zal opnieuw vertrokken worden van het logaritmische “random walk”-model zodat er gewerkt wordt met(continu samengestelde) rendementen in plaats van met prijsveranderingen.

Hoofdstuk 6: De Testen van de “Random Walk” 3 112
rendementen) en bijgevolg zullen de variantieratios gelijk zijn aan 1 onder de RW3-hypothese.50
De eigenschap van lineariteit onder de RW1 is echter moeilijk houdbaar bij het RW3-model daar
de variantie van de residuen kan variëren doorheen de tijd. De variantie van de residuen is dus
geen lineaire functie van het tijdsinterval onder de RW3. Zolang de varianties van de residuen
echter eindig zijn en de gemiddelde variantie naar een eindig positief getal convergeert, zullen de
variantieratios convergeren naar 1 onder de RW3-hypothese (LO A. en MACKINLAY A., 1989,
blz. 208).
Het modelleren van heteroscedasticiteit en afhankelijkheid
In het volgende deel zal de steekproefverdeling voor de variantieratios afgeleid worden. De
moeilijkheid zal zijn om de variantie van de variantieratios te bepalen. Het is namelijk zo dat de
asymptotische variantie van de variantieratios zal afhangen van het type en de graad van de
aanwezige heteroscedasticiteit en de afhankelijkheid. Door echter de graad van heterogeniteit en
afhankelijkheid te controleren, is het mogelijk om consistente schatters te bekomen voor de
asymptotische variantie. Lo en MacKinlay (1988) hebben een model voor de RW3 opgesteld dat
toelaat om de heterogeneteit en de afhankelijkheid te contoleren. Het model bestaat uit de
vergelijking ttr εµ += en uit de volgende samengestelde nulhypothese *0H :51
( ) [ ][ ] .00
,01≠=
=Η
− τεεε
τ iederevoorEtiederevoorE
tt
t
( ) { } ( ) ( )( ) ( )
( )[ ] .0
,0,1,1122
2 ∞<∆<>
≥>−−−−Η
+−
δτεεδ
τααφφε
rtt
t
Ezodatbestaateener
iederevoorentiederevoordatzodanigenrdatwaarbijrrgroottedevanmtencoëfficiënmetmixingisof
rrgroottedevanmtencoëfficiënmetmixingis
( ) [ ] .1lim31
22
=∞→∞<=Η
nq
ttnq
Enq
σε
( ) [ ] .0004 kjwaarbijkenjiederevoorentiederevoorE kttjtt ≠≠≠=Η −− εεεε
De voorwaarde ( )1Η is de eigenschap van de RW3 dat de residuen ongecorreleerd zijn met een
verwachtingswaarde 0. Dit moet uiteindelijk getest worden om de geldigheid van de RW3 na te
50 Ook voor de RW2 zou de dezelfde redenering kunnen gevolgd worden.51 Bij het opstellen van de nulhypothese hebben Lo en MacKinlay (1988) gebruik gemaakt van de “mixing” en“moment” condities zoals deze door White (1980) en White en Domowitz (1984) opgesteld zijn.

Hoofdstuk 6: De Testen van de “Random Walk” 3 113
gaan. Met de voorwaarde ( )2Η wordt er een beperking gelegd op de maximum toegelaten
afhankelijkheid tussen de residuen. De voorwaarde ( )3Η wordt ingevoerd om een beperking te
leggen op de maximum toegelaten heterogeniteit. De voorwaarden ( )2Η en ( )3Η zijn zodanig
geformuleerd dat het nog mogelijk is om gebruik te maken van de centrale limietstelling. Ten
slotte impliceert voorwaarde ( )4Η dat de steekproefautocorrelaties van de residuen tε
asymptotisch ongecorreleerd zijn. Deze voorwaarde wordt ingevoerd om de afleiding van de
verdeling voor de variantieratios simpeler te maken. Het is namelijk zo dat als men de variantie
moet afleiden van de variantieratio, die een lineaire combinatie is van autocorrelaties, de
afleiding veel gemakkelijker zal zijn indien de autocorrelaties ongecorreleerd zijn. Deze
voorwaarde zou eventueel weggelaten kunnen worden waardoor het noodzakelijk zou zijn om de
asymptotische covarianties te schatten van de schatters van de autocorrelaties om de variantie
van de variantiesratios af te leiden (LO A. en MACKINLAY A., 1989, blz. 208-209).
Algemeen kan er dus gezegd worden dat de samengestelde nulhypothese *0H veronderstelt dat
de prijzen tp ongecorreleerde residuen bezitten waarbij enkele algemene vormen van
heteroscedasticiteit en een zekere afhankelijkheid toegelaten zijn. Het ARCH-proces is een
voorbeeld van een proces dat voldoet aan de nulhypothese *0H . Daarnaast wordt in *
0H niet de
veronderstelling gemaakt dat de residuen normaal verdeeld moeten zijn. Dit is een belangrijk
gegeven aangezien de aandelenrendementen empirische afwijkingen vertonen van de normaliteit.
Er worden echter wel geen verdelingen toegelaten met een oneindige variatie zoals de stabiele
Pareto-verdelingen (CAMPBELL J. et al., 1997, blz. 54).
De steekproefverdeling van )(qVR onder de RW3
Vervolgens kan nu de steekproefverdeling afgeleid worden voor de schatter )(qVR van de
variantieratio )(qVR zodat er kan getest worden of de variantieraitos al dan niet significant
verschillend zijn van 1.52 De werkwijze die gevolgd wordt, is opnieuw deze van Lo en
MacKinlay (1988).
Eerst kan, gebruik makend van (4.6.6), de schatter )(qVR als volgt gedefinieerd worden:
52 Merk op dat de verdeling zal bepaald worden van de schatter van de variantieratio die gebaseerd is op de zuivereschatters 2~
aσ en ( )qc2~σ voor de variantie 2σ , gedefinieerd in (4.6.39) en (4.6.40).

Hoofdstuk 6: De Testen van de “Random Walk” 3 114
( ) ( )−
=
����
�−+=
1
1
121q
k
ak
qkqVR ρ , (6.1.1)
waarbij dat ( )kρ de geschatte k-de orde autocorrelatie is van de rendementen tr , zoals
gedefinieerd in (4.4.6).
Vervolgens kan uit (6.1.1) afgeleid worden dat de testwaarde )(qVR -1 naar nul zal convergeren
voor alle q indien n oneindig groot wordt (zie bijlage 10). De asymptotische
verwachtingswaarde van )(qVR -1 is dus gelijk aan 0.
Daarnaast kan ook de asymptotische variantie van )(qVR -1 afgeleid worden uit (6.1.1). Stel dat
kδ de asymptotische variantie is van elk van de ( )kρ ’s. Daar uit ( )4Η volgt dat de schatters
( )kρ voor de autocorrelatiecoëfficiënten asymptotisch ongecorreleerd zijn, kan er uit (6.1.1)
afgeleid worden dat de asymptotische variantie ( )qθ van )(qVR een gewogen som is van de
kδ ’s waarbij de gewichten het kwadraat zijn van de gewichten uit (6.1.1). Lo en MacKinlay
(1988) formuleerden de volgende heteroscedasticiteit-consistente schatter kδ voor kδ :
( ) ( )( )
22
1 1
21
2
1 1
���� −−
−−−−=
= −
−−−+= −
nq
j jj
kjkjnq
kj jjk
pp
pppp
µ
µµδ . (6.1.2)
Intuïtief kan deze schatter bekomen worden door de regressie uit te voeren van het rendement tr
op een constante en het k-de vertraagde rendement ktr − . De geschatte coëfficiënt van ktr − is dan
de autocorrelatiecoëfficiënt van de k-de orde en de variantie van de geschatte coëfficiënt is dan
gelijk aan de schatter kδ . De geschatte autocorrelatiecoëfficiënt ( )kρ is dan eigenlijk
asymptotisch normaal verdeeld met verwachtingswaarde 0 en variantie kδ (zie sectie 6.2).
Gebruik makend van (6.1.2), kan de heteroscedasticiteit-consistente schatter ( )qθ voor de
variantie ( )qθ van de variantieratio )(qVR afgeleid worden uit (6.1.1) en ziet er als volgt uit:
( )−
=
�
��
�
�−≡
1
1
2
14q
kk
q
kq δθ . (6.1.3)

Hoofdstuk 6: De Testen van de “Random Walk” 3 115
Uit (6.1.1) kan er nu afgeleid worden dat )(qVR een gewogen som is van de asymptotisch
normaal verdeelde variabelen ( )kρ zodat )(qVR ook asymptotisch normaal verdeeld zal zijn.
Uiteindelijk kan de steekproefverdeling voor )(qVR dan als volgt weergegeven worden (eigen
werk):
( )( )
( )( )1,0
1~Ν
���� −
=∗a
q
qVRq
θψ (6.1.4)
Deze verdeling kan dan, ondanks de aanwezigheid van heteroscedasticiteit, gebruikt worden om
de geldigheid van de RW3 na te gaan. Als de testwaarde ( )q∗ψ binnen het 95%
betrouwbaarheidsinterval valt, dan kan de RW3 aanvaard worden.
6.2 De Autocorrelatie-Test
De test voor de RW3 bestaat er eigenlijk in om na te gaan of de rendementen ongecorreleerd zijn
voor alle vertragingen. Indien de RW3 geldig is zullen alle rendementen ongecorreleerd zijn. Een
directe test hiervoor zal er dan ook in bestaan om de autocorrelatiecoëfficiënten te berekenen
voor verschillende vertragingen en na te gaan of ze gelijk zijn aan nul. Een steekproefverdeling
voor de autocorrelatiecoëfficiënten is opnieuw noodzakelijk (CAMPBELL J., 1997, blz. 44). In
sectie 4.4 werd reeds de steekproefverdeling voor de autocorrelatiecoëfficiënten opgesteld onder
de RW1-hypothese (zie (4.4.22)). Gebruik makend van deze verdeling en (6.1.2), kan de
verdeling voor de autocorrelatiecoëfficiënten onder de RW3, als volgt weergegeven worden
(eigen werk):
( ) ( )1,0~ Νa
k
k
δρ . (6.2.1)
Op basis van deze steekproefverdeling kan de geldigheid van de RW3 gemakkellijk nagegaan
worden (LO A en MacKinlay A, 1989, blz. 210).

Hoofdstuk 6: De Testen van de “Random Walk” 3 116
6.3 De Portmanteau Statistieken
Een derde test voor de RW3 bestaat erin om een Box-Pierce testwaarde op te stellen die rekening
houdt met de heteroscedasticiteit. Gebruik makend van (6.1.2), kan deze Box-Pierce testwaarde
mQ~ als volgt voorgesteld worden:
( )=
=m
k k
mkQ
1
~
δρ . (6.3.1)
Uit (6.2.1) volgt nu onmiddellijk dat de testwaarde mQ~ asymptotisch 2χ -verdeeld is met m
vrijheidsgraden. De test voor de RW3 kan dan ook uitgevoerd worden door middel van deze
verdeling (LO A. en MACKINLAY A, 1989, blz. 210-211).
6.4 Empirisch Onderzoek
De drie bekomen testen voor de RW3 worden nu toegepast op het aandeel UCB en de Bel20-
index. De test met de variantieratios wordt uitgevoerd voor tweevoudige en viervoudige
rendementen. Er wordt gebruik gemaakt van de verdeling (6.4.1) om de geldigheid van de RW3
na te gaan. De resultaten zijn weergegeven in tabel 8. De testwaarde ( )q∗ψ bevindt zich tussen
de vierkante haakjes. De variantieratios voor de week- en maandgegevens van het aandeel UCB
zijn niet significant verschillend van 1. De RW3 mag dus aanvaard worden. Dit was te
verwachten daar de wekelijkse en de maandelijkse rendementen ook voldoen aan de
veronderstellingen van de RW1 en als de rendementen onafhankelijk zijn dan zullen ze ook
ongecorreleerd zijn. Voor de daggegevens lijkt er enige twijfel te bestaan omtrent het al dan niet
aanvaarden van de RW3. De testwaarde ( )q∗ψ voor 4=q is lichtjes significant. De andere
testen kunnen hier meer uitsluitsel over geven.
Voor de daggegevens van de Bel20-index kan de RW3 met grote waarschijnlijkheid verworpen
worden. De RW3 wordt ook verworpen voor de weekgegevens, zij het dat de resultaten minder
uitgesproken zijn. Dus algemeen kan er gesteld worden dat zowel de RW1 als de RW3
verworpen wordt voor de dag- en weekgegevens van de Bel20-index. De rendementen zijn dus
positief gecorreleerd. De dagelijkse en wekelijkse rendementen lijken voor een deel voorspelbaar
te zijn.
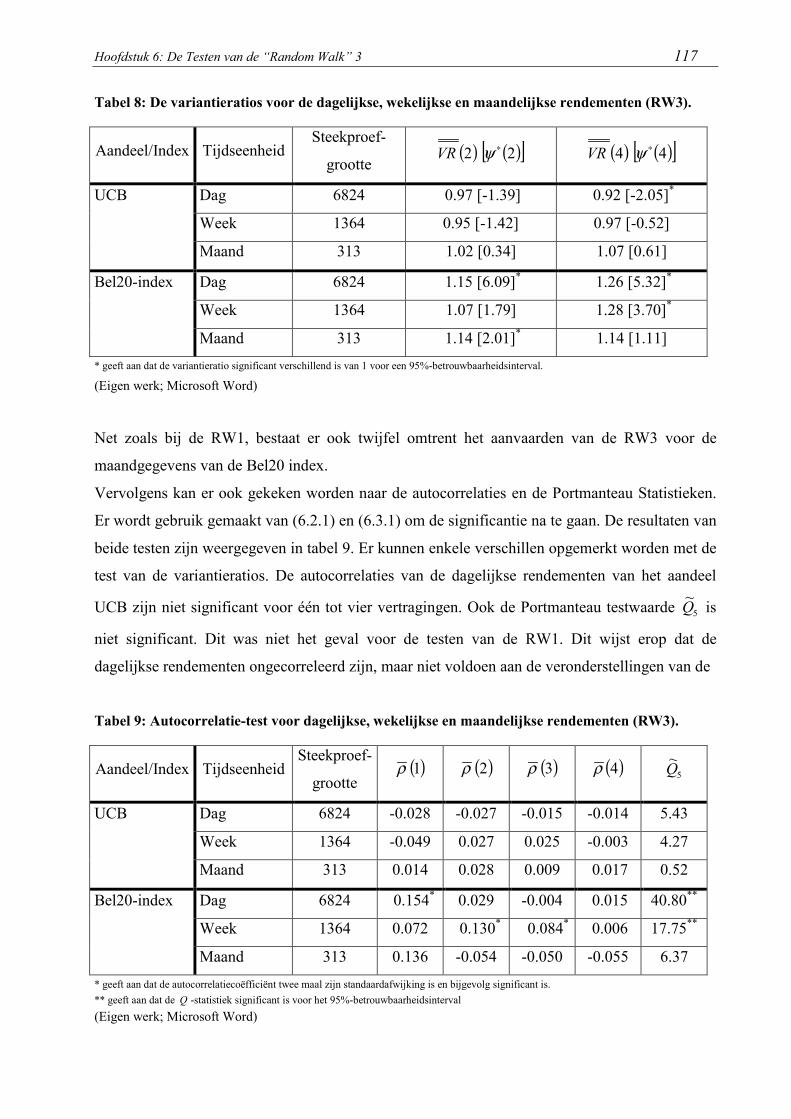
Hoofdstuk 6: De Testen van de “Random Walk” 3 117
Tabel 8: De variantieratios voor de dagelijkse, wekelijkse en maandelijkse rendementen (RW3).
Aandeel/Index TijdseenheidSteekproef-
grootte( )2VR ( )[ ]2∗ψ ( )4VR ( )[ ]4∗ψ
UCB Dag 6824 0.97 [-1.39] 0.92 [-2.05]*
Week 1364 0.95 [-1.42] 0.97 [-0.52]
Maand 313 1.02 [0.34] 1.07 [0.61]
Bel20-index Dag 6824 1.15 [6.09]* 1.26 [5.32]*
Week 1364 1.07 [1.79] 1.28 [3.70]*
Maand 313 1.14 [2.01]* 1.14 [1.11]* geeft aan dat de variantieratio significant verschillend is van 1 voor een 95%-betrouwbaarheidsinterval.
(Eigen werk; Microsoft Word)
Net zoals bij de RW1, bestaat er ook twijfel omtrent het aanvaarden van de RW3 voor de
maandgegevens van de Bel20 index.
Vervolgens kan er ook gekeken worden naar de autocorrelaties en de Portmanteau Statistieken.
Er wordt gebruik gemaakt van (6.2.1) en (6.3.1) om de significantie na te gaan. De resultaten van
beide testen zijn weergegeven in tabel 9. Er kunnen enkele verschillen opgemerkt worden met de
test van de variantieratios. De autocorrelaties van de dagelijkse rendementen van het aandeel
UCB zijn niet significant voor één tot vier vertragingen. Ook de Portmanteau testwaarde 5~Q is
niet significant. Dit was niet het geval voor de testen van de RW1. Dit wijst erop dat de
dagelijkse rendementen ongecorreleerd zijn, maar niet voldoen aan de veronderstellingen van de
Tabel 9: Autocorrelatie-test voor dagelijkse, wekelijkse en maandelijkse rendementen (RW3).
Aandeel/Index TijdseenheidSteekproef-
grootte( )1ρ ( )2ρ ( )3ρ ( )4ρ 5
~Q
UCB Dag 6824 -0.028 -0.027 -0.015 -0.014 5.43
Week 1364 -0.049 0.027 0.025 -0.003 4.27
Maand 313 0.014 0.028 0.009 0.017 0.52
Bel20-index Dag 6824 0.154* 0.029 -0.004 0.015 40.80**
Week 1364 0.072 0.130* 0.084* 0.006 17.75**
Maand 313 0.136 -0.054 -0.050 -0.055 6.37* geeft aan dat de autocorrelatiecoëfficiënt twee maal zijn standaardafwijking is en bijgevolg significant is.** geeft aan dat de Q -statistiek significant is voor het 95%-betrouwbaarheidsinterval(Eigen werk; Microsoft Word)

Hoofdstuk 6: De Testen van de “Random Walk” 3 118
RW1. Uit het verloop van de rendementen (zie bijlage 6) kan er afgeleid worden dat de
volatiliteiten veranderen doorheen de tijd. Er zijn perioden met grote volatiliteit en perioden met
een kleine volatiliteit. De verklaring voor het verwerpen van de RW1 is dus de aanwezigheid van
heteroscedasticiteit in het proces dat de dagelijkse rendementen genereert.
Dezelfde conclusies kunnen getrokken worden voor de maandelijkse rendementen van de Bel20-
index. Op basis van de autocorrelaties en de Portmanteau statistieken kan de RW3 verworpen
worden. Dit was niet het geval voor de RW1.
Niettemin kan er toch besloten worden dat de resultaten voor de RW1 en de RW3 niet zo ver uit
elkaar liggen.

Besluit 119
BesluitZijn de prijsveranderingen van de aandelen voorspelbaar? Via de testen voor de RW1 en de
RW3 werd geprobeerd om tot een besluit te komen. Vooraleer de testen uitgevoerd werden, was
men er reeds van overtuigd dat het RW3-model beter het proces van de aandelenprijzen zou
beschrijven. De veronderstellingen van de RW1 dat de prijsveranderingen onafhankelijk en
identiek verdeeld zijn, lijken niet echt realistisch. Er is namelijk vaak opgemerkt dat de
volatiliteiten van de aandelen over een lange tijdsperiode geleidelijk variëren doorheen de tijd.
De prijsveranderingen zijn dan niet identiek verdeeld zijn en kunnen zelfs afhankelijk zijn van
elkaar daar men eventueel de grootte van de prijsverandering kan voorspellen.
De veronderstelling van de RW3 dat de prijsveranderingen ongecorreleerd zijn , lijkt meer
plausibel. Uit het onderzoek dat uitgevoerd werd op het individueel aandeel UCB en de Bel20-
index, volgt er echter dat de resultaten van de testen voor RW1 en de resultaten voor de RW3
niet significant verschillend zijn van elkaar. Dit wijst erop dat de veranderende volatiliteiten
doorheen de tijd niet als oorzaak naar voor kan gebracht worden voor het verwerpen van de
RW1. Dit lijkt strijdig te zijn met de realiteit. De verklaring voor deze schijnbare inconsistentie
ligt voor de hand. De testen voor de “random walk” zijn namelijk uitgevoerd voor de
logaritmische prijzen omdat deze talrijke voordelen opleveren. Door het nemen van logaritmen
zal het verloop van de prijsveranderingen echter stationair gemaakt worden waardoor de
volatiliteiten niet meer veel zullen variëren doorheen de tijd. Vandaar dat de resultaten van de
RW1 en de RW3 dicht bij elkaar aansluiten. Moesten de testen uitgevoerd worden op de gewone
prijzen, dan zouden er wel significante verschillen optreden. Uit het verloop van de
prijsveranderingen van het aandeel UCB kan er namelijk opgemerkt worden dat de volatiliteiten
variëren doorheen de tijd.
Uit de bekomen resultaten voor het onderzoek kunnen enkele belangrijke gevolgtrekkingen
gemaakt worden. Zo werd er opgemerkt dat de wekelijkse en maandelijkse rendementen van het
aandeel UCB in overeenstemming zijn met de veronderstellingen van de RW1. Dit werd door
iedere test bevestigd. Deze resultaten zijn consistent met eerder uitgevoerde onderzoeken voor
individuele aandelen, van o.a. Moore (1964), Fama (1965) en meer recent Campbell et. al.
(1997). Dit is niet verwonderlijk. De rendementen van individuele aandelen worden namelijk
beïnvloed door het bedrijfsspecifieke of het idiosyncratisch risico dat het moeilijk maakt om
voorspelbare componenten te detecteren.

Besluit 120
De resultaten voor de Bel20-index zijn duidelijk verschillend. De dagelijkse en wekelijkse
rendementen van de Bel20-index zijn niet in overeenstemming met de RW1 en de RW3. De
autocorrelaties van de rendementen zijn niet allen verschillend van 0. Er is sprake van een
positieve afhankelijkheid tussen de rendementen van de Bel20-index. Dit lijkt zo te zijn voor de
meeste indices. De resultaten van Moore (1964) en Campbell et al. (1997) bevestigen dit. De
verklaring is dat door het vormen van portefeuilles van individuele aandelen de voorspelbare
systematische component merkbaar wordt. Het idiosyncratisch risico die verbonden is aan de
individuele aandelen wordt weggediversifieerd door het vormen van portefeuilles. De
systematische component of de marktfactor is in zekere zin voorspelbaar. De positieve
afhankelijkheid wordt nog versterkt door het feit dat sommige aandelen slechts met vertraging
reageren op nieuwe marktinformatie. De prijs van de index zal dan niet onmiddellijk maar
slechts geleidelijk evolueren naar zijn nieuwe waarde. Toch staat de licht negatieve
afhankelijkheid tussen de dagelijkse rendementen van het aandeel UCB in contrast met de sterke
positieve afhankelijkheid tussen de dagelijkse rendementen van de Bel20-index (CAMPBELL et
al., 1997, blz. 72-74).
Welke test levert nu de betrouwbaarste gevolgtrekkingen op? De autocorrelatie-test, de test met
de Portmanteau statistieken en de test met de variantieratios leveren over het algemeen dezelfde
resultaten op. Dit was ook te verwachten daar deze testen allen gebaseerd zijn op dezelfde
autocorrelaties. Algemeen wordt er toch gesteld dat de test met de variantieratios de krachtigste
test is. Deze test buit namelijk een belangrijke eigenschap van de “random walk” uit; namelijk
dat de varianties van de prijsveranderingen of de rendementen lineair zijn met het tijdsinterval
dat onderzocht wordt. De gebrekkigheid van de Cowles-Jones test en de runs-test wordt
blootgelegd door het bestuderen van de daggegevens van het aandeel UCB. Deze testen leveren
een positieve afhankelijkheid op tussen de dagelijkse rendementen terwijl de testen die
gebaseerd op de autocorrelaties wijzen op een lichte negatieve afhankelijkheid. De positieve
afhankelijkheid bij de Cowles-Jones test en de runs-test heeft te maken met het feit dat een
opeenvolging van rendementen gelijk aan 0 beschouwd wordt als een teken van positieve
afhankelijkheid terwijl dit in werkelijkheid niet zo is. Het groot aantal opeenvolgingen van
dagelijkse rendementen van 0 voor het aandeel UCB, in de jaren zeventig en begin de jaren
tachtig, is dan ook de oorzaak van de schijnbaar significante positieve afhankelijkheid tussen de
rendementen. Het probleem bij deze twee testen ligt eigenlijk in het feit dat ze enkel het teken
van de rendementen bestuderen en niet de grootte. Bij de testen gebaseerd op de autocorrelaties
stelt dit probleem zich niet. Deze testen zullen dan ook de betrouwbaarste resultaten opleveren

Besluit 121
Tot slot, kan er nu op basis het uitvoerde onderzoek een algemeen antwoord geformuleerd
worden op de vraag of de aandelenrendementen voorspelbaar zijn. De rendementen van goed
gediversifieerde portefeuilles of indices zijn gedeeltelijk voorspelbaar. De investeerder zou dus
in staat moeten zijn om op basis van het verloop van de rendementen van de indices een
bepaalde winst te genereren. Maar of hij een strategie kan ontwikkelen die altijd tot winst zal
leiden blijft nog altijd een open vraag.

BIJLAGE VI
Bibliografie• ALEXANDER S. S., 1961, Price Movements in Speculative Markets: Trends or Random
Walks, in COOTNER P. H., The Random Character of Stock Market Prices, Massachusetts
Institute of Technology Press, Cambridge MA, blz. 199-218.
• ALEXANDER S. S., 1964, Price Movements in Speculative Markets: Trends or Random
Walks No. 2, in COOTNER P. H., The Random Character of Stock Market Prices,
Massachusetts Institute of Technology Press, Cambridge MA, blz. 338-372.
• BACHELIER L., 1900, Theory of Speculation, in COOTNER P. H., The Random Character
of Stock Market Prices, Massachusetts Institute of Technology Press, Cambridge MA, blz.
17-78.
• BOX G. E. P. en PIERCE D. A., 1970, Distribution of Residual Autocorrelations in
Autoregressive Integrated Moving Average Time Series Models, Journal of the American
Statistical Association, vol. 65, nr. 332, december 1970, blz. 1509-1526.
• CAMPBELL J. Y. , LO A. W. en MACKINLEY A. C., 1997, Econometrics of Financial
Markets, Priceton University Press, New Jersey, 611 blz.
• COOTNER P. H., 1962, Random vs. Systematic Changes, in COOTNER P. H., 1964, The
Random Character of Stock Market Prices, Massachusetts Institute of Technology Press,
Cambridge MA, blz. 231-252.
• COOTNER P. H., 1964, The Random Character of Stock Market Prices, Massachusetts
Institute of Technology Press, Cambridge MA, 536 blz.
• COWLES A., 1960, A Revision of Previous Conclusions Regarding Stock Price Behaviour,
Econometrica, vol. 28, nr. 4, oktober 1960, blz. 909-915.
• DICKEY D. A. en FULLER W. A., 1979, Distribution of the Estimators for Autogressive
Time Series with a Unit Root, Journal of the American Statistical Association, vol. 74, nr.
366, juni 1979, blz. 427-431.
• ELTON E. en GRUBER M., 1995, Modern Portfolio Theory and Investment Analysis, John
Wiley & Sons, New York, 715 blz.
• EVIEWS, 1994-95, Eviews Help System, Quantitative Micro Software.
• FAMA E. F., 1963, Mandelbrot and the Stable Paretian Hypothesis, in COOTNER P. H.,
1964, The Random Character of Stock Market Prices, Massachusetts Institute of Technology
Press, Cambridge MA, blz. 297-306.

BIJLAGE VII
• FAMA E. F., 1965, The Behaviour of Stock Market Prices, Journal of Business, vol. 38 , nr.
1, januari 1965, blz. 34-105.
• FAMA E. F., 1970, Efficient Capital Markets: A Review of Theory and Empirical Work,
Journal of Finance, vol. 25, nr. 2, mei 1970, blz. 383-417.
• FAMA E. F., 1977, Foundations of Finance, Basil Blackwell, Oxford, 395 blz..
• FAMA E. F. en BLUME M., 1966, Filter Rules and Stoch Market Trading Profits, Journal of
Business, vol. 39, nr. 1, deel II, januari 1966, blz. 226-241.
• FULLER W. A., 1976, Introduction to Statistical Time Series, John Wiley & Sons, New
York, 470 blz.
• GREENE W. H., 1993, Econometric Analysis, Macmillan Publishing Company, New York,
791 blz.
• HAMILTON J. D., 1994, Time Series Analysis, Priceton University Press, New Jersey, 799
blz.
• HARRINGTON D. R., 1983, Modern Portfolio Theory & the Capital Asset Pricing Model, a
User’s Guide, Prentice-Hall, Inc., Englewood Cliffs, 136 blz.
• HAUSMAN J. A., 1978, Specification Tests in Econometrics, Econometrica, vol. 46, nr. 6,
november 1978, blz. 1251-1271.
• KENDALL M. G., 1953, The Analysis of Economic Time-Series-Part I: Prices, in
COOTNER P. H., 1964, The Random Character of Stock Market Prices, Massachusetts
Institute of Technology Press, Cambridge MA, blz. 85-99.
• LJUNG G. M. en BOX G. E. P., 1978, On a Measure of Lack of Fit in Time Series Models,
Biometrika, vol. 65, nr. 2, blz. 297-303.
• LO A. en MACKINLEY A.C., 1988, Stock Market Prices Do Not Folow Random Walks:
Evidence from a Simple Specification Test, Review of Financial Studies, vol.1, nr. 1, 1988,
blz. 41-66.
• LO A. en MACKINLEY A.C., 1989, The Size and Power of the Variance Ratio Test in
Finite Samples: A Monte Carlo Investigation, Journal of Econometrics, vol. 40, nr. 2,
februari 1989, 203-238.
• MANDELBROT B., 1963, The Variation of Certain Speculative Prices, in COOTNER P. H.,
1964, The Random Character of Stock Market Prices, Massachusetts Institute of Technology
Press, Cambridge MA, blz. 307-332.
• MANDELBROT B., 1966, Forecasts of Future Prices, Unbiased Markets, and “Martingale”
Models, Journal of Business, vol. 39, nr. 1, deel II, januari 1966, blz. 242-255.

BIJLAGE VIII
• MANDELBROT B., 1998, Fractals op de beurs, Natuur&Techniek, jr. 66, nr. 5, mei 1998,
blz. 62-71.
• MOORE A. B., 1964, Some Characteristics of Changes in Common Stock Prices, in
COOTNER P. H., 1964, The Random Character of Stock Market Prices, Massachusetts
Institute of Technology Press, Cambridge MA, blz. 139-161.
• O’DONOVAN T. M., 1983, Short Term Forecasting: An Introduction to the Box-Jenkins
Approach, John Wiley & Sons, Chichester, 282 blz.
• QOBRA INVEST,1999, URL:<http://bewoner.dma.be/Herbots/b_bel20>.(26/04/99).
• REYNAERTS H., 1995, Statistiek I, Cursus gedoceerd aan de Rijksuniversiteit Gent (RUG).
• REYNAERTS H., 1997, Econometrie I, Cursus gedoceerd aan de Rijksuniversiteit Gent
(RUG).
• REYNAERTS H., 1998, Econometrie II, Cursus gedoceerd aan de Rijksuniversiteit Gent
(RUG).
• ROBERTS H. V., 1959, Stock-Market “Patterns” and Financial Analysis: Methodological
Suggestions, in COOTNER P. H., 1964, The Random Character of Stock Market Prices,
Massachusetts Institute of Technology Press, Cambridge MA, blz 7-16.
• SUNDT B., 1993, An Introduction to Non-life Insurance Mathematics, Veröffentlichungen
des Instituts für Versicherungswissenschaft der Universität Mannheim, Band 28 , blz 199.
• UCB BELGIUM, 1998, URL: <http://www.ucbgroup.com>. (26/04/99).
• VANMAELE M., 1995, Wiskunde I, Cursus gedoceerd aan de Rijksuniversiteit Gent (RUG).
• VERBEEK M., 1998, Econometrics of Financial Markets I: Market efficiency and
predictability of assets returns, januari 1998.
• WORKING H., 1960, Note on the Correlation of First Differences of Averiging in a Random
Chain, Econometrica, vol. 28, nr. 4, oktober 1960, blz. 916-918.

BIJLAGE IX
BijlagenBIJLAGE 1a: Simulatie van prijzen voor de RW1
BIJLAGE 1b: Simulatie van prijsveranderingen voor de RW1
BIJLAGE 2a: Simulatie van standaardafwijkingen voor de residuen voor de RW2
BIJLAGE 2b: Simulatie van de residuen voor de RW2
BIJLAGE 2c: Simulatie van de prijzen voor de RW2
BIJLAGE 2d: Simulatie van de prijsveranderingen voor de RW2
BIJLAGE 3a: Simulatie van de residuen voor de RW3
BIJLAGE 3b: Simulatie van de prijzen voor de RW3
BIJLAGE 3c: Simulatie voor de prijsveranderingen voor de RW3
BIJLAGE 4: UCB: gewone prijzen
BIJLAGE 5: Bel20-index: gewone prijzen
BIJLAGE 6: UCB: logaritmische prijzen
BIJLAGE 7: Bel20-index: logaritmische prijzen
BIJLAGE 8: De kritische waarden van Dickey en Fuller
BIJLAGE 9: Afleiding zuivere schatter ( )cc2~σ voor de variantie 2σ
BIJLAGE 10: De asymptotische verwachtingswaarde van ( ) 1−qVR is gelijk aan 0
BIJLAGE 4
UCB: gewone prijzen
Het verloop van de dagelijkse prijzen. Het verloop van de dagelijkse prijs ∆ .
(Gegevens van Datastream; Eviews) (Gegevens van Datastream; Eviews)
Het verloop van de wekelijkse prijzen. Het verloop van de wekelijkse prijs ∆ .
(Gegevens van Datastream; Eviews) (Gegevens van Datastream; Eviews)
0
10
20
30
40
50
60
1/01/73 9/01/80 5/02/88 1/01/96
UCB
-6
-4
-2
0
2
4
6
1/01/73 9/01/80 5/02/88 1/01/96
DUCB
0
10
20
30
40
50
60
1/01/73 9/01/80 5/02/88 1/01/96
UCB
-6
-4
-2
0
2
4
6
1/01/73 9/01/80 5/02/88 1/01/96
DUCB

BIJLAGE 5
Bel20-index: gewone prijzen
Het verloop van de dagelijkse prijzen. Het verloop van de dagelijkse prijs ∆ .
(Gegevens van Datastream; Eviews) (Gegevens van Datastream; Eviews)
Het verloop van de wekelijkse prijzen. Het verloop van de wekelijkse prijs ∆ .
(Gegevens van Datastream; Eviews) (Gegevens van Datastream; Eviews)
0
200
400
600
800
1000
1/01/73 9/01/80 5/02/88 1/01/96
BEL20
-40
-20
0
20
40
1/01/73 9/01/80 5/02/88 1/01/96
DBEL20
0
200
400
600
800
1000
1/01/73 8/02/82 3/02/92
BEL20
-100
-50
0
50
100
1/01/73 8/02/82 3/02/92
DBEL20

BIJLAGE 6
UCB: logaritmische prijzen
Het verloop van de dagelijkse prijzen. Het verloop van de dagelijkse prijs ∆ .
(Gegevens van Datastream; Eviews) (Gegevens van Datastream; Eviews)
Het verloop van de wekelijkse prijzen. Het verloop van de wekelijkse prijs ∆ .
(Gegevens van Datastream; Eviews) (Gegevens van Datastream; Eviews)
Het verloop van de maandelijkse prijzen. Het verloop van de maandelijkse prijs ∆
(Gegevens van Datastream; Eviews) (Gegevens van Datastream; Eviews)
-2
-1
0
1
2
3
4
5
1/01/73 9/01/80 5/02/88 1/01/96
LNUCB
-0.3
-0.2
-0.1
0.0
0.1
0.2
0.3
1/01/73 9/01/80 5/02/88 1/01/96
DLNUCB
-2
-1
0
1
2
3
4
5
1/01/73 8/02/82 3/02/92
LNUCB
-0.3
-0.2
-0.1
0.0
0.1
0.2
0.3
1/01/73 8/02/82 3/02/92
DLNUCB
2
4
6
8
10
74 76 78 80 82 84 86 88 90 92 94 96 98
LNUCB
-0.4
-0.2
0.0
0.2
0.4
0.6
74 76 78 80 82 84 86 88 90 92 94 96 98
DLNUCB

BIJLAGE 7
Bel20-index: logaritmische prijzen
Het verloop van de dagelijkse prijzen. Het verloop van de dagelijkse prijs ∆ .
(Gegevens van Datastream; Eviews) (Gegevens van Datastream; Eviews)
Het verloop van de wekelijkse prijzen. Het verloop van de wekelijkse prijs ∆ .
(Gegevens van Datastream; Eviews) (Gegevens van Datastream; Eviews)
Het verloop van de maandelijkse prijzen. Het verloop van de maandelijkse prijs ∆
(Gegevens van Datastream; Eviews) (Gegevens van Datastream; Eviews)
4.0
4.5
5.0
5.5
6.0
6.5
7.0
1/01/73 9/01/80 5/02/88 1/01/96
LNBEL20
-0.15
-0.10
-0.05
0.00
0.05
0.10
1/01/73 9/01/80 5/02/88 1/01/96
DLNBEL20
4.0
4.5
5.0
5.5
6.0
6.5
7.0
1/01/73 8/02/82 3/02/92
LNBEL20
-0.2
-0.1
0.0
0.1
0.2
1/01/73 8/02/82 3/02/92
DLNBEL20
4.0
4.5
5.0
5.5
6.0
6.5
7.0
74 76 78 80 82 84 86 88 90 92 94 96 98
LNBEL20
-0.3
-0.2
-0.1
0.0
0.1
0.2
0.3
74 76 78 80 82 84 86 88 90 92 94 96 98
DLNBEL20

BIJLAGE 8
De kritische waarden van Dickey en Fuller
(Bron: HARVEY A. C., 1990, The Econometric Analysis of Time Series, Philip Allan, Hertfordshire, 387 blz.)

BIJLAGE 9
Afleiding zuivere schatter ( )qc
2~σ voor de variantie 2σ
Het volgende zal bewezen worden:
( ) ( )=
− −−≡nq
qkqkkc qpp
nqq 2
2
2 1 µσ is een onzuivere schatter voor 2σ
( ) ( )=
− −−≡nq
qkqkkc qpp
mq 22 1~ µσ is een zuivere schatter voor 2σ
( )�
��
�
�−+−≡
nq
qqnqqmmet 11
De zuivere schatter kan als volgt voorgesteld worden:
( )[ ] 22 σσ kqE c =
( )k
qc2σ is een zuivere schatter
Het komt er dus op aan om de k te berekenen. Dit zal gebeuren in verschillende stappen (de
overgangen die gemaakt worden bij de afleidingen zijn meestal vanzelfsprekend):
(1)
( )[ ][ ]
[ ] [ ] [ ] [ ]2
1211
12122
1
21
,2,2
22
σ
εεεεεε
εεεεεε
εε
q
CovCovVarVar
E
E
qqq
qqq
q
=
+++++=
+++++=
++
−
−
��
��
�

(2)
( )
[ ] [ ]
εµµ
µεµ
εµ
σεεµ
=−
+=
+=
Ν+=
tt
ttt
ErE
IIDmetr 2,0~
(3)
( ) ( )
( )=
+−
=+−
−+−=
+−
−−=
nq
qkqkk
nq
qkqkkc
qqnq
qrrnq
q
212
212
2
1
1
µµεε
µµ
µσ
(4)
( )[ ]( ) ( ) ( )( )[ ]( )[ ] ( )[ ] ( )( )[ ]
[ ] ( )[ ]1222
1222
1
1222
1
21
2
2
2
+−
+−+−
+−+−
+−
+−++=
+−+−++=
+−+−++=
−++
qkk
qkkqkk
qkkqkk
qkk
EqEqq
EqEqE
qqE
qqE
εεεεσ
εεµµµµεε
εεµµµµεε
µµεε
�
��
��
�
De afleidingen volgen uit (1) en (2).De tweede en de derde term worden nu afzonderlijk
uitgewerkt:
[ ] [ ] [ ]( )
qn
EVarE
2
22
σ
εεε
=
+=•

( )[ ]1+−++• qkkE εεε �
stel iqkk X=++ +− 1εε � ( n waarnemingen voor iX )
qn
XX i==ε
[ ]
( )[ ]
[ ] [ ]( )
[ ]
[ ] [ ]( )
qn
q
XEXVarqn
XXEqn
XXEXXEqn
XXXqn
Xqn
XEXXE
ii
ii
ini
in
ii
i
2
2
1
1
1
1
1
1
σ=
−=
=
++=
++=
�
���
�=
�
�
Deze afleidingen kunnen nu terug ingebracht worden in deel (4):
( )[ ]
2
222
2222
21
1
2
σ
σσ
σσσ
µµεε
�
��
�
�−=
−=
−+=
−++ +−
qn
qn
qn
qqqn
qqE qkk �

(5)
( )[ ] ( )[ ]
( ) 2
2
212
2
111
1
σ
µµεεσ
�
��
�
�−+−=
−++= +−=
qn
qqqqnqn
qqEqn
qE qkk
nq
qkc �
( )
( )�
��
�
�−+−
qn
qqqqnqn
qc
1112
2σ is een zuivere schatter
( )( ) ( )qqpp
qn
qqqnqc
nq
qkqkk
22 ~
11
1 σµ =−−�
��
�
�−+−
�=
− is een zuivere schatter.
(Eigen werk)

BIJLAGE 10
De aymptotische verwachtingswaarde van ( ) 1−qVR is gelijk aan 0
De werkwijze die gevolgd wordt is deze van Lo en MacKinlay (1988).Stel de volgende schatter
voor de autocorrelatiecoëfficiënt:
( )( )( )
( )( )( )kB
kA
rqn
rrqnk kn
ktt
qn
ktktt
≡−
−−
=
=
=−
21
1
µ
µµρ
1−−= ttt pprmet
Men kan gemakkelijk afleiden dat ( )kB zal convergeren naar 2σ indien het aantal
waarnemingen zeer wordt. ( )kB is namelijk een consistente schatter voor de variantie 2σ . Er
moet nu nog enkel bewezen worden dat ( )kA convergeert naar 0 voor een groot aantal
waarnemingen.. ( )kA kan eerst als volgt uitgewerkt worden:
( ) ( )( )
( )( )
( ) ( ) ( )=
−=
−=
=−
=−
+−+−+−+−=
+−+−=
−−≡
qn
ktktt
qqn
ktkt
qqn
ktt
qn
ktktt
qn
ktktt
qnqnqnqn
kqn
qn
rrqn
kA
εεεµµεµµµµ
εµµεµµ
µµ
1111
1
1
2
De eerste term is gelijk aan 0 voor een groot aantal waarnemingen daar µ dan zal convergeren
naar µ . Uit (H1) van de samengestelde nulhypothese *0H volgt onmiddellijk dat de drie andere
termen ook convergeren naar nul indien het aantal waarnemingen zeer groot is. ( )kA zal dan
convergeren naar nul zodat de schatter ( )kρ voor de autocorrelatie ook convergeert naar nul.
Daar ( )qVR -1 een lineaire combinatie is van de schatters voor de autocorrelatiecoëfficiënten, zal
ze ook convergeren naar nul indien het aantal waarnemingen zeer groot wordt. De asymptotische
verwachtingswaarde van ( )qVR -1 is dus gelijk aan nul.