情報学習理論 - 東京工業大学watanabe- · 教師あり学習の例 教師あり学習...
TRANSCRIPT

2015/10/13 Mathematical Learning Theory 1
情報学習理論
渡辺澄夫

2015/10/13 Mathematical Learning Theory 2
いろいろな学習
(1) 教師あり学習(2) 教師なし学習(3) そのほか
まず教師あり学習について学びます。教師あり学習は実世界で重要なので多くの方法があります。
(線形回帰) 今日(神経回路網) 来週以降(SVM) 来週以降

2015/10/13 Mathematical Learning Theory 3
教師あり学習とは
8,6,2…でしょう
先生
文字の例
文字を読めるように学習します
生徒…

2015/10/13 Mathematical Learning Theory 4
復習:確率密度関数
実数 x
q(x)
確率変数 X = 確率的にばらつく変数
A
「X ∈ A となる確率」
確率変数 X が確率密度関数 q(x) を持つとき
A= ∫ q(x) dx

2015/10/13 Mathematical Learning Theory 5
復習:条件つき確率密度関数
x
y
q(x,y)
O
q(x,y)
q(y|x) = ---------面積が q(x) q(x,y)q(x)
q(y|x) は「x が与えられたときの y の確率密度関数」

2015/10/13 Mathematical Learning Theory 6
教師あり学習は条件つき確率を推定する
真の分布q(x)
入力例 x1,x2,x3,…
真の推論q(y|x)
学習モデルp(y|x,w)
学習結果 p*(y|x)
答例 y1,y2,y3,…
…

2015/10/13 Mathematical Learning Theory 7
教師あり学習の例
教師あり学習画像認識、音声認識、時系列予測、ロボット制御など応用は極めて多数。「予測の正確さ」が必要になることが多い。
教師あり学習でないものデータのクラスタリングデータの構造化データの次元縮約など

2015/10/13 8牧場の5分後を予想するのが私の仕事です

2015/10/13 Mathematical Learning Theory 9
教師あり学習の例: 回帰問題
X
Y = g(X) +雑音
入力
教師・真
(1) 真の関数 g をモデル f で推測する。(2) g(x) を真の回帰関数という。(3) 例 { (Xi,Yi) ; i=1,2,…,n} から真を推測。(4) モデルは真を知らない人間が仮に定めたもの。
Y = f(X,w) +雑音生徒・モデル

2015/10/13 Mathematical Learning Theory 10
線形回帰
Xi =(Xi1,Xi2,…,Xid)入力(d次元)
Yi = w0・Xi+雑音真(1次元)
データ番号 i = 1,2,…, n
データ (Xi,Yi) が得られたときw0=(w01,w02,…,w0d) を推測する
Yi = w・Xi+雑音モデル(1次元)

2015/10/13 Mathematical Learning Theory 11
二乗誤差
データ {(Xi ,Yi ) ; i=1,2,…,n}
二乗誤差を最小にする w を見つける
E(w)=Σ (Yi – w・Xi)2n
i=1

2015/10/13 Mathematical Learning Theory 12
二乗誤差をパラメータで偏微分したとき0になるようなパラメータを見つければよい。
E(w) = Σ (Yi – Σ wjXij)2d
j=1
n
i=1
∂E/∂wk = 2 Σ (Yi – Σ wjXij)(-Xik )=0 n
i=1
d
j=1
k=1,2,…,d について
Σ Yi Xik = Σ wj Σ XijXik n
i=1
d
j=1
n
i=1
(w1,w2,…,wd) についての連立方程式が得られる。

2015/10/13 Mathematical Learning Theory 13
E(w) を最小にするパラメータ w は計算できる。
Sk = Σ Yi Xik
n
i=1
ベクトル S と行列 I を次のように定義する
Ijk = Σ XijXik
n
i=1
この量はどちらもデータから計算できる
Sk = Σ wj Ijk
d
j=1
連立方程式は
S = Iw行列を使って書くと
w = I-1 S答えは

2015/10/13 Mathematical Learning Theory 14
素朴な質問:最小二乗法について
(1) 何のための最小二乗法 ?
(2) 最小二乗法って最高?
「真のパラメータ w0 を知りたい」「未来の X についてYの予測誤差を小さくしたい」「 X の要素で必要なものと不要なものを分けたい」
最小二乗法は最初に学ぶ基本です。目的に応じてもっと高精度な方法があります。

2015/10/13 Mathematical Learning Theory 15
問1
二乗誤差
E(a)=Σ (Yi – aXi)2
データ { (Xi ,Yi ) ; i=1,2,…,n }
n
i=1
を最小にする a を求めよ。

2015/10/13 Mathematical Learning Theory 16
学習のモデルは毎年毎年よく似ているが学習理論の応用は毎年毎年移り変わる
2015/10/13 Mathematical Learning Theory 17
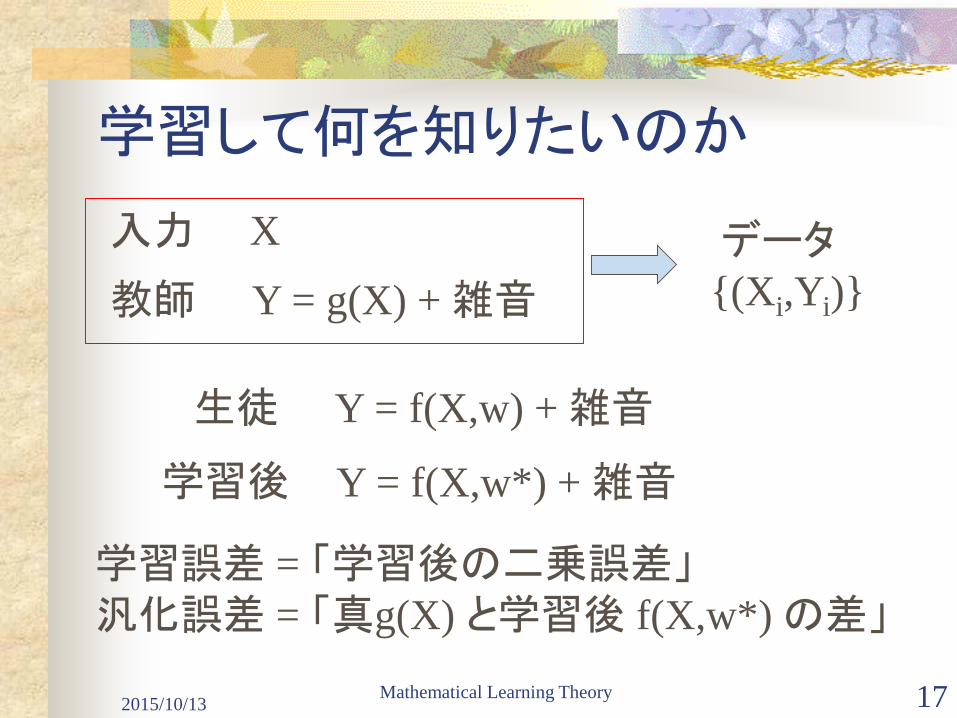
学習して何を知りたいのか
XY = g(X) + 雑音
入力
教師
Y = f(X,w) + 雑音生徒
Y = f(X,w*) + 雑音学習後
データ{(Xi,Yi)}
学習誤差 = 「学習後の二乗誤差」汎化誤差 = 「真g(X) と学習後 f(X,w*) の差」

2015/10/13 Mathematical Learning Theory 18
学習誤差と汎化誤差
E(w*) = (1/n) Σ (Yi – f(Xi,w*))2n
i=1
G(w*) = ∬ (y – f(x,w*))2 q(y|x)q(x)dxdy
二乗誤差を最小にするパラメータを w* とし、学習誤差 E(w*) と汎化誤差 G(w*) を次式で定義する。

2015/10/13 Mathematical Learning Theory 19
汎化誤差の原因
バイアス(関数近似誤差)
どんなにパラメータ w を工夫してもf(x,w) は g(x) になれない
バリアンス(統計的推定誤差)
データに雑音が含まれるのでw の推定がばらつく

2015/10/13 Mathematical Learning Theory 20
バイアスとバリアンス
バイアス モデルが複雑なほど小さいサンプル数が増えても減らない
バリアンス モデルが単純なほど小さいサンプル数が増えると減る
両立しない → バイアス・バリアンス問題
現実の問題において必ず現れる
☆ バイアスは分かりやすいがバリアンスは分かりにくい。実応用で「バイアスを減らすことだけに集中」が頻発する。

2015/10/13 Mathematical Learning Theory 21
(例題) 線形テンソルモデル
X=(X1,X2)入力
Y = Σ wjk (X1)j(X2)
k + 正規雑音生徒
学習例 { (X1i,X2i,Yi) ; i=1,2,…,n } が与えられればパラメータ wjk は最小二乗法で求められる。
0≦j,k≦4
Y = g(X1,X2) + 正規雑音教師

2015/10/13 Mathematical Learning Theory 22
実際に学習してみよう
教師:Y = X1X2 + 正規雑音ケース1
テンソルモデルで実現可能バイアス=0
教師:Y = exp(-5*(X12+X2
2))+ 正規雑音
ケース2
テンソルモデルで実現不可能バイアスは零ではない。

2015/10/13 Mathematical Learning Theory 23
問2
実現可能
実現不可能
n=100 n=1000
汎化誤差(Generalization Error)の値を計算して書き入れましょう。