企業システムにおける 大規模データの活用と hadoop の動向mas_ibm.pdf ·...
TRANSCRIPT

© 2010 IBM Corporation
企業システムにおける大規模データの活用と Hadoop の動向
日本アイ・ビー・エム株式会社Linux/OSS&Cloud サポートセンター中井 悦司

© 2010 IBM Corporation2
目次
Hadoop とは?
IBM InfoSphere BigInsightsBigSheets デモ

© 2010 IBM Corporation3
Hadoop とは?Hadoop とは?

© 2010 IBM Corporation4
Hadoop とは?
– HDFS (Hadoop Distributed File System)• 複数のノードのローカルファイルシステムを
論理的に結合して、1 つの共有ファイルシス
テムを作成します。
– Hadoop MapReduce• MapReduce と呼ばれる分散コンピューティ
ングモデルに基づくプログラムを Java で作
成するためのフレームワークを提供します。
Hadoop は、Google が提唱した分散データ処理を行うためのフレームワークを オープンソースとして再実装したものです。
OBCI Web 連載企画でHadoop を解説しています!
『企業システムで有効なオープンソース活用法』http://itpro.nikkeibp.co.jp/article/COLUMN/20100820/351294/

© 2010 IBM Corporation5
Google における MapReduce の利用
MapReduce はデータ処理の手続きを定めているだけであり、実際の Map 処理と Reduce 処理の内容は、解く
べき問題に応じて、個々に考えて実装する必要があります。– Google での例から分かる様に、静的データの解析(データマイニング)に向いています。(*)
Google では、次のようなデータ処理を MapReduce モデルで実装していると言っています。
– Web サイト内の文字列検索
– URL 毎のアクセスカウント(Web サーバーのアクセスログの解析)
– 特定の URL にリンクを貼っている Web サイトのリストの作成
– Web サイト毎の単語の出現回数のリストの作成
– 特定の単語が含まれる Web ページのリストの作成
– 大規模なソート処理
Google では、次のような規模の MapReduce 処理をよく実施していると言っています。
– 使用ノード数 2,000– map 処理の分割数 200,000– reduce 処理の分割数 5,000
(*) "MapReduce: Simplified Data Processing on Large Clusters" Jeffrey Dean, Sanjay Ghemawat (2004) http://labs.google.com/papers/mapreduce.html
© 2010 IBM Corporation6
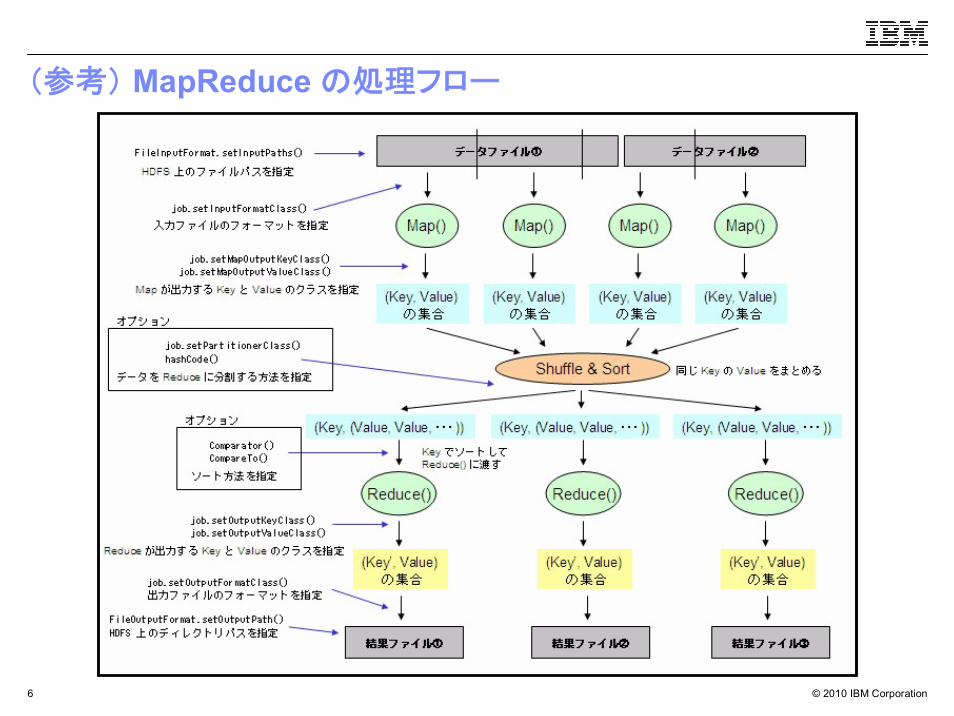
(参考) MapReduce の処理フロー

© 2010 IBM Corporation7
(参考) MapReduce のプログラムの例package batt;
import java.io.*;import org.apache.hadoop.conf.*;import org.apache.hadoop.fs.*;import org.apache.hadoop.io.*;import org.apache.hadoop.mapreduce.*;import org.apache.hadoop.mapreduce.lib.input.*;import org.apache.hadoop.mapreduce.lib.output.*;import org.apache.hadoop.util.*;
public class Batt extends Configured implements Tool {
public static void main( String[] args ) throws Exception {int status = ToolRunner.run( new Pairs(), args );System.exit( status );
}
@Overridepublic int run( String[] args ) throws Exception {
Job job = new Job( getConf(), "MapReduce Job" );job.setJarByClass( Pairs.class );job.setMapperClass( Map.class );job.setReducerClass( Reduce.class );
FileInputFormat.setInputPaths( job, new Path( args[ 0 ] ) );FileOutputFormat.setOutputPath( job, new Path( args[ 1 ] ) );job.setInputFormatClass( TextInputFormat.class );job.setOutputFormatClass( TextOutputFormat.class );
// Output format of Mapjob.setMapOutputKeyClass( Text.class );job.setMapOutputValueClass( IntWritable.class );
// Output format of Reducejob.setOutputKeyClass( Text.class );job.setOutputValueClass( IntWritable.class );
return job.waitForCompletion( true ) ? 0 : -1;}
public static class Map extendsMapper<LongWritable, Text, TextPair, IntWritable> {
protected void map( LongWritable key, Text value, Context context )throws IOException, InterruptedException {String line = value.toString();String[] cols = line.split( "¥¥s*,¥¥s*" );int batt = Integer.parseInt( colss[ 13 ] )if ( batt > 14 ) {
context.write( new Text( cols[ 0 ] ), new IntWritable( batt ) );}
}}
public static class Reduce extendsReducer<Text, IntWritable, Text, IntWritable> {
protected void reduce( Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {int battMax = 0;int batt = 0;for ( IntWritable i : values ) {
batt = i.get();if ( batt > batMax ) {
battMax = batt;}
}context.write( key, new IntWritable( battMax ) );
}}
}
CSV データから特定の列の値でフィルターする処理をMapReduce で記述した例です。
– MapReduce の処理を Java で直接プログラミングするのは、意外と手間がかかります。

© 2010 IBM Corporation8
一般企業での Hadoop 活用事例
このページは配布いたしません。

© 2010 IBM Corporation9
IBM InfoSphereBigInsights
IBM InfoSphereBigInsights

© 2010 IBM Corporation10
ネットワーク技術の進化やセンサーデバイスの普及により、
様々なデータが大規模に蓄積されています
資本市場のデータ量は2003年から2006年にかけて17.5倍も増加
2005年のRFIDタグの利用は13億個。2010年までには300億個。
2007年に携帯電話の利用者は33億人
2011年までにインターネットの利用者は20億人に達する
政府、国防組織,交通管理
世界中の総情報量は2年ごとに2倍になる
背景: データ量の爆発やデータの種類の多様化が急速に拡大
© 2010 IBM Corporation11
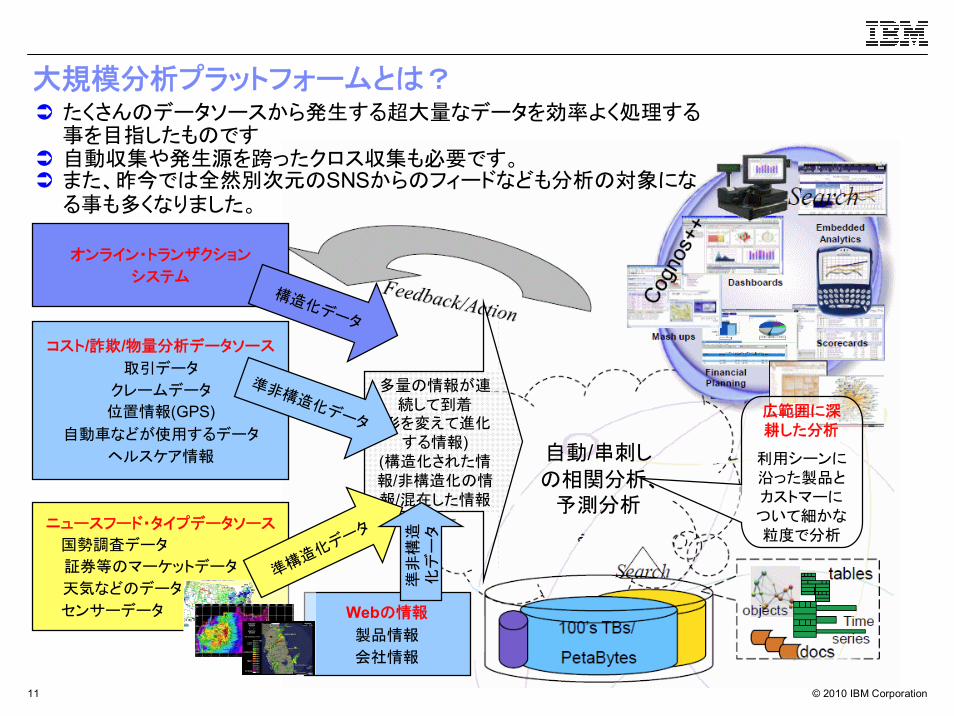
多量の情報が連続して到着
(形を変えて進化する情報)
(構造化された情報/非構造化の情報/混在した情報
広範囲に深耕した分析
利用シーンに沿った製品とカストマーについて細かな粒度で分析
Webの情報
製品情報
会社情報
ニュースフード・タイプデータソース
国勢調査データ□ □ □ □□
証券等のマーケットデータ □
天気などのデータ□ □ □ □
センサーデータ□ □ □ □ □
大規模分析プラットフォームとは?たくさんのデータソースから発生する超大量なデータを効率よく処理する事を目指したものです自動収集や発生源を跨ったクロス収集も必要です。また、昨今では全然別次元のSNSからのフィードなども分析の対象になる事も多くなりました。
コスト/詐欺/物量分析データソース
取引データ
クレームデータ
位置情報(GPS)自動車などが使用するデータ
ヘルスケア情報
オンライン・トランザクション
システム
準非構造化データ
準構造化データ
構造化データ
準非構造
化データ
自動/串刺し
の相関分析、予測分析

© 2010 IBM Corporation12
InfoSphere Information
Server
ETLETL
Data QualityData Quality
Data Synchronization
Replication Server
Classic Event Publisher
Classic Federation
Change Data Capture Federation
InfoSphere MDM Server
CDI/PIMCDI/PIM
WarehouseWarehouseCommon Meta Data
Common Meta Data
CubingCubing
MiningMining
InfoSphere Global Name Recognition
InfoSphere Entity Resolution
InfoSphere Warehouse
Dashboards
Financial Planning
Mash ups
ScorecardsInfoSphere Streams
Big Insights
大規模分析プラットフォームの全体イメージ
Embedded Analytics
• 従来は扱わなかったタイプの大量データ (Web から収集したデータなど)• 従来は保存しきれなかったタイプの大量データ (時系列の業務データなど)
Jaql

© 2010 IBM Corporation13
Jaql (JSON Query Language) とは?
IBM アルマデン研究所が開発した、準構造化データを解析するための再利用可能なスクリ
プト言語です。
分散ファイルシステムからデータを読み出して加工する処理を記述します。
処理は自動的に Hadoop ジョブとして実行されます。
Java 等で記述したユーザ定義関数をライブラリ化することができます。
R などの統計パッケージや IBM 提供のテキスト処理モジュールとインテグレートできます
source sinkoperator operator
read writeHadoopFile System
HadoopFile System
SQLのようなデータ操作•フィルター•プロジェクション•集約
・ Jaql はオープンソースとして公開されています。 http://code.google.com/p/jaql/・ Jaql のセットアップ手順は、こちらを参照ください。http://d.hatena.ne.jp/enakai00/20101115/1289804628
© 2010 IBM Corporation14
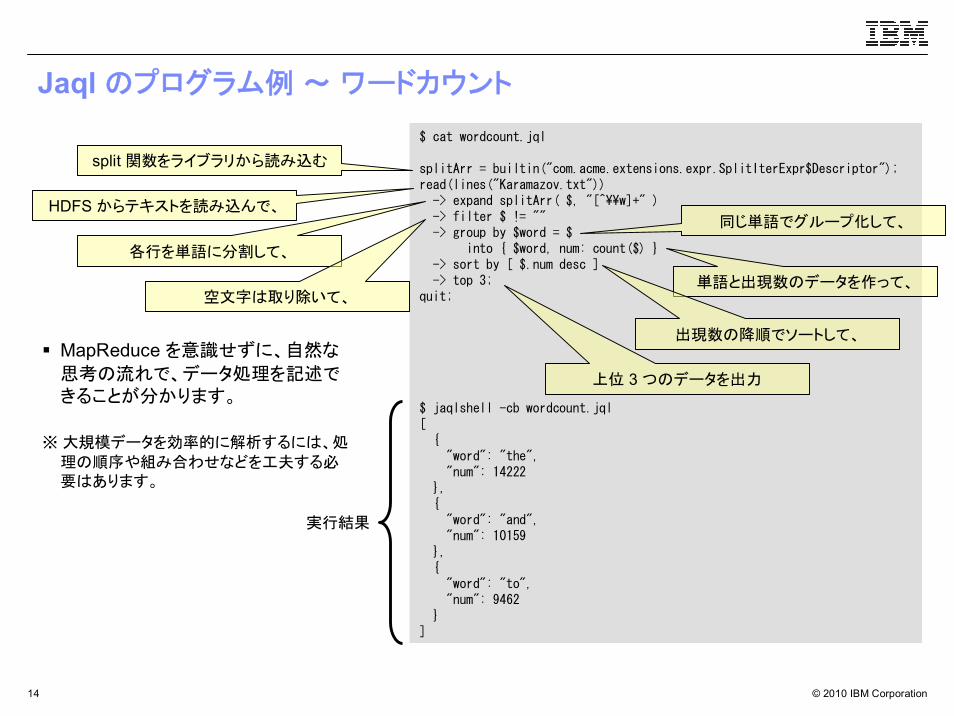
Jaql のプログラム例 ~ ワードカウント
$ cat wordcount.jql
splitArr = builtin("com.acme.extensions.expr.SplitIterExpr$Descriptor");read(lines("Karamazov.txt"))
-> expand splitArr( $, "[^¥¥w]+" )-> filter $ != ""-> group by $word = $
into { $word, num: count($) }-> sort by [ $.num desc ]-> top 3;
quit;
$ jaqlshell -cb wordcount.jql[
{"word": "the","num": 14222
},{"word": "and","num": 10159
},{"word": "to","num": 9462
}]
split 関数をライブラリから読み込む
HDFS からテキストを読み込んで、
各行を単語に分割して、
空文字は取り除いて、
同じ単語でグループ化して、
単語と出現数のデータを作って、
出現数の降順でソートして、
上位 3 つのデータを出力
実行結果
MapReduce を意識せずに、自然な
思考の流れで、データ処理を記述できることが分かります。
※ 大規模データを効率的に解析するには、処理の順序や組み合わせなどを工夫する必要はあります。

© 2010 IBM Corporation15
(参考) もう少し複雑な Jaql のプログラム例はこちらを参照ください。
http://slidesha.re/hWunA5
© 2010 IBM Corporation16
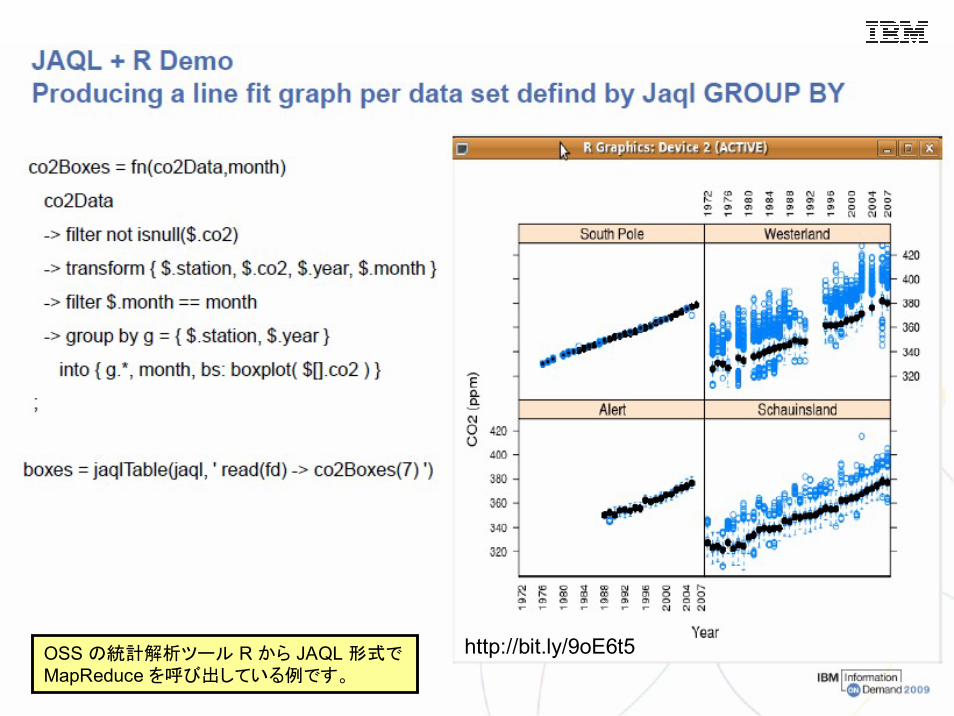
OSS の統計解析ツール R から JAQL 形式でMapReduce を呼び出している例です。
http://bit.ly/9oE6t5

© 2010 IBM Corporation17
BigSheetsBigSheets
© 2010 IBM Corporation18
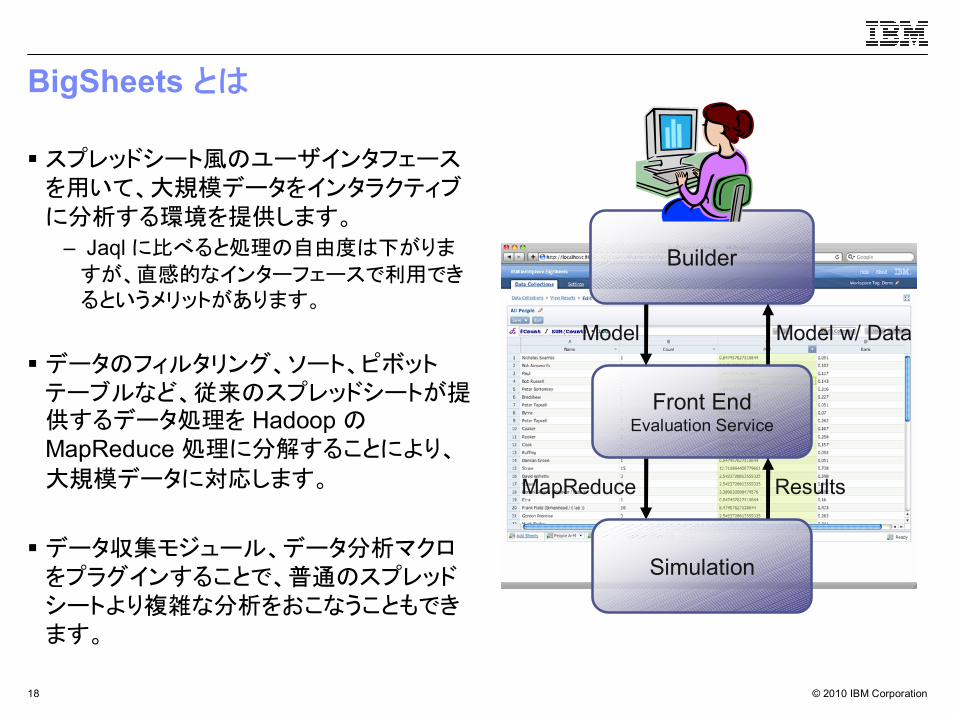
BigSheets とは
スプレッドシート風のユーザインタフェースを用いて、大規模データをインタラクティブに分析する環境を提供します。
– Jaql に比べると処理の自由度は下がりま
すが、直感的なインターフェースで利用できるというメリットがあります。
データのフィルタリング、ソート、ピボットテーブルなど、従来のスプレッドシートが提供するデータ処理を Hadoop のMapReduce 処理に分解することにより、
大規模データに対応します。
データ収集モジュール、データ分析マクロをプラグインすることで、普通のスプレッドシートより複雑な分析をおこなうこともできます。
Builder
Front EndEvaluation Service
Simulation
MapReduce Results
Model Model w/ Data

© 2010 IBM Corporation19
BigSheets の利用例 (1)
Twitter から、特定製品を『買いた
い』という意味のつぶやきを収集して、マーケット分析に利用
– Tweet の収集モジュールと自
然言語解析モジュールをプラグインとして使用。
http://www.youtube.com/watch?v=Jqq66INlQ0U

© 2010 IBM Corporation20
BigSheets の利用例 (2)
英国国会の Web サイトの情報を分析
– 1つの丸が1つの議案(丸が大きいほど、多くの議論がなされている議案)
– 丸の中は、発言した議員ごとに色分け(各議案についてどの議員がよく発言しているかが分かる。)
http://www.youtube.com/watch?v=Jqq66INlQ0U

© 2010 IBM Corporation21
ありがとうございました