fkframewor k s f or the tdeve lopment o f lpara llel and ... · i also useful for applying...
TRANSCRIPT

F k f th D l t f P ll l dFrameworks for the Development of Parallel andDistributed Real Time Embedded Systems
Luís Miguel Pinho(http://www.cister.isep.ipp.pt)
TORRENTS Workshop, 14/12/2012

CISTER Research Centre�• Associated to
�– ISEP IPP & INESC TEC
�• Created in 1997�– Formal centre in 2002
�• Focus areaFocus area�– Real time and embedded computing systems�– Areas of WorkAreas of Work
�• Real time multi core scheduling�• Adaptive real time systems�• Real time software�• Cyber physical systems�• Wireless sensor networks
2

CISTER�’s Team�• 15 PhD researchers�• 20 PhD students�• 6 MSc and undergrad students�• 2 support staff�• 18 Nationalities
3

Presentation Context�• The intersection of m* cores and real time
�– Effort being undertaken since 2005�• Start of multi core area
ff h l f d d�• Later joint effort with real time software and adaptive systems
�– Multi disciplinary activities, encompassing:�• Scheduling approaches for homogeneous and heterogeneous MC�• Scheduling approaches for homogeneous and heterogeneous MC�• Platform contention issues (NoC, cache, �…)�• Isolation of software componentsp�• Energy
�• Runtimes�• Programmability concerns�• Mainly COTS
4

Outline�• Current challenges
�– Nothing new but provides the context
�• Programming models�– Still important
�• Scaling for multi core �…Scaling for multi core �…�• �… and (not) scaling for many core
With real time guarantees�– With real time guarantees
�• Generalizing the model�– Parallel and distribution together
5

Current Challenges
�• An application engineer's ideal petascale system would have a singleprocessor, uniform memory, Fortran or C, Unix, a fast compiler, an exactdebugger and the stability to enable applications growth over time.
�• by contrast a computer scientist's ideal petascale system would have�• by contrast, a computer scientist s ideal petascale system would havetens of thousands of processors, different kinds of processors, nonuniform memory, C++ or Java, innovative architecture and radically newprogramming languagesprogramming languages.
�• Unfortunately, for many users, the computer scientist's system may bebuilt in the near future. The challenge is to build this kind of system butmake it look like the kind the applications software engineer wants."
* P l M i ( t th ti HPC U F t i itt h i )* Paul Muzio (at the time HPC User Forum steering committee chairman),IDC HPC User Forum meeting in 2005
6

Current Challenges�• Multi/many cores
�– The shift from processor speed to parallelism impactsheavily in software development
�– Amdahl�’s law is clear: the only way to improve Speedup isimproving p, the percentage of the program which can beparallelized (very low)parallelized (very low)
�– Virtualization helps but processors tend to be idleIt is not just a question of mapping tasks/threads to cores�– It is not just a question of mapping tasks/threads to cores�• More about that later �…
7

Current Challenges�• Currently many diverse efforts on specifyingarchitectures�– Core count and complexity�– Heterogeneous architectures�– Cache architecture�– Inter connection of cores�– Extensions to instructions sets�– �…
�• A lot of architecture experimentationp�– Trends are appearing
8

Current Challenges�• But there is more
�– Cyber Physical Systems, Cloud Computing ...�– Massive use of networked embedded computing devices(large scale dense deployments)
�– Highly distributed and parallel datacentres�– These blurs the distinction between parallel anddistributed programs
P i d l h ld b th�• Programming models should be the same�• Runtimes are required to perform the appropriate run timemapping
9

Programming models�• Current trend is to model the system, apply patternsand frameworks�– From model to HW
�• But it is necessary to support the tool and frameworkprogrammers
We are still far away from model and click�– We are still far away from model and click
�• Software development is increasingly importantill d�– However, we still need to program
�– At least while computers do not do it better
10

Programming models�• Programming should not be an artistic creation
�– Even less handicraft, as it often is�– It should be the result of applying science and engineeringmethodologies and results
�– Models should be used at all levels of softwared l tdevelopment
P i di th d l f th�• Programming paradigms are the models for thecorrect creation of computer programs
d h h d l d d�– We need the right models and paradigms�– But we still use the same of 20 years ago
11

Scaling to Multi core�• Requirements for programming paradigms andlanguages�– Generic attributes
�• Safety, Readability, Maintainability, Flexibility�• Simplicity, Portability, Efficiency
R l Ti E b dd d�– Real Time Embedded�• Concurrency, Resource Control, Hardware interface�• Predictability Temporal Reasoning�• Predictability, Temporal Reasoning
�– Multi cores do not add to this�• But re enforce concurrency, hardware interface, �…y, ,�• And make others (e.g. safety, simplicity, �…) more complex
12

Scaling to Multi core�• Current real time and embedded systems languagescan scale to multi core programming�– Concurrency must be central to the language design�– And should provide support for controlling the cores
�• An example: Ada 2012 just added multiprocessorsupport to its concurrency model�– Mapping the concurrent and parallel natures of thepp g penvironment and platform in the semantics of theprogram�• fundamental for a safe, readable, maintainable and reliableapplication
�– C++ is following the same path�– C++ is following the same path
13

Scaling to Multi core�• Ada is a complete concurrent and real time language
�– Scheduling, dispatching and timing issues are specified in alanguage Annex�• Priorities�• Dispatching model
�– From Ada 2005 it is possible to schedule a program withFrom Ada 2005, it is possible to schedule a program withdifferent (but simultaneous) dispatching policies (FP, EDF,Round Robin)
L ki d i li i (ICPP SRP)�• Locking and queuing policies (ICPP, SRP)�• Monotonic time�• Task controlTask control�• Execution time timers�• Timing events�• ...
14

Scaling to Multi core�• Ada 2012
�– Added the representation of cores to language�• Possibility for tasks to control affinity, even in runtime
�– Added the representation of dispatching domains�• Allows to group tasks in a cluster of cores, specifying differentscheduling policies between domainsscheduling policies between domains
�– The Ravenscar profile is also aware of multi core, and amodel is specifiedp�• Tasks can statically assigned to cores, and each core is a domain
15

Scaling to Multi core�• This model allows to build applications with
/tasks/threads for parallelization�– Equivalent to pthreads, but safer
type CPU_Range is range 0 .. implementation-defined; My Domain: Dispatching Domain := Create(10 20);My_Domain: Dispatching_Domain := Create(10, 20);
task My_Taskwith Dispatching Domain => My Domain;with Dispatching_Domain => My_Domain;
task My_Taskwith CPU => 10 Dispatching Domain => My Domain;with CPU > 10, Dispatching_Domain > My_Domain;
Set CPU(21, My Task'Identity); -- Dispatching Domain Error
16
Se _C U( , y_ as de y); spa c g_ o a _ o

Scaling to Many core�• No �“official�” definition of what is a many core
�– Too many cores is a possibility
�• Advancements in semiconductors area have allowedchips with increasing number of cores�– Traditional shared bus technology does not scale�– A shift to a more scalable interconnection medium: theNetwork on Chip
�– Division of the processing elements into �“tiles�” connectedby a NoC.�• Tile can be a set of cores, with cache and a network switch (orcrossbar) connected to neighbor tiles
17

Scaling to Many core�• Several changes
�– There are more cores than the number of concurrentactivities in our systems
�– Memory models are hierarchical�– Communication is hybrid shared data and message passing
�• Software is heavily impacted�– Needs to adapt and be parallel
�• If not, there is no gain from multi core�• But more complex and error prone
There is no consensus as to programming models�– There is no consensus as to programming models�• Sequential model with automatic parallelization; programming with lowlevel threads interface; task centric programming
18

Scaling to Many core�• The Free Lunch is Over�…
A F d l T T d C i S fA Fundamental Turn Toward Concurrency in SoftwareThe biggest sea change in software development since the OO revolution isknocking at the door, and its name is Concurrency.g , y
�• Quotes:�– The vast majority of programmers today don�’t grokThe vast majority of programmers today don t grokconcurrency, just as the vast majority of programmers 15years ago didn�’t yet grok objects
�– Applications will increasingly need to be concurrent if theywant to fully exploit continuing exponential CPUthroughput gains
Herb Sutter Dr Dobb's Journal 30(3) March 2005Herb Sutter, Dr. Dobb s Journal, 30(3), March 2005.
19

Scaling to Many core�• However
�– Confusion of concurrency with parallelism: comes fromconcurrency allowing coarse grained parallelism
�– There are more definitions than researchers, but aninteresting one is:�• Concurrency is a modelling concept which can (and should) be�• Concurrency is a modelling concept which can (and should) bemapped in programs
�• Parallelism is a platform concept which can (and should) bemapped in programs
�– Concurrency and Parallelism should not be confused (butb i d)can be mixed)
�• And distribution is not a completely different concept, just anissue with time scales
20

Scaling to Many core�• Revisit the task/thread concept
�– There is a logic unit of concurrency�– There is a logic unit of parallelizable operation�– Logic parallel units expressed in the code may not turninto parallel computations
�• Tasks do not map to tasks, but to parts of jobs�– Fork/join frameworks, data oriented parallelism,dispatching models all depend on lightweightparallelizable units at user level
�• Thread pools and work * algorithms�– Also useful for applying dataflow, actors, �…
21

Scaling to Many core�• Real time and embedded must look to other areas
�– Using threads for parallelism is too much overhead�• And confuses concepts
�– OpenMP, MPI, TBB, Cilk+, TPL, Ada Paraffin, Java Fork Join
�• Integration of Parallel Computation Units (tasks)�– In real time languages
�• Language based: Ada�• Library based: MTAPI�• Compiler based: OpenMP
Interaction of parallelism and real time scheduling�– Interaction of parallelism and real time scheduling�• First with more static mapping approaches�• But also more dynamic mapping with priority based approachesBut also more dynamic mapping, with priority based approaches
22

Scaling to Many core�• Such intra task parallelism can be achieved
�– Enforcing not only parallel for loops but also anysynchronous thread based construct available in parallel
i diprogramming paradigms�– This model is more portable since the same applicationcan be executed on any machine independently of thecan be executed on any machine independently of thenumber of processors
�• And applied to high performance real time systems�• And applied to high performance real time systems�– Beyond predictability, equal distribution of work andlocality of reference are desired within each processorlocality of reference are desired within each processor
23

Scaling to Many core�• (Outdated) Ada proposal
-- not AdaSum := 0;for I in Buffer'Range parallel loopfor I in Buffer Range parallel loop
for J in Buffer’First ..Buffer’Last loop
Sum’Partial := Sum’Partial + Buffer(J);Sum Partial : Sum Partial + Buffer(J);end loop;
end parallel loop;
for I in Sum’Partial_Array loopSum := Sum + Buffer’Partial(I);
end loop;
�– A better proposal being worked out
24

Scaling to Many core�• OpenMP
#pragma omp parallel for deadline(200)h d ( ) d i ( ){num_threads(3) reduction(+:sum){
for (i = 0; i < N; i++)sum += ;sum += ...;
}
25

Scaling to Many core�• Multicore Task API (MCA)
void fibonacciActionFunction( ) {// if (n < 2)if (n 2)
* result = n;else {
a = n – 1;;task = mtapi_task_start(
&fibonacciAction, , &a, , &x, );
b = n - 2;fibonacciActionFunction(&b, , &y, ,
);mtapi_task_wait(task, ); *result = x + y;
}
26
}

Scaling to Many core�• But we also need to change how we program
Cumulative(1) := Histogram(1);for I in 2 N loopfor I in 2 .. N loopCumulative (I) := Cumulative (I-1) + Histogram(I);end loop;
27

Scaling to Many coreCumulative(1) := Histogram(1);-- parallel inclusive scan phasefor I in 2 Partition parallel loop -- not Adafor I in 2 .. Partition parallel loop -- not Adafor J in Chunk_Start .. Chunk_Finish loopCumulative (J) := Cumulative (J-1) + Histogram (J);
end loop;Intermediate(I) := Cumulative ( Chunk_End);
end loop;
-- sequential exclusive scan phaseSum := Intermedate(1];for I in 2 .. Partition loopPrev_Sum := Sum;Sum := Sum + Intermediate(I];Sum : Sum + Intermediate(I];Intermediate(I] := Prev_Sum;
end loop;
-- parallel final phasep pfor I in 2 .. Partition parallel loop -- not Adafor J in Chunk_Start .. Chunk_Finish loopCumulative (J) := Cumulative (J) + Intermediate(I);
28
end loop;end loop;

Scaling to Many core�• Real time guarantees?
�– Scheduling many core applications is still challenging�– Multi core is already a problem
�• Traditional uniprocessor scheduling does not hold�• Simple (extreme) EDF example
C P D C1C P D C1C P D C1T1 2 8 4T2 2 8 4 C2T3 7 8 8
C P D C1T1 2 8 4T2 2 8 4 C2T3 7 8 8T3 7 8 8T3 7 8 8
29

Scaling to Many core�• Global Scheduling
�– Dynamic task assignment�• Any instance of any task may execute on any processor, and maymigratemigrate
�– One ready queue shared by all processors�• When selected for execution a task can be dispatched to any�• When selected for execution, a task can be dispatched to anyprocessor, even after being preempted
�• Any algorithm for single processor scheduling may work, buth d l b l l lschedulability analysis is non trivial
�– Advantages:�• Simple to implement�• Simple to implement�• Unused processor time can easily be reclaimed at run time(mixture of hard and soft RT tasks)
30

Scaling to Many core�• Global Scheduling
�– Disadvantages:�• Results from single processor cannot be used
�“ l�” l h k d l d (�• No �“optimal�” algorithms known except idealized assumption (e.g.PFair, which is not feasible)
�• Poor resource utilization for hard timing constraintsg�– No more than 50% resource utilization can be guaranteed forhard RT tasks
S ff f h d li li�• Suffers from scheduling anomalies�– Adding processors and reducing computation times and other
parameters can actually decrease optimal performance in some!scenarios!
31

Scaling to Many core�• Partitioned scheduling
�– Static task assignment�• Each task may only execute on a fixed processor
k�• No task migration
�– One ready queue per processorT k i t i t diti l bi ki bl�– Task assignment is a traditional bin packing problem
�– Lower flexibility
32

Scaling to Many core�• Partitioned scheduling
�– Advantages:�• Most techniques for single processor scheduling are alsoapplicable hereapplicable here
�• Partitioning of tasks can be automated�– Solving a bin packing algorithmg p g g
�– Disadvantages:�• Cannot exploit/share all unused processor time�• May have very low utilization�• Not work conservative
33

Scaling to Many core�• Semi partitioned scheduling
�– Static task assignment�• Each instance (or part of it) of a task is assigned to a fixedprocessorprocessor�– task instance or part of it may migrate (task splitting)
�– Advantages:Advantages:�• Most techniques for single processor scheduling are alsoapplicable here
�• Higher utilization is theoretically possible
�– Disadvantages:�• Migration overhead (theoretically can be lower thanpre emption)
�• Shared resource control
34

Scaling to Many core�• Supporting parallelism
�– RT scheduling continues mostly limited to sequentialmodels, despite multi core platforms ubiquity
�– There are few real time schedulers designed specifically tosupport parallelism within the threads�• Most consider that a job only executes in one core at a time�• Most consider that a job only executes in one core at a time�• Several analysis has been done on how to transform parallelism tosequential execution
�• Timing analysis is increasingly important�– Contention in the interconnect, caches,�…Contention in the interconnect, caches,�…�– Others (also in our centre) are looking at that�– But probably new models need to be usedBut probably new models need to be used
35

Scaling to Many core�• Supporting parallelism
�– Intra task parallelism refers to the subdivision of a taskinto new entities, so it can be executed simultaneously on
lti lmultiple cores�– When this subdivision results in a dynamic large amount ofshort living lightweight threads (not actual threads) weshort living lightweight threads (not actual threads), wecall it fine grained parallelism
�– Need for supporting tasks/lightweight threads and moreNeed for supporting tasks/lightweight threads and moreflexible work * approaches�• Mapping tasks to threads�• And scheduling threads in the cores
36
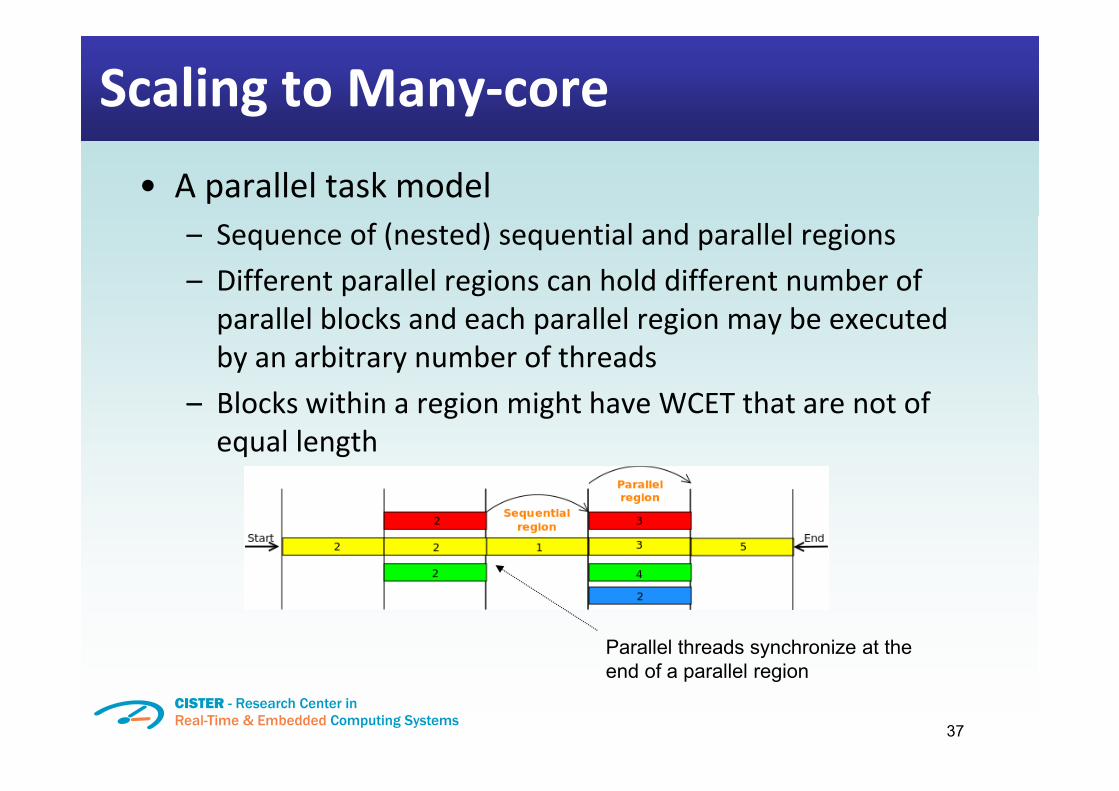
Scaling to Many core�• A parallel task model
�– Sequence of (nested) sequential and parallel regions�– Different parallel regions can hold different number ofparallel blocks and each parallel region may be executedby an arbitrary number of threadsBl k ithi i i ht h WCET th t t f�– Blocks within a region might have WCET that are not ofequal length
Parallel threads synchronize at the d f ll l i
37
end of a parallel region

Scaling to Many core�• Scheduling intra task parallelism
�– Combines global scheduler with a priority based workstealing load balancing scheme
�– Enables parallel real time tasks to be executed on morethan one processor at a given time without jeopardizingthe system�’s schedulabilitythe system s schedulability
�• Goalsd h d h i i d�– Reduce overheads, cache misses, contention and
communication costsEase programmers life by dynamically assigning threads'�– Ease programmers life by dynamically assigning threads'properties, efficiently mapping threads to processors,balancing the workloadbalancing the workload
38

Scaling to Many core�• Priority aware work stealing
�– A single global ready queue, ordered by non decreasingpriorities. At each instant, the higher priority threads areh d l d f tischeduled for execution
�– Spawned parallel blocks are not pushed to the globalqueue Instead they are maintained in the processor'squeue. Instead they are maintained in the processor slocal priority queue in a LIFO order.
�– Each entry in the local queue is deque where blocks areEach entry in the local queue is deque, where blocks arepushed and popped from the head by its core. A dequeholds one or more blocks of equal priority. When lookingfor work, a thread of the thread pool first tries to pick theleftmost block in the highest priority deque
39

Scaling to Many core�• Priority aware work stealing
�– If the local queue is empty, then a processor searches forwork in the global queue
�– If there is no eligible thread in the global queue, the core�’sthread pools will steal a block from the tail of the chosencore�’s highest priority dequecore s highest priority deque
�– Opposed to a local block, a stolen block preempted by anarriving job with a higher priority can be returned to thearriving job with a higher priority can be returned to theglobal queue or back in the respective deque
�– No migration of jobsg j
40

Scaling to Many core�• Priority aware work stealing
�– Two strategies to steal�• random (higher average performance)
b d (h h d )�• priority based (higher determinism)
�– Two strategies for preemption�• In one case an higher priority job when parallel preempts other�• In one case an higher priority job when parallel preempts othercores
�• Another is for the job only be parallelized when cores are idle
�– Partitioned scheduling can also be used�• Idle cores can �“steal�” load�• Work conservative
41

Scaling to Many core�• Experiments (with a EDF based variant)
�– Blocks are managed as threads�• Achieves better performance with intra task parallelism. Meanaverage response time was 30% lower in the 8 core experimentsaverage response time was 30% lower in the 8 core experiments
�– Less migration overhead than SCHED_DEADLINE, speciallyfor heavy workloadsfor heavy workloads�• Our decision to favor data locality, generating parallelism onlywhen required, appears to be efficient
�– Smaller number of context switches�• By not blindly assigning new tasks to processors and by notspreading parallel threads as they spawnspreading parallel threads as they spawn
�– For low system utilisations, RTWS is unable to distributethe load with more effectiveness than SCHED DEADLINEthe load with more effectiveness than SCHED_DEADLINE
42

Generalizing the model�• Collaboration paradigm
�– Several models have been proposed�• Mainly proven models proposed for multi chip multi processors.
h d d l h ll ll l�• Shared memory models assume that all parallel activities canaccess all of memory.
�• Message passing models assumes distributed non shared memoryg p g y�• Partitioned global address space models combine bothpartitioning space into disjoint subsets, but allowing inter subsetinteractioninteraction
�– Many core architectures are equivalent to distributedsystemssystems�• Cluster of shared date cores�• Interconnected by high speed networks
43

Generalizing the model�• Current models do not encompass all of this andhybrid models are a possibility�– Aligns with the current hardware trend, with both datasharing and message passing
�– Applications expose two levels of parallelism: coarsei d d fi i dgrained, and fine grained
�– Possible to combine both worlds (e.g. OpenMP and MPI)Th it ti i hi h th li ti i t�• There are situations in which the application requirements orsystem restrictions may limit the number of MPI processes(scalability problems)�– OpenMP can offer an additional amount of parallelism
�• OpenMP avoids the extra communication overhead withincomputer nodes induced by MPIcomputer nodes induced by MPI
44

Generalizing the model�• But it is not about combining OpenMP and MPI
�– It is combining a shared memory model with a messagepassing one
�– It is combining a pre processor based approach with alibrary based oneO h i t b ll i O MP�’ d l�– Our approach is to base all in OpenMP�’s model�• MPI is used transparently when it is required to go outside of thenode/clusternode/cluster
�– The approach is the same either for many cores or fordistributed parallel systems
�– But we need to guarantee hard real time systemsrequirements
45

Generalizing the model�• OpenMP
�– Set of compiler directives and libraries used to parallelizesequential code
�– Success relies on the simplicity of parallelizing programs
�• MPI�– A de facto standard for developing parallel distributedprograms.
�– Handling of distribution of work is explicit
�• Our model maps�– OpenMP constructs and MPI constructs�– into threads, enabling the timing analyzability
46
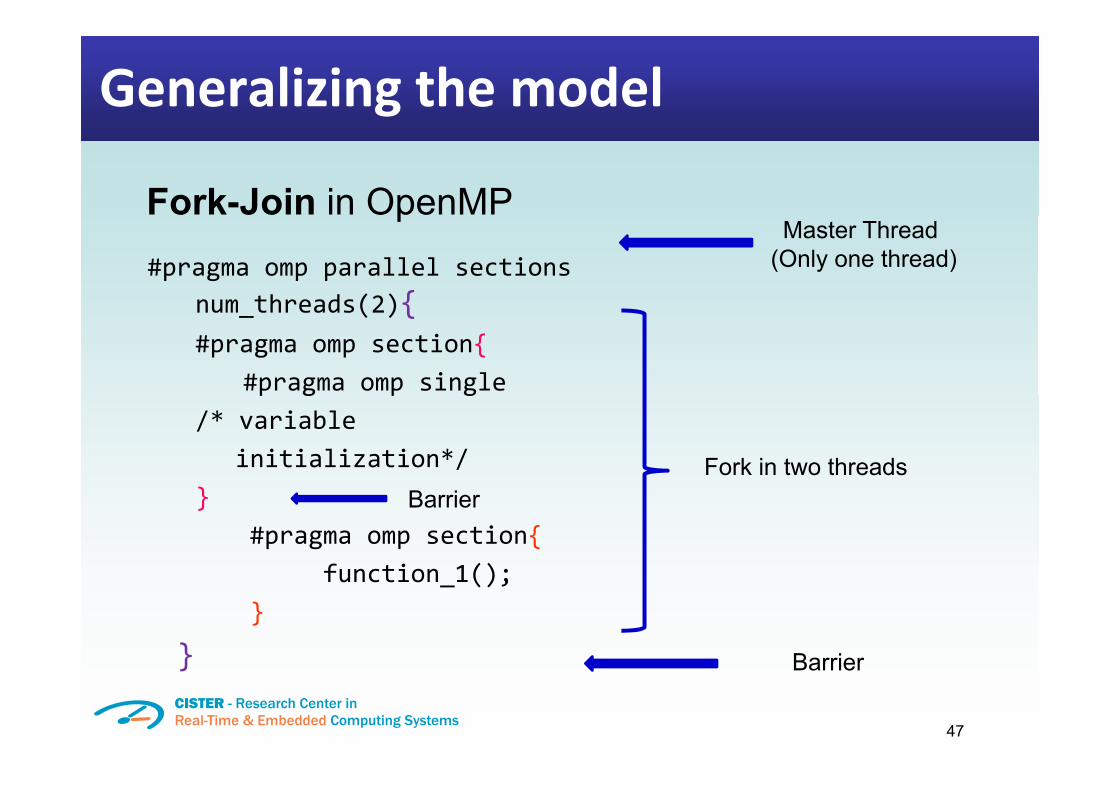
Generalizing the model
Fork-Join in OpenMP#pragma omp parallel sections
num threads(2){
Master Thread (Only one thread)
p
num_threads(2){#pragma omp section{
#pragma omp singlep g p g/* variable
initialization*/ Fork in two threads}
#pragma omp section{function 1();
Barrier
function_1();}
} Barrier
47
} Barrier

Generalizing the model
Fork-Join in MPI
/* Variables declaration*/MPI Init( );MPI_Init(�…);MPI_Comm_size(�…);MPI_Comm_rank(�…);if (rank == 0) {
explicit work distribution algorithmif (rank == 0) {
MPI_Send(�…);MPI_Recv(�…);
}
algorithm
communication
}if (rank !=0){
MPI_Recv(�…);/*E ti *//*Execution*/MPI_Send(�…);MPI_Finalize();
execution of the computations gathering result
48
}

Generalizing the model�• In our framework:
�– Code is written with minor extensions to the OpenMPspecification
�– The distributedParallel pragma, signals the compiler toenable parallelization on distributed nodes�• The compiler is responsible to generate the corresponding�• The compiler is responsible to generate the correspondingparallel/distributed code
#pragma omp distributedParallel for deadline (200)num_threads(X){
49
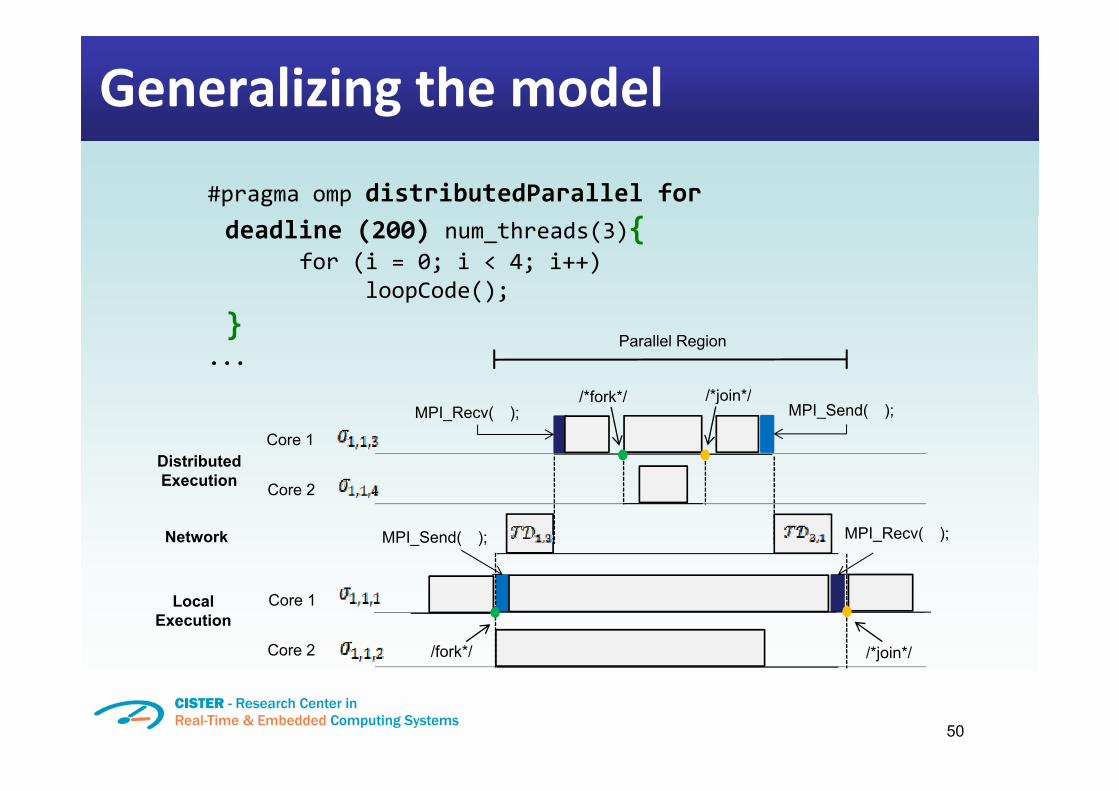
Generalizing the model
#pragma omp distributedParallel fordeadline (200) num_threads(3){
for (i = 0; i < 4; i++)loopCode();
}...
Parallel Region
/*fork*/ /*join*/
DistributedExecution
/*fork*/ / join /
Core 1
C 2
MPI_Send( );MPI_Recv( );
Execution
Network
Core 2
MPI_Send( ); MPI_Recv( );
LocalExecution
/fork*/ /*join*/Core 2
Core 1
50
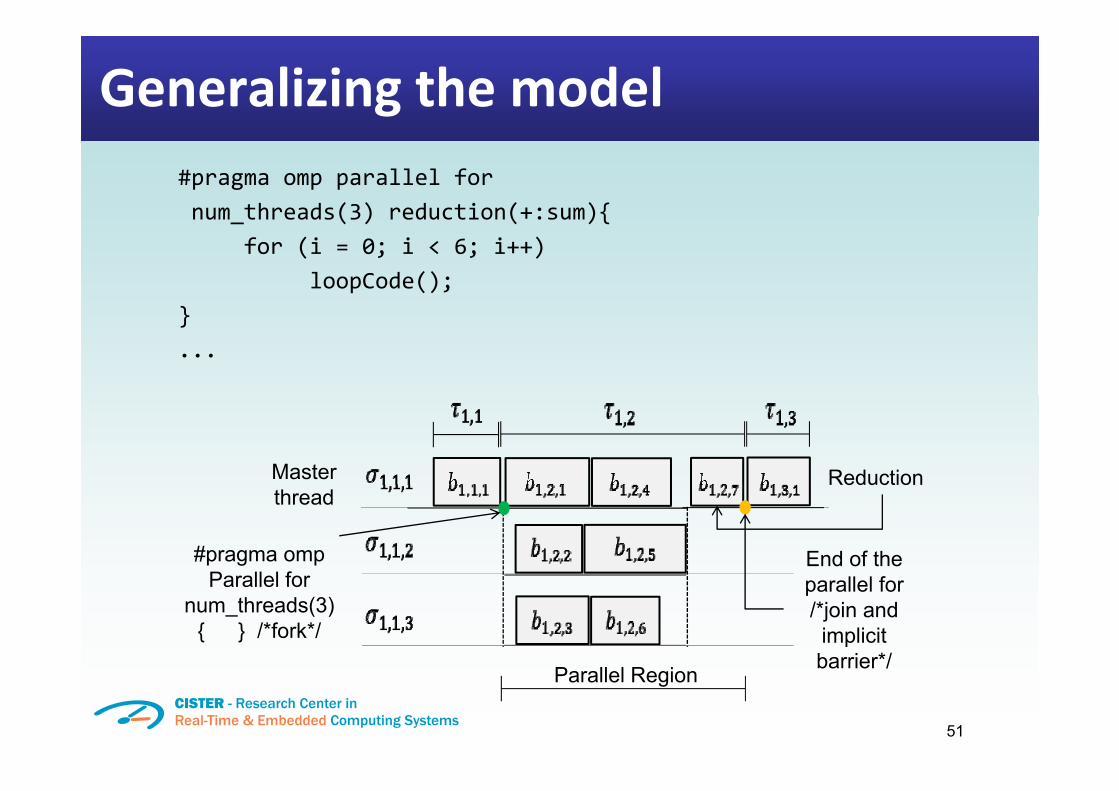
Generalizing the model#pragma omp parallel fornum threads(3) reduction(+:sum){num_threads(3) reduction(+:sum){
for (i = 0; i < 6; i++)loopCode();
}...
ReductionMaster
#pragma omp P ll l f
End of the
Reductionthread
Parallel for num_threads(3)
{ } /*fork*/
parallel for /*join and implicit barrier*/
51
barrier /Parallel Region

Generalizing the model�• Real time guarantees?
�– Maximum number of code blocks per thread:
�– MaximumWCET of a thread executed in parallel:
52
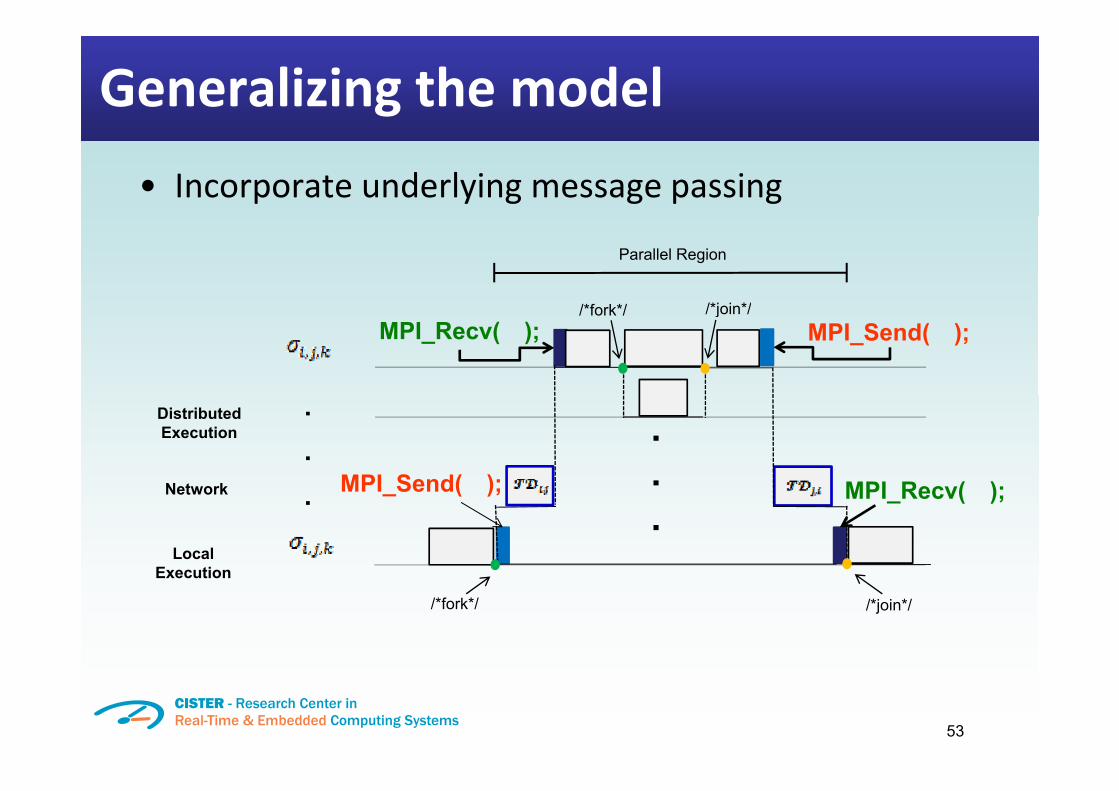
Generalizing the model�• Incorporate underlying message passing
Parallel Region
/*f k*/ /*j i *//*fork*/ /*join*/MPI_Send( );MPI_Recv( );
DistributedExecution
N t k MPI Send( ); MPI R ( )
.
.
.
.
LocalExecution
Network MPI_Send( ); MPI_Recv( );...
Execution
/*fork*/ /*join*/
53

Generalizing the model�• This allows to take the code block DAG
�– Models Dependencies between code blocks�– And synchronization points
Parallel Region
Local Execution
Parallel/Distributed Execution
54
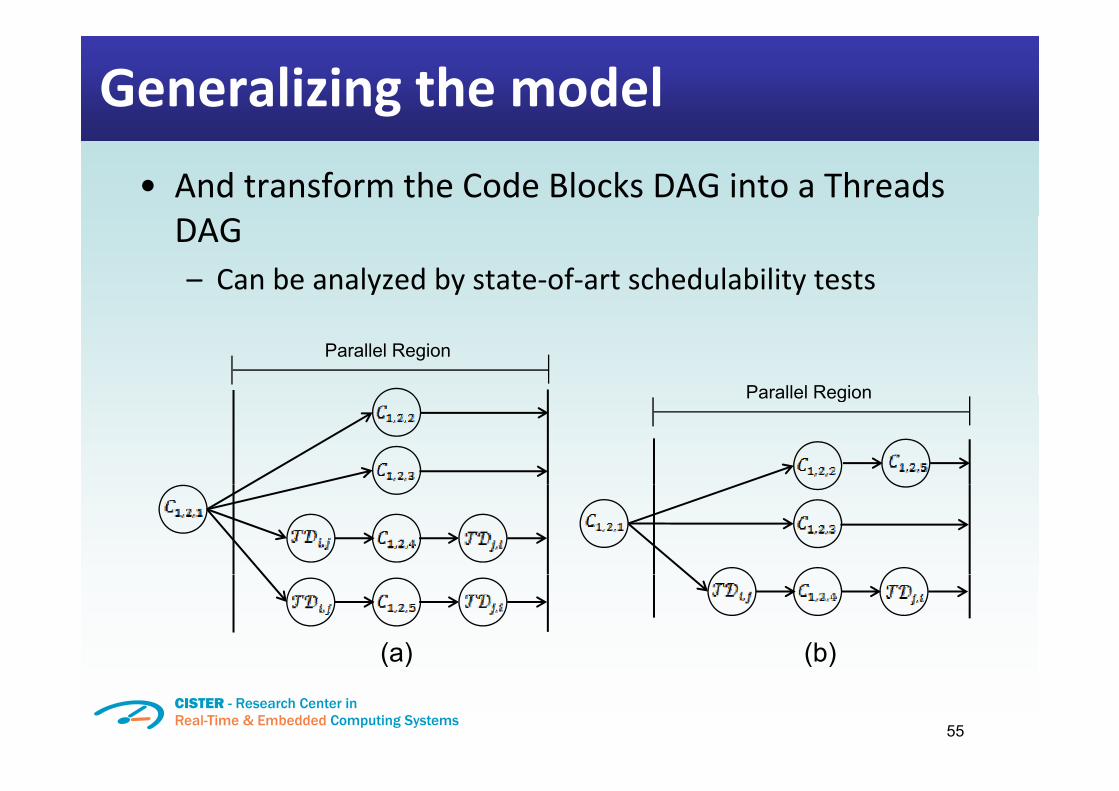
Generalizing the model�• And transform the Code Blocks DAG into a ThreadsDAG�– Can be analyzed by state of art schedulability tests
Parallel Region
Parallel RegionParallel Region
(a) (b)
55
( ) ( )

Generalizing the model�• This allows to propose a framework for thedevelopment of parallel and distributed embeddedsystems based on a hybrid programming model.�– A model with OpenMP transparently calling MPI for theunderlying exchange of data.
�– We also propose a technique which enables the timingcharacterization of these applications.U d l i ll f thi h ll l l ti�– Underlying all of this we can have parallel real timeschedulers
A l t f i k�• A lot of ongoing work�– Currently in the OpenMP integration�– And the WS schedulers
56

Summary�• Multi core at the top of the 10 most disruptivetechnologies�– Some say that even more disruptive than the web�– Architectures still experimenting�– Software is now lagging behind�– We are forced to use multi cores in all application domains
�• Embedded real time systems is not an exception
�• A lot of work still needed to provide multi core withthe same level of analysis as single core�– Many core is even more difficult
57

Summary�• Programming languages and paradigms matter
�– We need the right models and tools, if not, softwarecomplexity will become unmanageable
�• Real time systems need to exploit intra taskparallelism�– Architectures blur the distinction between parallel anddistributed
�• We need to change our mindset�– There is a lot to learn from integrating parallel anddistributed programming models
58

Summary�• Data locality is an important challenge
�– Memory will be of paramount importance�• This is where parallelism and distribution are mostly different
l b l h h�• Applications can be written to exploit constructive cache sharing,or non coherent models�– Either through static allocation or exploiting runtime locationg p goptimizing algorithms (such as work stealing)
�• It is always better to increase on chip communication than to havecache misses (impact on off chip communication)cache misses (impact on off chip communication)
�– Partitioned Global Address Space models, programmerspecified data access levels and memory affinities mayspecified data access levels and memory affinities mayhelp here�• Disclaimer: we have NOT been addressing that
59

Thank you!y
60