gunosyデータマイニング研究会 #118 これからの強化学習
TRANSCRIPT

これからの強化学習
大曽根 圭輔(Gunosy Inc.)2017年 4月 12日

- 1.3章- 価値反復に基づくアルゴリズム
- 1.4章- 方策勾配に基づくアルゴリズム
今日の範囲: これからの機械学習

発表者と強化学習の出会い
10年前に研究室配属された時に先輩がやってた
- そもそも当時はあまり流行ってなかった- 当時はロボットの文脈で使われことも多く、
環境の離散化に苦戦
- 難しそうなのであきらめた

これからの機械学習
- 1.3章- 価値反復に基づくアルゴリズム
行動価値関数Qを学習し、最適な方策を求める
- 1.4章- 方策勾配に基づくアルゴリズム
- 方策を行動価値関数と別に確率的にパラメタライズされた
モデルとして表現し、パラメタを最適化する

これからの機械学習
- 1.3章- 価値反復に基づくアルゴリズム
行動価値関数Qを学習し、最適な方策を求める
- 1.4章- 方策勾配に基づくアルゴリズム
- 方策を行動価値関数と別に確率的にパラメタライズされた
モデルとして表現し、パラメタを最適化する

1.3章でやること
行動価値関数を推定することで
=> 方策の良さを評価する
- 2つのアルゴリズムを紹介
- Sarsa- ある方策πのもとでの行動価値関数について成り立つベルマン方程式に基づく
- Q-learning- 最適行動価値関数について成り立つ再帰式であるベルマン最適方程式に基づく
- 価値反復法で学習

1.1節では多腕バンディットを紹介
状態も変化しない
環境も変化しない
おさらい

1.2節では状態をマルコフ決定過程で記述
状態空間 S
行動空間 A(s)
初期分布 P0
状態遷移確率 P(s’|s, a)
報酬関数 r(s, s’, a)
おさらい

おさらい
ステップtの際の
次の状態
報酬

エージェントの行動
- 方策 π(a|s)- 行動 A(st) ~ π(a|St)
報酬の扱い
- 割引報酬和- γが大きければより長期的に有益な行動を高く評価するようになる
おさらい

1.3章でやること
行動価値関数を推定することで
=> 方策の良さを評価する
- 2つのアルゴリズムを紹介
- Sarsa- ある方策πのもとでの行動価値関数について成り立つベルマン方程式に基づく
- Q-learning- 最適行動価値関数について成り立つ再帰式であるベルマン最適方程式に基づく
- 価値反復法で学習

1.3.1 価値関数の推定
状態価値関数 V(s)
=> 特定の方策におけるある状態以降の利得の期待値、これを最大化したい
行動価値関数 Q(s, a)
=> 特定の状態で特定の行動をした際の収益の期待値

状態価値関数を導出するよ
モンテカルロ法ですべての状況の状態価値関数を求めれば良いが時間がかかるよ
=> 各状況における各状況の勝率を求める
=> 次元が大きすぎて最適化できない
1.3.1 価値関数の推定

1.3.2 ベルマン方程式
ベルマン方程式の導出

1.3.2 ベルマン方程式
第一項
第二項

1.3.2 ベルマン方程式
第一項
第二項とみなせる

1.3.2 ベルマン方程式
第一項
第二項とみなせる

1.3.2 ベルマン方程式
これらをまとめると状態価値関数に関するベルマン方程式が得られる

1.3.2 ベルマン方程式
同様に、行動価値関数についても
次の状態(s’)に遷移する確率
現在の状態、行動、次の状態に応じたり利得
次の状態の割引報酬和
であるから

1.3.3 Sarsaベルマン方程式を試行錯誤による経験で解くアルゴリズム
は学習率

1.3.3 Sarsa TD誤差
Sarsaの式変形
TD誤差 (更新がなくなるとこの項が 0になるので収束を図ることができる )TD = Temporal Difference

1.3.4 ベルマン最適方程式
1.2節より最適行動価値関数というものがあるのでこれを代入
Vの右辺に方策 (π)が含まれていない

1.3.5 Q-learningQ-learning (Deep Q Networkで有名)
Sarsaと同様に学習が収束している場合には第 2項が0になる

SarsaやQ-learningで得た価値関数を指針として使うことで、良い方策へと更新する
- 1.4章で述べる方策反復法で方策を最適化する
- greedyアルゴリズムなどで価値関数から簡単に計算できる方策に限定する- ε-greedyアルゴリズムのように確率 εでランダムな行動を取るようにしないと収束しない
1.3.6 方策の獲得と価値反復法

- 1.3章- 価値反復に基づくアルゴリズム
行動価値関数Qを学習し、最適な方策を求める
- 1.4章- 方策勾配に基づくアルゴリズム
- 方策を行動価値関数と別に確率的にパラメタライズされた
モデルとして表現し、パラメタを最適化する
これからの機械学習

1.4 方策勾配に基づくアルゴリズム
ゴルフ問題の例
行動関数を関数近似する
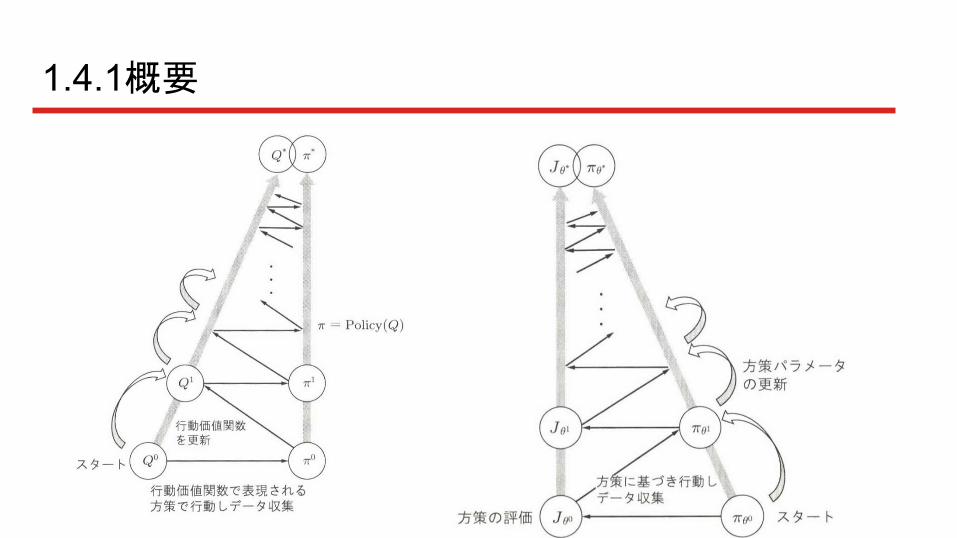
1.4.1概要

1.4.2 アルゴリズムの枠組み
方策勾配法は方策をモデル化して最適化すること
方策をパラメータθで記述し、下式で更新する
更新量 は以下で記述することができる

確率的方策による行動
方策の例として、ソフトマックス関数やガウス関数が考えられる
他にもいろいろありそう。一時期流行ったGAでのルーレット選択的な

方策の評価
方策の良さを評価したい
Jを具体的に定義する
平均報酬和
割引報酬和

方策の更新
最適なパラメータを解析的に導出することは困難であるため、勾配法でパラメータ推定
を行う
ηは更新幅を決定するパラメータ、 J(θ)は、偏微分を用いて下記のように表現できる

方策の更新
さらに変形して

勾配の近似
2つのアプローチがある
QをRで近似
Qを線形モデルで近似
方策のモデル (Actor)と行動価値関数のモデルの両方を別々にモデル化する方法を
Actor-Criticアルゴリズムという

Qを線形モデルで近似
勾配の近似
特徴ベクトルに確率的方策モデルの対数勾配を採用し、近似

自然方策勾配法
パラメータ間の距離をユークリッド距離ではなくKLダイバージェンスで定める
(KLダイバージェンスは距離尺度ではない)

REINFORCEアルゴリズム
行動価値関数QをRで近似する
に を代入し以下の式を得る

ベースラインを導入し、推定分散を小さくする
REINFORCEアルゴリズム
を用いて下式を更新

wというシンプルなパラメータのみで記述できる
自然方策勾配法

行動価値関数を学習する1.3章と異なり、方策を学習する
方策をパラメータ表現し、具体的なアルゴリズムを紹介
行動価値関数を学習するアルゴリズムと比較して、連続の状態を扱いやすくなるというメ
リットがある
まとめ