introduction to data mining
TRANSCRIPT

Prof. S. K. Pandey, I.T.S, Ghaziabad
Data Warehousing & Mining
UNIT – I

Prof. S.K. Pandey, I.T.S, Ghaziabad 2
Syllabus of Unit - ISyllabus of Unit - I
DSS-Uses, definition, Operational Database. Introduction to DATA Warehousing. Data-Mart, Concept of Data-Warehousing, Multi Dimensional Database Structures. Client/Server Computing Model & Data
Warehousing Parallel Processors & Cluster Systems. Distributed
DBMS implementations.

Introduction – Introduction – Decision Support Decision Support System (DSS)System (DSS)
A Decision Support System (DSS) is an interactive computer-based system or subsystem intended to help decision makers use communications technologies, data, documents, knowledge and/or models to identify and solve problems, complete decision process tasks, and make decisions.
It is clear that DSS belong to an environment with multidisciplinary foundations, including (but not exclusively):– Database research, – Artificial intelligence, – Human-computer interaction, – Simulation methods, – Software engineering, and – Telecommunications.
Prof. S.K. Pandey, I.T.S, Ghaziabad 3

Prof. S.K. Pandey, I.T.S, Ghaziabad 4
DSSDSS
• A Decision Support System (DSS) is a computer-based information system that supports business or organizational decision-making activities.
• DSSs serve the management, operations, and planning levels of an organization (usually mid and higher management) and help to make decisions, which may be rapidly changing and not easily specified in advance (Unstructured and Semi-Structured decision problems).
• Decision support systems can be either fully computerized, human or a combination of both.

Historical Evolution of DSSHistorical Evolution of DSS
Prof. S.K. Pandey, I.T.S, Ghaziabad 5

Prof. S.K. Pandey, I.T.S, Ghaziabad 6
Typical DSS ArchitectureTypical DSS Architecture
TPS: transaction processing system
MODEL: representation of a problem
OLAP: on-line analytical processing
USER INTERFACE: how user enters problem & receives answers
DSS DATABASE: current data from applications or groups
DATA MINING: technology for finding relationships in large data bases for prediction
TPSEXTERNAL
DATADSS DATA
BASE
DSS SOFTWARE SYSTEMMODELS
OLAP TOOLS
DATA MINING TOOLS
USERINTERFACE
USER

Why DSS?Why DSS?
Increasing complexity of decisions– Technology– Information:
“Data, data everywhere, and not the time to think!”– Number and complexity of options– Pace of change
Increasing availability of computerized support– Inexpensive high-powered computing– Better software– More efficient software development process
Increasing usability of computers
Prof. S.K. Pandey, I.T.S, Ghaziabad 7

Prof. S.K. Pandey, I.T.S, Ghaziabad 8
Operational DatabasesOperational Databases Operational database management systems (also referred to as OLTP
databases), are used to manage dynamic data in real-time. These types of databases allow you to do more than simply view archived
data. Operational databases allows to modify that data (add, change or delete data), doing it in real-time.
Since the early 90's, the operational database software market has been largely taken over by SQL engines.
Today, the operational DBMS market (formerly OLTP) is evolving dramatically, with new, innovative entrants and incumbents supporting the growing use of unstructured data and NoSQL DBMS engines, as well as XML databases and NewSQL databases.
Operational databases are increasingly supporting distributed database architecture that provides high availability and fault tolerance through replication and scale out ability.

Prof. S.K. Pandey, I.T.S, Ghaziabad 9

Prof. S.K. Pandey, I.T.S, Ghaziabad 10
FEATURES DATABASE DATA WAREHOUSECharacteristic It is based on Operational Processing. It is based on Informational Processing.
Data It mainly stores the Current data which always guaranteed to be up-to-date.
It usually stores the Historical data whose accuracy is maintained over time.
Function It is used for day-to-day operations. It is used for long-term informational requirements and decision support.
User The common users are clerk, DBA, database professional.
The common users are knowledge worker (e.g., manager, executive, analyst)
Unit of work Its work consists of short and simple transaction.
The operations on it consists of complex queries..
Focus The focus is on “Data IN” The focus is on “Information OUT”
Orientation The orientation is on Transaction. The orientation is on Analysis.
DB design The designing of database is ER based and application-oriented.
The designing is done using star/snowflake schema and its subject-oriented.
Summarization The data is primitive and highly detailed.
The data is summarized and in consolidated form.
View The view of the data is flat relational. The view of the data is multidimensional.
Differences between the Databases and Data Warehouses

Prof. S.K. Pandey, I.T.S, Ghaziabad 11
FEATURES DATABASE DATA WAREHOUSEFunction It is used for day-to-day operations. It is used for long-term informational
requirements and decision support.
User The common users are clerk, DBA, database professional.
The common users are knowledge worker (e.g., manager, executive, analyst)
Access The most frequent type of access type is read/write.
It mostly use the read access for the stored data.
Operations The main operation is index/hash on primary key.
For any operation it needs a lot of scans.
Number of records accessed
A few tens of records. A bunch of millions of records.
Number of users In order of thousands. In the order of hundreds only.
DB size 100 MB to GB. 100 GB to TB.
Priority High performance, high availability High flexibility, end-user autonomy
Metric To measure the efficiency, transaction throughput is measured.
To measure the efficiency, query throughput and response time is
measured.

Prof. S.K. Pandey, I.T.S, Ghaziabad 12
Concept ofConcept ofData WarehousingData Warehousing

Prof. S.K. Pandey, I.T.S, Ghaziabad 13
Why Separate Data Warehouse?Why Separate Data Warehouse?
High performance for both systems– DBMS— tuned for OLTP: access methods, indexing,
concurrency control, recovery– Warehouse—tuned for OLAP: complex OLAP queries,
multidimensional view, consolidation. Different functions and different data:
– missing data: Decision support requires historical data which operational DBs do not typically maintain
– data consolidation: DS requires consolidation (aggregation, summarization) of data from heterogeneous sources
– data quality: different sources typically use inconsistent data representations, codes and formats which have to be reconciled

Prof. S.K. Pandey, I.T.S, Ghaziabad 14
DATA Warehousing - IntroductionDATA Warehousing - Introduction
A data warehouse is a subject-oriented,
integrated, nonvolatile, time-variant collection
of data in support of management's decisions.
- WH Inmon

Prof. S.K. Pandey, I.T.S, Ghaziabad 15

Prof. S.K. Pandey, I.T.S, Ghaziabad 16
Data Warehouse UsageData Warehouse Usage Three kinds of data warehouse applications
– Information processing supports querying, basic statistical analysis, and reporting using
crosstabs, tables, charts and graphs
– Analytical processing multidimensional analysis of data warehouse data supports basic OLAP operations, slice-dice, drilling, pivoting
– Data mining knowledge discovery from hidden patterns supports associations, constructing analytical models, performing
classification and prediction, and presenting the mining results using visualization tools.
Differences among the three tasks

Prof. S.K. Pandey, I.T.S, Ghaziabad 17
Data Warehouse: Subject-OrientedData Warehouse: Subject-Oriented
Organized around major subjects, such as customer, product,
sales.
Focusing on the modeling and analysis of data for decision
makers, not on daily operations or transaction processing.
Provide a simple and concise view around particular
subject issues by excluding data that are not useful in the
decision support process.

Prof. S.K. Pandey, I.T.S, Ghaziabad 18
Subject-OrientedSubject-Oriented
Quotes Orders
ProspectsLeads
Operational Data Warehouse
Customers Products
Regions Time
Focus is on Subject Areas rather than ApplicationsFocus is on Subject Areas rather than Applications

Prof. S.K. Pandey, I.T.S, Ghaziabad 19
Data Warehouse—IntegratedData Warehouse—Integrated
Constructed by integrating multiple, heterogeneous data sources– relational databases, flat files, on-line transaction records
Data cleaning and data integration techniques are applied.– Ensure consistency in naming conventions, encoding
structures, attribute measures, etc. among different data sources
E.g., Hotel price: currency, tax, breakfast covered, etc.
– When data is moved to the warehouse, it is converted.

Prof. S.K. Pandey, I.T.S, Ghaziabad 20
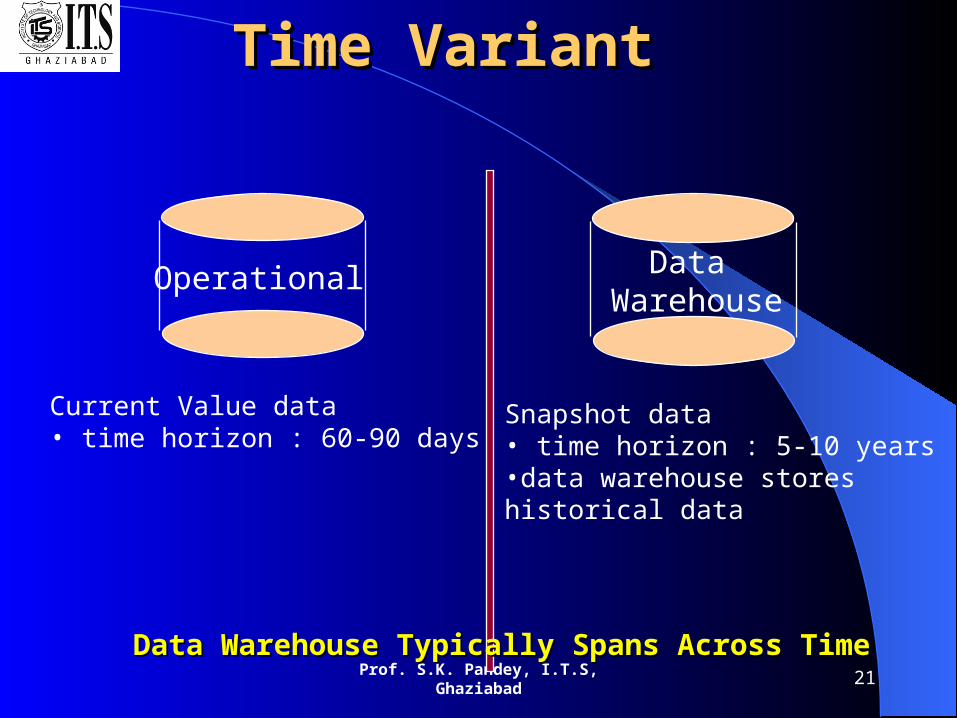
Data Warehouse—Time VariantData Warehouse—Time Variant
The time horizon for the data warehouse is significantly longer
than that of operational systems.
– Operational database: current value data.
– Data warehouse data: provide information from a historical
perspective (e.g., past 5-10 years)
Every key structure in the data warehouse
– Contains an element of time, explicitly or implicitly
– But the key of operational data may or may not contain
“time element”.
Prof. S.K. Pandey, I.T.S, Ghaziabad 21
Time VariantTime Variant
Operational Data Warehouse
Current Value data• time horizon : 60-90 days
Snapshot data• time horizon : 5-10 years•data warehouse stores historical data
Data Warehouse Typically Spans Across TimeData Warehouse Typically Spans Across Time

Prof. S.K. Pandey, I.T.S, Ghaziabad 22
Data Warehouse—Non-VolatileData Warehouse—Non-Volatile
A physically separate store of data transformed from the
operational environment.
Operational update of data does not occur in the data
warehouse environment.
– Does not require transaction processing, recovery, and
concurrency control mechanisms
– Requires only two operations in data accessing:
initial loading of data and access of data.

Prof. S.K. Pandey, I.T.S, Ghaziabad 23
Non-volatileNon-volatile
Operational Data Warehouse
replacechange
insert
changeinsert
delete load
read only access
Data Warehouse Is Relatively Static In NatureData Warehouse Is Relatively Static In Nature

Prof. S.K. Pandey, I.T.S, Ghaziabad 24
Data Warehouse vs. Heterogeneous Data Warehouse vs. Heterogeneous DBMSDBMS
Traditional heterogeneous DB integration: – Build wrappers/mediators on top of heterogeneous databases
– Query driven approach When a query is posed to a client site, a meta-dictionary is used to
translate the query into queries appropriate for individual heterogeneous sites involved, and the results are integrated into a global answer set
Complex information filtering, compete for resources
Data warehouse: update-driven, high performance– Information from heterogeneous sources is integrated in advance and
stored in warehouses for direct query and analysis

Prof. S.K. Pandey, I.T.S, Ghaziabad 25
Data Warehouse vs. Operational DBMSData Warehouse vs. Operational DBMS
OLTP (on-line transaction processing)
– Major task of traditional relational DBMS
– Day-to-day operations: purchasing, inventory, banking, manufacturing, payroll, registration, accounting, etc.
OLAP (on-line analytical processing)
– Major task of data warehouse system
– Data analysis and decision making Distinct features (OLTP vs. OLAP):
– User and system orientation: customer vs. market
– Data contents: current, detailed vs. historical, consolidated
– Database design: ER + application vs. star + subject
– View: current, local vs. evolutionary, integrated
– Access patterns: update vs. read-only but complex queries

Prof. S.K. Pandey, I.T.S, Ghaziabad 26
OLTP vs. OLAPOLTP vs. OLAP OLTP OLAP
users clerk, IT professional knowledge worker
function day to day operations decision support
DB design application-oriented subject-oriented
data current, up-to-date detailed, flat relational isolated
historical, summarized, multidimensional integrated, consolidated
usage repetitive ad-hoc
access read/write index/hash on prim. key
lots of scans
unit of work short, simple transaction complex query
# records accessed tens millions
#users thousands hundreds
DB size 100MB-GB 100GB-TB
metric transaction throughput query throughput, response

Prof. S.K. Pandey, I.T.S, Ghaziabad 27Slide 29- 27
Characteristics of Data WarehousesCharacteristics of Data Warehouses
Multidimensional conceptual view Generic dimensionality Unlimited dimensions and aggregation levels Unrestricted cross-dimensional operations Dynamic sparse matrix handling Client-server architecture Multi-user support Accessibility Transparency Intuitive data manipulation Consistent reporting performance Flexible reporting

Prof. S.K. Pandey, I.T.S, Ghaziabad28
Multi-Tiered ArchitectureMulti-Tiered ArchitectureComponents & Framework
Data Integration Stage

Prof. S.K. Pandey, I.T.S, Ghaziabad 29
Data MartData Mart
The data mart is a subset of the data warehouse that is usually oriented to a specific business line or team. Data marts are small slices of the data warehouse.
Whereas data warehouses have an enterprise-wide depth, the information in data marts pertains to a single department.
Data marts improve end-user response time by allowing users to have access to the specific type of data they need to view most often by providing the data in a way that supports the collective view of a group of users.

Contd………….Contd…………. A data mart is basically a condensed and more focused version
of a data warehouse that reflects the regulations and process specifications of each business unit within an organization.
Each data mart is dedicated to a specific business function or region.
This subset of data may span across many or all of an enterprise’s functional subject areas.
It is common for multiple data marts to be used in order to serve the needs of each individual business unit (different data marts can be used to obtain specific information for various enterprise departments, such as accounting, marketing, sales, etc.).
Prof. S.K. Pandey, I.T.S, Ghaziabad 30

Reasons for creating a data martReasons for creating a data mart
Easy access to frequently needed data Creates collective view by a group of users Improves end-user response time Ease of creation Lower cost than implementing a full data warehouse Potential users are more clearly defined than in a full
data warehouse Contains only business essential data and is less
cluttered.
Prof. S.K. Pandey, I.T.S, Ghaziabad 31

Types of Data MartsTypes of Data Marts Dependent Data Mart: A dependent data mart is one
whose source is another data warehouse, and all dependent data marts within an organization are typically fed by the same source — the enterprise data warehouse.
Prof. S.K. Pandey, I.T.S, Ghaziabad 32

Contd…Contd…
Independent Data Mart: An independent data mart is one whose source is directly from transactional systems, legacy applications, or external data feeds.
Prof. S.K. Pandey, I.T.S, Ghaziabad 33

Prof. S.K. Pandey, I.T.S, Ghaziabad 34
Data warehouse:
i. Holds multiple subject areasii. Holds very detailed informationiii. Works to integrate all data sourcesiv. Does not necessarily use a dimensional model but feeds dimensional models.
Data mart:
i. Often holds only one subject area- for example, Finance, or Sales ii. May hold more summarized data (although many hold full detail)iii. Concentrates on integrating information from a given subject area or set of source systemsiv. Is built focused on a dimensional model using a star schema.
Data mart vs data warehouse

Multi-Dimensional Database Multi-Dimensional Database StructureStructure
Prof. S.K. Pandey, I.T.S, Ghaziabad 35

Prof. S.K. Pandey, I.T.S, Ghaziabad 36
Multi Dimensional Database Multi Dimensional Database StructuresStructures
Sales volume as a function of product, month, and region
Pro
duct
Regio
n
Month
Dimensions: Product, Location, TimeHierarchical summarization paths
Industry Region Year
Category Country Quarter
Product City Month Week
Office Day

Prof. S.K. Pandey, I.T.S, Ghaziabad 37Slide 29- 37
Data Modeling for Data WarehousesData Modeling for Data Warehouses
Example of Two- Dimensional vs. Multi-Dimensional
REGION
REG1 REG2 REG3
P123
P124
P125
P126::
PRODUCT
Two Dimensional Model
::
Three dimensional data cube
Product
Reg 1P123
P124
P125
P126
Reg 2 Reg 3
Region

Prof. S.K. Pandey, I.T.S, Ghaziabad 38
From Tables and Spreadsheets From Tables and Spreadsheets to Data Cubesto Data Cubes
A data warehouse is based on a multidimensional data model
which views data in the form of a data cube
A data cube, such as sales, allows data to be modeled and viewed in
multiple dimensions
– Dimension tables, such as item (item_name, brand, type), or
time(day, week, month, quarter, year)
– Fact table contains measures (such as dollars_sold) and keys to
each of the related dimension tables
In data warehousing literature, an n-D base cube is called a base
cuboid. The top most 0-D cuboid, which holds the highest-level of
summarization, is called the apex cuboid. The lattice of cuboids
forms a data cube.

Prof. S.K. Pandey, I.T.S, Ghaziabad 39
Cube: A Lattice of CuboidsCube: A Lattice of Cuboids
all
time item location supplier
time,item time,location
time,supplier
item,location
item,supplier
location,supplier
time,item,location
time,item,supplier
time,location,supplier
item,location,supplier
time, item, location, supplier
0-D cuboid
1-D cuboids
2-D cuboids
3-D cuboids
4-D(base) cuboid

Prof. S.K. Pandey, I.T.S, Ghaziabad 40
Warehouse Database SchemasWarehouse Database Schemas
Star SchemaSnow-flake SchemaFact constellation (Gathering/ Togetherness)
schema

Prof. S.K. Pandey, I.T.S, Ghaziabad 41
Conceptual Modeling of Data Conceptual Modeling of Data WarehousesWarehouses
Modeling data warehouses: dimensions & measures
– Star schema: A fact table in the middle connected to a set of
dimension tables
– Snowflake schema: A refinement of star schema where some
dimensional hierarchy is normalized into a set of smaller
dimension tables, forming a shape similar to snowflake
– Fact constellations: Multiple fact tables share dimension
tables, viewed as a collection of stars, therefore called galaxy
schema or fact constellation

Prof. S.K. Pandey, I.T.S, Ghaziabad 42
Example of Star SchemaExample of Star Schema
time_keydayday_of_the_weekmonthquarteryear
time
location_keystreetcityprovince_or_streetcountry
location
Sales Fact Table
time_key
item_key
branch_key
location_key
units_sold
dollars_sold
avg_sales
Measures
item_keyitem_namebrandtypesupplier_type
item
branch_keybranch_namebranch_type
branch

Prof. S.K. Pandey, I.T.S, Ghaziabad 43
Example of Snowflake SchemaExample of Snowflake Schema
time_keydayday_of_the_weekmonthquarteryear
time
location_keystreetcity_key
location
Sales Fact Table
time_key
item_key
branch_key
location_key
units_sold
dollars_sold
avg_sales
Measures
item_keyitem_namebrandtypesupplier_key
item
branch_keybranch_namebranch_type
branch
supplier_keysupplier_type
supplier
city_keycityprovince_or_streetcountry
city

Prof. S.K. Pandey, I.T.S, Ghaziabad 44
Example of Fact ConstellationExample of Fact Constellation
time_keydayday_of_the_weekmonthquarteryear
time
location_keystreetcityprovince_or_streetcountry
location
Sales Fact Table
time_key
item_key
branch_key
location_key
units_sold
dollars_sold
avg_sales
Measures
item_keyitem_namebrandtypesupplier_type
item
branch_keybranch_namebranch_type
branch
Shipping Fact Table
time_key
item_key
shipper_key
from_location
to_location
dollars_cost
units_shipped
shipper_keyshipper_namelocation_keyshipper_type
shipper

Prof. S.K. Pandey, I.T.S, Ghaziabad 45
Client/Server Computing Model & Client/Server Computing Model & Data WarehousingData Warehousing
The fundamental characteristic of client/server computing is distribution of computing resources (e.g. data, compute power) across different computers.
The idea is to divide applications into logical segments (tasks) so that they are then performed on platforms most appropriate.
A client/server database system increases processing power by separating the database management system from the application; the client as the front-end system handling the user interface and the server as the back-end system accessing the database, which cooperate to run an application.

Contd….Contd….
Data Warehousing is a continual process which enables a corporation to assemble operational and other data from a variety of internal and external sources, and transform that data into consistent, high-quality, business information, distribute that information to the points of maximum value within the organizations, and provide easy, flexible and fast access for busy non-technical users.
Prof. S.K. Pandey, I.T.S, Ghaziabad 46

Reasons for using client/serverReasons for using client/server
Exploitation of centralized computing power /data capacity
Scalability Performance Flexibility (in order to adjust to changing demands) GUI on desktop Protection of investment, strategic software,
strategic data Client/server provides an integrated solution.
Prof. S.K. Pandey, I.T.S, Ghaziabad 47

Prof. S.K. Pandey, I.T.S, Ghaziabad 48
Parallel Processors & Cluster Parallel Processors & Cluster SystemsSystems

Prof. S.K. Pandey, I.T.S, Ghaziabad 49
Loosely Coupled - ClustersLoosely Coupled - Clusters Collection of independent whole uni-processors or SMPs
– Usually called nodes
Interconnected to form a cluster Working together as unified resource
– Illusion of being one machine
Communication via fixed path or network connections
Cluster BenefitsCluster Benefits Absolute scalability Incremental scalability High availability Superior price/performance

Prof. S.K. Pandey, I.T.S, Ghaziabad 50
Distributed DBMS implementationsWhat Is A Distributed DBMS?What Is A Distributed DBMS?
Decentralization of business operations and globalization of businesses created a demand for distributing the data and processes across multiple locations.
Distributed database management systems (DDBMS) are designed to meet the information requirements of such multi-location organizations.
A DDBMS manages the storage and processing of logically related data over interconnected computer systems in which both data and processing functions are distributed among several sites.
Distributed processing shares the database’s logical processing among two or more physically independent sites that are connected through a network.

DDBMS AdvantagesDDBMS Advantages
Data located near site with greatest demand Faster data access Faster data processing Growth facilitation Improved communications Reduced operating costs User-friendly interface Less danger of single-point failure Processor independence
Prof. S.K. Pandey, I.T.S, Ghaziabad 51

Prof. S.K. Pandey, I.T.S, Ghaziabad 52
Distributed ProcessingDistributed ProcessingShares database’s logical processing among physically, networked independent sites

Prof. S.K. Pandey, I.T.S, Ghaziabad 53
DDBMS ComponentsDDBMS Components Computer workstations that form the network
system. Network hardware and software components that
reside in each workstation. Communications media that carry the data from one
workstation to another. Transaction processor (TP) receives and processes
the application’s data requests. Data processor (DP) stores and retrieves data
located at the site. Also known as data manager (DM).

Prof. S.K. Pandey, I.T.S, Ghaziabad 54
Distributed DB TransparencyDistributed DB Transparency
A DDBMS ensures that the database operations are transparent to the end user.
Different types of transparencies are:– Distribution transparency– Transaction transparency– Failure transparency– Performance transparency– Heterogeneity transparency

55
Distributed Database DesignDistributed Database Design
All design principles and concepts discussed in the context of a centralized database also apply to a distributed database.
Three additional issues are relevant to the design of a distributed database:– data fragmentation– data replication– data allocation
Prof. S.K. Pandey, I.T.S, Ghaziabad

56
Data FragmentationData Fragmentation
Data fragmentation allows us to break a single object (a database or a table) into two or more fragments.
Three type of fragmentation strategies are available to distribute a table: - Horizontal, Vertical, Mixed.
Horizontal fragmentation divides a table into fragments consisting of sets of tuples:– Each fragment has unique rows and is stored at a different
node– Example: A bank may distribute its customer table by
location
Prof. S.K. Pandey, I.T.S, Ghaziabad

57
Contd……Contd……
Vertical fragmentation divides a table into fragments consisting of sets of columns– Each fragment is located at a different node and
consists of unique columns - with the exception of the primary key column, which is common to all fragments
– Example: The Customer table may be divided into two fragments, one fragment consisting of Cust ID, name, and address may be located in the Service building and the other fragment with Cust ID, credit limit, balance, dues may be located in the Collection building.
Prof. S.K. Pandey, I.T.S, Ghaziabad

58
Data FragmentationData Fragmentation
Mixed fragmentation combines the horizontal and vertical strategies.
A fragment may consist of a subset of rows and a subset of columns of the original table.
Example: Customer table may be divided by state and grouped by columns. The service building in Texas will store Customer service related information for customers from Texas.
Prof. S.K. Pandey, I.T.S, Ghaziabad

59
Data ReplicationData Replication
Data replication involves storing multiple copies of a fragment in different locations. For example, a copy may be stored in New Delhi and another in Mumbai.
It improves response time and data availability. Data replication requires the DDBMS to maintain data
consistency among the replicas. A fully replicated database stores multiple copies of each
database fragment. A partially replicated database stores multiple copies of
some database fragments at multiple sites.
Prof. S.K. Pandey, I.T.S, Ghaziabad

60
Data AllocationData Allocation Data allocation decision involves determining the location of
the fragments so as to achieve the design goals of cost, response time and availability.
Three data allocation strategies are: centralized, partitioned and replicated.
A centralized allocation strategy stores the entire database in a single location.
A partitioned strategy divides the database into disjointed parts (fragments) and allocates the fragments to different locations.
In a replicated strategy copies of one or more database fragments are stored at several sites.
Prof. S.K. Pandey, I.T.S, Ghaziabad