java の勉強 - ed.tus.ac.jp · java の勉強 和田@応用数学 @2017 masami wada ver.3.2...
TRANSCRIPT

Java の勉強
和田@応用数学@2017 Masami WADA
ver.3.2 (2018.9.18 作成)
(ver.3.2.3) 2019/6/5 未だ完結していませんが、ここまでのミスの修正をしました(ver.3.2.2) 10月中の授業で見つけたミスの修正をしました(ver.3.2.1) 9月中の授業で見つけたミスの修正をしました(ver.3.2) 再履クラスで使いながら加筆・修正していきます。完成することは無いですね (^_^;)

i
目次
第 I部 – プログラミング言語 Java 基礎 1 – 1
第 1章 Java 言語を学ぶ前に 2
1.1 Java 言語とは . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 他のプログラミング言語との違い . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.3 利用するソフトウェア . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.3.1 Eclipse と Pleiades . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.3.2 JDK と JRE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
第 2章 Java 言語の基本的な文法 I 5
2.1 プログラムの作り方と動かし方 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1.1 プロジェクトを作る . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1.2 パッケージを作る . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.1.3 ソースプログラムを作る . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.4 プログラム名を間違ってしまったとき . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.1.5 エディタとパッケージ・エクスプローラー . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.1.6 プログラムを実行する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2 プログラムの構造と決まりごと . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2.1 プログラム . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2.2 パッケージ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.2.3 プロジェクト . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.2.4 でも、個人的に使うとき... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.2.5 ファイルの在りかを把握する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.3 コンソールへの出力 I . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.3.1 System.out.print . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.3.2 System.out.println . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.4 文字コード . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.4.1 Unicode とは . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.5 コメント . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.5.1 単一行コメント . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.5.2 ブロックコメント . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.5.3 Javadoc 用コメント . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.6 基本型 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19

ii 目次
2.6.1 整数型 (integer type): byte, short, int, long . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.6.2 実数型 (real number type): float, double . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.6.3 論理値型: boolean . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.6.4 文字型: char . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.6.5 もっと大きな値はどうする? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.7 変数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.7.1 変数とリテラル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.7.2 変数の宣言と値の代入 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.8 五則演算 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.8.1 小かっこで計算順序の制御を . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.9 文字列の連結演算 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.10 1を加えるという操作 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.10.1 複合代入演算子 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
2.10.2 インクリメント・デクリメント演算子 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.10.3 多重代入文 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
2.11 キャスト . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
2.12 条件分岐 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
2.12.1 比較演算子 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
2.12.2 論理演算子 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
2.12.3 if 文 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
2.12.4 複数の分岐条件 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
2.12.5 処理が 1 つの場合の中かっこの省略 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
2.12.6 switch 文 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
2.12.7 条件演算子 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
2.12.8 boolean 型変数の真偽判定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
2.13 繰り返し . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
2.13.1 for 文 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
2.13.2 while 文 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
2.13.3 do while 文 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
2.13.4 変数のスコープ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
2.13.5 無限ループ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
2.13.6 繰り返しの入れ子 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
2.13.7 break と continue . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
2.14 配列 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
2.14.1 配列の宣言 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
2.14.2 配列の初期値 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
2.14.3 配列と繰り返し . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
2.14.4 多次元配列 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
2.14.5 凸凹配列 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
2.14.6 長さ 0 の配列や null . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
2.14.7 配列のコピー . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
2.14.8 拡張 for 文 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77

iii
2.14.9 行列とベクトルの計算 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
2.15 Math クラス . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
2.15.1 Math クラスのクラスメソッド . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
2.16 キーボードからのデータ入力 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
2.16.1 System.in と System.out . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
2.16.2 Scanner(System.in) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
2.17 コンソールへの出力 II . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
2.17.1 System.out.printf() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
2.18 メソッド I . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
2.18.1 API (Application Programming Interface) . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
2.18.2 クラスメソッド . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
2.18.3 実引数と仮引数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
2.18.4 行列とベクトルの計算 (続) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
2.18.5 再帰プログラム . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
2.18.6 main メソッドの引数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
2.18.7 System.arraycopy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
2.19 文字列型 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
2.19.1 文字型と文字列型 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
2.19.2 文字列のメソッド . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
2.19.3 エスケープシーケンス . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
2.20 応用プログラム (配列の要素のソーティング) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
2.20.1 選択法 (Selection sort) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
2.20.2 挿入法 (Insertion sort) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
2.20.3 泡立ち法 (Bubble sort) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
2.20.4 クィックソート (Quicksort) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
2.20.5 ヒープソート (Heap sort) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
2.20.6 マージソート (Merge sort) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
2.20.7 シェルソート (Shell’s sort) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
2.20.8 Java における時間測定について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
2.21 第 2 章のまとめ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
第 II部 – プログラミング言語 Java 基礎 2 – 128
第 3章 Java 言語の基本的な文法 II 129
3.1 オブジェクト指向とは . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
3.2 オブジェクトとインスタンス . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
3.2.1 クラス . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
3.2.2 ファイルとクラスの関係 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
3.2.3 コンストラクタ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134
3.2.4 フィールド . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141
3.2.5 メソッド . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 145

iv 目次
3.2.6 参照型配列 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151
3.2.7 オーバーロード . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153
3.3 カプセル化 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153
3.3.1 アクセス制御 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153
3.3.2 private . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154
3.3.3 package-private . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 156
3.3.4 protected . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 156
3.3.5 public . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 156
3.4 インヘリタンス (継承) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 157
3.4.1 単一継承 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161
3.4.2 Object クラス . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 164
3.4.3 オーバーライド . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 166
3.4.4 super いろいろ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 169
3.4.5 final 修飾子 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 170
3.4.6 キャスト . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172
3.5 ポリモルフィズム (多態性)と動的束縛 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 175
3.6 例外処理 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 177
3.6.1 例外 (Exception) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 177
3.6.2 Exception クラス . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 179
3.6.3 try ~ catch ~ finally . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 180
3.6.4 自作の例外 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185
3.7 Scanner を使ったテキストデータの入力 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 186
3.7.1 next と nextLine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 187
3.7.2 デリミターの設定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189
3.7.3 File . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 190
3.7.4 ファイルからのテキスト入力:Scanner(File) . . . . . . . . . . . . . . . . . . . . . . . . . . . 192
3.8 ファイルへの入出力 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193
3.8.1 ストリームとファイル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193
3.8.2 FileInputStream / FileOutputStream . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194
3.8.3 FileReader / FileWriter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 196
3.8.4 BufferedReader / BufferedWriter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 197
3.8.5 InputStreamReader / OutputStreamWriter . . . . . . . . . . . . . . . . . . . . . . . . . . 198
3.8.6 Java のデータを Excel や Mathematica に読ませる . . . . . . . . . . . . . . . . . . . . . . . 199
3.9 import 文 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 200
3.9.1 import 文の書き方 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 201
3.9.2 java.lang パッケージ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202
3.9.3 静的インポート . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202
3.10 抽象クラスとインタフェース . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202
3.10.1 抽象クラス . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202
3.10.2 インタフェース . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 205
3.10.3 デフォルトメソッド . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 209
3.11 ジェネリクス . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 210

v
3.11.1 ラッパークラス . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 210
3.11.2 オートボクシング . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 211
3.11.3 ジェネリクス . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212
3.11.4 パラメータ化された型 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 213
3.11.5 型パラメータ付きインスタンス・配列の生成不可 . . . . . . . . . . . . . . . . . . . . . . . . . 217
3.11.6 ワイルドカード型 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 217
3.11.7 Generic なメソッド . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 219
3.12 Java API . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 220
3.12.1 Collection 系データ構造 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 220
3.12.2 ArrayList . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 222
3.12.3 LinkedList . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 228
3.12.4 Stack と Queue . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 229
3.12.5 リスト構造を自作してみる . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 231
3.12.6 木構造を自作してみる . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 237
3.13 ネストしたクラスやインタフェース . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 242
3.13.1 静的なメンバークラス . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 242
3.13.2 非 static なメンバークラス (内部クラス) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 244
3.13.3 無名クラス . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 245
3.13.4 ローカルクラス . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 246
3.14 スレッド・並列処理 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 246
3.14.1 Thread クラスの継承 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 246
3.14.2 スレッドの制御 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 248
3.14.3 Runnable の実装 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 250
3.14.4 スレッドの排他制御 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 250
3.15 JavaFX とマルチメディア (執筆中) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 253
3.15.1 初めての JavaFX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 254
3.15.2 Stage クラス . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 257
3.15.3 Scene クラス . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 260
3.15.4 SceneGraph . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 261
3.16 列挙型 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 261
3.16.1 タイプセーフな一連の定数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 261
3.16.2 enum 定数のインポート . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 264
3.17 アノテーション . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 264
3.17.1 @Deprecated . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 265
3.17.2 @Override . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 265
3.17.3 @SuppressWarnings . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 266
3.18 可変長パラメータ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 266
第 III部 – 付録 – Apx.1
付録 A コンピュータ内の数の表現 Apx.2

vi 目次
A.1 2・8・16 進数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.2
A.2 基数変換 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.3
A.2.1 10 進数から 2 進数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.4
A.2.2 2 進数から 10 進数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.4
A.2.3 2 進数と 8 進数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.5
A.3 実数の基数表示 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.5
A.3.1 2 進小数と 10 進小数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.5
A.3.2 2 進小数から 8 進小数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.6
A.4 2 進数の桁数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.7
A.5 コンピュータ内の計算 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.8
A.6 コンピュータ内の数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.8
A.7 2 の補数表現 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.9
A.8 実数の表現方法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.10
A.9 IEEE 754 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.10
A.9.1 IEEE 754 の単精度実数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.10
A.10 表せる実数は一様ではない . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.12
付録 B Eclipse のインストール Apx.13
B.1 インストールの前に . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.13
B.2 Pleiades のダウンロード . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.13
B.3 Java API ドキュメントのダウンロード . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.14
B.4 Eclipse のインストール . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.15
B.4.1 既に前のバージョンがある場合 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.15
B.4.2 新しくインストールする場合 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.15
B.5 Java API ドキュメントのインストール . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.16
B.6 Eclipse の初めての起動 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.18
B.6.1 workspace の設定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.18
B.6.2 授業用プロジェクトの作成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.20
B.6.3 API ドキュメントの関連付け . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.20
B.6.4 Eclipse を見やすくする . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.22
B.7 Eclipse を更新したとき . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.25
付録 C javadoc:プログラムのマニュアル作り Apx.27
C.1 Javadoc とは . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.27
C.2 まずはやってみよう . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.27
C.3 Javadoc のタグ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.31
付録 D debug:プログラムの虫取り Apx.32
D.1 デバッギング . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.32
D.2 ビューいろいろ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.32
D.2.1 「デバッグ」ビュー . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.32
D.2.2 「変数」ビュー . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.33
D.2.3 「ブレークポイント」ビュー . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.33

vii
D.2.4 「式」ビュー . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.33
D.2.5 「表示」ビュー . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.33
D.3 デバッグの仕方 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.34
索引 Ind.1

viii
ソースコード目次
2.1 HelloJava.java (はじめまして Duke) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2 HelloJava2.java (はじめまして Duke 改行版) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.3 UnicodeCheck.java (UNICODE の値) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.4 Comments.java (コメント文いろいろ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.5 IntegerMaxAndMin.java (整数型の最大・最小値) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.6 RealNumberMaxAndMin.java (実数型の最大・最小値) . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.7 CharIsInteger.java (文字は整数だった) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.8 Substitution.java (リテラルの代入) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.9 Arithmetics.java (五則計算) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
2.10 PAdditionValues.java (2つの変数の和) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
2.11 SwapValues.java (2つの数の交換) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.12 AdditionValues2.java (2つの変数の和2) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.13 CompoundAssignment.java (複合代入演算) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
2.14 ErrorSubst.java (複合代入でのエラー) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.15 SubstInEquation.java (代入文は値を持つ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
2.16 SubstInEquation2.java (式中のインクリメントは混乱原因) . . . . . . . . . . . . . . . . . . . . . . . 32
2.17 MultipleSubst.java (多重代入文) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
2.18 MultipleSubst2.java (多重代入文は使わなくても) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
2.19 MultipleSubst3.java (複雑な多重代入文) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
2.20 Casting1.java (ムリやりキャスト) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.21 Casting2.java (丸め誤差とキャスト) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
2.22 CompoundAssign.java (複合代入文での隠れキャスト) . . . . . . . . . . . . . . . . . . . . . . . . . . 35
2.23 IfElse.java (if else 文) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
2.24 OddOrEven.java (偶数か奇数かで場合分け) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
2.25 Vote.java (投票プログラム) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
2.26 RankEvaluation.java (条件分岐で成績評価) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
2.27 IsVariable.java (boolean型変数の真偽判定) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
2.28 DoubleCounter.java (実数型の繰り返しカウンタ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
2.29 FibonacciNumbers.java (フィボナッチ数列) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
2.30 NoMultiple.java (3 の倍数以外を出力) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
2.31 CollatzSequence.java (コラッツ予想) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
2.32 WhileVSDoWhile.java (while 文と do while 文) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
2.34 InfiniteLoop.java (停止しない無限ループ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55

ix
2.35 GuessingGame.java (数当てゲーム) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
2.36 MultiplicationTable.java (九九の表) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
2.37 DoubleLoop.java (繰り返しの入れ子) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
2.38 DoubleLoop2.java (ラベル付き break 文) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
2.39 DoubleLoop3.java (ラベル付き continue 文) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
2.40 LoopParameter.java (繰り返し内から値の取り出し) . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
2.41 ArrayInitialization.java (配列の初期値指定) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
2.42 PrintArray.java (配列と繰り返し) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
2.43 ArrayInitialization2.java (繰り返しによる配列の初期化) . . . . . . . . . . . . . . . . . . . . . . . . 64
2.44 SumOfArray.java (配列の要素の合計) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
2.45 MaxOfArray.java (配列の要素の最大値) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
2.46 AverageOfPositive.java (配列内の正数の平均値) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
2.47 OlympicGame.java (オリンピック採点方式) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
2.48 DifferenceTwoArray.java (ベクトルの差) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
2.49 SwapArray.java (2つのベクトルの交換) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
2.50 ToReverseOrder.java (配列の要素の逆順化) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
2.51 EvaluateGrade.java (成績評価の集計) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
2.52 ShiftArray.java (配列の巡回シフト) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
2.53 ArrayInitialization3.java (行列の初期値指定) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
2.54 StudentDegrees.java (凸凹行列で成績管理) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
2.55 SetArrays.java (多次元配列の宣言と処理) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
2.56 ArrayIndexOutOfBounds.java (配列でよく出すエラー) . . . . . . . . . . . . . . . . . . . . . . . . . 75
2.57 ArrayCopy.java (配列のコピー) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
2.58 ArrayCopy2.java (配列のコピー失敗版) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
2.59 ArrayCopy3.java (多次元配列のコピー) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
2.60 ExtendedForEach.java (拡張 for 文) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
2.61 ExtendedForEach2.java (拡張 for 文2) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
2.62 ExtendedForEach3.java (拡張 for 文3) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
2.63 MatrixVector.java (行列とベクトルの積) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
2.64 MatrixMatrix.java (行列と行列の積) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
2.65 TrigonometricTable.java (三角関数表) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
2.66 MathMethods.java (基本関数の例) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
2.67 TriangulumArea.java (三角形の面積) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
2.68 OddEven.java (整数値のキーボード入力) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
2.69 QuadraticEquation.java (2次多項式の根) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
2.70 TrigonometricTable2.java (printf で三角関数表) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
2.71 NewtonMethod.java (浮動小数点数表示:Newton 法) . . . . . . . . . . . . . . . . . . . . . . . . . . 86
2.72 CircleArea.java (main メソッド内で円の面積) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
2.73 CircleArea2.java (クラスメソッドで円の面積) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
2.74 CircleArea3 (クラスメソッドでの円の面積2) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
2.75 SwapValues2.java (クラスメソッドで数の交換できる?) . . . . . . . . . . . . . . . . . . . . . . . . . 91
2.76 FormalParameter.java (配列をメソッドに渡す) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92

x ソースコード目次
2.77 LinearAlgebra.java (行列・ベクトルの積) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
2.78 FibonacciRecursive.java (再帰プログラムによるフィボナッチ数) . . . . . . . . . . . . . . . . . . . . 95
2.79 FactorialRecursive.java (再帰プログラムによる階乗) . . . . . . . . . . . . . . . . . . . . . . . . . . 95
2.80 HanoiTower.java (ハノイの塔) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
2.81 MainParameters.java (メインの引数を使う) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
2.83 ArrayCopyExample1.java (1次元配列のコピー) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
2.85 ArrayCopyExample2.java (多次元配列のコピー:失敗作) . . . . . . . . . . . . . . . . . . . . . . . . 100
2.86 ArrayCopyExample3.java (多次元配列のコピー) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
2.87 ArrayCloneExample.java (配列のクローン) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
2.88 StringvsChar.java (文字列と文字) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
2.89 StringMethods.java (文字列のメソッドいろいろ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
2.90 MyTools.java (乱数作成などのツール集) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
2.91 SortingExample.java (選択法によるソート) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
2.92 ArraySorting.java#selectionSort (選択法) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
2.93 SortingExample.java#main (追加:挿入法によるソート) . . . . . . . . . . . . . . . . . . . . . . . . 107
2.94 ArraySorting.java#selectionSort (挿入法) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
2.95 SortingExample.java#main (追加:泡立ち法によるソート) . . . . . . . . . . . . . . . . . . . . . . . 109
2.96 ArraySorting.java#bubbleSort (泡立ち法) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
2.97 SortingExample.java#main (追加:クィックソートによるソート) . . . . . . . . . . . . . . . . . . . 109
2.98 ArraySorting.java#quickSort (クィックソート) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
2.99 SortingExample.java#main (追加:ヒープソートによるソート) . . . . . . . . . . . . . . . . . . . . 112
2.100 ArraySorting.java#heapSort (ヒープソート) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
2.101 SortingExample.java#main (追加:マージソートによるソート) . . . . . . . . . . . . . . . . . . . . 113
2.102 ArraySorting.java#mergeSort (マージソート) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
2.103 SortingExample.java#main (追加:シェルソートによるソート) . . . . . . . . . . . . . . . . . . . . 115
2.104 ArraySorting.java#shellSort (シェルソート) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
2.105 TimePrecisionExample.java (時間測定) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
2.106 WrongAverage.java (間違いだらけの平均値) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
2.107 SwapRowOfMatrix.java (行列の行の交換) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
2.108 VectorNormalize.java (ベクトルの正規化) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
2.109 Combination.java (組み合わせ数) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
2.110 Maclaurin.java (マクローリン展開によるネイピア数 e の計算) . . . . . . . . . . . . . . . . . . . . . 122
2.111 MonteCarlo.java (モンテカルロ法によるπの計算) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
2.112 MargeArrays.java (2つの数ベクトルのマージ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
2.113 ArrayTransform.java (配列の変形) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125
2.114 InverseMatrix.java (逆行列を求める) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 126
3.1 Student.java (学生の成績情報) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
3.2 StudentExample.java (学生の成績処理) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132
3.3 Course.java (履修科目と成績のクラス) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
3.6 (改) StudentExample.java (複数のコンストラクタが必要) . . . . . . . . . . . . . . . . . . . . . . . . 136
3.7 (改) Student.java (コンストラクタのオーバーロード) . . . . . . . . . . . . . . . . . . . . . . . . . . 137
3.8 Point.java (平面上の点クラス) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140

xi
3.9 PointExample.java (コンストラクタ無しクラス) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140
3.10 (改) Student.java (クラスフィールドの追加) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142
3.11 MembershipExample.java (会員登録) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142
3.12 Entry.java (会員情報の配列への登録) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
3.13 Member.java (会員情報) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
3.16 TaroExample.java (クラスを作ってみる) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 146
3.19 ComplexNumberExample.java (複素数計算) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147
3.20 ComplexNumber.java (複素数のクラス) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 148
3.21 MyMathExample.java (自作 Math クラス) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 150
3.22 CentroidExample.java (参照型配列 Point[]) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151
3.24 PrivateFieldExample.java (private field へ直接アクセス) . . . . . . . . . . . . . . . . . . . . . . . . 154
3.25 (改)PrivateFieldExample.java (private field へ直接アクセス) . . . . . . . . . . . . . . . . . . . . . 154
3.26 InheritanceExample.java (継承関係) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 158
3.27 Human.java (人クラス) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 158
3.28 Professor.java (教授クラス) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159
3.29 Lecture.java (講義クラス) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159
3.30 Student.java (学生クラス) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159
3.31 PointExample3.java (点集合の重心点を求める) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 160
3.32 WeightedPoint.java (重み付きの点クラス) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161
3.34 ObjectExample.tex (Object クラスのメソッド) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 164
3.35 ArrayIsObject.java (配列の Object メソッド) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 165
3.36 StringIsObject.java ( == と equals() の違い) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 166
3.37 PointExample4.tex (メソッドをオーバーライド) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 166
3.38 ColoredWeightedPoint.java (色付き重み付き点クラス) . . . . . . . . . . . . . . . . . . . . . . . . . 166
3.39 OverrideExample2.java (オーバーライドにおけるアクセス権) . . . . . . . . . . . . . . . . . . . . . 167
3.40 SuperExample.java (supar.メソッドの例) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 169
3.41 FinalParameter.java (メソッドの仮引数に final) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 170
3.42 FinalExample.java (final な参照変数) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171
3.43 OverrideExample3.java (クラスのキャスト) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172
3.44 InstanceOfExample.java (インスタンスの型チェック) . . . . . . . . . . . . . . . . . . . . . . . . . . 175
3.45 PolymorphismExample.java (ポリモルフィズムで図形処理 (?)) . . . . . . . . . . . . . . . . . . . . . 176
3.46 DivideZeroExample.java (ゼロ割りの例外) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 177
3.47 OutOfBoundExample.java (配列の添字オーバーの例外) . . . . . . . . . . . . . . . . . . . . . . . . 178
3.48 (改) DivideZeroExample.java (スタックトレース) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 180
3.52 TwoCatchExample.java (複数の例外のキャッチ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182
3.54 RedirectExample.java (出力先をファイルにリダイレクト) . . . . . . . . . . . . . . . . . . . . . . . 183
3.55 FinallyExample.java (例外処理の finally ブロック) . . . . . . . . . . . . . . . . . . . . . . . . . . . 184
3.56 MyExceptionExample.java (自作の例外を作る) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185
3.57 ScannerExample.java (標準入力装置より整数の入力) . . . . . . . . . . . . . . . . . . . . . . . . . . 187
3.58 ScannerExample2.java (next) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 187
3.59 ScannerExample3.java (nextLine) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 188
3.60 ScannerExample4.java (Scanner でのデリミター) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 188

xii ソースコード目次
3.61 DelimiterExample.java (カンマをデリミターに) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189
3.62 ScannerExample5.java (正規表現でパターン読み込み) . . . . . . . . . . . . . . . . . . . . . . . . . 190
3.63 HelloJavaFromFile.java (ファイルから Duke) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191
3.66 FileScanner.java (Scanner でファイルから数値データ読み込み) . . . . . . . . . . . . . . . . . . . . 192
3.67 ScannerReadFile.java (hasNext() を使ったデータファイルの読み込み) . . . . . . . . . . . . . . . . 193
3.68 StreamExample01.java (FileOutputStream を使って文字列をファイルへ) . . . . . . . . . . . . . . . 194
3.69 StreamExample02.java (FileOutputStream を使って画像ファイルのコピー) . . . . . . . . . . . . . 195
3.70 StreamExample03.java (FileWriter を使ってテキストファイルを扱う) . . . . . . . . . . . . . . . . . 196
3.71 StreamExample04.java (BufferedWriter を使ってテキストファイルを扱う) . . . . . . . . . . . . . . 197
3.72 StreamExample05.java (OutputStreamWriter を使ってテキストファイルを扱う) . . . . . . . . . . . 198
3.73 CSV Example.java (CSV 形式ファイルに出力) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 200
3.74 ImportExamaple.java (インポート文の例題) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 201
3.75 StaticImportExample.java (静的インポート) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202
3.76 AbstractClass.java (抽象クラスで図形処理 (?)) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 203
3.77 InterfaceExample.java (インタフェースの例題) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 205
3.78 InterfaceExample2.java (インタフェースの instanceof) . . . . . . . . . . . . . . . . . . . . . . . . . 208
3.79 InterfaceExample3.java (デフォルトメソッド) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 209
3.80 IntegerExample.java (Integer クラスのインスタンス比較) . . . . . . . . . . . . . . . . . . . . . . . 210
3.81 BoxExample0.java (何でも入れられる箱0) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212
3.82 BoxExample1.java (何でも入れられる箱1) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212
3.83 BoxExample2.java (何でも入れられる箱2) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 214
3.84 改 BoxExample2.java (何でも入れられる箱2) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 214
3.87 CreateEtCetraExample.java (型パラメータ付き配列など . . . . . . . . . . . . . . . . . . . . . . . . 217
3.88 IntegersToObjects.java (Integerの配列は Objectの配列でもある) . . . . . . . . . . . . . . . . . . . 218
3.89 IntegersToObjects3.java (境界ワイルドカード型の例) . . . . . . . . . . . . . . . . . . . . . . . . . . 218
3.90 GenericMethod.java (Generic method の例) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 219
3.91 ArrayListExample.java (ArrayList クラスの例題) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 222
3.92 ArrayListExample2.java (整数配列を ArrayListに変換) . . . . . . . . . . . . . . . . . . . . . . . . 222
3.93 Point.java (Comparable を実装した平面の点クラス) . . . . . . . . . . . . . . . . . . . . . . . . . . 224
3.94 ShapesExample.java (図形リストで並び替え) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 227
3.95 LinkedListExample.java (LinkedList クラスの例題) . . . . . . . . . . . . . . . . . . . . . . . . . . 229
3.96 StackQueue.java (Stack と Queue の例題) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 230
3.97 students.txt (学生データファイル):src/section0312 に置く . . . . . . . . . . . . . . . . . . . . . . . 231
3.98 StudentListExample.java (main メソッド:両方向リストの自作) . . . . . . . . . . . . . . . . . . . . 232
3.99 Student.java (学生クラス) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232
3.100 Date.java (誕生日用の年月日クラス) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 233
3.101 StudentCell.java (リストのセル) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 234
3.102 StudentList.java (両方向リスト) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 235
3.103 BinarySearchTreeExample.java . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 238
3.104 NestedClassExample.java (静的なメンバークラスの例題) . . . . . . . . . . . . . . . . . . . . . . . . 242
3.105 InnerClassExample.java (内部クラスの例) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 244
3.106 AnonymouseClassExample.java (無名クラスの例) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 245

xiii
3.107 ThreadExample01.java (Thread の継承によるスレッド処理) . . . . . . . . . . . . . . . . . . . . . . 246
3.108 ”ThreadExample02.java (Thread の制御)” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 248
3.109 ”ThreadExample04.java (Runnable の実装によるスレッド処理)” . . . . . . . . . . . . . . . . . . . 250
3.110 BankBooks.java (お金が消える!) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 252
3.111 JavaFXExample01.java (初めての JavaFX) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 254
3.112 JavaFXExample02.java (窓の大きさを設定) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 257
3.113 JavaFXExample03.java (複数の窓を作成) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 259
3.114 PlayCardExample01.java (タイプセーフでない列挙) . . . . . . . . . . . . . . . . . . . . . . . . . . 261
3.115 PlayCardExample02.java (タイプセーフな列挙) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262
3.116 PlayCardExample new.java (enum による実現) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 263
3.117 RGBColor.java (列挙型で色) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 264
3.118 EnumImportExample.java (列挙型をインポート) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 264
3.119 DeprecatedExample.java (アノテーション:非推奨) . . . . . . . . . . . . . . . . . . . . . . . . . . . 265
3.120 VariableArityExample.java (可変長パラメータの例) . . . . . . . . . . . . . . . . . . . . . . . . . . 266
C.1 Circle.java (円クラス) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.27
C.2 Point.java (点クラス) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.28
C.3 Circle.java (円クラス) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.29
C.4 Point.java (点クラス) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Apx.30

第 I部
– プログラミング言語 Java 基礎1 –

2
第1章
Java 言語を学ぶ前に
コンピュータの中で処理されているプログラムは、コンピュータが理解できる言葉 機械語 (machine language) によって記述されて動いています。従って、コンピュータに新たな仕事をさせたいときは、機械語のプログラムを与えてやれば良いのですが、人の手でそれを直接作るというのは、複雑化したコンピュータ環境において現実的ではありません。そこで、まずは人が理解できる言葉でプログラムを記述し、それをコンパイラ (compiler) というソフトウェアを利
用して機械語にコンパイル (翻訳) (compile) し、それを動かすという方法が現在の一般的な方法です。この「人が理解できる言葉」がプログラミング言語 (programming language) です。Java 言語もその1つです。この授業では、プログラミング言語 Java の基礎を習得してもらい、各自のノートパソコンでプログラムを作成・実行してもらいます。プログラミング言語の習得は、文法を覚えるということに尽きるのでしょうが、外国語を学ぶことと一緒で「習うより慣れろ」が唯一の方法ではないでしょうか。私が学生の頃は、まだスマホも PS–4 もなかった頃なので、パソコン雑誌に載っているゲームプログラムをちまちま
とパソコンに打ち込んで遊ぶ、ということでプログラミング言語を覚えました。そうしたモチベーションがあったのでプログラミングが好きにもなったのです。みんなも、いろいろなプログラムを作ってくれれば自然と Java を習得できますので、頑張って下さい。このテキストは、まず「付録 A コンピュータ内の表現」を読み、次に「付録 B Eclipse のインストール」に従って
ソフトウェアのダウンロードとインストールを行った上で、という前提の元で書いています。従って、突然第1章から読み始めると難解な部分があるかと思います。また、各項目は全ての情報を書いていません(このテキストのみで Java は OK! と思われると困りますよ)。Java を習う最初の1年で知っておいたほうが良さそうなことだけを掻い摘んで書いているので、他の教科書で触れているのに書かれていないことが結構あります。よって、無事単位習得のあかつきには、独学で読めそうな Java の参考書を手に入れて、抜けているところを埋めていって下さい。
1.1 Java 言語とはJava 言語 (以降、単に Java と呼ぶことにします) は、1990年代初頭、Sun Microsystems 社 (現在の Oracle 社) の内部プロジェクトとして誕生したプログラミング言語 (最初は Oak という名前でした) で、すでに広く使われていた C
言語や C++に対抗して作られました。家電製品などに組み込むためには C 言語系のシステムは大きすぎてかつ複雑すぎたこと、世の中がインターネットの時代に入って Web ブラウザの中で動く軽量ソフトが必要だったことなどから、1996年 Java の最初のバージョンが発表されました。現在、Java の最新バージョンは 2017/9 に発表された ver. 9 です ( 2018/2 現在 )。ちなみに、Java はコーヒーの名前ですね。開発者たちが通っていたカフェの飲み物に由来しているとか。

1.2 他のプログラミング言語との違い 3
各自のパソコンに現在インストールされている Java のバージョンを知りたい時は、以下のページの説明を読みましょう。> https://www.java.com/ja/download/help/version manual.xml
Java の大きな特徴は、この言語が「オブジェクト指向 (Object oriented) 」のプログラミング言語である、ということです。オブジェクト指向とは、プログラミングのパラダイム (paradigm : 理論的枠組み・見方) の一つで、プログラムをデータとその振る舞いが結びつけられたオブジェクトの集まりとして構成するという見方です。この時点では、ちんぷんかんぷん (^^;)
このテキストでは、第 2 章では従来の (オブジェクト指向ではない) プログラミング言語(主に「手続き型プログラミング言語」)にも言える基本的な部分を、そして第 3 章では Java のオブジェクト指向としての側面を学んでいきます。プログラミング言語の世界は、より良いパラダイムを探して日々変化しています。新しい言語も次々出てきていますので、Java を習得後は新しい言語に挑戦してみて下さい。
1.2 他のプログラミング言語との違い同じオブジェクト指向のプログラミング言語 C++らと Java が大きく異なる点は、Java で作ったプログラムは、
Windows OS や Mac OS のような OS (Operating System) の上で直接動かないということです。(^^;)
例えば C++のコンパイラは特定の OS やハードウェアに合わせて最適化されて作られているので、翻訳した結果が直接コンピュータ上で高速に動きます。しかし OS やハードウェアが変更されると動かなかったり、挙動がおかしくなったりします。一方、Java は JVM (Java Virtual Machine:Java 仮想マシン) というソフトウェアによる仮想コンピュータ環境の中でプログラムを実行させる方法をとりました。それによって Java で書かれたプログラムは、JVM
が用意された環境なら OS やハードウェアに依存せずにどこでも動くのです。
Java のスローガン:「Write Once, Run Anywhere.」
Windows OS や Mac OS や linux (リナックス)、携帯電話やスマホなど、それぞれの OS に対応した JVM が用意されています (みんなのスマホにも入っているんですよ)。それにより、みんなが作ったプログラムがパソコン上と同様にスマホ上でも動くようになります (そう簡単ではないですけどね)。また、Java は後述する「型」の制約が厳しいのでプログラムの曖昧性が少なく(その分、柔軟性に乏しいかな?)、また後述する「ガーベージ・コレクション」を自動で行うのでメモリーについての問題が起き難いなど、最初に習得するプログラミング言語に適していると言われています( C 系言語ではメモリー管理をプログラマがプログラム中に明に書かねばならないので、高度なことができる一方、学習のハードルが少々高い)。> 最初に C++か? Java か? はいろいろ意見が分かれるところです。ところで、2018 年度の新入生が学ぶプログラミング言語が、「Python」に決まりました (橋口先生の趣味!?)。人工知能などで有名になっている新しい言語です (といっても、生まれた年は Java と同じ年です) が、Youtube や Instagram
などお馴染みの Web アプリも Python で作られています。Google が主に開発に使っている言語3つ「Java、C++、Python」にも選ばれています。システム系なら Java、学術分野なら Python なんて声もあります。ちなみに、Python は Java より簡単!と言われていますので、Java の後で Python を学ぶのは楽勝かもしれません。
1.3 利用するソフトウェア1.3.1 Eclipse と Pleiades
この授業では、 IDE (Integrated Development Environment:統合開発環境) というアプリケーションのひとつEclipse (エクリプス) を使用し、その中でプログラムを作成しながら Java を学んでいきます。統合開発環境とは、従

4 第 1章 Java 言語を学ぶ前に
来ならばテキストエディタ・コンパイラ・デバッガなど複数のアプリケーションを取っ替え引っ替えして行っていたプログラムの作成と実行をひとつの対話型操作環境で行えるようにしたものを言います。Java に対応した統合開発環境には、Eclipse の他にも NetBeans や IntelliJ IDEA などがあります。Eclipse は IBM 社によって開発されたオープンソースなアプリケーションで、Java 以外にも様々な言語によるアプリケーション開発に対応しています。plugin (プラグイン:部品) を追加することで、C++、PHP、Perl、C♯、D、TeX、Python、Ruby、JavaScript、AspectJ、Mathematica、SQL、UML などにも対応できます。Eclipse は 2018/2
現在、ver.4.7 コードネーム (Oxygen) を最新版としています。ちなみに、最近のコードネームは元素の名前に因んで付けられています (Oxygen は酸素だね)。Pleiades (プレイアデス) は英語仕様の Eclipse を日本語仕様に変えるプラグインの名前で、ダウンロードサイトで
は、Eclipse を含めた Pleiades の「All in one」ダウンロードを行うことができます (必要とされるものを一度に全てダウンロードできる) 。ちなみに pleiades は、日本人が大好きな「
すばる
昴」散開星団プレイアデスから名付けられています。以下では、Pleiades と Eclipse を区別せずに Eclipse と書きます。
1.3.2 JDK と JRE
Java を用いてプログラムを作ったり、作ったプログラムを実行させるには、必ずしも Eclipse を必要としません。(図 1.1 参照)Java プログラムの実行に必要な JVM の構築やコンパイルコマンドなどを実行するためには JRE
(Java Runtime Environment:Java 実行環境) が必要です。JRE さえあれば、Java プログラムを「実行」することができます。さらに Java プログラムを「作成」するには、JDK (Java Development Kit:Java 開発キット) をインストールすることが最もコンパクトです。JDK は Oracle 社のフリーソフトウェアとして各 OS に対応したバイナリ形式で配布しており、JDK のインストールで JRE も自動的にインストールされます。ただし、JDK はプログラムを作るための特別なエディタは含んでいないのと、コマンドプロンプトでコマンドを入力するなどの多少のマニアックさ?が必要です。一方、Eclipse をインストールすると、JDK・JRE も同時にインストールされるので、 Eclipse をモノにしたあかつきには JDK の使い方も学んで下さい。
OS: Operating System
JVM : Java Virtual Machine
JDK Eclipse
JRE
図 1.1 JDK と Eclipse (下から順に乗っかっていく)

5
第2章
Java 言語の基本的な文法 I
2.1 プログラムの作り方と動かし方まずは以下の Java プログラム HalloJava.java を例にして簡単に Eclipse での Java プログラムの作り方・動かし方を説明します。これが、Java 言語で書かれたプログラムです。日本語が一部にあるとはいえ、中学校レベルの英単語の意味不明の羅列「これを1年間学ぶのかぁ。退屈しそうだぁ...」ですかね? (^_^)
頑張ってください!
ソースコード 2.1 HelloJava.java (はじめまして Duke)
package section0201;
public class HelloJava {
public static void main( String[] args ) {
System.out.print( "はじめまして。" );
System.out.print( "Duke と言います。" );
}
}
図 2.1 Duke って何者? (Duke は Java のマスコットキャラクタです)
2.1.1 プロジェクトを作る
まず最初に、Java プロジェクト という入れ物 (フォルダ) を作ります。プロジェクトとは、事業計画とか研究課題などを意味する言葉ですが、これは Eclipse で定義されている言葉です(Java の言葉ではありません)。この授業では、「プログラミング基礎 1・2 及び演習」という科目の単位を取るという大きな事業計画?がありますから、これを我々のプロジェクト「プログラミングの授業」と名付けることにしましょう。プロジェクト名は、日本語でも、英語でも中国語でも構いません。好きな名前を付けられますが、みんなが同じだと説明しやすいので、「プログラミングの授業」で統一しましょう。

6 第 2章 Java 言語の基本的な文法 I
Eclipse のメニューで「ファイル (F) > 新規 (N) > Java プロジェクト」と順に選択し、表示された窓「新規 Java
プロジェクト」の「プロジェクト名 (P)」の欄に「プログラミングの授業」と入力し、「完了 (F)」ボタンをクリックして下さい。(図 2.2 参照)
図 2.2 プロジェクトを作る
プロジェクトは、プログラムを作る度に作るものではありません。従って、この授業では、これ以外にプロジェクトは作りません。授業とは別にプロジェクトを作成し、例えば「自習」とでも名前を付ければ、授業のプログラムと無関係にその中に自習プログラムを作ることもできます。
2.1.2 パッケージを作る
次に、出来上がったプロジェクトの中にパッケージを作ります。パッケージとは、関連するプログラムの集合を入れる入れ物 (フォルダ) で、今度は Java の言葉です。まず、パッケージ・エクスプローラーで、「プログラミングの授業」プロジェクトの左にある > のマークをクリック
します。すると、中に入っている「src」フォルダのアイコンが表示されます。Java のプロジェクトの中には幾つかのフォルダが入っていて、パッケージ・エクスプローラーは、そのうちの src のみを表示するようになっています。このsrc フォルダがプログラムを入れる入れ物となります。(図 2.3 参照)
図 2.3 パッケージを作る (1)
そこで、表示された src のアイコンを右クリックし、出てきた縦長のメニューの上の方「新規 (W) > パッケージ」を選択して下さい。(図 2.4 参照)
このテキストのプログラムは、章・節ごとに同じパッケージ内に入れることにしたいので、 section**** という名前のパッケージに入れることにします。**** の部分には章番号と節番号をそれぞれ 0 付きの 2 桁で入れていきます。

2.1 プログラムの作り方と動かし方 7
図 2.4 パッケージを作る (2)
従って、2.1 節にあるプログラム HelloJava は section0201 パッケージに入れることにします。そこで、表示された窓「新規 Java パッケージ」の「名前 (M)」の欄に section0201 と入力し、「完了 (F)」ボタンをクリックして下さい。これでパッケージ section0201 がプロジェクト「プログラミングの授業」の src パッケージ・フォルダ中に出来上がりました。(図 2.5 参照)
図 2.5 パッケージを作る (3)
パッケージは関連するプログラムの集合を入れる入れ物ですから、授業のテーマ (章や節) が変わるたびに異なるパッケージを作って、その中にプログラムを作っていくことになります。
2.1.3 ソースプログラムを作る
次は、いよいよプログラムファイルを作成します。人間が読める状態のプログラムのことをソースコード (source code) とか、ソースプログラムと言います 。逆に、コンピュータが実行できる状態のプログラムをバイナリーコード (binary code) と言います。一般にコンピュータはソー

8 第 2章 Java 言語の基本的な文法 I
スコードを直接実行できません(これは正確にはウソです)(^^;)。
package section0201;
public class HelloJava {
public static void main( String[] args ) {
System.out.print( "はじめまして。" );
System.out.print( "Duke と言います。" );
}
}
このプログラムの名前は、ソースコード2行目で public class の次に書かれている HelloJava です。Java のソースプログラムのファイル名は、プログラムの名前 (正確にはクラスの名前) に拡張子 java を付けます。つまり、このソースプログラムのファイル名は HelloJava.java となります。HelloJava と拡張子 java の間にはドット「.」が入りますので、忘れずに。(コンピュータの世界では、ピリオッドとは言わずドットというのが慣例です)
「パッケージ・エクスプローラ」のパッケージ「section0201」のアイコン上で右クリックし、「新規 (W) > クラス」と選択して下さい。表示された窓「新規 Java クラス」 の「名前 (M)」の欄にプログラム名の HelloJava を入力して下さい。(図 2.6 参照) 拡張子 .java は必要ありません。「どのメソッド・スタブを作成しますか?」という項目の1つ目の選択肢「public static void main(String[] args) (V)」のチェックを入れて下さい。そして、「完了 (F)」ボタンをクリックしましょう。
図 2.6 ソースプログラムを作る (1)
Eclipse がプログラムの外枠部分を事前に作ってくれています。(図 2.7 参照)
• このテキストでは空行を極力省いています。ただし、空行はプログラム中に自由に入れられるので、見やすさを考えて自由に挿入して下さい。コンパイル時には空行は無視されるので、実行に影響は与えません。
• // TODO で始まるコメント行が挿入されていますが、これは我々素人にはしばらくは必要のない行なので、1 行まるまる消しましょう。後で、初めから表示されないように設定します。
入力するのは 4 行目と 5 行目だけです。この 2 行を間違えずに入力して下さい。なお、プログラムの各行がそれぞれ意味ありげ (?)に右に数文字ずつ字下げされていますが、この字下げのことを、

2.1 プログラムの作り方と動かし方 9
図 2.7 ソースプログラムを作る (2)
インデント (indent) と言います。インデントはブランクキーを決まった個数 (慣例的に 3 · 4 個) 打ち込むのでも良いのですが、tab キーを打つことでも簡単に入力できます。プログラムは原則、半角文字 (英数字) で記述しますが、文字列などの一部に日本語など他の言語も利用できます (この辺りの話は後で触れます)。日本語入力が終わった後、英語入力モードに戻ることを忘れないで下さい。例えば、「はじめまして。」の直後の ” (ダブルクォーテーション) が全角文字のままだと、プログラムはエラーとなって稼働しません。インデント以外で単語間に空白がある部分は半角のブランクを 1 つ入れて下さい。例えば、1 行目で package と
section0201 の間には半角のブランクが 1 つ入っています。逆に、半角のブランクは文法的にエラーにならない限りはどこに幾つ入れても構わないことになっています。例えば、和田は System.out.print( の後と、その対となる ) の前に 1 つブランク入れる癖があります。入れない教科書が多いですが、和田は見易さを重視して開けています。こうした、Java の文法規則には無いけれど慣例的に行なわれていることは、先人たちのプログラムを数多く見ることで真似ましょう。入力が終わったら、メニューで「ファイル (F)>保管 (S)」と選択します。このとき、ショートカットの Command+s
を覚えて利用するのも良いでしょう。
2.1.4 プログラム名を間違ってしまったとき
ところで、プログラムの名前を間違って作ってしまったとき、例えば、HelloJava.java とするところをHalloJava.java としてしまった (e → a)!の場合、プログラム名の直し方を知っておきましょう。これは、間違っていなくても、クラス名を変更するなど頻繁に起こる操作です。「パッケージ・エクスプローラー」でそのファイル (例えば HalloJava.java) を右クリックし、出てきた窓で「リファクタリング (Alt+Shift+T)」そして「名前変更 (Alt+Shift+R)」と選択します。頻繁に行う操作ではないので、ショットカットを覚えるのは無理かな。そして、「新しい名前」で名前を編集し、「完了」を押すと、関連するプログラムを検査して (そのプログラムを呼び出している全てのプログラムをチェックしている)、変更して良いか聞いてきま

10 第 2章 Java 言語の基本的な文法 I
す。再度「完了」を押すと変更できます。
2.1.5 エディタとパッケージ・エクスプローラー
Eclipse のエディタ上でプログラムを作っていると、上部のファイル名のタグのところに*マークが付きます。そして、出来上がったプログラムをメニューで「ファイル (F) >保管 (S)」すると、その*マークが消えます。エディタ上のプログラムはメモリー内で作成中のもの、パッケージ・エクスプローラーはハードディスクに格納されたもの、です。プログラムを動かす場合、その2つが揃った状態でないと動かないように設定されているため、*マークが表示されたままで実行させると、Eclipse が先ずファイルの格納をするように言ってきます。その場合は、格納して下さい。
2.1.6 プログラムを実行する
Eclipse は、プログラマがソースプログラムを作成中、裏でプログラムのコンパイル (翻訳)作業を行っています。正確に言うと、ソースコードを中間言語という JVM 上で解読可能なコードに書き直す作業を行っています。そこで書き直しができない場合、つまり Java の文法規則に違反したソースコードの場合に、Eclipse は文法エラーメッセージを表示し、人間にコードの書き直しを要求してきます。エラーメッセージが表示されずにプログラムコードが完成すると、中間言語によるプログラムが完成し、あとは JVM 上での実行を待つこととなります。最初に行ったように、Eclipse というソフトは、ソースコードを作成するエディタであり、コンパイラ(中間言語への翻訳器)であり、そして出来上がったプログラムを実行するアプリケーションでもあるわけです。作成した HelloJava
に文法エラーがなければ、続いて実行に移ります。もし、エラーがあった場合は、その行の行頭に「ランプに赤い×のアイコン ( )」が表示されますので、修正しましょう。メニューで「実行 (R)>実行 (S)> Java アプリケーション」を選択するか、ツールバーの「緑色の円の中に白抜き
右向き三角 ( )」のアイコンをクリック、あるいは、その横の小さな下向き黒三角で「実行 (R)> Java アプリケーション」を選択など、幾つかの選択肢で実行ができます。この実行、前に動かしたプログラムとの関係で上手くいかない場合もあって、その場合は「実行の構成 (N)」で始めないといけなかったりで、ちょっと慣れが必要です (説明が難しい)。もし、表示しているプログラムでは無く、前回動かしたプログラムが動いてしまうようなら、次の設定をチェックして下さい。パッケージ・エクスプローラでプロジェクト「プログラミングの授業」が選択されている状態で、メニューの「ウィンドウ (W) >設定 (P)」を選択し、左の「実行/デバッグ」の「起動」を選んだ際に、右の画面の「起動操作」の2項目目の「選択したリソースまたはアクティブなエディター云々」と「関連プロジェクトを起動する」にチェックが入っていることを確かめて下さい。これが1項目目の「常に前回起動した云々」にチェックされていると、上記のようなことが起きます。
2.2 プログラムの構造と決まりごとここまでに出てきたプログラム・パッケージ・プロジェクトについて、より細かい決まりごとなどをここでまとめておきます。
2.2.1 プログラム
Java においてプログラムは、いくつかのクラス (class) の集合体です。HelloJava プログラムは唯一つのクラスHelloJava からできていますが、先に進むと複数のクラスが絡み合って 1 つのプログラムを形成するようになります。クラスを表記したテキストファイルをソースファイル (source file) と言います。ソースファイルは、拡張子に .java を

2.2 プログラムの構造と決まりごと 11
付けなければいけません。1つのクラスを複数のソースファイルに分けて格納することはできませんが、1つのソースファイル内に複数のクラスを格納することはできます。この時、クラスの名前とファイルの名前には、次のような規約があります。
• ファイルの中にクラスが1つだけの場合は、ファイル名とクラス名は一致する (今回の HelloJava はこの場合)
• ファイルの中に複数のクラスがある場合は、スコープ (後で学びます) が public なクラスの名前とファイル名は等しくなければならない
public というスコープについての説明は後にするとして、この規約よりファイル内には public なクラスが複数あってはいけないことになります。また、入っているクラスが全て public でなければ、ファイル名には特に制約はありません。ただし、中身と入れ物の名前が全く違うのは使いにくいものです。慣例的には、ファイル名は中に入っているクラスのいずれかと等しい名前とし、混乱を招きそうな場合は、各クラスを別個のファイルに分割して (1クラス1ファイル)、クラス名とファイル名を等しくする方法が取られます。今、これを読んでちんぷん・かんぷんでも一向に構いません。テキストを読み終わる頃には、ちゃんと理解できている?と思いますので。(^^;)
問題 2.2.1. 次のクラスとファイルの関係で許されるのはどれですか。
1. クラス A とクラス B をソースファイル A.java に格納する2. public クラス A と クラス B をソースファイル A.java に格納する3. クラス A と public クラス B をソースファイル A.java に格納する4. public クラス A と public クラス B をソースファイル A.java に格納する
Java での名前の付け方には幾つかの形式があります。
• スネーク形式で単語をつなげる。(例:graphical_tools)
• キャメル形式で単語をつなげる。(例:graphicalTools)
• パスカル形式:アッパーキャメル形式とも (例:GraphicalTools)
スネーク形式とは、単語は全て小文字に、単語間のブランクをアンダースコア (under score:下線) ” ” に変える書き方です。一方、キャメルはラクダのこと。全ての文字を小文字にしてから単語間のブランクを削除し、2単語目以降の1文字目を大文字にしてつなげる書き方です。そして、キャメル形式の特殊な場合として、最初の文字を大文字にするパスカル形式があります。クラス名はパスカル形式の名前にするのが慣例になっています。
2.2.2 パッケージ
パッケージは、何らかの関連のあるプログラムの集合のことを言い、一般にその関連性から付けられた名前が英数字を用いて付いています。慣例的に、全て小文字で書かれます。各パッケージはそれぞれコンピュータの中のフォルダに対応し、その名前がそのまま使用されるので、OS のフォルダ命名法にも従わないといけません (英数字以外の記号はほとんど使えない)。また、ネット上に公開するような場合を考えて、世界中のどのプログラムとも名前が重複しないよう組織や個人のドメイン名を逆順に記述したものをパッケージ名の頭に付けるという方法も用いられています。 (例:jp.ac.tus.ed.jmwada.programmingexamples)

12 第 2章 Java 言語の基本的な文法 I
Java の教科書によってはパッケージを設定せずに全てのプログラムを記述しているものもあります。その場合、デフォルトパッケージという無名のパッケージ内にプログラムが作られているとして処理されます。一般に、デフォルトパッケージによるプログラム作りは推奨されておらず、Eclipse でも作成することはできますが、この授業では必ずパッケージを作ってからプログラムを作ります。
図 2.8 デフォルトパッケージ
Eclipse でパッケージを指定せずにプログラムを作ると、図 2.8 のように、デフォルト・パッケージという名無しのパッケージ内にプログラムが作られます。その場合、パッケージ・エクスプローラー上で、そのプログラムのアイコン(白いファイルに J の文字) を別のパッケージの中にドラッグすることでパッケージの移動ができます。
2.2.3 プロジェクト
プロジェクトは Java の言葉ではなく、Eclipse の言葉です。関連する複数のパッケージを集めた集合体をプロジェクトとして定義します。プロジェクト名には特にルールはありませんが、一般的な Java の命名法に従うのが無難でしょう。また、パッケージと同様に、各プロジェクトはそれぞれコンピュータ内のフォルダに対応するので、OS のフォルダ命名法には従わないといけません。
2.2.4 でも、個人的に使うとき...
以上の命名ルールを守らないと必ずコンパイルエラーを起こすのか?というと、そうでもありません。(^^;)
プログラムをコンパイル・実行する際に、プロジェクト名・パッケージ名・クラス名(プログラム名)が一意に識別できて矛盾がないなら、ほとんどの場合スムーズに実行まで行えます。つまり、教授にレポートとして提出するとか学外に公開するとか、で無い個人的な場合は多少ルールを無視しても大丈夫です(こんなこと、教科書では書けない)。例えば、パッケージを「行列の練習」なんてのにして、プログラム名を「行列の掛け算の練習.java」なんてのにしても(拡張子の .java は変えられない)、(たぶん) 動きます (あくまでも、個人使用ですよ)。
2.2.5 ファイルの在りかを把握する
自分で作ったプログラムをメールで提出しなければならなくなった。でも、どこにあるのかわからない!では困りますから、自分のプログラム群がパソコンのどこにあるのか、しっかり把握しておきましょう。

2.3 コンソールへの出力 I 13
この授業では Eclipse をインストールした際に、workspace というプログラムの置き場 (フォルダ) を、C:Yjava に置きました。こ C:Yjava.workspace 中に Eclipse で作る全てのプログラムがあります。このフォルダをバックアップしておけば、Eclipse を再インストールしたりしても、以前のプログラムを再利用することができます (ただし、新しい Eclipse にその場所を教えてやらねばいけませんが)。
2.3 コンソールへの出力 I
HelloJava プログラムに戻りましょう。プログラムの1行目には、そのプログラムがどのパッケージに入っているかを書きます。今回は section0201 パッケージでしたね。2行目からが HelloJava クラスのブロックです。ブロックとは、対となる中かっこに囲まれた部分を言い、この場合、2 行目から 7 行目までの赤い中かっこ内が HelloJava クラスのブロックです。さらに、その中にもう1つブロックが入っています。public static void main( String[] args ) に続く青いブロック (3 行目から 6
行目まで)、これを main メソッドのブロックと呼びます。実行したい命令を main メソッドのブロック内に書きます。このプログラムでは、2つの System.out.print という命令が入っています。まず、この System.out.print という命令について見ていきましょう。
package section0201;
public class HelloJava {public static void main( String[] args ) {
System.out.print( "はじめまして。" );
System.out.print( "Duke と言います。" );
}}
2.3.1 System.out.print
Java プログラムでは、プログラムの実行結果を様々な出力装置に出力できますが、特に設定を変えない限り、標準出力装置「コンソール (console)」にテキストとして出力します。Eclipse ではコンソール・ビュー (コンソールの窓)
を表示させておけば、そこに出力が行われます。コンソールへの出力は System.out と名付けられたオブジェクトの持つ print というメソッド(method : 機能)を利用します。オブジェクトについては第 3 章に説明するので、今は呪文としておきます。第 2 章では呪文 (意味は後まわしにして、とにかく使う文) が多いです。System.out の print なので、ドットでつなげて System.out.print と書きます。単に出力するのに面倒臭い!と思うでしょう。はい、面倒です。(^^)
出力したい文字列を二重引用符 (double quotations)「” ”」で囲んで print に続く小かっこの中に書きます。最後に、1つの命令が終わったことを意味するセミコロン (semicolon)「 ; 」を書きます。Java では、命令の最後に必ずこの「セミコロン」を付けるので、忘れないように。定期試験でプログラムを書いてもらう際にセミコロンが抜けたら1点減点!なんてこと、ありますので宜しく。このプログラムを実行させると、文字列が次のようにコンソールに出力されます。
はじめまして。Duke と言います。

14 第 2章 Java 言語の基本的な文法 I
問題 2.3.1. Duke の代わりに、あなたの名前が「はじめまして。和田雅美 と言います。」みたいに書かれるように、HelloJava プログラムを改良しなさい。
2.3.2 System.out.println
出力結果を見てわかるように、print メソッドには改行する機能がなく、2つの出力命令の結果が1行に続けて書かれています。この2つの間で改行を行いたいとき、2通りの方法があります。
• 文字列内の改行したい場所にエスケープシーケンス Yn を置く• 出力後に改行してくれる別のメソッド println を使う
エスケープシーケンスによる方法は、後述します。以下は、println (プリントエルエヌ) メソッドの使い方の例です。これまで学んだ手順に沿って、新しいプログラムを作成しましょう。次のプログラムを読むと、そのプログラムがどのパッケージに入っていて、何というファイルにしたら良いかがわかるはずですが、如何かな。(^^)b?
ソースコード 2.2 HelloJava2.java (はじめまして Duke 改行版)
package section0203;
public class HelloJava2 {
public static void main( String[] args ) {
System.out.println( "はじめまして。" );
System.out.println( "Duke と言います。" );
}
}
このプログラムの名前は HelloJava2.java で、パッケージ section0203 内に作る、と読み取れましたか。では、このプログラムを実行させて下さい。
はじめまして。Duke と言います。
今度は、 System.out の別のメソッド println を使って出力させました。この命令は、出力が終わると自動的に改行を行ってくれます。System.out には、他にもより高度な出力のできる printf (プリントエフ) メソッドもあります(これは後述)。とりあえず、2つのメソッド print と println を使えるようになりましょう。ところで、 println のln に意味は?これは line の略です。
問題 2.3.2. 次のように1行あけて書くには、どうしたら良いでしょうか。
はじめまして。
Duke と言います。

2.4 文字コード 15
こうした場合、改行のエスケープシーケンスを書く、という方法もありますが、println メソッドを使うというのも良く行われます。その場合、改行だけで、文字を出力するわけではないので、小かっこの中に何も入れずに、System.out.println(); と書きます。HalloJava2.java に1行あける命令を挿入してみましょう。
2.4 文字コードコンピュータは欧米が起源なので、文字といえばローマ字によるアルファベットです。従って、最初のコンピュータでは a から Z までの 52 文字の大小英文字と 0 から 9 までの 10 文字の数字、そして幾つかの記号が使えれば構いませんでした。コンピュータ内は 2 進数でデータを表しているので、文字もそれぞれ 1 つずつ 2 進数で定義され、それを ASCII コード (アスキーコード:American Standard Code for Information Interchange) と呼びます。
0 1 2 3 4 5 6 7
0 NUL DEL SP 0 @ P ` p
1 SCH DC1 ! 1 A Q a q
2 STX DC2 “ 2 B R b r
3 ETX DC3 # 3 C S c s
4 EQT DC4 $ 4 D T d t
5 ENQ NAK % 5 E U e u
6 ACK SYN & 6 F V f v
7 BEL ETB ‘ 7 G W g w
8 BS CAN ( 8 H X h x
9 HT EM ) 9 I Y i y
A LF SUB * : J Z j z
B VT ESC + ; K [ k {
C FF FS , < L \ l |
D CR GS - = M ] m }
E SO RS . > N ^ n ~
F SI US / ? O _ o DEL
図 2.9 ASCII コード表
ASCII コード表 (図 2.9 参照) は、表の横・縦の順に 16 進数の数値として読みます。例えば、文字 A なら、横 4
縦 1 なので、16 進数の 41 (10 進数なら 65) が文字 A の ASCII コードになります。2 桁からなる 16 進数を 2 進数で表現するには、8 bitsで済みますよね。従って、ASCII コードは 8 bits で出来ています。うん?気づいた人がいるかな。表の横が 7 までしかないのだから、7 bits で済むんじゃないか?って。そうですね。でも 2 進数の世界では 7 という数はキリが悪く、余分な 1 bit の 0 を頭に置いて ASCII コードは 8 bits で表現されています。その後、日本のようなアルファベット以外の文字を持つ国がコンピュータを使い出し、それぞれの国で独自の文字コードを定義していきました。日本の場合、JIS コードと Shift JIS コードが今でもコンピュータのやインターネット上で利用されています。その話は、Java とは別のところで (「コンピュータ入門」あたりで聴けるかな)。で、世界中で様々な文字コードが発明されると、当然「コードを統一すべきだ!」ということになり、生まれたのが
「ユニコード (Unicode)」という万国共通の文字コードです。

16 第 2章 Java 言語の基本的な文法 I
2.4.1 Unicode とは
Unicode は、Xerox 社が発起として Microsoft、Apple、IBM、Sun Microsystems、Hewlett-Packard、JustSystems
などが参加した組織 The Unicode Consortium が、1993 年までに作り上げた国際標準の文字コードで、全ての国の文字を1つの文字コードの中に定義しようというものです。Java は Unicode を基本の文字コードと設定しています。幾つかの文字の Unicode を調べてみましょう。ここでは、半角の「A」と全角の「A・あ・Ω」の文字コードを出力しています。プログラムの中身は、とりあえずまた呪文ということで。(^^)
ソースコード 2.3 UnicodeCheck.java (UNICODE の値)
package section0204;
public class UnicodeCheck {
public static void main( String[] args ) {
System.out.println( "A の Unicode番号は、" + Integer.toHexString(’A’) );
System.out.println( "Aの Unicode番号は、" + Integer.toHexString(’A’) );
System.out.println( "あの Unicode番号は、" + Integer.toHexString(’あ’) );
System.out.println( "Ωの Unicode番号は、" + Integer.toHexString(’Ω’) );
}
}
半角の「A」の Unicode が ASCII コードの値を同じこと・半角の「A」と全角の「A」のコードが違うことをチェックしておいて下さい。その他の文字のコードは、次のページで見ることができます。自分の名前の Unicode 列を調べてみるのも面白いかも。> Unicode 一覧表 (https://ja.wikipedia.org/wiki/Unicode一覧表)
最後に、文字コードの注意点を1つ:日本に ASCII コードが持ち込まれた際に1文字だけ日本特有の文字に変更したものがあります。それは円マーク「¥」。ASCII コードの 5C の文字です。以下のテーブルを見比べると、本来バックスラッシュ「\」の文字が、日本でよく使う文字¥に入れ替わっています。多分使わないだろう!と思われた\のところに代わりに入れてしまったのですが、実はコンピュータの世界ではバックスラッシュはいたる所に出てくるので、以降、キーボードの¥のキーを押したら\が表示された!とか、英語モードのキーボードなので¥のキーが見当たらない!など、いろいろな問題が起こっています。とりあえず、ASCIIコードの世界では、この2つは同じもの! (コード 5C) です。なお、ユニコードでは、この2つは区別されていて、¥は Unicode 00A5、\は Unicode 005C です。面倒ですね。
2.5 コメントプログラムを頑張って作っても、しばらく時間が経つと「これって何のプログラムだっけ?」「この変数、何のためにあるんだっけ?」「入力データはどうやって入力するんだっけ?」と忘れてしまって使えない、なんてことになりがちです。操作マニュアルなる文章を作ることが良いわけですが、結構大変。そこで、最も簡単は方法はプログラム中にコメントを書いておくことです。コメントは、プログラムの実行時 (コンパイル時) には無視されているので、コメントが多くても実行が遅くなるなんてことはありません。和田がプログラミング言語を習ったときは、処理文よりコメント文の方が多いくらいのプログラムを書け!なんて教授に言われました。和田の試験では、過去に自分で作成したプログラムを参照しながらプログラムを作ってもらう問題もあるので、しっ
かりコメントを書いておくのは、試験対策としても役立ちます。なお、このテキストではプログラムリストには原則、コメントは入れていません。各自で自由に入れて下さい。コメントの書き方には以下の 3 種類があります。

2.5 コメント 17
0 1 2 3 4 5 6 7
0 NUL DEL SP 0 @ P ` p
1 SCH DC1 ! 1 A Q a q
2 STX DC2 “ 2 B R b r
3 ETX DC3 # 3 C S c s
4 EQT DC4 $ 4 D T d t
5 ENQ NAK % 5 E U e u
6 ACK SYN & 6 F V f v
7 BEL ETB ‘ 7 G W g w
8 BS CAN ( 8 H X h x
9 HT EM ) 9 I Y i y
A LF SUB * : J Z j z
B VT ESC + ; K [ k {
C FF FS , < L \ l |
D CR GS - = M ] m }
E SO RS . > N ^ n ~
F SI US / ? O _ o DEL
0 1 2 3 4 5 6 7
0 NUL DEL SP 0 @ P ` p
1 SCH DC1 ! 1 A Q a q
2 STX DC2 “ 2 B R b r
3 ETX DC3 # 3 C S c s
4 EQT DC4 $ 4 D T d t
5 ENQ NAK % 5 E U e u
6 ACK SYN & 6 F V f v
7 BEL ETB ‘ 7 G W g w
8 BS CAN ( 8 H X h x
9 HT EM ) 9 I Y i y
A LF SUB * : J Z j z
B VT ESC + ; K [ k {
C FF FS , < L ¥ l |
D CR GS - = M ] m }
E SO RS . > N ^ n ~
F SI US / ? O _ o DEL
図 2.10 ASCII コード表
• 単一行コメント:2 つの斜線 // で始めるコメント• ブロックコメント:/* で始まり */ で終わるコメント• Javadoc 用コメント:/** で始まり */ で終わるコメント
ソースコード 2.4 Comments.java (コメント文いろいろ)
package section0205;
public class Comments {
public static void main(String[] args) {
// このように始めると、単一行コメント@SuppressWarnings("unused")
int x = 10; // こうして命令の右にコメントを置くことが可能// int y = 20; でも、命令の左に斜線 2本を置くと、命令自体もコメントに/*
複数行のコメントを書きたいときこのように、ブロックコメントを使う間に挟まったものは全てコメントとなる
int z = 30; これもコメントになってしまう*/
/*
* Eclipse でブロックコメントを書くと、このように途中の行の行頭に * 星印が続きます*/
/**
* Javadoc 用のコメントの書き方は、付録 Cで解説します*/
}
}
ここで、Eclipse の表示について

18 第 2章 Java 言語の基本的な文法 I
上のプログラムを作っていくと、 5 行目の頭に「黄色いランプに黄色の注意標識のアイコン ( )」が付くと思います。これは「warning (ウォーニング:注意)」(文法的には間違っていないので実行はできるけれど、お薦めしないよ!)というアイコンです。このアイコンの上にポインタを持っていくと、Eclipse が「ローカル変数 x の値は使用されていません」と表示してくると思います。つまり、変数 xは宣言されて初期値も代入されたけど、その後で何も使っていないよね。これって無駄だよね!この変数いらないんじゃない?と言っているのです。こうした場合以外にも Eclipse はいろいろな場面で黄色のランプを表示してきます。さて、この表示、実行には支障ないとはいえ少々邪魔。そこで、「分かっているから、ランプの表示を消して!」と
Eclipse に言う方法を教えておきます。もちろん、本来はこの変数をちゃんと使うプログラムにするか、削除するかが正解です。
図 2.11 警告ランプの非表示
さて、今度は黄色ランプのアイコンを「クリック」して下さい。すると、Eclipse はこの問題の解決法をいくつか提案してくれます (図 2.11 参照)。解決法はいろいろありそうですが、その中から、「@SuppressWarnings 'unused' を'x' に追加します」を選択して Enter キーを押して下さい。Suppress は「隠す」ですから、warnings を隠す、unusedが「使っていない」ですから、次の行で使っていない変数について warning が表示されるんだけど、それを隠します!という意味になります。すると、プログラム中に @SuppressWarnings( "unused" ) という 1 行が挿入されたと思います。このアットマークで始まる行を、「アノテーション (annotation:注釈)」と言って、Java 5 で導入された Java の機能です。コメントとは違った意味で、プログラムを読む人とコンパイラに情報を与えるものです (コメントは、コンパイラに何の情報も与えない)。特に、コンパイラにはコンパイル時の付加情報としても利用できます (アノテーションについては後術)。これで、黄色ランプは消えたかと思います。以降も黄色ランプが出てきたら、まず理由を理解し正しい解決法を選択
できるようになって下さい。
2.5.1 単一行コメント
プログラム中に連続する 2 つの斜線 // を見つけると、コンパイラはそこからその行の終わりまでをコメントと判断します。従って、行の始めから 1 行まるまるコメントにするのも可能なら、書かれた処理のすぐ右にその処理のコメントを書くなんてことも可能です (「x = 1; // x に 1 を代入」なんて感じ)。一方、コメントの右に処理を書いても (
// x に 1 を代入 x = 1; )、それはコメントの一部と判断されるので、実行されません。このことを逆に利用して、ある行の実行を一時的に実行させないために、行頭に斜線 2 本を書き込んで (こうしたことを、コメントアウトすると言います)、コンパイルして様子を見る、なんてこともします。Eclipse では、Ctrl + 7 もしくは Ctrl + / で「コメントの切り替え」と言って現在カーソルのある行に単一行コ

2.6 基本型 19
メントを付けたり消したりしてくれます。知っておくと便利です。
2.5.2 ブロックコメント
連続した複数行のコメントを作成する場合、それらすべての行頭に // を付けても構いませんが、付けたり外したりする手間も大きいし、見栄えもよくありません。そうした場合、最初の行の行頭に /* を置き、最後の行の行末に */
を置くという方法があります。なお、ブロックコメントの中に別のブロックコメントを入れるとコンパイルエラーになりますので、ブロックコメントは単独でが原則です。Eclipse では、コメントにしたい行を選択した状態で Ctrl + Shift + / で「ブロックコメントの追加」、Ctrl +
Shift + \ で「ブロックコメントの削除」をしてくれます。
2.5.3 Javadoc 用コメント
付録 C でプログラムのマニュアル (仕様書) 作りについて解説します。プログラムは作ったけれど、コメントをいい加減に書いていたせいで後で使おうとしたら、動かない・改良できないなど、プログラムを結局無駄にした、なんてことが良くあります。そうならないために、マニュアルをこまめに作ることが望まれるのですが、結構手間が掛る。プログラムを作っているときは、今必要だから作っているので、後でどう使うかはあまり考えていない。で、ついついコメントも書かずに。そんなとき、ちょっとコメントを書く手間で簡単な仕様書が作れる「Javadoc」を学んでおくと、とても便利です。詳細は付録で書くとして、そのためのコメント「Javadoc 用コメント」は、ブロックコメントと同様に、最初の行の行頭に /** (* が 1 つ多い) を置き、最後の行の行末に */ を置くという方法です。Javadoc 用コメントには、@ で始まる特別な役割をする「タグ」が用意されていて、それらをちょっと覚えてもらって使うことになります。
2.6 基本型Java で取り扱えるデータは2つの型に分類されます。整数や実数などの一般的な値を扱う基本型 (primitive type)
と、より複雑なデータを表現する参照型 (reference type) です。まず、ここでは基本型について説明し、参照型については第 3 章で学びます。基本型には、次の4種類が用意されています。
• 整数型:名前どおり整数を扱います• 実数型:正式には、浮動小数点数型 (floating point number type) と言います• 論理値型:論理式の真偽を扱う際に用います• 文字型:文字列と区別し、1文字を表します
2.6.1 整数型 (integer type): byte, short, int, long
整数型にも4種類があります(本によっては文字型を整数型に含めて5種類あると書かれています。その理由は文字型のところで)。
• byte (バイト):8bits 符号付き整数• short (ショート):16bits 符号付き整数• int (イント):32bits 符号付き整数(デフォルトの整数型)• long (ロング):64bits 符号付き整数

20 第 2章 Java 言語の基本的な文法 I
使用する状況に応じて使い分けるのですが、述べた順に「表現できる整数値の範囲」が「狭い =⇒ 広い」となっています。Java では OS やコンパイラによらずデフォルトの整数型 intは 32bits を用いて1つの整数を表しますが、例えば C 言語ではコンパイラによって int型は 16bits だったり 32bits だったりします。符号付きとは、使用する bits の内、最高位の 1bit を符号のために使用するという意味です。一方、符号なしとは、
符号 bit を持たずに全ての bits を使って非負の整数を表現する場合を言います。
問題 2.6.1. 整数型で表現できる整数値の範囲を4種類の型でそれぞれ求めなさい。手計算で正確な値を求めるのは大変なので、Mathematica を利用しても良い。例えば、byte 型の整数値の最大値は、8bits のうち最上位の 1bit が符号として用いられるので、最大値は 7bits に全て 1 が立った 1111111 です。この値は、27 − 1 ですから、Mathematica にこの式を入れて Shift+Enter すると、127 が得られます。なお、負数の最小値については、その絶対値が正数の最大値より1大きくなります。つまり、byte 型では −128 です。
整数値は、特に断らなければ int型(デフォルトの整数型)の値と見なされ、メモリーの中では 32bitsの領域に記憶されます。では、long 型の値を扱うときはどうしたら良いでしょう。たとえば、整数値 1234 を long 型として記憶するには、1234L もしくは 1234l (末尾の l は小文字の L) と数値の末尾に半角のエルの文字を付けます。こうすることで、この値は 64bits の領域に記憶されます。一方、intより記憶領域の小さな short や byte 型の値とする場合は、後述のキャストという方法で記憶します。各整数型で表現できる整数値の最小値と最大値を次のプログラムで表示してみましょう。(先ほどの問題の答えが、これで分かります)
ソースコード 2.5 IntegerMaxAndMin.java (整数型の最大・最小値)
package section0206;
public class IntegerMaxAndMin {
public static void main(String[] args) {
System.out.println( "整数型4種類の最大値と最小値:" );
System.out.println( "byte 型:");System.out.println( " 最小値 = " + Byte.MIN_VALUE );
System.out.println( " 最大値 = " + Byte.MAX_VALUE );
System.out.println( "short 型:");System.out.println( " 最小値 = " + Short.MIN_VALUE );
System.out.println( " 最大値 = " + Short.MAX_VALUE );
System.out.println( "int 型:");System.out.println( " 最小値 = " + Integer.MIN_VALUE );
System.out.println( " 最大値 = " + Integer.MAX_VALUE );
System.out.println( "long 型:");System.out.println( " 最小値 = " + Long.MIN_VALUE );
System.out.println( " 最大値 = " + Long.MAX_VALUE );
}
}

2.6 基本型 21
2.6.2 実数型 (real number type): float, double
Java では、実数を表す型を「浮動小数点数型 (floating point number type)」と呼びます。これは 固定小数点数型(fixed point number type) に対する対語です。例えば、12.34 が固定小数点数型表示で、それを 1234.× 10−2 と書いたり、0.1234× 102 と書いたりするのが浮動小数点数型表示です。小数点がいろいろ動いている。(^^;)?
コンピュータの中での実数は、常に浮動小数点数型で記憶されています。Java の実数型には以下の2種類があります。
• float (フロート):32bits IEEE754 浮動小数点数• double (ダブル):64bits IEEE754 浮動小数点数(デフォルトの実数型)
IEEE とは、アメリカ電気電子学会 (Institude of Electrical and Elctrinics Engineers) の略記で、世界の標準規格を決めている機関、その規格 754 に従ったという意味です。IEEE の標準規格を知りたいなら、IEEE ジャパン・オフィス (http://jp.ieee.org/index.html) を覗いてみましょう。表現できる実数値の範囲は doubleの方が float より広く、doubleがデフォルトの実数型で、float 型はスマホのようにメモリが少ない環境で実数を扱う際などに利用されます。実数 12.34 を float 型として記憶するには、12.34Fもしくは 12.34f と数値の末尾に半角のエフの文字を付けます。また、あえて double型であることを強調したいとき、12.34D もしくは 12.34d と数値の末尾に半角のディーの文字を付けることも許されています。なお、このテキストでは、浮動小数点数 (型)と正式名で書くのはちょっと長いので、単に実数 (型)と書くことにします。
問題 2.6.2. 実数型で表現できる実数値の範囲をそれぞれ求めなさい。(付録 A 参照)
プログラムで実数型の最大値・最小値を表示してみましょう。次のプログラムでは、正の実数における最大値と最小値を表示しています。負の実数はこれらにマイナスを付けた値の範囲です。
ソースコード 2.6 RealNumberMaxAndMin.java (実数型の最大・最小値)
package section0206;
public class RealNumberMaxAndMin {
public static void main(String[] args) {
System.out.println( "実数型2種類の最大値と最小値:" );
System.out.println( "float 型:" );
System.out.println( " 正の最小値 = " + Float.MIN_VALUE );
System.out.println( " 正の最大値 = " + Float.MAX_VALUE );
System.out.println( "double 型:" );
System.out.println( " 正の最小値 = " + Double.MIN_VALUE );
System.out.println( " 正の最大値 = " + Double.MAX_VALUE );
}
}
ところで、この範囲内ならどんな実数でも扱える、と思ってはいけません。有効桁数という値があって、float 型なら約 7 桁、double型なら約 15 桁しか有効桁数がありません。つまり、範囲に入っている実数でも、16 桁を越す値は表現できないわけです。これを丸め誤差と言います。丸め誤差を含んだ数値計算については 2 年の計算数学の授業で学ぶでしょう。

22 第 2章 Java 言語の基本的な文法 I
2.6.3 論理値型: boolean
高校で習ったでしょうか。真偽値もしくは論理値、命題 etc.
Java でも論理値の「真」と「偽」を表す boolean (ブーリアン)型の値 true (トゥルー) と false (フォルス) が利用できます。
問題 2.6.3. x = 1 としたとき、次の式は true ですか? false ですか?(1) x+ 1 = 2 (2) 4 < x (3) 0 < x かつ x < 2 (4) x < 0 または 2 < x
他のプログラミング言語にも論理値型がありますが、その定義の方法は様々です。例えば、最も広く使われているC 言語の場合、boolean 型という独立な型が無く、false は整数値の 0、true は 0 以外の整数と定義されています。従って、2 < 1 という論理式の値は 0 となります。一方、C++言語になると、boolean 型は bool 型として登場し、true, false の文字が利用できるようになります。ただ、C 言語との互換性から整数値を論理値の代替えとして使うことが可能です。一般に false が定義され、true は定義せずに false でないものは全て true とする、のようになっている言語が多い中で、Java は厳密に両方の定義をしている数少ない言語の一つです。
2.6.4 文字型: char
文字には char 型が与えられています。さて、この char どう読むか?英語圏ではチャーと読むようですが、日本ではキャラと読む方が優勢のようです ( character の接頭語だからキャラ:実に日本的!? )。> char の読み方 (http://www.atmarkit.co.jp/bbs/phpBB/viewtopic.php?topic=10483& forum=3)
それに、私にとってチャーはギタリスト!なので、この授業ではキャラと読ませてもらいます。(^^)
さて、先に「教科書によっては、文字型も intや long と同じ整数型として書かれている」と書きました。その理由ですが、コンピュータ内部では char 型の値は整数値 (正確には符号なし整数値)で表されており、単純な四則計算ができるためです。次のプログラムでは、「犬」という文字が Unicode の値 29356(=0x72AC) で記憶されていて、そこに整数値を加減すれば、他の文字に変化する、というものです。「犬」に 127 を加えると「猫」の文字になるんですね。
ソースコード 2.7 CharIsInteger.java (文字は整数だった)
package section0206;
public class CharIsInteger {
public static void main(String[] args) {
System.out.println( "文字「犬」について" );
System.out.println( "犬を整数で表すと " + (int)’犬’ );
System.out.println( "16進数にすると " + Integer.toHexString(’犬’) );
System.out.println( "犬 + 127 = " + (char)(’犬’ + 127) );
}
}
プログラム中の解読不可能な部分は徐々に読めるようになっていきますから、もう少し我慢して下さい。
問題 2.6.4. Java の基本データ型の表を完成させなさい。同じ分類に属する型名を英単語で、表現出来る値の範囲の

2.7 変数 23
広さの狭い順に左から右へ並べなさい。
分類名 型名整数型
浮動小数点数型論理値型文字型
2.6.5 もっと大きな値はどうする?
整数型で扱える最も大きな値は long 型整数の最大値で 10 進数 19 桁程ですが、それを超える整数を扱いたいとき(宇宙規模のデータを扱いたいとか、安全な暗号プログラムを作りたいとか)、Java では無理なのでしょうか。同様に、double型で表現出来ない大きな値や逆に小さな値は?いずれも、基本型のデータとしては扱えませんが、参照型のデータとして扱えば利用できます (ちょっと扱いは不便ですが)。これについては第 3 章ですね。
2.7 変数2.7.1 変数とリテラル
Java では、具体的な値のことを「リテラル」と言います。一方、数学でみんなが慣れ親しんできた「変数」もあります。Java では、変数の名前 (変数名) を自由に付けることができます。使用できる文字は原則、半角文字のアルファベット (大文字・小文字)と数字、そして下線 ’ ’ とドルマーク ’$’ です。また、次のルールがあります。
• 数字から始めてはならない• アルファベットの大文字・小文字は区別する• Java の予約語は使用できない• 名前の長さの上限は int型の最大値 (事実上、上限なし)
そして、規則ではありませんが「変数名は小文字で始めること」が慣例化されています。そして、パッケージ名と同様に複数の単語からなる変数名の場合、スネーク形式もしくはキャメル形式で単語をつなげることも慣例化されています。なお、数学では行列を大文字アルファベットで表記するのが慣例ですから、Java を使って行列の問題を解く場合にも、行列変数を大文字で表記することを許しましょう。
問題 2.7.1. 次の変数名で使用できないのはどれですか。1. xy 2. x-y 3. $xy 4. 10xy 5. xy
6. int 7. main 8. Class
main も Class も一見予約語に見えますが、予約語ではありません。Java における予約語は以下の表 2.7.1 の単語です。ただ、予約語でなくても main や Class のようにプログラム内で使用すると混乱をきたしそうな変数名は避け

24 第 2章 Java 言語の基本的な文法 I
るのがルールです。
表 2.7.1 Java の予約語
abstract assert boolean break byte
case catch char class const
continue default do double else
enum extends final finally float
for goto if implements import
instanceof int interface long native
new package private protected public
return short static strictfp super
switch synchronized this throw throws
transient try void volatile while
変数名は「原則」半角文字で、使って良い文字は · · · · · ·、と書きましたが、実は Java の変数名には Unicode の複数バイト文字を使用すること「も」できます。つまり、日本語や韓国語の変数名ですね。ただ、国際性が無くなるので、使わないことが慣例となっています (個人的に使うことは構わないけど、試験で使ったら 0 点になるよ)。
2.7.2 変数の宣言と値の代入
int型の変数 xを定義することにしましょう。Java で変数を定義することを、「変数を宣言する」と言います。int
変数 x を宣言するには、int x; と書きます。プログラムで使う変数は必ず宣言してからでないと使えません。そして、変数の宣言は出来る限りプログラムの「使いたい場所の直前」に書きます。本によっては、プログラム中で使用する変数の宣言を全てプログラムの最初で行いなさいとするものもありますが、後に学ぶ「変数のスコープ」を考慮すると、変数は適宜、使う場所の直前で宣言するようにしましょう。そうすることで、何のための変数なのかがプログラムを読む人にわかりやすくなります。変数の宣言は、各変数ごとに行うのが原則ですが、同じ型の変数をカンマでつなげて、一度に宣言することもできます。例えば、int型変数 xと yを int x, y; とまとめて宣言することができます。ただし、この方法は、付録 C で解説するプログラムのアニュアル作りの際に適切なコメントが書けないなどの問題が起こるので、和田は薦めていません。つまり、変数の宣言は 1 行に 1 つずつが良いと思います (つまり、int x; と int y; と 2 行に分けて書く)。変数は値が入っていてなんぼ!ですから、次は宣言した変数に値を代入する方法です。変数に値を代入するには、「代入文」という処理を行います。代入文は、「変数 = 値;」なる等号で結ばれた文です。例えば、変数 xに 10 を代入するには、x = 10; と書きます。この場合の等号は「等しい」という意味ではありません。Java では、等号記号 ’=’ は、代入文での演算子の役割りをしていて、右辺の値を左辺の変数に代入する、という処理をしてくれます。2 つの値が等しいという意味では使いません。代入文ですから、左辺は変数のような値を代入できるものでなければいけません。10 = 10; とか 10 = x; のような式はエラーとなるわけです。変数の宣言と値の代入をまとめて一度に行うこともできます。その場合は、int x = 10; と書きます。
ソースコード 2.8 Substitution.java (リテラルの代入)
package section0207;
public class Substitution {
public static void main(String[] args) {
byte i = 12;

2.8 五則演算 25
short j = 123;
int k = 12345;
long l = 1234567L;
float x = 123.456f;
double y = 123.456;
boolean b = true;
char c = 'A';
}
}
今回のプログラムも変数の宣言と代入のみなので、ワーニングのオンパレードです。それぞれの変数宣言でアノテーションを付けるのも大変なので、今回はまとめて面倒みる方法で「@SuppressWarnings 'unused' を 'main()' に追加します」を選択して下さい。ところで、このプログラムでは、整数系には整数を・実数系には実数を代入していますが、実数系に整数や整数系に実数を代入することは出来ないのでしょうか。これについて、Java では「表現できる範囲のより広い変数には範囲の狭い型の値を代入できるが、その逆はできない」となっています。つまり、実数系の変数に整数値を代入することはできますが (⃝ double x = 123;)、整数系の変数に実数値を代入することはできない (× int y = 123.456;) ということになります。これは、同じ分類同士でも同様です。int 型の変数に long 型の値を代入することはできませんし、float 型の変数に double型の値を代入することはできません (その値がどんなに小さくても、int i = 1L; はダメ)。と、気づいた人はいるかな?上のプログラムで、byte i = 12; とか short j = 123; と言うのは、そのルールに違反していないか?と。違反していますね。(^^)
整数系の byte と short には、long のように、その型のリテラルを表現する (1234567L のような) 末尾記号が与えられていません。この 2 種類の整数型のみ例外として、それぞれの表現できる範囲内の int 型リテラルを直接代入することが許されているのです。つまり、12 ∈ [−128, 127] なので、byte i = 12; は OK なのです。もし、これがbyte i = 200; ならエラーになります。文法に厳しい Java らしからぬ特例処置です。
問題 2.7.2. 次の代入文で、エラーにならないものを選びなさい。1. byte x = 1234; 2. short x = 1234; 3. int x = 1234;
4. long x = 1234; 5. long x = 1234.0; 6. float x = 1234;
7. float x = 1234.0; 8. double x = 1234.0f; 9. double x = 1234L;
2.8 五則演算Java では、四則演算(+ − × ÷) の4つに % という2項演算記号が加えられて、五則演算が使えます。なお、キーボードに無い × と ÷ の代わりに ∗ と / を使います。
+:加算 −:減算 ∗:乗算 /:除算 %:剰余算
剰余とは、「割った余り」です。5 % 3 という計算は 5 を 3 で割った余り 2 を答えとします。剰余算は、実数でもできますが、実数計算には計算誤差が付きまとうことを忘れないで下さい (例えば、1.2 % 0.5 = 0.19999999999999996)。ちなみに、これら5つの記号を算術演算子 (arithmetic operator symbol) と呼びます。以下のプログラムは、整数同士の五則演算の結果を出力しています。println の小かっこの中に式を書くと、式を

26 第 2章 Java 言語の基本的な文法 I
計算した結果が書かれます。
ソースコード 2.9 Arithmetics.java (五則計算)
package section0208;
public class Arithmetics {
public static void main(String[] args) {
System.out.println( 13 + 5 );
System.out.println( 13 - 5 );
System.out.println( 13 * 5 );
System.out.println( 13 / 5 );
System.out.println( 13 % 5 );
}
}
このプログラム 5 つの値のうち 1 つが「腑に落ちない?!」値ですよね。13/5 の計算結果が 2.6 ではなく、2 になっている。五則演算では、算術演算子をはさむ 2 つの値の型が何であるかが計算結果に反映されます。そのルールとは「計算結果の型は、2 つの値の型の表現範囲の広い方に合わせられる」です。例えば int型リテラルと int型リテラルの和10 + 20 は int型リテラル 30 となりますが、int型リテラルと double型リテラルの和 10 + 20.0 は double型リテラル 30.0 になるのです。よって、13/5 は int型同士の割り算なので、結果も int型、このとき計算結果の 2.6 の小数点以下の部分 0.6 が int型には納まらないので「切り捨てられて」2 となります (四捨五入はされません)。では、2.6 を答えとして求めたいのなら、どうしたら良いでしょう? 13 と 5 のいずれか、もしくは両方を実数型にすれば良いわけですね。13.0/5, 13/5.0, 13./5. いずれでも OK です。
問題 2.8.1. 2つのリテラルの計算結果を左辺の変数 x に代入しています。x の値はそれぞれいくつになりますか。エラーになるものもありますよ。1. int x = 11 + 4; 2. int x = 11 - 4; 3. int x = 11 * 4;
4. int x = 11 / 4; 5. int x = 11 % 4; 6. double x = 11 / 4;
7. int x = 11.0 / 4; 8. double x = 11.0 / 4; 9. int x = 1 / 2;
10. double x = -1.0 / 2; 11. int x = -1 / 2.0;
問題 2.8.2. int型変数 x と y にそれぞれ 100 と 200 を代入し、その和 x+ y を新たな int型変数 z に代入するプログラムを完成させなさい。6 行目は、3つの変数の値を出力しています。
ソースコード 2.10 PAdditionValues.java (2つの変数の和)
package section0208;
public class AdditionValues {
public static void main(String[] args) {
// ここに、変数 x と y の宣言と初期値代入、そして新たな変数 z の宣言と代入の処理を書く
System.out.println( "x=" + x + ", y=" + y + ", x+y=" + z );
}
}

2.9 文字列の連結演算 27
問題 2.8.3. 与えられた 2 つの変数の中身を交換するプログラム SwapValues.java を作って下さい。
ソースコード 2.11 SwapValues.java (2つの数の交換)
package section0208;
public class SwapValues {
public static void main(Strings[] args) {
int a = 2;
int b = 3;
// a と b の中身を入れ替える処理をここに作って下さい
// 以下で交換が出来ているか出力するSystem.out.println( "a=" + a + ", b=" + b );
}
}
2.8.1 小かっこで計算順序の制御を
複雑な計算の場合、小かっこを使って計算順序を変更しましょう(中かっこや大かっこは使えません)。例えば、
int x = (1+2)*(3+4); double y = ((1+2)*(3+4))/(2.0*5);
さて、2 つ目の式で (1+2)*(3+4) をさらに囲む外側の小かっこは必要でしょうか。五則演算では小学校で習った四則演算と同様な計算優先度:乗除算が加減算より優先度が高い!が使われていて、加えて剰余算は乗除算と同等とされています。つまり、この場合、この小かっこを省略して (1+2)*(3+4)/(2.0*5) としても計算結果は一致します。ただし、(1+2)*(3+4)/2.0*5 はダメですね。これでは、2.0 で割った後 5 倍してしまいますから。Java の教科書には (この後も続々出てくる様々な) 演算子の優先順序が表として載っていますが、なかなか和田もその順序を正しく覚えきれません (従って? 試験で演算子の優先順序を聴いたりはしません)。そうしたときは、小かっこを付けて計算順序を制御しましょう。余分な小かっこになっても、あやふやな記憶での優先順序に従うより安全ですし、プログラムを読む人に親切です。
2.9 文字列の連結演算前節の問題 2.8.2 の出力文 System.out.println( "x=" + x + ", y=" + y + ", x+y=" + z ); に、加算記号
+ がいくつも出ていますが、これらは何を加えているのでしょう?実は、これらは加算ではありません。演算子 + には、もう一つ「文字列の連結」という役割があるのです。文字列リテラルを連結する、例えば "和田" + "雅美" とすると、"和田雅美" なる文字列リテラルが作られます。また、文字列に数値を連結することもできます。例えば、"答えは、" + 10 とすると、"答えは、10" なる文字列リテラルが作られます。演算子 + は、演算子をはさむ 2 つの値が数値の時は加算演算を、2 つの値のいずれかが文字列であるときは文字列の連結演算を行うのです。

28 第 2章 Java 言語の基本的な文法 I
問題 2.9.1. 次の出力文が、望むべき出力「10 + 20 の計算結果は、30」とならない理由を説明しなさい。そして、解決法を述べなさい。
System.out.println( "10 + 20 の計算結果は、" + 10 + 20 );
問題 2.9.2. double型変数 xに 1.5、 int型変数 yに 2 が代入されているとして、以下のようにコンソールに出力する出力文 (System.out.println) を書きなさい。
x = 1.5, y = 2
問題 2.9.3. コンソールに次のように表示するプログラムを完成させなさい。なお、int型変数 a と b の値を変えると、表示も正しく変わるように書くこと。例えば、a=10, b=20 としたら、出力も自動的に 10 + 20 = 30 と書かれるように。
ソースコード 2.12 AdditionValues2.java (2つの変数の和2)
package section0209;
public class AdditionValues2 {
public static void main(String[] args) {
int a = 12;
int b = 34;
System.out.println( /* この中身を完成させる */ );
}
}
12 + 34 = 46
なお、bに負の数を設定すると、10 + -20 = -10などと不自然になるが、この後で if文を学習すれば、10 - 20 = -10
と出力する方法を考え付くことができるでしょう。
2.10 1を加えるという操作int型変数 xに現在入っている値を 1 増やしたい!そんな時、どのような命令を書いたら良いでしょう。これは Java で良く出てくる場面なのですが、次のような代入文で書きます。
x = x + 1;
これを数学の等式と見てはいけません (こんなの成立しませんから)。’=’ は代入演算子でした。従って、これは代入文ですから、右辺の計算結果を左辺に代入ですね。つまり、変数 xに現在入っている値に 1 加えた値を計算し、それを再び変数 xに代入する。つまり、変数 xの値が 1 増えるわけです。ただ x + 1; と書いても 1 増えません。
問題 2.10.1. 変数 xの値を 2 増やしたり、 2 減らしたり、 2 倍したり、 2 で割ったり、 2 で割った余りにしたりす

2.10 1を加えるという操作 29
る代入文をそれぞれ書きなさい。
変数 xの値を 2 倍する処理は、x = x + x; でも OK ですね。同様に、変数 xに変数 yの値を加えなさい、という場合は x = x + y; で良いわけです。かつての試験で、変数 xと yの値をそれぞれ 1 ずつ増やしなさい!と書いたら、x,y = x,y + 1; なんて式を発明した先輩がいました。無茶です。これは、単純に x = x + 1; y = y + 1; と代入文を 2 つ書けば良かっただけ。
問題 2.10.2. 変数 xの値を 2 乗、3 乗する代入文をそれぞれ書きなさい。残念ながら、べき乗する演算子は Java には無いので、単純に掛け算を繰り返す。ただし、この書き方で 100 乗する計算は事実上無理ですよね。ではどうするか?は後で。
2.10.1 複合代入演算子
変数 xの現在の値に五則演算をほどこして xに戻す、という操作も頻繁に出てくるので、上記の方法以外にも次のような書き方が許されています。例えば、問題 2.10.1 の代入文は以下のようにも書けます。
x += 2; x -= 2; x *= 2; x /= 2; x %= 2;
プログラミング言語ぽくなってきましたね。これらの記号 (五則演算子と等号の対) を複合代入演算子と言います。+
と = は離さずに書きます。例えば、x += 2; は x = x + 2; と同じ操作をしてくれます。間違って、x =+ 2; と答案に書いた先輩がいましたが、これでは x = +2; (2 を代入しただけ) になってしまいますね。
問題 2.10.3. 変数 xに変数 yの値を加算、減算、乗算、除算、剰余算する複合代入文をそれぞれ書きなさい。
問題 2.10.4. 次のプログラムでコンソールに書かれる出力を書きなさい。(a の値は次々変化していきます)
ソースコード 2.13 CompoundAssignment.java (複合代入演算)
package section0210;
public class CompoundAssignment {
public static void main(String[] arge) {
int a = 0;
a += 7;
System.out.println( "a = " + a );
a -= 2;
System.out.println( "a = " + a );
a *= 5;
System.out.println( "a = " + a );
a /= 3;
System.out.println( "a = " + a );
a %= 3;
System.out.println( "a = " + a );
}

30 第 2章 Java 言語の基本的な文法 I
}
a /= 3 の所で間違わないで下さいよ (int型同士の計算ですから)。
問題 2.10.5. 複合代入文を用いて、変数 xの値を 2 乗する式を書きなさい。
問題 2.10.6. 次のプログラムがエラーになる理由を述べなさい。
ソースコード 2.14 ErrorSubst.java (複合代入でのエラー)
package section0210;
public class ErrorSubst {
public static void main(String[] args) {
int a;
a += 5;
System.out.println( "a = " + a );
}
}
今回は、エラーになるプログラムです。このとき、Eclipse はエラーがあると思われる行の頭に「ランプに赤い×のアイコン ( )」を表示します。これが点灯すると、コンパイルエラーなので、実行できません。ポインタを赤い×のアイコンの上に持っていくと「ローカル変数 a が初期化されていない可能性があります」との表示。おっしゃる通りですね。では、アイコンをクリックして下さい。そして 3 つほど解決策を提示してきますので、最初の「変数を初期化します」を選択しましょう。変数は宣言しただけでは、値が未決の状態です。そんな変数に 5 を加えろと言っても、無茶ですね。int a = 0; のように、初期値を代入しておいてからなら、5 を加えることは可能です。(Java はこういったところが融通が利きません、というか、厳密でよろしい!というのかな)
2.10.2 インクリメント・デクリメント演算子
さらに、特殊な場合:加算で変化量が ±1、つまり、ある変数の値を 1 増やすか 1 減らすという場合には、3 つめの書き方ができます。
• 変数 xに 1 加える場合、x++; もしくは ++x;
• 変数 xから 1 減じる場合、x--; もしくは --x;
++ も -- も演算子です。変数名と演算子 ++ は離して x ++; と書いても動きますが、慣例的に、変数に付けて書きます。これらは単項演算子 (1つの項に作用する演算子)で、++ をインクリメント演算子 (increment operator symbol)、-- をデクリメント演算子 (decrement operator symbol) と呼びます。この演算子の面白いところは、代入演算子 =
を使わずに単独 (例えば、x++;) で変数 xの値を 1 増やせるところです。(つまり、 x = x++; ではなく、単に x++;

2.10 1を加えるという操作 31
で1増える)
余談:C++というプログラミング言語を知っていますか。1983年にアメリカのベル研究所で C 言語の拡張として作られた言語ですが、その名前の由来は、C 言語に対して一歩先を行く!という意味だとか (インクリメントなんですね)。そして、C# という言語も知っていますか?こちらはマイクロソフト社が C++のまた一歩先を行く!ということで付けた、らしいです (++ を縦に2つ並べると#)。
問題 2.10.7. 変数 xの値を 1 増やす文を 4 種類を書きなさい。 (ヒント:インクリメント方式は 2 種類ありますね)
また先輩の珍解答を紹介!「変数 xの値を 2増やす方法を 2通りで書きなさい」に対して、彼の解答は「 x = x + 2;
と x++++;」これ無茶です! x++ は x = x + 1 に同等なので、x++++; は (x = x + 1)++; 代入文のインクリメントというのは定義から外れます。この場合の正解は、x = x + 2; と x += 2; ですね。また、「変数 xと yの和に 1
加えた値を変数 z に代入する式」を z = (x + y)++; と書くのも無茶です。無理やり書き換えると、(x + y)++ は、(x + y) = (x + y) + 1 となるので、これも無理。正解は、z = x + y + 1; ですね (無駄に難しく考えてはいけない)。ところで、インクリメントもデクリメントも2種類ずつ用意されていますが、違いがあるのでしょうか?
++x のように前に演算子を付ける場合を「前置型」、x++ のように後ろに演算子を付ける場合を「後置型」と呼びます。まず、単独で使う場合には 2 つに違いはありません。++x; と x++; のいずれも変数 xの値を 1 増加させるだけです。違いが出てくるのは、これらを式の中で使う場合です。つまり、int y = ++x + 3;とか int y = x++ + 3;なんて使い方です。えっ!こんな式変でしょ!?これまでの流れだと、int y = ++x + 3; は int y = (x = x + 1) + 3;
と解釈されるわけだから、式の中に代入文が入ってしまってエラーだよ!って?いいえ、この解釈は間違っていません。式の中に代入文があってもエラーにはならないのです。実は、代入文
x = x + 1 自体が値を持っているのです。代入文の値とは、その左辺の値となります。つまり、この場合 1 を加えたあとの変数 xの値ですね。よって、それにさらに 3 を加えた値を変数 yに代入するわけで、これはエラーではない。試しに、以下のプログラムを動かしてみましょう。
ソースコード 2.15 SubstInEquation.java (代入文は値を持つ)
package section0210;
public class SubstInEquation {
public static void main(String[] args) {
int x = 10;
int y = ( x = x + 1 ) + 3;
System.out.println( "x = " + x );
System.out.println( "y = " + y );
}
}
では、このプログラムの ( x = x + 1 ) の小かっこの中身を同等なインクリメント2種類 ++x と x++ に替えて動かしてみて下さい。変数 y の結果が違ってきますね。前置型インクリメント ++x だと、x = x + 1 の場合と同じですが、後置型インクリメント x++ の場合、y の値が 1 小さくなる。これは、インクリメント ( 1 加える)の処理を式の計算の前にやるか、後にやるかの違いなのです。次のようになります。
• 前置型の場合 (int y = (++x) + 3;):まず、x = x + 1; を処理し、その結果を用いて int y = x + 3;
よって、x=11, y=14 となります

32 第 2章 Java 言語の基本的な文法 I
• 後置型の場合 (int y = (x++) + 3;):まず、int y = x + 3; を処理し、その後で x = x + 1;
よって、x=11, y=13 となります
このようにインクリメント演算らを式の中に埋め込むと式が難しくなってしまいます。(でも無いですか?) 間違って読まれるより、式を (++x; int y = x + 3; などと) 2 つに分解したほうが良いかもしれません。
問題 2.10.8. 以下のプログラムの出力結果を書きなさい。注意:こんなプログラムは読む人を混乱させるだけなので、みんなは書かないように。あくまで、問題です。
ソースコード 2.16 SubstInEquation2.java (式中のインクリメントは混乱原因)
package section0210;
public class SubstInEquation2 {
public static void main(String[] args) {
int x = 1;
int y = ( ++x ) + ( x++ );
System.out.println( "x = " + x + ", y = " + y );
}
}
2.10.3 多重代入文
前節で書いたように、代入文を式の中に使える!ということから派生して、Java では多重代入文 (multiple
assignment statement) が書けます。つまり、複数の変数に同じ値を代入したいときに、つぎのような書き方ができるのです。
ソースコード 2.17 MultipleSubst.java (多重代入文)
package section0210;
public class MultipleSubst {
public static void main(String[] args) {
int a;
int b;
int c;
c = b = a = 1;
System.out.println( "a=" + a + ", b=" + b + ", c=" + c );
}
}
先ほどの「式の中の代入文」の考え方で、c = b = a = 1; は、まず右から順に代入文を読んでいき、a の値がまず 1
に、次に b = (a = 1) から b も 1 に、そして c = (b = 1) より c も 1 になるというわけです。でも、このプログラムは、以下のプログラムと同じですね。(^^;)
ソースコード 2.18 MultipleSubst2.java (多重代入文は使わなくても)
package section0210;
public class MultipleSubst2 {
public static void main(String[] args) {
int a = 1;

2.11 キャスト 33
int b = 1;
int c = 1;
System.out.println( "a=" + a + ", b=" + b + ", c=" + c );
}
}
なお、c = b*2 = a = 1; とか、c = b++ = a = 1; なんてのはできません。理由はわかるかな?
問題 2.10.9. 多重代入文に複合代入文演算子も使えます。以下のプログラムの出力結果を書きなさい。ただし、このプログラムもあくまで問題用ですね。
ソースコード 2.19 MultipleSubst3.java (複雑な多重代入文)
package section0210;
public class MultipleSubst3 {
public static void main(String[] args) {
int x = 2;
int y = 3;
int z = 4;
z += y *= x;
System.out.println( "x=" + x + ", y=" + y + ", z=" + z );
}
}
2.11 キャスト代入文において、代入する側 (右辺)の値の型と代入される側 (左辺)の変数の型が異なるとき、「表現できる範囲のより広い変数には範囲の狭い型の値を代入できるが、その逆はできない」と学びました。例えば int型のリテラルはdouble型の変数に代入することができる (double x = 2;) が、その逆はできない (int y = 2.0;) と。しかし、何らかの理由で double型の値を int型の変数に代入したい場合もあるでしょう。そこで、出てくる方法が「キャスト」 (cast) です。その方法は「値の前に変換したい型名を小かっこでくくって書く」。例えば 2.0 を y に代入する場合、int y = (int) 2.0; と書くと yには 2 が代入されます。キャストは直後の値のみ型変換してくれるので、例えば int y = (int) 2.0 + 1.0; はエラーになります。なぜでしょう?キャスト (int) が 2.0 にのみに掛かるので、実質 int y = 2 + 1.0; と見なされて、右辺の計算結果は double型の3.0、これは int型に自動変換されません。この場合、int y = (int)(2.0 + 1.0); とキャストしたい部分をかっこでくくってやれば、キャストの前に 2 つの実数の和を計算するので上手くいきます (このとき yには 3 が入ります)。キャストはリテラルだけでなく変数でも可能です。double型変数 xに格納されている値を int型変数 yに代入し
たい場合に、y = (int) x; とすれば良いのです。ところで、xに今 1.5 が格納されているとしたら、yにはキャストの結果いくつの値が入るのでしょう。それは、キャスト先の yの型に合わせて情報が切り捨てられます。つまり、1.5
の余分な小数点以下の値が切り捨てられて、1 が代入されるわけです。
問題 2.11.1. 以下の代入文で、エラーとなるものはどれですか。キャストが付いているが、実はキャストせずとも代入できるのはどれですか。

34 第 2章 Java 言語の基本的な文法 I
1. int x = (int) 2.5 - 1; 2. int x = 1.5 - 0.5; 3. float x = (float) 123.45;
4. int x = (int) 12345L; 5. long x = (long) 123; 6. double x = (double) 12.3F;
7. byte x = (byte) 100; 8. long x = (long) 1234; 9. char x = (char) 12354;
10. int x = (int) true; 11. int x = (int) 'A';
上の設問 7 では、int 型の値を表現できる範囲の狭い short, byte 型の変数に代入するには、ルール通りなら、キャストせずに代入できないはずですが、先にも触れたように、 int より表現できる範囲の狭い short, byte 型には特別ルールとして表現できる範囲内の整数リテラルであればキャストなしで代入できるようになっています。つまり、byte x = 100; は 100 という値が、byte 型変数の表現できる [−128, 127] 間の整数値になっていることから特別ルールで OK となります。ただし、 int a = 100; byte x = a; はエラーになります。この場合は、int a = 100; byte x = (byte) a; としなければいけません。リテラルは特別ルールが効くけれど、変数はダメということですね。何故でしょう?変数 a には今たまたま 100 が入るだけであって、範囲外の値も入る可能性があるからですね。従って、byte x = 200; byte x = (byte) a; はエラーです。200 が区間 [−128, 127] に含まれないからです。でも、以下のプログラムはエラーを出しません。確かめてみて下さい。
ソースコード 2.20 Casting1.java (ムリやりキャスト)
package section0211;
public class Casting1 {
public static void main(String[] arge) {
byte x = (byte) 200;
System.out.println( "x = " + x );
}
}
動きましたが、値が変ですよね。このキャストという操作をもう少し細かく見てみましょう。200 というリテラルはint型ですから、Java では 32bits 符号付き整数として表されています。一方、byte 型変数 xは 8bits 符号付き整数として記憶領域が確保されています。そこで、キャスト (byte) が行われると、32bits の情報の下位 8bits を残して上位 24bits の情報を捨ててしまうのです(むちゃくちゃです。符号くらい合わせても良いと思うのですがね)。よって、xには −56 なる値が代入されるというわけです。byte x = 100; の場合も図 2.11 のような図を書いて確かめて下さい。ということで、キャストで想定外の値になる可能性もあることを知っておいて下さい。この辺り、Java はまだ低レベルです。
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 1 0 0 0
32bits 符号付き整数の 200
1 1 0 0 1 0 0 0
8bits 符号付き整数 -56 (2の補数表現に注意)
キャスト (byte)
図 2.12 200 を byte 型にキャストすると

2.11 キャスト 35
問題 2.11.2. byte 型で表現できる整数の範囲 [−128, 127] の境界の値で、キャスト (byte) の結果 (xの値) がいくつになるか求めよ。1. byte x = (byte) -129; 2. byte x = (byte) -128;
3. byte x = (byte) 127; 4. byte x = (byte) 128;
キャストの話はまだ続きます。次のプログラムを実行してみましょう。
ソースコード 2.21 Casting2.java (丸め誤差とキャスト)
package section0211;
public class Casting2 {
public static void main(String[] arge) {
double x = 10.1;
int y = (int)( x / 0.1 );
System.out.println( "y = " + y );
}
}
y = 101 と出力されると思いきや、y = 100 と出力されます。なぜでしょう?理由を知るために、5 行目と 6 行目の間に System.out.println( x / 0.1 ); と入れてみて下さい。101.0 と出力されるはずが、100.99999999999999 と誤差を持って表示されます。従って、それを int型にキャストすれば、小数点以下が切り捨てられて、100 となるわけです。このように、キャストは丸め誤差が起こっているかも?にも気を付けねばいけません。とはいえ、便利な道具ではあります。
問題 2.11.3. 実数変数 xに入っている値を整数変数 yへ、小数点以下を四捨五入して代入する処理をキャストを利用して書きなさい。 (ヒント:キャストはあくまで切り捨てなので、0.5 加えてから . . .)
なお、後で、Math.round() という四捨五入メソッドを習います。
キャストの最後に、教科書にあまり載っていない複合代入文とキャストにまつわる話を。次のプログラム、エラーなく動いて x = 2 を出力します。でも、どこか違和感ありませんか?複合代入文とはいえ int型の変数 xに double型リテラル 2.5 を代入できている?のです。
ソースコード 2.22 CompoundAssign.java (複合代入文での隠れキャスト)
package section0211;
public class CompoundAssign {
public static void main(String[] arge) {
int x = 0;
x += 2.5;
System.out.println( "x = " + x );
}
}
ちなみに、x += 2.5; の部分を x = x + 2.5; と書き換えるとコンパイルエラーとなります。つまり、この2つの処理に違いがあるということです。実は複合代入文では、裏でキャストが行われているのです。この場合は、x =
(int)( x + 2.5 ); と左辺の変数の型にキャストする処理が隠れているのです。和田も、ちょっと前までこのことに気づいていませんでした (まだまだ知らないことがあるんだなぁ)。しっかりマニュアルを読まずにプログラミング言

36 第 2章 Java 言語の基本的な文法 I
語を使うと、思わぬミスが隠れているかもしれないということですね。ちなみに、こんなプログラムは書かないで。読む人を混乱させるだけです。
問題 2.11.4. 以下の代入文で変数 a の値はそれぞれ幾つになりますか。1. double a = 4 + 3 / 2 + 2; 2. double a = 4 + 3.0 / 2 + 2;
3. double a = (4 + 3) / 2 + 2; 4. double a = (double) 4 + 3 / 2 + 2;
5. double a = (double)(4 + 3) / 2 + 2; 6. double a = 4 + 3 / (2 + 2.0);
2.12 条件分岐ここからいよいよ、この前期の山場、制御構造「条件分岐・繰り返し・配列」に入っていきます。この 3 項目をしっかりモノにしてくれれば、前期は楽勝ですので、気を引き締めて勉強して下さい。まず、与えられた条件により複数の処理の中から次に行う処理を選択する「条件分岐」を学ぶために、幾つかの演算子を学びます。
2.12.1 比較演算子
比較演算子 (comparison operator) (関係演算子 (relational operator) とも言う) という 2 項演算子は、2 つの値を比較し boolean 型の値 (成立すれば true、しなければ false) を返すものです。比較演算子で書かれた式を「比較式」もしくは「関係式」と呼びます。比較演算子には、以下の 6 種類があります。最も右の列は、比較式の値が true
になる例です (表 2.12.1 参照)。比較する 2 つの値は intと doubleのように型が異なっていても、比較ができるもの同士なら OK です。なお、2
つの値が等しいかどうかの比較を行う演算子が == と 2 つの等号からなっていることにご注意を。1 = 1 と書いてしまうと、これは代入文となってしまうので、コンパイルエラーです (1 に 1 は代入できないですね)。
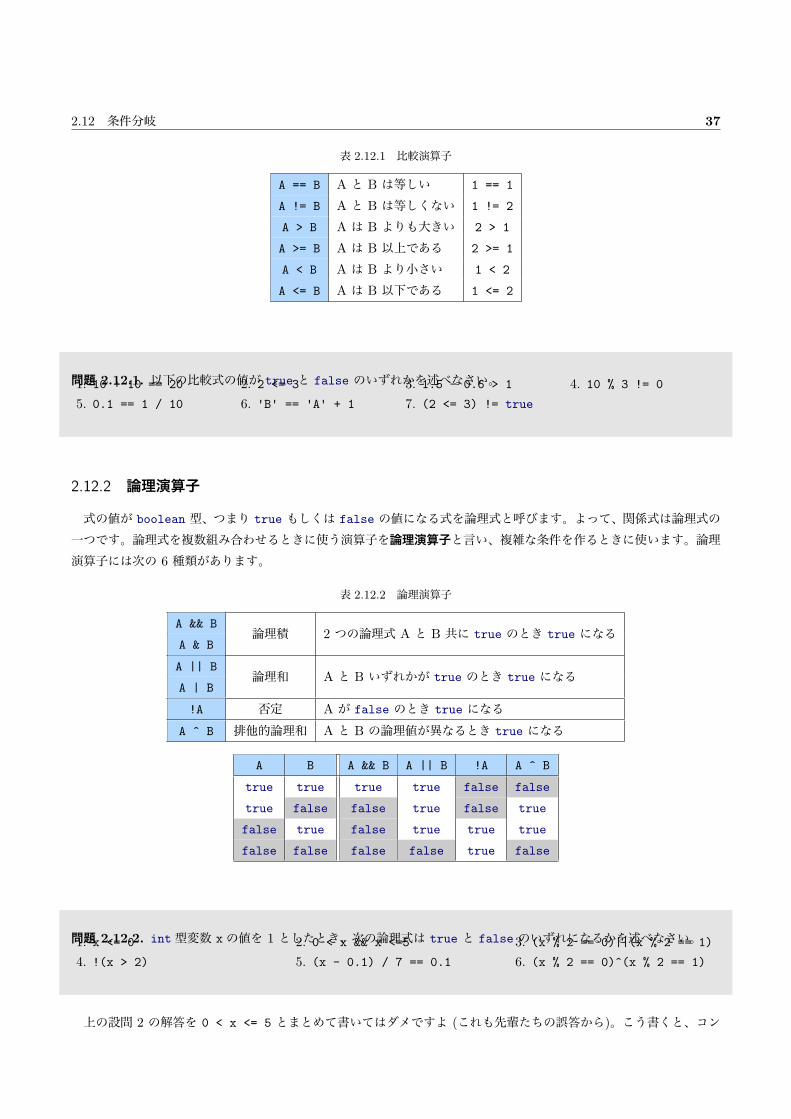
2.12 条件分岐 37
表 2.12.1 比較演算子
A == B A と B は等しい 1 == 1
A != B A と B は等しくない 1 != 2
A > B A は B よりも大きい 2 > 1
A >= B A は B 以上である 2 >= 1
A < B A は B より小さい 1 < 2
A <= B A は B 以下である 1 <= 2
問題 2.12.1. 以下の比較式の値が true と false のいずれかを述べなさい。1. 10 + 10 == 20 2. 2 <= 3 3. 1.5 - 0.6 > 1 4. 10 % 3 != 0
5. 0.1 == 1 / 10 6. 'B' == 'A' + 1 7. (2 <= 3) != true
2.12.2 論理演算子
式の値が boolean 型、つまり true もしくは false の値になる式を論理式と呼びます。よって、関係式は論理式の一つです。論理式を複数組み合わせるときに使う演算子を論理演算子と言い、複雑な条件を作るときに使います。論理演算子には次の 6 種類があります。
表 2.12.2 論理演算子
A && B論理積 2 つの論理式 A と B 共に true のとき true になる
A & B
A || B論理和 A と B いずれかが true のとき true になる
A | B
!A 否定 A が false のとき true になるA ^ B 排他的論理和 A と B の論理値が異なるとき true になる
A B A && B A || B !A A ^ B
true true true true false false
true false false true false true
false true false true true true
false false false false true false
問題 2.12.2. int型変数 xの値を 1 としたとき、次の論理式は true と false のいずれになるかを述べなさい。1. x <= 0 2. 0 < x && x <=5 3. (x % 2 == 0)||(x % 2 == 1)
4. !(x > 2) 5. (x - 0.1) / 7 == 0.1 6. (x % 2 == 0)^(x % 2 == 1)
上の設問 2 の解答を 0 < x <= 5 とまとめて書いてはダメですよ (これも先輩たちの誤答から)。こう書くと、コン

38 第 2章 Java 言語の基本的な文法 I
パイラは (0 < x) <= 5 と解釈し、true <= 5 これは無茶だ!とエラーメッセージを出します。ところで、論理積と論理和にはそれぞれ 2 通りの書き方、例えば A && B と A & B、がありますがこの違いは何でしょう。これは、論理式の「短絡評価」(short-circuit evalution) をするかしないか、という違いです。長い関係式の真偽値を求めているとき、それ以降を調べなくともその式の真偽値がわかる場合があります。例えば、論理積 A && B
において、もし論理式 A の値が false と確定した場合、B の値が true であろうと false であろうと、その論理積はfalse であることがわかりますよね (表 2.12.2 参照)。そんなときに、B のチェックを省略するのが短絡評価です。同様に、論理和 A || B において、もし論理式 A の値が true と確定した場合、B の値が true であろうと false であろうと、その論理積は true であることがわかります。この場合も B のチェックを省略するわけです。一方、A & B や A | B においては、短絡評価はせずに、A と B のチェックを必ず行って論理積・和の値を求めます。特別な理由がなければ、短絡評価の A && B と A || B を使う事になりますが、以下の例を見ると、両方の必要性も見えます。
• 短絡評価する場合:A && B
– A の処理時間に対し、B の処理時間が大幅に大きい時、少しでも全体の処理時間を短縮したい場合– B の処理中に実行時のエラーが起こるか否かを A でチェックする場合。A が false なら、B は実行してはならない場合(例:a != 0 && b / a > c)
• 短絡評価しない場合:A & B
A と B、いずれもその内部で補助的な処理(コンソールへの出力など) を行っている場合には真偽に関わらず、両方をチェックしないといけない場合 (例:methodA() & methodB())
問題 2.12.3. 次の論理式を Java の式として書きなさい。なお、数直線上で ○はその点を含まず、●はその点を含むとする。
1. 変数 xの値が、5 以上の偶数であるとき true になる式2. 変数 xの値が、以下の数直線の区間に入っているとき true になる式
‒2 0 2 4
3. 変数 xの値が、以下の数直線の区間に入っているとき true になる式
‒2 0 2 4
4. ある 2 次元平面上の点の座標を表す変数を xと yとするとき、その点が原点から距離 5 以内にあるとき true
になる式
問題 2.12.4. 西暦が int型変数 year に代入されているとして、この年がうるう年なら true を返す式を書きなさい。ただし、うるう年は、西暦の値が 4 で割り切れる年で、例外として 100 で割り切れるが 400 では割り切れない年は平年とする。というルールです。

2.12 条件分岐 39
論理演算子の中で特殊なのが「排他的論理和」(Exclusive OR) です (排他的論理積というのはありません)。2 つの命題の真偽値が異なると true になる、こんな論理演算子どんな場合に利用するのでしょうか?実は、コンピュータ内の 2 進数の計算でも利用しているのですが、このテキストでは解説しません。各自、排他的論理和を使う例を調べてみて下さい。
問題 2.12.5. ちょっと Java と離れてしまいますが。排他的論理和は、論理積と論理和と否定を用いて表現する事ができます。次の式を真偽値表を作って確かめなさい。(なお、式の中の = は数学の意味での等号です)
A ^ B = (A && !B) || (!A && B) = (A || B) && (!A || !B)
また、論理和と論理積は否定を用いて、互いに表現する事ができます。次の式も確かめなさい。A && B = !(!A || !B), A || B = !(!A && !B)
以上の全ての結果から、何が言えますか?
2.12.3 if 文
条件分岐 (brunch) とは、論理式で表されたある条件が true の場合に処理 A を、false の場合に処理 B を行うといった処理の分岐のことで、 Java では if 文を使用します。例えば、変数 xの値が 0 以上なら変数 yに 1 加え、0 未満なら yから 1 減じる、というプログラムは、以下のようになります。
ソースコード 2.23 IfElse.java (if else 文)
package section0212;
public class IfElse {
public static void main(String[] args) {
int x = 3;
int y = 0;
if( x >= 0 ) {
y += 1;
} else {
y -= 1;
}
System.out.println( "y = " + y );
}
}
if 文のフォーマットは、次のようになります。
if( 分岐条件 ) {
// 分岐条件が true の時に行う処理} else {
// 分岐条件が false の時に行う処理}
if に続く小かっこの中に分岐条件を論理式で書きます。この論理式は、その値が true になったとき何をするのか?を意識して書きましょう。そして、「if ブロック」と呼ばれる1つ目のブロック (中かっこの対) が続きます。その中に、前提の関係式が true になった場合に行う処理を書きます。ブロック内には処理を何行でも書けます。さらに続けて、else と書いた後、「else ブロック」と呼ばれる2つ目のブロック (中かっこの対) を書きます。else ブロッ

40 第 2章 Java 言語の基本的な文法 I
クには、分岐条件が false になった場合に行う処理を書きます。こちらもブロック内に処理を何行でも書けます。これで、条件分岐の完成です。if 文の分岐条件には、boolean 型の変数、および boolean 型の値を返す式を使うことができます。例えば、数値の入った xに対し、if( x + 100 > 1000 ) は OK ですが if( x + 100 ) はダメですね。
問題 2.12.6. int型変数 xの値が偶数なら、コンソールに「x は偶数です」と出力し、奇数なら「x は奇数です」と出力する以下のプログラムを完成させなさい。
ソースコード 2.24 OddOrEven.java (偶数か奇数かで場合分け)
package section0212;
public class OddOrEven {
public static void main(String[] args) {
int x = 100;
// ここに指示の処理を書く
}
}
条件分岐するとき、else ブロックで処理する処理が無い場合、else ブロックを空にするのではなく、else ブロックそのものを書かずに、以下のように if ブロックのみとします。
if( 分岐条件 ) {
// 分岐条件が true の時に行う処理}
この場合、分岐条件が false になったら何もせずに if ブロックの次に移行します。逆に if ブロックで処理する処理が無い場合は、if ブロックを省略するわけにはいかないので (空の if ブロックというのも慣例では作らない)、分岐条件の内容を「否定」を使って真偽値を逆にし、if ブロックのみの if 文になおしてやります。
2.12.4 複数の分岐条件
if 文では、場合分けは 2 通りしかできませんので、 3 つ以上の場合分けの場合は、次のように入れ子の if 文を用いて書きます。例えば、変数 x に入っている値が正か零か負かで分岐させたいときなど。
if( 分岐条件1 ) {
if( 分岐条件2 ) {
// 分岐条件1が true で、分岐条件2が true の時に行う処理} else {
// 分岐条件1が true で、分岐条件2が false の時に行う処理}
} else {
if( 分岐条件3 ) {
// 分岐条件1が false で、分岐条件3が true の時に行う処理} else {
// 分岐条件1が false で、分岐条件3が false の時に行う処理}
}

2.12 条件分岐 41
もちろん、いずれの else ブロックも省略できます。
問題 2.12.7. 2つの int 変数 x と y の値がそれぞれの偶奇の組み合わせ 4 パターンの場合分けをして、それぞれで「x は偶数で、 y は奇数でした」のような出力を行う処理を書きなさい。
問題 2.12.8. int 変数 x に入っている値が正か零か負かで分岐して、それぞれで「x は正値でした」「x は零でした」「x は負値でした」と出力する処理を書きなさい。
この問題の解答を次のように書く人が結構います。
if( x > 0 ) {
System.out.println( "x は正値でした" );
}
if( x == 0 ) {
System.out.println( "x は零でした" );
}
if( x < 0 ) {
System.out.println( "x は負値でした" );
}
決して間違ってはいませんが、例えば、 x=1 の場合で、「正値でした」と出力した場合でも、その後の 2 つの判定式を無駄に行ってしまうことに気付きますか。また、この程度の判定なら、3 つの判定式のいずれにも引っかからない値が無いことはわかりますが、もし判定式が複雑なら、いずれの式も true とならない値があった場合、何も出力無く終わるんだな!とか、複数の判定式に true となるのもあるのかな?とか余計な判断が湧いてきますね。
問題 2.12.9. int型の変数 vote の値を 1、2、3 とそれ以外、の 4 通りの場合分けをし、それぞれで「賛成」「反対」「棄権」「無効」の文字をコンソールに出力するプログラム Vote.java を作りなさい。
ソースコード 2.25 Vote.java (投票プログラム)
package section0212;
public class Vote {
public static void main(String[] args) {
int vote = 1;
// 以下に投票された値で場合分けして結果を出力する
}
}
この問題の解答も次のように書く人が結構います。
int vote = 1;
if( vote == 1 ) {
System.out.println( "賛成" );
}

42 第 2章 Java 言語の基本的な文法 I
if( vote == 2 ) {
System.out.println( "反対" );
}
if( vote == 3 ) {
System.out.println( "棄権" );
} else {
System.out.println( "無効" );
}
見た目はシンプルですが、こちらも無駄が多い上にミスもあるプログラムです。例えば、vote == 1 の場合に「賛成」の文字を出力後でも、残りの 2 つの if 文のチェックを無駄に行ってしまいます。そして、最後の vote == 3 の判定で else ブロックに入り「無効」を出力してしまいます。多重の条件分岐の書き方をしっかりと学んでおいて下さい。さて、分岐条件の入れ子状態が何重にもなってくると少々各ブロックが冗長に見えてきます。
if( x > 0 ) {
if( y > 0 ) {
// x > 0 かつ y > 0 の時に行う処理} else {
// x > 0 かつ y ≦ 0 の時に行う処理}
} else {
if( y > 0 ) {
// x ≦ 0 かつ y > 0 の時に行う処理} else {
// x ≦ 0 かつ y ≦ 0 の時に行う処理}
}
そこで、Java では、else ブロック内の 最初の if ブロックを次のように書くことができます。上下を比較して、その使い方を理解して下さい (中かっこの対が 1 つ減っています)。
if( x > 0 ) {
if( y > 0 ) {
// x > 0 かつ y > 0 の時に行う処理} else {
// x > 0 かつ y ≦ 0 の時に行う処理}
} else if( y > 0 ) {
// x ≦ 0 かつ y > 0 の時に行う処理} else {
// x ≦ 0 かつ y ≦ 0 の時に行う処理}
この書き方を利用すると、複数の選択肢で条件分岐する場合も以下のように書くことができます。
int x = 123;
if( x == 2 ) {
// x= 2の時に行う処理} else if( x % 2 == 0 ) {
// x が 2 以外の偶数の時に行う処理} else if( x > 2 ) {
// x が 2 より大きな奇数の時に行う処理 (x = 123 はここにやって来る)
} else {
// それ以外: x が 0 もしくは負の奇数の時に行う処理}

2.12 条件分岐 43
この場合も最後の else ブロックは中身が空なら省略できます。
問題 2.12.10. 学生の成績が入っている int型変数 degree の値に対して、ランク評価の S、A、B、C、D を以下のように出力するプログラム RankEvaluation.java を作りなさい。なお、ランク S は 90点以上、A は 80点以上、B は70点以上、C は 60点以上、D は 60点未満である。
ソースコード 2.26 RankEvaluation.java (条件分岐で成績評価)
package section0212;
public class RankEvaluation {
public static void main(String[] args) {
int degree = 85;
// if 文による条件分岐により以下のような出力が出るように作る
}
}
あなたの成績は A でした。
ところで、この問題の解答として以下のように書く人が結構多い。
if( degree >= 90 ) {
Systerm.out.println( "あなたの成績は S でした。" );
} else if( degree < 90 && degree >= 80 ) {
Systerm.out.println( "あなたの成績は A でした。" );
} else if( degree < 80 && degree >= 70 ) {
// :
// (以下省略)
えっ、何処がいけないの?論理的には間違ってはいません。ただ、最初の if 文の判定で false となった場合、必ず degree < 90 は成立しているのではないでしょうか。つまり、次の判定における degree < 90 の論理式は無駄だ!ということです。こうした場合、馬鹿マジメに判定式を書くのではなく、よく考えてから簡潔な論理式を書くようにしましょう (我々は応用数学科の学生なのだから)。
問題 2.12.11. 上の問題の条件分岐の順番を、最初に degree >= 70 から初めたときの条件分岐文を考え、それによるプログラム RankEvaluation2.java を作りなさい。そして、どのランクの点数も同じ確率で発生するとしたときの分岐回数の平均値を 2 つのプログラムで比較しなさい。
もしこの2つのプログラム RankEvalution と RankEvalution2 が大量のデータに対して行われるとしたら、後者の方が (プログラムソースとしては少々見にくくなりますが) 処理時間が短くなるのが予想されます。このような点も考えながらプログラミングして下さいな。

44 第 2章 Java 言語の基本的な文法 I
問題 2.12.12. 以下の論理積を含む if 文を、単独の (論理積を含まない) if 文の入れ子として書き直しなさい。なお、condition_A と condition_B はいずれも boolean 型の値を返す論理式とします。そして、この論理式が短絡評価式であることも注意して下さい。
if( condition_A && condition_B ) {
System.out.println( true );
} else {
System.out.println( false );
}
2.12.5 処理が 1 つの場合の中かっこの省略
if ブロックや else ブロックにおいて、ブロック内の処理が命令文 1 つだけの場合、ブロックを定義する中かっこの対を省略できます。つまり、次の条件分岐を
if( 分岐条件1 ) {
// この処理が1つだけのとき} else {
// この処理が1つだけのとき}
次のように省略して書けます。
if( 分岐条件1 )
// この処理が1つだけのときelse
// この処理が1つだけのとき
例えば、int型変数 xの値が 0 以上なら xを 2 倍し、負なら −2 倍するという条件分岐は、次のように書けます。
// 方法1if( x >= 0 )
x *= 2;
else
x *= -2;
あるいは、次のように、行う処理を if や else の右に書いても構いません。
// 方法2if( x >= 0 ) x *= 2;
else x *= -2;
これについて和田は、方法2の書き方を使って書くようにしており、方法1の書き方は使わないようにしています。なぜなら、以下のように書いた時、誤解を招きやすいからです。
int x = 1;
int y = 2;
if( x >= 0 )
x *= 2;
y += 2;

2.12 条件分岐 45
最後の y += 2; がインデントされているので、つい x >= 0 の場合に2つの処理が行われる、と読まれる可能性があるからです。実際には y +=2 は xの判定に関わらず行われますよね。インデントを正しく書けば良いのでは?と思うかな。でも、この場合は以下のように書くか、
int x = 1;
int y = 2;
if( x >= 0 ) x *= 2;
y += 2;
ブロックの中かっこは中味が 1 つでも必ず書く!とすれば、誤解は起きないですね。
int x = 1;
int y = 2;
if( x >= 0 ) {
x *= 2;
}
y += 2;
2.12.6 switch 文
条件分岐する条件式が整数型もしくは文字型である場合は、もう 1 つ、別の書き方ができます。switch 文です。ただし、switch 文で使われる条件式は if での条件式のように結果が boolean 型の値となる式ではなく、整数型・文字型もしくは文字列型となる式でないといけません。従って、「90 点以上」のような範囲で場合分けするのには向いていません。直接、90 ならどうする、 80 ならどうする、といった分岐になります。case で始まる部分を「case 節」と呼びます。「defult 節」は省略することができます。
int x = 123;
switch( x % 3 ) {
case 0:
// 整数 x が 3 で割り切れる場合の処理break;
case 1:
// 整数 x が 3 で割ると1余る場合の処理break;
default:
// 上記 2 つのケース以外の場合の処理 (この場合 3 で割ると 2 余る数)
break;
}
文字型でも判定できるので、先の例の続き、学生の成績からランク評価 char型変数 rank が得られたとしましょう。それらにより合格か否かを表示する処理を switch 文で書くと次のようになります。
switch( rank ) {
case 'S':
System.out.println( "あなたは S で合格です" );
break;
case 'A':
System.out.println( "あなたは A で合格です" );
break;
case 'B':
System.out.println( "あなたは B で合格です" );
break;
case 'C':

46 第 2章 Java 言語の基本的な文法 I
System.out.println( "あなたは C で合格です" );
break;
default:
System.out.println( "あなたは不合格です" );
break;
}
ここで、何度も登場する break; について説明しましょう。この命令は、「壊す」という意味ではなく、「中断する」という意味で使われていて、その後に続く case 節を読み飛ばして、switch ブロックの外に出る、という処理をしてくれます。つまり、 rank == 'S' の場合は、 S で合格 と出力後 break によって、 switch 文を抜け出します。また、最後の default 節には後に続く case 節が無いので、break; を書かなくても構いません。なお、 default 節自体が無くても構いません。その場合、それ以外のケースに合致しなかった場合は何もせずに
switch 文の外へ出ることになります。
問題 2.12.13. 上の switch 文による成績処理の分岐を if 文による分岐で書きなさい。
この問題のように、switch 文での分岐処理は if 文による分岐処理で書き直すことができます (見やすさが違いますが)。
問題 2.12.14. 文字列の入った変数 drink の値で次のような出力を行う switch 文を書きなさい。
• drink == "orange" なら、「オレンジジュースですね」• drink == "apple" なら、「リンゴジュースですね」• drink == "coffee" なら、「コーヒーですね」• drink == "tea" なら、「紅茶ですね」• その他の場合に、「申し訳ありません、それはご用意できません」
さて、switch 文は以下のような書き方ができます。この場合、 'S' から 'B' までの case 節に何も書かれていません。では、rank の値の違いによりどのように処理されるでしょう。rank == 'S' の場合、 case 'S': で条件を満たし、さて処理は?というと何も無い。そして、break; も無いので、処理は単純に下に移動して、case 'A':、case 'B':、case 'C': と通り過ぎて、"あなたは合格です" を出力、そして break; でやっと switch ブロックから抜け出すのです。rank == 'A' や、rank == 'B' の場合も同様に case 'C': の部分まで移って出力後 break; でswitch ブロックの外に出ます。一方、それらでない場合 ( rank=='D' ですかね) は、 defalut へ飛んで "不合格です" を出力、 break; は無いけれど終了、となります。このような幾つかの値に対して同じ処理を行うような場合にも対応することができます。
switch( rank ) {
case 'S':
case 'A':
case 'B':
case 'C':
System.out.println( "あなたは合格です" );
break;
default:

2.12 条件分岐 47
System.out.println( "あなたは不合格です" );
}
2.12.7 条件演算子
プログラムでは、条件式の真偽に応じて変数の値を切り替える処理が多く出てきます。例えば、2 つの変数 a と b の大きな方を変数 xに代入したいとき、if 文を使えば、以下のように書けますよね。
if( a > b ) {
x = a;
} else {
x = b;
}
ブロックの中かっこを省略して、
if( a > b ) x = a;
else x = b;
と、まだまだ冗長ですかね。そこで、これを1つの処理として書いてしまうのが「条件演算子 ?:」です。その書き方とは、
x = ( a > b ) ? a : b;
? の前に条件式を書き、それが true になる場合の値を ? の次に、false になる場合の値をコロン : の次に書くのです。a > b をくくっている小かっこは省略できますが、無いと読みにくくなりますかね ( x = a > b ? a : b; )。省略して、x = ( a > b ? a : b ); と外側に小かっこを付けるという流儀もあります。例えば、成績 degree が 60 点以上なら「合格です」そうでなければ「不合格です」と出力する文を、次のようにもかけますが、どうでしょう。和田は、1行があまり長くなりそうなら条件演算子は使わないようにしています (なので、こんなのは書かないな)。
System.out.println( "あなたは" + (degree >= 60 ? "合格" : "不合格") + "です" );
問題 2.12.15. boolean 型変数 isMale には、男性なら true が、女性なら false が入っているとします。条件演算子を使ってその値から 2 つの文字列 ”男性” と ”女性” のいずれかを選んで、以下のように出力する出力文を 1 行で書きなさい。
あなたは、女性ですね。
2.12.8 boolean 型変数の真偽判定
上の問題でも出てきましたが、if 文や条件演算子の条件式の中に boolean 型変数の真偽を判定することが結構出てきます。
ソースコード 2.27 IsVariable.java (boolean 型変数の真偽判定)
package section0212;

48 第 2章 Java 言語の基本的な文法 I
public class IsVariable {
public static void main(String[] args) {
boolean isMale = true; // 男性なら true、女性なら false
if( isMale == true ) {
System.out.println( "あなたは、男性ですね。" );
} else {
System.out.println( "あなたは、女性ですね。" );
}
}
}
ところで、論理変数 isMale と論理式 isMale == true の真偽値を比較してみると変数と式と形は違いますが、真偽値は等しいことがわかります。
表 2.12.3 is 型変数
isMale isMale == true
true true
false false
ならば、if( isMale == true ) と書く代りに、if( isMale ) と変数を単独に入れた条件式でも同じ分岐ができると思いませんか。このような boolean 型の変数は、何らかの状況を表しているので、「is 型変数」と呼ばれ、変数名を is+形容詞 とする慣例があります。こうした命名法は、他にも can+動詞 や has+過去分詞 などがあります。そうして、 if( isMale ) や ( isMale ) ? "男性" : "女性" のように判定式の代わりに単独で使われます。
2.13 繰り返しこの章では、同じ処理を何度も繰り返して行いたいときの書き方について学びます。
2.13.1 for 文
最初に学ぶのは、繰り返しの回数が決まっている、例えばある処理を 10 回繰り返したい、という場合です。そうした場合は、for 文という命令で書きます。
for(int i = 1; i <= 10; i++) {
// 繰り返したい処理}
中かっこで括られた部分を for ブロックと言い、この中に繰り返したい処理 (複数の文でも構わない) を書きます。for の次に続く小かっこの中に、繰り返しのカウンタについての処理を 3 項目で書きます。間をセミコロンで区切っています (最後の命令 i++ にはセミコロンが無いことに注意)。小かっこの中の書き方は、次のようになります。
for(カウンタの初期化; 繰り返し条件; 処理の最後に行うカウンタの処理)
まず、「カウンタの初期化」ですが、カウンタとなる変数の宣言と初期値を与えます。カウンタはカウントできる型ならば何でも良いので、整数型・実数型・文字型のいずれかが使えます。整数型のカウンタとしては、数学でも添字によく使われる i, j, k, l, m, n がよく使われますが、もちろん counter など意味を持つ変数名でも構いません。型宣言と初期化をするのが、この第 1 項目です。

2.13 繰り返し 49
次に、「繰り返し条件」ですが、ここにはカウンタがどんな条件を満たしているとき繰り返しを続けるかを論理式で書きます。カウンタがこの条件を満たさなくなったら、繰り返しの実行をやめることになります (初期値によっては最初からこの条件を満たさないので繰り返しを 1 度も行わないこともあるのでご注意あれ)。そして、最後の「処理の最後に行うカウンタの処理」ですが、これは繰り返しの処理を 1 回行なうたびに、その後で
カウンタに対して行う処理を書きます。例えば、カウンタを 1 から 10 まで 1 づつ増やして合計 10 回の繰り返しを行いたいなら、カウンタを 1 づつ増やすという処理を繰り返しのたびに行わないといけません。それをここに書きます。ここで、i++ などが登場するわけでが、もちろん、これを i+=1 と書いたり、i=i+1、++i と書いても OK です ( i++
を使う人が多いですね)。
問題 2.13.1. 実数カウンタ x を 0.0 から 10.0 まで 0.01 刻みで増やしながら繰り返す for 文の小かっこの中身を書きなさい。 for ブロックの方はいらない。
問題 2.13.2. コンソールに「ヤッホー」と 10 回出力する for 文による繰り返し処理を書きなさい。
問題 2.13.3. コンソールに「10 秒前」「9 秒前」…「1 秒前」とカウントダウンを出力する for 文による繰り返しを書きなさい。(出力のタイミングを実際に 1 秒間隔にしろという意味ではありません)
この場合、カウンタを 10 から 1 まで減らしていきながら、そのカウンタの値を出力すれば良いわけです。
問題 2.13.4. 上の問題のカウントダウンを 2 秒ごとで 10 から 0 まで行う for 文による繰り返しを書きなさい。(「0 秒前」はちょっと変ですけどね)
問題 2.13.5. 以下の for 文で繰り返される繰り返しは、それぞれ何回行われますか。1. for(int i=0; i<10; i++) 2. for(int i=10; i>0; i--)
3. for(int k=1; k<=100; k+=2) 4. for(int j=1; j<100; j*=2)
5. for(int i=1; i>-100 && i<100; i*=-2) 6. for(char c='A'; c<='Z'; c++)
7. for(double x=-1.0; x<=1.0; x+=1.0/50)
ところで、最後の double 型カウンタによる繰り返しでは、やはり計算誤差が生じるだろうな!という推測は正しいです。以下のプログラムを動かしてみましょう。
ソースコード 2.28 DoubleCounter.java (実数型の繰り返しカウンタ)
package section0213;
public class DoubleCounter {
public static void main(String[] args) {
int count = 0;
for(double x=-1.0; x<=1.0; x+=1.0/50) {

50 第 2章 Java 言語の基本的な文法 I
System.out.println( count + ":" + x );
count++;
}
}
}
変数 count は 1.0/50 を何回加えたかの数になります。案の定、本来 100 回加えて x==1.0 で終了するはずが計算誤差のせいで最後の 1 回が実行されていません (1.0 を超えてしまったのですね)。for 文は主に繰り返し回数がわかっている場合に使われます。問題 2.13.5 では、簡単にその回数が想像できないものもありましたが、本来そうした場合には for 文を使わずに次に学ぶ while 文などで書くことが多くなります。
問題 2.13.6. int 型変数 n に与えられた数だけ文字 '*' を横に並べるプログラム PrintStar.java を for 文を用いて作りなさい。次に、その処理をさらに別の for 文で囲むことで以下の出力(最初に n 個の星が出力され、改行して次の行は n-1 個の星、と順に1個ずつ減らして、最後は 1 個の出力)が行われるプログラム PrintStar2.java を作りなさい。ヒント:星を横に並べるには、改行しない出力文を用いれば良い。2 つ目のプログラムでは、外側の for 文のカウンタを i として、n から 1 まで減らし、内側の for 文のカウンタは 1 から i まで増やす、というようにする。ただし、1行毎に改行しなければいけないが、それは何も書かずに単に改行だけする命令を置けば良い。さあ、このヒントで作れるかな?
**********
*********
:***
**
*
問題 2.13.7. 次のプログラムがコンソールに出力するものを順に書きなさい。
ソースコード 2.29 FibonacciNumbers.java (フィボナッチ数列)
package section0213;
public class FibonacciNumbers {
public static void main(String[] args) {
int a = 1;
int b = 1;
System.out.print( a + " " + b + " " );
for(int i=3; i<=10; i++) {
int c = a + b;
System.out.print( c + " " );
a = b;
b = c;
}
System.out.println();
}
}

2.13 繰り返し 51
問題 2.13.8. 次のプログラムは、1 から与えられた n までの整数のうち、3 の倍数でないものを出力するプログラムです。これを参考に、1 から与えられた n までの整数のうち、2, 3, 5 のいずれの倍数でもないものを出力するプログラム NoMultiple2.java を作りなさい。
ソースコード 2.30 NoMultiple.java (3 の倍数以外を出力)
package section0213;
public class NoMultiple {
public static void main(String[] args) {
int n = 100;
System.out.println( "1 から " + n + " までをチェック:" );
for(int i=1; i<=n; i++) {
if( i % 3 != 0 ) {
System.out.println( "3の倍数でない数:" + i );
}
}
}
}
問題 2.13.9. 上の問題を参考に、1 から与えられた n までの整数のうち、 2, 3, 5 のうちいずれか 1 つの倍数で、他の2 数の倍数でないものを出力するプログラム NoMultiple3.java を作りなさい。
2.13.2 while 文
繰り返しの 2 つめの書き方は while 文です。繰り返し条件が複雑だったり、処理の最後に行うカウンタの処理が複雑だったりする場合、繰り返しの回数が推定しにくい場合があります。そのとき、while 文で書きます。これは、for
文では書けない!と言っているわけではありません。どんな繰り返しも for 文・while 文どちらでも書くことができますので、あくまで慣例ですね。繰り返しを 10 回行いたい場合の while 文での書き方です。
int i = 1;
while( i <= 10 ) {
// 繰り返したい処理i++;
}
for 文の小カッコの中の 3 処理がどこに書かれているかを見比べてもらえば分かるでしょうか。
問題 2.13.10. 問題 2.13.5 の各繰り返しを while 文を用いて書き直しなさい。

52 第 2章 Java 言語の基本的な文法 I
問題 2.13.11. コラッツ予想という問題は未だ解決されていない数論の問題です。問題は難しくとも、プログラムは簡単に作れます。ただ、初期値を大きくしていくと、Java の int や long の範囲内では収まりきれなくなり、まじめに取り組むと難しいプログラムとなります。整数 n に初期値を代入し、以下の処理を繰り返して数列が1に収束したら停止、その数列の変化と、経過途中での最大値を以下のようにコンソールに出力するプログラム CollatzSequence.java を作りなさい。配列は使わないこと。Collatz 予想:以下の操作は、いかなる n に対しても最終的に 1 に行き着く自然数 n に対して、次のような操作を続ける ・ n が偶数なら 2 で割る ・ n が奇数なら 3 倍して 1 を加える実行・出力例7→ 22→ 11→ 34→ 17→ 52→ 26→ 13→ 40→ 20→ 10→ 5→ 16→ 8→ 4→ 2→ 1
最大値は 52 です。
ソースコード 2.31 CollatzSequence.java (コラッツ予想)
package section0213;
public class CollatzSequence {
public static void main(String[] args) {
int n = 7;
System.out.print( "n = " + n );
// この後、繰り返しを用いて、"→ 次の値" を改行なしで書いていく// 繰り返しの終了条件は n == 1 なので、どの繰り返し文で書いたら// 良いか、想像は容易いかな。// 繰り返しを行いながら、最大値も求めないといけない。さて、どうする
}
}
2.13.3 do while 文
繰り返しの書き方には、もう 1 つあります。それが do while 文です。今回も繰り返しを 10 回行いたい場合のdo while 文での書き方です。
int i = 1;
do {
// 繰り返したい処理i++;
} while( i <= 10 );
今回も for 文の小カッコの中の 3 項目がどこに書かれているかを見比べてもらいましょう。do while 文での注意点は、つい忘れがちな最後のセミコロンです。さて、while 文と do while 文、似通った繰り返し文が 2 通りあるのはなぜでしょう。この 2 つは、「前判定」と
「後判定」の違いになります。つまり、i <= 10 という繰り返し判定を「繰り返したい処理」の前でチェックする while
文に対し、do while 文では、「繰り返したい処理」の後でチェックするということです。この違いはどうした場合に起こるのでしょう。次のプログラムを動かしてみましょう。
ソースコード 2.32 WhileVSDoWhile.java (while 文と do while 文)

2.13 繰り返し 53
package section0213;
public class WhileVSDoWhile {
public static void main(String[] args) {
int count = 0;
while( count > 0 ) {
System.out.println( "while 文の出力" );
}
do {
System.out.println( "do while 文の出力" );
} while( count > 0 );
}
}
コンソールへの出力から、2 つの違いを理解して下さい。
問題 2.13.12. 問題 2.13.5 の各繰り返しを do while 文で書き直しなさい。
2.13.4 変数のスコープ
ここで、少し寄り道です。先の問題 2.13.7のプログラム FibonacciNumbers.java において使われている 3 つの変数 a, b, c がプログラムの最後にどんな値になっているか知りたいと思いました。そこで、13 行目と 14 行目の間にSystem.out.println( "a="+a+", b="+b+", c="+c ); という出力文を入れました。すると、コンパイルエラーの赤い×が点灯し、「c を変数に解決できません」というちょっと意味不明のメッセージが表示されます。これはいったいどうしてでしょうか?
ソースコード 2.33 FibonacciNumbers.java (フィボナッチ数列)
package section0213;
public class FibonacciNumbers {
public static void main(String[] args) {int a = 1;
int b = 1;
System.out.print( a + " " + b + " " );
for(int i=3; i<=10; i++) {int c = a + b;
System.out.print( c + " " );
a = b;
b = c;
}System.out.println();
System.out.println( "a="+a+", b="+b+", c="+c );
}}
プログラム中で変数を宣言すると、その時点からその変数はメモリ内に領域を確保されて保持されるわけですが、ではいつまで確保され続けるのか?というと、「明示的に消去しない限り、その変数が宣言されたブロックの最も内側のものが終了するまで」となっています。ブロックとはこれまで if ブロックとかで出てきた中かっこで囲まれた領域ですね。従って、変数 a と b は main メソッドのブロック (赤い中かっこの対) が生存範囲となり、一方、変数 c が宣言された 8 行目を囲む最小のブロックは for 文のブロック (青い中かっこの対) となります。変数はプログラムがそれ

54 第 2章 Java 言語の基本的な文法 I
らブロックの外に出たとき、その変数をメモリ内から消去するので、 繰り返しが終了した 14 行目で 3 つの変数の出力をしようとしたとき、a, b の 2 つは、まだメモリ内に生きていますが、c はすでに消えている。よって、コンパイラが変数 c を見つけられないというメッセージを出してくる、というわけです。この変数の生存範囲のことを、「変数のスコープ」と言います。このプログラムにはもう 1 つ変数 i がありますね。では、この変数 i のスコープは何行目から何行目まででしょう? for 文の小かっこはちょっと特殊なのですが、この変数 i のスコープは、 7 行目から、12 行目までの for ブロックの内部です (まあ、そうでないと繰り返せないですね)。ということは、14 行目以降で i の出力をしようとしてもエラーになるというわけです。ちょっと、いたずらをしてみましょう。4 行目の int a = 1; を中かっこでくくってみて下さい (→ {int a = 1;}
)。コンパイルエラーがぼろぼろ出ますよね。変数 a が宣言・初期化されたけれど、それを囲む中かっこが自身を含む最も内側のブロックとなって、メモリからすぐ消去されたのです。中かっこと変数の型宣言の位置には注意が必要です。とはいえ、全ての変数をプログラムの最初に宣言しておいて、プログラムが稼働中常にメモリから消去されないようにするのは、資源の無駄使いです。変数を適切な位置で宣言し、適切なスコープが終了したら消えてもらうように書くのが良いプログラムの書き方です。また先輩のまずいプログラムの例です。2 つの繰り返しが続いて起こるプログラムを次のように書きました。
public static void main(String[] args) {
int i;
for(i=1; i<=10; i++) {
System.out.println( "i=" + i );
}
for(i=1; i<=20; i+=2) {
System.out.println( "i=" + i );
}
}
彼は、2 つの繰り返しのカウンタを for 文の前に宣言し、そのスコープを main メソッド全体としました。この書き方はエラーではありませんし、こうした書き方をしなければいけない状況はありえます。とはいえ、やはり繰り返しのカウンタはあくまでカウンタの役目を果たすべく、繰り返しの中でのみ生存し、外に出たら消去されるようにすべきなのです。この授業では触れませんが、Java では複数の CPU を利用した並列処理プログラムを作ることができます。そのとき、上のプログラムでは、2 つの繰り返しが変数 i で縛られてしまうので、別の CPU 上で処理できません。一方、下のように別個の繰り返しにしておけば、それぞれを別の CPU で処理するという効率化ができるのです。
public static void main(String[] args) {
for(int i=1; i<=10; i++) {
System.out.println( "i=" + i );
}
for(int i=1; i<=20; i+=2) {
System.out.println( "i=" + i );
}
}
ところで、while と do while 文による繰り返しを振り返ると、カウンタの宣言は何処でされていたでしょう?戻って見て下さい。そうなのです、これらの場合、カウンタの宣言は繰り返しブロックの中では無く、外で宣言されています。つまり、繰り返しが終了しても、このカウンタは消去されません。つまり、次のプログラムはエラーになります。
public static void main(String[] args) {
int i = 1;

2.13 繰り返し 55
while( i <= 10 ) {
System.out.println( i );
i++;
}
for(int i=1; i<=10; i++) {
System.out.println( i );
}
}
for 文でのカウンタ宣言が、「既に定義済みだ!」とエラーになってしまうわけです。では、どうしたら良いでしょうか?カウンタの名前を変える!それもありでしょうが...
for 文の小かっこ内の型宣言を消してしまって (i=1; i<=10; i++) にする?いえいえ、それでは先の先輩と同じような解答です。この場合、次のように while 関連の処理をブロックで囲めば良いのです。
public static void main(String[] args) {
{
int i = 1;
while( i <= 10 ) {
System.out.println( i );
i++;
}
}
for(int i=1; i<=10; i++) {
System.out.println( i );
}
}
こうすれば、while の繰り返しが終わると変数 i は一旦メモリから消去され、for 文で新たに出現できるわけです。とはいえ、while や do while のたびにブロックで囲んでいてはプログラムが読みにくくなりますね。こうした問題は、後に出てくるメソッドを利用するとか、後期のオブジェクトの考え方を導入するとかで解決するのが良い方法といえます。
2.13.5 無限ループ
繰り返し処理は条件分岐と比べて、より注意が必要な処理です。つまり、思いもしない (永久に止まらない) プログラムを作る可能性があるからです。以下のプログラムを動かして下さい。
ソースコード 2.34 InfiniteLoop.java (停止しない無限ループ)
package section0213;
public class InfiniteLoop {
public static void main(String[] args) {
int i = 10; // → int i = -1;
while( i != 0 ) {
System.out.println( "i=" + i );
i--;
}
}
}
何ということはない、カウンタを 10 から 1 まで減らしながら出力して、i が 0 になったら、出力せずに終了する、というプログラムです。このままでは、問題ないのですが、4 行目の i への初期値を −1 としてみて下さい。プログラムは止まらなくなります (ちょっとウソで、いつか止まります。どうしてかな?)。

56 第 2章 Java 言語の基本的な文法 I
とりあえず、止めましょうか。Eclipse の場合、コンソール内の「赤い四角のアイコン ( )」をクリックすれば、大体の暴走は止められます。さて、もともとは非負の数でカウンタを始めて、0 になるまで減らしていく、と考えていたのに、初期値が負の数になってしまったので、いつまでも繰り返しが止まらない。こういった現象を「無限ループ」と言います。自分のプログラムでは無限ループは起らない!と断言するのは、複雑なプログラムになるとかなり難くなります。いわゆる想定外ですね。計算途中の実験データをハードディスクに書き込んでいて、100個くらいで終わる予定が、無限ループになってしまっていて、ハードディスク全部をそのデータファイルが占拠してしまい、動きがとれなくなった、なんてこと、和田も経験済みです。(^^;)
他にもこんな無限ループが、
• for(int i=0; i<=10; i--) // i++ と書くのを間違えて• int i=0; while( i < 10 ) { System.out.println( i ); } // こちらも i++ を書き忘れて
一方、わざと無限ループを作っておいて、ある条件が満たされたとき (そうした状況が必ず起こるようにしないといけませんが) 、そのループから抜け出して終了する、そういったプログラムの作り方もあります。次のプログラムを見て下さい。まだ習っていないことが多いですが、要点は 10 行目の while( true ) と、20 行目の break; です。
ソースコード 2.35 GuessingGame.java (数当てゲーム)
package section0213;
import java.util.Scanner;
public class GuessingGame {
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
System.out.println( "数当てゲームです" );
System.out.println( " 1~99 の数を当てましょう" );
int value = (int)( 1 + Math.random()*99 );
int count = 0;
while( true ) {
count++;
System.out.print( "ここに数値を入れて Enter押して!" );
int n = scan.nextInt();
if( n < value ) {
System.out.println( "正解はもっと大きいです。" );
} else if( n > value ) {
System.out.println( "正解はもっと小さいです。" );
} else {
System.out.println( "当たりです。");
break;
}
}
System.out.println( "正解までに " + count + " 回かかりました。");scan.close();
}
}
while( true ) での繰り返し条件は boolean 型の常に真なる定数です。つまり、何時までたっても繰り返し条件が満たされているわけで、この繰り返しは無限ループになります。こうした無限ループの書き方は、for 文による繰り返しでも可能で、その場合は、for(;;) と書きます。実は、for の小かっこの中の 3 項目はそれぞれ独立に省略することができるのです。そうしたプログラムはあまり推奨されるものではないので、詳しくは紹介しませんが、3 項目を

2.13 繰り返し 57
全て省略すると、区切りのセミコロンのみ残って for(;;) これも無限ループになります。強制的に無限ループにした以上、必ずいつかこの繰り返しから抜け出せるようにしておかねばいけません。それが break; です。これは switch のところで出てきましたね。あのときは詳しく説明しませんでしたが、break; は「for、while、do while、switch のブロック内で使用され、ブロックの外に強制的に抜け出す」という処理をしてくれます。よって、この数当てゲームでは、数を当てるまで繰り返しが続き、当たると終了する、というわけです。
問題 2.13.13. 先の FibonacciNumbers.java を「点列の値が 10000 を超えたら出力をやめる。つまり、Fibonacci 数の 10000 未満のリストを出力するプログラム」に改良した FibonacciNumbers2.java を作りなさい。
この辺りから、同じ目的のプログラムでも様々な書き方があることがわかってきます。だから、プログラミングは面白い!?
2.13.6 繰り返しの入れ子
繰り返しの中で、さらなる繰り返しを行う。これを繰り返しを入れ子に (ネスト) すると言います。以下のプログラムは「九九の表」を出力するプログラムです。列を揃えるために、後で説明する System.out.printf メソッドが使われていますが、その辺りは呪文として目をつぶってもらって、注目は最後の2重ループです。カウンタ i による繰り返しの中に、カウンタ j による繰り返しが入っています。この繰り返し内の出力文での (i*j) の値は、カウンタが増える際に、どのように変化していくか手作業でチェックしてみて下さい。ところで、2重ループ内の最後にある System.out.println(); は何をやっているのでしょうね。(その役割りは、これをコメントアウトしてみるとわかります)
ソースコード 2.36 MultiplicationTable.java (九九の表)
package section0213;
public class MultiplicationTable {
public static void main(String[] args) {
System.out.print( " |" );
for(int j=1; j<=9; j++) {
System.out.printf( "%2d ",j );
}
System.out.println();
System.out.print( "---+" );
for(int j=1; j<=9; j++) {
System.out.print( "---" );
}
System.out.println();
for(int i=1; i<=9; i++) {
System.out.printf( "%2d |", i );
for(int j=1; j<=9; j++) {
System.out.printf( "%2d ", (i*j) );
}
System.out.println();
}
}
}

58 第 2章 Java 言語の基本的な文法 I
問題 2.13.14. 次の繰り返しで、それぞれどのような出力がされますか。
for(int i=0; i<5; i+=2){
for(int j=4; j>=0; j-=2){
System.out.println( i*j );
}
}
int i = 1;
while( i < 5 ){
int j = 10;
while( j > 4 ){
System.out.println( i*j );
j -= 2;
}
i+=1;
}
問題 2.13.15. 1 以上 9 以下の 3 つの整数の和が 15 になる数のパターンを全て出力するプログラム Fifteen.java を作りなさい。繰り返しを 3 重の入れ子にして、それぞれ 1 から 9 まで順に変えながら、3 つのカウンタの和が 15 になった時だけそれらを出力すれば良い。出力の例
1 5 9
1 6 8
1 8 6
1 9 5
2 4 9
2 5 8
:9 5 1
次に、3 つの整数の順番を考慮しないとしたときの出力は、どうしたら良いか考えよ。つまり、1 5 9 を出力したら、 1 9 5 などを出力しないようにする。プログラム名を Fifteen2.java としましょう。
問題 2.13.16. 元本 10000 円を年利率 5% の複利 (1円未満は切り捨て) で預金するとする。次の 2 つのプログラムを作りなさい。預金額を整数変数 money、年利率を実数変数 rate とすること。
• 10 年後に預金が何円になるか求めるプログラム ( CompoundInterest.java )。• 20000 円を超えるのに何年かかるか求めるプログラム ( CompoundInterest2.java )。

2.13 繰り返し 59
2.13.7 break と continue
break;で繰り返しから強制的に抜け出せる、と学びました。この break;と同じように利用されるのが、continue;です。continue; は英語圏ドラマの最後に表示される「続く!」の意味ですが、繰り返しブロックの中で利用されると、その回の繰り返しについては「その後に続く処理」を省略して、次の繰り返しに飛ぶ、という処理をします。次のプログラムを例にしましょう。
for(int i=1; i<=100; i++) {
if( i % 2 == 0 || i % 5 == 0 ) continue;
System.out.println( i );
}
これは、1 から 100 までの整数の中で、2 と 5 のいずれかの倍数であるときは、その値を出力しない、というものです。if の条件を満たすとき、コンソールへの出力をせずに、for の繰り返しを進めています。
問題 2.13.17. continue; を使わずに上のプログラムと同じ処理をするプログラムを書きなさい。
ところで、break; は繰り返しから強制的に抜け出せる、と書きましたが、次のように入れ子になった繰り返しの中で break; を使うと、どこへ抜け出せるのでしょうか。
ソースコード 2.37 DoubleLoop.java (繰り返しの入れ子)
package section0213;
public class DoubleLoop {
public static void main(String[] args) {
for(int i=1; i<=3; i++) {
System.out.println( "i=" + i +":開始");
for(int j=1; j<=3; j++) {
System.out.println( " j=" + j + ":開始");
if( i == 2 && j == 2 ) break;
}
}
}
}
抜け出す先は、定義通り「自分が入っているもっとも小さな繰り返しブロックから抜け出す」ですね。では、このプログラムでこの二重ループの外へ一気に抜け出したいとき、どうしたら良いでしょう。こうしたプログラムは、プログラムを読み難くするので、あまり多用してはいけないとどの教科書にも書かれています。しかし、ここで述べる「ラベル付き break 文」を使わないとより読みにくい場合もあるので、「どうしても使わないとまずいときのみ使用!」という制限のもと、次のように書きましょう。(^^;)
ソースコード 2.38 DoubleLoop2.java (ラベル付き break 文)
package section0213;
public class DoubleLoop2 {
public static void main(String[] args) {
loop_i:
for(int i=1; i<=3; i++) {
System.out.println( "i=" + i +":開始");
for(int j=1; j<=3; j++) {

60 第 2章 Java 言語の基本的な文法 I
System.out.println( " j=" + j + ":開始");
if( i == 2 && j == 2 ) break loop_i;
}
}
}
}
抜け出したい繰り返しの開始時点、この場合、カウンタ i による for 文の開始場所に、ラベルを書きます。ラベル名の付け方は変数名に準じます。ラベル (今回は loop_i) にはコロンを付けます。そして、break 文にそのラベル名を付けるのです。break に付けるラベルにはコロンは要りません。すると、抜け出す先は、ラベルの付けられた繰り返しブロックの外となります。ラベル付きは continue にも使えます。以下のプログラムのコンソールへの出力もチェックして下さい。
ソースコード 2.39 DoubleLoop3.java (ラベル付き continue 文)
package section0213;
public class DoubleLoop3 {
public static void main(String[] args) {
loop_i:
for(int i=1; i<=3; i++) {
System.out.println( "i=" + i +":開始");
for(int j=1; j<=3; j++) {
System.out.println( " j=" + j + ":開始");
if( i == 2 && j == 2 ) continue loop_i;
}
}
}
}
繰り返しの話の最後に、以前にも触れたカウンタの値を繰り返し終了後に出力したいという話をもう1度。次のプログラムで、 break 文で抜け出した直後、繰り返しのカウンタ i がいくつになっているかを知りたいとき、どうしたら良いでしょう。
public static void main(String[] args) {
loop_i:
for(int i=1; i<=3; i++) {
for(int j=1; j<=3; j++) {
if( i * j == 4 ) break loop_i;
}
}
// ここで i と j の値がいくつかを出力したい}
こうした場合、2つのカウンタの宣言を 2 重ループの外側で宣言するというのは賛否が分かれるところです。和田ならどうするか?カウンタはあくまでカウンタとして繰り返し内で消えゆく運命としておいて、値の取り出し用に別の変数を用意するプログラムにします。何だか、より面倒くさそう!とも思えますが、変数に役割分担を与えることは、それはそれでプログラムがすっきりすると考えます。
ソースコード 2.40 LoopParameter.java (繰り返し内から値の取り出し)
package section0213;
public class LoopParameter {
public static void main(String[] args) {
int ii = 0;

2.14 配列 61
int jj = 0;
loop_i:
for(int i=1; i<=3; i++) {
for(int j=1; j<=3; j++) {
if( i * j == 4 ) {
ii = i;
jj = j;
break loop_i;
}
}
}
System.out.println( "パラメータの値は、" + ii + " と " + jj + " でした。" );
}
}
ただ、こうした処理は後で習う「メソッド」化するのがベストですね。
2.14 配列複数のデータに同じような処理を行いたいとき、それらデータに番号を付けて、その番号順に自動で処理されるようにできれば、行列やベクトルの計算もプログラムで行うことができるようになります。こうした番号のついたデータを「配列」と呼びます。まず最初に、ベクトルに対応する 1 次元配列について学び、次に行列に対応する 2 次元配列について学びます。
2.14.1 配列の宣言
配列を使う場合も、最初にその型を宣言しないといけません。int型の 1 次元配列 xを宣言するには、intの後ろに対の大カッコを間に何も挟まずに付けて、int[] x; と宣言します。同様に実数型の 1 次元配列 yを宣言したいなら、double[] y; です。このように基本型の全てに対して配列を宣言することができます。配列は格納するデータの型が全て同じでないといけません。実数と整数の入り混じった配列なんてのは作れないわけです (多少ウソですが)。配列の宣言方法について「大カッコを変数名の後ろに付けて int x[]; と宣言する」と書いてある本も時折あります。これは他のプログラミング言語の方式に合わせての書き方で Java でもエラーにはなりません。ただ、Java の配列の構造と定義を考えると、変数名の後ろに付けるのは意味合いが少し違ってしまうかと思います。ただ、次の理由では両方知っておいたほうが良い、と言えなくもありません。
int[] a, b; // いずれも int 型配列int c[], d; // c は int 型配列で d は int 型変数
つまり、配列と変数をカンマで繋げて宣言する際に便利!というわけです。ただ、前にも書きましたが、複数の変数宣言をカンマで繋げて書くのは薦められていません。多少見栄えが悪くとも、変数や配列の宣言は 1 つ 1 行が良いと言われます。よって、この授業では、配列の宣言時の大かっこの位置は型名に付けて書く!とします。さて、int[] x; と宣言すると JVM の中に xと名前を付けられた領域が 1 つ確保されます (図 2.13 参照)。この時点では、配列 xの要素はまだ 1 つも入っていませんし、要素の個数さえ定義されていません。次に、この配列の要素数を与えます。今、要素数を 5 個としたいなら、代入文
x = new int[5];
と書きます。この代入文の右辺 new という演算子は、JVM 内の配列データ用の領域 (ヒープ領域と呼ぶ) に連続した領域 ( int[5]:整数値 5 個分) を確保します。確保された連続領域は、順に [0]、[1]、· · ·、[4] と番号が付けられ、それぞれ xの [i] 番目という意味で、x[i] などと呼ばれるようになります。

62 第 2章 Java 言語の基本的な文法 I
そして、その先頭 x[0] のアドレス が代入文によって xに代入されます (基本型の変数 xが置かれる領域をヒープ領域に対してスタック領域と言います)。つまり、new の役割は新たな配列領域を確保し、その先頭のアドレスを返す操作になります。xにこのアドレスが代入されたことで、xの値を使って配列のある場所にアクセス (このことを「参照する」と言います) できるようになります。なお、int[] x = new int[5]; と 1 行で書くことができます。
!"# new int[5] $%&'()*+
,-./ int 0 5 12#)*345
x
[0] [1] [2] [3] [4]
!"#$%&!"#$'()*
!"#$int[ ] x = new int[5]; %&'()*'+%,-.$
/0%12 x[0] %34567 x #,-89:$;<=>?@A
!"# int[] x; $ x %#&'( 1 )*+
図 2.13 配列の宣言
問題 2.14.1. 次の配列の宣言文を書きなさい。
1. double型配列 xを要素数 100 で宣言する2. boolean 型配列 check を要素数 10 で宣言する
2.14.2 配列の初期値
代入文 int[] x = new int[5]; では、まだ配列には値が入っていません。というのは多少ウソで (ウソばかり?(^^;))、右辺の new int[5]; の処理において、ヒープ領域に作られた 5 つの連続領域には、その配列の型のデフォルト値 (int型の場合 0 ) が代入されます。double 型など数値系は全て 0 が、boolean系は false がデフォルト値です。ただ、配列の初期値にデフォルト値が代入されることを前提にプログラムを書くことは、あまり薦められることではありません。言語によってデフォルト値が違ったり、自動的にデフォルト値が代入されない言語もあったりで、他の人に見せるプログラムでは言語によらないプログラムを心がけるべきです。この授業では、原則、デフォルト値に頼らずに、無駄なように見えますが初期値の 0 を手動で入れていきます。さて、配列の様子 (図 2.13 参照) を見ると、配列内の要素の番号は [0]、[1]、· · ·、[4] となっていて、 [1]、[2]、· · ·、[5] となっていません。そう、Java の配列の番号は 0 から始まります。従って、5 個の要素を持つ配列には [5] 番目の要素はありません。ご注意を!では、5 つの要素に値を代入しましょう。代入文 x[0] = 2; で、配列 xの先頭の要素に 2 を代入できます。順に
x[1] = -1; x[2] = 3; x[3] = 0; x[4] = 5; で全ての要素に代入ができます (図 2.14 参照)。
ソースコード 2.41 ArrayInitialization.java (配列の初期値指定)
package section0214;
public class ArrayInitialization {
public static void main(String[] args) {

2.14 配列 63
2 -1 3 0 5
x
[0] [1] [2] [3] [4]
図 2.14 配列の初期値
int[] x = new int[5];
x[0] = 2;
x[1] = -1;
x[2] = 3;
x[3] = 0;
x[4] = 5;
}
}
さて、各要素への代入にいちいち代入文を書いていくのは面倒ですね。そこで、Java には、配列の初期化の方法として、「リスト形式での初期化」ができるようになっています。リストとは、値をカンマで区切りながら全体を中かっこでくくった形式です。例えば、上の 5 つの値の代入は、リスト形式で書くと、次のように 1 行で書けます。
int[] x = {2, -1, 3, 0, 5};
このときは、new int[5]; は要りません。コンパイラがリスト内の要素の個数を数えて、スタック領域での int型 5
つ分の連続領域の確保も一緒に行った上で、それぞれの値の代入も順にしてくれます。ただしこの方式では、途中の要素を飛ばして代入するなんてことはできませんし、全体 100 個分の配列に最初の 5 個だけ値を代入、なんてこともできません。また、「リスト形式の初期化は、配列の宣言と同時に行うこと」という条件があります。どういうことかというと、次のように一旦宣言した配列に、行を変えてリスト形式での初期化ができないのです。あくまで 1 行で宣言と初期化を行う int[] x = {2, -1, 3, 0, 5}; 場合にのみ利用できます。
int[] x;
x = {1, 2, 3, 4, 5}; // このような、2 行に分けての初期値代入はできない。
せっかく便利なリスト形式の初期化ですが、宣言と同時でないと利用できないのは少々不便!ということで、実は宣言と同時でなくともリスト形式が使える方法があります。この方法は、「初期化付き無名配列の使用」と言って (なんか難しい名前!?)、次のように書きます。大カッコの中には要素数を入れたりしません (new int[5]{1, 2, 3, 4, 5};
ではない)。
int[] x;
x = new int[]{1, 2, 3, 4, 5}; // こうすると、2 行に分けてもエラーにならない。
実は、こちらの方が先に存在していて、new int[] を省略したものが後から出来たのです。プログラミング言語の世界では、読み書きのしやすさのために後からよりシンプルな書き方が追加されることが多く、シンタックスシュガー(糖衣構文) と言います。例えば i++; は i = i + 1; のシンタックスシュガーですね。ということで、以上 3 種類の初期値の与え方を知っておきましょう。
問題 2.14.2. 上記で説明した 3 通りの方法を使って、0.1 から 0.5 まで 0.1 刻みで 5 個の実数値の入った double型配列 yを宣言しなさい。

64 第 2章 Java 言語の基本的な文法 I
2.14.3 配列と繰り返し
配列は、繰り返しと実に相性の良い構造です。要素を番号で管理できるので、配列内の値を番号順に処理することを繰り返し命令で指示できます。まず、配列に入っている値をコンソールに順番に出力してみましょう。
ソースコード 2.42 PrintArray.java (配列と繰り返し)
package section0214;
public class PrintArray {
public static void main(String[] args) {
int[] degree = { 90, 85, 72, 100, 95 };
for(int i=0; i<degree.length; i++) {
System.out.println( degree[i] );
}
}
}
for文の 2項目の degree.length、この説明を先にしておきましょう。配列を定義すると、「配列名.length」で、その配列の要素数を得ることができます。この場合、degree.length は 5 ですね。要素は degree[0] から degree[4]
に入っていますが、要素数はあくまで 5 です。実際に入っている番号を考えると、for(int i=0; i<=4; i++) と直に書きたいところですが、ここは degree.length を使います。なぜかというと、データはプログラムが完成した後も変更があるかもしれないからです。もし配列の要素が増減したら、for 文も変更しなければなりません。プログラムの一部を変更したとき、他の場所も変更しなければならなくなるようでは、汎用性の低いプログラムです。配列の要素数が変わっても degree.length を使っておけば、for 文の変更は不必要になる、それが良いプログラムというわけです。と言うことで、for(int i=0; i<=degree.length-1; i++) と書くのかな?と思うと、こうした場合 Java を使う人たちの慣例で、等号を使わずに、for(int i=0; i<degree.length; i++) と書くんですね。i が int型ですから、これでも大丈夫。ちょっと慣れが必要ですかね。
問題 2.14.3. PrintArray.java を次のように改良しなさい。
1. 1 つずつの値の出力を改行せずに、値と値の間に 1 空白ずつ挟んで ( 90 85 72 100 95 )、全体で 1 行に出力するプログラム PrintArray2.java を作りなさい。最初のカッコと最後のカッコを繰り返しの前後に別に書きましょう。
2. PrintArray2.java の出力順を逆順にしたプログラム PrintArray3.java を作りなさい。つまり、要素を後ろから順に出力する ( 95 100 72 85 90 )。
3. 実は、配列の中身を出力したいときにこうして自分で繰り返し処理を書かなくても済む方法が Java には用意されています。 配列名 degree に対し、System.out.println( Arrays.toString( degree ) ); という命令で配列の中身を出力することができます。 ただし、 import java.util.Arrays; とインポート文を加えないといけません。PrintArray4.java として作りなさい。以降は、単純な配列の出力は繰り返しで頑張って書くのはやめて、これで行きましょう。
配列の初期値を繰り返しで作ってみましょう。長さ 10 の整数配列を作り、そこに初期値 { 1, 2, 3, ..., 10 }
を入れるのを繰り返し文で行っています。カウンタの i に 1 加えた値を代入する、というところがミソですね。
ソースコード 2.43 ArrayInitialization2.java (繰り返しによる配列の初期化)

2.14 配列 65
package section0214;
import java.util.Arrays;
public class ArrayInitialization2 {
public static void main(String[] args) {
int[] array = new int[10];
for(int i=0; i<array.length; i++) {
array[i] = i + 1;
}
System.out.println( "array = " + Arrays.toString( array ) );
}
}
問題 2.14.4. 次のような長さ 10 の初期ベクトルを作る繰り返し処理を書きなさい。1. a = {2, 4, 6, 8, 10, · · · , 20} 2. a = {1, 2, 4, 8, 16, 32, · · · , 512}3. a = {1,−1, 1,−1, 1,−1, · · · ,−1}
次は、配列内の要素の合計値を求めてみましょう。合計値を計算するには、配列とは別にその値を代入する変数が必要です。以下のプログラムでは sum がその変数ですが、配列の要素がすべて int型なのですから、その合計値も int型となりますね。そこで、int sum = 0; が必要となります。配列と違って、基本型の変数はデフォルト値が自動で代入されはしません。つまり、int sum; だけではその後の sum += degree[i]; ができないということです。ちゃんと初期値を代入します (int sum = 0;)。ところで、int sum = 0; この命令をプログラムの何処に置いたら良いか?ちゃんと理解して下さいね。結構、この置き場所がわからずに前期試験で敗退!の人が多いのです。よく間違えるのが、for(int i=0; i<degree.length;
i++) { の次に書く人です。それでは、繰り返しが行われるたびに、毎回 sum に 0 を代入されることになり、せっかく 1 つずつ要素を加えていっても、次の繰り返しで 0 クリアされてしまう。つまり、合計が計算できません。それに、for(int i=0; i<degree.length; i++) { の次に書いてしまったら、変数 sum のスコープはどこまででしょう?そう、繰り返しの中だけですよね。つまり、繰り返し後にその値を出力したくても、メモリから消えてしまいます。
ソースコード 2.44 SumOfArray.java (配列の要素の合計)
package section0214;
public class SumOfArray {
public static void main(String[] args) {
int[] degree = { 90, 85, 72, 100, 95 };
int sum = 0;
for(int i=0; i<degree.length; i++) {
// ここに int sum = 0; を入れて×になる人が多いsum += degree[i];
}
System.out.println( "要素の合計は、" + sum );
}
}
ということで、小さなプログラムですが、しっかり理解して下さい。続いて、配列内の要素の最大値を求めてみましょう。こちらも最大値を記憶するための変数 max の初期化 int max
= 0; の場所を間違わないで下さい。
ソースコード 2.45 MaxOfArray.java (配列の要素の最大値)

66 第 2章 Java 言語の基本的な文法 I
package section0214;
public class MaxOfArray {
public static void main(String[] args) {
int[] degree = { 90, 85, 72, 100, 95 };
int max = 0;
for(int i=0; i<degree.length; i++) {
if( degree[i] > max ) {
max = degree[i];
}
}
System.out.println( "最大値は、" + max );
}
}
少々難しくなってきましたが、まずは解読してみて下さい。これで最大値が変数 max に取り出されて出力される、ということを理解できましたか。定期試験では、こうした基本的なプログラムを解読する能力を問いますので。さて、このプログラム 1 箇所問題点があります。何処でしょう?最大値を代入するための変数 max に初期値として 0 を代入していますが、もし、配列の要素が全て負の数だったらどうなりますか?まずいですね。では maxには最初どんな値を代入すれば良いでしょう。方法は、2 通り考えられます。
1. 整数の最小値を代入する方法:Java でも無限大や無限小の値は表せません。そこで、代わりに int 型の最小値 Integer.MIN_VALUE を使います。(ソースコード 2.5 IntegerMaxAndMin.java 参照)。そうすれば、degree 内の値がどんなに小さな負の数でも、最小値より小さいことは無いので、degree[0] との比較で、必ずmax = degree[0]; が行なわれます。
2. degree[0] を代入する方法:1. の方法だと必ず繰り返しの初回に max = degree[0]; が行なわれます。ならば、繰り返しの前に max = degree[0]; を行ってしまおう、という方法です。そうしておいて、繰り返しはint i=1 から始めれば良いわけです。なお、こちらの方法は 1 つ弱点があって、もし配列の長さが 0 もしくは未定義だったとき、エラーが発生します (2.14.6 節 参照)。
プログラムを作るとき、想定しているデータがどんな範囲なのかを良く検討し、想定外だったので暴走!なんてことがないようにせねばいけません。この degree が試験の成績なら負の数は起こりませんが、気温とか実験データとかで負の数もあり得るようなら、上のプログラムは問題ですね。
問題 2.14.5. 同じ整数配列 degree を用いて、配列内の値の最小値を求めるプログラム MinOfArray.java を作りなさい。
問題 2.14.6. 同じ整数配列 degree を用いて、配列内の値の平均値を求めるプログラム AverageOfArray.java を作りなさい。ただし、平均値は実数になりますので、ご注意を!
配列自体は整数値の配列ですが、平均値は実数値ですね。単純に合計値を個数で割り算すると「整数÷整数」が起きて小数部の情報が消えてしまいます。それはまずいので、実数へのキャストを利用しなければいけません。この辺のデータ集計プログラムは基本処理として重要なので、しっかり自分のものにして下さい。

2.14 配列 67
問題 2.14.7. 整数配列 x に対して、配列内の正の値のみの平均値を求めるプログラム AverageOfPositive.java を作りなさい。配列の内容が変わっても破綻しないように作ること。なお、配列には必ず正の値が入っているものとします。入っていないと平均値は求められないからね。
ソースコード 2.46 AverageOfPositive.java (配列内の正数の平均値)
package section0214;
public class AverageOfPositive {
public static void main(String[] args) {
int[] x = { 15, -30, -18, 0, 25, 32, -5, 16, 51 };
// 繰り返しを用いて、x の値を1つずつ正か否かのチェックをし、// 正の数の和と個数をカウント、繰り返しが終わったら、平均値を求める// 和のための変数と個数のための変数、それを何処に置くか、誰にも聞かずに// 独力で書けますか?
}
}
問題 2.14.8. オリンピックの採点方式(与えられた実数配列に入っている点数の内で、最高点と最低点を1つずつ除いた残りの点数の平均点)を計算・出力するプログラム OlympicGame.java を作りなさい。なお、配列の長さは必らず 3 以上であるとします。
ソースコード 2.47 OlympicGame.java (オリンピック採点方式)
package section0214;
public class OlympicGame {
public static void main(String[] args) {
double[] points = {9.95, 9.82, 9.95, 10.0, 9.64, 9.55, 10.0};
// 配列 points に入っている点数の合計・最高点・最低点を求めて// 合計から最高点&最低点を引いて、points の長さより 2 小さい// 数で割ることで平均点が求まり、それをコンソールに出力する// 例えば、"成績は、9.872 でした" なんて感じに
}
}
次は、長さの等しい 2 つのベクトルの差ベクトルを求めてみましょう。結果の値を入れるベクトルを同じ長さで宣言しておいて、そこへ要素を 1 つずつ代入していきます。
ソースコード 2.48 DifferenceTwoArray.java (ベクトルの差)
package section0214;
import java.util.Arrays;
public class DifferenceTwoArray {
public static void main(String[] args) {
int[] x = { 90, 85, 72, 100, 95 };
int[] y = { 82, 70, 98, 68, 70 };
int[] z = new int[x.length];

68 第 2章 Java 言語の基本的な文法 I
for(int i=0; i<z.length; i++) {
z[i] = x[i] - y[i];
}
System.out.println( "x - y = " + Arrays.toString( z ) );
}
}
配列を扱うプログラムは、このように要素を 1 つずつ繰り返しの中で計算する場合が多いので、よく理解して下さい。
問題 2.14.9. 長さの等しい 2 つのベクトルに入っている値をすべて交換するプログラム SwapArray.java を作りなさい。
ソースコード 2.49 SwapArray.java (2つのベクトルの交換)
package section0214;
public class SwapArray {
public static void main(String[] args) {
int[] a = {13, 53, 24, 67, 83, 40};
int[] b = {20, 14, 61, 94, 92, 50};
// この2つのベクトルの対応する要素同士を交換する// a[0]⇔ b[0], ..., a[a.length-1]⇔ b[b.length-1]
// 交換が終わったら、以下でそれぞれを出力してみるSystem.out.println("a = " + Arrays.toString( a ) );
System.out.println("b = " + Arrays.toString( b ) );
}
}
問題 2.14.10. 整数配列 a に入っている中身を、他の配列を使わずに逆順にする、つまり a[0] と a[a.length− 1] を、a[1] と a[a.length− 2] を、… と交換するプログラム ToReverseOrder.java を作りなさい。
ソースコード 2.50 ToReverseOrder.java (配列の要素の逆順化)
package section0214;
public class ToReverseOrder {
public static void main(String[] args) {
int[] a = { 11, 19, 15, 17, 21, 13, 23, 27, 25 };
// この後、配列の値を出力し、// 続いて、要素を逆順に。// そして、再度 配列の値を出力する
}
}
出力例:11 13 15 17 19 21 23 25 27
27 25 23 21 19 17 15 13 11

2.14 配列 69
問題 2.14.11. int型配列 degree に学生の成績が入っているので、評価 ( S, A, B, C, D ) 毎の人数を集計したい。評価毎の人数を int型配列 grade に集計し、以下のように出力するプログラム EvaluateGrade.java を作りなさい。
ソースコード 2.51 EvaluateGrade.java (成績評価の集計)
package section0214;
public class EvaluateGrade {
public static void main(String[] args) {
int[] degree = {82, 90, 65, 30, 80, 66, 72, 59, 20, 90,
75, 84, 68, 75, 45, 76, 90, 98, 55, 42,
100, 92, 78, 85, 72, 45, 62, 70, 82, 95,
60, 38, 92, 85, 78, 55, 80, 74, 92, 83 };
// grade[0]:評価 S の人数を入れる ... grade[4]:評価 D の人数を入れるint[] grade = { 0, 0, 0, 0, 0 };
String[] gradeName = { "S", "A", "B", "C", "D" };
// ここに、degree の値を1つずつチェックし、どの評価になるか調べ、// grade の対応する要素に1加える処理を人数分繰り返す処理を書く// 例えば、点数が 90点以上なら S だから、grade[0] に1加える。となる
// 出来上がった評価の配列を以下で出力するfor(int i=0; i<grade.length; i++ ) {
System.out.println( "評価 " + gradeName[i] + " の人数は、" + grade[i]
+ "人です" );
}
}
}
問題 2.14.12. 整数配列に入っている要素を、n 個ずつ場所をシフトするプログラム ShiftArray.java を作りなさい。ただし、移動先が配列の上限を超えてしまったときは配列の先頭に回り込むように移動させます。例えば、int[] array = { 1, 2, 3, 4, 5 }; int n = 2; の場合、array = { 4, 5, 1, 2, 3}; となれば良い。(ヒントは、剰余計算 %)
ソースコード 2.52 ShiftArray.java (配列の巡回シフト)
package section0214;
import java.util.Arrays;
public class ShiftArray {
public static void main(String[] args) {
int[] array = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int n = 5;
// ここに、配列 array の要素を n ずつ増加方向にシフトさせる処理を// 書く。上限を超えたときは、先頭に回り込むようにする
System.out.println( Arrays.toString( array ) );
}
}
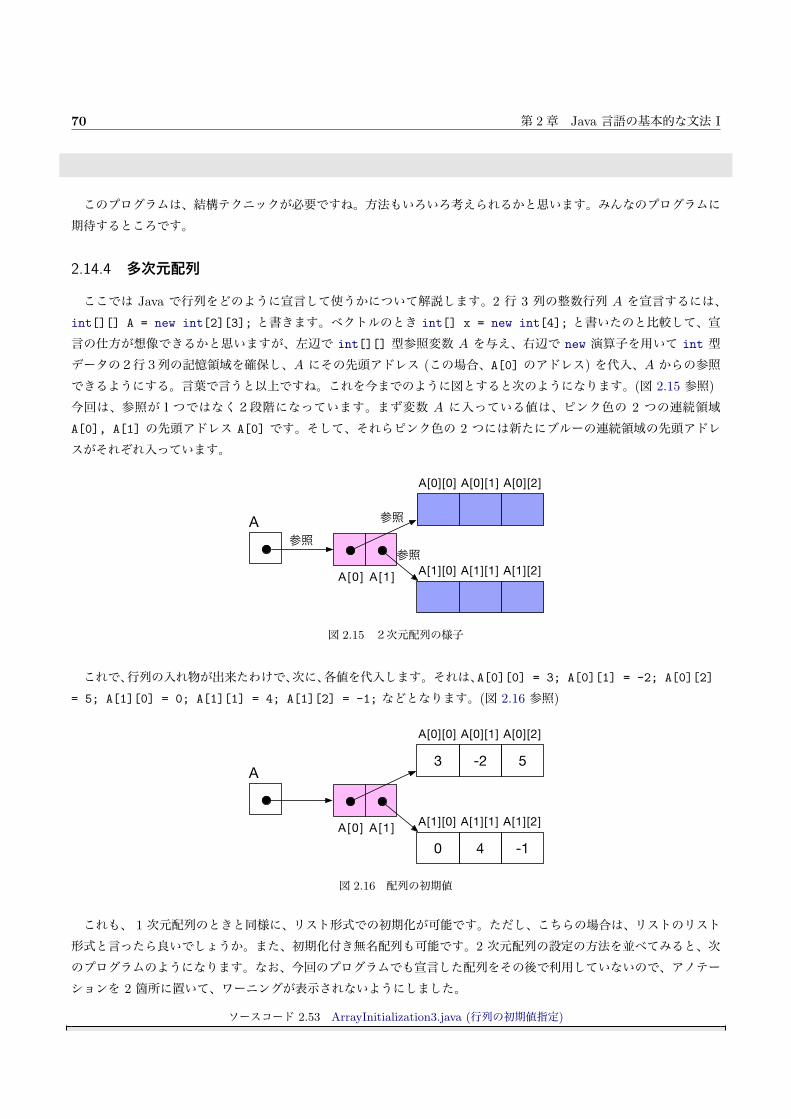
70 第 2章 Java 言語の基本的な文法 I
このプログラムは、結構テクニックが必要ですね。方法もいろいろ考えられるかと思います。みんなのプログラムに期待するところです。
2.14.4 多次元配列
ここでは Java で行列をどのように宣言して使うかについて解説します。2 行 3 列の整数行列 A を宣言するには、int[][] A = new int[2][3]; と書きます。ベクトルのとき int[] x = new int[4]; と書いたのと比較して、宣言の仕方が想像できるかと思いますが、左辺で int[][] 型参照変数 A を与え、右辺で new 演算子を用いて int 型データの2行3列の記憶領域を確保し、A にその先頭アドレス (この場合、A[0] のアドレス) を代入、A からの参照できるようにする。言葉で言うと以上ですね。これを今までのように図とすると次のようになります。(図 2.15 参照)
今回は、参照が1つではなく2段階になっています。まず変数 A に入っている値は、ピンク色の 2 つの連続領域A[0], A[1] の先頭アドレス A[0] です。そして、それらピンク色の 2 つには新たにブルーの連続領域の先頭アドレスがそれぞれ入っています。
A
A[0 ] A [1 ]
A[0][0] A[0][1] A[0][2]
A[1][0] A[1][1] A[1][2]
参照
参照参照
図 2.15 2次元配列の様子
これで、行列の入れ物が出来たわけで、次に、各値を代入します。それは、A[0][0] = 3; A[0][1] = -2; A[0][2]
= 5; A[1][0] = 0; A[1][1] = 4; A[1][2] = -1; などとなります。(図 2.16 参照)
A
A[0 ] A [1 ]
3 -2 5
A[0][0] A[0][1] A[0][2]
0 4 -1
A[1][0] A[1][1] A[1][2]
図 2.16 配列の初期値
これも、 1 次元配列のときと同様に、リスト形式での初期化が可能です。ただし、こちらの場合は、リストのリスト形式と言ったら良いでしょうか。また、初期化付き無名配列も可能です。2 次元配列の設定の方法を並べてみると、次のプログラムのようになります。なお、今回のプログラムでも宣言した配列をその後で利用していないので、アノテーションを 2 箇所に置いて、ワーニングが表示されないようにしました。
ソースコード 2.53 ArrayInitialization3.java (行列の初期値指定)

2.14 配列 71
package section0214;
public class ArrayInitialization3 {
public static void main(String[] args) {
// 空の入れ物を作っておいて、1つずつ代入する方法int[][] A = new int[2][3];
A[0][0] = 3;
A[0][1] = -2;
A[0][2] = 5;
A[1][0] = 0;
A[1][1] = 4;
A[1][2] = -1;
// リスト形式の初期化による方法@SuppressWarnings("unused")
int[][] B = { { 3, -2, 5 }, { 0, 4, -1 } };
// 初期化付き無名配列による方法@SuppressWarnings("unused")
int[][] C;
C = new int[][]{ { 3, -2, 5 }, { 0, 4, -1 } };
}
}
Java では変数名は 1 文字目を小文字にせよ!が慣例なのですが、数学や情報科学では行列を表すとき大文字のアルファベットにしますから、この授業でも、行列を意味する場合は大文字のアルファベットで表すことにします。ところで、上の行列 A の型は int[][] 型ですが、A[0] の型や A[0][0] の型は何でしょうか?A[0][0] の型は、実際に整数値が入っているので int 型ですね。一方、A[0] に入っているのは、A[0][0] からA[0][2] までの 1 次元配列の先頭アドレス、と考えると、その型は int[] 型ですね。では、先のプログラムの 12 行目に A[0] = new int[] { 1, 2, 3 }; と書いたら何が起こるでしょう (A[0] は既に宣言されているので A[0] = { 1, 2, 3 }; とはもう書けません。こうした場合は初期化付き無名配列を使えば良いわけです)。このとき、ヒープ領域に新らたに確保された整数 3 つ分の連続領域、そこに 1, 2, 3 の値が代入されて、その先頭アドレスが A[0] に代入される。そうです。それまで A[0] から参照されていたリスト { 3, -2, 5 } の代わりにリスト{ 1, 2, 3 } が参照されるようになるわけです。参照されなくなったリスト { 3, -2, 5 } の運命はいかに? (^^;)
誰も参照されないリストはプログラムとして意味が無くなる上に、メモリを占領しているのが無駄ですから、Java は時折、そうした領域を解放してくれます。これを GC (Garbage Collection) と言います。GC を自動でやってくれる点は Java の特徴の 1 つです。C++言語などでは GC はプログラム中に明に書かないと行われません。一方、GC
が起こるタイミングは Java 任せなので、プログラムの時間測定などを行っている最中には GC が起こっては正しい測定ができなくなります (最近はプログラミング言語やアルゴリズムの能力を実測で測ることはあまり意味がないとされていますが)。そうした場合は、強制的に GC を起こさせる命令もあります。その辺はこの授業の範囲を超えているので、自習で学んで下さい。
問題 2.14.13. 次のような 5× 5 の正方行列 A を初期化する処理を書きなさい (いずれも 2 重ループになりますね)。

72 第 2章 Java 言語の基本的な文法 I
(1)
1 0 0 0 0
0 1 0 0 0
0 0 1 0 0
0 0 0 1 0
0 0 0 0 1
(2)
1 2 3 4 5
2 1 2 3 4
3 2 1 2 3
4 3 2 1 2
5 4 3 2 1
(3)
1 0 1 0 1
0 1 0 1 0
1 0 1 0 1
0 1 0 1 0
1 0 1 0 1
(4)
0 0 0 0 1
0 0 0 1 0
0 0 1 0 0
0 1 0 0 0
1 0 0 0 0
(5)
1 1 1 1 1
0 1 1 1 1
0 0 1 1 1
0 0 0 1 1
0 0 0 0 1
(6)
0 0 0 0 1
0 0 0 2 2
0 0 3 3 3
0 2 3 4 4
1 2 3 4 5
問題 2.14.14. Java では、もっと多次元の配列を定義することができます。int型の 3 次元配列 A を、2× 3× 4 の大きさで宣言する命令文を書きなさい。また、int型配列 B をリスト形式の初期化によって{{{1,2,3,4},{5,6,7,8},{9,10,11,12}},{{13,14,15,16},{17,18,19,20},{21,22,23,24}}} とする命令文を書きなさい。最後に、これまでの 1 次元、2 次元の配列の図を参考に、配列 B のメモリ内の様子を図示しなさい。
2.14.5 凸凹配列
前節では、行列を表現するための 2 次元配列を説明しましたが、Java の 2 次元配列では行ごとに列数が異なるでこ
凸ぼこ
凹行列(和田が勝手に命名)を宣言することができます。図 2.17 は、凸凹行列 A の様子を描いています。0 行目には 4
要素が、1 行目には 2 要素が入っていて、長さが違います。こんな行列、何に使うんだ?と思うでしょうが、例えばA[0] の先には、英語を受けた人たちの成績が、A[1] の先には、数学を受けた人たちの成績が入っていると、人数が違うので、凸凹行列ですよね。
A
A[0] A[1]
A[0][0] A[0][1] A[0][2] A[0][3]
参照
参照
参照
A[1][0] A[1][1]
図 2.17 凸凹行列
この凸凹行列の宣言は次のように行います。まず、固定の行数のみを与え、可変の列数は空欄として宣言します(int[][] A = new int[2][];)。次に、A[0] と A[1] それぞれに int[] 型の 1 次元配列を参照させます。前の節でも言ったように A[0] は int[] 型ですから、A[0] からの参照だけを見ると、それは 1 つのベクトルの宣言と同じです。だから、A[0] = new int[4]; とすれば、A[0] に 4 つの連続領域の先頭アドレスが代入されるというわけです。

2.14 配列 73
int[][] A = new int[2][];
A[0] = new int[4];
A[1] = new int[2];
こうしておいてから、各要素に値を代入してやれば良いのです。
A[0][0] = 1;
:
A[1][1] = 5;
もちろんリスト形式の初期化や、初期化付き無名配列も可能です。
// リスト形式の初期化int[][] B = {{1, -2, 0, 3}, {-3, 5}};
// 初期化付き無名配列での初期化 その1int[][] C;
C = new int[][]{{1, -2, 0, 3}, {-3, 5}};
// 初期化付き無名配列での初期化 その2int[][] D = new int[2][];
D[0] = new int[]{1, -2, 0, 3};
D[1] = new int[]{-3, 5};
問題 2.14.15. int型配列 A には、各行が学生に対応し、行ごとにその学生が取得した科目の成績が入っているとする。このとき、各自の平均点を以下のように出力するプログラム StudentDegrees.java を完成させなさい。
ソースコード 2.54 StudentDegrees.java (凸凹行列で成績管理)
package section0214;
public class StudentDegrees {
public static void main(String[] args) {
int[] sno = {1401, 1402, 1403};
int[][] degrees = {
{80, 95, 65, 70},
{100, 55, 82, 78, 90},
{95, 85, 72}};
// ここに各自の平均点を計算し、出力する処理を書く}
}
1401 番の学生は 4 科目履修し、平均点は、77.50 点1402 番の学生は 5 科目履修し、平均点は、81.00 点1403 番の学生は 3 科目履修し、平均点は、84.00 点
問題 2.14.16. 次の図のような 3 つの int型配列を宣言・処理するプログラム SetArrays.java を作りなさい。

74 第 2章 Java 言語の基本的な文法 I
1 3 5 7 9
1 5 3 7 9
0 2 4
6 8
[0 ] [1 ] [2 ] [3 ] [4 ] [5 ]
[0 ] [1 ] [2 ] [3 ] [4 ]
[0 ] [1 ] [2 ] [3 ] [4 ]
[0 ] [1 ] [2 ]
[0 ] [1 ]
[0 ]
[1 ]
[2 ]
x
y
z
ソースコード 2.55 SetArrays.java (多次元配列の宣言と処理)
package section0214;
public class SetArrays {
public static void main(String[] args) {
// ここに3つの配列 x, y, z を宣言する。// x は領域のみを宣言し、y と z については// 初期値の代入も行う。
// その後, x の各値が順に 1, 2, 3, 4, 5 となるように// for 文によるループで値を代入しなさい。つまり、x[0]=1, x[1]=2, ...
// となるようにする。
// 続いて, y の要素の和を int 型変数 sum に計算し,
// 以下で出力しなさい。System.out.println( "配列 y の要素の和は、" + sum + " です" );
// 最後に, z の要素全てを -1 倍しなさい。}
}
2.14.6 長さ 0 の配列や null
配列という構造で、注意しなければならないのは、宣言した長さと代入する値の位置の不一致です。次のプログラムを動かしてみましょう。このプログラムにコンパイルエラーはありませんが、実行させると ArrayIndexOutOfBoundsException というエラーメッセージを表示します。これは、配列の範囲を超えているというメッセージで、当然ですかね。でも、これはコンパイルエラーにはならないので、実行してみないとエラーに気づきません。5 という直接的な値だったので、目で見て気付きますが、これが変数でプログラム中で変化するなら、気付かずに商品プログラムになってしまうかもしれま

2.14 配列 75
せん。
ソースコード 2.56 ArrayIndexOutOfBounds.java (配列でよく出すエラー)
package section0214;
public class ArrayIndexOutOfBounds {
public static void main(String[] args) {
int[] array = { 1, 2, 3, 4, 5 };
System.out.println( array[5] );
}
}
それから、配列は必ず要素が存在する、という思い込みもミスを招きます。要素数が 0 の配列を作ることが可能なのです。
int[] x = new int[0];
int[] y = { };
それから、次のような書き方もできます。
int[] x = null;
これは、長さ 0 の配列も持たない状態を与えます。えっ?どんな状態?と思うでしょう。参照する配列の実体が無い状態 (参照なしの状態:アドレスが入っていない状態) を与えるのです。いずれも何のためにあるの?と思いますが、これらの利用場所は後期になったら学びます。ちなみに、null は「ナル」と読みます。
2.14.7 配列のコピー
int型配列 xに入っている値を同じ長さの int型配列 yにコピーするプログラムを作りましょう。なお、以降、断らない限り配列は null にならないと仮定しておきます (長さが 0 にはなりうる?)
ソースコード 2.57 ArrayCopy.java (配列のコピー)
package section0214;
import java.util.Arrays;
public class ArrayCopy {
public static void main(String[] args) {
int[] x = { 1, 3, 0, -2, 4 };
int[] y = new int[x.length];
for(int i=0; i<x.length; i++) {
y[i] = x[i];
}
// ちゃんとコピーされたか y を出力してみるSystem.out.println( "y = " + Arrays.toString( y ) );
}
}
まず、xと同じ長さの整数配列 yを作る命令が、int[] y = new int[x.length]; です。x.length を使って、yの大きさを宣言していますね。そして、次の for による繰り返しで、要素を 1 つずつコピーしています。えっ、配列の要素のコピーって、こんなにダサいの? (^^;) 次のプログラムでコピー出来てるみたいなんだけど。
ソースコード 2.58 ArrayCopy2.java (配列のコピー失敗版)
package section0214;

76 第 2章 Java 言語の基本的な文法 I
import java.util.Arrays;
public class ArrayCopy2 {
public static void main(String[] args) {
int[] x = { 1, 3, 0, -2, 4 };
int[] y = x;
System.out.println( "y = " + Arrays.toString( y ) );
}
}
int[] y = x; これでコピーが出来たら、簡単ですね。確かにコンパイラエラーは出ないし、出力も xの中身に一致してるし、OK そうに見えます。でも、int[] y = x; の次に、x[0] = -1; という命令を入れてみて下さい。変数 yをイジッタわけではないのに、yの出力の y[0] に対応する値が -1 になっていませんか?なぜでしょう?これは、int[] y = x; が何をやっているのか?を理解できれば納得できます (図 2.18 参照)。変数 xの中には、配列の 5 つの値が入っているのではなく、x[0] のアドレスが入っている、でしたね。ということは、int[] y = x; によって、yには何が代入されるのでしょう。そう、x[0] のアドレスです。つまり、yが参照するのは xが参照するものと同じなのです。よって、x[0] = -1; とすると、あたかも y[0] に -1 代入されたと同じになるのです。これはコピーではありません。
1 3 0
x[0] [1] [2]
参照
-2 4
[3] [4]
y
コピー
-1
代入参照
図 2.18 配列のコピー?
ということで、この時点では、繰り返し文で要素をひとつずつコピーする基本のコピープログラムをモノにして下さい。あとで、便利な方法も教えます。
問題 2.14.17. 2 次元配列のコピープログラム ArrayCopy3.java を完成させなさい。
ソースコード 2.59 ArrayCopy3.java (多次元配列のコピー)
package section0214;
public class ArrayCopy3 {
public static void main(String[] args) {
int[][] A = { {1, 3, 0}, {-2, 4} };
// この後に、A と同じ大きさの int 型配列 B を// 作って、そこへ A の要素を全てコピーするプログラムを// 作りなさい
}
}
2 次元の配列の場合も 1 次元の配列と基本は一緒です。大きさの等しい空の行列を作っておいて、要素をひとつずつ

2.14 配列 77
コピーしてやれば OK です。これもかなり面倒な方法となりますが、基本的な操作なので、しっかりモノにして下さい。こちらも、後期になったら、便利な方法を教えます。
2.14.8 拡張 for 文
Java も日々進化しています。といっても、ここで説明する「拡張 for 文」は Java 5での仕様変更だから、もう 10
年以上前ですがね。この文章を書いている間も Java 9 への変化は続いています。拡張 for 文とは、C++言語などで既にある for-each 文を真似た繰り返し文で、ここまでに学んだ繰り返し文と違って、パラメータは使わない繰り返し文を定義します。パラメータを使えば、途中からとか、 1 つ飛びにとか、複雑な繰り返し文が作れますが、拡張 for 文による繰り返しは、「配列内の全ての要素を 1 回ずつ呼び出して処理する」という場合に使います。そして、要素の処理の順番もパラメータで言うところの [0] 番から順に行われていきます。拡張 for 文を用いた配列要素の出力プログラムを見てみましょう。
ソースコード 2.60 ExtendedForEach.java (拡張 for 文)
package section0214;
public class ExtendedForEach {
public static void main(String[] args) {
int[] x = { 1, 3, 0, -2, 4 };
for(int xi : x) {
System.out.print( xi + " " );
}
System.out.println();
}
}
拡張 for 文の小かっこの中は、(要素の型 要素の仮の名:配列) となっています。この例では、配列 xは int型配列ですから、要素の型は intですね。そこで、xの要素に適当な名前を付けます。ここでは、xi と名付けました。そして、コロンの後に配列名である x を書きます。つまり、「配列 x の要素 xi 1つずつに対し、以下の繰り返しを行うぞ!」という感じですかね。繰り返しのブロック内では、この xi を出力する処理が書かれています。こうして、全ての要素が 1 回ずつ xi という名前で呼び出され、処理 (出力)されます。
問題 2.14.18. double型配列 yの要素の合計値を計算するプログラム ExtendedForEach2.java を拡張 for 文を用いて書きなさい。
ソースコード 2.61 ExtendedForEach2.java (拡張 for 文2)
package section0214;
public class ExtendedForEach2 {
public static void main(String[] args) {
double[] y = { 12.34, 35.79, -10.01, 20.52, 16.70 };
// 以下に拡張 for 文を用いて、y の要素の合計値 sum を求める処理を書く
System.out.println( "要素の合計は、" + sum );
}
}

78 第 2章 Java 言語の基本的な文法 I
問題 2.14.19. 以下のプログラム ExtendedForEach3.java を完成させなさい。
ソースコード 2.62 ExtendedForEach3.java (拡張 for 文3)
package section0214;
public class ExtendedForEach3 {
public static void main(String[] args) {
int[][] A = { {1, 3, 0}, {-2, 4} };
// 拡張 for 文を用いて、A の要素を全てコンソールに出力させなさい
}
}
なお、この授業では、まず一般的なパラメータを用いた for 文が書けることを重視しますので、拡張 for 文を定期試験で聞くことはしません (もちろん、特に指示がなければ、解答を拡張 for 文で書いても OK です)。
2.14.9 行列とベクトルの計算
ここまでのまとめとして、行列とベクトルの計算を。まずは、行列とベクトルの積を求めるプログラムです。いずれも基本的な操作で出来ているので、良く理解して独力で作成できるようになって下さい。
ソースコード 2.63 MatrixVector.java (行列とベクトルの積)
package section0214;
public class MatrixVector {
public static void main(String[] args) {
int[][] A = {{1,2,3},{1,1,1},{0,1,-1}}; int[] x = {1,1,1};
// 行列の値を出力System.out.println( "A=" );
for(int i=0; i<A.length; i++) {
for(int j=0; j<A[i].length; j++) {
System.out.printf( "%3d", A[i][j] );
}
System.out.println();
}
System.out.println();
// ベクトルの値を出力System.out.println( "x=" );
for(int i=0; i<x.length; i++) {
System.out.printf( "%3d%n", x[i] );
}
System.out.println();
// 行列とベクトルの積を計算するint[] y = new int[A.length];
for(int i=0; i<A.length; i++) {
y[i] = 0;
for(int j=0; j<A[i].length; j++) {
y[i] += A[i][j] * x[j];
}
}
// ベクトルの値を出力System.out.println( "Ax=" );

2.15 Math クラス 79
for(int i=0; i<x.length; i++) {
System.out.printf( "%3d%n", y[i] );
}
System.out.println();
}
}
なお、行列の出力を見た目にこだわらなければ java.util.Arrays.deepToString() を用いて次のように書くこともできます。次は、行列と行列の積を求めるプログラムです。
ソースコード 2.64 MatrixMatrix.java (行列と行列の積)
package section0214;
import java.util.Arrays;
public class MatrixMatrix {
public static void main(String[] args) {
int[][] A = {{1,2,3},{1,1,1},{0,1,-1}};
int[][] B = {{1,0,1},{0,1,1},{1,1,0}};
// 行列の値を出力System.out.println( " A = " + Arrays.deepToString( A ) );
System.out.println( " B = " + Arrays.deepToString( B ) );
// 行列と行列の積を計算するint[][] C = new int[A.length][B[0].length];
for(int i=0; i<C.length; i++) {
for(int j=0; j<C[i].length; j++) {
C[i][j] = 0;
for(int k=0; k<B.length; k++) {
C[i][j] += A[i][k] * B[k][j];
}
}
}
// 行列の値を出力System.out.println( "AB = " + Arrays.deepToString( C ) );
}
}
2.15 Math クラスここまで、計算と言ったら五則計算のみでしたが、それでは小学生レベルの計算しかできません。平方根とか三角関数とか、レベルを中学生に上げましょう。
2.15.1 Math クラスのクラスメソッド
平方根や三角関数は、「Math クラスのクラスメソッド」という形で与えられています。代表的な関数を表にしてみましょう (表 2.15.1 参照)。他にもいろいろな数学関数があるので、調べてみて下さい (B.6.3 節 参照)。その中から、まずは三角関数のテーブルを作ってみましょう。
ソースコード 2.65 TrigonometricTable.java (三角関数表)
package section0215;
public class TrigonometricTable {
public static void main(String[] args) {

80 第 2章 Java 言語の基本的な文法 I
int sep = 12;
for(int k = 0; k<=sep; k++) {
double theta = Math.PI * k / sep;
double cosTheta = Math.cos(theta);
double sinTheta = Math.sin(theta);
System.out.println( "θ=" + k + "π/" + sep +
", cosθ=" + cosTheta + ", sinθ=" + sinTheta );
}
}
}
ここで、Math.PI は円周率πの値です。Java では、3.14 なんて数値で円周率を与えたりしません。この名前を覚えて下さい。Math クラスには、もう 1 つ数学定数があります。ネイピア数 (自然対数の底に使う e = 2.71828) です。これは Math.E と書きます。これも覚えておきましょう。このプログラム、出力される実数値の桁数が不揃いで読みにくいですが、ここでも実数値の計算誤差について感じることができますね。(^^;)
表 2.15.1 Math クラスのクラスメソッド
戻り値 メソッド名 (引数) 内容int abs(int)
絶対値を返すdouble abs(double)
double cos(double) radian に対する cos 関数double sin(double) radian に対する sin 関数double tan(double) radian に対する tan 関数double log(double) 自然対数 (底が e)
double log10(double) 対数 (底が 10)
double pow(double, double) べき乗 xy:pow(x, y)
int max(int, int)2 数の大きな方
double max(double, double)
int min(int, int)2 数の小さな方
double min(double, double)
double sqrt(double) 平方根double random() [0, 1) 間の乱数long round(double)
小数点以下を四捨五入int round(float)
次は、色々取りまとめて。
ソースコード 2.66 MathMethods.java (基本関数の例)
package section0215;
public class MathMethods {
public static void main(String[] args) {
double a = -12.34;
System.out.println( a + " の絶対値は、" + Math.abs(a) );
double x = 100;
System.out.println( "log_e(" + x + ") は、" + Math.log(x) );
System.out.println( "log_10(" + x + ") は、" + Math.log10(x) );

2.15 Math クラス 81
int p = 3;
System.out.println( "e^" + p + " は、" + Math.pow(Math.E,p) );
System.out.println( "√" + p + " は、" + Math.sqrt(p) );
int m = 5;
int n = 3;
System.out.println( "max(" + m + "," + n + ") は、" + Math.max(m,n) );
System.out.println( "min(" + m + "," + n + ") は、" + Math.min(m,n) );
System.out.println( "[0,1) 間の乱数 2つ:" + Math.random() + "," + Math.random());
System.out.println( a + " の小数点以下を四捨五入すると、" + (int)(Math.round(a)));
}
}
問題 2.15.1. 次の命令を正しい順序に並び替え、かつ幾つかのミスを修正して正しいプログラムとして完成させなさい。
}
}
static void mein(String args)
System.out.Println( '半径' + r + 'の円の面積は、' + area );
pakage section0215;
double r = 1.5;
pablic class CircleArea {
double area = r * r * Math.PAI;
問題 2.15.2. 三角形 ABC の2辺 AB と AC の長さをそれぞれ a, b とし、その 2 辺の間の角度 θ としたとき、三角形 ABC の面積は、(1/2)ab sin θ で表されます。それを計算するようにプログラムを作りなさい。なお、角度 theta
は度数で与えるので(以下のプログラムでは 30 度としている)、ラジアンに変換して Math.sin(double) に代入しないと正しい値が求まりません。
ソースコード 2.67 TriangulumArea.java (三角形の面積)
package section0215;
public class TriangulumArea {
public static void main(String[] args) {
double a = 1.0;
double b = 1.0;
double theta = 30.0;
// 面積の計算は必ずしも1行で書かなくても良い
double area =
System.out.println( "三角形の面積は、" + area );
}
}

82 第 2章 Java 言語の基本的な文法 I
問題 2.15.3. 乱数を作成するメソッド Math.random() を利用して、サイコロの目( 1 から 6 の整数の目が等確率でデタラメに出る)を出力するプログラム Dice.java を作りなさい。
4 の目が出ました。
問題 2.15.4. 上のプログラムを改良して 10 回サイコロが振られるプログラム Dice2.java を作りなさい。
1 回目のサイコロの目は、4 でした。2 回目のサイコロの目は、6 でした。:
9 回目のサイコロの目は、1 でした。10 回目のサイコロの目は、5 でした。
Math.random() による乱数について、一言。コンピュータで生成する乱数は、(規則性や再現性が無い) 真の乱数では無く「擬似乱数」と言って確定的な計算によって求められています。例えば、サイコロの目は、それまでに出た目から次の目が予測が不可能ですが、確定的な乱数は生成法と内部状態が既知なら、予測が可能となります。そこで、真の乱数列と見分けが付かないほどに乱数ぽいか?を統計的な処理「検定」で判断するのですが、Math.random() はあまり成績はよくありません。従って、学術的な結論を Java で出したい場合は、検定をクリアした別の擬似乱数発生アルゴリズムを使うべきと言われています。例えば、日本の研究者が発明した、メルセンヌ・ツイスタ (Mersenne twister) やそれを改良した SFMTという擬似乱数列生成器は Math.random() より高速で乱数の品質もちゃんと検定を通るものとして使われています。まあ、ちょっとしたゲームなどで乱数を使いたいなんてときは、Math.random() で十分ですがね。
2.16 キーボードからのデータ入力ここまでのプログラムではプログラム中で用いるデータはプログラム内で変数に直接代入していました。それではデータをいろいろ変えてプログラムを動かす際に、毎回プログラムを書き換えなければなりません。これは汎用性が全く無いに等しいですよね。そこで、ここではキーボードから数値や文字列を読み込む方法の一つ Scanner を学びます。
2.16.1 System.in と System.out
これまでかなりの数で、System.out.println() などの命令を使ってコンソールにデータを書いてきました。コンソールに書くだけなら、print() くらいの簡単な命令にしておけば良いのに、と思いますよね。実はこれまでに習った中に、これに似たものがあります。Math.cos()などの数学関数です。この Math と System は同じようなもの、正確に言うといずれも「クラス名」です。Math クラスには便利な数学関数や定数が「メソッド」と「フィールド」という形で定義されているのです。同様に、System クラスには、これから学ぶデータの入出力関連、スタック領域の無駄を省く GC (Garbage Collection) 、プログラムを動かすのに必要な環境変数の設定など重要な「メソッド」と「フィールド」が入っています。そして、System クラスには、Math クラスにおける PI のように、in と out という 2 つのフィールドがあります
(PI はフィールドではなく、定数ですが)。使い方は、Math.PI と同様にカンマで繋げて System.in や System.out

2.16 キーボードからのデータ入力 83
と使います。そうです。これまでコンソールの出力に利用していた System.out.println() は、この System.out がさらに持っているメソッド println() を使う!という意味なのです。System.out は「標準出力装置」を意味します。デフォルトでは「コンソール」ですね。System.out.println() は標準出力装置に改行付きでテキストを出力するメソッドということでした。一方、System.in は、想像が付くかと思いますが、「標準入力装置」を意味します。デフォルトでは「キーボード」になります。System.in にもいろいろなメソッドがあるのですが、それらはかなりマニアック。(^^;)
このテキストでは触れないので、独習して下さい。で、登場するのが Scanner というクラスです。
2.16.2 Scanner(System.in)
System や Math クラスのメソッドを使う場合は、クラス名の後に直接メソッド名を付ければ、特に断りなしに利用することができました。しかし、これから学ぶ Scanner クラスのメソッドは、Java のデフォルト状態では利用することはできません。Java には Scanner クラス以外にも便利なクラスが山のようにあるのですが、プログラムをコンパイルする際に、それらが使われているか否かをコンパイラが全てチェックするのは負担が多すぎる、ということで、標準的に使うクラス以外はデフォルトのコンパイルではチェックされません。そうした場合、import という命令で、「このプログラムではこのクラスを使いますよ!」と教えてやらねばいけません。次のプログラムはキーボードから整数値を 1 つ読み込んで、それが奇数か偶数かを出力するプログラムです。2 行目に import の命令が見えますね。
Scanner クラスの正式名は java.util.Scanner です。Eclipse はプログラム中に Scanner の文字を見つけると、こんなクラスはデフォルトでは無いぞ、ということでメッセージを表示しますので、その選択肢から java.util.Scanner
の import を選択することになります。なお、import 命令は、パッケージ名を設定している 1 行目の後すぐに書くことになっています。
ソースコード 2.68 OddEven.java (整数値のキーボード入力)
package section0216;
import java.util.Scanner;
public class OddEven {
public static void main(String[] args) {
Scanner scan = new Scanner( System.in );
System.out.print( "整数値を1つ入力して:" );
int n = scan.nextInt();
scan.close();
if( n % 2 == 0 ) {
System.out.println( n + " は、偶数です。" );
} else {
System.out.println( n + " は、奇数です。" );
}
}
}
次に、5 行目で、標準入力装置 System.in を Scanner クラスに渡して、Scanner 型の変数 scan を宣言しています。この辺りは後期に詳しく説明するので、ここでは Scanner 使うときの呪文と思って下さい。とりあえず、この 1
行を書くことで、scan という変数がキーボードの入り口になってくれます。scan は勝手に付けた変数名なので、他の名前でも OK ですが、この授業では scan で統一しましょう。こうして出来上がった scan は、入力用のメソッドをたくさん持っています。その 1 つが、nextInt() メソッドで

84 第 2章 Java 言語の基本的な文法 I
す。これは、int型の値を 1 つ読み込んでくれるメソッドで、7 行目で、読み込んだ値を左辺の変数 n に代入しています。では、実行してみて下さい。6 行目の出力文によりコンソールに「整数値を1つ入力して:」と出力されます。そこで、コンソールの窓内をクリックして下さい。カーソルの位置を表示するポインタが、「入力して:」の右の位置に移動したかと思います。6 行目で print 命令を使ったおかげで、「入力して:」の出力後に自動改行されなかったというわけです。コンソールが標準出力装置でかつ標準入力装置なっているおかげで、このようなことができるのです。整数値を 1 つ、キーボードで入力し、最後にエンターキーを押して下さい。エンターキーが入力されると、nextInt()
メソッドは、それまでに入力された文字列を整数値に加工して返してくれます。
整数値を1つ入力して:1212 は、偶数です。
Scanner クラスの変数は、使用が終わったら後片付け ( close() 命令でプログラムとの接続を切ること) が必要です。Eclipse で動かしている場合は、プログラムが終了する際に Eclipse が自動で後片付けしてくれるのですが、Eclipse を使わない場合は、プログラム終了後キーボード入力できなくなるなんてことも起こりうる、と言うことで、後片付けは習慣づけしておきましょう。n に値が代入されてキーボード入力が終了したので、8 行目で後片付け(scan.close()) しています。では、応用編!先に作った 2 次方程式 ax2 + bx + c = 0 の根を求めるプログラムを改良して、3 つの係数をキーボードから入力するようにしてみましょう。実数を読み込むのは nextDouble() メソッドになります。
問題 2.16.1. 2 次多項式 ax2 + bx+ c の根を求めるプログラムを作ってみましょう。キーボードから係数を 3 つ入力して (a ̸= 0 を仮定)、判別式 d = b2 − 4ac を場合分けして、根の値を出力します:
• 判別式 d < 0 の場合、根は複素数となるので、今回はパス。”根は複素数です” と出力のみとする。• 判別式 d > 0の場合、”根は 2根あります”と出力の後、”x1 = ” + (−b+
√d)/(2a)と ”x2 = ” + (−b−
√d)/(2a)
を出力します。平方根は Math.sqrt() メソッドを使いましょう。• 判別式 d == 0 の場合、根は重根なので、”根は重根です” と出力の後、”x=” + (-b)/(2a) を出力します。
ソースコード 2.69 QuadraticEquation.java (2次多項式の根)
package section0216;
import java.util.Scanner;
public class QuadraticEquation {
public static void main(String[] args) {
Scanner scan = new Scanner( System.in );
System.out.println("ax^2+bx+c の根を求めます。係数を実数で順に入力して下さい。");System.out.print( "a = " );
double a = scan.nextDouble();
System.out.print( "b = " );
double b = scan.nextDouble();
System.out.print( "c = " );
double c = scan.nextDouble();
scan.close();
// a, b, c から判別式を計算し、その値で処理を場合分けし// 結果を出力する処理を作って下さい
}
}

2.17 コンソールへの出力 II 85
Scanner クラスについては、後期により詳しく解説します。
2.17 コンソールへの出力 II
ここまで、コンソールへの出力メソッドとして、次の 2 つのメソッドを利用してきました。
• System.out.print():改行なし• System.out.println():改行付き
しかし、いずれもデータを綺麗に並べて出力するなどの機能がないので、「とりあえず出力!」というものでした。ここでは、フォーマット (出力形式) を定義し、それに沿ってデータを出力する System.out.printf() というメソッドを紹介します。これは C 言語で既によく知られている出力方式です。先の 2 つより少々難しくなりますが、使い方をマスターするとこれしか使わなくなるほど便利です。
2.17.1 System.out.printf()
System.out の printf() メソッド、とりあえず使用した例で見てみましょう。2.15.1 節で作った三角関数のテーブルを再度作ってみます。
ソースコード 2.70 TrigonometricTable2.java (printf で三角関数表)
package section0217;
public class TrigonometricTable2 {
public static void main(String[] args) {
int sep = 12;
for(int k = 0; k<=sep; k++) {
double theta = Math.PI * k / sep;
double cosTheta = Math.cos(theta);
double sinTheta = Math.sin(theta);
System.out.printf( "θ=%02dπ/%2d, cosθ=%9.6f, sinθ=%9.6f%n",
k, sep, cosTheta, sinTheta );
}
}
}
printf() はその第 1 引数にフォーマットとなる文字列を必ず置きます。この場合は"θ=%02dπ/%2d, cosθ=%9.6f, sinθ=%9.6f%n"
ですね。このフォーマットには、書式指示子という % から始まる文字列が使われます。上のプログラムでは、
• %kd:整数系の値を出力する。k には桁数を入れます (%2d)。値は右詰めで表示され、桁数の最初に 0 を付けると、その表示内の空白を 0 で埋めます (%02d)。
• %k.mf:実数系の値を固定小数点数表示で出力する。k には全体の文字数、m には小数点以下の桁数を書きます(%9.6f)。k には符号や小数点も含めます。
• %n:printf() では、自動改行してくれません (print() と一緒です)。そこで、強制改行させるのが %n です。
フォーマットの後に、カンマで区切って対応する変数を並べます。上の例だと、次のような対応になりますね。代表的な他の書式指示子を以下に並べましょう (表 2.17.1 参照)。指示子が大文字の場合は表示が大文字になります。

86 第 2章 Java 言語の基本的な文法 I
%02d %2d %9.6f %9.6f
k sep cosTheta sinTheta
表 2.17.1 代表的な書式指示子
書式指示子 内容%b, %B boolean 型%c, %C char 型%e, %E 浮動小数点数表記での実数%o 8 進数表示の整数
%s, %S 文字列%x, %X 16 進数表示の整数
数値計算系でよく使う %E 表記の例を作ってみましょう。2年生の計算数学で習う「Newton 法」という微分可能関数の実数解を求めるアルゴリズムです。
ソースコード 2.71 NewtonMethod.java (浮動小数点数表示:Newton 法)
package section0217;
public class NewtonMethod {
public static void main(String[] args) {
// f(x) = cos(1/log x) = 0 の x ≧ 1.2 の解を Newton 法で解く// f'(x) = sin(1/log x)/(x(log x)^2)
int count = 0;
double x = 1.6;
String format = "count=%d : x=%10.7f f(x)=%13.5e%n";
while( Math.abs(f(x)) > 1.0e-15 ) {
System.out.printf( format, count, x, f(x) );
x = x - f( x )/df( x );
count++;
}
System.out.printf( format, count, x, f(x) );
}
static double f(double x) {
return Math.cos(1.0/Math.log( x ));
}
static double df(double x) {
return Math.sin(1.0/Math.log( x ))/(x*Math.pow(Math.log( x ),2));
}
}
この後で学ぶメソッドが使われていたりで、プログラム全体を読み取ることは難しいでしょうが、 8 行目のフォーマットの文字列と、10, 14 行目だけ見て、実行結果と見比べて下さい。このようにフォーマットを printf() メソッドの外で文字列として定義しておいて使うこともよく行われます。%10.7f が固定小数点数表示で全体 10 桁で小数点以下 7
桁の表示、%13.5e が浮動小数点数表示で全体 13 桁(符号や小数点も 1 文字として含む)で仮数部の小数点以下 5 桁の表示、となります。ちなみに、Mathematica でこの問題を解いてみると (楽だねぇ! (^^;))。
f[x_] := Cos[1/Log[x]];
Print["f(x)=", f[x]]

2.18 メソッド I 87
Print["f'(x)=", D[f[x], x]]
Plot[f[x], {x, 1, 3}]
NSolve[{f[x] == 0, x >= 1.2}, x]
f(x)=Cos1
Log[x]
f'(x)=Sin 1
Log[x]
x Log[x]2
1.5 2.0 2.5 3.0
-1.0
-0.5
0.5
1.0
{{x 1.2364}, {x 1.89008}}
図 2.19 Mathematica の計算結果
2.18 メソッド I
2.18.1 API (Application Programming Interface)
これまで、プログラムは 1 つのクラスでした。そして、そのクラスの中に main というメソッドが入っていました。プログラムを動かすということは、この main メソッドを動かすということでした。そして、ここまでのプログラムでは、全ての処理が main メソッドの中に書かれていました。複雑なプログラムを作るようになってきて、全ての処理を main 内に書くことは、そこで行われている処理を解読するのが複雑になり、よって間違いを誘発しやすくなったり、無駄な部分に気付き難くもなってきました。それに、似通った処理は 1 度作ったら何度も作ることなく、再利用したいですよね。Java では、かつての先輩たちが作成した便利な道具の集合体 API (Application Programming Interface : 200 を超えるパッケージ、3, 500 を超えるクラスからなる) が利用できるようになっています。例えば、Math.cos() メソッドが入っていた java.lang.Math クラスなどもその 1 つです。プログラム中で何度も同じような処理が繰り返し行われたり、パラメータがちょっとだけ違う処理をいろいろなプロ
グラムで行いたいときなど、同じような処理を何度もコーディングするのは無駄です。そこで、そうした処理を数学の関数のように、メソッドとして main メソッドの外に置いて、それを呼び出して使う、という方法をここで学びます。まずは、main メソッドと同じクラス内に新たなメソッドを作って使う方法を、そして、他のクラスの中にメソッドを置いて使う方法について見ていきます。
2.18.2 クラスメソッド
ここで学ぶメソッドは、クラスメソッドと言います。以下の 2 つのプログラムを見比べてみましょう。

88 第 2章 Java 言語の基本的な文法 I
ソースコード 2.72 CircleArea.java (main メソッド内で円の面積)
package section0218;
public class CircleArea {
public static void main(String[] args) {
for(int r=1; r<=10; r++) {
double area = r * r * Math.PI;
System.out.printf( "半径=%2d の円の面積は、%8.4f です %n", r, area );
}
}
}
ソースコード 2.73 CircleArea2.java (クラスメソッドで円の面積)
package section0218;
public class CircleArea2 {
public static void main(String[] args) {
for(int r=1; r<=10; r++) {
printCircleArea( r );
}
}
// 半径 radius の円の面積 area を出力するメソッドstatic void printCircleArea( int r ) {
double area = r * r * Math.PI;
System.out.printf( "半径=%2d の円の面積は、%8.4f です %n", r, area );
}
}
いずれも半径を 1 から 10 までの整数値として、円の面積を順に出力するプログラムです。CircleArea.java は全ての処理を main メソッドの中で行っています。内容はもう理解できますよね?一方、CircleArea2.java は、面積計算とその出力処理を main メソッドとは別のメソッド printCircleArea に分離し、main メソッドでそれを呼び出して使用する、という方法で書かれています。「こんなに短いプログラムで、行数が増えるような面倒なこと何でするかな!」とは思わないで下さい。説明のために小さなプログラムで、敢えて分離しているのですから。printCircleArea メソッドをブラックボックス化 (main メソッドから printCircleArea メソッドの中でどんな処理がされているかは見えない) したことで、mainメソッドはスッキリ読やすくなっていませんか?呼び出すメソッドの名前をその内容が分かりやすいように付けておけば、main メソッドを読んでいるだけで、やっている内容がわかってしまうかも。mainメソッドから直接使うメソッドを「クラスメソッド」と言って、static という単語が宣言部に付いてるのが目印です。実は main メソッドもクラスメソッドです (static が付いていますよね)。なお、メソッドには、static の付いていない「インスタンスメソッド」というのもあります (こちらは、後期に習います)。メソッドの宣言部には static 以外にもいくつかの単語が付きます。まず、public。これは、そのメソッドをどのプ
ログラムから利用可能にするか、逆に言うと「どう制限 (アクセス制限) するか」の単語で、public は最も制限のないレベルを意味します。main メソッドには必ず public を付けることになっています。一方、今回の printCircleArea
メソッドには付いていませんね。付いていない場合、同じパッケージ内のクラスからのみアクセスを許す!という意味になります。つまり、printCircleArea メソッドは section0218 パッケージ内の他のプログラムからも利用が出来るというわけです (この詳細も後期になって習います)。宣言に付いている単語はまだあります。メソッドは数学の関数と似たようなもので、関数は何らかの計算の後で関数値を返しますが、Java では、呼び出したメソッドに対し何らかの値を返すとき、それを「戻り値」と言います。例え

2.18 メソッド I 89
ば、double x = Math.cos(Math.PI/4); という代入文では、cos メソッドに角度 π/4 を実数値で与えて、正弦の値0.70710678 (これが戻り値) を返してもらい、それを左辺の変数 x に代入しています。この戻り値の型をメソッド名の前に書く決まりになっています。では、この printCircleArea メソッドの戻り値は何か?と見ると、void 型と書かれています。この「void」という単語は空虚とかカラのとかいう意味で、戻り値が「ない」ことを意味します。数学の関数と違って、Java のメソッドでは戻り値が「ない」こともありなのです。ちなみに、main メソッド にも void が付いていますよね。このメソッドも戻り値なしなんです。最後に、小かっこの中に「引数」を入れます。main メソッドの場合 String 型の配列 args が、printCircleArea メソッドの場合 int型の変数 radius が入っています。main
メソッドの引数 String[] args はどう使うのか? (というか、これまでどう使ってきた?) については、後で説明します。以上を数学関数の y = f(x) と対応して考えると、x が引数、f がメソッド名、そして y に代入する f(x) の計算結果が戻り値、となりますね。では、次は戻り値のあるメソッドの例です。
ソースコード 2.74 CircleArea3 (クラスメソッドでの円の面積2)
package section0218;
public class CircleArea3 {
public static void main(String[] args) {
for(int r=1; r<=10; r++) {
printCircleArea( r );
}
}
// 円の面積情報を出力するメソッドstatic void printCircleArea( int r ) {
double area = circleArea( r );
System.out.printf( "半径=%2d の円の面積は、%8.4f です %n", r, area );
}
// 半径 radius の円の面積を返すメソッドstatic double circleArea( double radius ) {
double area = radius * radius * Math.PI;
return area;
}
}
今回のプログラムでは、さらに円の面積計算を分離しました。先のプログラムと見比べてみて下さい。circleArea メソッドの宣言部には void の代わりに double と書かれていますね。これが戻り値の型です。つまり、半径から円の面積を計算して返すメソッド circleArea() の戻り値は実数だ!というわけです。printCircleArea メソッドは circleArea メソッドの引数に半径の値を渡して円の面積を計算させ、その結果を返してもらって変数 area に代入し、コンソールに結果を出力しています。一方、circleArea メソッドは、引数に半径を与えられながら呼び出され、面積を計算し、自分を呼び出したメソッド (この場合 printCircleArea()) に計算結果を戻しています。その計算結果を戻すという命令が return area; です。return 命令の後ろに戻したい値の入った変数もしくは式を書きます。ちなみに、戻り値が void の printCircleArea
メソッドの方には return 命令がありません (return のある void メソッドも実は「有り」なのですが、その話は先の節で)。さて、プログラム CircleArea3 と CircleArea2 を比較してもらって、もう1つ気付くことがあるかと思います。
circleArea() メソッドの宣言と printCircleArea() での circleArea() メソッドの呼び出しが一致していない(引数の変数の型と名前が異なる) ことです。大丈夫なのでしょうか?

90 第 2章 Java 言語の基本的な文法 I
大丈夫です。まず、変数名が異なる件について、これって似たようなこと以前に学びましたよね。double型変数にint型リテラルを代入はできるけど、逆はダメ!という話です。同じことが、この引数でも言えるのです。circleArea
側で doubleで受取る!と宣言しているのなら、渡す値は、整数型でも実数型でも代入できて大丈夫なわけです。では、質問!上のプログラムにもう1つ次のメソッドを加えたらプログラムはどう動くでしょうか?
// 半径 radius の円の面積を返すメソッド2static double circleArea( int radius ) {
System.out.println( "新たなメソッドが呼ばれた" );
double area = radius * radius * Math.PI;
return area;
}
新たなメソッドも circleArea という名前のメソッドです。違うのは、引数の型だけ。実際にプログラムに追加して動かしてみると、想像通り、新たに追加したメソッドの方を呼び出しています。Java では、同じ名前のメソッドを複数持つことが許されています。ただし、次のルールが満たされないとエラーになります。
• 引数の個数が違う• 引数の個数が同じでも、いずれかの型が異なる
例えば、引数の型と個数は同じだけど戻り値の型が違うメソッド2つでは、ダメです。なぜなら、呼び出す側から見たとき見た目が同じで区別できない。今回のように、引数の個数が等しく1個で、でも型が違う、というのなら呼び出す側から、最も適合するメソッドを選択することが可能なわけです。例えば、main 側で半径の変数 r が実数型に変更されたら、呼び出されるメソッドは最初に在った circleArea メソッドとなります (int型の引数に実数を代入できないので)。
問題 2.18.1. 次の2つのメソッドが共存できるか、できないかを答えなさい。
1. double method(int a, int b) と double method(int x, int y)
2. double method(int a, int b) と int method(int a, int b)
3. double method(int a, double b) と double method(double a, int b)
4. double method(int a, int b) と double method(int a)
5. double method(int a, int b) と double method(double x, double y)
6. double method(int a, int b) と void method(int a, int b)
この問題で、設問3がちょっとモヤモヤする設問ですね。この場合、先のルールに基けば共存は可能です。ただ、もし method( 1, 2 ); のように両引数を整数値で呼んだ場合、いずれのメソッドも選択可能になってしまい、呼び出し側でエラーになってしまいます。呼び出す際に引数を共に整数としないなら、問題なく共存できるということで、答えとしては「共存できる」だけど、ニュアンスは「どちらとも言えない」ですかね。では、次は呼び出す側と呼び出される側で引数の変数名が異なる件について。
2.18.3 実引数と仮引数
printCircleArea() メソッドが circleArea() メソッドを呼び出す際に、引数に整数変数 r が渡されています。一方、circleArea() メソッドでは、その値を実数値変数 radius で受取っています。より広い領域を扱える型で受

2.18 メソッド I 91
け取っているので、型はOKですが、名前が違うのは大丈夫なのでしょうか?これも大丈夫です。この 2 つの変数、circleArea() メソッドにおいて、呼び出す際の引数 r を「実引数」、呼び出される側の引数 radius を「仮引数」と呼びます。printCircleArea() メソッドで circleArea() の実引数 r に最初の値 1 が代入されると、それが circleArea() メソッドの仮引数 radius に「コピー」されて、メソッド内で利用されます。(図 2.20 参照)
circleArea( ) メソッド側
printCircleArea( ) メソッド側
1int r
double area = circleArea( r );
static double circleArea( double radius ){
return area;
}
代入
コピー
値を戻す
図 2.20 実引数と仮引数
このとき、実引数と仮引数の「名前」はそれぞれのメソッド内で矛盾しない限り自由に付けることが可能です。このおかげで、複数のプログラマが協力して大きなプログラムを作成するとき、メソッド毎に分担してプログラムを作成することが可能になるのです。
Aさん 「実数を2つ渡すので、それらの大きい方を返してくれるメソッド作ってくれる?」Bくん 「よっしゃ!じゃぁ、double max(double, double) なるメソッド作るから、よろしく!」
Bくん、戻り値と引数 2 つの型だけ A さんに伝えていますね。細かい変数名などは、それぞれが自由に作れて、ただし引数の個数と型、そして戻り値の型は、事前に了解しておく。こうしてプログラムを分担して作成できるわけですね。ところで、続いて二人の間で次のような会話が:
Aさん 「整数を2つ渡すので、大きい順に並び替えするメソッド作ってくれる?」Bくん 「よっしゃ!じゃぁ、void swap(int, int) なるメソッド作るから、よろしく!」
で、Bくん、2 つの数の交換は 2.8 章で SwapValues.java を作った経験からすぐ出来上がって、彼らの合作プログラムが次のようにできました。
ソースコード 2.75 SwapValues2.java (クラスメソッドで数の交換できる?)
package section0218;
public class SwapValues2 {
public static void main(String[] args) {
int a = 1;
int b = 2;
swap( a, b );
System.out.println( "大きい方が、" + a );
System.out.println( "小さい方が、" + b );
}
static void swap( int x, int y ) {
// x >= y のときは何もせず、x < y の時だけ入れ替えるif( x < y ) {

92 第 2章 Java 言語の基本的な文法 I
int temp = x;
x = y;
y = temp;
}
}
}
main メソッド側
swap メソッド側
1 2
int b
交換しても、
main に戻していない
代入
代入
コピーコピー
int a
swap( a, b );
static void swap( int x, int y ){
図 2.21 仮引数の値は戻らない
ところが、実行してみると、上手く行かないようです。どうして?その答えは、この節の最初の 8 行の中に書かれています。(^^)b
引数に与えた変数をいくら呼び出したメソッドで変更しても、仮引数の値は、実引数に戻されないので、このような交換メソッドは作れないのです。(図 2.21 参照)
値を交換するメソッドは Java では作れない!?というのでは、残念なプログラミング言語になってしまいますが、次に少しヒントとなるプログラムを、そしてこの話題は後期にまた触れましょう。次のプログラムでは、整数配列を実引数として positiveArray() メソッドに渡しています。先の話だと、引数で受
け取った値を変化させてもメソッドから戻ってきたら、値は変化せずにメソッドの操作が無駄になる!と言うことでしたが、今回はどうでしょう。
ソースコード 2.76 FormalParameter.java (配列をメソッドに渡す)
package section0218;
import java.util.Arrays;
public class FormalParameter {
public static void main(String[] args) {
int[] array = { 1, -2, -3, 4, -5 };
positiveArray( array ); // 配列を全て正数に変換printArray( "array", array ); // 配列の情報を出力
}
static void positiveArray( int[] x ) {
for(int i=0; i<x.length; i++) {
x[i] = Math.abs( x[i] );
}
}
static void printArray( String name, int[] x ) {
System.out.println( name + " = " + Arrays.toString( x ) );
}
}

2.18 メソッド I 93
この結果をどう解釈したら良いのでしょう。そのためには、実引数に与えた array とは何か?がわからないといけません。整数値が 5 つ?いいえ、これは 5 つの値からなる配列の「先頭アドレス」ですよね。アドレスが postitiveArray()
メソッドの仮引数にコピーされるわけです。そして、そのメソッドの中の処理が行われ、終了すると main メソッドに制御が戻ってきます。戻り値が void ですから、 main メソッドには何も戻していません。もちろん、変数 array の値 (アドレス) も変化させていません。ただ、その先の整数データは変更されているわけです (理屈、わかりますか?)。こうすることで、メソッドに渡した値を変化させることができるのです。では、次のように positiveArray メソッドを変更させたら、どうなるでしょうか?
static void positiveArray( int[] x ) {
x = new int[]{ 1, 1, 1, 1, 1 };
}
引数に与えた配列の値を全て 1 に変更したいと思ったわけですが、どうも上手く行っていないようです。この場合、要素が全て 1 の新たな配列が作られて、その先頭アドレスが仮引数 x に代入されたことになります。しかし、この仮引数は mainメソッドには返されませんから、mainメソッドでの変数 arrayは以前のままデータ { 1, -2, -3, 4, -5 }
を指しています。
2.18.4 行列とベクトルの計算 (続)
配列を学んだとき、行列・ベクトルの積のプログラムを作りました。その際、まだメソッドを学んでいなかったので、行列の積の計算を main メソッドの中に直接書いていました。今回、そうした操作をメソッド化することで、プログラムがとても見やすく出来るはずです。行列とベクトルの積・行列と行列の積を、まとめてプログラム化してみましょう。
ソースコード 2.77 LinearAlgebra.java (行列・ベクトルの積)
package section0218;
import java.util.Arrays;
public class LinearAlgebra {
public static void main(String[] args) {
int[][] A = {{1,2,3},{1,1,1},{0,1,-1}};
printM( "A", A );
int[] x = {1,1,1};
printV( "x", x );
// y = Ax を計算int[] y = prodMV( A, x );
printV( "Ax", y );
int[][] B = {{1,0,1},{0,1,1},{1,1,0}};
printM( "B", B );
// C = AB を計算int[][] C = prodMM( A, B );
printM( "AB", C );
}
// 行列の値を出力static void printM( String name, int[][] A ) {
System.out.println( name + " = " + Arrays.deepToString( A ) );
}

94 第 2章 Java 言語の基本的な文法 I
// ベクトルの値を出力static void printV( String name, int[] x ) {
System.out.println( name + " = " + Arrays.toString( x ) );
}
// 行列とベクトルの積を返すstatic int[] prodMV( int[][] A, int[] x ) {
int[] y = new int[A.length];
for(int i=0; i<A.length; i++) {
y[i] = 0;
for(int j=0; j<A[i].length; j++) {
y[i] += A[i][j] * x[j];
}
}
return y;
}
// 行列と行列の積を返すstatic int[][] prodMM( int[][] A, int[][] B ) {
int[][] C = new int[A.length][B[0].length];
for(int i=0; i<C.length; i++) {
for(int j=0; j<C[i].length; j++) {
C[i][j] = 0;
for(int k=0; k<B.length; k++) {
C[i][j] += A[i][k] * B[k][j];
}
}
}
return C;
}
}
線形代数のプログラムは他にもいろいろありますね。配列と繰り返し処理の良い例題となりますので、いろいろ作ってみて下さい。
問題 2.18.2. main メソッド内で整数行列 A に初期値を与え、その転置行列を求める 2 種類のメソッドを以下のように作りなさい。
• static int[][] transMnew( int[][] A ):行列を引数に与えられたら、その転置行列を作って返すメソッド。自分自身を転置はしない
• static void transMself( int[][] A ):引数に与えられた行列 A 自身を転置するメソッド
問題 2.18.3. main メソッド内で 整数ベクトル x に初期値を与え、次で定義されるベクトルの長さを求めるメソッドstatic double lengthV( int[] x ) を作りなさい。
|x| =
Ãn∑
i=1
x2i , (n = x の要素数)

2.18 メソッド I 95
ところで、このメソッドに double length = lengthV( {1, 2, 3, 4, 5} ); と直接配列を代入して呼び出すと、残念ながらエラーです。こうしたときは、 double length = lengthV( new int[]{1, 2, 3, 4, 5} ); と型を指定しながら与えれば上手くいきます。また、配列を返すようなメソッドを作ったとして、次のように書くのもエラーです。
// 2引数を要素とするベクトルを返すメソッドstatic int[] toArray( int x, int y ) {
return {x, y};
}
この場合、 return new int[]{x, y}; と書けばOKです。
2.18.5 再帰プログラム
数学で、漸化式 (recurrence relation) というのを学んだかと思います。「各項がそれ以前の項の式として定まる」という数列・数学的帰納法に関連する理論ですが、プログラムの世界でもこれと同等な考え方でプログラムを作ることが可能です。以下のプログラムを解読してみて下さい。
ソースコード 2.78 FibonacciRecursive.java (再帰プログラムによるフィボナッチ数)
package section0218;
public class FibonacciRecursive {
public static void main(String[] args) {
int n = 10;
System.out.println( "Fibonacci 数列の " + n + "番目の値は、" + fibo( n ) );
}
static int fibo( int n ) {
if( n == 1 || n == 2 ) return 1;
else return fibo( n-1 ) + fibo( n-2 );
}
}
これは、フィボナッチ数(以前のプログラムでも作りましたね)を計算しています。フィボナッチ数列の n 番目の値Fn は、漸化式 Fn = Fn−1 + Fn−2, F1 = F2 = 1 を満たすので、それをそのままプログラムにしたわけです。引数に n を与えられたメソッド fibo は、n が 1 もしくは 2 の場合は 1 を値として返します (return 1;)。一方、
n > 2 の場合、fibo は自分のコピーに引数 n− 1 と n− 2 を渡してそれらの値を計算してもらい、その和を自分の戻り値として返しています。こうすることで、main メソッドは、フィボナッチ数列の 10 番目の値 55 を出力できるわけです。難しいですか?では、もう一つ例を。次のプログラムは何を計算しているでしょう?
ソースコード 2.79 FactorialRecursive.java (再帰プログラムによる階乗)
package section0218;
public class FactorialRecursive {
public static void main(String[] args) {
int n = 10;
System.out.println( n + "! の値は、" + fact( n ) );
}
static int fact( int n ) {
if( n == 1 ) return 1;
else return n * fact( n-1 );

96 第 2章 Java 言語の基本的な文法 I
}
}
10 の階乗 10! = 3628800 を計算していますね。n! = n × (n − 1)!, 1! = 1 をプログラム化したわけです。このように、メソッドが引数の値を変えながら自分のコピーを呼び出して処理が続くプログラムを再帰プログラム (recursive
program) と言います。では、さらにもう一例。ハノイの塔 (Tower of Hanoi) という話を聴いたことがありますか?フランスの数学者リュ
カが創作した「世界の中心にある寺院に 3 本のダイヤの棒が立てられていて、そのうちの 1 本に大きさの異なる 64 枚の純金の円盤が大きい円盤から順に刺さっている。それを僧侶たちが 1 枚 1 枚、小さい円盤の上に大きな円盤が乗らないようにしながら、他の棒に移動させている。全ての円盤の移動が終わるとこの世界も終わる。」という話です。
問題 2.18.4. 1 秒に 1 枚の移動を行ったとして、64 枚全ての円盤が移動し終わるのにどの位の時間がかかるでしょう。
では、円盤の枚数を与えてハノイの塔をシミュレートするプログラムを作ってみましょう。
ソースコード 2.80 HanoiTower.java (ハノイの塔)
package section0218;
public class HanoiTower {
public static void main(String[] args) {
int n = 3; // 円盤の数は3枚hanoi( n, 'A', 'B', 'C' );
}
static void hanoi( int n, char a, char b, char c ) {
if( n == 0 ) return;
hanoi( n-1, a, c, b );
System.out.println( n + "枚目の円盤を " + a + " から " + b + " に移動します" );
hanoi( n-1, c, b, a );
}
}
メソッド hanoi は、引数が 4 つで戻り値なしのメソッドです。第 1引数は円盤の枚数を整数値で、第 2 から 4 引数は棒の名前を文字で与えています。そして、メソッドが呼び出されると、hanoi メソッドは n 枚の円盤を第 2引数の棒 ( a )から第 3引数の棒 ( b )へ全ての移動させる!という処理を始めます。第 4引数 ( c )はその時の移動対象から外れている棒の名前を記憶しておくために使われます。さて、n 枚の円盤を棒Aから棒Bへ移動させる際に、必ず経由しなければならない状態があります。それは、上に乗っている n− 1 枚の円盤が全て棒Cに
ど
退いていて、最も下の最も大きな円盤を棒Aから棒Bへ移動する、図 2.23 の状態です。その状態を作るためには、1 枚円盤の少ないハノイの塔の問題、但し棒Aから棒Cへの移動、を行えば良い。つまり、メソッド hanoi を呼び出して、hanoi( n-1, 'A', 'C', 'B' ) を行ってもらうわけです。その後で、最も大きな円盤を棒Aから棒Bに移動し、再度、1 枚円盤の少ないハノイの塔の問題、但し棒Cから棒Bへの移動、をhanoi( n-1, 'C', 'B', 'A' ) で行えば、n 枚の円盤の移動は完了となります。こうして、n 枚の円盤の移動が、n− 1 枚の円盤の移動で「再帰的に」表され、それがさらに n− 2 枚の円盤の移動
で表され、· · · とメソッド hanoi が呼び出されていくわけです。もちろん、n の値がどんどん小さくなるとして、どこかで止めないと無限に再帰が続いてしまいます。それを実現するためには、移動する円盤の数が 0 枚になったとき、つ

2.18 メソッド I 97
A B C
図 2.22 ハノイの塔 (1)
A B C
図 2.23 ハノイの塔 (2)
まり hanoi( 0, a, b, c ) が呼び出されたとき、何もせずに呼び出し元へ戻って行けば良い。プログラムの 9 行目の命令がそれに対応します。メソッド hanoi は戻り値の無い void メソッドですから、戻り値を返す return 命令は書けませんが、単に自分を呼び出したメソッドへ帰る、戻り値を持たない単独の return 命令を置くことができます。先に、void メソッドはreturn 命令がないと学びましたが、実は、メソッドの最後に 1 つ return 命令が存在していて、メソッドの最後のreturn 命令は省略可能というルールがあったのです。つまり、メソッド hanoi には 9 行目に return 命令がありますが、実はもう 1 つ 12 行目の後に return 命令が隠れている、というわけです。return 命令は、戻り値のある・なしに関わらず、メソッド内のどこに置いても構いません。また個数にも制限がなく、複数個の return 命令を持つメソッドも可能です。ただし、return 命令を置いたために、その直後の命令にどこからも到達できなくなってはいけません。次のメソッドでは、if ブロックの中かっこを書き忘れたために 5 行目に到達不可能なプログラムになっています。
static void method( int a ) {
if( a < 0 ) // 次の 2 行を囲むブロックを書き忘れたSystem.out.println( "この命令を行った後、強制的に return" );
return;
System.out.println( "そのため、この命令は到達不可能" );
}
問題 2.18.5. 上のハノイの塔のプログラムで、n = 3 と設定したとき、最大で幾つの hanoi メソッドがメモリー内に同時に存在するか述べよ。
メソッドAがメソッドBを呼び出したとき、メソッドBが終了しない限り、メソッドAもメモリ内で待機状態になっています。つまり、この待機状態のメソッドが増えすぎてメモリーオーバーでプログラムが停止してしまう可能性を再帰プログラムは持っています。
問題 2.18.6. 次のようなハノイの塔の発展形をプログラム化しなさい。
1. 3本の棒の間の移動を A→ B → C → A のみしか許さないで棒 A から棒 B へ n 枚の円盤を移動させるハノ

98 第 2章 Java 言語の基本的な文法 I
イの塔のプログラム HanoiTower2.java を作りなさい。2. 上と同じルールのもとで、棒 Aから棒 C へ n枚の円盤を移動させるハノイの塔のプログラム HanoiTower3.java
を作りなさい。3. 円盤の移動ルールは基本と同じで、棒の数を4本 A,B,C,D とし、棒 A から棒 B へ n 枚の円盤を移動させるハノイの塔のプログラム HanoiProblem4.java を作りなさい。
2.18.6 main メソッドの引数
main メソッドは static なメソッド、クラスメソッド、でしたね。そして、その引数は、main(String[] args)
と文字列の配列になっています。では、これはどのように使われているのでしょうか。これまで、この引数に何か与えて動かしたことはありませんでしたが、実は裏で null が与えられていました。つまり、「何も与えない!」だったわけです。では、args に何か与えて動かすにはどうしたら良いでしょう?次のプログラムを動かしてみましょう。ただし、これまでとちょっと動かし方が違います。
ソースコード 2.81 MainParameters.java (メインの引数を使う)
package section0218;
public class MainParameters {
public static void main(String[] args) {
int a = Integer.valueOf( args[0] );
int b = Integer.valueOf( args[1] );
System.out.println( a + " + " + b + " = " + (a + b) );
}
}
プログラムが出来上がったら、いつものように「緑の円の中に白抜き右向き三角 ( )」で実行させるのではなく、その右に付いている「小さな下向き黒三角」をクリックし、「実行の構成 (N)」を選びます (図 2.24 参照)。「実行構成」という窓が開いたら、図 2.25 のようにこのプログラムが選択されていることを確かめて下さい。もし、異なるメイン・クラスが表示されていたら、右の方にある「参照」ボタンをクリックして、このプログラムを選択しましょう。次に「(x) =引数」というタグを選択し (図 2.26 参照)、「プログラムの引数 (A)」の中に、12 34 のように2つの整数を間にブランクを挟んで書いて下さい。そして「実行」ボタンをクリックしてみましょう。この「プログラムの引数」に書き込まれた文字列が main の引数 String[] args に読み込まれます。そのとき、半角の空白もしくは改行が要素と要素の区切りとして使われるので、12 34 と入力すると、args[0] = "12"、args[1]= "34" と代入されます。main メソッドは、文字列しか引数で受け取ることができませんから、このままでは数値としての計算は出来ないので、Integerクラスが持っている「文字列から整数値への変換」メソッド Integer.valuesOf()
を利用します。このメソッドは、引数に文字列を入れると、それを int型の整数値に変換してくれます。と、ここまで説明すれば、残りは解読できますね。余談:C 言語でも main メソッドがプログラムの中心ですが、main メソッドの宣言法が 1 つではありません。
int main(void) と int main(int args, char *argv[]) という 2 通りが主に利用され、いずれも int型の戻り値を持っています。言語によって、いろいろですねぇ。

2.18 メソッド I 99
図 2.24 実行の構成 1 図 2.25 実行の構成 2 図 2.26 main メソッドの引数の利用
2.18.7 System.arraycopy
配列間でデータをコピーするプログラムは、配列を理解する上で省けない基本操作です。まずは、以前作った以下のソースコード ?? のプログラムを見て下さい。
ソースコード 2.82 ArrayCopy.java (配列のコピー)
package section0214;
import java.util.Arrays;
public class ArrayCopy {
public static void main(String[] args) {
int[] x = { 1, 3, 0, -2, 4 };
int[] y = new int[x.length];
for(int i=0; i<x.length; i++) {
y[i] = x[i];
}
// ちゃんとコピーされたか y を出力してみるSystem.out.println( "y = " + Arrays.toString( y ) );
}
}
ベタに要素一つずつを対応する位置に格納してやることが基本となります。とはいえ、ちょっとダサい処理ですね。そこで、これをメソッドを使ってスッキリと実現する方法を紹介しましょう。
ソースコード 2.83 ArrayCopyExample1.java (1次元配列のコピー)
package section0218;
import java.util.Arrays;
public class ArrayCopyExample1 {
public static void main(String[] args) {
int[] x = { 1, 3, 0, -2, 4 };
int[] y = new int[x.length];
System.arraycopy(x, 0, y, 0, x.length);
// ちゃんとコピーされたか y を出力してみるSystem.out.println( "y = " + Arrays.toString( y ) );
}
}

100 第 2章 Java 言語の基本的な文法 I
System クラスのクラスメソッド arraycopy は5つの引数を持つメソッドで、配列間でデータのコピーを行います。arraycopy(a1,s1,a2,s2,len) は、「配列 a1 の [s1] 番要素を、配列 a2 の [s2] 番要素へコピーすることを開始として、順に len 個分のデータをコピーする」という処理を行います。つまり、上のプログラムでは、同じ大きさの2つの配列間で全ての要素をコピーしていることになりますね。len の値が配列の長さより短い場合、余った部分はデフォルトの 0 が代入されます。なお、 len が負だったり配列長より長かったりしてもコンパイルエラーにはならず、実行時に ArrayIndexOutOfBound 例外を投げるので、一般には事前のチェックが必要となります。では、2次元配列のコピーはどのように行いましょうか。これも前に問題 2.14.17 において作ったプログラムを書き換えてみましょう。
ソースコード 2.84 ArrayCopy3.java (多次元配列のコピー)
package section0214;
import java.util.Arrays;
public class ArrayCopy3 {
public static void main(String[] args) {
int[][] A = { {1, 3, 0}, {-2, 4} };
int[][] B = new int[2][];
for(int i=0; i<A.length; i++) {
B[i] = new int[A[i].length];
for(int j=0; j<A[i].length; j++) {
B[i][j] = A[i][j];
}
}
System.out.println( "B = " + Arrays.deepToString( B ) );
}
}
まず、駄目な方法から。
ソースコード 2.85 ArrayCopyExample2.java (多次元配列のコピー:失敗作)
package section0218;
import java.util.Arrays;
public class ArrayCopyExample2 {
public static void main(String[] args) {
int[][] A = { {1, 3, 0}, {-2, 4} };
int[][] B = new int[2][];
System.arraycopy(A, 0, B, 0, A.length);
A[0][0] = 0; // うまく行っているかのチェックSystem.out.println( "B = " + Arrays.deepToString( B ) );
}
}
一見出来ているように見えますが、 B[0][0] の値が 0 に変化しています。理由はもうOKですね。こうした、表面上はコピーしているようで、実際は同じデータを参照しているようなコピーを「浅いコピー (Shallow copy)」と言います。一方、新たな配列として中身までちゃんと別に作成する次のようなコピーを「深いコピー (Deep copy)」と言います。当然、コピーは深いコピーでないといけません。Arrays.toString() に対する Arrays.deepToString() のように多次元配列に拡張されたメソッドがあれば良いのですが、残念ながら無いので次のようにします。
ソースコード 2.86 ArrayCopyExample3.java (多次元配列のコピー)
package section0218;
import java.util.Arrays;

2.19 文字列型 101
public class ArrayCopyExample3 {
public static void main(String[] args) {
int[][] A = { {1, 3, 0}, {-2, 4} };
int[][] B = new int[2][];
for(int i=0; i<A.length; i++) {
B[i] = new int[A[i].length];
for(int j=0; j<A[i].length; j++) {
System.arraycopy(A[i], 0, B[i], 0, A[i].length);
}
}
System.out.println( "B = " + Arrays.deepToString( B ) );
}
}
「ところで、clone() というメソッドが配列にはあるようですが、これは使えないのでしょうか?」ほお、勉強していますね。では、 clone メソッドを使ったコピーのプログラムを作ってみましょう。
ソースコード 2.87 ArrayCloneExample.java (配列のクローン)
package section0218;
import java.util.Arrays;
public class ArrayCloneExample {
public static void main(String[] args) {
// 1次元配列の場合int[] x = { 1, 3, 0, -2, 4 };
int[] y = x.clone();
x[0] = 0; // Deep copy になっているかのチェック// ちゃんとコピーされたか y を出力してみるSystem.out.println( "y = " + Arrays.toString( y ) );
// 多次元配列の場合int[][] A = { {1, 3, 0}, {-2, 4} };
int[][] B = new int[A.length][];
for(int i=0; i<A.length; i++) {
B[i] = A[i].clone();
}
A[0][0] = 0; // Deep copy になっているかのチェック// ちゃんとコピーされたか B を出力してみるSystem.out.println( Arrays.deepToString( B ));
}
}
clone メソッドの場合も、多次元配列には対応していないので、2次元配列は arraycopy と同様な書き方になります。ただ、コピー先の配列の大きさを宣言せずに済んでいる分プログラムが簡潔になっていますね。さて、コピーには2通りあることがわかりましたが、 arraycopy メソッドはあくまで配列のコピーのみです。一方、
cloneメソッドは後期に学ぶオブジェクト一般でのコピーに使えます。ただし、浅いコピーになっていないか?の判断が大事です。後期にまた触れることがあるかな?
2.19 文字列型2.19.1 文字型と文字列型
Java では、文字 'A' と文字列 "A" を区別しています。文字は基本型の一つでしたが、文字列は「参照型」というデータ型の一つです。参照型の目印は、型名の 1 文字目が大文字であることです ( String の S)。参照型についての

102 第 2章 Java 言語の基本的な文法 I
詳細は、またしても後期で。(^^;)
文字列を表すデータ型の基本は String クラスです。String クラスでは、文字列の情報を内部に char 型の配列として持っていますが、その配列を外から直接は扱えません。さて、参照型と言っても、これまでと同じようにリテラルや変数を宣言する方法は基本型と同じです。まず、String 型リテラルは、2重引用符 (ダブルクォーテーション) でくくられた「"はじめまして。"」のような文字列です (既に頻繁に出てきましたね)。そして、String 型変数もString hello; のように「型名 変数名;」と宣言します。そして、これらを 1 行にまとめて「String hello = "はじめまして。";」と書けるのも想像通りです。では、文字型 char 型と文字列型 String 型の違いは何でしょう。
• char 型は1文字の Unicode データを扱うためにある (整数のように扱える)。変更ができる• String 型は0文字以上の文字列を扱うためにあり、メソッドを持つ
0文字?そう「空文字列」と言って、"" と2重引用符の間に何も書かない String リテラルのことです。char 型で空文字 '' はダメですが、文字列は文字の入っていない文字列というのが宣言できるのです。もちろん、'a' と "a" は等しくありません。char 型は「変更できる」とわざわざ書いてあるのは、 String 方は「変更できない」ということでしょうか。次のプログラムを見て下さい。
ソースコード 2.88 StringvsChar.java (文字列と文字)
package section0219;
public class StringvsChar {
public static void main(String[] args) {
char a = 'a';
a = 'b';
System.out.println( a );
String s = "a";
s = "b";
System.out.println( s );
}
}
文字と文字列いずれにも初期値を与えて、その後で別の値を代入しています。どちらも変更しているように見えますね。しかし、これらは全く違う処理がおこなわれています (図 2.19.1 参照)。まず、文字型は一文字分の情報を入れられる領域が確保されて、そこへ文字を入れます (このプログラムでは 'a' )。その後、値が変更される場合もその場所に代入されます (文字 'b' が代入されて 'a' は消される)。
‘a’
a s
“a”
“b”
‘b’
図 2.27 文字列と文字の記憶方法の違い
一方、文字列ではその変数の領域に直接文字列が代入されるのではなく、別の場所に記憶されます (文字列 "a" が変数 s の中には置かれない)。そして、そこへのリンク (C 言語風に言うとポインタ:上の図では黒丸で表現) が格納

2.19 文字列型 103
されます。その上で、他の文字列を代入しようとすると、新たに別の場所にその文字列 (上では "b" ) を置いて、そこへのリンクを文字列変数 ( s ) に代入します。この時、先の文字列 ( "a" ) の場所で値を変更するわけではありません(文字列は一旦与えられると、変更はされない!という意味になります)。後期になったらもっと詳しく説明します。
2.19.2 文字列のメソッド
char 型と String 型の違いは、String 型がメソッドを持っていることです。次のプログラムを実行してみて下さい。ちょっと難しいかな!?
ソースコード 2.89 StringMethods.java (文字列のメソッドいろいろ)
package section0219;
public class StringMethods {
public static void main(String[] args) {
String name = "野田 愛";
int length = name.length(); // 文字列の長さを返すメソッドSystem.out.println( "\"" + name + "\" の文字数は、" + length + "文字" );
int sep = name.indexOf( " " ); // 文字列内のある文字列の位置を返すメソッドString familyName = name.substring(0, sep); // 文字列の一部を取り出すメソッドString firstName = name.substring(sep+1);
System.out.println( "氏:" + familyName );
System.out.println( "名:" + firstName );
}
}
String 型変数 name が length、indexOf、subString などのメソッドを持っていることがわかります。メソッドと持つことは String 型特有のことではなく、参照型の変数やリテラル全てが持っている性質です。length メソッドは、名前からも想像付きますが、文字列の長さを整数で返してくれるメソッドです。length() と引数には何も入れません。文字数を数える場合、全角文字も半角文字も区別しませんので、この場合は、4 を返してくれます。indexOf メソッドは、引数に与えた文字列が何文字目に最初に現れるかを返してくれます。文字列の先頭なら 0 が、見つからなければ −1 が返されます。今回は、半角のブランクが何文字目にあるか?を調べて、sep = 2 が求められています。subString は、文字列の一部分を文字列として返してくれるメソッドで、引数の与え方が 2 種類あります。引数を単独に与えると、それは部分文字列の開始位置を与えて、文字列の最後までを取り出します。例えば、"abcdefg".substring( 3 ) は "defg" となります (最初の文字が 0 文字目ですよ)。一方、引数が 2 つの場合、第 1 引数が、部分文字列の開始位置、第 2 引数の位置の 1 文字前までを取り出してくれます。例えば、"abcdefg".substring( 2, 5 ) は "cde" ですね。いろいろな場所でよく使う String 型、他にもたくさんのメソッドを持っているので、徐々に覚えて下さい。これら以外にも文字列のメソッドはいろいろ用意されているので、調べてみて下さい。
2.19.3 エスケープシーケンス
ところで、StringMethods プログラムで、見かけぬ文字列 「\"」が出てきました。出力結果と見比べると、これは2 重引用符のようです。実は、2 重引用符を文字列として出力しようとする (""") と、エラーになってしまいます。1
つ引用符が余ってしまうわけですね。そこで、文字列内に 2 重引用符を書くには \" とバックスラッシュ (¥マーク)
と対で書くのです。Java において、文字列内のバックスラッシュは特別な意味を持ち、「エスケープ文字」と呼びます。

104 第 2章 Java 言語の基本的な文法 I
そして、エスケープ文字+特殊文字の対で、通常の文字列では表せない特殊文字や制御機能を表したものを「エスケープシーケンス」と呼んで利用します (表 2.19.1 参照)。
エスケープシーケンス 意味 エスケープシーケンス 意味\b バックスペース \n 改行\r 復帰 (行頭に戻る) \t タブ文字\u Unicode (例:\u3042) \\ バックスラッシュ\' 1 重引用符 \" 2 重引用符
表 2.19.1 よく使うエスケープシーケンス
ところで、Windows と UNIX 系 (MacOS も含む) ではテキスト内の改行コードが違うのは「プログラミング入門」で習ったかな。以前は MacOS と UNIX 系 (Linux など) も違っていたのですが、MacOS が UNIX 系に合わせたので、現在は 2 種類の改行コードが存在します。それをエスケープシーケンスで表すと、Windows の改行は \r\n で、UNIX 系は \n となっています。自分と異なる OS 上の Java ファイルをもらってきた時に、文字コードは Unicode
になっていたけれど、改行コードが違っていたので、プログラムの表示が変に!ということがあります。そうした場合は、一旦そうしたコードを変更できるエディタにて改行コードを変更してから Eclipse にコピーしてくればきれいに表示できます。この程度は自力で対応できるようになりましょう。ちなみに、自分の Eclipse が文字コードや改行コードに何を使っているか、調べる方法は、メニューで「ウィンドウ>設定>一般>ワークスペース」と進んで、右の最下部の「テキスト・ファイルのエンコード」に UTF-8 とあれば、UNICODE が使われており、その右の「新規テキスト・ファイルの行区切り文字」でデフォルト Unix となっていれば、UNIX 系の改行コードがデフォルトとなっています。これらは、全体で設定することも、プロジェクトごとに設定することも、ファイルのタイプごとに設定することもできますが、あまりいろいろ変更すると、汎用性が無くなるので、全体で一致している方が良いでしょう。Eclipse はデフォルトを UNIX 系としているので、Windows からファイルを持ってくると結構文字化けする。 (^^;)
2.20 応用プログラム (配列の要素のソーティング)
ここでは、前期に習ってきたことを総動員して、基本的なデータ処理「データの並び替え (sorting) 」プログラムを作ることにします。後期では、Java API に既に含まれているデータ構造を用いて、再度、データの並び替えプログラムを作ってみようと思っています。全順序の定義できるデータにおいて、その順序に沿ってデータを並べることが、多くの場合で必要となります。デー
タを検索する場合にデータがソートされていれば、2分探索法のような高速な検索アルゴリズムが利用できます。ここでは、整数配列のデータを昇順 (小さい順) に並び替える何種類かの方法 (sorting method) を見ていきます。まずは、乱数整数の入った配列を作ったりする道具を用意しておきましょう。
ソースコード 2.90 MyTools.java (乱数作成などのツール集)
package section0220;
import java.util.Arrays;
public class MyTools {
/**
* 整数乱数配列の作成* @param n 配列の長さ* @param min 要素の最小値* @param max 要素の最大値

2.20 応用プログラム (配列の要素のソーティング) 105
* @return 整数乱数配列*/
public static int[] makeRandomIntArray( int n, int min, int max ) {
int[] array = new int[n];
for(int i=0; i<n; i++) {
array[i] = (int)( Math.random() * ( max - min + 1 ) ) + min;
}
return array;
}
/**
* 整数配列の出力* @param name 配列の名前* @param array 整数配列* @param n 表示個数:最初と最後から n 個分を表示。配列長が 2n 以下ならば全て出力*/
public static void printIntArray( String name, int[] array, int n ) {
System.out.print( name + ": " );
if( n*2 >= array.length ) { // 配列要素を全て書き出すSystem.out.println( Arrays.toString( array ) );
} else { // 配列の最初と最後の n 個ずつを書き出すSystem.out.print( "[" );
for(int i=0; i<n; i++) {
System.out.print( array[i] + ", " );
}
System.out.print( "..." );
for(int i=array.length-n; i<array.length; i++) {
System.out.print( ", " + array[i] );
}
System.out.println( "]" );
}
}
/**
* 整数配列内の2つの要素の交換* @param array 整数配列* @param i 交換する要素の番号1* @param j 交換する要素の番号2*/
public static void swap( int[] array, int i, int j ) {
int dummy = array[i];
array[i] = array[j];
array[j] = dummy;
}
}
printIntArray メソッドでは、Arrays クラスの配列を文字列化するメソッド toString() を使っています。詳細は後期に。
2.20.1 選択法 (Selection sort)
整数がランダムに入った配列の値を昇順に並び替えたいと思った時、まず思いつく方法が「最も小さい値を見つけて先頭に、2番目に小さな値を見つけて2番めの場所に」と順に決定していく方法かと思います。この際、もともと先頭にあった値と見つけた最小値の値と互いの位置の交換を行えば、与えられた配列以外に余分な領域が必要となりません。こうしたアルゴリズムが「選択法」です。

106 第 2章 Java 言語の基本的な文法 I
5 3 7 1 4 2 3 6
1 3 7 5 4 2 3 6
1 2 7 5 4 3 3 6
最小値1を見つけ、先頭5と交換する
次に小さな値2を見つけ、3と交換する
…
1 2 3 3 4 5 6 7
図 2.28 選択法によるソート
ソースコード 2.91 SortingExample.java (選択法によるソート)
package section0220;
public class SortingExample {
public static void main(String[] args) {
// 区間 [1,1000] 内の整数 1000 個の乱数配列を作成int[] data = MyTools.makeRandomIntArray( 1000, 1, 1000 );
MyTools.printIntArray( "乱数整数配列", data, 5 );
/*
* 元配列をイジらずに別の配列にコピーする* パラメータ:* 元配列名、コピーする最初の要素位置、* 新配列、格納される最初の要素位置、コピーする要素数*/
int[] array = new int[data.length];
System.arraycopy( data, 0, array, 0, data.length );
// 選択法long startTime = System.nanoTime();
ArraySorting.selectionSort( array );
long endTime = System.nanoTime();
MyTools.printIntArray( "選択法の結果", array, 5 );
printTime( endTime - startTime );
}
// 経過時間の出力private static void printTime( long time ) {
System.out.printf( " 実行時間: %10d nsec (10^-9 sec)%n", time );
}
}
ソースコード 2.92 ArraySorting.java#selectionSort (選択法)
package section0220;
public class ArraySorting {
/**
* 選択法 (Selection method)
* @param array ソートする整数配列*/
public static void selectionSort( int[] array ) {
for(int i=0; i<array.length - 1; i++) {
int min = i;
for(int j=i+1; j<array.length; j++) {

2.20 応用プログラム (配列の要素のソーティング) 107
if( array[j] < array[min] ) min = j;
}
MyTools.swap( array, i, min );
}
}
}
こうしたアルゴリズムの評価については2年生のコンピュータ数学基礎などで学ぶことになりますが、直感的には、計算時間が早く・使用メモリー量が少ないものが良いアルゴリズムと言えるでしょう。そこで、上記のプログラムではSystem.nanoTime() メソッドを利用して、ソート処理の前後で時刻を取り出し、その差で経過時間を求めています。一方、使用メモリー量は、乱数配列以外には min,i,j などのデータ数に依存しない定数個の変数を使っているのみです。ただし、Java で時間測定するのはなかなか難しい問題が多く (それについては後に書くつもりですが)、簡単には結果を出すことは出来ません。選択法は、一つの場所に入る要素を決定するのにその場所以降の全ての要素での比較が必要となり、決して良いアルゴリズムとは言えません。ただ、プログラムは簡潔なのでメモリの少ない環境で配列の大きさが小さいときには利用の価値がアリます。
2.20.2 挿入法 (Insertion sort)
次に思いつきそうなアルゴリズムは、トランプの手札を揃える時に無意識に行う並び替えで、既に整列した列に新たなカードを挿入していく方法です。トランプの手札では気になりませんが、1枚を挿入するには、整列済みの部分に1つ空きを作らねばならないので、その位置以降の要素を移動させないといけません。この移動回数は、列の先頭に要素を挿入する場合に最も多くなります。また、容易に想像がつきますが、逆順に並んでいる列を並び替えする時に最悪の移動回数となりますね。
1 3 5 7 4 2 3 6
1 3 4 5 7 2 3 6
1 3 4 5 7 2 3 6
1 2 3 4 5 7 3 6
既に整列の済んでいる部分に
新たに4を挿入する
4を挿入するには、7と5を
移動させて空きを作ってから
次は2を挿入するので、4つ
の値を移動させる
図 2.29 挿入法によるソート
ソースコード 2.93 SortingExample.java#main (追加:挿入法によるソート)
// main メソッド内、選択法の後ろに以下を追加
System.arraycopy( data, 0, array, 0, data.length );
// 挿入法startTime = System.nanoTime();
ArraySorting.insertionSort( array );
endTime = System.nanoTime();

108 第 2章 Java 言語の基本的な文法 I
MyTools.printIntArray( "挿入法の結果", array, 5 );
printTime( endTime - startTime );
ソースコード 2.94 ArraySorting.java#selectionSort (挿入法)
// 選択法 (selectionSortメソッド) の後ろに以下を追加/**
* 挿入法 (Insertion method)
* @param array ソートする整数配列*/
public static void insertionSort( int[] array ) {
for(int i=1; i<array.length; i++) {
int val = array[i];
int j = i;
while( j > 0 ) {
if( array[j-1] <= val ) break;
array[j] = array[j-1];
j--;
}
array[j] = val;
}
}
2.20.3 泡立ち法 (Bubble sort)
バブルソートと言う名前を聴いたことのある人もいるかと思います。配列内を要素が泡のように一方向に移動していく様子から付いた名前です。泡立ち法は、泡の動く向きが配列前方へのバージョン (最小値が最初に先頭に移動) と後方へのバージョン (最大値が最初に最後尾に移動) の2種類があります。ここでは、後方へのバージョンのプログラムを紹介します。泡立ち法は、隣り合う要素の大小比較を前から順に行い、逆転している場合は2要素を交換し、最後尾まで走査します。1回目の走査が終わった時点で配列内の最大値が最後尾に移動しているのですが、OKですか。さらに、2回目の走査を、最後尾を除いた要素で行います。その結果、配列内の後ろから2番目に2番目に大きな値が置かれる(これもOK?)、以下同様にしていく、というものです。
5 3 7 1 4 2 3 6
3 5 7 1 4 2 3 6
3 5 1 7 4 2 3 6
隣り合う2つを比較、順序が逆のとき交換する
順に比較していくと、途中から最大値が
右に移動を始める
…
3 5 1 4 2 3 6 71回目の走査で、最大値が最後尾に
次は、残りの要素で再度走査を行う
図 2.30 泡立ち法によるソート

2.20 応用プログラム (配列の要素のソーティング) 109
ソースコード 2.95 SortingExample.java#main (追加:泡立ち法によるソート)
// main メソッド内、挿入法の後ろに以下を追加
System.arraycopy( data, 0, array, 0, data.length );
// 泡立ち法startTime = System.nanoTime();
ArraySorting.bubbleSort( array );
endTime = System.nanoTime();
MyTools.printIntArray( "泡立法の結果", array, 5 );
printTime( endTime - startTime );
ソースコード 2.96 ArraySorting.java#bubbleSort (泡立ち法)
// 挿入法 (insertionSortメソッド) の後ろに以下を追加/**
* 泡立ち法 (Bubble sorting method)
* @param array ソートする整数配列*/
public static void bubbleSort( int[] array ) {
for(int i=array.length - 1; i>=1; i--) {
for(int j=0; j<i; j++) {
if( array[j] > array[j+1] ) MyTools.swap( array, j, j+1 );
}
}
}
選択法や挿入法との違いは、とにかく2つの要素の交換がメインであるということです。つまり、交換処理の手間に依存するソート法です。
2.20.4 クィックソート (Quicksort)
分割統治法 (Divide and Conquer method) というアルゴリズムのグループのソート版、クィックソートやマージソートは、ここまでに述べたソート法より一般に高速なアルゴリズムと言われます。1960年に発表された「クィックソート」は、次の2つの処理を再帰的に繰り返して配列全体をソートする方法です。
• ソート対象部分からピボット (あるいはスプリッタ) と呼ばれる値を決め、ピボットより小さい値を対象部分の前方に、大きい値を対象部分の後方に移動 (分割) させる
• 分割された2つの部分列をそれぞれをソートする
このソート法の効率を考える時、問題となるのはピボットの値をどのように決めるかです。理想状態は、毎回のピボットが列の中の値の中央値 (大きさの順に並べた時の真ん中の値) を選択できれば最適なわけですが、例えば、毎回ソートする列の最小値をピボットに選んでしまうと、ピボットより小さな値の前方の列は空列・ピボットより大きな値の後方の列はピボットの1つを除いただけの列と、2分割する効果が全くなくなってしまいます。では、どうやって、中央値に近い値をピボットとするかですが、今回のプログラムのように先頭と中央と最後尾の3つの値の平均値とするとか、ランダムに数個選んで平均を取るとか、その配列のデータの持つ性質を考慮して決めることになるでしょう。ソートする前に列をランダムに並び替えしてピボットが偏らないようにする、なんてのもあるようです。
ソースコード 2.97 SortingExample.java#main (追加:クィックソートによるソート)
// main メソッド内、泡立ち法の後ろに以下を追加

110 第 2章 Java 言語の基本的な文法 I
5 3 7 1 4 2 3 64
3 3 2 1 4 7 5 6
3 3 2 1 4 7 5 6
ji
ji
left rightcenter
3 3 2 1 4 7 5 6
左より center より大きな値、
右より center より小さな値
を見つけては交換する操作を
すれ違うまで行う
分割した列ごとに、再帰的に
クィックソートを施していく
図 2.31 クィックソートによるソート
System.arraycopy( data, 0, array, 0, data.length );
// クィックソートstartTime = System.nanoTime();
ArraySorting.quickSort( array );
endTime = System.nanoTime();
MyTools.printIntArray( "quickの結果", array, 5 );
printTime( endTime - startTime );
ソースコード 2.98 ArraySorting.java#quickSort (クィックソート)
// 泡立ち法 (bubbleSortメソッド) の後ろに以下を追加/**
* クィックソート (Quick sorting method)
* @param array ソートする整数配列*/
public static void quickSort( int[] array ) {
quickSort( array, 0, array.length - 1 );
}
private static void quickSort( int[] array, int left, int right ) {
if( left >= right ) return;
int center = (array[left] + array[(left + right)/2] + array[right])/3;
int i = left;
int j = right;
while( i<= j ) {
while( array[i] < center ) i++;
while( array[j] > center ) j--;
if( i <= j ) {
MyTools.swap( array, i, j );
i++;
j--;
}
}
quickSort( array, left, j );
quickSort( array, i, right );
}

2.20 応用プログラム (配列の要素のソーティング) 111
2.20.5 ヒープソート (Heap sort)
配列内のデータは物理的に連続した領域に格納されていますが、物理構造とは別の論理的な順序と対応させて処理させることができます。ここで学ぶヒープソートは、配列内のデータを「ヒープ木 (Heap tree)」という論理構造と見ながら行うソーティング法です。
5 6 3 8 1 9 2 7 3 4
5
6 3
8 1 9 2
7 3 4
[0] [1 ] [2 ] [3 ] [4 ] [5 ] [6 ] [7 ] [8 ] [9 ]
[0]
[1] [2]
[3] [4] [5] [6]
[7] [8] [9]
図 2.32 配列と2分木
ヒープ木を学ぶ前に、まず「木構造」という論理構造を見ます (これらの話は2年生以降に詳しく学ぶかと思います)。木構造 (tree structure) とは、図 2.32 のような「木を逆さまにしたような構造」で、最も上のノードを「根 (root) 」、最も下の (子ノードを持たない) ノードたちを「葉 (leaces)」と呼び、それ以外のノードを「内点 (inner node)」と呼びます。上下で直接つながっているノードにおいて、上を「親ノード」下を「子ノード」、同じ親ノードの子供たちを「兄弟ノード」、一般には兄弟のノード間の位置は問わないのですが、位置まで考える場合は、兄弟で左側を「兄ノード」右側を「弟ノード」と呼びます。あるノードからその子供たち、またその子供たちと下方に連結したノード全体を「そのノードを根とする部分木」と呼びます。葉ノード以外のノード (根と内点) がいずれも子ノードを高々2つしか持たないような木構造を「2分木 (binary
tree)」と呼びます。配列におけるデータ処理に木構造を持ち出す場合、兄弟ノードの左右の位置関係も考慮し、各配列の位置と木構造内のノードの位置を対応させます。一般には配列の番号順に、根から葉へ向かって左から右へ対応させます (図 2.32 参照)。ここでは、配列における番号を2分木のノード番号と呼ぶことにします。そのとき、2分木における親ノードと子供ノードの番号は、以下の関係になります。
左の子の番号 = 親の番号 ∗ 2 + 1
右の子の番号 = 左の子の番号+ 1
問題 2.20.1. 上の式を証明しなさい。そして、ノードの数が n の2分木において、子ノードを持つ内点の数は根も含んで、⌊n/2⌋ であることを示しなさい。ここで、⌊·⌋ はガウス記号 (整数への切り捨て関数) です。
ヒープ木は、全ての点においてヒープ性「親の持つ値がその子供たちの持つ値以上である」を満たす2分木です。適

112 第 2章 Java 言語の基本的な文法 I
当に与えられた配列を2分木表現しても、一般にはヒープ条件を満たしてはいません。しかし、とりあえず何らかの方法でヒープ木に変換できたとすると、根 (つまり配列の先頭) には配列内の最大値が入っていることになります (つまり、ヒープ木を作ると最大値が先頭に現れる)。そこで、この最大値をヒープ木から除いて再度ヒープ木を修復する繰り返しを行うことで、降順に値を取り出すことが出来るはずです。では、取り除く最大値をどうするかですが、本来ソート完了時に配列の最後尾にあるべき値ですから、配列の最後尾 (ヒープ木における最後の葉) の値と交換してしまいます。ただ、こうすると根に移動した値がたぶんヒープ性を壊してしまいます。そこで、再度 (最後尾のノードを除いたノードたちで) ヒープ木の修復を行います。この結果、今度は2番目に大きな要素が根に現れます。これを最後尾の1つ前の値と交換します。以下、これを繰り返していけば、配列の後ろから順に値が決まっていくというわけです。さて、もともとはヒープ性を持っていた2分木の根の値が変わったためのヒープ木の修復方法は以下となります:
1. 根を修復点とする。2. 修復点が葉となるまで、以下を繰り返す:(a)修復点とその子供たちの中での最大値を誰が持つかを調べる。(b)修復点が最大値を持っていたら、終了する。(c)最大値を持つ子ノードと修復点の間で値を交換し、その子ノードを新たな修復点とする。
一方、最初に行うヒープ木の作成はと言うと、このヒープ木の修復法を「子を持つ最も番号の大きな点」[n/2] 番から 根 [0] 番まで1ノードずつさかのぼりながら、その点を根とする部分木上で修復操作を実行することで行います。(図 2.32 において、点 [4] から点 [0] まで)
問題 2.20.2. 上記の操作で、ヒープ木が完成されることを証明しなさい。
ソースコード 2.99 SortingExample.java#main (追加:ヒープソートによるソート)
// main メソッド内、クィックソートの後ろに以下を追加
System.arraycopy( data, 0, array, 0, data.length );
// ヒープソートstartTime = System.nanoTime();
ArraySorting.heapSort( array );
endTime = System.nanoTime();
MyTools.printIntArray( "heap の結果", array, 5 );
printTime( endTime - startTime );
ソースコード 2.100 ArraySorting.java#heapSort (ヒープソート)
// クイックソート (quickSortメソッド) の後ろに以下を追加/**
* ヒープソート (Heap sorting method)
* @param array ソートする整数配列*/
public static void heapSort( int[] array ) {
buildHeap( array );
for(int i=array.length-1; i>0; i--) {
MyTools.swap( array, 0, i );
heapUpdate( array, 0, i );
}
}

2.20 応用プログラム (配列の要素のソーティング) 113
private static void buildHeap( int[] array ) {
for(int i=array.length/2-1; i>=0; i--) {
heapUpdate( array, i, array.length );
}
}
private static void heapUpdate( int[] array, int parent, int last ) {
int left_child = 2 * parent + 1;
int right_child = left_child + 1;
int largest = parent;
if( left_child < last && array[left_child] > array[largest] ) largest =
left_child;
if( right_child < last && array[right_child] > array[largest] ) largest =
right_child;
if( largest != parent ) {
MyTools.swap( array, parent, largest );
heapUpdate( array, largest, last );
}
}
配列の長さ n に対し、最初のヒープ木を作成する際に O(n log n)、後半のヒープ木の修復反復も O(n log n) の時間計算量が掛かることが予想されます (詳しくは2年生以降ですね)。
2.20.6 マージソート (Merge sort)
既にソートされた配列2本を1本のソート列に合体させる操作をマージと言います。最も小さなソート列「1要素だけの列」から初めて、2要素の列のマージ、4要素の列のマージ、とマージする列の長さを倍にしながらマージを繰り返すことで、1本のソートされた配列を作るアルゴリズムがマージソートです。マージソートは、マージ操作を単純にするために、元配列と同じ大きさの配列をもう1本用意しなければなりません。従って、メモリの少ない環境には向いていないソート法です。ところで、クィックソート以降に説明しているソート法は最初に紹介した単純なアルゴリズム3種類とは異なり、複雑なアルゴリズムで、アルゴリズムの効率化による効果も大きいため、参考書やネットに紹介されている方法が微妙に異なっていたりします。このマージソートも、大きさ k のマージが全て終わってから大きさ 2k のマージに取り掛かるのではなく、k の列が2本でき次第、大きさ 2k のマージを行ってしまう、という方法も考えられます (他にもいろいろ)。
ソースコード 2.101 SortingExample.java#main (追加:マージソートによるソート)
// main メソッド内、ヒープソートの後ろに以下を追加
System.arraycopy( data, 0, array, 0, data.length );
// マージソートstartTime = System.nanoTime();
ArraySorting.mergeSort( array );
endTime = System.nanoTime();
MyTools.printIntArray( "mergeの結果", array, 5 );
printTime( endTime - startTime );
ソースコード 2.102 ArraySorting.java#mergeSort (マージソート)
// ヒープソート (heapSortメソッド) の後ろに以下を追加/**
* マージソート (Merge sorting method)

114 第 2章 Java 言語の基本的な文法 I
5 3 7 1 4 2 3 6
3 5 1 7 2 4 3 6
1 3 5 7 2 4 3 6
1 2 3 3 4 5 6 7
array
array2
array
array2
1 2 3 3 4 5 6 7array
図 2.33 マージソートによるソート
* @param array ソートする整数配列*/
public static void mergeSort( int[] array ) {
int[] array2 = new int[array.length];
int size = 1;
while( size < array.length ) {
merge( array, array2, size );
merge( array2, array, 2 * size );
size *= 4;
}
}
private static void merge( int[] from, int[] to, int size ) {
int start = 0;
while( start < from.length ) {
int k = start;
int i = start;
int j = start + size;
int iend = Math.min( start + size, from.length );
int jend = Math.min( start + 2 * size, from.length );
while( i < iend && j < jend ) {
if( from[i] < from[j] ) to[k++] = from[i++];
else to[k++] = from[j++];
}
while( i < iend ) to[k++] = from[i++];
while( j < jend ) to[k++] = from[j++];
start += 2 * size;
}
}

2.20 応用プログラム (配列の要素のソーティング) 115
2.20.7 シェルソート (Shell’s sort)
挿入法がほとんど整列された配列に対しては高速である一方で、あまり整列が進んでいない配列においては隣り合う要素同士の交換しか行わないので低速であることを逆手に取って、D.L.Shell が 1959年に発表したソート法である。まず、遠い要素同士を挿入法のアルゴリズムでソートし、徐々に間を狭くしていく。飛び飛びの要素の間隔の取り方で計算量は変わってしまうが、要素の間隔 hをデータ数 nに対し、点列 {hi} : hi+1 = 3hi+1, h1 = 1, hi < nの最大値から順に減らしながら取ると、O(n1.25) であることが Knuth によって示されています。({hi} = {1, 4, 13, 40, 121, 364, . . . })
5 3 7 1 4 2 3 6
4 2 3 1 5 3 7 6
h = 4 離れた(同じ色)同士で挿入法ソートを実行
h = 1 : デフォルトの挿入法を実行
1 2 3 3 4 5 6 7
図 2.34 シェルソートによるソート
ソースコード 2.103 SortingExample.java#main (追加:シェルソートによるソート)
// main メソッド内、マージソートの後ろに以下を追加
System.arraycopy( data, 0, array, 0, data.length );
// シェルソートstartTime = System.nanoTime();
ArraySorting.shellSort( array );
endTime = System.nanoTime();
MyTools.printIntArray( "Shellの結果", array, 5 );
printTime( endTime - startTime );
ソースコード 2.104 ArraySorting.java#shellSort (シェルソート)
// マージソート (mergeSortメソッド) の後ろに以下を追加/**
* シェルソート (Shell's sorting method)
* @param array ソートする整数配列*/
public static void shellSort( int[] array ) {
int h = 1;
while( h < array.length / 3 ) {
h = 3 * h + 1;
}
while( h > 0 ) {
for(int i=h; i<array.length; i++) {
int dummy = array[i];
// ここから:h飛びの挿入法int j = i;
while( j > h-1 && array[j-h] >= dummy ) {

116 第 2章 Java 言語の基本的な文法 I
array[j] = array[j-h];
j -= h;
}
array[j] = dummy;
// ここまで}
h = (h - 1)/3;
}
}
2.20.8 Java における時間測定について
ここまで、いろいろなソーティングアルゴリズムを紹介し、それらを同じデータに対する経過時間で比較してみましたが、果たしてこの実験結果はどれほどの信頼性があるのでしょうか。また、果たして、この経過時間は正確なのでしょうか。まず、Java において測定できる時間には、次の2種類があります。
• System.currentTimeMillis():ミリ秒単位での測定 (1 msec = 10−3 sec)
• System.nanoTime():ナノ秒単位での測定 (1 nsec = 10−9 sec)
currentTimeMillis() が現在の時刻に関連したミリ秒単位の値を返すのに対し、nanoTime() は時刻とは無関係な時間測定のためのナノ秒単位の値を返します。但し、API ドキュメントを読んでみると、必ずしも解像度がナノ秒であるという保証は無いとあります。とりあえず、プログラムの計測を行うのにミリ秒単位は利用価値が無いでしょうから、ナノ秒での測定について見ていきましょう。なお、こうしたプログラムの性能評価のことを、「ベンチマークテスト」と言います。
ソースコード 2.105 TimePrecisionExample.java (時間測定)
package section0220;
public class TimePrecisionExample {
public static void main(String[] args) {
final int N = 1000000;
int count = 50;
int x = 0;
for(int k=0; k<count; k++) {
long startTime = System.nanoTime();
for(int i=0; i<N; i++) {
x++;
}
long endTime = System.nanoTime();
System.out.printf( "%d nsec%n", (endTime - startTime) );
}
System.out.println( "x = " + x );
}
}
上記のプログラムを以下の2種類のマシーンで実行した結果が表 2.20.1 です。なお、こうした測定を行う場合は、他の要因が少しでも少なくなるように、他のアプリを停止したり、ネットから切断して実行しましょう。
• Windows 10 Pro / Intel Core i5-3337U 1.80GHz
• MacOS X 10.11.6/ Intel Core i7 2.20GHzz

2.20 応用プログラム (配列の要素のソーティング) 117
結果から読み取れることは何でしょうか?まず、実験自体は毎回同じ処理 (変数 x に 1 を N 回加える繰り返し) をしているはずです。従って、理論上は毎回同じ測定時間になるはずですね。しかし、いずれの場合も、最初の数回は極端に時間がかかっています。これは、Java がプログラムを開始するに際し、何らかの追加的な仕事を処理とは別に行っているということですね。Java は中間言語に翻訳された class ファイルをインタプリタが JVM 内で実行します。そのとき、クラスの設定、フィールド (変数) の確保等々、最初にいろいろな仕事をしなければいけません。それをやりながらプログラムは実行をしているので、初期の処理は本来の実行速度が測れないのです。その後、いずれのパソコンでも安定して同じような処理時間 (Windows が 0、Mac が 38) が続きます。処理をやっ
ているのですから、0 nsec ということはありえませんから、パソコンのタイマーが進む以前に終わってしまったということですね。では、Windows が MacOS より圧倒的に早いのでしょうか?いえ、Windows の値を見ると、時々 570
くらいの数値が顔を出します。つまり、タイマーは 0 nsec の次 (?) に大きな値として 570 nsec を測定できるけれど、その間の値は測定できないのでは (?) と考えられます。同様に MacOS の場合も、似通った値が飛び飛びに現れています。
k 0 1 2 3 4 5 6 7 8 9 10 11
Windows 7842292 6009725 2638235 570 0 6676269 2779070 0 0 0 0 0
MacOS X 2251628 4580460 125 38 38 38 39 38 38 39 38 38
k 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
Windows 0 0 0 0 571 0 0 0 570 0 0 0 0 0 0 0 0
MacOS X 38 38 38 38 39 38 38 38 38 26 72 38 39 38 38 38 38
表 2.20.1 Java による時間測定
表 2.20.2 では、繰り返し回数 N を変えて測定してみました。何と、N を増やすと測定時間 0 が現れます。このことは、繰り返し回数を増やすと、何らかの最適化が行われて、実際は繰り返しを行わないという結果になっていると考えられます。Java のコンパイラは、単純作業に対して最適化を行うので、それが時間測定の難しさにもなっています。Java のベンチマークテストについての詳細な説明が、以下のページで解説されていますので、参考にしてみて下さ
い。>「確実な Java ベンチマーク」(https://www.ibm.com/developerworks/jp/java/library/j-benchmark1.html)

118 第 2章 Java 言語の基本的な文法 I
n 0 1 2 3 4 5 6 7 8
10 1710 570 0 570 570 570 570 570 0
100 1710 1711 1141 1140 2281 1141 1140 1141 1141
1000 15395 14825 11973 11404 11974 11403 11404 11404 11404
10000 119169 116887 115747 116317 135703 116888 124870 115747 115177
100000 1732785 330135 283951 278249 608385 440181 441322 392286 466980
1000000 7842292 6009725 2638235 570 0 6676269 2779070 0 0
10000000 4146368 6632934 0 7951767 0 0 0 0 0
n 9 10 11 12 13 14 15 16 17 18
10 571 570 570 570 570 570 570 570 570 570
100 1140 5131 1140 2281 1711 1710 2281 1710 1140 1711
1000 11404 11404 10834 11404 13114 19957 19956 20526 19387 19956
10000 115176 115177 132283 49036 43334 46755 852993 46755 48465 41053
100000 433909 741237 80395 0 1579976 684790 436760 477243 476103 367197
1000000 0 0 0 0 0 0 0 571 0 0
10000000 0 570 0 0 570 0 0 0 0 0
表 2.20.2 配列の長さを変えて時間測定 (Windows)

2.21 第 2 章のまとめ 119
2.21 第 2 章のまとめまとめ、と言ってますが、ここまでに学んだことで解決可能な問題を並べていこうと思います。
問題 2.21.1. 次の代入文の最終的な結果を書きなさい。
1. int a = 123 / 4 % 8;
2. double x = (double) 123 / 4;
3. int a = 1; int b = 2; String s = "2つの和は、" + a + b;
4. int a = 10; int b = a++;
5. int a = 12; a /= 5;
問題 2.21.2. 次のプログラムは与えられた整数配列の要素の平均値を計算して出力するつもりのものです。しかし、間違いだらけで動きません。また (文法エラーではないけれど) やるべきでないことも入っているので、それも含めて全ての間違いを指摘しなさい。
ソースコード 2.106 WrongAverage.java (間違いだらけの平均値)
pakage section0220;
pablic class WrongAverage {
pablic void mein(String[] args) {
int a = { 1, 3, -2, 5, 2, 0, 9 };
int i;
for(i=1; i<=7; i++) {
int sum += a[i];
};
double average = sum / a.length;
system.out.println( "平均は", average, "です" );
}
}
問題 2.21.3. 線形代数で利用できそうな、行列の行の交換プログラムを作ってみましょう。
ソースコード 2.107 SwapRowOfMatrix.java (行列の行の交換)
package section0221;
public class SwapRowOfMatrix {
public static void main(String[] args) {
int[][] A = {{1, 2, 3, 4}, {5, 6, 7, 8}, {9, 10, 11, 12}};
int i = 0;
int j = 2;
// 以下に行列 A の i 行目と j 行目の値を交換する処理を作って下さい
// printf を使って、縦横を揃えて出力しています

120 第 2章 Java 言語の基本的な文法 I
for(int i=0; i<A.length; i++) {
for(int j=0; j<A[i].length; j++) {
System.out.printf( "%3d", A[i][j]);
}
System.out.println();
}
}
}
できましたか?ここまで良く理解できていれば楽勝かと思うのですが。さて実は、このプログラム、もっと簡単な書き方ができます。この部分、追記予定!
問題 2.21.4. 次の各説明文に対し、◯や△に当てはまる単語 (カタカナ)や記号を下線部に書きなさい。
1. 改行のような特殊文字を表すために使われるもので、\ 記号との組み合わせで特殊な文字を表す。それらの文字列を◯◯◯◯◯シーケンスと呼ぶ。
2. プログラムソースを読みやすくするために、命令文を右に数文字分、字下げする行為を◯◯◯◯◯させると言う。
3. プログラム中にプログラムの説明を書くためのコメント文には 3 種類あるが、一般に複数行に渡るコメントは、最初の行を ◯◯ で始め、最後の行を △△ で終わらす。
◯◯ = , △△ =
4. 例えば、浮動小数点数を整数型変数に代入することは、一般にエラーとなって実行できないが、情報の損失を覚悟の上で強制的に代入させることができる。その操作を浮動小数点数を整数に◯◯◯◯させると言う。
5. Java言語では、複数の単語を連結して 1 つの変数名を作るとき、2 つ目以降の単語の先頭文字だけを大文字にしてつなげる◯◯◯◯形式がよく用いられる。
6. 整数変数 a の値を 1 増やす単項演算子の ++ のことを ◯◯◯◯◯◯◯ と言い、前置と後置の 2 種類がある。
問題 2.21.5. 以下の繰り返しを行う for 文の宣言部 ( for(項目 1; 項目 2; 項目 3) ) をそれぞれ書きなさい。
1. 整数カウンタ i を 0 から 100 までの偶数のみ昇順で:つまり、i = 0, 2, 4, · · · , 1002. 整数カウンタ i を 5 から 1000 まで 5 の倍数で:つまり、i = 5, 10, 15, 20, · · · , 10003. 整数カウンタ i を 1 から 10000 まで、毎回、前回の 5 倍で:つまり、i = 1, 5, 25, 125, 625, 3125
4. 浮動小数点数カウンタ x を 0.0 から 1.0 まで 0.01 刻みで:つまり、x = 0.0, 0.01, 0.02, · · · , 1.0 (この場合、計算誤差で x は 1.0 に等しくなるとは言えないが)

2.21 第 2 章のまとめ 121
問題 2.21.6. 以下のようにキーボードから入力された整数値 n に対して、次のような一連の操作をするプログラムを作りなさい。途中で利用する変数名は自由に付けてよい。
1. キーボードからベクトルの要素数 n を読み込む。2. Math.random() を用いて n 次元の [0, 1) の乱数値による実ベクトル x = (x1, x2, · · · , xn) を作る。
3. ベクトルの長さ ∥x∥ を求める。 ∥x∥ =
Ãn∑
i=1
x2i
4. x と方向が等しく長さ 1 の実数ベクトル y を作る。 y =x
∥x∥5. y の値をコンソールに出力する。
ソースコード 2.108 VectorNormalize.java (ベクトルの正規化)
package section0221;
import java.util.Scanner;
public class VectorNormalize {
public static void main(String[] args) {
// (1)
Scanner scan = new Scanner(System.in);
System.out.println("ベクトルの要素数を入力して:");
int n = scan.nextInt();
// この後に、指示の処理 (2)(3)(4) の内容を書く
// (5)
System.out.println( "作成した長さ1のベクトル:");
for(int i=0; i<n; i++) {
System.out.println( "y[" + i + "]=" + y[i] );
}
}
}
問題 2.21.7. nCm:n 個の要素から m 個を取り出す組み合わせの数を求めるプログラムを作る。以下のように n を与えた時、コンソールに nC0, nC1, nC2, . . . , nCn−1, nCn を計算して出力するプログラムCombination.java を完成させなさい。なお、出力は (n,m) で nCm を意味するとする。なお、組み合わせ数は大きな数になりがちなので、long 型整数変数を用いた。ところで、このプログラムでコケずに動く最大の n は幾つだろう。
ソースコード 2.109 Combination.java (組み合わせ数)
package section0221;
import java.util.Scanner;
public class Combination {
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);

122 第 2章 Java 言語の基本的な文法 I
System.out.println("n を入力して:");int n = scan.nextInt();
for(int m=0; m<=n; m++) {
// ここに、nCm を計算して変数 comb に代入する処理を書くlong comb =
// 計算された組み合わせ数 comb を出力するSystem.out.println( "(" + n + "," + m +")=" + comb );
}
}
}
問題 2.21.8. 以下の公式は、指数関数 ex のマクローリン展開です。この公式を用いて、e = e1 を求めて下さい。
ex =∞∑
n=0
xn
n!
n = 0から nを1ずつ増やして 1
0!+
1
1!+
1
2!+ · · ·+ 1
n!と和を求めていって、ある項を加えてもその前の和と変わらなく
なったら(どんどん小さくなる値を加えていくので、最後は数を加えても和の値が変化しなくなります。これを丸め誤差と言います)、そうしたら新たな項を加えることをやめて、結果を出力します。この繰り返しは何回になるか事前にはわかりません、つまり for 文での繰り返しには向かないということですね。ちなみに、e = 2.7182818284590452354 · · ·です。
ソースコード 2.110 Maclaurin.java (マクローリン展開によるネイピア数 e の計算)
package section0221;
public class Maclaurin {
public static void main(String[] args) {
double x = 1.0;
// ヒント全くなしで、出来ますかね?// マクローリン展開を用いて 2.71828... の近似値が// 求められれば、多少の計算のムダなどは目をつぶりましょう
}
}
2 年生になるとこうした数値計算をしっかりやりますよ。
問題 2.21.9. 次の関数の x ∈ [1, 3] での定積分の値を求めたいのですが、関数の積分ができない。(^^;)
f(x) = sin(ecos x−x log x
)−→
∫ 3
1
f(x) dx
そこで、数値積分(もどき)を以下のように行って、定積分の値を求めなさい。
• double型変数 dx = 0.0001; sum = 0; とし、for(double x = 1; x<=3-dx; x+=dx)の繰り返しを行って

2.21 第 2 章のまとめ 123
• sum += f(x)*dx を繰り返し加えていき、• sum の値を定積分の結果として、出力する
なお、特殊関数は以下のようにMath クラスのメソッドを使って書きなさい。1. sin(x)→ Math.sin( x ); 2. cos(x)→ Math.cos( x ); 3. log(x)→ Math.log( x );
4. ex → Math.exp( x );
ちなみに、Mathematica による定積分の結果は 0.6382071777 でした。そして、関数の概形は下のようになります。ただし、dx = 0.0001 では細かすぎるので、ここでは dx = 0.1 にて図示しています。この点線による櫛形面積の合計が dx を小さくしていくほどに定積分の値に近づきます。
0.5 1.0 1.5 2.0 2.5 3.0
-0.5
0.5
1.0
問題 2.21.10. この問題も数値積分を確率で求める方法(モンテカルロ法)についてです。面積を求めたい領域 R が、面積が既知の領域 T に含まれるとき、T 内でランダムに点を発生させ、それが領域 R 内に入る確率 p を求めることができれば、R の面積は、T の面積の p 倍で近似できます。今、下図のように (0, 0), (1, 0), (1, 1), (0, 1) の 4 点で囲まれる正方領域を T とし、T 内の原点を中心とした半径 1 の円内 (紫色の部分)を R とする。T 内で、乱数点 (x, y) を 100, 000 回発生させて、その点が R に含まれる回数をカウントし(原点からの距離が 1 以下かを調べればよい)、それを 100, 000 で割れば、確率 p が求まり、T が面積 1 なので R の面積は p と求まります。この実験で、π を数値的に求めなさい(R の面積が π/4 となることから . . .)。乱数は、メソッド Math.random() を用いましょう(ちょっと数学的には怪しいのですが)。このメソッドは [0, 1)
の double 型の値をランダムに発生させることになっているので、double x = Math.random(); と double y =
Math.random(); で点 (x, y) の座標が求められます。

124 第 2章 Java 言語の基本的な文法 I
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
ソースコード 2.111 MonteCarlo.java (モンテカルロ法によるπの計算)
package section0221;
public class MonteCarlo {
public static void main(String[] args) {
int count = 100000; // 乱数発生回数// 以下に、count 回、乱数による2次元座標を発生させ、// 原点からの距離が 1 以下になる回数を数えて、// 確率 p を求め、それを 4 倍すれば、π を数値的に求めたことになります
}
}
問題 2.21.11. 2 つの単調増加列 (昇順、同じ要素が複数入っていても良い) の整数値配列 a と b があるとき、新らたな整数値配列 cに aと bの要素を小さい順に選びながら格納して、1つの単調増加列を作るプログラムMargeArrays.java
を作りなさい(この処理を配列のマージという)。注意:ループを使うけど、2 重ループにはならない。また、配列 a
と b がどんな場合でも正しく動くプログラムになるように。
ソースコード 2.112 MargeArrays.java (2つの数ベクトルのマージ)
package section0221;
import java.util.Arrays;
public class MargeArrays {
public static void main(String[] args) {
int[] a = { 2, 5, 7, 8, 12, 15, 21, 24, 25};
int[] b = { 1, 4, 5, 9, 11, 23, 26, 30};
int[] c = new int[a.length+b.length];
// ここにマージの処理を書く
// 結果を出力System.out.println( "c = " + Array.toString( c ) );
}
}

2.21 第 2 章のまとめ 125
問題 2.21.12. キーボードから次のように整数値を m を入力し、1 次元整数配列 a に入っている値を、列数 m の 2
次元配列 b に以下のようにコピーするプログラム ArrayTransform.java を作りなさい。 要素が入らなかった部分には、 0 を代入すること(初期化によるデフォルト値は信用せずに、プログラムで 0 を代入すること)。
ソースコード 2.113 ArrayTransform.java (配列の変形)
package section0221;
import java.util.Scanner;
public class ArrayTransform {
public static void main(String[] args) {
int[] a = {1,2,3,4,5,6,7,8,9,10,11,12,13,14,15};
// Scanner を用いて、列数 m を入力
// 配列 a の要素数と列数 m から// データを格納可能な行数 n が求まるはず
// それを使って、行列 b を宣言するint[][] b = new int[n][m];
// ここに、a から b へデータをコピーするプログラムを作る// 要素が入らなかった部分には 0 を代入することを忘れずに
// 出来上がった配列 b を出力for(int i = 0; i < b.length; i++) {
for(int j = 0; j < b[i].length; j++) {
System.out.printf( b[i][j] + "\t" ); // "\t" はタブ文字に対応}
System.out.println();
}
}
}
2次元配列 b の列数は:61 2 3 4 5 6
7 8 9 10 11 12
13 14 15
問題 2.21.13. Math.random() メソッドは、double型の [0, 1) の疑似乱数を発生してくれます (あまり精度は良くありませんが)。これを利用して次のような処理をプログラムしなさい。
1. (0, 1] の double型乱数 rand を作る2. 0 から 9 までの int型乱数 rand を作る3. true と false が当確率に発生する boolean 型乱数 rand を作る

126 第 2章 Java 言語の基本的な文法 I
問題 2.21.14. パスカルの三角形を以下のように並べた出力を n 行 n 列分出力するプログラムを以下の4つのやり方で作りなさい。
1. n× n の2次元整数値配列 p[][] を作り、以下のルールを用いて全ての値を求める:
p[i][j] =
ß1 (i = 0 | j = 0)p[i− 1][j] + p[i][j − 1] (i ̸= 0 & j ̸= 0)
2. 長さ n の1次元整数値配列 p[] を作り、以下のルールを用いて1行分ずつ求めることを n 回繰り返す:
p[j] =
ß1 (j = 0)p[j − 1] + p[j] (j = 1, 2, . . . , n− 1)
3. 各値を一つずつ独立に計算して求める:p[i][j] = i+jCj (i, j = 0, . . . , n− 1)
4. 以下のルールを用いて、各値を求める:
p[i][j] =
1 (i = 0 | j = 0)i+ j
jp[i][j − 1] (i ̸= 0 & j = 1, 2, . . . , n− 1)
1 1 1 1 1 1 1 1 1 11 2 3 4 5 6 7 8 9 101 3 6 10 15 21 28 36 45 551 4 10 20 35 56 84 120 165 2201 5 15 35 70 126 210 330 495 7151 6 21 56 126 252 462 792 1287 20021 7 28 84 210 462 924 1716 3003 50051 8 36 120 330 792 1716 3432 6435 114401 9 45 165 495 1287 3003 6435 12870 243101 10 55 220 715 2002 5005 11440 24310 48620
問題 2.21.15. 正方行列の逆行列を求めるプログラム InverseMatrix.java を以下のように作りなさい。
1. 与えられた n× n 行列 A = (aij) に対し、n× 2n の矩形行列 B = (bij) を作り、その左半分に A の中身、右半分に単位行列を代入する
2. 次の掃き出し操作を行って左半分の行列を単位行列化するi = 1, 2, . . . , n に対し、順に次の操作を行う
• B の i 行目を bii で割る (bii = 1 となる)
• k = 1, 2, . . . , n (k ̸= i) に対し、k 行目から i 行目の bki 倍を引く3. 左半分が単位行列になった時、右半分に逆行列 A−1 が完成する
なお、上のアルゴリズムでは bii 要素が 0 になった場合や計算誤差減少のためのピボット操作については触れていないので、それを追加する場合は線形計算の参考書を読んで下さい。

2.21 第 2 章のまとめ 127
ソースコード 2.114 InverseMatrix.java (逆行列を求める)
package section0221;
public class InverseMatrix {
public static void main(String[] args) {
double[][] A = { {2, 6, 9}, {1, 4, 6}, {0, 1, 2} };
double[][] B = new double[A.length][A[0].length*2];
// B の値を初期化した後、printMatrix( "%5.1f", "B", B );
// 掃き出し操作によって、行列 B の左半分を単位行列に変形するprintMatrix( "%5.1f", "B", B );
// その結果の右半分を A の逆行列として出力する
}
static void printMatrix( String format, String name, double[][] A ) {
System.out.println( name + " = ");
for(int i=0; i<A.length; i++) {
for(int j=0; j<A[0].length; j++) {
System.out.printf( format, A[i][j] );
}
System.out.println();
}
System.out.println();
}
}
// B 初期化直後B =
2.0 6.0 9.0 1.0 0.0 0.0
1.0 4.0 6.0 0.0 1.0 0.0
0.0 1.0 2.0 0.0 0.0 1.0
// 左半分を単位行列化した直後B =
1.0 0.0 0.0 2.0 -3.0 0.0
0.0 1.0 0.0 -2.0 4.0 -3.0
0.0 0.0 1.0 1.0 -2.0 2.0

第 II部
– プログラミング言語 Java 基礎2 –
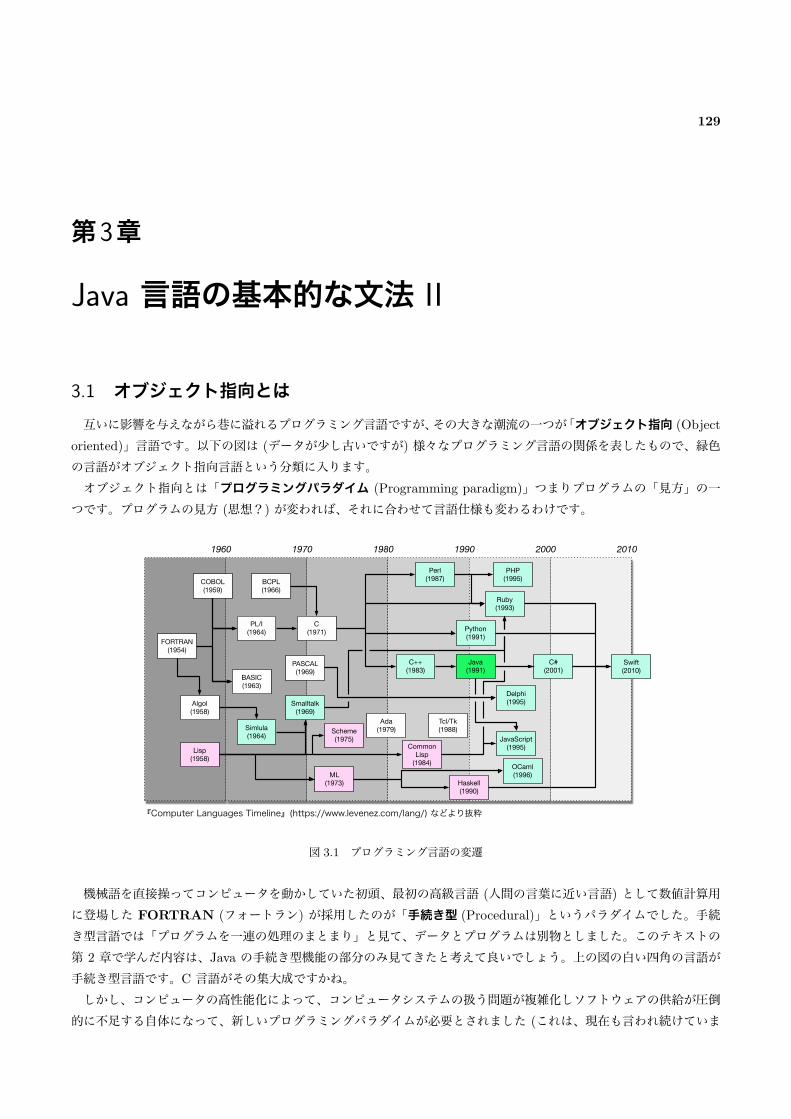
129
第3章
Java 言語の基本的な文法 II
3.1 オブジェクト指向とは互いに影響を与えながら巷に溢れるプログラミング言語ですが、その大きな潮流の一つが「オブジェクト指向 (Object
oriented)」言語です。以下の図は (データが少し古いですが) 様々なプログラミング言語の関係を表したもので、緑色の言語がオブジェクト指向言語という分類に入ります。オブジェクト指向とは「プログラミングパラダイム (Programming paradigm)」つまりプログラムの「見方」の一つです。プログラムの見方 (思想?) が変われば、それに合わせて言語仕様も変わるわけです。
1960 1970 1980 1990 2000
COBOL
(1959)
BCPL
(1966)
FORTRAN
(1954)
PL/I
(1964)
C
(1971)
PASCAL
(1969)BASIC
(1963)
Algol
(1958)
Simlula
(1964)
Smalltalk
(1969)
Lisp
(1958)
Scheme
(1975)
ML
(1973)
Perl
(1987)
C++
(1983)
Common
Lisp
(1984)
Haskell
(1990)
Java
(1991)
Python
(1991)
Ruby
(1993)
PHP
(1995)
C#
(2001)
Delphi
(1995)
JavaScript
(1995)
OCaml
(1996)
『Computer Languages Timeline』(https://www.levenez.com/lang/) などより抜粋
2010
Swift
(2010)
Tcl/Tk
(1988)
Ada
(1979)
図 3.1 プログラミング言語の変遷
機械語を直接操ってコンピュータを動かしていた初頭、最初の高級言語 (人間の言葉に近い言語) として数値計算用に登場した FORTRAN (フォートラン) が採用したのが「手続き型 (Procedural)」というパラダイムでした。手続き型言語では「プログラムを一連の処理のまとまり」と見て、データとプログラムは別物としました。このテキストの第 2 章で学んだ内容は、Java の手続き型機能の部分のみ見てきたと考えて良いでしょう。上の図の白い四角の言語が手続き型言語です。C 言語がその集大成ですかね。しかし、コンピュータの高性能化によって、コンピュータシステムの扱う問題が複雑化しソフトウェアの供給が圧倒的に不足する自体になって、新しいプログラミングパラダイムが必要とされました (これは、現在も言われ続けていま

130 第 3章 Java 言語の基本的な文法 II
す)。そうして登場したオブジェクト指向系のプログラミング言語は、「プログラムはモノとモノの関わりの表現」と捉え、プログラムもデータも全てモノ (オブジェクト object) として同等に考える、というものです。(と言っても、何のことやら? (^^;))
新しく作られたプログラミング言語のほとんどが、オブジェクト指向を採用して設計されています。そして、その中心が Java です。後期では Java のオブジェクト指向言語としての側面を学びますので、徐々にこの意味もわかってくるかと。なお、プログラミングパラダイムは、この他にも次々登場しています。例えば、上の図のピンクの四角は「関数型プログラミング (Functional programming)」言語の仲間です。プログラムは状態を持たずに全て関数の評価で表現するもの、というのが関数型プログラミング言語です。言語によっては複数のパラダイムを持つものもあります。例えば、Java の最新バージョンは関数型プログラミングの機能も追加されました。上の図には載せていませんが、「アスペクト指向 (Aspect oriented)」というパラダイムも最近話題になっています。オブジェクト指向では分離できない特徴を記述する言語で、 Java のアスペクト指向版として AspectJ という言語があります。Java をモノにした春休みにでも、別のパラダイムの言語を独習してみてはどうでしょう (参照:Wikipedia:プログラミングパラダイム)。オブジェクト指向の特徴とは、次の 3 つの概念であると言われます。
• カプセル化 (encapsulation)
• 継承 (inheritance)
• 多態性 (polymorphism)
◦ 動的束縛 (dynamic binding)
「動的束縛」は (それ以外の3つの関わりから導かれるので) 本によって 4 つ目として載っていたり載っていなかったり。この後、これら一つ一つを説明していきます。
3.2 オブジェクトとインスタンスオブジェクト指向言語によるプログラム作成の作業は、その世界にどのようなオブジェクトが存在し、それらがどんな「属性」(property) と「機能」(method) を持っているかを設定することから始まります。例えば、学生の成績処理をプログラム化しようとするとき、その世界を構成するオブジェクトとして「学生」「科目」
「教授」「教室」などを考えることになるでしょう。そして、「学生」オブジェクトには「氏名」「学籍番号」「所属学科」「履修科目」などの属性がきっと必要でしょうし、「科目」には「標準履修年次」「単位数」「担当教授」「教室番号」などの属性が欲しいでしょう。オブジェクトにはそれぞれ機能が与えられます。例えば、「学生」オブジェクトには「卒業までの残り単位数を求める機能」や「現在の GPA の値を求める機能」があれば便利ですし、「科目」オブジェクトには「受講している学生リストの出力機能」や「期末試験の平均点などを求める機能」が望まれるところです。こうした「オブジェクト」が関連しあった世界を想定して目的の結果を求める処理を書くのが「オブジェクト指向」プログラミングです。って、よくわからん!ですかね。(^^;)
「オブジェクト (object)」がモノの定義(宣言・設計図)なら、オブジェクトの実現値を「インスタンス (instance)」と言います。「学生」オブジェクトに対し、学生一人一人「野田 愛」「葛飾 拓哉」「神楽 健一」がインスタンスになります。そして、各インスタンスは、例えば「学籍番号」という属性に対し、「1419001」「1419002」「1419003」のような「属性値」が与えられることになります。

3.2 オブジェクトとインスタンス 131
問題 3.2.1. 「教授」オブジェクトには、どんな属性と機能を与えたら良いでしょう。
ちなみに、データベース (Database : 膨大なデータを整理・統合して検索しやすくしたシステム) の世界でも「オブジェクト指向データベース」という考え方があり、その他様々なソフトウェアにおいてオブジェクト指向という考え方が浸透しています。また、これはオブジェクト指向からは離れますが、プログラム開発において言語の選び方とは別に開発の手法をどうするかの研究も進んでおり、「アジャイル開発」なんて言葉を聴いたことがあるかと思います。2000
年代に入ってプログラム開発の世界は様々な新しい局面に突入していると言えます。Java に戻りましょう。(^_^;)
3.2.1 クラス
Java では、オブジェクトをクラスで表現します。前期に、プログラムの入れ物・ main メソッドの入れ物として使ってきた、あのクラスです。次のプログラムは「学生」オブジェクトを定義している例です。
ソースコード 3.1 Student.java (学生の成績情報)
package section0302;
// 学生を定義するクラスpublic class Student {
// フィールドprivate int idNo; // 学籍番号private String name; // 氏名private int countCourses; // 履修科目数private Course[] course; // 履修科目の成績情報の配列private static final int MAXCOUNT_COURSES = 100; // 取得可能な科目数の最大// コンストラクタpublic Student( int idNo, String name ) {
this.idNo = idNo;
this.name = name;
this.countCourses = 0;
this.course = new Course[MAXCOUNT_COURSES];
}
// メソット// 履修科目の成績情報の追加public void addRecord( Course course ) {
this.course[countCourses++] = course;
}
// 成績の表示public void printRecords() {
System.out.println( idNo + ":" + name + "さんの成績" );
if( countCourses == 0 ) {
System.out.println( " まだ、履修科目情報が入力されていません。" );
return; }
for(int i=0; i<countCourses; i++) {
System.out.printf( "「%s」の成績は、%d 点 %n",
course[i].getTitle(), course[i].getDegree() );
}
this.printAverage();
}
// 平均点を表示private void printAverage() {

132 第 3章 Java 言語の基本的な文法 II
int sum = 0;
for(int i=0; i<countCourses; i++) {
sum += course[i].getDegree();
}
System.out.printf( " 平均点は、%f 点です %n", (double) sum / countCourses );
}
}
このクラスには、前期では必ず入っていた main メソッドがありません。Java アプリケーションは、main メソッドが入ったクラスがあって、それを動かすことで初めてプログラムとして実行されます。つまり、このクラスは「学生」の定義をしていますが、単独で実行できるプログラムにはなっていないわけです。従って、このプログラムは main メソッドの入った別のクラスを作って、そこから利用するという形態になっています。ちなみにブラウザ内でインタラクティブな (ユーザがサーバと情報の受け渡しを行う) ホームページを表示する
「Java Applet」という Java のアプリケーションには main メソッドがなく、ブラウザが動かしてくれます (残念ながら、Java Applet は Java 9 で非推奨になりその後廃止されることに決まりました。今後は HTML5 と JavaScript がその代わりをすることになります。ちなみに、JavaScript は Java とは無関係で、文法的にも全く違う言語です)。さて、クラス名は先頭文字を大文字とする パスカル形式 (Pascal-case) で付けるのが慣例!とか、前期に触れた部分ちゃんと覚えていますか (構成している単語の1文字目を大文字とし、それ以外を小文字とする!でしたね)。クラスは、基本的に 3 つの要素 (以降、メンバー と呼びます) からなっています。
• フィールド (field):オブジェクトの属性値を保持するための変数• コンストラクタ (constructor):オブジェクトの定義に従ってインスタンスを作る際の処理• メソッド (method):オブジェクトの機能・動作
本によっては、コンストラクタはメンバーとしない、と書かれている場合もあります。その理由は、コンストラクタが「個々のインスタンスが持つものでは無い」からですが、ここでは「メンバー」という言葉を広い意味で使うことにして、これら3つをクラスのメンバーとします。この 3 つの要素は、いずれかが欠けていても構いません。例えば、前期のほとんどのプログラムは、(フィールドやコンストラクタの無い) main メソッドだけのクラスになっていましたよね (一番始めに学んだ HelloJava プログラムも HelloJava という main メソッドのみ含むオブジェクトだったわけです)。続いて、履修科目と成績を定義するクラス Course と、これらのクラスを利用して成績処理を行うクラス
StudentExample です。いずれのクラスもパッケージ section0302 の中にそれぞれ単独のファイルとして置きましょう。
ソースコード 3.2 StudentExample.java (学生の成績処理)
package section0302;
// 学生クラスを利用して成績処理を行うクラスpublic class StudentExample {
public static void main(String[] args) {
// 野田さんインスタンスを生成Student noda = new Student(1419001, "野田 愛");
// 野田さんの履修科目と成績を登録noda.addRecord( new Course("プログラミング", 85) );
noda.addRecord( new Course("微積分", 77) );
noda.addRecord( new Course("線形代数", 96) );
// 登録結果を出力noda.printRecords();
}
}

3.2 オブジェクトとインスタンス 133
ソースコード 3.3 Course.java (履修科目と成績のクラス)
package section0302;
// 履修科目と成績を定義するクラスpublic class Course {
// フィールド// 科目名private String title;
// 成績private int degree;
// コンストラクタpublic Course( String title, int degree ) {
this.title = title;
this.degree = degree;
}
// ゲッターメソッド// 科目名を返すpublic String getTitle() {
return title;
}
// 点数を返すpublic int getDegree() {
return degree;
}
}
3.2.2 ファイルとクラスの関係
前期では、プログラムは1つのクラスで出来ていて、1プログラム・1ファイル・1クラスが基本でした。クラスの中は、当初 main メソッド単独でしたが、後半、幾つかのメソッド (正確にはクラスメソッド) が入るものも出ていました。一方、後期はそのほとんどが複数のクラスからなるプログラムになります。また、1つのファイルに複数のクラスが
入る場合も出てきます。そこで、ファイルとクラスのルールをまとめておきましょう。
• Java プログラムは複数のクラスの集合体で、そのうち1つのみ main メソッドを持つ。• 1つのクラスを複数のファイルに分断することはできない。• 1ファイル内には、複数のクラスを入れることが出来るが、アクセス修飾子 public が付いたクラスは1つのファイルに高々1つしか入れられない。
• ファイル名は中に入るクラス名のいずれとも異なっていて構わないが、一般には、その中の中心となるクラスの名前と一致させる。ただし、public なクラスがある場合は、そのクラス名とファイル名は一致させねばならない。
慣例としては、1ファイルに1クラス!がベストと言われていますが、このテキストでは、小さなプログラムの場合に(どのプログラムも小さいけどね)、ひとまとめに1つのファイルに押し込むこともあります。

134 第 3章 Java 言語の基本的な文法 II
3.2.3 コンストラクタ
まずは、コンストラクタから見ていきましょう。クラスを記述してオブジェクト (ここでは、学生) を定義しても、具体的なインスタンス (ここでは、野田さん) を作らなければ、一般には何もできません。って、いつものようにちょっとウソです (前期のプログラムではインスタンスなんか作らずにプログラム出来てました)。これは、オブジェクト指向のプログラムとしてはインスタンスを作らなければ始まらない!ということです 。前期のプログラムはいずれもオブジェクト指向のプログラムとは言えませんでした。Java 言語はオブジェクト指向言語ですが、必ずしもオブジェクト指向で作らなければならない!というわけではありません。ものによっては、オブジェクト指向にすることの出来ない現象もあります。ただ、オブジェクト指向の方法論でプログラムを作ると、とてもわかりやすいプログラムになる場合が世の中には多いのです。Student クラスで定義された学生オブジェクト、その実現値「野田さん」を定義する処理を、別のプログラム
StudentExample.java の main メソッド内に作ることにします (ソースコード 3.2 参照)。これまで、同じクラス内の別のメソッドを呼び出すプログラムは作りましたが、別のクラス (それも別のファイルのクラス)を利用するプログラムは初めてですね。コンパイラがプログラムをコンパイルする際、定義されたクラスの記述を、まず同じファイル内で探します。そこに見つからなかった場合、今度は同じパッケージ内を探します。そこでも見つからなかった場合は、パッケージの外に探しに行きます。今回の場合、同じパッケージ section0302 内のファイル Student.java の中に Student クラスを見つけることが出来ました。もし同じ名前のクラスが複数ある場合にどうするかなどについては、後で触れます。このプログラム中の Student noda = new Student(1419001, "野田 愛"); の右辺で Student 型インスタンス
「野田さん」を作っています。そして、左辺の参照変数 noda に「野田さん」インスタンスの格納 (先頭) アドレスを代入することで、変数 noda からその情報を参照できるようにしています (図 3.2 参照)。変数 noda は Student 型インスタンスを参照しているので、Student 型で宣言 ( Student noda ) します。ところで、第 2 章では基本型の 8 種類を学びましたが、ちゃんと覚えています?そして、文字列型 String と基本型の配列 int[] などを学びました。String name = "野田 愛"; や int[] a =
{1, 2, 3}; とした場合、変数 name や a には何が入るんでしたっけ?右辺の文字列や配列のデータが格納されているメモリー上でのアドレスでしたね。こうした変数を参照変数と呼びました。これと同じで、変数 noda には、右辺 new Student(1419001, "野田 愛"); で作成されたインスタンスの情報が置かれているメモリ上のアドレスが代入されており、変数 noda も参照変数と言えます。後期では、このようにクラス型のオブジェクトを使ったプログラムが次々出てきます。Student がその最初の例です。new キーワードに続く Student(1419001, "野田 愛") の部分は、クラス Student の中の「コンストラクタ」に対応しています。この時、クラス内には、引数の個数と型の一致するコンストラクタを用意しておかねばなりません。この場合、第 1 引数に int 型の整数、第 2 引数に文字列を引数とするコンストラクタが必要です。今回 Student クラス内に置かれたコンストラクタはそれにフィットしており、よって、インスタンスを作る作業でこのコンストラクタが実行されます (というか、コンストラクタを用いずにインスタンスは作れません)。コンストラクタはメソッドと似たものですが、幾つかの違いがあります。
• コンストラクタは新たなインスタンスを作成するときにのみ使われる• コンストラクタ名はそのコンストラクタが入っているクラス名と同じでなければならない。 従って、コンストラクタ名は大文字で始めるパスカル形式である

3.2 オブジェクトとインスタンス 135
“野田 愛”
private name
public void addRecord( Record )
public void printRecords()
private void printAverage()
Student 型インスタンス
noda
0
private countCourses
1419001
private idNo参照
Course[ ] course
図 3.2 インスタンス「野田さん」
• コンストラクタは戻り値を持てない ( void も書かない)
コンストラクタによってメモリー内にインスタンスが生成されると、その中にはそのインスタンスの属性値を入れるフィールドとそのインスタンスの機能を表すメソッドが全て用意されます (図 3.2 参照)。なお、コンストラクタはそのインスタンスを作るときのみ動くものなのでインスタンス内には記憶されません。また static 修飾子の付いた変数やメソッド (クラスフィールド・クラスメソッドと言う) は別の場所に記憶されるので、入っていません (後で説明)。一般に、コンストラクタは、引数に与えられた値をフィールドに初期値として代入する処理を行います。このコンストラクタでも、this.idNo = idNo; や this.name = name; などで初期値の代入がされていますね。以下では、Eclipse での表示に合わせて文字に色を付けてみました。こうすると、同じ名前の変数でも実は違うものを指していることがわかります。
ソースコード 3.4 Eclipse での表示
// フィールドprivate int idNo; // 学籍番号private String name; // 氏名private int countCourses; // 履修科目数private Course[] cours; // 履修科目の成績情報の配列private static final int MAXCOUNT COURSES = 100; // 取得可能な科目数の最大// コンストラクタStudent( int idNo, String name ) {
this.idNo = idNo;
this.name = name;
this.countCourses = 0;
this.cours = new Course[MAXCOUNT COURSES];
}
代入文 this.idNo = idNo; の両辺に idNo という変数がありますが、この 2 変数は色が異なっています。周辺の変数の色と比較して気づくと思いますが、左辺の idNo が 1 行目で private int idNo; と宣言している「フィールドとしての idNo」で、右辺の idNo は「コンストラクタの引数の idNo」ですね。引数に与えられた値をフィールドに代入するという式なわけです。ところで、コンパイラが 2 変数の違いを区別できている理由は、何でしょう。それは、左辺に付いた this. です。

136 第 3章 Java 言語の基本的な文法 II
この this. は、このコンストラクタで作成されるインスタンスを指す単語です。つまり、this.idNo (インスタンスが持つ idNo) ですから、「インスタンスのフィールドとしての変数」というわけです。この this. が無ければ、コンパイラは 2 つを区別できません。もちろん、コンストラクタの引数の変数名はフィールド名と同じでなければならない!というルールはありません。例えば、このコンストラクタの引数を Student( int idNum, String sName ) と書き換えれば、変数名としての衝突が無くなるので、this. を外して idNo = idNum; と書いてもコンパイラは this. の無い idNo をフィールドとしての idNo と解釈して、問題なく翻訳してくれます。 (以下参照)。
ソースコード 3.5 this. の省略
private int idNo; // 学籍番号private String name; // 氏名private int countCourses; // 履修科目数private Course[] cours; // 履修科目の成績情報の配列private static final int MAXCOUNT COURSES = 100; // 取得可能な科目数の最大// コンストラクタStudent( int idNum, String sName ) {
idNo = idNum;
name = sName;
countCourses = 0;
cours = new Course[MAXCOUNT COURSES];
}
ただ、和田は this. の省略の目的で変数名を変えるのは本末転倒と思う人なのと、一般の変数とフィールドとを常に区別したいという目的も含めて、フィールド変数には (変数名の衝突が無くとも) なるべく this. を付けるようにしています。例えば this.countCourses = 0; や this.course = new Course[MAXCOUNT_COURSES]; には変数名の衝突が起きないので、もともと this. を省略しても良いのですが、和田は作為的に付けています。そうすれば、これらの代入文がインスタンスのフィールドへの代入文だ、ということが色分けされていなくても分かりますよね。なお、this. を付ける付けないでコンパイル結果は変わらないので、実行に違いは出てきません。コンストラクタはクラスに 1 つだけとは限りません。例えば、学生のオプション情報 (省略可として) として性別や年齢が追加されたとします。その場合、次のようにインスタンスの作り方がいろいろ出てくるでしょう。それに合わせてコンストラクタも複数必要になります。
ソースコード 3.6 (改) StudentExample.java (複数のコンストラクタが必要)
package section0302;
// 学生クラスを利用して成績処理を行うクラスpublic class StudentExample {
public static void main(String[] args) {
// 野田さんインスタンスを生成Student noda = new Student(1419001, "野田 愛");
// 野田さんの履修科目と成績を登録noda.addRecord( new Course("プログラミング", 85) );
noda.addRecord( new Course("微積分", 77) );
noda.addRecord( new Course("線形代数", 96) );
Student kagura = new Student( 1419002, "神楽 健一", 19 ); // 年齢が追加// 登録結果を出力noda.printRecords();
kagura.printRecords();
}
}

3.2 オブジェクトとインスタンス 137
こんなとき、それぞれにフィットするコンストラクタを用意してやらねばいけません。コンストラクタの名前はクラス名と一緒なので、第 2 章で「同じ名前のメソッドを複数持つ場合の条件」というのを学んだことを思い出して下さい。あの場合と同様に、コンストラクタも次のルールが満たされれば共存できます。
• 引数の個数が違う• 引数の個数が同じでも、いずれかの型が異なる
つまり、コンストラクタの引数が (String 氏名, double 体重) と (String 氏名, double 身長) は共存できませんが (何故ですかね?)、(String 氏名, double 体重) と (String 氏名, int 年齢) は共存できます。ただ、Student kagura = new Student("神楽 健一", 80); と書いたら、年齢 80 歳のおじいちゃん学生が出来てしまいますね。たぶん体重?なんだろうけど、小数点を忘れた、そんな想定外の値も考慮してプログラムは作成しないといけません。こうした問題は、基本型の値を引数に与えると起きる問題です。体重も身長も年齢も、値ではなくオブジェクトにすると、例えば Weight クラス、Height クラス、Age クラスなどのインスタンスとして与えれば、問題がなくなります。つまり、Student(String 氏名, Age 年齢) と Student(String 氏名, Weight 体重) なるコンストラクタを作ります。もちろん、Age や Weight なるクラスも定義しないといけませんが、そうすると Student kagura
= new Student(1419003, "神楽 健一", 80); ではなく Student kagura = new Student(1419003, "神楽 健一", new Weight(80)); なんて与え方が強制できて、80 が体重であることがプログラム上でも明示され、入力ミスがなくなります。こうした発想も「オブジェクト指向」の恩恵なのですが、まだ難しいですかね。最初は、そんなに凝らずに基本形データを与える方法で進めていきます。なお、このようにクラス内にコンストラクタを複数持ったり、同じ名前の (ただし、引数が異なる)メソッドを複数持ったりすることを「オーバーロード (overload)」すると言います。コンストラクタにはインスタンスを作るときにやらねばならないことを記述します。一般にフィールドの初期値を与えることが多いのですが、そこでは適切な値であるかをチェックする処理も必要でしょう。例えば、学籍番号に負の数は許されませんし、特定の範囲の番号だけが許されているはず。従って、コンストラクタの中で引数に与えられた値が適切であるかをチェックし、可能なら修正もしくはエラーメッセージを返すなどの処理もしてやらねばなりません。そうした処理もコンストラクタの役目です。コンストラクタはその中で、他のメソッドやコンストラクタを利用することもできます。先の Student クラスに年齢を含むコンストラクタを追加してみましょう。
ソースコード 3.7 (改) Student.java (コンストラクタのオーバーロード)
package section0302;
// 学生を定義するクラスpublic class Student {
// フィールドprivate int idNo; // 学籍番号private String name; // 氏名private int age; // 年齢private int countCourses; // 履修科目数private Course[] course; // 履修科目の成績情報の配列private static final int MAXCOUNT_COURSES = 100; // 取得可能な科目数の最大private static final int UNDEFINED_IDNO = 0; // 学籍番号未定義の値private static final String UNDEFINED_NAME = ""; // 氏名未定義の値private static final int UNDEFINED_AGE = -1; // 年齢未定義の値// デフォルトコンストラクタpublic Student() {
this.idNo = UNDEFINED_IDNO;
this.name = UNDEFINED_NAME;
this.age = UNDEFINED_AGE;

138 第 3章 Java 言語の基本的な文法 II
this.countCourses = 0;
this.course = new Course[MAXCOUNT_COURSES];
}
// コンストラクタ2public Student( int idNo, String name ) {
this();
this.idNo = idNo;
this.name = name;
}
// コンストラクタ3public Student( int idNo, String name, int age ) {
this( idNo, name );
this.age = age;
}
// メソッドについては printRecords() のみ以下に変更// 成績の表示public void printRecords() {
String strAge = (age == UNDEFINED_AGE)? "": String.valueOf(age);
System.out.println( idNo + ":" + name + "さん (" + strAge + ")の成績" );
if( countCourses == 0 ) {
System.out.println( " まだ、履修科目情報が入力されていません。" );
return; }
for(int i=0; i<countCourses; i++) {
System.out.printf( "「%s」の成績は、%d 点 %n",
course[i].getTitle(), course[i].getDegree() );
}
this.printAverage();
}
今回は、コンストラクタが 3 種類登場しています。最初のコンストラクタは引数が 0 個のコンストラクタです。引数が 0 個のコンストラクタを「デフォルトコンストラクタ (default constructor)」と呼びます。デフォルトコンストラクタは引数が無いので、学籍番号も氏名もわからないけど、とりあえず学生インスタンスを1つ作りたい!という場合に使うコンストラクタになります。従って、それぞれのフィールドに「未定義」の場合を意味する値を代入しています。一方、2 つ目のコンストラクタは学籍番号と氏名の2 引数、3 つ目のコンストラクタはそれに年齢も含めて 3 引数で与えています。まず、デフォルトコンストラクタで UNDEFINED_ が付いている変数について説明しましょう。これらの値は、いずれも private static final で宣言されています。修飾子 final は後で詳しく説明しますが、定数を定義するための修飾子です。定数は、一般に大文字のみからなる名前とし、単語間の区切りはアンダースコアを用います (スネーク形式でしたっけ)。では、デフォルトコンストラクタの1行目で、this.idNo = 0; と学籍番号未定義の値を直接代入せず、わざわざ定数を定義して、それを代入しているのは何故でしょう。その理由は、主に2つ:
• とりあえず、学籍番号が未定義の値は 0 としているが、将来変わるかもしれない。そのとき、その値を使っている場所全てに変更に行かないといけないが、定数にしておけば、定数の値を決めている場所のみ修正すれば良い
• this.idNo = 0; と書くと、何をやっているのか今ひとつわからない。でも、this.idNo = UNDEFINED_IDNO;
なら「ここは未定義の値を代入しているんだ!」と分かりやすい
さて次に、2つ目以降のコンストラクタ内の命令 this() と this( idNo, name ) は何をやっているのでしょう。この this(...) は「このクラスのコンストラクタ」という意味になります。その際、その引数にフィットしたコンストラクタ、が呼び出されます。つまり、コンストラクタ2は、 this(); と引数無しのコンストラクタ、つまりデフォ

3.2 オブジェクトとインスタンス 139
ルトコンストラクタを呼んでいるわけです。同様に、コンストラクタ3の最初では、自身が引数で受け取った値を使って2変数のコンストラクタ、つまりコンストラクタ2を呼び出しています。このようにコンストラクタは他のコンストラクタの力を借りて処理を行うことができます。例えば、コンストラクタ3が使われたとすると、(学生番号,氏名,年齢) の3つの値が引数で受け取られ、まずは学籍番号と氏名をコンストラクタ2に渡します。すると、コンストラクタ2は受け取った学籍番号と氏名をフィールドに代入する前に、デフォルトコンストラクタを呼び出します。デフォルトコンストラクタは、それぞれのフィールドに未定義の値を代入し戻ってきます。コンストラクタ2はその後で、自分の受け取った学籍番号と氏名をフィールドに代入し、コンストラクタ3に戻ります。そして、最後にコンストラクタ3が年齢をフィールドに代入して、コンストラクタの処理を終わるわけです。なんだか面倒臭いことやってるなぁ、次のように書いちゃいけないのかな?
// デフォルトコンストラクタpublic Student() {
this.idNo = UNDEFINED_IDNO;
this.name = UNDEFINED_NAME;
this.age = UNDEFINED_AGE;
this.countCourses = 0;
this.course = new Course[MAXCOUNT_COURSES];
}
// コンストラクタ2public Student( int idNo, String name ) {
this.idNo = idNo;
this.name = name;
this.age = UNDEFINED_AGE;
this.countCourses = 0;
this.course = new Course[MAXCOUNT_COURSES];
}
// コンストラクタ3public Student( int idNo, String name, int age ) {
this.idNo = idNo;
this.name = name;
this.age = age;
this.countCourses = 0;
this.course = new Course[MAXCOUNT_COURSES];
}
これでもOKです。でも、もし年齢未定義の場合の定数名 UNDEFINED_AGE を変更することになったとき、デフォルトコンストラクタとコンストラクタ2の2箇所での修正が必要になりますね。Eclipse で作っているときなら、変数が見当たらないとのメッセージを出してくれますが、複雑なプログラムになると、修正漏れが起こるかもしれません。一方、先のプログラムなら、デフォルトコンストラクタの1箇所のみの修正で済みますね。また、フィールド名の変更、例えば countCourses → numCourses が起こったとすると、後者は3つのコンストラクタ全てで変更が必要になりますが、前者だとデフォルトコンストラクタのみで済みます。ただし、それぞれのコンストラクタが何をやっているのか?をソースから読み解こうとする場合は、後者の方が分かりやすいかもしれませんね。また、デフォルトコンストラクタの中身を変更しようとすると、気づかぬうちに他のコンストラクタの処理内容にも影響を与えてしまうことになりますね。良いプログラムの条件は、効率が良いこと・解読しやすいこと、そして誤りが無いことです。つまり、必ずしも前者の方法でなければいけない、という訳ではなく、臨機応変に考えて下さい。なお、フィールド名の変化などに対応するには、この後で説明するセッターメソッドを利用する方法もあります。コンストラクタが別のコンストラクタを利用する場合、コンストラクタ名の代わりに「this(...)」を使うわけです

140 第 3章 Java 言語の基本的な文法 II
が、「コンストラクタ内で別のコンストラクタを呼び出す場合はそのコンストラクタの先頭で行わなければならない」というルールがあります (よって、1つのコンストラクタの中で複数のコンストラクタを呼び出すことは出来ません。何故かな?)。
問題 3.2.2. Student クラスに、以下の「葛飾 拓哉」さんのインスタンスも追加できるように、フィールドに性別 sex
を追加し、コンストラクタ4 Student( int idNo, String name, String sex ) と4つの属性 (学籍番号、氏名、年齢、性別) 全てを引数にするコンストラクタ5も追加しなさい。これらのコンストラクタ5つを効率よく機能させるには、どうしたら良いかを考えなさい。
Student katushika = new Student(1419003, "葛飾 拓哉", "男");
katushika.printRecords();
コンストラクタは必ず無ければならないものではありません。次のプログラムを見て下さい。この Point クラスは2次元平面上の点を定義するクラスですが、コンストラクタが定義されていません。しかし、続く PointExample クラスの main メソッドでは Point p = new Point(); と Point クラスのデフォルトコンストラクタを用いたインスタンス作成が行われています。
ソースコード 3.8 Point.java (平面上の点クラス)
package section0302;
// 平面上の点のためのクラスpublic class Point {
private double x;
private double y;
// セッターpublic void setX( double x ) {
this.x = x;
}
public void setY( double y ) {
this.y = y;
}
// ゲッターpublic double getX() {
return this.x;
}
public double getY() {
return this.y;
}
// 点情報の出力メソッドpublic void print() {
System.out.printf( "(%f,%f)%n", this.x, this.y );
}
}
ソースコード 3.9 PointExample.java (コンストラクタ無しクラス)
package section0302;
public class PointExample {
public static void main(String[] args) {
Point p = new Point(); // デフォルトコンストラクタを用いて点 p を作成

3.2 オブジェクトとインスタンス 141
p.setX( 1.5 ); // p の x 座標に 1.5 を代入p.setY( -0.3 ); // p の y 座標に -0.3 を代入p.print(); // p の情報を出力
}
}
デフォルトコンストラクタの書き忘れ?いえ、実はデフォルトコンストラクタを明記しない場合、コンパイラは陰で中身の空っぽなデフォルトコンストラクタを作成してくれるのです。ただ、その場合、フィールドへの初期値代入などはやってくれませんから、代わりの方法で代入しなければなりません。このプログラムでは、コンストラクタを使わない代わりに、フィールドの初期化を行う「セッター (setter)」メソッドを用意して使っています。単に「セッター」と呼ばれるセッターメソッドは、各フィールド毎に設定でき、引数に与えられた値をそのフィールドに代入する処理のみを行うものです。セッターは、慣例的にそのフィールド名の前に set を付けたメソッド名にします (従って、フィールド x のセッターは void setX( double )
)。セッターに対して、各フィールドの現在の値を返してくれる「ゲッター (getter)」メソッドもよく使われます。こちらは、単純にフィールドの中身を return します。例えば、点 p のフィールド x の値が欲しいときは、double px
= p.getX(); と書けば変数 px に 1.5 が返されます。ゲッターも、慣例的にフィールド名の前に get を付けたメソッド名にします。セッター・ゲッターについては、何でこんなものがあるのかも含めてメソッドの説明のところでもう少し詳しく触れます。さて、何もしないデフォルトコンストラクタは省略できる (コンパイラが陰で作ってくれる) のですが、一つ注意点があります。Point( double x, double y ) などの引数を持つコンストラクタを1つでも作成すると、コンパイラは「デフォルトコンストラクタを陰で作る」という処理を行ってくれなくなります。そんな時、デフォルトコンストラクタも必要なら (必要なければ書かなくても良い)、プログラム中に明記しなければいけません (いくら中身がカラでも)。と言うことで、このプログラム、やはり2座標を引数に持つコンストラクタがあった方が良さそうですね。
問題 3.2.3. Point クラス内に、点の座標値の 2 実数を引数として受け取るコンストラクタを追加し、PointExample
クラスの main メソッドではそのコンストラクタで点 p を作成するように変更しなさい。
3.2.4 フィールド
学生の成績処理プログラムでは、各「学生」インスタンスは、「学籍番号」「氏名」「履修科目の成績情報の配列」そして「年齢」や「性別」などの値を持っていました。これらインスタンスが持つ値 (それを入れる変数) のことをインスタンスの「フィールド」(属性) といいます。これらのフィールドは、コンストラクタを用いて新たなインスタンスが作成されるたびに、各インスタンスにそれぞれ与えられました。こうした各インスタンスが持つフィールドを「インスタンスフィールド (instance field)」(もしくは、インスタンス変数) と言います。インスタンスフィールドは、インスタンスそれぞれの値が与えられます。例えば、野田愛さんのインスタンスフィールド idNo には 1419001 が、葛飾拓哉さんのインスタンスフィールド idNo には 1419002 が入っています。フィールドには、もう一種類「クラスフィールド (class field)」(もしくは、クラス変数) があります。クラスフィールドは、インスタンス個々の属性ではなく、そのクラスのインスタンスなら全員が共通に持つ属性を格納する変数です。例えば、理科大生のみを扱うプログラムでは、大学名は学生全員一致なので、インスタンス各々に持たすのは無駄!そこで、次のプログラムのように、クラスフィールドに記憶します。クラスフィールドは、そのクラス専用の別の

142 第 3章 Java 言語の基本的な文法 II
領域にインスタンスの数に無関係にひとつだけ確保されます。クラスフィールドを宣言する場合は、修飾子 static を頭に付けます。Student クラスでは、 MAXCOUNT_COURSES 以下の変数に static が付いていますから、これらがクラスフィールドです。なお、クラスを定義する際、最初にインスタンスフィールドそしてクラスフィールド、コンストラクタ、最後にメソッドと並べるのが慣例のようです。
ソースコード 3.10 (改) Student.java (クラスフィールドの追加)
package section0302;
public class Student {
private int idNo; // 学籍番号private String name; // 氏名private int age; // 年齢private String sex; // 性別private int countCourses; // 履修科目数private Course[] course; // 履修科目の成績情報の配列private static final int MAXCOUNT_COURSES = 100; // 取得可能な科目数の最大private static final int UNDEFINED_IDNO = 0; // 学籍番号未定義の値private static final String UNDEFINED_NAME = ""; // 氏名未定義の値private static final int UNDEFINED_AGE = -1; // 年齢未定義の値private static final String UNDEFINED_SEX = ""; // 性別未定義の値public static final String UNIV_NAME = "東京理科大学"; // 大学名// 以下省略
さて、クラスフィールドも変数なので中身を変更することが可能ですが、一般的にそのクラス固有の値 (固定値) をとることが多く、定数として扱う場合、final 修飾子が付けられます。final を付けた変数は、一旦初期値を代入した以降は、その値を変更することができなくなります。変更できない変数とはちょっと変ですけどね (^^;)。さて、コンストラクタのところでフィールドの初期値を与えることがコンストラクタの役目の一つと言いましたが、このプログラムではクラスフィールドへの値の代入をコンストラクタではなく、フィールドの宣言時に行っています。これって、良いのでしょうか。よく考えてみて下さい。コンストラクタにこれらの代入文を書いてしまうと、インスタンスが作られるたびに定数の設定を行おうとします。これは変ですよね。インスタンスの存在の有無に関わらずにクラスフィールドは存在するので、こうして初期値を与えるわけです。では、インスタンスフィールドへの代入は必ずコンストラクタに行わせなくてはならないのでしょうか。例えば、学
生全員が持っている変数があるけれど、デフォルトの値を定義したい。そんなとき、フィールド宣言のところで、デフォルト値を代入しておきます。そして、コンストラクタには、そのインスタンス特有の値の代入を行わせます。例えば、先の学生クラスにおいて、学籍番号フィールドの宣言時に以下のようにデフォルト値を代入させてしまえば、コンストラクタにおいては、デフォルト値の代入を省略できます。
private int idNo = UNDEFINED_IDNO; // 学籍番号 デフォルト値は、未定義
話を戻しましょう。上記の Student クラスでは、全てのクラスフィールドに final 修飾子が付いていますから、いずれも定数で、初期値が代入された以降は変更することができなくなります。次のプログラムは、クラスフィールドの値が変わっていく例です。メンバーの登録と同時に順に会員番号を付加するためにクラスフィールドを利用しています。
ソースコード 3.11 MembershipExample.java (会員登録)
package section0302;
public class MembershipExample {
public static void main(String[] args) {
int n = 100; // 登録可能人数

3.2 オブジェクトとインスタンス 143
Entry entry = new Entry( n );
// 登録には、氏名と年齢が必要としてentry.add("神楽 健一", 19 );
entry.add("葛飾 拓哉", 20 );
entry.add("野田 愛", 18 );
entry.print();
}
}
ソースコード 3.12 Entry.java (会員情報の配列への登録)
package section0302;
public class Entry {
private int memberCount;
private Member[] member;
private static int memberNo = 1000; // このクラスフィールドには final が付いていないpublic Entry( int n ) {
member = new Member[ n ];
memberCount = 0;
}
public void add(String name, int age) {
memberNo++; // クラスフィールドの値をインスタンスが変更しているmember[memberCount++] = new Member( memberNo, name, age );
}
public void print() {
System.out.println( "現在登録者数:" + memberCount );
for(int i=0; i<memberCount; i++) {
member[i].printRecords();
}
}
}
ソースコード 3.13 Member.java (会員情報)
package section0302;
public class Member {
private int idNo;
private String name;
private int age;
Member( int idNo, String name, int age ) {
this.idNo = idNo;
this.name = name;
this.age = age;
}
void printRecords() {
System.out.printf( "%03d %s (%2d)%n", idNo, name, age );
}
}
問題 3.2.4. 上のプログラムで、年齢が未定義である場合 (値が -1 とする) の定数と年齢なしのコンストラクタを追加して、名前無しでも登録できるようにしなさい。出力も「年齢不詳」と出力されるように変えなさい。

144 第 3章 Java 言語の基本的な文法 II
作られたインスタンスのフィールドの値を利用するときは、大きく 2 種類の方法があります。
• そのフィールドの値を直接利用する• ゲッターを利用する
まず、そのフィールドの値を直接利用する場合、インスタンスフィールドとクラスフィールドで書き方が異なります。
• インスタンスフィールドの場合「インスタンス名.フィールド名」、例えば noda.idNo や katushika.name (野田さんの学籍番号、葛飾くんの名前) という感じですね。int idNo = noda.idNo とすれば野田さんの学籍番号が変数 idNo に代入されます。
• クラスフィールドの場合「クラス名.フィールド名」、例えば Student.UNIV_NAME 学生全員の大学名というわけです。
インスタンスからクラスフィールドを直接利用する、つまり noda.univName という使い方もアリではあるのですが、オブジェクト指向の考え方としてはあまり薦められていません。あくまで「クラスのフィールド」なんでしょうね(Eclipse では黄色の警告ランプが付きます)。一方、その逆 Student.idNo はエラーになります (学生の学籍番号はクラス内で一意に決まらないからですね)。もう一つの利用方法、ゲッターを利用する方法は、先の Point クラスにおける getX() と getY() のようなゲッターメソッド、例えば getIdNo() を作って利用する方法です。ところで、なんでわざわざ、こんなメソッドを用意して使うのでしょう?先の Point クラスのフィールドとゲッターを抜き出してみると、次のようになっています。
ソースコード 3.14 Point クラスのゲッター
package section0302;
// 平面上の点のためのクラスpublic class Point {
private double x;
private double y;
:
// ゲッターpublic double getX() {
return this.x;
}
public double getY() {
return this.y;
}
}
注目すべきは、フィールド x や y に付いている修飾子 private です。これは、Point クラスの外側から、そのフィールドの値を直接利用することを「拒否する」修飾子です。つまり、Point p = new Point(); とインスタンスを作成させても、Point クラスの外では p.x = 1.5; p.y = -0.3; のような直接的な値の代入や参照 (変数の値を見ること) はさせないぞ!という修飾子です。こうした修飾子を「アクセス修飾子 (access modifier)」と言いますが、データの入った変数をむやみに外部から覗かれたり、変更されたりすることを防いでいます (アクセス修飾子はこの後でまとめて解説します)。預金口座の金額が入った変数 int myMoney の値を外部プログラムで勝手に 0 にされては困りますよね。そんな場合に、変数に private
修飾子を付けて、外部から直接アクセスされることを防止しています。ただ、それでは正規な方法での値の代入などができません。そこで、その値を変更するメソッド (セッター) や、そ

3.2 オブジェクトとインスタンス 145
の値を取り出すメソッド (ゲッター) を限定公開し、それのみを「利用可」にするわけです (もちろん、そのメソッド内には正規利用者のアクセスか否かをチェックする機構も付けておかねばなりません)。限定されたメソッドを経由しないでこのフィールドにアクセスできないようにして、安全を確保する!というわけです。もう一つ、セッターやゲッターを作る目的が、 private にしたフィールドの名前を自由に変えられる、という利点
です。もしフィールドを外部に自由に使わせるように設定すると、名前の変更はユーザに各自のプログラムの変更を強制してしまうことになります。代わりに、セッターなどを使えば、(その名前を変更してはなりませんが) フィールド名の変更や内部構造の変更を外部に影響与えることなく行うことができます。これが次の章で詳しく学ぶ「カプセル化」です。一般に、フィールドには全て private を付け、ゲッターやセッターは public (自由に利用可能) で公開せよ!と言われます。
問題 3.2.5. ソースコード 3.1 の Student.java における次の変数のスコープ範囲をそれぞれ述べよ。
1. フィールド idNo
2. コンストラクタの引数 idNo
3. メソッド printRecords() の繰り返しカウンタ i
4. メソッド printAverage() の変数 sum
この問題より、フィールドの値は、(コンストラクタで初期値を代入したり、メソッドでその値を利用したり) そのクラス内の全ての要素からアクセスが可能であることがわかります。一方、メソッドの内部で宣言され、そのメソッドの使用が終わると同時にメモリから消える変数 (i や sum) をローカル変数 (local variable) と言いますが、それらはメソッドブロックの外部からは利用できませんので、メソッドが違えば同じ変数名を用いることもできるわけです。
3.2.5 メソッド
フィールドに 2 種類あるように、メソッドも「インスタンスメソッド (instance method)」と「クラスメソッド (class
method)」の 2 種類があります。前者が「インスタンス個々が持つメソッド」、後者が「クラスが持つメソッド」です。書き方も、前者は「インスタンス名.メソッド名」、後者は「クラス名.メソッド名」と書きます。ただし、同じクラス内で利用する場合に、インスタンス名やクラス名を省略できる場合があります。例えば、第 2 章に出てきたメソッドは全てクラスメソッドでした。でも、使用する際に「クラス名.メソッド名」なんてしませんでしたよね。それは、同じクラス内での利用だったため、クラス名が省略可能だったためです。例えば、2章で作った次のプログラムでは、 main メソッド内で printCircleArea( r ); メソッドを呼び出していますが、このメソッドはその定義においてクラスメソッドであることがわかります ( static の文字が見えたかな)。
ソースコード 3.15 CircleArea2.java (クラスメソッドで円の面積)
package section0218;
public class CircleArea2 {
public static void main(String[] args) {
for(int r=1; r<=10; r++) {
printCircleArea( r );
}
}
// 半径 radius の円の面積 area を出力するメソッドstatic void printCircleArea( int r ) {

146 第 3章 Java 言語の基本的な文法 II
double area = r * r * Math.PI;
System.out.printf( "半径=%2d の円の面積は、%8.4f です %n", r, area );
}
}
このメソッドの本来の呼び出し方は「クラス名 .printCircleArea( r )」でなければなりません。つまり、CircleArea2.printCircleArea( r ); が本来の書き方です。しかし、CircleArea2 クラスから見ると、自分の中にあるメソッドを使うのに毎回自分の名前を付けねばならないというのはちょっと面倒ですよね。そこで、問題 (名前の重複) が起きない限りは、自分のクラス名は省略可能となっているのです。もちろん、他のクラスから使う場合は、クラス名が必要になります。例えば、Math.cos(double) は Math クラスのクラスメソッドを使っているわけで、Math. は省略できませんでした。しかし、それも面倒な場合がありますよね。その場合は、 import 文を用いることになります (import 文は後で詳しく)。クラスメソッドはクラスの持つメソッドなので、インスタンスを作らなくとも利用することができます。一方、インスタンスメソッドは、インスタンス個々が持つメソッドですから、インスタンスを作って初めて使うことが出来るようになります。また、インスタンスごとに処理結果が違ってきます。学生の成績情報プログラムで、Student クラスの printRecords() メソッドは、インスタンスメソッドでした (static が付いていないですね)。同じメソッドでも、noda.printRecords(); と利用すれば野田さんの情報が出力され、kagura.printRecords(); と利用すれば神楽くんの情報が出力されるわけです。
問題 3.2.6. 以下のプログラムはオブジェクト指向とは言い難い (だって、どこにもインスタンスが発生していないから)。そこで、Human クラスを作り、名前を記憶する String 型フィールド name を与え、コンストラクタに文字列 "太郎" を与えて Human インスタンス taro を作り、taro のインスタンスメソッド hello に時刻を渡して以下と同じような挨拶の処理を行うように、TaroExample.java を改良 (?) しなさい。(ちょっと無理っぽいオブジェクト指向ですが)
ソースコード 3.16 TaroExample.java (クラスを作ってみる)
package section0302;
public class TaroExample {
public static void main(String[] args) {
String name = "太郎";
hello( name, "10:00" );
}
static void hello( String name, String time ) {
System.out.print( name + "さん " + time + " ですね。" );
if( time.compareTo("12:00") <= 0 ) { // 入力時刻が "12:00" 以前なら午前と認識するSystem.out.println( "おはようございます。" );
} else {
System.out.println( "こんにちは。" );
}
}
}
問題 3.2.7. 以下の main メソッドが動くように、先に作ったソースコード 3.8 の平面上の点のクラス Point にインス

3.2 オブジェクトとインスタンス 147
タンスメソッド public double length() を追加しなさい。なお、平方根は double Math.sqrt(double) メソッドを使うこと。
ソースコード 3.17 (改) PointExample.java
package section0302;
public class PointExample {
public static void main(String[] args) {
Point p = new Point(); // デフォルトコンストラクタを用いて点 p を作成Point q = new Point( 1.5, -0.3 );
p.print(); // p の情報を出力q.print();
// 原点からの距離を計算して出力するSystem.out.println( "原点から p までの距離は、" + p.length() );
}
}
問題 3.2.8. 問題 3.2.7 の Point クラスに対し次の改良を行い、以下のプログラムが動くようにしなさい。
• クラスメソッド:引数の2点の距離を求める public static double distance( Point, Point ) を作る• インスタンスメソッド:引数の点との距離を求める public double distance( Point ) を作る• クラス定数:座標 (0,0) を与えて点を作り、それを private static final Point ORIGIN に与えるそこで、原点からの距離 length() の計算方法を ORIGIN との距離を測るものとする
ソースコード 3.18 PointExample2.java
package section0302;
public class PointExample2 {
public static void main(String[] args) {
Point p = new Point( 1.0, 2.0 );
Point q = new Point( 2.0, -1.0 );
// クラスメソッド:引数の2点の距離を返すdouble dist1 = Point.distance( p, q );
System.out.println( "p と q の距離は (クラスメソッド版):" + dist1 );
// インスタンスメソッド:引数の点との距離を返すdouble dist2 = p.distance( q );
System.out.println( "p と q の距離は (インスタンスメソッド版):" + dist2 );
}
}
問題 3.2.9. 複素数のクラス ComplexNumber を完成させ、以下のプログラムが動くようにしなさい。
ソースコード 3.19 ComplexNumberExample.java (複素数計算)
package section0302;

148 第 3章 Java 言語の基本的な文法 II
public class ComplexNumberExample {
public static void main(String[] args) {
ComplexNumber c1 = new ComplexNumber( 1, 2 ); // c1 = 1 + 2i
ComplexNumber c2 = new ComplexNumber( 2,-3 ); // c2 = 2 - 3i
System.out.println("c1 = " + c1.toString() );
System.out.println("c2 = " + c2.toString() );
// インスタンスメソッドとクラスメソッドで同じ結果をSystem.out.println("c1 + c2 = " + c1.add( c2 ).toString() );
System.out.println("c2 + c1 = " + c2.add( c1 ).toString() );
System.out.println("c1 + c2 = " + ComplexNumber.add( c1, c2 ).toString() );
System.out.println("c1 * c2 = " + c1.multiply( c2 ).toString() );
}
}
ソースコード 3.20 ComplexNumber.java (複素数のクラス)
package section0302;
public class ComplexNumber {
private double real; // 実部private double imag; // 虚部public ComplexNumber( double r, double i ) {
this.real = r;
this.imag = i;
}
// 複素数を "( real, imag )" なる形式の文字列で返すメソッド@Override
public String toString() {
// この中身を作る}
// 自分と c との和の複素数を返すメソッドpublic ComplexNumber add( ComplexNumber c ) {
// この中身を作る}
// 引数の2複素数の和を返すクラスメソッドpublic static ComplexNumber add( ComplexNumber c1, ComplexNumber c2 ) {
// この中身を作る}
// 自分と c との積の複素数を返すメソッドpublic ComplexNumber multiply( ComplexNumber c ) {
// この中身を作る}
}

3.2 オブジェクトとインスタンス 149
なお、ComplexNumber クラスの 10 行目の @Override は「アノテーション (Annotation:注釈)」と言って (授業では詳しく触れませんが)、アットマーク @ で始まるタグ付けされた付加情報をコンパイラに教える機能です。Java SE
5 で追加されたもので、自作することもできます。@Override は、そのメソッドがスーパークラスのメソッドの書き換えだよ!と言っています。もし書き間違いなどでそのメソッド定義がスーパークラスの定義に反していたときは、エラーメッセージが表示されます。他に、@SuppressWarnings("unused") なんてのも、以前出てましたね。
問題 3.2.10. 問題 3.2.9 の複素数のクラスに次のメソッドを追加しなさい。
• 実部、虚部、それぞれのセッターとゲッターメソッド public void setReal(double) など• 自身の共役複素数を返すメソッド public ComplexNumber conjugate()
• 実数で自身を割った複素数を返すメソッド public ComplexNumber divide(double)
• 引数の複素数で自身を割った複素数を返すメソッド public ComplexNumber divide(ComplexNumber)
• 自身の絶対値を返すメソッド public double abs()
• 複素空間での実軸からの角度 (偏角)をラジアンで返すメソッド public double angle()
なお、偏角は、以下で場合分けする:複素数 x+ iy の偏角 θ は、
θ =
arctan(yx
)(x > 0)
arctan(yx
)+ π (x < 0, y ≧ 0)
arctan(yx
)− π (x < 0, y < 0)
π/2 (x = 0, y > 0)−π/2 (x = 0, y < 0)
=
2 arctan
Å√x2+y2−x
y
ã(y ̸= 0),
0 (x > 0, y = 0),π (x < 0, y = 0)
で計算され、1つの目の場合わけによる値は Math.atan2(y,x) で得られる。
問題 3.2.11. 先に作った点のクラス Point を利用して、パッケージ section0302 内に直線のクラス Line を次のように作成しなさい。
• 直線は ax+ by + c = 0 の標準形で表されるとし、従って、Line クラスは 3 つ実数フィールド a, b, c を持つ• 以下の 4 種類のコンストラクタを用意する
– 3 つの実数値 a, b, c を引数に与えるコンストラクタ Line( double a, double b, double c )
– 直線の傾き (実数値)と y 軸切片の値 (実数値)を引数に与えるコンストラクタ Line( double m, double
d )
– その直線が通る適当な 2 つの点 (Point クラスのインスタンス) を引数に与えるコンストラクタ Line(
Point p, Point q )。なお、水平線や垂直線も考慮すること– その直線が通る適当な点 (Point クラスのインスタンス) と直線の傾き (実数値) を引数に与えるコンストラクタ Line( Point p, double m )。この場合、垂直線は考慮しない
• 引数の点がその直線上にあれば true を返すメソッド boolean onLine( Point p )

150 第 3章 Java 言語の基本的な文法 II
• 引数の点とその直線の距離を返すメソッド double distance( Point p )
• その直線が引数の直線と交差するとき true を返すメソッド boolean isCross( Line other )
• その直線と引数の直線との交点を Point 型インスタンスで返すメソッド Point crossPoint( Line other )
なお、2 直線が重なった場合は交点なしとし、交点がない場合は NULL を返すとする
問題 3.2.12. 問題 3.2.11 の各メソッドのクラスメソッド版を以下のように作って、追加しなさい。
• 引数に直線と点を与えて、点が直線上にあれば trueを返すクラスメソッド static boolean onLine( Line,
Point )
• 引数に直線と点を与えて、それらの距離を返すクラスメソッド static double distance( Line, Point )
• 引数に2本の直線を与えて、それらが交差するとき true を返すクラスメソッド static boolean isCross(
Line, Line )
• 引数に2本の直線を与えて、それらの交点を返すクラスメソッド static Point crossPoint( Line, Line )
交点がない場合は、インスタンスメソッドと同様に処理すること
問題 3.2.13. 次のような2次元平面上の円を表わす public クラス Circle を作成しなさい。
• private なフィールドとして、Point 型インスタンス center (中心点) と double 型の値 r (半径) を持つ• 引数に中心点と半径を与えて、円のインスタンスを作るコンストラクタ public Circle( Point, double )
• その円の面積を返すメソッド public double area()
• その円の情報を文字列として返すメソッド public String toString()。返す文字列は、”中心点:(1.0, 2.0) 半径:3.0” のような形式で
• 引数に与えた点と中心点の距離を返すメソッド public double distance( Point )。
以下の 2 つのメソッドはこのメソッドを使って作る。
• 引数に与えた点がその円の内部 (境界も含む) にあるなら true を返すメソッド public boolean includes(
Point )
• 引数に与えた他の円と共通部分を持つ (接する場合も含む) とき true を返すメソッド public boolean
isCross( Circle )
問題 3.2.14. 以下のようないろいろな数の加算に対応できる専用クラス MyMath クラスを作り、その中にクラスメソッド plus() を作りなさい。
ソースコード 3.21 MyMathExample.java (自作 Math クラス)
package section0302;
public class MyMathExample {
public static void main(String[] args) {

3.2 オブジェクトとインスタンス 151
System.out.println( MyMath.plus( 10, 20 ) );
System.out.println( MyMath.plus( 10, 20, 30 ) );
System.out.println( MyMath.plus( 10.0, 20.0 ) );
System.out.println( MyMath.plus( new int[]{ 1, 2, 3, 4, 5 } ) );
}
}
問題 3.2.15. 以下のプログラムはいずれもエラーが発生します。その理由を述べなさい。
package section0302;
public class Problem0302 {
int a;
public static void main(String[] args) {
a = 123;
}
}
package section0302;
public class Problem0302 {
int a;
public static void main(String[] args) {
this.a = 123;
}
}
では、 main メソッドの中にどのように書いたら変数 a に 123 を代入できますか。逆に、最初のプログラムで main メソッドの中身 a = 123; を変えずにツジツマの合う (?) ようにするには、どうしたら良いでしょう。
3.2.6 参照型配列
第 2 章では基本型の配列 (例えば int[]) を学びました。一つ一つのデータは基本型ですが、配列として宣言された変数、例えば int[] x = new int[10]; の x は参照型変数となりました。ここでは、参照型データの配列を見ることにします (データを参照しているのを再度参照するんですね)。例えば、文字列の配列 (String[]) や 2 次元配列(int[][]) は参照型配列です。点 (Point クラスのインスタンス) の配列を作ってみましょう。ここでは、Point 型配列で与えれた点集合の重心を求める新たなクラスメソッド Point centroid( Point[] ) を
Point クラス内に作ります。
ソースコード 3.22 CentroidExample.java (参照型配列 Point[])
package section0302;
public class CentroidExample {
public static void main(String[] args) {
Point[] points = {
new Point( 0.5, 1.8 ),
new Point( 1.2, 0.9 ),

152 第 3章 Java 言語の基本的な文法 II
new Point( 1.5, 3.2 ),
new Point( 1.7, 2.2 ),
new Point( 3.0, 0.7 ),
new Point( 3.3, 3.1 ),
};
Point.centroid( points ).print();
}
}
ソースコード 3.23 Point.java (メソッド centroid の追加)
package section0302;
//平面上の点のためのクラスpublic class Point {
private double x;
private double y;
:
// 点配列の重心を求めるクラスメソッドpublic static Point centroid( Point[] points ) {
double xsum = 0.;
double ysum = 0.;
for( Point p : points ) {
xsum += p.x;
ysum += p.y;
}
return new Point( xsum/points.length, ysum/points.length );
}
}
さて、 main メソッドの 12 行目の処理 Point.centroid( points ).print(); は解読出来ましたか?左から順に読んでくれれば OK なのですが、まずは Point.centroid( points ) これは Point クラスのクラスメソッド centroid() の引数に点の配列 points を渡していますね。このメソッドは (この後作ってもらうわけですが)
重心を Point 型インスタンスとして返してくれます。つまり、その重心自体もフィールドやメソッドを持っているのです。従って、その .print() なわけですから、その重心点の持つインスタンスメソッド print() を動かして (情報を出力せよ)!という意味です。ドットでつなげることで、2つのメソッドを連続的に使って処理をしているわけです。もちろん以下のように一旦 Point 型インスタンス centroid を作成してから、 print() を動かす!と書いても良いですよ。
// Point.centroid( points ).print(); の代わりにPoint centroid = Point.centroid( points );
centroid.print();
}
}
ところで、 CentroidExample.java の main の中のエラー (?) に気づいた人いますか?配列 points の最後の点 new Point( 3.3, 3.1 ) の後に余分なカンマが!しかし実はこれ、知っていて付けています (コンパイラがエラーにしていないでしょ)。これは C 言語から受け継いだ隠れた仕様で (C++でも OK)、配列の最後の要素の後ろに余分なカンマを付けてもエラーとしない!というものです (文法に厳しい Java もこの仕様は継承しているのです)。理由は、データのコピペが楽にできる、というのが目的だったようですが、和田はあまり好きな仕様ではありません。int[] a = { 1, 2, 3, }; なんて気持ち悪いよね。カンマを付けておいても良い、というだけで

3.3 カプセル化 153
すから消しちゃいましょう。
3.2.7 オーバーロード
「オーバーロード (Overload)」とは、多重定義のことです。同じ名前のメソッドを複数定義してプログラムの流れに応じて選択出来るようにすることです。例えば、数の絶対値を求める Math.abs() メソッドは、int Math.abs(int)、long Math.abs(long)、float Math.abs(float)、double Math.abs(double) と 4 種類が用意されています。引数の型と戻り値の型を変えて用意してあるわけです。それ以外の組み合わせは用意されていません。さて、同じ名前のメソッドを共存させるには、どんなルールを守らなくてはならなかったかな?
3.3 カプセル化自動車を運転するドライバーは、各車種ごとにそのアクセルペダルの先にどんな機構が隠されているのか知らなくてもペダルを踏めばエンジン回転数が上がることを知っています。このブラックボックス化のことを「カプセル化」と言います。カプセル化は、データや処理に対しユーザに必要なものだけ公開し不必要なものは
いん
隠ぺい
蔽する操作を言います。カプセル化により、
• 限定された操作以外では利用できないようにする• 不必要なものが見えないようにできる• 中身を改変されることを防止できる• オブジェクト間の関連が減ることで制御しやすくなる• 公開した操作を改変しない限りは、外部に影響を与えない内部のバージョンアップが可能になる
Java のプログラムにおいては、メンバー (フィールド・コンストラクタ・メソッド) ごとに適切なアクセス制限をかけることで、カプセル化が実現できます。
3.3.1 アクセス制御
カプセル化を実現させるためには、各メンバーごとにどこまで公開 (利用・改変)を可能にするか?を設定することから始めます。ここまでに説明なしにちょくちょく出てきた public や private が、そのための「アクセス修飾子(access modifier)」です。Java では、全てのメンバー (クラス・コンストラクタ・フィールド・メソッド) にアクセス修飾子を付けることができます。まずはそれぞれに付けられるアクセス修飾子を表でまとめましょう。アクセス修飾子には、修飾子を書かないという選択 (package-private とも呼ばれる) を含めて 4 種類あります。
図 3.3 アクセス修飾子
メンバー修飾子
private省略
protected public(package-private)
クラス × ⃝ × ⃝コンストラクタ ⃝ ⃝ ⃝ ⃝フィールド (変数) ⃝ ⃝ ⃝ ⃝
メソッド ⃝ ⃝ ⃝ ⃝
クラスのアクセス制限に「private」と「protected」が選択できない以外は、いずれのメンバーも全ての修飾子を使

154 第 3章 Java 言語の基本的な文法 II
用することができます。ただ、ここでもまたちょっと嘘があって、「内部クラス (inner class)」というクラスでは全ての修飾子が利用できます。「内部クラス」は後で説明しますが、この授業では触れないかな。メンバーにアクセス修飾子を付けるには、型宣言の際に先頭に書きます。例えば、private int x = 123; や
public static double[] x = new double[100]; なんて感じですね。以下で1つずつ見ていきましょう。
3.3.2 private
private は、最も制限の強いアクセス修飾子で、コンストラクタ・フィールド・メソッドに付けることが出来ます。この修飾子が付いたメンバーは、含まれるクラスの外からは直接アクセスすることができません。アクセスできるのは、そのクラス内部のメンバーからのみです。直接アクセスするとは、次のような処理を言います。
ソースコード 3.24 PrivateFieldExample.java (private field へ直接アクセス)
package section0303;
public class PrivateFieldExample {
public static void main(String[] args) {
Circle circle = new Circle( 10.0 );
double radius = circle.radius;
double area = circle.getArea();
System.out.printf("半径 %f の円の面積は、%f%n", radius, area );
}
}
class Circle { // 円のクラスprivate double radius; // 半径Circle( double radius ) { // コンストラクタ
this.radius = radius;
}
double getArea() { // 面積を返すメソッドreturn radius * radius * Math.PI;
}
}
このプログラムでは Cirlce クラスのフィールド radius に private 修飾子が付けられています。そのため、main
メソッド内の double radius = circle.radius; でエラーが表示されます。変数 radius は、Circle クラスの外の PrivateFieldExample クラスからは直接アクセスできないということです。この「インスタンス名.メンバー名」の形式での呼び出しが、直接アクセスするということです。もし getArea() メソッドにも private 修飾子が付いていれば、次の行の double area = circle.getArea(); も直接アクセスとなってエラーになります。では、こうした場合の解決法はどうしたら良いでしょう。方法は2通りあります。
• フィールド radius の private を取り去る (この場合、同じパッケージ内なので package-private にする)
• radius のゲッターを作って circle.radius のような直接アクセスをやめる
なぜフィールドにわざわざ private 修飾子を付けるのでしょうか。それは、もし private が付いていなければ、main メソッドから直接 circle.radius = 10000.0; のように論外のデータを代入できてしまうからです。もしこの値が銀行口座のような場合、外部のプログラムで勝手に口座金額が
かい
改ざん
竄されてはいけませんよね。円の面積を求める例では少し難がありますが。(^^;) 従って、そのような場合、ゲッターを作り、それを正規の利用方法として使う(それしか使えなくする) のが一般的です。もちろん、ゲッターは private にはしません。
ソースコード 3.25 (改)PrivateFieldExample.java (private field へ直接アクセス)

3.3 カプセル化 155
package section0303;
public class PrivateFieldExample {
public static void main(String[] args) {
Circle circle = new Circle( 10.0 );
double radius = circle.getRadius();
double area = circle.getArea();
System.out.printf("半径 %f の円の面積は、%f%n", radius, area );
}
}
class Circle { // 円のクラスprivate double radius; // 半径Circle( double radius ) { // コンストラクタ
this.radius = radius;
}
double getRadius() { // 半径を返すゲッターreturn this.radius;
}
double getArea() { // 面積を返すメソッドreturn radius * radius * Math.PI;
}
}
ゲッターによるアクセスのもう一つの利点は、今、Circle クラスを設計している葛飾くんが、半径の変数をdouble hankei; と英語から日本語に替えようと思ったとします。このとき、直接のアクセスを許していると、PrivateFieldExample クラスを作っている野田さんに、circle.radius; から circle.hankei; への変更を連絡しなければいけません。radius への直接のアクセスを不許可として、野田さんが circle.getRadius() を使うことになれば、葛飾くんがゲッター getRadius() 内で return hankei; と変更しても、野田さんには影響なく済むわけです。
問題 3.3.1. 上のプログラムの Circle クラスを同じパッケージ section0303 内の別のファイル Circle.java に分離しなさい。その場合、クラス・コンストラクタ・メソッドをこのまま (package-private のまま) 利用できることを確かめなさい。
コンストラクタの private 化ところで、 コンストラクタに private を付けると、どうなるでしょう。この場合もそのクラスの外部からのコンストラクタの使用が出来なくなります。つまりこのコンストラクタを用いてインスタンス作成ができなくなる。えっ?じゃ、このコンストラクタ何に使うのでしょう?private なコンストラクタはインスタンスを作らせないためにあるのです!?例えば、三角関数の cos() メソッドなどが入っている Math クラスはクラスフィールドとクラスメソッドのみからなるクラスです。数学関数の集まりとして定義されたクラスで、Math クラスのインスタンスを作る!というようには定義されていません。というか、させません。従って、Math クラスにはコンストラクタがありません。しかし、コンストラクタを書かないでおくと、先に触れたようにコンパイラは「デフォルトコンストラクタ」を自動的に作ってしまいます。そこで、わざと Math クラスの内部には private なデフォルトコンストラクタが入っています。すると、既にデフォルトコンストラクタがあるので、自動的な作成が起きない上に、外部から Math クラスのインスタ

156 第 3章 Java 言語の基本的な文法 II
ンスを作ろうとしても、作れないよ!というわけです。他にも private なコンストラクタの利用価値に「シングルトン特性の強制」(あるクラスのインスタンスを1つだけ作るが2つ以上は作りたくないとき)に利用します。これはこのテキストの範囲外なので、ここでは省略!一方、クラスに private を付けられないのは、外部からクラス自体が見えないのではクラスの存在意味がなくなりますから当然ですかね。
3.3.3 package-private
アクセス修飾子が書かれていない (省略されている) 状況は、正確な用語では「デフォルトアクセス」のレベルと言うそうですが、一般的には「パッケージプライベート (package-private)」で通ります。アクセス修飾子が省略されている場合、そのメンバーは、そのクラスが含まれるパッケージ内のどのクラスからもアクセスすることができますが、パッケージの外からは直接アクセスできません。パッケージというグループ化をする目的からも、パッケージの内と外を分けるこのアクセス修飾子は意味がありますね。同じ名前のクラスを複数作りたいけれど、クラスに付けられるアクセス修飾子は package-private と public のみです。それらクラスにいずれも public を付けると、パッケージを超えて重複エラーになるので、常にパッケージ名を付けながら区別しないといけなくなり、結構面倒です。そこで、package-private にしてそれぞれ異なるパッケージ内に置けば、面倒が無くなります。セキュリティの観点からも、可能な限り public にせずに package-private にするよう、推奨されています。
3.3.4 protected
protected は、2 番目に制限の弱いアクセス修飾子です (package-private より弱い)。この修飾子の付いたメンバーは、含まれるパッケージ内のどのクラスからも直接アクセスできる上に、パッケージ外でもそのクラスを「継承」したクラス (サブクラスと言う) から、アクセスすることができるというものです。「継承」や「サブクラス」についてはこの後で説明しますが、要は、そのクラスを拡張しているなら外部からでも使って良いよ!という感じですかね。この授業のレベルでは protected を付ける機会はそれほど多くはありませんが、package-private だったメンバー
を protected に制限を緩めると、設計者が管理できない他人のプログラム内で (継承されることで) 勝手に利用されるようになるので、その差は大きいと言えます。
3.3.5 public
public は、最も制限の弱いアクセス修飾子で、クラスやパッケージに関わらず、どこからでも直接アクセスできます。事実上の制限なしです。4 つのアクセス修飾子は、メンバーごとに独立に与えられますが、例えば、package-private なクラス A の中に
public なメソッド a() を置くとどうなるでしょう?クラス A がそのパッケージの外からアクセスできないために、せっかくの public が生かせず、パッケージの外からa() を利用することができません。つまり、入れ物であるクラスのアクセス修飾子に対し、そのメンバーのアクセス制限は同等かより強くなければいけません。
問題 3.3.2. 次のプログラムにおいて、どの行でコンパイルエラーが表示されるでしょう。
package section0303;
public class Problem0332 {
public static void main(String[] args) {

3.4 インヘリタンス (継承) 157
A a1 = new A();
a1.setValue( 10 );
System.out.println( a1.value );
A a2 = new A( 10 );
System.out.println( a2.getValue() );
}
}
class A {
private int value;
A( int value ) {
this.value = value;
}
void setValue( int value ) {
this.value = value;
}
int getValue() {
return this.value;
}
}
問題 3.3.3. 問題 3.3.2 で文法エラーが表示されないように修正したとし、その上で、クラス A を別のパッケージsection0303a に移動したとします (Eclipse 上でプログラム移動を行うと、プログラム内に import 文が自動作成されます)。 新たに表示される文法エラーの表示理由を考察して、プログラムを修正しなさい。
アクセス制限を public にするということは、安易に削除したりアクセス制限を強めたりできない、という意味になります。何故なら、パッケージや継承を超えてそのクラスやメソッドを利用できるようにした以上は、多くの人がそれを使っている可能性があるからで、それらの人たちへの責任が出てくるわけです。従って、極力 public は止めましょう!となるんですね。それに、メソッド名をちょっと間違って書いたために、思いもしない大昔に作った public メソッドが勝手に動いていた、なんてこともありえるからね。
問題 3.3.4. 4 種類のアクセス修飾子をその制限の強い順に左から右に (最も強いアクセス修飾子を左に、弱い修飾子を右に) 並べて書きなさい。なお、アクセス修飾子を省略する場合の修飾子は「省略する」と書きなさい。次に、そのうちでクラスに付けることの出来ないものを選び並べなさい。
3.4 インヘリタンス (継承)
新しくクラスやメソッドを作るとき、以前作ったクラスやメソッドと共通点が多い場合に、共通する部分を再利用できれば生産性が上がりますよね。Java にもそうした仕組みがあり、「継承 (インヘリタンス:inheritance)」と言います。

158 第 3章 Java 言語の基本的な文法 II
例えば、「自動車」についてのプログラムを作ろうと思います。「セダン」「トラック」「スポーツカー」それぞれをオブジェクトとして定義するとき、いずれもが共通に持つフィールドやメソッドを重複して宣言するのは無駄ですし、どれか 1 つを修正したとき、他のオブジェクトのものも修正しなければならなくなって、面倒な上にミスさえ起こりやすくなります。そこで、「自動車」という共通概念のオブジェクトを作って共通のフィールドやメソッドはそれに持ってもらい、それぞれの車種特有の属性値や機能はそれぞれのオブジェクトに追加・補足として与えるわけです。「自動車」クラスのような継承される側のクラスを「スーパークラス (super class)」と言い、「トラック」クラスのような継承する側のクラスを「サブクラス (sub class)」と呼びます。数学の言葉では、(部分集合を subset と言うように) サブという単語が付くと部分的なものを指すので、サブクラスの方が属性値や機能が少なそうに思えますが、Java
の世界では逆で、サブクラスに当たる方が一般に属性値や機能が増えます。以下の例では、「学生」クラスと「教授」クラスを定義しています。その際に、それらの上位概念の「人」クラスを作って、それを継承するプログラムになっています。(ちょっと無理っぽい例ですけどね)
ソースコード 3.26 InheritanceExample.java (継承関係)
package section0304;
public class InheritanceExample {
public static void main(String[] args) {
Student noda = new Student( 1419001, "野田 愛" );
Professor hasiguchi = new Professor( "教授", "橋口 博樹", "男性" );
Lecture linearAlgebra1 = new Lecture( "A001", "線形代数1" );
noda.take( linearAlgebra1 );
hasiguchi.lectured( linearAlgebra1 );
}
}
まずは、「人」の定義です。「名前」などのフィールドの宣言の後、「氏名が未定義のときに代入する定数」などの定数クラスフィールドを宣言し、コンストラクタ、そしてゲッターを定義しています。
ソースコード 3.27 Human.java (人クラス)
package section0304;
//人クラスpublic class Human {
private String name; // 名前private int age; // 年齢private String sex; // 性別public static final String NAME_UNKNOWN = null; // 氏名未定義定数public static final int AGE_UNKNOWN = -1; // 年齢未定義定数public static final String SEX_UNKNOWN = null; // 性別未定義定数//コンストラクタpublic Human( String name, int age, String sex ) {
this.name = name;
this.age = age;
this.sex = sex;
}
//ゲッターpublic String getName() {
return this.name;
}
public int getAge() {
return this.age;
}
public String getSex() {
return this.sex;

3.4 インヘリタンス (継承) 159
}
}
「教授」は「人」を継承し、追加フィールドとして「職名」を、メソッドとして「講義する」を与えています。
ソースコード 3.28 Professor.java (教授クラス)
package section0304;
// 教授クラスpublic class Professor extends Human {
private String licence; // 職名// コンストラクタpublic Professor( String licence, String name, String sex ) {
super( name, AGE_UNKNOWN, sex );
this.licence = licence;
}
// メソッドpublic void lectured( Lecture lecture ) {
System.out.printf( "(%s) %sは、%sを講義する。%n", this.licence, this.getName(),
lecture.getName() );
}
}
講義クラスは、「講義番号」と「講義名」のシンプルなクラスとしています。
ソースコード 3.29 Lecture.java (講義クラス)
package section0304;
//講義クラスpublic class Lecture {
private String lecNo; // 講義番号private String lecName; // 講義名// コンストラクタpublic Lecture( String lNo, String lName ) {
this.lecNo = lNo;
this.lecName = lName;
}
// ゲッターpublic String getLecNo() {
return lecNo;
}
public String getName() {
return lecName;
}
}
「学生」も「人」を継承して定義します。追加フィールドとして「学籍番号」が与えられます。
ソースコード 3.30 Student.java (学生クラス)
package section0304;
public class Student extends Human {
private int idNo; // 学籍番号// コンストラクタpublic Student( int idNo, String name ) {
super( name, AGE_UNKNOWN, SEX_UNKNOWN );
this.idNo = idNo;
}

160 第 3章 Java 言語の基本的な文法 II
// メソッドpublic void take( Lecture lecture ) {
System.out.printf( "%s(%d)は、「%s」を受講する。%n",this.getName(), this.idNo, lecture.getName() );
}
}
サブクラスを宣言するときは、「class サブクラス名 extends スーパークラス名」とクラス名に続いてキーワードextends とスーパークラスの名前を書きます。クラスブロックには、スーパークラスで未定義なフィールド及びコンストラクタそしてメソッドを書きます。メソッドにおいては、中身を修正したいメソッドがあればそれも書きます。図 3.4 は、UML (Unified Modeling Language) というオブジェクト指向モデルを表現するためのグラフィカル言語グループのひとつ「クラス図 (class diagram)」という図式で今回のプログラムの世界を表現したものです。言語と言っていますが、言葉ではなく図で表現するもので、使用される記号や線の種類など慣れが必要です。静的・動的な UML の図式でプログラム化する世界を表現してからプログラム化する、大規模なオブジェクト指向開発には欠かせない道具となっています。残念ながら UML はこの授業では触れられませんが、ネットに解説ページが多くありますので是非、独習してみて下さい。クラス図で取り敢えず知っておくべきことは、白抜き実線の矢印が UML の言葉で「
はん汎
か化」と言い、Java の「継承」
を意味することです (他にもいろいろな形の矢印が定義されています)。よって、Human は Student の汎化 (一般化)
だよ!と言っていますね。Java で言うなら、Student は Human を継承している!ですね。プログラムと対比してもらえば簡単かと思います。
Human
- name : String - age : int- sex : String+ NAME_UNKNOWN : String = null+ AGE_UNKNOWN : int = -1+ SEX_UNKNOWN : String = null
+ getName() : String+ getAge() : int+ getSex() : String
<<constructor>>+ Human(name : String, age : int, sex : String )
Student
- idNo : int
+ take( lecture : Lecture ) : void<<constructor>>
+ Student( idNo : int, name : String )
Professor
- licence : String
+ lectured( lecture : Lecture )<<constructor>>
+ Professor( licence : String, name : String, sex : String )
Lecture
- lecNo : String- lecName : String
+ getLecNo() : String+ getName() : String
<<constructor>>+ Lecture( lNo : String, lName : String )
+ public
# protected
~ package private
- private
可視性
図 3.4 UML で継承関係の表現
問題 3.4.1. 問題 3.2.8 やソースコード 3.22で拡張した2次元平面の点のクラス Point をスーパークラスとして、さらに点の重さの属性値を追加したサブクラス WeightedPoint を作成しなさい。また、次のプログラムが動くように、WeightedPoint クラスに 2 点の重心を求めるメソッド WeightedPoint centroid( WeightedPoint ) を作りなさい。なお、この場合の重心点とは、2点を重さ0の棒の両端に置いたと思って釣り合いが取れる点のことで、重心点の重さを2点の和とするものです。

3.4 インヘリタンス (継承) 161
ソースコード 3.31 PointExample3.java (点集合の重心点を求める)
package section0304;
public class PointExample3 {
public static void main(String[] args) {
// 点の集合:それぞれ座標と重さからなるdouble[][] data = {
{0.5, 1.8, 2}, {1.2, 0.9, 1},
{1.5, 3.2, 3}, {1.7, 2.4, 2},
{2.5, 3.9, 4}, {1.9, 2.2, 1},
{3.0, 0.7, 3}, {3.5, 3.1, 2},
{4.2, 1.9, 2}, {4.0, 3.7, 1}
};
// 配列情報から重み付き点オブジェクトの配列 points[] を作成するWeightedPoint[] points = new WeightedPoint[data.length];
for(int i=0; i<points.length; i++) {
points[i] = new WeightedPoint( data[i][0], data[i][1], data[i][2] );
}
// 暫定的な重心を最初の点と同じ位置の点とする (このコンストラクタを作る)
WeightedPoint center = new WeightedPoint( points[0] );
// 重心点 center と新たな点 points[i] との重心点を求めて center に記憶するfor(int i=1; i<points.length; i++) {
center = center.centroid( points[i] );
}
// 求めた重心点 (全ての点の重心になる) の座標情報を出力するSystem.out.print( "点集合の重心点は、" );
center.print();
}
}
ソースコード 3.32 WeightedPoint.java (重み付きの点クラス)
package section0304;
import section0302.Point;
public class WeightedPoint extends Point {
private double weight; // 追加する重さの属性
// コンストラクタと新たなメソッド centroid を作る}
点集合の重心の求め方は、全ての点が同じ重さの場合にソースコード 3.22 で作ったように、n 点の重心をまとめて求めることもできる。授業ではそのクラスメソッドバージョンも作ってみよう。
3.4.1 単一継承
継承は連鎖的に行うことができます。つまり、クラス A がクラス B を継承し、そのクラス B が新たなクラス C を継承するような状況です (図 3.5 参照)。このとき、クラス A のインスタンスを作成すると、そこには、クラス A で宣言されたフィールド a (やメソッド) はもちろんのこと、クラス B のフィールド b、クラス C で宣言されたフィールド c を持つことになります。右の図は、クラス A のインスタンス instA を作成したときの概念的な図です。instA は、クラス A のインスタ

162 第 3章 Java 言語の基本的な文法 II
ンスですから、フィールド a をもちろん持ちますが、クラス B を継承しているので、フィールド b も持ち、同様にフィールド c も持つわけです。
A
+ a : int
B
+ b : int
C
+ c : int
int a
int b
int c
クラスBから
継承した部分
クラスCから
継承した部分
instA
クラスAのインスタンス型
図 3.5 単一継承
クラス C をスーパークラスとするクラスは、クラス B だけとは限りません。先に「人」クラスを「学生」クラスと「教授」クラスが継承しましたよね。しかし、複数のスーパークラスを持つこと「多重継承 (multiple inheritance)」はJava では許されていません。と言うか、ほとんどのオブジェクト指向言語は、多重継承を許していません (C++は許している)。Java のように多重継承を許さない継承方式を「単一継承 (single inheritance)」方式と言います。何か不便な気がする? そうですね。例えば、「水陸両用車」クラスと考えるとき、「自動車」と「船」の2つのクラスを定義して継承するのが順当な気がする。「電子ピアノ」は「ピアノ」と「電化製品」。「狼人間」は「狼」と「人間」。これらができない Java は C++に負けてる?なぜ Java は単一継承を選択しているのでしょう。それを示す例が次のプログラムです。
ソースコード 3.33 単一継承の理由
// 水陸両用車クラスが2つのクラスを継承できるとするclass AmphibiousCycle extends Car, Boat {
// どちらの speed と drive() を継承したら良いのでしょう?}
class Car { // 自動車クラスdouble speed; // 単位 km/h
void drive() { ・・・ } // 陸上をタイヤで運転}
class Boat { // 船クラスdouble speed; // 単位 knot : 1knot = 1852m/h
void drive() { ・・・ } // 水上をスクリューで運航}
多重継承を許すと、継承する 2 つのスーパークラスに同じフィールドや同じメソッドが存在したら、サブクラスはそのいずれを選択すべきか?の問題が生じます。また、同じクラスを重複して継承する問題も生じます (自動車のスーパークラスとしての乗り物クラスと船のスーパークラスとしての乗り物)。これらの問題を「菱形継承問題もしくはダイアモンド継承問題」と呼びます。C++はそうした選択をプログラマに任せている (明にプログラム中で選ぶ) のですが、Java などはその危険性 (プロ

3.4 インヘリタンス (継承) 163
自動車 船
乗り物
drive()
drive()drive()
水陸両用車
drive()
図 3.6 菱形継承問題
グラマを信じていない?) を重要視し、こうした多重継承を許していません。その代わりに、後で出てきます「インタフェース」という「クラスもどき?」を用いて単一継承の不便さを解消しています。なお、「スーパークラス・サブクラス」という言葉は、直接継承関係にある 2 つのクラス間の呼び方なので、クラス A
からクラス C を見るとき、本来「スーパークラスのさらにスーパークラス」と言わないといけません。これはちょっと不便なので、直接の継承関係になくとも、何段階かの継続関係にあるクラスの間で誤解が生まれない限り、このテキストでは「スーパークラス・サブクラス」の言葉を流用するか、ここだけの言葉として、「お爺さんのクラス・孫のクラス」などとよぶことにします。つまり、クラス C はクラス A のお爺さんクラスで、クラス A はクラス C の孫クラスである!と (孫のほうが一般に機能が多い!?)。
問題 3.4.2. 次の (a),(b),(c) のうち単一継承はどれですか。
A
+ a : int
B
+ b : int
C
+ c : int
A
+ a : int
B
+ b : int
C
+ c : int
A
+ a : int
B
+ b : int
C
+ c : int
D
+ d : int
(a) (b) (c)
問題 3.4.3. 左のような継承関係のとき、そのいずれかのクラスのインスタンスを書いたのが右の図である。下線部に適当なクラス名を入れ、3つのクラス内のフィールド名とメソッド名を右の図の妥当な場所に書き込みなさい。

164 第 3章 Java 言語の基本的な文法 II
A
+ x : double+ y : double
+ length() : double
B
+ w : double
+ getWeight() : double
C
+ c : java.Color
+ getColor() : java.Color
クラス のインスタンス クラス の情報
クラス の情報
3.4.2 Object クラス
任意のクラス、例えばクラス A を作成したとき、コンパイラは陰で Object という既存のクラスを A のスーパークラスとして必ず設定しています。また幾つかの継承関係のクラス群を作ったときも、それらのスーパークラスとしてObject クラスを位置付けます。例えば、先の Human クラスと Student クラスの例では Human クラスのスーパークラスとして、図 3.5 のクラス A, B, C の場合は C クラスのスーパークラスとして、Object クラスが設定されるのです。Object クラスの正式な名前は、java.lang.Object クラスです。パッケージ java.lang の中にあって、フィールドは持ちませんが、デフォルトコンストラクタと幾つかのメソッドを持つクラスです。以下は Object クラスの代表的なメソッドです。
表 3.4.1 Object クラスの代表的メソッド
メソッド 説明public boolean equals( Object obj ) 他のオブジェクトと等しいか否かを示すprotected Object clone() オブジェクトのコピーを作成して返すpublic String toString() オブジェクトの文字列表現を返す
どんなクラスでも Object クラスをスーパークラスに持つということは、 Object クラスに宣言されているメソッドをどんなクラスのインスタンスでも使える (持っている) ということです。以下のプログラムを見て下さい。適当に作ったクラス C のインスタンスで toString() メソッドなどを使ってみました。
ソースコード 3.34 ObjectExample.tex (Object クラスのメソッド)
package section0304;
public class ObjectExample {
public static void main(String[] args) {
C a = new C( 100 );
C b = a;

3.4 インヘリタンス (継承) 165
C c = new C( 100 );
System.out.println("a: " + a.toString() );
System.out.println("b: " + b.toString() );
System.out.println("c: " + c.toString() );
System.out.println( "a.equals(b): " + a.equals( b ) );
System.out.println( "a.equals(c): " + a.equals( c ) );
}
}
class C {
int value;
C( int value ) {
this.value = value;
}
}
とは言うものの、toString() メソッドの出力結果は、意味不明です。(^^;) これは、ハッシュコードといって、コンパイラが各インスタンスに適当に付けた名前 (アドレス情報の変形) が出力されているのです。JVM の状況に応じて名前は変わります。このプログラムでは便利そうなメソッド clone() の例は示されていませんが、これは先延ばし!
問題 3.4.4. 図 3.4 のクラス図に Human クラスのスーパークラスとして、Object クラスを描き、上で上げた Object
クラスの代表的な3つのメソッドをその中に書きなさい。また、ソースコード 3.26 の学生 noda と教授 hasiguchi において toString() メソッドや equals() メソッドが利用できることを確かめなさい。
なお、配列も (クラスではないのですが)、参照型オブジェクトとして Object のメソッドを全て持ちます。つまり、次のように書けます。
ソースコード 3.35 ArrayIsObject.java (配列の Object メソッド)
package section0304;
import java.util.Arrays;
public class ArrayIsObject {
public static void main(String[] args) {
int[] a = { 1, 2, 3 };
int[] b = { 1, 2, 3 };
System.out.println( "a: " + a.toString() ); // ハッシュコードが出力されるSystem.out.println( "a == b : " + ( a == b ) ); // a と b は等しくないSystem.out.println( "a.equals(b) : " + a.equals( b ) ); // a と b は等しくないSystem.out.println( "Arrays.equals(a, b) : " + Arrays.equals( a, b) ); // これだ
と中身までチェックする}
}
a と b が等しくない!?前期にやったよね。参照変数 a と b には何が入っているのでしたっけ。中身が同じ配列でも、メモリーの中では、別々の場所に領域を確保して置くことになります。従って、その参照変数の中身は異なってきます。そして、配列の場合の equals メソッドは、残念ながら中身までチェックしてくれないので、== と同じ結果になります。配列の中身まで等しいかどうかを知るには Arrays クラスの持つ equals メソッドに2つの配列を渡してチェックしてもらうと判定できます。

166 第 3章 Java 言語の基本的な文法 II
文字列の比較文字列比較において == と equals() の違いを認識しておきましょう。これは文字列が参照型であることから当然といえばそうなのですが、つい間違って使うことが多いからです。文字列比較において、== は参照変数の中身 (文字列の格納アドレス) が等しいかを比較し、equals() は文字列の中身が等しいかを比較しています。
問題 3.4.5. 次のプログラムを動かして、結果を吟味しなさい。
ソースコード 3.36 StringIsObject.java ( == と equals() の違い)
package section0304;
public class StringIsObject {
public static void main(String[] args) {
String a = "abcde";
String b = "abcde";
String c = "abc"; c += "de";
System.out.println( "a == b : " + ( a == b ) );
System.out.println( "a.equals(b) : " + a.equals( b ) );
System.out.println( "a == c : " + ( a == c ) );
System.out.println( "a.equals(c) : " + a.equals( c ) );
}
}
文字列の場合、コンパイル時に固定された文字列はメモリー内で同じ場所に格納されます。つまり、この場合のString a = "abcde"; と Sting b = "abcde"; の右辺の文字列はメモリーでは同じ場所に置かれて、つまり参照変数 a と b には同じ値が入ります。
3.4.3 オーバーライド
一般に、スーパークラスをサブクラスが継承するときは、新たなフィールドやメソッドを追加することが多いのですが、スーパークラスで既に存在するメソッドを書き換えたい、という場合もあります。以下のプログラムでは、ソースコード 3.32 で作成した WeightedPoint クラスを継承した ColoredWeightedPoint クラスを作成し、スーパークラスの WeightedPoint クラスの持っていた print() メソッドを色付き点用に書き換えています。
ソースコード 3.37 PointExample4.tex (メソッドをオーバーライド)
package section0304;
import javafx.scene.paint.Color; // javafx.scene.paint パッケージにある Color クラスを使用public class PointExample4 {
public static void main(String[] args) {
ColoredWeightedPoint p = new ColoredWeightedPoint(1.0, 2.0, 3.0, Color.RED );
p.print();
}
}
ソースコード 3.38 ColoredWeightedPoint.java (色付き重み付き点クラス)
package section0304;
import javafx.scene.paint.Color;

3.4 インヘリタンス (継承) 167
public class ColoredWeightedPoint extends WeightedPoint {
private Color color;
public ColoredWeightedPoint( double x, double y, double w, Color color ) {
super( x, y, w );
this.color = color;
}
@Override
public void print() {
System.out.printf( "(%f, %f), w=%f:c=%s%n", this.getX(), this.getY(),
this.getWeight(), this.color.toString() );
}
}
このとき、p.print(); と言う命令で、ColoredWeightedPoint クラスのメソッド print() とそのスーパークラスの WeightedPoint クラスのメソッド print() のどちらが使われるでしょうか?たぶん直感通り、ColoredWeightedPoint クラスの方ですよね。スーパークラスとサブクラスで引数の個数と型が一致した同じ名前のメソッドが存在する場合をメソッドの「オーバーライド」と言って、いわゆる再定義・重ね書きが行われます。ちょっと複雑になってきましたが、平面上の 3 種類の点のクラスの UML でのクラス図を以下に書いておきます。下線の引かれたメソッドはクラスメソッドです。print() メソッドがいずれのクラスにも定義されていますね。オーバーライドで書き換わっているわけです。
Point
- x : double - y : double- ORIGIN : Point {final}
+ setX( x : double ) : void+ setY( y : double ) : void+ getX( ) : double+ getY( ) : double+ print( ) : void+ length( ) : double+ distance( p : Point ) : double+ distance( p : Point, q : Point ) : double+ centroid( p : Point, q : Point ) : Point
<<constructor>>+ Point( x : double, y : double )
WeightedPoint
- weight : double
+ getWeight() : double+ print( ) : void+ centroid( WeightedPoint ) : WeightedPoint
<<constructor>>+ WeightedPoint( x : double, y : double, w : double )+ WeightedPoint( p : WeightedPoint )
ColoredWeightedPoint
- color : javafx.scene.paint.Color
+ print( ) : void<<constructor>>
+ ColoredWeightedPoint( x : double, y : double, w : double, color : Color )
+ public
# protected
~ package private
- private
可視性
図 3.7 オーバーライドを UML で
なお、プログラム中 9 行目の @Override は、以前も出てきましたが、「アノテーション」です。コンパイラにこのメソッドがスーパークラスのメソッドのオーバーライドであることを教える機能です。付けなくてもエラーにはなりませんが、付けるクセを付けておきましょう。メソッドをオーバーライドさせる場合、アクセス権を変えてはいけないのでしょうか?次のプログラムを作ってみると、SubClass の method() に文法エラーが発生します。
ソースコード 3.39 OverrideExample2.java (オーバーライドにおけるアクセス権)
package section0304;

168 第 3章 Java 言語の基本的な文法 II
public class OverrideExample2 {
public static void main(String[] args) {
SubClass a = new SubClass();
a.method();
}
}
// スーパークラスclass SuperClass {
public void method() {
System.out.println( "SuperClass.method()" );
}
}
// サブクラスclass SubClass extends SuperClass {
@Override
void method() {
System.out.println( "SubClass.method()" );
}
}
これは、スーパークラスでは public が付いていたメソッドを package-private にアクセス権を厳しくしたからです。これを逆にしてみると (スーパークラス側を package-private にして、サブクラス側を public にすると)エラーは起きません。つまり、オーバーライドするとき、アクセス権は同等かより緩いものにしなければいけません。これは、サブクラスではスーパークラスの全てのことが行える環境になければいけないわけで、勝手に厳しくしてはいけない!ということですね。例えば、Objectクラスの toString()や equals()メソッドは publicに定義されており、clone()は protected
に設定されていますので、自分のクラスでオーバーライドする際は、それらを踏襲しなければいけません。ハッシュコードなんかが出力される toString() メソッドを自分のクラスにフィットしたメソッドにオーバーライドすることはよく行われます。逆に、これらのメソッドをそのままにしておくと、外部からこれらのメソッドをオーバーライドしてクラスの情報を盗み見られる!ということもありです。Object クラスのメソッドは常に気を付けていなければいけません (この授業では気にかけていませんがね)。
問題 3.4.6. 先に作った Point クラス、および、そのサブクラスにおいて、 toString() メソッドをそれぞれオーバーライドし、Point クラスの print() メソッドは toString による文字列を出力するメソッドとして表し、サブクラス側の print() メソッドをいずれも削除しなさい。
問題 3.4.7. 以下のプログラム構成での5つの出力文がコンパイルエラーになるか、ならないかを述べよ。
package p1;
import p2.B;
public class C {
public static void main(String[] args) {
A a = new A();
a.method();
System.out.println( a.x );
System.out.println( a.b[0] );

3.4 インヘリタンス (継承) 169
System.out.println( a.y );
System.out.println( a.z );
}
}
class A extends B {
public int x = 100;
int[] b = {1,2,3};
void method() {
A a = new A();
System.out.println( a.z );
}
}
package p2;
public class B {
private int y = 123;
protected double z = 1.23;
}
3.4.4 super いろいろ
これまで、this という単語が何度か出てきました。
• this.x:そのクラスのインスタンスフィールド x
• this.method():そのクラスのインスタンスメソッド method()
• this(~):そのクラスのコンストラクタ
これらの使い方には慣れましたか。ここでは、継承関係のクラス間で用いる、 super という単語を学びます。
• super.x:スーパークラスのインスタンスフィールド x
• super.method():スーパークラスのインスタンスメソッド method()
• super(~):スーパークラスのコンストラクタ
以下のプログラムを見て下さい。
ソースコード 3.40 SuperExample.java (supar. メソッドの例)
package section0304;
public class SuperExample {
public static void main(String[] args) {
SubA b = new SubA();
b.print();
b.print2();
}
}
class SuperA {
int x = 1;
void print() {
System.out.println( "SuperA.print: this.x = " + x );

170 第 3章 Java 言語の基本的な文法 II
}
}
class SubA extends SuperA {
int x = 2;
@Override
void print() {
System.out.println( "SubA.print: this.x = " + x );
}
void print2() {
System.out.println( "SubA.print2: super.x = " + super.x );
super.print();
}
}
メソッド print2() では、スーパークラス A のメソッド print() を呼び出すのに super.print() としています。この super. が無いと、自身のオーバーライドした print() メソッドを呼び出してしまいますよね。なお、直接でなく、例えば祖父のメソッドを呼び出すのに、 super.super.print() なんて使い方は残念ながらできません。
3.4.5 final 修飾子
変数を定数にするために修飾子 final を学びましたが、final はコンストラクタを除くメンバーに付けることができます。
表 3.4.2 final 修飾子
メンバー修飾子
意味合いfinal
クラス ⃝ 継承を許さないコンストラクタ × もともとコンストラクタはオーバーライドできないフィールド (変数) ⃝ 定数を定義
メソッド ⃝ オーバーライドさせない
例えば、学籍番号は入学時に付加され、以降、変更されるものではありませんから、初期値が代入されたら間違って変更できないように「定数」にすべきでしょうか。学生管理のプログラムに勝手に「特待生」なる「学生」のサブクラスを付加して、「学費免除」処理されても困るので、「学生」クラスに final を付けて継承を不許可にしたりもしましょう。既存のクラスでは、String、System、Math なども、final が付けられていますね。えっ、文字列は変更できるよ!?文字列のクラスが継承できない!と言っているのです。勝手に String クラスに便利なメソッドを付けて!なんてことを許していないのです。メソッドに final を付けると、オーバーライドできなくなります。クラスを継承したとしても、このメソッドは書き換えを許しません!という宣言ですね。メソッドの仮引数に final を付けることも結構行われています。次のプログラムを見て下さい。
ソースコード 3.41 FinalParameter.java (メソッドの仮引数に final)
package section0304;
public class FinalParameter {
public static void main(String[] args) {
String x = "pen";

3.4 インヘリタンス (継承) 171
String y = "pineapple";
System.out.printf( "%s + %s = %s%n", x, y, add( x, y ) );
x = "apple";
System.out.printf( "%s + %s = %s%n", x, y, add( x, y ) );
}
static String add( String a, String b ) {
String c = a + "." + b;
b = "strawberry";
return c;
}
}
メソッドの内部で仮引数の値をいくら変更しても、メソッドの呼び出し元には影響を与えない、というのは前期でやりましたよね。にも関わらず、このプログラムでは、無駄な変更をしています。でもコンパイルエラーも実行エラーも出ない。それは何かマズイですよね。そこで、仮引数の部分に final を付けて、static String add(final String
a, final String b){ とする。そうすると、b="strawberry"; の行にコンパイルエラーが出てくれるようになります。コンパイラにミスをなるべく指摘してもらうため、デフォルトでこれをやっている人多いですね。
問題 3.4.8. 参照型変数および参照型仮引数に final を付けた場合、これを定数と呼べるか議論せよ。
問題 3.4.9. 以下のプログラムの結果を説明せよ。final Point q とすることで、q = new Point(0,0); がコンパイルエラーになることを議論し、次にこの final を消して実行する。そのとき、8 行目の p.print(); の出力結果を議論する。2つの変更の違いが何であるかを理解すること。
ソースコード 3.42 FinalExample.java (final な参照変数)
package section0304;
import section0302.Point;
public class FinalExample {
public static void main(String[] args) {
final Point p = new Point(1,2); // 点 p を変更不可にしたつもりp.setX( 0 );
p.setY( 0 );
p.print(); // 変更されている
final Point q = new Point(1,2);
q = new Point(0,0); // コンパイルエラーq.print();
}
}
最後に、コンストラクタにはなぜ final を付けられないのでしょう?それは、コンストラクタは他のメソッドと違って、継承もオーバーライドもできないからです。えっ?クラスのオーバーライドはできるよね?って、クラスとコンストラクタは別物です。インスタンスを作成する際に 1 度だけ使われるコンストラクタは、そのクラス専用 (そのクラスの名前のメソッドもどき) ですから、サブクラスでそれを書き換え

172 第 3章 Java 言語の基本的な文法 II
て使うというのはありえません。サブクラスのコンストラクタはサブクラスの名前で別に作られるはず。クラスは継承されても、それぞれのコンストラクタはそのクラスでしか定義できない。つまり、継承されないものをわざわざ final
で制御する必要はないわけです。
3.4.6 キャスト
前期、キャストを学びました。int x = 123; double y = x; は問題ないのだけど、その逆 double x = 123.5;
int y = x; はエラーとなる。狭い型に広い型の値は代入できない。そこで、無理やり押し込む方法が「キャスト」でした。double x = 123.5; int y = (int) x; とやれば、むりやり y に代入が行える。ただし、小数点以下が切り捨てられる、でしたね。今回出て来るのは、クラスの「キャスト」です。次のプログラムを見て下さい。
ソースコード 3.43 OverrideExample3.java (クラスのキャスト)
package section0304;
public class OverrideExample3 {
public static void main(String[] args) {
SubC e = new SubC();
System.out.println( "c=" + e.c );
// System.out.println( ((SuperC) e).c );
e.print();
// ((SuperC) e).print();
e.print2();
// ((SuperC) e).print2();
}
}
class SuperC {
int c = 1;
void print() {
System.out.println( "SuperC.print()" );
}
}
class SubC extends SuperC {
int c = 2;
@Override
void print() {
System.out.println( "SubC.print()" );
}
void print2() {
System.out.println( "SubC.print2()" );
}
}
このプログラムが何をしようとしているか読み解きましょう。クラス SubC のインスタンス e を作り、そのフィールド c と 2 つのメソッド print() と print2() を動かしています。print() メソッドがオーバーライドされているのは、チェックOKですか?では、3つのコメント部分の // を外してみて下さい。この部分に書かれているのが、クラスの「キャスト」です。インスタンス e にキャスト (SuperC) を付けると、それはスーパークラス SuperC のメンバーとして見られるようになります。クラスを継承すると、サブクラスの中にはスーパークラスから継承した部分とサブクラス独自の部分があります。この場合、print2() メソッドはサブクラス独自の部分なので、図 3.8 のような外側の四角内に位置に置かれます。一方、print() メソッドは 2 つのクラスの両方にあるのでオーバーライドされることになり、継承された部分 (内側の

3.4 インヘリタンス (継承) 173
SuperC
~ c : int = 1
~ print( ) : void
SubC
~ c : int = 2
~ print( ) : void~ print2( ) : void
int c = 1void print( )
SubC 型インスタンス
e
int c = 2void print2( )
オーバーライド
されていない
オーバーライド
されている
クラスSuperCから
継承した部分
図 3.8 メソッドのオーバーライドとクラスのキャスト
四角内) に置かれます。そのときの作り方は、まずクラス SuperC に入っているものをインスタンス e の中にコピーしてきて、その後で、クラス SubC の中身を書き込みます。よって、重複するもの (この場合、print() メソッド) は書き換わります。で、インスタンス e をスーパークラス SuperC にキャストしてみると、((SuperC) e) とは、インスタンス e のクラス SuperC から継承された部分のみを見よ!ですから、メソッド print2() は見えなくなってしまい、よってエラー。これは、実数を整数にキャストする際に、小数点以下 (整数に入れられない部分) が切り捨てられることと似た雰囲気ですかね。では、エラーの出た行をコメントアウトして、再び動かしてみて下さい。出力 2 行目の 1 の出力については、後で見ることにして、3 行目の出力が SubC.print() となることを解析してみて下さい。えっ?スーパークラスにキャストしたのに、サブクラスのメソッドが動いていますね。はい、スーパークラスから継承した部分がオーバーライドされているので。インスタンス e のスーパークラス部分の print() メソッドは、書き換えられているわけです。さて、2 行目の ((SuperC) e).c の出力 1 についてはどうでしょう。メソッドのオーバーライドと同様に変数 c もオーバーライドして値が 2 かと思いきや、1 です!どうして?結論から言うと、「フィールドはオーバーライドされない!」のです。一般的に、クラスを継承する際に、スーパークラスで定義されたフィールドはサブクラスでそのまま利用しますから、「再宣言」などしません (型も名前も等しくて値が違うなんて、値だけ入れ直せば良いわけですよね)。従って、このプログラムのような書き方をすると、ちょっと困った行動をコンパイラはします。つまり、サブクラス内に、同じ名前のフィールドを 2 つ持ってしまうのです。で、単に e.c とすれば、オーバーライドされていない、本来のクラスSubC の c の値が、((SuperC) e).c とすれば、継承した部分に含まれている c の値が使われてしまうのです。メソッドのオーバーライドは「あり」で、フィールドは「なし」はOKでしょうか。で、コンストラクタはどうでしょう。先にもちょっと触れましたね、「コンストラクタは継承されない」です。コンストラクタの名前はそのクラスの名前と同じですから、サブクラスと名前の違うスーパークラスのコンストラクタでは役に立たないわけで、継承もオーバーライドもできないわけです (ただし、サブクラスのコンストラクタ内でスーパークラスのコンストラクタを super() のように利用することはできますね)。とっても難しい!と思われるかな。このところは十分に時間を掛けて理解しておきましょう。

174 第 3章 Java 言語の基本的な文法 II
スーパークラス型への代入double x = 123; のような代入文では、右辺の整数型と左辺の実数型が違っても代入ができていますよね。これは継承関係にあるクラスの間ではどうでしょう。つまり、class A extends B であるとき、A a = new B(); とかB b = new A(); とか出来ないのでしょうか?double x = 123; の場合、右辺の整数リテラルを実数値に変えて左辺に代入できるので可能なわけでした。ならば同様に、右辺のコンストラクタで生成されたインスタンスが左辺の参照変数で参照可能か?を考えれば良いわけです。まず、スーパークラスである (情報が少ない?) B クラスのインスタンスにサブクラス型参照変数で参照 A a =
new B(); (図 3.8中央 参照) して大丈夫でしょうか?そう、クラス A 独自プラスαの部分が足りなそうですよね。つまり、A a = new B(); はマズイということです。一方、サブクラスである (情報が多い?) A クラスのインスタンスにはスーパークラスの継承部分が存在するので
(図 3.9右 参照)、スーパークラス型参照変数で参照 B b = new A(); しても情報が足りないということはありません。つまり、B b = new A(); はOKだということです。ただし、B b = new A(); としたとき、変数 b からは、A クラス独自の情報部分が見えていません。だって、b はあくまで、自分の参照先は B クラスのインスタンスと思っているのですから。ちゃんと理解できるかな。
A
B
A 型インスタンス
B 型インスタンス
a
A a = new B( );
A 型インスタンス
B 型インスタンス
b
B b = new A( );
この部分の情報が無い!
図 3.9 スーパークラス型の参照変数
サブクラス型への強制代入では、サブクラス型参照変数でスーパークラス型インスタンスを参照できない、と言いましたが、次の処理はどうでしょう?いま、class A extends B とします (図 3.9 と同様)。
A a = new A(); // サブクラスのインスタンスを作成B b = (B) a; // スーパークラス型参照変数に代入。b からはスーパークラスの情報のみ可視A c = b; // 再度、サブクラスの参照変数で参照
3 行目はやはり無理な操作ですね。コンパイラとしてはスーパークラスの (たぶんサブクラスのインスタンスより情報の少ない)インスタンスを情報の多いと思われるサブクラスの参照変数から参照させるのは無謀ということで、エラーが出されます。しかし、この場合 b の周辺 (?) にはクラス A の情報が囲んでいるのですから、プログラマの自己責任ということで、どうにかできないか?と思いますよね。これと同じようなことが、long l = 123L; int i = (int) l;
なんて処理で前期に出てきました。本来 long 型のデータは int 型の変数に入れるのは無謀と思われますが、キャストで無理やり押し込むことができる (このとき、値が壊れるか否かはプログラマの自己責任ですね)。今回の場合も、3 行目を A c = (A) b; とキャストで書き換えると、変数 c は変数 a と同じ情報を持つことができます。

3.5 ポリモルフィズム (多態性)と動的束縛 175
プログラマの自己責任とはいっても、なかなかミスは起こり得るので、そのクラスのインスタンスか否か (周りにサブクラスの情報がある?) を判定する演算子が欲しいところですね。それを実現するのが「instanceof」演算子です。これは、メソッドではなく、演算子 (五則演算などと一緒) です。「インスタンス instanceof クラス」と使うことで、そのクラスのインスタンスかどうかを boolean の値で返してくれます。ただし、このとき、「サブクラスのインスタンス instanceof スーパークラス」も true になるので、注意が必要です。
ソースコード 3.44 InstanceOfExample.java (インスタンスの型チェック)
package section0304;
import section0302.Point;
import javafx.scene.paint.Color;
public class InstanceOfExample {
public static void main(String[] args) {
ColoredWeightedPoint cp = new ColoredWeightedPoint( 1.0, 2.0, 10.0, Color.RED );
WeightedPoint wp = new WeightedPoint( 0.0, 0.0, 1.0 );
Point p = new WeightedPoint( -1.0, -2.0, 0.0) ; // ここに注意!System.out.println( "(1) " + (cp instanceof ColoredWeightedPoint) );
System.out.println( "(2) " + (cp instanceof WeightedPoint) );
System.out.println( "(3) " + (cp instanceof Point) );
System.out.println( "(4) " + (wp instanceof ColoredWeightedPoint) ); // false
System.out.println( "(5) " + (wp instanceof WeightedPoint) );
System.out.println( "(6) " + (wp instanceof Point) );
System.out.println( "(7) " + (p instanceof WeightedPoint) ); // true
System.out.println( "(8) " + (p instanceof Point) );
}
}
問題 3.4.10. 左の継承関係があるとき、次の処理は正しいですか。
C
Object
B
A
1. C c = new A();
2. B b = new C();
3. Object obj = new A();
4. A a = new Object();
5. A a = new A(); if( a instanceof A ) { B b = a; }
6. C c = new C(); if( c instanceof C ) { B b = c; }
7. A a = new A(); if( a instanceof C ) { B b = a; }
3.5 ポリモルフィズム (多態性)と動的束縛多態性というより「ポリモルフィズム (Polymorphism)」という言葉の方がよく用いられていると思います。異なるオブジェクトに同じ名前の処理を定義することを「多態性」を持たすと言います。対語は「単態性 (Monomorphism)」です。先の自動車のアクセルペダルもその 1 つです。セダンでもトラックでもF1カーでもアクセルを踏むという同じ処理が用意されています。結果はかなり違ってきますがね。また、Point クラスの点も WeightedPoint クラスの点も ColoredWeightedPoint クラスの点も同じ print() メソッドでそれぞれの異なる属性値が出力できます。先の節で学んだ、参照変数が同じでも代入されるインスタンスの型が異なると、オーバーライドされたメソッドが、それぞ

176 第 3章 Java 言語の基本的な文法 II
れ異なった動作をしてくれる、これがポリモルフィズムの効果です。ポリモルフィズムを用いると、つぎのようなことができます。
ソースコード 3.45 PolymorphismExample.java (ポリモルフィズムで図形処理 (?))
package section0305;
public class PolymorphismExample {
public static void main(String[] args) {
Shape[] shapes = {
new Circle( 1.2 ), // 円new Square( 1.5, 2.4 ), // 長方形new Trapezoid( 1.2, 3.0, 2.5 ) // 台形
};
for( Shape shape : shapes ) {
shape.printArea();
}
}
class Shape { // スーパークラス:一般図形String name; // 図形の名前double getArea() { // 面積を計算して返すメソッドの原型
return 0;
}
void printArea() {
System.out.println( this.name + "の面積は、" + this.getArea() );
}
}
class Circle extends Shape { // サブクラス:円double radius;
Circle( double radius ) {
this.name = "円";
this.radius = radius;
}
@Override
double getArea() {
return radius * radius * Math.PI;
}
}
class Square extends Shape { // サブクラス:長方形double height;
double width;
Square( double height, double width ) {
this.name = "長方形";
this.height = height;
this.width = width;
}
@Override
double getArea() {
return height * width;
}
}
class Trapezoid extends Shape { // サブクラス:台形double upper;
double lower;
double height;
Trapezoid( double upper, double lower, double height ) {
this.name = "台形";

3.6 例外処理 177
this.upper = upper;
this.lower = lower;
this.height = height;
}
@Override
double getArea() {
return ( upper + lower ) * height / 2;
}
}
このプログラムでは、インスタンスとなる図形により呼び出される面積の計算方法が違っていきます。こうした、呼び出すオブジェクトが実行時になって決定される (コンパイル時にはわからない) ことを、「動的束縛 (Dinamic
binding)」と言います。対語は「静的束縛」で、実行される処理は引数の型で静的に決まるものです。例えば、対話式のプログラムを作ったとすると、ユーザがどんな処理をどの順に発生させるかは、動かしてみないとわかりませんよね。そうした処理が「動的束縛」です。
3.6 例外処理プログラムを作っていくと、どうしてもエラーが発生します。これまで Java のプログラムを作ってきて、まだ 1 回も実行時にエラーを起こさなかった優等生は、いますかね?エラーを出した数だけプログラミングは上達すると言います。めげずに頑張りましょう。エラーには大きく3種類あります。
• アルゴリズムのエラー (algorithm error)
• 文法上のエラー (syntax error)
• 実行時のエラー (execution error)
まず、アルゴリズムのエラーですが、これはプログラム以前の問題ですから、コンピュータにはどうしようもありません。アルゴリズムの勉強をしっかりやって下さい。次が、文法上のエラー、つまり Java の文法に合わないプログラムを書いた場合です。これはプログラマとしてのミスですが、コンパイラが指摘してくれるので何とかなります。そして、最後が、実行時に起きるエラーです。コンパイラは、起こりうる全てのエラーを検査してはくれません。例えば、キーボードからの入力の際に整数のはず (scan.nextInt()) が実数が入力されたり、読み込もうとしたファイルがディスク上に無かったり。実行中にエラーが起こると、JVM (Java Virtual Machine) が「例外 (Exception)」という通知、正確には「例外インスタンス」をプログラムに返してきて、最悪の場合プログラムは強制終了されます。そこで、プログラマは「例外インスタンス」を受け取った際、どう対処するかをプログラムに事前に書いておくことで、プログラムの強制終了を回避するのです。
3.6.1 例外 (Exception)
Java では、プログラムの実行時にエラーが発生した時、「例外 (Exception)」というクラスのインスタンスを発生させます。このことを「例外を投げる (throw する)」と言います。投げられた例外は、プログラム中に書かれた「catch
文」で捕獲され、その catch 文のブロック内のエラー対処処理が行われます。もし、プログラム中にそうした catch
文がない場合は、プログラムの実行は強制終了させられます。次のプログラムは、よく起こりがちな「ゼロ割り」プログラムです。(こんなベタな誤りはありえませんがね)
ソースコード 3.46 DivideZeroExample.java (ゼロ割りの例外)

178 第 3章 Java 言語の基本的な文法 II
package section0306;
public class DivideZeroExample {
public static void main(String[] args) {
int x = 0;
int y = 10;
int z = y / x;
System.out.printf( "%d / %d = %d%n", y, x, z );
}
}
実行させると、次なるエラーメッセージが表示されます。
Exception in thread "main" java.lang.ArithmeticException: / by zero
at section0306.DivideZeroExample.main(DivideZeroExample.java:6)
このメッセージを解読してみると、
「main」というスレッドにおいての「0による除算」という例外 java.lang.ArithmeticException が、パッケージ section0306 のプログラム DivideZeroExample.java の main メソッド (DivideZeroExample.java
の 6 行目) において発生したよ!
スレッドとは、プログラムの流れのことです。私たちがここまで作ってきたプログラムは「シングルスレッド (single
thread)」プログラムと言って、プログラムが最初から最後まで 1 本の流れ、main スレッド、として実行されます。一方、Java では「マルチスレッド (multi thread)」プログラムと言って、複数の流れが同時に進行する並列プログラムを作ることが出来ます。スレッドについては後に書くつもりですが、この授業では触れられませんので、各自で自習してみて下さい。次のプログラムも、よくやる配列の添字操作のミスです。
ソースコード 3.47 OutOfBoundExample.java (配列の添字オーバーの例外)
package section0306;
public class OutOfBoundExample {
public static void main(String[] args) {
int[] array = new int[10];
for(int i=1; i<=array.length; i++) {
array[i] = i;
}
for(int x : array) {
System.out.print( x + " " );
}
System.out.println();
}
}
この場合のエラーメッセージは、
Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: 10
at section0306.OutOfBoundExample.main(OutOfBoundExample.java:6)
6 行目で、java.lang.ArrayIndexOutOfBoundsException なる例外が起こったと言っています。java.lang パッケージ内の ArrayIndexOutOfBoundsException クラスのインスタンスが投げられたんですね。コロンの後ろの 10
は何か?というと、配列の添字番号の限度 9 を超えて 10 が設定されたぞ!という意味です。これらのプログラムは、いずれもコンパイルエラーは起きません。つまり、文法的には間違っていない。Java のコ
ンパイラは残念ながらこのレベルのチェックはしないのです。実行してみて初めてエラーに気づく。このとき JVM は

3.6 例外処理 179
Exception クラスのサブクラスのインスタンスを作成し、それをプログラムに投げて きます。どちらのプログラムも、それを受け取る処理 (catch 文) が無いので、コンソールにエラーメッセージを吐き出した後、強制終了されています。
3.6.2 Exception クラス
実行時に投げられる例外は、全て java.lang.Exception クラスと java.lang.Error クラスのいずれかをスーパークラスとしたインスタンスになります (図 3.6.2 参照:この図はほんの一部、Error クラスのサブクラスは書いていません)。
java.lang.Object
java.lang.Throwable
java.lang.Exception
java.lang.RuntimeException
java.lang.Error
java.io.IOException
java.lang.IndexOutOfBoundsException
java.lang.ArrayIndexOutOfBoundsException
java.io.FileNotFoundException
java.lang.NullPointerExceptionjava.lang.ArithmeticException
図 3.10 Exception とは
まず、Error クラス系の例外が発生すると、プログラムでは回復が不可能な問題が起こっています。
• java.lang.OutOfMemoryError:必要なメモリーが確保できなかった• java.lang.StackOverflowError:再帰呼び出しなどによりスタック領域が足りなくなった
などが Error クラスのサブクラスとなり、これらのインスタンスが投げられたら、ハードウェアまでも考慮した解決法を考えなければいけません (ソフトでは対処しきれない)。一方、Exception 系の例外が発生した場合は、2 種類に分類して考えます。
• 非検査例外:java.lang.RuntimeException クラスのサブクラス• 検査例外:それ以外のサブクラス
非検査例外には、先に出てきた ArithmeticException や ArrayIndexOutOfBoundsException が含まれます。プログラムの多くの場所で発生する可能性があるので、例外発生時の処理 (catch 文など) を記述しないことが許されている例外です。とはいえ、例外が起こりそうなところでは、何らかの処理をしなければ当然、強制終了されます。一方、検査例外には、読み込もうとしたファイルが存在しない際の FileNotFoundException などが含まれます。これは、明らかに例外が起こる可能性のある場所が事前にわかるので、必ず対処の処理を書かなければいけません (書かないと文法エラー)。

180 第 3章 Java 言語の基本的な文法 II
問題 3.6.1. 以下の処理では、非検査例外の一つ NullPointerException が発生します。さて、どの行で発生しますか? (NullPointerException がどんなものかを説明しなくとも、以下から想像できるよね)
String str1 = "";
System.out.println( "str1.length = " + str1.length() );
String str2 = null;
System.out.println( "str2.length = " + str2.length() );
3.6.3 try ~ catch ~ finally
例外が起こった場所を特定し、どんな例外が起こったかを突き止め、その解決処理を書くわけですが、投げられた例外はそれに役立つ「スタックトレース (stack trace)」という情報を持っているので、まずはそれを出力させてみましょう。
ソースコード 3.48 (改) DivideZeroExample.java (スタックトレース)
package section0306;
public class DivideZeroExample {
public static void main(String[] args) {
int x = 0;
int y = 10;
try {
int z = y / x;
System.out.printf( "%d / %d = %d%n", y, x, z );
} catch( Exception e ) {
e.printStackTrace();
}
}
}
まず、例外が発生しそうな部分を try ブロック 「try { }」で囲みます。上のプログラムの場合、6 行目から 9
行目までが try ブロックですね。そして、try ブロックに続いて catch ブロック 「catch( 受け取る例外の型 変数名 ) { }」を置きます。上のプログラムの場合、9 行目から 11 行目が catch ブロックです。catch 文の小カッコ内には、投げられた例外を受け取るための引数を型宣言しながら置きます。2 つのブロックは連続しないといけませんが、try ブロックと catch ブロックの間を以下のように改行して書く方式もあります。このテキストでは行数の節約もあるので、前者で書くことにします。
try {
} // 改行してから catch ブロックcatch( Exception e ) {
}
プログラム中の try ブロック内で例外が発生すると、catch ブロックに制御が移動し、投げられた例外インスタンスがその引数と一致したとき、その中で問題を解決してプログラムを続行させるか、プログラムを終了させるかを決めます。catch ブロックで受け取る例外のクラスは正確 (?)なクラスでも良いのですが、スーパークラスで受け取るように書けば、そのサブクラスの例外全てを受け取ることができます。上のプログラムでは、Exception 型として受け取っ

3.6 例外処理 181
ています。従って Exception 系のどんな例外でも引き受ける catch ブロックということになります (逆に言うと、手抜き!?)。Exception 型インスタンスには、スタックトレース情報を標準出力してくれるメソッド printStackTrace() があるので、ひとまず、それを使っています。でも、これでは強制終了されただけと何ら変わりは無いので、ちょっとだけ対処したプログラムに換えましょう。
ソースコード 3.49 (改) DivideZeroExample.java
package section0306;
public class DivideZeroExample {
public static void main(String[] args) {
int x = 0;
int y = 10;
try {
int z = y / x;
System.out.printf( " %d / %d = %d%n", y, x, z );
} catch( ArithmeticException e ) {
System.err.println( "割り算で分母が 0 になりました。" );
System.err.println( "計算アルゴリズムが正しいかのチェックをお願いします。" );
}
}
}
今度は、起こり得る正しい (?)例外 ArithmeticException で受け取るようにしました。従って、それ以外の例外が起こった場合は受け損なって強制終了されます。
ソースコード 3.50 (改) OutOfBoundExample.java
package section0306;
import java.util.Arrays;
public class OutOfBoundExample {
public static void main(String[] args) {
int[] array = new int[10];
try {
for(int i=1; i<=array.length; i++) {
array[i] = i;
}
} catch( ArrayIndexOutOfBoundsException e ) {
System.err.println( "配列の範囲外のアクセスが行われました" );
}
System.out.println( Arrays.toString( array ) );
}
}
こちらは、ArrayIndexOutOfBoundsException を受け取るようにしました。この場合、正常に配列の初期化が終了すれば、catch ブロックは飛び越して配列の要素が標準出力されます。いずれのプログラムも、例外を無理に発生させている例ですが、そこは目をつぶりましょう。(^^;)
さて、try ブロックにおいて何種類かの例外が投げられる可能性もありますよね、そんな時は catch ブロックを複数並べて書くか、Java 7 から導入された「複数例外 catch」を使います。
ソースコード 3.51 (改2) DivideZeroExample.java
package section0306;
public class DivideZeroExample {

182 第 3章 Java 言語の基本的な文法 II
public static void main(String[] args) {
int x = 0;
int y = 10;
try {
int z = y / x;
System.out.printf( " %d / %d = %d%n", y, x, z );
} catch( ArithmeticException e ) {
System.err.println( "割り算で分母が 0 になりました。" );
System.err.println( "計算アルゴリズムが正しいかのチェックをお願いします。" );
} catch( Exception e ) {
System.err.println( "算術演算以外の例外が発生しました。" );
System.err.println( e );
}
}
}
このプログラムでは、2 つの catch ブロックを並べています。ひとつ目が ArithmeticException を、 2 つ目がException をキャッチしています。この 2つには継承関係がありましたよね。どっちがスーパークラス?catch ブロックは並んでいる順にチェックされます。投げられた例外がどの catch ブロックの例外と一致するかを順に調べていくので、この場合はゼロ割りの例外は1つ目が、それ以外は2つ目が受け取ってくれます。この2つの catch ブロックの順番を逆にすると文法エラーになるのですが、何故でしょう? ArithmeticException がException のサブクラスなので、ArithmeticException の例外も Exception の catch ブロックで受け取られてしまい、ArithmeticException の catch ブロックに到達できる例外がなくなってしまうからです。このように catch
ブロックで継承関係にある例外を並べる場合は、サブクラスの例外から並べます。なお、例外インスタンスを直接出力System.out.println( e ); すると、スタックトレース e.printStackTrace() の簡略版が出力できます。次のプログラムもかなり無茶な設定ですが:
ソースコード 3.52 TwoCatchExample.java (複数の例外のキャッチ)
package section0306;
public class TwoCatchExample {
public static void main(String[] args) {
int[] array = new int[5];
int x = (int)(Math.random() * 10);
try {
array[x] = 10 / x;
System.out.printf( " 配列の %d 番目に、%d%n", x, array[x] );
} catch( ArithmeticException e ) {
System.err.println( "例外をキャッチしました。" );
System.err.println( e );
} catch( ArrayIndexOutOfBoundsException e ) {
System.err.println( "例外をキャッチしました。" );
System.err.println( e );
}
}
}
この場合は、乱数の値によってゼロ割りか配列範囲外のいずれかの例外が発生するものです。この2つの例外は継承関係に無いので、順番は自由です。どちらも catch した後の処理が一致していますが、こうした場合、Java 7 で導入された「複数例外 catch」を使って、次のようにも書けます。
ソースコード 3.53 (改) TwoCatchExample.java

3.6 例外処理 183
package section0306;
public class TwoCatchExample {
public static void main(String[] args) {
int[] array = new int[5];
int x = (int)(Math.random() * 10);
try {
array[x] = 10 / x;
System.out.printf( " 配列の %d 番目に、%d%n", x, array[x] );
} catch( ArithmeticException | ArrayIndexOutOfBoundsException e ) {
System.err.println( "例外をキャッチしました。" );
System.err.println( e );
}
}
}
2つの例外の型を論理和記号で並べていますが、論理和の計算をしているわけではありません。従って、論理和の際に学んだ「短絡評価」( 縦線2本 ||) も使えません。ところで、System.err.println というのに気づきましたか? System.out (標準出力装置) ではなく、System.errとは「標準エラー出力装置」への出力を意味します。ただし、Eclipse では System.out も System.err も同じコンソールへの出力になります。この2つを別々の出力先に分けたいときは、「リダイレクト (redirect)」(出力先をファイルなどに変更) によって分離することができます。詳しい方法はここでは触れませんので、それは自分で調べてもらうとして、エラーだけでなく本来の出力と補助的な出力の出力先を分けて、などの場合にも利用できます。
ソースコード 3.54 RedirectExample.java (出力先をファイルにリダイレクト)
package section0306;
import java.io.FileNotFoundException;
import java.io.PrintStream;
public class RedirectExample {
public static void main(String[] args) {
// 一旦、出力先を変数に記憶PrintStream defaultSystemOut = System.out;
PrintStream defaultSystemErr = System.err;
// 標準出力先をそれぞれファイルにリダイレクトtry {
// out と err を別々のファイルに設定System.setOut( new PrintStream("src/section0306/output.txt") );
System.setErr( new PrintStream("src/section0306/error.txt") );
} catch (FileNotFoundException e) {
e.printStackTrace();
}
for(int i=-10; i<10; i++) {
try {
System.out.println( i + ":" + 10/i );
} catch( ArithmeticException e ) {
System.err.println( i + ":" + "零割りが起こりました。" );
}
}
// 標準出力先をデフォルトに戻しておくSystem.setOut( defaultSystemOut );
System.setErr( defaultSystemErr );
System.out.println( "処理が終了しました" );
}
}

184 第 3章 Java 言語の基本的な文法 II
一般に、try ブロック内で例外が発生した場合、その行以降の実行は行われずに catch ブロックへ制御が飛んでしまうわけですが、それでは困る場合がありますよね。特に、ファイル関連の処理を中途半端にしたまま try ブロックが終了するのはまずい!そこで、catch ブロックに続いて finally ブロック を置きます。例えば、データファイルを開いて、データを読み出そうとしたらそこで例外が起こった!仕方ないのでデータは読ま
ずに先に進むことにして、しかしファイルはちゃんと閉じておかないといけない。そこで、finally ブロックに「開けてしまったファイルを閉じる処理」を書いておく、なんて書き方をします。finally ブロックに書かれた処理は、例外が発生するしないに関わらず、 catch ブロックで強制終了させるさせないに関わらず、必ず「最後に」実行されることになっています。なお、finally ブロックは必要のない時は無くても良いブロックです。
ソースコード 3.55 FinallyExample.java (例外処理の finally ブロック)
package section0306;
import java.io.File;
import java.io.FileNotFoundException;
import java.util.Scanner;
public class FinallyExample {
public static void main(String[] args) {
Scanner scan = null;
try {
scan = new Scanner( new File( "src/section0306/input.txt" ) );
while( scan.hasNext() ) {
System.out.println( scan.nextLine() );
}
// scan.close();
// return;
} catch( FileNotFoundException e ) {
System.out.println( "そんなファイル無いよ" );
} finally {
if( scan != null ) {
System.out.println( "finally の処理が行われます!" );
scan.close();
}
}
}
}
このプログラムは、ファイルからテキストを読み込んで標準出力していますが、 3 種類の状況が起こります。
• 正常にファイルが読み込まれテキストが書かれる• ファイルは在ったけど、中身が無い• そんなファイルは無い:検査例外の FileNotFoundException が投げられる
FileNotFoundException は検査例外なので、必ずどこかで例外処理を行わないと実行できません。ファイルからデータを読む場合は、ファイルを開けて・読んで・閉じるという 3 ステップを行うことがルールになっています (詳しくは後の節で)。同時に開けるファイル数には限りがあることと、開けっ放しはメモリ的に無駄がおこるので、ファイルを閉じる処理 scan.close() がどこかに必要です。プログラムの 13 行目でコメントで殺してある scan.close() を活かせば finally ブロックは必要なくなりますが、一般には、このプログラムのようにファイルを閉じる処理を finally ブロックに書く (アピールする) ことで、はっきりしたプログラムになります (このテキストの後の節では、あまり finally ブロックに書いていませんがね)。(^^;)
ちなみに、finally ブロックは、例外がキャッチされてもされなくても (もし 14 行目のコメントで殺してある

3.6 例外処理 185
return を活かして、そこでプログラムを止めようとしても)、必ず実行されます。結構強力なブロックなんです。
3.6.4 自作の例外
Exception クラスを継承したクラスとして例外クラスを自作することができます。自分のプログラム特有の例外を作って投げて受け取るというわけです。
ソースコード 3.56 MyExceptionExample.java (自作の例外を作る)
package section0306;
import java.util.InputMismatchException;
import java.util.Scanner;
public class MyExceptionExample {
public static void main(String[] args) {
// キーボード入力を Scanner で設定Scanner scan = new Scanner( System.in );
int n = 0;
// 10 未満の正整数が入力されるまで繰り返すwhile( true ) {
try {
System.out.print( "10 未満の正整数を代入して下さい:" );
// メソッド inputInt で条件を満たすかをチェックするn = inputInt( scan );
// 正しく入力ができたら、繰り返しから抜けるbreak;
} catch( NoWithinRangeException e ) {
System.out.println( e.toString() );
}
System.out.println();
}
System.out.println( "読み込んだ値は、" + n );
}
// Scanner から [1,9] 内の整数値を入力するメソッドstatic int inputInt( Scanner scan ) throws NoWithinRangeException {
int n = scan.nextInt();
if( n <= 0 || n >= 10 ) {
throw new NoWithinRangeException();
}
return n;
}
}
@SuppressWarnings("serial")
class NoWithinRangeException extends Exception {
NoWithinRangeException() {
super( "\n入力された値は指定された範囲内ではありません!" );
}
}
まず、自作例外クラス NoWithinRangeException から見ていきます。自作例外クラスを作る場合、 Exception クラスを継承して作ります。慣例的に末尾に Exception を付けた名前にします。今回の例外クラスはフィールドもメソッドも無くコンストラクタだけ、それも super クラスである Exception クラスのコンストラクタに文字列を渡して呼び出しているだけです。なお、文字列の先頭の \n は、改行を意味するエスケープシーケンスですね。で、main メソッドでは、クラスメソッド inputInt( scan ) を使って整数値をキーボードから読み込もうとしています。inputInt メソッドでは、整数値を読み込んだ後、正の整数で 10 未満であることをチェックしています。

186 第 3章 Java 言語の基本的な文法 II
チェックでハネられた場合に、NoWithinRangeException クラスのインスタンスを作って、それを自分を呼び出したもの (この場合は main メソッドですね) へ投げています。例外を自分で try~ catch せずに、呼び出し元へ投げる場合、そのメソッドの宣言文に「throws 例外クラス名」を付けます。これを「throw 節」と言います。投げる例外クラスが複数ある場合は throws MyException1, MyException2 のようにカンマを使って並べます。例外を投げられたmain は catch ブロックでそれを受け取り、受け取った例外の内容を文字列化して出力し、再度データの入力を求めています。今回のプログラムでは、inputInt メソッドは、自身の中で例外を catch することを放棄し、自分を呼び出したメソッド main に例外 catch の仕事を委託しています。一般に、メソッドを設計する場合、なるべく単一・単純な仕事を行うようにメソッドを作ります。その方がバグが起こりにくいし見つけやすい。そして、条件に合わない場合に自身の中で条件に合うように対処するか、例外という形で呼び出したものへ知らせて、その対処は呼び出し元に行なわせるかの2通りを選びます。
問題 3.6.2. MyExceptionExample.java では、整数値以外の値を入力すると強制終了されてしまいます。実数値もしくは数値以外の入力があっても inputInt メソッドが強制終了されないようにプログラムを改良しなさい。
3.7 Scanner を使ったテキストデータの入力ここでは、これまでも使ってきた Scanner クラスを用いた入力をまとめると共に、 Scanner を用いてファイルからテキストを読み込む方法について触れます。従来、文字列で表現された数値をファイルやキーボードから読み出すには、読み出した文字列をそれぞれの数値の型への変換を必要としました。しかし、Java 5.0 より、既に C 言語に存在した scanf() 関数に相当する Scanner クラスが java.util パッケージ内に用意され、そうしたテキスト入力処理が容易になりました。また、正規表現を用いての構文解析も可能となり、複雑なテキストスキャナーとして利用もできます (このテキストでは触れない予定ですが、正規表現については一度勉強しておくと将来役立つかと) 。なお、java.util パッケージはデフォルトではインポートされないので import 文が必要です。最初に Scanner クラスのコンストラクタと代表的なメソッドを見ましょう (表 3.7.1・表 3.7.2 参照)。
表 3.7.1 Scanner のコンストラクタ
Scanner(InputStream source[, String charsetName]) [throws IllegalArgumentException]
指定された入力ストリームからのスキャナーを生成。キーボード (System.in) はこの一種。文字セットを指定することが可能Scanner(File source[, String charsetName])
throws FileNotFoundException[, IllegalArgumentException]
指定されたファイルからのスキャナーを生成。文字セットを指定することが可能Scanner(Path source[, String charsetName]) throws IOException[, IllegalArgumentException]
指定されたファイルからのスキャナーを生成。文字セットを指定することが可能Scanner(Readable source)
指定された Readable インタフェースを実装する文字ソースからのスキャナーを生成Scanner(ReadableByteChannel source[, String charsetName]) [throws IllegalArgumentException]
指定されたチャネルからのスキャナーを生成。文字セットを指定することが可能Scanner(String source)
指定された文字列からのスキャナーを生成

3.7 Scanner を使ったテキストデータの入力 187
表 3.7.2 Scanner の代表的なメソッド
void close() Pattern delimiter()
現在のスキャナーをクローズする 現在使用しているデリミタのパターンを返すboolean hasNext([Pattern pattern j String pattern])
次のトークンが[指定されたパタンに一致して]存在する際に true を返すboolean hasNextInt([int radix])
次のトークンが[指定された基数の] int 値として解釈可能な場合に true を返すboolean hasNextLine()
次の入力に別の行が存在する際に true を返すString next([Pattern pattern j String pattern])
[指定されたパターンに一致した]次のトークンを返すint nextInt([int radix])
入力の次のトークンを[指定された基数の]int 値として返すString nextLine()
スキャナーを現在行の先に進め、スキップした入力を返すScanner skip(Pattern pattern j String pattern)
指定されたパターンに一致した入力をスキップするScanner useDelimiter(Pattern pattern j String pattern)
スキャナーの区切り文字パターンを指定したパターンに設定するScanner useRadix(int radix)
スキャナーの基数を指定した整数に設定する
3.7.1 next と nextLine
ソースコード 3.57 ScannerExample.java (標準入力装置より整数の入力)
package section0307;
import java.util.Scanner;
public class ScannerExample {
public static void main(String[] args) {
System.out.print( "整数をここに入力して:" );
Scanner scan = new Scanner( System.in );
int n = scan.nextInt();
System.out.println( "入力されたのは " + n );
scan.close();
}
}
最初の例題はキーボードから整数値を一つ読み込んでいます。Scanner のコンストラクタに標準入力装置 (キーボードである System.in) を指定してスキャナー scan を宣言、整数読み込みメソッド nextInt を利用してキーボードから整数値をひとつ読み取り出力しています。そして、最後に close メソッドを用いてスキャナーを閉じています。Eclipse はプログラムが正常に終了されたとき、その時開いている装置オブジェクトを順次切り離してくれるのですが、一般のシステム上では確実ではありません。不必要な装置の接続やデータ保護のためにも、使わなくなった入力装置はその都度閉じる癖を付けましょう。次は next メソッドを利用して文字列を読み込む例です。next メソッドはデータのデリミター (区切り記号:
delimiter) として「空白 (漢字の空白文字も含む)・タブ・改行」を用いています。従って、文字列内に空白があると2つの文字列に分断されてしまいます。
ソースコード 3.58 ScannerExample2.java (next)

188 第 3章 Java 言語の基本的な文法 II
package section0307;
import java.util.Scanner;
public class ScannerExample2 {
public static void main(String[] args) {
Scanner scan = new Scanner( "abc def" );
System.out.println( "scan1 = " + scan.next() );
System.out.println( "scan2 = " + scan.next() );
scan.close();
}
}
では、空白入りの文字列を1つの文字列と認識したい場合どうするかと言うと、改行コードのみをデリミターとするnextLine メソッドを利用します。
ソースコード 3.59 ScannerExample3.java (nextLine)
package section0307;
import java.util.Scanner;
public class ScannerExample3 {
public static void main(String[] args) {
Scanner scan = new Scanner( "abc def" );
System.out.println( "scan1 = " + scan.nextLine() );
scan.close();
}
}
但し、注意しなければならないことが 1 つあります。next() メソッドは、空白や改行コードの直前までを文字列として切り出した後、 Scanner 内に残った空白や改行コードを残したままにします。続くメソッドが next() メソッドであれば先頭に残っている改行コードは読み飛ばされて次のデータを読んでくれるのですが、nextLine() メソッドは先頭の改行コードを読み飛ばすことはしません。
ソースコード 3.60 ScannerExample4.java (Scanner でのデリミター)
package section0307;
import java.util.Scanner;
public class ScannerExample4 {
public static void main(String[] args) {
// 改行コードが2つの文字列の間に挟まっている場合String lineCd = System.getProperty("line.separator");
Scanner scan = new Scanner( "abc"+ lineCd +"def" );
System.out.println( "scan1 = " + scan.next() );
System.out.println( "scan2 = " + scan.nextLine() );
scan.close();
}
}
まず、改行コードは可動しているプラットホームによって異なるので、以前はプラットフォームを判定し対応する改行コードを選ぶというプログラムで対処しましたが、最近は System クラスの getProperties() メソッドを用いて設定できるようになりました。このプログラムでは、文字列内に改行コードが入っているので、2行分の文字列データということになります。最初の next で、改行コード直前の abc が scan1 として出力されますが、改行コードが scan の中に残ってしまいます。そこへ nextLine メソッドが実行されるので、その改行コードの前まで、つまり空文字列が出力されています。「next() や nextInt() などの直後の nextLine() は注意せよ!」です。

3.7 Scanner を使ったテキストデータの入力 189
ではどうするか?最もダサい方法は、scan2 の読み込みの前に、空読みで「scan.nextLine();」の 1 行を入れて、その改行コードを空読みしてやれば、残りの文字列を読み込めます。(かなりダサい!)
もし入力データの並びに何らかの法則があるのなら、読み込みフォーマットを指定する方法がスマートです。それは、次の節で。
3.7.2 デリミターの設定
データの区切り記号はデフォルトでは「空白や改行」ですが、それ以外をデータの区切り記号としたい場合があります。例えば、2つの数値データの間にカンマがある、いわゆる「CSV 形式」のファイルからデータを読み込みたいなどの場合です。「CSV 」とは Comma-Separated Values の略で、項目が「カンマ ”,” 」で区切られているテキストを言い、ファイルの拡張子を .csv とすることになっています。Windows システムでは CSV ファイルは Excel に関連付けされていて、ダブルクリックすると Excel ファイルとして開かれます。さて、CSV 形式のデータファイルを Java で Scanner を用いて読み込むには、デリミターを変更しなければいけません。そこで使われるのが、 Scanner クラスのインスタンスメソッド useDelimiter です。
ソースコード 3.61 DelimiterExample.java (カンマをデリミターに)
package section0307;
import java.util.Scanner;
public class DelimiterExample {
public static void main(String[] args) {
String text = "10 hours, 20 minutes, 30 seconds";
// 数値とカンマ以外を削除String values = text.replaceAll("[^0-9,]", "");
// デリミターをカンマと改行に設定Scanner scan = new Scanner(values);
scan.useDelimiter( ",|" + System.getProperty("line.separator") );
// データの読み込み開始int hours = scan.nextInt();
int minutes = scan.nextInt();
int seconds = scan.nextInt();
scan.close();
System.out.printf("%2d:%2d:%2d%n", hours, minutes, seconds);
}
}
このプログラムでは、まず最初に数値とカンマ以外の余分な文字列を削除するために String クラスのインスタンスメソッド replaceAll を使っています。このメソッドは、文字列内の特定の部分文字列を他の文字列に変換します。ここでは、第1引数に「正規表現」(Regular Expression) を用いて数値以外の文字を選択し第2引数の空文字に変換しています。正規表現の解説はこのテキストでは行いませんが、ここでは、0-9, が数文字とカンマ、 ^ がそれらの否定、そして [ ] がその中のいずれか、を意味します。これによって、文字列 values には ”10,20,30” なる文字列が作成されました。あとは、useDelimiter を用いてデリミターの設定 (カンマと改行コードをデリミターとする) を行い、3つの整数値を読み込めばOKです。
問題 3.7.1. DelimiterExample.java において replaceAll メソッドを使わずに、デリミターを数値以外の文字列と改行に正規表現を用いて設定し、直接数値を読み込むプログラムに変更しなさい。ありがちなプログラムなので、

190 第 3章 Java 言語の基本的な文法 II
ネットで調べれば正解はすぐ見つかるはずです。 (ヒント:「\\s*,\\s*」)
次は、データのパターンを設定して読み込む例題です。Scanner には、指定したパターンを文字列内から探してくれるメソッド findInLine があります。正規表現を用いてパターンを指定した上で match メソッドを使うと、MathResult クラスの結果が出来上がり、そのメソッド group(int) を使って、対応する文字列を取り出せるというわけです (詳しくは解説しないので、これも自分で勉強して下さい)。
ソースコード 3.62 ScannerExample5.java (正規表現でパターン読み込み)
package section0307;
import java.util.Scanner;
import java.util.regex.MatchResult;
public class ScannerExample5 {
public static void main(String[] args) {
Scanner scan = new Scanner( "Usain Bolt:100m:9.58sec" );
/*
* \\w は A-Z, a-z, 0-9, _ のいずれか* | は論理和* [ ]+ はその要素の1回以上の反復* \\d は 0-9 のいずれか* ( ) は match メソッドで切り出したい部分に対応*/
scan.findInLine( "([\\w| ]+):(\\d+)m:([\\d]+.[\\d]+)sec" );
MatchResult result = scan.match();
scan.close();
// group の切り出しはインデックス 1 からString name = result.group(1);
int dist = Integer.valueOf(result.group(2));
double time = Double.valueOf(result.group(3));
System.out.println( name + " が、" + dist + " mを " + time + " 秒で走った");
}
}
3.7.3 File
次は、ファイルから文字データを Scanner で読み出す例ですが、先ずはファイルについて。Java でファイルを扱うには、まず、プログラムとデータファイルの相対的な位置関係を把握しておかないといけません。自分のノートパソコンの何処にこれまで作ってきたプログラムがあるか把握していますか?この授業で作るプログラムは、Windows なら全て C:Yjava フォルダの中の (MacOS なら書類フォルダの中) workspace フォルダ内に作っているはずです。そこに、「プログラミングの授業」なるプロジェクト (フォルダ) を作って、その中に
• src フォルダ:ソースプログラムが入っている• bin フォルダ:実行ファイルが入っている• .metadata フォルダ&その他:これらは、プログラムの位置関係のためのデータなので消さないこと
が入っているかな。これらのフォルダの構造や位置関係をしっかり理解して下さい。そうすれば、データファイルの扱いも容易になります。Eclipse では、ファイルの位置を、そのプログラムの入っている「プロジェクト」フォルダからの相対アドレスで表

3.7 Scanner を使ったテキストデータの入力 191
します。つまり、この授業のデフォルトの位置はプロジェクト「プログラミングの授業」フォルダですね。そこからどの位置にファイルが有るのかを相対的に指示してやれば、確実にファイルを扱うことができます。このテキストでは、データファイルは常にそのソースプログラムが入っている (パッケージ) フォルダに一緒に入っているとしました (別に他の場所でも構わないけれど、Eclipse のパッケージエクスプローラで表示しにくいので)。ということで、まずは以下のプログラムとデータファイルで実行してみましょう。
ソースコード 3.63 HelloJavaFromFile.java (ファイルから Duke)
package section0307;
import java.io.File;
import java.io.FileNotFoundException;
import java.util.Scanner;
public class HelloJavaFromFile {
public static void main(String[] args) throws FileNotFoundException {
// src フォルダ内の section0307 パッケージの中の helloJava.txt ファイルFile file = new File( "src/section0307/helloJava.txt" );
Scanner scan = new Scanner( file );
String message = scan.nextLine();
System.out.println( message );
scan.close();
}
}
プログラムが出来上がったら、同じパッケージ内に「helloJava.txt」というテキストファイルを作ります。プログラムファイルではないので、いつもとは違い、メニュー「ファイル > 新規 > ファイル」と選択します。ファイル名 (プログラムと違い、拡張子も含めてフルに入力して下さい) を入れると窓が開きますので、以下のテキストを入力して格納して下さい。
ソースコード 3.64 helloJava.txt (読み込みデータ)
また会いましたね。 Duke です。
入出力に用いるファイルを設定するには、File クラスのインスタンスを作ります。そのコンストラクタに、フォルダの包含関係をスラッシュで区切った、ファイルのデフォルト位置からの相対アドレスを文字列で指定します。
問題 3.7.2. 以下のファイルの位置関係において、それぞれの相対アドレス関係を文字列で表しなさい。
なお、自身の親フォルダはドット 2 つで表します。
folder0
folder1
folder2
file1
file2
file3
file4
1. file1 から見た file4 は、../file4
2. file4 から見た file1 は、folder1/file1
3. file1 から見た file2 は、 4. file1 から見た file3 は、 5. file3 から見た file4 は、

192 第 3章 Java 言語の基本的な文法 II
3.7.4 ファイルからのテキスト入力:Scanner(File)
キーボードからテキストデータを読み込むのに Scanner の nextInt() などのメソッドを利用しましたが、同じようにファイルからテキストデータを読み込むのにも利用できます。Scanner を使ってファイルにアクセスする場合、そのファイルの相対アドレスを文字列で File クラスのコンストラクタに与えて File 型インスタンスを作り、それをScanner クラスのコンストラクタに与えることで可能になります。Scanner が Java に導入される Java 5.0 より前では、ファイルからの簡単なデータ入力でも FileReader・
BufferedReader・InputStreamReader など複数のクラスを組み合わせて行なわなければいけませんでした。しかし、Scanner が導入されてからは、単純なテキストデータ入力は、全て Scanner で行えば良くなったので、覚えることが少なくなりました (情報処理の試験では Scanner だけでは合格できないけどね)。では、先ほどと同様にして、今回は数値データのファイル inputData.txt を作りましょう。作る場所は同じく、「プログラミングの授業/src/section0307」内です。エディタでテキストデータファイル inputData.txt を作り、次のようなテキストを書き込んで格納して下さい。
ソースコード 3.65 inputData.txt (読み込み数値データ)
2
3
4.5 6.7
次に、このデータを読むプログラムです。
ソースコード 3.66 FileScanner.java (Scanner でファイルから数値データ読み込み)
package section0307;
import java.io.File;
import java.io.FileNotFoundException;
import java.util.Scanner;
public class FileScanner {
public static void main(String[] args) throws FileNotFoundException {
Scanner scan = new Scanner( new File( "src/section0307/inputData.txt" ) );
int x = scan.nextInt();
int y = scan.nextInt();
int z = x * y;
System.out.printf( "%d * %d = %d %n", x, y, z );
double a = scan.nextDouble();
double b = scan.nextDouble();
double c = a * b;
System.out.printf( "%f * %f = %f %n", a, b, c );
scan.close();
}
}
もし作成したテキストファイルの場所が違ったり名前を間違ったりすると、入力ファイルが見つからないという例外 FileNotFoundException が投げられます。FileNotFoundException は IOException のサブクラスで検査例外であるため、必ず例外発生時の処理 (catch 文など) が必要です。このプログラムでは、それを catch せず throw 節(throws FileNotFoundException) を付けて例外処理を放棄しています。ファイルが存在すれば、キーボードから読み込んだ時のように Scanner を利用できます。Scanner の使用後に close() メソッドで閉じているところも、キーボード入力のときと同じです。Scanner はデータデリミターを「空白やタブ、改行」で行っています。従って、データファイルの後半の 2 つの実数

3.8 ファイルへの入出力 193
のように 1 行に 2 つのデータを空白 (複数の空白も可能) を挟んで置くことも出来ます。なお、数値を読み込む際は、nextInt()・nextLong()・nextDouble() と型に合ったメソッドを利用して読み込みます。ファイルからデータを読み込む際に、データの個数が事前に分かっていない場合がありますよね。ファイルに格納されている幾つ入っているか分からないけれど全てを読み込むという場合、「データがまだあるなら読み込む」という処理を行います。そのためには、Scanner クラスの hasNext() メソッドを利用します。hasNext() メソッドは、さらに読み込むデータが存在する場合に true を返してくれます。その際、データの読み込みは行わないので、あらためてnext メソッドなどでデータを読み込みます。今回のプログラムは、例外処理 (と言ってもエラーメッセージの表示のみ) を行ってみました。
ソースコード 3.67 ScannerReadFile.java (hasNext() を使ったデータファイルの読み込み)
package section0307;
import java.io.File;
import java.io.FileNotFoundException;
import java.util.Scanner;
public class ScannerReadFile {
public static void main(String[] args) {
try {
Scanner scan = new Scanner( new File( "src/section0307/number.txt" ) );
int count = 0;
while( scan.hasNext() ){
String str = scan.next();
count++;
System.out.printf( "%2d 個目のデータは、%s%n", count, str );
}
scan.close();
} catch(FileNotFoundException e) {
System.out.println("データファイルが見つかりません");
}
}
}
3.8 ファイルへの入出力ファイルからのテキスト入力は Scanner クラスのおかげで簡単になりましたが、ファイルへのテキスト出力やバイナリーデータの入出力に対しては昔からの方法が引き継がれました。将来、便利な方法が導入されるかもしれませんが、現在はそれぞれ面倒くさいままです。
3.8.1 ストリームとファイル
Java では「ストリーム」(stream) という機能を用いてファイルからデータを読み込んだり書き出したりしています(図 3.11 参照)。ストリームには入力用/出力用/テキストデータ用/バイナリデータ用/バッファリング付き、などいろいろとあり、選んだストリームに対応するクラスのインスタンスにデータを流し込んだり、ストリームから流れてくるデータを読み込んだりすることで、外部装置の細かい設定などを不必要にしています (と言ってもまだまだ複雑ですが)。入出力ストリームのクラスは全て java.io パッケージ内にあります。いずれもデフォルトでは読み込まれないので、importしないといけません。主に使われる「出力用のクラス」を以下にまとめました (図 3.12 参照)。「入力用のクラス」は図の各クラス名を

194 第 3章 Java 言語の基本的な文法 II
キーボード
ファイル
入力ストリーム プログラム 出力ストリーム
ファイル
画面
図 3.11 入力・出力ストリーム
Writer ⇒ Reader、Output ⇒ Input と書き換えて下さい。ここでは番号を付けた 4 種類について順に説明します。
java.io.Writer
java.io.BufferedWriter
java.io.OutputStreamWriter
java.io.FileWriter
バッファリングすることで書き込みを効率化
文字ストリームからバイトストリームへの橋渡し
文字ファイルへの書き込み簡易クラス
抽象クラス
java.io.OutputStream
java.io.FilterOutputStream
java.io.FileOutputStream
java.io.BufferedOutputStream
生のバイトストリームを書き込む際に使用
バッファリングされた出力ストリーム
抽象クラス : バイト出力ストリームを表現する全てのクラスのスーパークラス
1
2
3
4
図 3.12 出力ストリームとライタ
3.8.2 FileInputStream / FileOutputStream
FileInput(Output)Stream は直接ストリームを指定してファイルのバイナリデータを扱う最も基本的なクラスです。 従って、画像なども扱える一方、テキストもバイナリデータとして扱わないといけません。FileInput(Output)Stream のコンストラクタは、File インスタンスを引数にします。File は検査例外のFileNotFoundException の対処が必要です。読み込みはファイルサイズのバイト配列を引数とした read メソッドで、書き込みはバイト配列に変換してから write メソッドで行います。read メソッド・write メソッド共にIOException に対する例外処理が必要です。読み書きがバイト配列で行われるので、それらの前後で本来のデータ型への変換が必要になります。処理が終了したら close メソッドでストリームを閉じます。
ソースコード 3.68 StreamExample01.java (FileOutputStream を使って文字列をファイルへ)
package section0308;
import java.io.File;
import java.io.FileInputStream;

3.8 ファイルへの入出力 195
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class StreamExample01 {
public static void main(String[] args) {
// 前半は、文字列をファイルに書くFile file = new File( "src/section0308/file01.txt" );
String str = "abcdefg\nあいうえお";
try {
System.out.println( "ファイルへデータを書き出します。" );
FileOutputStream fos = new FileOutputStream( file );
// 文字列をバイト列としてファイルに書き込むfos.write( str.getBytes() );
fos.close(); // ストリームを閉じる} catch ( FileNotFoundException e ) {
System.out.println(
"ファイル名が正しくないのでファイルを作成できませんでした。" );
} catch ( IOException e ) {
System.out.println( "ファイルに正しく書き込めませんでした。" );
}
// 後半は、そのファイルから再度文字列データを読み込むtry {
System.out.println( "ファイルからデータを読み出します。" );
// ファイルのバイト数分の配列を用意するbyte[] bdata = new byte[(int) file.length()];
FileInputStream fis = new FileInputStream( file );
fis.read( bdata );
fis.close(); // ストリームを閉じる// バイト列を文字列に成形するstr = new String( bdata );
System.out.println( str );
} catch ( FileNotFoundException e ) {
System.out.println(
"ファイルが存在しないので、データを読込めませんでした。" );
} catch ( IOException e ) {
System.out.println( "ファイルのデータを正しく読込めませんでした。" );
}
}
}
次のプログラムは、画像ファイルを一旦読み込んで他の名前のファイルに書き出しています。ネットから適当な「画像ファイル」をダウンロードして、プログラムと同じパッケージ section0308 内に置いて、プログラム内のファイル名をそれに合わせて変更して下さい。出力ファイルのファイル拡張子は入力ファイルに合わせて下さい (画像フォーマットを変更したりはしていないので)。先ほどのプログラムと同じメソッドばかりなので、解読は容易かと思います。画像フォーマット、例えば jpeg や bitmap、を勉強してくれれば、色合いを変更して書き込むなんてことも出来るようになりますね。
ソースコード 3.69 StreamExample02.java (FileOutputStream を使って画像ファイルのコピー)
package section0308;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;

196 第 3章 Java 言語の基本的な文法 II
public class StreamExample02 {
public static void main(String[] args) {
File file = new File("src/section0308/doraemon.bmp");
File file2 = new File("src/section0308/copy.bmp");
byte[] bdata = null;
// 前半では、ビットマップ画像をバイトデータの配列に読み込むtry {
System.out.println("ファイルから画像データを読み出します。");
bdata = new byte[(int)file.length()];
FileInputStream fis = new FileInputStream( file );
fis.read( bdata );
fis.close();
} catch (FileNotFoundException e) {
System.out.println(
"ファイルが存在しないので、データを読込めませんでした。");
} catch (IOException e) {
System.out.println("ファイルのデータを正しく読込めませんでした。");
}
// 後半で、バイトデータ配列を同じフォーマットの画像ファイルに書き込むtry {
System.out.println("ファイルへデータを書き出します。");
FileOutputStream fos = new FileOutputStream( file2 );
fos.write( bdata );
fos.close();
} catch (FileNotFoundException e) {
System.out.println(
"ファイル名が正しくないのでファイルを作成できませんでした。");
} catch (IOException e) {
System.out.println("ファイルに正しく書き込めませんでした。");
}
}
}
3.8.3 FileReader / FileWriter
テキストデータを扱う場合は、Reader / Writer クラスのサブクラスを使うことでストリームを直接扱うより文字列処理が容易になります ( Scanner が登場してからは、これらも面倒ですがね)。FileReader・FileWriter はファイル入出力用の基本的な Reader / Writer クラスです。FileWriter の write メソッドは、引数に文字列を使えます。一方、FileReader では、read メソッドを使って、1文字ずつ読み出します。文字列として読むのではなく、1文字ずつ文字として読みますから、文字列にするには合体させないといけません。なお、ファイルの最後まで達すると read メソッドは −1 を返してくる (文字も整数値と見れるんだったよね) ので、それを繰り返しの終了判定に用います。
ソースコード 3.70 StreamExample03.java (FileWriter を使ってテキストファイルを扱う)
package section0308;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class StreamExample03 {
public static void main(String[] args) {

3.8 ファイルへの入出力 197
File file = new File("src/section0308/file01.txt");
String str = "abcdefg\nあいうえお";
// 前半では、文字列データをファイルに書きtry {
System.out.println("ファイルへデータを書き出します。");
FileWriter fw = new FileWriter( file );
fw.write( str );
fw.close();
} catch (IOException e) {
System.out.println("ファイルに正しく書き込めませんでした。");
}
// 後半で、ファイルから文字を読み込んでいるtry {
System.out.println("ファイルからデータを読み出します。");
str = "";
FileReader fr = new FileReader( file );
int c;
while( (c = fr.read())!=-1 ) {
str += (char) c;
}
fr.close();
System.out.println( str );
} catch (FileNotFoundException e) {
System.out.println(
"ファイルが存在しないので、データを読込めませんでした。");
} catch (IOException e) {
System.out.println("ファイルのデータを正しく読込めませんでした。");
}
}
}
3.8.4 BufferedReader / BufferedWriter
ハードディスクなどの外部装置に対するデータの入出力操作は四則計算などのメモリ内の動作に比べて、比べ物にならないほど時間が掛かります。例えば、コンソールに abc と文字列を表示させる場合に、プログラムが a を表示、b
を表示、c を表示と指示した場合、その度に OS の画面描画機能(システムコール)を呼び出していたのでは、毎回プログラムの実行がポーズされることになり、非常に効率の悪いプログラムとなります。そこで、(メモリなどの高速な記憶領域に)出力を要求された文字列をある程度ため込んでおいて、(これをバッファと言います) 実際に出力させるのは時々にさせるのです (人間の目には一瞬の間ですがね)。入力も同様です。 FileReader では1もじずつ読み込むわけですが、これも効率が悪い。そこで、バッファーに入力させて、1行分ずつ読み込むというわけです。このバッファリングを行うためのクラスが、BufferedReader / BufferedWriter クラスです。一般的に、BufferedWriter(Reader) クラスのコンストラクタに FileWriter(Reader) クラスのインスタンスをいれてインスタンスを作成します。文字列を出力する writer メソッドと改行コードを出力するための newLine メソッド、 改行コードまでを文字列として読込む readLine メソッドなどが使えます。readLine メソッドは、ファイルの最後になると null 値を返してくるので、それを繰り返しの終了判定に用います。そして、いつもと同様に close メソッドで閉じます。
ソースコード 3.71 StreamExample04.java (BufferedWriter を使ってテキストファイルを扱う)
package section0308;
import java.io.BufferedReader;

198 第 3章 Java 言語の基本的な文法 II
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class StreamExample04 {
public static void main(String[] args) {
File file = new File("src/section0308/file01.txt");
String str = "abcdefg\nあいうえお";
System.out.println("ファイルへデータを書き出します。");
// 前半では、文字列データをファイルに書きtry {
BufferedWriter bw = new BufferedWriter( new FileWriter( file ));
bw.write( str );
bw.newLine();
bw.close();
} catch (IOException e) {
System.out.println("ファイルに正しく書き込めませんでした。");
}
System.out.println("ファイルからデータを読み出します。");
// 後半で、ファイルから文字列を1行ずつ読み込んでいるtry {
BufferedReader br = new BufferedReader( new FileReader( file ));
String line;
while( (line = br.readLine()) != null ) {
System.out.println( line );
}
br.close();
} catch (FileNotFoundException e) {
System.out.println(
"ファイルが存在しないので、データを読込めませんでした。");
} catch (IOException e) {
System.out.println("ファイルのデータを正しく読込めませんでした。");
}
}
}
3.8.5 InputStreamReader / OutputStreamWriter
最後は、テキストデータを扱う際に文字コードを指定して扱う機能を持った InputStreamReader(Writer) です。日本語に関する文字コードとしては、Java のデフォルトが UNICODE ですので、その場合は文字コードを省略できます。それ以外には、ISO2022JP (JIS コード)、SJIS (シフト JIS コード)、EUC JP (日本語拡張 UNIX コード) などがあります。次のプログラムでは、EUC JP で書いたファイルを SJIS で読み出していますので、Eclipse 上では出力表示がいわゆる文字化けになりますね。他のエディタで読んでみて下さい。
ソースコード 3.72 StreamExample05.java (OutputStreamWriter を使ってテキストファイルを扱う)
package section0308;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;

3.8 ファイルへの入出力 199
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
public class StreamExample05 {
public static void main(String[] args) {
File file = new File( "src/section0308/file02.txt" );
String str = "abcdefg\nあいうえお";
System.out.println( "ファイルへデータを書き出します。" );
// 文字列をファイルへ EUC コードで書き込みtry {
BufferedWriter bw = new BufferedWriter(
new OutputStreamWriter( new FileOutputStream( file ),"EUC_JP") );
bw.write( str );
bw.newLine();
bw.close();
} catch ( IOException e ) {
System.out.println( "ファイルに正しく書き込めませんでした。" );
}
System.out.println( "ファイルからデータを読み出します。" );
// ファイルから文字列を "SJIS" コードに変更しながら読み込むtry {
BufferedReader br = new BufferedReader(
new InputStreamReader( new FileInputStream( file ), "SJIS") );
String line;
while( (line = br.readLine()) != null ) {
System.out.println( line );
}
br.close();
} catch (FileNotFoundException e) {
System.out.println(
"ファイルが存在しないので、データを読込めませんでした。" );
} catch (IOException e) {
System.out.println( "ファイルのデータを正しく読込めませんでした。" );
}
}
}
3.8.6 Java のデータを Excel や Mathematica に読ませる
やりたいことを全て Java でプログラムすることも可能ですが、他のアプリケーションが得意とする仕事をわざわざJava でプログラムすることもありません。例えば、データの集計やグラフ化は Excel の得意分野なので、Java で計算した結果を Excel に渡し、Excel 側で集計・グラフ化する方法は知っておくべきでしょう。Mathematica のプログラミングができるなら、Mathematica 単独でも処理できますが、Java の計算結果を Mathematica にわたすこともできます。いずれの場合も、データファイル CSV 形式にしておくと簡単です。拡張子が csv の CSV 形式ファイルはこれは
Comma Separated Values の略で、データをカンマで区切って並べたファイル形式です。従って、データをファイルに書き出すとき、区切り記号のカンマも書き込むようにしないといけませんが、こうしておくと、Excel がインストールされている環境では関連付けされるので、ファイルをダブルクリックするだけでデータが Excel のテーブルとして表示されます。また、Mathematica は Import 関数で CSV ファイルをリスト形式に変換しながら読み込んでくれます。

200 第 3章 Java 言語の基本的な文法 II
ソースコード 3.73 CSV Example.java (CSV 形式ファイルに出力)
package section0308;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
public class CSV_Example {
public static void main(String[] args) throws IOException {
// 減衰振動のデータをファイルに書き込むBufferedWriter bw
= new BufferedWriter(new FileWriter("src/section0308/curve.csv"));
bw.write("θ, Sin(θ)/θ");
bw.newLine();
// 範囲 [0.1, 30.0] の間の関数値を 0.1 刻みで求めるfor(int i=1; i<=300; i++) {
double x = i / 10.0;
bw.write( String.valueOf(x) );
bw.write(",");
bw.write( String.valueOf(func(x)) );
bw.newLine();
}
bw.close();
System.out.println("ファイル出力終了しました。");
}
static double func(double x) {
return Math.sin( x )/x;
}
}
Eclipse 内でも、このデータファイルを Excel に読み込ませることができます。まず、出来上がったファイルはプログラムを動かした時点では表示されていないので、パッケージ・エクスプローラーでパッケージ「section0308」のアイコンを右クリックし、「リフレッシュ」を選択すると、エクスプローラーに表示されます。そうしたら、表示された curve.csv ファイルのアイコンを右クリックし、「次で開く>システム・エディター」を選択します。こうすると、Excel がデフォルトアプリケーションとして登録されているので、Excel でこのファイルが開くはずです。Mathematica の場合は、Mathematica 上で「 data = Import[ ];ListPlot[data] 」として、 [ ]内に、このファイルの URLを入れてやれば図が書けるはずです。
3.9 import 文Java では、パッケージ内に同じ名前のクラスを複数置くことは許されません。パッケージが違えば許されますが、それらを区別する際にはパッケージ名を付けて扱うことになります。パッケージ名を含めた名前のことを「完全修飾名」と言って、例えば、java.util パッケージの ArrayList クラスのインスタンスの生成は、java.util.ArrayList list = new java.util.ArrayList(); と書くことになります。ただ、これではあまりに冗長ですね。そこで、登場するのが import 文です。プログラムの先頭、パッケージ名の宣言の次に完全修飾名でのクラス名を登録しておけば、以降は (パッケージ名を省略して) クラス名のみでOKとなるのです。例えば、import
java.util.ArrayList; と書いておけば、プログラム中で ArrayList クラスと言ったら、このことだ!となるので、ArrayList list = new ArrayList(); とパッケージ名を省略できるわけです。また、import 文を見れば、どんなクラスを利用しているのかが分かるので、プログラム構造が理解しやすくなります。なお、同じ名前のクラス名を同時に使う場合は、いずれかを完全修飾名にして区別します。

3.9 import 文 201
3.9.1 import 文の書き方
import 文は、プログラムの先頭行の package 文の次に並べます。完全修飾名は、java.util.ArrayList のように、パッケージ java の中のサブパッケージ util の中のクラス ArrayList と言った長い名前になるものもあります。また、あるパッケージ内の複数のクラスを import しなければならないときは、「オンデマンドインポート」(on
demand import) と言って、クラス名の部分をアスタリスクを使って表記することができます。例えば、同じパッケージ java.util 内の 3 つのクラスを利用したいとき、
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.Hashmap;
↓import java.util.*;
このようにアスタリクスでまとめる (ワイルドカード化とも言う) と、コンパイラはこのパッケージ内の全てのクラスを持ち込んでコンパイルしてくれます。ただし、そのパッケージにサブパッケージがあった場合、その中のクラスまでは持ち込んでくれません。例えば、以下のように、サブパッケージはサブパッケージでまとめることになります。
import java.awt.Canvas;
import java.awt.Color;
import java.awt.event.ActionEvent;
import java.awt.event.MouseAapter;
↓import java.awt.*;
import java.awt.event.*;
このオンデマンドインポートですが、あまり推奨はされていません。先程言ったように、この import 文を読むことで、プログラムの構造がわかりやすくなるわけで、ここを省略してしまうと、java.awt の何を使っているのかがソース本体を読まないとわからないわけです。従って、冗長には見えますが、import はオンデマンド化せずに書きましょう。なお、同じ名前のクラスを同時には import できないので、いずれかは完全修飾名を使わないといけません (ソースコード 3.74 参照)。
ソースコード 3.74 ImportExamaple.java (インポート文の例題)
package section0309;
import section0309.sub1.A;
public class ImportExamaple {
public static void main(String[] args) {
A.print(); // import 文で宣言されたデフォルトのクラスsection0309.sub2.A.print(); // 区別のため、完全修飾名で
}
}
package section0309.sub1;
public class A {
public static void print() {
System.out.println( "section0309.sub1.A が呼ばれました");
}
}

202 第 3章 Java 言語の基本的な文法 II
package section0309.sub2;
public class A {
public static void print() {
System.out.println( "section0309.sub2.A が呼ばれました");
}
}
3.9.2 java.lang パッケージ
java.lang パッケージは、Java の最も基本的な機能を提供するパッケージです。System.out.println の System
クラスもこのパッケージに入っているクラスです。他にも、 全てのクラスのスーパークラスである Object、数学メソッドの集まり Math、文字列の String、後で出てくる並列処理のための Thread などもこのパッケージのメンバーです。あまりに重要なパッケージということで、このパッケージについては import しないでも良いことになっています。System.out.println や Math.cos は、本来は java.lang.System.out.println や java.lang.Math.cos
なわけです。
3.9.3 静的インポート
Java 5.0 で、他のクラスのクラス変数やクラスメソッドをインポート宣言することができるようになりました。これを「静的インポート」 (static import) と呼びます。以下の例は良い例とは言えませんが、 java.lang.Math クラスのクラス定数の円周率とクラスメソッドのべき乗関数に対しインポート文を書くことで、クラス名 Math が省略できています。一般の import 文と同様にワイルドカード化も使うこともできます。
ソースコード 3.75 StaticImportExample.java (静的インポート)
package section0309;
import static java.lang.Math.PI;
import static java.lang.Math.pow;
public class StaticImportExample {
public static void main(String[] args) {
double radius = 1.2;
System.out.println( "半径 " + radius + " の円の面積は、" + pow(radius,2) * PI );
}
}
ただし、この静的インポートもやりすぎると、それら定数やメソッドの出どころが分かりにくくなるためにコードの可読性が落ちるというデメリットがあるので、ほどほどに。
3.10 抽象クラスとインタフェース3.10.1 抽象クラス
抽象クラスとは、インスタンスを作れないクラスです。って?例えば、「自動車」のサブクラスに「リムジン」「トラック」「スポーツカー」などがあって、それぞれインスタンスを作れ!と言ったら、まあ作れそうかな?と思いますが、「自動車」と「電車」と「飛行機」らのスーパークラスとして、「乗り物」というクラスを作ったとして、「乗り物」クラスのインスタンスを作れ!となると、ちょっと無理そうですよね(自動車でもなく電車でもなく飛行機でもないそれらの共通部分となるオブジェクトって具体的にどんな形のもの?)。

3.10 抽象クラスとインタフェース 203
でも、それら乗り物の共通部分を定義する「乗り物」クラスを作っておいて、そのサブクラスたちは差分の部分のみ定義すれば効率良さそう。この「乗り物」クラスのような、直接インスタンスは作らない (作れない) けれどスーパークラスとして在ったらよさそうなものを「抽象クラス (abstract class) 」と言います。それに対して、インスタンスを作れるクラスのことを「具象クラス (concrete class)」と呼びます。ということで、抽象クラスの特徴とは、
• クラスの宣言文にキーワード abstract を付ける• フィールド、コンストラクタおよびメソッドを具象クラスと同様に持てる• 中身の定義されていない「抽象メソッド (abstract method)」を1つ以上持つ
中身が定義されていない抽象メソッドを持つため、このクラスはそのままではインスタンスを作ることができません。一方、このクラスを継承する具象クラスは、この抽象メソッドの中身を必ずオーバーライドしなければなりません。これを「オーバーライドの強制」と言います。以前、ポリモルフィズムのところで作った平面図形のクラスを抽象クラスを用いて再表現しましょう。
ソースコード 3.76 AbstractClass.java (抽象クラスで図形処理 (?))
package section0310;
public class AbstractClass {
public static void main(String[] args) {
Shape[] shapes = {
new Circle( 1.2 ), // 円new Square( 1.5, 2.4 ), // 長方形new Trapezoid( 1.2, 3.0, 2.5 ) // 台形
};
for( Shape shape : shapes ) {
shape.printArea();
}
}
}
// 抽象クラス:一般図形(ただし、面積を求めることができる)abstract class Shape {
String name; // 図形の名前Shape( String name ) { // コンストラクタ
this.name = name;
}
void printArea() {
System.out.println( this.name + "の面積は、" + this.getArea() );
}
// 抽象メソッド:メソッドブロックが無い代わりにセミコロンで終わるabstract double getArea();
}
// 具象クラス:円class Circle extends Shape {
double radius;
Circle( double radius ) {
super( "円" );
this.radius = radius;
}
@Override
double getArea() { // 抽象メソッドをオーバーライドreturn radius * radius * Math.PI;

204 第 3章 Java 言語の基本的な文法 II
}
}
// 具象クラス:長方形class Square extends Shape {
double height;
double width;
Square( double height, double width ) {
super( "長方形" );
this.height = height;
this.width = width;
}
@Override
double getArea() { // 抽象メソッドをオーバーライドreturn height * width;
}
}
// 具象クラス:台形class Trapezoid extends Shape {
double upper;
double lower;
double height;
Trapezoid( double upper, double lower, double height ) {
super( "台形" );
this.upper = upper;
this.lower = lower;
this.height = height;
}
@Override
double getArea() { // 抽象メソッドをオーバーライドreturn ( upper + lower ) * height / 2;
}
}
このプログラムでは、Shape クラスで「面積を求められる図形」を定義しています。前回は Shape も具象クラスとして面積 0 を返すようにしていましたが、今回は、 Shape クラスでは直接面積を計算せず、サブクラス毎に面積計算のメソッドを定義させています。抽象メソッドでは、引数と戻り値の宣言は行っていますが中身の処理を定義していません。面積を計算する getArea() メソッドを抽象メソッドにするには abstract を付け、メソッドブロックの代わりに文の終わりを表すセミコロンを付けます ( abstract double getArea(); )。引数と戻り値の型は定義できますが処理は書かない (書けない?) というわけです。引数のある抽象メソッドは、例えば abstract int calc( int x, int
y ); のように引数名は自由につけて構いません (引数と戻り値の型が重要なだけだから)。抽象メソッドを中身のあるメソッドとしてオーバーライドした具象クラスならば、インスタンスが作れるわけで、Shape クラスを継承する円や長方形のクラスは、面積計算のメソッド double getArea() をオーバーライドして具象クラス化しています。さて、各クラスのコンストラクタでは super("円"); などとスーパークラスである Shape クラスのコンストラクタを利用しています。同じクラス内の別のコンストラクタを使う時は、this(); などを使いましたが、スーパークラスのコンストラクタを使う時は、this() の代わりに super() を使います。なお、スーパークラスのコンストラクタ呼び出しも、そのコンストラクタの最初で行なわなければいけません。ところで、main メソッドの後半、各 shape に対し、shape.printArea(); としていますが、抽象クラス Shape においては printArea メソッド内には抽象メソッド getArea() が使われていて、その中身が未定義なんだけど大丈夫なんでしょうか?オーバーライドの意味が分かっていれば、OKとなるかと思うのですが … いかが?

3.10 抽象クラスとインタフェース 205
問題 3.10.1. 「電話 (Telephone:抽象クラス)」とそれを継承する2つの具象クラス「携帯電話 (Cellular)」と「固定電話 (FixedLinePhone)」を定義し、それぞれに思いつくフィールドとメソッド (抽象メソッドを含む) を与えなさい。
Telephone
Cellular FixedLinePhone
抽象クラス・抽象メソッドは
名前を斜体で
上の関係に「スマートフォン」を加えるとなると、「コンピュータ」と「電話」の2つの抽象クラスをスーパークラスとして持ちたい気がしますよね。そうした多重継承状況を解決するのは、次のインタフェースです。
3.10.2 インタフェース
Java は多重継承は許していない!単一継承のみである!というのを学びましたが、それでは「自動車」と「船」の2つのクラスを継承する「水陸両用車」や「電話」と「コンピュータ」を継承する「スマートフォン」が作れません。C++では出来るのに、負けるのは悔しい!そこで、Java はその対抗策として、「インタフェース」 (interface) という「クラスもどき?」を導入しました。正確に言うと「継承関係にないクラス間でポリモルフィズム (多態性) を実現するための手段」がインタフェースです。
ソースコード 3.77 InterfaceExample.java (インタフェースの例題)
package section0310;
public class InterfaceExample {
public static void main(String[] args) {
Dog pochi = new Dog( "ぽち" ); // 普通の犬Dog peace = new HearingDog( "ピース" ); // 聴導犬Dog hope = new RescureDog( "ホープ" ); // 救助犬Dog lucky = new RescureHearingDog( "ラッキー" ); // 聴導・救助犬
Dog[] myDogs = { pochi, peace, hope, lucky };
for(Dog dog : myDogs) {
dog.print();
}
System.out.println();
// 救助犬だけの配列を宣言Rescurable[] rescurableDogs = RescureDog.selectRescureDog( myDogs );
for(Rescurable dog : rescurableDogs) {
dog.rescure();
}
}
}
// 犬のクラス (スーパークラス)
class Dog {
String name;
Dog( String name ) {
this.name = name;
}
void print() {

206 第 3章 Java 言語の基本的な文法 II
System.out.printf( "「%s」は普通の犬です。%n", this.name );
}
}
// 聴導犬のクラスclass HearingDog extends Dog implements Hearable {
HearingDog( String name ) {
super( name );
}
@Override
void print() {
System.out.printf( "「%s」は聴導犬です。%n", this.name );
}
@Override
public void hearing() {
System.out.printf( "「%s」はご主人の耳の代わりをします。%n", this.name );
}
}
// 救助犬のクラスclass RescureDog extends Dog implements Rescurable {
RescureDog( String name ) {
super( name );
}
@Override
void print() {
System.out.printf( "「%s」は救助犬です。%n", this.name );
}
@Override
public void rescure() {
System.out.printf( "「%s」はご主人を災害から救助します。%n", this.name );
}
// 与えられた犬の配列内から救助可能な犬のみを配列で取り出すpublic static Rescurable[] selectRescureDog( Dog[] dogs) {
Rescurable[] selectedDog = new Rescurable[dogs.length];
int count = 0;
for(Dog dog : dogs) {
if( dog instanceof Rescurable ) {
selectedDog[count++] = (Rescurable) dog;
}
}
Rescurable[] rescurableDogs = new Rescurable[count];
System.arraycopy(selectedDog, 0, rescurableDogs, 0, count);
return rescurableDogs;
}
}
// 救助犬でも聴導犬でもある犬のクラスclass RescureHearingDog extends Dog implements Hearable, Rescurable {
RescureHearingDog( String name ) {
super( name );
}
@Override
void print() {
System.out.printf( "「%s」は聴導・救助犬です。%n", this.name );
}
@Override
public void rescure() {

3.10 抽象クラスとインタフェース 207
System.out.printf( "「%s」はご主人を災害から救助します。%n", this.name );
}
@Override
public void hearing() {
System.out.printf( "「%s」はご主人の耳の代わりをします。%n", this.name );
}
}
// 聴導のためのインタフェースinterface Hearable {
void hearing(); // 抽象メソッド (聴く) を持つ}
// 救助のためのインタフェースinterface Rescurable {
void rescure(); // 抽象メソッド (助ける) を持つ}
ここでは、4匹の犬を定義しています。幾つかのクラスとインタフェースが登場しているので、まずはそれを図示しましょう。
Dog
~ name : String
~ print( ) : void
HearingDog RescureDog
<<interface>>Rescurable
~ rescue( ) : void
<<interface>>Hearable
~ hearing( ) : void
RescureHearingDog
図 3.13 インタフェースの実装
インタフェースの特徴とは、
• インタフェースは「アクセス修飾子 interface インタフェース名」で始まるブロックである• インタフェース名はクラス名と同じくパスカル形式で付けるのが一般的• アクセス修飾子はクラスと同じく public と package-private が使える• メンバーとして抽象メソッドとクラス定数のみを持ち、いずれも public とする• 抽象メソッドの修飾子 public abstract を省略することが許されている• クラス定数の修飾子 public static final を省略することが許されている• 他のインタフェースを多重継承 ( extends ) できる
インタフェースは抽象クラスと似ていますが、クラスではありません。従って、コンストラクタがありません。全てのメソッドが抽象メソッドなので、それを具象化するクラスではそれら全てをオーバーライドしないといけません。インタフェースに対し、それを具象化したクラスは、継承 (extends) するとは言わず、実装 (implements) すると言います。なお、UML ではインタフェースの実装を白抜き点線の矢印で表します (図 3.13 参照)。

208 第 3章 Java 言語の基本的な文法 II
クラスがインタフェースを実装する時は、キーワード implements を使って class クラス名 implements インタフェース名 {・・・} と書きます。クラスが多重継承できないのに対し、インタフェースは多重実装することができます。多重実装するときはインタフェース名をカンマを挟んで並べます。例えば、上の例で RescureHearingDog が 2
つのインタフェース Hearable と Rescurable を実装しています。
問題 3.10.2. 次の設問に答えよ。
1. 抽象クラスとインタフェースの定義を比較し、違いを再認識しなさい。2. 抽象クラスを多重継承出来ないのに、インタフェースは多重実装できる理由を適当な例を作って説明せよ。3. インタフェースが他のインタフェースを多重継承する例を作って、それが可能であることを説明せよ。その際、インタフェースが複数のインタフェースを「実装」では無いことも説明せよ。
問題 3.10.3. 以下のプログラムの出力のうち、false が出力されるのはどれですか。
ソースコード 3.78 InterfaceExample2.java (インタフェースの instanceof)
package section0310;
public class InterfaceExample2 {
public static void main(String[] args) {
B a = new A();
System.out.println("a instanceof A = " + (a instanceof A) );
System.out.println("a instanceof B = " + (a instanceof B) );
System.out.println("a instanceof C = " + (a instanceof C) );
A b = new A();
System.out.println("b instanceof A = " + (b instanceof A) );
System.out.println("b instanceof B = " + (b instanceof B) );
System.out.println("b instanceof C = " + (b instanceof C) );
B c = new B();
System.out.println("c instanceof A = " + (c instanceof A) );
System.out.println("c instanceof B = " + (c instanceof B) );
System.out.println("c instanceof C = " + (c instanceof C) );
C d = new A();
System.out.println("d instanceof A = " + (d instanceof A) );
System.out.println("d instanceof B = " + (d instanceof B) );
System.out.println("d instanceof C = " + (d instanceof C) );
}
}
class A extends B implements C {
public void method() {
System.out.println( "yahoo!" );
}
}
class B {
final int CONST = 100;
}
interface C {

3.10 抽象クラスとインタフェース 209
void method();
}
参照変数 d の型に注目して下さい。この変数の型はインタフェース C となっています。サブクラスのインスタンスをスーパークラスの変数で参照する、というのをやりましたよね。それと同様に、実装クラスのインスタンスをインタフェースの変数で参照する、というのもアリなのです。この変数 d はクラス A のデフォルトコンストラクタで生成されたインスタンスの C の部分だけを参照している変数です。つまり、 method() だけですね。クラス B で定義されている定数 CONST は見えていません ( main の最後に System.out.println( d.CONST ); と入れるとエラーになりますが、 System.out.println( ((A).d).const ); とするとちゃんと 100 が出力されます )。ちなみに、d.method(); と書いて「yahoo!」が出力されるのはOKですか?
3.10.3 デフォルトメソッド
さて、インタフェースについてまとめたましたが、Java 8 でインタフェースの仕様が大きく変わりました。なんと、インタフェースが具象メソッド (中身のあるメソッド) 「デフォルトメソッド」を持っても良くなったのです。Java が推し進めてきた「多重継承は悪!」という風潮も他の言語に押し切られてきたというところでしょうか。何故、そんな危険を?と思いますが、それはインタフェースにメソッドを後から追加したい場合に (Java 8 の API の拡張で実際に行われている)、それを実装していたクラス全部が動かなくなる事態を回避したかった (何故かわかるよね) と言われています。インタフェースの設計が完全でなかったということでしょうか。デフォルトメソッドについては授業で触れないので、独習して下さい。
ソースコード 3.79 InterfaceExample3.java (デフォルトメソッド)
package section0310;
public class InterfaceExample3 {
public static void main(String[] args) {
// インタフェースを1つ実装TestClass tc = new TestClass();
tc.hello();
// 2つのインタフェースを実装し、メソッドをオーバーライドTestClass2 tc2 = new TestClass2();
tc2.hello();
// 2つのインタフェースを実装し、片方のメソッドをそのまま使用TestClass3 tc3 = new TestClass3();
tc3.hello();
}
}
interface Interface1 { // 具象メソッドありのインタフェース1// インタフェースに中身のあるメソッドを定義する場合、頭に default を付けるdefault void hello() { System.out.println( "Hello interface1" ); }
}
interface Interface2 { // 具象メソッドありのインタフェース2default void hello() { System.out.println( "Hello interface2" ); }
}
class TestClass implements Interface1 { }
class TestClass2 implements Interface1, Interface2 {
@Override
public void hello() { System.out.println( "Hello TestClass2" ); }

210 第 3章 Java 言語の基本的な文法 II
}
class TestClass3 implements Interface1, Interface2 {
// インタフェース名.super.メソッド名 としていずれのメソッドを使うかを示す@Override
public void hello() { Interface1.super.hello(); }
}
この例には載せていませんが、インタフェースは static なメソッドも利用できるようになりました。クラスでは無いので、「クラスメソッド」とは言いませんが (何というのかな?インタフェースの static メソッドですかね)。これも独習してね。
3.11 ジェネリクス3.11.1 ラッパークラス
ジェネリクスという機能を説明する前に、各基本型に対応して存在するラッパークラス (wrapper class) というクラスについて説明します。ラッパークラスは、基本型の値をオブジェクト化するために作られたクラスで、8 つの基本型全てに対応して存在します (表 3.11.1 参照)。
表 3.11.1 基本型とそのラッパークラス
基本形 byte short int long float double boolean char
ラッパークラス Byte Short Integer Long Float Double Boolean Character
例えば int x = 123; と宣言したとき、変数 x は値を持っているだけで機能(メソッド)はありません。整数に追加属性や機能を与えよう!というのがラッパークラスです。実は、既にラッパークラスについて少しだけ学んでいるんですね。int 型の変数に代入できる最大値として Integer.MAX_VALUE というが出てきました。これは int 型のラッパークラスである Integer クラスが持つクラス定数 MAX_VALUE を利用しているのです。Integer クラスを例にして、フィールドやメソッドをあげてみましょう (表 3.11.2 参照)。なお、アクセス制限はいずれも public です。Integer クラスのインスタンスを作るには、コンストラクタに値を渡して作ります (Integer wrapInt = new
Integer(123);)。これによって、整数値 123 を持つ Integer 型インスタンスが出来上がります。このインスタンスに格納した整数値を取り出すときはメソッド intValue() を使います (int i = wrapInt.intValue();)。面倒だな!と思いますが、この後で説明するジェネリクスや Java API の利用においてラッパークラスは本領を発揮してくれます。
問題 3.11.1. 以下のプログラムの結果を吟味しなさい。
ソースコード 3.80 IntegerExample.java (Integer クラスのインスタンス比較)
package section0311;
public class IntegerExample {
public static void main(String[] args) {
Integer value1 = new Integer( 100 );
Integer value2 = new Integer( "100" );
System.out.println( value1.intValue() == value2.intValue()?"等しい":"等しくない");
System.out.println( value1 == value2 ? "等しい":"等しくない" );
System.out.println( value1.compareTo( value2 ) == 0 ? "等しい":"等しくない" );

3.11 ジェネリクス 211
表 3.11.2 Integer クラス
フィールドstatic int MAX_VALUE int 型での最大値 231 − 1 を保持する定数static int MIN_VALUE int 型での最小値 −231 を保持する定数
コンストラクタInteger(int) 引数の整数値を表わす Integer インスタンスを作るInteger(String) 引数の文字列が表わす Integer インスタンスを作る
クラスメソッドstatic int compare(int, int) 2つの int 値を数値的に比較するstatic int max(int, int) 2つの int 値の大きい方を返すstatic int min(int, int) 2つの int 値の小さい方を返すstatic int parseInt(String) 引数の文字列を整数値にして返すstatic Integer valueOf(int) 引数の整数値を Integer インスタンスにして返すstatic Integer valueOf(String) 引数の文字列を Integer インスタンスにして返す
インスタンスメソッドint compareTo(Integer) 引数の Integer インスタンスと数値的に比較するboolean equals(Object) 引数の Object インスタンスと比較するint intValue() 値を int の値として返すString toString() 値を文字列にして返す
System.out.println( value1.equals( value2 ) ? "等しい":"等しくない" );
}
}
ところで、基本型においては型の異なる変数間でキャストを用いてデータの移行が可能でした。例えば、double a =
123.; long b = (long) a; のように。しかし、ラッパークラスにおいてはクラス間に継承関係がありません。従って、キャストによるデータ移行、例えば Double a = new Double( 123. ); Long b = (Long) a; は出来ません。その代わりに、各クラスの持つメソッド、例えば Double a = new Double( 123. ); Long b = a.longValue();
でデータを移行します。
3.11.2 オートボクシング
前節で面倒臭いと言いましたが、Java の開発者たちもそう思ったのか、次のような代入を許しています。
Integer v1 = 100; // 定義通りなら、Integer v1 = new Integer( 100 );
int v2 = v1; // 本来なら、int v2 = v1.intValue();
System.out.println( v1.equals( v2 ) ); // 本来なら、v1.equals( new Integer( v2 ) )
期末試験でこんな解答したら減点されそう?と思いきや、コンパイルエラー無しで、しかも出力は true となります。基本型の値をラッパークラスのインスタンスへ直接代入する機能を「オートボクシング (autoboxing)」、その逆のラッパークラスのインスタンスを基本型変数に直接代入する機能を「オートアンボクシング (autounboxing)」とい言

212 第 3章 Java 言語の基本的な文法 II
います。基本型とラッパークラスの間の行き来をコンパイラが自動変換してくれているのです。
問題 3.11.2. 問題 3.11.1 のプログラムにおける2つ目の代入文をオートボクシングを利用して Integer value2 =
100; と書き換えて、上手くいくことを確かめなさい。
3.11.3 ジェネリクス
次のプログラムは、何でも入れられる?箱 Box0 クラスを定義しているプログラムです。コンストラクタの引数に整数・文字列・実数のいずれかを入れて箱を作り、対応するゲッタを用いて格納したデータを取り出しています。
ソースコード 3.81 BoxExample0.java (何でも入れられる箱0)
package section0311;
public class BoxExample0 {
public static void main(String[] args) {
Box0 intBox = new Box0( 123 );
int n = intBox.getInt();
System.out.println( n );
Box0 strBox = new Box0( "Hello" );
String hello = strBox.getStr();
System.out.println( hello );
Box0 dblBox = new Box0( 12.3 );
double m = dblBox.getDbl();
System.out.println( m );
}
}
class Box0 {
int intValue;
String strValue;
double dblValue;
Box0( int value ) { this.intValue = value; }
Box0( String value ) { this.strValue = value; }
Box0( double value ) { this.dblValue = value; }
int getInt() { return intValue; }
String getStr() {return strValue; }
double getDbl() {return dblValue; }
}
見てわかるように、データの種類分のフィールド・コンストラクタ・ゲッタメソッドが用意されています。一方、次のプログラムは箱に入れられるデータを Object 型データとそのサブクラスとし、Integer・String・
Double 型のインスタンスを代入して取り出しています。こうすることで、フィールド・コンストラクタ・ゲッタは 1
つで済むようになりました。ただし、メソッド get() で取り出されるデータは必ず Object 型のデータなので、もとの基本型に戻すためキャストしなければいけません (なお、その際に先に説明したオートアンボクシング、ラッパークラスのインスタンスを基本型に変換、が使われています)。
ソースコード 3.82 BoxExample1.java (何でも入れられる箱1)
package section0311;

3.11 ジェネリクス 213
public class BoxExample1 {
public static void main(String[] args) {
Box1 intBox = new Box1( new Integer(123) );
int n = (Integer) intBox.get();
System.out.println( n );
Box1 strBox = new Box1( "Hello" );
String hello = (String) strBox.get();
System.out.println( hello );
Box1 dblBox = new Box1( new Double(12.3) );
int m = (Integer) dblBox.get();
System.out.println( m );
}
}
class Box1 {
Object obj;
Box1( Object obj ) { this.obj = obj; }
Object get() { return obj; }
}
ところで、このプログラムコンパイルエラーは表示されませんが、実行すると実行エラーが表示されます。短いプログラムなので、すぐおかしなところに気付き、修正(double m = (Double) dblBox.get(); )できますが、もし、巨大なプログラム中で代入と取り出しが遠く離れていたとすると、問題の特定にかなり苦労することになるでしょう。で、この問題の解決策として Java 5 で導入されたのが ジェネリクス (generics) です。ジェネリクスは、クラスに「型パラメータ (type parameter)」という型情報を付けることで「コンパイル時の型キャストを省略しながら、プログラムの安全性と簡潔性を高める」機能です。
3.11.4 パラメータ化された型
まず、以下に出てくる用語をあげておきましょう (表 3.11.3 参照)。
表 3.11.3 ジェネリクスの用語
用語 例ジェネリック型 (generic type:総称型) List<E>
型パラメータ (type parameter), 型変数 (type variable) <E>
パラメータ化された型 (parameterized type) List<String>
原型 (raw type) List
実型パラメータ (actual type parameter), 実型変数 <String>
境界型パラメータ (bounded type parameter) <E extends Number>
非境界ワイルドカード型 (unbounded wildcard type) List<?>
上限境界ワイルドカード型 (upper bounded wildcard type) List<? extends Number>
下限境界ワイルドカード型 (lower bounded wildcard type) List<? super Number>
さて、先のプログラム 3.82 の問題点は「何でも入れることができるけれど、取り出すときに元の型にキャストしなければならない」でした。キャストが間違っていてもコンパイルエラーが表示されず、実行させて初めて Integer 型にキャストできないという実行時エラーが発生しました。こうした状況を「コンパイル時にタイプセーフ (type safe)

214 第 3章 Java 言語の基本的な文法 II
でない」と言います。そこで、Java 5 で登場したのがジェネリクスです。次のジェネリクス導入後のプログラム 3.83
では、ちゃんと?コンパイルエラーが表示されます。コンパイラが誤ったキャストを検知してくれたのです。
ソースコード 3.83 BoxExample2.java (何でも入れられる箱2)
package section0311;
public class BoxExample2 {
public static void main(String[] args) {
Box<Integer> intBox = new Box<Integer>( 123 );
int n = (Integer) intBox.get();
System.out.println( n );
Box<String> strBox = new Box<String>( "Hello" );
String hello = (String) strBox.get();
System.out.println( hello );
Box<Double> dblBox = new Box<Double>( 12.3 );
int m = (Integer) dblBox.get();
System.out.println( m );
}
}
class Box<E> {
E e;
Box( E e ) { this.e = e; }
E get() { return e; }
}
クラス Box においてクラス名の後ろに付いている <E> が型パラメータ (型変数とも言う) で、このパラメータに設定するクラスでその箱に入れることの出来る型を限定します。つまり、new Box<Integer> で作成されるインスタンスは、Integer インスタンスを格納できる箱となります。従って、Box<Integer> intBox = new Box<Integer>(
new Integer( 123 ) ); は整数用の箱に整数データを格納します。なお、オートボクシングの機能を使って引数を123 に変えているのが上のプログラムです。型パラメータを用いたおかげで、代入されるデータを限定できるため、取り出しの際のキャストが間違っていれば、コンパイラは文法エラーとして指摘することが出来るようになります。ついでに、コンパイラにはもっと仕事をしてもらえるようになりました。
ソースコード 3.84 改 BoxExample2.java (何でも入れられる箱2)
package section0311;
public class BoxExample2 {
public static void main(String[] args) {
Box<Integer> intBox = new Box<>( 123 );
int n = intBox.get();
System.out.println( n );
Box<String> strBox = new Box<>( "Hello" );
String hello = strBox.get();
System.out.println( hello );
Box<Double> dblBox = new Box<>( 12.3 );
double m = dblBox.get();
System.out.println( m );
}
}

3.11 ジェネリクス 215
// class Box は省略
Box<Integer> intBox = new Box<>( 123 ); という代入文の左辺のパラメータ Integer と右辺の引数の値 123
から作成する箱インスタンスのパラメータをコンパイラが推論できるとして、コンストラクタの実型パラメータを省略することができます (参照変数の型パラメータまでは省略できません)。また、Box<Integer> 型の箱に入れられたデータは Integer 型のインスタンスと決まるので、取り出しの際、キャストも省略されています。これらのお陰で、まるで基本型データを直接箱に入れて直接取り出しているようなプログラムの完成です。ただし、1つ注意しなければならないことがあります。ラッパークラスはあくまで参照型クラスですから、参照先が無い (値が null) という場合があります。例えば、上のプログラムで Box2<Integer> intBox = null; とすると、コンパイルエラーでは無く、null ポインタ・アクセスの注意が表示されるだけです。その場合、実行させると基本型への代入ができずに NullPointerException の例外が発生してしまいます。このことは、あまり教科書に書かれていません。さて、Box クラスの方を読み解きましょう。クラスの型パラメータを <E> としています。
ソースコード 3.85 型パラメータ付き Box
class Box<E> {
E e;
Box( E e ) {
this.e = e;
}
E get() {
return e;
}
}
一旦、コンパイラによって class ファイルに変換されたものを逆にソースコードに戻すことを逆コンパイルと言います。コンパイラが変換したものは、最適化などが行われるので、必ずしも元のソースコードには戻りませんが、コンパイラがどんな変換をしているのかを知るのにも逆コンパイルという変換をしてみるのも Eclipse に逆コンパイラのプラグインを導入すると (後で自分で調べて Eclipse に導入してみて下さい)、BoxExample2.java は次のように解釈されていることがわかります。
ソースコード 3.86 BoxExample2.java (逆コンパイラの結果)
package section0311;
import section0311.Box;
public class BoxExample2 {
public static void main(String[] args) {
Box2 ibox = new Box2(Integer.valueOf(123));
int n = ((Integer)ibox.get()).intValue();
System.out.println(n);
Box2 strbox = new Box2("Hello");
String hello = (String)strbox.get();
System.out.println(m);
Box2 dblbox = new Box2(Double.valueOf(12.3D));
double m = ((Double)dblbox.get()).doubleValue();
System.out.println(hello);

216 第 3章 Java 言語の基本的な文法 II
}
}
}
class Box2 {
Object e;
Box2( Object e ) {
this.e = e;
}
Object get() {
return e;
}
}
コンパイラは、型パラメータを捨て去った代わりに、それぞれの代入と取り出しで正しいキャストや変換を添加したプログラムに翻訳しています。一方、Box2 の方は、型パラメータ部分が消去されスーパークラスである Object 型で統一されています。なお、C++でも総称型プログラムが作れますが、その場合はパラメータに代入される型の数だけクラスが生成されます (つまり、 Integer 用・String 用・Double 用と複数の Box2 クラスができるわけです (Java の方がエコですかね)。ジェネリクスはコンパイル時のみ機能するものであって、実行時には型パラメータの型情報を全て捨て去った原型で実行される というわけで、コンパイラにこうした翻訳を行わせるための仕組みがジェネリクスです。以上を踏まえて、型パラメータにおける注意点をあげておきましょう。
[注意 1] 型パラメータに対して、基本データ型を指定できない=⇒ Box<int> box とかが出来ないということです。Object インスタンスに変換できないですからね
[注意 2] 型パラメータのインスタンスを直接生成できない=⇒ E e = new E() が出来ないということです。 これは次の節で解説します
[注意 3] 型パラメータの配列を直接生成できない=⇒ E[] e = new E[10] が出来ないということです。これも次の節で解説します
[注意 4] メソッドの戻り値として型パラメータの配列を返しても Object の配列となる[注意 5] 型パラメータは static メンバーと static 初期化子には適用できない
=⇒ static なメンバーはクラス内に1つしかないからです。[注意 6] コンパイル後 (型パラメータの削除後) にシグネチャ (見た目) が同じになるメソッドは定義できない
問題 3.11.3. 次のようなパラメータ付き例外の catch 節が指定できないことを考察せよ。
try {
//
} catch( MyException<String> e ) {
//
} catch( MyException<Integer> e ) {
//
}

3.11 ジェネリクス 217
3.11.5 型パラメータ付きインスタンス・配列の生成不可
注意の2と3を次のプログラムで見てみましょう。このプログラムは、Integer を入れられる箱・Integer インスタンスそのもの・Integer インスタンスの配列を生成してくれる Create というクラスを定義しようとしています。このプログラムでは、型パラメータの付いた intBox は生成できていますが、コメントで殺してあるところ (型パラメータでのインスタンスや配列の生成) を活かすとコンパイラがエラーを出します。なお、ここでは型パラメータに E ではなく T (クラスの型 Type の意味で) を使っています。型パラメータの名前はクラス名と同じ命名規則が許されていて、本来何を使っても良いのですが、慣例的に E (Element) 、T (Type) やその次の S、そして K (Key) や V (Value) などが使われます。
ソースコード 3.87 CreateEtCetraExample.java (型パラメータ付き配列など
package section0311;
public class CreateEtCetraExample {
@SuppressWarnings("unused")
public static void main(String[] args) {
Create<Integer> cint = new Create<Integer>();
Box2<Integer> intBox = cint.makeBox(100);
// Integer i = cint.makeT();
// Integer[] intArray = cint.makeArray(10);
}
}
class Create<T> {
Box2<T> makeBox(T e) {
return new Box2<T>(e);
}
/*
T makeT() {
return new T(null);
}
T[] makeArray(int n) {
return new T[n];
}
*/
}
コンパイルは文法エラーをチェックした後に、型パラメータを消去したプログラムに変換するんでしたね。Createクラスがどのようにコンパイルされるか考えてみて下さい。まず Box2<T> makeBox(T e)は、Box2 makeBox(Object
e) とコンパイラが変換し、問題ありません。では、T makeT() の場合はどうでしょう。これは Object makeT() となります。従って、もしコンパイルが成功したとしても cint.make() は Object 型のインスタンスを返して来ますので、Integer i に直接代入できません。同様に、 T[] makeArray(int n) の場合も返されるのは Object[] でInteger[] に直接代入できません。よって、型パラメータを使ってはインスタンスや配列の生成はできない、というわけです。
3.11.6 ワイルドカード型
Integer は Object のサブクラスであるので、 Integer の配列は、 Object の配列と見ることはできます。ただし、次のプログラムでコメントで殺している行を活かすとコンパイルエラーは出ませんが (問題ですね)、実行エラーArrayStoreException が発生します。

218 第 3章 Java 言語の基本的な文法 II
ソースコード 3.88 IntegersToObjects.java (Integerの配列は Object の配列でもある)
package section0311;
import java.util.Arrays;
public class IntegersToObjects {
public static void main(String[] args) {
Integer[] integers = {1, 2, 3};
Object[] objects = integers;
objects[0] = 1.23;
System.out.println( Arrays.toString( objects ) );
String[] strings = {"a", "b", "c"};
objects = strings;
System.out.println( Arrays.toString( objects ) );
}
}
一方、次のプログラムはコメントで殺した行を活かすといずれもコンパイルエラーになります。Integer は Object
のサブクラスですが、Box<Integer> は Box<Object> のサブクラスでは無いわけです。
package section0311;
public class BoxExample4 {
public static void main(String[] args) {
Box<Object> box = new Box<Object>(null);
// box = new Box<Integer>( 100 );
// System.out.println( box.get() );
// box = new Box<String>( "Hello" );
System.out.println( box.get() );
}
}
このように、 Box<Integer> と Box<String> のいずれも吸収するような箱は Box<Object> では無いので、ではどうしましょう。このとき使われるのが、「ワイルドカード型 (wildcard type)」です。
package section0311;
public class BoxExample4 {
public static void main(String[] args) {
Box<?> box = null;
box = new Box<Integer>( 100 );
System.out.println( box.get() );
box = new Box<String>( "Hello" );
System.out.println( box.get() );
}
}
ワイルドカード型では、型パラメータに?を書きます。Box<?> とすることで、型パラメータを特定しないままの箱が生成できるので、どんな型パラメータの箱でも代入できるようになります。ただし、このままでは代入できるものの限定ができませんから、せっかくのジェネリクスが生かされません。そこで、「境界ワイルドカード型」を用いて次のように書きます。
ソースコード 3.89 IntegersToObjects3.java (境界ワイルドカード型の例)
package section0311;
public class IntegersToObjects3 {
public static void main(String[] args) {
NBox<? extends Number> nbox = null;

3.11 ジェネリクス 219
nbox = new NBox<Integer>( 100 );
System.out.println( nbox.get() );
nbox = new NBox<Double>( 12.34 );
System.out.println( nbox.get() );
// nbox = new NBox<String>( "abc" );
}
}
class NBox<E extends Number> {
E e;
NBox( E e ) {
this.e = e;
}
E get() {
return e;
}
}
ここでは、整数や実数のスーパークラスである Number クラスを利用して、 Number クラスを継承する ( Number クラスのサブクラスの) データを格納できる箱を作っています。コメントで殺した行を活かすとコンパイルエラーになります。文字列は Number クラスのサブクラスでは無いからですね。ところで、コメントで殺した行の上に次の命令を入れても、残念ながらコンパイルエラーが起きないことを確かめて下さい。ワイルドカードにすると、やっぱりこうした問題は発生するわけです。
int n = (Integer) nbox.get();
System.out.println( n );
3.11.7 Generic なメソッド
クラスだけでなく、メソッドをジェネリクス化することができます。次のプログラムでは、どんな型の配列でも要素交換ができるメソッド swap を与えています。
ソースコード 3.90 GenericMethod.java (Generic method の例)
package section0311;
import java.util.Arrays;
public class GenericMethod {
public static void main(String[] args) {
String[] s = {"a", "b", "c"};
swap(s,1,2);
System.out.println( Arrays.toString( s ) );
Integer[] i = {1, 2, 3};
swap(i,1,2);
System.out.println( Arrays.toString( i ) );
Object[] o = {new Integer(10), "a", new Long(0)};
swap(o,1,2);
System.out.println( Arrays.toString( o ) );
}
static <T> void swap(T[] array, int i, int j) {
T temp = array[i];
array[i] = array[j];
array[j] = temp;
}
}

220 第 3章 Java 言語の基本的な文法 II
メソッドをジェネリクス化するには、戻り値 (今回は void) の前に型パラメータを書きます。クラスの場合とは違い、利用するときに明示的に型パラメータを指定する必要がありません。 swap<String>( s ); なんてしないで良いわけです。
問題 3.11.4. 任意の型の1次元配列2本を1本にまとめて (ソートする必要はない) 返すクラスメソッド T[]
merge(T[], T[]) を GenericMethod.java に追加しなさい。
3.12 Java API
API (Application Programming Interface) とは、 主に OS が提供する機能をアプリケーションから呼び出せるようにするソフトもしくはソフト群のことです。プログラマーは自分のアプリケーションから API を呼び出すことでOS の機能を利用することができます。Java では JVM に OS の API にあたる機能を持たせているので、Java プログラムは直接 OS の API にアクセスするのではなく、Java クラスライブラリを経由して利用することになります。便利なクラスやインタフェースの集合体であるこのライブラリのことを Java API と呼びます。Java API の中心となる標準ライブラリは「rt.jar」という zip 形式で圧縮されたファイルに入っています。Eclipse のパッケージ・エクスプローラ-で、Java プロジェクト中の「JREシステム・ライブラリー」を開けると、中に rt.jar が入っているのがわかります。中を除くと、知ったクラスの名前が並んでいるかと思います。Java API を使う利点は、
• よく精査されていて、信頼できること• 簡単で便利な機能が揃っていること• 世界中の人が利用していて、機能の共有が容易なこと
です。ここでは、いわゆる「データ構造」を実現する Collection グループについて見ていきます。
3.12.1 Collection 系データ構造
これまで、複数のデータを扱うには配列を用いてきました。学生データ処理を行いたいなら、学生の配列 Student[]
students = new Student[100]; と宣言しました。ただし、配列はメソッドなどを持つことが出来ませんから、学籍番号で並び替えのような操作を students.idNoSort(); のような書き方で行うことはできません (たぶん Student
クラス内にクラスメソッド sort() を置いて、Student.idNoSort( students ); なんてするのかな)。つまり、配列は低水準なデータ構造なのです。そこで配列の代わりに使うのが、Java API の java.util パッケージ内にある Collection インタフェースとその
継承インタフェース及び実装クラスです。以下の図 3.14 は、その代表的なものの継承・実装関係を表しています。緑色がインタフェース、青色がそれらを実装したクラスです。
Collection の仲間は、3 系統のデータ構造に分けることができます。
• リスト・配列構造 (List インタフェースとその実装クラス)
• キュー構造 (Queue インタフェースとその実装クラス)
• 集合・木構造 (Set インタフェースとその実装クラス)
この「実装クラス」とはそのクラスが実装しているインタフェースの抽象メソッドが既に実装済みの (具象) クラスを

3.12 Java API 221
<<interface>>
Collection
<<interface>>
List
<<interface>>
Queue
<<interface>>
Set
TreeSet
ArrayList LinkedListStack<<interface>>
SortedSetHashSet
LinkedHashSet<<interface>>
NavigableSet
実装 : implements
継承 : extends
PriorityQueue
図 3.14 Collection インタフェースの仲間
意味します。例えば、 ArrayList クラス内には、 List インタフェースの抽象メソッドが既に出来上がっているので、ユーザが新たにオーバーライドする必要がありません。これらのクラス・インタフェースを使用すると、配列ではキレイに書けなかったプログラムがスッキリと書けるようになります。以下で、これら実装クラスの幾つかを見ていきます。
図 3.15 型パラメータ付き ArrayList クラス

222 第 3章 Java 言語の基本的な文法 II
なお、知っておくと良いデータ構造で、 Collection インタフェースを実装したものでない Map や SortedMap クラスがあります。これらはデータがキーと値の対でなっているもので、データの検索をキーの値で行うものです。例えば、会員番号と会員情報のような関係ですね。これは、自分で勉強してみて下さい。
3.12.2 ArrayList
List インタフェースの実装クラス ArrayList は、これまで学んできた配列の高機能版にあたります。その大きな特徴は、宣言時に配列の大きさを宣言することなく定義でき、要素数の変化に合わせて自動的に大きさが増減してくれることです。ArrayList をデフォルトコンストラクタで宣言すると配列の大きさはデフォルトの 10 になります。そして、格納要素数がそれを超えるとき、自動的にその時点の配列の大きさの 1.5 倍程度に拡張してくれるのです。List インタフェースに定義された抽象メソッドが全て実装されて (中身が与えられて) いるので、それらメソッドを用いてデータ処理を行うことになります。配列と違い、基本的な操作が全てメソッドによって行われます。ということで、最初は少々面倒臭いと感じますが、Java でデータ処理を行うならこちらを利用するのが正解です。
ソースコード 3.91 ArrayListExample.java (ArrayList クラスの例題)
package section0311;
import java.util.List;
import java.util.ArrayList;
import java.util.Comparator;
public class ArrayListExample {
public static void main(String[] args) {
List<Integer> list = new ArrayList<Integer>(); // 整数を格納する配列を宣言するlist.add( new Integer(10) ); // 整数 10 を追加するlist.add( new Integer("20") ); // Integer のコンストラクタでは文字列も OK
list.add( 30 ); // オートボクシングのおかげで int 型も直接代入できるlist.add( 2, 40 ); // list の [2]番要素として 40 を挿入 (30 が後ろにずれる)
System.out.println( "ArrayList 現在のデータ数:" + list.size() );
System.out.println( list.toString() );
list.sort( Comparator.naturalOrder() ); // 数値の昇順で並び替えが行われるSystem.out.println( list.toString() );
list.remove(1); // array の [1]番要素を削除 (後から詰められる)
System.out.println( list.toString() );
}
}
このプログラムでは、整数値のリスト ArrayList<Integer> を作っています。クラス ArrayList のメソッドはインタフェース List の実装メソッドなので、変数 list は List インタフェースの変数として宣言しています。ArrayList のコンストラクタの引数に整数値を入れることで、初期リストの大きさが与えられます。例えば、ArrayList<Point> points = new ArrayList<Point>(100); なら 100 個分の領域を最初から確保してくれるわけです 。このプログラムのようなデフォルトコンストラクタなら 10 個分になります。大量のデータの入るリストを作りたいとき、初期値を多めに取っておけば、途中で 1.5 倍に拡張する手間が減るのでプログラムの処理時間が減りますね。以下に ArrayList の主なメソッドを表にします (表 3.12.1 参照)。ところで、このプログラムでは、データを1つ1つ add メソッドで追加していますが、配列とかを用いて一度にデータを設定する方法はあるのでしょうか。それは Arrays クラスのクラスメソッド asList を使って次のようにします。
ソースコード 3.92 ArrayListExample2.java (整数配列を ArrayListに変換)
package section0312;
import java.util.ArrayList;
import java.util.Arrays;

3.12 Java API 223
表 3.12.1 ArrayList<E> クラス (E は型パラメータ)
コンストラクタArrayList() 初期容量 10 の空リストを作るArrayList(int) 与えられた初期容量の空リストを作る
インスタンスメソッドboolean add(E) リストの最後に引数の要素を追加するvoid add(int, E) 第1引数の位置に第2引数の要素を挿入するvoid clear() リストから全ての要素を削除するObject clone() インスタンスのシャローコピーを作るE get(int) リスト内の指定位置の要素を返すint indexOf(Object) リスト内で指定された要素が最初に見つかった位置を返すboolean isEmpty() リストに要素がない場合に true を返すboolean remove(Object) 指定された要素があったらその最初のものを削除するE remove(int) 指定された位置の要素を取り出すE set(int, E) 第1引数の位置の要素を取り出し、第2引数の要素に置き換えるint size() リスト内の要素数を返すvoid sort(Comparator<? super E>) 指定した比較子を利用して要素を並び替えるObject[] toArray() リスト内の要素を配列にして返す
public class ArrayListExample2 {
public static void main(String[] args) {
// オートボクシングにより int 配列から Integer 配列へInteger[] intArray = { 10, 20, 30, 40 };
ArrayList<Integer> intList =
new ArrayList<Integer> (Arrays.asList( intArray ) );
intList.add(2, 50);
System.out.println( intList.toString() );
}
}
問題 3.12.1. もし、 List<Integer> や List<Double> が List<Number> のサブクラスで無いことは先に説明したが、もしサブクラスであったら、 list.add( new Double(12.3) ) という処理が可能になってしまう。
Comparable と Comparator
ここでは、ソースコード 3.91 でデータの並び替えで使われた Comparator.naturalOrder メソッドを説明します。2つのオブジェクト間に何らかの順序付けしたいとき、Javaでは 2つのインターフェース Comparableと Comparator
が利用できます。java.lang.Comparable<T> インタフェースは int compareTo(T) メソッドだけからなるインタフェースで、このメソッドをオーバーライドして実装させることでオブジェクトに比較ルールを与えることになります。compareTo(T)
メソッドは、自身と引数のオブジェクトの比較によって −1, 0, 1 の 3 つの整数のいずれかを返すインスタンスメソッ

224 第 3章 Java 言語の基本的な文法 II
ドです。与える順序において、自身が引数のオブジェクトより順序位数が小さいとき −1 を返し、大きいとき 1 を、等しいとき 0 を返すようにします。
ソースコード 3.93 Point.java (Comparable を実装した平面の点クラス)
package section0312;
/**
* 2次元空間の点 (原点からの距離で順序を設定) を表すクラス*/
class Point implements Comparable<Point> {
/** 点の x 座標 */
double x;
/** 点の y 座標 */
double y;
Point( double x, double y ) {
this.x = x;
this.y = y;
}
/** 点情報を文字列化する */
@Override
public String toString() {
return String.format( "(%4.1f,%4.1f)", this.x, this.y );
}
/**
* 原点からの距離を返す* @return その点の原点からの距離 (実数)
*/
double dist() {
return Math.sqrt( x*x + y*y );
}
/**
* 原点からの距離で比較し、結果を整数値 (-1,0,1 のいずれか) で返す* @return 自身の距離と引数の点の距離で比較し、<br>
* 自身の距離 < 引数の点の距離 → -1,<br>
* 自身の距離 = 引数の点の距離 → 0,<br>
* 自身の距離 > 引数の点の距離 → 1 を返す*/
@Override
public int compareTo(Point other) {
double thisDist = this.dist();
double otherDist = other.dist();
if( thisDist > otherDist ) return 1;
else if( thisDist < otherDist ) return -1;
else return 0;
}
}
このクラスを使って、Point 配列のソートを行うには、 Arrays.sort メソッドを使います。
package section0312;
import java.util.Arrays;
public class ComparableExample {
public static void main(String[] args) {
Point[] points = {
new Point( 1, 3), new Point( 2, 2),
new Point(-2, 1), new Point( 4, 0),

3.12 Java API 225
new Point( 1,-1), new Point( 0, 3),
new Point( 3, 2)
};
Arrays.sort( points );
for(Point point : points) {
System.out.print( point.toString() + " " );
}
System.out.println();
}
}
同様に、 Point 型 List のソートを行うには、 Collections.sort メソッドを使えばOKです。
package section0312;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
public class ComparableExample2 {
public static void main(String[] args) {
List<Point> points = new ArrayList<Point>(
Arrays.asList( new Point[]{
new Point( 1, 3), new Point( 2, 2),
new Point(-2, 1), new Point( 4, 0),
new Point( 1,-1), new Point( 0, 3),
new Point( 3, 2) }
)
);
Collections.sort( points );
for(Point point : points) {
System.out.print( point.toString() + " " );
}
System.out.println();
}
}
Comparable インタフェースは、オブジェクト自身に比較ルールを実装させるときに利用します。一方、java.util.Comparator<T> インタフェースは、 compare(T o1, T o2) という static メソッドが抽象メソッドとして定義されていて、これをオーバーライドして使い、外からオブジェクト同士の比較ルールを適用する方法です。
package section0312;
import java.util.Arrays;
import java.util.Comparator;
public class ComparatorExample {
public static void main(String[] args) {
Point[] points = {
new Point( 1, 3), new Point( 2, 2),
new Point(-2, 1), new Point( 4, 0),
new Point( 1,-1), new Point( 0, 3),
new Point( 3, 2)
};
Arrays.sort( points, new PointComparator() );
for(Point point : points) {
System.out.print( point.toString() + " " );
}

226 第 3章 Java 言語の基本的な文法 II
System.out.println();
}
}
class PointComparator implements Comparator<Point> {
@Override
public int compare(Point p, Point q) {
double pdist = p.dist();
double qdist = q.dist();
if( pdist > qdist ) return -1;
else if( pdist < qdist ) return 1;
else return 0;
}
}
既に Point クラスに与えている順序 (原点から近い順) とは別に原点から遠い順を Comparator<Point> を実装したクラス PointComparator を別に作り、そのインスタンスを並び替えメソッドのパラメータに与えています。先のプログラム ArrayListExample.javaでは、まず List系のクラスが持っている sort()メソッドを利用しています。sort() メソッドは、引数に Comparator を与えて利用します。そこで、 Comparator.naturalOrder() を引数に与えています。これは Comparator インタフェースが持つ static メソッド naturalOrder() で、並び替えしようとしているオブジェクトが既に Comparable インタフェースを実装している場合に、その自然な順序の Comparator
を作成するメソッドです。つまり、List の中身が Integer で、 Integer クラスには、値の大小関係で比較できるように Comparable インタフェースが既に実装されており、それを利用しなさいという意味です。(なお、インタフェースが静的なメソッドを持てるようになったのは Java 8 からなので、それより前のコンパイラではエラーになります)
問題 3.12.2. プログラム ComparableExample2.java の Collections.sort( points ); の行をComparator.naturalOrder() を利用した命令に書き換えてみよ。また、自然順序の逆順コンパレータを与えるメソッド Comparator.reverseOrder() を利用して逆順に並べてもみよ。
問題 3.12.3. 氏名 (String)・身長 (double)・体重 (double) の 3 つのフィールドを持つ Person クラスのインスタンス配列 pienuts が以下のようにあるとして、これを身長の高い順&体重の重い順で並び替えて出力するプログラムBodyMeasurement.javaを作りなさい。並び替えは Comparator インタフェースを実装した BodyComparator クラスを作って、 Array.sort( pienuts, new BodyComparator() ) で行うこと。 なお、以下のデータはデタラメに作りました。
Person[] pienuts = {
new Person("Snoopy", 80.0, 15.5),
new Person("Charlie", 140.0, 35.5),
new Person("Linus", 140.0, 32.0),
new Person("Sally", 135.0, 26.5),
new Person("Lucy", 142.0, 30.5),
new Person("Schroeder", 142.0, 31.0),
new Person("Peppermint", 144.0, 33.5),
new Person("Marcie", 135.0, 29.5)
};

3.12 Java API 227
Comparator は、Java 8 で導入された関数合成・メソッド参照などを利用することで、ここで説明した書き方とは格段の容易さで利用できるようになりました。それはこのテキストでは解説しないので、各自調べてみて下さい。と言いながら、次のプログラムは、以前抽象クラスの勉強の際に作った図形クラスの配列をリスト形式にし、更に面
積の小さい順に並び替えするプログラムですが、Comparator の部分に、「メソッド参照」を用いてみました。この部分、和田もまだ勉強中で上手く説明できないので、説明はなし! (^_^;)
ソースコード 3.94 ShapesExample.java (図形リストで並び替え)
package section0311;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
public class ShapesExample {
public static void main(String[] args) {
List<Shape> shapes = new ArrayList<Shape>();
shapes.add( new Circle( 1.2 ) );
shapes.add( new Square( 1.5, 2.4 ) );
shapes.add( new Trapezoid( 1.2, 3.0, 2.5 ) );
// メソッド参照を用いて面積の昇順で図形の並び替えshapes.sort( Comparator.comparing(Shape::getArea) );
for( Shape shape : shapes ) {
shape.printArea();
}
}
}
// 抽象クラス「面積を求めることのできる図形」abstract class Shape {
String name; // 図形の名前Shape( String name ) { // コンストラクタ
this.name = name;
}
abstract double getArea(); // 抽象メソッド:メソッドブロックが無い代わりにセミコロンvoid printArea() { // 図形の情報を出力するメソッド
System.out.printf( "%sの面積は、%8.5f%n", this.name, this.getArea() );
}
}
// 具象クラス:円class Circle extends Shape {
double radius;
Circle( double radius ) {
super( "円" );
this.radius = radius;
}
@Override
double getArea() { // 抽象メソッドをオーバーライドreturn radius * radius * Math.PI;
}
}
// 具象クラス:長方形class Square extends Shape {
double height;
double width;
Square( double height, double width ) {
super( "長方形" );

228 第 3章 Java 言語の基本的な文法 II
this.height = height;
this.width = width;
}
@Override
double getArea() { // 抽象メソッドをオーバーライドreturn height * width;
}
}
// 具象クラス:台形class Trapezoid extends Shape {
double upper;
double lower;
double height;
Trapezoid( double upper, double lower, double height ) {
super( "台形" );
this.upper = upper;
this.lower = lower;
this.height = height;
}
@Override
double getArea() { // 抽象メソッドをオーバーライドreturn ( upper + lower ) * height / 2;
}
}
3.12.3 LinkedList
ArrayList と同じくよく利用されるインタフェース List の実装クラスが LinkedList クラスです。ArrayList
がいわゆる配列の拡張で連続した領域に要素を格納するのに対し (従って、連続領域が無いとそれを確保するため少々時間が掛かる) 、LinkedList は、各要素がメモリ内の空き領域に飛び飛びに格納され、但し、各要素はそれぞれ前後の要素へのリンク (それぞれのアドレス) を持っているような構造です (図 3.16 参照)。つまり、連続領域確保をしなくて良い代わりに余分なリンク容量が必要というデータ構造です。
10 3020
list
40
10 3020
list
図 3.16 LinkedList への要素挿入

3.12 Java API 229
ArrayList と LinkedList を比較すると:
• リストの 100 番目の要素に到達するには、– ArrayList は、データの大きさ ×100 個分先のアドレス!といった計算で一気に到達する– LinkedList は、最初の要素から順にリンクをたどっていかないといけない
• リストの 100 番目への要素の挿入や削除は、– ArrayList は、101 番目以降の要素を1つずつ後へシフトさせて空き場所を作成した後に要素を挿入する。1つずつ前へシフトして削除となる
– LinkedList は、99 番目と 101 番目のポインタを書き換えるだけで済む (図 3.16 参照)
ソースコード 3.95 LinkedListExample.java (LinkedList クラスの例題)
package section0311;
import java.util.List;
import java.util.LinkedList;
import java.util.Comparator;
public class LinkedListExample {
public static void main(String[] args) {
List<Integer> list = new LinkedList<Integer>();
list.add( new Integer(10) );
list.add( new Integer("20") );
list.add( 30 );
list.add( 2, 40 );
System.out.println( "LinkedList 現在のデータ数:" + list.size() );
System.out.println( list.toString() );
list.sort( Comparator.naturalOrder() );
System.out.println( list.toString() );
list.remove(1);
System.out.println( list.toString() );
}
}
プログラムを見て分かるように、LinkedList のメソッドは ArrayList のメソッドと同じものが使えて、結果も同じです。それは、いずれもインタフェース List が持っているメソッドをそれぞれ自分の構造に合わせてオーバーライドしているおかげですが、行っている処理は大きく異なります。2つのクラスの長所短所をよく理解して目的に応じて使い分けないといけません。
問題 3.12.4. ArrayList と LinkedList に対し、100000 個の実数乱数を格納するに掛かる時間を測定し、またそこから先頭 [0] 番目の要素を 100 回削除するに掛かる時間を測定し、それぞれ比較して、両リストの長所と短所を考察せよ。
3.12.4 Stack と Queue
Stackx (スタック) と Queue (キュー) は対で説明されることが多いので、ここでも一緒に説明します。Stack はLIFO (Last In First Out:後入れ先出し) な構造で、Queue は FIFO (First In First Out:先入れ先出し) な構造である!と言います。言葉で言うより、以下の図のような構造を実現するものだと言ったほうが分かりやすいかな (図 3.17
参照)。Stack に記憶される要素は最後に追加されたものが取り出されますが、 Queue は別名「待ち行列」と言い、古

230 第 3章 Java 言語の基本的な文法 II
い順に取り出されます。
3
2
1
54
Stack
1
2 3 4
5
Queue
図 3.17 Stack と Queue
表 3.12.2 Stack<E> クラスと Queue<E> インタフェースの特徴的メソッド
Stack のインスタンスメソッドE peek() 先頭のインスタンスをスタックから削除せずに取り出すE pop() 先頭のインスタンスをスタックから削除しながら取り出すE push(E) スタックの先頭にインスタンスを入れる
Queue のインスタンスメソッドE peek() 先頭のインスタンスをキューから削除せずに取り出すE poll() 先頭のインスタンスをキューから削除しながら取り出すboolean offer(E) キューの最後尾にインスタンスを入れる
Java では、Stack は List インタフェースの実装クラスとして定義されていますが、 Queue は List インタフェースとは別のインタフェースとして宣言されていて、Queue の実装クラスとして LinkedList と PriorityQueue があります (図 3.14 参照)。つまり、LinkedList は List としての利用と Queue としての利用の両方ができるということですね。なお、 PriorityQueue は優先度付きキューと言って、キューの構築時に Comparatorによって順序付けがされるので、取り出す際にはその時点で並び替えされた順で取り出すことができるキューです (自分で調べてみて)。以下のプログラムでは、Stack と Queue を用いた整数を要素とするデータ構造を作っています。
ソースコード 3.96 StackQueue.java (Stack と Queue の例題)
package section0311;
import java.util.LinkedList;
import java.util.Queue;
import java.util.Stack;
public class StackQueue {
public static void main(String[] args) {
Stack<Integer> stack = new Stack<Integer>();
stack.push( 100 ); // スタックの先頭に順にデータを挿入stack.push( 200 );
stack.push( 300 );
stack.push( 400 );
System.out.println( "Stackの大きさ:" + stack.capacity() );
System.out.println( "現在のデータ数:" + stack.size() );
System.out.println( stack.toString() );
stack.pop();

3.12 Java API 231
System.out.println( "Stack からデータの取り出し" );
System.out.println( stack.toString() );
stack.push( 500 );
System.out.println( "Stack に 500 を追加" );
System.out.println( stack.toString() );
// LinkedList を Queue として操作しているQueue<Integer> queue = new LinkedList<Integer>();
queue.offer( 100 ); // キューの最後尾に順にデータを挿入queue.offer( 200 );
queue.offer( 300 );
queue.offer( 400 );
System.out.println( "Queueの大きさ:" + ((LinkedList<Integer>) queue).size() );
System.out.println( "現在のデータ数:" + queue.size() );
System.out.println( queue.toString() );
queue.poll();
System.out.println( "Queue からデータの取り出し" );
System.out.println( queue.toString() );
queue.offer( 500 );
System.out.println( "Queue に 500 を追加" );
System.out.println( queue.toString() );
}
}
3.12.5 リスト構造を自作してみる
Java に LinkedList クラスがあるのですから、それを使うのが本筋ですが、ここではそれらを使わずに、自作でリンクリストを作ってみましょう。そうすることで、LinkedList クラスのメソッドが内部でどんなことをやっているのかが理解できます。また、データの並び替えも先に挙げた Comparator などを使うべきですが、ここではそれも自作で行うことにします。以下のような学生データをリンクリストにして管理することにします。リスト内では、学籍番号順に並ぶようにし、次のようなメソッドを持たすことにします。かなり欲張りすぎ!?
コンストラクタとメソッド:• StudentList():空リスト作成コンストラクタ• void add(String):引数のファイル名のファイルから学生データを読み込んでリストに加える• void add(int, String, Date, double):引数の学生データから学生インスタンスを作ってリストに加える
• void add(Student):引数の学生インスタンスをリストに加える• StudentCell find(int):引数の学籍番号の学生を見つける• boolean delete(int):引数の学籍番号の学生をリストから削除し、成功したら true を返す• void print():リスト内の学生データを標準出力するプログラム (クラス) 構成:• studentslist: package 名• public StudentListExample:main メソッドのみ持つ• StudentList:学生データの自作両方向リスト• StudentCell:学生リスト StudentList の各セル• Student:学生データ

232 第 3章 Java 言語の基本的な文法 II
ソースコード 3.97 students.txt (学生データファイル):src/section0312 に置く
1419004, 大野 智, 1980,11,26, 166.0
1419011, 櫻井 翔, 1982,1,25, 171.0
1419016, 二宮 和也, 1983,6,17, 168.0
1419018, 松本 潤, 1983,8,30, 172.0
1419001, 相葉 雅紀, 1982,12,24, 175.0
1419014, 長瀬 智也, 1978,11,7, 184.0
1419017, 松岡 昌宏, 1977,1,11, 181.0
1419012, 城島 茂, 1970,11,17, 173.0
1419021, 山口 達也, 1972,1,10, 167.0
1419009, 国分 太一, 1974,9,2, 167.0
1419005, 岡田 准一, 1980,11,18, 169.0
1419019, 三宅 健, 1979,7,2, 164.0
1419020, 森田 剛, 1979,2,20, 163.0
1419003, 井ノ原 快彦, 1976,5,17, 172.0
1419010, 坂本 昌行, 1971,7,24, 175.0
1419015, 長野 博, 1972,10,9, 172.0
1419002, 稲垣 吾郎, 1973,12,8, 176.0
1419006, 香取 慎吾, 1977,1,31, 181.0
1419008, 草\UTF{5F45} 剛, 1974,7,9, 176.0
ソースコード 3.98 StudentListExample.java (main メソッド:両方向リストの自作)
package section0311;
import java.io.FileNotFoundException;
public class StudentListExample {
public static void main(String[] args) throws FileNotFoundException {
StudentList slist = new StudentList();
slist.add( "src/section0312/students.txt" );
slist.add( 1419013, "中居 正広", new Date(1972,8,18), 165.0 );
slist.add( 1419007, "木村 拓哉", new Date(1972,11,13), 176.0 );
slist.print();
System.out.println();
// 同じデータを再度挿入しようとするslist.add( 1419013, "中居 正広", new Date(1972,8,18), 165.0 );
// 今度は削除命令slist.delete( 1419001 ); // "稲垣 吾郎" 削除slist.delete( 1419006 ); // "香取 慎吾" 削除slist.delete( 1419008 ); // "草\UTF{5F45} 剛" 削除slist.delete( 1419021 ); // "山口 達也" 削除slist.print();
}
}
ソースコード 3.99 Student.java (学生クラス)
package section0311;
/**
* 学生を表わすクラス* @author 和田@応用数学.東京理科大学* @version 1.0
*/
class Student {
/** 学籍番号 */
int idNo;

3.12 Java API 233
/** 氏名 */
String name;
/** 誕生日 {@link Date} 参照 */
Date birthday;
/** 身長 */
double height;
/**
* 引数で各値を与えて学生インスタンスを作るコンストラクタ* @param idNo 学籍番号* @param name 氏名* @param birthday 誕生日 {@link Date} 参照* @param height 身長*/
Student( int idNo, String name, Date birthday, double height ) {
this.idNo = idNo;
this.name = name;
this.birthday = birthday;
this.height = height;
}
/**
* 1行分の csv 形式文字列から学生インスタンスを作成して返すメソッド* @param csvText カンマ切りによる csv形式での学生データ<br>
* 構成は、学籍番号,氏名,誕生年,誕生月,誕生日,身長* @return 学生型インスタンス*/
static Student makeStudent( String csvText ) {
String[] term = csvText.split(",", 0);
int idNo = Integer.parseInt( term[0].trim() );
String name = term[1].trim();
Date birthday = new Date( Integer.parseInt( term[2].trim() ),
Integer.parseInt( term[3].trim() ),
Integer.parseInt( term[4].trim() ) );
double height = Double.parseDouble( term[5].trim() );
return new Student( idNo, name, birthday, height );
}
/**
* 他の学生インスタンスを学籍番号による大小比較するメソッド* @param other 比較する学生インスタンス* @return 比較結果を ${\1,0,1\}$ のいずれかで返す*/
public int compareTo( Student other ) {
if( this.idNo < other.idNo ) return -1;
else if( this.idNo == other.idNo ) return 0;
else return 1;
}
/**
* 学生データの標準出力*/
void print() {
System.out.printf( "%d %-6s (%s) %5.1f%n", idNo, name, birthday.toString(),
height );
}
}

234 第 3章 Java 言語の基本的な文法 II
ソースコード 3.100 Date.java (誕生日用の年月日クラス)
package section0311;
/**
* 年月日を表わすクラス* @author 和田@応用数学.東京理科大学* @version 1.0
*/
class Date {
/** 年 */
int year;
/** 月 */
int month;
/** 日 */
int day;
/**
* 年月日を表わすインスタンスを作るコンストラクタ* @param year 年* @param month 月* @param day 日*/
Date( int year, int month, int day ) {
this.year = year;
this.month = month;
this.day = day;
}
/**
* インスタンスの情報を文字列として返す*/
public String toString() {
return String.format( "%4d/%02d/%02d", year, month, day );
}
}
ソースコード 3.101 StudentCell.java (リストのセル)
package section0311;
/**
* 自作の学生リスト {@link StudentList} のセルを表わすクラス* @author 和田@応用数学.東京理科大学* @version 1.0
*/
class StudentCell {
/** セルのデータ:学生インスタンス */
Student student;
/** 前方セルへのポインタ */
StudentCell preCell;
/** 後方セルへのポインタ */
StudentCell nextCell;
/**
* 引数に与えられた学生データを用いて孤立セルを作成するコンストラクタ* @param student 学生データ*/
StudentCell( Student student ) {
this.student = student;
preCell = null;

3.12 Java API 235
nextCell = null;
}
/** 他のセルと学籍データによる大小比較するメソッド* @param other 比較する他のセル* @return 比較結果を ${\1,0,1\}$ のいずれかで返す*/
public int compareTo( StudentCell other ) {
return (this.student).compareTo( other.student );
}
}
ソースコード 3.102 StudentList.java (両方向リスト)
package section0311;
import java.io.File;
import java.io.FileNotFoundException;
import java.util.Scanner;
/**
* 自作の双方向リストによる学生リストを表わすクラス* @author 和田@応用数学.東京理科大学* @version 1.0
*/
class StudentList {
/** リストの先頭セルへのポインタ */
StudentCell firstCell; //
/** リストの最後尾セルへのポインタ */
StudentCell lastCell; //
/** 空リスト作成コンストラクタ */
StudentList() {
this.firstCell = null;
this.lastCell = null;
}
/**
* ファイルより学生データの読み込み* @param fileName 読み込みデータファイル名:ファイルはカンマ区切りの csv 形式<br>
* 1レコードの構成は {@link Student#makeStudent(String) Student.makeStudent} を参照* @throws FileNotFoundException データファイルが見つからなかった場合に返される例外*/
void add( String fileName ) throws FileNotFoundException {
Scanner scan = new Scanner( new File( fileName ) );
while( scan.hasNextLine() ) {
String csvText = scan.nextLine();
Student newStudent = Student.makeStudent( csvText );
add( newStudent );
}
scan.close();
}
/**
* 1学生の属性データを引数で渡された場合の学生データの追加<br>
* add(Student) を呼び出す* @param idNo 学籍番号* @param name 氏名* @param birthday Date 型による誕生日* @param height 身長*/
void add( int idNo, String name, Date birthday, double height ) {

236 第 3章 Java 言語の基本的な文法 II
add( new Student( idNo, name, birthday, height ) );
}
/**
* 引数で渡された学生データを追加* @param newStudent Student 型の学生データ<br>
* 引数が null の場合には対応していない*/
void add( Student newStudent ) {
StudentCell newCell = new StudentCell( newStudent );
// リストが空だった場合if( firstCell == null && lastCell == null ) {
firstCell = newCell;
lastCell = newCell;
return;
}
// リストには1つ以上のセルがあった場合StudentCell nextCell = firstCell;
while( nextCell != null ) { // 最後まで読み込むとループから抜け出すswitch( nextCell.compareTo( newCell ) ) {
case -1: // 検索データは未だ見つからないnextCell = nextCell.nextCell;
break;
case 0: // 追加データが見つかったので、追加を中止System.out.println( "以下の学生は既に登録済みで、追加することを止めました。");
newCell.student.print();
System.out.println();
return;
case 1: // 追加データがまだ無いことが判明 (行き過ぎた)
if( nextCell == firstCell ) { // 挿入データが先頭の場合newCell.nextCell = firstCell;
firstCell.preCell = newCell;
firstCell = newCell;
} else { //挿入データは第2データ以降、ラストでは無いStudentCell preCell = nextCell.preCell; // 一つ前のデータpreCell.nextCell = newCell;
newCell.preCell = preCell;
newCell.nextCell = nextCell;
nextCell.preCell = newCell;
}
return;
}
}
// 追加データは最後のデータとなる場合newCell.preCell = lastCell;
lastCell.nextCell = newCell;
lastCell = newCell;
}
/**
* 学生データの検索:学籍番号が一致したとき、見つかったとする* @param idNo 検索したい学生の学籍番号* @return 見つかった場合はそのセル、見つからなかった場合は null を返す*/
StudentCell find( int idNo ) {
StudentCell nextCell = firstCell;
while( nextCell != null ) {

3.12 Java API 237
if( nextCell.student.idNo == idNo ) return nextCell;
if( nextCell.student.idNo > idNo ) return null;
nextCell = nextCell.nextCell;
}
return null;
}
/**
* 学生データの削除:学生番号が一致したとき、そのデータを削除する<br>
* 同じ学籍番号のデータは複数無いものと考える* @param idNo 削除学生の学籍番号* @return 学生データの削除が成功したとき、true を返す*/
boolean delete( int idNo ) {
StudentCell findCell = find( idNo );
if( findCell == null ) return false; // 無ければ中止if( findCell == firstCell ) { // リストの先頭を削除
if( findCell == lastCell ) { // リストが1レコードの場合firstCell = null;
lastCell = null;
} else {
firstCell = firstCell.nextCell;
firstCell.preCell = null;
}
} else if( findCell == lastCell ) { // リストの最後尾を削除lastCell = lastCell.preCell;
lastCell.nextCell = null;
} else { // リストの途中の要素を削除findCell.preCell.nextCell = findCell.nextCell;
findCell.nextCell.preCell = findCell.preCell;
}
return true;
}
/**
* リストの情報出力*/
void print() {
StudentCell nextCell = firstCell;
System.out.println( "現在の登録学生リスト" );
while( nextCell != null ) {
nextCell.student.print();
nextCell = nextCell.nextCell;
}
System.out.println();
}
}
3.12.6 木構造を自作してみる
コンピュータのデータ構造には、リストやスタック・キューなどの他にも様々な構造がありますが、データ処理の高速性を必要とされる際によく使われる構造に「木構造」があります。Java には木構造だけのデータ構造はなく、他のデータ構造の裏で利用されています。例えば、 TreeSet や TreeMap などで使われています。木構造については2年生に詳しく学ぶと思いますが、今回も簡単な木構造を自作してみましょう。ここでは木構造

238 第 3章 Java 言語の基本的な文法 II
を、図 3.18 のような「木を逆さまにしたような構造 (上下関係を意識する) で全ての点がつながっており、各点は何らかのデータを持っているもの」と定義します。最も上のノードを「根 (ルート:root)」と呼び、最も下のノードたちを「葉 (リーフ:leaves)」と呼び、それ以外のノードを「内点 (innner node)」と呼びます。上下でつながっているノードを、上を「親ノード」下を「子供ノード」、同じ親ノードの子供たちを「兄弟ノード」、兄弟で左側を「兄ノード」、右側を「弟ノード」と呼びます。各点は、親ノードを複数持てませんが、子供ノードは複数持つことができます。根は親がないノード、葉は子供がないノードです。木構造は、子供の数や各点が持つデータによっていろいろな種類があります。葉ノードを除いたどのノードも子供
を高々2人しか持たないような木構造を「2分木 (Binary tree)」と呼び、親とその2人の子供において、「左の子のデータ<親のデータ<右の子のデータ」が成立する2分木を「2分探索木 (Binary search tree)」と言います。以下の図 (図 3.18 参照)では、2次元平面上の点の集合をデータとする2分探索木で、左の子・親・右の子に分かれる条件は原点からの距離の大小関係としています (左の子は親より原点に近く、右の子は親より原点から遠い) 。各ノードの番号は挿入した順序。2次元の値が座標、ノードの下の値はその点の原点からのおよその距離です。また、最も上の青いノードが根、ピンクのノードらが葉となります。
(-2.1,2.6)1
(-1.6,-0.5)3 (-2.5,2.3)2
(0.6,-1.1)14
(0.5,1.0)4 (1.6,-3.1)5
(2.3,3.2)6
(3.7,0.8)7 (5.6,-5.1)8
(1.0,3.6)11 (7.3,-3.1)10
(6.1,0.5)12
(6.6,2.5)9
(4.8,-1.7)13
(4.3,3.8)15(3.9,-2.4)16
(7.9,0.3)17
(-0.9,5.2)18
3.342
1.676
1.118
1.253
3.397
3.489
3.941
3.785
3.736
7.574
7.058
6.120
5.092
4.579 5.738
5.277
7.931
7.906
図 3.18 二分探索木
この2分探索木を作るプログラムを作りましょう。
ソースコード 3.103 BinarySearchTreeExample.java
package section0311;
/**
* 2次元空間上の点の集合を2分探索木に記憶するサンプルプログラム<br>
* 木の左右を決めるデータは各点の原点からの距離とする*/

3.12 Java API 239
public class BinarySearchTreeExample {
public static void main(String[] args) {
// 点情報の行列:各行は1つの点を表し、それぞれの x座標、y座標 からなるdouble[][] pointData = {
{-2.1, 2.6}, {-2.5, 2.3}, {-1.6,-0.5}, { 0.5, 1.0},
{ 1.6,-3.1}, { 2.3, 3.2}, { 3.7, 0.8}, { 5.6,-5.1},
{ 6.6, 2.5}, { 7.3,-3.1}, { 1.0, 3.6}, { 6.1, 0.5},
{ 4.8,-1.7}, { 0.6,-1.1}, { 4.3, 3.8}, { 3.9,-2.4},
{ 7.9, 0.3}, {-0.9, 5.2}
};
// 生データの配列から点をデータとして持つノードの配列を作成Node[] nodes = PNode.makeNodeArray( pointData );
// ノードの配列を与えて2分探索木を作成(円の比較は半径の長さで)BinarySearchTree pointTree = new BinarySearchTree( nodes );
// 情報の出力は以下のいずれかを選択する// 深さ優先・左優先順に出力する// pointTree.dpsPrint();
// 幅優先・左優先順に出力するpointTree.bfsPrint();
}
}
/**
* 2分探索木のノードを表す抽象クラス<br>
* 何をデータにするか、データの大小比較メソッドをどうするか、は未定!*/
abstract class Node implements Comparable<Node> {
/** 探索木に追加されたノードに番号をふるためのクラス変数 */
static int sno = 0;
/** ノードの探索木への挿入番号 */
int no;
/** 親ノード */
Node parent;
/** 左の子ノード */
Node left;
/** 右の子ノード */
Node right;
Node() {
this.no = ++sno;
this.parent = null;
this.left = null;
this.right = null;
}
}
/**
* 2分探索木のノードを表すクラス:データは2次元平面の点情報*/
class PNode extends Node {
/** 2次元平面上の点のデータ */
Point point;
PNode(Point point ) {
super();
this.point = point;
}
/** ノードの情報を文字列化するメソッド */
public String toString() {

240 第 3章 Java 言語の基本的な文法 II
String sleft = (left==null)?" .":String.valueOf(left.no);
String sright = (right==null)?" .":String.valueOf(right.no);
String sparent = (parent==null)?" .":String.valueOf(parent.no);
return String.format("%2d%s: l=%2s r=%2s p=%2s", this.no, point.toString(),
sleft, sright, sparent);
}
/**
* 座標情報の実数2次元配列から PNode インスタンスの配列を作成する* @param pointData 各行が1つの点に対応し、x 座標、y 座標 の* 2実数で出来ている座標情報の2次元配列* @return PNode 型インスタンスを要素をする1次元配列*/
static PNode[] makeNodeArray( double[][] pointData ) {
PNode[] nodes = new PNode[pointData.length];
for(int i=0; i<pointData.length; i++) {
nodes[i] = new PNode(new Point( pointData[i][0], pointData[i][1] ));
}
return nodes;
}
/**
* 他のノードとの大小比較<br>
* ノードの持つデータの大小比較(整数値)を返す* @return 自身のデータと引数のノードのデータで比較し、<br>
* 自身のデータが引数のデータより大きければ1,小さければ-1、等しければ0を返す*/
@Override
public int compareTo(Node other) {
return this.point.compareTo(((PNode)other).point);
}
}
/**
* 2分探索木を表すクラス<br>
* 平衡化は行っていない*/
class BinarySearchTree {
/** 探索木の根 */
Node root = null;
/**
* Point の配列を与えて2分探索木を作成する* @param points Point 型インスタンスを要素とする1次元配列*/
BinarySearchTree(Node[] nodes) {
for(int i=0; i<nodes.length; i++) {
add( root, nodes[i] );
}
}
/**
* 第1引数のノードを根とする探索木に第2引数のノードを挿入する* @param currentNode このノードを根とする部分探索木に新たなノードを挿入する* @param newNode 挿入するノード* */
void add( Node currentNode, Node newNode ) {
if( currentNode == null ) { // 挿入するのが topセルroot = newNode;
return;

3.12 Java API 241
} else {
int check = currentNode.compareTo( newNode );
if( check < 0 ) {
if( currentNode.right == null ) {
currentNode.right = newNode;
newNode.parent = currentNode;
} else {
add( currentNode.right, newNode );
}
} else if( check > 0 ) {
if( currentNode.left == null ) {
currentNode.left = newNode;
newNode.parent = currentNode;
} else {
add( currentNode.left, newNode );
}
} // if( check == 0 ) 既にデータは存在するので、挿入せず}
return;
}
/** 深さ優先左優先で探索木の情報を標準出力する */
void dpsPrint() {
System.out.println( "2分探索木を深さ優先左優先で出力:");
if( root == null ) {
System.out.println( "現在、2分探索木は空です");
System.out.println();
return;
}
dpsPrint( root );
System.out.println();
}
/**
* 深さ優先左優先での出力メソッド dpsPrint() から呼び出され、* 引数のノードを根とする探索木の情報を標準出力する* @param currentNode 出力した部分探索木の根となる Node
*/
void dpsPrint( Node currentNode ) {
if( currentNode == null ) return;
dpsPrint( currentNode.left );
System.out.println( currentNode.toString() );
dpsPrint( currentNode.right );
}
/** 幅優先左優先で探索木の情報を標準出力する */
void bfsPrint() {
System.out.println( "2分探索木を幅優先左優先で出力:");
if( root == null ) {
System.out.println( "現在、2分探索木は空です");
System.out.println();
return;
}
bfsPrint( root );
System.out.println();
}
/**
* 幅優先左優先での出力メソッド bfsPrint() から呼び出され、

242 第 3章 Java 言語の基本的な文法 II
* 引数のノードを根とする探索木の情報を標準出力する* @param currentNode 出力した部分探索木の根となる Node
*/
void bfsPrint( Node currentNode ) {
if( currentNode == null ) return;
System.out.println( currentNode.toString() );
bfsPrint( currentNode.left );
bfsPrint( currentNode.right );
}
}
3.13 ネストしたクラスやインタフェースこれまで、一つのファイルの中に複数のクラスを入れたプログラムを作ったことがありましたが、その際に誤って片方のクラス内にもう一方のクラスを入れてしまったためエラーが発生!という経験をした人がいますかね。ここでは、それについて学びます。クラスやインタフェースのメンバーは、これまで「フィールド」と「メソッド」、そして「コンストラクタ」(一般的
に、コンストラクタをメンバーとはしない)の3つとしてきましたが、実は、クラスやインタフェースの中に「クラス」や「インタフェース」を宣言して、それらをメンバーとすることができます。こうしたクラスやインタフェースを「ネストクラス」(nested class) などと呼びます。ここでは、クラスのネストについて触れ、インタフェースのネストについては省略します。ネストされたクラスには以下の 4 種類があります。
• 静的 (static) なメンバークラス (static member class)
• 非 static なメンバークラス (nonstatic member class)
• 無名クラス (anonymous class)
• ローカルクラス (local class)
最初の静的なメンバークラスを除いた残り 3 つのクラスを総称して「内部クラス」(inner class) と呼びます。また、包含関係にある2つのクラスの外側のクラスを「囲いクラス」(enclosing class) もしくは「外部クラス」(outer
class) と呼びます。
3.13.1 静的なメンバークラス
静的なメンバークラスは囲いクラスに付随するクラスで「囲いクラス名.クラス名」で表現されます。
ソースコード 3.104 NestedClassExample.java (静的なメンバークラスの例題)
package section0312;
public class NestClassExample {
public static void main(String[] args) {
A a = new A();
a.print();
A.B b = new A.B(3, 4);
b.print();
A.B.sprint();
}
}
// 外部クラス

3.13 ネストしたクラスやインタフェース 243
class A {
int ia;
static int sa;
A() {
this.ia = 1;
A.sa = 2;
}
void print() {
System.out.printf( "A's print():ia=%d, sa=%d, sb=%d%n", ia, sa, B.sb );
}
// 静的メンバークラスstatic class B {
int ib;
static int sb = 0;
B(int ib, int sb) {
this.ib = ib;
B.sb = sb;
}
void print() {
System.out.printf( "B's print():sa=%d, ib=%d, sb=%d%n", sa, ib, sb );
}
static void sprint() {
System.out.printf( "B's sprint():sa=%d, sb=%d%n", sa, sb );
}
}
}
B クラスは A クラス内に静的なクラスとして存在し、「A クラスのインスタンスを作らなくても A に付随するクラス」として定義されています。B クラスは A クラスを無視しては単独で使用できないので、main メソッドにおいてB b = new B( 1 ) などとは出来ません。また、static が付いているため、クラス A のインスタンスメンバーではありませんから、a.B b = new a.B(); なんてことはできませんし、B クラス内から A クラスのインスタンフィールド b やインスタンスメソッドに直接アクセスすることもできません ( static なメンバーにはアクセスできる)。ネストされるクラスは、外部クラスのメンバーとして、一般のクラスのアクセス性 (package-pribate と publi) だけでなく、(クラスでありながら) 全てのアクセス性を (private や protected も) 与えることができます。
問題 3.13.1. 上のプログラムで、クラス B のアクセス性を private にして、エラーを解析しなさい。
次のプログラムでは、銀行口座クラス (BankAccount) の中に、許可行為クラス (Permissions) が入っています。口座のオーナー (?) のような全ての行為を許された人と、一部の行為のみ許された人が存在するという状況を想定していますかね。このように、外部クラスに関するクラスとして補助的に存在するクラスの場合に内部クラスとして定義するわけです。
package section0312;
public class StaticMemberExample {
public static void main(String[] args) {
BankAccount nodaAi = new BankAccount( 1234567, "野田 愛" );
nodaAi.setPermissions( new BankAccount.Permissions( true, false, false ) );
nodaAi.printForClose();
}
}

244 第 3章 Java 言語の基本的な文法 II
class BankAccount { // 銀行口座int number; // 口座番号String name; // 名義名Permissions permissions; // 許可されている行為BankAccount( int number, String name ) {
this.number = number;
this.name = name;
}
void setPermissions( Permissions permissions ) {
this.permissions = permissions;
}
void printForClose() { // 口座の解約が可能か否かを出力System.out.println( name + "さんは、解約" +
(permissions.canClose ? "できます。":"できません。") );
}
// static メンバーとしてのクラスstatic class Permissions { // 口座に対する許可行為
boolean canDeposit; // 預け入れboolean canWithdraw; // 引き下ろしboolean canClose; // 口座を閉じるPermissions( boolean canD, boolean canW, boolean canC ) {
this.canDeposit = canD;
this.canWithdraw = canW;
this.canClose = canC;
}
}
}
インタフェースにおいてのネストは常に static で、構造的な仕組みを単に提供するだけのものとなります。static なメンバークラスには、識別子として、 public, private, protected, package-private, final,
abstract などを付けることができます。
3.13.2 非 static なメンバークラス (内部クラス)
今度は、クラスの中に static 修飾子の付いていないクラスが入っている場合を考えます。本によっては、このケースのクラスを「内部クラス (inner class)」と呼び、前節の static の付いた内部クラスを「static ネストクラス」と区別しています。以下のプログラムを前節のプログラムと比較して違いを理解して下さい。
ソースコード 3.105 InnerClassExample.java (内部クラスの例)
package section0312b;
public class InnerClassExample {
public static void main(String[] args) {
A a = new A();
a.print();
A.B ab = a.new B(5, 6);
ab.print();
}
}
class A { // エンクロージングクラスint ia;
static int sa;
B b;
A() {

3.13 ネストしたクラスやインタフェース 245
this.ia = 1;
A.sa = 2;
this.b = new B(3, 4);
}
void print() {
System.out.printf( "A's print():ia=%d, sa=%d%n", ia, sa );
}
class B { // 内部クラスint ib=3;
B( int ib, int sb ) {
this.ib = ib;
ia = ib;
sa = sb;
}
void print() {
System.out.printf( "B's print():ia=%d, sa=%d, ib=%d%n", ia, sa, ib );
}
}
}
static が付いていないので、このクラスのインスタンスは、外部クラスのインスタンスを通してアクセスすることになります。外部クラスのインスタンス無しでは内部クラスのインスタンスは作れないということですね。従って、A.B ab = new A.B(4); は無理。内部クラスには、識別子として、 public, private, protected, package-private, final, abstract などを付けることができます。
3.13.3 無名クラス
無名クラスは「匿名クラス」とも呼ばれ、メソッドなどの処理の中で定義と同時に一度だけインスタンスが生成されて使われるクラスなので、一般にはインスタンス名を与えずに定義します。一般に、無名クラスの中身は1つの機能(メソッド) 程度の簡単なものです。例えば、以下の例では Arrays クラスのクラスメソッド sort の引数に渡す比較器を無名クラスを用いて宣言しています。
ソースコード 3.106 AnonymouseClassExample.java (無名クラスの例)
package section0312;
import java.util.Arrays;
import java.util.Comparator;
public class AnonymouseClassExample {
public static void main(String[] args) {
String[] array = {"b", "B", "A", "C", "a", "c"};
Arrays.sort( array, new Comparator<String>() {
public int compare(String s1, String s2) {
return s1.compareTo(s2);
}
});
for(String s : array) System.out.println( s );
}
}
クラス内の機能が多い場合や、同じ無名クラスが度々使われる、コンストラクタが必要となった、クラス名があった方がプログラムの可読性が上がる、などの場合は他のメンバークラスを使うべきです。

246 第 3章 Java 言語の基本的な文法 II
3.13.4 ローカルクラス
メソッドやコンストラクタなどの中でクラスを定義すると、「ローカルクラス」と呼びます。ローカル変数などと同様にそのブロック内でのみ利用できるクラスになり、外部からは全くアクセスできません。従って、アクセス修飾子やstatic などの修飾子を付けることはできません。
3.14 スレッド・並列処理並列処理 (parallel computing) について解説します。並列処理というと、次の 2つの意味があります。
• マルチプロセス (multi-process):複数のソフトウェアを並列に処理する。それぞれが固有のメモリ空間を持っていて、独立に処理される。「マルチタスク」が同義語
• マルチスレッド (multi-thread):プログラム内の処理の並列処理。メモリ空間を共有するので、スレッドセーフ・排他制御などさまざまな対応が必要。「シングルスレッド」の対語。ここでは、こちらについて触れます
これまで学んできたプログラムは、プログラム中でオブジェクトを作ってそれに処理を行わせたりもしましたが、あくまで main メソッドに書かれた処理が始まって・終わるまでがプログラムでした。この main メソッドが始まってから終わるまでの一連の処理を、「main スレッド」と呼びます。これまでのプログラムでは main スレッド1つが動く「シングルスレッド」プログラムでした。一方、これから学ぶ「マルチスレッド」プログラムは、main スレッド以外のスレッドを作って main スレッドから独り立ち (?) させて動かすものです。Java でマルチスレッドを実現する方法には次の 2 種類があります。
• Thread クラスの継承• Runnable インタフェースの実装
Java の単一継承の制約から、Thread クラスを継承したオブジェクトは他のクラスを継承できなくなるので、一般にはRunnable インタフェースを実装することになります。とは言え、まずは Thread クラスの継承によるマルチスレッドプログラムを見てみましょう。
3.14.1 Thread クラスの継承
まず Thread クラスを継承したクラスを作ります。Thread クラスには、start メソッドと run メソッドが用意されています。コンストラクタによりインスタンスを作り、その start メソッドが実行されると、そのインスタンスによるスレッドが生成されます。スレッドを生成されると、自動的にそのインスタンスの run メソッドをが実行されます。この run メソッド内に書かれた処理が、そのスレッドの処理となります。run メソッドが終了すると、そのスレッドは自動的に消滅します。一方、 start メソッドを実行させた元のスレッド (例えば main スレッド) は、新たなスレッドとは独立に次の仕事に取り掛かります。こうして、複数のスレッドが実行され始めるわけです。run メソッドを外部から直接実行することはできますが、その場合 run メソッドは呼び出し元のスレッド内で動いてしまうのでマルチスレッドプログラムにはなりません。なお、スーパークラスの Thread クラスの run メソッドは中身が空で出来ているので、 Thread クラスを継承したクラスは run メソッドをオーバーライドしないと何も処理を行わないスレッドになってしまいます。

3.14 スレッド・並列処理 247
ソースコード 3.107 ThreadExample01.java (Thread の継承によるスレッド処理)
package section0314;
public class ThreadExample01 {
public static void main(String[] args) {
System.out.println( "main thread start..." );
MyThread thread_A = new MyThread();
MyThread thread_B = new MyThread();
thread_A.start();
thread_B.start();
System.out.println( "main thread end...." );
}
}
class MyThread extends Thread {
@Override
public void run() {
System.out.println( getName() + " thread start..." );
working();
System.out.println( getName() + " thread end...." );
}
private void working() {
int sum = 0;
for(int i=1; i<=100000; i++) {
sum += i;
}
System.out.println( getName() + ": sum = " + sum );
}
}
以下は、このプログラムの実行結果例です。まず、最初に main メソッドにより「main thread start...」の出力がされ、コンストラクタにより2つのスレッド・インスタンスが作成されます。そして、それぞれの start メソッドで2つのスレッドの実行が開始されます。
main thread start...
Thread-0 thread start...
Thread-1 thread start...
main thread end....
Thread-0: sum = 705082704
Thread-0 thread end....
Thread-1: sum = 705082704
Thread-1 thread end....
各スレッドはすぐに run メソッドを実行します。ここでは、 Thread クラスが持っているインスタンスメソッドgetName() によってスレッド名が出力されています (スレッドの名前をデフォルトの値以外にしたい場合は、コンストラクタに文字列を与えるか setName(String) で設定するかできます)。main スレッドは 2 つのスレッドを実行させたあと、それらとは独立に自分の処理に戻るので、この例ではスレッドたちの処理の終了より先に自身の処理を終了しています。各スレッドは run メソッドを終了すると自動的に消滅し、全てのスレッドが消滅した時点でプログラムが終了します。スレッドは、それぞれ一度しか start メソッドを利用することができません。例えば、命令 thread_A.start();」を連続して行わせると、「IllegalThreadStateException:呼び出したスレッドが既に起動済みである」と例外を返してきます。
Exception in thread "main" java.lang.IllegalThreadStateException
at java.lang.Thread.start(Thread.java:705)

248 第 3章 Java 言語の基本的な文法 II
at threadexamples.ThreadExample01.main(ThreadExample01.java:9)
ところで、このプログラムを何度か実行してみると、出力結果がいつも同じでないことがわかります。以下の実行では、後から start したはずの thread B が thread A より先に実行を開始し終了しています。このように、スレッドの実行はその時点での環境に依存し、プログラムに記述された順に実行されるという保証がありません。
main thread start...
main thread end....
Thread-1 thread start...
Thread-0 thread start...
Thread-1: sum = 704982704
Thread-1 thread end....
Thread-0: sum = 704982704
Thread-0 thread end....
3.14.2 スレッドの制御
スレッドは、それぞれが独立に実行されるので、スレッドの順序が無視されると困る場合が起こります。次のプログラムでは、2 人の振込の結果を main スレッドの最後で出力しようとしていますが、なかなか正しい集計が成されません (何度か実行してみて下さい)。
ソースコード 3.108 ”ThreadExample02.java (Thread の制御)”
package section0314;
public class ThreadExample02 {
public static void main(String[] args) throws InterruptedException {
Deposit deposit = new Deposit();
DepositThread thread_A = new DepositThread("Aさん", deposit, 1000);
thread_A.start();
DepositThread thread_B = new DepositThread("Bさん", deposit, 1000);
thread_B.start();
// Thread.sleep(100L);
System.out.println( "2人の振込の結果は、" + deposit.getDeposit() + "円です。" );
}
}
class DepositThread extends Thread {
Deposit deposit;
int money;
DepositThread( String name, Deposit deposit, int money ) {
super( name );
this.deposit = deposit;
this.money = money;
}
@Override
public void run() {
System.out.println( getName() + "が、" + money + "円振り込みました。" );
deposit.addDeposit( money );
}
}
class Deposit {
int deposit;
public Deposit() {
this.deposit = 0;
}

3.14 スレッド・並列処理 249
int getDeposit() {
return deposit;
}
void addDeposit( int money ) {
this.deposit = this.getDeposit() + money;
}
}
こうした場合、他のスレッドの終了を待ってから続きの処理を行うべく、スレッドの処理を一時停止させる命令があります。
• sleep() : そのスレッドの処理を一時停止する Thread クラスのクラスメソッド• join() : そのスレッドの処理が終わるのを待つ Thread クラスのインスタンスメソッド
sleep メソッドpublic static void な sleep メソッドは InterruptedException と IllegalArgumentException を投げてきます。IllegalArgumentException は引数の値が負だったり範囲に含まれなかったりした場合になります。
• sleep(long) : 現在実行中のスレッドを引数に指定されたミリ秒数の間、一時停止• sleep(long, int) : 与えられたミリ秒とナノ秒 ( 0~999999 ) の和だけ実行中のスレッドを一時停止
上のプログラムのコメントで殺した行を活かすと、 main スレッドが 100 msec だけ一時停止するので、正しい結果が出力されます。
join メソッドpublic final void な join メソッドは、そのインスタンスのスレッドが終了するまで自身の処理を待機させます。なお、InterruptedException が投げてきます。
• join() : そのスレッドの終了を待機する。 join(0) と同等• join(long) : 与えられたミリ秒だけスレッドの終了を待機。 引数に 0 を与えると無期限に終了するまで待機する
• join(long, int) : 与えられたミリ秒とナノ秒 ( 0~999999 ) の和だけスレッドの終了を待機する
上のプログラムに以下の 2 行を入れてみましょう。
public static void main(String[] args) throws InterruptedException {
Deposit deposit = new Deposit();
DepositThread thread_A = new DepositThread("Aさん", deposit, 1000);
thread_A.start();
DepositThread thread_B = new DepositThread("Bさん", deposit, 1000);
thread_B.start();
// Thread.sleep(100L);
thread A.join();
thread B.join();
System.out.println( "2人の振込の結果は、" + deposit.getDeposit() + "円です。" );
}
main スレッドは、2人の振り込み作業が終了してから出力作業に入るので、正しく出力してくれます。

250 第 3章 Java 言語の基本的な文法 II
3.14.3 Runnable の実装
次は、Runnable インタフェースを実装したマルチスレッドの例を見ましょう。先に言ったように、スレッドクラスを作る際に Thread クラスを継承してしまうと、他のクラスを継承することが出来なくなってしまいます。そんな場合に、Runnable インタフェースを利用します。Runnable はメソッド run のみからなるインタフェースです。従って、 Runnable インタフェースを実装するクラスを、この run メソッドをオーバーライドした上で、 Thread クラスのコンストラクタに渡してスレッド化してやれば、start メソッドで実行されるようになります。
ソースコード 3.109 ”ThreadExample04.java (Runnable の実装によるスレッド処理)”
package section0314;
public class ThreadExample04 {
public static void main(String[] args) {
System.out.println( "main thread start..." );
Thread thread_A = new Thread( new SubThread("thread_A") );
thread_A.start();
Thread thread_B = new Thread( new SubThread("thread_B") );
thread_B.start();
System.out.println( "main thread end...." );
}
}
class SubThread implements Runnable {
String name;
SubThread( String name ) {
this.name = name;
}
String getName() {
return this.name;
}
@Override
public void run() {
System.out.println( getName() + " thread start..." );
working();
System.out.println( getName() + " thread end...." );
}
private void working() {
int sum = 0;
for(int i=1; i<=100000; i++) {
sum += i;
}
System.out.println( getName() + ": sum = " + sum );
}
}
3.14.4 スレッドの排他制御
先に作った ThreadExample02.java を以下のように変更して実行してみて下さい。出力結果がおかしいときがあるかと思います。
package section0314;
public class ThreadExample02 {

3.14 スレッド・並列処理 251
public static void main(String[] args) throws InterruptedException {
for( int i=0; i<100; i++) {
Deposit deposit = new Deposit();
DepositThread thread_A = new DepositThread("Aさん", deposit, 1000);
thread_A.start();
DepositThread thread_B = new DepositThread("Bさん", deposit, 1000);
thread_B.start();
// Thread.sleep(100L);
thread_A.join();
thread_B.join();
System.out.print( "2人の振込の結果は、" + deposit.getDeposit() + "円です。" );
if( deposit.getDeposit() != 2000 ) {
System.out.print( "<" );
}
System.out.println();
}
}
}
class DepositThread extends Thread {
Deposit deposit;
int money;
DepositThread( String name, Deposit deposit, int money ) {
super( name );
this.deposit = deposit;
this.money = money;
}
@Override
public void run() {
// System.out.println( getName() + "が、" + money + "円振り込みました。" );
try {
Thread.sleep(5L);
} catch (InterruptedException e) {
e.printStackTrace();
}
deposit.addDeposit( money );
}
}
class Deposit {
int deposit;
public Deposit() {
this.deposit = 0;
}
int getDeposit() {
return deposit;
}
void addDeposit( int money ) {
this.deposit += money;
}
}
join メソッドによって2人の振り込み操作が終了してから出力しているのに、集計金額が 2000 円になっていないときがあります。挿入したのは、スレッドを 5 msec ずつ一時停止させただけです。この場合のスレッドの操作を図にすると、以下のようになります (図 3.19 参照)。それぞれのスレッドでメソッド addDeposit() によって預金額を変更しているのですが、そのタイミングが時間の

252 第 3章 Java 言語の基本的な文法 II
流れ上で重なってしまう (以下の図の下の例) と正しい書き込みができなくなっているのです。こうした場合、先に預金のデータにアクセスしたスレッドが一連の処理を終了するまでは、他のスレッドがアクセスすることを留めておかねばなりません。こうしたスレッドの排他制御を「メソッドにロックを掛ける」または「メソッドの同期をとる」と言います。
addDeposit(1000)
addDeposit(1000)
thread_A
thread_B
deposit 1000円
1000円
時間の流れ
0円
0円
thread_A
thread_B
deposit
addDeposit(1000)
1000円
1000円
時間の流れ
0円
addDeposit(1000)
2000円
図 3.19 スレッドの問題点 (上は問題なく、下は 1000 円が消える)
この例の場合、addDeposit メソッドを2つのスレッドが同時に利用しているために問題が起こるわけですから、このメソッドをあるスレッドが利用している間は、他のスレッドに利用させなくすればよいのです。それには、メソッドに修飾子 synchronized を付けます。この場合、addDeposit メソッドをあるスレッドが利用し始めたら、他のスレッドはその処理が終わるまでこのメソッドの利用を待機することになります。
synchronized void addDeposit( int money ) {
this.deposit += money;
}
問題 3.14.1. 以下のプログラムをスレッドの排他制御を用いて、正しく動くように直しなさい。
ソースコード 3.110 BankBooks.java (お金が消える!)
package section0314;
public class BankBooks {
public static void main(String[] args) {
BankBook bankbook1 = new BankBook( "通帳 1", 10000 ); // 通帳1には 10000円BankBook bankbook2 = new BankBook( "通帳 2", 20000 ); // 通帳2には 20000円// 通帳1から通帳2へ 1000円の移動}
BankingThread banking1 = new BankingThread( bankbook1, bankbook2, 1000 );
// 通帳2から通帳1へ 5000円の移動BankingThread banking2 = new BankingThread( bankbook2, bankbook1, 5000 );
// スレッドの開始banking1.start();
banking2.start();

3.15 JavaFX とマルチメディア (執筆中) 253
// それぞれの結果を出力bankbook1.print();
bankbook2.print();
System.out.printf( "本来の結果は、%n%s : %d 円 %n%s : %d 円 %n",
bankbook1.name,14000,bankbook2.name,16000 );
}
}
// 預金の移動スレッドclass BankingThread extends Thread {
BankBook book1; // 移動元の通帳BankBook book2; // 移動先の通帳int money; // 移動金額BankingThread( BankBook book1, BankBook book2, int money ) {
this.book1 = book1;
this.book2 = book2;
this.money = money;
}
public void run() {
book1.setDeposit(book1.getDeposit() - money); // 移動元から預金を引き出してbook2.setDeposit(book2.getDeposit() + money); // 移動先の預金に加える
}
}
// 貯金通帳のクラスclass BankBook {
String name; // 通帳の名前int deposit; // 預金金額
BankBook( String name, int money ) {
this.name = name;
this.deposit = money;
}
// 現在の預金額を返すint getDeposit() {
return this.deposit;
}
// 預金金額を更新するvoid setDeposit(int money) {
this.deposit = money;
}
// 現在の状況を出力するvoid print() {
System.out.printf( "%s : %d 円 %n", this.name, this.deposit );
}
}
3.15 JavaFX とマルチメディア (執筆中)
Java が生まれた 1996年、最初のバージョン Java 1.0 に GUI (Graphical User Interface) プログラムを作るためのツールキット AWT (Abstract Window Toolkit) が導入されました。GUI とは、窓の中にボタンなどの部品を配置し

254 第 3章 Java 言語の基本的な文法 II
た視覚的なインタフェースのことで、それ以前の文字ベースで命令を指示するインタフェース CUI (Character-based
User Interface) の対語になります。残念ながら Java の理念『どんな OS 上でも共通の環境を提供しよう「write once, run anywhere」(一度作成すれば、どこでも動作する)』は、AWT の上ではあまりうまく行きませんでした。そこで 2 年後の Java 2 で標準 GUI ライブラリーが Swing に変わりました。Swing は、OS のネイティブな部品 (各 OS が持っている GUI 機能) を使用した AWT に対し、全ての操作を Java で完結させようとしました。ただ、その代償として低速でかつ見劣りするインタフェースとなり、後に登場する Flash の派手さに負けることになります。そこで Sun Microsystems 社は Flash の対抗として 2007年 JavaFX を導入します。ただ、その初期 JavaFX Script
という独自の言語を利用したので、一般にはあまり使われませんでした。2011年、Sun Microsystem 社から後を継いだ Oracle 社は JavaFX Script を捨て Java に一体化させることで、完全に Swing に見切りをつけて、JavaFX をJava 7 以降の正式な GUI ライブラリーとしました。さて、JavaFX は生き残っていけるのでしょうか? (^_^;)
3.15.1 初めての JavaFX
Eclipse が生成するプロジェクトはデフォルトでは JavaFX に関連付けされていません。従って、JavaFX のプログラムを作りたいときは、JavaFX のライブラリに関連付けされたプロジェクトを作るか、既にあるプロジェクトなら、後付けで JavaFX のライブラリを関連づけることになります。ここでは、既に存在するプロジェクト「プログラミングの授業」に JavaFX ライブラリを関連づけすることにします。Eclipse のパッケージ・エクスプローラーで、プロジェクト「プログラミングの授業」を右クリックで選択、「ビルド・パス>ライブラリーの追加」・「JavaFX SDK」を選択して完了して下さい。パッケージ・エクスプローラーでプロジェクトの中に「JRE システム・ライブラリー」と一緒に「JavaFX SDK」が並んでくれたらOKです。では、新たにパッケージ section0315 を作り、その中に最初の JavaFX のプログラム JavaFXExample01.java を作成しましょう。
ソースコード 3.111 JavaFXExample01.java (初めての JavaFX)
package section0315;
import javafx.application.Application;
import javafx.event.ActionEvent;
import javafx.event.EventHandler;
import javafx.scene.Scene;
import javafx.scene.control.Button;
import javafx.scene.layout.BorderPane;
import javafx.stage.Stage;
public class JavaFXSample01 extends Application {
public static void main(String[] args) {
showThreadInfo( "main" );
launch( args );
}
@Override
public void init() throws Exception {
showThreadInfo( "init" );
}
@Override
public void start(Stage primaryStage) throws Exception {
showThreadInfo( "start" );
Button button = new Button();
button.setText( "Say 'Hello World'" );
button.setOnAction(new EventHandler<ActionEvent>() {
public void handle( ActionEvent event ) {

3.15 JavaFX とマルチメディア (執筆中) 255
System.out.println( "Hello World!" );
}
});
BorderPane pane = new BorderPane();
pane.setCenter( button );
Scene scene = new Scene( pane, 300, 250 );
primaryStage.setTitle( "Hello World!" );
primaryStage.setScene( scene );
primaryStage.show();
System.out.println( " main : stop" );
}
@Override
public void stop() throws Exception {
showThreadInfo( "stop" );
}
// スレッド情報の出力メソッドstatic void showThreadInfo(String label) {
Thread thread = Thread.currentThread();
System.out.printf("%5s : id=%2d name=%s%n", label, thread.getId(),
thread.getName());
}
}
図 3.20 初めての JavaFX
実行すると、中央にボタンが1つある窓が表示されます。ボタンをクリックすると、コンソールに文字列が表示されます。これまでのプログラムと違って、プログラムが最後まで実行されると自動で停止する!とはいきません。窓もしくはコンソールの停止ボタンをクリックして初めてプログラムは停止します。コンソールには、各メソッド内で呼び出される showThreadInfo メソッドの出力(実行されたスレッドのスレッド id とスレッド名) が表示されています。
main : id= 1 name=main
init : id=14 name=JavaFX-Launcher
start : id=12 name=JavaFX Application Thread
main : stop
Hello World!
Hello World!
stop : id=12 name=JavaFX Application Thread
窓を閉じずに再度プログラムを実行させると、新らたな窓が出現し、それぞれの窓が独立に実行されていることがわかります (全ての窓を閉じて停止させること)。JavaFX アプリケーションでは、 main メソッドの入ったクラスは必ず javafx.application.Application クラ

256 第 3章 Java 言語の基本的な文法 II
スを継承させないといけません。Application クラスは次のようなメソッドを持つ抽象クラス (start メソッドが抽象メソッド) です。従って、抽象メソッド start を必ずオーバーライドすることになります。
メソッド 説明void init() 初期化処理(デフォルトでは何もしない)abstract void start(Stage)
throws Exception
この中身が実行される。引数の Stage クラスのオブジェクト上にコンテンツを配置していくことになる
void stop() 終了時の後処理(デフォルトでは何もしない)static void launch(String...) JavaFX スレッドを起動するためのメソッド。main から呼ばれて main
メソッドの引数をその引数に引き継ぐ
表 3.15.1 Application クラス
main(String[])
launch(String. . .) init() start(Stage) stop()
図 3.21 Application クラスのメソッドの呼び出し順
ところで、JavaFX プログラムは、これまでのプログラムと違って main メソッドを必ずしも書く必要がありません。コンパイラが陰に launch メソッドを呼び出すだけの main メソッドを作ってくれるからです(つまり、このプログラムの main メソッドを消しても、実はちゃんと動きます)。しかし、操作環境によってはコンパイラがそれらの操作を行わない場合もあるので、通常は main メソッドを記述し、その中で launch メソッドを呼び出します。launch メソッドが実行されると、自動的に init メソッドが呼び出され、初期化処理が行われます。何か前処理を行いたいときはこのメソッドをオーバーライドします。init メソッドが終了すると、次は start メソッドが自動的に呼び出されます。この start メソッドの中身が実際の処理内容となります。start メソッドは引数として Stage クラスのインスタンス (窓の情報) を受け取り、その show メソッドを使って窓を表示します (show メソッドが無いと窓は作られても表示されません)。そして、窓を閉じるなどの終了処理に入ると stop メソッドが呼び出されて、メモリのクリーンアップなどの後処理が行われます。
クラス 説明Stage 表示される窓に対応するクラス。デフォルトのステージインスタンスが
Application クラス内で自動生成され、start メソッドの引数として渡される
Scene 窓の中の表示領域に対応するクラス。シーングラフを保持するためのコンテナ (?)で、ウィンドウの表示領域のサイズとシーングラフのルート・ノードを決定する
Node シーン内に描写する全てのオブジェクトのデータを保持する木構造 (シーングラフ) を構成するノードクラス
表 3.15.2 基本となる3つのクラス

3.15 JavaFX とマルチメディア (執筆中) 257
図 3.22 3つのクラス
プログラム JavaFXExample01.java では start メソッドの引数に与えられる Stage クラスのインスタンスprimaryStage が表示される窓に対応します。この primaryStage の上に諸々の部品を置いていくわけですが、それら部品のことを「コンポーネント (components)」と言います。コンポーネントの中には、他のコンポーネントをその上に配置できるものがあり、それらを特に「コンテナ (container)」と呼びます。主に Pane クラスのサブクラスがコンテナですが (図 3.23 参照)、Stage の上に直接 Pane 系のコンテナを置くのではなく、一旦 Scene クラスというシーングラフを保持するためのクラスのコンポーネントを置き、その上に様々なコンポーネントを配置していきます(上にコンポーネントを置く、という意味では Stage や Scene もコンテナである、と言えます)。プログラム JavaFXExample01.java では、BorderPane pane = new BorderPane(); というレイアウトを決めるコンテナを Scene scene = new Scene( pane, 300, 250 ); と Scene クラスのコンストラクタに渡して、横 300
縦 250 の白紙の領域を作っています。そして、pane の上にボタンが置かれています。
3.15.2 Stage クラス
start メソッドの引数に与えられている Stage クラスのオブジェクトが窓となります。窓には既に「最大化ボックス」「最小化ボックス」「クローズボックス」が付けられています。Stage クラスのインスタンスを複数作れば、複数の窓を作れます。次のプログラム JavaFXExample02 では、Stage クラスの様々な属性を設定しています。窓のタイトルを設定し、窓の大きさを変更可にしています。実はこの命令を書かなくても、デフォルトは変更可です。引数を false にすれば、窓の大きさを変更不可にできます。次に、初期サイズと最大幅・最小幅を定義しています。同じように最大高・最小高も定義できます。このサイズは、タイトルバーや枠を含めた大きさなので、環境が代わる場合に (Windows と MacOS ではタイトルバーや枠の幅が異なるので) 注意が必要です。窓の大きさの設定の方法には他にもいろいろありますから各自調べてみて下さい。
ソースコード 3.112 JavaFXExample02.java (窓の大きさを設定)
package section0315;
import javafx.application.Application;
import javafx.stage.Stage;
public class JavaFXExample02 extends Application {
public static void main(String[] args) {

258 第 3章 Java 言語の基本的な文法 II
javafx.scene
Node
Parent
Group
Camera
LightBase
SubScene
Cursor
Canvas
javafx.scene.canvas
ImageView
javafx.scene.image
Scene
Region
javafx.scene.layout
Control
javafx.scene.control
MediaView
javafx.scene.media
Shape3D
javafx.scene.shape
Shape
javafx.scene.shape
Control
javafx.scene.control
Button CheckBox LabelRadioButton ScrollBar Slider TextArea
Pane
Pane
javafx.scene.layout
AnchorPane BorderPane DialogPane FlowPane
GridPane
HBox VBox
StackPane TilePane
TextFlow
javafx.stage
Stage
Window
PopupWindow
FileChooser
Popup
WindowEvent
図 3.23 javaFX パッケージ群
launch(args);
}
@Override
public void start(Stage primaryStage) throws Exception {
// 窓のタイトルを設定primaryStage.setTitle( "窓の大きさを設定" );
// 窓の大きさを変更可 (= true)
primaryStage.setResizable( true );
// 初期サイズ 480 × 240
primaryStage.setWidth( 480 );
primaryStage.setHeight( 240 );
// 最大幅 640, 最小幅 360
primaryStage.setMaxWidth( 640 );
primaryStage.setMinWidth( 360 );

3.15 JavaFX とマルチメディア (執筆中) 259
// で、表示!primaryStage.show();
}
}
属性 デフォルト値 説明alwaysOnTop false 窓を他の窓より前面に表示するとき true
fullScreenExitKey 全画面の終了キーの組合せのプロパティを取得fullScreen false フルスクリーンのときに true
iconified false アイコン表示のとき true
maxWidth, maxHeight Double.MAX_VALUE 窓の最大の幅と高さを指定minWidth, minHeight 0 窓の最小の幅と高さを指定width, height 0 窓の幅と高さを指定resizable true 窓のサイズ変更を不可にするとき false
title 空文字列 窓のタイトルを指定opacity 1.0 窓の不透明度を 0.0~1.0 で指定scene null 現在指定されているシーンx, y 窓のスクリーン上での水平位置と垂直位置
表 3.15.3 Stage クラスの主な属性
表 3.15.3 は Stage の代表的な属性 (いずれも public final なフィールド) です。これらの属性に値を設定するセッターや値を取得するゲッターもしくは is型メソッドが用意されています。次は複数の窓を作るプログラム JavaFXExample03.java です。
ソースコード 3.113 JavaFXExample03.java (複数の窓を作成)
package section0315;
import javafx.application.Application;
import javafx.scene.Scene;
import javafx.scene.layout.FlowPane;
import javafx.scene.paint.Color;
import javafx.stage.Stage;
public class JavaFXExample03 extends Application {
public static void main(String[] args) {
launch(args);
}
@Override
public void start(Stage primaryStage) throws Exception {
primaryStage.setTitle( "メインウィンドウ" );
primaryStage.setWidth( 640 );
primaryStage.setHeight( 480 );
primaryStage.show();
Stage newStage = new Stage();
newStage.setTitle( "サブウィンドウ" );
newStage.setWidth( 320 );
newStage.setHeight( 240 );
newStage.setAlwaysOnTop(true); // 常に最も上に表示されるようにnewStage.setResizable(false); // 窓の大きさを変更できなくするnewStage.show();

260 第 3章 Java 言語の基本的な文法 II
Stage newStage2 = new Stage();
newStage2.setTitle( "シーン有りウィンドウ" );
newStage2.setScene( new Scene(new FlowPane(), 480, 360, Color.PINK ) );
newStage2.show();
}
}
図 3.24 3つの窓
3 つの窓を作っています (図 3.24 参照)。start メソッドの引数から受け取った窓が最も大きな窓「メインウィンドウ」で、デフォルトの窓の作り方で表示しています。次に最も小さな窓「サブウィンドウ」を、常に最も上に存在するように設定しました。この窓はサイズを変更することができません (setResizable(false)) 。最後の「シーン有りウィンドウ」は Scene を設定したものです。今回は、Scene の上に何も部品を載せていないので、コンテナとして FlowPane を選んでいますが、特に意味はありません。ここでは、大きさと背景色のピンクを指定しています (一般に Stage には直接色を付けられません)。Scene をセットすると窓の大きさがその大きさに合わされます。
3.15.3 Scene クラス
Stage クラスで窓を作りますが、その中に部品を置くにはコンテナとして Scene クラスを使います。一般的に、Stage インスタンスの setScene メソッドに Scene オブジェクトを渡して生成します。Scene にコンポーネントを配置する場合、Scenegraph という部品の相互位置関係を木構造で記憶させる方式をとります。最初にルートとなるレイアウトオブジェクトを置き、その中に様々な GUI 要素を配置していきます。GUI 要素、例
えばボタンやラベルなどの表示物は、相互の位置関係などを木構造として記憶され、レイアウト (先に紹介した VBox
などの6種類) がその最上位の概念 (ルート) となるわけです。シーンは、窓であるステージとは別に後で変更することも出来ます。レイアウトが決まったシーンはsetScene メソッドでは、

3.16 列挙型 261
Stage 内に並べる視覚的な部品を「コントロール」と呼びます。このプログラムでは、 Label と Button という2つのコントロールを縦に並べています。コントロールの並べ方 (レイアウト) には、直接位置を指定して並べる方法以外に、次の 6 種類の方法があります。
VBox 縦一列に並べる。領域からはみ出したものは表示しない (今回はこれを使用)
HBox 横一列に並べる。領域からはみ出したものは表示しないAnchorPane 領域の境界からの位置を指定して配置するFlowPane 横優先で並べ、はみ出した場合は次の段に流し込むように下方向に拡張するBorderPane 領域の上下左右及び中央の5つの場所の指定場所に配置するGridPane 縦横格子状の指定場所に配置する
表 3.15.4 レイアウトクラス
3.15.4 SceneGraph
3.16 列挙型3.16.1 タイプセーフな一連の定数
Java には、int や double などの「基本型」とクラス・インタフェース・文字列・配列などの「参照型」の 2 種類がありますが、Java 5 でもう一つ新しい「列挙型」(enumerated type) が導入されました (実際は、コンパイラが裏でクラス型にコンパイルするので、参照型の一種と思って良いのですが)。列挙型は、有限個の「定数」をオブジェクトとして列挙定義するもので、一連の定数を安全に処理できるようになります。既に C や C++で提供されていた enum 型をタイプセーフなクラス型として導入したものです。列挙する(enumerate) はイニューメレイトと発音するので、 enum はイニュームと読むべきでしょうが、一般的には「イナム」と呼ばれている。タイプセーフはジェネリックスの登場理由でもありましたね。
ソースコード 3.114 PlayCardExample01.java (タイプセーフでない列挙)
package section0316;
public class PlayCardExample01 {
public static void main(String[] args) {
// ハートの8Card1 card = new Card1( Card1.HEARTS, 8 );
System.out.println( card.toString() );
}
}
// トランプカードclass Card1 {
int suit; // 絵柄int number; // 数static final int CLUBS = 0;
static final int DIAMONDS = 1;
static final int HEARTS = 2;
static final int SPADES = 3;
Card1( int suit, int number ) {
this.suit = suit;
this.number = number;
}
public String toString() {

262 第 3章 Java 言語の基本的な文法 II
String suitName = null;
switch( this.suit ) {
case CLUBS:
suitName = "クラブ"; break;
case DIAMONDS:
suitName = "ダイヤ"; break;
case HEARTS:
suitName = "ハート"; break;
case SPADES:
suitName = "スペード"; break;
default:
throw new IllegalArgumentException();
}
return suitName + "の" + this.number;
}
}
このプログラムの問題点は、
• トランプの絵柄の指定に、任意の int 値を渡すことができること (Card1 card = new Card1( 5, 8 ); )
• 従って、4 つの値 0, 1, 2, 3 以外の値の場合を例外処理しなければならない• 4 つの定数に与えられている int 値に特に意味がないのでプログラムが美しくない• 4 つの定数はコンパイル時に単なる int 値として bin ファイルに埋め込まれてしまうので、これらを変更すると (static final int CLUBS = 4;) 参照している他のクラスを再度コンパイルし直さないといけない
などが挙げられます。つまり、このプログラムはタイプセーフでないわけです。列挙型導入前も次のプログラムのようにすれば、タイプセーフな書き方は出来ました。
ソースコード 3.115 PlayCardExample02.java (タイプセーフな列挙)
package section0316;
public class PlayCardExample02 {
public static void main(String[] args) {
Card2 card = new Card2( Card2.Suit.HEARTS, 8 );
System.out.println( card.toString() );
}
}
class Card2 {
Suit suit;
int number;
Card2( Suit suit, int number ) {
this.suit = suit;
this.number = number;
}
public String toString() {
return this.suit.suitName + ":" + this.number;
}
// ネストクラスによる絵柄static class Suit {
private final String suitName;
static final Suit CLUBS = new Suit("クラブ");
static final Suit DIAMONDS = new Suit("ダイア");
static final Suit HEARTS = new Suit("ハート");
static final Suit SPADES = new Suit("スペード");
private Suit( String suitName ) { // 外部からインスタンスを生成させない

3.16 列挙型 263
this.suitName = suitName;
}
}
}
Card2 クラス内にネストクラス Suit を置き、Card2 のコンストラクタでは、Suit クラスのインスタンスを受け取るようにしています。また、Suit クラスのコンストラクタを private とすることで、Suit クラスの 4 つの定数以外を作成することも出来なくしており、安全なプログラムになっていると言えます。Java 5 では、これらの処理をより簡便にしてくれる enum 型が導入されました。enum 型は、抽象クラス
java.lang.Enum を継承したクラスとしてコンパイルされます。なお、ここでは、 enum 型の Suit を Card3 クラスの内部クラス (内部 enum ?) として定義しています。別に、(外部)列挙型で定義してもよいのですが、やはり絵柄はトランプカードの属性でもあるので、内部ですかね。
ソースコード 3.116 PlayCardExample new.java (enum による実現)
package section0316;
public class PlayCardExample3 {
public static void main(String[] args) {
Card3 card = new Card3( Card3.Suit.HEARTS, 8 );
System.out.println( card.toString() );
// Card3.Suit.suitPrint();
}
}
class Card3 {
int number;
Suit suit;
Card3( Suit suit, int number ) {
this.suit = suit;
this.number = number;
}
public String toString() {
return this.suit.toString() + ":" + this.number;
}
// (内部)列挙型による絵柄enum Suit {
// 列挙子 (定数)
CLUBS("クラブ"),
DIAMONDS("ダイア"),
HEARTS("ハート"),
SPADES("スペード"); // 以下がない場合はセミコロンは省略できる// フィールドprivate final String name;
// コンストラクタprivate Suit( String name ) {
this.name = name;
}
// メソッドstatic void suitPrint() {
for( Suit suit : Suit.values()) {
System.out.printf( "[%d] %s(%s)%n", suit.ordinal(), suit.name(),
suit.name );
}
}
}

264 第 3章 Java 言語の基本的な文法 II
}
列挙型は、クラスの宣言 class クラス名 { } と同じように enum 列挙型名 { } と宣言します。ブロックの中、最初に列挙する定数 (列挙子という) をカンマで並べ、必要なら (無くても良い) フィールド・コンストラクタ・メソッドなどのメンバーを続けて置きます。各列挙子は定数なので、定数の命名規則に基づいて全て大文字にし、コンストラクタを定義する場合は、それに渡す引数を小カッコに入れます。このプログラムが先の2つのプログラムより簡潔で安全であることを考察して下さい。コメントで殺してある部分を活かすと、列挙型には ordinal() や name() などのメソッドが既に定義されていることがわかります。ordinary() メソッドはその列挙定数が何番目に定義されているものかを、 name() はその列挙定数名をフィールド name とは別に返してくれます。
3.16.2 enum 定数のインポート
enum 型の各項目は静的なクラス変数と言えたので静的インポートすることができ、表示を簡略化することができます。
ソースコード 3.117 RGBColor.java (列挙型で色)
package section0316;
public enum RGBColor {
RED( "赤", 0xff0000 ),
GREEN( "緑", 0x00ff00 ),
BLUE( "青", 0x0000ff );
String jname;
int value;
RGBColor( String jname, int value ) {
this.jname = jname;
this.value = value;
}
@Override
public String toString() {
return jname + "(" + String.format("%06x", Value) + ")";
}
}
ソースコード 3.118 EnumImportExample.java (列挙型をインポート)
package section0316;
import static section0316.RGBColor.*;
public class EnumImportExample {
public static void main(String[] args) {
RGBColor c = GREEN; // RGBColor.GREEN とせずに済んでいるSystem.out.println( "選択した色は、" + c.toString() );
}
}
3.17 アノテーション「アノテーション (annotation)」は、パッケージ・クラス・メソッドなどに対してメタ情報を付加するために Java
5 で導入されたもので、それ自身が何かを行うのではなく、ほかのツール (例えば Eclipse) がアノテーションを読み

3.17 アノテーション 265
取って何らかの処理を行うためのものです。将来的には、これらを用いてソフトウェア開発の負荷を減らすことを目的としていますが、現状ではあまり利用されていません (Eclipse はいくらか使っている)。アノテーションは、クラスやフィールド、変数などのメンバーの宣言の際に「修飾子」として付加します。慣例的に全ての修飾子より前に書くことになっていて、以下の例のように1行独立に書かれることが多いです。アノテーションはアットマーク @ で始まるタグで表記し、引数を持つものもあり、また自作することもできます。正確に言うと、アノテーションは java.lang.annotation.Annotation というインタフェースの実装クラスです。java.lang に宣言されているそれら継承クラス (標準アノテーション) はインポートの必要なく使えますが、それ以外に宣言されているアノテーションはインポートの必要があります。アノテーションの自作についてはこのテキストでは解説しませんので、各自調べてみて下さい。ここでは、代表的な標準アノテーション 3 種について触れます。
3.17.1 @Deprecated
@Deprecated は、従来 Javadoc のタグ @deprecated で示していた「非推奨」をアノテーションでも指定できるようにしたものです。何らかの理由で「使用は可能であるが、使うべきでない!」というのが非推奨の意味で、Javadoc
ではその理由を文字列で指定しますが、アノテーションでは、注意喚起するのみです。
ソースコード 3.119 DeprecatedExample.java (アノテーション:非推奨)
package section0317;
public class DeprecatedExample {
public static void main(String[] args) {
System.out.println( plus(1, 2) );
System.out.println( add(1, 2) );
}
// plus から add に変更するが plus も取り敢えず残しておく@Deprecated
public static int plus(int a, int b) { return a + b; }
public static int add(int a, int b) { return a + b; }
}
このプログラムでは、メソッド名の改変 (plus → add) 、Eclipse はメソッド plus に取り消し線を引いて、非推奨を喚起してくれますが、使用することに例外を出したりはしません。
3.17.2 @Override
@Override が書かれたメソッドはオーバーライドされていることを意味します (これはこれまでも使いましたね)。コンパイラは、そのメソッドがオーバーライドされていない場合にコンパイルエラーを表示してくれます。例えば、コーディングミスでメソッド名を誤ったり引数が異なったりした場合に気づかせてくれます。以下のプログラムでは、オーバーライドしたつもりが、引数が異なるのでオーバーロードになってしまって、アノテーションなしではエラーが表示されませんが、アノテーションを付けることで、コンパイルエラーを表示してくれます。
public class A {
public void print() { /* 省略 */ }
}
class B extends A {
@Override
public void print( int x ) { /* 省略 */ }
}

266 第 3章 Java 言語の基本的な文法 II
3.17.3 @SuppressWarnings
@SuppressWarnings は引数を持つアノテーションで、コンパイラが出す警告メッセージ (Warning) を抑制するために使います。コンパイラの出す警告メッセージの原因をプログラマが理解した上で、ソース・コードを修正せずにメッセージの表示を停止させる場合に書きます。以下のプログラムでは、宣言された変数 aLength が使用されていないので、Eclipse は黄色のランプを表示します。授業で用いる例題では、こうした使わないけど宣言するということが多いので、アノテーションをつけて黄色ランプを消しています。一方、整数配列 a に付けたアノテーションは alength への代入文で a が利用されているので、無駄なアノテーションであると逆に警告メッセージが表示されます。
public static void main(String[] args) {
@SuppressWarnings("unused")
int[] a = { 1, 2, 3 };
@SuppressWarnings("unused")
int aLength = a.length;
}
3.18 可変長パラメータこれまで使ってきたメソッドの中で、System.out.printf メソッドの不思議に気づいた人はいますか?
int x = 100;
int y = 200;
System.out.printf( "x = %d%n", x );
System.out.printf( "%d + %d = %d%n", x, y, (x+y) );
printf メソッドは第 1 引数に出力フォーマットを持つことは周知かと思いますが、それに続く引数は 1 個だったり3 個だったり。これはどのように処理しているのでしょうか。複数の printf を用意するオーバーロードでしょうか?いいえ、これには Java 5 から導入された「可変長パラメータ (variable arity parameter)」が使われています。(arity
とは関数や処理での「引数の数」を意味する言葉です)
メソッドの引数に可変長パラメータを用いると、引数には任意個の変数を宣言することができます。
ソースコード 3.120 VariableArityExample.java (可変長パラメータの例)
package section0318;
public class VariableArityExample {
public static void main(String[] args) {
System.out.println( "sum(1, 2) = " + sum( 1, 2 ) );
System.out.println( "sum(1, 2, 3) = " + sum( 1, 2, 3 ) );
// {11, 12, 13, 14, 15} の [2]番目を求めるcheck( 2, 11, 12, 13, 14, 15 );
}
static int sum( int... x ) {
int sum = 0;
for(int i : x) {
sum += i;
}
return sum;
}
static void check( int n, int... x ) {
System.out.printf( "x[%d] = %d%n", n, x[n] );

3.18 可変長パラメータ 267
}
}
なんだ、配列と同じようなことやってるだけじゃん!と思われそうですが、とりあえず。整数型の可変長パラメータを宣言するのに、int... x と型名 int の後にドットを 3 つ打っています。メソッドの仮引数に可変長パラメータを使う場合、残念ながら複数のパラメータに適応させることはできません。つまり、sum( int... x, int... y )
なるメソッドは作れないのです (何故って、x と y の境界が分からないから)。同様に、複数のパラメータを持つ場合に可変長パラメータはパラメータの最後でないといけません。sum( int x, int... y ) はOKだけど、sum(
int... x, int y ) はダメなんです。コンパイラがパラメータの後ろからも読みこんでくれれば良いのにダメなんですね。可変長パラメータで読み込んだ値は配列に格納され、その個数は .length で利用できます (上の例だと x.length
は5)。配列ということは、長さ 0 の配列もありえますね。つまり、上のプログラムで sum() というのもアリなわけですし、 check( 2 ); もアリになります。後者はこのままでは ArrayIndexOutOfBoundsException の実行エラーが発生してしまいますので、何らかの対処が必要ですね。

第 III部
– 付録 –

Apx.2
付録A
コンピュータ内の数の表現
A.1 2・8・16 進数10 進数は知っていますよね。10 進数には 10 という数字はありません。0 から 9 までの 10 種類の文字で数を表し、
9 より 1 大きい数は 1 文字で表せないので、繰り上がらせて 2 桁の文字を用いて 10 と表しています(人間の手の指の数が 10 本だったから 10 進数に、が定説ですが、もし人間の指が 11 本だったら、どうなっていたでしょうね...)。さて、整数の 2 進数表現は高校で習いましたか? (図 A.1 参照)
図 A.1 2進数表示
2 進数の世界では 2 という数字は無く、0 と 1 のみで数を表現します。従って、0, 1 の次は繰り上がりが起こって 2
桁の 10 となります。コンピュータの内部では、データもプログラムも全て電気信号です。それは、電気が流れているか流れていないか、
記憶媒体に正の電荷と負の電荷のどちらが記憶されているか、など 2 つの値で状態を表現するに適した環境です。従って、コンピュータでは 2 進数を用いて情報を扱うのが便利!ということで、全ての情報が 2 進数で表現されています。(電荷の段階を 2 段階でなく 10 段階に分離すれば 10 進数コンピュータが設計できます。実際に、かつて 10 進コンピュータもありました)では、8 進数表現は想像できますか? (図 A.2 参照) そして、16 進数表現は? (図 A.3 参照)
16 進数は 0~9 だけでは数字が足りないので、一般に A~F (小文字でも良い) を追加して 0~F で 16 種類の数値を表します。

A.2 基数変換 Apx.3
図 A.2 8進数表示
図 A.3 16 進数表示
問題 A.1.1. 10 進数の 1234 を 2 進数、8 進数、16 進数表示でそれぞれ表しなさい。
コンピュータや情報の世界では、10 進数表示の値と区別するため 8 進数表示は数値の先頭に余分の 0 を付けて 0172
などと書き、16 進数表示は数値の先頭に 0x (x は hexadecimal:16 進数の略)を付けて 0x7a や 0x7A と書いたりします。この 2 進数 1 桁分を 1 bit(ビット) と言い、8 bits を 1 つのまとまりとして 1 byte(バイト) と言います。
A.2 基数変換2 や 8 や 10 や 16 のことを基数と言います。2 進数表示の数を 10 進数表示に変換したり、16 進数表示を 8 進数表示に変換したりすることを、基数変換と言います。ここでは、基数変換の方法を学びましょう。

Apx.4 付録 A コンピュータ内の数の表現
A.2.1 10 進数から 2 進数
まず、10 進数表示を 2 進数表示に変換するのは簡単。どんどん 2 で割っては、余りを右から左に並べていけば良いのです。これで上手くいくことを、各自確かめて下さい。
2 ) 1 0 5
2 ) 5 2 ・・・1
2 ) 2 6 ・・・0
2 ) 1 3 ・・・0
2 ) 6 ・・・1
2 ) 3 ・・・0
2 ) 1 ・・・1
0 ・・・1
1101001₂
図 A.4 10 進数から 2 進数
A.2.2 2 進数から 10 進数
では、逆に 2 進数表示を 10 進数表示に変換するのは?こちらはちょっと手間がかかります。1 の立っている位の 2
のべき
冪を全て加えるのです。但し、この方法はコンピュータに行わせるには少々無駄で、アルゴリズムとしてもスマート
図 A.5 2 進数から 10 進数
ではありませんね。コンピュータ・アルゴリズムとしては、次の方法がスマートです。これで上手くいくことを、各自確かめて下さい。

A.3 実数の基数表示 Apx.5
与えられた n 桁の 2 進数を b1b2b3 · · · bn とするx ← 0
x ← 2x + bi, (i = 1, 2, . . . , n)x を与えられた数の 10 進数として出力する
A.2.3 2 進数と 8 進数
次は、2 進数表示と 8 進数表示の変換です。これは、これまで以上に簡単で、2 進数を下位から順に 3 桁ずつ区切ってそれぞれを 8 進数に変換すれば良いのです。最高位の桁数が 3 桁に満たなければ頭に 0 を付けて考えれば良い。逆に、8 進数表示から 2 進数表示に変換するには、8 進数の各桁を 3 桁の 2 進数表示に変換して並べれば完成です。
図 A.6 2 進数と 8 進数
問題 A.2.1.
1. 2 進数表示と 16 進数表示の変換を 2 進数表示と 8 進数表示の変換を参考に構成しなさい。2. 今年の西暦を 2 進数、8 進数、16 進数表示でそれぞれ表しなさい。3. 16 進数の A3 を 8 進数表示で表しなさい。
A.3 実数の基数表示ここでは、2 · 8 · 16 進数表示での「実数」を定義します。
10 進数の小数の定義を思い返すと、0.1 は「1 の 10 分の 1」、0.01 は「1 の 100 分の 1」・・・でした。つまり、p 進数表示での 0.1 は「1 の p 分の 1 (= p−1)」、 0.01 は「1 の p2 分の 1 (= p−2)」と考えれば良さそうです。
A.3.1 2 進小数と 10 進小数
つまり、ちょっと手間がかかりますが、次のように 2 進数表示の小数から 10 進数表示に変換できそうです。

Apx.6 付録 A コンピュータ内の数の表現
図 A.7 2 進小数から 10 進小数
そして、10 進数表示の小数は、2 進数表示の小数に次のよう変換できます。まず、与えられた数を 2 倍するとどうなるか考えて下さい。(図 A.8 参照) 2 進数表示では、数を 2 倍すると 1 桁左へシフトされます。つまり、2 進数表示の小数部 1 桁目に 1 が立っている場合、数を 2 倍すると、整数部に 1 がシフトされてくる( 1 より大きな値になる)ということです。
0.828125 = 0.1101012
= 2-1
+ 2-2
+ 2-4
+ 2-6
0.828125 × 2
= 20 + 2
-1 + 2
-3 + 2
-5
= 1.101012
図 A.8 2 進数小数の 2 倍
このことから、以下のように小数部を 2 倍して整数部にシフトされた値を順に並べる、という作業で変換できることがわかります。(図 A.9 参照)
図 A.9 10 進数小数から 2 進数小数
A.3.2 2 進小数から 8 進小数
2進数表示の小数を 8 進数表示の小数に変換するには、整数のときと同じように 3 桁ずつ 8 進数に変換します。その逆は想像できますよね。

A.4 2 進数の桁数 Apx.7
図 A.10 2 進小数から 8 進小数
問題 A.3.1.
1. 30.140625 を 2 進数表示で表しなさい。2. 0.1 を 2 進数表示で表しなさい。3. 上の結果を考察して、有限桁の 2 進小数に変換できない簡単な 10 進実数をもう1つ書きなさい。
A.4 2 進数の桁数ちょっと寄り道です。
n 桁の 10 進整数を 2 進数表示すると、何桁になるでしょう。それを求めるため、次の表を解析してみます。
図 A.11 2 進数の桁数
この表より、与えられた基数 p での数値の logp の値を求めれば、おおよその桁数が求められることがわかります。
問題 A.4.1.
1. 与えられた実数 n の p 進数表示の桁数を logp とガウス記号 (小数部の切り捨て) [ ] を用いた式で表しなさい。2. 3.32 < log2 10 < 3.33 であることを用いて、整数 12345678 の 2 進数表示がおおよそ何桁になるかを求めよ。

Apx.8 付録 A コンピュータ内の数の表現
A.5 コンピュータ内の計算先に述べたように、2 進数の 2 倍や 2 分の 1 (= 2−1 倍) は、小数点を右もしくは左に 1 bit 分シフトすることに対応しました。従って、コンピュータ内での 2 の
べき
冪計算はシフト計算で高速に行えます。(図 A.12 参照) さらに、乗算、例えば 2.5 倍する (2 進数の世界で 10.12 倍する) という操作は、加算とシフトで実現できます。この程度なら高速に計算できますが、一般に乗算は加算に比べて格段に時間がかかる操作です。
図 A.12 2.5 倍の計算
A.6 コンピュータ内の数コンピュータは、1 度に扱える 2 進数の桁数によって、32 bits マシンとか 64 bits マシンとか呼ばれます。自分のパソコンがどちらなのかは、Windows OS の場合、「コントロールパネル>システムとセキュリティ>システム」で知ることができます。なお、64 bits マシンでも、ソフトウェアが 32 bits 用だと 32 bits Emulator (エミュレータ:模倣ソフト) によって 32 bits マシンのように動きます。もちろん負の数も表したいので、コンピュータの中では最高位の 1 bit は符号のために使われます(正なら 0、負なら 1 とする)。以下では、説明が容易になるように、架空の 16 bits マシンを想定します。そこでは、整数は 16 bits で表現されます。さて、16 bits マシンでの正の最大整数の値は幾つでしょう?正の数なので、最高位は 0 そして残りの bits に全て 1
の立った数が最大値ですから、111|1111|1111|11112 = 214 + 213 + · · ·+ 22 + 21 + 1 = 215 − 1 = 32767 となります。(図 A.13 参照)
問題 A.6.1. 32 · 64 bits マシンで扱える正の最大整数の値をそれぞれ求めなさい(2 の冪を使った式で表せば良い)。

A.7 2 の補数表現 Apx.9
正の最大整数
図 A.13 16 bits の整数
A.7 2 の補数表現コンピュータ内で負の整数を表す場合、多くは『 2 の補数表現』という方式を用います (一般の表現を真数表現と言
う)。再度、架空の 16 bits マシンで負の数 −100 を考えてみましょう。−100 とは、100 に加えると 0 になるような数ですから、次のように表現すれば都合が良いと思われます。
図 A.14 補数表現
上のように −100 の 2 進表示を定義すると 100 + (−100) の 17 bits の値は、16 bits に収まらず最高位の 1 が消されてしまいます。このように定義された負の数の 2 進数表示を 2 の補数表現と言います。この数は、与えられた数の2 進数表示において、最も下位に立っている 1 を除いて、それより上位の bits 全ての 0 と 1 を逆転させれば求まります。
問題 A.7.1.
1. 16 bits マシンにおいて、−3000 を 2 の補数表現を用いた 2 進数として表しなさい。2. 16 bits マシンにおける負の整数で絶対値最大の値を求めなさい。

Apx.10 付録 A コンピュータ内の数の表現
A.8 実数の表現方法実数の表現方法には 2 種類あります。
• 0.00123 のような 固定小数点数表示 (Fixed Decimal Point Number)
• 0.123× 10−2 のような 浮動小数点数表示 (Floating Decimal Point Number)
コンピュータ科学では、浮動小数点数表示の数を 0.123E-2 と書くことが多いです。この E は指数 (Exponential) の略号で、Java でもこの書き方が使えます。ちなみに、コンピュータ内では、実数は全て、この浮動小数点数で扱われます。もちろん基数は 2 です。例えば、12.375 = 1100.0112 = 0.11000112×21002 となります。このとき、0.11000112 の部分を仮数部 (Mantissa)、
2 の肩の 1002 の部分を 指数部 (Exponent) と呼びます。この呼び方は 10 進数での浮動小数点数表示でも同じです。以下の図は、16 bits マシンで 12.375 を表現したものです。(図 A.15 参照)
図 A.15 16 bits マシンでの 12.375
A.9 IEEE 754
コンピュータ内の浮動小数点数表示には多くの方式があり、その中で最も広く採用されている規格が IEEE 754 です。IEEE は「あいとりぷるいー」と読み、アメリカ電気電子学会 (Institude of Electrical and Elctrinics Engineers)
の略号です。IEEE 754 では、単精度実数を 32 bits で、倍精度実数を 64 bits で表現します。bits 数が多いほど情報 (表現できる桁数) が多くなります。IEEE 754 では、先に説明した 2 の補数表現は使用しません。>おやおや! (^^;)
その代わりとして (この後で説明する) バイアス値 127 を使用します。
A.9.1 IEEE 754 の単精度実数
バイアスとは、実際の値にある固定値(この場合 127)を加えて、指数部の符号を無くす操作です。このおかげで表現できる範囲が増えます。IEEE 754 の単精度実数の様子は以下のように、数の符号 (1 bit)・バイアスを加えた指数部 (8 bits)・そして正規化した仮数部 (23 bits) の合計 32 bits となっています。(図 A.16 参照)
−118.625 を例にして、どのように記憶されるか見てみましょう。
• まず、負の数なので最初の 1 bit は 1 です• 絶対値 118.625 を 2 進数で表すと、1110110.101 になります

A.9 IEEE 754 Apx.11
• 整数部が 1 となるように小数点を移動すると 1.110110101× 26 (これを正規化と言います)
• 整数部の 1 を省き (これでちょっとエコ)、仮数部を作る• 指数部にバイアス (127) を加える 6 + 127 = 133 = 100001012
図 A.16 IEEE 754 の単精度実数
記憶された値を本来の数に戻す操作は、この手順を逆にたどれば良いわけです。
問題 A.9.1.
次の IEEE 754 の単精度実数 32 bits が表している実数を求めなさい。(符号・指数部・仮数部を区別するため | を入れました)
0|1000 0011|0101 1011 0000 0000 0000 0000
問題 A.9.2.
1. IEEE 754 の倍精度実数 64 bits は、符号に 1 bit、指数部 11 bits、仮数部 52 bits、指数部のバイアスに 1023
を使います。このルールで、14.5 がどのように記憶されるか求めなさい。2. IEEE 754 の単精度実数 32 bits として、0.1 を表しなさい。
指数部の値によって、特殊な値も表現します。(表 A.9.1 参照) なお、NaN は Not a Number の意味で、不正な結果や未定義な結果を表します。
種類 符号 指数部 仮数部正規化数 0 / 1 1 ~ 254 0 ~ 223 − 1
ゼロ 0 / 1 0 0
非正規化数 0 / 1 0 0 以外無限大 0 / 1 255 0
NaN 0 / 1 255 0 以外
表 A.9.1 IEEE 754 の単精度実数

Apx.12 付録 A コンピュータ内の数の表現
A.10 表せる実数は一様ではない仮想 6 bits マシンでの実数を考えてみましょう。なお、そこでは、符号 1 bit、指数部 2 bits、仮数部 3 bits、バイ
アスを 2 とします。このとき、表現できる実数を図と表にすると、次のようになります。(図 A.17 参照) なお、表は正の実数のみで、これと同数の負の数があります。
図 A.17 実数は一様で分布しない
表現できる実数を数直線上に並べると、−1.875 から 1.875 までの数が表せますが、その間で表現できる値の分布が一様でないことがわかります。−0.5 と 0.5 の間には 0 以外の実数がありません。つまり、このマシンでは 0.1 などが表現できないということです。この現象は、IEEE 754 の倍精度実数 64 bits の場合でも起こっていることです。
問題 A.10.1. IEEE 754 に従っている Java の正の単精度実数の正の最大値と正の最小値を求めて下さい。> ヒント:Float.MAX_VALUE, Float.MIN_VALUE

Apx.13
付録B
Eclipse のインストール
B.1 インストールの前にこの資料では、以前のバージョンの Eclipse が既にあっても、それを削除して最新版を再インストールする方法で説明しています。従って、Eclipse の更新機能を使ってバージョンアップする場合は、ネットなどで方法を調べて自力で行って下さい。なお、Eclipse のバージョンと Java のバージョンとはベツモノです。従って、Eclipse はそのままでJava のバージョンのみ上げることは可能です。凝ったことをしない限りは、既にインストールされている(慣れた)Eclipse を用いて作業する方が楽かもしれません。この時点での最新版 Eclipse Neon から Apple 社の MacOS に対しても Windows 用と同じページから All in One
がダウンロードすることができるようになりました。但し、64bits 版のものしか置かれていないので、かなり以前のMacOS の場合は、ネットで情報を調べて下さい。
B.2 Pleiades のダウンロードこの授業では、日本語化した Eclipse を用いて Java プログラムの作成を行っていきますので、各自のパソコンにネット上から Pleiades アプリケーションをダウンロード&インストールしてもらいます。Windows 用の Pleiades はzip 形式、MacOS 用の Pleiadesは dmg 形式の圧縮されたファイルを1つダウンロードすることで JDK や JRE、もちろん Eclipse 関連の全てのファイルをインストールできるようになっています。まずは、以下のページからファイルをダウンロードしましょう。> http://mergedoc.osdn.jp
この資料を書いている時点で Eclipse 4.6 Neon に対応した Pleiades が最新バージョンです。ページ上に並んでいる選択肢ボタンの中から最新版を選んで下さい。(図 B.2 参照)
次のページ (図 B.2参照) では、使用するパソコンの OS が 32bits 版か 64bits 版か、そして、全ての道具を必要とする Full Edition か標準的な道具のみの Standard Edition か、そして、どんな目的のための道具をインストールするかで、36 個の選択肢が表示されます。自分の Windows OS が 32bits 版か 64bits 版かは既知になっているかと思いますが、わからない人は「コントロールパネル」→「システムとセキュリティ」→「システム」で「システムの種類」の欄を見て下さい。「64 ビット オペレーティング システム」の文字があれば 64bits 版です。OS の bit 数に関わらず、( Full Edition , Java ) を選択することにします。授業で使用するものとしては、かなり余分なものが付いてくるのですが、JRE と JDK が入っていたほうが何かと便利なので、これを選びましょう。(図 B.2
赤丸のいずれか選択)
画面が変わって、自動でダウンロードが開始されます。Windows / MacOS いずれの場合も、ダウンロードされた場所をちゃんと把握して下さい。後で見つからない、では困ります。この文章を書いている時点でダウンロードされた

Apx.14 付録 B Eclipse のインストール
図 B.1 Pleiades のダウンロードの開始ページ 図 B.2 Pleiades の Edition の選択
図 B.3 Pleiades のダウンロード開始 (Windows)
ファイル名は、
Windows 用:pleiades-4.6.3-java-win-64bit-jre_20170422
MacOS 用:pleiades-4.6.3-java-mac-jre_20170421.dmg
でした。
B.3 Java API ドキュメントのダウンロードEclipse では、プログラムの作成中に Java で用意されているクラスやメソッドのドキュメント (Java API docu-
ments) をネットを介して見ることができるのですが、そのドキュメントを事前に各自のパソコンにダウンロードしておけば、ネットに接続していない環境でも利用出来るようになり便利です。そこで、ドキュメントをダウンロードするため、Oracle のダウンロードページに移動します。> http://www.oracle.com/technetwork/jp/java/javase/documentation/api-jsp-316041-ja.html
URL からわかるように、マニュアルの改変で URL が変わる可能性があるので、その場合は Google などでキーワード「Java API ドキュメント」と検索して下さい。日本語版ドキュメントのダウンロードはページの下のほうにアーカイブ・ファイルへのリンクがありますので、それをクリックします。(図 B.4 参照)
最新バージョンの日本語版ドキュメントをダウンロードすることにします。この文章を書いている時点でダウンロー

B.4 Eclipse のインストール Apx.15
図 B.4 API ドキュメントのページ 図 B.5 日本語ドキュメントのダウンロード
ドされたファイル名はバージョン番号の 8.zip でした。(図 B.5参照)
Java と Eclipse に関するダウンロードは以上で終了です。この後のインストール作業は、ネットに接続していなくても実行できます。
B.4 Eclipse のインストールEclipse はどこへインストールしても良いのですが、授業中の説明が楽になるように、全員同じ場所にインストールすることにします。
B.4.1 既に前のバージョンがある場合
この節は、この科目が好きで (?) 昨年に引き続き受講している人に対して書いています。新入生は、次の「新しくインストールする場合」へ飛んで下さい。で、昨年に引き続き受講している人は、Eclipse と授業で作った Java プログラム群がどこに存在するかを把握して下さい。昨年、私の講義を聴いた人は、今年も昨年と同じ場所にインストールするので、昨年の環境のままで構いません。新しい Eclipse に変更しなくても問題は無いと思います。Windows の場合、ローカルディスク(C:Y) の直下に次の2フォルダがあることを確かめて下さい。
• pleiades フォルダ:Eclipse 一式が入っている• java フォルダ:昨年までの授業で作ったプログラムが入っている
一方、MacOS の場合、アプリケーションフォルダに pleiades.app が入っていること、昨年までの授業で作ったプログラムの入ったフォルダが何処に在ったか把握しておきましょう。以下の手順で新しい Eclipseをインストールをする場合は、javaフォルダはこれまでの成果なので消さずに、pleiadesフォルダ (MacOS なら pleiades.app) のみ削除して、以下の処理を行って下さい。
B.4.2 新しくインストールする場合
ダウンロードしたファイルは、Windows の場合 pleiades-***.zip、MacOS の場合 pleiades-***.dmg と、それぞれファイルの大きさを小さくするためのファイル圧縮が掛かっています。いずれもファイルアイコンをダブルクリックすることで、もとの大きさに展開することができます。

Apx.16 付録 B Eclipse のインストール
Windows の場合 アイコンをダブルクリックし、pleiades というフォルダが表示されたら「すべて展開」を選択し(図 B.6 参照)、展開される pleiades フォルダの展開先を C:Yに変更して展開を開始して下さい。(図 B.7 参照)
この結果、C:Ypleiades というフォルダができます。このフォルダ内に
C:YpleiadesYeclipseYclipse.exe
というファイルが見つかれば(たぶん)ソフトのインストールは成功です。(図 B.8 参照)
MacOS の場合 アイコンをダブルクリックすることで、Eclipse をアプリケーションフォルダに挿入する!という窓が表示されるので (図 B.9 参照)、左の Eclipse のアイコン画像を右のアプリケーションフォルダ画像の上にドラッグして下さい。この操作でアプリケーションフォルダに Eclipse が展開されます。
図 B.6 Pleiades のアーカイブの展開 (1) 図 B.7 Pleiades のアーカイブの展開 (2)
図 B.8 Eclipse のインストール場所 (Windows) 図 B.9 Pleiades のアーカイブの展開 (Mac)
B.5 Java API ドキュメントのインストールドキュメントは、zip 形式の圧縮ファイルなので、ダブルクリックで展開できます。展開されるフォルダ名が特殊です(この文章を書いている時点では E54527 01 なんてフォルダ名でした)。

B.5 Java API ドキュメントのインストール Apx.17
Windows の場合 アプリケーション Eclipse と一緒になるように、展開先のフォルダを C:Ypleiades フォルダとして、展開して下さい (図 B.10, B.11 参照)。この結果、C:YpleiadesYE54527 01YapiYindex.html なるファイルが見つかれば(たぶん)ドキュメントのインストールは成功です。 (図 B.12 参照)
MacOS の場合 Pleiades 自体がフォルダではなく、 1 つのアプリケーションとなっているので、その中にドキュメントを入れるのは少々困難です (出来ないことはないけれど)。そこで、展開先は、アプリケーションフォルダとするのが良いと思います。ファイル 8.zip をダブルクリックすると、8.zip と同じ場所にフォルダ E54527_01
を展開します。そこで、そのフォルダを自分のアプリケーションフォルダに移動しましょう。この場合も、Applications\E54527 01\api\index.html が見つかれば(たぶん)成功です。
ダウンロードされた zip ファイルや dmg ファイルははすぐに削除しても構いませんが、とりあえず Eclipse が順調に稼働することを確かめてから削除しましょう。
図 B.10 API ドキュメントの展開 (1) 図 B.11 API ドキュメントの展開 (2)
図 B.12 API ドキュメントのインストール場所

Apx.18 付録 B Eclipse のインストール
B.6 Eclipse の初めての起動B.6.1 workspace の設定
Windows の場合 C:YpleiadesYeclipseYeclipse.exe というファイルが Eclipse アプリケーション本体です。(図 B.8
参照) これを起動させれば良いのですが、毎回このフォルダまで移動するのは面倒です。そこで、Eclipse のショートカットをタスクバーもしくはデスクトップにピン留めしておくと良いと思います。eclipse.exe のアイコンを右クリックし、「タスクバーにピン留めする (K)」を選択します。(図 B.13 参照) これで、以降は、タスクバーから Eclipse を起動できます。(図 B.14 参照)
MacOS の場合 Eclipse アプリケーションの本体は、アプリケーションフォルダ内に置かれたのですぐ分かるかと思います。インストール後は LaunchPad にも登録されているので、そこから起動できますから Windows のような面倒は無いかと思います。
図 B.13 Eclipse をタスクバーにピン留め
図 B.14 起動はタクスバーから
では、Eclipse を起動して下さい。Windows の場合、最初に、これから作成するプログラムの置き場 workspace の場所を聞いてきます。既に入っている文字列を消して、代わりに C:Yjava と設定して下さい。(図 B.15 参照) そして、左下の「今後この質問を表示しない」にもチェックを入れておきましょう。前のバージョンの続きの場合、そのまま使用するかと英語で聞いてくるので、OK ボタンをクリックします。こうすることで、アプリケーション Eclipse と作成プログラム群を別のフォルダに分離できるので、アプリケーションを削除しても、作成したプログラムを間違って一緒に消すことが無くなります。MacOS の場合も、プログラムの置き場 workspace を別のフォルダを作成して、指定しましょう。それは、Windows
の場合と同様な理由です。使い始めに「ようこそ」画面が表示されるかもしれませんが、これは右下の「始動時に常に「ようこそ」を表示」の
チェックを外して、閉じましょう。(図 B.16 参照) ちなみに、「ようこそ」画面は、メニューのヘルプ (H)>ようこそ

B.6 Eclipse の初めての起動 Apx.19
図 B.15 ワークスペースの選択
(W) でいつでも見れます。また、このページから行ける「チュートリアル」や「サンプル」は自習の手助けとなるかな。
図 B.16 ようこそ画面
これで、Eclipse のメイン画面になりました。次は、この授業で使用する窓を配置します。既に開いている窓の中、パッケージ・エクスプローラー以外の窓(「アウトライン」と「問題」が開いていますかね?)を閉じて、逆にメニューから「ウィンドウ (W)>ビューの表示 (V)>コンソール」と選んで、「コンソール」窓を開けて下さい (図 B.17・図 B.18 参照)。
図 B.17 初期画面 図 B.18 授業用画面

Apx.20 付録 B Eclipse のインストール
B.6.2 授業用プロジェクトの作成
次に、授業用のプロジェクトを作成します。メニュー最も左で、「ファイル (F)>新規 (N)> Java プロジェクト」と順に選択し、「新規 Java プロジェクト」窓の「プロジェクト名 (P)」の欄に「プログラミングの授業」と入力して下さい。(図 B.19–B.20 参照)
この時、「実行環境 JRE の使用」に最新版の Java(この時点では JavaSE-1.8 )が選択されているかチェックして下さい。Java は幾つかのバージョンをダウンロードして、そこから選択して利用できます。従って、Eclipse は新しくしたのに Java のバージョンが古いのは寂しい。
図 B.19 Java プロジェクトの作成 (1) 図 B.20 Java プロジェクトの作成 (2)
関連付けされたパースペクティブを開くか?と聞いてくる場合は「いいえ (N)」を選択して下さい。このとき、左のチェックも忘れずに。いらないビューを折角消したのに、ここで「はい」を選択すると復活してしまいます。
B.6.3 API ドキュメントの関連付け
プロジェクト「プログラミングの授業」にダウンロードした日本語ドキュメントを関連付けさせます。Windows の場合、メニューで「ウィンドウ>設定」と選び、MacOS の場合、メニューで「Eclipse>環境設定」と選び、その後「設定」窓を表示、左の「Java」の中の「インストール済みの JRE」を選択して、右の「インストール済みの JRE(J)」で、「java 8」(MacOS の場合は Java SE 8) を選択、「編集 (E)」ボタンをクリックします。(図 B.21 参照)
「JRE の編集」窓で、「JRE システム・ライブラリー」内の全てを選択します。JRE システム・ライブラリーの中をクリックした後、Ctrl+A と押せばできます (MacOS の場合は Command+A)。そして、右の「Javadoc ロケーション」ボタンをクリックします。(図 B.22 参照)
「Javadoc ロケーション・パス」にネット上の URL が書かれているかと思います。このままだと、プログラム作成中にドキュメントを参照する度にインターネット上のこのアドレスにアクセスすることになります。先にダウンロード

B.6 Eclipse の初めての起動 Apx.21
図 B.21 Javadoc ロケーションの設定 (1) 図 B.22 Javadoc ロケーションの設定 (2)
図 B.23 Javadoc ロケーションの設定 (3) 図 B.24 Javadoc ロケーションの設定 (4)
したドキュメントをそのかわりとするため、右の「参照」ボタンをクリックして、
• Windows なら、C:YpleiadesYE54527 01Yapi
• MacOS なら、アプリケーションフォルダ内の E54271 01 フォルダ
を選択します (図 B.23 参照)。そして、「検証」ボタンをクリックして「有効のようです」であることをチェックし、戻って下さい (図 B.24 参照)。これで、全てのインストールが完了です。

Apx.22 付録 B Eclipse のインストール
B.6.4 Eclipse を見やすくする
Eclipse は多機能な多言語開発環境なので、様々なオプションの設定で自分に合った環境に変形させることができます。と言っても、あまり大きく変化させると、授業でみんなと動作が違って不便にもなりますので、そこそこにしましょう。
• エディタの表示フォントを変える• プログラムの各行に文番号を付ける• 自動的に付けられるコメントを消す• メニューの余分なアイコンを消す• コンソールの表示幅を変更する• 選択したプログラムを実行させる
以上 6 点をここで変更します。
エディタの表示フォントを変えるJava の表示フォントは、Windows の場合 OS のデフォルト・フォントである「MSゴシック」が使われています。このフォントは等幅フォント (アルファベットの文字が全て同じ幅で設計されている) で、日本語文字 (全角文字)とアルファベット (半角文字)の文字幅が2:1に揃っているので、プログラムのように文字を揃えて出力したい場合に重宝します。ただ、MSゴシックのデザインは、あまり美しいものではありません。そこで、自分の気に入ったフォントに変更すると良いと思います。ここでは、フォントを変える代わりに表示サイズのみ大きくすることにします。メニューで「ウィンドウ > 設定」と進み (MacOS の場合はメニューで「Eclipse > 環境設定」)、左のリストで「一般 > 外観 > 色とフォント」と進み、右の四角の中で「Java > Java エデイター・テキスト・フォント(デフォルト値…」を選択し、右の「編集...」のボタンを押して、後は、文字サイズを大きくしてから、OK 押して帰れば完了です。(図 B.25 参照)
図 B.25 表示 Font の変更

B.6 Eclipse の初めての起動 Apx.23
エディタ以外の表示フォント、例えばコンソールのテキストサイズを変更するには、メニューで「ウィンドウ > 設定」、左の窓で「一般 > 外観 > 色とフォント」と進んだ後、右の四角の中で「デバッグ > コンソール・フォント」を選択して、右の「編集...」のボタンを押して、文字サイズを大きくしてから OK 押して帰れば完了です。一方、パッケージ・エクスプローラー内のテキストサイズは、Eclipse 内では変更できないので次のように行います。
「コントロールパネル > デスクトップのカスタマイズ > ディスプレイ」と進み、「テキストサイズのみを変更する」で「メッセージボックス」を選択し文字サイズを変更してから「適用」を押すことで出来ます。但し、これをやるとEclipse 以外の全てのアプリケーションにも影響を与えてしまいます。一方、MacOS でパッケージ・エクスプローラー内のテキストサイズを変更するには、Eclipse の設定ファイル
eclipse.ini を書き換えるという方法があります。和田のMacBookAir ではあまり違いが見えなかったのですが、次の方法で若干テキストサイズが大きくなるそうです。まず、「アプリケーション」フォルダのファイル「Eclipse.app」を右クリックし、「パッケージ内容を表示」を選択します。「Contents/Eclipse/eclipse.ini」ファイルをテキストエディタで開けます。「-Dorg.eclipse.swt.internal.carbon.smallFonts」という行が2行あるので、いずれも削除し、ファイルを格納後、eclipse を再起動します。MacOS における Eclipse の再起動 (Windows での -clean 付き起動) は、「ターミナル」を使って、「Applications/Eclipse.app/Contents/MacOS/eclipse -clean」とを実行させれば行えます。
プログラムの各行に行番号を付けるプログラムの実行エラーは、行番号でその位置を教えてくれます。また、授業中に「プログラムの何行目を」と指示することもあるかと思いますので、Eclipse の設定を変えておきましょう。Windows の場合はメニューで「ウィンドウ > 設定」、MacOS の場合はメニューで「Eclipse > 環境設定」と進み、左の窓で「一般 > エディター > テキスト・エディター」と選び、右の窓の「行番号の表示」をチェックします (図 B.26 参照)。この 2 つ下の「空白文字を表示」のチェックを入れて、「全角空白」の 3 つのチェックを全て入れると (他のチェックは全て外す)、漢字の空白が入っていることが見やすくなるので、和田はこれも行っています。
図 B.26 行番号を付加
自動的に付けられるコメントを消すEclipse はプログラムを作る際に幾つかのコメントを自動的に付けるようになっています。これは、上級者になれば必要なコメントなのでアリガタイのですが、初心者には宝の持ち腐れ。そこで、それらのコメントを自動的に表示しないように設定しましょう。必要になったら、簡単に復活させられます。

Apx.24 付録 B Eclipse のインストール
Windows の場合はメニューで「ウィンドウ > 設定 」、MacOS の場合はメニューで「Eclipse > 環境設定」と進み、左の窓で「Java > コード・スタイル > コード・テンプレート」と進みます。そして、右の窓で、「生成されるコードとコメントを構成します」の窓内で「コード > メソッド本文」と選びます。「パターン」の窓内に図 B.27 の右図のような表示が出たら、右上の「編集」ボタンをクリックして、1行目の「// ${todo} 自動生成されたメソッド・スタブ」を消して戻りましょう。(図 B.27 参照)
図 B.27 自動的に付くコメントを消す
メニューの余分なアイコンを消すインストールした Eclipse は機能盛りだくさんの上級者向けになっています。メニューにも今は使わないなというアイコンがずらっと並んでいて、これ消せるとスッキリするなと思いますね。必要なものだけ残して他のアイコンを消しておきましょう。必要になったら簡単に復活させられます。メニューで「ウィンドウ > パースペクティブ > パースペクティブのカスタマイズ」と進みます。その後は、表示したいものだけ残して、それ以外の選択を解除します。例えば、「ツール・バー可視性」で、次のように「新規ウィザード」「実行」のみ残して、他のチェックを外してしまうと、スッキリします。最初はこの 2 つしか使わないですからね。(図 B.28 参照)
もとに戻したいときは、メニューで「ウィンドウ > パースペクティブ > パースペクティブのリセット」と進めば、初期設定に戻せます。
コンソールの表示幅を変更する出力結果をそのまま印刷することを考えると、デフォルトの固定幅 80 文字は適当な大きさかもしれませんが、出力の列幅はプログラムで管理するとして、この固定幅を解除しましょう。Windows の場合はメニューで「ウィンドウ > 設定 」、MacOS の場合はメニューで「Eclipse > 環境設定」と進み、
左の窓で「Java > 実行/デバッグ > コンソール」と進みます。右の窓の「デバッグ・コンソールの設定」の「固定幅コンソール」のチェックを外します。「適応」して戻りましょう。
選択したプログラムを実行させる最近の Eclipse の改版で行われた設定変更で、我々素人には逆に不便になったと思われる部分が、「プログラムを実行する際に、エディタで作成中のプログラムではなく、前回実行されたプログラムが実行される」です。アプリケーションの開発というレベルだとこれが便利かと思われますが、授業の形態には合わない設定なので、この設定を「プロ

B.7 Eclipse を更新したとき Apx.25
図 B.28 メニューのアイコンを整理
グラムの実行は、エディタで作成中のプログラムが優先される」と変更します。メニューで「ウィンドウ > 設定」と進み、左のメニューで「実行/デバッグ > 起動」と選択、右の窓で「起動操作」のチェックを「選択したリソースまたは・・・」そして「関連プロジェクトを起動する」に変えて OK で帰って下さい。
B.7 Eclipse を更新したときこの資料では Eclipse の更新はアプリケーションの入れ替えとしていますが、入れ替えではなく更新したりプラグインを追加したりした場合には、最初に一度だけ -clean という起動パラメータを付けて Eclipse を起動して下さい。Windows での方法は、Eclipse アプリケーション eclipse.exe が入っているフォルダ (C:YpleiadesYeclipse) 内にeclipse.exe -clean.cmd というバッチファイルが同梱されているので、それをダブルクリックで起動させることで出来ます。(図 B.29 参照)
一方、MacOS の場合は、そうしたアプリケーションが同包されていないので、ターミナルから次のコマンドで直接Eclipse を -clean 起動させます。
/Appications/Eclipse.app/Contents/MacOS/eclipse -clean
これで、追加したプラグインなどを Eclipse が把握してくれます。なお、それまでに作ったプログラムの入っているフォルダ C:Yjava はそのままに、c:Ypleiades のアプリケーション
全体をインストールし直した場合、C:Yjava がプログラムの在りかであることを Eclipse に教えてやらねばなりませ

Apx.26 付録 B Eclipse のインストール
図 B.29 eclipse.exe -clean.cmd
ん。メニューの「ファイル > ワークスペースの切り替え > その他...」でプログラムの入っているフォルダ C:Yjava
をリンクし直してあげましょう。

Apx.27
付録C
javadoc:プログラムのマニュアル作り
C.1 Javadoc とはJava の API リファレンスを表示させると (図 C.1 参照)、こんなリファレンスマニュアルを自分の作ったプログラムにも付けてみたいな、と思いませんか。ここでは、プログラム中のコメントを決まったルールで記述することで、「リファレンスマニュアル」をそこそこの手間で作成できる!という Javadoc (Java ドキュメンテーション) を解説します。Javadoc は、Sun Microsystems 社が Java のソース・コードから HTML 形式の API 仕様書を作成するソフトウェ
アの名前です。
図 C.1 API ドキュメント
C.2 まずはやってみよう習うより慣れろ!ということで、とにかく作ってみましょう。
ソースコード C.1 Circle.java (円クラス)
package sectionc01;
// 円のクラスpublic class Circle {

Apx.28 付録 C javadoc:プログラムのマニュアル作り
// 半径private double radius;
// 中心点private Point center;
// 中心点と半径を与えて円を作るコンストラクタpublic Circle( Point center, double r ) {
this.center = center;
this.radius = r;
}
// 中心点のx座標とy座標と半径を与えて円を作るコンストラクタpublic Circle( double x, double y, double r ) {
this.center = new Point(x, y);
this.radius = r;
}
// 面積を返すメソッドpublic double area() {
return Math.PI * Math.pow( this.radius, 2 );
}
// 円周を返すメソッドpublic double circumference() {
return 2 * Math.PI * this.radius;
}
// 与えられた点が円の内部に有る場合に true を返すメソッドpublic boolean includes( Point p ) {
if( p.distance( this.center ) <= this.radius ) {
return true;
} else {
return false;
}
}
}
ソースコード C.2 Point.java (点クラス)
package sectionc01;
// 平面上の点を定義するクラスpublic class Point {
// x座標private double x;
// y座標private double y;
// x座標とy座標を与えて点を作るコンストラクタPoint( double x, double y ) {
this.x = x;
this.y = y;
}
// 他の点 p との距離を返すメソッドpublic double distance( Point p ) {
return Math.sqrt( Math.pow( this.x - p.x, 2 ) + Math.pow( this.y - p.y, 2 ) );
}
}
このプログラムのリファレンスマニュアルを作ることにしましょう。とりあえず、全ての単一行コメントを javadoc
用ブロックコメント (/** で始まって */ で終わる) に変えて下さい。と言って、結構面倒ですね。そこで、Eclipse の「検索/置換」機能の「正規表現」を使ってみましょう。

C.2 まずはやってみよう Apx.29
上記のプログラムをエディター上で「すべて選択」した状態で、メニュー「編集 > 検索/置換」を選択し、検索欄に「//\s*(.+)」置換欄に「/** $1 */」と入力し、オプションの「正規表現」のチェックを入れて、「すべて置換」ボタンをクリックして下さい。正規表現は、様々なソフトウェアに導入されているので、勉強しておくとこのような複雑な操作を簡単に行うことができます。ちなみに、上の正規表現は 「// の後ろに空白 \s が 0個以上続いた * 後の文字列全部 (.+) を 置換文字 /** の後ろに置いて */ でくくれ」と言う意味になります。(^^;)
さて、2つのプログラムのコメントが Javadoc 用のブロックコメントに変換できたら、パッケージエクスプローラにて、「パッケージ section01」を選択した状態で、メニューで「プロジェクト > Javadoc の生成」を選択して下さい。まず、「Javadoc が生成される型の選択」の欄でパッケージ sectionc01 内の 2 つのクラス Circle.java とPoint.java を選択されていることをチェックし、「次の可視性を持つメンバーの Javadoc を作成:」のチェックをPrivate にしておきましょう。そして、「標準ドックレットを使用」の「宛先」(授業のプロジェクトフォルダ内の doc
フォルダとなっているはず) の URL を記憶して下さい。その場所にドキュメント一式が出来上がるからです。生成作業が終わると、その URL の場所に、index.html なるファイルがあるかと思います。これを、パッケージエクスプローラにて、「次で開く > Webブラウザー」で開きます。これが最も簡単な Javadoc の作成方法です。Javadoc には アットマーク @ で始まる「Javadoc タグ」という特別な記法が利用できるので、これを幾つか覚えると良いでしょう。また、Javadoc の文章は HTML として記述されるので、HTML のマークアップタグ (例えば <br>
で強制改行) を含んで書くこともできます。上のコメントを Javadoc タグも入れて、書き直してみましょう。
ソースコード C.3 Circle.java (円クラス)
package sectionc01;
/** 円のクラス* @author 和田@応用数学科.東京理科大学* @version 1.0
*/
public class Circle {
/** 半径 */
private double radius;
/** 中心点 */
private Point center;
/** 中心点と半径を与えて円を作るコンストラクタ* @param center 中心点<br>null はチェックしていないので、許さない* @param r 半径<br>正の実数であることが不可欠だが、チェックしていない*/
public Circle(Point center, double r) {
this.center = center;
this.radius = r;
}
/** 中心点のx座標とy座標と半径を与えて円を作るコンストラクタ* @param x 中心点のx座標* @param y 中心点のy座標* @param r 半径<br>正の実数であることが不可欠だが、チェックしていない*/
public Circle(double x, double y, double r) {
this.center = new Point(x, y);
this.radius = r;
}
/** 面積を返すメソッド* @return 面積を表わす実数値*/

Apx.30 付録 C javadoc:プログラムのマニュアル作り
public double area() {
return Math.PI * Math.pow( this.radius, 2 );
}
/** 円周を返すメソッド* @return 円周長を表わす実数値*/
public double circumference() {
return 2 * Math.PI * this.radius;
}
/** 与えられた点が円の内部に有る場合に true を返すメソッド<br>
* 円周上にある点は円の内部と判定する* @param p 円の内部に有るかをチェックする点<br>null はチェックしていないので、許さない* @return 円の内部にあれば true を、そうでなければ false を返す*/
public boolean includes( Point p ) {
if( p.distance( this.center ) <= this.radius ) {
return true;
} else {
return false;
}
}
}
ソースコード C.4 Point.java (点クラス)
package sectionc01;
/** 点のクラス* @author 和田@応用数学科.東京理科大学* @version 1.0
*/
public class Point {
/** x座標 */
private double x;
/** y座標 */
private double y;
/** x座標とy座標を与えて点を作るコンストラクタ* @param x x座標を表わす実数値* @param y y座標を表わす実数値*/
Point( double x, double y ) {
this.x = x;
this.y = y;
}
/** 他の点 p との距離を返すメソッド* @param other 距離を測る他の点<br>null をチェックしていないので、許さない* @return 距離を表す実数値*/
double distance( Point other ) {
return Math.sqrt( Math.pow( this.x - other.x, 2 ) + Math.pow( this.y - other.y,
2 ) );
}
}
今回は、著者と版も出力するようにしたので、パッケージエクスプローラにて、「パッケージ section01」を選択した状態で、メニューで「プロジェクト > Javadoc の生成」を選択し、「完了」ボタンをすぐにはクリックせず、「次へ」

C.3 Javadoc のタグ Apx.31
ボタンをクリックします。次のページで、「これらのタグの記述」の「@author」と 「@version」のチェックを入れてから「完了」ボタンをクリックして下さい。
C.3 Javadoc のタグJava のソース・コード内に、/** で始まり、*/ で終わるコメントを記述すると、それが仕様書作成に利用されます。そして、@ で始まる Javadoc タグが様々な項目の記述に用いられます。
表 C.3.1 よく使う Javadoc のタグ
タグ 内容@author 開発者名の記述
@deprecated廃止されたクラスやメソッドに付けて、使用されたときに警告が発せられるようにする。アノテーション @Deprecated でも同じことが出来る
@exception そのメソッドが投げる例外クラスについて記述する@param メソッドの引数やゲネリックスのパラメ-タの型について1つずつ記述する@return メソッドの戻り値について記述する。void の場合は無くても良い@see 関連する他のクラスやメソッドへのリンクを別枠で記述する@since 導入された時のバージョンを記述する@throws @exception と同義@version クラスやメソッドのバージョン番号を記述する
{@link}関連する他のクラスやメソッドへのリンクをテキスト内にインラインで記述する。記述例:「このメソッドは {@link Sample01#getX() getX}も参照のこと」
ドキュメントの文章の書き方は、Java 8 の API ドキュメントを見ながら自習するのが良いかと思います。

Apx.32
付録D
debug:プログラムの虫取り
D.1 デバッギング複雑なプログラムを作成するようになると、予想される動作と異なる結果が出たりして悩むことが増えてきます。プログラム内の問題箇所を見つけ出す操作を「デバッギング (debugging:虫取り)」と言います。Eclipse では、「デバッグモード」というモードが用意されています。メニューから「ウィンドウ > パースペクティブ > パースペクティブを開く > デバッグ」と進むと外観が「デバッグ」パースペクティブに変わります。(図 D.1
参照)
図 D.1 Debug mode へ
D.2 ビューいろいろ「デバッグ」パースペクティブでは、幾つかのビューが用意されています。(図 D.2 参照)
D.2.1 「デバッグ」ビュー
実行しているプログラムのプロセスの状況を逐次表示するものです。Java のプログラムは、様々なオブジェクトがそれぞれ他のオブジェクトを呼び出すように実行されていきます。それらは「スレッド」と呼ばれる処理単位で実行され、それが「デバッグ」ビュー内に履歴として階層的に整理表示されます。また、ビューの上部に用意されたアイコン

D.2 ビューいろいろ Apx.33
図 D.2 Debug perspective
を選んで、実行中のプロセスを特定の場所で中断したり、1ステップごとに停止させながら実行するなどが行え、その際の状況の変化を確認することが出来ます。
D.2.2 「変数」ビュー
プログラム実行中、その時点で使用されている変数とその値を表示してくれます。変数の値は、このビュー以外にもソース中の変数にポインタを重ねるだけで見ることができます。
D.2.3 「ブレークポイント」ビュー
設定されたブレークポイントの一覧を表示してくれます。ブレークポイントとは、プログラムの実行がそこまで進むと自動的に処理が中断され、デバッグモードになる行です。ソースの文番号でダブルクリックすることで設定することができ、ダブルクリックで設定・解除のトグルになっています。
D.2.4 「式」ビュー
「監視式」と呼ばれる式とその値を表示するためのビューで、メニューの「ウィンドウ > ビューの表示 > 式」で表示されます。監視式は、実行中の変数やオブジェクトの状態などを使った式を、実行中に追加することができます。
D.2.5 「表示」ビュー
これもデフォルトでは表示されていませんが、式などを直接入力して実行させたり、結果を表示したりすることができます。

Apx.34 付録 D debug:プログラムの虫取り
D.3 デバッグの仕方1. デバッグモードにパースペクティブを変更します。メニュー「ウィンドウ>パースペクティブ>パースペクティブを開く>デバッグ」to 選択するか、メニューバー上に「デバッグ」なる (甲虫の) アイコンが表示されていたらそれをクリックすることで、デバッグモードに変更されます。デバッグモードでプログラムを「実行>デバッグ」すると、プログラムはブレークポイントで一時的に実行を中断した状態になり、その時の情報をいろいろなビューに表示してくれます。ここでは変数ビューくらいしか見ませんが、他のビューの使い方は自分で調べてみて下さい。
2. ソース・コードの中にブレークポイントを設定します。ブレークポイントを設定すると、プログラムの実行時にここで一時停止します。ブレークポイントを設定したい行の行番号をマウスをダブルクリックすることで、青丸のアイコンが表示されます。これがブレークポイントのアイコンです。再度ダブルクリックすると外れます。ブレークポイントは複数設定することができます。
3. 変数の値を見るブレークポイントで停止した状態で、「変数」ビューに宣言されている変数のその時点での値が表示されます。ソース・コード上の変数にポインタを持っていくとその変数のその時の値が表示されます。また、「式ビュー」で、そのときの各変数による式を書くことでその値を見ることができます。
4. プログラムを 1 ステップずつ進行させるデバッグの実行制御はいろいろあります。プログラムを 1 ステップずつ進行させては変数の変化などを見ていくと、問題が明らかになっていきます。
名前 icon Shortcut 処理
再開 F8 次のブレークポイントまで進む
Step in F5 1 ステップ進む (メソッド呼び出しなら、その中へ入る)
Step over F6 1 ステップ進む (メソッド呼び出しなら、その中はスキップする)
Step return F7 実行中のメソッドから呼び出し元へ戻るRun to Line Ctrl+R カーソルのある行まで移動する条件付き停止 ブレークポイントプロパティで条件を設定
表 D.3.1 デバッグの実行制御

Ind.1
索引
?:, → 条件演算子
Abstract Window Toolkit, 253annotation, → アノテーションAPI, 87, 220Application Programming Interface, → APIASCII コード, → アスキーコードAWT, → Abstract Window Toolkit
binary code, → バイナリーコードbinary tree, → 2分木bit, → ビットbreak, 46byte, 19, → バイト
case 節, 45catch, 177catch ブロック, 180Character-based User Interface, 254class, → クラスcompile, → コンパイル (翻訳)compiler, → コンパイラconsole, → コンソールCSV, 189CSV 形式, 199CUI, → Character-based User Interface
debugging, → デバッギングdeep copy, 100default 節, 45do while, → whiledouble, 21
emulator, → エミュレータenclosing class, → 外部クラスexclusive OR, → 排他的論理和
FIFO (First In First Out), 229FileInputStream, 194FileOutputStream, 194final, 138finally ブロック, 184fixed decimal point number, → 固定小数点数表示fixed point number type, → 固定小数点数型float, 21floating decimal point number, → 浮動小数点数表示floating point number type, → 浮動小数点数型for, 48, 77FORTRAN, 129
Garbage Collection, → GC, 82GC, 71, 82generics, → ジェネリクスGraphical User Interface, 253GUI, → Graphical User Interface
Heap tree, → ヒープ木
IDE (Integrated Development Environment), → 統合開発環境IEEE, 21, → アメリカ電気電子学会IEEE 754, 21, Apx.10if, 39import, 201indent, → インデントinner class, → 内部クラスint, 19integer type, → 整数型is 型変数, 48
Java API, 220Java 仮想マシン, 3java.lang, 202Javadoc, Apx.27JavaFX, 254JDK (Java Development Kit), 4JRE (Java Runtime Environment) , 4JVM (Java Virtual Machine), → Java 仮想マシン, → Java 仮想
マシン
LIFO (Last In First Out), 229long, 19
machine language, → 機械語Math.E, 80Math.PI, 80method, → メソッド
nested class, → ネストクラスnew, 134null, 75
object oriented, → オブジェクト指向outer class, → 外部クラス
package-private, → パッケージプライベートparadaigm, → パラダイムplugin, 4primitive type, → 基本型private, 144Python, 3
real number type, 21reference type, → 参照型
shallow copy, 100short, 19source code, 7static, 135super, 204Swing, 254switch, 45

Ind.2 索引
System.err.println, 183System.out.print, 13System.out.printf, 14System.out.println, 14
this() , → デフォルトコンストラクタthrow 節, 186try ブロック, 180
UML, 160, 207Unicode, → ユニコードUnified Modeling Language, → UML
while, 51
アクセス修飾子, 144, 153浅いコピー, 100アスキーコード, 15アスペクト指向, 130後判定, 52アノテーション, 18, 149, 167, 264アメリカ電気電子学会, 21, Apx.10アンダースコア, 11, 138インクリメント演算子, 30インスタンス, 130インスタンスフィールド, 141インスタンスメソッド, 88, 145インタフェース, 205, 207インデント, 9インヘリタンス, → 継承エスケープシ-ケンス, 104エスケープ文字, 103エミュレータ, Apx.8オブジェクト, 130オブジェクト指向, 3, 129オンデマンドインポート, 201オートアンボクシング, 211オートボクシング, 211オーバーライド, 167オーバーライドの強制, 203オーバーロード, 137, 153拡張 for 文, 77囲いクラス, 242仮数部, Apx.10型パラメータ, 213カプセル化, 153可変長パラメータ, 266仮引数, 91関係演算子, → 比較演算子関係式, → 比較式関数型プログラミング, 130完全修飾名, 200外部クラス, 242機械語, 2木構造, 111基数, Apx.3基数変換, Apx.3機能, 130基本型, 19キャスト, 33キャメル形式, 11, 23キュー, 229境界ワイルドカード型, 218空文字列, 102クラス, 10クラス図, 160クラスフィールド, 141クラスメソッド, 87, 88, 145具象クラス, 203継承, 157
検査例外, 179ゲッター, 141後置型, 31固定小数点数型, 21固定小数点数表示, Apx.10コメントアウト, 18コンストラクタ, 132, 134コンソール, 13コンテナ, 257コントロール, 261コンパイラ, 2コンパイル(翻訳), 2, 10コンポーネント, 257再帰プログラム, 96サブクラス, 158参照, 62参照型, 19, 101算術演算子, 25指数, Apx.10指数部, Apx.10初期化付き無名配列, 63書式指示子, 85シングルスレッド, 178真数表現, → 補数表現シンタックスシュガー, 63ジェネリクス, 213実数型, 21実装, 207実装クラス, 220実引数, 91条件演算子, 47スコープ, 54スタック, 229スタックトレース, 180スタック領域, 62ストリーム, 193スネーク形式, 11, 23スーパークラス, 158正規表現, 189, Apx.28整数型, 19静的インポート, 202セッター, 141選択法, 105前置型, 31ソースコード, 7ソースファイル, 10属性, 130タイプセーフ, 213, 261多重継承, 162, 208多重代入文, 32多態性, 175単一継承, 162単態性, 175短絡評価, 38ダイアモンド継承問題, 162代入文, 24抽象クラス, 203抽象メソッド, 203定数, 138手続き型, 129デクリメント演算子, 30デバッギング, Apx.32デフォルトコンストラクタ, 138デフォルトパッケージ, 12デフォルトメソッド, 209デリミター, 187糖衣構文, → シンタックスシュガー統合開発環境, 3動的束縛, 177内部クラス, 154, 242, 244

Ind.3
ネストクラス, 242排他的論理和, 39配列, 61ハノイの塔, 96汎化, 160バイナリーコード, 7パスカル形式, 11, 132パッケージプライベート, 156パラダイム, 3比較演算子, 36比較式, 36非検査例外, 179菱形継承問題, 162ヒープ木, 111ヒープ領域, 61フィールド, 132, 141深いコピー, 100複合代入演算子, 29複数例外 catch, 182浮動小数点数型, 19, 21浮動小数点数表示, Apx.10ブロック, 13プラグイン, 4プログラミング言語, 2プログラミングパラダイム, 129プロジェクト, 5
並列処理, 246変数, 23変数を宣言, 24補数表現, Apx.9ポリモルフィズム, → 多態性前判定, 52マルチスレッド, 178, 246マルチプロセス, 246無限ループ, 56メソッド, 13, 132メンバー, 132文字列の連結, 27戻り値, 88ラッパークラス, 210リスト形式での初期化, 63リダイレクト, 183リテラル, 23レイアウト, 261例外, 177列挙型, 261論理演算子, 37ローカル変数, 145ワイルドカード型, 218ユニコード, 15
2分木, 111