matlab® における分類・パターン認識 入門編 - …...guiアプリケーションに...
TRANSCRIPT

1 © 2012 The MathWorks, Inc.
MATLAB® における分類・パターン認識 - 入門編 -
MathWorks Japan アプリケーションエンジニアリング部(テクニカルコンピューティング部) アプリケーションエンジニア 大開 孝文

2
アジェンダ
回帰モデルと分類モデルについて
分類手法を使ったワインの品質モデリング
まとめ
3
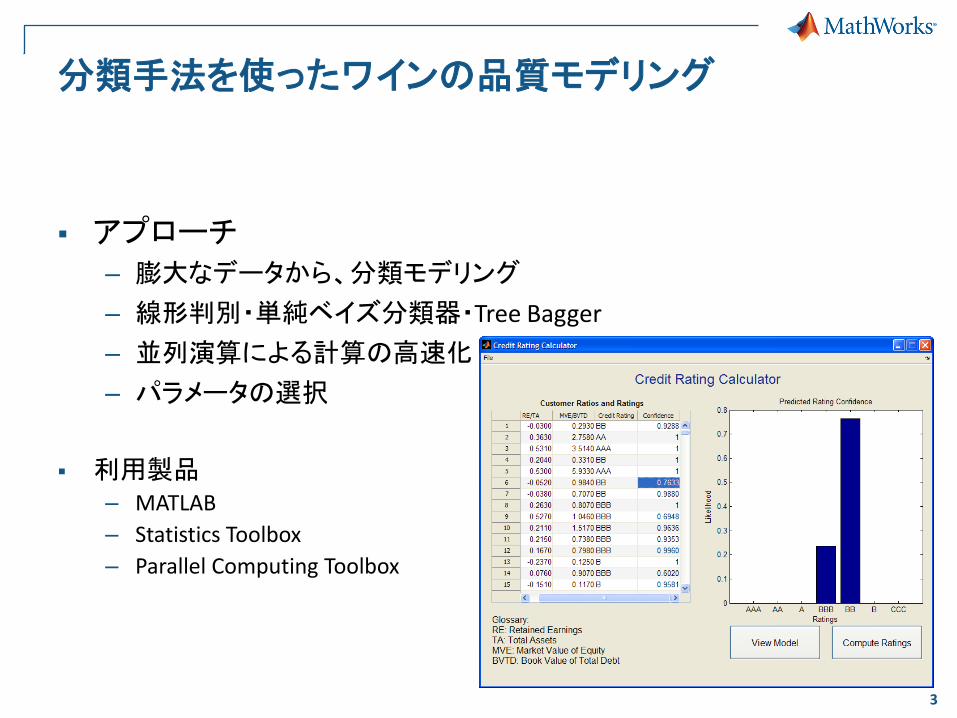
分類手法を使ったワインの品質モデリング
アプローチ – 膨大なデータから、分類モデリング
– 線形判別・単純ベイズ分類器・Tree Bagger
– 並列演算による計算の高速化
– パラメータの選択
利用製品 – MATLAB
– Statistics Toolbox
– Parallel Computing Toolbox

4
予測モデル(回帰モデル) Y = F(X1, X2, X3, … Xn)
数値

5
予測モデル(分類モデル) Y = F(X1, X2, X3, … Xn)
数値(名義尺度・順序尺度)
6
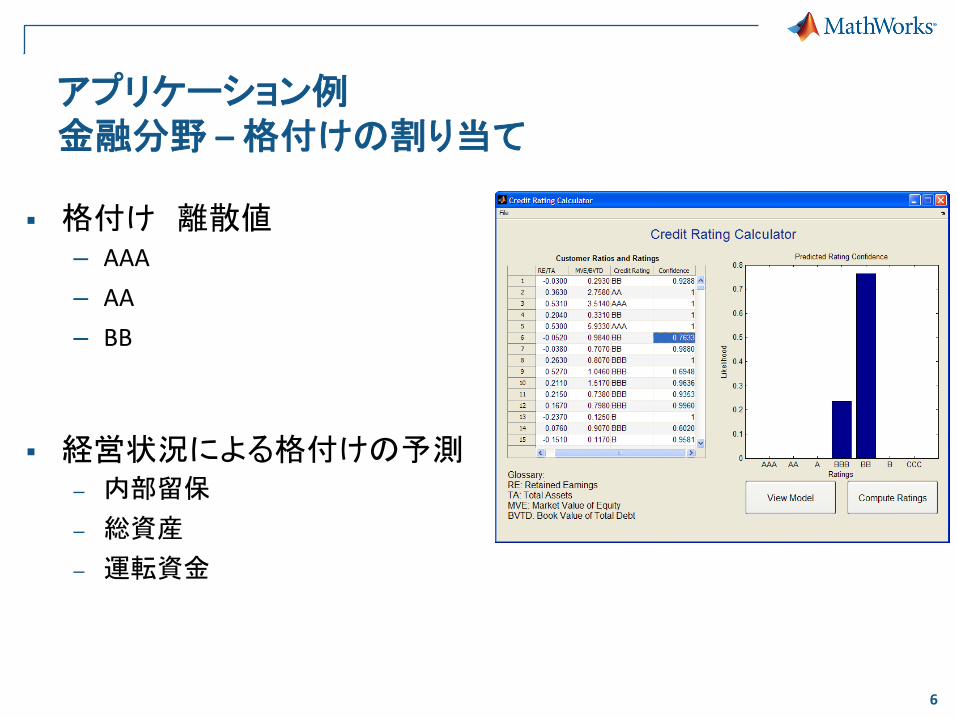
アプリケーション例 金融分野 – 格付けの割り当て
格付け 離散値 – AAA
– AA
– BB
経営状況による格付けの予測 – 内部留保
– 総資産
– 運転資金

7
分類・パターン認識における課題
市販のプログラムでは解析手法がよくわからない
分類される訓練について時間がかかる
よく分かる専門家が必要

8
分類手法を使ったワインの品質モデリング
各種データ量からグルーピングを行う(分類)
白ワインの糖分・PH・濃さなどデータ量から、
品質のいいワインの傾向をつかむ
本デモのダウンロード http://www.mathworks.co.jp/matlabcentral/fileexchange/28770-introduction-to-classification

9
精度の測定
(検定)
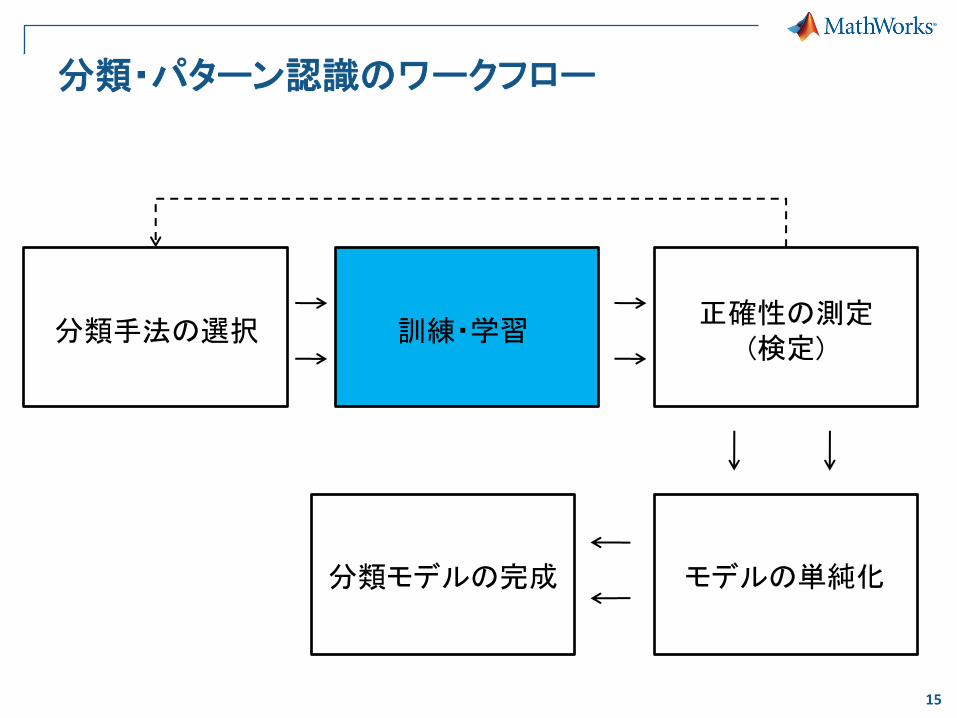
分類・パターン認識のワークフロー
分類手法の選択 訓練・学習
モデルの単純化 分類モデルの完成

10
MATLABで可能な分類・パターン認識のアルゴリズム
Statistics Toolbox – 判別分析
– ロジスティック回帰
– 単純ベイズ分類器
– バギングされた決定木
Bioinformatics Toolbox – サポートベクターマシーン
Neural Network Toolbox – ニューラルネットワーク

11
アルゴリズム選択
線形 判別分析
バギング された 決定木
アルゴリズム 複雑さ
前提条件の 厳しさ
12
アルゴリズム選択 大雑把なやり方
シンプルな方法が(たいてい)いい – シンプルなモデル
解釈が簡単
説明がかんたん
– メモリ消費量少なくて、高速に学習
単純なモデルは前提条件となる過程が厳しい – 前提条件に違反しているかどうかチェック
– 予備となるデータ解析が重要
13
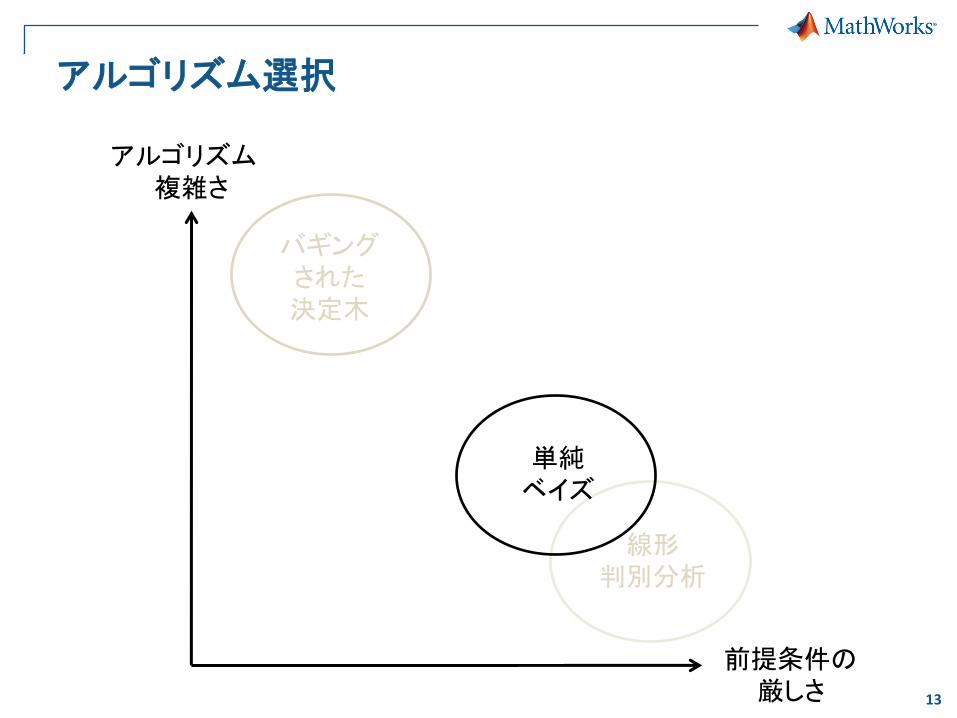
アルゴリズム選択
線形 判別分析
バギング された 決定木
アルゴリズム 複雑さ
前提条件の 厳しさ
単純 ベイズ
14
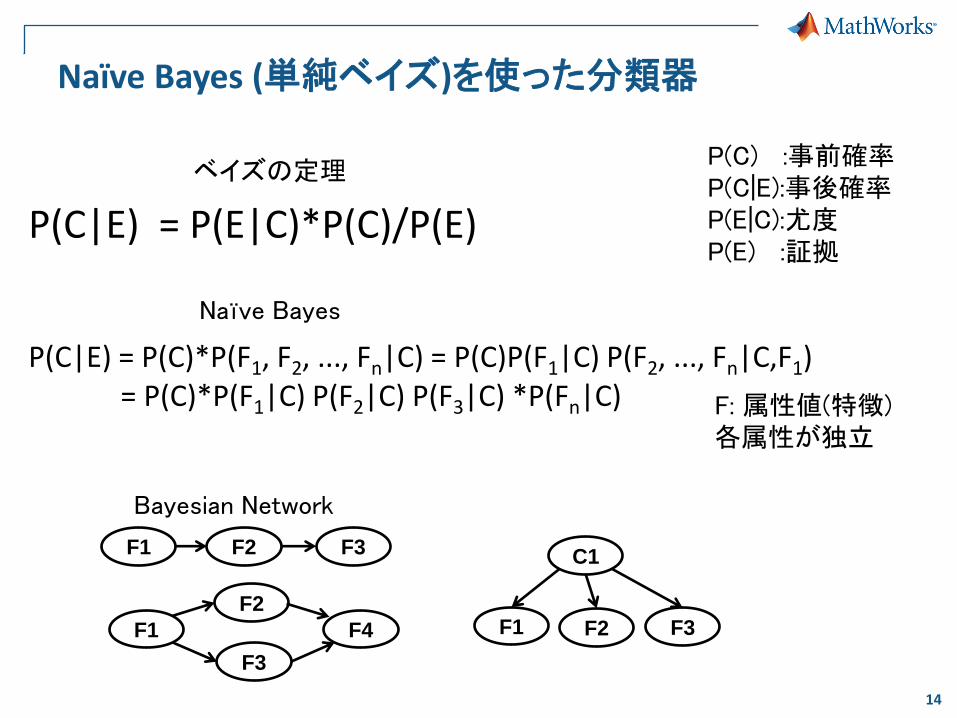
Naïve Bayes (単純ベイズ)を使った分類器
ベイズの定理
P(C|E) = P(E|C)*P(C)/P(E)
P(C) :事前確率 P(C|E):事後確率 P(E|C):尤度 P(E) :証拠
Naïve Bayes
F: 属性値(特徴) 各属性が独立
P(C|E) = P(C)*P(F1, F2, ..., Fn|C) = P(C)P(F1|C) P(F2, ..., Fn|C,F1) = P(C)*P(F1|C) P(F2|C) P(F3|C) *P(Fn|C)
C1
F1 F2 F3
Bayesian Network
F1 F2 F3
F1
F2
F4
F3
15
正確性の測定 (検定)
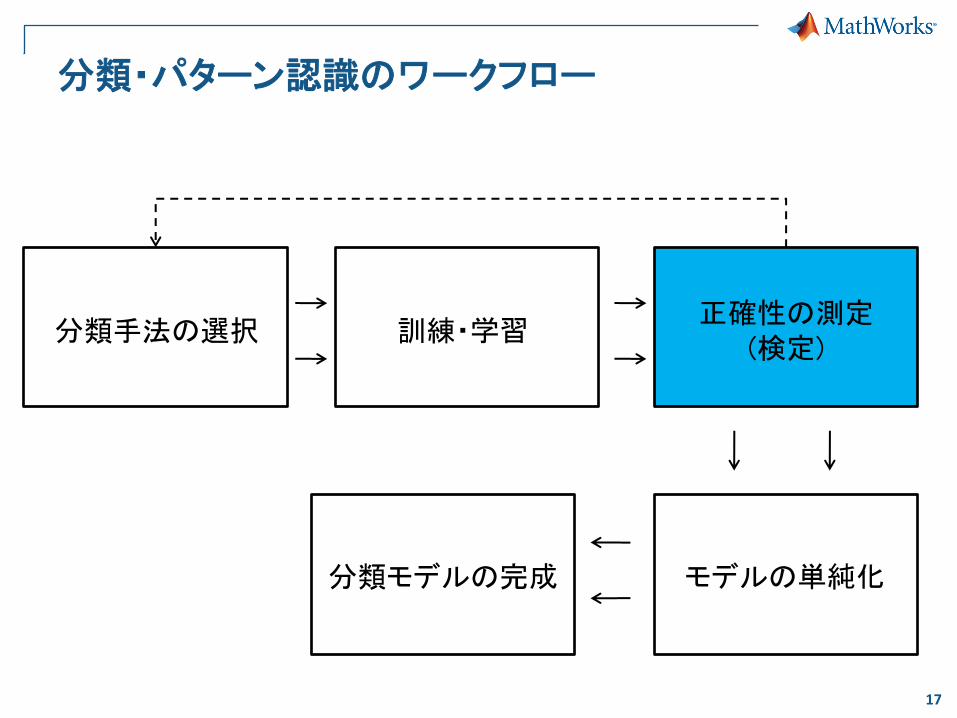
分類・パターン認識のワークフロー
分類手法の選択 訓練・学習
モデルの単純化 分類モデルの完成

16
訓練・学習
特徴を持ったデータと出力となるクラスをもったデータセットの作成 – クラス: 予測子 (Y)
– 特徴: 応答データ (X)
このデータを使って訓練・学習 – 特徴とクラスとの関係を繰り返し作成するルールを発展
通常、データを2種類に分割 – 訓練データ (モデルのルールを構築)
X_train/Y_train
– 検証用データ (アルゴリズムの正確性のバリデーション)
X_test/Y_test
fit/train :学習 predict :予測
17
正確性の測定 (検定)
分類・パターン認識のワークフロー
分類手法の選択 訓練・学習
モデルの単純化 分類モデルの完成

18
A B C D E F G
A 0 1 1 2 1 0 0
B 0 9 16 15 10 0 0
C 4 22 275 146 43 0 0
D 6 16 198 283 240 3 2
E 1 0 39 59 181 7 0
F 0 0 8 7 31 5 0
G 0 0 0 0 1 1 0
分類器の正確性の測定 - 混同行列 -
A B C D E F G
A 0 1 1 2 1 0 0
B 0 9 16 15 10 0 0
C 4 22 275 146 43 0 0
D 6 16 198 283 240 3 2
E 1 0 39 59 181 7 0
F 0 0 8 7 31 5 0
G 0 0 0 0 1 1 0
予測したクラス
実際
のク
ラス

19
正確性の測定 (検定)
分類・パターン認識のワークフロー
分類手法の選択 訓練・学習
モデルの単純化 分類モデルの完成

20
モデルの単純化
目標: 特徴情報を最小化、できるだけ同じ結果を得る
理由 – オーバーフィッティングの回避 (ロバスト性が失われる)
– サイズ
– モデルをシンプルに (重要なパラメータが分かりやすい)
手法 – 前方逐次特徴選択
sequentialfs
– “Out of Bag” における特徴の重要度
Treebagger で有効

21
モデルの単純化
[fs,history] = sequentialfs( fun , X,Y,'cv',c2) fun=@(Xtrain,Ytrain,Xtest,Ytest)... sum(Ytest~=predict(NaiveBayes.fit(Xtrain,Ytrain),Xtest));
fun : 基準・尺度関数 分類モデルの誤判別された観測総数 Ytest とXtestを入力して予測した結果との誤差の和を計算する関数 例) 実際: 予測 2 : 1 一致していない 3 : 3 5 : 4 一致していない fun : 2
回帰モデルにも活用可

22
正確性の測定 (検定)
分類・パターン認識のワークフロー
分類手法の選択 訓練・学習
モデルの単純化 分類モデルの完成

23
TreeBagger とは?
分類木でモデリングしたものの拡張版
分類木
Y = F(X1, X2, X3, … Xn)
Y1 = F1(X1, X2, X3, … Xn)
Y2 = F2(X1, X2, X3, … Xn)
Yk = Fk(X1, X2, X3, … Xn)
弱学習器を多数作成して、 結果の多数決を取る
TreeBagger
一つだけの学習器だと ロバスト性が悪い

24
Parallel Computing Toolbox を使った最適化
TreeBagger関数の計算は時間が掛かりますが、
以下の環境で、高速化が実現
Windows XP 64 bit
Intel Xeon CPU W3550 @3.07GHz (クアッドコア)
Memory 12.0G
136 sec → 39 sec (約 3.4 倍)

25
分類器の正確性の測定
平行座標プロット ROC 曲線
感度(陽性/+)/偽陽性率(陽性/-) との関係曲線 AUCは、曲線で分けられた下側の面積
色付きの線:実際のクラス 各曲線のピーク:推定クラス 高さ:尤度

26
分類モデルの完成
GUIアプリケーションに 分類器を統合 – 格付けアプリケーション
アプリケーションとして、システムに実装 – センサーネットワーク
– 自動トレーディングシステム
– スパムメールフィルター

27
分類・パターン認識における課題の解決
市販のプログラムでは解析手法がよくわからない – 様々なアルゴリズムを提供
– Statistics Toolbox
– Bioinformatics Toolbox
– Neural Network Toolbox
分類される訓練について時間がかかる – Parallel Computing Toolboxによる並列処理
よく分かる専門家が必要 – ヘルプドキュメント記載を参照
– テクニカルサポート
– 弊社トレーニングサービス
– 弊社コンサルティングサービス

28
まとめ
MATLABにおける分類・パターン識別の
ワークフローを紹介
Statistics Toolbox では、多種な分類器を提供 – 判別分析、単純ベイズ、分類木、バギング、ブースティング etc
Parallel Computing Toolbox との相性がよく、 高速処理が可能
サポートベクターマシーンはBioinformatics Toolbox
ニューラルネットワークはNeural Network Toolbox

29
まとめ 関数一覧(Statistics Toolbox)
(Bioinformatics Toolbox)
サポートベクターマシーン – svmtrain
(Neural Network Toolbox)
ニューラルネットワーク – train
判別分析 – Classify
単純ベイズ(Naïve Bayes) – NaiveBayes
K近傍分類 – ClassificationKNN
分類木 – ClassificationTree
バギング – TreeBagger
ブースティング – fitensamble
30
© 2012 The MathWorks, Inc. MATLAB and Simulink are registered trademarks of The MathWorks, Inc. See www.mathworks.com/trademarks for a list of additional trademarks. Other product or brand names may be trademarks or registered trademarks of their respective holders.
お問い合わせ
営業部へのお問い合わせ http://www.mathworks.co.jp/contact_us/
TEL: 03-6367-6700
メールアドレス: [email protected]
本日のご参加ありがとうございました。