modelowanie i analiza kapitału społecznego - ibspan.waw.pl · 1 p. bochniarz, k. gugała,...
TRANSCRIPT

INSTYTUT BADAŃ SYSTEMOWYCH
POLSKIEJ AKADEMII NAUK
mgr Julia Siderska
Modelowanie i analiza kapitału społecznego
firm informatycznych
z zastosowaniem sztucznych sieci neuronowych
Streszczenie rozprawy doktorskiej
Promotor:
prof. dr hab. inż. Stanisław Walukiewicz (Instytut Badań Systemowych PAN)
Recenzenci:
dr hab. Izabela Rejer (Zachodniopomorski Uniwersytet Technologiczny)
prof. dr hab. inż. Stanisław Skowron (Politechnika Lubelska)
Warszawa, 2016

2
Spis treści
Wprowadzenie ................................................................................................. 3
1. Problem badawczy i jego uzasadnienie ................................................ 4
2. Cele i hipotezy badawcze ...................................................................... 5
3. Metodyka badań .................................................................................... 6
4. Struktura i zakres pracy ........................................................................ 7
5. Rezultaty badawcze............................................................................... 8
Podsumowanie ................................................................................................. 24
Spis treści rozprawy doktorskiej ..................................................................... 26
Nota o doktorantce .......................................................................................... 28
Wykaz publikacji doktorantki z zakresu tematyki rozprawy .......................... 29
Wybrane pozycje literaturowe ........................................................................ 30

3
Wprowadzenie
Bill Gates, założyciel i wieloletni szef Microsoft, największego przedsiębiorstwa
informatycznego na świecie, powiedział: Zabierz moich dwudziestu najlepszych ludzi,
a Microsoft stanie się firmą o marginalnym znaczeniu.1 Jego słowa, stanowiące myśl
przewodnią pracy doktorskiej, świadczą o przekonaniu, że o sukcesie firmy informatycznej2
decydują przede wszystkim jej pracownicy, ich talent, doświadczenie, umiejętność
programowania oraz relacje pomiędzy pracownikami różnych szczebli, ich wzajemne
zaufanie, współpraca, lojalność, umiejętność twórczego rozwiązywania problemów
i konfliktów. Są to najbardziej istotne czynniki stanowiące kapitał społeczny każdego
przedsiębiorstwa.
Pojawienie się tych nowych czynników, wpływających na wartość giełdową
przedsiębiorstw, spowodowało konieczność opracowania metod ich analizy i sposobów
pomiaru ich wartości. Algorytmów i narzędzi do szacowania wartości niematerialnych jest
wiele. Znaczna ich część bazuje na bilansach finansowych, publikowanych przez jednostki na
koniec każdego kwartału. Jak dotąd nie opracowano jednak jednej, powszechnie
akceptowalnej metody wyznaczania wartości kapitału ludzkiego i społecznego
przedsiębiorstw. Propozycja regresyjnego modelu neuronowego umożliwiającego takie
szacunki oraz metodyka opracowywania takich modeli jest przedmiotem tej rozprawy.
W literaturze przedmiotu, jako najbardziej znane i najpowszechniej stosowane metody
i techniki analizy wartości niematerialnych przedsiębiorstw wymienia się: oparte na
kapitalizacji rynkowej, kartach punktowych, bezpośrednim pomiarze kapitału intelektualnego
i inne3. Pomiaru aktywów niematerialnych w firmie można dokonać wykorzystując także
niefinansowe modele, takie jak: monitor aktywów niematerialnych K. Sveiby’ego4,
zrównoważoną kartę wyników R. Kaplana i D. Nortona5 czy Nawigator Skandii
L. Edvinssona6.
Zaproponowane w literaturze narzędzia, zwłaszcza te bazujące na bilansach
finansowych, powodują, że określanie wartości aktywów niematerialnych jest procesem
pracochłonnym, czasochłonnym i budzi wiele metodologicznych zastrzeżeń. W związku
z tym przedsiębiorstwa rzadko decydują się na ich wykorzystywanie do szacowania wartości
ich kapitału społecznego. Ponadto, z badań empirycznych autorki wynika, że korzystanie
z opracowanych dotąd algorytmów obliczeniowych wprowadza kilka innych, istotnych
trudności, do których należy zaliczyć przede wszystkim:
brak możliwości określenia istotności poszczególnych zmiennych,
1 P. Bochniarz, K. Gugała, Budowanie i pomiar kapitału ludzkiego w firmie, Poltex, Warszawa, 2005, s. 33. 2 W pracy doktorskiej pojęcie firma i przedsiębiorstwo są traktowane synonimicznie. 3 K. E. Sveiby, The new organisational wealth. Managing and measuring knowledge – based assets, Berret-
Koehler Publishers Inc., San Francisco CA 1997, s. 195 - 200. 4 Tamże, s. 195 - 200. 5 R.S. Kaplan, D.P. Norton, Using the Balanced Scorecard as a Strategic Management System, “Harvard
Business Review”, nr 1-2, 1996, s. 35-61. 6 L. Edvinsson, M.S. Malone, Intellectual Capital. The Proven Way to Establish your Company’s Real Value by
Measuring its Hidden Brainpower, HarperBusiness, Londyn 1997; wyd. pol. Kapitał intelektualny. Poznaj
prawdziwą wartość swojego przedsiębiorstwa odnajdując jego ukryte korzenie, Wydawnictwo Naukowe PWN,
Warszawa 2001, s. 56.

4
potrzebę analizy wielu różnych źródeł, na przykład bilansów finansowych przedsiębiorstw,
sprawozdań giełdowych i innych wewnętrznych dokumentów firmy,
konieczność wykonania pogłębionych badań i uwzględnienia specyfiki warunków
gospodarki.
Wśród wymienionych wad opracowanych dotąd algorytmów obliczeniowych
najistotniejszą, z punktu widzenia autorki, barierą jest brak możliwości oceny istotności
poszczególnych zmiennych, wpływających na wartość kapitału społecznego.
Przeprowadzono studia literaturowe systematyzujące wiedzę zarówno na temat narzędzi
i metod wyznaczania wartości kapitału społecznego, jak i możliwości zaimplementowania
metod szeroko rozumianej sztucznej inteligencji do tego typu obliczeń i analiz. W polskiej
literaturze przedmiotu, według wiedzy autorki, nie ma oryginalnych publikacji w tym
zakresie. Zastosowanie narzędzi sztucznej inteligencji nie było dotychczas opisywane
w kontekście analizy kapitału społecznego przedsiębiorstw informatycznych.
1. Problem badawczy i jego uzasadnienie
Przegląd piśmiennictwa pozwolił na wskazanie luk badawczych w zakresie badań
metodologicznych oraz rozważań teoretycznych w tym obszarze. Są to: luka teoretyczna –
w literaturze przedmiotu brak jest opracowań proponujących wykorzystanie narzędzi
sztucznej inteligencji do szacowania wartości kapitału społecznego przedsiębiorstw IT; luka
metodyczna – wynikająca z braku metodyki budowania regresyjnych modeli neuronowych
do szacowania wartości kapitału społecznego. Na podstawie obserwacji własnych oraz
przeprowadzonych studiów literaturowych został sformułowany problem naukowy
rozprawy: w jaki sposób możliwe jest zastosowanie sztucznych sieci neuronowych do analizy
i modelowania kapitału społecznego firm informatycznych?
Dlatego w pracy doktorskiej podjęto próbę wypełnienia luk badawczych oraz
opracowania modelu sieci neuronowej do szacowania wartości kapitału społecznego firm
informatycznych oraz pozwalającej na wskazanie i analizę zmiennych istotnie wpływających
na jego wartość. Szacowanie wartości kapitału społecznego firmy jest, jak wynika z przeglądu
literatury, procesem bardzo trudnym i żmudnym. Zaproponowany model sztucznej sieci
neuronowej usprawni dokonanie takich obliczeń i analiz.
2. Cele i hipotezy badawcze
Głównym celem prac badawczych było opracowanie regresyjnego modelu
neuronowego do szacowania wartości kapitału społecznego przedsiębiorstw informatycznych,
prowadzących działalność na rynku informatycznym.
Do zakładanego celu głównego pracy sformułowano cele szczegółowe, obejmujące trzy
obszary: poznawczy, metodyczny i utylitarny. W aspekcie poznawczym celem pracy była
systemowa analiza sektora informatycznego, w tym przede wszystkim rynku oprogramowania
oraz systematyzacja wiedzy na temat algorytmów szacowania wartości kapitału społecznego
w firmach informatycznych. Ponadto, przeprowadzone studia literaturowe pozwoliły na
identyfikację zmiennych wejściowych, istotnie wpływających na wartość kapitału

5
społecznego. Podstawowym celem metodycznym było opracowanie metodyki budowania
regresyjnych modeli neuronowych do szacowania wartości kapitału społecznego. W aspekcie
utylitarnym zostały zaproponowane narzędzia informatyczne, wykorzystujące obliczenia
inteligentne, umożliwiające modelowanie i szacowanie wartości kapitału społecznego
przedsiębiorstw informatycznych.
Przedstawiony problem i cele pracy pozwoliły na sformułowanie następującej głównej
hipotezy badawczej pracy: sztuczne sieci neuronowe są użytecznym i praktycznie
przydatnym narzędziem do modelowania, analizy i szacowania wartości kapitału społecznego
przedsiębiorstw informatycznych.
Do tak sformułowanej hipotezy głównej przyjęto następujące hipotezy szczegółowe:
H1: Regresyjny model sieci neuronowej, z tangensem hiperbolicznym jako funkcją aktywacji,
pozwala na szacowanie wartości kapitału społecznego z większą dokładnością niż regresja
liniowa.
H2: W przedsiębiorstwach prowadzących działalność w segmencie oprogramowania udział
kapitału społecznego w wartości giełdowej jest znaczący. Udział kapitału społecznego
w wartości giełdowej polskich przedsiębiorstw informatycznych jest mniejszy w porównaniu
do liderów branży IT na świecie.
W rozprawie powyższe hipotezy były przedmiotem weryfikacji zarówno teoretycznej,
jak i empirycznej.
3. Metodyka badań
W celu weryfikacji hipotezy głównej i hipotez szczegółowych rozprawy
zaprojektowano i zrealizowano logiczny ciąg następujących po sobie zadań badawczych.
Planowane zadania badawcze oraz metodykę, jaką przyjęto do osiągnięcia celów pracy oraz
konfirmacji hipotezy badawczej przedstawiono na rysunku 1.
Przegląd literatury i krytyczna analiza piśmiennictwa pozwoliły na rozpoznanie
aktualnego stanu wiedzy na temat algorytmów i narzędzi, pozwalających na szacowanie jego
wartości oraz na systematyzację wiedzy na temat zmiennych istotnie wpływających na tę
wartość. Metoda analizy i konstrukcji logicznej oraz metoda analizy dokumentów pozwoliły
na systemową analizę rynku informatycznego oraz na opracowanie modelu koncepcyjnego.
Za pomocą metod matematycznych, to jest równania fundamentalnego, dokonano
oszacowania wartości kapitału społecznego wybranych przedsiębiorstw informatycznych,
stanowiącego zmienną wyjściową w zaproponowanym modelu sieci neuronowej. Metoda
ta umożliwiała także pomiar wartości zmiennych wejściowych analizowanych
przedsiębiorstw, stanowiących wektor uczący niezbędny do trenowania opracowanego
modelu. Metody symulacji komputerowych pozwoliły na zaprojektowanie modelu oraz
przeprowadzenie eksperymentów symulacyjnych, mających na celu wskazanie parametrów
pozwalających na otrzymanie najwyższych współczynników jakości modelu. Regresyjny
model neuronowy opracowano oraz jego scoring7 przeprowadzono przy wykorzystaniu
pakietu statystycznego STATISTICA (moduł Automatyczne Sieci Neuronowe).
7 Koronacki J., Ćwik J., Statystyczne systemy uczące się, Wydawnictwa Naukowo-Techniczne, Warszawa 2005.

6
Rysunek 1. Metodyka badań przyjęta w pracy doktorskiej
Źródło: opracowanie własne.
4. Struktura i zakres pracy
Rozprawa ma charakter metodyczno-empiryczny i została podzielona na pięć
rozdziałów, stanowiących dokumentację kolejnych etapów badań. Struktura rozprawy została
także określona przez przyjęte cele oraz hipotezy badawcze. Praca składa się z wprowadzenia,
pięciu rozdziałów, podsumowania, aneksu (kod źródłowy autorskiego programu SOCAP
Neural Network, nota o badaniach autorki), spisu literatury oraz spisu tabel i rysunków.
W rozdziale pierwszym dokonano systemowej analizy rynku informatycznego, w tym
rynku oprogramowania Pokazano, że chociaż IT jest jedną z najszybciej rozwijających się
gałęzi i siłą napędową gospodarki w Polsce, to sytuacja polskich przedsiębiorstw nie jest
stabilna, a powodzenie ich funkcjonowania w dużej mierze zależy od otrzymywanych
kontraktów na informatyzację państwowych instytucji.

7
Rozdział drugi dotyczy rynku oprogramowania otwartego. Omówiono początki idei
powszechnego dostępu do kodu źródłowego oraz wskazano pionierów otwartych rozwiązań.
Wyjaśniono istotę oraz różnicę pomiędzy katedralnym i bazarowym modelem budowy
oprogramowania. Pokazano także, w jaki sposób analiza systemowa może być zastosowana
do analizy procesu tworzenia takiego oprogramowania.
W rozdziale trzecim pracy omówiono istotę oraz rolę wartości niematerialnych firm
informatycznych. Zaprezentowano genezę oraz twórców pojęcia kapitału ludzkiego i kapitału
społecznego. Omówiono profil przedsiębiorstwa Prokom Software SA – pierwszej firmy
prowadzącej działalność na polskim rynku IT oraz wieloletniego lidera tego segmentu rynku.
Ponadto zaprezentowano, jak za pomocą równania fundamentalnego jest możliwe
oszacowanie wartości kapitału społecznego tej firmy.
W rozdziale czwartym skoncentrowano się na istocie sztucznej inteligencji i sieci
neuronowych i omówiono rozwój badań oraz wzrostu zainteresowania świata nauki i biznesu
tą tematyką.
W rozdziale piątym udowodniono osiągnięcie celu głównego, metodycznego oraz
utylitarnego rozprawy. Omówiono w nim koncepcję regresyjnego modelu sieci neuronowej,
opracowanego przez autorkę oraz zaproponowano metodykę budowania modeli neuronowych
do modelowania i analizy kapitału społecznego firm informatycznych. Zaprezentowano także
wyniki badań symulacyjnych i eksperymentalnych, przeprowadzonych z wykorzystaniem
tego modelu, do szacowania wartości kapitału społecznego przedsiębiorstw Red Hat,
Microsoft oraz IBM. Udowodniono w ten sposób osiągnięcie celu metodycznego
i utylitarnego tej rozprawy.
Wartością dodaną pracy doktorskiej jest także załączony kod autorskiego programu
SOCAP Neural Network, napisanego w języku C++, umożliwiającego szybkie oszacowanie
wartości kapitału społecznego przedsiębiorstw informatycznych.
5. Proces badawczy
Ocena możliwości zastosowania sztucznych sieci neuronowych do analizy
i modelowania wartości kapitału społecznego możliwa była dzięki wykorzystaniu sieci
neuronowej jako instrumentu do rozwiązywania problemu regresyjnego. Wybrano regresję,
ponieważ istota problemu badawczego, którego rozwiązanie stanowi cel niniejszej rozprawy,
polega na badaniu zależności pomiędzy zbiorem zmiennych objaśniających a zmienną
objaśnianą. Skuteczne przetwarzanie informacji podczas pracy sieci neuronowej jest
uzależnione od poprawnego określenia8: przyjętych modeli neuronów (wybranych funkcji
agregacji oraz funkcji aktywacji dla neuronów w poszczególnych warstwach sieci), wartości
współczynników wagowych neuronów, liczby neuronów w poszczególnych warstwach sieci
oraz przyjętych sposobów połączeń neuronów.
8 P. Lula, G. Paliwoda – Pękosz, R. Tadeusiewicz, dz. cyt., s. 84.

8
Dobór zmiennych wejściowych
Przy budowie sieci neuronowych jedną z pierwszych, ale strategicznych decyzji jest
wybór zmiennych wejściowych. W początkowych fazach projektowania struktury sieci
powinno opierać się na intuicji oraz znajomości specyfiki badanych zagadnień. Pozwala
to na wybór sygnałów wejściowych, oddziaływujących w istotny sposób na wyjście sieci
neuronowej. Dlatego też struktura pierwszej sieci, opracowywanej do rozwiązania
określonego problemu, powinna uwzględniać wszystkie zmienne, które zdaniem projektanta
mają znaczenie. Zbiór ten, w wyniku przeprowadzonych symulacji i eksperymentów, podlega
w dalszej kolejności redukcji9.
Analiza piśmiennictwa z zakresu szacowania wartości niematerialnych pozwoliła
na zidentyfikowanie zbioru zmiennych objaśniających, wpływających na kapitał społeczny
przedsiębiorstwa. Spośród nich do pierwszych analiz wybrano 12 zmiennych wejściowych
o charakterze ilościowym: liczba akcji, cena akcji, wartość księgowa, zysk netto, wartość
giełdowa, aktywa, zobowiązania, przychody ogółem, dochód netto, zatrudnienie, liczba
klientów oraz zysk na jednego zatrudnionego.
Autorka miała świadomość, że zbiór tych zmiennych jest zbyt liczny do analizowanego
problemu. Dodatkowo, zauważono zjawisko redundancji zmiennych, zatem konieczne było
zredukowanie części informacji i użycia tylko podzbioru z nich. Przeprowadzono selekcję
zmiennych wejściowych. Zastosowano metodę usuwania danych silnie skorelowanych oraz
globalną analizę wrażliwości, która umożliwiła wybór tylko tych zmiennych, które istotnie
wpływają na wyjście sieci neuronowej. Dodatkowo, oparto się na rekomendacjach
R. Tadeusiewicza, z których wynika, że w celu zabezpieczenia przed przeuczeniem sieci
neuronowej przyjmuje się, że najbardziej korzystna jest mała liczba zmiennych wejściowych.
Zaleca się zatem odrzucenie części zmiennych zawierających nawet oryginalne dane10.
Wybór tych narzędzi spowodowany był wnioskami z przeglądu literatury, w której podkreśla
się, że są one właściwe do tego typu zastosowań11.
W tabeli 1 przedstawiono wyniki wartości globalnej analizy wrażliwości 12 zmiennych
wejściowych. Interpretuje się je w ten sposób, że gdy jej wartość dla danej zmiennej wynosi
ponad 1, to usunięcie tej zmiennej ze zbioru uczącego może spowodować pogorszenie jakości
modelu i odwrotnie: wartości poniżej 1 informują powodują, że możliwe jest usunięcie
zmiennej ze zbioru bez straty na jakości modelu. W zbiorze uczącym pozostawiono zatem
te zmienne, których wartość analizy wrażliwości wyniosła ponad 1.
9 R. Tadeusiewicz, P. Lula, STATISTICA Neural Networks PL. Przewodnik problemowy, StatSoft, Kraków,
2001. 10 R.Tadeusiewicz, Wprowadzenie do sieci neuronowych, StatSoft Polska, Kraków 2001. 11 R. Tadeusiewicz, M. Szaleniec, Leksykon sieci neuronowych, Wydawnictwo Fundacji „Projekt Nauka”,
Wrocław 2015, s. 24.

9
Tabela 1. Wartości globalnej analizy wrażliwości zmiennych objaśniających
Nazwa zmiennej wejściowej Wartość analizy wrażliwości
dla zmiennej
liczba akcji 1,37
cena akcji 1,55
wartość księgowa 0,88
zysk netto 0,87
wartość giełdowa 2,55
aktywa 2,11
zobowiązania 1,66
przychody ogółem 1,43
dochód netto 1,11
zatrudnienie 1,22
liczba klientów 0,75
zysk na jednego zatrudnionego 0,84
Źródło: opracowanie własne
Dodatkowo, w analizowanym przypadku zastosowano usuwanie danych silnie
skorelowanych. Do takich zmiennych należały: wartość giełdowa, liczba akcji i cena akcji.
Spowodowane było to faktem, że wartość giełdowa (rynkowa) przedsiębiorstwa wyznaczana
jest jako iloczyn liczby wyemitowanych akcji oraz ceny 1 akcji na koniec danego okresu
(kwartału). Usunięto zatem ze zbioru uczącego zmienne liczba akcji i cena akcji.
Założenia dotyczące wybranych zmiennych objaśniających wpływających na zmienną
objaśnianą zostały sformułowane w postaci koncepcyjnego modelu:
𝑽(𝑺𝑪, 𝒕) = 𝒇(𝑴𝑽, 𝑨, 𝑳, 𝑻𝑹, 𝑵𝑰, 𝑬𝒎𝒑)
(dla każdego t) gdzie: MV – wartość giełdowa,
A – aktywa,
L – zobowiązania,
TR – przychody ogółem,
NI – dochód netto,
Emp – zatrudnienie.
Kolejnym istotnym zadaniem badawczym było ustalenie optymalnej liczby przypadków
uczących. W literaturze przedmiotu podaje się pewne reguły heurystyczne uzależniające ich
liczbę od rozmiaru sieci neuronowej. Podstawowa z tych reguł, opracowana
i rekomendowana przez R. Tadeusiewicza zakłada, że liczba przypadków powinna być około
dziesięciokrotnie większa od liczby połączeń występujących w sieci neuronowej. Liczba
ta zdeterminowana jest także zależnością funkcyjną poddawaną modelowaniu12. Zbiór danych
uczących obejmował informacje dotyczące 115 przypadków, to jest kwartałów wyznaczonych
12http://www.statsoft.pl/textbook/stathome_stat.html?http%3A%2F%2Fwww.statsoft.pl%2Ftextbook%2Fstneun
et.html%23multilayerc (19.07.2015)

10
dla czterech przedsiębiorstw informatycznych: Microsoft, Red Hat, Prokom Software SA oraz
Asseco Poland SA w latach 2006 – 2014.
Analiza regresji liniowej
Jednym z zadań badawczych autorki była ocena zależności między zmiennymi
niezależnymi, a zmienną zależną, czyli wartością kapitału społecznego. W tym celu
przeprowadzono analizę regresji liniowej. W analizowanym przypadku na wartość zmiennej
zależnej wpływają wartości sześciu zmiennych niezależnych, zatem zasadne było
sformułowanie modelu regresji liniowej. Analiza została przeprowadzona na całym zbiorze,
czyli na 115 obserwacjach.
Zasadniczym celem regresji liniowej była identyfikacja ilościowych związków
pomiędzy zmiennymi objaśniającymi (niezależnymi) 𝑋1, 𝑋2, … , 𝑋6, a zmienną objaśnianą
(zależną) Y.
Liniowy model regresji wyrażony jest wzorem:
𝑌 = 𝛽0 + 𝛽1 ∗ 𝑋1 + 𝛽2 ∗ 𝑋2 + … + 𝛽6 ∗ 𝑋6 + 𝜀
gdzie:
𝑌 − zmienna zależna, objaśniana przez model,
𝑋1, 𝑋2, … , 𝑋6 − zmienne niezależne, objaśniające,
𝛽0, 𝛽1, … , 𝛽6 − parametry,
𝜀 – składnik losowy (reszta modelu).
W celu identyfikacji wzajemnego oddziaływania zmiennych niezależnych na zmienną
zależną, dokonano estymacji parametrów modelu regresji liniowej. Na tej podstawie możliwe
było wnioskowanie o istotności oddziaływania zmiennych objaśniających na zmienną
objaśnianą. Miarą dopasowania modelu jest współczynnik determinacji wielorakiej R2,
którego wartość mieści się w przedziale <0;1>, czyli jest miarą siły liniowego związku
między zmiennymi. Mierzy on część zmienności zmiennej objaśnianej Y, która została
wyjaśniona liniowym oddziaływaniem zmiennej objaśniającej X13. Wartości współczynnika
determinacji w pobliżu zera wskazują, że model nie jest przydatny do predykcji wartości
zmiennej zależnej Y za pomocą zmiennych niezależnych, natomiast wartości zbliżone
do 1 wskazują, że równanie regresji jest bardzo przydatne do przewidywania wartości
zmiennej zależnej Y za pomocą zmiennych niezależnych. Współczynnik determinacji określa
w jakiej części zmienność zmiennej Y została wyjaśniona przez model. W analizowanym
przypadku współczynnik determinacji jest wysoki, ponieważ jego wartość wynosi 0,88.
Po zbudowaniu modelu możliwe było dokonanie jego weryfikacji statystycznej
poprzez przeanalizowanie ocen parametrów modelu regresji oraz miar dopasowania modelu14,
których wartości zostały zaprezentowane w tabeli 2.
13http://home.agh.edu.pl/~bartus/index.php?action=dydaktyka&subaction=statystyka&item=regresja_i_korelacja
(02.04.2016) 14 http://manuals.pqstat.pl/statpqpl:wielowympl:wielorpl (02.04.2016)
11
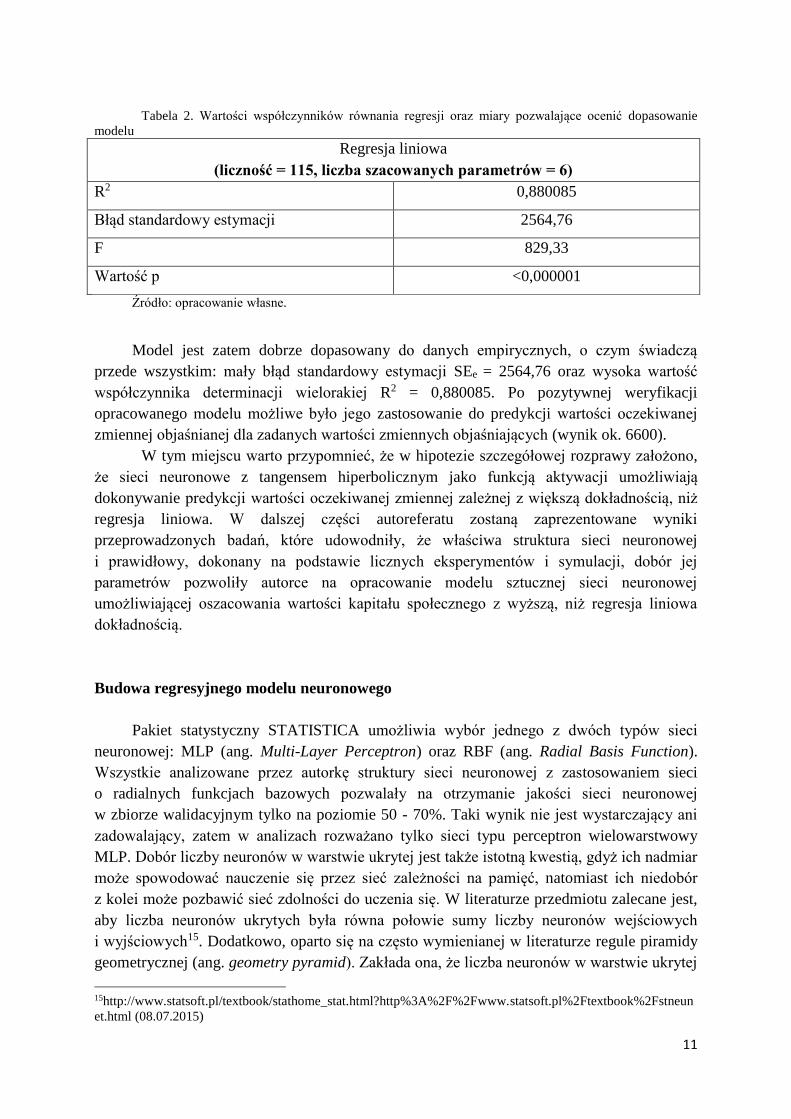
Tabela 2. Wartości współczynników równania regresji oraz miary pozwalające ocenić dopasowanie
modelu
Regresja liniowa
(liczność = 115, liczba szacowanych parametrów = 6)
R2 0,880085
Błąd standardowy estymacji 2564,76
F 829,33
Wartość p <0,000001
Źródło: opracowanie własne.
Model jest zatem dobrze dopasowany do danych empirycznych, o czym świadczą
przede wszystkim: mały błąd standardowy estymacji SEe = 2564,76 oraz wysoka wartość
współczynnika determinacji wielorakiej R2 = 0,880085. Po pozytywnej weryfikacji
opracowanego modelu możliwe było jego zastosowanie do predykcji wartości oczekiwanej
zmiennej objaśnianej dla zadanych wartości zmiennych objaśniających (wynik ok. 6600).
W tym miejscu warto przypomnieć, że w hipotezie szczegółowej rozprawy założono,
że sieci neuronowe z tangensem hiperbolicznym jako funkcją aktywacji umożliwiają
dokonywanie predykcji wartości oczekiwanej zmiennej zależnej z większą dokładnością, niż
regresja liniowa. W dalszej części autoreferatu zostaną zaprezentowane wyniki
przeprowadzonych badań, które udowodniły, że właściwa struktura sieci neuronowej
i prawidłowy, dokonany na podstawie licznych eksperymentów i symulacji, dobór jej
parametrów pozwoliły autorce na opracowanie modelu sztucznej sieci neuronowej
umożliwiającej oszacowania wartości kapitału społecznego z wyższą, niż regresja liniowa
dokładnością.
Budowa regresyjnego modelu neuronowego
Pakiet statystyczny STATISTICA umożliwia wybór jednego z dwóch typów sieci
neuronowej: MLP (ang. Multi-Layer Perceptron) oraz RBF (ang. Radial Basis Function).
Wszystkie analizowane przez autorkę struktury sieci neuronowej z zastosowaniem sieci
o radialnych funkcjach bazowych pozwalały na otrzymanie jakości sieci neuronowej
w zbiorze walidacyjnym tylko na poziomie 50 - 70%. Taki wynik nie jest wystarczający ani
zadowalający, zatem w analizach rozważano tylko sieci typu perceptron wielowarstwowy
MLP. Dobór liczby neuronów w warstwie ukrytej jest także istotną kwestią, gdyż ich nadmiar
może spowodować nauczenie się przez sieć zależności na pamięć, natomiast ich niedobór
z kolei może pozbawić sieć zdolności do uczenia się. W literaturze przedmiotu zalecane jest,
aby liczba neuronów ukrytych była równa połowie sumy liczby neuronów wejściowych
i wyjściowych15. Dodatkowo, oparto się na często wymienianej w literaturze regule piramidy
geometrycznej (ang. geometry pyramid). Zakłada ona, że liczba neuronów w warstwie ukrytej
15http://www.statsoft.pl/textbook/stathome_stat.html?http%3A%2F%2Fwww.statsoft.pl%2Ftextbook%2Fstneun
et.html (08.07.2015)

12
powinna być równa pierwiastkowi iloczynu liczby neuronów w warstwie wejściowej
i wyjściowej. Reguła ta wyrażona jest wzorem16:
𝐻 = √𝑁 ∗ 𝑀
gdzie:
H – liczba neuronów w warstwie ukrytej,
N – liczba neuronów w warstwie wejściowej,
M – liczba neuronów w warstwie wyjściowej.
Znalazło to odzwierciedlenie w analizowanym przypadku, zatem zdefiniowano
3 neurony w warstwie ukrytej. W wyniku przeprowadzonych studiów literaturowych oraz
prac badawczych mających na celu tzw. preprocessing zmiennych wejściowych wybrano sieć
neuronową typu MLP 6-3-1, o strukturze złożonej z sześciu neuronów w warstwie
wejściowej, trzech neuronów w warstwie ukrytej (h1, h2, h3) oraz jednego neuronu
w warstwie wyjściowej.
Bardzo ważnym etapem badań był także wybór właściwej funkcji błędu, pozwalającej
na ocenę jakości sieci neuronowej w trakcie trenowania lub w czasie jej późniejszego
uruchomienia. W iteracyjnych algorytmach uczących pochodna funkcji błędu stanowi
podstawę do modyfikacji wag17. Przy modelowaniu problemu regresyjnego funkcją błędu jest
suma kwadratów (ang. Sum of squares). Błąd jest sumą kwadratów różnic (odchyleń)
pomiędzy wartościami zadanymi i wartościami otrzymanymi na wyjściach każdego neuronu
wyjściowego. Powstający wskaźnik SSE (ang. Sum Square Errors) wyrażony jest wzorem18:
𝑆𝑆𝐸 = ∑ ∑ (𝑑𝑝𝑘 𝑀𝑘=1
𝑅𝑝=1 − 𝑦𝑝𝑘)2
gdzie:
𝑑𝑝𝑘 – wzorcowa odpowiedź, która powinna pojawić się przy prezentacji przypadku uczącego
o numerze p na wyjściu sieci o numerze k,
𝑦𝑝𝑘 – faktyczna wartość, jaka pojawiła się na wyjściu.
Eksperymentom poddano kilkaset konfiguracji sieci neuronowych różniących się także
rodzajami funkcji aktywacji. Przeprowadzone symulacje pozwoliły na ocenę jakości modeli
i wybór tej, która pozwalała na otrzymanie najwyższej wartości jakości w zbiorze
walidacyjnym. Jakość wyrażana jest za pomocą współczynnika korelacji Pearsona pomiędzy
wartościami zmiennej zależnej, a przewidywaniami sieci, wyrażonego wzorem:
𝑟𝑥𝑦 = ∑ (𝑥𝑖 − x )(𝑦𝑖 − 𝑦)𝑛
𝑖=1
√∑ (𝑥𝑖 − x )2𝑛
𝑖=1 √∑ (𝑦𝑖 − 𝑦)𝑛𝑖=1
gdzie:
x - jest wartością średnią.
16 T. Masters, Practical Neural Network Recipes in C++, Academic Press Elsevier, USA 1993. 17 C. M. Bishop, Neural Networks for Pattern Recognition, Oxford University Press, Oxford 1995. 18 R. Tadeusiewicz, M. Szaleniec, Leksykon sieci neuronowych, Wydawnictwo Fundacji „Projekt Nauka”,
Wrocław 2015, s. 101.

13
Przeprowadzony proces badawczy obejmował analizy symulacyjne pozwalające
na ocenę zmian współczynników jakości i błędów sieci neuronowej w odpowiedzi na zmianę
rodzajów funkcji błędów, funkcji aktywacji w neuronach ukrytych i wyjściowych oraz testy
różnych algorytmów trenowania sieci. W tabeli 3 przedstawiono kilka wybranych struktur
i parametrów sieci neuronowych, poddanych eksperymentom, wraz ze wskazaniem
uzyskanych dzięki nim różnym współczynnikom jakości w zbiorze uczącym, walidacyjnym
i testowym. Warto zauważyć, że o radialnych funkcjach bazowych pozwalają,
w analizowanym przypadku, na korzystanie z modelu z dużą niższą jakością w zbiorze
walidacyjnym, niż sieci typu perceptron wielowarstwowy MLP. Przeprowadzone testy
pozwoliły także na udowodnienie, że funkcje S-kształtne (sigmoidalna i tangens
hiperboliczny) minimalizują funkcję błędu sieci. Zastosowanie funkcji liniowej albo
wykładniczej w tym przypadku nie jest uzasadnione. Warto też zauważyć, że na wartość
współczynnika jakości sieci duży wpływ ma zastosowana funkcja aktywacji w neuronie
wyjściowym. Mniejsze wartości błędów sieci można uzyskać stosując funkcję liniową, niż
wykładniczą, czy funkcje S-kształtne. Duże znaczenie miał w tym przypadku także
zastosowany algorytm trenowania sieci neuronowej. Z danych zaprezentowanych w tabeli 3
można wywnioskować, że algorytm BFGS pozwala na budowę modelu generalizującego
nowe przypadki z większą dokładnością, niż algorytm gradientów sprzężonych czy
najszybszego spadku.
Najwyższy współczynnik jakości sieci w zbiorze walidacyjnym (0,99) otrzymano
budując sieć o parametrach uwzględnionych w pierwszym wierszu tej tabeli, tj. stosując:
tangens hiperboliczny jako funkcję aktywacji w neuronach ukrytych i funkcję liniową
w neuronie wyjściowym; sumę kwadratów jako funkcję błędów oraz algorytm BFGS
do trenowania. Struktura i parametry wybranej do dalszych analiz sieci zaprezentowane
zostały w tabeli 4. Takie parametry modelu, wybrane na podstawie wielu przeprowadzonych
symulacji, pozwoliły na zaproponowanie sieci umożliwiającej generalizowanie danych
z najlepszym z możliwych współczynników jakości.
Na podstawie tych eksperymentów podjęto decyzję o zastosowaniu tangensu
hiperbolicznego (w pakiecie STATISTICA oznaczanego jako tanh), jako funkcji aktywacji
w neuronach ukrytych, wyrażonego wzorem:
f(x) = a ∙ tanh (𝑏𝑥) = a ∙ 𝑒𝑏𝑥−𝑒−𝑏𝑥
𝑒𝑏𝑥+𝑒−𝑏𝑥
W większości modelów sztucznych sieci neuronowych stosuje się normalizację
zmiennych wejściowych. Polega to na zastosowaniu przeskalowania wartości każdej
zmiennej i sprowadzenia ich do określonego, zazwyczaj małego, zakresu (przedziału).
Ta procedura ma za zadanie przydzielenie każdej zmiennej wejściowej jednakowego
znaczenia (wagi) w stosunku do innych zmiennych19. Dane liczbowe stanowiące wejścia sieci
neuronowej przyjmują wartości należące do zupełnie różnych przedziałów i rzędów wartości.
W literaturze podaje się, że w celu uzyskania dobrej efektywności procesu trenowania
najkorzystniejsze jest podawanie na wejściu wartości z przedziału (0,1). Takie podejście
19 J. Morajda, Metody sztucznej inteligencji w zarządzaniu portfelem inwestycyjnym (praca doktorska), Kraków
1999, s. 59.

14
umożliwia lepsze wykorzystanie nieliniowego fragmentu przebiegu funkcji przejścia
w poszczególnych warstwach sieci, w tym przede wszystkim w warstwie ukrytej.
Skalowanie nieliniowe nie jest realizowane przez moduł Automatyczne Sieci
Neuronowe w pakiecie STATISTICA, zatem w analizowanym przypadku zastosowano
normalizację liniową, wyrażoną wzorem:
𝑦 = 𝑎 ∗ 𝑥 + 𝑏
gdzie:
𝑎 = 1
xmax −𝑥𝑚𝑖𝑛 ; 𝑏 =
−𝑥𝑚𝑖𝑛
𝑥𝑚𝑎𝑥− 𝑥𝑚𝑖𝑛
w zakresie [min - max] -> [0, 1].

15
Tabela 3. Wybrane parametry sieci i współczynniki jakości
Network type
6-3-1
Error function Activation
function
(hidden
neurons)
Activation function
(output neuron)
Training
algorithm
Quality
(training
set)
Quality
(validation
set)
Quality
(test set)
MLP Sum of squares Tanh Linear BFGS 0,97 0,99 0,99
MLP Sum of squares Tanh Linear Steepest descent 0,92 0,90 0,91
MLP Sum of squares Tanh Linear Gradient - based 0,86 0,82 0,83
MLP Sum of squares Tanh Sinus BFGS 0,95 0,97 0,95
MLP Sum of squares Tanh Exponential BFGS 0,85 0,87 0,84
MLP Sum of squares Sinus Tanh BFGS 0,96 0,96 0,96
MLP Sum of squares Sinus Tanh Steepest descent 0,93 0,93 0,92
MLP Sum of squares Logistic Sinus Steepest descent 0,95 0,94 0,94
MLP Sum of squares Logistic Linear Gradient - based 0,89 0,88 0,88
MLP Sum of squares Linear Exponential Gradient - based 0,92 0,94 0,94
MLP Sum of squares Exponential Logistic BFGS 0,78 0,79 0,71
RBF Sum of squares Gauss Linear K-means 0,77 0,86 0,78
Źródło: opracowanie własne.

16
Trenowanie sieci neuronowej
W analizowanym przypadku zastosowano uczenie nadzorowane (ang. supervised
learning), przeprowadzone w oparciu o 115 przypadków wartości kapitału społecznego (Y),
obliczonego za pomocą równania fundamentalnego oraz wartości zmiennych wejściowych
analizowanych przedsiębiorstw informatycznych na koniec każdego kwartału w okresie 2006
– 2014. Parametry sieci, czyli wartości wag i wartości progowe neuronów, dobrano w sposób
pozwalający na minimalizację funkcji błędu sieci. W tym celu zastosowano odpowiedni
algorytm uczenia, który umożliwił automatyczną modyfikację wartości współczynników
wagowych, opierając się na danych wejściowych i odpowiadających im prawidłowym
rozwiązaniom. Trenowanie zbudowanego modelu sieci przeprowadzono metodą wstecznej
propagacji błędów (ang. backpropagation). Przetestowano wrażliwość sieci na zmianę
algorytmów uczenia. Podjęto decyzję o implementacji algorytmu BFGS (Broyden–Fletcher–
Goldfarb–Shanno), opartego na metodzie gradientowej drugiego rzędu, będącego alternatywą
dla gradientu prostego. Algorytm BFGS należy do algorytmów quasi-newtonowskich (tak
zwanych metod zmiennej metryki) o szybkiej zbieżności. Ten algorytm trenowania umożliwił
otrzymanie minimalnych błędów w zbiorze walidacyjnym.
Wyniki eksperymentów
Podsumowanie parametrów trójwarstwowego perceptronu zaprezentowano w tabeli 4.
Modelowaną sieć charakteryzują następujące współczynniki jakości: 0,97 dla zbioru
uczącego; 0,99 dla zbioru testowego oraz 0,99 dla zbioru walidacyjnego. Przy analizie
regresji jakość sieci wyrażona jest za pomocą współczynnika korelacji liniowej Pearsona
pomiędzy wartościami zmiennej zależnej (wyjściowej), a przewidywaniami sieci.
Tabela 4. Parametry charakteryzujące zbudowaną sieć neuronową
Nazwa
sieci
Funkcja aktywacji
(neurony ukryte)
Funkcja aktywacji
(neurony wyjściowe)
Błąd sieci Algorytm uczenia
MLP
6-3-1
Tangens hiperboliczny
Liniowa
Suma
kwadratów
(SOS – sum of
squares)
BFGS (oparty na
metodzie
gradientowej
drugiego rzędu)
Źródło: opracowanie własne.
Przeprowadzone studia literaturowe dotyczące struktury sieci, prace badawcze
dotyczące preprocessingu zmiennych wejściowych oraz eksperymenty mające na celu
określenie cech sieci pozwoliły autorce na opracowanie modelu, opartego na sztucznej sieci
neuronowej, odwzorowującego proces wyznaczania wartości kapitału społecznego. Został on
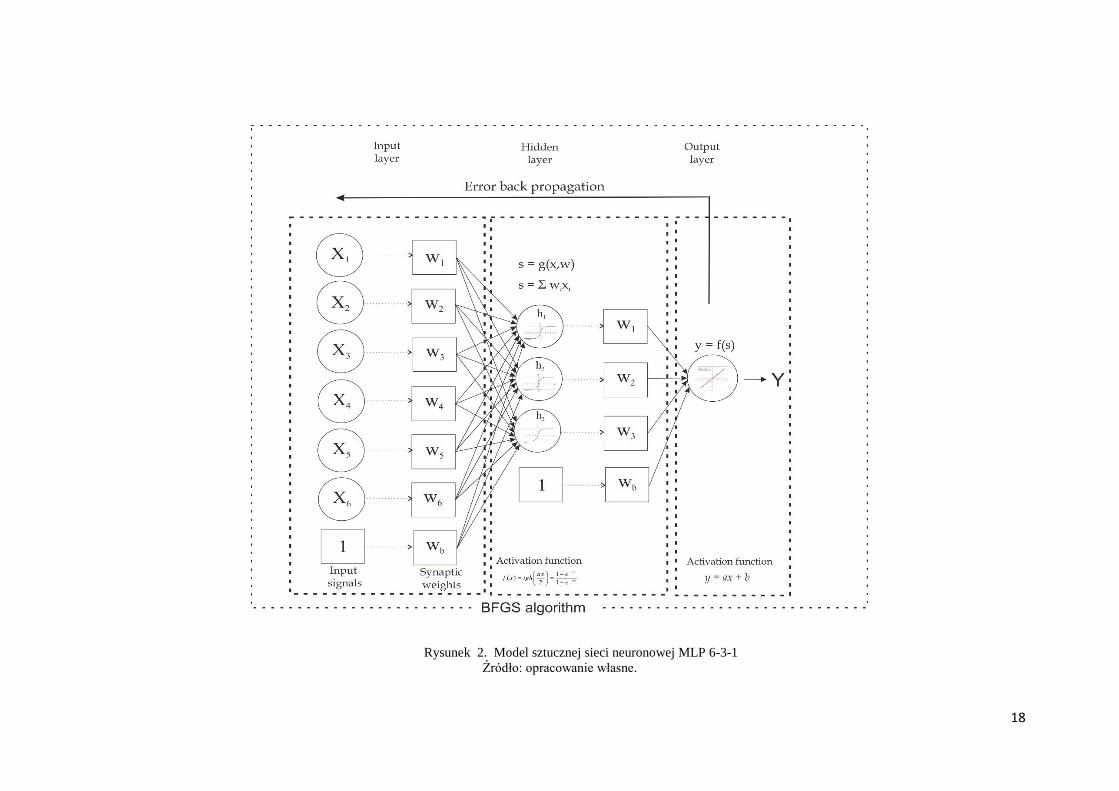
zaprezentowany na rysunku 2.
W modelu tym na wejścia wprowadzane są numeryczne wartości wejściowe 𝑥0 ,…, 𝑥6,
tworzące wektor wartości wejściowych 𝑿 = [𝑥0 ,…, 𝑥6 ]. Każdej z sześciu zmiennych
wejściowych przyporządkowane zostały odpowiadające im współczynniki wagowe

17
(w0,…,w6), określające siłę ich wpływu na zmienną wyjściową Y. Wartości tych
współczynników, zwanych wagami synaptycznymi, tworzą wektor wag neuronu
𝑊 = [𝑤0 ,…, 𝑤6 ] i wyznaczone zostały podczas uczenia sieci neuronowej. Wektor wag
zdefiniowany został jako20:
𝑊 = [𝑤0, 𝑤2, … , 𝑤6]𝑇
gdzie:
T - symbol transpozycji,
W – wektor wyznaczający punkt w n-wymiarowej przestrzeni wag.
Dane wejściowe zostały zagregowane poprzez zsumowanie iloczynów wartości
wejściowych i odpowiadających im współczynników wagowych, co opisać można wzorem:
𝑠 = ∑ 𝑤𝑖
𝑛
𝑖=0
𝑥𝑖
Przy wyznaczaniu wartości wyjściowej neuronu zastosowana została funkcja aktywacji,
oznaczana jako f(WTX). Argumentem tej funkcji była zagregowana wcześniej wartość
wejściowa s. W neuronach ukrytych miała ona postać tangensu hiperbolicznego, a w neuronie
wyjściowym zastosowano funkcję liniową.
Wyjście neuronu opisać można za pomocą relacji:
𝑦 = 𝑓(𝑊𝑇𝑋) = 𝑓 (∑ 𝑤𝒊
𝒏
𝒊=𝟎
𝑥𝒊)
gdzie:
n - liczba wejść,
x0, x2, ..., x6 - wartości sygnałów wejściowych dla neuronu,
w0, w2, ..., w6 - wartości wag połączeń wejściowych, określające znaczenie poszczególnych
wejść,
f - funkcja aktywacji określająca zależność wyjścia od ważonej sumy wejść.
20 R . Tadeusiewicz, Sieci neuronowe…, s. 28.
18
Rysunek 2. Model sztucznej sieci neuronowej MLP 6-3-1
Źródło: opracowanie własne.

19
Zastosowanie i ocena opracowanego modelu
Zaproponowana metodyka badawcza jest nowa, dlatego istniała konieczność
zweryfikowania jej poprawności poprzez zestawienie wyników uzyskanych przy jej użyciu,
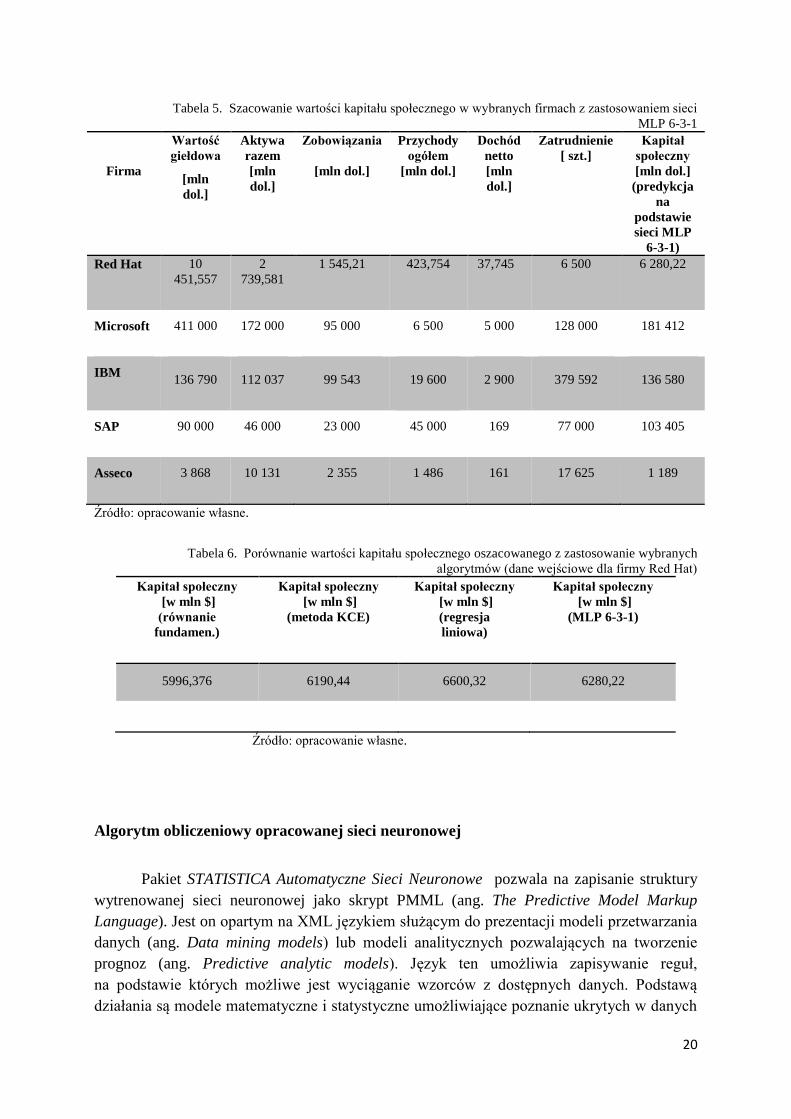
z wynikami otrzymanymi za pomocą innych narzędzi. W tabeli 5 porównano wyniki wartości
kapitału społecznego oszacowanego za pomocą równania fundamentalnego oraz
z wykorzystaniem zbudowanego modelu (sieci neuronowej MLP 6-3-1). Wielkość kapitału
społecznego została podana przez nauczoną zależności sieć neuronową (ostatnia kolumna).
Przeprowadzono badania eksperymentalne, mające na celu symulację wartości kapitału
społecznego przedsiębiorstw Red Hat, Microsoft, IBM, SAP oraz Asseco. Zaprezentowane
w tabeli 5 wartości zmiennych wejściowych wszystkich przedsiębiorstw nie należały
do zbioru uczącego (w przypadku firm Red Hat, Microsoft oraz Asseco dane te obejmują inne
okresy, niż te na których trenowana była sieć). Wartość kapitału społecznego wyznaczona
z zastosowaniem sieci MLP 6-3-1 jest większa o około 5% w stosunku do wartości kapitału
społecznego obliczonej za pomocą równania fundamentalnego. Różnica jest niewielka
i akceptowalna, co uwiarygodnia zaproponowaną metodykę jako sprawne narzędzie
informatyczne do tego typu szacunków, charakteryzujące się dużą zdolnością do generalizacji
danych.
Warto przytoczyć wyniki predykcji (dla tych samych wartości zmiennych) dokonanej
przy użyciu modelu regresji. Prognozowana wartość kapitału społecznego z zastosowaniem
modelu regresji wielorakiej wynosi 6 600 mln dolarów, zatem różnica ta wynosi dwa razy
więcej, czyli około 10%. Wyniki te potwierdzają słuszność postawionej hipotezy mówiącej,
że regresyjny model sztucznej sieci neuronowej z tangensem hiperbolicznym jako funkcją
aktywacji pozwala na szacowanie wartości kapitału społecznego z większą dokładnością niż
regresja liniowa.
W tabeli 6 zestawiono porównanie wyników wartości kapitału społecznego
przedsiębiorstwa Red Hat o szacowanych przy użyciu kilku wybranych algorytmów.
Dane te nie znajdowały się w zbiorze uczącym, zatem nie były poddane trenowaniu.
Z zaprezentowanych wyników można wywnioskować, że szacowanie wartości kapitału
społecznego z zastosowaniem opracowanego modelu neuronowego różni się
w stosunku do obliczeń otrzymanych przy wykorzystaniu równania fundamentalnego oraz
metody KCE (ang. Knowledge Capital Earnings), odpowiednio o 3% i 5%. Prognozowana
wartość kapitału społecznego z zastosowaniem modelu regresji wielorakiej wynosi 6 600,32
mln dolarów, zatem różnica ta wynosi dwa razy więcej, czyli około 10%. Moj model daje
szacunki bliższe równaniu fundamentalnemu i metodzie KCE, algorytmów wskazywanych
w literaturze jako użyteczne do tego typu analiz, niż regresja liniowa. Wyniki też
potwierdzają słuszność hipotezy szczegółowej, że regresyjny model sztucznej sieci
neuronowej z nieliniową funkcją aktywacji pozwala na szacowanie z większą dokładnością
niż regresja liniowa.
20
Tabela 5. Szacowanie wartości kapitału społecznego w wybranych firmach z zastosowaniem sieci
MLP 6-3-1
Firma
Wartość
giełdowa
[mln
dol.]
Aktywa
razem
[mln
dol.]
Zobowiązania
[mln dol.]
Przychody
ogółem
[mln dol.]
Dochód
netto
[mln
dol.]
Zatrudnienie
[ szt.]
Kapitał
społeczny
[mln dol.]
(predykcja
na
podstawie
sieci MLP
6-3-1)
Red Hat
10
451,557
2
739,581
1 545,21
423,754
37,745
6 500
6 280,22
Microsoft
411 000
172 000 95 000 6 500 5 000 128 000 181 412
IBM
136 790
112 037
99 543
19 600
2 900
379 592
136 580
SAP 90 000
46 000 23 000 45 000 169 77 000 103 405
Asseco 3 868
10 131 2 355 1 486 161 17 625
1 189
Źródło: opracowanie własne.
Tabela 6. Porównanie wartości kapitału społecznego oszacowanego z zastosowanie wybranych
algorytmów (dane wejściowe dla firmy Red Hat)
Kapitał społeczny
[w mln $]
(równanie
fundamen.)
Kapitał społeczny
[w mln $]
(metoda KCE)
Kapitał społeczny
[w mln $]
(regresja
liniowa)
Kapitał społeczny
[w mln $]
(MLP 6-3-1)
5996,376 6190,44 6600,32 6280,22
Źródło: opracowanie własne.
Algorytm obliczeniowy opracowanej sieci neuronowej
Pakiet STATISTICA Automatyczne Sieci Neuronowe pozwala na zapisanie struktury
wytrenowanej sieci neuronowej jako skrypt PMML (ang. The Predictive Model Markup
Language). Jest on opartym na XML językiem służącym do prezentacji modeli przetwarzania
danych (ang. Data mining models) lub modeli analitycznych pozwalających na tworzenie
prognoz (ang. Predictive analytic models). Język ten umożliwia zapisywanie reguł,
na podstawie których możliwe jest wyciąganie wzorców z dostępnych danych. Podstawą
działania są modele matematyczne i statystyczne umożliwiające poznanie ukrytych w danych

21
wzorców. Fragment kodu opracowanej sieci neuronowej, zapisany w języku PMML,
pokazano na rysunku 3.
Rysunek 3. Fragment sieci neuronowej zapisany w języku PMML (z pakietu STATISTICA)
Jednak takie informacje zapisane tylko w pliku XML, bez wsparcia bibliotecznego,
nie są użyteczne z punktu widzenia ich możliwości praktycznego wykorzystania. Dlatego
w rozprawie zaproponowano algorytm obliczeniowy, który następnie został
zaimplementowany w języku programowania C++. Na podstawie pliku zapisanego w języku
PMML odwzorowano matematyczną strukturę sieci w arkuszu kalkulacyjnym Excel, stosując
odpowiednie formuły (m. in. wzór na funkcję liniową do obliczenia wartości
znormalizowanych). Otrzymana w ten sposób sekwencja instrukcji umożliwia szacowanie
wartości wyjściowej na podstawie wprowadzonych wartości sześciu zmiennych wejściowych.

22
Aplikacja SOCAP Neural Network
Opracowany algorytm obliczeniowy jest przykładem oprogramowania otwartego.
Pakiet statystyczny STATISTICA, jako oprogramowanie komercyjne, wprowadza w tym
zakresie ograniczenia. Zaprojektowany algorytm obliczeniowy został zatem w dalszej
kolejności zaimplementowany przez autorkę w języku C++. Poniżej pokazano kod źródłowy
najważniejszej części tego programu, tj. funkcji siec(), która zwraca wynik działania sieci
neuronowej, czyli obliczoną wartość kapitału społecznego:
double siec(double market_value, double employment, double assets, double
liabilities, double total_revenue, double net_income)
{
double we[6] = {market_value, employment, assets, liabilities,
total_revenue, net_income};
double norm[6][2] = {
{-0.000308112824204855, 0.00000305062202183025},
{-0.0142630744849445 , 0.00000792393026941363},
{-0.00675711190408055 , 0.00000584020043567895},
{-0.00252251343238403 , 0.0000126125671619201 },
{-0.00335556737733764 , 0.0000409215533821664 },
{ 0.0698129014241832 , 0.000139625802848366 }
};
double warstwa_1[7] = {0, 0, 0, 0, 0, 0, 1};
double polaczenia_1[7][3] = {
{ 0.46535603101202 , -0.0164468035572661, -0.250930985777859},
{ 0.22116783994935 , -0.196107365007555 , -0.474374588736207},
{ 0.114347980891993 , -0.138367451462913 , -0.361710187889834},
{ 0.234993575725989 , -0.0569468946987624, -0.239846232639002},
{ 0.147142390436937 , -0.213611184499937 , -0.446705285279842},
{ 0.0760911172068558, -0.192986983255022 , -0.405620792517231},
{-0.249733005512385 , 0.0348090181539225, 0.10984820926091 }
};
double warstwa_2[4] = {0, 0, 0, 1};
double polaczenia_2[4] = {0.923069249830434, 0.213109912388641, -
0.192673861949869, 0.236188008027543};
double norm_wynik[2] = {-228.509830684168, 184411.130119774};
double wynik = 0;
int i, j;
for(i=0; i<6; ++i)
warstwa_1[i] = norm[i][0]+we[i]*norm[i][1];
for(j=0; j<3; ++j)
for(i=0; i<7; ++i)
warstwa_2[j] += warstwa_1[i]*polaczenia_1[i][j];
for(i=0; i<3; ++i)
warstwa_2[i] = std::tanh(warstwa_2[i]);

23
for(i=0; i<4; ++i)
wynik += warstwa_2[i]*polaczenia_2[i];
return norm_wynik[0] + wynik*norm_wynik[1];
}
Pełen kod źródłowy do aplikacji SOCAP Neural Network stanowi załącznik
do pracy doktorskiej. Graficzny interfejs aplikacji SOCAP Neural Network, wraz
z przykładem szacowania wartości kapitału społecznego firmy Red Hat, pokazano na rysunku
4. Działanie aplikacji jest następujące: po wprowadzeniu wartości sześciu zmiennych
wejściowych charakteryzujących przedsiębiorstwo informatyczne, algorytm opracowanego
modelu sieci neuronowej oblicza wartość zmiennej wyjściowej.
Rysunek 4. Przewidywania opracowanej sieci neuronowej w aplikacji SOCAP Neural Network
Źródło: opracowanie własne.
Podsumowanie
Podjęta w rozprawie doktorskiej problematyka zastosowania sztucznych sieci
neuronowych jako narzędzia do modelowania i analizy kapitału społecznego firm
informatycznych stanowiła duże wyzwanie badawcze ze względu na chaos pojęciowy
i metodologiczny w literaturze przedmiotu oraz w praktyce szacowania wartości kapitału
społecznego. Zaproponowana metodyka badawcza jest rozwiązaniem innowacyjnym,
ponieważ w literaturze nie opisano modelu wykorzystującego obliczenia inteligentne
do modelowania kapitału społecznego firm informatycznych. Treści zaproponowane
w rozprawie mogą stanowić wypełnienie luki badawczej polegającej na braku opracowań
teoretycznych oraz narzędzi informatycznych. Dodatkowo, autorka zaproponowała metodykę,
którą rekomenduje jako skuteczną przy budowie regresyjnych modeli neuronowych
do szacowania wartości kapitału społecznego przedsiębiorstw z innych sektorów gospodarki.
Została ona zaprezentowana na rysunku 5.

24
Rys. 5. Schemat metodyki budowania regresyjnych modeli neuronowych.
Źródło: opracowanie własne.
Przeprowadzony proces badawczy pozwolił na sformułowanie następujących
rekomendacji dotyczących opracowywania regresyjnych modeli neuronowych do szacowania
wartości kapitału społecznego przedsiębiorstw:
należy redukować liczbę zmiennych wejściowych, żeby nie komplikować struktury
sieci neuronowej,
perceptrony wielowarstwowe są najbardziej efektywnymi sieciami neuronowymi do
rozwiązywania problemów regresyjnych,
sieci o radialnych funkcjach bazowych dają niższe współczynniki jakości niż sieci
MLP przy rozwiązywaniu problemów regresyjnych,
funkcja aktywacji wyrażona jako tangens hiperboliczny minimalizuje funkcję błędu
sieci,
należy implementować gradientowe algorytmy trenowania regresyjnych modeli
neuronowych.
W opinii doktorantki zasadnicze zadanie naukowe rozprawy, polegające
na opracowaniu regresyjnego modelu neuronowego do szacowania wartości kapitału
społecznego firm IT, zostało rozwiązane pomyślnie. Przeprowadzone badania mają charakter
interdyscyplinarny i łączą wiedzę z kilku dziedzin (informatyka, ekonomia, data mining).
W rozprawie sformułowana została jedna hipoteza główna oraz dwie hipotezy
szczegółowe. Wszystkie postawione hipotezy badawcze zostały pozytywnie zweryfikowane
w treści pracy na gruncie rozważań teoretycznych i empirycznych poprzez wykonanie
Etap 1
• Identyfikacja zmiennych wejściowych istotnie wpływających na zmienną objaśnianą.
Etap 2
•Redukcja liczności zbioru wejściowego z zastosowaniem wskazanych w literaturze metod preprocessingu danych.
Etap 3
•Opracowanie modelu koncepcyjnego (teoretycznych zależności między zmiennymi).
Etap 4
•Budowa zbioru uczącego (danych wejściowych i wyjściowych).
Etap 5
•Określenie struktury sieci.
Etap 6
•Eksperymenty symulacyjne pozwalające na wybór parametrów sieci (funkcje aktywacji, funkcja błędu, algorytm uczenia sieci).
Etap 7
•Testowanie parametrów sieci – trenowanie.
Etap 8
•Opracowanie regresyjnego modelu neuronowego.
Etap 9
•Zastosowanie modelu neuronowego.
Etap 10
•Ocena modelu neuronowego.

25
logicznego ciągu zadań badawczych, przedstawionych w punkcie 3. Realizacja
wymienionych zadań badawczych pozwoliła też na osiągnięcie zakładanych celów rozprawy.
Opracowany model sztucznej sieci neuronowej MLP 6-3-1 zastosowano
do oszacowania wartości kapitału społecznego przedsiębiorstw informatycznych, takich jak
Red Hat oraz IBM. Okazało się, że oszacowane w ten sposób wartości kapitału społecznego
tych firm nie różnią się w znaczący sposób od wartości obliczonych za pomocą
zaproponowanych dotąd w literaturze przedmiotu algorytmów. Jest to argument pozwalający,
zdaniem doktorantki, na uznanie zaproponowanego jednokierunkowego, wielowarstwowego
perceptronu MLP 6-3-1 jako wiarygodnego narzędzia do takich szacunków.

26
Spis treści rozprawy doktorskiej
Wprowadzenie ..................................................................................................................... 3
Problem badawczy i jego uzasadnienie ............................................................................... 3
Cele i hipotezy badawcze .................................................................................................... 8
Metodyka badań .................................................................................................................. 10
Struktura pracy .................................................................................................................... 13
Rozdział 1.
Rynek informatyczny .......................................................................................................... 16
1.1. Podstawowe definicje ................................................................................................... 17
1.2. Rynek informatyczny na świecie ................................................................................. 22
1.2.1. USA ........................................................................................................................... 23
1.2.2. Europa ....................................................................................................................... 24
1.3. Rynek informatyczny w Polsce .................................................................................... 29
1.3.1. Segment oprogramowania ......................................................................................... 32
1.3.2. Kondycja polskiej branży informatycznej ................................................................. 35
Podsumowanie .................................................................................................................... 38
Rozdział 2.
Rynek otwartego oprogramowania ..................................................................................... 41
2.1. Historia oraz idea otwartego oprogramowania ............................................................ 42
2.2. Modele biznesowe wykorzystujące otwarte rozwiązania ............................................ 45
2.3. Model katedralny i model bazarowy ............................................................................ 48
2.4. Firma Red Hat .............................................................................................................. 49
2.5. Zastosowanie WTP do analizy procesu budowy oprogramowania ............................. 52
2.6. System operacyjny LINUX jako przykład oprogramowania otwartego ...................... 55
2.7. Przyszłość rynku otwartego oprogramowania ............................................................. 60
Podsumowanie .................................................................................................................... 62
Rozdział 3.
Szacowanie kapitału społecznego firm informatycznych ................................................... 64
3.1. Geneza pojęć kapitał ludzki i kapitał społeczny .......................................................... 65
3.1.1. Kapitał ludzki ............................................................................................................ 65
3.1.2. Kapitał społeczny ...................................................................................................... 70
3.1.3. Pomiar kapitału społecznego ..................................................................................... 73
3.2. Zasada ortogonalności .................................................................................................. 76
3.3. Istota równania fundamentalnego ................................................................................ 79
3.4. Charakterystyka firmy Prokom .................................................................................... 81
3.4.1. Historia firmy ............................................................................................................ 81
3.4.2. Kompleksowy System Informatyczny ZUS .............................................................. 83
3.4.3. Wartość giełdowa i księgowa firmy Prokom ............................................................ 86
3.5. Wartości niematerialne firmy Prokom ......................................................................... 89
Podsumowanie .................................................................................................................... 96

27
Rozdział 4.
Sztuczne sieci neuronowe ................................................................................................... 99
4.1. Istota sztucznej inteligencji .......................................................................................... 99
4.2. Historia sieci neuronowych .......................................................................................... 101
4.3. Zastosowanie sztucznych sieci neuronowych w badaniach naukowych ..................... 104
4.4. Budowa i własności sieci neuronowych ....................................................................... 106
4.4.1. Sztuczny neuron ........................................................................................................ 108
4.4.2. Przetwarzanie informacji w sieciach neuronowych .................................................. 114
4.5. Uczenie sztucznych sieci neuronowych ....................................................................... 117
Podsumowanie .................................................................................................................... 119
Rozdział 5. Modelowanie kapitału społecznego z zastosowaniem sieci neuronowych ...... 120
5.1. Problem badawczy ....................................................................................................... 121
5.2. Budowa modelu regresyjnego ...................................................................................... 124
5.2.1. Dobór zmiennych wejściowych ................................................................................ 124
5.2.2. Zmienne wejściowe ................................................................................................... 127
5.2.3. Zbiór uczący .............................................................................................................. 129
5.2.4. Analiza regresji liniowej ........................................................................................... 132
5.3. Budowa sztucznej sieci neuronowej ............................................................................ 135
5.3.1. Struktura sieci neuronowej ........................................................................................ 135
5.3.2. Cechy sieci neuronowej............................................................................................. 137
5.4. Trenowanie sieci neuronowej ....................................................................................... 142
5.5. Wyniki eksperymentów ................................................................................................ 149
5.5.1. Model sieci neuronowej MLP 6-3-1 ......................................................................... 150
5.5.2. Globalna analiza wrażliwości .................................................................................... 154
5.6. Algorytm obliczeniowy opracowanej sieci neuronowej .............................................. 157
5.7. Aplikacja SOCAP Neural Network .............................................................................. 160
5.8. Zastosowanie opracowanego modelu ........................................................................... 163
Podsumowanie .................................................................................................................... 170
Aneks ................................................................................................................................... 175
Załącznik 1. Kod źródłowy autorskiego program SOCAP Neural Network ...................... 175
Załącznik 2. Nota o badaniach autorki ................................................................................ 182
Literatura ............................................................................................................................. 184
Spis tabel ............................................................................................................................. 193
Spis rysunków ..................................................................................................................... 195

28
NOTA O DOKTORANTCE
Wykształcenie:
Instytut Badań Systemowych Polskiej Akademii Nauk w Warszawie; Studia
Doktoranckie „Techniki informacyjne – teoria i zastosowania” (2010 – 2016);
Politechnika Białostocka, Wydział Informatyki, studia podyplomowe „Informatyka”
(2007 – 2008);
Politechnika Białostocka, Wydział Zarządzania, studia magisterskie; kierunek:
zarządzanie i marketing, specjalność: informatyka gospodarcza, 1999-2004.
Zatrudnienie:
Politechnika Białostocka, Wydział Zarządzania, Katedra Informatyki Gospodarczej
i Logistyki.
Zainteresowania naukowe:
sztuczne sieci neuronowe i inne metody sztucznej inteligencji;
rynek informatyczny w Polsce i na świecie;
systemy informatyczne w logistyce i inżynierii produkcji.
Osiągniecia naukowo - badawcze:
Stypendium naukowe w ramach projektu Urzędu Marszałkowskiego Województwa
Podlaskiego „Stypendia dla doktorantów województwa podlaskiego” finansowanego
w ramach Działania 8.2 – Transfer Wiedzy, Poddziałanie 8.2.2; Priorytet VIII PO KL,
współfinansowanego ze środków EFS, budżetu państwa oraz środków budżetu
województwa podlaskiego; okres: 1.05.2014 – 28.04.2015.
Staż naukowy w Instytucie Badań Systemowych PAN w ramach projektu
Politechniki Białostockiej „Podniesienie potencjału uczelni wyższych jako czynnik
rozwoju gospodarki opartej na wiedzy” finansowanego z funduszy PO Kapitał Ludzki;
okres stażu: 1.12.2012 – 28.02.2013.
Stypendium naukowe młodym doktorom i doktorantom w ramach projektu
Politechniki Białostockiej „Podniesienie potencjału uczelni wyższych jako czynnik
rozwoju gospodarki opartej na wiedzy” (Program Operacyjny Kapitał Ludzki); okres
pobierania stypendium naukowego: lipiec 2013 – czerwiec 2014 (laureatka 9. edycji
konkursu).
Stypendium naukowe dla najlepszych doktorantów za wyniki w nauce w roku
akademickim 2014/2015 (przyznane przez Instytut Badań Systemowych PAN).
Informacje dodatkowe:
Współzałożyciel i Członek Zarządu Stowarzyszenia Absolwentów Politechniki
Białostockiej;
Członek IEEE;
Director of Women in iEEE, IEEE Poland Section Technology and Engineering
Management Society Chapter;
Członek Zarządu International Society for Manufacturing, Service and Management
Engineering (ISMSME);
Członek Polskiego Towarzystwa Zarządzania Produkcją.

29
Wykaz publikacji doktorantki z zakresu tematyki rozprawy
1. Siderska J., System analysis of IT market in Poland, Zeszyty Naukowe Politechniki
Śląskiej „Organizacja i zarządzanie”, Zeszyt 82, 2015, s. 201 – 2011.
2. Siderska J., The role of social capital in a modern IT company, [w]: Techniki
informacyjne - teoria i zastosowania pod red. Andrzeja Myślińskiego, Tom 5 (17)
Instytut Badań Systemowych PAN, Warszawa 2015, s. 99-110.
3. Siderska J., Soft computing for modelling the value of social capital at Red Hat
Corporation, Metody Ilościowe w Badaniach Ekonomicznych, SGGW, Vol. 15, Nr 2,
s. 223 – 231, Warszawa 2014.
4. Siderska J., Polska branża informatyczna na tle rynków zagranicznych, [w]: Techniki
informacyjne - teoria i zastosowania pod red. Andrzeja Myślińskiego, Tom 4 (16)
Instytut Badań Systemowych PAN, Warszawa 2014, s. 113 -122.
5. Siderska J., Analiza możliwości zastosowania sieci neuronowych do modelowania
wartości kapitału społecznego w firmach IT; Ekonomia i Zarządzanie, Tom 5 (1),
s. 84 – 97, 2013.
6. Siderska J., Application of neural network for social capital analysis, Technical
Transactions – Automatic Control, 2-AC/2013, Cracow 2013, s. 57 – 66.
7. Siderska J., Kapitał społeczny firmy Asseco Poland SA, [w]: Techniki informacyjne -
teoria i zastosowania pod red. Andrzeja Myślińskiego, Tom 3 (15) Instytut Badań
Systemowych PAN, Warszawa 2013, s. 54 – 67.
8. Siderska J., Zastosowanie wirtualnej taśmy produkcyjnej w tworzeniu
oprogramowania, Studia i Materiały Informatyki Stosowanej, Polskie Towarzystwo
Informatyczne, Tom 5, nr 11, s. 33 - 38, 2013.
9. Siderska J., The benefits of using open source software in business models
[w]: Innowacyjność i przedsiębiorczość w warunkach kryzysu; Wydawnictwo KUL,
Lublin 2013, s. 385 – 391.
10. Siderska J., Czy na oprogramowaniu open source można zarobić?, [w]: Techniki
informacyjne - teoria i zastosowania pod red. Andrzeja Myślińskiego, Tom 2 (14),
Instytut Badań Systemowych PAN, Warszawa 2012, s. 84 – 91.
11. Siderska J., Porównanie roli wartości niematerialnych w firmach IT w Polsce i na
świecie, [w]: Uwarunkowania rozwoju przedsiębiorstw w zmiennym otoczeniu, pod
red. Pawła Antonowicza, Wydawnictwo Uniwersytetu Gdańskiego, Sopot 2012,
s. 155 – 165.
12. Siderska J., Wstępna ocena roli wartości niematerialnych w firmie Prokom,
[w]: Techniki informacyjne - teoria i zastosowania pod red. Jerzego Hołubca, Tom 1
(2011), Instytut Badań Systemowych PAN, Warszawa 2011, s. 147 – 168.

30
Wybrane pozycje literaturowe
1. Blicharz P., Skowron S., Kapitał intelektualny jako czynnik rozwoju partnerstwa
publiczno-prywatnego, Wydawnictwo Politechniki Lubelskiej, Lublin 2013
2. Bochniarz P., Gugała K., Budowanie i pomiar kapitału ludzkiego w firmie, Poltex,
Warszawa 2005
3. Gołębiowski G., Szczepankowki P., Analiza wartości przedsiębiorstwa, Difin,
Warszawa 2007
4. Grodzki J., Rola kapitału ludzkiego w rozwoju gospodarki globalnej, Wydawnictwo
Uniwersytetu Gdańskiego, Gdańsk 2003
5. Knosala R., Zastosowanie metod sztucznej inteligencji w inżynierii produkcji,
Wydawnictwo Naukowo – Techniczne, Warszawa 2002
6. Koronacki J., Ćwik J., Statystyczne systemy uczące się, Wydawnictwa Naukowo-
Techniczne, Warszawa 2005
7. Korbicz J., Obuchowicz A., Uciński D., Sztuczne sieci neuronowe. Podstawy i
zastosowania, Akademicka Oficyna Wydawnicza PLJ, Warszawa 1994
8. Lula P., Paliwoda – Pękosz G., Tadeusiewicz R., Metody sztucznej inteligencji i ich
zastosowania w ekonomii i zarządzaniu, Wydawnictwo Akademicki Ekonomicznej,
Kraków 2007
9. Łukasiewicz G., Kapitał ludzki organizacji. Pomiar i sprawozdawczość, PWN,
Warszawa 2009
10. Rutkowska D., Piliński M., Rutkowski L., Sztuczne sieci neuronowe, algorytmy
genetyczne i systemy rozmyte, Wydawnictwo Naukowe PWN, Warszawa 1997
11. Rutkowski L., Metody i techniki sztucznej inteligencji, Wydawnictwo Naukowo PWN,
Warszawa 2009
12. Sibi P., Allwyn - Jones A., Siddarth P., Analysis of different activation function using
back propagation neural network, “Journal of Theoretical and Applied Information
Technology” 2013, t. 47 nr 3
13. Śledzik K., Kapitał intelektualny a wartość rynkowa banków giełdowych (rozprawa
doktorska), Fundacja Rozwoju Uniwersytetu Gdańskiego, Sopot 2012
14. Tadeusiewicz R., Sieci neuronowe, Akademicka Oficyna Wydawnicza, Warszawa
1993
15. Tadeusiewicz R., Morajda J., Artificial Intelligence Methods , [w:] Analysis and Data
Processing Computer Methods, Wydawnictwo Uniwersytetu Ekonomicznego,
Krakow 2012
16. Urbanek G., Pomiar kapitału intelektualnego i aktywów niematerialnych
przedsiębiorstwa, Wydawnictwo Uniwersytetu Łódzkiego, Łódź 2007
17. Walczak S., Methodological Triangulation Using Neural Networks for Business
Research, “Advances in Artificial Neural Systems” 2012, t. 2012
18. Walukiewicz S., Kapitał społeczny, Instytut Badań Systemowych PAN, Warszawa
2012
19. Walukiewicz S., Two-Dimentional Economics, Polskie Wydawnictwo Ekonomiczne,
Warszawa 2015
20. Zhang G., Patuwo B. E., Hu M.Y., Forecasting with artificial neural networks: The
state of the art, “International Journal of Forecasting” 1998, nr 14.