nips2010読み会: a new probabilistic model for rank aggregation
DESCRIPTION
NIPS2010読み会の発表資料T. Qin, X. Geng, T.-Y LiuA New Probabilistic Model for Rank AggregationNIPS2010TRANSCRIPT

NIPS2010読み会
2010-12-26
Yoshihiko Suhara
@sleepy_yoshi
1

挨拶
• 名前 – 数原 良彦 (すはら よしひこ)
– @sleepy_yoshi
• ランキング萌え
• 本当は他の論文を紹介する予定だったが,論文がむずかしく理解でき やはりランキングを愛しているため,本論文を選択 – rank aggregationは未知の領域
2

A New Probabilistic Model for Rank Aggregation
T. Qin†, X. Geng‡, T.-Y. Liu† † Microsoft Research Asia
‡ Chinese Academy of Sciences
0354
3

一言要約
• Rank aggregationのための新しい確率モデルを提案。
4

Rank aggregation?
5

Rank Aggregationとは
• 課題
– 複数のランキングリストを入力として受け取り,評価値の高いリストを出力することを目指す
• アプリケーション
– メタサーチエンジン
– 複数のリストを統合するようなアプリケーション
– Etc..
6

メタサーチエンジン
hoge search
Search engine A
hoge search
Search engine B
hoge search
Search engine C
Final ranking:
Ranking: Ranking: Ranking:
Rank aggregation
hoge search
Meta search engine
7

メタサーチエンジン
hoge search
Search engine A
hoge search
Search engine B
hoge search
Search engine C
Final ranking:
Ranking: Ranking: Ranking:
Rank aggregation
hoge search
Meta search engine
Rank aggregation
8

Rank aggregation is NOT
learning to rank
9

Learning to rankとの違い
• Learning to rank (≒ Learning to rank “documents”)
– 入力: 文書集合
– 出力: 各文書のスコア or ランキングリスト
• Rank aggregation
– 入力: 複数のランキングリスト
– 出力: ひとつのランキングリスト
10
※ 公開データセットや学会のセッション分けではRank aggregationはlearning to rank とされていることもあるが,ここでは区別のため,Learning to rankではないとした

表記法
11
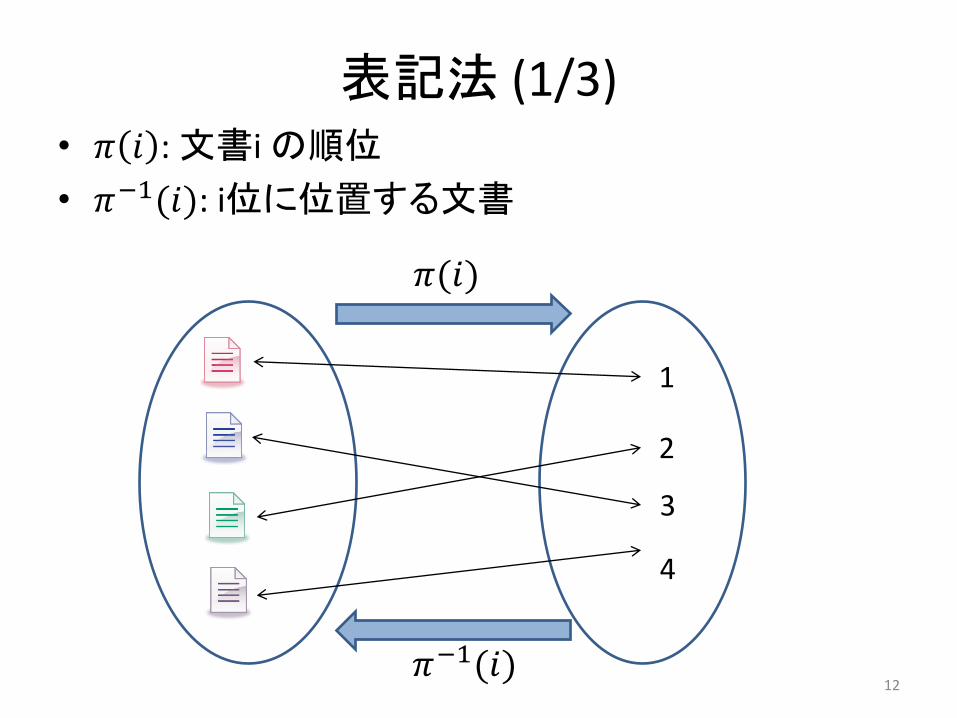
表記法 (1/3) • 𝜋 𝑖 : 文書i の順位
• 𝜋−1(𝑖): i位に位置する文書
𝜋(𝑖)
𝜋−1(𝑖)
1
2
3
4
12

表記法 (2/3)
• 順列𝜋 = 𝜋−1 1 , 𝜋−1 2 , … , 𝜋−1(𝑛)
• n次の対称群𝑆𝑛
– 「n個のものを並び替える」操作を元とする群
– 集合 {1, 2, ..., n} の上の置換(全単射)全体
• 𝑆𝑛−𝑘: 上位k件が固定された群
– 𝑆𝑛−𝑘 = 𝜋 ∈ 𝑆𝑛|𝜋 𝑖 = 𝑖, ∀𝑖 = 1, … , 𝑘
13

表記法 (3/3)
• 𝑆𝑛−𝑘𝜋: 上位k件が𝜋と同様に順序づけられた群
– 𝑆𝑛−𝑘𝜋 = 𝜍|𝜍 ∈ 𝑆𝑛, 𝜍−1 𝑖 = 𝜋−1 𝑖 , ∀𝑖 = 1, … , 𝑘
上位k件が𝜋と等しい
14

既存手法の俯瞰
15

Rank aggregationの分類と 本論文が扱う課題
16
Supervised Unsupervised
Order-based Weighted BordaCount
Mallows model BordaCount
Mallows model Luce model
Score-based Linear Combination
CombMNZ
[Aslam+ 02]を参考

BordaCount (Borda-fuse) [Aslam+ 02]
• 選挙のための得点方式
• 候補者数N人に対し,投票者は順位を付けて投票 – 1位にN点,2位にN-1点,…
17
hoge search
Search engine A
hoge search
Search engine B
hoge search
Search engine C
A
B
C
D
+4
+3
+2
+1
A
B
C
D
+4
+3
+2
+1
A
B
C
D
+4
+3
+2
+1
A
B
C
D
9
11
4
6
score
Final results
訓練データが不要 (unsupervised)

Weighted BordaCount (Borda-fuse)
• 検索エンジンの性能に基づいて得点に重みづけを行う – 訓練データにおける各エンジンの検索評価指標の値を利用
18
hoge search
Search engine A
hoge search
Search engine B
hoge search
Search engine C
A
B
C
D
+4
+3
+2
+1
A
B
C
D
+4
+3
+2
+1
A
B
C
D
+4
+3
+2
+1
A
B
C
D
8.3
13.9
3.7
10.1
score
Final results x0.5 X3.0 X0.1
BordaCountよりも性能が良い [Aslam+ 02]

MallowsモデルとLuceモデル
19

既存の順位モデル
• Mallowsモデル [Mallows 57]
– 距離ベース手法
• Luceモデル [Luce 59][Plackett 63]
– 多段階手法
20

順序の距離を用いたRank aggregationの例
• 入力: M個のリスト𝜍𝑖(𝑖 = 1, … 𝑀)
• 出力: 各リストに対する距離の和が最小のリスト
21
𝜋 = argmin𝜋 𝑑(𝜋, 𝜍𝑖)
𝑀
𝑖=1
どのようにリスト間の距離を測るか?

順序リスト間の距離
• 代表的な距離
22
𝑑𝑟 𝜋, 𝜍 = 𝜋 𝑖 − 𝜍 𝑖2
𝑛
𝑖=1
𝑑𝑓 𝜋, 𝜍 = 𝜋 𝑖 − 𝜍(𝑖)
𝑛
𝑖=1
𝑑𝑡 𝜋, 𝜍 = 1 𝜋𝜎−1 𝑖 >𝜋𝜎−1 𝑗
𝑗>𝑖
𝑛
𝑖=1
1 𝑥 = 1 if x is true, 0 otherwise
Spearman距離
Spearman footrule
Kendall距離

補足: xx距離とxx相関係数の関係
• Spearmanの順位相関係数𝜌は,Spearman距離を−1,1 に正規化したもの
• Kendallの順位相関係数𝜏は,Kendall距離を −1,1に正規化したもの
23
/ ̄ ̄ ̄\ / ─ ─ \ これ豆知識な。 / (●) (●) \. | (__人__) | \ ` ⌒´ / / \

Mallowsモデル
• 距離ベースの確率モデル
𝑃 𝜋 𝜃, 𝜍 =1
𝑍(𝜃, 𝜍)exp(−𝜃𝑑 𝜋, 𝜍 )
𝜍 ∈ 𝑆𝑛 , 𝜃 ∈ 𝑅
24 計算に膨大なコスト (𝑂(𝑛!)) がかかる
𝑍 𝜃, 𝜍 = exp(−𝜃𝑑 𝜋, 𝜍 )
𝜋∈𝑆𝑛
分散 パラメータ
𝜋 = max1
𝑍(𝜽, 𝝈)exp(− 𝜃𝑖𝑑(𝜋, 𝜍𝑖
𝑀
𝑖=1
)
Rank aggregationへの利用法 [Lebanon+ 02]

Luce (Plackett-Luce) モデル
• 各順位ごとに確率を計算する多段階の確率モデル
• 個々の文書iに対するスコア𝜔𝑖を用いて以下の通り計算
25
exp(𝜔𝜋−1 1 )
exp(𝜔𝜋−1 𝑖 )𝑛𝑖=1
exp(𝜔𝜋−1 2 )
exp(𝜔𝜋−1 𝑖 )𝑛𝑖=2
𝜋−1(1)が1位にランクされる確率
𝜋−1(2)が2位にランクされる確率
𝑃 𝜋 = exp(𝜔𝜋−1 𝑖 )
exp(𝜔𝜋−1 𝑗 )𝑛𝑗=𝑖
𝑛
𝑖=1
文書のスコアの関数として定義しているため, 多目的の順列間距離を用いることができない
順列𝜋の確率は,

提案法
26

提案手法のアプローチ
• Mallowsモデルのように距離ベースの確率モデルであり,Luceモデルのように段階ごとに効率よく確率を計算できるモデル
• 右剰余類 (right coset) を用いた距離のモデル化
27

右剰余類𝑆𝑛−𝑘𝜋
28
A
B
C
D
E
F
A
B
C
D
E
F
E
D
F
A
B
C ・・・
𝑆𝑛 𝑆𝑛−4𝜋
全順列 (=6!)
A
B
C
D
E
F
𝜋
A
B
C
D
E
F A
B
C
D
E
F
上位4件が𝜋と等しい 全順列の部分集合
𝜋と同じ

提案手法: CPSモデル (1/2)
• Coset-permutation distance based stagewise (CPS)
29
𝑑 𝑆𝑛−𝑘𝜋, 𝜍 =1
𝑆𝑛−𝑘𝜋 𝑑(𝜏, 𝜍)
𝜏∈𝑆𝑛−𝑘𝜋
exp(−𝜃𝑑 𝑆𝑛−𝑘𝜋, 𝜍 )
exp(−𝜃𝑑 𝑆𝑛−𝑘 𝜋, 𝑘, 𝑗 , 𝜍 )𝑛𝑗=𝑘
𝑆𝑛−𝑘 𝜋, 𝑘, 𝑗
右剰余類に含まれる全リスト𝜏とリスト𝜍の距離
の平均
Luceモデルよろしく,k位のランクの確率は,

提案手法: CPSモデル (2/2)
• リスト𝜋の確率は
30
𝑃 𝜋 𝜃, 𝜍 = exp(−𝜃𝑑 𝑆𝑛−𝑘𝜋, 𝜍 )
exp(−𝜃𝑑 𝑆𝑛−𝑘 𝜋, 𝑘, 𝑗 , 𝜍 )𝑛𝑗=𝑘
𝑛
𝑘=1
𝑃 𝜋 𝜽, 𝝈 = exp(− 𝜃𝑚𝑑 𝑆𝑛−𝑘𝜋, 𝜍𝑚
𝑀𝑚=1 )
exp(− 𝜃𝑚𝑑 𝑆𝑛−𝑘 𝜋, 𝑘, 𝑗 , 𝜍𝑚𝑀𝑚=1 )𝑛
𝑗=𝑘
𝑛
𝑘=1
𝜽 = *𝜃1, … , 𝜃𝑀+
𝝈 = *𝜍1, … , 𝜍𝑀+
m番目の入力リスト
• 入力リスト𝜍が複数与えられた場合には,

CPSモデルを用いたRank aggregation
• 確率が最大となるランキングリストを選択
31
𝑃 𝜋 𝜽, 𝝈 = exp(− 𝜃𝑚𝑑 𝑆𝑛−𝑘𝜋, 𝜍𝑚
𝑀𝑚=1 )
exp(− 𝜃𝑚𝑑 𝑆𝑛−𝑘 𝜋, 𝑘, 𝑗 , 𝜍𝑚𝑀𝑚=1 )𝑛
𝑗=𝑘
𝑛
𝑘=1
𝜽 = *𝜃1, … , 𝜃𝑀+
𝝈 = *𝜍1, … , 𝜍𝑀+
𝜋 = argmax𝜋 𝑃(𝜋|𝜽, 𝝈)

効率的な計算
• 𝑂 𝑛 − 𝑘 ! の計算量が必要に見えるが,実際には
𝑂(𝑛2)の計算量で済む.
– 詳細は論文を参考
32

既存モデルとの関係
• Mallowsモデル
– 距離ベースであること
– Mallowsモデルとの大きな違いは計算効率
• Luceモデル
– 段階ごとに確率を計算すること
33

4. Algorithms for Rank Aggregation
34

学習
• 訓練データ 𝐷 = 𝜋 𝑙 , 𝝈(𝑙)
– 𝜋 𝑙 : ground truthランキング
– 𝝈(𝑙): M個の入力ランキング
𝜃の最尤推定を行うため,以下の対数尤度を𝜃について最大化
𝐿(𝜃)は上に凸であるため, 勾配法などで大域的最適な𝜃を求めることができる
35
eは凸関数かつ対数凸関数であるため

出力ランキングの推定
• 入力: M個のランキング,学習したパラメータ𝜽
• 出力: 最終ランキング
36
M個のランキング𝝈とパラメータ𝜽を用いて 最適なランキング𝜋を推定する
• 推定手法1: global inference
• 推定手法2: sequential inference
– 高速化した手法

推定手法1: global inference
• Mallowsモデルと同様に全順列 (𝜋 ∈ 𝑆𝑛全て) について確率を計算する • 計算量はんぱない
37
𝑃 𝜋 𝜽, 𝝈 = exp(− 𝜃𝑚𝑑 𝑆𝑛−𝑘𝜋, 𝜍𝑚
𝑀𝑚=1 )
exp(− 𝜃𝑚𝑑 𝑆𝑛−𝑘 𝜋, 𝑘, 𝑗 , 𝜍𝑚𝑀𝑚=1 )𝑛
𝑗=𝑘
𝑛
𝑘=1

推定手法2: Sequential inference
38
• 最終ランキングの最上位から文書をひとつずつ決定していく

実験
39

実験条件 (1/2)
• データセット
– LETORデータセット (MQ2007-agg, MQ2008-agg)
– MQ2008-smallを作成 • 8文書以下のクエリに限定
– 3段階の適合性評価: (Highly relevant, relevant, irrelevant)
• 評価方法
– 評価指標: NDCG
– 5-fold Cross validationの結果を平均
40

補足: NDCG
• Normalized Discounted Cumulative Gain – [0, 1]
• 適合性評価が多段階のタスクを評価する指標
41
𝐷𝐶𝐺@𝑘 = 2𝑟𝑒𝑙𝑖 − 1
log2(1 + 𝑖)
𝑘
𝑖=1
e.g., 𝑟𝑒𝑙𝑖 = *4,3,2,1+
𝑁𝐷𝐶𝐺@𝑘 =𝐷𝐶𝐺@𝑘
𝐼𝐷𝐶𝐺@𝑘
𝐼𝐷𝐶𝐺@𝑘: 理想的なランキングにおけるDCG@kの値

実験条件 (2/2)
• 比較手法
– CPS-G: CPSモデル (global inference)
– CPS-S: CPSモデル (sequential inference)
– Mallows: Mallowsモデル (最尤推定)
– MallApp: Mallowsモデル (MCMCサンプリングによる推定)
– BordaCount
• MQ2008-smallのみの利用
– CPS-G, Mallows, MallAppは計算量の問題で大規模データに適用不可能なため,MQ2008-smallのみを用いて評価
42

結果
43

結果
44
WeightedBordaCountじゃないみたい

まとめ
• Rank aggregationのための新しい確率モデルであるCPSモデルを提案した
• Coset-permutation distanceを利用する
• Luceモデル (高速に計算可能) と Mallowsモデル (高い表現力) の利点を引き継いでいる
• Future work – (1) 3つの距離以外にも効率よく計算可能なモデルを
– (2) unsupervisedなrank aggregationにも適用したい
– (3) 提案モデルの他の利用方法を模索したい
45

参考文献
• 引用文献 – [Aslam+ 01] J. A. Aslam, M. Montague. Models for
Metasearch. SIGIR2001.
– [Lebanon+ 02] G. Lebanon, J. Lefferty. Cranking: Combining Rankings Using Conditional Probability Models on Permutation. ICML2002.
• 距離の確率モデルについては下記のサーベイ文献を参考にした – [神嶌 09] 神嶌敏弘. 順序の距離と確率モデル. SIG-
DMSM-A902-07. 2009.
46

Thank you!
47