「plyrパッケージで君も前処理スタ☆」改め「plyrパッケージ徹底入門」
DESCRIPTION
第30回R勉強会@東京(#TokyoR)の資料TRANSCRIPT

plyrパッケージで君も前処理スタ☆
第30回 勉強会@東京(#TokyoR)
@teramonagi

plyrパッケージで君も前処理スタ☆
第30回 勉強会@東京(#TokyoR)
@teramonagi
plyrパッケージ徹底入門

自己紹介
• ID:@teramonagi
•お仕事:遊撃
•興味:/C++/R/python/F#/数理/可視化/金融/web/
3
春ですね。新たな出会いの季節ですね。

春は出会いの季節
•各所に配属される新人
•バイト先に新しく入って来たイケメン
•隣に越してきた美人のおねぇさん
•進振りで一緒になった同級生
•たまたま講義で横に座ったあの子
etc……
4

そんな季節の病
•恋煩い • 【意味】恋するあまりの悩みや気のふさぎ。恋のやまい
(Goo辞書より引用)
5

似たような病
•分析煩い •分析するあまりの悩みや気のふさぎ。業務上の病。
(teramonagi語録より引用)
• 「分析したい…でもその前の処理が面倒くさい…集計も面倒くさい…」
6

そんな貴方にお勧めしたい
plyrパッケージ
(“プライヤー”と読む)
7


最近だとビッグデータの可視化も
9 Revolutionsブログ(http://blog.revolutionanalytics.com/) 2013/4/8の記事より

10
plyrで何が出来るの?

plyrの主なお仕事
•データを分割し、それぞれに処理を適用し、そして結合して戻すという、分析の基本的な流れを楽にしてくれる
•例:年齢・性別ごとデータを分割し、ある需要予測モデルを適用し予測を実施、その結果を再結合して出力したい
11

plyrの思想
• Split(分割):
–指定した特徴量でデータ分割
• Apply(適用)
–分割データに対する関数を適用
• Combine(結合)
–適用した結果を再結合し出力
12

使用するデータ:airquality • ニューヨークの大気状態観測値 • 各列の説明 – Ozone:オゾン量(ppb) – Solar.R:太陽光の強さ(Langley) – Wind:平均風速(mph) – Temp:最高気温 (degrees F) – Month:月 – Day:日 13

何はともあれ可視化しておく
14
Ozone50
100
150
0 50 100 150
Cor : 0.3485: 0.2436: 0.7187: 0.429
8: 0.539: 0.18
Cor : -0.6125: -0.4516: 0.357
7: -0.6678: -0.749: -0.61
Cor : 0.6995: 0.6136: 0.6687: 0.7238: 0.6059: 0.828
Solar.R100
200
300
0 100 200 300
Cor : -0.1275: -0.2176: 0.612
7: -0.2348: -0.188
9: -0.0939
Cor : 0.2945: 0.4826: 0.6477: 0.3318: 0.4579: 0.123
Wind10
15
20
5 10 15 20
Cor : -0.4975: -0.299
6: -0.08777: -0.4698: -0.4769: -0.579
Temp70
80
90
60 70 80 90
Month
5
6
7
8
9
GGallyパッケージを用い筆者作成(「美しい ペアプロット クオンツ」あたりで検索)

一番良く使う関数(群)
15
入力
出力

入出力の型に応じた関数表
入力/出力 array data. frame
list なし
array aaply adply alply a_ply data. frame daply ddply dlply d_ply
list laply ldply llply l_ply 繰り返し(repeat) raply rdply rlply r_ply 関数引数 (multi?) maply mdply mlply m_ply
16 赤字:本資料で取り扱う関数

従来のRの関数との対応
入力/出力 array data. frame
list なし
array apply adply alply a_ply
data. frame
daply aggregate by d_ply
list sapply ldply lapply l_ply
繰り返し(repeat)
replicate rdply replicate r_ply
関数引数 (matrix)
mapply mdply mapply m_ply
17 http://www.slideshare.net/hadley/04-wrapupより

パッケージの導入&読込 > install.packages("plyr")
trying URL 'http://cran.rstudio.com/bin/windows/contrib/3.0/plyr_1.8.zip'
……(途中省略)
> #ライブラリの読み込み
> library(plyr)
18

データをざっとチェック > head(airquality)
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6
19

Misson 1
20
私よ。
すぐに月毎の平均気温を出して

ddply関数でやってみる > #名前を短くしておく
> aq <- airquality
> #月ごとの平均気温を出す
> ddply(aq,"Month“,summarize, AveTemp=mean(Temp))
Month AveTemp
1 5 65.54839
2 6 79.10000 ………………………
21

忘れちゃいけないplyrの思想 > #名前を短くしておく
> aq <- airquality
> #月ごとの平均気温を出す
> ddply(aq,"Month“,summarize, AveTemp=mean(Temp))
Month AveTemp
1 5 65.54839
2 6 79.10000 ………………………
22
•Split(分割) •月(Month)毎に
•Apply(適用) •気温(Temp)の平均を算出し
•Combine(結合) •data.frameとして戻す

月ごとの平均気温を出す2 > #月ごとの平均気温2 with “.()”関数
> ddply(aq, .(Month), summarize, AveTemp=mean(Temp))
Month AveTemp
1 5 65.54839
2 6 79.10000
3 7 83.90323
4 8 83.96774
5 9 76.90000
23

• Excelだと…(既に目にくる)
月ごとの平均気温を出す3
24

複数の結果も算出可能 > #複数の結果でもOK
> ddply(aq, .(Month), summarize, AveTemp=mean(Temp), SdTemp=sd(Temp))
Month AveTemp SdTemp
1 5 65.54839 6.854870
2 6 79.10000 6.598589
3 7 83.90323 4.315513
4 8 83.96774 6.585256
5 9 76.90000 8.355671
25

Misson 2
26
あの男に連絡よっ!
すぐに月毎の平均オゾン量を出させなきゃ…

同じように…しかしデータにNAが
> ddply(aq, .(Month), summarize, AveOzone=mean(Ozone))
Month AveOzone
1 5 NA
2 6 NA
3 7 NA
4 8 NA
5 9 NA
27

meanにna.rm=TRUEを追加 > ddply(aq, .(Month), summarize, AveOzone=mean(Ozone, na.rm=TRUE))
Month AveOzone
1 5 23.61538
2 6 29.44444
3 7 59.11538
4 8 59.96154
5 9 31.44828
28

プログレスバーも導入可能 > ddply(aq, .(Month), summarize, AveTemp=mean(Temp), .progress="text")
|===============================| 100%
Month AveTemp
1 5 65.54839
2 6 79.10000
3 7 83.90323
4 8 83.96774
5 9 76.90000
29

.parallel引数について
• XYply系関数に.parallel引数が存在
• 「重い…」とdisられるXYplyの救世主
•字面通り処理を並列化してくれる
(私のwindows環境で動かせなかったので言及のみ…誰かはよ)
30

Misson 3
31
気温についてより細かく場合分けしたいわね…

transform:変数操作で列追加 > #各月の平均気温以上の場合1、そうじゃないなら0となるフラグを追加
> aq<-ddply(aq,.(Month),transform,HighTemp=ifelse(Temp-mean(Temp)>0,1,0))
> aq Ozone Solar.R Wind Temp Month Day HighTemp
1 41 190 7.4 67 5 1 1
2 36 118 8.0 72 5 2 1
3 12 149 12.6 74 5 3 1
4 18 313 11.5 62 5 4 0 32

月・平均気温毎の平均風速 > #月・平均気温以上(以下)毎に平均風速を計算
> ddply(aq, .(Month, HighTemp), summarize, AveWind=mean(Wind))
Month HighTemp AveWind
1 5 0 12.800000
2 5 1 10.518750
3 6 0 10.383333
4 6 1 10.091667
5 7 0 9.820000
33

Misson 4
34
ところでこのデータってどのくらい欠損値があった?

colwise:列毎への関数適用 > #nmissing関数:欠損値の個数をカウント
> nmissing<-function(x)sum(is.na(x))
> #各列に対して関数を適用した結果を抽出
> colwise(nmissing)(aq)
Ozone Solar.R Wind Temp Month Day HighTemp
1 37 7 0 0 0 0 0
> #plyrなしの生のRで書くと↓となる
> colSums(aq,is.na(aq))
35

ddply + colwise = 強力 > #月毎の各列の欠損値の個数
> ddply(aq,.(Month),colwise(nmissing))
Month Ozone Solar.R Wind Temp Day HighTemp
1 5 5 4 0 0 0 0
2 6 21 0 0 0 0 0
3 7 5 0 0 0 0 0
4 8 5 3 0 0 0 0
5 9 1 0 0 0 0 0
36

生Rで書くと… >miss.by.month<-by(aq,aq$Month,colwise(nmissing))
>cbind(expand.grid(dimnames(miss.by.month)), do.call("rbind",miss.by.month))
aq$Month Ozone Solar.R Wind Temp Month Day HighTemp
5 5 5 4 0 0 0 0 0
6 6 21 0 0 0 0 0 0
7 7 5 0 0 0 0 0 0
8 8 5 3 0 0 0 0 0
9 9 1 0 0 0 0 0 0
37

Misson 5
38
Excel野郎に分
析させるから月毎にデータを全部csvで保存してくれ

d_ply:出力なしのddply > #月毎に分割したデータをファイルに保存
> d_ply(aq, .(Month), function(x){
+ month <- x$Month[1]
+ write.csv(x,paste0("airquality_",month,".csv"))
+ })
39

40
plyr is Ready for Business

41
以下、その他便利関数紹介

rlply:指定回数繰り返し処理
42
> #オゾン量と気温の回帰分析を100ランダムサンプリングして実施する関数
> f <- function(){lm(Ozone~Temp,aq[sample(nrow(aq),100,replace=TRUE),])}
> #俗にいうブートストラップ
> lms <- rlply(100, f)
> #生Rで書くなら…lms <- lapply(1:100,function(i){f()})

rlply:指定回数繰り返し処理
43
> library(ggplot2)
> qplot(laply(lms, function(x)coef(x)[2]), geom = "blank") +
+ geom_histogram(binwidth=0.2,aes(y = ..density..),fill="dodgerblue",colour="black")
0.0
0.5
1.0
1.5
1.5 2.0 2.5 3.0 3.5
laply(lms, function(x) coef(x)[2])
de
nsity

mdply:引数として同一関数適用
> #(平均・分散)={(1,1),(2,2),(3,3)}となるような正規分布に従う乱数をn=2個ずつ生成
> mdply(data.frame(mean=1:3,sd=1:3),rnorm,n=2)
mean sd V1 V2
1 1 1 0.9676560 2.165706
2 2 2 5.2022971 3.457268
3 3 3 0.3475657 -1.151282
44

arrange:ソート > arrange(aq,Ozone)
Ozone Solar.R Wind Temp Month Day HighTemp
1 1 8 9.7 59 5 21 0
2 4 25 9.7 61 5 23 0
3 6 78 18.4 57 5 18 0
4 7 NA 6.9 74 5 11 1
5 7 48 14.3 80 7 15 0
> #普通にRで書くならこんなかんじ
> aq[with(aq,order(Ozone)),]
45

arrange:ソート > #降順でのならべかえ
> arrange(aq,desc(Ozone))
Ozone Solar.R Wind Temp Month Day HighTemp
1 168 238 3.4 81 8 25 0
2 135 269 4.1 84 7 1 1
3 122 255 4.0 89 8 7 1
4 118 225 2.3 94 8 29 1
5 115 223 5.7 79 5 30 1
6 110 207 8.0 90 8 9 1
46

arrange:ソート > #複数の列も指定可能
> arrange(aq,Ozone,desc(Solar.R))
Ozone Solar.R Wind Temp Month Day HighTemp
1 1 8 9.7 59 5 21 0
2 4 25 9.7 61 5 23 0
3 6 78 18.4 57 5 18 0
4 7 49 10.3 69 9 24 0
5 7 48 14.3 80 7 15 0
6 7 NA 6.9 74 5 11 1
47

rbind.fill:欠損値補完付きrbind
> df<-data.frame(Ozone=33.00)
> rbind(aq,df)
Error in rbind(deparse.level, ...) : 引数の列の数が一致しません
> rbind.fill(aq,df)
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
.......
153 20 223 11.5 68 9 30
154 33 NA NA NA NA NA 48

count:データ数勘定 > #各月ごとに何個データあるか
> count(aq,.(Month)) Month freq
1 5 31
2 6 30
3 7 31
4 8 31
5 9 30
> #↓とほぼ同じ
> ddply(aq,"Month",nrow)
49

name_rows:行名保存&復元 > # arrange等,plyrの関数は行名非保存
> arrange(aq, Ozone)
Ozone Solar.R Wind Temp Month Day
1 1 8 9.7 59 5 21
2 4 25 9.7 61 5 23
3 6 78 18.4 57 5 18
4 7 NA 6.9 74 5 11
50

name_rows:行名保存&復元 > arrange(name_rows(aq), Ozone) Ozone Solar.R Wind Temp Month Day .rownames
1 1 8 9.7 59 5 21 21
2 4 25 9.7 61 5 23 23
3 6 78 18.4 57 5 18 18
> # 二回name_rowsを噛ませると行名保存されて出力
> name_rows(arrange(name_rows(aq),Ozone))
Ozone Solar.R Wind Temp Month Day
21 1 8 9.7 59 5 21
23 4 25 9.7 61 5 23
18 6 78 18.4 57 5 18
51

splat:同名の列処理 > ozone.per.solar<-function(Ozone,Solar.R,...){Ozone/Solar.R}
> head(aq,1)
Ozone Solar.R Wind Temp Month Day HighTemp
1 41 190 7.4 67 5 1 1
> splat(ozone.per.solar)(aq[1,])
[1] 0.2157895
> splat(ozone.per.solar)(aq)
[1] 0.21578947 0.30508475 0.08053 ……………
52

round_any:値の丸め込み > # 10の位に丸め込み(1の位で四捨五入)
> round_any(135,10)
[1] 140
> # 10の位に丸め込み(1の位で切り捨て)
> round_any(135,10,floor)
[1] 130
> # 100の位に丸め込み(10の位で切り上げ)
> round_any(135,100,ceiling)
>[1] 200
53

rename:列名の置換 > # Ozone列をOooozoneという列名へ
>rename(aq,replace=c(Ozone="Oooozone"))
Oooozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6
54

mapvalues,revalue:値の置換 > x <- c("a", "b", "c")
> #a⇒AAA,c⇒CCCと変換。数値もいける
>mapvalues(x,c("a“,"c"),c("AAA","CCC"))
[1] "AAA" "b" "CCC"
> #a⇒AAA,c⇒CCCと変換。文字・ファクター向き
> revalue(x, c("a"="AAA","c"="CCC"))
[1] "AAA" "b" "CCC"
55
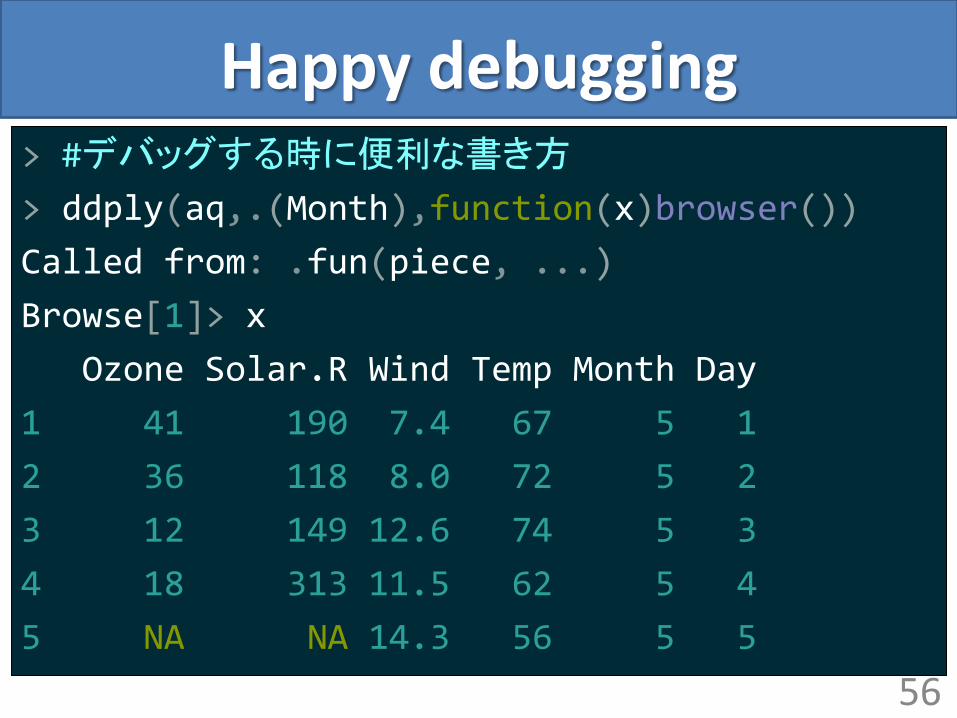
Happy debugging > #デバッグする時に便利な書き方
> ddply(aq,.(Month),function(x)browser())
Called from: .fun(piece, ...)
Browse[1]> x
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
56

Enjoy!!! 57 ぽんちん

参考
• H.Wickham氏の各種slide – http://www.slideshare.net/hadley/presentations
• Stackoverflowの[plyr]tag – http://stackoverflow.com/questions/tagged/plyr
• The Split-Apply-Combine Strategy for Data Analysis, H.Wickham
– http://www.jstatsoft.org/v40/i01/paper
58