rusltc at tsd-2014 (brno)
TRANSCRIPT

RUSSIAN LEARNER TRANSLATOR CORPUS:
design, research potential and applications
Andrey Kutuzov National Research University Higher School of Economics
Maria Kunilovskaya Tyumen State University
17th International Conference on Text, Speech and Dialogue Brno, Czech Republic, September 8–12 2014

General description
• inspired by MeLLANGE • online and downloadable http://rus-ltc.org • 1.3 mln tokens • translations from 10 universities • 11 source text genres (inc. essays, educational,
informational) • multiple: 263 sources, 1952 translations • bi-directional:
approx. 200 English ST(≈300K tokens) with their 1300 Russian translations (≈700 thousand tokens), and over 40 Russian ST and approx. 600 English translations
• 10 types of linguistic and extralinguistic meta data • Lexical and POS query interface (Freeling-based linguistic
mark-up) RusLTC at TSD-2014 2

Corpus design
1) Txt-archive structured by file-naming conventions RU_1_23.txt and EN_1_23_9.txt RU_1_23.head.txt and EN_1_23_9.head.txt 2) TMX file • pair-wise alignment with LF aligner batch mode • manual correction (Olifant /Heartsome tmx-editors) • merging TUVs with identical source segments + adding XML tags to
link segments to head files (a homegrown script) 3) Error-tagged subcorpus • a collection of 265 annotated translations (for 33 sources); • stand-off machine readable annotation • pre-defined error classification • 6,471 error tags • online tag-editor based of brat http://brat.nlplab.org/index.html
RusLTC at TSD-2014 3
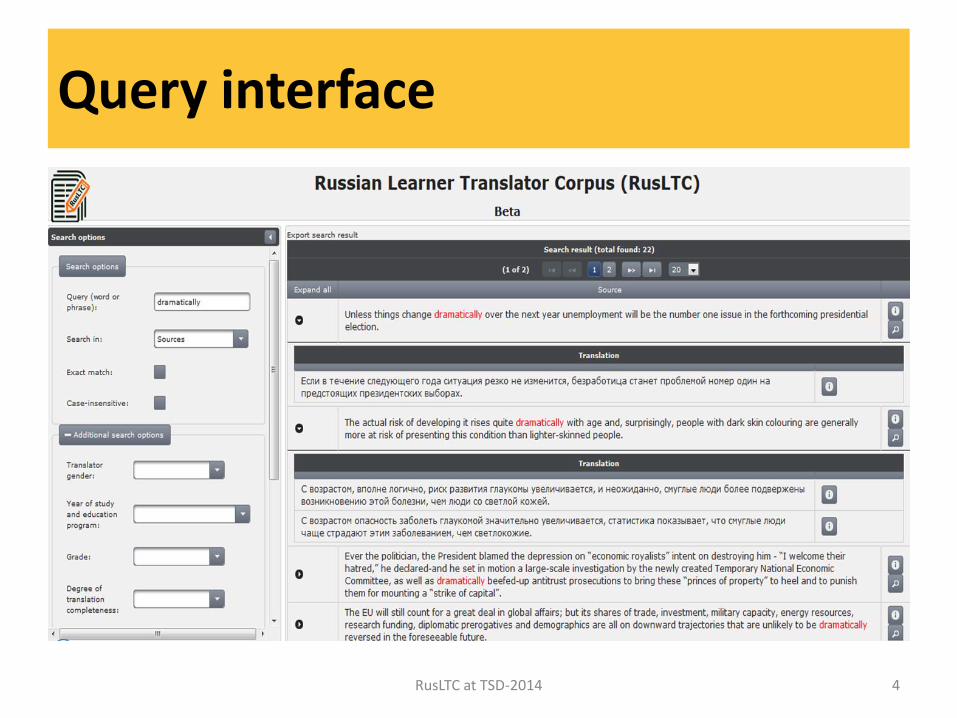
Query interface
RusLTC at TSD-2014 4

BRAT-based online error tag editor
RusLTC at TSD-2014 5

Application and Research
RusLTC is a general purpose data source for translation studies and translation education research, inc. study of 1. variation and choice in translation; 2. ’translationese’ and the translator interlanguage; 3. interdependence between the translation characteristics
and various meta data (direction and conditions of translation, source text genre);
4. translation-related “problem areas” or rich points in source texts;
5. translation quality and translation quality assessment (TQA) Direct use • in the curriculum and materials design • as a teaching and learning aid.
RusLTC at TSD-2014 6

RusLTC research: gender asymmetry in translated texts
1) The same gender asymmetry in male and female translations as in Russian original (based on lexical variety)
2) Sentence length figures for female translations contradict similar statistics for originals
RusLTC at TSD-2014 7

Research based on RusLTC: splitting in EN-RU translation
1) types of syntactic structures that undergo splitting in English-Russian translation: – coordination with “, and”
– non-restrictive relative clauses
2) most frequent mistakes associated with splitting: – loss or misinterpretation of semantic relations
between propositions,
– issues with anaphora resolution and
– greater communicative value acquired by upgraded sentences.
RusLTC at TSD-2014 8

Error-tagged part: inter-rater reliability
AIM: to gauge reliability of mark-up results based on error classification proposed and establish the areas of disagreement
RusLTC at TSD-2014 9
23 38
112
130
30
114
30
30
112
130
38
93
α=0.734 versus α=0.569

Error statistics analysis to inform translation didactics
Hypothesis 1: The better one knows L1 the better she understands the source/the better the transfer skills.
Hypothesis 2: Final year students make less mistakes than 4th year students
Hypothesis 3: Test translations show better results than routine translations because students are more motivated to perform better
Hypothesis 4: The quantitative results of the error annotation depend on the order of translations in the set (“order effect”)
RusLTC at TSD-2014 10

Use in the classroom
1) Students have online access to:
• their own error-tagged and commented translations;
• peer translations;
• mistakes statistics which reflects their individual progress and difficulties.
RusLTC at TSD-2014 11
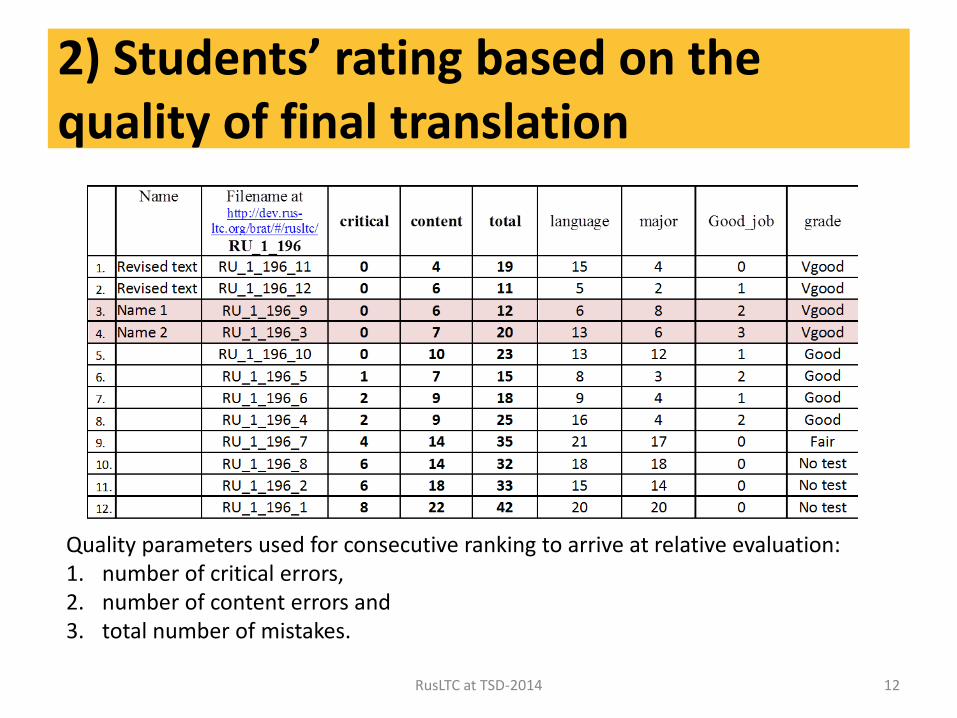
2) Students’ rating based on the quality of final translation
RusLTC at TSD-2014 12
Quality parameters used for consecutive ranking to arrive at relative evaluation: 1. number of critical errors, 2. number of content errors and 3. total number of mistakes.
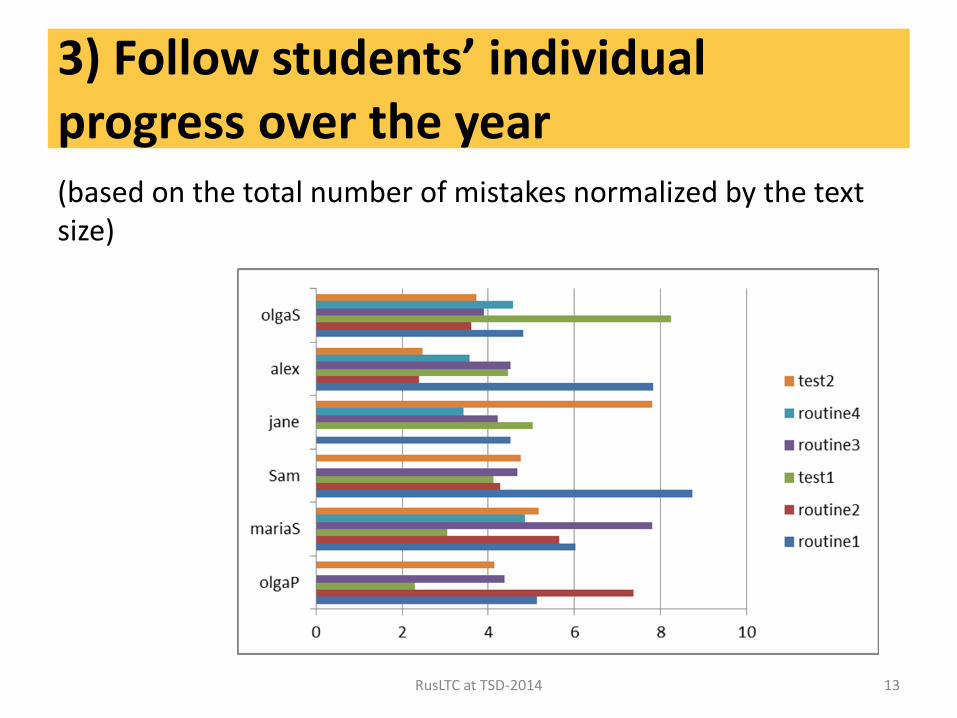
3) Follow students’ individual progress over the year (based on the total number of mistakes normalized by the text size)
RusLTC at TSD-2014 13

4) Think of remedial activities
RusLTC at TSD-2014 14
The top ten mistakes in the sample

1) Theory-based exercises utilizing multiple concordances • discussing translation strategies, identifying translation problems
and comparing/evaluating solutions • developing skills to overcome known transfer issues in English-
Russian translation which are due to interlingual typological differences
2) Corpus-driven exercises to prevent most common mistakes • developing L1 competence through building up corpus-querying
and documentary research skills; • extending the scope of world knowledge through information
search and developing text analysis and text comprehension aptitude.
5) Design materials and teaching aids
RusLTC at TSD-2014 15

Summary
1) Russian Learner Translator Corpus is an available and extensive source of data for translation studies and translator education research (http://www.rus-ltc.org/);
2) The error-tagged subcorpus (http://dev.rus-ltc.org/brat/#/rusltc/) is a method to provide students extensive feedback on their translations
3) and a means of accumulating research data on TQA;
4) RusLTC content is used in designing teaching materials.
Thank you!
RusLTC at TSD-2014 16