search engines chapter 2 summary
TRANSCRIPT

2 Architecture of a Search Engine
SUHARA YOSHIHIKO(id:sleepy_yoshi)

2
本章で学ぶこと• 検索エンジンの構造
– インデクシング処理に必要な要素– 検索処理に必要な要素
• 各構成要素について一言ずつ
• 検索エンジンに必要なイメージをつける
3
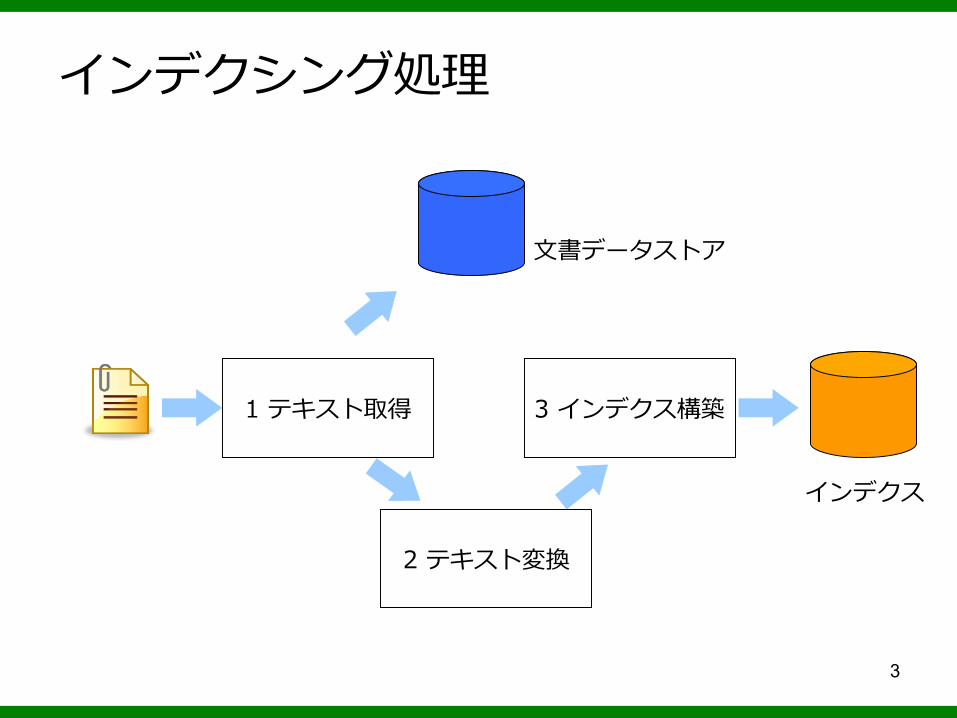
インデクシング処理
1 テキスト取得 3 インデクス構築
2 テキスト変換
文書データストア
インデクス
4
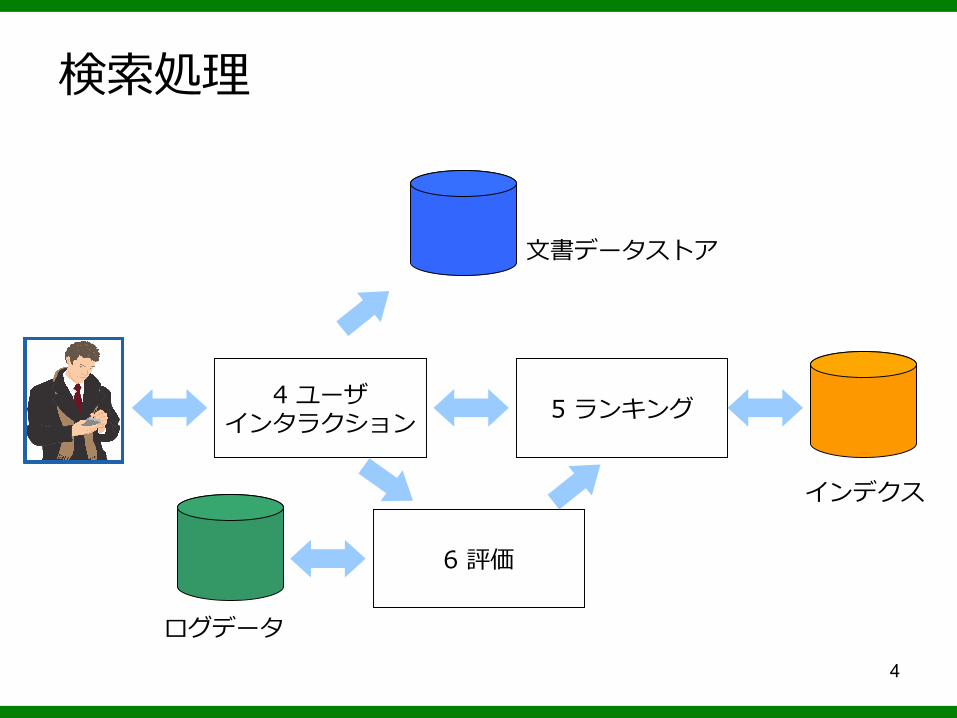
検索処理
4 ユーザインタラクション 5 ランキング
6 評価
文書データストア
インデクス
ログデータ

5
1 テキストの取得• クローラ (Crawler)
– ウェブクローラ• ウェブ検索エンジン用.新鮮な情報を取得
– 特別なページを重点的にクロールすることもある• バーティカル(トピック)検索用途
• フィード (Feeds)– RSSによって最新情報を取得する方法のひとつ
• 変換 (Conversion)– ファイル形式の変換
• HTML, XML, PDF, WORD, EXCEL, ...– 文字コードの変換
• 文書データストア (Document data store)– 元文書やリンク情報等のメタデータを格納– RDBやkey-value storeが利用される

6
2 テキスト変換• パーサ (Parser)
– テキストをトークン化– HTMLやXMLを解析
• ストップワードの除去 (Stopping)– the, of, to, forなどの機能語を除去– ストップワードリストを利用– 過剰な除去は精度低下につながる
• ステミング (Stemming)– 単語を語幹 (stem) にまとめる
• 例)fish, fishes, fishing => “fish”– 過剰なステミングは精度低下につながる– 語形変化が著しい言語や,ない言語がある

7
2 テキスト変換(2)• リンク抽出と分析 (Link extraction and analysis)
– パーサによって抽出されたリンク情報を解析することで文書の重要度,人気度などを計算
• 例:PageRank, HITSなど– 同様にアンカーテキスト情報も検索に効果的
• 情報抽出 (Information extraction)– 構文解析などを用いた高度な情報抽出によって索引語を決定
• 例:品詞付与,固有表現抽出
• 分類器 (Classifier)– 文書や文書内のコンテンツを分類
• 例:スパム分類,文書内の広告部分の判別など– クラスタリングによって文書をグループ化

8
3 インデクス構築• 文書の統計値 (Document statistics)
– 単語や文書に関する統計情報をあらかじめ計算し,lookup tableに格納
• 重み付け (Weighting)– 単語の重みをlookup tableに格納.重み付け方法はランキングモデルに
よって異なる• 例:TF-IDFなど
• 転置 (inversion)– 入力された文書-単語情報を単語-文書情報に変換
• インデクス分散 (Index distribution)– 文書分散 (document distribution)
• 並列にクエリ処理が可能– 単語分散 (term distribution)– レプリケーション

9
4 ユーザインタラクション• クエリ入力 (Query input)
– 入力されたクエリをクエリ言語に変換– クエリ言語
• ブーリアン検索: AND, OR, NOTなどの演算子• SQL: エンドユーザ向けではない
• クエリ変換 (Query transformation)– クエリログを利用した機能
• スペルチェック• クエリサジェスション• クエリ拡張
– 適合性フィードバック (relevance feedback)• ユーザが検索結果に対してフィードバック
• 結果の出力 (Result output)– スニペットの生成– 重要語,重要文の強調

10
5 ランキング• スコアリング (Scoring)
– ランキングアルゴリズムによってスコアを付与• 例:TF-IDF, BM25,クエリ尤度モデルなど
– 高速に計算される必要性
• パフォーマンス最適化 (Performance optimization)– レスポンスタイムの高速化とクエリスループットの向上– スコアの計算方法
• 単語毎に計算 (term-at-a-time)• 文書毎に計算 (document-at-a-time)
– top-kの高速な取得• 安全な最適化 (safe optimization):スコアを保証(通常計算と同様)• 安全でない最適化 (unsafe optimization):スコアが保証されない
• 分散処理 (Distribution)– クエリブローカ (query broker) によってランキング処理を分散 – キャッシュ (chache)
• クエリに対するランキング結果をメモリに保存

11
6 評価• 検索ログ (Logging)
– ログは検索エンジンの改善に価値のある情報源– クエリログ
• スペルチェック,クエリキャッシュなどに活用– クリック履歴 (clickthrough log)
• ランキングアルゴリズムの評価や訓練
• ランキングの評価 (Ranking analysis)– ログデータ,または明示的な適合性評価が必要– 様々な評価指標
• 検索結果上位を強調するようなものが適切
• 性能評価 (Performance analysis)– レスポンスタイム,スループットなどを計測– 分散アプリケーションの場合,ネットワーク速度も測定– 実測の代わりにシミュレーションすることも

12
実際どのように動くのか?• 検索エンジンの基本構造を学んだ• 次章以降で詳しく解説する• 後でGalagoのソースコードを眺めてみよう

13
文献情報• データベースの教科書
– Elmastri and Navathe (2006):• Fundamentals of database systems (5th ed.)
• 古典的なウェブ検索エンジン構造について– Brin and Page (1998): 初期のGoogle– Callan et al. (1992): Inquery
• Luceneの構造について– Hatcher and Gospodnetic:
• Lucene in Action 第2版近日発売!