simple techniques for plagiarism detection in student programming projects szymon grabowski,...
Post on 20-Dec-2015
214 views
TRANSCRIPT

Simple techniques for plagiarism detection
in student programming projectsSzymon Grabowski, Wojciech Bieniecki
Computer Engineering Dept., Tech. Univ. of Łódź, Poland
{SGrabow, WBieniec}@kis.p.lodz.pl
Sieci i Systemy Informatyczne, Łódź, październik 2006
We plagiarized it...

2Sz. Grabowski & W. Bieniecki, Simple techniques for plagiarism detection...
http://library.kcc.hawaii.edu/main/images/plagiarism_cartoon.gif
What is plagiarism?

3
Plagiarism everywhere
Sz. Grabowski & W. Bieniecki, Simple techniques for plagiarism detection...
• text (articles, scientific papers (also self-plagiarisms), essays
...or just plot ideas in fiction books)
• music (melodies, “sampling”)
• images (copy/paste e.g. from web pages)
Our interest: text plagiarism.

4
Text plagiarism
• stealing natural language (NL) texts
• stealing software code
Sz. Grabowski & W. Bieniecki, Simple techniques for plagiarism detection...

5
Previous work (1/3)
Faidhi & Robinson (1987): six levels of program modification in a plagiarism attempt:
(i) changing comments, (ii) changing identifier names,
(iii) reordering variable positions, (iv) procedure combination,
(v) changing program statements, (vi) changing control logic.
Changes in the program control logic are most laborious (and vulnerable to hard-to-detect errors) but also hardest to properly identify as plagiarism.
Sz. Grabowski & W. Bieniecki, Simple techniques for plagiarism detection...

6
Previous work (2/3)
Irving (2004): finding local similarity with a variant of
the Smith-Waterman classic algorithm (1982). Aim: taking care of both precision/recall and speed.
Pretchelt et al. (2000):JPlag online system.
Basic technique: find a set of indentical substrings of strings A and B, adhering to a few simple rules.
Quite robust to reordering parts of the text.
Sz. Grabowski & W. Bieniecki, Simple techniques for plagiarism detection...

7
Previous work (3/3)
Many algorithms based on various code complexity measures
(like e.g. the number of execution paths through a program). (See [Clough, 2000] for details.)
Mozgovoy et al. (2005):Suffix array based alg.
to decrease the computation complexity ofall-against-all file comparison.
Sz. Grabowski & W. Bieniecki, Simple techniques for plagiarism detection...

8
Our motivation
Some say that laziness is a professional feature...
Therefore we wanted to keep things simple(as opposed to many algs from the literature).
Our task: find plagiarisms in student homeworks.Namely, in Java projects.
Small projects: not more than a few hundred lines expected.
Sz. Grabowski & W. Bieniecki, Simple techniques for plagiarism detection...

9
We conjecture that the relative order and frequency of the keywords of a given language
is quite a good indicator if two documents were created independently or not.
Because it is not easy to find synonymous constructs without some understanding of the code.
Our approach
Why keywords? Maybe operators instead?
Rather not. Examples (in C and similar lang.): x = y / 2; x = y * 0.5;
x-=2; x--, x--;
Sz. Grabowski & W. Bieniecki, Simple techniques for plagiarism detection...

10
Java keywords
Sz. Grabowski & W. Bieniecki, Simple techniques for plagiarism detection...
http://java.sun.com/docs/books/tutorial/java/nutsandbolts/_keywords.html

11
Three variantsExtracting keywords, that’s easy. What then?
What similarity measure?
We propose 3 variants:
• based on the context-free counts of the keywords, i.e., order-0 statistics;
• based on the similarity of the statistics of pairs of successive keywords in the source files, i.e., order-1 rather than order-0 statistics;
• based on the similarity between the whole sequences of used keywords, in the order of their appearances, with aid of
the LCS (longest common subsequence) measure.
Sz. Grabowski & W. Bieniecki, Simple techniques for plagiarism detection...
In all variants we measure pair-wise file similarity.

12
Algorithm I (order-0 statistics)1. For both files we create a dictionary (Dict1 and Dict2,
respectively) of occurring keywords with the number of occurrences (a histogram).
2. We calculate the total number of keywords C.
2121
1\22
2\11
;maxDictDictk
DictDictkDictDictk
kcountkcount
kcountkcountC
3. We calculate the number of keyword repetitions R:
21
21 ;maxDictDictk
kcountkcountR
4. We evaluate the similarity S = R / C.
Sz. Grabowski & W. Bieniecki, Simple techniques for plagiarism detection...

13
Algorithm II (order-1 statistics)
1. For both files create a sequence of keywords (List1 and List2).
2. For each element i of List1 (except from the last one) take its successor List1(i+1) and add the pair to the list lp1. Delete the repeated records from lp1.
3. Analogously for lp2.
4. Evaluate the similarity measure S:
2,1min
21
lplp
lplpS
Sz. Grabowski & W. Bieniecki, Simple techniques for plagiarism detection...

14
Given strings A, B, |A| = n, |B| = m, find the longest subsequence shared by both strings.
Sometimes we are interested in a simpler problem:finding only the length of the LCS (LLCS), not the
matching sequence.
Longest Common Subsequence (LCS)
A = m a t t e rB = b r o t h e r s
LLCS(A, B) = 3.
LCS(A, B) = t e r
LCS example
Sz. Grabowski & W. Bieniecki, Simple techniques for plagiarism detection...

15
Algorithm IIILCS on strings where the “characters”
are keywords
Sz. Grabowski & W. Bieniecki, Simple techniques for plagiarism detection...
1. Denote the sequence of keywords in file1 and file2with Word1, Word2, respectively.
2. Use the formula for similarity measure S:
2,1min
2,1
WordWord
WordWordLCSS

16
Implementation / test setup
All codes in Python 2.4(perfect language for reluctant coders).
Test machine: Pentium4 3 GHz, 512 MB of RAM, Windows XP SP2.
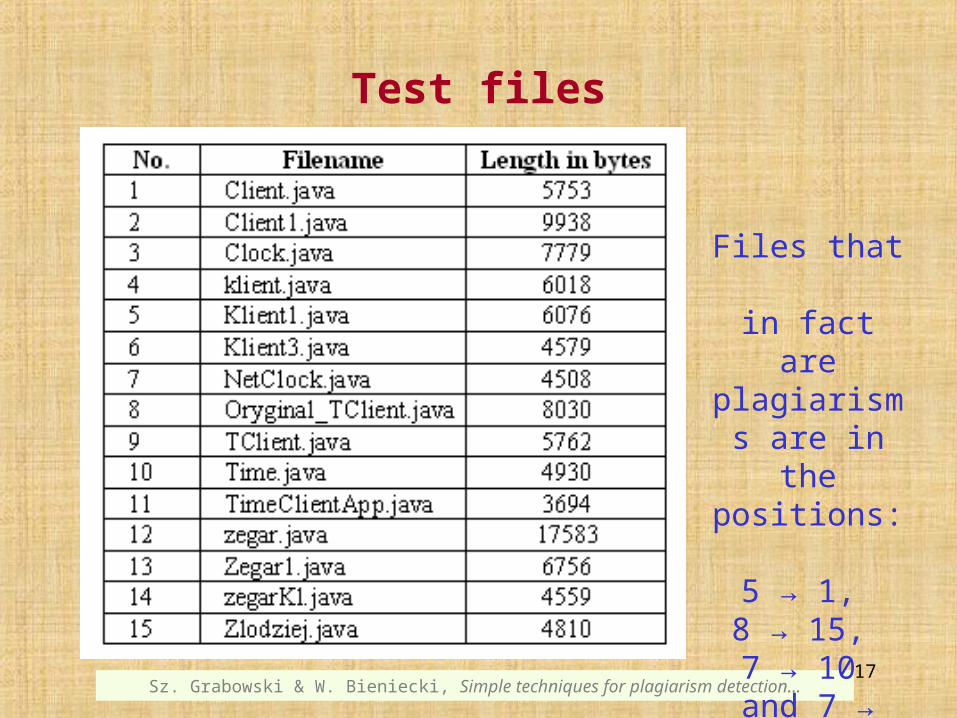
Input files:15 student Java projects (single source files)
solving the same task: displaying time on an analog clock, using a client-server technology
(a server provides the system time, and many clients can be connected to the server).
Sz. Grabowski & W. Bieniecki, Simple techniques for plagiarism detection...
17Sz. Grabowski & W. Bieniecki, Simple techniques for plagiarism detection...
Test files
Files that in fact are
plagiarisms are in the positions:
5 → 1, 8 → 15, 7 → 10
and 7 → 13.
18
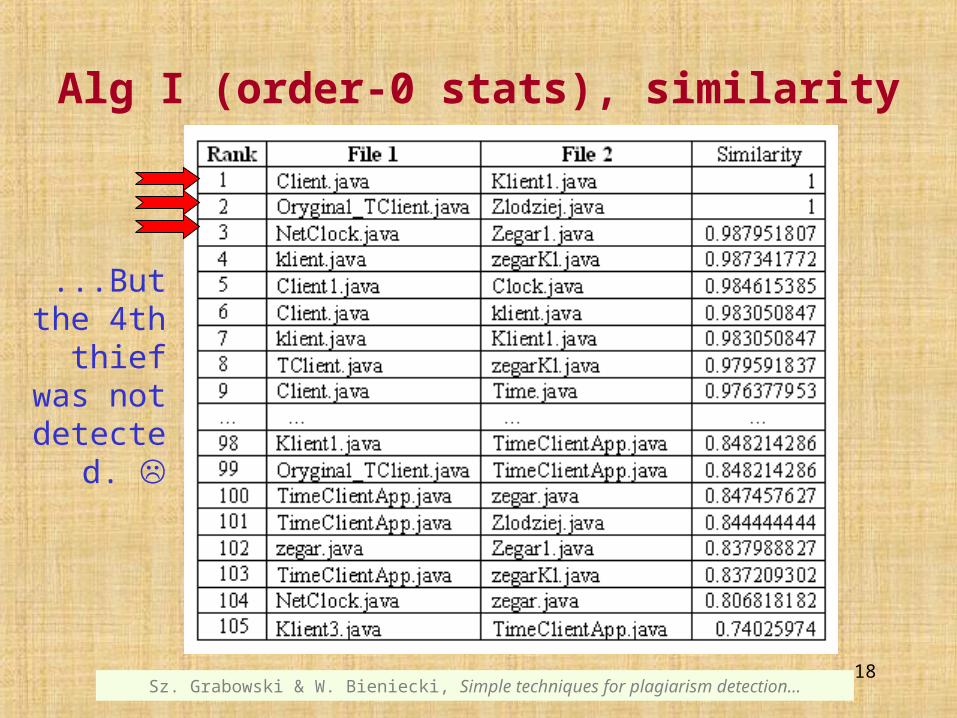
Alg I (order-0 stats), similarity measure
Sz. Grabowski & W. Bieniecki, Simple techniques for plagiarism detection...
...But the 4th thief was not
detected.
19
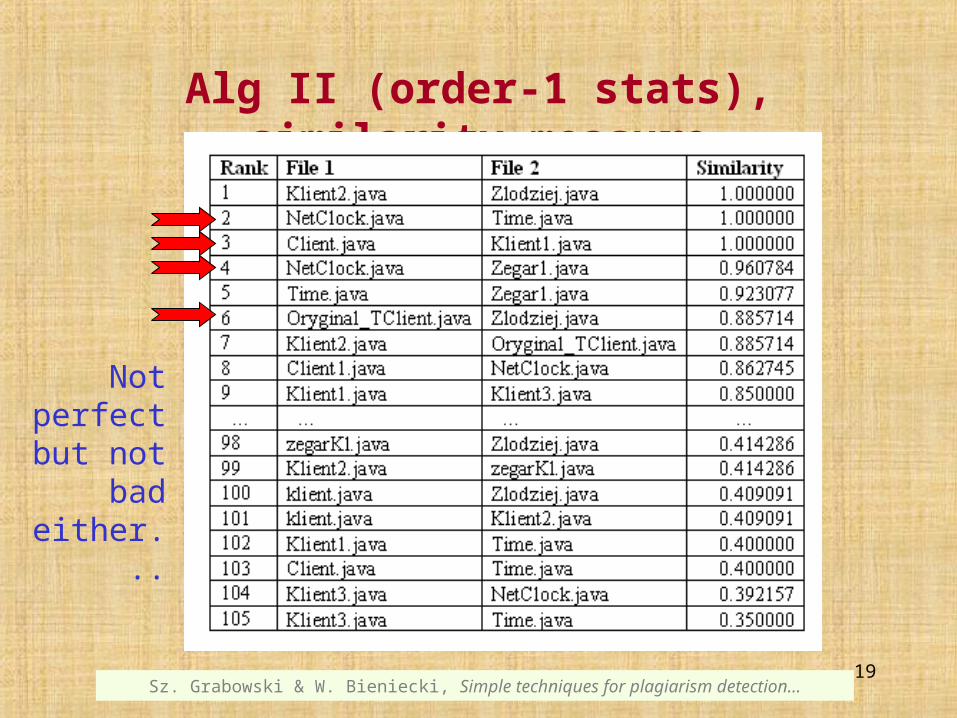
Alg II (order-1 stats), similarity measure
Sz. Grabowski & W. Bieniecki, Simple techniques for plagiarism detection...
Not perfectbut not
bad either...
20
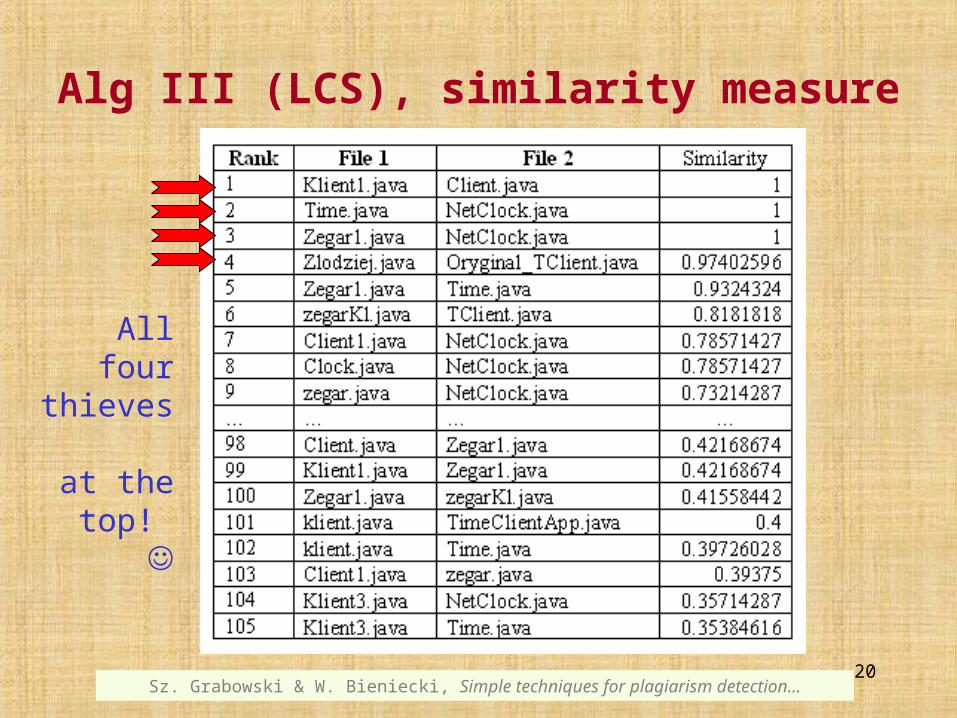
Alg III (LCS), similarity measure
Sz. Grabowski & W. Bieniecki, Simple techniques for plagiarism detection...
Allfour
thieves at the
top!

21
Conclusions
Sz. Grabowski & W. Bieniecki, Simple techniques for plagiarism detection...
All the presented algorithms seem to indicate the plagiarized codes properly.
But in practice it is impossible to set the threshold similarity value for each algorithm above which the files are plagiarisms.
In Algorithm I the values of similarity vary from 0.75 to 1 and all below 0.98 don’t indicate a plagiarism.
This algorithm is the most resistant to changing the order of instructions and functions.

22
Algorithm II is pretty resistant to changing the order of functions and blocks of instructions.
The range of obtained similarity measure values is much wider comparing to the first case.
Algorithm III, based on the LCS measure, is vulnerable to changing the order of functions and instructions in the file.
In the inspected case, however, students stealing the code did not bother to mix the functions
so the results are comparable to Algorithm II.
Conclusions, cont’d
All presented algorithms should work properly if a stolen homework is only a part of the original code.
Sz. Grabowski & W. Bieniecki, Simple techniques for plagiarism detection...

23
Future plans
Sz. Grabowski & W. Bieniecki, Simple techniques for plagiarism detection...
Making it more robust to function reordering(even Algorithm II).
Idea: convert a source file to a cannonical form,sorting functions according to their signatures.
More experiments (also for sources in C++, PHP...).
Handling multi-file projects.
Use not only keywords but standard library function names too?
Several independent similarity measures and the detection based on training?