spis treści - mif.pg.gda.pl · przemawiającym na korzyść surowców rolnych są rosnące...
TRANSCRIPT

Spis treści
1 Wstęp (Edyta Koziara, Iwona Lorenz) 4
1.1 Przedstawienie aktywów . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2 Analiza danych (Iwona Lorenz) 9
2.1 Charakterystyki liczbowe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.2 Testy normalności . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3 Miary ryzyka 15
3.1 Koherentne miary ryzyka (Edyta Koziara) . . . . . . . . . . . . . . . . . . . . . . . 15
3.2 Value-at-Risk (Edyta Koziara) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.3 Expected Shortfall (Iwona Lorenz) . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4 Modelowanie rozkładów dwuwymiarowych 21
4.1 Test Mardia (Edyta Koziara) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
4.2 Estymacja gęstości (Edyta Koziara) . . . . . . . . . . . . . . . . . . . . . . . . . . 22
4.3 Kopuły (Iwona Lorenz) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4.3.1 Podstawowy podział kopuł . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4.4 Inwestycja łączna (Edyta Koziara) . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4.5 Porównanie inwestycji (Iwona Lorenz) . . . . . . . . . . . . . . . . . . . . . . . . . 29
5 Podsumowanie (Edyta Koziara, Iwona Lorenz) 31
Załączniki 32
Dodatek A . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
Dodatek B . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
Dodatek C . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
Wykaz literatury 46
3

1 Wstęp
Praca przedstawia ocenę ryzyka straty inwestycji w akcje dwóch wybranych aktywów. Prze-
analizowane zostały różne portfele inwestycyjne (jednoskładnikowe oraz złożone) w łącznej kwocie
1 mln dolarów na okres jednego miesiąca. Do oszacowania potrzebnych zabezpieczeń finansowych
posłużono się wybranymi miarami ryzyka, Value at Risk oraz Expected Shortfall. Praca złożona
jest z 5 rozdziałów.
Pierwszy rozdział zawiera wstęp oraz podstawowe wiadomości dotyczące aktywów: pszenicy
oraz soi. Ponadto w tym rozdziale przedstawione zostały historyczne notowania na otwarcie i
zamknięcie miesiąca z ostatnich 5 lat, razem 61 obserwacji.
W rozdziale drugim napisanym przez Iwonę Lorenz znajdują się dane, wartości stóp strat
wyliczone na podstawie wszystkich obserwacji. Przedstawiona została także statystyczna analiza
danych oraz test na normalność rozkładu stóp strat.
W trzecim rozdziale, wprowadzona została teoria miar ryzyka. W podrozdziale 3.1 oraz
3.2 napisanym przez Edytę Koziarę wyróżniono koherentność miary oraz opis i interpretację war-
tości zagrożonej ryzykiem. Kolejny podrozdział zawierający omówienie i interpretację uśrednionej
wartości zagrożonej napisała Iwona Lorenz.
Rozdział czwarty zawiera badanie dwuwymiarowego rozkładu, niezbędnego przy analizie
dwuskładnikowego portfela inwestycyjnego. Pierwsze dwa podrozdziały napisane przez Edytę Ko-
ziarę przedstawiają test Mardia oraz estymację gęstości. W kolejnym podrozdziale napisanym przez
Iwonę Lorenz umieszczona została koncepcja funkcji kopuły oraz równania i wykresy wybranych
kopuł archimedejskich i eliptycznych. Na podstawie wyestymowanych danych otrzymano parametry
kopuł, decydujące o najlepiej dopasowanej funkcji do danych. Podrozdział omawiający dywersyfi-
kacje portfela łącznego napisała Edyta Koziara. Podsumowanie rozdziału zawierające porównanie
inwestycji jednoskładnikowej z dwuskładnikową, napisała Iwona Lorenz. Do oszacowania ryzyka
inwestycji złożonej posłużono się wybraną wcześniej kopułą. Jest to najważniejsza część pracy, w
której podsumowano i porównano różne portfele, dla których przeanalizowano wysokości rezerw
koniecznych do zabezpieczenia inwestycji.
Na końcu pracy umieszczono Załączniki. W Dodatku A przedstawione są dodatkowe de-
finicje, wzory oraz przeprowadzone dowody. W Dodatku B zawarty jest kod do programu SAS
9.3, dzięki któremu wygenerowano wykresy oraz wartości użyte w pracy. W ostatnim Dodatku C
załączono tablicę kwantyli rozkładu normalnego.
Abstract
This thesis evaluated the risk of loss of investment in the shares of the two selected assets.
Different investment portfolios (one-and complex) were analyzed for a period of one month. I took
the total amount 1 million U.S. dollars. To estimate the necessary financial security was used
to selected risk measures, Value at Risk and Expected Shortfall. The BA thesis consists of five
chapters.
The first chapter contains an introduction and basic information concerning the assets
of wheat and soybeans. In addition, this chapter presents the historical stock quotes for for the
opening and closing of the month in the last five years. It included 61 observations.
The second section contains data, the feet losses calculated on the based on all observations.
Also presents the a statistical analysis of the data and test for normality of distribution losses feet.
Iwona Lorenz did it.
4

In the third chapter, was introduced the theory of risk measures. In subsection 3.1 and
3.2 written by Edyta Koziara, distinguished coherence in the measurement and description and
interpretation of value at risk. The next section contains a discussion and interpretation of averaged
value at risk. That wrote Iwona Lorenz.
The fourth chapter presents the study of two-dimensional distribution, which is necessary in
the analysis of two-component of the investment portfolio. The first two sections written by Edyta
Koziara present Mardia test and density estimation. In the next section written by Iwona Lorenz
was placed in the dome of the concept of functions and equations and graphs of selected archimedes’
and elliptical domes.Based on assessment data, the parameters of the domes, determining the best-
fit function to the data. Subsection discusses the joint portfolio diversification wrote Edyta Koziara.
Summary of Chapter containing a comparison of investment mono-component. Iwona Lo-
renz wrote it. To estimate the risk of the investment complex was used previously selected dome.
This is the most important part of the thesis, which summarizes and compares the different port-
folios, which were analyzed for the amount of reserves necessary to protect your investment.
On the end placed Attachments. Appendix A shows the additional definitions, formulas,
and carried out the evidence. In Appendix B is contained code to the SAS 9.3 by which the
generated charts and the values used in the work. In the last Appendix C attached array quantile
of the normal distribution.
1.1 Przedstawienie aktywów
Każda inwestycja powiązana jest ściśle z ryzykiem, bez względu na to czy dotyczy ona dzia-
łalności gospodarczej, zakupu towaru, czy inwestycji na rynku finansowym. Samo pojęcie ryzyka
oznacza zagrożenie osiągnięcia określonych planów, spotykane przy podejmowaniu codziennych de-
cyzji. Szacujemy wówczas prawdopodobieństwo zdarzeń za pomocą rozsądku, doświadczenia czy
też rachunku prawdopodobieństwa. W naszej pracy przedstawimy ryzyko inwestycji, będące mie-
rzalną niepewnością. Wyliczone rezerwy określone na podstawie miar ryzyka wykorzystamy do
oszacowanie potrzebnych zabezpieczeń przed stratną inwestycją.
Analizując wspomniane ryzyko skupimy się na dwóch zbożach pszenicy oraz soi. Są to
najpowszechniejsze rośliny odpowiednio wśród zbóż i roślin oleistych. Zboża te są istotnymi skład-
nikami paszy i stanowią wartościową część pożywienia dla człowieka.
Soja to roślina jednoroczna należąca do rodziny bobowatych. Pochodzi z południowo-
wschodniej Azji. Jest jedną z najbardziej popularnych roślin oleistych w handlu. Stanowi cenny
pokarm dla człowieka i jest ważnym surowcem do produkcji pasz (jej nasiona zawierają 25% tłusz-
czu i 50% białka). Na bazie jej nasion wytwarza się m.in. olej, mączkę, kaszę oraz mleko sojowe.
Preparaty z soi podnoszą wartości odżywcze pokarmów, dodawane są do przetworów, m.in. kon-
serw mięsnych, wędlin. Wyhodowanie dużej liczby odmian soi umożliwiło jej uprawę we wszystkich
klimatach. Obecnie największe uprawy znajdują się na obszarach o klimacie umiarkowanym cie-
płym. Prawie 1/3 światowej produkcji soi podlega eksportowi. Do największych eksporterów należą:
Brazylia, Stany Zjednoczone, kraje Ameryki Południowej, Paragwaj, Kanada i Ukraina, a do naj-
większych importerów: Chiny, kraje Europy, Japonia oraz Australia. Na wartości notowań soi na
giełdzie znaczący wpływ mają etapy rozwoju rośliny.
5

Pszenica jest jednym z najstarszych zbóż. Uprawia się ją od co najmniej 6 tysięcy lat.
Pochodzi z południowo-zachodniej i środkowej Azji. Uprawiana jest przede wszystkim w strefach
klimatu umiarkowanego i podzwrotnikowego (wymaga okresu wegetacyjnego powyżej 100 dni). Na
świecie zajmuje pierwsze miejsce w strukturze zasiewów z powierzchnią 220 mln hektarów. Tak
jak i soja, stanowi cenny pokarm dla człowieka. Z pszenicy produkuje się najlepsze gatunki mąk,
które służą do wyrobu chleba, makaronów oraz produktów cukierniczych. Spożycie globalne wynosi
około 70 kg na osobę rocznie. Na świecie zbiera się około 690 mln ton ziaren pszenicy rocznie, co
daje jej trzecie miejsce po ryżu i kukurydzy. Średnio 20% światowej produkcji jest przedmiotem
międzynarodowego handlu. Do czołowych producentów tego zboża zaliczamy: Chiny, Indie, Rosję,
Francję, Australię i Kanadę, do czołowych eksporterów: Stany Zjednoczone, Kanadę, Francję, Au-
stralię i Argentynę, natomiast do czołowych importerów: Rosję, Chiny, Japonię, Egipt, Brazylię i
Włochy.
Dlaczego akurat surowce rolne?
Bardzo dobrą odpowiedź na to pytanie udzielił Biznes.pl1:„Obrót surowcami rolnymi skupia uwagę
inwestorów na całym świecie. Jedną z przyczyn tego zainteresowania jest stosunkowo niska korelacja
rynku z rynkiem obrotu akcjami. Dodatkowo rynek surowców rolnych charakteryzuje bardzo duża
zmienność – ceny poszczególnych towarów rządzą się własnymi prawami, podlegając jednocześnie
wypadkowym specyficznym dla tego sektora. Nie są tu rzadkością na przykład kilkuprocentowe
wzrosty cen w skali dnia, które poprzedzone znacznymi spadkami w okresie miesiąca, generują kil-
kunastoprocentowe zyski w ujęciu kwartalnym czy półrocznym. Niekwestionowanym argumentem
przemawiającym na korzyść surowców rolnych są rosnące potrzeby konsumpcyjne przy jednocześnie
trudnej do zwiększenia w wielu przypadkach podaży, która mimo rosnącej efektywności produkcji,
ograniczana jest wieloma czynnikami o charakterze lokalnym i globalnym. Na wskaźniki popytu
wyraźnie oddziaływują obecnie państwa wschodzące, które przeobrażając się generują znaczne za-
potrzebowanie w zakresie artykułów żywnościowych czy pasz. Z drugiej strony podaż ograniczana
jest w wyniku kurczenia się areału upraw, rekalibrowania produkcji czy wreszcie np. na skutek
decyzji politycznych, jak wstrzymanie eksportu. Ogromny wpływ posiada tu także niemożliwa do
przewidzenia zmienna, czyli pogoda. Powodzie, susze, stopniowa zmiana klimatu czy gwałtowne
zjawiska pogodowe w oczywisty sposób wpływają na lokalne i światowe poziomy cen surowców
rolnych.”
1Czy rynek surowców rolnych to efektywna alternatywa?, artykuł internetowy [1]
6

Poniżej zaprezentujemy wykresy notowań opisanych surowców z ostatnich 5 lat.
Rysunek 1: Wykres notowań soi z lat 2009-2014
Rysunek 2: Wykres notowań pszenicy z lat 2009-2014
Na pierwszy rzut oka widać, że ceny obydwu surowców rosną i maleją w tych samych okresach.
Wynika to ze wspomnianej wcześniej zmienności pogody i decyzji politycznych. Dokładniej
będzie można to zauważyć na wykresie łącznym. Kolorem niebieskim oznaczone są notowania dla
soi a kolorem różowym dla pszenicy.
Rysunek 3: Łączny wykres notowań soi (niebieski) i pszenicy (różowy) z lat 2009-2014
7

Rysunek 3 pokazuje, iż notowania soi jak i pszenicy w tych samych momentach spadają a za
chwilę gwałtownie rosną. Mimo to trudno jest przewidzieć ceny tych surowców w najbliższym
czasie. Niełatwo zatem na podstawie takich danych stwierdzić, która inwestycja (w soję czy
pszenicę) jest mniej ryzykowna. W tym celu wylicza się historyczne stopy strat, które mówią o
wielkości poniesionych strat na przestrzeni kolejnych miesięcy.
8

2 Analiza danych
Dane jakie analizujemy to ceny poszczególnych zbóż (cent/buszel) z okresu 01.01.2009-
31.01.2014 roku pozyskane z oficjalnej strony internetowej stooq.com. Bierzemy pod uwagę wartości
notowań na otwarciu i na zamknięciu w poszczególnych miesiącach. Stopy strat wyliczamy na
podstawie wzoru:
L =Wo −Wz
Wo(2.1)
gdzie:
Wo-wartość notowania początkowego,
Wz-wartość notowania końcowego.
Wszystkie dane zostały zaprezentowane w Tablicy 1 i 2.
Tablica 1: Notowania na giełdzie
Data Pszenica Soja
Rok Miesiąc Otwarcie Zamknięcie Stopy strat Otwarcie Zamknięcie Stopy strat
2014 styczeń 602.88 555 0.07942 1288.88 1283.88 0.00388
2013
grudzień 669.12 605.12 0.09565 1337.62 1289.38 0.03606listopad 667.62 668.25 -0.00094 1266.12 1337 -0.05598październik 678.12 667.38 0.01583 1277.88 1265.62 0.00959wrzesień 662.62 679.12 -0.02490 1396.62 1281.38 0.08251sierpień 663.25 654.88 0.01262 1247.75 1356.38 -0.08706lipiec 655.5 663.62 -0.01239 1427.12 1247.25 0.12604czerwiec 707.88 656.88 0.07205 1509.62 1429.38 0.05315maj 731.38 706.62 0.03385 1396.62 1510.12 -0.08127kwiecień 682.88 730.25 -0.06937 1402.5 1396.5 0.00428marzec 716.38 688.25 0.03927 1452.88 1404.38 0.03338luty 780.25 716.12 0.08219 1470 1451.62 0.01250styczeń 786.62 780.5 0.00778 1433 1471.12 -0.02660
2012
grudzień 869.38 778.5 0.10453 1444 1409.88 0.02363listopad 867.38 863.5 0.00447 1552.38 1440.62 0.07199październik 901 867.25 0.03746 1596.75 1552.25 0.02787wrzesień 892.12 899.38 -0.00814 1773.62 1598.38 0.09881sierpień 889.75 888.63 0.00126 1657.88 1754.37 -0.05820lipiec 764.75 890.88 -0.16493 1495.62 1653.5 -0.10556czerwiec 646.25 758.88 -0.17428 1344.25 1480.88 -0.10164maj 654.38 644.13 0.01566 1503.38 1340.75 0.10818kwiecień 662.12 655.13 0.01056 1406.62 1505 -0.06994marzec 665.75 658.88 0.01032 1319.13 1401.88 -0.06273luty 666.75 667.88 -0.00169 1202.38 1319.12 -0.09709styczeń 666.38 666.62 -0.00036 1236.5 1200.38 0.02921
9

Tablica 2: Notowania na giełdzie
Data Pszenica Soja
Rok Miesiąc Otwarcie Zamknięcie Stopy strat Otwarcie Zamknięcie Stopy strat
2011
grudzień 614.88 653.12 -0.06219 1134.25 1211.88 -0.06844listopad 629.62 615.75 0.02203 1215.62 1134.12 0.06704październik 608.62 630.12 -0.03533 1176.38 1219.62 -0.03676wrzesień 788.38 606.88 0.23022 1455.12 1176.62 0.19139sierpień 671.12 789.88 -0.17696 1350.12 1456.12 -0.07851lipiec 615.75 672.5 -0.09216 1309 1346.38 -0.02856czerwiec 767.75 614.25 0.19994 1371.5 1300.5 0.05177maj 809.25 780.25 0.03584 1392 1377.25 0.01060kwiecień 761.75 804 -0.05546 1405 1394.75 0.00730marzec 818 762.5 0.06785 1372.5 1406 -0.02441luty 840 816.25 0.02827 1423.5 1365.75 0.04057styczeń 816 840 -0.02941 1407.25 1411.75 -0.00320
2010
grudzień 717.5 791.25 -0.10279 1265.25 1402.75 -0.10867listopad 721.5 689.25 0.04470 1234.75 1245.75 -0.00891październik 669 715.5 -0.06951 1098.75 1232 -0.12127wrzesień 698.75 674.75 0.03435 1013 1102.25 -0.08810sierpień 688.5 684.25 0.00617 1021 1006.75 0.01396lipiec 481.25 660.25 -0.37195 904 1005 -0.11173czerwiec 454.5 482 -0.06051 936.4 902 0.03674maj 505.75 457.75 0.09491 997 937.75 0.05943kwiecień 452.5 504.5 -0.11492 944 999.5 -0.05879marzec 517 450.5 0.12863 955.25 939.75 0.01623luty 474.5 519.25 -0.09431 915 961.75 -0.05109styczeń 554.5 472.75 0.14743 1065.75 914.75 0.14168
2009
grudzień 590 540.25 0.08432 1068.4 1048.25 0.01886listopad 497 585.4 -0.17787 984 1060.4 -0.07764październik 450 493.4 -0.09644 925 976.4 -0.05557wrzesień 491.4 456.4 0.07122 983 927 0.05697sierpień 542 499 0.07934 1032 979.4 0.05097lipiec 540 528 0.02222 1000 982 0.01800czerwiec 656 545 0.16921 1202 981 0.18386maj 541 636.4 -0.17634 1055 1184 -0.12227kwiecień 528 537 -0.01704 956 1055 -0.10356marzec 510.4 532 -0.04232 851 952 -0.11868luty 559 520 0.06977 970 872 0.10103styczeń 602 567 0.05814 970 980 -0.01031
W związku, ze wzorem (2.1) ujemne stopy strat są zyskami, zaś dodatnie - stratami. W
przypadku obu surowców kolorem czerwonym zostały oznaczone 3 największe straty a kolorem
niebieskim największe zyski.
10

2.1 Charakterystyki liczbowe
Oceniając ryzyko inwestycji warto przeprowadzić analizę zebranych danych. Zaczniemy od
wyznaczenia charakterystyk liczbowych wyznaczonych na podstawie danych statystycznych oraz
od przeanalizowania rozkładu. Poniżej przedstawiamy podstawowe definicje opracowane na pod-
stawie pozycji [6] umieszczonej w Wykazie literatury.
”Punktem wyjścia badania statystycznego cechy X jest wylosowanie z całej populacji pewnej
skończonej liczby n elementów. Uzyskane w ten sposób wartości x1, x2, ..., xn są zaobserwowanymi
wartościami n-elementowej próby o rozkładzie X.
Do najważniejszych form wnioskowania statystycznego należą:
• estymacja (ocena) nieznanych parametrów bądź ich funkcji. Parametry te charakteryzują roz-
kład badanej cechy populacji,
• weryfikacja (badanie prawdziwości) postawionych hipotez statystycznych.
Wnioskowanie statystyczne dostarcza jedynie wniosków wiarygodnych - a nie absolutnie prawdzi-
wych. Dowolne dwie n-elementowe próbki z tej samej populacji są na ogół różne. Wygodnie jest
traktować ciąg x1, x2, ..., xn jako realizację ciągu X1, X2, ..., Xn, gdzie Xi, i=1,2,...,n jest ciągiem
niezależnych zmiennych losowych. Ciąg tych zmiennych losowych X1, X2, ..., Xn będziemy nazywali
n-elementową próbą losową. Ciąg liczb x1, x2, ..., xn będziemy nazywali zaobserwowaną próbą lo-
sową, bądź po prostu próbką.” [6]
Definicja 2.1.1. Estymator wartości oczekiwanej [6]
Estymatorem wartości oczekiwanej µ = E(X), inaczej średnią z próby x1, ...xn nazywamy liczbę x
określoną wzorem:
µ = x = 1n
n∑i=1
xi.
Definicja 2.1.2. Estymator mediany
Miedianą nazywamy kwantyl rzędu 12 , co oznaczamy q0.5(F ).
Zachodzi równość:
q0.5(F ) = me,
gdzie me jest medianą próbki.
Uzupełnienie znajduje się w Dodatku A.1. i A.2.
Definicja 2.1.3. Estymator odchylenia standardowego i wariancji
Estymatory miar rozproszenia wyrażają się wzorami:
a) wariancja:
σ2 = 1n−1
n∑i=1
(xi − x)2,
b) odchylenie standardowe:
σ =√σ2 =
√1
n−1
n∑i=1
(xi − x)2.
Odchylenie standardowe mówi, jak rozlegle rozrzucone są wartości wokół średniej.
11

Definicja 2.1.4. Estymator skośności
Estymator skośności wyraża się wzorem:
A = M3σ3 =
1n
n∑i=1
(xi−x)3
σ3 ,
gdzie:
M3-trzeci moment centralny [Dodatek A.6],
σ-odchylenie standardowe.
Ujemna wartość skośności wskazuje na lewostronną asymetrię (wydłużone lewe ramię rozkładu),
dodatnia na prawostronną (wydłużone prawe ramię rozkładu), natomiast skośność równa zeru
oznacza rozkład symetryczny.
Definicja 2.1.5. Estymator kurtozy
Estymator kurtozy wyraża się wzorem:
K = M4σ4 − 3 =
1n
n∑i=1
(xi−x)4
σ4 − 3,
gdzie:
M4-czwarty moment centralny,
σ-odchylenie standardowe.
Im większa kurtoza, tym bardziej dane skupiają się wokół średniej. Jeśli jej wartość jest ujemna
to dane są bardziej skoncentrowane niż przy rozkładzie normalnym, a jeśli dodatnia to odwrotnie.
Gdy kurtoza wynosi zero, spłaszczenie rozkładu jest podobne do spłaszczenia rozkładu
normalnego.
Po zdefiniowaniu charakterystyk liczbowych przejdźmy do omówienia poszczególnych war-
tości dla stóp strat pszenicy i soi uzyskanych w wyniku działania programu SAS 9.3.
Tablica 3: Wyestymowane charakterystyki liczbowe dla pszenicy
Momenty
N 61 Suma wag 61Średnia -0.0002295 Mediana 0.01Odchylenie std. 0.10124844 Wariancja 0.01025125Skośność -0.7755391 Kurtoza 2.25383341
Tablica 3 prezentuje wyestymowane wartości dla pszenicy. Średnia arytmetyczna jest ujemna, co
wskazuje, że średnio z inwestycji w to zboże osiągamy nieznaczne zyski. Odchylenie standardowe
jest bliskie zeru, zatem dane nie odstają daleko od średniej. Mediana ma również wartość nie-
znacznie różną od zera, co oznacza, że zysków i strat jest mniej więcej po równo. Ujemna skośność
świadczy o lewostronnej asymetrii (czyli dłuższym lewym ogonie). Dodatnia kurtoza mówi o więk-
szej smukłości rozkładu danych próbki pszenicy niż w przypadku rozkładu normalnego.
12

Tablica 4: Wyestymowane charakterystyki liczbowe dla soi
Momenty
N 61 Suma wag 61Średnia -0.0038689 Mediana 0.004Odchylenie std. 0.07690589 Wariancja 0.00591452Skośność 0.40859525 Kurtoza -0.2697633
Tablica 4 prezentuje oszacowane wartości dla soi. Średnia arytmetyczna również jest ujemna,
co wskazuje, że średnio z inwestycji osiągamy zyski. Odchylenie standardowe jest bliskie zeru, zatem
dane nie odstają daleko od średniej. Mediana ma wartość nieznacznie różną od zera, co oznacza,
że zysków i strat jest mniej więcej po równo, tak jak i w przypadku pszenicy. Dodatnia skośność
świadczy o dłuższym prawym ogonie. Bliska zeru kurtoza sugeruje zbliżenie danych do rozkładu
normalnego.
Histogramy (najbardziej popularne wykresy statystyczne) potwierdzają liczbowe wartości
statystyk.
Rysunek 4: Histogramy dla zmiennej L1 (pszenica) i zmiennej L2 (soja)
Jak łatwo zauważyć na Rysynku 4 histogramy dla obu aktywów wyglądają inaczej. W przy-
padku zmiennej L1 wartość skośności była ujemna, zatem widoczna jest asymetria lewostronna,
natomiast w przypadku zmiennej L2 skośność była dodatnia i zauważamy wydłużenie prawego
ogona rozkładu. Ewidentna różnica jest również w smukłości rozkładów. Tak jak wskazywały war-
tości kurtozy dla próbki soi (zmienna L2) dane są rozłożone a wykres przypomina rozkład normalny.
Dane dotyczące pszenicy (zmienna L1) są bardziej skoncentrowane, dzięki czemu wykres jest bar-
dziej spiczasty.
Należy jednak pamiętać, iż histogramy jedynie potwierdzają zmienność i kształt analizowanych
danych. Zawsze należy wykonać testy statystyczne, a nie tylko sugerować się wyglądem wykresu.
2.2 Testy normalności
Mając już pewne wyobrażenie na temat naszych danych po przeanalizowaniu charaktery-
styk liczbowych przystąpimy do analizy rozkładu. W tym celu skorzystamy z testów normalności.
Testy te sprawdzają, czy rozkład danych różni się od założonego rozkładu teoretycznego, gdy znana
jest tylko pewna skończona liczba obserwacji. Naszym założonym rozkładem teoretycznym będzie
13

rozkład normalny. Badając normalność stawiamy hipotezę zerową o dopasowaniu danych do roz-
kładu normalnego, wobec hipotezy alternatywnej, że dane takiego rozkładu nie mają.
Formalny zapis hipotez:
H0- dane pochodzą z rozkładu normalnego,
HA- dane nie pochodzą z rozkładu normalnego.
Przyjmujemy poziom istotność α = 0, 05. Jest to maksymalne ryzyko błędu, jakie możemy dopu-
ścić. Wykonując test porównujemy poziom istotności α z wyliczoną wartością p zgodnie z regułami
decyzyjnymi. Jeśli wartość p jest większa od poziomu istotności α to nie mamy podstaw do odrzu-
cenia H0, w przeciwnym przypadku odrzucamy H0 na korzyść HA.
Formalna definicja rozkładu normalnego umieszczona jest w Dodatku A.7.
Korzystając z programu SAS 9.3 przeprowadzimy dwa testy: test Shapiro-Wilka oraz
Kołmogorowa-Smirnowa. Bezsporną zaletą użytych testów jest możliwość korzystania z nich w
przypadku analizy rozkładów niedużych prób. Ponadto test Shapiro-Wilka jest jednym z najbar-
dziej preferowanych testów na normalność rozkładu ze względu na moc w porównaniu z innymi
dostępnymi testami.
Tablica 5: Testy normalności dla pszenicy
Test Statystyka Wartość p
Shapiro-Wilka W 0.952981 Pr.<W 0.0200Kołmogorowa-Smirnowa D 0.115975 Pr.>D 0.0407
Jak wskazuje Tablica 5 wartość p dla dwóch testów jest mniejsza niż zadany poziom istotności α.
Jak wcześniej było powiedziane, w takim przypadku odrzucamy hipotezę o normalności rozkładu
danych pszenicy i przyjmujemy hipotezę alternatywną.
Tablica 6: Testy normalności dla soi
Test Statystyka Wartość p
Shapiro-Wilka W 0.964099 Pr.<W 0.0706Kołmogorowa-Smirnowa D 0.095331 Pr.>D >0.1500
W przypadku próbki soi wartość p jest większa niż poziom istotniści α, co potwierdza Tablica
6. Biorąc pod uwagę otrzymane wyniki nie mamy podstaw do odrzucenia hipotezy zerowej. W
związku z tym przyjmujemy, że dane mają rozkład normalny.
Kod z programu SAS 9.3, użyty do wyznaczenia statystyk i wykonania testów, znajduje się w
Dodatku B.1.
14

3 Miary ryzyka
Oceniając ryzyko inwestycji należy oszacować rezerwy, jakie trzeba zgromadzić by inwe-
stycja nie przyniosła straty (w najgorszym przypadku). Funkcje obliczające wysokości tych rezerw
nazywane są miarami ryzyka, w szczególności koherentnymi miarami ryzyka. Rozdział ten został
opracowany głownie na podstawie pozycji [2].
3.1 Koherentne miary ryzyka
Aby określić czym jest koherentna miara ryzyka zaczniemy od zdefiniowania miary ryzyka.
Ustalmy pewną przestrzeń probabilistyczną (Ω,F,P) a ∆ oznaczmy przedział czasowy inwestycji.
Poprzez L0(Ω,F,P) oznaczmy zbiór wszystkich zmiennych losowych określonych na (Ω,F ). Ele-
menty zbioru zmiennych losowych stożka wypukłego M [Dodatek A.8.] należącego do L0(Ω,F,P)
będziemy rozumieli jako stopy strat inwestycji w przedziale czasowym ∆. Wówczas miarę ryzyka
definiujemy nastepująco:
Definicja 3.1.1. Miara ryzyka [5]
Miarą ryzyka nazywamy pewną funkcję rzeczywistą działającą ze zbioru zmiennych losowych okre-
ślonych na stożku wypukłym na zbiór liczb rzeczywistych
ρ : M → R.
Mając formalną Definicję 3.1.1. przejdźmy do interpretacji.
Miarę ryzyka ρ(L) rozumiemy jako wielkość rezerw dołożonych do inwestycji. W przypadku ujem-
nej bądź zerowej wartości (ρ(L)¬0) możemy stwierdzić, że nie trzeba tworzyć dodatkowych rezerw,
gdyż ujemna stopa strat to zysk. W sytuacji odwrotnej (ρ(L)>0) należy przygotować odpowiednią
ilość rezerw finansowych.
Po wyjaśnieniu czym jest miara ryzyka przejdziemy do omówienia koherentności miar.
Definicja 3.1.2. Koherentne miary ryzyka [2]
Funkcję ρ : M → R nazywamy koherentną miarą ryzyka, jeśli:
1. jest niezmiennicza na translacje, czyli dla dowolnego l ∈ R oraz L ∈M
ρ(l + L) = l + ρ(L) (3.1)
Jeżeli mamy inwestycję na kwotę L i l jest kwotą, którą jesteśmy dłużni to rezerwy ρ(L)
naszej inwestycji musimy powiększyć o kwotę l.
2. jest subaddytywna
ρ(L1 + L2) ¬ ρ(L1) + ρ(L2) (3.2)
Subaddytywność oznacza, że jeśli mamy dwie inwestycje A i B (o stratach odpowiednio L1 i
L2) to ryzyko poniesienia straty dla portfela złożonego z tych inwestycji (A+B) jest mniejsze
lub równe niż suma ich indywidualnych ryzyk.
3. jest dodatnio jednorodna, czyli jeśli λ > 0
ρ(λL) = λρ(L) (3.3)
15

Jeżeli ryzyko wzrasta λ-krotnie to rezerwy też muszą być λ-krotnie większe.
4. jest monotoniczna, jeśli L1 ¬ L2 prawie wszędzie to
ρ(L1) ¬ ρ(L2). (3.4)
Jeżeli strata L1 dla inwestycji A jest mniejsza niż strata L2 dla inwestycji B, wówczas ryzyko
poniesienia straty z inwestycji A jest mniejsze niż z inwestycji B.
Lemat 1. Równoważność warunków miary ryzyka
Jeśli miara ryzyka ρ spełnia warunki o subaddytywności i dodatniej jednorodności to warunek mo-
notoniczności jest równoważny z:
∀L∈M L ¬ 0⇒ ρ(L) ¬ 0.
Dowód powyższego lematu znajduję się w Dodatku A.11.
3.2 Value-at-Risk
Jedną z najpopularniejszych miar ryzyka jest miara nazywana wartością zagrożona, w skró-
cie V aRα (ang. Value-at-Risk). Estymuje ona maksymalną kwotę, jaką można stracić inwestując
w przedziale czasowym ∆ przy ustalonym poziomie ufności α.
Definicja 3.2.1. Value-at-Risk [2]
Niech X zmienna losowa. Wówczas wartością zagrożoną (kwantylem) X nazywamy:
V aRα(X) = qα(X) = infx : FX(x) α (3.5)
gdzie FX oznacza dystrybuantę.
Mniej formalnie mówiąc jest to pierwszy moment przecięcia poziomu α na wykresie dystrybuanty.
W ujęciu probabilistycznym, V aRα interpretuje się jako kwantyl rzędu α. Poziom ufności α
ustala się dowolnie, jednak najczęściej przyjmuje się α=0.95. Co oznacza, że isnieje 95% szansy, iż
strata będzie mniejsza niż oszacowana wartość tej miary. Przedział czasowy ∆ również ustalamy
dowolnie.
Wartość zagrożona nie jest koherentną miarą ryzyka, nie spełnia warunku subaddytywności.
Dowód znajduje się w Dodatku A.12. Z uwagi na to, że indeksy pszenicy nie formują rozkładu
normalnego skorzystamy z programu SAS 9.3, aby wyznaczyć kwantyl nieznanego nam rozkładu
[Dodatek B.1.]. Przyjrzyjmy się wartościom otrzymanym dla naszych danych.
Tablica 7: Wyestymowana wartość zagrożona
Value-at-Risk
pszenica soja
0.147 0.126
Na podstawie Tablicy 7 możemy stwierdzić, że możliwa strata inwestycji w soję jest mniejsza niż
strata przy inwestycji w pszenicę, gdyż mniejsza wartość Value-at-Risk świadczy o mniejszym
ryzyku. Oszacujmy więc potrzebne rezerwy przy inwestycji 1 mln dolarów w każde aktywo, przy
pomocy wzoru (3.3):
16

Dla pszenicy
V aR0.95(1000000 · L1) = 1000000 · V aR0.95(L1) = 1000000 · 0.147 = 147000[USD]
Dla soi
V aR0.95(1000000 · L2) = 1000000 · V aR0.95(L2) = 1000000 · 0.126 = 126000[USD]
Zastanówmy się czy można zredukować to ryzyko, estymując dane znanym rozkładem
normalnym. Przyjmijmy za parametry rozkładu wcześniej oszacowane wartości średniej oraz
odchylenia standardowego, umieszczone w Tablicy 3 i 4.
Zatem załóżmy, że:
• stopy strat dla pszenicy mają rozkład normalny: N(-0.0002295;0.10124844),
• stopy strat dla soi mają rozkład normalny: N(-0.0038689;0.07690589).
Na podstawie wzoru umieszczonego w Dodatku A.10. wyznaczymy wartości kwantyli poszczegól-
nych aktywów przyjmując wartość kwantyla standardowego rozkładu normalnego rzędu 0.95 równą
1.6449 [Dodatek C.1.] :
Dla pszenicy:
V aRα = 0.10124844 · 1.6449 + (−0.0002295) = 0.1663141
Dla soi:
V aRα = 0.07690589 · 1.6449 + (−0.0038689) = 0.1226336
Wyliczmy rezerwy pamiętając, że inwestujemy 1 mln dolarów :
Dla pszenicy
V aR0.95(1000000 · L1) = 1000000 · V aR0.95(L1) = 1000000 · 0.1663141 = 166314.1[USD]
Dla soi
V aR0.95(1000000 · L2) = 1000000 · V aR0.95(L2) = 1000000 · 0.1226336 = 122633.6[USD]
Porównując powyższe wyniki z wcześniej wyznaczonymi [Tablica 7] stwierdzamy, że program SAS
9.3 generuje mniejsze wartości Value-at-Risk nieznanego nam rozkładu dla stóp strat pszenicy,
natomiast dla soi większe. Warto też zauważyć, że w przypadku soi liczby te, wyliczone dwoma
sposobami, niewiele się różnią. Stąd też potwierdzenie zbliżenia rozkładu stóp strat soi do rozkładu
normalnego.
3.3 Expected Shortfall
Kolejną miarą ryzyka jaką omówimy jest tzw. zagrożona wartość oczekiwana lub uśred-
niona wartość zagrożona, w skrocie ESα (ang. Expected Shortfall). Jej wartość jest większa niż
wartość V aRα, gdyż określa ile średnio stracimy jeśli strata przekroczy poziom α. Miara ta oddaje
własności ogonów rozkładu. Estymuje średnią stratę dla przypadków znajdujących się w (1-α) ogo-
nie procentowym rozkładu.
17

Definicja 3.3.1. Expected Shortfall [2]
Niech X zmienna losowa, taka że E|X| < ∞. Wówczas uśrednioną wartością zagrożoną (ang.
Expected shortfall) nazywamy:
ESα(X) =1
1− α
1∫α
V aRu(X)du, (3.6)
gdzie FX oznacza dystrybuantę.
Jak wynika wprost z Definicji 3.3.1. Expected Shortfall jest miarą powiązaną z wartością
zagrożoną, zachodzi nierówność:
ESα(X) V aRα(X)
Zagrożona wartość oczekiwana jest koherentną miarą ryzyka. Dowód umieszczony jest w Dodatku
A.13.
Po teoretycznym wprowadzeniu przejdźmy do wyliczenia wartości Expected Shortfall dla naszych
danych, w tym celu posłużymy się następującym lematem:
Lemat 2. [5]
Niech L1, L2, ... będzie ciągiem niezależnych zmiennych losowych o tym samym rozkładzie FL. Wów-
czas
limn→∞
bn(1−α)c∑i=1
Li,n
bn(1− α)c= ESα(L) p.w., (3.7)
gdzie L1,n L2,n ... Ln,n są statystykami pozycyjnymi L1, L2, ..., Ln.
Jak wynika z Lematu 2. będziemy sumować bn(1−α)c największych strat. Obliczmy: bn(1−α)c =
b61 · (1− 0.95)c = 3. Wspomniane 3 największe straty zostały oznaczone w Tablicy 1 i 2 kolorem
czerwonym.
Wartości Expected Shortfall dla naszych danych zostały wyliczone za pomocą programu SAS 9.3.
Kod został umieszczony w Dodatku B.2.
Tablica 8: Wyestymowana uśredniona wartość zagrożona
Expected Shortfall
pszenica soja
0.1996667 0.1723333
Z Tablicy 8 wynika, że tak jak i w przypadku wartości zagrożonej, wartość dla pszenicy jest więk-
sza. Sprawdźmy zatem wysokości rezerw jakie musimy zgromadzić by inwestycja nie przyniosła
nam straty. Jak już wcześniej było powiedziane będziemy inwestować kwotę w wysokości 1 mln
dolarów w każde aktywo. Wykorzystując dodatnią jednorodność uśrednionej wartości zagrożonej:
ESα(1000000 · L) = 1000000 · ESα(L) dla danych zapiszmy:
18

Dla pszenicy
ES0.95(1000000 · L1) = 1000000 · ES0.95(L1) = 1000000 · 0.1996667 = 199666.7[USD]
Dla soi
ES0.95(1000000 · L2) = 1000000 · ES0.95(L2) = 1000000 · 0.1723333 = 172333.3[USD]
Istnieje jeszcze jeden sposób obliczenia uśrednionej wartości zagrożonej. W tym celu skorzystamy
z twierdzenia.
Twierdzenie 1. Expected Shortfall dla rozkładu normalnego [5]
W przypadku, gdy α ∈(0,1) oraz dystrybuanta straty FL ma rozkład normalny o średniej µ oraz o
wariancji σ2, czyli FL ∼ N(µ,σ2), możemy zapisać
ESα = µ+ σφ(Φ−1(α))
1− α(3.8)
gdzie φ jest gęstością standardowego rozkładu normalnego, a Φ−1 dystrybuantą odwrotną.
Jak wynika z Twierdzenia 1. analizowana zmienna musi mieć rozkład normalny. Załóżmy zatem,
że obie nasze zmienne (pszenica i soja) mają taki rozkład. Zbadamy na podstawie powyższego
twierdzenia, czy dzięki estymacji rozkładem normalnym możemy zmniejszyć ryzyko, a co za tym
idzie wysokości potrzebnych rezerw. Jak łatwo zauważyć wzór zależy tylko od parametrów µ i σ,
które zostały wyestymowane z rozkładu poszczególnych stóp strat (Tablica 2 i 3), gdyż wartość
φ(Φ−1(α)) jest stała (gęstość kwantyla rzędu α standardowego rozkładu normalnego).
Posługując się programem SAS 9.3 bez większej trudności wyznaczymy potrzebne wielkości.
Tablica 9: Wyestymowana uśredniona wartość zagrożona
Expected Shortfall
pszenica soja
0.2086010 0.1547537
W tym przypadku również wartość ES dla pszenicy jest znacznie większa. Mając dane z
Tablicy 9 wyliczmy wysokości rezerw.
Dla pszenicy
ES0.95(1000000 · L1) = 1000000 · ES0.95(L1) = 1000000 · 0.2086010 = 208601[USD]
Dla soi
ES0.95(1000000 · L2) = 1000000 · ES0.95(L2) = 1000000 · 0.1547537 = 154753.7[USD]
Wartości Expected Shortfall wyliczone dwoma sposobami różnią się od siebie. Korzystając z Le-
matu 2. braliśmy pod uwagę tylko konkretne trzy wartości, natomiast korzystając z Twierdzenia
1. parametry rozkładu całej próby, zatem te wyniki są bardziej dokładne. Wyliczając z defini-
cji miarę ryzyka dla próbki pszenicy założyliśmy jej pochodzenie z rozkładu normalnego. Wynik
jednak okazał się większy niż przy wykorzystaniu Lematu 2. Możemy zatem stwierdzić, że nasza
próba dopasowania próbki pszenicy do rozkładu normalnego nie przyniosła zamierzonego efektu,
ponieważ nie zmniejszyliśmy ryzyka. Wartości ES wyliczone dla soi są mniejsze niezależnie od wy-
boru metody. Najmniejszą wartość otrzymaliśmy analizując parametry rozkładu całej próby, czyli
korzystając z Twierdzenia 1.
19

Podsumujmy wszystkie zebrane wyniki.
Tablica 10: Porównanie rezerw
Pszenica [USD] Soja [USD]
Varoszacowany kwantyl rzędu 0.95 147000 126000z założenia o normalności rozkładu 166314.1 122633.6
ESz Lematu 2. 199666.7 172333.3z Twierdzenia 1. 208601 154753.7
Jak wynika z Tablicy 10, wszystkie wyliczone wartości dla próbki soi są mniejsze niż dla próbki
pszenicy. Zatem dla portfeli jednoskładnikowych stwierdzamy, że inwestując tę samą kwotę w
wybrane dwa aktywa, korzystniejsza jest inwestycja w soję, ponieważ potrzebne są mniejsze
rezerwy finansowe.
20

4 Modelowanie rozkładów dwuwymiarowych
Przeanalizowaliśmy już ryzyko inwestycji portfeli jednoskładnikowych. W tym rozdziale
rozpoczniemy badanie portfeli dwuskładnikowych, czyli zajmiemy się znalezieniem rozkładu łącz-
nego portfela. Poznaliśmy już rozkłady obu inwestycji, które w przypadku portfela dwuskład-
nikowego stają się rozkładami brzegowymi. Rozkład stóp strat dla soi miał rozkład normalny
natomiast rozkład dla pszenicy niestety nie (uzasadnienie znajduje się w rozdziale poprzednim).
W takim przypadku zweryfikujemy normalność dwuwymiarowego rozkładu. Na początku jednak
przedstawimy podstawową definicję wielowymiarowego rozkładu normalnego opracowaną na pod-
stawie pozycji [2].
Definicja 4.1.1. Wielowymiarowy rozkład normalny [2]
Wektor X = (X1, X2, ..., Xp)′ ma niezdegenerowany rozkład normalny (gaussowski) X ∈ N(µ,Σ)
jeśli
EX = µ ∈ Rp, Σ = E(X− µ)(X− µ)T
dla macierzy kowariancji detΣ 6= 0 zaś gęstość x ∈ Rp
f(x) = 1
(2π)p2 |Σ|
12exp(− 1
2 (x− µ)TΣ−1(x− µ)).
Definicja 4.1.1. przedstawia p-wymiarowy rozkład gaussowski wektora losowego X jednoznacznie
określony przez p-wymiarowy wektor wartości oczekiwanej µ oraz kwadratową symetryczną i nie-
ujemną macierz kowariancji Σ o wymiarach p x p (oznaczenie X ∼ Np(µ,Σ) - zmienna X ma
p-wymiarowy rozkład normalny).
Jak już wspomnieliśmy we wstępie tego rozdziału będziemy analizować portfel dwuskładnikowy,
zatem interesuje nas dwuwymiarowy rozkład normalny (biorąc pod uwagę ww. definicję
przyjmujemy p=2).
Dla dwuwymiarowego rozkładu normalnego prawdziwe jest twierdzenie.
Twierdzenie 2.
Niech X = (X1, X2, ..., Xp)′ ma rozkład eliptyczny. Wówczas dla L1,L2 ∈M zachodzi:
V aRα(L1 + L2) ¬ V aRα(L1) + V aRα(L2).
Jak wynika z Twierdzenia 2. w przypadku dwuwymiarowości rozkładu normalnego Value-at-Risk
jest koherentną miarą ryzyka.
4.1 Test Mardia
Istnieje wiele metod badania dwuwymiarowej normalności. Jedną z nich jest Test Mardia
[2].
Maridia-test jest oparty na mierze skośności
β1,p = E((X− µ)TΣ−1(Y− µ))3
gdzie X,Y są niezależne oraz kurtozie
21

β2,p = E((X− µ)TΣ−1(Y− µ))2.
Dla wektorów losowych X,Y wielowymiarowego rozkładu normalnego, jeśli X, Y są niezależne
wówczas β1,p = 0 zaś β2,p = p(p+ 2).
Przejdźmy do wykonania tego testu dla naszych danych. Ustalamy standardowo poziom
istotności α = 0.05 oraz zakładamy hipotezę zerową:
H0 - dane pochodzą z dwuwymiarowego rozkładu normalnego
wobec hipotezy alternatywnej:
HA - dane nie pochodzą z rozkładu normalnego.
Bierzemy pod uwagę:
• kurtozę wielowymiarową znormalizowaną - jeśli jej wartość mieści się w przedziale
(-1.96,1.96), to nie mamy podstaw do odrzucenia H0, w przeciwnym wypadku hipotezę tę
odrzucamy;
• kappę według Mardii, średnią skalowaną kurtozę wielowymiarową oraz skorygowaną średnią
skalowaną kurtozę wielowymiarową - wszystkie wartości powinny być większe od wartości
krytycznej K = − 2p+2 = − 1
2 (p liczba wymiarów), wówczas nie mamy podstaw do
odrzucenia H0, w przeciwnym wypadku hipotezę odrzucamy.
Wyniki przedstawia Tablica 11 na podstawie Dodatku B.3.
Tablica 11: Test na dwuwymiarową normalność
Kurtoza warość hipoteza zerowa
Kurtoza wielowymiarowa znormalizowana 1.4103 nie odrzucamyKappa według Mardii 0.1806 nie odrzucamyŚrednia skalowana kurtoza wielowymiarowa 0.3305 nie odrzucamySkorygowana średnia skalowana kurtoza wielowymiarowa 0.3305 nie odrzucamy
W wykonanym teście wszystkie kryteria wskazują, że nie mamy podstaw by odrzucić H0. Mogli-
byśmy zatem przyjąć, że nasze dane mają dwuwymiarowy rozkład normalny, jednak nie jest to
jednoznacznie stwierdzone (brak podstaw do odrzucenia hipotezy nie jest równoważny z jej przy-
jęciem). Dlatego w kolejnym rozdziale sprawdzimy czy dopasowania znanymi nam kopułami nie
przybliżą precyzyjniej naszego rozkładu danych.
Warto w tym miejscu wspomnieć, że jeżeli mamy dane dwuwymiarowe o rozkładzie normalnym to
rozkłady brzegowe (dla rozkładu łącznego) również mają taki rozkład. Niestety w naszym przy-
padku nie jest to jasne, gdyż jak wykazały testy na normalność jeden z rozkładów brzegowych nie
był normalny oraz w przypadku dwuwymiarowych danych także nie mamy co do tego pewności.
4.2 Estymacja gęstości
Estymacja nieznanej funkcji gęstości polega na aproksymacji (zastąpieniu matematycznych
wielkości innymi, o przybliżonych własnościach, łatwiejszymi do badania i zastosowania) przy wy-
korzystaniu znanej funkcji (np. gęstości rozkładu normalnego). Inaczej mówiąc funkcja ta uśrednia
dane obserwowane w próbie i tworzy estymator - wygładzoną aproksymację. Dokonujemy tego przy
użyciu procedury KDE (kernel density estimation) w programie SAS 9.3. [Dodatek B.4.]
22

Poniżej znajduje się graficzne przedstawienie estymacji dla naszych danych.
Rysunek 5: Rozkład i gęstość danych (wykres dwuwymiarowy)
Rysunek 6: Gęstość danych (wykres trójwymiarowy)
23

4.3 Kopuły
Jednym ze sposobów wyznaczania rozkładu łącznego jest zastosowanie kopuł. Kopuła jest
funkcją wyznaczającą dystrybuantę łączną przy użyciu jednostajnych dystrybuant brzegowych, o
czym mówi Twierdzenie Sklara. Zanim jednak przejdziemy do wyznaczania rozkładu przedstawimy
niezbędną definicję i twierdzenie.
Definicja 4.3.1. Kopuła dwuwymiarowa [9]
Kopuła dwuwymiarowa C : [0, 1]2 → [0, 1] jest to funkcja spełniająca następujące warunki:
a) C(0, t) = C(t, 0) = 0 , dla t ∈ I
b) C(1, t) = C(t, 1) = t , dla t ∈ I
c) C(u2, v2) − C(u1, v2) − C(u2, v1) + C(u1, v1) 0 dla wszystkich u1, u2, v1, v2 ∈ I, takich że
u1 ¬ u2 i v1 ¬ v2.
Dla wyżej opisanej kopuły dwuwymiarowej możemy sformułować twierdzenie:
Twierdzenie 2. (Sklar’a) [5]
Niech F będzie dystrybuantą łączną o rozkładach brzegowych F1, F2. Wówczas istnieje kopuła C :
[0, 1]2 → [0, 1] taka, że
∀(x1,x2)∈R2=[−∞,∞] F (x1, x2) = C(F1(x1), F2(x2)). (5.1)
Ponadto, jeżeli rozkłady brzegowe są ciągłe, wówczas C jest określona jednoznacznie.
4.3.1 Podstawowy podział kopuł
Kopuły dzielimy na dwie rodziny: archimedejskie i eliptyczne. Do kopuł archimedejskich
należą: kopuła Claytona, Franka oraz Gumbela, natomiast rodzina kopuł eliptycznych składa się z
kopuły Normalnej i T (T-studenta). Poniżej prezentujemy wzory wymienionych kopuł dla jedno-
stajnych rozkładów brzegowych x1, x2 (kopuły dwuwymiarowe).
Kopuły archimedejskie
Clayton
Cθ(x1, x2) = (x−θ1 + x−θ2 − 1)−1θ , gdzie 0 < θ <∞ (5.2)
Frank
Cθ(x1, x2) = −1θln[1 +
(exp(−θx1)− 1)(exp(−θx2)− 1)exp(−θ)− 1
] , gdzie θ ∈ R\0 (5.3)
Gumbel
Cθ(x1, x2) = exp−((−lnx1)θ + (−lnx2)θ)1θ , gdzie 1 < θ <∞ (5.4)
Kopuły eliptyczne
T-student
Cν,ρ(x1, x2) =
t−1ν (x1)∫−∞
t−1ν (x2)∫−∞
1
2π(1− ρ2)12
[1 +u2 − 2ρuv + v2
ν(1− ρ2)]−
ν+22 du dv, (5.5)
24

gdzie ν, ρ - parametry kopuły, t−1ν - funkcja odwrotna do dystrybuanty rozkładu T-Studenta z ν
stopniami swobody.
Normalna
Cρ(x1, x2) =
Φ−1(x1)∫−∞
Φ−1(x2)∫−∞
1
2π(1− ρ2)12exp−u
2 − 2ρuv + v2
2(1− ρ2) du dv, (5.6)
gdzie ρ - parametr kopuły, Φ−1 - funkcja odwrotna do dystrybuanty rozkładu normalnego.
Jak wynika ze wzorów dla odpowiednich kopuł z rodziny archimedejskich są ode zależne od para-
metrów θ. Parametr ten mówi o zależności pomiędzy rozkładami brzegowymi. Jeżeli θ zbiega do
dolnego ograniczenia parametru (w zależności od rodzaju kopuły) to mamy niezależne rozkłady
brzegowe. Najlepsze dopasowanie tych parametrów dobiera nam program SAS 9.3 przy użyciu
procedury proc copula. W przypadku kopuł z rodziny eliptycznych otrzymujemy macierze korela-
cji. Ponadto program generuje podstawowe kryteria najlepszego dopasowania kopuły do naszych
danych. I kolejno otrzymujemy:
• parametr Log Likelihood (w skrócie LOG) - im większa wartość tym lepsze dopasowanie;
• parametr Akaike (w skrócie AIC) - im mniejsza wartość tym lepsze dopasowanie.
W przypadku niejasności wyboru, tzn. gdy wartości LOG i AIC nie wskazują jednoznacznie na któ-
rąś z kopuł bierzemy pod uwagę trzeci parametr. Jest to tzw. kryterium Schwarza (baysowskie),
w skrócie SBC - i tak jak w przypadku AIC im mniejsza jego wartość tym lepsze dopasowanie.
Poniżej przedstawiamy kopuły wraz z kryteriami dopasowania oraz miarami ryzyka odpowiednimi
dla każdej z nich. Kod generujący znajduje się w Dodatku B.5.
Kopuła Claytona
Tablica 12: Kopuła Claytona - wykrestrójwymiarowy
Tablica 13: Kopuła Claytona
θ 1.170232
kryteria
Log Likelihood 13.6296AIC -25.2592SBC -23.14833
25

Kopuła Franka
Tablica 14: Kopuła Franka - wykrestrójwymiarowy
Tablica 15: Kopuła Franka
θ 4.740441
kryteria
Log Likelihood 14.43497AIC -26.86993SBC -24.75906
Kopuła Gumbela
Tablica 16: Kopuła Gumbela - wykrestrójwymiarowy
Tablica 17: Kopuła Gumbela
θ 1.798871
kryteria
Log Likelihood 15.90243AIC -29.80487SBC -27.69399
Kopuła Normalna
Tablica 18: Kopuła Normalna - wykrestrójwymiarowy
Tablica 19: Kopuła Normalna
macierz korelacji[
1 0.6549046050.654904605 1
]
26

Kopuła T
Tablica 20: Kopuła T - wykres trójwy-miarowy
Tablica 21: Kopuła T
macierz korelacji[
1 0.6845337270.684533727 1
]v 100
kryteria
Log Likelihood 17.16300AIC -30.32599SBC -26.10425
Po zaprezentowaniu wszystkich kopuł wróćmy jeszcze do kopuł eliptycznych. Otrzymali-
śmy dwie macierze korelacji. Jedną dla kopuły Normalnej:[1 0.654904605
0.654904605 1
]drugą dla kopuły T: [
1 0.684533727
0.684533727 1
]
Zanim zinterpretujemy otrzymane wielkości zdefiniujmy potrzebny w tym celu współczynnik ko-
relacji.
Definicja 4.3.2 Współczynnik korelacji [7]
Współczynnik korelacji między zmiennymi X i Y określonymi na tej samej przestrzeni probabili-
stycznej, dla których 0 < V ar(X) <∞ i 0 < V ar(Y) <∞, jest liczbą zdefiniowaną następująco:
Corr(X,Y) = ρXY =Cov(X,Y)√
V ar(X) · V ar(Y)(5.7)
Jeżeli X, Y są niezależnymi zmiennymi losowymi, to Cov(X,Y) = 0 oraz ρXY = 0.
Jak wynika z Definicji 4.3.2. współczynnik korelacji mówi o zależności między zmiennymi. Im
wartość bliższa 1 tym większa zależność (jak wiadomo ρXY ∈ [−1, 1]). Współczynniki korelacji dla
naszych kopuł wynoszą odpowiednio 0.654904605 dla kopuły Normalnej i 0.684533727 dla kopuły
T. Obie wielkości są porównywalne. Ponadto dla dużej liczby stopni swobody (w naszym przy-
padku ν=100) rozkład T-Studenta praktycznie pokrywa się z rozkładem normalnym. Dzięki temu
i dzięki podobnym wartościom współczynnika korelacji możemy założyć, że kopuły T i Normalna
nie różnią się znacznie. Zatem w dalszej części nie będziemy brać pod uwagę kopuły Normalnej.
27

Tablica 22: Porównanie kopuł
kopuła θ Log Likelihood AIC SBC VaR ES
Clayton 1.170232 13.6296 -25.2592 -23.14833 0.120580 0.142799Gumbel 1.798871 15.90243 -29.80487 -27.69399 0.144757 0.178801Frank 4.740441 14.43497 -26.86993 -24.75906 0.120395 0.149366T - 17.163 -30.32599 -26.10425 0.142617 0.174153
Na podstawie Tablicy 22 możemy wybrać najlepiej dopasowaną kopułę do naszych danych. Wyniki
są jednoznaczne. Według pierwszego (Log Likelihood) jak i drugiego kryterium (Akaike) najlepiej
dopasowaną kopułą okazała się kopuła T. Dodatkowo w tablicy zostały umieszczone wartości miar
ryzyka dla portfela dwuskładnikowego złożonego z 12 kapitału przeznaczonego na aktywo pierw-
sze i 12 kapitału przeznaczonego w aktywo drugie, dzięki którym wyliczymy rezerwy potrzebne do
inwestycji łącznej (uzyskane za pomocą kodu znajdującego się w Dodatku B.6).
4.4 Inwestycja łączna
Kwota inwestycji łącznej jest taka sama jak w przypadku inwestycji pojedynczych, czyli
1 mln dolarów. Dywersyfikując portfel przeznaczymy połowę kapitału na inwestycję w pszenicę a
połowę na inwestycję w soję, tzn. po 500000 dolarów w każde aktywo. Miary ryzyka dla inwestycji
łącznej zostały policzone przy pomocy danych wygenerowanych z najlepiej dopasowanej kopuły T,
dzięki którym możemy wyliczyć potrzebne rezerwy.
V aR0.95(1000000 · L3) = 1000000 · V aR0.95(L3) = 1000000 · 0.142617 = 142617[USD]
ES0.95(1000000 · L3) = 1000000 · ES0.95(L3) = 1000000 · 0.174153 = 174153[USD]
Jak łatwo zauważyć wyliczone rezerwy finansowe wg pierwszej miary są mniejsze niż wg
miary drugiej, czyli ES. Różnica wynika z faktu, że ES bada 5% najgorszych przypadków inwesty-
cyjnych, a VaR jest miarą dokładniejszą i szacuje rezerwy na podstawie całej próby.
Zastanówmy się jeszcze jak zmienią się wysokości potrzebnych rezerw przy innym podziale
kapitału. W tym celu posłużymy się dodatnią jednorodnością zarówno wartości zagrożonej jak i
zagrożonej wartości oczekiwanej, co możemy zapisać następująco:
V aR0.95(A · L1 +B · L2) = (A+B) · V aR0.95 · (A
A+B· L1 +
B
A+B· L2) (5.8)
oraz
ES0.95(A · L1 +B · L2) = (A+B) · ES0.95 · (A
A+B· L1 +
B
A+B· L2), (5.9)
gdzie:
A+B - całkowity kapitał (1 mln dolarów),
A - kwota inwestycji w pszenicę,
B - kwota inwestycji w soję.
28

Korzystając z programu SAS 9.3, do którego kod znajduję się w Dodatku B.7. oraz za-
leżności (5.8) i (5.9), przyjrzyjmy się wybranym dywersyfikacjom naszego portfela. Posługując się
Tablicami 23 i 24 wybierzemy najbardziej optymalną inwestycję, którą porównamy z wcześniej
omówioną, czyli dzielącą kapitał pomiędzy dwoma aktywami po równo.
Tablica 23: Wybrane dywersyfikacje portfela
14 · L1 + 3
4 · L234 · L1 + 1
4 · L215 · L1 + 4
5 · L245 · L1 + 1
5 · L2
VaR 140414.6 154660.1 143100.5 158258.2
ES 171185.9 190552.9 172291.5 194749.3
Tablica 24: Wybrane dywersyfikacje portfela
25 · L1 + 3
5 · L235 · L1 + 2
5 · L218 · L1 + 7
8 · L278 · L1 + 1
8 · L2
VaR 142493 146093 143270.1 162698.6
ES 171626.4 179472.4 174692 201211.8
Analizując powyższe tablice łatwo zauważyć, że najmniej ryzykowną inwestycją jest pierwsza
spośród analizowanych, czyli składająca się z 14 kapitału przeznaczonego w akcje pszenicy i 3
4
kapitału w akcje soi. Rezerwy te wynoszą kolejno 140414.6 USD wg VaR i 171185.9 USD wg ES.
Wybierzmy zatem najkorzystniejszą inwestycję łączną. Weźmiemy pod uwagę dwie z nich:
12 · L1 + 1
2 · L214 · L1 + 3
4 · L2
rezerwy wg VaR: 142617[USD] rezerwy wg VaR: 140414.6[USD]
rezerwy wg ES: 174153[USD] rezerwy wg ES: 171185.9[USD]
Jak nie trudno zauważyć mniejsze wartości w przypadku obydwu miar otrzymaliśmy dla inwestycji
drugiej, czyli 14 kapitału przeznaczonego na pszenicę i 3
4 na soję. I tę oto inwestycję uznajemy za
najmniej ryzykowną spośród inwestycji łącznych, gdyż wielkości rezerw bez wątpienia wskazują
właśnie na nią.
4.5 Porównanie inwestycji
Podsumujmy wszystkie przeanalizowane w pracy inwestycje. Jak już wcześniej ustalili-
śmy bardziej ryzykowną inwestycją pojedynczą okazały się akcje pszenicy, i co do tego nie mamy
żadnych wątpliwości, gdyż obie miary ryzyka oszacowały większe niezbędne zabezpieczenia finan-
sowe. Na tej podstawie za mniej ryzykowną inwestycję uznajemy akcje soi i to właśnie tę inwestycję
będziemy porównywać z inwestycją złożoną. Następnie analizowaliśmy różne inwestycje łączne spo-
śród których najkorzystniejszą okazała się inwestycja składająca się z 14 kapitału przeznaczonego
na akcje pszenicy i 34 kapitału przeznaczonego na akcje soi. W Tablicy 25 umieściliśmy wyliczone
rezerwy dla tych portfeli.
29

Tablica 25: Rezerwy jakie należy przeznaczyć na poszczególne inwestycje
Soja[USD] Łączna[USD]
VaR 122633.6 140414.6ES 154753.7 171185.9
Porównując te dwie wybrane inwestycje łatwo zauważyć, że większe wartości otrzymaliśmy
w przypadku inwestycji łącznej. Stąd też najmniej ryzykowną inwestycją okazała się inwestycja w
kwocie 1 mln dolarów na okres jednego miesiąca w akcje soi. Rezerwy te wynoszą odpowiednio
wg Value-at-Risk 123 tysiące dolarów, czyli około 12% wartości zainwestowanego kapitału, zaś
wg Expected Shortfall około 155 tysięcy dolarów, co stanowi niecałe 15,5% wartości całkowitego
kapitału.
30

5 Podsumowanie
W pracy przeanalizowano inwestycje jedno i dwuskładnikowe (dzielące kapitał w wysoko-
ści 1 mln dolarów w różnych proporcjach) w akcje pszenicy oraz soi szacując niezbędne rezerwy,
by inwestycje te nie przyniosły strat. W tym celu posłużono się dwiema miarami ryzyka, Value
at Risk oraz Expected Shortfall. Na ich podstawie stwierdzono, że w przypadku inwestycji jedno-
składnikowych mniej ryzykowną inwestycją okazała się inwestycja w soję, gdyż wymagała znacznie
mniejszych zabezpieczeń finansowych niż pszenica. Ponadto wykonano testy Shapiro-Wilka, Koł-
mogorowa Smirnowa oraz Mardia test sprawdzające normalność rozkładów stóp strat dla wspo-
mnianych aktywów.
Poprzedzając analizę inwestycji łącznej wprowadzono teorię dotyczącą dwuwymiarowego
rozkładu normalnego oraz sprawdzono dopasowanie danych do rozkładów innych znanych funk-
cji, funkcji kopuł z rodziny archimedejskich i eliptycznych. Korzystając z dwóch parametrów, Log
Likelihood i Akaike wybrano najlepiej dopasowaną kopułę, którą okazała się kopuła zbliżona do
normalnej, czyli kopuła T. Mając wybraną kopułę wyliczono wartości omówionych wcześniej miar
ryzyka i na ich podstawie oszacowano wysokości rezerw dla inwestycji łącznych dywersyfikując
portfel w różnych proporcjach. Najmniej ryzykowną inwestycją dwuskładnikową okazała się inwe-
stycja składająca się z 14 kapitału przeznaczonego na akcje pszenicy i 3
4 kapitału przeznaczonego
na akcje soi.
Biorąc pod uwagę wszystkie omówione w pracy portfele stwierdzono, że najmniej ryzy-
kowną inwestycją okazała się inwestycja w soję. Oszacowane wielkości zabezpieczeń wynosiły ko-
lejno wg VaR 123 tysiące dolarów, a wg ES około 155 tysięcy.
31

Załączniki
Dodatek A
A.1. Definicja Kwantyl [5]
Niech F będzie dystrybuantą funkcji zmiennej losowej X, uogólnioną funkcją odwrotną F← nazy-
wamy kwantylem funkcji F. Dla α ∈ (0, 1), α - kwantyl funkcji F jest postaci:
qα(F ) := F←(α) = infx ∈ R : F (x) α
A.2. Definicja Mediana próbki [6]
Medianą próbki x1, ...xn nazywamy środkową liczbę w uporządkowanej niemalejąco próbce: x(1) ¬x(1) ¬ ... ¬ x(n), gdy n jest liczbą nieparzystą, albo średnią arytmetyczną dwóch środkowych liczb,
gdy n jest liczbą parzystą, tzn.
me =
x(n+12 ) gdy n nieparzyste12 (x(n2 ) + x(n2+1)) gdy n parzyste.
A.3. Definicja Odchylenie standardowe i wariancja [6]
a) Wariancją zmiennej losowej X nazywamy liczbę σ2(X) = V ar(X) daną wzorem:
V ar(X) = EX2 − (EX)2.
b) Odchyleniem standardowym zmiennej losowej X nazywamy liczbę σ(X) =√V ar(X).
A.4. Definicja Skośność [6]
Skośność jest to współczynnik asymetrii wyrażony wzorem:
A = M3σ3 ,
gdzie:
M3-trzeci moment centralny,
σ-odchylenie standardowe.
A.5. Definicja Kurtoza [6]
Kurtoza jest to współczynnik koncentracji (skupienia) wyrażony wzorem:
K = M4σ4 − 3,
gdzie:
M4-czwarty moment centralny ,
σ-odchylenie standardowe.
32

A.6. Definicja Moment Centralny [6]
Moment centralny rzędu r wyraża się wzorem:
Mr = E(X− µ)r = 1n
n∑i=1
(xi − x)r,
gdzie µ jest pierwszym momentem zwykłym, czyli estymatorem wartości oczekiwanej.
A.7. Definicja Rozkład normalny N(µ, σ2) [7]
Gęstość rozkładu normalnego N(µ, σ2) jest postaci
f(x) = 1σ√
2πexp[− (x−µ)2
2σ2 ],
gdzie µ ∈ R, σ > 0.
Fakt
Jeżeli zmienna losowa X ma rozkład N(µ, σ2), to E(X) = µ, V ar(X) = σ2,
ϕ(t) = exp(iµt− σ2t2
2 ).
Rozkład normalny N(0, 1) nazywa się standardowym rozkładem normalnym. Jego dystrybuanta
wyraża się wzorem:
Φ(x) = 1√2π
x∫−∞
e−t22 dt
Z postaci funkcji charakterystycznej łatwo wywnioskować, że jeżeli zmienne losowe X, Y są nie-
zależne i mają rozkłady odpowiednio N(µ1, σ21), N(µ2, σ
22), to suma X+Y ma rozkład normalny
N(µ1 + µ2, σ21 + σ2
2).
A.8. Definicja Stożek [2]
Zbiór zmiennych losowych jest stożkiem M jeśli:
a) stałe należą do M,
b) L1,L2 ∈ M to L1 + L2 ∈ M,
c) λ >0 i L ∈M to λL ∈ M.
A.9. Definicja Uogólniona funkcja odwrotna [5]
Niech funkcja niemalejąca F, będzie określona następująco F : R→ R, uogólniona funkcja odwrotna
do funkcji F jest zdefiniowana następująco:
F←(y) := infx ∈ R : F (x) y,
używamy konwencji, że kres dolny zbioru pustego jest równy nieskończoności (inf∅ =∞).
33

A.10. Wzór Wartość zagrożona dla rozkładu normalnego[3]
Jeśli założymy, że rozkład stóp strat ma rozkład normalny (ozn. L ∼ N(µ, σ2), wówczas:
V aRα = (σ · qα + µ) ·W
gdzie:
µ - wyestymowana średnia z próbki,
σ - wyestymowane odchylenie standardowe dla próbki,
qα- kwantyl standarowgo rozkładu normalnego rzędu α,
W -wartość portfela finansowego.
A.11. Dowód. Lemat 1.
Dowód.
”⇒ ”
Niech L1 ¬ L2 ⇒ ρ(L1) ¬ ρ(L2)
Przyjmijmy L2 = 0, wówczas:
L1 ¬ 0⇒ ρ(L1) ¬ ρ(0) = 0, z jednorodności miary.
”⇐ ”
Niech L ¬ 0⇒ ρ(L) ¬ 0 oraz L1, L2 ∈M .
Przymijmy, że L1 ¬ L2 ⇒ L1 − L2 ¬ 0. Z założenia otrzymujemy, że ρ(L1 − L2) ¬ 0.
L1 = L1 − L2 + L2
Wykorzystując subaddytywność miary mamy:
ρ(L1) = ρ(L1 − L2 + L2) ¬ ρ(L1 − L2) + ρ(L2) ¬ ρ(L2).
A.12. Dowód Badanie koherentności VaR
Ad.1 Niezmienniczość na translacje, czyli dla dowolnego l ∈ R oraz L ∈M
V aRα(l + L) = l + V aRα(L)
Dowód. [8]
V aRα(l + L) = inft ∈ R : P (l + L > t) ¬ 1− α = inft ∈ R : Fl+L(t) α =
= inft ∈ R : P (l + L ¬ t) α = inft ∈ R : P (L ¬ t− l) α =
= inft ∈ R : FL(t− l) α = inft− l + l ∈ R : FL(t− l) α =
= l + inft− l ∈ R : FL(t− l) α = l + V aRα(L).
Ad.3 Dodatnia jednorodność, czyli jeśli λ > 0
V aRα(λL) = λV aRα(L)
Dowód. [8]
V aRα(λL) = qα(λL) = infx ∈ R : FλL(x) α = infx ∈ R : P (λL ¬ x) α =
= infx ∈ R : P (L ¬ xλ ) α = infλ · xλ ∈ R : P (L ¬ x
λ ) α =
= λ · infxλ ∈ R : P (L ¬ xλ ) α = λ · infxλ ∈ R : FL(xλ ) α =
= λ · qα(L) = λ · V aRα(L).
34

Ad.4 Monotoniczność, jeśli L1 ¬ L2 prawie wszędzie to
V aRα(L1) ¬ V aRα(L2)
Dowód. [8]
Korzystając ze wzoru 3.5 mamy:
V aRα(L1) = qα(L1) = infx ∈ R : FL1(x) αV aRα(L2) = qα(L2) = infx ∈ R : FL2(x) α
Niech L1, L2 ∈M oraz x ∈ R takie, że L1 ¬ L2 ¬ x.
Zauważmy, że jeśli L2 ¬ x⇒ L1 ¬ x to zachodzi również L2 ¬ x ⊆ L1 ¬ x.Stąd:
α ¬ P (L2 ¬ x) ¬ P (L1 ¬ x)
P (L2 ¬ x) α⇒ P (L1 ¬ x) αx : FL2 α ⊆ x : FL1 α wiedząc, że infinium podzbioru zbioru jest większe otrzymujemy:
infx : FL2 α infx : FL1 α.Zatem:
V aRα(L1) ¬ V aRα(L2).
Ad.2 Brak subaddytywności
V aRα(L1 + L2) ¬ V aRα(L1) + V aRα(L2)
Dowód. [4]
Rozważmy 100 akcji, których stopy zwrotu są niezależne. Strata przyjmuje następujące wartości:
-5 z prawdopodobieństwem 0.98 oraz 100 z prawdopodobieństwem 0.02. Porównamy ryzyko dwóch
portfeli mierzone wartością zagrożoną:
A. 100 odrębnych akcji różnych spółek
B. 100 jednakowych akcji (jednej spółki)
Na tej podstawie otrzymujemy funkcje straty określone w następujący sposób:
Li = 100 · Yi − 5 · (1− Yi) = 105 · Yi − 5,
gdzie i oznacza i-tą akcję (i ∈ 1, 2, ..., 100), Yi jest zmienną binarną, taką że:
Yi = 0⇔ Li = −5
Yi = 1⇔ Li = 100
Mając podstawowe informacje na temat inwestycji obliczmy VaR dla poziomu ufności α = 0.95 dla
obydwu portfeli:
A.
V aRα(A) = V aRα(100∑i=1
Li) = V aRα(105 ·100∑i=1
Yi−500) = 105 ·V aRα(100∑i=1
Yi)−500 = 525−500 = 25,
gdyż (100∑i=1
Yi) ma rozkład Bernoulliego B(100,0.02) stąd qα(100∑i=1
Yi) = 5.
B.
V aRα(B) = V aRα(100 · L1) = 100 · V aRα(L1) =100∑i=1
(V aRα(Li)) = 100 · (−5) = −500.
Zatem otrzymujemy:
V aRα(A) = 25 6¬ −500 = V aRα(B).
35

Powyższa nierówność wskazuje, że portfel A jest o wiele bardziej ryzykowny od portfela B, co
jest sprzeczne z warunkiem subaddytywności, który mówi o odwrotnej sytuacji. To portfel jedno-
składnikowy B powinien być bardziej ryzykowny.
Stąd potwierdzenie, że VaR nie jest koherentną miarą ryzyka.
A.13. Dowód Koherentność ES [8]
Ad.1 Niezmienniczość na translacje, czyli dla dowolnego l ∈ R oraz L ∈M
ESα(l + L) = l + ESα(L)
Dowód. Korzystając z niezmienniczości na translacje dla VaR zapiszmy:
ESα(l+L) = 11−α
1∫α
V aRu(l+L)du = 11−α
1∫α
(l+V aRu(L))du = 11−α
1∫α
ldu+ 11−α
1∫α
V aRu(L)du =
= l + ESα(L).
Ad.3 Dodatnia jednorodność, czyli jeśli λ > 0
ESα(λL) = λESα(L)
Dowód. Korzystając z dodatniej jednorodności VaR mamy:
ESα(λL) = 11−α
1∫α
V aRu(λ · L)du = 11−α
1∫α
λ · V aRu(L)du = λ1−α
1∫α
V aRu(L)du = λESα(L).
Ad.4 Monotoniczność, jeśli L1 ¬ L2 prawie wszędzie to
ESα(L1) ¬ ESα(L2)
Dowód. Korzystając z monotoniczności VaR otrzymujemy:
ESα(L1) = 11−α
1∫α
V aRu(L1)du ¬ 11−α
1∫α
V aRu(L2)du = ESα(L2).
Ad.2 Subaddytywność
ESα(L1 + L2) ¬ ESα(L1) + ESα(L2)
Dowód.
Weźmy ciąg uporządkowanych, niezależnych zmiennych losowych L1,n L2,n . . . Ln,n.
Ustalmy dowolnie wybrane m takie, że 1 ¬ m ¬ n. Wówczas otrzymujemy zależność:m∑i=1
Li,n = supLi1 , Li2 , . . . , Lim : 1 ¬ i1 ¬ i2 ¬ . . . ¬ im ¬ m
Rozpatrzmy dwie zmienne losowe L oraz L o określonej dystrybuancie łącznej F .
Biorąc ciąg niezależnych wektorów losowych (L1, L1), (L2, L2), ..., (Ln, Ln) o jednakowym rozkła-
dzie F, określmy: (L+ L)i := Li + Li oraz (L+ L)i,n dla uporządkowanych wektorów
(L1 + L)1, . . . , (Ln + L)n.
Zachodzi wówczas:m∑i=1
(L+ L)i;n = sup(L1 + L1)i1 , . . . , (Ln + Ln)im : 1 ¬ i1 ¬ . . . ¬ im ¬ m ¬
¬ supLi1 , Li2 , . . . , Lim : 1 ¬ i1 ¬ i2 ¬ . . . ¬ im ¬ m++supLi1 , Li2 , . . . , Lim : 1 ¬ i1 ¬ i2 ¬ . . . ¬ im ¬ m =
=m∑i=1
Li,n +m∑i=1
Li,n
Podstawiając za m = bn(1 − α)c i korzystając z Lematu 2. przy założeniu n → ∞ otrzy-
mujemy warunek subaddytywności dla ES przy poziomie ufności α:
ESα(L+ L) ¬ ESα(L) + ESα(L).
36

Dodatek B
Kod z programu SAS 9.3 do wyliczenia stóp strat dla pszenicy oraz soi.
data DANE2.stopyPSZ;
set DANE2.PSZENICA;
Lp=ROUND(((Wo-Wz)/Wo),0.001);
run;
data DANE2.stopySO;
set DANE2.SOJA;
Ls=ROUND(((Wo-Wz)/Wo),0.001);
run;
Dodatek B.1.
Kod generujący opisowe statystyki, histogramy, wyniki testów normalności oraz wartości kwantyli
rzędu 0.95 dla stóp strat pszenicy i soi.
TITLE1 ”Statystyki dla PSZENICY”;
TITLE2 ”Rezultaty 1”;
PROC UNIVARIATE data =DANE2.stopyPSZ normal;
var Lp;
histogram Lp;
RUN;
TITLE1 ”Statystyki dla SOI”;
TITLE2 ”Rezultaty 1”;
PROC UNIVARIATE data =DANE2.stopySO normal;
var Ls;
histogram Ls;
RUN;
Dodatek B.2.
Kod generujący wielkości uśrednionych wartości zagrożonych dla stóp strat pszenicy oraz soi.
PROC SORT DATA =DANE2.stopyPSZ OUT =DANE2.esPSZ;
BY DESCENDING Lp;
PROC MEANS DATA = DANE2.esPSZ( OBS =3) MEAN;
var Lp;
TITLE ”Expected Shortfall dla PSZENICY”;
RUN;
PROC SORT DATA =DANE2.stopySO OUT =DANE2.esSO;
BY DESCENDING Ls;
PROC MEANS DATA = DANE2.esSO( OBS =3) MEAN ;
var Ls;
TITLE ”Expected Shortfall dla SOI”;
RUN ;
37

Dodatek B.3.
Program użyty do uzyskania wyniku testu na normalność dwuwymiarowego rozkładu.
proc calis data =dane2.razem kurtosis;
title1 ”Output 1.1”;
title2 ”Computation of Mardia’s Kurtosis”;
lineqs
L1 = e1,
L2 = e2;
std
e1=L1, e2=L2;
run ;
Dodatek B.4.
Program użyty do uzyskania wykresów rozkładu i gęstości jądra dla L1 i L2
ods graphics on;
proc kde data =dane2.razem;
title ′Wykresy kde′; bivar L1 L2 / plots = all plots = SURFACE (ROTATE = 150);
run;
Dodatek B.5.
Programy generujące kopuły wraz z parametrami.
/*Clayton*/
proc copula data = dane2.razem;
title ”Clayton”;
var L4 L5;
fit clayton / marginals = EMPIRICAL
plots = (data = BOTH SCATTER)
outcopula = dane2.CLwyniki;
simulate / ndraws = 1000
seed = 1234
out = dane2.CLgenerowane
plots = (data = BOTH MATRIX distribution = CDF);
run ;
/*Frank*/
proc copula data = dane2.razem;
title ”Frank”;
var L1 L2;
fit frank / marginals = EMPIRICAL
plots = (data = BOTH SCATTER)
outcopula = dane2.FRwyniki;
simulate / ndraws = 1000
seed = 1234
38

out = dane2.FRgenerowane
plots = (data = BOTH MATRIX distribution = CDF);
run ;
/*Gumbel*/
proc copula data = dane2.razem;
title ”Gumbel”;
var L1 L2;
fit gumbel / marginals = EMPIRICAL
plots = (data = BOTH SCATTER)
outcopula = dane2.GUwyniki;
simulate / ndraws = 1000
seed = 1234
out = dane2.GUgenerowane
plots = (data = BOTH MATRIX distribution = CDF);
run ;
/*T*/
proc copula data = dane2.razem;
title ”T”;
var L1 L2;
fit t / marginals = EMPIRICAL
plots = (data = BOTH SCATTER)
outcopula = dane2.Twyniki;
simulate / ndraws = 1000
seed = 1234
out = dane2.Tgenerowane
plots = (data = BOTH MATRIX distribution = CDF);
run ;
/*Normalna*/
proc copula data = dane2.razem; title ”Normal”;
var L1 L2;
fit normal / marginals = EMPIRICAL
plots = (data = BOTH SCATTER)
outcopula = dane2.Nwyniki;
simulate / ndraws = 1000
seed = 1234
out = dane2.Ngenerowane
plots = (data = BOTH MATRIX distribution = CDF);
run ;
39

Dodatek B.6.
Kod generujący miary ryzyka dla poszczególnych kopuł.
/*Clayton - miary ryzyka*/
data dane2.CLvar;
set dane2.CLgenerowane;
L3 = 0.5 * L1 + 0.5 * L2;
run;
TITLE ”VaR - Clayton”;
proc means data= dane2.CLvar P95;
var L3;
run;
PROC SORT DATA =dane2.CLvar OUT =dane2.CLes;
BY DESCENDING L3;
PROC MEANS DATA =dane2.CLes (OBS =50) MEAN;
var L3;
TITLE ”Expected Shortfall - Clayton”;
RUN ;
/* Frank - miary ryzyka*/
data dane2.FRvar;
set dane2.FRgenerowane;
L3 = 0.5 * L1 + 0.5 * L2;
run;
TITLE ”VaR - Frank”;
proc means data= dane2.FRvar P95;
var L3;
run;
PROC SORT DATA =dane2.FRvar OUT =dane2.FRes;
BY DESCENDING L3;
PROC MEANS DATA =dane2.FRes (OBS =50) MEAN;
var L3;
TITLE ”Expected Shortfall - Frank”;
RUN;
/* Gumbel - miary ryzyka*/
data dane2.GUvar;
set dane2.GUgenerowane;
L3 = 0.5 * L1 + 0.5 * L2;
run;
TITLE ”VaR - Gumbel”;
proc means data= dane2.GUvar P95;
var L3;
run;
PROC SORT DATA =dane2.GUvar OUT =dane2.GUes;
BY DESCENDING L3;
40

PROC MEANS DATA =dane2.GUes (OBS =50) MEAN;
var L3;
TITLE ”Expected Shortfall - Gumbel”;
RUN;
/* T - miary ryzyka*/
data dane2.Tvar;
set dane2.Tgenerowane;
L3 = 0.5 * L1 + 0.5 * L2;
run;
TITLE ”VaR - T”;
proc means data= dane2.Tvar P95;
var L3;
run;
PROC SORT DATA =dane2.Tvar OUT =dane2.Tes;
BY DESCENDING L3;
PROC MEANS DATA =dane2.Tes (OBS =50) MEAN;
var L3;
TITLE ”Expected Shortfall - T”;
RUN;
/* Normalna- miary ryzyka*/
data dane2.Nvar;
set dane2.Ngenerowane;
L3 = 0.5 * L1 + 0.5 * L2;
run;
TITLE ”VaR - Normalna”;
proc means data= dane2.nvar P95;
var L3;
run;
PROC SORT DATA =dane2.Nvar OUT =dane2.Nes;
BY DESCENDING L3;
PROC MEANS DATA =dane2.Nes (OBS =50) MEAN;
var L3;
TITLE ”Expected Shortfall - Normalna”;
RUN ;
Dodatek B.7
Kod generujący wartości miar ryzyka dla kopuły T z wybranymi dywersyfikacjami portfela.
data dane2.Tvar;
set dane2.Tgenerowane;
L3 = 1/4 * L1 + 3/4 * L2;
run;
TITLE ”VaR - T”;
proc means data= dane2.Tvar P95;
41

var L3;
run;
PROC SORT DATA =dane2.Tvar OUT =dane2.Tes;
BY DESCENDING L3;
PROC MEANS DATA =dane2.Tes (OBS =50) MEAN;
var L3;
TITLE ”Expected Shortfall - T”;
RUN ;
data dane2.Tvar;
set dane2.Tgenerowane;
L3 = 3/4 * L1 + 1/4 * L2;
run;
TITLE ”VaR - T”;
proc means data= dane2.Tvar P95;
var L3;
run;
PROC SORT DATA =dane2.Tvar OUT =dane2.Tes;
BY DESCENDING L3;
PROC MEANS DATA =dane2.Tes (OBS =50) MEAN;
var L3;
TITLE ”Expected Shortfall - T”;
RUN ;
data dane2.Tvar;
set dane2.Tgenerowane;
L3 = 1/5 * L1 + 4/5 * L2;
run;
TITLE ”VaR - T”;
proc means data= dane2.Tvar P95;
var L3;
run;
PROC SORT DATA =dane2.Tvar OUT =dane2.Tes;
BY DESCENDING L3;
PROC MEANS DATA =dane2.Tes (OBS =50) MEAN;
var L3;
TITLE ”Expected Shortfall - T”;
RUN ;
data dane2.Tvar;
set dane2.Tgenerowane;
L3 = 4/5 * L1 + 1/5 * L2;
run;
TITLE ”VaR - T”;
proc means data= dane2.Tvar P95;
var L3;
42

run;
PROC SORT DATA =dane2.Tvar OUT =dane2.Tes;
BY DESCENDING L3;
PROC MEANS DATA =dane2.Tes (OBS =50) MEAN;
var L3;
TITLE ”Expected Shortfall - T”;
RUN ;
data dane2.Tvar;
set dane2.Tgenerowane;
L3 = 2/5 * L1 + 3/5 * L2;
run;
TITLE ”VaR - T”;
proc means data= dane2.Tvar P95;
var L3;
run;
PROC SORT DATA =dane2.Tvar OUT =dane2.Tes;
BY DESCENDING L3;
PROC MEANS DATA =dane2.Tes (OBS =50) MEAN;
var L3;
TITLE ”Expected Shortfall - T”;
RUN ;
data dane2.Tvar;
set dane2.Tgenerowane;
L3 = 3/5 * L1 + 2/5 * L2;
run;
TITLE ”VaR - T”;
proc means data= dane2.Tvar P95;
var L3;
run;
PROC SORT DATA =dane2.Tvar OUT =dane2.Tes;
BY DESCENDING L3;
PROC MEANS DATA =dane2.Tes (OBS =50) MEAN;
var L3;
TITLE ”Expected Shortfall - T”;
RUN ;
data dane2.Tvar;
set dane2.Tgenerowane;
L3 = 1/8 * L1 + 7/8 * L2;
run;
TITLE ”VaR - T”;
proc means data= dane2.Tvar P95;
var L3;
run;
43

PROC SORT DATA =dane2.Tvar OUT =dane2.Tes;
BY DESCENDING L3;
PROC MEANS DATA =dane2.Tes (OBS =50) MEAN;
var L3;
TITLE ”Expected Shortfall - T”;
RUN ;
data dane2.Tvar;
set dane2.Tgenerowane;
L3 = 7/8 * L1 + 1/8 * L2;
run;
TITLE ”VaR - T”;
proc means data= dane2.Tvar P95;
var L3;
run;
PROC SORT DATA =dane2.Tvar OUT =dane2.Tes;
BY DESCENDING L3;
PROC MEANS DATA =dane2.Tes (OBS =50) MEAN;
var L3;
TITLE ”Expected Shortfall - T”;
RUN ;
44
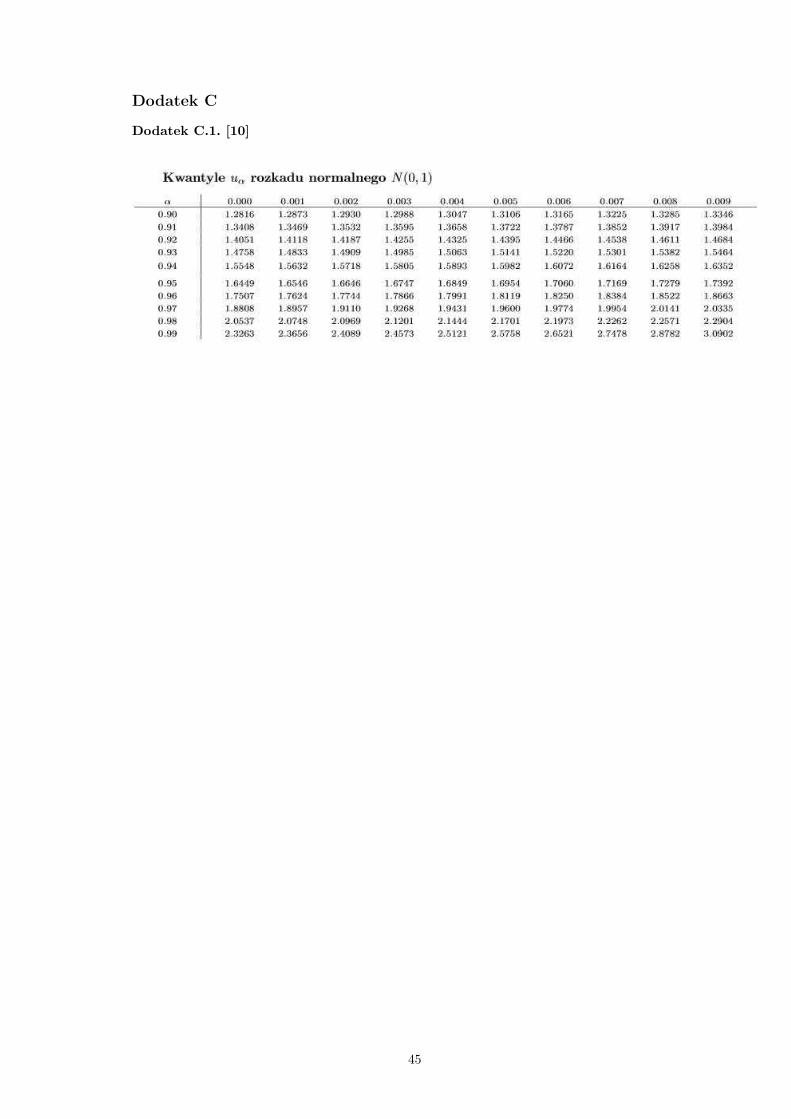
Dodatek C
Dodatek C.1. [10]
45

Wykaz literatury
1. Biznes, http://biznes.pl/rynki/gielda/analizy/czy-rynek-surowcow-rolnych-to-efektywna-
alternatyw,5576594,news-detal.html, 12.09.2013, (data dostępu 02.06.2014 r.).
2. Dziedziul K.: Teoria ryzyka z SAS, http://www.mif.pg.gda.pl/homepages/kdz/
teoriaryzyka/ryzyko.pdf , 2013.
3. Gierszewski J.: Alokacja kapitału, WFTiMS PG, 2014.
4. Jajuga K.: Zarządzanie ryzykiem. Wydawnictwo naukowe PWN, Warszawa 2007.
5. Kantowska A.: Analiza ryzyka portfela: inwestycje w srebro i złoto. Projekt dyplomowy
inżynierski. WFTiMS PG, 2011.
6. Krysicki W., Bartos J., Dyczka w., Królikowska K., Wasilewski M.: Rachunek
prawdopodobieństwa i statystyka matematyczna w zadaniach. Wydawnictwo naukowe
PWN, Warszawa 1998.
7. Krzyśko M.: Statystyka Matematyczna. Wydawnictwo naukowe UAM, Poznań 1994.
8. McNeil A., Frey R., Embrechts P.: Quantitative Risk Management: Concepts, Techniques,
and Tools, Princeton University Press, 2005.
9. Wikipedia, http://pl.wikipedia.org/wiki/Kopuła (matematyka),
(data dostępu 02.06.2014 r.)
10. Zieliński W.: Wybrane tablice statystyczne, http://wojtek.zielinski.statystyka.info/Innosci/
T01 normalny.pdf, (data dostępu 02.06.2014 r.)
11. stooq.com/
46