spss guide
DESCRIPTION
חוברת SPSSTRANSCRIPT

לוי-אבינח בר
1
: SPSS –תוכנת ה
חלק )חוברת הסברים מפורטת לסטודנט ('א
לוי -אבינח בר: עריכה

לוי-אבינח בר
2
תוכן עניינים
3..............................................................................................................................: בניית קובץ נתונים
5...................................................................................................................................: טרנספורמציות
RECODE ............................................................................................................................................5
COMPUTE ........................................................................................................................................8
FREQUENCIES :................................................................................................................................ 11
17 ................................................................................................................. :אופרציות בגיליון הנתונים
SORT CASES ................................................................................................................................... 17
SPLIT FILE ....................................................................................................................................... 19
SELECT CASES ................................................................................................................................ 22
26 ............................................................................................................... :(אלפא קרונבך)מהימנות
29 .........................................................................................: מתאם פירסון וספירמן: קשר בין משתנים
32 ............................................................................................................: רגרסיה לניארית חד משתנית
37 ...........................................................................................................: הבדלים בין קבוצות - tמבחני
37 ....................................................................................................................... לבלתי תלוייםtמבחן
39 ................................................................................................................................ לתלוייםtמבחן
CROSSTABS 41 ...................................................................................................: וחי בריבוע לאי תלות
45 ......................................................................................................................: ניתוח שונות חד כיווני
לוי-אבינח בר
3
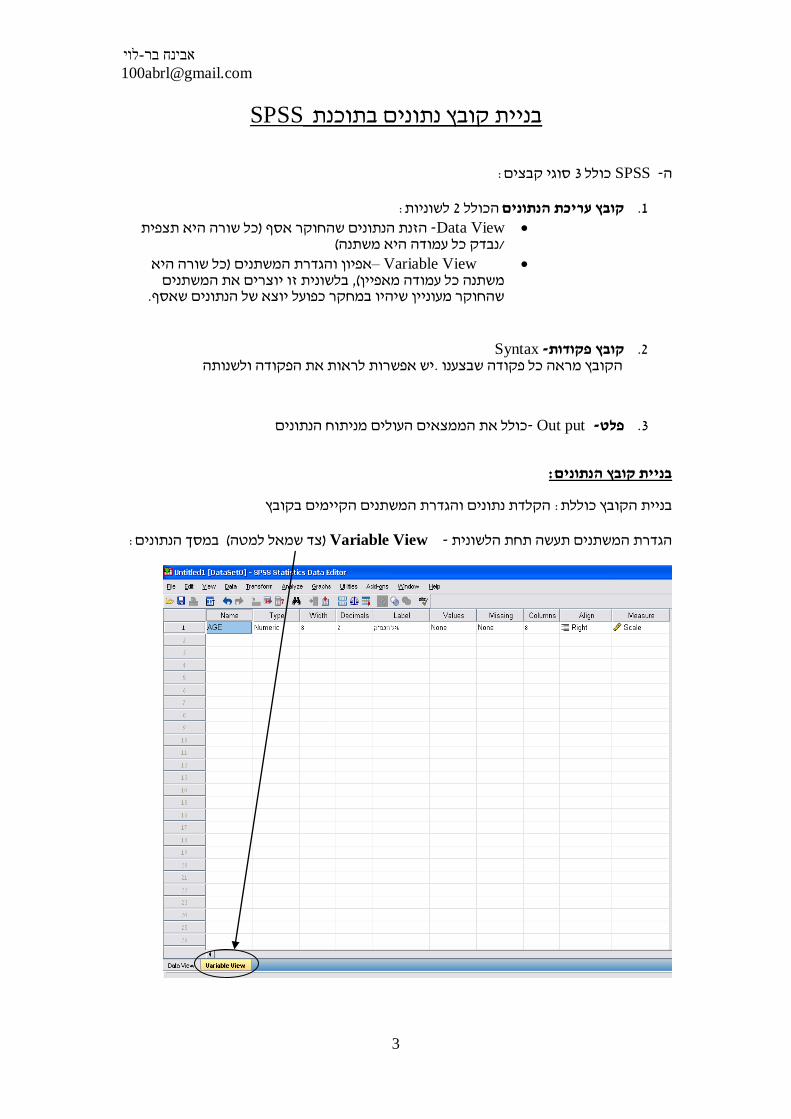
SPSSבניית קובץ נתונים בתוכנת
: סוגי קבצים3 כולל SPSS-ה
: לשוניות2 הכולל קובץ עריכת הנתונים .1 Data View - כל שורה היא תצפית )הזנת הנתונים שהחוקר אסף
(נבדק כל עמודה היא משתנה/
Variable View – כל שורה היא )אפיון והגדרת המשתניםבלשונית זו יוצרים את המשתנים , (משתנה כל עמודה מאפיין
.שהחוקר מעוניין שיהיו במחקר כפועל יוצא של הנתונים שאסף
Syntax -קובץ פקודות .2יש אפשרות לראות את הפקודה ולשנותה .הקובץ מראה כל פקודה שבצענו
כולל את הממצאים העולים מניתוח הנתונים - Out put- פלט .3
: בניית קובץ הנתונים
הקלדת נתונים והגדרת המשתנים הקיימים בקובץ : בניית הקובץ כוללת
: במסך הנתונים (צד שמאל למטה) Variable View- הגדרת המשתנים תעשה תחת הלשונית

לוי-אבינח בר
4
לשונית המשתנים מופיעות הגדרות והמאפיינים של כל אחד מהמשתנים שבקובץ , בלשונית זו: הנתונים
Name -שם המשתנה
Type - מסמנים האם הוא משתנה מספרי )הגדרת סוג המשתנה– numeric או שהוא (string –משתנה המורכב מאותיות
Decimals -הגדרת מספר הספרות אחרי הנקודה העשרונית
Width -תווים8ברירת המחדל היא . הגדרת רוחב הערכים של המשתנה
Label -תיאור המשתנה בתווית
Values -הגדרת תווית לקידוד המספרי של ערכים קטגוריאלים
Missing -הגדרת ערכים חסרים
Columns -הגדרת רוחב העמודה
Align - (שמאל או מרכז, לימין)יישור הטקסט
Measure - הגדרת סולם המדידה( שמי– nominal , סדר– ordinal ,רווח /מנה– scale.)
כלומר את הנבדקים או את התצפיות, לאחר הגדרת המשתנים ניתן להזין את הנתונים
. כל נבדק או תצפית היא שורה. Data View- תחת הלשונית , שהחוקר אסף

לוי-אבינח בר
5
SPSS- טרנספורמציות ב
כאשר בכדי לבצע טרנספורמציות אנו משתמשים בלשונית . בתוכנה קיים סרגל כלים איתו נעבוד :
Transform –שינוי ערכים ויצירת משתנים חדשים על בסיס משתנים קיימים .
:Transform – פקודות מיתוך אפשרויות ה 3נשתמש ב 1. Recode -קידוד מחדש, פקודה הממירה ערכים.
2. Compute - מבצעת חישובים מתמטיים בין המשתנים על ידי .יצירת משתנה חדש בקובץ הנתונים
3. Count - ספירת מספר הפעמים שערך או רשימת ערכים מופיעים (עדיין לא למדנו) משתנים בקבוצת
Recode .1
: מטרות עיקריות שבהם נשתמש3לפקודה זו
בכדי למנוע מילוי שרירותי של , לעיתים בשאלונים– הפיכת סקאלות של שאלות הפוכות .אהנבדקים ישנם שאלות שמנוסחות הפוך ולפני הניתוחים הסטטיסטיים נדרש להפוך את
. הסקאלות שלהם
למשל כאשר רוצים להפוך את המשתנה גיל -הפיכת משתנה כמותי למשתנה קטגוריאלי .ב . מבוגר וקשיש, צעיר: קטגוריות3הנבדק שהוא רציף למשנה בעל
צמצום מספר הקטגוריות של משתנה .ג
לוי-אבינח בר
6
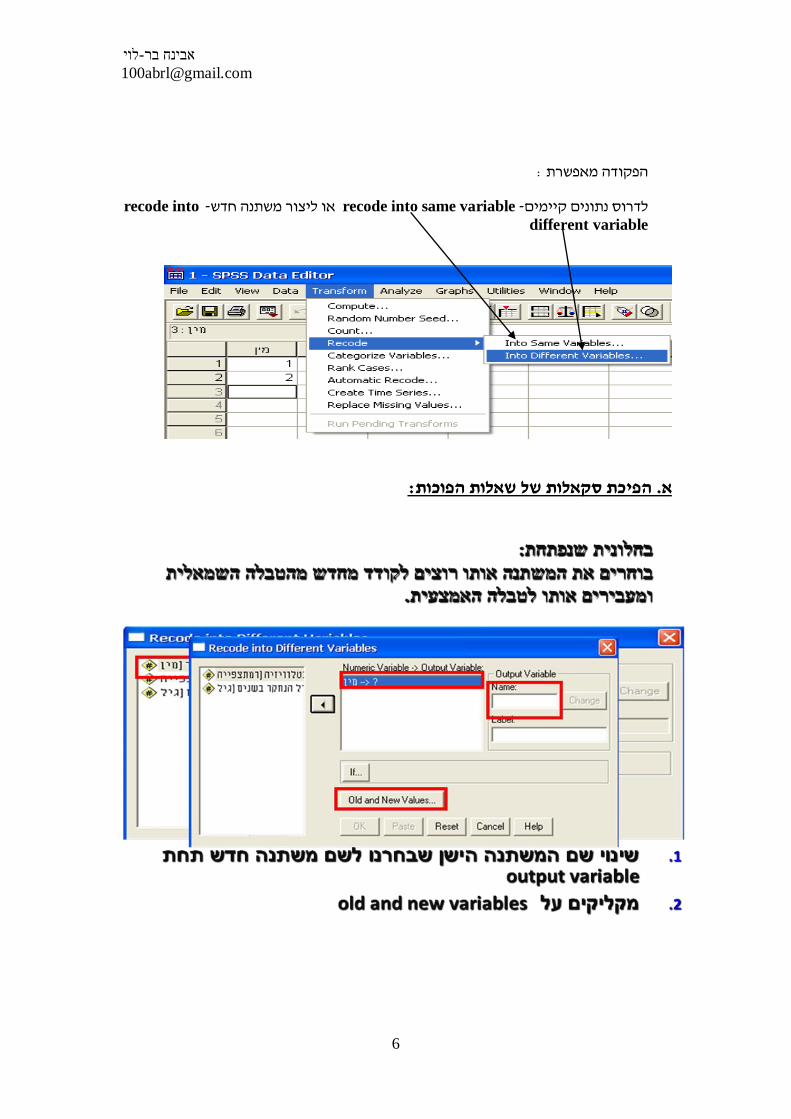
: הפקודה מאפשרת
recode into - או ליצור משתנה חדשrecode into same variable- לדרוס נתונים קיימים
different variable
:הפיכת סקאלות של שאלות הפוכות. א
לוי-אבינח בר
7
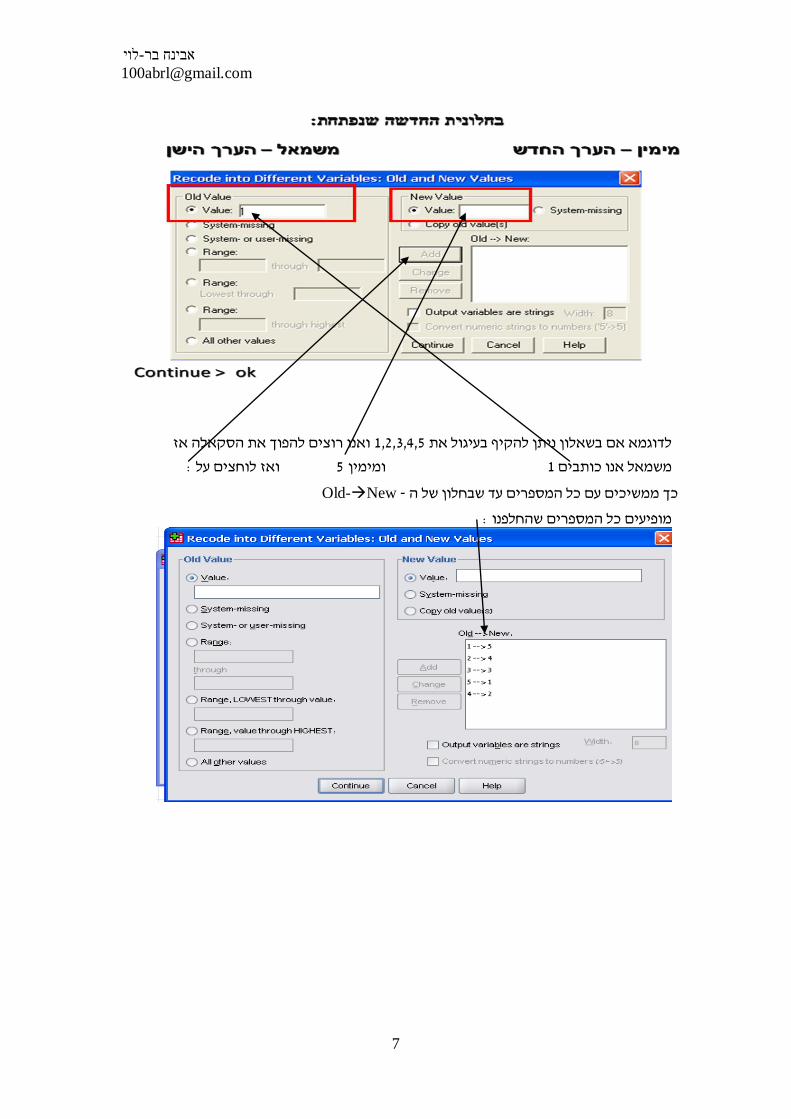
ואנו רוצים להפוך את הסקאלה אז1,2,3,4,5לדוגמא אם בשאלון ניתן להקיף בעיגול את
: ואז לוחצים על 5 ומימין 1משמאל אנו כותבים
Old-New - כך ממשיכים עם כל המספרים עד שבחלון של ה
:מופיעים כל המספרים שהחלפנו

לוי-אבינח בר
8
הפיכת משתנה כמותי למשתנה קטגוריאלי. ב
:Range כפי שעשינו בהיפוך הסקאלות נשתמש ב - Value – במקום להשתמש ב
אפשרויות 3יש , מבוגר וזקן, צעיר: בדוגמת משתנה הגיל שאנו מעוניינים להפוך אותו לקטגוריות
: לקודד את הקטגוריות
ואז צריך לסמן כאן (50 –בדוגמא )מהגיל הנמוך ביותר שקיים במשתנה ועד לגיל מסויים .1
ואז צריך לסמן כאן (70 עד גיל 51בדוגמא מגיל )טווח מסויים של גילאים .2
ועד הגיל הגבוה ביותר ואז צריך לסמן כאן (71 –בדוגמא )מגיל מסויים . 3
('מבוגר וכו, כמו צעיר)בכדי לכתוב בערך החדש קידוד של מילים : הערה
:וי כאן- נדרש לסמן ב
Compute .2
(ממוצע או סכום)יצירת מדד כללי לשאלון : השימוש השכיח ביותר
שאלות הבוחנות את מידת האהבה של כל נבדק 5שאלון אהבה לדברי מתיקה כלל : לדוגמא
בסופו של דבר המטרה היא לבחון את האהבה לדברי מתיקה באופן כללי ולא .לדברי מתיקה
על בסיס שאלה אחת ולכן נדרש לחשב משתנה חדש שיעשה ממוצע או סכום של כל היגד
. והיגד
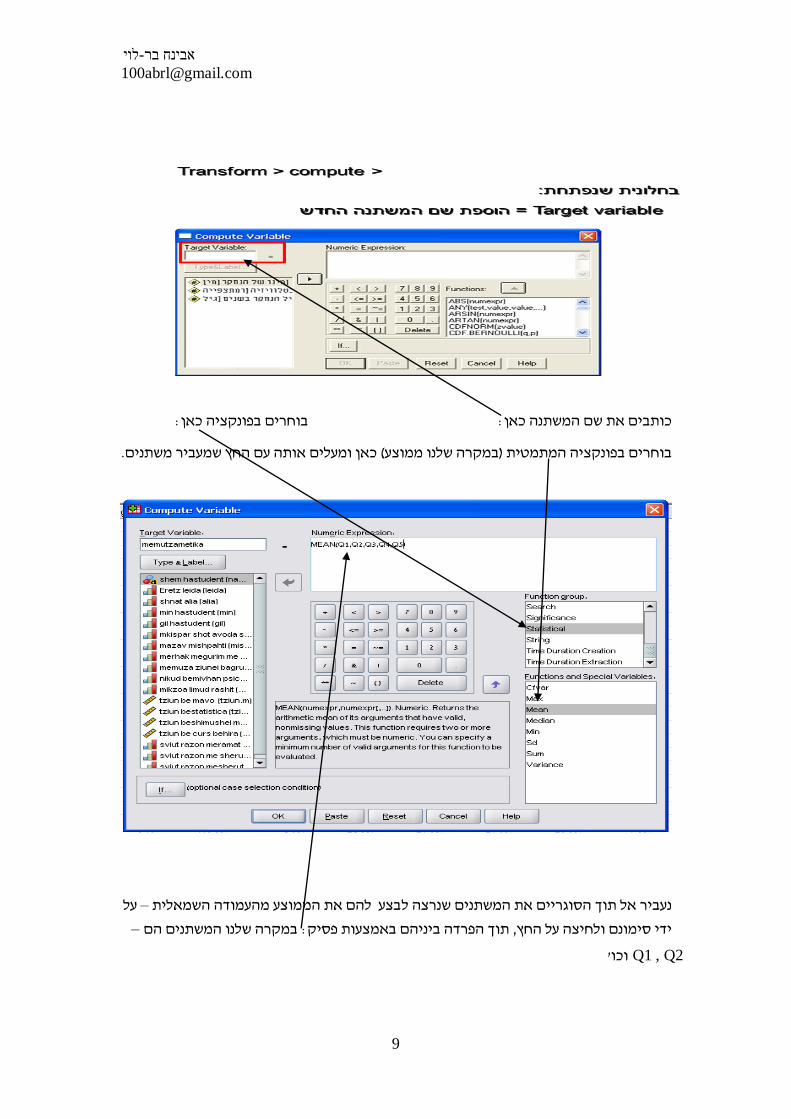
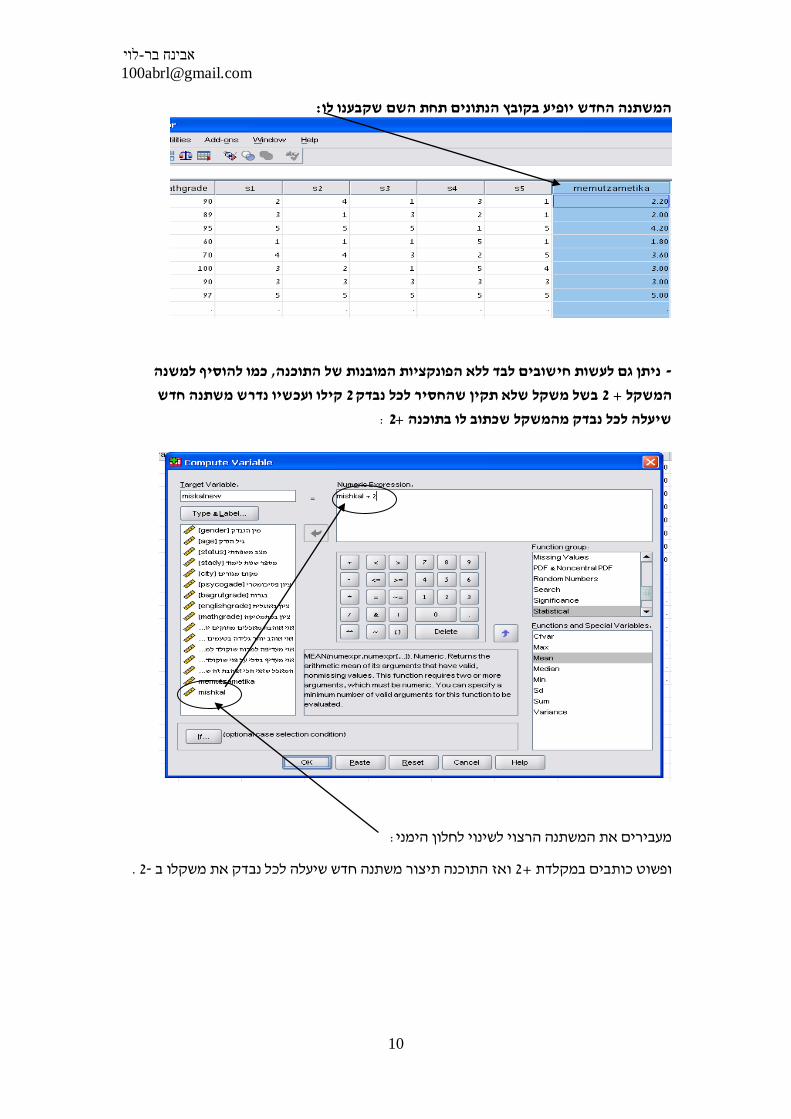
? איך מייצרים את הממוצע של השאלון ובעצם יודעים כמה כל נבדק אוהב דברי מתיקה
א ממוצע ברמת נבדק או ציון של סכום כולל ברמת "ז: יש ליצור ציון כללי לכל נבדק בשאלון
COMPUTEהנבדק באמצעות פקודת
לוי-אבינח בר
9
:בוחרים בפונקציה כאן: כותבים את שם המשתנה כאן
.כאן ומעלים אותה עם החץ שמעביר משתנים (במקרה שלנו ממוצע)בוחרים בפונקציה המתמטית
על – מהעמודה השמאלית בצע להם את הממוצענעביר אל תוך הסוגריים את המשתנים שנרצה ל
–במקרה שלנו המשתנים הם : פסיקתוך הפרדה ביניהם באמצעות, ידי סימונם ולחיצה על החץ
'וכו Q1 , Q2
לוי-אבינח בר
10
: המשתנה החדש יופיע בקובץ הנתונים תחת השם שקבענו לו
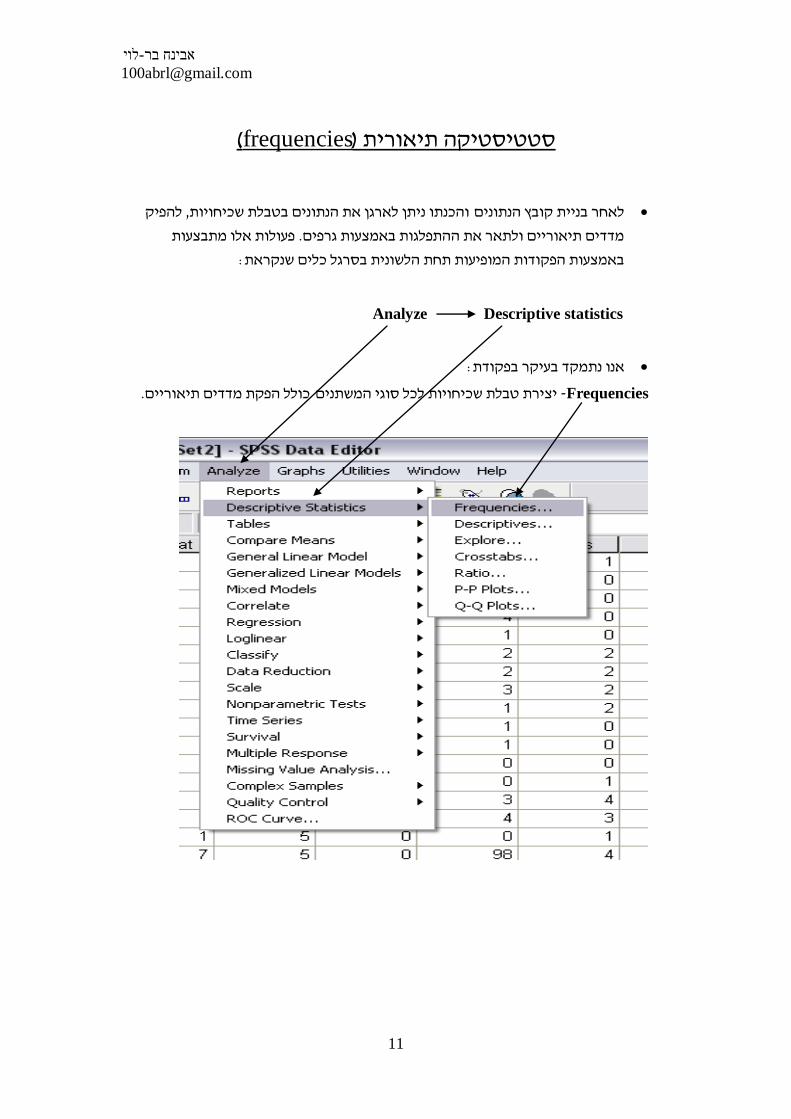
כמו להוסיף למשנה , ניתן גם לעשות חישובים לבד ללא הפונקציות המובנות של התוכנה-
קילו ועכשיו נדרש משתנה חדש 2 בשל משקל שלא תקין שהחסיר לכל נבדק 2+ המשקל
: 2+שיעלה לכל נבדק מהמשקל שכתוב לו בתוכנה
:מעבירים את המשתנה הרצוי לשינוי לחלון הימני
. 2- ואז התוכנה תיצור משתנה חדש שיעלה לכל נבדק את משקלו ב 2+ופשוט כותבים במקלדת
לוי-אבינח בר
11
( frequencies)סטטיסטיקה תיאורית
להפיק , והכנתו ניתן לארגן את הנתונים בטבלת שכיחויות לאחר בניית קובץ הנתונים
מתבצעות אלופעולות .מדדים תיאוריים ולתאר את ההתפלגות באמצעות גרפים
: הלשונית בסרגל כלים שנקראתבאמצעות הפקודות המופיעות תחת
Analyze Descriptive statistics
בעיקר בפקודתאנו נתמקד:
Frequencies -כולל הפקת מדדים תיאוריים יצירת טבלת שכיחויות לכל סוגי המשתנים .

לוי-אבינח בר
12
משתנים הרצויים מרשימת המשתנים בצד שמאל לחלון / נפתח חלון ומעבירים את המשתנה
. הריק מצד ימין
הפקודה תיצור טבלת שכיחויות עבור , בברירת מחדל של התוכנה כאשר לא משנים שום דבר
המחשב יציג לנו בקובץ okכלומר במידה והשארנו את הסימון וי ונעשה : המשתנה הנבחר
במקרה )המשתנים שהועברו לחלון הימני / את טבלת השכיחויות של המשתנהoutput))הפלט
(ארץ לידה של הנבדק- שלנו
: טבלת שכיחויות- קריאת פלט
: 1טבלה
Statistics
Eretz leida
N Valid 60
Missing 0
. מראה כמה נבדקים במחקר ענו על השאלה וכמה נבדקים לא ענו על השאלה -

לוי-אבינח בר
13
: 2טבלה
Eretz leida
Frequency
Percent Valid Percent
Cumulative
Percent
Valid Israel 40 66.7 66.7 66.7
Hever Haamim 9 15.0 15.0 81.7
Ethiopia 4 6.7 6.7 88.3
aher 7 11.7 11.7 100.0
Total 60 100.0 100.0
: מראה את טבלת התפלגות שכיחויות של המשתנה ארץ לידה
ערכי המשתנה ארץ לידה: עמודה ראשונה
Frequency :הפעמים שמופיע כל אחד מערכי המשתנה' שכיחות מס
Percent :אחוזים מסך כל התצפיות
Valid Percent :האחוזים מסך כל התצפיות ללא ערכים חסרים
Cumulative Percent :שכיחות מצטברת באחוזים - אחוזים מצטברים
הפקת מדדים סטטיסטיים וגרפים
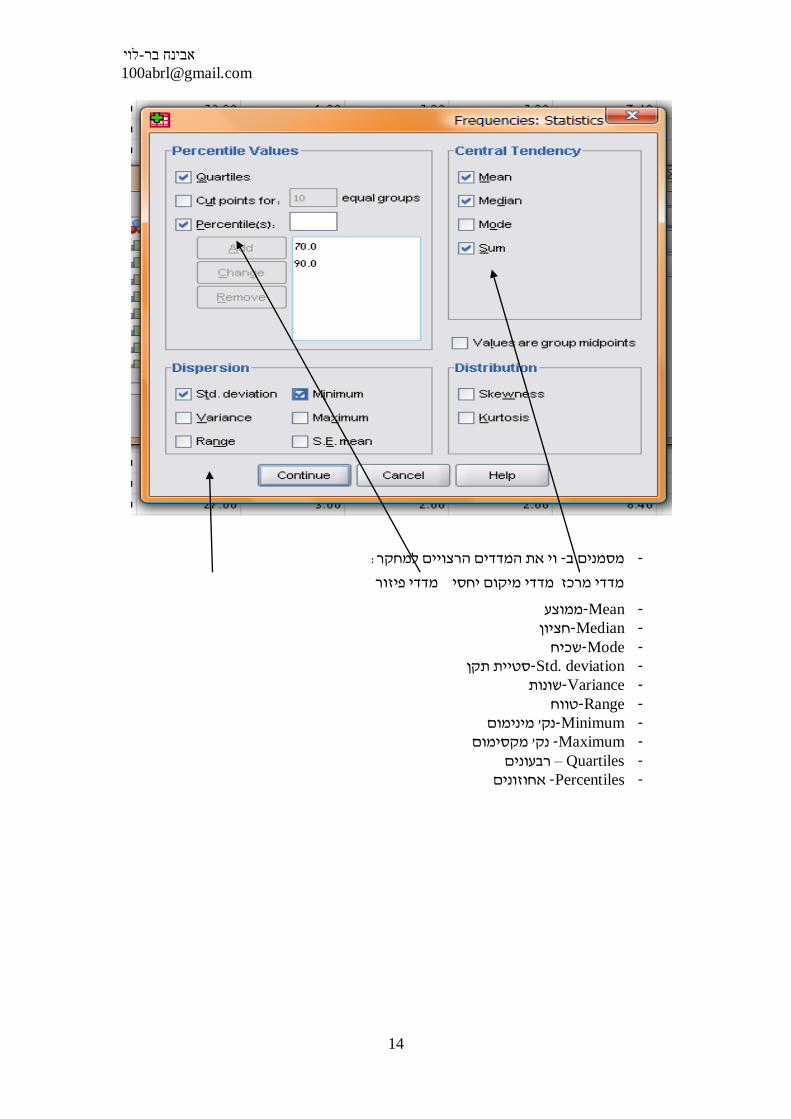
ואז Frequency בפקודת ה STATISTICS- בכדי להפיק מדדים סטטיסטים נלחץ על כפתור ה
: יפתח את החלון הבא
לוי-אבינח בר
14
:וי את המדדים הרצויים למחקר- מסמנים ב -
מדדי מרכז מדדי מיקום יחסי מדדי פיזור
- Mean- ממוצע- Median- חציון- Mode- שכיח- Std. deviation- סטיית תקן- Variance- שונות- Range- טווח- Minimum-מינימום ' נק- Maximum -מקסימום' נק
- Quartiles – רבעונים
- Percentiles - אחוזונים

לוי-אבינח בר
15
: מדדים סטטיסטיים–קריאת פלט
במקרה שלנו בחרנו כמעט את )זו הצורה בה מופיעים המדדים הסטטיסטיים שנבחרו -
. כאשר את האחוזונים ואת הרבעונים הפלט מחבר על פי גובה האחוז (כולם
: גרפים Frequencies - בפקודת הChartsניתן ליצור גרפים תחת הלשונית
Statistics
gil hastudent
N Valid 60
Missing 0
Mean 25.5667
Median 25.0000
Mode 24.00
Std. Deviation 3.39674
Variance 11.538
Range 17.00
Minimum 21.00
Maximum 38.00
Sum 1534.00
Percentiles 25 23.2500
50 25.0000
70 26.0000
75 26.7500
90 30.0000

לוי-אבינח בר
16
: נפתח החלון הבא
Pie = עבור משתנה שמי –עוגה
Bar = עבור משתנה בדיד– מקלות
Histogram - היסטוגרמה עבור משתנה כמותי רציף
לוי-אבינח בר
17
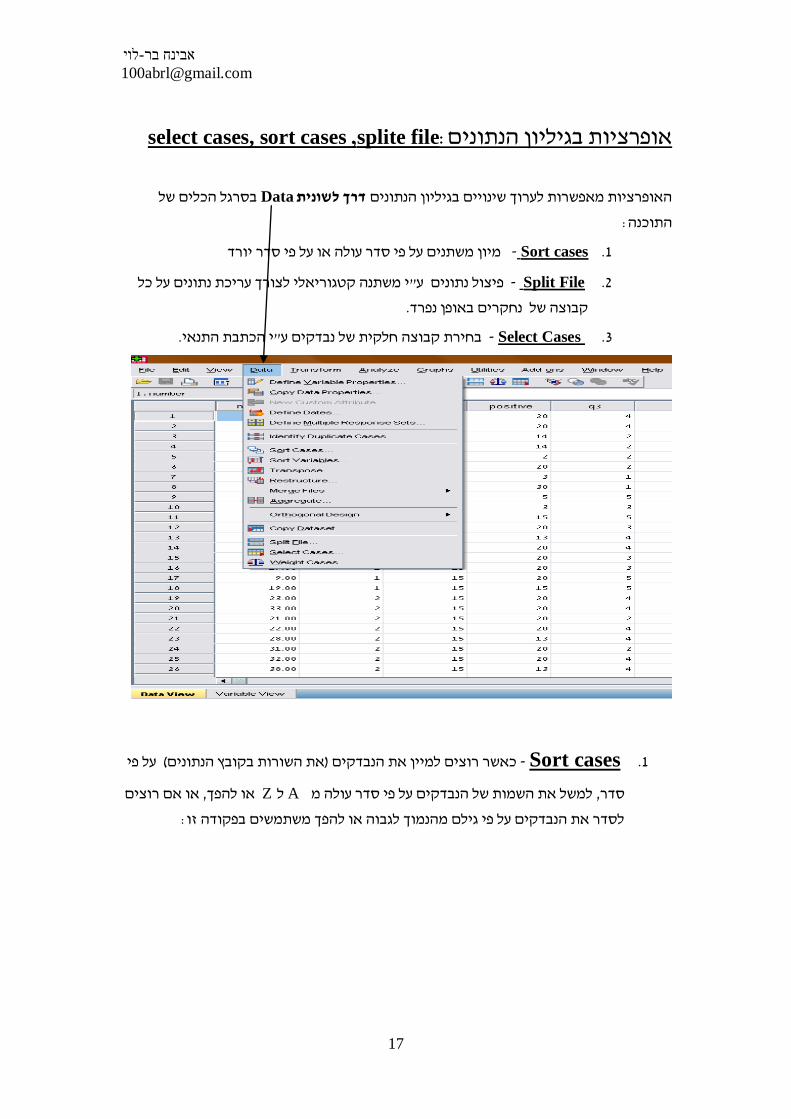
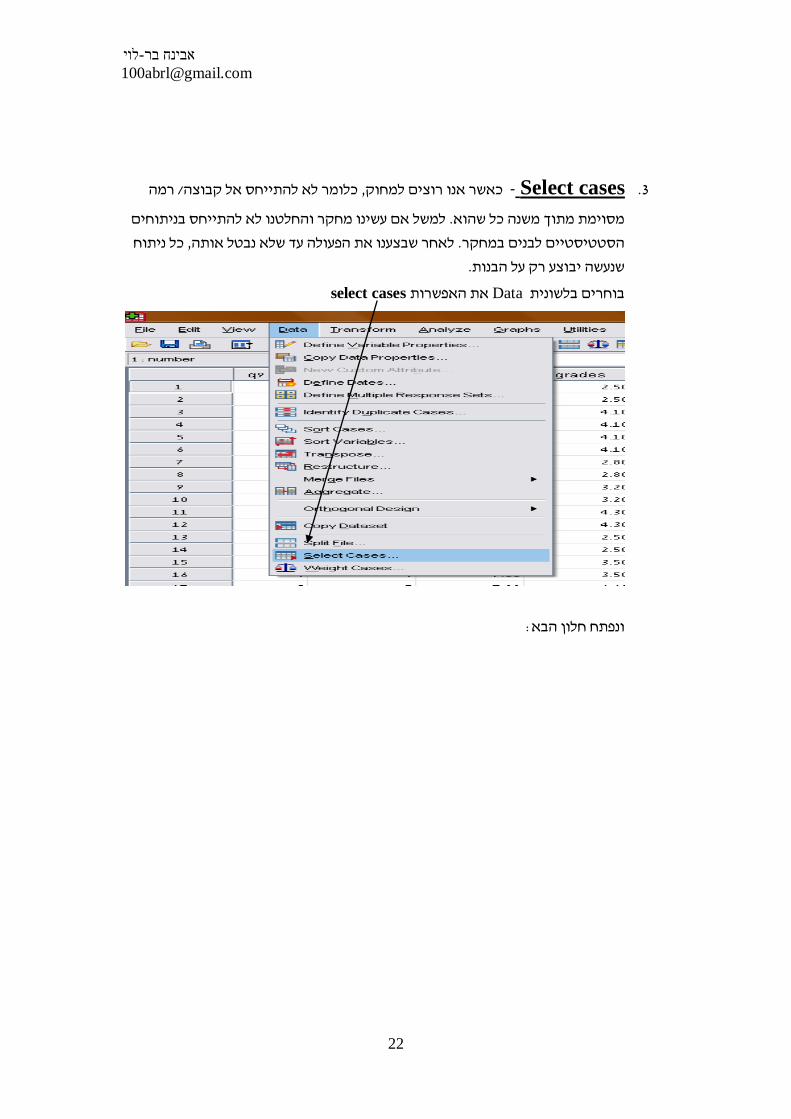
splite file ,select cases, sort cases:אופרציות בגיליון הנתונים
בסרגל הכלים של Dataדרך לשונית האופרציות מאפשרות לערוך שינויים בגיליון הנתונים
: התוכנה
1. Sort cases -מיון משתנים על פי סדר עולה או על פי סדר יורד
2. Split File -י משתנה קטגוריאלי לצורך עריכת נתונים על כל "פיצול נתונים ע
.קבוצה של נחקרים באופן נפרד
3. Select Cases - י הכתבת התנאי"בחירת קבוצה חלקית של נבדקים ע.
1. Sort cases - על פי (את השורות בקובץ הנתונים)כאשר רוצים למיין את הנבדקים
או אם רוצים , או להפךZ ל Aלמשל את השמות של הנבדקים על פי סדר עולה מ , סדר
: לסדר את הנבדקים על פי גילם מהנמוך לגבוה או להפך משתמשים בפקודה זו

לוי-אבינח בר
18
: בוחרים באופציה כאן
: ונפתח החלון הבא
(. age-במקרה שלנו גיל)מעבירים לחלון הימני את המשתנה אותו נהיה מעוניינים לסדר
: כלומר בסדר עולה ואז נבחר ב, ובוחרים האם אנו מעוניינים בסידור מהנמוך לגבוה
: כלומר בסדר יורד ואז נבחר ב, או שנרצה לסדר מגבוה לנמוך

לוי-אבינח בר
19
:(בחרנו בסדר עולה)סידור המשתנה יעשה כמובן בקובץ הנתונים ויראה כך -
2. Splite file - כאשר החוקר מעוניין להציג או להשוואת בין נתונים סטטיסטיים
אך לא לכל המשתנה באופן כללי כפי שהתוכנה עושה בברירת מחדל אלא לבדוק כל
למשל ממוצע של הגילאים אצל הבנות במחקר לעומת )רמה של המשתנה בנפרד /קבוצה
. (הבנים במחקר או השוואה בין ממוצע ציון הבגרות של אנשים בתל אביב לעומת אריאל
לבחור משתנה קטגוריאלי שאותו אנחנו מפצלים ? מה צריך לעשות ברמה התיאורטית
תל אביב , אריאל: רמות3שבו " מקום מגורים"לדוגמא המשתנה )לרמות השונות
כל עיבוד סטטיסטי שנבצע הוא יעשה , עד שלא נבטל את הפקודה, ומכאן והלאה (ורעננה
.אריאל ורעננה, א"אותו בנפרד לנבדקים מת
?איך עושים זאת

לוי-אבינח בר
20
splite file את האפשרות Dataבוחרים בלשונית
: נפתח חלון עם האפשרויות הבאות
. למסך הימני (מעשן או לא , smoking –בדוגמא שלנו )מכניסים את המשתנה
אם רוצים שהניתוחים יופיעו הנתונים של המעשנים והלא מעשנים בטבלה נפרדת :organize output by groups- בוחרים באפשרות הזאת
אם רוצים שבניתוחים הסטטיסטיים יופיעו הנתונים של המעשנים והלא מעשנים באותה : compare groups –טבלה בוחרים באפשרות הזאת
: כאשר רוצים לבטל את הפיצול של המשתנה בוחרים באפשרות הזאת

לוי-אבינח בר
21
? splite fileאיך רואים שהתוכנה ביצעה split by smoking: בצד ימין למטה של קובץ הנתונים יופיע המשפט
הוא , ת של כל משתנה בקובץ"כאשר נבצע למשל חישוב של ממוצע וס? איך נראה את זה בפלט. יבצע את הניתוחים בנפרד לכאלו שמעשנים וכאלו שלא
–ת התקן של גיל הנבדקים וכפי שניתן לראות בקובץ ה "בדוגמא להלן חישבנו את הממוצע וסoutput הפלט להלן הוא , אגב) שלא מעשנים וכאלו שמעשנים יופיעו הניתוחים בנפרד לכאלו
: (כאשר נבחר לעשות שהקבוצות יופיעו בטבלה אחת
Statistics
age
no N Valid 10
Missing 0
Mean 39.40
Std. Deviation 11.187
yes N Valid 30
Missing 0
Mean 33.67
Std. Deviation 10.469
לוי-אבינח בר
22
3. Select cases -רמה / כלומר לא להתייחס אל קבוצה, כאשר אנו רוצים למחוק
למשל אם עשינו מחקר והחלטנו לא להתייחס בניתוחים . מסוימת מתוך משנה כל שהוא
כל ניתוח , לאחר שבצענו את הפעולה עד שלא נבטל אותה. הסטטיסטיים לבנים במחקר
. שנעשה יבוצע רק על הבנות
select cases את האפשרות Dataבוחרים בלשונית
: ונפתח חלון הבא

לוי-אבינח בר
23
if : ואז נפתחת האפשרות לבוחר אתif condition is satisfiedבוחרים באפשרות של
: ונפתח החלון הבא
: מעבירים לחלונית מצד ימין את המשתנה בו נרצה להוריד קבוצה מסוימת

לוי-אבינח בר
24
: דוגמאות 3
שנים 10-נבחר רק בנבדקים בעלי וותק גבוה מ
2 או 3נבחר רק באלו שהם בעלי רמת השכלה

לוי-אבינח בר
25
? כיצד זה נראה בקובץ
1=מחק את מי שבעל השכלה
35-לחילופין נבחר רק את הגברים שגילם צעיר מ
? איך זה נראה בקובץ הנתונים

לוי-אבינח בר
26
35 עומדים בתנאי ולכן לא מחוקים בקו הן גם גברים וגם מעל גיל 13, 5, 1רק הנבדקים
. כל פעולה שנבצע כעת תיקח בחשבון רק את שלושת הנבדקים
מהימנות כעקיבות פנימית
נעשה בשני דרכים . באיזה מידה כל פריטיו בודקים את אותה תכונה :בודקת האם המדד הומוגני
(לא למדנו)מהימנות מבחן חצוי .א
מחושבת על ידי נוסחה המודדת מתאם של כל פריט עם שאר - אלפא של קורנבאך .ב
ככל שאלפא גבוהה יותר המבחן יותר הומוגני ובעל עקיבות פנימית גבוהה . הפריטים
0.6אנחנו צריכים להגיע לאלפא ששווה לפחות . יותר
הוא משקלל . הערך אלפא מתבסס על המתאמים שבין כל פריט לכל אחד מהפריטים האחרים
1 ל0הערך שמתקבל נע בין . את ממוצע המתאמים ומספר הפריטים שנכנסו לניתוח
. במידה ומתקבלת אלפא נמוכה ורוצים לשפר את מהימנות השאלון ניתן לבצע ניתוח פריטים
. לבדוק איזה פריטים כדאי להוציא מהשאלון על מנת לשפר את את המהימנות
: שתי דרכים
אם נמוך ניתן לשקול לוותר עליו . מחשבים את המתאם של הפריט עם המבחן כולו .א
. המתאם גבוה סימן שהוא בודק את אותה תכונה שהשאלון בודק אם
אם המהימנות .מחשבים את האלפא שהייתה מתקבלת אם היינו משמיטים את הפריט .ב
.גבוהה יותר בלעדיו ניתן לוותר עליו

לוי-אבינח בר
27
כאשר המתאם : על ידי הניתוח ניתן לראות האם יש שאלה שייתכן והסקאלה שלה הפוכה, בנוסף
בינה לבין שאר הפריטים הוא שלילי עולה חשד כי קיימת שאלה שהסקאלה שלה הפוכה משאר
(יפורט בהמשך, 0אבל לא קרוב ל )השאלות ולכן המתאם בינה לבין שאר המבחן הוא שלילי
ביצוע המבחן
Analyze scale reliability analysis
: ואז נפתח החלון הבא
כ כל פריטי "בד)מעבירים את הפריטים שאנו רוצים שיכללו בניתוח המהימנות של השאלון
: לחלון הימני ולוחצים על (השאלון
scale if item deletedובו מסמנים את האפשרות : ונפתח החלון הבא
לוי-אבינח בר
28
ניתוח פלט.ב
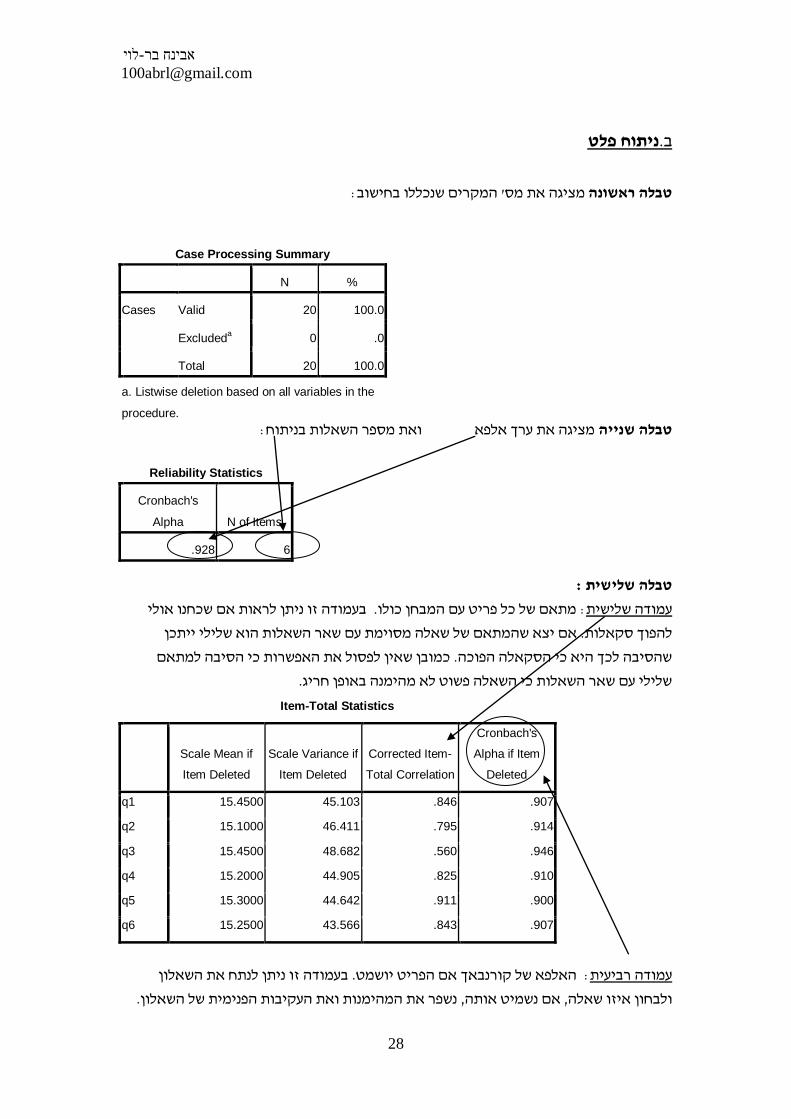
: המקרים שנכללו בחישוב' מציגה את מסטבלה ראשונה
Case Processing Summary
N %
Cases Valid 20 100.0
Excludeda 0 .0
Total 20 100.0
a. Listwise deletion based on all variables in the
procedure.
: מציגה את ערך אלפא ואת מספר השאלות בניתוחטבלה שנייה
Reliability Statistics
Cronbach's
Alpha N of Items
.928 6
: טבלה שלישית
בעמודה זו ניתן לראות אם שכחנו אולי . מתאם של כל פריט עם המבחן כולו: עמודה שלישית
אם יצא שהמתאם של שאלה מסוימת עם שאר השאלות הוא שלילי ייתכן . להפוך סקאלות
כמובן שאין לפסול את האפשרות כי הסיבה למתאם . שהסיבה לכך היא כי הסקאלה הפוכה
. שלילי עם שאר השאלות כי השאלה פשוט לא מהימנה באופן חריג
Item-Total Statistics
Scale Mean if
Item Deleted
Scale Variance if
Item Deleted
Corrected Item-
Total Correlation
Cronbach's
Alpha if Item
Deleted
q1 15.4500 45.103 .846 .907
q2 15.1000 46.411 .795 .914
q3 15.4500 48.682 .560 .946
q4 15.2000 44.905 .825 .910
q5 15.3000 44.642 .911 .900
q6 15.2500 43.566 .843 .907
בעמודה זו ניתן לנתח את השאלון . האלפא של קורנבאך אם הפריט יושמט: עמודה רביעית
. נשפר את המהימנות ואת העקיבות הפנימית של השאלון, אם נשמיט אותה, ולבחון איזו שאלה

לוי-אבינח בר
29
היא שאלה , תעלה באופן משמעותי (המהימנות הפנימית)האלפא , כלומר שאלה שאם נוריד אותה
. שפוגעת לנו במהימנות וייתכן כי כדאי להוריד אותה ובכך לשפר מהימנות השאלון
ל 0.928 היא שאלה שבמידה ונשמיט אותה המהימנות תעלה מ 3בדוגמא שלהלן נראה כי שאלה
, תרד (המהימנות)במידה ונשמיט אותם האלפא , שאר השאלות. ולכן כדאי להשמיטה0.946
כלומר הם תורמים ליצירת מהימנות טובה לשאלון ואין צורך להשמיטם
בשיקול דעת כיוון שככל שלשאלון תצריך כמובן לזכור כי להוריד שאלה הוא דבר שצריך להיעשו)
יש יותר פריטים הוא מקיף את התכונה או הנושא אותו הוא בודק מכיוונים שונים שייתכן
(וחשובים לבחינת כל הפנים והצדדים של הנושא
דיווח
6בבדיקת מהימנות באמצעות אלפא של קורנבך עבור השאלון אהבה לדברי מתיקה הכולל
.0.946α= נתקבלה 3' לאחר השמטת פריט מס . α 0.928=פריטים נתקבלה
מתאם פירסון וספירמן –קשר בין משתנים
כלומר מה וכמה השינוי במשתנה מסויים , משתנים2כאשר באים לבדוק האם קיים קשר בין
: כאשר. משתמשים במתאם פירסון וספירמן, כאשר המשתנה השני משתנה
Spearman: המשתנה השני מסולם סדר ומעלה. סדרמשתנה אחד לפחות מסולם
Pearson : מנה שני המשתנים מסולם רווח או .
הקשר כיוון ואת המשתנים בין הקשר עוצמת את מתאר( מספר )המתאם מקדם -
+(1- )ל-( 1 )בין נעים המתאם מקדם של הערכים -
סימן המתאם מעיד על כיוונו -
r>0 חיובי מתאם( ש ככלX גם כך גדל Yש ככל או גדלXקטן Y קטן.)
r<0 שלילי מתאם( ש ככלX כך גדל Yש ככל או קטןXקטן Y גדל.)
r=0 המשתנים בין קשר אין.
אומרת זאת. (ללא הסימנים) מוחלט בערך המתאם של ערכו פי על נמדדת המבחן עוצמת -
.יותר חזק המשתנים בין הקשר כך ,יותר גדול ׀r׀ ש ככל , הקשר לכיוון קשר ללא
r=0אין קשר לינארי
r=±1 המשתנים בין מושלם/ מלא קשר קיים .
קשר חלש - 0-0.39
קשר בינוני - 0.4-0.59
קשר חזק- 0.6-1

לוי-אבינח בר
30
Spss - ביצוע מתאם בתוכנת ה
Analyze Correlate Bivariate
: לאחר מיכן נפתח החלון הבא
ניתן . ובו מעבירים לחלון הימני את המשתנים שאנו מעוניינים לבדוק את הקשר בינם
. להכניס יותר משני משתנים אך המתאמים יעשו בין כל שני מתאמים בלבד
ואם נדרש מתאם . אם נדרש לעשות מתאם פירסון אין צורך לסמן כי זה ברירת המחדל
paste- ומסיימים ב: נסמן את, ספירמן

לוי-אבינח בר
31
ניתוח הפלט
אופן ניתוח הפלט וכן צורת הדיווח זהה בין מתאם פירסון לספירמן ועל כן מכאן מוצג רק -
.מתאם פירסון לצורך הדוגמא
Correlations
gil hastudent ממוצע ציוני בגרות ציון פסיכומטרי
Pearson Correlation 1 .739 ציון פסיכומטרי** -.152
Sig. (2-tailed) .000 .247
N 60 52 60
Pearson Correlation .739 ממוצע ציוני בגרות** 1 -.055
Sig. (2-tailed) .000 .697
N 52 52 52
gil hastudent Pearson Correlation -.152 -.055 1
Sig. (2-tailed) .247 .697
N 60 52 60
**. Correlation is significant at the 0.01 level (2-tailed).
. אופקית ואנכית: הפלט בנוי כמטריצה בה אותו משתנה מופיע פעמים
: ערכים 3עבור כל משתנה מתקבלים
עם המשתנה השני (( 1עם עצמו תמיד שווה ) המתאם : שורה ראשונה-
. המבחן מובהק סטטיסטית. 0.05 קטן מ sig-מובהקות המבחן : שורה שנייה-
מספר הנבדקים שנכללו בחישוב המתאם : שורה שלישית-
בין ציון sig<0.05))ומובהק ( r=0.739)בדוגמא לעיל קיים מתאם חיובי חזק -
כלומר ככל שציון הבגרות עולה כך גם ציון הפסיכומטרי , פסיכומטרי לבין ציוני בגרות
. עולה
נמצאו לא מובהקים (הקשר בין בגרות וגיל והקשר בין פסיכומטרי וגיל)שאר הקשרים -
(sig<0.05) ועל כן לא מצביעים מבחינתנו על קשרים בין המשתנים.
דיווח
ציוני בגרות ומבחן פסיכומטרי נערך מתאם פירסון , בכדי לבחון האם קיים קשר בין גיל הנבדק
בין המשתנים ונמצא כי קיים קשר חיובי מובהק בין ציון בגרות וציון פסיכומטרי
r=0.739, p<0.01)) כך שככל שציון הבגרות גבוה יותר ציון הפסיכומטרי גבוה יותר .
(. p>0.05)לא נמצא קשר מובהק בין המשתנים ציון בגרות וגיל וכן בין פסיכומטרי וגיל

לוי-אבינח בר
32
רגרסיה לניארית
ערכי את ביותר הטוב באופן המנבא ישר קו למצוא אפשר משתנים שני בין קשר קיים כאשר
.רגרסיה קו- השני המשתנה ערכי מתוך אחד משתנה
מקבץ מקבלים ,משתנים שני בין( מתאם על מבוססים רגרסיה מבחני )מתאם חישוב לאחר
.x נקודות של כפונקציה y נקודות
קיימת כאשר.. X של כפונקציה y את להסביר אפשר כמה .ניבוי יכולת רגרסיה מאפשרת לנו
פיזור של ממוצע קו נמצא אנו השני של כפונקציה אחד משתנה של ליניארישיטתי שינוי או מגמה
x לכל yשל המנובאות הנקודות כל עליו שנמצאות קו : רגרסיה קו הנקודות
. המקוריy מנובא שאינו בהכרח הyבאמצעות קו הרגרסיה נוצר -
: מאפייני קו הרגרסיה -
אפס הוא המקוריות לנקודות ממנו הסטיות סכום .1
מינימלי הוא ממנו הנקודות כל של הסטיות ריבועי סכום .2
על מניבוי הנובע הדיוק בחוסר המתחשב באופן לאוכלוסייה ממדגם להסיק היא הסופית המטרה
.מושלם שאינו מתאם ערך פי
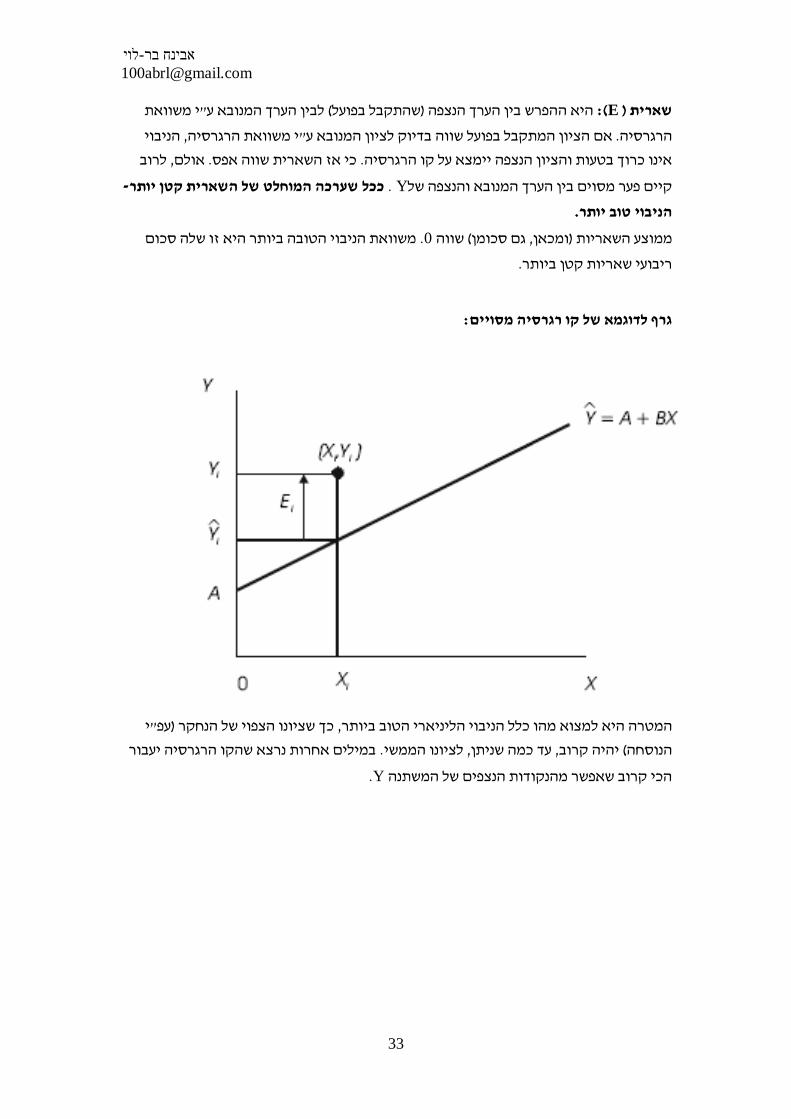
: נדרש למצואיליניארבשביל להגדיר קו -
b- קצב השינוי- שיפוע .1
y – a( constant) ה ציר עם חיתוך נקודת .2
:המשוואה מורכבת מ . Ŷ= bx+a- משוואת הרגרסיה היא
Xi - הבלתי תלוי-המנבא ציונו של נחקר במשתנה .
Yi - ציון שמקבל הנחקר למעשה במשתנה התלוי .
Ŷi - ציונו הצפוי של הנחקר על פי ניבוי של קו ישר .
a - נקודת החיתוך של קו הרגרסיה עם ציר ה"- קבוע"ה -y .
b - תלוי ביחידות המדידה של - השיפוע של קו הרגרסיה- מקדם הרגרסיהX . מציין בכמה
. ביחידה אחתxלכל עלייה של ערך , yיחידות משתנה ערך
לוי-אבינח בר
33
י משוואת "לבין הערך המנובא ע (שהתקבל בפועל)הפרש בין הערך הנצפה היא ה:( E ) שארית
הניבוי , י משוואת הרגרסיה"אם הציון המתקבל בפועל שווה בדיוק לציון המנובא ע .הרגרסיה
לרוב , אולם. כי אז השארית שווה אפס. אינו כרוך בטעות והציון הנצפה יימצא על קו הרגרסיה
- ככל שערכה המוחלט של השארית קטן יותר. Y קיים פער מסוים בין הערך המנובא והנצפה של
.הניבוי טוב יותר
משוואת הניבוי הטובה ביותר היא זו שלה סכום . 0שווה (גם סכומן, ומכאן)ממוצע השאריות
.ריבועי שאריות קטן ביותר
: גרף לדוגמא של קו רגרסיה מסויים
הליך זה מאפשר לנבא את המשתנה התלוי באמצעות משתנה בלתי תלוי Linear Regression
ניתוח פלט
י "עפ)כך שציונו הצפוי של הנחקר , מצוא מהו כלל הניבוי הליניארי הטוב ביותרהמטרה היא ל
במילים אחרות נרצא שהקו הרגרסיה יעבור . לציונו הממשי, עד כמה שניתן, יהיה קרוב (הנוסחה
.Yהכי קרוב שאפשר מהנקודות הנצפים של המשתנה
לוי-אבינח בר
34
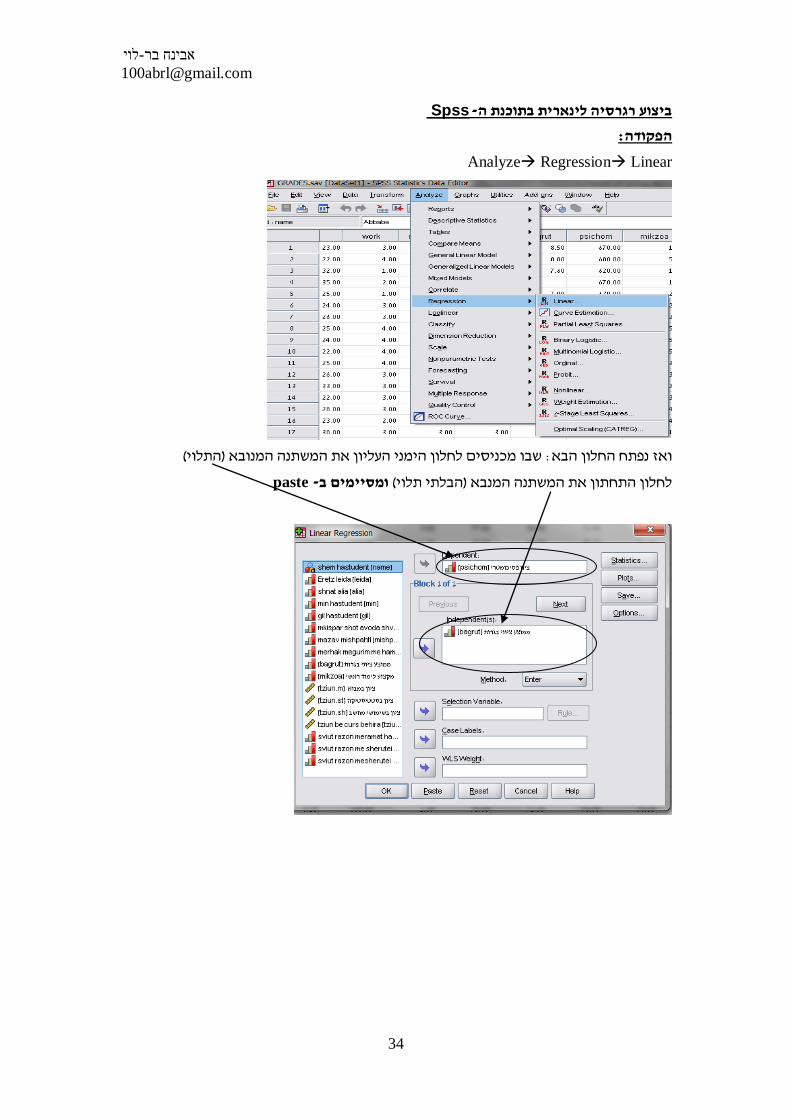
Spss - ביצוע רגרסיה לינארית בתוכנת ה
:הפקודה
Analyze Regression Linear
(התלוי)שבו מכניסים לחלון הימני העליון את המשתנה המנובא : ואז נפתח החלון הבא
paste- ומסיימים ב (הבלתי תלוי)לחלון התחתון את המשתנה המנבא

לוי-אבינח בר
35
ניתוח הפלט
: (הראשונה אינה מוצגת)טבלה שנייה של הפלט
Model Summary
Model R R Square
Adjusted R
Square
Std. Error of the
Estimate
1 .739a .546 .537 28.76846
a. Predictors: (Constant), בגרות ציוני ממוצע
R -ברגרסיה חד. לבין התלוי, תלויים במודל-בין כל המשתנים הבלתי- זהו המתאם המרובה-
. 0.739במקרה שלנו הוא . זהו ערכו של מדד פירסון, משתנית
R square -את 100מכפילים ב ) 54.6%כי ניתן להסביר : הפירוש יהיה. אחוז השונות המוסברת
. של המשתנה ציון פסיכומטרי על ידי השונות במשתנה ציון ציון בגרות מהשונות (המתאם בריבוע
Adjusted R Square -לצורך השוואה בין מודלים אשר בהם מספר - שונות מוסברת מתוקננת
. (נלמד בהמשך)משתנים מסבירים שונה
: (בה ניתן לדעת מה המשתנה המנבא ומה המשתנה המנובא) טבלה שלישית
ANOVAb
Model Sum of Squares df Mean Square F Sig.
1 Regression 49688.007 1 49688.007 60.037 .000a
Residual 41381.224 50 827.624
Total 91069.231 51
a. Predictors: (Constant), בגרות ציוני ממוצע
b. Dependent Variable: פסיכומטרי ציון
Sum of Squares -סכום הריבועים :
Regression -סכום הריבועים של שונות הרגרסיה .
Residual -סכום הריבועים של הטעויות.
Total -כ סכום הריבועים"סה .
רואים שכאן . הבוחן את מובהקות המודל- F- של מודל הרגרסיהילסטטיסט מתייחסים אנו
. מובהקות המודל- Sigפירוש .(sig = 0.000 )מובהק הואש
. סיכוי לטעות5%כלומר יש . 95%- מודל הרגרסיה מובהק בsig < 0.05כאשר
. סיכוי לטעות1%כלומר יש . 99%- מודל הרגרסיה מובהק בsig < 0.01אם
הסיכוי לטעות גדול יותר ממה שהחוקר מוכן . מודל הרגרסיה לא מובהקsig > 0.05אם
. לקחת

לוי-אבינח בר
36
: (טבלת המקדמים)טבלה רביעית
Coefficientsa
Model
Unstandardized Coefficients
Standardized
Coefficients
t Sig. B Std. Error Beta
1 (Constant) 313.555 44.148 7.102 .000
000. 7.748 739. 5.218 40.427 ממוצע ציוני בגרות
a. Dependent Variable: פסיכומטרי ציון
B -ציון כשציון הפסיכומטרימלמד בכמה יחידות משתנה : לדוגמה- מקדם הרגרסיה הגולמי
:נמצא בשורה השנייה מול המשתנה המנבא- משתנה ביחידה אחתהבגרות
Constant - הקבוע(a) -תחת , שורה ראשונהB .
Beta( נלמד בהמשך) - מקדם הרגרסיה המתוקנן כלומרr . בציון הבגרותכל עלייה ביחידה נוספת
. יחידות תקן0.739- בהציון הפסיכומטרי תעלה את
על ידי טבלה זו ניתן לבנות את משוואת הרגרסיה לניבוי ציון פסיכומטרי על ידי ציון -
, בבגרות8כלומר לנבדק שיש לו ציון . Ŷ= 40.42x+313.55 במקרה שלנו זה . בגרות
: ונקבל כי ציון הפסיכומטרי של המנובא של אותו נבדק יהיהX ,8נציב במקום ה
651.92 .
דיווח
לבדיקת ניבוי ציון הפסיכומטרי על ידי ציון הבגרות בוצע ניתוח רגרסיה ליניארית ונמצא כי ככל
F(1,50)=60.03, p<0.01,R=0.739, B=40.42))שציון הבגרות עולה גם הציון בפסיכומטרי עולה
. מהשונות במשתנה ציון פסיכומטרי54.6%ציון הבגרות מסביר

לוי-אבינח בר
37
לבלתי תלויים tמבחן
ובוחן האם קיים הבדל בינם, מבחן המשווה ממוצעים של שתי קבוצות שאינן תלויות אחת בשניה
כאשר רוצים לגלות , למשל. (קבוצות ומשתנה תלוי אחד/ רמות2משתנה בלתי תלוי אחד בעל )
. בין בנים ובנות בממוצע ציון הבגרותהאם קיימים הבדלים
Spss - ביצוע המבחן בתוכנת ה
: הפקודה
ANALYZE > COMPARE MEANS > INDEPENDENT SAMPLES T TEST
. ומכניסים את המשתנה התלוי והמשתנה הבלתי תלוי לחלונות הימניים: ואז נפתח החלון הבא
הקבוצות אותם נשווה /לאחר שהכנסנו את המשתנה הבלתי תלוי אנו נדרשים הגדיר את הרמות
2תל אביב ורעננה וכאמור ניתן להשוואת רק , אריאל: קבוצות3למשל אם יש )במשתנה זה
בנים ובנות - ובו נגדיר את הקבוצות: ויפתח החלון הבאdefine groupsונלחץ על (קבוצות
לוי-אבינח בר
38
:פלטה ניתוח
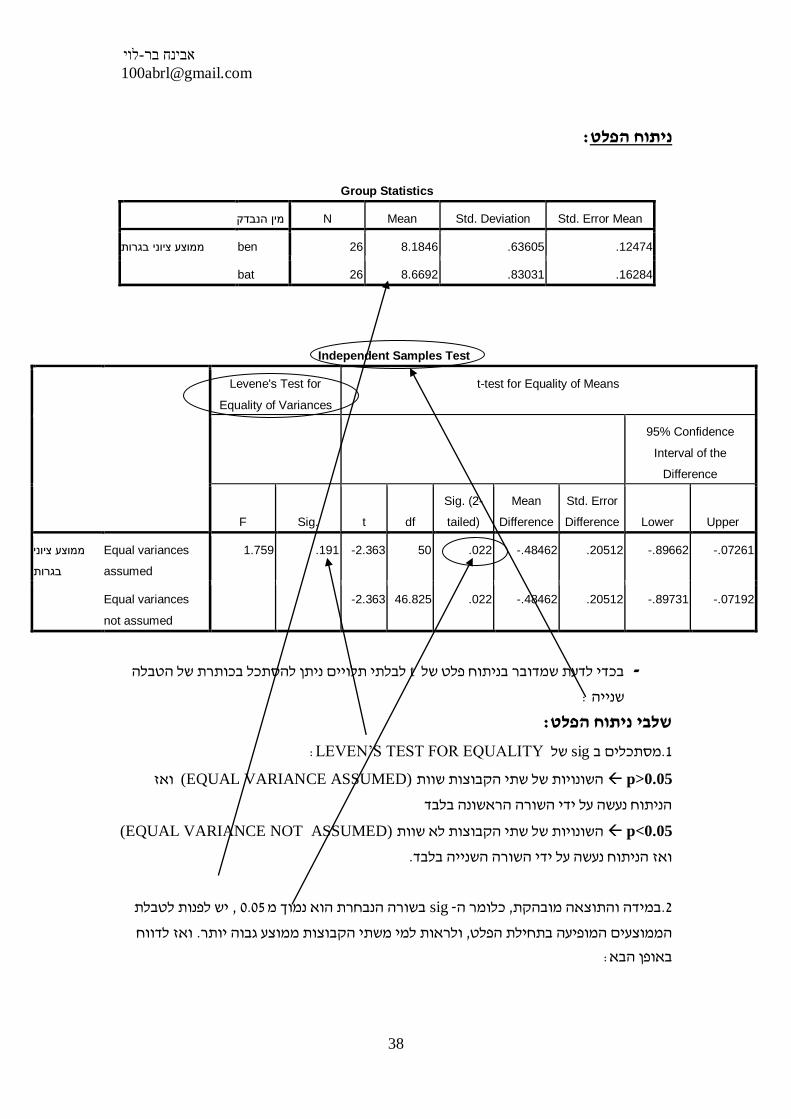
Group Statistics
N Mean Std. Deviation Std. Error Mean מין הנבדק
ben 26 8.1846 .63605 .12474 ממוצע ציוני בגרות
bat 26 8.6692 .83031 .16284
Independent Samples Test
Levene's Test for
Equality of Variances
t-test for Equality of Means
95% Confidence
Interval of the
Difference
F Sig. t df
Sig. (2-
tailed)
Mean
Difference
Std. Error
Difference Lower Upper
ממוצע ציוני
בגרות
Equal variances
assumed
1.759 .191 -2.363 50 .022 -.48462 .20512 -.89662 -.07261
Equal variances
not assumed
-2.363 46.825 .022 -.48462 .20512 -.89731 -.07192
לבלתי תלויים ניתן להסתכל בכותרת של הטבלה tבכדי לדעת שמדובר בניתוח פלט של -
:שנייה
: שלבי ניתוח הפלט
: LEVEN’S TEST FOR EQUALITY של sig מסתכלים ב.1
p>0.05 השונויות של שתי הקבוצות שוות(EQUAL VARIANCE ASSUMED) ואז
הניתוח נעשה על ידי השורה הראשונה בלבד
p<0.05 שונויות של שתי הקבוצות לא שוות ה(EQUAL VARIANCE NOT ASSUMED)
. ואז הניתוח נעשה על ידי השורה השנייה בלבד
יש לפנות לטבלת , 0.05 בשורה הנבחרת הוא נמוך מ sig- כלומר ה, במידה והתוצאה מובהקת.2
ואז לדווח .ולראות למי משתי הקבוצות ממוצע גבוה יותר, הממוצעים המופיעה בתחילת הפלט
: באופן הבא

לוי-אבינח בר
39
: אופן הדיווח
t בין נשים לגברים נערך מבחן בממוצע ציוני הבגרותעל מנת לבחון האם קיימים הבדלים
גבוה יותר באופן ( M=8.66, sd=0.83 )ממוצע הבגרות של בנות ונמצא כילמדגמים בלתי תלויים
(. .M=8.18, sd=0.63( )t(50)=-2.36, p<0.05 )מובהק מממוצע הבגרות של בנים
: היינו מדווחים כךבמידה וההבדל בין הקבוצות לא היה מובהק
t בין נשים לגברים נערך מבחן בממוצע ציוני הבגרותעל מנת לבחון האם קיימים הבדלים
(.p>0.05)ונמצא אין הבדל מובהק בין בנות ובנים בממוצע הבגרות למדגמים בלתי תלויים
לתלויים tמבחן
. ובוחן האם קיים הבדל בינם, מבחן המשווה ממוצעים של שתי קבוצות התלויות אחת בשניה
במצב שבו בקבוצה אחת , למשל, תלות קיימת כאשר ישנו קשר בין הנבדקים משתי הקבוצות
מצב שכיח נוסף קורה כאשר משווים בין שני ציונים של . ובשניה נחקרים בעליהן, נחקרות הנשים
. (משווים את ציוני הפסיכומטרי לפני ואחרי הקורס, לדוגמא)אותה קבוצה
Spss - ביצוע המבחן בתוכנת ה
: הפקודה
ANALYZE > COMPARE MEANS > PAIRED-SAMPLES T TEST
pasteומסיימים ב ובו נכניס ברצף את שני המשתנים : ואז נפתח החלון הבא
לוי-אבינח בר
40
:פלטה ניתוח
: לתלויים ניתן לראות כי כותרות הטבלה הן tבכדי לדעת כי הפלט הוא של מבחן -
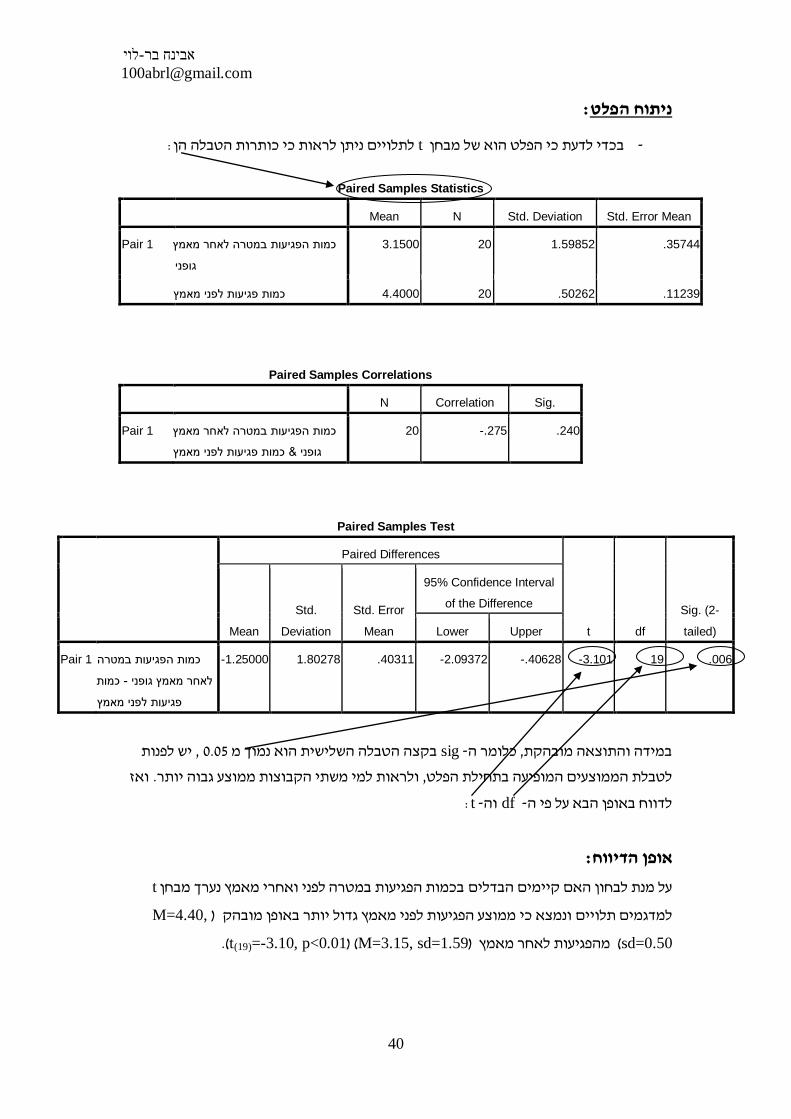
Paired Samples Statistics
Mean N Std. Deviation Std. Error Mean
Pair 1 כמות הפגיעות במטרה לאחר מאמץ
גופני
3.1500 20 1.59852 .35744
11239. 50262. 20 4.4000 כמות פגיעות לפני מאמץ
Paired Samples Correlations
N Correlation Sig.
Pair 1 כמות הפגיעות במטרה לאחר מאמץ
כמות פגיעות לפני מאמץ& גופני
20 -.275 .240
יש לפנות , 0.05 בקצה הטבלה השלישית הוא נמוך מ sig- כלומר ה, במידה והתוצאה מובהקת
ואז .ולראות למי משתי הקבוצות ממוצע גבוה יותר, לטבלת הממוצעים המופיעה בתחילת הפלט
: t- וה df - לדווח באופן הבא על פי ה
: אופן הדיווח
t נערך מבחן לפני ואחרי מאמץ בכמות הפגיעות במטרהעל מנת לבחון האם קיימים הבדלים
,M=4.40 )ממוצע הפגיעות לפני מאמץ גדול יותר באופן מובהק ונמצא כילמדגמים תלויים
sd=0.50 ) מהפגיעות לאחר מאמץ ( M=3.15, sd=1.59( )t(19)=-3.10, p<0.01 .)
Paired Samples Test
Paired Differences
t df
Sig. (2-
tailed)
Mean
Std.
Deviation
Std. Error
Mean
95% Confidence Interval
of the Difference
Lower Upper
Pair 1 כמות הפגיעות במטרה
כמות - לאחר מאמץ גופני
פגיעות לפני מאמץ
-1.25000 1.80278 .40311 -2.09372 -.40628 -3.101 19 .006

לוי-אבינח בר
41
CROSSTABS : טבלת צילווח וחי בריבוע לאי תלות
. באחוזיםבמספרים וגם גם מציגה שכיחות משותפת של שני משתנים קטגוריאלייםהפקודה
כלומר לבדוק האם קיים : בין שני המשתנים, בעזרת חי בריבועניתן להפיק מתאם קרמר, כמו כן
. משתנים קטגוריאליים2בין (קשר)תלות
Spss - ביצוע המבחן בתוכנת ה
: הפקודה
Analyze ----- descriptive statistics ------- crosstabs
ובו מכניסים את שני המשתנים הקטגוריאליים לחלונות הימניים : ואז נפתח החלון הבא
בדוגמא )ואחד לטורים של הטבלה )בדוגמא מצב משפחתי)כאשר אחד מוכנס לשורות הטבלה
: (מין הנבדק
: ונפתח החלון הבאststisticsלוחצים על , במידה ומעוניינים לבדוק קשר בין המשתנים

לוי-אבינח בר
42
continueולוחצים על phi and cramer- ואת chi square –את ה " וי"ומסמנים ב
: ונפתח החלון הבאcellלוחצים על , כמו כן
" . וי" ב percentages– ובו מסמנים את שלושת ה

לוי-אבינח בר
43
:פלטה ניתוח
מוצגת טבלת פילוח של המשתנים הקטגוריאליים (הראשונה המוצגת כאן)בטבלה השנייה
: שנבחרו גם באחוזים וגם במספרים
Crosstabulationמין הנבדק * מצב משפחתי
מין הנבדק
Total נקבה זכר
Count 20 7 27 רווק מצב משפחתי
% within 100.0% 25.9% 74.1% משפחתי מצב
% within 45.0% 23.3% 66.7% הנבדק מין
% of Total 33.3% 11.7% 45.0%
Count 5 18 23 נשוי
% within 100.0% 78.3% 21.7% משפחתי מצב
% within 38.3% 60.0% 16.7% הנבדק מין
% of Total 8.3% 30.0% 38.3%
Count 5 5 10 גרוש
% within 100.0% 50.0% 50.0% משפחתי מצב
% within 16.7% 16.7% 16.7% הנבדק מין
% of Total 8.3% 8.3% 16.7%
Total Count 30 30 60
% within 100.0% 50.0% 50.0% משפחתי מצב
% within 100.0% 100.0% 100.0% הנבדק מין
% of Total 50.0% 50.0% 100.0%
: הטבלה הראשונה כוללת
( רווקים שהם זכרים20לדוגמא ישנם ) את השכיחות במספרים בכל תא .א
74.1%, מיתוך הרווקים: לדוגמא) מתוך המשתנה שבשורות% התייחסות לשכיחות ב .ב
(הם זכרים
הם 66.7%, מיתוך הזכרים: לדוגמא) מתוך המשתנה שבטורים% התייחסות לשכיחות ב .ג
(רווקים
מיתוך כלל הנבדקים במחקר : לדוגמא) כ המדגם"מתוך סה% התייחסות לשכיחות ב .ד
( הם גברים רווקים33.3%

לוי-אבינח בר
44
: הטבלה השנייה והשלישית כוללת
את דרגות החופש ואת רמת המובהקות , מסתכלים בשורה הראשונה שכוללת את ערך החי בריבוע
בטבלה השלישית רואים בשורה הראשונה את עוצמת . שמגלה לנו האם יש תלות בין המשתנים
: הקשר בין המשתנים
Chi-Square Tests
Value df
Asymp. Sig. (2-
sided)
Pearson Chi-Square 13.607a 2 .001
Likelihood Ratio 14.327 2 .001
Linear-by-Linear Association 5.164 1 .023
N of Valid Cases 60
a. 0 cells (.0%) have expected count less than 5. The minimum expected
count is 5.00.
Symmetric Measures
Value Approx. Sig.
Nominal by Nominal Phi .476 .001
Cramer's V .476 .001
N of Valid Cases 60
: אופן הדיווח
קיים קשר בין מין הנבדק למצב המשפחתי נערך מבחן חי בריבוע לאי תלות על מנת לבחון האם
(. x2(2)=13.60, p<0.05))ונמצא כי קיימת תלות בין המשתנים

לוי-אבינח בר
45
חד כיוונית (אנובה) ניתוח שונות
. ( קבוצות ומעלה3)במבחן זה נשתמש כאשר נרצה לגלות האם קיימים הבדלים בין כמה קבוצות
מקום )בתל אביב ובחיפה , תושבים באריאלבין (משתנה תלוי) האם קיימים הבדלי משקל , למשל
רמות זה 2) רמות או יותר 3כלומר משתנה בלתי תלוי אחד בעל . ( משתנה בלתי תלוי–מגורים
. ומשתנה תלוי אחד (t וניתוח שונות זה הרחבה של tמבחן
Spss - ביצוע המבחן בתוכנת ה
: הפקודה
ANALYZE >>>>> COMPARE MEANS >>>> > ONE WAY ANOVA
משכורת : בדוגמא)ובו מכניסים בחלון הימני העליון את המשתנה התלוי : ונפתח החלון הבא
ותיק , צעיר, גיל בקטגוריות: בדוגמא)ואת המשתנה הבלתי תלוי לחלון הימני התחתון (נוכחית
. (וזקן
לוי-אבינח בר
46
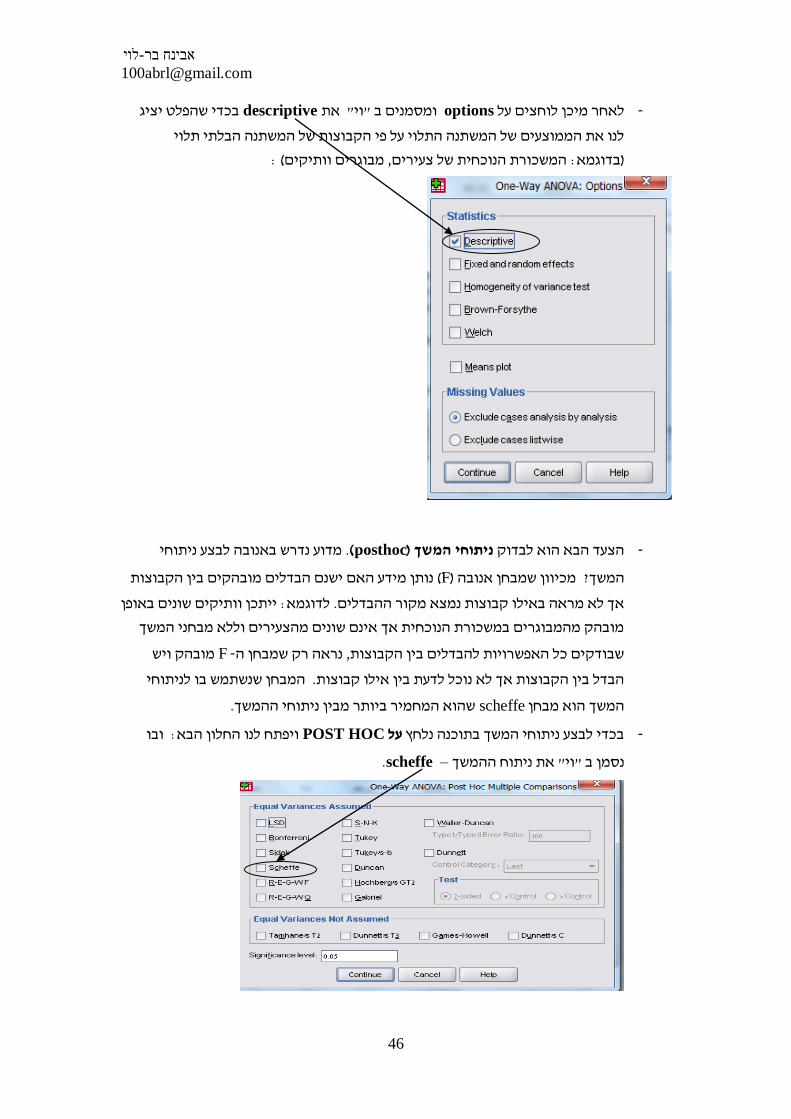
בכדי שהפלט יציג descriptiveאת " וי" ומסמנים ב optionsלאחר מיכן לוחצים על -
לנו את הממוצעים של המשתנה התלוי על פי הקבוצות של המשתנה הבלתי תלוי
: (מבוגרים וותיקים, המשכורת הנוכחית של צעירים: בדוגמא)
מדוע נדרש באנובה לבצע ניתוחי . (posthoc)ניתוחי המשך הצעד הבא הוא לבדוק -
נותן מידע האם ישנם הבדלים מובהקים בין הקבוצות ( F)מכיוון שמבחן אנובה ? המשך
ייתכן וותיקים שונים באופן : לדוגמא. אך לא מראה באילו קבוצות נמצא מקור ההבדלים
מובהק מהמבוגרים במשכורת הנוכחית אך אינם שונים מהצעירים וללא מבחני המשך
מובהק ויש F- נראה רק שמבחן ה, שבודקים כל האפשרויות להבדלים בין הקבוצות
המבחן שנשתמש בו לניתוחי . הבדל בין הקבוצות אך לא נוכל לדעת בין אילו קבוצות
. שהוא המחמיר ביותר מבין ניתוחי ההמשךscheffeהמשך הוא מבחן
ובו : ויפתח לנו החלון הבאPOST HOCעל בכדי לבצע ניתוחי המשך בתוכנה נלחץ -
. scheffe –את ניתוח ההמשך " וי"נסמן ב

לוי-אבינח בר
47
:פלטה ניתוח
ניתן לראות מהו המשתנה התלוי במחקר וכן לראות את הממוצעים בטבלה הראשונה
(ותיק ומבוגר, צעיר)וסטיות התקן וכן מספר הנבדקים של כל קבוצה
Descriptives
משכורת נוכחית
N
Mean Std. Deviation
Std. Error
95% Confidence Interval for
Mean
Minimum Maximum Lower Bound Upper Bound
36250 7260 13360.93 11828.98 388.044 5089.147 12594.95 172 צעיר
54000 6960 17612.15 15407.92 559.042 8081.979 16510.04 209 ותיק
26000 6300 10366.45 9182.37 298.092 2874.698 9774.41 93 מבוגר
Total 474 13767.83 6830.265 313.724 13151.36 14384.29 6300 54000
בין SS- מראה לנו את ה: ניתן לראות האם יש הבדלים מובהקים בין הקבוצותבטבלה השנייה
בין MSאת , בין הקבוצות ובתוך הקבוצות (DF)את דרגות החופש , הקבוצות ובתוך הקבוצות
. המחושב וכן את רמת המובהקותF -את ערך ה, ובתוך הקבוצות
ANOVA
משכורת נוכחית
Sum of Squares df Mean Square F Sig.
Between Groups 3291338110.020 2 1645669055.010 41.283 .000
Within Groups 18775301159.795 471 39862635.159
Total 22066639269.814 473
יש הבדל מובהק בין הקבוצות ובכדי לדעת בין אלו 0.05 הוא נמוך מ sigכאשר ה , כרגיל -
: ניתוחי ההמשך של בטבלה השלישיתנסתכל , קבוצות טמון ההבדל
לוי-אבינח בר
48
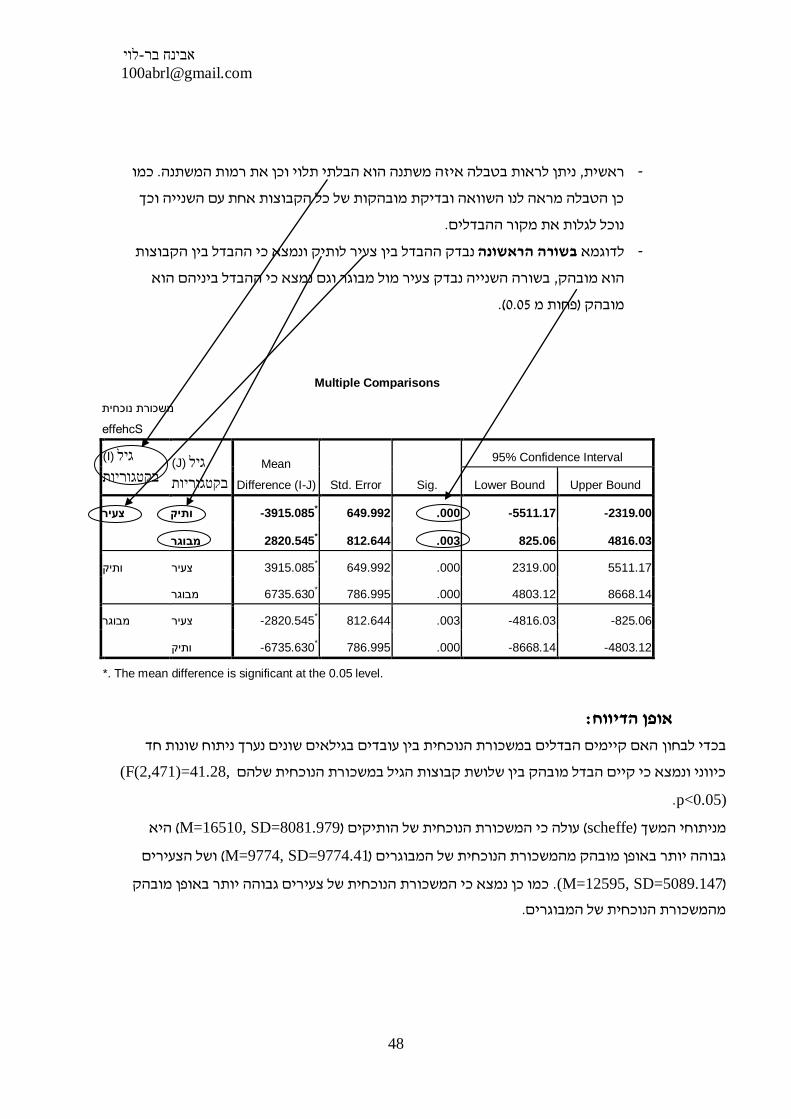
כמו . ניתן לראות בטבלה איזה משתנה הוא הבלתי תלוי וכן את רמות המשתנה, ראשית -
כן הטבלה מראה לנו השוואה ובדיקת מובהקות של כל הקבוצות אחת עם השנייה וכך
. נוכל לגלות את מקור ההבדלים
נבדק ההבדל בין צעיר לותיק ונמצא כי ההבדל בין הקבוצות בשורה הראשונהלדוגמא -
בשורה השנייה נבדק צעיר מול מבוגר וגם נמצא כי ההבדל ביניהם הוא , הוא מובהק
(. 0.05פחות מ )מובהק
Multiple Comparisons
משכורת נוכחית
effehcS
(I) גיל
בקטגוריות
(J) גיל
בקטגוריות
Mean
Difference (I-J) Std. Error Sig.
95% Confidence Interval
Lower Bound Upper Bound
3915.085- ותיק צעיר* 649.992 .000 -5511.17 -2319.00
2820.545 מבוגר* 812.644 .003 825.06 4816.03
3915.085 צעיר ותיק* 649.992 .000 2319.00 5511.17
6735.630 מבוגר* 786.995 .000 4803.12 8668.14
2820.545- צעיר מבוגר* 812.644 .003 -4816.03 -825.06
6735.630- ותיק* 786.995 .000 -8668.14 -4803.12
*. The mean difference is significant at the 0.05 level.
: אופן הדיווח
האם קיימים הבדלים במשכורת הנוכחית בין עובדים בגילאים שונים נערך ניתוח שונות חד חוןבכדי לב
,F(2,471)=41.28)כיווני ונמצא כי קיים הבדל מובהק בין שלושת קבוצות הגיל במשכורת הנוכחית שלהם
p<0.05) .
היא (M=16510, SD=8081.979)עולה כי המשכורת הנוכחית של הותיקים (scheffe)מניתוחי המשך
ושל הצעירים (M=9774, SD=9774.41)גבוהה יותר באופן מובהק מהמשכורת הנוכחית של המבוגרים
((M=12595, SD=5089.147 . כמו כן נמצא כי המשכורת הנוכחית של צעירים גבוהה יותר באופן מובהק
. מהמשכורת הנוכחית של המבוגרים