sql server 2016download.microsoft.com/download/f/d/3/fd3b890b-2043-4d0c...sql server 2016...
TRANSCRIPT

SQL Server 2016 自習書シリーズ No.2
Operational Analytics ~OLTP とデータ分析の両立~
Published: 2016 年 9 月 30 日
有限会社エスキューエル・クオリティ
SQL Server 2016

SQL Server 2016 自習書 No.2 Operational Analytics
2
この文章に含まれる情報は、公表の日付の時点での Microsoft Corporation の考え方を表しています。市場の変化に応える必要
があるため、Microsoft は記載されている内容を約束しているわけではありません。この文書の内容は印刷後も正しいとは保障で
きません。この文章は情報の提供のみを目的としています。
Microsoft、SQL Server、Visual Studio、Windows、Windows XP、Windows Server、Windows Vista は Microsoft Corporation
の米国およびその他の国における登録商標です。
その他、記載されている会社名および製品名は、各社の商標または登録商標です。
この文章内での引用(図版やロゴ、文章など)は、日本マイクロソフト株式会社からの許諾を受けています。
© Copyright 2016 Microsoft Corporation. All rights reserved.

SQL Server 2016 自習書 No.2 Operational Analytics
3
目次
STEP 1. SQL Server 2016 Operational Analytics の概要 ........................................................ 4
1.1 SQL Server 2016 評価版のダウンロード ..................................................................... 5
1.2 SQL Server 2016 で提供された主な新機能 ................................................................. 11
1.3 Operational Analytics の概要 ~OLTP とデータ分析の両立~ .......................................... 13
STEP 2. Operational Analytics の検証の詳細 ....................................................................... 22
2.1 Operational Analytics の検証の詳細 .......................................................................... 23
2.2 インメモリ OLTP の検証(もちろん OLTP に強い) ..................................................... 27
2.3 Operational Analytics の検証環境 ............................................................................. 35
2.4 Operational Analytics を試す方法 ............................................................................. 36
2.5 Operational Analytics を試すスクリプト .................................................................... 49
STEP 3. 列ストア インデックスを 利用した Operational Analytics .......................................... 56
3.1 列ストア インデックスを利用した Operational Analytics ............................................... 57
3.2 列ストア インデックスの基本的な利用方法 .................................................................. 59
3.3 列ストア インデックスの性能比較 .............................................................................. 62
3.4 列ストア インデックスでのデータ更新とインデックスの再構築 ........................................ 78
3.5 BULK INSERT で 10 万件分のデータを一括インポート .................................................. 82
3.6 インメモリ OLTP の利用 ......................................................................................... 87
STEP 4. インメモリ OLTP の基本操作 ................................................................................ 91
4.1 インメモリ OLTP の主な特徴 ................................................................................... 92
4.2 インメモリ OLTP の基本操作 ................................................................................... 94
4.3 メモリ最適化テーブルの作成/性能比較 ...................................................................... 97
4.4 テーブル サイズ(メモリ使用量)の確認 ................................................................... 102
4.5 ネイティブ コンパイル ストアド プロシージャによる性能向上 ...................................... 104
4.6 データの永続化(SCHEMA_AND_DATA) ................................................................. 111
4.7 メモリ最適化テーブルでの同時更新(Write-Write 競合) ............................................. 118

SQL Server 2016 自習書 No.2 Operational Analytics
4
STEP 1. SQL Server 2016
Operational Analytics の概要
この STEP では、SQL Server の最新バージョンである「SQL Server 2016」
で提供される「Operational Analytics」機能の概要を説明します。
この STEP では、次のことを学習します。
SQL Server 2016 評価版のダウンロード
SQL Server 2016 の主な新機能
Operational Analytics の概要

SQL Server 2016 自習書 No.2 Operational Analytics
5
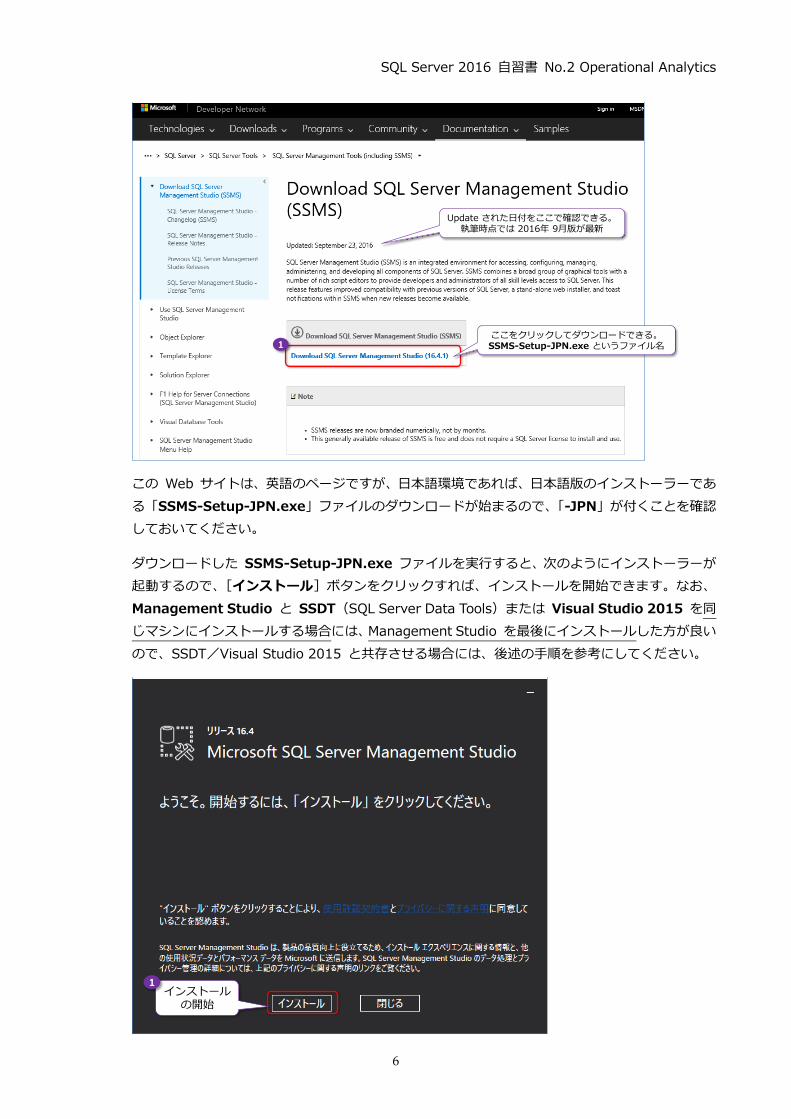
1.1 SQL Server 2016 評価版のダウンロード
SQL Server の最新バージョンである 「SQL Server 2016」は、2016 年 6 月に発売されました。
SQL Server 2016 を評価するための評価版 (Evaluation Edition)は、次の URL からダウンロー
ドすることができます。
評価版のダウンロード:Microsoft SQL Server 2016
http://www.microsoft.com/ja-jp/evalcenter/evaluate-sql-server-2016
Management Studio はダウンロード提供に変更
SQL Server 2016 からは、Management Studio (SQL Server の管理ツール)がダウンロード版
の提供のみに変更されました。これは、クラウド (Microsoft Azure の提供する各種サービス)の
アップデートにイチ早く対応したり、製品へのフィードバックをイチ早く反映させるためです。執
筆時点 (2016 年 9 月)では、2016 年 6 月に提供された RTM (製品)版を皮切りに、7 月、8 月、
9 月と、1 ヶ月ごとに Update 版の Management Studio が提供されています(今後も定期的な
間隔での最新版の提供が予定されています)。
最新版の Management Studio は、次の URL からダウンロードすることができます。
Management Studio の最新版のダウンロード
http://msdn.microsoft.com/en-us/library/mt238290.aspx
SQL Server 2016 自習書 No.2 Operational Analytics
6
この Web サイトは、英語のページですが、日本語環境であれば、日本語版のインストーラーであ
る 「SSMS-Setup-JPN.exe」ファイルのダウンロードが始まるので、 「-JPN」が付くことを確認
しておいてください。
ダウンロードした SSMS-Setup-JPN.exe ファイルを実行すると、次のようにインストーラーが
起動するので、[インストール]ボタンをクリックすれば、インストールを開始できます。なお、
Management Studio と SSDT(SQL Server Data Tools)または Visual Studio 2015 を同
じマシンにインストールする場合には、Management Studio を最後にインストールした方が良い
ので、SSDT/Visual Studio 2015 と共存させる場合には、後述の手順を参考にしてください。
1
Update された日付をここで確認できる。執筆時点では 2016年 9月版が最新
ここをクリックしてダウンロードできる。SSMS-Setup-JPN.exe というファイル名
インストールの開始
1

SQL Server 2016 自習書 No.2 Operational Analytics
7
Management Studio のインストール中は、次のように進行状況が表示されます。
「セットアップが完了しました」と表示されれば、Management Studio のインストールが完了で
す(環境によっては、完了後に再起動が促される場合があります)。
SSDT/Visual Studio 2015 と共存する場合は、インストール順に注意
SSDT (SQL Server Data Tools)は、SQL Server 2008 R2 までは、BIDS (Business Intelligence
Development Studio)と呼ばれていた BI 向け(Reporting Services や Analysis Services、
Integration Services)のプロジェクトを作成するためのツールです。SQL Server 2012 と 2014
では、データベース プロジェクト(.dacpac)を作成するための SSDT と、BIDS の後継ツール
となる SSDT-BI の 2 種類の SSDT がありましたが、SQL Server 2016 からは 1 つの SSDT
に統合されました(SSDT のダウンロードおよびインストール方法については後述します)。
執筆時点(2016 年 9 月)での Management Studio の最新版では、SSDT または Visual
Studio 2015 を同じマシンにインストールする場合には、Management Studio をインストール
する前に、SSDT または Visual Studio 2015 を先にインストールしておく必要があります。も
し、Management Studio を先にインストールした後に、後から SSDT や Visual Studio 2015
をインストールする場合には、インストールに失敗してしまうからです。
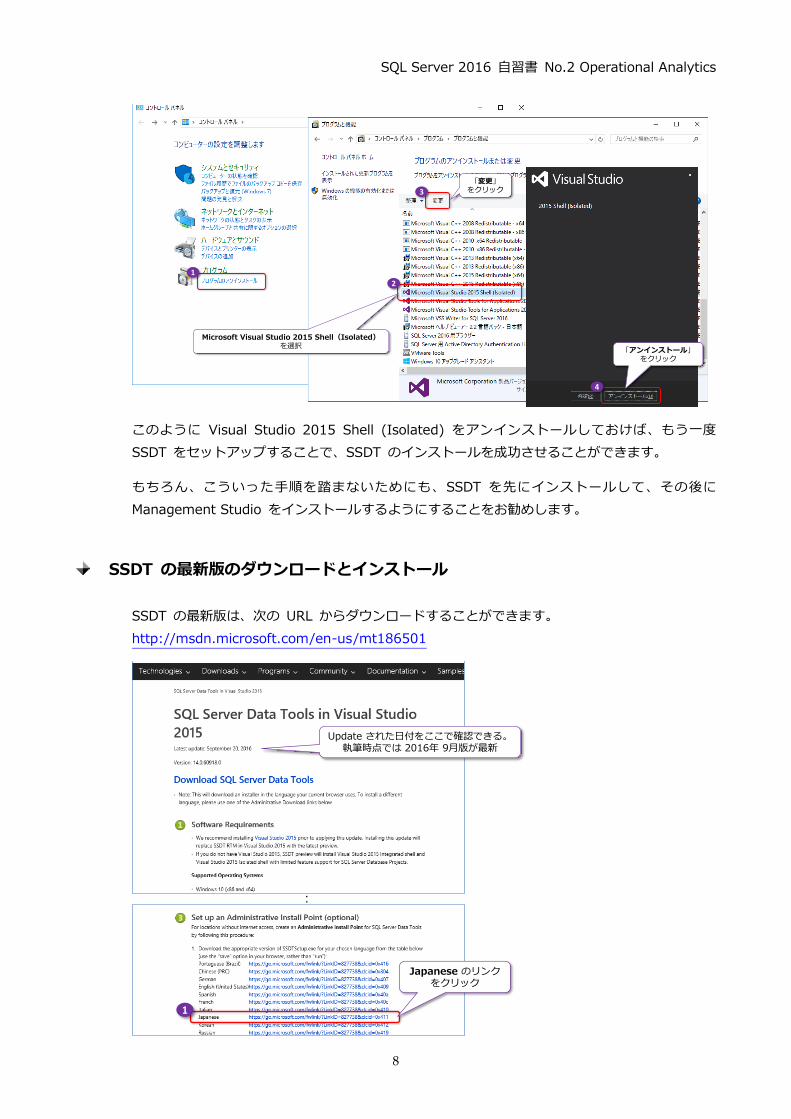
なお、SSDT のインストールに失敗してしまった場合には、次のように [コントロール パネル]の
[プログラムのアンインストール]から[Microsoft Visual Studio 2015 Shell (Isolated)]
を選択して、[変更]ボタンをクリックし、Visual Studio 2015 Shell (Isolated) をアンインスト
ールするようにします。
インストール中の画面
インストールが完了すると「セットアップが完了しました」
と表示される
SQL Server 2016 自習書 No.2 Operational Analytics
8
このように Visual Studio 2015 Shell (Isolated) をアンインストールしておけば、もう一度
SSDT をセットアップすることで、SSDT のインストールを成功させることができます。
もちろん、こういった手順を踏まないためにも、SSDT を先にインストールして、その後に
Management Studio をインストールするようにすることをお勧めします。
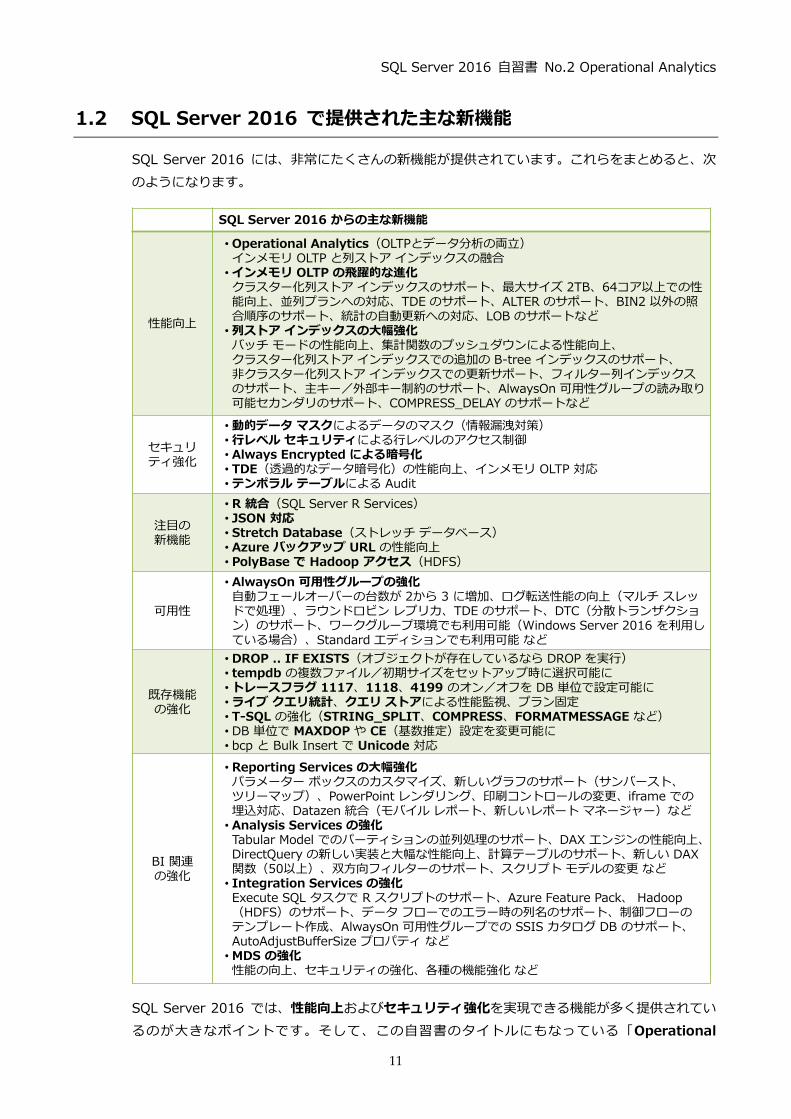
SSDT の最新版のダウンロードとインストール
SSDT の最新版は、次の URL からダウンロードすることができます。
http://msdn.microsoft.com/en-us/mt186501
1
2
3
4
Microsoft Visual Studio 2015 Shell(Isolated)を選択
「アンインストール」をクリック
「変更」をクリック
:
1
Japanese のリンクをクリック
Update された日付をここで確認できる。執筆時点では 2016年 9月版が最新

SQL Server 2016 自習書 No.2 Operational Analytics
9
この Web サイトも英語のページですが、Japanese のリンクをクリックすれば、日本語版のイン
ストーラー(SSDTSetup.exe)をダウンロードすることができます。
ダウンロードした SSDTSetup.exe ファイルをダブル クリックすると、次のようにインストー
ルを開始することができます。
インストール中は、次のように進行状況が表示されます (最初にファイルのダウンロードが行われ
るので、数十分ぐらい時間がかかります)。
1
23
インストールする機能の選択

SQL Server 2016 自習書 No.2 Operational Analytics
10
「セットアップに成功しました」と表示されれば、SSDT のインストールが完了です (環境によっ
ては、完了後に再起動が促される場合があります)。
Management Studio と SSDT、Visual Studio 2015 の 3 つを共存させる場合
Management Studio と SSDT、Visual Studio 2015 の 3 つを共存させる場合には、Visual
Studio 2015 を一番最初にインストールしておくことが重要です。これを行っておけば、
Management Studio の後に SSDT をインストールしても、インストールに失敗しません。
もし、SSDT や Management Studio をインストール済みの環境に、後から Visual Studio 2015
をインストールしなければいけない場合には、Visual Studio 2015 の Update 2 以降が組み込ま
れたインストーラー (with Update 2 または with Update 3 など)を利用するようにしてくだ
さい。Visual Studio 2015 の with Update 1 のインストーラーを利用する場合は、インストー
ルに失敗してしまうので注意してください。
なお、Visual Studio 2015 のインストールに失敗してしまった場合は、SSDT のときと同様、
Visual Studio 2015 Shell (Isolated) のアンインストールを行います。Visual Studio 2015 の場
合は、これに加えて、Visual Studio 2015 自体(中途半端にインストールされてしまった Visual
Studio 2015)もアンインストールを行います。これを行った後に、Visual Studio 2015 のインス
トールを再度実行すれば、今度はインストールを成功させることができます。こうした事態になら
ないためにも、with Update 2 以降のインストーラーを利用する、あるいは Visual Studio 2015
を先にインストールしておくようにすることをお勧めします。
インストールが完了すると「セットアップに成功しました」
と表示される
インストール中の画面。最初にファイルのダウンロードが行われるので時間がかかる
SQL Server 2016 自習書 No.2 Operational Analytics
11
1.2 SQL Server 2016 で提供された主な新機能
SQL Server 2016 には、非常にたくさんの新機能が提供されています。これらをまとめると、次
のようになります。
SQL Server 2016 では、性能向上およびセキュリティ強化を実現できる機能が多く提供されてい
るのが大きなポイントです。そして、この自習書のタイトルにもなっている「Operational
SQL Server 2016 からの主な新機能
性能向上
• Operational Analytics(OLTPとデータ分析の両立)インメモリ OLTP と列ストア インデックスの融合
•インメモリ OLTP の飛躍的な進化クラスター化列ストア インデックスのサポート、最大サイズ 2TB、64コア以上での性能向上、並列プランへの対応、TDE のサポート、ALTER のサポート、BIN2 以外の照合順序のサポート、統計の自動更新への対応、LOB のサポートなど
•列ストア インデックスの大幅強化バッチ モードの性能向上、集計関数のプッシュダウンによる性能向上、クラスター化列ストア インデックスでの追加の B-tree インデックスのサポート、非クラスター化列ストア インデックスでの更新サポート、フィルター列インデックスのサポート、主キー/外部キー制約のサポート、AlwaysOn 可用性グループの読み取り可能セカンダリのサポート、COMPRESS_DELAY のサポートなど
セキュリティ強化
•動的データ マスクによるデータのマスク(情報漏洩対策)•行レベル セキュリティによる行レベルのアクセス制御• Always Encrypted による暗号化• TDE(透過的なデータ暗号化)の性能向上、インメモリ OLTP 対応•テンポラル テーブルによる Audit
注目の新機能
• R 統合(SQL Server R Services)• JSON 対応• Stretch Database(ストレッチ データベース)• Azure バックアップ URL の性能向上• PolyBase で Hadoop アクセス(HDFS)
可用性
• AlwaysOn 可用性グループの強化自動フェールオーバーの台数が 2から 3 に増加、ログ転送性能の向上(マルチ スレッドで処理)、ラウンドロビン レプリカ、TDE のサポート、DTC(分散トランザクション)のサポート、ワークグループ環境でも利用可能(Windows Server 2016 を利用している場合)、Standard エディションでも利用可能 など
既存機能の強化
• DROP .. IF EXISTS(オブジェクトが存在しているなら DROP を実行)• tempdb の複数ファイル/初期サイズをセットアップ時に選択可能に•トレースフラグ 1117、1118、4199 のオン/オフを DB 単位で設定可能に•ライブ クエリ統計、クエリストアによる性能監視、プラン固定• T-SQL の強化(STRING_SPLIT、COMPRESS、FORMATMESSAGE など)• DB 単位で MAXDOP や CE(基数推定)設定を変更可能に• bcp と Bulk Insert で Unicode 対応
BI 関連の強化
• Reporting Services の大幅強化パラメーター ボックスのカスタマイズ、新しいグラフのサポート(サンバースト、ツリーマップ)、PowerPoint レンダリング、印刷コントロールの変更、iframe での埋込対応、Datazen 統合(モバイル レポート、新しいレポート マネージャー)など
• Analysis Services の強化Tabular Model でのパーティションの並列処理のサポート、DAX エンジンの性能向上、DirectQuery の新しい実装と大幅な性能向上、計算テーブルのサポート、新しい DAX関数(50以上)、双方向フィルターのサポート、スクリプト モデルの変更 など
• Integration Services の強化Execute SQL タスクで R スクリプトのサポート、Azure Feature Pack、 Hadoop(HDFS)のサポート、データ フローでのエラー時の列名のサポート、制御フローのテンプレート作成、AlwaysOn 可用性グループでの SSIS カタログ DB のサポート、AutoAdjustBufferSize プロパティ など
• MDS の強化性能の向上、セキュリティの強化、各種の機能強化 など

SQL Server 2016 自習書 No.2 Operational Analytics
12
Analytics」(OLTP とデータ分析の両立)が一番の目玉機能で、Operational Analytics は今後の
データベースのあり方を大きく変えるのではないかと思えるほど、非常に大きな可能性を感じさせ
るものです(次の項以降で詳しく説明します)。
セキュリティに関しては、マイナンバーや各種の情報漏洩事件など、業界全体のセキュリティ意識
の高まりもあって、ここ数年弊社へのお問い合わせが非常に増えている分野です。SQL Server
2016 には、セキュリティを向上させることができる機能が数多く提供されているので、そういっ
たニーズに答えることができます。
その他、R 統合 (SQL Server R Services)や、JSON 対応、PolyBase、Hadoop 対応など、最
近のマイクロソフト社の方向性と同様、SQL Server でもオープン化が非常に進んでいます。
セキュリティや R 統合、JSON 対応、PolyBase、Hadoop 対応、T-SQL の強化などの既存の機能
の強化については、本自習書シリーズの No.1 「SQL Server 2016 新機能の概要」編で詳しく説
明しているので、こちらもぜひご覧いただければと思います。

SQL Server 2016 自習書 No.2 Operational Analytics
13
1.3 Operational Analytics の概要 ~OLTPとデータ分析の両立~
SQL Server 2016 の一番の目玉の新機能は「Operational Analytics」です。Operational は
「OLTP」(オンライン トランザクション処理)、Analytics は 「データ分析」と捕らえると分かり
やすい言葉で、機能面で言うと、 インメモリ OLTP」と 列ストア インデックス」の進化/融合
です(インメモリ OLTP と列ストア インデックスの良いとこどりをして、OLTP とデータ分析を
両立できるようにしたものです)。
これまでの SQL Server では、「Operational ワークロード」と「Analytics ワークロード」に
対しては、別々のテクノロジー/機能を利用して、使い分ける必要がありましたが (同時に利用す
るのが難しいところがありましたが)、SQL Server 2016 からは 「インメモリ OLTP」と 「列スト
ア インデックス」が飛躍的な進化を遂げたことで両立できるようになりました。具体的には、次の
3 つのパターンで実現することができます。
1. インメモリ OLTP + クラスター化列ストア インデックス(完全なインメモリ実装)
2. 通常リレーショナル テーブル + 非クラスター化列ストア インデックス
3. 通常リレーショナル テーブル + クラスター化列ストア インデックス
SQL Server 2014 までのインメモリ OLTP は、OLTP 向けのインメモリ リレーショナル データ
ベース エンジン、列ストア インデックスは、データ分析/集計に強いカラム指向データベースの
SQL Server 実装として別々に提供されてきましたが、SQL Server 2016 からは、インメモリ
OLTP と列ストア インデックスが融合して、それぞれの良いとこどりをして (OLTP にもデータ分
析にも強くなって)、完全なインメモリで Operational Analyticsを実現 (OLTP とデータ分析を
両立)できるようになりました。
また、これまでは読み取り専用として提供されていた 「非クラスター化列ストア インデックス」が、
SQL Server 2016 からは更新可能になったことで、通常のリレーショナル テーブルに、容易に列
ストア インデックスを追加できるようになりました。これによって、従来ながらの b-tree インデ
ックスを追加するのと同じような感覚で、列ストア インデックスを追加できるようになって、これ
を追加すれば、Analytics ワークロード (データ集計/分析クエリ)の性能を大幅に向上させるこ
とができます(Operational Analytics の実現)。
また、SQL Server 2016 では、列ストア インデックスそのものの性能向上(バッチ モードの強
化、プッシュダウン、更新性能の向上、パラレル Insert など)も実現しているので、現在の SQL
Operational Analytics(OLTPとデータ分析の両立)
Operational ワークロード= OLTP(オンライン トランザクション処理)など
Analytics ワークロード= データ集計/分析処理、DWH、夜間バッチなど
SQL Server 2016 では両立可能次の 3パターンで実装できる1. インメモリ OLTP + クラスター化列ストア インデックス(完全なインメモリ実装)2. 通常リレーショナル テーブル + 非クラスター化列ストア インデックス3. 通常リレーショナル テーブル + クラスター化列ストア インデックス
SQL Server 2014 まではインメモリ OLTP や通常リレーショナル テーブルを利用
SQL Server 2014 までは列ストア インデックスやAnalysis Services などを利用

SQL Server 2016 自習書 No.2 Operational Analytics
14
Server で性能に問題を抱えているという方には、ぜひ試してみてほしい機能です。
インメモリ OLTP の飛躍的な進化 ~Analytics ワークロードにも対応~
インメモリ OLTP は、SQL Server 2014 から提供されたものですが、SQL Server 2014 のとき
には、(最初のバージョンであったこともあり)制限事項が非常に多くありました。SQL Server
2016 からは、そういった制限事項が大きく取り払われて、インメモリ OLTP が飛躍的に進化しま
した。一番の進化は、前述したようにクラスター化列ストア インデックスを追加できるようになっ
たことで(完全なインメモリでの Operational Analytics の実現)、その他の具体的な強化内容
は、次のとおりです。
SQL Server 2016 からのインメモリ OLTP の強化ポイント
インメモリ OLTP で列ストア インデックスのサポート(インメモリ OLTP のメモリ最
適化テーブルにクラスター化列ストア インデックスを追加可能に)
最大サイズが 2TB に拡張(大量データへの対応)
64コア以上での性能向上に対応(スケールアップが可能)
並列プランへの対応(メニー コアの活用が可能に)
TDE(透過的なデータ暗号化)のサポート(セキュリティの強化)
ALTER/BIN2 以外の照合順序のサポート (既存環境からの移行しやすさが大幅に向上)
統計の自動更新のサポートや、LOB のサポート (varchar(max) や varbinary(max) な
どのラージ オブジェクトのサポート)
SQL Server 2014 のときには、制限事項の多さや、大規模環境でのスケール面 (64 コア以上だと
スケールしない)、集計クエリでの性能面 (並列プランに未対応)など、既存環境 (ディスク ベー
スのテーブル)をインメモリに移行するのが難しかったところがありましたが、SQL Server 2016
からは、そういった制限事項が大きく取り払われました。特に ALTER のサポートや BIN2 以外
の照合順序のサポートは、移行という観点で非常に大きく、SQL Server 2014 のときには、これ
が原因で移行を断念しているというお客さんを見てきたので、SQL Server 2016 からは格段と移
行しやすくなりました。
また、SQL Server 2016 からはインメモリ OLTP の最大サイズが 2TB に増えたことで(SQL
Server 2014 のときは 512GBが最大サイズ)、データ量が多くてもインメモリ OLTP に移行で
きるようになりました。
検証結果:インメモリ OLTP + クラスター化列ストア インデックス
実際に、SQL Server 2016 のインメモリ OLTP とクラスター化列ストア インデックス(完全な
インメモリでの Operational Analytics の実装)を利用して、どれぐらいの性能が出るのかを検証
してみたのが、次のグラフです。

SQL Server 2016 自習書 No.2 Operational Analytics
15
このグラフは、SQL Server 2016 の RTM(製品版)に CU1(累積的な修正プログラム 1)を
適用したものと、SQL Server 2014 に SP1 を適用したものを利用して、1 億件のデータに対す
る GROUP BY 演算 (データ集計処理)を行った結果です (テーブル構成や実行した SQL の詳細
は後述します)。
ディスク ベースの通常テーブルでは 1.97 秒かかった集計処理が、インメモリ OLTP にすること
で 1.58 秒(19.8%の性能向上)、さらに列ストア インデックス(クラスター化列ストア インデ
ックス)を作成することで、わずか 197ミリ秒で処理できるようになり、10 倍もの性能向上を確
認することができました。これに対して、SQL Server 2014 では、2.03 秒かかっていた処理が、
インメモリ OLTP を利用することで 38.36 秒もかかってしまい、18.9 倍も遅い結果になってし
まっています(SQL Server 2014 で遅くなる理由については後述します)。
このように、SQL Server 2016 のインメモリ OLTP は、クラスター化列ストア インデックスを
追加できるようになったことで、データ分析/集計(Analytics ワークロード)にも強くなりまし
た。
列ストア インデックスの進化 ~カラム指向とリレーショナルDBの融合~
列ストア インデックス (Column-store Index)は、大量のデータを分析/集計するときに強さを
発揮するカラム指向データベースの SQL Server 実装として、SQL Server 2012 のときに提供
されたものです。列ストア インデックスは、「xVelocity 列ストア インデックス」と呼ばれるこ
ともあり、PowerPivot および Analysis Services の Tabular Mode(テーブル モード)で採用
されているインメモリの BI エンジンである 「xVelocity エンジン」を RDB (リレーショナル デ
ータベース)に応用したものです。なお、このエンジンは、SQL Server 2008 R2 のときに開発さ
れて(PowerPivot for Excel として実装)、その当時は VertiPaq エンジンと呼ばれていました。
列ストア インデックスの xVelocity エンジンでは、次のように列単位でインデックスを格納し、
構成できない
SQL Server 2014 のインメモリ OLTPは
全件スキャンに弱かった
SQL Server 2016 のインメモリ OLTPは
全件スキャンに強くなりディスク ベースと遜色なし
SQL Server 2016 のインメモリ OLTPは
列ストア インデックスを作成することで 10倍の性能向上
* ベンチマークの結果の公表は、使用許諾契約書で禁止されていますが、その効果をわかりやすく表現するため、日本マイクロソフト株式会社の監修のもと、数値を掲載しております。
■ テスト内容1億件のデータに対してGROUP BY 集計を実行(詳細は本文に記載)
■ テスト環境日立様提供のサーバー機(詳細は本文に記載)CPU:24コア (Xeon E5-2697 v2)メモリ: 128GBフラッシュストレージ (FC 8Gbps)ソフトウェア:
SQL Server 2014 SP1SQL Server 2016 RTM CU1
10倍!
SQL Server 2016 自習書 No.2 Operational Analytics
16
それらは高度に圧縮されています。
このインデックスによって、大量のデータに対する集計処理 (GROUP BY 演算など)の性能を大
きく向上させることができます。性能が向上する理由は、次のような集計クエリを考えると分かり
やすいと思います。
列ストア インデックス (カラム ストア)であれば、集計対象となる列データを読み込むだけで済
み、かつそのデータは高度に圧縮されているので、読み込み時間を大幅に短縮することができます。
例えば、弊社のお客様 (100億件の DWH)では、列ストア インデックスを作成することで、531GB
のテーブル(Row ストア)が 90GB(カラム ストア)へと、約 1/6 のサイズにまで圧縮するこ
とができています。このことからも、読み込み量を小さくできることが分かると思います。
列ストア インデックスは、SQL Server 2012 では、読み取り専用モードの 「非クラスター化列ス
トア インデックス」のみがサポートされていましたが、SQL Server 2014 からは更新可能な列ス
トア インデックスとして 「クラスター化列ストア インデックス」が提供されました。そして、今
回の SQL Server 2016 からは、これらが大幅に強化されて、その主なものは次のとおりです。
インメモリ OLTP にクラスター化列ストア インデックスを作成可能に
(=完全なインメモリでの Operational Analytics の実装)
列ストア インデックスの性能向上(バッチ モードの性能向上、集計のプッシュダウン、
更新性能の向上、ウィンドウ関数のバッチ モード対応など)
非クラスター化列ストア インデックスが更新可能に
非クラスター化列ストア インデックスでフィルター列が利用可能に
テーブル
a b c
a b c
従来ながらの Row ストア
…
行単位で格納
カラム(Column)ストア
a b c
列単位で格納
高度に圧縮されている
列ストア インデックス(xVelocityエンジン)
集計クエリの動作の違い
集計クエリSELECT b, COUNT(*) FROM テーブルGROUP BY b
Row ストア
カラム ストア(列ストア インデックス)
a b c
Row ストアは行単位なので
すべての列(a, b, c)の読み込みが必要になる
カラム ストアなら列単位なので
b 列の読み込みのみで済む
しかも高度に圧縮されているので読み込みサイズが小さくなり
その分読み込み時間を速くできる
a b c…

SQL Server 2016 自習書 No.2 Operational Analytics
17
クラスター化列ストア インデックスでの追加の B-tree インデックスのサポート
主キー/外部キー制約のサポート
AlwaysOn 可用性グループの読み取り可能セカンダリのサポート
COMPRESS_DELAY(遅延圧縮)のサポート
これまでは Analytics ワークロード (データ集計/分析)に特化していた列ストア インデックス
が、SQL Server 2016 からは Operational ワークロード (OLTP)にも対応して、Operational
Analytics (OLTP とデータ分析の両立)を実現できるようになりました。特に、OLTP ワークロー
ドで強さを発揮する「インメモリ OLTP」にクラスター化列ストア インデックスを作成できるよ
うになったことが大きな進化で、その効果は前掲のグラフのとおりです。
また、従来は、読み取り専用で提供されていた 「非クラスター化列ストア インデックス」が更新可
能になったことで、今まで利用していたシステムに、容易に列ストア インデックスを追加できるよ
うになりました。現在、「データ分析/集計で時間がかかってしまっている」や 「夜間バッチの実行
に時間がかかってしまっている」などの悩みを抱えている場合には、まず非クラスター化列ストア
インデックスを作成してみることをお勧めします。夜間バッチの前に (バッチ実行時の最初の処理
として)非クラスター化列ストア インデックスを追加して、夜間バッチが完了したら削除する、と
いった使い方もできるので、性能に問題を抱えている場合は、ぜひ試してみてください。
既存環境からの移行という観点では、PRIMARY KEY 制約がサポートされるようになった点は大
きく、これまでの構成を大きく変更することなく移行できるようになりました。
今回の SQL Server 2016 の列ストア インデックスは、バッチ モードの性能向上や、更新性能の
向上も実現しているので、SQL Server 2014 のときに試したことがあるという方も、ぜひもう一
度試してみてください。
列ストア インデックスはハイブリッドな動作が可能
完全なインメモリでの Operational Analytics(インメモリ OLTP と列ストア インデックスの
組み合わせ)を利用する場合には、インメモリ OLTP が完全にインメモリで動作するので、メモリ
上の制限 (最大サイズが 2TB までという上限)を受けます。したがって、数 TB (テラバイト)規
模になるなど、メモリに載りきらないデータ量になる場合には、インメモリ OLTP を利用すること
ができません。
このような場合には、通常のリレーショナル テーブル (従来ながらのディスク ベースのテーブル)
に、列ストア インデックスを追加して、Operational Analytics を実現することができます。列ス
トア インデックスは、基本はインメモリで動作しますが (データ量が物理メモリに載りきる場合は
インメモリで動作)、メモリに載りきらないデータがあった場合には、ディスクを利用して動作させ
ることができるからです(ハイブリッドな動作ができます)。
このように性能向上に関するオプションが増えたことは、本当にワクワクします(今回の SQL
Server 2016 の進化は、今後のデータベースのあり方を左右するのではないかと思えるほど、非常
に大きな可能性を感じています)。
SQL Server 2016 自習書 No.2 Operational Analytics
18
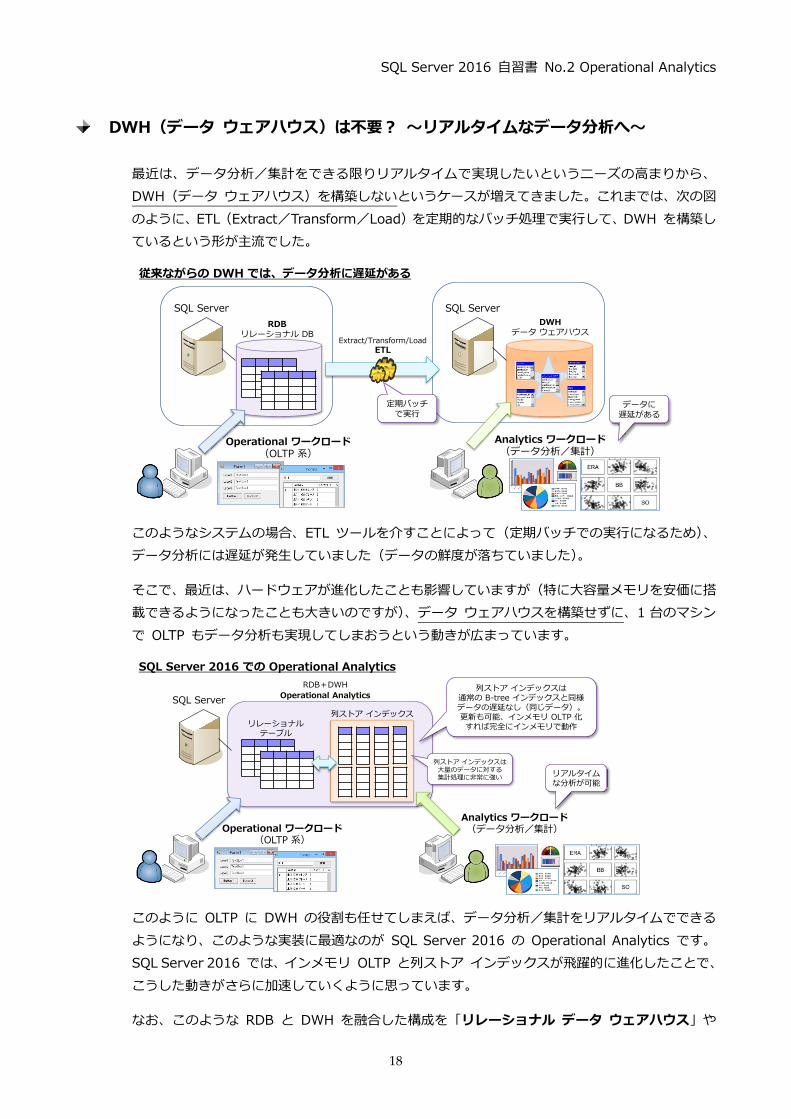
DWH(データ ウェアハウス)は不要? ~リアルタイムなデータ分析へ~
最近は、データ分析/集計をできる限りリアルタイムで実現したいというニーズの高まりから、
DWH (データ ウェアハウス)を構築しないというケースが増えてきました。これまでは、次の図
のように、ETL (Extract/Transform/Load)を定期的なバッチ処理で実行して、DWH を構築し
ているという形が主流でした。
このようなシステムの場合、ETL ツールを介すことによって(定期バッチでの実行になるため)、
データ分析には遅延が発生していました(データの鮮度が落ちていました)。
そこで、最近は、ハードウェアが進化したことも影響していますが (特に大容量メモリを安価に搭
載できるようになったことも大きいのですが)、データ ウェアハウスを構築せずに、1 台のマシン
で OLTP もデータ分析も実現してしまおうという動きが広まっています。
このように OLTP に DWH の役割も任せてしまえば、データ分析/集計をリアルタイムでできる
ようになり、このような実装に最適なのが SQL Server 2016 の Operational Analytics です。
SQL Server 2016 では、インメモリ OLTP と列ストア インデックスが飛躍的に進化したことで、
こうした動きがさらに加速していくように思っています。
なお、このような RDB と DWH を融合した構成を「リレーショナル データ ウェアハウス」や
DWHデータ ウェアハウス
RDBリレーショナル DB
SQL Server
Extract/Transform/Load
ETL
SQL Server
Operational ワークロード(OLTP 系)
Analytics ワークロード(データ分析/集計)
定期バッチで実行
従来ながらの DWH では、データ分析に遅延がある
データに遅延がある
RDB+DWH
Operational AnalyticsSQL Server
Operational ワークロード(OLTP 系)
Analytics ワークロード(データ分析/集計)
SQL Server 2016 での Operational Analytics
リアルタイムな分析が可能
リレーショナルテーブル
列ストア インデックス
列ストア インデックスは通常の B-tree インデックスと同様データの遅延なし(同じデータ)。更新も可能、インメモリ OLTP 化すれば完全にインメモリで動作
列ストア インデックスは大量のデータに対する集計処理に非常に強い

SQL Server 2016 自習書 No.2 Operational Analytics
19
「Real-Time Operational Analytics」と呼んでいる人もいます。
SQL Server 2016 では 480 スレッドでもスケール
最近は、1 個の CPU あたりのコア数がどんどん増える ”メニー コア” 時代になりましたが、コア
数が増えてもスケールしないデータベースが存在する中(特に 64 コアを超える K グループ環境
に対応していないデータベースがある中)、SQL Server はメニー コア環境でも、K グループをま
たがったとしてもスケールします。昨年 (2015 年)に開催された SQL Server の世界最大規模の
イベントである「PASS Summit 2015」の基調講演では、480 スレッド分もの CPU を 100%
フル活用して、スケールしているデモが行われました(以下の写真)。
これはデータ分析/集計クエリを実行しているときの画面で、CPU をフル活用できていることが
分かります。1 個の CPU で 15 コア(30 スレッド)というのも時代の流れを感じますが、こうし
たメニー コアに対応できるのも SQL Server の大きな特徴です。
SQL Server 2016 は TPC-H ベンチマークの 10TB でワールド レコード
TPC-H は、データ ウェアハウス/意志決定支援システム向けのベンチマーク テストとして有名
なものですが、SQL Server 2016 は、10TB (テラ バイト)規模のベンチマーク テストで世界記
録 (ワールド レコード)を更新しました。執筆時点 (2016 年 9 月)では、Non-Clustered の 10TB
部門では、上位 1、2 位を SQL Server 2016、3 位~7 位を SQL Server 2014 が獲得して、SQL
Server だけで上位 1 位~7 位を独占しています(以下の URL で最新のベンチマーク結果を参照
できます)。
TPC-H - Top Ten Performance Results - Non-Clustered
http://www.tpc.org/tpch/results/tpch_perf_results.asp?resulttype=noncluster
この世界記録に関しては、SQL Server チームの Blog にも投稿されているので、以下の記事が参
考になると思います。
* PASS Summit 2015 の基調講演中のデモを筆者が撮影した写真
Hewlett-Packard 社の Superdome でXeon E7-2890v2 15コアの CPU を 16基
(合計240コア) 搭載したマシンでHyper-Threadingオンで 480スレッド分すべてのスレッドが 100% になってる様子
SQL Server 2016 自習書 No.2 Operational Analytics
20
SQL Server Team Blog:
SQL Server 2016 posts world record TPC-H 10 TB benchmark
http://blogs.technet.microsoft.com/dataplatforminsider/2016/07/18/sql-server-2016-
posts-world-record-tpc-h-10-tb-benchmark/

SQL Server 2016 自習書 No.2 Operational Analytics
21
Note: SQL Server のインメモリ技術の歴史は長い (CEP、BI、ビッグデータもカバー)
SQL Server では、既に多くのインメモリ技術が提供されています。3つ前のバージョンである
SQL Server 2008 R2 から提供された StreamInsight および PowerPivot に始まり、以下の
インメモリ技術が提供されています。
StreamInsight は、CEP(Complex Event Processing:複合イベント処理)を実現するこ
とができる機能で、SQL Server 2008 R2 から提供されています。CEP は、各種のセンサー
データや株取引情報、Web サーバーのログ(クリック ストリーム)などのように、絶え間な
く大量に流れてくるようなストリーム データ(イベント)を処理することができるアプリケー
ションのことを指し、StreamInsight は、インメモリで動作することで高速なイベント処理が
可能です。現在、StreamInsight は、Microsoft Azure 上のクラウド サービスである
「Stream Analytics」として利用することもできます(IoT:Internet of Things データの
処理に利用することができます)。
PowerPivot は、インメモリの BI 機能で、こちらも SQL Server 2008 R2 から提供されま
した。SQL Server 2008 R2 では、クライアント版の PowerPivot for Excel、サーバー版の
PowerPivot for SharePoint が提供され、数億件レベルのデータでも、非常に高速な集計処理
ができるインメモリの BI エンジン(インメモリで動作するカラムベースのエンジン)です。
PowerPivot のエンジンは、SQL Server 2012 からは、xVelocity エンジンへと名称変更・
改良されて、Analysis Services(分析サーバー)でも利用できるようになりました(テーブル
モデル:Tabular Model と呼ばれる)。これにより、ビッグデータ/より大量のデータにも対応
可能なサーバー版のインメモリ BI 機能が利用できるようになりました。そして、この
xVelocity エンジンを RDB に応用したのが「列ストア インデックス」です。
SQL Server 2014 からは、OLTP 向けの「インメモリ OLTP」が提供され、そして今回の
SQL Server 2016 では「インメモリ OLTP と列ストア インデックスの進化/融合」によっ
て、OLTP もデータ分析も両立できるようになりました。
このように、SQL Server のインメモリ技術の歴史は古く、CEP から BI、ビッグデータ、
OLTP まで、幅広くカバーしています。
SQL Server のインメモリ技術
StreamInsight PowerPivot
(VertiPaq Engine)
SQL Server
2008 R2
SQL Server
201 2
SQL Server
201 4
SQL Server
201 6
Analysis Services Tabular Mode(xVelocity Engine)
非クラスター化列ストア インデックス(読み取り専用)
インメモリ OLTP クラスター化列スト
ア インデックス(更新可能)
インメモリ OLTP とクラスター化列ストア インデックスの融合
インメモリ OLTP の性能向上 列ストア インデックスの性能向上 更新可能な非クラスター化列スト
ア インデックス

SQL Server 2016 自習書 No.2 Operational Analytics
22
STEP 2. Operational Analytics
の検証の詳細
この STEP では、SQL Server 2016 を利用して Operational Analytics の検証
を行った、その検証の詳細を説明します。また、インメモリ OLTP の検証として、
多重度 150 で 5,000 万件の INSERT を行った場合の性能も測定しているの
で、これについても説明します。
この STEP では、次のことを学習します。
Operational Analytics の検証内容
検証で利用したスクリプト
インメモリ OLTP の検証(多重度 150 で 5,000 万件の INSERT)
検証環境(株式会社 日立製作所様のハーモニアス・コンピテンス・センター)

SQL Server 2016 自習書 No.2 Operational Analytics
23
2.1 Operational Analytics の検証の詳細
1 章で紹介した Operational Analytics の検証結果を再掲します。
このグラフは、SQL Server 2016 の RTM(製品版)に CU1(累積的な修正プログラム 1)を
適用したものと、SQL Server 2014 に SP1 を適用したものを利用して、1 億件のデータに対す
る GROUP BY 演算 (データ集計処理)を行った結果です (テーブル構成や実行した SQL の詳細
は後述します)。
ディスク ベースの通常テーブルでは 1.97 秒かかった集計処理が、インメモリ OLTP にすること
で 1.58 秒(19.8%の性能向上)、さらに列ストア インデックスを作成することで、わずか 197
ミリ秒で処理できるようになり、10倍もの性能向上を確認することができました。
SQL Server 2014 では、2.03 秒かかっていた処理が、インメモリ OLTP を利用することで
38.36 秒もかかってしまい、18.9 倍も遅い結果になってしまっている理由は、スキャン性能の差
によるものですが、詳しくは後述します。
検証の詳細 ~テーブル構成、1億件のデータ~
検証で使用したテーブルは、次のように作成しています。
構成できない
SQL Server 2014 のインメモリ OLTPは
全件スキャンに弱かった
SQL Server 2016 のインメモリ OLTPは
全件スキャンに強くなりディスク ベースと遜色なし
SQL Server 2016 のインメモリ OLTPは
列ストア インデックスを作成することで 10倍の性能向上
* ベンチマークの結果の公表は、使用許諾契約書で禁止されていますが、その効果をわかりやすく表現するため、日本マイクロソフト株式会社の監修のもと、数値を掲載しております。
■ テスト内容1億件のデータに対してGROUP BY 集計を実行(詳細は本文に記載)
■ テスト環境日立様提供のサーバー機(詳細は本文に記載)CPU:24コア (Xeon E5-2697 v2)メモリ: 128GBフラッシュストレージ (FC 8Gbps)ソフトウェア:
SQL Server 2014 SP1SQL Server 2016 RTM CU1
10倍!
検証で使用したテーブル構成
ディスク ベースの通常テーブル インメモリ OLTP のメモリ最適化テーブル
PRIMARY KEY はHASH インデックス

SQL Server 2016 自習書 No.2 Operational Analytics
24
3種類のテーブル (ディスク ベースの通常テーブル、インメモリ OLTP のメモリ最適化テーブル、
メモリ最適化テーブルに列ストア インデックスを追加したもの)を、同じ列構成(col1~col5 の
5 列)で作成しています。
1 億件のデータは、次のように作成しています。
col1 (PRIMARY KEY)には IDENTITY で生成した連番、col2、col3、col4、col5には乱数 (RAND
関数で生成した値)を格納して、実際のデータは次のようになっています。
3 種類のテーブルには、同じデータが格納されるようにするために(公平な検証にするために)、
data100M という名前の中間テーブルに 1 億件のデータを格納していて、これを INSERT ..
SELECT でそれぞれのテーブルにデータ複製するようにしています。
インメモリ OLTP のメモリ最適化テーブルに列ストア インデックスを追加
PRIMARY KEY はHASH インデックス
クラスター化列ストアインデックスを追加
1億件のデータの追加(乱数を利用) col2、col3、col4、col5 には乱数が格納されるように
RAND 関数を利用
col1 intIDENTITY で1 からの連番
col5 datetime2009/1/1 以降の日付の乱数
col3 int0~999,999
の乱数
col2 int0~19,999,999
の乱数
col4 int0~9,999
の乱数

SQL Server 2016 自習書 No.2 Operational Analytics
25
検証で使用した集計クエリ(col4 で GROUP BY)
検証では、次のように col4 列で GROUP BY(データ集計)をしたクエリを使用しています。
-- 検証で使用したクエリ(1億件のデータを集計、col4 列で GROUP BY)
SELECT col4, COUNT(*) AS cnt FROM <テーブル名>
GROUP BY col4
ORDER BY col4
col4 列には、0~9,999 の範囲の乱数が格納されているので、1万件の結果が返ります。
検証結果の詳細 ~実行プランなど~
ディスク ベースの通常テーブルで、集計クエリを実行したときの結果は、次のとおりです(SET
STATISTICS TIME/IO ON で計測した実行時間と I/O 数)。
また、このときの実行プランは、次のように Clustered Index Scan になっています。
これに対して、インメモリ OLTP のメモリ最適化テーブルで同じクエリを実行したときの実行プ
ランは、次のようになります。
各値には約 1万件のデータがあり1万件*1万件=1億件のデータ
col4 で GROUP BY をすることで 1万件の結果
が返る
ディスク ベースの通常テーブルに対して実行
1万件の結果が返っていることが分かる
実行時間は 約2秒(SQL Server 2016 の場合)
ディスク ベースではClustered Index Scan

SQL Server 2016 自習書 No.2 Operational Analytics
26
Table San で実行されて、Parallelism (並列実行)になっているのがポイントです (実行時間は、
前述のグラフのとおり、約 1.6 秒です)。SQL Server 2016 からは並列プランに対応するように
なったので、Parallelism で処理されています。
これと同じクエリを SQL Server 2014 で実行した場合は、次のように Parallelism にはなりま
せん (SQL Server 2014 は、並列プランに対応していないので、シングル スレッド実行になって
しまいます)。
同じクエリを、SQL Server 2016 のインメモリ OLTP(メモリ最適化テーブル)にクラスター化
列ストア インデックスを追加したテーブルで実行すると次のようになります。
実行プランには、Columnstore インデックス スキャンと表示されて、列ストア インデックスが
利用されていることが分かります。また、実行時間もわずか約 200 ミリ秒であることが分かり、
1 億件のデータ集計を 200 ミリ秒以内で実行できるという、圧倒的な性能 (ディスク ベースより
も 10 倍も速い)が出ていることを確認できます。
このように、SQL Server 2016 のインメモリ OLTP は、列ストア インデックスと融合すること
によって、データ分析/集計にも強くなっています。
インメモリ OLTP のメモリ最適化テーブルに対して実行
Table Scan(並列実行)
Table Scan(シングル実行)
Columnstore インデックス スキャン(並列実行)
実行時間はわずか 約 200ミリ秒
インメモリ OLTP のメモリ最適化テーブルにクラスター化列ストアインデックスを追加

SQL Server 2016 自習書 No.2 Operational Analytics
27
2.2 インメモリ OLTP の検証(もちろん OLTP に強い)
ここまでは、インメモリ OLTP + 列ストア インデックス (OLTP とデータ分析の両立)の検証結
果を説明しましたが、インメモリ OLTP は、その名のとおり OLTP に強いのが最大の特徴です。
例えば、SQL Server 2014 の時点で、次のような導入効果がありました。
インメモリ OLTP は、ロック フリー/ラッチ フリーのアーキテクチャなので (ロックとラッチを
利用しないアーキテクチャで、ロック待ちやラッチ待ちを回避することができるので)、大量のユー
ザーによる同時更新が発生するシステム (いわゆる OLTP システム)で大きな効果を発揮します。
bwin社 (bwin.party)では、ASP.NET のセッション状態データベースにインメモリ OLTP を採
用して、SQL Server 2014 のときにはラボ環境で 45万 Batch Requests/sec (1 秒あたり 45
万件ものバッチ要求を処理)を達成していました。さらに、昨年開催された SQL Server の世界最
大規模のイベントである「PASS Summit 2015」では、同システムで 66 万 Batch
Requests/sec を達成したというアナウンスもありました(以下のスライドの最後の行に記載)。
社名/システム概要 システムの特性 導入効果
bwin 社オンライン ゲームなどを提供
大量のユーザーによる同時更新。トランザクションとしては小さい。毎日 15万人以上のアクティブ ユーザー。毎年 100万人以上の新規ユーザーが増加。ASP.NET のセッション状態データベースで利用。
約 16.7倍の性能向上15,000 バッチ要求/sec が250,000 バッチ要求/sec へ向上。450,000 バッチ要求/sec も確認(約 30倍の性能向上)
SBIリクイディティ・マーケット株式会社FX 取引(オンライントレード)
大量のユーザーによる同時更新。トランザクションとしては小さい。顧客のトレーディング データ(取引履歴)をリアルタイムに集計
約 2.5倍の性能向上52,080 件/sec が131,921 件/sec へ向上。ピーク時の Latency(遅延)は、約 4秒だったのを、1秒以下に短縮
Edgenet 社商品データを提供するデータ プロバイダー
DWH 環境でのステージング テーブルで利用。ETL 処理など。バッチ処理での大量のデータ更新。更新中の参照アクセスあり
約 8~11倍の性能向上2時間 20分かかっていたバッチ処理が、わずか 20分に短縮。更新中の参照アクセスが、更新によってブロック(ロック待ちなど)されることがなくなり、読み取り性能も向上
TPP 社臨床ソフトウェアの提供
大量のユーザーによる同時更新。トランザクションとしては小さい。1秒あたり 72,000 ユーザーが同時アクセス(ピーク時)
約 7倍の性能向上34,700 Transaction/sec が数十万 Transaction/sec へ向上
弊社のお客様 A社ポイントカード システム
大量のユーザーによる同時更新。トランザクションとしては小さい。ポイントカードにおけるポイントの入金や出金、残高照会処理
約 2.8倍の性能向上
* 弊社執筆の SQL Server 2014 実践シリーズ No.1「インメモリ OLTP の実践的な利用方法」の 1.3 から引用

SQL Server 2016 自習書 No.2 Operational Analytics
28
1 秒あたりに 66 万ということは、1 分(60 秒)に換算すると 66 万*60 秒=3,960 万ものバッ
チ要求を処理できるようという数値です。このような驚異的な数値が出せるのは、インメモリ
OLTP ならではです。
検証結果: インメモリ OLTP は、単純 INSERT にも強い
単純 INSERT の性能検証は、SQL Server 2014 の実践シリーズでも行いましたが、今回、日立様
のハードウェア(詳細は後述)をお借りすることができたので、SQL Server 2016 でも検証を行
ってみました。想定しているシステムは、大規模イベントでの登録や予約、投票のみを受け付ける
ようなシステムや、IoT などセンサー系データを常に INSERT し続けるようなシステムで、多数
のユーザーが同時に INSERT を行う状況を検証しました。結果は、次のとおりです。
* PASS Summit 2015 での「SQLCAT:SQL Server 2016 Early Adopter Experiences」セッションのスライドを引用。吹き出しは筆者が追加
SQL Server 2016 で66万 Batch Requests/sec を達成
SQL Server 2014 では45万 Batch Requests/sec
ディスク ベースで36分 41秒かかったものが
5分 1秒で完了
* ベンチマークの結果の公表は、使用許諾契約書で禁止されていますが、その効果をわかりやすく表現するため、日本マイクロソフト株式会社の監修のもと、数値を掲載しております。
■ テスト内容10列のテーブルに対して150多重で INSERT を実行(詳細は本文に記載)
■ テスト環境日立様提供のサーバー機(詳細は本文に記載)CPU:24コア (Xeon E5-2697 v2)メモリ: 128GBフラッシュストレージ (FC 8Gbps)SQL Server 2016 RTM CU1
6倍
7.3倍
7.2倍

SQL Server 2016 自習書 No.2 Operational Analytics
29
ディスク ベースの通常テーブルでは 36 分 41 秒かかった実行時間が、インメモリ OLTP のメモ
リ最適化テーブルの Durable (永続化 :SCHEMA_AND_DATA)にした場合は 6分 8秒 (6 倍の
性能向上)、Delayed Durability(遅延永続化)にした場合は 5 分 7 秒(7.2 倍の性能向上)、
SCHEMA_ONLY(永続化なし)にした場合はわずか 5 分 1 秒で完了し、7.3 倍もの性能向上を
確認することができました。また、このときの 1 秒あたりのトランザクション数を計算すると、次
のようになります(実行時間を 5,000 万件で割り算したもの)。
SCHEMA_ONLY では、1秒あたり 16.6 万件も INSERT できることを確認できました。
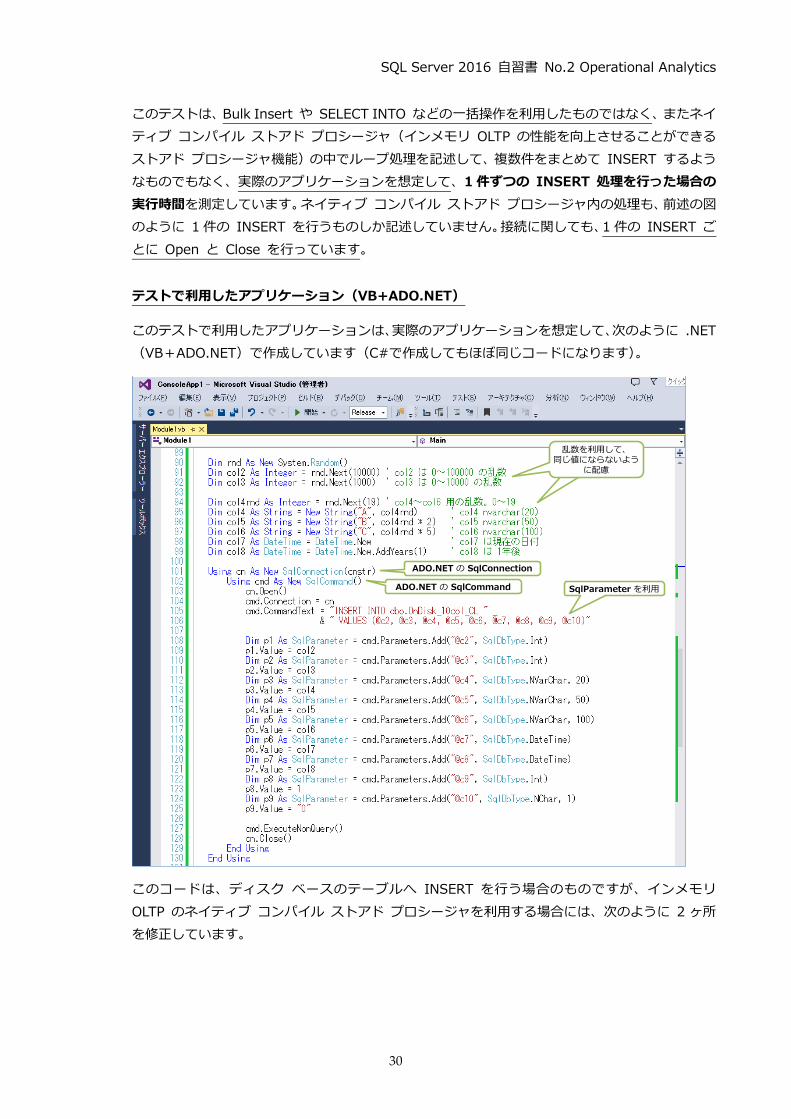
この検証は、10個の列を持ったテーブルを作成して、そのテーブルへデータを 1件ずつ INSERT
を行って、5,000 万件分を INSERT したときの実行時間を測定したものです。データには、実際
のアプリケーションを想定して、乱数を利用し、同じ値が格納されないようにしています。
Transaction/sec
ディスク ベース OnDisk 22,717
インメモリ OLTP
Durable 135,870
Delayed Durability 162,870
SCHEMA_ONLY 166,109
1秒あたり 16.6万件もINSERT できる
HASH インデックス
データの永続化の設定
1件のデータを INSERT するネイティブ コンパイルストアド プロシージャ
インメモリ OLTP のテーブル
テストに使用したテーブル、ネイティブ コンパイル ストアド プロシージャ
テーブルには10個の列
従来ながらのディスク ベース
のテーブル
col1int連番
col2 int0~10000
の乱数
col3 int0~1000の乱数
col4 nvarchar(20)0~19バイト(乱数)の文字
col5 nvarchar(50)0~38バイト(乱数)の文字
col6 nvarchar(100)0~95バイト(乱数)の文字
col7 datetime現在の日付
col8 datetime現在の日付+1年 col9 int
1 のみ
col10 nchar(1)”0” のみ
テスト実行後に格納されるデータ(実際のアプリケーションを想定して、乱数を利用し、同じ値にならないように考慮)
SQL Server 2016 自習書 No.2 Operational Analytics
30
このテストは、Bulk Insert や SELECT INTO などの一括操作を利用したものではなく、またネイ
ティブ コンパイル ストアド プロシージャ (インメモリ OLTP の性能を向上させることができる
ストアド プロシージャ機能)の中でループ処理を記述して、複数件をまとめて INSERT するよう
なものでもなく、実際のアプリケーションを想定して、1件ずつの INSERT 処理を行った場合の
実行時間を測定しています。ネイティブ コンパイル ストアド プロシージャ内の処理も、前述の図
のように 1 件の INSERT を行うものしか記述していません。接続に関しても、1 件の INSERT ご
とに Open と Close を行っています。
テストで利用したアプリケーション(VB+ADO.NET)
このテストで利用したアプリケーションは、実際のアプリケーションを想定して、次のように .NET
(VB+ADO.NET)で作成しています(C#で作成してもほぼ同じコードになります)。
このコードは、ディスク ベースのテーブルへ INSERT を行う場合のものですが、インメモリ
OLTP のネイティブ コンパイル ストアド プロシージャを利用する場合には、次のように 2 ヶ所
を修正しています。
SqlParameter を利用
乱数を利用して、同じ値にならないよう
に配慮
ADO.NET の SqlConnection
ADO.NET の SqlCommand

SQL Server 2016 自習書 No.2 Operational Analytics
31
SqlCommand の CommandType を変更して、CommandText をネイティブ コンパイル スト
アド プロシージャの名前に変更するだけで、ネイティブ コンパイル ストアド プロシージャを実
行することができます。
以上のコードを、多重実行 (並行実行)して、実行時間を計測したのが前掲のグラフです (150多
重で実行したときを測定しました)。
このように、インメモリ OLTP は、常に INSERT をし続けるようなシステムでも大きな効果を発
揮します。
ディスク ベースの通常テーブルで性能が向上しない理由 ~ラッチ待ち~
ディスク ベースの通常テーブルは、多重度が上がれば上がるほど、性能が頭打ちになります (多重
度が上がるほど遅くなります)。性能が上がらない一番の理由は、ラッチ待ち (Latch Wait)やロッ
ク待ち (Lock Wait)などのブロッキングによるものです。これに対して、インメモリ OLTP では
ラッチ/ロックを利用しないアーキテクチャなので、ラッチ待ち/ロック待ちに悩まされることは
ありません(インメモリ OLTP であれば、多重度が上がってもスケールします)。
ディスク ベースで利用されるラッチ(Latch)には、主にページ ラッチ(PAGELATCH_SH、
PAGELATCH_EX)と IO ラッチ (PAGEIOLATCH_SH、PAGEIOLATCH_EX)がありますが、
前者は、ページへの同時アクセスを制御するための、SQL Server が内部的にページに対してかけ
るロックのようなもの、後者は、データ ファイル (.mdf)からメモリ内のデータ バッファへペー
ジを取り出すとき/書き出すときにかけるロックのようなものです。
ページ ラッチ (PAGELATCH_SH や PAGELATCH_EX)は、次の図のように、同じページに対
して、多数のユーザーからの同時アクセスが発生した場合を制御するためのもので、同時に同じペ
ージを操作させないように、後からきたラッチを "待ち" にします(ページ ラッチ待ちの発生)。
CommandType を変更
ネイティブ コンパイル ストアドプロシージャの名前に変更
ページ
同じページへの同時アクセスは、ページ ラッチ待ちが発生する
INSERT
INSERT
UPDATE
UPDATE
INSERT
SELECT
PageLatch_EXPageLatch_EX
PageLatch_EX
PageLatch_EX
PageLatch_EX
PageLatch_SH
1
3
2
5
4
6
獲得
待ち
待ち 待ち
待ち
待ち

SQL Server 2016 自習書 No.2 Operational Analytics
32
更新系のステートメント (INSERT/UPDATE/DELETE)では、PAGELATCH_EX (排他ページラ
ッチ。EX は Exclusive:排他の略)をかけにいき、SELECT ステートメントによる参照時には
PAGELATCH_SH (共有ページラッチ。SH は Shared :共有の略)をかけにいきます。このとき、
先にアクセスしている処理がある場合は (ラッチが既にかかっている場合には)、それが解放される
まで、"待ち" が発生します。このような、同時アクセスによって待ちが発生する状態は、ラッチ競
合(Latch Contention)とも呼ばれています。
このように、ラッチ待ちが発生すると、ユーザー数が増えれば増えるほど、ラッチ待ちも増えるこ
とになるので、スループットが低下していきます。
これでは、同時実行数が増えれば増えるほど、システムの処理能力は頭打ちになり、スケールしな
くなってしまいます。
これに対して、インメモリ OLTP が採用している、ラッチを利用しない 「ラッチ フリー」のアー
キテクチャであれば、ユーザー数が増えてたとしても性能低下は発生しにくくなります。
ラッチ待ちの様子 ~インデックスの最終ページがホットスポット~
今回の検証で利用したテーブルは、col1 列を IDENTITY(1, 1) の PRIMARY KEY に設定し
ているので、ディスク ベースのテーブルでは、多数のユーザーが同時にデータを追加することによ
って、次のようにインデックスの最終ページにアクセスが集中します。
ページ
ラッチ待ちが発生するとスループットが低下
ユーザー数
性能
同時アクセスがブロックされる
ユーザー数が増えるほどスループットが低下。性能が頭打ちになる
ラッチ フリーならユーザー数が増えても性能低下を抑えられる
ユーザー数
性能
同時アクセス可能
ユーザー数が増えても性能が低下しにくくなる
インデックスの最終ページがホットスポットになる
多数の同時追加
インデックスの最終ページでページ ラッチ待ちが多発する

SQL Server 2016 自習書 No.2 Operational Analytics
33
ディスク ベースのテーブルの場合は、PRIMARY KEY 制約を作成することで、自動的にクラスタ
ー化インデックス (b-tree)が作成されるので、データが追加されると、最終ページに値が集中す
ることになります。連番系の列 (IDENTITY を設定した列や、シーケンスを設定した列)など、デ
ータを追加するたびに連続した値(1、2、3、…)が格納されていくような場合には、このような
インデックスの最終ページでページ ラッチ待ちが多発する (最終ページがホット スポットになる)
ことがよくあります。これは、シングル実行(1 人のユーザーによる単体実行)では、発生しない
ものですが、多数のユーザーが同時にデータを追加する場合には発生してしまいます。
ラッチ待ちが発生しているかどうかは、パフォーマンス カウンターの Latch Waits/sec
(SQLServer: Latches オブジェクト)を参照することで簡単に確認することができます。実際
に、検証を行ったときのパフォーマンス カウンターは、次のようになりました。
Batch Request (バッチ要求数)が 2.3 万ぐらいを推移しているのに対して、ラッチ待ち (Latch
Waits)が 6.5 万(2 倍以上)も発生してしまっています。このようなラッチ待ちは、多重度が
200、300 と上がっていくとさらに顕著に表れて、性能がどんどん低下していくことになります。
一方、インメモリ OLTP ではラッチ待ちは発生しないので、次のような性能が出ます。
このように、インメモリ OLTP は、大量ユーザーからの INSERT/常に INSERT をし続けるよう
Batch Request(バッチ要求数)
150多重で 5,000万件を INSERT しているときのラッチ待ちの様子(ディスク ベース)
ラッチ待ちがBatch Request の
2倍以上発生している
インメモリ OLTP(SCHEMA_ONLY)の場合
インメモリ OLTP ではラッチ待ちが発生しない
Batch Request が16.5万近辺を推移

SQL Server 2016 自習書 No.2 Operational Analytics
34
なシステムでも大きな効果を発揮します。
なお、今回の検証では、実際のアプリケーションを想定していたので、1 件の INSERT ごとに接続
の Open と Close 処理を行っていましたが、もし接続をキープできるような状況 (接続の Open
と Close を行わずに同じ接続を再利用する形)であれば、次のような性能を出すことができます。
ディスク ベースでは、接続をキープしても、ラッチ待ちがボトルネックになっているので、性能は
ほとんど変わりません。これに対して、インメモリ OLTP の SCHEMA_ONLY では、1 秒あたり
に 32万件ものトランザクションを処理できるようになっています。
1秒あたり 32万件もINSERT できる
5000万件の INSERTがわずか 2分 36秒で完了
■ テスト内容前掲のテストと同様。接続の Open と Close を行わないようにアプリを修正したのみ
■ テスト環境前掲のテストど同様
Transaction/sec
ディスク ベース OnDisk 23,697
インメモリ OLTP
Durable 211,862
Delayed Durability 252,525
SCHEMA_ONLY 320,521

SQL Server 2016 自習書 No.2 Operational Analytics
35
2.3 Operational Analytics の検証環境
前掲の Operational Analytics の検証では、株式会社 日立製作所様のご厚意でハードウェアをお
借りすることができましたので、ここで環境をご紹介します。
今回利用させていただいた日立様の施設は、品川にある 「ハーモニアス・コンピテンス・センター」
です。
検証で利用させていただいたハードウェアは、「統合サービスプラットフォーム BladeSymphony
BS500」の 24 コア マシン(Xeon E5-2697v2 を 2 個搭載したサーバー)とエンタープライズ
ディスク アレイ システムである「Hitachi Virtual Storage Platform G1000」です。
ハーモニアス・コンピテンス・センターのマシンの様子
サーバーBladeSymphony BS500ブレード: BS520H サーバブレードCPU: Xeon E5-2697v2 × 2 (24core)メモリ: 128G内蔵HDD: 600GB×2ストレージ接続: 8Gbps FC
検証で利用させていただいたハードウェア
ストレージHitachi Virtual Storage Platform G10001.6TBフラッシュモジュールドライブ ×9 (RAID5:3D+1P (4915.19GB) ,エミュレーション:OPEN-V×2、スペアディスク×1

SQL Server 2016 自習書 No.2 Operational Analytics
36
2.4 Operational Analytics を試す方法
ここでは、インメモリ OLTP とクラスター化列ストア インデックスを利用した Operational
Analytics を試す方法を説明します。
インメモリ OLTP の基本的な利用方法
まずは、インメモリ OLTP の基本的な利用方法を説明します。インメモリ OLTP では、インメモ
リ化したテーブルのことを 「メモリ最適化テーブル」と呼び、次のように作成することができます。
このようにメモリ最適化テーブルを作成するには、次の作業が必要になります。
通常の SQL Server と同様、SQL Server のインストール時に [データベース エンジン
サービス]をインストールしておく
データベースの互換性レベルを 130 にする (これは必須ではありませんが、インメモリ
OLTP で並列プランを利用するために必要になるので、130 にしておくことを強く推奨)
メモリ最適化テーブルを格納するためのファイル グループの作成
(CONTAINS MEMORY_OPTIMIZED_DATA を指定したファイル グループをデータ
ベースに追加する)
メモリ最適化テーブルの作成
(CREATE TABLE ステートメントで MEMORY_OPTIMIZED = ON を指定)
MEMORY_OPTIMIZED=ONを指定するとメモリ最適化テーブルになる
メモリ最適化テーブルではHASH インデックスが基本になる
DURABILITY=SCHEMA_AND_DATAでデータを永続化できる
メモリ最適化テーブルを作成するにはCONTAINS MEMORY_OPTIMIZED_DATA を指定したファイル グループを追加しておく

SQL Server 2016 自習書 No.2 Operational Analytics
37
通常と同様 データベース エンジン サービス」のインストール
インメモリ OLTP は、SQL Server のデータベース エンジンに完全に統合されているので、通常
どおりに SQL Server をインストールするだけで利用できます。インストール時には、次のように
[機能の選択]ページで、通常どおり 「データベース エンジン サービス」を選択しておけば、イ
ンメモリ OLTP を利用することができます。
データベースの互換性レベルを 130」へ設定
データベースの互換性レベルを確認/設定するには、次のようにデータベースのプロパティの [オ
プション]ページを利用します。

SQL Server 2016 自習書 No.2 Operational Analytics
38
SQL Server 2016 では、データベースを新しく作成したときの既定の互換性レベルは「130」に
なります(130 は、SQL Server 2016 の内部バージョン番号である 13.0 という意味です)。
130 レベルでは、インメモリ OLTP での並列プランや、INSERT..SELECT でのマルチ スレッ
ド、列ストア インデックスでのバッチ モードの動作の違い (MAXDOP 1 でもバッチ モードで動
作する)など、性能に関する大きな違いが出るので、130 レベルを利用することを強くお勧めしま
す。SQL Server 2014 や 2012 など、古いバージョンの SQL Server で取得したバックアップ
を SQL Server 2016 上にリストアしたり、古いバージョンのデータベース ファイル (.mdf/.ldf)
を SQL Server 2016 上にアタッチした場合には、そのバージョンの互換性レベルが保たれるの
で、130 レベルに上げても問題ないか、検証してみることをお勧めします。
ファイル グループの作成
メモリ最適化テーブルを格納するためのファイル グループを作成するには、CREATE DATABASE
ステートメントで、次のように FILEGROUP句で CONTAINS MEMORY_OPTIMIZED_DATA
を指定します。
-- インメモリ OLTP を利用するためのファイル グループを作成する例
CREATE DATABASE testDB
ON PRIMARY (
NAME = testDB_data,
FILENAME = 'C:\testDB\testDB_data.mdf',
SIZE = 10GB ) ,
FILEGROUP fg1 CONTAINS MEMORY_OPTIMIZED_DATA
( NAME = testDB_InMem,
FILENAME = 'C:\testDB\testDB_InMem' )
LOG ON
( NAME = testDB_log,
FILENAME = 'C:\testDB\testDB_log.ldf',
SIZE = 10GB )
FILEGROUP に続けてファイル グループ名を指定して(ここでは fg1 という名前を指定)、
「CONTAINS MEMORY_OPTIMIZED_DATA」と記述することで、メモリ最適化テーブルを格
メモリ最適化テーブルを作成するにはCONTAINS MEMORY_OPTIMIZED_DATA を指定したファイル グループを追加しておく
FILENAME はファイルを作成する場所

SQL Server 2016 自習書 No.2 Operational Analytics
39
納できるファイル グループを作成することができます。FILENAME には作成先となるファイル
パスを指定しますが、ここで指定するファイル名は、NAME で指定する論理ファイル名 (上記では
oaTestDB_InMem)と同じ名前にするようにします。
なお、CREATE DATABASE ステートメントでの新規データベースの作成時ではなく、既存のデー
タベースに対して、後からファイル グループを追加したい場合には、次のように ALTER
DATABASE ステートメントを 2 つ実行します。
-- 既存のデータベースにファイル グループを追加する例
ALTER DATABASE testDB
ADD FILEGROUP fg1
CONTAINS MEMORY_OPTIMIZED_DATA
ALTER DATABASE testDB
ADD FILE ( NAME = testDB_InMem,
FILENAME = 'C:\testDB\testDB_InMem' )
TO FILEGROUP fg1
1 つ目の ALTER DATABASE ステートメントでは、ADD FILEGROUP に続けてファイル グル
ープ名を指定して、「CONTAINS MEMORY_OPTIMIZED_DATA」を記述します。2 つ目では、
ADD FILE で、論理ファイル名とファイルの作成場所を指定し、TO FILEGROUP で 1 つ目で作
成したファイル グループを指定します。
メモリ最適化テーブルの作成
ファイル グループを作成した後は、次のようにメモリ最適化テーブルを作成することができます。
-- メモリ最適化テーブルを作成する例
CREATE TABLE t1_InMem
( col1 int NOT NULL
PRIMARY KEY NONCLUSTERED
HASH WITH (BUCKET_COUNT = 2000000)
,col2 nvarchar(100) )
WITH ( MEMORY_OPTIMIZED = ON,
DURABILITY = SCHEMA_AND_DATA )
メモリ最適化テーブルは、CREATE TABLE ステートメントの末尾の WITH 句で「MEMORY_
MEMORY_OPTIMIZED=ONを指定するとメモリ最適化テーブルになる
メモリ最適化テーブルではHASH インデックスが基本になる
DURABILITY=SCHEMA_AND_DATAでデータを永続化できる
メモリ最適化テーブルでは NONCLUSTEREDなインデックスが必須
SCHEMA_AND_DATA ではPRIMARY KEY が必須になる

SQL Server 2016 自習書 No.2 Operational Analytics
40
OPTIMIZED = ON」を追加することで作成することができます。「DURABILITY = SCHEMA_
AND_DATA」の部分は、データを保存/永続化するかどうか (Durable かどうか)を指定すると
ころになりますが、SCHEMA_AND_DATA を指定すると永続化、SCHEMA_ONLY を指定する
と永続化なしに設定することができます。永続化なし (SCHEMA_ONLY)の場合は、SQL Server
を再起動した場合には ”データが空” になり、永続化有り(SCHEMA_AND_DATA)の場合は、
ディスク ベースの通常テーブルと同様、SQL Server を再起動してもデータが消えることはあり
ません(∵トランザクション ログに更新履歴を記録しているため)。
col1 列には、NONCLUSTERED (非クラスター化)な HASH インデックスを作成していますが、
メモリ最適化テーブルでは、NONCLUSTERED のインデックスを作成するのが必須になるので、
このように指定しています。また、SCHEMA_AND_DATA (永続化有り)の場合には、PRIMARY
KEY 制約も必須になるので、これを設定しています(こうしたメモリ最適化テーブルを作成する
ための条件については、後述します)。
なお、HASH インデックスを作成しなくても、次のようにメモリ最適化テーブルを作成することが
できますが、この場合は bw-tree インデックスという種類のインデックスが作成されます。bw-
tree インデックスは、通常のディスク ベースのインデックスである ”b-tree インデックス” の
インメモリ版です。
この bw-tree インデックスは、HASH インデックスよりも範囲スキャン(Range Scan)に強い
というメリットがありますが、更新性能(INSERT/UPDATE/DELETE の性能)は HASH イン
デックスよりも劣るというデメリットがあるので、まずは HASH インデックスを利用することを
お勧めします (もちろん、更新操作よりも、範囲スキャンのようがより重要なクエリになるという
場合には、bw-tree インデックスを作成することを検討してみてください)。
メモリ最適化テーブルでは HASH インデックスが基本、BUCKET_COUNT
HASH インデックスは、メモリ最適化テーブルでは基本となるインデックスで、次のようなイメー
ジのものです。
HASH インデックスを指定しない場合はbw-tree インデックスが作成される
(b-tree インデックスのインメモリ版)

SQL Server 2016 自習書 No.2 Operational Analytics
41
格納する値に対して、内部的にハッシュ値が計算されてハッシュ テーブルに格納され、これをもと
に Index Seek でピンポイント検索ができるようになっています。ハッシュ テーブルの大きさ
(何個のハッシュ値を格納できるようにするのか)は、BUCKET_COUNT (バケット数)で指定し
ます。前の例では「HASH WITH (BUCKET_COUNT=2000000)」と指定して、200 万個のバ
ケットを作成しました。
BUCKET_COUNT は、SQL Server 2014 ではテーブルを作成した後に変更することができませ
んでしたが (∵ALTER TABLE ステートメントがサポートされなかったため)、SQL Server 2016
からは ALTER TABLE ステートメントがサポートされるようになったので、後から変更すること
ができるようになりました。これは、次のように実行することができます。
-- BUCKET_COUNT を後から変更する場合(SQL Server 2016)
ALTER TABLE t1_InMem
ALTER INDEX インデックス名
REBUILD WITH ( BUCKET_COUNT = 50000000 )
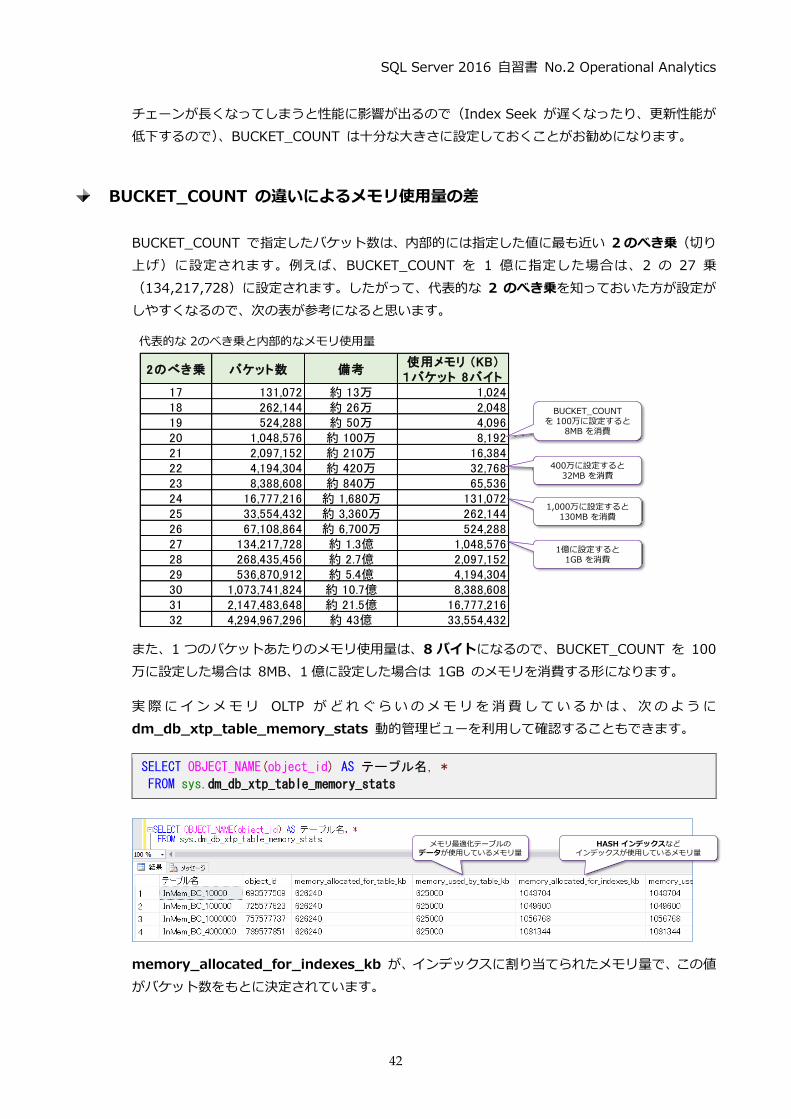
PRIMARY KEY に対して設定した HASH インデックスの BUCKET_COUNT は、実際のデータ
件数~データ件数の 2 倍ぐらいの大きさに設定するのがお勧めです。例えば、データ件数が 5,000
万件になる予定なら、BUCKET_COUNT は 5,000 万~1 億ぐらいに設定するようにします。
もし、BUCKET_COUNT を実際のデータ件数よりも小さい値に設定している場合には、ハッシュ
コリジョン(ハッシュ値の衝突)が発生して、次のようにチェーンが長くなってしまいます。
012345:
INSERT INTO ~ (col1)
VALUES (111)
INSERT INTO ~ (col1)
VALUES (123)
ハッシュ値 1
ハッシュ値 3
ハッシュ値 5
ハッシュ インデックスのイメージ
BUCKET_COUNT(バケット数)
格納する値
col1 のHASHインデックス
INSERT INTO ~ (col1)
VALUES (222)
SELECT * FROM ~
WHERE col1 = 123
データの検索 ハッシュ値 3
Index Seek でピンポイント検索でデータを取得できる
01234
(111)
(123)
(222)
(123)
ハッシュ値 1
ハッシュ値 3
ハッシュ値 3
ハッシュ値 3
ハッシュ インデックスのチェーン
(333)
(123)
ハッシュ値 3
ハッシュ値 3
● ● ●
ハッシュ コリジョン(衝突)によってチェーンが長くなってしまう
BUCKET_COUNT(バケット数)が小さいと違う値でも、同じハッシュ値になることがあり(=衝突が発生)、チェーンが伸びてしまう
● ●
BUCKET_COUNTが小さい場合
SQL Server 2016 自習書 No.2 Operational Analytics
42
チェーンが長くなってしまうと性能に影響が出るので(Index Seek が遅くなったり、更新性能が
低下するので)、BUCKET_COUNT は十分な大きさに設定しておくことがお勧めになります。
BUCKET_COUNT の違いによるメモリ使用量の差
BUCKET_COUNT で指定したバケット数は、内部的には指定した値に最も近い 2のべき乗 (切り
上げ)に設定されます。例えば、BUCKET_COUNT を 1 億に指定した場合は、2 の 27 乗
(134,217,728)に設定されます。したがって、代表的な 2 のべき乗を知っておいた方が設定が
しやすくなるので、次の表が参考になると思います。
また、1 つのバケットあたりのメモリ使用量は、8 バイトになるので、BUCKET_COUNT を 100
万に設定した場合は 8MB、1 億に設定した場合は 1GB のメモリを消費する形になります。
実 際 に イ ン メ モ リ OLTP が ど れ ぐ ら い の メ モ リ を 消 費 し て い る か は 、 次 の よ う に
dm_db_xtp_table_memory_stats 動的管理ビューを利用して確認することもできます。
SELECT OBJECT_NAME(object_id) AS テーブル名, *
FROM sys.dm_db_xtp_table_memory_stats
memory_allocated_for_indexes_kb が、インデックスに割り当てられたメモリ量で、この値
がバケット数をもとに決定されています。
2のべき乗 バケット数 備考使用メモリ (KB)
1バケット 8バイト17 131,072 約 13万 1,02418 262,144 約 26万 2,04819 524,288 約 50万 4,09620 1,048,576 約 100万 8,19221 2,097,152 約 210万 16,38422 4,194,304 約 420万 32,76823 8,388,608 約 840万 65,53624 16,777,216 約 1,680万 131,07225 33,554,432 約 3,360万 262,14426 67,108,864 約 6,700万 524,28827 134,217,728 約 1.3億 1,048,57628 268,435,456 約 2.7億 2,097,15229 536,870,912 約 5.4億 4,194,30430 1,073,741,824 約 10.7億 8,388,60831 2,147,483,648 約 21.5億 16,777,21632 4,294,967,296 約 43億 33,554,432
BUCKET_COUNTを 100万に設定すると
8MB を消費
1,000万に設定すると130MB を消費
400万に設定すると32MB を消費
1億に設定すると1GB を消費
代表的な 2のべき乗と内部的なメモリ使用量
メモリ最適化テーブルのデータが使用しているメモリ量
HASH インデックスなどインデックスが使用しているメモリ量
SQL Server 2016 自習書 No.2 Operational Analytics
43
メモリ最適化テーブルにクラスター化列ストア インデックスを追加
メモリ最適化テーブルにクラスター化列ストア インデックス(Clustered Column-store Index)
を追加して、Operational Analytics を実現するには、次のようにテーブルを作成します。
-- メモリ最適化テーブルにクラスター化列ストア インデックスを追加
CREATE TABLE InMem_ccsi
( col1 int IDENTITY(1,1) NOT NULL
PRIMARY KEY NONCLUSTERED
HASH WITH (BUCKET_COUNT = 100000000)
,col2 int NOT NULL
,col3 int NOT NULL
,col4 int NOT NULL
,col5 datetime NOT NULL
,INDEX idx_InMem_ccsi CLUSTERED COLUMNSTORE
) WITH ( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA )
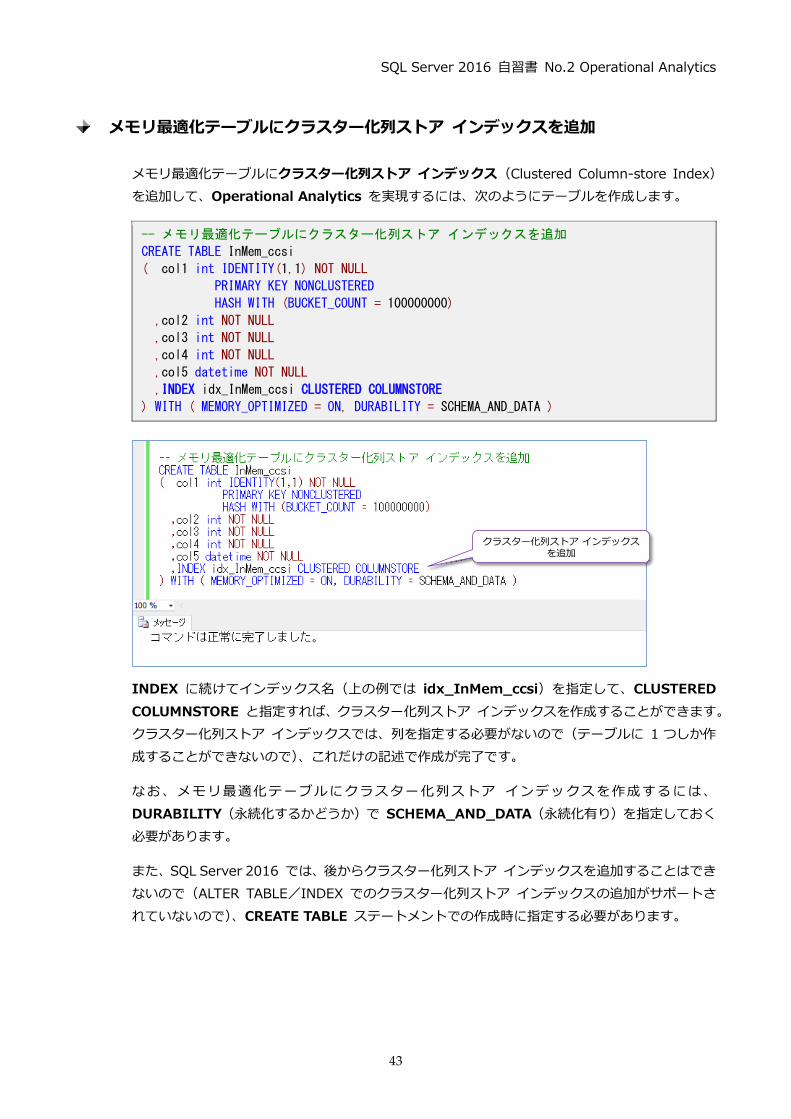
INDEX に続けてインデックス名(上の例では idx_InMem_ccsi)を指定して、CLUSTERED
COLUMNSTORE と指定すれば、クラスター化列ストア インデックスを作成することができます。
クラスター化列ストア インデックスでは、列を指定する必要がないので(テーブルに 1 つしか作
成することができないので)、これだけの記述で作成が完了です。
なお、メモリ最適化テーブルにクラスター化列ストア インデックスを作成するには、
DURABILITY (永続化するかどうか)で SCHEMA_AND_DATA (永続化有り)を指定しておく
必要があります。
また、SQL Server 2016 では、後からクラスター化列ストア インデックスを追加することはでき
ないので(ALTER TABLE/INDEX でのクラスター化列ストア インデックスの追加がサポートさ
れていないので)、CREATE TABLE ステートメントでの作成時に指定する必要があります。
クラスター化列ストア インデックスを追加

SQL Server 2016 自習書 No.2 Operational Analytics
44
メモリ最適化テーブルを利用する条件
メモリ最適化テーブルを利用するための条件や利用にあたってのポイントは、次のとおりです。
データベースの互換性レベルを 130 にしておくことでパラレル処理が可能
メモリ最適化テーブルにクラスター化列ストア インデックスを追加する場合は、
SCHEMA_AND_DATA(永続化)が必須になる。
SCHEMA_AND_DATA(永続化)を利用する場合は、PRIMARY KEY 制約も必須
メモリ最適化テーブルには非クラスター化列ストア インデックスを追加できない
メモリ最適化テーブルでは、1 つ以上の非クラスター化 (NONCLUSTERED)の HASH
または bw-tree インデックスを作成する必要がある。
SCHEMA_AND_DATA(永続化)の場合は、PRIMARY KEY 制約も必須になる。
SCHEMA_ONLY (永続化なし)の場合は、PRIMARY KEY 制約は必須ではないが、イン
デックスが必須になる。
HASH または bw-tree インデックスは、1 つのテーブルに最大 8個まで作成可能。
なお、SQL Server 2014 のときには、インデックスを作成する列に NOT NULL が必須
だったが、SQL Server 2016 からは必須ではなくなった。
HASH インデックスを利用する場合は、適切な BUCKET_COUNT(バケット数)を設
定しておくことが重要 (SQL Server 2016 からは後から BUCKET_COUNT を変更する
ことも可能/ALTER TABLE で REBUILD が可能になった)
IDENTITY は (1, 1) のみがサポートされる(SEQUENCE を利用することも可能)
利用できないデータ型には、xml、sql_variant、datetimeoffset、hierarchyid、
geography、geometry、rowversion、UDT(ユーザー定義データ型)がある
その他、メモリ最適化テーブルを利用するにあたっての細かい制限事項としては、次のようなもの
があります。
TRUNCATE TABLE ステートメントがサポートされない (DELETE ステートメントでデ
ータを削除する必要がある)
SELECT INTO ステートメントでのターゲット テーブルには指定することができない
MERGE ステートメントでのターゲット テーブルには指定することができない
CLR アクセスがサポートされない
データベースをまたがったクエリ/トランザクションがサポートされない
READ COMMITTED 分離レベル (SQL Server の既定の分離レベル)は、自動コミット
トランザクションのみでサポートされる
ト ラ ン ザ ク シ ョ ン 内 で サ ポ ー ト さ れ る 分 離 レ ベ ル は 、 SNAPSHOT ま た は
REPEATABLE READ、SERIALIZABLE のみで、WITH 句でのテーブル ヒントとして
指定、または ALTER DATABASE で ELEVATE_TO_SNAPSHOT を有効化しておく

SQL Server 2016 自習書 No.2 Operational Analytics
45
ようにする。ネイティブ コンパイル ストアド プロシージャを利用している場合には
BEGIN ATOMIC 句の ISOLATION LEVEL で分離レベルを指定する
SQL Server 2014 との違い(多くの制限が取り払われた)
SQL Server 2014 のときには、インメモリ OLTP の最初のバージョンであったこともあり、メモ
リ最適化テーブルを利用するにあたって多くの制限がありましたが、SQL Server 2016 からはそ
ういった制限の多くが取り払われました。その主なものは、次のとおりです。
ALTER TABLE のサポート
後から列を追加/削除したり、データ型を変更したり、テーブル変更が可能。SQL Server
2014 では、後からインデックスを作成することができなかった。
後からインデックスを追加可能に
SQL Server 2014 では、後からインデックスを作成することができなかった。
インデックスでの NULL のサポート
SQL Server 2014 では、インデックスを作成するには NOT NULL が必須だった。
BIN2 以外の照合順序のサポート
SQL Server 2014 では、インデックスを作成する列が char 系の場合に、BIN2 照合順
序が必須だった。
varchar/char でのコードページ 1252 以外のサポート
SQL Server 2014 では、varchar/char では、コードページ 1252 が必須だった。そ
の他のコードページを利用するには nvarchar/nchar など n 付きのデータ型を利用す
るのが必須だった。
LOB(ラージ オブジェクト)のサポート
SQL Server 2014 では、行サイズの上限が 8060 バイトだった。
CHECK 制約や FOREIGN KEY 制約のサポート
SQL Server 2014 では、CHECK 制約と FOREIGN KEY 制約を利用できなかった。
その他の SQL Server 2014 との違いについては、オンライン ブックの以下のトピックがお勧め
です。
データベース エンジンの新機能
http://msdn.microsoft.com/ja-jp/library/bb510411.aspx

SQL Server 2016 自習書 No.2 Operational Analytics
46
メモリ最適化テーブルへの移行
SQL Server 2016 からは、ディスク ベースのテーブルを、メモリ最適化テーブルに移行するにあ
たって、移行可能かどうかをチェックしてくれる 「In-Memory OLTP 移行チェックリスト」機能
が提供されました。これは、次のようにデータベースを右クリックして、[タスク]メニューの [In-
Memory OLTP 移行チェックリストの生成]をクリックすることで起動することができます。
移行できるかどうかをチェックしたいテーブルや
ストアド プロシージャの選択
チェックリストの保存先となるフォルダーの指定。既定では「ドキュメント」配下

SQL Server 2016 自習書 No.2 Operational Analytics
47
なお、執筆時点の最新版である 2016 年 9 月版の Management Studio(日本語版)だと、この
次の画面から先に進むことができなので、2016 年 6 月版(RTM)の Management Studio を利
用する必要があります (今後の Management Studio のアップデート版では修正される予定です)。
チェックが完了すると、次のように表示されます。
ウィザード完了後は、保存先として指定したフォルダーに、次のようにレポートが作成されていて、
移行できるかどうかを確認することができます。
このように、SQL Server 2016 からは、データベース内のオブジェクトが移行可能かどうかをま
とめてチェックできるようになったので、大変便利です。
それぞれのオブジェクトごとにレポートが作成される
外部キー制約がある場合はいったん削除してから、
移行後に再作成する必要があるなどが提示される

SQL Server 2016 自習書 No.2 Operational Analytics
48
メモリ最適化アドバイザーによる自動移行
メモリ最適化テーブルに移行可能なオブジェクトは、[メモリ最適化アドバイザー]ウィザードを利
用することで、自動移行(テーブルを自動変換して、データも丸ごと複製)することもできます。
このウィザードは、SQL Server 2014 から提供されているツールで、次のように利用できます。
該当テーブルを右クリックして、[メモリ最適化アドバイザー]をクリックすれば、ウィザードが起
動して、(移行可能な場合は)次のように自動移行を実行することができます。
このように、既存のテーブルをメモリ最適化テーブルに移行することも簡単に行えます。
自動移行の設定
データを丸ごと複製する場合はこれを
チェックする
インデックスをどうするかを設定する(HASH にするのか bw-tree にするのか、BUCKET_COUNT はどうするのか etc)

SQL Server 2016 自習書 No.2 Operational Analytics
49
2.5 Operational Analytics を試すスクリプト
ここでは、前掲の検証 (1 億件のデータに対する GROUP BY 集計)と同じものを試すためのスク
リプトを紹介します。なお、この手順どおりに 1 億件のデータを試すには、物理メモリを 64GB
以上搭載しているマシンが必要になります (∵中間テーブルや通常テーブルのデータ格納用のメモ
リも必要になるため)。物理メモリが 32GB 以下の場合には、データ件数を 1 千万件にするなど
して試してみてください。
1. まずは、データベースを作成します。
CREATE DATABASE oaTestDB_1oku
ON PRIMARY (
NAME = oaTestDB_1oku_data,
FILENAME = 'M:\testDB\oaTestDB_1oku_data.mdf',
SIZE = 100GB ) ,
FILEGROUP fg1 CONTAINS MEMORY_OPTIMIZED_DATA
( NAME = oaTestDB_1oku_InMem,
FILENAME = 'M:\testDB\oaTestDB_1oku_InMem' )
LOG ON
( NAME = oaTestDB_1oku_log,
FILENAME='M:\testDB\oaTestDB_1oku_log.ldf',
SIZE = 100GB )
ファイルの作成先となるフォルダーには 「M:\testDB」を指定していますが、皆さんの環境に
合わせて適宜変更してください。また、データ ファイルおよびトランザクション ログ ファ
イルのサイズは 100GB で作成しています。
2. 次に、データベースのバックアップとログの切り捨てを行っておきます (∵公平な検証にする
ため、NUL デバイスにダミー バックアップを取得しておきます)。
-- DB バックアップ
BACKUP DATABASE oaTestDB_1oku
TO DISK = 'NUL' WITH COMPRESSION, STATS
-- ログの切り捨て
BACKUP LOG oaTestDB_1oku
TO DISK = 'NUL' WITH COMPRESSION, STATS
3. 次に、1 億件のデータを格納するためのテーブル(中間テーブル)を作成します。
-- 1億件のデータ格納用のテーブル作成
USE oaTestDB_1oku
CREATE TABLE data100M
( col1 int IDENTITY(1,1) NOT NULL
,col2 int NOT NULL
,col3 int NOT NULL
,col4 int NOT NULL
,col5 datetime NOT NULL )

SQL Server 2016 自習書 No.2 Operational Analytics
50
このテーブルは、検証用の 3 種類のテーブルにデータをコピーするための、コピー元となるテ
ーブルです。3 種類のテーブルには、同じデータが格納されるように (公平な検証にするため
に)、この中間テーブルを作成しています。
4. 次に、WHILE ループ (1 億回のループ)を利用して、1億件のデータを追加します。この実
行には、2~6 時間ぐらいかかります (実行時間は、CPU のクロック数などで大きく変わりま
す)。
-- 1億件のデータ追加.
SET NOCOUNT ON
DECLARE @i int = 1
WHILE @i <= 100000000
BEGIN
DECLARE @col2 int = CONVERT(int, RAND() * 20000000)
,@col3 int = CONVERT(int, RAND() * 1000000)
,@col4 int = CONVERT(int, RAND() * 10000)
,@col5rnd int = CONVERT(int, RAND() * 2628000) + 1
DECLARE @col5 datetime = DATEADD(minute, @col5rnd, '2009/01/01')
INSERT INTO data100M VALUES (@col2, @col3, @col4, @col5)
SET @i += 1
END
SET NOCOUNT OFF
col1 (PRIMARY KEY)には IDENTITY で生成した連番、col2、col3、col4、col5には乱
数(RAND 関数で生成した値)を格納するようにしています。
1 億件のデータの追加が完了すると、次のように乱数が格納されていることを確認できます。
col1 intIDENTITY で1 からの連番
col5 datetime2009/1/1 以降の日付の乱数
col3 int0~999,999
の乱数
col2 int0~19,999,999
の乱数
col4 int0~9,999
の乱数

SQL Server 2016 自習書 No.2 Operational Analytics
51
3 種類のテーブルの作成(通常、インメモリ OLTP、Operational Analytics)
次に、検証で利用する 3 種類のテーブルを作成します。
1. まずは、ディスク ベースの通常テーブルを作成します。
-- ディスク ベースの通常テーブル
CREATE TABLE OnDisk_CL
( col1 int IDENTITY(1,1) NOT NULL
PRIMARY KEY CLUSTERED
,col2 int NOT NULL
,col3 int NOT NULL
,col4 int NOT NULL
,col5 datetime NOT NULL )
2. 次に、Operational Analytics を試すための、インメモリ OLTP のメモリ最適化テーブルに、
クラスター化列ストア インデックスを追加したテーブルを作成します。
-- Operational Analytics (InMemoery OLTP + CCSI)
CREATE TABLE InMem_HASH_ccsi
( col1 int IDENTITY(1,1) NOT NULL
PRIMARY KEY NONCLUSTERED
HASH WITH (BUCKET_COUNT = 100000000)
,col2 int NOT NULL
,col3 int NOT NULL
,col4 int NOT NULL
,col5 datetime NOT NULL
,INDEX idx_InMem_HASH_ccsi CLUSTERED COLUMNSTORE
) WITH ( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA )
HASH インデックスの BUCKET_COUNT(バケット数)は 1 億に設定して、WITH 句で
「MEMORY_OPTIMIZED = ON」をしてメモリ最適化テーブルを作成しています。また、
「INDEX ~ CLUSTERED COLUMNSTORE」を指定することで、クラスター化列ストア イ
ンデックスを追加しています。
3. 次に、インメモリ OLTP のみのテーブル (クラスター化列ストア インデックスを追加しない、
単純なメモリ最適化テーブル)を作成します。
-- InMemoery OLTP のみ(CCSI なし)
CREATE TABLE InMem_HASH
( col1 int IDENTITY(1,1) NOT NULL
PRIMARY KEY NONCLUSTERED
HASH WITH (BUCKET_COUNT = 100000000)
,col2 int NOT NULL
,col3 int NOT NULL
,col4 int NOT NULL
,col5 datetime NOT NULL
) WITH ( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA )

SQL Server 2016 自習書 No.2 Operational Analytics
52
1 億件のデータのコピー
1. 3 種類のテーブルの作成が完了したら、中間テーブル 「data100M」から、1 億件のデータを
コピーします。これには INSERT .. SELECT ステートメントを利用します。
-- 1億件のデータをコピー
INSERT INTO OnDisk_CL
SELECT col2, col3, col4, col5 FROM data100M
INSERT INTO InMem_HASH_ccsi
SELECT col2, col3, col4, col5 FROM data100M
INSERT INTO InMem_HASH
SELECT col2, col3, col4, col5 FROM data100M
それぞれの実行時間は、環境によって大きく異なりますが、3 分~数十分程度なので、合計で
9 分~1 時間程度かかります。
2. データのコピーが完了した後、インメモリ OLTP のメモリ使用量を確認するには、次のよう
に dm_db_xtp_table_memory_stats システム ビューを利用します。
SELECT OBJECT_NAME(object_id), *
FROM sys.dm_db_xtp_table_memory_stats
検証の実行 ~集計クエリの実行~
データのコピーが完了したら、GROUP BY を利用した集計クエリを実行して、性能をチェックし
てみましょう。
1. SET STATISTICS TIME ON を付けて、実行時間を計測するようにして、次の 3 つのクエ
リを実行してみます。
SET STATISTICS TIME ON
-- On Disk
SELECT col4, COUNT(*) AS cnt FROM OnDisk_CL
GROUP BY col4
ORDER BY col4
-- Operational Analytics
SELECT col4, COUNT(*) AS cnt FROM InMem_HASH_ccsi
GROUP BY col4
ORDER BY col4
-- InMemory OLTP のみ
SELECT col4, COUNT(*) AS cnt FROM InMem_HASH
GROUP BY col4

SQL Server 2016 自習書 No.2 Operational Analytics
53
ORDER BY col4
SET STATISTICS TIME OFF
実行時の注意点は、1 回目の実行時には、コンパイルと統計の作成時間が含まれるので、これ
を除外するようにします。SQL Server では、GROUP BY で指定した列に統計が作成されて
いない場合には、初回実行時に統計を自動的に作成するので、その分の実行時間が余分にかか
ってしまいます。2 回目以降は、統計の作成は行われないので、2 回、3 回、4 回、5 回と実行
して、そのときの実行時間を比較(3~5 回目の実行時の平均値を計算するなど)してみてく
ださい。
このクエリを筆者が日立様のハードウェア(24 コア機)で検証したときの結果が、次のグラ
フ(再掲)です。
性能が確認できない場合の対処方法
もし、クラスター化列ストア インデックスを追加した効果 (性能向上)を確認できない場合は、次
の手順を試してみてください。
1. まずは、dm_db_column_store_row_group_physical_stats 動的管理ビュー(DMV)
を利用して、データの状態を確認します。
-- データの格納状態を確認
SELECT OBJECT_NAME(object_id), *
FROM sys.dm_db_column_store_row_group_physical_stats
WHERE OBJECT_NAME(object_id) = 'InMem_HASH_ccsi'
構成できない
SQL Server 2014 のインメモリ OLTPは
全件スキャンに弱かった
SQL Server 2016 のインメモリ OLTPは
全件スキャンに強くなりディスク ベースと遜色なし
SQL Server 2016 のインメモリ OLTPは
列ストア インデックスを作成することで 10倍の性能向上
* ベンチマークの結果の公表は、使用許諾契約書で禁止されていますが、その効果をわかりやすく表現するため、日本マイクロソフト株式会社の監修のもと、数値を掲載しております。
■ テスト内容1億件のデータに対してGROUP BY 集計を実行(詳細は本文に記載)
■ テスト環境日立様提供のサーバー機(詳細は本文に記載)CPU:24コア (Xeon E5-2697 v2)メモリ: 128GBフラッシュストレージ (FC 8Gbps)ソフトウェア:
SQL Server 2014 SP1SQL Server 2016 RTM CU1
10倍!
SQL Server 2016 自習書 No.2 Operational Analytics
54
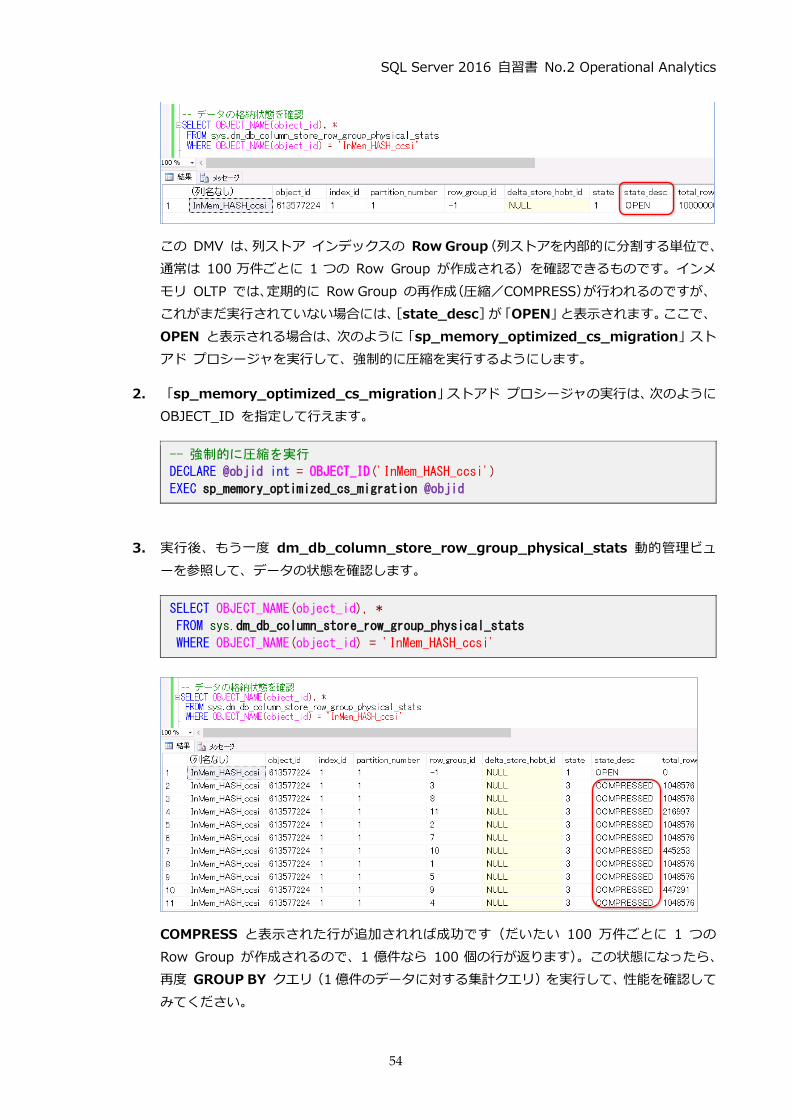
この DMV は、列ストア インデックスの Row Group (列ストアを内部的に分割する単位で、
通常は 100 万件ごとに 1 つの Row Group が作成される)を確認できるものです。インメ
モリ OLTP では、定期的に Row Group の再作成 (圧縮/COMPRESS)が行われるのですが、
これがまだ実行されていない場合には、 [state_desc]が 「OPEN」と表示されます。ここで、
OPEN と表示される場合は、次のように 「sp_memory_optimized_cs_migration」スト
アド プロシージャを実行して、強制的に圧縮を実行するようにします。
2. 「sp_memory_optimized_cs_migration」ストアド プロシージャの実行は、次のように
OBJECT_ID を指定して行えます。
-- 強制的に圧縮を実行
DECLARE @objid int = OBJECT_ID('InMem_HASH_ccsi')
EXEC sp_memory_optimized_cs_migration @objid
3. 実行後、もう一度 dm_db_column_store_row_group_physical_stats 動的管理ビュ
ーを参照して、データの状態を確認します。
SELECT OBJECT_NAME(object_id), *
FROM sys.dm_db_column_store_row_group_physical_stats
WHERE OBJECT_NAME(object_id) = 'InMem_HASH_ccsi'
COMPRESS と表示された行が追加されれば成功です(だいたい 100 万件ごとに 1 つの
Row Group が作成されるので、1 億件なら 100 個の行が返ります)。この状態になったら、
再度 GROUP BY クエリ (1 億件のデータに対する集計クエリ)を実行して、性能を確認して
みてください。
SQL Server 2016 自習書 No.2 Operational Analytics
55
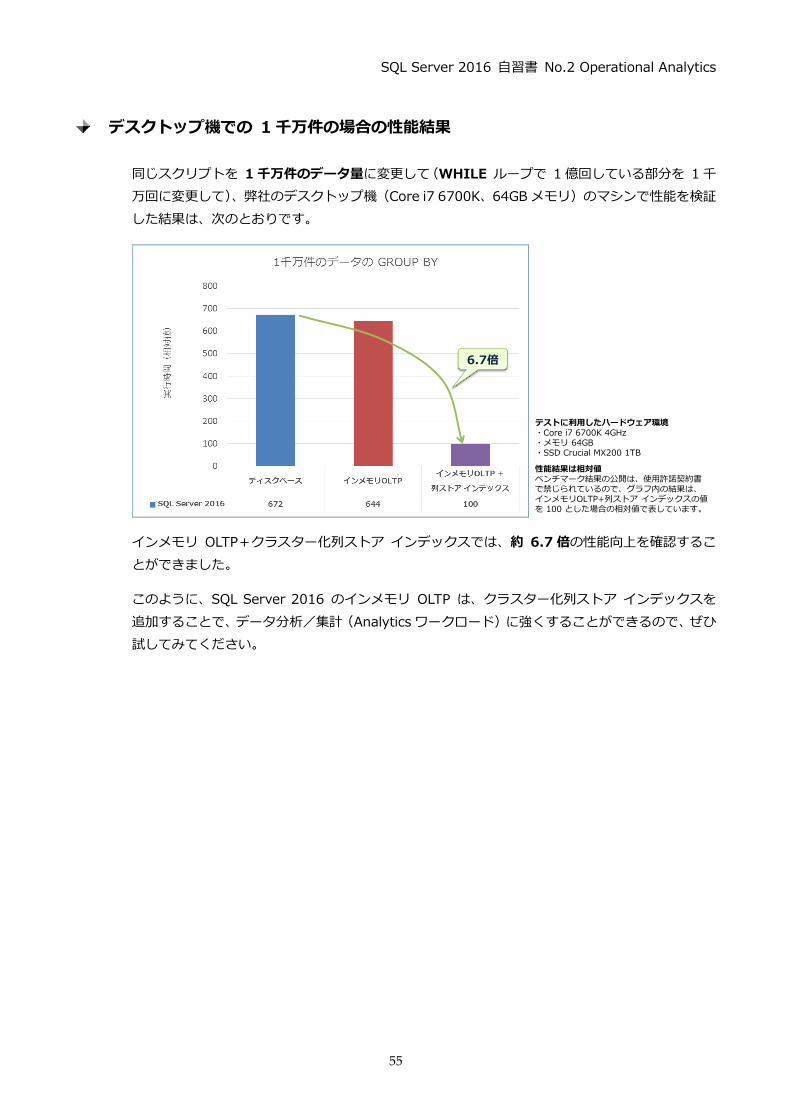
デスクトップ機での 1 千万件の場合の性能結果
同じスクリプトを 1 千万件のデータ量に変更して (WHILE ループで 1 億回している部分を 1 千
万回に変更して)、弊社のデスクトップ機 (Core i7 6700K、64GB メモリ)のマシンで性能を検証
した結果は、次のとおりです。
インメモリ OLTP+クラスター化列ストア インデックスでは、約 6.7 倍の性能向上を確認するこ
とができました。
このように、SQL Server 2016 のインメモリ OLTP は、クラスター化列ストア インデックスを
追加することで、データ分析/集計 (Analytics ワークロード)に強くすることができるので、ぜひ
試してみてください。
6.7倍
テストに利用したハードウェア環境・Core i7 6700K 4GHz・メモリ 64GB・SSD Crucial MX200 1TB
性能結果は相対値ベンチマーク結果の公開は、使用許諾契約書で禁じられているので、グラフ内の結果は、インメモリOLTP+列ストア インデックスの値を 100 とした場合の相対値で表しています。

SQL Server 2016 自習書 No.2 Operational Analytics
56
STEP 3. 列ストア インデックスを
利用した Operational Analytics
この STEP では、インメモリ OLTP を利用しない形での Operational Analytics
(通常のリレーショナル テーブルに列ストア インデックスを追加するパター
ン)を実現する方法として、列ストア インデックスの基本的な利用方法を説明し
ます。
この STEP では、次のことを学習します。
列ストア インデックスの基本的な利用方法
1,000 万件のデータを格納した通常テーブルでの性能チェック
非クラスター化列ストア インデックスでの性能チェック
クラスター化列ストア インデックスでの性能チェック
列ストア インデックスの圧縮率の比較
データ更新とインデックスの再構築
10 万件の BULK INSERT を実行したときの性能比較

SQL Server 2016 自習書 No.2 Operational Analytics
57
3.1 列ストア インデックスを利用した Operational Analytics
ここまでに説明してきたインメモリ OLTP とクラスター化列ストア インデックスの組み合わせ
は、完全なインメモリでの Operational Analytics の実装になりますが、インメモリ OLTP を
利用しなくても、次のように Operational Analytics を実装することができます (以下は、冒頭で
紹介した図を再掲)。
インメモリ OLTP と列ストア インデックスを組み合わせて利用する場合には、インメモリ OLTP
が完全にインメモリで動作するので、メモリ上の制限 (最大サイズが 2TB までという上限)を受
けます。このため、数 TB (テラバイト)規模になるなど、メモリに載りきらないデータ量になる場
合には、インメモリ OLTP を利用することができません。
このような場合には、通常のリレーショナル テーブル (従来ながらのディスク ベースのテーブル)
に、列ストア インデックスを追加して、Operational Analytics を実現することができます。列ス
トア インデックスは、基本はインメモリで動作しますが (データ量が物理メモリに載りきる場合は
インメモリで動作)、メモリに載りきらないデータがあった場合には、ディスクを利用して動作させ
ることができるからです(ハイブリッドな動作ができます)。
更新可能になった非クラスター化列ストア インデックス
SQL Server 2016 の列ストア インデックスに関して、私たちが一番喜んでいるのは、これまでは
読み取り専用だった 「非クラスター化列ストア インデックス」が更新可能になったことです。これ
を利用すれば、通常のリレーショナル テーブルに、容易に列ストア インデックスを追加すること
ができます(従来ながらの B-tree インデックスを追加するのと同じような感覚で、列ストア イ
ンデックスを簡単に追加できるようになりました)。
現在、「データ分析/集計で時間がかかってしまっている」や 「夜間バッチの実行に時間がかかって
しまっている」などの悩みを抱えている場合には、まず非クラスター化列ストア インデックスを作
成してみることをお勧めします。夜間バッチの前に (バッチ実行時の最初の処理として)非クラス
ター化列ストア インデックスを追加して、夜間バッチが完了したら削除する、といった使い方もで
きるので、性能に問題を抱えている場合は、ぜひ試してみてください。
また、SQL Server 2016 では、列ストア インデックスそのものの性能向上(バッチ モードの強
Operational Analytics(OLTPとデータ分析の両立)
Operational ワークロード= OLTP(オンライン トランザクション処理)など
Analytics ワークロード= データ集計/分析処理、DWH、夜間バッチなど
SQL Server 2016 では両立可能次の 3パターンで実装できる1. インメモリ OLTP + クラスター化列ストア インデックス(完全なインメモリ実装)2. 通常リレーショナル テーブル + 非クラスター化列ストア インデックス3. 通常リレーショナル テーブル + クラスター化列ストア インデックス
SQL Server 2014 まではインメモリ OLTP や通常リレーショナル テーブルを利用
SQL Server 2014 までは列ストア インデックスやAnalysis Services などを利用

SQL Server 2016 自習書 No.2 Operational Analytics
58
化、プッシュダウン、更新性能の向上、パラレル Insert など)も実現しているので、現在の SQL
Server で性能に問題を抱えているという方には、ぜひ試してみてほしい機能です。
SQL Server 2016 からの列ストア インデックスの飛躍的な進化
SQL Server 2016 からの列ストア インデックスの強化ポイントをまとめると、次のようになりま
す。
インメモリ OLTP にクラスター化列ストア インデックスを作成可能に
(=完全なインメモリでの Operational Analytics の実装)
列ストア インデックスの性能向上(バッチ モードの性能向上、集計のプッシュダウン、
更新性能の向上、ウィンドウ関数のバッチ モード対応など)
非クラスター化列ストア インデックスが更新可能に
非クラスター化列ストア インデックスでフィルター列が利用可能に
クラスター化列ストア インデックスでの追加の B-tree インデックスのサポート
主キー/外部キー制約のサポート
AlwaysOn 可用性グループの読み取り可能セカンダリのサポート
COMPRESS_DELAY(遅延圧縮)のサポート
何度も繰り返しになりますが、本書のタイトルにもなっている Operational Analytics に対応し
たことが一番のポイントです。これまでは Analytics ワークロード(データ集計/分析)に特化
していた列ストア インデックスが、SQL Server 2016 からは Operational ワークロード (OLTP)
にも対応して OLTP とデータ分析を両立できるようになりました。
既存環境からの移行という観点では、PRIMARY KEY 制約がサポートされるようになった点は大
きく、これまでの構成を大きく変更することなく移行できるようになりました。

SQL Server 2016 自習書 No.2 Operational Analytics
59
3.2 列ストア インデックスの基本的な利用方法
ここでは、列ストア インデックスの基本的な利用方法を説明します。
非クラスター化列ストア インデックスの作成方法
既存のディスク ベースのテーブルに対して、非クラスター化列ストア インデックスを追加する場
合には、次のように CREATE NONCLUSTERED COLUMNSTORE INDEX ステートメントを利
用します。
CREATE NONCLUSTERED COLUMNSTORE INDEX インデックス名
ON テーブル名 (列名1, 列名2, 列名3, ・・・)
[WHERE フィルター条件]
WHERE を付けて、フィルター条件を追加できるようになったのは、SQL Server 2016 からの新
機能です。フィルターを利用すれば、インデックス サイズを小さくすることができるので、集計ク
エリで扱うデータのフィルター条件と合致する場合には、ぜひ試してみてください。
なお、非クラスター化列ストア インデックスでは、列名を指定して、作成することができるので、
次のように特定のクエリにのみ強いインデックスを作成することも可能です。
ただし、テーブルに作成できる非クラスター化列ストア インデックスは 1 つのみなので、列ごと
に非クラスター化列ストア インデックスを作成しようとすると(b 列と c 列に対するインデック
スをそれぞれ作成しようとすると)、次のようにエラーが返されます。
このように、複数の列ストア インデックスはサポートされていないので、前掲の例のように集計ク
エリで b と c 列を利用するのであれば、b, c を含めた非クラスター化列ストア インデックスを
作成するようにします。
b 列で集計して、c 列のデータの MAX を取得しているので、非クラスター化列ストア イン
デックスには b, c のみを含めれば良い
テーブルに 2つ目の非クラスター化列ストア インデックス
を作成することはできない

SQL Server 2016 自習書 No.2 Operational Analytics
60
クラスター化列ストア インデックスの作成方法
既存のテーブルに対して、クラスター化列ストア インデックスを追加する場合には、次のように
CREATE CLUSTERED COLUMNSTORE INDEX ステートメントを利用します。
CREATE CLUSTERED COLUMNSTORE INDEX インデックス名
ON テーブル名
クラスター化列ストア インデックスは、すべての列に対してカラム ストアを作成するので、列名
を指定する必要はありません。
クラスター化列ストア インデックスを作成するための条件は、次のようになります。
テーブルに対して作成できるのは 1つのみ
b-tree のクラスター化インデックスとは共存できない(非クラスター化インデックスと
は共存できる)
PRIMARY KEY 制約を作成している場合には、既定で b-tree のクラスター化インデッ
クスが作成されるので、これは非クラスター化インデックスに変更しておく必要がありま
す(SQL Server 2014 では、非クラスター化インデックスとも共存することができませ
んでしたが、SQL Server 2016 からは共存できるようになりました)
クラスター化列ストア インデックスを作成したテーブルに、非クラスター化列ストア イ
ンデックスを追加することはできない(複数の列ストア インデックスは作成できない)
テーブルの作成時にクラスター化列ストア インデックスを作成する場合
テーブルの作成時にクラスター化列ストア インデックスを作成する場合には、次のように
CREATE TABLE ステートメントを記述します。
CREATE TABLE テーブル名
( 列名1 データ型
,列名2 データ型
:
,INDEX インデックス名 CLUSTERED COLUMNSTORE )
INDEX キーワードに続けてインデックス名を指定し、CLUSTERED COLUMNSTORE を付ける
SQL Server 2016 自習書 No.2 Operational Analytics
61
ことでクラスター化列ストア インデックスを作成することができます。
列ストア インデックスによる性能向上
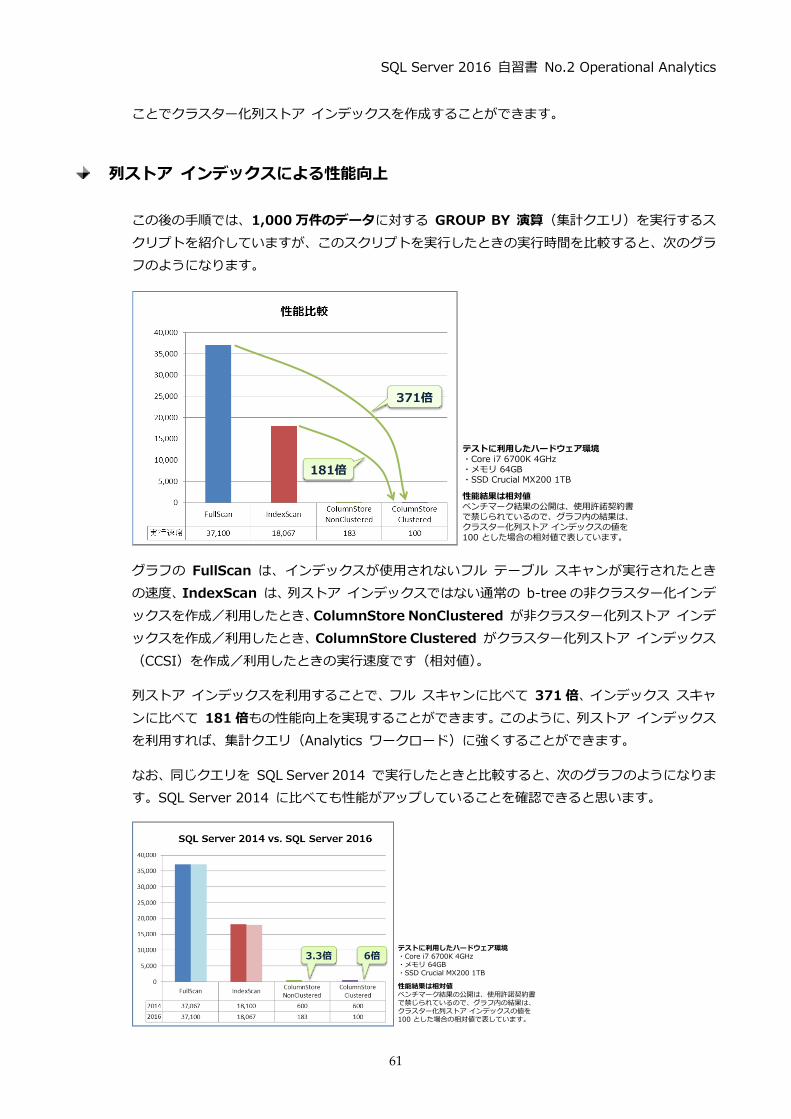
この後の手順では、1,000 万件のデータに対する GROUP BY 演算(集計クエリ)を実行するス
クリプトを紹介していますが、このスクリプトを実行したときの実行時間を比較すると、次のグラ
フのようになります。
グラフの FullScan は、インデックスが使用されないフル テーブル スキャンが実行されたとき
の速度、IndexScan は、列ストア インデックスではない通常の b-tree の非クラスター化インデ
ックスを作成/利用したとき、ColumnStore NonClustered が非クラスター化列ストア インデ
ックスを作成/利用したとき、ColumnStore Clustered がクラスター化列ストア インデックス
(CCSI)を作成/利用したときの実行速度です(相対値)。
列ストア インデックスを利用することで、フル スキャンに比べて 371倍、インデックス スキャ
ンに比べて 181 倍もの性能向上を実現することができます。このように、列ストア インデックス
を利用すれば、集計クエリ(Analytics ワークロード)に強くすることができます。
なお、同じクエリを SQL Server 2014 で実行したときと比較すると、次のグラフのようになりま
す。SQL Server 2014 に比べても性能がアップしていることを確認できると思います。
371倍
181倍
テストに利用したハードウェア環境・Core i7 6700K 4GHz・メモリ 64GB・SSD Crucial MX200 1TB
性能結果は相対値ベンチマーク結果の公開は、使用許諾契約書で禁じられているので、グラフ内の結果は、クラスター化列ストア インデックスの値を100 とした場合の相対値で表しています。
テストに利用したハードウェア環境・Core i7 6700K 4GHz・メモリ 64GB・SSD Crucial MX200 1TB
性能結果は相対値ベンチマーク結果の公開は、使用許諾契約書で禁じられているので、グラフ内の結果は、クラスター化列ストア インデックスの値を100 とした場合の相対値で表しています。
3.3倍 6倍

SQL Server 2016 自習書 No.2 Operational Analytics
62
3.3 列ストア インデックスの性能比較
それでは、列ストア インデックスを試してみましょう。インデックスを何も作成していない場合
や、b-tree のインデックスを作成した場合、非クラスター化列ストア インデックスを作成した場
合、クラスター化列ストア インデックスを作成した場合の性能比較などを行います。
列ストア インデックスは、複数コア環境でより威力を発揮するので、検証する際には、複数コアを
搭載した物理マシン、または複数コアを割り当てた仮想マシンを利用するのがお勧めです。なお、
SQL Server 2014 のときには、1 コア環境だとバッチ モード(内部的に列ストア インデックス
を処理する際の動作モード)で動作することができなったので、1 コア環境だと列ストア インデッ
クスの性能を確認することができなかったのですが、SQL Server 2016 からは、1 コアでもバッ
チ モードがサポートされるようになったので、1 コアでも性能差を確認できるようになりました。
データベースの作成
1. まずは、データベースを作成します。データベースの名前は「csTestDB」として、次のよう
に CREATE DATABASE ステートメントを実行します。
CREATE DATABASE csTestDB
ON PRIMARY ( NAME = 'csTestDB'
,FILENAME = 'C:\testDB\csTestDB_data.mdf'
,SIZE = 15GB )
LOG ON ( NAME = 'csTestDB_log'
,FILENAME = 'C:\testDB\csTestDB_log.ldf'
,SIZE = 10GB )
FILENAME で指定しているファイル パス (データ ファイルとトランザクション ログ ファ
イルの作成先となるフォルダー)には、「C:\testDB」フォルダーを指定していますが、皆さ
んの環境に合わせて適宜変更してください。
テーブル t1」の作成(ディスク ベースの通常テーブル)
1. 次に、CREATE TABLE ステートメントを利用して、通常どおりに 「t1」という名前のテーブ
ルを作成します。
USE csTestDB
CREATE TABLE t1
( a int IDENTITY(1, 1) PRIMARY KEY
,b int
,c char(200) DEFAULT 'dummy1'
,d char(200) DEFAULT 'dummy2'
)

SQL Server 2016 自習書 No.2 Operational Analytics
63
a、b、c、d の 4 つの列を作成して、a 列には IDENTITY(1 からの連番)と PRIMARY
KEY 制約を設定しておきます (これによって、内部的には、b-tree のクラスター化インデッ
クスが自動作成されています)。
1,000 万件のデータの INSERT
1. 次に、WHILE ループを利用して、1,000 万件のデータを INSERT します。
SET NOCOUNT ON
DECLARE @i int = 1, @b int = 1
WHILE @i <= 10000000
BEGIN
IF @i % 10000 = 0 SET @b = @i
INSERT INTO t1(b) VALUES(@b)
SET @i += 1
END
SET NOCOUNT OFF
1,000 万件のデータを追加しているので、環境にもよりますが、実行には 10 分~数時間くら
いの時間がかかります(ディスクが低速な場合には、より実行時間が長くなります)。
2. データの追加が完了したら、次のように SELECT ステートメントを実行して、追加されたデ
ータを確認しておきましょう。
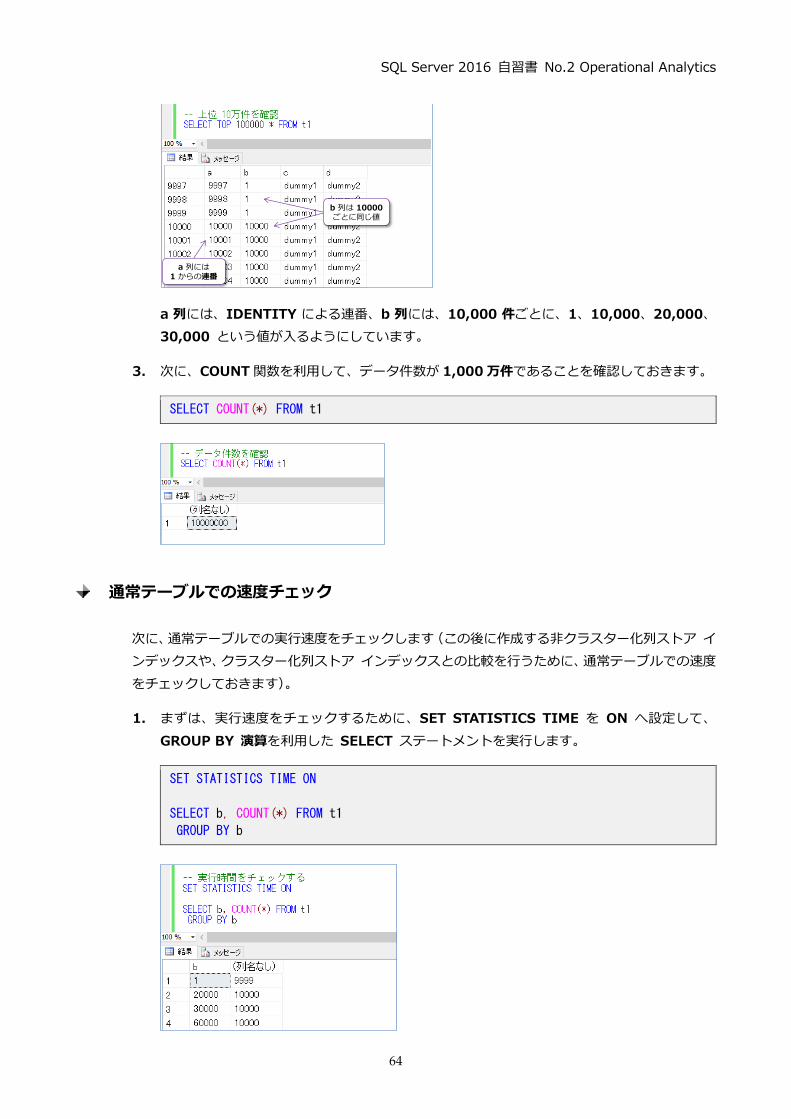
-- 上位 10万件を確認
SELECT TOP 100000 * FROM t1
SQL Server 2016 自習書 No.2 Operational Analytics
64
a 列には、IDENTITY による連番、b 列には、10,000 件ごとに、1、10,000、20,000、
30,000 という値が入るようにしています。
3. 次に、COUNT関数を利用して、データ件数が 1,000 万件であることを確認しておきます。
SELECT COUNT(*) FROM t1
通常テーブルでの速度チェック
次に、通常テーブルでの実行速度をチェックします (この後に作成する非クラスター化列ストア イ
ンデックスや、クラスター化列ストア インデックスとの比較を行うために、通常テーブルでの速度
をチェックしておきます)。
1. まずは、実行速度をチェックするために、SET STATISTICS TIME を ON へ設定して、
GROUP BY 演算を利用した SELECT ステートメントを実行します。
SET STATISTICS TIME ON
SELECT b, COUNT(*) FROM t1
GROUP BY b
a 列には1 からの連番
b 列は 10000ごとに同じ値

SQL Server 2016 自習書 No.2 Operational Analytics
65
実行が完了したら、[メッセージ]タブを開きます。
経過時間のところで実行時間を確認することができるので、これをメモしておいてください。
2. 次に、SELECT ステートメントを選択して、ツールバーの [推定実行プラン]ボタンをクリッ
クし、実行プランを確認します。
Clustered Index Scan(全データのスキャン)が選択されていることを確認できます。t1
テーブルの a 列には、PRIMARY KEY 制約を設定しているので、クラスター化インデックス
が自動作成されていて、このインデックス(実データ)が全スキャンされています。
3. 次に、テーブルのプロパティを開いて、テーブル サイズを確認します。
オブジェクト エクスプローラーで、t1 テーブルを右クリックして、[プロパティ]をクリッ
実行時間を確認する
1
2
2
SELECT ステートメントを選択
1
Clustered Index Scan
3
1
2
3

SQL Server 2016 自習書 No.2 Operational Analytics
66
クし、 [ストレージ]ページを開くと、 [データ領域]でテーブル サイズを確認することができ
ます(約 4GBのサイズであることを確認できます)。
b-tree 非クラスター化インデックスの作成(通常のインデックスの場合の性能)
次に、非クラスター化インデックス (列ストア インデックスではなく、通常の b-tree インデック
ス)を作成した場合の性能を調べてみましょう。
1. 今回作成する非クラスター化インデックスは、前掲の GROUP BY 演算 (b 列の COUNT)を
速く実行するためのものになるので、次のように b列に対して作成します。
CREATE NONCLUSTERED INDEX idx1
ON t1(b)
2. インデックスの作成が完了したら、SELECT ステートメントを実行して、実行時間を確認しま
す。
SELECT b, COUNT(*) FROM t1
GROUP BY b
経過時間が小さくなっていることを確認できると思います (弊社環境では、約 61% 速く実行
できることを確認しています)。
3. 次に、SELECT ステートメントを選択して、ツールバーの [推定実行プラン]ボタンをクリッ
クし、実行プランも確認しておきます。
Index Scan と表示されていることを確認できると思います。
実行時間を確認する
1
Index Scan1

SQL Server 2016 自習書 No.2 Operational Analytics
67
4. 次に、テーブル サイズとインデックス サイズも確認します。
データ領域 (テーブル サイズ)が約 4GB、インデックス領域 (インデックスのサイズ)が約
151MBであることを確認できます。
非クラスター化列ストア インデックスの作成、性能チェック
次に、非クラスター化列ストア インデックスを作成した場合の性能を調べてみましょう。
1. まずは、非クラスター化列ストア インデックスを試すためのテーブルを 「t1_nccsi」という
名前で作成します(t1 テーブルと全く同じ構造にします)。
CREATE TABLE t1_nccsi
( a int IDENTITY(1, 1) PRIMARY KEY
,b int
,c char(200) DEFAULT 'dummy1'
,d char(200) DEFAULT 'dummy2'
)
2. 次に、1 千万件分のデータを INSERT しますが、t1 テーブルと同じデータにするために、
次のように INSERT .. SELECT ステートメントを利用して、データを丸ごとコピーします。
INSERT INTO t1_nccsi (b, c, d)
SELECT b, c, d FROM t1
1
2

SQL Server 2016 自習書 No.2 Operational Analytics
68
3. 次に、CREATE NONCLUSTERED COLUMNSTORE INDEX ステートメントを利用して、
非クラスター化列ストア インデックスを作成します。
CREATE NONCLUSTERED COLUMNSTORE INDEX idx1
ON t1_nccsi(a, b, c, d)
4. 作成が完了したら、同じ SELECT ステートメントを実行して、実行時間を確認します。
SELECT b, COUNT(*) FROM t1_nccsi
GROUP BY b
経過時間が桁違いに小さくなっていることを確認できると思います (弊社環境では、約 202倍
速く実行できることを確認しています。1 回目の実行は、コンパイル時間もあるので、それは
除外して、2 回、3 回、4 回と実行したときの、それらの平均実行時間で比較しています)。
5. 次に、SELECT ステートメントを選択して、ツールバーの [推定実行プラン]ボタンをクリッ
クし、実行プランも確認しておきます。
実行時間を確認する
1

SQL Server 2016 自習書 No.2 Operational Analytics
69
Columnstore インデックス スキャン (NonClustered)と表示されて、非クラスター化列
ストア インデックスのスキャンで実行されていることを確認できると思います。
6. 次に、インデックス サイズも確認します。
インデックス領域(インデックスのサイズ)が約 49MB であることを確認できます(b-tree
の非クラスター化インデックスの場合は 約 151MBでした)。
SQL Server 2016 からは更新可能に
SQL Server 2016 からは、非クラスター化列ストア インデックスでも、更新ができるようになっ
たので、これも試してみましょう(SQL Server 2012/2014 では読み取り専用でした)。
1. まずは、UPDATE ステートメントを実行して、データを更新してみます。
UPDATE t1_nccsi
SET c = 'zzzz'
WHERE a = 1
NonClustered(非クラスター化)のColumnstore インデックス スキャン
1
1

SQL Server 2016 自習書 No.2 Operational Analytics
70
問題なくデータが更新できたことを確認できると思います。なお、SQL Server 2012/SQL
Server 2014 で同じステートメントを実行した場合には、次のようにエラーが返されていま
した。
2. 次に、更新したデータを確認してみます。
SELECT * FROM t1_nccsi
WHERE a = 1
3. 次に、INSERT ステートメントを実行して、データを追加してみます。
INSERT INTO t1_nccsi (b, c, d)
VALUES(222, 'aaa', 'aaa')
データの追加も問題なくできることを確認できます。

SQL Server 2016 自習書 No.2 Operational Analytics
71
4. 次に、DELETE ステートメントを実行して、データを削除してみます。
DELETE FROM t1_nccsi
WHERE b = 222
データの削除も問題なくできることを確認できます。
このように、SQL Server 2016 からは、非クラスター化列ストア インデックスを作成して
も、データを更新/追加/削除できるようになったので、Operational Analytics を実現
(OLTP とデータ分析の両立)できるようになりました。
クラスター化列ストア インデックスの作成、性能チェック
次に、クラスター化列ストア インデックスを作成した場合の性能を調べてみましょう。
1. まずは、クラスター化列ストア インデックスを試すためのテーブルを 「t1_ccsi」という名前
で作成します(t1、t1_nccsi テーブルと全く同じ構造にします)。
CREATE TABLE t1_ccsi
( a int IDENTITY(1, 1) PRIMARY KEY
,b int
,c char(200) DEFAULT 'dummy1'
,d char(200) DEFAULT 'dummy2'
)
2. 次に、1 千万件分のデータを INSERT しますが、t1 テーブルと同じデータにするために、
次のように INSERT .. SELECT ステートメントを実行します。
INSERT INTO t1_ccsi (b, c, d)
SELECT b, c, d FROM t1

SQL Server 2016 自習書 No.2 Operational Analytics
72
3. 次に、CREATE CLUSTERED COLUMNSTORE INDEX ステートメントを利用して、クラス
ター化列ストア インデックスを作成します (非クラスター化列ストア インデックスでは、ON
句で列名を指定しましたが、クラスター化列ストア インデックスの場合は、すべての列を含
める必要があるので、ON 句ではテーブル名を指定するだけになります)。
CREATE CLUSTERED COLUMNSTORE INDEX idx1
ON t1_ccsi
しかし、結果はエラーになります。クラスター化列ストア インデックスを作成するには、テー
ブル内にクラスター化インデックスがないことが条件になるためです。t1_ccsiテーブルには、
PRIMARY KEY 制約を設定しているので、自動的に b-tree のクラスター化インデックスが
作成されているので、このエラーが返っています。これを回避するには、クラスター化インデ
ックスを非クラスター化インデックスに変更するか、PRIMARY KEY 制約を削除するように
します。
なお、SQL Server 2014 では、クラスター化列ストア インデックスで PRIMARY KEY 制約
がサポートされていなかったので、PRIMARY KEY 制約を削除する方法しかとれませんでし
た。SQL Server 2016 からは、PRIMARY KEY 制約がサポートされるようになったので、制
約は残しつつ、インデックスのみを変更するという方法がとれるようになりました。
4. 次に、PRIMARY KEY 制約で作成されたクラスター化インデックスを非クラスター化インデッ
クスに変更するために、次のように sp_help システム ストアド プロシージャを実行して、
PRIMARY KEY 制約の名前(インデックス名)を確認します。
EXEC sp_help 't1_ccsi'

SQL Server 2016 自習書 No.2 Operational Analytics
73
index_name に表示される「PK__t1_ccsi__~」が PRIMARY KEY 制約の名前(および
インデックスの名前)になるので、これをコピーします。
5. コピーした名前を、次のように ALTER TABLE ステートメントの DROP CONSTRAINT の
部分に貼り付けて、PRIMARY KEY 制約をいったん削除します。
ALTER TABLE t1_ccsi
DROP CONSTRAINT PK__t1_ccsi__~
6. PRIMARY KEY 制約の削除が完了したら、今度は ALTER TABLE ステートメントの ADD
CONSTRAINT で PRIMARY KEY NONCLUSTERED を指定して、非クラスター化インデ
ックスとして PRIMARY KEY 制約を作成します(制約の名前は pk_t1_ccsi にします)。
ALTER TABLE t1_ccsi
ADD CONSTRAINT pk_t1_ccsi PRIMARY KEY NONCLUSTERED(a)
1
sp_help で調べたインデックス名に置換する

SQL Server 2016 自習書 No.2 Operational Analytics
74
7. PRIMARY KEY 制約の再作成後は、もう一度、CREATE CLUSTERED COLUMNSTORE
INDEX ステートメントを実行して、クラスター化列ストア インデックスを作成します。
CREATE CLUSTERED COLUMNSTORE INDEX idx1
ON t1_ccsi
今度は、作成が完了することを確認できます。
なお、SQL Server 2014 のときには、上と同じように PRIMARY KEY 制約が存在している
場合には、次のようにクラスター化列ストア インデックスを作成することができませんでし
た(SQL Server 2014 では、PRIMARY KEY 制約を削除しなければなりませんでした)。
8. クラスター化列ストア インデックスの作成が完了したら、同じ SELECT ステートメントを
実行して、実行時間を確認します。
SELECT b, COUNT(*) FROM t1_ccsi
GROUP BY b
1 回目の実行はコンパイル時間が加算されるので、2 回、3 回、4 回と実行して、そのときの
実行時間を確認してみてください。経過時間が桁違いに小さくなっていることを確認できると
思います(弊社環境では、非クラスター化列ストア インデックスのときよりも速く実行でき
実行時間を確認する
1
SQL Server 2016 自習書 No.2 Operational Analytics
75
ることを確認しています。b-tree の非クラスター化インデックスのときと比べると、約 181
倍 速く実行)。
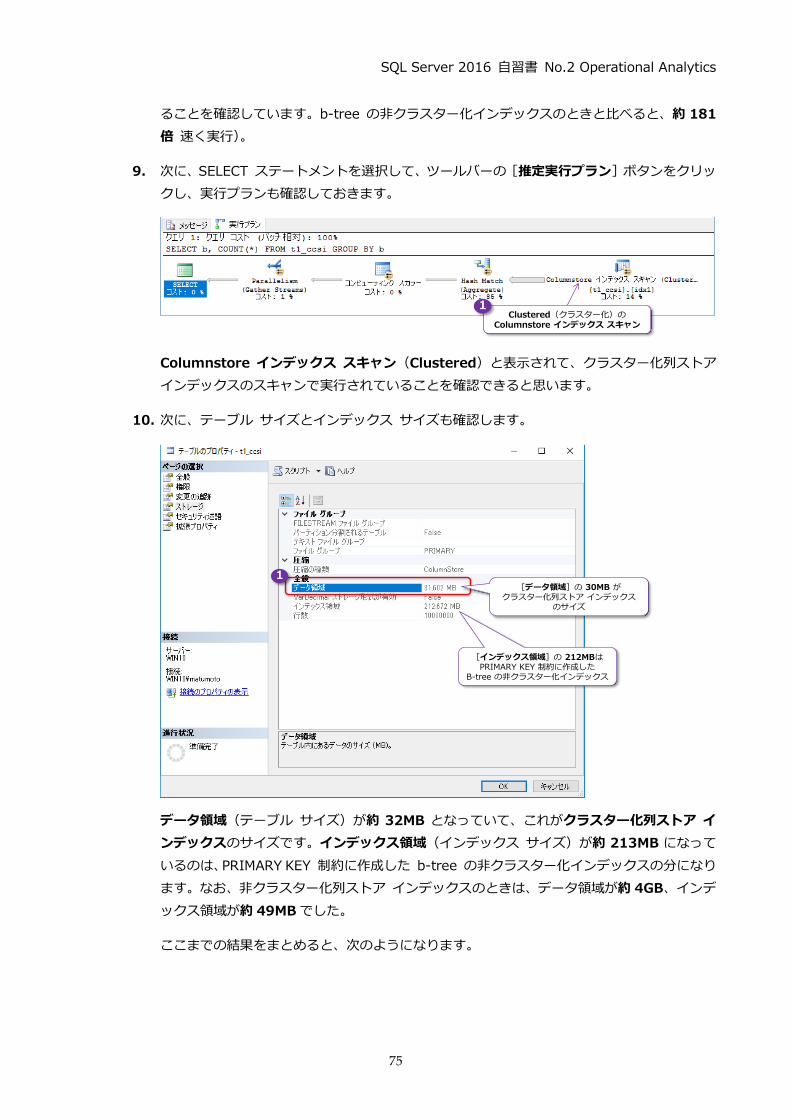
9. 次に、SELECT ステートメントを選択して、ツールバーの [推定実行プラン]ボタンをクリッ
クし、実行プランも確認しておきます。
Columnstore インデックス スキャン(Clustered)と表示されて、クラスター化列ストア
インデックスのスキャンで実行されていることを確認できると思います。
10. 次に、テーブル サイズとインデックス サイズも確認します。
データ領域(テーブル サイズ)が約 32MB となっていて、これがクラスター化列ストア イ
ンデックスのサイズです。インデックス領域(インデックス サイズ)が約 213MB になって
いるのは、PRIMARY KEY 制約に作成した b-tree の非クラスター化インデックスの分になり
ます。なお、非クラスター化列ストア インデックスのときは、データ領域が約 4GB、インデ
ックス領域が約 49MBでした。
ここまでの結果をまとめると、次のようになります。
Clustered(クラスター化)のColumnstore インデックス スキャン
1
1
[インデックス領域]の 212MBはPRIMARY KEY 制約に作成した
B-tree の非クラスター化インデックス
[データ領域]の 30MB がクラスター化列ストア インデックス
のサイズ
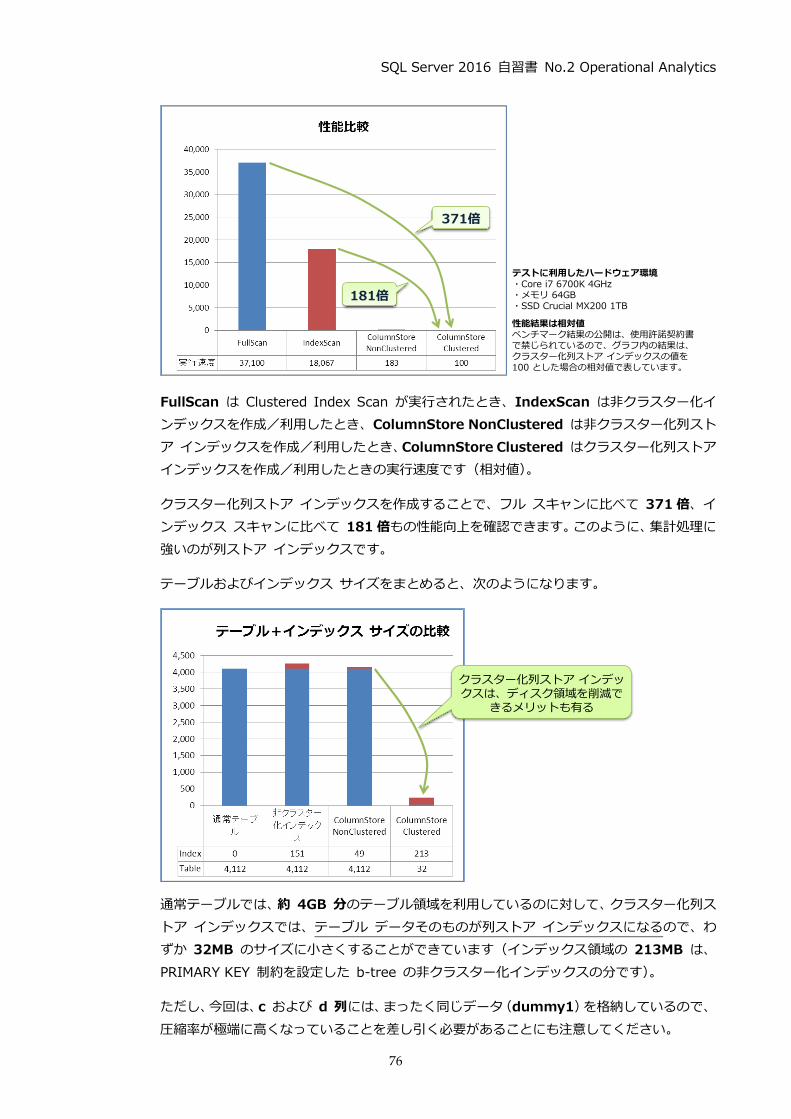
SQL Server 2016 自習書 No.2 Operational Analytics
76
FullScan は Clustered Index Scan が実行されたとき、IndexScan は非クラスター化イ
ンデックスを作成/利用したとき、ColumnStore NonClustered は非クラスター化列スト
ア インデックスを作成/利用したとき、ColumnStore Clustered はクラスター化列ストア
インデックスを作成/利用したときの実行速度です(相対値)。
クラスター化列ストア インデックスを作成することで、フル スキャンに比べて 371 倍、イ
ンデックス スキャンに比べて 181 倍もの性能向上を確認できます。このように、集計処理に
強いのが列ストア インデックスです。
テーブルおよびインデックス サイズをまとめると、次のようになります。
通常テーブルでは、約 4GB 分のテーブル領域を利用しているのに対して、クラスター化列ス
トア インデックスでは、テーブル データそのものが列ストア インデックスになるので、わ
ずか 32MB のサイズに小さくすることができています(インデックス領域の 213MB は、
PRIMARY KEY 制約を設定した b-tree の非クラスター化インデックスの分です)。
ただし、今回は、c および d 列には、まったく同じデータ (dummy1)を格納しているので、
圧縮率が極端に高くなっていることを差し引く必要があることにも注意してください。
371倍
181倍
テストに利用したハードウェア環境・Core i7 6700K 4GHz・メモリ 64GB・SSD Crucial MX200 1TB
性能結果は相対値ベンチマーク結果の公開は、使用許諾契約書で禁じられているので、グラフ内の結果は、クラスター化列ストア インデックスの値を100 とした場合の相対値で表しています。
クラスター化列ストア インデックスは、ディスク領域を削減で
きるメリットも有る

SQL Server 2016 自習書 No.2 Operational Analytics
77
弊社のお客様データでの圧縮例(100億件の DWH で 1/6 に)
弊社のお客様のデータ(100 億件の DWH)で、クラスター化列ストア インデックスを作成した
場合の圧縮効果は、次のようになりました。
通常テーブルが 531GB であるところを、90GB へと、約 1/6 のサイズにすることができまし
た。このように、クラスター化列ストア インデックスは、ディスク領域を削減できるメリットもあ
ります。また、ディスクから読み取るサイズが小さくなる分、性能向上にも貢献します (圧縮およ
び解凍に伴う CPU パワーとのトレードオフも存在します)。
約 1/6に圧縮

SQL Server 2016 自習書 No.2 Operational Analytics
78
3.4 列ストア インデックスでのデータ更新とインデックスの再構築
次に、クラスター化列ストア インデックスに対して、データの更新を行った場合の性能を確認して
みましょう。
10 万件のデータの INSERT
1. まずは、SET STATISTICS TIME コマンドを OFF へ設定して、実行時間の記録を停止して
おきます(これは、次の手順の WHILE ループを実行前に、必ず実行しておいてください)。
SET STATISTICS TIME OFF
2. 次に、10万件のデータを INSERT します。
SET NOCOUNT ON
DECLARE @i int = 1
WHILE @i <= 100000
BEGIN
INSERT INTO t1_ccsi(b) VALUES(8888)
SET @i += 1
END
SET NOCOUNT OFF
何の問題もなく、データを INSERT できることを確認できたと思います。
なお、もしこのスクリプトを実行する前に、SET STATISTICS TIME を OFF にし忘れてし
まった場合は、10 万件分の結果メッセージが出力されることになり、実行時間が非常に長く
なってしまうので注意してください (出力メッセージ数が多いと、Management Studio が終
了してしまう場合もあります)。
3. 次に、SET STATISTICS TIME ON を実行して、前の Step と同じ SELECT ステートメン
ト(GROUP BY 演算)の実行時間を計測してみます。

SQL Server 2016 自習書 No.2 Operational Analytics
79
SET STATISTICS TIME ON
SELECT b, COUNT(*) FROM t1_ccsi
GROUP BY b
10 万件追加しただけにも関わらず、実行時間が長くなっていることを確認できると思います。
これは、クラスター化列ストア インデックスでは、更新されたデータは、 「Delta ストア」と
呼ばれる、更新データの格納用の領域に格納されているためです。
クラスター化列ストア インデックスでは、カラム(列)単位でデータを格納しているカラム
ストア領域と、更新データのための Delta ストア (差分領域)があり、Delta ストアにデータ
がある場合は、読み取り時のオーバーヘッドが発生します。これを回避するには、インデック
スを再構築するようにします。再構築を行うことで、Delta ストア内の差分データをカラム ス
トアへ移動させることができるからです。
クラスター化列ストア インデックスの再構築(REBUILD)
それでは、インデックスを再構築してみましょう。
1. クラスター化列ストア インデックスの再構築は、通常のインデックスを再構築するのと同様、
ALTER INDEX ステートメントを利用して、次のように実行します。
ALTER INDEX idx1
ON t1_ccsi REBUILD
実行時間を確認する
1
a b c
Delta ストア(Row ストア)
… 行単位で格納
カラム(Column)ストア
a b c列単位で格納
インデックスの再構築によってカラム ストアへ移動
更新されたデータを格納する領域

SQL Server 2016 自習書 No.2 Operational Analytics
80
2. 再構築が完了したら、もう一度 SELECT ステートメントを実行してみましょう。
SELECT b, COUNT(*) FROM t1_ccsi
GROUP BY b
今度は、1,000 万件のときとほとんど同じスピードで検索できたことを確認できると思います。
このように、列ストア インデックスでは、データの更新を行うことができますが、より良いパ
フォーマンスを保つには、定期的にインデックスを再構築することが重要になります。
Note: COLUMNSTORE_ARCHIVE(列ストア アーカイブ)
クラスター化列ストア インデックスでは、さらに圧縮率を高めた、「COLUMNSTORE_ARC
HIVE」(列ストア アーカイブ)というモードもあります。
さらに圧縮をすることで、ディスク使用領域をより小さくできることがメリットです(圧縮率
を高くする分、さらに CPU パワーを余分に使うことになるので、それとのトレードオフにな
ります)。
データ パーティションを利用して、複数のパーティションを作成している場合は、特定のパー
ティションのみを COLUMNSTORE_ARCHIVE へ設定することもできるので、アクセスされ
実行時間を確認する
1
カラム(Column)ストア
さらに圧縮
Columnstore Archive
ca b c ba

SQL Server 2016 自習書 No.2 Operational Analytics
81
る頻度の低いパーティションのみを COLUMNSTORE_ARCHIVE へ設定するという使い方も
できます。
COLUMNSTORE_ARCHIVE を設定するには、次のように ALTER INDEX ステートメント
での REBUILD 時に DATA_COMPRESSION を指定します。
ALTER INDEX idx1
ON t1_ccsi REBUILD WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE
前掲の弊社のお客様(100 億件の DWH)で、これを設定した場合には、次のような効果があ
りました。
COLUMNSTORE_ARCHIVE を設定することで、通常テーブルが 531GB であるところを、
65GB へと、約 1/8 のサイズにすることができました。クラスター化列ストア インデックス
の 90GB と比べても、27.7% も圧縮することができています。
このように、さらに圧縮率を高めることができるのが、COLUMNSTORE_ARCHIVE のメリ
ットです(圧縮率を高くする分、CPU パワーを余計に利用することになるので、それとのトレ
ードオフになります)。
なお、COLUMNSTORE_ARCHIVE へ設定したテーブル(やパーティション)をもとに戻した
い場合(通常の列ストアに戻したい場合)には、次のように ALTER INDEX ステートメントを
実行します(DATA_COMPRESSION で COLUMNSTORE を指定します)。
ALTER INDEX idx1
ON t1_ccsi REBUILD WITH (DATA_COMPRESSION = COLUMNSTORE)
約 1/6に圧縮
約 1/8に圧縮
27.7%圧縮
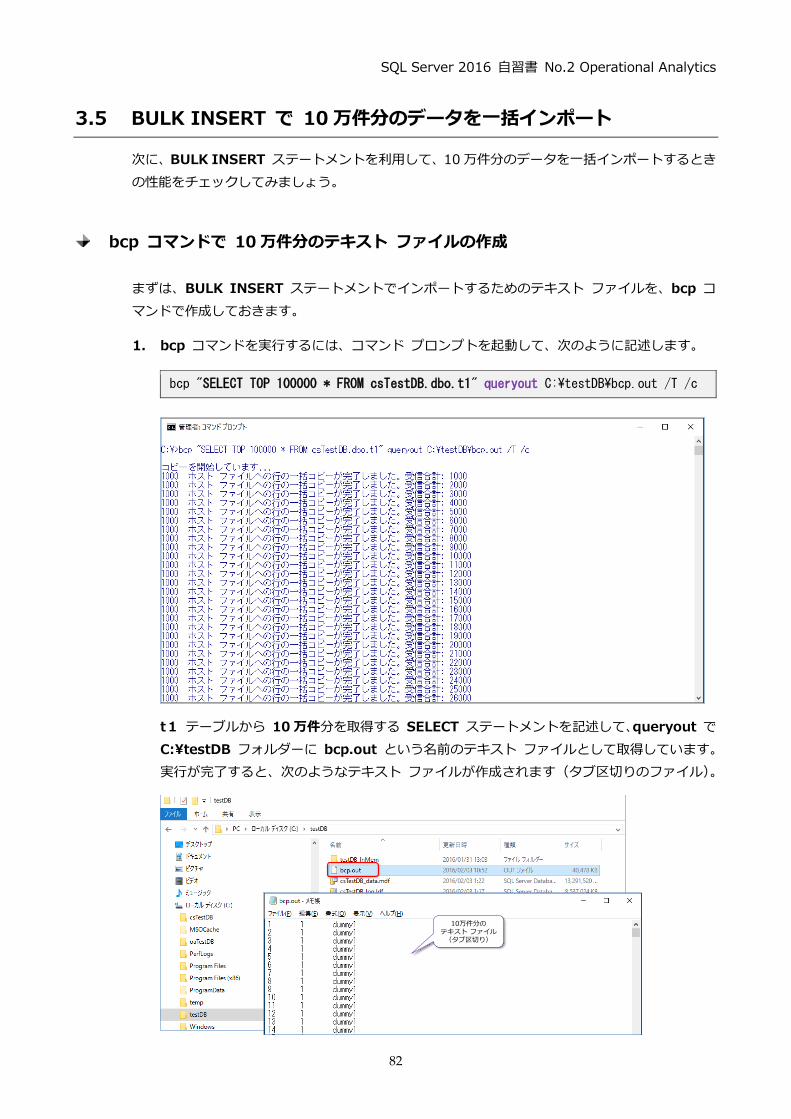
SQL Server 2016 自習書 No.2 Operational Analytics
82
3.5 BULK INSERT で 10万件分のデータを一括インポート
次に、BULK INSERT ステートメントを利用して、10 万件分のデータを一括インポートするとき
の性能をチェックしてみましょう。
bcp コマンドで 10万件分のテキスト ファイルの作成
まずは、BULK INSERT ステートメントでインポートするためのテキスト ファイルを、bcp コ
マンドで作成しておきます。
1. bcp コマンドを実行するには、コマンド プロンプトを起動して、次のように記述します。
bcp "SELECT TOP 100000 * FROM csTestDB.dbo.t1" queryout C:\testDB\bcp.out /T /c
t1 テーブルから 10万件分を取得する SELECT ステートメントを記述して、queryout で
C:\testDB フォルダーに bcp.out という名前のテキスト ファイルとして取得しています。
実行が完了すると、次のようなテキスト ファイルが作成されます(タブ区切りのファイル)。
10万件分のテキスト ファイル(タブ区切り)

SQL Server 2016 自習書 No.2 Operational Analytics
83
BULK INSERT ステートメントで 10 万件を一括インポート
次に、BULK INSERT ステートメントを利用して、10 万件分のデータを一括インポートしてみま
しょう。
1. まずは、t1 テーブル (b-tree の非クラスター化インデックスを付与したテーブル)にインポ
ートしてみましょう(実行時間は SET STATISTICS TIME ON で確認します)。
SET STATISTICS TIME ON
-- 10万件分のデータを一括インポート
BULK INSERT t1
FROM 'C:\testDB\bcp.out'
実行が完了したら、さらに 2 回、3 回と同じステートメントを実行して、そのときの実行時間
も確認してみてください。
2. 次に、t1_nccsi テーブル (非クラスター化列ストア インデックスを作成しているテーブル)
にインポートしてみましょう。
-- 非クラスター化列ストア インデックスのテーブルにインポート
BULK INSERT t1_nccsi
FROM 'C:\testDB\bcp.out'
3. 次に、t1_ccsi テーブル(クラスター化列ストア インデックスを作成しているテーブル)に
インポートしてみましょう。
実行時間を確認する
1
実行時間を確認する
1

SQL Server 2016 自習書 No.2 Operational Analytics
84
-- クラスター化列ストア インデックスのテーブルにインポート
BULK INSERT t1_ccsi
FROM 'C:\testDB\bcp.out'
ここまでの結果をまとめると、次のようになります。
非クラスター化列ストア インデックスを作成したテーブル (t1_nccsi)は 33%、クラスタ
ー化列ストア インデックスを作成したテーブル(t1_ccsi)は 59% のオーバーヘッドにな
りました。クラスター化列ストア インデックスを作成したテーブルには、PRIMARY KEY 制
約があるので、b-tree の非クラスター化インデックスも作成されているので、もし、次のよう
に PRIMARY KEY 制約を外している場合は、オーバーヘッドを軽減できます。
-- PK を外したクラスター化列ストア インデックスのテーブル
CREATE TABLE t1_ccsi_notPK
( a int IDENTITY(1, 1)
,b int
,c char(200) DEFAULT 'dummy1'
,d char(200) DEFAULT 'dummy2'
,INDEX ccsi_t1_ccsi_notPK CLUSTERED COLUMNSTORE )
-- 1千万件のコピー(∵他のテーブルと条件を合わせるため)
INSERT INTO t1_ccsi_notPK (b, c, d) SELECT b, c, d FROM t1
-- 10万件の一括インポート
BULK INSERT t1_ccsi_notPK
FROM 'C:\testDB\bcp.out'
実行時間を確認する
1
テストに利用したハードウェア環境・Core i7 6700K 4GHz・メモリ 64GB・SSD Crucial MX200 1TB
性能結果は相対値ベンチマーク結果の公開は、使用許諾契約書で禁じられているので、グラフ内の結果は、通常テーブル(t1)の値を 100 とした場合の相対値で表しています。

SQL Server 2016 自習書 No.2 Operational Analytics
85
なお、t1 テーブルでも、PRIMARY KEY 制約を外したり、b 列に対する b-tree の非クラス
ター化インデックスを削除することで(ヒープにすることで)、BULK INSERT の性能を向上
させることができます。このあたりのインデックスと一括インポートの考え方 (インデックス
のオーバーヘッドへの対処方法)は、従来どおりです。
インポート後はインデックスの再構築
一括インポートを行った後は、集計クエリの性能が低下することになるので、前の項で紹介したイ
ンデックスの再構築(REBUILD)を行っておくのがお勧めになります。
1. これを確認するには、これまでと同じ SELECT ステートメント (GROUP BY 演算)を実行
します。
SET STATISTICS TIME ON
SELECT b, COUNT(*) FROM t1_ccsi
GROUP BY b
実行時間が長くなっていることを確認できると思います。
2. 次に、ALTER INDEX ステートメントを利用して、インデックスを再構築します。
ALTER INDEX idx1
ON t1_ccsi REBUILD
PK なしなら15%のオーバーヘッド
実行時間を確認する
1
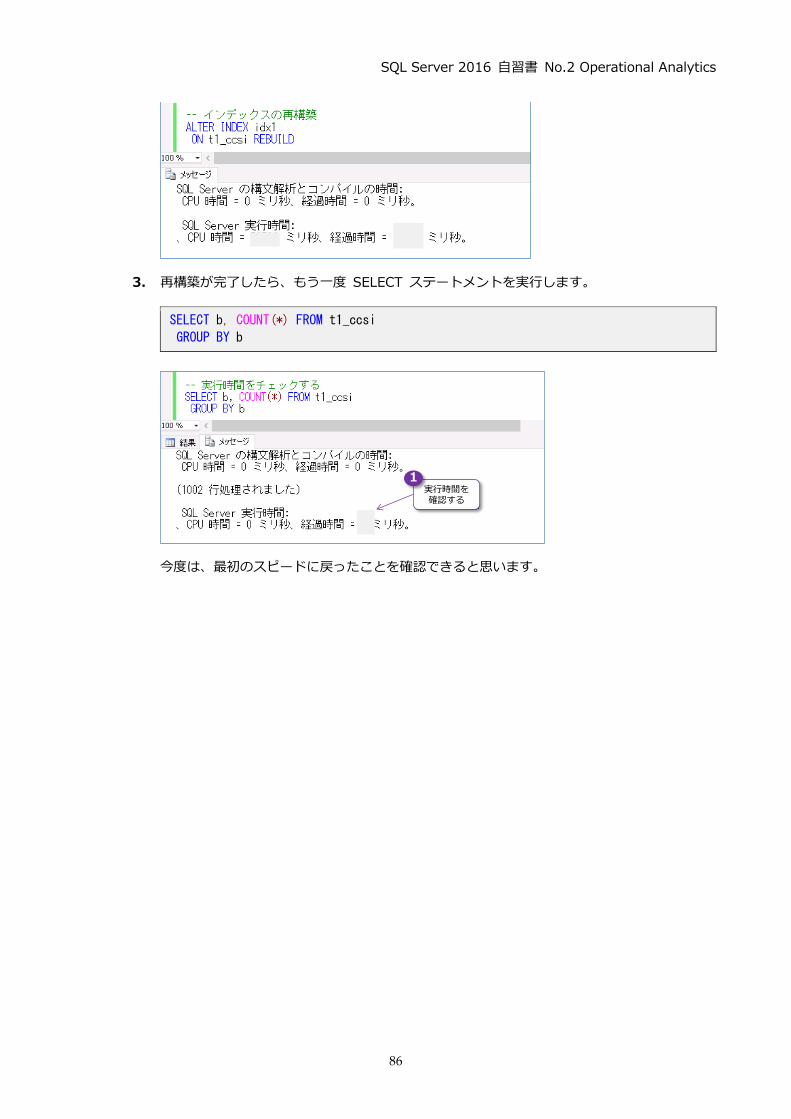
SQL Server 2016 自習書 No.2 Operational Analytics
86
3. 再構築が完了したら、もう一度 SELECT ステートメントを実行します。
SELECT b, COUNT(*) FROM t1_ccsi
GROUP BY b
今度は、最初のスピードに戻ったことを確認できると思います。
実行時間を確認する
1

SQL Server 2016 自習書 No.2 Operational Analytics
87
3.6 インメモリ OLTP の利用
次に、インメモリ OLTP を利用して、完全なインメモリでの Operational Analytics を確認して
みましょう。
Let's Try
1. まずは、インメモリ OLTP を利用するために、データベースにファイル グループを追加しま
す。
-- ファイルグループの追加
ALTER DATABASE csTestDB
ADD FILEGROUP fg1
CONTAINS MEMORY_OPTIMIZED_DATA
ALTER DATABASE csTestDB
ADD FILE ( NAME = csTestDB_InMem,
FILENAME = 'C:\testDB\csTestDB_InMem' )
TO FILEGROUP fg1
2. 次に、CREATE TABLE ステートメントを利用してメモリ最適化テーブルを作成しますが、こ
のときにクラスター化列ストア インデックスを作成するようにします。
-- メモリ最適化テーブルの作成
USE csTestDB
CREATE TABLE t1_InMem_ccsi
( a int IDENTITY(1, 1)
PRIMARY KEY NONCLUSTERED
HASH WITH (BUCKET_COUNT = 10000000)
,b int
,c char(200) DEFAULT 'dummy1'
,d char(200) DEFAULT 'dummy2'
,INDEX idx_InMem_ccsi CLUSTERED COLUMNSTORE
) WITH ( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA )
t1 テーブルと同じ構成で、「t1_InMem_ccsi」という名前で作成します。WITH 句では
MEMORY_OPTIMIZED=ON を指定することでメモリ最適化テーブルにして、a 列には非
クラスター化の HASH インデックス (BUCKET_COUNT は 1,000 万に設定)を作成してい
ます。また、INDEX キーワードに続けてインデックス名 (idx_InMem_ccsi)を指定して、
CLUSTERED COLUMNSTORE を指定することで、クラスター化列ストア インデックスを
作成しています。インメモリ OLTP のクラスター化列ストア インデックスでは、
DURABILITY で SCHEMA_AND_DATA(データの永続化有り)が必須になるので、これ
も指定しています。
3. 次に、INSERT..SELECT を利用して、t1 テーブルから 1 千万件分のデータをコピーします。

SQL Server 2016 自習書 No.2 Operational Analytics
88
-- 1千万件のデータをコピー
INSERT INTO t1_InMem_ccsi (b, c, d)
SELECT b, c, d FROM t1
4. データのコピーが完了したら、これまでと同じ SELECT ステートメント (GROUP BY 演算)
を実行します。
SET STATISTICS TIME ON
SELECT b, COUNT(*) FROM t1_InMem_ccsi
GROUP BY b
弊社環境では、非クラスター化列ストア インデックス(NCCSI)を作成したときとほとんど
同じスピードで結果が返ることを確認できました。
性能が確認できない場合の対処方法
もし、性能効果を確認できない場合は、次の手順を試してみてください。
1. まずは、dm_db_column_store_row_group_physical_stats 動的管理ビュー(DMV)
を利用して、データの状態を確認します。
-- データの格納状態を確認
SELECT OBJECT_NAME(object_id), *
FROM sys.dm_db_column_store_row_group_physical_stats
WHERE OBJECT_NAME(object_id) = 't1_InMem_ccsi'
実行時間を確認する
1

SQL Server 2016 自習書 No.2 Operational Analytics
89
この DMV は、列ストア インデックスの Row Group (列ストアを内部的に分割する単位で、
通常は 100 万件ごとに 1 つの Row Group が作成される)を確認できるものです。インメ
モリ OLTP では、定期的に Row Group の再作成 (圧縮/COMPRESS)が行われるのですが、
これがまだ実行されていない場合には、 [state_desc]が 「OPEN」と表示されます。ここで、
OPEN と表示される場合は、次のように 「sp_memory_optimized_cs_migration」スト
アド プロシージャを実行して、強制的に圧縮を実行するようにします。
2. 「sp_memory_optimized_cs_migration」ストアド プロシージャの実行は、次のように
OBJECT_ID を指定して行えます。
-- 強制的に圧縮を実行
DECLARE @objid int = OBJECT_ID('t1_InMem_ccsi')
EXEC sp_memory_optimized_cs_migration @objid
3. 実行後、もう一度 dm_db_column_store_row_group_physical_stats 動的管理ビュ
ーを参照して、データの状態を確認します。
SELECT OBJECT_NAME(object_id), *
FROM sys.dm_db_column_store_row_group_physical_stats
WHERE OBJECT_NAME(object_id) = 't1_InMem_ccsi'
COMPRESS と表示された行が追加されれば成功です(だいたい 100 万件ごとに 1 つの
Row Group が作成されるので、1 千万件だと 10 個ぐらいの行が返ります)。この状態になっ
たら、再度 GROUP BY クエリを実行して、性能を確認してみてください。

SQL Server 2016 自習書 No.2 Operational Analytics
90
弊社環境での性能結果は、次のようになりました。
インメモリ OLTP とクラスター化列ストア インデックス (CCSI)の組み合わせでは、非クラスタ
ー化列ストア インデックス(NCCSI)を利用した場合とほとんど同じ性能が出ることを確認でき
ました。
列ストア インデックスのまとめ
以上のように、列ストア インデックスは、大きな性能向上およびディスク領域の削減を期待でき
る、大変便利な機能です。圧縮/解凍に伴う CPU パワーとのトレードオフや、更新時のデータを
格納するための Delta ストアを利用することによるオーバーヘッドなどがありますが、インデッ
クスを定期的に再構築するなど、うまく活用することで、大きな性能向上を実現することができる
ので、ぜひ試してみてください。
また、インメモリ OLTP と組み合わせ利用することで、OLTP にも強くすることができる (特に多
重度が上がった場合の同時実行性能に強くできる)ので、ぜひ試してみてださい。
テストに利用したハードウェア環境・Core i7 6700K 4GHz・メモリ 64GB・SSD Crucial MX200 1TB
性能結果は相対値ベンチマーク結果の公開は、使用許諾契約書で禁じられているので、グラフ内の結果は、クラスター化列ストア インデックスの値を100 とした場合の相対値で表しています。
90倍
186倍

SQL Server 2016 自習書 No.2 Operational Analytics
91
STEP 4. インメモリ OLTP
の基本操作
この STEP では、まだインメモリ OLTP を試したことがない方のために、インメ
モリ OLTP の基本的な利用方法を説明します。
なお、この Step で説明する内容は、SQL Server 2014 自習書シリーズの 「イン
メモリ OLTP 入門」編とほとんど同じ内容になるので、これを試したことがある
方は、読み飛ばしていただいて大丈夫です。
この STEP では、次のことを学習します。
インメモリ OLTP の概要
インメモリ OLTP の基本操作(メモリ最適化テーブルの作成)
ネイティブ コンパイル ストアド プロシージャの作成
同時更新の場合の動作の確認(Write-Write 競合)

SQL Server 2016 自習書 No.2 Operational Analytics
92
4.1 インメモリ OLTP の主な特徴
インメモリ OLTP は、SQL Server 2014 から提供された、インメモリのデータベース エンジン
で、当時の開発コード名は「Hekaton」(ヘカトン)と呼ばれていました。このエンジンの一番の
特徴は、なんといっても 「インメモリ」で動作することで、非常に高速に処理できる点です。テー
ブル内のデータを、全てメモリ内に載せることができるので、従来のディスク ベースのデータベー
ス エンジンよりも非常に高速に動作させることができます。
インメモリ OLTP 機能の主な特徴
インメモリ OLTP 機能の主な特徴は、次のとおりです。
インメモリで動作するので、従来のデータベース エンジンよりも非常に高速
SQL Server のデータベース エンジンと完全に統合されている。
SQL Server のデータベース エンジンに完全に統合されているので、従来どおりの
Transact-SQL ステートメントおよびツールを利用してインメモリの操作が可能。
シームレスに利用できるので、"移行"が容易に行える。新しいハードウェアを購入する必
要もない。
AlwaysOn 可用性グループによるデータの保護/可用性向上もサポートされる
メモリ内にのみテーブル データを配置することが可能(ディスク上にはデータを配置し
ない)。メモリ内に配置したテーブルは、「メモリ最適化テーブル」(Memory-optimized
Table)と呼ばれる
「ネイティブ コンパイル ストアド プロシージャ」(Natively Compiled Stored
Procedure)を作成することで、さらに高速な処理が可能
SQL Server の再起動後も、データ復旧が可能な Durability(永続化)オプションも用
意されている(ディスク上に更新ログを記録して、再起動後にデータの復旧が可能)
ブロッキングの最小化(ロックやラッチ待ちがほとんど発生しない同時実行性を提供)
SQL Server 2016 からは、クラスター化列ストア インデックスを作成できるようにな
り、Analytics ワークロードにも対応
ネイティブ コンパイル ストアド プロシージャの作成例
インメモリ OLTP では、ネイティブ コンパイル ストアド プロシージャを作成することで、さら
なる性能向上が可能です。これは、通常のストアド プロシージャと同じように CREATE
PROCEDURE ステートメントを利用して、次のように作成することができます。
-- メモリ最適化テーブルの作成例
CREATE TABLE t1_InMem
( col1 int NOT NULL

SQL Server 2016 自習書 No.2 Operational Analytics
93
PRIMARY KEY NONCLUSTERED
HASH WITH (BUCKET_COUNT = 10000000)
,col2 nvarchar(100) )
WITH ( MEMORY_OPTIMIZED = ON
,DURABILITY = SCHEMA_AND_DATA )
-- ネイティブ コンパイル ストアドプロシージャの作成例
CREATE PROC nativeTest
@i int
WITH
NATIVE_COMPILATION,
EXECUTE AS OWNER,
SCHEMABINDING
AS
BEGIN ATOMIC
WITH (
TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'japanese')
INSERT INTO dbo.t1_InMem VALUES(@i, N'AAAAA')
END
CREATE PROCEDURE の WITH 句で NATIVE_COMPILATION を指定すると、ネイティブ
コンパイル ストアド プロシージャを作成することができます。
ブロッキングの最小化(ロック待ちやラッチ待ちを最小化した同時実行性を提供)
従来のデータベース エンジンでは、データの更新時 (INSERT/UPDATE/DELETE 時)に、ロッ
ク待ち(Lock Wait)やラッチ待ち(Latch Wait)が原因で、同時実行性が低下することがありま
したが、インメモリ OLTP 機能では、このようなブロッキングはほとんど発生しません。インメモ
リ OLTP 機能では、ロックを利用しないマルチ バージョンの楽観的同時実行制御(Optimistic
Concurrency Control)が採用されているからです。これは、SQL Server 2005 からサポートさ
れているスナップショット分離機構をインメモリ OLTP 向けに改良したものですが、この新しい
スナップショット分離機構は、tempdb を利用しない、完全なインメモリ アーキテクチャです。
このように、インメモリ OLTP 機能では、ロック待ちやラッチ待ちがほとんど発生しない、同時実
行性を実現することができるので、大量のユーザーからの多数の更新要求が発生するシステム (オ
ンライン ゲームやオンライン トレード、チケット予約、ポイントカード システム)など、トラン
ザクションとしては小さく (実行されるステートメントが単純で、短いトランザクション)、多数の
同時実行によるブロッキングが発生しやすいシステムで最も効果を発揮します。

SQL Server 2016 自習書 No.2 Operational Analytics
94
4.2 インメモリ OLTP の基本操作
それでは、インメモリ OLTP の基本的な利用方法を試してみましょう。
データベースの作成(testDB)
1. まずは、データベースを作成します。データベースの名前は「testDB」として、次のように
CREATE DATABASE ステートメントを実行します。
CREATE DATABASE testDB
ON PRIMARY (
NAME = testDB_data,
FILENAME = 'C:\testDB\testDB_data.mdf',
SIZE = 2GB )
LOG ON
( NAME = testDB_log,
FILENAME = 'C:\testDB\testDB_log.ldf',
SIZE = 2GB )
FILENAME で指定しているファイル パス (データ ファイルとトランザクション ログ ファ
イルの作成先となるフォルダー)には、「C:\testDB」フォルダーを指定していますが、皆さ
んの環境に合わせて適宜変更してください。
各ファイルのサイズ (SIZE)を 2GB に設定しているのは、この後の性能検証で、100 万件
のデータを INSERT したりするので、ファイルのサイズを大きくしておかないと、ファイル
の自動拡張が発生して、その分実行速度が遅くなってしまうのを避けるためです。もし、ファ
イルの自動拡張が発生してしまうと、メモリ最適化テーブルにとって有利な検証になってしま
うので、そうならないようにしています (サイズを大きくして自動拡張が発生しないようにし、
公平な検証になるようにしています)。
通常テーブルの作成(t1_disk)
1. 次に、CREATE TABLE ステートメントを利用して、通常のテーブル (従来どおりのディスク

SQL Server 2016 自習書 No.2 Operational Analytics
95
ベースのテーブル)を、「t1_disk」という名前で作成します。
USE testDB
CREATE TABLE t1_disk
( col1 int PRIMARY KEY CLUSTERED
,col2 nvarchar(100) )
col1 列を CLUSTERED(クラスター化インデックス)の PRIMARY KEY(主キー制約)、
col2 列を nvarchar(100) で作成しています。
通常テーブルへの 100 万件のデータ INSERT
1. 次に、WHILE ループを利用して、100万件のデータを INSERT し、そのときの実行時間を
調べておきます。
SET NOCOUNT ON
BEGIN TRAN
DECLARE @i int = 1
WHILE @i <= 1000000
BEGIN
INSERT INTO t1_disk VALUES (@i, N'AAAAA')
SET @i += 1
END
COMMIT TRAN
SET NOCOUNT OFF
実行が完了したら、実行にかかった時間をメモしておいてください。
SQL Server 2016 自習書 No.2 Operational Analytics
96
2. 次に、SELECT ステートメントを実行して、きちんとデータが INSERT されたかどうかを確
認します。
-- データの確認
SELECT TOP 1000 * FROM t1_disk
3. また、COUNT 関数を利用して、データ件数が 100 万件であることも確認しておきます。
-- データ件数の確認
SELECT COUNT(*) FROM t1_disk

SQL Server 2016 自習書 No.2 Operational Analytics
97
4.3 メモリ最適化テーブルの作成/性能比較
次に、メモリ最適化テーブルを作成して、性能をチェックしてみましょう。メモリ最適化テーブル
を作成するには、次の作業が必要になります。
メモリ最適化テーブルを格納するためのファイル グループの作成(CONTAINS
MEMORY_OPTIMIZED_DATA を指定)
メモリ最適化テーブルの作成(MEMORY_OPTIMIZED = ON を指定)
ファイル グループの作成
まずは、メモリ最適化テーブルを格納するためのファイル グループを作成します。
1. ファイル グループを作成するには(既存のデータベースにファイル グループを追加するに
は)、次のように ALTER DATBASE ステートメントを実行します。
ALTER DATABASE testDB
ADD FILEGROUP fg1
CONTAINS MEMORY_OPTIMIZED_DATA
ALTER DATABASE testDB
ADD FILE ( NAME = testDB_InMem,
FILENAME = 'C:\testDB\testDB_InMem' )
TO FILEGROUP fg1
ADD FILEGROUP に続けてファイル グループ名を指定して(ここでは fg1 という名前を
指定)、「CONTAINS MEMORY_OPTIMIZED_DATA」と記述することで、メモリ最適化テ
ーブルを格納できるファイル グループを作成することができます。
次の ALTER DATABASE ステートメントの ADD FILE では、ファイル グループ内(fg1
内)にファイルを作成しますが、FILENAME に指定するファイル名は、NAME で指定する
論理ファイル名(上記では testDB_InMem)と同じ名前に設定します。
このように、通常のデータベースに、メモリ最適化テーブル用のファイル グループを追加す
ることで、通常のテーブル (従来どおりのディスク ベースのテーブル)と、メモリ最適化テー
ブルを同じデータベース内に共存させることができます。

SQL Server 2016 自習書 No.2 Operational Analytics
98
メモリ最適化テーブルの作成
次に、メモリ最適化テーブルを作成します。
1. メモリ最適化テーブルを作成するには、次のように CREATE TABLE ステートメントを実行
します。
USE testDB
CREATE TABLE t1_InMem
( col1 int NOT NULL
PRIMARY KEY NONCLUSTERED
HASH WITH (BUCKET_COUNT = 2000000)
,col2 nvarchar(100) )
WITH ( MEMORY_OPTIMIZED = ON,
DURABILITY = SCHEMA_ONLY )
「t1_InMem」という名前で作成し、col1 列を PRIMARY KEY(主キー)へ設定し、
NONCLUSTERED(非クラスター化)の HASH インデックスを作成します(∵メモリ最適
化テーブルを作成するには、NONCLUSTERED のインデックスを作成するのが必須になるた
め。なお、NOT NULL は SQL Server 2014 のときには必須でしたが、SQL Server 2016
からは必須ではなくなったので省略しても大丈夫です)。BUCKET_COUNT は、ハッシュ イ
ンデックスの Bucket サイズ (バケット数)になりますが、この後 100 万件のデータを挿入
するので、200 万に設定しています (良好なパフォーマンスを得るためには、BUCKET_COUNT
をデータサイズと同程度~2 倍ぐらいの大きさに設定しておくようにします)。
WITH 句では、「MEMORY_OPTIMIZED = ON」を記述することで、メモリ最適化テーブ
ルとして設定することができます。また、「DURABILITY = SCHEMA_ONLY」とすること
で、メモリ内にのみ存在するテーブル (ディスクにはデータを保存しないテーブル)を作成す
る こ と が で き ま す 。 デ ー タ を 保 存 / 永 続 化 し た い 場 合 に は 、DURABILITY で
SCHEMA_AND_DATA を指定します。
100 万件のデータ INSERT
1. 次に、メモリ最適化テーブル 「t1_InMem」へ 100 万件のデータを INSERT してみましょ
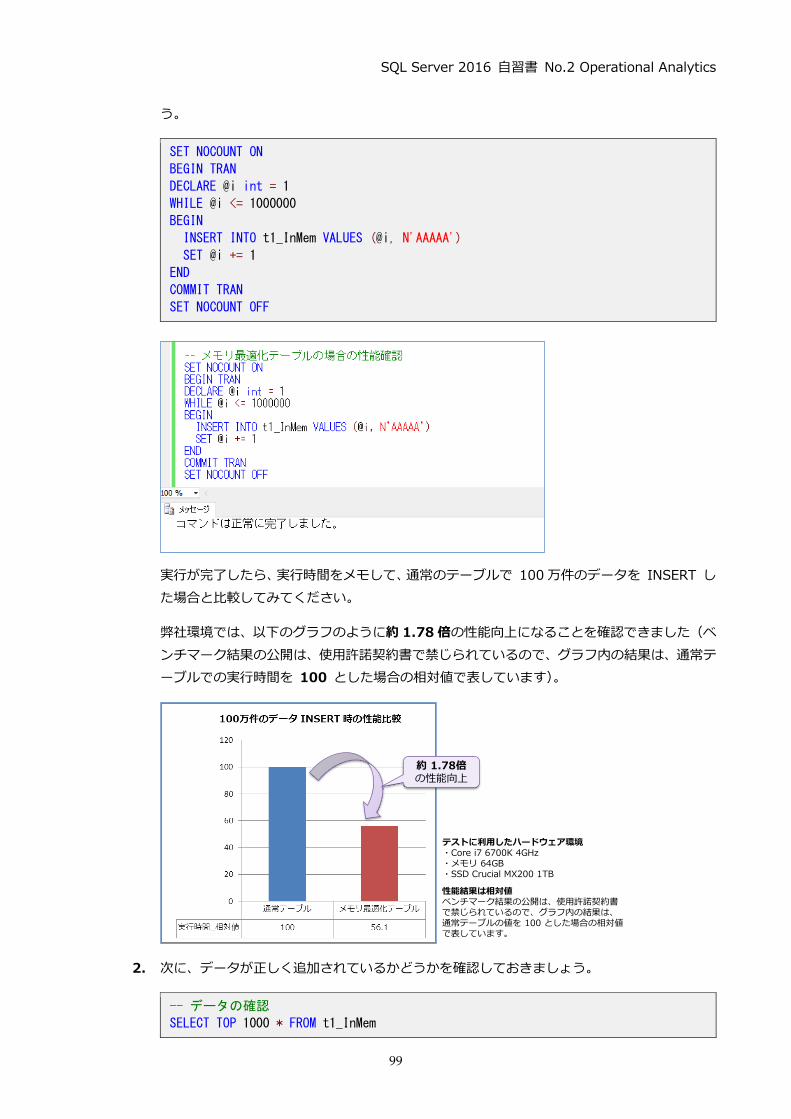
SQL Server 2016 自習書 No.2 Operational Analytics
99
う。
SET NOCOUNT ON
BEGIN TRAN
DECLARE @i int = 1
WHILE @i <= 1000000
BEGIN
INSERT INTO t1_InMem VALUES (@i, N'AAAAA')
SET @i += 1
END
COMMIT TRAN
SET NOCOUNT OFF
実行が完了したら、実行時間をメモして、通常のテーブルで 100 万件のデータを INSERT し
た場合と比較してみてください。
弊社環境では、以下のグラフのように約 1.78 倍の性能向上になることを確認できました (ベ
ンチマーク結果の公開は、使用許諾契約書で禁じられているので、グラフ内の結果は、通常テ
ーブルでの実行時間を 100 とした場合の相対値で表しています)。
2. 次に、データが正しく追加されているかどうかを確認しておきましょう。
-- データの確認
SELECT TOP 1000 * FROM t1_InMem
約 1.78倍の性能向上
テストに利用したハードウェア環境・Core i7 6700K 4GHz・メモリ 64GB・SSD Crucial MX200 1TB
性能結果は相対値ベンチマーク結果の公開は、使用許諾契約書で禁じられているので、グラフ内の結果は、通常テーブルの値を 100 とした場合の相対値で表しています。

SQL Server 2016 自習書 No.2 Operational Analytics
100
メモリ最適化テーブルでは、col1 列に HASH インデックスを作成しているので、データが
バラバラに表示されていますが、実際にデータが格納されていることを確認できます。
3. COUNT 関数を利用して、データ件数が 100万件であることも確認しておきましょう。
-- データ件数の確認
SELECT COUNT(*) FROM t1_InMem
ディスク ベースで自動拡張が発生する場合の性能差
今回の検証では、データベース (testDB)を作成するときに、ファイル サイズ (SIZE)を大きく
設定して、データ ファイル (.mdf)およびトランザクション ログ ファイル (.ldf)の自動拡張が
発生しないようにして、公平な検証を行っていましたが、もし自動拡張が発生する場合 (SIZE を
指定しないでデータベースを作成した場合)は、次のような結果になります (弊社の HDD 環境の
場合)。
2.8倍の性能向上
テストに利用したハードウェア環境・Core i7 6700K 4GHz・メモリ 64GB・SSD Crucial MX200 1TB・HDD Western Digital WD30EZRX
性能結果は相対値ベンチマーク結果の公開は、使用許諾契約書で禁じられているので、グラフ内の結果は、通常テーブルの値を 100 とした場合の相対値で表しています。

SQL Server 2016 自習書 No.2 Operational Analytics
101
自動拡張が発生した場合と比較すると、メモリ最適化テーブルは 2.8 倍の性能向上になります。こ
のように、従来のディスク ベースのテーブルでは、ファイルの自動拡張によるパフォーマンス低下
が発生するのに対して、メモリ最適化テーブルは自動拡張の影響は受けません (∵メモリ内にのみ
テーブルが存在して、SCHEMA_ONLY オプションでは、ログへの書き込みを行わないため)。
なお、ファイルの自動拡張は、ストレージの速度にも大きな影響を受けます。したがって、SSD な
ど、より速度の速いストレージを利用すれば、自動拡張のオーバーヘッドを小さくすることができ、
次のような結果になります(弊社の SSD 環境の場合)。
このように、従来のディスク ベースのエンジンでは、自動拡張の影響や、ストレージの性能に大き
な影響を受けます。インメモリ OLTP 機能では、メモリ内にテーブルを配置するので。自動拡張は
発生しませんし、ストレージの性能に影響を受けることもありません (ただし、後述の Durability
オプションでデータの永続化を設定した場合には、ストレージへの書き込みが発生します)。
SSD 環境の場合は自動拡張のオーバーヘッド
が小さくなる
テストに利用したハードウェア環境・Core i7 6700K 4GHz・メモリ 64GB・SSD Crucial MX200 1TB
性能結果は相対値ベンチマーク結果の公開は、使用許諾契約書で禁じられているので、グラフ内の結果は、通常テーブルの値を 100 とした場合の相対値で表しています。

SQL Server 2016 自習書 No.2 Operational Analytics
102
4.4 テーブル サイズ(メモリ使用量)の確認
次に、通常テーブルおよびメモリ最適化テーブルのテーブル サイズ (メモリ使用量)を確認してみ
ましょう。
1. 通常のテーブルは、次のように sp_spaceused システム ストアド プロシージャを利用し
て、テーブル サイズを確認することができます。
EXEC sp_spaceused 't1_disk'
2. これに対して、メモリ最適化テーブルでは、次のように sp_spaceused システム ストアド
プロシージャを利用しても、テーブル サイズを確認することができません。
EXEC sp_spaceused 't1_InMem'
3. メモリ最適化テーブルでは、テーブル サイズを確認するには、動的管理ビューまたは
Management Studio のレポート機能を利用します。動的管理ビューを利用する場合は、次
のように「dm_db_xtp_table_memory_stats」ビューを参照します。
SELECT OBJECT_NAME(object_id), *
FROM sys.dm_db_xtp_table_memory_stats
4. Management Studio のレポート機能を利用する場合には、次のようにオブジェクト エクス
プローラーで該当データベース (testDB)を右クリックして、 [レポート]の [標準レポート]
から[メモリ最適化オブジェクトによるメモリ使用量]をクリックします。

SQL Server 2016 自習書 No.2 Operational Analytics
103
メモリ最適化テーブルの一覧が表示されて、 [テーブルの使用メモリ]でテーブル サイズ (メ
モリ使用量)を確認することができます。
このように、メモリ最適化テーブルのテーブル サイズ (メモリ使用量)を確認するには、動的
管理ビューまたはレポート機能を利用するようにします。
1
メモリ最適化テーブルの名前
テーブルサイズ

SQL Server 2016 自習書 No.2 Operational Analytics
104
4.5 ネイティブ コンパイル ストアド プロシージャによる性能向上
メモリ最適化テーブルでは、ネイティブ コンパイル ストアド プロシージャ (Natively Compiled
Stored Procedure)を作成することで、さらなる性能向上を実現することができます。
ネイティブ コンパイル ストアド プロシージャの作成
ネイティブ コンパイル ストアド プロシージャは、次のように作成することができます。
CREATE PROC ストアドプロシージャ名
WITH
NATIVE_COMPILATION,
EXECUTE AS OWNER,
SCHEMABINDING
AS
BEGIN ATOMIC
WITH (
TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'japanese')
-- 実行したいステートメント
END
CREATE PROCEDURE ステートメントで、「WITH NATIVE_COMPILATION」を指定するこ
とで、ネイティブ コンパイル ストアド プロシージャとして、ストアド プロシージャを作成する
ことができます。また、ネイティブ コンパイル ストアド プロシージャでは、BEGIN ATOMIC
と END で囲んで、1 つのトランザクションとして、ステートメントを実行するようにし、
EXECUTE AS OWNER と SCHEMABINDING も指定する必要があります。
100 万件のデータ INSERT
次に、100 万件のデータを INSERT するネイティブ コンパイル ストアド プロシージャを作成
してみましょう。
1. 次のように、nativeTest という名前で作成します。
CREATE PROC nativeTest
@LoopCount int
WITH
NATIVE_COMPILATION,
EXECUTE AS OWNER,
SCHEMABINDING
AS
BEGIN ATOMIC
WITH (
TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'japanese')
SQL Server 2016 自習書 No.2 Operational Analytics
105
DECLARE @i int = 1
WHILE @i <= @LoopCount
BEGIN
INSERT INTO dbo.t1_InMem VALUES (@i, N'AAAAA')
SET @i += 1
END
END
go
ネイティブ コンパイル ストアド プロシージャ内では、テーブル名をスキーマ名付きで指定
する必要があるため、「dbo.t1_InMem」と指定しています。
2. 作成が完了したら、次のように DELETE ステートメントを実行して、t1_InMem テーブル
のデータをすべて削除します。
DELETE FROM t1_InMem
3. 削除後、@LoopCount 入力パラメーターに「1000000」を与えて、100 万件のデータを
INSERT します。
EXEC nativeTest @LoopCount = 1000000

SQL Server 2016 自習書 No.2 Operational Analytics
106
実行が完了したら、実行時間をメモして、通常のテーブルで 100 万件のデータを INSERT
した場合と比較してみてください。
弊社環境では、以下のグラフのように約 1/8 の実行時間(8.3 倍の性能向上)になることを
確認できました(通常テーブルでの実行時間を 100 とした場合の相対値)。
4. 次に、データが正しく追加されているかどうかを確認しておきましょう。
SELECT TOP 1000 * FROM t1_InMem
SELECT COUNT(*) FROM t1_InMem
100 万件のデータが INSERT されていることを確認できると思います。
実行時間が約 1/8 に短縮
8.3倍の性能向上!
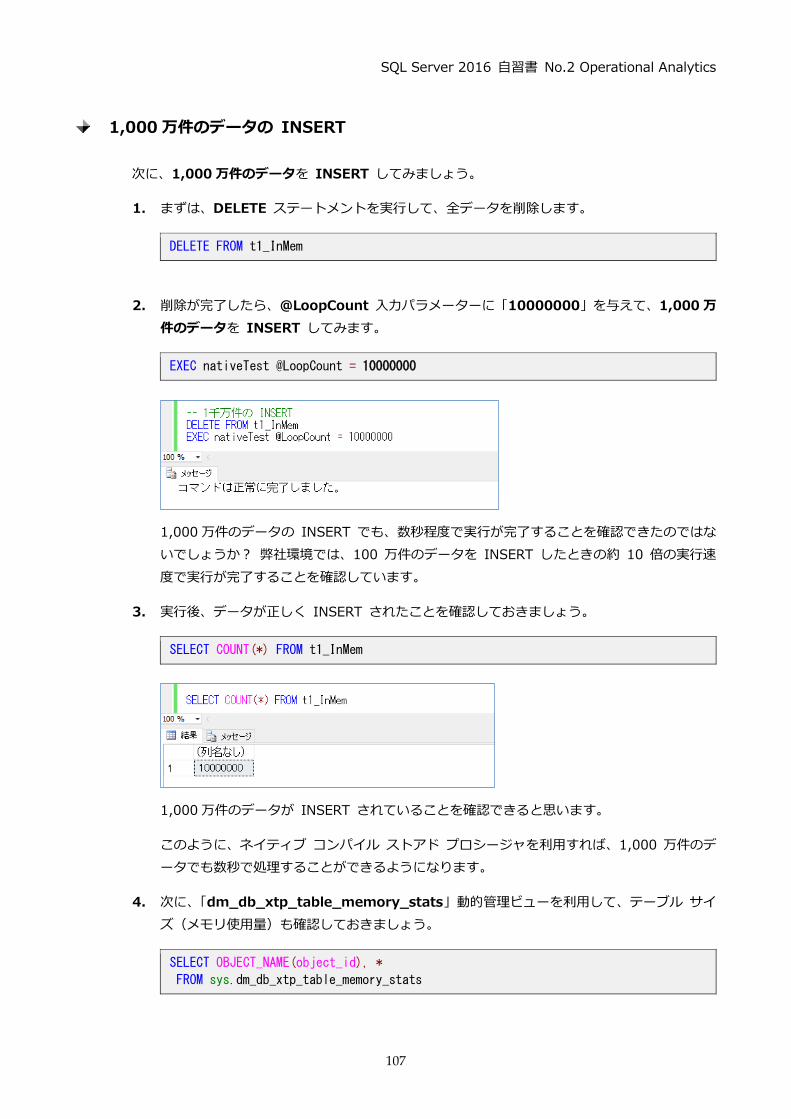
SQL Server 2016 自習書 No.2 Operational Analytics
107
1,000 万件のデータの INSERT
次に、1,000 万件のデータを INSERT してみましょう。
1. まずは、DELETE ステートメントを実行して、全データを削除します。
DELETE FROM t1_InMem
2. 削除が完了したら、@LoopCount 入力パラメーターに 「10000000」を与えて、1,000 万
件のデータを INSERT してみます。
EXEC nativeTest @LoopCount = 10000000
1,000 万件のデータの INSERT でも、数秒程度で実行が完了することを確認できたのではな
いでしょうか? 弊社環境では、100 万件のデータを INSERT したときの約 10 倍の実行速
度で実行が完了することを確認しています。
3. 実行後、データが正しく INSERT されたことを確認しておきましょう。
SELECT COUNT(*) FROM t1_InMem
1,000 万件のデータが INSERT されていることを確認できると思います。
このように、ネイティブ コンパイル ストアド プロシージャを利用すれば、1,000 万件のデ
ータでも数秒で処理することができるようになります。
4. 次に、「dm_db_xtp_table_memory_stats」動的管理ビューを利用して、テーブル サイ
ズ(メモリ使用量)も確認しておきましょう。
SELECT OBJECT_NAME(object_id), *
FROM sys.dm_db_xtp_table_memory_stats

SQL Server 2016 自習書 No.2 Operational Analytics
108
Note: メモリが足りない場合の動作
もし、メモリが足りない場合には(物理メモリのサイズが小さく、メモリ最適化テーブルを格納しきれない場合
には)、次のようにエラーが発生します。
■ メモリ サイズの見積もり
メモリ サイズの見積もり方法については、SQL Server 2014 実践シリーズの「No.1 インメモリ OLTP の実
践的な利用方法」で説明しているので、こちらもぜひご覧いただければと思います。
インメモリ OLTP の実践的な利用方法
https://www.microsoft.com/ja-jp/sqlserver/2014/technology/self-learning.aspx#practical_contents
1 件の INSERT をネイティブ コンパイル ストアド プロシージャ化
ここまで作成したネイティブ コンパイル ストアド プロシージャは、100 万件のデータを
INSERT するものでしたが、次のように 1 件のデータだけを INSERT するものも、もちろん作
成できます。
CREATE PROC nativeInsert1
@p1 int,
@p2 nvarchar(100)
WITH
NATIVE_COMPILATION,
EXECUTE AS OWNER,
SCHEMABINDING
AS
BEGIN ATOMIC
WITH (
TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'japanese')
INSERT INTO dbo.t1_InMem VALUES (@p1, @p2)
END
go
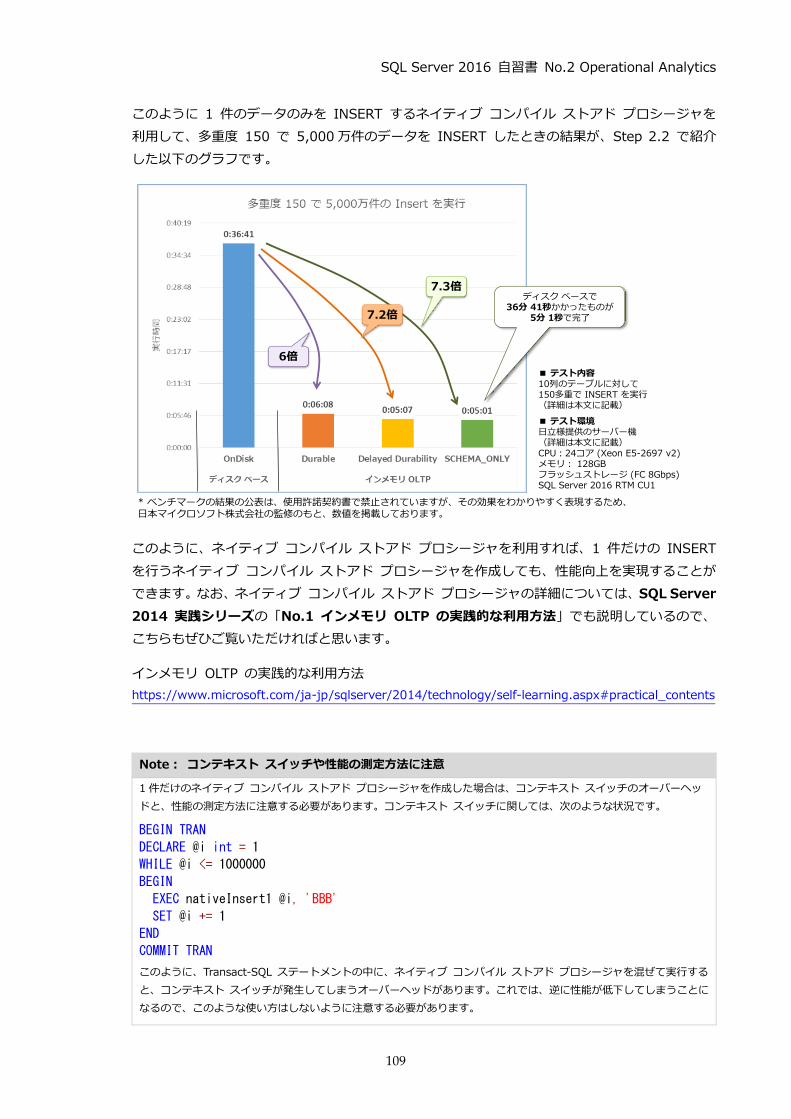
SQL Server 2016 自習書 No.2 Operational Analytics
109
このように 1 件のデータのみを INSERT するネイティブ コンパイル ストアド プロシージャを
利用して、多重度 150 で 5,000 万件のデータを INSERT したときの結果が、Step 2.2 で紹介
した以下のグラフです。
このように、ネイティブ コンパイル ストアド プロシージャを利用すれば、1 件だけの INSERT
を行うネイティブ コンパイル ストアド プロシージャを作成しても、性能向上を実現することが
できます。なお、ネイティブ コンパイル ストアド プロシージャの詳細については、SQL Server
2014 実践シリーズの「No.1 インメモリ OLTP の実践的な利用方法」でも説明しているので、
こちらもぜひご覧いただければと思います。
インメモリ OLTP の実践的な利用方法
https://www.microsoft.com/ja-jp/sqlserver/2014/technology/self-learning.aspx#practical_contents
Note: コンテキスト スイッチや性能の測定方法に注意
1 件だけのネイティブ コンパイル ストアド プロシージャを作成した場合は、コンテキスト スイッチのオーバーヘッ
ドと、性能の測定方法に注意する必要があります。コンテキスト スイッチに関しては、次のような状況です。
BEGIN TRAN
DECLARE @i int = 1
WHILE @i <= 1000000
BEGIN
EXEC nativeInsert1 @i, 'BBB'
SET @i += 1
END
COMMIT TRAN
このように、Transact-SQL ステートメントの中に、ネイティブ コンパイル ストアド プロシージャを混ぜて実行する
と、コンテキスト スイッチが発生してしまうオーバーヘッドがあります。これでは、逆に性能が低下してしまうことに
なるので、このような使い方はしないように注意する必要があります。
ディスク ベースで36分 41秒かかったものが
5分 1秒で完了
* ベンチマークの結果の公表は、使用許諾契約書で禁止されていますが、その効果をわかりやすく表現するため、日本マイクロソフト株式会社の監修のもと、数値を掲載しております。
■ テスト内容10列のテーブルに対して150多重で INSERT を実行(詳細は本文に記載)
■ テスト環境日立様提供のサーバー機(詳細は本文に記載)CPU:24コア (Xeon E5-2697 v2)メモリ: 128GBフラッシュストレージ (FC 8Gbps)SQL Server 2016 RTM CU1
6倍
7.3倍
7.2倍

SQL Server 2016 自習書 No.2 Operational Analytics
110
また、1 件だけのステートメントの実行時間を計測する場合は、性能の測定方法に注意する必要があります。たとえ
ば、次のように SET STATISTICS TIME コマンドを利用した場合は、0ミリ秒と結果が表示されます。
SQL Server は、1 件のみを扱うステートメントは、インメモリ OLTP を利用しているかどうかに関わらず、通常のテ
ーブルに対してもマイクロ秒単位で処理ができるので、SET STATISTICS TIME コマンドのようにマイクロ秒単位で
の性能測定ができないコマンドでは、0ミリ秒と表示されて、正しい計測をすることができません。
また、.NET Framework での Stopwatch クラスを利用する場合も、マイクロ秒単位での性能測定ができないことに
注意する必要があります。これは、次のような状況です。
マイクロ秒で処理された場合には、0 ミリ秒と表示されて、正しく計測をすることができません。
また、.NET Framework を利用する場合は、デバッグ実行を利用した場合には、デバッグのオーバーヘッドがあるこ
とにも注意する必要があります。このほかにも注意点がありますが、それらについても、SQL Server 2014 実践シリ
ーズの「No.1 インメモリ OLTP の実践的な利用方法」で説明しているので、こちらもぜひご覧いただければと思い
ます。
ネイティブ コンパイル ストアド プロシージャを利用すれば、性能向上を実現することができる
ので、ぜひ検討してみてください。
実行速度がマイクロ秒だと0ミリ秒と表示される
実行速度がマイクロ秒だと0ミリ秒と表示される

SQL Server 2016 自習書 No.2 Operational Analytics
111
4.6 データの永続化(SCHEMA_AND_DATA)
メモリ最適化テーブルでは、SQL Server の再起動後にも、データを復旧できる、Durability (永
続化)オプションが用意されています。これは、次のように利用することができます。
CREATE TABLE テーブル名
( 列名1 データ型 NOT NULL
PRIMARY KEY NONCLUSTERED
HASH WITH (BUCKET_COUNT=バケット数)
,列名2 データ型, … )
WITH ( MEMORY_OPTIMIZED = ON,
DURABILITY = SCHEMA_AND_DATA )
今まで試してきたメモリ最適化テーブルは、DURABILITY=SCHEMA_ONLY と指定して作成し
ていましたが、この場合はスキーマ (テーブルやインデックスの定義)のみを永続化 (ディスクへ
保存)して、データは永続化されません (SQL Server が再起動されるとデータが失われます)。こ
れに対して、DURABILITY=SCHEMA_AND_DATA と指定した場合は、スキーマだけでなく、
データも永続化することができ、SQL Server が再起動されたとしても、データが失われることは
ありません。このオプション(SCHEMA_AND_DATA)では、データに対する更新情報をディス
ク(ログ)へ記録しておくことで、永続化を可能にしています。
Let's Try
それでは、これを試してみましょう。
1. 次のように t1_InMem_Durable という名前で、DURABILITY=SCHEMA_AND_DATA
を指定してメモリ最適化テーブルを作成します。
CREATE TABLE t1_InMem_Durable
( col1 int NOT NULL
PRIMARY KEY NONCLUSTERED
HASH WITH (BUCKET_COUNT = 2000000)
,col2 nvarchar(100) )
WITH ( MEMORY_OPTIMIZED = ON,
DURABILITY = SCHEMA_AND_DATA )
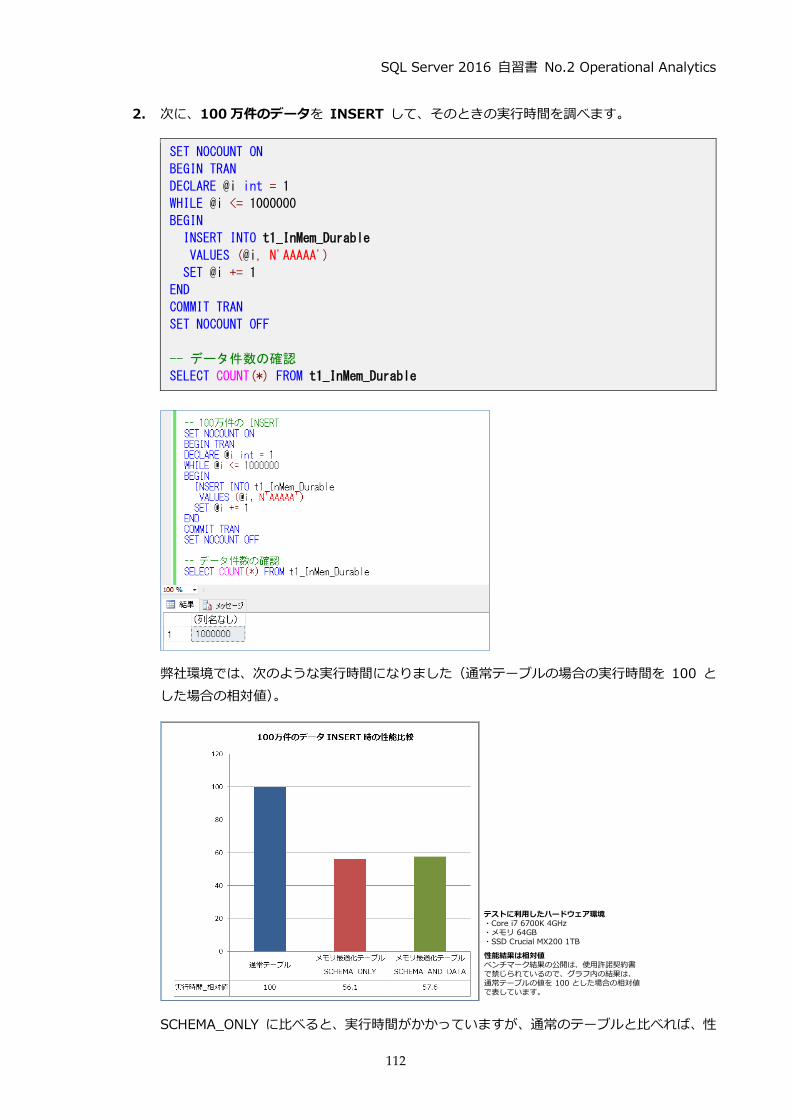
SQL Server 2016 自習書 No.2 Operational Analytics
112
2. 次に、100万件のデータを INSERT して、そのときの実行時間を調べます。
SET NOCOUNT ON
BEGIN TRAN
DECLARE @i int = 1
WHILE @i <= 1000000
BEGIN
INSERT INTO t1_InMem_Durable
VALUES (@i, N'AAAAA')
SET @i += 1
END
COMMIT TRAN
SET NOCOUNT OFF
-- データ件数の確認
SELECT COUNT(*) FROM t1_InMem_Durable
弊社環境では、次のような実行時間になりました (通常テーブルの場合の実行時間を 100 と
した場合の相対値)。
SCHEMA_ONLY に比べると、実行時間がかかっていますが、通常のテーブルと比べれば、性
テストに利用したハードウェア環境・Core i7 6700K 4GHz・メモリ 64GB・SSD Crucial MX200 1TB
性能結果は相対値ベンチマーク結果の公開は、使用許諾契約書で禁じられているので、グラフ内の結果は、通常テーブルの値を 100 とした場合の相対値で表しています。

SQL Server 2016 自習書 No.2 Operational Analytics
113
能向上していることを確認できると思います。なお、SCHEMA_AND_DATA では、更新情報
をログ(ディスク)に書き込むので、HDD 環境の場合は、オーバーヘッドがもう少し大きく
なります(上のグラフは SSD を利用した場合の結果です)。
3. 次に、 [メモリ最適化オブジェクトによるメモリ使用量]レポートを表示して、メモリ サイズ
も確認しておきましょう。
SQL Server 再起動後のデータ復旧の確認
次に、SQL Server を再起動して、データが復旧できるかどうかを確認してみましょう。
1. まずは、オブジェクト エクスプローラーで、SQL Server の名前を右クリックして、 [再起動]
をクリックし、SQL Server を再起動します。
1
2

SQL Server 2016 自習書 No.2 Operational Analytics
114
2. 再起動が完了したら、SCHEMA_ONLY のメモリ最適化テーブル「t1_InMem」に対して
SELECT ステートメントを実行してみましょう。
SELECT COUNT(*) FROM t1_InMem
結果は 0 件と表示されて、SQL Server の再起動によって、データが失われていることを確
認できます。
3. 次に、SCHEMA_AND_DATA のメモリ最適化テーブル「t1_InMem_Durable」に対して
SELECT ステートメントを実行してみましょう。
SELECT COUNT(*) FROM t1_InMem_Durable
今度は、100 万件と表示されて、データが復旧していることを確認できます。
4. 次に、SELECT * で実際のデータも確認してみましょう。
SELECT * FROM t1_InMem
SCHEMA_ONLY の「t1_InMem」テーブルは、0 件であることを確認できます。
5. SCHEMA_AND_DATA の 「t1_InMem_Durable」テーブルには、100 万件のデータが有
ることを確認できます。
SELECT * FROM t1_InMem_Durable

SQL Server 2016 自習書 No.2 Operational Analytics
115
Delayed Durability(遅延永続化)
SCHEMA_AND_DATA でデータを永続化する場合には、更新のオーバーヘッドが発生しますが、
このオーバーヘッドを軽減するためのオプションとして 「Delayed Durability」 (遅延永続化)が
用意されています。これは、データの永続化を遅延させる (非同期に書き込む)ことで、更新性能
を向上させて、その分データ ロス (データの損失)が発生する可能性がある、というオプションで
す。
Delayed Durability を利用するには、次のように ALTER DATABASE ステートメントの SET
オプションで、データベース レベルで許可をしておく必要があります。
ALTER DATABASE データベース名
SET DELAYED_DURABILITY = ALLOWED
DELAYED_DURABILITY に ALLOWED を指定することで、Delayed Durability を利用でき
るようになります。ここで DISABLED を指定した場合は、無効化して、元に戻すことができます。
また、FORCED を指定した場合は、どんなトランザクションでも強制的に Delayed Durability
で実行するという設定にすることもできます。
ALLOWED を指定した場合は、次のようにトランザクションの COMMIT TRAN 時に、WITH
オプションで DELAYED_DURABILITY を ON に指定することで、Delayed Durability を有
効化することができます。
BEGIN TRAN
:
COMMIT TRAN
WITH ( DELAYED_DURABILITY = ON )
ネイティブ コンパイル ストアド プロシージャの場合は、次のように BEGIN ATOMIC の
WITH オ プ シ ョ ン で DELAYED_DURABILITY を ON に 指 定 す る こ と で 、Delayed
Durability を有効化することができます。
CREATE PROC ストアド プロシージャ名
WITH NATIVE_COMPILATION,
EXECUTE AS OWNER,
SCHEMABINDING
AS

SQL Server 2016 自習書 No.2 Operational Analytics
116
BEGIN ATOMIC
WITH (
DELAYED_DURABILITY = ON,
TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'japanese')
:
END
Let's Try
それでは、これを試してみましょう。
1. まずは、データベースに対して、Delayed Durability を許可しておきます。
ALTER DATABASE testDB
SET DELAYED_DURABILITY = ALLOWED
2. 次に、t1_InMem_Delay という名前でメモリ最適化テーブルを作成します。
CREATE TABLE t1_InMem_Delay
( col1 int NOT NULL
PRIMARY KEY NONCLUSTERED
HASH WITH (BUCKET_COUNT = 2000000)
,col2 nvarchar(100) )
WITH ( MEMORY_OPTIMIZED = ON,
DURABILITY = SCHEMA_AND_DATA )
3. 次に、100万件のデータを INSERT して、そのときの実行時間を調べます。
SET NOCOUNT ON
BEGIN TRAN
DECLARE @i int = 1
WHILE @i <= 1000000
BEGIN
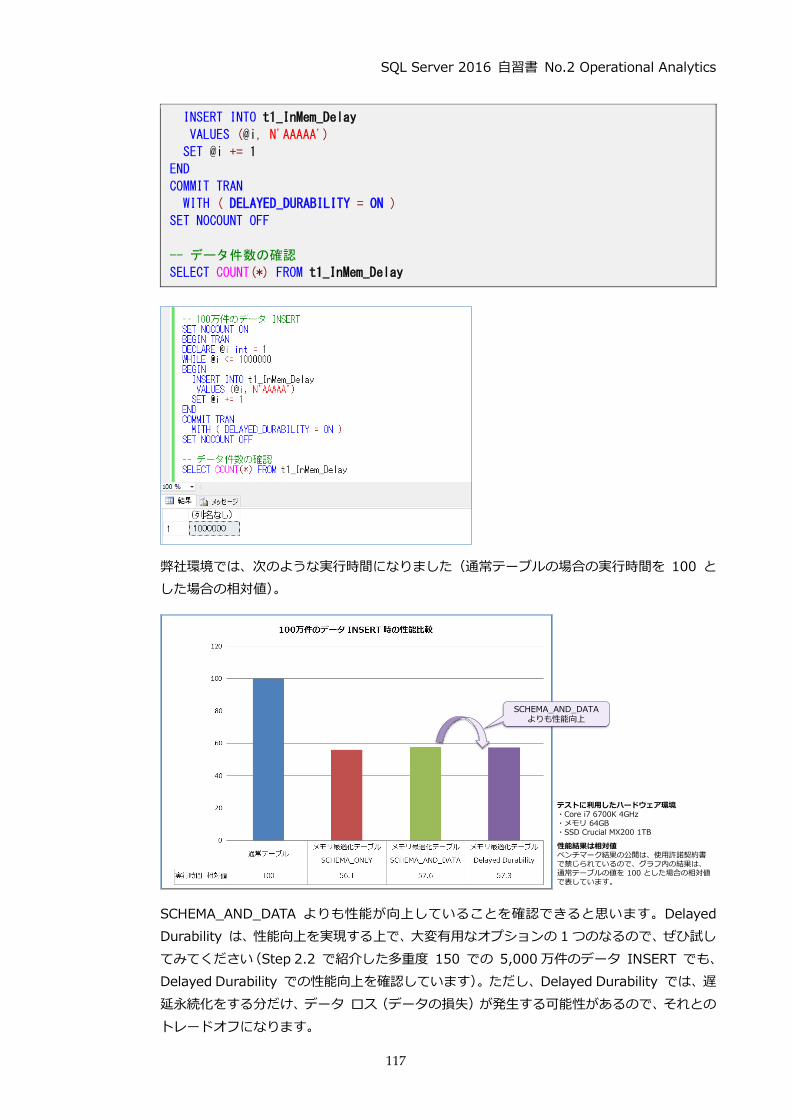
SQL Server 2016 自習書 No.2 Operational Analytics
117
INSERT INTO t1_InMem_Delay
VALUES (@i, N'AAAAA')
SET @i += 1
END
COMMIT TRAN
WITH ( DELAYED_DURABILITY = ON )
SET NOCOUNT OFF
-- データ件数の確認
SELECT COUNT(*) FROM t1_InMem_Delay
弊社環境では、次のような実行時間になりました (通常テーブルの場合の実行時間を 100 と
した場合の相対値)。
SCHEMA_AND_DATA よりも性能が向上していることを確認できると思います。Delayed
Durability は、性能向上を実現する上で、大変有用なオプションの 1 つのなるので、ぜひ試し
てみてください (Step 2.2 で紹介した多重度 150 での 5,000 万件のデータ INSERT でも、
Delayed Durability での性能向上を確認しています)。ただし、Delayed Durability では、遅
延永続化をする分だけ、データ ロス (データの損失)が発生する可能性があるので、それとの
トレードオフになります。
SCHEMA_AND_DATAよりも性能向上
テストに利用したハードウェア環境・Core i7 6700K 4GHz・メモリ 64GB・SSD Crucial MX200 1TB
性能結果は相対値ベンチマーク結果の公開は、使用許諾契約書で禁じられているので、グラフ内の結果は、通常テーブルの値を 100 とした場合の相対値で表しています。

SQL Server 2016 自習書 No.2 Operational Analytics
118
4.7 メモリ最適化テーブルでの同時更新(Write-Write 競合)
ここでは、メモリ最適化テーブルに対して、同時更新 (書き込みの競合)が発生した場合の動作を
確認してみましょう。結論から言うと、先に更新した方が勝つ方式(First Writer Win)です。
Let's Try
それでは、これを試してみましょう。
1. まずは、次のように UPDATE ステートメントを実行して、 「t1_InMem_Durable」テーブ
ルの「col1 = 1」のデータを更新します。
BEGIN TRAN
UPDATE t1_InMem_Durable WITH(SNAPSHOT)
SET col2 = '1111'
WHERE col1 = 1
BEGIN TRAN でトランザクションを開始し、わざと COMMIT TRAN を省略して、トラン
ザクション中のままにしておきます。
また、WITH(SNAPSHOT) を付けて、スナップショット分離レベルを指定していますが、メ
モリ最適化テーブルでは、トランザクション内でのステートメントは READ COMMITTED 分
離レベル (既定の分離レベル)が許可されないため、スナップショット分離レベルなどで実行
しなければなりません。
Note: WITH(SNAPSHOT) を付けない場合
もし、トランザクション内で WITH(SNAPSHOT) を付けていない場合は、次のようにエラーが返されます。
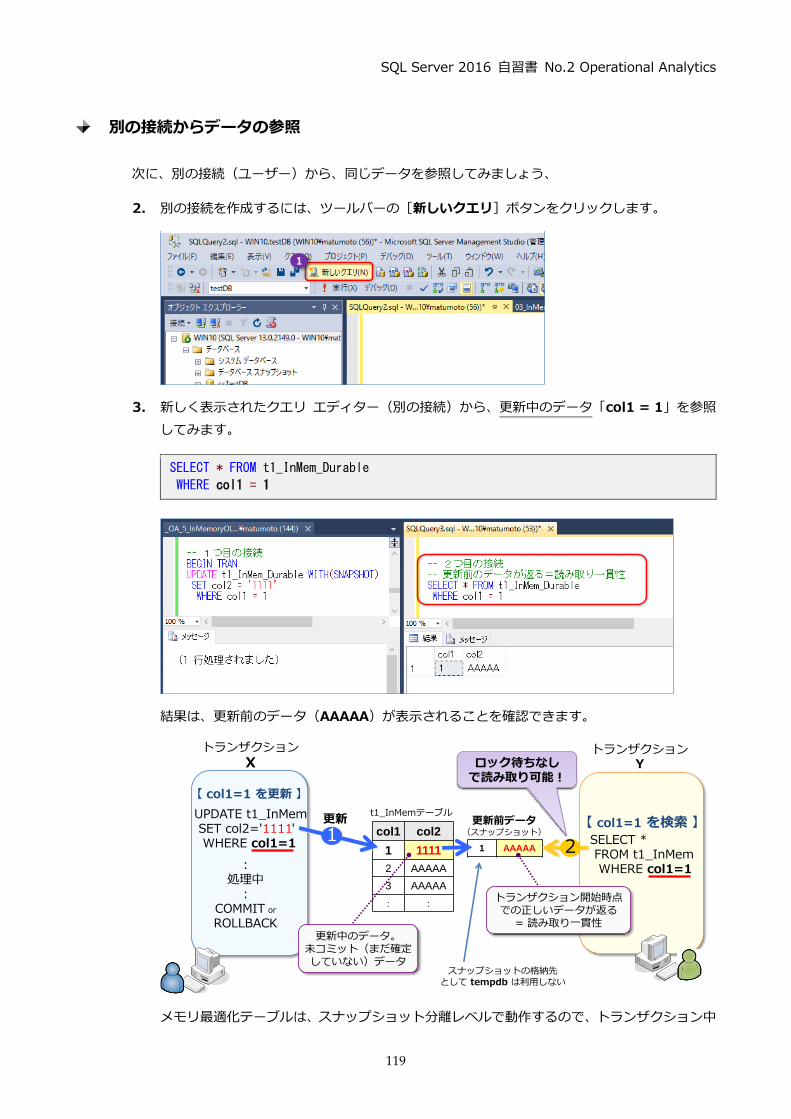
SQL Server 2016 自習書 No.2 Operational Analytics
119
別の接続からデータの参照
次に、別の接続(ユーザー)から、同じデータを参照してみましょう、
2. 別の接続を作成するには、ツールバーの[新しいクエリ]ボタンをクリックします。
3. 新しく表示されたクエリ エディター(別の接続)から、更新中のデータ「col1 = 1」を参照
してみます。
SELECT * FROM t1_InMem_Durable
WHERE col1 = 1
結果は、更新前のデータ(AAAAA)が表示されることを確認できます。
メモリ最適化テーブルは、スナップショット分離レベルで動作するので、トランザクション中
1
トランザクション
X
UPDATE t1_InMemSET col2='1111'WHERE col1=1
col1 col2
1 1111
2 AAAAA
3 AAAAA
: :
t1_InMemテーブル
トランザクションY
SELECT *FROM t1_InMemWHERE col1=1
更新
【 col1=1 を更新 】
【 col1=1 を検索 】1
1 AAAAA
更新前データ(スナップショット)
2:
処理中:
COMMIT or
ROLLBACK
ロック待ちなしで読み取り可能!
更新中のデータ。未コミット(まだ確定していない)データ
トランザクション開始時点での正しいデータが返る
= 読み取り一貫性
スナップショットの格納先として tempdb は利用しない

SQL Server 2016 自習書 No.2 Operational Analytics
120
のデータは更新前のデータを返すことで、読み取り一貫性を実現しています。また、ロックを
利用しない、マルチバージョンの楽観的同時実行制御も実装されています (従来型のスナップ
ショット分離機構のように、更新前のデータが tempdb へ保存されることもありません)。
4. 続いて、更新中のデータ「col1 = 1」に対して、同時更新をしてみます。
BEGIN TRAN
UPDATE t1_InMem_Durable WITH(SNAPSHOT)
SET col2 = '2222'
WHERE col1 = 1
結果は、エラー 「41302」が発生して同時更新が検出され、トランザクションが中止されてい
ることを確認できます。また、トランザクションがロールバック (取り消し)されていること
も確認できます。
このように、メモリ最適化テーブルでは、同時更新が発生した場合は、先に更新した方が勝つ
方式(First Writer Win)が採用されています。
5. 最後に、最初の接続側のクエリ エディターへ戻って、COMMIT TRAN を実行して、トラン
ザクションを完了しておきます。
COMMIT TRAN
Note: ネイティブ コンパイル ストアド プロシージャでの同時更新発生時の再処理
ネイティブ コンパイル ストアド プロシージャでは、BEGIN TRY や THROW を利用することもできるので、
同時更新が発生した場合(エラー 41302 が発生した場合)に再試行を行うような作り込みも可能です。これに

SQL Server 2016 自習書 No.2 Operational Analytics
121
ついては、SQL Server 2014 実践シリーズの「No.1 インメモリ OLTP の実践的な利用方法」で、具体的な実
装方法を例に説明しているので、こちらもぜひご覧いただければと思います。
インメモリ OLTP の実践的な利用方法
https://www.microsoft.com/ja-jp/sqlserver/2014/technology/self-learning.aspx#practical_contents
INSERT 競合(同じ値を INSERT)
次に、同じ値を INSERT した場合の競合についても見ていきましょう。
1. まずは、1 つ目の接続から、次のように INSERT ステートメントを実行して、「col1」が
「9999999」のデータを追加します。
BEGIN TRAN
INSERT t1_InMem_Durable
VALUES(9999999, 'AAAAA')
BEGIN TRAN でトランザクションを開始し、COMMIT TRAN を省略して、トランザクシ
ョン中のままにしておきます。
2. 次に、ツールバーの [新しいクエリ]ボタンをクリックして、2 つ目の接続を作成します。新
しく表示されたクエリ エディター(別の接続)から、追加中のデータ「col1 = 9999999」
を参照します。
SELECT * FROM t1_InMem_Durable
WHERE col1 = 9999999
結果は、データが表示されず、追加中のデータは参照できないことを確認できます。
3. 続いて、同じデータを追加してみます。
BEGIN TRAN
INSERT t1_InMem_Durable
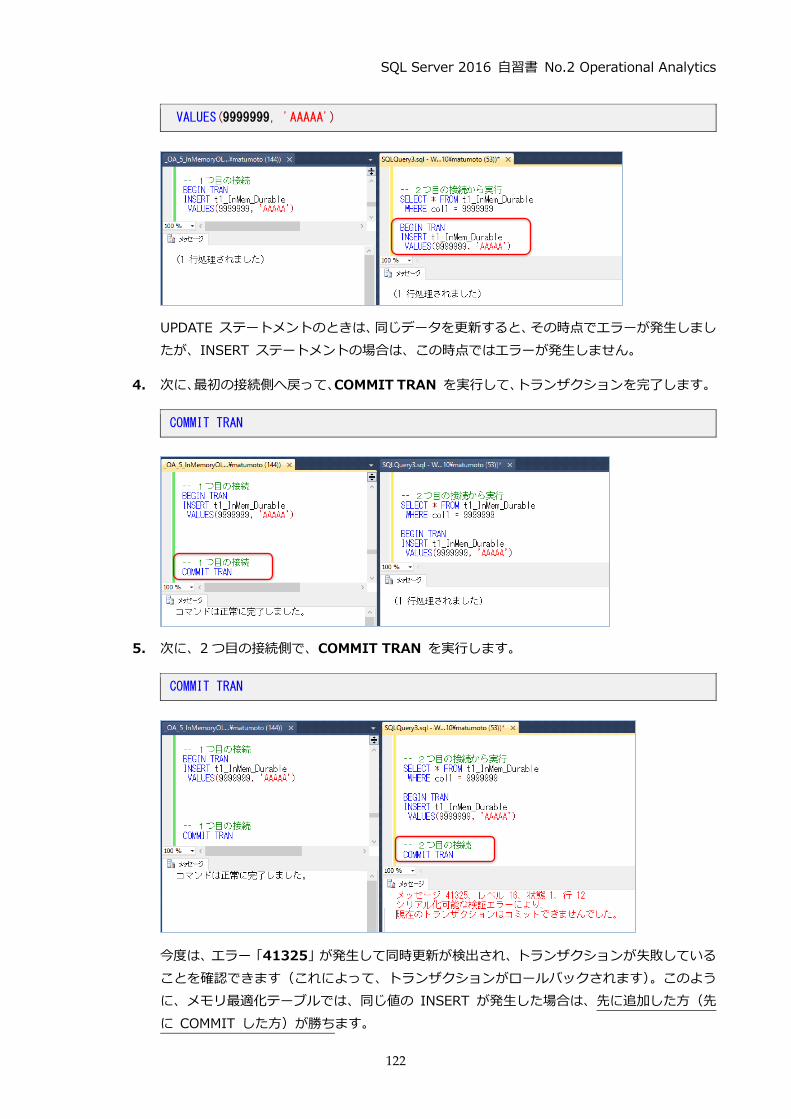
SQL Server 2016 自習書 No.2 Operational Analytics
122
VALUES(9999999, 'AAAAA')
UPDATE ステートメントのときは、同じデータを更新すると、その時点でエラーが発生しまし
たが、INSERT ステートメントの場合は、この時点ではエラーが発生しません。
4. 次に、最初の接続側へ戻って、COMMIT TRAN を実行して、トランザクションを完了します。
COMMIT TRAN
5. 次に、2 つ目の接続側で、COMMIT TRAN を実行します。
COMMIT TRAN
今度は、エラー 「41325」が発生して同時更新が検出され、トランザクションが失敗している
ことを確認できます(これによって、トランザクションがロールバックされます)。このよう
に、メモリ最適化テーブルでは、同じ値の INSERT が発生した場合は、先に追加した方(先
に COMMIT した方)が勝ちます。

SQL Server 2016 自習書 No.2 Operational Analytics
123
おわりに
最後まで試された皆さん、いかがでしたでしょうか? インメモリ OLTP とクラスター化列ストア
インデックスの融合 (Operational Analytics)は、今後のデータベースのあり方を左右するのでは
ないかと思えるほど、非常に大きな可能性を感じています (弊社のお客様でも、インメモリ OLTP
に移行できるケースが多々あるのではないかとワクワクしています)。
また、非クラスター化列ストア インデックスが更新可能になったことも、私たちは大変気に入って
います。こちらはテーブルを移行することなく、インデックスを追加するだけで利用できるものな
ので、皆さんも、ぜひ試してみていただければと思います。
SQL Server 2016 では、R 統合や JSON 対応、PolyBase、Hadoop 対応など、最近のマイクロ
ソフト社の方向性と同様、SQL Server でもオープン化が非常に進んでいます。また、SQL Server
2016 では、セキュリティの強化や、既存機能の強化も怠ってはおらず、私たちが特に気に入って
いるのは 「動的データ マスク」と 「透過的なデータ暗号化の性能向上&インメモリ OLTP 対応」、
「可用性グループでのログ転送性能の向上」、「ライブ クエリ統計」、「クエリ ストア」です。
これらについては、SQL Server 2016 自習書シリーズ No.1「SQL Server 2016 の新機能の概
要」編で説明しているので、こちらもぜひご覧いただければと思います。

SQL Server 2016 自習書 No.2 Operational Analytics
124
執筆者プロフィール
有限会社エスキューエル・クオリティ(http://www.sqlquality.com/)
SQLQuality (エスキューエル・クオリティ)は、日本で唯一の SQL Server 専門の独立系コンサルティング
会社です。過去のバージョンから最新バージョンまでの SQL Server を知りつくし、多数の実績と豊富な経
験を持つ、OS や .NET にも詳しい SQL Server の専門家 (キャリア 20年以上)がすべての案件に対応し
ます。人気メニューの 「パフォーマンス チューニング サービス」は、100%の成果を上げ、過去すべてのお
客様環境で驚異的な性能向上を実現。チューニング スキルは世界トップレベルを自負、検索エンジンでは (英
語情報を含めて)ヒットしないノウハウを多数保持。ここ数年は BI/DWH システム構築支援のご依頼が多
く、支援だけでなく実際の構築も行う。
主なコンサルティング実績/構築実績
大手製造業の「CAD 端末の利用状況の見える化」システム構築
Oracle や CSV(Notes)、TSV ファイル、Excel からデータを抽出し、SQL Server 2012 上に DWH を構築
見える化レポートには Reporting Services を利用
大手映像制作会社の BI システム構築(会計/業務システムにおける予実管理/原価管理など)
従来 Excel で管理していたシートを Reporting Services のレポートへ完全移行。
Oracle や勘定奉行からデータを抽出して、SQL Server 上に DWH を構築
大手流通系の DWH/BI システム構築支援(POS データ/在庫データ分析/ABC 分析/ポイントカード分析)
大手アミューズメント企業の BI システム構築支援(人事システムにおける人材パフォーマンス管理)
Reporting Services による勤怠状況の見える化レポートの作成、PostgreSQL/人事システムからのデータ抽出
外資系医療メーカーの BI システム構築支援(Analysis Services と Excel による販売分析システム)
OLAP キューブによる売上および顧客データの多次元分析/自由分析(ユーザーによる自由操作が可能)
大手流通系の DWH システムのパフォーマンス チューニング
データ量 100億件の DWH、総ステップ数2万越えのストアド プロシージャのパフォーマンス チューニング
ミッション クリティカルな金融システムでのトラブル シューティング/定期メンテナンス支援
SQL Server の下位バージョンからの移行/アップグレード支援(32 ビットから x64 への対応も含む)
複数台の SQL Server の Hyper-V 仮想環境への移行支援(サーバー統合支援)
ハードウェア リプレース時のハードウェア選定(最適なサーバー、ストレージの選定)、高可用性環境の構築
2時間かかっていた日中バッチ実行時間を、わずか 5分へ短縮(95.8% の性能向上)
Java 環境(Tomcat、Seasar2、S2Dao)の SQL Server パフォーマンス チューニング etc
コンサルティング時の作業例(パフォーマンス チューニングの場合)
アプリケーション コード(VB、C#、Java、ASP、VBScript、VBA)の解析/改修支援
ストアド プロシージャ/ユーザー定義関数/トリガー(Transact-SQL)の解析/改修支援
インデックス チューニング/SQL チューニング/ロック処理の見直し
現状のハードウェアで将来のアクセス増にどこまで耐えられるかを測定する高負荷テストの実施
IIS ログの解析/アプリケーション ログ(log4net/log4j)の解析
ボトルネック ハードウェアの発見/ボトルネック SQL の発見/ボトルネック アプリケーションの発見
SQL Server の構成オプション/データベース設定の分析/使用状況(CPU, メモリ, ディスク, Wait)解析
定期メンテナンス支援(インデックスの再構築/断片化解消のタイミングや断片化の事前防止策など)etc
松本美穂(まつもと・みほ)
有限会社エスキューエル・クオリティ 代表取締役 Microsoft MVP for SQL Server(2004 年 4 月~)
経産省認定データベース スペシャリスト/MCDBA/MCSD for .NET/MCITP Database Administrator
SQL Server の日本における最初のバージョンである 「SQL Server 4.21a」から SQL Server に携わり、現在、SQL Server
を中心とするコンサルティングを行っている。得意分野はパフォーマンス チューニングと Reporting Services。著書の
『SQL Server 2000 でいってみよう』と『ASP.NET でいってみよう』(いずれも翔泳社刊)は、トップ セラー(前者は
28,500 部、後者は 16,500 部発行)。近刊に『SQL Server 2016 の教科書』(ソシム刊)がある。
松本崇博(まつもと・たかひろ)
有限会社エスキューエル・クオリティ 取締役 Microsoft MVP for SQL Server(2004 年 4 月~)
経産省認定データベース スペシャリスト/MCDBA/MCSD for .NET/MCITP Database Administrator
SQL Server の BI システムとパフォーマンス チューニングを得意とするコンサルタント。アプリケーション開発 (ASP/
ASP.NET、C#、VB 6.0、Java、Access VBA など)やシステム管理者(IT Pro)経験もあり、SQL Server だけでなく、
アプリケーションや OS、Web サーバーを絡めた、総合的なコンサルティングが行えるのが強み。Analysis Services と
Excel による BI システムも得意とする。マイクロソフト認定トレーナー時代の 1998 年度には、Microsoft CPLS トレーナ
ー アワード(Trainer of the Year)を受賞。