streaming platform overview 2014
TRANSCRIPT

流处理技术平台Overview和设计模式
2015/1/31
钟翔 Storm PMC Mail: [email protected]
Weibo:http://weibo.com/clockfly
上海Intel亚太研发中心 | Intel 软件与服务部 Big Data Technology Department

About me
• Intel大数据开发部,Storm PMC
• 2014年之前做IDH Hadoop发行版,现从事Hadoop开源工作,
• 历史工作包括 MapReduce NativeTask,HBase图像存储 Large Object Store (MOB),Storm性能优化,创立Gearpump项目等。

什么是流处理?

流处理 vs.批处理
• 批处理:一批数据处理一次,不要求实时流入,实时输出
数据实时流入 事件处理 实时输出结果
中间状态存储

为什么需要流处理? • 大数据的价值迅速流失
价值

流处理有哪些应用?
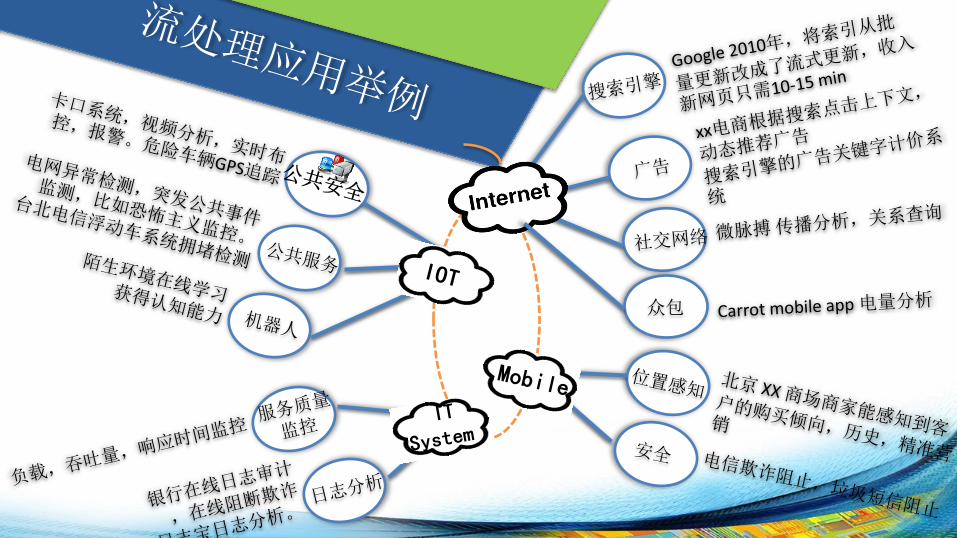
众包

流处理应用: 按响应速度分类 • 实时决策支持,必须立刻输出结果
– 广告推荐,必须在click的session里面返回 – 银行诈欺中止交易
• 实时响应,在时间窗内处理才有价值 – 嫌疑人车辆排查布控 – 突发事件公共监测
• 近实时数据处理,越快处理价值越高 – Google 索引更新 – 日志分析

流处理应用: 按数据一致性分类
• 对消息丢失不敏感 – IT 服务响应时间等Metrics指标监控等
• At least once – 手机短信验证码
• Exactly Once – 搜索引擎Ads关键字计价系统(每一个广告点击需要向广告主收费,计费必须且只能被计一次)

如何支撑流处理应用? 流处理平台

流处理技术平台 • 支持复杂的分布式 DAG计算
log
存储
流处理平台
Queue
各种 数据源
批处理
SQL
数据 分析
可视化
监控/报警
用户
消息 预处理
实时模型训练
业务决策
存储 源数据存储

流处理平台在大数据技术栈中的位置
分布式存储
数据可视化
批处理 流处理
SQL 查询 Catalyst StreamSQL Impala
集群管理 数据监控/通知 /报警
数据科学 / 机器学习
Graphx
Cloudera Manager
存储层
计算平台
数据分析
可视化
storm
数据探索 交互式,启发式 价值发现

流平台历史演进 1. 关系数据库 -> 流处理 (streamInsight, CEP System) 2. 消息队列 -> 流处理 (activemq, kafka, samza) 3. 批处理 -> 流处理 (spark, summingbird) 4. 其他, Storm, Millwheel, Gearpump
演进脉络: 热门系统: Storm,Spark Streaming SAMZA,

怎样的流平台才是够好的?

Michael Stonebraker 流八条
1. In-Stream,数据长流不息,没有沉淀(不经存储) 2. StreamSQL 3. 容忍数据的延迟、乱序和丢失 4. 输出结果可预期、可重复 5. 实时处理、实时响应 6. Join历史数据和当前数据 7. 高可用,不宕机 8. 数据可以水平切割,计算可以水平扩展

我的总结:一流的流处理技术平台 活
– 能满足各行各业的特殊需求, – 计算图动态灵活可定制 – 支持物联网,移动设备等各种数据源, – 支持各种高级语言,方便数据科学家
快 – 满足实时性要求,ms秒级响应
大 – 每秒能处理数百万消息
准 – 数据不丢不重,绝对准确,比如金融应用

如何开发高效的流平台? 技术模式总结

技术模式总结 从实现层面的视角
1. 高效的分布式消息传递
2. 检测流数据丢失
3. 流重放
4. 去重, Exactly once delivery
5. 在流计算 Pipelining
6. 高阶StreamSQL语言

高效的分布式消息传递

分布式消息传递的挑战
Partition and Shuffle
1. Partition & Shuffle, 数据通道多,数据碎!
2. 流内每个节点能力不同,处理速度不匹配,容易内存OOM,IO阻塞,CPU Hang等
N * N 个数据通道!
select * from R join S on R.key = S.key

Batch越大, 吞吐量越高 Batch越大, 延时越大
消息传递主要设计模式 • 中间数据落地
–消息队列持久化(AMQP, SAMZA KAFKA)
–中间状态 Checkpoint到磁盘 (MapReduce, Spark)
• 中间数据不落地(Millwheel, Storm)
– Effective Batching
– 流控

数据高效归组
Storm-297: 性能2.5倍, 延时大幅下降! http://storm.incubator.apache.org/2014/06/25/storm092-released.html
Storm-297: Storm Message passing IA Optimization
解决连接多,数据碎片的问题。 根据网络状况,自适应,兼顾吞吐量和延时

流控 – 滑动窗
sink
sink
sink
Process 时间轴
滑动窗
send seq id ack seq id Sliding window
timeline
对每一个连接
流控控制线
….
控制Pending 的总消息数
由于数据在内存中不落地,如果节点速率不匹配,内存会OOM。所以必须流控。
主要难点在于星型结构下流控压力的的反向传播(BackPressure)
和TCP协议实现原理相似。

检测流数据丢失

为什么需要检测流数据丢失?
• 有些应用有很高的一致性需求,必须确保不丢。
– 比如搜索引擎Ads关键字计价系统,每一个广告点击都需要向广告主收费,一次点击只能计费一次
• 我们需要高效的跟踪哪些消息已经被处理了,哪些消息还没有被处理,哪些消息丢失了,需要恢复。
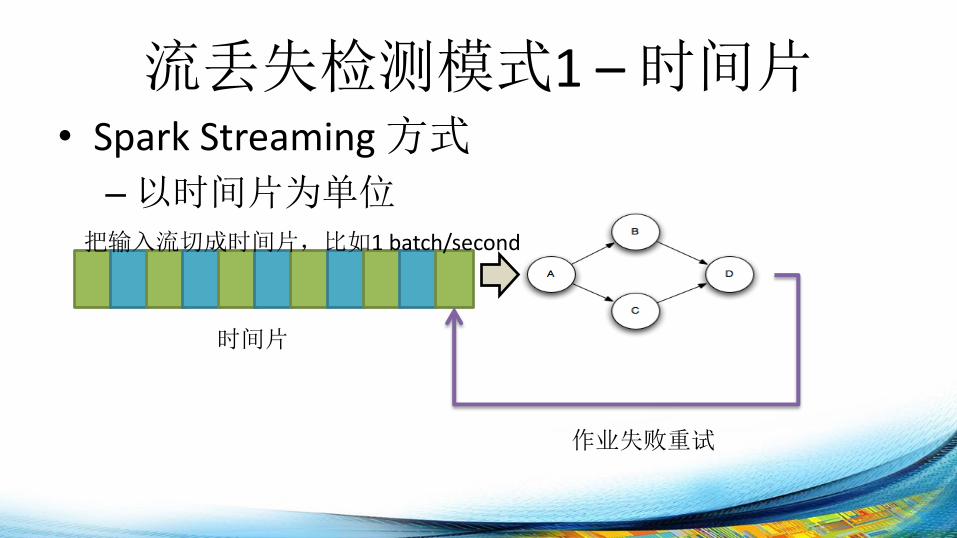
流丢失检测模式1 – 时间片 • Spark Streaming 方式
–以时间片为单位
把输入流切成时间片,比如1 batch/second
作业失败重试
时间片

流丢失检测模式2:持久化
• SAMZA 方式
–中间数据持久化,保证不丢
持久化存储

流丢失检测模式3: 细粒度Request & Ack
• Millwheel 方式
–以消息为单位,细粒度
– Task之间 Request & Ack,每个 消息独立Ack
– Msg Id 是UUID,不重复
A B
时间线
Msg(id=4534)
Ack(id=4533)
Msg(id=6327)
Ack(id=6327)
… Msg(id=1352)
Ack(id=1352)

流丢失检测模式4: Storm方式
acker acker
acker acker
将异或值发送给Acker节点:输入消息ID XOR 输出消息ID

流重放

为什么需要流重放?
• 有些应用消息不能丢失,丢失后必须重新发送。
–比如银行短信验证码等,如果丢失,用户不能继续转账。

两种流重放模式 1. 数据源头重放 (比如Storm)
2. 各级消息上游重放(比如Millwheel)
Source
Store 2. 消息上游重放,
1. 数据源流重放
Store 基于kafka 的数据源重放

消息去重复

为什么要消息去重复?
• 在流重放后,一个消息可能会被重复发送多次,需要去除重复的影响,确保:
–去重保证Exactly Once Delivery
–对存储状态的修改是一致的,不能影响应用
–错误不会传递,今天的错误不会传播到明天

去重策略1:幂等运算
• 本身是幂等,或者可以转成幂等运算,重复运算不影响结果
–比如广告推荐,通知等

去重策略2:接收端去重
• 消息接收端去重
– Google Millwheel 使用 Bloom Filter ,判断是否收到过。需要配合状态操作的原子性
过滤
处理
消息 第一次发送①
Bloom Filter 查询②
处理消息④
过滤
处理
消息 第二次发送①
Bloom Filter 查询②
进一步确认④
已经存在③ 不存在③
Hot Path Cold Path

去重策略3:增量状态ID
• 增量Transaction Id (Trident使用这个方法)
1. 消息Id 是增量的, 0, 1, 2, 3, 4, 5…..
2. 收到新消息id=3,处理,保存状态 State(id=“3”)
3. 重复收到消息id=3,读取状态的ID,和当前消息id相同,说明已经处理过,丢弃当前消息。
4. 各个Id消息的计算可以同时进行,但对状态State的commit必须按照ID的顺序

去重策略4:vector clock去重方法
• Vector clock是分布式系统的时钟技术,用来保持数据的一致性。
流处理系统
数据源1
数据源2
数据源3
c1
c2
c3
每个消息都有 当前时钟的 Timestamp ① Checkpoint at
Clock (t1, t2, t3)
clock(t1, t2, t3)之前的累积状态
②系统当时钟超过(t1, t2, t3时) checkpoint状态
③失败时重放,从上一个状态恢复

在流计算(IN-STREAM)

在流计算 - 数据不落地
• 在流内计算,数据不落地直接往下游传,数据流长流不止 – 系统本身不应该有固有的延时
• 中间数据落地的代价 – 数据太多,存储代价太高 – 增加延时
• Millwheel:200CPU, 中位数延时3.6 ms!

STREAMSQL

高阶StreamSQL语言
• StreamSQL 由 Stonebraker 提出,扩展了SQL的语法,支持Stream select, Stream join, Windows 运算。
• 实现模式 – 关系库方案扩展(状态存储在关系库中), 使用关系库的SQL
– 新的SQL引擎, 比如Intel Team在Spark SQL基础上的工作。

其他:Join历史数据和当前数据
• Spark Streaming中,每一个准实时Batch都是一个RDD,历史数据也是一个RDD,RDD间很容易Join。

设计模式总结
• 通用流处理平台的设计模式: 1. 高效的分布式消息传递
2. 检测流数据丢失
3. 流重放
4. 去重, Exactly once delivery
5. 在流计算 Pipelining
6. 高阶StreamSQL语言

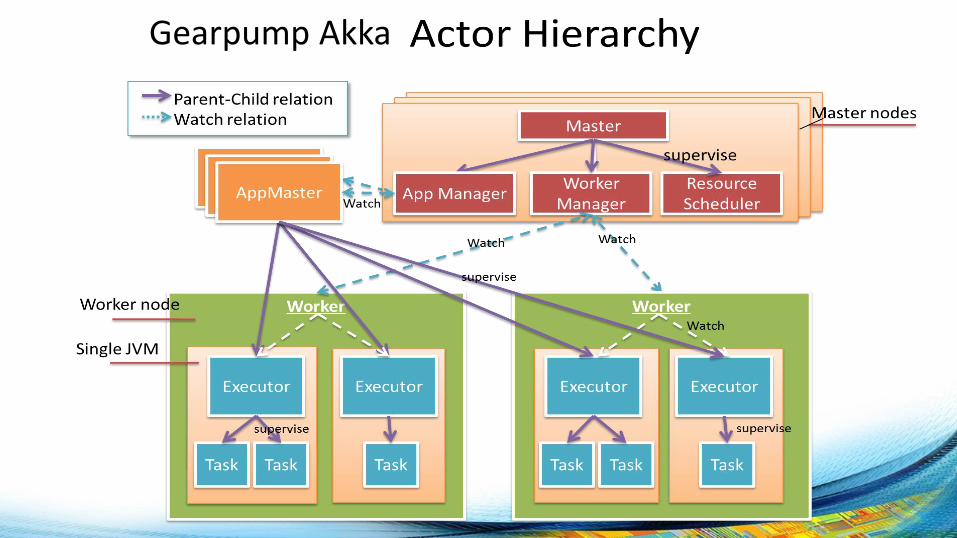
Gearpump流引擎: 上述模式 + Akka 开源项目地址: https://github.com/intel-hadoop/gearpump
设计目标:
– Exactly Once 消息处理
– 毫秒级延时,每秒千万消息的吞吐量
– 灵活编程模型,动态可调整的图,可视化编程
– 轻量的两层资源调度器,可嵌入使用
– 支持应用时钟, 时间窗支持乱序消息(时间窗结果仍然准确)
– Stream SQL
– 基于Gossip协议的Master HA设计。
– 更好的Metrics,dashboard
Gearpump Akka

References • 吴甘沙 低延迟流处理系统的逆袭, 程序员期刊2013年10期 • Stonebraker http://cs.brown.edu/~ugur/8rulesSigRec.pdf • Gearpump: https://github.com/intel-hadoop/gearpump • http://highlyscalable.wordpress.com/2013/08/20/in-stream-big-data-processing/ • https://engineering.linkedin.com/kafka/benchmarking-apache-kafka-2-million-
writes-second-three-cheap-machines • Sqlstream http://www.sqlstream.com/customers/ • http://www.statsblogs.com/2014/05/19/a-general-introduction-to-stream-
processing/ • http://www.statalgo.com/2014/05/28/stream-processing-with-messaging-
systems/
