tagconf 13 - sphinxsearch - 2
TRANSCRIPT

Нестандартное использование SphinxSearch(Сага о красных телевизорах)
Кудлай РоманВедущий разработчик

Нам на сайте нужен поиск
Заказчик: нам на сайте нужен поиск!
Заказчик: Быстро и «по-простому»!!!
Разработчик: Будет медленно работать!
Заказчик: Ничего, главное – быстро запустить!
Разработчик: SELECT * FROM news WHERE text LIKE %query%
Заказчик: А почему так медленно?
Разработчик: Ну так «по-простому» же!!!

Немного про эволюцию одного проекта
● Шаг 1: Нам нужен поиск
● Шаг 2: Нам нужен поискс фильтром
● Шаг 3: Нам нужен фильтр

Постановка задачи
1. Имеется каталог товаров
2. У товаров есть ряд свойств (не зависят от категории): город, спецпредложение, новинка, категория, подкатегория, цена, производитель и др.
3. У товаров есть ряд характеристик (зависят от категории): Цвет, вес, поддерживаемые стандарты
4. Необходимо фильтровать товары по свойствам и/или характеристикам: новинки в Таганроге, спецпредложения в телевизорах с поддержкой 3D, товары, похожие на sku1248134
5. И это еще с возможностью поиска: синий мобильные телефоны «i9000» или просто «телевизоры LG»
6. Необходимо выводить только те категории, в которых присутствуют товары с определенными параметрами
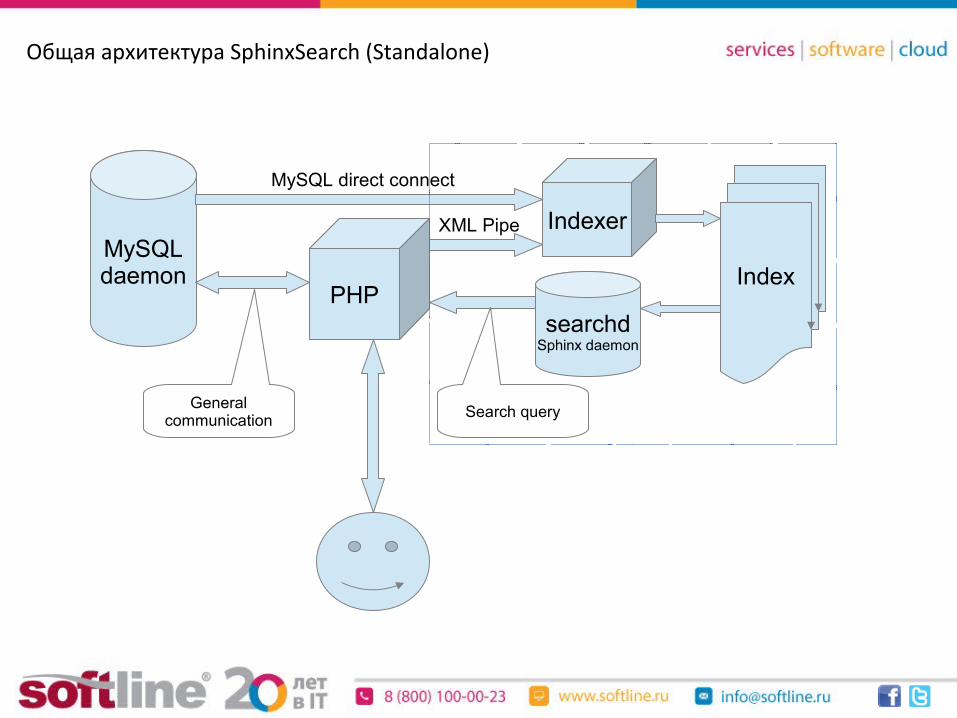
Общая архитектура SphinxSearch (Standalone)
PHP
MySQLdaemon
searchdSphinx daemon
MySQL direct connect
Index
IndexerXML Pipe
Generalcommunication Search query
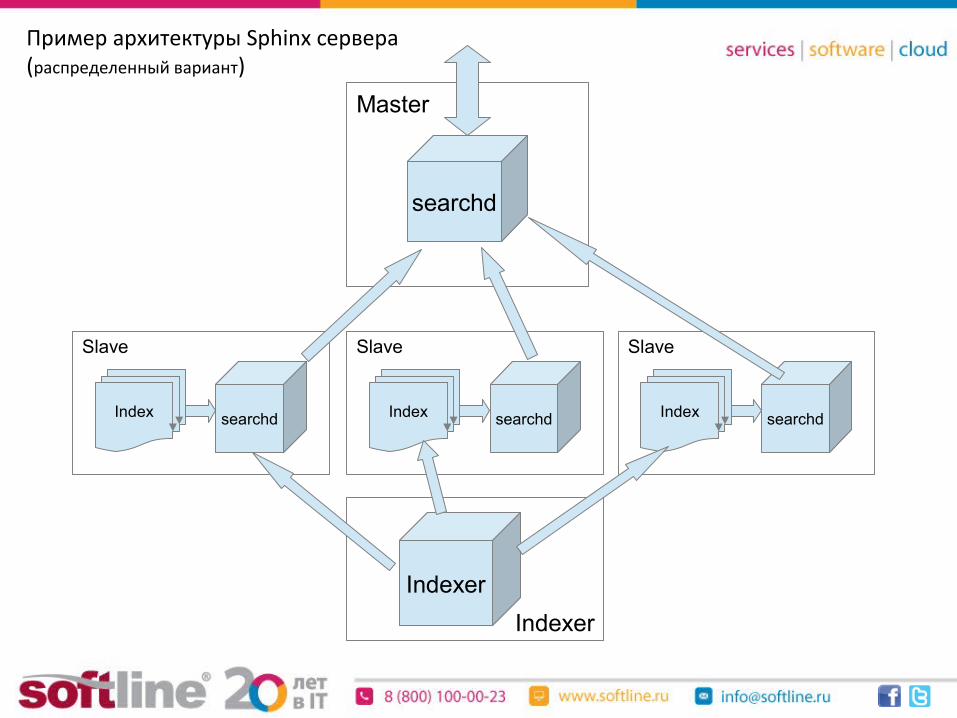
Пример архитектуры Sphinx сервера(распределенный вариант)
Index
Indexer
searchd
Master
searchd
Slave
Index searchd
Slave
Index searchd
Slave
Indexer
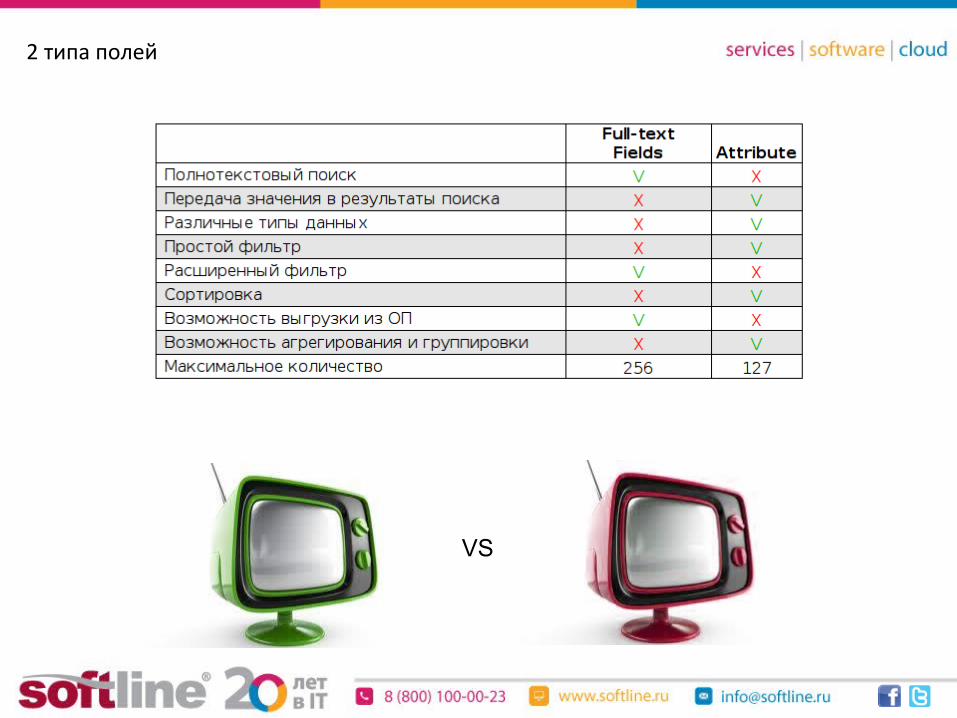
2 типа полей
VS

Что рекомендует официальная документация
Example sphinx.conf part:
sql_query = SELECT id, title, content, \
author_id, forum_id, post_date FROM my_forum_posts
sql_attr_uint = author_id
sql_attr_uint = forum_id
sql_attr_timestamp = post_date
Example application code (in PHP):
// only search posts by author whose ID is 123
$cl->SetFilter ( "author_id", array ( 123 ) );
// only search posts in sub-forums 1, 3 and 7
$cl->SetFilter ( "forum_id", array ( 1,3,7 ) );
// sort found posts by posting date in descending order
$cl->SetSortMode ( SPH_SORT_ATTR_DESC, "post_date" );
http://sphinxsearch.com/docs/2.1.1/attributes.html

Что рекомендует официальная документация
Example sphinx.conf part:
sql_query = SELECT id, title, content, \
author_id, forum_id, post_date FROM my_forum_posts
sql_attr_uint = author_id
sql_attr_uint = forum_id
sql_attr_timestamp = post_date
Example application code (in PHP):
// only search posts by author whose ID is 123
$cl->SetFilter ( "author_id", array ( 123 ) );
// only search posts in sub-forums 1, 3 and 7
$cl->SetFilter ( "forum_id", array ( 1,3,7 ) );
// sort found posts by posting date in descending order
$cl->SetSortMode ( SPH_SORT_ATTR_DESC, "post_date" );
Все л
гут!
Все л
гут!
http://sphinxsearch.com/docs/2.1.1/attributes.html


Что рекомендует Аксенов*
● Храните данные для фильтрации в полнотекстовых индексных полях.
● Храните всю полезную информацию об элементе в одном атрибуте в сериализованном виде.
● В своих запросах
NEWS FROM LIKE %query% WHERE SELECT *
(SELECT * FROM news WHERE tit le LIKE %query%)
Вы не используйте
*На самом деле, на картинке изображен не Андрей Аксенов, а магистр Йода

Секретный ингредиент
Инвертированный индекс (англ. inverted index) — в процессе индексации для всех ключевых слов строится список документов, в которых оно встречается
++ =

Как это работает

Хранение информации об объекте в записи сфинкса
@id = '100'
@category = 'TV'
@keywords = 'телевизор LG T900 цвет красный новинка'
@features = '_ID_100_ _CAT_TV_ _CAT_VIDEO_ _LASTCAT_TV_
_BRAND_LG_ _CITY_TAGANROG_ _CITY_ROSTOV_
_FEATURE_COLOR_RED_ _NEW_
_HASH_c7c9b697cb717d6a5d2ab76'
@price_taganrog = '10000'
@price_rostov = '9500'
@info = '{cities: [rostov, taganrog], brand: LG, picture: red_tv.jpg, new:
true}
Profit
● Результат запроса вернет сразу все данные по объекту. Нет необходимости в использовании дорогих join.
● Полнотекстовый поиск и фильтрация по множеству элементов работает очень быстро
● Можно сортировать объекты по похожести: чем больше одинаковых свойств — тем выше релевантность.

Почему не реляционные СУБД
● Индекс в реляционных СУБД — отсортированный столбец
● Либо, добавлять под новое свойство новый столбец, либо создавать M:M связи
● Нормализация: зло
JOIN

Поиск
1. Спецпредложения в Таганроге в категориях TV и DVD@features =_SPEC_ =_CITY_TAGANROG_ =( _CAT_TV_ | _CAT_DVD_ )
2. Фен remington в Ростове@keywords ('фен remington' | '*фен remington*') @features =_CITY_ROSTOV_
3. Поиск товара по ЧПУ@features =_CODEHASH_c7c97af638909b697cb717d6a5d2ab76_
4. Товары в категории «приготовление пищи» в Таганроге, у которых есть картинка@features =_CITY_TAGANROG_ =_CAT_COOKING_ =_HAS_PICTURE_
5. Телевизоры в Васюки от 3 разных производителей@features =_LASTCAT_TV_ =_CITY_VASYUKI_ =( _MANUFACTURER_LG_ | _MANUFACTURER_SAMSUNG_ | _MANUFACTURER_BBK_ )
6. Товары, похожие по характеристикам на необходимый@features _FEATURE_COLOR_RED_ _FEATURE_INTERFACE_HDMI_ _FEATURE_INTERFACE_VGA_ _FEATURE_LED_YES_ _FEATURE_WIFI_NO_ _FEATURE_SMART_YES_
Управление поиском:
Поисковый запрос
MatchMode, Sort, Group и пр.

Benchmarks
● На реальном сервере до 150 запросов в секунду. Дальше тормозит все, кроме Sphinx
● Время запроса 0-3 мс (точнее в логи не пишется)
● Среднее время запроса по логам 0-1мс
● 1-4 запроса на странице
● Синтетическая нагрузка:18000 элементов i7m 2.4 Ghz, 2 ядра, 12 потоков, 2200-2400 запр/сек

А теперь о грустном

Минусы реализации
● Дополнительное звено — больше потенциальных проблем
● Необходимо индексирование. Данные не всегда актуальны
● Для группировки и сортировки надо выносить данные в отдельные атрибуты
● До конца не решен вопрос с диапазонами значений (сейчас решается созданием атрибутов)

Спасибо
Вопросы?