unsupervised object discovery and localization in the wild:part-based matching with bottom-up region...
TRANSCRIPT

CVPR 2015読み会
Unsupervised Object Discovery and Localization in the Wild:Part-Based Matching With Bottom-Up Region Proposals
牛久 祥孝losnuevetoros

お前は誰だ?~ 2014.3 博士 ( 情報理工学 ) 、東京大学• 画像説明文の自動生成
• 大規模画像分類
2014.4 ~ NTT コミュニケーション科学基礎研究所

お前は誰だ?~ 2014.3 博士 ( 情報理工学 ) 、東京大学• 画像説明文の自動生成
• 大規模画像分類
2014.4 ~ NTT コミュニケーション科学基礎研究所

そうだ、新しい問題に取り組もう
まずはデータセットだWeb で白い犬の画像を集めよう
一番しんどい作業は何だろうかサーベイ?背景 ( の後付け ) ?手法設計?コーディング?

そうだ、新しい問題に取り組もう
まずはデータセットだWeb で白い犬の画像を集めよう

大漁の白い犬画像
しろい、いぬ しろい、いぬ

大漁の白い犬画像
しろい、いぬ しろい、いぬ
これを画像 1 万枚分とかやったりする

無理…

でも周りを見回すと…• PASCAL VOC (2012): 1 万枚超、矩形領域やセグメントも
• ImageNet: 1400 万枚超、単一ラベル
• Microsoft COCO: 30 万枚超、セグメントや説明文も

誰か(主に Turker の方々)の偉業が必要なのか…

太古の人々は(きっと)自分たちが見たものに名前を付けただけ
こいつ、今までも何度か見たやつと同じだ。水飲まないで葉っぱばっかり食ってるから、「水を飲まない(コアラ)」と呼ぼう。

太古の人々は(きっと)自分たちが見たものに名前を付けていった
こいつ、今までも何度か見たやつと同じだ。水飲まないで葉っぱばっかり食ってるから、「水を飲まない(コアラ)」と呼ぼう。
データの形態( 2 次元静止画像)は実世界とちがうかもしれないが…
計算機も見習うべきでは?!
こんな訓練用データで学習したわけじゃない!

ラベル情報を一切与えないで、同一物体の見分けや位置の把握ができるか?

この研究の立ち位置• Supervised localization
Bounding Box を学習する、よくある Object detection
• Weakly-supervised localization画像全体のラベルだけ今回の CVPR でも発表有
• Colocalization / Cosegmentation同じ種類の物体がいるとわかっている画像群に対して物体検出
• Fully-unsupervised discovery ← 今ここ
[Felzenszwalb+, TPAMI 2010]
[Oquab+, CVPR 2015]
[Joulin+,ECCV 2014]
教師あり
教師なし
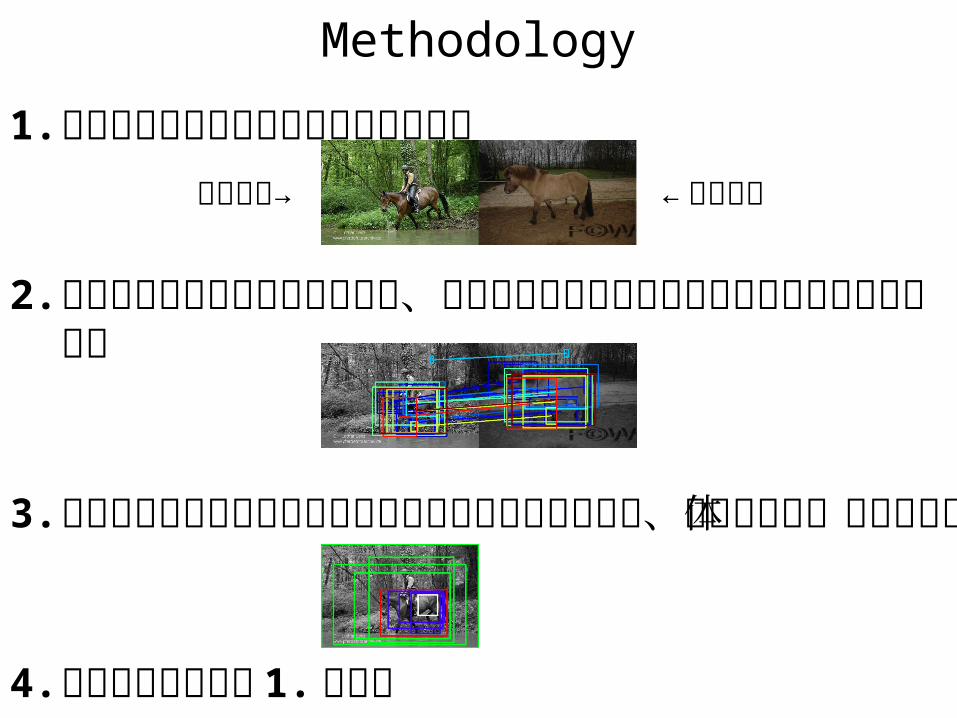
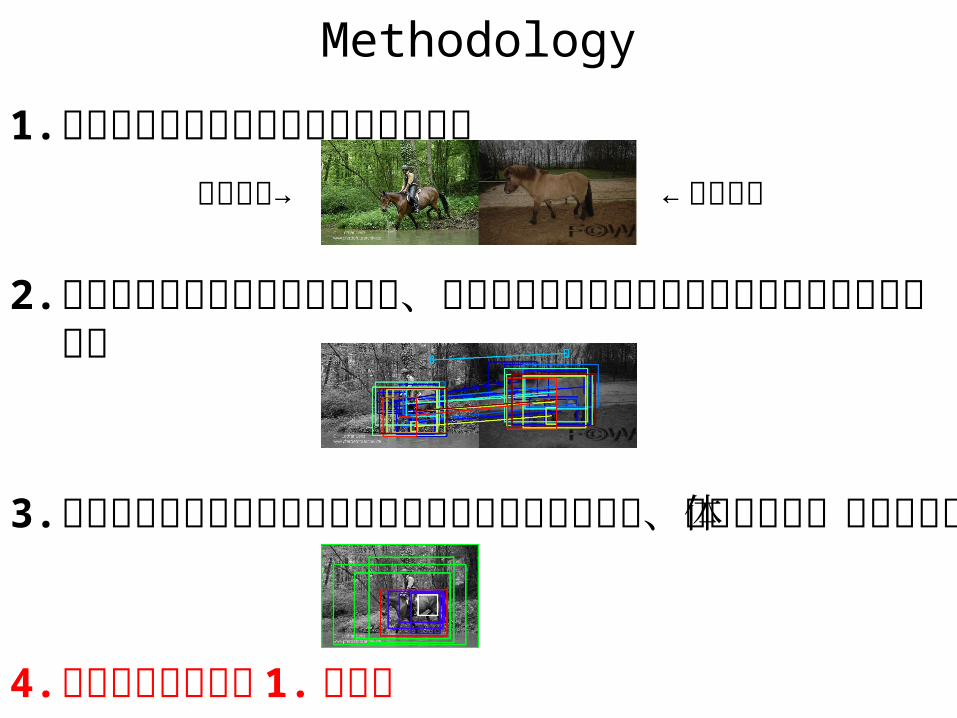
Methodology
1. 入力された画像に類似した画像を検索
2. 入力画像から領域候補を列挙し、同様に抽出した類似画像の領域候補とマッチング
3. 複数の重なり合った領域でとれたマッチング結果から、最終的な物体領域を更新
4. 満足いくまで手順 1. に戻る
入力画像→ ← 類似画像
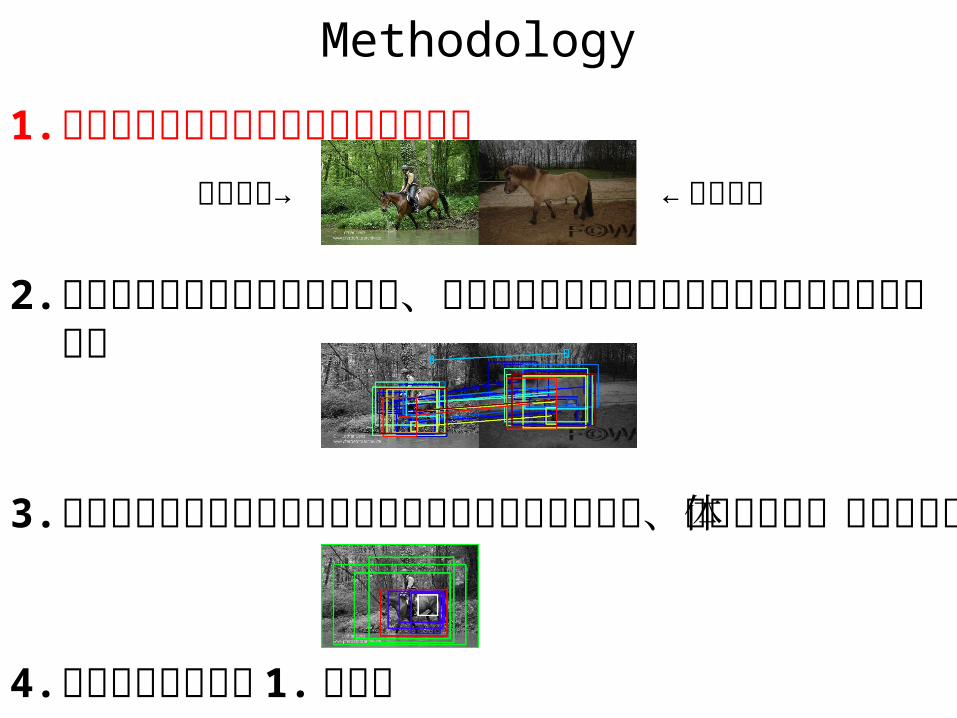
Methodology
1. 入力された画像に類似した画像を検索
2. 入力画像から領域候補を列挙し、同様に抽出した類似画像の領域候補とマッチング
3. 複数の重なり合った領域でとれたマッチング結果から、最終的な物体領域を更新
4. 満足いくまで手順 1. に戻る
入力画像→ ← 類似画像
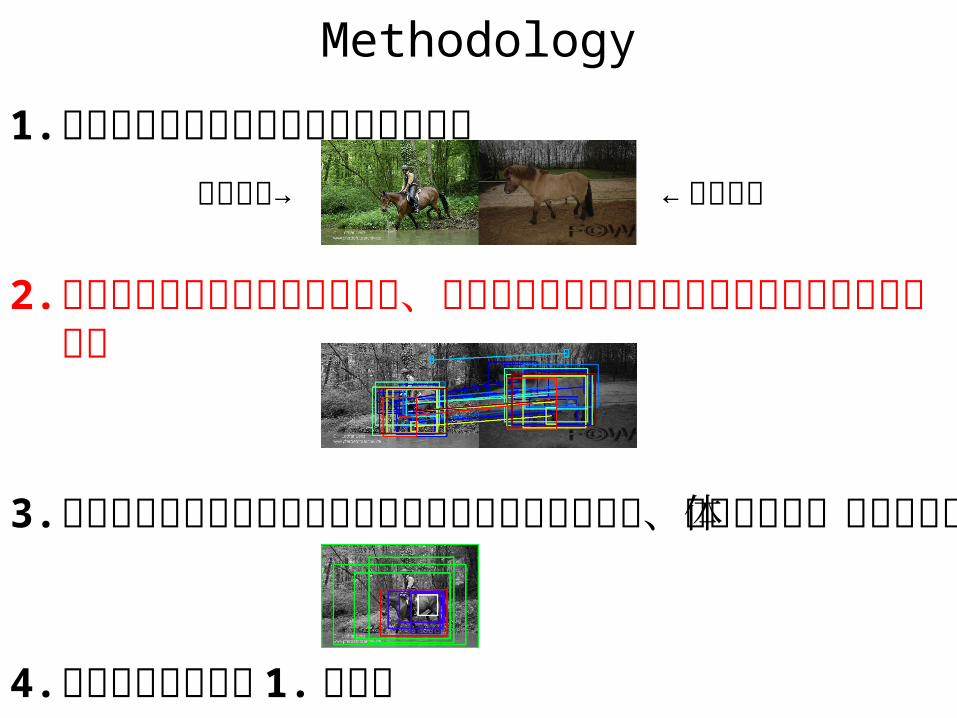
Methodology
1. 入力された画像に類似した画像を検索
2. 入力画像から領域候補を列挙し、同様に抽出した類似画像の領域候補とマッチング
3. 複数の重なり合った領域でとれたマッチング結果から、最終的な物体領域を更新
4. 満足いくまで手順 1. に戻る
入力画像→ ← 類似画像

パーツに基づいた領域マッチング
入力画像 類似画像の 1 つ
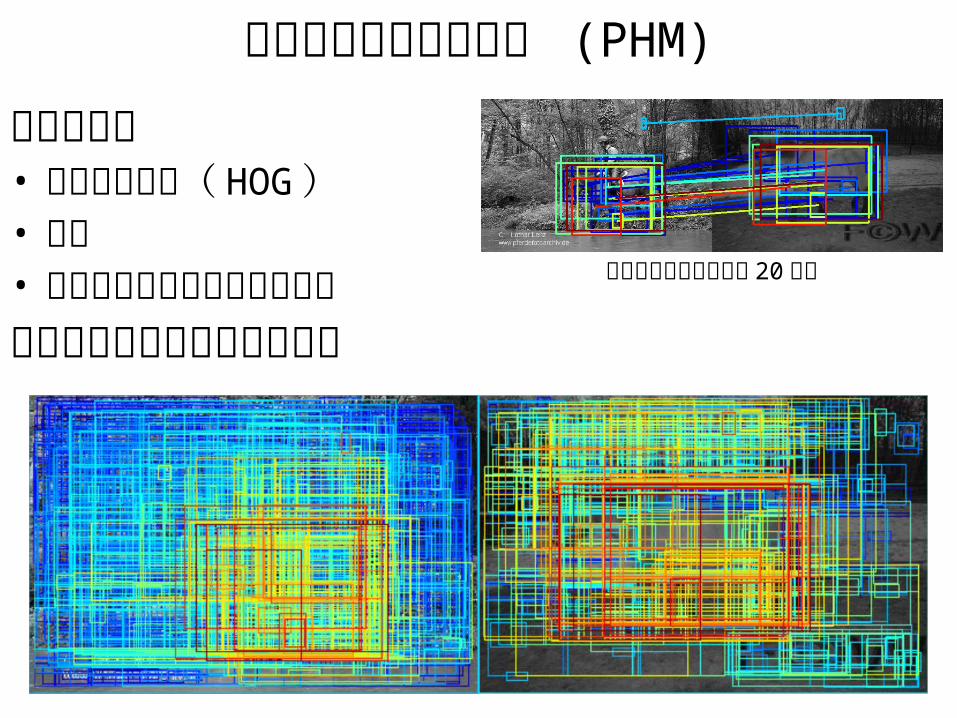
確率的ハフマッチング (PHM)
領域同士の• アピアランス( HOG )• 座標• 近隣領域のマッチングスコアに基づいてマッチングを計算
マッチした領域の上位 20 ペア
Methodology
1. 入力された画像に類似した画像を検索
2. 入力画像から領域候補を列挙し、同様に抽出した類似画像の領域候補とマッチング
3. 複数の重なり合った領域でとれたマッチング結果から、最終的な物体領域を更新
4. 満足いくまで手順 1. に戻る
入力画像→ ← 類似画像

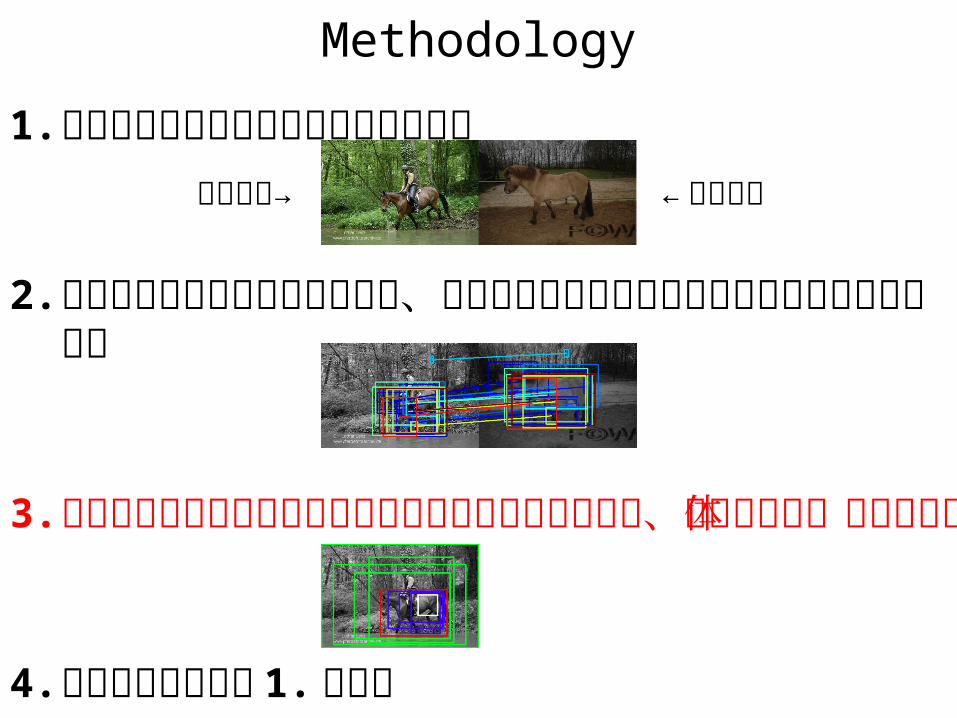
前景位置推定この入力画像に対して…
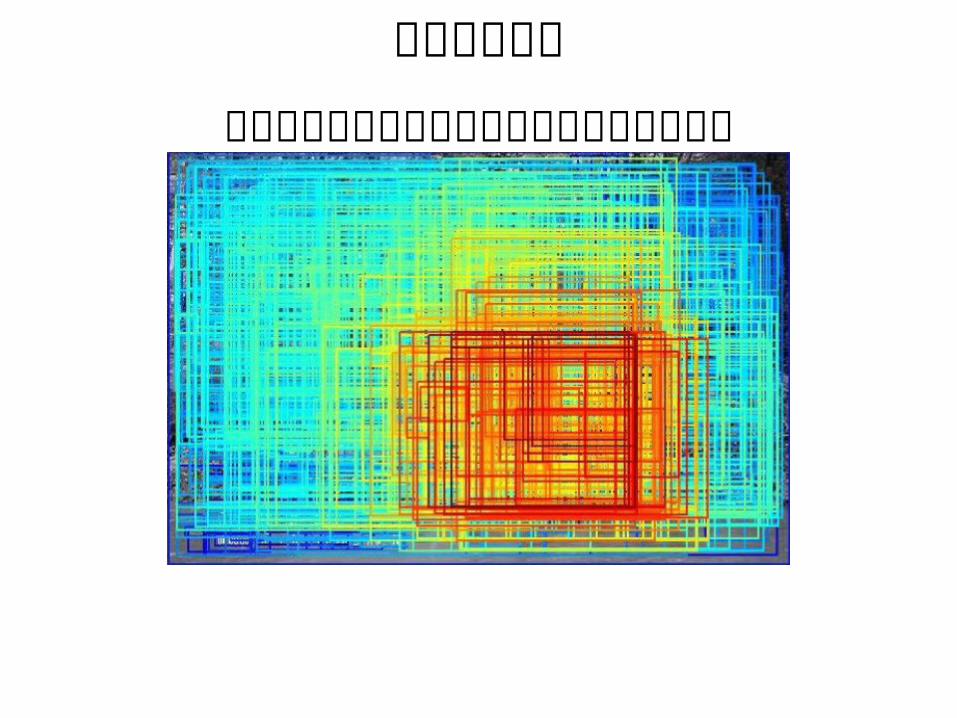
前景位置推定このような信頼度つき領域候補が出たとする
前景位置推定このような信頼度つき領域候補が出たとする
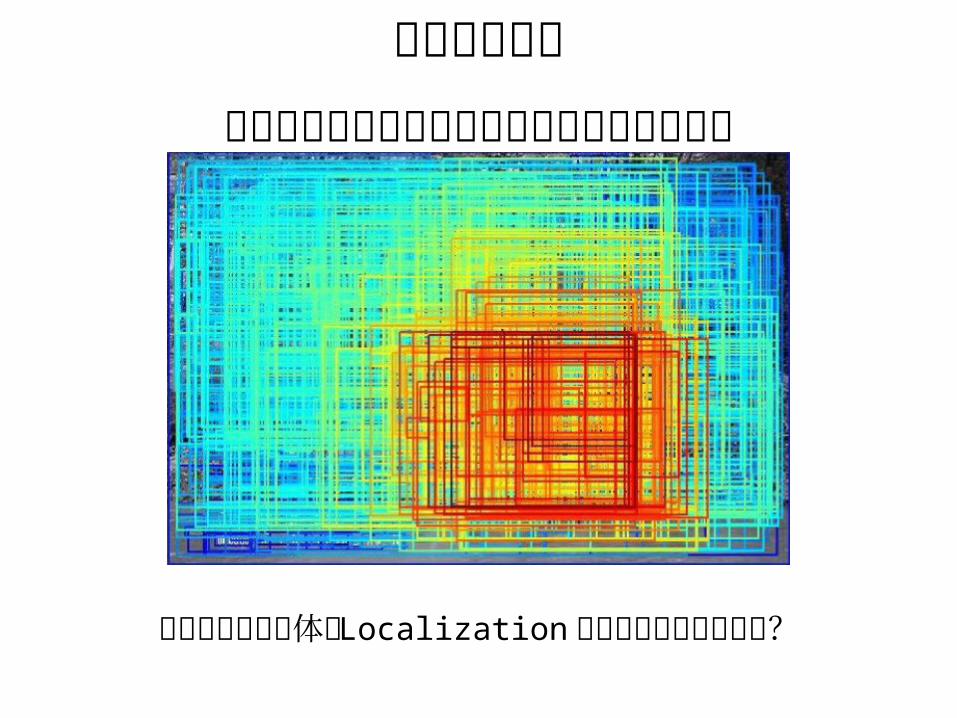
どんな領域が物体の Localization にふさわしいだろうか?
信頼度が最も高い領域?
オブジェクトの一部だけしか囲ってないような領域の方が、他の画像の同種オブジェクトとマッチして信頼度が高い
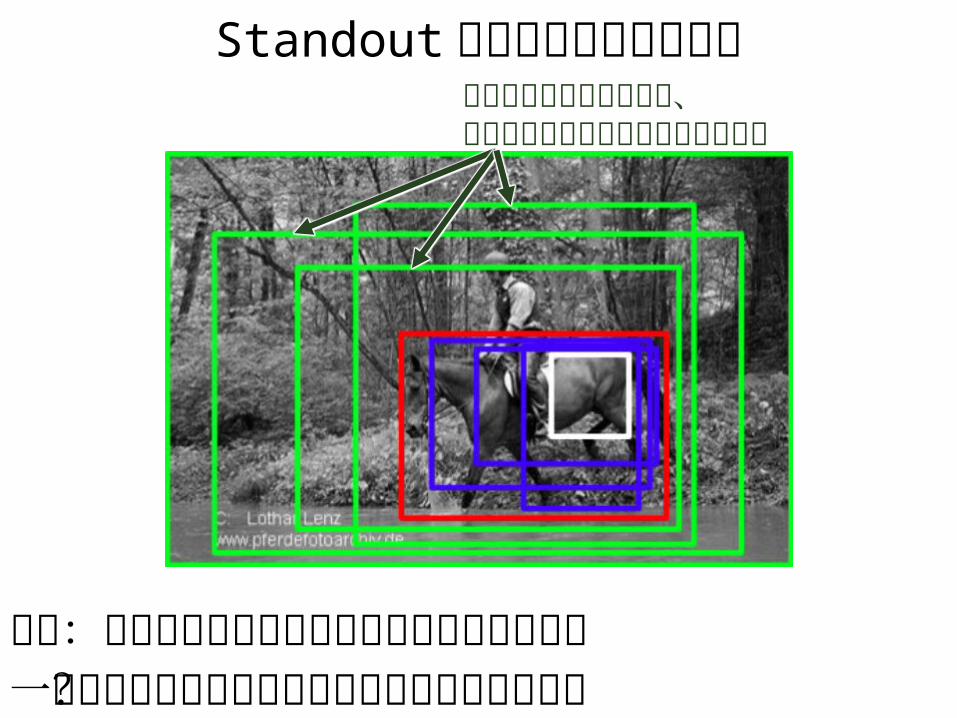
Standout スコアによる前景検出
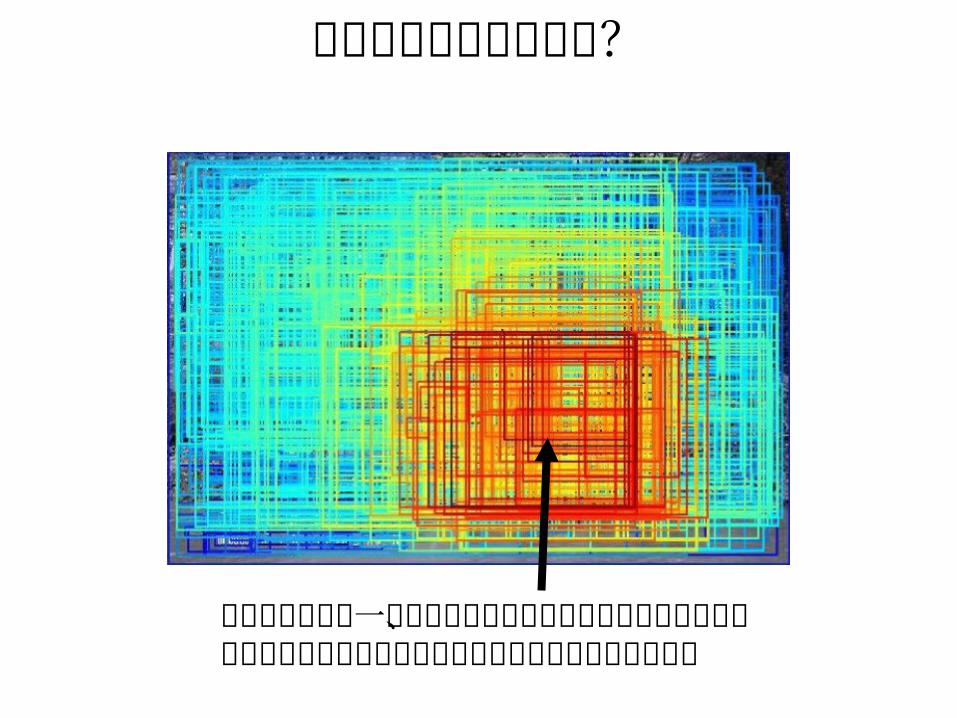
仮説:信頼度が最も大きく変動しやすいあたりが一番タイトにオブジェクトを囲っているのでは?
ちょっと領域がずれても、信頼度は低い値であまり変わらない
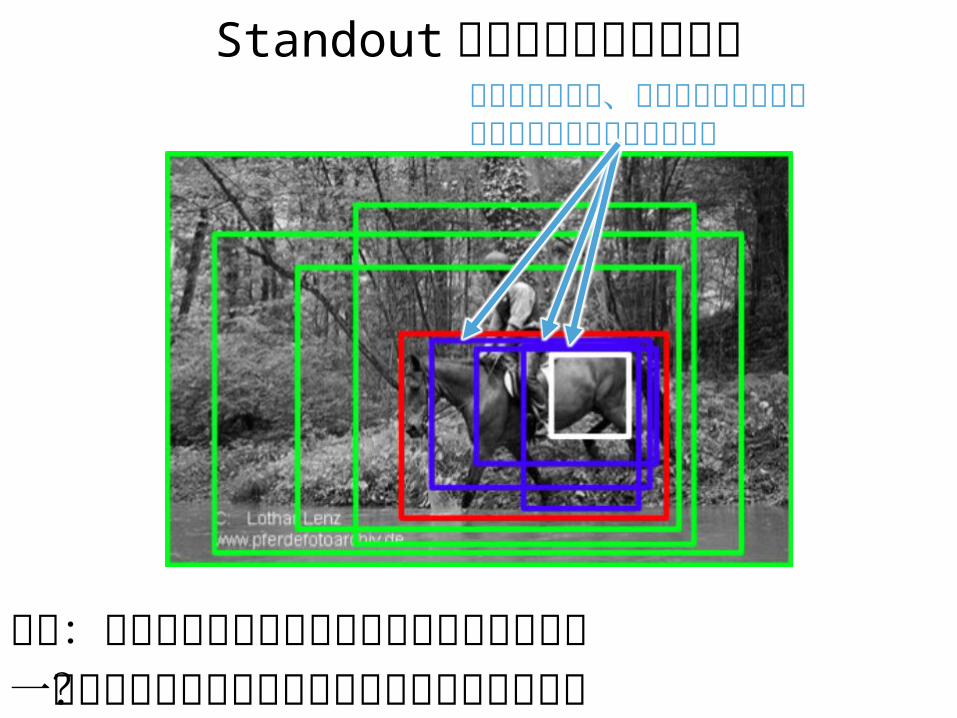
Standout スコアによる前景検出
仮説:信頼度が最も大きく変動しやすいあたりが一番タイトにオブジェクトを囲っているのでは?
信頼度は高いが、領域が多少ずれても高いままであまりかわらない
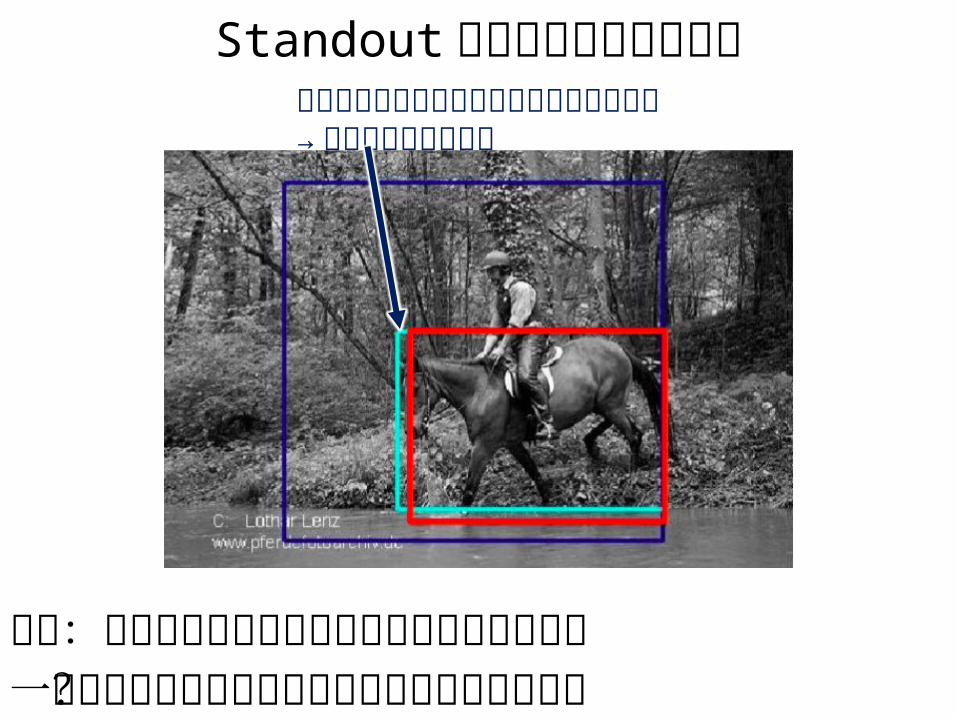
Standout スコアによる前景検出
仮説:信頼度が最も大きく変動しやすいあたりが一番タイトにオブジェクトを囲っているのでは?
ちょっとずらすと信頼度が大きく変動する→ この矩形領域に更新
Methodology
1. 入力された画像に類似した画像を検索
2. 入力画像から領域候補を列挙し、同様に抽出した類似画像の領域候補とマッチング
3. 複数の重なり合った領域でとれたマッチング結果から、最終的な物体領域を更新
4. 満足いくまで手順 1. に戻る
入力画像→ ← 類似画像
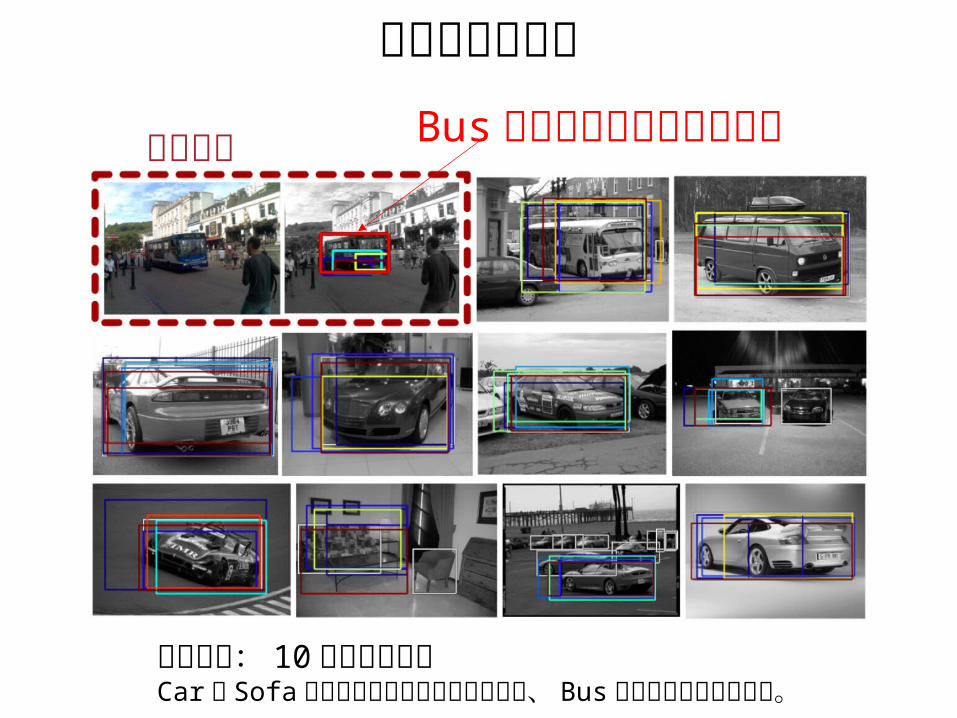
上手くいった例
入力画像 Bus が上手く検出されている
他の画像: 10 枚の類似画像Car や Sofa といったクラスの画像があるが、 Bus をちゃんと検出できた。

評価実験• データセット: Object Discovery + PASCAL VOC 2007
• Separate-class experiments– あるクラスの物体が写った画像群のみでテスト– CorLoc (Correct Localization) 「推定矩形領域が正解領域と結構重なったか?」
• Mixed-class experiments– あらゆるクラスの物体が写った画像群でテスト– CorRet (Correct Retrieval)「同じ物体が写った画像が検索されているか?」– CorLoc 、 CorRet 両方で評価
3 クラス、全 300 枚 20 クラス、全 4548 枚
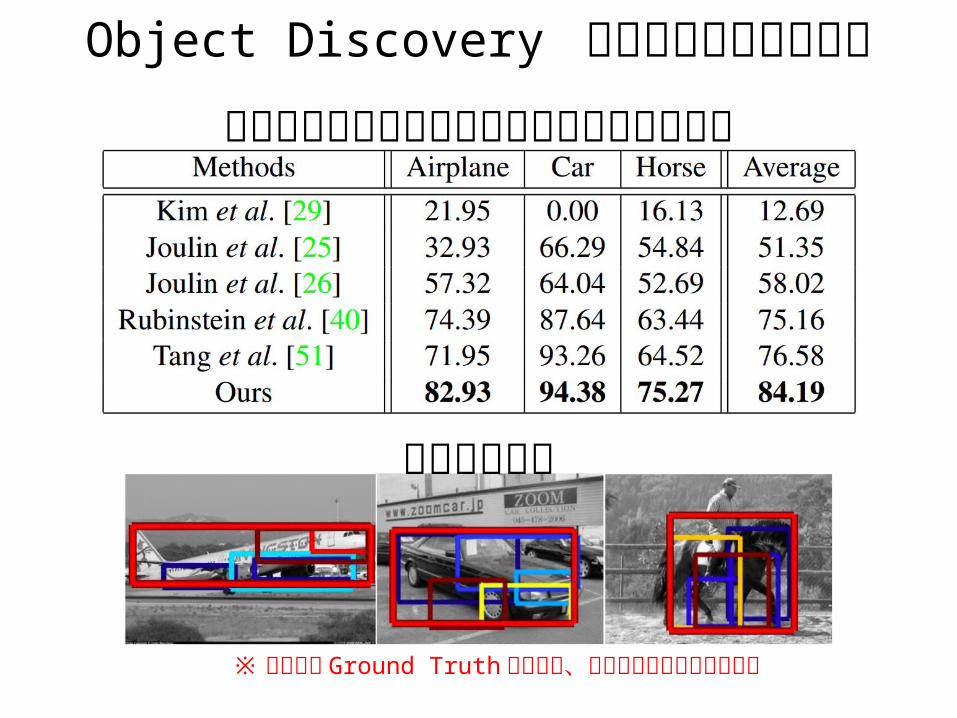
Object Discovery データセットでの結果先行研究より少ない教師情報でも性能は向上
位置推定の例
※ 赤大枠は Ground Truth であって、推定結果ではないので注意

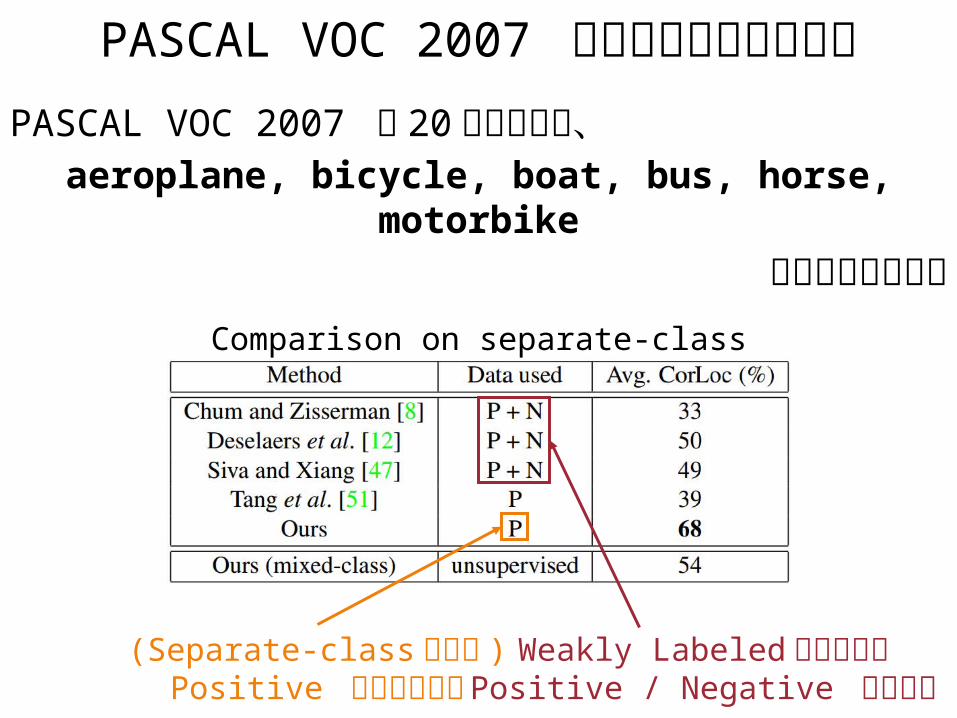
PASCAL VOC 2007 のサブセットでの結果PASCAL VOC 2007 の 20 クラスから、
aeroplane, bicycle, boat, bus, horse, motorbikeを抜き出したもの
位置推定の例
PASCAL VOC 2007 のサブセットでの結果PASCAL VOC 2007 の 20 クラスから、
aeroplane, bicycle, boat, bus, horse, motorbikeを抜き出したもの
(Separate-class なので )Positive サンプルのみ
Weakly Labeled な先行研究Positive / Negative サンプル
Comparison on separate-class

PASCAL VOC 2007 のサブセットでの結果Q. 色々組み合わせてるけど、何が効いてんの?• 画像毎に複数の領域を残して更新(ロバスト性の為)→ 最良の領域のみ残す Ours w/o MOR• 位置とアピアランス両方でマッチングする PHM→ アピアランスだけでマッチング Ours w/o PHM• 自信度が一番動くあたりを探す Stand Out 度で領域更
新→自信度自体で領域更新 Ours w/o STO
※資料用に編集済
(意外と?)Stand Out 度重要!
CorLoc

PASCAL VOC 2007 での結果• 先程の例はこの実験から
• 定量評価から…– 何も教師データ無い (=P のみ ) なのに、ちょっとで
も教師データ使う先行研究 (=P+N) に勝った!– [56] は ILSVRC2012 学習した AlexNet使ってるので、教師あり外部データ使ってるわけで、別に負けてても自然かな…

まとめ• 完全に教師情報が無い設定で Object discovery–従来の教師なし object discovery は…
separate-class のような制限されたデータでしか、まともな精度が出なかった
• 提案手法:パーツに基づく object discovery– 確率的ハフ変換に基づく頑健なマッチング– Standout スコアによる前景検出
• Challenging (と著者らは言う)データセット–完全に教師情報が無くても、先行研究の一部教師あ
りの場合と同等–教師情報の統合は可能なので、性能 up は簡単
所感• Pros– 挑戦的な課題– 教師なし学習でも一部教師あり学習と同等の精度
• 位置とアピアランス両方によるマッチング• 単に信頼度を見るのではなく、その差分をみる Stand out によ
る領域更新
• Cons : Wild とは– この論文では=複数のクラスが混じっているデータ
• 従来研究では Separate-class でしか性能が出なかったので– 個人的な最初の期待=Web で収集した大規模データ
• 多種多様な物体• しかも一部の物体のみ偏って頻出…など• 全画像に対して類似画像検索するのが大変になりそう
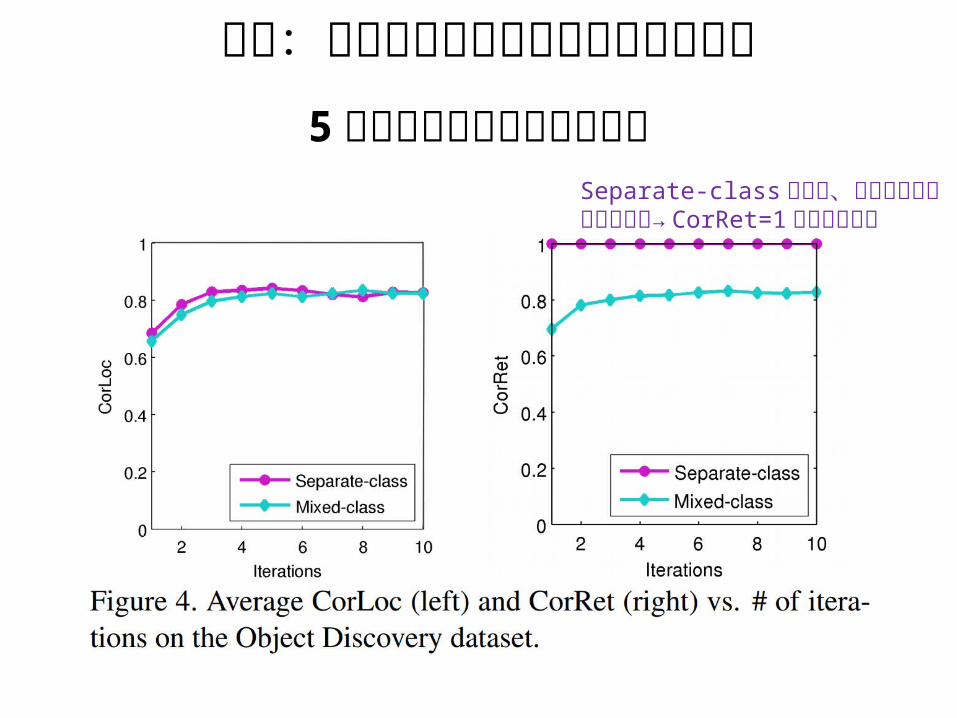
付録:学習を何回繰り返せば収束するか5 回も繰り返せば十分らしい
Separate-class なので、全ての画像が同じクラス→ CorRet=1 はトリビアル
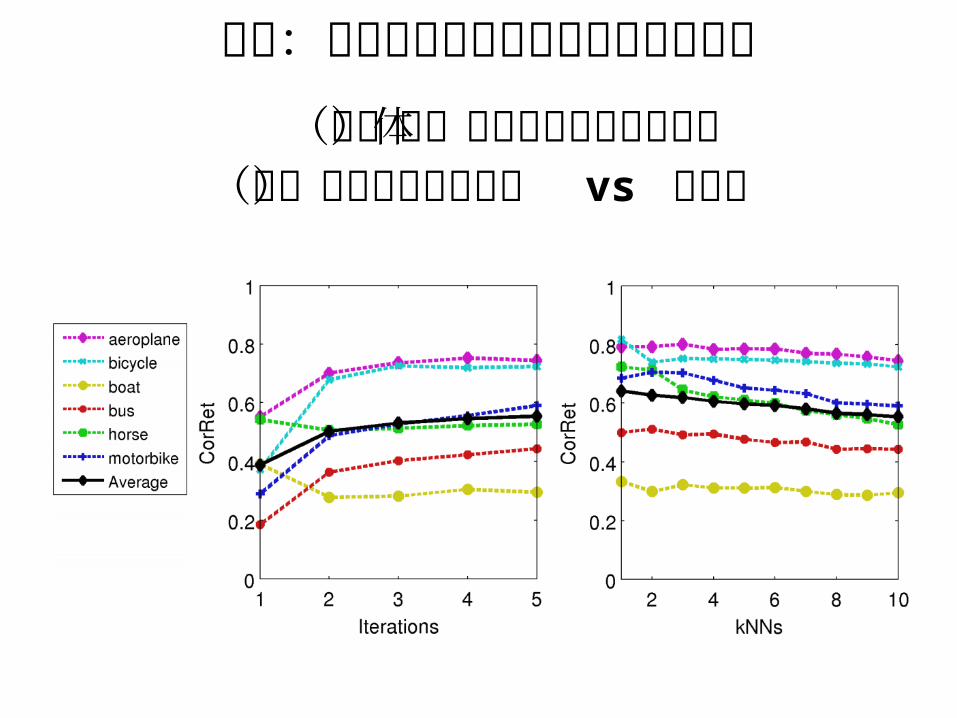
付録:学習を何回繰り返せば収束するか(左)物体の種類ごとの収束結果
(右)類似画像検索枚数 vs 正解率