Повышаем отказоустойчивость без дорогих решений
TRANSCRIPT

Повышаем отказоустойчивость без дорогих решений
Технический директор «Ленвендо»
Виталий Гаврилов

Предпосылки
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
Выполнение обновления ПО (ну, например, часовые
пояса) потребовало даунтайма сайта на время
перезапуска сервиса СУБД
Изменились требования SLA

Предпосылки
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
Сервер «умер» и выяснилось, что восстановление
займет длительное время
Сервер еще не умер, но вы об этом задумались…
… а денег на железо много не дадут… кризис
Просто захотелось сделать надежнее

Требования
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
Не дорого
Надежно
Быстро (без сильных потерь производительности)
Масштабируемо
Низкая стоимость владения (простота поддержки)

Требования
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
Обновления, требующие перезапуска сервисов или
серверов без потери доступности
Условная аппаратная независимость (отказ одного
сервера не должен приводить к отказу в доступности)
Минимизация неиспользованных ресурсов (не должно
быть незадействованных вычислительных мощностей)
Защита от потери данных за счет дублирования

Принимаемые риски
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
Риск сетевой недоступности ЦОД в целом
Риск нарушения сетевой связности внутри
инфраструктуры
Риск «выгорания» стойки и аналогичные форс-
мажорные обстоятельства
Риск ДДОС (должен решаться за пределами системы)

Минимальные аппаратные требования
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
Минимум 2 физических сервера
Обязательное использование Hardware RAID с BBU
Производительная дисковая подсистема SAS 10k+
Минимум 2, желательно 4 сетевых интерфейса на
сервер
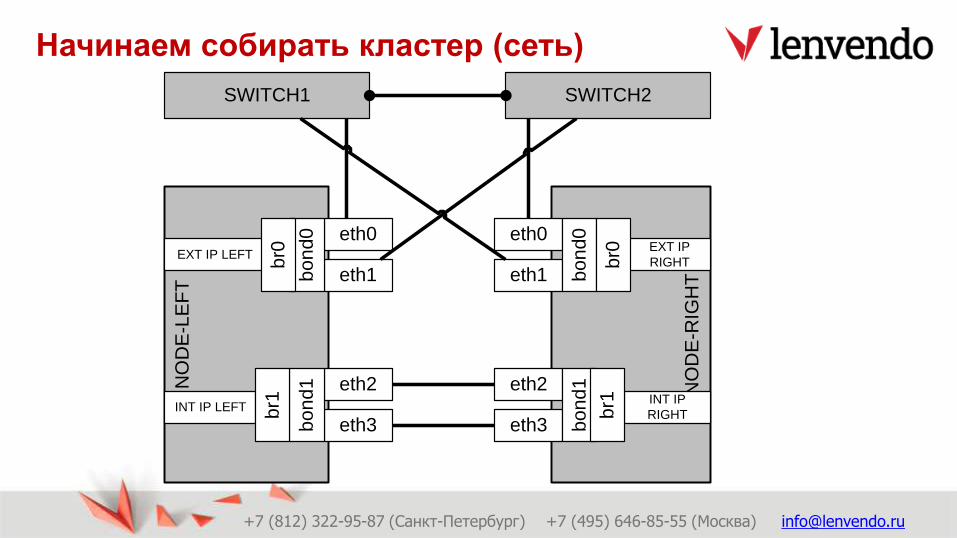
Начинаем собирать кластер (сеть)
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
NO
DE
-LE
FT
NO
DE
-RIG
HT
eth0
eth1
eth2
eth3
eth0
eth1
eth2
eth3
bo
nd0
bon
d1
bon
d1
bo
nd0
SWITCH1 SWITCH2
EXT IP
RIGHTEXT IP LEFT
INT IP
RIGHTINT IP LEFT
br0
br1
br0
br1

Продолжаем собирать кластер (диски)
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
/boot/ - 200 Mb
SWAP – от 0.5 до 2.0 от объема RAM
Остальное под LVM (группа vg0)
/ - 10Gb (volume_name = root)
Остальное не распределяем
swapboot
data
root

Приступаем к реализации
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
Операционная система с поддержкой кластерной ФС (я
рекомендую Oracle Linux и OCFS2)
LVM для динамического управления размером томов
drbd для синхронизации данных между узлами
KVM как платформу виртуализации
virsh как интерфейс управления виртуализацией

Собираем кластер (операционная система)
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
Операционная система – Oracle Linux
Бесплатная поддержка (обновления)
Единый репозиторий как для коммерческих, так и для платных
условий поддержки
Продолжительный период поддержки

Можно переходить к настройке системы
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
Чего мы добились
Физическое оборудование слинковано
Операционная система, поддерживающая кластерные
ФС, установлена

Настраиваем сеть (bonding)
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
/etc/sysconfig/network-scripts/eth[0-1]
DEVICE="eth[0-1]"
BOOTPROTO="static"
HWADDR=“XX:XX:XX:XX:XX:XX"
NM_CONTROLLED="no"
ONBOOT="yes"
MASTER=bond0
SLAVE=yes
TYPE="Ethernet"
/etc/sysconfig/network-scripts/bond0
DEVICE=bond0
BOOTPROTO=none
ONBOOT=yes
IPADDR=EXT IP (LEFT|RIGHT)
NETMASK=X.X.X.X
TYPE=Bonding
USERCRL=no
BONDING_OPTS="mode=1 miimon=100"
/etc/sysconfig/network-scripts/eth[2-3]
DEVICE="eth[2-3]"
BOOTPROTO="static"
HWADDR=“XX:XX:XX:XX:XX:XX"
NM_CONTROLLED="no"
ONBOOT="yes"
MASTER=bond1
SLAVE=yes
MTU=9000
TYPE="Ethernet“
/etc/sysconfig/network-scripts/bond1
DEVICE=bond0
BOOTPROTO=none
ONBOOT=yes
IPADDR=INT IP (LEFT|RIGHT)
NETMASK=255.255.255.252
TYPE=Bonding
USERCRL=no
MTU=9000
BONDING_OPTS="mode=0 miimon=100"

Настраиваем сеть (bridge)
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
/etc/sysconfig/network-scripts/bond0
DEVICE=bond0
BOOTPROTO=none
ONBOOT=yes
TYPE=Bonding
USERCRL=no
BONDING_OPTS="mode=1 miimon=100"
BRIDGE=br0
/etc/sysconfig/network-scripts/ifcfg-br0
DEVICE=br0
BOOTPROTO=static
IPADDR=EXT IP (LEFT|RIGHT)
NETMASK=X.X.X.X
ONBOOT=yes
TYPE=Brige
IPV6INIT=no
STP=(on|off)
/etc/sysconfig/network-scripts/bond1
DEVICE=bond0
BOOTPROTO=none
ONBOOT=yes
TYPE=Bonding
USERCRL=no
BONDING_OPTS="mode=0 miimon=100“
MTU=9000
BRIDGE=br1
/etc/sysconfig/network-scripts/ifcfg-br1
DEVICE=br1
BOOTPROTO=static
IPADDR=INT IP (LEFT|RIGHT)
NETMASK=255.255.255.252
ONBOOT=yes
TYPE=Brige
IPV6INIT=no
MTU=9000
STP=off

Настраиваем Firewall (на каждом сервере)
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
#/etc/sysconfig/iptables
-A INPUT -i br1 -j ACCEPT
#service iptables restart

Разметка дисков LVM на каждом сервере
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
# lvcreate --name=data --size= (полный объем
свободного места в группе) vg0

Конфигурируем DRBD
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
/etc/drbd.d/shared.res
resource shared {
protocol C;
net {
allow-two-primaries;
sndbuf-size 0;
}
disk {
no-disk-barrier;
no-disk-flushes;
}
startup {
become-primary-on both;
}
on HOSTNAME_LEFT {
device minor 1;
disk /dev/vg0/data;
address INT IP LEFT:7789;
meta-disk internal;
}
on HOSTNAME_RIGHT {
device minor 1;
disk /dev/vg0/data;
address INT IP RIGHT:7789;
meta-disk internal;
}
}

Инициализируем DRBD
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
Инициализируем раздел на обоих серверах:
# drbdadm create-md shared
Запускаем DRBD на обоих серверах:
# service drbd start
# chkconfig drbd on
На любом сервере
# drbdadm invalidate shared
Ожидаем пока #service drbd status покажет завершение синхронизации
На обоих узлах
# drbdadm primary shared

Файловая система
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
Ставим нужные пакеты
# yum install ocfs2-tools
Конфигурируем /etc/ocfs2/cluster.conf
# service o2cb configure
# /etc/ocfs2/cluster.confnode:ip_port = 7777ip_address = INT IP LEFTnumber = 0name = HOSTNAME_LEFTcluster = ocfs2
node:ip_port = 7777ip_address = INT IP RIGHTnumber = 1name = HOSTNAME_RIGHTcluster = ocfs2
cluster:node_count = 2name = ocfs2

Файловая система
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
Создаем файловую систему на любом сервере# mkfs.ocfs2 -F -N 3 -J block64 -L drbd_ocfs --mount cluster -T
(datafiles|vmstore) /dev/drbd/by-res/shared
Настраиваем таблицу разделов на обоих серверах
# /etc/fstab
/dev/drbd1 /mnt/shared ocfs2 defaults,noexec,nosuid,noacl,nouser_xattr,errors=remount-
ro,localflocks,commit=60,localalloc=4,data=writeback,barrier=0
Монтируем файловую систему на обоих узлах# mkdir –p /mnt/shared/;chkconfig ocfs2 on;service ocf2 start

Проверка
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
Перезагружаем любой сервер и убеждаемся, что все
работает…
…делаем, чтобы работало
Не забываем, что узлов 2

Получили два сервера с общей файловой системой, которая остается доступна даже после падания любого из серверов… но зачем?
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
Результат
Сервера настроены, корректно видят друг друга
Имеют достаточно надежное файловое хранилище
До какой-то степени серверам не опасны проблемы
потери связи (bonding)

Что дальше…?
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
А дальше мы будем делать виртуальные машины
Их диски в виде файлов будут размещены на
высокодоступной файловой системе
Конфиги виртуальных машин также сохраним в
высокодоступную файловую систему
Обеспечим балансировку запросов внутри виртуальных
машин

Структура раздела /mnt/shared
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
/mnt/shared/
/mnt/shared/data/
/mnt/shared/data/image1.bin
…
/mnt/shared/xml/
/mnt/shared/xml/vhost1.xml
…

Создаем виртуальную машину
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
Запускаем установку ОС
# virt-install -n vhost1 -l
http://mirror.yandex.ru/centos/7/os/x86_64/ --vnc --
disk path=/mnt/shared/data/iamge1-root.bin,size=200 –
prompt
Устанавливаем ОС через VNC
Сохраняем конфигурацию
# virsh dumpxml vhost1 > /mnt/shared/xml/vhost1.xml

Тестируем различные фишки
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
Живая миграция виртуальной машины
# virsh --connect=qemu:///system --quiet migrate --
live vhost1 qemu+ssh://INT_IP/system
(лучше прописать внутренние адреса серверов в /etc/hosts)
Один сервер умер, срочно запускам на втором
# virsh define /mnt/shared/xml/vhost1.xml
# virsh start vhost1

+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
Что мы получили
Ферму, на которой работает несколько независимых
виртуальных машин
Каждая виртуальная машина может быть мигрирована
на любой из двух узлов в случае аварии или с целью
оптимизации ресурсов

Добились ли мы цели?
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
Тут должен быть красивый
вопросик, но я его не нашел

Тогда продолжим
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
Делаем «правильные» виртуальные машины для web-
проекта
Настраиваем сервисы повышающие доступность
Тестируем
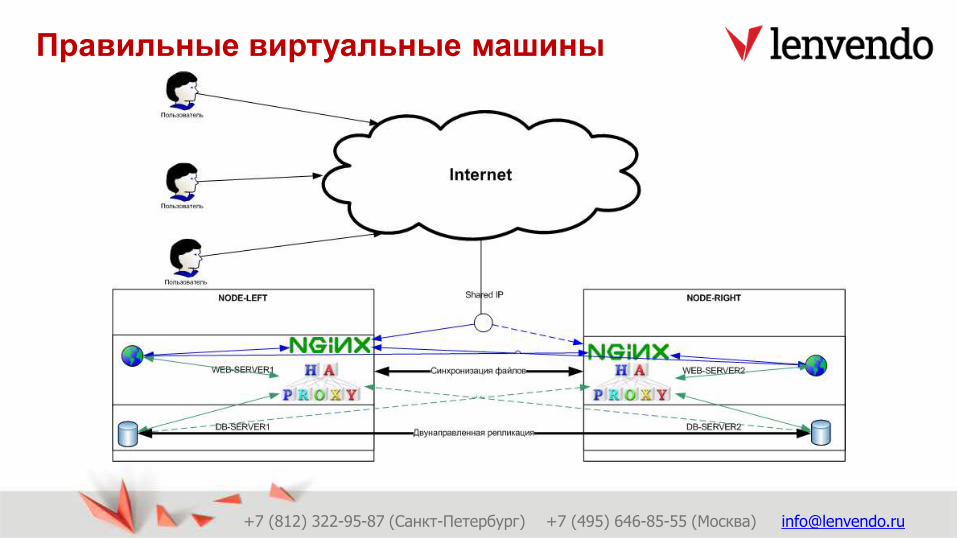
Правильные виртуальные машины
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]

Инструменты
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
Отказоустойчивые адреса – ucarp, corosync+pacemaker
и т.д.
Файловая синхронизация – csync2, OCFS2
БД – зависит от БД

Инструменты – отказоустойчивые адреса
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
HSRP – надежное аппаратное решение, требует наличия
поддерживающего оборудования. Не знает ничего про другие сервисы,
чем и ограничивается возможность применения
carp/ucarp – просто, надежно. Не знает ничего про другие сервисы, чем и
ограничивается возможность применения
Heartbeat – фактически предок pacemaker/corosync. Конфигурировать
сложно
Pacemaker/corosync – аналог heartbeat но проще настраивать

Инструменты – отказоустойчивые адреса
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
ИнструментУправление
сервисамиПростота настройки Особенности
HSRP НетЗависит от конечного
решения
Требуется аппаратная
поддержка
UCARP Нет Просто
heartbeat Да Сложно
Может некорректно работать
при высокой нагрузке на
систему
pacemaker/corosync Да Средне
Может некорректно работать
при высокой нагрузке на
систему

Инструменты – файловая синхронизация
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
Асинхронная – csync2
Работает по cron
Нагружает дисковую подсистему на время
синхронизации
Позволяет выполнять обновления кода с проверкой
до публичного показа посетителю

Инструменты – файловая синхронизация
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
Синхронная – OCFS2, GFS2
Не любит конкурентные операции записи (не
пригодна для ведения файлового кеша
динамичного проекта)
Плохо кешируется средствами ОС (в отличии от
NFS/CIFS)
Гарантирует синхронность изменения на всех узлах

Инструменты – СУБД
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
Mysql multimaster replication
«подводные камни» всем известны, обходные
решения достаточно широко распространены
Классическая асинхронность со своими «+» и «–»
MySQL Galera
Синхронная репликация со своими «+» и «-»

Инструменты – СУБД
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
PostgreSQL BDR
Есть ряд ограничений, но они обычно обходятся для
типового проекта

Инструменты – СУБД
+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
Oracle RAC
К сожалению не удалось заставить стабильно
работать. Скорость репликации на уровне drbd
оказалось недостаточно для работы ASM.

+7 (812) 322-95-87 (Санкт-Петербург) +7 (495) 646-85-55 (Москва) [email protected]
Вопросы..?
И снова тут должен быть
красивый вопросик, но я его
так и не нашел…

Бесперебойного полета Вашим проектам!
www.lenvendo.ru
Мы поддерживаем: