שפת מכונה – מבוא
DESCRIPTION
שפת מכונה – מבוא. נושאים היסטוריה גישה לזיכרון פקודות אריתמטיות. מבוסס על פרק 3 של Computer Systems – a programmers perspective / Bryant & O’hallrron. מעבדי IA32. IA32 הוא השם של 'שפת המכונה' של מחשבי אינטל. "שפת מכונה" = ISA – Instruction Set Architecture - PowerPoint PPT PresentationTRANSCRIPT
שפת מכונה – מבוא
שפת מכונה – מבוא
נושאיםנושאים
היסטוריההיסטוריה
גישה לזיכרוןגישה לזיכרון
פקודות אריתמטיותפקודות אריתמטיות
של של 33מבוסס על פרק מבוסס על פרק Computer Systems – a programmers perspective / Bryant & O’hallrronComputer Systems – a programmers perspective / Bryant & O’hallrron

– 2 –
IA32מעבדי IA32מעבדי
IA32IA32.הוא השם של 'שפת המכונה' של מחשבי אינטל. הוא השם של 'שפת המכונה' של מחשבי אינטל
ISA – Instruction Set ArchitectureISA – Instruction Set Architecture"שפת מכונה" = "שפת מכונה" = אבל הוסיפו פקודות במשך הזמן8086 עם 1978התחיל ב ,
שפה מסוגComplex Instruction Set Computer (CISC) .פקודות רבות מאוד )מאות(, למרות שברובן לא משתמשים בפועל
קיימת גישה שלReduced Instruction Set Computer (RISC)
פחות פקודות --< מעבד קטן ומהיר יותר בפועל אינטל הצליחו להגיע לביצועים שווים ואף מהירים יותר(
.(RISKממחשבי

– 3 –
ProcessorsProcessors
Progress of proceessors
0
5000
10000
15000
20000
25000
30000
35000
40000
45000
Model
# T
ran
sist
ors
)k(
Series1
2001
1978
– 4 –
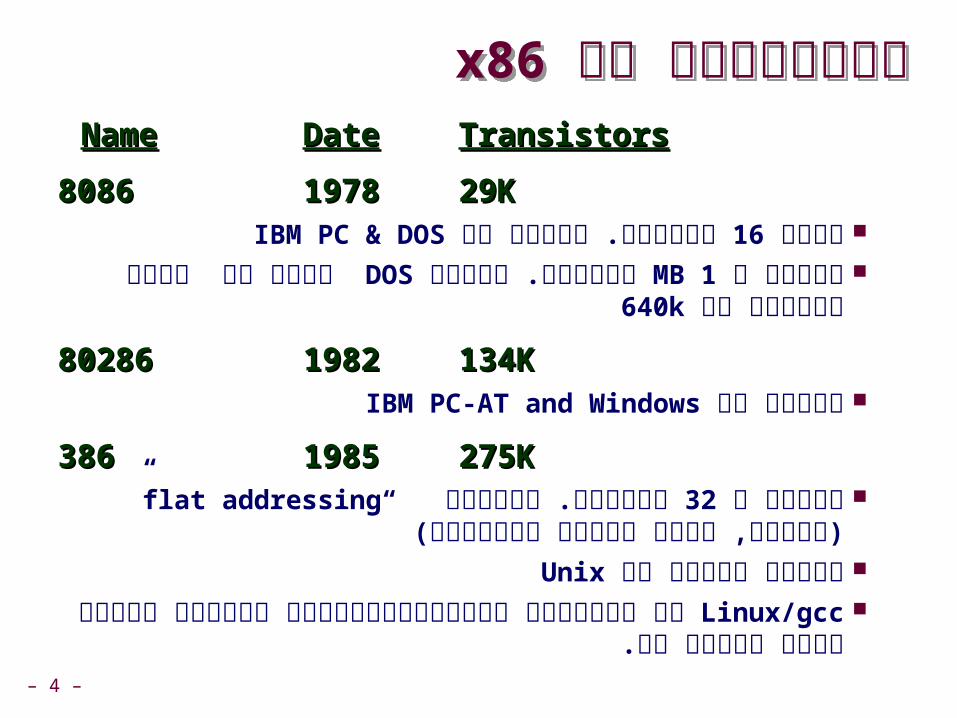
x86היסטוריה של x86היסטוריה של NameName DateDate TransistorsTransistors
80868086 19781978 29K29K סיביות. הבסיס של 16מעבד IBM PC & DOS 1מוגבל ל MB זיכרון. ממילא DOS נתנה רק מרחב זיכרון של
640k
8028680286 19821982 134K134K הבסיס שלIBM PC-AT and Windows
386386 19851985 275K275K סיביות. הוסיפו 32הרחבה ל “flat addressing” כלומר, צורה(
אחידה לכתובות( מסוגל להריץ אתUnixLinux/gcc לא משתמשים בפונקציונאליות שנוצרה מאוחר יותר
ממעבד זה.

– 5 –
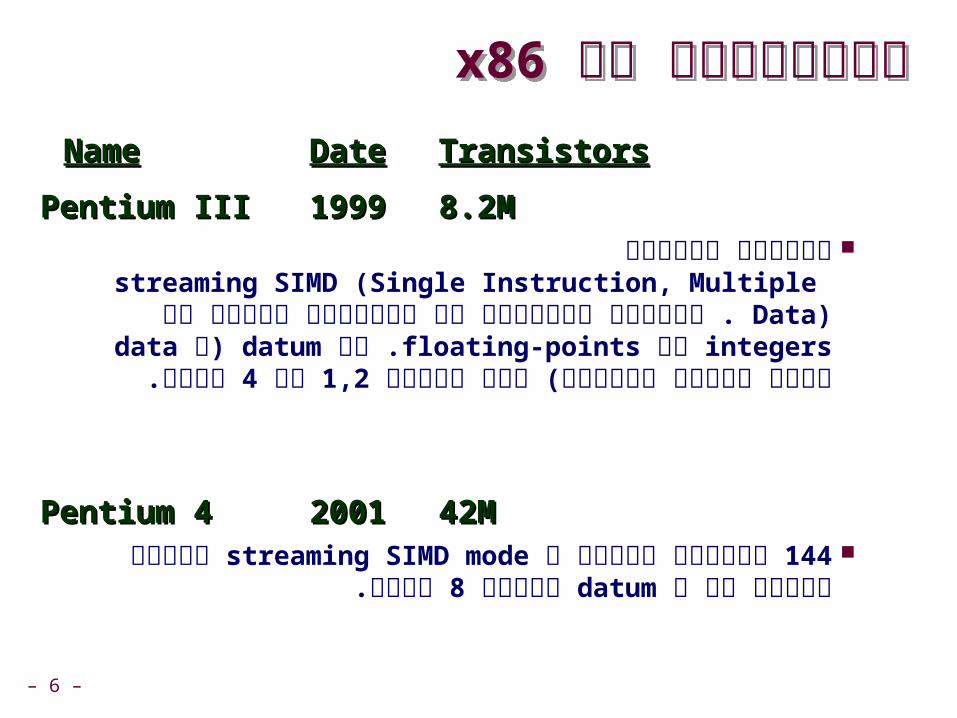
x86היסטוריה של x86היסטוריה של
NameName DateDate TransistorsTransistors
486486 19891989 1.9M1.9M
PentiumPentium 19931993 3.1M3.1M
PentiumProPentiumPro 19951995 6.5M6.5M הוסיפו פקודותconditional move שינויים רבים במיקרו-ארכיטקטורה
Pentium/MMXPentium/MMX 19971997 4.5M4.5M סיביות. 64הוסיפו קבוצת פקודות חדשה לטיפול בוקטורים באורך
. multimediaמיועד לתוכניות
– 6 –
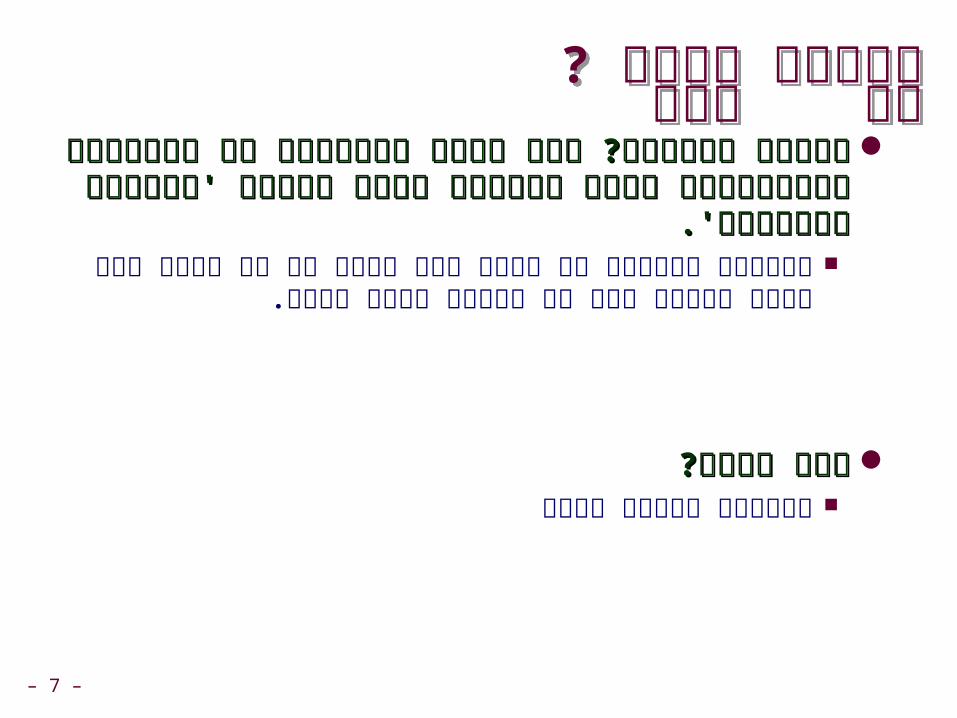
x86היסטוריה של x86היסטוריה של
NameName DateDate TransistorsTransistors
Pentium IIIPentium III 19991999 8.2M8.2Mהוסיפו פקודות
streaming SIMD (Single Instruction, Multiple Data) .-floating או integersהכוונה לפעולות על וקטורים שלמים של
points כל .datum ה( data הוא בגודל )1,2 עליה עובדת הפקודה בתים. 4או
Pentium 4Pentium 4 20012001 42M42M144 פקודות חדשות ל streaming SIMD mode לצורך טיפול גם
בתים.8בגודל datumב
– 7 –
JלJאHן JלJאHן ? מJאHיין ו ? מJאHיין ו
מאיין הסיבוך? חלק גדול מהסיבוך של המעבדים מאיין הסיבוך? חלק גדול מהסיבוך של המעבדיםהמודרניים נובע מהצורך שלהם להיות 'תואמים המודרניים נובע מהצורך שלהם להיות 'תואמים
אחורנית'.אחורנית'. תוכנית שהודרה על מחשב ישן יותר או עם מהדר ישן יותר עדיין
רצה על המעבד החדש יותר.
?לאן הלאה?לאן הלאהמעבדים מרובי ליבה

– 8 –
תואמים...תואמים...
Advanced Micro Devices (AMD)Advanced Micro Devices (AMD) בדר"כ קצת מאחוריIntel.)הרבה יותר זולים )לפחות בארה"ב , כיום יש להם מעבדים שמתחרים עם אלה שלIntel.גם במהירות
– 9 –
IA64 שפה חדשה: IA64 שפה חדשה:
NameName DateDate TransistorsTransistors
ItaniumItanium 20012001 10M10M סיביות 64ארכיטקטורת שפה שונה לגמרי, עם התמקדות מוחלטת בביצועים )בניגוד לנוחות
אימפלמנטציה של מהדרים, למשל(:המהדר במקבילמכיל פקודות לביצוע אחד המאפיינים המרכזיים .
יכול להחליט ששתי פעולות אינן תלויות ולהכריז עליהן ככאלה עם .IA64פקודות
בניגוד לארכיטקטורת IA32 ששם הדבר נעשה באופן מוגבל וברמת החומרה.
יודע להריץ גם תוכניותIA32 (On-board “x86 engine”)
Itanium 2Itanium 2 20022002 221M221Mהאצה משמעותית בביצועים
– 10 –
text
text
binary
binary
Compiler (gcc -S)
Assembler (gcc or as)
Linker (gcc or ld)
C program (p1.c p2.c)
Asm program (p1.s p2.s)
Object program (p1.o p2.o)
Executable program (p)
Static libraries (.a)
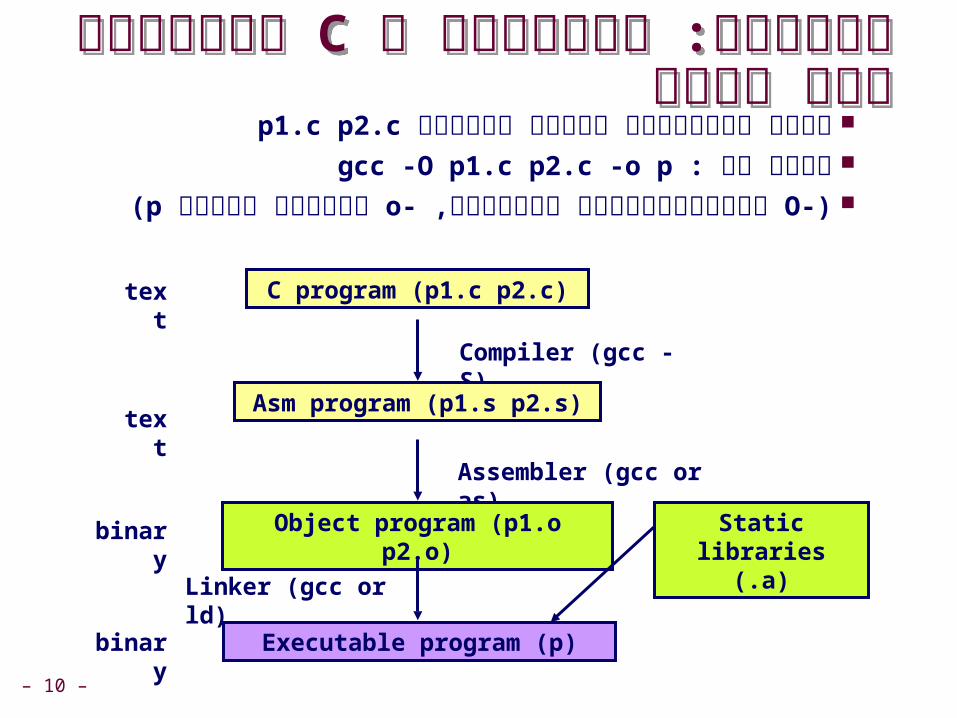
לתוכנית ברת Cמתוכנית ב תזכורת:הרצה
לתוכנית ברת Cמתוכנית ב תזכורת:הרצה
נניח שהתוכנית נמצאת בקבציםp1.c p2.c נהדר עם :gcc -O p1.c p2.c -o p(-O אופטימיזציות בסיסיות ,-o בינארי בקובץ p)
– 11 –
מנקודת המבט של assembly...
מנקודת המבט של assembly...
PC
Registers
CPU Memory
Object CodeProgram Data
OS Data
Addresses
Data
Instructions
Stack
ConditionCodes
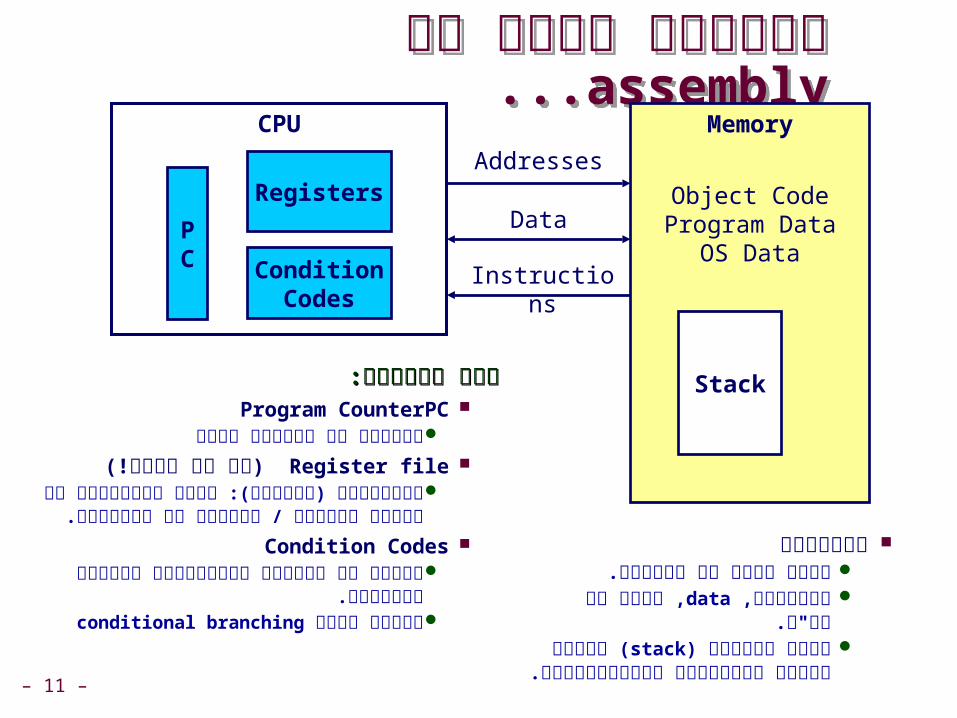
הזיכרון.מערך בתים עם כתובות ,תוכניותdata .מידע של מע"ה , מכיל מחסנית)stack( לצורך
תמיכה בתוכניות פרוצדורליות.
מצב המערכת:מצב המערכת:PCProgram Counter
הכתובת של הפקודה הבאהRegister file(!זה לא קובץ)
:(אוגרים) מידע שמשתמשים בו רגיסטריםלעתים קרובות / השתמשו בו לאחרונה.
Condition Codes סטטוס של פקודות אריתמטיות שבוצעו
לאחרונה. מיועד עבורconditional branching

– 12 –
Assemblyמאפיינים של Assemblyמאפיינים של datadataקבוצה מינימלית של סוגי קבוצה מינימלית של סוגי
בתים1,2,4שלמים בגודל .או ערכים, או כתובות
Floating point בתים.10 או 8, 4 בגודל )... ,אין מבני נתונים מורכבים יותר )מערכים, מבנים
.מיוצגים על ידי רצף של בתים בזיכרון
פעולות בסיסיות בלבדפעולות בסיסיות בלבדפעולה אריתמטית על רגיסטר או ערך בזיכרוןהעברת מידע בין זיכרון לרגיסטר פקודותcontrol
קפיצות מ ואל פרוצדורות קפיצות מותנות(conditional branches)

– 13 –
(Assemblyהידור )תרגום ל (Assemblyהידור )תרגום ל
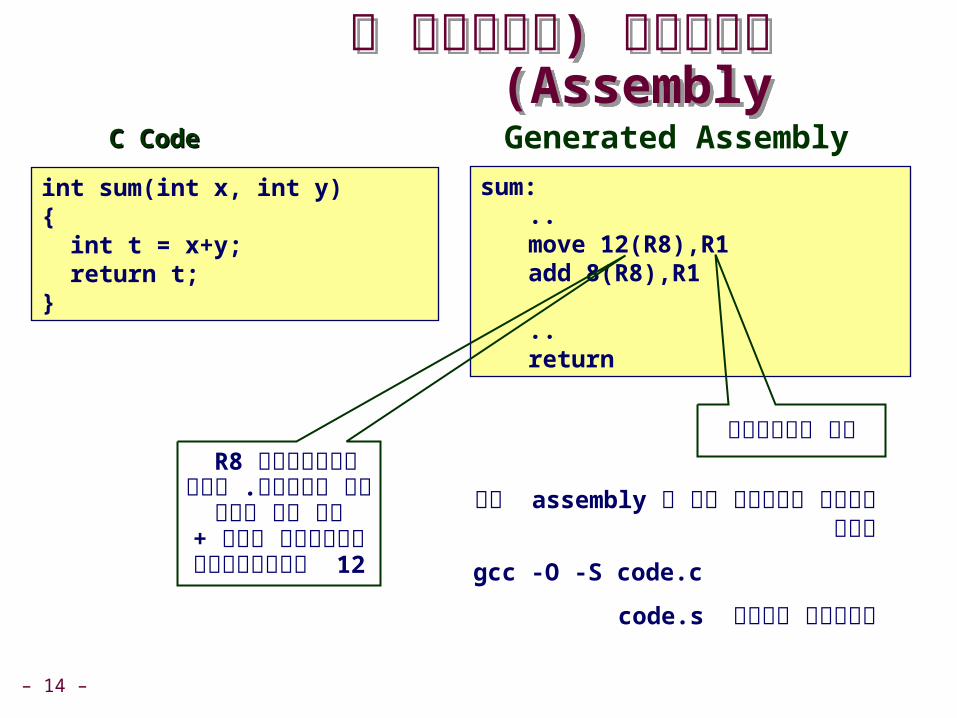
C CodeC Code
int sum)int x, int y({ int t = x+y; return t;}
Generated Assemblysum:..move src target add src target
..return
על ידי assemblyניתן לראות את ה
gcc -O -S code.c
code.sמייצר קובץ
– 14 –
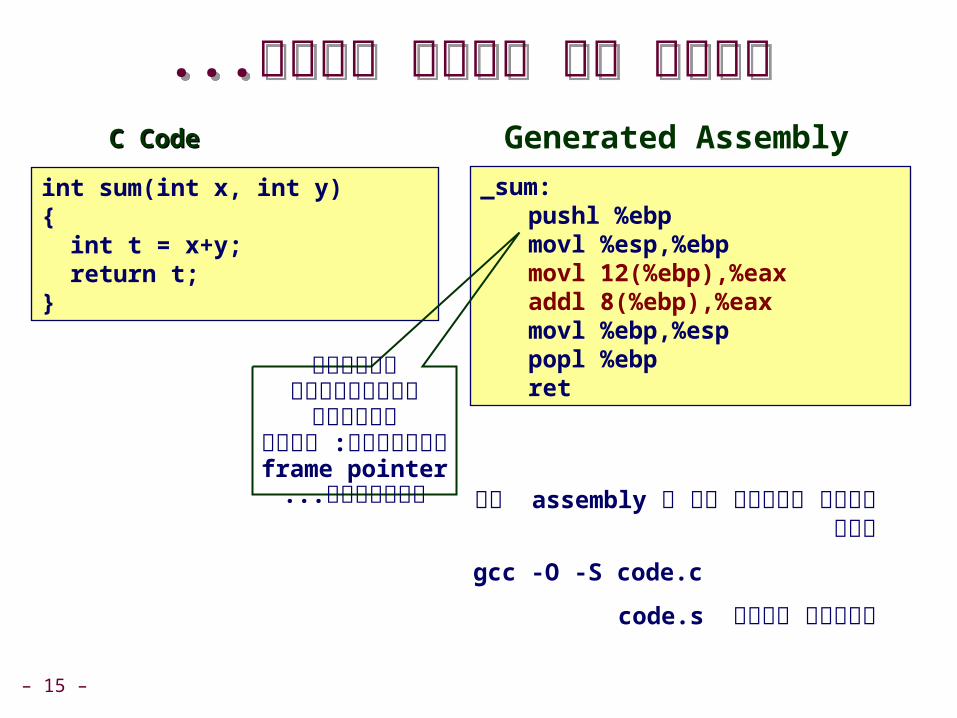
(Assemblyהידור )תרגום ל (Assemblyהידור )תרגום ל
C CodeC Code
int sum)int x, int y({ int t = x+y; return t;}
Generated Assemblysum:..move 12)R8(,R1add 8)R8(,R1
..return
על ידי assemblyניתן לראות את ה
gcc -O -S code.c
code.sמייצר קובץ
יש R8ברגיסטר כתובת. הבא את מה שיש בכתובת
12 זאת +מהזיכרון
שם רגיסטר
– 15 –
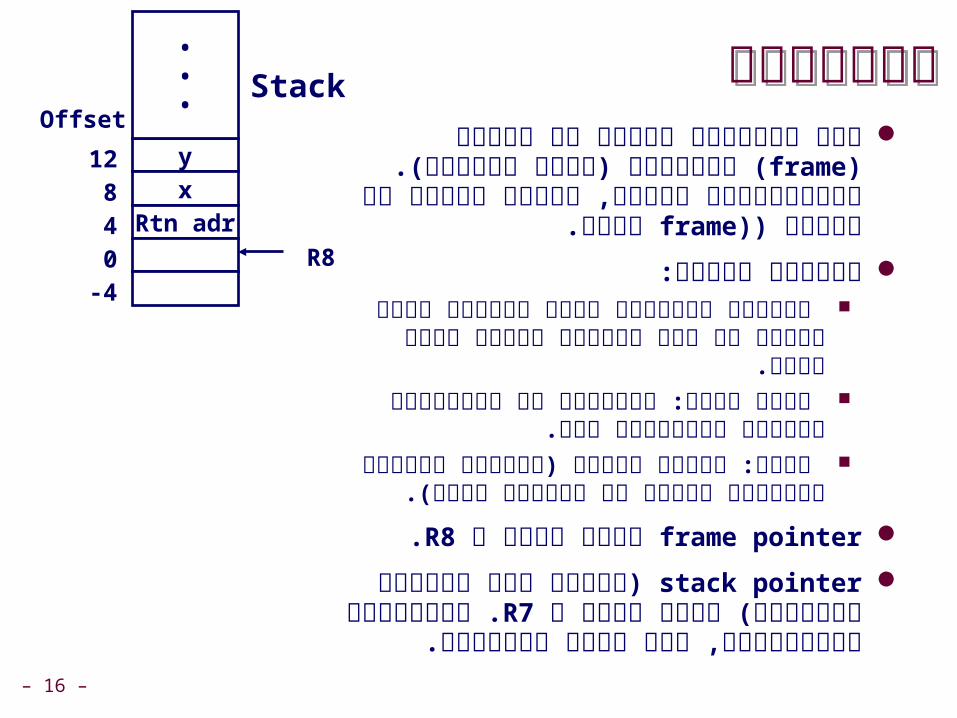
כיצד זה באמת נראה...כיצד זה באמת נראה...
C CodeC Code
int sum)int x, int y({ int t = x+y; return t;}
Generated Assembly
על ידי assemblyניתן לראות את ה
gcc -O -S code.c
code.sמייצר קובץ
_sum:pushl %ebpmovl %esp,%ebpmovl 12)%ebp(,%eaxaddl 8)%ebp(,%eaxmovl %ebp,%esppopl %ebpret
פקודות האופיניות לתחילת
שמור פונקציה:frame pointer
במחסנית...
– 16 –
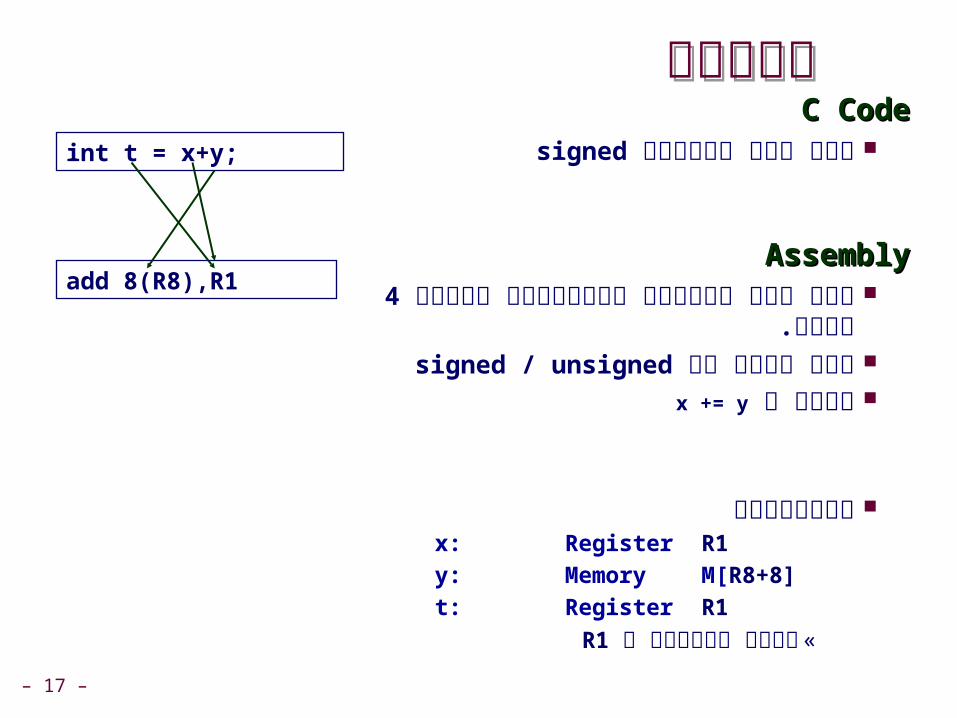
המחסניתהמחסנית לכל פונקציה פעילה יש מסגרת)frame(
במחסנית (טווח כתובות). כשהפונקציה נקראת, נעשית הקצאה של מסגרת
))frame .חדשה
:המסגרת מכילה משתנים מקומיים שאין רגיסטר פנוי עבורם
או שהם מטיפוס מורכב כגון מערך. לפני הסוף: פרמטרים של הפונקציה
הנקראת מפונקציה זאת.:כתובת לחזרה (הכוונה לכתובת בסוף
בזיכרון הראשי של הפקודה הבאה).
frame pointer נשמר תמיד ב R8.
stack pointer המקום הבא לכתיבה) . כשחוזרים R7במחסנית) נשמר תמיד ב
מהפונקציה, הוא נסוג במחסנית.
Stack
yx
Rtn adrR8 0
4 8 12
Offset
•••
-4
– 17 –
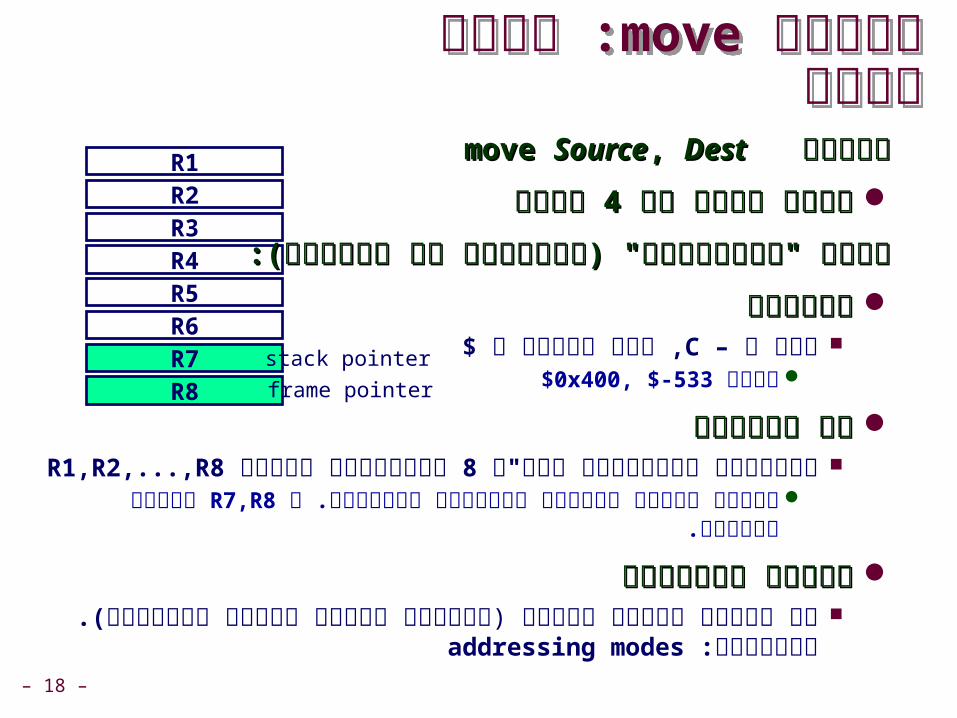
דוגמהדוגמהC CodeC Code
חבר שני מספריםsigned
AssemblyAssembly 4חבר שני מספרים בינאריים בגודל
בתים. אין הבדל אםsigned / unsigned דומה לx += y
אופרנדיםx: Register R1y: Memory M[R8+8]t: Register R1
R1הערך המוחזר ב «
int t = x+y;
add 8)R8(,R1
– 18 –
הזזת :moveפקודת מידע
הזזת :moveפקודת מידע
R1R2R3R4R5R6R7R8
movemove SourceSource, , DestDest פקודתפקודת
בתים בתים44מזיז מילה של מזיז מילה של
סוגי "אופרנדים" )פרמטרים של הפקודה(:סוגי "אופרנדים" )פרמטרים של הפקודה(:
קבועיםקבועים – כמו בC$ אבל מתחיל ב ,
$0למשלx400, $-533
שם רגיסטרשם רגיסטר רגיסטרים שנכנה 8במעבדים מודרניים בדר"כ R1,R2,...,R8
לחלקם שימוש ייעודי בפקודות מסוימות. לR7,R8.תפקיד ספציפי
מיקום בזיכרוןמיקום בזיכרון אופנים שונים לפנות לזיכרון). שיטות מיעון )יש שמונה
addressing modesבאנגלית:
stack pointer
frame pointer

– 19 –
moveשילובים אפשריים ב moveשילובים אפשריים ב
.לא מאפשר העברה מזיכרון לזיכרון בפעולה אחת
move $0x4,R1
move $-147,)R1(
move R1,R2
move R1,)R2(
move )R1(,R2
Cאיך זה נראה ב
temp = 0x4;
*p = -147;
temp2 = temp1;
*p = temp;
temp = *p;
move constant register
move constant memory
move register register
move register memory
move memory register
תבנית דוגמה

– 20 –
שיטות מיעון פשוטותשיטות מיעון פשוטות
1. Normal1. Normal (R)(R) Mem[Reg[R]]Mem[Reg[R]]
רגיסטרRמכיל כתובת בזיכרון :דוגמהmove )R3(,R1
2. Displacement2. Displacement D(R)D(R) Mem[Reg[R]Mem[Reg[R]+D]+D]
רגיסטרR .מציין התחלה של אזור בזיכרון הקבועD מציין את ה offset.)תזוזה ממקום זה( :דוגמהmove 8)R8(,R2

– 21 –
שיטת מיעון המתייחסת למערכיםשיטת מיעון המתייחסת למערכים
3. move (R4,R6,4) R2
R4.מכיל כתובת של תחילת מערך
R6.מכיל את מספר הקפיצות קדימה במערך בבתים
4.)הוא גודל הקפיצה )נקבע על פי הטיפוס
התוצאה מועברת לR2.
:למשל, ניתן לממש כך את
int a[10];
int j = a[3];

– 22 –
lealהפקודה lealהפקודה
leal – load effective address (long)leal – load effective address (long)הפקודה הפקודה
leal (R1 R2 4) R3leal (R1 R2 4) R3
דומה ל דומה לmovemove אבל במקום להעביר את התוכן של אבל במקום להעביר את התוכן של הזיכרון, מעביר את הכתובת. הזיכרון, מעביר את הכתובת.
כמוכמו
x = &y;x = &y;
– 23 –
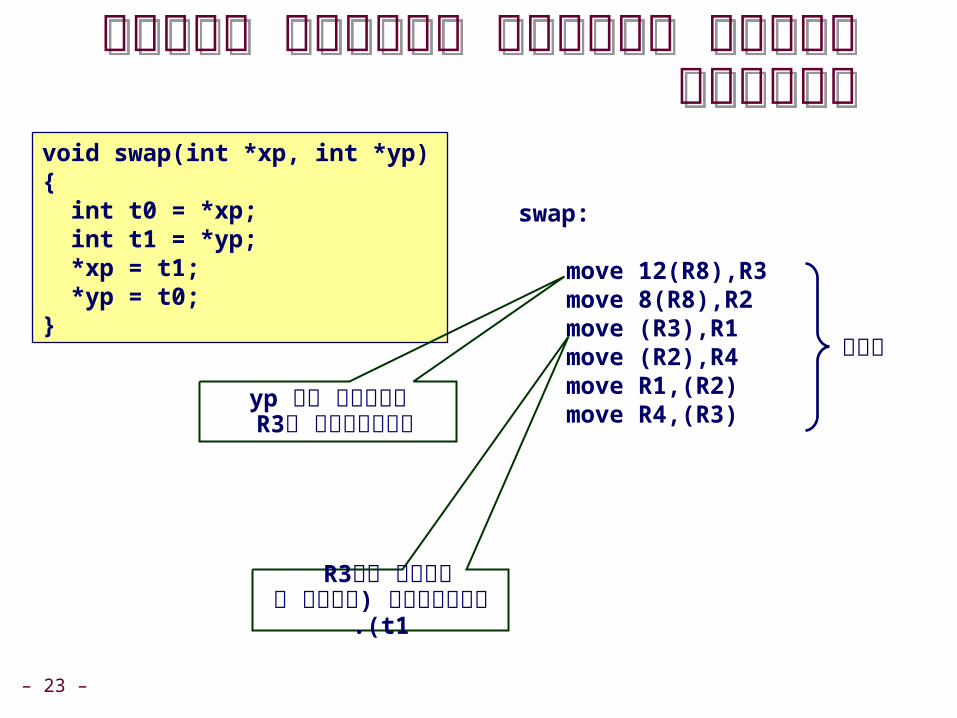
דוגמה לשימוש בשיטות מיעון פשוטות
דוגמה לשימוש בשיטות מיעון פשוטות
void swap)int *xp, int *yp( { int t0 = *xp; int t1 = *yp; *xp = t1; *yp = t0;}
swap:
move 12)R8(,R3move 8)R8(,R2move )R3(,R1move )R2(,R4move R1,)R2(move R4,)R3(
גוף
מזיכרון ypכתובת של R3ל
לרגיסטר R3תוכן של(.t1)שקול ל
– 24 –
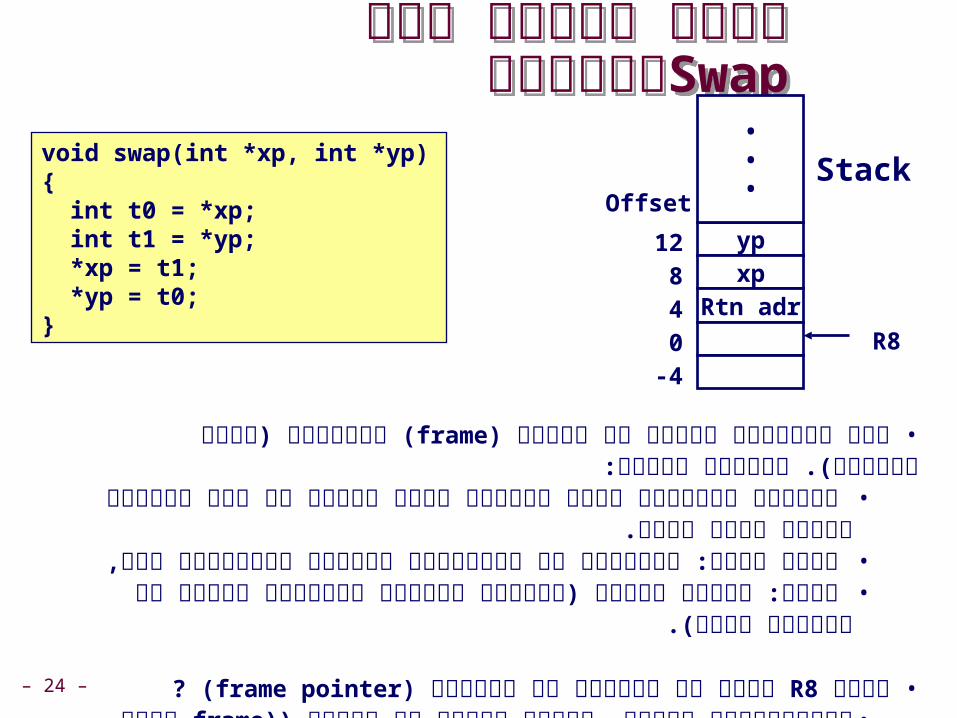
מבוצעתSwap ננסה להבין איך מבוצעתSwap ננסה להבין איך
void swap)int *xp, int *yp( { int t0 = *xp; int t1 = *yp; *xp = t1; *yp = t0;}
Stack
ypxp
Rtn adrR8 0
4 8 12
Offset
•••
-4
במחסנית (טווח כתובות). )frame( לכל פונקציה פעילה יש מסגרת • המסגרת מכילה:
משתנים מקומיים שאין רגיסטר פנוי עבורם או שהם מטיפוס מורכב •כגון מערך.
לפני הסוף: פרמטרים של הפונקציה הנקראת מפונקציה זאת, •כתובת לחזרה (הכוונה לכתובת בזיכרון הראשי של הפקודה בסוף:•
הבאה).
? )frame pointer( מכיל את הכתובת של המסגרת R8 כיצד • חדשה. frame(כשהפונקציה נקראת, נעשית הקצאה של מסגרת (•
. R8המצביע למקום זה בזיכרון מוכנס באופן אוטומטי ל
– 25 –
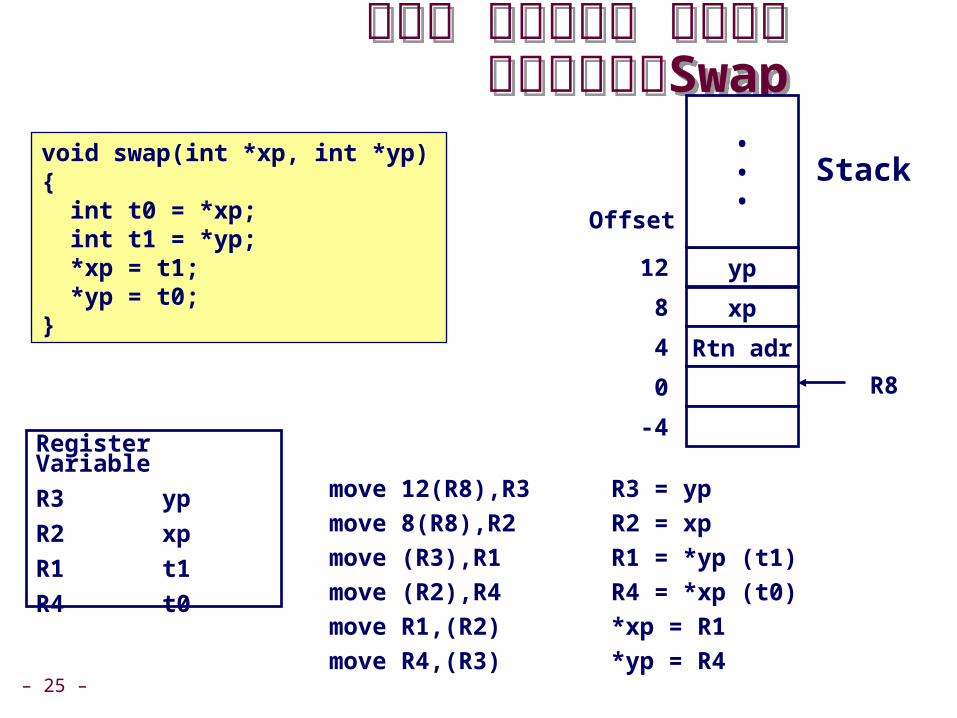
מבוצעתSwap ננסה להבין איך מבוצעתSwap ננסה להבין איך
void swap)int *xp, int *yp( { int t0 = *xp; int t1 = *yp; *xp = t1; *yp = t0;}
move 12)R8(,R3 R3 = yp
move 8)R8(,R2 R2 = xp
move )R3(,R1 R1 = *yp )t1(
move )R2(,R4 R4 = *xp )t0(
move R1,)R2( *xp = R1
move R4,)R3( *yp = R4
Stack
RegisterVariable
R3 yp
R2 xp
R1 t1
R4 t0
yp
xp
Rtn adr
R8 0
4
8
12
Offset
•••
-4
– 26 –
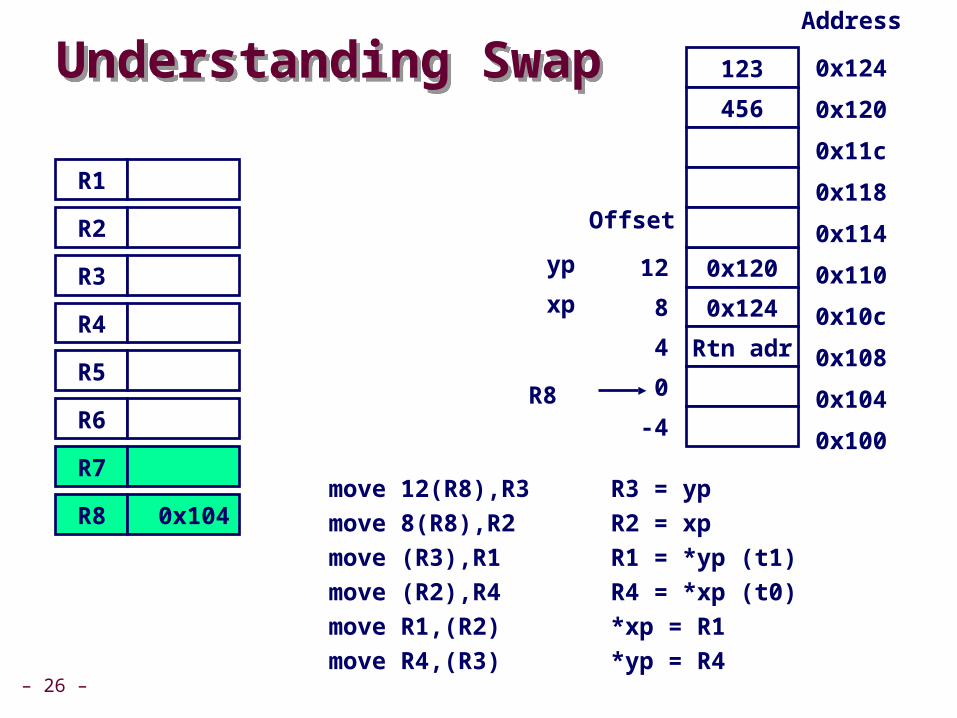
Understanding SwapUnderstanding Swap
move 12)R8(,R3 R3 = yp
move 8)R8(,R2 R2 = xp
move )R3(,R1 R1 = *yp )t1(
move )R2(,R4 R4 = *xp )t0(
move R1,)R2( *xp = R1
move R4,)R3( *yp = R4
0x120
0x124
Rtn adr
R8 0
4
8
12
Offset
-4
123
456
Address
0x124
0x120
0x11c
0x118
0x114
0x110
0x10c
0x108
0x104
0x100
yp
xp
R1
R2
R3
R4
R5
R6
R7
R8 0x104
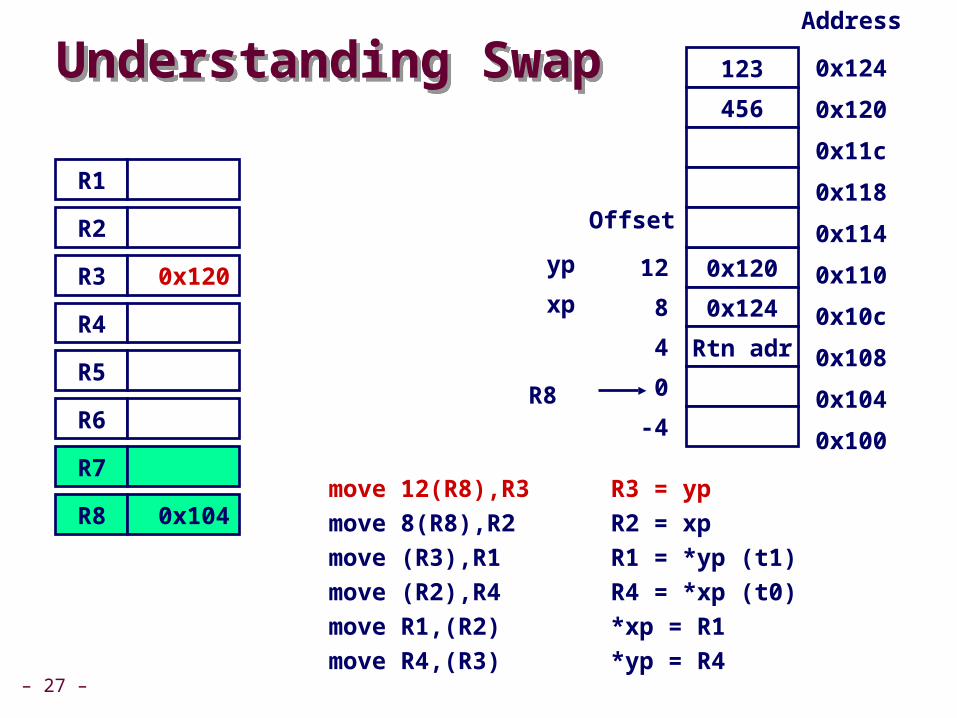
– 27 –
Understanding SwapUnderstanding Swap
move 12)R8(,R3 R3 = yp
move 8)R8(,R2 R2 = xp
move )R3(,R1 R1 = *yp )t1(
move )R2(,R4 R4 = *xp )t0(
move R1,)R2( *xp = R1
move R4,)R3( *yp = R4
0x120
0x124
Rtn adr
R8 0
4
8
12
Offset
-4
123
456
Address
0x124
0x120
0x11c
0x118
0x114
0x110
0x10c
0x108
0x104
0x100
yp
xp
R1
R2
R3
R4
R5
R6
R7
R8
0x120
0x104
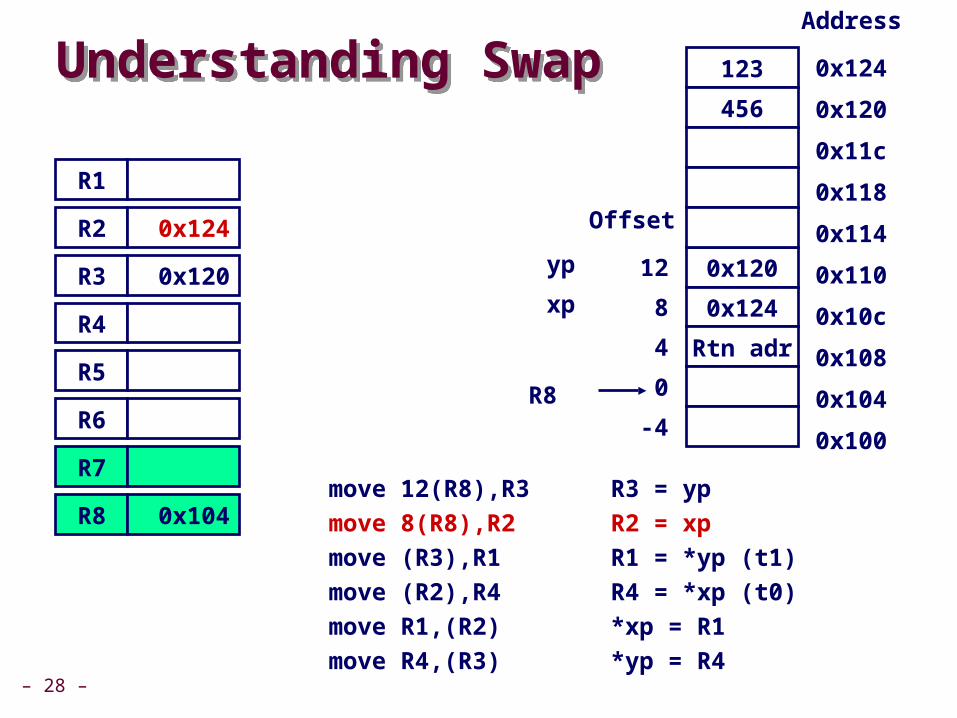
– 28 –
Understanding SwapUnderstanding Swap
move 12)R8(,R3 R3 = yp
move 8)R8(,R2 R2 = xp
move )R3(,R1 R1 = *yp )t1(
move )R2(,R4 R4 = *xp )t0(
move R1,)R2( *xp = R1
move R4,)R3( *yp = R4
0x120
0x124
Rtn adr
R8 0
4
8
12
Offset
-4
123
456
Address
0x124
0x120
0x11c
0x118
0x114
0x110
0x10c
0x108
0x104
0x100
yp
xp
R1
R2
R3
R4
R5
R6
R7
R8
0x124
0x120
0x104
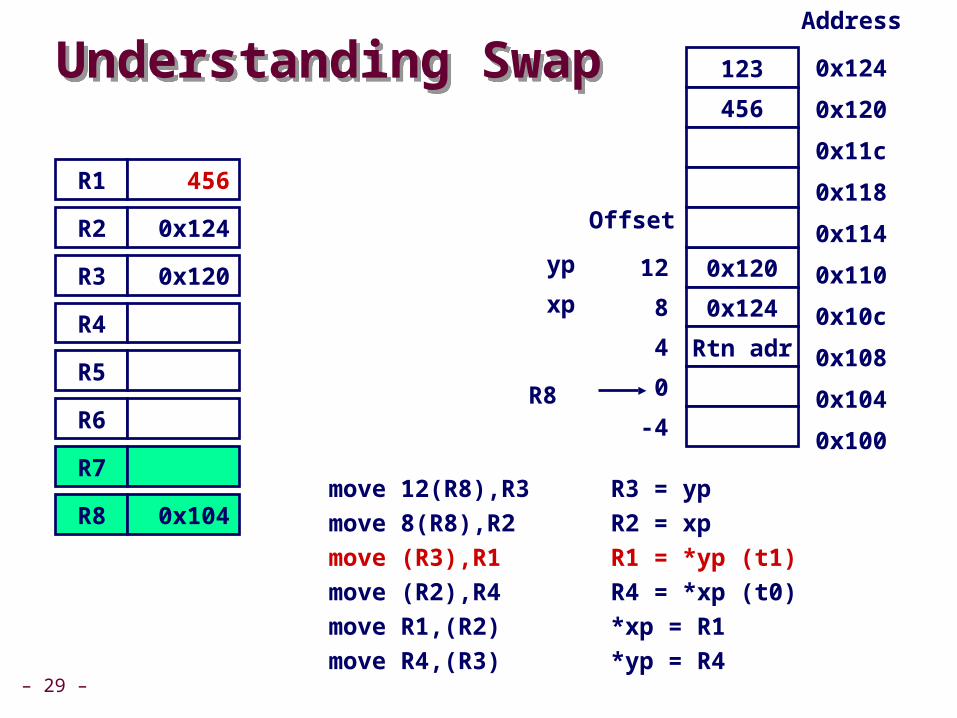
– 29 –
Understanding SwapUnderstanding Swap
move 12)R8(,R3 R3 = yp
move 8)R8(,R2 R2 = xp
move )R3(,R1 R1 = *yp )t1(
move )R2(,R4 R4 = *xp )t0(
move R1,)R2( *xp = R1
move R4,)R3( *yp = R4
0x120
0x124
Rtn adr
R8 0
4
8
12
Offset
-4
123
456
Address
0x124
0x120
0x11c
0x118
0x114
0x110
0x10c
0x108
0x104
0x100
yp
xp
R1
R2
R3
R4
R5
R6
R7
R8
456
0x124
0x120
0x104

– 30 –
Understanding SwapUnderstanding Swap
move 12)R8(,R3 R3 = yp
move 8)R8(,R2 R2 = xp
move )R3(,R1 R1 = *yp )t1(
move )R2(,R4 R4 = *xp )t0(
move R1,)R2( *xp = R1
move R4,)R3( *yp = R4
0x120
0x124
Rtn adr
R8 0
4
8
12
Offset
-4
123
456
Address
0x124
0x120
0x11c
0x118
0x114
0x110
0x10c
0x108
0x104
0x100
yp
xp
R1
R2
R3
R4
R5
R6
R7
R8
456
0x124
0x120
123
0x104
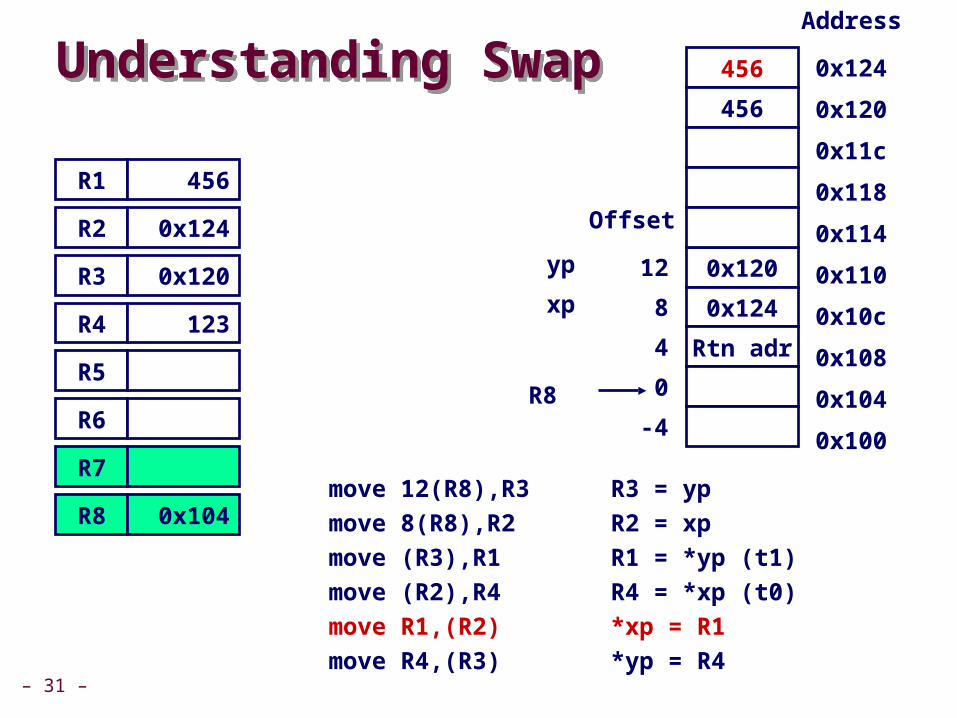
– 31 –
Understanding SwapUnderstanding Swap
move 12)R8(,R3 R3 = yp
move 8)R8(,R2 R2 = xp
move )R3(,R1 R1 = *yp )t1(
move )R2(,R4 R4 = *xp )t0(
move R1,)R2( *xp = R1
move R4,)R3( *yp = R4
0x120
0x124
Rtn adr
R8 0
4
8
12
Offset
-4
456
456
Address
0x124
0x120
0x11c
0x118
0x114
0x110
0x10c
0x108
0x104
0x100
yp
xp
R1
R2
R3
R4
R5
R6
R7
R8
456
0x124
0x120
123
0x104
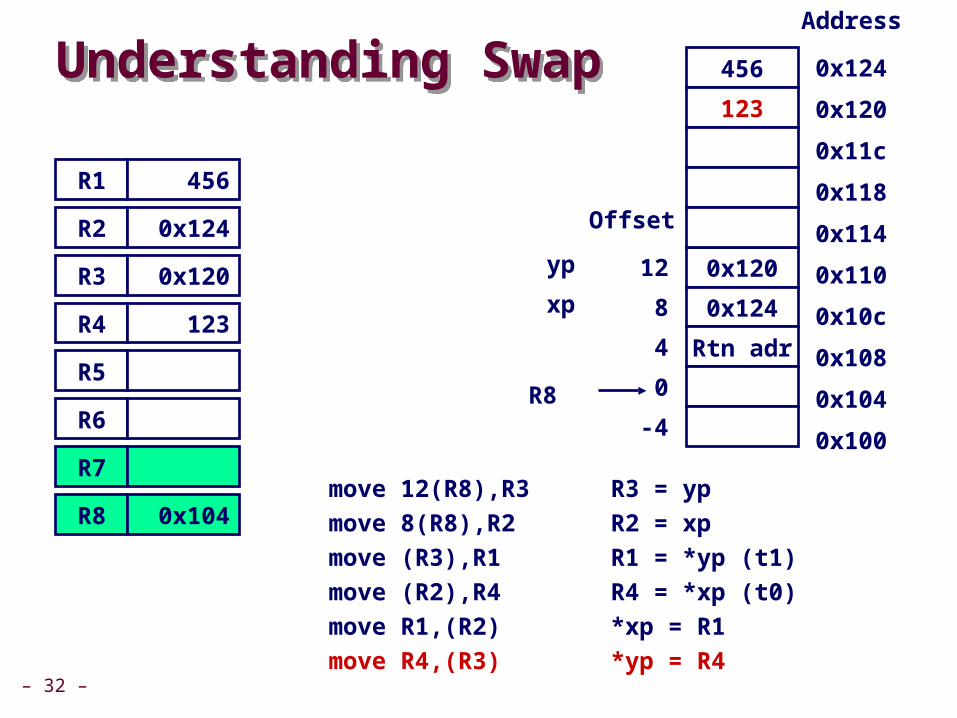
– 32 –
Understanding SwapUnderstanding Swap
move 12)R8(,R3 R3 = yp
move 8)R8(,R2 R2 = xp
move )R3(,R1 R1 = *yp )t1(
move )R2(,R4 R4 = *xp )t0(
move R1,)R2( *xp = R1
move R4,)R3( *yp = R4
0x120
0x124
Rtn adr
R8 0
4
8
12
Offset
-4
456
123
Address
0x124
0x120
0x11c
0x118
0x114
0x110
0x10c
0x108
0x104
0x100
yp
xp
R1
R2
R3
R4
R5
R6
R7
R8
456
0x124
0x120
123
0x104

– 33 –
פעולות אריתמטיות – שני אופרנדים
פעולות אריתמטיות – שני אופרנדים
תבנית ...מחשב את
add Src,Dest Dest = Dest + Src
subtract Src,Dest Dest = Dest - Src
multiply Src,Dest Dest = Dest * Src
shiftal Src,Dest Dest = Dest << SrcAlso called shll
shiftar Src,Dest Dest = Dest >> SrcArithmetic
shiftr Src,Dest Dest = Dest >> SrcLogical
xor Src,Dest Dest = Dest ^ Src
and Src,Dest Dest = Dest & Src
or Src,Dest Dest = Dest | Src

– 34 –
פעולות אריתמטיות – אופרנד אחד
פעולות אריתמטיות – אופרנד אחד
תבנית ...מחשב את
increment Dest Dest = Dest + 1
decrement Dest Dest = Dest - 1
negate Dest Dest = - Dest
not Dest Dest = ~ Dest

– 35 –
דוגמה נוספתדוגמה נוספת
int logical)int x, int y({ int t1 = x^y; int t2 = t1 >> 17; int mask = )1<<13( - 7; int rval = t2 & mask; return rval;}
logical:
move 8)R8(,R1xor 12)R8(,R1shiftar $17,R1and $8185,R1
Body
move 8)R8(,R1 R1 = xxor 12)R8(,R1 R1 = x^y )t1(shiftar $17,R1 R1 = t1>>17 )t2(and $8185,R1 R1 = t2 & 8185
213 – 7 = 8185מי ביצע את החישוב
? הזה