Принципы и приёмы обработки очередей / Константин...
TRANSCRIPT

Очереди: теория и практика
КонстантинОсипов
Москва, 2015-05-21

Очереди как паттерн отказоустойчивой архитектуры
• СУБД – пионер технологии очередей• транзакции необходимы, но не достаточны• пример: банковский перевод

Очереди: за и против
+ клиент и сервер полностью “развязаны”+ состояние задачи всегда известно+ применимо для load balancing+ поддержка приоритетов- дополнительная. сущность- больше операций на задачу- очередь должна быть персистентной

Очереди в Web Apps
● Рассылка email● Сжатие картинок ← мультиплексирование● Сборка email!● мессенджеры

Практика применения
● отложенное выполнение● управление “плохими” задачами● таймауты выполнения● приоритеты и повторное выполнение ● вложенные очереди и зависимые задачизависшие воркеры

Балансировка нагрузки
● задачи балансировки нагрузки● два подхода к балансировке нагрузки: моделирование (теория очередей) и симуляция (бенчмарки).
● типичные ошибки при бенчмаркинге● предотвращение перегрузки

1
10
100
1000
10000
Запросов/секунду
Время обработки
одного запроса
Диаграмма насыщения системы массового обслуживания
Перегрузка
Насыщение
МинимумОптимально

Что такое load balancingWikipedia: “…методология
распределения запросов на несколько компьютеров … позволяющая достичь
оптимальной утилизации ресурсов, максимизировать пропускную
способность системы, минимизировать время ответа на запрос, и избежать
перегрузки”
Все части графика нагрузки

1
10
100
1000
10000
Запросов/секунду
Время обработки
одного запроса
Ограничиваем latency
Перегрузка
Насыщение
МинимумОптимально
Допустимый максимум

1
10
100
1000
10000
Запросов/секунду
Время обработки
одного запроса
Максимизируем RPS
Перегрузка
Насыщение
МинимумОптимально
Максимальный RPS при разумном latency

Основы теории очередей
• Виды очередей – нотация Кендалла• Модель с одним сервером• Модель с несколькими серверами –
лучше не влезать...

Нотация Кендалла (Kendall)
A/B/c/K/m/Z• A — распределение времени между
прибытиями• B — распределение времени
обслуживания• c — количество серверов• K — ёмкость системы обслуживания• m — популяция источника клиентов• Z — принцип обслуживания

Модели для одного сервера
= / = степень утилизации (traffic intensity)
k = вероятность k задач в очереди
0 = 1 – и k = k(1 – )
L = мат. ожидание числа задач в очереди
L = /(-) если
Lq = 2/(-)мат. ожидание длины очереди (не включая задачи в работе)
Lq = 2/(-)
2
(-)

Теория очередей: выводы
• среднее время выполнения запроса отличается от минимального пропорционально длине очереди
• при приближении загрузки к 100% длина очереди может расти полиномиально
• единая очередь на несколько серверов позволяет снизить дисперсию, и, повысить утилизацию при сохранении необходимого latency
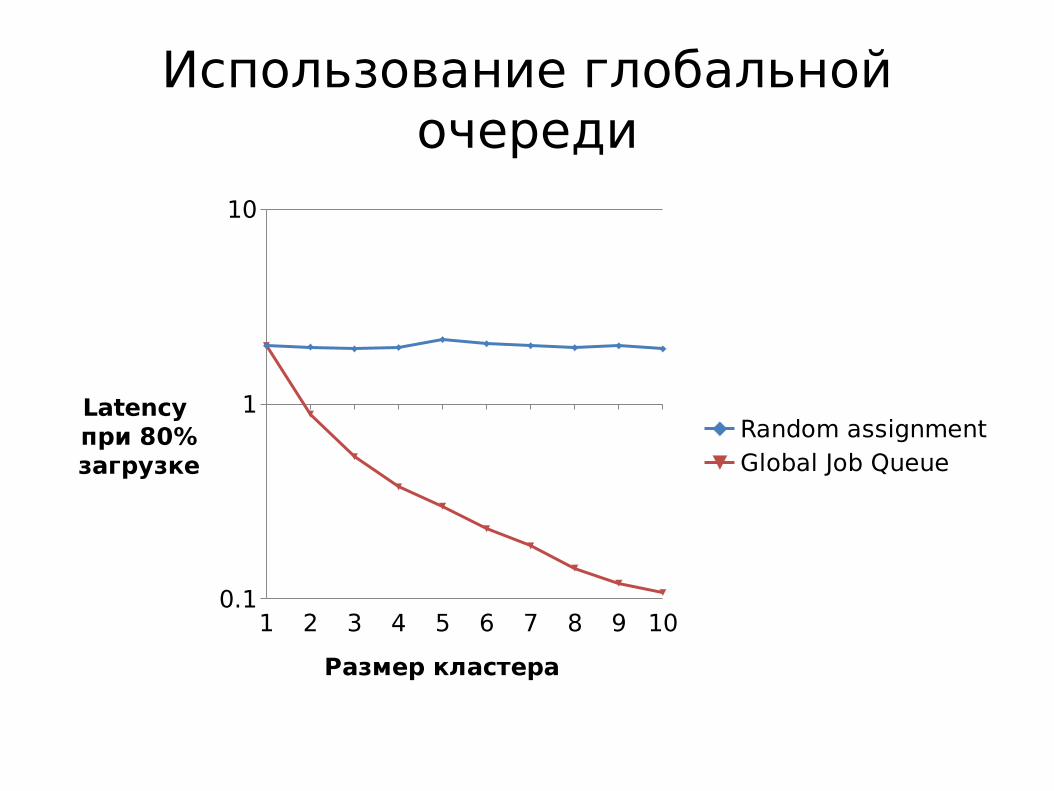
Использование глобальной очереди
1 2 3 4 5 6 7 8 9 100.1
1
10
Random assignmentGlobal Job Queue
Размер кластера
Latency при 80%загрузке

Закон Литтла
Q = R*W
• (Q)ueue size = (R)ate * (W)ait-time• Q – средняя длина очереди• R – скорость поступления запросов
(запросов/секунду)• W – среднее время ожидания (секундах)• для любой (!) системы в стабильном
состоянии

Закон Литтла – пример
Q = R*W
• Система получает R=10,000 запросов в секунду
• Врема обработки одного запроса – 1 мс (W = 0.001)
• Закон Литтла: средняя длина очереди 10

Закон Литтла: выводы
Q = R*W
• В распределённой системе:– R масштабируется с ростом числа
серверов–W остаётся неизменным или несколько
ухудшается
• Для масштабирования, необходимо пропорционально увеличивать число задач “в обработке”

Конфликт требований к оптимизации
• Для того, чтобы снизить latency, необходимо уменьшить среднюю длину очереди (очередей) в системе
• Для того, чтобы увеличить RPS (throughput), необходимо увеличить среднюю длину очередей в системе, чтобы избежать простоев на фoне неравномерной нагрузки
• Для равномерного распределения нагрузки в распределённой системе, необходимо, чтобы очереди к разным узлам были примерно одного размера

Симуляция/бенчмарки
Лучший способ исследования поведения распределённой системы
Что измеряем:- конечно rps!?- время обработки одного запроса- средняя длина очереди- осцилляцию?→ ищем причины задержек

Как правильно измерять время выполнения запроса
• Необходимо измерять распределение (гистограмма) времени обработки, а не среднее
• Обращаем внимание на среднее, минимум, максимум, и дисперсию (!)

Гистограмма распределения latency

Определяем SLA

Проблема наивной симуляции: coordinated omission

Проблема наивной симуляции: coordinated omission

1
10
100
1000
10000
Запросов/секунду
Время обработки
одного запроса
Борьба с перегрузкой
Перегрузка

Ограничение размера очереди
0 2 4 6 8 10 12 14 16 18 200
5
10
15
20
25
30
35
40
Queued job limit
% of dropped jobs

Каскад очередей

Общая идея: backpressure

Колебания производительности
1 1.5 2 2.5 3 3.5 4 4.5 50
10
20
30
40
50
60
70
Node ANode B
Utilization %

Сглаживаем колебания
• Это уже теория управления —avoid if possible!
• Чем выше частота контроля, тем сложнее добиться результата
• Стратегии:– Увеличить масштаб (реже изменять
параметры системы)– “загрубить” контроль, т.е. не реагировать
на мелкие колебания

Спасибо!