2010/12/17 b4 真境名 郁
DESCRIPTION
先端論文紹介ゼミ 「 A fuzzy self-organizing map algorithm for biological pattern recognition 」 (生物学的パターン認識のための曖昧な自己組織化マップアルゴリズム). 2010/12/17 B4 真境名 郁. 目次:. Abstract (要約) Introduction (紹介) Method (方法) Clustering quality measurements (クラスタリング性質測定) Experimental results and discussion (実験結果と議論) - PowerPoint PPT PresentationTRANSCRIPT
先端論文紹介ゼミ「A fuzzy self-organizing map algorithm for biological pattern recognition」(生物学的パターン認識のための曖昧な自己組織化マップアルゴリズム)
2010/12/17B4 真境名 郁
1

目次:• Abstract (要約)• Introduction (紹介)• Method (方法)• Clustering quality measurements (クラスタリング性質測定)• Experimental results and discussion (実験結果と議論)• Conclusion (結論)
2

Abstract
• データクラスタリングは連続分析とパターン認識を含む様々な過程のための主要課題。
• 本論文では、 DNA 配列のような生物学的データに働くとき、精度と感度を増加させることを目指したクラスタリングアルゴリズムを研究。
• 提案するアルゴリズムが SOM と FCM(Fuzzy-C-Means) よりクラスタリングと分類精度能力に関して優れる可能性を示す。
3

Introductionグループへのパターンの教師無し分類はクラスタリング
と定義され、データセットのデータグループ、またはクラスタは相似概念の使用で特定される。
これより、データクラスタリングはデータセットの同じ、または異なったパターンを発見することを目指している。
クラスタリングアルゴリズムは、パターン分析などの多く分野で応用の範囲が広く、広く使用されるクラスタリングアルゴリズムには、 SOM 、 fuzzy C-means(FCM) 、 K-means ( K 平均法)等がある。
この研究では、 FCM の不可欠な局面と SOM アルゴリズムを取り入れた「 fuzzy organizing map(FOM) 」を紹介する。
4

Method• SOM algorithm
SOM(Self Organizing Maps) 多次元データを低い次元のマップに変える
ニューラルネットワークベースのクラスタリング技法。
SOM の一般的な構造体は、相互接続されたニューロン、ノードの格子であり、二次元格子位相が広く使用される。
SOM の目的は、ランダムに初期化されたノードの重みベクトルから成る格子に関する入力データを表すこと。
5

Method
6

Method• FCM clustering algorithm
Fuzzy C-means(FCM) FCMは、入力値により近いクラスターの中心を徐々に動かすための反
復演算。(式(1),(2))
:メンバーシップ値の計算
:クラスターの中心
を更新 7

Method
8

Method• Fuzzy organizing map(FOM)
FOM アルゴリズムは、2つのクラスタリングアルゴリズム、 SOM および FCM を利用している。
SOM の主な欠点:近隣ノードの更新をするのに計算上高価な操作を必要とする。
この点 SOM と異なり、 FCM は交互に最適化手法を利用する
比較的速いアルゴリズム。 FOM アルゴリズムの基本的な訓練周期は SOM と同じで
ある。
9

Method
10

Clustering quality measurements• 様々なクラスタリング基準はクラスタリング性質
を測定するために提案されている。• この研究では、3つの一般的なクラスタリング性
質測定法を利用している。( Table 1 )①Quantization error( 量子化誤差 )②Graph-based cohesion error( グラフベースの結
合誤差 )③Prototype-based cohesion error( 原型ベースの結
合誤差 )
11

Clustering quality measurementsx: 各入力n: 入力要素の数c: グリッド上のノー
ドm: ノードの数p: 特定のノードの
データ ベクトル数
dist(distance function):ユークリッド距離
12

Clustering quality measurements①Quantization error( 量子化誤差 )
ネットワークがどのくらい上手く与えられた入力に反応することができるのかを示している。
これはデータセットにおける全ての入力の勝利距離の平均とみなす。
② Graph-based cohesion error( グラフベースの結合誤差 )
クラスター分析の1つの主要な目的は、同じクラスタのデータベクトル間の距離を最小にすることであり、これがどのくらい優れるかを示す。
同じクラスタで各入力を他のものと比較することで計算。
13

Clustering quality measurements③Prototype-based cohesion error( 原型ベースの結
合誤差 ) 同じクラスタでの入力の間の距離がどれくら
いよく最小にされるかを測定。 入力とクラスタの中心の間に平均距離誤りを
取ることによって計算。
14

Clustering quality measurements3.1.Performance-based quality
クラスタリング性質測定のみでの使用は、クラスタリングアルゴリズムの性能を示すのに十分ではないため、他にいくつかの測定基準を追加して使用する必要がある。
Table2 に最もよく利用される一般的な測定基準を示す。TP(true positive);TN(true negative);FP(false positive) FN(false negative)
15

Experimental results and discussion
• ここでは異なるデータセットを用いて、FOM アルゴリズムの性能を示し、 SOMと FOM の比較を行う。
• FOM を SOM と FCM と比較するために、計7つのデータセット(4つの DNAモチーフデータと3つの生物学的データセット)を利用している。
16
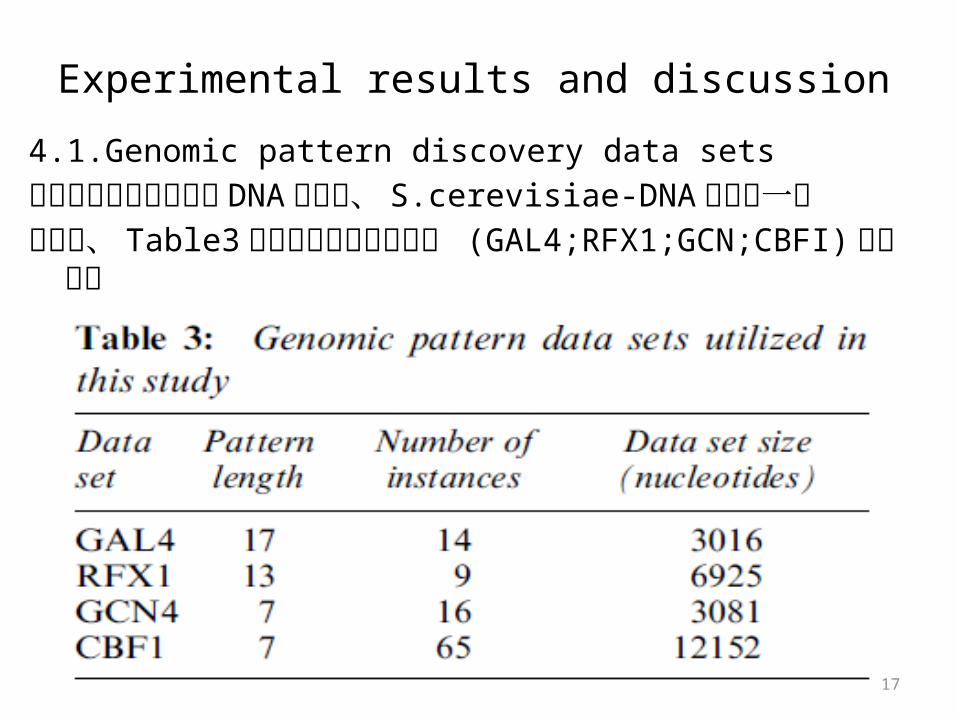
Experimental results and discussion4.1.Genomic pattern discovery data setsこの研究で用いている DNA 配列は、 S.cerevisiae-DNA 配列の一部
であり、 Table3 に4つのデータセット (GAL4;RFX1;GCN;CBFI)を示す。
17

Experimental results and discussion4.1.Genomic pattern discovery data sets 正確にアルゴリズムの性能を測定するため、様々な長さ、大
きさ、異なる数のパターン例を用いている。 これらのデータセットに関して、3つのアルゴリズムの性能
の違いを以下の3つの異なる指標で示す。① Clustering quality measures(Table 4)② Classification accuracy measures(Table 5)③ Sequence logos(Table 6)
18

Experimental results and discussion4.1.Genomic pattern discovery data sets 指標: Clustering quality measures クラスタリング性能の値は低い値程良い。 12つの性能の値中、9つで FOM が優れている結果となっ
た。
19

Experimental results and discussion4.1.Genomic pattern discovery data sets 指標: Classification accuracy measures
20

Experimental results and discussion4.1.Genomic pattern discovery data sets 指標: Sequence logosゲノムパターン発見のための別の最も一般的な方
法は、系列ロゴを用いた視覚により結果を提示することである。
系列ロゴは、様々な長さの文字の系列から構成される。
Table 5 より、ゲノム系列パターンの発見においても FOM は SOM と FCM の両方より更に効率的であることが示されている。
21

Experimental results and discussion4.1.Genomic pattern discovery data sets
22
Experimental results and discussion
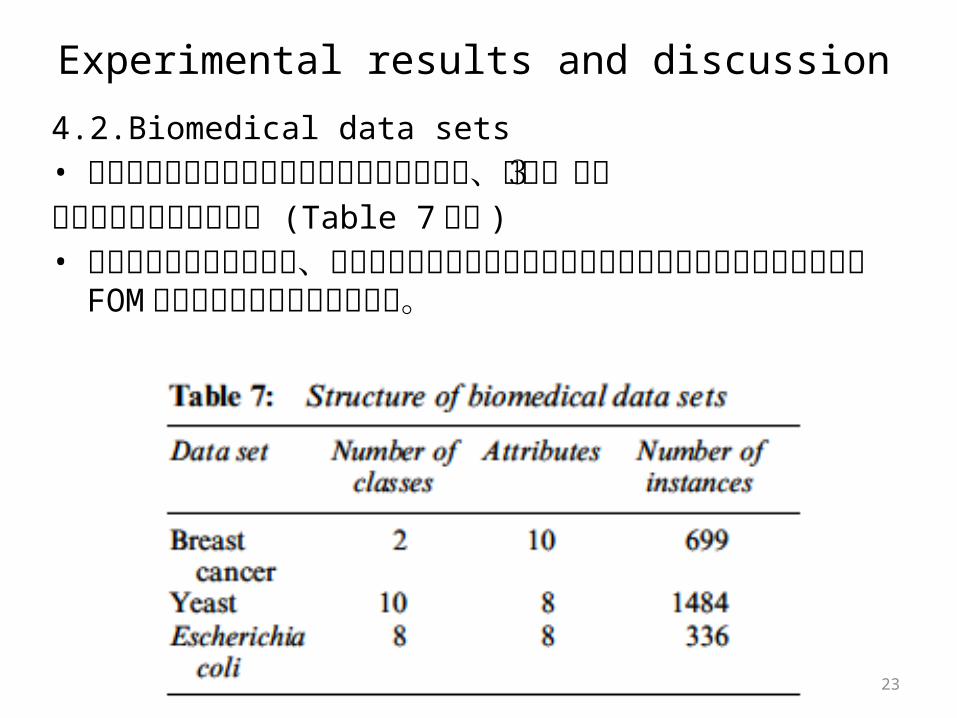
4.2.Biomedical data sets• この生物学的データセットを用いた実験では、次の3つ
のデータセットを用いる。 (Table 7参照 )• これらのデータセットは、様々なデータセットからの信号の特徴を抽出することにおいて FOM の性能を示すために役に立つ。
23
Experimental results and discussion
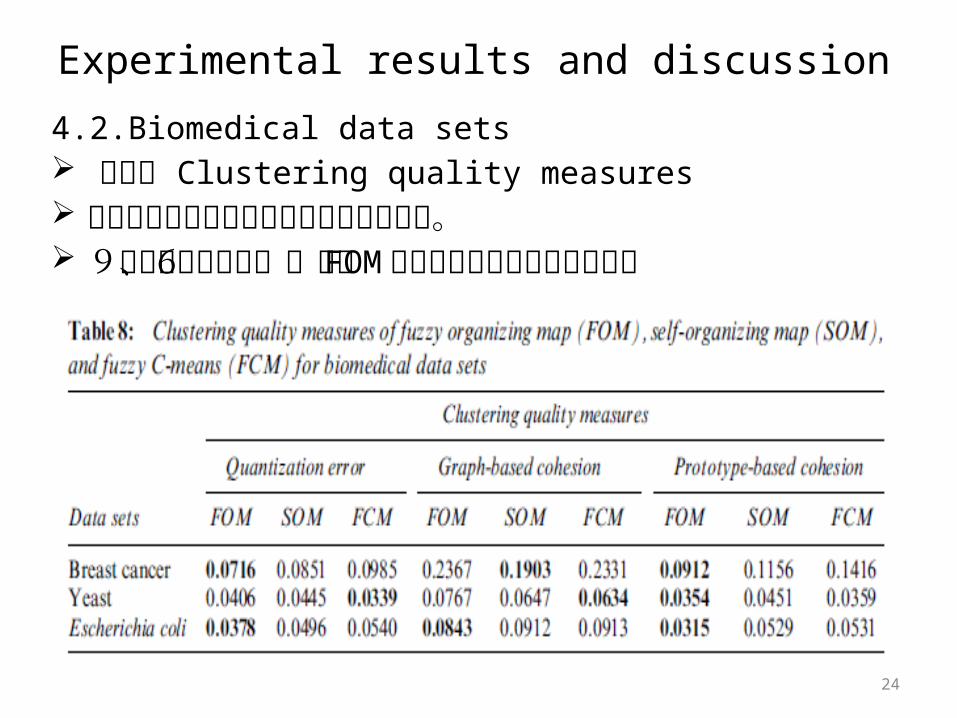
4.2.Biomedical data sets 指標: Clustering quality measures クラスタリング性能の値は低い値程良い。 9つの性能の値中、6つで FOM が優れている結果となっ
た。
24

Experimental results and discussion
4.2.Biomedical data sets 指標: Classification accuracy measures
25

Experimental results and discussion
4.2.Biomedical data sets
26

Experimental results and discussion
4.3.Comparison of FOM with other hybrid algorithms このセクションでは、2つの高度なアルゴリズムとの比
較を行っている。 (Table 10参照 ) Fuzzy Kohonen clustering networks(FKCN) Improved FKCN Fuzzy-self organizing map(FSOM)
27

Experimental results and discussion
4.4.Discussion• FOM アルゴリズムはグリッド上のクラスタの中心を更新
するノードを特定する性能のために、 SOM と FCM よりクラスタリング性能と分類精度において優れる可能性を持っている。
• FOM はグリッドを SOM のようにグリッドを視覚マップに変換しようせず、代わりにグリッド上の必要な信号を強化して、データ入力を表そうとする。これは FOM アルゴリズムの強みであり、
このアプローチはより良いクラスタリング結果につながる。
• FOM はクラスタリング性能が想像より重要である問題に適している。
28

Conclusion• この研究において、提案した FOM アルゴリズム
は SOM と FCM との比較により有望なクラスタリングアルゴリズムであることを示した。
• FOM アルゴリズムは DNA 配列などのゲノムデータセットによって明確に役に立ち、また他のアプリケーション部においてもよく振る舞うと予想される。
29

ご清聴ありがとうございました。
30