ai on ia 英特尔人工智能技术分享
TRANSCRIPT

AI ON IA
英特尔人工智能技术分享
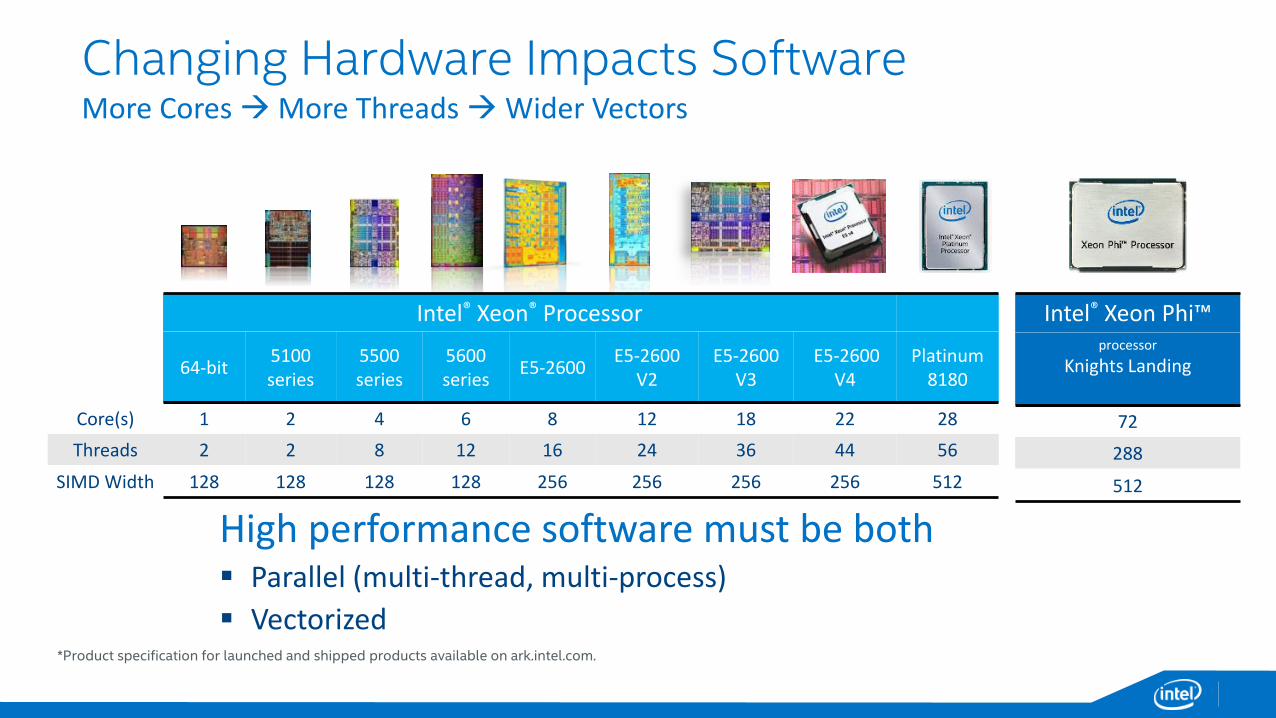
Intel® Xeon® Processor
64-bit5100 series
5500 series
5600 series
E5-2600E5-2600
V2E5-2600
V3E5-2600
V4Platinum
8180
Core(s) 1 2 4 6 8 12 18 22 28
Threads 2 2 8 12 16 24 36 44 56
SIMD Width 128 128 128 128 256 256 256 256 512
Intel® Xeon Phi™ processor
Knights Landing
72
288
512
*Product specification for launched and shipped products available on ark.intel.com.
High performance software must be both▪ Parallel (multi-thread, multi-process)
▪ Vectorized
Changing Hardware Impacts SoftwareMore Cores →More Threads →Wider Vectors
2
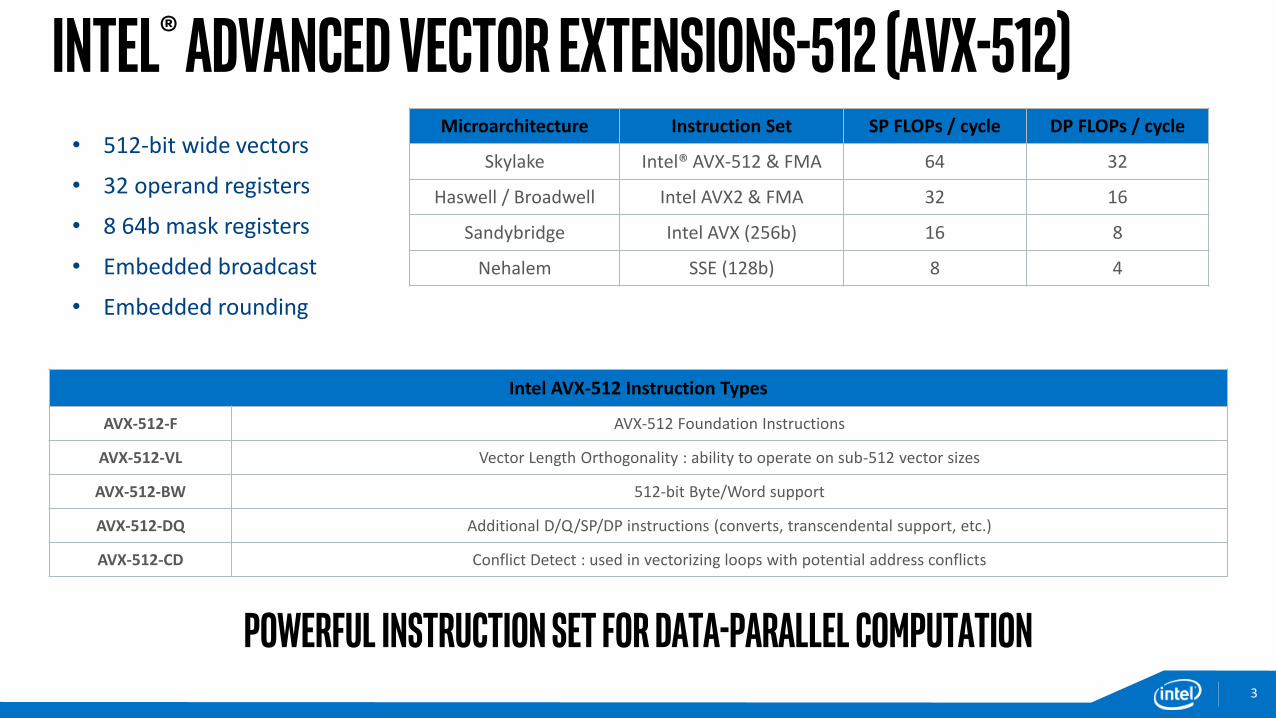
• 512-bit wide vectors
• 32 operand registers
• 8 64b mask registers
• Embedded broadcast
• Embedded rounding
Microarchitecture Instruction Set SP FLOPs / cycle DP FLOPs / cycle
Skylake Intel® AVX-512 & FMA 64 32
Haswell / Broadwell Intel AVX2 & FMA 32 16
Sandybridge Intel AVX (256b) 16 8
Nehalem SSE (128b) 8 4
Intel AVX-512 Instruction Types
AVX-512-F AVX-512 Foundation Instructions
AVX-512-VL Vector Length Orthogonality : ability to operate on sub-512 vector sizes
AVX-512-BW 512-bit Byte/Word support
AVX-512-DQ Additional D/Q/SP/DP instructions (converts, transcendental support, etc.)
AVX-512-CD Conflict Detect : used in vectorizing loops with potential address conflicts
Powerful instruction set for data-parallel computation3
Intel® Advanced Vector Extensions-512 (AVX-512)

4
VNNI (Vector Neural Network Instructions)a0a1a2a3a62a63
...
b0b1b2b3b62b63...
a3b3 + a2b2 +a1b1 + a0b0 + c0
...a63b63 + a62b62 +
a61b61 + a60b60 + c15
for i = 0 .. 15
for j = 0 .. 3
dst32[i] += src1u8[4i + j] * src2s8[4i + j]
AVX-512 BW VNNI
vpmaddubsw zmms16, src1u8, src2s8vpmaddwd zmms16, zmms16, [16 x 116]vpaddd dsts32, dsts32, zmms16
vpdpbusd dsts32, src1u8, src2s8
• 64 multiply-adds in 3 instructions• potential intermediate saturation after vpmaddubsw
saturate<s16>(u8*s8 + u8*s8)• 1.33x throughput of F32 equivalent (4x vfmadd231ps)
• 64 multiply-adds in 1 instruction• no potential intermediate saturation• src2 (s8) operand can be broadcasted from memory• 4x throughput of F32 equivalent (4x vfmadd231ps)
src1
src2
dst
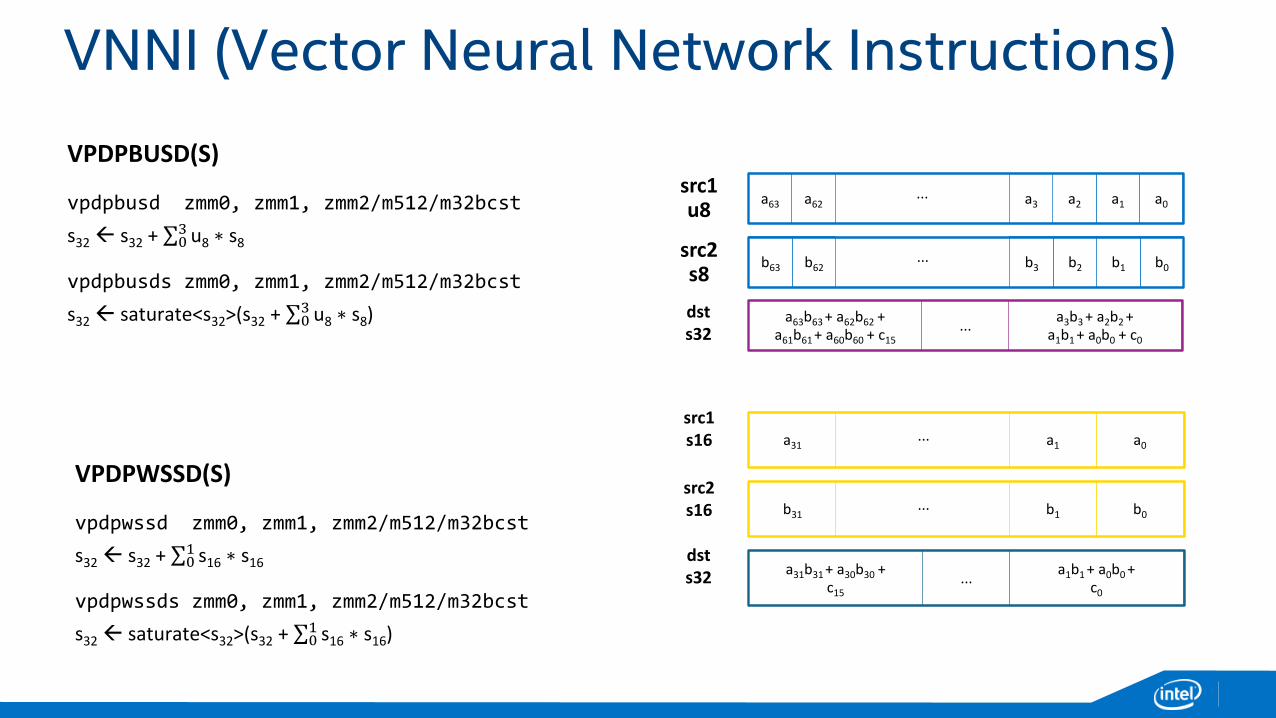
VNNI (Vector Neural Network Instructions)
VPDPBUSD(S)
vpdpbusd zmm0, zmm1, zmm2/m512/m32bcst
s32 s32 + σ03 u8 ∗ s8
vpdpbusds zmm0, zmm1, zmm2/m512/m32bcst
s32 saturate<s32>(s32 + σ03 u8 ∗ s8)
a0a1a2a3a62a63...
b0b1b2b3b62b63...
a3b3 + a2b2 +a1b1 + a0b0 + c0
...a63b63 + a62b62 +
a61b61 + a60b60 + c15
src1u8
src2s8
dsts32
a0a1a31...
b0b1b31...
a1b1 + a0b0 +c0
...a31b31 + a30b30 +
c15
src1s16
src2s16
dsts32
VPDPWSSD(S)
vpdpwssd zmm0, zmm1, zmm2/m512/m32bcst
s32 s32 + σ01 s16 ∗ s16
vpdpwssds zmm0, zmm1, zmm2/m512/m32bcst
s32 saturate<s32>(s32 + σ01 s16 ∗ s16)

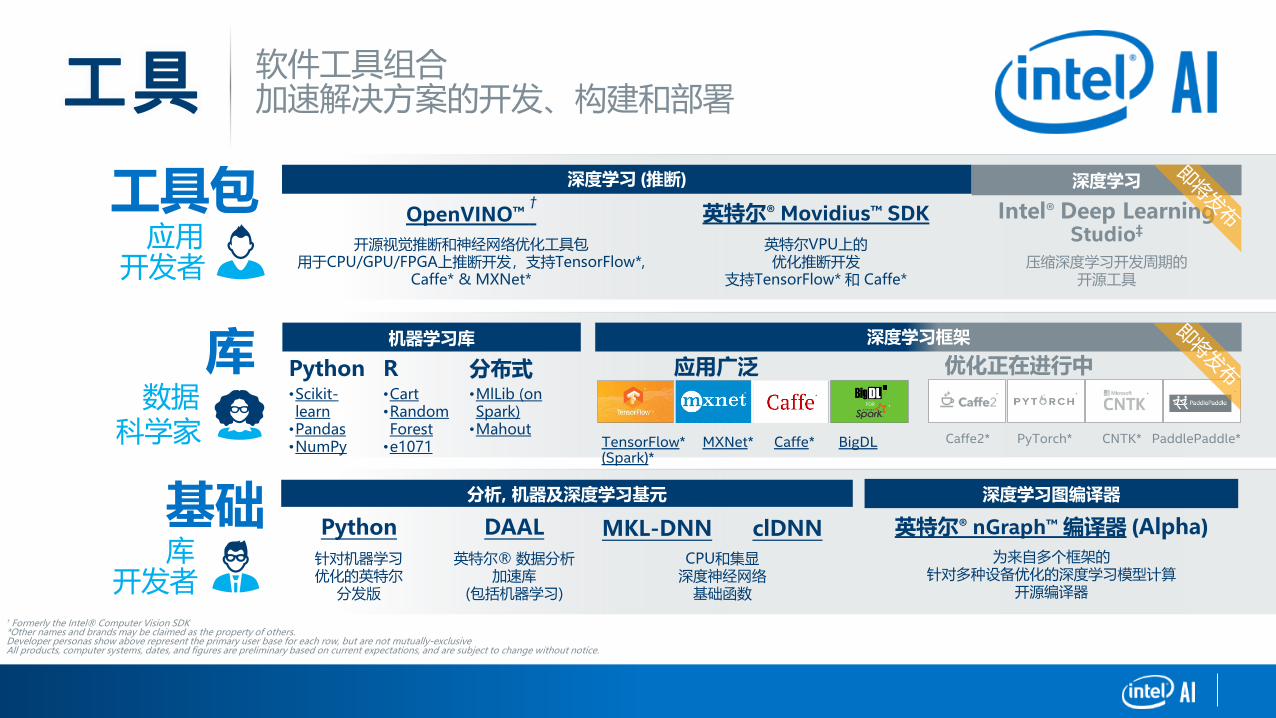
† Formerly the Intel® Computer Vision SDK*Other names and brands may be claimed as the property of others.Developer personas show above represent the primary user base for each row, but are not mutually-exclusiveAll products, computer systems, dates, and figures are preliminary based on current expectations, and are subject to change without notice.
工具包应用
开发者
深度学习 (推断)
OpenVINO™ †
英特尔® Movidius™ SDK
开源视觉推断和神经网络优化工具包用于CPU/GPU/FPGA上推断开发,支持TensorFlow*,
Caffe* & MXNet*
英特尔VPU上的优化推断开发
支持TensorFlow* 和 Caffe*
工具
库数据
科学家
基础库
开发者
深度学习框架
应用广泛 优化正在进行中
TensorFlow* MXNet* Caffe* BigDL (Spark)*
Caffe2* PyTorch* CNTK* PaddlePaddle*
深度学习
Intel® Deep Learning Studio‡
压缩深度学习开发周期的开源工具
*
**
*FOR
* * * *
机器学习库
Python R 分布式•Scikit-learn•Pandas•NumPy
•Cart•RandomForest•e1071
•MlLib (on Spark)•Mahout
分析, 机器及深度学习基元
Python DAAL MKL-DNN clDNN针对机器学习优化的英特尔
分发版
英特尔® 数据分析加速库
(包括机器学习)
CPU和集显深度神经网络
基础函数
深度学习图编译器
英特尔® nGraph™ 编译器 (Alpha)
为来自多个框架的针对多种设备优化的深度学习模型计算
开源编译器
软件工具组合加速解决方案的开发、构建和部署

8
深度学习框架
更多……
另请参阅:面向 Python(Scikit-learn、Pandas、NumPy)、R (Cart、randomForest、e1071) 和 Distributed (MlLib on Spark、Mahout) 的机器学习函数库* 目前数量有限其他的名称和品牌可能是其他所有者的资产。
* * * *
许多主流深度学习框架目前都已针对 CPU 进行了优化
安装指南请访问 ai.intel.com/framework-optimizations/
更多框架正在优化:
*
**
*在

9
software.intel.com/intel-distribution-for-python
开箱即用,轻松访问高性能Python
▪ 预构建,专为数值计算、数据分析和 HPC 而优化
▪ 逐步更换现有的 Python (无需更改代码)
通过多种优化技术提升性能▪ 借助英特尔® MKL 提升
NumPy/SciPy/Scikit-Learn 的速度
▪ 使用 pyDAAL 进行数据分析,使用Jupyter* Notebook 接口、Numba、Cython 增强线程调度
▪ 使用经优化的 MPI4Py 和 Jupyter notebooks 轻松扩展
更快地获得适用于英特尔架构的最新优化功能
▪ 可通过 conda 和 Anaconda Cloud 获取分发版和个人版优化包
▪ 向上优化至 Python 主干
面向使用人工智能最热门和发展最快编程语言的开发人员
Python 的英特尔分发版让 Python* 的性能更接近本地速度
所有产品、计算机系统、日期和数字信息均为依据当前期望得出的初步结果,可随时更改,恕不另行通知。
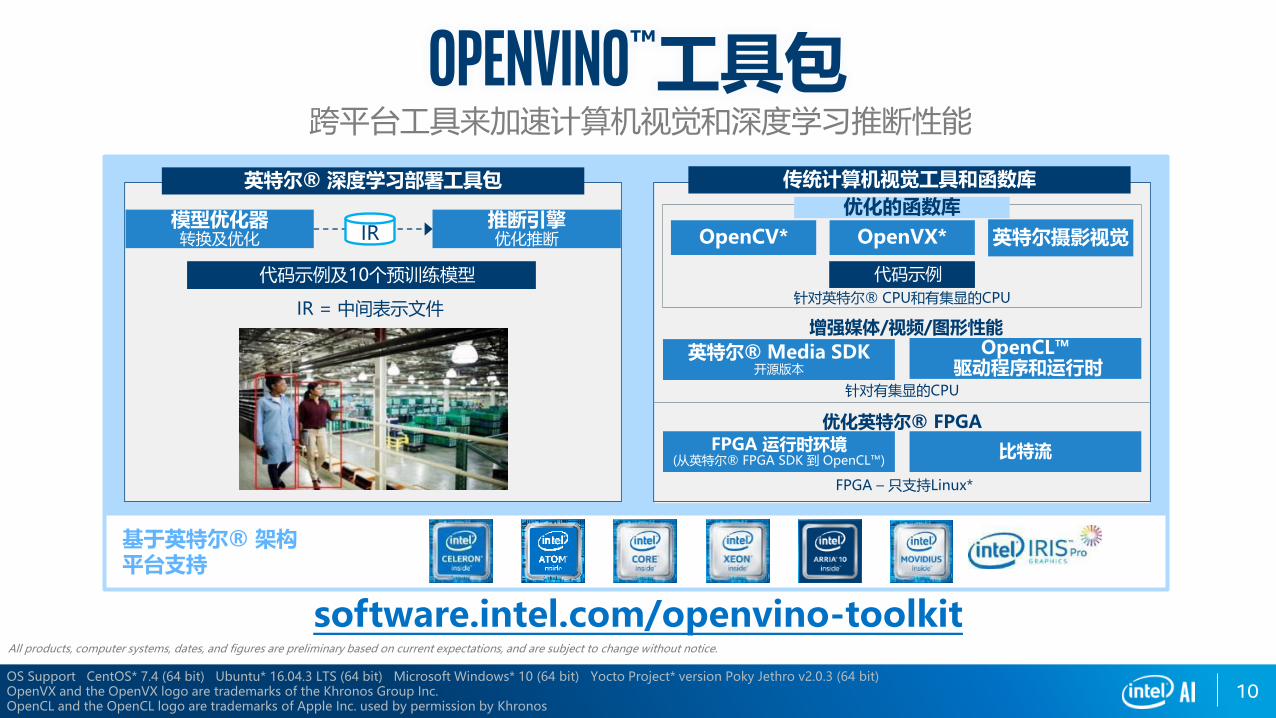
10OS Support CentOS* 7.4 (64 bit) Ubuntu* 16.04.3 LTS (64 bit) Microsoft Windows* 10 (64 bit) Yocto Project* version Poky Jethro v2.0.3 (64 bit)OpenVX and the OpenVX logo are trademarks of the Khronos Group Inc.OpenCL and the OpenCL logo are trademarks of Apple Inc. used by permission by Khronos
基于英特尔® 架构平台支持
英特尔® 深度学习部署工具包 传统计算机视觉工具和函数库
模型优化器转换及优化
推断引擎优化推断IR OpenCV* OpenVX* 英特尔摄影视觉
优化的函数库
IR = 中间表示文件针对英特尔® CPU和有集显的CPU
增强媒体/视频/图形性能
英特尔® Media SDK开源版本
OpenCL™ 驱动程序和运行时
针对有集显的CPU
优化英特尔® FPGAFPGA 运行时环境
(从英特尔® FPGA SDK 到 OpenCL™)比特流
FPGA – 只支持Linux*
代码示例及10个预训练模型 代码示例
Openvino™工具包跨平台工具来加速计算机视觉和深度学习推断性能
software.intel.com/openvino-toolkitAll products, computer systems, dates, and figures are preliminary based on current expectations, and are subject to change without notice.
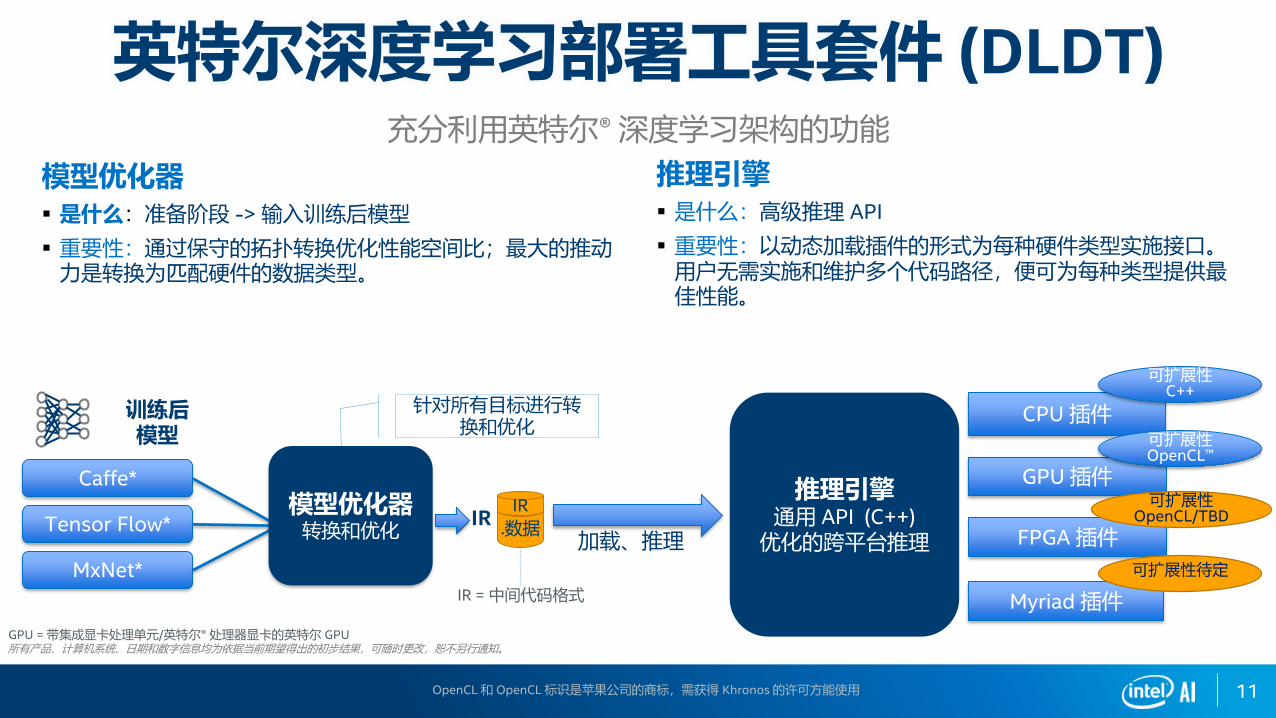
11
Caffe*
Tensor Flow*
MxNet*
.数据IRIR
IR = 中间代码格式
针对所有目标进行转换和优化
加载、推理
CPU 插件
GPU 插件
FPGA 插件
Myriad 插件
模型优化器转换和优化
可扩展性C++
可扩展性OpenCL™
可扩展性OpenCL/TBD
可扩展性待定
模型优化器▪ 是什么:准备阶段 -> 输入训练后模型
▪ 重要性:通过保守的拓扑转换优化性能空间比;最大的推动力是转换为匹配硬件的数据类型。
推理引擎▪ 是什么:高级推理 API
▪ 重要性:以动态加载插件的形式为每种硬件类型实施接口。用户无需实施和维护多个代码路径,便可为每种类型提供最佳性能。
训练后模型
推理引擎通用 API (C++)
优化的跨平台推理
OpenCL 和 OpenCL 标识是苹果公司的商标,需获得 Khronos 的许可方能使用
GPU = 带集成显卡处理单元/英特尔® 处理器显卡的英特尔 GPU
英特尔深度学习部署工具套件 (DLDT)充分利用英特尔® 深度学习架构的功能
所有产品、计算机系统、日期和数字信息均为依据当前期望得出的初步结果,可随时更改,恕不另行通知。
Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice
12
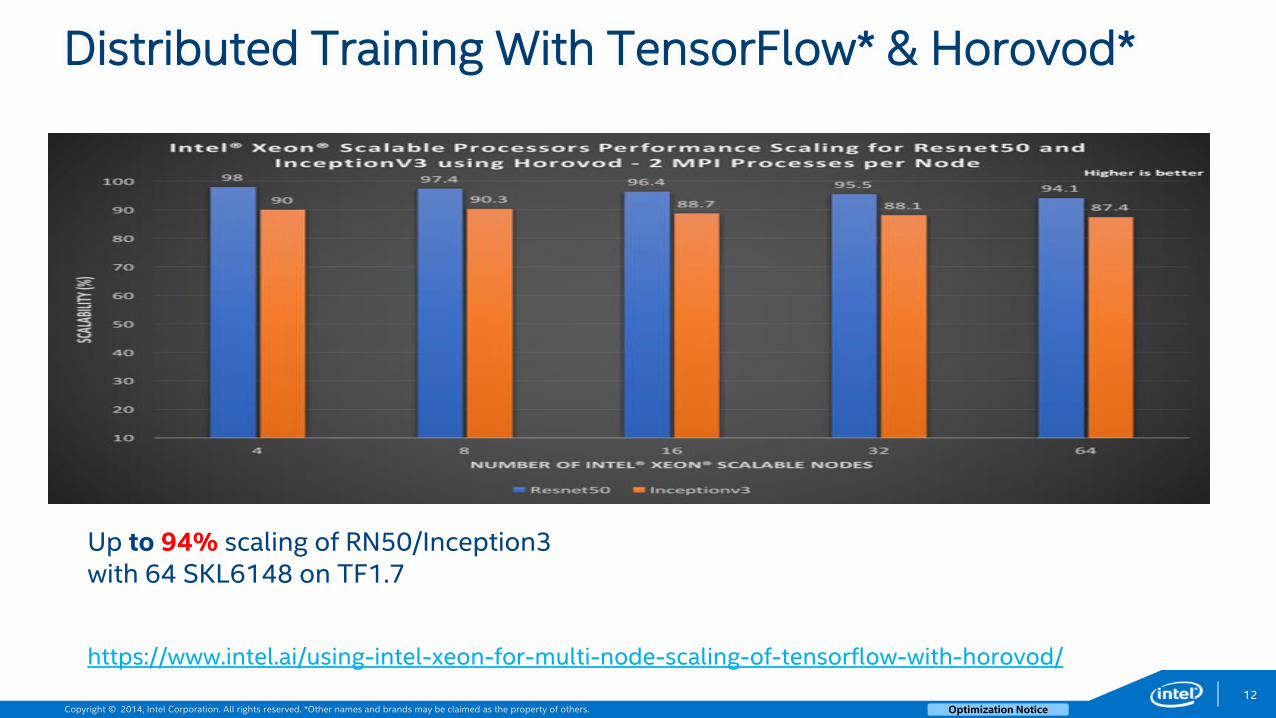
Distributed Training With TensorFlow* & Horovod*
https://www.intel.ai/using-intel-xeon-for-multi-node-scaling-of-tensorflow-with-horovod/
Up to 94% scaling of RN50/Inception3 with 64 SKL6148 on TF1.7

Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice
13
Running TensorFlow Benchmark using Horovod with TensorFlow
Only 3 steps:
Step1: Install MPI(OpenMPI/Intel MPI)
Step2: Install intel-tensorflow (#pip install intel-tensorflow)
Step3: Install horovod (#pip install horovod)
#mpirun --allow-run-as-root -np 16 -cpus-per-proc 18 --bind-to core --map-by socket -H $HOSTLIST … --batch_size 64 python xxx (8 nodes, 2 mpi/per nodes)
https://www.intel.ai/using-intel-xeon-for-multi-node-scaling-of-tensorflow-with-horovod/

14
https://ai.intel.com/white-papers/best-known-methods-for-scaling-deep-learning-with-tensorflow-on-intel-xeon-processor-based-clusters/

15
Intel® Optimization of Tensorflow*: How To Get?Tensorflow install guide is →https://software.intel.com/en-us/articles/intel-optimization-for-tensorflow-installation-guide
• IDP Full→ conda create –n IDP intelpython3_full
• Main trunk→ conda install tensorflow –c anaconda
• Intel Channel→ conda install tensorflow –c intel
Conda Package
• $ pip install https://anaconda.org/intel/tensorflow/1.12.0/download/tensorflow-1.12.0-cp36-cp36m-linux_x86_64.whl
• $ pip install https://storage.googleapis.com/intel-optimized-tensorflow/tensorflow-1.12.0-cp27-cp27mu-linux_x86_64.whl
Python Wheels
• $ docker pull docker.io/intelaipg/intel-optimized-tensorflow:<tag>
• $ docker run -it -p 8888:8888 intelaipg/intel-optimized-tensorflowDocker Images
• https://github.com/tensorflow/tensorflow
• Refer install guide for more detailsBuild from Source
OS: Linux/Windows/MacOS
Python:2.7 | 3.5 | 3.6

更多信息请访问:
ai.intel.com