caeworkshop 2017-12-06 01.ver1 - high performance ...ƒ»メニーコアにおける...
TRANSCRIPT

GPU・メニーコアにおけるOpenFOAMの高度化支援紹介
第1回CAEワークショップ― 流体・構造解析アプリケーションを中心に ―
2017年12月6日 秋葉原 UDX Gallery NEXT
山岸孝輝 井上義昭 青柳哲雄 浅見曉(高度情報科学技術研究機構)
1ver 1.3

outlineRISTの高度化支援についてGPU・メニーコアについてOpenFOAMとGPU
GPU対応版OpenFOAMの最適化新しいGPU版OpenFOAM開発について
OpenFOAMとメニーコアIntel KNLでの基礎性能調査
まとめ2

RISTの高度化支援文科省委託事業「HPCIの運営」代表機関として
「京」を中核とするHPCIの高度化を支援利用者の要望にワンストップで対応
様々な場面に、様々なメニューを提供しますOpenFOAMの高度化支援
GPU・メニーコア対応を紹介RISTの高度化支援の具体例としても
3

スパコンとGPU・メニーコア低消費電力・低コスト
スパコンランキング(TOP500) 上位を占めており、その割合は増加傾向暁光(4位), Oakforest-PACS(9位), TSUBAME 3.0(13位)など多数ランク入り
利用者の視点からは現実的には使いにくいのが現状(移植、高速化、コードの保守管理etc.)
4
RISTの高度化支援にて最も大きな課題の一つ

OpenFOAMとGPU・メニーコア
GPU:NVIDIA GPU実装に手間(CUDA, OpenACC, Thrust, etc.)性能を出すのは容易ではないGPU実装版(RapidCFD)が公開されている
メニーコア:Intel Xeon Phi KNL移植は比較的楽(Intelコンパイラ, MPI)性能については試行錯誤の段階
5

RapidCFD 概要GPU対応版OpenFOAM
simFlow社がGPUに移植開発中: “Let’s make RapidCFD rock solid!”
リリースは3年前、最後のbug fixは2年前特徴
大半のソルバに対応全ての計算をGPUに移植(GPU-CPU間メモリ転送コストの削減)
6
Githubでソースコード公開https://github.com/Atizar/RapidCFD-dev

RapidCFD性能評価事例(1/2)
7
simFlow社ウェブサイトから引用
同世代のCPU比較で2倍強高速
1GPU vs 1CPU
[秒]

RapidCFD性能評価事例(2/2)
8
simFlow社ウェブサイトから引用
4GPUから性能が鈍化
複数GPUでのスケーリング性能
GPU数
加速率

設定したターゲットRapidCFDの高速化
フル移植済みの環境を活用する単体性能(1GPU)の向上
CPUと理論で10倍違う性能を引き出す複数GPUでのスケーリング性能の向上
大きな問題サイズへの対応実行時間の削減
TSUBAME 3.0での試みをRISTの高度化支援の流れと共に紹介
9

TSUBAME 3.0 測定環境項目 内容
HW TSUBAME 3.0 SGI ICE XACPU Xeon E5-2680v4[426GF, 2.4GHz, 14core], 2socketGPU Tesla P100 with NVLink[5.3TF, 16GB], 4boardノード間接続 Intel Omni-Path 100Gb/s x4
SW C++ Icc 17.0.4MPI OpenMPI 2.1.1CUDA CUDA 8.0.61
AP OpenFOAM 2.3.0RapidCFD 2.3.1+ThrustライブラリによるGPU実装解析ソルバ pisoFoam/pimpleFoam
解析データ (1)弱スケーリング 128x128x128 cells/processor~(2)強スケーリング 240x130x96 cells/1-64processros
10

2CPU + 4GPU構成
TSUBAME3.0 ノード構成
TSUBAME3.0Webから引用
ノード内のリソースを使いこなしつつ、ノード間で効率的に並列化させる
GPUDirect RDMAノード間転送
CPU-GPU間はPCIeGPU間は高速な
NVLink
11
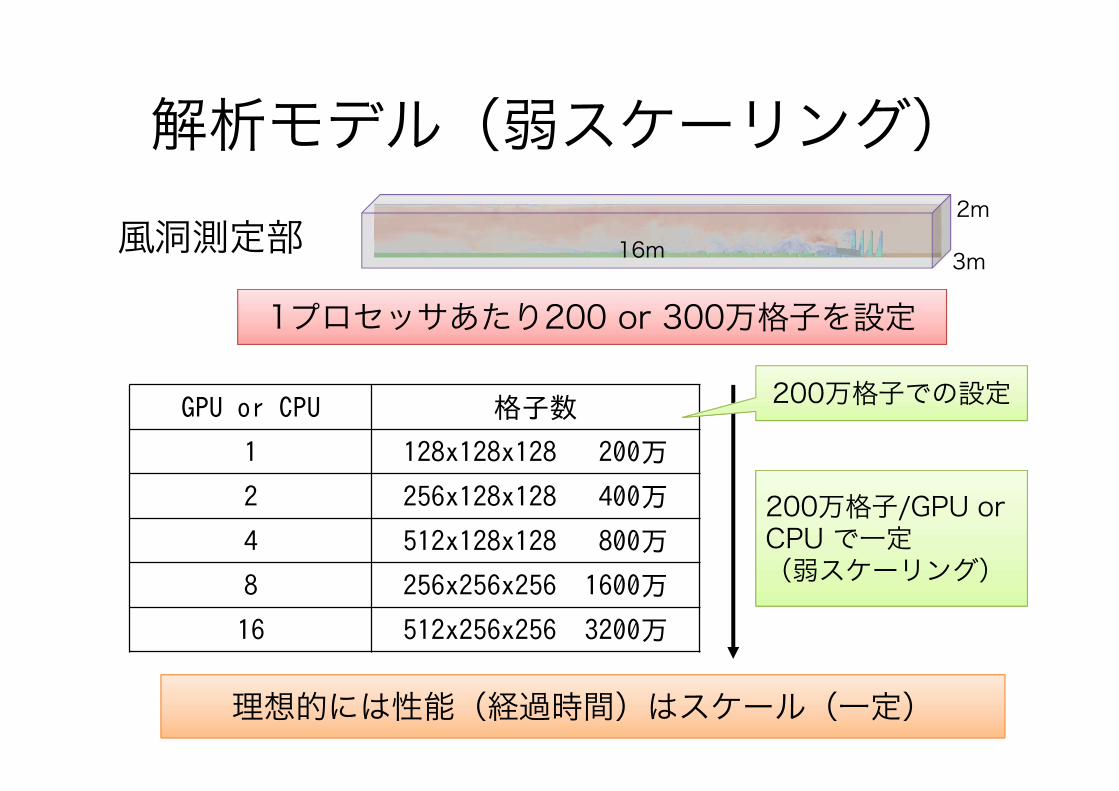
解析モデル(弱スケーリング)16m 3m
2m風洞測定部
200万格子/GPU or CPU で一定(弱スケーリング)
GPU or CPU 格子数
1 128x128x128 200万
2 256x128x128 400万
4 512x128x128 800万
8 256x256x256 1600万
16 512x256x256 3200万
12理想的には性能(経過時間)はスケール(一定)
1プロセッサあたり200 or 300万格子を設定
200万格子での設定

性能計測方法メインループの前後にタイマ挿入
最初はざっくりとした方法で計測
timer_start("runT",1,1);
while (runTime.loop()){
<メイン処理>
}
timer_stop("runT",1,1);
Info<< "End¥n" << endl;
return 0;
目的はコスト分布の把握経過時間計測範囲
CPU・GPUに縛られない方法で計測・比較する
13
余計な情報を入れない
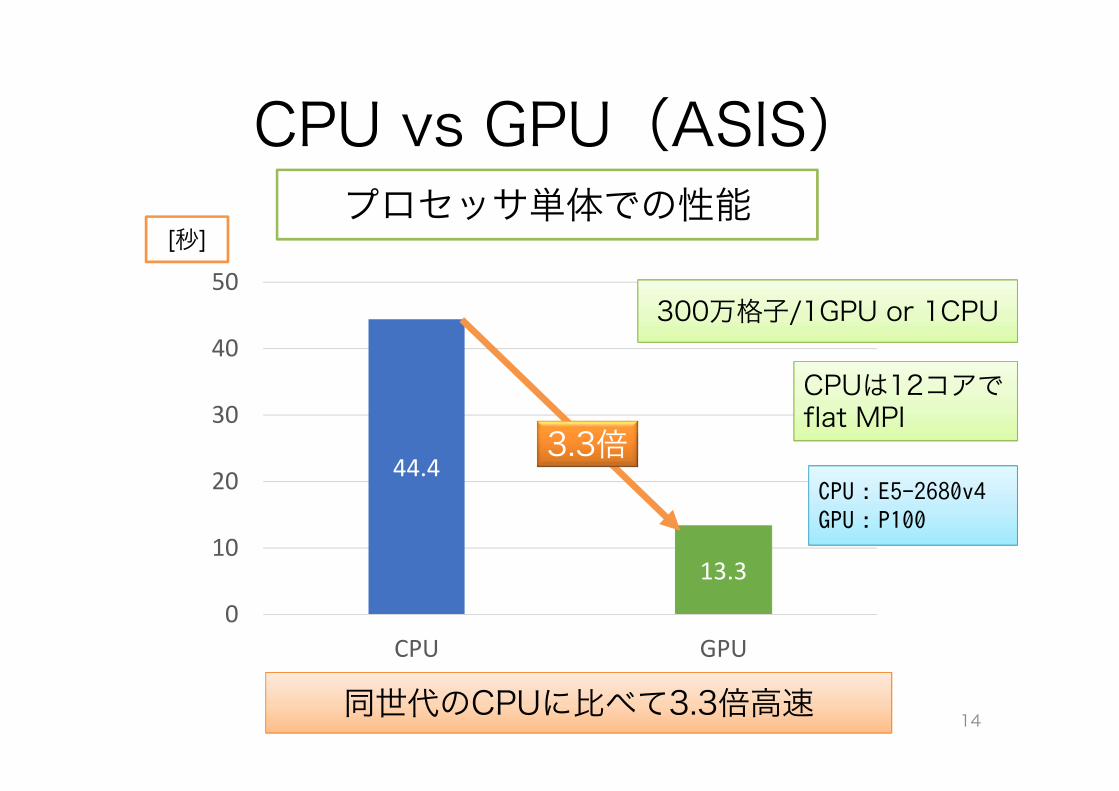
CPU vs GPU(ASIS)
14同世代のCPUに比べて3.3倍高速
44.4
13.3 0
10
20
30
40
50
CPU GPU
300万格子/1GPU or 1CPU
CPUは12コアでflat MPI
プロセッサ単体での性能
3.3倍
[秒]
CPU:E5-2680v4GPU:P100

GPU 弱スケーリング性能(ASIS)
15GPUのノード内並列で性能劣化 4GPUで2倍低速
2種類のGPU配置方法で計測(1→4GPU)
10.6 14.9
23.2
0
5
10
15
20
25
1 2 4
10.6 11.5 12.1
0
5
10
15
20
25
1 2 4
X4ノード内並列
ノード間並列
200万格子/1GPU[秒] [秒]
GPU数 GPU数

処理プロセスごとに分類して計測
16
0.1 0.1 0.1
6.0 8.4
13.5 0.7
1.0
1.5
0.8
1.0
1.5
1.5
2.1
3.6
1.1
1.6
2.1
0.2
0.3
0.4
0
5
10
15
20
25
1 2 4
othersUEqn.2UEqn.3UEqn.4PISO.2pEqn.2pEqnpEqn.3pEqn.4
ノード内並列
[秒]
GPU数
メインループでの分類

ソースコード解析 性能阻害箇所template<>scalar sumProd(const gpuList<scalar>& f1, constgpuList<scalar>& f2){
if (f1.size() && (f1.size() == f2.size())){
thrust::device_vector<scalar> t(f1.size());
thrust::transform(
f1.begin(),f1.end(),f2.begin(),t.begin(),multiplyOperatorFunctor<scalar,scalar,scalar>()
);
return thrust::reduce(t.begin(),t.end());}
else{
return 0.0;}
}総和計算
thrustライブラリによるGPU実装
本来ならライブラリが得意とする処理
17
総和計算処理にて性能が悪化と判明

Visual Profilerによる詳細分析
18
マイクロ秒単位
切り出して計測
カーネル・APIレベル
タイムラインを追う
4GPU時
1GPU時
cudaMalloc reduce
cudaMalloc cudaFreereduce
GPU上のメモリ確保・解放のコストがGPU数につれて増大GPU上のメモリ確保・解放のコストがGPU数につれて増大
cudaFree

総和計算 CUDAによるGPU実装
目的GPU上の無駄なメモリ確保・解放の除去総和計算の高速化
実装についてインタリーブ方式最初の足し込みステップでスレッドの削減ウォープダイバージェンスの回避低データ並列性からのCPUへの切り替え
19
Thrust::reduce(1行)→CUDAカーネル(260行)

44.4
13.3 10.1 0.05.0
10.015.020.025.030.035.040.045.050.0
CPU GPU ASIS GPU TUNED
CPU vs GPU(TUNED)
20
プロセッサ単体での性能
3.3倍 → 4.4倍 高速に
4.4倍
300万格子/1GPU or 1CPU
CPUは12コアでflat MPI
3.3倍
1.3倍
[秒]

GPU 弱スケーリング性能(TUNED)
多数GPU設定(4, 8, 16)にて2倍改善21
1ノード4GPU30.7 31.2 31.6
34.0 32.2
10.6
14.9
23.2 24.4 24.9
7.2 9.0
12.0 13.1 13.2
0.0
5.0
10.0
15.0
20.0
25.0
30.0
35.0
40.0
1 2 4 8 16
CPUGPU ASISGPUTUNED
200万格子/1GPU
[秒]
GPU数

解析モデル2(強スケーリング)
今野雅氏 第4回OpenFOAMワークショップ 発表資料から引用http://www.hpci-office.jp/materials/ws_openfoam_161216_imano
https://github.com/opencae/OpenFOAM-BenchmarkTest
22
240x130x96 300万格子/1-64 CPU or GPUで分割
理想的にはGPUの増加に比例して高速化
1, 2, 4, 8, 16, 32, 64

GPU 強スケーリング性能
23
65.1
42.3
28.7
20.2 16.5 15.9 17.7
51.4
35.1
24.1 19.2
15.4 13.4 21.2
0
10
20
30
40
50
60
70
1 2 4 8 16 32 64
Case1 Case2
16PEから飽和64PEからは逆スケーリング
GPU数増加につれてホスト(CPU)デバイス(GPU)メモリ間転送コスト割合が増加
処理プロセスごとに分類して分析
[秒]
GPU数
Caseの違いは乱流モデルの扱い

GPUDirect RDMA転送
NIC
GPU1
GPU2
GPUGPUメモリ
GPUGPUメモリ
CPU
CPUCPUメモリ
NIC
GPU1
GPU2
GPUGPUメモリ
GPUGPUメモリ
CPU
CPUCPUメモリ
network
ノード 0 ノード 1
異なるノード間でGPUメモリが直接転送/やりとりできる
24
東大Reedbush, 東工大TSUBAME 3.0などで採用

RapidCFD 改善の余地についてOpenFOAMのversionが古い
最新の5.0よりも約3年前のものThrustライブラリでのGPU実装
柔軟な最適化が難しいコンピュートケイパビリティが3.0に設定プロファイラ結果の解析が困難
Time(%) Time Calls Avg Min Max Name0.47% 50.343ms 21318 2.3610us 1.6960us 49.216us Foam::reduce_C_5(double*,double*,int)
25
Time(%) Time Calls Avg Min Max Name0.47% 50.761ms 523 97.057us 5.3120us 1.0682ms void thrust::system::cuda::detail::bulk_::detail::launch_by_value<unsigned
int=0, thrust::system::cuda::detail::bulk_::detail::cuda_task<thrust::system::cuda::detail::bulk_::parallel_group<thrust::system::cuda::detail::bulk_::concurrent_group<thrust::system::cuda::detail::bulk_::agent<unsigned long=1>, unsigned long=0>, unsigned long=0>, thrust::system::cuda::detail::bulk_::detail::closure<thrust::system::cuda::detail::for_each_n_detail::for_each_kernel, thrust::tuple<thrust::system::cuda::detail::bulk_::detail::cursor<unsigned int=0>, thrust::zip_iterator<thrust::tuple<thrust::detail::normal_iterator<thrust::device_ptr<Foam::Vector<double> const >>, thrust::detail::normal_iterator<thrust::device_ptr<Foam::Vector<double> const >>, thrust::detail::normal_iterator<thrust::device_ptr<double>>, thrust::null_type, thrust::null_type, thrust::null_type, thrust::null_type, thrust::null_type, thrust::null_type, thrust::null_type>>, thrust::detail::wrapped_function<thrust::detail::binary_transform_functor<Foam::dotOperatorFunctor<Foam::Vector<double>, Foam::Vector<double>, double>>, void>, unsigned int, thrust::null_type, thrust::null_type, thrust::null_type, thrust::null_type, thrust::null_type, thrust::null_type>>>>(unsigned long=1)
CUDA
Thrust

新しいGPU版OpenFOAM開発へ最新のOpenFOAMをベースに開発開発の方針、特徴
GPU実装はすべてCUDAメインループ内の処理は全てGPUで処理GPUDirect RDMA転送に対応
現在のstatus代表的なソルバをCUDAで実装本発表内容を再現することから
目標高速な大規模実行の実現GPUを用いた大規模アプリに適用しうる知見の蓄積
26

GPUでの話題 まとめGPU対応OpenFOAM, RapidCFDの性能評価と最適化を行った
総和計算のCUDAによる実装で、無駄なメモリ確保・解放コストを削減GPU単体では3.3→4.4倍高速に(CPU比較)複数GPUでのスケーリング性能は最大で2倍改善強スケーリングでの通信ボトルネック解消にはGPUDirect RDMA転送が有効
新しいGPU版OpenFOAM開発へ
27

メニーコア:Intel Xeon Phi KNL
28
項目 内容HW KNL搭載PCクラスタ CX6000M1/CX1640M1x4
ノード数 4モード設定 flat/cache/MCDRAM + Quadrant/AlltoAll/SNC2/SNC4CPU Intel Xeon Phi 7250[3TFLOPS, 1.4GHz, 68core]
Intel Omni-PathSW C++/Fortran Icc 17.0.1
MPI Intel MPI 2017 update 1コンパイルオプション -O3 -xMIC-AVX512
AP OpenFOAM 2.3.1(RIST最適化版)解析ソルバ pimpleFoam
解析データ 強スケーリング 240x130x96 cells/1-64processros
支援前の基礎調査としてRIST所有のKNL搭載PCクラスタで性能評価

メモリ モード変更
29
OpenFOAM 2.3.1 channelReTau110DRAMDRAM cachecache MCDRAMMCDRAM
PCG,前処理DIC
DRAM設定時、並列数を増加させると演算処理部の時間が急増、スケーリング性能劣化
1ノード内並列数の増加(16→32→64PE)参考:京
メモリモード変更(DRAM→cache/MCDRAM)でメモリモード変更(DRAM→cache/MCDRAM)で3倍弱高速に

クラスターモード+Hyper-threading
30
• All-to-all (a2a): Uniform mesh interconnect
• Quadrant (quad): Four virtual address spaces (one NUMA domain)
• Sub-NUMA-2 (snc2): Two distinct NUMA domains
• Sub-NUMA-4 (snc4): Four distinct NUMA domains
KNLでの最速クラスターモード及びHyper-threading効果を検証
全て 1node
各種モード(quad,a2a,snc2or4/flat,cache等)×Hyper-threading
最速:snc2/flat+128mpi[64corex2HT]最大で17%のコスト削減
HT 2HT無 HT 4
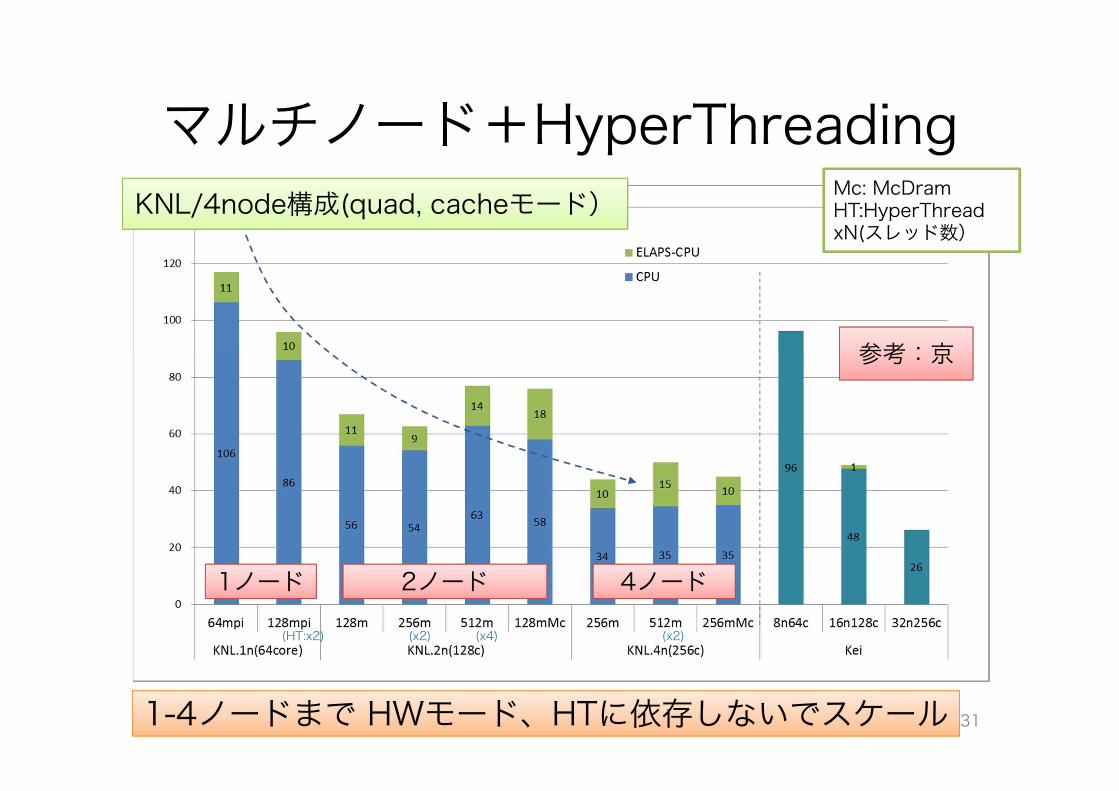
マルチノード+HyperThreading
31
(HT:x2) (x2) (x4) (x2)
Mc: McDramHT:HyperThreadxN(スレッド数)
KNL/4node構成(quad, cacheモード)
1-4ノードまで HWモード、HTに依存しないでスケール
2ノード1ノード 4ノード
参考:京

KNLでの話題 まとめKNL4ノードでのOpenFOAMの性能評価を実施メモリモード変更(DRAM→cache/MCDRAM)3倍弱高速にクラスターモード・HTの設定は最大で17%影響
Quad, SNC2, HT ON(2)が良好4ノードまではクラスターモード・HTの設定に依存しないでスケーリングする
32

まとめRISTは「京」を中核とするHPCIの高度化を支援しています支援を通じたOpenFOAMのGPU・メニーコア対応について紹介しました
GPU:高速化(2倍)とGPU版OpenFOAM構築に向けた取り組みについて
メニーコア:メモリ設定、HWモード、HT、スケーリング性能についての基礎調査結果
33

RISTの高度化支援
34
詳細な評価と分析カーネル・APIレベル
(マイクロ秒)
全て無料 ワンストップ窓口が対応
利用の始まりから終わりまで 幅広い内容に対応
ざっくりと評価プロセスレベル(秒)
コードの改善へCUDA実装も対応
//====dummy code=====template<class Type>Type minMagSqr(const gpuList<Type>& f){
if (f.size()){
gpuList<scalar>& ms (f.size());
thrust::transform(
f.begin(),f.end(),ms.begin(),magSqrUnaryFunctionFunctor<Type,scalar>()
);
typename thrust::device_vector<scalar>::iterator iter = thrust::min_element(ms.begin(), ms.end());
unsigned int position = iter - ms.begin();
return f.get(position);}else{
return pTraits<Type>::rootMax;}
}
template<class Type>scalar sumProd(const gpuList<Type>& f1, const gpuList<Type>& f2){
if (f1.size() && (f1.size() == f2.size())){
fapp_start("sumProd",1,2);gpuList<scalar> tmp(f1.size());
thrust::transform(
//=====dummy code=====
thrust::reduce();
1行
260行
RIST 高度化支援 検索

謝辞本発表の内容は,HPCIシステム利用研究課題「流体・粒子の大規模連成解析を用いた竜巻中飛散物による建物被害の検討(課題番号:hp170055),課題代表者:菊池浩利(清水建設(株)技術研究所)」の高度化支援に基づくものです.
35