画像を説明する多言語音声データを利用した クロスモーダル探索 ·...
TRANSCRIPT

Copyright©2019 NTT corp. All Rights Reserved.
NTT コミュニケーション科学基礎研究所メディア情報研究部
大石康智,木村昭悟,川西隆仁,柏野邦夫
画像を説明する多言語音声データを利用したクロスモーダル探索
Spoken Language Systems Group,MIT Computer Science and Artificial Intelligence Laboratory
David Harwath, James Glass

2Copyright©2019 NTT corp. All Rights Reserved.
はじめに
画像と多言語音声キャプションペアを利用した知識獲得
① 教師なしで画像領域と音声区間を対応づける(視聴覚知識獲得)
画像
日本語音声キャプション
英語音声キャプション
(少し雲のある青空の下,緑の木々に囲まれた屋外に,年代物の蒸気機関車が止まっている)
(In this picture, we can see multiple steam engines and railroad tracks can also see lush green trees behind them with the clear blue skies overhead)
② 教師なしで音声区間を対応づける(翻訳知識獲得)
①視聴覚知識
② 翻訳知識
(ラベル無し)
(書き起こし無し)
(書き起こし無し)
3Copyright©2019 NTT corp. All Rights Reserved.
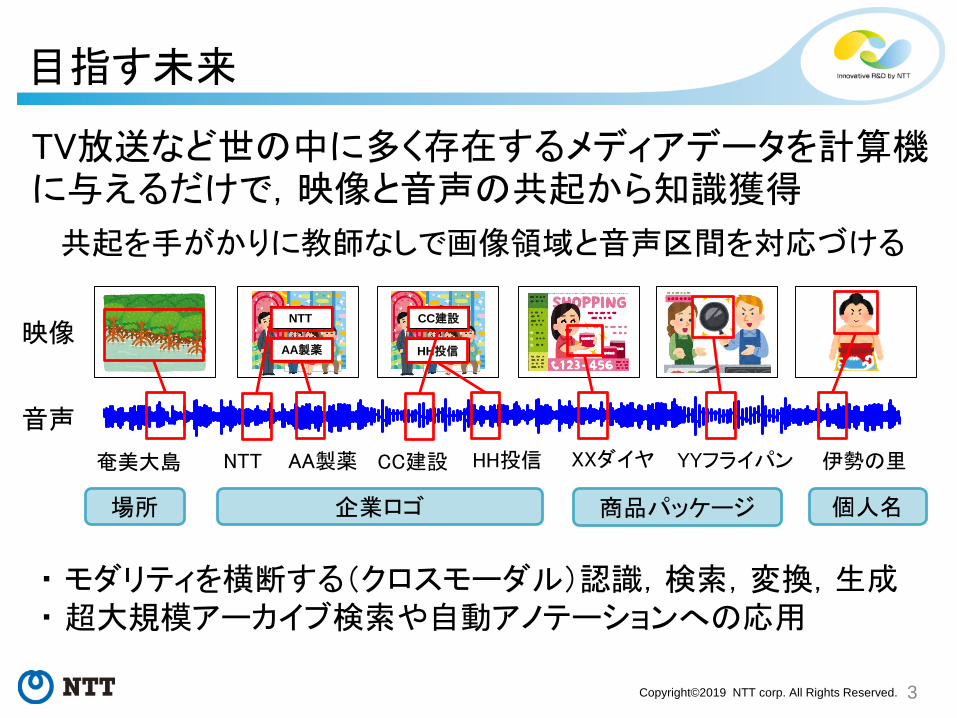
目指す未来
TV放送など世の中に多く存在するメディアデータを計算機に与えるだけで,映像と音声の共起から知識獲得
映像
音声
NTT CC建設
共起を手がかりに教師なしで画像領域と音声区間を対応づける
奄美大島 NTT AA製薬 CC建設 HH投信 XXダイヤ YYフライパン 伊勢の里
場所 企業ロゴ 商品パッケージ 個人名
・ モダリティを横断する(クロスモーダル)認識,検索,変換,生成・ 超大規模アーカイブ検索や自動アノテーションへの応用
HH投信AA製薬

4Copyright©2019 NTT corp. All Rights Reserved.
自然言語と音声言語
少し雲のある青空の下,緑の木々に囲まれた屋外に,年代物の蒸気機関車が止まっている
自然言語による画像説明文生成,質問応答の先行研究は多いが,音声言語を利用した研究は少ない [Harwath+2016]
自然言語
音声言語
・ 音声言語はより連続的でセグメンテーションが難しく,話者性や発話様式などを含むため,自然言語とは異なる難しさを持つ
・ 将来的に,少数言語で文字をもたない言語へ対象を広げるためにも音声言語に着目する

5Copyright©2019 NTT corp. All Rights Reserved.
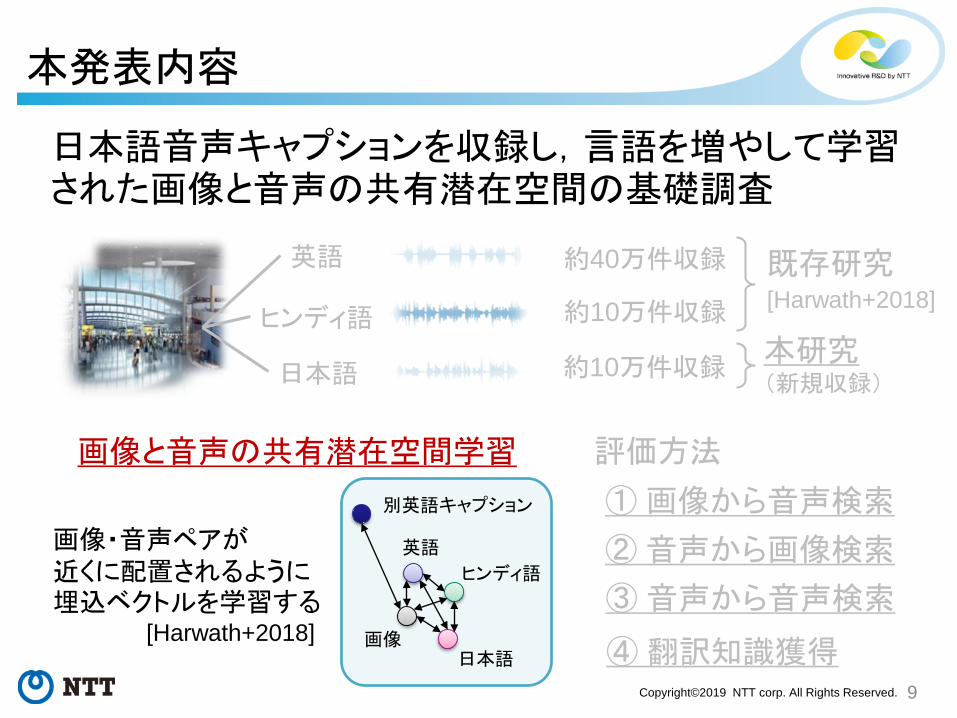
本発表内容
日本語音声キャプションを収録し,言語を増やして学習された画像と音声の共有潜在空間の基礎調査
英語
ヒンディ語
日本語
既存研究
約10万件収録
約40万件収録
約10万件収録
本研究(新規収録)
① 画像から音声検索
画像と音声の共有潜在空間学習
[Harwath+2018]
② 音声から画像検索
③ 音声から音声検索
④ 翻訳知識獲得
画像・音声ペアが近くに配置されるように埋込ベクトルを学習する
[Harwath+2018]
ヒンディ語
英語
画像日本語
別英語キャプション
評価

6Copyright©2019 NTT corp. All Rights Reserved.
本発表内容
日本語音声キャプションを収録し,言語を増やして学習された画像と音声の共有潜在空間の基礎調査
英語
ヒンディ語
日本語
既存研究
約10万件収録
約40万件収録
約10万件収録
本研究(新規収録)
① 画像から音声検索
画像と音声の共有潜在空間学習
[Harwath+2018]
② 音声から画像検索
③ 音声から音声検索
④ 翻訳知識獲得
画像・音声ペアが近くに配置されるように埋込ベクトルを学習する
[Harwath+2018]
ヒンディ語
英語
画像日本語
別英語キャプション
評価

7Copyright©2019 NTT corp. All Rights Reserved.
音声キャプションの収録
英語・ヒンディ語と日本語の収録方法の違い
英語・ヒンディ語 日本語
画像データ Places205画像データセット(※1)1枚の画像に対して1つの音声キャプションを収録
収録被験者Amazon
Mechanical Turk音声収録経験者からなる
クラウドソーシング
収録方法 PC収録 PC or スマートフォン収録
発話形態 画像に写るモノや情景を2~3文程度で自由発話
収録音声の採用判断基準
8単語以上,音声認識されること
検聴作業を実施長さが短かったり,画像に無関係なこと
を発話していたら再収録
(※1) 205クラスのシーン(場所)からなる約2.5Mの画像集合

8Copyright©2019 NTT corp. All Rights Reserved.
音声キャプション収録の結果
英語 ヒンディ語 日本語
音声キャプション数 403,384件 114,771件 98,555件
収録被験者数 2,683名 112名 303名
平均音声長 9.5秒 11.4秒 19.7秒
平均単語数(※1) 19.3語 20.4語 44.6語
・ 日本語は発話長の長い音声が収録された
・ 同じ画像を説明する異なる言語の音声キャプションの内容は必ずしも対訳にならない
(※1) 平均単語数は音声キャプションを音声認識して書き起こされた単語を数え上げた
9Copyright©2019 NTT corp. All Rights Reserved.
本発表内容
日本語音声キャプションを収録し,言語を増やして学習された画像と音声の共有潜在空間の基礎調査
英語
ヒンディ語
日本語
既存研究
約10万件収録
約40万件収録
約10万件収録
本研究(新規収録)
① 画像から音声検索
画像と音声の共有潜在空間学習
[Harwath+2018]
② 音声から画像検索
③ 音声から音声検索
④ 翻訳知識獲得
画像・音声ペアが近くに配置されるように埋込ベクトルを学習する
[Harwath+2018]
ヒンディ語
英語
画像日本語
別英語キャプション
評価方法

10Copyright©2019 NTT corp. All Rights Reserved.
画像と音声の共有潜在空間の学習
英語
ヒンディ語
日本語
4つ組以外の音声
画像CNN (Pre-trained VGG16)
英語CNN
ヒンディ語CNN
日本語CNN
画像と音声の
共有潜在空間
meanpooling
4つ組以外の
音声/画像
幅:14高:14
時間:128 (10秒)
時間:128 (10秒)
時間:128 (10秒)
チャネル
:10
24チャネル:
1024
チャネル
:10
24チャネル
:10
24 meanpooling
meanpooling
meanpooling
1024
1024
1024
1024
後半の可視化で利用する

11Copyright©2019 NTT corp. All Rights Reserved.
共有潜在空間の学習の損失関数
損失関数: Margin ranking criterion
: 基点となる埋込ベクトル (Anchor) : マージン(ハイパーパラメータ )
「ペアの埋め込みベクトル間の類似度はペアでない埋め込みベクトル間の類似度よりも少なくともマージン分大きくなるように」
類似度は「内積」とする
: Anchorとペアになる埋込ベクトル (Positive)
: Anchorとペアにならない埋込ベクトル (Negative)
: ミニバッチサイズ( )
※Negativeはミニバッチの中からランダムに選択
12Copyright©2019 NTT corp. All Rights Reserved.
本発表内容
日本語音声キャプションを収録し,言語を増やして学習された画像と音声の共有潜在空間の基礎調査
英語
ヒンディ語
日本語
既存研究
約10万件収録
約40万件収録
約10万件収録
本研究(新規収録)
① 画像から音声検索
画像と音声の共有潜在空間学習
[Harwath+2018]
② 音声から画像検索
③ 音声から音声検索
④ 翻訳知識獲得
画像・音声ペアが近くに配置されるように埋込ベクトルを学習する
[Harwath+2018]
ヒンディ語
英語
画像日本語
別英語キャプション
評価

13Copyright©2019 NTT corp. All Rights Reserved.
評価実験
評価方法
使用データ
・ 学習データ:97,555件の画像,英語・ヒンディ語・日本語音声キャプション
・ 評価データ:1,000件の画像,英語・ヒンディ語・日本語音声キャプション
①クロスモーダル探索:以下の3点をRecall@10による評価
②画像に対応づく音声区間の可視化
③異なる言語の翻訳知識の可視化
・ 画像から音声検索(image2speech)
・ 音声から画像検索(speech2image)
・ 音声から別言語の音声検索(English2Japanese 等)
画像埋め込みベクトルと,音声埋め込みベクトルの時系列の内積を図示
異なる言語でペアとなる音声埋込ベクトルの時系列間の内積(類似度行列)を図示
14Copyright©2019 NTT corp. All Rights Reserved.英語 ヒンディ語 日本語
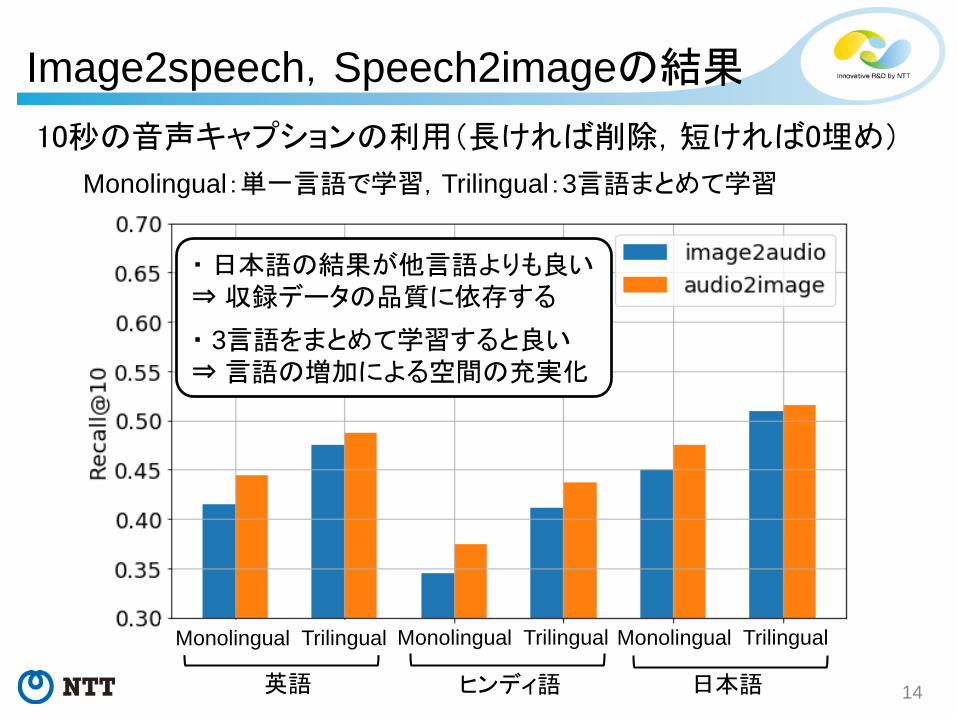
Image2speech,Speech2imageの結果
10秒の音声キャプションの利用(長ければ削除,短ければ0埋め)
・ 日本語の結果が他言語よりも良い⇒ 収録データの品質に依存する
・ 3言語をまとめて学習すると良い⇒ 言語の増加による空間の充実化
Monolingual Trilingual Monolingual Trilingual Monolingual Trilingual
Monolingual:単一言語で学習,Trilingual:3言語まとめて学習

15Copyright©2019 NTT corp. All Rights Reserved.英語/日本語 日本語/ヒンディ語 ヒンディ語/英語
条件1 条件2 条件3 条件1 条件2 条件3 条件1 条件2 条件3
Speech2speechの結果
3つの条件を評価 (条件1:画像を使わない学習,条件2:異なる言語の音声を近づけない学習,条件3:画像かつ異なる言語の音声間近づける学習)

16Copyright©2019 NTT corp. All Rights Reserved.英語/日本語 日本語/ヒンディ語 ヒンディ語/英語
条件1 条件2 条件3 条件1 条件2 条件3 条件1 条件2 条件3
Speech2speechの結果
・ 画像-音声検索に比べてRecallが低下する⇒ 異言語の音声キャプションが必ずしも対訳になっていないため。それでも画像がアンカー(中間言語)として,音声同士を対応付ける
3つの条件を評価 (条件1:画像を使わない学習,条件2:異なる言語の音声を近づけない学習,条件3:画像かつ異なる言語の音声間近づける学習)

17Copyright©2019 NTT corp. All Rights Reserved.
画像に対応づく音声区間の可視化 1/2
空港の様子です。天井がアーチ状になった空港を中から写しています。床面は銀色をし
ています。所々に黄色い色をした看板が立っていて、沢山の人が空港を利用しています。
屋内のスケート施設の様子で、スケートをしている人が何人もいます。手前には男の人と女の人が手をつないで男の人がリードしているように見えます。手前には子供がいます。
空港の入り口。外は暗くなっており、街灯がともっている。中にはまばらに人がいるようだ。
探索結果1位(正解)
[sec.]
探索結果2位
探索結果3位
内積
内積
内積

18Copyright©2019 NTT corp. All Rights Reserved.
画像に対応づく音声区間の可視化 2/2
男性がいます。髪の毛は短いです。歯を見せて笑っています。男性はスーツを着ています。
黒いネクタイをしています。男性は足を組んでいます。
男性がいます。男性は、黒い野球帽子をかぶっています。
右手にグローブをつけています。男性は野球ボールを左手に持ち振りかぶっています。
男の人が絵を描いている。絵はカラフル。男の人は半そでにチェックのグレーの服を着ている。
探索結果1位
[sec.]
探索結果2位
探索結果3位(正解)
内積
内積
内積

19Copyright©2019 NTT corp. All Rights Reserved.
獲得した翻訳知識の可視化 1/2A
man
and
a w
oman
dre
ssed
up
dan
cing
on th
e ru
g
男性と女性が社交ダンスを踊っている。女性は男性の肩に手を置き、男性は女性の背中に手をまわしている。女性は黒いひざ丈のワンピースに黒いストッキングをはいている。 男性は黒いシャツに黒いパンツをはいている。
・ 異なる言語でペアとなる音声キャプションの埋込ベクトルの時系列間の内積(類似度行列)を算出
・言語間の対応関係(色の濃い部分)

20Copyright©2019 NTT corp. All Rights Reserved.
獲得した翻訳知識の可視化 2/2S
tairs
lead
ing
up to
dou
ble
woo
den
door
s in
a b
rick
build
ing
手前に階段が写っていて、階段を上ると、えー、一つの大きな木でできたドアが、えー、写っている。家は、えー、赤いレンガでできていて落書きのようなものも少し見られる。
・ 異なる言語でペアとなる音声キャプションの埋込ベクトルの時系列間の内積(類似度行列)を算出
・言語間の対応関係(色の濃い部分)

21Copyright©2019 NTT corp. All Rights Reserved.
まとめ
画像を説明する多言語音声データを利用したクロスモーダル探索
① 画像の内容を説明する音声のペアデータを収集
③ 画像と音声の相互探索(クロスモーダル探索)による評価と知識獲得の可視化
・ クラウドソーシングを利用して新たに日本語音声キャプションを収録
② 画像領域と音声言語の対応関係を学習
・ Margin ranking criterionを利用して,4つ組(画像,英語・ヒンディ語・日本語
音声キャプション)のペアを近づけるように,音声と画像の潜在空間を学習
・ 収録品質が探索性能に影響すること(日本語の性能が高い)
・ 3言語で潜在空間を学習することの有効性
・ 音声キャプションに頻出する単語と画像が対応づけられる.
より詳細な「状態」や「程度」に関する画像と音声の関連付けは今後の課題