deep learningもくもくハッカソンまとめup用
TRANSCRIPT

h2o deep learningによる化学物質分析時の 保持時間予測モデル構築
Twi0er: @siero5335 5/23-‐24@東銀座ドワンゴ様
Deep learningもくもくハッカソン
PCBs (x+y = 1~10)

自己紹介 Twitter ID: @siero5335
仕事: 某大学で 化学物質曝露影響の解析 測定法の開発してます 専門: 環境化学、分析化学

PCBs (x+y = 1~10) コンデンサ
トランスの絶縁油 209種類の異性体
高次生物に高蓄積 発がん性・催奇形性
ポリ塩化ビフェニル (PCBs)

コンデンサ トランスの絶縁油
ポリ塩化ビフェニル (PCBs)
PCBs (x+y = 1~10)
*測定結果のイメージ図
保持時間 (RTs)
ピーク強度
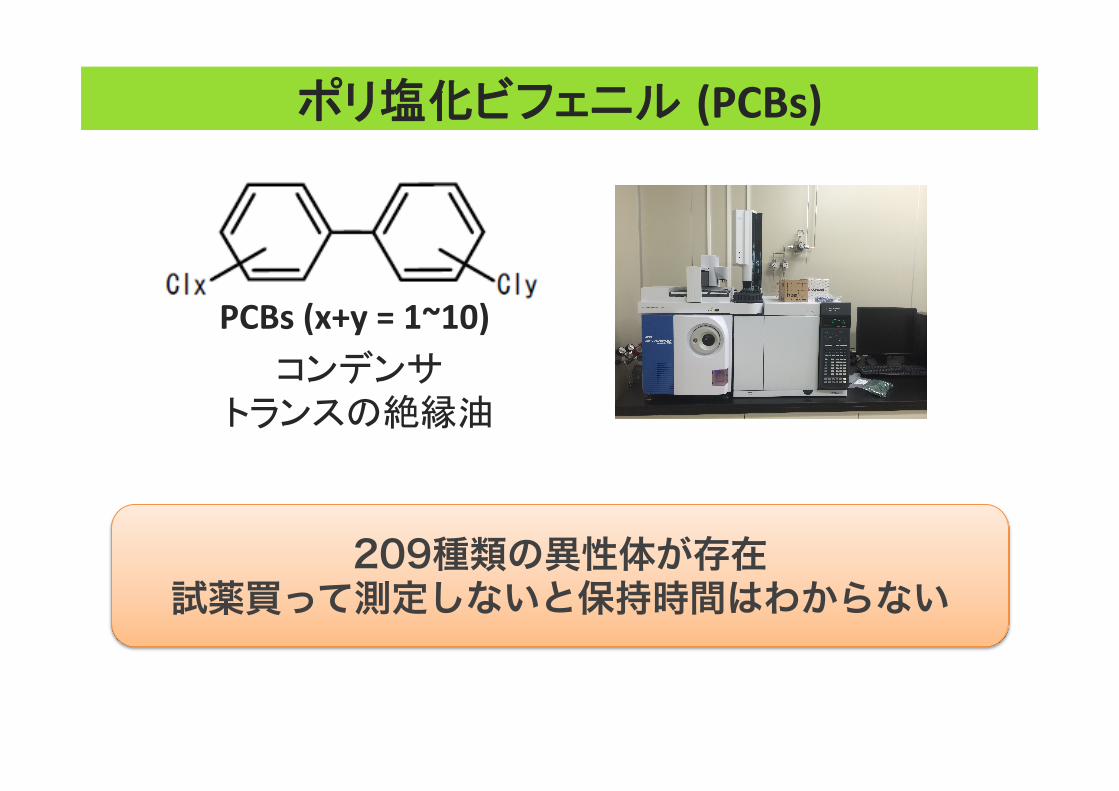
209種類の異性体が存在 試薬買って測定しないと保持時間はわからない
ポリ塩化ビフェニル (PCBs)
コンデンサ トランスの絶縁油
PCBs (x+y = 1~10)

物理化学パラメータからの溶出時間予測 化学物質の物理化学的なパラメータから 分析時の保持時間 (RTs) を予測するための手法 未知物質の保持時間を構造が似てる 化合物のパラメータを使って予測したい →未知物質が特定できると(分野的に)熱い

目 的
h2o deep learningによるPCBsのRTs予測モデル構築 19種のPCBsのRTsから190種のPCBsのRTsを予測

目 的
h2o deep learningによるPCBsのRTs予測モデル構築 19種のPCBsのRTsから190種のPCBsのRTsを予測 どんな試料からも検出される代表的な異性体+α
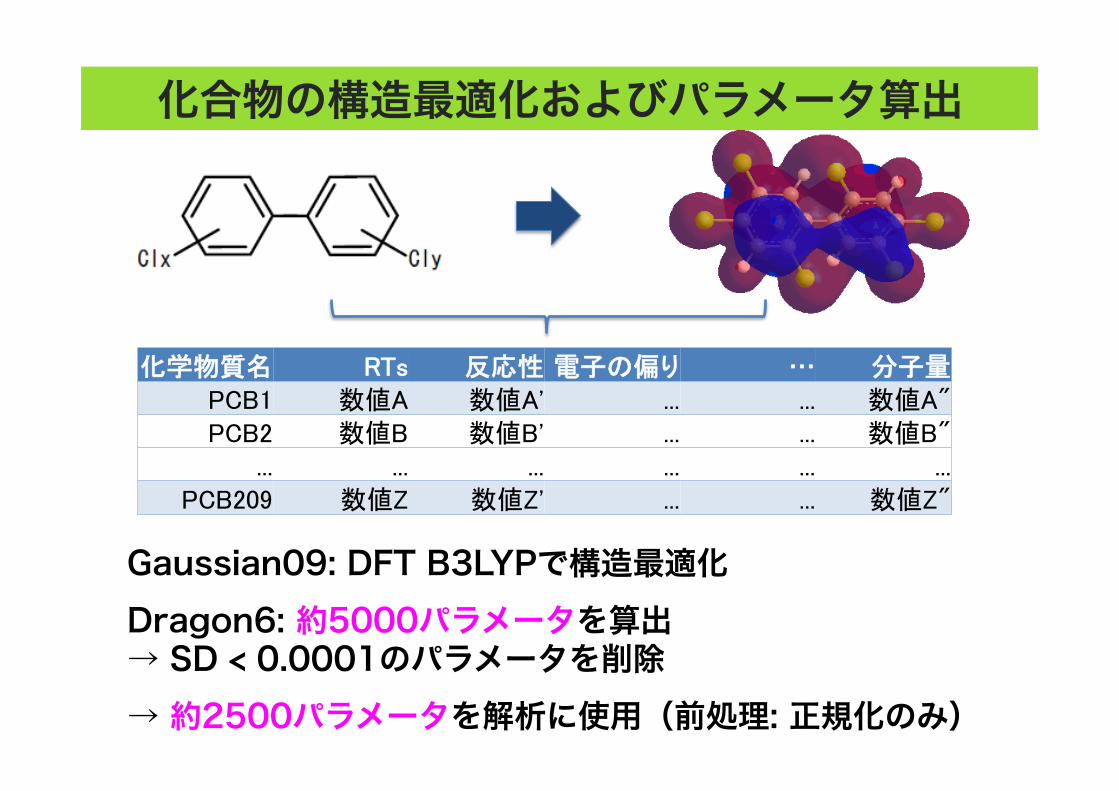
化合物の構造最適化およびパラメータ算出
化学物質名 RTs 反応性 電子の偏り … 分子量
PCB1 数値A 数値A' ... ... 数値A"
PCB2 数値B 数値B' ... ... 数値B"
... ... ... ... ... ...
PCB209 数値Z 数値Z' ... ... 数値Z"
Gaussian09: DFT B3LYPで構造最適化
Dragon6: 約5000パラメータを算出 → SD < 0.0001のパラメータを削除
→ 約2500パラメータを解析に使用(前処理: 正規化のみ)
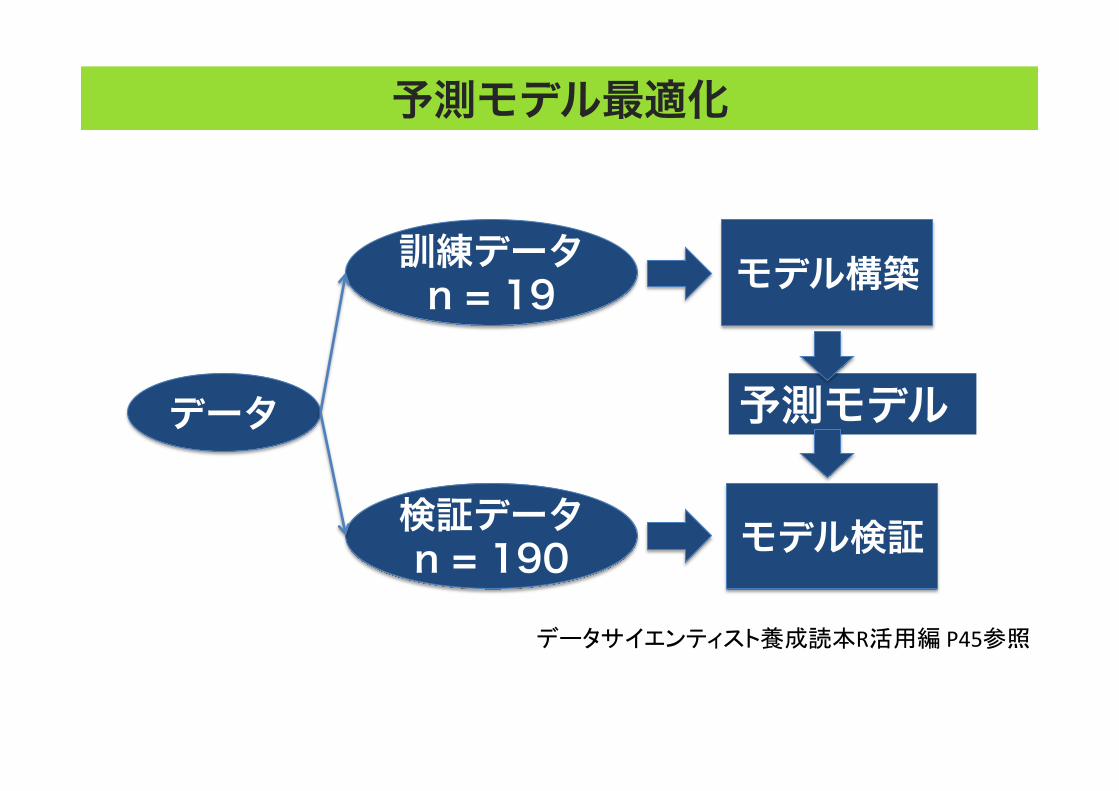
解析手法 (機械学習) 予測モデル最適化
データ
訓練データ n = 19
検証データ n = 190
モデル構築
モデル検証
予測モデル
データサイエンティスト養成読本R活用編 P45参照

結果

一番良いパフォーマンスが出た際のコード deeptest16 <-‐ h2o.deeplearning(x = setdiff(colnames(trainingPCBRT), c("ID","RT")), y = "RT", training_frame = trainingPCBRT, validaTon_frame = testPCBRT, acTvaTon = "RecTfier", hidden = c(50), epochs = 10000, loss = "Huber”)

一番良いパフォーマンスが出た際のコード
層を深くすればするほど精度低下... (Deepじゃなかった)
Dropoutや正則化項を取り除けば取り除くほど精度が上昇 他の活性化関数(Tanh, Maxout)は良くなかった
→今回くらいのデータサイズだと小細工しないほうが良い?
deeptest16 <-‐ h2o.deeplearning(x = setdiff(colnames(trainingPCBRT), c("ID","RT")), y = "RT", training_frame = trainingPCBRT, validaTon_frame = testPCBRT, acTvaTon = "RecTfier", hidden = c(50), epochs = 10000, loss = "Huber”)

H2ORegressionMetrics: deeplearning ** Reported on training data. **
MSE: とても良い R2 :とても良い H2ORegressionMetrics: deeplearning ** Reported on validaTon data. **
MSE:とても良い R2 : とても良い
結果
先行して実験してたElastic netの結果を上回る Training R2 = 割と良い, Training MSE = 割と良い Test R2 = 割と良い, Test MSE = 割と良い

deeptest_layer1 = h2o.deepfeatures(deeptest16, trainingPCBRT, layer = 1)
head(deeptest_layer1)
特徴量の確認
…が、生成された特徴量を見ても何が何やらさっぱり 正則化したわけでもないのに割とスパースになっていた
→保持時間に関係するパラメータは多くないということ?

Deepじゃなかった…とはいえ 自分のフィールドのデータセットに対しても十分適用できそう チューニングはシンプルなところから始めるほうがいい いきなりDropoutとか正則化とかをしても結局遠回りかも... 多層よりも単層からとりあえずやってみるほうがいい? 特徴量が何なのか確認するためには修行が足りなかった… AWS上でRstudio + h2o動かすまでの記録はblogに投稿済み http://statchiraura.blog.fc2.com/blog-entry-20.html
学び