Download - PPT Analyse de Donnes Mkg

jean-Claude Liquet 1
Analyse des données

jean-Claude Liquet 2
4 séances
1- Les données: nature, traitement quanti-quali. Analyse univarié et bivarié.
2- L’analyse de variance, l’analyse factorielle ACP AFC AFCM
3-Les méthodes explicatives : régression linéaire et multilinéaire, l’analyse structurelle des variables latentes.
4-Analyse discriminante. Analyse conjointe et analyse multidimensionnelle des similarités

jean-Claude Liquet 3
Bibliographie : analyse de données en marketing.Proposée par J.C. Liquet :
Audigier 1995 “ les études marketing ” Dunod fiches express.Bouroche et Saporta 1992 “ l’analyse des données ” P.U.F. Que sais je n=°1854.Cibois 1995 “ l’analyse factorielle ” Que Sais Je 2095.Baleo JN et al 2003 « Méyhodologie expérimentale Tech et DocBon , Gregory 1995 “ les techniques marketing ” Vuibert.Croutsche Jean-Jacques 1997 “ Pratique de l’Analyse des données ” Editions EskaDickes P et al 1994 “ la psychométrie” Puf. Foucart Thierry 1997 “ l’analyse de données ”presses universitaires de RennesEscoffier et Pagès 1988 “ analyses factorielles simples et multiples : objectifs, méthodes et interprétation ” Dunod.Escoffier et Pagès 1997 « Initiation aux traitements statistiques, méthodes, méthodologie » Presse Universitaire de Rennes.Evrad et Lemaire 1976 “ information et décision en marketing ” Dalloz.Fenelon 1992 “ qu’est ce que l’analyse des données ”, Lefonen.Gianelloni, Vernette 1994 “ étude de marché ” Vuibert.Giard 7ième ed 1995 “ statistique appliquée à la gestion ” Economica.Green,Tull 1974 “ recherche et décisions en marketing ”, Presses Universitaires de Grenoble.Hooley et Hussey 1994 “ quantitative methods in marketing ” The Dryden Press.Lagarde Jean de 1995(réedition) “ initiation à l’analyse de données ” DunodLadwein 1996 “ les études marketing ” Economica.Lambin 1993 “la recherche en marketing ” Ediscience.Liquet J C, Flambard S, Jean S 2003 « Cas d’analyse des données en marketing Tech et Doc»Moscarola. 1990 “ enquêtes et analyse des données ” Vuibert.Perrien Cherron 1984 “ recherches en marketing , méthodes de décision ” Gaëtan Morin.Pras, Evrad, Roux 1994 “ market ” VuibertS.P.S.S. manuels d’utilisation.

jean-Claude Liquet 4
Biblio suite
Roussel P et al 2002 « Méthodes d’équation structurelles: recherche et applications en gestion » Economica
Saporta 1990 “ probabilités, analyse des données et statistique ” éditions Technip.
Thiétart Alain et al. 1999 “Méthodes de recherche en management ” Dunod.
Vedrine J.P . 1991 “ Le traitement des données ” éditions d’organisation.
Vandercammen, Gauthy-Sinéchal 1999 « Recherche Marketing, outil fondamental du marketing » De Boeck Université
Volle M. 1989 “ analyse des données ” Economica.
Wonnacott. 1972, 4ième ed 1994. “ statistique ” Economica
La collection Sage et Amos user guide

jean-Claude Liquet 5
Origine des données
Données primaires Observation Expérimentation Enquête
Données secondaires Insee Organisme public Observatoire spécialisé (Xerfi etc.)

jean-Claude Liquet 6
Nature des données
Les données nominales Genre homme femme que l’on peut coder 0 et 1
Les données ordinales Relation d’ordre antisymétrie et transitivité
Les données quantitatives de ratio Y=aX
Les données quantitatives d’intervalle Y=aX +b (la température et les échelles de lickert
ou à différentiel sémantique)

jean-Claude Liquet 7
les échelles de Lickert ou à différentiel sémantique
Différentiel sémantiquePour vous le produit estAmer___1 __2 __3 __4 __5__ 6__ 7__ Doux Echelle de lickertLe produit que je viens de goûter est amerPas du tout Pas d’accord ni d’accord d’accord Tout à fait d’accord ni pas d’accord d’accord
/___1____/______2______/______3________/_____4_____/____5_/
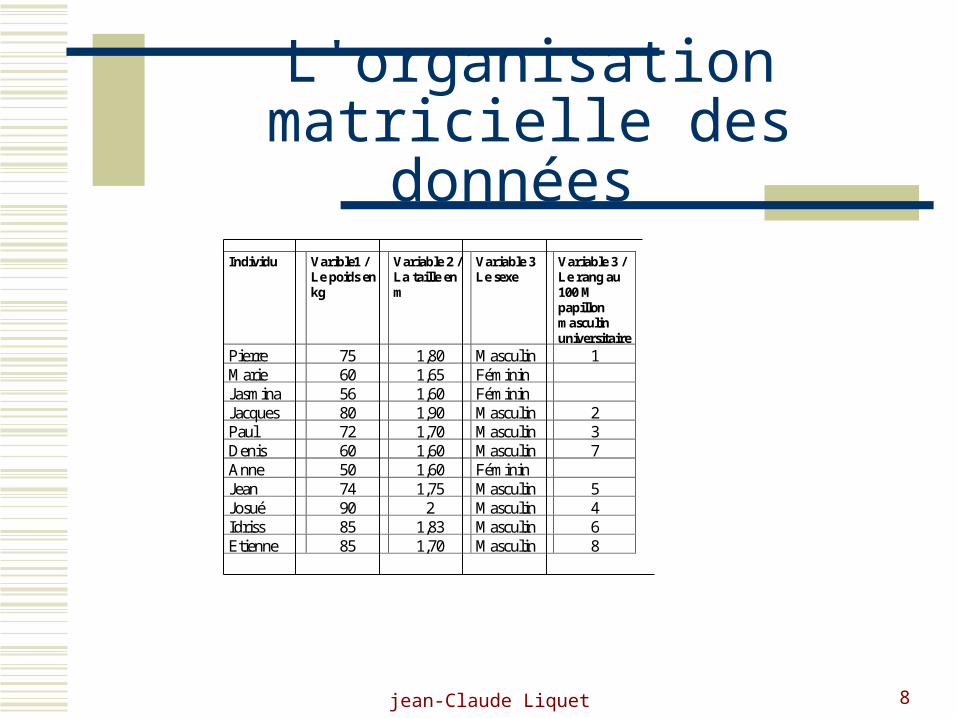
jean-Claude Liquet 8
L'organisation matricielle des données
Individu Varible1 / Le poids en kg
Variable 2 / La taille en m
Variable 3 Le sexe
Variable 3 / Le rang au 100 M papillon masculin universitaire
Pierre 75 1,80 Masculin 1 Marie 60 1,65 Féminin Jasmina 56 1,60 Féminin Jacques 80 1,90 Masculin 2 Paul 72 1,70 Masculin 3 Denis 60 1,60 Masculin 7 Anne 50 1,60 Féminin Jean 74 1,75 Masculin 5 Josué 90 2 Masculin 4 Idriss 85 1,83 Masculin 6 Etienne 85 1,70 Masculin 8

jean-Claude Liquet 9
L'analyse univariée ou tri à platVariables quantitatives
nxxn
i
1
élémentsdnombreleestn
iableladequelconqueélémentunestx
moyennelaestxoù
i
'
var
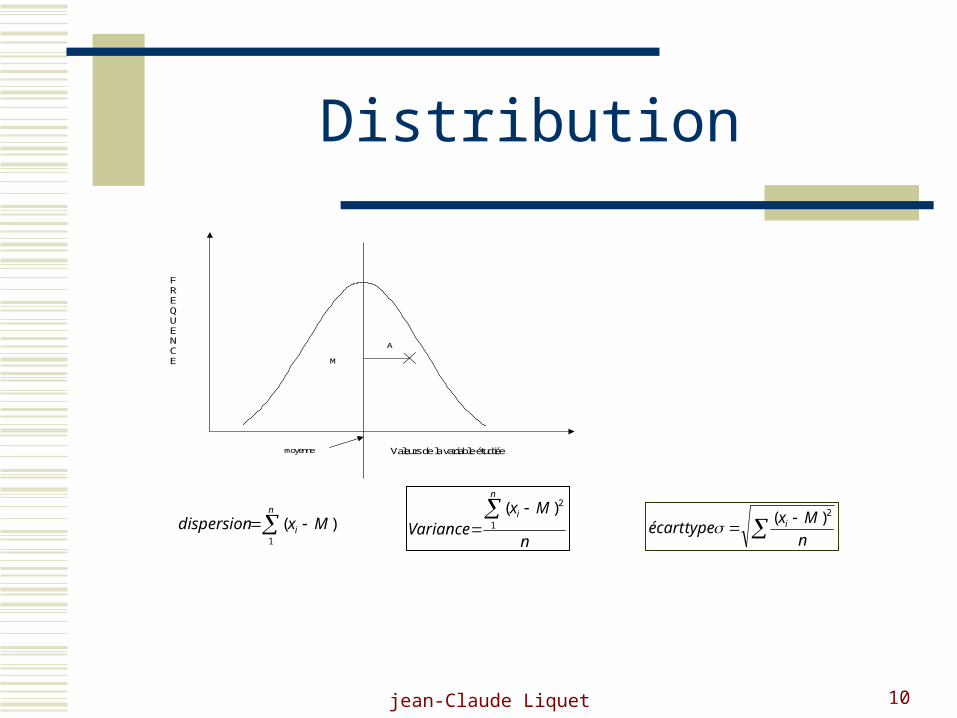
jean-Claude Liquet 10
Distribution
Variable étudiée
Courbe de Gauss
Fre
quence
moyenne
A
M
F R E Q U E N C E
Valeurs de la variable étudiée
n
i Mxdispersion1
)(n
MxVariance
n
i 1
2)(
n
Mxtypeécart i
2)(

jean-Claude Liquet 11
Propriétés de la loi normale
Variable étudiée
Courbe de GaussF
requence
68 % de la population entre - et +
95 % de la population entre - 2 et +2

jean-Claude Liquet 12
Les autres indicateurs de tendance centrale
La médiane : C'est la valeur de la variable
qui divise la population en deux sous populations d'effectif égal.
Le mode : C'est la valeur de la variable qui a la fréquence la plus importante.
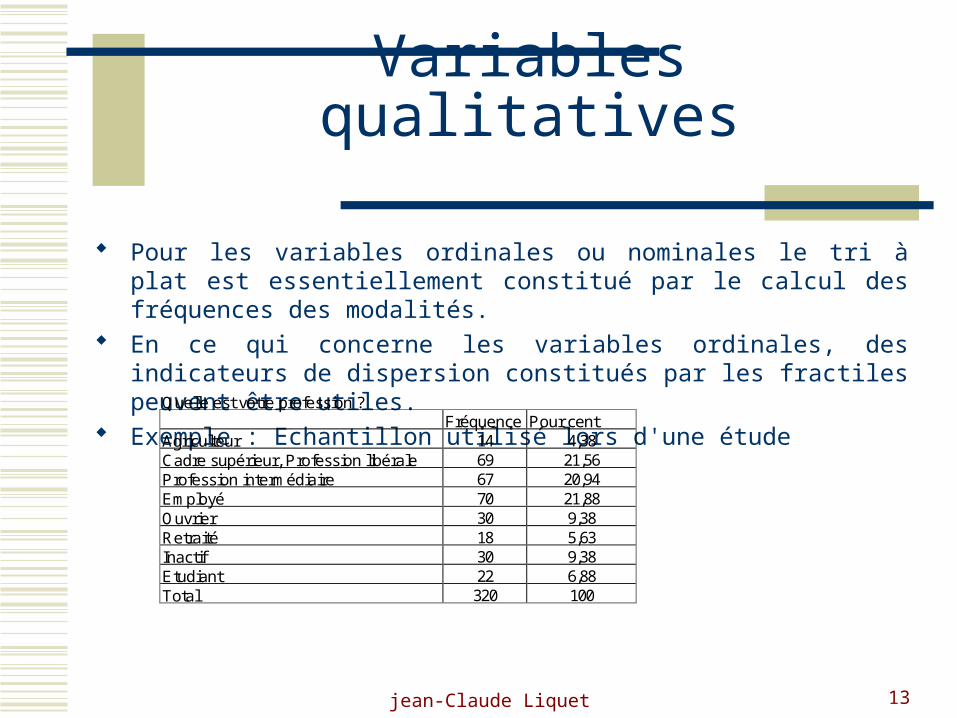
jean-Claude Liquet 13
Variables qualitatives
Pour les variables ordinales ou nominales le tri à plat est essentiellement constitué par le calcul des fréquences des modalités.
En ce qui concerne les variables ordinales, des indicateurs de dispersion constitués par les fractiles peuvent être utiles.
Exemple : Echantillon utilisé lors d'une étudeQuelle est votre profession ?
Fréquence Pour cent Agriculteur 14 4,38 Cadre supérieur, Profession libérale 69 21,56 Profession intermédiaire 67 20,94 Employé 70 21,88 Ouvrier 30 9,38 Retraité 18 5,63 Inactif 30 9,38 Etudiant 22 6,88 Total 320 100
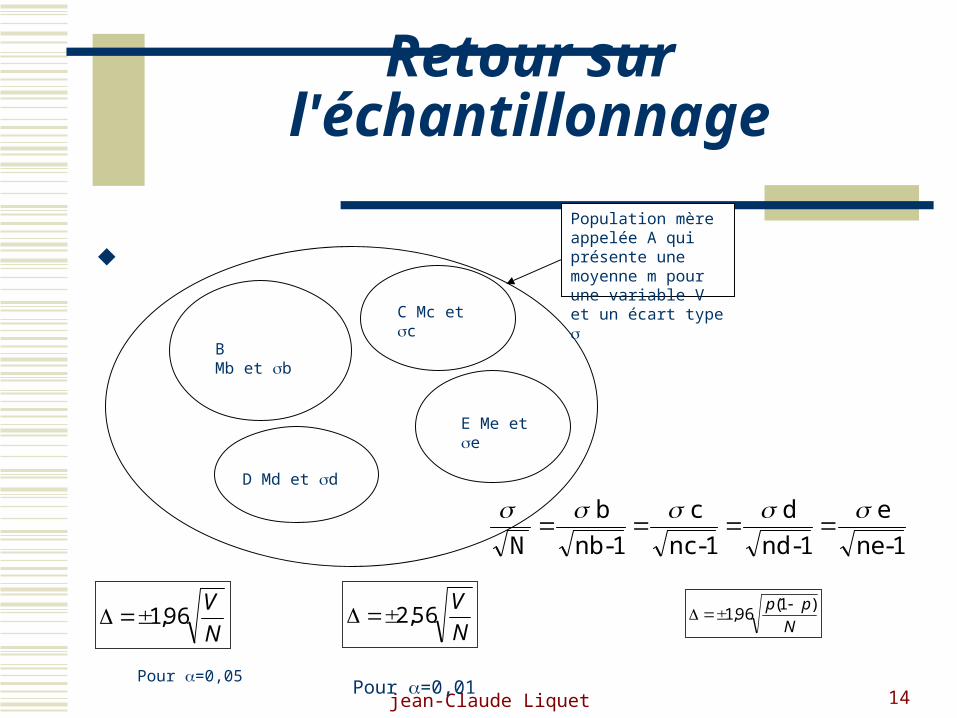
jean-Claude Liquet 14
Retour sur l'échantillonnage
BMb et b
Population mère appelée A qui présente une moyenne m pour une variable V et un écart type
C Mc et c
D Md et d
E Me et e
1-ne
e
1-nd
d
1-nc
c
1-nb
b
N
N
V96,1
N
V56,2
N
pp )1(96,1
Pour =0,05Pour =0,01

jean-Claude Liquet 15
Incertitude sur échantillonnage
Population 1/N Incertitude
100 0,01 0,1 400 0,0025 0,05 500 0,002 0,044
1000 0,001 0,031 40000 0,000025 0,005

jean-Claude Liquet 16
L'analyse bivariée descriptive ou tri croisé
Deux variables quantitativesY) de ypeX)(écart t de e(écart typ
Yet X blesdeux varia de CovarianceR
1-n
)(
1-n
)(
1n))((
R
i
21i
i
21i
i
2i1i
mymx
mymx
i
21i
i
21i
i2i1i
)()(
))((R
mymx
mymx
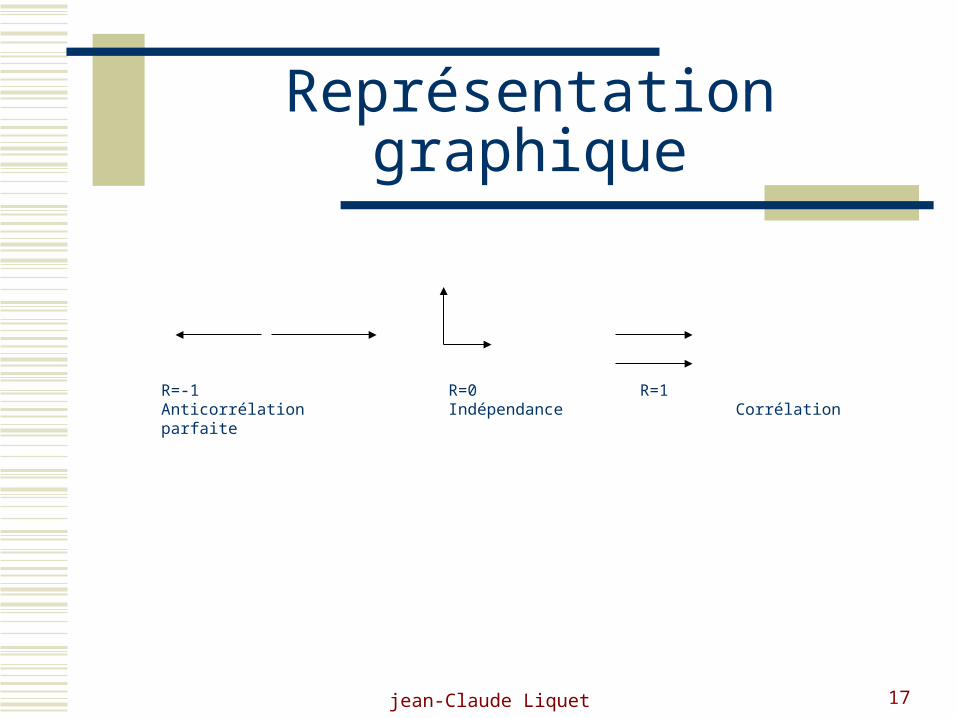
jean-Claude Liquet 17
Représentation graphique
R=-1 R=0 R=1Anticorrélation Indépendance Corrélation parfaite

jean-Claude Liquet 18
Deux variables qualitatives
Le but de l'analyse est de déterminer si deux variables qualitatives sont indépendantes ou dépendantes. Autrement dit, il s’agit de déterminer l’existence ou non d’un lien.
D'où les hypothèses suivantes. Ho : Les deux variables sont indépendantes H1 : Les deux variables sont dépendantes. Le test consiste à rejeter l'hypothèse Ho Le test le plus fréquemment utilisé est le test de Chi2.

jean-Claude Liquet 19
En colonne variable V1En ligne la variable V2
m1 m2 m3
L1 A B C
L2 D E F
l3 G H I
Tableau de contingence

jean-Claude Liquet 20
En colonne variable V1En ligne la variable V2
m1 m2 m3
L1 A' B' C'
L2 D' E' F'
l3 G' H' I'
Tableau des effectifs théoriques
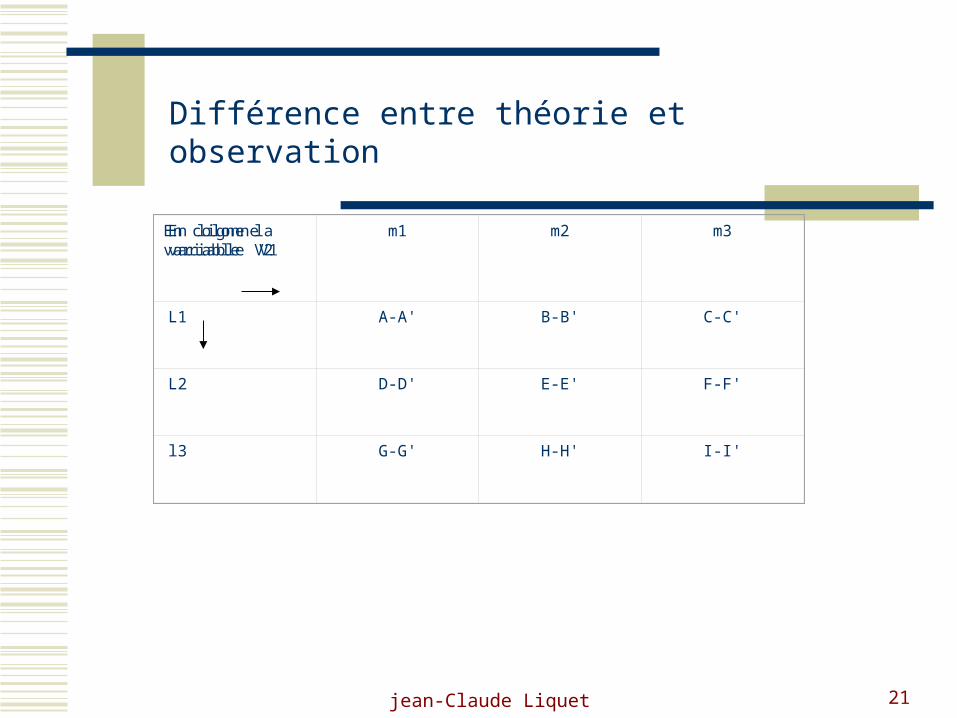
jean-Claude Liquet 21
En colonne variable V1En ligne la variable V2
m1 m2 m3
L1 A-A' B-B' C-C'
L2 D-D' E-E' F-F'
l3 G-G' H-H' I-I'
Différence entre théorie et observation

jean-Claude Liquet 22
En colonne variable V1En ligne la variable V2
m1 m2 m3
L1 (A-A')x(A-A') (B-B')x(B-B') (C-C')x(C-C')'
L2 (D-D')x(D-D') (E-E')x(E-E') (F-F')x(F-F')
l3 (G-G')x(G-G') (H-H')x(H-H') (I-I')x(I-I')
Carré des valeurs

jean-Claude Liquet 23
En colonne variable V1En ligne la variable V2
m1 m2 m3
L1 (A-A')x(A-A')/A' (B-B')x(B-B')/B' (C-C')x(CxC')/C'
L2 (D-D')x(D-D')/D' (E-E')x(E-E')/E' (F-F')x(F-F')F'
l3 (G-G')x(G-G')/G' (H-H')x(H-H')/H' (I-I')x(I-I')/I'
théoriqueeffectif
) théoriqueeffectif-observé (effectifji,
2
2
Carrés relatifs

jean-Claude Liquet 24
En colonne variable V1
En ligne la variable V2
m1 m2 m3 Somme des lignes
L1 A B C A+B+C
L2 D E F D+E+F
l3 G H I G+H+I
Somme des colonnes
A+D+G B+E+H C+F+I N
A' = (la probabilité d'appartenir à la première ligne x par la probabilité d'appartenir à la première colonne)X N
NN
GDA
N
CBAA'

jean-Claude Liquet 25
Ce calcul est réitéré autant de fois qu'il y a de cellules.Si les deux variables sont indépendantes, le résultat apporte peu de sens pour l'étude. Par contre si un lien existe, il faut expliquer le sens sous-jacent. C'est l'écart entre l’effectif théorique et l’effectif observé qui sera déterminant, les plus grands écarts permettront de déterminer les écarts de l'expérimentation à un contexte dû au hasard.
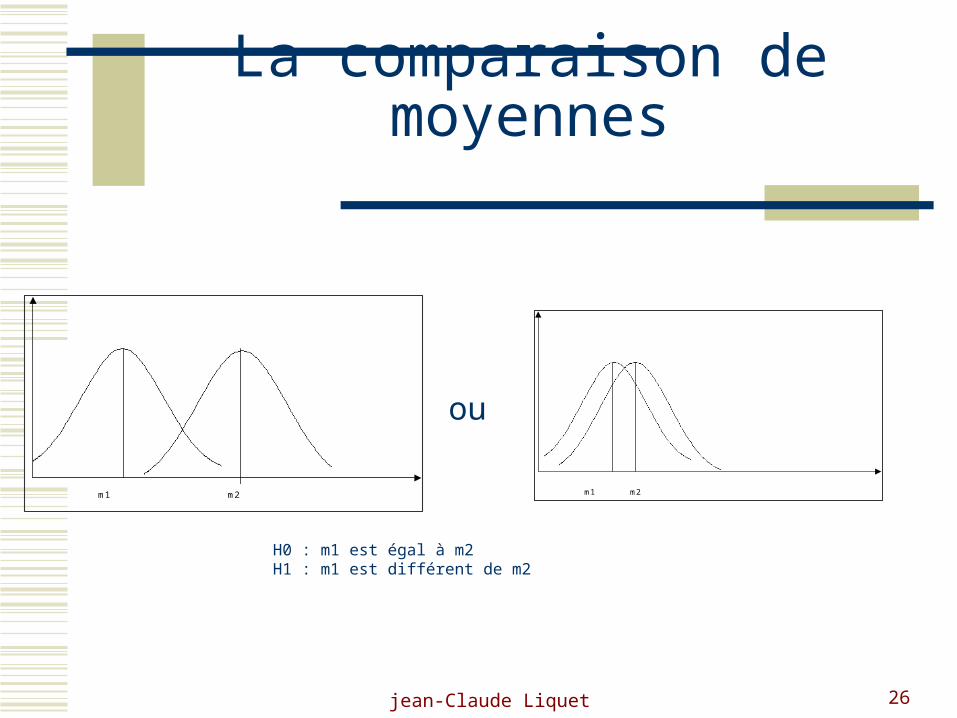
jean-Claude Liquet 26
La comparaison de moyennes
m1 m2 m1 m2
ou
H0 : m1 est égal à m2H1 : m1 est différent de m2

jean-Claude Liquet 27
Ce qui revient à calculer une valeur z qui sera comparée à la valeur du z de la loi normale centrée réduite au risque .
1n2) de e(écart typ
1n1) de e(écart typ
m2-m1
2
2
1
2
z
Dans le cas de deux proportions le calcul se fait de façon semblable
)n
1
n
1)(1(
p2-p1
21
pp
z21
2211
nn
pnpnp
Pour répondre au test il faut comparer ce z à la valeur limite de la table, autrement dit de vérifier au risque de 5% si z est supérieur à 1,96, car l'hypothèse de départ est la normalité des distributions

jean-Claude Liquet 28
L’analyse de variance
On cherche à comparer deux (ou plusieurs) expérimentations, c'est à dire à mettre en relation une série de résultats avec une autre série de résultats. Ce qui peut se traduire par l'expression " on recherche la relation entre une variable quantitative(les résultats) et une variable qualitative ( la première ou la deuxième mesure)".
Par exemple la couleur de l'emballage d'un paquet de lessive est-il un élément qui a de l'influence sur la quantité de vente ? Les quantités de vente constituent une variable quantitative, la couleur est qualitative même si elle est codée 1 ou 2 .
Comparer deux populations revient à comparer les moyennes d'une variable commune

jean-Claude Liquet 29
analyse à un facteur.
t a b l e a u d ' e x p é r i m e n t a t i o n . m o d a l i t é d u t r a i t e m e n t .
O b s e r v a t i o n n °
1 2 j k
1 Yj1
2 . . . . . . Y ij
I Yij
. . . N Y
nj
Y
ijn m
j .
Y N M
ij .

jean-Claude Liquet 30
Le modèle
Yij j ij
est la moyenne de l'ensemble des résultats
j est le coefficient du au traitement particulier, ainsi un traitement particulier s'écrit
j
ij
correspond à un facteur résiduel.
M est la grande moyenne, elle s'écrit : i j
ij
n.k
YM C'est à dire la somme de toutes les valeurs
du tableau divisée par le nombre de cases.

jean-Claude Liquet 31
Première grandeur caractéristique
Pour chacune des colonnes, c'est à dire pour chacune des modalités on peut calculer la moyenne
du traitement.
i
ijj n
Ym

jean-Claude Liquet 32
Deuxième grandeur caractéristique
C h a q u e r é s u l t a t c o n t e n u d a n s c h a c u n e d e s c a s e s d u t a b l e a u e s t u n e m e s u r e , l ' e n s e m b l e d e
l ' i n f o r m a t i o n d e t o u t e s c e s m e s u r e s p e u t ê t r e m i s s o u s l a f o r m e d e l a d i s p e r s i o n d e c e s m e s u r e s
a u t o u r d e l a m o y e n n e d e s m e s u r e s , l a d i s p e r s i o n e s t m e s u r é e i c i c o m m e l a s o m m e d e s d i s t a n c e s
c a r r é e s à l a m o y e n n e , n o t é e S C
i j
2ij M)(YSCT
L a d i s p e r s i o n d e s f a c t e u r s a u t o u r d e l a g r a n d e m o y e n n e c o n s t i t u e l a d i s p e r s i o n f a c t o r i e l l e .
j
2j M)(mn.SCF
C e t t e d i s p e r s i o n e s t a u s s i a p p e l é e d i s p e r s i o n e n t r e c o l o n n e s o u e n t r e m o d a l i t é s o u b e e t w e n .

jean-Claude Liquet 33
Troisième grandeur caractéristique
U n e t r o i s i è m e g r a n d e u r p e u t ê t r e d é f i n i e c ' e s t l a s o m m e d e s d i s p e r s i o n a u t o u r d e c h a c u n e d e s
m o d a l i t é s a p p e l é e a u s s i d i s p e r s i o n r é s i d u e l l e o u d i s p e r s i o n i n t r a o u d i s p e r s i o n w i t h i n ;
i j
2jij )m(YSCR
C e q u i r e v i e n t à c a l c u l e r l ’ e n s e m b l e d e s d i s p e r s i o n s d e c h a q u e m o d a l i t é a u t o u r d e s a p r o p r e
m o y e n n e e t e n s u i t e d ' a d d i t i o n n e r t o u t e s c e s d i s p e r s i o n s , o n a b i e n l a d i s p e r s i o n d e s r é s i d u s a u t o u r
d e s m o y e n n e s d e m o d a l i t é .

jean-Claude Liquet 34
L'équation d'analyse de variance.
SCT=SCF+SCR
. La dispersion est commode pour le raisonnement mais ce qui a une signification pour comparer des mesures c'est la variance, c'est à dire la dispersion ramenée à l'unidimensionnalité.
Le nombre de degrés de liberté doit être déterminé pour faire la liaison entre la dispersion et la variance.

jean-Claude Liquet 35
Retour à l’unidimensionnalité
La dispersion factorielle ou dispersion inter a été calculée à partir d'une relation entre les
différents facteurs, cette relation fait baisser d'une unité la dimension du ddl, c'est ainsi que pour
k facteurs le degré de liberté est k-1.
La dispersion résiduelle ou dispersion intra est une dispersion de toutes les mesures n.k autour
des moyennes au nombre de k : le nombre de degré de liberté est donc n.k-k ou N-k.
D'où les variances :
VF=SCF/(k-1)
VR=SCR/(N-k)

jean-Claude Liquet 36
Le test de Fischer.
On recherche si l'hypothèse nulle d'égalité des moyennes est vraie. Elle le sera si les données de
chaque colonne sont extraites d'une même loi de probabilité. Dans ce cas la variance factorielle
est approximativement égales à la variance résiduelle et donc on peut émettre la proposition
suivante :
L'hypothèse H0 sera retenu si le rapport F=VF/.VR est inférieur à la valeur de F au degré
de liberté près, qui est la limite de la signification.
Plus ce rapport est élevé 'au dessus du F limite) plus on s'éloigne de l'hypothèse nulle.

jean-Claude Liquet 37
Tableau récapitulatif
D'où le tableau de l'analyse d'e variance :
d.d.l. Somme des carrés
carrés moyens
F
Variance factorielle
k-1 SCF VF=SCF/K-1
variance résiduelle
N-k SCR VR=SCR/N-k
F=VF/VR
total N-1 SCT
F suit une loi de Fischer-Snedecor dans la mesure de trois conditions
Les traitements sont additifs
les observations sont indépendantes
Les résidus ont une distribution normale
Le F calculé à partir de la table précédente doit être comparé au F lu sur la table de Fisher-
Snedecor dans la colonne k-1 et la ligne N-k pour le seuil de risque accepté .

jean-Claude Liquet 38
Analyse à deux facteurs croisés.
Il est possible d'étendre le raisonnement précédent à plusieurs facteurs contrôlés, dans le cas
précédent on recherchait l'effet de la couleur d'un paquet de lessive par exemple sur les ventes,
maintenant on rajoute un facteur , la couleur. Il y a deux variables qualitatives.(par exemple A et
B)
On veut arriver à l'élaboration d'un modèle.
ij11jij1 εβαμY
Cette quantité est la vente de chacun des paquets de lessive ayant une couleur et une forme, c'est
à dire deux caractéristiques A et B.
j représente le résultat de la vente d'un paquet ayant la couleur j et 1 l'effet de la modalité 1 du facteur B

jean-Claude Liquet 39
Généralisation
L e t a b l e a u s e p r é s e n t e s o u s l a f o r m e s u i v a n t e : M o d a l i t é s d u f a c t e u r A
M o d a l i t é d u f a c t e u r B
1 2 j k A
1 Y j1
2 . . . . . . i Y I 1 Y ij Y Im
. . .
K B Y nj
Y K mij ij j
Y N Mij .
L ' é q u a t i o n d e d i s p e r s i o n s ' é c r i t :
S C T = S C F ( A ) + S C F ( B ) + S C R
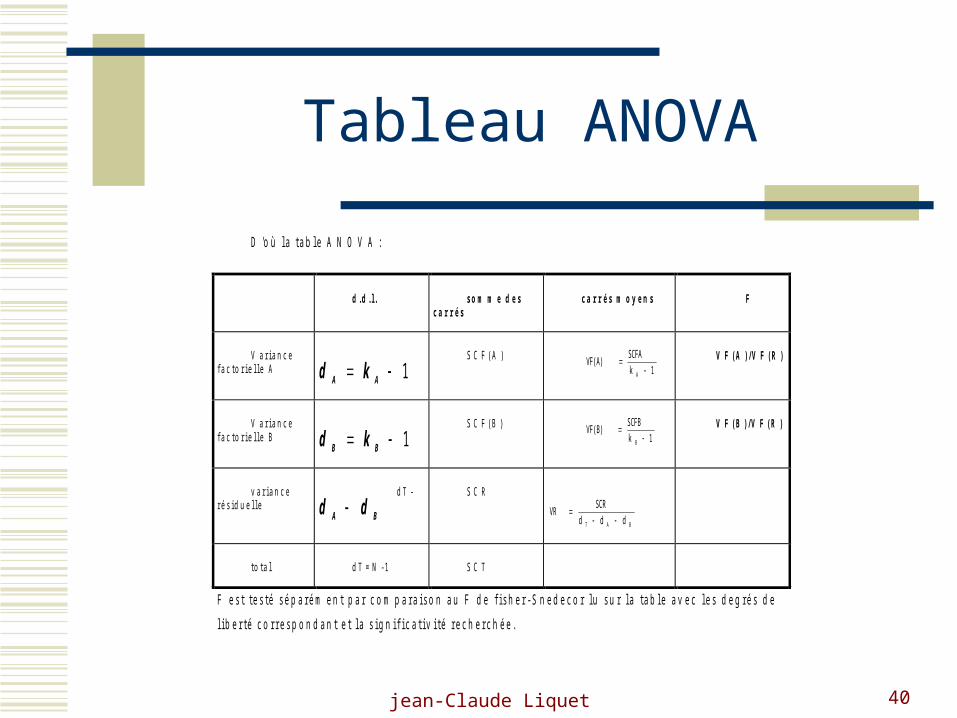
jean-Claude Liquet 40
Tableau ANOVA
D ' o ù l a t a b l e A N O V A :
d . d . l . s o m m e d e s c a r r é s
c a r r é s m o y e n s F
V a r i a n c e f a c t o r i e l l e A
d kA A 1
S C F ( A ) 1k
SCFAVF(A)
A V F ( A ) / V F ( R )
V a r i a n c e f a c t o r i e l l e B
d kB B 1
S C F ( B ) 1k
SCFBVF(B)
B V F ( B ) / V F ( R )
v a r i a n c e r é s i d u e l l e
d T -
d dA B
S C R
BAT ddd
SCRVR
t o t a l d T = N - 1 S C T
F e s t t e s t é s é p a r é m e n t p a r c o m p a r a i s o n a u F d e f i s h e r - S n e d e c o r l u s u r l a t a b l e a v e c l e s d e g r é s d e
l i b e r t é c o r r e s p o n d a n t e t l a s i g n i f i c a t i v i t é r e c h e r c h é e .

jean-Claude Liquet 41
l'interdépendance.
A i n s i l ' a n a l y s e d e v a r i a n c e p e r m e t d e t r a i t e r e n m ê m e t e m p s p l u s i e u r s f a c t e u r s , c e p e n d a n t n o u s
a v o n s f a i t l ' a p p r o x i m a t i o n d e l ' i n d é p e n d a n c e d e c e s f a c t e u r s .
U n e h y p o h è s e f o r t e e s t q u e l e m o d è l e e s t a d d i t i f
Y i j k j k i j k
C e p e n d a n t s ' i l y i n t e r a c t i o n o n p e u t a m é l i o r e r l e m o d è l e p a r u n t e r m e d e c o n f u s i o n :
Y i j k j k j k i j k ( )
I l s u f f i t d e c o n s i d é r e r c e t e r m e c o m m e l ' i n t r o d u c t i o n d ' u n n o u v e a u f a c t e u r e t l e c o n s i d é r e r a i n s i .
E x t e n s i o n à n f a c t e u r s .
P a r e x t e n s i o n o n p e u t r e p r e n d r e l ' e n s e m b l e d e s r a i s o n n e m e n t s p r é c é d e n t s q u i s ' a p p l i q u e n t à n
f a c t e u r s a v e c a u t a n t d e f a c t e u r s d e c o n f u s i o n l e m o d è l e g é n é r a l s ' é c r i t :
Y i j kl j k l j k j l ki j kl i j kl ( ) ( ) ( ) ( )

jean-Claude Liquet 42
Un exemple L’âge de mariage des hommes et des femmes
M o y e n n e s
Tableau de bord
Age lors de votre (premier) mariage
24,16 492 4,87
21,84 710 4,93
22,79 1202 5,03
Sexe du répondantHomme
Femme
Total
Moyenne N Ecart-type
O n e w a y
ANOVA
La vie est-elle excitante ou ennuyeuse ?
,383 1 ,383 1,029 ,311
370,652 995 ,373
371,035 996
Inter-groupes
Intra-groupes
Total
Sommedes carrés ddl
Moyennedes carrés F Signification

jean-Claude Liquet 43
Le salaire des hommes et des femmes
M o y e n n e s
Tableau de bord
Revenu du répondant
14,14 482 5,23
11,55 512 5,69
12,80 994 5,62
Sexe du répondantHomme
Femme
Total
Moyenne N Ecart-type
O n e w a y
ANOVA
Revenu du répondant
1670,855 1 1670,855 55,798 ,000
29705,282 992 29,945
31376,137 993
Inter-groupes
Intra-groupes
Total
Sommedes carrés ddl
Moyennedes carrés F Signification

jean-Claude Liquet 44
l’analyse factorielle ACPAnalyse en composantes principales
Cette analyse est la base de toutes les analyses multifactorielles. Elle consiste à regrouper des
variables quantitatives en combinaisons linéaires appelées composantes ou facteurs.
Du point de vue de sa résolution mathématique, la position du problème est simple. elle consiste
à partir de n variables quantitatives quelconques constituant un repère à n dimensions (la matrice
des données) à passer à un repère orthonormé à n dimension. Ces nouvelles dimensions sont les
facteurs. La résolution de ce problème consiste à diagonaliser la matrice des variances
covariances, les composantes principales sont constituées des facteurs dont les valeurs propres
sont les plus importantes.

jean-Claude Liquet 45
Réduire la dimensionnalité
- un bilan des liaisons entre variables (on peut ainsi déterminer celles qui sont liées
positivement entre elles ou celles qui s'opposent, déterminer des groupes de variables corrélées
entre elles, trouver une typologie des variables, etc.), donc diminuer la dimensionnalité des
données en colonnes.
C'est cette étude des variables qui permettra de résumer l'ensemble des variables à un petit
nombre de variables synthétiques appelées composantes principales (une composante principale
représentant un groupe de variables liées entre elles).

jean-Claude Liquet 46
La révolution copernicienne
Le soleil tourne-t-il autour de la terre ou est ce le contraire?
Quid du référentiel?

jean-Claude Liquet 47
La matrice de variance covariance
1RRR
R1RR
RR1R
RRR1
434241
343231
242321
141312
jean-Claude Liquet 48
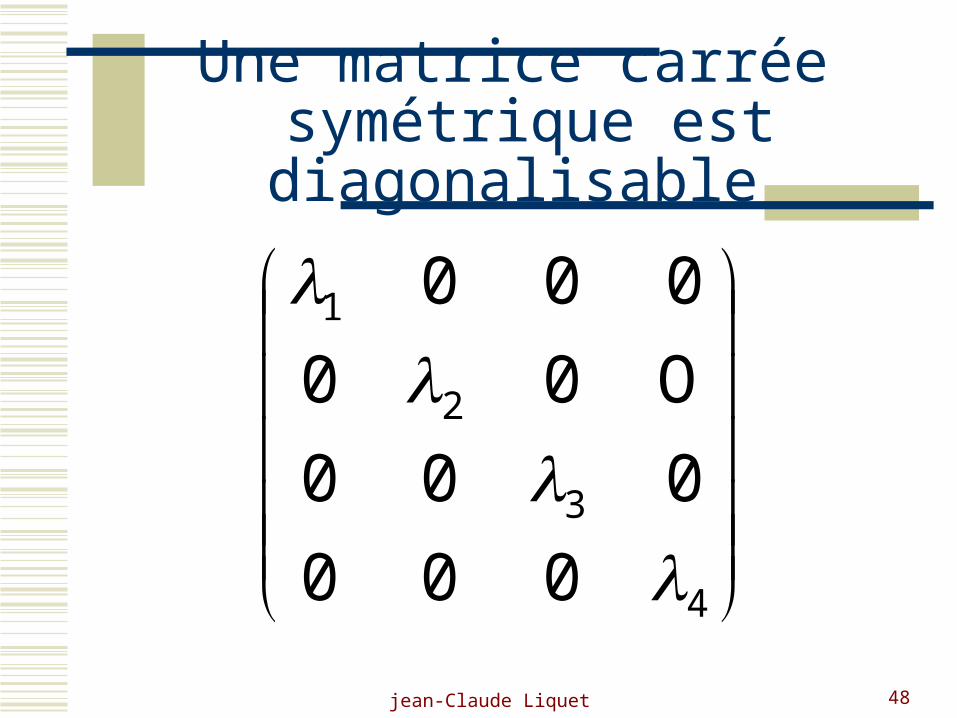
Une matrice carrée symétrique est diagonalisable
4
3
2
1
000
000
O00
000

jean-Claude Liquet 49
Les résultats
Il est possible de conserver tous les axes, cependant cela devient très vite sans objet. A partir du
moment où un axe contient moins d'information que n'importe quelle autre variable de départ, il
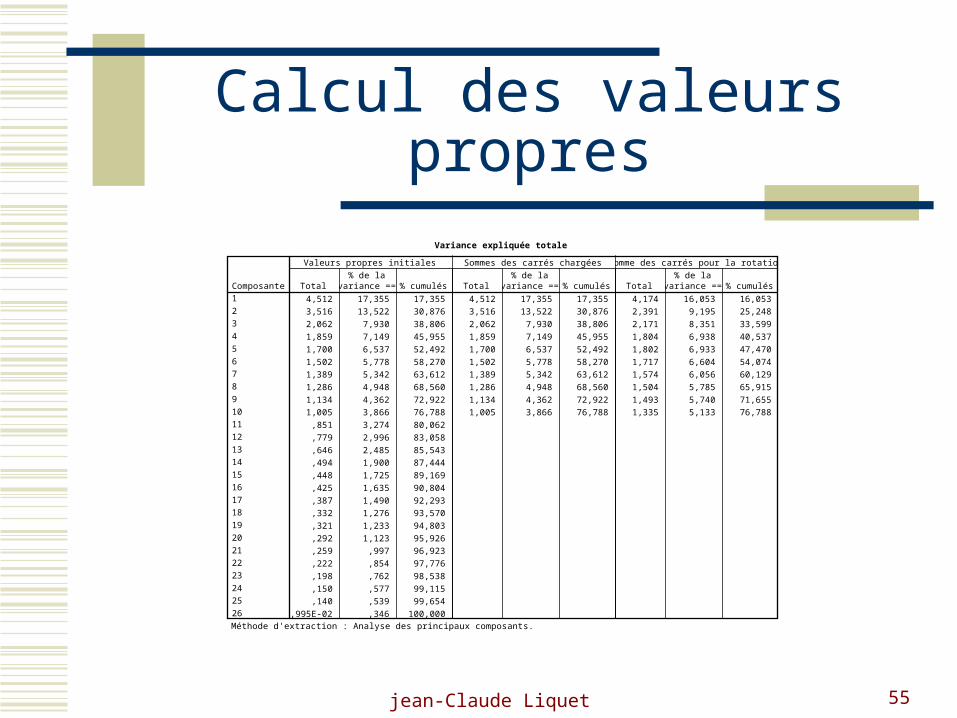
n'a plus beaucoup de sens. C'est pourquoi l'habitude est de ne conserver que les axes dont les
valeurs propres sont supérieures à 1. D'autres règles de conservation des axes existent comme par
exemple le critère du coude (la perte d'information entre deux axes consécutifs est dans un
rapport nettement inférieur aux gains précédents). Dans la pratique plusieurs essais sont faits qui
permettent de mieux décrire le contexte, il ne faut pas oublier à ce niveau que l'ACP est une
méthode descriptive, par conséquent le but est de décrire le mieux possible un contexte.
Il est à noter que le nouveau repère constitué est une hyper sphère trigonométrique. La projection
des variables sur les axes sont des cosinus qui permettent de calculer les contributions de chaque
variable au facteur considéré.

jean-Claude Liquet 50
Une application à l’analyse sensorielle
Le but de l’étude est de rechercherles descripteurs permettant d’élaborer un profil sensoriel de 4 spoupes aux légumes verts
Existe-t-il des différences significatives entre les soupes?
Peut on valider un profil sensoriel issu de cette analyse

jean-Claude Liquet 51
Mode opératoire
Reconnaissance des saveurs fondamentales Dégustation par 24 personnes entraînées de 4
soupes : Royco minute soupe aux sept légumes, Auchan velouté de légumes vert, Knorr moulinée aux légumes verts Maggi panier de légumes moulinés légumes verts persillés

jean-Claude Liquet 52
Les descripteurs
Aspects : 8 descripteurs Odeur : 11 descripteurs Flaveur : 11descripteurs Texture : 3 descripteursOn recherche à réduire le nombre de
descripteurs afin de ne retenir que les plus pertinents
jean-Claude Liquet 53
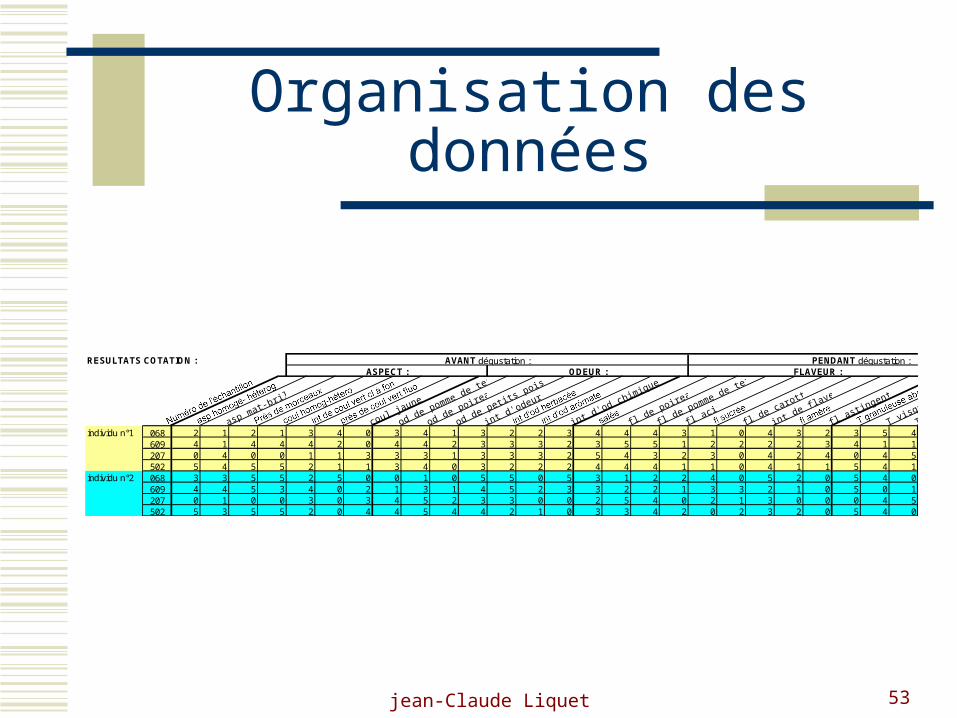
Organisation des données
RESULTATS COTATION :FLAVEUR :
PENDANT dégustation :ODEUR :ASPECT :
AVANT dégustation :
asp mat-brillant
coul jaune
od de pomme de terre
od de poireaux
od de petits pois
int d'odeur
int d'od chimique
fl de poireaux
fl de pomme de terre
fl acidefl de carotte
int de flaveur
fl astingente
T visqueuse liq- visq
T onctueuse
fl astringente
t collantT visqueuse liq- visq
T hom ( morc-phase)
individu n°1 068 2 1 2 1 3 4 0 3 4 1 3 2 2 3 4 4 4 3 1 0 4 3 2 3 5 4609 4 1 4 4 4 2 0 4 4 2 3 3 3 2 3 5 5 1 2 2 2 2 3 4 1 1207 0 4 0 0 1 1 3 3 3 1 3 3 3 2 5 4 3 2 3 0 4 2 4 0 4 5502 5 4 5 5 2 1 1 3 4 0 3 2 2 2 4 4 4 1 1 0 4 1 1 5 4 1
individu n°2 068 3 3 5 5 2 5 0 0 1 0 5 5 0 5 3 1 2 2 4 0 5 2 0 5 4 0609 4 4 5 3 4 0 2 1 3 1 4 5 2 3 3 2 2 1 3 3 2 1 0 5 0 1207 0 1 0 0 3 0 3 4 5 2 3 3 0 0 2 5 4 0 2 1 3 0 0 0 4 5502 5 3 5 5 2 0 4 4 5 4 4 2 1 0 3 3 4 2 0 2 3 2 0 5 4 0

jean-Claude Liquet 54
Analyse des données
Analyse de chaque descripteur (univariée) permettant de vérifier les normalités.
Analyse ACP afin de déterminer des regroupements
jean-Claude Liquet 55
Calcul des valeurs propres
Variance expliquée totale
4,512 17,355 17,355 4,512 17,355 17,355 4,174 16,053 16,053
3,516 13,522 30,876 3,516 13,522 30,876 2,391 9,195 25,248
2,062 7,930 38,806 2,062 7,930 38,806 2,171 8,351 33,599
1,859 7,149 45,955 1,859 7,149 45,955 1,804 6,938 40,537
1,700 6,537 52,492 1,700 6,537 52,492 1,802 6,933 47,470
1,502 5,778 58,270 1,502 5,778 58,270 1,717 6,604 54,074
1,389 5,342 63,612 1,389 5,342 63,612 1,574 6,056 60,129
1,286 4,948 68,560 1,286 4,948 68,560 1,504 5,785 65,915
1,134 4,362 72,922 1,134 4,362 72,922 1,493 5,740 71,655
1,005 3,866 76,788 1,005 3,866 76,788 1,335 5,133 76,788
,851 3,274 80,062
,779 2,996 83,058
,646 2,485 85,543
,494 1,900 87,444
,448 1,725 89,169
,425 1,635 90,804
,387 1,490 92,293
,332 1,276 93,570
,321 1,233 94,803
,292 1,123 95,926
,259 ,997 96,923
,222 ,854 97,776
,198 ,762 98,538
,150 ,577 99,115
,140 ,539 99,654
8,995E-02 ,346 100,000
Composante1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
Total% de la
variance == % cumulés Total% de la
variance == % cumulés Total% de la
variance == % cumulés
Valeurs propres initiales Sommes des carrés chargées Somme des carrés pour la rotation
Méthode d'extraction : Analyse des principaux composants.

jean-Claude Liquet 56
Regroupement des variables en facteur
Matrice des composantes a
,888
,834
,826
,822
-,758
-,599 ,366
,742
,621 ,459 -,324
,599 ,325 ,368 -,342
-,592 ,367 -,323
-,521 ,321 -,324
-,515 ,402
,482 ,309 ,362
,634 ,427
,496 -,426 -,348
-,439 -,409
,623 -,335
,380 -,304 ,500 ,317
-,454 ,487 ,438
,466
,392 ,480 ,341 ,377
,377 ,665 ,327
-,437 ,454 -,302
-,314 ,303 -,642 ,363
,398 ,350 ,590
-,415 ,370 ,427
coul homog-hétero
T granuleuse abs-prés
asp homogé- héterog
Prés de morceaux
T onctueuse
coul jaune
fl de poireaux
od de poireaux
od de pomme de terre
int d'od chimique
fl sucrée
prés de coul vert fluo
salée
T visqueuse liq- visq
flaveur acide
fl de carotte
amère
int d'od herbacée
int d'od arômate
fl astingente
fl de pomme de terre
int d'odeur
od de petits pois
asp mat-brillant
int de flaveur
int de coul vert cl à fon
1 2 3 4 5 6 7 8 9 10
Composante
Méthode d'extraction : Analyse en composantes principales.
10 composantes extraites.a.

jean-Claude Liquet 57
Interprétation
Élimination des descripteurs non pertinents Nommer les facteurs Scorer les facteurs

jean-Claude Liquet 58
AFC AFCM
L'analyse factorielle des correspondances (AFC) est une application spécifique de l'analyse en
composantes principales (ACP) au cas des tableaux de contingence.
Un tableau de contingence est un tableau d'effectifs croisant les modalités de deux variables
qualitatives définies sur n individus. Il permet donc de mesurer le lien entre deux variables
qualitatives, voir le tri croisé de deux variables qualitatives et l’indication du lien par le Chi2.
Lorsqu'un tableau de contingence est de grande dimension, il est difficile d'en retirer les
informations essentielles. L'utilisation de l'AFC présente donc un double intérêt :
- faciliter l'étude des liens éventuels existant entre les modalités des deux variables ;
- offrir des possibilités de représentation graphique relativement simple à interpréter.

jean-Claude Liquet 59
Un exemple pédagogique
Un étudiant observateur regarde les jeunes filles qui entrent dans notre institut un matin
ordinaire. Son observation sur deux variables le type de vêtement et la couleur du vêtement sont
consignés dans un tableau de contingence (de contexte).
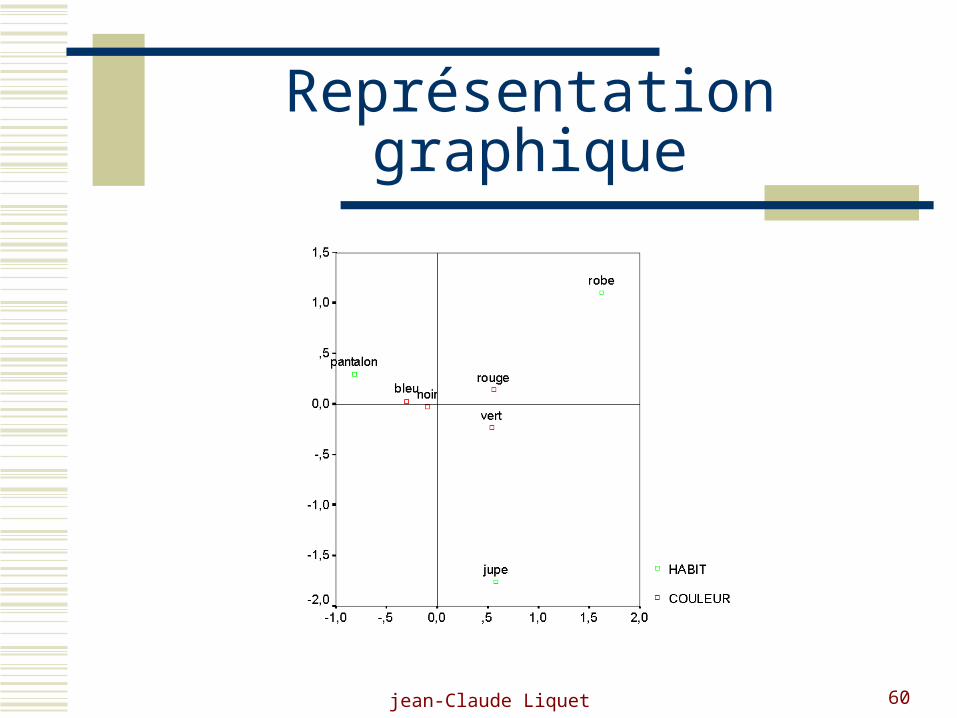
Pantalon Jupe Robe Bleu 45 11 7 Noir 55 20 15 vert 5 7 6 Rouge 11 8 14
L’analyse habituelle d’un tel tableau est la recherche du lien qui peut exister entre le
type de vêtement et la couleur de celui-ci. Le lien est mesuré par le chi2. Un chi2 significatif indique une liaison non due au hasard. Dans ce cas il est possible de rechercher une représentation graphique. La représentation graphique obtenue par l’application de l’AFC a la m^me signifacation que l’analyse du Chi2. Cependant pour des tableaux de contingence important, l’AFC permet une interprétation facilitée.
jean-Claude Liquet 60
Représentation graphique

jean-Claude Liquet 61
Analyse factorielle des correspondances multiples.
L’AFCM est une technique qui permet de visualiser plus de deux variables qualitatives.
Elle se déduit de l’AFC à la condition de transformer le tableau de contingence en tableau
disjonctif complet. Elle permet de visualiser plus de deux variables croisées. Son intérêt est
essentiellement la constitution d’un mapping qui résume une étude de croisements multiples.
Un exemple étudié est l ‘étude de la lecture des magazines par les femmes.
Les variables explicatives étaient
- Les tranches d’âge
- Les PCS
- Les magazines eux mêmes
- Le niveau scolaire

jean-Claude Liquet 62
Le mapping obtenu
43210-1-2
3
2
1
0
-1
-2
-3
-4
plus de 60 ans
41 à 60 ans
26 à 40 ans
retraitées
femmes au foyer
ouvrières noouvrières qu
employées
Pro inter
cadres et pr
artisans, co
agricultrice
autres revue
mag économiq
mag santé/en
revues loisi
mag scientifique
mag culturel
mag déco/maimag féminins
mag TV
mag fin de s
hebdo d'info
aucun diplôme
2/3èmes cycl
DEUG/DUT/BTS
Bac/BP/BT
CAP-BEP
BEPC
certificat d
pqn
pqr

jean-Claude Liquet 63
Les méthodes explicatives La régression linéaire
La régression simple

jean-Claude Liquet 64
Recherche d’une équation
Il s’agit de trouver la droite moyenne de la forme y=ax+b. Les mathématiques élémentaires
nous ont appris à tracer des droites connaissant les paramètres a et b. Ici, c’est la position
inverse, les couples (x,y) sont déterminés, il s’agit de déterminer les paramètres a et b.
Deux inconnues à déterminer appellent deux équations indépendantes à écrire.
La première est relative au centre de gravité des points.
ba_y
_
x La deuxième est un calcul d’optimisation sous contrainte de linéarité.

jean-Claude Liquet 65
Quelques rappels
Il s’agit de trouver la droite moyenne de la forme y=ax+b. Les mathématiques élémentaires
nous ont appris à tracer des droites connaissant les paramètres a et b. Ici, c’est la position
inverse, les couples (x,y) sont déterminés, il s’agit de déterminer les paramètres a et b.
Deux inconnues à déterminer appellent deux équations indépendantes à écrire.
La première est relative au centre de gravité des points.
ba_y
_
x La deuxième est un calcul d’optimisation sous contrainte de linéarité.

jean-Claude Liquet 66
Détermination des paramètres
C o m m e i l e s t d ’u s a g e p o u r u n e d is t r ib u t io n d e p o in ts , e t d o n c u n e s o m m a t io n , c ’e s t le s d is ta n c e s q u a d r a t iq u e s q u i s o n t le s p lu s p e r t in e n te s , d ’o ù l ’ e x p re s s io n :
n
ii YyE1
22 )(
L a m in im is a t io n d e c e t t e e x p re s s io n c o n s is te e n u n e d é r iv é e p a r t ie l le p a r r a p p o r t a u x d e u x p a ra m è tr e s e t l ’ é g a l is a t io n à 0 . L e s d e u x e x p re s s i o n s p e rm e t te n t la r é s o lu t io n d u s y s tè m e d ’é q u a t io n s e t p a r , c o n s é q u e n t , le s e x p re s s io n s d e a e t d e b .
L a ré s o lu t io n c o m p lè te p e rm e t d e d é te rm in e r a
varx
cov(xy)a
e t b s e d é d u i t d e la p r e m iè re e x p re s s io n ba_y
_
x __
varx
cov(xy)- xyb
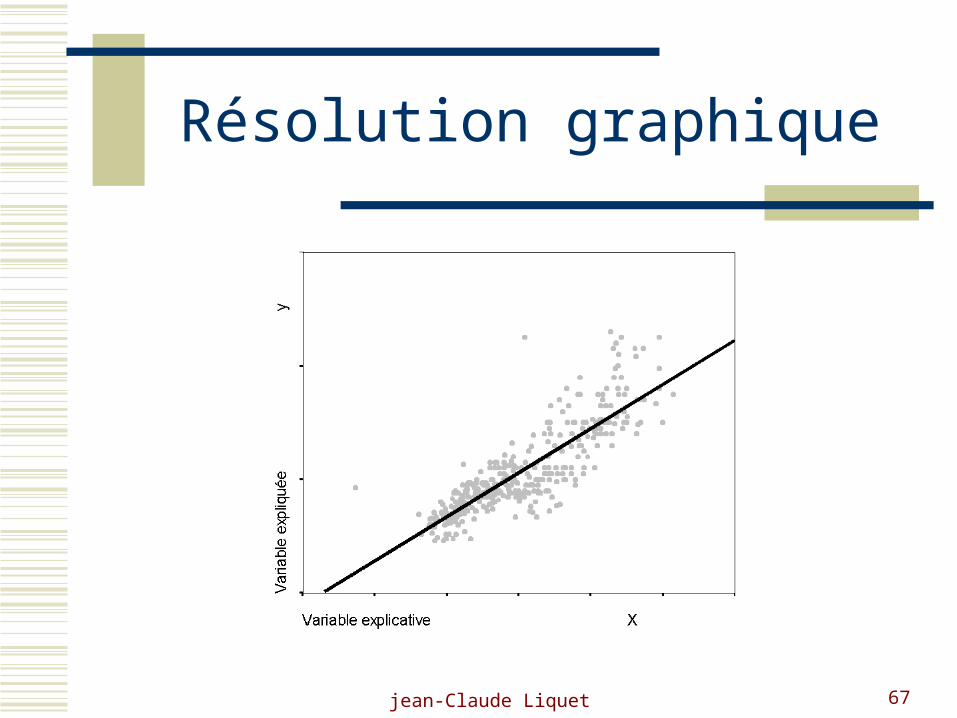
jean-Claude Liquet 67
Résolution graphique

jean-Claude Liquet 68
Validation
Deux précautions - Les résidus doivent avoir une distribution normale - La pente de la droite doit être significativement différente de 0, une droite parallèle à
l’axe des x indique une corrélation nulle. La distribution normale des résidus permet de vérifier que ces résidus sont bien du au hasard, qu’il n’y a pas d’autres éléments qui interviennent dans l’observation. Le test KS est possible. C’est une condition nécessaire, elle n’est pas suffisante.
Par ailleurs vérifier que la pente n’est pas nulle (que a n’est pas nul) revient à comparer a à o.
Le test approprié est le test de Student à n degré de liberté. Il suffit donc de calculer le t de Student et de vérifier qu’il est supérieur à 1,96 pour un risque alpha de 0,05.

jean-Claude Liquet 69
Régression multiple
La régression multiple est utilisée lorsqu’il y a plusieurs variables explicatives. Dans le cas de deux variables explicatives, le nuage de points est représenté dans un espace à 3 dimensions, la régression consiste à rechercher un plan de régression de la même manière que précédemment. Une hypothèse forte est cependant introduite. Le raisonnement étant fait dans un espace orthogonal, les variables explicatives doivent être indépendantes. Chacun des coefficients de régression doit faire l’objet d’un test de Student selon les mêmes modalités que pour le cas de la régression simple. L’expression générale s’écrit de la manière suivante :
......332211 XaXaXaY
Les ia sont les coefficients qui doivent être non nuls qui font donc l’objet d’un test t.
Les iXsont les variables explicatives. Celles qui sont affectées d’un coefficient non nul
interviennent dans l’observation et réciproquement. est l’incertitude ou le résidu.

jean-Claude Liquet 70
L'analyse structurelle
L’analyse structurelle a pour objet l’analyse de modèles. Se basant sur les liens linéaires entre les variables mesurant des concepts, il s’agit de tester un modèle par rapport à un autre. Il importe de faire une analyse des variances et covariances, ainsi que des régressions linéaires. Des indices d’ajustement permettent de tester l’expérimentation par rapport au modèle théorique. Cette technique fait partie des méthodes dites de deuxième génération, elle a le mérite de combiner des méthodes statistiques habituelles en une combinatoire maintenant admise. Les techniques sous jacentes sont d’une part l’analyse factorielle et d’autre part les équations simultanées (système d’équations linéaires). Les logiciels les plus couramment utilisées sont EQS, LISREL, PLS et AMOS

jean-Claude Liquet 71
Les variables latentes.
engagement
Q1 e1
Q2 e2
Q3 e3
Q4 e4
Quatre équations sont générées :
Q1=a1(engagement) +e1
Q2=a2(engagement) +e2
Q3=a3(engagement) +e3
Q4=a4(engagement) +e4
Les ei sont les incertitudes de mesure.

jean-Claude Liquet 72
Les structures
engagement
Q4e41
1 Q3e31 Q2e21 Q1e1 11
fidelite
Q5 e511
Q6 e61
Q7 e71
Q8 e81
Q9 e91
µ
e101
C’est la détermination de µ qui est l’objet du problème. L’équation déterminante est la suivante : Fidélité=µ * engagement+e10 Les deux variables latentes étant déterminées par le même type d’équation que dans le paragraphe précédent. A ce stade c’est un ensemble d’équations de régression linéaire qui va lever les indéterminations et permettre de calculer les coefficients de régression. Les tests de pertinence sont les mêmes que dans les systèmes linéaires. Cependant les moments statistiques que sont les variances covariances vont permettre de tester la pertinence de la structure. Le principe consiste à comparer la matrice de variance covariance O des variables observées avec la matrice théorique T. La comparaison est naturellement le chi2, nous verrons par la suite les limites de cette distance entre deux matrices.

jean-Claude Liquet 73
Comme pour un tableau de contingence la question de l’optimisation théorique est délicate. Ici l’optimisation est fondée sur une fonction de maximum de vraisemblance. X est la matrice des variables observée. (p variables sur n observations) L la matrice des variables latentes I la matrice des incertitudes de mesure C la matrice des contributions. Le modèle peut s’écrire X=CL+I L’analyse de structure de variance covariance s’écrira : T=C£C’+E T est la matrice théorique que l’on calcule à partir de C calculé précédemment comme matrice des contributions, C’ étant sa transposée £ la matrice de variance covariance des variables latentes E est la matrice des résidus.

jean-Claude Liquet 74
Le « fit » ou ajustement global sera jugé par le chi2 ou mieux le chi2 relatif=chi2/ddl la probabilité du chi2 est d’autant meilleure qu’elle est proche de 1. On admet un chi2 relatif inférieur à 2 comme reflétant un bon ajustement. Du fait de la très forte sensibilité du chi2 à la taille de l’échantillon, d’autres indices d’ajustement sont employés, less plus courants sont : - Le GFI et l’AGFI qui varient de 0 à 1 indiquent la part de variances et covariances des variables observées pris en compta par le modèle. L’AGFI est ajusté au nombre de degré de liberté. - Le RMR Root Mean Square Residual est la mesure de la variance résiduelle La limite supérieure couramment admise est 0,08. - Le RMSEA a lui aussi une limite supérieure de 0,08. Les limites n’ont de sens que dans l’absolu, en fait il est beaucoup plus intéressant de comparer les modèles et de retenir celui qui a les meilleurs indices d’ajustement, et de continuer à rechercher des modèles qui infirment le premier et ainsi de suite.

jean-Claude Liquet 75
Un exemple agro-alimentaire
Figure 1 : Modèle structurel complet et principaux résultats
OSL
Tendance à la recherche de
variété en alimentaire
Appréciation sensorielle
OSL1 OSL2 OSL3 OSL4 OSL5 OSL6 OSL7
VSK1 VSK2 VSK3 VSK4 VSK5 VSK6 VSK7 VSK8
0.57
0.32
0.20
0.45
Golden Royal Gala Red Chief Jonagold

jean-Claude Liquet 76
Recherche de variété et perceptions sensorielles

jean-Claude Liquet 77
Plan de l ’exposé
La spécificité de comportements alimentaires La recherche de variété Les préférences Problématique Mesure Résultats, limites et perspectives.

jean-Claude Liquet 78
Les comportements alimentairesImportance, risque ,plaisir
Pilgrim 1957Les déterminants généraux
Shepherd 1985Les déterminants du goût
Sirieix 1999Rôle de la recherche de variété

jean-Claude Liquet 79
La recherche de Variété
Comme facteur de stimulation (Van Trijp 1992)
Réduction de monotonie Un optimum (le niveau optimum de
stimulation OSL) Berlyne 1960, Driver et Streufert 1964

jean-Claude Liquet 80
Les préférences sensorielles
Les déterminants des préférences de couleur : l ’âge, le sexe,la personnalité, la culture ( Divard et Urier 2001)
On peut s ’attendre à des déterminants du même ordre en ce qui concerne le goût
Le déterminisme socio-culturel selon Bourdieu (1979), des socio styles selon le CCA : La golden pour le conservateur la Granny pour l ’aventurier

jean-Claude Liquet 81
La problématique
Un lien existe entre la tendance à la recherche de variété en alimentaire et les préférences gustatives.
Plus un individu présente une forte tendance à la recherche de variété plus son appréciation sensorielle est élevée
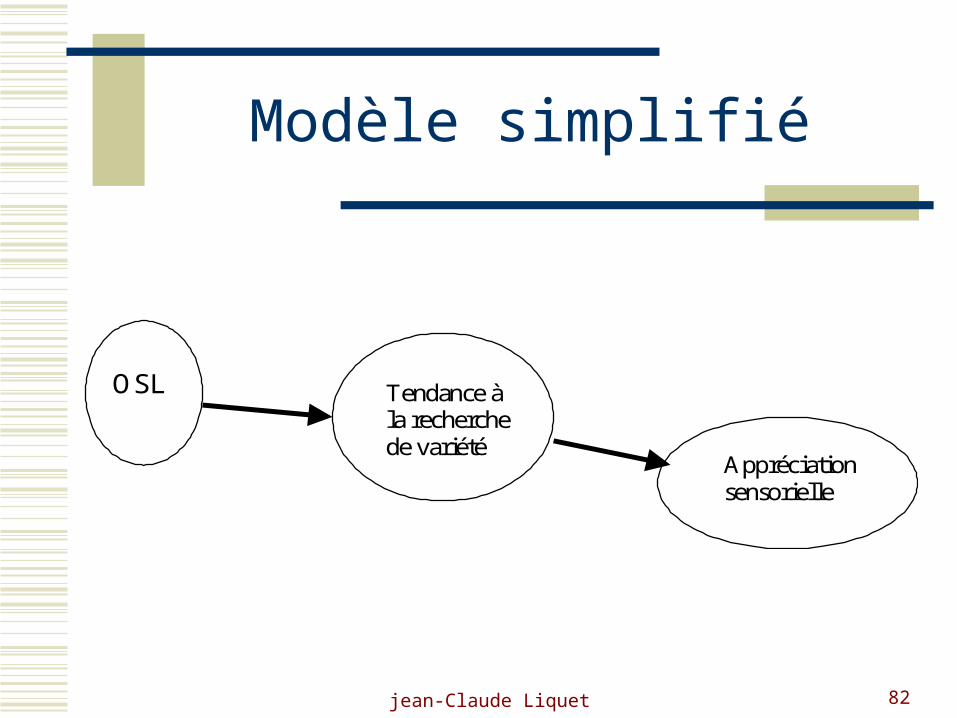
jean-Claude Liquet 82
Modèle simplifié
OSL Tendance àla recherchede variété
Appréciationsensorielle

jean-Claude Liquet 83
Mesure de l ’OSL
Le choix s’est porté sur CSI version courte en 7 items de Giannelloni (1997)
Les autres échelles à disposition Steenkamp et Baumgartner (1992) ont
comparé SSS, AST-II, CSI, NES, ils proposent CSI

jean-Claude Liquet 84
Mesure de la tendance à la recherche de Variété
Choix de VARSEEK de Van Trijp et Steenkamp, 1992 ; cette échelle est en anglais, elle est ici traduite et testée.

jean-Claude Liquet 85
Mesure de l ’appréciation sensorielle
Élaboration d’un index de préférence sur un produit de consommation courante : la pomme. La Granny Smith, la Golden, la Royal Gala, la Red Chief et la Jonagold

jean-Claude Liquet 86
Échantillon et mise en œuvre empirique
79 répondants en laboratoire d ’analyse sensorielle (contrôle des variables externes), les répondants sont des volontaires de l ’univers de l ’Institut Agroalimentaire de Lille
39 répondants goûtent avant de remplir le questionnaire, 40 après.

jean-Claude Liquet 87
Contrôle de l ’échelle unidimensionnelle OSL
Item Communautés Loading % Var. OSL 1OSL 2OSL 3OSL 4OSL 5OSL 6OSL 7
0,496 (0,56)0,553 (0,69)0,511 (0,58)0,554 (0,63)0,604 (0,61)0,517 (0,41)0,492 (0,55)
0,704 (0,75)0,743 (0,83)0,715 (0,76)0,744 (0,79)0,776 (0,78)0,719 (0,64)0,702 (0,74)
53,2 (57,6) 0, 852 (0,876)
Tableau 1 : Analyse en composantes principales exploratoire de l’OSL (les valeurs entre parenthèses
rappellent les résultats de Giannelloni, 1997)

jean-Claude Liquet 88
Traduction et validation de l ’échelle VARSSEK
Tableau 2 : Analyse en composantes principales exploratoire de la tendance à la recherche de variété (les valeurs entre parenthèses rappellent les résultats de Van Trijp et Steenkamp, 1992)
Item Communautés
Loading % Var.
VSK1VSK2VSK3VSK4VSK5VSK6VSK7VSK8
0,6260,3310,7150,6470,6170,7010,4980,590
0,7910,5750,8460,8050,7850,8370,7060,768
59,0(0,58)
0,896(0,90)
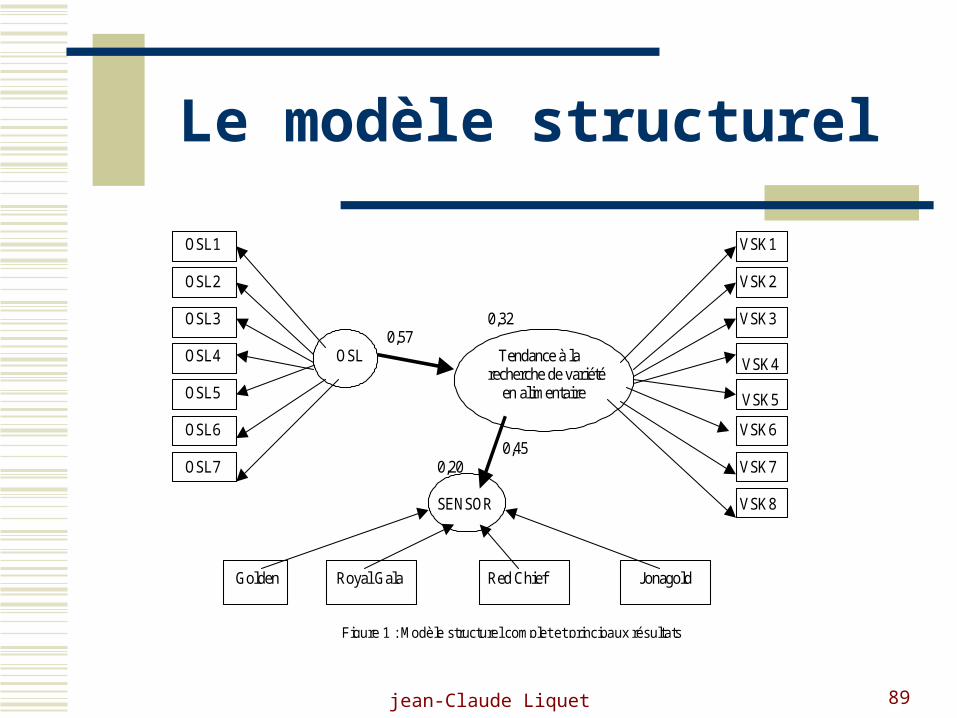
jean-Claude Liquet 89
Le modèle structurel
OSL1 VSK1
OSL2 VSK2
OSL3 0,32 VSK30,57
OSL4 OSL Tendance à la VSK4recherche de variété
OSL5 en alimentaire VSK5
OSL6 VSK6 0,45
OSL7 0,20 VSK7
SENSOR VSK8
Golden Royal Gala Red Chief Jonagold
Figure 1 : Modèle structurel complet et principaux résultats

jean-Claude Liquet 90
Indices d ’ajustement
2 = 133,58 (ddl : 100 ; p : 0,014) ;
2 /ddl = 1,33 ; CFI = 0,93 ; TLI = 0,92.

jean-Claude Liquet 91
Limites perspectives et implications
Une échelle est traduite et testée Les relations cherchées sont montrées Reste à valider les variables pertinentes de
recherche de variété. Si il y a recherche de variété cela implique que dans
le temps les goûts évoluent L ’élaboration des gammes doit se faire en fonction
de cette nouvelle donnée

jean-Claude Liquet 92
Analyse discriminante
Cette méthode est connue aussi sous le nom de scoring. Elle est très employée par les organisations qui veulent prédire le comportement des clients. Lors d'un prêt le banquier se pose inévitablement la question "est ce que mon client va bien rembourser ou non ?». En fait il souhaite pouvoir prédire la case de bon payeur ou mauvais payeur. Pour ce faire il va comparer à ce qu'il sait de ses autres clients avec ce qu'il sait de son emprunteur. En d'autre terme il va chercher une fonction explicative qui affecte les clients à une case ou l'autre et ensuite il applique cette fonction à son nouvel emprunteur. Ne nous y trompons pas, le questionnaire que le banquier fait remplir est tout simplement les réponses de l'unité statistique aux variables explicatives.

jean-Claude Liquet 93
L'analyse discriminante peut être considérée comme la recherche de groupes sous jacents. Il s'agit de rechercher des axes qui décrivent ces deux groupes alors que les variables qui ont servi à la mesure ne les "discriminent pas" Le graphique suivant permet de visualiser cet état des choses.
Il y a bien deux nuages de points mais leurs projections sur x et y ne permettent pas de les distinguer. De fait la solution consiste à trouver un axe sur lequel on va projeter et qui distingue bien deux groupes.

jean-Claude Liquet 94
F a i r e u n e a n a l y s e d i s c r i m i n a n t e r e v i e n t a i n s i à t r o u v e r l 'a x e q u i p e r m e t d 'o b t e n i r q u e l e s d e u x m o y e n n e s s o i e n t s i g n i f i c a t i v e m e n t d i s t i n c t e s L a n o u v e l l e v a r i a b l e e s t u n e c o m b i n a i s o n l i n é a i r e d e s p r é c é d e n t e s . I c i l 'a n a l y s e s e f a i t s u r d e u x d i m e n s i o n s d e d é p a r t e t u n a x e d i s c r i m i n a n t . D a n s l a p r a t i q u e o n p e u t a v o i r u n e s p a c e d e p l u s d e d e u x d i m e n s i o n s , l e n o m b r e d 'a x e s d i s c r i m i n a n t s e s t a i n s i a u g m e n t é . E n f a i t c e l a r e s s e m b l e b e a u c o u p à l 'a n a l y s e d e v a r i a n c e , l a p r e m i è r e d e s c o n d i t i o n s e s t l e c a l c u l d e l a q u a n t i t é . : L e deux gro upes étant représentés par les deux ellipses, ce rappo rt se co m pare à la d istributio n de
F , ainsi il apparaît qu'il faut m ax im iser le num érateur et m in im iser le déno m inateur. O n r e m a r q u e r a q u e l a d é m a r c h e s 'a p p a r e n t e f o r t e m e n t à u n e a n a l y s e e n c o m p o s a n t e s p r i n c i p a l e s . E n p a r t i c u l i e r e n l a r e c h e r c h e d e c o m b i n a i s o n s l i n é a i r e s .
groupeintra Variance
groupeinter Variance

jean-Claude Liquet 95
Validation de l’analyse discriminante
Les indicateurs statistiques de validation sont
Le V de Bartlett
Le test de Rao
Le de wilks est utilisé plus simplement si le nombre de classe est 2 ou 3. C’est le rapport de
la variation intra-groupe à la variation totale.

jean-Claude Liquet 96
Analyse conjointe

jean-Claude Liquet 97
Compromis et Modèle de Choix
« Mieux vaut être riche et en bonne santé que pauvre et malade … »
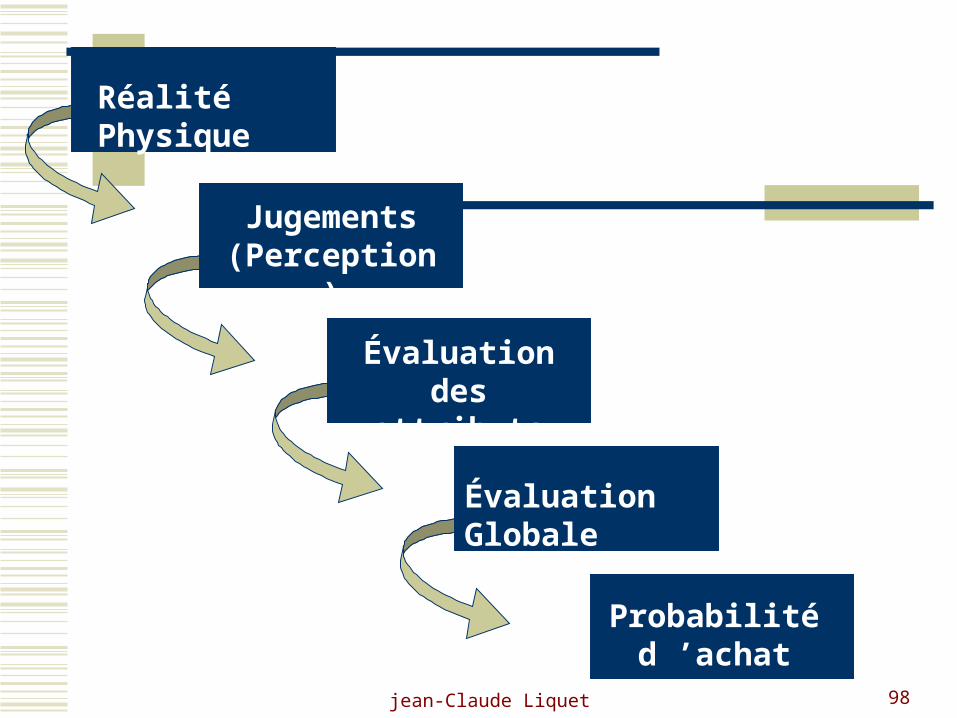
jean-Claude Liquet 98
Réalité Physique
Jugements (Perception)
Évaluation des
attributs
Évaluation Globale
Probabilité d ’achat
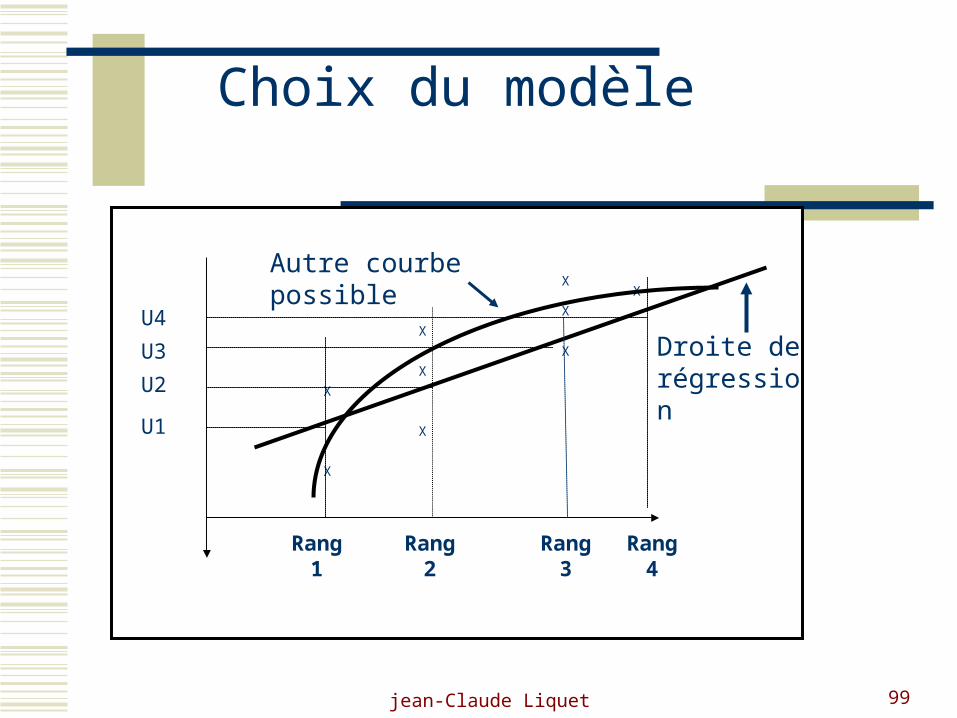
jean-Claude Liquet 99
X
X
X
X
X
X
X Droite de régression
X
X
Rang 1
Rang 2
Rang 3
Rang 4
U1
U2
U3
U4
Autre courbe possible
Choix du modèle
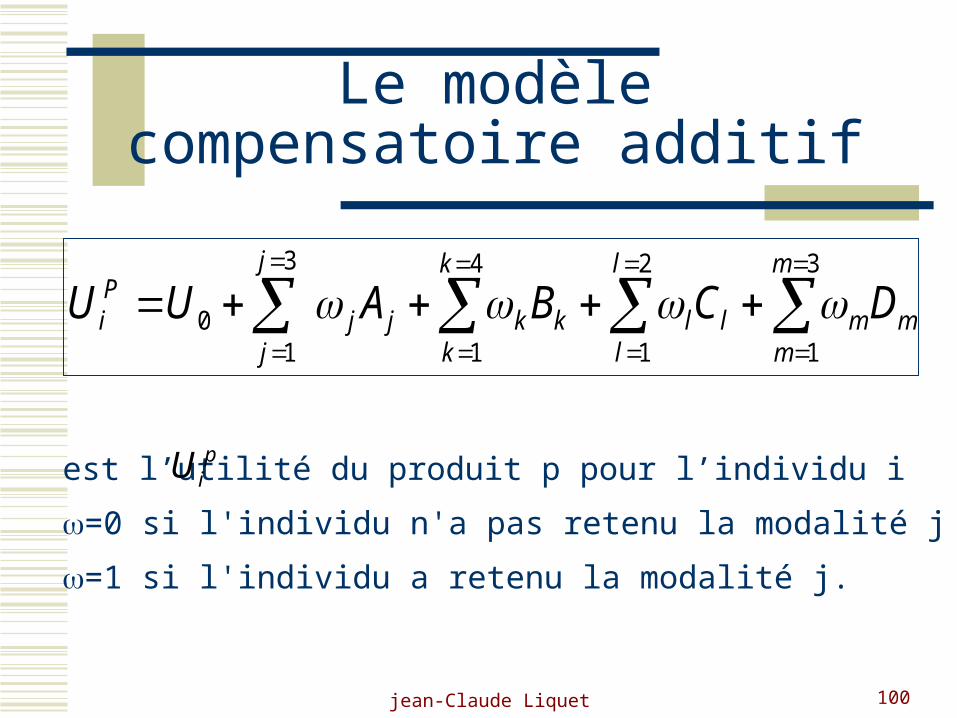
jean-Claude Liquet 100
Le modèle compensatoire additif
m
m
mml
l
llk
k
kkjj
j
j
Pi DCBAUU
3
1
2
1
4
1
3
10
est l’utilité du produit p pour l’individu i
=0 si l'individu n'a pas retenu la modalité j
=1 si l'individu a retenu la modalité j.
piU
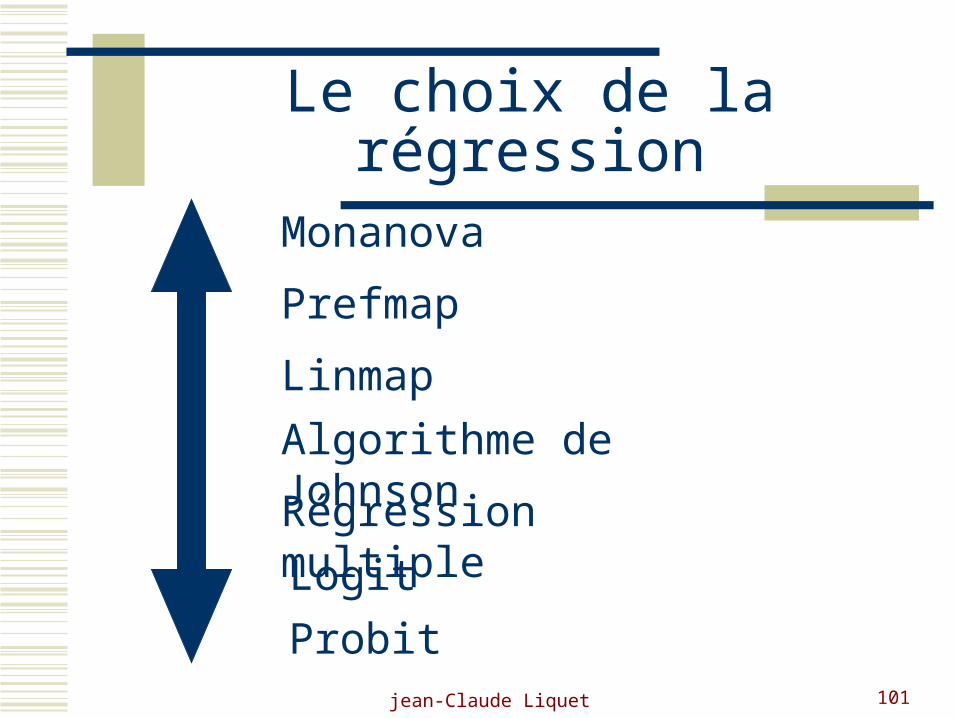
jean-Claude Liquet 101
Le choix de la régression
Monanova
Prefmap
Linmap
Algorithme de Johnson
Régression multipleLogit
Probit

jean-Claude Liquet 102
Processus d ’analyse
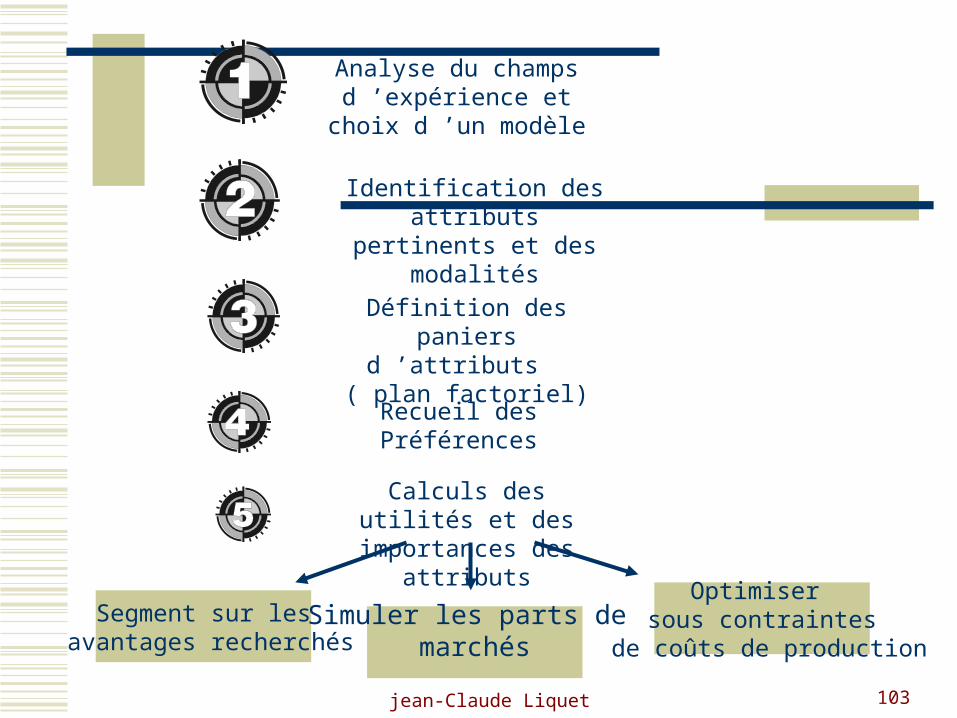
jean-Claude Liquet 103
Analyse du champs d ’expérience et choix
d ’un modèle
Identification des attributs pertinents et
des modalités
Définition des paniers d ’attributs ( plan
factoriel)
Recueil des Préférences
Calculs des utilités et des importances des
attributs
Segment sur les avantages recherchés
Simuler les parts de marchés
Optimiser sous contraintes
de coûts de production

jean-Claude Liquet 104
Un exemple
Le choix du pain par les enfants

jean-Claude Liquet 105
Les caractéristiques du pain
ATTRIBUT MODALITES
INGREDIENTS - type 5S : pain blanc
- pain complet
- aux germes
MODE DE FABRICATION - artisanal
- moderne : pétrissage intensifié
TEMPS DE CUISSON - court : croûte claire
- longue : croûte foncée
FORME -petit pain : 80 grammes
- pain : 500 grammes.
-baguette : 250 grammes

jean-Claude Liquet 106
Le plan d ’expérience
Réduction du nombre de concepts.
Le nombre de concepts est 3X2X2X3=36 ; une réduction permet la présentation de 9 .Procédure orthoplan.
ORTHOPLAN /FACTORS=ingredie 'ingredient' ( 1 'pain blanc' 2 'pain complet' 3 'aux'+ ' germes') fabricat 'mode fabrication' ( 1 'artisanal' 2 'pétrissage'+ ' intensifié') temps 'temps de cuisson' ( 1 'court' 2 'long') forme 'forme' ( 1 'petit pain' 2 'pain' 3 'baguette') /OUTFILE='C:\Program Files\SPSS\ORTHO.SAV' .

jean-Claude Liquet 107
Pain 1 : petit pain, pétri à la machine, aux germes et peu cuit.
Pain 2 : petit pain, pétrissage artisanal, mie blanche, cuitlonguement.
Pain 3 : pain boulot, pétrissage artisanal, aux germes, cuitlonguement..
Pain 4 : pain boulot, pétrissage artisanal, complet, peu cuit.
Pain 5 : pain boulot, pétri à la machine, mie blanche, peu cuit.
Pain 6 : baguette, pétrissage artisanal, aux germes, peu cuit.
Pain 7 : baguette, pétrissage artisanal, mie blanche, peu cuit.
Pain 8 : petit pain, pétrissage artisanal, complet, peu cuit.
Pain 9 : baguette, pétri à la machine, complet, cuit longuement.
Les différentes combinaisons

jean-Claude Liquet 108
La procédure
Data list free /ID PREF1 TO PREF9.BEGIN DATA 01 04 01 08 06 09 03 07 05 0202 05 07 02 04 03 01 09 08 0603 07 05 03 04 09 06 01 08 0204 07 02 05 03 04 01 08 06 0905 07 02 05 08 01 09 03 04 0606 02 07 05 09 03 04 06 01 0807 07 05 02 01 08 03 09 04 0608 05 02 07 01 09 08 04 06 0309 01 03 05 09 07 08 04 06 0210 02 06 03 01 04 09 08 07 05 … ….. …. … … … … …
… … … … … … … … … … … … 48 02 07 01 05 09 08 06 03 0449 02 01 06 08 05 09 07 03 04
END DATA.CONJOINT PLAN='a:\orthopain.sav'/DATA=*/SEQUENCE=PREF1 TO PREF9/SUBJECT=ID/FACTORS=ingredie (DISCRETE) mode (Discrete) temps (discrete)forme (discrete)/PRINT=ALL/plot all/utilite="exercice.sav".

jean-Claude Liquet 109
Les résultats - 1
SUBJECT NAME: 1,00Importance Utility(s.e.) Factor
+---------+ INGREDIE ingredientI61,22 I -3,0000( ,7328) ----I pain blanc+---------+ 2,0000( ,7328) I--- pain complet I 1,0000( ,7328) I- aux germes I I MODE mode de fabrication ,00 I ,0000( ,5496) I artisanal I ,0000( ,5496) I moderne I +----+ TEMPS temps de cuisson30,61I I 1,2500( ,5496) I-- court
+----+ -1,2500( ,5496) --I long I ++ FORME forme 8,16 II ,3333( ,7328) I petit pain ++ ,0000( ,7328) I pain I -,3333( ,7328) I baguette I 4,5833( ,5794) CONSTANT
Pearson's R = ,959 Significance = ,0000Kendall's tau = ,833 Significance = ,0009

jean-Claude Liquet 110
SUBFILE SUMMARY AveragedImportance Utility Factor+---------+ INGREDIE ingredientI38,40 I 1,1875 I---- pain blanc+---------+ -,9306 ---I pain complet I -,2569 -I aux germes I +--+ MODE mode de fabrication13,42 I I -,0990 I artisanal +--+ ,0990 I moderne I +---+ TEMPS temps de cuisson14,28 I I -,2188 -I court +---+ ,2188 I- long I +--------+ FORME forme I33,90 I ,6806 I-- petit pain +--------+ -,0833 I pain I -,5972 --I baguette I 5,1059 CONSTANT
Pearson's R = ,971 Significance = ,0000Kendall's tau = ,833 Significance = ,0009
Les résultats - 2

jean-Claude Liquet 111
Les résultats - 3
ingredient
aux germespain completpain blanc
1,5
1,0
,5
0,0
-,5
-1,0
-1,5
mode de fabrication
moderneartisanal
,2
,1
0,0
-,1
-,2
jean-Claude Liquet 112
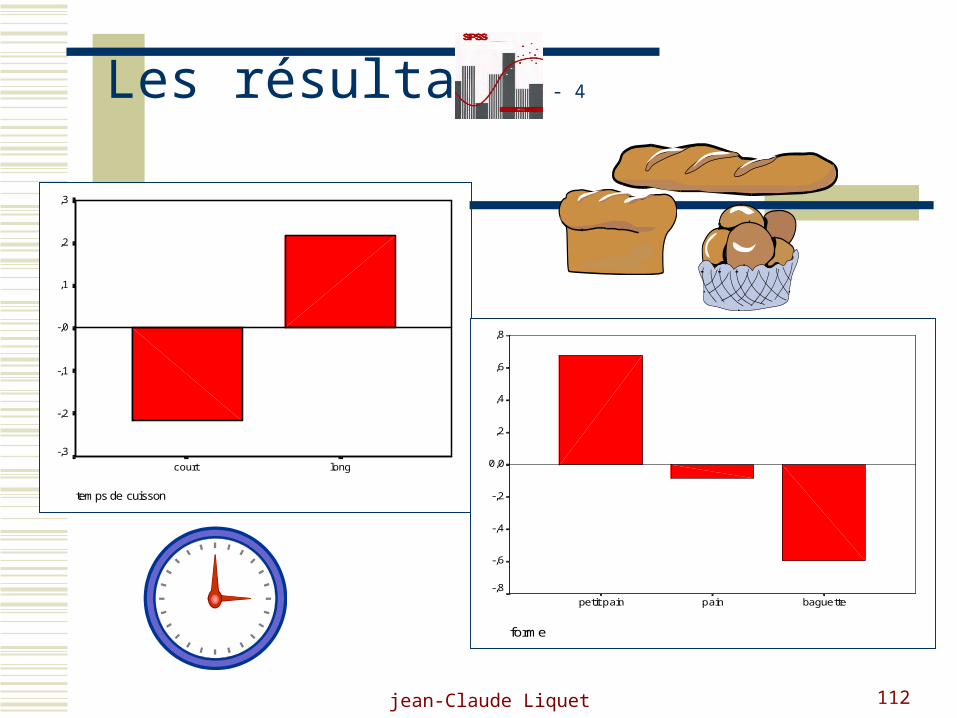
Les résultats - 4
temps de cuisson
longcourt
,3
,2
,1
-,0
-,1
-,2
-,3
forme
baguettepainpetit pain
,8
,6
,4
,2
0,0
-,2
-,4
-,6
-,8
jean-Claude Liquet 113
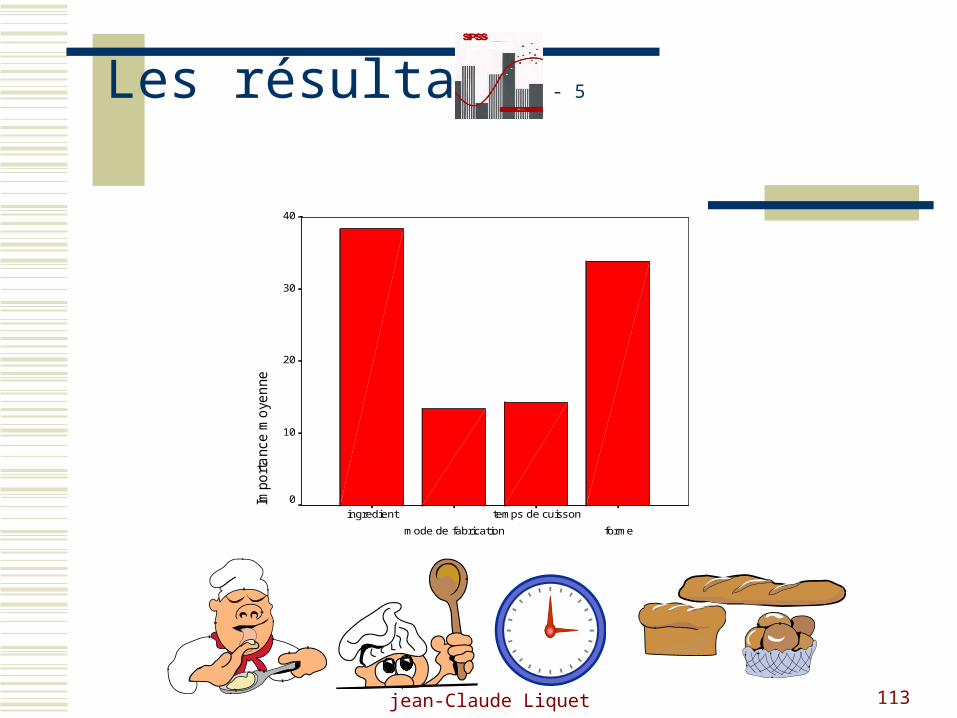
Les résultats - 5
forme
temps de cuisson
mode de fabrication
ingredient
Impo
rta
nce
mo
yen
ne
40
30
20
10
0

jean-Claude Liquet 114
Un exemple
Les stéréotypes des vendeurs

jean-Claude Liquet 115
Les résultats - 1
Habits 55,22% Décontractés -0,3226Stricts 0,6237De travail -0,3011
Sexe 20,39% Homme 0,4919
Femme -0,4919
Age 24,28% 20 à 35 ans 0,096835 à 45 ans 0,0108Plus de 45 ans -0,0860
Attributs ImportanceModalités Utilités
Tau de Kendall = 0,556 Risque alpha = 0,0185

jean-Claude Liquet 116
Les résultats - 2
Tableau : fiche de l'entreprise Dupont
Attributs Importance Modalités UtilitésHabits 28,57% Décontractés 1,3333
Stricts -0,3333De travail -1
Sexe 42,86% Homme 1,7500Femme -1,7500
Age 8,57% 20 à 35 ans 0333335 à 45 ans 1Plus de 45 ans -1,3333

jean-Claude Liquet 117
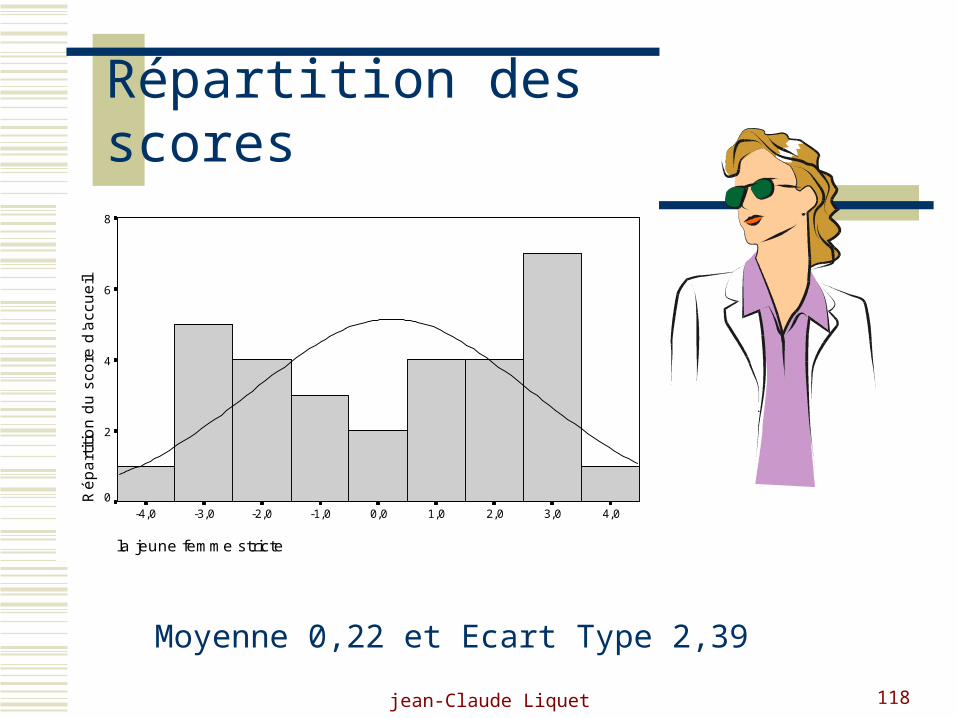
Calcul des utilités
L’entreprise “ Dupont ” vient de s’adjoindre comme collaborateur Madame Germain qui a 28 ans,
elle est habituellement habillée d’un tailleur noir.
On peut calculer “ l’utilité ” totale pour chacune des entreprises de ce négociateur.
Utotal= utilité ( habit strict ) + utilité (sexe féminin ) + utilité (âge entre 25 et 35 ans).
jean-Claude Liquet 118
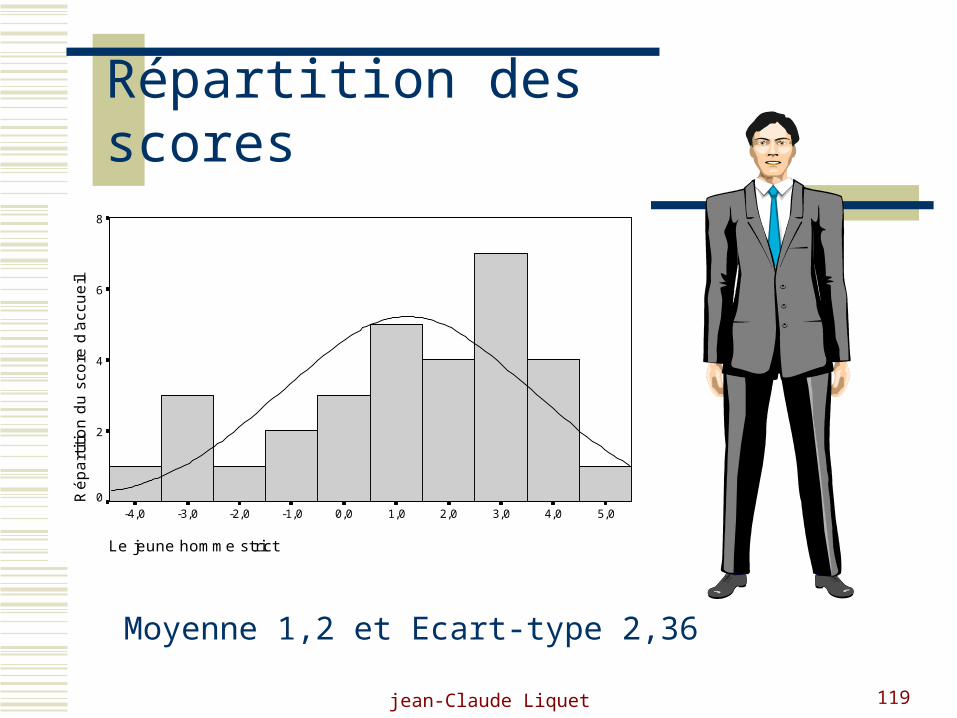
Répartition des scores
la jeune femme stricte
4,03,02,01,00,0-1,0-2,0-3,0-4,0
Rép
artit
ion
du s
core
d'a
ccue
il
8
6
4
2
0
Moyenne 0,22 et Ecart Type 2,39
jean-Claude Liquet 119
Répartition des scores
Le jeune homme strict
5,04,03,02,01,00,0-1,0-2,0-3,0-4,0
Rép
artit
ion
du s
core
d'a
ccue
il
8
6
4
2
0
Moyenne 1,2 et Ecart-type 2,36

jean-Claude Liquet 120
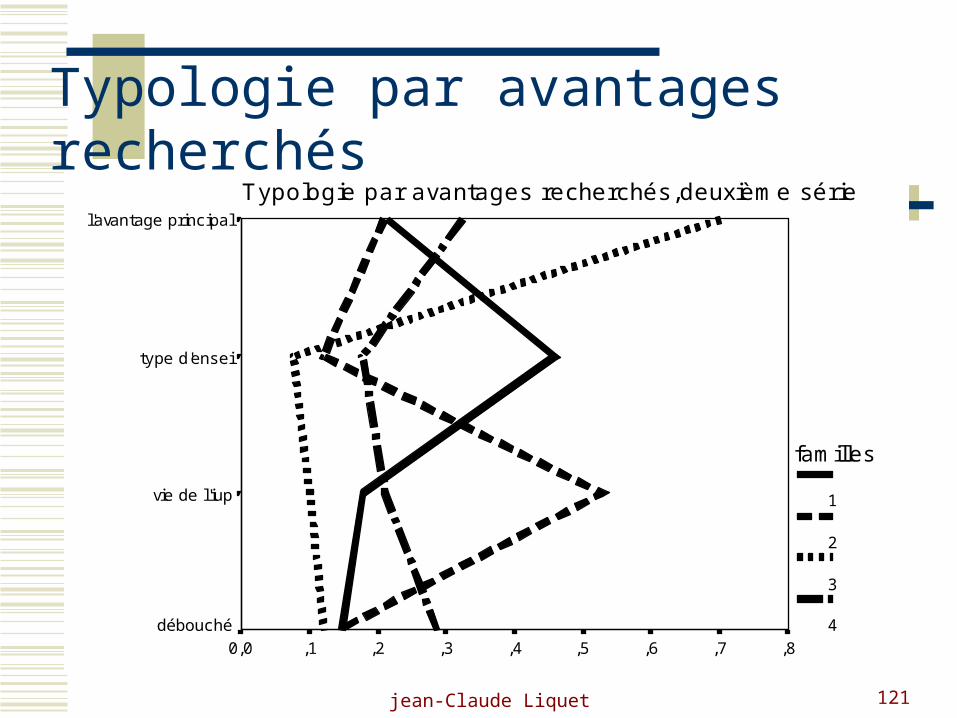
Segmentation par avantages recherchés
typologies et cartes perceptuelles.
jean-Claude Liquet 121
familles
1
2
3
4
Typologie par avantages recherchés,deuxième sériel'avantage principal
type d'ensei
vie de l'iup
débouché,8,7,6,5,4,3,2,10,0
Typologie par avantages recherchés
jean-Claude Liquet 122
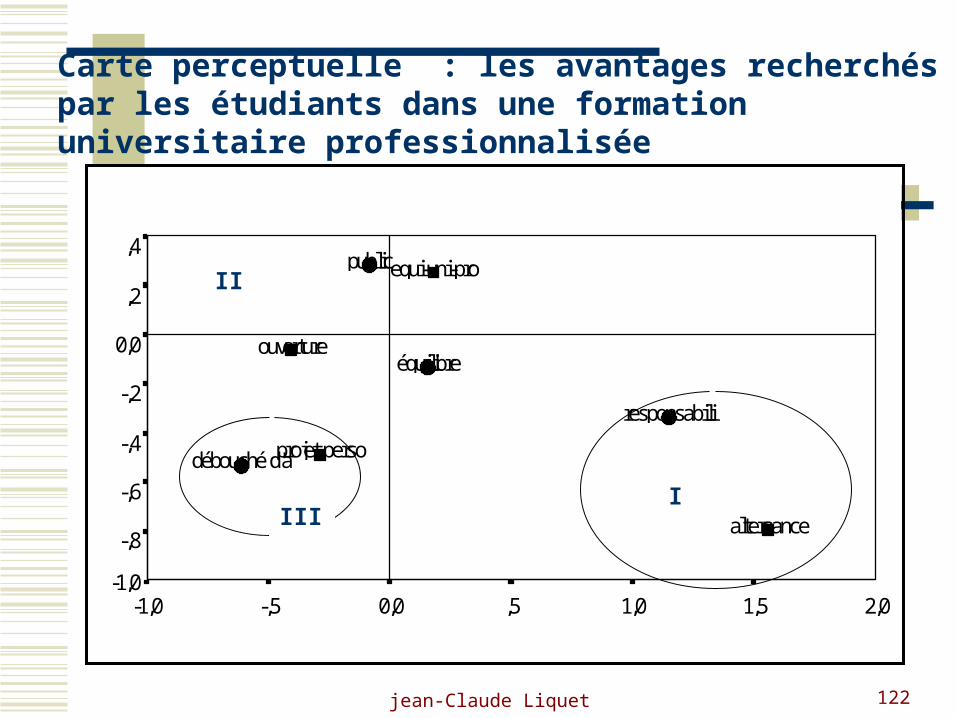
Carte perceptuelle : les avantages recherchés par les étudiants dans une formation universitaire professionnalisée
équilibre
débouchéd'a
responsabili
public
projet perso
ouverture
alternance
equi-uni-pro
2,01,51,0,50,0-,5-1,0
,4
,2
0,0
-,2
-,4
-,6
-,8
-1,0
II
IIII

jean-Claude Liquet 123
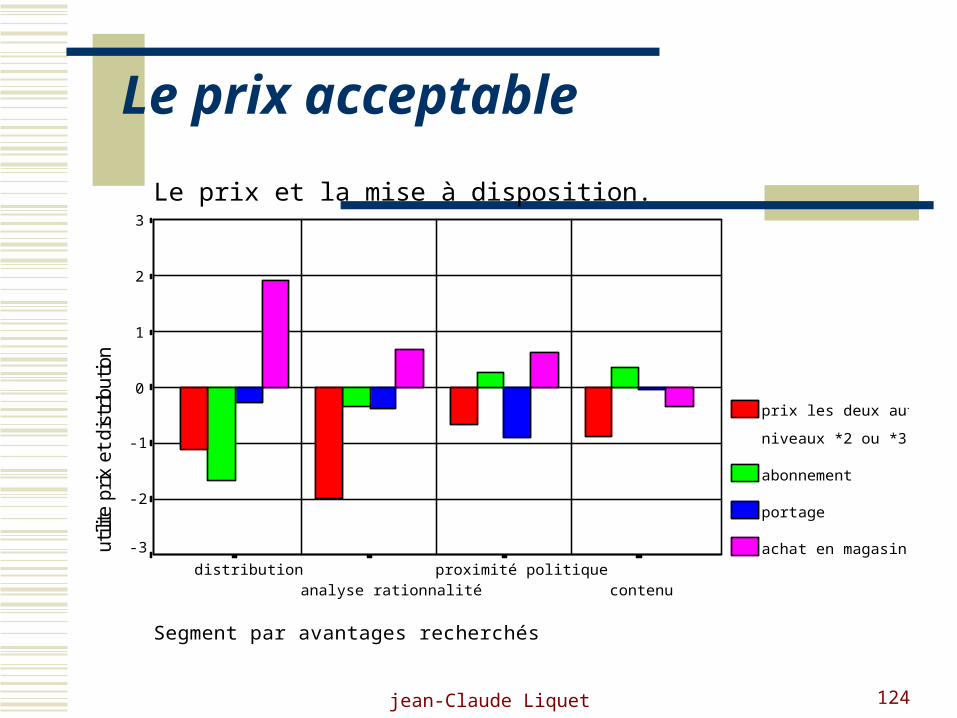
Autre exemple : la presse
-1,5
-1
-0,5
0
0,5
1
1,5
-1,2 -1 -0,8 -0,6 -0,4 -0,2 0 0,2 0,4 0,6 0,8 1
les échos
image de soi risquée
distribution
ne lit rien
le plaisir
proximité de pensée
analyse
pqr le monde lefigaro
besoin sans risque
le monde
contenu
l'humanité
rationnalité
passion
pas impliqué
"les accros"
Libé
jean-Claude Liquet 124
Le prix acceptable
prix les deux autres
niveaux *2 ou *3
abonnement
portage
achat en magasin
Le prix et la mise à disposition.
Segment par avantages recherchés
contenuproximité politique
analyse rationnalitédistribution
utili
te p
rix e
t dis
trib
utio
n
3
2
1
0
-1
-2
-3

jean-Claude Liquet 125

jean-Claude Liquet 126

jean-Claude Liquet 127
L ’ANALYSE DE SURVIE

jean-Claude Liquet 128
Les modèles de survie:Les modèles de survie:
- stratégie de fidélisation
- outils de CRM

jean-Claude Liquet 129
A partir des fichiers clients évaluer les pratiques commerciales.
Par l’analyse des durées de vie de vos lecteurs
Comment ?

jean-Claude Liquet 130
Optimiser les actions de fidélisation
avec les Modèles de Survie:
Décrire
Expliquer

jean-Claude Liquet 131
La fidélité à un journal dépend:
de son contenu
de la qualité de la livraison
de la pression commerciale sur la diffusion de leur parution
Mais les précautions n’empêchent pas les résiliations

jean-Claude Liquet 132
une des solutions ?
Anticiper la résiliation, intervenir en amont de la prise de décision de résiliation.

jean-Claude Liquet 133
Un exemple d ’étude a été publié dans « Décisions Marketing »
Le mode de recrutement
La périodicité du paiement
Le mode de livraison
Le prix de l ’abonnement
Les variables retenues dans le cadre du quotidien:

jean-Claude Liquet 134
La mesure de la durée de vie des abonnés:La mesure de la durée de vie des abonnés:
L ’analyse de survie se décompose en deux phases complémentaires:
L ’analyse de survie descriptive
L ’analyse de survie explicative

jean-Claude Liquet 135
Les analyses de survie descriptives :
Renseignent sur la valeur actualisée client :
Life Time Value
Examen de la population suivant la méthode des démographes

jean-Claude Liquet 136
Les analyses de survie explicatives:
la probabilité de survie du client
une gestion pertinente des résiliations d ’abonnements

jean-Claude Liquet 137
Modélisation de l ’analyse de survie:Modélisation de l ’analyse de survie:
Temps

jean-Claude Liquet 138
- recherche d ’une fonction qui rende compte de la forme de la courbe
- prévoit les chances qu ’un lecteur fidèle possédant un certain profil le soit encore au bout d ’un certain temps.
Modélisation des durées de survie :

jean-Claude Liquet 139
Un exemple d ’application:Un exemple d ’application:
L ’application des analyses de survie nécessite:
une variable de durée
un indicateur de censure
jean-Claude Liquet 140
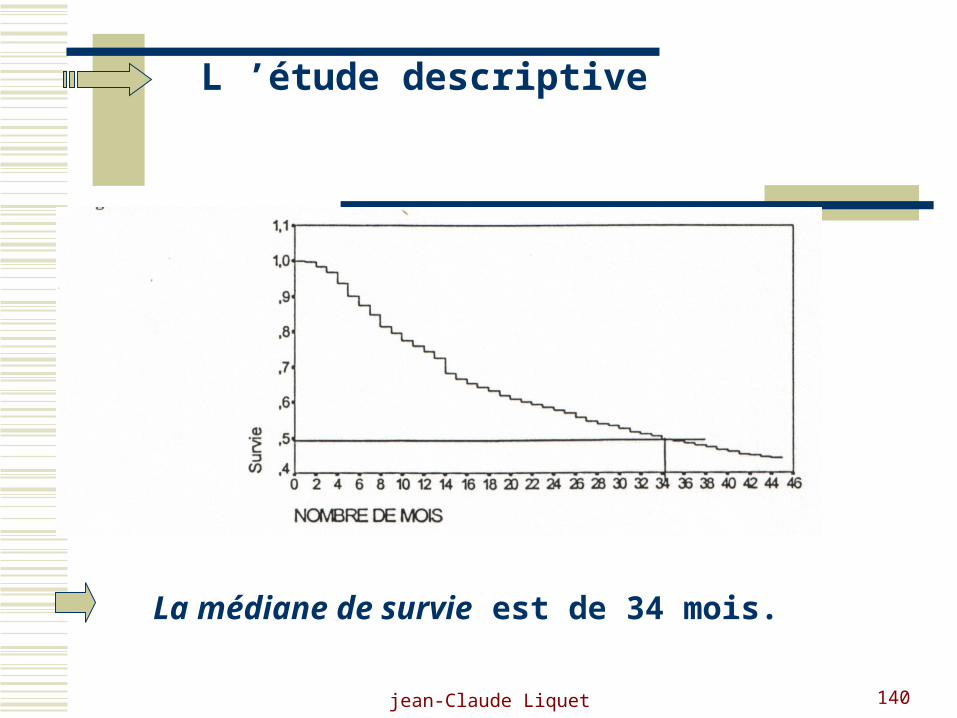
L ’étude descriptive
La médiane de survie est de 34 mois.
jean-Claude Liquet 141
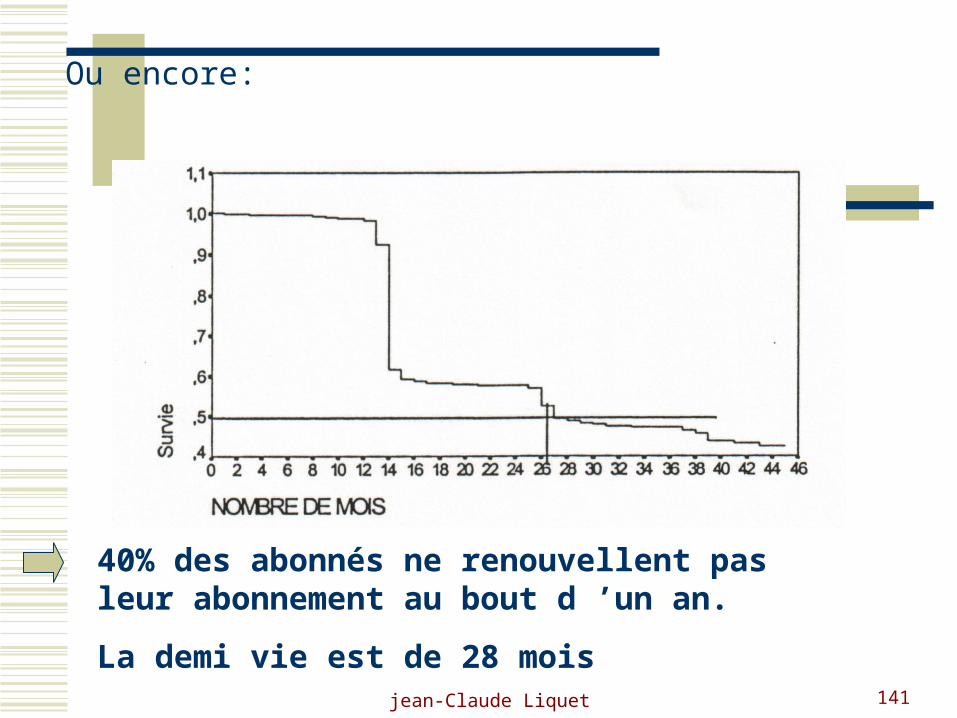
Ou encore:
40% des abonnés ne renouvellent pas leur abonnement au bout d ’un an.
La demi vie est de 28 mois
jean-Claude Liquet 142
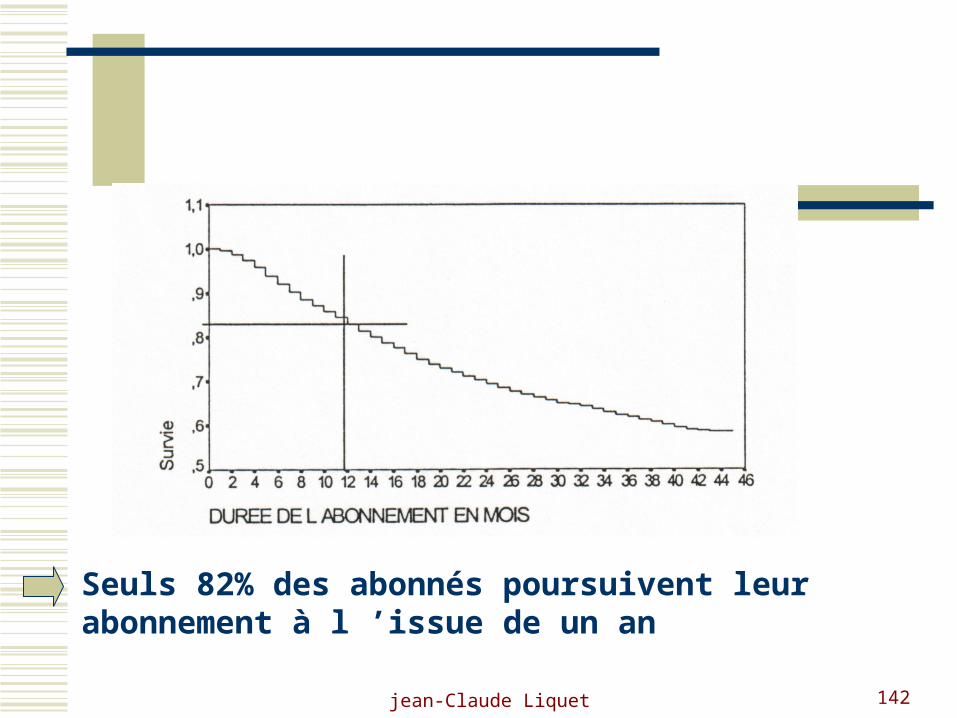
Seuls 82% des abonnés poursuivent leur abonnement à l ’issue de un an
jean-Claude Liquet 143
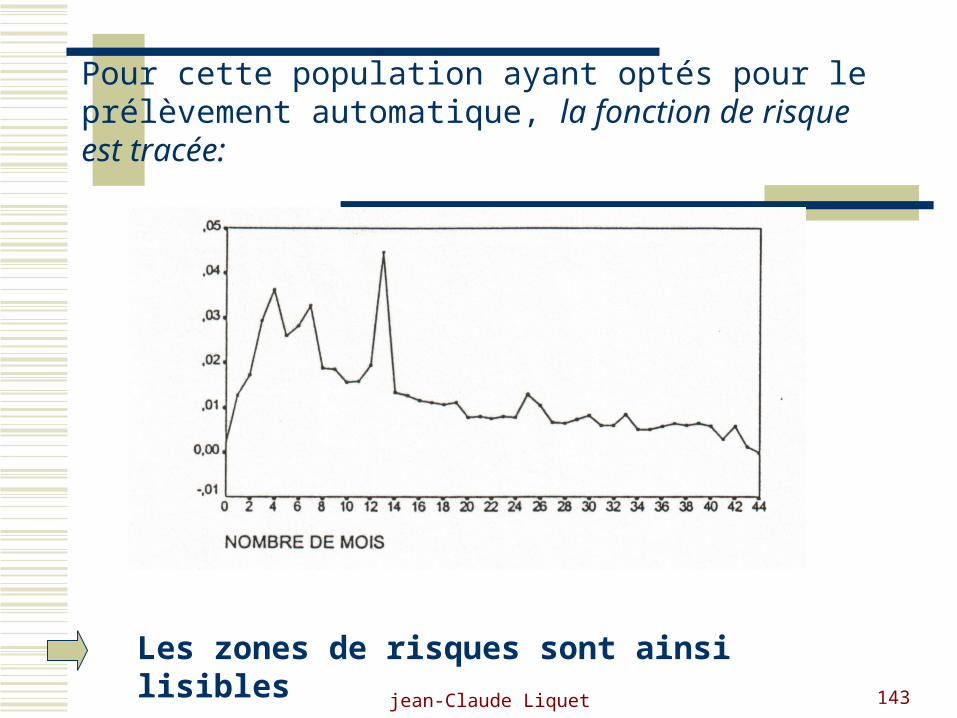
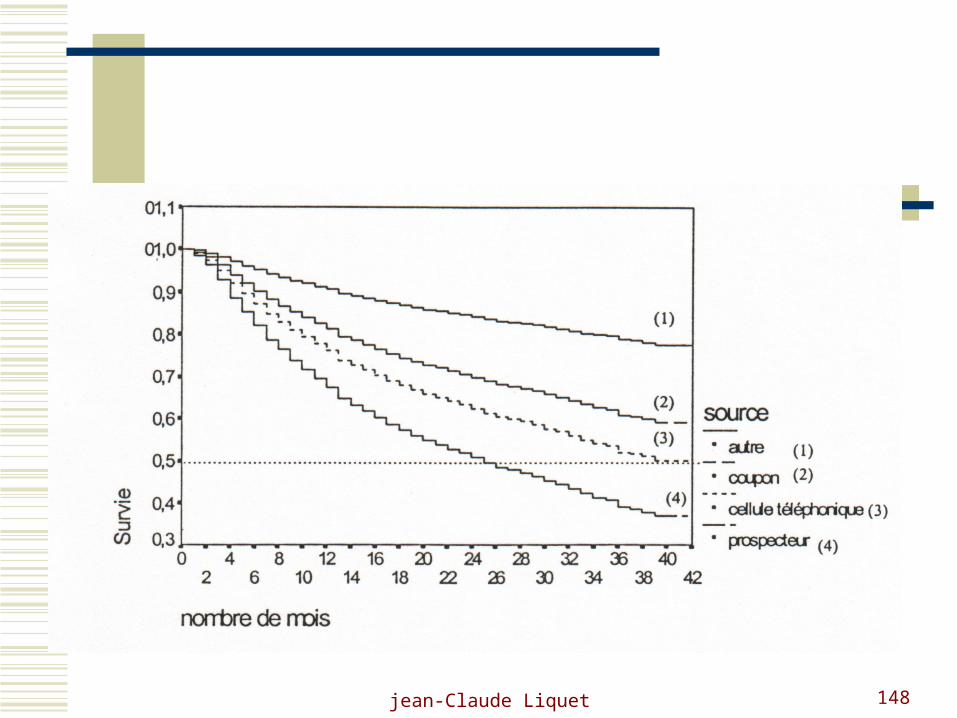
Pour cette population ayant optés pour le prélèvement automatique, la fonction de risque est tracée:
Les zones de risques sont ainsi lisibles

jean-Claude Liquet 144
La valeur actualisée du client:
Les clients les plus fidèles n ’ont pas toujours la valeur la plus élevée

jean-Claude Liquet 145
Modélisation des durées de survie individuelles:
différentes variables explicatives :
- la tranche d ’âge de l ’abonné (plus et moins 50 ans)
- le mode d ’abonnement
- le mode de distribution
- le mode de paiement
Le modèle de Cox

jean-Claude Liquet 146
La probabilité de survie de chaque lecteur est estimé suivant son profil et pour un horizon de temps fixé.
On détermine ainsi:
Qui doit faire l ’objet d ’actions ?
Quand agir ?
jean-Claude Liquet 147
jean-Claude Liquet 148

jean-Claude Liquet 149
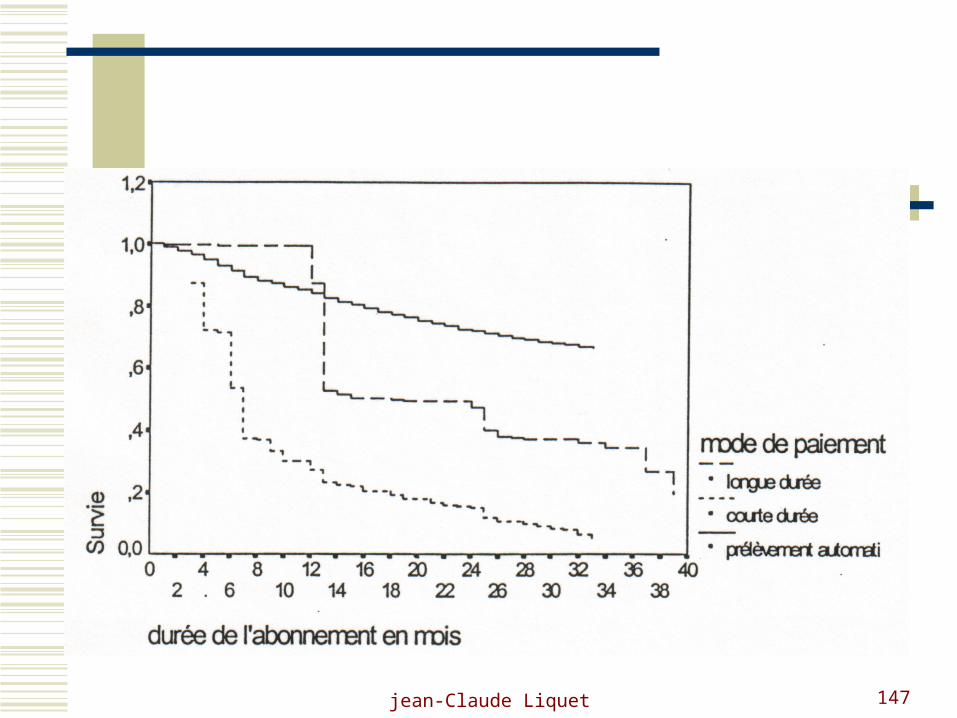
Les conclusions induites :
Les abonnés servis par portage sont plus fidèles
Le prélèvement automatique est un facteur de fidélité
L ’abonnement volontaire est plus durable
Les plus âgés sont les plus fidèles
jean-Claude Liquet 150
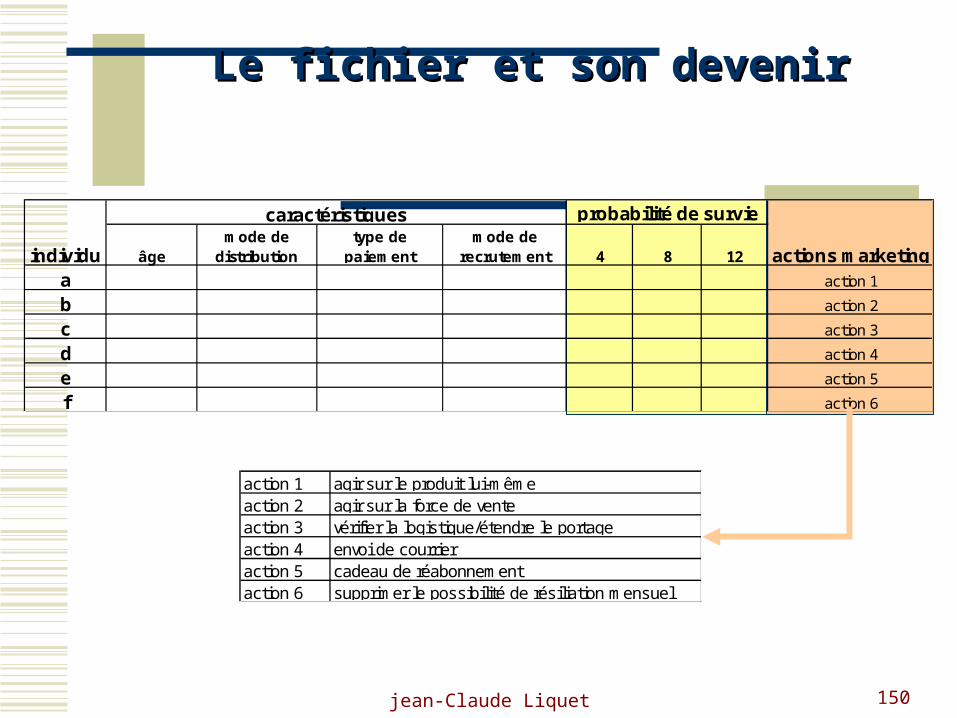
âgemode de
distributiontype de
paiementmode de
recrutement 4 8 12
abcdef
individu
caractéristiques
action 4
action 5
action 6
probabilité de survie
actions marketingaction 1
action 2
action 3
action 1action 2action 3action 4action 5action 6
agir sur le produit lui-même
envoi de courrier cadeau de réabonnementsupprimer le possibilité de résiliation mensuel
agir sur la force de ventevérifier la logistique/étendre le portage
Le fichier et son devenirLe fichier et son devenir

jean-Claude Liquet 151
Les perspectives possibles
L ’analyse de survie est bien adaptée à la presse pour mettre en place des programmes de fidélisation.
Les données comportementales des lecteurs abonnés ou portés peuvent être enrichies également par d ’autres
méthodes de scoring.







