빅 데이터 분석의 새로운 패러다임을 제시합니다 · 빅 데이터 분석의...
TRANSCRIPT

ZDNet Korea Tech Inside
빅 데이터 분석의 새로운 패러다임을 제시합니다
Powered by

빅 데이터 분석의 새로운 패러다임을 제시합니다.2
Bigdata Cluster Part
Cubedoop ClusterTM
BICube는 빅데이터 머신러닝 플랫폼을 보유한 회사로써 빅데이터 머신러닝 플랫폼 내에 파일을 저장
하고 MapRedue를 실행 해야 하는 요소가 필 수였다. 이에 BICube는 플랫폼 내에서 안정성과 성능, 그
리고 효율성을 위해서 Apache Hadoop 을 이용해 Cubedoop Cluster™라는 빅데이터 클러스터 플랫
폼을 만들었으며, 자체 빅데이터 클 러스터를 개발 운영하면서 축적한 노하우를 바탕 으로 Cubedoop
Cluster™를 상품화 했다.
Cluster Appliance
Cubedoop Cluster™ 는 Rack 단위로 확장 해 갈 수 있는 S/W & H/W 일체형의 Cluster Appliance
이다. 일단 Cluster 전문가에 의해 고객의 문제 해결 에 적합한 클러스터 사이즈가 결정되면, 성능 최적
화 H/W Spec을 따라 구성된 Cluster 위에 최적화 Parameter를 갖는 Cubedoop이 얹어진 Cubedoop
Cluster™이 고객에게 제공 된다.
Cluster S/W 특징
Cubedoop 최적화 파라메터 가이드를 통해 각 클러스터 타입에 맞는 Cubedoop Cluster가 세팅 이 되며,
일정 주기 별로 Cubedoop 설정 파라메터 에 대한 평가가 클러스터 사용자에게 레포팅되어 분산작업 시
간을 최소화 시켜준다. 또한 다른 Hadoop 배포판과 마찬가지로 노드들 을 효율적으로 관리 할 수 있는
모니터링 Tool이 별도로 제공이 되며, 분산 Job 처리시에 각 노드로 분산되는 로깅을 일괄적으로 편하게
확인 할 수 있 는 등 Job 처리 편의성을 높였다.
Cluster H/W 특징
클러스터를 구성하는 노드들의 하드웨어 관리를 편하고 효율적으로 하기 위해서 메인보드와 하드 디스
크 그리고 파워서플라이를 분리 시켜 그룹화 했으며, 각 노드들의 상태(Status)와 전력 상태등 을 전담
모니터링하는 서버를 각 Rack 마다 하나 씩 추가했다. 그 결과 고장난 노드 교체 비용을 최 소화 했으며,
복잡한 클러스터 운영을 많은 부분 단순화 시켰다.

빅 데이터 분석의 새로운 패러다임을 제시합니다. 3
Cluster 종류(노드수)
Type – A : 16 * 8 = 128 nodes
Type – B : 16 * 16 = 256 nodes
Type – C : 16 * 24 = 384 nodes
Type – D : 24 * 24 = 576 nodes
Cluster 종류
표준형 : 실행 잡이 CPU 계산 혹은 파일 I/O 작업 어느 한쪽으로 편중 되지 않고 분산처리 작업의 유 형
이 다향한 경우 선택 CPU 편중형 : 데이터 마이닝 혹은 파생 데이터를 이용한 계산이 많은 경우 선택
(예: 자연어처리, HPPC) I/O 편중형 : 파일 입/출력이 많은 작업의 비중이 높은 경우 선택 (예:전형적인
MapReduce job, Sorting)
Appliance + 지원 서비스
거대 규모의 빅데이터 클러스터를 안정적으로 운 영하기 위해서는 클러스터 전문가의 기술이 절대적 으
로 필요하다. 일반적으로 클러스터 운영의 노하우는 오랜 기간 에 걸쳐 쌓이기 때문에 빅데이터 클러스
터 전문가 를 보유하기가 쉽지 않은 고객사는 빅데이터 클러 스터 도입을 망설일 수 밖에 없다. 당사는
고객사에 대한 빅데이터 클러스터 전문가 의 지속적인 지원 계획을 통해, 빅데이터 클러스터 어플라이언
스를 도입한 고객이 안정적인 클러스터 운영을 보장 받을 수 있도록 최대한 노력할 것이다.
CubePi ClusgterTM
CubePi Cluster는 분산처리의 성능을 벤치마킹하 기 위해 BICube가 디자인한 Raspberry Pi 2 Cluster
에서 시작되어 상품화 되었다. Raspberry Pi 2 각각의 성능은 PC와 비교가 안될 정도로 미약하지만
다수의 Raspberry Pi 2가 클러 스터링 됐을 때 분산처리의 성능은 엔터프라이즈 용도로도 손색이 없
을 정도로 훌륭하다. BICube는 CubePi Cluster™의 잠재적 고객 니 즈를 예상해 제품화했다. (HPCC
(HighPerformance Computing Cluster), or DAS (Data Analytics Supercomputer)

빅 데이터 분석의 새로운 패러다임을 제시합니다.4
BICubeTM: 빅데이터 머신러닝 플랫폼 Part
BICube™는 빅데이터 비즈니스 모델을 고객의 니즈에 맞게 One-stop 으로 구현하기 위한 빅데이터 머
신러닝 플랫폼이다.
빅데이터 솔루션의 한계
대부분의 빅데이터관련 솔루션들은 단일 기능을 구현 하는데 촛점이 맞춰져 있기 때문에 원하는비즈니
스 모델을 구현하기 위해서는 아키텍터가 다양한 솔루션을 직접 선택해서 조합해야한다. 이러한 상황은
툴간의 호환성 문제와 솔루션 추가 구매 시 발생하는 비용문제 그리고 새롭게 추가된 솔루션의 안정적인
운영과 기술지원등 다양한 이슈를 야기하게 되고 결국 고객이 원하는 빅데이터 비즈니스 모델을 구현하
는데 어려움을 겪을 가능성이 높아지게 된다.
BICubeTM: 단일 플랫폼
BICube™는 각각의 기능별 레이어가 합해진 단일 빅데이터 플랫폼이다.
▶ Layer 1 - 데이터 추출, 변환 및 로딩
▶ Layer 2 - 데이터 저장
▶ Layer 3 - 머신러닝 엔진
▶ Layer 4 - 애플리케이션 레이어 (비즈니스 모델이 구현되는 레이어) 이렇게 Vertical 한 구조를 갖는
빅데이터 플랫폼은 세계에서도 유일한 플랫폼이며 비즈니스 모델 구현 이 단일 플랫폼에
서 이뤄진다.

빅 데이터 분석의 새로운 패러다임을 제시합니다. 5
다양한 데이터 커넥터 다양한 데이터 커넥터
빅데이터 분석 플랫폼에서 데이터의 연결은 가장 기본이며 중요한 부분이다. BICube™의 기본데이터
저장소인 HDFS로 데이터를 가져오기 위한 다양한 데이터 커넥터가 제공 되며 이를 이용하여 다양한 소
스의 데이터를 BICube™로 가져 올 수 있다.
리얼타임 스트리밍
BICube™는 실시간 분석을 위해 스트리밍을 위한 오픈소스를 다수 채택하고 있으며, 성능 향상을 위해
자체적으로 개발된 스트리밍 처리 모듈도 보유하고 있다.
데이터 변환 모듈
정형데이터를 전처리 하는 다양한 데이터 변환 모듈 이 내장되어 있어 플랫폼 안에서 기본적인 데이터
변 환을 간편하게 수행할 수 있다. - 데이터 탐색기, table 관련 연산, row/column 연산, summary 연산,
릴레이션 연결등.
Cubedoop
BICube™는 기본 저장소로 Hadoop을 사용한다. Apache에서 제공되는 Hadoop을 그대로 엔터프라
이즈 용으로 사용하면 운영상 번거로운 점들이 많이 있다. Hadoop의 원활한 모니터링과 관리를 위해
Cubedoop 이라는 BICube에 특화된 Hadoop 배포판을 만들었으며 BICube™의 저장소로 사용된다.
왜 머신러닝인가?
업계에서 빅데이터 붐이 시작된지 4~5년이 다 되어 가지만 아직 이렇다할 빅데이터 관련 성공 사례가 전
무 하다시피 하다. 빅데이터 관련 성공사례가 없는 가장 큰 이유는 비즈니스 접근이 잘못됐기 때문이다.
많은 사람들이 빅데이터 비즈니스를 과거 그대로의 데이터 분석 모델에 분석할 데이터만 많아진 상태로
인지했다. 이러한 답보 상태에서 벗어나게 해줄 가장 중요한 Key가 바로 머신러닝이다. 분석대상이 되
는 엄청난 데이터위에 머신러닝의 기술이 올라가면 이전에 생각하지 못했던 새로운 가치들이 창출 될 수

빅 데이터 분석의 새로운 패러다임을 제시합니다.6
있다. 실제로 여러 회사들이 머신러닝을 이용해서 새로운 비즈니스를 만들고 있으며 활용사례도 보고되
고 있다.
비즈니스 로직의 구현
BICube™의 애플리케이션 레이어는 프레임워크의 가장 상위 레이어로써 비즈니스 로직이 구현되는 레
이어다. 총 8개의 그룹으로 나눌 수 있으며 각 그룹의 역할은 아래와 같다.
▶ Manipulation: 각종 리모트 시스템 제어관련 컴포넌트 (java, Spark, Scalar, Python, R, Hadoop,
Graph)
▶ Mashup: 데이터 커넥터와 크롤러, 오픈API 컴포넌트
▶ Preprocess: 자연어처리, 각종파서, 인코더 컴포넌트
▶ Classify: 각종 분류 알고리즘이 구현된 컴포넌트
▶ Cluster: 각종 군집 알고리즘이 구현된 컴포넌트
▶ Associate: 연관분석 관련 알고리즘이 구현된 컴포넌트
▶ Bioinfomatic: 바이오 분석을 위한 컴포넌트
▶ Visual: 각종 시각화 컴포넌트 → 각 컴포넌트들을 이용하여 고객이 원하는 비즈니스 모델을 구현할
수 있다.

빅 데이터 분석의 새로운 패러다임을 제시합니다. 7
왜 머신러닝인가?
리카온-에프(Lycaon-F)는 이상금융거래 탐지를 위해 (주)비아이큐브에서 제작한 Neural Stream-
FDS(Fraud Detection System) 어플라이언스이다.
NeuralStream 구조 채택
Neural Steam은 복잡한 대량의 데이터를 빠르고 정확하게 처리하기 위해 고안된 BICube만의 독자적
인 스트림 처리 방식이다.
뇌신경이 동작하는 방식에 아이디어를 얻어 만들어 졌으며 기능단위의 뉴런들을 원하는 순서와 구조로
구성할 수 있다.
[Neural Stream에서 뉴런]
입력을 받아들여 연산/저장 후 결과를 내보내는 가장 작은 단위의 계산 유닛
NeuralStream 특징
▶ 빠른 스트림 처리
뉴런 - 초당 최대 200만 메세지 처리
▶ 뉴런을 서로 이어서 원하는 동작을 구현
→ 프로그래밍 언어 방식의 코딩 아님
→ 프로그래밍이 힘든 기능을 구현 가능
→ 일부 CQL(continuous query language)방식처리
▶ 분산처리 가능
→ 뉴런의 기능그룹을 코텍스로 묶어서 원하는 만큼 복제 가능
▶ 가독성 높음
→ 뉴런의 구성을 GUI 작업 공간에서 한눈으로 조망할 수 있음
FDS part

빅 데이터 분석의 새로운 패러다임을 제시합니다.8
사용자 프로파일 생성
모든 사용자의 거래 프로파일, 고객속성 프로파일, 기기정보 프로파일을 실시간 분석하면서 검사한다
FP를 낮추기 위한 기법
▶ Danger Zone
Danger Zone 이라는 용어는AIS(인공면역시스템) 의 Danger Theory에서 사용되는 용어이다.
Danger Theory는 면역 시스템이 위험을 감지했을 때 항원이나 외부 침입자를 kill하는 하는 매커니
즘으로써 이상 거래가 의심되는 트랜젝션을 Danger Zone으로 넘겨서 재 검사 함으로써 탐지 정확
도를 높인다.
Danger Zone → AIS(인공면역시스템)으로 구성
▶ Artificial Immune System(AIS)
인간의 면역체계의 메커니즘을 그대로 재현한 인공면역시스템을 오탐/과탐을 낮추는데 사용
빅 데이터 분석의 새로운 패러다임을 제시합니다. 9
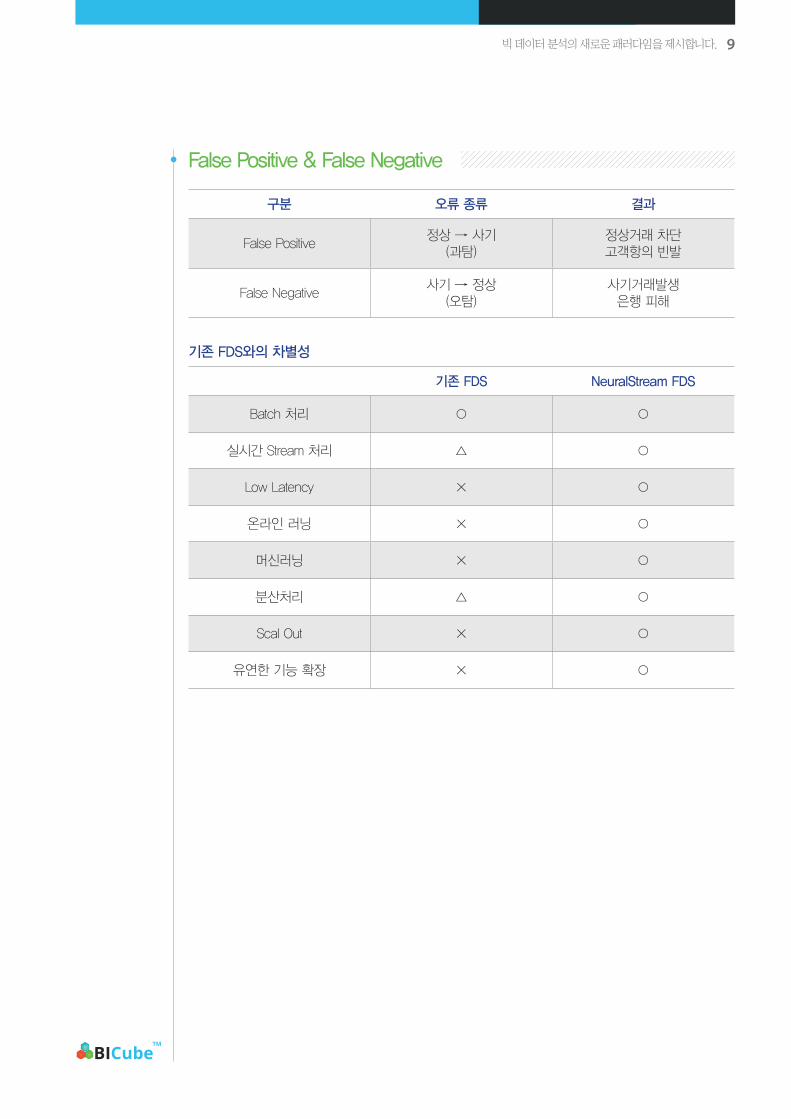
False Positive & False Negative
구분 오류 종류 결과
False Positive정상 → 사기
(과탐)정상거래 차단고객항의 빈발
False Negative사기 → 정상
(오탐)사기거래발생
은행 피해
기존 FDS와의 차별성
기존 FDS NeuralStream FDS
Batch 처리 ○ ○
실시간 Stream 처리 △ ○
Low Latency × ○
온라인 러닝 × ○
머신러닝 × ○
분산처리 △ ○
Scal Out × ○
유연한 기능 확장 × ○

•주소: 서울시 서초구 반포대로12길 33 305호
•구매 및 상담 문의: 070-7568-1166
•E_mail: [email protected]
•홈페이지: www.bicube.co.kr