「googleを支える技術」の解説 2010.08.23
TRANSCRIPT

ULS Copyright © 2010 UL Systems, Inc.
社内勉強会
「 Google を支える技術」の解説
ウルシステムズ株式会社http://www.ulsystems.co.jp
mailto:[email protected]: 03-6220-1420 Fax: 03-6220-1402
2010 年 8 月 23 日
講師役:近棟 稔

ULS Copyright © 2010 UL Systems, Inc. 2
書籍紹介
「 Google を支える技術」という書籍を取り上げます。
2008/3/28 に出た書籍です。 Google App Engine が出る数ヶ月前に、 Googleが公開している論文等を元に西田 圭介という日本人によって書き下ろされた本です。
内容は、 Google の開発してきたアーキテクチャの紹介を含んでいます。この本の著者が参考にしている情報を元に、 Hadoopも作られています。
http://research.google.com/pubs/papers.html
このサイトに論文が PDFで配布されています。

ULS Copyright © 2010 UL Systems, Inc. 3
相手にするマシン数を考えてみる
Google の「小規模データセンター」– 数千台のマシン規模のものを「小規模」と呼びます。
Google の「大規模データセンター」– 数十万台のマシン規模のものを「大規模」と呼びます。
( 「小規模データセンター」の 100 倍のマシン数に相当 ) 規模感を感じるために、現在のスーパーコンピュータの規模を考えてみる
と・・( 単純比較は危険だけど )
日本の「地球シミュレータ」8CPU の計算ノードを 160 台繋げたもの。計 1,280CPU で動作。
世界第 2 位アメリカの「 Roadrunner 」6,912 個の AMD Opteron プロセッサとPowerXCell 8i 12,960 個で動作。
世界第 1 位アメリカの「 Jaguar 」224,256 個の AMDOpteron プロセッサコアで動作。OS は Linux 。
最近 10 位以内に入っているスパコンの CPUは、 AMD の Opteron か、 Intel の Xeon か、 IBMの Power が使われている。 OS は、ほとんどLinux 。

ULS Copyright © 2010 UL Systems, Inc. 4
日本の大規模データセンターの例
さくらインターネットの大規模データセンター: 60 万台規模

ULS Copyright © 2010 UL Systems, Inc. 5
単純計算でのメモリー、 HDD 容量の皮算用
Google が 2003 年頃に用いていた 1 ノードあたりの能力はそれほど高くなく、以下のようなものだったようです。当時の高性能サーバーはメモリ 64GB程を載せていたようですので、かなり安めのサーバーを使っていたようです。
– CPU Xeon 2GHz x 2 個 ← Xeon はスパコンでもよく用いられる CPU– メモリー 2GB– HDD 80GB
Google の「小規模データセンター」 : 数千台– メモリー 数 TB– HDD 数百 TB
Google の「大規模データセンター」 : 数十万台– メモリー 数百 TB– HDD 数十 PB
たとえば、この広大なメモリー空間を使って何が出来るかを考えてみてください。普通のデータ規模なら、すべてのデータをメモリーに乗せてしまうことも可能です!

ULS Copyright © 2010 UL Systems, Inc. 6
アーキテクチャを考える上での前提知識

ULS Copyright © 2010 UL Systems, Inc. 7
C10K 問題 ( クライアント 1 万台問題 ) がクラスタの上限を決める
C10K 問題というのは、 1 台のサーバーマシンは、ソフトウエア側の制限によって、おおよそ 1 万台程度のクライアントまでしか捌けないという問題です。 なお、大抵のハードウエアは 1 万台以上の接続に耐えられるようです。
C10K 問題とデータセンターとの関係– 小規模データセンターで数千台、大規模データセンターで数十万台のマシン
があるとして、それらをうまく協調させるための中心となるサーバーマシンを置くとすると、この C10K 問題が関係してきます。 中心となるサーバーと接続を持つマシン達の上限が 1 万台という制約を持つと、小規模データセンターでは大丈夫ですが、大規模データセンターではうまくハンドリングできなくなって来ます。
1つのクラスタは、おおよそ 1 万台まで
ただし、上記のように中心となるマシンが居ない構成も考えられ、その場合はこの制約を超えられます。たとえば Cassandra はこのような構成になっています。 Google の場合、このような構成は取っていません。
マスター
クラスタ

ULS Copyright © 2010 UL Systems, Inc. 8
マシンが大量にあると、どれか壊れる
1台あたりの稼働率が 99% のマシンを大量に使った想定で、全部が問題なく動作する稼働率をグラフにすると・・・。数十万台なら?
全体の稼働率
(
%)
マシン台数
つまり、どれかのマシンは大抵壊れている。

ULS Copyright © 2010 UL Systems, Inc. 9
パオーマンスを引き出す原則
[原則1 ]読み取りスピードを上げるには複製を作るマスター系データのようにデータが変化しにくいものに関しては、複数台マシンにデータのコピーを作ると、読み取りパフォーマンスが向上します。
[原則2 ]一過性のコピーを可能な限り排除 (目指せ「ゼロ・コピー」 )処理のたびにコピーをすると、コピーそのものに非常に時間がかかり、パフォーマンスが出ません。理想的には処理の際には「ゼロ・コピー」を目指します。[ コピーの典型例 ]・ DB からプログラム側にデータを持ってくる際に発生するコピー・ DAO層とロジック層間など、層をまたぐ際に行う Bean のコピー
[原則3 ] データはメモリー上に置くOracle のキャッシュヒット率は 90%以上を保つことが目安であることからも分かるとおり、十分なパフォーマンスを得るためにはデータがメモリーに乗っている事が必要です。
[番外 ]適切なデータ構造とアルゴリズムを使用するアーキテクチャの話からそれますが、やはりデータ構造とアルゴリズムの選択がパフォーマンスを大きく左右します。

ULS Copyright © 2010 UL Systems, Inc. 10
Google のアーキテクチャ

ULS Copyright © 2010 UL Systems, Inc. 11
取り上げる技術
この勉強会では書籍で紹介のあった以下の技術を取り上げます。
上記のすべての仕組みは C10K 問題の範囲内での動作が前提です。 すべてのアーキテクチャは多重化されています。
名前 分類 内容 規模
ChubbyLOCKEVENTDISK
分散ロックサービス5 台構成のサーバーで1 万台のクライアントを扱える
GFS (Google File System) DISK 分散ファイルシステム
数百台のクライアント数千台のサーバーペタバイト規模
MapReduce CPU 分散処理のための基盤技術 数千台のサーバー
Bigtable DB構造データのための分散ストレージ
数百台のクライアント数千台のサーバーペタバイト規模

ULS Copyright © 2010 UL Systems, Inc. 12
全体 アーキテクチャ
アーキテクチャの全体 構成を以下に示します。
Chubby
Bigtable+MapReduce GFS+MapReduce
利用 利用
利 用
各種ロック , 同期とりDNS代わり各マシンの生死確認
巨大な分散 DB+分散バッチ処理
巨大なディスクスペース+ファイル操作型の分散バッチ処理
DB Disk
Lock

ULS Copyright © 2010 UL Systems, Inc. 13
Chubby
分散ロックサービス イベント通知 (Hadoop には該当サービスは無い )
Chubby: 「まるぽちゃの」の意味

ULS Copyright © 2010 UL Systems, Inc. 14
Chubby とは
Chubby は本質的には 1 台のサーバーによって提供されるリモートディスクです。リモートディスク上にファイルを作ることでロックを実現します。
ロック対象を監視しているマシンたちは、ロック対象の状態が変化したといったイベント通知を受け取ることも可能です。
Chubby は、冗長性を考慮しなければ、かなり単純な機構で実現可能です。仕組み上は TCP/IP を用いたチャットシステムなんかに似た機構で実現可能です。たとえば、 TCP/IP 接続を 1 万台まで受け付けるようにサーバーを構築し、クライアントはサーバーに接続しっぱなしの状態を作ります。あとはロック対象の資源をクライアント側で操作可能し、状態の変更通知をクライアント側に戻せるように作れば良さそうです。
C10K の 1 万台までChubby
ロック対象
ロックを取得したいマシンたち

ULS Copyright © 2010 UL Systems, Inc. 15
Chubby の使われ方
Bigtableや GFS はファイルのロックやレコードロックの仕組みを持っていないため、これを補完する目的で用いられます。ファイルのロックやレコードロックの代わりに、 Chubby の資源をロックする事で代替とします。( ただしパフォーマンスが出なくなるため、このようなロックは避けます )
Chubby 上のロックを取り合うことで、冗長化されたマシンのどれが動くかを決めることができます。現在動作中のマシンが止まるとロックが解除され、待機していたマシン達がロックを取り合います。最初にロックを取ったマシンが成り代わります。
Chubby の一時ファイル機能を用いると、マシンの生死確認が可能です。各マシンは Chubby 上に自分が生きている事を示す一時ファイルを作成し、自分の IP アドレスを記入しておきます。もしも一時ファイルを作成したマシンが停止した場合、一時ファイルは Chubby 上から自動的に削除されるため、この変更通知がフォルダーを監視しているマシンに即座に通知されます。
高速に IP アドレス変更が可能な DNS として動作可能です。たとえばマシン名を Chubby 上のロックオブジェクト名とし、これに IP アドレスを記入しておきます。もしも障害復帰等の目的で IP アドレス変更をする場合は、このロックオブジェクトの内容を変更します。そうすると、この変更はイベントとして伝播し、素早く IP アドレス変更が通知されます。

ULS Copyright © 2010 UL Systems, Inc. 16
Chubby が耐障害性のためにやっていること
Chubby は実際には 5 台のマシンから構成されます。この 5 台のマシンを「 Chubby セル」と呼びます。この中の 1 台がマスターで、このマシンが健在の間はすべてのリクエストをこのマスター 1 台で処理します。他の 4 台は、いつでもマスターに成り代わることのできるバックアップマシンです。更に、 Chubby セルの 5 台のうち 1 台は、必ず別のデータセンターのマシンが選ばれます。
マスターを選ぶ際には、 Paxos というコンセンサスアルゴリズムを用います。初回起動時や障害発生時は、生きているマシン達は投票によって誰が次のマスターになるかを決めます。
マスターがすべて対処
どれか 1 台は別のデータセンターに配置

ULS Copyright © 2010 UL Systems, Inc. 17
GFS (Google File System)
ペタバイト規模の分散ファイルシステム Hadoop では HDFS が該当

ULS Copyright © 2010 UL Systems, Inc. 18
GFS とは
GFS はログのような末尾追記型の書き込みと、大量の読み出し要求に応えることに特化した分散ファイルシステムです。
GFS が得意なこと
大量の読み出し要求に応えられる。マシンの台数によってスケールする。 設定によって 1 つのデータのコピーを多く作ることによって、更に性能を上げられる。大量の書き込み要求に対しても、書き込みファイルが別々ならスケールする。サイズの大きなファイル ( 最低でも数百 MB) を扱うことが得意。「追記」なら複数同時書き込みが可能。「スナップショット」というコピー機能で、ファイルの大きさによらず一瞬でコピー可能。 (SVNのコピーと同じ )
GFS が苦手なこと
小さなファイルは苦手。おそらくオーバーヘッドが非常に大きくなる。ランダムな場所への書き込み。複数クライアントから単一ファイルにこれをやるとファイルが壊れる。ファイルをロックする機能が無い (やりたければ Chubby を使う )追記データが重複する場合があり、 利 用者側が重複を除去する必要がある。
GFS
クライアント
追記読み出し
クライアント
追記同時追記 読み出し
同時読出

ULS Copyright © 2010 UL Systems, Inc. 19
GFS のアーキテクチャ
以下に GFS のアーキテクチャを示します。
Chubby のロックの取り合いによって複数台のマスタ候補からマスタは選択される。
1 つのファイルは 64MBずつの「チャンク」に分けられて保存されます。これは TCP の「パケット分割」に似ています。少し違うのは、 1対 1 通信の TCP とは違い、 GFS の場合は 1 つのファイルに対して複数クライアントからの読み書
きがあることです。
マスタはどのデータがどのチャンクサーバで管理されているかを知っている。クライアントからの問い合わせには、チャンクの場所を教えるのみ。
クライアントは読みたいデータの場所をマスタに問い合わせ、その後、それぞれのチャンクサーバにデータを取りに行く。
実データはチャンクサーバと直接やりとりするため、帯域幅を有効に生かせる。
マスタはメモリー中にディレクトリ階層をすべて持つ。また、ファイルの中身がどのチャンク達に書かれているかを知っている。

ULS Copyright © 2010 UL Systems, Inc. 20
追記処理の挙動
GFS では追記の一塊のデータを「レコード」と呼びます。 1 レコードは 16MB以下である必要があります。書き込まれるレコードは一旦メモリーに貯められ、順次チャンクに追記されます。
どこかでエラーが発生すると、一部のディスク書き込み ( チャンク追記 ) に成功している場合であっても全体 としてはエラーとし、書き込み処理をリトライします。チャンクにゴミが残りますが、データ書き込みの際に付加するチェックサムやシリアル番号を読み取り時に確認し、壊れたデータや重複データをより分けます。
1. クライアントはマスターにどのチャンクサーバーに書き込めばいいのか問い合わせる。
2. マスターは少なくとも 3 台のマシンを書き込み先と決め、その一台をプライマリ、それ以外をセカンダリのチャンクサーバと決める。
3. クライアントは最寄りのチャンクサーバにデータを渡す。データはチャンクサーバから別のチャンクサーバへチェーンされ、データが渡る。データはまだ各チャンクサーバのメモリー内にある。
4. クライアントからプライマリに書き込み要求をする。プライマリはチャンクにデータを追記する。ディスク書き込み。
5. セカンダリにも書き込み要求をチェーン。6. 書き込み成功をプライマリに通知。7. 書き込み成功をクライアントに通知。

ULS Copyright © 2010 UL Systems, Inc. 21
読み取り処理の挙動
GFS 上の1つのファイルは 64MBずつのチャンク ( パケット ) に分割され、保存されています。また、1つ1つのチャンクは最低3つの別のチャンクサーバーにコピーされています。よって、読み取り操作は、この 3 つ以上あるコピーのうち、自分に近いサーバーからデータを持ってくるだけです。ただし、書き込み時に生じている可能性のあるゴミデータはより分ける必要があります。データの複製の数をデフォルトの 3 以上に増やすと、書き込み性能は犠牲になりますが、読み取り性能は高めることが出来ます。

ULS Copyright © 2010 UL Systems, Inc. 22
Bigtable
構造データのための分散ストレージ Hadoop では HBase という名前で提供

ULS Copyright © 2010 UL Systems, Inc. 23
前提知識:分散 KVS について
スケールアウトが容易にできる「分散 KVS(NoSQL) 」が、クラウドの世界では必須のものとなりつつあります。分散 KVS は数千台のマシンを束ねて 1 つの巨大なハッシュマップのような物として 利 用可能にするものです。 KVS というと、 memcached のような簡単なキャッシュ用途のものが思い浮かぶかもしれませんが、クラウドでの分散 KVS はメインの DB です。 なお、 KVS の Key の扱いに関しては、ハッシュ値を使った方式を使うか、 Key でソートして探索する sorted map にするなどの選択肢があります。 sorted map の場合は範囲検索が可能だという 利点 があります。 通常、アトミックな操作は1度の Key,Value操作のみです。
分散 KVS の典型的なアーキテクチャ
マスター
実際のデータを保管するサーバー。データは基本的にはディスク上に保管される。キャッシュに乗せる量がマシン台数次第でとても大きくできるため、高性能化しやすい。
クライアント
Key, Value →
Key値によって適切な保管サーバーを決定。この決定アルゴリズムとして有名なのはConsistent Hashing です。このような特殊なアルゴリズムを使うと、サーバーを追加したり削除したりする事が容易に行えます。

ULS Copyright © 2010 UL Systems, Inc. 24
GFS は分散 KVS の一種
GFS は KVS の一種です。 Key の構造が特殊で、テーブルのような論理データ構造を扱えるようになっています。
通常の KVS では Key,Value のペアをバラバラのサーバー群に保存しようとしますが、それだと 1 レコードを取り出す操作が遅いです。 Bigtable の場合は行キーでまとめたレコードを 1 つのまとまりとします。アトミック操作も 1 レコード操作内になります。
複数レコードをまとめた物を「タブレット」と呼び、このタブレットをタブレットサーバーで管理します。よって、1つのテーブルは複数のタブレットサーバーによって管理されます。データは GFS に置かれます。
Key(3 つの複合キー )
・行キー (PK)・コラムキー・タイムスタンプ
Value ・ BLOB
1 タブレット: 100~ 200MB 程度

ULS Copyright © 2010 UL Systems, Inc. 25
タブレットの読み書き方法
Bigtable の読み書きの基本はタブレット操作です。以下に処理内容を説明します。
書き込み方法書き込みはコミットログに内容を書き、 memtable 上に値を保持して完了。 memtable が溢れた場合、データをまとめてSSTable に書き出し、コミットログをクリアする。
読み込み方法直近の書き込みデータはオンメモリにあるため、それを返して終わり。値が GFS のファイル中のデータを指している場合は、そのデータを GFS から取得して返す。もちろんタブレットサーバにキャッシュがあればそれを使う。
value1value2・・・・・・・・・・・・・・・・・・
インデックス
SSTable
key1 value1へのポインタ
key2 value2へのポインタ
key3 value3 そのもの
・・・ ・・・
memtable(オンメモリインデックス )
memtableへの操作ログ (追記 )SSTable には未反映
コミットログ
GFS
value1value2・・・・・・・・・・・・・・・・・・
インデックス
value1value2・・・・・・・・・・・・・・・・・・
インデックス
value1value2・・・・・・・・・・・・・・・・・・
インデックス
クライアント
タブレットサーバ (オンメモリ処理 )
GFS の得意な追記と、複数ファイル並行読取をうまく使っている。
読み書き
オンメモリに直近の ( まだ SSTableに保存していない ) 情報と、全体 のインデックス情報の2つのデータを保持。
タブレットサーバーはローカルディスクを使いません。おそらく GFS との同居も可能です。
2重化しない

ULS Copyright © 2010 UL Systems, Inc. 26
Bigtable を 利 用しているシステム
Google のクローラ– クロールした html データを保存するために使っているそうです。
Google Maps, Earth (maps.google.com, earth.google.com)– 地図情報の置き場などに 利 用
Orkut (www.orkut.com) Personalized Search (www.google.com/psearch) Google Finance (www.google.com/finance) Google Analytics (analytics.google.com)
– トラフィック解析ツール
バックエンド向けからエンドユーザー向けまで幅広く 利 用可能

ULS Copyright © 2010 UL Systems, Inc. 27
MapReduce
分散処理のための基盤技術 Hadoop でも MapReduce という名前で提供

ULS Copyright © 2010 UL Systems, Inc. 28
MapReduce とは
大量の CPU がある環境で簡単に分散処理を動かす時の考え方として、計算ノードに ID を付け、その計算ノードにプログラムとデータを送りつけるというものがあります。
MapReduce では、計算ノードの ID を Key 、データを Value と位置づけます。
それに加えて、 MapReduce は計算の流れを「 Map 」処理と「 Reduce 」処理に緩く定義しました。
この MapReduce は、完全にバッチ処理向けの仕組みになります。
ULS Copyright © 2010 UL Systems, Inc. 29
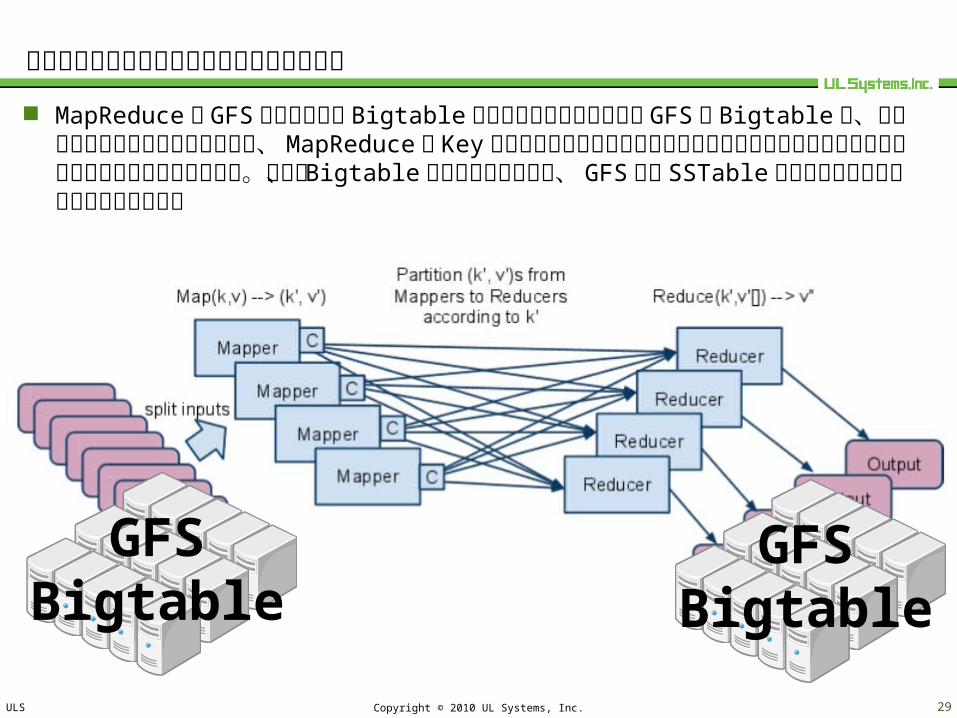
コピー処理が無い方がパフォーマンスが出る
MapReduce は GFS のデータでも Bigtable のデータでも動作します。 GFS もBigtable も、元々データを分散保持しているため、 MapReduce の Key値をうまくデータを保持しているサーバーに結び付けられれば処理はローカル処理に出来ます。なお、 Bigtable が対象データの場合、 GFS 上の SSTable を直接読み込む事もしているようです。
GFSBigtable
GFSBigtable

ULS Copyright © 2010 UL Systems, Inc. 30
おしまい