jsai2017:敵対的訓練を利用したドメイン不変な表現の学習
TRANSCRIPT

敵対的訓練によるドメイン不変な表現の学習
東京大学 岩澤有祐
上智大学 矢入郁子
東京大学 松尾豊
1

研究背景:ドメインバイアス
• DL含む多くの検証・一般的な学習理論は左を前提– MNIST,CIFAR10など
• 一部の機械学習タスクはドメインバイアスがある(つまり右)– 訓練時と異なるユーザを対象とする,ユーザの行動が変化するなど
– ドメインバイアスを無視すると,テストに対して精度が悪化2
P(X)
訓練データ
テストデータ
P(X)
訓練データ
テストデータ
P’(X)
w/oドメインバイアス w/ドメインバイアス
≒
同じ真の分布からサンプルされたデータ
異なる真の分布からサンプルされたデータ

研究背景:ドメイン汎化 [Blanchard, 2011]
• ドメインシフト有 + 未知ドメインのラベルデータを得にくい場合に重要– 加速度センサによる行動認識,医療(フローサイトメトリー [Blanchard, 2011])
3
P1(X)
ユーザ1
データ未知ユーザ
P’(X)
ドメイン汎化:未知ドメインに有用な知識を関連ドメイン群から獲得する
P2(X)
ユーザ2
データ
P3(X)
ユーザ3
データ
…
任意の数の関連ドメインの観測データ(例:学習時にいるユーザ)
未知のドメインのデータ(例:未知のユーザ)
≒ ≒ ≒

研究背景:ドメイン汎化へのアプローチ
• アプローチの1つにドメイン不変な表現を学習するもの(i.e., ドメイン間の違いを吸収するような表現を学習する)
• 例:Domain Invariant Component Analysis [Muandet, 2014]
– ドメイン間の類似度をカーネルにより計測し,その差を最小化
• 本研究では,任意の構造を持つニューラルネットが学習する表現のドメイン不変性を高める方法を提案
4

提案:敵対的訓練のドメイン不変な表現の学習への応用
5
G Network
z ~ N(0, 1)
Fake Real
D Network
Real / Fake識別ネット:入力がR/Fのどちらかを識別
生成ネット:識別ネットが
区別出来ないようにzを写像
X ~ P1(X)
D1
特徴D2
特徴
D Network
Domain1/Domain2/
Domain3/…識別ネット:
入力がどのドメインのサンプルか識別
Domain1
X ~ P2(X)
...
... 識別ネットがドメインを識別出来ないようにXを特徴空間に写像
Domain2
画像生成に利用[Goodfellow, 2014]
提案手法:ドメイン汎化に応用
P1(z) P2(z)PG(X) PR(X)

ここまでのまとめ
• ドメイン汎化とは,未知のドメインに対する認識精度を高めるための問題設定
– [Blanchard 11]が初出
– 複数の類似ドメインのデータを使い,ドメイン不変な表現を学習するのがアプローチの1つとして検討されている
• 本研究では,敵対的訓練の応用によりドメイン不変な表現を学習するニューラルネットを提案
– 学習時にドメインを識別するドメイン分類器を用意し,騙す
6

関連研究:ドメイン適応
• ドメイン適応:ある対象ドメインのデータが観測された元で関連ドメインのデータから有用な知識を獲得
• 類似点:ドメインの違いを吸収することで対策可能
– Domain Adversarial Neural Networks [Ajakan, 2014]
– Deep Domain Adaptation [Long, 2015]
• 相違点(ドメイン適応/ドメイン汎化)
– 対象ドメインのデータが観測される/されない
– (通常は)関連ドメインが1つ/関連ドメインが複数
• 今回はドメイン汎化の設定で有効性を検証
– 未知のドメインへの有効性,複数ドメインを扱う
7

関連研究:ドメイン汎化
• カーネルベースのアプローチ– [Blanchard et al., 2011]:ドメイン汎化の問題を初めて定義
– (Unsupervised) Domain Invariant Component Analysis [Muandet et al., 2013]:カーネルPCAをドメインの類似度を考慮するように拡張
• ニューラルネットベースのアプローチ– Constractive Autoencoder [Rifai, 2013]:AEやDAEより良い
※ドメイン汎化目的で開発された方法ではない
– Multitask AutoEncoder [Ghifary, 2015]:複数ドメインのXを予測するAE
• 課題:多くの場合教師なし => 認識には2ステップの学習
• 本研究は、任意の構造の教師ありNNと併用可能– ラベルYの予測精度と不変性を同時最適化できる
– 対象タスクで予測精度の良いモデルを再活用できる
8

提案手法の全体像
9
特徴抽出器
ドメイン分類器ラベル分類器
X
特徴量R
y1,y2,… d1,d2,…
通常のNNとの違い1ドメインDの
負の交差エントロピーLdを最小化
通常のNNとの違い2ラベルYの
交差エントロピー Ly+ λLdを最小化

特徴抽出器
ド メ イン分類器ラベル分類器
W earab les
X
特徴量R
y1, y2, … d1, d2, …
提案手法の学習方法
10
Step1 Step2
固定
固定固定
交互最適化
現在の特徴量Rを使ってドメイン分類器を訓練
特徴抽出器
ド メ イン分類器ラベル分類器
W earab les
X
特徴量R
y1, y2, … d1, d2, …
現在のドメイン分類器を騙す+ Yを分類するように訓練

工夫:重みλのスケジューリング
• 特徴抽出器は最終的にLy + λLdを最小化するが,最終的に重要なのは未知のドメインに対するLy
• 単純に最初からLdを考慮した学習を行うと,Lyが下がり切らない傾向(Ldだけを考慮しても☓)
=> λを徐々に大きくするスケジューリングにより改善(後述)
11

評価用データセット:Opportunity Challenge Dataset
• キッチンにおける行動を計測したデータ(慣性センサ中心,w/o vision)
• 認識対象:Locomotion -> 5種類,Gestures -> 18種類
• 4人のユーザ(各ユーザを別のドメインとして扱う),合計50,000サンプル強12

評価:評価指標
13
評価1: R->Yの予測精度の高さ
- 未知のドメイン(ユーザ)に対する認識精度で比較
評価2: R->Dの予測精度の低さ
- 認識精度が低い->識別しにくい- モデル学習後に,評価用分類器を
新たに学習させ評価
D評価用分類器γ
表現Rの良さをラベル分類精度 + ドメイン(非)分類精度で検証
特徴抽出器
ド メ イン分類器ラベル分類器
W earab les
X
特徴量R
y1, y2, … d1, d2, …

評価:提案手法ADV-MLPAの具体的な構造
14
特徴抽出器:畳み込み×3 + 全結合層×1
[Jian, 2015]を参考に構築
ラベル分類器:ロジスティック回帰
ドメイン分類器:3層MLP (800ユニット)

評価:比較対象
1. 通常のCNN(敵対的訓練なし)
=> 敵対的訓練の有効性
2. 学習時のドメイン分類器を変更したモデルADV-LR
(MLP -> ロジスティック回帰)
=>ドメイン分類器の強さが学習される表現に与える影響
3. λのスケジューリングを行わないモデル ADV-MLP
=>スケジューリング導入の効果15

評価に関するその他の情報
比較対象について
• CNNに加えて行動認識で良く利用される特徴量を比較(詳しくは予稿3P右下参照)– MV [Yang, 2015]:各軸の平均値と分散値
– ECDF [Hammerla, 2013]:Empirical Cumulative Distribution Function
ドメイン損失Ldについて
• ドメイン分類はSoftmax + 交差エントロピー
学習方法・パラメタについて
• 150エポックAdamで学習
• λ= 0.1(焼きなましを行う場合は前後15エポックを固定)
• Leave-One-Subject-Out評価の平均で評価 16

結果:Locomotion Task(赤がw/敵対的訓練)
17
0.87
0.5160.48 0.501
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
ドメイン不変性
(ドメイン予測精度)
CNN
Adv-LR
Adv-MLP
Adv-MLPA
0.557
0.547
0.551
0.566
0.535
0.54
0.545
0.55
0.555
0.56
0.565
0.57
ドメイン汎化性能
CNN
Adv-LR
Adv-MLP
Adv-MLPA
• ドメイン不変性は大幅改善 • ドメイン汎化性能はAdv-MLPAのみ改善(F値で約0.01ポイント)
• λのスケジューリングしないと微減

結果:Gestures Task (赤がw/敵対的訓練)
18
0.903
0.5790.543 0.55
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
ドメイン不変性
(ドメイン予測精度)
CNN
Adv-LR
Adv-MLP
Adv-MLPA
0.794
0.786
0.781
0.804
0.765
0.77
0.775
0.78
0.785
0.79
0.795
0.8
0.805
0.81
ドメイン汎化性能
CNN
Adv-LR
Adv-MLP
Adv-MLPA
• ドメイン不変性は大幅改善 • ドメイン汎化性能はAdv-MLPAのみ改善(F値で約0.01ポイント)
• λのスケジューリングしないと微減

分析:クラスタリングによる学習表現の可視化
19
可視化
N個のサンプルをNNの上から2番目の層で出力でクラスタリングしてクラスタIDをN個得る
各サンプルへのクラスタIDとユーザIDをクロス集計して各クラスタに特定のユーザが占める割合を計算し可視化

結果:特徴量のクラスタリングによる比較
20
既存手法:CNN (λ=0.0) 提案手法:UANNMLP (λ=0.1)
Opp-G(20クラスタ)
USC(30クラスタ)
特徴空間で特定のユーザのみ同じ位置にいない=>学習された表現はユーザに関する情報をより持たない

結果:評価用ユーザ分類器を変更した場合の比較
21
LR MLP (50) MLP (800)
None(CNN)
0.870 0.963 0.983
LR 0.516 0.955 0.981
MLP (800) 0.501 0.774 0.950
学習
用分
類器
評価用に作成した分類器γ
1. γによらず強い分類器がベター 2. γが強いと分類可能
提案手法はよりドメイン不変になるが,完全に不変ではない

考察:ドメイン汎化性の改善が微量である理由
• 理由1:完全にドメイン不変でない
– 提案法の表現はCNNよりはドメイン不変だがランダムよりはドメイン依存
– 学習時の敵対的分類器の選択が重要になりそう(直感的には強い分類器を選ぶほど不変性は高まるが,学習が難しい)
• 理由2:ドメイン不変性とラベル予測性のトレードオフ
– 単にドメイン不変性をあげるだけだとラベル予測性は下がる(例:ランダム写像は完全にドメイン不変だが予測性は無い)
– 焼きなまし以外のベターなヒューリスティックの模索が必要
22

考察:表現の不変性の応用先
• プライバシー保護 [Iwasawa, 2017]
– “Privacy Issues Regarding Applications of DNNs to Activity Recognition using Wearable and Its Countermeasure”, IJCAI2017
– 特徴量が任意の情報を学習して良いとするとプライバシー情報を予測可能な情報を持つ可能性がある(例:歩き方に紐づく病気の有無など)
• 異なるエージェント間でのスキルの転移 in RL[Gupta, 2017]
– エージェント不変な空間を学習して転移
– これ自体は敵対的訓練は使っていない
23

まとめ・将来課題
• ドメイン汎化に向けドメイン不変な表現を学習するNNを提案
• 各ユーザをドメインとみなし,行動認識データセットで検証
– ドメイン不変性:通常のNNとくらべて大幅に改善
– ドメイン汎化性能:λのスケジューリングにより微改善
• 将来課題
– 不変性を高める方法・パラメタの探索
– P(Z)の不変性+P(Y|X)の維持を実現する方法・ヒューリスティック
– 行動認識以外のデータでの検証(画像認識,医療系のデータ)
– ドメイン汎化との理論的接続
24

ドメイン依存性はユニットレベルかレイヤレベルか
• A. ユニットレベルでもある
• レイヤレベルで依存していることを示す事実:
– 高精度に分類が可能
– 第1主成分がドメイン(ユーザ)依存になっている
– クラスタリングすると、ドメイン毎にまとまる
• ユニットレベルで依存していることを示す事実:
– ユニットを落としたときの認識精度の劣化がドメインごとに異なる(が全てが異なるわけではない)
25

関連研究:敵対的訓練の応用研究
• Generative Adversarial Nets [Goodfellow, 2014]
– 敵対的訓練を画像生成に利用
• Domain-Adversarial Neural Nets [Ajakan, 2014]
– ドメイン適応に利用
• Adversarial Learned Fair Representations [Edwards, 2016]
– 公正性配慮データマイニングに利用
本研究は敵対的訓練の新たな応用方法として位置づけ
26
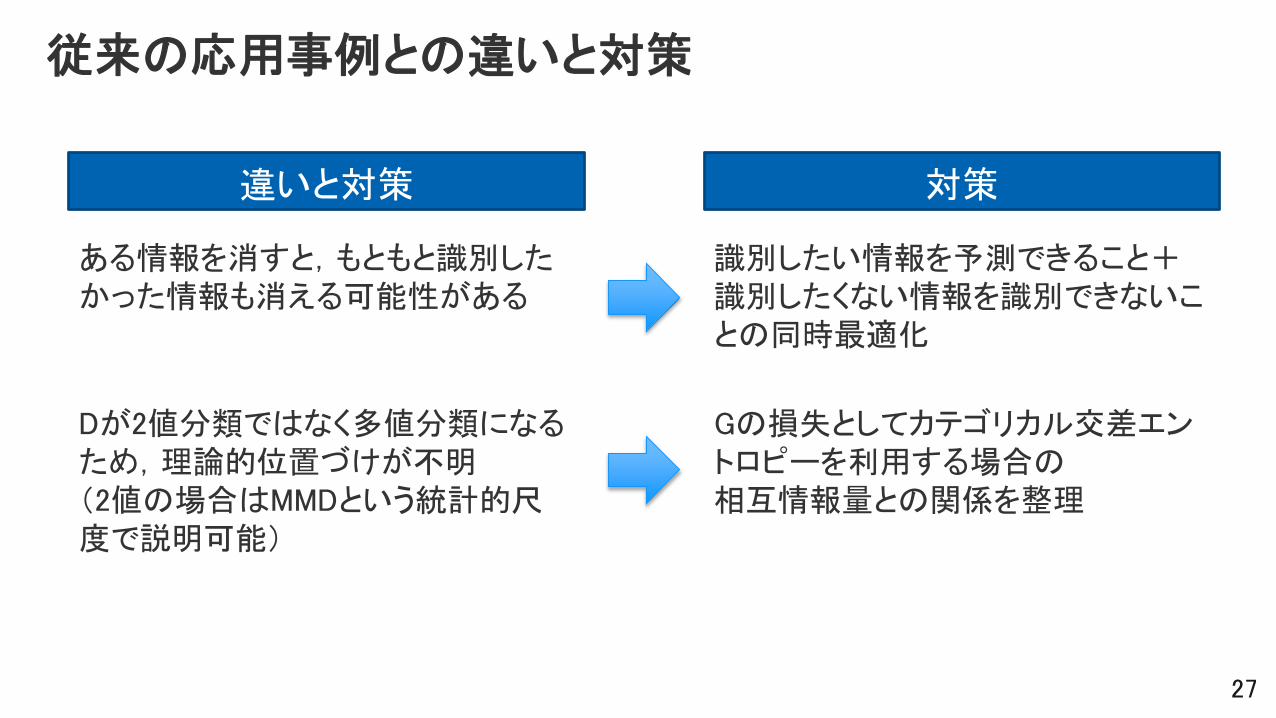
従来の応用事例との違いと対策
27
ある情報を消すと,もともと識別したかった情報も消える可能性がある
Dが2値分類ではなく多値分類になるため,理論的位置づけが不明(2値の場合はMMDという統計的尺度で説明可能)
識別したい情報を予測できること+識別したくない情報を識別できないことの同時最適化
違いと対策 対策
Gの損失としてカテゴリカル交差エントロピーを利用する場合の相互情報量との関係を整理

関連研究:ドメイン汎化
• カーネルベースのアプローチ
– [Blanchard et al., 2011]:ドメイン汎化の問題を初めて定義
– (Unsupervised) Domain Invariant Component Analysis [Muandet et al., 2013]:カーネルPCAをドメインの類似度を考慮するように拡張
• ニューラルネットベースのアプローチ
– Constractive Autoencoder [Rifai, 2013]:AEやDAEより良い※ドメイン汎化目的で開発された方法ではない
– Multitask AutoEncoder [Ghifary, 2015]:複数ドメインのXを予測するAE
本研究は教師ありニューラルネットが学習する表現がドメイン不変になるようする手法を提案
28