laporan ke2
TRANSCRIPT

BAB IPENDAHULUAN
1.1 Latar BelakangAnalisis cluster adalah analisis yang digunakan untuk
mengelompokkan obyek-obyek berdasarkan kesamaan karakteristik di antara obyek-obyek tersebut. Obyek tersebut akan diklasifikasikan ke dalam satuatau lebih cluster (kelompok) sehingga obyek-obyek yang berada dalam satu cluster akan mempunyai kemiripan satu dengan yang lainnya.
Analisis cluster bertujuan untuk mengelompokkan isi variabel, juga bisa disertai dengan pengelompokkan variabel, sedangkan analisis faktor lebih bertujuan untuk mereduksi variabel.
Analisis cluster dapat digunakan di berbagai bidang kehidupan, misal di bidang psikologi analisis cluster digunakan untuk mengelompokkan orang berdasarkan respon mereka terhadap stimulasi tertentu atau pengelompokkan orang berdasarkan kepribadian mereka. Lalu dalam biologi analisis cluster dapat membantu proses taksonomi untuk mengelompokkan organism tertentu. Dalam bidang manajemen membantu mengelompokkan konsumen berdasarkan pendapatan mereka terhadap produk tertentu.
Lain halnya dengan analisis cluster analisis faktor digunakan untuk mengidentifikasi underlying dimensions (factors) yang dapat menjelaskan korelasi sekumpulan variabel. Selain itu juga digunakan untuk mengidentifikasi variabel baru, yag digunakan untuk analisis lainnya, mengidentifikasi satu atau beberapa variabel dari variabel yang banyak jumlahnya, dan mengkonfirmasi konstruksi suatu variabel laten. Karena analisis faktor dan analisis cluster sangat penting sekali untuk dipelajari, maka praktikum kali ini dibahas mengenai dua analisis di atas1.2 Tujuan1. Mahasiswa mampu melakukan analisis faktor dan
menginterpretasikannya2. Mahasiswa mampu melakukan analisis cluster dan
menginterpretasikannya
1

2

BAB IITINJAUAN PUSTAKA
Analisis faktor adalah salah satu analisis yang banyak digunakan pada statistik peubah ganda, diperkenalkan pertama kali oleh Spearman (1904), dan dikembangkan oleh Thurstone (1947), Thomson (1951), Lawley (1940, 1941) dan lainnya. Pada awalnya analisis ini tergolong sulit dan kontroversial, namun dalam perkembangaannya dirasakan menjadi alat yang sangat berguna. Terutama setelah perkembangan komputer dan paket-paket piranti lunak statistik., serta pada tahun 1970-an banyak terbit buku dan publikasi lain yang membahas penerapannya di berbagai bidang seprti biologi, kimia, ekologi, ekonomi, pendidikan, ilmu politik, psikologi, dan sosiologi. Penerapan tentang analisis ini secara detail di berbagai bidang dapat dirujuk pada berbagai terbitan. (Assyiehab, 2012)
Di dalam analisis faktor, variabel tidak dikelompokkan menjadi variabel bebas dan tak bebas, sebaliknya penggantinya seluruh set hubungan interdependen antar variabel diteliti. Analisis faktor dapat pula dipandang sebagai perluasan dari analisis komponen utama. Keduanya merupakan teknik analisis yang menjelaskan struktur hubungan di antara banyak variabel dalam sistem konkret. Analisis faktor bisa digunakan untuk dua fungsi utama dalam data analisis. Pertama digunakan untuk mengidentifikasi struktur dasar dalam data, yang kedua analisis faktor mudah digunakan untuk mereduksi ukuran variabel agar lebih dimudahkan. Secara matematis analisis faktor sedikit mirip dengan regresi linier berganda bahwa setiap variabel dinyatakan sebagai suatu kombinasi linear dari faktor yang mendasari (underlying factors). Jumlah varian yang disumbangkan oleh suatu variabel dengan variabel lainnya yang tercakup dalam analisis disebut communality. Kovariansi antara variabel yang diuraikan, dinyatakan dalam suatu common factors yang sedikit jumlahnya ditambah dengan faktor yang unik untuk setiap variabel. Faktor-faktor ini tidak secara jelas terlihat. Kalau variabel-variabel dibakukan (standardized) model faktor bisa ditulis sebagai berikut (Ansori, 2011):
X i=B i1 F1+Bi 2 F2+B i3 F3+……..+Bij F j+V i μi
Xi : variabel ke I yang dibakukan (rata-ratanya nol, standar deviasinya satu)Bij : koefisien regresi parsial yang dibakukan untuk variabel I pada common factor ke j
3

Fj : common factor ke j
Vi : koefisien regresi yang dibakukan untuk variable ke i pada faktor yang unik ke i (unique factor)µi : Faktor unik variabel ke im : Banyaknya common factorLangkah-langkah melakukan analisis faktor (Ansori, 2011):1. Identifikasi masalah
Yang dimaksud identifikasi masalah di sini adalah mengidentifikasi tujuan analisis faktor, variabel yang dipergunakan dalam analisis faktor harus dispesifikasi berdasarkan penelitian sebelumnya, teori dan pertimbangan dari peneliti, pengukuran variabel berdasarkan skala interval atau rasio, banyaknya elemen sampel (n) harus cukup/memadai sebagai petunjuk kasar, kalau k banyaknya jenis variabel maka n=4 atau 5 kali k.
2. Bentuk matriks korelasiProses analisis didasarkan pada suatu matriks korelasi agar variabel pendalaman yang berguna bisa diperoleh dari penelitian matriks ini. Agar analisis faktor bisa tepat dipergunakan variabel-variabel yang akan dianalisis harus berkorelasi.
3. Menentukan metode analisis faktorAda dua cara atau metode yang bisa dipergunakan dalam analisis faktor khususnya untuk menghitung koefisien skor faktor yaitu principle components analysis dan common factor analysis. Di dalam principle component analysis jumlah varian dalam data dipertimbangkan. Metode ini direkomendasikan untuk menentukan banyaknya faktor harus minimum dengan memperhitungkan varian maksimum. Sedangkan common factors analysis, dianggap tepat bila tujuan utamanya ialah mengenali/mengidentifikasi dimensi yang mendasari dan common variance yang menarik perhatian.
4. Penentuan banyaknya faktorUntuk menentukan banyaknya faktor ada beberapa prosedur yaitu penentuan secara a priori atau berdasarkan eigenvalues, screeplot, split-half reliability dan significance test.
4

Analisis cluster atau analisis gerombol merupakan teknik peubah ganda yang mempunyai tujuan utama untuk mengelompokkan objek-objek berdasarkan kemiripan karakteristik yang dimilikinya. Karakteristik objek-objek dalam suatu gerombol memiliki tingkat kemiripan yang tinggi, sedangkan karakteristik antar objek pada suatu gerombol dengan gerombol lain memiliki tingkat kemiripan yang rendah. Dengan kata lain, keragaman dalam suatu gerombol minimum sedangkan antar keragaman antar gerombol maksimum. Variabel-variabel yang dilibatkan dalam analisis gerombol dipilih sesuai dengan tujuan penggerombolan. Misalnya dalam suatu kajian ingin dibentuk gerombol objek berdasarkan kemampuan prestasi akademik. Variabel-variabel yang relevan dimasukan dalam kajian ini antara lain nilai rapor setiap mata pelajaran yang diambil dan nilai ujian nasional. Berbeda dengan teknik multivariat lainnya, analisis ini tidak memilih gugus variabel secara empiris tetapi menggunakan gugus variabel yang ditentukan oleh peneliti itu sendiri sesuai dengan tujuan penggerombolan. Kemiripan antar objek diukur dengan menggunakan ukuran jarak. Beberapa ukuran jarak yang sering digunakan antara lain jarak Euclid, jarak mahalanobis, jarak City-block (Manhattan), dan lain-lain. (Ansori, 2011)
1. Jarak Euclidean
Ini merupakan tipe jarak yang paling umum dipilih. Kemudahannya adalah jarak geometrik dalam ruang dimensi ganda. Perhitungannya sebagai berikut: Jarak (x,y)={i(xi-yi)2}1/2. Perhatikan bahwa jarak Euclidean (dan kuadrat Euclidean) biasanya dihitung dari data mentah, dan tidak dari data standar. Metode ini memiliki beberapa keuntungan, antara lain jarak dari 2 objek apa saja tidak dipengaruhi oleh penambahan dari objek baru untuk di analisis, yang mungkin merupakan pencilan. Namun demikian, jarak bisa menjadi sangat besar, disebabkan hanya karena perbedaan skala. Sebagai contoh, jika suatu dimensi di ukur dalam satuan jarak cm, dan dikonversi dalam mm (dengan mengkalikan nilai dengan 10), hasil dari jarak Euklidean atau kuadrat Euklidean ( dihitung dari dimensi ganda) bisa sangat berbeda, dan konsekuensinya, hasil dari analisis kluster mungkin menjadi berbeda.
2. Jarak Kuadrat Euclidean
5

Mungkin kita ingin mengkuadratkan jarak Euclidean standar untuk menempatkan bobot yang lebih besar secara progresif pada objek yang jaraknya jauh. Jarak ini perhitungannya sbb: jarak ( x.y)=i(xi-yi)2 .
3. Jarak City-Block (Manhattan)
Jarak ini memudahkan jarak rata-rata dimensi-dimensi secara menyilang. Dalam banyak kasus, ukuran jarak ini mendapatkan hasil yang mirip terhadap jarak Euklidean sederhana. Bagaimanapun, perhatikan bahwa dalam ukuran ini, efek dari perbedaan besar yang tunggal (pencilan) dibuang, karena tidak dikuadratkan. Jarak city block ditulis jarak (x,y) = i|xi- yi|
4. Jarak Chebychev
Ukuran jarak ini mungkin cocok untuk kasus menentukan 2 objek, sebagai “Berbeda” jika mereka berbeda terhadap segala sesuatu pada dimensi. Jarak Chebychev dihitung sbb : jarak (x,y) = maksimum |xi- yi|
5. Jarak Kuasa
Untuk meningkatkan atau menurunkan bobot progresiv yang ditempatkan pada dimensi yang respektif terhadap objek yang berbeda bisa dipenuhi oleh jarak kuasa. Jarak kuasa dihitung sbb: jarak (x,y) = ( i|Xi-Yi|p)1/r Dimana r dan p adalah parameter yang ditentukan. Beberapa contoh penghitungan akan didemonstrasikan, bagaimana ini mengukur “perilaku”. Parameter p mengontrol bobot progresiv yang ditempatkan pada perbedaan di dimensi individu, parameter r mengontrol bobot progresiv yang ditempatkan pada perbedaan yang lebih besar antara objek . jika r dan p bernilai 2, maka jarak ini sama dengan jarak Euklidean.
Terdapat tiga metode yang umum digunakan dalam analisis cluster, yaitu metode grafik, metode hirarki dan metode tak berhirarki (Santoso,2002).
1. Metode grafikMetode grafik, terdiri atas tiga jenis yaitu plot profil, plot Andrew dan plot Andrew termodifikasi. Pendekatan grafik yang paling sederhana adalah menggunakan plot profil dari setiap pengamatan. Plot ini hanya efektif untuk data yang tidak terlalu banyak pengamatannya sehingga
6

pembakuan data sangat membantu dalam hal ini. Plot yang biasa digunakan lainnya adalah plot Andrew dan plot Andrew termodifikasi. Kedua plot ini memberikan hasil yang lebih efektif dalam penggerombolan objek.
2. Metode hirarkiMetode ini digunakan untuk menggerombolkan pengamatan secara terstuktur berdasarkan kemiripan sifatnya dan gerombol yang diinginkan belum diketahui banyaknya. Ada dua cara untuk mendapatkan gerombol dengan metode penggerombolan hirarki yaitu dengan cara penggabungan (aglomerative) dan pemisahan gerombol (devisive). Metode hirarki dengan cara penggabungan didapat dengan menggabungkan pengamatan atau gerombol secara bertahap, sehingga pada akhirnya didapat hanya satu gerombol saja. Sebaliknya cara pemisahan pada metode hirarki dimulai dengan membentuk satu gerombol besar beranggotakan seluruh pengamatan. Gerombol besar tersebut kemudian dipisah menjadi gerombol yang lebih kecil, sampai satu gerombol hanya beranggotakan satu pengamatan saja. Kedua cara dalam metode hirarki ini tidak berbeda dalam pembentukan gerombol yang terjadi tetapi hanya berbeda dalam tahapan pembentukan gerombol saja. Metode Single Linkage atau disebut juga dengan motode pautan tunggal, jarak antara dua cluster (kelompok) dapat ditentukan dari dua obyek berpasangan yang memiliki kesamaan atau memiliki jarak terdekat (nearest neighbor) dalam cluster yang berbeda. Hal ini berlaku jika pengelompokan itu mempunyai makna atau tujuan yang jelas, terdapatnya kumpulan-kumpulan obyek yang bersama-sama membentuk cluster serta kecenderungan dari hasil pengelompokan itu menggambarkan rantai “chain” yang panjang. Pertama kali yang harus dilakukan untuk mendapatkan pautan tunggal ini adalah harus menemukan jarak terdekat antar cluster-cluster tersebut, dirumuskan dengan D ={dik}. Kemudian menggabungkan obyek-obyek yang sesuai, misalkan obyek tersebut dilambangkan dengan cluster U dan cluster V untuk mendapatkan cluster gabungan (UV). Untuk menghitung jarak cluster (UV) dengan cluster-cluster yang lain dapat dirumuskan dengan : d(UV)W = min {dUW,dVW}.Jarak antar cluster pada metode Complete Linkage atau disebut juga metode pautan lengkap, ditentukan dari jarak terjauh antara dua obyek pada cluster yang berbeda (furthest neighbor). Metode ini dapat digunakan dengan baik untuk kasus dimana obyek-obyek yang ada berasal dari kelompok yang benar-benar berbeda. Langkah pertama
7

yang harus dilakukan adalah sama seperti kasus single linkage yaitu harus menemukan jarak terdekat antar cluster-cluster tersebut, dirumuskan dengan D ={dik}. Kemudian menggabungkan obyek-obyek yang sesuai, misalkan obyek tersebut dilambangkan dengan cluster U dan cluster V untuk mendapatkan cluster gabungan (UV). Untuk menghitung jarak cluster (UV) dengan cluster-cluster yang lain dapat dirumuskan dengan : d(UV)W = max {dUW,dVW}.Jarak antar cluster pada metode Average Linkage atau disebut juga metode pautan rataan, ditentukan dari rata-rata jarak seluruh objek suatu cluster terhadap seluruh objek pada cluster lainnya. Pada berbagai keadaan, metode ini dianggap lebih stabil dibandingkan dengan kedua metode di atas. Langkah pertama yang harus dilakukan adalah sama seperti kasus single atau complete linkage yaitu harus menemukan jarak terdekat antar cluster-cluster tersebut, dirumuskan dengan D ={dik}. Kemudian menggabungkan obyek-obyek yang sesuai, misalkan obyek tersebut dilambangkan dengan cluster U dan cluster V untuk mendapatkan cluster gabungan (UV). Untuk menghitung jarak cluster (UV) dengan cluster-cluster yang lain dapat dirumuskan dengan : d(UV)W = rata-rata {dUW,dVW}
3. Metode tak berhirarkiSalah satu metode dalam metode penggerombolan tak berhirarki yaitu metode k-means. Algoritma dari metode ini sebagai berikut pertama tentukan besarnya k (yaitu banyaknya gerombol, dan tentukan juga centroid di tiap gerombol), kedua hitung jarak antara setiap objek dengan setiap centroid, ketiga hitung kembali rataan (centroid) untuk gerombol yang baru terbentuk dan keempat ulangi langkah 2 sampai tidak ada lagi pemindahan objek antar gerombol. Dua masalah utama yang harus diketahui dalam penggerombolan non hierarki adalah jumlah gerombol dan pemilihan pusat gerombol (centroid). Lebih lanjut, hasil penggerombolan mungkin tergantung pada pusat (centers) dipilih. Banyak program pengerombolan non-hierarki, memilih k objek (kasus) yang pertama sebagai pusat gerombol (centroid). Sehingga hasil penggerombolan mungkin tergantung pada urutan observasi dalam data. Bagaimanapun juga, penggerombolan non-hierarki lebih cepat daripada metode hirarki dan lebih menguntungkan jika jumlah objek/kasus atau observasi besar sekali(sampel besar). MacQueen menyarankan penggunaan K-rataan untuk menjelaskan algoritma dalam penentuan suatu objek ke dalam gerombol tertentu
8

berdasarkan rataan terdekat. Dalam bentuk yang paling sederhana, proses ini terdiri dari tiga tahap: 1. Bagi objek-objek tersebut ke dalam K gerombol awal. 2. Masukkan tiap objek ke suatu gerombol berdasarkan rataan
terdekat. Jarak biasanya ditentukan dengan menggunakan Euclidean. Hitung kembali rataan untuk gerombol yang mendapat objek dan yang kehilangan objek.
3. Ulangi langkah 2 sampai tidak ada lagi pemindahan objek antar gerombol.
Dalam membagi objek ke dalam K kelompok permulaan (pada langkah 1), sebelumnya dapat ditentukan rataan untuk K inisial, baru kemudian dilanjutkan dengan langkah berikutnya. Penentuan terakhir suatu objek ke suatu gerombol tertentu tidak tergantung dari K inisial yang pertama kali ditentukan. Pengalaman menunjukkan bahwa perubahan terbesar hanya terjadi pada realokasi yang pertama saja.
9

BAB IIIMETODOLOGI
1. Buka software SPSS dan masukkan data ke dalam lembar kerja
2. Selanjutnya data yang ada distandardized terlebih dahulu. Klik Analyze Descriptive statistics Descriptive
10

3. Selanjutnya akan muncul kotak dialog seperti di bawah ini
Masukkan semua variabel yang ada pada kolom variable(s). Lalu centang save standardized values as variables. Klik OK
4. Lalu klik Analyze Correlate Bivariate
5. Kemudian akan muncul kotak dialog seperti di bawah ini
11

Masukkan data yang telah distandardized tadi ke dalam kolom variables centanf correlate coefficients . Test of significance two-tailed. Dan klik OK
6. Selanjutnya dilakukan analisis faktor. Klik Dimension reduction Factor.
7. Akan muncul kotak dialog seperti di bawah ini
12

Masukkan zscore. Lalu klik descriptive.8. Akan muncul kotak dialog di bawah ini
Centang statistics initial solution dan correlation matrix KMO and Barlett’s test of sphericity. Lalu klik continue.
9. Selanjutnya klik extraction. Akan muncul kotak dialog seperti di bawah ini
13

Pilih method principal components. Pada analyze centang covariance matrix dan pada extract pilih based on eigenvalue. Dan klik continue
10. Lalu klik rotation. Akan muncul kotak dialog seperti di bawah ini
Pada method pilih varimax. Lalu klik continue11. Selanjutnya klik score. Akan muncul kotak dialog di bawah ini
14
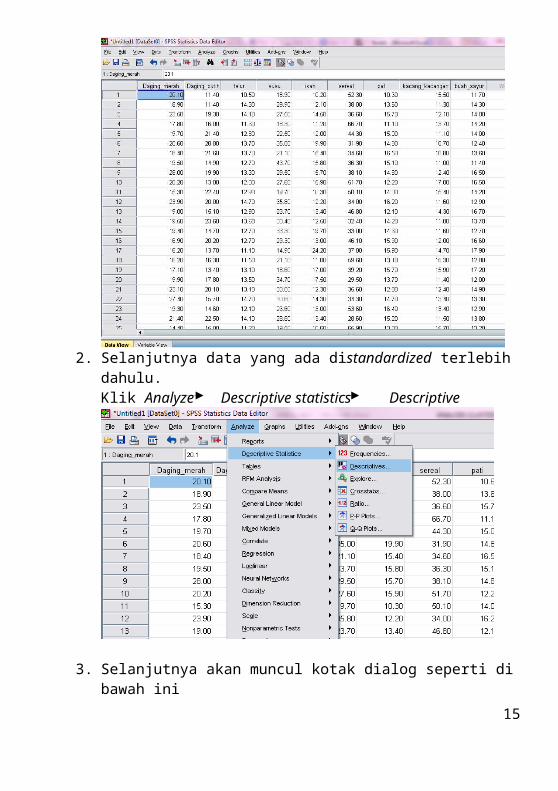
Centang save as variables lalu pilih method regression dan centang display factor score coefficient matrix. Klik continue dan OK.
12. Selanjutnya kita lakukan analisis cluster menggunakan metode hirarki. Caranya klik classify hierarchical cluster.
15
13. Klik plots. Akan muncul kotak dialog seperti di bawah ini. Centang Dendrogram. Centang icicle all clusters. Orientation vertical. Dan klik continue.
14. Klik statistics. Lalu akan muncul kotak dialog seperti di bawah ini
16
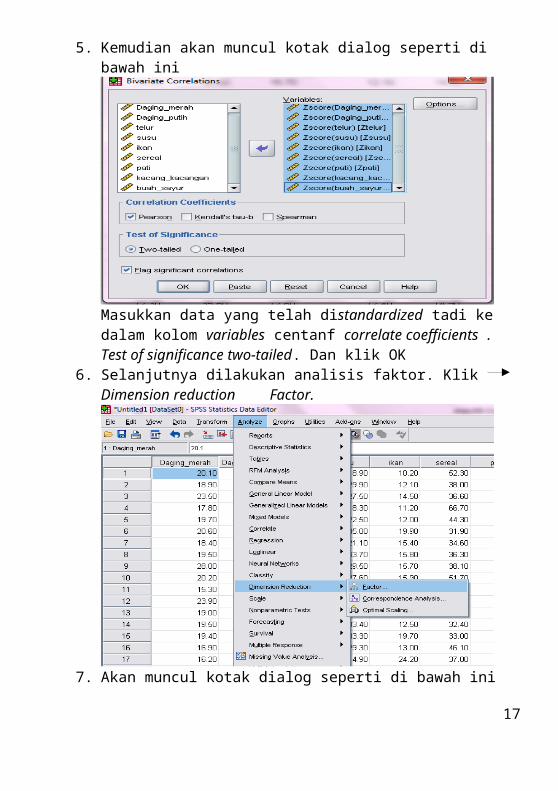
Pada cluster membership klik none. Karena kita memakai metode hirarki dan tidak tahu dibagi menjadi berapa cluster.
15. Pada cluster method pilih between-groups lingkage. Pada measure interval pilih Euclidean distance. Lalu klik continue.
16. Setelah itu akan muncul kotak dialog seperti di bawah ini. Pada kolom variable(s). Masukkan factor score, lalu pada label cases by isi negara. Klik OK
17

17. Lalu untuk metode non hirarki caranya klik statistics. Akan muncul kotak dialog seperti di bawah ini
18. Lalu klik continue. Selanjutnya klik save. Dan OK
18

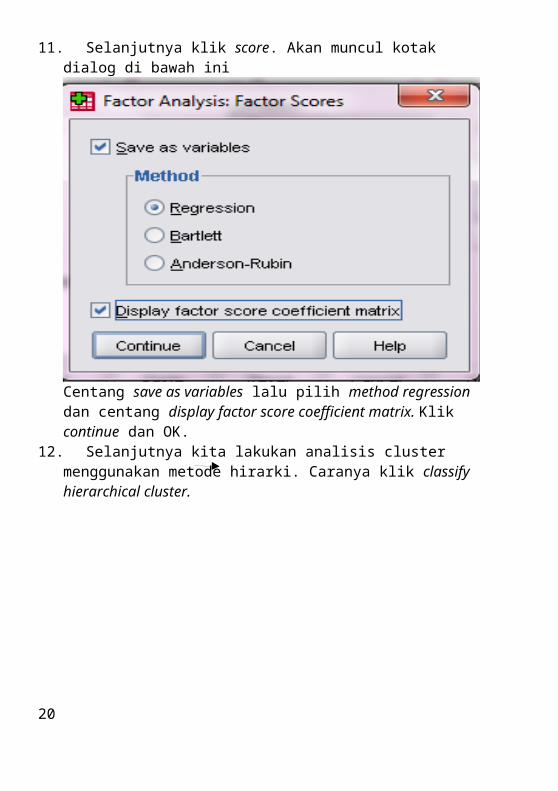
19. Langkah selanjutnya klik data pilih select cases
20. Akan muncul kotak dialog seperti di bawah ini. Pilih if condition satisfied. Pilih if.
19
21. Lalu akan muncul kotak dialog seperti di bawah ini
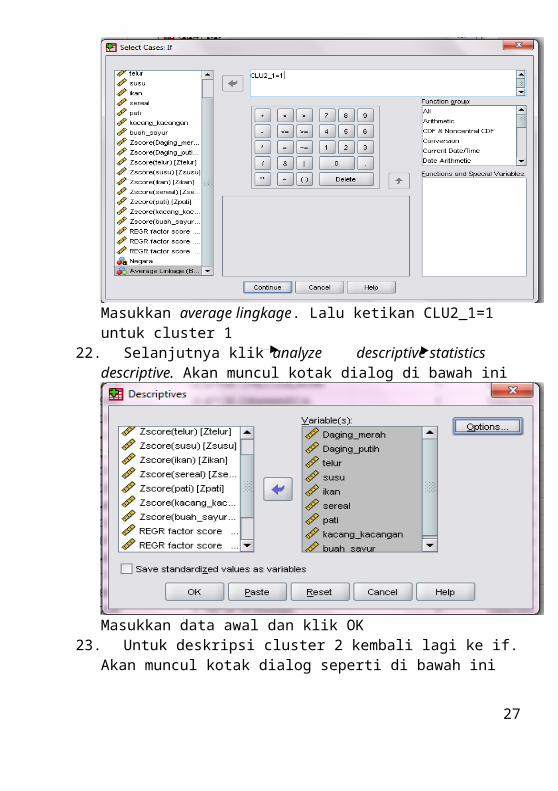
Masukkan average lingkage. Lalu ketikan CLU2_1=1 untuk cluster 122. Selanjutnya klik analyze descriptive statistics descriptive.
Akan muncul kotak dialog di bawah ini
Masukkan data awal dan klik OK23. Untuk deskripsi cluster 2 kembali lagi ke if. Akan muncul kotak dialog
seperti di bawah ini
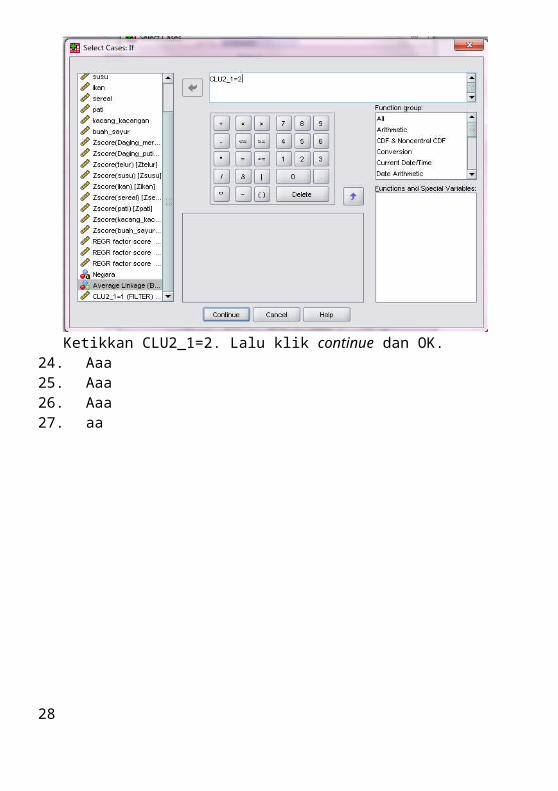
20

Ketikkan CLU2_1=2. Lalu klik continue dan OK.24. Aaa25. Aaa26. Aaa27. aa
21
22
BAB IV ANALISIS DAN PEMBAHASAN
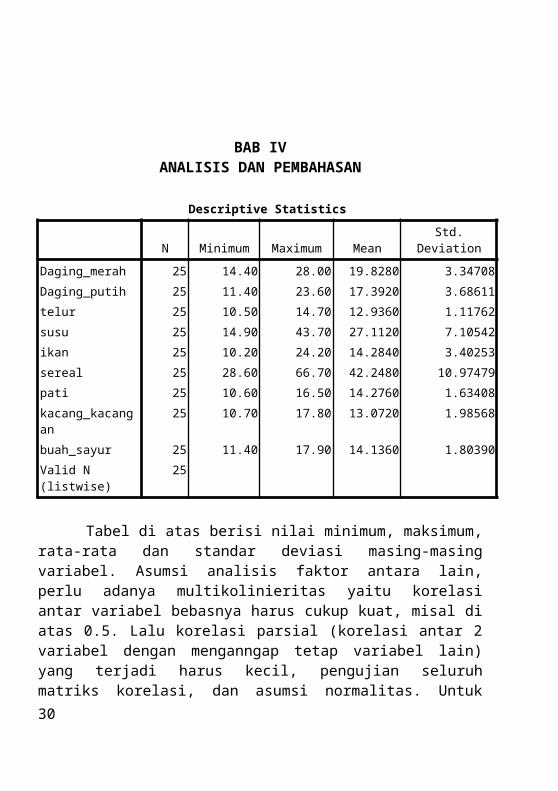
Descriptive Statistics
N Minimum Maximum Mean Std. Deviation
Daging_merah 25 14.40 28.00 19.8280 3.34708
Daging_putih 25 11.40 23.60 17.3920 3.68611
telur 25 10.50 14.70 12.9360 1.11762
susu 25 14.90 43.70 27.1120 7.10542
ikan 25 10.20 24.20 14.2840 3.40253
sereal 25 28.60 66.70 42.2480 10.97479
pati 25 10.60 16.50 14.2760 1.63408
kacang_kacangan 25 10.70 17.80 13.0720 1.98568
buah_sayur 25 11.40 17.90 14.1360 1.80390
Valid N (listwise) 25
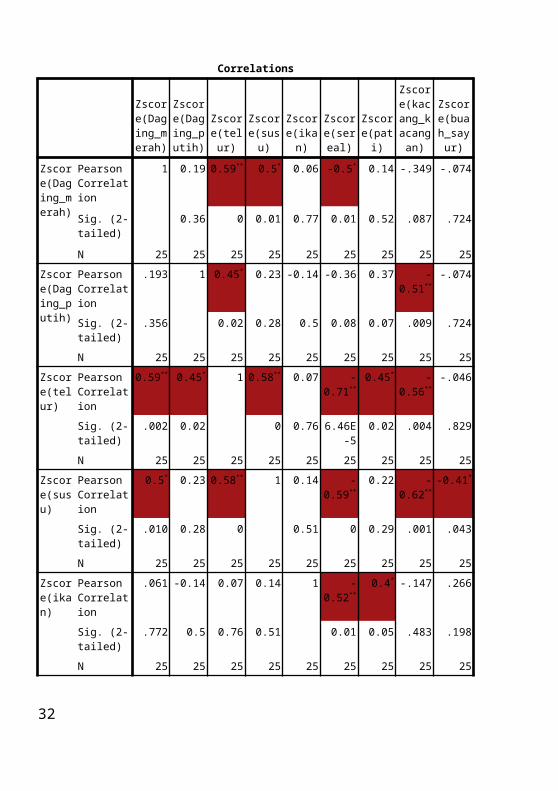
Tabel di atas berisi nilai minimum, maksimum, rata-rata dan standar deviasi masing-masing variabel. Asumsi analisis faktor antara lain, perlu adanya multikolinieritas yaitu korelasi antar variabel bebasnya harus cukup kuat, misal di atas 0.5. Lalu korelasi parsial (korelasi antar 2 variabel dengan menganngap tetap variabel lain) yang terjadi harus kecil, pengujian seluruh matriks korelasi, dan asumsi normalitas. Untuk memeriksa adanya multikolinieritas dapat menggunakan korelasi pearson. Tabel di bawah menunjukkan korelasi antar masing-masing variabel. Yang diberi warna merah menunjukkan adanya korelasi. Karena ada korelasi antar masing-masing variabel (terjadi multikolinieritas) maka selanjutnya dapat dilakukan analisis faktor
23

Correlations
Zscore(Daging_merah
)
Zscore(Daging_putih)
Zscore(telur)
Zscore(susu)
Zscore(ikan)
Zscore(sereal)
Zscore(pati)
Zscore(kacang_kacan
gan)
Zscore(buah_sayur)
Zscore(Daging_merah)
Pearson Correlation
1 0.19 0.59** 0.5* 0.06 -0.5* 0.14 -.349 -.074
Sig. (2-tailed)
0.36 0 0.01 0.77 0.01 0.52 .087 .724
N 25 25 25 25 25 25 25 25 25
Zscore(Daging_putih)
Pearson Correlation
.193 1 0.45* 0.23 -0.14 -0.36 0.37 -0.51** -.074
Sig. (2-tailed)
.356 0.02 0.28 0.5 0.08 0.07 .009 .724
N 25 25 25 25 25 25 25 25 25
Zscore(telur)
Pearson Correlation
0.59** 0.45* 1 0.58** 0.07 -0.71** 0.45* -0.56** -.046
Sig. (2-tailed)
.002 0.02 0 0.76 6.46E-5 0.02 .004 .829
N 25 25 25 25 25 25 25 25 25
Zscore(susu)
Pearson Correlation
0.5* 0.23 0.58** 1 0.14 -0.59** 0.22 -0.62** -0.41*
Sig. (2-tailed)
.010 0.28 0 0.51 0 0.29 .001 .043
N 25 25 25 25 25 25 25 25 25
Zscore(ikan)
Pearson Correlation
.061 -0.14 0.07 0.14 1 -0.52** 0.4* -.147 .266
Sig. (2-tailed)
.772 0.5 0.76 0.51 0.01 0.05 .483 .198
N 25 25 25 25 25 25 25 25 25
Zscore(sereal)
Pearson Correlation
-0.5* -0.36 -0.71** -0.59** -0.52** 1 -0.53** 0.65** .047
Sig. (2-tailed)
.011 0.08 6.46E-5 0 0.01 0.01 .000 .825
N 25 25 25 25 25 25 25 25 25
Zscore(pati)
Pearson Correlation
.135 0.37 0.45* 0.22 0.4* -0.53** 1 -0.47* .084
Sig. (2-tailed)
.519 0.07 0.02 0.29 0.05 0.01 .017 .688
N 25 25 25 25 25 25 25 25 25
24
Zscore(kacang_kacangan)
Pearson Correlation
-.349 -0.51** -0.56** -0.62** -0.15 0.65** -0.47* 1 .375
Sig. (2-tailed)
.087 0.01 0 9.22E-4 0.48 4.25E-4 0.02 .065
N 25 25 25 25 25 25 25 25 25
Zscore(buah_sayur)
Pearson Correlation
-.074 -0.07 -0.05 -0.41* 0.27 0.05 0.08 .375 1
Sig. (2-tailed)
.724 0.72 0.83 0.04 0.2 0.83 0.69 .065
N 25 25 25 25 25 25 25 25 25
**. Correlation is significant at the 0.01 level (2-tailed).
*. Correlation is significant at the 0.05 level (2-tailed).
KMO and Bartlett's Testa
Kaiser-Meyer-Olkin Measure of Sampling Adequacy. .713
Bartlett's Test of Sphericity Approx. Chi-Square 97.588
df 36
Sig. .000
a. Based on correlations
Pengujian yang kedua adalah pengujian seluruh matriks korelasi dengan uji KMO dan Barlett’s. Hipotesisnya adalah:H0 : sampel (variabel) belum memadai untuk dianalisis lebih lanjutH1 : sampel (variabel) sudah memadai untuk dianalis lebih lanjutDari tabel KMO and Bartlett’s Test dapat dilihat bahwa nilai KMO sebesar 0.713 dan signifikansi sebesar 0.000 < α = 0.05 maka keputusannya tolak H0. Jadi variabel ini dapat dilakukan analisis lebih lanjut, yaitu analisis faktor
25
Communalities
Raw Rescaled
Initial Extraction Initial Extraction
Zscore(Daging_merah) 1.000 .503 1.000 .503
Zscore(Daging_putih) 1.000 .845 1.000 .845
Zscore(telur) 1.000 .701 1.000 .701
Zscore(susu) 1.000 .797 1.000 .797
Zscore(ikan) 1.000 .825 1.000 .825
Zscore(sereal) 1.000 .869 1.000 .869
Zscore(pati) 1.000 .693 1.000 .693
Zscore(kacang_kacangan) 1.000 .730 1.000 .730
Zscore(buah_sayur) 1.000 .650 1.000 .650
Extraction Method: Principal Component Analysis.
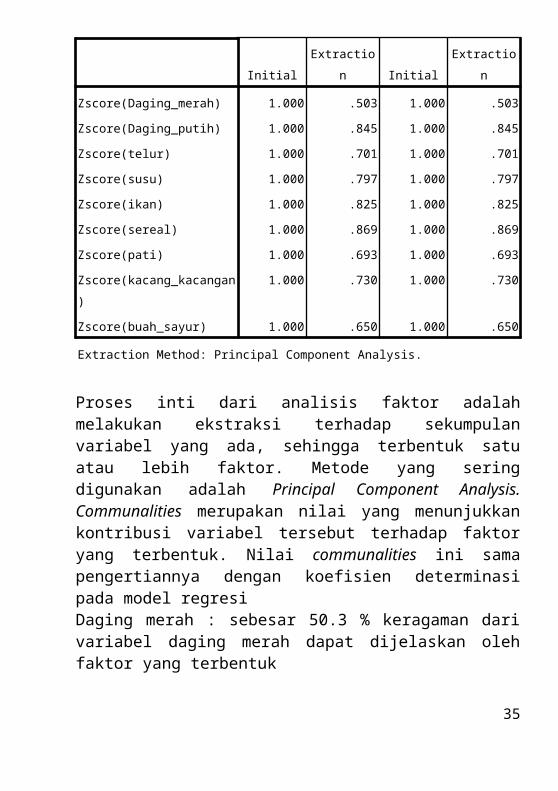
Proses inti dari analisis faktor adalah melakukan ekstraksi terhadap sekumpulan variabel yang ada, sehingga terbentuk satu atau lebih faktor. Metode yang sering digunakan adalah Principal Component Analysis. Communalities merupakan nilai yang menunjukkan kontribusi variabel tersebut terhadap faktor yang terbentuk. Nilai communalities ini sama pengertiannya dengan koefisien determinasi pada model regresiDaging merah : sebesar 50.3 % keragaman dari variabel daging merah dapat dijelaskan oleh faktor yang terbentukDaging putih : sebesar 84.5 % keragaman dari variabel daging putihdapat dijelaskan oleh faktor yang terbentukTelur : sebesar 70.1 % keragaman dari variabel telur dapat dijelaskan oleh faktor yang terbentukSusu : sebesar 79,7 % keragaman dari variabel susu dapat dijelaskan oleh faktor yang terbentuk
26
Ikan : sebesar 82.5 % keragaman dari variabel ikan dapat dijelaskan oleh faktor yang terbentukSereal : sebesar 86.9 % keragaman dari variabel sereal dapat dijelaskan oleh faktor yang terbentukPati : sebesar 69.3 % keragaman dari variabel pati dapat dijelaskan oleh faktor yang terbentukKacang-kacangan : sebesar 73 % keragaman dari variabel kacang-kacangan dapat dijelaskan oleh faktor yang terbentukBuah sayur : sebesar 65 % keragaman dari variabel buah sayur dapat dijelaskan oleh faktor yang terbentuk
Semakin besar sebuah nilai communalities maka semakin erat hubungannya dengan faktor yang terbentuk
27
Total Variance Explained
Com
pon
ent
Initial Eigenvaluesa
Extraction Sums of Squared
Loadings
Rotation Sums of Squared
Loadings
Total
% of
Variance
Cumulative
% Total
% of
Variance
Cumulativ
e % Total
% of
Variance
Cumula
tive %
Raw 1 3.933 43.697 43.697 3.933 43.697 43.697 2.936 32.618 32.618
2 1.601 17.787 61.484 1.601 17.787 61.484 1.973 21.924 54.542
3 1.080 12.004 73.488 1.080 12.004 73.488 1.705 18.946 73.488
4 .954 10.605 84.093
5 .428 4.761 88.854
6 .363 4.038 92.891
7 .272 3.021 95.913
8 .255 2.832 98.745
9 .113 1.255 100.000
Res
cale
d
1 3.933 43.697 43.697 3.933 43.697 43.697 2.936 32.618 32.618
2 1.601 17.787 61.484 1.601 17.787 61.484 1.973 21.924 54.542
3 1.080 12.004 73.488 1.080 12.004 73.488 1.705 18.946 73.488
4 .954 10.605 84.093
5 .428 4.761 88.854
6 .363 4.038 92.891
7 .272 3.021 95.913
8 .255 2.832 98.745
9 .113 1.255 100.000
Extraction Method: Principal Component Analysis.
28

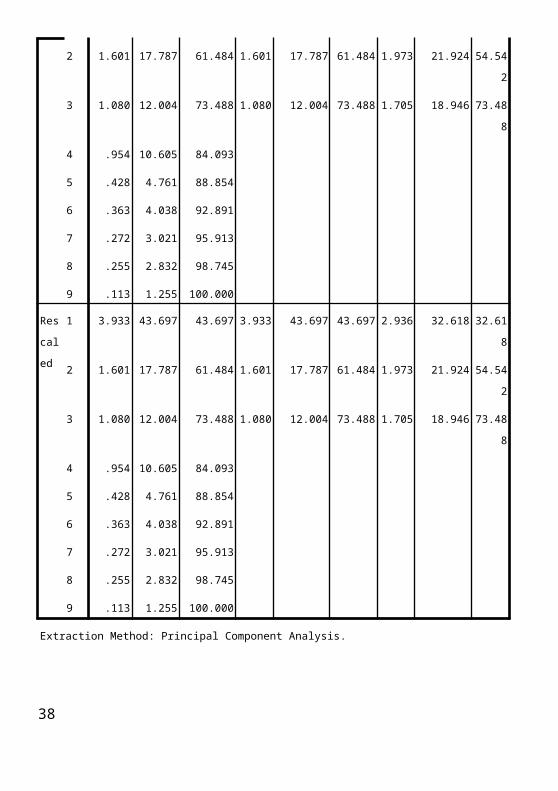
Setelah dilakukan ekstraksi maka muncullah output Total variance explained. Untuk melihat jumlah faktor yang terbentuk, kita dapat melihat dari nilai eigen value yang lebih dari 1. Karena faktor yang memiliki nilai eigen values < 1, berarti tidak memiliki anggota variabel pembentuk faktor. Dari tabel di atas dapat dilihat bahwa faktor yang terbentuk sebanyak 3. Dengan faktor 1 memiliki eigen value sebesar 3.933. Faktor kedua 1.601 dan faktor ketiga 1.080. Melihat banyaknya faktor yang terbentuk juga dapat dilihat dari nilai cumulativenya, apabila sudah mencapai 80% berhentilah disitu. Lalu dapat dicari variansinya
Variansi faktor-1 = 3.933
9×100 %=43.7 %
Variansi faktor-2 = 1.601
9×100 %=17.78 %
Variansi faktor-3 = 1.080
9×100 %=12 %
Total variansi = 73.48 %
Artinya bahwa sebesar 43.7 % keragaman dari variabilitas pembentuk faktor-1 dapat dijelaskan faktor tersebut dan sebesar 17.78 % keragaman dari variabilitas pembentuk faktor-2 dapat dijelaskan faktor tersebut. Sebesar 12% keragaman dari variabilitas pembentuk faktor-3 dapat dijelaskan faktor tersebut. Sedangkan total ketiga faktor tersebut akan mampu menjelaskan sekitar 73.48% keragaman dari variabilitas kesembilan variabel asli tersebut.
29
Component Matrixa
Raw Rescaled
Component Component
1 2 3 1 2 3
Zscore(Daging_mer
ah)
.621 -.131 -.316 .621 -.131 -.316
Zscore(Daging_putih
)
.547 -.174 .718 .547 -.174 .718
Zscore(telur) .833 -.031 .078 .833 -.031 .078
Zscore(susu) .757 -.296 -.369 .757 -.296 -.369
Zscore(ikan) .304 .776 -.360 .304 .776 -.360
Zscore(sereal) -.881 -.270 .138 -.881 -.270 .138
Zscore(pati) .614 .447 .342 .614 .447 .342
Zscore(kacang_kaca
ngan)
-.827 .188 -.105 -.827 .188 -.105
Zscore(buah_sayur) -.222 .744 .215 -.222 .744 .215
Extraction Method: Principal Component Analysis.
30

a. 3 components extracted.
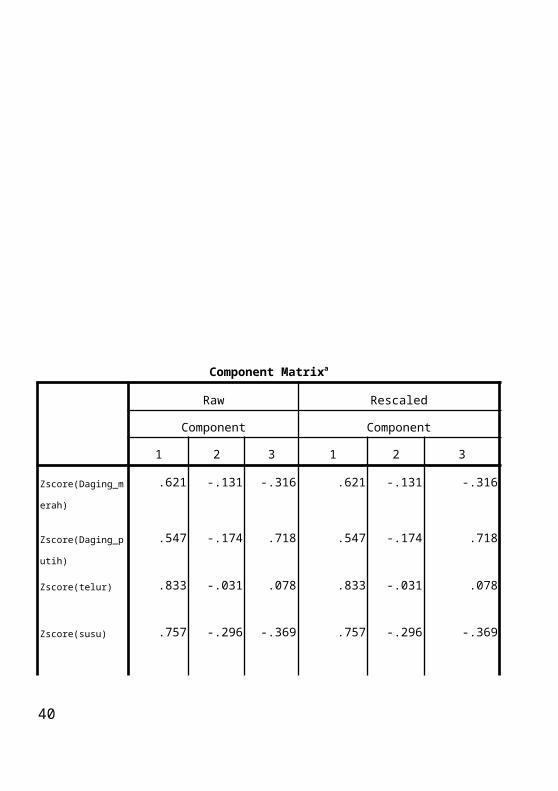
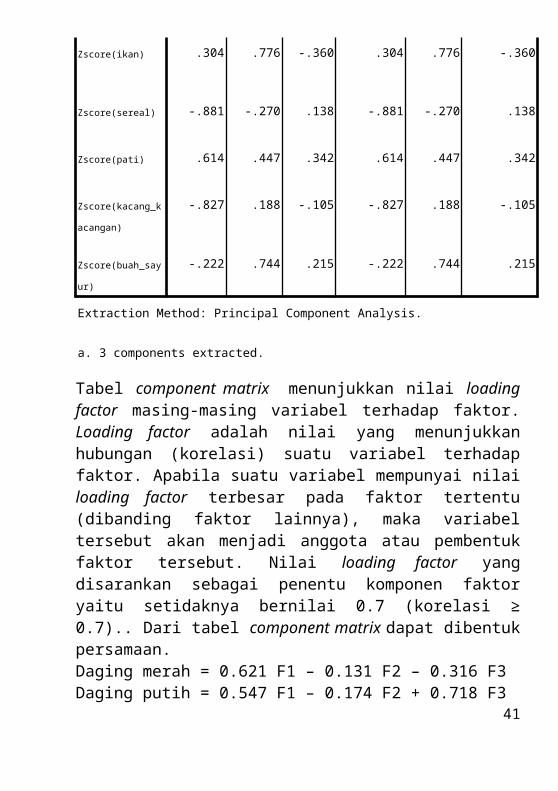
Tabel component matrix menunjukkan nilai loading factor masing-masing variabel terhadap faktor. Loading factor adalah nilai yang menunjukkan hubungan (korelasi) suatu variabel terhadap faktor. Apabila suatu variabel mempunyai nilai loading factor terbesar pada faktor tertentu (dibanding faktor lainnya), maka variabel tersebut akan menjadi anggota atau pembentuk faktor tersebut. Nilai loading factor yang disarankan sebagai penentu komponen faktor yaitu setidaknya bernilai 0.7 (korelasi ≥ 0.7).. Dari tabel component matrix dapat dibentuk persamaan.Daging merah = 0.621 F1 – 0.131 F2 – 0.316 F3Daging putih = 0.547 F1 – 0.174 F2 + 0.718 F3Telur = 0.833 F1 – 0.31 F2 + 0.78 F3Susu = 0.757 F1 – 0.296 F2 - 0.396 F3Ikan = 0.304 F1 + 0.776 F2 – 0.360 F3Sereal = -0.881 F1 – 0.270 F2 + 0.138 F3Pati = 0.614 F1 + 0.447 F2 + 0.342 F3Kacang-kacangan = -0.827 F1 + 0.188 F2 – 0.105 F3Buah sayur = -0.222 F1 + 0.744 F2 + 0.215 F3. Koefisien pada persamaan di atas merupakan nilai loadingnya jadi misal pada daging merah korelasi variabel daging merah dengan faktor 1 sebesar 0.621, korelasi daging merah terhadap faktor 2 sebesar 0.131 dan korelasi daging merah terhadap faktor 3 sebesar 0.316. Begitu pula dengan variabel lainnya. Untuk melihat variabel tersebut merupakan pembentuk faktor yang mana, dapat dilihat dari tabel di bawah components matrix. Daging merah pembentuk faktor 1, daging putih pembentuk faktor 3. Telur pembentuk faktor 1, susu pembentuk faktor 1, ikan pembentuk faktor 2, sereal pembentuk faktor 1, pati pembentuk faktor 1, kacang-kacangan pembentuk faktor 1, buah sayur pembentuk faktor 2. Karena nilai component matrix tidak saling tumpang tindih dan kita mudah untuk menentukan variabel pembentuk faktor, maka tidak perlu melihat tabel rotated component matrix.Jadi variabel pembentuk faktor 1 adalah daging merah, telur, susu, sereal, pati, kacang-kacangan. Variabel pembentuk faktor 2 adalah
31
ikan dan buah sayur. Sedangkan variabel pembentuk faktor 3 adalah daging putih.
Rotated Component Matrixa
Raw Rescaled
Component Component
1 2 3 1 2 3
Zscore(Daging_mera
h)
.701 .083 .072 .701 .083 .072
Zscore(Daging_putih) .105 .897 -.170 .105 .897 -.170
Zscore(telur) .632 .530 .146 .632 .530 .146
Zscore(susu) .885 .112 -.045 .885 .112 -.045
Zscore(ikan) .210 -.112 .876 .210 -.112 .876
Zscore(sereal) -.698 -.385 -.484 -.698 -.385 -.484
Zscore(pati) .179 .636 .507 .179 .636 .507
Zscore(kacang_kaca
ngan)
-.658 -.546 .010 -.658 -.546 .010
Zscore(buah_sayur) -.506 .070 .624 -.506 .070 .624
Extraction Method: Principal Component Analysis.
Rotation Method: Varimax with Kaiser Normalization.
a. Rotation converged in 6 iterations.
32

Component Transformation Matrix
Component 1 2 3
1 .797 .559 .228
2 -.288 .021 .957
3 -.531 .829 -.178
Extraction Method: Principal Component
Analysis.
Rotation Method: Varimax with Kaiser
Normalization.
Component Score Coefficient Matrixa
Component
1 2 3
Zscore(Daging_merah) .305 -.156 .009
Zscore(Daging_putih) -.210 .626 -.191
Zscore(telur) .136 .178 .017
Zscore(susu) .388 -.179 -.072
Zscore(ikan) .099 -.223 .541
Zscore(sereal) -.198 -.023 -.235
Zscore(pati) -.124 .356 .246
Zscore(kacang_kacangan) -.150 -.196 .082
Zscore(buah_sayur) -.285 .143 .397
Extraction Method: Principal Component Analysis.
Rotation Method: Varimax with Kaiser Normalization.
Component Scores.
a. Coefficients are standardized.
33

Component Score Covariance Matrix
Compo
nent 1 2 3
1 1.000 .000 .000
2 .000 1.000 .000
3 .000 .000 1.000
Extraction Method: Principal Component
Analysis.
Rotation Method: Varimax with Kaiser
Normalization.
Component Scores.
Analisis cluster
Case Processing Summarya,b
Cases
Valid Missing Total
N Percent N Percent N Percent
25 100.0 0 .0 25 100.0
a. Euclidean Distance used
b. Average Linkage (Between Groups)
34
Agglomeration Schedule
Stage
Cluster Combined
Coefficients
Stage Cluster First
Appears
Next StageCluster 1 Cluster 2 Cluster 1 Cluster 2
1 20 22 .173 0 0 5
2 4 18 .271 0 0 3
3 4 25 .425 2 0 20
4 14 24 .522 0 0 11
5 8 20 .620 0 1 10
6 3 9 .665 0 0 9
7 7 16 .669 0 0 12
8 13 23 .704 0 0 18
9 3 6 .759 6 0 14
10 2 8 .773 0 5 13
11 12 14 .903 0 4 15
12 5 7 .956 0 7 17
13 2 15 .989 10 0 19
14 3 21 1.080 9 0 15
15 3 12 1.216 14 11 19
16 17 19 1.410 0 0 24
17 5 11 1.416 12 0 22
18 10 13 1.453 0 8 20
19 2 3 1.632 13 15 22
20 4 10 1.791 3 18 21
21 1 4 2.108 0 20 23
22 2 5 2.311 19 17 23
35

23 1 2 2.504 21 22 24
24 1 17 3.387 23 16 0
Banyaknya cluster yang terbentuk dapat dilihat dari tabel agglomeration schedule. Dari tabel tersebut selisih terbesar nilai coefficients yaitu pada stage 23 dan 24. Lalu jumlah pengamatan sebanyak 25, jadi cluster yang terbentuk adalah 25-23 =2.
Cluster Membership
36

Case 2 Clusters
1:ALBANIA 1
2:AUSTRIA 1
3:BELGICA 1
4:BULGARIA 1
5:CHECOSLAVIA 1
6:DINAMARCA 1
7:ALEMANIA Or. 1
8:FINLANDIA 1
9:FRANCIA 1
10:GRECIA 1
11:HUNGRIA 1
12:IRLANDIA 1
13:ITALIA 1
14:HOLANDA 1
15:NORUEGA 1
16:POLONIA 1
17:PORTUGAL 2
18:RUMANIA 1
19:ESPANA 2
20:SUECIA 1
21:SUIZA 1
22:REINO UNIDO 1
23:UNION SOV. 1
24:ALEMANIA Occ. 1
25:YUGOSLAVIA 1
37
Pada cluster membership dapat dilihat bahwa semua negara masuk
ke dalam anggota cluster 1 kecuali negara ke 17 dan ke 19 portugal
dan espana. Lalu kedua cluster ini kita lakukan descriptive statistics.
Descriptive Statistics
N Minimum Maximum Mean Std. Deviation
Daging_merah 23 14.40 28.00 20.1043 3.34738
Daging_putih 23 11.40 23.60 17.7261 3.65541
telur 23 10.50 14.70 13.0087 1.09665
susu 23 18.30 43.70 28.0130 6.64498
ikan 23 10.20 19.90 13.7348 2.74037
sereal 23 28.60 66.70 42.6087 11.38356
pati 23 10.60 16.50 14.1435 1.63786
kacang_kacangan 23 10.70 17.80 12.8783 1.94374
buah_sayur 23 11.40 16.70 13.8391 1.54500
Valid N (listwise) 23
Hasil di atas merupakan descriptive statistics untuk cluster 1. Jumlah anggota cluster 1 sebanyak 23. Dan dari tabel di atas dapat dilihat masing-masing nilai minimum, maksimum, mean dan standar deviasi tiap-tiap variabel. Misalnya pada cluster 1 rata-rata wilayah konsentrasi daging merah sebesar 20.1043
38

Descriptive Statistics
N Minimum Maximum Mean
Std.
Deviation
Daging_merah 2 16.20 17.10 16.6500 .63640
Daging_putih 2 13.40 13.70 13.5500 .21213
telur 2 11.10 13.10 12.1000 1.41421
susu 2 14.90 18.60 16.7500 2.61630
ikan 2 17.00 24.20 20.6000 5.09117
sereal 2 37.00 39.20 38.1000 1.55563
pati 2 15.70 15.90 15.8000 .14142
kacang_kacangan 2 14.70 15.90 15.3000 .84853
buah_sayur 2 17.20 17.90 17.5500 .49497
Valid N (listwise) 2
Hasil di atas merupakan descriptive statistics untuk cluster 2. Jumlah anggota cluster 2 sebanyak 2. Dan dari tabel di atas dapat dilihat masing-masing nilai minimum, maksimum, mean dan standar deviasi tiap-tiap variabel.
39
40
BAB VPENUTUP
5.1 KesimpulanAnalisis cluster adalah analisis yang digunakan untuk
mengelompokkan obyek-obyek berdasarkan kesamaan karakteristik di antara obyek-obyek tersebut. Obyek tersebut akan diklasifikasikan ke dalam satuatau lebih cluster (kelompok) sehingga obyek-obyek yang berada dalam satu cluster akan mempunyai kemiripan satu dengan yang lainnya.
Analisis cluster bertujuan untuk mengelompokkan isi variabel, juga bisa disertai dengan pengelompokkan variabel, sedangkan analisis faktor lebih bertujuan untuk mereduksi variabel. Lain halnya dengan analisis cluster analisis faktor digunakan untuk mengidentifikasi underlying dimensions (factors) yang dapat menjelaskan korelasi sekumpulan variabel. Selain itu juga digunakan untuk mengidentifikasi variabel baru, yag digunakan untuk analisis lainnya, mengidentifikasi satu atau beberapa variabel dari variabel yang banyak jumlahnya, dan mengkonfirmasi konstruksi suatu variabel laten.
Pada analisis faktor di atas terbentuk dua faktor yaitu faktor 1 dan faktor 2, dengan variabel pembentuk faktor 1 adalah daging merah, telur, susu, sereal, pati, kacang-kacangan. Variabel pembentuk faktor 2 adalah ikan dan buah sayur. Sedangkan variabel pembentuk faktor 3 adalah daging putih.
Pada analisis cluster terbentuk 2 cluster, cluster 1 terdiri dari 23 negara, yaitu semua negara kecuali Portugal dan espana. Karena Portugal dan Espana masuk ke dalam anggota cluster 2.
5.2 Saran
Data untuk analisis cluster dan analisis faktor ini sebaiknya lebih dijelaskan lagi apa satuannya. Agar tidak terjadi kebingungan dalam langkah standardized. Namun bila melihat angkanya tidak perlu dibakukan karena data ini termasuk homogen, angkanya tidak terlalu bervariasi
41

42

DAFTAR PUSTAKA
Ansori, Ahmad. 2011. Sidik Peubah Ganda dengan menggunakan SAS.
IPB Press: Bandung
Assyiehab. 2012. Analisis Faktor Multivariat. http://statistikaku.16mb.com.
diakses : 23 Maret 2013
Santoso, Singgih. 2002. Buku Latihan SPSS Statistik Multivariat. PT Elex
Media Komputindo : Jakarta
43