「分散処理システム」 サンプルページ ·...
TRANSCRIPT


「分散処理システム」
サンプルページ
この本の定価・判型などは,以下の URL からご覧いただけます.
http://www.morikita.co.jp/books/mid/081071
※このサンプルページの内容は初版第 1刷発行時のものです.


i
「情報工学レクチャーシリーズ」の序
本シリーズは,大学・短期大学・高専の学生や若い技術者を対象として,情報工学の基礎知識の理解と応用力を養うことを目的に企画したものである.情報工学における数理,ソフトウェア,ネットワーク,システムをカバーし,その科目は基本的な項目を中心に,つぎの内容を含んでいる.「情報数学,アルゴリズムとデータ構造,形式言語・オートマトン,信号処理,符号理論,コンピュータグラフィックス,プログラミング言語論,オペレーティングシステム,ソフトウェア工学,コンパイラ,論理回路,コンピュータアーキテクチャ入門,コンピュータアーキテクチャの設計と評価,ネットワーク技術の基礎,データベース,AI・知的システム,並列処理,分散処理システム」各巻の執筆にあたっては,情報工学の専門分野で活躍し,優れた教育経験をもつ先生方にお願いすることができた.本シリーズの特長は,情報工学における専門分野の体系をすべて網羅するのではなく,本当の知識として,後々まで役立つような本質的な内容に絞られていることである.加えて丁寧に解説することで内容を十分理解でき,かつ概念をつかめるように編集されている.情報工学の分野は進歩が目覚しく,単なる知識はすぐに陳腐化していく.しかし,本シリーズではしっかりとした概念を学ぶことに主眼をおいているので,長く教科書として役立つことであろう.内容はいずれも基礎的なものにとどめており,直感的な理解が可能となるように図やイラストを多用している.数学的記述の必要な箇所は必要最小限にとどめ,必要となる部分は式や記号の意味をわかりやすく説明するように工夫がなされている.また,新しい学習指導要領に準拠したレベルに合わせられるように配慮されており,できる限り他書を参考にする必要がない,自己完結型の教科書として構成されている.一方,よりレベルの高い方や勉学意欲のある学生のための事項も容易に参照できる構成となっていることも本シリーズの特長である.いずれの巻においても,半期の講義に対応するように章立ても工夫してある.以上,本シリーズは,最近の学生の学力低下を考慮し,できる限りやさしい記述を目指しているにもかかわらず,さまざまな工夫を取り込むことによって,情報工学の基礎を取りこぼすことなく,本質的な内容を理解できるように編集できたことを自負している.
高橋直久 松尾啓志和田幸一

ii
序 文
複数の計算機をネットワークで相互接続することは,いまでは一般的なこととなっている.たとえば,金融機関のオンラインシステムにより,地球のどこでも金融サービスを受けることが可能になっているし,Webページにより世界中の知識を机上のディスプレイ上に表示することも可能となっている.われわれの生活にとって,計算機ネットワークは不可欠なものとなっている.しかしながら,実は多数の計算機をネットワークで接続した分散システムを正しく動作させることは容易なことではなく,問題も多い.このため,多くの研究が行われているが,あまり一般には認識されていないのが現状であろう.そこで本書では,初学者に,その基礎となるアルゴリズムの有用さをなるべくわかりやすく説明することを目的とした.各章の冒頭ではなるべく身近な具体例を示すことにより,興味をもって学習できるようにした.また,アルゴリズムの理解のためには具体例での動作を自分できちんと確かめることが必要であるので,各章の終わりの演習問題では実例で確かめる問題の比率を高くした.章の構成についてはつぎのとおりである.第 1章では分散システムのモデルと実例について説明する.第 2章では時刻と時計,第 3
章では分散スナップショット,第 4章ではリーダ選挙問題,第 5章では分散相互排除問題,第 6章では放送型通信,第 7章では合意問題,第 8章では自己安定アルゴリズムについて述べる.本書は大学・短大・高専などの学部,学科での分散システムに関する講義の教科書もしくは参考書となることを想定しており,基本的な内容に絞っている.本書の程度を超える発展的内容に興味をもった読者は,巻末に挙げた参考書を参照してほしい.また,本書の内容に関する意見や質問,および,著者の間違いへの指摘などは,著者のメールアドレス([email protected])まで電子メールにてお送りいただけると幸いである.最後に,本書の刊行にあたってお世話になった方々への感謝を記したい.本書の執筆の機会を与えていただいただけではなく,草稿に多くの適切な助言や指摘をしていただいた法政大学の和田幸一先生に心から感謝する.また,出版作業にご尽力いただいた森北出版の加藤義之氏にも深く感謝する.そして,本書執筆にあたり精神的な支えとなってくれた妻の美穂にも感謝する.
2013年 8月
真鍋義文

iii
目 次
第 1章 はじめに 1
1.1 分散システムとは ................................................................................ 1
1.2 分散システムの意義 ............................................................................. 3
1.3 計算機間の通信 ................................................................................... 5
1.4 実際の分散システム Hadoop ............................................................. 10
1.5 分散システム構築上の課題 ................................................................... 18
1.6 分散システムのモデル ......................................................................... 19
演習問題 ................................................................................................... 27
第 2章 時刻と時計 28
2.1 前後関係 ........................................................................................... 30
2.2 論理時計 ........................................................................................... 32
2.3 ベクトル時計 ..................................................................................... 34
演習問題 ................................................................................................... 38
第 3章 分散スナップショット 39
3.1 分散スナップショットの概要 ................................................................ 40
3.2 分散スナップショットによる故障検出 .................................................... 46
3.3 分散スナップショットによる障害復旧 .................................................... 48
演習問題 ................................................................................................... 50
第 4章 リーダ選挙問題 51
4.1 リングネットワークにおけるリーダ選挙問題 ........................................... 52
4.2 通信計算量の小さいリーダ選挙アルゴリズム ........................................... 59
演習問題 ................................................................................................... 64
第 5章 分散相互排除問題 66
5.1 相互排除問題とは ............................................................................... 66
5.2 許可ベースのアルゴリズム ................................................................... 67
5.3 複数の管理プロセスによるアルゴリズム ................................................. 77
5.4 コータリーを用いた相互排除 ................................................................ 82
演習問題 ................................................................................................... 84

iv 目 次
第 6章 放送型通信 86
6.1 放送型通信問題の定義 ......................................................................... 88
6.2 因果順序通信アルゴリズム ................................................................... 90
6.3 全順序通信アルゴリズム ...................................................................... 94
6.4 全順序通信と因果順序通信が混在する場合 .............................................. 95
演習問題 ................................................................................................. 102
第 7章 合意問題 103
7.1 合意問題の定義 ................................................................................ 104
7.2 非同期システムにおける合意問題 ........................................................ 105
7.3 停止故障のある同期システムにおける合意問題 ...................................... 110
7.4 ビザンチン将軍問題 .......................................................................... 114
演習問題 ................................................................................................. 122
第 8章 自己安定アルゴリズム 123
8.1 自己安定とは ................................................................................... 124
8.2 相互排除問題を解く自己安定アルゴリズム ............................................ 127
8.3 リーダ選挙問題を解く自己安定アルゴリズム ......................................... 131
8.4 自己安定アルゴリズムの利用例 ........................................................... 134
演習問題 ................................................................................................. 136
さらなる勉強のために 137
演習問題解答 138
索 引 150

1
第 1 章
はじめに
キーワード分散システム,ネットワーク,アルゴリズム,協調処理,モデル
分散システムとは,どういうシステムだろうか.どうして分散システムが使われるようになってきたのだろうか.どのような所に分散システムは使われているのだろうか.本章ではまずこれらの疑問について答えていこう.そして,本書で用いる分散システムのモデルについて説明する.
1.1 分散システムとは
無人島や森の奥で一人で生きているという人の話は,小説にあるし,稀にではあるが実話にもある.一人で生きるということは,食料の調達から怪我をしたときの治療まで,すべてのことを自分で行わなければならず,他人との摩擦はないかもしれないが,生活はそんなに簡単なことではない.この一人で生きる困難さを回避するべく,人間は,たくさんで集まって社会を形成して生きていく道を選択した(図 1.1).社会を形成したことの恩恵として,苦手な仕事は他人に任せ,自分は得意な仕事に専念することができる,分業化がある.分業化によって,すべてを一人でやっている場合より,それぞれの技術は向上しやすく,社会全体としてより高い成果を得ることができるようになる.また,社会形成のもうひとつの恩恵として,ひとつの仕事を複数人で協力して進められるということもある.たとえば,複数人が協力することによって,一人ではできない大規模な仕事を短時間に終えることができるようになるだろう.ただし,このような社会をうまく運営していくためには人々が意思疎通を行うための言語が必要であり,また法律など,社会生活を行うにあたって,人が従わなければならないルールづくりも必要である.これらは,計算機をとりまく環境においてもいえる.計算機も,単体で動作させるより,ネットワークで相互接続し,複数の計算機をひとつのシステムとして構築して協調処理を行ったほうが,役割を分担できて効率がよい.このような,ネットワークで相互接続された複数の計算機から構成された,ある共通の目的を果たすシステムのことを分散システムという.分散システム構築のためには,人間社会の構築と同様に,“共通の言葉”と“ルール”が必要である.まず,共通に話す言葉(プロトコル)は,TCP/IPという形でデファクト化されて

2 第 1章 はじめに
図 1.1 社会と分散システムの類似点
いる.これは英語が世界共通語となったのと同じ構図である.その上で,ネットワークで接続された計算機が協調して所望の処理を行うための取り決め“アルゴリズム”が必要となる.このアルゴリズムの設定はシステムの効率の良し悪しに直接影響するので,ネットワークで接続された計算機システムをうまく動かすにはよりよいアルゴリズムが必要である.また,人間社会でもルールに従わない人がいるように,システム内にもルールに従わない,故障した計算機が存在することが多い.故障した計算機があると,システム全体として望む処理が行われないことがある.たとえば電子メール送信では,故障した計算機が受け取った電子メールの転送を行わないと受信者に電子メールが届かなくなってしまう.このため,故障した計算機がある場合でも正しく動作するアルゴリズムが必要である.このほかにも,よりよい分散システムを構築するには,知っておかなければならない注意事項がある(詳細は第 2章以降参照).
分散処理の例 計算機が作られた当初,計算機をネットワークで接続することは想定されていなかった.それは,計算機がその名のとおり“計算を行うための装置”であったからである.その後,計算機間で処理したデータをやりとりするために,複数の計算機を接続するようになってきた.さらに,計算機が小さく,安く,手軽なものになるにつれ,オフィスでも家庭でも複数の計算機がネットワークで相互接続されているのがあたりまえとなった.いまでは,

1.2 分散システムの意義 3
電子メールやWebページの閲覧など,通信を主目的として計算機を使っている人も多い.通信路で接続された複数の計算機は,分散システムとして協調し合ってひとつの動作を行うことが多い.電子メールの送信を例に,協調して行う処理を考えてみよう.図 1.2に示すように,田中さんが山田さんに電子メールを送ろうとしている.田中さんは,foo社の経理部門に所属しており(メールアドレス:[email protected]),山田さんは,bar社の広報部門に所属している(メールアドレス:[email protected]).
図 1.2 電子メール送受信のしくみ
田中さんが送った電子メールは,①経理部の PC(計算機)を通して foo社のメールサーバBへ,そして,②インターネットを介して bar社のメールサーバ Cへ送られ,③そこから山田さんのいる広報部の PCに届けられる.インターネットの部分でも複数台のサーバが仲介して作業をしており,この作業全体は,バケツリレーのように行われている.このとき,ここに登場する PC,メールサーバはどれも,ネットワーク全体の状態を知らない.知っているのは,送られてきたものをどこに渡せばよいかということだけで,それぞれは自分の仕事をこなすだけである.このように分散システムでは,それぞれは自分の仕事をこなすだけだが,それぞれの仕事が連携させられることで,ひとつの仕事を成し遂げる.
1.2 分散システムの意義
分散システムの対極をなすのが,集中型システムである.集中型システムでは,1つの計算機がすべての処理を実行する.前節で説明した電子メールの送信を集中型システムで実現することを考えてみよう.集中型システムなので,全世界のユーザは 1つの計算機に接続されていることになる.このとき,すべてのメールアドレスは,その 1つの計算機内に記録されているため,ある計算機がネットワークのどこにあるのかという情報を求める必要はない.たとえば,さきほどの例で考えると,田中さんが山田さんに電子メールを送る場合には,田中さんからのメール送信コマン

4 第 1章 はじめに
ドを受けた計算機は,山田さんのメールボックスにおくだけでよく,電子メールの処理は非常に簡単になる.一般に,集中型システムでは処理は単純になることが多い.ただし,集中型システムは現実的ではない場合も多い.その理由はいくつかある.分散システムの長所とともにつぎにまとめておこう.
( 1 ) 処理のパフォーマンス
全世界の電子メールを 1台で処理するにはきわめて高い処理スピードが必要であり,そのような能力をもつ計算機がもし構築できたとしても非常に高価なものとなる.安価で能力の低い計算機で分散システムを構築して同等のサービスを提供できるのであれば,分散システムのほうがコストパフォーマンスがよいだろう.また,分散処理であれば,たとえば,ある地域からの電子メールの流量が増えて処理しきれなくなったときにも,その地域に計算機を増設して拡張することが容易である.
( 2 ) 処理の局所性
たとえば,ある大学のユーザから送信される電子メールのかなりの数は,その大学内のほかのユーザにあてたものである可能性が高い.集中型システムでは,このような状況でも処理手順は変わらない.一方,分散システムでは,大学内の計算機でまず学内あてのメールをすべて処理して,学外へのメールだけ,ほかの計算機と協調して処理すればよい.このような処理を各組織(大学・企業など)で行えば,組織間で協調して処理する量は非常に少なくてすむ.また,情報のセキュリティの観点からも集中型システムにはデメリットがある.たとえば,
A銀行と B銀行があり,どちらも預金の処理はほぼ同じであるとする.このとき,両銀行は1台の計算機で共同して口座を管理することもできるが,現実には行われない.それは,たとえば,A銀行がシステムの管理を行ったとすると,B銀行がもっている顧客情報(重要な機密情報)はすべて A銀行が知っていることになり,B銀行としては,許容できないからである.近年,一般的になりつつあるサービスとして,社外に置いた外部の業者の提供する計算機に自社のデータをおいて,業者の計算機資源を利用する“クラウドコンピューティング”という形態がある.この場合にも,業者はある企業のデータが他社に流出することがないように,仮想化などの手法を用いて論理的に分離して処理を行うことが一般的である.各企業は他社に秘密にしたいデータは自社の計算機,あるいは自社が委託したクラウド計算機におき,他社と協調して仕事を行いたくなったときだけ(たとえばA銀行の口座から B銀行の口座への振込みなど),そのデータを一部利用して協調作業を行う.
( 3 ) 可用性
集中型システムは,その計算機が停止した場合に全員が被害を被ることになり,その影響は非常に大きい.したがって,集中型システムの計算機は,故障の可能性がきわめて低いものである必要がある.それに対して,分散システムでは,一部の計算機が故障しても,その影響はその計算機を使っていた一部のユーザに限定される.また,ほかの計算機がバックアップすることにより,耐故障性をもたせることも可能である.
このように,分散システムには処理が複雑になるという欠点もあるが長所も存在する.こ

51
第 4 章
リーダ選挙問題
キーワード単一プロセス,選挙,通信計算量,リングネットワーク
わたしたちの社会では,メンバーの中から代表者を決めることがよくある.たとえば,選挙もそうであるし,鬼ごっこの鬼を決めることもそうである.分散システムにおいても,わたしたちの社会と同様,唯一の代表者を決めなければならない場合があり,そのような問題をリーダ選挙問題という.たとえば,第 1章で説明した耐故障のために 2つの計算機をおいたとき,それらのどちらをプライマリとするかといった場合である.本章では,リーダ選挙問題,リーダ選挙アルゴリズムの概要,およびその通信計算量について説明していき,どのようなアルゴリズムを使えば効率的に単一プロセスを代表者として決めることができるのかを説明する.まず,前章で説明したトークンリングにおけるトークン再生の問題を考えてみよう.
トークンリングの問題
トークンリングでは,トークンが 1つだけであるかどうかを,分散スナップショットアルゴリズムを利用して調査できることを述べたが,トークンが 1つも存在しないとわかった場合にはトークンを再生させなければならず,どのプロセスにトークンの再生を任せるかを決める必要がある.トークン再生の問題のもっとも単純な解は,再生を行うプロセスをあらかじめ固定しておくことである.しかし,この方法では,その固定したプロセスが故障などで一時停止していれば,トークンは再生されない.どのプロセスが故障していても,トークンを再生可能であるためのアルゴリズムを考えてみよう.求められる要求条件はつぎのとおりである.(1)トークン再生開始がいつ,どのタイミングで,どの(一般に複数の)プロセスに同時に届くかはわからない.
(2)再生開始時点で,ネットワークに接続されているプロセスの集合は,どのプロセスも知らない.
(3)唯一のプロセスがトークン再生を行う.このような,プロセス群の中から唯一のプロセスを選ぶ問題を,リーダ選挙問題という.リーダ選挙問題のアルゴリズムが終了したとき,図 4.1に示すように,

52 第 4章 リーダ選挙問題
図 4.1 リーダ選挙問題
(1)唯一のプロセスがリーダとして選出する.(2)リーダとなったプロセスは,自分がリーダとして選ばれたことを知る.かつ(3)リーダとならなかったプロセスは,自分がリーダとして選ばれなかったことを知る.
このような問題をどのようにすれば,効率的に解くことができるのだろうか.
4.1 リングネットワークにおけるリーダ選挙問題
ここでは,トークンリングネットワークを想定し,ネットワークのトポロジーは,図 4.2に
図 4.2 リングネットワーク
示すようなリング状であると仮定する.また,各通信路は FIFOであるとする.各プロセスには ID がついているので,図 4.3
に示すように,現在無故障でアルゴリズムに参加してるプロセスの中で,たとえば IDの数字が最大のものをリーダとすればよい.この考えのもとにリーダ選挙アルゴリズムを考えてみよう.

4.1 リングネットワークにおけるリーダ選挙問題 53
図 4.3 IDをもとにしたリーダ選挙アルゴリズム
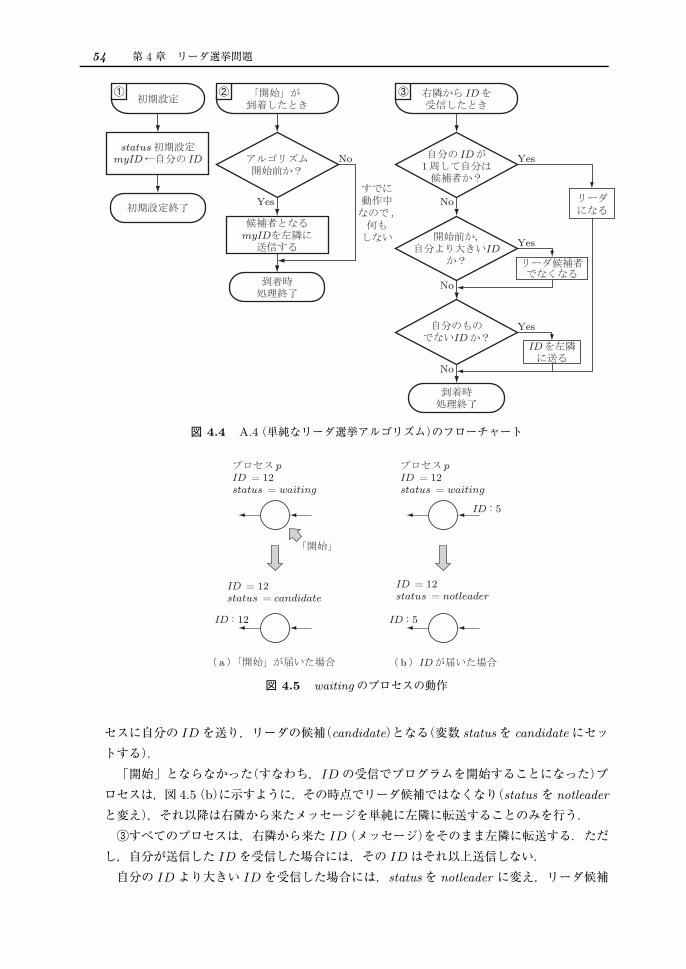
4.1.1 単純なリーダ選挙アルゴリズム全プロセスがほかの IDの値を知っていれば,IDの数字が最大の値を求めることができる.そこで,IDの数字が最大のプロセスを知るために,各プロセスは自分の IDをほかのプロセスに送る.この考えに基づく単純な手法として,A.4(単純なリーダ選挙アルゴリズム)が考えられる.図 4.4にアルゴリズム A.4のフローチャートを示す.まず,図 4.5(a)に示すように,①初期設定後,②「開始」となったプロセスが左隣のプロ
54 第 4章 リーダ選挙問題
図 4.4 A.4(単純なリーダ選挙アルゴリズム)のフローチャート
図 4.5 waitingのプロセスの動作
セスに自分の IDを送り,リーダの候補(candidate)となる(変数 statusを candidateにセットする).「開始」とならなかった(すなわち,IDの受信でプログラムを開始することになった)プロセスは,図 4.5(b)に示すように,その時点でリーダ候補ではなくなり(status を notleader
と変え),それ以降は右隣から来たメッセージを単純に左隣に転送することのみを行う.③すべてのプロセスは,右隣から来た ID(メッセージ)をそのまま左隣に転送する.ただし,自分が送信した IDを受信した場合には,その IDはそれ以上送信しない.自分の IDより大きい IDを受信した場合には,statusを notleader に変え,リーダ候補

4.1 リングネットワークにおけるリーダ選挙問題 55
ではなくなる.自分の IDを受信したときにまだ自分がリーダ候補であれば(すなわち,自分の IDより大きい IDを受け取っていない),自分がリーダであると判定する.このアルゴリズムの動作例を図 4.6に示す.右隣のプロセスからメッセージが到着するより前に「開始」が届いたのは,ID = 3,ID = 10,ID = 14の 3つのプロセスとする.これらのプロセスは,自分の IDの値を左隣のプロセスに送る.すべてのプロセスは,受け取ったIDが自分の IDと異なる場合には単に左隣に転送するので,ID : 3,ID : 10,ID : 14というメッセージはすべてこのネットワークを 1周する.ID = 3であるプロセスは,ID : 14というメッセージを受信した時点で,自分の IDが最大でないことを知り,statusを notleader
に変更する.ID = 10であるプロセスも同様である.ID = 14であるプロセスは,ID : 14
というメッセージが 1周してきた時点で自分がまだ candidateであるので,自分の IDより大きな IDを受信しなかったことを知る.これにより,自分の IDが最大とわかり,leader
となる.
図 4.6 A.4(単純なリーダ選挙アルゴリズム)の動作例
図 4.7 イベントの例
アルゴリズム A.4の正しさを示そう.「開始」となったときに,waiting であったプロセスが candidate となるが,candidate となるプロセスは少なくとも必ず 1つは存在する.理由は,「開始」イベントが e1, e2, . . . , em
である場合の,イベント間の前後関係(happened-before)を考えることによりわかる.ei がプロセス Pi,ej がプロセス Pj で発生したと仮定する.ここで,Pj は,「開始」となるより前に,Pi からの IDが届いたとすると,ei → ej が成立する.したがって,Pj がcandidate とならない場合,ほかの開始イベントに対して ei → ej が成立する.e1, e2, . . . , em の中で,すべてのイベント ej に対してあるイベント ei が存在し,ei → ej
となることはない.なぜなら,もしもそのようなことがあったとすれば,ej から開始して,ei → ej の ei に対して,ek → ei となるイベント ek というように,イベントを並べていくと(図 4.7),イベントはm個しかないので,いつかは,(1)すでに選んだイベントが再度選ばれる
あるいは(2)選ぶイベントがなくなる(すなわち,あるイベント ei0 に対して,e→ ei0 となるイベント eが存在しない)

56 第 4章 リーダ選挙問題
ことが発生する.(1)は再度選ばれたイベントを ei1 とすると,その時点での列の先頭のイベント ei0 に対して,ei0 → ei1 かつ ei1 → ei0 が成立することになる.これは,前後関係の性質からありえない.したがって,(2)が成立するが,これはすなわち,ei0 が発生したプロセス Pi0 において,ei0 以前に ID がほかのプロセスから届いていないことを意味する.すなわち,candidate となるプロセスが少なくとも 1つ存在する.つぎに,以下の補題を証明する.
▼ 補題 4.1
▼
アルゴリズム A.4で,candidate となったプロセスから送られた ID は,いつかはそのプロセスに戻ってくる.
▼
▼
証明 すべてのプロセスは,自分の ID に一致したメッセージ以外は単に転送するのみである.したがって,すべての ID はいつかは自分のプロセスに戻ってくる.
▼ 補題 4.2
▼
アルゴリズム A.4で通信路が FIFOであれば,自分の ID が自分のプロセスに戻ってくるまでの間に,ほかの candidate の ID がすべて送られてくる.
▼
▼
証明 もしも自分の ID(ID1とする)が戻ってきた後に,ある candidate からの ID(ID2
とする)が届いたと仮定する.このとき,ID2 を送るプロセス P2 では,ID1 が届いた後にID2 を送信することになる.これは,P2 の開始イベントが ID1 の受信後に発生することを意味する.しかし,ほかのプロセスから ID を受信した後に開始が起こった場合,P2 はcandidate とはならないので矛盾する.よって,このようなことは起こらない.
● 定理 4.1 ●
アルゴリズム A.4はリーダ選挙問題を正しく解く.
証明 このアルゴリズムの開始後,candidate は少なくとも 1つ存在する.補題 4.1より,すべての ID はリングを一周する.補題 4.2より,各 candidateにおいて,自分の ID が一周するまでの間に,ほかの candidate
の ID をすべて受信することになる.よって,その中で最大値が唯一に決まる.したがって,candidate の中で ID が最大のものがリーダになり,それ以外のプロセスはリーダにならない.
アルゴリズム A.4は単純でわかりやすい.しかし,実際のところ,このアルゴリズムは,通信計算量の面では効率的ではない.それは,すべての candidate の ID が 1周しなければならないからである.candidate の数をm,プロセスの総数を nとすると,通信計算量はmn
となり,m = nとなる最悪の場合には n2 となってしまう.通信計算量のより少ない方法を考えてみよう.

4.1 リングネットワークにおけるリーダ選挙問題 57
4.1.2 ID転送の少ないリーダ選挙アルゴリズムアルゴリズムA.4では,ほかの candidate を notleader にするために,大きな ID が 1周する必要がある.このとき,送信されているほかの ID1よりも小さい ID2は,ほかの candidate
を notleader にするために 1周する必要がない.すなわち,ID2 を用いてある candidate をnotleader にできるのであれば,ID1 が送られたときにもその candidate は notleader にできるため,ID2 を送信する必要はないのである.この考えに基づいて,不必要な ID の送信を減らせば,通信計算量を減らすことができる.これを実現したのが,A.5(ID転送の少ないリーダ選挙アルゴリズム)である.図 4.8にアルゴリズム A.5のフローチャートを示す.
①各プロセスは,新たな変数maxIDを用意する.maxIDには,自分がいままでに知っている最大の ID の値を格納する.maxIDの初期値は 0(どの IDよりも小さな値)とする.②「開始」となったときは,maxIDに自分の IDをセットするほかはアルゴリズム A.4と同じである.③各プロセスは,その時点のmaxIDよりも,右隣から受信した ID が大きければ,左隣に送るとともにmaxIDを更新し,小さければ,その ID をそれ以上左隣には送信しない.これにより,小さな ID は,それより大きな ID が通ったことがあるプロセスに来ると,それ以上は送信されなくなる.このアルゴリズムでは,最大でない ID は 1周するまでの間に自分より ID が大きなプロ

58 第 4章 リーダ選挙問題
図 4.8 A.5(ID 転送の少ないリーダ選挙アルゴリズム)フローチャート
セスを必ず通ることになり,途中で転送されなくなるため,自分の ID が一周したことを検出したプロセスは,自分が leaderであると判定することができる.アルゴリズム A.5の正しさは,つぎの補題を示すことによって証明できる.
▼ 補題 4.3
▼
アルゴリズムA.5において,candidateの中で最大の ID は,必ずすべてのプロセスを通る.
▼
▼
証明 任意のプロセス P から送られた ID0 の転送が途中で停止するのは,ID0 より大きい ID をもつ candidate か,ID0 より大きな ID が通った candidate に来たときである.したがって,最大の ID の転送は途中で停止することなく 1周する.
● 定理 4.2 ●
アルゴリズム A.5はリーダ選挙問題を正しく解く.
証明 補題 4.3より,最大の ID はリングネットワークを必ず 1周するので,最大の ID をもつプロセスは必ず leader になる.また,最大でない ID がリングを転送されるときに一周することはない.もし最大でない ID が一周したとすると,それまで通過したプロセスには,最大の ID をもった候補者プロセス P が含まれていなかったことになり,矛盾するからである.したがって,最大でない ID をもったプロセスが自分をリーダと誤って判定することはない.

4.2 通信計算量の小さいリーダ選挙アルゴリズム 59
それでは,アルゴリズム A.5の効率はど
図 4.9 A.5(ID転送の少ないリーダ選挙アルゴリズム)での最悪の場合
うだろうか.アルゴリズム A.4より,通信計算量がすぐれていることは明らかだが,通信計算量が最悪の場合を計算してみよう.プロセスPiの IDの値を ID(Pi)と書く.図 4.9に示すように,ID(Pi) > ID(Pi+1)
(i = 0, 1, . . . , n − 2) を満足する.すなわち,ID は降順に並んでいるものとする.この状態ですべてのプロセスが同時に起動し,すべてのプロセスの動作速度およびすべてのリンクの遅延が同一であったとする.このとき,図 4.10に示すように,Pi から出発した ID(Pi)は,自分より小さい ID をもつプロセス Pi+1, Pi+2, . . .を通って,P0 に来たときに初めて自分より大きな ID をもつプロセスの存在を知り,ID の転送を停止する.ID(Pn−1)は 1回送信され,ID(Pn−2)は 2回送信され,一般に ID(Pi)は n − i回送信されるので,通信計算量は 1 + 2 + . . .+ n = n(n+ 1)/2となり,O(n2)である.
図 4.10 A.5(ID転送の少ないリーダ選挙アルゴリズム)の実行時のメッセージ送信状況
この結果,アルゴリズム A.5は,すべてのプロセスが開始プロセスとなった場合,オーダー的には,アルゴリズム A.4と同じ通信計算量ということになってしまった.
4.2 通信計算量の小さいリーダ選挙アルゴリズム
通信計算量を O(n2)より小さくすることは可能だろうか.A.6(通信計算量の小さいリーダ選挙アルゴリズム)を考えてみよう.図 4.11にアルゴリズムA.6のフローチャートを示す.②まず,変数 phase を 1から順に 1ずつ増加させていく.

60 第 4章 リーダ選挙問題

4.2 通信計算量の小さいリーダ選挙アルゴリズム 61
図 4.11 A.6(通信計算量の小さいリーダ選挙アルゴリズム)のフローチャート(1)
左右の candidate に対して,自分の ID を送信する.ここで“左右”とは,notleader をカウントに入れない場合のすぐ右隣,すぐ左隣の candidate であるプロセスのことである(図4.12(a)).すべての candidate プロセスが同じ動作を行うと,③,④すべての candidate は左右の candidate から ID を受け取る.このとき,左右のどちらの candidate よりも自分のID が大きいときにのみ,candidate は candidate であり続ける.もし,左右どちらかの ID

114 第 7章 合意問題
残りで,その場合の合意問題を考える.
7.4 ビザンチン将軍問題
太古のビザンチウム帝国の軍隊がある街を包囲している.軍隊はそれぞれ部隊長のいる複数の部隊から構成されており,将軍の指揮命令の下,複数ある街の入口をそれぞれの部隊が監視している.将軍は,街を攻撃するかあるいは和解するかを決定し,各部隊長に伝令を出す.総攻撃であれば敵の兵力は分散し,勝つ可能性が高いが,一部の部隊のみが攻撃を行った場合は,敵は兵力を集中させて応戦できるので,負ける可能性が高い.ただし,将軍と部隊長たちは敵と内通している可能性がある.もし将軍が敵と通じていれば,一部の部隊長には“攻撃”,別の部隊長には“和解”と伝える可能性があり(図 7.13),この場合,一部の部隊は攻撃し,一部の部隊は“和解を行う”と理解して攻撃を行わない,という状態になり負けてしまう可能性が高くなる.部隊長が敵と内通している場合は,たとえば,“攻撃”という命令を受けても攻撃せず,“和解”という命令を受けても攻撃して兵力の無駄使いをするなど,どのような命令が届いたとしても,勝手に行動することがある.したがって,この状況で目指すべき状況はつぎのとおりである.• 内通していない部隊長は全員,攻撃するか,和解を行うか,について合意する.
図 7.13 ビザンチン将軍問題

7.4 ビザンチン将軍問題 115
• 将軍が内通していない場合には,合意した値は将軍が送ろうとしていた値に等しい.この問題をビザンチン将軍問題という.これは合意問題の変形版である.ビザンチン将軍問題では,故障したプロセスの動作は任意と仮定する.たとえば,コンピュータウィルスに感染して敵に乗っ取られたプロセスは,どのような動作を行うのか予想がつかない.このような最悪の故障状況をモデル化したものがビザンチン故障である.このような問題を解くには,どのようにすればがよいだろうか.
7.4.1 ビザンチン将軍問題の定義ビザンチン将軍問題を定義しよう.n個のプロセス P0, P1, . . . , Pn−1 のうち,P0 が値 b0 ∈ {0, 1}をもつ.アルゴリズム終了後,各プロセスが値 bi ∈ {0, 1}をもち,
•(条件 1)故障していないすべてのプロセスにおいて,biの値は一致した値 b ∈ {0, 1}をもつ.•(条件 2)P0 が故障していない場合,b = b0 が成立する.
合意問題に関する定義と同じく,条件 2がない場合,「どのような場合も bi = 0とする」というアルゴリズムが考えられる.このアルゴリズムは明らかに条件 1を満足する.しかし,これは,結果がつねに固定されているので,「合意する」問題とはいえない.このため,条件2は,この問題を合意問題とするために必須の条件である.また,ここではつぎの仮定をおく.• 通信路は無故障である.• 同期システムである.
ビザンチン将軍問題は,ビザンチン故障が存在する場合の合意問題と定義が異なるが,両者は本質的には同一の問題である.なぜなら,ビザンチン将軍問題を解くアルゴリズムが存在したと仮定すると,各プロセス Pi は,自分がもつ初期値 xi について,自分が将軍となってビザンチン将軍問題を実行し,各プロセスが最後に,Piが送ろうとした値に関する合意値yi を用いて f(y1, y2, . . . , yn)を実行すれば,合意問題を解くことができるからである.また逆に,関数 f に関する合意問題を解くアルゴリズムが存在した場合にも,ビザンチン将軍問題を解くことができる.将軍は,f(x1, x2, . . . , xn)が(高々 tプロセスの故障の場合に)自分の送りたい値 xになるように,各プロセスに与えるべき初期値 xiを決定して 1),プロセス Piに xiを送信する.その後,各プロセスは将軍から送られた初期値をもとにして(将軍から初期値を送られなかったプロセスは任意の値を初期値として)f に関する合意問題を解く.このとき,将軍が正しければ,各無故障プロセスは正しい値 xiを初期値として合意問題を解くので,無故障プロセスは xに合意できる.将軍が正しくない場合には,各プロセスにでたらめな値が初期値として届くが,各無故障プロセスは f を正しく計算するので同じ値に合意できる.
1) ここで,f は,過半数のような,故障プロセスがでたらめな値を初期値としても,合意値が変わらない関数を想定している.

116 第 7章 合意問題
7.4.2 ビザンチン将軍問題を解くことができない場合まず,ビザンチン将軍問題を解くことができない場合について示そう.
● 定理 7.2 ●
故障プロセスの数を tとする.n = 3,t = 1の場合にビザンチン将軍問題を解くアルゴリズムは存在しない.
証明 t = 1であるので,P1,P2 のうちのどちらかは故障していない.一般性を失うことなく,故障していないプロセスを P1とする.P1が P0から何も受け取らずに自分の値 b1を決定すると,明らかにビザンチン将軍問題を解くことができないので,P0から値を受信することを期待する.図 7.14(a)に示すように,P1 は P0 から値 0を受け取った場合を考える.ここで,P1はこの値を無条件で信用して b1 = 0としてはならない.図(b)に示すように,P0
が故障していて,P0 が P1 には 0,P2 には 1を送信している可能性があるからである.もし,「P0からの受信内容をそのまま biにする」というのが無故障なプロセスの実行するアルゴリズムであった場合,実際の故障プロセスが P0 で,P0 が P1 に値 0,P2 に値 1を送った場合に b1 = 0,b2 = 1となって無故障プロセスでの合意はできない.したがって,P1 は P0 以外のプロセスからの情報ももとにして,b1 を決定する必要がある.ほかのプロセスは P2しかないので,P2から「P0は何を送ってきたか」の情報を受けることが唯一できることである.このとき,図 7.15(a)に示すように,P1が P2から「P0は P2に対して値 1を送ってきた」という情報を得た場合を考える.この場合,P1 からみてつぎの 2つのケースが考えられる.
図 7.14 n = 3の場合のビザンチン将軍問題
図 7.15 P2 からのメッセージを受信した場合

7.4 ビザンチン将軍問題 117
•(ケース 1)P0 が故障していて,P0 は P1 に 0,P2 に 1を送っている(図(b)).•(ケース 2)P2 が故障していて,P0 が P1 と P2 に対して 0を送ったが,P2 が誤ったメッセージを P1 に送っている(図(c)).
P1 は,届いたメッセージからではこれら 2つのケースを区別できない.ケース 2が実際に起こっている場合には,b1 = 0としなければならないが,それを達成するために「P0 とほかのプロセスの送信内容が矛盾した場合には P0 の値を優先する」というアルゴリズムを実行した場合には,実際に起こっているのがケース 1の場合に b1 = 0,b2 = 1となって合意できない.また,「P0 とほかのプロセスの送信内容が矛盾した場合には,ほかのプロセスの値を優先する」というアルゴリズムを実行した場合には,実際に起こっているのがケース 2の場合にb1 = 1となるが,無故障 P0 の値 b0 = 0であるので,正しい合意ができない.さらに,「P0とほかのプロセスの送信内容が矛盾した場合には固定値(たとえば 1)とする」というアルゴリズムを実行した場合にも,実際に起こっているのがケース 2であった場合に,P0 は無故障であるにもかかわらず,P1 は b1 = 1としてしまい,合意できない.あと考えられるのは,P0,P2からさらに情報を送ってもらうことであるが,実際に起こっているのがケース 1でもケース 2でも,その後に送られるすべてのメッセージが同一になるようにビザンチン故障プロセスがふるまうことが可能である.したがって,n = 3,t = 1の場合にビザンチン将軍問題を解くアルゴリズムは存在しない.
上記定理をもとにして,プロセス数が多い場合の定理を求めることができる.
● 定理 7.3 ●
n ≤ 3tの場合に,ビザンチン将軍問題を解くアルゴリズムは存在しない.
証明 n ≥ 4,n ≤ 3tを満足するある (n, t)の組に対して,故障が高々 tの場合にビザンチン将軍問題を解くアルゴリズム Aが存在したと仮定する.このとき,n = 3,t = 1の場合のビザンチン将軍問題を解くアルゴリズム Bをつぎのようにして構成することができる.n個のプロセス P0, P1, . . . , Pn−1 をつぎのように 3つの集合に分ける.
V0 = {P0, P3, . . .}V1 = {P1, P4, . . .}V2 = {P2, P5, . . .}
|V0|, |V1|, |V2| ≤ tが成立する.n = 3,t = 1の問題を解くアルゴリズム Bの各プロセスP0
′,P1′,P2
′ は,それぞれ内部に V0,V1,V2 のプロセス集合を生成して,それらの間でアルゴリズム Aを実行する(図 7.16).ここで,P0
′に対して与えられた値 bを P0に与えて P0
を送り手として Aを実行する.Bにおいて故障しているプロセスは,アルゴリズム Aの動作のシミュレーションを正しく実行するとは限らず,任意の動作を行う可能性がある.しかし,Bにおいて故障の数は 1で

118 第 7章 合意問題
図 7.16 n = 3,t = 1のビザンチン将軍問題のシミュレーション
あるので,シミュレーションして実行している Aにおける故障プロセスの数は高々 tである.したがって,Aは正しくビザンチン将軍問題を解くことができる.よって,P1
′ およびP2
′ は,(もし自分が故障していない場合には)シミュレーションした Aのプロセスの合意値を元の問題の合意値として出力すればよい.したがって,n = 3,t = 1の場合にビザンチン将軍問題を解くことができ,矛盾する.
7.4.3 ビザンチン将軍問題を解くアルゴリズムつぎに,n > 3tの場合にビザンチン将軍問題を解く A.16(ビザンチン将軍問題アルゴリズム)を示す.ここで,V はプロセス集合,Pi が送り手である.図 7.17にアルゴリズム A.16
のフローチャートを示す.
t = 1の場合には,「P0が 0を送った」かどうかの判定をするために,Pi(i = 1, 2, . . . n−1)が相互に「P0 が何を送った」かの情報を送りあって決める.t > 1の場合には,これを再帰的に利用して,「Piが送った「Pj が送った「...「P0が送った値」. . .」」」に関する合意を行うことで,ビザンチン将軍問題を解く.ここで,majorityは過半数が同じ値であればその値を選び,そうでなければ 0を選ぶ関数とする.

7.4 ビザンチン将軍問題 119
図 7.17 A.16(ビザンチン将軍問題アルゴリズム)のフローチャート
このアルゴリズムの動作例を n = 4,t = 1,V = {P0, P1, P2, P3}で,送り手が P0の場合について示す.ケース 1(P1が故障している場合) P0が送る値 b = 1とする.また,値 d1, d2, . . .を,故障プロセスが決める任意の値(0または 1)とする.

120 第 7章 合意問題
OM(P0, V, 1)を実行すると,③まず P0が全員に自分のもつ値を送る(7行目).P0は故障していないので,v2 = 1,v3 = 1となる.P1 は故障しているため,P0 の送った値を正しく v1 に格納するとは限らない.④つぎに,P1,P2,P3はそれぞれ自分が送り手となって,OM(Pi, V −{P0}, 0)を実行する
(9行目).① t = 0の場合は送り手の値をそのまま結果の値とするので,② v1,2 = d1,v1,3 =
d2,v2,3 = 1,v3,2 = 1 となる(10 行目).P1 は故障しているため,P2 や P3 が送った値を正しく v2,1,v3,1 に格納するとは限らない.よって,これらの値は不明である.また,v2,2 = 1,v3,3 = 1となる(11行目).d1,d2の値が何であっても,b2 = majority(d1, 1, 1)
= 1,b3 = majority(d2, 1, 1) = 1となり(12行目),b2,b3 は bと一致する.ケース 2(P0 が故障している場合) OM(P0, V, 1)を実行すると,まず P0 が全員に自分のもつ値を送る(7行目).P0 が P1,P2,P3 にそれぞれ値 d1,d2,d3 を送ったとする.つぎに,P1,P2,P3はそれぞれ自分が送り手となってOM(Pi, V −{P0}, 0)を実行する(9行目).t = 0の場合は送り手の値をそのまま結果の値とするので,v1,2 = d1,v1,3 = d1,v2,1 =
d2,v2,3 = d2,v3,1 = d3,v3,2 = d3となる(10行目).また,v1,1 = d1,v2,2 = d2,v3,3 = d3
となる(11行目).d1,d2,d3 の値が何であっても,b1 = majority(d1, d2, d3),b2 = majority(d1, d2, d3),
b3 = majority(d1, d2, d3)となり,b1 = b2 = b3 である(12行目).アルゴリズム A.16の正しさの証明はつぎのとおりである.
▼ 補題 7.5
▼OM(Pi, V,m)は,故障プロセス数が高々 tで |V | > 2t + mである場合に条件 2を満足する.
▼
▼
証明 mに関する帰納法で証明する.条件 2のみを考えるので,送り手 Pi は故障していないものと仮定する.m = 0の場合は,送り手が故障していないので,明らかに OM(Pi, V, 0)により V は正しく合意できる.したがって,以下ではm− 1のときに成立していると仮定して mの場合の証明を行う.最初に,PiがV の全員に値を送る.つぎに,V の各受け手Pjが,前のステップでPiから受けた値についてOM(Pj , V −{Pi},m−1)を実行する.|V | > 2t+mより,|V |−1 > 2t+(m−1)が成立するので,それぞれの Pj に対して実行される OM(Pj , V − {Pi},m − 1)のうち,送り手 Pj が故障していない |V | − 1 − t 個の実行については,帰納法の仮定より,無故障なプロセス全員が同じ値を得る.故障数は高々 t なので,故障している送り手によるOM(Pj , V − {Pi},m− 1)の数は高々 tである.よって,最後にmajority()を実行するときに,正しくない可能性のある値は高々 t個で,|V | − 1− t > tより,majority()の結果,無故障プロセスは全員同じ値をもつ.
上記補題をもとに,つぎの定理が証明される.

7.4 ビザンチン将軍問題 121
● 定理 7.4 ●
n > 3tの場合に,OM(P, V, t)はビザンチン将軍問題を正しく解く.
証明 tに関する帰納法で証明を行う.t = 0の場合,故障プロセスは存在しない.したがって,OM(P, V, 0)の送り手 P は故障していないので,補題 7.5より合意できる.つぎに,OM(P, V, t−1)が正しくビザンチン将軍問題を解くことを仮定して,OM(P, V, t)
が正しく解くことを証明する.まず,P が無故障の場合は,OM(P, V, t)は補題 7.5においてm = tの場合に相当するので正しく合意できる.つぎに,P が故障している場合について考える.アルゴリズムA.16の 9行目において,各受け手 Pjを送り手とした n−1個のOM(Pj , V −{P}, t−1)を実行することとなる.P が故障しているので,OM(Pj , V −{P}, t−1)における故障の数は高々 t−1である.総プロセス数 n−1は n−1 > 3(t−1)を満足する.よって,帰納法の仮定より,OM(Pj , V −{P}, t−1)
はビザンチン将軍問題を正しく解ける.すなわち,各 Pj に対して,「P が Pj に対して送った値」に関して合意できる.したがって,任意の無故障プロセスはアルゴリズム A.16の 12
行目でそれらの合意値のmajority()を取ることにより,同じ値に合意できる.
上記のビザンチン将軍問題の定義では,合意する値を 0または 1の 1ビットの値としたが,関数majority( )をほかの関数に入れ替えることで,整数値などの合意問題を解くこともできる.majority( )の満たすべき条件は,「過半数の値が同じ場合にはその値を結果の値とすること」である.整数値の場合には,majority(v1, v2, . . . , vn)を,「v1, v2, . . . , vnの中央値(これらの値をソートして小さいものから並べたときに中央にくる値)」とすることもできる.このアルゴリズムを用いれば,複数のプロセスでの時計合わせは,つぎのようにして実現できる.各プロセス Piにおける現在の時計の値を viとする.各プロセスが送り手になって,ビザンチン将軍問題を実施する.そのときの合意値を v′i とする.各プロセスはある(あらかじめ決めておいた)関数 f により,f(v′1, v
′2, . . . , v
′n)で時計の値を決める.
ビザンチン故障は起こりうる最悪の故障状態を理論的に定義したものであり,アルゴリズム A.16そのものを実際のシステムに適用した例は報告されていない.しかし,非常に高い信頼性を必要とされるシステムを構築する際に,同じ計算を 3台の計算機で実行させて,3つの実行結果の多数決をとった結果を最終的な実行結果とする,という三重冗長化(Triple-Modular Redundancy:TMR)計算機は実用化されている.このような最悪の故障を考えることは,どのような故障を防止することができるか,という理論的限界を知っておくために必要なことである.


情報工学レクチャーシリーズ分散処理システム © 真鍋義文 2013
2013 年 9 月 20 日 第 1 版第 1 刷発行 【本書の無断転載を禁ず】
著 者 真鍋義文発 行 者 森北博巳発 行 所 森北出版株式会社
東京都千代田区富士見 1-4-11(〒 102-0071)電話 03-3265-8341 / FAX 03-3264-8709http://www.morikita.co.jp/日本書籍出版協会・自然科学書協会 会員 <(社)出版者著作権管理機構 委託出版物>
落丁・乱丁本はお取替えいたします.
Printed in Japan/ ISBN978-4-627-81071-6
著 者 略 歴真鍋 義文(まなべ・よしふみ)1983 年 大阪大学基礎工学部情報工学科卒業1985 年 大阪大学基礎工学研究科博士前期課程修了1985 年 日本電信電話株式会社入社2013 年 工学院大学情報学部コンピュータ科学科教授 現在に至る 博士(工学) 研究分野 分散アルゴリズム,暗号理論,ゲーム理論
編集担当 加藤義之(森北出版)編集責任 水垣偉三夫(森北出版)組 版 アベリー印 刷 シナノ印刷製 本 同