oracle database 12c 并行执行基础...3 | oracle database 12c 并行执行基础 图...
TRANSCRIPT

Oracle Database 12c 并行执行基础
O R A C L E 白皮书 | 2 0 1 4 年 12 月

ORACLE DATABASE 12C 并行执行基础
目录
引言 1
并行执行概念 2
为什么采用并行执行? 2
并行执行原理 2
Oracle 中的并行执行 4
处理并行 SQL 语句 4
内存中并行执行 16
控制并行执行 18
启用并行执行 18
管理并行度 18
管理并行操作的并发性 21
控制并行执行的初始化参数 23
总结 26

1 | ORACLE DATABASE 12C 并行执行基础
引言
近些年,事务和数据仓库环境中数据库存储的数据量一直呈指数级增长。除了数据量的巨大增长,用户
还需要更快地处理数据来满足业务需求。
并行执行对大规模数据处理至关重要。采用并行方法,只需几分钟(而不是几小时或几天)即可处理数百
TB 的数据。并行执行使用多个进程完成一项任务。数据库越是能够有效地利用所有硬件资源(多个
CPU、多个 IO 通道、多个存储单元、集群中的多个节点),便会越高效地处理查询和其他数据库操作。 大型数据仓库应始终使用并行执行方法来实现良好的性能。OLTP 应用程序中的特定操作(如批量操
作)也可在很大程度上受益于并行执行。本白皮书包括三大主题:
» 并行执行的基本概念 — 为什么应使用并行执行及其背后的基本原则是什么。
» Oracle 并行执行的实现和增强 — 在此,您将熟悉 Oracle 并行架构、学习 Oracle 特有的并行执行术
语、了解如何控制和识别并行 SQL 处理的基本知识。
» 控制 Oracle 数据库中的并行执行 — 最后这节介绍如何在 Oracle 环境中启用和控制并行执行,让您
大致了解 DBA 需要考虑的问题。

2 | ORACLE DATABASE 12C 并行执行基础
并行执行概念
并行执行是一种常用的方法,通过将任务分为更小的子任务来提高操作速度。在本节中,我们将讨论使用并行执行
的基本原因及其基本概念。此外,我们还将详细讨论 Oracle 并行执行的一些概念。
为什么采用并行执行? 设想您的任务是统计某条街道中的汽车数量。有两种方法来完成此任务,一种方法是您可以自己穿过整条街道统计
汽车数量,另一种方法是,您可以邀请朋友帮忙,你们两个人各自从街道的两端开始统计汽车数量直到两人相遇,
然后将两人的统计结果相加即可完成任务。
假设您朋友的统计速度和您一样快,那么你们完成统计街道中所有汽车数量这项任务所需的时间预计约为您单独执
行此工作所需时间的一半。如果这样,则您的汽车数量统计操作量呈线性扩展;以两倍的资源让总处理时间减半。
数据库与统计汽车数量这个例子并没有很大区别。如果您分配两倍的资源量,所用处理时间是使用原先资源量时所
用时间的一半,则操作量呈线性扩展。无论是统计汽车数量还是通过数据库操作提供答案,并行处理的最终目标都
是线性扩展。
并行执行原理
在统计汽车数量的例子中,我们做了一些基本假设以实现线性扩展。这些假设反映了并行处理的一些原理。
首先,我们选择仅用两个人完成统计工作。在此,我们确定了数据库中称之为并行度 (DOP) 的值。为了最快地解决
问题,适合用多少人来执行这一任务?工作量越大,我们所用人员就会越多,当然,如果街道较短并且只有 4 辆汽
车,则我们应避免任何并行,因为与其确定谁从哪里开始,不如直接统计汽车数量来的快。
在此例中,我们确定用两个人来统计和协调的“开销”是劳有所值的。在数据库中,数据库引擎应基于操作的总开销
来做出这个决定。
其次,在汽车示例中,我们将工作分为两等份,每个人在街道的一端开始,并且假设每个人的统计速度相同。对于
数据库中的并行处理也是如此:第一步是将所处理的数据分为多个大小差不多的块,从而使它们的处理时间相同。
通常,使用某种形式的散列算法来均匀地划分数据。
并行处理的这种“数据分区”通常有两种基本方法,但这两种方法从根本上是不同的。主要区别在于是否使用物理数
据分区(布局)作为基础,进而作为并行执行工作的静态先决条件。
这两种概念上根本不同的方法分别称为全共享架构和无共享架构。
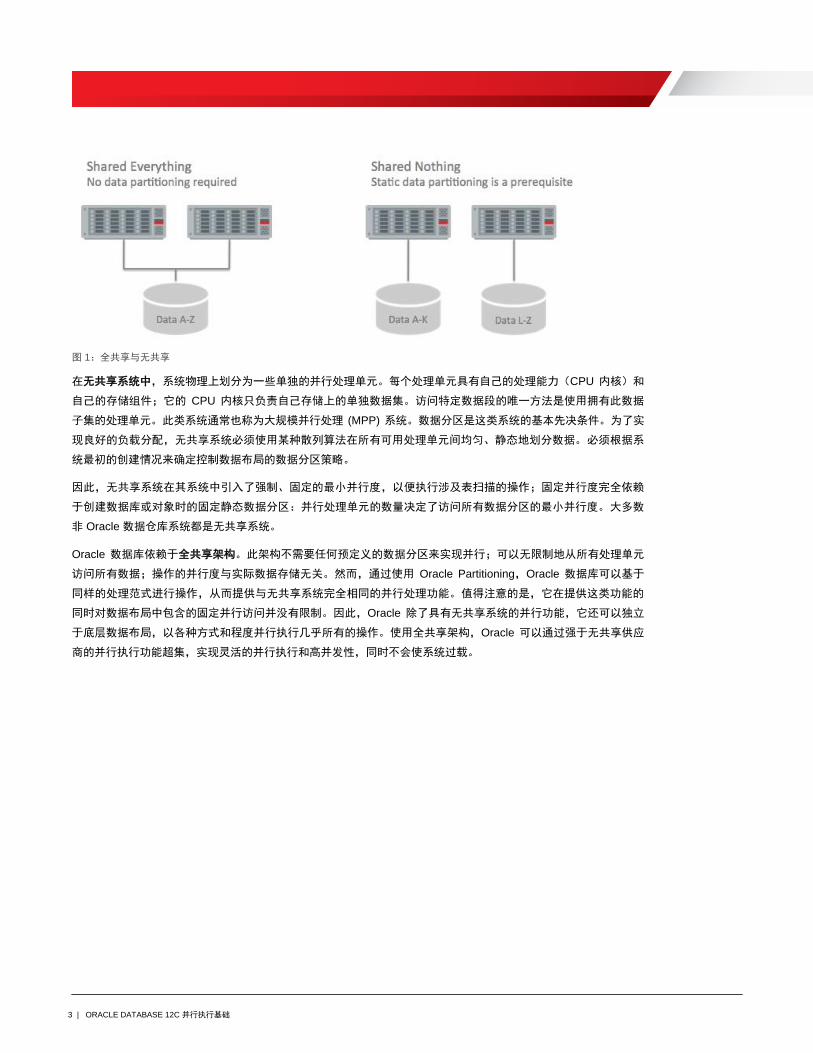
3 | ORACLE DATABASE 12C 并行执行基础
图 1:全共享与无共享
在无共享系统中,系统物理上划分为一些单独的并行处理单元。每个处理单元具有自己的处理能力(CPU 内核)和
自己的存储组件;它的 CPU 内核只负责自己存储上的单独数据集。访问特定数据段的唯一方法是使用拥有此数据
子集的处理单元。此类系统通常也称为大规模并行处理 (MPP) 系统。数据分区是这类系统的基本先决条件。为了实
现良好的负载分配,无共享系统必须使用某种散列算法在所有可用处理单元间均匀、静态地划分数据。必须根据系
统最初的创建情况来确定控制数据布局的数据分区策略。
因此,无共享系统在其系统中引入了强制、固定的最小并行度,以便执行涉及表扫描的操作;固定并行度完全依赖
于创建数据库或对象时的固定静态数据分区:并行处理单元的数量决定了访问所有数据分区的最小并行度。大多数
非 Oracle 数据仓库系统都是无共享系统。
Oracle 数据库依赖于全共享架构。此架构不需要任何预定义的数据分区来实现并行;可以无限制地从所有处理单元
访问所有数据;操作的并行度与实际数据存储无关。然而,通过使用 Oracle Partitioning,Oracle 数据库可以基于
同样的处理范式进行操作,从而提供与无共享系统完全相同的并行处理功能。值得注意的是,它在提供这类功能的
同时对数据布局中包含的固定并行访问并没有限制。因此,Oracle 除了具有无共享系统的并行功能,它还可以独立
于底层数据布局,以各种方式和程度并行执行几乎所有的操作。使用全共享架构,Oracle 可以通过强于无共享供应
商的并行执行功能超集,实现灵活的并行执行和高并发性,同时不会使系统过载。

4 | ORACLE DATABASE 12C 并行执行基础
Oracle 中的并行执行
Oracle 数据库提供了无需人工干预即可并行执行复杂任务的功能。可以并行执行的操作包括但不限于:
» 数据加载
» 查询
» DML 语句
» RMAN 备份
» 对象创建,例如索引或表创建
» 优化器统计信息收集
本白皮书仅着重探讨 SQL 并行执行,其中包括并行查询、并行 DML(数据操作语言)和并行 DDL(数据定义语
言)。本文侧重于 Oracle Database 12c,但本文的信息也适用于 Oracle Database 11g,除非明确说明。
处理并行 SQL 语句
当您在 Oracle 数据库中执行一条 SQL 语句时,该语句被分解为各个步骤或行源,它们在执行计划中标识为不同的
行。下面是一个简单的只涉及一个表的 SQL 语句及其执行计划的示例。此语句返回 CUSTOMERS 表中的客户总数:
SELECT COUNT(*) FROM customers c;
图 2:对 CUSTOMERS 表的 COUNT(*) 串行执行计划
一个更复杂的串行执行计划可能包括多个表之间的联接。在下面的示例中,将请求有关客户购买的信息。这需要
CUSTOMERS 表和 SALES 表之间的联接。
SELECT c.cust_first_name, c.cust_last_name, s.amount_sold
FROM customers c, sales s
WHERE c.cust_id=s.cust_id;
图 3:显示两表联接的更复杂的串行执行计划

5 | ORACLE DATABASE 12C 并行执行基础
如果您并行执行一条语句,则 Oracle 数据库将并行执行尽可能多的单独步骤,并在执行计划中反映这一点。如果以
并行方式重新执行上面的两个语句,我们可以得到下面的执行计划:
图 4:对 CUSTOMERS 表的 COUNT(*) 并行执行计划
图 5:客户购买信息,并行计划
这些计划看起来与前面的颇为不同,这主要是因为,现在的并行处理带来了以前所没有的一些额外的后勤处理步骤。
Oracle 数据库中的 SQL 并行执行基于几个基本概念。下一节将讨论这些概念来帮助您了解数据库中的并行执行,
并提供如何阅读并行 SQL 执行计划的基础知识。
查询协调器 (QC) 和并行执行 (PX) 服务器
Oracle 数据库中的 SQL 并行执行基于协调器(通常称为查询协调器,简称 QC)和并行执行 (PX) 服务器进程的原
则。QC 是启动并行 SQL 语句的会话,PX 服务器是代表启动会话并行执行工作的各个进程。QC 将工作分配给 PX
服务器,并且可能还须执行那些无法并行执行的极少的一部分工作(主要是后勤工作)。例如,包含 SUM() 运算的
并行查询需要最后将每个 PX 服务器各自计算得到的各个小计全部相加,这由 QC 完成。
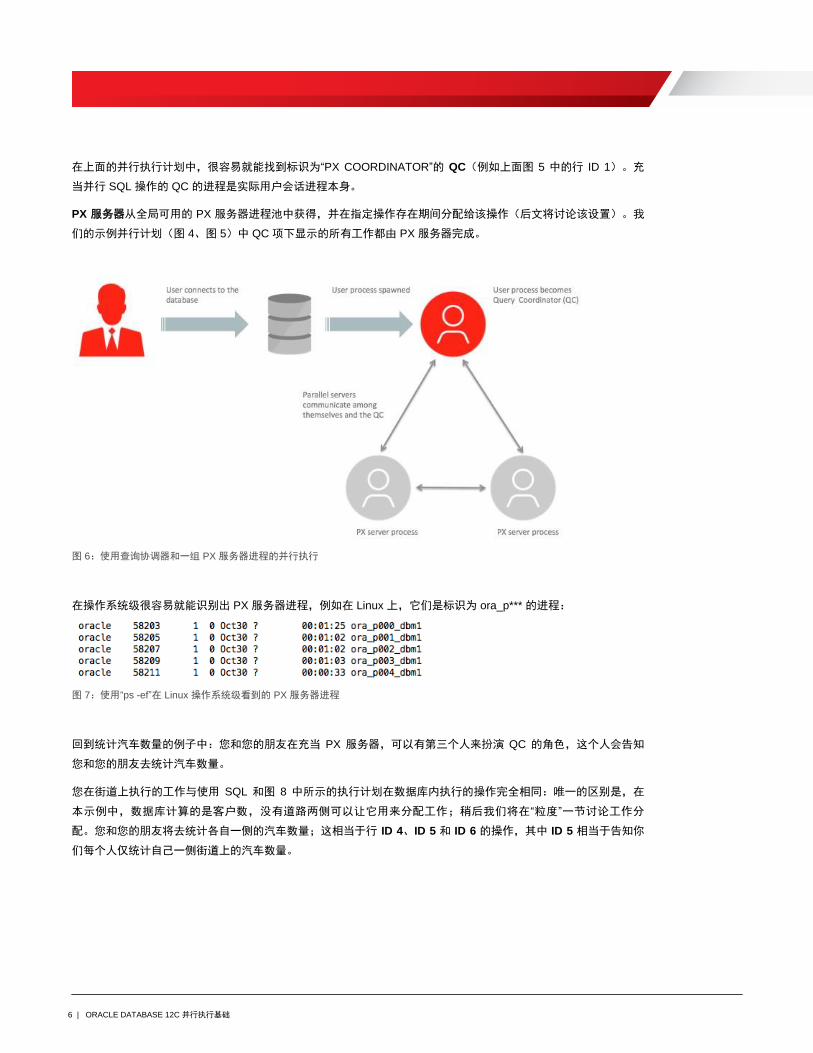
6 | ORACLE DATABASE 12C 并行执行基础
在上面的并行执行计划中,很容易就能找到标识为“PX COORDINATOR”的 QC(例如上面图 5 中的行 ID 1)。充
当并行 SQL 操作的 QC 的进程是实际用户会话进程本身。
PX 服务器从全局可用的 PX 服务器进程池中获得,并在指定操作存在期间分配给该操作(后文将讨论该设置)。我
们的示例并行计划(图 4、图 5)中 QC 项下显示的所有工作都由 PX 服务器完成。
图 6:使用查询协调器和一组 PX 服务器进程的并行执行
在操作系统级很容易就能识别出 PX 服务器进程,例如在 Linux 上,它们是标识为 ora_p*** 的进程:
图 7:使用“ps -ef”在 Linux 操作系统级看到的 PX 服务器进程
回到统计汽车数量的例子中:您和您的朋友在充当 PX 服务器,可以有第三个人来扮演 QC 的角色,这个人会告知
您和您的朋友去统计汽车数量。
您在街道上执行的工作与使用 SQL 和图 8 中所示的执行计划在数据库内执行的操作完全相同:唯一的区别是,在
本示例中,数据库计算的是客户数,没有道路两侧可以让它用来分配工作;稍后我们将在“粒度”一节讨论工作分
配。您和您的朋友将去统计各自一侧的汽车数量;这相当于行 ID 4、ID 5 和 ID 6 的操作,其中 ID 5 相当于告知你
们每个人仅统计自己一侧街道上的汽车数量。

7 | ORACLE DATABASE 12C 并行执行基础
图 8:执行计划中显示的 QC 和 PX 服务器进程
统计完您自己的一侧后,你们每个人向第三人 (QC) 告知各自的小计(行 ID 3),于是第三人将这些小计加起来得
到最终结果(行 ID 1)。这是从 PX 服务器(执行实际工作的进程)到 QC 的移交,以便最终“组装”结果,从而将
结果返回到用户进程。
使用 SQL Monitor1 有助于轻松识别 PX 服务器完成的工作 — 特定操作前面的许多小蓝“人”或小红“人”,与串行执行
相比,后者只有单个小绿人。
生成者/使用者模型
继续我们的汽车数量统计示例,设想现在的工作是按汽车颜色统计汽车数量。如果您和您的朋友各自负责街道一
侧,你们每个人可能看到相同的颜色并针对每种颜色进行小计,但这不是这条街道的特定颜色车的整个结果。您可
能会去记下所有这些信息并将其告诉给第三人(“负责人”)。但是,这个可怜的负责人然后必须自己总结所有结果
— 如果街道中所有汽车的颜色都各不相同,将会怎样?第三人将会完全重做您和您的朋友刚刚做过的工作。
为了并行执行每种颜色的统计工作,您只是邀请另外两个朋友帮忙:这两个朋友和你们一起在街道中间行走,一个
人统计您和您朋友各自查看的一侧的所有暗色汽车,另一个人统计所有亮色汽车(假设这种“汽车分色”大致将信息
分成两半)。每当统计新的一辆汽车时,您会将新遇到的汽车告知负责此颜色的人员 — 您生成信息,根据颜色信息
重新分配此信息,而颜色统计者使用此信息。最后,两个统计颜色的朋友向负责人 (QC) 告知结果,工作就完成
了;我们有两组并行工作人员,每组有两个朋友携手执行一部分工作。
数据库同样以这种方式工作:为了高效地并行执行语句,多组 PX 服务器配对工作:一组生成行(生成者),一组
使用行(使用者)。例如,对于 SALES 和 CUSTOMERS 表之间的并行联接,一组 PX 服务器读取表中的数据并将数
据发送给另一组,另一组接收数据(使用者)并联接两个表,如图 9 所示,DBMS_XPLAN 包的标准计划输出。
1 SQL Monitor 是在 Oracle Database 11g 中引入的,它为详细监视和分析 SQL 执行步骤提供了一个非常高效的方法。有关详细信息,请参见 Oracle
技术网中 有关 SQL Monitor 的页面。
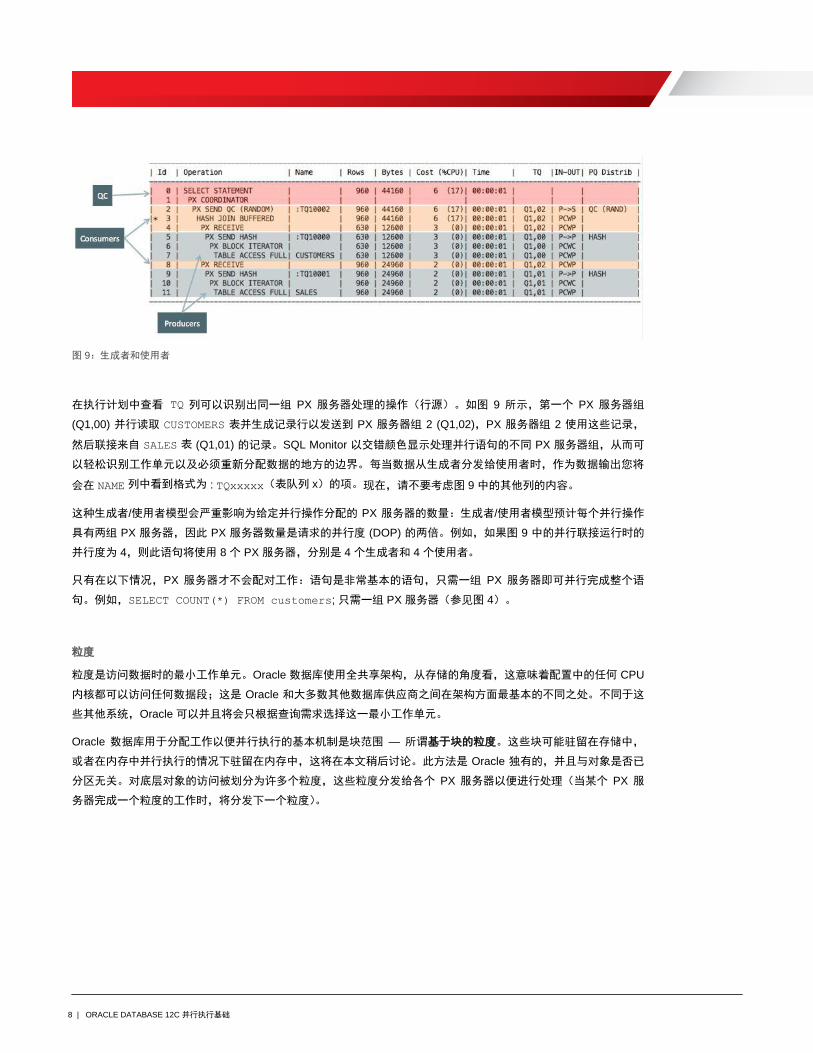
8 | ORACLE DATABASE 12C 并行执行基础
图 9:生成者和使用者
在执行计划中查看 TQ 列可以识别出同一组 PX 服务器处理的操作(行源)。如图 9 所示,第一个 PX 服务器组
(Q1,00) 并行读取 CUSTOMERS 表并生成记录行以发送到 PX 服务器组 2 (Q1,02),PX 服务器组 2 使用这些记录,
然后联接来自 SALES 表 (Q1,01) 的记录。SQL Monitor 以交错颜色显示处理并行语句的不同 PX 服务器组,从而可
以轻松识别工作单元以及必须重新分配数据的地方的边界。每当数据从生成者分发给使用者时,作为数据输出您将
会在 NAME 列中看到格式为 : TQxxxxx(表队列 x)的项。现在,请不要考虑图 9 中的其他列的内容。
这种生成者/使用者模型会严重影响为给定并行操作分配的 PX 服务器的数量:生成者/使用者模型预计每个并行操作
具有两组 PX 服务器,因此 PX 服务器数量是请求的并行度 (DOP) 的两倍。例如,如果图 9 中的并行联接运行时的
并行度为 4,则此语句将使用 8 个 PX 服务器,分别是 4 个生成者和 4 个使用者。
只有在以下情况,PX 服务器才不会配对工作:语句是非常基本的语句,只需一组 PX 服务器即可并行完成整个语
句。例如,SELECT COUNT(*) FROM customers; 只需一组 PX 服务器(参见图 4)。
粒度
粒度是访问数据时的最小工作单元。Oracle 数据库使用全共享架构,从存储的角度看,这意味着配置中的任何 CPU
内核都可以访问任何数据段;这是 Oracle 和大多数其他数据库供应商之间在架构方面最基本的不同之处。不同于这
些其他系统,Oracle 可以并且将会只根据查询需求选择这一最小工作单元。
Oracle 数据库用于分配工作以便并行执行的基本机制是块范围 — 所谓基于块的粒度。这些块可能驻留在存储中,
或者在内存中并行执行的情况下驻留在内存中,这将在本文稍后讨论。此方法是 Oracle 独有的,并且与对象是否已
分区无关。对底层对象的访问被划分为许多个粒度,这些粒度分发给各个 PX 服务器以便进行处理(当某个 PX 服
务器完成一个粒度的工作时,将分发下一个粒度)。

9 | ORACLE DATABASE 12C 并行执行基础
图 10:客户统计示例中的基于块的粒度
粒度数量始终远高于请求的 DOP,以便在 PX 服务器之间平均分配工作。图 10 所示的操作 “PX BLOCK
ITERATOR”表示对所有生成的块范围粒度进行迭代。
虽然基于块的粒度是大多数操作实现并行执行的基础,但有一些操作可以受益于底层分区数据结构因而可以利用各个
分区作为工作粒度。使用基于分区的粒度,对于单个分区,只使用一个 PX 服务器来处理其所有数据。如果操作中访问
的(子)分区数量至少等于 DOP(如果各个(子)分区的大小可能存在偏差,则远高于 DOP 较为理想),则 Oracle
优化器将考虑基于分区的粒度。使用基于分区的粒度的最常见操作是智能化分区联接(稍后将进行讨论)。
根据 SQL 语句和 DOP,Oracle 数据库确定是基于块的粒度还是基于分区的粒度可产生更优的执行;您无法影响此
行为。
在汽车统计示例中,可以将街道的一侧(甚至长街道的街区)视为等同于基于块的粒度。将现有数据量(街道)细
分为多个物理段,PX 服务器(您和您的朋友)各自对这些物理段进行处理。如果长街道有许多街区,并且只有您和
您朋友参与工作,则每人负责一半的街区(“粒度”)。如果您和三个朋友一起工作,则每人负责四分之一的街区。
您可以选择与您一起工作的朋友数量,您的统计能力将扩展。
如果我们将街道看做是“静态分区的”,只有左右两侧分区,那么您只能邀请一位朋友帮忙:您的其他朋友则无事可
做。纯粹的无共享系统正是使用这样的静态方法工作的,从中可以看出这种架构的局限性。
数据重新分配
并行操作(除了最基本的并行操作之外)通常需要重新分配数据。需要重新分配数据以便执行诸如并行排序、聚合
和联接之类的操作。在块粒度级别,并不知道单个粒度中包含的实际数据;块粒度只是物理块,没有逻辑内涵。因
此,只要后续操作依赖实际内容,就需要重新分配数据。在汽车示例中,汽车颜色至关重要,但您不知道(甚至无
法控制)哪些颜色的汽车停泊在街道上哪些位置。根据另外两个朋友所负责的颜色,您将有关每种颜色的汽车数量
的信息重新分配给这两个朋友,使他们对其负责的颜色统计总数量。

10 | ORACLE DATABASE 12C 并行执行基础
数据重新分配在各个 PX 服务器组之间发生,而这些 PX 服务器或者运行于一台机器上,或者运行于 Real
Application Clusters (RAC) 系统的多台机器(节点)上。当然,在后一种情况下,使用互连通信重新分配数据。
数据重新分配不是 Oracle 数据库所独有的。实际上,这是并行处理的一个最基本的原则,提供并行功能的每个产品
都使用它。但是,Oracle 提供的功能的基本不同之处和优势是并行数据访问(已在前面“粒度”一节中讲过)以及所
需的数据重新分配不受任何特定硬件架构或数据库设置(数据分区)的限制。
与全共享系统类似,无共享系统也需要数据重新分配,除非操作能够完全依靠智能化分区联接(本节后面将进一步
说明)。在无共享系统中,无法受益于智能化分区联接的并行操作(例如一个简单的基于两个不同联接键的三方表
联接)总是需要数据重新分配,因此总是大量使用互连通信。由于 Oracle 数据库能在节点的环境中启用并行执行,
因此并行操作不必总是使用互连通信,从而避免了潜在的互连瓶颈。
下一节将通过无需任何辅助数据结构(例如索引或物化视图以及其他优化)的简单表联接示例,介绍 Oracle 的数据
重新分配功能。
串行联接 在串行两方联接中,单个会话读取涉及的两个表并执行联接。在此示例中,我们假设联接涉及到两个大型表
CUSTOMERS 和 SALES。数据库使用全表扫描来访问两个表,如前面的图 3 所示。
在串行联接中,单个串行会话扫描两个表并执行完全联接。图 11 描述了串行联接。
图 11:串行联接
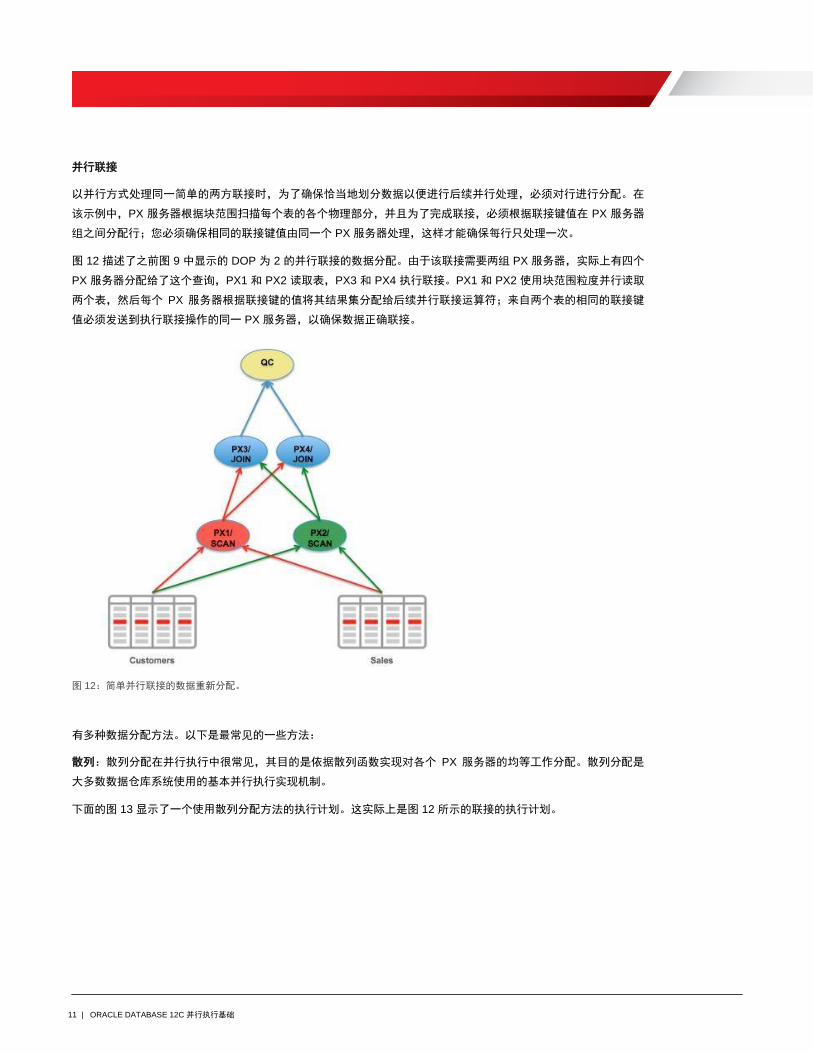
11 | ORACLE DATABASE 12C 并行执行基础
并行联接 以并行方式处理同一简单的两方联接时,为了确保恰当地划分数据以便进行后续并行处理,必须对行进行分配。在
该示例中,PX 服务器根据块范围扫描每个表的各个物理部分,并且为了完成联接,必须根据联接键值在 PX 服务器
组之间分配行;您必须确保相同的联接键值由同一个 PX 服务器处理,这样才能确保每行只处理一次。
图 12 描述了之前图 9 中显示的 DOP 为 2 的并行联接的数据分配。由于该联接需要两组 PX 服务器,实际上有四个
PX 服务器分配给了这个查询,PX1 和 PX2 读取表,PX3 和 PX4 执行联接。PX1 和 PX2 使用块范围粒度并行读取
两个表,然后每个 PX 服务器根据联接键的值将其结果集分配给后续并行联接运算符;来自两个表的相同的联接键
值必须发送到执行联接操作的同一 PX 服务器,以确保数据正确联接。
图 12:简单并行联接的数据重新分配。
有多种数据分配方法。以下是最常见的一些方法:
散列:散列分配在并行执行中很常见,其目的是依据散列函数实现对各个 PX 服务器的均等工作分配。散列分配是
大多数数据仓库系统使用的基本并行执行实现机制。
下面的图 13 显示了一个使用散列分配方法的执行计划。这实际上是图 12 所示的联接的执行计划。

12 | ORACLE DATABASE 12C 并行执行基础
图 13:散列分配的执行计划
假设该计划的 DOP 为 2,一个 PX 组(PX1 和 PX2)读取 CUSTOMERS 表,对联接列应用散列函数并将行发送给
另一个 PX 组中的 PX 服务器(PX3 和 PX4),通过这种方式,根据计算的散列值,PX3 得到了一些行,PX4 得到
了其他行。然后,PX1 和 PX2 读取 SALES 表,对联接列应用散列函数并将行发送给另一个 PX 组(PX3 和
PX4)。PX3 和 PX4 现在都有了来自两个表的匹配的行,可以执行联接了。
每个表的分配方法可以在该计划的 PQ Distrib 和 Operation 列中看出,在第 5 行和第 9 行中,PQ Distrib
显示两个表的 HASH,而 Operation 显示 PX SEND HASH。
广播:当联接操作中的两个结果集之一远小于另一个结果集时,便会发生广播分配。数据库将较小的结果集发送到
所有 PX 服务器以确保各个服务器能够完成其联接操作,而不是分配两个结果集中的行。对联接操作的较小表进行
广播,其优势在于,根本不必重新分配大型表。
下面的图 14 显示了一个使用广播分配方法的执行计划。
图 14:广播分配的执行计划
假设该计划的 DOP 为 2,一个 PX 组(PX1 和 PX2)读取 CUSTOMERS 表,并将它的所有结果集广播给另一个 PX
组(PX3 和 PX4)。PX3 和 PX4 现在可以读取 SALES 表并执行联接,因为它们都有了来自 CUSTOMERS 表的所
有行。
在该执行计划中,我们可以从第 5 行中看出分配方法,该行的 PQ Distrib 列显示 BROADCAST,Operation 列
显示 PX SEND BROADCAST。
范围:范围分配通常用于并行排序操作。各个 PX 服务器处理各个数据范围,这样 QC 不必进行任何排序,而是仅
以正确顺序显示各个 PX 服务器的结果。
图 15 显示了一个对简单 ORDER BY 查询使用范围分配方法的执行计划。
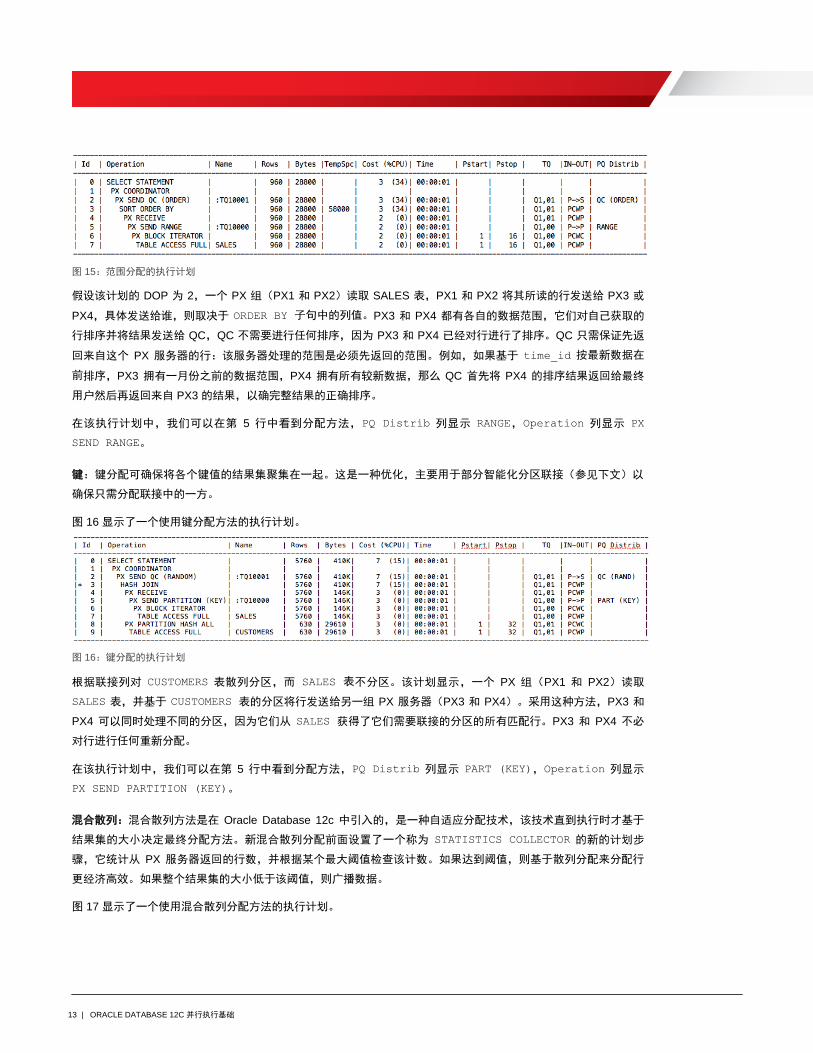
13 | ORACLE DATABASE 12C 并行执行基础
图 15:范围分配的执行计划
假设该计划的 DOP 为 2,一个 PX 组(PX1 和 PX2)读取 SALES 表,PX1 和 PX2 将其所读的行发送给 PX3 或
PX4,具体发送给谁,则取决于 ORDER BY 子句中的列值。PX3 和 PX4 都有各自的数据范围,它们对自己获取的
行排序并将结果发送给 QC,QC 不需要进行任何排序,因为 PX3 和 PX4 已经对行进行了排序。QC 只需保证先返
回来自这个 PX 服务器的行:该服务器处理的范围是必须先返回的范围。例如,如果基于 time_id 按最新数据在
前排序,PX3 拥有一月份之前的数据范围,PX4 拥有所有较新数据,那么 QC 首先将 PX4 的排序结果返回给最终
用户然后再返回来自 PX3 的结果,以确完整结果的正确排序。
在该执行计划中,我们可以在第 5 行中看到分配方法,PQ Distrib 列显示 RANGE,Operation 列显示 PX
SEND RANGE。
键:键分配可确保将各个键值的结果集聚集在一起。这是一种优化,主要用于部分智能化分区联接(参见下文)以
确保只需分配联接中的一方。
图 16 显示了一个使用键分配方法的执行计划。
图 16:键分配的执行计划
根据联接列对 CUSTOMERS 表散列分区,而 SALES 表不分区。该计划显示,一个 PX 组(PX1 和 PX2)读取
SALES 表,并基于 CUSTOMERS 表的分区将行发送给另一组 PX 服务器(PX3 和 PX4)。采用这种方法,PX3 和
PX4 可以同时处理不同的分区,因为它们从 SALES 获得了它们需要联接的分区的所有匹配行。PX3 和 PX4 不必
对行进行任何重新分配。
在该执行计划中,我们可以在第 5 行中看到分配方法,PQ Distrib 列显示 PART (KEY),Operation 列显示
PX SEND PARTITION (KEY)。
混合散列:混合散列方法是在 Oracle Database 12c 中引入的,是一种自适应分配技术,该技术直到执行时才基于
结果集的大小决定最终分配方法。新混合散列分配前面设置了一个称为 STATISTICS COLLECTOR 的新的计划步
骤,它统计从 PX 服务器返回的行数,并根据某个最大阈值检查该计数。如果达到阈值,则基于散列分配来分配行
更经济高效。如果整个结果集的大小低于该阈值,则广播数据。
图 17 显示了一个使用混合散列分配方法的执行计划。

14 | ORACLE DATABASE 12C 并行执行基础
图 17:混合散列分配的执行计划
在该执行计划中,我们可以在第 5 行和第 10 行中看到分配方法,PQ Distrib 列显示 HYBRID HASH,
Operation 列显示 PX SEND HYBRID HASH。可以在第 6 行中看到新的计划步骤 STATISTICS COLLECTOR。
作为数据分配方法的一个变化,您可以在 Real Application Clusters (RAC) 数据库的并行执行计划中看到 LOCAL
后缀。LOCAL 分配是针对 RAC 环境的一种优化,可最大程度减少节点间并行查询的互连流量。例如,您可以在执
行计划中看到 BROADCAST LOCAL 分配,表示行集在本地节点上生成并且只发送到此节点上的 PX 服务器。
并行智能化分区联接
即使数据库试图根据优化器统计信息选择最好的分配方法,PX 组之间的行分配也需要进程间,有时是实例间通
信。而完全智能化联接或部分智能化联接等技术则可以尽量减少甚至避免数据分配,从而可能极大地提高并行执
行性能。
如果联接中访问的至少一个表基于联接键进行了分区,则数据库可以决定使用智能化分区联接。如果两个表都基于
联接键进行了同样的分区,则数据库可以使用完全智能化分区联接。否则,可以使用部分智能化分区联接,其中一
个表在内存中进行动态分区,然后进行完全智能化分区联接。
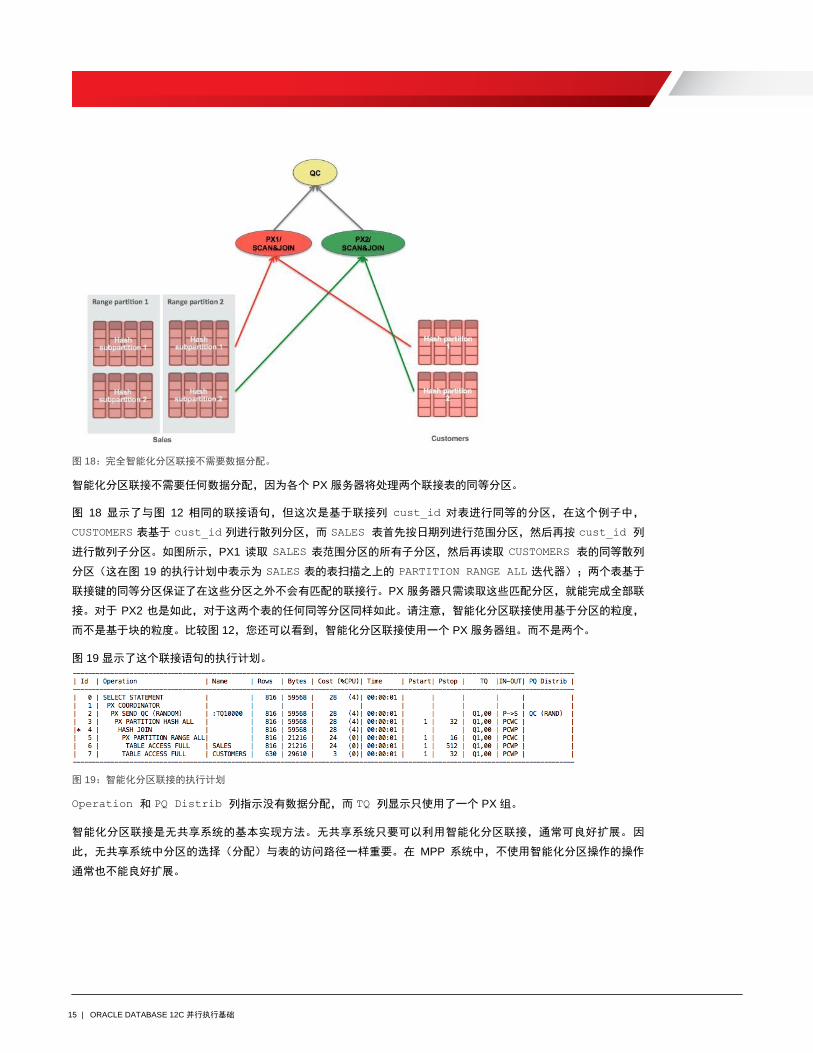
15 | ORACLE DATABASE 12C 并行执行基础
图 18:完全智能化分区联接不需要数据分配。
智能化分区联接不需要任何数据分配,因为各个 PX 服务器将处理两个联接表的同等分区。
图 18 显示了与图 12 相同的联接语句,但这次是基于联接列 cust_id 对表进行同等的分区,在这个例子中,
CUSTOMERS 表基于 cust_id 列进行散列分区,而 SALES 表首先按日期列进行范围分区,然后再按 cust_id 列
进行散列子分区。如图所示,PX1 读取 SALES 表范围分区的所有子分区,然后再读取 CUSTOMERS 表的同等散列
分区(这在图 19 的执行计划中表示为 SALES 表的表扫描之上的 PARTITION RANGE ALL 迭代器);两个表基于
联接键的同等分区保证了在这些分区之外不会有匹配的联接行。PX 服务器只需读取这些匹配分区,就能完成全部联
接。对于 PX2 也是如此,对于这两个表的任何同等分区同样如此。请注意,智能化分区联接使用基于分区的粒度,
而不是基于块的粒度。比较图 12,您还可以看到,智能化分区联接使用一个 PX 服务器组。而不是两个。
图 19 显示了这个联接语句的执行计划。
图 19:智能化分区联接的执行计划
Operation 和 PQ Distrib 列指示没有数据分配,而 TQ 列显示只使用了一个 PX 组。
智能化分区联接是无共享系统的基本实现方法。无共享系统只要可以利用智能化分区联接,通常可良好扩展。因
此,无共享系统中分区的选择(分配)与表的访问路径一样重要。在 MPP 系统中,不使用智能化分区操作的操作
通常也不能良好扩展。

16 | ORACLE DATABASE 12C 并行执行基础
内存中并行执行
在传统并行处理中,数据会绕过所有共享缓存直接传输到 PX 服务器进程的内存 (PGA) 中,而与传统并行处理不同
的是,内存中并行执行(内存中 PX)会利用共享内存缓存 (SGA) 来存储数据以便进行后续并行处理。内存中 PX
利用当今数据库服务器中不断增长的内存;这对大规模集群环境来说尤其有用,在这种环境中,聚合的总内存量可
以达数 TB,即使单个数据库服务器“只”拥有数十或数百 GB 的内存。使用内存中 PX,Oracle 可以在 Real
Application Clusters (RAC) 环境中使用聚合的服务器内存缓存,从而有效地跨所有节点的内存缓存分配的对象。这
确保了后续并行查询将从所有节点的缓存读取数据,而不是从存储读取数据,从而可以极大提高处理速度。
Oracle Database 12c 版本 12.1.0.2 引入了 Oracle Database In-Memory 选件,这是专门针对内存中处理而设计的
列式内存中数据存储,用以支持实时海量数据分析。其压缩列格式及针对内存中技术优化的数据处理算法提供了最
佳的内存中处理。我们推荐的内存中处理方法就是利用 Oracle 新的数据库内存中技术。有关该特性的详细信息,请
参见白皮书“Oracle 数据库内存中技术”。
未配置 Database In-Memory 选件的系统也可以利用内存中 PX,但无法使用内存中压缩列存储及优化的内存中算
法。从 Oracle Database 11g 第 2 版开始,数据库就对内存中 PX 使用标准的数据库缓冲区缓存,这也是联机事务
处理使用的缓存。因为 OLTP 与并行操作使用同一缓存,因此它们之间存在着“争抢”缓冲区缓存的风险,为了确保
并行操作不会占用整个缓存,Oracle 数据库将内存中 PX 能用的缓冲区缓存百分比限制为 80%。使用该模型,内存
中 PX 的好处可能会受到限制,具体取决于并行处理的数据量以及 OLTP 应用程序的内存需求。具有较少数据量和
具有更多混合(及变化的)负载特征的最常见的系统会从该方法受益。
为了拓宽内存中 PX 的适用性 — 无论是在适合使用内存中处理的对象的大小方面,还是为了提供最佳的全表扫描感知
的缓存,Oracle Database 12c 引入了自动大表缓存 (ABTC),它会专门为并行内存中处理保留部分专用缓冲区内存。
使用 ABTC,会保留一部分数据库缓冲区缓存来在内存中存储大对象(或大对象的一部分),这样就可以有更多的
查询能利用内存中并行执行。适合缓存的对象的大小最多可以是保留的可用内存的三倍。ABTC 使用优化段和基于
热度的算法,确保可用缓存得到最佳使用。
要启用使用 ABTC 的内存中 PX,必须设置下面两个参数:
» PARALLEL_DEGREE_POLICY:必须设置为 AUTO 或 ADAPTIVE
» DB_BIG_TABLE_CACHE_PERCENT_TARGET:指定为内存中 PX 保留的数据库缓冲区缓存的百分比。
使用内存中 PX 和 ABTC,数据库将决定语句访问的对象是否应该缓存在 ABTC 中。对象可以是表、索引,在分区
对象的情况下,也可以是一个或多个分区。

17 | ORACLE DATABASE 12C 并行执行基础
这一决定根据一组高级试探而做出,这些试探包括对象的大小、对象访问的频率,以及 ABTC 的大小。如果该对象
符合这些条件,内存中处理将被启用,访问的对象将缓存在 ABTC 中。在具有多个节点的 RAC 环境情况下,对象
将被分段(分为多个段)并分配给所有参与节点;每个分段将确定地映射(关联)到一个特定的 RAC 节点并存储
在该节点的缓冲区缓存中。分段可以是某个表的块的物理范围,在分区对象的情况下,也可以是各个分区。
映射分段之后,对此分段的所有后续访问都将在此节点上发生。如果从集群中的任意节点发出需要相同数据的后续
并行 SQL 语句,则数据所在的节点上的 PX 服务器将访问自己的ABTC 缓存中的数据,并且只将结果返回到发出语
句的节点;并没有通过缓存融合在节点之间移动数据。
如果决定不缓存对象,则通过直接路径 IO 访问该对象。
图 20:某个分区表跨两节点 RAC 集群的内存中并行执行的示例数据分配

18 | ORACLE DATABASE 12C 并行执行基础
控制并行执行
为了以高效的方式使用并行执行,您需要考虑如何启用它、如何指定语句的并行度 (DOP),以及如何在可能同时运
行多个并行语句的并发环境中使用它。
启用并行执行
默认情况下,Oracle 数据库对查询和 DDL 语句均启用并行执行。对 DML 语句,您需使用 ALTER SESSION 语句
在会话级启用它。
ALTER SESSION ENABLE PARALLEL DML;
管理并行度
即使启用了并行执行,对于是否以并行方式运行一个语句的决定还取决于一些其他因素。您可以使用 Oracle 的自动
并行度 (Auto DOP) 框架让 Oracle 完全控制对并行度的选择和管理,也可以人工控制并行度的选择。使用 Auto
DOP 是 Oracle 推荐的在 Oracle Database 12c 环境中控制并行执行的方法。
自动并行度 (Auto DOP)
使用 Auto DOP,数据库将自动决定是否应并行执行某个语句以及应使用的 DOP。系统根据语句的资源需求(也称
“开销”)来决定是否使用并行执行并选择 DOP。如果语句预计花费的时间小于 PARALLEL_MIN_TIME_THRESHOLD
(默认为 AUTO,相当于 10 秒),则该语句将串行运行。
如果预计花费时间大于 PARALLEL_MIN_TIME_THRESHOLD,则优化器根据执行计划中所有扫描操作(全表扫描、
索引快速全扫描、聚合、联接等)的开销来确定语句的理想 DOP。Oracle Database 12c 使用所有操作的 CPU 开
销和 IO 开销,而 Oracle Database 11g 则只使用 Auto DOP 计算的 IO 开销。
根据语句的开销,理想的 DOP 可能变得很大。为了确保您不会为单个语句分配太多的并行执行服务器,优化器将
对实际使用的 DOP 设置上限。该上限通过参数 PARALLEL_DEGREE_LIMIT 来设置。此参数的默认值是 CPU,这
意味着最大 DOP 受系统的默认 DOP 的限制。用于推算默认 DOP 的公式为:
PARALLEL_THREADS_PER_CPU * SUM(CPU_COUNT across all cluster nodes)
优化器将其理想 DOP 与 PARALLEL_DEGREE_LIMIT 进行比较,并取较小值。
ACTUAL DOP = MIN(IDEAL DOP, PARALLEL_DEGREE_LIMIT)
将 PARALLEL_DEGREE_LIMIT 设置为特定数值可以控制 Auto DOP 将会在系统范围使用的最大 DOP。对不同用
户组或应用程序的更细粒度控制,Oracle Database Resource Manager (DBRM) 允许为各个资源用户组设置不同的
DOP 限制。除了通过 PARALLEL_DEGREE_LIMIT 设置系统范围的上限 DOP,我们还建议使用 Database
Resource Manager 来对最大 DOP 进行细粒度控制。
下图从理论上说明没有 Database Resource Manager 时如何在系统范围决定是否并行执行语句以及要使用的
DOP。使用 Database Resource Manager 时,理想 DOP 的计算将变为:

19 | ORACLE DATABASE 12C 并行执行基础
ACTUAL DOP = MIN(IDEAL DOP, PARALLEL_DEGREE_LIMIT, DBRM limit)
图 21:没有 Database Resource Manager 时,Auto DOP 的决定过程(理论上)
执行计划的备注部分显示和说明了所选的实际 DOP。对于使用 explain plan 命令和实际执行的语句
(V$SQL_PLAN 中存储的信息)解释的语句都提供了该信息。例如,下面显示的执行计划是在 CPU_COUNT =
32、PARALLEL_THREADS_PER_CPU = 2 和 PARALLEL_DEGREE_LIMIT = CPU 的情况下在单实例数据库上生
成的。在备注部分,您会注意到所选 DOP 为 64。在此系统上,并行度 64 是 PARALLEL_DEGREE_LIMIT 允许的
最大 DOP (2 * 32)。
图 22:执行计划的备注部分中显示的自动并行度
Auto DOP 由初始化参数 PARALLEL_DEGREE_POLICY 控制,并通过 LIMITED、AUTO 或 ADAPTIVE 设置来启用。
可以在系统级或会话级应用此初始化参数。此外,还可以使用提示 PARALLEL 或 PARALLEL(AUTO) 对特定 SQL 语
句启用 Auto DOP:
SELECT /*+ parallel(auto) */ COUNT(*) FROM customers;

20 | ORACLE DATABASE 12C 并行执行基础
手动设置并行度
PARALLEL_DEGREE_POLICY 设置为 MANUAL 时,Auto DOP 功能被禁用,最终用户必须自己管理系统中的并行执
行使用。您可以在会话、语句或对象级请求所谓的默认 DOP 或 DOP 的特定固定值。
DEFAULT 并行度
DEFAULT 并行度 使用一个公 式基于初始 化参数确定 DOP 。在单 实例数据库 中 ,该计算 公式为
PARALLEL_THREADS_PER_CPU * CPU_COUNT, 在 RAC 环境中,为 PARALLEL_THREADS_PER_CPU *
SUM(CPU_COUNT)。因此,在每个节点设置为 CPU_COUNT=8 和 PARALLEL_THREADS_PER_CPU=2 的四节点集
群上,默认 DOP 将为 2 * 8 * 4 = 64。
您可以使用下列方法之一获得 DEFAULT 并行度。
1. 设置对象的并行子句。
ALTER TABLE customers PARALLEL;
2. 使用语句级提示 parallel(default)。
SELECT /*+ parallel(default) */ COUNT(*) FROM customers;
3. 使用对象级提示 parallel(table_name, default)。
SELECT /*+ parallel(customers, default) */ COUNT(*) FROM customers;
注意,上面第一种方法中显示的表设置以人工模式为您提供默认 DOP,即当 PARALLEL_DEGREE_POLICY 设置为
MANUAL。
DEFAULT 并行度针对单用户负载,旨在使用最多资源(假设使用的资源越多,操作就会越快完成)。数据库不检
查并行度是否有意义,即不检查并行度是否会为您提供任何可扩展性。例如,您可以运行 SELECT * FROM emp;
使用前面介绍的系统上的默认并行度,但您在返回的这 14 个记录中将看不到任何可扩展性。在多用户环境下,
DEFAULT 并行度将迅速用完系统资源,没有留下可用资源以便其他用户并发执行并行语句。
固定并行度 (DOP) 与 DEFAULT 并行度不同,可以从 Oracle 数据库请求特定 DOP。您可以使用下列方法之一获得固定 DOP。
1. 为对象设置固定 DOP。
ALTER TABLE customers PARALLEL 8 ;
ALTER TABLE sales PARALLEL 16 ;
2. 使用语句级提示 parallel(integer)。
SELECT /*+ parallel(8) */ COUNT(*) FROM customers;
3. 使用对象级提示 parallel(table_name, default)。
SELECT /*+ parallel(customers, 8) */ COUNT(*) FROM customers;
注 意 , 上 面 第 一 种 方 法 中 显 示 的 表 设 置 只 在 人 工 模 式 和 限 制 模 式 下 为 您 提 供 固 定 DOP , 即 当
PARALLEL_DEGREE_POLICY 设置为 MANUAL 或 LIMITED 时。在 AutoDOP 模式(AUTO 或 ADAPTIVE)下,将
忽略任何表修饰。
还要注意,对第一种方法的示例设置,Oracle 将按以下方式选择请求的 DOP:
» 只访问 CUSTOMERS 表的查询使用请求的 DOP 8。
» 访问 sales 表的查询将请求 DOP 16。

21 | ORACLE DATABASE 12C 并行执行基础
» 访问 sales 和 customers 两个表的查询将以 DOP 16 进行处理。Oracle 使用更高的 DOP2
在并行处理需要两组 PX 服务器分别用于生成者/使用者处理的情况下,所分配的服务器的数量总会是所请求的 DOP
的两倍。
管理并行操作的并发性
无论预期负载模式如何,您都希望确保 Oracle 的并行执行功能在您的环境中得到最佳使用。这意味着除了控制并行
度还有三个基本任务:
1. 确保系统不会因并行处理过载
2. 确保任何特定语句都能获得所需的并行资源
3. 遵循对不同的用户组可能不同的优先级。
Oracle 的 Auto DOP 框架不仅无需任何用户干预就能全面控制并行处理的使用,而且满足前两个需求。与
Database Resource Manager(负责第三个需求)相结合,Oracle 提供了全面的负载管理框架,可以满足世界上最
复杂的混合负载需求。
管理并行执行 (PX) 服务器进程的数量
Oracle 数据库将进程从 PX 服务器进程池中分配给并行操作。通过 PARALLEL_MAX_SERVERS 参数设置池中允许
的最大 PX 服务器进程数。这是一个硬性限制,用于防止系统因太多进程而过载。默认情况下,此参数设置为
5 * concurrent_parallel_users * CPU_COUNT * PARALLEL_THREADS_PER_CPU
concurrent_parallel_users 的值按如下方法计算:
» 如果设置了 MEMORY_TARGET 或 SGA_TARGET 初始化参数,则数量为
concurrent_parallel_users = 4。
» 如果没有设置 MEMORY_TARGET 和 SGA_TARGET,则检查 PGA_AGGREGATE_TARGET。如果设置了
PGA_AGGREGATE_TARGET 的值,则 concurrent_parallel_users = 2。如果没有设置
PGA_AGGREGATE_TARGET 的值,则 concurrent_parallel_users = 1。
当池中的所有进程都分配出去后,需要并行执行的新操作要么串行执行,要么以降级的 DOP 来执行,因而这些操
作的性能会降低。
为了防止达到 PARALLEL_MAX_SERVERS 进而操作串行执行或降级执行,Auto DOP 通过参数
PARALLEL_SERVERS_TARGET 使用一个额外的限制设置。
默认情况下,此参数设置为:
2 * concurrent_parallel_users * CPU_COUNT * PARALLEL_THREADS_PER_CPU
PARALLEL_SERVERS_TARGET 是使用语句排队之前可用于运行并行语句的 PX 服务器进程的数量。将它设置为小
于 PARALLEL_MAX_SERVERS,以确保每个并行语句可获得所有需要的 PX 服务器资源并防止因 PX 服务器而使系
2 某些语句并不遵循此规则,例如并行 CREATE TABLE AS SELECT;对这些例外情况的讨论超出本白皮书的范围。

22 | ORACLE DATABASE 12C 并行执行基础
统过载。注意,即使已激活语句排队,所有串行(非并行)语句也会立即执行。还要注意,仅当在
PARALLEL_DEGREE_POLICY 设置为 AUTO 或 ADAPTIVE(该强制初始设置是为了调用 Auto DOP 的全部功能)下
运行时才需要考虑 PARALLEL_SERVERS_TARGET 这个更低的限制。
图 23:一个显示 PX 服务器进程数量限制的示例配置
使用语句排队管理并发并行处理
SQL 语句以特定 DOP 开始执行之后,在整个执行过程中都不会更改 DOP。因此,如果以低 DOP 开始执行 — 例
如;如果没有足够的可用 PX 服务器 — 则完成 SQL 语句执行所需的时间可能超出预期。
使用语句排队时,Oracle 会将那些所需并行资源比当前可用资源要多的 SQL 语句排入队列。一旦所需资源变得可
用,会将 SQL 语句从队列中取出并允许其执行。通过对语句进行排队而不是让它们以较低的 DOP 执行甚至串行执
行,Oracle 可确保任何语句都将以请求的 DOP 执行。
图 24:语句排队工作原理

23 | ORACLE DATABASE 12C 并行执行基础
语句队列是基于语句发出时间的先进先出 (FIFO) 队列。一旦系统上的活动并行服务器进程数量等于或大于
PARALLEL_SERVERS_TARGET,便会启动语句排队3。
注意,并行语句排队的主要目的不是让语句“永远”在队列中,而是确保让语句短暂地排队等待一段时间,直到请
求的资源量变为可用。如果碰巧有些语句在队列中等待了很长一段时间,您要么必须重新审视允许的最大 DOP
(PARALLEL_DEGREE_LIMIT) 来允许更高的并发性,要么是您的系统对负载而言资源过紧。
您可以使用 [GV|V]$SQL_MONITOR 或 Oracle Enterprise Manager (EM) 中的 SQL Monitor 屏幕识别哪些 SQL 语
句进行了排队。
SELECT sql_id, sql_text
FROM [GV|V]$SQL_MONITOR
WHERE status=’QUEUED’;
还有一个等待事件可帮助您识别语句是否进行了排队。等待事件 resmgr:pq queued 指示会话在队列中处于等
待状态。
使 用 提 示 NO_STATEMENT_QUEUING 的 语 句 , 以 及 通 过 用 户 将 Database Resource Manager 指 令
PARALLEL_STATEMENT_CRITICAL 设置为 BYPASS_QUEUE 而执行的语句,都可以绕过语句排队,立即执行。
仅当参数 PARALLEL_DEGREE_POLICY 设置为 AUTO 或 ADAPTIVE 时,语句排队才会处于活动状态。
使用 Database Resource Manager 管理并发并行处理
利用 Database Resource Manager (DBRM),您可以设定 Oracle 数据库内工作的优先级、限制特定用户组对资源
的访问。如果您正在并发环境中使用并行执行,强烈建议使用 DBRM。使用 DBRM,您可以控制单个语句或整个用
户组可以使用的 DOP 限制和 PX 服务器数量;能够跨所有用户组设定并行语句的优先级,这样,高优先级请求就可
以得到更多的 PX 资源;还能对不同用户使用不同的队列,这样,高优先级请求就不会排在低优先级请求的后面
(使用 Oracle Database Resource Manager 11.2.0.2 及以上版本,不是所有用户共用一个队列,而是可以对不同
的用户组使用单独的队列)。
如何结合使用 DBRM 与并行执行的深入讨论超出了本文的范围。有关 DBRM 与并行执行结合使用的更详细信息和
操作示例,请参见白皮书“运营数据仓库的并行执行和负载管理”。
控制并行执行的初始化参数
可以使用一些初始化参数来控制或管理数据库中的并行执行行为。但是,您真正需要关心的只是控制 Oracle 数据库
并行执行的几个最基本的参数:
PARALLEL_DEGREE_POLICY:控制是否启用内存中 PX、Auto DOP 和语句排队。出于向后兼容的目的,默认
值为 MANUAL,它禁用了以上三个特性。
3 使用 Oracle Database Resource Manager 时,每个用户组有自己的并行语句队列和 parallel_servers_target 总量百分比。

24 | ORACLE DATABASE 12C 并行执行基础
当设置为 LIMITED 时,仅启用 AUTO DOP。内存中 PX 和语句排队均处于禁用状态。Auto DOP 仅应用于这样的
语句:这些语句访问以 PARALLEL 子句修饰但未指定显式 DOP 作为表属性的表或索引;指定了特定 DOP 的表和
索引将使用此指定的 DOP。
当设置为 AUTO 或 ADAPTIVE 时,Auto DOP、语句排队和内存中 PX 均处于启用状态。Auto DOP 将应用于所有
SQL 语句,而无论这些语句所访问的对象是否显式地以 PARALLEL 子句修饰。
建议将该参数设置为 AUTO。
PARALLEL_SERVERS_TARGET:该参数指定使用语句排队之前允许运行的并行服务器进程的数量,仅当参数
PARALLEL_DEGREE_POLICY 设置为 AUTO 或 ADAPTIVE 时它才有效,届时,如果不能提供所需数量的 PX 服务
器进程,则 Oracle 将对需要并行执行的 SQL 语句进行排队。一旦系统上的活动 PX 服务器进程数量等于或大于
PARALLEL_SERVERS_TARGET,便会启动语句排队。该参数的默认值为 PARALLEL_MAX_SERVERS 的 40%,确
保为其他操作,如绕过语句排队的并行语句,预留一些资源以备不时之需。
建议在考虑到为并行处理分配的可用系统资源的情况下,将此参数设置为由 Auto DOP 管理的并行操作需要的值。
PARALLEL_DEGREE_LIMIT:使用自动并行度时,Oracle 将自动决定某语句是否应并行执行以及该语句应使用的
并行度。优化器会根据语句的资源需求自动确定它的并行度。但是,优化器将对使用的并行度进行限制,以确保并
行服务器进程不会导致系统过载。这个限制通过 PARALLEL_DEGREE_LIMIT 参数来实施。默认情况下,此参数设
置为 CPU,这将最大 DOP 限制为系统的默认 DOP。建议将该参数保留为默认值,并且使用 Database Resource
Manager 对最大 DOP 进行细粒度控制。
25 | ORACLE DATABASE 12C 并行执行基础
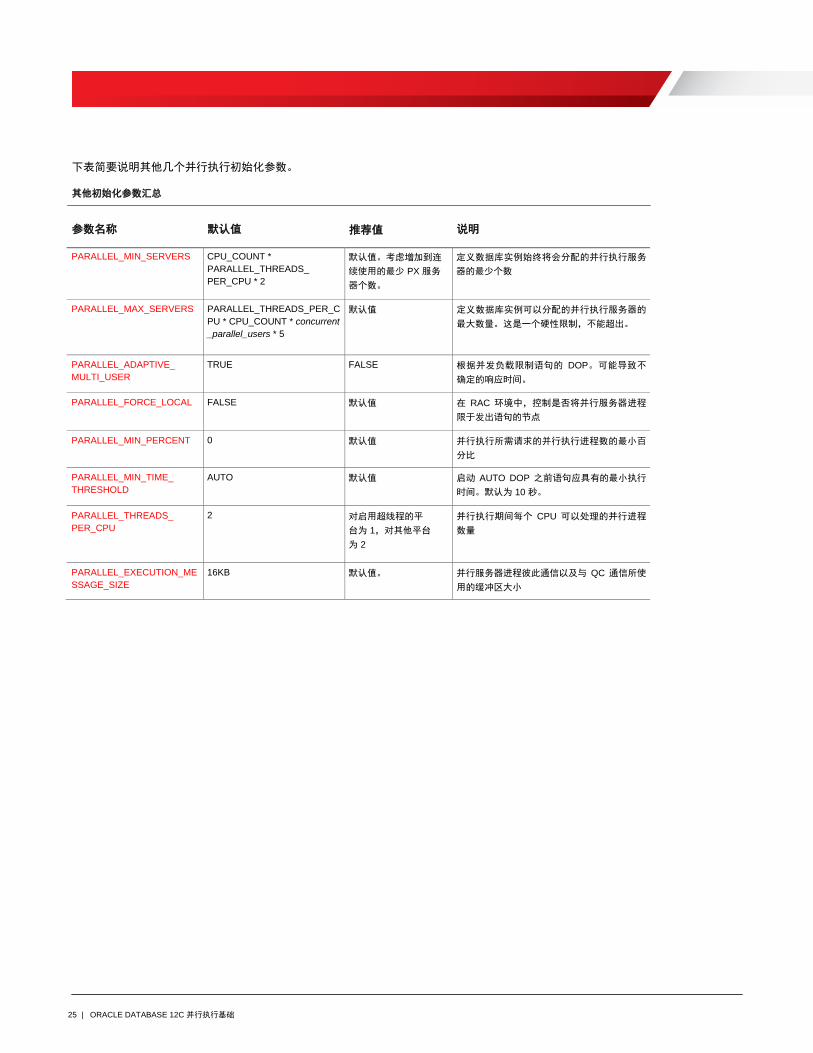
下表简要说明其他几个并行执行初始化参数。
其他初始化参数汇总
参数名称 默认值 推荐值
说明
PARALLEL_MIN_SERVERS CPU_COUNT *
PARALLEL_THREADS_
PER_CPU * 2
默认值。考虑增加到连
续使用的最少 PX 服务
器个数。
定义数据库实例始终将会分配的并行执行服务
器的最少个数
PARALLEL_MAX_SERVERS PARALLEL_THREADS_PER_C
PU * CPU_COUNT * concurrent
_parallel_users * 5
默认值 定义数据库实例可以分配的并行执行服务器的
最大数量。这是一个硬性限制,不能超出。
PARALLEL_ADAPTIVE_
MULTI_USER TRUE FALSE 根据并发负载限制语句的 DOP。可能导致不
确定的响应时间。
PARALLEL_FORCE_LOCAL FALSE 默认值 在 RAC 环境中,控制是否将并行服务器进程
限于发出语句的节点
PARALLEL_MIN_PERCENT 0 默认值 并行执行所需请求的并行执行进程数的最小百
分比
PARALLEL_MIN_TIME_
THRESHOLD AUTO 默认值 启动 AUTO DOP 之前语句应具有的最小执行
时间。默认为 10 秒。
PARALLEL_THREADS_
PER_CPU 2 对启用超线程的平
台为 1,对其他平台
为 2
并行执行期间每个 CPU 可以处理的并行进程
数量
PARALLEL_EXECUTION_ME
SSAGE_SIZE 16KB 默认值。 并行服务器进程彼此通信以及与 QC 通信所使
用的缓冲区大小

26 | ORACLE DATABASE 12C 并行执行基础
总结
并行执行通过使用多个系统资源显著缩短了数据库操作的响应时间。对于可扩展的并行执行,资源可用性是最重要
的先决条件。
本文详细揭示了 Oracle 数据库中并行执行的工作方式,并就如何成功地启用和使用并行执行给出了建议。
Oracle 数据库提供了强大的 SQL 并行执行引擎,它可以并行执行任何基于 SQL 的操作 — DDL、DML 和查询。
Oracle 的 Auto DOP 与 Database Resource Manager 相结合,提供了全面的负载管理框架,能够满足任何类型数
据库应用程序的全球最复杂的混合负载需求。

甲骨文(中国)软件系统有限公司
北京远洋光华中心办公室
地址:北京市朝阳区景华南街5号远洋光华中心C座21层
邮编:100020
电话:(86.10) 6535-6688
传真:(86.10) 6515-1015
北京汉威办公室
地址:北京市朝阳区光华路7号汉威大厦10层1003-1005单元
邮编:100004
电话:(86.10) 6535-6688
传真:(86.10) 6561-3235
北京甲骨文大厦
地址:北京市海淀区中关村软件园24号楼甲骨文大厦
邮编:100193
电话:(86.10) 6106-6000
传真:(86.10) 6106-5000
北京国际软件大厦办公室
地址:北京市海淀区中关村软件园9号楼国际软件大厦二区308单元
邮编:100193
电话:(86.10) 8279-8400
传真:(86.10) 8279-8686
北京孵化器办公室
地址:北京市海淀区中关村软件园孵化器2号楼A座一层
邮编:100193
电话:(86.10) 8278-6000
传真:(86.10) 8282-6401
上海名人商业大厦办公室
地址:上海市黄浦区天津路155号名人商业大厦12层
邮编:200001
电话:(86.21) 2302-3000
传真:(86.21) 6340-6055
上海腾飞浦汇大厦办公室
地址:上海市黄浦区福州路318号腾飞浦汇大厦508-509室
邮编:200001
电话:(86.21) 2302-3000
传真:(86.21) 6391-2366
上海创智天地10号楼办公室
地址:上海市杨浦区凇沪路290号创智天地10号楼512-516单元
邮编:200433
电话:(86.21) 6095-2500
传真:(86.21) 6107-5108
上海创智天地11号楼办公室
地址:上海市杨浦区淞沪路303号创智天地科教广场3期11号楼7楼
邮编:200433
电话:(86.21) 6072-6200
传真:(86.21) 6082-1960
上海新思大厦办公室
地址:上海市漕河泾开发区宜山路926号新思大厦11层
邮编:200233
电话:(86.21) 6057-9100
传真:(86.21) 6083-5350
广州国际金融广场办公室
地址:广州市天河区珠江新城华夏路8号合景国际金融广场18楼
邮编:510623
电话:(86.20) 8513-2000
传真:(86.20) 8513-2380
成都中海国际中心办公室
地址:成都市高新区交子大道177号中海国际中心7楼B座02-06单元
邮编:610041
电话:(86.28) 8530-8600
传真:(86.28) 8530-8699
深圳飞亚达科技大厦办公室
地址:深圳市南山区高新南一道飞亚达科技大厦16层
邮编:518057
电话:(86.755) 8396-5000
传真:(86.591) 8601-3837
深圳德赛科技大厦办公室
地址:深圳市南山区高新南一道德赛科技大厦8层0801-0803单元
邮编:518057
电话:(86.755) 8660-7100
传真:(86.755) 2167-1299
大连办公室
地址:大连软件园东路23号大连软件园15号楼502
邮编:116023
电话:(86.411) 8465-6000
传真:(86.755) 8465-6499
苏州办公室
地址:苏州工业园区星湖街328号苏州国际科技园5期11幢1001室
邮编:215123
电话:(86.512) 8666-5000
传真:(86.512) 8187-7838
沈阳办公室
地址:沈阳市和平区青年大街390号皇朝万鑫国际大厦A座39层3901&3911室
邮编:110003
电话:(86.24) 8393-8700
传真:(86.24) 2353-0585
济南办公室
地址:济南市泺源大街150号中信广场11层1113单元
邮编:250011
电话:(86.531) 6861-1900
传真:(86.531) 8518-1133
南京办公室
地址:南京市玄武区洪武北路55号置地广场19层1911室
邮编:210018
电话:(86.25) 8579-7500
传真:(86.25) 8476-5226
西安办公室
地址:西安市高新区科技二路72号西安软件园零壹广场主楼1401室
邮编:710075
电话:(86.29) 8834-3400
传真:(86.25) 8833-9829

重庆办公室
地址:重庆市渝中区邹容路68号大都会商厦1611室
邮编:400010
电话:(86.23) 6037-5600
传真:(86.23) 6370-8700
杭州办公室
地址:杭州市西湖区杭大路15号嘉华国际商务中心810&811室
邮编:310007
电话:(86.571) 8168-3600
传真:(86.571) 8717-5299
福州办公室
地址:福州市五四路158号环球广场1601室
邮编:350003
电话:(86.591) 8621-5050
传真:(86.591) 8801-0330
南昌办公室
地址:江西省南昌市西湖区沿江中大道258号
皇冠商务广场10楼1009室
邮编:330025
电话:(86.791) 8612-1000
传真:(86.791) 8657-7693
呼和浩特办公室
地址:内蒙古自治区呼和浩特市新城区迎宾北路7号
大唐金座19层北侧1902-1904室
邮编:010051
电话:(86.471) 3941-600
传真:(86.471) 5100-535
郑州办公室
地址:河南省郑州市中原区中原中路220号
裕达国际贸易中心A座2015室
邮编:450007
电话:(86.371) 6755-9500
传真:(86.371) 6797-2085
武汉办公室
地址:武汉市江岸区中山大道1628号
武汉天地企业中心5号大厦23层2301单元
邮编:430010
电话:(86.27) 8221-2168
传真:(86.27) 8221-2168
长沙办公室
地址:长沙市芙蓉区韶山北路159号通程国际大酒店1311-1313室
邮编:410011
电话:(86.731) 8977-4100
传真:(86.731) 8425-9601
石家庄办公室
地址:石家庄市中山东路303号石家庄世贸广场酒店14层1402室
邮编:050011
电话:(86.311) 6670-8080
传真:(86.311) 8667-0618
昆明办公室
地址:昆明市三市街六号柏联广场写字楼11层1103A室
邮编:650021
电话:(86.871) 6402-4600
传真:(86.871) 6361-4946
合肥办公室
地址:安徽省合肥市蜀山区政务新区怀宁路1639号平安大厦18层1801室
邮编:230022
电话:(86.551) 6595-8200
传真:(86.551) 6371-3182
广西办公室
地址:广西省南宁市青秀区民族大道136-2号华润大厦B座2302室
邮编:530028
电话:(86.771) 391-8400
传真:(86.771) 577-5500

Oracle Database 12c 并行执行基础
2014 年 12 月
公司网址:http://www.oracle.com(英文)
中文网址:http://www.oracle.com/cn(简体中文)
销售中心:800-810-0161
售后服务热线:800-810-0366
培训服务热线:800-810-9931
欢迎访问:
http://www.oracle.com(英文)
http://www.oracle.com/cn(简体中文)
版权© 2014 归 Oracle 公司所有。未经允许,不得以任何
形式和手段复制和使用。
本文的宗旨只是提供相关信息,其内容如有变动,恕不另
行通知。Oracle 公司对本文内容的准确性不提供任何保证,
也不做任何口头或法律形式的其他保证或条件,包括关于
适销性或符合特定用途的所有默示保证和条件。本公司特
别声明对本文档不承担任何义务,而且本文档也不能构成
任何直接或间接的合同责任。未经 Oracle 公司事先书面许
可,严禁将此文档为了任何目的,以任何形式或手段(无论
是电子的还是机械的)进行复制或传播。
Oracle 是 Oracle 公司和/或其分公司的注册商标。其他名
字均可能是各相应公司的商标。