oracle maximum availability architectureホワイト・ペーパー · oracle fusion middleware soa...
TRANSCRIPT

Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス Oracle Maximum Availability Architectureホワイト・ペーパー Oracleホワイト・ペーパー | 2017年12月

1 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
目次 Oracle Fusion Middleware SOA のマルチ・データセンター・アクティブ-アクティブ・
デプロイメントを設計するためのパラダイム.....................................................................................5
可用性:RTO および RPO ...............................................................................................................5
パフォーマンス ................................................................................................................................6
管理....................................................................................................................................................7
サイト間の待機時間、ジッター、パケット損失、および帯域幅 .............................................7
要件 ......................................................................................................................................................... 15
トポロジ ......................................................................................................................................... 15
ネットワーク ................................................................................................................................. 15
トランザクション・ログと永続ストアに対する共有ストレージとデータベースの比較 .. 15
ロードバランサ ............................................................................................................................. 16
Oracle Fusion Middleware SOA コンポーネントおよび対象範囲のバージョン ................. 16
ハードウェア・リソースおよび容量の使用率 ......................................................................... 16
Oracle Fusion Middleware SOA アクティブ-アクティブ・マルチ・データセンター・
デプロイメントのトポロジ・モデル ................................................................................................. 17
データベース層 ............................................................................................................................. 18
ロードバランサおよび Web サーバー ....................................................................................... 18
アプリケーション・レイヤー ..................................................................................................... 19
設計の特性 .............................................................................................................. 21
その他のリソース ......................................................................................................................... 24
Oracle Fusion Middleware SOA アクティブ-アクティブ・トポロジの構成 ................................ 25
Oracle Fusion Middleware SOA マルチ・データセンター・アクティブ-アクティブ・
デプロイメントのためのロードバランサおよびグローバル・ロードバランサの構成 ...... 25
ローカル・ロードバランサの構成 .......................................................................... 26
グローバル・ロードバランサの構成 ....................................................................... 26
Oracle Fusion Middleware SOA マルチ・データセンター・アクティブ-アクティブ・
デプロイメントのための Oracle HTTP Server の構成 ............................................................. 28

2 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
ストレッチ・クラスタのための Oracle Fusion Middleware SOA AA DR システムの
アプリケーション層の構成 ......................................................................................................... 28
Oracle Fusion Middleware SOA マルチ・データセンター・アクティブ-アクティブ・
デプロイメントのためのデータソースの構成 ......................................................................... 40
コンポジットおよび MDS のデプロイメントと更新:Oracle Coherence の構成 ............................ 42
インメモリ soa ...................................................................................................................................... 47
同期および非同期操作のための適切なタイムアウトの設定 .......................................................... 47
セッション・レプリケーションの影響 ............................................................................................. 52
Oracle Net Services のパフォーマンスの最適化 .............................................................................. 52
データベース・サーバー内の I/O バッファ・サイズの構成 .................................................. 53
Oracle Fusion Middleware ノード上の I/O バッファ・サイズの構成 .................................. 54
セッション・データ・ユニットの構成 ..................................................................................... 55
各層での障害とスイッチオーバー/フェイルオーバーの動作 ........................................................ 57
あるサイト内のすべての Oracle HTTP Server インスタンスの障害 ..................................... 57
あるサイト内のすべての Oracle WebLogic Server SOA サーバーの障害 ............................ 57
管理サーバーの障害 ..................................................................................................................... 57
データベース障害:Data Guard のスイッチオーバーとフェイルオーバー ........................ 59
Oracle Fusion Middleware SOA マルチ・データセンター・アクティブ-アクティブ・
デプロイメントのパフォーマンスとスケーラビリティへの影響 .................................................. 60
容量の使用および計画 ................................................................................................................. 60
起動待機時間 ................................................................................................................................. 61
トランザクションの平均アクティブ時間とトランザクション・リカバリ .......................... 66
まとめ ..................................................................................................................................................... 67
付録 A:ファイル・アダプタのロックおよび Muxer...................................................................... 68
付録 B:JMS JDBC 永続ストアに対するインプレース再起動の構成 ............................................ 69
付録 D:Oracle Service Bus(OSB)の考慮事項 ............................................................................. 73
ロードバランサの考慮事項 ......................................................................................................... 73
アプリケーション層の考慮事項 ................................................................................................. 73

3 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
OSB シングルトン・サービス ................................................................................. 73
データソースの構成 ................................................................................................ 74
ストレッチ・クラスタにおける OSB のパフォーマンス ........................................................ 75
参考 ......................................................................................................................................................... 80

4 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
はじめに
ビジネス継続性は、多くの E-Business 運用のための重要な要件です。ミッション・クリティカ
ルなアプリケーションの停止時間は、生産性やサービス品質の低下、さらには収益の減少に直
接つながります。ミッション・クリティカルなアプリケーション・サービスには、ローカルの
高可用性ソリューションとディザスタ・リカバリ・ソリューションの両方が必要です。ローカ
ルの高可用性ソリューションは、1 つのデータセンターでの冗長性を提供します。さらに、ア
プリケーションには、データセンター全体に影響を与える可能性のある予期せぬ障害、自然災
害、および停止時間からの保護が必要です。アプリケーション・サービスを無効にする障害と
は、必ずしもデータセンター全体を破壊する災害(洪水や火災など)ではなく、むしろ 1 つの
特定の種類のリソースを無効にするものである可能性の方が高くなります。たとえば、企業の
ゲートウェイまたは ISP ネットワーク接続の障害、すべての HTTP リスナー・ノードへのウイル
スの拡散、構成の誤り、停電、または正しくないパッチのすべてが、何日間にもわたる完全な
サービス損失につながる可能性があります。同じことが計画停止にも当てはまります。ネット
ワーク・インフラストラクチャの更新やファイアウォールのアップグレードなどが、データセ
ンター内の停止時間に同様の影響を与える場合があります。サービス指向アーキテクチャ
(SOA)では、複数の企業システムが固有のサービス・プロバイダに依存している可能性があ
ります。これらのアーキテクチャの採用が拡大するにつれ、障害や停止時間からの保護の必要
性もまた、単一マシンの範囲だけでなく、マシンのグループ、部屋全体、またはビル全体を停
止させる可能性のあるイベントにまで拡大します。従来の障害保護システムは、可能性のある
フェイルオーバー・シナリオを防止するために、1 つのサイトが実行中で別のサイトはスタン
バイ状態にあるモデルを使用します(マルチ・データセンター・アクティブ-パッシブまたはア
クティブ-パッシブ障害保護とも呼ばれます)。このようなアプローチでは通常、運用コストと
管理コストが増加します。その一方で、リソースの継続的な使用やスループットの向上(つま
り、スタンバイ・マシンがアイドル状態である状況を回避すること)の必要性は、ここ数年に
わたって拡大しています。IT システムの設計は、ますます容量の使用率や、場合によっては負
荷の分散によって主導されるようになっています。これが、使用可能なすべてのリソースを
(できる限り)使用する障害保護ソリューションの採用につながります(マルチ・データセン
ター・アクティブ-アクティブまたはアクティブ-アクティブ障害保護と呼ばれます)。
このホワイト・ペーパーでは、Oracle Fusion Middleware 12c SOA システムを複数の場所におい
て停止時間から保護するために使用できる、推奨されるアクティブ-アクティブ・ソリューショ
ンについて説明します(SOA アクティブ-アクティブ・ディザスタ・リカバリ・ソリューション
または SOA マルチ・データセンター・アクティブ-アクティブ・デプロイメントと呼ばれます)。
推奨されるトポロジを設定するための必要な構成手順、およびこのような構成のパフォーマン
スやフェイルオーバーへの影響に関するガイダンスを提供します。

5 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
Oracle Fusion Middleware SOAのマルチ・データセンター・アクティブ-
アクティブ・デプロイメントを設計するためのパラダイム
マルチ・データセンター・デプロイメントの設計を主導できる要因には、複数のものがあります。通常は、以下が考慮されます。
可用性:RTOおよびRPO ディザスタ・リカバリ設計では、リカバリ・ポイント目標(RPO)とリカバリ時間目標(RTO)のメトリックを最小限に抑える必要があります。RPO が、障害が発生した場合に失われる可能性のあるデータ量を測定するのに対して、RTO は、障害が発生した場合にシステムが使用不可になる時間を測定します。
ほとんどのマルチ・データセンター・アクティブ-アクティブ・デプロイメントまたはアクティブ-アクティブ・ディザスタ・リカバリ・システムでは、実際のところ、データベース層は通常 1 つのサイトでのみアクティブになります。Oracle Real Application Clusters on Extended Distance Clusters、クロスサイト・キャッシング(Oracle GoldenGate)、データベース・レプリケーション(Streams)など、このアプローチの代替策は存在しますが、これらのソリューションは、必要なインフラストラクチャの点で非常に要求が厳しいか、またはすべてのアプリケーションが準拠するとは限らない特定のデータ型やルールを必要とするかのどちらかです。
従来のマルチ・データセンター・アクティブ-パッシブ・ディザスタ・リカバリ設計と比較した場合のマルチ・データセンター・アクティブ-アクティブ・デプロイメント・システムのおもな利点は、あるサイトで完全な中間層の障害が発生した場合(すべての中間層サーバーが 1 箇所に存在)、引き続き使用可能なピア・サイトに中間層が存在するため、システムがリクエストを実行できる点にあります。つまり、マルチ・データセンター・アクティブ-アクティブ・デプロイメントの RTO およびRPO は、このタイプのシナリオではゼロです。このためには、代替の場所にある中間層サーバーは、すべての場所の合計した負荷を維持できる必要があります。このようなシナリオに対応するには、適切な容量計画を実行する必要があります。設計によっては、1 つのサイトだけがアクティブなときは、エンド・クライアントからのリクエストの抑制が必要になる場合があります。それ以外の場合は、過剰な能力でサイトを設計することによって、一定かつ効率的に容量を使用する目標を部分的に無視する必要があります。
データベース層で障害が発生した場合は、データベースはリカバリの原動力であるため、マルチ・データセンター・アクティブ-アクティブ・デプロイメントとマルチ・データセンター・アクティブ-パッシブの両方が同様の RTO および RPO を示し、どちらの場合もあるサイトでのみアクティブで、別のサイトではパッシブになります。マルチ・データセンター・アクティブ-アクティブ・デプロイメント・システムの唯一の利点は、適切なデータソース構成によって中間層からのデータベース接続のフェイルオーバーを自動化し、それによって RTO を削減できる点にあります(中間層の再起動は必要ないため、リカバリ時間が減少します)1。
1 さまざまな側面に応じて、Oracle WebLogic Server の再起動が必要になることがあります。データベース・リースを使用している場合は、データベース
が(スイッチオーバーまたはフェイルオーバー中に)使用不可のままになっていると、Oracle WebLogic Server がシャットダウンすることがあります。

6 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
パフォーマンス 単一データセンター設計に適用される一般的なパフォーマンス・パラダイムに加えて、Oracle Fusion Middleware SOA マルチ・データセンター・アクティブ-アクティブ・システムでは、システムのスループットへの待機時間の影響を軽減するために、サイト間のトラフィックを最小限に抑える必要があります。標準的な Oracle Fusion Middleware SOA システムでは、データベース・アクセス(デハイドレーションやメタデータ・アクセスの他、システムに参加するカスタム・サービスが実行する可能性のあるその他のデータベースの読取り/書込み操作)の他に、各層間の通信が、おもに次のプロトコル経由で実行される場合があります。
» ロードバランサ(LBR)または Oracle HTTP Server(OHS)や HTTP コールバックからの受信HTTP 呼出し
» Oracle WebLogic Server 間の JNDI/RMI および JMS 呼出し
» ファイル/FTP アダプタのファイル・システムへの読取り/書込みリクエスト
パフォーマンスを向上させるには、上のすべてを(できる限り)1 つの単一サイトに制限する必要があります。つまり、SiteN 内のサーバーは、理想的には SiteN 内の Oracle HTTP Server からの呼出しだけを受信する必要があります。SiteN 内のサーバーへの JMS、RMI、および JNDI 呼出しのみを行い、SiteX 内のサーバーによって生成されたコールバックのみを取得する必要があります。また、サーバーは競合を解消するために、そのサイトに対してローカルなストレージ・デバイスを使用する必要があります(サイト間の NFS 書込みの待機時間によって、パフォーマンスが大幅に低下する可能性があります)。
さらに、以下に示すようなその他の種類の呼出しが、トポロジに参加する各種の SOA サーバーの間で実行される可能性があります。
» Oracle Coherence 通知:すべての SOA リクエストに一貫性のあるコンポジットおよびメタデータ・イメージを提供するために、Oracle Coherence 通知は、どちらのサイトで処理されるかにかかわらずシステム内のすべてのサーバーに到達する必要があります。
» HTTP セッション・レプリケーション:一部の Oracle Fusion Middleware SOA コンポーネントは、サーバー間でのセッションの透過的なフェイルオーバーを有効にするために、セッション・レプリケーションに依存する可能性のあるステートフル Web アプリケーション(Composer や Workspace など)を使用します。使用パターンやユーザー数によっては、これによって膨大な量のレプリケーション・データが生成される可能性があります。ビジネス・ケースごとにレプリケーションやフェイルオーバーの要件を分析する必要がありますが、サイト間のセッション・レプリケーション・トラフィックをできる限り削減することが理想的です。
» LDAP/ポリシー/ID ストアへのアクセス:ポリシーおよび ID ストアへのアクセスは、認可や認証の目的で、Oracle WebLogic Server インフラストラクチャおよび SOA コンポーネントによって実行されます。どちらのサイトからもユーザーにシームレスにアクセスできるようにするには、共通のポリシーまたは ID ストア・ビューを使用する必要があります。理想的には、あるサイトから別のサイトへの呼出しを最小限に抑えるために、定期的に同期される独立した ID およびポリシー・ストアを各サイトに備える必要があります。あるいは、両方のサイトで同じストアを共有できます。ストアを共有することの影響は、ストアの種類や SOA システムの使用パターンによって異なります。

7 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
管理 Oracle Fusion Middleware SOA マルチ・データセンター・デプロイメントの設計およびデプロイメントの別の重要な側面は、このソリューションによって導入される管理オーバーヘッドです。リクエストへの一貫性のある応答を維持するために、関連するサイトでは、これらのリクエストがどのサイトによって処理されるかには関係なく、システムの機能的な動作が同じであるような構成を使用する必要があります。Oracle Fusion Middleware SOA は、その構成およびメタデータを Oracle データベース内に保持します。固有のアクティブ・データベースを備えたマルチ・データセンター・アクティブ-アクティブ・デプロイメントによって、コンポジットおよびメタデータ・レベルでの一貫性のある動作が保証されるのはこのためです(関連するアーティファクトにとって唯一の信頼できる情報源が存在します)。ただし、Oracle WebLogic Server 構成は、Oracle WebLogic Server インフラストラクチャによって同じドメイン内の複数のノードにわたって同期された状態に保持されます。この構成のほとんどは通常、管理サーバーのドメイン・ディレクトリに存在します。この構成は、Oracle WebLogic Server を含む、同じドメイン内の他のノードに自動的に伝播されます。そのため、マルチ・データセンター・アクティブ-アクティブ・デプロイメント・システムの管理オーバーヘッドは、構成変更の定常的なレプリケーションが必要な、どのアクティブ-パッシブ・アプローチに比べても非常に小さくなります。
サイト間の待機時間、ジッター、パケット損失、および帯域幅 Oracle Fusion Middleware SOA マルチ・データセンター・アクティブ-アクティブ・デプロイメント・システムの全体的なネットワーク・スループットはおもに、異なるサイト間でリクエストが(おもにデータベース・アクセスのために)保持する必要のあるルートの長さ、および TCP の信頼性と混雑制御プロトコルの間の相互作用という 2 つの要因によって主導されます。Oracle Fusion Middleware SOA が実行されているプロセッサの速度やソフトウェアの効率性には関係なく、このシステムは、限りある時間を使用してデータを操作し、それをあるサイトから別のサイトに"提供"します。ネットワーク転送システム内の時間間隔の 2 つの重要な測定値として、待機時間とジッターと呼ばれるものがあります。ネットワーク待機時間は、パケットをネットワーク経由でエンド・ツー・エンドに転送するためにかかる時間であり、複数の変数(サイト間のスイッチの種類や数、ケーブルの種類など)で構成されます。ネットワーク内の待機時間は、一方向(パケットを送信するソースから、それを受信する宛先までの時間)、またはラウンドトリップ(ソースから宛先までの一方向の待機時間と、宛先から元のソースまでの一方向の待機時間)のどちらかで測定されます。ラウンドトリップ時間(RTT)の待機時間は、(両方向のトラフィックを反映した)遅延のより実際的な数値を示し、ほとんどのシステムで ping ユーティリティを使用して測定できるため、より頻繁に使用されます。ジッターは、同じデータ・フローからのパケットの到着率における差異を指す用語です。待機時間とジッターはどちらも、サイトにまたがって通信を行うアプリケーションに悪影響を与えます。これらは、Oracle Fusion Middleware SOA マルチ・データセンター・アクティブ-アクティブ・デプロイメントの適切な動作にとって重要です。ただし、ジッターがより高い関連性を持つのは通常、待機時間がきわめて短いシステムの場合です。そのため、待機時間は実質的に、マルチ・データセンター・アクティブ-アクティブ・デプロイメントで制御する必要がある主要な側面になります。待機時間のおもな原因は次のとおりです。
» 伝播/距離遅延
» シリアライズ
» データ・プロトコル
8 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
» ルーティングおよびスイッチング
» キューイングおよびバッファリング
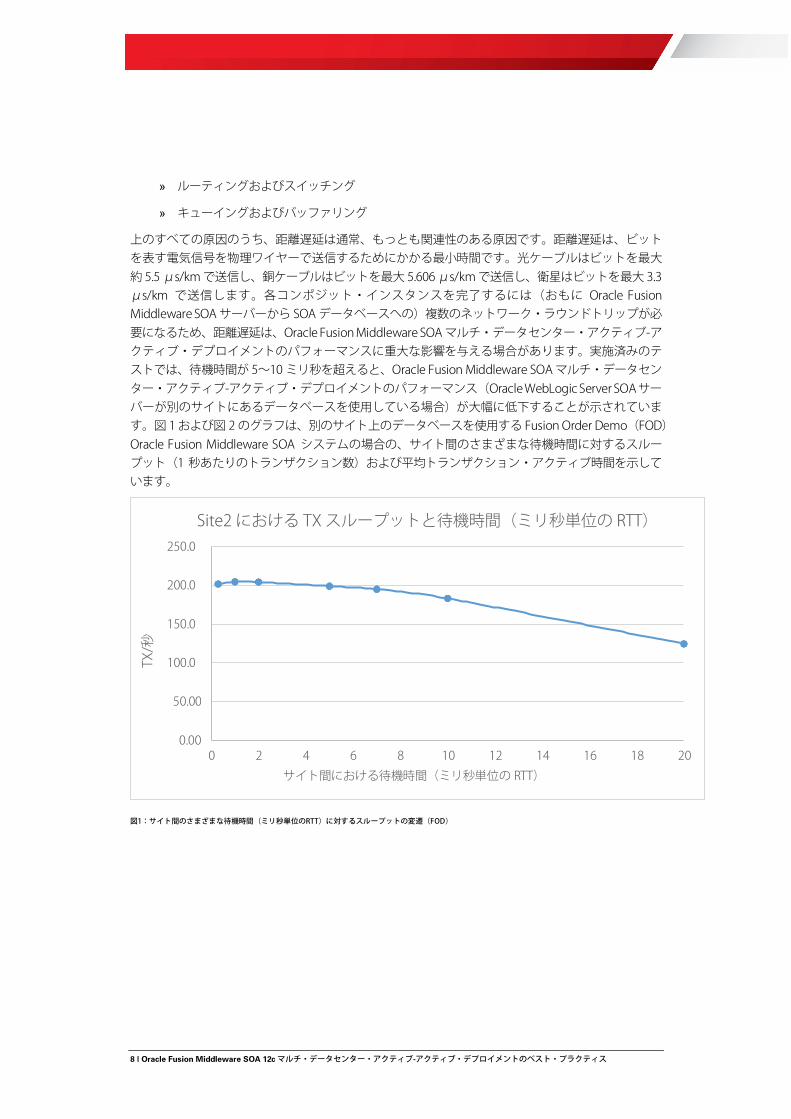
上のすべての原因のうち、距離遅延は通常、もっとも関連性のある原因です。距離遅延は、ビットを表す電気信号を物理ワイヤーで送信するためにかかる最小時間です。光ケーブルはビットを最大約 5.5 μs/km で送信し、銅ケーブルはビットを最大 5.606 μs/km で送信し、衛星はビットを最大 3.3 μs/km で送信します。各コンポジット・インスタンスを完了するには(おもに Oracle Fusion Middleware SOA サーバーから SOA データベースへの)複数のネットワーク・ラウンドトリップが必要になるため、距離遅延は、Oracle Fusion Middleware SOA マルチ・データセンター・アクティブ-アクティブ・デプロイメントのパフォーマンスに重大な影響を与える場合があります。実施済みのテストでは、待機時間が 5~10 ミリ秒を超えると、Oracle Fusion Middleware SOA マルチ・データセンター・アクティブ-アクティブ・デプロイメントのパフォーマンス(Oracle WebLogic Server SOA サーバーが別のサイトにあるデータベースを使用している場合)が大幅に低下することが示されています。図 1 および図 2 のグラフは、別のサイト上のデータベースを使用する Fusion Order Demo(FOD)Oracle Fusion Middleware SOA システムの場合の、サイト間のさまざまな待機時間に対するスループット(1 秒あたりのトランザクション数)および平均トランザクション・アクティブ時間を示しています。
図1:サイト間のさまざまな待機時間(ミリ秒単位のRTT)に対するスループットの変遷(FOD)
Site2 における TX スループットと待機時間(ミリ秒単位の RTT) 250.0
200.0
150.00
100.0
50.00
0.00 0 2 4 6 8 10 12 14 16 18 20
サイト間における待機時間(ミリ秒単位の RTT)
TX/秒

9 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
図2:SOAサーバーとデータベースの間の待機時間(ミリ秒単位のRTT)が増加した場合の、トランザクションが引き続きアクティブになる時間の変遷
図 3 は、さまざまな待機時間に対して、全体的なシステムのスループット(両方のサイトが連携して動作)で観測された低下を示しています。約 20 ミリ秒の RTT の待機時間では、スループットがほぼ25%低下することに注目してください。
図3:さまざまな待機時間(ミリ秒単位のRTT)に対するスループットの低下
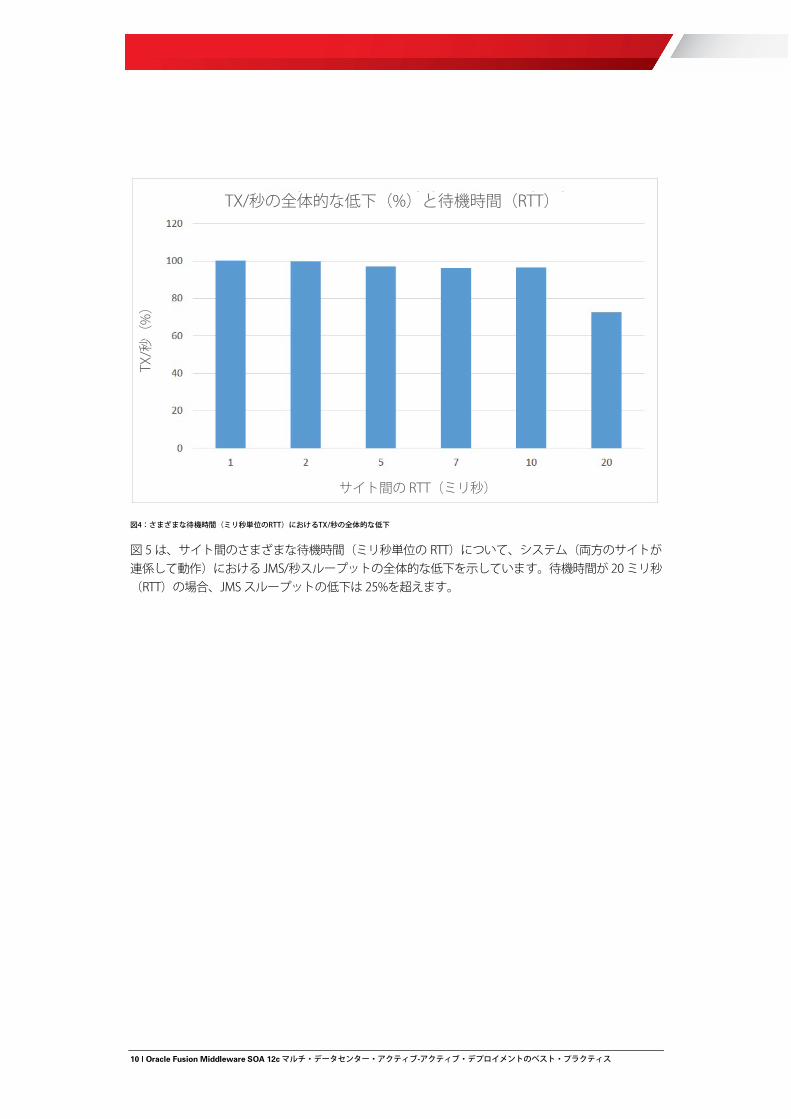
図 4 は、さまざまな待機時間について、システム(両方のサイトが連係して動作)が処理した、秒あたりの総トランザクション数の低下を示しています。待機時間が 20 ミリ秒(RTT)の場合におけるTX/秒スループットは、ほぼ 25%低下することに注目してください。
20 18 16 14 12 10 RTT(ミリ秒)
8 6 4 2 0
0.45
0.40
0.35
0.30
0.25
0.20
0.15
0.10
Site2 における平均 TX アクティブ時間と待機時間(ミリ秒単位の RTT)
スループットの低下(%)と待機時間(ミリ秒単位の RTT)
WLS
スル
ープ
ット
の低
下(
%)
RTT(ミリ秒)
平均
TXア
クテ
ィブ
時間
(秒
)
10 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
図4:さまざまな待機時間(ミリ秒単位のRTT)におけるTX/秒の全体的な低下
図 5 は、サイト間のさまざまな待機時間(ミリ秒単位の RTT)について、システム(両方のサイトが連係して動作)における JMS/秒スループットの全体的な低下を示しています。待機時間が 20 ミリ秒(RTT)の場合、JMS スループットの低下は 25%を超えます。
TX/秒の全体的な低下(%)と待機時間(RTT)
TX/秒
(%
)
サイト間の RTT(ミリ秒)

11 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
図5:サイト間のさまざまな待機時間(ミリ秒単位のRTT)におけるJMSメッセージ/秒の全体的な低下
図 6 は、サイト間のさまざまな待機時間について、両方のサイトが連係して動作した場合の Site2 のみが処理した総トランザクション数/秒の低下を、同じテストを実行中の Site1 サーバーが処理したトランザクション数/秒と比較したものです。Site2 における、待機時間が 20 ミリ秒(RTT)の場合のトランザクション・スループットが約 35%低下していることに注目してください。
JMS メッセージ/秒の全体的な低下(%)と待機時間(RTT)
JMS
メッ
セー
ジ/秒
(%
)
サイト間の RTT(ミリ秒)

12 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
図6:サイト間のさまざまな待機時間(RTT)について、同じテスト実行中のSite1が処理したTX/秒と比較した、Site2のTX/秒の低下
以下の図は、サイト間のさまざまな待機時間(ミリ秒単位の RTT)について、SOA データソースでストレス・ロードがかかっている間の、Site1 および Site2 のサーバーの総アクティブ接続数を示しています。Site2 のサーバーについて、アクティブな時間がより長いため、データソースにおけるアクティブ接続数がより多いこと、そしてサーバーとデータベース間の待機時間が長いとアクティブ接続数が増加することに注目してください。この増加は、データソース・サイズのチューニング時に、長い待機時間に対する調整の必要性よりも考慮する必要があります。さらにこの増加は、データベースでの障害発生時における Site2 のサーバーのリカバリ時間にも影響があり、再作成の必要がある接続が増加し、リカバリの必要があるトランザクション数が増加します。
Site2 における TX/秒の低下(%)とサイト間の待機時間(RTT)
サイト間の RTT(ミリ秒)
TX/秒
(%
)

13 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
図7:Site1およびSite2のサーバーのロード・テスト時における、SOAデータソースの平均アクティブ接続数
図 8 は、Site2 サーバーでコンポジットの展開に要した時間を、Site1 サーバー(同じサイトに SOAサーバーとデータベース)での展開に要した時間と比較した場合の増加を示しています。データベースとの間の待機時間が長いため、Site2 のサーバーでは展開時間が長くなっています。コンポジット(ファースト・バージョン、または新バージョンへのアップデート)をマルチ・データセンター・デプロイメントに展開する場合、コンポジットは、Site2 サーバーよりも Site1 サーバーでの方が短時間で展開できる可能性がありますが、クラスタ内のすべてのメンバーが利用可能になるまでアクティブ化されません。詳細については、「コンポジットおよび MDS のデプロイメントと更新:Oracle Coherence の構成」の項を参照してください。
図8:SOAデータベースが別のサイト上に存在する場合、待機時間(ミリ秒単位のRTT)が増加したときにコンポジットのデプロイメントに消費される追加の時
間(ミリ秒)
平均サーバーごとの SOADS アクティブ接続数と RTT
平均
SOAD
Sア
クテ
ィブ
接続
(
サー
バー
ごと
)
RTT(ミリ秒)
追加展開時間(ミリ秒)と待機時間(RTT)
RTT(ミリ秒)
追加
展開
時間

14 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
Oracle Data Guard が 2 つのサイト間で構成されている場合、データベース・パフォーマンスにおけるサイト間待機時間の影響は、使用している Data Guard の保護モードによって変わります。Oracle Data Guard は、Maximum Availability、Maximum Performance、または Maximum Protection のいずれかのモードで構成できます。Maximum Performance(デフォルト)で構成している場合、REDOデータはトランザクション・コミットメントに関し、非同期式にスタンバイ・データベースに書き込まれます。そのため、プライマリ・データベースのパフォーマンスは、REDO データを送信し、スタンバイ・データベースからの確認応答を受信するのに要する時間の影響は受けません。この保護モードは、最大可用性モードに比べてデータ保護が若干弱く、プライマリ・データベースのパフォーマンスへの影響は最小限に抑えられます。
Data Guard が Maximum Availability または Maximum Protection で構成されている場合、トランザクションのリカバリに必要なすべての REDO データをスタンバイ・データベースが受信するまで、トランザクションはコミットされません。この保護モードは、より高いレベルのデータ保護が可能ですが、パフォーマンスに与える影響もより大きくなります。
待機時間の影響が、2 つのサイト間の帯域幅には直接関係しない(つまり、メッセージやペイロードが大きくても小さくても、均一に影響を与える)ことに注意してください。たとえば、SOA サーバーが 100 行の CUBE_INSTANCE、MEDIATOR_INSTANCE、および DLV_MESSAGES 表をリクエストする SQL データベース問合せを、待機時間が 60 ms のリンクを経由して、一度に 1 行ずつ実行した場合は、各行のデータ量とは独立に、トランザクションの完了に約6秒(60 ms * 100回)かかります。同じデータベース・サーバーに接続された LAN 上のユーザーによって実行される同じ問合せは、LAN 全体の距離による待機時間が無視できるため、完了に 2~3 ms もかかりません。これは、各行のサイズには関係ありません。より大きな行はより高い帯域幅で取得できますが、トランザクション全体には同じ時間がかかります。
上のすべてを念頭におき、また多くのテストで観測されたパフォーマンス低下を考慮し、オラクルでは、待機時間がデータベース通信に影響を与える場合、SOA マルチ・データセンター・アクティブ-アクティブ・システムでは 10 ミリ秒の待機時間(RTT)を超えないようにすることを推奨しています。システムが問題なく動作する可能性はありますが、トランザクション時間は大幅に増加します。また、待機時間が 10 ミリ秒(RTT)を超えると、デプロイメントに使用される Coherence クラスタでも問題が発生したり、JTA や Web サービスがもっとも一般的なコンポジットでもタイムアウトしたりします。このホワイト・ペーパーで提示されているソリューションが、おもにサイト間の待機時間が短い Metropolitan Area Network(MAN)に適しているのはこのためです(たとえば、サンフランシスコからボストンまでの距離は約 4330 km であり、標準的な待機時間は約 30~40 ミリ秒です)。

15 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
要件
トポロジ このホワイト・ペーパーに含まれている分析および推奨事項は、「Oracle Fusion Middleware SOA アクティブ-アクティブ・マルチ・データセンター・デプロイメントのトポロジ・モデル」の項で説明されているトポロジに基づいています。各サイトでは、Oracle Fusion Middleware SOA エンタープライズ・デプロイメント・トポロジ(WSM-PM サーバー、共有ストレージ、ディレクトリ構造などの分 離 ) を ロ ー カ ル で 使 用 し ま す 。 シ ス テ ム 要 件 は 、 『 Oracle Fusion Middleware Enterprise Deployment Guide for Oracle SOA Suite』で指定されているものと同じです。
さらに、以下の要件を満たす必要があります。
ネットワーク 設計で使用される 2 つのサイト間の待機時間を、10 ミリ秒の RTT より高くする必要があります。帯域幅の要件は、各 SOA システムで使用されるペイロードの種類によって異なります。
トランザクション・ログと永続ストアに対する共有ストレージとデータベースの比較 このホワイト・ペーパーで扱うトポロジは、Oracle WebLogic Server のトランザクション・ログとOracle WebLogic Server の JMS 永続ストアに対してデータベース・ベースの永続ストアを使用してテストされました。トランザクション・ログと永続ストアをデータベース内に格納すると、基盤となるデータベース・システムに固有のレプリケーションや高可用性の利点が提供されます。Data Guard データベース内の JMS、TLOG、および SOA データにより、サイト間の同期が簡素化され、中間層での NAS や SAN などの共有ストレージ・サブシステムの必要性が軽減されます(これらは引き続き、管理サーバーのフェイルオーバーやデプロイメント・プラン、ファイル・アダプタなどの一部のアダプタに適用されます)。ただし、データベースで TLOG や JMS を使用すると、システムのパフォーマンスが低下します。この低下は、いずれかのサイトが、別のサイトにあるデータベースと相互通信する必要がある場合にさらに大きくなります。この低下はまた、AQ の宛先を使用するJMS サーバーにも適用されます。パフォーマンスの観点から見て、各サイトに対してローカルな共有ストレージを両方の種類のストアに使用し、パフォーマンス低下のないデータ損失ゼロを保証するために、ストレージ・レベルで適切なレプリケーションおよびバックアップ戦略をプロビジョニングする必要があります。共有ストレージによって提供される保護のレベルはデータベースの保証よりはるかに低いため、システムにとってデータベース・ストアの使用が共有ストレージより適しているかどうかは、JMS やトランザクション・データの重要度によって異なります。
さらに、WLS サーバーの全体的状態における永続ストアの重要度が理由で、関連するデータソースに Test Connections On Reserve(予約テスト接続)を使用し、関連する JMS サーバーと永続ストアに対してインプレース再起動を構成することをお薦めします。インプレース再起動の構成について詳しくは、付録 B を参照してください。

16 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
ロードバランサ ロードバランサが『Oracle Fusion Middleware Enterprise Deployment Guide for Oracle SOA Suite』の2.2.3 項に記載されている要件を満たしている限り、任意のベンダーのロードバランサがサポートされます。グローバル・ロードバランサは、送信元のサーバーの IP に基づいたルールを許可する必要があります(F5 Networks の例が提供されています)。
Oracle Fusion Middleware SOAコンポーネントおよび対象範囲のバージョン このドキュメントは、Oracle Fusion Middleware SOA 12.2.1 PS3(12.2.1.3)に基づいています。これ以降のリリースはすべて、同様の構成で動作します。検証済みの Oracle Fusion Middleware SOA コンポーネントは以下のとおりです。
» Oracle BPEL
» Oracle Mediator
» Oracle Rules
» Oracle EDN
» Oracle テクノロジー・アダプタのファイル、データベース、および JMS アダプタ
» Oracle Service Bus
このドキュメントは、静的(構成済み)クラスタについて、構成の詳細と結果を取り上げます。動的クラスタは、このドキュメントの範囲外です。
ハードウェア・リソースおよび容量の使用率 マルチ・データセンター・アクティブ-アクティブ・デプロイメントは通常、複数のサイトで使用可能なリソースを効率的に使用するように設計されています。ただし、2 つのサイト間のフェイルオーバー・シナリオに対応するには、適切な容量計画を実行する必要があります。サイト全体で中間層が失われた場合に備えて、別のサイトを、追加された負荷を維持するように設計する、または適切なリクエスト抑制および拒否メカニズムを(通常は GLBR で)有効にする必要があります。そうしないと、連鎖障害(フェイルオーバーによって使用可能なサイトに大きなオーバーヘッドがかかり、そのサイトが無応答になる場合)が発生することがあります。これは、通常運用中は、中間層ノードをある程度まで十分に活用されていない状態にしておく必要があることを示します。ただし、この程度は、フェイルオーバーの状況で使用可能にする必要がある容量によって異なります。

17 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
Oracle Fusion Middleware SOAアクティブ-アクティブ・マルチ・
データセンター・デプロイメントのトポロジ・モデル
図 9 は、このホワイト・ペーパーで扱う Oracle Fusion Middleware SOA マルチ・データセンター・アクティブ-アクティブ・デプロイメントの主要な部分(特定のルーティングまたは Oracle WebLogic Server ドメインの側面に関する詳細はなし)を示しています。
図9:Oracle FusionミドルウェアSOAアクティブ-アクティブ・マルチ・データセンター・デプロイメントに含まれるコンポーネント
図 9 には、2 つの個別のサイトが存在します(このドキュメントでは今後、Site1 および Site2 と呼びます)。これらは、トラフィックをどちらかのサイトに転送する 1 つの固有のアクセス・ポイントであるグローバル・ロードバランサによってアクセスされます(提供されるルーティング・アルゴリズムはベンダーごとに異なります)。各サイトには独自のローカル・アクセス・ポイント、つまりローカル・ロードバランサが存在します。ローカル・ロードバランサは、リクエストを複数のOracle HTTP Server に分散させます。最終的には、ローカル HTTP サーバーが、Oracle Fusion Middleware SOA コンポーネント(サービス・エンジン、アダプタ、およびインフラストラクチャ)をホストしている特定の Oracle WebLogic Server にリクエストを割り当てます。この 2 つの環境が、両方のサイト内のサーバーによって同時にアクセスされる 1 つの固有のデータベースを共有しています。次の各項では、各層について詳しく説明します。

18 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
データベース層 同期の要件や、さまざまな Oracle Fusion Middleware SOA Suite コンポーネントで使用されるデータ型によって、マルチ・データセンター・アクティブ-アクティブ・デプロイメント内の Oracle Fusion Middleware SOA データベースに対して考えられるアプローチが制限されます。このドキュメントでは、Oracle Fusion Middleware SOA データベースが Data Guard を使用して、Site1 内のアクティブ・データベースを Site2 内のパッシブ・データベースと同期するソリューションについてのみ説明します。その他のアクティブ-アクティブのアプローチも機能する可能性はありますが、オラクルによってテストおよび認定されておらず、それらはこのドキュメントの範囲外です。この構成では、Oracle Fusion Middleware SOA がデプロイされている両方のサイトが同じデータベース(さらには、そのデータベース内の同じスキーマ)にアクセスすること、およびそのデータベースが Data Guard 構成で設定されていることを前提としています。Data Guard は、データベースのための包括的なデータ保護ソリューションを提供します。これは、本番サイトとは地理的に異なる場所にあるスタンバイ・サイトで構成されます。スタンバイ・データベースは通常、パッシブ・モードになっており、本番サイト(データベース・アクティビティの観点から"本番"と呼ばれます)が使用できなくなった場合に起動されます 2。Oracle Database は、Oracle Real Application Clusters(Oracle RAC)内の各サイトで構成されます。Oracle RACを使用すると、Oracleデータベースは同じデータセンター内のサーバーのクラスタにわたって動作し、アプリケーションを変更する必要なく、フォルト・トレランス、パフォーマンス、およびスケーラビリティを提供できます。Oracle Fusion Middleware 層
ロードバランサおよびWebサーバー グローバル・ロードバランサ(GLBR)は、すべてのサイトおよび外部にある場所のユーザーによってアドレスとしてアクセス可能なように構成されたロードバランサです。デバイスは、接続しようとしているサイトには関係なく、任意のクライアントからアクセス可能な DNS 名にマッピングされた仮想サーバーを提供します。GLBR は、構成済みの条件やルールに基づいて、トラフィックをどちらかのサイトに転送します。これらの条件は、たとえば、クライアントの IP に基づくようにすることができます。これは、最初のリクエストおよびそれ以降のリクエストで LBR がユーザーを同じサイトにマッピングできるようにする永続化プロファイルを作成するために使用します。GLBR は、すべてのローカル・ロードバランサのアドレスで構成されたプールを保持しています。いずれかのサイトの障害が発生した場合、ユーザーは、存続しているアクティブなサイトに自動的にリダイレクトされます。
各サイトでは、ローカル・ロードバランサが GLBR からのリクエストを受信し、そのリクエストを適切な HTTP サーバーに転送します。いずれの場合も、アフィニティを維持するとともに、クライアントが適切に転送されることを保証するために、ローカル・ロードバランサは、Cookie の Active Insertなどの永続メソッドで構成されます。GLBR ではまた、望ましくないルーティングやコストのかかる再ハイドレーションを排除するために、生成元のサーバーに対してローカルな LBRにのみコールバックをルーティングする特定のルールも構成されています。また、これは、SOA サービスの内部のコンシューマにも役立ちます。これらの GLBR ルールの概要は以下のとおりです。
2 Oracle Database 12c Enterprise Edition で使用可能な Oracle Active Data Guard オプションを使用すると、REDO Apply が引き続き本番データベースから
の変更を適用している間、フィジカル・スタンバイ・データベースを開いて、レポート作成のための読取り専用アクセス、単純または複雑な問合せ、
またはソートを実行できます。SOA コンポーネントは、起動されるとすぐに、データベース内の SOA コンポジット・インスタンスに関連した情報を実
行および更新するため、Oracle Fusion Middleware SOA は Oracle Active Data Guard をサポートしていません。

19 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
» Site1 からリクエストが来た場合(Site1 内の SOA サーバーからのコールバック、または Site1 内のコンシューマからのエンドポイント呼出し)、GLBR は Site1 内の LBR にルーティングします。
» Site2 からリクエストが来た場合(Site2 内の SOA サーバーからのコールバック、または Site2 内のコンシューマからのエンドポイント呼出し)、GLBR は Site2 内の LBR にルーティングします。
» その他のいずれかのアドレスからリクエストが来た場合(クライアント呼出し)、GLBR は接続を両方の LBR にロードバランシングします。
» 特定のクライアントを特定のサイトにルーティングするために、GLBR で追加のルーティング・ルールを定義できます(たとえば、2 つのサイトの応答時間が、各ケースでのハードウェア・リソースによって異なる可能性があります)。
アプリケーション・レイヤー 各サイトは、そのサイトに対して"ローカルな"(つまり、サーバーの近くに配置されたファイル・システム内の)Oracle Fusion Middleware SOA インストールから実行されます。各ローカル・トポロジは、可用性とセキュリティを最大化するために、Oracle Fusion Middleware SOA エンタープライズ・デプロイメント・トポロジを使用します。必要な高可用性の原則に基づいて、その他のトポロジも許可されます。このホワイト・ペーパーで使用されている Oracle WebLogic Server ドメイン・モデルは、Oracle Fusion Middleware SOA Suite コンポーネントに対し 1 つの単一ドメインと 1 つの単一クラスタを使用します。このモデルは、ストレッチ・クラスタとも呼ばれます。このトポロジでは、すべてのサーバー(WSM-PM および SOA)が固有の Oracle WebLogic Server ドメインの一部になります。これらのサーバーは、2 つのサイトのいずれかに存在する 1 つの管理サーバーで管理されます。各サイトは、永続ストアのために同じデータベースを使用し、サイト間同期は Data Guard に基づいています。競合やセキュリティ上の理由から、サイトをまたがって共有ストレージを使用することは推奨されません。Site1 から Site2 へ、またその逆方向のディスクのミラー化およびレプリケーションを使用すると、各サイトでこのアーティファクトの回復可能なコピーを提供します。固有のOracle WebLogic Server 管理コンソールおよび Oracle Enterprise Manager Fusion Middleware Controlは、すべてのサーバーのための中央の管理ポイントを提供します。両方のサイト内の SOA サーバーは固有のクラスタ(SOA_Cluster)の一部であり、WSM-PM サーバーも同様です(WSM_Cluster)。コンポジット・デプロイメントに使用される Coherence クラスタと MDS 更新もまた、2 つのサイトで同じものです。SOA には 1 つの RAC データベースが使用され、すべての Oracle WebLogic Serverが同じ SOA および MDS スキーマを指します。図 10 は、このトポロジについて説明しています。

20 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
図10:マルチ・データセンター・アクティブ-アクティブ・デプロイメントのストレッチ・クラスタ・モデル

21 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
設計の特性
可用性:ストレッチ・クラスタ設計では、(Oracle HTTP Server プラグインによって提供され、標準的な 1 か所でのデプロイメントで使用される"動的"リストではなく)各サイト内のサーバーの固定されたリストに基づいた Oracle HTTP Server 構成を使用します。これは、あるサイトから別のサイトへの望ましくないルーティングを排除するために行われます。これには、Oracle WebLogic Server 内の障害に対する応答時間が遅くなるというデメリットがあります。データベース接続フェイルオーバーの動作や、JMS および RMI フェイルオーバーの動作は、標準のエンタープライズ・デプロイメント・トポロジで実行される動作に似ています。特に BPEL では、インスタンスを発信したノードには 関 係 な く 、 ど ちら の サ イ ト から で も 自 動 リカ バ リを 実 現 で き ま す 。常 に 、 1 つの 単 一CLUSTER_MASTER サーバーが存在します。つまり、自動リカバリを実行できるのは、マルチ・データセンター・アクティブ-アクティブ・デプロイメント内のすべての使用可能なサーバーの中で 1 つのサーバーだけです。パートナー・サイトで障害が発生した場合は、Site1 と Site2 から均等にインスタンスをリカバリできます。
1. Site2 が稼働しているとき、CLUSTER MASTER が Site1 に存在する場合は Site1 から
2. Site1 が稼働しているとき、CLUSTER MASTER が Site2 に存在する場合は Site2 から
3. Site2 が停止しているときは Site1 から
4. Site1 が停止しているときは Site2 から
Site1 ですべての中間層に影響を与える障害が発生した場合は、Oracle Enterprise Manager Fusion Middleware Control および Oracle WebLogic Server 管理コンソールを再開するために管理サーバーのリカバリが必要です。管理サーバーは仮想 IP でリスニングを行い、あるサイトで使用される仮想 IPが別のサイトで有効である可能性は(顧客のインフラストラクチャによっては)低くなります。Site1 で最初に使用可能だったリスニング・アドレスを Site2 で有効にしたり、その逆を行ったりするには通常、追加の介入が必要です。
管理サーバーに対してリモートのサーバーは、通常のエンタープライズ・デプロイメント・トポロジの場合に比べて再起動に長い時間がかかります。それは、(起動時にドメイン構成を取得するための)管理サーバーとの通信や、初期の接続プール作成およびデータベース・アクセスのすべてが、サイト間の待機時間によって影響を受けるためです。
RPO の観点から見ると、サイト障害によって停止されたトランザクションは、引き続き使用可能なサイトで、手動による作業を行わなくても、自動サービス移行を使用して再開できます。JMS とTLOG の永続化にデータベースが使用されていない限り、サイトにまたがる自動化された移行は推奨されません。そうでなければ、適切な永続ストアの定常的なレプリカをサイト間に設定する必要があります。
サーバー移行と比較して、このトポロジでは仮想 IP が必要なサービス移行が推奨、使用されています。そのため、Site1 で最初に使用可能だったリスニング・アドレスを Site2 で有効にしたり、その逆を行ったりするには追加の介入が必要となる可能性があります。この介入は移行前のスクリプトで自動化できますが、一般に、標準的な(1 つのデータセンターの範囲で実行される)自動化されたサーバー移行や VIP を必要としない自動サービス移行と比べて RTO は増加します。

22 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
管理:マルチ・データセンター・アクティブ-アクティブ・デプロイメントでは、Oracle WebLogic Server インフラストラクチャは、構成変更をドメインで使用される各種のドメイン・ディレクトリのすべてにコピーする役割を果たします。SOA のために構成された Coherence クラスタは、コンポジットまたはメタデータが更新されたときに、クラスタ内のすべてのサーバーの更新を担当します 3。ファイル・システムにまたがるランタイム・アーティファクト(ファイル・アダプタ、TLOG など)のレプリケーション要件を除き、マルチ・データセンター・アクティブ-アクティブ・デプロイメントは標準クラスタのように管理されます。これにより、その管理オーバーヘッドは非常に低くなっています。
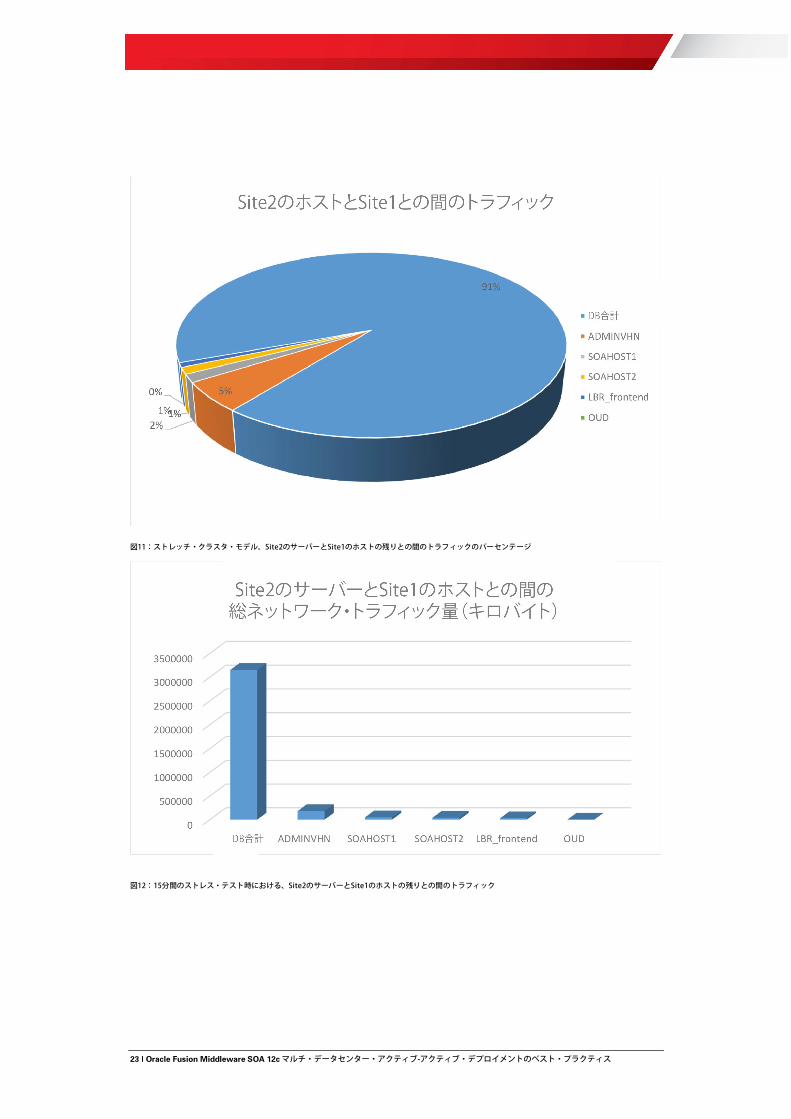
パフォーマンス:適切なロードバランシングおよびトラフィック制限が構成されている場合(以下の項を参照)、サイト間の待機時間の短いストレッチ・クラスタのパフォーマンスは、1 つの単一サイトに存在する同じ数のサーバーを含むクラスタのパフォーマンスと同程度になります。以下の項で示されている構成手順は、もっとも一般的な通常運用の場合に、各サイト内部のトラフィックを制約することを目的にしています。ただし、この分離は非確定的です(たとえば、2 つのサイトにまたがって JMS 呼出しが実行される可能性があるフェイルオーバー・シナリオの余地はあります)。それでも、ほとんどのトラフィックは Oracle Fusion Middleware SOA サーバーと SOA データベースの間で実行されます。これが、マルチ・データセンター・アクティブ-アクティブ・デプロイメントのパフォーマンスにとって重要になります。図 11 は、ストレス・テスト中の、Site2 内の SOA サーバーと Site1 内の別のアドレスの間のトラフィックの割合(%)を示しています。トラフィックの90%超がサーバーとデータベース(これも Site1 に配置されています)の間で発生していることに注意してください。
3 管理の観点から見た場合の、システム内の考えられる待機時間の影響について詳しくは、コンポジット・デプロイメントおよび MDS 更新に関連した
項を参照してください。
23 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
図11:ストレッチ・クラスタ・モデル。Site2のサーバーとSite1のホストの残りとの間のトラフィックのパーセンテージ
図12:15分間のストレス・テスト時における、Site2のサーバーとSite1のホストの残りとの間のトラフィック

24 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
その他のリソース 2 つのサイトが他の外部リソースを共有している場合と、共有していない場合があります。これらのリソースには、LDAP、ID ストア、ポリシー・ストア、外部の JMS 宛先、外部の Web サービスなどが含まれます。これらの外部リソースの構成の詳細は、このドキュメントの範囲外です。ただし、これらのリソースが両方のサイトで一致していることが必要です。非同期コールバックは、別のサイトで開始されたインスタンスを再ハイドレートする可能性があることに注意してください。これらが一貫性のある動作を示すようにするには、両方のサイトで同じ外部リソースを使用できる必要があります(これは、自動リカバリのためにも必要です。どの Oracle WebLogic Server もクラスタ・マスターになり、どちらのサイトでもリカバリを実行できます)。

25 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
Oracle Fusion Middleware SOAアクティブ-アクティブ・トポロジの構成
次の各項では、Oracle Fusion Middleware SOA マルチ・データセンター・アクティブ-アクティブ・デプロイメントを構成するための手順を示します。Oracle WebLogic Server の一般的な管理タスクの基本的な理解の他、『Oracle Fusion Middleware Enterprise Deployment Guide for Oracle SOA Suite』に含まれている手順や構成手順に精通していることが前提となります。以下の手順は、このガイドで説明されている手順に非常に似ていますが、サイト間のトラフィックを最小限に抑えるために、EDGのいくつかの項で特定の構成変更が適用されます。手順の概要は以下のとおりです。
1. 『Oracle Fusion Middleware Enterprise Deployment Guide for Oracle SOA Suite』に従ってGLBR と LBR を構成しますが、ローカル・ルーティングには適切なルールを使用します。
2. 『Oracle Fusion Middleware Enterprise Deployment Guide for Oracle SOA Suite』に従ってOracle HTTP Server を構成しますが、各サイトへのルーティングが制限されます。
3. 以下に対して、特殊な手順でアプリケーション層を構成します。
o 共有ストレージ/ディレクトリ構成
o サービス移行構成
o JMS 構成
o JMS アダプタおよびファイル・アダプタ構成
o データソース構成
o サイト間の待機時間が 10 ミリ秒の制限に近づいているかどうかに応じて、Oracle Coherence の設定、Oracle Net の設定、および JTA/タイムアウトの設定を調整します。
以下の項では、これらの各側面について詳細に説明します。
Oracle Fusion Middleware SOAマルチ・データセンター・アクティブ-アクティブ・デプロイメントのためのロードバランサおよびグローバル・ロードバランサの構成 前の項で説明したように、グローバル・ロードバランサ(GLBR)は、複数のローカル・ロードバランサの間でのリクエストのスマート・ルーティングを実行する役割を果たします。このスマート・ルーティングは通常、送信元のリクエストに基づいて実行されます。Oracle Fusion Middleware SOAマルチ・データセンター・アクティブ-アクティブ・デプロイメントでは、特定のサイト内のサーバーから再度同じサイトに来たコールバックや呼出しを制限することを推奨します。GLBR は通常、2 つのサイトのいずれかに(物理的に)配置されているため、これにより、このようなサイトへの呼出しもより効率的になります。以下の手順は、F5 製品での構成の例を示します。

26 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
ローカル・ロードバランサの構成
ローカル・ロードバランサ(LBR)は、グローバル・ロードバランサからのリクエストを受信し、そのリクエストを Oracle HTTP Server に送信します。各 LBR は、『Oracle Fusion Middleware Enterprise Deployment Guide for Oracle SOA Suite』に示されているように構成する必要があります。このドキュメントで扱うすべてのコンポーネントが Oracle Fusion Middleware SOA サービス・インフラストラクチャ・アプリケーションの可用性に依存するため、LBR を、/soa-infra/の URL4を監視してSOA サーバーの可用性を判定するように設定することを推奨します。これにより、SOA Oracle WebLogic Server は実行されているが、SOA サブシステムがまだ実際に使用可能になっていない場合の望ましくないルーティングが排除されます(これらのルーティングは、ルート・コンテキスト(/)の URL にモニターが設定されているときに発生する場合があります)。
グローバル・ロードバランサの構成
以下の手順は、F5 BIG-IP グローバル・トラフィック・マネージャ(GTM)および LBR に固有のものです。この手順は、必要な構成の例として示されています。詳しくは、F5 のナレッジ・ベースまたは GTM 固有のドキュメントを参照してください 5。
1. 適切なリスナーがすでに GTM 内に存在することを前提としています。
2. F5 管理コンソールの Global Traffic Menu で、2 つのデータセンター(マルチ・データセンター・デプロイメント構成に参加しているサイトごとに 1 つ)を作成します(データセンターによって、ネットワーク上の同じサブネットを共有するサーバーおよびリンクが定義されます)。これらのデフォルト値は適切です。
3. F5 管理コンソールの Global Traffic Menu で、サイトごとに 1 つのサーバーを作成し(LBR はサイトごとに 1 つと仮定します)、それを以下のように適切なサイトに割り当てます(サーバーによって、ネットワーク上の特定の物理システムが定義されます)。
a. Address:このサーバーには、最初のサイトのローカル LBR のアドレスを使用します。
b. Product には、「BIG-IP System」(1 つ)を選択します。
c. Health Monitor:サーバーのヘルス・モニターとして適切なものを使用します(ローカル LBR で実行しているサービスに応じて、TCP モニターまたは複数のモニターの組合せになる場合があります)。
d. 仮想サーバーとして、ローカル LBR が SOA リクエストをリスニングするアドレスを追加します。サイト間の待機時間が長い場合、この仮想サーバーには、サイトに応じて異なるモニターを使用することもできます(長い待機時間には、より許容幅の大きいプローブが必要になることがあります)。
4. F5 管理コンソールの Global Traffic Menu で、新しいプール(今後、MDCpool と呼びます)を作成します。プールは、ネットワーク上で共通の役割を共有する 1 つ以上の仮想サーバーを表します。GTM のコンテキストでは、仮想サーバーは、ネットワーク上の特定のリソースを指す IP アドレスとポート番号の組合せです。
4 URL の最後にバックスラッシュを含めてください。そうしないと、Oracle WebLogic Server がフロントエンド・アドレスにリダイレクトされるため、
モニターが失敗します。 5 冗長性や、GTM サーバーに冗長性を提供するために必要な DNS サーバー構成は、このホワイト・ペーパーの範囲外です。

27 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
ローカル LBR 内のシステムのプロトコルに応じて、サーバーに対して適切なヘルス・モニター(デバイスの出荷時構成には、HTTP または HTTPS が存在します)を使用します(通常は、HTTP になります)。メンバーとして、前の手順で作成された仮想サーバーを割り当てます。このモニターは、各サイトに使用される 2 つのモニターのうち許容幅の大きい方にする必要があります。
5. F5 管理コンソールの Global Traffic Menu で、新しいワイド IP を作成します。ワイド IP は、完全修飾ドメイン名(FQDN)を、以下のようにドメイン・コンテンツをホストする一連の仮想サーバーにマッピングします。
a. SOA マルチ・データセンター・デプロイメント・システムにアクセスするために使用される FQDN を使用します。
b. 前に作成されたプールをワイド IP に追加します。
c. プールの永続化を有効にします。
d. ロードバランシングの方法としてラウンド・ロビンを使用します。
これらの設定により、F5 GTM は、リクエストを両方のサイトまたはデータセンターにラウンド・ロビンします。コールバックや内部の Web サービス呼出しなどに必要なスマート・ルーティングを行うには、さらに 2 つのプールを定義します。
» Site1 内の LBR のみを含むプール(Site1pool)
» Site2 内の LBR のみを含むプール(Site2pool)
グローバル・トラフィックに次の iRule を追加し、それをシステムのワイド IP に割り当てます。
各データセンターまたはサイトに適用される適切な IP アドレス範囲および定義を使用します。これにより、システムは、送信元のリクエストの IP に基づいてリクエストを各ローカル LBR にリダイレクトできるようになります。詳しくは、http://support.f5.com/kb/en-us/products/big-
ip_gtm/manuals/product/gtm-concepts-11-2-0.html にある F5 GTM のドキュメントを参照してください。
when DNS_REQUEST { if { [IP::addr [IP::client_addr] equals 10.10.10.10/24 ] } { pool Site1pool
} elseif { [IP::addr [IP::client_addr] equals 20.20.20.10/24] } { pool Site2pool
} else { pool MDCPool
} }

28 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
Oracle Fusion Middleware SOAマルチ・データセンター・アクティブ-アクティブ・デプロイメントのためのOracle HTTP Serverの構成 ストレッチ・クラスタ・モデルでは、サイト間のトラフィックを削減するために、Oracle HTTP Server は動的なクラスタ通知を使用せず、代わりにサーバーの静的リストが構成されています。これには、障害検出が遅くなる(SOA サーバーのクラッシュ時、HTTP サーバーが障害を検出するのに動的リストの場合より長い時間がかかる)という注意点があり、新しいサーバーが追加された場合は構成の更新が必要になります。ただし、システムのパフォーマンスは向上します。Oracle HTTP Server 内の mod_wl_ohs.conf ファイルから抜粋した以下のコードは、soa-infra Web アプリケーションへのルーティングに必要な構成の例を示しています。
Site1:
Site2:
ストレッチ・クラスタのためのOracle Fusion Middleware SOA AA DRシステムのアプリケーション層の構成 ストレッチ・クラスタ設計は、Site2 内の 2 つの追加サーバーにスケールアウトされたエンタープライズ・デプロイメント・トポロジです。システムをよりスケーラブルにするとともに、サイト間の待機時間によって発生する場合があるパフォーマンス低下を最小限に抑えることができるいくつかの側面を考慮する必要があります。
最初のサイトは、『Oracle Fusion Middleware Enterprise Deployment Guide for Oracle SOA Suite』の説明に従ってインストールされます。Oracle WSM-PM Cluster を、SOA クラスタやその他の高可用性トポロジと同じ場所にインストールするという点から見て、ある程度の変更は許可されます。2 番目のサイト(Site2)は、『Oracle Fusion Middleware Enterprise Deployment Guide for Oracle SOA Suite』の 24 項で示されている手順を使用して構成されます。以下の側面を考慮する必要があります。
# SOA soa-infra app <Location /soa-infra>
WLSRequest ON WebLogicCluster
Site2_server1.mycompany.com:8001,Site2_server2.mycompany.com:8001 DynamicServerList OFF ..
</Location>
# SOA soa-infra app <Location /soa-infra>
WLSRequest ON WebLogicCluster
Site2_server1.mycompany.com:8001,Site2_server2.mycompany.com:8001 DynamicServerList OFF ..
</Location>

29 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
» バイナリ/インストール:2 番目のサイトは、独自の冗長なバイナリを使用します(つまり、高可用性のために、サイトごとに少なくとも 2 つのバイナリ・インストールを使用する必要があります)。
» パス:Site2内のバイナリ・インストール、aserverドメイン・ディレクトリ、デプロイメント・プラン、ファイル・アダプタの各ディレクトリは、Site1 と同じパスを使用する必要があります。
» 共有ストレージ:バイナリ・インストール、aserver ドメイン・ディレクトリ、デプロイメント・プラン、ファイル・アダプタの各ディレクトリは、『Oracle Fusion Middleware Enterprise Deployment Guide for Oracle SOA Suite』に示されている共有ストレージ上に存在しますが、各サイトは、そのサイトに対してローカルな共有ストレージを使用します。つまり、Site2 内のサーバーが Site1 上の共有ストレージにアクセスしたり、その逆を行ったりすることが必要になる設計は避けるべきです。これは、ストレッチ・クラスタではアーティファクト(ファイル・アダプタおよびデプロイメント・プラン)の"手動の"分離が実行されることを示します。このシナリオでファイル永続ストアを使用する場合、トランザクションや JMS メッセージのリカバリが除外されるため、(サービス移行がすべてのマシンを候補として使用するよう構成されている、1 つの単一サイトのコンテキストでの標準的なスケールアウト・シナリオとは異なり)サイトにまたがる自動的なサービス移行は不可能です。したがって、JDBC 永続ストアの使用が推奨されます。このシナリオでは、JMS と TLOG のデータが両方のサイトから利用可能で、これらが Data Guard を使用して Site1 から Site2 にレプリケートされていれば、サイトにまたがる自動サービス移行が可能です。
» Oracle HTTP Server 構成:Oracle HTTP Server のルーティングを構成するときは、「Oracle Fusion Middleware SOA マルチ・データセンター・アクティブ-アクティブ・デプロイメントのための Oracle HTTP Server の構成」で詳細を確認してください。
» SOA クラスタの構成:「Oracle Fusion Middleware SOA マルチ・データセンター・アクティブ-アクティブ・デプロイメントのためのロードバランサおよびグローバル・ロードバランサの構成」の項で作成された GLBR 仮想サーバーのアドレスを、システムのフロントエンドとなるコールバックURLとして(すなわち、SOAクラスタのフロントエンド・アドレスとして)指定します。
クラスタ・アドレスは、クラスタ内のすべてのサーバーを含む明示的なリストで設定する必要はありません。リストが空の場合、クラスタ・アドレスは自動的に生成されます。この場合、クラスタ・アドレスの自動生成時にリストに含めるサーバー数を制限する"Number of Servers In Cluster Address"プロパティに、クラスタ内のすべてのサーバーがリストに含まれる十分な値が設定されていることを確認してください。

30 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
» 自動サービス移行構成:オラクルは、エンタープライズ・デプロイメント・トポロジに対し、JDBC 永続ストアとともに自動サービス移行を構成することを推奨しています。このシナリオでは、JMS と TLOG のデータが両方のサイトから利用可能で、これらが Data Guard を使用してSite1 から Site2 にレプリケートされていれば、サイトにまたがる自動サービス移行が可能です。ストレッチ・クラスタの自動サービス移行について、特に考慮すべきことはありません。
ただし、Site1 から Site2 へのサービス移行に要する時間は、サイト間の待機時間が長い場合、増加する可能性があります。この増加は、障害の検出にかかる時間が原因ではなく、もう一方のサーバーのメッセージのリカバリにおいて、データベースの永続ストアからメッセージを読み取る分時間がかかることが原因です。以下の図は、Site1 のサーバーから Site2 のサーバーへのサービス移行における所要時間(永続ストア内のメッセージ数が非常に少ない場合)を示しています。待機時間が 20 ms(RTT)の場合のみ、サービス移行の所要時間が増加していることに注目してください。
図13:JMSサービスとTLOGサービスをSite1のサーバーからSite2のサーバーに移行する場合の自動サービス移行時間
永続ストアに保留中のメッセージが多く存在している場合、増加分が大きくなります。以下の図は、永続ストアのうちの 1 つに多数の保留中メッセージ(約 8,000 個)が存在している場合の、自動サービス移行時間の一例です。
自動サービス移行時間(秒)と RTT(ミリ秒)
自動
サー
ビス
移行
時間
(秒
)
サイト間の RTT(ミリ秒)

31 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
図14:自動サービス移行時間の悪化とサイト間の待機時間(永続ストアに保留中のメッセージが多い状況でのSite1サーバーからSite2サーバーへのサービス移行)
ファイルストアが使用されている場合に限り、ストレッチ・ドメイン設計のサーバーは、移行のための候補として同じサイト内のサーバーのみを使用します。以下の追加の考慮事項を使用してサービス移行を構成するには、『Oracle Fusion Middleware Enterprise Deployment Guide for Oracle SOA Suite』の手順を使用します(これは、JDBC ストアを使用する場合で、サイト間のサービス移行が可能な場合は不要です)。
• Site1 の移行可能なターゲットそれぞれについて、候補として Site1 のサーバーのみを選択します。
• Site2 の移行可能なターゲットそれぞれについて、候補として Site2 のサーバーのみを選択します。
自動サービス移行時間の増加分(%)と 保留中のメッセージ
サイト間の RTT(ミリ秒)

32 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
サイト間の待機時間に応じて、サービス移行のためにヘルス・チェックの間隔を増やすことが必要になる場合があります。デフォルト値は 10000 ミリ秒であり、ほとんどの場合はこれで十分です。ただし、ビジー状態の期間や過負荷により、各場合に応じて、より大きな値の使用が必要になることがあります。この設定がストレッチ・クラスタ内のすべてのサーバーのヘルス・チェックに影響を与え、それによって、すべてのサーバーのクラッシュを検出するためにかかる時間が長くなることに注意してください。ヘルス・チェックの間隔を増やすには、以下に示すように、クラスタのHealth Monitoring タブを使用します。
» トランザクション・ログおよび JMS の永続化構成:
• データベース JMS や TLOG ストアの場合は、2 つのサイト内のサーバーが同じデータベースおよび同じスキーマを指すことができます。これは、データベースでの TLOG および JMS ストアの使用には、Data Guard を使用してトランザクション・ログの伝播を Site2 に組み込めるという利点があるため、このトポロジの場合に推奨される手法です。サイト間での自動サービス移行は、追加の介入なしで実行される場合があります。
注:これにより、パフォーマンスが FOD の例では平均約 5~10%低下する場合があります(この影響は、アプリケーションやコンポジットのタイプによって異なります)。この影響は、サーバーが別のサイト内のデータベースにアクセスする必要がある場合にはさらに悪化します。マルチ・データセンター・アクティブ-アクティブ・デプロイメントで Oracle WebLogic Server JMS をデータベース永続性とともに使用すると、特に大容量ペイロードの場合、パフォーマンスにさらに大きな影響を与えます。メッセージの自動保存の利点と、それによって発生するパフォーマンス低下について考慮する必要があります。

33 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
• ファイル・ベースの永続ストアには、2 つの共有ストレージを使用し、(各サイト内部のサービス移行を有効にするために)それぞれを各サイトに対してローカルにします。永続ストアはサーバーの名前で修飾されるため、一貫性のために、またバックアップ手順やその他の管理操作を簡素化するために、両方のサイトで同じパスを使用できます。ただし、リカバリを容易にするには、各サイトを識別する異なるパスを使用することを推奨します(Site2 が Site1 から TLOG をリカバリしたり、その逆を行ったりする必要があるシナリオ)。たとえば、Site1 では、永続ストアに以下のパスを使用します。
ORACLE_RUNTIME/domain_name/soa_cluster_name/tlogs_Site1
Site2 では、以下のパスを使用します。
ORACLE_RUNTIME/domain_name/soa_cluster_name/tlogs_Site2
• ファイル・ベースの永続化シナリオにおいて、サーバーで障害が発生し、同じサイト内のその他のサーバーが引き続き使用可能な場合は、サービス移行によってトランザクションが再開されます。あるサイト内のすべてのサーバーが使用不可になり、別のサイトがトランザクションを再開する必要がある場合は、以下の手順に従って、使用可能なサイト内の適切なサービスを手動で移行する必要があります。
1. 適切なトランザクション・ログと永続ストアを(適切なディスク・レプリケーションまたはバックアップを使用して)新しいサイトで使用可能にします。
2. 障害が発生したサーバーのうち、移行可能なサーバーを他のサイトの別のサーバーに手動で移行します。
» レプリケートされたサービス:サイト間のトラフィックを排除するには、JNDI コンテキスト・ファクトリの解決にローカル・アフィニティを使用することを推奨します。これを行うには、Default Load Algorithm を「round-robin affinity」(デフォルトは round_robin)またはいずれかの "affinity-based" ア ル ゴ リズ ム に 設定 し ま す。 こ れは 、以 下 に 示 すよ う に 、 SOA Cluster Configuration の General タブで実行できます。

34 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
» JMS 宛先:Oracle WebLogic Server には、クライアント接続のための初期コンテキストおよびサーバー・アフィニティが用意されています。JMS コネクション・ファクトリを使用すると、さらに接続を制限したり、ストレッチ・クラスタのためのサイト・アフィニティを提供したりすることができます。コネクション・ファクトリは、クラスタ内のレプリケートされたオブジェクトです。クライアントは JNDI コンテキストを取得し、これらの JNDI コンテキストから、適切なコネクション・ファクトリへの参照を取得します。クラスタのデフォルトのロードバランシング・アルゴリズムをいずれかのアフィニティ・タイプ・プロトコル(round-robin-affinity、weight-affinity、random-affinity)に設定することによって、最初のオプションとして、ローカル・サーバーからコネクション・ファクトリのスタブが生成されます。コネクション・ファクトリのクライアント・スタブは、次に、コネクション・ファクトリのターゲットとなっているすべてのサーバーのリストを使用します。コネクション・ファクトリ・レベルのローカル・アフィニティ(デフォルトで設定済み)を使用して、コネクション・ファクトリは最初の選択として、ローカルである JMS サーバーに接続します。そのため、アフィニティは(前の項で構成された)クラスタ・レベルで、またコネクション・ファクトリでも使用することを推奨します(これがデフォルトです)。これにより、Uniformed Distributed Destination(UDD)や Uniform Distributed Topic(UDT)での望ましくないサイト間通信が削減されます。ただし、このメカニズムは確定的ではありません。JMS 宛先を集中的に使用し、かつ大容量のペイロードが存在するシステムの場合は、JMS 呼出しのためのサイト間のトラフィックを完全に回避することを推奨します。これは、各サイトで下位デプロイメント・モジュールの選択的なターゲティングを使用して実現できます。たとえば、特定の UDD(例:DemoSupplierQueueUDD)を両方のサイトで使用可能にする必要があるが、システムが大容量の JMS ペイロードを集中的に使用している場合を考えてみます。各サイトで個別の JMS モジュールを使用して、トラフィックを確定的に 1 つのサイトに制限できます。このタイプのアプローチでは、以下の手順を実行します。
注:この構成では、宛先が強制的に分離されます(つまり、各サーバーでローカルでのみ使用できます)。そのため、以降の処理が特定のメッセージ・プロパティに依存する可能性がある一部のシステムや、クライアントが宛先に対してリモートである場合には適用できない可能性があります。

35 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
1. Oracle WebLogic Server 管理コンソールを使用して「Services」>「Messaging」>「JMS Modules」を選択し、サイトごとに個別の JMS モジュールを作成します。モジュールごとに、ターゲットとしてそれぞれ各サイト内のサーバーを選択します。
2. 宛先をホストする JMS サーバーのための個別の下位デプロイメント・モジュールを作成します。
3. 必要な UDD とそれに関連するコネクション・ファクトリを作成します。UDD の場合は、両方のサイトで同じ JNDI 名を使用します。コネクション・ファクトリの場合は、ローカルの JNDI 名のみを指定します。この名前は、ローカル・サーバー・インスタンスにのみバインドされ、クラスタの残りの部分には伝播されません。そのため、コネクション・ファクトリのスタブは、接続を確立するときに、ローカルの JMS サーバーへの参照のみを保持します。

36 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
4. 前の手順で作成された下位デプロイメントをコネクション・ファクトリと UDDに割り当て、すべての変更をアクティブ化します。
これにより、各サーバーがローカルの宛先のみを使用し、サイトにまたがる JMS 呼出しが回避されることが保証されます。
» JMS アダプタ構成:JMS アダプタでは、JNDI コンテキストの検索に使用できるサーバーのリストを含む特定のコネクション・ファクトリ・プロパティを構成する必要があります。『SOA Enterprise Deployment Guide 12c』では、構成をシンプルにするため、t3 クラスタ構文(例:cluster:t3://cluster_name)の使用が推奨されています。このクラスタ構文を使用することで、クラスタ内のメンバーの詳細リストが呼出しによってフェッチされます。それにより初期サーバーへの依存が回避され、その時点においてクラスタ内で稼働状態にある各メンバーが確認されます。

37 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
JMS 宛先を集中的に使用し、ペイロードが大きいシステムの場合、上の"JMS 宛先"の項で説明した考慮事項に加えて、アダプタで使用される JNDI URL に各サイト内の"ローカル"サーバーのリストを含める(つまり、Site1 の構成には Site1 内のサーバーのみを使用し、Site2 の構成には Site2 内のサーバーのみを使用する)ことを推奨します。これにより、サイト・コンテキストのアフィニティが保証されます 6。この構成を実現するには、以下の手順を実行します。
6. アダプタが使用するインスタンスの Outbound Connection Pool プロパティを更新します(『Oracle Fusion Middleware Enterprise Deployment Guide for Oracle SOA Suite』の 13.13.1.2 項で説明されているように、java.naming.provider.url として Site1 内のサーバーのリストを指定します)。以下に例を示します。
java.naming.provider.url=t3://Site1_server1:8001,Site1_server2:8001
7. 管理コンソールで更新を保存します。
8. 生成されたデプロイメント・プランを Site2 上のミラーの場所にコピーします。たとえば、server1_Site1 から以下のように指定します。
scp /u01/oracle/config/dp/soaedg_domain/SOA_cluster/JMSPlan.xml
Site2_server1:/u01/oracle/config/dp/soaedg_domain/SOA_cluster/
9. Site2 内のデプロイメント・プランを編集し、サーバー・リストを Site2 内のサーバーのリストに置き換えます。
Site1 のデプロイメント・プランの抜粋:
6 コンシューマ・シナリオの場合、JMS アダプタは"局所性"の影響が軽減されるように、Distributed Destination 内の各メンバーに対して少なくとも 1 つ
のコンシューマを暗黙的に設定します。
<name>ConfigProperty_FactoryProperties_Value_13243793917130</name> <value>java.naming.factory.initial=weblogic.jndi.WLInitialContextFact ory;java.naming.provider.url= t3://Site1_server1:8001,Site1_server2:8001;java.naming.security.princ ipal=weblogic;java.naming.security.credentials=welcome1 </value>

38 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
Site2 のデプロイメント・プランの抜粋:
10. 変更されたデプロイメント・プランを使用して JMS アダプタのデプロイメントを更新します(両方のサイトで同じ場所ですが、実質的に別のファイルです)。この更新では、Site1 内のサーバーには Site1 内のデプロイメント・プラン・ファイルを、Site2 内のサーバーには Site2 内のデプロイメント・プラン・ファイルを使用します。
» ファイル・アダプタの考慮事項:2 つのサイトは(サイトごとに個別の共有ストレージを使用して)個別に動作してファイルを処理しますが、デフォルトでは、ファイル・ロックやファイル・ミューテックスには同じスキーマおよび表とともに同じデータソースが使用されます。このスキーマは、同じファイルが一度に 1 つのサーバーによってのみ処理されること、および 2 つのアダプタ・インスタンスが同じファイルに同時に書き込まないことを保証するために使用されます。ファイルの上書きを防止するために使用されるミューテックスには一意のシーケンスが使用されるため、アウトバウンド操作に同じデータベースを使用することは適切です。ただし、インバウンド操作の場合は、2 つのサイトが(デフォルトでは)同じデータベース内の同じスキーマを使用するため、"処理中"シナリオが発生する可能性があります。これは、どちらかのサイト内のファイル・アダプタ・インスタンスがファイル名を"ブロック済み"とマークする場合があるためです。両方のサイトで同じファイル名を使用できるため、これにより両方の場所でそのファイルの処理がブロックされますが、そのファイルはそのうちの 1 つのサイトだけで消費されます。このような状況を回避するために、以下のいくつかの代替策があります。
o サイトにまたがる入力操作のために一意のファイル名を保証する(対応する jca ファイルがストレッチ・クラスタ内で一意であるため、パスは同じであることに注意してください)。
o 正しい処理を保証するために、同じデータベース内で異なるスキーマを使用する。
o 前の代替策より優れたパフォーマンスを実現し、かつ両方のサイトの入力ディレクトリ内に同じファイルが存在する場合でもロックの競合を発生させない完全なパラレル処理を可能にするために、ミューテックスとロックには個別のデータベースを使用する。
注:サイト・レベルでの中間層の障害のために Site1 のサーバーを Site2 で起動する(またはその逆を行う)必要がある場合は、パフォーマンス向上のために、ローカルのデータベース/スキーマを指すようにデータソースを更新する必要があります。
<name>ConfigProperty_FactoryProperties_Value_13243793917130</name> <value>java.naming.factory.initial=weblogic.jndi.WLInitialContextFact ory;java.naming.provider.url= t3://Site2_server1:8001,Site2_server2:8001;java.naming.security.princ ipal=weblogic;java.naming.security.credentials=welcome1 </value>

39 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
異なるデータベースまたは SOA データベース内の個別のスキーマを使用するには、適切なスキーマ所有者および表を作成する必要があり、またファイル・アダプタには新しいデータソースを使用する必要があります。以下の手順は、アダプタを再構成するための詳細を示しています。
1. Site1 では、デフォルトのスキーマを使用します。
2. Site2 には、既存のもの(SOINFRA)とは異なるスキーマを使用します(異なるデータベースを使用している場合、実際には同じスキーマを使用できます)。その他の既存のスキーマ(サービス移行のリースに使用されるスキーマなど)を再利用するか、または新しいスキーマを作成できます。
3. 新しいスキーマを備えたデータベースに接続します。
4. 「付録 A:ファイル・アダプタのロックおよび Muxer」にある FILEADAPTER スクリプトを使用して、適切なミューテックスおよびデータベース・ロック・オブジェクトを作成します。
5. スキーマの新しい GridLink データソースを作成します。これは、"Oracle's Driver (Thin XA) for GridLink Connections Versions:Any"タイプである必要があります。
6. データソースの FAN を有効にします。JDBC URL および ONS プロパティは、既存のSOA スキーマからコピーできます。
7. データソースのターゲットとして、「SOA_Cluster」を選択します。
8. ファイル・アダプタのデプロイメント・プランのバックアップを作成します。
cp /u01/oracle/config/dp/soaedg_domain/FileAdapterPlan.xml
/u01/oracle/config/dp/soaedg_domain/FileAdapterPlan.xml.orig
9. インバウンド・データソースを新しいデータソースで使用される JNDI 名で更新します。
jdbc/Fileadapter_Site2
10. 管理コンソールで更新を保存します。
11. 生成されたデプロイメント・プランを Site2 上のミラーの場所にコピーします。以下に例を示します。

40 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
scp /u01/oracle/config/dp/soaedg_domain/FileAdapterPlan.xml
12. Site2_server:/u01/oracle/config/dp/soaedg_domain/FileAdapterPlan. xml
13. Site1 内の元のファイルに戻ります。
cp
/u01/oracle/config/dp/soaedg_domain/FileAdapterPlan.xml.orig
/u01/oracle/config/dp/soaedg_domain/FileAdapterPlan.xml
14. Oracle WebLogic Server 管理コンソールの Deployments 画面にアクセスし、変更されたデプロイメント・プランを使用してファイル・アダプタのデプロイメントを更新します。Site1 では元のデータソースを使用するのに対して、Site2 では新しいデータソースを使用します。
Oracle Fusion Middleware SOAマルチ・データセンター・アクティブ-アクティブ・デプロイメントのためのデータソースの構成 Oracle Fusion Middleware SOA Suite で使用されるデータソースは、アクティブ・データベースのフェイルオーバーまたはスイッチオーバーが発生した場合の接続のフェイルオーバーを自動化するように構成する必要があります。Oracle WebLogic Servers を再起動することなく、(スタンバイ・データベースが新しいプライマリ・データベースになる)Data Guard のデータベース・ロール移行を実行できます 7。このフェイルオーバーを自動化するには、以下のデータソースを正しく構成する必要があります。
» EDNDataSource
» EDNLocalTxDataSource
» LocalSvcTblDataSource
» mds-owsm
» mds-soa
» opss-audit-DBDS
» opss-audit-viewDS
» opss-data-source
» OraSDPMDataSource
» SOADataSource
» SOALocalTxDataSource
» WLSSchemaDataSource
7 データベース・ロールの変更が実行された場合のサーバー移行の影響について詳しくは、「データベース障害:Data Guard のスイッチオーバーと
フェイルオーバー」を参照してください。

41 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
さらに、フェイルオーバーを自動化するため、何らかのカスタム・データソース(永続ストア、データソースのリース、DB アダプタなどに使用)を構成する必要もあります。『Oracle WebLogic Server と高可用性 Oracle Database:オラクルの統合 Maximum Availability ソリューション』のホワイト・ペーパーには、SOA データベースのディザスタ・リカバリ・シナリオで透過的なフェイルオーバーを実行するようにデータソースを構成するために必要なすべての詳細が記載されています。必要なデータベース構成(サービス、Oracle Net、および Data Guard)というだけでなく、デフォルトの推奨事項でも GridLink データソースを使用するため、中間層に対する変更は通常、次の操作に制限する必要があります。
» 本番サイトとスタンバイ・サイトの両方の ONS を含めるための ONS 構成の更新
» 両方のサイトに適切なサービスを含めるための JDBC URL の更新
データベース接続プールのサイズ設定については、データベース内のプロセスの総数が、両方のサイトのプールの追加に耐える必要があることを考慮してください。以下に、データベースが Data Guard を使用している Oracle Fusion Middleware SOA マルチ・データセンター・アクティブ-アクティブ構成での SOA データソースのサンプルの JDBC URL を示します。
データソースの構成に加え、両方のサイトに適切なサービスを含めるため、OPSS Security Stores のJDBC URL を更新する必要があります。この接続文字列は、ASERVER_HOME/config/fmwconfig/フォルダにある jps-config.xml というファイルで構成します。このファイルをデータソースで使用されるJDBC URL と同じ URL で更新するには、『Oracle Fusion Middleware Disaster Recovery Guide』の 4.2.2項「Configuring Data Sources for Oracle Fusion Middleware Active-Passive Deployment」を参照してください。
jdbc:oracle:thin:@ (DESCRIPTION=
(CONNECT_TIMEOUT=15) (RETRY_COUNT=5) (RETRY_DELAY=5) (ADDRESS_LIST= (LOAD_BALANCE=on) (ADDRESS=(PROTOCOL=TCP)(HOST=scanSite1.mycompany.com)(PORT=1521)) ) (ADDRESS_LIST= (LOAD_BALANCE=on) (ADDRESS=(PROTOCOL=TCP)(HOST=scanSite2.mycompany.com)(PORT=1521)) ) (CONNECT_DATA=(SERVICE_NAME=soaedg.us.oracle.com))
)

42 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
コンポジットおよびMDSのデプロイメントと更新:Oracle Coherenceの構成
Oracle Fusion Middleware SOA Suite は、コンポジット・デプロイメントとメタデータ(MDS)更新の両方をクラスタ全体に伝播するために Oracle Coherence を使用します。オラクルでは、Oracle FMW SOA Suite EDG のコンテキストでの Coherence 通信にユニキャストを使用することを推奨しています。ユニキャストがもっとも頻繁に使用されるのは、環境内でマルチキャスト・ネットワークが望ましくないか、または使用できない場合や、環境がマルチキャストをサポートするように正しく構成されていない場合です。これは通常、MAN にまたがるシステムの場合です。Well Known Address(WKA)機能は、クラスタ・メンバーがマルチキャストの代わりにユニキャストを使用してクラスタを検出したり、クラスタに参加したりできるようにする Coherence メカニズムです。WKAが有効になっている場合は、すべてのマルチキャスト通信が Coherence クラスタに対して無効になります。Oracle Fusion Middleware 製品およびそのコンポーネントは、Well Known Address(WKA)リストをデフォルトにしています。そのため、Oracle Coherence は SOA クラスタ内の通信にユニキャストを使用します。
Coherence は、クラスタの形成や、クラスタに含まれているメンバーからのハートビートへの応答性において遅延の影響を大きく受けます。待機時間が 5~10 ミリ秒の RTT の範囲にある場合は、SOAで使用されている Coherence インフラストラクチャに関連するさまざまな操作で問題は検出されませんでした(クラスタの作成、サイトにまたがるクラスタへの新しいノードの参加、MDS 更新、およびコンポジット・デプロイメント)。
10 ミリ秒の RTT を超える長い待機時間の場合、Coherence はクラスタの形成と、メンバーを最新の状態に維持する処理の両方でエラーを報告する可能性があります。このような状況では、以下のようなメッセージがサーバーで最初に表示されることが予測されます。
<TIME> <Warning> <com.oracle.coherence> <BEA-000000> <TIME/159.625 Oracle
Coherence GE 12.2.1.3.0 <Warning> (thread=Cluster, member=n/a):This
Member(Id=0, Timestamp=TIME, Address=X.X.X.X:34483, MachineId=40262,
Location=machine:HOSTNAME,process:5863,member:WLS_SERVER, Role=CLUSTER_NAME)
has been attempting to join the cluster using WKA list [/site1_server1:9991,
/site1_server2:9991, /site2_server1:9991, /site2_server2:9991] for 51
seconds without success; this could indicate a mis-configured WKA, or it may
simply be the result of a busy cluster or active failover.>

43 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
クラスタに参加しようとする試みが複数回失敗した場合は、参加しようとしているノードが以下のようなメッセージを報告します。
<TIME> <Warning> <com.oracle.coherence> <BEA-000000> <TIME Oracle Coherence GE
12.2.1.3.0 <Warning> (thread=Cluster, member=n/a):Received a discovery
message that indicates the presence of an existing cluster:
Message "NewMemberAnnounceReply"
{
FromMember=Member(Id=1, Timestamp=TIME, Address=x.x.x.x:38785,
MachineId=40260, Location=machine:HOSTNAME,process:269986,member:WLS_SERVER,
Role=CLUSTER_NAME)
FromMessageId=0
MessagePartCount=0
PendingCount=0
Delivered MessageType=8
ToPollId=0
Poll=null
Packets
{
}
Service=ClusterService{Name=Cluster, State=(SERVICE_STARTED, STATE_JOINING),
Id=0}
ToMemberSet=null
NotifyDelivery=false
ToMember=Member(Id=0, Timestamp=TIME, Address=10.133.41.137:34483,
MachineId=40262,
Location=machine:HOSTNAME,process:5863,member:THIS_WLS_SERVER,
Role=CLUSTER_NAME)
PrevSentTimestamp=TIMESTAMP
PrevRecvTimestamp=TIMESTAMP
ThisSentTimestamp=TIMESTAMP
ThisRecvTimestamp= TIMESTAMP
MaxDeliveryVariance=501
}>

44 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
最終的に、エラーが引き続き発生する場合は、参加しようとしている新しいメンバーが障害を報告し、Coherence サービスが停止された後、しばらくしてから以下の内容が報告されます。
<TIME> <Error> <com.oracle.coherence> <HOSTNAME> <WLS_SERVER>
<Logger@2008407832 12.2.1.3.0> <<anonymous>> <> <ID> <1506347752198>
<[severity-value:8] [rid:0] [partition-id:0] [partition-name:DOMAIN] >
<BEA-000000> <TIME Oracle Coherence GE 12.2.1.3.0 <Error> (thread=Cluster,
member=n/a):Failure to join a cluster for 300 seconds; stopping cluster service.>
<TIME> <Trace> <com.oracle.coherence> <HOSTNAME> <WLS_SERVER>
<Logger@9219882 12.2.1.3.0> <<anonymous>> <> <ID> <1506509839389>
<[severity-value:256] [rid:0] [partition-id:0] [partition-name:DOMAIN] >
<BEA-000000> <[com.tangosol.coherence.component.util.logOutput.Jdk:log] TIME
Oracle Coherence GE 12.2.1.3.0 <D5> (thread=Cluster, member=n/a):Service Cluster
left the cluster>
<TIME> <Error> <CoherenceIntegration> <HOSTNAME> <WLS_SERVER> <[ACTIVE]
ExecuteThread:'7' for queue: 'weblogic.kernel.Default (self-tuning)'> <<WLS
Kernel>> <> <ID> <1506509839390> <[severity-value:8] [rid:0] [partition- id:0]
[partition-name:DOMAIN] > <BEA-2194507> <The Coherence cluster service failed to
start or failed to join cluster due to
com.tangosol.net.RequestTimeoutException:Timeout during service
start:ServiceInfo(Id=1, Name=TransportService,
..
at
com.tangosol.coherence.component.util.daemon.queueProcessor.service.Grid.onS
tartupTimeout(Grid.CDB:3)
at
com.tangosol.coherence.component.util.daemon.queueProcessor.Service.start(Se
rvice.CDB:28)
at
com.tangosol.coherence.component.util.daemon.queueProcessor.service.Grid.sta
rt(Grid.CDB:6)
at
com.tangosol.coherence.component.net.Cluster.startSystemServices(Cluster.CDB
:11)
at
com.tangosol.coherence.component.net.Cluster.onStart(Cluster.CDB:53)
at
com.tangosol.coherence.component.net.Cluster.start(Cluster.CDB:12)
このような状況では、ネットワークのタイムアウトに関する coherence パラメータの調整をお勧めします。
» multicast-listener/join-timeout-milliseconds 参加タイムアウトは、もとはマルチキャスト構成のために設計されたものですが、ユニキャストの場合にも影響します。参加タイムアウトは、初期ノードがクラスタを形成し始めるまでの時間、およびその時間の経過後、各ノードが自らクラスタを形成(そのノードが WKA リストに含まれている場合)する前に、形成されたクラスタを探索する時間を決定します。ネットワークの信頼性が低い場合、新たにクラスタを形成する前に、パケットの損失が理由で、より長い時間クラスタの探索が必要となる可能性があります。

45 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
» packet-publisher/packet-delivery/timeout-milliseconds このタイムアウトは大きめの値にします。デフォルト値の 5 分で十分ですが、クラスタ参加時のタイムアウトを回避するため、この値を増やすことができます。
» packet-publisher/packet-delivery/resend-milliseconds パケット再送信間隔は、バケットを再送信する前に、パケット・パブリッシャが応答 ACK パケットを待機する最小限の時間を単位ミリ秒で指定します。この値は、RTT の倍数にします。10 倍が最適です。
» tcp-ring-listener/ip-timeout and ip-attempts クラスタ・メンバーをホストしているコンピュータが到達不可能になったと判断する前に試行する時間と回数です。Ip-timeout は、少なくとも 5 秒に設定し、RTT のおおむね 10 倍以上の値にしてください。
Coherence オーバーライド・ファイルを使用すると、デフォルト値を変更できます。以下に示すように custom-coherence-override-.xml ファイルを作成し、クラスタ内のすべてのサーバーについて、このファイルを一貫性のあるものとし、利用可能にします。
<?xml version='1.0'?> <!-- This is a custom operational configuration override --> <coherence xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://xmlns.oracle.com/coherence/coherence- operational-config" xsi:schemaLocation="http://xmlns.oracle.com/coherence/coherence- operational-config coherence-operational-config.xsd"
> <cluster-config>
<multicast-listener> <join-timeout-milliseconds>5000</join-timeout-milliseconds>
</multicast-listener> <tcp-ring-listener>
<ip-timeout>20s</ip-timeout> <ip-attempts>3</ip-attempts>
</tcp-ring-listener> <packet-publisher>
<packet-delivery> <timeout-milliseconds>650000</timeout-milliseconds> <resend-milliseconds>200</resend-milliseconds>
</packet-delivery> </packet-publisher> </cluster-config>
</coherence>

46 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
このファイルは、java プロパティの tangosol.coherence.override で指定します。以下の例に示すように setUserOverrides.sh ファイルの EXTRA_JAVA_PROPERTIES java プロパティで設定できます。
必要に応じて、tcp-ring のサービス終了の検出をチューニングしたり、無効にしたりすることができます。チューニングするために、サービス終了検出ハートビートの間隔を大きくすることができます。間隔を大きくすると、ネットワーク・トラフィックへの影響が少なくなりますが、障害が発生したメンバーの検出時間も長くなります。ハートビートのデフォルト値は 1 秒です。サービス終了検出ハートビートの間隔を変更するには、運用中のオーバーライド・ファイルを編集し、ハートビートの値を含む<heartbeat-milliseconds>要素を追加します。以下に例を示します。
サービス終了の検出を無効にすると、ネットワーク・トラフィックが軽減される場合がありますが、障害が発生したメンバーの検出時間も長くなります。無効になっている場合、クラスタ・メンバーはパケット・パブリッシャの再送信タイムアウト間隔を使用して、別のメンバーが UDP パケットへの応答を停止したことを特定します。デフォルトでは、このタイムアウト間隔は 5 分に設定されています。パケット再送信タイムアウトの変更については、Coherence のドキュメントを参照してください。サービス終了の検出を無効にするには、tangosol-coherence-override.xml ファイルを編集し、false に設定された enabled 要素を追加します。以下に例を示します。
EXTRA_JAVA_PROPERTIES="${EXTRA_JAVA_PROPERTIES} - Dtangosol.coherence.override=/u01/oracle/config/coherence_custom/custom -coherence-override-.xml"
<?xml version='1.0'?> <coherence xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://xmlns.oracle.com/coherence/coherence-operational-config"
xsi:schemaLocation="http://xmlns.oracle.com/coherence/ coherence-operational-config coherence-operational-config.xsd"> <cluster-config>
<packet-publisher> <packet-delivery>
<heartbeat-milliseconds>5000</heartbeat-milliseconds> </packet-delivery>
</packet-publisher> </cluster-config>
</coherence>

47 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
コンポジット・デプロイメント(最初のバージョン、または新しいバージョンへの更新)は、クラスタのすべてのメンバーで使用可能になるまで、SOA サーバーでアクティブ化されません(サーバーが実行状態で、soa-infra アプリケーションはアクティブ状態である必要があります)。このコンポジット・バージョンは soa-infra アプリケーションによって、SOA サーバーの出力ファイルでロード済みとしてリストされますが、このバージョンを他のサーバーへのデプロイ中に呼び出すと SOA障害が生成されます(つまり、すべてのサーバーがデプロイメントを完了するまで、アクティブ化が除外されます)。マルチ・データセンター・デプロイメントでは、MDS スキーマへのリモート・アクセスにより、データベースに対する待機時間が長いサーバーでのコンポジットのアクティブ化で長い遅延が発生する可能性があるため、このことが特に影響します。計画停止時間やアクティブ化ウィンドウは、これらの"もっとも遅い"メンバーに基づいて計画する必要があります。
インメモリsoa
インメモリ soa は、WebLogic Server に関連付けられた Coherence キャッシュを利用し、非トランザクション・ビジネス・プロセスをメモリで実行する機能です。この機能により、読取りと書込みの操作がキャッシュ外で実行されるため、非トランザクション・ビジネス・プロセスのパフォーマンスとスケーラビリティが向上します。プロセスの状態は、障害発生時のみ、またはライト・ビハインド・スレッドを使用して、遅延ありで定期的に書き込まれます。BPEL 状態情報は、Coherenceキャッシュとの間でデハイドレートおよび再ハイドレートが行われます。
ストレッチ・クラスタでは遅延の影響を非常に受けやすい Coherence キャッシュの使用を最小限にしなければならず、インメモリ soa のストレッチ・クラスタでの使用はサポートされていません。
同期および非同期操作のための適切なタイムアウトの設定
タイムアウトは、実行中の Oracle Fusion Middleware SOA システム内の Oracle Fusion Middleware スタックのさまざまなレイヤーで発生する可能性があります。データベース内のトランザクション、トランザクション・ブランチ、EJB メソッド呼出し、Web サービスなどに対してタイムアウト期間が指定されています。Oracle Fusion Middleware SOA マルチ・データセンター・アクティブ-アクティブ・デプロイメントは、一部のサーバーによって実行される複数の操作で別の場所にあるデータベースにアクセスする必要があるため、特にタイムアウト設定の影響を大きく受けます。このよう
<?xml version='1.0'?> <coherence xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://xmlns.mycompany.com/coherence/coherence-operational- config"
xsi:schemaLocation="http://xmlns.mycompany.com/coherence/ coherence-operational-config coherence-operational-config.xsd"> <cluster-config> <tcp-ring-listener>
<enabled>false</enabled> </tcp-ring-listener>
</cluster-config> </coherence>

48 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
な種類のシステムでは、関連する待機時間のために、タイムアウトを長くすることが必要になる場合があります。ストレッチ・クラスタ・モデルでは、両方のサイトでドメイン設定が共有されます。そのため、最悪のケースに対応したタイムアウトを使用する必要があります。さらに、該当する層全体が正しく動作するように、タイムアウトが SOA システムのさまざまなレイヤーで構成されることが必要です(たとえば、データベース・タイムアウトがグローバル WLS のタイムアウトより低い値に設定されている場合は、他のブランチ上の動作が完了する前にトランザクション ID がデータベースから"削除される"可能性があります)。要約すると、タイムアウトは以下のように構成する必要があります。
» システム内の待機時間に対応している
» さまざまなレイヤーにわたる呼出しのチェーン内で正しく期限切れになる
さまざまなレイヤーでリクエストを期限切れにするために構成できる各種のパラメータが存在します。そのうちのおもなものを以下に示します。
» アプリケーション・サーバー呼出しのタイムアウト(グローバル・トランザクション・タイムアウトとも呼ばれます)。これは、アクティブなトランザクションに対する Oracle WebLogic Server のグローバル・トランザクション・タイムアウト(秒単位)です。Oracle WebLogic Server 管理コンソールを使用して構成されます。Oracle WebLogic 管理コンソールで、左側のナビゲーション・ツリーの「Domain」を選択してから、「Services」>「JTA」>「Timeout Seconds」を選択します。
» XA データソースのタイムアウト:これは、データソースのトランザクション・ブランチ・タイムアウトを設定するために Oracle WebLogic Server で使用されます(XA リソースに対するデフォルトのタイムアウト値を超える、長時間実行されるトランザクションがある場合にも設定できます)。XA データソースごとに、Transaction タブで構成されます。

49 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
» データベース内の分散ロッキングのタイムアウト(distributed_lock_timeout):これは、分散トランザクションがロックされたリソースを待つ時間(秒単位)を指定します。以下に示すように、適切な ALTER 文または Oracle Enterprise Manager Database Control を使用して変更できます。
Oracle Fusion Middleware SOA マルチ・データセンター・アクティブ-アクティブ・デプロイメントでは、データベースに対する分散ロッキングのタイムアウトを、実行時間がもっとも長いデータベース・トランザクション操作に対応する(サイト間の待機時間によって導入される遅延に対応する)ように設定する必要があります。この値を設定した後、以下に示すように、XA データソースおよびグローバル・トランザクション・タイムアウトをそれより低い値に構成します。
distributed_lock_timeout >= XA DS タイムアウト >= グローバル・トランザクション・タイムアウト
50 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
さらに、BPEL 同期プロセスでは、タイムアウトを制御できるその他のパラメータが存在します。
» 同期クライアントが応答を待つ時間(syncMaxWaitTime)。このプロパティは、タイムアウトするまでにリクエストおよびレスポンス操作に費やす最大時間を定義します。指定された時間内に BPEL プロセス・サービス・コンポーネントが応答を受信しなかった場合、アクティビティは失敗します。Oracle Enterprise Manager Fusion Middleware Control を使用してこれを変更するには、「soa-infra」を右クリックしてから、「SOA Administration」>「BPEL Properties」>「More BPEL Configuration Properties」>「syncMaxWaitTime」を選択します。
» EJB のタイムアウト(特に BPEL に適用可能):BPEL EJB メソッドが関連する場合、これはトランザクション・タイムアウト期間(秒単位)を指定します(デフォルトは、すべての BPEL EJB に対して 300)。「Deployment」を選択してから soa_infra アプリケーションを展開し、特定の BPEL EJB をクリックすることにより、Oracle WebLogic Server 管理コンソールを使用して変更できます。

51 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
Oracle Fusion Middleware SOA マルチ・データセンター・アクティブ-アクティブ・デプロイメントで、プロセスが完了する前にトランザクションが削除される(通常、"スレッドがトランザクションに関連付けられていない"として報告される)例外や SOA 障害を回避するには、以下のように設定することを推奨します。
syncMaxWaitTime < BPEL EJB のトランザクション・タイムアウト < グローバル・トランザクション・タイムアウト
また、システムが公開しているすべての Web サービス・クライアントに、最悪の待機時間に対して十分な許容幅を持つタイムアウトを構成する必要があります(つまり、呼出しが Site1 経由では 3 秒かかるが、Site2 を経由すると 10 秒になる場合は、後者が呼出しの一般的な制限になります)。
最後に、BPEL システムが特定のリクエスト・リプライ(同期)および入力のみ受信(非同期)タイムアウトを使用している場合、それらの値は、マルチ・データセンター・デプロイメント・トポロジのコンテキストでの SOA 呼出しに対する最悪のケースに基づいて定義する必要があります。これは、この呼出しが、SOA データベースへのアクセスにおいてもっとも待機時間の長いサイトにルーティングされるケースになります。これらの設定は BPEL プロセス定義の一部であり、固有の MDS/コンポジット・リポジトリが存在するため、サイトごとにカスタマイズすることはできません。BPEL プロセスでのイベントおよびタイムアウトの使用について詳しくは、『Oracle Fusion Middleware Developer's Guide for Oracle SOA Suite』を参照してください。

52 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
セッション・レプリケーションの影響
HTTP セッション・オブジェクトを集中的に使用するいくつかのアプリケーションが存在します(特に、SOA のコンポーザー、Oracle Business Process Management BPM Composer、Oracle BPM Workspace、Oracle B2B コンソールなどの管理コンソール)。Oracle Fusion Middleware SOA マルチ・データセンター・アクティブ-アクティブ・デプロイメントの利点の 1 つに、これらのコンソールにアクセスしているユーザーをあるサイトから別のサイトにシームレスにフェイルオーバーする機能があります。ただし、データセンターにまたがるセッション・レプリケーションによって、システム内で重大なパフォーマンス低下が発生する可能性があります。オラクルでは、2 つのサイトにまたがってレプリケーションが発生する可能性を最小限に抑えるために、2 つの異なるレプリケーション・グループ(サイトごとに 1 つ)を定義することを推奨しています。セッション・レプリケーション・グループを構成するには、Oracle WebLogic 管理コンソールを使用して、以下に示すように「Environment」>「Servers」>「Server Name」>「Cluster SubTab」にアクセスします。
Site1 内の各サーバーに対して、同じレプリケーション・グループ名(たとえば、Site1RG)を入力します。Site2 内のサーバーについて、そのすべてに Site1 で使用したものとは異なる共通名(たとえば、Site2RG)を使用して操作を繰り返します。
注:レプリケーション・グループの使用は、同じサイト内のサーバーにのみ状態をレプリケートするための最善の努力ですが、確定的な方法ではありません。あるサイトで 1 つの単一サーバーが使用可能で、別のサイトで他のサーバーが使用可能な場合、レプリケーションは MAN 全体にわたって発生し、サーバーが同じサイトでオンラインに戻った場合でもそのセッションに対して続行されます。
Oracle Net Servicesのパフォーマンスの最適化
オペレーティング・システムおよびOracle Netのチューニングは、Metropolitan Area Network(MAN)全体にわたるデータ転送において重要な役割を果たします。ただし、これらの調整の影響は、JDBCクライアントとサーバーの間の待機時間が長い場合により関連性があります。Oracle Fusion Middleware SOA マルチ・データセンター・アクティブ-アクティブ・デプロイメントでは、データベースへのアクセスにおいてもっとも待機時間の長いサーバーが、ネットワーク・バッファやOracle Net の調整の原動力になります。オペレーティング・システムのデフォルト構成の中には、現在のイーサネットの速度に対して最適化されていないものがあるため、データ転送をより効率的に

53 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
するために一部のパラメータを調整することが非常に重要になります。最適な構成を決定するうえで重要なメトリックの 1 つが帯域幅遅延積です。これは、ネットワーク帯域幅と、ネットワークを通過するデータのラウンドトリップ時間/遅延の積です。ラウンドトリップ時間(RTT)を特定するための単純な方法は、あるホストから別のホストに対して ping などのコマンドを使用し、返された応答時間を使用する方法です。理想的には、一時的な偏差を排除するために、このパラメータは数分間にわたる平均として取得する必要があります。Linux では、ping コマンドを直接使用して、この平均を取得できます。
[orcl@host1_Site1~]$ ping host1_Site2
64 bytes from host1_Site2 icmp_seq=0 ttl=61 time=7.64 ms
64 bytes from host1_Site2 icmp_seq=1 ttl=61 time=8.43 ms
64 bytes from host1_Site2 icmp_seq=2 ttl=61 time=7.62 ms
64 bytes from host1_Site2 icmp_seq=3 ttl=61 time=7.76 ms
64 bytes from host1_Site2: icmp_seq=4 ttl=61 time=6.71 ms
--- host1_Site2 ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 4014ms
rtt min/avg/max/mdev = 6.715/7.634/8.430/0.552 ms, pipe 2
TCP ソケット・バッファの設定によって、ネットワーク経由で一度に送信されるパケット数が制御されます。一部のオペレーティング・システムでは、使用可能な帯域幅の使用率を向上させるにはデフォルト設定を増やす必要があります。ネットワーク待機時間が長い場合、ネットワーク帯域幅を十分に活用するにはソケット・バッファ・サイズが大きい方が適しています。最適なソケット・バッファ・サイズは、帯域幅遅延積(BDP)のサイズの 2 倍であり(RTT が 2*遅延であるため、これは通常 RTT*BW になります)、データベース・サーバーと Oracle Fusion Middleware ノードの両方に対して設定する必要があります。2xBDP より大きなバッファはほとんどの場合に(RTT の偏差を大きくする可能性がある長い待機時間では全体的に)有効ですが、消費されるメモリも増えます。リソース使用率を監視する必要があり、メモリが使用可能な場合は、バッファを大きくするとデータ転送の動作が改善されます。ソケット・バッファのサイズは、Oracle Fusion Middleware ノードとデータベース・サーバーの両方で調整する必要があります。
データベース・サーバー内のI/Oバッファ・サイズの構成 データベース・サーバーはおもにクライアントにデータを書き込むため、通常は、サーバー側でSEND_BUF_SIZE パラメータを設定するだけで十分です。データベース・サーバーが大きなリクエストを受信している場合は、RECV_BUF_SIZE パラメータも設定します。telnet や ssh などの通常の TCPセッションが追加メモリを使用しないように、これらのパラメータはデータベース内の Oracle Net のレベルで設定することを推奨します。ただし、最適化のために、これらのその他のプロトコルを同様に必要としている場合を除きます。データベース・サーバーを構成するには、listener.ora およびsqlnet.ora ファイルでバッファ領域サイズを設定します。listener.ora ファイルでは、特定のプロトコル・アドレスまたは記述のバッファ領域パラメータを指定します。以下に、標準的な Oracle RAC-scan リスナー構成の設定例を示します。

54 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
Oracle Fusion Middlewareノード上のI/Oバッファ・サイズの構成 Oracle 12c JDBC の時点では、残念ながら、シン・クライアントはソケット・バッファ・サイズを指定できないため、バッファはオペレーティング・システムで調整する必要があります。Linux の最新バージョン(バージョン 2.6.17 以降)では、4 MB の最大バッファ・サイズによる自動チューニングを 使 用 し ま す 。 自 動 チ ュ ー ニ ン グ の 有 効 化 ま た は 無 効 化 は 、/proc/sys/net/ipv4/tcp_moderate_rcvbuf パラメータによって決定されます。tcp_moderate_rcvbufパラメータが存在し、その値が 1 である場合は、自動チューニングが有効になっています。自動チューニングでは、受信側のバッファ・サイズ(および TCP ウィンドウ・サイズ)は接続ごとに動的に更新(自動チューニング)されます。送信側の自動チューニングは以前から存在し、Linux カーネルでは長年にわたって無条件に有効になっています。接続あたりのメモリ領域のデフォルトは、以下の 2 つの要素ファイルで設定されます。
/proc/sys/net/ipv4/tcp_rmem - TCP 受信バッファのために予約されたメモリ
/proc/sys/net/ipv4/tcp_wmem - TCP 送信バッファのために予約されたメモリ
これらのファイルには、最小、初期、および最大バッファ・サイズの 3 つの値が含まれています。これらの値は、自動チューニングの範囲を設定したり、メモリに負荷がかかっているときにメモリ使用率のバランスをとったりするために使用されます。最大値は、2xBDP の最大値より大きくする必要があります。自動チューニングでは、過剰に大きな初期バッファはメモリを浪費するだけでなく、パフォーマンス低下の原因にもなります。さらに、アプリケーションがリクエストできる最大バッファ・サイズも、以下の/proc 変数で制限できます。
/proc/sys/net/core/rmem_max - 最大受信ウィンドウ
/proc/sys/net/core/wmem_max - 最大送信ウィンドウ
LISTENER_SCAN3 = (DESCRIPTION = (ADDRESS = (PROTOCOL =
IPC)(SEND_BUF_SIZE=10485760)(RECV_BUF_SIZE=10485760)(KEY = LISTENER_SCAN3)) ) LISTENER_SCAN2 = (DESCRIPTION = (ADDRESS = (PROTOCOL =
IPC)(SEND_BUF_SIZE=10485760)(RECV_BUF_SIZE=10485760)(KEY = LISTENER_SCAN2)) )
LISTENER_SCAN1 = (DESCRIPTION = (ADDRESS = (PROTOCOL =
IPC)(SEND_BUF_SIZE=10485760)(RECV_BUF_SIZE=10485760)(KEY = LISTENER_SCAN1)) )

55 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
以下に、Linux での TCP の最適化に関する推奨事項のサンプルを示します。
» カーネル(2.4.27、2.6.7)では TCP 自動チューニングを使用します。
/proc/sys/net/ipv4/tcp_moderate_rcvbuf (1=on)
» TCP 最大メモリをチューニングします。
/proc/sys/net/ipv4/tcp_rmem and tcp_wmem
– 4096 87380 174760
最大値(この例での最後の値=174760)を 2xBDP より大きな値に設定します。
» ソケット・ウィンドウ・サイズをチューニングします。
/proc/sys/net/core/rmem_max and wmem_max
これを 2xBDP より大きな値に設定します。
» TCP パフォーマンス機能が有効になっている(以下のすべてが 1 に設定されている)ことを確認します。
/proc/sys/net/ipv4/tcp_sack
/proc/sys/net/ipv4/tcp_window_scaling
/proc/sys/net/ipv4/tcp_timestamps
セッション・データ・ユニットの構成 Oracle Net は、特定のサイズを持つパッケージでデータを送信します。Oracle Net は、ネットワーク経由で送信する前に、これらのユニットが"いっぱいになる"のを待ちます。これらの各バッファは、セッション・データ・ユニット(SDU)と呼ばれます。SDUのサイズを Oracle Net に提供されるデータ量まで調整すると、待機時間が 5 ミリ秒の RTT より長い Oracle Fusion Middleware SOA マルチ・データセンター・アクティブ-アクティブ・デプロイメントでパフォーマンス、ネットワーク使用率、およびメモリ消費量を改善できます。SDU のサイズは、512 バイトから 2 MB の間で設定できます。クライアントおよび専用サーバーのデフォルトの SDU は 8192 バイトです。共有サーバーのデフォルトの SDU は 65535 バイトです。実際に使用される SDU のサイズは、接続時にクライアントとサーバーの間でネゴシエートされ、クライアントとサーバーの値のうちの小さい方になります。デフォルトとは異なる SDU のサイズを構成するには、共有サーバーを使用していない限り、クライアントとサーバー・コンピュータの両方で SDU を構成する必要があります。共有サーバーの場合は、共有サーバーのデフォルトが最大値であるため、クライアントの値を変更するだけで済みます。オラクルでは、SDU を利用可能な最大値(64k)に設定することを推奨しています。この値は、さまざまな待機時間を持つシステムで最良の結果を出すことが検証されています。Oracle Fusion Middlewareサーバー上で SDU を設定するには、SOA データソースで使用される各接続プール内の JDBC URL 接続文字列を更新します。以下に例を示します。

56 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
データベース・サーバー上で SDU を設定するには、リスナー構成ファイル(LISTENER.ORA)を変更するか(これにより、SDU が"接続ごとに"設定されます)、または sqlnet.ora ファイル内のプロファイル・パラメータ DEFAULT_SDU_SIZE を使用して、すべての Oracle Net 接続の SDU を設定できます。以下の例では、SDU を、Oracle RAC Database の各 SCAN リスナーで Oracle Fusion Middleware SOA マルチ・データセンター・アクティブ-アクティブ・デプロイメントに対して推奨される値に設定します。
SDU の値を大きくする利点は、データベースに大容量ペイロードが転送されるシナリオで顕著になります。いずれの場合も、断片化を回避するために、SDU のサイズはソケット・バッファと同じかそれ以下にする必要があります。
jdbc:oracle:thin:@ (DESCRIPTION=
(CONNECT_TIMEOUT=15) (RETRY_COUNT=5) (RETRY_DELAY=5) (ADDRESS_LIST= (LOAD_BALANCE=on) (ADDRESS=(PROTOCOL=TCP)(HOST=scanSite1.mycompany.com)(PORT=1521)
(SDU=65535)) ) (ADDRESS_LIST= (LOAD_BALANCE=on) (ADDRESS=(PROTOCOL=TCP)(HOST=scanSite2.mycompany.com)(PORT=1521)
(SDU=65535)) ) (CONNECT_DATA=(SERVICE_NAME=soaedg.us.oracle.com))
)
LISTENER_SCAN3 = (DESCRIPTION = (ADDRESS = (PROTOCOL = IPC) (SDU=65535)(SEND_BUF_SIZE=10485760)(RECV_BUF_SIZE=10485760)(KEY =
LISTENER_SCAN3)) )
LISTENER_SCAN2 = (DESCRIPTION = (ADDRESS = (PROTOCOL = IPC) (SDU=65535)(SEND_BUF_SIZE=10485760)(RECV_BUF_SIZE=10485760)(KEY =
LISTENER_SCAN2)) )
LISTENER_SCAN1 = (DESCRIPTION = (ADDRESS = (PROTOCOL = IPC) (SDU=65535)(SEND_BUF_SIZE=10485760)(RECV_BUF_SIZE=10485760)(KEY =
LISTENER_SCAN1)) )

57 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
各層での障害とスイッチオーバー/フェイルオーバーの動作
Oracle Fusion Middleware SOA マルチ・データセンター・アクティブ-アクティブ・トポロジは、どのコンポーネントの障害に対しても弾力性があります。各サイトは Oracle Fusion Middleware SOA EDGトポロジを使用し、各コンポーネントに対するローカルの冗長性を備えているため、コンポーネント・レベル(LBR、Oracle HTTP Server インスタンス、Oracle WebLogic Server、データベース・インスタンス)の障害によって中断が発生することはありません。サイト内の層全体で障害が発生した場合は、以下の項で説明しているように、さまざまな側面を考慮する必要があります。
あるサイト内のすべてのOracle HTTP Serverインスタンスの障害 Oracle HTTP Server インスタンスは通常、セキュリティおよび管理のために、分離されたハードウェア内に存在します。各インスタンスをホストしているハードウェア内の障害のために、あるサイト内のすべての Oracle HTTP Server インスタンスが使用不可になる可能性があります。サイトがすべてのインスタンスを失った場合でも、HTTP コールバックが発生しない限り、Oracle WebLogic Server SOA サーバーは SOA インスタンスの処理を続行できます。内部で生成されたコールバックが発生した場合は、コールバックを生成したサイトにルーティングするルールが LBR に構成されているため、それらのコールバックは失敗します。ただし、サーバーは、JMS やローカルで最適化された呼出しの処理を続行できます。失われた Oracle HTTP Server インスタンスのリストアを短期間で行うことができない場合は、別のサイト内のインスタンスを使用して、リクエストを"Oracle HTTP Server が孤立した"サイト上の SOA サーバーにルーティングできます。ストレッチ・クラスタ・モデルでこれを行うには、DynamicServerList を ON に設定する必要があります。この変更をローリング方式で適用すると、停止時間を解消できます。さらに、リクエストの発信元に基づいて各サイトにスマート・ルーティングを実行するルールが定義されているため、このタイプの障害が発生したときに、Oracle HTTP Server へのルーティングを停止するための適切なモニターが GLBR 内に設定されていることを確認してください。
あるサイト内のすべてのOracle WebLogic Server SOAサーバーの障害 あるサイト内のすべての Oracle WebLogic Server SOA サーバーが停止した場合は、別のサイトがリクエストの処理を続行します。ローカル LBR は、対応する Oracle HTTP Server サーバーへのルーティングを停止します(GLBR がそのサイトへのルーティングを停止します)。BPEL の観点から見ると、障害が発生したサーバーで自動リカバリ・クラスタ・マスターがホストされていた場合は、使用可能なサイトで新しいクラスタ・マスターが立ち上がります。このサーバーは、別のサイトで開始されたインスタンスの自動リカバリを実行できます。
JDBC 永続ストアとともに自動サービス移行を使用する場合、JMS サービスと TLOG は別のサイトのサーバーに自動的に移行されます(上記の構成の項におけるサービス移行の記述を参照)。
管理サーバーの障害 Oracle Fusion Middleware SOA マルチ・データセンター・アクティブ-アクティブ・デプロイメントには、単一データセンターのトポロジで適用される、管理サーバーの障害のシナリオに対する標準的な考慮事項が適用されます。ノード障害には、『Oracle Fusion Middleware High Availability Guide』および『Oracle Fusion Middleware Enterprise Deployment Guide for Oracle SOA Suite』で説明されている標準的なフェイルオーバー手順で対処する必要があります(管理サーバー・ドメイン・ディレクトリをホストしていた共有ストレージを指す、同じデータセンター内に存在する別のノードで管

58 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
理サーバーを再起動します)。さらに、管理サーバーのドメイン・ディレクトリの定期的なコピーを作成するために、適切なバックアップおよびリストア手順をデプロイする必要があります。管理サーバーをホストしているサイトに影響を与える(すべてのノードに関連する)障害が発生した場合は、別のサイトでのサーバーの再起動が必要になることがあります。これを行うには、以下の手順を実行します。
1. フェイルオーバー・サイトで使用可能な、管理サーバーのドメイン・ディレクトリのバックアップ(またはディスクのミラー/コピー)を作成します。
scp
/u01/orcl/backups/Multi_Data_Center_Deployment_soaedg_domain
_STRETCHED.gz server1_Site2:/u01/ oracle/config/soaedg_domain
2. 管理サーバーのドメイン・ディレクトリに対して元のサイトとまったく同じドメイン・ディレクトリ構造が作成されるように、フェイルオーバー・サイトで aserver/ディレクトリ(soaedg_domain とアプリケーション・ディレクトリの両方を含む)をリストアします。
cd /u01/oracle/config/soaedg_domain/
tar -xzvf
/u01/oracle/config/soaedg_domain/Multi_Data_Center_Deployment_so
aedg_domain_STRETCHED.gz
3. 管理サーバーのリストア先である Site2 のサーバーで$NM_HOME/nodemanager.domains を修正し、以下のように ASERVER_HOME が含まれるようにします。
domain_name=MSERVER_HOME;ASERVER_HOME
4. 管理サーバーがリストアされるノードでノード・マネージャを再起動します。
5. 同様に、管理サーバーは別のサブネットにフェイルオーバーされるため、他のノードから到達可能な別の仮想 IP(VIP)を使用する必要があります。
この VIP が、Site1 で管理サーバーがリスニング・アドレスとして使用していた元の仮想ホスト名にマッピングされるように、このサブネット内のホスト名解決システムの適切な変更を行います(たとえば、Site1 では ADMINHOSTVHN1 が 10.10.10.1 にマッピングされる可能性があるのに対して、Site2 では、ADMINHOSTVHN1 が 20.20.20.1 にマッピングされるように、ローカルの/etc/hosts または DNS サーバーのどちらかを更新する必要があります。管理サーバーに到達するためのアドレスとして、すべてのサーバーが ADMINHOSTVHN1 を使用します)。『Oracle Fusion Middleware Enterprise Deployment Guide for Oracle SOA Suite』で規定されているように管理サーバーが Oracle HTTP Server や LBR をフロントエンドにしている場合は、クライアントがこの変更を認識する必要はありません。クライアントが管理サーバーのリスニング・ホスト名に直接アクセスする場合は、それらのクライアントもそれぞれの DNS 解決で更新する必要があります。
管理サーバーが Site1 で実行されている場合の/etc/hosts のサンプル:
10.10.10.1 ADMINHOSTVHN1.mycompany.com ADMINHOSTVHN1
管理サーバーが Site2 で実行されている場合の/etc/hosts のサンプル:
20.20.20.1 ADMINHOSTVHN1.mycompany.com ADMINHOSTVHN1

59 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
6. WLST を起動し、nmstart を使用して、管理サーバーに対して設定された nmconnect と資格証明でノード・マネージャに接続します。元のサイトで使用されていたノード・マネージャのユーザー名とパスワードを入力します。
cd ORACLE_COMMON_HOME/common/bin
./wlst.sh
WLST シェルに移動した後:
wls:/offline>nmConnect('nodemanager_username','nodemanager_passw
ord ','ADMINVHN','5556','domain_name','ASERVER_HOME' ,'PLAIN')
wls:/nm/domain_name> nmStart('AdminServer')
Oracle WebLogic Server 管理コンソールと Oracle Enterprise Manager Fusion Middleware Control の両方にアクセスすることによって、管理サーバーが正しく動作していることを確認します。
データベース障害:Data Guardのスイッチオーバーとフェイルオーバー SOA データソースに対して提供されている JDBC URL 文字列および ONS 構成によって、データベース・レベルでフェイルオーバーまたはスイッチオーバーが実行されると、自動的に再接続が実行されることが保証されます。ただし、データベース・リースとともに構成されているすべての SOAサーバーは、リース表を更新できない場合、自らシャットダウンします。そのサーバーは、重要なサブシステムに障害が発生して自動的にシャットダウンされるため、FAILED 状態になります。デフォルトでは、FAILED 状態になるまでの時間は関連のチェックが開始されるタイミングによって変化しますが、通常 1 分未満です。
SOA システムのデータベース・スイッチオーバーには通常、数分以上かかります。SOA データベースの Data Guard のスイッチオーバーまたはフェイルオーバー中、サーバーは自動的にシャットダウンされ、ノード・マネージャにより再起動されます。
ヘルス・チェックの間隔(デフォルト値は 10 秒)は、リース表を更新する間隔です。値を増やしてデータベース障害への許容度を上げることはできますが、他のシナリオにおけるサーバーのクラッシュ検出にかかる時間も増加します。データベース・リースを使用するサーバーについて、データベースの停止に対する耐障害性を向上させるのに、より適している 2 つのパラメータがあります。これらは、database-leasing-basis-connection-retry-count(デフォルト値は 1)および database-leasing-basis-connection-retry-delay(デフォルト値は 1 秒)です。これらのパラメータを変更する例です。

60 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
リトライ・カウントとリトライ遅延の積がデータベース停止の合計時間よりも大きい場合、サーバーは再起動せず、データベースの再開時にデータベースに再接続します。とはいえ、データベースが利用できない間は、データベースに接続できません。
リース表の更新のための合計リトライ数が上限に達し、サーバーが FAILED 状態になった場合、サーバーはノード・マネージャにより自動的に再起動されます。デフォルトでは 2 回再起動が試行され、サーバーが正常に起動できない場合、そのサーバーは FAILED_NOT_RESTARTABLE としてマークされます。ノード・マネージャによる再起動の試行回数も調整できます。サーバーの Health Monitoringタブで、Max Restarts Within Interval パラメータを使用し、ノード・マネージャがこのサーバーを再起動できる回数(Restart Interval で指定した間隔の範囲内)を定義します。
あるいは、スイッチオーバー操作の前に、サーバーを正しくシャットダウンできます(フェイルオーバー・シナリオには適用されません)。システム上の負荷やビジネス・ニーズに応じて、この 2つのアプローチのうちのどちらかを使用できます。
Oracle Fusion Middleware SOAマルチ・データセンター・アクティブ-アク
ティブ・デプロイメントのパフォーマンスとスケーラビリティへの影響
容量の使用および計画 マルチ・データセンター・デプロイメント設計では、サイト間の待機時間によって導入されるスループット低下に対応する必要があります。最悪のケースは、アクティブ・データベースと同じサイト(この例では Site1)に存在する中間層が、このデータベースが稼働状態を維持している最中に使用不可になるような場合です。このケースでは、2 つのサイトが一緒に処理していた負荷を Site2で維持することが必要になり、すべてのリクエストがリモート・データベースにアクセスする必要があるため、待機時間によって平均応答時間は悪化することが予測されます。
以下の図は、こうした状況下のシステムにおける、トランザクション・スループット(TX/秒)の低下を示しています(すべてのサーバーが同じ待機時間で稼働している場合に、サイト間のさまざまな待機時間について TX/秒の値で比較)。
./wlst.sh connect('weblogic','password','t3://ADMINVHN:7001') edit() startEdit() cd('/Clusters/' + 'SOA_Cluster') cmo.setDatabaseLeasingBasisConnectionRetryCount(10) cmo.setDatabaseLeasingBasisConnectionRetryDelay(10000L) save() activate() disconnect() exit()

61 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
図15:Site2のSOAサーバーのみが稼働し、Site1にデータベースが存在する場合のトランザクション・スループットの低下(サイト間のさまざまな待機時間
(ミリ秒単位のRTT)における、待機時間が同じシステム(両サイトが稼働)の総合的スループットで比較)
このようなケースでは、Site1 内の中間層がオンラインに戻るまで、データベースをスイッチオーバーすることが推奨される場合があります。Site2 は、Site1 の中間層からのフェイルオーバーが発生したときに追加される負荷を維持するために、通常運用中に十分な予備容量を備えている必要があります。あるいは、このようなフェイルオーバー・モードでは、リクエストを抑制することが必要になります。最適なアプローチは、システムへのエントリ・ポイント(GLBR、またはファイル/FTPアダプタや JMS クライアントの場合のファイル・システムなどのリソース・アダプタ・アクセス・ポイント)でのリクエストの抑制です。リクエストは、ルーティングの適切なルールを使用して、GLBR で抑制できます。同様に、JMS メッセージ(JMS アダプタの場合)、データベース・エントリ(データベース・アダプタの場合)、またはファイル(ファイルまたは FTP アダプタの場合)を生成しているクライアントは、適切な IP フィルタリングを使用してシステム内の負荷を減らすことができます。これらのルールの定義は、このドキュメントの範囲外です。
起動待機時間 SOA コンポーネントで使用される各種データソースのための接続プールの初期容量の作成に、サーバーでは膨大な時間が費やされます。デフォルトでは、ほとんどの SOA データソースで、その接続プールに使用する初期容量はゼロです。ただし、実行時のシステムの応答時間を短縮するために、初期容量を増やすことが推奨される場合があります。"リモート"サイト(SOA データベースに対するリモート)に存在するサーバーの場合は、初期プール容量を増やすと、サーバー起動での遅延が大きくなります。理想的な初期容量の設定を見つけるには、通常運用中の応答時間の改善と、システムのリカバリにかかる可能性のある時間の間でバランスのとれた決定を行う必要があります。ストレッチ・クラスタでは、初期容量はデータソース・レベル(接続プール)で設定されるため、初期
Site2 のみ稼働 - TX/秒の低下(%)と待機時間(RTT)
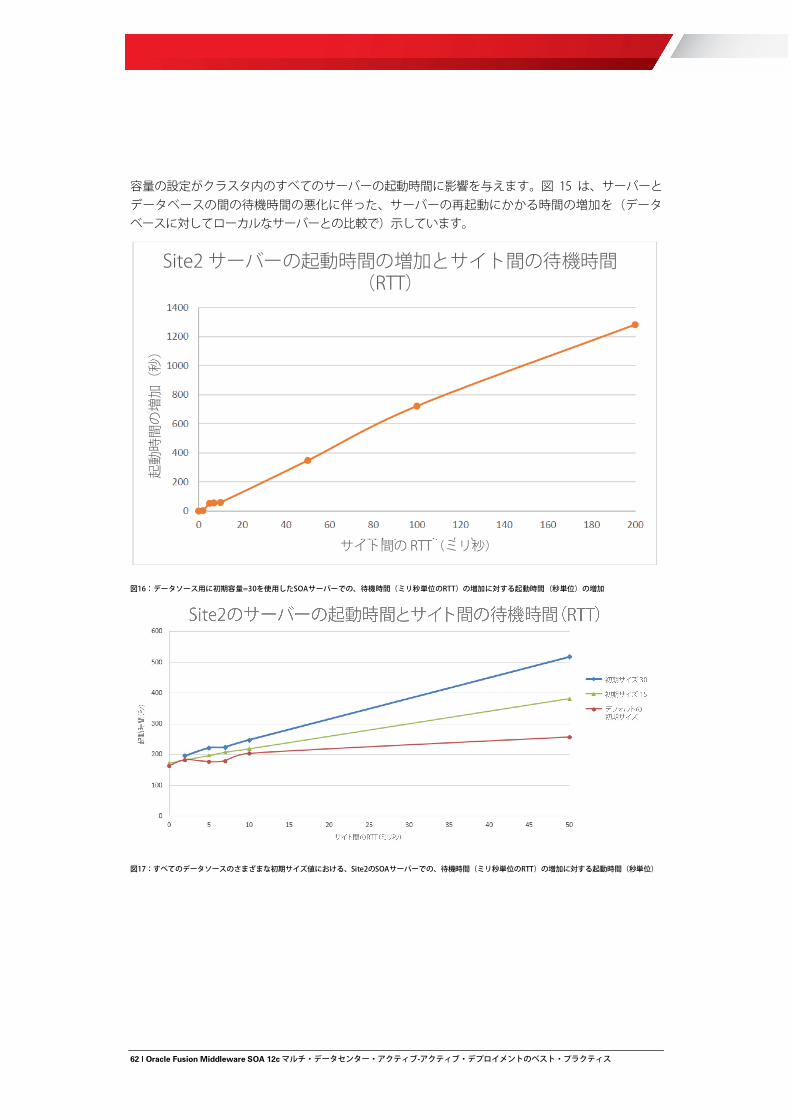
62 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
容量の設定がクラスタ内のすべてのサーバーの起動時間に影響を与えます。図 15 は、サーバーとデータベースの間の待機時間の悪化に伴った、サーバーの再起動にかかる時間の増加を(データベースに対してローカルなサーバーとの比較で)示しています。
図16:データソース用に初期容量=30を使用したSOAサーバーでの、待機時間(ミリ秒単位のRTT)の増加に対する起動時間(秒単位)の増加
図17:すべてのデータソースのさまざまな初期サイズ値における、Site2のSOAサーバーでの、待機時間(ミリ秒単位のRTT)の増加に対する起動時間(秒単位)
Site2 サーバーの起動時間の増加とサイト間の待機時間 (RTT)
起動
時間
の増
加(
秒)
サイト間の RTT(ミリ秒)

63 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
図18:データソースのさまざまな初期サイズ値における、待機時間(ミリ秒単位のRTT)増加に伴うSite2のSOAサーバーの起動時間のペナルティ(%)
SOA サーバーを再起動するプロセスには、適切な Oracle WebLogic Server の立ち上げの他、適切なコンポジットのロードおよびアクティブ化が含まれます。SOA をホストしている Oracle WebLogic Server が実行状態に達すると、コンポジットが使用可能かどうかにかかわらず、Oracle HTTP Serverから SOA アプリケーションへのルーティングを妨げるものはなくなります。
SOA 12c より、レイジー・ローディングという新しい機能が導入されています。コンポジットがアクティブになる前にコンポジットへのリクエストが到着する場合、必要なアーティファクトが利用可能になって、コンポジットがアクティブ状態になるまでの間、HTTP リクエストは保留状態になります。ただし、JCA バインディング、EJB、および ADF バインディングを含むコンポジットは、レイジー・ロードできません。これらのコンポジットに対し、SOA は、“503 Service unavailble” HTTP コードとともにリクエストを拒否するよう有効化されています。Oracle HTTP Server は、他の使用可能なサーバーに対してリクエストを自動的に再試行し、それを正常に処理します(その他のいずれかのサーバーがコンポジットのロードを完了している場合)。コンポジットのロードをまだ完了していない SOA サーバーにルーティングしている Oracle HTTP Server サーバーから抜粋した以下の出力は、予測される動作を示しています。
Oracle HTTP Server は、実行中ではあるが、コンポジットをまだロードしていない SOA サーバーにルーティングします。
[TIMESAMP] [weblogic:debug] [pid 1671:tid 140542142777088]
ApacheProxy.cpp(2570): [client CLIENT_IP:45584]
<005NfNA0CA36qI9_VdP5ic0000Pv00008^> got a pooled connection to server
'SERVER1_IP/8001/8001' from general list for '/soa-
infra/services/soaFusionOrderDemo/OrderBookingComposite/orderprocessor_
cl ient_ep', Local port:13056

64 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
[TIMESTAMP [weblogic:debug] [pid 1671:tid 140542142777088]
BaseProxy.cpp(611): [client CLIENT_IP:45584]
<005NfNA0CA36qI9_VdP5ic0000Pv00008^> Entering method
BaseProxy::sendRequest
コンポジットがまだロードされていないため、SOA は 503 エラーを返します。
[TIMESTAMP] [weblogic:debug] [pid 1671:tid 140542142777088]
URL.cpp(850): [client CLIENT_IP:45584]
<005NfNA0CA36qI9_VdP5ic0000Pv00008^>
URL::parseHeaders:CompleteStatusLine set to [HTTP/1.1 503 Service
Unavailable]
[TIMESTMP] [weblogic:debug] [pid 1671:tid 140542142777088]
ApacheProxy.cpp(288): [client CLIENT_IP:45584]
<005NfNA0CA36qI9_VdP5ic0000Pv00008^> sendResponse() : r->status = '503'
Oracle HTTP Server は、次のプロキシ・プラグインの更新までそのサーバーを使用不可とマークし、別のサーバーに対して再試行します。
[TIMESTAMP] [weblogic:debug] [pid 1671:tid 140542142777088]
BaseProxy.cpp(218): [client CLIENT_IP:45584]
<005NfNA0CA36qI9_VdP5ic0000Pv00008^> Marking SERVER1_IP:8001 as
unavailable for new requests
[TIMESTAMP] [weblogic:error] [pid 1671:tid 140542142777088] [client
CLIENT_IP:45584] <005NfNA0CA36qI9_VdP5ic0000Pv00008^> *******Exception
type [FAILOVER_REQUIRED] (Service Unavailable) raised at line 241 of
BaseProxy.cpp
[TIMESTAMP] [weblogic:debug] [pid 1671:tid 140542142777088]
ap_proxy.cpp(682): [client CLIENT_IP:45584]
<005NfNA0CA36qI9_VdP5ic0000Pv00008^> got exception in sendResponse
phase:FAILOVER_REQUIRED [line 241 of BaseProxy.cpp]:Service Unavailable
at line 682
[TIMESTAMP] [weblogic:debug] [pid 1671:tid 140542142777088]
ap_proxy.cpp(687): [client CLIENT_IP:45584]
<005NfNA0CA36qI9_VdP5ic0000Pv00008^> Failing over after
FAILOVER_REQUIRED exception in sendResponse()

65 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
[TIMESTAMP] [weblogic:error] [pid 1671:tid 140542142777088] [client
CLIENT_IP:45584] ap_proxy: trying POST /soa-
infra/services/soaFusionOrderDemo/OrderBookingComposite/orderprocessor_
cl ient_ep at backend host SERVER1_IP/8001, client CLIENT_IP/45584,
total tries 1; got exception 'FAILOVER_REQUIRED [line 241 of
BaseProxy.cpp]:Service Unavailable'; state: reading status line or
response headers from WLS; failing over
[TIMESTAMP] [weblogic:debug] [pid 1671:tid 140542142777088]
ap_proxy.cpp(556): [client CLIENT_IP:45584]
<005NfNA0CA36qI9_VdP5ic0000Pv00008^> attempt #1 out of a max of 5
[TIMESTAMP] [weblogic:debug] [pid 1671:tid 140542142777088]
ApacheProxy.cpp(2575): [client CLIENT_IP:45584]
<005NfNA0CA36qI9_VdP5ic0000Pv00008^> general list: trying connect to
'SERVER2_IP'/8001/8001 at line 2575 for '/soa-
infra/services/soaFusionOrderDemo/OrderBookingComposite/orderprocessor_
cl ient_ep'
[TIMESTAMP] [weblogic:debug] [pid 1671:tid 140542142777088]
URL.cpp(1805): [client CLIENT_IP:45584]
<005NfNA0CA36qI9_VdP5ic0000Pv00008^> URL::Connect:Connected
successfully
Oracle HTTP Server は、そのリクエストをクライアントに対して透過的にフェイルオーバーし、コンポジットをロードしているサーバーを(Oracle HTTP Server 構成でのデフォルトの MaxSkipTime 期間である 10 秒間)"不良"とマークしてから、その不良サーバーを再試行します。コンポジットはリモート・データベースからロードされるため、再起動後に SOA サーバーが実質的に使用可能になるまでにかかる合計時間はおもに、データソース・プールの初期容量(サーバーが Oracle HTTP Serverから使用可能になるまで)と、コンポジットのサイズ(SOA システムが 503 コードでのリクエストの拒否を停止するまで)によって影響を受けます。
SOA サーバーの起動中、WebLogic JMS 宛先は、所有するサービスの準備ができるまで、JNDI 内で自らを通知しません。自動サービス移行を使用する場合、サービスがクラスタ・リースと同期をとらなければ起動できないため、JMS 宛先が JNDI ツリーで利用可能になるまで多少の遅延(秒単位)が予測されます。この遅延の間、JMS アダプタは JMS リソースに接続しようとして JNDI 解決エラーを返す可能性があります。これがコンポジットでのエラーの原因となる場合、JNDI バインド障害の場合にリトライするよう JMS アダプタでの障害の扱いを構成することを検討してください。
66 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
トランザクションの平均アクティブ時間とトランザクション・リカバリ Oracle Fusion Middleware SOA マルチ・データセンター・アクティブ-アクティブ・デプロイメントでは、データベースに対する待機時間が長いサイトではトランザクションがより長期間にわたって引き続きアクティブになります。より長期間にわたって引き続きアクティブなトランザクションは、障害の影響を受けやすくなる可能性があります。図 18 は、Site2 とデータベースの間の待機時間が増加した場合の、FOD の例でのトランザクションが引き続きアクティブになる平均時間の増加を示しています。
図19:サイト間の待機時間(ミリ秒単位のRTT)が増加した場合の、FODを使用したOracle Fusion Middleware SOAマルチ・データセンター・アクティブ-ア
クティブ・デプロイメントでトランザクションが引き続きアクティブになる平均時間
データ損失ゼロがビジネス要件である場合は、適切なトランザクション・ログ保護メカニズムを備えていることが重要です。このような場合は、保護のために JMS とトランザクション・ログに JDBC永続ストアを使用することが推奨されます。単一サービス障害の場合は、サービス移行を実行すると、自動的にリカバリが発生します。あるサイトの中間層全体が失われた場合、Site2 にも JMS および TLOGS の JDBC 永続ストアが利用可能となり、サービスは別のサイトに自動的に移行できます。ストレッチ・クラスタ・システムでは、ログの読取りと再開が透過的である必要があります。
JMS および TLOG にファイルストアを使用する場合、適切な永続ストアの定常的なレプリカをサイト間に設定する必要があります。設定されない場合、あるサイトから別のサイトへの自動サービス移行は回避され、新しいサイトでトランザクション・ログと永続ストアを利用可能にした後、Site1 から Site2 へ手動でサービスを移行する必要があります。
平均 TX アクティブ時間と待機時間(ミリ秒)
平均
TXア
クテ
ィブ
時間
(秒
)
RTT(ミリ秒)

67 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
まとめ
Oracle Fusion Middleware SOA Suite は、複数の Oracle Fusion Middleware SOA サーバーが、いずれかのデータセンターに配置された中央データベースを使用してリクエストをアクティブに処理しているマルチ・データセンター・デプロイメントで使用できます。この構成では、すべてのサイト内のサーバーが同じクラスタ(ストレッチ・クラスタとも呼ばれます)に参加し、Data Guard を使用して SOA データベースの保護を実現する、1 つの Oracle WebLogic Server ドメイン・モデルを使用します。呼出し時の遅延によって発生するパフォーマンスの低下を回避し、デプロイメントと実行時のシナリオで発生し得る非一貫性を解消するには、サイト間のネットワーク待機時間を十分に低くする必要があります。オラクルでは、これらのトポロジを、SOA サーバーとデータベースの間の待機時間が 10 ミリ秒(RTT)未満の Metropolitan Area Network で使用することを推奨しています。システムの最適なフェイルオーバーとパフォーマンスを保証するために、SOA マルチ・データセンターごとにデプロイメント、ペイロード、コンポジット・タイプ、スループットの各要件を分析するとともに、タイムアウトなどのパラメータを細かくチューニングすることを推奨します。

68 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
付録A:ファイル・アダプタのロックおよびMuxer
以下のスクリプトを使用して、ファイル・アダプタのミューテックスおよびロック表を作成できます。
CREATE TABLE FILEADAPTER_IN
(
FULL_PATH VARCHAR2(4000) NOT NULL,
ROOT_DIRECTORY VARCHAR2(3000) NOT NULL,
FILE_DIRECTORY VARCHAR2(3000) NOT NULL,
FILE_NAME VARCHAR2(1000) NOT NULL,
FILE_ENDPOINT_GUID VARCHAR2(2000) NOT NULL,
FILE_LAST_MODIFIED NUMBER,
FILE_READONLY CHAR(1),
FILE_PROCESSED CHAR(1) DEFAULT '0',
CREATED NUMBER NOT NULL,
UPDATED NUMBER ,
TENANT_ID NUMBER(18,0) DEFAULT -1
);
ALTER TABLE FILEADAPTER_IN ADD CONSTRAINT FILEADAPTER_IN_PK PRIMARY KEY
(FULL_PATH);
CREATE INDEX IDX_ROOT_DIRECTORY ON FILEADAPTER_IN (ROOT_DIRECTORY );
CREATE INDEX IDX_FILE_DIRECTORY ON FILEADAPTER_IN (FILE_DIRECTORY );
CREATE INDEX IDX_FILE_PROCESSED ON FILEADAPTER_IN (FILE_PROCESSED );
CREATE INDEX IDX_FILE_READONLY ON FILEADAPTER_IN (FILE_READONLY );
-----------------------------------------------------------------------
-- FILEADAPTER_MUTEX
---------------------------------------------------------------------
CREATE TABLE FILEADAPTER_MUTEX
(
MUTEX_ID VARCHAR2(4000) NOT NULL,
MUTEX_CREATED TIMESTAMP,
MUTEX_LAST_UPDATED TIMESTAMP,
MUTEX_SEQUENCE NUMBER ,
TENANT_ID NUMBER(18,0) DEFAULT -1
);
ALTER TABLE FILEADAPTER_MUTEX ADD CONSTRAINT FILEADAPTER_MUTEX_PK
PRIMARY KEY (MUTEX_ID);

69 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
付録B:JMS JDBC永続ストアに対するインプレース再起動の構成
JMS JDBC 永続ストアにインプレース再起動を構成するには、関連する JMS サーバーと永続ストアのターゲットを移行可能なターゲットに設定する必要があり、この移行可能なターゲットは“Restart on Failure”を使用している必要があります。これを構成するには、以下の手順を実行します。
» 移行可能なターゲットにおける障害時の再起動を有効化:
1. WLS 管理コンソールにログインします。
2. 「Lock and Edit」をクリックします。
3. 左側のナビゲーション・ツリーで、「Environment」を展開し、「Migratable Targets」をクリックします。
4. 「WLS_SOA1 (migratable)」をクリックします。
5. 「Migration」タブをクリックします。
6. 下部にある「Restart On Failure」ボックスを選択します。
図20:移行の構成

70 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
7. 「Save」をクリックします。
8. す べ て の SOA JMS サ ー バ ーに つ い て、 適 切な 移 行 可能 タ ー ゲ ット ( WLS_SOA1 (migratable)、WLS_SOA2 (migratable)など。JMS サーバーが関連する WLS サーバーによる)を使用し、手順 4~7 を繰り返します。
9. 変更を有効化します。
» JMS サーバーおよび永続ストアの再ターゲット化:
SOA 12.2.1.3 環境の場合、ドメイン構成時に“Enable Automatic Service Migration”オプションが選択されていれば、この構成はすでに実装されています。この構成が実装されておらず、事後の手順として自動サービス移行を手動で構成する必要のある場合は、以下の手順に従って、適切な移行可能ターゲットを永続ストアのターゲットに設定します。
1. WLS 管理コンソールにログインします。
2. 「Lock and Edit」をクリックします。
3. 左側のナビゲーション・ツリーで「Services」>「Messaging」の順に展開し、「JMS Servers」をクリックします。
4. 「JMS Servers」の表で、「SOAJMSServer_auto_1」をクリックします。
5. 「Targets」タブをクリックします。
6. 「WLS_SOA1 (migratable)」をターゲットとして選択します。
図21:移行可能なターゲットの構成
7. 「 Save 」 を ク リ ッ ク し ま す ( 永 続 ス ト ア と し て 同 じ タ ー ゲ ッ ト に 対 しSOAJMSServer_auto_1 がターゲット化されていないという、JMS サーバーまたは SAF エージェントに関するエラーは無視してかまいません)。
8. JDBC 永続ストアを使用するすべての JMS サーバーについて、手順 4~7 を繰り返します。
9. 左側のナビゲーション・ツリーで「Services」を展開し、「Persistent Stores」をクリックします。
10. SOAJMSServer_auto_1 JMS サーバーに関連付けられている永続ストアをクリックします(永続ストアは「Services」>「Messaging」>「JMS Servers table」で確認できます)。

71 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
11. 「WLS_SOA1 (migratable)」をターゲットとして選択します。
12. 「Save」をクリックします。
13. 適切な移行可能ターゲット(WLS_SOA1 (migratable)、WLS_SOA2 (migratable)など)を使用する JMS JDBC 永続ストアすべてについて、手順 10~12 を繰り返します。
14. 変更を有効化します。
15. SOA サーバーを再起動します。
イ ン プ レ ー ス 再 起 動 を 構 成 し た ら 、 サ ー バ ー の 起 動 プ ロ パ テ ィ で あ る “ - Dweblogic.debug.DebugSingletonServices=true”および“-Dweblogic.StdoutDebugEnabled=true”を設定し、JMS JDBC 永続ストアの動作を検証できます。データベース障害時には、サーバーの出力ファイルに以下のイベントが記録されます。
移行可能なターゲットへのストアの追加:
<Debug> <SingletonServices> <BEA-000000> <MigratableGroup: adding migratable SOAJMSJDBCStore_auto_1 to group WLS_SOA1 (migratable) Migratable class - weblogic.management.utils.GenericManagedService$ManagedDeployment>
データベースへの到達: <Info> <Store> <BEA-280071> <JDBC store "SOAJMSJDBCStore_auto_1" opened table "JMSJDBC_1WLStore" and loaded 0 records.For additional JDBC store information, use the diagnostics framework while the JDBC store is open.>
データベースのクラッシュ: <Emergency> <Store> <BEA-280060> <The persistent store "SOAJMSJDBCStore_auto_1" encountered a fatal error, and it must be shut down: weblogic.store.PersistentStoreFatalException: [Store:280065]java.sql.SQLException:Connection has been administratively destroyed.Reconnect. (server="WLS_SOA1" store="SOAJMSJDBCStore_auto_1" table="JMSJDBC_1WLStore"):(Linked Cause, "java.sql.SQLException:Connection has been administratively destroyed.Reconnect.")
ストアの障害: <Error> <Store> <BEA-280074> <The persistent store "SOAJMSJDBCStore_auto_1" encountered an unresolvable failure while processing transaction "BEA1-148701EFAE50DC04072E".Shutdown and restart to resolve this transaction. weblogic.store.gxa.GXAException: weblogic.store.PersistentStoreException: weblogic.store.PersistentStoreFatalException: [Store:280032]The persistent store suffered a fatal error and it must be re-opened

72 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
ストアの非アクティブ化: <Debug> <SingletonServices> <BEA-000000> <MigratableGroup:Going to call migratableDeactivate on SOAJMSJDBCStore_auto_1 for WLS_SOA1 (migratable)>
ストアの再アクティブ化: <Debug> <SingletonServices> <BEA-000000> <MigratableGroup: activating migratable 'SOAJMSJDBCStore_auto_1' for WLS_SOA1 (migratable)>
表に対する所有権のロックおよびアクティブ化失敗(1 回目の試行): <Warning> <Store> <BEA-280076> <Database table "JMSJDBC_1WLStore" for store "SOAJMSJDBCStore_auto_1" is currently owned by "[name={server=WLS_SOA1!host=192.168.48.58!domain=soaexa_domain!store=SOAJMSJDBCStore_auto_1!table=JMSJDBC_1WLStore}:random=5074588073335957339:timestamp=1401991210748]".Trying to wait for ownership.>
永続ストアのアクティブ化の新規試行: <Debug> <SingletonServices> <BEA-000000> <MigratableGroup: activating migratable 'SOAJMSJDBCStore_auto_1' for WLS_SOA1 (migratable)>
ストアのアクティブ化成功: <Info> <Store> <BEA-280071> <JDBC store "SOAJMSJDBCStore_auto_1" opened table "JMSJDBC_1WLStore" and loaded SOAJMSJDBCStore_auto_1 records.For additional JDBC store information, use the diagnostics framework while the JDBC store is open.>
ロギングのオーバーヘッドを減らすため、正しい動作が検証できたら、 “-Dweblogic.debug.DebugSingletonServices=true”および“-Dweblogic.StdoutDebugEnabled=true”の両フラグをサーバーの起動プロパティから削除します。

73 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
付録D:Oracle Service Bus(OSB)の考慮事項
マルチ・データセンター・アクティブ-アクティブ・デプロイメントにおける SOA の構成について本ドキュメントに記載されている推奨事項および構成の詳細は、すべて OSB にも有効です。これまでのチャプターで説明した、クラスタの構成、自動サービス移行の構成、トランザクション・ログと永続ログの構成、レプリケートされたサービス、JMS 宛先は、OSB クラスタにも適用可能です。
Oracle Service Bus に関する特別な考慮事項は以下のとおりです。
ロードバランサの考慮事項 OSB について作成された仮想サーバーは、「Oracle Fusion Middleware SOA マルチ・データセンター・アクティブ-アクティブ・デプロイメントのためのロードバランサおよびグローバル・ロードバランサの構成」の項で示されているものと同じ推奨事項に従う必要があります。
OSB 仮想サーバーの場合、LBR モニターを WSIL 検査 URL の/sbinspection.wsil に設定して OSB サーバーの可用性を判別し、OSB WebLogic Server が利用できない場合の望ましくないルーティングを排除することを推奨します。
アプリケーション層の考慮事項 OSB シングルトン・サービス
FTP、File、Mail ポーラーは、クラスタ内の 1 つのサーバーでのみ実行される、OSB サービスです。グローバル・プロパティの“OSB Singleton Components Automatic Migration”が有効の場合、これらのサービスはシングルトンとして動作し、障害の発生時やサーバーのシャットダウン時にはクラスタ内の別のサーバーに自動的に移行します。このサーバーは、Site1 または Site2 のどちらに存在してもかまいません。これらのサービスがポーリングするリソースは、理想的には両方のサイトから到達可能でなければならず、少なくともシングルトン・サービスが実行されているサイトからは到達可能でなければなりません。リソースが FTP または Mail サーバーの場合、これらは、シングルトンが Site1 または Site2 のどちらで実行されているかに関係なくアクセス可能でなければなりません。ストレッチ・クラスタ・トポロジでは、サイト間の共有ストレージがなく、リソースがファイル・システム・フォルダの場合、サービスを実行して処理を行うサイトからリソースが利用可能でなければなりません。このストレージの継続的なレプリケーションは、ファイルの一貫性処理を行う別のサイトに対して実行する必要があります。
これらのサービスを手動で移行する方法はなく、どのサイトでサービスがアクティブ化されているかを判別できることが重要です。これらのシングルトン・サービスをアクティブ化する OSB サーバーは、ログに以下の種類のメッセージが記録されます。

74 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
<TIMESTAMP> <Info> <Cluster> <HOSTNAME> <SERVER_NAME> <[ACTIVE]
ExecuteThread:'5' for queue: 'weblogic.kernel.Default (self-tuning)'>
<<WLS Kernel>> <> <2108ed22-dbea-46d4-8a25-2164f202fa6a-00000397>
<1497264860902> <[severity-value:64] [rid:0] [partition-id:0]
[partition-name:DOMAIN] > <BEA-003130> <default-TransportPollers-
MyFilePollerPS successfully activated on server SERVER_NAME.>
<TIMESTAMP> <Info> <Cluster> <HOST_NAME> <SERVER_NAME> <[STANDBY]
ExecuteThread:'17' for queue: 'weblogic.kernel.Default (self-tuning)'>
<<WLS Kernel>> <> <36c0d769-2602-4b0c-aa4c-2ab5d217ae67-000000db>
<1510130044907> <[severity-value:64] [rid:0] [partition-id:0]
[partition-name:DOMAIN] > <BEA-003130>
<Appscoped_Singleton_Service_Initializer successfully activated on
server SERVER_NAME.>
代わりの方法として、データベース・リース表をチェックし、OSB シングルトンを実行しているサーバーを判別できます。以下に例を挙げます。
アグリゲータ・サーバーもクラスタ内の 1 つのサーバーでのみ実行されるシングルトン・サービスで、障害の発生時またはサーバーのシャットダウン時には自動的に別のサーバーへフェイルオーバーします。この場合は、特別な考慮事項を適用する必要はありません。
データソースの構成
OSB Cluster が使用するデータソースは、「Oracle Fusion Middleware SOA マルチ・データセンター・アクティブ-アクティブ・デプロイメントのためのデータソースの構成」の項で説明したように、アクティブなデータベースのフェイルオーバーまたはスイッチオーバーが発生した場合に、接続を自動的にフェイルオーバーするよう構成する必要があります。OSB ドメインでこのフェイルオーバーを自動化するには、以下のデータソースを正しく構成する必要があります。
-4188121437114911506/WLS_OSB4 -4188121437114911506/WLS_OSB4 -4188121437114911506/WLS_OSB4 2589091175644382971/WLS_OSB2 8011168529714146120/WLS_OSB3
service.Appscoped_Singleton_Service_Initializer -4188121437114911506/WLS_OSB4 service.WLS_OSB4 (migratable) service.SINGLETON_MASTER service.WLS_OSB4 service.WLS_OSB2 (migratable) service.WLS_OSB3
service.WLS_OSB1 (migratable) -3338612690579104383/WLS_OSB1
INSTANCE ---------------------------
2589091175644382971/WLS_OSB2 -3338612690579104383/WLS_OSB1 8011168529714146120/WLS_OSB3
SQL> select server, instance from ACTIVE; SERVER ---------------------------------- service.WLS_OSB2 service.WLS_OSB1 service.WLS OSB3 (migratable)

75 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
» LocalSvcTblDataSource
» mds-owsm
» opss-audit-DBDS
» opss-audit-viewDS
» opss-data-source
» OraSDPMDataSource
» SOADataSource
» wlsbjmsrpDataSource
» WLSSchemaDataSource
他のカスタム・データソースも、自動的にフェイルオーバーするよう構成します。
ストレッチ・クラスタにおけるOSBのパフォーマンス ストレッチ・クラスタ・トポロジでは、サイト間の待機時間が増加した場合、OSB のパフォーマンスは SOA の場合ほど低下しません。これは、OSB が SOA ほどデータベースを集中的に使用するわけではなく、Site2 の OSB サーバーとデータベースの間の待機時間はそれほどボトルネックになるわけではありません。以下の図は、3 つの異なるシナリオ(FOD アプリケーションを実行する SOA クラスタ、Web サービス・ルーティング・ベースのシナリオを実行する OSB クラスタ、および JCA DBAdapter ベースのシナリオを実行する OSB クラスタ)における Site2 から Site1 へのトラフィックの比較を示しています。
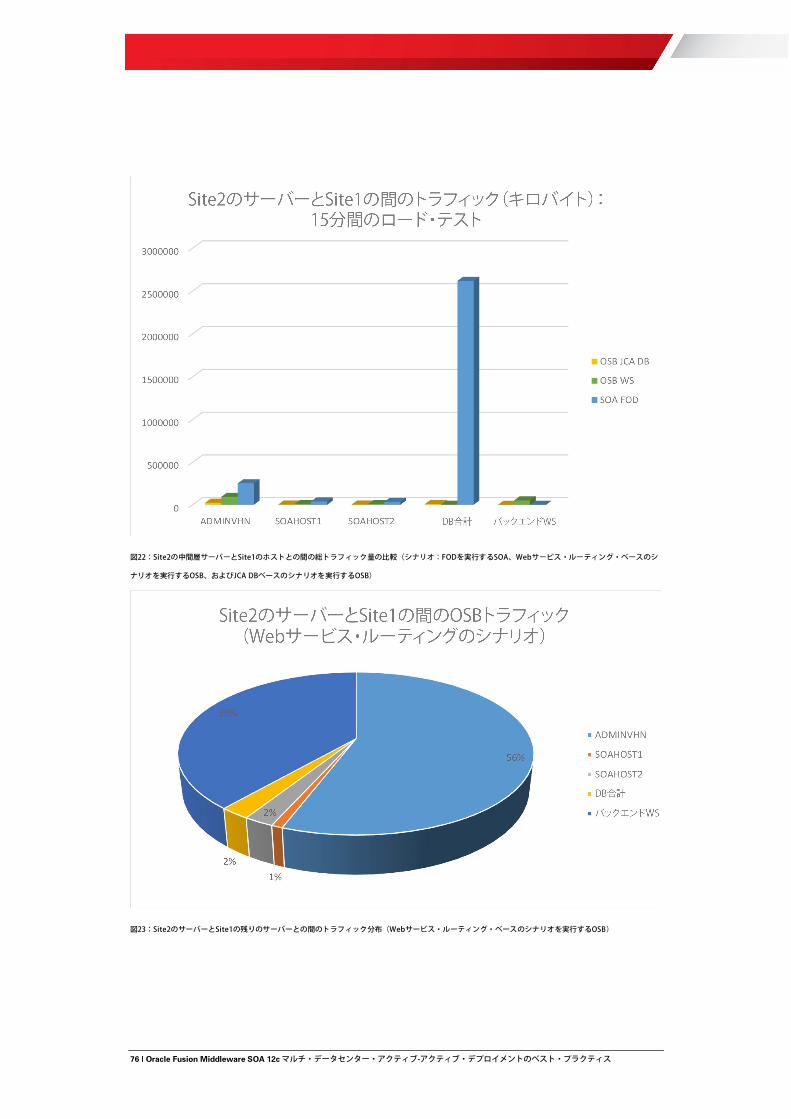
76 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
図22:Site2の中間層サーバーとSite1のホストとの間の総トラフィック量の比較(シナリオ:FODを実行するSOA、Webサービス・ルーティング・ベースのシ
ナリオを実行するOSB、およびJCA DBベースのシナリオを実行するOSB)
図23:Site2のサーバーとSite1の残りのサーバーとの間のトラフィック分布(Webサービス・ルーティング・ベースのシナリオを実行するOSB)
77 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
図24:Site2のOSBサーバーとSite1の残りのサーバーとの間のトラフィック分布(JCA DBアダプタ・ベースのシナリオ)
これを念頭に置くと、Web サービスの純粋なルーティングに基づく、OSB 非トランザクション・シナリオでのパフォーマンスの低下は、ほぼ無視できるものです。
ただし、サイト間の待機時間は、中間層とデータベースとの間の通信だけには影響しません。OSBバックエンド・エンドポイント(データベースまたは Web サービス)は、他のサイトのサーバーにアクセスすると、待機時間の増加に見舞われる可能性があります。このようになった場合、その影響はプロキシ・サービスの平均レスポンス時間に直接及びます。

78 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
図25:異なる待機時間における各サイトの平均プロキシ・サービス時間(OSBがJCA DBAdapterシナリオを実行し、DBが別のサイトにある場合)
図26:Site2サーバーにおける平均プロキシ・サービス時間(OSBがWebサービス・ルーティング・シナリオを実行し、バックエンドWebサービスが別のサイ
トにある場合)
OSB プロキシ・サービス平均サービス時間と RTT
平均
サー
ビス
時間
(ミ
リ秒
)
RTT(ミリ秒)
プロキシ・サービスの平均レスポンス時間(ミリ秒)と RTT
79 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
以下の図は、JCA DB アダプタ挿入がベースのシナリオにおけるスループット(システム(両サイトが稼働)が秒あたりに処理するプロキシ・サービス・リクエスト数)を示しています。
図27:サイト間のさまざまな待機時間(ミリ秒単位のRTT)における、秒あたりのプロキシ・サービス・リクエストの低下(%)(JCA DBAdapterベースのシナリオ)
プロキシ・サービスとビジネス・サービスが使用するプロトコル、エンドポイントの場所、ロード、およびペイロードのサイズによって、パフォーマンスへの影響は変化する可能性がありますが、一般に、サイト間の待機時間が同じ SOA システムほどパフォーマンスは低下しません。
秒あたりのプロキシ・サービス・リクエストの低下(%)と 待機時間(ミリ秒)(JCA DB シナリオ)

80 | Oracle Fusion Middleware SOA 12c マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス
参考
1. 『Oracle Fusion Middleware SOA 11g マルチ・データセンター・アクティブ-アクティブ・デプロイメントのベスト・プラクティス』
http://www.oracle.com/technetwork/database/availability/fmw11gsoamultidc-aa-1998491.pdf
2. 『Oracle Fusion Middleware Enterprise Deployment Guide for Oracle SOA Suite』
https://docs.oracle.com/middleware/12213/lcm/SOEDG/toc.htm
3. 『Fusion Middleware Administering Oracle SOA Suite and Oracle Business Process Management Suite』
https://docs.oracle.com/middleware/12213/soasuite/administer/toc.htm
4. 『Fusion Middleware Developing SOA Applications with Oracle SOA Suite』
https://docs.oracle.com/middleware/12213/soasuite/develop/toc.htm
5. 『Fusion Middleware Administering Oracle Service Bus』
https://docs.oracle.com/middleware/12213/osb/administer/toc.htm
6. 『Fusion Middleware Developing Services with Oracle Service Bus』
https://docs.oracle.com/middleware/12213/osb/develop/toc.htm
7. 『Oracle Fusion Middleware User's Guide for Technology Adapters』
http://docs.oracle.com/cd/E23943_01/integration.1111/e10231/toc.htm
8. 『Oracle Fusion Middleware Understanding Technology Adapters』
https://docs.oracle.com/middleware/12213/adapters/develop-soa-adapters/TKADP.pdf
9. 『F5’s Big IP Global Traffic Manager Documentation』
http://support.f5.com/kb/en-us/products/big-ip_gtm.html
10. 『Oracle WebLogic Server と高可用性 Oracle Database:オラクルの統合 Maximum Availability ソリューション』
http://www.oracle.com/technetwork/database/features/availability/wlsdatasourcefordataguard-1534212.pdf
11. 『Best Practices for Active-Active Fusion Middleware: Oracle WebCenter Portal』
http://www.oracle.com/technetwork/database/availability/webcenteractiveactive-1621358.pdf
12. 『Fusion Middleware Developing Applications with Oracle Coherence』
https://docs.oracle.com/middleware/12213/coherence/develop-applications/toc.htm

Oracle Corporation, World Headquarters
500 Oracle Parkway
Redwood Shores, CA 94065, USA
海外からのお問い合わせ窓口
電話:+1.650.506.7000
ファクシミリ:+1.650.506.7200
C O N N E C T W I T H U S
blogs.oracle.com/oracle
facebook.com/oracle
twitter.com/oracle
oracle.com
Copyright © 2017, Oracle and/or its affiliates.All rights reserved.本文書は情報提供のみを目的として提供されており、ここに記載される内容は予告なく
変更されることがあります。本文書は、その内容に誤りがないことを保証するものではなく、また、口頭による明示的保証や法律による黙示的保証
を含め、商品性ないし特定目的適合性に関する黙示的保証および条件などのいかなる保証および条件も提供するものではありません。オラクルは本
文書に関するいかなる法的責任も明確に否認し、本文書によって直接的または間接的に確立される契約義務はないものとします。本文書はオラクル
の書面による許可を前もって得ることなく、いかなる目的のためにも、電子または印刷を含むいかなる形式や手段によっても再作成または送信する
ことはできません。
Oracle および Java は Oracle およびその子会社、関連会社の登録商標です。その他の名称はそれぞれの会社の商標です。
Intel および Intel Xeon は Intel Corporation の商標または登録商標です。すべての SPARC 商標はライセンスに基づいて使用される SPARC International,
Inc.の商標または登録商標です。AMD、Opteron、AMD ロゴおよび AMD Opteron ロゴは、Advanced Micro Devices の商標または登録商標です。UNIX
は、The Open Group の登録商標です。0615
ホワイト・ペーパー・タイトル
2017 年 12 月