overview of data analytics service: treasure data service
TRANSCRIPT

Overview of data analytics service Treasure Data Service
NAVITIME College: Feb 22, 2016 Satoshi "Moris" Tagomori (@tagomoris)

Satoshi "Moris" Tagomori (@tagomoris)
Fluentd, MessagePack-Ruby, Norikra, ...
Treasure Data, Inc.


http://www.treasuredata.com/

Data Analytics Flow
Collect Store Process Visualize
Data source
Reporting
Monitoring

What I'll talk about today• Architecture Overview • Semantics for Distributed Systems • Queue/Worker and Scheduler • Data Processing: Hive and Presto • Data Storage: PlazmaDB • All about Our Infrastructure • Data Collection: Fluentd and Embulk • Data and Open Source Software Products • Disposable Services and Persistent Data

Treasure Data Architecture Overview
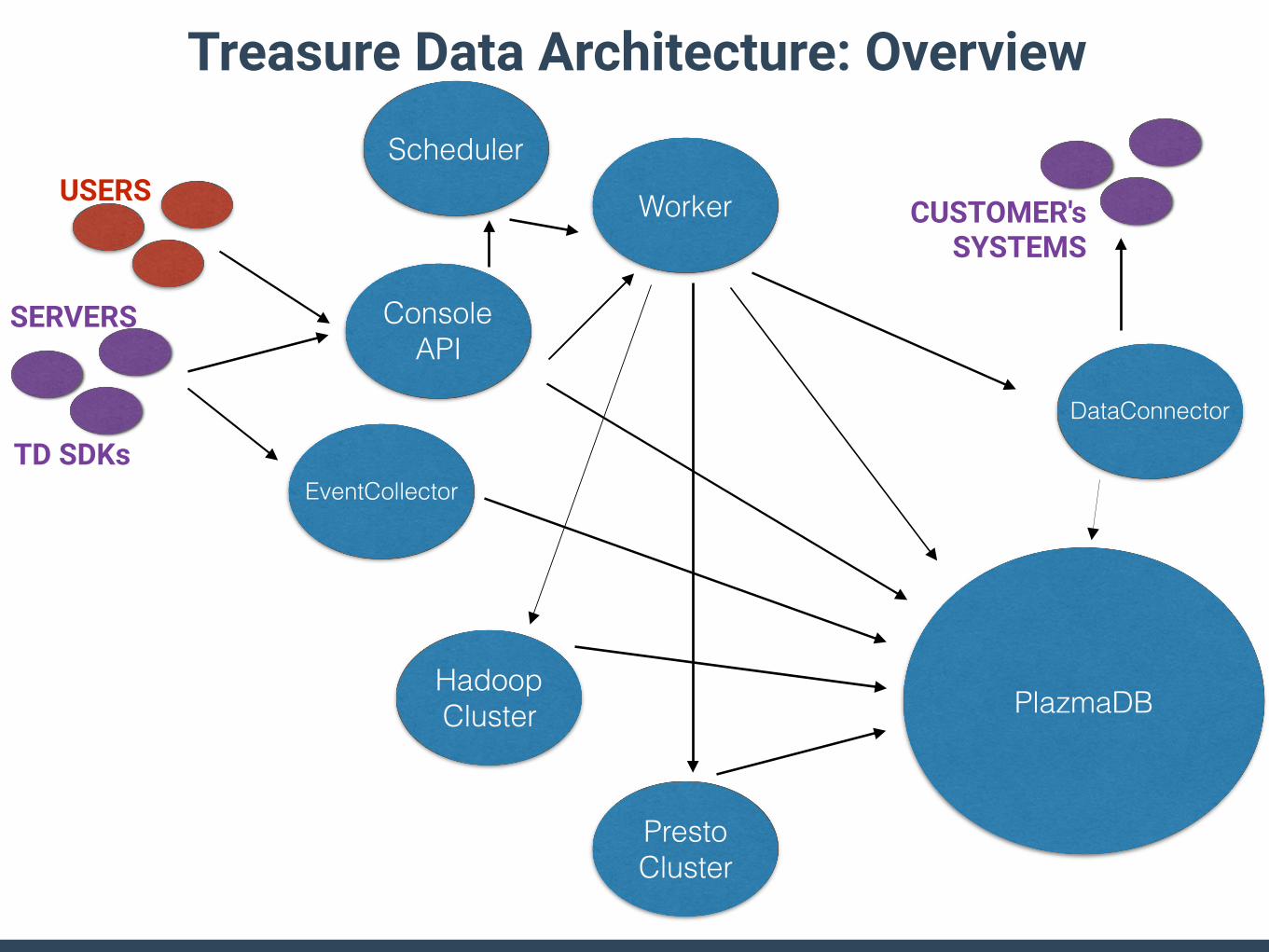
Console API
EventCollector
PlazmaDB
Worker
Scheduler
Hadoop Cluster
Presto Cluster
USERS
TD SDKs
SERVERS
DataConnector
CUSTOMER's SYSTEMS
Treasure Data Architecture: Overview
Console API
EventCollector
PlazmaDB
Worker
Scheduler
Hadoop Cluster
Presto Cluster
USERS
TD SDKs
SERVERS
DataConnector
CUSTOMER's SYSTEMS
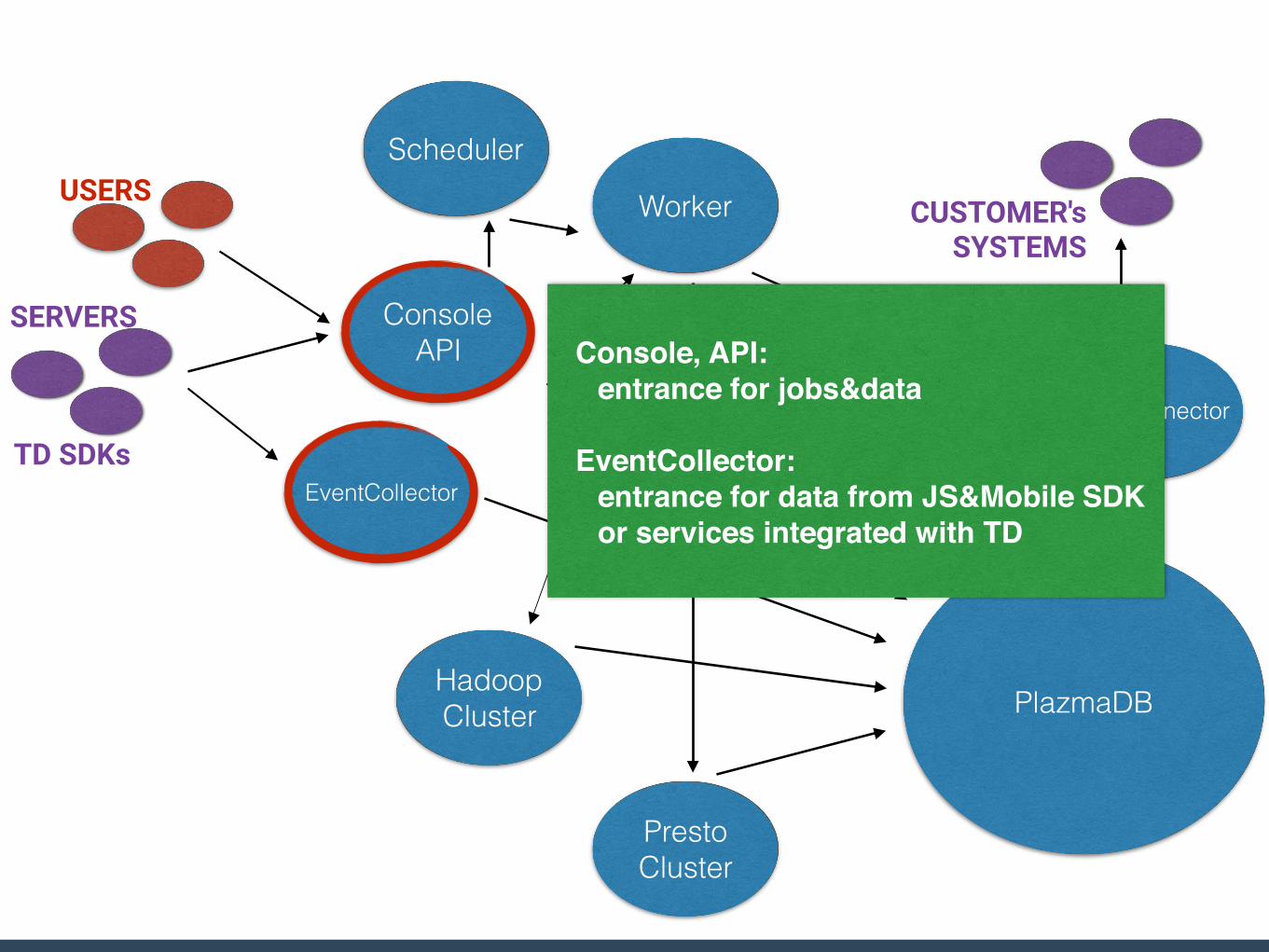
Console, API:entrance for jobs&data
EventCollector:entrance for data from JS&Mobile SDK or services integrated with TD
Console API
EventCollector
PlazmaDB
Worker
Scheduler
Hadoop Cluster
Presto Cluster
USERS
TD SDKs
SERVERS
DataConnector
CUSTOMER's SYSTEMS
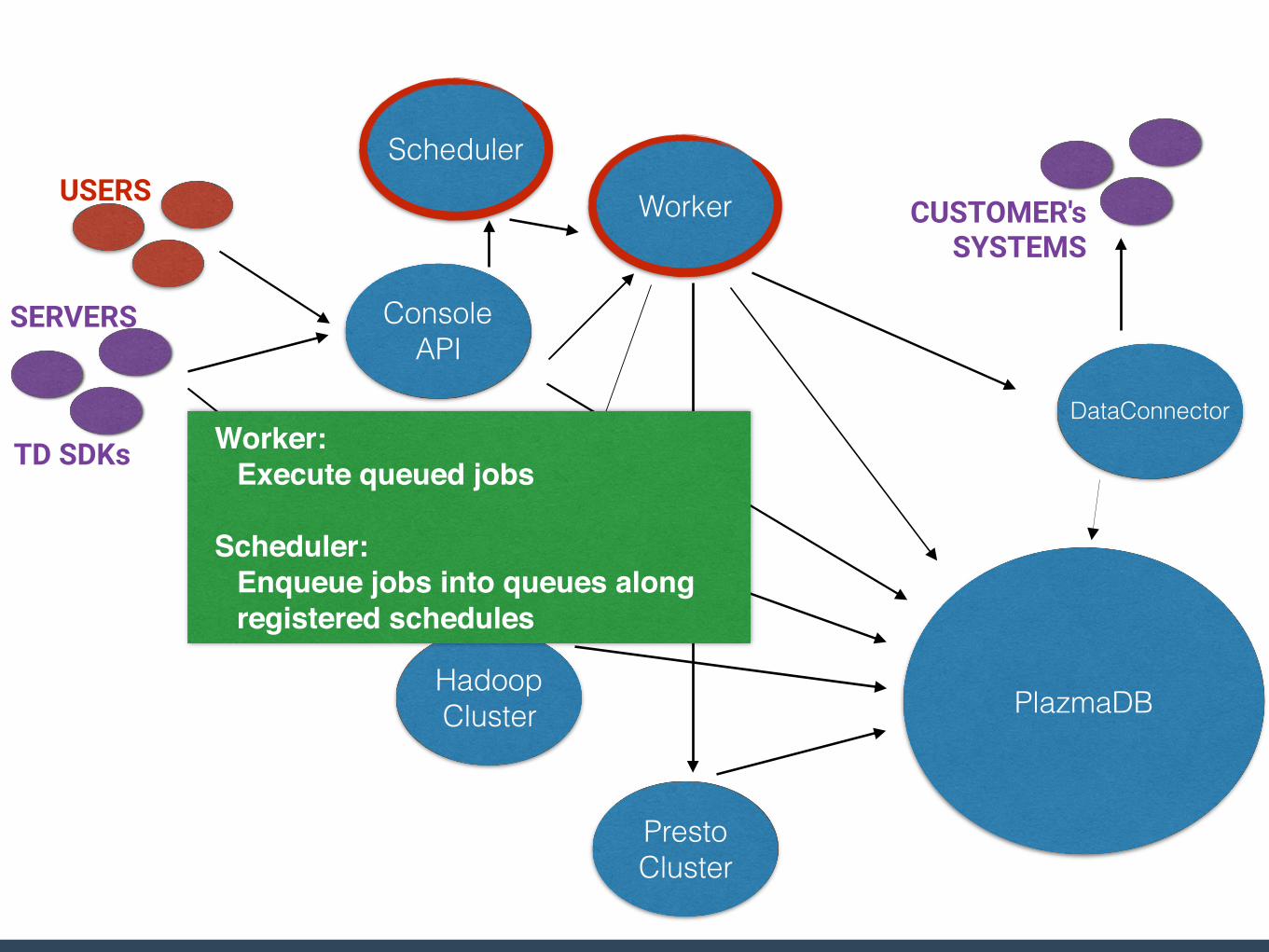
Worker:Execute queued jobs
Scheduler:Enqueue jobs into queues along registered schedules
Console API
EventCollector
PlazmaDB
Worker
Scheduler
Hadoop Cluster
Presto Cluster
USERS
TD SDKs
SERVERS
DataConnector
CUSTOMER's SYSTEMS
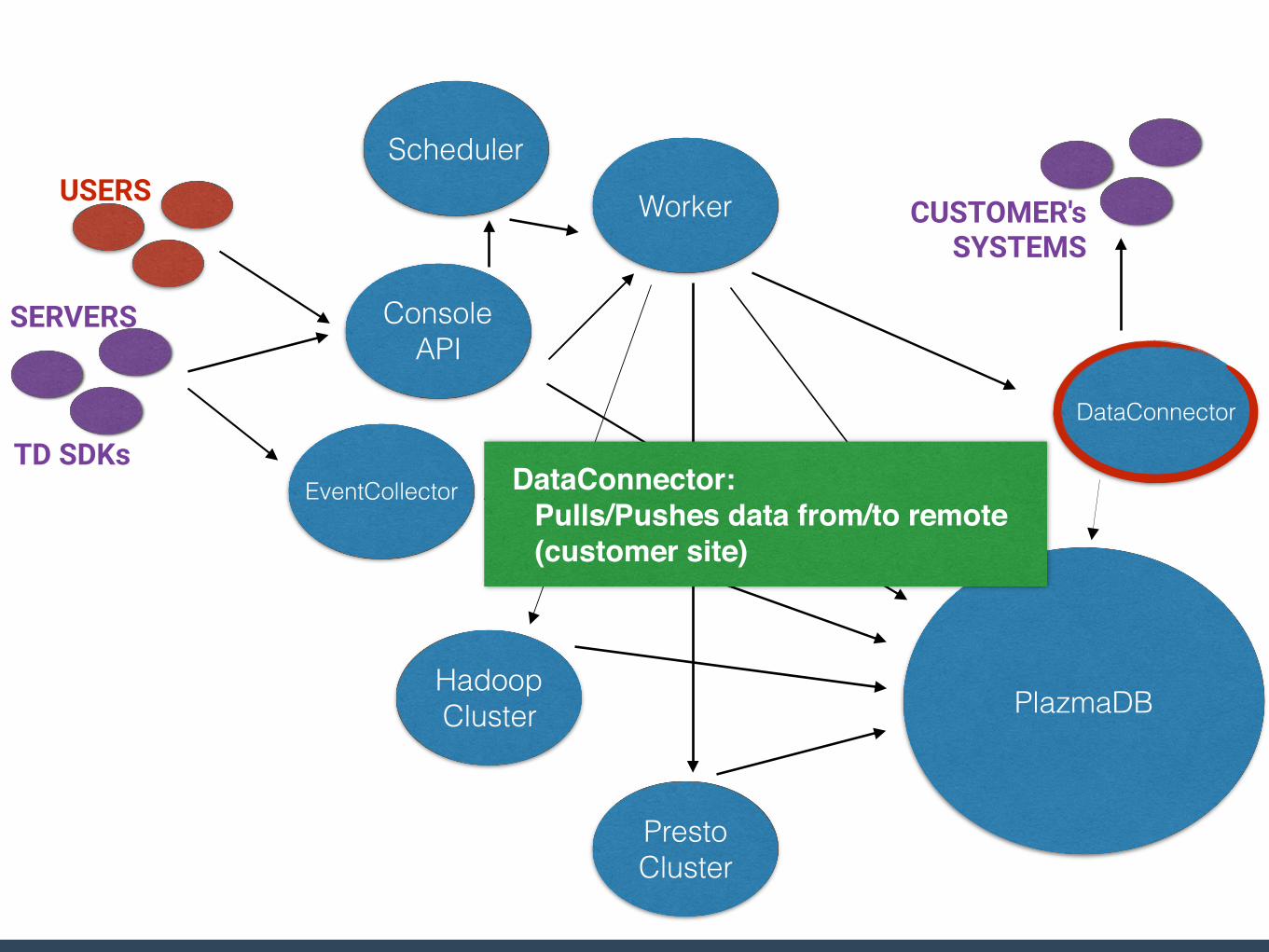
DataConnector:Pulls/Pushes data from/to remote (customer site)
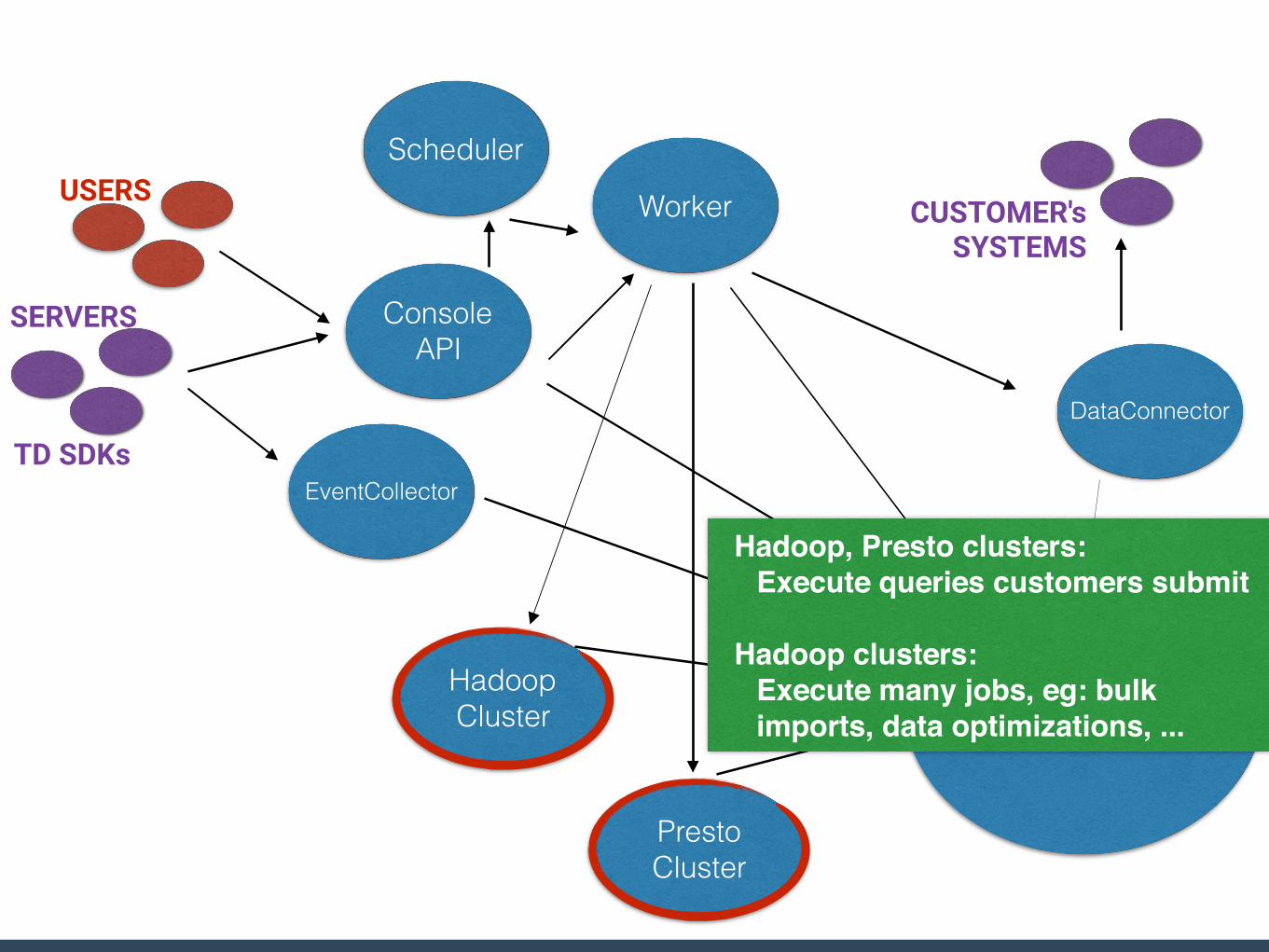
Console API
EventCollector
PlazmaDB
Worker
Scheduler
Hadoop Cluster
Presto Cluster
USERS
TD SDKs
SERVERS
DataConnector
CUSTOMER's SYSTEMS
Hadoop, Presto clusters:Execute queries customers submit
Hadoop clusters:Execute many jobs, eg: bulk imports, data optimizations, ...
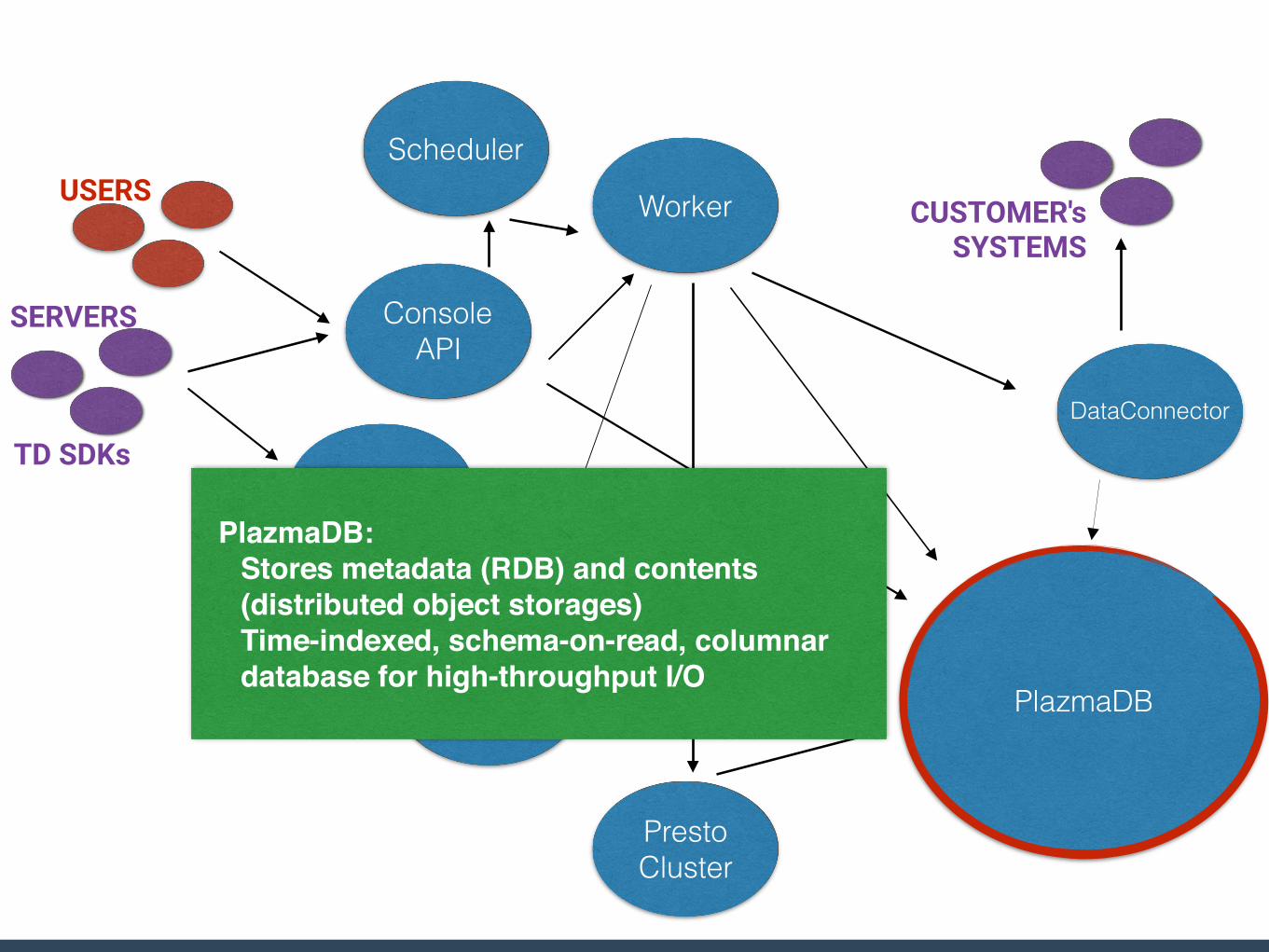
Console API
EventCollector
PlazmaDB
Worker
Scheduler
Hadoop Cluster
Presto Cluster
USERS
TD SDKs
SERVERS
DataConnector
CUSTOMER's SYSTEMS
PlazmaDB:Stores metadata (RDB) and contents (distributed object storages)Time-indexed, schema-on-read, columnar database for high-throughput I/O

Console API
EventCollector
PlazmaDB
Worker
Scheduler
Hadoop Cluster
Presto Cluster
USERS
TD SDKs
SERVERS
DataConnector
CUSTOMER's SYSTEMS
50k/day
200k/day
12M/day (138/sec)

Semantics for Distributed Systems "At most once" "Exactly once" "At least once"

Semantics
• Send messages / execute jobs once, then: • Exactly once
• If any error occurs, it will be retried if needed • At least once
• If any error occurs, it will be retried either way • At most once
• If any error occurs, do nothing anymore

Semantics• Send messages / execute jobs once, then: • Exactly once
• If any error occurs, it will be retried if needed • Hard to implement, poor performance (e.g. TCP for users)
• At least once • If any error occurs, it will be retried either way • Possibly duplicated events (e.g. TCP packets)
• At most once • If any error occurs, do nothing anymore • Possibly missing events (e.g. UDP packets)

Idempotence (冪等性)
• "describing an action which, when performed multiple times on the same subject, has no further effect on its subject after the first time it is performed." (wikipedia)
• Exactly-once operations • by idempotent operation w/ at-least-one semantics

Queue/Worker and Scheduler

Queue/Worker and Scheduler
• Treasure Data: multi-tenant data analytics service • executes many jobs in shared clusters (queries,
imports, ...) • CORE: queues-workers & schedulers
• Clusters have queues/scheduler... it's not enough • resource limitations for each price plans • priority queues for job types • and many others

PerfectSched
• Provides periodical/scheduled queries for customers • it's like reliable "cron"
• Highly available distributed scheduler using RDBMS • Written in CRuby
• At-least-once semantics
• PerfectSched enqueues jobs into PerfectQueue
https://github.com/treasure-data/perfectsched

Jobs in TD: for queuesLOST
Retriedafter
ErrorsThroughput Execution
time
QUERY NGOK or
NGLOW
SHORT (secs) or
LONG (mins-hours)
DATAimport/export NG
OK or
NGHIGH SHORT
(secs-mins)

PerfectQueue• Highly available distributed queue using RDBMS
• Enqueue by INSERT INTO • Dequeue/Commit by UPDATE • Using transactions
• Flexible scheduling rather than scalability • Workers do many things
• Plazmadb operations (including importing data) • Building job parameters • Handling results of jobs + kicking other jobs
• Using Amazon RDS (MySQL) internally (+ Workers on EC2)
https://github.com/treasure-data/perfectqueue
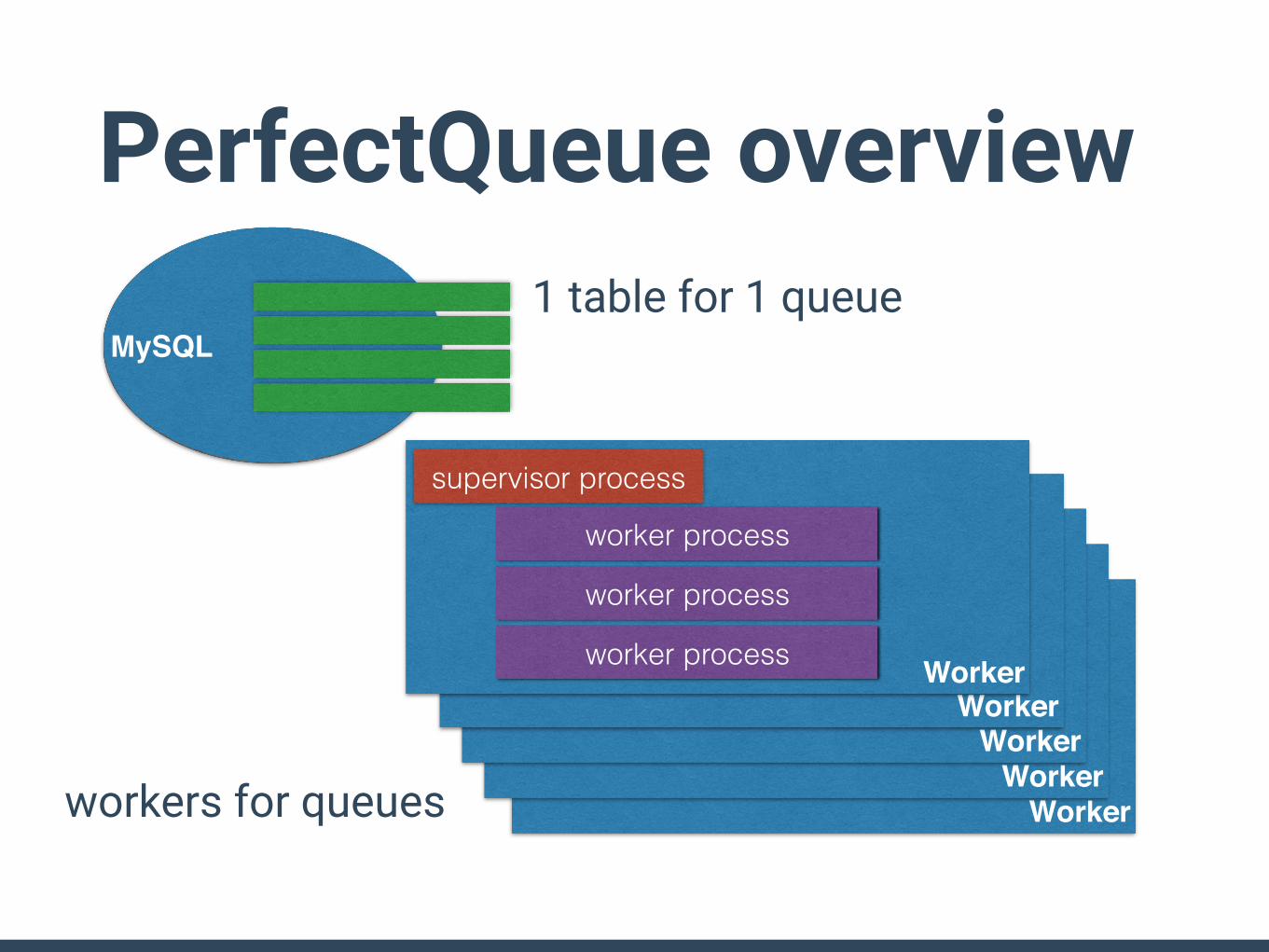
WorkerWorker
WorkerWorker
PerfectQueue overview
Worker
MySQL1 table for 1 queue
workers for queues
supervisor process
worker process
worker process
worker process

Features
• Priorities for query types
• Resource limits per accounts
• Graceful restarts • Queries must run long time (<= 1d) • New worker code should be loaded, besides
running job with older code

Data Processing: Hive and Presto

Hive and Presto• Hive: SQL executor on Hadoop
• Parse SQL, compile&submit MapReduce jobs • Good for large/complex query (e.g. JOINs) • Stable, high throughput but high latency for small
queries
• Presto: MPP engine for SQL • MPP: Massively Parallel Processing (using threads) • Good for small-or-middle size query • High performance and low latency for small queries
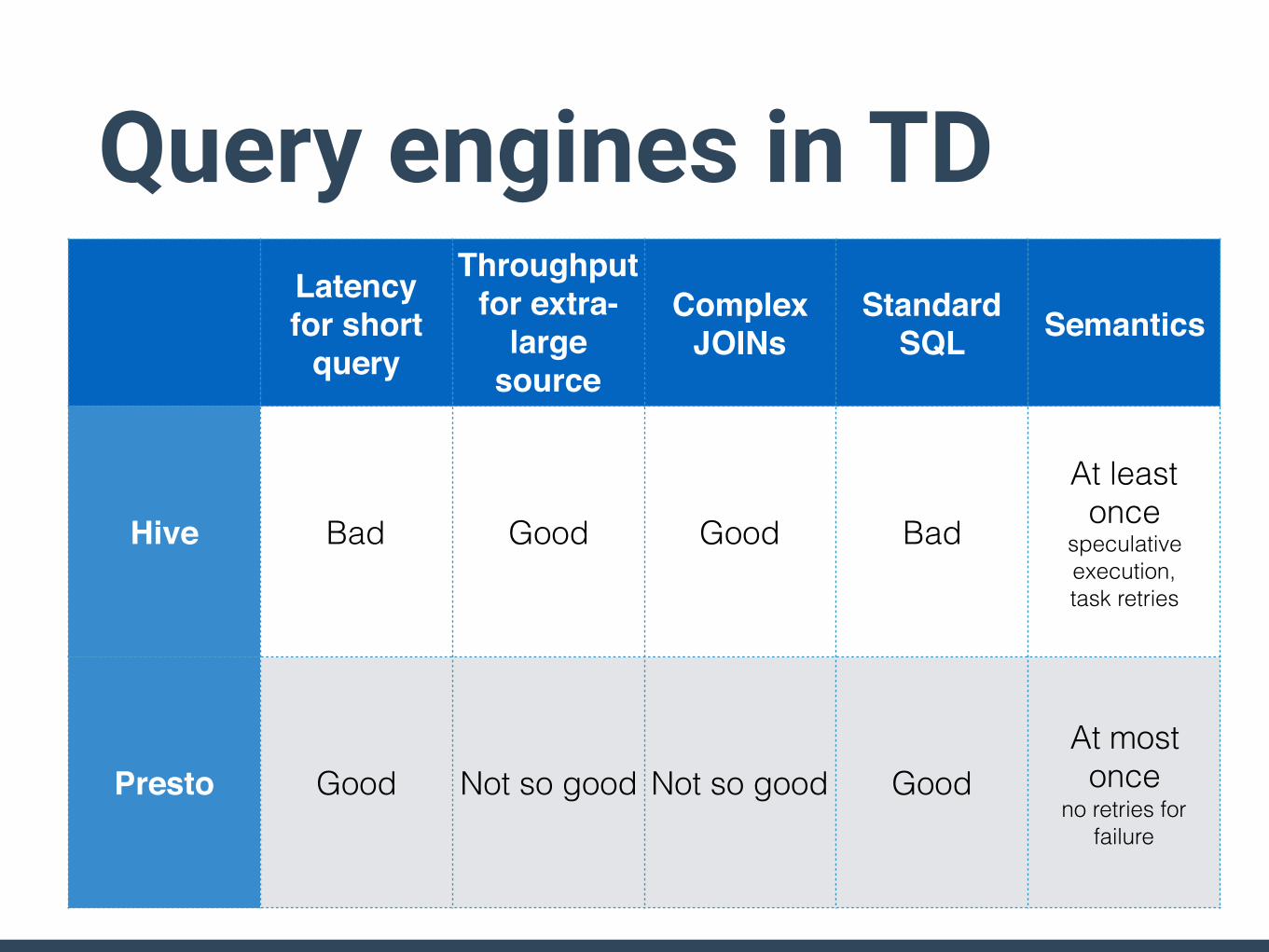
Query engines in TDLatencyfor short
query
Throughputfor extra-
largesource
data
Complex JOINs
Standard SQL Semantics
Hive Bad Good Good Bad
At least once
speculative execution, task retries
Presto Good Not so good Not so good GoodAt most
once no retries for
failure
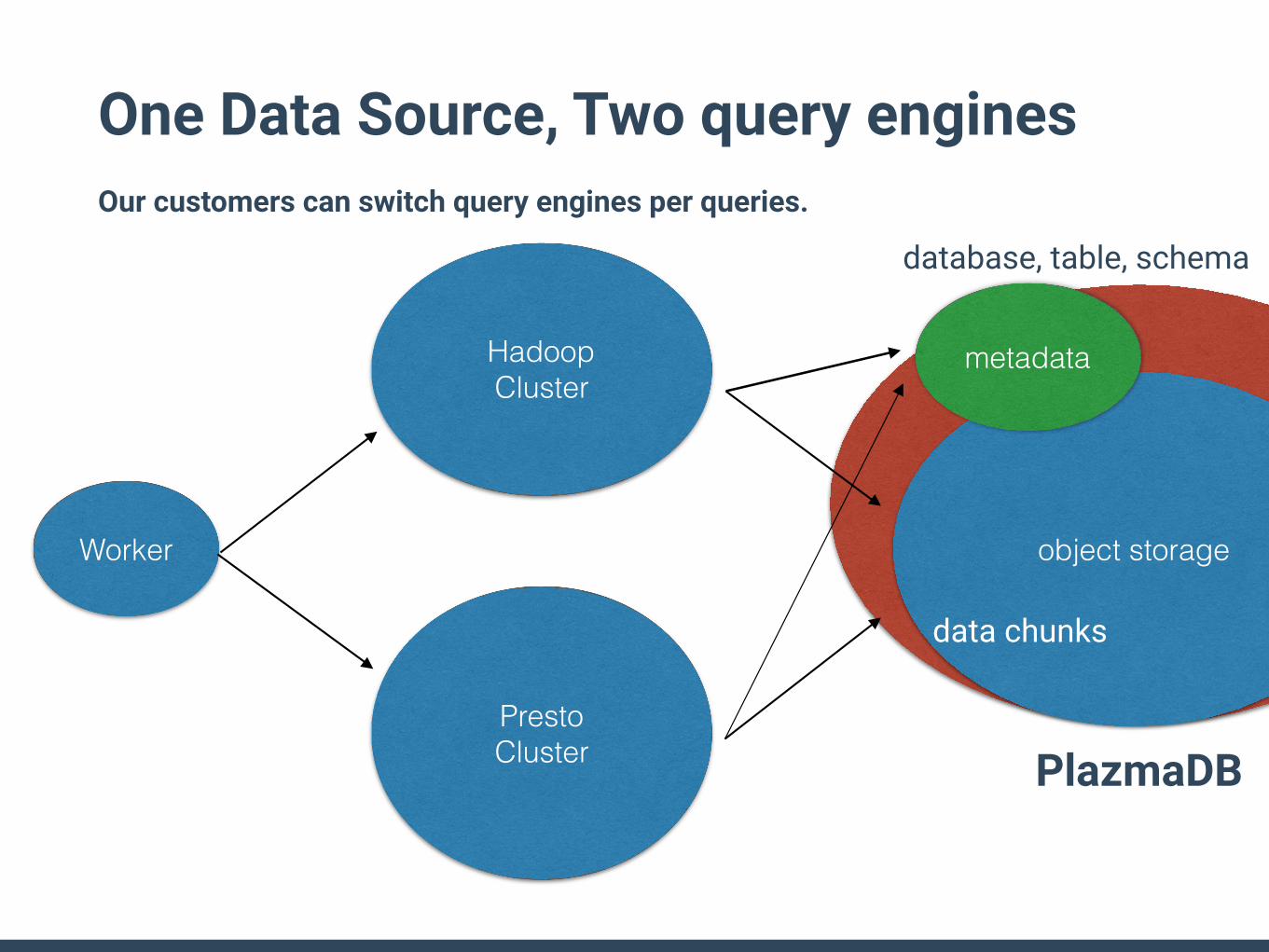
PlazmaDB
One Data Source, Two query engines Our customers can switch query engines per queries.
object storageWorker
Hadoop Cluster
Presto Cluster
metadata
database, table, schema
data chunks
PlazmaDB

Data Storage: PlazmaDB

PlazmaDB• Just only one persistent component in TD
• stores all customers' data
• Distributed database • time indexed, columnar, schema-on-read • transparent 2-layered storage (realtime, archive)
• realtime: to append recent data • archive: to store long-term data
• metadata (PostgreSQL) + object storage (S3/RiakCS)
• all operations are idempotent
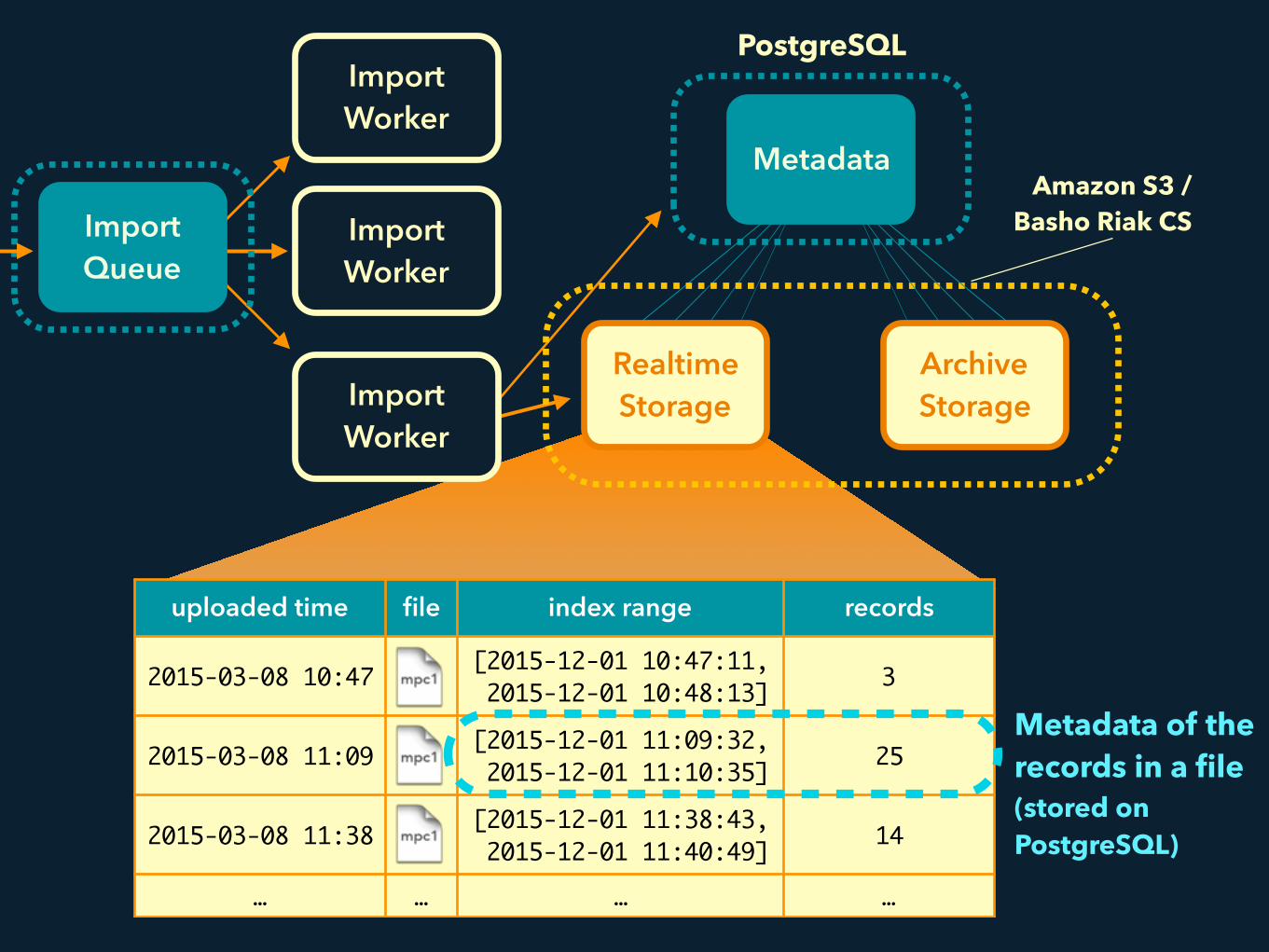
Realtime Storage
PostgreSQL
Amazon S3 / Basho Riak CS
Metadata
Import Queue
Import Worker
Import Worker
Import Worker
uploaded time file index range records
2015-03-08 10:47 [2015-12-01 10:47:11, 2015-12-01 10:48:13] 3
2015-03-08 11:09 [2015-12-01 11:09:32, 2015-12-01 11:10:35] 25
2015-03-08 11:38 [2015-12-01 11:38:43, 2015-12-01 11:40:49] 14
… … … …
Archive Storage
Metadata of the records in a file (stored on PostgreSQL)
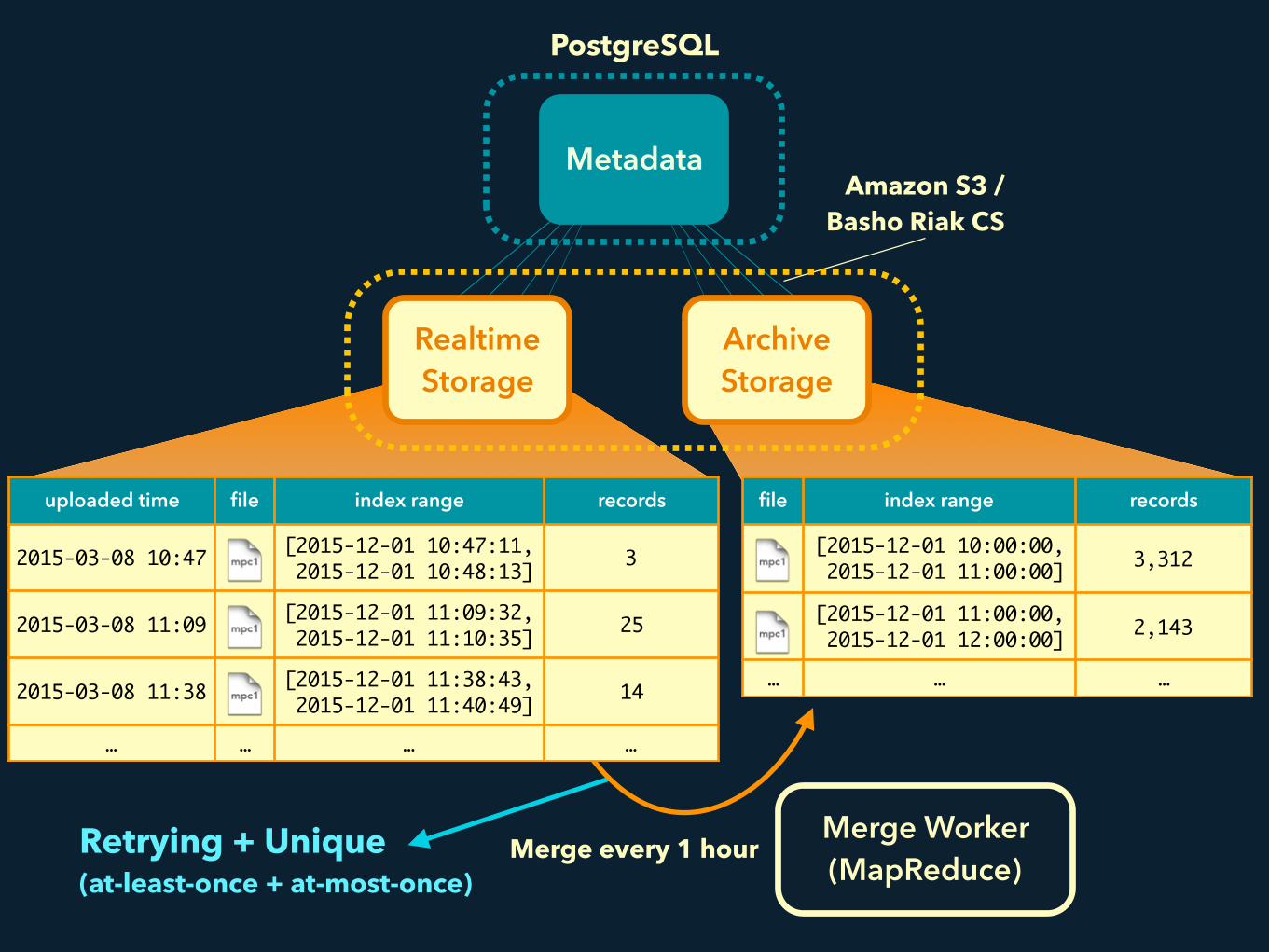
Amazon S3 / Basho Riak CS
Metadata
Merge Worker(MapReduce)
uploaded time file index range records
2015-03-08 10:47 [2015-12-01 10:47:11, 2015-12-01 10:48:13] 3
2015-03-08 11:09 [2015-12-01 11:09:32, 2015-12-01 11:10:35] 25
2015-03-08 11:38 [2015-12-01 11:38:43, 2015-12-01 11:40:49] 14
… … … …
file index range records
[2015-12-01 10:00:00, 2015-12-01 11:00:00] 3,312
[2015-12-01 11:00:00, 2015-12-01 12:00:00] 2,143
… … …
Realtime Storage
Archive Storage
PostgreSQL
Merge every 1 hourRetrying + Unique (at-least-once + at-most-once)
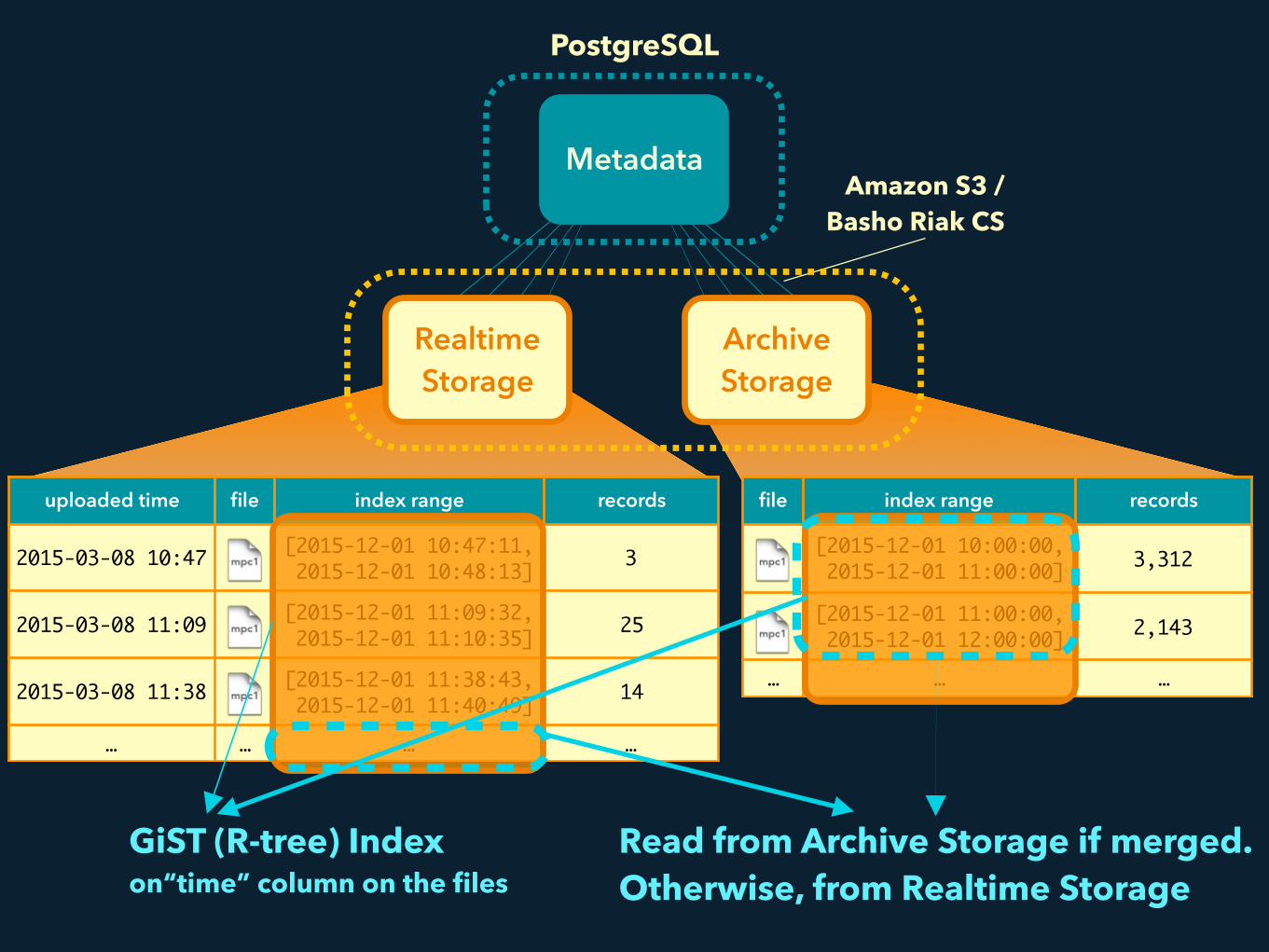
Amazon S3 / Basho Riak CS
Metadata
uploaded time file index range records
2015-03-08 10:47 [2015-12-01 10:47:11, 2015-12-01 10:48:13] 3
2015-03-08 11:09 [2015-12-01 11:09:32, 2015-12-01 11:10:35] 25
2015-03-08 11:38 [2015-12-01 11:38:43, 2015-12-01 11:40:49] 14
… … … …
file index range records
[2015-12-01 10:00:00, 2015-12-01 11:00:00] 3,312
[2015-12-01 11:00:00, 2015-12-01 12:00:00] 2,143
… … …
Realtime Storage
Archive Storage
PostgreSQL
GiST (R-tree) Index on“time” column on the files
Read from Archive Storage if merged. Otherwise, from Realtime Storage
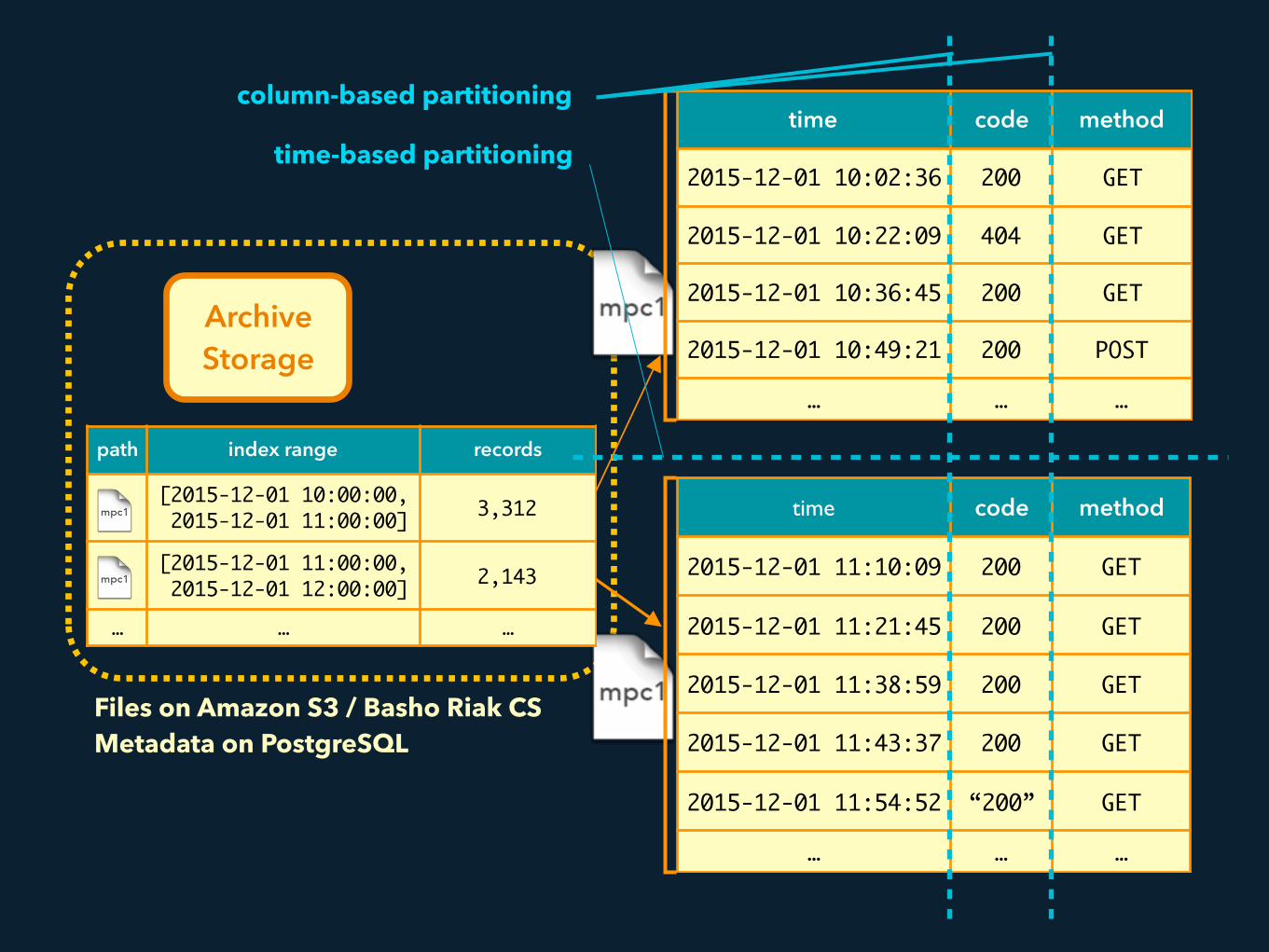
time code method
2015-12-01 10:02:36 200 GET
2015-12-01 10:22:09 404 GET
2015-12-01 10:36:45 200 GET
2015-12-01 10:49:21 200 POST
… … …
time code method
2015-12-01 11:10:09 200 GET
2015-12-01 11:21:45 200 GET
2015-12-01 11:38:59 200 GET
2015-12-01 11:43:37 200 GET
2015-12-01 11:54:52 “200” GET
… … …
Archive Storage
path index range records
[2015-12-01 10:00:00, 2015-12-01 11:00:00] 3,312
[2015-12-01 11:00:00, 2015-12-01 12:00:00] 2,143
… … …
column-based partitioning
time-based partitioning
Files on Amazon S3 / Basho Riak CS Metadata on PostgreSQL

More about PlazmaDB:
http://www.slideshare.net/treasure-data/td-techplazma

What I'll talk about today• Architecture Overview • Semantics for Distributed Systems • Queue/Worker and Scheduler • Data Processing: Hive and Presto • Data Storage: PlazmaDB • All about Our Infrastructure • Data Collection: Fluentd and Embulk • Data and Open Source Software Products • Disposable Services and Persistent Data

All about Our Infrastructure

Infrastructure: fully on cloud• AWS, IDCF Cloud, Heroku, Fastly for service core
• S3, EC2, RDS, ElastiCache, ... (in AWS) • Not locked-in for cloud services
• And many services for DevOps • Github, CircleCI, DataDog, PagerDuty, StatusPage.io,
Chef.io, JIRA/Confluence, Airbrake, NewRelic, Artifactory, zendesk, OneLogin, Box, Orbitz, Slack, ...
• No self-hosted servers for non-core services • w/o VPN servers :P

Policies about Infrastructure• Concentrate on development of our own service
• decrease operation costs as far as possible
• Keep initiative about deployment/performance • be not locked-in by any environments or services • solve our problems by our own technologies
• Keep it simple and not too much • use our time on service as much as possible, not
so much for processes

Data Collection: Fluentd & Embulk

http://www.fluentd.org/
Fluentd Unified Logging Layer
For Stream Data Written in CRuby
http://www.slideshare.net/treasure-data/the-basics-of-fluentd-35681111
- At-most-once / At-least-once- HA (failover) - Load-balancing

Fluentd• Stream based log collector
• Written in CRuby • Plugin based architecture using rubygems.org
• Open Source Software: Apache License v2 • Committers from TD and others (e.g. DeNA)
• Packaging for many environments: td-agent • Package w/ Fluentd + some selected plugins
- Using Docker logging driver for Fluentd(fully OSS)

Bulk Data Loader High Throughput&Reliability
Embulk Written in Java/JRuby
http://www.slideshare.net/frsyuki/embuk-making-data-integration-works-relaxed
http://www.embulk.org/
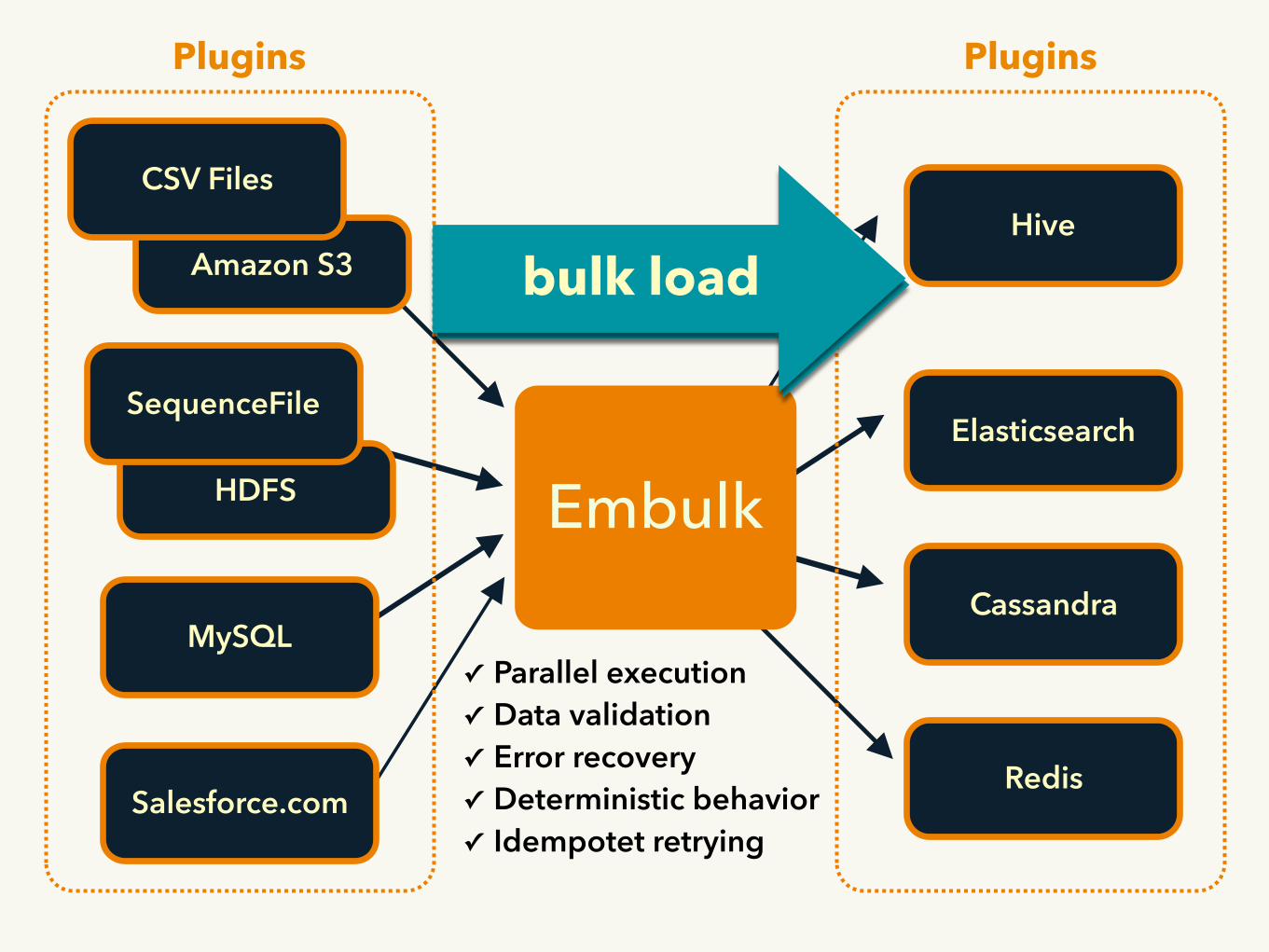
HDFS
MySQL
Amazon S3
Embulk
CSV Files
SequenceFile
Salesforce.com
Elasticsearch
Cassandra
Hive
Redis
✓ Parallel execution ✓ Data validation ✓ Error recovery ✓ Deterministic behavior ✓ Idempotet retrying
Plugins Plugins
bulk load

Embulk• Batch based log collector
• Written in Java + JRuby • Plugin based architecture using rubygems.org
• Open Source Software: Apache License v2 • Committers from TD and many external
contributors
• Hosted embulk: DataConnector in TD • With no customizations

DATA and
Open Source Software Products

Treasure Data: "an open source company at its core"
• To enlarge the world about data
• To make the world better by software
• What important is data, not tools nor services

Disposable Service Components and
Persistent Data

Disposable components• Blue-green deployment ready
• Console&API servers: Heroku/EC2 • Event collector • Workers and schedulers • Hadoop&Presto clusters
• It makes operations much easier! :D • no care about long-life servers/processes • no complex operation steps for server crashes
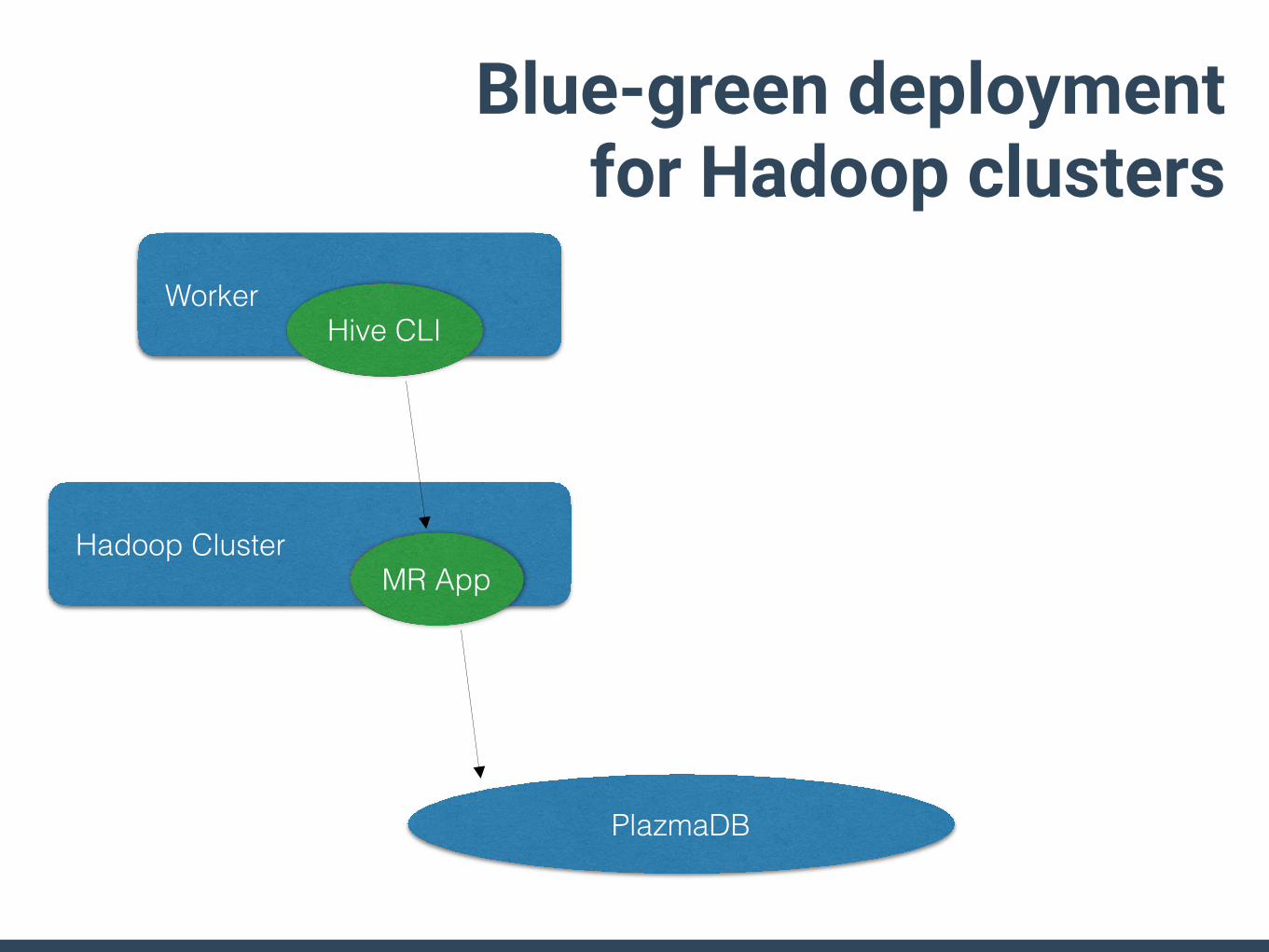
Blue-green deployment for Hadoop clusters
PlazmaDB
Worker
Hadoop ClusterMR App
Hive CLI
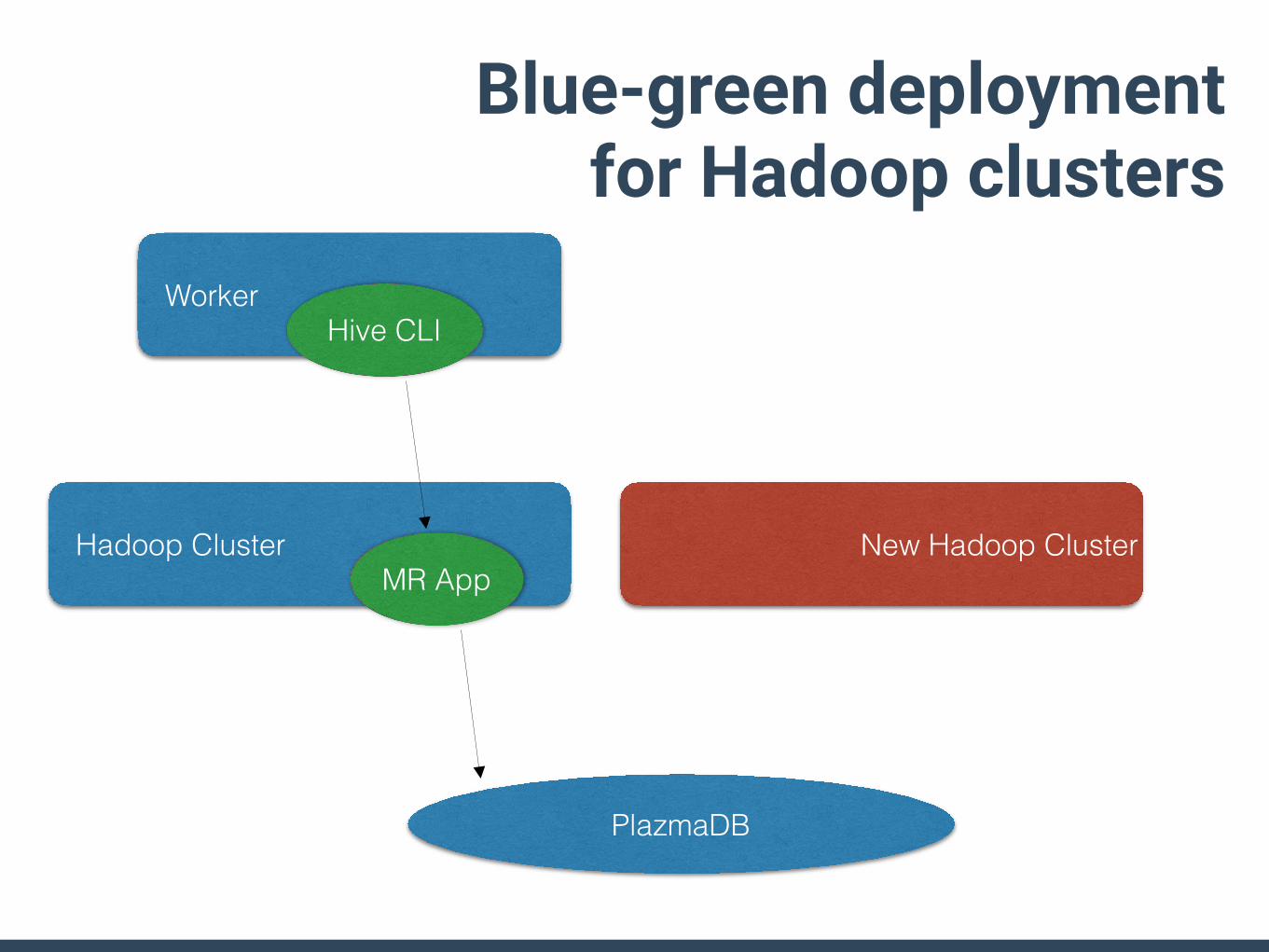
PlazmaDB
Worker
Hadoop ClusterMR App
Hive CLI
New Hadoop Cluster
Blue-green deployment for Hadoop clusters
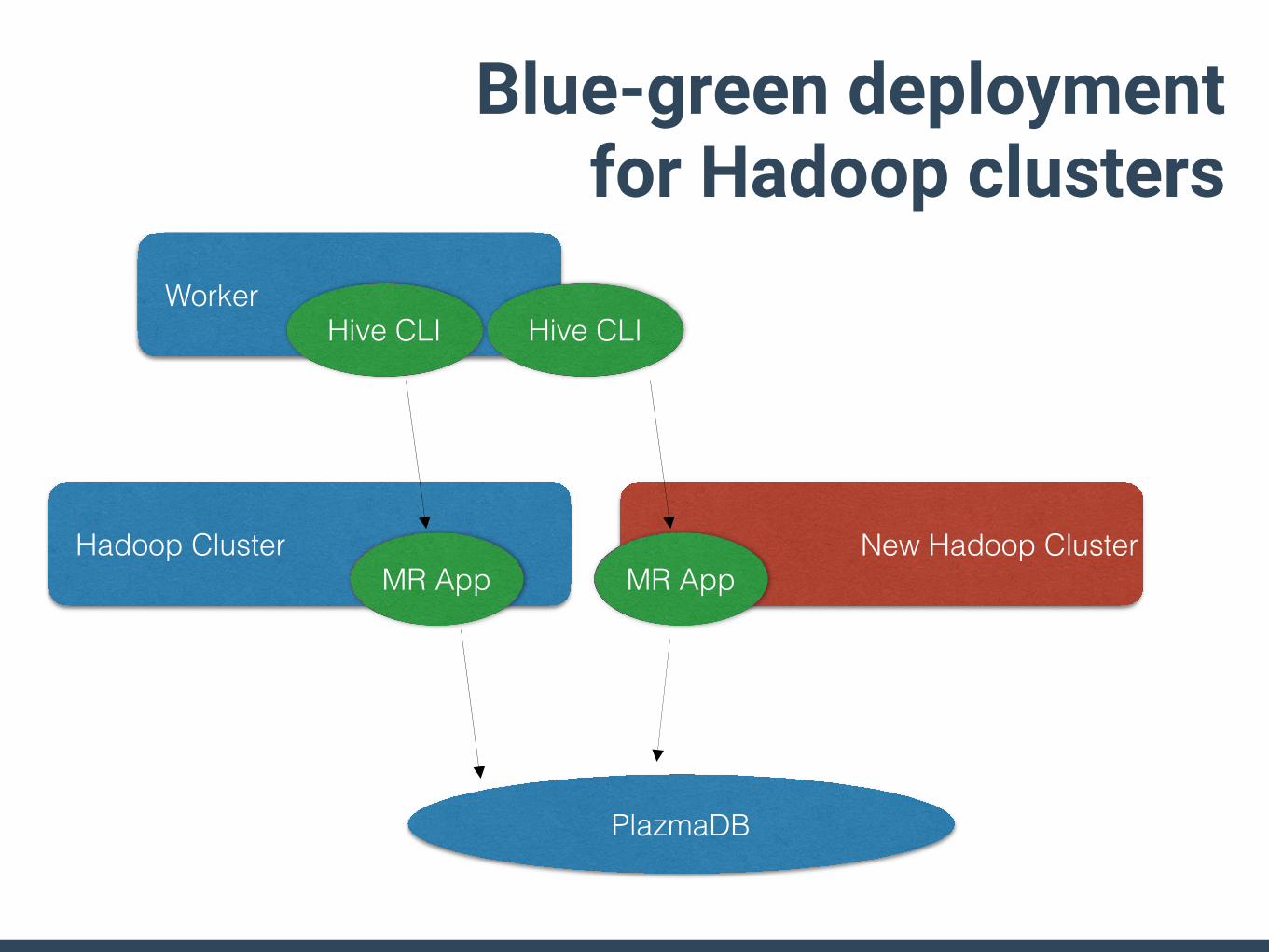
PlazmaDB
Worker
Hadoop ClusterMR App
Hive CLI
New Hadoop Cluster
Hive CLI
MR App
Blue-green deployment for Hadoop clusters
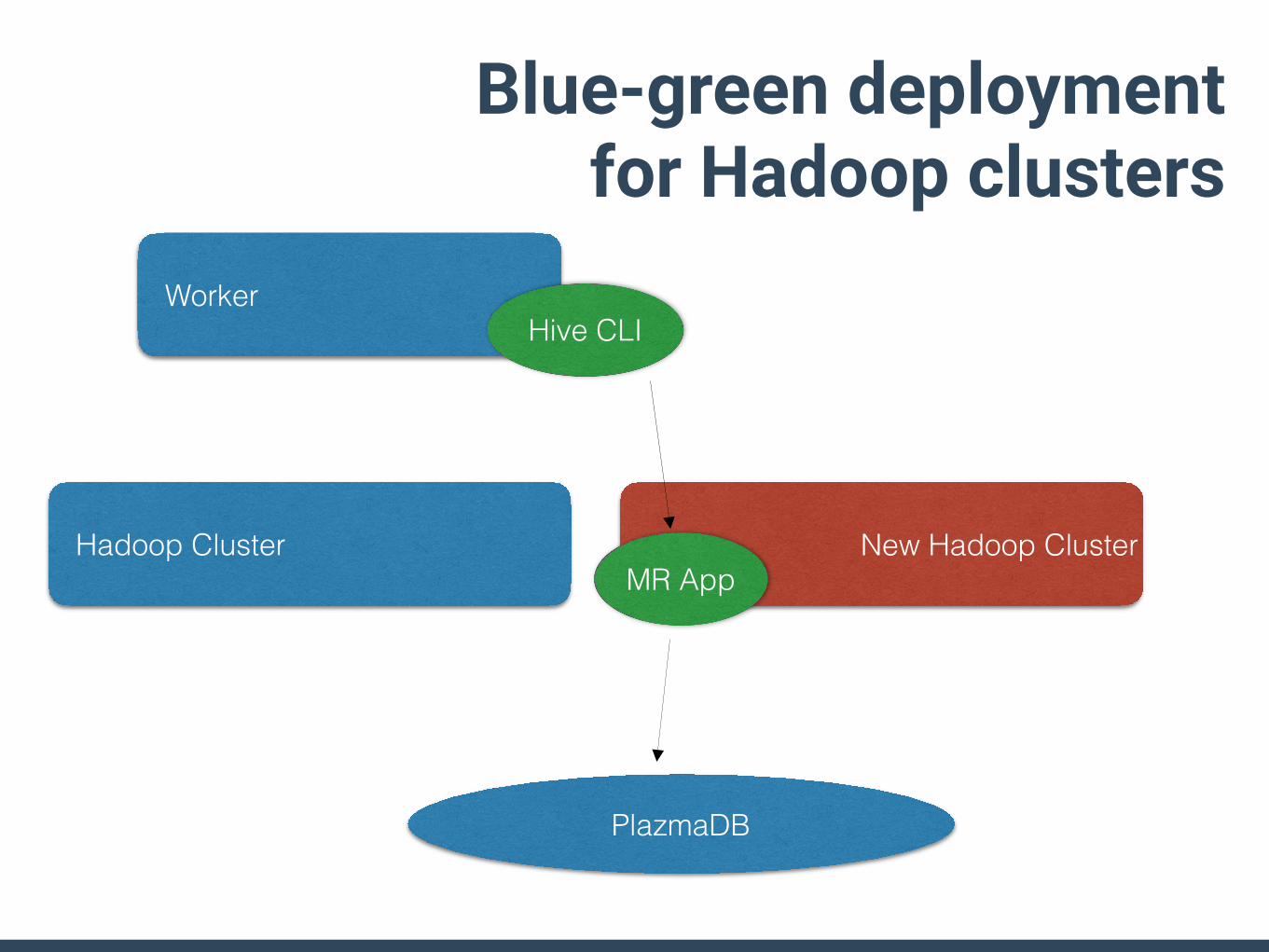
PlazmaDB
Worker
Hadoop Cluster New Hadoop Cluster
Hive CLI
MR App
Blue-green deployment for Hadoop clusters
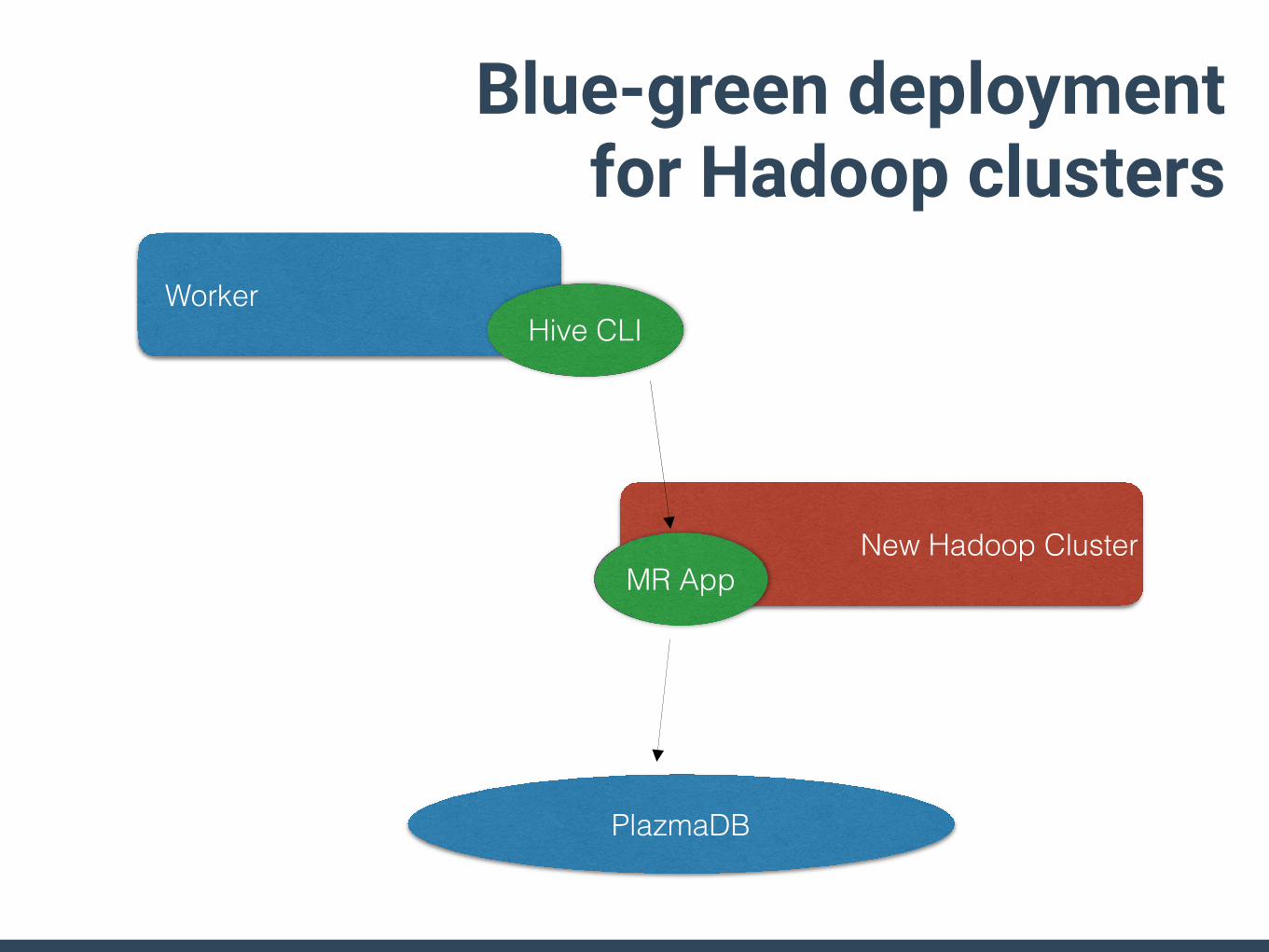
PlazmaDB
Worker
New Hadoop Cluster
Hive CLI
MR App
Blue-green deployment for Hadoop clusters

Persistent Data• 2 RDBMSs
• API DB for customer data • PlazmaDB metadata
• Object Storage for PlazmaDB
• That's it! • We can concentrate on these very few
components :D

Think about Data at first, then processing :D

Thank you!